
Calculateurs Haute Performance: concepts générauxjylexcel/master0506/hpc-concepts.pdfx 1.5 – 2...
100
Calculateurs Haute Performance: concepts g´ en´ eraux Calculateurs haute-performance: concepts g´ en´ eraux Introduction Organisation des processeurs Organisation m´ emoire Organisation interne et performance des processeurs vectoriels Organisation des processeurs RISC M´ emoire cache M´ emoire virtuelle Interconnexion des processeurs Les supercalculateurs du top 500 en Juin 2005 Conclusion 1/ 98
Transcript of Calculateurs Haute Performance: concepts générauxjylexcel/master0506/hpc-concepts.pdfx 1.5 – 2...

Calculateurs Haute Performance: conceptsgeneraux
Calculateurs haute-performance: concepts generauxIntroductionOrganisation des processeursOrganisation memoireOrganisation interne et performance des processeurs vectorielsOrganisation des processeurs RISCMemoire cacheMemoire virtuelleInterconnexion des processeursLes supercalculateurs du top 500 en Juin 2005Conclusion 1/ 98

Plan
Calculateurs haute-performance: concepts generauxIntroductionOrganisation des processeursOrganisation memoireOrganisation interne et performance des processeurs vectorielsOrganisation des processeurs RISCMemoire cacheMemoire virtuelleInterconnexion des processeursLes supercalculateurs du top 500 en Juin 2005Conclusion
2/ 98

Introduction
I Conception d’un supercalculateurI Determiner quelles caracteristiques sont importantes (domaine
d’application)I Maximum de performance en respectant les contraintes de coutI Conception d’un processeur :
I Jeu d’instructionsI Organisation fonctionnelle et logiqueI Implantation (integration, alimentation, . . . )
I Exemples de contraintes fonctionnelles vs domained’application
I Machine generaliste : performance equilibree sur un largeensemble de traitements
I Calcul scientifique : arithmetique flottante performanteI Gestion : base de donnees, transactionnel, . . .
3/ 98

I Utilisation des architecturesI Besoins toujours croissants en volume memoire :
x 1.5 – 2 par an pour un code moyen (soit 1 bit d’adresse tousles 1-2 ans)
I 20 dernieres annees remplacement assembleur par langages dehaut niveau → compilateurs / optimisation de code
I Evolution technologiqueI Circuits integres (CPU) : densite + 50 % par anI Semi-conducteurs DRAM (memoire) :
I Densite + 60 % par anI Temps de cycle : -30 % tous les 10 ansI Taille : multipliee par 4 tous les 3 ans
4/ 98

Plan
Calculateurs haute-performance: concepts generauxIntroductionOrganisation des processeursOrganisation memoireOrganisation interne et performance des processeurs vectorielsOrganisation des processeurs RISCMemoire cacheMemoire virtuelleInterconnexion des processeursLes supercalculateurs du top 500 en Juin 2005Conclusion
5/ 98

CPU performance
I CPUtime = #ProgramCyclesClockRate
I IC = #instructions for program
I CPI = average number of cycles per instruction
I Thus CPUtime = IC×CPIClockRate
I CPU performance on a program depends on three factors :
1. clock cycle time2. #cycles per instruction3. number of instructions
But they are inter-dependent :
I Cycle time depends on hardware technology and processororganization
I CPI depends on organization and instruction set architecture
I IC depends on instruction set and compiler
6/ 98

Pipeline
I Pipeline = principe du travail a la chaıneI un traitement est decoupe en un certain nombre de
sous-traitements realises par des unites differentes (etages dupipeline)
I les etages fonctionnent simultanement sur des operandesdifferents (elements de vecteurs par exemple)
I apres amorcage du pipeline, on obtient un resultat par tempsde cyle de base
I Processeur RISC :I Pipeline sur des operations scalaires independantes :
a = b + cd = e + f
I Code executable plus complexe sur RISC :
do i = 1, na(i) = b(i) + c(i)
enddo
7/ 98

I Code correspondant :
i = 1boucle : load b(i) dans registre #1
load c(i) dans registre #2registre #3 = registre #1 + registre #2store registre #3 dans a(i)i = i + 1 et test fin de boucle
I Exploitation du pipeline → deroulage de boucle
do i = 1, n, 4a(i ) = b(i ) + c(i )a(i+1) = b(i+1) + c(i+1)a(i+2) = b(i+2) + c(i+2)a(i+3) = b(i+3) + c(i+3)
enddo
8/ 98

I Sur processeur vectoriel :
do i = 1, na(i) = b(i) + c(i)
enddo
load vector b dans registre #1load vector c dans registre #2effectuer register #3 = register #1 + register #2store registre #3 dans vecteur a
Stripmining : si n > nb (taille registres vectoriels)
do i = 1, n, nbib = min( nb, n-i+1 )do ii = i, i + ib - 1
a(ii) = b(ii) + c(ii)enddo
enddo
9/ 98

Problemes dans la conception des pipelines
I Accoıtre le nombre d’etages (reduction du temps de cycle) ↔Accroıtre le temps d’amorcage
I Probleme des dependances de donnees :I Exemple :
do i = 2, na(i) = a(i-1) + 1
enddo
a(i) initialises a 1.I Execution scalaire :
Etape 1 : a(2) = a(1) + 1 = 1 + 1 = 2
Etape 2 : a(3) = a(2) + 1 = 2 + 1 = 3
Etape 3 : a(4) = a(3) + 1 = 3 + 1 = 4.....
10/ 98

I Execution vectorielle : pipeline a p etages → p elements dansle pipeline
Etages du pipe-------------------------------------------
Temps 1 2 3 ... p sortie-------------------------------------------------------t0 a(1)t0 + dt a(2) a(1)t0 + 2dt a(3) a(2) a(1)....t0 + pdt a(p+1) a(p) ... a(2) a(1)-------------------------------------------------------
D’ou :
a(2) = a(1) + 1 = 1 + 1 = 2a(3) = a(2) + 1 = 1 + 1 = 2...
car on utilise la valeur initiale de a(2).
Resultat execution vectorielle 6= execution scalaire
11/ 98

Overlapping (recouvrement)
I Utiliser des unites fonctionnelles en parallele sur desoperations independantes. Exemple:
do i = 1, nA(i) = B(i) * C(i)D(i) = E(i) + F(i)
enddo
A
DE
F
B
C
Pipelined multiplier
Pipelined adder
Timeoverlapping = max{Startupmul ,Startupadd +dt}+n×dt
Timeno overlap. = {Startupmul+n×dt}+{Startupadd+n×dt}I Avantages: parallelisme entre les unites fonctionnelles
independantes et plus de flops par cycle
12/ 98

Chaining (chaınage)
I La sortie d’une unite fonctionnelle est dirigee directement versl’entree d’une autre unite fonctionnelle
I Exemple :
do i = 1, nA(i) = ( B(i) * C(i) ) + D(i)
enddo
D
A
Pipelined multiplier Pipelined adderB
C
Timechaining = Startupmul + Startupadd + n × dtTimenochaining = Startupmul + n × dt + Startupadd + n × dt
I Avantages : plus de flops par cyle, exploitation de la localitedes donnees, economie de stockage intermediaire
13/ 98

Plan
Calculateurs haute-performance: concepts generauxIntroductionOrganisation des processeursOrganisation memoireOrganisation interne et performance des processeurs vectorielsOrganisation des processeurs RISCMemoire cacheMemoire virtuelleInterconnexion des processeursLes supercalculateurs du top 500 en Juin 2005Conclusion
14/ 98

Locality of references
Programs tend to reuse data and instructions recently used
I Often program spends 90% of its time in only 10% of code.
I Also applies - not as stronly - to data accesses :
I temporal locality : recently accessed items are likely to beaccessed in the future
I spatial locality : items whose addresses are near one anothertend to be referenced close together in time.
15/ 98

Concept of memory hierarchy - 1
In hardware : smaller is faster
Example :
I On a high-performance computer using same technology(pipelining, overlapping, . . . ) for memory:
I signal propagation is a major cause of delay thus largermemories → more signal delay and more levels to decodeaddresses.
I smaller memories are faster because designer can use morepower per memory cell.
16/ 98

Concept of memory hierarchy - 2
Make use of principle of locality of references
I Data most recently used - or nearby data - are very likely tobe accessed again in the future
I Try to have recently accessed data in the fastest memory
I Because smaller is faster → use smaller memories to holdmost recently used items close to CPU and successively largermemories farther away from CPU
→ Memory hierarchy
17/ 98
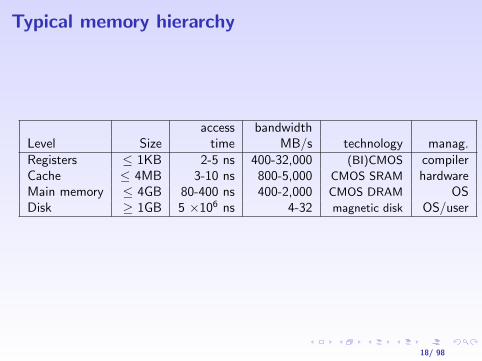
Typical memory hierarchy
access bandwidthLevel Size time MB/s technology manag.Registers ≤ 1KB 2-5 ns 400-32,000 (BI)CMOS compilerCache ≤ 4MB 3-10 ns 800-5,000 CMOS SRAM hardwareMain memory ≤ 4GB 80-400 ns 400-2,000 CMOS DRAM OSDisk ≥ 1GB 5 ×106 ns 4-32 magnetic disk OS/user
18/ 98

High memory bandwidthSpeed of computation
Adder
MemoryX <--- Y + Z
Flow requirementData
Intruction
NI LI NO Cycle time
Required(in nsec)
Bandwidth
Digital α 21064
1 CPU CRAY-C90
Intel i860 XP 2 1/2 3/2 20 0.275GW/sec
2 1/2 1
4
5
4.2
0.6GW/sec
2.8GW/sec
1 CPU NEC SX3/14 16 2.9 16GW/sec
Y Z
X
Example:
cycle time
(NI*LI+3*NO) (in Words/sec)Bandwidth required:
Intruction
NI = Nb. Instructions/cycle
1 Word = 8 Bytes
LI = Nb. Words/Instruction
NO = Nb. Operations/cycle

Banks
1
2
3
4
5
6
7
8
Banks
1
2
3
4
5
6
7
8
a(1), a(9), ..., a(249)
a(2), a(10), ..., a(250)
a(3),a(11), ..., a(251)
a(4),...
a(5), ...
a(6), ...a(7), ..., a(255)
a(8), a(16), ..., a(256)
Two basic ways of distributing the addresses
Memory size 210
=1024 Words divided into 8 banks
a(1), a(2), ..., a(128)
a(129), ..., a(256)
Low order interleaving
Real a(256)
"well adapted to pipelining memory access"
Memory Interleaving
"The memory is subdivided into several independent memory modules (banks)"
Example:
High order interleaving
20/ 98

1
3
2
Bank
4
1
3
2
Bank
4
... = a(i,j)
EnddoEnddo
Do i=1,4
Real a(4,2)
Do j=1,2
... = a(i,j)Enddo
Real a(4,2)
Do i=1,4Do j=1,2
Enddo
cannot be referenced again
Time interval during which the bank
Example
a(1,1) a(1,2)
1 CP
Low order interleaved memory, 4 banks, bank cycle time 3CP.
% column access %row access
Bank cycle time:
10 Clock Period 18 Clock Period
Bank Conflict: Consecutive accesses to the same bank in less than bank cycle time.
Stride: Memory address interval between successive elements
time
a(3,1)
a(4,1) a(4,2)
a(2,2)a(2,1)
a(1,2)a(1,1)
a(3,2)
a(4,1) a(4,2)
a(2,1) a(2,2)
a(3,1) a(3,2)
21/ 98

Performance improvement due to the use of a cache
I Using Amdahl’s law
I cache 10 times faster than memory, hits 90% of the time.I What is the gain from using the cache ?
I Cost cache miss: mI Cost cache hit: 0.1×mI Average cost: 90%(0.1×m) + 10%×mI gain = m
90%×(0.1×m)+10%×m = 1(0.9×0.1)+0.1 = 1
0.19 = 5.3
CPU execution time can also be expressed as:
CPUtime = (CPUcycles + MemoryStallCycles)× clock (1)
MemoryStallCycles = #miss × Cmiss
= IC × (#mem.refs/inst.)×%miss × Cmiss
where Cmiss = miss penalty22/ 98

Plan
Calculateurs haute-performance: concepts generauxIntroductionOrganisation des processeursOrganisation memoireOrganisation interne et performance des processeurs vectorielsOrganisation des processeurs RISCMemoire cacheMemoire virtuelleInterconnexion des processeursLes supercalculateurs du top 500 en Juin 2005Conclusion
23/ 98

Organisation interne et performance des processeursvectoriels (d’apres J. Dongarra)
I Soit l’operation vectorielle triadique :
do i = 1, ny(i) = alpha * ( x(i) + y(i) )
enddoI On a 6 operations :
1. Load vecteur x2. Load vecteur y3. Addition x + y4. Multiplication alpha × ( x + y )5. Store dans vecteur y
24/ 98

I Organisations de processeur considerees :
1. Sequentielle2. Arithmetique chaınee3. Load memoire et arithnetique chaınees4. Load memoire, arithmetique et store memoire chaınes5. Recouvrement des loads memoire et operations chaınees
I Notations :
a : startup pour load memoireb : startup pour additionc : startup pour multiplicationd : startup pour store memoire
25/ 98

Sequential Machine Organization
a
a
b
c
d
memory path busy
load x
load y
add.
mult.
store
Chained Arithmetic
a load x
a load y
b add.
c mult.
d store
memory path busy
26/ 98

a
a
memory path busy
load x
load y
a load x
a load y
memory path busy
Chained Load and Arithmetic
b add.
mult.c
d store
Chained Load, Arithmetic and Store
add. b
c mult.
d store
27/ 98

a load x
Overlapped Load with Chained Operations
a load y
b add.
c mult.
stored
memory path 2 busy
memory path 3 busy
memory path 1 busy
28/ 98

Plan
Calculateurs haute-performance: concepts generauxIntroductionOrganisation des processeursOrganisation memoireOrganisation interne et performance des processeurs vectorielsOrganisation des processeurs RISCMemoire cacheMemoire virtuelleInterconnexion des processeursLes supercalculateurs du top 500 en Juin 2005Conclusion
29/ 98
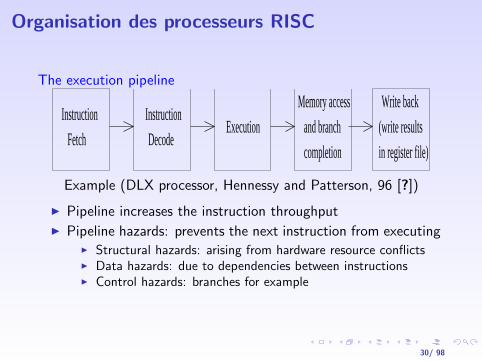
Organisation des processeurs RISC
The execution pipeline
Instruction
Decode
Instruction
FetchExecution
Memory access
and branch
completion
(write results
in register file)
Write back
Example (DLX processor, Hennessy and Patterson, 96 [?])
I Pipeline increases the instruction throughputI Pipeline hazards: prevents the next instruction from executing
I Structural hazards: arising from hardware resource conflictsI Data hazards: due to dependencies between instructionsI Control hazards: branches for example
30/ 98

Instruction Level Parallelism (ILP)
I Pipelining: overlap execution of independent operations →Instruction Level Parallelism
I Techniques for increasing amount of parallelism amonginstructions:
I reduce the impact of data and control hazardsI increase the ability of processor to exploit parallelismI compiler techniques to increase ILP
I Major techniquesI loop unrollingI basic and dynamic pipeline schedulingI dynamic branch predictionI Issuing multiple instructions per cycleI compiler dependence analysisI software pipeliningI trace scheduling / speculationI . . .
31/ 98

Instruction Level Parallelism (ILP)
I Simple and common way to increase amount of parallelism isto exploit parallelism among iterations of a loop : Loop LevelParallelism
I Several techniques :I Unrolling a loop statically by compiler or dynamically by the
hardwareI Use of vector instructions
32/ 98

ILP: Dynamic scheduling
I Hardware rearranges the instruction execution to reduce thestalls.
I Advantage: handle cases where dependences are unknown atcompile time and simplifies the compiler
I But : significant increase in hardware complexity
I Idea : execute instructions as soon as their data are availableOut-of-order execution
I Handling exceptions becomes tricky
33/ 98

ILP: Dynamic scheduling
I Scoreboarding: technique allowing instruction out-of-orderexecution when resources are sufficient and when no datadependences
I full responsability for instruction issue and execution
I goal : try to maintain an execution rate of one instruction /clock by executing instrcutions as early as possible
I requires multiple instructions to be in the EX stagesimultaneously → multiple functional units and/or pipelinedunits
I Scoreboard table: record/update data dependencesI Limits:
I amount of parallelism available between instructionsI number of scoreboard entries : set of instructions examined
(window)I number and type of functional units
34/ 98

ILP: Dynamic scheduling
I Other approach : Tomasulo’s approach (register renaming)
I Suppose compiler has issued:
F10 <- F2 x F2F2 <- F0 + F6
I Rename F2 to F8 in the second instruction (assuming F8 isnot used)
F10 <- F2 x F2F8 <- F0 + F6
35/ 98

ILP : Multiple issue
I CPI cannot be less than one except if more than oneinstruction issued each cycle → multiple-issue processors(CPI: average nb of cycles per instruction)
I Two types :I superscalar processorsI VLIW processors (Very Long Instruction Word)
I Superscalar processors issue varying number of instructionsper cycle either statically scheduled by compiler ordynamically (e.g. using scoreboarding). Typically 1 - 8instructions per cycle with some constraints.
I VLIW issue a fixed number of instructions formatted either asone large instruction or as a fixed instruction packet :inherently statically scheduled by compiler
36/ 98

Impact of ILP : example
This example is from J.L. Hennessy and D.A. Patterson (1996) [?].
I Original Fortran code
do i = 1000, 1x(i) = x(i) + temp
enddo
I Pseudo-assembler code
R1 <- address(x(1000))load temp -> F2
Loop : load x(i) -> F0F4 = F0 + F2store F4 -> x(i)R1 = R1 - #8 % decrement pointerBNEZ R1, Loop % branch until end of loop
37/ 98
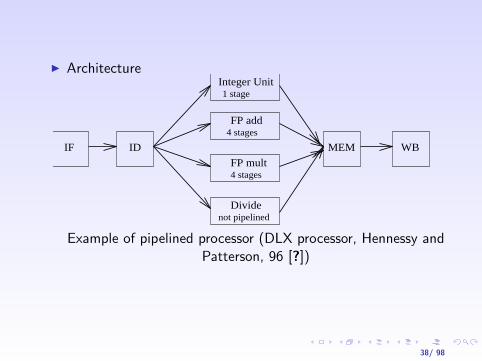
I Architecture
IF ID MEM WB
Integer Unit1 stage
FP add
FP mult
Dividenot pipelined
4 stages
4 stages
Example of pipelined processor (DLX processor, Hennessy andPatterson, 96 [?])
38/ 98
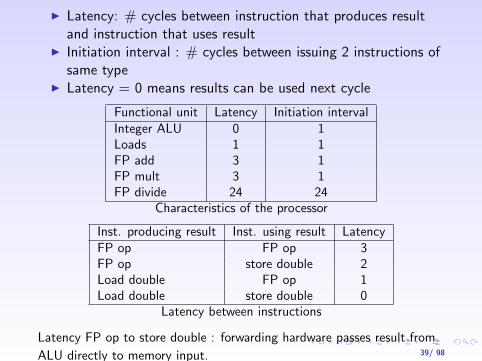
I Latency: # cycles between instruction that produces resultand instruction that uses result
I Initiation interval : # cycles between issuing 2 instructions ofsame type
I Latency = 0 means results can be used next cycle
Functional unit Latency Initiation intervalInteger ALU 0 1Loads 1 1FP add 3 1FP mult 3 1FP divide 24 24
Characteristics of the processor
Inst. producing result Inst. using result LatencyFP op FP op 3FP op store double 2Load double FP op 1Load double store double 0
Latency between instructions
Latency FP op to store double : forwarding hardware passes result from
ALU directly to memory input. 39/ 98

I Straightforward code
#cycleLoop : load x(i) -> F0 1 load lat. = 1
stall 2F4 = F0 + F2 3stall 4 FP op -> store = 2stall 5store F4 -> x(i) 6R1 = R1 - #8 7BNEZ R1, Loop 8stall 9 delayed branch 1
I 9 cycles per iteration
I Cost of calculation 9,000 cycles
I Peak performance : 1 flop/cycle
I Effective performance : 19 of peak
40/ 98

I With a better scheduling
#cycleLoop : load x(i) -> F0 1 load lat. = 1
stall 2F4 = F0 + F2 3R1 = R1 - #8 4 Try keep int. unit busyBNEZ R1, Loop 5store F4 -> x(i) 6 Hide delayed branching
by store
I 6 cycles per iteration
I Cost of calculation 6,000 cycles
I Effective performance : 16 of peak
41/ 98

I Using loop unrolling (depth = 4)
do i = 1000, 1, -4x(i ) = x(i ) + tempx(i-1) = x(i-1) + tempx(i-2) = x(i-2) + tempx(i-3) = x(i-3) + temp
enddo
42/ 98

I Pseudo-assembler code (loop unrolling, depth=4):#cycle
Loop : load x(i) -> F0 1 1 stallF4 = F0 + F2 3 2 stallsstore F4 -> x(i) 6load x(i-1) -> F6 7 1 stallF8 = F6 + F2 9 2 stallsstore F8 -> x(i-1) 12load x(i-2) -> F10 13 1 stallF12= F10+ F2 15 2 stallsstore F12-> x(i-2) 18load x(i-3) -> F14 19 1 stallF16= F14+ F2 21 2 stallsstore F16-> x(i-3) 24R1 = R1 - #32 25BNEZ R1, Loop 26stall 27
I 27 cycles per iterationI Cost of calculation 1000
4 × 27 = 6750 cyclesI Effective performance : 1000
6750 = 15% of peak
43/ 98
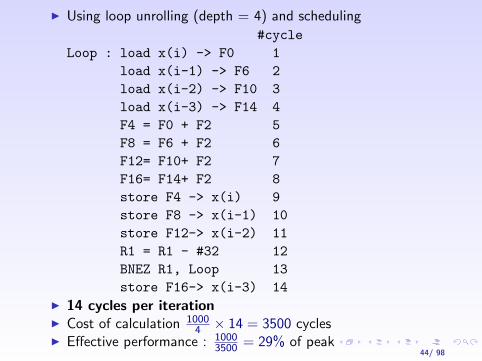
I Using loop unrolling (depth = 4) and scheduling
#cycleLoop : load x(i) -> F0 1
load x(i-1) -> F6 2load x(i-2) -> F10 3load x(i-3) -> F14 4F4 = F0 + F2 5F8 = F6 + F2 6F12= F10+ F2 7F16= F14+ F2 8store F4 -> x(i) 9store F8 -> x(i-1) 10store F12-> x(i-2) 11R1 = R1 - #32 12BNEZ R1, Loop 13store F16-> x(i-3) 14
I 14 cycles per iterationI Cost of calculation 1000
4 × 14 = 3500 cyclesI Effective performance : 1000
3500 = 29% of peak44/ 98

I Now assume superscalar pipeline : integer and floating pointoperations can be issued simultaneously
I Using loop unrolling with depth = 5Integer inst. | Float.inst.|#cycle
___________________________________________Loop: load x(i) -> F0 | | 1
load x(i-1)-> F6 | | 2load x(i-2)-> F10| F4 =F0 +F2 | 3load x(i-3)-> F14| F8 =F6 +F2 | 4load x(i-4)-> F18| F12=F10+F2 | 5store F4 ->x(i) | F16=F14+F2 | 6store F8 ->x(i-1)| F20=F18+F2 | 7store F12->x(i-2)| | 8store F16->x(i-3)| | 9R1 = R1 - #40 | | 10BNEZ R1, Loop | | 11store F20->x(i-4)| | 12
I 12 cycles per iterationI Cost of calculation 1000
5 × 12 = 2400 cyclesI Effective performance : 1000
2400 = 42% of peakI Performance limited by balance between int. and float. instr.
45/ 98

Survol des processeurs RISC
I Processeur RISC pipeline: exemple pipeline d’execution a 4etages
decode execute write result
stage #1 stage #2
fetch
stage #3 stage #4
46/ 98

Survol des processeurs RISC
I Processeur RISC superscalaire :I plusieurs pipelinesI plusieurs instructions chargees + decodees + executees
simultanement
decode execute write result
stage #1 stage #2
fetch
stage #3 stage #4
write result
write result
write result
execute
execute
execute
decode
decode
decode
fetch
fetch
fetch
pipeline #1
pipeline #3
pipeline #4
pipeline #2
I souvent operation entiere / operations flottante / loadmemoire
I probleme : dependancesI largement utilises : DEC, HP, IBM, Intel, SGI, Sparc, . . .
46/ 98

Survol des processeurs RISC
I Processeur RISC superpipeline :I plus d’une instruction initialisee par temps de cycleI pipeline plus rapide que l’horloge systemeI exemple : sur MIPS R4000 horloge interne du pipeline est 2
(ou 4) fois plus rapide que horloge systeme externe
I Superscalaire + superpipeline : non existant
46/ 98
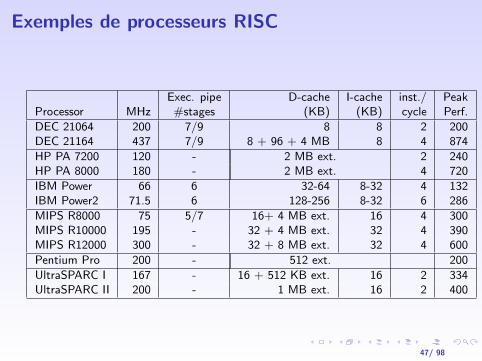
Exemples de processeurs RISC
Exec. pipe D-cache I-cache inst./ PeakProcessor MHz #stages (KB) (KB) cycle Perf.
DEC 21064 200 7/9 8 8 2 200DEC 21164 437 7/9 8 + 96 + 4 MB 8 4 874
HP PA 7200 120 - 2 MB ext. 2 240HP PA 8000 180 - 2 MB ext. 4 720
IBM Power 66 6 32-64 8-32 4 132IBM Power2 71.5 6 128-256 8-32 6 286
MIPS R8000 75 5/7 16+ 4 MB ext. 16 4 300MIPS R10000 195 - 32 + 4 MB ext. 32 4 390MIPS R12000 300 - 32 + 8 MB ext. 32 4 600
Pentium Pro 200 - 512 ext. 200
UltraSPARC I 167 - 16 + 512 KB ext. 16 2 334UltraSPARC II 200 - 1 MB ext. 16 2 400
47/ 98

Plan
Calculateurs haute-performance: concepts generauxIntroductionOrganisation des processeursOrganisation memoireOrganisation interne et performance des processeurs vectorielsOrganisation des processeurs RISCMemoire cacheMemoire virtuelleInterconnexion des processeursLes supercalculateurs du top 500 en Juin 2005Conclusion
48/ 98

Memoire cache
I CacheI Buffer rapide entre les registres et la memoire principaleI Divise en lignes de cache
I Ligne de cacheI Unite de transfert entre cache et memoire principale
I Defaut de cacheI Reference a une donnee pas dans le cacheI Une ligne de cache contenant la donnee est chargee de la
memoire principale dans le cache
I Probleme de la coherence de cache sur les multiprocesseurs amemoire partagee
I Rangement des donnees dans les cachesI correspondance memoire ↔ emplacements dans le cache
49/ 98

I Strategies les plus courantes :I “direct mapping”I “fully associative”I “set associative”
I Conception des caches :I L octets par ligne de cacheI K lignes par ensembleI N ensembles
I Correspondance simple entre l’adresse en memoire et unensemble :
I N = 1 : cache “fully associative”I K = 1 : cache “direct mapped”
50/ 98
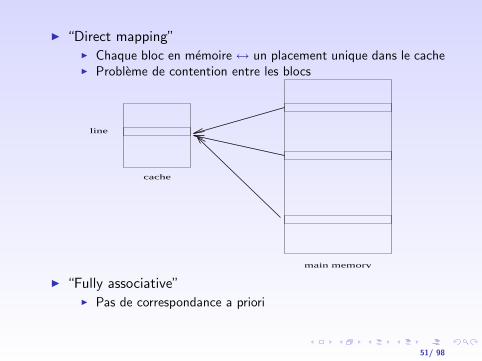
I “Direct mapping”I Chaque bloc en memoire ↔ un placement unique dans le cacheI Probleme de contention entre les blocs
line
cache
main memory
I “Fully associative”I Pas de correspondance a priori
51/ 98
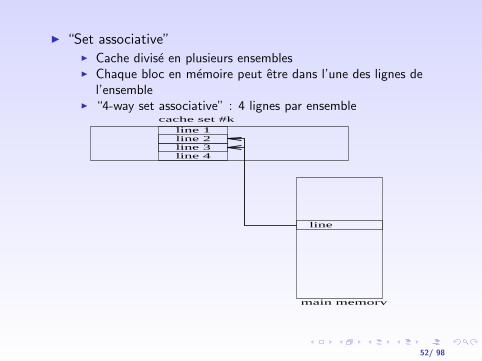
I “Set associative”I Cache divise en plusieurs ensemblesI Chaque bloc en memoire peut etre dans l’une des lignes de
l’ensembleI “4-way set associative” : 4 lignes par ensemble
line
main memory
line 1line 2line 3
cache set #k
line 4
52/ 98

Gestion des caches
I Cout d’un defaut de cache :I IBM RS/6000 : 8-11 CI SUN SPARC 10 : 25 C
I “Copyback”I Pas de m-a-j lorsqu’une ligne de cache est modifiee, excepte
lors d’un cache flush ou d’un defaut de cache
Memoire pas toujours a jourPas de probleme de coherence si les processeurs modifient des
lignes de cache independantes
I “Writethrough”I Donnee ecrite en memoire chaque fois qu’elle est modifiee
Donnees toujours a jourPas de probleme de coherence si les processeurs modifient des
donnees independantes
53/ 98

Cache coherency problem
cache cache
Y
Processor # 2Processor # 1
X
cache line
I Cache coherency to:I Avoid processors accessing old copies of data (copyback and
writethrough)I Update memory using copyback
54/ 98
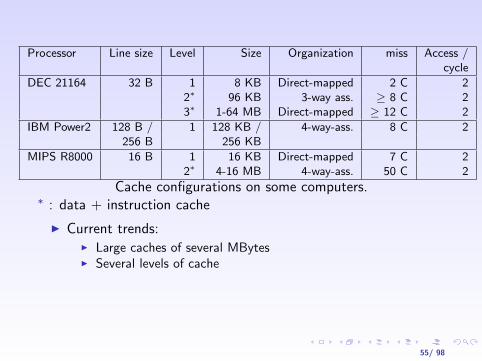
Processor Line size Level Size Organization miss Access /cycle
DEC 21164 32 B 1 8 KB Direct-mapped 2 C 22∗ 96 KB 3-way ass. ≥ 8 C 23∗ 1-64 MB Direct-mapped ≥ 12 C 2
IBM Power2 128 B / 1 128 KB / 4-way-ass. 8 C 2256 B 256 KB
MIPS R8000 16 B 1 16 KB Direct-mapped 7 C 22∗ 4-16 MB 4-way-ass. 50 C 2
Cache configurations on some computers.∗ : data + instruction cache
I Current trends:I Large caches of several MBytesI Several levels of cache
55/ 98

Plan
Calculateurs haute-performance: concepts generauxIntroductionOrganisation des processeursOrganisation memoireOrganisation interne et performance des processeurs vectorielsOrganisation des processeurs RISCMemoire cacheMemoire virtuelleInterconnexion des processeursLes supercalculateurs du top 500 en Juin 2005Conclusion
56/ 98

Memoire virtuelle
I Memoire reelle : code et donnees doivent etre loges enmemoire centrale (CRAY)
I Memoire virtuelle : mecanisme de pagination entre lamemoire et les disques
Une pagination memoire excessive peut avoir desconsequences dramatiques sur la performance !!!!
I TLB :I Translation Lookaside Buffer : correspondance entre l’adresse
virtuelle et l’adresse reelle d’une page en memoireI TLB sur IBM RS/6000 : 128 entreesI Defaut de TLB : 36 C environ
57/ 98

Plan
Calculateurs haute-performance: concepts generauxIntroductionOrganisation des processeursOrganisation memoireOrganisation interne et performance des processeurs vectorielsOrganisation des processeurs RISCMemoire cacheMemoire virtuelleInterconnexion des processeursLes supercalculateurs du top 500 en Juin 2005Conclusion
58/ 98

Interconnexion des processeurs
I Reseaux constitues d’un certain nombre de boıtes deconnexion et de liens
I Commutation de circuits : chemin cree physiquement pourtoute la duree d’un transfert (ideal pour un gros transfert)
I Commutation de paquets : des paquets formes de donnees +controle trouvent eux-meme leur chemin
I Commutation integree : autorise les deux commutationsprecedentes
I Deux familles de reseaux distincts par leur conception et leurusage :
I Reseaux mono-etageI Reseaux multi-etage
59/ 98

Reseau Crossbar
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
o
0
1
2
3
1 2 3o
Toute entree peut etre connectee a toute sortie sans blocage.Theoriquement, le plus rapide des reseaux mais concevableseulement pour un faible nombre d’Entrees/Sortie.Utilise sur calculateurs a memoire partagee : Alliant, Cray, Convex,. . .
60/ 98
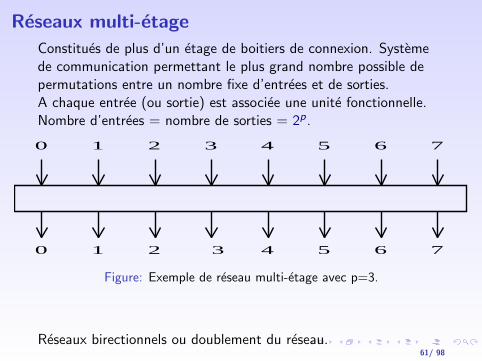
Reseaux multi-etage
Constitues de plus d’un etage de boitiers de connexion. Systemede communication permettant le plus grand nombre possible depermutations entre un nombre fixe d’entrees et de sorties.A chaque entree (ou sortie) est associee une unite fonctionnelle.Nombre d’entrees = nombre de sorties = 2p.
0 1 2 3 4 5 6
0 1 2 3 4 5 6 7
7
Figure: Exemple de reseau multi-etage avec p=3.
Reseaux birectionnels ou doublement du reseau.61/ 98

Boıte de connexion elementaireElement de base dans la construction d’un reseau : connexionentre deux entrees et deux sorties
I Boıte a deux fonctions (B2F) permettant les connexionsdirecte et croisee controlee par un bit
I Boıte a quatre fonctions (B4F) permettant les connexionsdirecte, croisee,a distribution basse et haute controlee pardeux bits.
62/ 98

I Topologie : mode d’assemblage des boıtes de connexion pourformer un reseau de N = 2p entrees / N sorties. La plupartdes reseaux sont composes de p etages de N
2 boıtes.
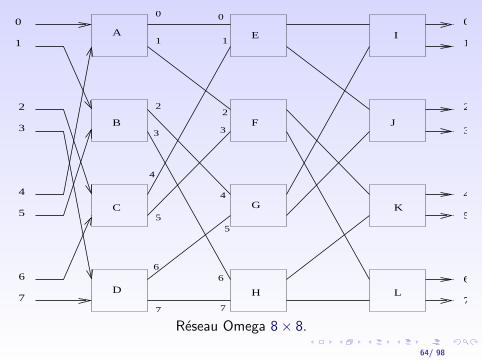
I Exemple : Reseau OmegaTopologie basee sur le “Perfect Shuffle”, permutation sur desvecteurs de 2p elements.
0 1 2 4 5 6
3 4 6
3 7
75210Le reseau Omega reproduit a chaque etage un “PerfectShuffle”. Autorise la distribution d’une entree sur toutes lessorties (“broadcast”).
I Reseau “Butterfly” sur les machines BBN, Meiko CS2, . . .
63/ 98
0
1
2
4
0
3
5
6
1
2
3
4
5
6
77
0
1
2
3
4
5
6
7
0
1
2
4
5
6
7
3
A
B
C
D
E
F
G
H
I
J
K
L
Reseau Omega 8× 8.
64/ 98
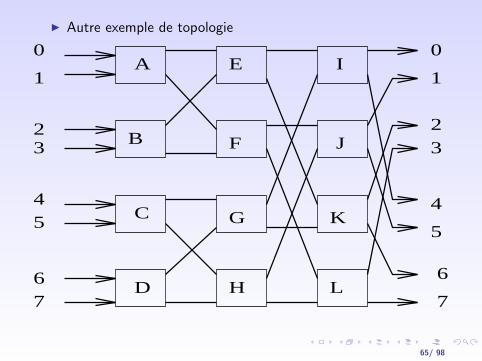
I Autre exemple de topologie
0
1
2
4
6
3
5
7
6
4
3
0
1
2
5
7
A
B
C
D
E
F
G
H
I
J
K
L
65/ 98
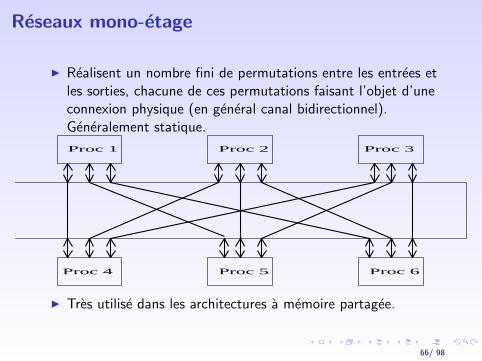
Reseaux mono-etage
I Realisent un nombre fini de permutations entre les entrees etles sorties, chacune de ces permutations faisant l’objet d’uneconnexion physique (en general canal bidirectionnel).Generalement statique.
Proc 1 Proc 2 Proc 3
Proc 4 Proc 5 Proc 6
I Tres utilise dans les architectures a memoire partagee.
66/ 98

I Exemples :I Bus partage
Proc#0
Proc#n
Cache LocalMemory
MemoryLocalCache
MainMemory
BUS
Largement utilise sur SMP (SGI, SUN, DEC, . . . )67/ 98

I Anneau
Proc 1 Proc 2 Proc nProc 0
I GrilleProc Proc Proc Proc
ProcProcProc
Proc Proc Proc Proc
ProcProcProcProc
Proc
Utilise sur Intel DELTA et PARAGON, . . .68/ 98

I Shuffle Exchange : Perfect Shuffle avec en plus Proc # iconnecte a Proc # (i+1)
1 2 3 4 5 6 70
I N-cube ou hypercube : Proc #i connecte au Proc # j si i et jdifferent d’un seul bit.
0 1 2 3 4 5 6 7
I Grand classique utilise sur hypercubes Intel (iPSC/1, iPSC/2,iPSC/860), machines NCUBE, CM2, . . .
69/ 98
Figure: 4-Cube in space.
70/ 98

Topologies usuelles pour les architectures distribuees
I Notations :I # procs = N = 2p
I diametre = d (chemin critique entre 2 procs)I # liens = w
I Anneau : d = N2 ,w = N
I Grille 2D : d = 2× (N12 − 1),w = 2× N
12 × (N
12 − 1)
I Tore 2D (grille avec rebouclage sur les bords) :
d = N12 ,W = 2× N
Proc Proc Proc Proc
ProcProcProc
Proc Proc Proc Proc
ProcProcProcProc
Proc
I Hypercube ou p-Cube : d = p,w = N×p2
71/ 98

Remarques
I Tendance actuelle:I Reseaux hierarchiques/multi-etagesI Beaucoup de redondances (bande passante, connections
simultanees)
I Consequence sur les calculateurs haute performance:I Peu de difference de cout selon sources/destinationsI La conception des algorithmes paralleles ne prend plus en
compte la topologie des reseaux (anneaux, . . . )
72/ 98

Plan
Calculateurs haute-performance: concepts generauxIntroductionOrganisation des processeursOrganisation memoireOrganisation interne et performance des processeurs vectorielsOrganisation des processeurs RISCMemoire cacheMemoire virtuelleInterconnexion des processeursLes supercalculateurs du top 500 en Juin 2005Conclusion
73/ 98

Statistiques Top 500 (voir www.top500.org)
I Liste des 500 machines les plus puissantes au monde
I Mesure: GFlops/s pour pour la resolution de
Ax = b
ou A est une matrice dense.
I Mis a jour 2 fois par an.I Sur les 10 dernieres annees la performance a augmente plus
vite que la loi de Moore:I 1993:
I #1 = 59.7 GFlop/sI #500 = 422 MFlop/s
I 2005:I #1 = 136 TFlop/sI #500 = 1 TFlop/s
74/ 98

Quelques remarques generales
I Arrivee massive d’architectures de type IBM Blue Gene dansle top 10.
I NEC ”Earth simulator supercomputer” (40Tflops, 5120processeurs vectoriels) est reste en tete de Juin 2002 a Juin2005.
I Il faut 15 Tflops/s pour entrer dans le Top 10.
I Le 500 ieme (1.17 Tflops) aurait ete 299 eme il y a 6 mois.
I Somme accumulee: 1.69 PFlop/s (contre 1.127 il y a 6 mois).
75/ 98

Remarques generales (suites)
I Domaine d’activiteI Recherche 22%, Accademie 19%, Industrie 53%I Par contre 100% du TOP10 pour recherche et accademie.I France (10/500) dont 8 pour l’industrie.
I ProcesseursI 333 systemes bases sur de l’IntelI 52 sur de l’IBM Power 3 ou 4I 36 sur des HP PA-RISCI 25 sur des AMDI 9 sur des CRAYI 7 sur des NecI 18/500 bases sur des processeurs vectoriels.
I Architecture117 MPP (Cray SX1, IBM SP, NEC SX, SGI ALTIX, HitatchiSR) pour 383 Clusters
76/ 98

Analyse des sites - Definitions
I Rang: Position dans le top 500 en Juin 2004.
I Rpeak: Performance maximum de la machine en nombred’operations flottantes par secondes.
I Rmax: Performance maximum obtenue sur le test LINPACK.
I Nmax: Taille du probleme ayant servi a obtenir Rmax.
77/ 98

Constructeur Nombre Pourcent.∑
Rmax∑
Rpeak∑
Procs(TFlop/s) (TFlop/s)
IBM 259 51.8 977 1660 374638HP 131 26.2 224 373 80792NEC 8 1.6 54 62 7448SGI 24 4.8 125 148 3032Dell 21 4.2 69 107 17038Cray Inc. 16 3.2 72 89 16656Sun 5 1 9 13 3440Fujitsu 4 0.8 25 47 7488Self-made 6 1.2 23 40 5360All 500 100 1686 2632 580336Statistiques constructeurs Top 500, nombre de systemes installes.

Top 7 mondial
Rang-Configuration Implantation #proc. Rmax Rpeak Nmax
TFlops TFlops 103
1-IBM eServer BlueGene Solution DOE/NNSA/LLNL 65536 136 183 12782-IBM eServer BlueGene Solution IBM TJWatson Res. Ctr. 40960 91 114 9833-SGI Altix 1.5GHz NASA/Ames Res.Ctr./NAS 10160 51 60 12904-NEC Earth simulator Earth Simul. Center. 5120 36 41 10755-IBM cluster, PPC-2.2GHz-Myri. Barcelona Supercomp. Ctr. 4800 27 42 9776-IBM eServer BlueGene Solution ASTRON/Univ. Groningen 12288 27 34 5167-NOW Itanium2-1.4GHz-Quadrix Los Alamos Nat. Lab. 8192 19 22 975
Stockage du probleme de taille 106 = 8 Terabytes
79/ 98
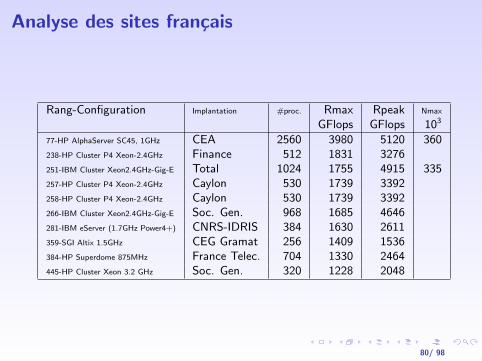
Analyse des sites francais
Rang-Configuration Implantation #proc. Rmax Rpeak Nmax
GFlops GFlops 103
77-HP AlphaServer SC45, 1GHz CEA 2560 3980 5120 360238-HP Cluster P4 Xeon-2.4GHz Finance 512 1831 3276251-IBM Cluster Xeon2.4GHz-Gig-E Total 1024 1755 4915 335257-HP Cluster P4 Xeon-2.4GHz Caylon 530 1739 3392258-HP Cluster P4 Xeon-2.4GHz Caylon 530 1739 3392266-IBM Cluster Xeon2.4GHz-Gig-E Soc. Gen. 968 1685 4646281-IBM eServer (1.7GHz Power4+) CNRS-IDRIS 384 1630 2611359-SGI Altix 1.5GHz CEG Gramat 256 1409 1536384-HP Superdome 875MHz France Telec. 704 1330 2464445-HP Cluster Xeon 3.2 GHz Soc. Gen. 320 1228 2048
80/ 98
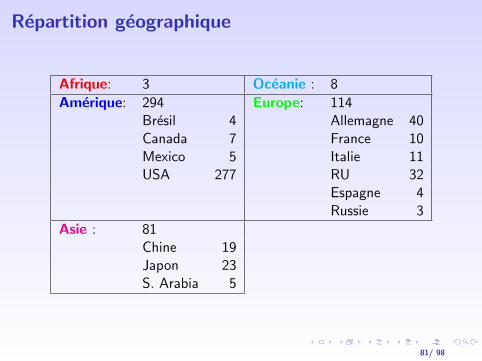
Repartition geographique
Afrique: 3 Oceanie : 8
Amerique: 294 Europe: 114Bresil 4 Allemagne 40Canada 7 France 10Mexico 5 Italie 11USA 277 RU 32
Espagne 4Russie 3
Asie : 81Chine 19Japon 23S. Arabia 5
81/ 98
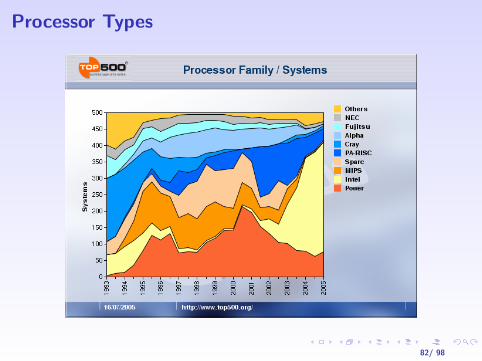
Processor Types
82/ 98

Exemples d’architecture de supercalculateurs
I Machines de type scalaireI MPP IBM SP (NERSC-LBNL, IDRIS (France))I Cluster HP (Los Alamos Nat. Lab.)I Non-Uniform Memory Access (NUMA) computer SGI Altix
(Nasa Ames)I Blue Gene L
I Machines de type vectorielI NEC (Earth Simulator Center, Japon)I Cray X1 (Oak Ridge Nat. Lab.)
83/ 98

MPP IBM SP NERSC-LBNL
Réseau
P1 P16 P1 P16
Noeud 1 Noeud 416
12Gbytes 12Gbytes
Remarque: Machine pécédente (en 2000)
Cray T3E (696 procs à 900MFlops et 256Mbytes)
416 Noeuds de 16 processeurs
375MHz processeur (1.5Gflops)Mémoire: 4.9 Terabytes
6656 processeurs (Rpeak=9.9Teraflops)
Supercalculateur du Lawrence Berkeley National Lab. (installe en2001)
84/ 98
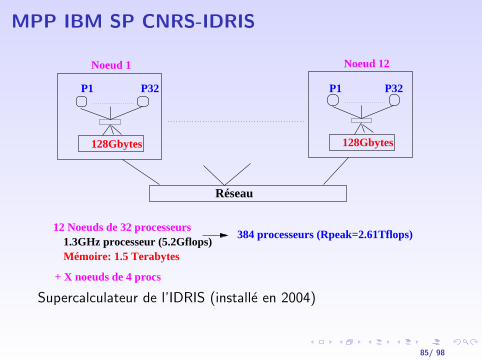
MPP IBM SP CNRS-IDRIS
Réseau
P1 P32
1.3GHz processeur (5.2Gflops)Mémoire: 1.5 Terabytes
384 processeurs (Rpeak=2.61Tflops)
128Gbytes 128Gbytes
P1 P32
Noeud 12Noeud 1
12 Noeuds de 32 processeurs
+ X noeuds de 4 procs
Supercalculateur de l’IDRIS (installe en 2004)
85/ 98

ASCI Q Cluster de Los Alamos (12eme mondial)
I Performance: 20Tflops, 22Terabytes, Rmax (13.8Tera)I Architecture (8192 procs):
I 2 Segments de 1024 noeuds (HP AlphaServer ES45s)I 4 processeurs HP Alpha21264 EV-68 par noeudI 2.6Gbytes/proc
86/ 98

Non Uniform Memory Access Computer SGI Altix
4.1Tbytes de memoire globalement adressable
Remarque: NUMA et latence
Réseau
P1 P2P1 P2Noeud 1 Noeud 2
C−Brick 128
Noeud (145nsec); C−Brick (290ns); Entre C−Bricks(+ 150 à 400ns);
P1 P2
C−Brick 1
P1 P2Noeud 1 Noeud 2
16Gb 16Gb 16Gb 16Gb
128 C−Bricks de 2 Noeuds de 2 procs
1.5GHz Itanium 2 (6Gflops/proc)Mémoire: 4.1 Terabytes
512 processeurs (Rpeak=3.1Teraflops)
Supercalculateur SGI Altix (installe a NASA-Ames en 2004)
87/ 98

NEC Earth Simulator Center (characteristiques)
I 640 NEC/SX6 nodes
I 5120 CPU (8 GFlops) −− > 40 TFlops
I 2 $ Billions, 7 MWatts.
88/ 98

NEC Earth Simulator Center (architecture)
unit
cacheRegisters
Scalar
unit
cacheRegisters
Scalar
Arithm. Proc 1 Arith. Proc. 8
UnitUnit
Noeud 640
unit
cacheRegisters
Scalar
unit
cacheRegisters
Scalar
Arithm. Proc 1 Arith. Proc. 8
UnitUnit
Noeud 1
Réseau (Crossbar complet)
640 Noeuds (8 Arith. Proc.) −> 40Tflops
(Rpeak −−> 16 flops // par AP)
Vector Vector Vector Vector
Mémoire partagée (16Gbytes) Mémoire partagée (16Gbytes)
Mémoire totale 10TBytes
Vector unit (500MHz): 8 ens. de pipes (8*2*.5= 8Glops)
Supercalculateur NEC (installe en 2002)
89/ 98

Cray X1 d’Oak Ridge National Lab.
I Performance: 6.4Tflops, 2Terabytes, Rmax(5.9TFlops)I Architecture 504 Muti Stream processeurs (MSP):
I 126 NoeudsI Chaque Noeud a 4 MSP et 16Gbytes de memoire “flat”.I Chaque MSP a 4 Single Stream Processors (SSP)I Chaque SSP a une unite vectorielle et une unite superscalaire,
total 3.2Gflops.
90/ 98
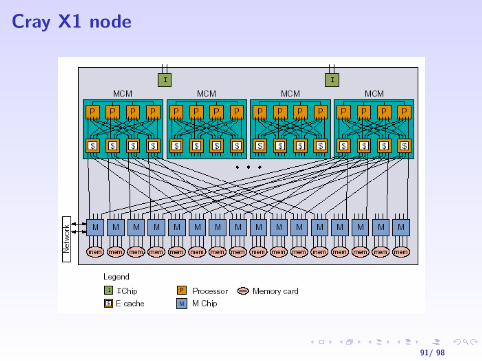
Cray X1 node
91/ 98

Blue Gene L (65536 procs, 183.5 TFlops peak)I Systeme
d’exploitationminimal (nonthreade)
I Consommationlimitee:
I Seulement 256MB de memoirepar noeud !!
I un noeud = 2PowerPC a 700MHz
I 2.8 GFlops ou 5.6GFlops crete parnoeud
I Plusieurs reseauxrapides avecredondances
92/ 98

Machines auxquelles on a acces depuis le LIP
I Calculateurs des centres nationauxI IDRIS: 1024 processeurs Power4 IBM, 3 noeuds NEC SX1I CINES: 9 noeuds de 32 Power4 IBM, SGI Origin 3800 (768
processeurs), . . .
I Calculateurs regionaux/locaux:I icluster2 a Grenoble: 100 bi-processeurs itaniumI Clusters de la federation lyonnaise de calcul haute performanceI Grid 5000 node in Lyon: 55 bi-processeurs opteron pour
l’instant
93/ 98

Programmes nationaux d’equipement
USA: Accelerated Strategic Computing
I http://www.nnsa.doe.gov/asc/home.htmI Debut du projet : 1995 DOE (Dept. Of Energy)I Objectifs : 100 Tera (flops and bytes) en 2004
France: le projet Grid 5000(en plus des centres de calcul CNRS (IDRIS et CINES))
I http://www.grid5000.orgI Debut du projet : 2004 (Ministere de la Recherche)I Objectifs : reseau de 5000 machines sur 8 sites repartis
(Bordeaux, Grenoble, Lille, Lyon, Nice, Rennes, Toulouse)
94/ 98

Accelerated Strategic Computing (Initiative)
I Debut du projet : 1995 (DOE)I Objectifs :
I 10 TFlops en 2000I 30 TFlops en 2001I 100 TFlops en 2004
I Principaux sites :I Blue-Mountain : SGI + Los Alamos NL
I Clusters SGI
I Blue-Pacific : IBM + Lawrence Livermore NLI Clusters IBM SP
I Red : Intel + Sandia NLI Clusters Intel
I White-Pacific : IBM + Lawrence Livermore NLI Clusters IBM SP
95/ 98

Previsions
I La machine Blue Gene/L du LLNL une fois complete aura uneperformance crete de 360 TFlops.
I BlueGeneL et ses successeurs: ≈ 3 PFlops en 2010
I Fujitsu prevoit de construire une machine au moins aussipuissante (3 PFlops) d’ici 2010.
96/ 98

Plan
Calculateurs haute-performance: concepts generauxIntroductionOrganisation des processeursOrganisation memoireOrganisation interne et performance des processeurs vectorielsOrganisation des processeurs RISCMemoire cacheMemoire virtuelleInterconnexion des processeursLes supercalculateurs du top 500 en Juin 2005Conclusion
97/ 98

Conclusion
I Performance :I Horloge rapideI Parallelisme interne au processeur
I Traitement pipelineI Recouvrement, chaınage des unites fonctionnelles
I Parallelisme entre processeurs
I Mais :I Acces aux donnees :
I Organisation memoireI Communications entre processeurs
I Complexite du hardwareI Techniques de compilation : pipeline / vectorisation /
parallelisation
Programmation efficace ?
98/ 98


















