







Langages
Pages
Légal


CGR de Calais
No d’ordre ULCO 2008.** – Annee 2008
Une approche basee sur la regression
par les machines a vecteurs supports :
application au suivi d’objets en
mouvement dans les sequences
d’images
THESE
presentee et soutenue publiquement le ** *** 2008
pour l’obtention du grade de
Docteurde l’Universite du Littoral Cote d’Opale
(Specialite Genie Informatique, Automatique et Traitement du Signal)
par
Johan Colliez
Composition du jury
President : **** ******
Professeur des Universites Universite de Technologie de Compiegne
Rapporteurs : *********** ********
Professeur a l’ENST ENST ParisYves Sorel
Directeur de Recherche INRIA Rocquencourt
Examinateurs : *********** ************
Professeur des Universites Universite du Littoral Cote d’Opale****** *******
Maıtre de Conference CUST – Universite Blaise Pascal
Directeurs : Denis Hamad Directeur de TheseProfesseur des Universites Universite du Littoral Cote d’Opale
Franck Dufrenois Co-Directeur de TheseMaıtre de Conferences Universite du Littoral Cote d’Opale
Laboratoire d’Analyse des Systemes du Littoral – UPRES EA 260050, rue Ferdinand Buisson – Extension Batiment B – B.P. 699 – 62228 CALAIS Cedex, FRANCE

Mis en page avec la classe thloria.

Je dédie cette thèseÀ ma famille et ma compagne.
i

ii

Avant-propos
VOICI la partie des remerciements à compléter.
Johan Colliez
iii

iv

Table des matières
Table des figures x
Liste des tableaux xii
Introduction générale 1
Chapitre 1
Problème des données aberrantes dans la vision assistée par ordinateur 4
1.1 Sources d’erreurs dans les données images . . . . . . . . . . . . . . . . . . 4
1.1.1 Capteur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.1.2 Prétraitements . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
1.1.3 Flot optique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
1.1.4 Mise en correspondance . . . . . . . . . . . . . . . . . . . . . . . . 9
1.2 Extraction d’une structure dominante vue comme un problème de régression 11
1.2.1 Définition générale de la régression . . . . . . . . . . . . . . . . . . 12
1.2.2 Régression linéaire . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
1.2.3 Moindres carrés . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
1.3 Comment traiter les points aberrants? . . . . . . . . . . . . . . . . . . . . 16
1.3.1 Définition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
1.3.2 Classification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
1.3.3 Techniques de détection et de contrôle des outliers . . . . . . . . . . 19
1.3.4 Fonctions de pertes . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
1.4 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
Chapitre 2
Méthodes de régression robustes 32
v

Table des matières
2.1 Méthodes de régression déterministes . . . . . . . . . . . . . . . . . . . . . 32
2.1.1 Moindres modules . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
2.1.2 Moindres carrés totaux . . . . . . . . . . . . . . . . . . . . . . . . . 33
2.1.3 X-estimateurs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
2.2 Méthodes de vote . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
2.2.1 Moindre médiane des carrés . . . . . . . . . . . . . . . . . . . . . . 38
2.2.2 Moindres carrés tronqués . . . . . . . . . . . . . . . . . . . . . . . . 39
2.2.3 Transformée de Hough . . . . . . . . . . . . . . . . . . . . . . . . 41
2.2.4 Approche du RANSAC . . . . . . . . . . . . . . . . . . . . . . . . . 43
2.2.5 vbQMDPE : approche basée sur la Meanshift . . . . . . . . . . . . . 44
2.3 Méthodes de régularisation . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
2.3.1 Régression Ridge . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
2.3.2 Régression par machines à vecteurs supports . . . . . . . . . . . . . 47
2.4 Évaluation de la robustesse . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
2.4.1 Définition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
2.4.2 Point de cassure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
2.4.3 Fonction d’influence . . . . . . . . . . . . . . . . . . . . . . . . . . 51
2.4.4 Courbe de biais . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
2.5 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
Chapitre 3
Régression par les machines à vecteurs supports et modifications 55
3.1 Méthode standard . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
3.1.1 Idée de base : Cas linéaire . . . . . . . . . . . . . . . . . . . . . . . 55
3.1.2 Formulation duale et programmation quadratique . . . . . . . . . . 57
3.1.3 Calcul de b . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
3.1.4 Cas non-linéaire . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
3.2 Modifications apportées aux SVR . . . . . . . . . . . . . . . . . . . . . . . 63
3.2.1 Procédure itérative avec une marge adaptative . . . . . . . . . . . . 64
3.2.2 Pondération du SVR . . . . . . . . . . . . . . . . . . . . . . . . . . 65
3.2.3 Performances et résultats comparatifs . . . . . . . . . . . . . . . . . 73
3.3 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
vi

Chapitre 4
Application à l’estimation du mouvement : le flot optique 82
4.1 Le flot optique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
4.1.1 Définition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
4.1.2 La théorie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
4.2 Problèmes liés au flot optique . . . . . . . . . . . . . . . . . . . . . . . . . 85
4.2.1 Le problème d’ouverture . . . . . . . . . . . . . . . . . . . . . . . . 85
4.2.2 L’existence du gradient . . . . . . . . . . . . . . . . . . . . . . . . . 86
4.2.3 Les phénomènes d’occlusions . . . . . . . . . . . . . . . . . . . . . . 86
4.2.4 La périodicité de structure dans l’image . . . . . . . . . . . . . . . 86
4.2.5 Les variations lumineuses . . . . . . . . . . . . . . . . . . . . . . . . 87
4.2.6 Les déplacements trop importants . . . . . . . . . . . . . . . . . . . 88
4.3 Les différentes approches . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88
4.3.1 Approches par optimisation locale . . . . . . . . . . . . . . . . . . . 88
4.3.2 Approches par optimisation globale . . . . . . . . . . . . . . . . . . 89
4.3.3 Modèles paramétriques . . . . . . . . . . . . . . . . . . . . . . . . . 92
4.3.4 Approches multirésolutions ou multiéchelles . . . . . . . . . . . . . 95
4.4 Expérimentation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 96
4.4.1 Une base de comparaison répandue : Yosemite . . . . . . . . . . . 97
4.4.2 Séquence simulée : les "carrés texturés" . . . . . . . . . . . . . . . . 101
4.4.3 Séquences réelles . . . . . . . . . . . . . . . . . . . . . . . . . . . . 107
4.5 conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111
Chapitre 5
Application à l’estimation du mouvement par mise en correspondance113
5.1 État de l’art . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 114
5.1.1 Définition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 114
5.1.2 Extraction de points caractéristiques . . . . . . . . . . . . . . . . . 114
5.1.3 Mise en correspondance . . . . . . . . . . . . . . . . . . . . . . . . 122
5.2 Expérimentations et résultats . . . . . . . . . . . . . . . . . . . . . . . . . 124
5.2.1 Données simulées . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124
5.2.2 Données réelles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 125
5.3 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 129
vii

Table des matières
Conclusion générale 131
Bibliographie 134
Publications personnelles 140
Résumé 144
Abstract 144
viii


Table des figures
1.1 Chaîne de traitement des données . . . . . . . . . . . . . . . . . . . . . . . 41.2 Discrétisation d’une scène . . . . . . . . . . . . . . . . . . . . . . . . . . . 61.3 Bruit apparaissant dans une scène trop peu éclairée . . . . . . . . . . . . . 61.4 Effet d’une erreur sur les dérivées spatiales . . . . . . . . . . . . . . . . . . 71.5 Exemple de la séquence Yosemite . . . . . . . . . . . . . . . . . . . . . . . 81.6 Résultat du flot optique calculé par Lucas-Kanade sur Yosemite . . . . . 91.7 Zones d’erreurs du flot optique en cas d’occlusions . . . . . . . . . . . . . . 101.8 Présence de faux appariements . . . . . . . . . . . . . . . . . . . . . . . . . 111.9 Erreurs de reconstruction 3D . . . . . . . . . . . . . . . . . . . . . . . . . . 121.10 Quelle est la meilleure droite? . . . . . . . . . . . . . . . . . . . . . . . . . 131.11 Ensemble de données sans erreurs . . . . . . . . . . . . . . . . . . . . . . . 151.12 1 point aberrant dans la direction-Y . . . . . . . . . . . . . . . . . . . . . 151.13 1 point aberrant direction-X . . . . . . . . . . . . . . . . . . . . . . . . . . 161.14 Classification des outliers dans une régression linéaire simple . . . . . . . . 181.15 Facteur local d’aberration LOF (K=3) . . . . . . . . . . . . . . . . . . . . 201.16 Voisinage géométrique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 211.17 Fonction perte linéaire . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 251.18 Fonction perte quadratique . . . . . . . . . . . . . . . . . . . . . . . . . . . 251.19 Fonction perte de Huber (C = 1) . . . . . . . . . . . . . . . . . . . . . . . 261.20 Fonction perte de Beaton-Tukey (C = 1) . . . . . . . . . . . . . . . . . 271.21 Fonction perte linéaire d’insensibilité (ε = 1) . . . . . . . . . . . . . . . . . 281.22 Fonction perte quadratique d’insensibilité (ε = 1) . . . . . . . . . . . . . . 281.23 Fonction perte de Wang-Liang (ε = 1, M = 3) . . . . . . . . . . . . . . . 291.24 Représentation de g(z,α) (T = 2,α = 5,ε = 1,M = 3) . . . . . . . . . . . . 30
2.1 Classification des méthodes de régression . . . . . . . . . . . . . . . . . . . 332.2 Passage de l’espace des observations à celui des paramètres . . . . . . . . . 422.3 Visualisation du point d’effondrement sur un exemple . . . . . . . . . . . . 50
3.1 Illustration de la fonction perte . . . . . . . . . . . . . . . . . . . . . . . . 563.2 Représentation de la marge douce . . . . . . . . . . . . . . . . . . . . . . . 573.3 Représentation du point selle . . . . . . . . . . . . . . . . . . . . . . . . . 583.4 Exemple de la sensibilité du SVR face aux y-outliers. . . . . . . . . . . . . 633.5 Illustration 2D de la détection des outliers . . . . . . . . . . . . . . . . . . 653.6 Trois familles de M-estimateurs . . . . . . . . . . . . . . . . . . . . . . . . 69
x

3.7 Limite de l’influence des outliers sur la régression. . . . . . . . . . . . . . . 723.8 Influence des observations dans le cas linéaire. . . . . . . . . . . . . . . . . 773.9 Influence des observations dans le cas non linéaire. . . . . . . . . . . . . . . 783.10 Illustration de l’estimation de modèles linéaires avec différentes approches
robustes. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 793.11 Extraction d’une structure non-linéaire dominante avec le SVR, le MME
et le R-SVR. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 803.12 Comparaison du point d’effondrement du R-SVR sur l’exemple de la section
2.4.2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
4.1 Représentation du problème d’ouverture. A : fenêtre d’observation d’uneportion rectiligne. B : fenêtre d’observation d’une portion possédant un coin. 85
4.2 Représentation du problème de périodicité de structure. . . . . . . . . . . . 874.3 Image de la séquence "Yosemite". . . . . . . . . . . . . . . . . . . . . . . 984.4 Flot optique correct de la séquence "Yosemite". . . . . . . . . . . . . . . 994.5 Apport du coefficient w. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 994.6 Flot optique sur la séquence Yosemite avec 6% de bruit ajouté . . . . . . 1024.7 Flot optique sur la séquence Yosemite avec 6% de bruit ajouté (suite) . . 1034.8 Séquence simulée des "carrés texturés". . . . . . . . . . . . . . . . . . . . . 1034.9 Flot optique estimé sur la séquence "carrés texturés" (expérience 2). . . . . 1054.10 Flot optique estimé sur la séquence "carrés texturés" (expérience 4). . . . . 1064.11 Résultats obtenus sur le "taxi de Hambourg". . . . . . . . . . . . . . . . 1084.12 Résultats obtenus sur le "rubicube". . . . . . . . . . . . . . . . . . . . . . 1094.13 Image de la séquence "parking". . . . . . . . . . . . . . . . . . . . . . . . . 1104.14 Flot optique sur la séquence Parking avec le R-SVR (modèle constant) . . 111
5.1 Recherche des maxima locaux . . . . . . . . . . . . . . . . . . . . . . . . . 1165.2 Détection avec l’opérateur d’Harris en niveaux de gris (seuil=0.1%) . . . 1165.3 Détection avec l’opérateur d’Harris en niveaux de gris (seuil=0.001%) . . 1175.4 Extraction des points d’intérêts (Algorithme SIFT) . . . . . . . . . . . . . 1185.5 Détection avec l’opérateur d’Harris en couleurs (seuil=5%) . . . . . . . . 1195.6 Détection avec l’opérateur d’Harris en couleurs (seuil=0.5%) . . . . . . . 1205.7 Détection avec l’opérateur d’Harris en couleurs (seuil=0.05%) . . . . . . 1205.8 Mise en correspondance avec l’algorithme du SIFT (best-bin-first) . . . . . 1245.9 Extraction du mouvement dominant dans un exemple multistructure. . . . 1265.10 Estimation du mouvement dans la séquence réelle des livres. . . . . . . . . 1285.11 Estimation du mouvement et suivi dans la séquence réelle "parking". . . . 130
xi

Liste des tableaux
1.1 Récapitulatif des différentes fonctions pertes . . . . . . . . . . . . . . . . . 31
2.1 Exemples de fonctions d’influence utilisées dans les M-estimateurs . . . . . 362.2 Récapitulatif des points d’effondrements de différentes méthodes . . . . . . 54
3.1 Détection des outliers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
4.1 Résultats comparatifs sur la séquence Yosemite sur l’AAE . . . . . . . . 1014.2 Résultats comparatifs sur la séquence Yosemite sur l’écart-type . . . . . 1014.3 Résultats comparatifs sur la séquence "carrés texturés" . . . . . . . . . . . 104
xii

Introduction générale
DEPUIS toujours, l’homme invente des machines dans le but de l’assister dans son
travail, de le décharger de tâches fastidieuses, répétitives et peu intéressantes. Avec
l’avênement de l’électronique et de l’informatique, cette science de l’automatisation a
profitée d’une importante avancée : l’introduction d’une forme d’intelligence, logique et
programmée, dans la machine. Grâce à une croissance incessante de la puissance de calcul
des ordinateurs, l’utilisation de ces machines est devenu indispensable dans de nombreux
domaines. Désormais, l’homme cherche dans le fonctionnement de son propre cerveau des
idées, des procédures, des automatismes, afin d’apprendre aux machines à appréhender
leurs environnements, à prendre des décisions, etc, en bref à penser comme nous. Cette
tentative d’automatiser diverses tâches jusqu’alors réservées à un opérateur humain, de
par leurs complexités, est sans doute un des challenges les plus important de notre époque.
Le domaine de la vision par ordinateur en est l’un des plus gros chantier, d’une part à cause
de la grande complexité de notre système de vision, mais surtout grâce à l’enthousiasme
sucité par les applications qui pourraient en découler dans divers domaines : navigation,
surveillance, médecine, etc.
Objectif de la thèse
LES travaux présentés dans ce rapport de thèse concernent le thème de la vision dy-
namique appliquée dans le cadre du transport terrestre automatisé. Il s’agit, plus
précisément, de travaux ayant trait aux méthodes d’estimation du mouvement dans les
séquences d’images pour la création d’un attelage virtuel entre un véhicule tracteur et un
véhicule tracté.
Dans le cadre de notre travail, nous avons uniquement utilisé la vision monoculaire comme
source d’informations. Il est évident que pour élaborer un système complet d’attelage vir-
tuel, l’utilisation d’autres capteurs, par exemple une vision stéréoscopique ou un télémètre
laser, s’avèrerait judicieuse afin d’améliorer la perception de l’environnement, et ainsi la
fiabilité du système.
1

Introduction générale
Afin de garantir la fiabilité et la sécurité de l’attelage virtuel dans un environnement
complexe et changeant, nous avons besoin d’utiliser des méthodes d’estimation robustes.
C’est à dire des méthodes qui nous fournissent des résultats de qualité, et ce même si
les données provenant de l’environnement s’avèrent difficiles à exploiter. En effet, dans le
cadre de notre étude, l’environnement routier est très riche en terme de changement, par
exemple la traversée d’un tunnel, une mauvaise visibilité due au brouillard ou à la pluie,
etc.
Nos travaux se focaliseront principalement sur cet aspect de robustesse des méthodes.
Plus précisément, nous présentons dans ce rapport divers modifications que nous avons
apportées à une méthode de régression émergente : la régression par les machines à vecteurs
supports. Notre choix s’est porté sur cette méthode car celle-ci posséde quelques avantages
qui nous sont apparus assez intéressants. Nous montrerons l’apport des modifications ap-
portées dans des applications de suivi d’objets en mouvement dans les séquences d’images.
La contribution de ce travail porte sur les points suivants :
– L’étude et l’amélioration d’une méthode de régression proposée dans la littérature,
méthode basée sur les machines à vecteurs supports.
– L’étude de techniques de détection et de contrôle des données aberrantes dans les
ensembles de données.
– l’étude de méthodes de régression disponibles dans la littérature.
– L’étude de deux techniques d’estimation du mouvement proposée dans la littérature,
et l’intégration dans ces techniques de la méthode proposée.
Ce rapport de thèse se décompose en cinq chapitres que nous allons sucsintement présen-
ter dans ce paragraphe.
Organisation du manuscrit
DANS le chapitre 1, nous discuterons des problèmes liés à la présence de données
aberrantes dans le cadre de la vision assistée par ordinateur. D’abord, nous présen-
terons différents phénomènes pouvant provoquer l’apparition d’erreurs dans les données
images. Ensuite, nous expliquerons comment le problème de l’extraction d’une structure
de mouvement dominante peut être vu comme un problème de régression. Enfin, nous
nous intérrogerons sur la façon de traiter les données aberrantes dans le processus de la
régression.
Dans le chapitre 2, nous nous concentrerons sur les méthodes de régression disponibles
2 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

dans la littérature. Nous les classerons en trois familles qui formeront chacune une section
de ce chapitre. La première section présentera les méthodes déterministes, la seconde les
méthodes de vote, et la troisième les méthodes de régularisation. Une section portant sur
l’évaluation de la robustesse dans les méthodes de régression achèvera ce chapitre.
Le chapitre 3 sera consacré à la présentation de la méthode de régression par les ma-
chines à vecteurs supports, ainsi qu’à la présentation des modifications que nous y avons
apportées. Dans la première des deux sections constituant ce chapitre, nous détaillerons
la méthode originale développée et publiée par Vapnik. Dans la seconde section, nous
proposerons des modifications afin d’améliorer la robustesse de cette méthode face aux
différents types de données aberrantes.
Les chapitres 4 et 5 seront dédiés à l’application de la méthode proposée pour l’esti-
mation du mouvement dans les séquences d’images.
Dans le chapitre 4, nous présenterons le calcul du mouvement apparent, aussi appelé
le flot optique. Nous définirons tout d’abord la partie théorique de ce calcul, puis nous en
détaillerons les difficultés fondamentales liées à son utilisation. Nous rapporterons ensuite
les différentes approches publiées dans la littérature pour effectuer ce calcul. La dernière
section montrera les résultats obtenus par ces différentes méthodes, ainsi que par la mé-
thode proposée, sur des séquences vidéos aussi bien simulées que réelles.
Le dernier chapitre de ce rapport portera sur les méthodes d’extraction de points ca-
ractéristiques et de leur mise en correspondance. Les opérateurs les plus utilisés et les
méthodes de mise en correspondance principales, d’après la littérature, seront exposés.
Une section présentant des résultats issus de la méthode proposée sur des données simu-
lées, puis réelles, cloturera le chapitre.
Bien entendu, ce rapport de thèse s’achèvera par une conclusion générale sur nos tra-
vaux. Cette dernière ouvrira également des perspectives sur les évolutions et les améliora-
tions envisageables de la méthode proposée, ainsi que sur d’autres domaines d’application.
3

Chapitre 1
Problème des données aberrantes dans
la vision assistée par ordinateur
DANS le cadre de la vision dynamique qu’est le suivi d’objets en mouvement dans
une séquence d’images, les images d’une scène réelle contiennent naturellement des
défauts et erreurs qui tendent à perturber les algorithmes de suivi. Ces défauts et erreurs
sont issus de différentes sources que nous exposons dans la première partie de ce chapitre.
Nous observons ensuite que le problème d’estimation du mouvement dans les images peut
être résolu comme un problème de régression linéaire, où nous cherchons à estimer les
paramètres du mouvement. Nous nous intéressons à la méthode des moindres carrés,
méthode de régression classique, afin d’observer les effets des données aberrantes sur son
estimation des paramètres. Nous terminons ce chapitre par un tour d’horizon des différents
moyens pour traiter les erreurs afin de limiter leurs effets.
1.1 Sources d’erreurs dans les données images
Dans l’optique d’un suivi d’objets en mouvement dans une séquence d’images, il est
important de prendre conscience des multiples sources d’erreurs pouvant influencer ou
fausser l’estimation d’un déplacement. La figure 1.1 représente la chaîne de traitement des
données : à partir de la capture d’une scène quelconque, nous devons parvenir à prétraiter
les images pour ensuite estimer le(s) mouvement(s) présent(s) dans cette scène.
Fig. 1.1 – Chaîne de traitement des données
4

1.1. Sources d’erreurs dans les données images
Obtenir une estimation fiable s’avère une opération délicate, la précision de cette der-
nière dépend grandement de la qualité des images requises. Or, chaque maillon de la
chaîne va détériorer, plus ou moins fortement, les images. Si les perturbations engendrées
sont trop importantes, l’estimation s’avèrera peu fiable, voire incohérente.
Dans la suite, nous recensons les différentes perturbations pouvant être rencontrées
pendant notre étude. Nous y évoquons, sans entrer dans les détails, les difficultés dans
l’application du flot optique et le problème de la mise en correspondance pour une esti-
mation 2D ou 3D du mouvement.
1.1.1 Capteur
Le capteur est le premier maillon dans la chaîne d’acquisition et de traitement des
données, il s’agit également de la première source de perturbation de ces données. Dans
notre problèmatique de vision assistée par ordinateur, les capteurs utilisés sont de type
passif : il s’agit d’une ou de plusieurs caméras numériques (de type CDD) offrant le plus
souvent une acquisition couleur de l’environement situé dans le champ de vision. Ces ca-
méras fournissent une projection 2D de la scène observée, contrairement par exemple aux
télémètres laser qui permettent directement l’obtention de données 3D. L’utilisation de
ces caméras numériques pose d’emblé le problème de la discrétisation du monde réel.
En effet, une caméra numérique possède une résolution d’acquisition, exprimée en
pixels et liée à son capteur CDD, représentée par une grille sur laquelle l’image de la
scène est projetée. Chaque case de la grille, ou pixel, prendra une valeur qui dépend de
la quantité de lumière reçue depuis la scène. Une représentation du fonctionnement est
visible sur la figure 1.2. L’exemple y est extrêmement simplifié pour faciliter la compré-
hension du problème de discrétisation d’une scène réelle. On remarque aisément que le
toit de la maison, de forme triangulaire, créera un effet d’aliasing, ou crénelage, sur la
grille de pixels suite à la capture numérique de la scène. En fait, la discrétisation de la
scène implique forcément une perte d’information : plus la résolution est faible et plus
on perd de l’information. Cependant, l’utilisation d’une plus grosse résolution n’est pas
une solution miracle. En plus d’augmenter sensiblement le temps de mesure, c’est à dire
de diminuer la fréquence d’acquisition de la caméra ; effectuer des acquisitions avec une
résolution importante va démultiplier le nombre de pixels à manipuler et donc ralentir les
algorithmes de traitement. Par conséquent, un compromis est nécessaire entre la quantité
et la qualité des données, il dépendra de l’application visée.
5

Chapitre 1. Problème des données aberrantes dans la vision assistée par ordinateur
Fig. 1.2 – Discrétisation d’une scène
Hormis les effets de la numérisation, causant par exemple de petites erreurs sur la
position exacte d’un point se déplacant durant une séquence vidéo, les caméras numériques
souffrent également d’une forte sensibilité à la lumière. Si l’éclairage environnant n’est
pas stable, pas assez important ou au contraire trop intense, l’acquisition des données
s’en trouve très perturbée. Dans le cas d’un environnement sombre, on constate qu’un
bruit additionnel fait son apparition sur les données vidéos. Un exemple est visible sur la
figure 1.3. Il s’agit d’une portion de mur lisse peint d’une seule couleur sous un éclairage
insuffisant, on remarque que les données capturées sont bruitées : on a l’impression que le
mur est texturé alors que ce n’est pas du tout le cas dans la réalité.
Fig. 1.3 – Bruit apparaissant dans une scène trop peu éclairée
6 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

1.1. Sources d’erreurs dans les données images
1.1.2 Prétraitements
Une fois l’ensemble de données images obtenu, il est souvent nécessaire d’effectuer une
étape de pré-traitement avant d’appliquer les méthodes de suivi. On retrouvera dans ces
pré-traitements le calcul de dérivées premières ou secondes suivant les variables spatiales,
mais aussi suivant la variable temporelle comme pour le flot optique. Or, il est admis
que le calcul des dérivées est très sensible aux bruits et aux erreurs. Nous avons illustré
cette sensibilité sur la figure 1.4. Il s’agit encore une fois d’un exemple simple. La figure
représente une image de 5× 5 pixels tous de même valeur (en blanc) sauf le pixel central
(en noir). On constate que suivant les deux directions x et y les dérivées effectuent un
creux puis un pic. La présence d’un pixel faux, le pixel central, provoque l’apparition de
deux valeurs fausses dans chaque dérivée d′1 et d′2.
Fig. 1.4 – Effet d’une erreur sur les dérivées spatiales
Pour diminuer l’amplitude des effets du bruit sur le calcul des dérivées, on utilise une
étape de lissage des données images, généralement un lissage de type Gaussien. Le principe
du lissage est d’adoucir les surfaces afin de diminuer l’écart entre le pixel faux et ses voisins.
En pratique, cela a pour effet de diluer le bruit sur les pixels du voisinage, on passe d’un
ensemble de données avec une seule erreur importante à un ensemble de données avec
plusieurs erreurs plus petites. Le lissage est aussi utilisé dans les processus d’extraction de
7

Chapitre 1. Problème des données aberrantes dans la vision assistée par ordinateur
points caractéristiques, il permet d’étaler les contours, faisant se chevaucher les dérivées
issues de ces contours et ce afin d’extraire les coins plus facilement. Bien que cette étape
de lissage amène une perte d’information, de précision sur les données images, elle s’avère
néanmoins nécessaire.
1.1.3 Flot optique
Le calcul du flot optique permet de représenter par un champ de vecteurs les dépla-
cements perceptibles dans une séquence vidéo. Une source importante d’erreurs dans le
calcul du flot optique provient des variations de l’intensité lumineuse. En effet, le flot
optique étant basé sur une hypothèse de conservation d’énergie, en l’occurence l’intensité
lumineuse, le non respect de cette hypothèse a pour conséquence une mauvaise estimation
des vecteurs. Les figure 4.6 1.6 nous montre un exemple de ce phénomène. La figure 4.6-(a)
représente une image issue de la séquence vidéo Yosemite, et la figure 4.6-(b) le champ
de vecteurs correct de cette séquence. La figure 1.6 montre le résultat du calcul du flot
optique avec la méthode de Lucas et Kanade [LK81]. Alors que le ciel nuageux effectue
un mouvement constant vers la droite, on remarque qu’à l’endroit où la lune apparaît
à travers les nuages, le champ de vecteurs est dévié. Cette erreur est due à la variation
d’intensité causée par l’apparition de la lune, le flot optique exprime cette variation par
un mouvement.
(a) image issue de la séquence−10 0 10 20 30 40 50 60 70
−10
0
10
20
30
40
50
60
70
(b) flot optique correct
Fig. 1.5 – Exemple de la séquence Yosemite
Le non respect de l’hypothèse de conservation de l’intensité n’est cependant pas la
8 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

1.1. Sources d’erreurs dans les données images
−5 0 5 10 15 20 25 30 35 40 45
0
5
10
15
20
25
30
35
40
Fig. 1.6 – Résultat du flot optique calculé par Lucas-Kanade sur Yosemite
seule cause d’erreurs dans le calcul du flot optique, les phénomènes d’occlusion sont aussi
très perturbateurs. Les effets négatifs d’une occlusion peuvent être de deux formes et se
localisent le long des frontières séparant différents mouvements. Un exemple est illustré
sur la figure 1.7. Cette dernière montre deux rectangles se déplaçant dans deux direc-
tions opposées, l’un derrière l’autre. Le premier problème est l’apparition d’une variation
d’intensité lorsque le déplacement d’un rectangle découvre ou occulte l’environnement en
arrière plan de celui-ci. Les contours concernés sont les contours horizontaux et sont re-
présentés par la couleur bleue sur la figure. Comme nous l’avons vu précédemment, cette
variation provoque l’estimation d’un mouvement qui n’existe pas en réalité. Le second
problème concerne les contours verticaux, représentés par la couleur verte sur la figure.
En effet, le calcul du flot optique utilisant un petit voisinage autour d’un pixel pour en
estimer le mouvement apparent, un pixel qui appartient à une frontière verte possède dans
son voisinage deux mouvements différents. L’estimation du flot optique en ce pixel s’en
trouve perturbée.
1.1.4 Mise en correspondance
Les méthodes de mise en correspondance créent, de par leur nature, des erreurs qui
peuvent être très importantes. En effet, ces méthodes tentent de faire correspondre entre
deux images soit successives, soit stéréoscopiques, des éléments invariants représentatifs.
Ces éléments, appelés primitives, peuvent être de différentes formes : des contours, des
9

Chapitre 1. Problème des données aberrantes dans la vision assistée par ordinateur
Fig. 1.7 – Zones d’erreurs du flot optique en cas d’occlusions
points caractéristiques, des formes, etc. La recherche du même élément dans les deux
images n’est pas aisée, il arrive très souvent que de faux appariements soient effectués.
Dans le cas de l’utilisation de la mise en correspondance pour l’estimation du mouve-
ment, la méthode recherchant la transformation correcte à l’aide de tous les appariements
doit être capable de faire abstraction des erreurs de mise en correspondance afin de fournir
l’estimation la plus précise. Pour illustrer la présence de ces fausses mises en correspon-
dance, un résultat est présenté sur la figure 1.8.
Il s’agit d’une image issue d’une séquence vidéo montrant une boite de lessive effec-
tuant une rotation. La mise en correspondance a été obtenue en utilisant l’algorithme
du Sift [Low03] entre l’image représentée et l’image suivante. On observe sur la figure
les couples de points caractéristiques obtenus, représentés par des segments. On note que
malgré le nombre important de bons appariements, la répétition de motifs sur la boîte,
en l’occurence des bouteilles de lessive, provoque quelques erreurs, visibles dans le bas de
l’image.
Dans le cas d’une mise en correspondance utilisée pour la reconstruction 3D d’une scène
10 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

1.2. Extraction d’une structure dominante vue comme un problème de régression
Fig. 1.8 – Présence de faux appariements
à l’aide d’images stéréoscopiques, les données images obtenues sont là aussi perturbées
par un leger bruit. La reconstruction d’un point en 3D subit le cumul des erreurs dûes
aux capteurs, aux prétraitements ainsi qu’à la mise en correspondance. Un exemple est
présenté sur la figure 1.9. La figure se décompose en trois parties : en haut à gauche, une
image de la scène ; en bas à gauche, la reconstruction 3D de la scène, et à droite, un
zoom sur la reconstruction de la boîte. On observe sur le zoom que la surface planaire
du dessus de la boîte est reconstruite par un nuage de points qui ne sont pas coplanaires.
Une imprécision sur la position des points est visible et la surface discrétisée est bruitée.
1.2 Extraction d’une structure dominante vue comme
un problème de régression
Dans les applications de suivi d’objet en mouvement dans les séquences d’images, on
cherche à calculer la transformation que subit l’objet-cible entre l’instant t et l’instant
t+1, en supposant que cet objet est non-déformable. Les données représentant l’objet, ou
son déplacement, se doivent d’occuper une portion importante de l’ensemble de données,
une majorité relative. Ainsi, lorsque nous cherchons à extraire une structure de mouve-
ment dominante des données, nous cherchons à estimer les paramètres du modèle linéaire
de transformation de l’objet dans son environnement à partir de données 2D ou 3D. Le
problème du suivi se ramène alors à un problème de régression linéaire simple ou multiple.
Cette section présente le problème de la régression dans le cas linéaire simple. Elle a
11

Chapitre 1. Problème des données aberrantes dans la vision assistée par ordinateur
Fig. 1.9 – Erreurs de reconstruction 3D
pour vocation de montrer les problèmes rencontrés dans les cas imparfaits, où la proportion
de bruit dans les données est non-négligeable. On y utilise la méthode des moindres carrés,
qui est la méthode la plus connue mais qui s’avère aussi la moins robuste. Les résultats
obtenus avec cette méthode nous permettent de discuter de l’influence du bruit sur les
résultats, et d’aborder les différents moyens pouvant être mis en oeuvre afin de rendre
plus robuste une méthode d’estimation.
1.2.1 Définition générale de la régression
D’une manière simple, on peut définir la régression comme la relation entre deux ou
plusieurs variables. Il s’agit d’une méthode d’estimation qui permet d’interpoler, voire
d’extrapoler ou de prédire, la valeur des données en recherchant une relation entre celles-
ci. On retrouve son utilisation dans de nombreux domaines, comme par exemple dans
l’économie. À partir de données expérimentales, on tente de calculer la fonction qui re-
produit le mieux les variations d’une grandeur étudiée. Dans les cas triviaux, cette fonction
passe par tous les points, mais les cas pratiques sont rarement parfaits. On cherchera donc
à minimiser une mesure de distance entre la fonction et les données afin d’obtenir une
solution la plus proche possible de la réalité. On nomme la grandeur étudiée la réponse
ou le vecteur réponse, et les grandeurs dont elle dépend les variables explicatives, ces
dernières constituent la matrice d’observation.
12 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —
1.2. Extraction d’une structure dominante vue comme un problème de régression
1.2.2 Régression linéaire
Lorsqu’une variable réponse, notée Y , semble liée à une variable explicative, notée
X1, par une relation de type affine, c’est à dire que Y = aX1 + b dans un problème à 2
dimensions, on nomme régression linéaire simple l’estimation des deux paramètres a et
b. La généralisation à un problème à p + 1 dimensions avec p variables explicatives, telle
que Y = θ0 + X1θ1 + X2θ2 + · · · + Xpθp, donne ce que l’on appelle la régression linéaire
multiple. Les paramètres à estimer sont notés sous la forme d’un vecteur θ de dimension
égale à la dimension du problème. On obtient alors une réécriture sous forme matricielle
telle que Y = Xθ avec :
Y1
Y2
...
Yn
=
1 X11 X12 · · · X1p
1 X21 X22 · · · X2p
......
.... . .
...
1 Xn1 Xn2 · · · Xnp
·
θ0
θ1
...
θp
(1.1)
Pour une facilité de lecture, nous resterons dans le cadre de la régression linéaire simple.
On considère un ensemble de données composé d’un certain nombre de couples (X1,Y ).
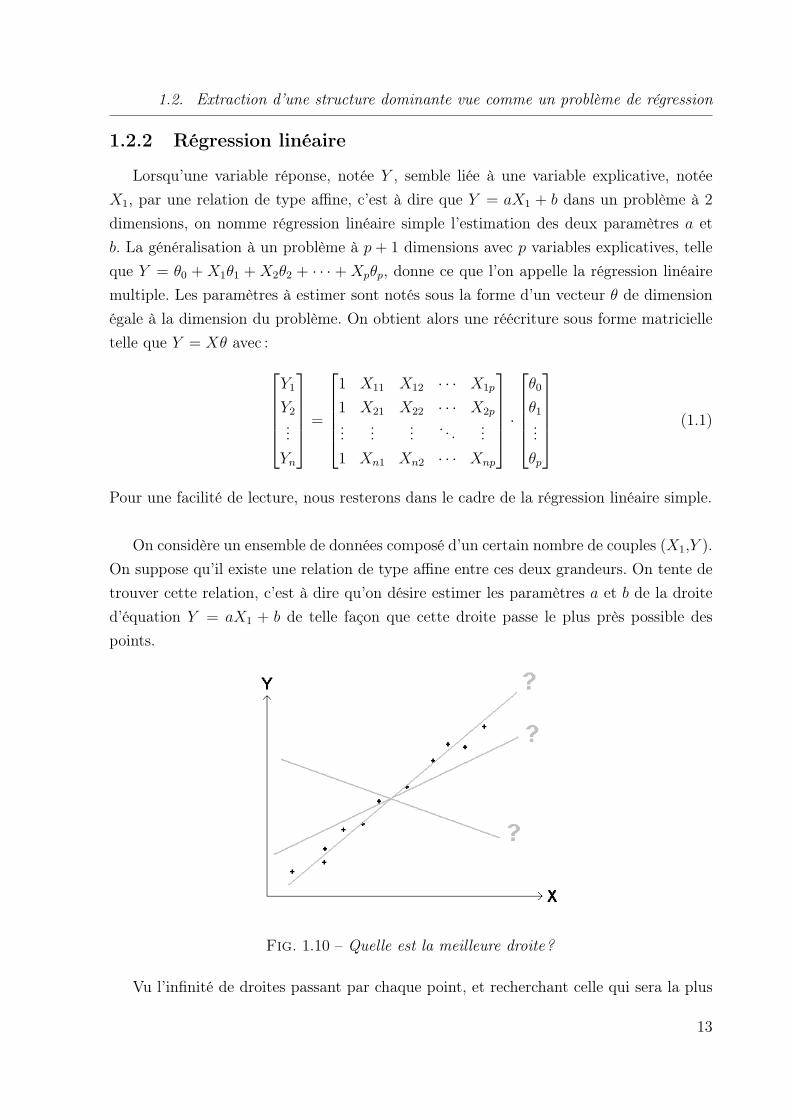
On suppose qu’il existe une relation de type affine entre ces deux grandeurs. On tente de
trouver cette relation, c’est à dire qu’on désire estimer les paramètres a et b de la droite
d’équation Y = aX1 + b de telle façon que cette droite passe le plus près possible des
points.
Fig. 1.10 – Quelle est la meilleure droite?
Vu l’infinité de droites passant par chaque point, et recherchant celle qui sera la plus
13

Chapitre 1. Problème des données aberrantes dans la vision assistée par ordinateur
proche de tous les points en même temps, il nous faut définir un critère d’évaluation des
droites afin de sélectionner celle qui semble être la plus proche des points, et ainsi obtenir
une solution unique à notre problème. Le critère utilisé sera une mesure d’écart entre
la droite et les points. Cet écart, nommé résidu et noté ri pour le point i, représente
l’erreur commise suivant l’axe de la réponse Y entre la droite et le point i. La plupart
des méthodes de régression tente de minimiser ce critère d’erreur, ou un critère proche,
afin d’obtenir la meilleure solution possible. Nous allons nous intéresser à la méthode la
plus connue et la plus utilisée : la méthode des moindres carrés. Cette méthode va nous
permettre d’aborder les difficultés de résolution d’un problème de régression.
1.2.3 Moindres carrés
La méthode des moindres carrés, notée LS pour Least Squares en anglais, est la mé-
thode d’estimation de la régression la plus communément rencontrée. On peut aussi la
rencontrer sous le nom de L2-régression. Nous verrons, au chapitre 4, que la méthode de
Lucas-Kanade (1981) [LK81] utilise l’estimation par les moindres carrés pour résoudre
le problème du flot optique.
L’estimation θLS de θ de l’équation 1.1 est définie comme le p-vecteur qui minimise la
somme avec un facteur 12
de toutes les valeurs résiduelles au carré, c’est à dire :
θLS = minθ
1
2
n∑
i=1
r2i (1.2)
où ri = Yi − Xiθ (1.3)
De point de vue pratique, la solution peut être obtenue en utilisant la pseudoinverse de
la matrice d’observation X, notée X+ :
θLS = X+Y (1.4)
On calculera cette pseudoinverse en utilisant l’équation matricielle suivante :
X+ = (XT X)−1XT (1.5)
L’utilisation d’une fonction perte, fonction qui attribue un poids à chaque résidu, de type
quadratique induit une efficacité maximum de cette méthode pour une distribution Gaus-
sienne du bruit.
14 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —
1.2. Extraction d’une structure dominante vue comme un problème de régression
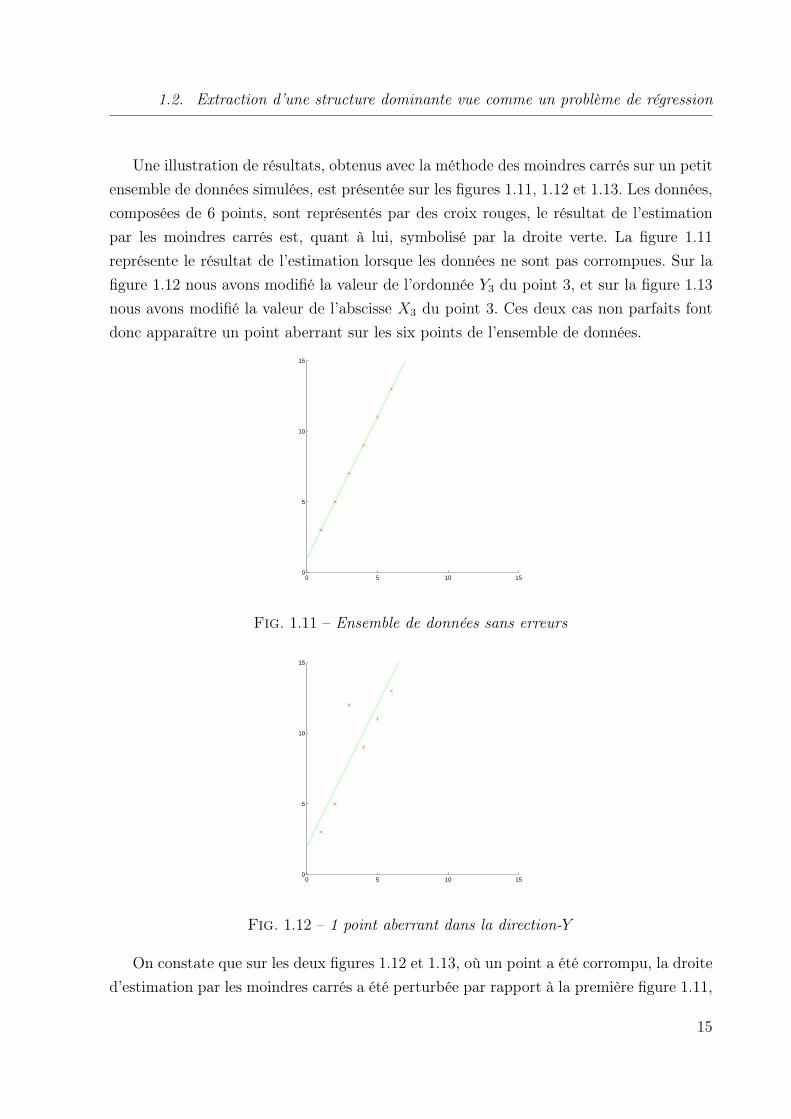
Une illustration de résultats, obtenus avec la méthode des moindres carrés sur un petit
ensemble de données simulées, est présentée sur les figures 1.11, 1.12 et 1.13. Les données,
composées de 6 points, sont représentés par des croix rouges, le résultat de l’estimation
par les moindres carrés est, quant à lui, symbolisé par la droite verte. La figure 1.11
représente le résultat de l’estimation lorsque les données ne sont pas corrompues. Sur la
figure 1.12 nous avons modifié la valeur de l’ordonnée Y3 du point 3, et sur la figure 1.13
nous avons modifié la valeur de l’abscisse X3 du point 3. Ces deux cas non parfaits font
donc apparaître un point aberrant sur les six points de l’ensemble de données.
0 5 10 150
5
10
15
Fig. 1.11 – Ensemble de données sans erreurs
0 5 10 150
5
10
15
Fig. 1.12 – 1 point aberrant dans la direction-Y
On constate que sur les deux figures 1.12 et 1.13, où un point a été corrompu, la droite
d’estimation par les moindres carrés a été perturbée par rapport à la première figure 1.11,
15

Chapitre 1. Problème des données aberrantes dans la vision assistée par ordinateur
0 5 10 150
5
10
15
Fig. 1.13 – 1 point aberrant direction-X
où la droite d’estimation est correcte. Bien entendu le taux de données corrompues est
de 16
dans les figures 1.12 et 1.13, ce qui n’est pas négligeable, mais nous obtiendrions le
même résultat pour n’importe quel taux non nul. À partir d’une seule donnée corrompue,
l’estimation par les moindres carrés est corrompue, elle n’est pas capable de supporter la
présence d’erreurs dans les données. Cet inconvénient nous amène à nous intéresser aux
points aberrants : quels sont leurs effets? Existe-t-il des moyens de les détecter?
1.3 Comment traiter les points aberrants?
Comme il a été vu précédemment, la présence de points aberrants pose un sérieux
problème à l’analyse standard par les moindres carrés, cette méthode est considérée comme
une méthode non robuste. Nous verrons qu’il existe deux approches pour gérer le problème
que pose la présence de points aberrants dans les ensembles de données :(a) le diagnostic
de la régression, qui révèle les points ayant une forte influence afin de les corriger ou
de les retirer du processus d’estimation, et (b) la régression robuste, qui essaie d’utiliser
des estimateurs faiblement affectés par des points aberrants. Avant de parcourir plus en
détails les différents outils de diagnostic de la régression, nous allons tout d’abord tenter
de définir ce qu’est un point aberrant.
1.3.1 Définition
Le terme "point aberrant" est l’équivalent du terme anglais "outlier", mot qui est égale-
ment employé dans la littérature francophone. Nous utiliserons donc indifférement l’un ou
16 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

1.3. Comment traiter les points aberrants?
l’autre de ces termes dans la suite de ce manuscrit.
En 1978, Barnett et Lewis [BL78] ont défini un point aberrant comme étant : une
observation, ou un sous-ensemble d’observations, qui paraît être incohérent
avec le reste de l’ensemble des données.
Cette définition, très générale, induit que la décision de traiter une observation comme
étant un outlier est le fruit du jugement subjectif des chercheurs. Par la suite, Judge et
al. (1988) [JHG+88] ont utilisé le terme d’outlier pour désigner les observations induisant
une importante valeur résiduelle. Puis Krasker et al. (1983), Hampel et al. (1986),
ainsi que Rousseeuw et Leroy (1987), ont présenté une classification des outliers en
différentes catégories sans pour autant en donner une définition plus formelle.
En 1993, Davies et Gather ont présenté une définition considérée plus précise. Soit
F la distribution cible. Pour une simplicité de présentation, F sera choisie comme une
distribution normale univariable avec sa moyenne notée µ (pouvant être inconnue) et sa
variance notée σ2 (pouvant être inconnue aussi). Pour α strictement compris entre 0 et 1,
Davies et Gather introduisent le concept de région d’outliers comme :
out(α,µ,σ2) = x : |x − µ| > z1−α/2σ (1.6)
avec zq le q-quantile de la distribution normale standard. Une observation xi sera appelée
un α-outlier selon F si xi ∈ out(α,µ,σ2). Par conséquent, une "bonne" observation, c’est
à dire appartenant à la distribution cible F , pourra être classée comme un α-outlier. Il
est à noter qu’avec cette définition, xi peut être n’importe quel nombre réel, il ne doit pas
coïncider nécessairement avec l’une des observations.
Le point important de cette définition est qu’elle se base sur les paramètres réels µ et
σ2. Elle ne dépend donc pas de la méthode de détection des outliers choisie. Selon la
méthode utilisée pour estimer les paramètres µ et σ2, les observations labelisées comme
étant des outliers seront différentes. La définition de Davies et Gather permet de faire
une distinction entre d’un côté les "vrais" outliers et de l’autre les observations labelisées
comme outliers à partir d’une méthode d’identification.
À partir de ces différentes définitions, nous allons maintenant présenter une classifica-
tion des points aberrants utilisée dans la littérature.
17

Chapitre 1. Problème des données aberrantes dans la vision assistée par ordinateur
1.3.2 Classification
Les outliers peuvent être de différents types selon leurs positions dans l’ensemble de
données. Une classification possible des outliers dans le cas d’un modèle de régression
linéaire, c’est à dire Y = aX1 + b, est illustrée sur la figure 1.14 qui suit.
Fig. 1.14 – Classification des outliers dans une régression linéaire simple
La figure nous présente un ensemble de données composé d’un certain nombre de points
que nous classerons en différentes catégories. Le regroupement en bas à gauche est supposé
représenter les données correctes, la structure principale dont nous souhaitons obtenir la
relation. Les groupes d’outliers numérotés 1, 2 et 3, ainsi que les outliers uniformément
distribués dans l’espace, sont les données qui posent problème. Ces données peuvent être
structurées, c’est le cas des groupes 1, 2 et 3, mais elles peuvent aussi être totalement
aléatoires et ne correspondre à aucune structure. Nous identifions trois classes d’outliers :
– les outliers verticaux (suivant l’axe des y) : il s’agit des points appartenant à la
plage des abscisses de la majorité des données, mais se trouvant éloignées de l’esti-
mation linéaire des données. Elles possèdent une valeur résiduelle plus importante
que la plupart des autres données. Ces outliers verticaux sont représentés par le
groupe n1 sur la figure 1.14. Ils ont une influence relativement faible sur la solution
de la régression, il perturbe généralement le biais b plutôt que la pente a de la droite
solution.
– les outliers horizontaux, dits à effet levier (suivant l’espace des x) : il s’agit
des points n’appartenant pas à la plage des abscisses de la majorité des données,
c’est à dire qu’elles provoquent une discontinuité dans les données suivant l’axe des
18 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

1.3. Comment traiter les points aberrants?
abscisses. On peut séparer ces observations en 2 groupes :
– les outliers à effet levier favorable : le groupe des outliers à effet favorable se
trouve proche de l’estimation linéaire des données, c’est à dire que ces outliers
possèdent une valeur résiduelle du même ordre que celle de la majorité des
données, ils sont réprésentés par le groupe n2.
– les outliers à effet levier défavorable : le groupe des outliers à effet défavorable
est placé relativement loin de l’estimation linéaire, ces outliers obtiennent une
valeur résiduelle plus importante que la majorité des données, ils sont repré-
sentés par le groupe n3.
L’influence des outliers à effet levier sur la solution de la régression est nettement
plus importante que celle des outliers verticaux. Ils vont perturber autant le biais b
de la droite solution que la pente a de cette dernière. Leur influence est fonction de
la distance qui sépare ces outliers de la majorité des données. Plus cette distance
est importante, plus la solution est influencée par ces données aberrantes (d’où le
terme d’effet levier).
Maintenant que nous avons défini ce que sont les outliers, et que nous en avons pro-
posé une classification, une question se pose quant à la résolution de notre problème de
régression. Comment pouvons-nous détecter, avant ou pendant le processus d’estimation,
les outliers dans l’ensemble de données? L’objectif de cette détection sera de minimiser
l’impact de ces erreurs sur la solution, ou tout simplement les ignorer dans le calcul de la
solution.
1.3.3 Techniques de détection et de contrôle des outliers
Les approches existantes pour la détection d’outliers peuvent être regroupées en 3
catégories : les mesures basées sur le K-voisinage, les mesures basées sur les modèles pro-
babilistes, et les mesures basées sur le voisinage géométrique :
– Les approches basées sur le K-voisinage : ces approches reposent sur l’idée pro-
posée par Breunig et al. [BKNS00] et relative au facteur local d’aberration (ou local
outlier factor, noté LOF, de chaque point-donnée, qui dépend de la densité locale
de son voisinage. Ce voisinage est défini par la distance entre le point-observation et
son K-ième plus proche voisin. K est une variable définissant un nombre minimal de
points dans le voisinage, le choix de sa valeur est important. Les points possédant
un LOF élevé sont étiquetés comme outliers. Un exemple est représenté sur la figure
1.15.
19

Chapitre 1. Problème des données aberrantes dans la vision assistée par ordinateur
Fig. 1.15 – Facteur local d’aberration LOF (K=3)
Le point aberrant en haut à droite de la figure possède un LOF élevé, la distance
entre ce point et son 3ème plus proche voisin est importante. En revanche, la "bonne"
donnée en bas à gauche possède un LOF "normal", c’est à dire que son LOF n’est
pas significativement plus important que le LOF moyen des données.
– Les approches basées sur les modèles probabilistes : elles utilisent différents
modèles de distribution standard (normale, Poisson, etc) et labelisent les obser-
vations qui dévient du modèle comme des outliers. Cependant, ces méthodes sont
inappropriées pour des ensembles de données à plusieurs dimensions (souvent ce type
d’approches utilise des modèles univariables). De plus, pour un ensemble de données
arbitraire sans connaissance a priori sur sa distribution, on doit user de tests aux
coûts calculatoires élevés afin de déterminer le modèle statistique qui correspond le
mieux aux données, si tenté qu’il existe.
– Les approches basées sur le voisinage géométrique : elles exploitent l’idée
proposée originellement par Knorr et Ng en 1997. Une observation dans l’ensemble
de données noté P est un outlier selon la distance si au moins une fraction β des
observations de P se trouvent éloignés d’au moins la distance r de celui-ci. Cette
définition d’un outlier est basée sur un critère simple et global déterminé par les
paramètres r et β. On peut utiliser cette méthode pour les problèmes où l’ensemble
de données possède dans le même temps des régions denses et des régions éparses.
Un exemple est présenté sur la figure 1.16.
Le point aberrant en haut à droite est éloigné des 11 autres données d’une distance
plus grande que r, alors que le "bon" point en bas à gauche possède 5 points dans
son voisinage géométrique.
20 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

1.3. Comment traiter les points aberrants?
Fig. 1.16 – Voisinage géométrique
Hormis ces trois types d’approches de détection d’outliers, il est également possible
d’utiliser les outils de diagnostic de la régression [CW82][BKW80][KKMN98] afin de
contrôler, voire supprimer les outliers ayant une forte influence sur le modèle de régression.
Nous allons présenter parmi ces différents outils qui mesurent l’influence des observations :
la matrice "chapeau" notée H, les résidus, ainsi que la distance de Cook.
La matrice chapeau
Soit X la matrice d’observation, ou matrice des prédicteurs, on construit la matrice cha-
peau H telle que :
H = X(XT X)−1XT (1.7)
Nous avons donc une expression des prédictions Yi comme une combinaison linéaire des
réponses Yi :
Yi =n∑
j=1
HijYj (1.8)
Les éléments qui nous intéresse dans cette matrice sont ceux appartenant à la diagonale :
Hii =XiX
Ti∑n
j=1 XjXTj
(1.9)
Les éléments Hii représentent le poids de la ième réponse Yi sur la ième valeur prédite Yi.
Ils permettent donc de mesurer l’importance de la contribution de Yi dans la prédiction
de Yi. Ce critère est également relié à l’éloignement de Xi par rapport à la moyenne X. La
valeur moyenne des Hii est Hii = pn, où p est le nombre de coefficients θi du modèle et n le
21

Chapitre 1. Problème des données aberrantes dans la vision assistée par ordinateur
nombre d’observations. D’après la littérature [HW78], il convient de porter une attention
particulière aux observations dont la valeur Hii serait supérieure à 2 ou 3 fois la valeur
moyenne. En effet, un élément sur la diagonale de la matrice chapeau H qui possède une
valeur importante, va attirer l’hyperplan de régression vers l’observation correspondante.
Les résidus
Les résidus mesurent l’écart entre la ième réponse Yi et la ième valeur prédite Yi par
l’estimation de la régression.
ri = Yi − Yi (1.10)
Même si les erreurs sont indépendantes et de même variance, les résidus issus de l’esti-
mation n’ont pas la même variance : E(ri) = 0 et var(ri) = σ2(1 − Hii). On va donc en
calculer des versions standardisées afin de les rendre comparables.
Les résidus standardisés
Les résidus peuvent être divisés par une estimation de leur propre variance afin d’obtenir
des résidus dits standardisés ou studentisés.
ristand=
ri
σ√
1 − Hii
(1.11)
Avec :1
n≤ Hii < 1 (1.12)
Et :
σ2 =n∑
i=1
r2i
n − p(1.13)
Le problème avec ces résidus standardisés est que le numérateur et le dénominateur ne
sont pas indépendants, on utilise ri pour estimer la variance σ2. Pour ne pas souffrir de
ce biais, les résidus Jackknife sont préférés [KKMN98].
Les résidus Jackknife
Les résidus Jackknife, notés aussi résidus R-Student, sont les quotients des résidus sur
leurs propres variances en estimant la variance σ2 avec toutes les observations exceptée
l’observation i.
riR−Student=
ri
σ−i
√1 − Hii
(1.14)
22 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

1.3. Comment traiter les points aberrants?
Avec :
σ−i2 = (
n∑
i=1
r2i
n − p) − r2
i
n − p(1.15)
Il est admis, dans la littérature, qu’il convient d’examiner les observations pour lesquelles
la valeur absolue du résidu Jackknife est supérieure à 2.
La distance de Cook
La distance de Cook [Coo77] est un des critères les plus utilisés pour juger de l’influence
d’une observation i. Elle consiste à comparer les paramètres estimés du modèle utilisant
toutes les observations avec ceux estimés sans la ième observation. On peut l’écrire sous
cette forme :
Dicook=
(θ − θ(−i))T (XT X)(θ − θ(−i))
ps2(1.16)
Où θ et θ(−i) représentent respectivement les paramètres estimés avec toutes les observa-
tions et sans l’observation i. On peut aussi écrire la distance de Cook sous une forme
plus simple qui est :
Dicook=
r2istand
p
Hii
1 − Hii
(1.17)
Ce critère mesure donc l’influence d’une observation sur l’ensemble des prévisions en pre-
nant en compte l’effet levier et l’importance des résidus. En pratique, la stratégie de
détection des valeurs atypiques consiste à rechercher les distances de Cook avec une va-
leur supérieure à 1.
Afin de clore cette section portant sur la caractérisation des outliers, nous allons abor-
der un élément clé utilisé par certaines méthodes d’estimation de la régression : la fonction
de perte. Ainsi, le prochain paragraphe aura pour objectif de définir ce qu’est une fonction
de perte et en présentera différentes formes.
1.3.4 Fonctions de pertes
La fonction de perte est également nommée la fonction de coût dans la littérature,
nous utiliserons donc indifféremment les termes de "perte" ou "coût" par la suite.
La fonction de perte définit un coût, ou une perte, pour chaque donnée par rapport à
une solution intermédiaire du processus de régression. Cette perte est fonction de l’éloi-
gnement géométrique entre la donnée et cette solution intermédiaire, c’est à dire le résidu.
Ainsi, pour chaque solution intermédiaire est associé une perte totale, qui est la somme
23

Chapitre 1. Problème des données aberrantes dans la vision assistée par ordinateur
des pertes causées par chaque donnée de l’ensemble de données.
Prenons l’exemple de la méthode des moindres carrés. La fonction de perte associée à
cette méthode est la fonction "carré" : le coût d’une donnée, qui sera associé à la solution
intermédiaire, est égale au résidu de cette donnée élevé au carré. L’objectif de la méthode
de régression sera de déterminer la solution à laquelle est associée la perte totale minimale,
cette solution sera la solution finale du processus de régression.
Définition
Posons (X,Y,Y ) le triplet composé de : la matrice d’observations X appartenant à
l’ensemble des matrices d’observations, noté X , du vecteur réponse Y ainsi que de la
prédiction Y appartenant tous deux à l’ensemble des vecteurs réponses, noté Y .
La fonction c définie par :
c : X × Y × Y → [0,∞)
telle que :
c(X,Y,Y = Y ) = 0
sera nommée une fonction de perte.
Notons qu’il est requis que la fonction c soit une fonction non-négative. Cela signifie
qu’une prédiction exacte Yi = Yi, qui ne cause aucune perte, n’implique également aucune
récompense.
Il existe de nombreuses fonctions de perte dans la littérature, le choix de celle-ci repose
sur l’hypothèse que fait le chercheur quant à la forme du bruit qu’il pense trouver sur ses
données. Nous allons présenter, dans la suite de cette section, les fonctions de perte le
plus souvent rencontrées.
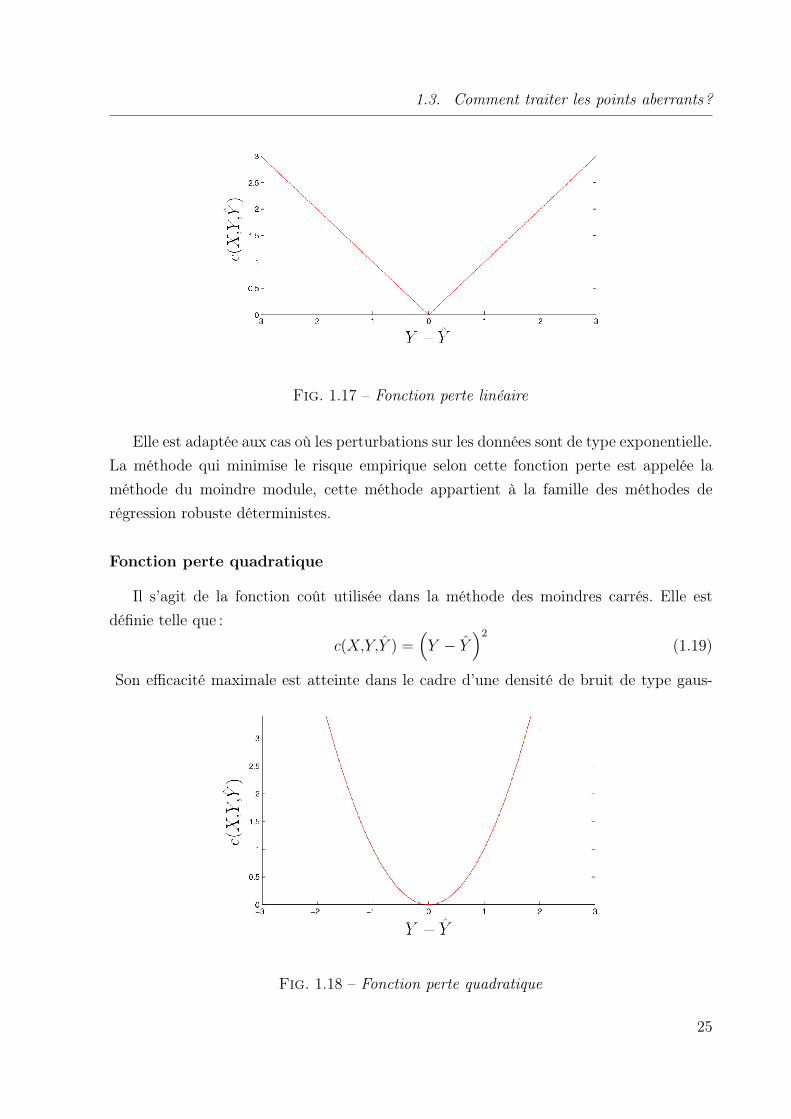
Fonction perte linéaire
Huber, en 1964, [Hub64] a développé une théorie qui permet de trouver la meilleure
stratégie pour choisir la fonction perte en utilisant seulement une information générale à
propos du modèle de bruit. En particulier, il a montré que si l’on sait uniquement que
la densité décrivant le bruit est une fonction symétrique lisse, alors la meilleure stratégie
minimax pour l’approximation de la régression fournit la fonction perte représentée sur
la figure 1.17 et définie par :
c(X,Y,Y ) =∣∣∣Y − Y
∣∣∣ (1.18)
24 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —
1.3. Comment traiter les points aberrants?
Fig. 1.17 – Fonction perte linéaire
Elle est adaptée aux cas où les perturbations sur les données sont de type exponentielle.
La méthode qui minimise le risque empirique selon cette fonction perte est appelée la
méthode du moindre module, cette méthode appartient à la famille des méthodes de
régression robuste déterministes.
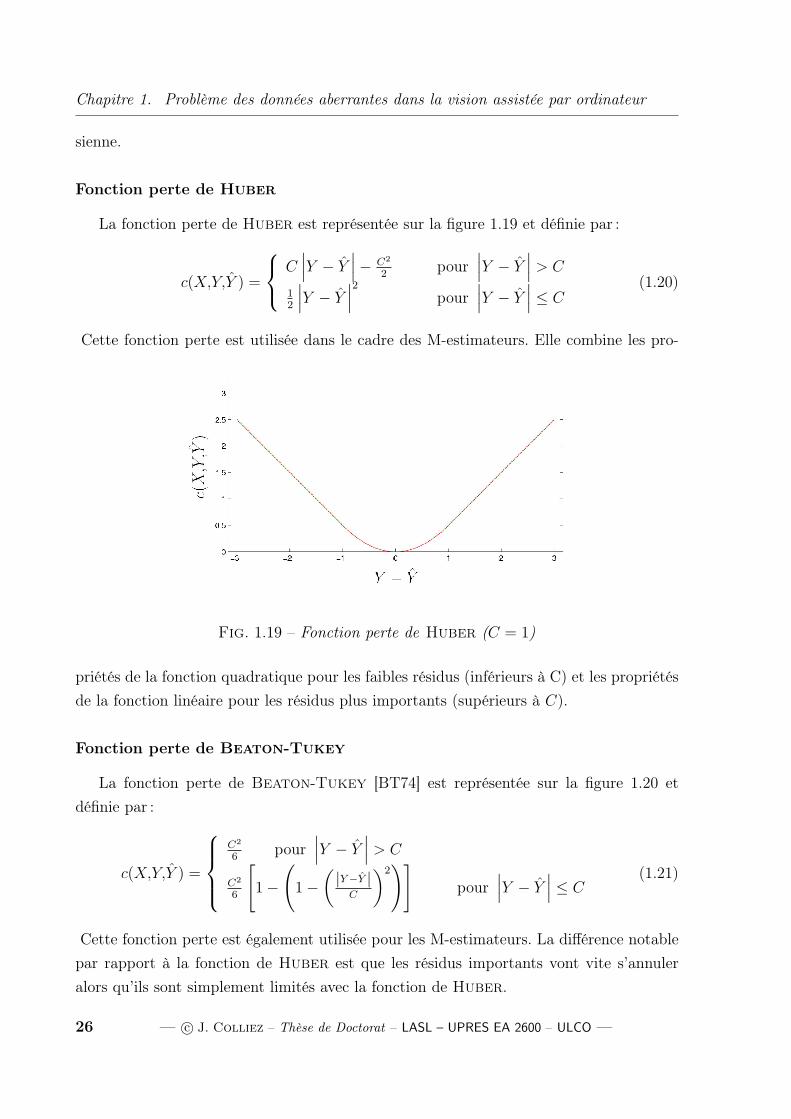
Fonction perte quadratique
Il s’agit de la fonction coût utilisée dans la méthode des moindres carrés. Elle est
définie telle que :
c(X,Y,Y ) =(Y − Y
)2
(1.19)
Son efficacité maximale est atteinte dans le cadre d’une densité de bruit de type gaus-
Fig. 1.18 – Fonction perte quadratique
25
Chapitre 1. Problème des données aberrantes dans la vision assistée par ordinateur
sienne.
Fonction perte de Huber
La fonction perte de Huber est représentée sur la figure 1.19 et définie par :
c(X,Y,Y ) =
C
∣∣∣Y − Y∣∣∣ − C2
2pour
∣∣∣Y − Y∣∣∣ > C
12
∣∣∣Y − Y∣∣∣2
pour∣∣∣Y − Y
∣∣∣ ≤ C(1.20)
Cette fonction perte est utilisée dans le cadre des M-estimateurs. Elle combine les pro-
Fig. 1.19 – Fonction perte de Huber (C = 1)
priétés de la fonction quadratique pour les faibles résidus (inférieurs à C) et les propriétés
de la fonction linéaire pour les résidus plus importants (supérieurs à C).
Fonction perte de Beaton-Tukey
La fonction perte de Beaton-Tukey [BT74] est représentée sur la figure 1.20 et
définie par :
c(X,Y,Y ) =
C2
6pour
∣∣∣Y − Y∣∣∣ > C
C2
6
[1 −
(1 −
(|Y −Y |
C
)2)]
pour∣∣∣Y − Y
∣∣∣ ≤ C(1.21)
Cette fonction perte est également utilisée pour les M-estimateurs. La différence notable
par rapport à la fonction de Huber est que les résidus importants vont vite s’annuler
alors qu’ils sont simplement limités avec la fonction de Huber.
26 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

1.3. Comment traiter les points aberrants?
Fig. 1.20 – Fonction perte de Beaton-Tukey (C = 1)
Fonctions perte d’insensibilité ε
Pour construire les machines à vecteurs supports, un autre type de fonctions perte
nommées les fonctions perte d’insensibilité ε est utilisé :
c(X,Y,Y ) = L(∣∣∣Y − Y
∣∣∣ε
)(1.22)
Où∣∣∣Y − Y
∣∣∣ε=
0 si
∣∣∣Y − Y∣∣∣ ≤ ε∣∣∣Y − Y
∣∣∣ − ε autrement(1.23)
Ce type de fonctions perte décrit un modèle d’insensibilité ε : on peut se représenter cette
fonction comme un tube de rayon ε et d’axe la fonction estimée Y à l’intérieur duquel les
observations sont considérées comme correctes et ne provoquent aucune erreur. La perte
obtenue en Xi est égale à 0 si l’écart entre la valeur prédite Yi et l’observation Yi est
inférieur à ε, c’est à dire si le point (Xi,Yi) est à l’intérieur du tube. Pour les points situés
à l’extérieur de ce tube, la perte vaudra la différence entre : la distance de la réponse Yi à
la prédiction Yi, et le rayon du tube ε.
Fonction perte linéaire d’insensibilité ε
La fonction perte linéaire d’insensibilité ε est représentée sur la figure 1.21 et est définie
telle que :
L(∣∣∣Y − Y
∣∣∣ε) =
∣∣∣Y − Y∣∣∣ε
(1.24)
Cette fonction perte coïncide avec la fonction perte linéaire (eq. 1.18) lorsque ε = 0.
27
Chapitre 1. Problème des données aberrantes dans la vision assistée par ordinateur
Fig. 1.21 – Fonction perte linéaire d’insensibilité (ε = 1)
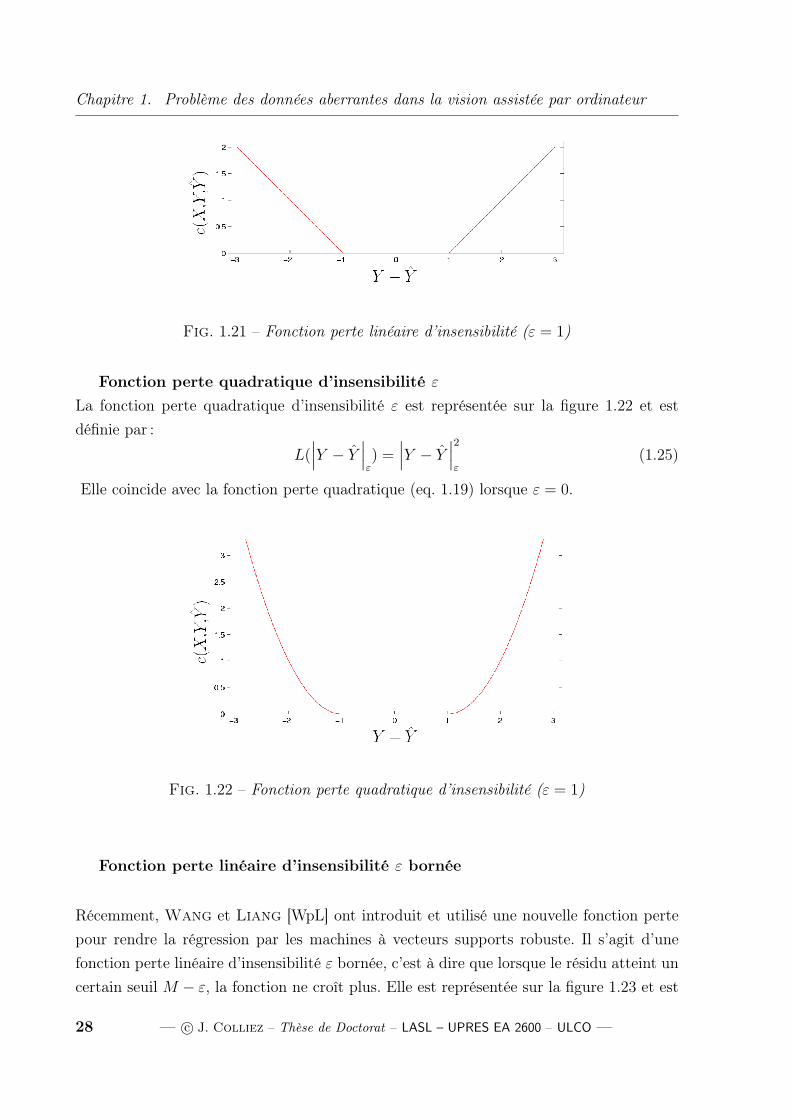
Fonction perte quadratique d’insensibilité ε
La fonction perte quadratique d’insensibilité ε est représentée sur la figure 1.22 et est
définie par :
L(∣∣∣Y − Y
∣∣∣ε) =
∣∣∣Y − Y∣∣∣2
ε(1.25)
Elle coincide avec la fonction perte quadratique (eq. 1.19) lorsque ε = 0.
Fig. 1.22 – Fonction perte quadratique d’insensibilité (ε = 1)
Fonction perte linéaire d’insensibilité ε bornée
Récemment, Wang et Liang [WpL] ont introduit et utilisé une nouvelle fonction perte
pour rendre la régression par les machines à vecteurs supports robuste. Il s’agit d’une
fonction perte linéaire d’insensibilité ε bornée, c’est à dire que lorsque le résidu atteint un
certain seuil M − ε, la fonction ne croît plus. Elle est représentée sur la figure 1.23 et est
28 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

1.3. Comment traiter les points aberrants?
définie telle que :
L(∣∣∣Y − Y
∣∣∣ε) =
∣∣∣Y − Y∣∣∣ε,M
(1.26)
Où
∣∣∣Y − Y∣∣∣ε,M
=
0 si∣∣∣Y − Y
∣∣∣ ≤ ε∣∣∣Y − Y∣∣∣ − ε si ε <
∣∣∣Y − Y∣∣∣ ≤ M
M − ε si∣∣∣Y − Y
∣∣∣ > M
(1.27)
Ici 0 < ε < M , la constante M est un seuil qui détermine si une observation est un outlier.
Fig. 1.23 – Fonction perte de Wang-Liang (ε = 1, M = 3)
Lorsque l’erreur∣∣∣Y − Y
∣∣∣ est supérieure à ce seuil M , la perte associée n’augmente plus.
Cependant, cette fonction n’est plus convexe. Ainsi, il est impossible de transformer le
problème vers un équivalent convexe ou vers un problème de programmation quadratique.
La solution ne peut plus être trouvée de façon analytique. Wang et Liang proposent
donc d’utiliser une fonction continue pour approximer la fonction perte, cette fonction
d’approximation doit respecter quelques règles : elle doit être continue, positive, symé-
trique et croissante. De plus, la précision de l’approximation doit être la plus importante
sur le domaine [0,ε].
Dans leur travail, les auteurs utilisent par exemple la fonction d’approximation, notée
V , représentée sur la figure 1.24 et définie par :
V (z,α) = g(z,α) + g(−z,α) (1.28)
Où g(z,α) est de la forme :
g(z,α) =1
Tlog
1 + eα(z−ε)
1 + eα(z−M)(1.29)
Pour résumer ce paragraphe, on peut mentionner que le choix d’une fonction perte
29

Chapitre 1. Problème des données aberrantes dans la vision assistée par ordinateur
Fig. 1.24 – Représentation de g(z,α) (T = 2,α = 5,ε = 1,M = 3)
s’effectue dans un espace infini : on peut utiliser n’importe quelle fonction perte convexe
c(X,Y,Y ). Huber nous apprend cependant qu’une "bonne" fonction perte doit croître
moins rapidement que la fonction quadratique pour accorder moins d’influence aux points
possédant un fort résidu. Tukey, et plus récemment Wang et Liang, ont proposé tout
simplement de borner la fonction perte afin d’attribuer un poids nul à ces points. Le
tableau 1.1 récapitule les différentes fonctions pertes que nous avons présenté.
1.4 Conclusion
Dans les données images, la contamination de l’ensemble de données provient de
sources variées et prend différentes formes causant des perturbations plus ou moins fortes.
Depuis les capteurs jusqu’aux méthodes de traitement et prétraitement, tous les éléments
de la chaîne d’acquisition ajoutent leurs lots de perturbations dans les données. Or, l’ex-
traction d’un mouvement ou d’un déplacement, vu comme un problème de régression
linéaire, devient difficile à résoudre lorsque les données sont bruitées. Le cas de la mé-
thode des moindres carrés en est le meilleur exemple : une seule donnée érronée suffit
à biaiser l’estimation des paramètres. L’utilisation de méthodes de régression robustes
s’avère donc être une nécessité afin d’obtenir une estimation fiable des paramètres. Ces
méthodes de régression tirent leur robustesse de différents outils qui aident à détecter
les points aberrants, à diminuer leurs influences, voire à les supprimer de l’ensemble des
données purement et simplement.
30 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

1.4. Conclusion
fonction perte c(t) représentation
c(X,Y,Y ) =∣∣∣Y − Y
∣∣∣
c(X,Y,Y ) =(Y − Y
)2
c(X,Y,Y ) =
C
∣∣∣Y − Y∣∣∣ − C2
2si
∣∣∣Y − Y∣∣∣ > C
12
∣∣∣Y − Y∣∣∣2
si∣∣∣Y − Y
∣∣∣ ≤ C
c(X,Y,Y ) =
C2
6si
∣∣∣Y − Y∣∣∣ > C
C2
6
[1 −
(1 −
(|Y −Y |
C
)2)]
sinon
L(∣∣∣Y − Y
∣∣∣ε) =
0 si
∣∣∣Y − Y∣∣∣ ≤ ε∣∣∣Y − Y
∣∣∣ − ε sinon
L(∣∣∣Y − Y
∣∣∣ε) =
0 si
∣∣∣Y − Y∣∣∣ ≤ ε
(∣∣∣Y − Y
∣∣∣ − ε)2 sinon
L(∣∣∣Y − Y
∣∣∣ε) =
0 si∣∣∣Y − Y
∣∣∣ ≤ ε∣∣∣Y − Y∣∣∣ − ε si ε <
∣∣∣Y − Y∣∣∣ ≤ M
M − ε si∣∣∣Y − Y
∣∣∣ > M
Tab. 1.1 – Récapitulatif des différentes fonctions pertes
31

Chapitre 2
Méthodes de régression robustes
IL existe, dans la littérature scientifique, un grand nombre de méthodes de régression
plus ou moins robustes, variantes améliorées d’anciennes méthodes ou nouvelles ap-
proches. Certaines sont considérées comme des méthodes classiques et sont très répan-
dues. Citons la méthode des moindres carrés ainsi que les M-estimateurs, d’autres sont
plus récentes, par exemple l’approche du variable bandwidth Quick Maximum Density
Power Estimator (vbQMDPE). Chacune de ces méthodes possède des avantages et des
inconvénients, le choix d’une ou d’une autre dépend beaucoup du problème. Dans ce cha-
pitre, nous présentons un ensemble de méthodes de régression robustes. Nous les classons
en trois catégories représentées sur la figure 2.1 suivante et qui feront l’objet des trois
prochaines sections. Ces trois classes de méthodes sont : les méthodes déterministes, les
méthodes de vote, et les méthodes de régularisation. Pour clore le chapitre, nous discu-
terons de diverses techniques d’évaluation de la robustesse d’une méthode telles que le
point de cassure, la fonction d’influence et la courbe de biais.
2.1 Méthodes de régression déterministes
Les méthodes de régression que nous nommons déterministes utilisent la totalité des
données pour estimer les paramètres du modèle recherché. Elles emploient différentes
fonctions pertes qui leur garantissent une certaine robustesse.
2.1.1 Moindres modules
La régression des moindres modules est souvent appelée la L1-régression. Son estima-
tion θL1 de θ est définie comme le p-vecteur qui minimise la somme de toutes les valeurs
absolues des résidus :
θL1 = minb
QL1(θ) (2.1)
32

2.1. Méthodes de régression déterministes
Fig. 2.1 – Classification des méthodes de régression
où QL1(θ) =n∑
i=1
|ri| (2.2)
Contrairement à la méthode des moindres carrés, la L1-régression est robuste contre les
outliers dans la direction y. Cependant, elle reste très vulnérable face aux outliers suivant
la direction x.
2.1.2 Moindres carrés totaux
Dans la méthode des moindres carrés classique (équation 1.2), les erreurs sont définies
par la distance, au carré, séparant les réponses Yi et les estimations Yi, c’est à dire les
résidus au carré. Dans le cas de la régression pour les moindres carrés totaux, aussi appelée
régression par la distance orthogonale, la distance entre les observations et l’estimation
n’est plus mesurée suivant l’axe de la variable réponse Y , mais perpendiculairement au
modèle estimé. L’utilisation de cette méthode implique la linéarité du modèle recherché,
qui est une droite, un plan ou un hyperplan selon la dimension du problème.
33

Chapitre 2. Méthodes de régression robustes
2.1.3 X-estimateurs
On regroupe sous le sigle X-estimateurs une famille d’estimateurs comprenant : les
M-estimateurs, les W-estimateurs, les S-estimateurs, les R-estimateurs, etc.
M-estimateurs
Comme il a été vu dans le chapitre précédent, la méthode des moindres carrés n’est
pas robuste, aussi bien pour les outliers suivant y que suivant x. Cette non-robustesse
est due à la fonction objectif de la forme :∑n
i=1 r2i , qui augmente très rapidement avec le
résidu ri. Huber, en 1973, a introduit la notion de M-estimateur, dit estimateur du maxi-
mum de vraisemblance, afin de limiter l’influence des données érronées sur l’estimation.
Estimer θ par la méthode du maximum de vraisemblance, c’est proposer comme valeur de
θ celle qui rend maximale la vraisemblance, à savoir la probabilité d’observer les données
comme réalisation d’un échantillon suivant une certaine loi de probabilité. Pour calculer
le maximum de vraisemblance, il faut déterminer les valeurs pour lesquelles la dérivée de
la vraisemblance s’annule.
Il s’agit de la méthode la plus simple tant au niveau calculatoire que théorique. Elle
est encore très utilisée dans le domaine de l’analyse de données où la contamination
est principalement située dans le vecteur réponse Y . Au lieu d’utiliser la fonction perte
quadratique, comme dans les moindres carrés, à laquelle est associée une loi de probabilité
gaussienne, les estimateurs d’Huber du type M-estimateur minimisent une somme de
valeurs résiduelles calculées via une fonction perte c qui croît moins rapidement que la
quadratique :
θM = minθ
QM(θ) (2.3)
QM(θ) =n∑
i=1
c(ri) (2.4)
L’estimation optimale est déterminée en annulant les dérivées de la somme par rapport
aux p coefficients de θ, soit :∂c(ri)
∂θj
= ψ(ri)Xij (2.5)
n∑
i=1
ψ(ri)Xij = 0 ∀j = 1, . . . ,p (2.6)
où la fonction ψ est la dérivée de la fonction perte c. La M-estimation est obtenue en résol-
vant ce système de p équations nonlinéaires. Cependant, la solution n’est pas équivariante
34 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

2.1. Méthodes de régression déterministes
par rapport à l’echelle. En effet, si l’on multiplie les résidus par une valeur quelconque,
c’est à dire que l’on modifie l’echelle, la solution obtenue sera différente. On doit donc
standardiser les résidus à l’aide d’une estimation de l’écart type σ. Ainsi la solution peut
s’écrire :n∑
i=1
ψ(ri/σ)Xi = 0 (2.7)
Où l’écart type σ doit être estimé simultanément. Une des possibilités souvent employée
pour son estimation est d’utiliser un multiple de la médiane de la déviation absolue (notée
MAD pour median absolute deviation). Cette utilisation suppose implicitement que le taux
de contamination dû au bruit soit de 50%. La médiane de la déviation absolue est définie
ainsi :
MAD(Xi) = medi |Xi − medj(Xj)| (2.8)
Et donc l’estimateur de l’écart type s’écrit :
σ = β.MAD (2.9)
Où β est le facteur multiplicatif. La valeur utilisée communément pour β est 1.483, cette
valeur ajuste l’échelle pour une efficacité maximale lorsque les données proviennent d’une
distribution gaussienne [].
Différents M-estimateurs utilisant différentes fonctions pertes ont été proposées, le
tableau 2.1 présente les principales versions.
Dans le but de réduire l’influence des données contaminées, la fonction perte c doit être
choisie en accord avec la densité de probabilité qui définie la loi des erreurs de mesure. La
fonction c doit respecter certaines conditions. Elle doit être symétrique, positive avec un
minimum unique en zéro et avec une croissance moins rapide que la fonction quadratique.
Bien que les M-estimateurs soient plus robustes que la L1-régression ou les moindres
carrés en ce qui concerne les points aberrants verticaux, le point de cassure (notion expli-
citée dans le paragraphe 2.4.2) théorique des M-estimateurs est considéré nul. Ils restent
très vulnérables face à des points aberrants horizontaux. Afin d’améliorer leurs robustesses
contre ces erreurs, les W-estimateurs ont été introduits.
W-estimateurs
Les W-estimateurs, ou Generalized M-estimators, sont des M-estimateurs pondérés.
35

Chapitre 2. Méthodes de régression robustes
méthode fonction d’influence
L1-régression ψ(t) = sgn(r)
L2-régression ψ(t) = r
Huber minimax ψ(r) =
r si |r| < BB.sgn(r) si |r| ≥ B
Minimax descendant ψ(r) =
r si |r| < AB.sgn(r).tanh
[12B(C − |r|)
]si A ≤ |r| < C
0 autrement
Hampel ψ(r) =
r si |r| < AA.sgn(r) si A ≤ |r| < BC−|r|C−B
.A.sgn(r) si B ≤ |r| < C
0 autrement
Andrew ψ(r) =
sin(r) si − π ≤ |r| < π0 autrement
Tukey ψ(r) =
r(1 − ( r
C)2)2 si |r| < C
0 autrement
Tab. 2.1 – Exemples de fonctions d’influence utilisées dans les M-estimateurs
Chaque W-estimateur possède une fonction poids caractéristique, notée w(.), qui repré-
sente l’importance de chaque observation dans l’estimation de θ. L’estimation optimale
est déterminée en résolvant le système de p équations non-linéaires suivant :
n∑
i=1
w(Xi)ψ(ri/σ)Xij = 0 ∀j = 1, . . . ,p (2.10)
R-estimateurs
Dans cette approche, chaque résidu est pondéré par une fonction score basée sur le
36 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

2.1. Méthodes de régression déterministes
rang du résidu. Soit Ri le rang du résidu ri = Yi − Xiθ, l’objectif est alors de minimiser
suivant θ la somme des résidus pondérés par cette fonction score :
θR = minθ
QR(θ) (2.11)
QR(θ) =n∑
i=1
an(Ri)ri (2.12)
où la fonction score an(Ri) est monotone et satisfait :
n∑
i=1
an(Ri) = 0 (2.13)
Différentes fonctions scores ont été proposées, parmi lesquelles :
– la fonction score de Wilcoxon :
an(Ri) = Ri −n + 1
2(2.14)
– la fonction score de Van der waerden :
an(Ri) = Φ−1(Ri
n + 1) (2.15)
où Φ−1 est la fonction cumulative inverse d’une distribution normale.
– la fonction score médiane :
an(Ri) = sgn(Ri −n + 1
2) (2.16)
Un inconvénient majeur des R-estimateurs est qu’ils ne sont pas aisément optimisables. De
plus, la définition de la fonction score nécessite implicitement une connaissance a priori du
taux de contamination des données. Enfin, les R-estimateurs ne sont pas robustes contre
les outliers dans la direction x. En revanche, un avantage important des R-estimateurs
comparés aux M-estimateurs est qu’ils sont automatiquement équivariants par rapport à
l’echelle, aucune estimation de l’écart type n’est nécessaire.
S-estimateurs
Les S-estimateurs sont une autre classe de M-estimateurs automatiquement équiva-
37

Chapitre 2. Méthodes de régression robustes
riants. Ils sont définis par la minimisation de la dispersion des résidus :
θS = minθ
QS(θ) (2.17)
QS(θ) = s(r1, . . . ,rn) (2.18)
où la dispersion s(r1, . . . ,rn) est définie comme la solution de :
1
n
n∑
i=1
c(ri
s
)= K (2.19)
Avec c la fonction perte et K souvent posé égal à EΦ[c], Φ étant la distribution normale
standard.
Les S-estimateurs sont coûteux au niveau calculatoire car ils sont résolus de manière
itérative à partir d’une équation non-linéaire pour chaque essai de θ.
2.2 Méthodes de vote
Nous nommons méthodes de vote toutes méthodes n’utilisant qu’une partie des don-
nées. Ces méthodes utilisent souvent une technique de type Monte Carlo pour obtenir
des sous-ensembles aléatoires de données. Les méthodes résolvent ainsi le problème de
la régression sur ces différents sous-ensembles et sélectionnent la meilleure des solutions
obtenues à l’aide d’une fonction objectif, ou d’accumulateurs dans le cas de la transformée
de Hough.
2.2.1 Moindre médiane des carrés
La moindre médiane des carrés (LMedS pour Least Median of Squares en anglais),
aussi appelée la régression médiane, est une des premières méthodes de régression de type
robuste apparue (Rousseeuw et Leroy, 1987) [RL87]. Elle se base sur les hypothèses
suivantes :
– le modèle à estimer doit occuper la majorité des données, c’est à dire qu’au moins
50% des données doivent appartenir au modèle recherché,
– la solution correcte devrait correspondre à la solution obtenue par la moindre mé-
diane des carrés. Or, ce critère n’est pas toujours vérifié, par exemple lorsque les don-
nées contiennent des structures multiples ou encore lorsque la variance des "bonnes"
observations est importante.
38 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

2.2. Méthodes de vote
L’estimation de la moindre médiane des carrés est définie comme le p-vecteur qui minimise
la kème valeur des résidus au carré ordonnés :
θLMS = arg minθ
QLMS(θ) (2.20)
où QLMS(θ) = r2(k) (2.21)
Les valeurs résiduelles au carré r2i = (Yi − Xiθ)
2 ont été classées par ordre croissant :
r2(1) ≤ r2
(2) ≤ · · · ≤ r2(n) (2.22)
Le paramètre k est défini dans l’intervalle :
n
2+ 1 ≤ k ≤ 3n + p + 1
4(2.23)
Les avantages de l’estimation de la médiane des carrés sont :
– elle possède un point de cassure élevé, théoriquement de 50%,
– elle dispose d’une très bonne robustesse globale.
Cependant, l’efficacité relative de la méthode est faible lorsqu’un bruit de type gaussien
est présent dans les données. En fait, la méthode souffre d’un taux de convergence très
faible, de l’ordre de n− 1
3 , à comparer au taux de convergence des M-estimateurs qui est
de l’ordre de n− 1
2 .
Dans la pratique, on utilise une approximation de la moindre médiane des carrés
basée sur une sélection aléatoire d’observations afin de réduire le temps de calcul à une
valeur "raisonnable". Une technique de type Monte Carlo est employée pour effectuer les
tirages aléatoires de données, c’est pourquoi nous classons cette méthode LMedS dans
les méthodes de vote. On retrouvera l’utilisation de cette technique de tirages aléatoires
dans l’algorithme RANSAC (paragraphe 2.2.4), ou encore dans la méthode vbQMDPE
(paragraphe 2.2.5).
2.2.2 Moindres carrés tronqués
L’estimation des moindres carrés tronqués (LTS pour Least Trimmed Squares), a été
introduite par Rousseeuw [RL87] afin d’améliorer la faible efficacité dont souffre la
moindre médiane des carrés. Cette méthode est définie comme le p-vecteur qui minimise
39

Chapitre 2. Méthodes de régression robustes
la somme des k plus petites valeurs résiduelles au carré :
θLTS = arg minθ
QLTS(θ) (2.24)
où QLTS(θ) =k∑
i=1
r2(i) (2.25)
Les valeurs résiduelles au carré r2i = (Yi − Xiθ)
2 ont été classées par ordre croissant :
r2(1) ≤ r2
(2) ≤ · · · ≤ r2(n) (2.26)
Le paramètre k est défini dans l’intervalle :
n
2+ 1 ≤ k ≤ 3n + p + 1
4(2.27)
L’estimation des moindres carrés tronqués possède également un point de cassure élevé,
théoriquement égal à n−kn
. Elle surclasse l’estimation de la moindre médiane des car-
rés, ainsi que les M-estimateurs, grâce à deux avantages : une fonction objective lissée
(moins sensible aux effets locaux) et une meilleure efficacité statistique (car la méthode
des moindres carrés tronqués est asymptotiquement normale).
D’un point de vue pratique, l’implémentation des moindres carrés tronqués utilise
également un échantillonage aléatoire des données. Pour cela, deux méthodes sont com-
munément employées pour générer un k-sous-ensemble :
– soit on génère aléatoirement un k-sous-ensemble à partir des n données, le nombre
de k-sous-ensembles augmentant rapidement avec le nombre d’observations,
– soit on utilise une technique de type Monte Carlo pour générer un p-sous-ensemble
qui servira à estimer les paramètres du modèle, calculer et classer les résidus, et
récupérer le k-sous-ensemble.
Bien que la première méthode soit plus simple, le k-sous-ensemble ainsi généré peut conte-
nir beaucoup de données aberrantes. En fait, les chances d’obtenir un k-sous-ensemble
"propre" avec cette méthode tendent vers zéro lorsque le taux de contamination aug-
mente. À contrario, il est plus facile d’obtenir un p-sous-ensemble "propre", la seconde
méthode fournit plus de "bons" sous-ensembles initiaux car elle utilise un nombre minimal
d’observations. Un algorithme, nommé FAST-LTS, a été développé par Rousseeuw et
Van-Driessen en 1998 [RL87], celui-ci permet de réduire le temps de calcul et fournit
une meilleure précision que l’algorithme original des moindres carrés tronqués.
40 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

2.2. Méthodes de vote
Une version modifiée des moindres carrés tronqués, nommée PTS pour Penalised Trim-
med Squares estimator, a récemment été développé par Zioutas [ZAP07]. Comme il vient
d’être vu, la méthode des moindres carrés tronqués cherche à minimiser la somme des h
plus petits résidus, avec la valeur k définie a priori. La méthode de Zioutas ajoute une
somme de n − k termes pénalisants dans la fonction objective. Celle-ci s’écrit alors :
θPTS = arg minθ
QPTS(θ) (2.28)
où QPTS(θ) =k∑
i=1
r2(i) +
n∑
i=k+1
(Cσ)2 (2.29)
où la taille k du sous-ensemble "propre" est inconnue, σ est une estimation robuste de la
variance des résidus, et la valeur (Cσ)2 peut être interprétée comme un terme pénalisant
pour enlever une observation dans le calcul de la solution, C étant défini à priori. En
diminuant le terme de pénalité, le PTS converge vers le LTS : d’après l’auteur, sous des
conditions gaussiennes et en fixant C à environ 0.7, la solution du PTS tend vers celle du
LTS.
L’estimation du PTS peut être définie telle que :
θPTS = arg minθ
QPTS(θ) (2.30)
où QPTS(θ) =n∑
i=1
cCσ(ri) (2.31)
où cCσ est la fonction perte définie par :
cCσ(t) =
r2i si ri < Cσ
√1 − Hii
(Cσ)2 si ri ≥ Cσ√
1 − Hii
(2.32)
Pour les résidus importants, l’influence est rapidement bornée par la valeur fixée (Cσ)2,
les observations associées peuvent être considérées comme effacées car elles n’influencent
plus indéfiniment la solution de la régression.
2.2.3 Transformée de Hough
La transformée de Hough a été développée par Hough en 1962 [Hou62] afin de dé-
tecter des courbes simples telles que des droites ou des cercles, il s’agit d’une technique
41
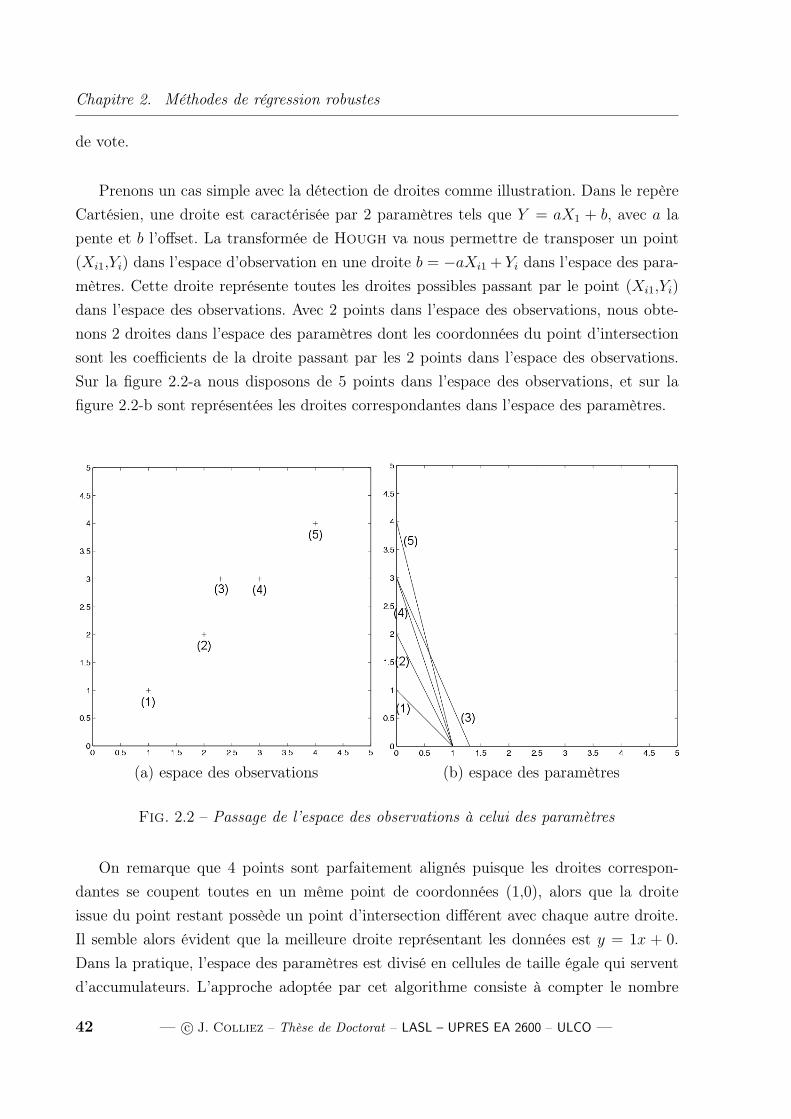
Chapitre 2. Méthodes de régression robustes
de vote.
Prenons un cas simple avec la détection de droites comme illustration. Dans le repère
Cartésien, une droite est caractérisée par 2 paramètres tels que Y = aX1 + b, avec a la
pente et b l’offset. La transformée de Hough va nous permettre de transposer un point
(Xi1,Yi) dans l’espace d’observation en une droite b = −aXi1 + Yi dans l’espace des para-
mètres. Cette droite représente toutes les droites possibles passant par le point (Xi1,Yi)
dans l’espace des observations. Avec 2 points dans l’espace des observations, nous obte-
nons 2 droites dans l’espace des paramètres dont les coordonnées du point d’intersection
sont les coefficients de la droite passant par les 2 points dans l’espace des observations.
Sur la figure 2.2-a nous disposons de 5 points dans l’espace des observations, et sur la
figure 2.2-b sont représentées les droites correspondantes dans l’espace des paramètres.
(a) espace des observations (b) espace des paramètres
Fig. 2.2 – Passage de l’espace des observations à celui des paramètres
On remarque que 4 points sont parfaitement alignés puisque les droites correspon-
dantes se coupent toutes en un même point de coordonnées (1,0), alors que la droite
issue du point restant possède un point d’intersection différent avec chaque autre droite.
Il semble alors évident que la meilleure droite représentant les données est y = 1x + 0.
Dans la pratique, l’espace des paramètres est divisé en cellules de taille égale qui servent
d’accumulateurs. L’approche adoptée par cet algorithme consiste à compter le nombre
42 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

2.2. Méthodes de vote
d’intersections réparties dans chaque cellule de l’espace des paramètres afin de déterminer
quelle cellule, et donc quels paramètres, est la plus représentative des observations. On
utilise d’ailleurs généralement le système de coordonnées polaires plutôt que cartésiennes
pour avoir un nombre fini de cellules dans l’espace des paramètres.
Bien que la transformée de Hough fournisse de bons résultats même en présence de
données aberrantes, elle souffre d’un besoin important tant en capacité de stockage qu’en
capacité calculatoire. Par ailleurs, la précision des paramètres dépend de la taille des
cellules dans l’espace des paramètres. Or, améliorer la présicion en diminuant la taille des
cellules provoquera une augmentation du temps de calcul. On notera tout de même que
la transformée de Hough peut être appliquée avec succès pour l’estimation de structures
multiples. L’analyse de l’espace des paramètres au lieu de l’espace des observations permet
de retrouver plusieurs modèles représentant des données qui s’accumuleront dans leurs
cellules respectives.
2.2.4 Approche du RANSAC
L’approche du RANSAC, pour Random Sample Consensus, se base sur un certain
nombre N de sélections aléatoires d’observations pour rechercher la meilleure estimation.
Pour déterminer N , on doit posséder une connaissance a priori sur le taux de conta-
mination, noté 1 − w, ou tout du moins une borne supérieure. Si on cherche N pour
une probabilité P (fixée par l’utilisateur) d’avoir trouvé un sous-ensemble sans donnée
aberrante, ce qui nous donne :
N =log(1 − P )
log(1 − wm)(2.33)
où m est le nombre d’observations composant un sous-ensemble.
Afin d’optimiser le temps de calcul, on sélectionne un sous-ensemble de l’ensemble de
données contenant le nombre minimal d’observations néssecaire à l’estimation des para-
mètres du modèle, c’est à dire que m doit être égal au nombre de paramètres p du modèle.
Le modèle est ensuite estimé pour un sous-ensemble d’observations. À partir de cette es-
timation, on calcule le résidu pour chaque observation. Toutes les observations, dont le
résidu est inférieur à un seuil de tolérance prédéfini, formeront l’ensemble de consensus
du modèle.
Visuellement, on conserve les observations comprises dans une marge autour du modèle
estimé. Si le nombre d’observations formant l’ensemble de consensus est supérieur à une va-
leur prédéfinie, on suppose que l’ensemble de consensus contient suffisamment de "bonnes"
43

Chapitre 2. Méthodes de régression robustes
données pour obtenir une bonne estimation. En revanche, si le nombre d’observations
dans l’ensemble de consensus est trop faible, on recommence la procédure avec un nou-
veau sous-ensemble. Il n’est donc pas nécessaire de faire l’estimation du modèle sur tous
les sous-ensembles : aussitôt qu’un sous-ensemble fournit un ensemble de consensus suffi-
sant, on utilise cet ensemble pour affiner l’estimation sur toutes les données de consensus.
On peut employer tous les estimateurs possibles, en particulier des estimateurs peu ro-
bustes même si cela s’avère sous-optimal, car l’ensemble de consensus est sensé contenir
uniquement de "bonnes" observations.
2.2.5 vbQMDPE : approche basée sur la Meanshift
Hanzi WANG et David SUTER [WS03] ont présenté un nouvel estimateur robuste
basé sur leurs travaux antérieurs. Au lieu d’utiliser une largeur de fenêtre fixe, ce nouvel
estimateur, appelé variable bandwidth Quick Maximum Density Power Estimator, utilise
les données pour mettre à jour cette largeur de fenêtre itérativement. Les auteurs affirment
que cette méthode semble rarement donner une mauvaise estimation pour un taux d’out-
liers inférieur à 80%.
Le point de départ de cette approche est basé sur deux hypothèses :
– les inliers ont une distribution de type gaussienne,
– les inliers représentent une majorité relative des données.
La première hypothèse est courante et très souvent rencontrée dans les méthodes de régres-
sion. En revanche, la seconde n’est que rarement utilisée : en effet, les estimateurs robustes
traditionnels (LMS, LTS, etc.) supposent que les inliers représentent une majorité abso-
lue des données, c’est à dire qu’ils occupent au moins 50% des observations. Alors que
l’hypothèse de majorité relative impose simplement que les inliers forment la structure do-
minante dans l’ensemble des observations, même si elle occupe moins de 50% des données.
De la même façon que pour l’approche RANSAC, on va sélectionner aléatoirement des
sous-ensembles de taille minimale dans l’ensemble de données afin de faire des estimations
grossières du modèle. Une partie cruciale de l’algorithme est l’utilisation de la procédure
du "meanshift", afin de repérer le maximum local de la densité dans l’espace des résidus.
La procédure du meanshift est utilisée itérativement, avec la position initiale au zéro de
l’espace des résidus et la largeur de la fenêtre h, afin de trouver le centre Xc de la fenêtre
de convergence.
44 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

2.2. Méthodes de vote
Lorsqu’un modèle est ajusté aux données :
– le centre Xc de la fenêtre de convergence dans l’espace des résidus doit être le plus
proche possible de zéro,
– et la densité de probabilité f(Xc) au point Xc doit être la plus élevée possible.
Ainsi est définie la fonction objectif ψ telle que :
ψ =(f(Xc))
a
exp(Xc)(2.34)
Où a est un facteur d’ajustement entre l’infuence relative de la densité de probabilité et
la valeur résiduelle du point correspondant au centre de la fenêtre de convergence (expé-
rimentalement réglé à 2.0).
La densité de probabilité peut être estimée par l’estimateur de Parzen [Par62] :
f(x) =1
nhd
n∑
i=1
K(x − Xi
h) (2.35)
Où d est la dimension de l’espace Euclidien, n le nombre de données et h la largeur de la
bande passante. La fonction noyau d’Epanechnikov est utilisée :
Ke(x) =
12c−1d (d + 2)(1 − xT x) si xT x < 1
0 autrement(2.36)
Où cd est le volume de la sphère unité de dimension d, par exemple : c1 = 2, c2 = π,
c3 = 4π/3.
Une question cruciale dans l’estimation non-paramétrique de la densité et dans la
méthode du meanshift est comment choisir h la largeur de la fenêtre. La méthode employée
vient de Wand et Jones [WJ95] :
h =
[243R(K)
35u2(K)2n
] 1
5
s (2.37)
Où R(K) =∫ 1
−1K(ζ)2dζ et u2(K) =
∫ 1
−1ζ2K(ζ)dζ, s étant l’écart type de l’échantillon.
Un estimateur robuste de l’échelle médiane est donné par Rousseeuw et Leroy [RL87] :
s = 1.4826medixi (2.38)
45

Chapitre 2. Méthodes de régression robustes
2.3 Méthodes de régularisation
La régularisation est une technique mathématique développée par Andre Tikhonov
[TA77]. Il travaillait sur les solutions de problèmes inverses mal posés, des problèmes
mathématiques pour lesquels aucune solution unique n’existe à cause d’un manque d’in-
formations. Dans le domaine de l’apprentissage des machines, la régularisation consiste à
prévenir le sur-apprentissage des données par un modèle.
2.3.1 Régression Ridge
La régression ridge a été présentée en 1970 par Hoerl et Kennard [HK70], il s’agit
d’une méthode de résolution des problèmes de régression linéaire mal conditionnés. Ces
problèmes souffrent, dans le calcul de la matrice inverse (XT X)−1, d’instabilité numérique
en présence de bruit dans les données.
Comme il a été vu précédemment, la régression par la méthode des moindres carrés
consiste à faire le calcul suivant :
θ = (XT X)−1XT Y (2.39)
Le problème, c’est que parfois la matrice XT X est singulière : l’estimateur obtenu a
alors une variance très élevée. On peut contourner ce problème de singularité en ajoutant
une constante à toutes les valeurs propres de la matrice XT X, et en calculant :
θ = (XT X + kI)−1XT Y (2.40)
Où I est la matrice identité et k est un paramètre de régularisation positif. Nous devons
résoudre un système de p équations linéaires à p inconnus. Cette solution permet de ré-
duire la variance, en revanche l’estimateur obtenu est biaisé.
On peut aussi présenter la regression ridge comme une régression pénalisée, au lieu de
chercher θ qui minimise l’expression :
n∑
i=1
(Yi − Xiθ)2 (2.41)
46 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

2.3. Méthodes de régularisation
On cherchera plutôt à minimiser :
n∑
i=1
(Yi − Xiθ)2 + k
p∑
j=1
θ2j (2.42)
L’ajout du terme pénalisant permet d’éviter que les coefficients de θ soient trop grands.
Le paramètre k règle le compromis entre l’attache aux données et la pénalité. Une petite
valeur de k signifie que la solution s’ajustera très près des données sans causer de pénalités
importantes. Dans le cas contraire, une forte valeur induit que l’ajustement sera sacrifié
s’il requiert des coefficients importants. Le biais ainsi introduit dans l’estimateur favorise
les solutions usant de petits coefficients, l’effet sera de lisser la solution alors que des
coefficients importants rendent la solution plus "variable".
2.3.2 Régression par machines à vecteurs supports
Le sigle SVR signifie Support Vector Regression ou régression par les machines à vec-
teurs supports. Il s’agit de la méthode de régression que nous avons choisie dans nos
travaux. Cette méthode étant plus détaillée dans le chapitre suivant afin d’expliquer les
modifications que nous y avons apportées, nous nous contenterons ici d’une présentation
succincte.
L’objectif de la régression par les machines à vecteurs supports est de trouver la
fonction f(X) qui cause, au plus, une erreur résiduelle de ε entre les estimations Yi et les
cibles Yi. Dans le même temps, un terme de régularisation tend à rendre aussi "plate" que
possible la solution. La méthode utilise la fonction perte d’insensibilité ε pour le calcul
des résidus. Voici la formulation primale du problème :
minw
L(w,ξi,ξ∗i ) =
1
2‖w‖2 + C.
n∑
i=1
(ξi + ξ∗i ) (2.43)
Sous les contraintes :
yi− < w,xi > −b ≤ ε + ξi
< w,xi > +b − yi ≤ ε + ξ∗i
ξi,ξ∗i ≥ 0
∀ i ε 1, . . . ,n (2.44)
On y retrouve le terme d’optimisation 12‖w‖2 et le paramètre C qui règle le compromis.
Les variables ξi et ξ∗i sont appelés variables ressorts, elles sont positives et définies telles
47

Chapitre 2. Méthodes de régression robustes
que ξi = yi− < w,xi > −b − ε et ξ∗i =< w,xi > +b − yi − ε. Nous devons donc résoudre
un problème d’optimisation convexe sous contraintes, cette résolution se fera à l’aide de
la programmation quadratique.
2.4 Évaluation de la robustesse
2.4.1 Définition
D’une façon générale, la robustesse est définie comme la capacité d’un système à
maintenir ses performances malgré des changements dans les conditions d’utilisation ou
la présence d’incertitudes liées à ses paramètres ou à ses composants. On ne cherchera pas
à supprimer les causes d’une variabilité mais plutôt à en minimiser les effets. De fait, la
robustesse implique une insensibilité aux écarts dûs à une non-conformité des hypothèses
sous-jacentes au problème traité. Les méthodes robustes garantissent de bons résultats
pour une grande collection d’hypothèses sans pour autant avoir les meilleurs résultats
pour une en particulier.
2.4.2 Point de cassure
Le point de cassure est aussi appelé point d’effondrement ou de rupture dans la litté-
rature. Tout ensemble de données réelles comporte une part plus ou moins importante de
données corrompues. Le rapport du nombre de ces données corrompues sur le nombre de
données totales, exprimé en pourcentage, est nommé le taux de données corrompues, ou
plus simplement le pourcentage d’erreurs. Le point d’éffondrement représente la borne de
ce taux de données corrompues au-delà de laquelle le changement du résultat de l’estima-
teur est illimité. C’est à dire qu’une fois le point d’éffondrement dépassé, la modification
sans restriction des valeurs des données corrompues implique un changement illimité du
résultat de l’estimation. Ce pourcentage d’erreur accepté au maximum nous donne un
indice sur la résistance d’une méthode d’estimation.
Soit l’ensemble Z représentant un ensemble de n données tel que :
Z = (X11, . . . ,X1p,Y1) , . . . , (Xn1, . . . ,Xnp,Yn) (2.45)
Considèrons maintenant tous les ensembles corrompus possibles, notés Z ′, obtenus en
remplacant m données originales par des valeurs arbitraires, et posons le biais maximum
48 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

2.4. Évaluation de la robustesse
causé par une contamination tel que :
biais(m,µ,Z) = supZ′ ‖µ(Z ′) − µ(Z)‖ (2.46)
Où µ est une fonctionnelle telle que la moyenne, la médiane ou une méthode de régression
quelconque.
Si la valeur de ce biais maximum est infinie, cela signifie que m erreurs peuvent avoir
un effet arbitraire important sur la fonctionnelle µ, on dit que celle-ci "s’éffondre". Le
seuil minimal de corruption de la fonctionnelle µ sur l’ensemble Z est appelé le point
d’éffondrement, et est défini tel que :
PEn(µ,Z) = minm
ntel que biais(m,µ,Z) est infini
(2.47)
Formalisons ce critère et prenons 2 exemples : la moyenne et la médiane.
Dans le cas du calcul de la moyenne d’un ensemble de données, si la valeur d’une seule
donnée est modifiée sans limite, le résultat de la moyenne sera lui aussi modifié sans limite.
La moyenne n’est donc pas un processus d’estimation résistant, son point d’éffondrement
vaut :
PEn(moyenne) =1
n
Il tend vers 0 lorsque le nombre de données tend vers l’infini.
En revanche en utilisant le calcul de la médiane sur ces mêmes données, le résultat
pourra certes varier selon la valeur de la donnée erreur mais cette modification se fera
de façon limitée, peu importe la valeur de l’erreur. La médiane est donc un processus
d’estimation résistant, son point d’éffondrement vaut :
PEn(mediane) =
12− 1
nsi n est pair
12− 1
2nsi n est impair
Il tend vers 12
lorsque le nombre de données tend vers l’infini.
Pour qu’un estimateur soit considéré comme résistant, il faut que son point d’éffon-
drement soit strictement supérieur à 0%. Selon Rappacchi [], le point d’éffondrement d’un
estimateur traitant les données de façon uniforme ne peut dépasser les 50% ; cependant
il existe des estimateurs ayant un point d’éffondrement supérieur à ces 50%, citons par
exemple le vbQMDPE.
49
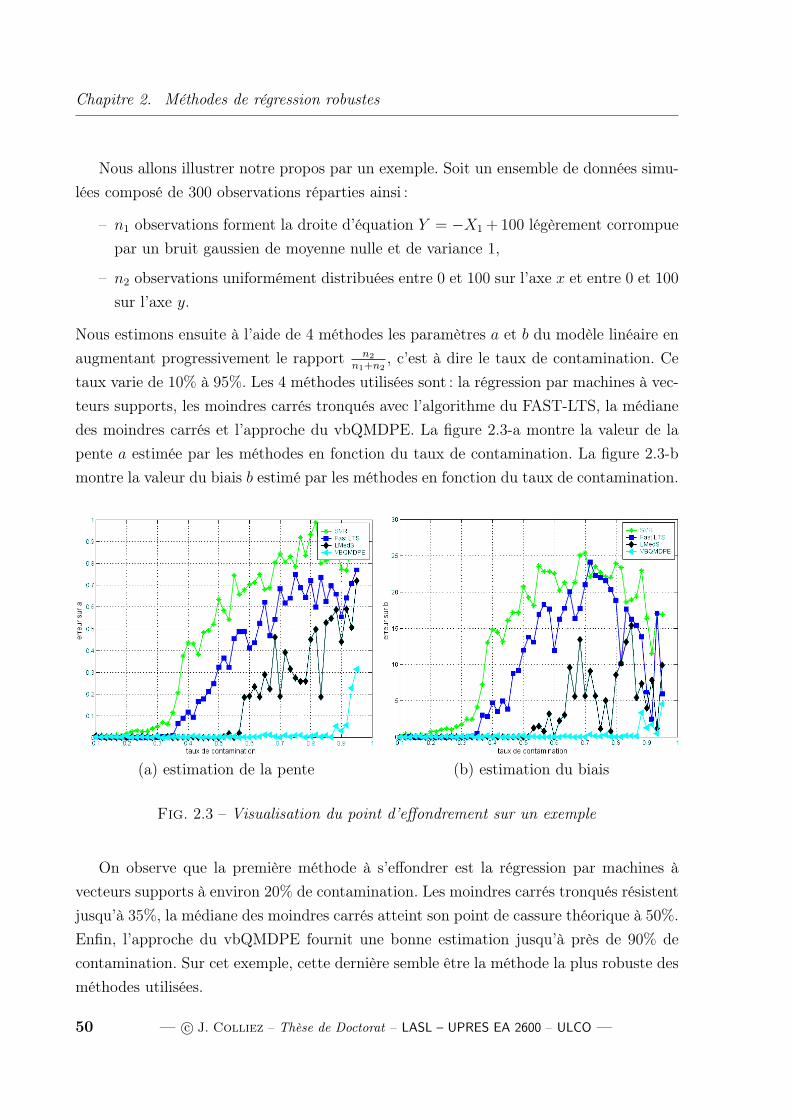
Chapitre 2. Méthodes de régression robustes
Nous allons illustrer notre propos par un exemple. Soit un ensemble de données simu-
lées composé de 300 observations réparties ainsi :
– n1 observations forment la droite d’équation Y = −X1 + 100 légèrement corrompue
par un bruit gaussien de moyenne nulle et de variance 1,
– n2 observations uniformément distribuées entre 0 et 100 sur l’axe x et entre 0 et 100
sur l’axe y.
Nous estimons ensuite à l’aide de 4 méthodes les paramètres a et b du modèle linéaire en
augmentant progressivement le rapport n2
n1+n2
, c’est à dire le taux de contamination. Ce
taux varie de 10% à 95%. Les 4 méthodes utilisées sont : la régression par machines à vec-
teurs supports, les moindres carrés tronqués avec l’algorithme du FAST-LTS, la médiane
des moindres carrés et l’approche du vbQMDPE. La figure 2.3-a montre la valeur de la
pente a estimée par les méthodes en fonction du taux de contamination. La figure 2.3-b
montre la valeur du biais b estimé par les méthodes en fonction du taux de contamination.
(a) estimation de la pente (b) estimation du biais
Fig. 2.3 – Visualisation du point d’effondrement sur un exemple
On observe que la première méthode à s’effondrer est la régression par machines à
vecteurs supports à environ 20% de contamination. Les moindres carrés tronqués résistent
jusqu’à 35%, la médiane des moindres carrés atteint son point de cassure théorique à 50%.
Enfin, l’approche du vbQMDPE fournit une bonne estimation jusqu’à près de 90% de
contamination. Sur cet exemple, cette dernière semble être la méthode la plus robuste des
méthodes utilisées.
50 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

2.4. Évaluation de la robustesse
2.4.3 Fonction d’influence
Alors que le point d’éffondrement permet d’obtenir une mesure globale de fiabilité, la
fonction d’influence (FI), introduite par Hampel [RRRS86], mesure l’effet de perturba-
tions infinitésimales sur l’estimateur. Il s’agit principalement d’un outil heuristique avec
une part importante d’interprétation intuitive. On cherche à répondre à la question : que
se passe-t-il si nous ajoutons une donnée supplémentaire de valeur z dans un très large
ensemble de données?
La fonction d’influence d’un estimateur µ à une distribution F est donnée par :
FI(z,F,µ) = limη→0
µ((1 − η)F + η∆z) − µ(F )
η(2.48)
aux points z de l’espace des observations où la limite existe. Notons que µ(F ) représente
la valeur de l’estimateur pour la distribution originale F , et que µ((1 − η)F + η∆z)
représente la valeur de l’estimateur pour la distribution légérement perturbée (1− η)F +
ηδz. ∆z représente la fonction de distribution cummulative qui place toute la masse au
point z. Ainsi, le numérateur capture la différence entre la valeur de l’estimateur pour
la distribution orginale et la valeur de ce même estimateur pour une version légérement
perturbée de la distribution originale. Le dénominateur prend soin de standardiser à
l’aide de la fraction de contamination. L’importance de la fonction d’influence est liée
à son interprétation heuristique : elle décrit les effets d’une contamination infinitésimale
au point z de l’estimée, standardisée par la masse de la contamination. On pourrait dire
qu’elle donne une image du comportement infinitésimal de la valeur asymptotique, donc
qu’elle mesure le biais asymptotique causé par la contamination des données. Elle fournit
une approximation linéaire de l’estimateur pour telle ou telle distribution contaminée :
µ((1 − η)F + η∆z) ≈ µ(F ) + ηFI(z,F,T ) (2.49)
Dans le cas d’un travail sur un nombre fini d’observations, nous pouvons utiliser la forme
discrète de la fonction d’influence, nommée la courbe de sensibilité (CS) :
CS(z) =µ(n−1
nFn + 1
n∆z) − µ(Fn)
1/n≈ FI(z,F,µ) (2.50)
où Fn est la distribution empirique générée par les observations
Z = z1, . . . ,zn = (x11, . . . ,x1p), . . . ,(xn1, . . . ,xnp). Si nous remplaçons une observation par
51

Chapitre 2. Méthodes de régression robustes
un outlier z, nous trouvons :
µ(z1, . . . ,zn−1,z) = µ(Fn) +1
nCS(z) (2.51)
De même, il est possible de remplacer une petite fraction η = m/n des observations :
µ(z1, . . . ,zn−1,z) ≈ µ(Fn) +m
nFI(z,F,µ) (2.52)
Le point d’éffondrement nous fournit la borne supérieure pour la fraction d’outliers.
Tous les estimateurs possèdent un point d’éffondrement mais pas nécessairement une
fonction d’influence. Pour les estimateurs asymptotiquement normaux
√n(µn − µ(F )) ∼= N(0,V (µ,F )) (2.53)
où la variance asymptotique est reliée à la fonction d’influence à travers :
V (µ,F ) =
∫FI(z,F,µ)2dF (y) (2.54)
Des exemples d’estimateurs asymptotiquement normaux sont les L-, R- et M-estimateurs.
mesures de robustesse dérivées de la fonction d’influence
Du point de vue de la robustesse, il y a au moins trois valeurs importantes issues de
la fonction d’influence : la sensibilité aux grosses erreurs, la sensibilité au décalage local
et le point de rejet.
sensibilité aux grosses erreurs : elle est définie pour l’estimateur µ à la distribution
F par :
γ∗(F,µ) = supz
|FI(z,F,µ)|
Cette mesure est prise sur tous les z où FI(z,F,µ) existe. La sensibilité aux grosses
erreurs mesure la mauvaise influence (approximative) qu’une petite portion de conta-
mination de taille fixée peut avoir sur la valeur de l’estimateur. En fait, elle peut
être vue comme une borne supérieure du biais asymptotique standardisé. Il est
souhaitable que γ∗(F,µ) soit finie, au quel cas l’estimateur µ est dit B-robuste à
la distribution F [?], la lettre B venant du mot "biais". Typiquement, placer une
borne sur γ∗ est la première étape dans la robustification d’un estimateur.
52 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

2.5. Conclusion
sensibilité au décalage local : elle représente l’effet mesurable sur l’estimateur lorsque
quelques valeurs sont déplacées légèrement. Intuitivement, l’effet de légèrement dé-
caler une observation du point z à un point du voisinage y peut être mesuré par la
différence FI(y,F,µ) − FI(z,F,µ), parce qu’une observation a été ajoutée en y et
une autre retirée en z. La sensibilité au décalage local fournit donc une mesure de
l’effet néfaste d’une "agitation" autour de z telle que :
γ∗ = supz 6=y
1
|y − z| |FI(y,F,µ) − FI(z,F,µ)|
point de rejet : Dans le cadre d’une distribution F symétrique centrée en zero, le point
de rejet se définit par :
ρ∗ = inf r > 0; FI(z,F,µ) = 0 lorsque |z| > r
Toutes les observations plus lointaines que ρ∗ sont rejetées complètement. Il est donc
souhaitable que ρ∗ soit finie.
2.4.4 Courbe de biais
Ce paragraphe présente le changement maximum (absolu) du résultat d’un estimateur
obtenu en modifiant arbitrairement une fraction des observations originales. La courbe de
biais trace le changement maximum par rapport à la fraction des observations altérées.
Le principal avantage de cette courbe est qu’elle comprend les informations obtenues
par le point d’éffondrement. En effet, celui-ci nous fournit la fraction de contamination
maximale qu’un estimateur peut tolérer ; alors que la courbe de biais nous représente
le biais maximum d’un estimateur en fonction de la fraction de contamination. D’après
Hampel [RRRS86], la courbe de biais est donnée par :
supG |µ((1 − η)F + ηG) − µ(F )| (2.55)
Où G est une distribution arbitraire.
2.5 Conclusion
Nous venons de parcourir les trois familles de méthodes de régression robustes, nous
avons présenté les plus connues mais aussi de nouvelles approches. Nous avons vu qu’il
existe des outils pour quantifier la robustesse d’une méthode de régression afin de la com-
53

Chapitre 2. Méthodes de régression robustes
parer aux autres. Dans nos travaux, nous avons uniquement utilisé le point d’effondrement
comme mesure de la robustesse pour sa facilité de mise en oeuvre. Le tableau 2.2 fait le
rappel des points d’effondrements, théoriques ou expérimentaux, de différentes méthodes
présentées dans ce chapitre.
méthodes d’estimation point d’effondrement
Moindres carrés ≈ 0%M-estimateurs ≈ 0%
Moindres carrés tronqués ≈ 50%Médiane des moindres carrés ≈ 50%
Régression par machines à vecteurs supports ≈ 20%vbQMDPE ≈ 80%
Tab. 2.2 – Récapitulatif des points d’effondrements de différentes méthodes
Dans nos travaux sur le suivi d’objets en mouvement dans les séquences d’images, nous
avons choisi d’utiliser la régression par les machines à vecteurs supports. Cette méthode
possède l’avantage d’être utilisable dans les cas linéaires comme non-linéaires grâce aux
fonctions noyaux. De plus, elle offre une classification des données comme outliers, ou
non-outliers, à l’aide de la fonction perte linéaire d’insensibilité ε. En revanche, cette
méthode possède un point d’effondrement relativement faible, c’est pourquoi nous allons
tenter d’améliorer la méthode pour gagner en robustesse. Le prochain chapitre présentera
dans le détail la méthode de régression par les machines à vecteurs supports, ainsi que les
modifications que nous y avons apportées.
54 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

Chapitre 3
Régression par les machines à vecteurs
supports et modifications
LA régression par les machines à vecteurs supports (SVR pour Support Vector Regres-
sion) est une extension des machines à vecteurs supports développées par l’équipe de
VAPNIK [Vap95]. Le but de cette approche est de déterminer l’hyperplan optimal repré-
sentant le jeu de données. Cet hyperplan doit interpoler les observations avec une certaine
marge ε, marge définie par la fonction perte d’insensibilité ε. Les principaux avantages de
cette approche sont : sa robustesse contre le bruit et les erreurs, ainsi que la possibilité de
son utilisation dans les cas non-linéaires grâce aux fonctions noyaux.
3.1 Méthode standard
Par soucis de familiarité avec le formalisme des machines à vecteurs supports, nous
allons en adopter les notations. Cela induit quelques changements avec les notations uti-
lisées précédemment dans ce manuscrit. Le produit scalaire sera noté < ...,... > et les
paramètres du mouvement w à la place de θ.
3.1.1 Idée de base : Cas linéaire
Soit un ensemble de données (x1,y1) , . . . , (xn,yn) ⊂ χ, où χ représente l’espace des
données. Dans la régression par vecteurs supports, notre objectif est de trouver la fonction
f(x) qui possède, au plus, une déviation de ε par rapport aux cibles yi de toutes les don-
nées de l’ensemble, et dans le même temps, qui soit aussi "plate" que possible. En d’autres
termes, nous ne ferons pas attention aux erreurs tant que celles-ci seront inférieures à ε,
mais nous n’accepterons aucune déviation qui lui soit supérieure.
55

Chapitre 3. Régression par les machines à vecteurs supports et modifications
Pour des raisons pédagogiques, nous commencerons par décrire le cas des fonctions
linéaires f , prises sous la forme :
f(x) =< w,x > +b avec w ∈ χ,b ∈ < (3.1)
Où 〈.,.〉 représente le produit scalaire dans χ. La platitude dans le cas linéaire signifie que
l’on cherche le plus petit w. La façon la plus simple de s’en assurer est d’utiliser la norme
Euclidienne au carré, c’est à dire ‖w‖2. Formellement, nous pouvons écrire ce problème
comme un problème d’optimisation convexe présenté ci-dessous dans sa forme primale :
minimiser 12‖w‖2
sous les contraintes
yi− < w,xi > −b ≤ ε
yi− < w,xi > −b ≥ −ε
(3.2)
Cependant, une hypothèse tacitement admise dans cette équation est qu’il existe une fonc-
tion f qui approxime tous les couples de données (xi,yi) avec une précision ε, ou en d’autres
termes, que le problème d’optimisation convexe possède une solution. Mais, bien souvent,
ceci n’est pas le cas et nous devons donc nous résoudre à autoriser quelques erreurs. De
façon analogue aux machines à vecteurs supports, nous pouvons utiliser la fonction perte
linéaire d’insensibilité ε et ainsi introduire les variables ressorts (ou variables de relâche-
ment) ξi, ξ∗i pour gérer les contraintes irréalisables du problème d’optimisation convexe,
ce qui est appelé la marge douce (soft margin). La fonction perte linéaire d’insensibilité ε
est représentée sur la figure 3.1 et s’écrit sous la forme :
l(ξ)ε =
0 si | ξ |≤ ε
| ξ | −ε sinon(3.3)
ξ
ε−ε
Fig. 3.1 – Illustration de la fonction perte
Nous devons résoudre un problème d’optimisation convexe sous contraintes dont voici la
56 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

3.1. Méthode standard
Fig. 3.2 – Représentation de la marge douce
formulation primale :
min L(w,ξi,ξ∗i ) =
1
2‖w‖2 + C.
n∑
i=1
(ξi + ξ∗i ) (3.4)
Sous les contraintes :
yi− < w,xi > −b ≤ ε + ξi
< w,xi > +b − yi ≤ ε + ξ∗i
ξi,ξ∗i ≥ 0
∀ i ε 1,...,n (3.5)
La constante C détermine le compromis entre la "platitude" de f et l’attache aux
données, c’est à dire qu’elle donne plus ou moins d’importance (de poids) aux erreurs
ξi, ξ∗i par rapport à la solution régulière 1
2‖w‖2. Pour faire un parallèle avec les notions de
risque, minimiser 3.4 reviens à minimiser le risque empirique régularisé.
Afin de résoudre ce problème d’optimisation, nous utilisons sa formulation duale car
il est beaucoup plus aisé d’y calculer la solution. De plus, la formulation duale apporte la
clef d’une extension des machines à vecteurs supports aux fonctions non-linéaires. Pour
obtenir cette formulation duale, nous utilisons une méthode standard de dualisation basée
sur les coefficients du Lagrangien.
3.1.2 Formulation duale et programmation quadratique
L’idée est d’utiliser une fonction Lagrangienne, issue de la formulation primale eq.3.4
(qui est notre fonction objectif) ainsi que des contraintes lui étant associées eq.3.5, en
introduisant un ensemble de variables duales. Il a été montré que cette fonction possède
57
Chapitre 3. Régression par les machines à vecteurs supports et modifications
un "point selle" par rapport aux variables primales et duales, où se trouve la solution
optimale.
L’expression du "point selle", aussi appelé "point col", illustre la géométrie de la fonc-
tion. Lorsque que l’on franchit un col, on passe d’une vallée à une autre en atteignant une
altitude maximale dans la direction vallée-vallée. Maintenant dans la direction perpen-
diculaire (montagne-montagne), nous sommes à une altitude minimale et nous pouvons
monter vers un des deux sommets. Ainsi, en un "point selle", il existe une direction où
la fonction va croître, et une direction où la fonction va décroître. On remarque aisément
sur la figure 3.3 le point col ou selle.
Fig. 3.3 – Représentation du point selle
Le Lagrangien associé aux équations 3.4 et 3.5 s’écrit :
L(w,b,ξi,ξ∗i ,αi,α
∗i ,ηi,η
∗i ) = 1
2‖w‖2 + C
∑ni=1(ξi + ξ∗i ) . . .
−∑ni=1 αi(ε + ξi − yi+ < w,xi > +b) . . .
−∑ni=1 α∗
i (ε + ξ∗i + yi− < w,xi > −b) . . .
−∑ni=1(ηiξi + η∗
i ξ∗i )
(3.6)
Où il est sous-entendu que les variables duales doivent satisfaire les contraintes de positi-
vité, c’est à dire que αi,α∗i ,ηi,η
∗i ≥ 0.
On doit donc minimiser cette fonction suivant les variables primales ainsi que les
paramètres du modèle w, b, ξi et ξ∗i , tout en la maximisant suivant les multiplicateurs
Lagrangiens αi, α∗i , ηi et η∗
i . Pour ce faire, nous allons annuler les dérivées partielles de
58 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

3.1. Méthode standard
cette fonction Lagrangienne 3.6 suivant les w, b, ξi et ξ∗i . Ce qui nous donne :
∂L
∂b= −
n∑
i=1
αi +n∑
i=1
α∗i ⇒
n∑
i=1
(α∗i − αi) = 0 (3.7)
∂L
∂w= w −
n∑
i=1
αixi +n∑
i=1
α∗i xi ⇒ w =
n∑
i=1
(αi − α∗i )xi (3.8)
∂L
∂ξi
= C − αi − ηi ⇒ ηi = C − αi (3.9)
∂L
∂ξ∗i= C − α∗
i − η∗i ⇒ η∗
i = C − α∗i (3.10)
On se trouve maintenant sur la courbe rouge centrale de la figure 3.3. On va remplacer
dans l’expression du Lagrangien les variables w, ηi et η∗i . Il ne reste plus qu’à maximiser
cette expression par rapport aux variables duales du lagrangien αi et α∗i afin de trouver
le point selle (le maximum de la courbe rouge), et ainsi la solution optimale. Voici le
développement :
L(αi,α∗i ) = 1
2
∑ni=1
∑nj=1(αi − α∗
i )(αj − α∗j ) < xi,xj > +C
∑ni=1(ξi + ξ∗i ) . . .
−∑ni=1 αi(ε + ξi − yi +
∑nj=1(αj − α∗
j ) < xi,xj > +b) . . .
−∑ni=1 α∗
i (ε + ξ∗i + yi −∑n
j=1(αj − α∗j ) < xi,xj > −b) . . .
−∑n
i=1((C − αi)ξi + (C − α∗i )ξ
∗i )
(3.11)
L(αi,α∗i ) = 1
2
∑ni=1
∑nj=1(αi − α∗
i )(αj − α∗j ) < xi,xj > +C
∑ni=1(ξi + ξ∗i ) . . .
−∑n
i=1 αiε −∑n
i=1 αiξi +∑n
i=1 αiyi −∑n
i=1 αib . . .
−∑n
i=1 αi
∑nj=1(αj − α∗
j ) < xi,xj > . . .
−∑n
i=1 α∗i ε −
∑ni=1 α∗
i ξ∗i +
∑ni=1 α∗
i yi +∑n
i=1 α∗i b . . .
+∑n
i=1 α∗i
∑nj=1(αj − α∗
j ) < xi,xj > . . .
−C∑n
i=1(ξi + ξ∗i ) +∑n
i=1(αiξi + α∗i ξ
∗i )
(3.12)
L(αi,α∗i ) = 1
2
∑ni=1
∑nj=1(αi − α∗
i )(αj − α∗j ) < xi,xj > . . .
−∑ni,j=1(αi − α∗
i )(αj − α∗j ) < xi,xj > . . .
+bn∑
i=1
(α∗i − αi)
︸ ︷︷ ︸=0
+∑n
i=1(αi − α∗i )yi − ε
∑ni=1(αi + α∗
i )(3.13)
59

Chapitre 3. Régression par les machines à vecteurs supports et modifications
Le résultat de ce développement nous donne la formulation duale du problème :
maxL(αi,α∗i ) = −1
2
∑ni=1
∑nj=1(αi − α∗
i )(αj − α∗j ) < xi,xj > . . .
−ε∑n
i=1(αi + α∗i ) +
∑ni=1 yi(αi − α∗
i )
sous les contraintes
∑ni=1(α
∗i − αi) = 0
αi,α∗i ∈ [0,C]
(3.14)
Maximiser L est un problème de programmation quadratique mais son expression n’est
pas sous la forme standard utilisée par les "packages" de programmation quadratique,
lesquels effectuent bien souvent une minimisation. Ce problème d’optimisation pour une
fonction perte linéaire d’insensibilité ε peut se réécrire sous une forme matricielle telle
que :
minx
1
2xT Hx + cT x (3.15)
Où :
H =
[XXT −XXT
−XXT XXT
], c =
[ε + Y
ε − Y
], x =
[α
α∗
](3.16)
X =
x1
...
xn
, Y =
y1
...
yn
(3.17)
Avec les contraintes suivantes :
x · (1, · · · ,1, − 1, · · · , − 1) = 0, αi,α∗i ≥ 0 ∀iε1,...,n (3.18)
Nous pouvons ainsi utiliser la programmation quadratique pour obtenir les αi et α∗i , à
l’aide desquels nous pouvons recontruire le vecteur paramètre ~w comme suit :
~w =∑n
i=1(αi − α∗i )xi (3.19)
La fonction objectif peut se réécrire comme suit :
f(x) =∑n
i=1(αi − α∗i ) < xi,x > +b (3.20)
On remarque que le vecteur paramètre w peut être complètement décrit comme une com-
binaison linéaire des observations xi. D’une certaine façon, la complexité de représentation
d’une fonction par les vecteurs supports est indépendante de la dimension de l’espace des
entrées, mais dépend seulement du nombre de vecteurs supports. En effet, seuls les vec-
60 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

3.1. Méthode standard
teurs supports possèdent l’un des 2 coefficients αi ou α∗i non-nul. Ainsi, uniquement les
vecteurs supports servent à la reconstruction du vecteur paramètre w.
3.1.3 Calcul de b
Les conditions de Karush-Khun-Tucker (KKT) [Kar39][KT51] stipulent que pour trou-
ver la solution optimale, le produit des variables duales par les contraintes doit s’annuler.
Dans notre cas, cela signifie que :
αi(ε + ξi − yi+ < w,xi > +b) = 0
α∗i (ε + ξ∗i + yi− < w,xi > −b) = 0
(3.21)
ainsi que :ηiξi = 0
η∗i ξ
∗i = 0
(3.22)
D’après l’équation 3.9, on peut remplacer ηi par C − αi ce qui donne :
(C − αi)ξi = 0
(C − α∗i )ξ
∗i = 0
(3.23)
On peut déduire de ces équations plusieurs conclusions utiles :
– tout d’abord, seules les données (xi,yi) ayant une des deux variables duales égale à
C (αi = C ou α∗i = C) se trouvent à l’extérieur du tube de rayon ε autour de f ,
– ensuite, le produit des deux variables duales d’une donnée doit être nul, c’est à
dire que αiα∗i = 0. En effet, on ne peut pas avoir ces deux variables non-nulles
simultanément auquel cas nous aurions les deux variables ressorts ξi et ξ∗i non-nulles,
c’est à dire une erreur dans les deux directions,
– finalement, lorsque αi ∈ [0,C[ nous avons ξi = 0, ou lorsque α∗i ∈ [0,C[ nous avons
ξ∗i = 0. Ainsi, pour annuler les équations 3.21, il faut annuler le second terme ξi ou
ξ∗i , et par suite donc calculer b tel que :
b = yi− < w,xi > −ε pour αi ∈ [0,C[
b = yi− < w,xi > +ε pour α∗i ∈ [0,C[
(3.24)
3.1.4 Cas non-linéaire
Certains noyaux, appelés noyaux de MERCER, ont la propriété suivante :
il existe une transformation Φ telle que k(x,z) =< Φ(x),Φ(z) >
61

Chapitre 3. Régression par les machines à vecteurs supports et modifications
Plus précisément, il existe un espace de Hilbert F muni d’un produit scalaire < .,. > tel
que :Φ : χ 7−→ F
x −→ x = Φ(x)(3.25)
Et :
k(x,z) =< Φ(x,Φ(z) > ∀(x,z) ∈ χ2 (3.26)
Le problème traité est donc transformé dans un espace F de dimension supérieure à la
dimension de χ où il existe un solution linéaire.
Voici deux exemples de fonctions noyaux utilisées :
– les noyaux polynomiaux
kpoly1(x,z) = (xT z)m (3.27)
kpoly2(x,z) = (xT z + c)m (3.28)
– les noyaux Gaussiens
kG(x,z) = exp(−‖x − z‖2
2σ2) (3.29)
L’astuce du noyau consiste donc à remplacer un produit scalaire par un noyau. Dans
le cas de notre problème, nous obtenons les équations suivantes :
– la formulation primale
min L(w,ξi,ξ∗i ) =
1
2‖w‖2 + C.
n∑
i=1
(ξi + ξ∗i ) (3.30)
Sous les contraintes :
yi− < w,Φ(xi) >≤ ε + ξi
< w,Φ(xi) > −yi ≤ ε + ξ∗i
ξi,ξ∗i ≥ 0
∀iε1,...,n (3.31)
– la formulation duale
max L(αi,α∗i ) = −1
2
∑ni,j=1(αi − α∗
i )(αj − α∗j ) < Φ(xi),Φ(xj) > . . .
−ε∑n
i=1(αi + α∗i ) +
∑ni=1 yi(αi − α∗
i )
sous les contraintes
∑ni=1(α
∗i − αi) = 0
αi,α∗i ∈ [0,C]
(3.32)
62 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —
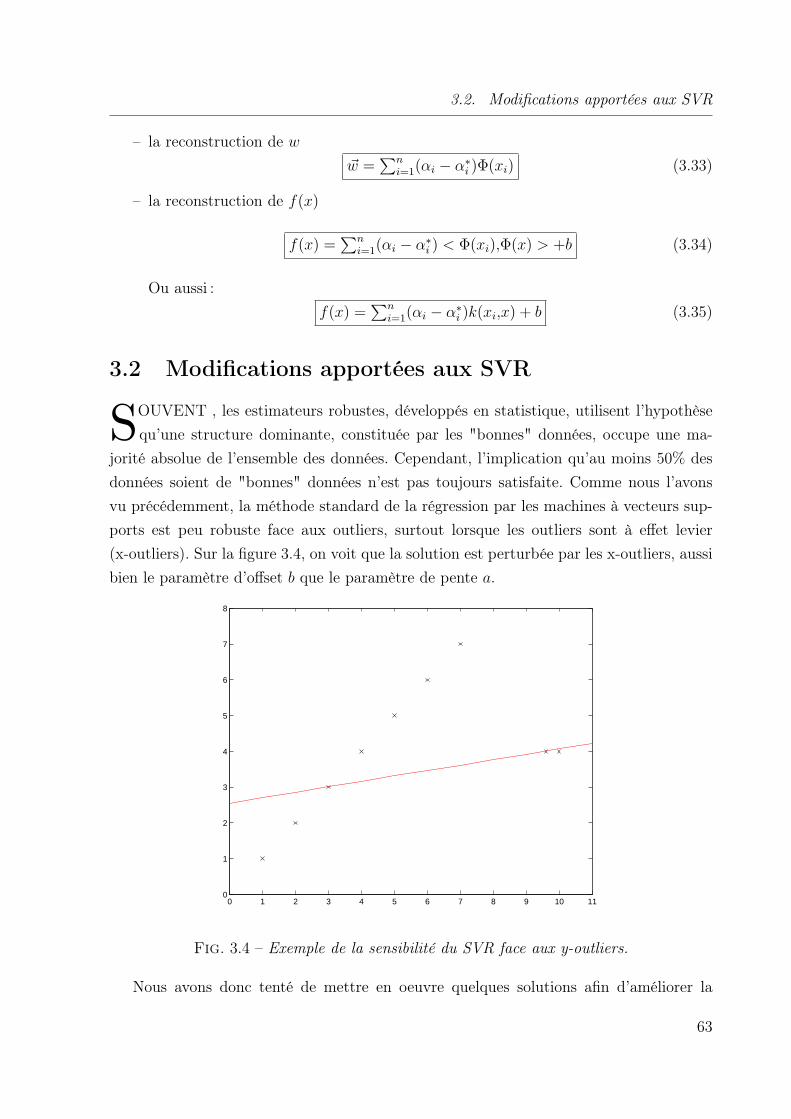
3.2. Modifications apportées aux SVR
– la reconstruction de w
~w =∑n
i=1(αi − α∗i )Φ(xi) (3.33)
– la reconstruction de f(x)
f(x) =∑n
i=1(αi − α∗i ) < Φ(xi),Φ(x) > +b (3.34)
Ou aussi :
f(x) =∑n
i=1(αi − α∗i )k(xi,x) + b (3.35)
3.2 Modifications apportées aux SVR
SOUVENT , les estimateurs robustes, développés en statistique, utilisent l’hypothèse
qu’une structure dominante, constituée par les "bonnes" données, occupe une ma-
jorité absolue de l’ensemble des données. Cependant, l’implication qu’au moins 50% des
données soient de "bonnes" données n’est pas toujours satisfaite. Comme nous l’avons
vu précédemment, la méthode standard de la régression par les machines à vecteurs sup-
ports est peu robuste face aux outliers, surtout lorsque les outliers sont à effet levier
(x-outliers). Sur la figure 3.4, on voit que la solution est perturbée par les x-outliers, aussi
bien le paramètre d’offset b que le paramètre de pente a.
0 1 2 3 4 5 6 7 8 9 10 110
1
2
3
4
5
6
7
8
Fig. 3.4 – Exemple de la sensibilité du SVR face aux y-outliers.
Nous avons donc tenté de mettre en oeuvre quelques solutions afin d’améliorer la
63

Chapitre 3. Régression par les machines à vecteurs supports et modifications
robustesse de la méthode standard. Dans un premier temps, nous avons étudié une pro-
cédure itérative de la méthode standard, puis dans un second temps, nous proposons une
pondération de la technique de régression par vecteurs supports qui s’avère tolérer plus
de 50% de contamination du jeu de données.
3.2.1 Procédure itérative avec une marge adaptative
Cette méthode a été publiée par Weiyu Zhu et al. [ZWLL01]. Il s’agit d’appliquer
la méthode de régression par les machines à vecteurs supports de façon itérative. À la
première itération, la valeur initiale de la marge ε est réglée avec une valeur importante,
puis cette valeur sera diminuée à chaque itération afin d’affiner le résultat de l’estimation.
Détection des outliers
Un des points clefs de la robustesse de la marge adaptative est que l’on a la possibilité de
détecter les points aberrants et donc de les retirer du jeu de données. Un exemple en deux
dimensions de la procédure de détection de ces points aberrants est donné sur la figure 3.5.
La ligne continue représente l’hyperplan optimal, elle est encadrée de 2 lignes pointillées
qui représentent les limites de la marge d’insensibilité ε. Les points positionnés à l’extérieur
de cette marge sont appelés les outliers-SVs et les points positionnés sur les limites de
cette marge sont appelés les margin-SVs. Ces deux catégories de points représentent les
vecteurs supports. Quant aux points à l’intérieur de la marge, ils sont nommés non-SVs
ce qui signifient que ceux-ci ne sont pas des vecteurs supports, ils sont considérés comme
les données correctes. Dans la dernière colonne du tableau 3.1 sont rappelées les valeurs
que prennent les variables duales pour chacune des catégories de points. On remarque
que les points aberrants, c’est à dire les outliers-SVs, possèdent une des 2 variables égale
au paramètre C. Ainsi, en effectuant un simple test sur les valeurs des variables duales,
nous sommmes capables de déterminer à quelles catégories appartiennent chacune de nos
données. D’où l’idée d’utiliser cette information pour repérer et enlever les points aberrants
du jeu de données afin de calculer, de nouveau, la régression par les machines à vecteurs
supports sur les données conservées dans le but d’obtenir une estimation plus précise car
moins perturbée. Il faut, bien sûr, diminuer la valeur ε de la marge car toutes les données
conservées entrent dans la marge précédente. Cette procédure itérative se poursuit tant
que 2 conditions sont respectées : la valeur de ε doit être supérieure à un seuil défini, et
le taux des données conservées sur les données initiales doit être, lui aussi, supérieur à un
seuil.
64 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

3.2. Modifications apportées aux SVR
non-SVs •• αi = α∗i = 0
margin-SVs 22 αiε]0,C[⇒ α∗i = 0
Outlier-SVs ** αi = C ⇒ α∗i = 0
Tab. 3.1 – Détection des outliers
Fig. 3.5 – Illustration 2D de la détection des outliers
3.2.2 Pondération du SVR
AFIN d’augmenter les performances de la méthode standard de régression par les ma-
chines à vecteurs supports, nous avons apporté différentes modifications soit d’un
point de vue algorithmique soit directement dans la formulation du problème. Du point de
vue algorithmique, nous avons utilisé une procédure itérative qui diminue progressivement
la largeur de la marge tout en éliminant du jeu de données les points considérés comme
des outliers, ce qui est appelé la régression par les machines à vecteurs supports avec
marge adaptative. Du point de vue mathématique, nous avons pondéré l’erreur commise
sur un point par un poids soit binaire (0 ou 1) dans le cas d’une pondération dure, soit
réel dans le cas d’une pondération douce. Le principe de la régression par les machines à
vecteurs supports pondérée est d’assigner à chaque donnée un coefficient de pénalité en
accord avec un critère prédéfini. Ce principe a déjà été utilisé dans les machines à vecteurs
supports pour la classification [HL02] [WB06].
Soit β(k)i qui représente le facteur poids associé au point (xi,yi) à l’itération k. Le
principe de l’approche proposée consiste à affiner le vecteur de paramètre w(k) (estimé à
l’itération k) avec la régression modifiée par les SVM, où chaque terme de pénélisation ξ(∗)i
dans la somme est pondéré par le poids β(k)i . Le problème d’optimisation sous contraintes
65

Chapitre 3. Régression par les machines à vecteurs supports et modifications
de la régression pondérée par les SVM prend alors la forme suivante :
min L(w(k),ξi,ξ∗i ) =
1
2‖w(k)‖2 + C.
n∑
i=1
β(k)i (ξi + ξ∗i ) (3.36)
Sous les contraintes :
yi− < w(k),xi > −b(k) ≤ ε + ξi
< w(k),xi > +b(k) − yi ≤ ε + ξ∗i
ξi,ξ∗i ≥ 0
∀ i ∈ 1,...,n (3.37)
Le Lagrangien de ce système s’écrit :
L(w(k),b(k),ξi,ξ∗i ,αi,α
∗i ,ηi,η
∗i ) = 1
2‖w(k)‖2 + C
∑ni=1 β
(k)i (ξi + ξ∗i ) . . .
−∑ni=1 αi(ε + ξi − yi+ < w(k),xi > +b(k)) . . .
−∑ni=1 α∗
i (ε + ξ∗i + yi− < w(k),xi > −b(k)) . . .
−∑ni=1(ηiξi + η∗
i ξ∗i )
(3.38)
Seule la dérivée suivant ξ(∗)i sera différente par rapport à la régression standard des ma-
chines à vecteurs supports :
∂L
∂ξ(∗)i
= Cβ(k)i − α
(∗)i − η
(∗)i (3.39)
La formulation duale de la régression pondérée sera la même que celle de la régression
standard, c’est à dire :
max L(αi,α∗i ) = −1
2
∑ni,j=1(αi − α∗
i )(αj − α∗j ) < xi,xj > . . .
−ε∑n
i=1(αi + α∗i ) +
∑ni=1 yi(αi − α∗
i )(3.40)
Avec une différence uniquement sur les contraintes :
∑ni=1(α
∗i − αi) = 0
αi,α∗i ∈ [0,Cβ
(k)i ]
(3.41)
En fait , seule la limite supérieure des coefficients de Lagrange αi et α∗i est modifiée de
façon dynamique à chaque itération. Pour comprendre l’effet des facteurs poids sur la
régression, nous devons analyser les propriétés des variables duales αi et α∗i ainsi que des
variables ressorts associées ξi et ξ∗i . Souvenons-nous du tableau 3.1 accompagnant la figure
3.5, il nous montrait que seules les données sur ou à l’extérieur de la marge étaient des
66 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

3.2. Modifications apportées aux SVR
vecteurs supports et contribuaient au calcul de la solution. Les points à l’intérieur de la
marge n’étant pas des vecteurs supports, ils n’y contribuaient pas. Ces propriétés étant
définies par les valeurs des variables duales, nous avons eu l’idée de forcer ces valeurs à 0
pour un point jugé comme aberrant, ce qui permet de ne plus prendre en compte ce point
pour le calcul de la solution.
Pondération "dure" du SVR
La pondération dure des données, c’est à dire à l’aide de poids binaire, s’effectue
de la manière suivante : les points appartenant à la structure dominante, ou les points
considérés comme des données correctes, ont un poids associé βi = 1, et les données
considérées comme des outliers ont un poids associé βi = 0. Pour un point, la valeur du
poids est fixée en calculant la différence entre la valeur absolue du résidu en ce point et
un seuil M (k), comme suit :
β(k+1)i =
1
2
(1 + sgn(M (k) −
∣∣yi− < w(k),xi > −b(k)∣∣)
)∀ i ∈ 1,...,n (3.42)
Où la valeur du seuil M (k) est proportionelle à la valeur absolue maximale des résidus,
c’est à dire :
M (k) = µ · max∀i∈1,...,n
((β
(k)i ·
∣∣yi− < w(k),xi > −b(k)∣∣)
)(3.43)
Et µ est un facteur appartenant à ]0,1[. Ce facteur règle la proportion de données à
éliminer du jeu de données. Sa valeur doit être fixée de façon heuristique afin de guarantir
la convergence de la solution : une valeur faible éliminera une grosse partie du jeu de
données et n’assurera pas une bonne convergence, une valeur forte éliminera une petite
partie du jeu de données et assurera une bonne convergence mais peut être trop lentement.
Pondération "douce" du SVR
La pondération douce du SVR s’effectue, quant à elle, à l’aide d’une fonction de pondé-
ration adaptative. nous allons donc rappeler les propriétés d’une fonction de pondération
robuste, que l’on notera ξ(x). Ensuite, nous nous intéresserons à l’importance du point
de coupure τ .
Définition
Une fonction de pondération robuste, notée χ(r), doit vérifier un certain nombre de
67

Chapitre 3. Régression par les machines à vecteurs supports et modifications
propriétes que nous allons rappeler, r représente l’erreur résiduelle mesurée entre les don-
nées et le modèle estimé.
(i) χ doit être continue, le poids varie de manière continue en fonction de l’erreur.
(ii) χ doit être symétrique, le poids dépend uniquement de l’amplitude de l’erreur et non
de son signe.
(ii) χ doit être définie positive, le poids a une valeur toujours positive.
(iv) χ doit être décroissante, la valeur du poids décroit lorsque l’amplitude de l’erreur
augmente.
(v) limr→inf‖rχ(r)‖ ≺ inf, l’asymptote de ‖rχ(r)‖ est bornée. Pour satisfaire cette der-
nière propriété, il est nécessaire que limr→infχ(r) → 0, c’est à dire que le poids des
données qui causent des erreurs importantes doit tendre vers 0.
Dans l’exemple des M-estimateurs, le problème de régression est résolu comme un
problème de moindres carrés pondérés dans lequel la fonction poids vérifie les propriétés
énoncées précédemment. Comme il a été vu dans le chapitre 2 précédent paragraphe 2.1.3,
la fonction poids est liée mathématiquement à une fonction perte c(r) grâce à l’expression
suivante :
χ(r) =∂c(r)∂r
r(3.44)
Où la fonction perte c(r) est symétrique, définie positive avec un minimum unique en 0,
et choisie pour être moins croissante que la fonction carré. Sa dérivée, notée ψ(r), est
appelée la fonction d’influence et doit être bornée. Les M-estimateurs sont classés en trois
types selon la forme de la fonction d’influence ψ :
– les M-estimateurs monotones, tels que le propose Huber[Hub81] avec une fonction
d’influence non-décroissante et bornée.
– les hard-redescenders, tels que le propose Tukey[BT74] avec une fonction d’in-
fluence égale à zéro pour toute erreur dont l’amplitude serait supérieure à un seuil
donné, appelé point de coupure noté τ .
– les soft-redescenders, tels que le propose Welsch[HW77] avec une fonction d’in-
fluence ne possédant pas de point de coupure τ défini, mais devant tendre vers zéro
lorsque r tend vers l’infini.
Ces trois types de M-estimateurs sont représentés sur la figure 3.6. Il existe bien entendu
de nombreux autres M-estimateurs pouvant être classés dans une de ces catégories, un
évantail plus détaillé est présenté dans le livre "Robust statistics" de Huber [Hub81].
68 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —
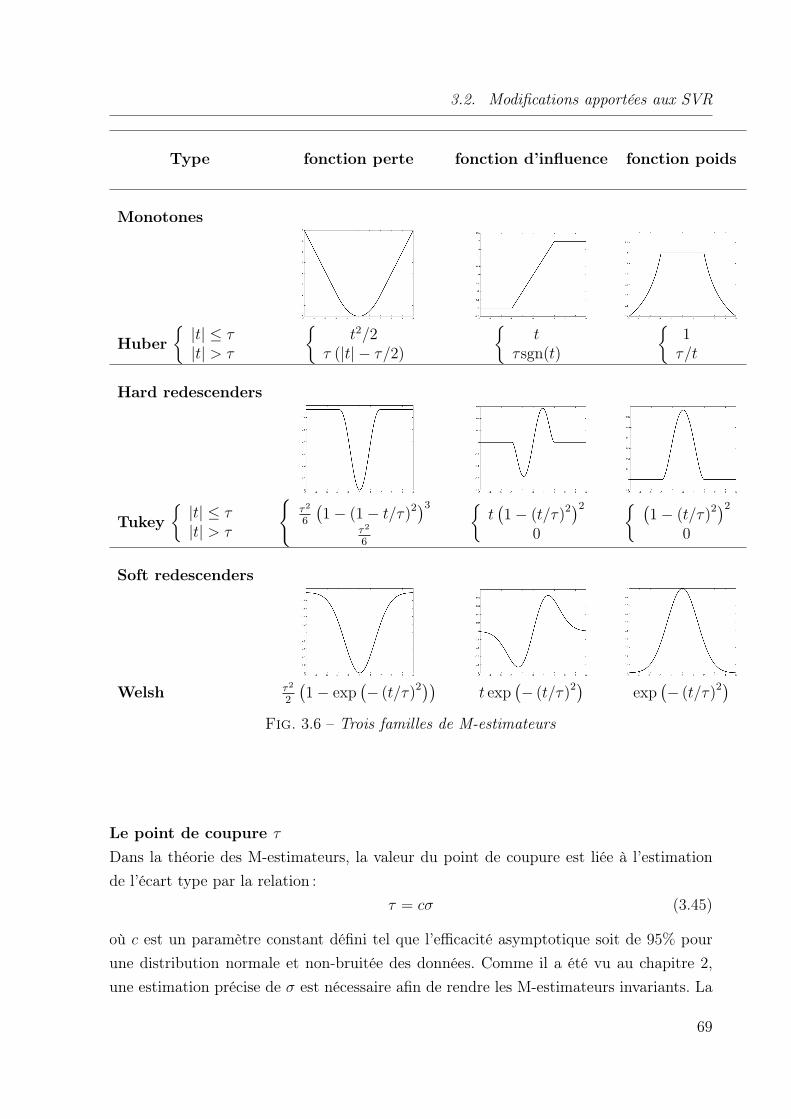
3.2. Modifications apportées aux SVR
Type fonction perte fonction d’influence fonction poids
Monotones
Huber
|t| ≤ τ|t| > τ
t2/2
τ (|t| − τ/2)
t
τsgn(t)
1
τ/t
Hard redescenders
Tukey
|t| ≤ τ|t| > τ
τ2
6
(1 − (1 − t/τ)2)3
τ2
6
t(1 − (t/τ)2)2
0
(1 − (t/τ)2)2
0
Soft redescenders
Welsh τ2
2
(1 − exp
(− (t/τ)2)) t exp
(− (t/τ)2) exp
(− (t/τ)2)
Fig. 3.6 – Trois familles de M-estimateurs
Le point de coupure τ
Dans la théorie des M-estimateurs, la valeur du point de coupure est liée à l’estimation
de l’écart type par la relation :
τ = cσ (3.45)
où c est un paramètre constant défini tel que l’efficacité asymptotique soit de 95% pour
une distribution normale et non-bruitée des données. Comme il a été vu au chapitre 2,
une estimation précise de σ est nécessaire afin de rendre les M-estimateurs invariants. La
69

Chapitre 3. Régression par les machines à vecteurs supports et modifications
médiane de l’écart type absolu est souvent utilisée :
MAD(Xi) = 1.483medi |Xi − medj(Xj)| (3.46)
où le facteur 1.483 ajuste l’echelle pour une efficacité maximale lorsque les données
proviennent d’une distribution gaussienne. Cependant, dans de nombreuses applications
images, la présence d’outliers due au bruit ou à des structures résiduelles rendent cette
estimation peu fiable. Dans cette situation, la convergence des M-estimateurs n’est plus
garantie.
Afin de contourner ce problème, nous proposons d’utiliser une valeur adaptative pour le
point de coupure, valeur qui ne dépendrait pas d’une estimation de l’écart type. La stra-
tégie porposée consiste à diminuer graduellement la valeur du point de coupure pendant
le processus d’estimation afin d’atteindre le minimum global. Sur la fonction perte c(r),
la région [−τ,τ ] est définie comme un intervalle sur r où la fonction est convexe :
[−τ,τ ] =
r/
∂2c(r)
∂r2≥ 0
(3.47)
À chaque étape d’itération k, τ est choisi tel que :
τ (k) = βB(k)H (3.48)
avec 0 < β < 1. BH est une borne supérieure adaptée selon le type d’erreurs, pour l’ins-
tant nous utilisons dans la pratique la valeur résiduelle maximale absolue. À chaque étape
d’itération, la valeur de BH est mise à jour en accord avec une règle basée sur les poids
des observations. Le paramètre β est fixé à une certaine valeur, celle-ci délimite un seuil
pour les valeurs résiduelles au-delà duquel le poids des observations doit être décroissant.
Diminuer l’influence des y-outliers
Les y-outliers sont définis comme les observations pour lesquelles la valeur résiduelle ri
est importante relativement aux autres valeurs résiduelles issues des observations de l’en-
semble de données. Ainsi, pour réduire l’influence de ces y-outliers, la fonction poids
χ(ri)(k) doit attribuer un faible poids aux observations dont la valeur résiduelle est supé-
rieure à un point de coupure τ(k)y donné :
τ (k)y = βyB
(k)H avec 0 < βy < 1 (3.49)
70 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

3.2. Modifications apportées aux SVR
où la borne supérieure B(k)H est proportionnelle à la valeur résiduelle maximale absolue :
B(k)H = maxi∈[1,n](χ(ri)
(k)‖ri‖(k)) (3.50)
Le paramètre βy règle la proportion d’observations considérées comme y-outliers et dont le
poids doit être diminué. Une valeur trop faible peut provoquer une divergence du proces-
sus d’estimation, la proportion d’observations pour lesquelles le poids a été diminué étant
trop importante. A contrario, une valeur trop forte assure la convergence de l’estimation
au détriment du temps d’exécution, le nombre d’itérations étant démultiplié. Nous avons
choisi la valeur βy = 0.7 qui nous apparaît comme un bon compromis entre la stabilité
d’exécution et le temps de calcul.
Diminuer l’influence des x-outliers
Les x-outliers sont définis comme les observations éloignées de la structure de données
dominante suivant l’espace des x, c’est à dire des observations à effet levier. On distingue
les x-outliers en deux types selon leur influence sur l’estimation : les observations à effet
levier défavorable et les observations à effet levier favorable. Dans notre étude, nous consi-
dérons uniquement l’impact des x-outliers défavorables à l’estimation. Comme il a été vu
au chapitre 1, le concept d’effet levier est lié à la matrice chapeau H = X(XT X)−1XT où
X est la matrice des prédicteurs. Si la ième observation est un outlier suivant l’espace des
x, ce sera indiqué par une valeur importante du coefficient de la diagonale Hii ∈ [0,1]. Le
diagnostic d’effet levier considère comme x-outliers toutes les observations dont la valeur
Hii est supérieure à une valeur de calibration proportionnelle à la moyenne des éléments
de la diagonale, qui est égale à pn. Ainsi, afin de réduire l’influence de ces x-outliers, la
fonction poids χ(Hii)(k) doit attribuer un faible poids à l’observation i dont le coefficient
diagonal Hii est supérieur à un point de coupure τ(k)x donné :
τ (k)x = βxB
(k)H (3.51)
où la valeur de βx est souvent réglée égale à 2, et où la borne supérieure B(k)H est inverse-
ment proportionnelle au nombre d’observations n(k) :
B(k)H =
p
n(k)(3.52)
où n(k) représente le nombre d’observations dont le poids χ(Hii)(k) est supérieur ou égal
71

Chapitre 3. Régression par les machines à vecteurs supports et modifications
à la moyenne entre le poids minimum et le poids maximum pour l’itération k :
χ(Hii)(k) ≥ 1
2
(min(χ(Hii)
(k)) + max(χ(Hii)(k))
)(3.53)
Le point de coupure τx permet de limiter rapidement l’influence des observations à effet
levier important et devient inopérant lorsque la répartition des observations sur l’espace
des x est équilibrée.
Bien sûr, comme le diagnostic d’effet levier proposé est basé sur l’hypothèse de linéarité
du modèle, il est uniquement valable pour la fonction noyau linéaire.
L’algorithme du R-SVR
(i) Initialisation : k = 0 , χ(k)i =1, 1 ≤ i ≤ n , βx = 2 , βy = 0.7
(ii) Regression : Calculer w(k) et b(k) avec R-SVR
(iii) Partition des données (fig. 3.7) :
– Limiter l’influence des y-outliers : Calculer les résidus ri et τ(k)y . Mettre à
jour χ(k)i
– Limiter l’influence des x-outliers : Calculer les coefficients hii et τ(k)x . Mettre
à jour χ(k)i
(iv) Critère d’arrêt : Si l’erreur de reconstruction ‖f(x)(k)− f(x)(k−1)‖ ≤ ζ(¿ 1), alors
arrêt. Autrement, incrémenter k et retourner à l’étape (ii).
Fig. 3.7 – Limite de l’influence des outliers sur la régression.
Nous allons illustrer comment cette limitation de l’influence des outliers prend forme
de manière itérative lors de l’estimation de la régression. Nous utilisons deux exemples : la
figure 3.8 présente le processus d’estimation de la régression dans un cas linéaire, alors que
la figure 3.9 présente le cas non linéaire. Sur ces figures, nous pouvons observer deux zones
72 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

3.2. Modifications apportées aux SVR
colorées, une zone bleue et une zone rose. Les colonnes de gauche (figure 3.8-a, c, e et g,
ainsi que figure 3.9-a, c, e et g) illustrent ces zones dans le cadre de la pondération dure
du SVR. La zone bleue représente la zone où l’influence des observations sur l’estimation
des paramètres est nulle (poids égal à zéro), alors que la zone rose correspond à la zone
où l’influence des observations est maximale (poids égal à un). Les colonnes de droite
(figure 3.8-b, d, f et h, ainsi que figure 3.9-b, d, f et h) illustrent les zones d’influence dans
le cadre de la pondération douce du SVR. Ainsi, la zone bleue correspond à la zone où
l’influence des observations sur l’estimation des paramètres est diminuée (poids tend vers
zéro) ; alors que la zone rose correspond à la zone où l’influence des observations reste
maximale (poids tend vers un).
3.2.3 Performances et résultats comparatifs
Estimateurs de comparaison et réglage des paramètres
Dans cette section, les performances de notre algorithme pour l’estimation de modèles
linéaires sont montrés et comparés avec la méthode standard de régression par les machines
à vecteurs supports, la méthode de Cherkassky (MME) [CM02] et d’autres estimateurs
robustes tels que les MM-estimateurs [?], la moindre médiane des carrés (LMedS) [RL87],
les moindres carrés tronqués (LTS) [RL87], et la méthode plus récente du vbQMDPE
[WS03]. Dans les tests suivants, nous avons utilisé les valeurs ε = 0.001 et C = 10 pour
les méthodes basées sur la régression par les machines à vecteurs supports. Pour la mé-
thode de Cherkassky [CM02], nous supposons que le niveau de bruit σ pour la structure
dominante est connu et la valeur du seuil est constante (= 2σ). Par la suite, nous effec-
tuons d’autres tests dans le cas non-linéaire.
Tests sur la régression linéaire
On se propose de tester la régression linéaire sur deux exemples. Le premier exemple,
illustré sur la figure 3.10-a, comprend trois segments constituant trois paliers. Le second
exemple, illustré sur la figure 3.10-b, est constitué de trois droites qui se croisent. Dans
ces deux exemples, chaque droite (ou segment de droite) est corrompue par un bruit de
type gaussien de moyenne nulle et de variance σ variable. La ième droite (ou segment) est
composée d’un nombre d’observations noté ni. nous avons ajouté n0 outliers uniformément
distribués sur l’intervalle [0,100] et sur l’espace des x. Pour le premier exemple, l’ensemble
de données est défini ainsi :
– n1 = 60 observations composant le premier segment de droite d’équation y = 30
(σ = 1) pour x ∈ [0,60] et représentées par des ’o’,
73

Chapitre 3. Régression par les machines à vecteurs supports et modifications
– n2 = 20 observations composant le second segment de droite d’équation y = 60
(σ = 2) pour x ∈ [60,100] et représentées par des ’4’,
– n3 = 30 observations composant le troisième segment de droite d’équation y = −10
(σ = 2.5) pour x ∈ [110,160] et représentées par des ’2’,
– n0 = 50 outliers uniformément distribués sur l’intervalle [0,100] et sur l’espace des
x, et représentés par des ’+’.
Et voici la composition de l’ensemble de données du second exemple :
– n1 = 50 observations composant la première droite d’équation y = x + 3 (σ = 3)
pour x ∈ [20,100] et représentées par des ’2’,
– n2 = 60 observations composant la seconde droite d’équation y = 35 (σ = 1) pour
x ∈ [0,100] et représentées par des ’o’,
– n3 = 100 observations composant la troisième droite d’équation y = −x + 100
(σ = 2) pour x ∈ [10,80] et représentées par des ’4’,
– n0 = 80 outliers uniformément distribués sur l’intervalle [0,100] et sur l’espace des
x, et représentés par des ’+’.
Le résultat d’estimation des modèles linéaires est montré sur les figures 3.10.a et 3.10.b.
La figure 3.10.a illustre, par exemple, trois paliers formant deux sauts discontinus. Cet
exemple met en avant le fait que l’examen des résidus seul peut ne pas détecter les ob-
servations à effet levier ayant une mauvaise influence, celles appartenant au second palier
par exemple. Sans le diagnostic d’effet levier, extraire un modèle à partir de ce type de
données s’avère délicat. Une méthode d’estimation classique telle que les moindres carrés
sera faussée, elle aura tendance à traverser (ou faire un pont) les ensembles de points for-
mant les paliers principaux, plaçant l’estimation au plus près de ces ensembles de points.
C’est plus ou moins ce qui arrive avec les différentes méthodes présentes, exceptés pour
l’algorithme du vbQMDPE ainsi que la méthode R-SVR proposée. Ces deux approches
restent "accrochées" au premier palier qui représente la structure dominante, leurs solu-
tions sont horizontales.
Le second test, représenté sur la figure 3.10.b., montre trois droites qui se croisent. En
dépit d’un niveau de bruit important, la structure dominante est correctement estimée par
l’approche R-SVR proposée. L’algorithme du vbQMDPE se trompe de structures mais ex-
trait tout de même correctement la seconde structure dominante. En revanche, les autres
méthodes échouent complètement à extraire une structure. Ces exemples démontrent la
capacité de la méthode proposée à extraire correctement une structure dominante à par-
tir d’un ensemble de données fortement corrompu. Des travaux complémentaires, comme
74 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

3.2. Modifications apportées aux SVR
ceux de Stewart [Ste99], sont toutefois à envisager afin de caractériser les limites de
robustesse de la méthode proposée dans le cas de structures multiples.
Tests sur la régression non-linéaire
Un des avantages important de la méthode de régression par les machines à vecteurs
supports, en comparaison avec d’autres méthodes robustes de régression, est qu’elle est
capable de traiter le cas de structures non-linéaires simplement en utilisant les fonctions
noyaux. Pour l’expérience suivante, nous comparons les résultats obtenus par l’approche
R-SVR proposée avec ceux obtenus par la méthode standard de SVR ainsi que la mé-
thode de Cherkassky [CM02]. Le réglage des paramètres est identique aux expériences
précédentes, seul le processus de pondération lié aux effets leviers est inactif. La fonction
noyau que nous utilisons est la fonction à base radiale avec une largeur fixée à 1.
Nous générons deux ensembles de données, chacun possédant un total de 350 obser-
vations.
Le premier exemple, illustré sur les figures 3.11-a et 3.11-b, est composé de :
– n1 = 100 observations issues d’un signal sinusoïdale perturbé par un bruit de type
gaussien (de moyenne nulle et d’écart type σ = 0.3), et représentées par des ’o’,
– n2 = 250 outliers uniformément distribués dans l’intervalle [60,100] sur l’espace des
x, et représentés par des ’+’.
Le second exemple, illustré sur les figures 3.11-c et 3.11-d, est composé de :
– n1 = 150 observations issues d’un signal sinusoïdal perturbé par un bruit de type
gaussien (de moyenne nulle et d’écart type σ = 0.3), et représentées par des ’o’,
– n2 = 100 observations issues d’un second signal sinusoïdal perturbé par un bruit de
type gaussien (de moyenne nulle et d’écart type σ = 0.3), et représentées par des
’2’,
– n3 = 100 outliers uniformément distribués dans l’intervalle [60,100] sur l’espace des
x, et représentés par des ’+’.
Les estimations des structures dominantes dans ces deux ensembles de données sont
également représentées sur la figure 3.11. Sur chaque figure 3.11-a, b, c et d, la courbe verte
illustre le résultat obtenu par la méthode standard de régression par les machines à vec-
teurs supports. Ce résultat constitue la première itération de la méthode de Cherkassky
ainsi que de la méthode R-SVR proposée. Sur les figures 3.11-a et 3.11-c, le résultat fi-
nal de la méthode de Cherkassky, notée MME, est représentée par la courbe rouge, et
les résultats intermédiaires issus du processus d’itération sont représentés par les courbes
pointillées. Sur les figures 3.11-b et 3.11-d, le résultat final de la méthode proposée, notée
75

Chapitre 3. Régression par les machines à vecteurs supports et modifications
R-SVR, est représenté par la courbe rouge, et les résultats intermédiaires issus du proces-
sus d’itération sont représentés par les courbes pointillées. Les résultats confirment que la
méthode R-SVR proposée est capable d’extraire correctement les structures non-linéaires
même dans un environnement très perturbé. On constate que la méthode standard est,
quant à elle, incapable de résoudre ce genre de problème, elle ne retrouve aucune struc-
ture de données. On remarque également que la méthode de Cherkassky, bien qu’elle
apporte une légère amélioration des résultats, ne parvient pas à extraire la structure
prépondérante dans l’ensemble de données.
Point d’effondrement du R-SVR
Pour clore ce chapitre et évaluer l’apport des modifications proposées, nous avons
réutilisé l’exemple présenté dans la section 2.4.2. La figure 3.12 montre les résultats déjà
présentés auxquels s’ajoutent les résultats de la méthode proposée "la régression robuste
par les machines à vecteurs supports". On remarque que le gain de robustesse de la
méthode proposée par rapport à la méthode standard est conséquent. En effet, on atteint
un point de cassure légérement supérieur à 70%, soit plus de trois fois le point de cassure
de la méthode standard. Ces résultats sont encourageants et nous allons consacrer les deux
prochains chapitres à l’application de la méthode proposée dans le cadre de l’estimation
du mouvement dans les séquences d’images.
3.3 Conclusion
La régression par machines à vecteurs supports a été présentée dans sa forme stan-
dart dans les cas de modèles linéraires et non-linéaires. Différentes améliorations ont été
apportées à cette forme standart pour la rendre robuste : marge adaptative, pondérations
adaptatives hard et soft. Ces techniques de pondération tentent de réduire progressive-
ment l’influence des outliers en x et y sur l’estimation. Nous avons testé les performances
de ces approches sur des exemples de modèles multistructures linéaires et non-linéaires
fortement bruités. Le chapitre suivant montre l’intérêt de l’approche R-SVR pour l’esti-
mation du flot optique dans un contexte de vision dynamique.
76 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

3.3. Conclusion
(a) : étape k = 1, pondération dure du SVR (b) : étape k = 1, pondération douce du SVR
(c) : étape k = 4, pondération dure du SVR (d) : étape k = 4, pondération douce du SVR
(e) : étape k = 8, pondération dure du SVR (f) : étape k = 9, pondération douce du SVR
(g) : étape k = 12, pondération dure du SVR (h) : étape k = 15, pondération douce du SVR
Fig. 3.8 – Influence des observations dans le cas linéaire. 77

Chapitre 3. Régression par les machines à vecteurs supports et modifications
(a) : étape k = 1, pondération dure du SVR (b) : étape k = 1, pondération douce du SVR
(c) : étape k = 4, pondération dure du SVR (d) : étape k = 4, pondération douce du SVR
(e) : étape k = 8, pondération dure du SVR (f) : étape k = 8, pondération douce du SVR
(g) : étape k = 13, pondération dure du SVR (h) : étape k = 17, pondération douce du SVR
Fig. 3.9 – Influence des observations dans le cas non linéaire.
78 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —
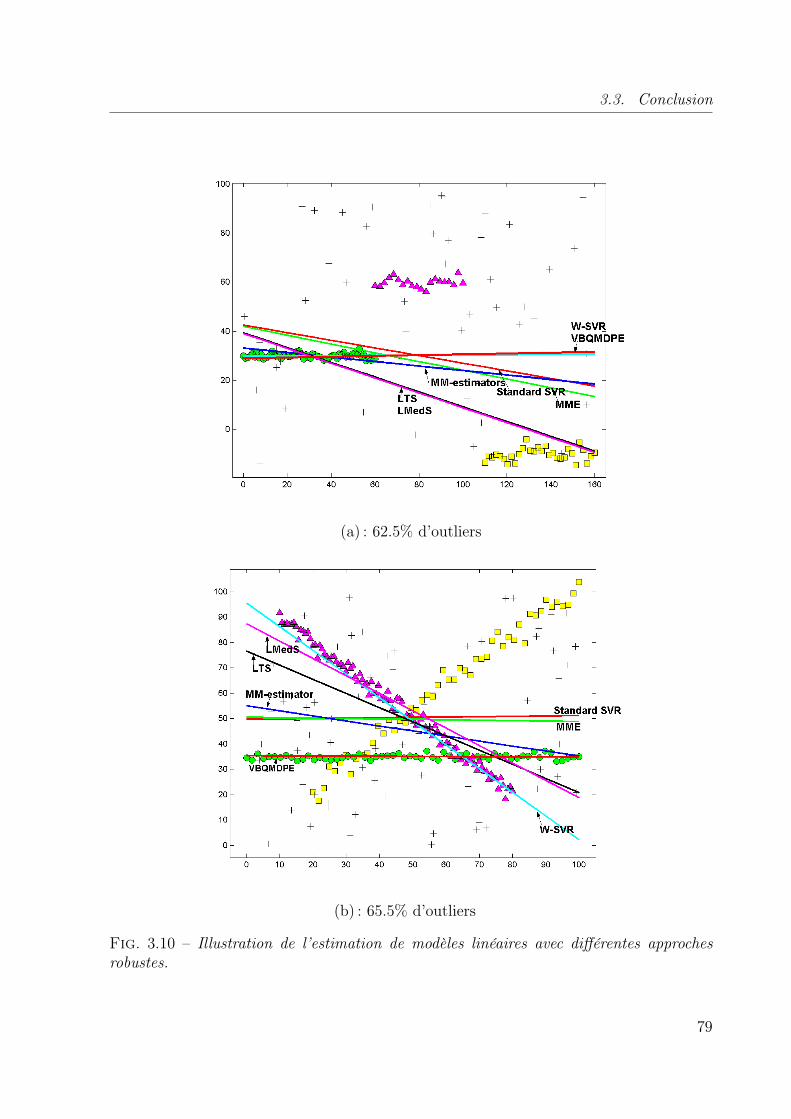
3.3. Conclusion
(a) : 62.5% d’outliers
(b) : 65.5% d’outliers
Fig. 3.10 – Illustration de l’estimation de modèles linéaires avec différentes approchesrobustes.
79

Chapitre 3. Régression par les machines à vecteurs supports et modifications
(a) : 1 structure et 71% d’outliers (b) : 1 structure et 71% d’outliers
(c) : 2 structures et 57% d’outliers (d) : 2 structures et 57% d’outliers
Fig. 3.11 – Extraction d’une structure non-linéaire dominante avec le SVR, le MME etle R-SVR.
80 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —
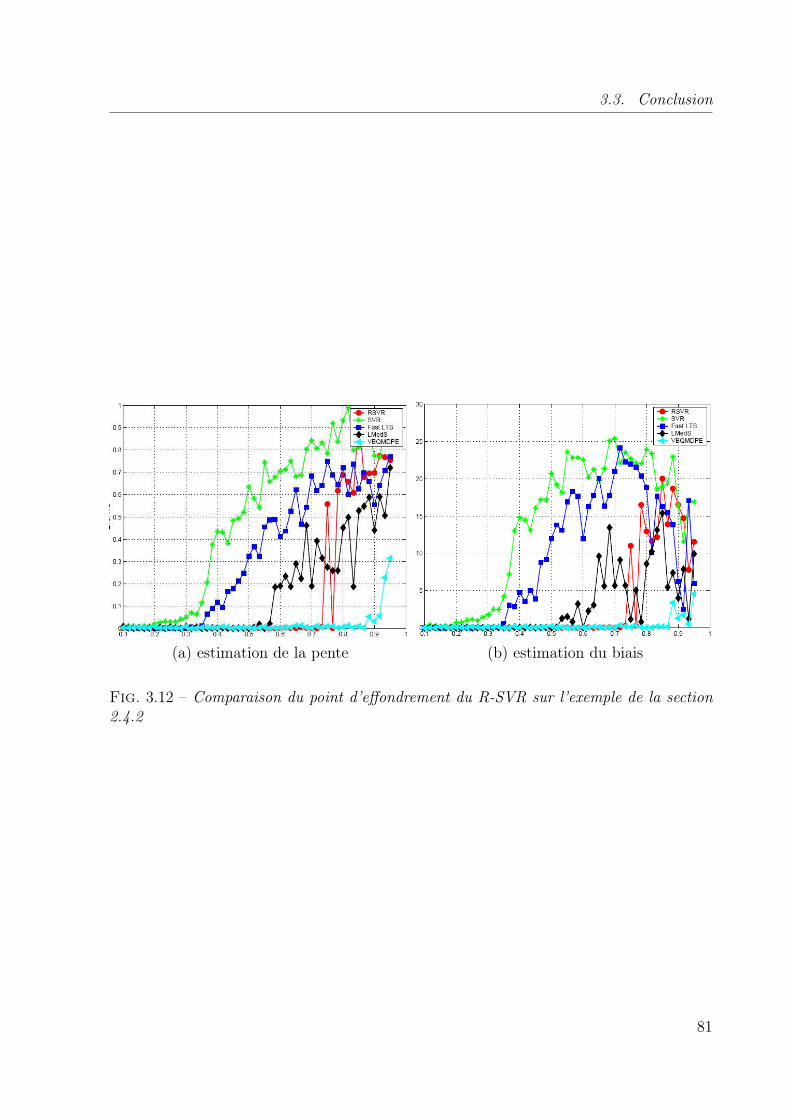
3.3. Conclusion
(a) estimation de la pente (b) estimation du biais
Fig. 3.12 – Comparaison du point d’effondrement du R-SVR sur l’exemple de la section2.4.2
81

Chapitre 4
Application à l’estimation du
mouvement : le flot optique
EN vision par ordinateur, le terme "flot optique" désigne le mouvement reflété par
la variation de l’intensité lumineuse dans une séquence vidéo. Plus précisément, Le
flot optique est le champ des vitesses, dans le plan des images, associé aux variations
spatio-temporelles de l’intensité dans ces images. Basée sur l’hypothèse de la conserva-
tion de l’intensité des pixels le long de leurs trajectoires, cette approche d’estimation du
mouvement présente, dans sa formulation initiale, quelques difficultés liées à la théorie
[BHB03] telles que :
– le problème d’ouverture, induit par la sous-détermination du problème ; nous avons
une équation avec deux inconnues à résoudre,
– la sensibilité au bruit : un seul point bruité induit au moins une erreur sur chaque
dérivée partielle (en x, y et t),
– la mauvaise estimation des déplacements importants,
– les discontinuités de l’intensité,
– etc.
Depuis la première présentation du flot optique en 1981 [HS81], de nombreuses mé-
thodes ont été publiées afin de résoudre ses problèmes. On peut classer les différentes
approches d’estimation du flot optique en quatre grandes familles :
- les approches d’optimisation locale,
- les approches d’optimisation globale,
- les approches à base de modèles paramétriques,
- les approches multirésolutions (ou multiéchelles).
82

4.1. Le flot optique
Afin de s’affranchir des discontinuités spatiales et/ou temporelles, il est primordial de
développer des algorithmes d’estimation robuste. Pour rendre l’estimation invariante au
bruit ou aux erreurs, plusieurs techniques locales d’estimation robuste peuvent être uti-
lisées [BFB94] telles que : les moindres carrés totaux, les M-estimateurs, la médiane des
moindres carrés, la transformation robuste de Hough, etc.
Dans le cadre de notre travail, nous avons utilisé une approche basée sur un modèle
paramétrique, de type constant ou affine, où l’estimation du flot optique s’effectue à l’aide
de la régression par les machines à vecteurs supports. Nous avons vu dans le chapitre 3
que l’extension à la régression des machines à vecteurs supports, développée par l’équipe
de Vapnik [Vap95], pouvait être utilisée comme un nouvel estimateur robuste du flot
optique.
4.1 Le flot optique
Avant d’appliquer les différentes méthodes qui ont été développées dans le but de
résoudre le problème du flot optique, nous allons effectuer un petit rappel sur la théorie
du flot optique, ainsi que sur ses problèmes inhérents, dans les trois paragraphes suivants.
Tout d’abord, qu’est ce que le flot optique? Comment le définir?
4.1.1 Définition
Le flot optique désigne le champ bidimensionnel des vitesses mesurées à partir des
variations de l’intensité lumineuse dans les séquences vidéos. La première formalisation
le caractérisant est due à Horn et Shunck [HS81] ; elle n’est pas issue d’une analyse
physique rigoureuse mais se base sur l’hypothèse de conservation de l’intensité : il s’agit
d’une équation de conservation. L’intensité d’un pixel est supposée constante le long de
sa trajectoire entre deux images successives. Cela implique que toute variation d’intensité
est la conséquence d’un mouvement ; nous verrons plus loin que ce n’est pas toujours le
cas en pratique. Le flot optique nous donne la possibilité de percevoir le mouvement (sa
direction, son amplitude relativement aux autres mouvements) mais ne représente pas le
mouvement réel dans la séquence.
Dans la suite, nous détaillons la théorie à partir de cette hypothèse de conservation
de l’intensité jusqu’à l’équation de contrainte du flot optique.
83

Chapitre 4. Application à l’estimation du mouvement : le flot optique
4.1.2 La théorie
L’estimation du flot optique est développée à partir de l’utilisation du gradient de
l’intensité. L’hypothèse principale est qu’un point (x,y) d’une image conserve son intensité
lumineuse entre les instants t et t + dt le long de sa trajectoire (on suppose qu’entre deux
images successives le déplacement de ce point reste limité (dx,dy)), c’est à dire :
I(x,y,t) = I(x + dx,y + dy,t + dt) (4.1)
Le développement limité au premier ordre de cette équation (4.1) en série de Taylor
nous donne :
I(x + dx,y + dy,t + dt) ∼= I(x,y,t) +∂I
∂x× dx +
∂I
∂y× dy +
∂I
∂t× dt (4.2)
Remplaçons ce développement (4.2) dans l’équation initiale (4.1), nous obtenons :
∂I
∂x× dx +
∂I
∂y× dy +
∂I
∂t× dt = 0 (4.3)
Divisons enfin cette dernière équation (4.3) par dt afin d’obtenir ce qui se nomme
l’équation de contrainte du flot optique (ECFO) :
∂I
∂x× dx
dt+
∂I
∂y× dy
dt+
∂I
∂t= 0 (4.4)
L’équation de contrainte du flot optique (4.4) peut aussi être ré-écrite sous une forme
vectorielle utilisant l’opérateur du gradient spatial 5I :
5I =
(∂I∂x∂I∂y
)(4.5)
Ce qui nous donne la forme vectorielle suivante :
< 5I,V > +It = 0 (4.6)
Où < .,. > représente le produit scalaire, V = (dxdt
,dydt
)T le vecteur vitesse du pixel (x,y)
et It = ∂I∂t
le gradient temporel de l’intensité.
L’équation du flot optique étant maintenant définie, nous présentons les problèmes
souvent rencontrés lors du calcul du flot optique.
84 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

4.2. Problèmes liés au flot optique
4.2 Problèmes liés au flot optique
En fait, le mouvement ayant lieu dans le plan image n’est perçu qu’à travers des
variations temporelles de l’intensité. C’est cette variation qui sert de base à l’estimation
du mouvement. La mesure du mouvement apparent se heurte donc à plusieurs problèmes
fondamentaux. Tout d’abord, une variation d’intensité dans l’image n’est pas forcément
la conséquence d’un mouvement physique, il peut s’agir d’une variation locale ou globale
de l’éclairage de la scène, voire d’un bruit d’acquisition. Par ailleurs, certains mouvements
dans la scène peuvent ne pas provoquer de variations temporelles de l’intensité.
4.2.1 Le problème d’ouverture
Le problème d’ouverture constitue une difficulté fondamentale dans l’évaluation d’un
mouvement, ce phénomène est représenté sur la figure 4.1. Si l’on observe un objet de
couleur uniforme à travers une petite ouverture et que l’on ne voit qu’une portion recti-
ligne du contour de cet objet, on ne pourra percevoir que la composante du mouvement
perpendiculaire à ce contour. Ce cas est représenté par le cadre A sur la figure 4.1. En re-
vanche, lorsque la portion visible comporte un coin, l’ambiguïté du déplacement est levée :
le problème d’ouverture n’existe plus. Ce cas est représenté par le cadre B. En traitement
d’images, on préférera appeler "point d’intérêt" un coin, cette notion correspondant à une
courbure d’une surface suivant les deux axes de coordonnées.
Fig. 4.1 – Représentation du problème d’ouverture. A : fenêtre d’observation d’une portionrectiligne. B : fenêtre d’observation d’une portion possédant un coin.
85

Chapitre 4. Application à l’estimation du mouvement : le flot optique
4.2.2 L’existence du gradient
L’oeil humain perçoit le mouvement d’un objet par l’identification des mêmes points,
et/ou régions, et/ou contours aux positions successives de l’objet observé. Cette correspon-
dance est habituellement déterminée en supposant que la couleur, la forme ou l’intensité
ne change pas ou peu durant un déplacement. Cependant, dans certaines situations, ce
mouvement pourra ne pas être perçu ou pourra même être interpreté de manière erronée.
Par exemple : un objet homogène se déplacant sur un fond homogène de même couleur.
Dans ce cas, l’existence du gradient spatial n’est pas respectée (cela implique que le gra-
dient temporel est nul) donc aucun mouvement ne peut être perçu. Par ailleurs, même si
la couleur du fond est différente de celle de l’objet observé, et que cet objet est un disque
tournant autour d’un axe passant par son centre et perpendiculaire au plan image, alors
aucun mouvement n’est perceptible. En effet, les points appartenant au contour du disque
possèdent bien un gradient spatial non-nul, mais leur gradient temporel est nul. Inver-
sement, la présence d’un mouvement caméra va modifier en chaque point possédant un
gradient spatial la valeur du gradient temporel. Le mouvement étant observé par rapport
à la position de la caméra, tout mouvement perçu sera la combinaison du mouvement
observable d’un objet par rapport à la caméra, ainsi que du mouvement propre de la
caméra (obtenu via le mouvement apparent de toute la scène).
4.2.3 Les phénomènes d’occlusions
Dans une séquence d’images, lorsqu’un objet a un mouvement relatif, par rapport au
fond ou à d’autres objets, il masque ou découvre une partie de l’image. De ce fait, il
apparaît au bord de son contour des variations d’intensité qui permettent de détecter le
mouvement mais qui ne le représente pas. Le champ des vecteurs vitesse est discontinu
aux contours des objets en mouvement, sauf le cas rare où le fond est uniforme. Aux points
présents sur les contours, la contrainte de conservation n’est pas respectée, c’est à dire que
l’équation de contrainte du flot optique n’est pas applicable et qu’il n’est théoriquement
pas possible d’effectuer l’estimation du mouvement. Malheureusement, c’est bien souvent
sur le bord d’un objet que l’on trouve des gradients forts, c’est à dire plus d’informations
sur son mouvement.
4.2.4 La périodicité de structure dans l’image
La périodicité de structure apparaît lorsque l’image contient des structures pério-
diques, comme par exemple une roue à rayons, ou encore des textures régulières. Elle est
86 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

4.2. Problèmes liés au flot optique
liée à la fréquence d’acquisition de la caméra ainsi qu’à la vitesse de déplacement/rotation
de ses structures. Il s’agit en fait d’un problème de mise en correspondance des valeurs
d’intensité de chaque pixel dans des images successives. Dans le cas d’une roue, ce pro-
blème se pose lorsque la fréquence de Nyquist n’est pas respectée, ce qui est repré-
senté sur la figure 4.2. En effet, si la vitesse angulaire de la roue est plus grande que
(πn× la fréquence d’acquisition), où n représente le nombre de rayons, il y aurait une
ambiguïté dans le processus de correspondance et le mouvement perçu ne sera certaine-
ment pas représentatif du mouvement réel. Les téléspectateurs de courses automobiles
connaissent bien cette illusion optique. Ce phénomène a également lieu dans le cas de
textures régulières si le déplacement de la zone texturée entre deux images est supérieur
ou égal à la moitié de la période spatiale de la texture.
Fig. 4.2 – Représentation du problème de périodicité de structure.
4.2.5 Les variations lumineuses
La théorie du flot optique s’appuie sur la conservation de l’intensité, c’est à dire
que l’illumination est supposée constante temporellement. Pourtant, dans les séquences
d’images réelles, il arrive très fréquemment que la luminance subit une variation locale,
voire globale. Les ombres portées, les sources lumineuses à intensité variable et les reflets
sont autant de causes à ces variations. Sauf cas particuliers où la variation lumineuse
est explicitement prise en compte, la plupart des algorithmes la supposent inexistante ou
négligeable, et interprètent donc ces variations comme les conséquences de mouvements
87

Chapitre 4. Application à l’estimation du mouvement : le flot optique
qui n’existent pas physiquement.
4.2.6 Les déplacements trop importants
La formulation du flot optique repose sur un développement limité à l’ordre 1 de
Taylor (linéaire très localement). Si le décalage spatial entre 2 images ou si le déplace-
ment, donc la vitesse relative, d’un objet sont trop importants (de l’ordre de 3 à 4 pixels en
pratique), l’hypothèse implicite de petit déplacement issue du développement de Taylor
à l’ordre un n’est plus respectée. Les vecteurs vitesse ne seront alors plus représentatifs
des mouvements réels.
Après cette introduction des différents problèmes rencontrés lors de l’estimation du
flot optique, nous allons étudier les diverses stratégies mises en oeuvre afin de résoudre ce
problème et de limiter l’influence de ces difficultés dans les résultats.
4.3 Les différentes approches
Le problème de la résolution de l’équation de contrainte du flot optique est un pro-
blème mal posé. En effet, le système à résoudre est sous-déterminé : il y a deux inconnues
pour une seule équation. Depuis sa première présentation, de nombreuses contributions
ont tenté de contourner ce problème en utilisant différentes approches. Ces approches
peuvent être regroupées en quatre familles : l’optimisation locale, l’optimisation globale,
les modèles paramètriques et la multirésolution.
4.3.1 Approches par optimisation locale
Les approches par optimisation locale proposent de combiner plusieurs équations de
type équation de contrainte du flot optique en chaque point/pixel, ce qui crée un système
linéaire sur-déterminé, afin d’optimiser l’estimation du vecteur vitesse en ce point/pixel.
Certaines techniques utilisent des sources d’information multiples, dites multispectrales,
telles que les méthodes de Mitiche et al. [MB96] ou de Wohn et al. [WXDR83]. D’autres
effectuent des opérations sur les images pour fournir d’autres informations décorrélées
telles que le contraste, l’entropie ou les dérivées d’ordre supérieur à 1, citons dans ce
cadre les approches de Tretiak et Pastor [TP84], de Campani et Verri [CV90].
Enfin, d’autres techniques utilisent la décomposition fréquentielle de l’image, ou sur des
bases d’ondelettes telle que l’approche de Baaziz et Labit [BL91].
88 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

4.3. Les différentes approches
4.3.2 Approches par optimisation globale
Les approches d’optimisation globale sont plus fréquemment rencontrées dans la litté-
rature. Elles ajoutent aux solutions recherchées via l’équation de contrainte du flot optique
une contrainte de lissage ; il s’agit en fait de techniques de régularisation. Aux prix d’un
coût calculatoire plus important, ces techniques s’avèrent plus robustes et fournissent des
résultats de meilleure qualité que les approches par optimisation locale. Cette famille
d’approches se base donc sur l’apport d’une information complémentaire qui privilégie
l’aspect continu du champ des vecteurs vitesses. Le problème d’estimation du flot optique
peut être mis sous la forme d’une minimisation tel qu’il faut trouver à chaque pixel (x,y)
le déplacement d = (dx,dy) qui minimise J(d) avec :
J(d) =∑
x
∑
y
(I(x,y,t) − I(x + dx,y + dy,t + dt))2 (4.7)
Qui peut aussi être écrite sous forme continue :
J(d) =
∫ ∫(∂I
∂x.u +
∂I
∂y.v +
∂I
∂t)2dxdy (4.8)
avec u = dxdt
et v = dydt
.
Il s’agit d’un problème de minimisation classique pour lequel on peut utiliser un al-
gorithme de descente suivant la plus grande pente en chaque point. Toutefois, à cause du
problème d’ouverture, le problème reste mal posé et la solution n’est pas unique. Pour
palier à cela, le problème est reformulé en utilisant la théorie de la régularisation. Une
contrainte, qui est une information a priori, est introduite dans le but d’assurer l’existence,
l’unicité et la stabilité de la solution. Dans ce cadre, deux approches fondamentales ont
été développées : la régularisation déterministe et la régularisation statistique.
Les techniques de régularisation déterministes
Approche de Horn et Schunck
Horn et Schunck [HS81] proposent une méthode d’estimation du flot optique en ajou-
tant à l’équation de contrainte du flot optique une contrainte de régularité de la variation
des vecteurs vitesses de l’image. Cette méthode consiste à minimiser sur toute l’image la
somme pondérée au carré du développement limité au premier ordre de l’intensité et des
89

Chapitre 4. Application à l’estimation du mouvement : le flot optique
carrés des gradients de vitesse :
G =
∫ ∫ [(∂I
∂x.u +
∂I
∂y.v +
∂I
∂t)2 + α2
((∂u
∂x)2 + (
∂u
∂y)2 + (
∂v
∂x)2 + (
∂v
∂y)2
)]dxdy (4.9)
Ou noté plus simplement :
G =
∫ ∫ ((Ix.u + Iy.v + It)
2 + α2(u2x + u2
y + v2x + v2
y))dxdy (4.10)
La minimisation de G sur toute l’image va permettre de trouver en chaque point un vec-
teur vitesse (u,v)T . Le facteur de pondération α2 sera important dans les zones où les
gradients de l’intensité sont faibles, ce qui veut dire que lorsque les gradients de l’intensité
sont nuls, le vecteur vitesse sera une moyenne des vecteurs vitesses voisins. Ce facteur
α peut être choisi en fonction de la régularité souhaitée de la solution. Le schéma de
résolution sera itératif afin de propager la contrainte dans le champ des vecteurs vitesses.
Cette formulation proposée par Horn et Schunck apporte une solution aux problèmes
de l’ouverture et de l’existence du gradient. Cependant, aux points ne souffrant pas du
problème d’ouverture, le vecteur vitesse subira tout de même l’influence de son voisinage
et s’éloignera donc de la solution.
Approche de Nagel et Enkelmann
Les travaux de Nagel et Enkelmann [NE86] ont introduit le concept de contrainte de
régularité orientée. De la même façon que la méthode précédente, une contrainte addi-
tionnelle de régularité est utilisée. La fonctionelle à minimiser s’écrit :
G =
∫ ∫ [(Ix.u + Iy.v + It)
2 + α2trace((∇V )T W (∇V )
)]dxdy (4.11)
avec :
W =F
trace(F )(4.12)
Où :
F =
(I2y + γ(I2
xy + I2yy) −IxIy − γIxy(Ixx + Iyy)
−IxIy − γIxy(Ixx + Iyy) I2x + γ(I2
xx + I2xy)
)(4.13)
Dans la contrainte de régularisation, ∇V est le gradient de vitesse et W une matrice de
pondération. Cette matrice a pour but de forcer la régularité uniquement de la composante
orthogonale du vecteur vitesse au gradient de l’intensité. Quant au terme γ, il permet de
s’assurer de la non-singularité de F . Comme pour la méthode de Horn et Schunck, cette
méthode utilise un schéma de résolution itératif afin de diffuser la contrainte de régularité
90 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

4.3. Les différentes approches
dans le champ des vecteurs vitesses. De même que l’approche de Horn et Schunck,
l’approche de Nagel et Enkelmann apporte une solution aux problèmes de l’ouver-
ture et de l’existence du gradient, de plus, elle évite en grande partie le problème de la
continuité forcée induite dans l’approche de Horn et Schunck. En revanche, son emploi
dans la pratique est délicat du fait de l’utilisation des dérivées secondes de l’intensité, très
difficiles à obtenir sur des images réelles souvent bruitées.
Les techniques de régularisation statistiques
Les méthodes de régularisation précédentes imposent une contrainte de régularité
sur la variation du champ des vecteurs vitesses. Horn et Schunck appliquent cette
contrainte inconditionellement à toute l’image, Nagel et Enkelmann utilisent une
condition d’orientation locale pour diriger la propagation de cette contrainte. On peut
remarquer que le mouvement d’un pixel n’est influencé que par ses voisins presque par-
tout dans l’image. Cette remarque conduit à l’utilisation d’un modèle Markovien. En effet,
dans un processus de Markov, on fait l’hypothèse que la probabilité qu’un point prenne
une valeur sachant la valeur des points de son voisinage est égale à la probabilité en ce
point sachant celle de tous les autres points. Le théorème de Hammersley-Clifford
donne l’équivalence, dans un processus de Markov, entre une distribution de probabilité
et une distribution de Gibbs d’une fonction d’énergie. Cette énergie est la somme des
fonctions de potentiels exprimant les intéractions locales, qui sont représentées par les
gradients de vitesse ux, uy, vx et vy dans le cas du mouvement.
Appliquée à l’équation de contrainte du flot optique, cette approche amène à une
formulaion du type de celle de Horn et Schunck, dans laquelle il faut minimiser sur
toute l’image le terme G défini par :
G =
∫ ∫ [(Ix.u + Iy.v + It)
2 +(Φ(u2
x) + Φ(u2y) + Φ(v2
x) + Φ(v2y)
)]dxdy (4.14)
Où la fonction Φ (telle que 0 ≤ Φ(x) ≤ 1), approximation de la distribution de probabi-
lité, permet de ne propager la contrainte de régularité que si celle-ci est en dessous d’un
certain seuil. La régularité est évaluée a posteriori dans un schéma itératif.
L’intérêt de cette modélisation réside dans la prise en compte des intéractions locales
entre les pixels tout en ayant une approche globale. C’est une approche stochastique dont
le but est de prendre en compte les discontinuités du champ des vecteurs vitesses.
91

Chapitre 4. Application à l’estimation du mouvement : le flot optique
4.3.3 Modèles paramétriques
Une alternative à l’introduction de lissage global du champ des vecteurs vitesses est
de proposer un modèle paramétrique de ce dernier, en spécifiant sa nature sur l’ensemble
d’une région. L’utilisation d’une modélisation paramétrique permet de représenter le mou-
vement par régions (ou blocs) du plan image dans lesquelles il est supposé se trouver un
mouvement cohérent dans le sens du modèle choisi. Classiquement, ces modèles sont des
fonctions utilisant 2 à 12 paramètres qui modélisent le mouvement. Chaque pixel de la
région contribue à l’estimation de ces paramètres afin d’obtenir une estimation fiable du
mouvement. Cependant, l’utilisation d’un modèle paramétrique suppose que les objets
sont rigides et qu’ils sont composés de surfaces planes.
Les modèles paramétriques du mouvement les plus utilisés sont :
1) Modèle de mouvement constant (ou translation) :
Vθ(x,y) =
(a
b
)(4.15)
Il s’agit de paramétrer la translation dans le plan image d’un pixel (x,y). Ce modèle
est approprié pour modéliser des surfaces ayant subi une translation parallèle au
plan image. On retrouve son utilisation dans les applications de type compression
vidéo où il s’applique à des blocs de petite taille (typiquement 8× 8 ou 16× 16). En
fait, sur des blocs de taille réduite, le champ de mouvement peut être correctement
représenté par un modèle constant même si le mouvement global est plus complexe.
2) Modèle de mouvement affine simplifié :
Vθ(x,y) =
(a0 −b0 a1
b0 a0 b1
).
x
y
1
(4.16)
Il s’agit d’une généralisation du modèle constant. Il permet de caractériser une
classe importante de mouvements 2D, tels que les translations, les rotations, les
homothéties ainsi que leurs combinaisons.
3) Modèle de mouvement affine :
Vθ(x,y) =
(a0 a1 a2
b0 b1 b2
).
x
y
1
(4.17)
92 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

4.3. Les différentes approches
Il rajoute au modèle simplifié les déformations du type afinité et cisaillement. Il
s’agit probablement du modèle le plus utilisé dans les algorithmes d’analyse du
mouvement car il permet une bonne représentativité des mouvements.
4) Modèle de mouvement homographique :
Vθ(x,y) =
(A1
A3
A2
A3
)(4.18)
Avec
A1 =(
a0 a1 a2
).
x
y
1
(4.19)
A2 =(
a3 a4 a5
).
x
y
1
(4.20)
A3 =(
a6 a7 a8
).
x
y
1
(4.21)
En pratique, ce modèle est peu fiable lorsque l’amplitude du mouvement est faible,
ce qui est souvent le cas pour deux images successives d’une séquence d’images. On
trouve son utilisation pour estimer le mouvement entre des images plus éloignées
temporellement ou lorsque les mouvements de la caméra sont de forte amplitude.
5) Modèle de mouvement quadratique :
Vθ(x,y) =
(a0 a1 a2 a3 a4 a5
b0 b1 b2 b3 b4 b5
).
x2
y2
xy
x
y
1
(4.22)
Ce modèle, comme le modèle homographique, prend en compte des mouvements
plus complexes que les simples tanslations, rotations 2D ou zooms. Il permet de
mieux estimer les déformations globales dues à la projection dans le plan image
d’objets en mouvements dans la scène 3D. Il s’avère que la partie affine du mo-
dèle quadratique contient en pratique la majeure partie de l’information, tandis que
93

Chapitre 4. Application à l’estimation du mouvement : le flot optique
le raffinement qu’apportent les termes de second degré est souvent bruité et instable.
Pour conclure, il est important de noter que plus la région considérée est petite, plus
le modèle employé est simple.
Le respect de la contrainte du flot optique mène alors à minimiser l’erreur résiduelle
en chaque point :
Erreur(x,y) =< ∇I(x,y),Vθ(x,y) > +It(x,y) (4.23)
Ce qui peut être optimisé au sens des moindres carrés, comme l’ont proposé Lucas et
Kanade dès 1981 [LK81] avec un modèle constant et un facteur poids pour chaque point.
La méthode de Lucas et Kanade permet de calculer au point (x,y) un vecteur vitesse
V , constant sur un petit voisinage spatial Ω, par minimisation de :
∑
(x,y)∈Ω
W 2(x,y)[< ∇I(x,y),Vθ(x,y) > +It(x,y)]2 (4.24)
Où W (x,y) représente une matrice de pondération qui donne plus d’importance aux
contraintes au centre du voisinage par rapport à celles de la périphérie. Cette méthode
utilise uniquement l’équation de contrainte du flot optique, en faisant l’hypothèse d’une
vitesse uniforme sur le voisinage Ω. Dans le cas où tous les poids sont égaux, la résolution
est équivalente à la méthode des moindres carrés. Dans leur étude sur les performances
des techniques d’estimation du flot optique, Barron et al. [BFB94] utilisent un voisinage
spatial 5 × 5 et une matrice de pondération Gaussienne W 2(x,y) dont le noyau 1D est
[0.0625,0.25,0.375,0.25,0.0625].
D’autres méthodes de type stochastiques [SAH91] seront aussi implémentées pour
modéliser les incertitudes afin d’accorder plus de confiance à un résultat parmi plusieurs
provenant soit du voisinage, soit de calculs avec différentes méthodes. La pondération
peut également être construite à partir d’une mesure d’erreur définie sur chaque pixel au
voisinage, comme par exemple |Ixu + Iyv + It| où (u,v) est le résultat sur le voisinage.
Enfin, après normalisation, la mesure d’erreur peut également être considérée comme une
probabilité. Dans une approche multiéchelle, Weber et Malik [WM95] utilisent un tel
calcul d’erreur locale. Les champs de vecteurs vitesses sont calculés à chaque échelle par
les moindres carrés, puis pondérés par leurs erreurs locales et regroupés dans un système
d’équations global, lui aussi résolu par les moindres carrés. Cette approche a l’intérêt de
combiner les avantages de l’approche multiéchelle ainsi que ceux de l’approche stochas-
tique.
94 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

4.3. Les différentes approches
Les techniques plus récentes [OB95][BHS98][OS99][Far01][YH00][WS03] proposent d’iden-
tifier le paramètre θ par estimation robuste. Cela permet de gérer les discontinuités du
champ des vecteurs vitesses en indiquant les points non conformes au modèle d’ensemble
estimé (les outliers). On peut alors procéder récursivement à une nouvelle identification
de paramétrage sur ce sous-ensemble de points, et ainsi de suite. Bab-hadiashar et
Suter (1996) [BHS98], ainsi que Ong et Spann (1999) [OS99], ont utilisé des méthodes
basées sur la moindre médiane des carrés pour résoudre le problème du flot optique. Ye
et Haralick (2000) [YH00] ont, quant à eux, utilisé une méthode basée sur les moindres
carrés tronqués. Enfin, Wang et Suter [WS03] ont utilisé leur technique du vbQMDPE.
L’implémentation des machines à vecteurs supports en qualité de régresseur pour résoudre
le problème du flot optique se classe dans cette catégorie d’approches basées sur un modèle
paramétrique.
4.3.4 Approches multirésolutions ou multiéchelles
Afin d’améliorer l’estimation du champ des vecteurs vitesses, de nombreux travaux
ont utilisé une approche multirésolution. Cette approche, qui est applicable à la plupart
des méthodes de calcul du flot optique, est bâtie sur une pyramide d’images d’une même
scène à des résolutions de pluss en pluss fines. La méthode de calcul choisie est ensuite
appliquée depuis l’image de plus basse résolution jusqu’à l’image de résolution la plus fine.
Un avantage de cette approche est une meilleure gestion des grands déplacements. En effet,
les mouvements plus importants deviennent accessibles par l’estimation aux résolutions
basses. Ensuite, chaque niveau supplémentaire permet de préciser la solution obtenue
aux niveaux supérieurs. Les résultats à une résolution donnée servent de prédiction au
calcul de la résolution supérieure. On peut relier à l’échelle immédiatement supérieure le
déplacement dl du point pl de l’échelle l, ce qui, dans le cas d’échelles progressivement
étagées d’un facteur 2, s’exprime par :
dl = 2dl+1 + ∆dl (4.25)
On peut ainsi reformuler l’équation de contrainte du flot optique dans ce cadre multié-
chelles. Un développement de Taylor de l’hypothèse d’invariance de l’intensité de ce
point au cours de son déplacement nous donne :
I(pl + dl,t + dt) = I(pl,t) (4.26)
95

Chapitre 4. Application à l’estimation du mouvement : le flot optique
Ce qui permet d’obtenir :
∇I(pl + 2dl+1,t + dt) · ∆dl
dt+
I(pl + 2dl+1,t + dt) − I(pl,t)
dt= 0 (4.27)
Cette expression est connue sous le nom de version incrémentale de l’équation de contrainte
du flot optique.
Les avantages majeurs des approches multirésolutions sont :
– de proposer des solutions de meilleure qualité qui nécessitent un temps de conver-
gence moins élevé,
– d’appréhender les situations de déplacements importants, nécessitant tout de même
des zones de recouvrement relativement larges pour rester valides.
4.4 Expérimentation
Comme il a été vu précédemment, l’équation 4.6 de contrainte du flot optique s’écrit :
< 5I,V > +It = 0 (4.28)
Où < .,. > représente le produit scalaire et V = (dxdt
,dydt
)T le vecteur vitesse du pixel (x,y).
Dans notre approche, nous avons utilisé le modèle paramétrique de mouvement où le
vecteur vitesse représente les paramètres à estimer. Deux modèles linéaires ont été rete-
nus : le modèle constant et le modèle affine.
- Modèle constant : (dxdtdydt
)=
(a
b
)(4.29)
- Modèle affine :(
dxdtdydt
)=
(a0 a1 a2
b0 b1 b2
).
x
y
1
(4.30)
Nous allons donc résoudre ce problème d’optimisation à l’aide de la régression robuste
par les machines à vecteurs supports. Nous devons réécrire l’équation 4.6 afin de respecter
le formalisme du SVR :
< 5I,V >=< W,X >= −It (4.31)
Par la suite, seul le modèle affine sera traité car il implique le modèle constant.
96 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

4.4. Expérimentation
En remplaçant le vecteur vitesse V par le modèle affine dans l’équation 4.6, nous
obtenons :(
Ix Iy
).
(a0.x + a1.y + a2
b0.x + b1.y + b2
)+ It = 0 (4.32)
Ce qui peut être développé comme suit :
a0.x.Ix + a1.y.Ix + a2.Ix + b0.x.Iy + b1.y.Iy + b2.Iy + It = 0 (4.33)
L’équation 4.33 peut être écrite sous forme du produit scalaire suivant :
(a0 a1 a2 b0 b1 b2
).
x.Ix
y.Ix
Ix
x.Iy
y.Iy
Iy
+ It = 0 (4.34)
Où X est égal à (x.Ix,y.Ix,Ix,x.Iy,y.Iy,Iy)T et W représente le vecteur des paramètres
du modèle affine. Nous obtenons ainsi l’équation suivante qui respecte le formalisme de
la régression par les machines à vecteurs supports :
W T .X + It = 0 (4.35)
4.4.1 Une base de comparaison répandue : Yosemite
La séquence Yosemite est une séquence synthétique représentant le survol d’une re-
construction en 3 dimensions de la vallèe de Yosemite, une image tirée de la séquence
est montrée sur la figure 4.3. La vallée a été créée en appliquant une image aérienne de
la vallée sur une carte de profondeur, le ciel est construit avec une séquence d’images
représentant des nuages passant devant la lune. Cette séquence est très utilisée dans les
travaux traitant du problème du flot optique : il s’agit d’une des séquences synthétiques
les plus compliquées. Tout d’abord car cette séquence combine un mouvement divergeant,
le sol, avec un mouvement de translation, le ciel. De plus, la séquence est pauvrement
échantillonnée en temps et les déplacements importants sont sujets à un mauvais "alia-
sing" temporel. Enfin, il est à noter que l’équation de contrainte du flot optique n’est pas
respectée dans la zone nuageuse à cause de la variation d’intensité de la lune à travers les
97

Chapitre 4. Application à l’estimation du mouvement : le flot optique
nuages. Cependant, cette séquence possède un grand intérêt : elle permet de mesurer qua-
litativement et comparativement les méthodes grâce à la connaissance du champ correct
des vecteurs vitesses, représenté sur la figure 4.4.
Fig. 4.3 – Image de la séquence "Yosemite".
La figure 4.5-a montre le résultat obtenu avec le critère des moindres carrés utilisé
avec un modèle affine. Comme nous pouvons le voir, le champ de vecteur est localement
divergent au niveau de la lune. Dans la littérature, de nombreux articles excluent la
zone du ciel des résultats car celle-ci ne respecte pas la contrainte de conservation de
l’intensité. Afin de prendre en compte les variations d’intensité dans une séquence d’images
qui ne seraient pas issues d’un mouvement, nous avons légèrement modifié l’équation de
contrainte du flot optique en y ajoutant un terme inconnu w.
Ix.u + Iy.v + w + It = 0 (4.36)
L’objectif de ce terme est d’absorber la variation d’intensité indésirable dans le bloc
traité afin de ne pas perturber l’estimation du vecteur paramètre W . D’un point de vue
géométrique, il s’agit de l’offset du plan dont on cherche à estimer les paramètres : si
l’équation de contrainte du flot optique est respectée, le plan passe par l’origine (si Ix et
98 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —
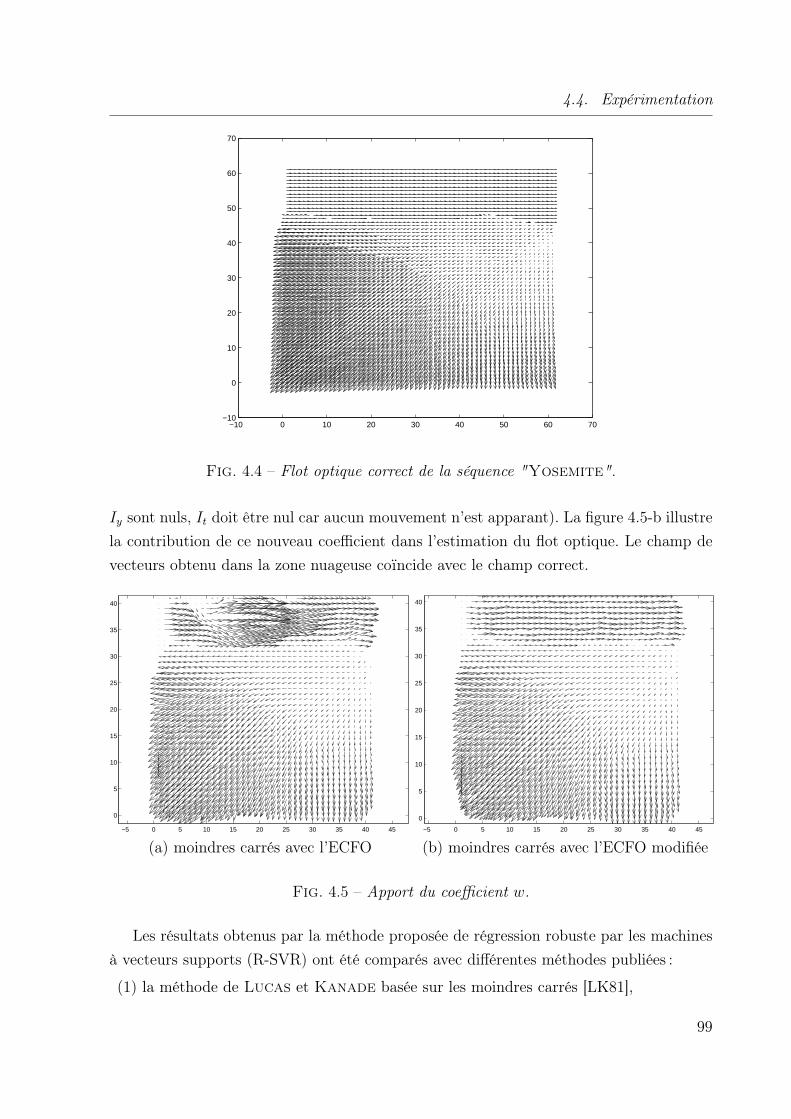
4.4. Expérimentation
−10 0 10 20 30 40 50 60 70−10
0
10
20
30
40
50
60
70
Fig. 4.4 – Flot optique correct de la séquence "Yosemite".
Iy sont nuls, It doit être nul car aucun mouvement n’est apparant). La figure 4.5-b illustre
la contribution de ce nouveau coefficient dans l’estimation du flot optique. Le champ de
vecteurs obtenu dans la zone nuageuse coïncide avec le champ correct.
−5 0 5 10 15 20 25 30 35 40 45
0
5
10
15
20
25
30
35
40
(a) moindres carrés avec l’ECFO−5 0 5 10 15 20 25 30 35 40 45
0
5
10
15
20
25
30
35
40
(b) moindres carrés avec l’ECFO modifiée
Fig. 4.5 – Apport du coefficient w.
Les résultats obtenus par la méthode proposée de régression robuste par les machines
à vecteurs supports (R-SVR) ont été comparés avec différentes méthodes publiées :
(1) la méthode de Lucas et Kanade basée sur les moindres carrés [LK81],
99

Chapitre 4. Application à l’estimation du mouvement : le flot optique
(2) la méthode de Ye basée sur les moindres carrés tronqués [YH00]. Pour réduire
le temps de calcul prohibitif de l’estimateur des moindres carrés tronqués, l’im-
plémentation est basée sur l’algorithme du Fast-LTS [RL87], un des plus efficaces
actuellement,
(3) la méthode de Ong basée sur la médiane des moindres carrés [OS99],
(4) l’approche basée sur le MeanShift de Wang [WS03],
(5) l’approche basée sur la régression par les machines à vecteurs supports standard
[Vap95].
Dans nos tests, un bloc de 7 × 7 pixels est utilisé pour calculer le vecteur vitesse lo-
calement. Les dérivées sont calculées par un filtre linéaire avec les coefficients suivants :112
(−1, 8, 0, −8, 1). Nous avons également paramétré la valeur du compromis C et la valeur
initiale de largeur de marge ε ainsi : C = 10, ε = 0.001. Enfin, les paramètres βx et βy de
la méthode R-SVR proposée ont été fixés respectivement à 2 et 0.8.
Nous avons complèté les tests comparatifs avec un algorithme efficace d’estimation du
flot optique récemment proposé par Färneback [Far01]. Dans cette approche, le mou-
vement paramétrique est estimé en utilisant des tenseurs d’orientation 3D. Nous avons
utilisé la dernière version de cet algorithme, qui est basée sur la combinaison d’un modèle
de mouvement affine et d’un algorithme de segmentation par croissance de régions.
Afin d’étudier la robustesse des différents estimateurs cités, la séquence d’images a été
dégradée par l’ajout d’un bruit uniforme impulsionnel de type sel et poivre d’un niveau
croissant. Le niveau de ce bruit est défini dans l’ensemble : 0, 2, 4, 6, 8, 10 (%). Ce bruit
impulsionnel cause localement une importante discontinuité dans le mouvement apparent.
Les figures 4.6 et 4.7 nous montrent les champs de vecteurs vitesses obtenus sur la
séquence Yosemite avec un niveau de bruit égal à 6% par les différentes méthodes. Nous
pouvons remarquer que la méthode de la médiane des moindres carrés, la méthode du
vbQMDPE ainsi que la méthode de la régression par les vecteurs supports avec marge
adaptative conservent leurs efficacités même dans un context dégradé. Leurs résultats
s’approchent du champ de vecteurs correct. En revanche, la régression par les vecteurs
supports avec une marge fixe, bien qu’obtenant de meilleurs résultats que la méthode des
moindres carrés, échoue globalement à retrouver le champ correct.
Les tableaux 4.1 et 4.2 récapitulent les résultats obtenus par les méthodes étudiées et
confirment nos impressions sur les résultats graphiques. La mesure de l’erreur angulaire
100 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

4.4. Expérimentation
moyenne (AAE), utilisée par Baron [BFB94], a été adoptée comme notre mesure de per-
formance afin de comparer les méthodes dont les résultats sont reportés sur le tableau 4.1.
L’écart type est quant à lui rapporté dans le tableau 4.2. Toutes les méthodes présentées
obtiennent une densité du champ de vecteurs vitesses égale à 100%.
Contrairement à la méthode standard de régression par les machines à vecteurs sup-
ports, nous pouvons remarquer que la diminution progressive de l’influence des outliers
améliore nettement les résultats en présence de données aberrantes. Sur le tableau 4.1,
nous pouvons observer que la méthode proposée surpasse les méthodes d’estimation tradi-
tionnelles. On observe également qu’elle fournit de meilleurs résultats en présence d’out-
liers que ceux obtenus par les approches de Wang et de Färneback.
Tab. 4.1 – Résultats comparatifs sur la séquence Yosemite sur l’AAE
Bruit Farneback LS SVR R-SVR FastLTS LMedS vbQMDPE(%) [Far01] [LK81] [YH00] [OS99] [WS03]0.00 7.5621 8.1487 8.0808 8.2077 7.5409 8.1876 8.15850.02 12.122 48.103 9.8131 8.2594 7.4919 8.4215 8.48080.04 16.371 49.729 15.118 8.9902 10.422 9.3268 9.71110.06 20.194 49.941 22.121 9.997 20.9 11.119 11.520.08 22.622 49.97 34.573 12.751 34.901 16.651 16.3220.10 24.946 50.361 42.349 17.914 46.017 25.1 23.032
Tab. 4.2 – Résultats comparatifs sur la séquence Yosemite sur l’écart-type
Bruit Farneback LS SVR R-SVR FastLTS LMedS vbQMDPE(%) [Far01] [LK81] [YH00] [OS99] [WS03]0.00 11.585 13.177 13.215 12.985 11.523 11.945 12.2240.02 12.148 17.808 23.758 13.044 11.861 12.786 13.1520.04 15.442 17.574 23.933 13.053 14.625 13.856 14.4070.06 17.436 17.856 22.552 14.221 20.363 15.418 16.3650.08 17.896 17.515 19.564 16.008 22.289 18.266 19.0520.10 18.101 17.487 18.073 18.392 20.503 20.136 20.899
4.4.2 Séquence simulée : les "carrés texturés"
Il s’agit d’une séquence générée afin de tester les différentes approches en présence de
mouvements bien définis et bien délimités dans l’espace, une image issue de la séquence
101

Chapitre 4. Application à l’estimation du mouvement : le flot optique
(a) image de la séquence avec 6% de bruit
5 10 15 20 25 30
5
10
15
20
25
(b) moindres carrés
5 10 15 20 25 300
5
10
15
20
25
(c) moindres carrés tronqués
0 5 10 15 20 25 30
0
5
10
15
20
25
(d) médiane des moindres carrés
−5 0 5 10 15 20 25 30 35 40 45−5
0
5
10
15
20
25
30
35
(e) méthode de Färneback
0 5 10 15 20 25 30
0
5
10
15
20
25
(f) méthode du vbQMDPE
Fig. 4.6 – Flot optique sur la séquence Yosemite avec 6% de bruit ajouté
est représentée sur la figure 4.8-a. La scène se compose de deux carrés texturés effectuant
des mouvements de translation sur un fond également texturé. Cet arrière-plan se déplace
102 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —
4.4. Expérimentation
5 10 15 20 25 30
5
10
15
20
25
(g) SVR standard
0 5 10 15 20 25 30
0
5
10
15
20
25
(h) R-SVR proposée
Fig. 4.7 – Flot optique sur la séquence Yosemite avec 6% de bruit ajouté (suite)
suivant une translation horizontale vers la gauche à la vitesse de 1 pixel/image. Une
représentation du champ de vecteur vitesse correct est représentée sur la figure 4.8-b.
(a) image de la séquence (b) flot optique correct
Fig. 4.8 – Séquence simulée des "carrés texturés".
Dans le but d’étudier la sensibilité des différents estimateurs par rapport à l’amplitude
des mouvements ainsi que par rapport au bruit, nous avons réalisé quatre expérimentations
décrites ci-dessous :
– cas 1 : le plus petit carré texturé effectue une translation verticale vers le bas à la
vitesse de 1 pixel/image et le plus grand carré texturé une translation verticale vers
le haut à la vitesse de 1 pixel/image, chevauchant ainsi le premier carré.
– cas 2 : le plus petit carré texturé effectue une translation verticale vers le bas à
la vitesse de 1 pixel/image et le plus grand carré texturé une translation diagonale
vers le coin haut-gauche à la vitesse de√
2 pixel/image, chevauchant ainsi le premier
carré.
103

Chapitre 4. Application à l’estimation du mouvement : le flot optique
Méthode Exp. 1 Exp. 2 Exp. 3 Exp. 4
LS 5.56 (14.00) 4.86 (11.31) 5.71 (12.47) 17.66 (13.20)MM 3.76 (13.01) 3.40 (10.00) 4.36 (1087) 7.97 (13.00)LTS 2.58 (11.83) 3.00 (8.55) 4.19 (10.04) 5.18 (11.00)LMedS 1.40 (9.36) 2.87 (7.73) 4.62 (11.10) 3.71 (8.85)vbQMDPE 1.33 (9.25) 6.88 (15.99) 9.89 (20.34) 8.10 (18.32)FAR 2.75 (10.36) 3.49 (8.78) 5.17 (11.77) 20.09 (18.73)SVR 4.14 (13.91) 3.82 (10.69) 4.79 (11.31) 6.80 (12.96)R-SVR 1.65 (9.59) 2.50 (7.53) 4.00 (10.13) 3.30 (8.65)
Tab. 4.3 – Résultats comparatifs sur la séquence "carrés texturés"
– cas 3 : le plus petit carré texturé effectue une translation verticale vers le bas à
la vitesse de 2 pixel/image et le plus grand carré texturé une translation diagonale
vers le coin haut-gauche à la vitesse de√
2 pixel/image, chevauchant ainsi le premier
carré.
– cas 4 : nous ajoutons 6% de bruit impulsionnel uniformément distribué. Ce bruit
impulsionnel génère localement et arbitrairement une importante discontinuité du
mouvement.
Les figures 4.9 et 4.10 illustrent les champs de vecteurs vitesses obtenus par diffé-
rentes approches respectivement pour les expériences 2 et 4. Les résultats présentés sont
issus des approches suivantes : les moindres carrés, la médiane des moindres carrés, les
moindres carrés tronqués, l’approche du vbQMDPE, la régression par les machines à vec-
teurs supports standard, ainsi que l’approche R-SVR proposée. Chaque représentation du
flot optique est superposée à une image en niveau de gris illustrant l’erreur locale angulaire.
Dans ces images, l’intervalle des niveau de gris [0,255] correspond à l’intervalle d’erreur
angulaire [0,π]. Ainsi, une valeur importante du niveau de gris du pixel i indique une er-
reur angulaire importante du vecteur vitesse calculé en ce pixel. Ces résultats qualitatifs
sont accompagnés d’une évaluation quantitative rapportées dans le tableau 4.3. Nous y
comparons les erreurs angulaires moyennes (AAE) ainsi que les dispersions standards des
résultats obtenus par les différentes méthodes étudiées.
À la vue de ces différents résultats, on peut émettre quelques remarques. Tout d’abord,
les moindres carrés ainsi que le SVR standard semblent avoir l’inconvénient de lisser le
champ de vecteurs vitesses aux frontières des mouvements (contour des carrés), ce phéno-
mène est visible sur les figures 4.9-a et 4.9-e). Par contre, ces méthodes tolèrent légèrement
mieux que les autres l’augmentation de l’amplitude des vitesses, leurs résultats sont net-
tement meilleurs sur l’expérience 2 par rapport à l’expérience 1. En présence d’un bruit
impulsionnel, ces approches échouent globalement à retrouver le champ correct de vec-
104 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

4.4. Expérimentation
(a) : LS (b) : LMedS
(c) : LTS (d) : vbQMDPE
(e) : SVR Standard (f) : R-SVR
Fig. 4.9 – Flot optique estimé sur la séquence "carrés texturés" (expérience 2).
teurs vitesses (fig. 4.10-a et 4.10-e). Sans surprise, la valeur de l’erreur angulaire moyenne
105

Chapitre 4. Application à l’estimation du mouvement : le flot optique
(a) : LS (b) : LMedS
(c) : LTS (d) : vbQMDPE
(e) : SVR Standard (f) : R-SVR
Fig. 4.10 – Flot optique estimé sur la séquence "carrés texturés" (expérience 4).
obtenue par la méthode des moindres carrés est la plus faible et confirme la non-robustesse
106 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

4.4. Expérimentation
de ce type d’approches. En ce qui concerne les approches basées sur un échantillonnage
aléatoire, telles que les moindres carrés tronqués, la médiane des moindres carrés ou encore
l’algorithme vbQMDPE, il est aisé de constater que les discontinuités du flot optique sont
mieux préservées (figures 4.9-b, 4.9-c et 4.9-e). Cependant, on observe une diminution de
performances de ces approches dans les zones où l’amplitude du flot optique augmente.
Cette remarque est particulièrement vraie pour l’algorithme vbQMDPE (figures 4.9-d et
4.10-d) où le flot optique présente des instabilités lorsque l’amplitude du mouvement est
supérieure à 1 pixel par image. D’ailleurs, nous pouvons observer dans le tableau 4.3 que
l’erreur angulaire moyenne (AAE) augmente drastiquement. Ces mauvais résultats, bien
qu’il contredisent les résultats présentés par Huang dans [HL02], révèlent la limite de
cette approche. En fait, l’algorithme vbQMDPE est basé sur une méthode d’échantillon-
nage aléatoire de type Monte-Carlo qui sélectionne un certain nombre de p-sous-ensembles
parmi les observations (p = 2 pour le problème du flot optique). Les paramètres du mou-
vement sont ensuite déterminés par le p-sous-ensemble correspondant à la plus haute
fonction de densité locale. Sans lissage, cette approche s’avère plus sensible que les autres
approches lorsque l’amplitude du flot optique augmente. En revanche, l’introduction d’un
bruit impulsionnel dans les données confirme la robustesse de ce type d’approche. Fi-
nalement, on peut remarquer que l’approche proposée de la régression robuste par les
machines à vecteurs supports fournit les meilleurs résultats en ce qui concerne l’ampli-
tude et la discontinuité du mouvement (voir le tableau 4.3 ainsi que les figures 4.9-f et
4.10-f).
4.4.3 Séquences réelles
Le taxi de Hambourg
La séquence du taxi de Hambourg représente la surveillance d’un carrefour par une
caméra statique placée en hauteur. Cette séquence contient 4 objects en déplacement : un
taxi arrivant de la droite et tournant vers sa droite, un van arrivant de la droite et se
dirigeant vers la gauche (ce véhicule est légèrement masqué par la présence d’un arbre),
une voiture arrivant de la gauche et se dirigeant vers la droite, et un piéton difficilement
discernable en haut à gauche. Les vitesses de ces objets dans le repère image sont res-
pectivement de 1.0, 3.0, 3.0 et 0.3 pixels par image. Une image tirée de cette séquence
est présentée sur la figure 4.11-(a). Le point d’observation de la scène étant statique, les
mouvements apparents sur cette séquence ne sont pas modifiés par le mouvement propre
du capteur puisqu’il est nul.
107
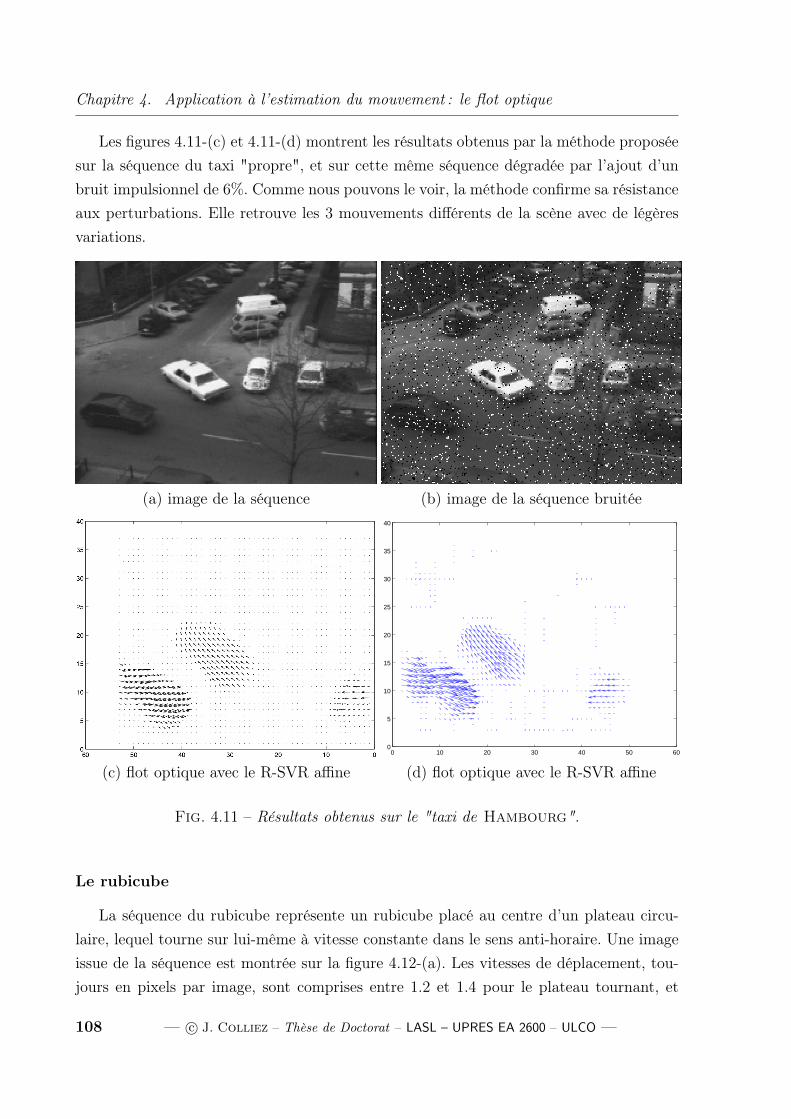
Chapitre 4. Application à l’estimation du mouvement : le flot optique
Les figures 4.11-(c) et 4.11-(d) montrent les résultats obtenus par la méthode proposée
sur la séquence du taxi "propre", et sur cette même séquence dégradée par l’ajout d’un
bruit impulsionnel de 6%. Comme nous pouvons le voir, la méthode confirme sa résistance
aux perturbations. Elle retrouve les 3 mouvements différents de la scène avec de légères
variations.
(a) image de la séquence (b) image de la séquence bruitée
(c) flot optique avec le R-SVR affine
0 10 20 30 40 50 600
5
10
15
20
25
30
35
40
(d) flot optique avec le R-SVR affine
Fig. 4.11 – Résultats obtenus sur le "taxi de Hambourg".
Le rubicube
La séquence du rubicube représente un rubicube placé au centre d’un plateau circu-
laire, lequel tourne sur lui-même à vitesse constante dans le sens anti-horaire. Une image
issue de la séquence est montrée sur la figure 4.12-(a). Les vitesses de déplacement, tou-
jours en pixels par image, sont comprises entre 1.2 et 1.4 pour le plateau tournant, et
108 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —
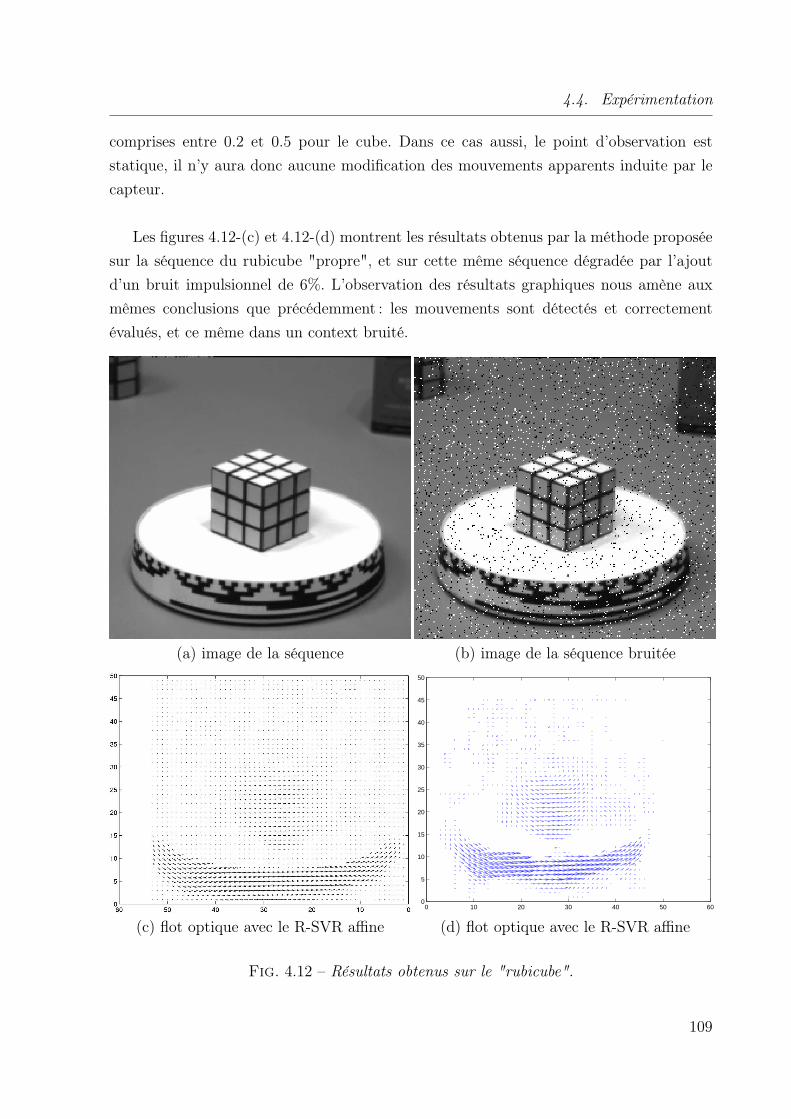
4.4. Expérimentation
comprises entre 0.2 et 0.5 pour le cube. Dans ce cas aussi, le point d’observation est
statique, il n’y aura donc aucune modification des mouvements apparents induite par le
capteur.
Les figures 4.12-(c) et 4.12-(d) montrent les résultats obtenus par la méthode proposée
sur la séquence du rubicube "propre", et sur cette même séquence dégradée par l’ajout
d’un bruit impulsionnel de 6%. L’observation des résultats graphiques nous amène aux
mêmes conclusions que précédemment : les mouvements sont détectés et correctement
évalués, et ce même dans un context bruité.
(a) image de la séquence (b) image de la séquence bruitée
(c) flot optique avec le R-SVR affine
0 10 20 30 40 50 600
5
10
15
20
25
30
35
40
45
50
(d) flot optique avec le R-SVR affine
Fig. 4.12 – Résultats obtenus sur le "rubicube".
109

Chapitre 4. Application à l’estimation du mouvement : le flot optique
Le parking
La séquence du parking simule le suivi d’un véhicule. Elle a été réalisée sur le par-
king de l’université à l’aide de deux véhicules : le véhicule suiveur équipé d’une caméra
embarquée, et le véhicule cible. Contrairement aux deux séquences précédentes, le point
d’observation est dynamique. Le capteur est placé à l’avant du véhicule suiveur, il va donc
apparaitre un mouvement global de l’environement dans la séquence. Une image issue de
la séquence est présentée sur la figure 4.13.
La figure 4.14 montre le résultat obtenu par la méthode proposée sur cette séquence.
On remarque que le mouvement de la caméra provoque un mouvement divergeant de
l’environnement, qui semble avancer vers l’observateur. Le mouvement d’éloignement du
véhicule est correctement estimé, ainsi que le mouvement de son ombre (bien qu’une ombre
soit immatérielle).
Fig. 4.13 – Image de la séquence "parking".
110 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

4.5. conclusion
Fig. 4.14 – Flot optique sur la séquence Parking avec le R-SVR (modèle constant)
4.5 conclusion
Nous avons présenté l’estimation du mouvement apparent dans une séquence d’images.
Le flot optique est basée sur l’hypothèse de conservation de l’énergie dans la séquence. Il
111

Chapitre 4. Application à l’estimation du mouvement : le flot optique
présente des problèmes liés à l’occlusion, aux variations de l’intensité, aux déplacements
importants, à l’ouverture, etc. Différentes approches ont été développées pour estimer le
flot optique. L’approche robuste SVR proposée a montré de bonnes performances sur deux
séquences d’images artificielles "Yosemite" et "carrés texturés". Elle a aussi été appliquée à
trois séquences réelles "taxi de Hamburg", "Rubicube" et "Parking". Les résultats obtenus
sont très encourageants, même en présence de bruit impulsionnel. Dans le chapitre 5, nous
présentons une autre application de l’approche R-SVR pour l’estimation du mouvement
par mise en correspondance.
112 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

Chapitre 5
Application à l’estimation du
mouvement par mise en correspondance
DANS ce chapitre, nous nous intéressons à l’estimation du mouvement dans les sé-
quences d’images 2D couleurs. En utilisant la mise en correspondance entre deux
images successives comme source de données, nous souhaitons estimer le mouvement do-
minant à l’aide de la régression par les machines à vecteurs supports.
Différentes approches existent pour effectuer la mise en correspondance, elles se basent
sur la photométrie, la géométrie, ou une combinaison des deux. Les approches du pre-
mier groupe utilisent les informations de texture contenues dans les images pour réaliser
la mise en correspondance. Parmi ces approches, on citera les méthodes de corrélation
[GCB01], les méthodes basées sur des descripteurs statistiques [JZHW06] tel que les his-
togrammes couleur, et enfin les méthodes utilisant les invariants différentiels [MGD98].
Le second groupe, basé sur la géométrie, rassemble les approches qui utilisent les données
géométriques de chaque image. La ressemblance se calcule alors sur la structure globale
des contours de l’image en utilisant des techniques telles que la relaxation. Cependant,
ce type d’approche ne sera pas développé dans ce chapitre, notre choix s’étant porté sur
les approches photométriques, qui nous fourniront des ensembles de données en vue de la
régression.
Notre objectif est d’exploiter le résultat de la mise en correspondance, c’est à dire un
ensemble d’appariements de points, afin d’estimer la transformation principale entre deux
images successives. Pour ce faire, nous devons tout d’abord extraire, à l’aide d’informa-
tions couleur, un ensemble de points caractéristiques dans chaque image. Ces points sont
ensuite appariés dans le temps (entre deux images successives) grâce aux méthodes de
mise en correspondance, ce qui fournit un ensemble de couples de points représentant la
position d’un point sur les deux images successives. Enfin, à partir de cet ensemble nous
113

Chapitre 5. Application à l’estimation du mouvement par mise en correspondance
pouvons estimer le déplacement prépondérant et ainsi suivre un objet en mouvement dans
la séquence d’images.
Dans ce chapitre, nous commencerons par présenter un bref état de l’art des détecteurs
de points caractétistiques. Ensuite, nous passerons en revue quelques méthodes de mise
en correspondance. Enfin, les résultats de la méthode RSVR proposée, appliquée au suivi
d’objets dans les séquences d’images, seront présentés sur des exemples simulés et réels.
5.1 État de l’art
5.1.1 Définition
Un point d’intérêt correspond à une variation bidimensionnelle du signal représentant
l’image, c’est à dire un coin "L", une jonction "T", ou encore une zone où la texture varie
fortement.
5.1.2 Extraction de points caractéristiques
Nous allons séparer cette section en deux parties selon que les images traitées soient
en niveaux de gris ou en couleurs.
a) Image en niveau de gris
- Opérateur de Kitchen-Rosenfeld
L’algorithme de Kitchen-Rosenfeld [KR82] est l’un des premiers détecteurs de coins
que l’on trouve dans la littérature. Cet algorithme calcule la valeur de courbure CKR
comme étant le produit entre l’amplitude du gradient local et le changement de sa direc-
tion. Cette valeur est donnée par :
CKR =IxxI
2y + IyyI
2x − 2IxyIxIy
I2x + I2
y
(5.1)
où I est la valeur de l’intensité, et Ix la dérivée première de I suivant x, etc. Les points
d’une image sont considérés comme des coins si la valeur de CKR correspondante est in-
férieure à un seuil défini : plus la valeur de CKR est faible, meilleur est le coin.
114 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

5.1. État de l’art
- Opérateur de Harris-Stephens
Harris-Stephens [JM88] ont présenté un algorithme de détection de points d’intérêts
qui utilise les dérivées premières du signal représentant l’image en niveau de gris. Cet
algorithme est basé sur l’hypothèse sous-jacente que les coins sont accosiés aux maximum
locaux de la fonction d’autocorrélation de l’image. L’algorithme s’avère peu sensible au
bruit, en effet il utilise uniquement des dérivées premières de l’image. Notons qu’une étape
de lissage est souvent requise pour augmenter son efficacité afin de faire se chevaucher les
dérivées spatiales. Cependant, le lissage, par nature, diminue nettement la précision de
localisation des points d’intérêts.
L’opérateur, souvent nommé opérateur d’Harris, s’exprime sous la forme matricielle
suivante :
Mgris = exp
(−x2 + y2
2σ2
)⊗
[I2x IxIy
IxIy I2y
](5.2)
Où le premier terme représente un lissage gaussien de variance σ, ⊗ est l’opérateur de
convolution et le deuxième terme est appelé gradient multi-spectral. Ix et Iy représentent
respectivement les dérivées de l’image I suivant l’axe des x et suivant l’axe des y. Les
valeurs propres de Mgris sont les courbures principales de la fonction d’auto-corrélation
de l’image. Une courbure élevée indique la présence d’un point d’intérêt. Dans la pratique,
on va rechercher les maxima locaux de l’expression suivante :
Det(M) − k × Trace2(Mgris) (5.3)
La figure 5.1 représente la surface sur laquelle nous recherchons les maxima locaux.
Les figures 5.2 et 5.3 illustrent les maxima locaux retenus car supérieurs à un seuil fixé.
Sur la figure 5.2, le seuil est fixé à 0.1%, et sur la figure 5.3, ce seuil est fixé à 0.001%. On
constate que plus le seuil est faible, plus le nombre de coins extraits est important. Il y a
un compromis à trouver en ce qui concerne le nombre de points caractéristiques retenus :
le nombre doit être suffisant pour obtenir une mise en correspondance satisfaisante entre
2 images afin d’estimer le ou les mouvements, mais il ne doit pas être trop important pour
ne pas démultiplier le temps de calcul de l’étape de mise en correspondance.
- Invariants différentiels de Hilbert
Hilbert [Hil90] a montré qu’il existe, dans une image en niveau de gris d’intensité I,
un ensemble de 5 invariants différentiels du premier ou second ordre, indépendants de la
115

Chapitre 5. Application à l’estimation du mouvement par mise en correspondance
Fig. 5.1 – Recherche des maxima locaux
Fig. 5.2 – Détection avec l’opérateur d’Harris en niveaux de gris (seuil=0.1%)
rotation image lorsqu’ils sont exprimés dans les coordonnées de Gauge. Ces invariants
sont : I, Iη, Iηη, Iηξ et Iξξ. η représente le vecteur unitaire tel que η = ∇I‖∇I‖
, c’est à dire
le vecteur gradient normalisé de l’intensité I, et ξ représente le vecteur unitaire tel que ξ
orthogonal à η.
- Opérateur du SIFT
L’algorithme du SIFT [Low03], pour scale-invariant feature transform, fut publié par
Lowe en 1999. Il cherche à identifier les zones dans l’image qui sont partiellement inva-
116 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

5.1. État de l’art
Fig. 5.3 – Détection avec l’opérateur d’Harris en niveaux de gris (seuil=0.001%)
riantes par rapport aux translations, rotations et mouvements d’échelle. Ces zones clés
correspondent aux maxima et minima locaux d’une différence entre deux fonctions gaus-
siennes appliquées à l’image. D’après l’auteur, l’efficacité de cette approche repose sur
la construction d’une pyramide d’images avec un rééchantillonage entre chaque niveau.
L’algorithme du SIFT se décompose de fait en 2 étapes : la construction de la pyramide
d’images, puis l’étape de détection.
Pour construire chaque étage de la pyramide, l’auteur utilise un filtre de lissage gaus-
sien 1D dans les directions horizontales et verticales de l’image initiale (σ =√
2, taille
du filtre égale à 7). L’image d’entrée est donc convoluée avec une fonction gausienne ce
qui fournit l’image A. L’opération est répétée une seconde fois à partir de l’image A et
fournit l’image B. La différence entre les deux fonctions gaussiennes est obtenue en sous-
trayant l’image B de l’image A. Ensuite, pour générer l’étage suivant de la pyramide,
l’auteur rééchantillonne l’image lissée B à l’aide d’une interpolation bilinéaire avec un pas
de 1.5 pixels, ce qui fournit une image B’. Cette image est ensuite convoluée par une fonc-
tion gausienne afin d’obtenir l’image C, et ainsi pouvoir calculer la différence entre C et B’.
Une fois la pyramide d’images formée, il reste à détecter les points caractéristiques.
Cette détection s’effectue en recherchant les maxima ou minima locaux dans les images
résultant des différences calculées. Cette étape détecte les pixels dont l’intensité est supé-
rieure ou inférieure à leur voisinage immédiat.
117

Chapitre 5. Application à l’estimation du mouvement par mise en correspondance
Fig. 5.4 – Extraction des points d’intérêts (Algorithme SIFT)
Les points ainsi extraits sont fortement invariants aux transformations d’échelle et de
rotation dans l’image. Ils sont aussi considérés comme robustes dans les cas de distortion
affine, changement de point de vue, changement d’illumination ou encore addition de
bruit. Une récente évaluation publiée par Mikolajczyk et Schmid [MS05] suggère que
les descripteurs basés sur le SIFT sont les meilleurs en terme de distinction et de robustesse
face à des changements divers dans les conditions d’observation.
b) Image couleur
Notons les plans couleurs ainsi : R pour le plan rouge, G pour le plan vert et B pour
le plan bleu.
- Opérateur de Harris-Stephens
La généralisation de l’opérateur d’Harris-Stephens à des images couleurs à 3 canaux
R, G, B donne la matrice suivante :
Mcouleur = exp
(−x2 + y2
2σ2
)⊗
[R2
x + G2x + B2
x RxRy + GxGy + BxBy
RxRy + GxGy + BxBy R2y + G2
y + B2y
](5.4)
Où Rx, Gx et Bx représentent respectivement les dérivées des plans couleurs rouge (R),
vert (G) et bleu (B) en x. De même, Ry, Gy et By représentent respectivement les dérivées
118 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

5.1. État de l’art
des plans couleurs rouge (R), vert (G) et bleu (B) en y. En notant G =
[G11 G12
G21 G22
]
le deuxième terme de l’équation précédente 5.4 (gradient multi-spectral) et en calculant
ses valeurs et vecteurs propres, on obtient la norme λmax et l’orientation θ du gradient
multi-spectral par les formules suivantes :
λmax =1
2
(G11 + G12 +
√∆
)(5.5)
θ =1
2arctan
(2G12
G11 − G22
)(5.6)
Où ∆ = (G11 − G22)2 + 4G2
12. Dans la pratique, on va rechercher les maxima locaux de
l’expression :
Det(M) − k × Trace2(Mcouleur) (5.7)
Les figures 5.5,5.6 et 5.7 représentent les points caractéristiques couleurs obtenus par
l’opérateur d’Harris sur la même image couleur avec des valeurs pour le seuil respecti-
vement de 5%,0.5%,0.05%.
Fig. 5.5 – Détection avec l’opérateur d’Harris en couleurs (seuil=5%)
- Opérateur de Kitchen-Rosenfeld
L’opérateur de Kitchen-Rosenfeld peut être généralisé aux images en couleur en consi-
dérant une courbe sur le plan image dont la tangente présente avec l’axe des x une orien-
119

Chapitre 5. Application à l’estimation du mouvement par mise en correspondance
Fig. 5.6 – Détection avec l’opérateur d’Harris en couleurs (seuil=0.5%)
Fig. 5.7 – Détection avec l’opérateur d’Harris en couleurs (seuil=0.05%)
tation θτ . L’opérateur s’exprime alors en fonction de θτ de la manière suivante :
CKR =dθτ
ds=
∂θ
∂x
dx
ds+
∂θ
∂y
dy
ds(5.8)
avec :dx
ds= −sinθ et
dy
ds= cosθ (5.9)
120 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

5.1. État de l’art
et :
∂θ
∂x=
ABxBxy + BBxxBy − 2VxVxyV2y + 2B2
xBxxBy + 2BxBxyB2y − 2BxByRxRxx + ARxRxy−
2BxBxxRxRy + 2BxyByRxRy + ArxxRy − 2R2xRxxRy + 2BxByRxyRy + 2RxRxyR
2y−
2BxByVxVxx − 2RxRyVxVxx + AVxVxy − 2BxBxxV xVy + 2BxyByVxVy − 2RxRxxVxVy+
2RxyRyVxVy + AVxxVy − 2V 2x VxxVy + 2BxByVxyVy + 2RxRyVxyVy
A2 + 4(BxBy + RxRy + VxVy)2
(5.10)
où A = B2x − B2
y + R2x − R2
y + V 2x − V 2
y , et :
∂θ
∂y=
−2B2xBxyBy + 2BxB
2yByy − 2BxByRxRxy − 2BxBxyRxRy + 2ByByyRxRy − 2R2
xRxyRy+
2BxByRyRyy + 2RxR2yRyy − 2BxByVxVxy − 2RxRyVxVxy − 2BxBxyVxVy + 2ByByyVxVy−
2RxRxyVxVy + 2RyRyyVxVy − 2V 2x VxyVy + ABxyBy + ABxByy + ARxyRy + ARxRyy+
AVxyVY + 2BxByVyVyy + 2RxRyVyVyy + 2VxV2y Vyy + AVxVyy
A2 + 4(BxBy + RxRy + VxVy)2
(5.11)
Voici un résumé de l’algorithme de détection des coins couleurs par l’opérateur de
Kitchen-Rosenfeld :
1. on extrait les points d’intérêts par le calcul de la valeur propre maximale λmax du
gradient multispectral suivant la direction θ du vecteur propre associé (équations
5.5 et 5.6) suivi d’un seuillage,
2. on calcule la courbure couleur, Kcouleur = CKR × λmax,
3. on extrait les points possédant la plus forte valeur de courbure couleur en maximisant
Kcouleur dans la direction de θ, ce qui nous donne Kmax,
4. on recherche des points d’intérêt parmi Kmax,
5. enfin, on extrait les coins couleurs, à l’aide d’un seuil, parmi les maxima locaux des
points d’intérêts précédemment trouvés.
- Invariants différentiels de Hilbert
Dans le cas d’une image couleur à trois canaux rouge, vert et bleu, les invariants diffé-
rentiels du premier et du second ordre s’élèvent au nombre de 17 [MGD98]. Ce nombre
correspond aux 5 invariants par plan de couleur, auquels s’ajoutent 2 invariants spéci-
fiques à la couleur parmi : ∇R∇V , ∇R∇B et ∇V ∇B. Dans un soucis d’efficacité et de
fiabilité (problème du bruit avec les dérivées secondes), on préfére se limiter aux invariants
du premier ordre ainsi qu’aux invariants spécifiques à la couleur. On utilise donc des vec-
teurs à 8 composantes (R,‖∇R‖2,V,‖∇V ‖2,B,‖∇B‖2,∇R∇V,∇R∇B) qui regroupe toute
l’information photométrique couleur du voisinage d’un point.
121

Chapitre 5. Application à l’estimation du mouvement par mise en correspondance
5.1.3 Mise en correspondance
Une fois l’étape d’extraction des points caractéristiques achevée, nous disposons pour
chaque image d’un ensemble de coins. La mise en correspondance consiste à retrouver
chaque point de l’ensemble de points issu de l’image n1 dans l’ensemble de points issu de
l’image n2. On recherche le meilleur candidat pour chaque point en utilisant des mesures
de ressemblance, par exemple la photométrie pour le SIFT, ou des mesures géométriques.
Distance géométrique (Euclidienne)
On nomme distance géométrique la distance euclidienne, exprimée en pixels, entre un
coin de l’image n1 et chaque coin de l’image n2. Cependant, on ne peut utiliser seule
cette mesure afin de mettre en correspondance les ensembles de points. En effet, même sous
une hypothèse de petits déplacements, le point de l’image n2 géométriquement le plus
près du point de l’image n1 n’est généralement pas le bon candidat. Dans la pratique, on
recherche tous les coins de l’image n2 dont la distance euclidienne par rapport au coin de
l’image n1 est inférieur à une limite donnée. En fait, cette distance géométrique permet
de définir un groupe de candidats pouvant être le coin de l’image n1 dans l’image n2.
Une mesure de ressemblance permet ensuite de choisir le meilleur candidat.
Distance de Bhattacharya
La distance de Bhattacharya est une mesure de similarité entre deux distributions
de probabilité discrètes. Dans le cadre de nos travaux, nous avons utilisé cette distance
afin de mesurer la distance entre les distributions de probabilité de la couleur issues des
voisinages des points caractéristiques. Pour chaque point caractéristique, nous calculons la
distribution de probabilité de la couleur des pixels voisins. En sous-échantillonant chaque
intervale de couleur (en n intervales), nous obtenons une matrice à 3 dimensions où chaque
composante est la probalité de rencontrer la couleur correspondante dans le voisinage du
point caractéristique. Soit A et B deux points caractéristiques dans deux images consé-
cutives, pdcA et pdcB les distributions de probabilité couleur associées, la distance de
Bhattacharya s’exprime telle que :
distanceBhattacharya =n∑
r=1
n∑
g=1
n∑
b=1
pdcA(r,g,b)pdcB(r,g,b) (5.12)
En revanche, le calcul étant trop lourd pour l’effectuer entre tous points, nous utilisons
d’abord la distance euclidienne afin de limiter le nombre de candidats possibles qui pour-
raient correspondre au point caractéristique traité.
122 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

5.1. État de l’art
Distance de Mahalanobis
La distance de Mahalanobis est très utilisée dans l’évaluation de la similarité entre
deux vecteurs. Dans l’optique de mettre en correspondance des invariants dans les images,
elle permet de mesurer la ressemblance entre deux vecteurs d’invariants, où les compo-
santes de ces vecteurs seront modélisés par des variables aléatoires gaussiennes. La distance
de Mahalanobis est une mesure statistique basée sur la matrice de covariance des deux
vecteurs, cette dernière permet de prendre en compte les différences d’amplitudes entre les
différentes composantes des vecteurs, ainsi que leur corrélation. On peut exprimer cette
distance telle que :
distanceMahalanobis =√
(~v1 − ~v2)T M−1cov(~v1 − ~v2) (5.13)
Avec Mcov la matrice de covariance, et ~v1,~v2 les vecteurs d’invariants entre lesquels la
distance est calculée. Si la matrice de covariance est la matrice identité, la distance de
Mahalanobis est égale à la distance euclidienne. Si la matrice de covariance est diago-
nale, on obtient la distance euclidienne normalisée.
Best-Bin-First (BBF) et PCA-SIFT
Les méthodes de mise en correspondance basées sur les descripteurs du SIFT uti-
lisent un algorithme d’approximation de la correspondance, généralement le Best-Bin-
First [BL97] ou le PCA-SIFT [KS04]. L’algorithme du Best-Bin-First est similaire à l’al-
gorithme de k -d tree, excepté qu’il impose une limite temporelle à l’étape de recherche.
Ainsi, l’algorithme du BBF retourne le plus proche voisin avec la plus forte probabilité
de correspondance. L’algorithme du PCA-SIFT, d’un autre côté, réduit le nombre de di-
mensions des descripteurs en se basant sur l’analyse du composant principal. Ces deux
algorithmes induisent un certain nombre de pertes parmi les correspondances correctes,
pertes compensées par une vitesse d’exécution accrue. La figure 5.8 montre le résultat de
l’algorithme du Best-Bin-First. Les segments cyan illustrent les couples de points d’intérêts
mis en relation entre deux images successives, ils représentrent le déplacement supposé de
ces points. On peut voir sur cette figure que la majorité des points effectuent une rotation,
mais on remarque également que quelques erreurs de mise en correspondance, dues à la
répétition des motifs dans l’image, sont retournées par l’algorithme.
123

Chapitre 5. Application à l’estimation du mouvement par mise en correspondance
Fig. 5.8 – Mise en correspondance avec l’algorithme du SIFT (best-bin-first)
5.2 Expérimentations et résultats
5.2.1 Données simulées
Nous avons tout d’abord étudié le comportement de l’algorithme du RSVR proposé
dans le cadre de données synthétiques. Pour ce faire, nous allons utilisé un champ de
vecteurs simulé représentant plusieurs mouvements, dominants ou secondaires, auquels
s’ajoute un bruit, sous la forme d’un mouvement non structuré. Ce champ de vecteurs
simulé est illustré sur la figure 5.9-a, on peut y observer :
– un mouvement dominant effectuant une rotation horaire, composé de 45 vecteurs
de couleur bleu,
– un mouvement résiduel effectuant une rotation anti-horaire, composé de 20 vecteurs
de couleur rouge,
– un mouvement résiduel effectuant une translation vers le coin supérieur droit de
l’image, composé de 20 vecteurs de couleur cyan,
– un mouvement non structuré qui bruite les données, composé de 50 vecteurs de
couleur noir.
Le taux d’outliers présents dans cet exemple est de 66%. Nous allons tenter d’extraire le
mouvement dominant à l’aide le l’algorithme du RSVR.
Le premier résultat, visible sur la figure 5.9-b, a été obtenu par l’algorithme du RSVR en
124 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

5.2. Expérimentations et résultats
utilisant une fonction de pondération dure. On observe que le mouvement dominant est
clairement identifié, même si quelques vecteurs en bordure du mouvement n’ont pas été
retenus.
Le second résultat, visible sur la figure 5.9-c, provient de l’algorithme du RSVR mais en
utilisant une fonction de pondération de type Tuckey avec le paramètre. On peut y voir
que le mouvement dominant est correctement extrait, cependant quelques vecteurs des
mouvements résiduels ont été conservés.
Le troisième résultat, visible sur la figure 5.9-d, est également issu de l’algorithme du
RSVR avec une fonction de pondération de type Tuckey avec le paramètre. Il apparaît
que le mouvement dominant est toujours bien extrait. Le nombre de vecteurs conser-
vés, comparativement au second résultat, est moins élevés : il reste néanmoins quelques
vecteurs provenant du premier mouvement résiduel, et quelques vecteurs du mouvement
dominant ont été exclus.
Dans le cadre de notre expérimentation sur des données simulées, les résultats obtenus
par l’algorithme proposé du RSVR nous semble encourageants. Le mouvement dominant
présent dans le champ de vecteurs simulés, bien que représentant seulement 33% des
données, a été correctement extrait. Nous allons donc tester la fiabilité et l’efficacité de
l’algorithme RSVR sur des données réelles.
5.2.2 Données réelles
Dans cette partie, nous allons illustrer les performances de l’approche proposée pour
l’estimation et la segmentation de mouvements dans les séquences d’images. Nous en-
tendons par segmentation de mouvements la recherche du mouvement dominant qui cor-
respond à la transformation géométrique principale d’un objet image entre deux images
consécutives. Afin d’obtenir une estimation valide, une détection correcte des correspon-
dances est essentielle, ce qui n’est pas toujours facile en pratique et ce à cause de trois
facteurs : (1) la similarité, ou ressemblance, possible de différents points caractéristiques ;
(2) les occlusions et (3) le bruit. Ainsi, il est important de développer une technique de
mise en correspondance robuste.
Dans nos travaux, ce problème de mise en correspondance est résolu par un algorithme
en deux étapes. La première étape consiste à obtenir sur deux images consécutives des
points d’intérêt. Pour ce faire, nous avons utilisé l’opérateur d’Harris [JM88] pour les
images couleur. Ensuite, la seconde étape effectue la mise en correspondance des points
caractéristiques entre ces deux images. On va recherche la meilleure correspondance dans
le sens où les intensités et les formes doivent être similaires. La mesure de ressemblance
125
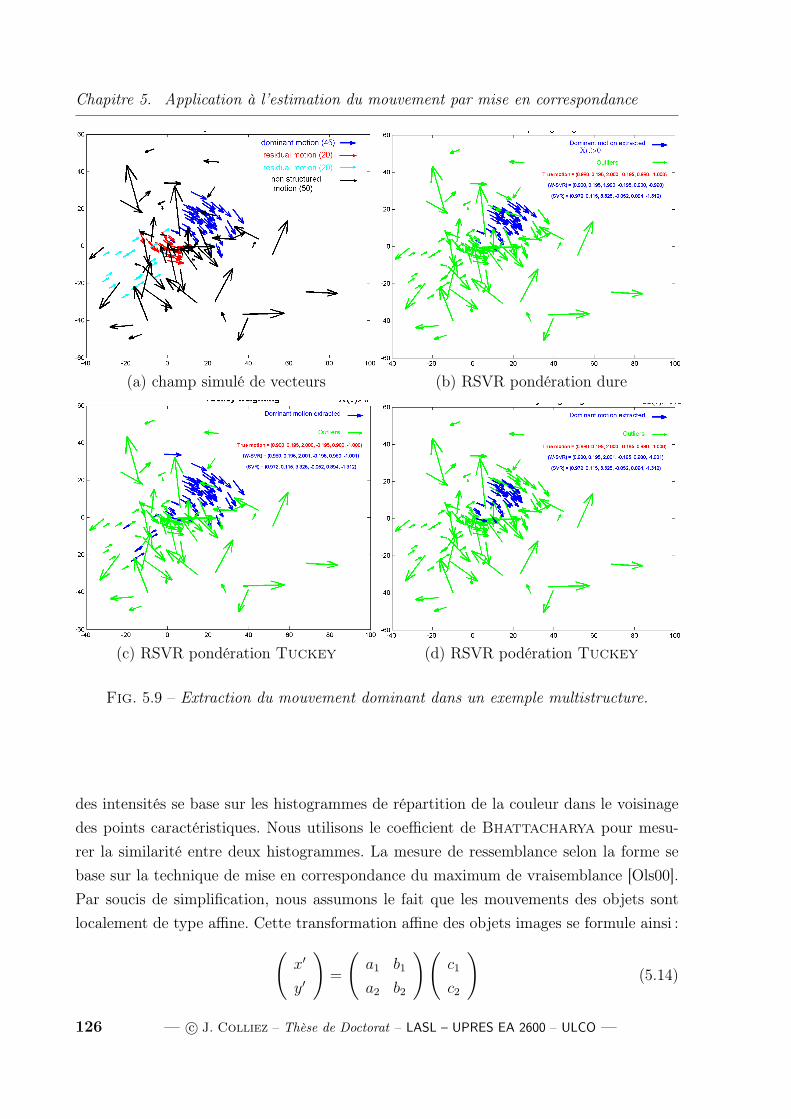
Chapitre 5. Application à l’estimation du mouvement par mise en correspondance
(a) champ simulé de vecteurs (b) RSVR pondération dure
(c) RSVR pondération Tuckey (d) RSVR podération Tuckey
Fig. 5.9 – Extraction du mouvement dominant dans un exemple multistructure.
des intensités se base sur les histogrammes de répartition de la couleur dans le voisinage
des points caractéristiques. Nous utilisons le coefficient de Bhattacharya pour mesu-
rer la similarité entre deux histogrammes. La mesure de ressemblance selon la forme se
base sur la technique de mise en correspondance du maximum de vraisemblance [Ols00].
Par soucis de simplification, nous assumons le fait que les mouvements des objets sont
localement de type affine. Cette transformation affine des objets images se formule ainsi :
(x′
y′
)=
(a1 b1
a2 b2
) (c1
c2
)(5.14)
126 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

5.2. Expérimentations et résultats
où les coefficients a1,a2,b1,b2,c1,c2 sont les paramètres du modèle affine, et (x′,y′) sont
les points dans l’image cible. L’estimation des paramètres affine peut être reformulée
comme un problème de régression. Sous le formalisme du SVR, si nous posons w =
(a1,b1,c1,a2,b2,c2), nous obtenons les deux contraintes suivantes :
rx′
i= x′
i −(w,φx′
i(xi,yi)
)− b ≤ ε + ξx′
i
−rx′
i= −x′
i +(w,φx′
i(xi,yi)
)+ b ≤ ε + ξ∗x′
i
(5.15)
ry′
i= y′
i −(w,φy′
i(xi,yi)
)− b ≤ ε + ξy′
i
−ry′
i= −y′
i +(w,φy′
i(xi,yi)
)+ b ≤ ε + ξ∗y′
i
(5.16)
où φx′
i(xi,yi) = (xi,yi,1,0,0,0) et φy′
i(xi,yi) = (0,0,0,xi,yi,1). Ainsi, le problème d’estimation
revient à extraire indépendamment deux plans dans l’ensemble de données. Les paramètres
w et b sont estimés par la méthode proposée de régression robuste par les machines à
vecteurs supports (RSVR). Il est à noter que la valeur des paramètres c1 (w(3)) et c2
(w(6)) doivent être mis à jour avec la valeur de b (c1 = c1 + b, c2 = c2 + b).
Séquence des livres
L’application concerne l’extraction d’une structure dominante dans une séquence d’images
couleur. Le mouvement dominant correspond au mouvement du livre cible au premier
plan. Pendant cette séquence, un mouvement résiduel occasionné par un second livre en
arrière plan est présent. L’extraction des points d’intérêt et la mise en correspondance
sont effectuées sur les images entières. La figure 5.10 montrent les résultats obtenus sur
la séquence avec un pas de 25 images. Les résultats sont représentés par un champ de
vecteurs superposé à l’image en cours, ces vecteurs sont le résultat de l’étape de mise
en correspondance. Sur cette figure, nous observons clairement un mouvement dominant
(livre cible) perturbé par un mouvement secondaire (second livre) ainsi que des mouve-
ments abérrants (mauvaises correspondances). Comme nous pouvons le voir, l’approche
proposée du RSVR sépare avec précision le mouvement dominant, dont nous avons coloré
les vecteurs en bleu, des autres mouvements (vecteurs rouges).
Séquence Parking
Nous avons ensuite mis en oeuvre l’estimation du mouvement dans une séquence si-
mulant un attelage virtuel. La séquence "Parking", déjà présentée dans la partie résultats
du chapitre 4, a été utilisée afin de vérifier la fiabilité de l’extraction du mouvement.
Pour ce faire, nous avons utilisé une fenêtre encadrant le véhicule sur la première image
127

Chapitre 5. Application à l’estimation du mouvement par mise en correspondance
(a) résultat obtenu à t=1 (b) résultat obtenu à t=50
(c) résultat obtenu à t=100 (d) résultat obtenu à t=150
(e) résultat obtenu à t=200 (f) résultat obtenu à t=250
Fig. 5.10 – Estimation du mouvement dans la séquence réelle des livres.
128 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

5.3. Conclusion
de la séquence. Nous avons réglé les dimensions de cette fenêtre, ainsi que sa position,
manuellement. Ensuite, nous utilisons une méthode d’extraction de points d’intérêt dans
cette fenêtre et dans l’image suivante. Les deux ensembles de points ainsi obtenus sont
traités afin d’extraire un ensemble de couples formé des points se correspondant entre
les 2 images. Nous utilisons la méthode R-SVR de régression robuste par les machines à
vecteurs supports sur ces couples dans le but d’extraire le mouvement dominant et ainsi
obtenir le déplacement du véhicule entre l’image initiale et l’image suivante. On peut
maintenant calculer le déplacement de la fenêtre encadrante pour pouvoir la positionner
autour du véhicule sur l’image 2. Nous répétons ainsi toute la procédure pendant toute
la durée de la séquence afin de suivre le véhicule cible.
Les résultats de cette expérimentation sont présentés dans la figure 5.11.
Cette figure montre le résultat des vecteurs de déplacement obtenus par la méthode
de mise en correspondance (segment bleu), ainsi que la fenêtre encadrante représentée en
bleu. Les 6 images qui composent la figure sont extraites de la séquence à interval régulier.
On remarque tout d’abord que la fenêtre de suivi reste bien en position autour du véhicule
tout au long de la séquence, et que sa taille s’adapte proportionnellement à l’arrière du
véhicule. Cela signifie que l’estimation obtenue avec la méthode de régression robuste par
les machines à vecteurs supports est correcte.
On remarque aussi que plus le véhicule est éloigné du point de vue, moins les vecteurs de
déplacement sont nombreux, ce qui est normal car moins de points d’intérêt sont extraits.
5.3 Conclusion
Nous avons présenté une application au suivi 2D d’objets en mouvement dans les sé-
quences d’images. À l’aide de méthodes d’extraction de points d’intérêts et d’algorithmes
de mise en correspondance, nous pouvons estimer la transformation 2D subie par l’objet
entre deux images successives. Quelques méthodes d’extraction de descripteurs locaux ont
été présentées, ainsi que des techniques de mise en correspondance. Les performances de
l’approche R-SVR proposée, basée sur la régression par les machines à vecteurs supports,
sont montrées sur des exemples simulés ou réels. Les résultats obtenus sont très satisfai-
sants, la méthode proposée se révèle efficace et fiable dans l’extraction de la structure de
mouvement dominante, ainsi que dans l’estimation du déplacement de l’objet ciblé.
129

Chapitre 5. Application à l’estimation du mouvement par mise en correspondance
(a) résultat obtenu à t=2 (b) résultat obtenu à t=17
(c) résultat obtenu à t=30 (d) résultat obtenu à t=44
(c) résultat obtenu à t=64 (d) résultat obtenu à t=90
Fig. 5.11 – Estimation du mouvement et suivi dans la séquence réelle "parking".
130 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

Conclusion générale
LE travail présenté concerne une approche basée sur la régression par les machines
à vecteurs supports, appliquée au suivi d’objets en mouvement dans les séquences
d’images.
Nous avons d’abord parcouru différentes sources d’erreurs succeptibles de fausser les
données images. Après avoir vu comment résoudre un problème d’extraction d’une struc-
ture de mouvement dominante à l’aide de la régression, nous avons pris l’exemple de la
méthode des moindres carrés. Cette méthode, très utilisée, s’est avérée non-robuste, c’est à
dire qu’une seule donnée erronée suffit à perturber la solution. Dans l’optique de travailler
sur l’estimation du mouvement dans les images, et après avoir pris conscience du nombre
de sources d’erreurs possibles, il nous est apparu indispensable d’étudier les différentes
façons de traiter ce problème de données aberrantes afin d’obtenir une estimation la plus
fiable possible.
Ayant pris connaissance des techniques de contrôle et de détection des outliers, nous
avons étudié différentes méthodes de régression robustes issues de la littérature. Nous les
avons classées en trois catégories : les méthodes déterministes, les méthodes de vote et les
méthodes de régularisation. Ces méthodes possèdent une robustesse aux outliers plus ou
moins importante. Nous nous sommes donc intéressés aux différents critères d’évaluation
de la robustesse, et avons choisi d’utiliser dans nos travaux le calcul du point de cassure
afin de pouvoir comparer les méthodes de façon simple et empirique.
Le chapitre 3 développe la partie théorique de la méthode de régression que nous avons
décidé d’utiliser : la régression par les machines à vecteurs supports. Cette méthode pos-
sède certains avantages :
(1) la forme de la fonction de perte linéaire d’insensibilité ε utilisée par les machines à
vecteurs supports lui assure une certaine robustesse,
(2) les deux paramètres ε et C règlent respectivement la largeur de la marge (l’insensibilité
131

Conclusion générale
de la fonction de perte) et le compromis entre la simplicité de la solution et l’attache aux
données,
(3) les vecteurs supports dépendent directement des variables duales, permettant ainsi
d’identifier les outliers dans l’ensemble de données.
Dans la seconde partie de ce chapitre, nous avons apporté des modifications à cette mé-
thode afin de la rendre nettement plus robuste, aussi bien face aux y-outliers qu’aux
x-outliers. Le calcul du point de cassure confirme l’augmentation de la robustesse par
rapport à la méthode standard, où l’on passe d’environ 20% à plus de 70% d’outliers
supportés.
Nous avons présenté une application qui consiste à estimer le mouvement apparent
dans une séquence d’images. Autrement dit, à calculer le flot optique. Après avoir intro-
duit la théorie du flot optique ainsi que ses difficultés, nous avons présenté différentes
méthodes de calcul du flot optique issues de la littérature. À l’aide d’une séquence si-
mulée de référence, la séquence "Yosemite", nous avons pu comparer quantitativement
les résultats obtenus par ces différentes techniques avec la méthode standard de régres-
sion par les machines à vecteurs supports et la méthode améliorée proposée. Les résultats
montrent l’efficacité de l’approche, vu que celle-ci surclasse les diverses techniques hormis
la technique du vbQMDPE. Des exemples de résultats sur données réelles sont également
exposés afin d’apprécier qualitativement le bon fonctionnement de l’approche.
Une seconde application de la méthode a été proposée, toujours dans le cadre de l’esti-
mation du mouvement. Cette fois-ci, nous nous sommes intéressés aux méthodes de mise
en correspondance de caractéristiques invariantes dans les images. Plus particulièrement,
nous avons étudié les différentes méthodes d’extraction de points d’intérêt dans les images,
aussi bien en niveau de gris qu’en couleur. Nous avons cité quelques distances permet-
tant de mettre en correspondance ces points d’intérêt dans deux images successives. puis
nous avons utilisé la méthode proposée afin d’extraire la structure de mouvement domi-
nante et d’en estimer les paramètres de transformation affine. Les résultats obtenus sur
les séquences simulées ou réelles sont encourageants et permettent de suivre un objet en
déplacement dans une séquence d’images.
La principale contribution concerne la modification de la méthode standard de régres-
sion par les machines à vecteurs supports dans le but de rendre celle-ci plus robuste face
aux différents types de données aberrantes. La seconde contribution majeure concerne
l’utilisation de la régression par les machines à vecteurs supports dans le calcul du flot
132 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

optique, aussi bien la méthode standard que la méthode améliorée proposée.
Perspectives
À moyen ou long terme, plusieurs études pourraient être développées sur les points sui-
vants :
– l’application de la méthode proposée à l’estimation du mouvement 3D. En effet,
les méthodes d’acquisition en trois dimensions s’étant développées, par exemple
l’utilisation de multiples caméras (stéréoscopiques, triscopiques) ou encore la fusion
d’informations provenant de radar-laser et de caméras. Elles ouvrent la voie à de
nouvelles possibilités d’application des méthodes d’estimation du mouvement. Que
ce soit le calcul du flot optique ou des méthodes de mise en correspondance, l’ap-
plication de la méthode proposée dans le cadre d’une estimation du mouvement en
3D reste à entreprendre.
– l’intégration de la méthode proposée dans une architecture multi-processeurs, par
exemple dans le cadre du calcul du flot optique. En effet, ce calcul dans sa résolution
paramétrique se compose d’autant d’exécution d’une régression que de vecteurs de
mouvement désirés en sortie. Ces calculs de régression pourraient aisément être pa-
rallélisés afin de résoudre l’équation du flot optique en plusieurs endroits de l’image
en même temps, et ainsi fortement diminuer le temps de calcul.
– Enfin, l’application temps réel de la régression par les machines à vecteurs supports
soulèvent quelques difficultés de par la complexité calculatoire et le nombre de don-
nées. Cela nécessite une optimisation de l’algorithme, aussi bien au niveau du code
que de l’approche elle-même (échantillonage par exemple), on trouve déjà dans la
littérature quelques développements dans cette optique [BDW02][Pla98]. Une implé-
mentation dans un language offrant une meilleure portabilité et rapidité que Matlab
est également une solution à envisager. D’un point de vue matériel, l’utilisation de
processeurs multi-coeurs ou de multi-processeurs permettrait de paralléliser les cal-
culs.
133

Bibliographie
[BA93] M.J. Black et P. Anandan. A framework for the robust estimation of opticflow. Dans Int. Conf. on Computer Vision, pages 231–236, 1993.
[BA96] M.J. Black et P. Anandan. The robust estimation of multiple notion : para-metric and piecewise-smooth flow fields. J. of Computer Vision and ImageUnderstanding, 63 :75–104, 1996.
[BDW02] J. Balcazar, Y. Dai, et O. Watanabe. Provably fast support vector regressionusing random sampling. Dans SIAM Workshop in Discrete Mathematics andData Mining, pages 19–29, 2002.
[BFB94] J.L. Barron, D.J. Fleet, et S. Beauchemin. Performance of optic Flow Tech-niques. Dans Int. J. of Computer Vision, volume 12, pages 43–77, 1994.
[BHB03] P. Barnum, B. Hu, et C. Brown. Exploring the Pratical Limits of OpticalFlow. Rapport technique, university of Rochester, 2003.
[BHS98] A. Bab-Hadiashar et D. Suter. Robust optic flow computation. Dans Int. J.of Computer Vision, volume 29, pages 59–77, 1998.
[BKNS00] M.M. Breuning, H.-P. Kriegel, R.T. Ng, et J. Sander. LOF : Identifyingdensity-based local outliers. Dans ACM International Conference on Ma-nagement of Data SIGMOD, pages 93–104, 2000.
[BKW80] D.A. Belsley, E. Kuh, et R.E. Welsch. Regression Diagnostics. Wiley, 1980.
[BL78] V. Barnett et T. Lewis. Outliers in Statistical Data. Wiley, 1978.
[BL91] N. Baaziz et C. Labit. Multigrid motion estimation on wavelet pyramidsfor image sequence coding. Dans 7th Scandinavian Conference on ImageAnalysis, pages 1053–1061, 1991.
[BL97] J. Beis et D.G. Lowe. Shape indexing unsing approximate nearest-neighboursearch in high-dimensional spaces. Dans Conference on Computer Vision andPattern Recognition, pages 1000–1006, 1997.
[Bla92] M.J. Black. Robust incremental optical flow. PhD thesis, Yale University,Department of computer science, 1992.
[Bla97] Thierry Blaszka. Approches par Modèles en Vision Précoce. PhD thesis,Université de NICE SOPHIA-ANTIPOLIS, 1997.
[BT74] A.E. Beaton et J.W. Tukey. The fitting of power series, meaning polynomials,illustrated on bandspectroscopic data. Technometrics, 16 :147–185, 1974.
[BW02] T. Brox et J. Weickert. Nonlinear matrix diffusion for optic flow estimation.Pattern Recognition, Lecture Notes in Computer Science, 2449 :446–453, 2002.
134

[CD89] C.H. Chu et E.J. Delp. Estimating displacement vector from an image se-quence. J. Opt. Soc. Am., 6 :871–878, 1989.
[CH88] S. Chatterjee et A. Hadi. Sensitivity Analysis in Linear regression. Wiley,1988.
[CM02] V. Cherkassky et Y. Ma. Selection of Meta-parameters for Support VectorRegression. Dans Int. Conf. Artificial Neural Networks, pages 687–693, 2002.
[COh93] I. COhen. Non-linear variational method for optical flow computation. Dans8th SCIA, volume 1, pages 523–530, 1993.
[Coo77] R.D. Cook. Detection of Influential Observations in Linear Regression. Tech-nometrics, 19 :15–18, 1977.
[CST00] N. Cristianini et J. Shawe-Taylor. Introduction to Support Vector Machines.Cambridge University Press, 2000.
[CV90] M. Campani et A. Verri. Computing Optical Flow from an Overconstrai-ned System of Linear Algebraic Equations. Dans IEEE Int. Conference onComputer Vision, pages 22–26, 1990.
[CW82] R.D. Cook et S. Weisberg. Residuals and Influence in Regression. Chapman& Hall, 1982.
[Debon99] R. Debon, B. Solaiman, J. M. Cauvin, et C. Roux. Fusion de l’informa-tion : fusion de données et de modèles appliqués à la segmentation d’imagesécho-endoscopiques. Dans 17ème Colloque sur le Traitement du Signal et desImages, GRETSI, pages 1065–1068, 1999.
[DKA99] R. Deriche, P. Kornprobst, et G. Aubert. Computing optical flow via varia-tional techniques. SIAM J. on Applied Mathematics, 60 :156–182, 1999.
[Far01] G. Farneback. Very high accuracy velocity estimation using orientation ten-sors, parametric motion, and simultaneous segmentation of the motion field.Dans IEEE int. conf. on Computer Vision, pages 171–177, 2001.
[FB81] M.A. Fischer et R.C. Bolles. Random sample consensus : a paradigm for modelfitting with applications to image analysis and automated cartography. DansComm. ACM, volume 24, pages 381–395, 1981.
[GCB01] C. GARCIA, X. CUFI, et J. Batle. Detection of Matching in a Sequenceof Underwater Images through Texture Analysis. Dans IEEE Int. Conf. onImage Processing, volume 1, pages 361–364, 2001.
[GP96] S.N. Gupta et J.L. Prince. Div-Curl regularization for motion estimation in3-D volumetric imaging. Dans ICIP, pages 929–932, 1996.
[GR96] F. Guichard et L. Rudin. Accurate estimation of discontinuous optical flowby minimizing divergence related functionals. Dans Int. Conf. on Image Pro-cessing, volume 1, pages 497–500, 1996.
[Hil90] D. Hilbert. Theory of Algebric Invariants. Cambridge University Press, 1890.[HK70] A.E. Hoerl et R.W. Kennard. Ridge Regression : Biased estimation for non-
orthogonal problems. Technometrics, 12 :55–67, 1970.[HL02] H.P. Huang et Y.H. Liu. Fuzzy Support Vector Machines for Pattern Recogni-
tion and Data Mining. International Journal of Fuzzy Systems, 4(3) :826–835,2002.
135

Bibliographie
[Hou62] P.V.C. Hough. Methods and Means for Recognizing Complex Pattern. US.Patent 3069654, 1962.
[HS81] B.K.P. Horn et B.G. Schunck. Deterniming optic flow. 1981.[Hub64] P.J. Huber. Robust estimation of a location parameter. Ann. Math. Statist.,
35 :73–101, 1964.[Hub81] P. Huber. Robust Statistics. Wiley, 1981.[HW77] P.W. Holland et R.E. Welsch. Robust Regression Using Iteratively Reweigh-
ted Least-Squares. Communications in Statistics, pages 813–827, 1977.[HW78] D. Hoaglin et R. Welsch. The hat matrix in regression and anova. The
American Statistician, 1978.[JBJ96] S.X. Ju, M.J. Black, et A.D. Jepson. Skin and Bones : Multi-layer, Locally
Affine, Optical Flow and Regularization with Transparency. Dans ComputerVision and Pattern Recognition, CVPR96, pages 307–314, 1996.
[JHG+88] G.G. Judge, R.C. Hill, W.E. Griffiths, H. Lütkepohl, et T.-C. Lee. Introduc-tion to the Theory and Practice of Econometrics. Wiley, 1988.
[JM88] Harris J. et Stephens M. A combined corner and edge detector. Dans 4thALVEY Vision Conference, pages 147–151, 1988.
[JZHW06] W.J. Jia, H.F. Zhang, X.J. He, et Q.A. Wu. A Comparison on HistogramBased Image Matching Methods. Dans IEEE Int. Conf. on Video and SignalBased Surveillance, pages 97–97, 2006.
[Kar39] W. Karush. Minima of functions of several variables with inequalities as sideconstraints. PhD thesis, University of Chicago, Dept. of Mathematics, 1939.
[KKMN98] D.G. Kleinbaum, L.L. Kupper, K.E. Muller, et A. Nizam. Applied regressionanalysis and other multivariable methods. Duxbury press, 1998.
[KR82] L. Kitchen et A. Rosenfeld. Gray-level corner detection. Pattern Recognitionletters, 1 :95–102, 1982.
[KS04] Y. Ke et R. Sukthankar. PCA-SIFT : A more distinctive representation forlocal image descriptors. pages 506–513, 2004.
[KT51] H.W. Kuhn et A.W. Tucker. Nonlinear programming. Dans Berkeley Sym-posium on Mathematical Statistics and Probabilistics, pages 481–492, 1951.
[KTB96] A. Kumar, A.R. Tannenbaum, et G.J. Balas. Optical flow : a curve evolutionapproach. 5 :598–611, 1996.
[LK81] B.D. Lucas et T. Kanade. An Iterative Image Registration Technique withan Application to Stereo Vision. Dans 7th Int. Joint Conf. on ArtificialIntelligence, pages 674–679, 1981.
[LMP98] K.M. Lee, P. Meer, et R.H. Park. Robust Adaptive Segmentation of the OpticFlow with Robust Techniques. IEEE trans. on Pattern Analysis and MachineIntelligence, 20 :200–205, 1998.
[Low03] D. Lowe. Distinctive image features from scale-invariant keypoints. DansInternational Journal of Computer Vision, volume 20, pages 91–110, 2003.
[MB96] A. Mitiche et P. Bouthemy. Computation and analysis of image motion : asynopsis of current problems and methods. Int. Journal of Computer Vision,19 :29–55, 1996.
136 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

[Mem03] E. Memin. Estimation du flot optique : contributions et panorama de diffe-rentes approches. Rapport technique, universite de Rennes 1, 2003.
[MF04] D.R. Musicant et A. Feinberg. Active Set Support Vector regression. DansIEEE Transactions on Neural Networks, pages 268–275, 2004.
[MGD98] P. Montesinos, V. Gouet, et R. Deriche. Differential Invariants for ColorImages. Dans Int. Conf. on Pattern Recognition, 1998.
[MJ94] M.Bober et J.Kittler. Estimation of complex multimodal motion : an approachbased on robust statistics and Hough transform. Dans Image and VisionComputing, volume 12, pages 661–668, 1994.
[MP98] E. Memin et P. Perez. Dense Estimation and Object-based Segmentation ofthe Optic Flow with Robust Techniques. IEEE trans. on Image Processing,7 :703–719, 1998.
[MS96] J.V. Miller et C.V. Stewart. MUSE : Robust Surface Fitting Using UnbiasedScale Estimates. Dans Computer Vision and Pattern Recognition, CVPR96,pages 300–306, 1996.
[MS05] K. Mikolajczyk et C. Schmid. A Performance Evaluation of Local Descriptors.IEEE Transactions on Pattern Analysis and Machine Intelligence, 27 :1015–1030, 2005.
[NE86] H.H. Nagel et W. Enkelmann. An investigation of smoothness constraintsfor the estimation of displacement vector fields from image sequences. DansIEEE Trans. on Pattern Analysis and Machine Intelligence, volume 8, pages565–593, 1986.
[Nes93] P. Nesi. Variational approach to optical flow estimation managing disconti-nuities. Image and Vision Computing, 11 :419–439, 1993.
[Nit] Supot Nitsuwat. Optical Flow Estimation. Rapport technique, university ofNew South Wales, Sydney.
[OB95] J.M. Odobez et P. Bouthemy. Robust Multiresolution Estimation of Parame-tric Motion Models. J. of Visual Communication and Image Representation,6 :348–365, 1995.
[Ols00] C. Olson. Maximum-likelihood template matching. Dans International conf.on Computer Vision, pages 52–57, 2000.
[OS99] E.P. Ong et M. Spann. Robust optical flow computation based on least-median of squares regression. Int. J. of Computer Vision, 31 :51–82, 1999.
[Par62] E. Parzen. On the estimation of a probability density function and the mode.1962.
[PJBJJ05] Gabriel P., Hayet J-B., Piater J., et Verly J. Utilisation des Points dIntérêtsCouleurs pour le Suivi dObjets. Dans ORASIS, 2005.
[Pla98] J. Platt. Fast Training of Support Vector Machines using Sequential MinimalOptimization. 1998.
[PVR98] Montesinos P., Gouet V., et Deriche R. Differential invariants for color images.Dans International Conference on Pattern Recognition, pages 838–840, 1998.
[RL87] P. J. Rousseeuw et A. M. Leroy. Robust regression and outlier detection.Wiley, 1987.
137

Bibliographie
[RRRS86] Hampel R., Elvezio M. Ronchetti, Peter J. Rousseeuw, et Werner A. Stahel.Robust Statistics : The Approach Based on Influence Functions. Wiley, 1986.
[SAH91] E.P. Simoncelli, E.H. Adelson, et D.J. Heeger. Probability distributions ofoptical flow. Dans Computer Vision and Pattern Recognition, CVPR91, pages310–315, 1991.
[SBLV02] J.A.K. Suykens, J.De Brahanter, L. Lukas, et J. Vandewalle. Weighted LeastSquares Support Vector Machines : robustness and sparse approximation.Neurocomputing, pages 85–105, 2002.
[SBM04] Z. Sun, G. Bebis, et R. Miller. On-Road Vehicle Detection Using OpticalSensors : A Review. Dans IEEE Intelligent Transportation Systems Conf.,pages 585–590, 2004.
[SM96] Cordelia Schmid et Roger Mohr. Mise en Correspondance par InvariantsLocaux. Traitement du Signal, 13 :591–606, 1996.
[SS98] A.J. Smola et B. Schölkopf. A Tutorial on Support Vector Regression. Rap-port technique, 1998.
[SS02] B. Scholkopf et A. Smola. Learning with Kernels. MIT press, 2002.
[Ste99] C.V. Stewart. Robust parameter estimation in computer vision. Society forIndustrial and Applied Mathematics Reviews, 41 :513–537, 1999.
[TA77] A.N. Tikhonov et V.Y. Arsenin. Solutions of Ill-Posed Problems. John Wiley,1977.
[TP84] O. Tretiak et L. Pastor. Velocity Estimation from Image Sequences withSecond Order Differential Operators. Dans IEEE Int. Conference on PatternRecognition, pages 16–19, 1984.
[UGVT88] S. Uras, F. Girosi, A. Verri, et V. Torre. A Computational Approach to MotionPerception, volume 60. 1988.
[Vap95] V.N. Vapnik. The Nature Of Statistical Learning Theory, 1995.
[VGS97] V. Vapnik, S. Golowich, et A. Smola. Support vector method for functionapproximation, regression estimation and signal processing. MIT press, 1997.
[VH06] J. Valyon et G. Horvath. A Robust LS-SVM Regression. International Journalof Computational Intelligence, 3(3) :243–248, 2006.
[Wan04] Hanzi Wang. Robust Statistics for Computer Vision : Model Fitting, ImageSegmentation and Visual Motion Analysis. PhD thesis, Monash University,2004.
[WB06] W. Waegeman et L. Boullart. An ensemble of weighted support vector ma-chines for ordinal regression. Transactions on Engineering, Computing andTechnology, 12 :71–75, 2006.
[WJ95] M.P. Wand et M. Jones. Kernel Smoothing. Chapman & Hall, 1995.
[WM95] J. Weber et J. Malik. Robust computation of optical flow in a multiscaledifferential framework. Int. J. of computer vision, 14 :67–81, 1995.
[WMR92] S. Wang, V. Markandey, et A. Reid. Total least squares fitting spatiotem-poral derivatives to smooth optical flow field. Dans SPIE : Signal and Dataprocessing of Small Targets, volume 1698, pages 42–55, 1992.
138 — c© J. Colliez – Thèse de Doctorat – LASL – UPRES EA 2600 – ULCO —

[WpL] Song Wang et Zhi pei Liang. Robust Support Vector Machines for Regression.[WS01] J. Weickert et C. Schnorr. Variational Optic Flow Computation with a
Spatio-Temporal Smoothness Constraint. Mathematical Imaging and Vision,14 :245–255, 2001.
[WS03] Hanzi Wang et David Suter. Variable Bandwidth QMDPE and Its Applicationin Robust Optical Flow Estimation. Dans ICCV, pages 178–183, Nice, France,2003.
[WXDR83] K. Wohn, H. Xie, L.S. Davis, et A. Rosenfeld. Smoothing optical flow fields.Dans Image Understanding Workshop, pages 61–66, 1983.
[YBK94] X. Yu, T.D. Bui, et A. Krzyzak. Robust Estimation for Range Image Seg-mentation and Reconstruction. IEEE trans. on Pattern Analysis and MachineIntelligence, 16 :530–538, 1994.
[YH00] Ming Ye et Robert M. Haralick. Optical Flow from a Least-Trimmed SquaresBased Adaptive Approach. Dans ICPR, pages 7064–7067, 2000.
[ZAP07] G. Zioutas, A. Avramidis, et L. Pitsoulis. Penalized trimmed squares and amodification of support vectors for unmasking outliers in linear regression.REVSTAT, 5, 2007.
[ZWLL01] Weiyu Zhu, Song Wang, Ruei-Sung Lin, et Stephen Levinson. Tracking of Ob-ject with SVM Regression. Dans IEEE Computer Vision Pattern RecognitionConf., pages 240–245, 2001.
139

Publications personnelles
Colliez Johan, Dufrenois Franck et Hamad Denis. Optical Flow Estimation by Support
Vector Regression. Dans Proceedings of 9th International Conference on Engineering Ap-
plications of Neural Networks, pages 69-76, 2005.
Colliez Johan, Dufrenois Franck et Hamad Denis. Optic flow estimation by support vector
regression. Dans International Journal on Engineering Applications of Artificial Intelli-
gence, vol. 19, Issue 7, pages 761-768, octobre 2006.
Colliez Johan, Dufrenois Franck et Hamad Denis. Robust Regression and Outlier Detec-
tion with SVR : Application to Optic Flow Estimation". Dans Proceedings of the 17th
British Machine Vision Conference, vol. III, pages 1229-1238, 2006.
Colliez Johan, Dufrenois Franck et Hamad Denis. Robust Optic Flow Computation with
Support Vector Regression. Dans Proceedings of the 16th IEEE Signal Processing Society
Workshop on Machine Learning for Signal Processing, pages 409-414, 2006.
Dufrenois Franck, Colliez Johan et Hamad Denis. Weighted Support Vector Regression for
robust single model estimation : application to motion segmentation in image sequences.
Dans International Joint Conference on Neural Networks, pages -, 2007.
Dufrenois Franck, Colliez Johan et Hamad Denis. Crisp Weighted Support Vector Regres-
sion for robust model estimation : application to object tracking in image sequences. Dans
IEEE Computer Society Conference on Computer Vision and Pattern Recognition, pages
-, 2007.
Dufrenois Franck, Colliez Johan et Hamad Denis. Bounded influence Support Vector Re-
gression for robust single model estimation : application to motion segmentation in image
sequences. Dans International Journal IEEE Transactions on Neural Networks, pages -,
140

2007.
141



Résumé
Le problème de la modélisation par régression robuste est abordé dans le cadre del’estimation du mouvement dans une séquence d’images. L’approche par les machines àvecteurs supports (SVR) est employée pour cet objectif. Afin de rendre l’approche robusteface aux bruits et aux données abérrantes, nous utilisons la technique de seuillage adap-tatif, aussi bien hard que soft, pour la sélection des données candidates à l’estimation dumodèle. Pour évaluer l’efficacité et la robustesse de notre approche, nous l’avons appliquéeà l’estimation du mouvement par flot optique, sur des exemples bien connus dans la litté-rature. Par ailleurs, dans un contexte d’attelage virtuel de véhicules, l’approche proposéea été appliquée à l’estimation du mouvement par mise en correspondance d’images issuesd’une scène routière à l’aide d’une caméra embarquée.Le contenu du mémoire est divisé en cinq chapitres. Dans le chapitre 1, le problème desdonnées abérrantes dans la vision par ordinateur est posé pour ensuite présenter, dans lechapitre 2, différentes méthodes de régression robuste déterministes, de vote et de régula-risation. Le chapitre 3 présente la régression par machines à vecteurs supports standard,avec marge adaptative et avec pondération. Enfin, les chapitres 4 et 5 présentent l’appli-cation de l’approche SVR robuste à l’estimation du mouvement par flot optique et parmise en correspondance.
Mots-clés: Machines à vecteurs supports, Régression robuste, Séquence d’images, Suivid’objets, Flot optique, Mise en correspondance
Abstract
The problem of modeling by robust regression is addressed in the context of motionestimation in a sequence of images. The support vector machines (SVR) approach isemployed for this purpose. In order to make robust against noises and outliers, we usethe technique of adaptative threshold, as well hard as soft, for the selection of candidatedata in model estimation. To evaluate the efficacity and robustness of our approach, weapply it for motion estimation by optic flow, on well established examples. Moreover, inthe context of virtual coupling of vehicles, the porposed approach is applied for motionestimation by matching images from a road scene with in-car camera.The content of this memory is divided into five chapters. In chapter 1, the problem ofoutliers in computer vision is posed to present, in chapter 2, different methods of robustregression. Chapter 3 presents the standard regression by support vector machines, thenmodifications like adaptative margin and hard or soft weighting. Finally, chapters 4 and5 show the application of the robust SVR approach to motion estimation by optic flowand images matching.
Keywords: Support vector machines, Robust regression, Video, Tracking, Optic flow,Matching
Top Related