
theses.univ-oran1.dz · t Départemen d'Informatique THÈSE p our tion l'obten du Diplôme De Do...
141
Transcript of theses.univ-oran1.dz · t Départemen d'Informatique THÈSE p our tion l'obten du Diplôme De Do...

Département d'InformatiqueTHÈSEpour l'obtention duDipl�me De Do torat En S ien es(INFORMATIQUE)
Pla ement Dynamique D'Appli ations EmbarquéesIntensives sur des Réseaux de Pro esseurs sur Pu eparMOHAMMED KAMEL BENHAOUAsoutenue publiquement le � �- 2014JuryB. BELDJILALI Pr. à l'Université d'Oran Président du JuryA. E. H. BENYAMINA MCA à l'Université d'Oran Dire teur de ThèseP. BOULET Pr. à l'Université de Lille1 Co-Dire teur de ThèseM. BENMOHAMED Pr. à l'Université de Constantine ExaminateurM. BENYETTOU Pr. à l'Université USTO ExaminateurM. SENOUCI Pr. à l'Université d'Oran Examinateur

RésuméAujourd'hui les utilisateurs demandent d'avoir des systèmes embarqués perfor-mants, apables d'o�rir de grande puissan e de al ul pour un large spe tre d'ap-pli ations, tout en respe tant les ontraintes du monde de l'embarqué. L'évolutiondes systèmes embarqués pose un problème au niveau des on eptions ar ils doiventtrouver un ompromis entre leurs apa ités (puissan es de al ul, re on�gurabi-lité) et les di�érentes ontraintes (surfa e de sili ium, onsommation). La solutionà envisager pour le problème de puissan e de al ul, est don de passer à des sys-tèmes multipro esseurs (MPSoCs). Les systèmes multipro esseurs sur pu e (MP-SoC) onstituent une solution in ontournable pour les exigen es de performan e desappli ations omplexes embarquées futures. En outre, les réseaux sur pu e ont vu lejour pour faire fa e aux limites des supports de ommuni ations telles que les bus,bus hiérar hiques, point à point. L'infrastru ture d'inter onnexion fondée sur les ré-seaux sur pu e (NoC) est en passe de devenir une appro he privilégiée pour fa iliterla ommuni ation entre les éléments de traitements (PEs) des MPSoCs. Il est pluse� a e d'intégrer plusieurs petits pro esseurs spé ialisés, ou non, inter onne tés parun réseau sur pu e (NoC) dont la puissan e de al ul et l'e� a ité énergétique sontmeilleurs plut�t que d'améliorer les performan es d'un seul pro esseur. L'hétéro-généité des MPSoCs est également en augmentation en employant di�érents typesd'éléments de traitements, a�n de répondre aux exigen es fon tionnelles et non fon -tionnelles. Le �ot de on eption de e type de système est omplexe et est ara térisépar la o-modélisation. Une des étapes importante de e �ot de on eption est l'as-so iation logi iel/matériel lors de l'exploration ar hite turale. Durant ette phased'asso iation il ne su�t pas d'a�e ter les tâ hes ( odes et données) aux ressour esphysique du MPSoC (pro esseurs, liens de ommuni ation, mémoire, et .) mais de her her une a�e tation qui doit satisfaire ertaines exigen es (obje tifs à optimi-ser, ontraintes à satisfaire). Ce problème d'a�e tation est dit pla ement de tâ he(Mapping). Les dé isions de pla ements peuvent onsidérablement in�uen er les per-forman es du système. Selon le moment où il est dé�ni, le pla ement des tâ hes peut1

être lassé omme statique (o�-line), ou dynamique (on-line). Dans le premier as,le pla ement des tâ hes est dé�ni au moment de la on eption, ses te hniques nesont pas appropriées pour les harges de travail de s énario dynamique en raison deleur omplexité et du temps d'exé ution onséquent. Pour faire fa e aux limites deste hniques de pla ement statique, le vrai hallenge est de passer aux te hniques depla ement dynamique durant l'exé ution. Le but de notre travail est d'étudier leste hniques de pla ement dynamique qui existent et d'essayer de proposer d'autresméthodes permettant d'optimiser les oûts ( onsommation d'énergie, temps d'exé- ution, laten e, et .) et de répondre aux ontraintes du monde de l'embarqué, touten prenant en onsidération l'optimisation des ommuni ations. Dans ette thèse,quatre te hniques e� a es ont été proposées pour réaliser des algorithmes de pla e-ment dynamique pour les plateformes MPSoC hétérogènes basée NoC. A�n d'évaluerles performan es de es te hniques, et vu le manque de simulateurs libres et à hautniveau d'abstra tion qui pourraient nous aider à tester et à valider nos propositionsalgorithmiques, la né essité de développer un simulateur à haut niveau d'abstra -tion s'avère impérative dans notre travail. En premier, nous proposons une nouvelleplateforme de tests et de simulations qui permet de simuler n'importe quelles pla-teformes MPSoCs hétérogènes, homogènes et à n'importe quelles dimensions dontles pro esseurs sont inter onne tées via un réseau sur pu e. Le simulateur permetaussi d'exé uter, de omparer les di�érents algorithmes de pla ement existants ave eux qui seront proposés dans ette thèse et de simuler le tra� sur des réseaux surpu e en vue d'étudier leurs performan es. Il permet aussi de supporter des plate-formes mono-tâ he 'est à dire que haque unité de traitement ne permet l'exé utionque d'une seule tâ he. Dans un deuxième travail une nouvelle stratégie de pa kingen spirale a été proposée pour le pla ement des di�érentes tâ hes d'une même ap-pli ation sur le NoC ible. Dans e pla ement on essaye de pla er les tâ hes qui ommunique le plus sur deux pro esseurs voisins est libres a�n de réduire les oûtsdes ommuni ations. En plus, une te hnique de pla ement des ommuni ations endynamique basée sur l'algorithme du plus ourt hemin de Dijkstra modi�é, a étéproposée et implémentée. Les évaluations par simulation de nos deux premières pro-2

positions ont montré de bons résultats par rapport aux te hniques existantes. Dansun troisième travail, proposé i i, nous ne ontentons pas seulement d'optimiser lepla ement des tâ hes, mais de her her parmi les te hniques permettant de le réa-liser elle né essitant le plus petit temps de re her he. Autrement dit, au ontrairedu pla ement statique, le solveur du pla ement dynamique, a son ode embarquéave elui de l'appli ation à exé uter. Sans oublier que le temps de re her he de lasolution optimale (par le pla ement dynamique) doit être ajouté au temps totaled'exé ution de l'appli ation. Ce qui nous amène à trouver la te hnique de pla ementdynamique permettant de trouver une ou plusieurs solutions optimales de bonnequalité et en un temps très ourt. Pour répondre à et obje tif nous proposons lastratégie de pa king basée sur la distan e de Manhattan pour le pla ement des tâ hesd'appli ation sur des pro esseurs voisins ayant un temps de re her he minimum parrapport aux te hniques existantes. Vu que la plupart des te hniques proposées pourle pla ement des ommuni ations dans la littérature dans e type de système sontstatiques, une autre te hnique de pla ement dynamique des ommuni ations multi-obje tifs (MORA) qui vise à minimiser le temps d'exé ution et la onsommationd'énergie a été proposée. Les résultats obtenus par simulation sur di�érents typesd'appli ations : appli ations générées par l'outil TGFF, appli ations : Multi-WindowDisplay (MWD), Video Obje t Plane De oder (VOPD), Pe ture-In Pi ture (PIP)et multiples appli ations MPEG4 ont montrés que nos propositions sont béné�questout en o�rant des gains onsidérables.
3

Remer iementCe do ument re�ète l'aboutissement de plusieurs années de travaux de thèse en-tamés entre les universités d'ORAN et Lille1. Ce résultat n'est qu'une étape dans lepro essus de re her he qu'on a réellement lan é depuis plusieurs années ave P. Bou-let et A. E. H. Benyamina dans l'équipe DART de l'université de Lille1 et LAPECIde l'université d'Oran. Mon plus grand espoir est que les propositions présentées i ipourront être utiles en servant de base à nos futurs travaux et à d'autres propositionss ienti�ques plus avan ées.Je tiens à remer ier vivement mon Co-en adreur le professeur Pierre Boulet dem'avoir fait on�an e et de m'avoir en adré dans e thème. Sa générosité s ienti�queet sa disponibilité m'ont permis d'avan er dans mes travaux et de surmonter ave lui toutes les di� ultés.Mes remer iements vont aussi, ave la même intensité, à mon En adreur MrBenyamina Abbou El Hassen qui n'a jamais essé de roire en moi. Sa on�an etémoignée et es ritiques obje tives. Il s'est montré toujours disponible pour m'ap-porter onseils et motivation. Plus qu'un en adrant, un grand frère qui m'a dirigédans mes travaux en dé�nissant mes priorités ainsi que mes obje tifs. Grâ e à sesen ouragements, ses onseils judi ieux et son aide pour rédiger e manus rit quenotre but est atteint.Je tiens à remer ier vivement le Dr. A. Kumar et Dr. A. Singh d'avoir a eptéla ollaboration ave notre laboratoire LAPECI. Je tiens à remer ier en parti ulierDr. A. Singh pour le temps qui m'a réservé durant plus d'une année. Ces débatsont été fru tueux pour moi, e qui m'a permet de bien e positionnée sur et axe dere her he.Mer i au Professeur B. Beldjilali qui nous a fait l'honneur d'a epter de présiderle jury de soutenan e. Mer i aux professeurs M. Benmohamed et M. Senou i et M.Benyetou d'avoir a epté d'examiner e travail.En�n je tiens à exprimer ma profonde gratitude à l'équipe DART de LIFL, qui4

ave P.Boulet m'ont a ueilli au sein de leur équipe en mettant à ma dispositiontous les moyens de l'équipe. En�n, à toutes elles et tous eux qui ont ontribué deprés ou de loin à l'a omplissement de e travail.
5

Table des matières1 Introdu tion 121.1 Révolution des Multipro esseurs sur pu e (MPSoCs) . . . . . . . . . 121.2 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 141.3 But de la thèse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 161.4 Prin ipales ontributions de la thèse . . . . . . . . . . . . . . . . . . . 161.5 Organisation de la thèse . . . . . . . . . . . . . . . . . . . . . . . . . 181.6 Liste des publi ations résultant . . . . . . . . . . . . . . . . . . . . . 192 État de l'Art 202.1 Tendan es des Multipro esseurs sur pu e (MPSoCs) . . . . . . . . . . 222.1.1 Nombre de ÷urs de traitement . . . . . . . . . . . . . . . . . 222.1.2 Réseau sur pu e (NoC) pour la s alabilité . . . . . . . . . . . 232.1.3 Hétérogénéité dans les ÷urs de traitement . . . . . . . . . . . 232.2 Ar hite tures Multipro esseurs sur pu e . . . . . . . . . . . . . . . . 242.2.1 Ar hite tures homogènes . . . . . . . . . . . . . . . . . . . . . 262.2.2 Ar hite tures hétérogènes . . . . . . . . . . . . . . . . . . . . 272.2.3 Inter onnexions pour les ar hite tures sur Pu e . . . . . . . . 292.2.4 Con eption de plateformes Systèmes MultiPro esseurs sur Pu e 302.3 Pla ement d'appli ations sur Multipro esseurs sur pu e . . . . . . . . 342.3.1 Pla ement Statique (Design-time Mapping) . . . . . . . . . . 362.3.2 Pla ement Dynamique (Run-time Mapping) . . . . . . . . . . 382.4 Analyse des heuristiques de pla ement et Con lusion . . . . . . . . . 473 Simulateur 503.1 Introdu tion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 503.2 Outils utilisés . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 513.2.1 Langage de développement . . . . . . . . . . . . . . . . . . . . 513.2.2 Environnement de développement . . . . . . . . . . . . . . . . 516

TABLE DES MATIÈRES TABLE DES MATIÈRES3.3 Quelques simulateurs et Motivation . . . . . . . . . . . . . . . . . . . 523.4 Con eption détaillée . . . . . . . . . . . . . . . . . . . . . . . . . . . 553.4.1 Identi� ation des a teurs et des as d'utilisations . . . . . . . 553.4.2 Pa kages de la plateforme . . . . . . . . . . . . . . . . . . . . 553.4.3 Création de l'ar hite ture . . . . . . . . . . . . . . . . . . . . 593.4.4 Création d'appli ations . . . . . . . . . . . . . . . . . . . . . . 613.4.5 Modèle de simulation . . . . . . . . . . . . . . . . . . . . . . . 643.4.6 Mesures de performan es . . . . . . . . . . . . . . . . . . . . . 703.5 Con lusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 704 Heuristiques pour le routage et le pla ement dynamique de tâ hesen spirale sur un MPSoC basée NoC 714.1 Introdu tion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 714.2 Classi� ation des pla ements statique et dynamique . . . . . . . . . . 734.2.1 Te hniques de pla ement statique . . . . . . . . . . . . . . . . 734.2.2 Te hniques de pla ement Dynamique . . . . . . . . . . . . . . 744.3 Ar hite ture MPSoC Hétérogène . . . . . . . . . . . . . . . . . . . . 764.4 Appro hes proposées . . . . . . . . . . . . . . . . . . . . . . . . . . . 774.4.1 Dé�nitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . 784.4.2 Heuristiques de pla ement dynamique de référen e . . . . . . . 794.4.3 Heuristique proposée basée sur la stratégie de pa king en spi-rale et le routage dynamique . . . . . . . . . . . . . . . . . . . 824.5 Con�gurations expérimentales et Résultats . . . . . . . . . . . . . . . 834.5.1 Con�gurations expérimentales . . . . . . . . . . . . . . . . . . 844.5.2 Résultats expérimentaux . . . . . . . . . . . . . . . . . . . . . 854.6 on lusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 865 Heuristiques pour le pla ement dynamique de tâ hes et ommuni- ations sur un MPSoC basée NoC 875.1 Introdu tion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 885.2 État de l'Art . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 907

TABLE DES MATIÈRES TABLE DES MATIÈRES5.2.1 Te hniques de pla ement statique . . . . . . . . . . . . . . . . 905.2.2 Te hniques de pla ement dynamique . . . . . . . . . . . . . . 905.3 Modélisation du problème de pla ement et heuristiques de référen e . 945.3.1 Graphe de tâ hes d'appli ation . . . . . . . . . . . . . . . . . 945.3.2 Graphe d'ar hite ture MPSoC hétérogène basée NoC . . . . . 955.3.3 Pla ement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 965.4 Heuristiques de pla ement de référen e . . . . . . . . . . . . . . . . . 985.4.1 Pa king-based Nearest Neighbor (PNN) . . . . . . . . . . . . 995.4.2 Pa king-based Best Neighbor (PBN) . . . . . . . . . . . . . . 1015.5 Stratégies de pa king et de routage proposées . . . . . . . . . . . . . 1015.5.1 Manhattan Pa king Strategies . . . . . . . . . . . . . . . . . . 1025.5.2 Multi-Obje tive Routing Algorithm (MORA) . . . . . . . . . 1045.5.3 Cal ul du Temps d'exé ution globale et la onsommation d'éner-gie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1075.6 Validation par Simulation . . . . . . . . . . . . . . . . . . . . . . . . 1105.6.1 Con�guration de Simulations . . . . . . . . . . . . . . . . . . 1115.6.2 Résultats de Simulations . . . . . . . . . . . . . . . . . . . . . 1145.7 Con lusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1206 Con lusion générale et perspe tives 1226.1 Con lusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1226.2 Perspe tives . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124
8

Table des �gures1.1 Poursuite de la loi de Moore . . . . . . . . . . . . . . . . . . . . . . 132.1 ITRS Roadmap montre le nombre roissant de ÷urs de traitement [1℄ 222.2 La loi d'Amdahl indiquant que l'a élération obtenue en utilisant plu-sieurs pro esseurs est limitée par la partie séquentielle du programme[2℄ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 252.3 Flow de on eption MPSoC IMEC [3℄ . . . . . . . . . . . . . . . . . . 322.4 Pro essus de liaison de tâ he (Task binding pro ess) . . . . . . . . . . 432.5 Pla ement dynamique suivie par l'outil SMIT Mapper [4℄ . . . . . . . 443.1 Diagramme de as d'utilisation . . . . . . . . . . . . . . . . . . . . . 563.2 Diagramme de lasses du simulateur . . . . . . . . . . . . . . . . . . 583.3 Ar hite ture hétérogène d'un NoC . . . . . . . . . . . . . . . . . . . . 593.4 Diagramme de lasses du pa kage Ar hite ture . . . . . . . . . . . . . 603.5 Appli ations maitre/es lave . . . . . . . . . . . . . . . . . . . . . . . 623.6 Exemple d'une appli ation . . . . . . . . . . . . . . . . . . . . . . . . 623.7 Representation d'une appli ation en XML . . . . . . . . . . . . . . . 633.8 Diagramme de lasses du pa kage Appli ation . . . . . . . . . . . . . 643.9 Diagramme de séquen e illustrant l'intera tion entre maître/es lave . 653.10 Diagramme d'a tivité . . . . . . . . . . . . . . . . . . . . . . . . . . . 694.1 Ar hite ture on eptuelle MPSoC . . . . . . . . . . . . . . . . . . . . 784.2 Maître-Es lave et la modélisation de l'appli ation . . . . . . . . . . . 794.3 Pla ement des tâ hes initiale et la strategie de pa king en spirale. . . 844.4 Comparaison du temps d'exe ution de l'appro he proposée ave NNet BN respe tivement . . . . . . . . . . . . . . . . . . . . . . . . . . . 864.5 Comparaison de la onsommation d'énergie de l'appro he proposéeave NN et BN respe tivement . . . . . . . . . . . . . . . . . . . . . . 865.1 Modélisation du graphe de tâ hes d'appli ation et la pair Maître-Es lave 959

TABLE DES FIGURES TABLE DES FIGURES5.2 Ar hite ture MPSoC hétérogène . . . . . . . . . . . . . . . . . . . . . 965.3 Pla ement des tâ hes initiales pour le pla ement de 9 appli ationssimultanément. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 985.4 pla ement par les stratégies MPNN et PNN. . . . . . . . . . . . . . . 1045.5 XY et MORA. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1075.6 Flux d'exé ution de la simulation. . . . . . . . . . . . . . . . . . . . . 1105.7 Appli ations générer par l'outil TGFF (3-4 Niveau, 1-3 �ls). . . . . . 1125.8 Appli ations (a) MWD, (b) VOPD, ( ) PIP. . . . . . . . . . . . . . . 1125.9 Appli ation MPEG-4. . . . . . . . . . . . . . . . . . . . . . . . . . . . 1125.10 Comparaison du temps d'exé ution de PNN et PBN ave MPNN etMPBN respe tivement lors de l'utilisation du routage XY et MORApour trois s énarios. . . . . . . . . . . . . . . . . . . . . . . . . . . . 1135.11 Comparaison de la onsommation d'énergie de PNN et PBN ave MPNN et MPBN respe tivement lors de l'utilisation du routage XYet MORA pour trois s énarios. . . . . . . . . . . . . . . . . . . . . . . 1165.12 Temps d'exé ution de 10 appli ations pour quatre séries d'appli a-tions (s énario 4), où haque appli ation ontient 5, 10, 15 et 20 tâ hes.1195.13 Consommation d'énergie de 10 appli ations pour quatre séries d'ap-pli ations (s énario 4), où haque appli ation ontient 5, 10, 15 et 20tâ hes. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 120
10

Liste des tableaux3.1 Synthèse des simulateurs . . . . . . . . . . . . . . . . . . . . . . . . . 543.2 Liste des événements . . . . . . . . . . . . . . . . . . . . . . . . . . . 673.3 Exemple d'un déroulement de la simulation . . . . . . . . . . . . . . . 684.1 Etat de l'art lassé pour les te hniques de pla ement statique . . . . . 754.2 Etat de l'art lassé pour les te hniques de pla ement dynamique . . . 775.1 Rédu tion en (%) du temps d'exé ution et onsommation d'énergieave l'utilisation des stratégies de pla ement proposées utilisant XYet MORA omparées à PNN et PBN pour trois s énarios. . . . . . . . 1175.2 Dédu tion du temps d'exé ution et la onsommation d'énergie parMORA sur XY lors de l'utilisation des heuristiques PNN, PBN, MPNNet MPBN pour trois s énarios. . . . . . . . . . . . . . . . . . . . . . . 1185.3 Nombre de re her hes pour toutes les tâ hes dans di�érentes sériesd'appli ations pour le s énario 4 on utilisant des stratégies de Man-hattan et existantes. . . . . . . . . . . . . . . . . . . . . . . . . . . . 120
11

Chapitre 1Introdu tionSommaire1.1 Révolution des Multipro esseurs sur pu e (MPSoCs) . . . . . . . . . 121.2 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 141.3 But de la thèse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 161.4 Prin ipales ontributions de la thèse . . . . . . . . . . . . . . . . . . . 161.5 Organisation de la thèse . . . . . . . . . . . . . . . . . . . . . . . . . . 181.6 Liste des publi ations résultant . . . . . . . . . . . . . . . . . . . . . . 191.1 Révolution des Multipro esseurs sur pu e (MPSoCs)L'évolution extraordinaire des systèmes éle troniques modernes nous a permisd'entrer dans l'ère des Systèmes Multipro esseurs sur pu e (MPSoC). Permettantle traitement d'appli ations omplexes. En 1965, la loi de Moore prédisait que lenombre de transistors dans la même surfa e de la pu e allez roître de façon ex-ponentielle [5℄. Cette tendan e, illustrée à la �gure.1.1 à permis l'augmentation desperforman es des appareils éle troniques telles que la vitesse de traitement, la apa- ité de la mémoire, le nombre de pixels sur un é ran d'a� hage, et . Les premières onséquen es de ette tendan e sont d'ordre matériel et logi iel :� D'une part, les on epteurs du matériel sont en mesure a tuellement de fournirdes moyens de traitement plus e� a e et plus rapide,� d'autre part, les développeurs d'appli ations doivent maximiser l'utilisation dela puissan e de traitement par une a élération des �ots de on eption et deréalisation du logi iel.La haute densité d'intégration permettait la mise en ÷uvre de plusieurs pro es-seurs sur une seule pu e a entrainé le développement des MPSoC [6℄. Le pro esseur12

1.1 Révolution des Multipro esseurs sur pu e (MPSoCs) Chapitre 1 : Introdu tiond'Intel, d'abord publié en 1971, 4004, omptait environ 2.300 transistors. Ce pro es-seur fon tionne à la vitesse de 400 KHz. En revan he, un pro esseur à ÷ur uniquepar exemple, Intel Pentium 4 a plus d'un milliard de transistors, fon tionnant àplus de 3 GHz. Les onstru teurs ont été obligés de limiter la fréquen e maximaledu pro esseur et la transition vers la on eption de pu es de plusieurs pro esseurs,fon tionnant à des fréquen es plus basses. Dans la �gure.1.1, il est intéressant d'ob-server l'introdu tion du pro esseur Dual- ore, à partir de 2005 : C'est le début del'ère multi- ÷urs. En outre, la omplexité roissante des appli ations temps-réels,ne peut être traitée simplement en augmentant la fréquen e d'un pro esseur à ÷urunique. Au lieu de elà, il a besoin de plusieurs pro esseurs ohérents, pouvant om-muniquer et fournir un parallélisme a ru. Le on ept fondamental est de onsidérerl'appli ation onstituée de nombreuses petites tâ hes qui peuvent être distribuéese� a ement sur plusieurs pro esseurs a�n d'être exé utées en parallèle et ainsi derépondre à la demande roissante de performan es des appli ations omplexes.
Figure 1.1 � Poursuite de la loi de Moore13

1.2 Motivation Chapitre 1 : Introdu tion1.2 MotivationC'est un fait bien onnu, que la personnalisation d'un seul pro esseur pour l'ap-pli ation, peut améliorer les performan es. Toutefois, les exigen es de performan edes appli ations embarquées omplexes modernes ont onsidérablement augmentées, e qui rend in ontournable l'utilisation de plusieurs pro esseurs o�rant un parallé-lisme a ru. L'exigen e de ommuni ation d'un grand nombre de pro esseurs, peutêtre satisfaite par l'e� a ité des réseaux sur pu e (Networks-on-Chip (NoC)). Lespro esseurs eux-mêmes doivent être de types di�érents pour exé uter di�érentestâ hes de manière e� a e a�n d'atteindre une meilleure performan e en présen e deblo s matériels re on�gurables dans les MPSoCs hétérogènes. Ces blo s de matérielpeuvent être on�gurés au moment de l'exé ution en fon tion de la fon tionnaliténé essaire à al uler des tâ hes intensives en o�rant également une grande �exibilitéau même niveau que elui des pro esseurs à usage général. L'a élération fourniepar le matériel peut être utilisée pour satisfaire les exigen es de performan es im-posées. De même, il est possible de on�gurer d'autres types de pro esseurs a�n deles exploiter au maximum de leur apa ité. Ainsi, Les MPSoCs hétérogènes serontné essaires à mesure que la performan e demandée augmente. Les systèmes embar-qués modernes (par exemple, les téléphones intelligents, PDA, tablettes) emploientdes MPSoCs a�n de prendre en harge plusieurs appli ations en même temps :par exemple, un téléphone intelligent peut être utilisé pour a� her une image enutilisant une appli ation de dé odage JPEG sur Internet et en même temps pouré outer de la musique en utilisant une appli ation de dé odage MP3. Les omposants(tâ hes et leurs ommuni ations) d'appli ations doivent être pla és et ordonnan ése� a ement sur les ressour es du MPSoC, a�n de répondre à des ontraintes de per-forman e pour haque appli ation. Le problème de pla ement et d'ordonnan ementest similaire à un problème d'a�e tation quadratique onnue omme un problèmeNP-di� ile [7℄. Par onséquent, trouver une solution optimale répondant à toutes les ontraintes données est très di� ile et prend du temps. Ainsi, en explorant toutesles tâ hes pour des ombinaisons de ressour es, de manière exhaustive et ensuite hoisir la ombinaison optimale, peut prendre des jours ou des semaines pour un14

1.2 Motivation Chapitre 1 : Introdu tiongrand nombre de tâ hes et de pro esseurs. C'est pourquoi, les heuristiques baséessur la onnaissan e du domaine d'appli ation, doivent être prises en ompte pourtrouver une solution appro hée (presque optimale). Le pla ement d'appli ations surune plateforme MPSoC peut être a ompli soit au moment de la on eption soit lorsde l'exé ution : Les te hniques de pla ement au moment de la on eption (design-time) ne onviennent que pour les s énarios à harge de travail statique et sont don in apables de gérer le dynamisme dans les appli ations à harge de travail dyna-mique (run-time) (telles les appli ations réseau et multimédia). En e�et, souventles appli ations solli itées sont de type de télé hargement multimédia, appli ationsJava dans un téléphone mobile ou d'autres appli ations prisent en harge durantl'exé ution. Pour e type d'appli ations (dites dynamiques ar solli itées durantl'exé ution) le pla ement doit lui aussi se faire pendant l'exé ution, e qui expliquesa désignation par "pla ement dynamique". Les te hniques, pour e type de pla e-ment, doivent a�e ter de nouvelles appli ations sur les ressour es de la plateformeave une onnaissan e pré ise de leur o upation a�n de satisfaire leurs exigen es deperforman e. Le pla ement dynamique de nouvelles appli ations peut être onsidéré,selon les di�érents types de s énarios utilisés, ave ou sans résultats pré-analysés.Lorsque les appli ations qui doivent être prises en harge sur une plateforme nesont pas onnues au moment de la on eption, au une pré-analyse n'est né essaire.Cela exige des heuristiques e� a es à dé�nir pour pla er de nouvelles tâ hes surles ressour es de la plateforme et pour e�e tuer tous les traitements au momentde l'exé ution. Elles ne peuvent pas garantir les é héan es temporelles stri tes enraison de l'absen e de toute analyse préalable et la puissan e de al ul limitée aumoment de l'exé ution. Toutefois, es heuristiques sont indépendantes de la plate-forme ar n'utilisant pas les résultats d'analyse spé i�ques de la plateforme al ulésà l'avan e. Les appli ations qui doivent être prises en harge par la plateforme,devraient être onnues au moment de la on eption a�n de les pla er grâ e aux ré-sultats pré-analysés. Dans de tels as, des heuristiques légères sont né essaires pourséle tionner les pla ements les plus e� a es pour haque appli ation au moment dela on eption (o�ine) à partir des pla ements analysés et sto kés sur le système. La15

1.3 But de la thèse Chapitre 1 : Introdu tionséle tion devrait être imposée aux ressour es système disponibles et la performan esouhaitée. Les pla ements devraient ontenir les allo ations et ordonnan ements etêtre séle tionnés pour on�gurer la plateforme. L'analyse au moment de la on ep-tion doit e�e tuer tout le traitement de al ul intensif, e qui fa ilite au gestionnaire(Manager) de plateforme dynamique la on�guration des appli ations de manière ef-� a e. L'analyse au moment de la on eption pour explorer les pla ements, à savoirl'a�e tation exhaustive des tâ hes aux ressour es, n'est pas réalisable dans un tempslimité pour des appli ations et plateforme de grande taille, par onséquent, des stra-tégies d'analyse plus rapides que d'explorer tous les pla ements e� a es doivent êtredéveloppées en prenant en ompte les spé i� ations de la plateforme pour e�e tuerl'exploration, de sorte que les résultats d'analyse ne seront pas appli ables à toutesles plateformes.1.3 But de la thèseL'obje tif prin ipal de ette thèse est de développer des te hniques et des mé-thodes e� a es pour le pla ement dynamique d'appli ations embarquées sur desplateformes MPSoC hétérogènes basées NoC a�n de maximiser les performan es.Ce hoix a été fait dans le sou i de pla er des appli ations quel onques sur desplateformes les plus générales possibles et extensibles (s alables).1.4 Prin ipales ontributions de la thèseNous donnons un aperçu des prin ipales ontributions qui ont été faites au oursde ette thèse et qui peuvent être résumées omme suit :� Réalisation d'une plateforme de simulation qui permet de simuler n'importequelle plateforme multi- ÷ur inter onne tée par un réseau sur pu e homogèneou hétérogène. Elle permet aussi d'exé uter et de tester les propositions algo-rithmiques de pla ement dynamique d'appli ations sur des plateformes simu-lées.� Heuristique de pla ement dynamique en spirale pour le pla ement e� a e des16

1.4 Prin ipales ontributions de la thèse Chapitre 1 : Introdu tiontâ hes d'appli ations sur une plateforme MPSoC hétérogène basée NoC onte-nant des éléments de traitement (PE) qui ne supportent qu'une seule tâ he. Late hnique proposée pla e les tâ hes d'appli ations sur les éléments de traite-ment MPSoC de manière à e que toutes les tâ hes es laves par maître soientpla ées le plus pro he possible de la tâ he maître (les tâ hes es laves sont pla- ées autour de la tâ he maître), onduisant à un pla ement des tâ hes e� a es.� Une autre heuristique de pla ement des ommuni ations est proposée a�n deréduire les oûts des ommuni ations. Cette te hnique est basée sur l'algorithmeDijkstra modi�é a�n de trouver le hemin le plus ourt et le moins hargéa�n d'optimiser les oûts des ommuni ations. Ces te hniques montrent uneamélioration des performan es par rapport aux te hniques existantes.� Heuristique de pla ement dynamique pour le pla ement e� a e d'appli ationssur une plateforme MPSoC hétérogène basée NoC ontenant des éléments detraitement (PE) qui ne supportent qu'une seule tâ he. On onstate que leste hniques de pla ement existantes ne peuvent pas fournir de bons résultatsdans le as des appli ations plus larges (appli ations qui ontiennent un nombrede tâ hes important). La te hnique proposée pla e les tâ hes d'appli ations surles éléments de traitement MPSoC de manière très systématique. L'appro heproposée utilise une stratégie de pa king basée sur la distan e de Manhattan etmet le point sur le temps de pla ement (le temps de re her he d'une ressour elibre) qui peut in�uen er les performan es du système. Ce temps est minimiséd'une façon onsidérable pendant que les performan es sont optimisées.� La plupart des travaux existants traitant la même problématique, utilisent pourle pla ement des ommuni ations, le routage statique à savoir le XY, pour sasimpli ité d'implémentation. Nous avons proposé une heuristique de routagemulti-obje tifs (MORA) pour le pla ement dynamique des ommuni ations.Le but du MORA est d'a heminer les paquets é hangés par le lien le moins hargé sur les liaisons point à point et vers la destination de façon à réduireles oûts des ommuni ations. L'appro he MORA montre une amélioration desperforman es par rapport aux te hniques existantes à savoir le routage statique17

1.5 Organisation de la thèse Chapitre 1 : Introdu tionXY.1.5 Organisation de la thèseLe reste de la thèse est organisé omme suit :� Chapitre 2 : État de l'ArtCe hapitre présente une synthèse sur l'importan e des ar hite tures MPSoCbasée NoC dans les systèmes embarqués modernes. Les dé�s et méthodolo-gies pour on evoir les MPSoCs ainsi que les te hniques et les méthodologiesde pla ement d'appli ations sur les ar hite tures MPSoCs basée NoC serontprésentées. Par la suite, les stratégies de pla ement existantes sont analyséespour mettre en éviden e leurs limites et les stratégies les plus appropriées sontidenti�ées pour une éventuelle investigation.� Chapitre 3 : Simulateur de pla ement dynamique d'appli ations Em-barquéesDans e hapitre, Nous donnons une vue globale sur les simulateurs NoCs,puis un état de omparaison. Par la suite nous détaillons notre simulateur depla ement dynamique d'appli ations sur une ar hite ture MPSoC basée NoC : on eption, modélisation, fon tionnement, et . L'extension du simulateur a�nde supporter une simulation de plateforme multi-tâ hes sera onsidérée dansnotre futur publi ation.� Chapitre 4 : Heuristiques pour le routage et le pla ement de tâ hedynamique en spirale sur des MPSoCs hétérogènes basée NoCDans e hapitre des dé�nitions sur les modèles de al ul seront présentées.Le modèle utilisé Maître-es lave sera détaillé et l'ar hite ture MPSoC baséeNoC mono tâ he. Comme ontribution dans e hapitre notre premier papierpublié intitulé "Heuristi s for Routing and Spiral Run-time Task Mapping inNoC-based Heterogeneous MPSOCs" est détaillé. La ontribution est basée surun pla ement mono-tâ he en spirale et pla ement des ommuni ations basé surl'algorithme dijkstra modi�é.� Chapitre 5 : Heuristiques pour le pla ement dynamique de tâ he et18

1.6 Liste des publi ations résultant Chapitre 1 : Introdu tion ommuni ations sur des MPSoCs hétérogènes basée NoCCe hapitre sera onsa ré aux dé�nitions des modèles de al ul utilisés, l'ar hi-te ture MPSoC basée NoC mono-tâ he. Comme ontribution dans e hapitrenotre papier publié intitulé "Heuristi s For Dynami Task And Communi a-tions Mapping In NoC-Based Heterogeneous MPSoCs" sera détaillé. La ontri-bution est basée sur un pla ement mono-tâ he en utilisant une stratégie depa king Manhattan a�n de minimiser le temps de pla ement en plus de laprise en harge des ommuni ations par la proposition d'une heuristique depla ement dynamique des ommuni ations multi-obje tifs (MORA).1.6 Liste des publi ations résultantLe travail présenté dans ette thèse a été publié dans les revues internationalessuivantes :Revues Internationales[J-1℄ The Mediterranean Journal of Computers and Networks, Vol. 9, No 4, O to-ber 2013, ISSN : 1744-2397 �Heuristi s For Dynami Task And Communi a-tions Mapping In No -Based Heterogeneous Mpso s� M. K. Benhaoua, A.K. Singh, A. E. H. Benyamina, A. Kumar, P. Boulet.[J-2℄ IJCSI International Journal of Computer S ien e Issues, Vol. 10, Issue 4, No1, July 2013 ISSN (Print) : 1694-0814 | ISSN (Online) : 1694-0784 : �Heuristi sfor Routing and Spiral Run-time Task Mapping in NoC-based Heteroge-neous MPSOCs� Abbou El Hassen Benyamina, Mohammed kamel Benhaoua andPierre Boulet.
19

Chapitre 2État de l'ArtSommaire2.1 Tendan es des Multipro esseurs sur pu e (MPSoCs) . . . . . . . . . 222.1.1 Nombre de ÷urs de traitement . . . . . . . . . . . . . . . . . . . . . . . 222.1.2 Réseau sur pu e (NoC) pour la s alabilité . . . . . . . . . . . . . . . . . 232.1.3 Hétérogénéité dans les ÷urs de traitement . . . . . . . . . . . . . . . . 232.2 Ar hite tures Multipro esseurs sur pu e . . . . . . . . . . . . . . . . 242.2.1 Ar hite tures homogènes . . . . . . . . . . . . . . . . . . . . . . . . . . 262.2.2 Ar hite tures hétérogènes . . . . . . . . . . . . . . . . . . . . . . . . . . 272.2.3 Inter onnexions pour les ar hite tures sur Pu e . . . . . . . . . . . . . . 292.2.4 Con eption de plateformes Systèmes MultiPro esseurs sur Pu e . . . . . 302.3 Pla ement d'appli ations sur Multipro esseurs sur pu e . . . . . . . 342.3.1 Pla ement Statique (Design-time Mapping) . . . . . . . . . . . . . . . . 362.3.2 Pla ement Dynamique (Run-time Mapping) . . . . . . . . . . . . . . . . 382.4 Analyse des heuristiques de pla ement et Con lusion . . . . . . . . . 47Dans e hapitre, nous examinons les tendan es des systèmes MultiPro esseurssur pu e à la se tion 2.1. La se tion 2.2 présente quelques plateformes MPSoC ho-mogènes et hétérogènes existantes, iblées pour di�érents domaines d'appli ationsembarquées. Dans la même se tion, nous dis uterons sur l'inter onnexion sur pu ené essaires pour répondre aux besoins en ommuni ation des di�érentes PEs et les hallenges dans la on eption des plateformes MPSoC ave diverses méthodologiesde on eption existants. Diverses te hniques de pla ement proposées dans la littéra-ture plaçant les appli ations sur les plateformes MPSoC seront dis utées à la se tion2.3. Une étude approfondie de es te hniques est réalisée pour mettre en éviden eleurs limites, e qui nous a donné la motivation prin ipale de ette thèse.Les systèmes embarqués modernes (par exemple, les téléphones intelligents, PDA,tablettes) emploient les Systèmes MultiPro esseurs sur pu e (MPSoCs) a�n de satis-20

Chapitre 2 : État de l'Artfaire les exigen es de performan e toujours roissante des appli ations embarquées omplexes modernes, tout en réduisant la onsommation d'énergie. Par onséquent,les plateformes MPSoC onstituées de plusieurs pro esseurs embarqués sont plusprésentes dans les traitements embarqués [8℄. Ces plateformes peuvent augmenterles performan es par l'exé ution parallèle des tâ hes d'appli ations sur des pro es-seurs di�érents.En outre, les pro esseurs fon tionnent à des fréquen es inférieures, ontrairementaux systèmes à ÷ur unique basé sur un pro esseur où la fréquen e est très élevée,répondant ainsi à l'exigen e de faible puissan e. Intel rapporte que sous horloge(under- lo king) de 20 % d'un seul ÷ur é onomise la moitié de l'énergie en sa ri-�ant juste 13 pour ent de la performan e [9℄. Don , si le travail est réparti surdeux pro esseurs fon tionnant à 80 % de la fréquen e d'horloge, on obtient 74 % deperforman es meilleurs pour la même énergie. Cependant, la haleur est dissipée endeux points plut�t qu'un seul. Les plateformes MPSoC sont tenues à ontenir unplus grand nombre d'éléments de traitement (PEs) vu que la te hnologie progresse.Les plateformes peuvent être homogènes ou hétérogènes selon le type de PEs présentsdans la plateforme. Les plateformes homogènes ontiennent des PEs identiques, equi les rend très appropriées pour la mise en ÷uvre VLSI. D'autre part, les plate-formes hétérogènes ontiennent di�érents types d'éléments de traitements (PEs) quisatisfont les exigen es de performan e plus élevée en exploitant des ara téristiquesdistin tes des PEs.La plateforme d'éléments de traitement (PEs) né essite une infrastru ture de om-muni ation pour avoir une bonne ommuni ation entre plusieurs éléments de traite-ment (PEs). Le pla ement des appli ations sur la plateforme de multiples élémentsde traitement (PEs) utilisant des te hniques de pla ement e� a e, est un sujet dere her he très a tif traité par plusieurs organismes de re her he [10, 11℄.21

2.1 Tendan es des Multipro esseurs sur pu e (MPSoCs) Chapitre 2 : État de l'Art2.1 Tendan es des Multipro esseurs sur pu e (MPSoCs)Cette se tion dé rit les tendan es dans les MPSoC, ette te hnologie a évolué etla demande de performan es est roissante.2.1.1 Nombre de ÷urs de traitementEn ontinuant ave la loi de Moore, le nombre de transistors va roître de fa-çon exponentielle, ainsi que le nombre de ÷urs à peu près. En outre, Internatio-nal Te hnology Roadmap for Semi ondu tors (ITRS) prévoit que ette tendan e sepoursuivra omme le montre la �gure.2.1. Ainsi, omme la nanote hnologie évolue,il deviendra possible d'intégrer des milliers de ÷urs sur la même pu e omme préditpar les sour es telles qu'Intel et Berkeley [12, 13℄. Les ÷urs sont envisagés ommedes portes logiques du 21ème siè le.Presque toutes les so iétés d'informatique ont annon é les pu es ave multiples ÷urs de pro esseurs. En outre, les fournisseurs de feuilles de route assure que lenombre de ÷urs par pu e se double à plusieurs reprises. Ces pu es doivent êtreutilisées à l'avenir et sont diversement appelées MultiPro esseurs, Multi-Core etMulti-C÷urs sur pu e. Les systèmes omplets sont généralement appelés MPSoCs.
Figure 2.1 � ITRS Roadmap montre le nombre roissant de ÷urs de traitement [1℄22

2.1 Tendan es des Multipro esseurs sur pu e (MPSoCs) Chapitre 2 : État de l'Art2.1.2 Réseau sur pu e (NoC) pour la s alabilitéLes pro esseurs présents dans les MPSoCs font appel à une ertaine infrastru turepour avoir une bonne ommuni ation entre eux. Celle i peut être basée sur les bus,les liaisons point à point ou les réseaux sur pu e (NoC) [14℄. Dans les infrastru turesà base de bus, omme le nombre de pro esseurs augmente, le goulot d'étranglementde l'arbitrage augmente d'où le besoin de hausse du nombre de bus maîtres. En plus,la bande passante du bus est partagée par tous les pro esseurs onne tés, e qui lerend non évolutif (s alable). Dans des liaisons point à point, ave l'augmentationdu nombre de pro esseurs, des �ls plus longs sont né essaires, e qui provoque desretards dans la ommuni ation. Ainsi, ette infrastru ture est aussi non évolutive.Cependant, 'est dans un réseau sur pu e (Network On hip (NoC)) que l'arbitrageest distribué et que des segments de �l sont obligatoires. De plus, la bande passantese redimensionne à la taille du réseau, 'est à dire le nombre de pro esseurs. Ainsi,l'infrastru ture de ommuni ation NoC est e� a e et hautement évolutive [15, 16℄.2.1.3 Hétérogénéité dans les ÷urs de traitementLa loi d'Amdahl évalue les béné� es réels du al ul multi- ÷ur [17℄. Il indiqueque l'a élération de l'appli ation par le traitement MPSoC est limitée par le tempsné essaire pour l'exé ution de la partie séquentielle de l'appli ation. La �gure 2.2montre la vitesse obtenue en utilisant un nombre de pro esseurs di�érents à diversniveaux de parallélisations. Il est lair que si 5% de l'appli ation ne peut être parallé-lisée (95% parallélisée), l'a élération maximale obtenue est multipliée par 20, mêmesi un plus grand nombre de pro esseurs est utilisé. L'a élération peut être augmen-tée par l'exé ution a élérée de la partie non parallélisée (5%) ou par l'exé utionde la partie séquentielle en temps minime à l'aide d'un pro esseur à performan eséquentielle meilleure.La loi de Gustafson [18℄ est une loi théorique qui permet d'obtenir une bornemaximale au gain que l'on peut avoir en utilisant plusieurs pro esseurs pour paral-léliser du ode via le parallélisme de données.Cette loi donne le gain que l'on peut avoir ave N pro esseurs en exé utant23

2.2 Ar hite tures Multipro esseurs sur pu e Chapitre 2 : État de l'Artun programme parallélisé dans le as où il est possible d'augmenter la quantitéde données traitées, ontrairement à la loi d'Amdahl, qui s'applique à quantité dedonnées �xe. Elle traduit le fait qu'on peut traiter plus de données en augmentantle nombre de pro esseurs.Elle dit que le gain de vitesse est égal à S + ( N x P ), ave :S : le pour entage de ode non parallélisable.P : le pour entage de ode parallélisable.N : le nombre de pro esseurs.Quand la plateformeMPSoC hétérogène est utilisée, les ara téristiques distin tesdes di�érents types de pro esseurs peuvent être exploitées par les di�érentes partiesde l'appli ation, a�n d'augmenter l'a élération. Ainsi, les MPSoCs hétérogènes sontdevenus des alternatives de al uls formidables où les preuves ont été montrées ave l'amélioration apportée sur les grandes appli ations par rapport aux plateformeshomogène. En outre, les MPSoCs hétérogènes peuvent ontenir des pro esseurs àusage général (GPP) pour la �exibilité, des a élérateurs pour le al ul des tâ hesintensives, des blo s matériels re on�gurables pour l'e� a ité, la �exibilité et le al ul de traitement intensif et des pro esseurs spé ialisés omme les pro esseurs detraitements de signaux numériques (DSP) pour les tâ hes de traitement de signal,o�rant ainsi une �exibilité, l'augmentation des performan es de al ul et la rédu tionde la onsommation d'énergie en même temps. À l'avenir, l'hétérogénéité peut êtreen ore augmentée pour atteindre les exigen es de performan e élevée des appli ations omplexes.2.2 Ar hite tures Multipro esseurs sur pu eUn système MultiPro esseurs sur pu e (MPSoC) peut être vu omme un ensemblede deux parties. Une matérielle onstituée de plusieurs pro esseurs et l'autre softwareappelée système sur pu e. L'appro he d'ar hite ture Multi-C÷urs peut être adoptéepour mettre en ÷uvre les éléments de traitements dans les C÷urs, omme ils ontmontré leurs su ès pour la plupart des domaines d'appli ations [8℄. Ces C÷urs de24

2.2 Ar hite tures Multipro esseurs sur pu e Chapitre 2 : État de l'Art
Figure 2.2 � La loi d'Amdahl indiquant que l'a élération obtenue en utilisant plusieurs pro es-seurs est limitée par la partie séquentielle du programme [2℄traitement peuvent être mis en ÷uvre dans une pu e a�n de développer un MPSoC.L'ar hite ture Multi-C÷ur a un ertain nombre d'avantages [8℄ :� La méthode la plus appropriée pour les futures te hnologies de traitement :plus de C÷urs seront disponibles ave l'avan ement de la te hnologie mais la omplexité des C÷urs ne peut augmenter.� Les petits C÷urs peuvent être optimisés largement.� É helles de performan e de al ul fon tionnant presque linéairement ave lenombre de C÷urs.� Certains C÷urs peuvent être ommutés ON/OFF en fon tion des exigen es.� Les C÷urs défe tueux peuvent être é artés pour rendre le on ept Multi-C÷urtolérant aux pannes.� Plusieurs C÷urs peuvent être on�gurés en parallèle pour améliorer les perfor-man es.� Le domaine d'horloge individuelle par C÷ur est possible, et la re on�gurationdynamique partielle éventuelle sur la base d'un C÷ur pour les C÷urs re on�-gurables.25

2.2 Ar hite tures Multipro esseurs sur pu e Chapitre 2 : État de l'Art2.2.1 Ar hite tures homogènesTous les C÷urs présents dans une ar hite ture MPSoCs homogènes sont iden-tiques. Ainsi, les C÷urs peuvent être fa ilement reproduits, e qui les rend trèsappropriés pour l'implémentation VLSI. De plus, ils sont fa iles à programmer parrapport aux plateformes hétérogènes. Les re her hes A adémiques proposent sou-vent des ar hite tures MPSoCs homogènes et les plus re onnues sont introduitesdans ette partie. Massa husetts Institute of Te hnology a proposé une ar hite -ture de 16 C÷urs de pro esseur Raw Ar hite ture Workstation (RAW) [19℄. 167C÷urs de pro esseurs Asyn hronous Array of Simple Pro essors (AsAP) a été pro-posé par University of California Davis [20℄. L'université de Texas d'Austin proposesTera-op, Reliable, Intelligently adaptive Pro essing System (TRIPS) qui utilise 32 hips ha un ontenant 2-C÷urs [21℄. Le pro esseur WaveS alar a été proposé parl'université de Washington qui ontient approximativement 2K d'éléments de al ulsimple (PEs) arrangés dans 16 lusters [22℄. Dans [23℄, un MPSoC s alable pourl'ar hite tures de future génération a été proposé. Cette ar hite ture est basée surun pro esseur RISC et une mémoire distribué. Cette pu e a été développée pouro�rir des performan es élevées. Ré emment, les so iétés Intel et Tilera ont proposédes MPSoCs homogènes [23, 24℄. Dans [23℄, Intel propose un MPSoC homogène onstitué de 80 C÷urs reliés entre eux par un réseau d'inter onnexion où ha un ontient deux unités �ottantes. Le réseau d'inter onnexion est disposé en tant quematri e 2D de 10x8 dans une zone de 275mm qui ontient 80 C÷urs et routeurs à ommutation par paquets, fon tionnant à 4 GHz. Le MPSoC est onçu en te hno-logie de 65nm. Intel a également mis sur le mar hé Core i3, Core i5 et Core i7,une famille de pro esseurs Multi-C÷urs pour ordinateurs de bureau et mobiles [25℄.Dans [24℄, la so iété Tilera a annon é � TILE-Gx100 �, le premier 100 C÷urs dansle monde, à pro esseurs d'usage général, qui o�re des performan es élevées parmitous les mi ropro esseurs déjà annon és par un fa teur de quatre. Ils ont égalementsimpli�é la programmation Multi-C÷urs ave leur per ée � Environnement dedéveloppement Multi-C÷urs (MDE) � qui dispose d'un déploiement rapidedes produits. Hewlett-Pa kard a annon é un MPSoC omposé de plusieurs C÷urs26

2.2 Ar hite tures Multipro esseurs sur pu e Chapitre 2 : État de l'Artde pro esseurs MIPS [26℄. Kalray [27℄ propose un MPSoC, le MPPA-256 (Multi-Purpose Pro essor Array) qui renvoi à l'idée d'un pro esseur multi-fon tions et nonspé ialisé type FPGA, il est avant tout destiné aux appli ations dont le ritère nu-méro un est la puissan e par watt et orientées basse onsommation puisqu'on parled'une onsommation typique de 5 W (10 Watts au maximum). Mais à un niveau deperforman es bien supérieur à elui d'un FPGA. MPPA intègre 256 ÷urs VLIW(Very Long Instru tion Word) 32-bit organisés en 16 groupes de 16 ÷urs ha un(+ 1 ÷ur système). la so iété propose un environnement logi iel adéquat le MMPAA ess ore, un SDK utilisant un langage de programmation de haut niveau pro hedu C. Il y a beau oup d'autres fabri ants qui ont annon é leurs pu es Multi-C÷urs iblant di�érents domaines de al ul tel que le al ul s ienti�que, embarqués et àusage général. Certaines pu es Multi-C÷urs sont répertoriés dans [25℄.2.2.2 Ar hite tures hétérogènesLes MPSoCs hétérogènes sont onstitués de di�érents types d'éléments de trai-tement (PEs) implémentés dans les C÷urs. Les éléments de traitements peuventêtre des pro esseurs à usage général (GPPs), des éléments de traitements spé ialisés omme des DSP, des FPGA, des IPS (intelle tual property dédiés), des mémoiresspé ialisées, et . En exploitant les ara téristiques distin tes des di�érents types dePEs, la performan e de al ul peut être augmentée pendant que la onsommationd'énergie peut être diminuée tout en maintenant l'extensibilité de l'ar hite ture.A tuellement, les her heurs universitaires visent aussi les ar hite tures MPSoCshétérogènes. Celles proposées par les universités sont présentées dans [28, 29, 30, 31℄.Nollet et al. [28℄ présente un MPSoCs ontenant quatre di�érents types de PEs :GPPs, DSPs, des a élérateurs et des blo s matériels re on�gurables. Les di�érentsPEs sont reliés entre eux par un réseau maillé 3x3. Smit et al. [29℄ proposent desar hite tures re on�gurables où les PEs sont reliés par un réseau sur pu e et unear hite ture parti ulière nommée � Annabelle �. Dans les pu es intelligentes pourle projet [30℄ Environnement intelligents (4S) à l'Université de Twente, une ar hi-te ture MPSoC dynamiquement re on�gurable a été proposée : le C÷ur peut être27

2.2 Ar hite tures Multipro esseurs sur pu e Chapitre 2 : État de l'Artà unité re on�gurable au niveau bit (par exemple, FPGA) au niveau mots (parexemple Montium [32℄), ou programmable à usage général (GPP). La programmabi-lité des C÷urs dans les ar hite tures re on�gurables aide le système à être la ible deplusieurs domaines d'appli ation. Arpinen et al. [31℄ présente un MPSoC omposéde plusieurs C÷urs de pro esseurs Altera Nios II soft- ore et a élérateurs maté-riels personnalisés, reliés par un réseau de ommuni ation appelé inter onnexion deblo ks IP hétérogène (HIBI ). Le MPSoC est réé sur un FPGA Altera [33℄. DeuxMPSoCs hétérogènes : CHAMELEON et Pleiades sont proposés par les universitésde Twente et l'UC Berkeley, respe tivement. Ces MPSoCs visent les algorithmesDSP. Le CHAMELEON SoC ontient le pro esseur à usage général (Core ARM),la partie re on�gurable à grain �n (Core FPGA) et la partie re on�gurable à grosgrains (Core montium [32℄). Les parties de al ul régulier d'un algorithme sont exé- utées dans des parties re on�gurables et les parties irrégulières sur le pro esseur àusage général. Les Chips Pléiades ontiennent des pro esseurs à domaines spé i�quesà faible énergie.L'Industrie vise également les MPSoCs hétérogènes. Certaines propositions in-dustrielles sont présentées dans [34, 35, 36℄ et [25℄. Dans [34℄, STMi roele troni sprésente un MPSoC �exible appelé StepNP qui ontient plusieurs pro esseurs multi-thread on�gurables, PEs on�gurables et des Entrées / Sorties orientées réseau,tous reliés sur pu e. Il répond à l'exigen e de �exibilité, un développement rapideet la produ tivité de l'utilisateur �nal. Leijten et al. [35℄ proposent un MPSoC quiest onçu par une méthode onnue sous le nom PROPHID. L'ar hite ture PRO-PHID ontient un pro esseur d'usage général pour le ontr�le et pour le traitementdu signal de faible et moyenne performan e. En plus, des pro esseurs spé i�quesau domaine pour le traitement du signal à haute performan e. Rutten et al. [36℄proposent un MPSoC appelé E lipse qui ontient des opro esseurs de domaine spé- i�ques pour l'exé ution des tâ hes d'une ou plusieurs appli ations en même tempsa�n de fournir des performan es élevées. Dans [25℄, les MPSoCs proposés par plu-sieurs so iétés sont listés. Ils ontiennent un nombre varié de PEs implémentés dansdes C÷urs en fon tion de la né essité du domaine d'appli ation iblée. Certains28

2.2 Ar hite tures Multipro esseurs sur pu e Chapitre 2 : État de l'ArtMPSoCs ontemporains montrent que la plupart d'entre eux ontiennent plus desPEs spé i�ques à l'appli ation que des PEs à usage général et sont introduits par lasuite.� CELL� Nexperia� OMAP� Nomadik� XPP� AVISPA CH� Con�gurable Cores� Fine-grain Re on�gurable Hardware� Exynos Sumsung� SnapDragon2.2.3 Inter onnexions pour les ar hite tures sur Pu eUne inter onnexion sur pu e est né essaire pour onne ter les PEs des MPSoCsa�n de satisfaire leurs besoins de ommuni ation. En dehors des options d'inter on-nexion disponibles, telles les onnexions point à point, bus et réseaux sur pu e (NoC),il a été observé que le NoC est le plus e� a e et hautement s alable [14, 15, 16℄. Leterme NoC est utilisé dans plusieurs ontextes variant du bus segmenté en multi-niveaux au réseau sur pu e [37℄. Plusieurs her heurs se on entrent sur la on eptionde NoC e� a es, qui implique plusieurs dé�s. Mar ules u et al. [38℄ dé rivent lesproblèmes de re her he dans la on eption des NoCs et les lasses en inq atégories :� modélisation de l'appli ation,� l'optimisation de la ommuni ation dans le NoC,� la séle tion de paradigme de ommuni ation,� synthèse de l'infrastru ture de ommuni ation,� évaluation et validation.Certaines solutions e� a es ontre haque problème ont également été suggérées.Elles doivent être étudiées à partir des perspe tives de re her he des futurs NoCs.29

2.2 Ar hite tures Multipro esseurs sur pu e Chapitre 2 : État de l'ArtDes exemples de NoCs de re her he bien onnus sont SPIN [39℄, AEthereal [40℄,QNoC [41℄, Xpipes [16℄, PNoC [42℄, ProtoNoC [43℄, Nostrum [44℄, MANGO [45℄et HERMES [46℄. Les appro hes de on eption pour les NoCs mentionnées sontdé rites dans leurs référen es respe tives. D'autres appro hes de on eption ont étémentionnées dans [47, 48, 49℄.Bjerregaard et al. [45℄ fournissent une ex ellente étude de re her he des NoCsexistants et leurs pratiques. Dernièrement, plusieurs so iétés start-up omme Soni s[50℄ et Arteris [51℄ ont ommen é à ommer ialiser les on epts des NoCs ave leursproduits NoCs. Les NoCs né essitent des mé anismes de routage intelligents pourtransférer e� a ement des données d'un PE à un autre PE du MPSoC. Certains de es mé anismes sont présentés dans [52℄ et [53℄. Dans [52℄, un nouveau s héma deroutage intitulé DyAD est proposé, qui prend les avantages à la fois des systèmesde routage déterministe et adaptatif par ommutation entre eux en fon tion de la ongestion du réseau. Dans [53℄, une stratégie de routage multi- hemin est présentéequi garantit la délivran e de données dans l'ordre par la di�usion optimale du tra� dans le NoC a�n de réduire les besoins en bande passante du réseau. L'ar hite tureNoC impose aussi de nouveaux dé�s de gestion dynamique (run-time). Par exemple,le réa heminement de ommuni ation, à savoir : hanger le hemin de ommuni ationentre un PE sour e et un PE destination au moment de l'exé ution. En outre,les algorithmes de gestion des ressour es doivent tenir ompte des propriétés del'inter onnexion.2.2.4 Con eption de plateformes Systèmes MultiPro esseurs sur Pu eComme mentionné pré édemment, les MPSoCs peuvent fournir des solutions ar- hite turales des plus e� a es pour soutenir di�érents domaines d'appli ations. En onséquen e, des outils pour la on eption et la simulation de es systèmes sont né- essaires. La on eption des MPSoC implique plusieurs dé�s [54℄ en l'o urren e lenombre et le type de pro esseurs, la taille des mémoires, les infrastru tures de om-muni ation et di�érents a élérateurs à prendre en onsidération dans la on eptiond'un MPSoC prometteur pour un ensemble d'appli ations donné. Les universités30

2.2 Ar hite tures Multipro esseurs sur pu e Chapitre 2 : État de l'Artet l'industrie ont proposé plusieurs méthodes de on eption logi ielle ou matérielle,intégrées dans des outils di�érents.Te hniques de on eption basées sur le logi ielLes appro hes de on eption basées sur les logi iels fournissent des plateformesde simulation pour les MPSoCs, qui sont relativement plus fa iles à on evoir quedes plateformes matérielles. Toutefois, les plateformes de simulation fournissent desrésultats très pro hes de l'exa t et prennent parfois beau oup de temps dans la si-mulation. Des travaux existant, dans e sens, sont présentés dans [55, 56, 57, 58℄.Benini et al. [55℄ proposent une méthode pour la on eption de e genre de plate-forme, appelée MP-ARM, qui ontient des pro esseurs ARM sur SystemC [59℄ etar hite ture de ommuni ation ompatible ave le bus AMBA. Paulin et al. [60℄présentent une autre te hnique pour la on eption d'une plateforme de simulationMPSoC sur SystemC appelé StepNP. Mon hiero et al. [56℄ présentent un frame-work de on eption appelée GRAPES. Le framework o�re �exibilité et modularitéen maintenant une vitesse de simulation élevée. Les entités SystemC ou C ++ sontutilisés pour modéliser les modules IP (intelle tual property). Les modules sont ap-turés en objets C ++ appelés plugins et sont gérés par le noyau (kernel) GRAPES,qui est le ÷ur du framework de simulation. Cong et al. [57℄ présentent une métho-dologie pour une génération rapide automatique, vrai y le, simulateur à base de Cpour les opro esseurs utilisant un outil de synthèse de haut niveau a�n de l'intégrerà leur framework de simulation MC-Sim. Le framework est apable de simuler ave pré ision une gamme de pro esseurs, mémoires, on�gurations NoC et opro esseursspé i�ques à l'appli ation. Atat et al. [58℄ proposent une appro he de on eption auniveau système pour le prototypage rapide de MPSoCs à partir de spé i� ationsMatlab / Simulink. Beltrame et al. [61℄ présentent une méthode à partir de la des- ription d'une appli ation en ode séquentiel standard, pro�lée tout d'abord dans lebut de paralléliser, e qui donne un nombre minimum de pro esseurs requis pour une ontrainte donnée. Ensuite une plateforme de simulation basée StepNP est onçuesur la base des omposants parallélisés et le nombre de pro esseurs. Le débit est31

2.2 Ar hite tures Multipro esseurs sur pu e Chapitre 2 : État de l'Artappliqué à un en odeur MPEG4 VGA en temps réel pour l'étude de as industriel.Interuniversity Mi roele troni s Centre (IMEC) [3℄ présente un �ot de on eption2.3 utilisant trois outils :� I) CleanC pour le nettoyage de ode sour e : Le CleanC permet aux on epteursd'é rire un ode séquentiel de haut niveau optimisé pour la parallélisation.� II) MultiPro essor Assist (MPA) pour la parallélisation du ode séquentiel :L'outil MPA permet aux on epteurs d'extraire la parallélisation potentielleprésente dans une appli ation en utilisant le parallélisme fon tionnel et desdonnées.� III) Memory Hierar hy (MH) destiné à e�e tuer la gestion de la mémoire :L'outil MH ordonnan e automatiquement les transferts de données entre lamémoire prin ipale et la mémoire lo ale par l'analyse du ode sour e d'entrée.Les MPSoCs onçus basés sur le framework de simulation, sont visés par de nom-breux her heurs ar ils sont fa iles à on evoir et ont besoin de moins de temps aumoment de la on eption.
Figure 2.3 � Flow de on eption MPSoC IMEC [3℄32

2.2 Ar hite tures Multipro esseurs sur pu e Chapitre 2 : État de l'ArtTe hniques de on eption basées sur le matérielLes plateformes matérielles sont di� iles à on evoir par rapport aux plateformesde simulation bien qu'elles fournissent une exé ution plus rapide que les simulateurs.Quelques méthodes pour on evoir des plateformes matérielles sont données dans[62, 63, 64, 65, 66℄.� Nikolov et al. [62℄ présentent une méthodologie mise en ÷uvre dans un outilappelé Embedded System level Platform synthesis and Appli ation Mapping(ESPAM) pour la on eption automatisée, la programmation et la mise en÷uvre de MPSoCs. Cette méthodologie onsidère une appli ation plateformeau niveau du système, et des spé i� ations de pla ement en entrée pour e�e -tuer l'automatisation. La méthode proposée est évaluée par la produ tion et laprogrammation automatique de plusieurs MPSoCs pour exé uter des appli a-tions en temps réel.� STMi roele troni s [63℄ proposent une appro he modulaire à faible oût pourgénérer des plateformes matérielles o�rant la on eption et la véri� ation deMPSoCs omplexes.� Atienza et al. [64℄ présentent un framework pour on evoir un MPSoCs surFPGA, onçu pour fournir une a élération de trois ordres de grandeur parrapport au y le pré is.� Sun et al. [65℄ proposent une méthodologie implémentée pour la synthèse MP-SoC, utilisant la plateforme Xtensa de Tensili a In [67℄, évaluée en générantautomatiquement des MPSoCs personnalisés pour plusieurs ben hmarks om-plexes de logi iels embarqués, les résultats montrent que MPSoCs synthétisésfournissent des résultats plus rapides.� Kumar et al. [66℄ présentent une méthodologie mise en ÷uvre dans un outilappelé Multi-Appli ation Multi-Pro essor Synthesis (MAMPS) pour générerdes MPSoCs de manière systématique et entièrement automatisée pour les ap-pli ations multimédia. L'outil génère des MPSoCs pour FPGA Xilinx.Pour des ar hite tures évolutives, les te hniques pour générer les MPSoC à basede NoC sur FPGA, sont présentées dans [68, 69, 70℄. Jusqu'à présent, les te hniques33

2.3 Pla ement d'appli ations sur Multipro esseurs sur pu e Chapitre 2 : État de l'Artde on eption des MPSoCs ont été dé rites, mais ertaines te hniques de on eptionde MPSoCs générales devront être iblées pour le pla ement d'appli ations à desstades ultérieurs [55, 58, 63℄, tandis que d'autres appli ations spé i�ques MPSoCsseront vues dans [61, 3, 62, 65, 66℄.Pour gérer le dynamisme, omme l'ajout d'une nouvelle appli ation dans le sys-tème au moment de l'exé ution, les MPSoCs sont obligatoires. A�n de gérer desappli ations omplexes modernes né essitant grand nombre de pro esseurs, les MP-SoCs doivent être à base de NoC pour l'e� a ité et l'évolutivité. Cependant, il a étéobservé que la plupart des méthodes de on eption produisent des MPSoCs qui nesont pas à base de NoC et que les MPSoCs sur FPGA pour plateformes matériellessont une nouveauté à tendan e de plus en plus importante [62, 64, 66, 68, 69, 70℄.Dorta et al. [71℄ donnent un bon aperçu des MPSoCs sur FPGA. Cela fa ilite leprototypage rapide et permet la re her he de nouvelles ar hite tures au ontraire del'appro he ASIC. Toutefois, es performan es ont diminué par rapport à leur homo-logue ASIC mais o�rent plusieurs avantages tels que la �exibilité, la re on�guration,temps de produ tion réduit et à moindre oût. Les FPGA modernes peuvent a - ueillir 80 à 100 pro esseurs soft- ores dans une seule pu e et le NoC est la meilleuresolution pour gérer un si grand nombre de ÷urs [72℄. Des te hniques sont égalementdisponibles pour on evoir mille noyaux systèmes, en utilisant plusieurs FPGA, untel système a été dénommé Resear h A elerator for Multiple Pro essors (RAMP)[73℄.2.3 Pla ement d'appli ations sur Multipro esseurs sur pu eLes appli ations ont besoin du traitement suivant avant d'entamer leur pla ementsur les plateformes MPSoC :� Parallélisations de l'appli ation, ajout de la syn hronisation et de la ommuni- ation inter-tâ hes. Gestion de la ommuni ation de l'environnement externe.Ce travail est dé rit par l'état de l'art des outils de parallélisations des appli- ations [74, 3℄.� Les tâ hes peuvent être exé utées en parallèle sur di�érentes ressour es de la34

2.3 Pla ement d'appli ations sur Multipro esseurs sur pu e Chapitre 2 : État de l'Artplateforme a�n d'a élérer l'exé ution de l'appli ation.� Véri� ation du ode parallélisé (faire en sorte qu'il soit fon tionnellement or-re t et optimisé pour un ensemble de paramètres de plateforme donnée).� Dans le as des plateformes hétérogènes, un pro édé de liaison de tâ hes estrequis (task binding). Pour ha une, le pro essus de liaison dé�nit les types depro esseurs sur lesquels elle peut être pla ée. Il pré ise également le oût dupla ement sur les di�érents types de pro esseurs.Le pla ement des tâ hes des appli ations sur une plateforme MPSoC implique leura�e tation, leur ordonnan ement et le pla ement des ommuni ations sur le NoC ensatisfaisons ertains ritères d'optimisation omme la rédu tion de la onsommationd'énergie, l'amélioration des performan es de al ul et . L'optimisation est né essairepour satisfaire les ontraintes de performan e des appli ations. Les te hniques depla ement ont besoin des paramètres suivants :� Un modèle d'appli ation (par exemple, Task Graph [75℄, Data Flow Graph [76℄et .)� Un modèle d'ar hite ture de la plateforme MPSoC (par exemple, la topologie,le nombre d'unités de traitement et leur type, le s héma d'inter onnexion, et .)� Les ontraintes de l'appli ation (par exemple, la performan e de al ul et / oules exigen es de puissan e et .).� Le modèle de performan e de ommuni ation inter-tâ hes (temps d'exé ution,la onsommation d'énergie, et .).� Une estimation de as du pire temps d'exé ution des tâ hes de l'appli ationsur di�érents PEs.Le problème de pla ement est abordé par plusieurs her heurs ommuniquantleurs points de vue par le biais de divers forums tels que [11℄, International Forumon Embedded MPSoC and Multi ore [10℄, diverses onféren es et revues internatio-nales. Les te hniques de pla ement peuvent aussi être distinguées selon la spé i� itéde l'appli ation et le type de la plateforme MPSoC ible. Le pla ement des tâ hesdes appli ations sur les ressour es de la plateforme MPSoC peut être a ompli soitau moment de la on eption (statique) ou lors de l'exé ution (dynamique). Les35

2.3 Pla ement d'appli ations sur Multipro esseurs sur pu e Chapitre 2 : État de l'Artte hniques de pla ement au moment de la on eption (design-time) onsidèrent unensemble d'appli ations prédé�nies ave un al ul, omportement de ommuni ationet une plateforme statique onnus. Par onséquent, ils ne sont pas adaptés pour des harges dynamiques telles que l'ajout d'une nouvelle appli ation dans la plateformeau moment de l'exé ution. Les te hniques de pla ement dynamique (run-time) sontné essaires pour les s énarios où les tâ hes d'appli ation sont hargées dans la pla-teforme au moment de l'exé ution. Après le pla ement des tâ hes, la migration detâ hes peut être utilisée pour réviser le pla ement d'une partie des tâ hes déjà en ours d'exé ution, si l'exigen e de l'utilisateur est modi�ée ou si une nouvelle ap-pli ation entre en jeu dans le système. Au ours des sous se tions suivantes, nousprésenterons quelques te hniques de pla ement statique et dynamique rapportéesdans la littérature. Mais par la suite, nos travaux se on entreront prin ipalementsur le pla ement dynamique. Nous explorerons largement les te hniques de pla e-ment dynamique après avoir fourni une introdu tion aux te hniques de pla ementstatique.2.3.1 Pla ement Statique (Design-time Mapping)Les te hniques de pla ement statique ont une vue globale du système qui aide àprendre de meilleures dé isions pour l'utilisation des ressour es du système. Ainsi,une meilleure qualité de pla ement peut être réalisée par rapport aux te hniques depla ement dynamique qui sont limités à une vue lo ale. La plupart des travaux liés aupla ement rapportés dans la littérature traitent le pla ement statique. Les te hniquesde pla ement statique pour les MPSoCs à base de bus et de NoC sont présentéesdans [77, 78, 79, 80, 81, 82℄ respe tivement. Les ar hite tures à base de bus ne sontpas s alables et onstituent don une limite pour leurs te hniques de pla ement. Huet al. [79℄ en proposent une appelée � Communi ation Weighted Model (CWM) �et montrent que la onsommation d'énergie globale est réduite en diminuant ellede l'énergie des ommuni ations. Mar on et al. [80℄ prolongent le travail dans [79℄ etproposent une te hnique appelée � Communi ation Dependen e and ComputationModel (CDCM) �. Le CWM onsidère seulement le volume de la ommuni ation,36

2.3 Pla ement d'appli ations sur Multipro esseurs sur pu e Chapitre 2 : État de l'Artalors que CDCM onsidère le volume et la période de la ommuni ation. Murali etal. [81℄ font part d'une méthodologie qui pla e plusieurs as d'utilisation sur unear hite ture NoC où les ontraintes de performan es pour haque as d'utilisationsont respe tées. Rhee et al. [82℄ étudient le problème de � ore-swit h mapping �(CSM) qui pla e d'une manière optimale les C÷urs sur l'ar hite ture NoC a�n deminimiser la onsommation d'énergie ou la ongestion NoC. Di�érentes appro hesde re her he bien établies sont également utilisées pour élaborer les te hniques depla ement statique a�n de trouver un pla ement optimal des tâ hes sur les unitésde al uls (PEs) de la plateforme. L'appro he génétique est utilisée dans [83, 84℄,re her he Tabu dans [85℄ et re uit simulé dans [86, 87℄. Lei et al. [83℄ présententun algorithme de pla ement génétique en deux étapes visant à optimiser le tempsd'exé ution de l'appli ation. Wu et al. [84℄ présentent un algorithme de pla ementgénétique qui utilise � Dynami Voltage Frequen y S aling � (DVFS) pour réduire la onsommation d'énergie. Manola he et al. [85℄ étudient le pla ement de tâ hes visantà garantir la laten e des paquets réseaux a�n de garantir le temps de réponse desappli ations pour le pire de as. Orsila et al. [87℄ proposent un algorithme de re uitsimulé qui optimise le temps d'exé ution et la onsommation mémoire, alors queles appro hes traditionnelles se on entrent uniquement sur le temps d'exé ution.D'autres te hniques ré entes de pla ement statique sont résumées dans [88, 89, 90,91℄.Benyamina et al. [92℄ ont traité le pla ement statique dans les NoCs. La phasede mapping dans les systemes sur pu e représente une phase entrale lors de leurmise en ÷uvre. Ce mapping a une parti ularité, dans e ontexte, ar il ne s'agitpas uniquement d'un pla ement lassique qu'on a l'habitude de ren ontrer dans lessystèmes parallèles mais il englobe trois phases : Assignation, A�e tation et S heduling (AAS). Ce type de pla ement ou mapping dans sa globalité est onnu ommeétant un pla ement GILR : Globally Irregular Lo ally Regular, il onsiste à exploiterle parallélisme de tâ hes et de données dans une ar hite ture multipro esseurs. Be-nyamina et al. [92℄ ont traité le problème dans sa globalité, ils ont utilisé l'algorithmegénétique pour le pla ement de tâ hes sur des PEs et dijkstra pour les ommuni-37

2.3 Pla ement d'appli ations sur Multipro esseurs sur pu e Chapitre 2 : État de l'Art ations. Un se ond projet sous la responsabilité de P.Boulet et Benyamina traité lemême problème à l'aide de l'algorithme PSO à la pla e d' AG. La omparaison entreles deux appro hes a montré que l' AG est mieux que PSO. A. AROUI [93℄ s'estintéressé à la partie régulière. En e�et, dans les appli ations DSP on a généralementun �ot de données in�ni qui sont traitées par des tâ hes répétitives. Ces tâ hes ont laparti ularité de présenter les mêmes ara téristiques : le nombre de y les d'exé u-tion et la taille des données traitées. En plus es tâ hes s'appliquent sur des donnéesde même dimension et stru ture, qu'on appelle motifs. Don il sera béné�que de pla- er es tâ hes sur la partie homogène (régulière) de l'ar hite ture ible (MPSoC).A.AROUI [93℄ a proposé une nouvelle te hnique de pla ement des tâ hes répétitivesd'une appli ation sur une partie d'une ar hite ture multipro esseurs sur pu e, a�nde minimiser le oût de ommuni ations et la onsommation d'énergie et de res-pe ter les di�érentes ontraintes de on eption. Pour ela, sa démar he onsistaità proposer et de mettre en ÷uvre une méthode hybride pour solutionner e genrede problème, onstituée d'une part, d`une méthode exa te : Bran h and Bound biobje tifs, permettant de trouver le meilleur pla ement des ta hes selon plusieursobje tifs. D'autre part de l'algorithme Dijkstra modi�é et amélioré en bi-obje tifspour le mapping des ommuni ations.Toutes les te hniques de pla ement statique trouvent le pla ement des tâ hes aumoment de la on eption. Par onséquent, es te hniques ne onviennent pas pourdes harges de travail variables dynamiques dans les systèmes qui exige un pla ementet un repla ement dynamique d'appli ations (par exemple, les appli ations réseau etmultimédia). Même si les te hniques de pla ement statique sont insu�santes pourles s énarios à harge de travail dynamique elles peuvent être utiles pour trouver lepla ement initiales des tâ hes, ou être optimisées lors de l'exé ution.2.3.2 Pla ement Dynamique (Run-time Mapping)Contrairement au pla ement statique, le pla ement dynamique doit tenir omptedu temps pris pour pla er haque tâ he ar il ontribu à la durée totale de l'exé utionde l'appli ation. Par ailleurs, les tâ hes sont pla ées une par une, à la di�éren e du38

2.3 Pla ement d'appli ations sur Multipro esseurs sur pu e Chapitre 2 : État de l'Art as statique où elles sont toutes pla ées à la fois en examinant le système d'une fa-çon globale. Par onséquent, les algorithmes gloutons sont utilisés pour le pla emente� a e dans le but d'optimiser les mesures de performan e telle que la onsomma-tion d'énergie, la laten e de ommuni ation, le temps d'exé ution, et . En plus del'aptitude des te hniques de pla ement dynamique par rapport aux te hniques depla ement statique, dans le as de s énarios de harge de travail dynamique, elleso�rent également un ertain nombre d'autres avantages :� Adaptabilité aux ressour es disponibles : les ressour es disponibles varient au�l du temps, les appli ations de s énario à harge de travail dynamique entrentau moment de l'exé ution.� Possibilité d'a tiver des mises à niveau imprévisibles : il est possible de mettreà niveau le système pour de nouvelles appli ations ou des normes hangeantespas onnus au moment de la on eption, même après la livraison du système àl'utilisateur �nal.� Le vieillissement peut onduire à des unités de traitement défe tueuses impré-visibles au moment de la on eption.� Capa ité à éviter les parties défe tueuses d'un SoC : Si une ou plusieurs unitésde traitement ne fon tionnent pas orre tement après la produ tion d'un SoC,alors les unités défe tueuses peuvent être désa tivées et les harges qui leursont été a�e tées seront réa�e tées à d'autres pro esseurs à l'aide du pla ementdynamique [94℄.Les te hniques de pla ement dynamique répartit les tâ hes et leurs ommuni a-tions aux unités de traitement (PEs) et les liens d'inter onnexion, respe tivement,pour toutes les appli ations à pla er. Lorsque les appli ations mappées démarrentleur exé ution, le pla ement d'une ou plusieurs d'entre elles en ours d'exé ution,doit être réexaminé en as d'événements suivants :� Lorsqu'une nouvelle appli ation ayant besoin de ressour es déjà en exé ution,est entrée dans le système.� Lorsque les paramètres d'une appli ation en exé ution sont modi�és.39

2.3 Pla ement d'appli ations sur Multipro esseurs sur pu e Chapitre 2 : État de l'Art� Quand une appli ation en ours d'exé ution doit être tuée pour libérer sesressour es o upées.� Lorsque les exigen es de performan e d'une appli ation en ours d'exé utionsont modi�ées. Elle pourrait avoir besoin de ressour es supplémentaires pourexé uter des fon tionnalités supplémentaires.� Lorsque le pla ement a tuel n'est pas su�samment optimal, il exige un repla- ement.Les problèmes mentionnés i-dessus ne peuvent être traités que par des te h-niques de pla ement dynamique 'est à dire au moment de l'exé ution. Au momentde e dernier, le pla ement de nouvelles appli ations qui doivent être soutenues surune plateforme, peuvent être manipulées soit en e�e tuant tout le traitement enmême temps 'est à dire par un traitement à la volée (on-the-�y pro essing) soit enutilisant les résultats analysés pré édemment. Pour le traitement à la volée, des heu-ristiques e� a es sont né essaire pour assigner les nouvelles tâ hes arrivant sur lesressour es de la plateforme. Ces heuristiques ne peuvent garantir que les é héan estemporelles stri tes respe tées en raison des ressour es de traitement limitées lors del'exé ution. Toutefois, elles sont appli ables à toute plateforme omme elles n'uti-lisent pas de résultats d'analyse spé i�que de plateforme al ulés à l'avan e. Pourle pla ement utilisant des résultats pré édemment analysés lors de la on eption,des heuristiques de pla ement dynamique sont né essaires. On peut dire aussi quele pla ement pré-analysé permet de faire un meilleur pla ement d'appli ations que elui du pla ement à la volée. Mais les résultats d'analyse ne seront pas appli ables àtoutes les plateformes. Ensuite, nous dis utons entre des heuristiques de pla ement àla volée et les stratégies de pla ement qui utilisent les résultats d'analyse au momentde la on eption, rapportées dans la littérature.Pla ement à la volée (Mapping On-the-�y)Les te hniques de pla ement iblent les MPSoCs homogènes ou hétérogènes enfon tion de l'exigen e d'appli ation.Te hniques iblant les MPSoCs homogènes40

2.3 Pla ement d'appli ations sur Multipro esseurs sur pu e Chapitre 2 : État de l'ArtCertaines te hniques de pla ement dynamique visant les MPSoCs homogènessont présentées dans [95, 96, 97, 98, 99, 100, 101, 102℄. Chou et al. [95℄ proposentune te hnique qui in orpore les informations de omportement de l'utilisateur dansle pro essus d'allo ation de ressour es qui permet au système de mieux répondreaux hangements en temps réel et de s'adapter dynamiquement aux besoins desutilisateurs. Cette onsidération é onomise 60% de l'énergie de ommuni ation parrapport à une te hnique d'allo ation des tâ hes arbitraires.Peter et al. [96℄ présentent un algorithme distribué sur les pro esseurs pouvantdon être appliquées aux systèmes de tailles aléatoires. En outre, les tâ hes ajou-tées au moment de l'exé ution peuvent être manipulées sans au une di� ulté. Cequi permet une optimisation en ligne. La migration des tâ hes s'e�e tue sur la basedes informations lo ales sur la harge de travail du pro esseur, la taille de la tâ he,les exigen es de ommuni ation, et le lien. Les résultats de pla ement sur plusieursexemples d'ensemble de tâ hes montrent que la qualité obtenue par l'algorithme pré-senté est à moins de 25% de elle de l'algorithme exa t, pour un réseau de pro esseur3X3.Briao et al. [97℄ présentent des stratégies basées sur des algorithmes bin-pa kingpour exé uter des appli ations à temps réel souple. Ils ombinent di�érents typesd'algorithmes pour obtenir des résultats d'allo ation meilleurs. A�n d'é onomiserl'énergie, le système désa tive les pro esseurs ina tifs.Chou et al. [98℄ proposent une te hnique qui onsidère di�érentes unités de al ul(PEs) qui opèrent sur des niveaux de voltage di�érents pour un pla ement prenanten ompte la onsommation d'énergie.Ngouanga et al. [99℄ dé rivent une te hnique basée sur les for es d'attra tionentre les tâ hes ommuni antes. La te hnique tente de pla er les tâ hes pro hes surles unités de al uls (PEs) voisines de la plateforme MPSoC a�n de réduire le oûtdes ommuni ations.Mehran et al. [100℄, quant à eux, proposent une heuristique nommé � Dynami Spiral Mapping � (DSM) pour une topologie 2D maillée où le pla ement est re her hédans un hemin en spirale, essayant de pla er les tâ hes ommuni antes pro hes les41

2.3 Pla ement d'appli ations sur Multipro esseurs sur pu e Chapitre 2 : État de l'Artunes des autres. Avant de ommen er la re her he en spirale, le degré de haque tâ hedans une appli ation est trouvé et elle à degré maximal est pla ée au entre de lamaille pour réaliser un pla ement des plus ommuni antes le plus pro he possiblel'une de l'autre.Sassatelli et al. [101℄ proposent deux te hniques di�érentes appelées ommuni- ations proa tives et réa tives, et pro èdent à des évaluations du y le pré is de es te hniques. Les auteurs a�rment que les systèmes homogènes à y le pré is,peuvent devenir une alternative viable dans un avenir pro he apportant des avan-tages tels que haute performan e, faible onsommation d'énergie et équilibrage de harge dynamique.Moreira et al. [102℄ présentent une te hnique a�e tant d'abord les tâ hes à desC÷urs virtuels (VCs), tout en essayant d'en minimiser le nombre total et la bandepassante utilisée. Par la suite, les VCs sont mappés à des C÷urs réels.Te hniques iblant les MPSoCs hétérogènesA tuellement les MPSoCs sont très hétérogènes pour mieux répondre aux exi-gen es des appli ations. Dans e as , le pro essus de liaison de tâ he (Task bindingpro ess) est réalisé avant de ommen er le pla ement. Pour haque tâ he, e pro- essus dé�nit les types de PE sur lequel la tâ he peut être mappée ave le oût deson pla ement. La �gure 2.4 présente le pro essus de liaison (pro�lage au momentde la on eption) pour un exemple d'appli ation, où les tâ hes sont analysées surdi�érents types d'unités de al ul telles que GPP, DSP, matériel re on�gurable àgros grain et . Le pro�lage fournit la performan e, la puissan e et l'utilisation deressour es pour haque tâ he sur di�érents types de PEs.Smit et al. [4℄ présentent un algorithme plaçant en premier lieu, les tâ hes né- essitant des ressour es ritiques, puis toutes les autres en prenant en ompte ladisponibilité des ressour es de la plateforme. Plusieurs te hniques pour le pla ementdes appli ations de streaming sur des ar hite tures multi-C÷urs sont présentées dans[29℄.Dans le projet des pu es intelligentes pour un environnement intelligent (4S) [30℄,un outil de pla ement spatial nommé SMIT est développé. Il est dé len hé par un42

2.3 Pla ement d'appli ations sur Multipro esseurs sur pu e Chapitre 2 : État de l'Art
Figure 2.4 � Pro essus de liaison de tâ he (Task binding pro ess)RTOS lorsqu'une appli ation doit être mappée sur le MPSoC. L'outil prend la des- ription de l'ar hite ture du système, la des ription fon tionnelle de l'appli ation,la réalisation du pro essus, l'état du système a tuel et les ontraintes de perfor-man e en entrée et en sortie. Un pla ement fournit le pla ement des tâ hes et des ommuni ations dans l'ar hite ture et est utilisé pour on�gurer le système, ommele montre la �gure 2.5. La réalisation est obtenue par l'appli ation du pro essus deliaison de tâ he (Task binding pro ess) pré édemment dé rite. L'outil SMIT e�e tuel'optimisation sur toutes les unités de traitements (PEs) du système et le réseau de ommuni ation.Holzenspies et al. [103℄ présentent une te hnique de pla ement spatial dynamique omposée de quatre étapes pour les appli ations de streaming sur un MPSoC hé-43

2.3 Pla ement d'appli ations sur Multipro esseurs sur pu e Chapitre 2 : État de l'Art
Figure 2.5 � Pla ement dynamique suivie par l'outil SMIT Mapper [4℄térogène. L'algorithme est mis en ÷uvre sur un ARM926 fon tionnant à 100 MHz( ela prend moins de 4 ms pour exé uter le HIPERLAN / 2 par exemple).Braak et al. [104℄ proposent une autre te hnique de pla ement spatial dynamiquequi ouvre à la fois le graphe de tâ hes et la plateforme MPSoC pour trouver leurpla ement optimal.Nollet et al. [28℄ dé rivent une heuristique d'assignation de tâ hes pour un pla- ement e� a e dans un MPSoC ontenant de tuiles FPGA, grâ e auxquelles l'heu-ristique est apable de gérer une hiérar hie de on�guration permettant d'améliorerla qualité et le taux de su ès de l'assignation des tâ hes.Faruque et al. [105℄ présentent une te hnique de pla ement dynamique d'appli a-tions basée sur des agents distribués iblant les grands MPSoCs omme les systèmes32X32 et 32X64. Pour les grands MPSoCs, la te hnique de pla ement distribuée estmeilleure que les te hniques de pla ement dynamique de l'état de l'art qui utilisentl'appro he du manager entralisé (Centralized Manager (CM)). L'appro he CM pourles grandes MPSoCs peut faire fa e aux problèmes suivants :� Point de défaillan e unique. 44

2.3 Pla ement d'appli ations sur Multipro esseurs sur pu e Chapitre 2 : État de l'Art� Grand volume du tra� de surveillan e par le CM� Le oût élevé pour al uler le pla ement à l'intérieur du CM.� Un goulot d'étranglement autour du CM omme haque C÷ur envoie son étatau CM après haque instan e de pla ement. Ainsi, le CM devient un point haud.La te hnique distribuée réduit le tra� de surveillan e et de l'e�ort de al ul.S hranzhofer et al. [106℄ proposent une heuristique en plusieurs étapes en tempspolynomial onstituée de solutions initiales suivies par des algorithmes de re-pla ementde tâ hes en prenant en ompte les ontraintes d'énergie. Premièrement, les solutionsinitiales pour le s énario d'optimisation d'énergie sont trouvées, puis le re-pla ementde tâ hes est réalisé a�n d'améliorer les solutions.Lei et al. [107℄ présentent un algorithme génétique en deux étapes qui trouve lepla ement des tâ hes sur les ÷urs disponibles visant à minimiser le temps d'exé u-tion global.Carvalho et al. [108℄ présentent des heuristiques où les tâ hes sont pla ées à lavolée (on-the-�y) en fon tion des demandes de ommuni ation et de la harge dansles liens du NoC. Au moment de l'exé ution, ertaines te hniques de pla ementutilisent la migration des tâ hes d'un PE à un autre lorsque le goulot d'étranglementdes performan es est déte té ou lorsque la harge de travail doit être répartie defaçon homogène dans l'ensemble du système [96, 97℄. La migration de tâ hes peutégalement être utilisée au as où le besoin de l'utilisateur est modi�é ou une nouvelleappli ation entre dans le système a�n de réviser le pla ement d'une partie des tâ hesen exé ution. La migration des tâ hes doit être exé utée sans omplètement arrêteret redémarrer les appli ations déjà en exé ution.Pla ement Basés sur les résultats d'analyse au moment de la on eptionLes stratégies de pla ement basées sur les résultats d'analyse lors de la on eption,e�e tuent l'analyse du al ul intensif au moment du design et utilisent les résultatsanalysés au moment de l'exé ution.Cela aide pour une légèreté de gestion de plateforme qui mappe dynamiquement45

2.3 Pla ement d'appli ations sur Multipro esseurs sur pu e Chapitre 2 : État de l'Artet e� a ement les appli ations basées sur l'état des ressour es de la plateforme.L'analyse au moment du design est e�e tuée en prenant la des ription de l'appli a-tion, les spé i� ations de la plateforme et les obje tifs de on eption pris en omptepour explorer les points utilisés lors de l'exé ution qui ontiennent des tâ hes àdes regroupements PEs, à savoir les pla ements, représentant des ompromis entreles di�érentes mesures de performan es. Explorer toutes les ombinaisons possiblesdes tâ hes sur les PEs n'est exhaustivement pas possible dans un temps limité.Par onséquent, des stratégies d'analyse plus rapides à obje tifs de on eption sontné essaires pour explorer des pla ements pour une appli ation (se tion 2.3.1) quipeuvent être utilisés pour réaliser une telle analyse. Elles e�e tuent l'exploration envue de ertains paramètres d'optimisation tels que la performan e de al ul et del'énergie.L'exploration du pla ement unique ne peut pas gérer le dynamisme de disponi-bilité de ressour es et les exigen es de performan es au moment de l'exé ution.Les stratégies d'analyse au moment de la on eption génèrant plusieurs pla e-ments pour l'appli ation ont ré emment été rapportés dans pas mal de travaux. Cespla ements peuvent être utilisés pour gérer le dynamisme de la disponibilité desressour es et l'exigen e de performan e au moment de l'exé ution.Dans [109℄, l'exploration est e�e tuée en vue d'optimiser la onsommation d'éner-gie et la performan e a�n d'identi�er le meilleur ompromis du rapport performan e/ puissan e onsommée.Stuijk et al. [110℄ optimisent pour l'utilisation des ressour es, Beltrame et al.[111℄ pour l'énergie et le délai. Ils essaient de minimiser le nombre de simulationsné essaires pour identi�er les pla ements fournissant un ompromis d'énergie / délai.Palermo [112℄ o�re un adre d'exploration multi-obje tifs qui fournit aussi des pontsde ompromis d'énergie / délai. Jia et al. [113℄ présentent une infrastru ture appeléeNASA (Non Ad-ho Sear h Algorithm), qui utilise di�érentes ombinaisons de stra-tégies de re her he pour explorer le pla ement. Il y a eu beau oup de re her hes dansd'exploration des systèmes lors de la on eption (DSE) des appli ations multiples.Certains her heurs se on entrent sur une appro he fondée sur plusieurs s énarios46

2.4 Analyse des heuristiques de pla ement et Con lusion Chapitre 2 : État de l'Artde pla ement d'appli ations examinés au moment du design pour gérer le dynamismedu nombre de demandes a tives au moment de l'exé ution.2.4 Analyse des heuristiques de pla ement et Con lusionDans la se tion pré édente on a fait une des ription très on ise des te hniquesde pla ement sur MPSoC onnues jusqu'à maintenant. Les te hniques existantes,pertinentes pour les pla ements des appli ations sur les plateformes MPSoC ont étédé rites dans ette se tion jusqu'à l'heure a tuelle. L'obje tif de ette sous-se tionest d'examiner de manière ritique les te hniques existantes et d'identi�er des pistesde re her he. Les ritères d'évaluation sont l'aptitude à la harge de travail dyna-mique dans les systèmes, le gain dans di�érentes mesures de performan es et de la omplexité de al ul pour l'évolutivité. Les te hniques de pla ement au moment de la on eption dé rites dans la se tion 2.3.1 examinent un ensemble �xe d'appli ationset une plateforme statique en entrée, et trouvent don un pla ement en ayant unevision globale du système. Par onséquent, ils peuvent fournir une meilleure qua-lité de pla ement par rapport aux te hniques dynamiques ayant normalement unevue lo ale. Cependant, les te hniques de pla ement statique ne sont pas adaptéespour les s énarios de harge de travail dynamiques tels que l'ajout d'une nouvelleappli ation dans le système au moment de l'exé ution, mais elles sont né essairespour gérer de tels s énarios. Les te hniques de pla ement dynamique dé rites dans lase tion 2.3.2, réparties en deux dire tions, hargent des tâ hes de l'appli ation dansle système au moment de l'exé ution lorsque l'appli ation doit être prise en harge.Certains attaquent le problème de pla ement en dé�nissant des heuristiques e� a esdé rites à la se tion 2.3.2, où de nouvelles tâ hes sont a�e tées sur les ressour essystème lors de l'exé ution et tout le traitement se fait soit au même moment, soità la volée. Ces heuristiques à la volée ne peuvent pas garantir l'ordonnan ement, 'est à dire pour les délais du temps stri t (stri t timing deadlines) en raison dela puissan e de traitement limitée au moment de l'exé ution. D'autres analysentdes appli ations au moment de la on eption (o�-line) en dé�nissant des stratégiesd'analyse e� a es, dé rites à la se tion 2.3.2, où les allo ations et l'ordonnan ement47

2.4 Analyse des heuristiques de pla ement et Con lusion Chapitre 2 : État de l'Art( 'est à dire les pla ements) sont al ulés et véri�és, puis sto kés sur le système. A�nde prendre en harge une appli ation au moment de l'exé ution, le meilleur pla e-ment est hoisi parmi eux sto kés sur la base des ressour es système disponibles, etde la performan e requise par la suite, utilisés pour on�gurer le système. Cela estplus e� a e pour une légère gestion de système dynamique et pla ement d'appli a-tions que les heuristiques à la volée. Toutefois, la �exibilité dans es appro hes estlimitée ar toutes les appli ations potentielles doivent être onnues intégralementau moment de la on eption et les résultats d'analyse appli ables uniquement à laplateforme analysée. Par onséquent, l'analyse au moment de la on eption doit êtrerépétée lors de hangements de l'ensemble d'appli ation ou plateforme. En outre, lesrésultats d'analyses sto kées introduisent une harge supplémentaire. En revan he,les heuristiques à la volée sont appli ables à n'importe quel ensemble d'appli ationset à n'importe quelle plateforme. Il a été observé que les te hniques de pla ement iblent les MPSoCs hétérogènes pour mieux répondre aux exigen es des appli ationspar rapport à leurs homologues homogènes. En outre, les MPSoCs sont basés sur lesinfrastru tures de ommuni ation NoC pour des ar hite tures e� a es et évolutives.Au début de ette re her he, nous avons été témoins que la plupart des heuristiquesà la volée existantes pour les MPSoCs hétérogènes basés NoC, ne supportent pasd'appli ations ave un nombre très grand de tâ hes, et ave l'hypothèse que l'exé u-tion des tâ hes et des ommuni ations sont de même niveau. Les travaux existantsne mettent pas l'a ent sur la minimisation du temps de re her he (temps de pla e-ment) .à.d le temps né essaire pour trouvée une ressour es qui peut supporter unetâ he prête à l'exé ution. Ainsi la plupart des travaux utilisent pour le pla ementdes ommuni ations des stratégies de routage statique à savoir le routage XY, vu sasimpli ité d'implémentation. Pour une harge de travaille dynamique, l'utilisation dete hniques de pla ement des ommuni ations dynamiques ne peut qu'être béné�quepour de tels systèmes. Les performan es fournies par les te hniques existantes depla ement, demeurent une préo upation prin ipale en raison des goulots d'étran-glement de ommuni ation. Par onséquent, des te hniques de pla ements meilleursdevraient être étudiées pour o�rir de meilleures performan es. Le Chapitre 4 traite48

2.4 Analyse des heuristiques de pla ement et Con lusion Chapitre 2 : État de l'Artnos te hniques de pla ement dynamique proposées, basées sur une stratégie de pa- king en spirale et un routage basé sur l' algorithme de plus ourt hemin de Dijkstramodi�é, iblant les MPSoCs ontenant des PEs qui supportent une seul tâ he, nousmontrons que la performan e (temps d'exé ution et onsommation d'énergie) estaméliorée. Le Chapitre 5 traite nos te hniques de pla ement dynamique proposéesbasées sur un pla ement mono-tâ he en utilisant une stratégie de pa king Man-hattan a�n de minimiser le temps de pla ement en plus de la prise en harge des ommuni ations par la proposition d'une heuristique de pla ement dynamique des ommuni ations. Le hapitre 3 présente une vue d' ensemble sur les simulateurs puisun état de omparaison. Notre ontribution dans e hapitre, sera de détailler notresimulateur de pla ement dynamique d'appli ations sur une ar hite ture MPSoC ba-sée NoC : on eption, modélisation, fon tionnement et . L'extension du simulateura�n de supporter une simulation de plateforme multi-tâ hes sera onsidérée dansnotre futur travail. En �n le Chapitre 6 ontient une on lusion de la thèse et uneidenti� ation de quelques perspe tives.
49

Chapitre 3SimulateurSommaire3.1 Introdu tion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 503.2 Outils utilisés . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 513.2.1 Langage de développement . . . . . . . . . . . . . . . . . . . . . . . . . 513.2.2 Environnement de développement . . . . . . . . . . . . . . . . . . . . . 513.3 Quelques simulateurs et Motivation . . . . . . . . . . . . . . . . . . . 523.4 Con eption détaillée . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 553.4.1 Identi� ation des a teurs et des as d'utilisations . . . . . . . . . . . . . 553.4.2 Pa kages de la plateforme . . . . . . . . . . . . . . . . . . . . . . . . . . 553.4.3 Création de l'ar hite ture . . . . . . . . . . . . . . . . . . . . . . . . . . 593.4.4 Création d'appli ations . . . . . . . . . . . . . . . . . . . . . . . . . . . 613.4.5 Modèle de simulation . . . . . . . . . . . . . . . . . . . . . . . . . . . . 643.4.6 Mesures de performan es . . . . . . . . . . . . . . . . . . . . . . . . . . 703.5 Con lusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 703.1 Introdu tionLe premier obje tif de notre re her he est, de proposer d'autres te hniques de pla- ement dynamique permettant de pla er les tâ hes d'appli ations et leurs ommu-ni ations sur une plateforme MPSoC basée NoC tout en réduisant la onsommationd'énergie et le temps d'exé ution. Cependant, pour tester es di�érentes te hniqueset les omparer, un outil de tests et de simulation s'avère né essaire. En l'absen ed'une plateforme libre permettant de réaliser es fon tionnalités, la on eption etla réalisation d'un outil qui permet de tester di�érentes te hniques de pla ementdynamique et simuler le tra� sur un NoC ont été réalisés. Dans e hapitre, notresimulateur développé en ollaboration entre les deux équipes DART et LAPECI50

3.2 Outils utilisés Chapitre 3 : Simulateursera détaillé. Ce simulateur permet de simuler à un haut niveau d'abstra tion le omportement d'un système MPSoC qui utilse un réseau sur pu e pour la ommu-ni ation. Ce niveau, permet de simuler le omportement de pla ement et d'exé u-tion des tâ hes d'appli ations. Le simulateur repose sur des modèles d'ar hite tureet d'appli ation. L'appli ation est un ensembles de tâ hes qui ommuniquent entreelles, où toutes les données liées aux tâ hes et aux ommuni ations sont onnues.A l'ar hite ture on asso ié un modèle qui dé�nit les di�érentes ara téristiques ettypes d'éléments de traitement. l'avantage du simulateur vis a vis de notre axe dere her he, et qu'il nous permettra d'intégrer fa ilement nos propositions algorith-miques et d'avoir les mesures de performan es souhaitées, qui sont dans notre as letemps d'exé ution et la onsommation d'énergie.3.2 Outils utilisésDans e qui suit, les outils utilisés pour la réalisation de la plateforme de simula-tion sont présentés.3.2.1 Langage de développementLe langage Java a été utilisé omme outil de développement. Ce langage présenteles avantages suivants :� simple à maitriser.� il est orienté objet, e qui a permis d'implémenter la plateforme de manièremodulaire et de fa iliter son extension.� il est indépendant de la plateforme d'exé ution, e qui rend l'appli ation om-patible ave d'autres systèmes d'exploitation.3.2.2 Environnement de développementLa plateforme de simulation a été développée sous le système d'exploitation Win-dows ave l'environnement E lipse.E lipse est un environnement de basé sur la démar he IDM (MDE). Il est orien-tée objet, assurant une grande interopérabilité des outils les onstituant. Il permet51

3.3 Quelques simulateurs et Motivation Chapitre 3 : Simulateurle développement d'appli ations en vue de leur déploiement sous Windows ou sousLinux. Il trouve son origine au sein de la so iété IBM qui a dé idé en 2001 de mettreà disposition de la ommunauté Open Sour e l'ébau he d'une plateforme de déve-loppement ouverte, entièrement é rite en Java et apable d'intégrer des extensionsadaptées à diverses a tivités (débogage, modélisation, interfa es graphiques, et .).3.3 Quelques simulateurs et MotivationLes réseaux sur pu e (NoCs) ont attiré une grande attention au ours des der-nières années omme étant un nouveau paradigme d'inter onnexion des di�érents omposants d'une pu e. En tant que tel, il y a eu un besoin a ru de dé�nir et dedévelopper des logi iels de simulation de l'exé ution d'appli ations sur des réseauxde pro esseurs sur pu e. Quelques simulateurs sont présentés dans e qui suit :• GPNoCSim : Pour General Purpose Simulator for Network-on-Chip [114℄, 'estun simulateur de NoC open sour e, développé entièrement en java. Il est �exible ar il permet aux designers de rajouter de nouvelles ar hite tures ainsi que la on�guration du tra� . Le but �nal de e simulateur est de omparer entre lesdi�érente topologies du NoC en mesurant la laten e, l'utilisation des liens, et .• BookSim : Est un simulateur d'inter onnexion des réseaux [115℄. La versiona tuelle majeure, BookSim 2.0, prend en harge un large éventail de topologies omme le mesh2D, tore et fat tree. Il fournit divers algorithmes de routage etin lut de nombreuses options de personnalisation de mi ro-ar hite ture routeurdu réseau. Il a été développé par des her heurs de l'université de Stanford auxUSA.• Noxim : Ce simulateur a été proposé par l'équipe d'ar hite ture des ordinateursde l'Université de Catane [116℄. Il est développé en Langage SystemC. Il permetà l'utilisateur de dé�nir un NoC ayant une topologie en 2d mesh ave desparamètres di�érents : taille du réseau, taille du bu�er, la taille des paquets,algorithme de routage et taux d'inje tion de paquets. Noxim permet l'évaluationdes NoC en termes de débit, de laten e et la onsommation d'énergie.52

3.3 Quelques simulateurs et Motivation Chapitre 3 : Simulateur• NS-2 : A été développé pour le prototypage et la simulation de réseaux informa-tiques ordinaires. Cependant, puisque les NoCs ont de nombreuses similaritésave les réseaux lassiques, NS-2 [117℄ a été largement utilisé par de nombreux her heurs pour simuler un NoC. De nombreuses études ont utilisé NS-2 ommeun outil de simulation e qui en fait une référen e �able, surtout lorsque l'on ompare les performan es de deux ar hite tures di�érentes. En�n, NS-2 estopen sour e, axé sur simulateur à événements dis rets et développé en C++.• Darsim : Est un simulateur de NoC qui a été développé à Massa husetts Instituteof Te hnology (MIT) [118℄. Ce framework permet la simulation d'ar hite turesmailles de 2 et 3 dimensions. Il o�re une multitude de on�gurations de simu-lation ave des paramètres di�érents, tels que la taille du réseau, la taille desVC (Virtual hannel), le modèle de mémoire, et .La plupart des simulateurs existants fo alisent sur le tra� réseau sur di�érentestopologies en ignorant les éléments d'exé ution. C'est e qui nous a motivé à on e-voir un simulateur à haut niveau d'abstra tion. Notre obje tif dans ette thèse estde développer d'autres te hniques de pla ement dynamique sur des réseaux de pro- esseurs sur pu e. La simulation et l'évaluation des algorithmes de pla ement dyna-mique proposés, né essitent un outil de simulation qui permet d'a élérer les déve-loppements en Co-design à un niveau d'abstra tion plus haut. Ce besoin n'est o�ertpar au un des simulateurs ités pré édemment. La plus part des travaux qui traitentla problématique du Co-design utilisent des outils de développement matériel ou lo-gi iel. Pour le logi iel, ils utilisent des outils à bas niveau. Ce qui provoque un tempsde on eption et un y le de développement onséquent, vu la omplexité de ettephase. Toutes es limites, nous ont poussé à développer un simulateur de haut ni-veau d'abstra tion. Ce hoix se justi�e par la simpli ité qui pourrait être obtenupour la on eption et le y le de développement plus au moins, avant de passer auniveau le plus bas. Nous pensons à e que notre simulateur permet d'a élérer lespré-résultats des �ots de on eption. Le simulateur a été développé en ollaborationentre les équipes LAPECI et DaRT de Lille1. Il permet le pla ement des tâ hes et53

3.3 Quelques simulateurs et Motivation Chapitre 3 : Simulateurdes ommuni ations. Il permet aussi de simuler di�érents types d'éléments de trai-tements (GPP, FPGA, DSP, ASIC, et .) et les réseaux de ommuni ation (routeurs,liens, a hes, mémoires, et .). La plus plus petite unité é hangée dans le réseauest un paquet. Don , le simulateur permet de simuler parfaitement le déroulementdes propositions algorithmiques de pla ement des tâ hes et des ommuni ations. Laplateforme de simulation supporte le mono et le multi-tâ hes. Pour le mono-tâ he, haque ressour e ne permet l'exé ution que d'une seule tâ he. Par ontre le multi-tâ hes permet pour haque ressour e d'exé uter plusieurs tâ hes. A partir de etteplateforme de simulation, deux autres thèses sont en ours pour étendre l'outil. Lapremière thèse, va traiter les ommuni ations à grain �n (phit, �it). La migrationde tâ hes pour un équilibrage de harge meilleurs. La deuxièmes thèse va prendreen onsidération les tâ hes temps réel. Pour ela, le modèle d'appli ation va êtrerendu plus général. Une on eption pour la simulations d'appli ations temps réelest prévue. Une étape d'observation pour prendre les bonnes dé isions va être ajou-tée. Nous voulons arriver à un standard de simulation qui pourrait être un supportde validations des futures travaux de nos équipes.Le tableau 3.1 résume les di�érentes ara téristiques des simulateurs vus pré édem-ment. Année Equipe Topologie Outil dedéveloppementGPNoCSim 2006 Université de Ben-gladesh Mesh2D, Tore, Fattree javaBOOKSIM 2010 Université de Stan-ford Mesh2D, Tore, Fattree C++Noxim 2010 Université de Ca-tagne Mesh2D C++NS-2 1995 Lawren e BerkleyNational Laboratory Mesh2d, Tore, Fattree C++Darsim 2009 MIT Mesh 2D, Mesh 3D C++Table 3.1 � Synthèse des simulateurs54

3.4 Con eption détaillée Chapitre 3 : Simulateur3.4 Con eption détailléeA�n de omprendre les fon tionnalités fournies par la plateforme de simulation,une modélisation UML (Uni�ed Modeling Language) est présentée. Celle- i om-prend une identi� ation des a teurs des di�érents as d'utilisations.3.4.1 Identi� ation des a teurs et des as d'utilisationsLe simulateur vise une seule lasse d'a teurs, à savoir des utilisateurs qui peuventêtre des on epteurs.L'utilisateur, un demandeur de servi e, est une personne qui utilise la plateformepour réaliser une simulation de pla ement de di�érentes appli ations dé�nit selonun modèle bien pré is. Ces pla ements se font lors de l'exé ution, à d pour haqueappli ation les tâ hes se génèrent au fur et à mesure dans le temps et sont pla éessur la plateforme simulée dynamiquement. Pour haque simulation des mesures deperforman es sont produites selon un modèles mathématique dé�nit dans la on ep-tion du simulateur. Il est possible de simuler le tra� du NoC et ainsi analyser lesperforman es.le diagramme de as d'utlisation (3.1) permet de visualiser de façon globale les ser-vi es o�erts par le simulateur. DesignNOC est le seul as d'utilisation, il o�re lapossibilité de tester les te hniques de pla ement dynamique, de routage, de simulera�n d'obtenir les performan es du NoC.Dans e qui suit, une vue statique des éléments qui omposent le simulateur etun diagramme de lasses global qui explique les di�érentes intera tions entre ses omposants sont présentés.3.4.2 Pa kages de la plateformeLa plateforme a été réalisée autour de inq grandes fon tionnalités, à savoir :• la réation d'un NoC.• la réation d'appli ations. 55

3.4Con eptiondétailléeChapitre3:Simulateur
Generate Architecture
Create ArchitectureOpen Architecture
Generate Application
Create ApplicationOpen Application
perform mapping
Simulate
view the results
Design NoC
User
Create Architecture
Open Architecture Edit architecture
Create Application
Open Application Edit application
«includes»
«includes»
«includes»
«includes»
«includes»
« Extends»
« Extends»
« Extends»
« Extends»
« Extends»
« Extends»
Figure 3.1 � Diagramme de as d'utilisation
56

3.4 Con eption détaillée Chapitre 3 : Simulateur• le pla ement des appli ations sur le NoC.• le routage des ommuni ations.• la simulation du NoC résultant et a� hage des performan es.Les di�érents pa kages assurant es fon tionnalités sont :
• Pa kage Ar hite ture Ce pa kage permet de générer l'ar hite ture d'un réseausur pu e ave une topologie en mesh 2d. Il est omposé de la lasse CreateNOC.Cette dernière rée et dé rit l'ensemble des tuiles et liens physiques.• Pa kage Appli ation Le pa kage Appli ation harge les di�érentes appli ationsà partir d'un � hier XML qui seront plus tard pla ées sur l'ar hite ture. Uneappli ation est dé rite par un graphe omposé de tâ hes et de liens de ommu-ni ations entre les di�érentes tâ hes.• Pa kage Dynami Mapping Il ontient di�érentes heuristiques de pla ementdynamique permettant le pla ement des appli ations sur une ar hite ture hé-térogène.• Pa kage Routing Le pa kage Routage permet le routage des ommuni ationsentre les tâ hes. Ce pa kage ontient les algorithmes de routage, à savoir : lesméthodes statique tel que le XY et dynamiques tel que le MORA.• Pa kage Simulation Ce pa kage se harge de la simulation du pla ement desdi�érentes tâ hes et du routage de leurs ommuni ations ainsi que toutes lesappli ations sur l'ar hite ture rées. La lasse simulateur est le noyau du simu-lateur, elle permet de gérer les di�érentes a tions menées par une simulation.• Pa kage Results Ce pa kage a pour fon tion l'a� hage des mesures de perfor-man e souhaitées par la simulation.Diagramme de lassesLe diagramme i-dessous 3.2 présente les di�érentes lasses du simulateur et lesintera tions entre elles.
57

3.4Con eptiondétailléeChapitre3:Simulateur
Application
Create_Application
+Application_Number: Int
+Read_XML_File(Lien F)
Task
+Id: Int
+Type: Int
+Size: Int
+Succ: List<Tasks>
+Shared_Data: List<Task,Int>
+X: Int
+Y: Int
+Get_Size()
+Get_Succ()
Application
+Id: Int
+Task_Number: Int
+Execution_Time: Int
+Energy_Consumption: Int
+Set_Execution_Time(Int Time)
+Set_Energy_Consumption(Int Energy)
Architecture
Create_NoC
+Line_Number: Int
+Column_Number: Int
+CreateNoC()
ProcessorElement
+Id: Int
+Type: Int
+Frequency: Int
+Memory_Size: Int
+State: Boolean
+Run_Task(Task t)
+Set_State()
Physical_Link
+Id_Proc_Source: Int
+Id_Proc_Destination: Int
+Link_load: Int
+File_Paquets: FIFO
+Add_Paquet(Paquet p)
+Delete_Paquet()
+Get_Load()
Routing
Send
+Methods: String
+X,Y_Source: Int
+X,Y_Destination: Int
+launch_Routing(x,y,x1,y1)
XY
+X,Y_Source: Int
+X,Y_Destination: Int
+Start_Routing()
+Return_Traject()
MORA
+X,Y_Source: Int
+X,Y_Destination: Int
+Start_Routing()
+Return_Traject()
Dynamic Mapping
Mapping_Methods
+Methods: String
+Research_Strategy: String
+Courent_Proc: Int
+Task_to_map: task
+Launch_Mapping()
NN
+X: Int
+Y: Int
+Start_GBHD()
+Return_Manhattan()
BN
+X: Int
+Y: Int
+Start_GBHD()
+Start_Manhattan()
Simulator
Simulator
+Tnow: Int
+T_next_event: List<Int>
+Add_event(int Time)
+Start_simulation()
Results
Results
+Execution_Time: Int
+Energy_Consumption: Int
Figure 3.2 � Diagramme de lasses du simulateur
58

3.4 Con eption détaillée Chapitre 3 : Simulateur3.4.3 Création de l'ar hite tureLe simulateur proposé permet de on evoir une ar hite ture NoC hétérogène enMesh-2D. Cette ar hite ture est omposée de plusieurs types de pro esseurs, à savoirdes GP, ASIC, FPGA, DSP. Ces derniers peuvent exé uter du mono ou multi-tâ hes,on parle alors d'une plateforme Mono ou Multi-tâ hes. La �gure 3.3 montre unexemple d'une ar hite ture qui peut être générée par le simulateur. L'ar hite ture rée est subdivisée en lusters.
Figure 3.3 � Ar hite ture hétérogène d'un NoCManager :Un des pro esseurs (GP) du NoC est utilisé omme un pro esseur manager.Ce dernier permet le ontr�le et la gestion entralisée du NoC. Les prin ipalesfon tionnalités assurées par le manager sont :� le pla ement des tâ hes : re her he le PE dans l'ar hite ture suivant uneheuristique de pla ement a�n de lui allouer une tâ he,� l'ordonan ement des tâ hes : dé�nit l'ordre d'exé ution des tâ hes,� le routage des ommuni ations : détermine le hemin à emprunter entre59

3.4 Con eption détaillée Chapitre 3 : Simulateurdeux tâ hes ommuni antes (maître/es lave) qui ont été déjà pla ées aupa-ravant,� la mise à jour de la plateforme : mise à jour en temps réel des tuiles etdes liens de ommuni ations.Diagramme de lassesLe diagramme suivant 3.4 illustre les di�érentes lasses et ara téristiques qui omposent le pa kage Ar hite ture.Create_NoC
+Line_Number: Int
+Column_Number: Int
+CreateNoC()
ProcessorElement
+Id: Int
+Type: Int
+Frequency: Int
+Memory_Size: Int
+State: Boolean
+Run_Task(Task t)
+Set_State()
Physical_Link
+Id_Proc_Source: Int
+Id_Proc_Destination: Int
+Link_load: Int
+File_Paquets: FIFO
+Add_Paquet(Paquet p)
+Delete_Paquet()
+Get_Load()
Manager
+Mapping()
+Routing()
+Update()Figure 3.4 � Diagramme de lasses du pa kage Ar hite ture• Pro essorElement :La lasse Pro essorElement représente les pro esseurs. Chaque pro esseur est ara térisé par :� Id : identi�ant du pro esseur,� Type : et argument représente le type de pro esseur(GP, FPGA, ASIC,60

3.4 Con eption détaillée Chapitre 3 : SimulateurDSP),� x,y : 'est les oordonnées de la ligne et la olone dans le NoC,� State : variable qui détermine si le pro esseur est libre ou pas,� Memory : mémoire d'un pro esseur,� Frequen y : 'est le nombre de y les d'horloge par unité de temps (se onde,ms, e t),� Energy : 'est l'énergie onsommée pendant l'exé ution d'un y le d'horloge,(en unité d'énergie "joul, mj, e t" ),� Mode : variation de la fréquen e d'exé ution.• Physi al_Link : un lien physique a les arguments suivants :� Id : identi�ant du lien,� Idpro sour e : Id du pro esseur sour e,� Idpro destination : Id du pro esseur destination,� Load : représente la taille des données qui doivent transiter par e lien.3.4.4 Création d'appli ationsUne appli ation est représentée par un graphe de tâ hes orienté TG = (T,L), oùT est l'ensemble des tâ hes d'une appli ation et L est l'ensemble des liens qui relientles tâ hes de ette appli ation (�gure 3.5.(a)). Chaque appli ation a une seule tâ heinitiale et plusieurs tâ hes softwares et hardwares. La onnexion entre deux tâ hesest une onnexion maître-es lave (3.5.(b)). La tâ he début de l'appli ation est latâ he initiale, ette dernière n'a pas de maître. Les liens ontiennent respe tivementles données partagées entre haque maître-es lave.Représentation des appli ations :La liste des appli ations est représentée par un � hier XML donné en entré. Les�gures 3.6 et 3.7 montrent un exemple d'une appli ation et sa représentation en� hier XML, respe tivement. 61

3.4 Con eption détaillée Chapitre 3 : Simulateur
Figure 3.5 � Appli ations maitre/es lave
Figure 3.6 � Exemple d'une appli ationDiagramme de lassesLe diagramme suivant 3.8 montre les di�érentes lasses du pa kage appli ation.Appli ation : Les prin ipaux attributs de l'appli ation sont :� TaskList : la liste des tâ hes qui omposent l'appli ation,� Exe utionTime : le temps d'exé ution global de l'appli ation,� EnergyConsumption : l'énergie onsommée lors de son exé ution.Task : Chaque tâ he est asso iée aux attributs suivants :� Id : Identi�ant de la tâ he,� Type : le type de pro esseur sur lequel la tâ he peut s'exé uter(GP, FPGA,et .),� Size : la taille de la tâ he selon le type (en nombre d'unité de donnée "o tet,62

3.4 Con eption détaillée Chapitre 3 : Simulateur
Figure 3.7 � Representation d'une appli ation en XML63

3.4 Con eption détaillée Chapitre 3 : SimulateurCreate_Application
+Application_Number: Int
+Read_XML_File(Lien F)
Task
+Id: Int
+Type: Int
+Size: Int
+Succ: List<Tasks>
+Shared_Data: List<Task,Int>
+X: Int
+Y: Int
+Get_Size()
+Get_Succ()
+Set_Position(Int x1, Int x2)
Application
+Id: Int
+Task_Number: Int
+Execution_Time: Int
+Energy_Consumption: Int
+List_Tasks: List<tasks>
+Id_Cluster
+Set_Execution_Time(Int Time)
+Set_Energy_Consumption(Int Energy)
+Set_Id_Cluster(Int Id)Figure 3.8 � Diagramme de lasses du pa kage Appli ationbit, et ."),� y les : le nombre de y les né essaire à l'exé ution de la tâ he selon le type,� SharedData : la taille de donnée partagée ave haque �ls (en unités dedonnées),� x,y : les oordonnées du pro esseur sur lequel la tâ he sera pla ée.Diagramme de séquen e :Le diagramme de séquen e 3.9 illustre l'intera tion entre la tâ he maître et satâ he es lave.3.4.5 Modèle de simulationDans ette se tion nous expliquons l'intérêt et les on epts de la simulation.La simulation est par dé�nition une imitation ou une représentation d'un sys-tème par un autre. En tant que telle, plusieurs aspe ts de la simulation sont dessimpli� ations du système réel ou proviennent de dédu tion faites à partir d'étudessur des systèmes similaires.Quand un système est simulé, il est représenté omme un ensemble de modulesqui sont inter onne tés les uns aux autres. La manière dont es modules s'exé utentet interagissent les uns ave les autres est appelée un modèle de simulation. Parmi lesmodèles de simulation on distingue la simulation à événement dis ret et la simulation64

3.4 Con eption détaillée Chapitre 3 : Simulateur
Figure 3.9 � Diagramme de séquen e illustrant l'intera tion entre maître/es laveà pas �xe.Le simulateur que nous avons onçu utilise l'appro he par événement dis ret. Lapro haine se tion dé rit ette appro he.La simulation à évènement dis ret :En simulation à événement dis ret, seuls les points où l'état du système hangedans le temps sont représentés. En d'autres termes, le système est modélisé ommeune suite d'événements, 'est-à-dire les instants où les hangements d'état du sys-tème se produisent. Des événements omme les arrivées des entités, le début deservi e d'une entité, une reprise de servi e d'une ressour e où ha un se produit àun instant[119℄. Dans la simulation à événements dis rets, il existe une �le d'at-65

3.4 Con eption détaillée Chapitre 3 : Simulateurtente globale dans laquelle est sto kée la liste des événements qui vont se produire.L'avantage de ette te hnique se résume au fait que le système est vu omme étant omposé d'une olle tion d'événements, ha un de es événements s'exé utant ins-tantanément vis-à-vis de l'horloge de simulation, hangeant l'état de l'objet modélisé,séle tionnant et programmant l'événement su esseur qui se réalisera dans le futur.L'in onvénient majeur de ette appro he est que le programmeur doit expli itementpartitionner un modèle en événements, e qui rend la stru ture du modèle di� ileà omprendre.Les omposants de base du modèle de simulationQuelque soit le système simulé il doit omporter trois omposants prin ipaux :• entités : sont des objets omportant des attributs propres qui in�uent dans le hangement d'état du système,• �les d'attente : les entités attendent généralement dans une �le d'attentejusqu'à être servies,• ressour es : traitent ou servent les entités en �le d'attente. Ces ressour essont libres quand elles sont disponibles pour le traitement ou o upées quandelles traitent des entités.Par analogie dans notre système, es omposants sont représentés respe tive-ment par :• les appli ations,• �le d'attente des appli ations,• l'ensemble des PEs et liens physiques.La liste des événements du simulateur :Le tableau 3.2 ite quelques événements, hangement d'état ainsi que les événe-ments programmés qui sont gérés par le simulateur.A�n de mieux omprendre le déroulement des événements lors de la simulation ;le tableau 3.3 présente un exemple de la simulation du pla ement de 2 appli ationsen parallèle. Cha unes de es deux appli ations est omposée de 2 tâ hes (une tâ he66

3.4 Con eption détaillée Chapitre 3 : SimulateurEvénemnt Changement d'état Evénement programméArrivée des Ajouter les appli ations à la �le Pla ement des tâ hesAppli ations d'attente des appli ations initialesPla ements des tâ hes Rendre le luster o upée Débutinitiales Rendre le PE du milieu du luster o upée exé utionDébut exé ution Rendre le PE o upée Fin exé utionFin exé ution Libérer le PE Pla ement des tâ hes �lsPla ement dynamiques Assigner une tâ he à un PE Début dedes tâ hes �ls routageDébut de routage Modi�er la harge des liens Fin de routageFin de routage Modi�er la harge des liens Début exé utionTable 3.2 � Liste des événementsinitiale et sa tâ he es lave).
67

3.4 Con eption détaillée Chapitre 3 : SimulateurTemps Evénemnt0 Arrivée de l'appli ation 1 et 2Pla ement statique des tâ hes initiales de l'appli ation 1 et 2Début exé ution des deux tâ hes initiales400 Demande de pla ement de la tâ he es lave de l'appli ation 1Pla ement dynamique de la tâ he es lave500 Pla ement de la tâ he es lave (appli ation 1) terminéDébut de routage (du maître vers l'es lave)600 Demande de pla ement de la tâ he es lave de l'appli ation 2Pla ement dynamique de la tâ he es lave700 Pla ement de la tâ he es lave terminé de l'appli ation 2Début de routage (du maître vers l'es lave)3100 Fin de routage entre la tâ he maître et son es lave (appli ation 1)Début exé ution de la tâ he es lave3300 Fin de routage entre la tâ he maître et son es lave (appli ation 2)Début exé ution de la tâ he es lave3600 Fin d'exé ution de la tâ he es lave (appli ation 1)Lan ement du routage (de l'es lave vers le maître)3700 Fin d'exé ution de la tâ he es lave (appli ation 2)Lan ement du routage (de l'es lave vers le maître)4100 Fin de routage entre la tâ he es lave et son maître (appli ation 1)Reprise d'exé ution de la tâ he maître4300 Fin de routage entre la tâ he es lave et son maître (appli ation 2)Reprise d'exé ution de la tâ he maître5000 Fin d'exé ution de la tâ he initiale (maître) (appli ation 1)Fin d'exé ution de l'appli ation 15300 Fin d'exé ution de la tâ he initiale (maître) (appli ation 2)Fin d'exé ution de l'appli ation 2Fin de simulationTable 3.3 � Exemple d'un déroulement de la simulation68
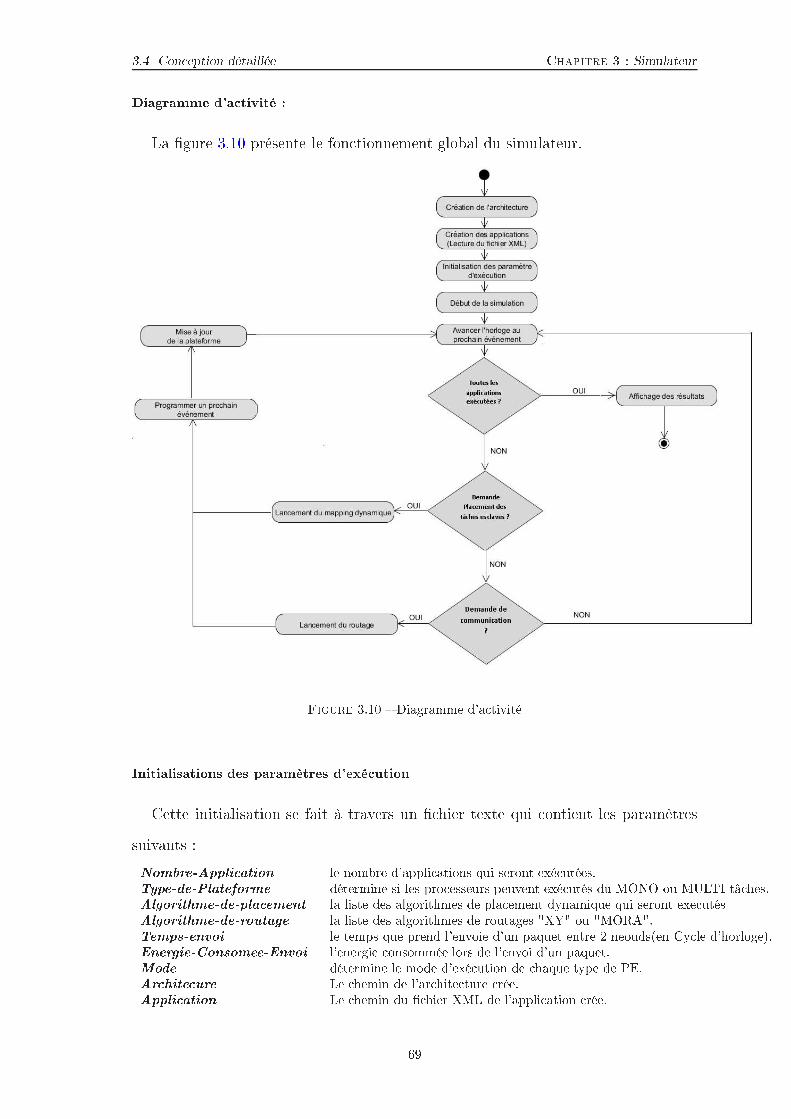
3.4 Con eption détaillée Chapitre 3 : SimulateurDiagramme d'a tivité :La �gure 3.10 présente le fon tionnement global du simulateur.
Figure 3.10 � Diagramme d'a tivitéInitialisations des paramètres d'exé utionCette initialisation se fait à travers un � hier texte qui ontient les paramètressuivants :Nombre-Appli ation le nombre d'appli ations qui seront exé utées.Type-de-Plateforme détermine si les pro esseurs peuvent exé utés du MONO ou MULTI tâ hes.Algorithme-de-pla ement la liste des algorithmes de pla ement dynamique qui seront exe utésAlgorithme-de-routage la liste des algorithmes de routages "XY" ou "MORA".Temps-envoi le temps que prend l'envoie d'un paquet entre 2 neouds(en Cy le d'horloge).Energie-Consomee-Envoi l'energie onsommée lors de l'envoi d'un paquet.Mode détermine le mode d'exé ution de haque type de PE.Ar hite ure Le hemin de l'ar hite ture rée.Appli ation Le hemin du � hier XML de l'appli ation rée.69

3.5 Con lusion Chapitre 3 : Simulateur3.4.6 Mesures de performan esLe simulateur que nous avons mis en ÷uvre permet de simuler plusieurs te h-niques de pla ement dynamique d'appli ations sur une ar hite ture NoC a�n demesurer et omparer les performan es de es te hniques en termes de temps d'exé- ution et de onsommation d'énergie.3.5 Con lusionLe manque d'outils qui permettent d'e�e tuer le pla ement dynamique d'appli a-tions sur des plateformes MPSoCs hétérogène basée NoC, de simuler le tra� etd'évaluer les performan es des systèmes basés sur ette stru ture nous ont pous-sés à on evoir un nouveau simulateur. Ce hapitre a été entièrement onsa ré auxdétails de la on eption des di�érentes fon tionnalités de e nouveau simulateur età quelques tests qui ont été présentés à la �n du hapitre. Néanmoins de par sa on eption orientée objet, et outil est fa ilement extensible et peut être enri hi et omplété par d'autres fon tionnalités s'intégrant dans la phase de on eption desMPSoCs basée NoCs.
70

Chapitre 4Heuristiques pour le routage et lepla ement dynamique de tâ hes enspirale sur un MPSoC basée NoCSommaire4.1 Introdu tion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 714.2 Classi� ation des pla ements statique et dynamique . . . . . . . . . 734.2.1 Te hniques de pla ement statique . . . . . . . . . . . . . . . . . . . . . 734.2.2 Te hniques de pla ement Dynamique . . . . . . . . . . . . . . . . . . . . 744.3 Ar hite ture MPSoC Hétérogène . . . . . . . . . . . . . . . . . . . . . 764.4 Appro hes proposées . . . . . . . . . . . . . . . . . . . . . . . . . . . . 774.4.1 Dé�nitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 784.4.2 Heuristiques de pla ement dynamique de référen e . . . . . . . . . . . . 794.4.3 Heuristique proposée basée sur la stratégie de pa king en spirale et leroutage dynamique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 824.5 Con�gurations expérimentales et Résultats . . . . . . . . . . . . . . . 834.5.1 Con�gurations expérimentales . . . . . . . . . . . . . . . . . . . . . . . . 844.5.2 Résultats expérimentaux . . . . . . . . . . . . . . . . . . . . . . . . . . . 854.6 on lusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 864.1 Introdu tionLes systèmes Multipro esseurs (MPSoCs) sont une solution qui implémente unnombre multiple d'éléments de traitements (PEs) sur une même pu e. L'avan ée dela nanote hnologie prédit que les MPSoCs futurs ontiendront des milliers d'unitésde traitement (PEs) sur une seule pu e d'i i 2015 [120℄. Les MPSoCs sont de plus71

4.1 Introdu tionChapitre 4 : Heuristiques pour le routage et le pla ement dynamique de tâ hes en spirale surun MPSoC basée NoCen plus utilisés dans les appli ations embarquées omplexes. Le Network-On-Chip(NoC) a été introduit omme un mé anisme d'inter onne tions entre les di�érentesunités de traitements qui se trouvent sur une même pu e, permettant une énergiee� a e, une onne tique évolutive (s alable) [14, 121℄. Le pla ement (Mapping) estune très importante phase dans l'exploration ar hite turale dans les systèmes MP-SoCs basés NoC. Les plateformes d'ar hite ture et d'appli ation sont représentéespar des graphes. Considérant le moment où le pla ement des tâ hes est exé uté, lesappro hes peuvent être statiques ou dynamiques. Le pla ement statique dé�nit lepla ement des tâ hes lors de la on eption, qui dispose d'une vue globale sur lesressour es du MPSoCs et omme il est exé uté lors de la on eption, il utilise desalgorithmes omplexes pour mieux explorer les ressour es d'un MPSoC, résultantd'une solution optimisée [122, 123, 124, 125, 126, 127, 128℄. Cependant, le pla ementstatique n'est pas apable de gérer la harge de travail dynamique, qui se présentesous forme de nouvelles tâ hes ou appli ations hargées lors de l'exé ution. Pourfaire fa e aux exigen es de harge de travail dynamique sur les MPSoCS a tuels,les te hniques de pla ement dynamique sont né essaires pour le pla ement sur lesressour es de la plateforme [129, 130, 131, 98, 95, 100, 132℄. Le but prin ipal de e hapitre est de présenter une nouvelle heuristique de pla ement dynamique detâ hes d'appli ations en spirale. L'heuristique présentée est appliquée sur une plate-forme MPSoC hétérogène. Deux types d'unités de traitements (PEs) sont onsidérées"instru tion set pro essors" (ISPs) et "Re on�gurable Areas" (RA). "Instru tionsset pro essors" sont utilisés pour exé uter les tâ hes logi ielles et "Re on�gurableAreas" pour les matérielles. L'heuristique essaye aussi de pla er les tâ hes d'appli a-tion en des régions de lusterisation pour réduire les sur harges des ommuni ationsdes tâ hes ommuni antes. L'heuristique proposée dans e hapitre tente de pla erles tâ hes d'une appli ation les plus ommuni antes en spirale, dans le but de mini-miser les oûts de ommuni ation. Un algorithme de routage basé sur l'algorithmede Dijkstra est également présenté dans e hapitre. L'obje tive de pla ement des ommuni ations (routage) est de trouver la meilleure harge possible du hemin quiminimise les outs de ommuni ation. La nouvelle heuristique présentée montre une72

4.2 Classi� ation des pla ements statique et dynamiqueChapitre 4 : Heuristiques pour le routage et le pla ement dynamique de tâ hes en spirale surun MPSoC basée NoCamélioration de performan es signi� ative par rapport aux dernières heuristiques depla ement rapportées dans la littérature. Les mesures de la performan e in luent letemps d'exé ution et la onsommation d'énergie.Le reste de e hapitre est organisé omme suit :La Se tion 2 présente une lassi� ation des te hniques de pla ement statique etdynamique à partir d'un état de l'art.La Se tion 3 présente l'ar hite ture du MPSoC.Dans la Se tion 4, la stratégie de pla ement des tâ hes en spirale et la stratégie depla ement des ommuni ations à base de l'algorithme dijkstra sont présentées.L'expérimental et les résultats sont présentés dans la Se tion 5.La Se tion 6 on lut e hapitre.4.2 Classi� ation des pla ements statique et dynamiqueLe pla ement des tâ hes sur la plateforme MPSoC onsiste à trouver l'a�e tationdes tâ hes sur les éléments de la plateforme qui satisfait ertains ritères d'opti-misation omme la rédu tion de la onsommation d'énergie, la rédu tion du tempstotal d'exé ution et l'optimisation de l'o upation des anaux. Si la plateforme esthétérogène, alors le pro essus de "task binding" (liaison de tâ hes) est né essaireavant de trouver le pla ement d'une tâ he. Cela onsiste à dé�nir les ressour es dela plateforme pour haque type de tâ he telle que � instru tion set pro essors �pour les tâ hes logi ielles et les � FPGA tiles � pour les tâ hes matérielles. Le pla e-ment des tâ hes est réalisé soit par pla ement statique (design-time) ou dynamique(run-time) [120℄.4.2.1 Te hniques de pla ement statiqueLa plupart des travaux existant dans la littérature qui traitent le problème depla ement sur des ar hite tures MPSoC basées NoC, sont du genre statique, e quidé�nit le pla ement des tâ hes lors de la on eption (design time). Cette démar he onsiste à avoir une vue globale sur les ressour es de la plateforme MPSoC et les73

4.2 Classi� ation des pla ements statique et dynamiqueChapitre 4 : Heuristiques pour le routage et le pla ement dynamique de tâ hes en spirale surun MPSoC basée NoCtâ hes d'appli ations (graphes de tâ hes). Etant donné, qu'elles sont exé utées lorsde la on eption, elles utilisent des algorithmes omplexes pour mieux explorer lesressour es de l'MPSoC, résultant de solutions optimisées. Des heuristiques ommel'appro he génétique ou PSO et des méthodes exa tes omme la re her he Tabou oule re uit simulé, sont présentées dans [122, 124, 125, 127, 128℄. Dans [123, 126℄ desalgorithmes de pla ement pour une énergie e� a e, sont présents. Ces te hniquestrouvent des pla ements �xes des tâ hes lors de la on eption ave un omporte-ment de al ul et de ommuni ations bien onnu. Un état de l'art lassi�e pourles te hniques de pla ements statique est montré dans la Table 4.1. Cependant, lespla ements statiques ne sont pas apables de gérer une harge de travail dynamique,où on a de nouvelles tâ hes ou appli ations hargées à l'exé ution. Pour faire fa eà ette ara téristique des MPSoCs a tuelle et future, les te hniques de pla ementdynamique (run-time) s'avèrent né essaires pour palier aux besoins de harge dyna-mique, et ainsi prendre en harge les pla ements dynamiques sur les ressour es dela plateforme.4.2.2 Te hniques de pla ement DynamiqueLe dé� dans les derniers travaux pour la résolution du problème de pla ement surles MPSoCs hétérogènes basés NoC, est de présenter des te hniques de pla ementdynamique pour le pla ement e� a e des tâ hes ou d'appli ations qui demandent àêtre exé utées lors de l'exe ution.Wildermann et al. [133℄ ont évalué les avantages de l'utilisation d'une heuristiquede pla ement dynamique (fon tions de oûts de ommuni ation et de voisinage),qui permet de diminuer la sur harge de ommuni ation. Holzenspies et al. [103℄ ontétudié une autre te hnique de pla ement dynamique spatiale, et onsidèrent desappli ations de streaming pour le pla ement sur des MPSoCs hétérogènes, visant àréduire la onsommation d'énergie imposée par de tels omportements d'appli ation.S hranzhofer et al. [134℄ suggèrent une stratégie dynamique basée sur les pla- ements pré- al ulés (modèles dé�nis lors de la on eption) utilisés pour pla er lestâ hes nouvellement a quises sur les PEs au moment de l'exé ution.74
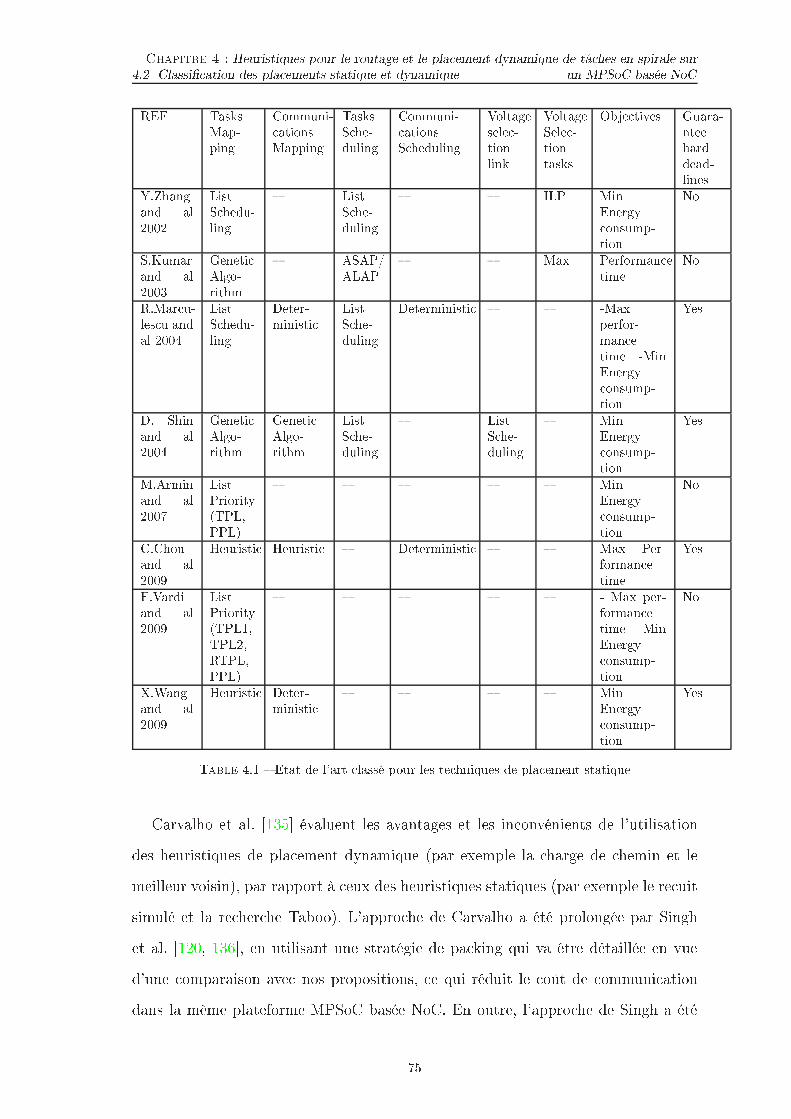
4.2 Classi� ation des pla ements statique et dynamiqueChapitre 4 : Heuristiques pour le routage et le pla ement dynamique de tâ hes en spirale surun MPSoC basée NoCREF TasksMap-ping Communi- ationsMapping TasksS he-duling Communi- ationsS heduling Voltagesele -tionlink VoltageSele -tiontasks Obje tives Guara-nteeharddead-linesY.Zhangand al2002 ListS hedu-ling � ListS he-duling � � ILP MinEnergy onsump-tion NoS.Kumarand al2003 Geneti Algo-rithm � ASAP/ALAP � � Max Performan etime NoR.Mar u-les u andal 2004 ListS hedu-ling Deter-ministi ListS he-duling Deterministi � � -Maxperfor-man etime -MinEnergy onsump-tionYes
D. Shinand al2004 Geneti Algo-rithm Geneti Algo-rithm ListS he-duling � ListS he-duling � MinEnergy onsump-tion YesM.Arminand al2007 ListPriority(TPL,PPL) � � � � � MinEnergy onsump-tion NoC.Chouand al2009 Heuristi Heuristi � Deterministi � � Max Per-forman etime YesF.Vardiand al2009 ListPriority(TPL1,TPL2,RTPL,PPL) � � � � � - Max per-forman etime -MinEnergy onsump-tion NoX.Wangand al2009 Heuristi Deter-ministi � � � � MinEnergy onsump-tion YesTable 4.1 � Etat de l'art lassé pour les te hniques de pla ement statiqueCarvalho et al. [135℄ évaluent les avantages et les in onvénients de l'utilisationdes heuristiques de pla ement dynamique (par exemple la harge de hemin et lemeilleur voisin), par rapport à eux des heuristiques statiques (par exemple le re uitsimulé et la re her he Taboo). L'appro he de Carvalho a été prolongée par Singhet al. [120, 136℄, en utilisant une stratégie de pa king qui va être détaillée en vued'une omparaison ave nos propositions, e qui réduit le oût de ommuni ationdans la même plateforme MPSoC basée NoC. En outre, l'appro he de Singh a été75

4.3 Ar hite ture MPSoC HétérogèneChapitre 4 : Heuristiques pour le routage et le pla ement dynamique de tâ hes en spirale surun MPSoC basée NoCaméliorée pour permettre un pla ement dynamique Muli-tâ hes des appli ations surle même PE. Di�érentes heuristiques de pla ement ont été utilisées pour évaluer laperforman e. Selon les auteurs, le oût de ommuni ation de l'ensemble du systèmeest réduit, e qui diminue la onsommation d'énergie.Faruque et al. [105℄ proposent une appro he dé entralisée de pla ement dyna-mique à base d'agents, iblant les MPSoCs hétérogènes à grandes é helles à basede NoC (un MPSoC de 32x64 est utilisé omme étude de as). Les travaux les plusré ents proposés dans la littérature, sont lassés et montrés dans la Table 4.2. Lesheuristiques de pla ement dynamique du plus pro he voisin (Nearest Neighbor (NN))et meilleur voisin (Best Neighbor (BN)) présentées dans les travaux de Carvalho etMoraes [108℄ et les deux démar hes de pla ement dynamique sont aussi présentéesdans le travail de Singh et al. [120℄ elles sont en outre utilisées pour l'évaluationet la omparaison de performan e ave nos heuristiques proposées de pla ementdynamique.4.3 Ar hite ture MPSoC HétérogèneL'ar hite ture MPSoC utilisée dans e travail ontient un ensemble d'élémentsde traitement di�érents, qui interagissent via un réseau de ommuni ation [14℄. Lestâ hes logi ielles s'exé utent sur "instru tion set pro essors" (ISPs) et les tâ hesmatérielles sur "Re on�gurable Area" (RA) ou sur des IPs dédiées. L'une des uni-tés de traitement (PE) est utilisée omme pro esseur Manager (M) responsable del'ordonnan ement des tâ hes et appli ations (s heduling), la liaison des tâ hes (Taskbinding), le pla ement de tâ he (Mapping), l'a heminement des ommuni ations, le ontr�le de ressour es et de re on�guration. Le M ne onnaît que les tâ hes initialesdes appli ations. La première tâ he de haque appli ation est lan ée par le M etde nouvelles demandes de ommuni ations ave d'autres tâ hes sont demandées aufur et à mesure par les tâ hes déjà pla ées sur la plateforme du MPSoC au mo-ment de l'exé ution. Les tâ hes demandées sont hargées de la mémoire quand une ommuni ation est né essaire. 76
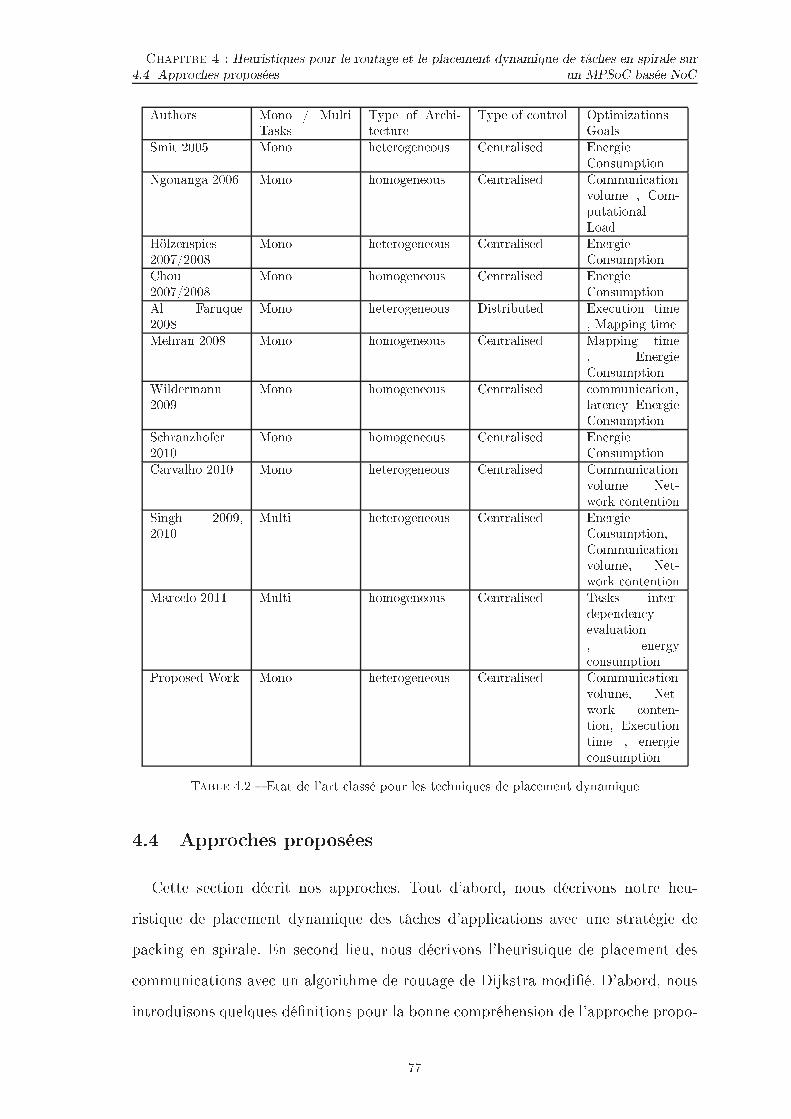
4.4 Appro hes proposéesChapitre 4 : Heuristiques pour le routage et le pla ement dynamique de tâ hes en spirale surun MPSoC basée NoCAuthors Mono / MultiTasks Type of Ar hi-te ture Type of ontrol OptimizationsGoalsSmit 2005 Mono heterogeneous Centralised EnergieConsumptionNgouanga 2006 Mono homogeneous Centralised Communi ationvolume , Com-putationalLoadHölzenspies2007/2008 Mono heterogeneous Centralised EnergieConsumptionChou2007/2008 Mono homogeneous Centralised EnergieConsumptionAl Faruque2008 Mono heterogeneous Distributed Exe ution time, Mapping timeMehran 2008 Mono homogeneous Centralised Mapping time, EnergieConsumptionWildermann2009 Mono homogeneous Centralised ommuni ation,laten y EnergieConsumptionS hranzhofer2010 Mono homogeneous Centralised EnergieConsumptionCarvalho 2010 Mono heterogeneous Centralised Communi ationvolume Net-work ontentionSingh 2009,2010 Multi heterogeneous Centralised EnergieConsumption,Communi ationvolume, Net-work ontentionMar elo 2011 Multi homogeneous Centralised Tasks inter-dependen yevaluation, energy onsumptionProposed Work Mono heterogeneous Centralised Communi ationvolume, Net-work onten-tion, Exe utiontime , energie onsumptionTable 4.2 � Etat de l'art lassé pour les te hniques de pla ement dynamique4.4 Appro hes proposéesCette se tion dé rit nos appro hes. Tout d'abord, nous dé rivons notre heu-ristique de pla ement dynamique des tâ hes d'appli ations ave une stratégie depa king en spirale. En se ond lieu, nous dé rivons l'heuristique de pla ement des ommuni ations ave un algorithme de routage de Dijkstra modi�é. D'abord, nousintroduisons quelques dé�nitions pour la bonne ompréhension de l'appro he propo-77

4.4 Appro hes proposéesChapitre 4 : Heuristiques pour le routage et le pla ement dynamique de tâ hes en spirale surun MPSoC basée NoC
Figure 4.1 � Ar hite ture on eptuelle MPSoCsée. La première dé�nit le modèle d'appli ation, la deuxième le modèle d'ar hite tureutilisé et la troisième la fon tion de pla ement.4.4.1 Dé�nitionsModèle de al ul d'appli ationUn graphe de tâ hes d'appli ation est représenté par un graphe dire te a y liqueTG = (T, E), où T est l'ensemble des tâ hes d'une appli ation et E l'ensemble desliens de ommuni ations entre les tâ hes d'une appli ation. La �gure 4.2(a) dé ritune appli ation qui ontient une tâ he initiale, des tâ hes logi ielles et des tâ hesmatérielles ave tous les liens de ommuni ations les onne tant (E) et la �gure4.2(b) montre une paire maître-es lave ( ommuni ating tasks). La tâ he de départd'une appli ation est la tâ he initiale qui n'a pas de tâ he maître. E ontient toutesles paires de tâ hes ommuni antes et est représenté par (mtid, stid, (Vms, Vsm )),où mtid représente l'identi�ant de la tâ he maître, stid représente l'identi�ant dela tâ he es lave, Vms est le volume de données du maître vers l'es lave, Vsm est levolume de données de l'es lave vers le maître.78

4.4 Appro hes proposéesChapitre 4 : Heuristiques pour le routage et le pla ement dynamique de tâ hes en spirale surun MPSoC basée NoC
Figure 4.2 � Maître-Es lave et la modélisation de l'appli ationModèle de al ul d'ar hite tureL'ar hite ture MPSoC basée NoC est un graphe dire te AG = (P, V), où P estun ensembles de tuiles pi. vi,j , représente le anal physique entre deux tuiles pi etpj. Une tuile pi, est onstituée d'un routeur, une interfa e de réseau, un élément detraitement hétérogène, une mémoire lo ale et une mémoire a he.Fon tion de pla ementLe pla ement des tâ hes d'appli ation sur une plateforme MPSoC basée NoC estreprésenté par la fon tion mpg : ti (∈ T)⇒ pi (∈ P).4.4.2 Heuristiques de pla ement dynamique de référen eThe First Free (FF)heuristi Le FF onsiste à trouver la première ressour e libre en suivant un par ours desressour es olonne par olonne et de haut en bas, en ommençant à haque fois àpartir de la première ressour e (PE00).Minimum Maximum Channel load (MMC) heuristi Cela onsidère tous les pla ements possibles pour une tâ he donnée et hoisit elui qui augmente le moins la harge maximale des anaux du NoC.
79

4.4 Appro hes proposéesChapitre 4 : Heuristiques pour le routage et le pla ement dynamique de tâ hes en spirale surun MPSoC basée NoCAlgorithm 1 ALGORITHME FFEntrées : tâ he−à−Pla er. Sortie : PE.x,PE.y ; /** Position du pro esseur sur le quel la tâ hesera pla é */1: non-pla é ← true ;2: /*re her her une ressour e libre */3: for i=0 to Nombre−PE−Total do4: /* Si le type de la tâ he est le même que elui du PE */5: if (tâ he−à−Pla er.type = PEi[X℄[Y℄.type) then6: /* Si PE est libre */7: if (PEi[X℄[Y℄.isfree()) then8: non-pla é ← false ;9: tâ he-à-Pla er.x← PEi.x ;10: tâ he-à-Pla er.y← PEi.y ;11: end if12: end if13: end for14: if non-pla é then15: /* Mettre la tâ he dans la liste des tâ hes non pla é */16: List−tâ he−non−pal é ← tâ he−à−Pla er ;17: end ifMinimum Average Channel load (MAC)heuristi Cela on erne tous les pla ements possibles pour une tâ he donnée en hoisissant elui qui augmente le moins la harge moyenne des anaux du NoC.The Nearest Neighbor (NN) heuristi Le NN re her he la première ressour e libre parmi ses voisines. Pour mapper unetâ he qui demande à être pla ée, l'algorithme essaye en premier lieu, de pla er latâ he-�ls sur un PE autour de la ressour e sur laquelle la tâ he-père a été pla ée ave un saut égal à 1. Les PEs sont re her hés ave la séquen e gau he, bas, haut, droit.Si au une ressour e adéquate n'est trouvée, l'algorithme reprend la même séquen eà partir des pro esseurs déjà par ourus jusqu'à atteindre la limite du NoC.The Path Load (PL) heuristi Cal ule la harge dans haque anal utilisé dans la voie de ommuni ation. PL al ule le oût de la voie de ommuni ation entre la tâ he sour e et ha une desressour es disponibles. Le pla ement séle tionné équivaut à un oût minimal.80

4.4 Appro hes proposéesChapitre 4 : Heuristiques pour le routage et le pla ement dynamique de tâ hes en spirale surun MPSoC basée NoCAlgorithm 2 ALGORITHME DU NNEntrées : tâ he−à−Pla er, X,Y Sortie : PE.x,PE.y ; /** Position du pro esseur sur le quel latâ he sera pla é */1: non-pla é ← true ; Saut ← 1 ; i ← 0 ;2: /*re her her une ressour e libre au Saut=1 suivant la séquen e Gau he, Bas, Haut,Droit*/3: re her her−gau he−bas−haut−droit(tâ he−à−Pla er, X,Y) ;4: /* A partir du saut=2 jusqu'à la limite du NOC, répéter la même séquen e de re her he àpartir des ressour e déja onsulté avant */5: while (non-pla é and (Saut ≤ NoC-limit )) do6: Saut++ ;7: re her her−gau he−bas−haut−droit(tâ he−à−Pla er, X,Y-Saut) ;8: if (non-pla é) then9: re her her−gau he−bas−haut−droit(tâ he−à−Pla er, X+Saut,Y) ;10: end if11: if (non-pla é) then12: re her her−gau he−bas−haut−droit(tâ he−à−Pla er, X-Saut,Y) ;13: end if14: if (non-pla é) then15: re her her−gau he−bas−haut−droit(tâ he−à−Pla er, X,Y+Saut) ;16: end if17: end while18: if (non-pla é) then19: List−tâ he−non−pal é ← tâ he−à−Pla er ;20: end ifAlgorithm 3 re her her−gau he−bas−haut−droitEntrées : tâ he−à−Pla er, X,Y Sortie : PE.X,PE.Y ;1: /* Si x,y ne dépasse pas la limite du NOC */2: if (0≤x≤NOC−LIMIT) and (0≤y≤NOC−Limit) then3: /* Si le type de la tâ he est le même que elui du PE */4: if (tâ he−à−Pla er.type=PE[X℄[Y℄.type) then5: /* Si PE est libre */6: if (PE[X℄[Y℄.isfree()) then7: non-pla é ← false ;8: tâ he-à-Pla er.x← PE.x ;9: tâ he-à-Pla er.y← PE.y ;10: end if11: end if12: end if
81

4.4 Appro hes proposéesChapitre 4 : Heuristiques pour le routage et le pla ement dynamique de tâ hes en spirale surun MPSoC basée NoCThe Best Neighbor (BN) heuristi Le BN utilise une stratégie de re her he présentée dans le travail de Singh ; etalgorithme n'a�e te pas la tâ he à la première ressour e trouvée (NN) mais elle quia le lien le moins hargé.4.4.3 Heuristique proposée basée sur la stratégie de pa king en spiraleet le routage dynamiqueStratégie de pa king en spiralePour pla er les appli ations, on pro ède d'abord par le pla ement des tâ hes ini-tiales de manière à les éloigner le plus possible lors du pla ement en hoisissant enpriorité les milieux des lusters, en utilisant une stratégie de lustérisation ommemontré dans la �gure 4.3. Ce qui permet que le pla ement des tâ hes d'une mêmeappli ation dans une même région, réduisant ainsi les oûts de ommuni ation. Lesfrontières des lusters sont virtuelles et les régions ommunes pourraient être par-tagées par les tâ hes des di�érentes appli ations. Après le pla ement des tâ hesinitiales d'appli ations, les tâ hes ommuni atives demandent à être pla ées. Pour ela, le pro esseur maître ( M ) essaye de pla er la tâ he ommuni ante qui demandeà être exé utée autour du pro esseur exé utant la tâ he appelante et ela à partird'une distan e égale à 1 ( hop ) jusqu'à la limite du NoC. La ressour e ( le pro es-seur en fon tion du type de la tâ he ) est re her hé ave une stratégie de pa king enspirale selon le séquen ement 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , omme le montre la Figure4.3. On explore les voisins en spirale en e�e tuant le pla ement de telle façon qu'ilempê he le al ul du oût de toutes les solutions possibles, omme dans le PL etle al ul du meilleur voisin omme dans l' heuristique BN. Ce qui réduit le tempsd'exé ution pour le pla ement.Algorithme de routage dijkstra modi�éAprès avoir pla é les tâ hes ommuni antes, nous avons besoin d'un pla ement des ommuni ations. Notre nouvelle heuristique de pla ement des ommuni ations pro-posée tente de re her her un meilleur hemin ave une bande passante la moins éle-82

4.5 Con�gurations expérimentales et RésultatsChapitre 4 : Heuristiques pour le routage et le pla ement dynamique de tâ hes en spirale surun MPSoC basée NoCAlgorithm 4 Spiral Heuristi Entrées : NoFreeResour es , CurrentPro essor, PE, FreeResour es, HopDistan e, No Limit Sor-tie : FreeElement1: HopDistan e ← 02: HopX ← 03: HopY ← 04: while (FreeElement = NULL) AND HopX != No Limit AND HopY != No Limit do5: if (CurrentPro essor.left.isFree()) then6: FreeElement ← CurrentPro essor.left ;7: else8: HopX- - ;9: end if10: if CurrentPro essor.top.isFree() then11: FreeElement ← CurrentPro essor.top ;12: else13: HopY- - ;14: end if15: if CurrentPro essor.right.isFree() then16: FreeElement ← CurrentPro essor.right ;17: else18: HopX+ + ;19: end if20: if CurrentPro essor.bottom.isFree() then21: FreeElement ← CurrentPro essor.bottom ;22: else23: HopY+ + ;24: end if25: end whilevée. L'heuristique proposée réduit le temps d'exé ution et de onsommation d'éner-gie.Algorithm 5 modified dijkstra routing algorithmEntrées : IdSour e , IdDestination Sortie : BestTraje t/*While we did not rea h the destination */2: while (stop=false) do/*Got ba k the neighbor who has the least used link*/4: min ← minWeight() ;if min <> idDest then6: /*Add the link in the list of the path*/Listpath.add(min)8: elsestop ← true10: end ifend while12: BestTraje t ← Listpath4.5 Con�gurations expérimentales et RésultatsPour l'expérimentation nous avons utilisé un langage à haut niveau d'abstra tionà savoir JAVA qui nous a permis rapidement de omparer di�érentes heuristiques83

4.5 Con�gurations expérimentales et RésultatsChapitre 4 : Heuristiques pour le routage et le pla ement dynamique de tâ hes en spirale surun MPSoC basée NoC
Figure 4.3 � Pla ement des tâ hes initiale et la strategie de pa king en spirale.de pla ement dynamique sur une ar hite ture MPSoC basée NoC.4.5.1 Con�gurations expérimentalesNous avons réalisé une plateforme hétérogène simulée de 64 unités de traitements(8x8) dont 14 de type matériel (RA), 49 de type software et une unité de traite-ment utilisée omme Manager responsable du pla ement des tâ hes d'appli ations.La on�guration, la mise à jour de la plateforme, Le pla ement des ommuni ations( ommuni ations routing). Cette plateforme utilise un réseau sur pu e pour la om-muni ation. Nous avons utilisé un � hier XML pour la des ription des graphes detâ hes utilisées qui sont les mêmes que dans le travail de A.K.Singh, tâ hes (initiale,software et hardware). Leur temps d'exé ution dépend de la spé i� ité et de la a-pa ité du pro esseur. Nous avons �xé des paramètres, pour un pro esseur logi ieldont l'exé ution d'une instru tion né essite 40 y les. Par ontre un pro esseur ma-tériel est plus rapide et né essite 20 y les seulement,mai il onsomme plus d'énergieque le pro esseur logi iel ( on les a �xé a 20 et 10 y les respe tivement). La taille84

4.5 Con�gurations expérimentales et RésultatsChapitre 4 : Heuristiques pour le routage et le pla ement dynamique de tâ hes en spirale surun MPSoC basée NoCdes tâ hes est représentée en nombre d'instru tions. La taille des données é hangéesest �xée en 100 paquets qui peuvent être hangés. Le s énario utilisé exé ute une,trois, sept et dix appli ations où haque appli ation ontient de 7 à 9 tâ hes. Laplateforme est divisée en 09 lusters qui permettent de lan er neuf (09) appli ationsen parallèle. Ce i n'est pas une ontrainte ar n'importe quel nombre d'appli ationpeut être exé utée sur la plateforme en utilisant une �lle d'attente quand le nombreest supérieur à 9. Pour le pla ement des tâ hes d'appli ations, nous avons implé-menté notre algorithme de pla ement dynamique de tâ hes basées sur la stratégiede pa king en spirale et la méthode de routing basée sur le dijkstra modi�é. Late hnique en spirale essaye de pla er les tâ hes les plus ommuni ante ave un mi-nimum d'exploration de l'espa e du NoC. L'implémentation de notre méthode depla ement des ommuni ations (modi�ed Dijkstra routing) a minimisé onsidéra-blement le temps d'exé ution et la onsommation d'énergie du système. Pour une omparaison ave nos propositions nous avons implémenté aussi les heuristiques depla ements de référen e dans la littérature NN et BN.4.5.2 Résultats expérimentauxNous avons simulé l'exé ution des méthodes de pla ement dynamique NearestNeighbor (NN) et Best Neighbor (BN) pour le s enario de pla ement d'une, trois,sept, et dix appli ations en parallèle sur la plateforme simulée de 64 unités de trai-tements (8x8) dont 14 unités de traitements hardware, 49 unités software et uneunité de traitement Manager (M). Nous avons aussi simulé l'exé ution de nos heu-ristiques, proposé des pla ements dynamiques en spirale des tâ hes et des ommuni- ations. Pour les mesures de performan es nous avons al ulé le temps d'exé utionet la onsommation d'énergie. La Figure 4.4 montre l'optimisation apportée parnotre proposition en terme de temps d'exé ution par rapport à l'utilisation des deuxautres méthodes de référen e. La �gure 4.5 montre la rédu tion d'énergie apportéepar l'utilisation de notre appro he qui donne de meilleurs résultats par rapport auxdeux autres méthodes implémentées.85

4.6 on lusionChapitre 4 : Heuristiques pour le routage et le pla ement dynamique de tâ hes en spirale surun MPSoC basée NoC
Figure 4.4 � Comparaison du temps d'exe ution de l'appro he proposée ave NN et BN respe -tivement
Figure 4.5 � Comparaison de la onsommation d'énergie de l'appro he proposée ave NN et BNrespe tivement4.6 on lusionUne nouvelle heuristique de pla ement dynamique de tâ hes, qui essaye de pla erles tâ hes d'appli ations les plus ommuni antes, de façon à réduire le oût des ommuni ations et minimiser l'espa e de re her he dans le NoC. Pour réduire aumaximum le oût des ommuni ations, un routage Dijkstra modi�é est égalementproposé dans le présent travail. Grâ e à l'environnement de simulation que nousavons réalisé, nous avons fait une étude omparative entre le plus pro he voisin(NN), le meilleur voisin (BN) et l'heuristique de pla ement dynamique proposéebasée sur une stratégie de pa king en spirale. Ave le pla ement des ommuni ationsave un algorithme de Dijkstra modi�é, nous avons montré l'optimisation o�erte parnotre appro he. Le dé�t du pro hain travail présenté dans le hapitre suivant est laproposition de nouvelles stratégies de re her hes et appro hes de routage dynamique.86

Chapitre 5Heuristiques pour le pla ementdynamique de tâ hes et ommuni ations sur un MPSoCbasée NoCSommaire5.1 Introdu tion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 885.2 État de l'Art . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 905.2.1 Te hniques de pla ement statique . . . . . . . . . . . . . . . . . . . . . . 905.2.2 Te hniques de pla ement dynamique . . . . . . . . . . . . . . . . . . . . 905.3 Modélisation du problème de pla ement et heuristiques de référen e 945.3.1 Graphe de tâ hes d'appli ation . . . . . . . . . . . . . . . . . . . . . . . 945.3.2 Graphe d'ar hite ture MPSoC hétérogène basée NoC . . . . . . . . . . . 955.3.3 Pla ement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 965.4 Heuristiques de pla ement de référen e . . . . . . . . . . . . . . . . . 985.4.1 Pa king-based Nearest Neighbor (PNN) . . . . . . . . . . . . . . . . . . 995.4.2 Pa king-based Best Neighbor (PBN) . . . . . . . . . . . . . . . . . . . . 1015.5 Stratégies de pa king et de routage proposées . . . . . . . . . . . . . 1015.5.1 Manhattan Pa king Strategies . . . . . . . . . . . . . . . . . . . . . . . 1025.5.2 Multi-Obje tive Routing Algorithm (MORA) . . . . . . . . . . . . . . . 1045.5.3 Cal ul du Temps d'exé ution globale et la onsommation d'énergie . . . 1075.6 Validation par Simulation . . . . . . . . . . . . . . . . . . . . . . . . . 1105.6.1 Con�guration de Simulations . . . . . . . . . . . . . . . . . . . . . . . . 1115.6.2 Résultats de Simulations . . . . . . . . . . . . . . . . . . . . . . . . . . . 1145.7 Con lusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12087

5.1 Introdu tionChapitre 5 : Heuristiques pour le pla ement dynamique de tâ hes et ommuni ations sur unMPSoC basée NoC5.1 Introdu tionLes systèmes embarqués intensif utilisent des Systèmes Multipro esseurs sur pu e(MPSoCs), qui o�rent un parallélisme a ru pour atteindre la haute performan e[6℄. Pour faire fa e aux limites de pro esseur à usage général unique, la demande roissante de al ul et les exigen es de performan e. Un MPSoC ontient plusieurséléments de traitement (PEs) dans la même pu e. Il existe deux types de MPSoCs :homogènes et hétérogènes. Un MPSoC homogène ontient des PE identiques [86,23, 66, 137, 16℄, alors que di�érents types de PEs sont intégrés dans un MPSoChétérogène [138, 4, 139, 140℄. Le réseau sur pu e (NoC) a été introduit omme uneinter onnexion évolutive et à énergie e� a e pour soutenir la ommuni ation entreles PEs [14, 15, 46℄.Le on epteur doit pla er les tâ hes de l'appli ation sur les di�érentes ressour esde traitement du MPSoC. Les te hniques de pla ement statique dé�nit le pla ementde la tâ he au moment du design, d'avoir une vue globale des ressour es MPSoC.Ces te hniques de pla ement peuvent utiliser des algorithmes omplexes a�n demieux explorer les ressour es MPSoC en vue d'obtenir des solutions optimisées [122,123, 126℄. Les te hniques de pla ement dynamique (run-time) sont né essaires pourgérer es harges de travail variables (dynamiques) [98, 95, 100, 132, 108, 133℄. Ceste hniques trouve le pla ement des tâ hes sur les ressour es MPSoC au moment del'exé ution. Les dernières appro hes de pla ement dynamique, essayent de pla er lestâ hes ommuni antes sur les PEs voisins disponibles, 'est à dire le plus près les undes autres a�n de réduire la sur harge de ommuni ation [135, 120℄. Cependant, esappro hes ne fon tionnent pas bien lorsque les appli ations ontiennent un grandnombre de tâ hes. En outre, la plupart des travaux de pla ement rapportés dans lalittérature utilisent un algorithme de routage déterministe à savoir l'algorithme deroutage XY [120, 100, 132, 133, 103, 135, 105, 141℄. Cependant, pour un système quidoit gérer un �ux de travail dynamique, l'utilisation d'une méthode de pla ementdynamique des ommuni ations peut onduire à de meilleurs résultats.Dans e hapitre nous présentons une stratégie de pa king Manhattan qui per-met d'explorer et de pla er les tâ hes d'appli ation plus rapidement que les der-88

5.1 Introdu tionChapitre 5 : Heuristiques pour le pla ement dynamique de tâ hes et ommuni ations sur unMPSoC basée NoCnières stratégies de pla ement existantes, entraînant des oûts optimisés de pla e-ment des tâ hes. Nous présentons également un algorithme de routage dynamiquemulti-obje tifs (MORA) qui réduit les oûts de ommuni ations par rapport aux ap-pro hes de routage souvent employées. Le modèle utilisé pour la représentation desappli ations est le modèle maître-es lave. Ce type de modèle est utilisé pour repré-senter les appli ations qui ont des tâ hes ommuni antes parallèles. La plateformeMPSoC hétérogène onsidérée ontient deux types de PEs : "Instru tion Set Pro es-seurs" (ISPs) et "Re on�gurable Areas" (RAs), qui exé utent des tâ hes matérielleset logi ielles, respe tivement. Toutefois, les PEs peuvent être on�gurés pour exé u-ter divers types de tâ hes. Pour le pla ement dynamique des tâ hes, les te hniquesde pla ement de l'état de l'art réduisent les oûts de ommuni ation par le pla ementdes tâ hes ommuni antes sur les plus pro hes PEs disponibles [100, 135, 120℄. Lesderniers travaux utilisent une stratégie de pa king pour réaliser et obje tif. Cepen-dant, la plupart d'entre eux ne mettent pas l'a ent sur la minimisation du temps dere her he (pla ement). Dans notre stratégie de pa king Manhattan proposée, nous her hons non seulement de pla er les tâ hes ommuni antes sur les plus pro hes PEsdisponibles, mais aussi de minimiser le temps de re her he. En outre, les appro hesexistantes utilisent des te hniques de routage déterministes pour fa iliter la ommu-ni ation. En revan he, le MORA dynamique tente de trouver le hemin point a pointde la ommuni ation qui a la harge la plus faible (la plus large bande passante),résultant à un temps d'exé ution et onsommation d'énergie optimisés. La stratégiede pa king Manhattan montre des améliorations signi� atives de performan e parrapport aux dernières appro hes de pla ement. Les appro hes de pla ement dyna-mique utilisant la méthode de routage MORA onduisent aussi à des améliorationsde performan es par rapport aux appro hes employant d'autres méthodes de rou-tage tel que XY. Le reste du hapitre est organisé omme suit. Se tion 5.2 donneun aperçu de l'état de l'art. La se tion 5.3 dé rit le modèle de l'ar hite ture MP-SoC onsidérée. Dans la se tion 5.5, la stratégie de pa king Manhattan proposée etl'algorithme de routage multi-obje tif (MORA) ont été présentés. La on�gurationexpérimentale et les résultats sont présentés dans la se tion 5.6. La se tion 5.789

5.2 État de l'ArtChapitre 5 : Heuristiques pour le pla ement dynamique de tâ hes et ommuni ations sur unMPSoC basée NoC on lut le hapitre.5.2 État de l'ArtLe pla ement des tâ hes dans une plateforme MPSoC né essite de trouver lepla ement des tâ hes sur les ressour es de la plateforme en vue de ertains ri-tères d'optimisation omme la rédu tion de la onsommation d'énergie, le tempstotal d'exé ution et l'optimisation de l'o upation des anaux de ommuni ations.Le pla ement peut être réalisé soit par des te hniques de pla ement statiques (aumoment du design) ou dynamique (au moment de l'exé ution).5.2.1 Te hniques de pla ement statiqueLa plupart des travaux existants dans la littérature pour résoudre le problèmede pla ement sur une plateforme MPSoC sont des te hniques de pla ement statique[122, 123, 125, 127, 128, 142, 143℄. Méta-heuristiques omme l'appro he génétique[83, 84℄ et des méthodes omme la re her he Tabou [85, 81℄ et le re uit stimulés[80, 87℄ sont présentées. Ces te hniques trouvent un pla ement �xe des tâ hes aumoment du design ave un omportement d'exé ution et de ommuni ation bien onnu. Cependant, le pla ement statique n'est pas apable de gérer la harge detravail dynamique des tâ hes ou des appli ations qui ont besoin d'être hargé dansle MPSoC à l'exé ution. Les te hniques de pla ement dynamique (run-time) sontné essaires pour gérer le pla ement de es harges de travail sur les ressour es de laplateforme.5.2.2 Te hniques de pla ement dynamiqueLes derniers travaux rapportés dans la littérature traitent le problème de pla- ement dynamique des tâ hes des appli ations sur les ar hite tures MPSoCs enoptimisant les di�érentes métriques de performan e.Wildermann et al. [133℄ évaluent l'avantage d'utiliser une heuristique de pla e-ment dynamique, qui diminue le oût de ommuni ation. Une fon tion de oût devoisinage a été utilisé pour réduire les oûts de ommuni ation.90

5.2 État de l'ArtChapitre 5 : Heuristiques pour le pla ement dynamique de tâ hes et ommuni ations sur unMPSoC basée NoCHolzenspies et al. [103℄ étudient une autre te hnique de pla ement dynamiquespatiale pour le pla ement d'appli ations de streaming sur MPSoC hétérogène, Vi-sant à réduire la onsommation d'énergie.S hranzhofer et al. [134℄ proposent une stratégie de pla ement dynamique baséesur les pla ements pré- al ulées(modèle dé�nis au moment de la on eption), quisont utilisés pour dé�nir le pla ement des tâ hes nouvellement arrivés aux PEs lorsde l'exé ution.Chou et al. [98℄ utilisent une plateforme NoC ave multiples niveaux de voltage.leur te hnique de pla ement est basée sur un algorithme de séle tion de région quiminimise la onsommation d'énergie de ommuni ation. L'energie de la ommuni a-tion est diminué de 50%. La te hnique de pla ement est appliquée a une plateformeNoC homogène.In [95℄, les auteurs intègrent les informations de omportement de l'utilisateurdans le pro essus d'allo ation des ressour es. Cela permet au système de mieuxrépondre aux hangements en temps réel et à s'adapter aux besoins des utilisateursde façon dynamique.Ost et al. [144℄ proposent une te hnique de pla ement dynamique a énergie e� a equi minimise la onsommation d'énergie de 16% dans le meilleur as.Mehran et al [100℄ proposent une te hnique de pla ement dynamique en spirale(DSM) pour le pla ement de tâ hes durant l'exé ution. le pla ement d'une tâ he estre her hé dans un hemin en spirale du entre vers la limite du NoC, de sorte queles tâ hes ommuni antes peuvent être pla ées à proximités les unes des autres. ilstentent également de réduire le temps d'exé ution en réduisant le temps de pla ementdynamique, temps de re- on�guration et le temps de migration de tâ he.Faruque et al. [105℄ proposent une appro he de pla ement dé entralisée a based'agent iblant les grandes MPSoCs hétérogènes à base de NoC tels que les systèmes32x64. L'heuristique proposée pla e les appli ations d'une manière dé entralisée enutilisant une appro he basée sur les agents. Plusieurs agents sont utilisés pour réaliserla gestion de ressour es. Il existe deux types d'agents : Global Agent (GA) et ClusterAgents (CAs). Toute la plateforme est divisée en petits lusters et haque CA mis à91

5.2 État de l'ArtChapitre 5 : Heuristiques pour le pla ement dynamique de tâ hes et ommuni ations sur unMPSoC basée NoCjour es onnaissan es de ses ressour es de luster. Le GA onserve des informationsglobales sur tous les lusters. Les agents négo ient les uns ave les autres pour trouverun PE appropriés pour le pla ement d'une tâ he. Le pla ement a base d'agentsréduit l'e�ort de al ul et d'observation du tra� pour le pro essus de pla ement,par rapport aux appro hes entralisées.Carvalho et al. [108℄ présentent des heuristiques pour le pla ement dynamique detâ hes en deux phases. La première phase trouve le pla ement des tâ hes initialesdes di�érentes appli ations sur l'ar hite ture MPSoC, tandis que la deuxième phaseutilise des mèthodes di�érentes ( par exemple, First Free (FF), Nearest Neighbor(NN), MinimumMaximumChannel Load (MAC) et Path Load (PL)) pour trouver lepla ement des autres tâ hes a la volée en fon tion des demandes de ommuni ationset les harges dans les liens des NoCs. La harge anal NoC, la ongestion et lalaten e paquet se réduit lorsque l'on utilise des méthodes di�érentes. l'ar hite tureMPSoC basée NoC iblé ontient des PEs supportant ha un mono-tâ he.In [135℄, Les auteurs évaluent les heuristiques de pla ement dynamique et les ompare ave les te hniques de pla ement statique omme le re uit simulé et lare her he tabou.Singh et al. [120℄ iblent l'ar hite ture MPSoC hétérogène ontenant des PEslogi iel et matériel. Dans l'ar hite ture, parmis les unités de traitement disponible,une seul unité de traitement agit omme un pro esseur manager qui est responsablede la liaison de tâ he (Task binding), pla ement de tâ he, la migration de tâ he, ontr�le de ressour es et le ontr�les de re- on�guration. L'état de la ressour e estmis a jour lors de l'exé ution et le pro esseur Manager assure le suivi de l'informationsur l'o upation des ressour es. Leurs heuristiques de pla ement pla e les tâ hes ommuni antes d'une appli ation a proximité les unes des autres de tel sorte àminimiser le oût de ommuni ation en vue d'améliorer la performan e globale.L'heuristique [120℄ examines les ressour es disponibles avant de re ommander lestâ hes adja entes sur le même PE. Le pro essus de pla ement est e�e tuée en deuxphases. Tout d'abord, les tâ hes initiales sont pla ées au entre des lusters qui sontobtenus en divisant le NoC en régions. Par la suite, les tâ hes ommuni antes sont92

5.2 État de l'ArtChapitre 5 : Heuristiques pour le pla ement dynamique de tâ hes et ommuni ations sur unMPSoC basée NoCdemandées et pla ées par leurs appro hes de pla ement proposées.en général, les travaux proposés dans [108℄ sont étendues dans [120℄ en em-ployant une stratégie de pa king qui minimise le sur oût de la ommuni ation dansla plateforme MPSoC basée NoC.Une heuristique d'énergie e� a e pour le pla ement dynamique de tâ he, nommée onsommation d'energie basse basée sur les dépendan es des voisinages (LEC-DN)a été présenté dans [145, 132℄. La prin ipale fon tion de oût i i n'est pas seulementla distan e en sauts entre les tâ hes ommuni antes, mais également la proximité dunombre de sauts et le volume de ommuni ation entre les tâ hes, puisque le nombrede �its transmises dé�nit l'énergie de ommuni ation. Lorsque la tâ he ible a uneseule tâ he ommuni ante qui a déja été pla é, LEC-DN utilise la re her he du pluspro he voisin (NN) d'une manière en spirale. D'un autre �té, s'il y'a plus qu'unetâ hes ommuni antes qui sont déjà pla és, il re her he un PE à l'intérieur de lazone de délimitation dé�ni par la position d'une telle tâ he en fon tion du volumede ommuni ation.In [146℄, un pla ement dynamique de entralisée axée appli ation et ressour ese� a e a été proposé, où les tâ hes peuvent être intégrés progressivement à une tâ heprédé esseur déjà pla é. Il s'agit d'une appro he auto-embarqué qui est entièrementdé entralisé et autonome.Les appro hes de pla ement dynamique existantes onsomme un grand tempsd'exploration pour trouver le pla ement des tâ hes. La stratégie de Manhattan pro-posée e�e tue l'exploration plus rapide ave obje tifs de pla er les tâ hes ommu-ni antes sur des PEs plus pro he entre eux. Les heuristiques de pla ement du pluspro he voisin (NN) et meilleur voisin (BN) présentées dans [135℄ ainsi que la stra-tégie de pa king présenté dans [120℄ sont pris pour l'évaluation et la omparaisonde performan e par rapport a notre stratégie de pa king Manhattan. La plupartdes travaux existants utilisent un algorithme de routage déterministe, a savoir XY[120, 100, 132, 133, 103, 135, 105℄.Toutefois, pour un système qui a une harge de travail dynamique, l'utilisationd'une méthode de routage dynamique peut onduire a des améliorations signi� a-93

5.3 Modélisation du problème de pla ement et heuristiques de référen eChapitre 5 : Heuristiques pour le pla ement dynamique de tâ hes et ommuni ations sur unMPSoC basée NoCtives. Le NN et BN emploient l'algorithme de routage XY, alors que notre appro hede pla ement emploie l'algorithme de routage dynamique multi-obje tif (MORA)etdonne de meilleurs résultats.5.3 Modélisation du problème de pla ement et heuristiquesde référen e5.3.1 Graphe de tâ hes d'appli ationUn graphe de tâ hes d'appli ation est représenté omme un graphe a y liqueorientéTG = (T,E), où T est l'ensemble de toutes les tâ hes d'une appli ation et Eest l'ensemble des liens entres les tâ hes d'une appli ation. Figure 5.1(a) montre uneappli ation qui a des tâ hes initiale, logi iel et matériel ave les arêtes (E) onne tant es tâ hes. Figure 5.1(b) montre la paire Maître-Es lave ( ommuni ating tasks). Latâ he de départ d'une appli ation est la tâ he initiale qui n'a pas de maître. Chaquetâ he est asso iée ave les attributs suivants : l'identi�ant de la tâ he tid, le type dela tâ he ttype (hardware, software, initial), et le temps d'exé ution de la tâ he texecsur haque type de PE. L'ensemble de liens E ontient toutes les arêtes reliant lestâ hes ommuni antes. Chaque lien (5.1 (b)) à les attributs suivant : l'identi�ant dela tâ he maître mtid représentant la tâ he maître onne té, l'identi�ant de la tâ hees lave stid représentant la tâ he es lave onne té, le volume de données envoyédu maître à l'es lave (Vms), et le volume de données envoyé de l'es lave au maître(Vsm). S'il ya de multiples tâ hes es lave ommuniquant ave la tâ he maître , lestâ hes es laves sont pla és dans l'ordre de leur numéro d'identi� ation assignée. Cesidenti�ants de tâ hes es lave sont attribués au moment du design pour optimiser lesperforman es, basée sur les arêtes et les outs de ommuni ations entres les tâ hesmaître-es lave. Par exemple, soit l'identi� ateur de la tâ he maître est de 0 et lesidenti�ons des es deux tâ hes ommuni antes sont 1 et 2, puis premièrement latâ he ave l'identi�ant 1 demande a être pla é. Pour transmettre et re evoir desmessages par une tâ he, notre algorithme de routage (MORA) hoisit le hemin leplus ourt et la harge des liens point a point qui dispose d'une faible harge dans94

5.3 Modélisation du problème de pla ement et heuristiques de référen eChapitre 5 : Heuristiques pour le pla ement dynamique de tâ hes et ommuni ations sur unMPSoC basée NoCInitial
SW
Task HW
Task
(Vms , Vsm) (Vms , Vsm)
(Vms , Vsm)
(Vms , Vsm)
Master
Slave
(a)
(b)
Figure 5.1 � Modélisation du graphe de tâ hes d'appli ation et la pair Maître-Es lavel'ar hite ture MPSoC.5.3.2 Graphe d'ar hite ture MPSoC hétérogène basée NoCFig. 5.2 montre le modèle de l'ar hite ture MPSoC hétérogène utilisé dans etravail. L'ar hite ture omprend un ensemble de di�érents éléments de traitement(PEs) qui interagissent via un réseau de ommuni ation [14℄. Les PEs peuvent êtrede divers types, tels que instru tion set pro essors (ISPs), re on�gurable logi s (re- on�gurable area-RA), dedi ated intelle tual properties (IPs), et . Tâ hes à exé u-ter sur les PEs sont lassés en tant que logi iel et matériel, qui mettent en ÷uvrenormalement des fon tions simple et al ules intensives, respe tivement. Les tâ heslogi ielles s'exé utent sur les ISPs et les tâ hes matérielles s'exé utent sur RAs ouIPs dédiée. ISPs exé ute les tâ hes logi iels e� a ement. L'indu tion des RAs dansla plateforme o�re une �exibilité au matériel à un niveau similaire à la programma-bilité ISPs. Cependant, la hausse des overheads de re on�guration des RAs doiventêtre prises en ompte.Le réseau de ommuni ation né essaire pour fa iliter la ommuni ation entre lesPEs est disposés dans une topologie 2D maillé [108℄, omme illustré dans Fig. 5.2.Proto ole de ommuni ation réseau utilise la ommutation de paquets wormhole, le ontr�le de �ux handshake, les bu�ers d'entrée et l'algorithme de routage XY. Dansle routage XY, les paquets sont transférés en premier dans la dire tion X, puis dans ladire tion Y a�n de les transférer à partir de PE sour e au PE de destination. En plus95

5.3 Modélisation du problème de pla ement et heuristiques de référen eChapitre 5 : Heuristiques pour le pla ement dynamique de tâ hes et ommuni ations sur unMPSoC basée NoC
IP ISP RA ISP IP
ISP ISP ISP ISP ISP
ISP ISP IP ISP ISP
RA ISP ISP ISP RA
R R R
R
R
R
R
R
R
R
R
R
R
R
R
R
R
R
R
R
ISP: Instruction Set Processor
RA: Reconfigurable Area
IP: Intellectual Property
Task
Memory
Manager Processor (M)
Routing
Application
Task
Scheduling
Task
Mapping
Configuration and
Ressource Control
Task Binding
Figure 5.2 � Ar hite ture MPSoC hétérogènedu routage XY, notre algorithme de routage dynamique multi-obje tif (MORA) aégalement été in orporé, qui sera détaillé dans la se tion suivante. La ommuni ationinter-tâ hes est supporté par un mé anisme de passages de messages similaires à eluiutilisé dans [108℄.L'ar hite ture MPSoC hétérogène basée NoC est un graphe orienté AG = (P, V),où P est l'ensemble de tuiles et V représente les anaux physique entre les tuiles.Chaque tuile (in P) à les attributs suivants : l'identi�ant de la tuile pid, l'adresse dela tuile padd qui est utilisée pour re evoir les paquets transmis a partir d'autres tuiles,type de la tuile ptype (hardware, software, initial). Chaque anal physique onserveles informations en paquets et le pour entage d'utilisation de la bande passantedisponible en vue de fa iliter la transmission e� a e des données.5.3.3 Pla ementDans l'ar hite ture MPSoC, un PE est utilisé omme pro esseur manager (MP)qui est responsable de la liaison des tâ hes(task binding), pla ement des tâ hes(pla ement),l'ordonnan ement des tâ hes d'appli ation, routage des ommuni ations, re- on�gurationet ontr�le de ressour es. Task binding est né essaire avant le pla ement de tâ hesdans le as des MPSoCs hétérogène. Pour haque tâ he, le binding pro ess dé�nit letype des PEs sur les quelles la tâ he peut être pla é et exé uté. Par exemple, tâ heslogi iels seront pla és et exé utés dur les ISPs, alors que les tâ hes matérielles sur96

5.3 Modélisation du problème de pla ement et heuristiques de référen eChapitre 5 : Heuristiques pour le pla ement dynamique de tâ hes et ommuni ations sur unMPSoC basée NoCles RAs et les IPs. pla ement de tâ he identi�e la position d'un PE dans l'ar hite -ture en vue d'attribuer une tâ he. l'ordonnan ement des tâ hes d'appli ation dé�nitl'ordre d'exé ution des tâ hes initiales des appli ations sur les lusters. routage des ommuni ations dé�nit le mé anisme à utiliser pour le routage de données d'un PEa l'autre. Contr�le de ressour e est maintenue par le mise à jour de l'état des res-sour es au moment de l'exé ution en vue de fournir au MP des informations pré isessur l'o upation des ressour es. L'information a tualisée des ressour es aide le MPa prendre de meilleures dé isions de pla ement au moment de l'exé ution, qui estbasée sur l'utilisation des liens du No et les PEs lors de l'exé ution. Les résultatsde on�gurations généraux sont utilisés pour simuler le pro essus de ontr�le de on�guration [147℄.Le MP onnais que les tâ hes initiales des appli ations. La tâ he initiale de haqueappli ation est lan é par le MP et les nouvelles tâ hes ommuni antes sont hargéesdans la plateforme MPSoC lors de l'exé ution a partir de la mémoire des tâ heslorsque une ommuni ation entre eux est né essaire et ils ne sont pas déjà pla é.Le pla ement de la tâ he est représenté par mpg(ti ⇒ pi), où la tâ he ti d'uneappli ation est pla é sur la tuile pi dans l'ar hite ture MPSoC. Le pla ement de l'ap-pli ation onsiste aux pla ement de toutes les tâ hes de l'appli ation sur di�érentsPEs de l'ar hite ture tout en optimisant ertains mesures de performan e tels quele temps d'exé ution, la onsommation d'énergie, la laten e, la ongestion, et . Lepla ement multiples d'appli ations implique le pla ement de tâ hes à partir de dif-férentes appli ations en parallèle tout en optimisant la performan e de ha une desappli ations. Ce travail onsidère le pla ement simultanée de plusieurs appli ationssur l'ar hite ture MPSoC.Le pla ement de la tâ he initiale a un impa t signi� atif sur la performan edu pla ement dynamique. Les tâ hes initiales sont onsidérés omme des tâ heslogi ielles et don sont pla és sur des ressour es logi ielles (ISPs). Les tâ hes initialesd'appli ations sont pla és de manière distribuée sur toute l'ar hite ture. Pour ela,l'ar hite ture est divisée en plusieurs lusters répartis et les tâ hes initiales sontpla és au entre des lusters, omme représenté sur la Fig. 5.3. Un tel pla ement97

5.4 Heuristiques de pla ement de référen eChapitre 5 : Heuristiques pour le pla ement dynamique de tâ hes et ommuni ations sur unMPSoC basée NoC 3
1
2
M
M Hardware
Resources
Software
Resources
Initial task
Placement
Manager
Processor Virtual
Cluster
4
Figure 5.3 � Pla ement des tâ hes initiales pour le pla ement de 9 appli ations simultanément.des tâ hes initiales des di�érentes appli ations fa ilite le pla ement des tâ hes de haque appli ation pro hes les unes des autres à l'intérieur de régions parti ulière( lusters).Cela réduit les outs de ommuni ations puisque les tâ hes ommuni antes de haque appli ations sont pla és a proximité. Les frontières des lusters sont virtuelset ainsi des régions ommunes pourraient être partagés par les tâ hes d'appli ationsdi�érentes. après que les tâ hes initiales de haque appli ation sont pla és, les de-mandes de ommuni ations sont envoyés aux tâ hes ommuni antes a�n de trouverleur pla ement.5.4 Heuristiques de pla ement de référen eNous utiliserons les heuristiques de pla ement Pa king-based Nearest Neighbor(PNN) et Pa king-based Best Neighbor (PBN) proposées dans [120℄ omme desheuristiques de référen e à utiliser pour l'étude omparative.98

5.4 Heuristiques de pla ement de référen eChapitre 5 : Heuristiques pour le pla ement dynamique de tâ hes et ommuni ations sur unMPSoC basée NoC5.4.1 Pa king-based Nearest Neighbor (PNN)A�n de trouver le pla ement pour une tâ he, PNN ommen e à re her her unPE libre apable d'exé uter (supporté) la tâ he à proximité du PE ontenant latâ he maître. L'heuristique PNN a été introduit dans l'algorithme 6. L'algorithmeprend en entrée : NoC_limit, requestedTask, position (X, Y) du PE ontenant latâ he maître et fournit la position X', Y' de la ressour e libre qui peu exé uter latâ he. Premièrement, les ressour es les plus pro hes au PE sur lequel s'exé ute latâ he maître sont re her hées pour leurs disponibilités et leurs supports (de mêmetype). Ces PEs voisins sont situés à une distan e de saut égale a 1 depuis le PEde la tâ he maître de la manière Gau he, Bas, Haut, Droite. Si au un des PEs à ladistan e hop 1 est disponible pour supporté la tâ he alors PEs à distan e de sautde 2 sont re her hées. Le pro essus de re her he se poursuit jusqu'à la limite NoC.Pour re her her les PEs à un saut parti ulier (>1), la re her he ommen e a partirde haque ressour e visitée au saut pré édent et la même séquen e de re her hedu saut 1 est suivie. Le pro essus de re her he similaire est répété en augmentantla distan e de saut jusqu'à e qu'un PE libre et qui permet d'exé uter la tâ hedemandée est trouvé. Le pro essus s'arrête dès qu'un PE libre et qui permet desupporter la tâ he est trouvé. Si toutes les ressour es dans le NoC_limit ne sont pas apable de supporter la tâ he demandée, alors la tâ he est ajoutée dans la liste deList_Task_not_mapped et son pla ement sera re her hé dès qu'une ressour e PEsera libre. L'algorithme retourne la position de la ressour e apable de supporter latâ he demandée (X' = PE.X et Y' = PE.Y).L'algorithm 7 montre le fon tionnement de la fon tion de re her he, qui est suiviepour évaluer le PE. Les tests de la fon tion est si la ressour e à une position donnéeest libre et si elle est en mesure de supporter la tâ he demandée. La même fon tionest appelée pour évaluer les ressour es aux positions Gau he, Bas, Haut et Droitepar rapport à la position de la tâ he maître où elle est pla ée. La ressour e peutsupporter la tâ he demandée si la ressour e est libre (PE[X℄[Y℄.isFree) et le typede la ressour e est le même que le type de la tâ he demandée (requestedTask.type= PE[X℄[Y℄.type). La fon tion hange la valeur de la variable mapped à true pour99

5.4 Heuristiques de pla ement de référen eChapitre 5 : Heuristiques pour le pla ement dynamique de tâ hes et ommuni ations sur unMPSoC basée NoCAlgorithm 6 PNN AlgorithmRequire: NoC_limit, requestedTask, X, YEnsure: X', Y'1: mapped←False ; hop←1 ; i=0 ;2: sear h_Left_Down_Up_Right(requestedTask,X,Y)3: while ((mapped=false)and(i<NoC_limit)) do4: i++ ;5: sear h_Left_Down_Up_Right(requestedTask,X,Y-i)6: if (mapped=false) then7: sear h_Left_Down_Up_Right(requestedTask,X+i,Y)8: end if9: if (mapped=false) then10: sear h_Left_Down_Up_Right(requestedTask,X-i,Y)11: end if12: if (mapped=false) then13: sear h_Left_Down_Up_Right(requestedTask,X,Y+i)14: end if15: end while16: if (mapped=false) then17: List_Task_not_mapped←requestedTask18: else19: X'←PE.X ;20: Y'←PE.Y ;21: end ifindiquer que la ressour e est apable de supporter la tâ he demandée et la positionde la ressour e est marquée omme X′ et Y′. Si la ressour e n'est pas en mesure desupporter la tâ he alors l'algorithme 6 ontinue ave les PEs restants dans le mêmeordre de sequen e.Par onséquent, le pro essus de re her he évalue tous les voisins à une distan e den-hop, où n varie de 1 à NoC_limit. Dans le as où un PE libre apable de supporterla tâ he demandée n'est pas trouvé à des sauts antérieures. La disponibilité et lesupport doivent être véri�és omme un PE pourrait être libre mais ne peut passupporter la tâ he si les deux ne sont pas du même type (par exemple, matériel).Le NoC_limit est la distan e de saut maximale jusqu'à laquelle le réseau peut êtreanalysée pour trouver un pla ement. La distan e du hop maximale est la distan e deManhattan à partir du point de départ de la re her he jusqu'au oin le plus éloignéde la frontière NoC. L'heuristique se termine dès qu'un PE libre et qui permet desupporter la tâ he est trouvé. A haque saut (hop), les PEs sont re her hés ave la séquen e gau he, bas, haut et droite. Par exemple, la séquen e de re her he estmontré par 1 : gau he, 2 : bas, 3 : haut, et 4 : droite, sur la Fig. 5.3. La même stratégieest suivie pour pla er toutes les tâ hes demandées pour haque appli ation.100

5.5 Stratégies de pa king et de routage proposéesChapitre 5 : Heuristiques pour le pla ement dynamique de tâ hes et ommuni ations sur unMPSoC basée NoCAlgorithm 7 Sear h AlgorithmRequire: requestedTask, NoC_limit, X, YEnsure: X', Y'1: if ((0 ≤ X ≤ NoC_limit)&&(0 ≤ Y ≤ NoC_limit)) then2: if ((PE[X℄[Y℄.isFree)&&(requestedTask.type = PE[X℄[Y℄.type)) then3: mapped←true ;4: X'←PE.X ;5: Y'←PE.Y ;6: end if7: end if5.4.2 Pa king-based Best Neighbor (PBN)L'heuristique PNN ne onsidère que la proximité d'une ressour e disponible pourexé uter une tâ he donnée. L'heuristique PBN ombine la stratégie de re her he dePNN ave l'appro he de al ul de la harge du hemin (PL). Contrairement à PNNqui s'arrête une fois qu'une ressour e libre et apable de supporté une tâ he esttrouvée, PBN évalue tous les PEs qui sont libres et apables de supporter une tâ hedonnée sur une même distan e. Pour tous les PEs libres et qui peuvent supporterune tâ he donnée leurs harges de hemin est al ulées et le PE ave le PL minimumest hoisie pour le pla ement �nale a�n d'obtenir le meilleur voisin des voisins dispo-nibles. Le lien qui doit transférer un nombre minimum de paquets est elui qui a lePL minimum. Si le pla ement est trouvée ave les PEs dans la distan e hop a tuel,le pro essus d'évaluation est arrêté pour d'autres distan es hop plus élevées. Lesautres étapes de l'heuristique PBN sont semblables à elles de l'heuristique PNN.5.5 Stratégies de pa king et de routage proposéesCette se tion dé rit nos appro hes de pla ement dynamique proposées. L'ap-pro he proposée her he à minimiser le temps de re her he pour trouver une res-sour e libre en mesure d'exé uter une tâ he donnée a�n d'optimiser le pro essus depla ement de tâ he. La stratégie de pa king Manhattan proposée réduit le tempsd'exé ution globale et la onsommation d'énergie pour le pla ement dynamique destâ hes de manière signi� ative. Les ommuni ations entre les tâ hes sont établies enutilisant un nouveau algorithme proposé de routage multi-obje tif pour une om-muni ation e� a e en vue de réduire les oûts de ommuni ation en termes detemps et d'énergie de ommuni ation. Les tâ hes ommuni antes qui sont pla ées101

5.5 Stratégies de pa king et de routage proposéesChapitre 5 : Heuristiques pour le pla ement dynamique de tâ hes et ommuni ations sur unMPSoC basée NoCsur deux PEs di�érents dans l'ar hite ture MPSoC ont besoin de ommuniquer àtravers le NoC, e qui pourrait né essiter une énergie onsidérable. Cela nous a mo-tivé à proposer un algorithme de routage multi-obje tifs a�n de réduire le oût dela ommuni ation.5.5.1 Manhattan Pa king StrategiesAvant de dé rire les stratégies de pa king Manhattan proposées, nous montronsun exemple de pla ement par la stratégie PNN pour mettre en éviden e ses limites.PNN a été onsidérée omme l'une des heuristiques de pla ement de référen e.Pour pla er une tâ he demandée, d'abord, la tâ he est tentée d'être pla ée sur lesPEs autour du PE sur lequel s'exé ute la tâ he maître à une distan e de saut égale à1. Les PEs sont re her hés dans la séquen e de gau he, bas, haut et droite, notée 1, 2,3 et 4, respe tivement en Fig. 5.4 (a). La même stratégie est suivie du saut 1 jusqu'à e qu'un PE libre et qui peut supporter la tâ he est trouvé. Chaque appli ationsuit la même stratégie pour le pla ement des tâ hes demandées sur les ressour esde la plateforme MPSoC. Le reste des tâ hes est pla é omme représenté sur la Fig.5.4 (a). Les limitations de l'appro he PNN sont observées lorsque le nombre destâ hes dans les appli ations onsidérées est très important. La plupart des travauxexistants et référen es ne onsidèrent pas les appli ations à grand nombre de tâ hes.Dans le as d'un grand nombre de tâ hes dans l'appli ation, la PNN n'est pas trèsperformante en termes de temps de pla ement. En outre, pour la position appropriéede la ressour e matérielle dans la plateforme, PNN en ourt un temps de pla ementélevé ar il doit her her pour 20 PEs avant d'atteindre le PE matériel, ommereprésenté sur la Fig. 5.4 (a). La séquen e de re her he est mentionnée omme étantde 1 à 20. L'appro he proposée permet de réduire le temps de pla ement pour lesappli ations à grand nombre de tâ hes.Manhattan Pa king-based Nearest Neighbor (MPNN)Pour pla er une tâ he demandée, la stratégie MPNN tente d'abord de trouverun pla ement sur une distan e de saut de 1 d'une manière similaire à elle de PNN.102

5.5 Stratégies de pa king et de routage proposéesChapitre 5 : Heuristiques pour le pla ement dynamique de tâ hes et ommuni ations sur unMPSoC basée NoCLa séquen e de re her he pour les PEs est 1, 2, 3 et 4 omme montré dans laFig. 5.4 (b). Pour le deuxième saut, les PEs sont re her hés dans la séquen e gau he,gau he-bas, bas, droite-bas, droite, haut-droite, haut and haut-gau he, désignée parles di�érents numéros à une distan e PEs de deux sauts à partir de 5. La mêmestratégie de re her he est utilisée en augmentant la distan e du saut. Pour pla erune tâ he matérielle demandée, La stratégie PNN a besoin d'évaluer 20 PEs(nombrede re her he) jusqu'à e qu'un PE matériel libre est trouvé, omme montré dans laFig 5.4 (a). En revan he, notre stratégie MPNN évalue seulement 9 PEs(nombre dere her he).L'heuristique MPNN a été introduite dans l'algorithme 8. Pour le pla ement d'unetâ he demandée, l'algorithme prend en entrée requestedTask, les oordonnées X & Ydu PE qui exé ute la tâ he maître et la taille de la plateforme (NoC_limit) et fourniten sortie les oordonnées (X′ & Y′) du PE qui est en mesure d'exé uter la tâ he.Une variable mapped est utilisée pour tester si la tâ he a été pla ée ou pas, et elleest initialement a�e té à faux. Hop (distan e ou pas) est utilisé pour déterminer ladistan e en nombre de saut (allant de 1 jusqu'à NoC_limit) entre le PE qui exé utela tâ he maître et le PE qui exé ute la tâ he demandées. Le pla ement de la tâ heest re her hé a partir de la distan e hop 1 jusqu'à NoC_limit et il est arrêté dèsqu'un PE libre et en mesure de supporter la tâ he est trouvé.Pour le hop=1, le MPNN évalues les PEs en suivant la sequen e gau he, bas, droiteand haut. Pour le hop supérieur ou égal à 2, la séquen e d'évaluation est gau he,gau he-bas, bas, droite-bas, droite, haut-droite, haut et haut-gau he, omme dé ritdans l'algorithme. Pour haque évaluation, le MPNN fait appel a la fon tion dere her he présentée dans l'algorithme 7, à savoir, re her he similaire à elle appliquépar PNN. Cette fon tion teste si la position du PE est dans le NoC_limit et si ilpeux supporter la tâ he. La fon tion retourne la position du PE si 1) le PE est dansle NoC_limit, 2) le type de la tâ he est le même que elui du PE et 3) le PE estlibre. En outre, la fon tion attribue la variable mapped à true pour indiquer qu'uneressour e libre et en mesure d'exé uter la tâ he est trouvée.103

5.5 Stratégies de pa king et de routage proposéesChapitre 5 : Heuristiques pour le pla ement dynamique de tâ hes et ommuni ations sur unMPSoC basée NoC
4
7
1 9
6 2 8
3 51
3
6,9
7,13
2
4 5 8,11,14,17
10
12,18
15
16,19
20
(a) Left!Down!Up!Right packing strategy (b) Manhattan packing strategy
Hardware
Resources
Software
Resources
Initial Task
Placement Figure 5.4 � pla ement par les stratégies MPNN et PNN.Manhattan Pa king-based Best Neighbor (MPBN)L'espa e de re her he de la stratégie MPBN est similaire à MPNN. Contrairementà MPNN qui pla e la tâ he sur le premier PE libre et qui permet de supporter latâ he, le MPBN évalue tous les PEs sur une même distan e hop et séle tionne eluiqui a la harge du lien minimum. Si un PE libre et qui supporte la tâ he est trouvésur la distan e hop ourante, après évaluations pour les autres distan es hop estannulé et l'algorithme se termine.5.5.2 Multi-Obje tive Routing Algorithm (MORA)La plus part des heuristiques de référen e qui traitent les pla ements dynamiques(par exemple, [120, 135, 108℄) utilisent l'algorithme de routage déterministe XY pourfa iliter les ommuni ations entre les tâ hes ommuni antes une fois qu'elles sontpla és sur les PEs. Exemple d'un tel routage est montré dans la Fig. 5.5 (a). La�gure montre un exemple d'un NoC où deux tâ hes ommuni antes sont pla ées surdeux PEs sour e et destination, elles ont besoin de ommuniquer entre elles. Lesvaleurs mentionnées prés des liens représente le volume de données présent dansle lien , .à.d le nombre de paquets à transmettre sur le lien. Fig. 5.5 (a) montreque pour transférer un paquet d'un PE sour e à un PE destination, le paquet esttransféré d'abord sur une distan e de deux hop dans la dire tion X, puis sur unedistan e de deux hop dans la dire tion Y en suivant le mé anisme de routage XY.104

5.5 Stratégies de pa king et de routage proposéesChapitre 5 : Heuristiques pour le pla ement dynamique de tâ hes et ommuni ations sur unMPSoC basée NoCAlgorithm 8 MPNN Heuristi Require: NoC_limit, requestedTask, X, YEnsure: X', Y'1: mapped←False ; hop←1 ;2: while ((hop < NoC_limit)&&(mapped=false)) do3: sear h(requestedTask, X, Y-hop) {sear h Left}4: for (i = 1 ; i < hop ; i++) do5: if (mapped=false) then6: sear h(requestedTask, X+i, Y-(hop-i)){sear h Left Down}7: end if8: end for9: if (mapped=false) then10: sear h(requestedTask, X+hop, Y){sear h Down}11: end if12: for (i = 1 ; i < hop ; i++) do13: if (mapped =false) then14: sear h(requestedTask, X+(hop-i), Y+i){sear h Right Down}15: end if16: end for17: if (mapped=false) then18: sear h(requestedTask, X, Y+hop){sear h Right}19: end if20: for (i = 1 ; i < hop ; i++) do21: if (mapped=false) then22: sear h(requestedTask, X-i, Y+(hop-i)){sear h Top Right}23: end if24: end for25: if (mapped=false) then26: sear h(requestedTask, X-hop, Y){sear h Top}27: end if28: for (i = 1 ; i < hop ; i++) do29: if (mapped=false) then30: sear h(requestedTask, X-(hop-i), Y-i){sear h Top Left}31: end if32: end for33: hop++ ;34: end whileLes paquets sont envoyés un par un sur le même hemin rée par le premier paquet.Dans la Fig. 5.5 (a), le premier lien hoisi dans la dire tion de X a un volume de(150) qui est plus important que elui du volume présent dans la dire tion Y qui estde (110). De même, le deuxième lien hoisis dans la dire tion de X a un plus grandvolume que elui présent dans la dire tion de Y (250 vs. 80). Ce mé anisme routeles paquets à travers un hemin qui entraîne des oûts de ommuni ation élevésdus à des volumes élevés présents dans les liens hoisis pour la ommuni ation.Ce qui entraîne des oûts élevés de ommuni ation. Ainsi, le hoix de es voies de ommuni ation peut entraîner des temps de ommuni ation et de onsommationd'énergie plus élevés.A�n de fournir une ommuni ation e� a e entre les PEs sour e et destination,une stratégie de routage e� a e doit être développée. La stratégie de routage doitêtre en mesure de hoisir les liens qui disposent de la moindre harge au moment del'exé ution. Fig. 5.5 (b) dé rit un exemple pour le fon tionnement de l'algorithme105

5.5 Stratégies de pa king et de routage proposéesChapitre 5 : Heuristiques pour le pla ement dynamique de tâ hes et ommuni ations sur unMPSoC basée NoCde routage dynamique proposé, présenté dans l'algorithme 9. Contrairement à l'al-gorithme XY, le MORA hoisit un hemin de routage e� a e où les paquets sonttransférés par les liens ayant les harges les plus faibles. La dire tion à prendre àpartir du PE sour e à PE de destination suit des hemins di�érents en fon tion del'empla ement des PEs et des harges des liens. Si la oordonnée X du PE sour e(Xsource) est inférieure à la oordonnée x du PE de destination, alors la traje -toire (path) sera du haut en bas, sinon du bas en haut. Pour le bas en haut, si les oordonnée Y du PE sour e (Ysource) est inférieure à la oordonnée Y du PE dedestination (Ydest), alors le hemin sera du gau he à droite, Sinon de la droite à lagau he. Pour tous les di�érents liens, l'algorithme hoisit la dire tion du lien qui a lamoindre harge. Par exemple, l' Algorithme 10 montre omment le lien qui disposede la moindre harge est trouvé dans le as de haut_en_bas-gau he_à_droite. Enfon tion des valeurs de harges des liens, l'algorithme hoisit la dire tion du lien degau he à droite (X'=Xsource,Y'=Ysource + 1) ou du haut en down, qui a la moindre harge. Une appro he similaire à elle de l'algorithme 10 est suivie pour les autres as où haut, bas, gau he et droite sont ontenues dans la fon tion appelante. Dans le as ou Ysource et Ydest sont les mêmes 'est à dire dans la même olonne, la dire tionest de haut en bas ou de bas en haut et il n'y a pas d'évaluation pour l'obtentionde la harge du lien. La dire tion est automatiquement pris dans l'une des deuxdire tions. De même, si Xsource et Xdest sont les mêmes, C'est à dire dans la mêmeligne alors la dire tion du lien hoisi est de gau he à droite ou de droite à gau he.Ce genre de séle tion de liens vers le PE de destination fa ilite de hoisir les liens lesmoins hargés. Une fois un lien hoisi devient plus hargé, un autre lien moins hargéest hoisi pour la transmission de paquet si le PE sour e et le PE de destination nesont pas dans la même ligne ou la même olonne. Sinon, le même lien est utilisé.Pour toutes les tâ hes ommuni antes, les paquets à transférer utilisent la mêmestratégie.Toutes les fon tions ont le même prin ipe.106

5.5 Stratégies de pa king et de routage proposéesChapitre 5 : Heuristiques pour le pla ement dynamique de tâ hes et ommuni ations sur unMPSoC basée NoC
(a) XY Routing (b) MORA Routing Figure 5.5 � XY et MORA.Algorithm 9 Multi-Obje tive Routing AlgorithmRequire: Xsource, Ysource, Xdest, YdestEnsure: X', Y'{Up to Down}1: if Xsource < Xdest then2: if Ysource < Ydest then3: Up_to_Down-Left_to_Right(Xsource, Ysource)4: else5: Up_to_Down-Right_to_Left(Xsource, Ysource)6: end if7: else8: {Down to Up}9: if Ysource < Ydest then10: Down_to_Up-Left_to_Right(Xsource, Ysource)11: else12: Down_to_Up-Right_to_Left(Xsource, Ysource)13: end if14: end if15: if Xsource=Xdest then16: Right_to_Left-Left_to_Right(Xsource, Ysource){in the same row}17: end if18: if Ysource=Ydest then19: Up_to_Down-Down_to_Up(Xsource, Ysource){in the same olumn}20: end if5.5.3 Cal ul du Temps d'exé ution globale et la onsommation d'énergieModélisation et Formulation mathématiqueT ti(s/h)exe : temps d'exé ution de la tâ he ti sur la ressour e (la tâ he logi ielle surla ressour e logi ielle et la tâ he matérielle sur la ressour e matérielle).
Qij : le volume de données é hangés entre ti and tj.
R : débit (nombre de paquets envoyés sur un seul envoi).T timap : le temps de pla ement de la tâ he ti.
Tcomti
mastermap : temps de pla ement de ommuni ation de la tâ he maître à la tâ he107

5.5 Stratégies de pa king et de routage proposéesChapitre 5 : Heuristiques pour le pla ement dynamique de tâ hes et ommuni ations sur unMPSoC basée NoCAlgorithm 10 Up_to_Down-Left_to_RightRequire: Xsource, YsourceEnsure: X', Y'1: if get_value_Link(Xsource,Ysource+1) < get_value_Link(Xsource+1,Ysource) then2: X′ ← Xsource3: Y ′ ← Ysource+1 {Left to Right}4: else5: X′ ← Xsource+1 {Up to Down}6: Y ′ ← Ysource7: end ifes lave.T
commasterti
map : temps de pla ement de ommuni ation de la tâ he es lave à la tâ hemaître.T tiupload : temps de hargement de la tâ he ( on�guration) ti.
ECsti : onsommation d'énergie logi ielle.
EChti : onsommation d'énergie matérielle.
ECRs : onsommation d'énergie d'un seul paquet ave le débit R.
ECdw : onsommation d'énergie pour l'attente de données d.
ECsinst : onsommation d'énergie d'une instru tion sur une ressour e logi ielle.
EChinst : onsommation d'énergie d'une instru tion sur une ressour e matérielle.
ECRstjti
: onsommation d'énergie d'un paquet envoyé de ti vers tj ave un débitR.ECw : onsommation d'énergie pour l'attente de données sur le lien pour l'envoide données de ti vers tj.ECTotal : onsommation d'énergie totale.T appexe : temps d'exé ution d'appli ation.
TTotalexec : temps d'exé ution totale.Cal ul de la onsommation d'énergie : La façon de al ul des di�érentesvaleurs de onsommation d'énergie sont introduits par la suite.La onsommation d'énergie pour la tâ he logi iel :ECs
ti= ECs
inst ∗ T instst (5.1)La onsommation d'énergie pour la tâ he du matériel :
EChti= ECh
inst ∗ T instht (5.2)108

5.5 Stratégies de pa king et de routage proposéesChapitre 5 : Heuristiques pour le pla ement dynamique de tâ hes et ommuni ations sur unMPSoC basée NoCLa onsommation d'énergie pour l'envoi d'un paquet de ti à tj ave un débit R :ECR
stjti
= ECRs ∗
Qij
R(5.3)La onsommation d'énergie pour l'attente de données dur le lien lors de l'envoide données de ti à tj :
ECw = ECdw ∗
Qij
R(5.4)En�n, la onsommation d'énergie totale est al ulée omme suit :
ECTotal =∑
ECw +∑
ECR
stjti
+∑
ECsti+
∑ECh
ti(5.5)Cal ul du temps d'exé ution : Le temps d'exé ution d'une tâ he ti (softwareou hardware), T ti
exe, est la somme des temps né essaires pour trouver un pla ementpour la tâ he (T timap) et ses ommuni ations , temps de on�guration pour la tâ heti (T ti
upload) et le temps d'exé ution de la tâ he (T ti(s/h)exe ) dans la ressour e on�gurée(ressour e logi ielle ou matérielle). Le temps de pla ement des ommuni ations se ompose du temps pris pour le pla ement des ommuni ations de la tâ he maître tià la tâ he es lave tj et de la tâ he es lave tj à la tâ he maître ti. La tâ he maîtreti ne termine pas jusqu'à e que toutes es tâ hes es laves soient terminées. Commeles es laves s'exé utent en parallèle, elle qui prend le temps maximum ontribueau temps d'exé ution de la tâ he maître ti. Le temps d'exé ution de l'appli ation se ompose du temps des ommuni ations en plus de eux mentionnés i-dessus.Le temps d'exé ution pour haque tâ he est al ulé de façon ré ursive de la façonsuivante :
T tiexe = T
tiupload+T ti(s/h)
exe +T timap+T com
timaster
map +Tcommaster
timap +
slaves−number∑
n=1
Max T tnexe (5.6)Le temps d'exé ution global est al ulé omme le temps d'exé ution maximumparmi toutes les appli ations en ours d'exé ution en parallèle.
109
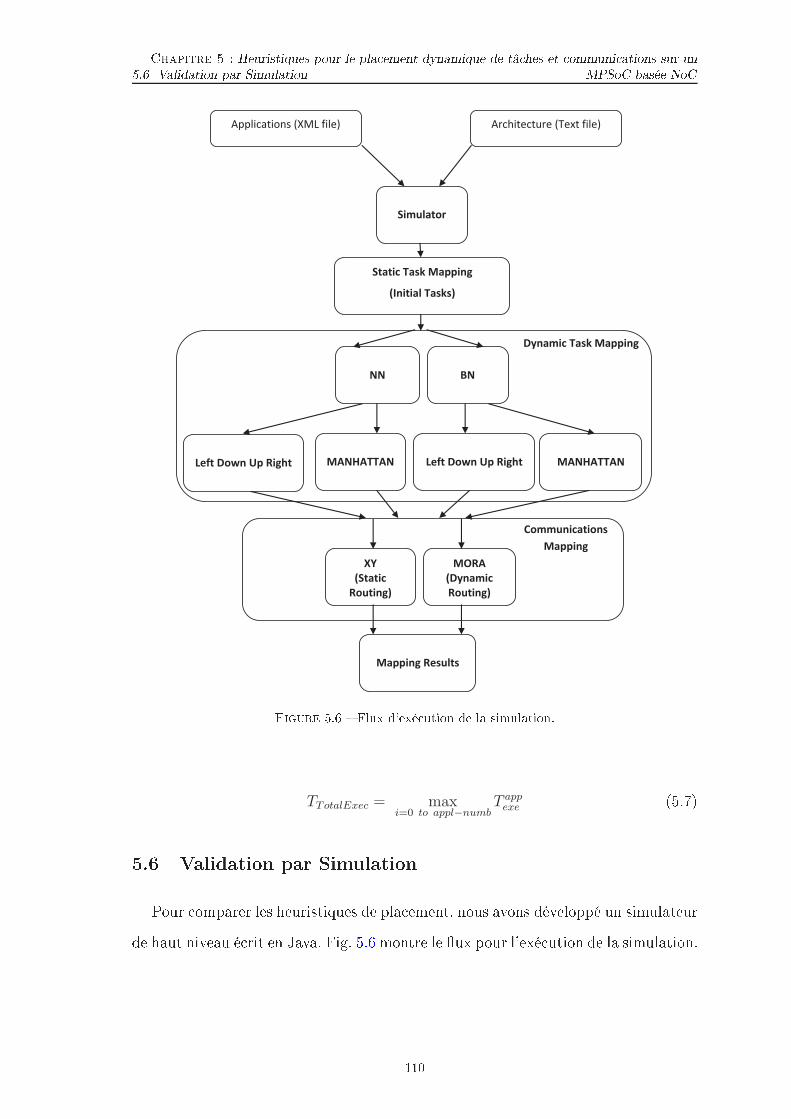
5.6 Validation par SimulationChapitre 5 : Heuristiques pour le pla ement dynamique de tâ hes et ommuni ations sur unMPSoC basée NoC
Applications (XML file)
Simulator
Architecture (Text file)
Static Task Mapping
(Initial Tasks)
BN
NN
MANHATTAN
Left Down Up Right
MANHATTAN
Left Down Up Right
MORA
(Dynamic
Routing)
XY
(Static
Routing)
Mapping Results
Communications
Mapping
Dynamic Task Mapping
Figure 5.6 � Flux d'exé ution de la simulation.TTotalExec = max
i=0 to appl−numbT appexe (5.7)5.6 Validation par SimulationPour omparer les heuristiques de pla ement, nous avons développé un simulateurde haut niveau é rit en Java. Fig. 5.6 montre le �ux pour l'exé ution de la simulation.
110

5.6 Validation par SimulationChapitre 5 : Heuristiques pour le pla ement dynamique de tâ hes et ommuni ations sur unMPSoC basée NoC5.6.1 Con�guration de SimulationsCette se tion dé rit la on�guration expérimentale utilisée. Toutes les appli a-tions sont modélisées omme illustré sur la Fig. 5.1 (a), ave des tâ hes initiales,matérielles et logi ielles. Les valeurs présentes sur les liens orrespondent au volumedes données qui doivent être envoyées et reçues par le maître omme il est expli-qué dans la dé�nition 5.3.1. Le NoC est modélisé omme dans la Fig. 5.3 ave lestâ hes initiales pla ées au milieu de haque luster. Nous avons réalisé une plate-forme hétérogène qui ontient 64 éléments de traitement (PEs) : 12 hardware, 51software, et un pro esseur Manager. Le Manager est responsable de trouver le pla e-ment des tâ hes d'appli ations, la liaison des tâ hes (task binding),la on�gurationdes tâ hes(upload), la mise à jour des ressour es de la plateforme et le routage des ommuni ations. La plateforme utilise un réseau sur pu e (Network-on-Chip (NoC))en tant que support de ommuni ation, qui est responsable de la transmission desdonnées entre les tâ hes. Le pro esseur Manager ne onnait que les tâ hes initiales.Lorsque les tâ hes initiales ommen ent leurs exé utions, les tâ hes es laves sontpla ées dynamiquement, en fon tion des demandes de ommuni ations. Le tempsd'exé ution des tâ hes dépend du type et de la apa ité du pro esseur (PE). Nouspouvons varier plusieurs paramètres via un � hier de on�guration d'entrée (� hierde paramètres) qui ontient tous les paramètres tels que la on�guration de la pla-teforme, le hoix des heuristiques de pla ement dynamique, la méthode de routage,et . Les simulations sont e�e tuées sur di�érents s énarios :� S enario 1 : Appli ations générées par l'outilTask Graph For Free (TGFF [75℄) omme illustré dans la Fig. 5.7 (3-4 Niveau, 1-3 �ls). Appli ations ontiennentun maximum de 9 tâ hes.� S enario 2 : Appli ationsMulti-Window Display (MWD), Video Obje t PlaneDe oder (VOPD), Pe ture-In Pi ture (PIP) omme illustré dans la Fig. 5.8. Lesappli ations MWD, VOPD et PIP ontiennent 12, 15 et 8 tâ hes, respe tive-ment.� S enario 3 : Plusieurs appli ations MPEG-4. L'appli ation ontient 13 tâ hes111

5.6 Validation par SimulationChapitre 5 : Heuristiques pour le pla ement dynamique de tâ hes et ommuni ations sur unMPSoC basée NoC Figure 5.7 � Appli ations générer par l'outil TGFF (3-4 Niveau, 1-3 �ls).
(a) (b) (c) Figure 5.8 � Appli ations (a) MWD, (b) VOPD, ( ) PIP.(Fig. 5.9).
11 12
10
7
5 2 9 6 8 4 3
0
1
Figure 5.9 � Appli ation MPEG-4.� S enario 4 : quatre séries d'appli ations : 1er série - haque appli ation ayant5 tâ hes, 2eme série - haque appli ation ayant 10 tâ hes, 3eme série - haqueappli ation ayant 15 tâ hes, et 4eme série - haque appli ation ayant 20 tâ hes.Pour haque s énario, nous essayons de pla er et d'exé uter un total de dix (10)appli ations, alors que n'importe quel nombre d'appli ations peut être envisagés.112
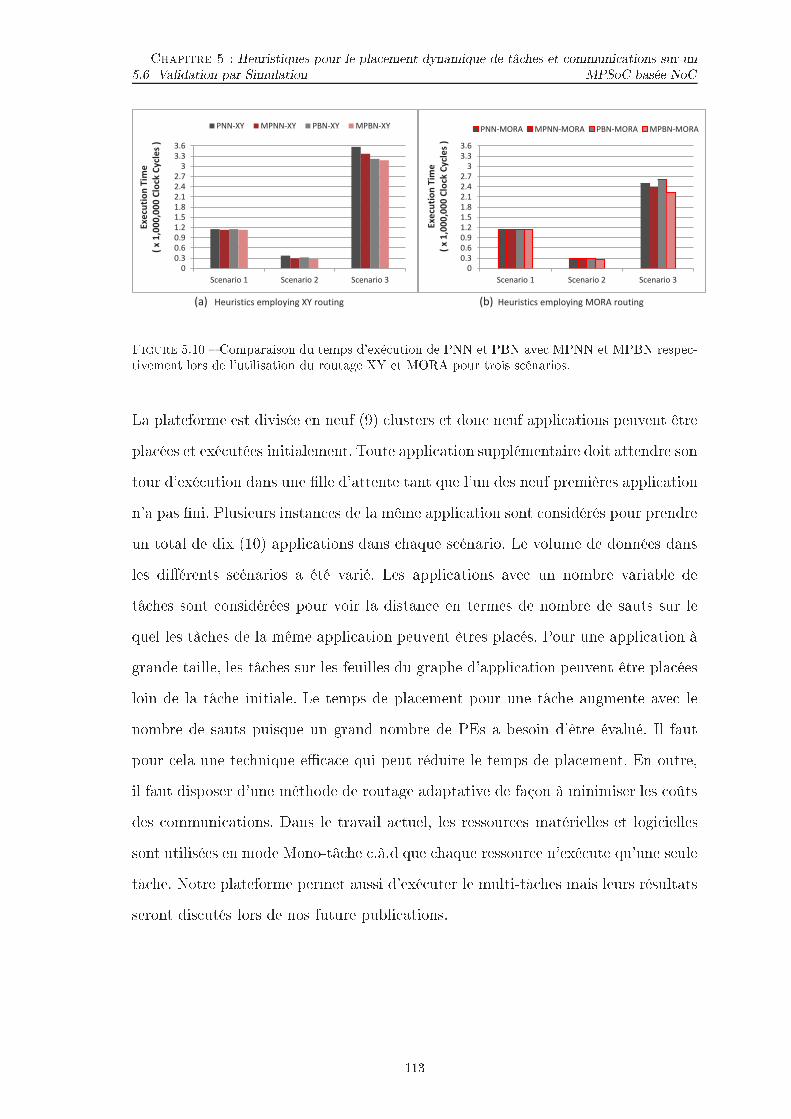
5.6 Validation par SimulationChapitre 5 : Heuristiques pour le pla ement dynamique de tâ hes et ommuni ations sur unMPSoC basée NoC
Figure 5.10 � Comparaison du temps d'exé ution de PNN et PBN ave MPNN et MPBN respe -tivement lors de l'utilisation du routage XY et MORA pour trois s énarios.La plateforme est divisée en neuf (9) lusters et don neuf appli ations peuvent êtrepla ées et exé utées initialement. Toute appli ation supplémentaire doit attendre sontour d'exé ution dans une �lle d'attente tant que l'un des neuf premières appli ationn'a pas �ni. Plusieurs instan es de la même appli ation sont onsidérés pour prendreun total de dix (10) appli ations dans haque s énario. Le volume de données dansles di�érents s énarios a été varié. Les appli ations ave un nombre variable detâ hes sont onsidérées pour voir la distan e en termes de nombre de sauts sur lequel les tâ hes de la même appli ation peuvent êtres pla és. Pour une appli ation àgrande taille, les tâ hes sur les feuilles du graphe d'appli ation peuvent être pla éesloin de la tâ he initiale. Le temps de pla ement pour une tâ he augmente ave lenombre de sauts puisque un grand nombre de PEs a besoin d'être évalué. Il fautpour ela une te hnique e� a e qui peut réduire le temps de pla ement. En outre,il faut disposer d'une méthode de routage adaptative de façon à minimiser les oûtsdes ommuni ations. Dans le travail a tuel, les ressour es matérielles et logi iellessont utilisées en mode Mono-tâ he .à.d que haque ressour e n'exé ute qu'une seuletâ he. Notre plateforme permet aussi d'exé uter le multi-tâ hes mais leurs résultatsseront dis utés lors de nos future publi ations.113

5.6 Validation par SimulationChapitre 5 : Heuristiques pour le pla ement dynamique de tâ hes et ommuni ations sur unMPSoC basée NoC5.6.2 Résultats de SimulationsLes résultats obtenus pour nos heuristiques Manhattan proposées MPNN etMPBN sont omparées ave les heuristiques de pla ement dynamique existantesPNN et PBN. Nos heuristiques montrent un temps de pla ement (r her he) infé-rieure. L'appro he de routage proposée MORA a été utilisée ave les heuristiquesde pla ement existantes et proposées a�n d'optimiser les oûts de ommuni ations.L'adaptation de MORA dans les heuristiques de pla ement montre des améliorationsde performan e.Temps d'exé ution totalTemps d'exé ution total omprend le temps de pla ement (le temps né essairepour trouver un pla ement), temps de on�guration, temps de ommuni ation,temps de al ul et temps d'attente lorsque au une ressour e libre n'est disponiblesur la plateforme. L'adaptation de la stratégie de pa king dans le pro essus de pla- ement fa ilite le pla ement des tâ hes ommuni antes à proximité et tout en rédui-sant le temps de ommuni ation. Il a été également observé que le temps de mapping ontribuant au temps d'exé ution total se réduit lorsque l'on utilise les heuristiquesManhattan par e que l'espa e de re her he pour trouver le pla ement d'une tâ heest minimisé. L'utilisation d'un routage déterministe omme XY peut in�uer surles oûts de ommuni ations. En utilisant le routage dynamique MORA proposé,nous pouvons réduire onsidérablement le temps de ommuni ation. Dans MORA,les paquets peuvent prendre plus d'une traje toire ( hemin) pour fa iliter une om-muni ation plus rapide, résultant en une rédu tion des oûts de ommuni ation.Les graphes de la Fig. 5.10 montrent le temps d'exé ution totale pris pour lepla ement des 10 appli ations onsidérées pour les di�érents s énarios où di�érentesheuristiques sont appliquées. Fig. 5.10 (a) et (b) montre les temps d'exé ution lorsqueles heuristiques utilisent les appro hes de routage XY et MORA, respe tivement.Un ouple d'observations peuvent être faits à partir des �gures. Tout d'abord, lesappro hes proposées MPNN et MPBN réduisent le temps d'exé ution par rapport àPNN et PBN, respe tivement. Ce i peut être observé lorsque les deux appro hes de114

5.6 Validation par SimulationChapitre 5 : Heuristiques pour le pla ement dynamique de tâ hes et ommuni ations sur unMPSoC basée NoCroutage XY et MORA sont utilisées. Deuxièmement, les appro hes existantes PNNet PBN ont un temps d'exé ution qui est réduit lors de l'utilisation de l'appro hede routage MORA par rapport à l'utilisation du routage XY. Cela est dû à l'adap-tation dynamique des trajets par MORA. La di�éren e des temps d'exé ution peutêtre observée en regardant la Fig. 5.10 (a) et (b).Les résultats similaires peuventêtre observés pour les heuristiques proposées MPNN et MPBN lorsque l'appro hede routage est modi�ée de XY à MORA. Ces observations montrent que nos ap-pro hes réduisent le temps d'exé ution par rapport aux appro hes existantes, mêmesi l'appro he de routage existante XY est employée. Une rédu tion supplémentaireest obtenue lorsque l'appro he de routage proposé MORA est utilisée.Dans le s énario 1, nos appro hes proposées MPNN et MPBN employant MORAréduisent le temps d'exé ution total par 1% et 2% par raport à PNN et PBN em-ployant le routage MORA. Pour le s énario 1, la rédu tion du temps d'exé utionn'est pas importante puisque le nombre de tâ hes dans les appli ations sont est in-férieur à dix (10) et il ya au maximum trois es laves par maître, e qui limite lesavantages de nos appro hes. Dans le s énario 2, nos appro hes proposées MPNN etMPBN employant MORA réduisent le temps d'exé ution total par 4% and 5% parraport à PNN et PBN employant le routage MORA. La rédu tion meilleur que elleobtenue ave le s énario 1, puisque le nombre de tâ hes dans les appli ations envi-sagées a été augmenté mais le nombre d'es laves par maître reste onstant. Dans les énario 3, Nos appro hes proposées MPNN et MPBN employant MORA réduisentle temps d'exé ution total par 6% et 15% par raport à PNN et PBN employant leroutage MORA. La rédu tion est plus grande que le s énarios 1 et 2 puisque l'ap-pli ation MPEG-4 ontient 13 tâ hes et une des tâ hes maître ontiennent sept (7)tâ hes es laves. Les appro hes proposées fourniront de meilleurs résultats lorsque lesappli ations ontiennent un grand nombre de tâ hes tout en ayant un grand nombrede tâ hes es lave par maître.115
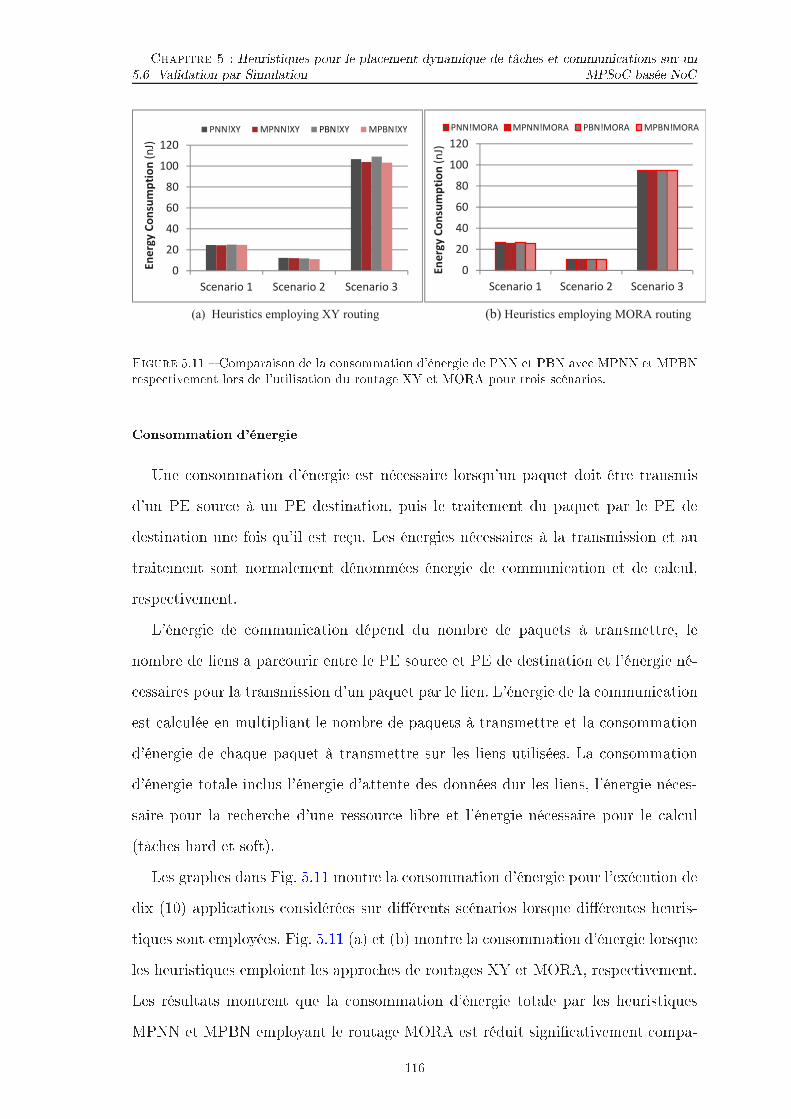
5.6 Validation par SimulationChapitre 5 : Heuristiques pour le pla ement dynamique de tâ hes et ommuni ations sur unMPSoC basée NoC
Figure 5.11 � Comparaison de la onsommation d'énergie de PNN et PBN ave MPNN et MPBNrespe tivement lors de l'utilisation du routage XY et MORA pour trois s énarios.Consommation d'énergieUne onsommation d'énergie est né essaire lorsqu'un paquet doit être transmisd'un PE sour e à un PE destination, puis le traitement du paquet par le PE dedestination une fois qu'il est reçu. Les énergies né essaires à la transmission et autraitement sont normalement dénommées énergie de ommuni ation et de al ul,respe tivement.L'énergie de ommuni ation dépend du nombre de paquets à transmettre, lenombre de liens a par ourir entre le PE sour e et PE de destination et l'énergie né- essaires pour la transmission d'un paquet par le lien. L'énergie de la ommuni ationest al ulée en multipliant le nombre de paquets à transmettre et la onsommationd'énergie de haque paquet à transmettre sur les liens utilisées. La onsommationd'énergie totale in lus l'énergie d'attente des données dur les liens, l'énergie né es-saire pour la re her he d'une ressour e libre et l'énergie né essaire pour le al ul(tâ hes hard et soft).Les graphes dans Fig. 5.11 montre la onsommation d'énergie pour l'exé ution dedix (10) appli ations onsidérées sur di�érents s énarios lorsque di�érentes heuris-tiques sont employées. Fig. 5.11 (a) et (b) montre la onsommation d'énergie lorsqueles heuristiques emploient les appro hes de routages XY et MORA, respe tivement.Les résultats montrent que la onsommation d'énergie totale par les heuristiquesMPNN et MPBN employant le routage MORA est réduit signi� ativement ompa-116
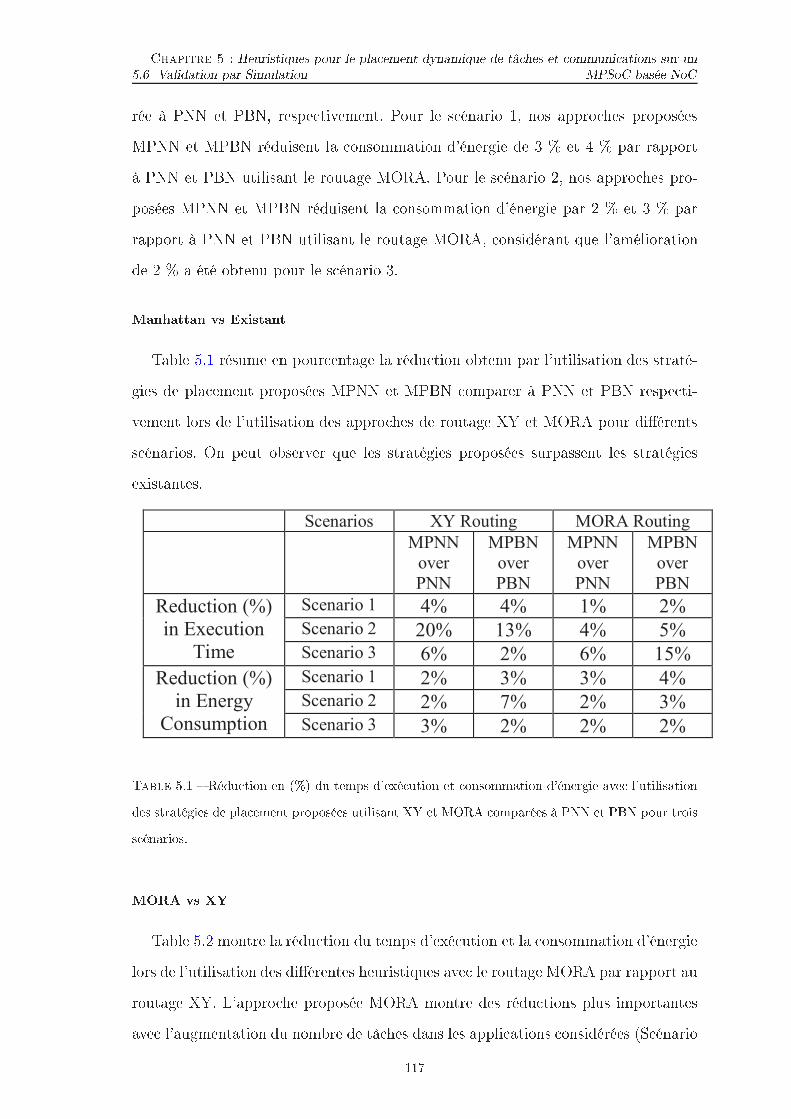
5.6 Validation par SimulationChapitre 5 : Heuristiques pour le pla ement dynamique de tâ hes et ommuni ations sur unMPSoC basée NoCrée à PNN et PBN, respe tivement. Pour le s énario 1, nos appro hes proposéesMPNN et MPBN réduisent la onsommation d'énergie de 3 % et 4 % par rapportà PNN et PBN utilisant le routage MORA. Pour le s énario 2, nos appro hes pro-posées MPNN et MPBN réduisent la onsommation d'énergie par 2 % et 3 % parrapport à PNN et PBN utilisant le routage MORA, onsidérant que l'améliorationde 2 % a été obtenu pour le s énario 3.Manhattan vs ExistantTable 5.1 résume en pour entage la rédu tion obtenu par l'utilisation des straté-gies de pla ement proposées MPNN et MPBN omparer à PNN et PBN respe ti-vement lors de l'utilisation des appro hes de routage XY et MORA pour di�érentss énarios. On peut observer que les stratégies proposées surpassent les stratégiesexistantes.% and
MORA
scenarios 1 and 2 as
13 tasks and one master contains
The proposed approaches will provide better results
when the applications containing more number of tasks and
nergy is required when a packet needs to be transmitted from
source PE to destination PE and then to process the packet at
3. Scenarios XY Routing MORA Routing
MPNN
over
PNN
MPBN
over
PBN
MPNN
over
PNN
MPBN
over
PBN
Reduction (%)
in Execution
Time
Scenario 1 4% 4% 1% 2%
Scenario 2 20% 13% 4% 5%
Scenario 3 6% 2% 6% 15%
Reduction (%)
in Energy
Consumption
Scenario 1 2% 3% 3% 4%
Scenario 2 2% 7% 2% 3%
Scenario 3 3% 2% 2% 2%
Table 1: Execution time and Energy consumption Reduction (%)
Scenarios PNN PBN MPNN MPBN
MORA
over
MORA
over
MORA
over
MORA
over
Reduction (%) Scenario 1 3% 0% 4% 1%
Scenario 2 20% 5% 13% 4%
Scenario 3 30% 29% 19% 31%
Reduction (%)
in Energy
Scenario 1 0% 0% 0% 0%
Scenario 2 15% 14% 12% 8%
Scenario 3 12% 9% 14% 13%
Table 5.1 � Rédu tion en (%) du temps d'exé ution et onsommation d'énergie ave l'utilisationdes stratégies de pla ement proposées utilisant XY et MORA omparées à PNN et PBN pour troiss énarios.MORA vs XYTable 5.2 montre la rédu tion du temps d'exé ution et la onsommation d'énergielors de l'utilisation des di�érentes heuristiques ave le routage MORA par rapport auroutage XY. L'appro he proposée MORA montre des rédu tions plus importantesave l'augmentation du nombre de tâ hes dans les appli ations onsidérées (S énario117
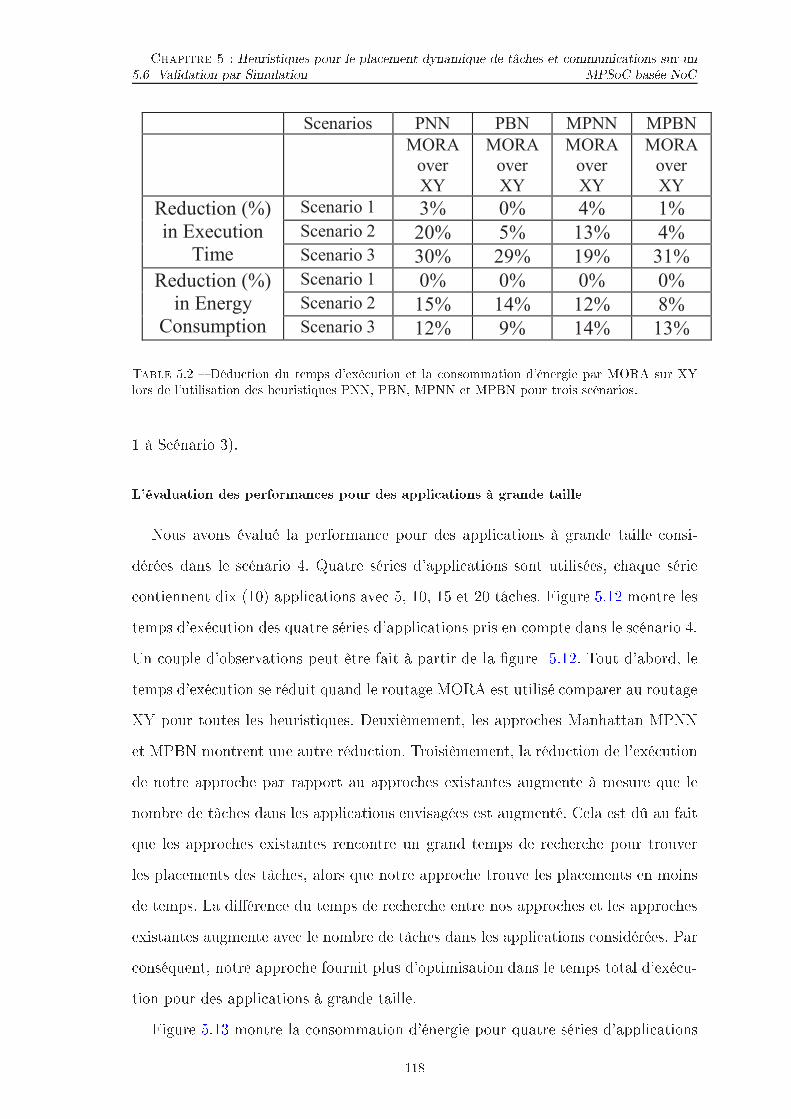
5.6 Validation par SimulationChapitre 5 : Heuristiques pour le pla ement dynamique de tâ hes et ommuni ations sur unMPSoC basée NoCThe communication energy depends on the number of packets
to be transmitted, the number of links to be traversed between
both the PEs and energy required in transmitting one packet
energy is calculated by multiplying the
energy consumption
through the used links. Total energy
data in the links,
required
Scenarios PNN PBN MPNN MPBN
MORA
over
XY
MORA
over
XY
MORA
over
XY
MORA
over
XY
Reduction (%)
in Execution
Time
Scenario 1 3% 0% 4% 1%
Scenario 2 20% 5% 13% 4%
Scenario 3 30% 29% 19% 31%
Reduction (%)
in Energy
Consumption
Scenario 1 0% 0% 0% 0%
Scenario 2 15% 14% 12% 8%
Scenario 3 12% 9% 14% 13%
Table2: Execution time and Energy consumption Reduction for XY Table 5.2 � Dédu tion du temps d'exé ution et la onsommation d'énergie par MORA sur XYlors de l'utilisation des heuristiques PNN, PBN, MPNN et MPBN pour trois s énarios.1 à S énario 3).L'évaluation des performan es pour des appli ations à grande tailleNous avons évalué la performan e pour des appli ations à grande taille onsi-dérées dans le s énario 4. Quatre séries d'appli ations sont utilisées, haque série ontiennent dix (10) appli ations ave 5, 10, 15 et 20 tâ hes. Figure 5.12 montre lestemps d'exé ution des quatre séries d'appli ations pris en ompte dans le s énario 4.Un ouple d'observations peut être fait à partir de la �gure 5.12. Tout d'abord, letemps d'exé ution se réduit quand le routage MORA est utilisé omparer au routageXY pour toutes les heuristiques. Deuxièmement, les appro hes Manhattan MPNNet MPBN montrent une autre rédu tion. Troisièmement, la rédu tion de l'exé utionde notre appro he par rapport au appro hes existantes augmente à mesure que lenombre de tâ hes dans les appli ations envisagées est augmenté. Cela est dû au faitque les appro hes existantes ren ontre un grand temps de re her he pour trouverles pla ements des tâ hes, alors que notre appro he trouve les pla ements en moinsde temps. La di�éren e du temps de re her he entre nos appro hes et les appro hesexistantes augmente ave le nombre de tâ hes dans les appli ations onsidérées. Par onséquent, notre appro he fournit plus d'optimisation dans le temps total d'exé u-tion pour des appli ations à grande taille.Figure 5.13 montre la onsommation d'énergie pour quatre séries d'appli ations118

5.6 Validation par SimulationChapitre 5 : Heuristiques pour le pla ement dynamique de tâ hes et ommuni ations sur unMPSoC basée NoC
Figure 5.12 � Temps d'exé ution de 10 appli ations pour quatre séries d'appli ations (s énario4), où haque appli ation ontient 5, 10, 15 et 20 tâ hes. onsidérées dans le s énario 4. On peut observer que la rédu tion de la onsomma-tion d'énergie par notre appro he par rapport aux appro hes existantes augmentede la même manière que le nombre de tâ hes dans les appli ations envisagées estaugmentée. Par onséquent, notre appro he donne de meilleurs optimisations pourles appli ations à grandes tailles.Comparaison de omplexité : Nombre de re her hesNous avons al ulé la omplexité des di�érentes heuristiques en termes de nombrede re her hes à e�e tuer pour le pla ement de toutes les tâ hes dans une série d'ap-pli ations. Il a déjà été démontré que le nombre de re her hes de la stratégie proposéeManhattan est inférieure aux stratégies existantes, par exemple 9 par rapport à 20 omme représenté sur la Fig. 5.4. Table 5.3 montre le nombre de re her hes pardi�érentes heuristiques pour quatre séries d'appli ations, où haque série ontient10 appli ations. Chaque appli ation dans les quatre séries ontient 5, 10, 15 et 20tâ hes, respe tivement. Un ouple d'observations peuvent être faites à partir de laTable5.3. Tout d'abord, le nombre de re her hes est fortement réduit par les stra-tégies Manhattan MPNN et MPBN par rapport à PNN et PBN, respe tivement.Deuxièmement, les stratégies Manhattan proposées montrent une rédu tion plus119

5.7 Con lusionChapitre 5 : Heuristiques pour le pla ement dynamique de tâ hes et ommuni ations sur unMPSoC basée NoC
Figure 5.13 � Consommation d'énergie de 10 appli ations pour quatre séries d'appli ations (s é-nario 4), où haque appli ation ontient 5, 10, 15 et 20 tâ hes.Apps-5tasks Apps-10tasks Apps-15tasks Apps-20tasksPNN 1690 10370 16360 46650MPNN 1540 7950 12470 43210PBN 2280 10800 17200 51130MPBN 2260 9800 15130 48150Table 5.3 � Nombre de re her hes pour toutes les tâ hes dans di�érentes séries d'appli ationspour le s énario 4 on utilisant des stratégies de Manhattan et existantes.élevée du nombre de re her hes pour les appli ations à grand nombre de tâ hes. Ila également été observé que le nombre de re her hes ne dépend pas de l'appro hede routage appliquée. L'appro he de routage est destinée aux pla ements des om-muni ations, mais pas les tâ hes. Ainsi, les stratégies de Manhattan réduisent la omplexité et une autre rédu tion pour les appli ations à grand nombre de tâ hes.La omparaison de la omplexité des di�érents algorithmes en termes de tempsd'exé ution montre que nos appro hes ont réduit la omplexité.5.7 Con lusionNous avons présenté dans e hapitre, une appro he de pla ement qui e�e tue lepla ement dynamique des appli ations maître-es lave sur des MPSoCs hétérogènesdans deux phases di�érentes. La première phase utilise de nouvelles stratégies de120

5.7 Con lusionChapitre 5 : Heuristiques pour le pla ement dynamique de tâ hes et ommuni ations sur unMPSoC basée NoCpla ement proposées sur la base de la distan e de Manhattan pour pla er les tâ hesde l'appli ation à proximité a�n de réduire les oûts de ommuni ation. Autre avan-tage, est que les stratégies de Manhattan réduisent le temps de pla ement de haquetâ he. La deuxième phase pla e les ommuni ations entre les tâ hes sur un réseausur pu e. Pour réduire les oûts de ommuni ations, un algorithme de routage multi-obje tifs ( MORA ) a été proposé . Les simulations ont montré que les stratégiesproposées de pla ement Manhattan ainsi que le MORA montrent une rédu tion si-gni� ative dans le temps total d'exé ution et la onsommation d'énergie par rapportaux appro hes existantes.
121

Chapitre 6Con lusion générale et perspe tivesDans e hapitre, nous résumons les ontributions présentées dans ette thèseet nous on luons sur les possibles orientations futures de la re her he sur ettethématique.6.1 Con lusionDans ette thèse nous avons proposé un ertain nombre de nouvelles te hniquesde pla ement dynamique d'appli ations sur des ar hite tures hétérogènes MPSoC àbase de NoC. Un état de l'art approfondi nous a permis de bien se positionner et depouvoir extraire et d'identi�er les limites et les insu�san es des propositions exis-tantes. Il a également été établi que la né essité de passer aux MPSoCs s'avère indis-pensables vu la omplexité roissante des appli ations a tuelles et futurs. De mêmele passage aux MPSoCs hétérogènes garantit de meilleures performan es. Le passageaux réseaux sur pu e (NoCs) répond aux besoins de ommuni ation roissants entreles diverses unités de traitement sur une même pu e. Les goulots d'étranglement de ommuni ation ontinuent d'être un sujet de préo upation, e qui limite les gainsde performan e dans les grandes réalisations de grande envergure. Dans ette thèse,nous avons proposé une nouvelle heuristique de pla ement dynamique en spiralepour le pla ement e� a e des tâ hes d'appli ations sur une plateforme MPSoC hé-térogène basée NoC ontenant des éléments de traitement (PE) qui ne supportentqu'une seule tâ he. Les te hniques de pla ement existantes ne peuvent pas fournirde meilleurs résultats en omparaison ave notre proposition. La te hnique proposéepla e les tâ hes d'appli ation sur les éléments de traitement MPSoC de manière à eque toutes les tâ hes es laves par maître soient pla ées le plus pro he possible de la122

6.1 Con lusion Chapitre 6 : Con lusion générale et perspe tivestâ he maître (les tâ hes es laves sont pla ées autour de la tâ he maître), onduisantà un pla ement des tâ hes e� a es. Nous avons ainsi proposé une deuxième nouvelleheuristique de pla ement des ommuni ations, a�n de réduire les oûts des ommu-ni ations. Cette te hnique est basée sur l'algorithme Dijkstra modi�é a�n de trouverle hemin le plus ourt et le moins hargé a�n d'optimiser les oûts des ommuni a-tions. Ces te hniques montrent une amélioration des performan es par rapport auxte hniques existantes. Une troisième nouvelle heuristique de pla ement dynamiquepour le pla ement e� a e d'appli ations sur une plateforme MPSoC hétérogène ba-sée sur un NoC ontenant des éléments de traitement (PE) qui ne supportent qu'uneseule tâ he a été aussi proposée. On onstate que les te hniques de pla ement exis-tantes ne peuvent pas fournir de meilleurs résultats dans le as des appli ations pluslarges (appli ations qui ontiennent un nombre de tâ hes important). La te hniqueproposée pla e les tâ hes d'appli ations sur les éléments de traitement MPSoC demanière très systématique. L'appro he proposée utilise une stratégie de pa king ba-sée sur la distan e de Manhattan et met le point sur le temps de mapping (le tempsde re her he d'une ressour e libre) qui peut in�uen er les performan es du système, e temps est minimisé d'une façon onsidérable pendant que les performan es sontoptimisées. La plupart des travaux existants traitant la même problématique, uti-lisent pour le pla ement des ommuni ations, le routage statique à savoir le XY,pour sa simpli ité d'implémentation. Une quatrième nouvelle heuristique de routagemulti-obje tif (MORA) pour le pla ement dynamique des ommuni ations a aussiété proposée dans e travail. Le but du MORA est d'a heminer les paquets é hangéspar le lien le moins hargé sur les liaisons point a point et vers la destination defaçon à réduire les oûts des ommuni ations. L'appro he MORA montre une amé-lioration des performan es par rapport aux te hniques existantes à savoir le routagestatique XY. Ces te hniques montrent une amélioration des performan es par rap-port aux te hniques existantes. Comme dernière ontribution dans ette thèse est laréalisation d'une plateforme de simulation qui permet de simuler n'importe quelleplateforme multi- ÷urs inter onne tés par un réseau sur pu e homogène ou hété-rogène de n'importe quelle taille. Exé uter et tester les propositions algorithmiques123

6.2 Perspe tives Chapitre 6 : Con lusion générale et perspe tivesde pla ement dynamique d'appli ations sur une plateforme simulé. En on lusion, ette thèse a présenté de nouvelles te hniques de pla ement dynamique pour gérerle dynamisme dans les appli ations qui sont lan ées au moment de l'exé ution. Leste hniques ont montrées un grand potentiel pour divers type d'appli ations multi-médias et ont un potentiel de données de bons résultats pour autre domaine d'ap-pli ations qui présentent un dynamisme. Il est à noter que les te hniques proposéesminimisent les temps d'exé utions sans ompromettre à la performan e globale de al ul.6.2 Perspe tivesCette se tion présente brièvement quelques orientations de travaux de re her hesfuturs qui peuvent étendre ou ompléter le travail de ette thèse.• L'extension du simulateur a�n de permettre aux ressour es (éléments de traite-ments) de supporter du multi-tâ hes .à.d que haque ressour e peut supporterplusieurs tâ hes. le simulateur a tuel ne permet pour haque ressour e de sup-porter qu'une seule tâ he (Mono-tâ he).• L'augmentation de l'hétérogénéité dans les éléments de traitement : Les te h-niques de pla ement proposées dans ette thèse tiennent ompte essentielle-ment de deux types d'éléments de traitement (PEs), pro esseur à usage géné-ral (GPP) et le matériel re on�gurable (RA). Cependant, il serait intéressantd'étendre e travail à prendre en harge l'augmentation du degré d'hétérogé-néité et d'intégrer di�érents types de PEs. Ce i doit être adressé ave pré autionen raison de l'explosion potentielle du nombre de permutations qui doivent êtreprises en ompte à haque étape. Bien que les te hniques proposées puissentêtre étendues pour l'hétérogénéité a rue dans les PEs, ils auront besoin pourétablir une limite supérieure d'hétérogénéité dans le but de maintenir la faible omplexité des te hniques.• Réaliser le pla ement dynamique sur une plateformematérielle à base de FPGA :Il serait intéressant d'évaluer les te hniques de pla ement dynamique proposéessur une telle plateforme. Celle i prévoit l'évaluation détaillée de la ommuni-124

6.2 Perspe tives Chapitre 6 : Con lusion générale et perspe tives ation et de al ul des oûts pour ha une des méthodes proposées. En outre,les ressour es supplémentaires né essaires et leurs onséquen es sur les perfor-man es de al ul peuvent être examinées en détail. Il est utile d'explorer lapossibilité d'a élérer le pro essus de pla ement dynamique dans le matériel.• Ar hite ture Dynamique re on�gurable pour l'amélioration de la performan e :Les te hniques de pla ement visent une ar hite ture �xe a tuellement. Cepen-dant, ave la possibilité de mettre en ÷uvre une plateforme hétérogène MPSoCà base de NoC sur un FPGA, les te hniques de pla ement pourraient être en- ore étendues pour supporter la personnalisation dynamique de l'ar hite tureMPSoC de manière à optimiser l'utilisation des PEs. Il est envisagé que l'ar- hite ture de MPSoC pourrait être modi�ée pour supporter des s énarios depla ement alternatifs pour satisfaire à la fois les exigen es fon tionnelles et nonfon tionnelles. La personnalisation dynamique omprendra la re on�gurationdes blo s FPGA pour di�érents type de PEs a�n d'atteindre une performan emaximale. La performan e devrait s'améliorer ave l'hétérogénéité a rue dansl'ar hite ture, mais ave le sûr out d'une re on�guration. Par onséquent, leste hniques étendues devront maximiser la performan e tout en minimisant letemps de on�guration.• Migration et équilibrage de harge : Pour permettre un redéploiement d'ap-pli ations pour des besoins de performan es ou de nouvelles appli ations quidemandes a être pla ée des propositions de dé ision de migration doivent êtreprise en harge. De même pour garantir un redéploiement en as de panned'un ou plusieurs ÷urs de al ul dans la plateforme. Finalement garantir unéquilibrage de harge dans la plateforme.• Solveur Dynamique pour la lusterisation : Le travail a tuel onsidère une lus-terisation statique prédé�nie au départ pour une bonne répartition des tâ hesinitiales d'appli ations di�érentes a�n de garantir une bonne répartition destâ hes d'appli ations sur la plateforme. Pour des besoins de performan es tra-vailler sur des propositions de lusterisations dynamique pour des ar hite turesa grandes é helles ne peu qu'augmenter les performan es.125

Bibliographie[1℄ INTERNATIONAL TECHNOLOGY ROADMAP FOR SEMICONDUC-TORS (ITRS), 2008. http ://www.itrs.net/Links/2008ITRS/Home2008.htm.[2℄ Amdahls Law Demonstration. http ://en.wikipedia.org/wiki/Amdahlslaw.[3℄ IMEC MPSoC Mapping Tools, 2008. http ://www.ime .be/S ienti� Report/SR2008/HTML/1225004.html.[4℄ L. Smit, G. Smit, J. Hurink, H. Broersma, D. Paulusma, and P. Wolkotte. Run-time mapping of appli ations to a heterogeneous re on�gurable tiled system on hip ar hite ture. In Pro . of International Conferen e on Field-ProgrammableTe hnology, pages 421�424, De ember 2004.[5℄ E. Gordon. Cramming more omponents onto integrated ir uits. Ele troni sMagazine, 4 :114�117, 1965.[6℄ Jerraya Ahmed Amine, Tenhunen Hannu, and Wolf Wayne. Guest editors'introdu tion : Multipro essor systems-on- hips. IEEE Computer, 38(7) :36�40, 2005.[7℄ Mi hael R. Garey and David S. Johnson. Computers and Intra tability : AGuide to the Theory of NP-Completeness. W. H. Freeman & Co., 1979.[8℄ The keys to su ess in multi ore appli ation development, 2009.http ://www.embedded. om/design/operating-systems/4008333/2/The-keys-to-su ess-in-multi ore-appli ation-development.[9℄ P. Ross. Why CPU Frequen y Stalled, April 2008.http ://spe trum.ieee.org/ omputing/hardware/why- pu-frequen y-stalled.[10℄ MPSoC Forum. http ://www.mpso -forum.org/.[11℄ Mapping Appli ations to MPSoCs, 2009. http ://www.artistembedded.org/artist/Overview1614.html.[12℄ S. Borkar. Thousand ore hips : a te hnology perspe tive. In Pro . of DesignAutomation Conferen e, pages 746�749, 2007.126

BIBLIOGRAPHIE BIBLIOGRAPHIE[13℄ Asanovi Krste, Bodik Ras, Catanzaro Bryan Christopher, Gebis JosephJames, Husbands Parry, Keutzer Kurt, Patterson David, Plishker William Les-ter, Shalf John, Williams Samuel Webb, and Yeli k Katherine. The lands apeof parallel omputing resear h : A view from berkeley. Te hni al report, EECSDepartment, University of California, Berkeley, De 2006.[14℄ L. Benini and G. De Mi heli. Networks on hips : a new so paradigm. IEEEComputer, 35(1) :70 � 78, 2002.[15℄ J. Henkel, W. Wolf, and S. Chakradhar. On- hip networks : A s alable, ommuni ation- entri embedded system design paradigm. In Pro . of VLSIDesign, pages 845�851, 2004.[16℄ D. Bertozzi and L. Benini. Xpipes : a network-on- hip ar hite ture for gigas alesystems-on- hip. Cir. and Sys. Magazine, IEEE, 4(2) :18�31, 2004.[17℄ M. Hill and M. Marty. Amdahls law in the multi ore era. Computer, 41(7) :33�38, July 2008.[18℄ John L. Gustafson. Reevaluating amdahl's law. Commun. ACM, 31(5) :532�533, may 1988.[19℄ Raw Ar hite ture Workstation (RAW), 2003.http ://groups. sail.mit.edu/ ag/raw.[20℄ Asyn hronous Array of Simple Pro essors (AsAP).http ://www.e e.u davis.edu/ v l/asap/.[21℄ Tera-op, Reliable, Intelligently adaptive Pro essing System (TRIPS).http ://www. s.utexas.edu/ trips/index.html.[22℄ WaveS alar pro essor, 2006. http ://waves alar. s.washington.edu/index.html.[23℄ S. Vangal, J. Howard, G. Ruhl, S. Dighe, H. Wilson, J. Ts hanz, D. Finan,P. Iyer, A. Singh, T. Ja ob, S. Jain, S. Venkataraman, Y. Hoskote, and N. Bor-kar. Hs-s ale : a hardware-software s alable mp-so ar hite ture for embeddedsystems. In Pro . of ISVLSI, pages 21�28, 2007.[24℄ First 100- ore Pro essor with the New TILE-Gx Family, 2009.http ://www.tilera. om/. 127

BIBLIOGRAPHIE BIBLIOGRAPHIE[25℄ Multi- ore hips by a ademia and industry.http ://en.wikipedia.org/wiki/Multi ore.[26℄ S. Ri hardson. Mpo : A hip multipro essor for embedded systems. Te hni alreport, HP Laboratories Te hni al Report HPL, 186, Palo Alto, CA, USA,2002.[27℄ MPPA 256. http ://www.kalray.eu/produ ts/mppa-many ore/mppa-256/.[28℄ V. Nollet, P. Avasare, H. Ee khaut, D. Verkest, and H. Corporaal. Run-timemanagement of a mpso ontaining fpga fabri tiles. IEEE Trans. Very LargeS ale Integr. Syst., 16 :24�33, January 2008.[29℄ G. J. Smit, A. B. Kokkeler, P. T. Wolkotte, and M. D. van de Burgwal. Multi- ore ar hite tures and streaming appli ations. In Pro . of international work-shop on System level inter onne t predi tion, pages 35�42, 2008.[30℄ 4S - Smart ChipS for Smart Surroundings, 2007.http :// aes.ewi.utwente.nl/resear h/8-proje ts/8.[31℄ T. Arpinen, P. Kukkala, E. Salminen, M. Hiken, and T. D. Hlen. Con�gurablemultipro essor platform with rtos for distributed exe ution of uml 2.0 designedappli ations. In Pro . of Design, automation and test in Europe, pages 1324�1329, 2006.[32℄ P. Heysters and G. Smit. Mapping of dsp algorithms on the montium ar hite -ture. In pro . of International Parallel and Distributed Pro essing Symposium,pages 22 � 26, April 2003.[33℄ Altera FPGAs. http ://www.altera. om/.[34℄ P. G. Paulin, C. Pilkington, E. Bensoudane, M. Langevin, and D. Lyonnard.Appli ation of a multi-pro essor so platform to high-speed pa ket forwarding.In Pro . of onferen e on Design, automation and test in Europe, pages 58�63.,2004.[35℄ J. Leijten, J. van Meerbergen, A. Timmer, and J. Jess. Prophid : a heteroge-neous multi-pro essor ar hite ture for multimedia. In Pro . of InternationalConferen e on Computer Design, pages 164�169, 1997.128

BIBLIOGRAPHIE BIBLIOGRAPHIE[36℄ M. J. Rutten, J. T. J. van Eijndhoven, E. G. T. Jaspers, P. van der Wolf,E.-J. D. Pol, O. P. Gangwal, and A. Timmer. A heterogeneous multipro essorar hite ture for �exible media pro essing. IEEE Des. Test, 19 :39�50, 2002.[37℄ E. Salminen, A. Kulmala, and T. D. Hamalainen. On network-on- hip ompari-son. In Pro . of Euromi ro Conferen e on Digital System Design Ar hite tures,Methods and Tools, pages 503�510, 2007.[38℄ R. Mar ules u, U. Ogras, L.-S. Peh, N. Jerger, and Y. Hoskote. Outstandingresear h problems in no design : System, mi roar hite ture, and ir uit pers-pe tives. IEEE Transa tions on Computer-Aided Design of Integrated Cir uitsand Systems, 28(1) :3�21, January 2009.[39℄ A. Adriahantenaina, H. Charlery, A. Greiner, L. Mortiez, and C. A. Zeferino.Spin : A s alable, pa ket swit hed, on- hip mi ro-network. In Pro . of Design,Automation and Test in Europe, pages 70 �73, 2003.[40℄ K. Goossens, J. Dielissen, and A. Radules u. Aethereal network on hip :Con epts, ar hite tures, and implementations. IEEE Des. Test, 22(5) :414�421, 2005.[41℄ E. Bolotin, I. Cidon, R. Ginosar, and A. Kolodny. Qno : Qos ar hite tureand design pro ess for network on hip. J. Syst. Ar hit, 50 :105�128, February2004.[42℄ C. Hilton and B. Nelson. Pno : a �exible ir uit-swit hed no for fpga-basedsystems. In Pro . of IEEE Pro eedings on Computers and Digital Te hniques,volume 153, pages 181 �188, May 2006.[43℄ D. Castells-Rufas, J. Joven, and J. Carrabina. A validation and performan eevaluation tool for protono . In Pro . of International Symposium on System-on-Chip, pages 1 � 4, November 2006.[44℄ M. Millberg, E. Nilsson, R. Thid, and A. Jants h. Guaranteed bandwidthusing looped ontainers in temporally disjoint networks within the nostrumnetwork on hip. In Pro . of Design, automation and test in Europe, pages890 � 895, 2004. 129

BIBLIOGRAPHIE BIBLIOGRAPHIE[45℄ T. Bjerregaard and S. Mahadevan. A survey of resear h and pra ti es ofnetworkon- hip. ACM Comput. Surv., 38(1), 2006.[46℄ F. Moraes, N. Calazans, A. Mello, L. Mller, , and L. Ost. Hermes : an in-frastru ture for low area overhead pa ket-swit hing networks on hip. Integr.VLSI J., 38(1) :69�93, 2004.[47℄ U. Y. Ogras and R. Mar ules u. Energy- and performan e-driven no om-muni ation ar hite ture synthesis using a de omposition approa h. In Pro .of Design, Automation and Test in Europe, pages 352�357, 2005.[48℄ A. Chagoya-Garzon, X. Guerin, F. Rousseau, F. Petrot, D. Rossetti, A. Lo-nardo, P. Vi ini, and P. S. Paolu i. Synthesis of ommuni ation me hanismsfor multitile systems based on heterogeneous multi-pro essor system-on- hips.In Pro . of IEEE/IFIP International Symposium on Rapid System Prototy-ping, pages 48�54, 2009.[49℄ Z. Yang, A. Kumar, and Y. Ha. An area-e� ient dynami ally re on�gurablespatial division multiplexing network-on- hip with stati throughput guaran-tee. In Pro . of International Conferen e on Field-Programmable Te hnology,pages 389 �392, De ember 2010.[50℄ Soni s In : The Nettwork-on-Chip Company. http ://www.soni sin . om/.[51℄ Arteris : The Nettwork-on-Chip Company. http ://www.arteris. om/.[52℄ J. Hu and R. Mar ules u. Dyad : smart routing for networks-on- hip. In Pro .of Design Automation Conferen e, pages 260 � 263, 2004.[53℄ S. Murali, D. Atienz, L. Benini, and G. De Mi hel. A multi-path routingstrategy with guaranteed in-order pa ket delivery and fault-toleran e for net-works on hip. In Pro . of 43rd annual Design Automation Conferen e, pages845�848, 2006.[54℄ G. Martin. Overview of the mpso design hallenge. In Pro . of Design Auto-mation Conferen e, pages 274�279, 2006.130

BIBLIOGRAPHIE BIBLIOGRAPHIE[55℄ L. Benini, D. Bertozzi, A. Bogliolo, F. Meni helli, and M. Olivieri. Mparm :Exploring the multi-pro essor so design spa e with system . J. VLSI SignalPro ess. Syst, 41(2) :169�182, 2005.[56℄ M. Mon hiero, G. Palermo, C. Silvano, and O. Villa. A modular approa h tomodel heterogeneous mpso at y le level. In Pro . of EUROMICRO Confe-ren e on Digital System Design Ar hite tures, pages 158�164, 2008.[57℄ J. Cong, K. Gururaj, G. Han, A. Kaplan, M. Naik, , and G. Reinmanin. M -sim : an e� ient simulation tool for mpso designs. In Pro . of IEEE/ACMInternational Conferen e on Computer-Aided Design, pages 364�371, 2008.[58℄ Y. Atat and N.-E. Zergainoh. Simulink-based mpso design : New approa h tobridge the gap between algorithm and ar hite ture design. In Pro . of IEEEComputer So iety Annual Symposium on VLSI, pages 9�14, 2007.[59℄ SystemC. http ://www.a ellera.org/home/.[60℄ P. Paulin, C. Pilkington, and E. Bensoudane. Stepnp : A system-level explo-ration platform for network pro essors. IEEE Des. Test, 19 :17� 26, 2002.[61℄ G. Beltrame, D. S iuto, C. Silvano, P. Paulin, and E. Bensoudane. An ap-pli ation mapping methodology and ase study for multi-pro essor on- hipar hite tures. In Pro . of IFIP International Conferen e on Very Large S aleIntegration, pages 146�151, O tober 2006.[62℄ H. Nikolov, T. Stefanov, and E. Deprettere. Systemati and automated multi-pro essor system design, programming, and implementation. IEEE Transa -tions on Computer-Aided Design of Integrated Cir uits and Systems, 27 :542�555, Mar h 2008.[63℄ M. D. Nava, P. Blouet, P. Teninge, M. Coppola, T. Ben-Ismail, S. Pi hiot-tino, and R. Wilson. An open platform for developing multipro essor so s.Computer, 38(7) :60�67, 2005.[64℄ D. Atienza, P. G. Del Valle, G. Pa i, F. Poletti, L. Benini, G. De Mi heli, andJ. M. Mendias. A fast hw/sw fpga-based thermal emulation framework for131

BIBLIOGRAPHIE BIBLIOGRAPHIEmultipro essor system-on- hip. In Pro . of 43rd annual Design AutomationConferen e, pages 618�623, 2006.[65℄ F. Sun, S. Ravi, A. Raghunathan, and N. Jha. Appli ation-spe i� hetero-geneous multipro essor synthesis using extensible pro essors. Pro . of IEEETransa tions on Computer-Aided Design of Integrated Cir uits and Systems,25(9) :1589�1602, September 2006.[66℄ A. Kumar, S. Fernando, Y. Ha, B. Mesman, and H. Corporaal. Multipro essorsystems synthesis for multiple use- ases of multiple appli ations on fpga. ACMTrans. Des. Autom. Ele tron. Syst., 13(3) :1�27, 2008.[67℄ Tensili a In . http ://www.tensili a. om/.[68℄ S. Lukovi and L. Fiorin. An automated design �ow for no -based mpso son fpga. In Pro . of IEEE/IFIP International Symposium on Rapid SystemPrototyping, pages 58�64, 2008.[69℄ S. V. Tota, M. R. Casu, M. R. Ro h, L. Ma hiarulo, and M. Zamboni. A asestudy for no -based homogeneous mpso ar hite tures. IEEE Trans. VeryLarge S ale Integr. Syst., 17 :384�388, Mar h 2009.[70℄ A. Kumar, A. Hansson, J. Huisken, and H. Corporaal. Intera tive presenta-tion : An fpga design �ow for re on�gurable network-based multi-pro essorsystems on hip. In Pro . of Design, automation and test in Europe, pages117�122, 2007.[71℄ T. Dorta, J. Jimenez, J. Martin, U. Bidarte, and A. Astarloa. Overview offpga based multipro essor systems. In Pro . of International Conferen e onRe on�gurable Computing and FPGAs, pages 273�278, De ember 2009.[72℄ G.-G. Mplemenos and I. Papaefstathiou. Mplem : An 80-pro essor fpga ba-sed multipro essor system. In Pro . of International Symposium on Field-Programmable Custom Computing Ma hines, pages 273�274, April 2008.[73℄ A. Krasnov, A. S hultz, J. Wawrzynek, G. Gibeling, and P.-Y. Droz. Rampblue : A message-passing many ore system in fpgas. In Pro . of Internatio-132

BIBLIOGRAPHIE BIBLIOGRAPHIEnal Conferen e on Field Programmable Logi and Appli ations, pages 54�61,August 2007.[74℄ J. Ceng, J. Castrillon, W. Sheng, H. S harwa hter, R. Leupers, G. As heid,H. Meyr, T. Isshiki, and H. Kunieda. Maps : an integrated framework formpso appli ation parallelization. In Pro . of Design Automation Conferen e,pages 754�759, 2008.[75℄ R. P. Di k, D. L. Rhodes, and W. Wolf. Tg� : task graphs for free. In Pro . ofinternational workshop on Hardware/software odesign, pages 97�101, 1998.[76℄ S. Stuijk, M. Geilen, and T. Basten. Sdf3 : Sdf for free. In Pro . of InternationalConferen e on Appli ation of Con urren y to System Design, pages 276�278,June 2006.[77℄ M. Ruggiero, A. Guerri, D. Bertozzi, F. Poletti, and M. Milano. Communi- ation aware allo ation and s heduling framework for stream-oriented multi-pro essor systems-on- hip. In Pro . of onferen e on Design, automation andtest in Europe, pages 3�8, 2006.[78℄ M. Ruggiero, A. Guerri, D. Bertozzi, M. Milano, and L. Benini. A fast anda urate te hnique for mapping parallel appli ations on stream-oriented mpso platforms with ommuni ation awareness. Int. J. Parallel Program., 36(1) :3�36, 2008.[79℄ J. Hu and R. Mar ules u. Energy- and performan e-aware mapping for regularno ar hite tures. IEEE Transa tions on Computer-Aided Design of IntegratedCir uits and Systems, 24(4) :551�562, April 2005.[80℄ C. Mar on, A. Borin, A. Susin, L. Carro, and F.Wagner. Time and energye� ient mapping of embedded appli ations onto no s. In Pro . of Asia andSouth Pa i� Design Automation Conferen e, pages 33�38, 2005.[81℄ S. Murali, M. Coenen, A. Radules u, K. Goossens, and G. De Mi heli. Amethodology for mapping multiple use- ases onto networks on hips. In Pro .of onferen e on Design, automation and test in Europe, pages 118�123, 2006.133

BIBLIOGRAPHIE BIBLIOGRAPHIE[82℄ C.-E. Rhee, H.-Y. Jeong, and S. Ha. Many-to-many ore-swit h mapping in2-d mesh no ar hite tures. In Pro . of IEEE International Conferen e onComputer Design, pages 438�443, 2004.[83℄ Lei Tang and Kumar Shashi. Algorithms and tools for network on hip basedsystem design. In Pro . of Integrated ir uits and systems design, page 163,2003.[84℄ D. Wu, B. M. Al-Hashimi, and P. Eles. S heduling and mapping of onditionaltask graphs for the synthesis of low power embedded systems. In Pro . of onferen e on Design, Automation and Test in Europe, page 10090, 2003.[85℄ S. Manola he et al. Fault and energy-aware ommuni ation mapping withguaranteed laten y for appli ations implemented on no . In Pro . of DAC,pages 266�269, 2005.[86℄ L. Lin et al. Communi ation-driven task binding for multipro essor with la-ten y insensitive network-on- hip. In Pro . of ASP-DAC, pages 39�44, 2005.[87℄ H. Orsila et al. Automated memory-aware appli ation distribution for multi-pro essor system-on- hips. J. Syst. Ar hit., 53(11) :795�815, 2007.[88℄ M. Bran a, L. Camerini, F. Ferrandi, P. L. Lanzi, C. Pilato, D. S iuto, andA. Tumeo. Evolutionary algorithms for the mapping of pipelined appli ationsonto heterogeneous embedded systems. In Pro . of Annual onferen e on Ge-neti and evolutionary omputation, pages 1435�1442, 2009.[89℄ L. Thiele, I. Ba ivarov, W. Haid, and K. Huang. Mapping appli ations totiled multipro essor embedded systems. In Pro . of International Conferen eon Appli ation of Con urren y to System Design, pages 29�40, 2007.[90℄ G. Chen, F. Li, S. Son, and M. Kandemir. Appli ation mapping for hipmultipro essors. In Pro . of ACM/IEEE Design Automation Conferen e, pages620�625, June 2008.[91℄ N. Satish, K. Ravindran, and K. Keutzer. A de omposition-based onstraintoptimization approa h for stati ally s heduling task graphs with ommuni a-134

BIBLIOGRAPHIE BIBLIOGRAPHIEtion delays to multipro essors. In Pro . of onferen e on Design, automationand test in Europe, pages 57�62, 2007.[92℄ Abou El Hassan Benyamina, Ordonnan ement Hierar hique Multi-Obje tif DAppli ation Embarquees Intensives, de embre 2008, Oran, 2008.http ://forge.li�.fr/AASGaspard/wiki/Do umentsDeReferen e.[93℄ Aroui Abdelkader, Ordonna ement des ta hes repetitives, 2011, Oran, 2011.http ://forge.li�.fr/AASGaspard/wiki/Travaux2010-2011/MagistAroui.[94℄ P. Marwedel, J. Tei h, G. Kouveli, I. Ba ivarov, L. Thiele, S. Ha, C. Lee,Q. Xu, and L. Huang. Mapping of appli ations to mpso s. In Pro . ofIEEE/ACM/IFIP international onferen e on Hardware/software odesignand system synthesis, pages 109�118, 2011.[95℄ Chou Chen-Ling and Mar ules u Radu. User-aware dynami task allo ationin networks-on- hip. In Pro . of Design, Automation and Test in Europe,DATE'08, pages 1232�1237, 2008.[96℄ Z. Peter, S. Gilles, U. Nurten, S. Ni olas, B. Pas al, and G. Manfred. A de- entralised task mapping approa h for homogeneous multipro essor network-on- hips. International Journal of Re on�gurable Computing, 2009, 2009.[97℄ E. W. Briao, D. Bar elos, and F. R. Wagner. Dynami task allo ation strate-gies in mpso for soft real-time appli ations. In Pro . of onferen e on Design,automation and test in Europe, pages 1386�1389, 2008.[98℄ Chou Chen-Ling and Mar ules u Radu. In remental run-time appli ationmapping for homogeneous no s with multiple voltage levels. In Pro . of 5thIEEE/ACM/IFIP International Conferen e on Hardware/Software Codesignand System Synthesis (CODES+ISSS,07), pages 161�166, 2007.[99℄ A. Ngouanga, G. Sassatelli, L. Torres, T. Gil, A. Soares, and A. Susin. A ontextual resour es use : a proof of on ept through the apa hes platform.In Pro . of IEEE Design and Diagnosti s of Ele troni Cir uits and systems,pages 42�47, 2006. 135

BIBLIOGRAPHIE BIBLIOGRAPHIE[100℄ A. Mehran et al. Dsm : A heuristi dynami spiral mapping algorithm fornetwork on hip. IEICE Ele troni s Express, 5(13) :464�471, 2008.[101℄ G. Sassatelli, N. Saint-Jean, P. Benoit, L. Torres, M. Robert, C. Woszezenki,I. A. Grehs, and F. Moraes. Run-time mapping and ommuni ation strategiesfor homogeneous no -based mpso s. In Pro . of IEEE Symposium on Field-Programmable Custom Computing Ma hines, 2007.[102℄ O. Moreira, J. J.-D. Mol, and M. Bekooij. Online resour e management ina multipro essor with a network-on- hip. In Pro . of ACM symposium onApplied omputing, pages 1557�1564, 2007.[103℄ P.Holzenspies, J.Hurink, J.Kuper, and G.Smit. Run-time spatial mappingof streaming appli ations to a heterogeneous multi-pro essor system-on- hip(mpso ). In Pro . of Design, Automation and Test in Europe, DATE '08,pages 212�217, 2008.[104℄ T. D. ter Braak, P. K. F. Hlzenspies, J. Kuper, J. L. Hurink, , and G. J. M.Smit. Run-time spatial resour e management for real-time appli ations onheterogeneous mpso s. In Pro . of Conferen e on Design, Automation andTest in Europe, pages 357�362, 2010.[105℄ M.Faruque, R.Krist, and J.Henkel. Adam : Run-time agent-based distributedappli ation mapping for on- hip ommuni ation. In Pro . of 45th ACM/IEEEDesign Automation Conferen e, DAC' 08, pages 760�765, 2008.[106℄ A. S hranzhofer, J.-J. Chen, and L. Thiele. Power-aware mapping of proba-bilisti appli ations onto heterogeneous mpso platforms. In Pro . of IEEEReal-Time and Embedded Te hnology and Appli ations Symposium, 2009.[107℄ Tang. Lei and Shashi. Kumar. A two-step geneti algorithm for mapping taskgraphs to a network on hip ar hite ture. In Pro . of the Euromi ro Symposiumon DSD, page 180, 2003.[108℄ E.Carvalho and F.Moraes. Congestion-aware task mapping in heterogeneousmpso s. In Pro . of International Symposium on System-on-Chip, SOC '08,pages 1�4, 2008. 136

BIBLIOGRAPHIE BIBLIOGRAPHIE[109℄ G. Mariani, P. Avasare, G. Vanmeerbee k, C. Ykman-Couvreur, G. Palermo,C. Silvano, and V. Za aria. An industrial design spa e exploration frameworkfor supporting run-time resour e management on multi- ore systems. In Pro .of Conferen e on Design, Automation and Test in Europe, pages 196�201,2010.[110℄ S. Stuijk, M. Geilen, and T. Basten. A predi table multipro essor design �owfor streaming appli ations with dynami behaviour. In Pro . of Euromi roConferen e on Digital System Design : Ar hite tures, Methods and Tools, pages548�555, 2010.[111℄ B. Giovanni, L. Fossati, and D. S iuto. De ision-theoreti design spa e explo-ration of multipro essor platforms. Trans. Comp. Aided Des. Integ. Cir. Sys.,29 :1083�1095, July 2010.[112℄ G. Palermo, C. Silvano, and V. Za aria. Multi-obje tive design spa e ex-ploration of embedded systems. J. Embedded Comput., 1 :305�316, August2005.[113℄ Z. J. Jia, A. Pimentel, M. Thompson, T. Bautista, and A. Nunez. Nasa :A generi infrastru ture for system-level mp-so design spa e exploration. InPro . of IEEE Workshop on Embedded Systems for Real-Time Multimedia,pages 41�50, O tober 2010.[114℄ Hemayet Hossain, Mostak Ahmed, Abdullah Al-Nayeem, Tanzima Zerin Is-lam, and Md. Mostofa Akbar. gpno sim - a general purpose simulator fornetwork-on- hip. In International Conferen e on Information and Communi- ation Te hnology (ICICT), 2007.[115℄ Nan Jiang, Daniel U. Be ker, George Mi helogiannakis, James Balfour, BrianTowles, John Kim, and William J. Dally. A detailed and �exible y le-a uratenetwork-on- hip simulator. In IEEE International Symposium on Performan eAnalysis of Systems and Software, 2013.[116℄ Noxim : the NoC Simulator. http ://noxim.sour eforge.net/.[117℄ The Network Simulator ns-2. http ://www.isi.edu/nsnam/ns/.137

BIBLIOGRAPHIE BIBLIOGRAPHIE[118℄ Darsim : A Parallel Cy le-Level NoC Simulator.http ://dspa e.mit.edu/handle/1721.1/59832.[119℄ Con eption d'un simulateur de mapping dynamiquesur une ar hite ture heterogene MP-SOC basee NOC.http ://forge.li�.fr/AASGaspard/wiki/Travaux2012-2013/REKKABNABIL.[120℄ A. K. Singh et al. Communi ation-aware heuristi s for run-time task mappingon no -based mpso platforms. Journal of Systems Ar hite ture, 56(7) :242 �255, 2010.[121℄ D.Bertozzi and L.Benini. A network-on- hip ar hite ture for gigas ale systems-on- hip. Cir uits and Systems Magazine, IEEE, 4(2) :18�31, 2004.[122℄ Y. Zhang et al. Task s heduling and voltage sele tion for energy minimization.In Pro . of Design Automation Conferen e, pages 183 � 188, 2002.[123℄ Shin Dongkun and Kim Jihong. Power-aware ommuni ation optimization fornetworks-on- hips with voltage s alable links. In Pro . of CODES and ISSS,pages 170�175, 2004.[124℄ CL.Chou, C.Wu, and J.Lee. Integrated mapping and s heduling for ir uit-swit hed networkon- hip ar hite tures. In pro . of 4th IEEE InternationalSymposium on Ele troni Design, Test and Appli ations, DELTA 2008., pages415�420, 2008.[125℄ F.Vardi, S.Saeidi, and A.Khademzadeh. Crinkle : A heuristi mapping al-gorithm for network on hip. IEICE Ele troni s Express, 6(24) :1737�1744,2009.[126℄ M.Armin, S.Saeidi, and A.Khademzadeh. Spiral : A heuristi mapping algo-rithm for network on hip. IEICE Ele troni Express, 4(15) :478�484, 2007.[127℄ X.Wang, M.Yang, Y.Jiang, and P.Liu. Power-aware mapping for network-on- hip ar hite tures under bandwidth and laten y onstraints. ACM Transa -tions on Ar hite ture and Code Optimization (TACO), 7(1) :6, 2010.[128℄ P.Ghosh, A.Sen, and A.Hall. Energy e� ient appli ation mapping to no pro essing elements operating at multiple voltage levels. In Pro . of 3rd138

BIBLIOGRAPHIE BIBLIOGRAPHIEACM/IEEE International Symposium on Networks-on-Chip, NoCS'09, pages80�85, 2009.[129℄ E. Carvalho et al. Evaluation of stati and dynami task mapping algorithmsin no -based mpso s. In Pro . of 12th Euromi ro Conferen e on Digital SystemDesign, Ar hite tures, Methods and Tools, pages 87�90, 2009.[130℄ Smit et al. Run-time mapping of appli ations to a heterogeneous so . In Pro .of Design, Automation and Test in Europe Conferen e and Exhibition, 2004.[131℄ P. Holzenspies et al. Mapping streaming appli ations on a re on�gurable mp-so platform at run-time. In Pro . of International Symposium on System-on-Chip, SOC'07, pages 1�4, 2007.[132℄ Mar elo Mandelli et al. Multi-task dynami mapping onto no -based mpso s.In Pro eedings of the 24th symposium on Integrated ir uits and systems design,SBCCI'11, pages 191�196, 2011.[133℄ S.Wildermann, T.Ziermann, and J.Tei het. Run time mapping of adap-tive appli ations onto homogeneous no -based re on�gurable ar hite tures.In Pro . of International Conferen e on Field-Programmable Te hnology,FPT'09, pages 514 � 517, 2009.[134℄ A.S hranzhofer, C.Jian-Jia, L.Santinelli, and L.Thiele. Dynami and adaptiveallo ation of appli ations on mpso platforms. In Pro . of 15th Asia and SouthPa i� Design Automation Conferen e, ASP-DAC '10, pages 885 �890, 2010.[135℄ E.Carvalho, N.Calazans, and F.Moraes. Dynami task mapping for mpso s.IEEE Design Test of Computers, 27(5) :26�35, 2010.[136℄ A. K. Singh et al. E� ient heuristi s for minimizing ommuni ation overheadin no -based heterogeneous mpso platforms. In Pro . of IEEE/IFIP Inter-national Symposium on Rapid System Prototyping, RSP '09, pages 55 � 60,2009.[137℄ S. Vangal et al. An 80-tile 1.28t�ops network-on- hip in 65nm mos. In Pro .of IEEE Int. Solid-State Cir uits Conf., pages 98�589, Feb. 2007.139

BIBLIOGRAPHIE BIBLIOGRAPHIE[138℄ V. Nollet et al. Centralized run-time resour e management in a network-on- hip ontaining re on�gurable hardware tiles. In Pro . of DATE, pages234�239, 2005.[139℄ Chip multipro essor wat h, 2008. http://view.ee s.berkeley.edu/wiki/Chip_Multi_Pro essor_Wat h.[140℄ M. Kistler et al. Cell multipro essor ommuni ation network : Built for speed.IEEE Mi ro, 26(3) :10�23, 2006.[141℄ A. K. Singh et al. A elerating throughput-aware runtime mapping for hete-rogeneous mpso s. ACM Trans. Design Autom. Ele tr. Syst., 18(1) :9, 2012.[142℄ A. Benyamina et al. Mapping real time appli ations on no ar hite ture withhybrid multi-obje tive algorithm. In Pro . of META, 2010.[143℄ Pradip Kumar. Sahu and Santanu. Chattopadhyay. A survey on appli ationmapping strategies for network-on- hip design. Journal of Systems Ar hite -ture - Embedded Systems Design, 59(1) :60�76, 2013.[144℄ Lu iano Ost et al. Power-aware dynami mapping heuristi s for no -basedmpso s using a uni�ed model-based approa h. ACM Trans. Embedded Comput.Syst., 12(3) :75, 2013.[145℄ Mar elo Mandelli et al. Energy-aware dynami task mapping for no -basedmpso s. In Pro . of ISCAS, 2011.[146℄ Andreas Wei hslgartner et al. Dynami de entralized mapping of tree-stru tured appli ations on no ar hite tures. In Pro . of NOCS, 2011.[147℄ Leandro Möller, Ismael Grehs, Ewerson Carvalho, Rafael Soares, Ney Cala-zans, and Fernando Moraes. A no -based infrastru ture to enable dynami self re on�gurable systems, 2007.
140


















