
UNIVERSITÉ DU QUÉBEC MÉMOIRE PRÉSENTÉ À … · CHAPITRE 1 INTRODUCTION GENERALE ... 1...
49
UNIVERSITÉ DU QUÉBEC MÉMOIRE PRÉSENTÉ À L'UNIVERSITÉ DU QUÉBEC À TROIS-RIVIÈRES COMME EXIGENCE PARTIELLE DE LA MAÎTRISE EN MATHÉMATIQUES ET INFORMATIQUE APPLIQUÉES PAR KARIM LAROUSSI DÉVELOPPEMENT D’UN MODÈLE DE RÉGRESSION POUR LA DÉTECTION D’INTRUSIONS DANS LES RÉSEAUX VÉHICULAIRES AD HOC (VANETS) MARS 2015
Transcript of UNIVERSITÉ DU QUÉBEC MÉMOIRE PRÉSENTÉ À … · CHAPITRE 1 INTRODUCTION GENERALE ... 1...

UNIVERSITÉ DU QUÉBEC
MÉMOIRE PRÉSENTÉ À L'UNIVERSITÉ DU QUÉBEC À TROIS-RIVIÈRES
COMME EXIGENCE PARTIELLE DE LA MAÎTRISE EN MATHÉMATIQUES ET INFORMATIQUE
APPLIQUÉES
PAR KARIM LAROUSSI
DÉVELOPPEMENT D’UN MODÈLE DE RÉGRESSION POUR LA DÉTECTION D’INTRUSIONS DANS LES RÉSEAUX VÉHICULAIRES AD
HOC (VANETS)
MARS 2015

CE MÉMOIRE A ÉTÉ ÉVALUÉ PAR UN JURY COMPOSE DE
Boucif Amar Bensaber, directeur de recherche.
Professeur au département de Mathématiques et d’Informatique, Université du
Québec à Trois-Rivières.
Ismail Biskri, évaluateur.
Professeur au département de Mathématiques et d’Informatique, Université du
Québec à Trois-Rivières.
François Meunier, évaluateur
Professeur au département de Mathématiques et d’Informatique, Université du
Québec à Trois-Rivières.
Université du Québec à Trois-Rivières

Service de la bibliothèque
Avertissement
L’auteur de ce mémoire ou de cette thèse a autorisé l’Université
du Québec à Trois-Rivières à diffuser, à des fins non lucratives,
une copie de son mémoire ou de sa thèse.
Cette diffusion n’entraîne pas une renonciation de la part de
l’auteur à ses droits de propriété intellectuelle, incluant le droit
d’auteur, sur ce mémoire ou cette thèse. Notamment, la
reproduction ou la publication de la totalité ou d’une partie
importante de ce mémoire ou de cette thèse requiert son
autorisation.
Remerciements

À mon directeur de mémoire, Monsieur Amar Bensaber Boucif, que je remercie vivement
pour son aide dans la réalisation de ce travail. Je suis vraiment très honoré d'avoir collaboré
avec lui. J'apprécie beaucoup sa modestie, sa disponibilité et ses grandes qualités scientifiques
et humaines. J'espère que ce travail lui donnera satisfaction.
J'exprime aussi ma reconnaissance à toute ma famille, à mes parents pour leur soutien et leur
encouragement sans faille. Ce travail n'aurait pu aboutir sans l'aide et la patience de ma
fiancée qui m'a énormément soutenu pendant ces années.
Je remercie également tous les professeurs ainsi que tous les membres du département de
mathématiques et d'informatique.
LISTE DES ABRÉVIATIONS

CA: Central Authority.
DOS: Denial Of service
DSRC: Dedicated Short Range Communication.
MAC: Medium Access Control.
MANET: Mobile Ad hoc Network.
OBU: On Board Unit.
RSU: Road Side Unit.
VANETs: Vehicular Ad hoc Network.
V2V: Vehicular-to-Vehicular.
V2I: Vehicular-to-Infrastructure.
RREP: Route Reply Packet
I2V: Infrastructure to Vehicule
TPM : Trusted Platform Module
IDS : Intrusion Detection System

Table des matières
Page
REMERCIEMENTS…………………………………………………………………………..iii
LISTE DES ABREVIATIONS………………………………………………………………..iv
Table des matières………….……………………………………………………………...…vii
RESUME…...…………………………………………………………………………………ix
ABSTRACT……………………………………………………………………………………x
CHAPITRE 1 INTRODUCTION GENERALE………………………………………………1
CHAPITRE 2 LES RESEAUX VEHICULAIRES Ad Hoc VANETs………………….….....3
CHAPITRE 3 APERÇU DES ATTAQUES SUR LES RESEAUX
VANETs…………………………………………………………………………………......…8
CHAPITRE 4 REGRESSION LOGISTIQUE…………………………………………….....12
CHAPITRE 5 PROBLEMATIQUE…………………………………………………………21
CHAPITRE 6 ARTICLE…………………………………………………………………….26
CHAPITRE 7 CONCLUSION ET PERSPECTIVES……………………………………….33
REFERENCES………………………………………………………………………………..35
AFFICHE SCIENTIFIQUE « NSERC DIVA, 2014, Ottawa »…………………….………..38

Listes des figures
Page
Figure 1. Modèle VANET
simplifié…………………………………………………..………..3
Figure 2. Les patterns de communications dans
VANET………………………………………5

RESUME
Le rôle principal du protocole IDS (Intrusion Detection System) est de détecter une attaque
sur un réseau. Lors de la détection d’une attaque les informations relatives à cette dernière
sont envoyées et une politique de sécurité est amorcée. Dans ce mémoire, nous allons
optimiser la détection et la prévention d’attaques en développant un modèle de prévision
mathématique.
Notre méthode s’appuie sur le modèle probabiliste suivant : Lorsqu’un véhicule d’un cluster
détecte une attaque, il partage la signature avec les membres de son cluster, ces derniers
transmettent à la tête du cluster un avis positif (négatif) d’une attaque (ou non). La tête du
cluster renvoie alors les informations au RSU (Road Side Unit). Celui-ci envoie la signature à
un cluster voisin sur la route afin d’avoir son avis sur l’attaque. Pour la corroborer, le RSU
calcule le ratio entre le nombre de véhicules ayant répondu positivement et le nombre total de
véhicules. Lorsque le ratio est supérieur à (50%), l’attaque est validée et le protocole est
amorcé.
Pour améliorer cette méthode de corroboration, nous concevons un modèle Probabiliste
innovateur basé sur la régression Logistique. Cette méthode permet d’estimer l’occurrence
d’un événement (ici, une attaque) en fonction des connaissances acquises préalablement. Elle
se base sur un historique d’une base de connaissance (BC) qui permet d’estimer les
paramètres de la régression logistique. La BC est constituée dans un premier temps de la
quantification du nombre de véhicules ayant répondu positivement lors de la recherche d’un
patron d’attaque dans les paquets de données. Il faut au préalable fournir à la BC des données
testées sur des véhicules dans un contexte simulé (réel). La base est ensuite implantée dans le
RSU. Lorsque le modèle de régression est validé, il est utilisé pour estimer la probabilité
d’une attaque et si cette dernière est supérieure au seuil fixé à l’avance (50%), l’attaque est
corroborée.

ABSTRACT
The main role of an IDS (Intrusion Detection System) protocol is to detect an attack in the
network. Once the detection of an attack is confirmed, the relative information about this
attack are sent and a security policy is initiated. In this work, we will optimize the attack
detection and prevention system by developing a mathematical prediction model.
Our method is based on the following probabilistic model: When a cluster of vehicles detects
an attack, it shares its signature with the members of its cluster, after that, these later transmit
a positive (Negative) opinion about the attack to the head cluster. The head cluster then
resends the information to the RSU. The RSU sends the signature to a nearby cluster on the
road in order to get his opinion on the attack. To corroborate this signaled attack, the RSU
(Road Side Unit) calculates the ratio of vehicles having responded positively and the total
number of vehicles. When the ratio is higher (50%), the attack is validated and the protocol is
initiated.
To improve this method of corroboration, we developed an innovative probabilistic model
based on Logistic regression. This model estimates the occurrence of an event (in this case an
attack) according to previously acquired knowledge. It is based on a history of a knowledge
base (KB) to estimate the parameters of the logistic regression. The « KB » consists initially
of quantifying the number of vehicles that responded positively when seeking for a pattern of
attack in the data packets. We should first provide the KB data on tested vehicles from a
simulated environment (real). The knowledge base is then implanted in the RSU.
When the regression model is validated, it will be used to estimate the probability of an attack
and if it exceeds a given threshold in advance (50%), the attack is confirmed.

CHAPITRE 1
INTRODUCTION GENERALE
L'avancement et le large déploiement de la technologie des communications sans fil ces
dernières années ont révolutionné les modes de vie humaines en fournissant plus de
commodité et de flexibilité pour l'accès aux services Internet et aux différents types
d’applications de communication personnels.
Actuellement, les constructeurs automobiles et les compagnies de télécommunications sont en
train de préparer chaque voiture avec les technologies qui permettent aux conducteurs et aux
passagers de communiquer les uns avec les autres ainsi qu'avec les infrastructures routières,
qui peuvent être situées à quelques sections critiques de la route, comme à chaque feu de
circulation ou à une intersection ou à un panneau d'arrêt, afin d'améliorer l'expérience et offrir
une conduite plus sûre. Par exemple, MSN TV et KVH de Microsoft Corp. Industries, Inc. ont
introduit une automobile munie d’un système d'accès à Internet appelé TracNet [33]. Ce
dernier transforme l'ensemble du véhicule en une borne (hotspot Wi-Fi IEEE 802.11), pour
que les passagers puissent utiliser leurs ordinateurs portables sans fil compatibles et se
connecter avec. En outre, en utilisant un tel dispositif de communication, également connus
sous le nom d’unités embarquées (OBU), les véhicules peuvent communiquer les uns avec les
autres ainsi qu'avec l’unité routière (RSU).
Un réseau auto-organisé peut être formé en reliant les véhicules et les RSU, il est appelé
réseau véhiculaires ad hoc (VANET). L'intérêt a été soulevé récemment pour les applications
de communications de route-à-véhicule (RVCS) et la communication inter véhiculaire (IVC),
visant à améliorer la sécurité et la gestion de la circulation tout en fournissant une conduite
sécuritaire et un accès Internet aux passagers.
La sécurité dans VANET devrait être considérée comme aussi importante que dans les autres
réseaux filaires et sans fil. En raison de la sensibilité de l’information diffusée via le réseau

VANET, toutes les applications conçues pour ce réseau véhiculaire ont besoin d'être
protégées

2
contre toute manipulation malveillante. Une panoplie d’attaques sur ce réseau existe déjà, ces
dernières peuvent être classifiées en trois types comme cités dans [1].
- Les Bugs d’informations
- La divulgation d’identité
- Le Déni de service
Dans ces trois catégories, on peut citer quelques attaques telles que la falsification d’identité,
la localisation de position, la répudiation, le DoS (Deni de Service), l’attaque de routage, etc.
Dans ce mémoire, on présentera un modèle mathématique «modèle de régression logistique »
qui permettra de prévoir et de corroborer les intrusions malveillantes sur notre réseau en se
basant sur une base de données conçue suite à une simulation de trois types d’attaques. Les
simulations seront effectuées tout en adoptant les comportements basiques des attaques
traitées dans notre cas. À la fin, nous utiliserons les résultats de ces simulations pour les
implémenter dans notre modèle de prévision mathématique qui lui-même donnera des
prévisions et des possibilités d’attaques sur notre réseau VANETs.
Le reste de ce mémoire sera organisé comme suit. Dans le chapitre 2, on introduit les réseaux
VANETs et leurs différentes entités et les modèles de communication. Dans le chapitre 3, on
présentera les différents types d’attaques présents sur les réseaux VANETs, leurs
caractéristiques et leurs comportements. Par la suite, le chapitre 4 portera sur la présentation
du modèle de régression logistique, la démarche mathématique et son principe de
fonctionnement. Dans le chapitre 5, nous présenterons la problématique de notre travail ainsi
qu’une modélisation du protocole proposé. Ensuite dans le chapitre 6, nous présenterons notre
contribution, étude et solution à travers le développement d’un modèle de régression pour la
détection d’intrusions dans les réseaux véhiculaires Ad Hoc, sous forme d’article scientifique
présenté à une conférence internationale. Enfin, nous conclurons et présenterons quelques
perspectives dans le chapitre 7.

CHAPITRE 2
LES RESEAUX VEHICULAIRE Ad Hoc (VANETs)
Aujourd'hui, les activités de la route sont l'une des plus importantes routines quotidiennes
dans le monde entier. Transport de passagers et de fret sont essentiels pour le développement
humain. Ainsi, des améliorations dans ce domaine sont réalisées chaque jour, de meilleurs
mécanismes de sécurité et des carburants plus écologiques sont utilisés, etc. La circulation
routière et la conduite sont l’un des facteurs qui touche principalement à la sécurité routière
d’où le besoin évident de le rendre plus sécuritaire. Une description météorologique précise
ou des alertes précoces de dangers (par exemple, les goulots d'étranglement, accidents)
seraient très utiles pour les conducteurs. À cette fin, un nouveau type de technologie de
communication appelé VANETs (Ad-hoc Vehicular Networks) a vu le jour et la recherche est
en plein essor dans ce domaine [32].
1. APERÇU DU MODÈLE
Il existe de nombreuses entités impliquées dans un déploiement du réseau VANET. Bien que
la grande majorité des nœuds VANET soit des véhicules, il y a d'autres entités qui constituent
la base les opérations dans ces réseaux. En outre, ils peuvent communiquer les uns avec les
autres de différentes façons. Dans cette section, nous allons tout d'abord décrire les entités les
plus communes qui apparaissent dans les réseaux VANETs. Dans la deuxième partie, nous
allons analyser les différents paramètres de communications des réseaux VANETs qui
peuvent être utilisés entre les véhicules, et entre les véhicules et les entités restantes.
2. Entités VANET communes
Plusieurs entités différentes sont généralement supposées exister dans les réseaux VANETs.
Pour comprendre les questions de sécurité connexes de ces réseaux, il est nécessaire
d'analyser ces entités et leurs relations. La figure 1 montre le schéma d’un réseau VANET
typique.

4
Figure 1. Modèle VANET simplifié .
(Source: Overview of security issues in Vehicular Ad-hoc Networks José María de Fuentes,
Ana Isabel González-Tablas, Arturo Ribagorda [35])
Ad-hoc environnement : Dans cette partie du réseau, les communications sont établies à
partir de véhicules. Du point de vue VANET, ils sont équipés de trois dispositifs différents.
Tout d'abord, ils sont équipés d’une unité de communication (OBU, On-Board Unit) qui
permet une communication de véhicule à véhicule (V2V) et une communication véhicule à
infrastructure (V2I, I2V). D'autre part, ils ont un ensemble de capteurs pour mesurer leur
propre statut (par exemple, la consommation de carburant) et son environnement (par
exemple, route glissante, la distance de sécurité). Ces données sensorielles peuvent être
partagées avec d'autres véhicules afin de les sensibiliser et d'améliorer la sécurité routière.
Enfin, un module TPM (Trusted Platform Module) est souvent monté sur les véhicules. Ces
dispositifs sont particulièrement intéressants pour des raisons de sécurité, car ils offrent un
stockage fiable et computationnel. Ils ont généralement une horloge interne fiable et sont
censés être inviolable ou au moins protégés contre les manipulations. De cette façon, les
informations sensibles peuvent être stockées de manière sécuritaire.
Comme mentionné précédemment, les réseaux VANETs sont considérés comme un réseau de
communications qui impose plusieurs exigences. Les véhicules se déplacent à une vitesse
relativement élevée et, d'autre part, le grand nombre de véhicules présents dans une route
pourrait conduire à un énorme réseau. Ainsi, un spécifique standard de communication
‘Dedicated Short Range Communications’ (DSRC) [20] a été mis au point pour faire face à

5
ces exigences (Armstrong Consulting Inc.). Cette norme spécifie qu'il y aura certains
dispositifs de communication situés à côté des routes, appelés Unités bord de la route (RSU).
De cette façon, les RSU deviennent des passerelles entre l'infrastructure et les véhicules et
vice-versa.
3. Paramètres VANETs
Plusieurs applications sont activées par les réseaux VANETs, affectant principalement la
sécurité routière. Dans ce type d'application, les messages échangés sur VANETs ont un
caractère et un but différent. Compte tenu de ceci, quatre modèles différents de
communication (voir figure 2) peuvent être identifiés:
V2V propagation d’avertissement (fig. 2-a). Il existe des situations dans lesquelles il
est nécessaire d’envoyer un message à un véhicule spécifique ou à un groupe de
véhicules. Par exemple, lorsqu'un accident est détecté, un message d'avertissement
doit être envoyé à l'arrivée des véhicules afin d’accroître la sécurité de la circulation.
D'autre part, si un véhicule d'urgence public est en route, un message doit être envoyé
aux véhicules sur la même route. De cette façon, il serait plus facile au véhicule
d'urgence d'avoir une voie libre. Dans les deux cas, un protocole de routage est alors
nécessaire pour transmettre ce message à la destination.
V2V communication de groupe (Fig. 2-b). En vertu de ce modèle, seuls les
véhicules ayant certaines fonctionnalités peuvent participer à la communication. Ces
caractéristiques peuvent être statiques (par exemple, les véhicules de la même
entreprise) ou dynamiques (par exemple, les véhicules sur la même zone dans un
intervalle de temps).
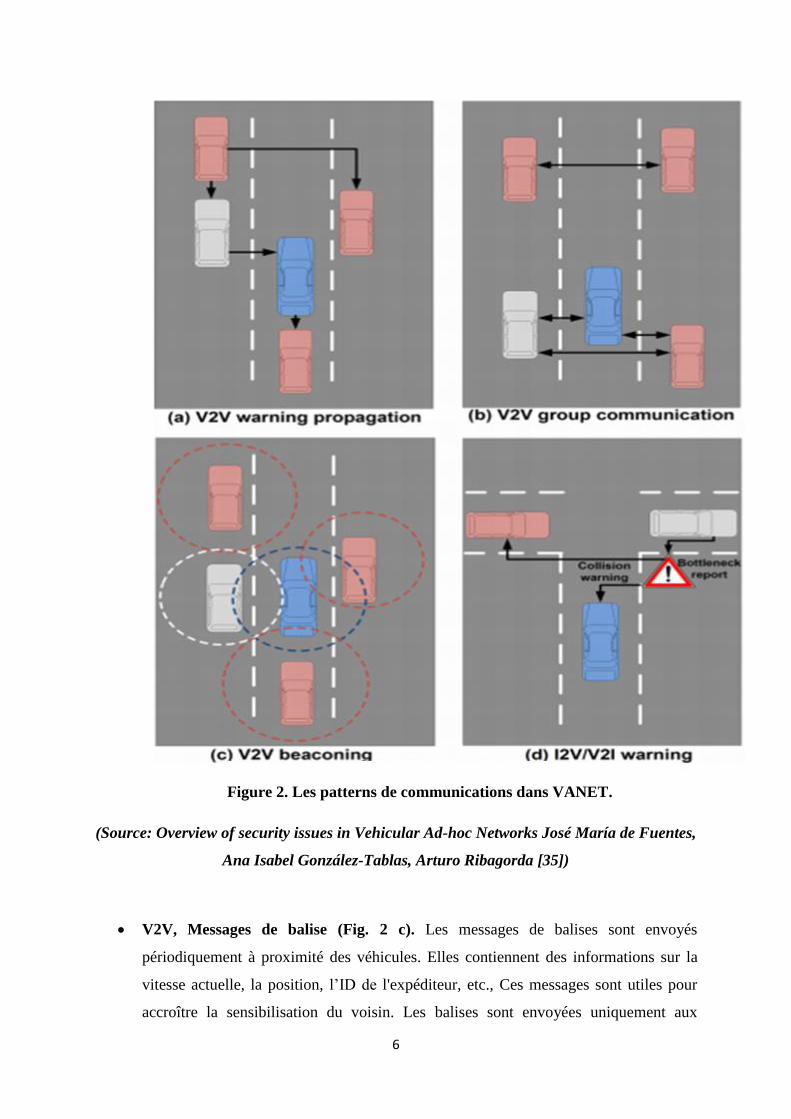
6
Figure 2. Les patterns de communications dans VANET.
(Source: Overview of security issues in Vehicular Ad-hoc Networks José María de Fuentes,
Ana Isabel González-Tablas, Arturo Ribagorda [35])
V2V, Messages de balise (Fig. 2 c). Les messages de balises sont envoyés
périodiquement à proximité des véhicules. Elles contiennent des informations sur la
vitesse actuelle, la position, l’ID de l'expéditeur, etc., Ces messages sont utiles pour
accroître la sensibilisation du voisin. Les balises sont envoyées uniquement aux

7
véhicules a une distance d’un seul saut de l’expéditeur, sinon elles ne seront pas
transmissent. En effet, ils sont utiles pour les protocoles de routage, car ils permettent
aux véhicules de découvrir le meilleur voisin pour acheminer un message.
I2V / V2I Message d’avertissement (Fig. 2 d). Ces messages sont transmis soit par
l'infrastructure (RSU) ou d'un véhicule quand un danger potentiel est détecté. Ils sont
utiles pour l'amélioration de la sécurité routière. A titre d'exemple, un avertissement
peut être transmis par l'infrastructure aux véhicules qui approchent d’une intersection
quand une collision potentielle pourrait se produire.
Comme expliqué dans ce chapitre, le réseau VANETs est constitué de différentes
composantes et entités qui communiquent entre elles, ce qui ouvre la porte à de nombreuses
attaques malveillantes sur ce dernier. Dans le chapitre qui suit, un aperçu d’attaques sera
présenté tout en expliquant leurs comportements et leurs effets sur le réseau.

CHAPITRE 3
APERÇU DES ATTAQUES SUR LE RESEAU VANETs
Une fois que les exigences de sécurité ont été établies pour VANETs, de nombreuses
attaques peuvent être identifiées pour les compromettre. Dans cette section, nous
élaborons sur ces attaques, expliquant comment elles peuvent être effectuées et leurs
conséquences potentielles. Pour des raisons de clarté, les attaques ont été classées en
fonction de l'exigence principale touchée, [2] [3] [4].
1. Attaques sur l'identification et l'authentification
Il y a deux principales attaques liées à l'identification et l'authentification:
Usurpation d'identité. L'attaquant fait semblant d'être une autre entité. Cette attaque
peut être réalisée en volant d’autres entités des titres de leurs compétences. En
conséquence, des avertissements transmis à (ou reçu par) une entité spécifique serait
envoyé à (ou reçu par) un indésirable
o Fausse possession d'attribut. Ceci est un sous-type d'usurpation d'identité,
dans lequel l'attaquant tente de montrer la possession d'un attribut (par
exemple, pour être un membre d'une entreprise) pour obtenir certains
avantages. Elle pourrait être réalisée si de fausses informations
d’identification sont construites, ou si les informations d’identifications
révoquées pourraient être utilisées normalement. En conséquence, un
véhicule ordinaire pourrait envoyer des messages prétendant être une
patrouille de police, dans le but d'avoir une voie libre.
Sybil. L'attaquant utilise différentes identités dans le même temps. De cette façon, un seul
véhicule pourrait signaler l'existence d'un faux goulot d'étranglement. Comme présenté
dans le modèle VANETs, un module TPM monté sur des véhicules peut stocker les
informations sensibles comme des identifiants. De cette manière, la menace Sybil est
atténuée. Cependant, la sécurité des mécanismes doit être conçue pour fournir

9
l'identification et l'authentification, protégeant ainsi contre les attaques par usurpation
d'identité [21].
2. Les attaques sur la vie privée
Les attaques de la vie privée sur VANETs sont principalement liées à l'obtention illégale
d’informations sensible sur les véhicules. Comme il existe une relation entre un véhicule et
son conducteur, en prenant des données privées sur la situation de ce véhicule on pourrait
affecter la vie privée de son pilote [12]. Ces attaques peuvent ensuite être classées comme
atteinte aux données :
Identité révélée. Obtenir l'identité de propriétaires d'un véhicule donné pourrait
mettre sa vie privée en danger. Habituellement, le conducteur d'un véhicule est le
propriétaire de cette dernière, ce qui simplifiera la tâche de l'attaquant à avoir les
informations personnelles de ce dernier.
Suivi de localisation. La localisation d'un véhicule à un moment donné, ou suivre
sa trajectoire tout au long d'une période de temps sont considérées comme une
infraction des données personnelles. Le suivi permet de bâtir le profil du véhicule
et, par conséquent, celui de son conducteur.
Des mécanismes pour faire face à ces deux d’attaques sont nécessaires dans VANETs. Ils
doivent satisfaire au compromis entre la vie privée et l’utilité. De cette manière, les
mécanismes de sécurité devraient éviter des divulgations non autorisées d'informations, mais
les applications devraient avoir suffisamment de données pour travailler correctement [14].
3. Attaques sur la non-répudiation
La principale menace liée à la non-répudiation est la non reconnaissance d'une action par une
des entités impliquées. La non-répudiation peut être contournée si deux ou plusieurs entités
partagent les mêmes informations d'identification. Cette attaque est différente de celle sur
l'identité décrite précédemment, dans ce cas, deux ou plusieurs entités complotent pour avoir
les mêmes informations d'identification. De cette façon, ils deviennent indiscernables, de sorte
que leurs actions peuvent être répudiées. Bien que le stockage fiable ait été supposé dans les
véhicules (par leurs TPMs), les informations d'identification dans différents véhicules doivent
être évitées [25]. En outre, des mécanismes qui fournissent une preuve de la participation
doivent être également mis en œuvre [28].

10
4. Attaques sur la confidentialité
L’écoute des informations privées est l'attaque la plus importante sur VANETs. A l’exécution,
les attaquants peuvent être situés dans un véhicule (arrêté ou en mouvement) ou dans une
fausse borne RSU. Leur but est d'obtenir illégalement l'accès à des données confidentielles
[14]. Comme la confidentialité est nécessaire dans le groupe de communications, des
mécanismes doivent être mis en place pour protéger ces scénarios.
5. Attaques sur la disponibilité
Comme tout autre réseau de communication, la disponibilité dans VANETs devrait être assuré
à la fois dans le canal de communication et dans les nœuds participants [10]. Une
classification de ces attaques, en fonction de leur cible, est comme suit:
Déni de service (DoS). L’attaquant surcharge le canal de communication ou rend
son utilisation difficile (par exemple, en utilisant les interférences). L’attaque peut
être effectuée pour compromettre suffisamment d'RSU, ou en faisant diffuser des
messages infinis dans une période de temps. [7]
o Anomalies de routage. C’est un cas particulier d'une attaque réseau qui
pourrait conduire à un déni de service. Dans ce cas, les attaquants ne
participent pas correctement dans un message sur le réseau. Ils ne font pas
suivre (sinkhole attack) tous les messages reçus ou seulement quelques-
uns selon leurs intérêts (comportement égoïste).
Computation DoS. Ici, l’attaque surcharge les capacités de calcul d'un véhicule
donné. Elle force le véhicule à exécuter des opérations difficiles, ou stocker trop
d'informations ce qui pourrait conduire à son arrêt.
.
6. Attaques sur la confiance de données
La confiance de données peut être compromise de différentes manières dans VANETs [12].
Des données inexactes de calcul et d’envoie affecte la fiabilité, car ils ne reflètent pas la
réalité. Ceci pourrait être réalisée par la manipulation de capteurs dans le véhicule, ou en
modifiant les informations envoyées. Imaginons qu'un véhicule signale un accident dans la
route X, alors qu'il a vraiment pris place dans la route Y. De telles informations doivent
compromettre la confiance d'un message. Pire encore, l'envoi de fausses alertes (par exemple
l'accident n’allait pas avoir lieu) saura également affecter l'ensemble de la fiabilité du

11
système. De cette façon, les mécanismes de protection contre de telles données inappropriées
devraient être mis en pratique dans des véhicules contextes.

CHAPITRE 4
LA REGRESSION LOGISTIQUE
Ce chapitre est un tutoriel sur les modèles de régression logistique.
L’analyse de la régression logistique versus la régression multiple
La régression logistique s’apparente à la régression multiple. En effet, une personne
familiarisée avec les grands principes de fonctionnement de l'analyse de régression multiple,
n'aurait aucune difficulté à percevoir les nombreuses ressemblances qu'elle conserve avec la
régression logistique. Effectivement, nous constatons la présence d'une variable dépendante Y
que nous cherchons à prédire ou à expliquer à l'aide d’une ou de plusieurs variables
prévisionnelles X. Ces variables prévisionnelles X1, X2, X3 participent de façon additive à
l’équation de régression et la pondération de chaque variable prévisionnelle est évaluée par
son coefficient de régression.
Toutefois, l’analyse de régression logistique se distingue d’autre part de la régression
multiple. Par ailleurs, il y a de nombreux côtés par lesquels une analyse de régression
logistique se distingue d'une régression multiple conventionnelle. La plus évidente est bien
entendu le fait que la variable Y à prédire est dichotomique plutôt que continue. En ce sens,
c'est une technique qui se classe parmi les concepts d'analyse de Tacq (1997), dans la même
catégorie que l'analyse discriminante. Du moment que la variable dépendante est
dichotomique, le modèle logistique correspond à une situation où l’on cherche à prédire à quel
groupe (zéro ou un) appartient un sujet. De plus, la relation entre les variables prédictives X1,
X2, X3 et la variable critère Y, peut être considérée comme un autre point distinctif de la
régression logistique. De ce fait, la variable dépendante Y est supposée non linéaire pour ce
qui est de la régression logistique.

13
1. Champ d’application
La régression logistique est utilisée pour la classification. Cette dernière est jugée très
efficace, dans le sens où elle n’exige pas des conditions et/ou des informations
supplémentaires. Elle est largement répandue dans de nombreux domaines dont le domaine de
la médecine, le domaine des assurances, le domaine bancaire et l’économie. En effet, elle
permet de trouver les facteurs relatifs au groupe de sujets sains pour les distinguer des groupes
de sujets malades, par exemple. D’autre part, dans le domaine bancaire par exemple, la
régression logistique donne l’habilité de cibler une fraction de la clientèle qui sera sensible à
une police d’assurance sur tel ou tel risque particulier et de détecter les groupes à risque lors
de la souscription d’un crédit. Elle permet également d’expliquer une variable discrète,
comme les intentions de vote aux élections, d’où le succès de la régression logistique.
Effectivement, la multitude des outils de la régression logistique aide à interpréter
efficacement les résultats donnés par le modèle.
2. Modèle
Soit un échantillon de n observations indépendantes : avec Y la variable à prédire (variable
expliquée), et X = (X1, X2,..., XJ) les variables prédictives (variables explicatives). Puisque
nous sommes dans le cadre de la régression logistique binaire, Y représente la valeur de la
variable dépendante dichotomique prenant soit la valeur zéro pour présenter l’absence,
l’échec ou le « non », soit la valeur un pour présenter contrairement la présence, le succès ou
bien le « oui », tandis que X représente les valeurs des différents attributs prédictifs relatifs à
chaque échantillon ou participant pouvant avoir des valeurs discrètes ou continues.
Effectivement, la variable Y prend deux modalités possibles {1,0}. Les variables Xj sont
exclusivement continues ou binaires.
Soit Π (x) la probabilité conditionnel d’avoir Y=1 sachant que X=x, notée :
Π (x)= P (Y=1 |X=x). (1)
S’il y a plusieurs variables prévisionnelles, l’équation de régression logistique est représentée
comme suit :
Y = β0 + β1 X1 + β 2 X2 + β 3 X3 + … + βj Xj + ε, j =1,…, n (Formule standard).
(L’équation de régression logistique nous rappelle l’équation de régression habituelle
représentant une fonction linéaire, sauf qu’elle n’exige pas la normalité des variables
indépendantes).

14
Vu la nature sinusoïdale de la fonction logistique, l'analyse de régression logistique doit
forcément transposer cette équation linéaire en expression logarithmique. En d'autres termes,
au lieu de prédire un scores-Y, la régression logistique prédit la probabilité d’obtenir une
certaine valeur cible (1 ou 0) sur Y. Deux formules alternatives et parfaitement équivalentes
permettent de calculer cette probabilité
P(Y) = Π(x) = 𝐞𝐠(𝐱)
𝟏+ 𝐞𝐠(𝐱)
Ou (2)
P(Y) = Π(x) = 𝟏
𝟏+ 𝐞−𝐠(𝐱)
Dans ces deux équations « e » correspond au logarithme naturel ou népérien,
approximativement 2,71828... et g(x) correspond à l’équation de régression linéaire
conventionnelle, avec g (x) = β0 + β1 X1 + β 2 X2 + β 3 X 3 + …+ βj Xj.
Ainsi, le modèle logistique s’apparente au modèle linéaire habituellement représenté. Son
expression sera donc sous la forme suivante :
Π(x) = 𝑒𝛽0 +𝛽1𝑋1+𝛽2𝑋2+𝛽3𝑋3+⋯+𝛽𝑛𝑋𝑛
1+𝑒𝛽0 +𝛽1𝑋1+𝛽2𝑋2+𝛽3𝑋3+⋯+𝛽𝑛𝑋𝑛
Notamment Π(x) ϵ [0,1] car d’abord c’est une probabilité et encore, mathématiquement
parlant, le dénominateur est supérieur au numérateur
𝟏 + 𝑒𝛽0 +𝛽1𝑋1+𝛽2𝑋2+𝛽3𝑋3+⋯+𝛽𝑛𝑋𝑛+⋯+𝜷𝒋𝑿𝒋² > 𝑒𝛽0 +𝛽1𝑋1+𝛽2𝑋2+𝛽3𝑋3+⋯+𝛽𝑛𝑋𝑛
Ce modèle peut être utilisé pour décrire la nature de relation entre la probabilité espérée d’un
succès pour la variable réponse (Y=1) et les variables explicatives X, comme il peut prédire la
probabilité espérée d’un succès étant donné les valeurs des variables X (par exemple, la
probabilité d’acheter une maison en sachant le revenu annuel d’un citoyen).
3. Démarche mathématique
a) Problématique
Comment peut-on écrire le modèle sous la forme :
g (x) = β0 + β1 X1 + β 2 X2 + β 3 X3 + … + βj Xj

15
Ou encore comment estimer les paramètres notés𝛽1, 𝛽2, 𝛽3,…, 𝛽𝑗 en fonction des données
Π (x) = 𝑒𝛽0+𝛽1𝑋1+𝛽2𝑋2+𝛽3𝑋3+⋯+𝛽𝑛𝑋𝑛
1+𝑒𝛽0+𝛽1𝑋1+𝛽2𝑋2+𝛽3𝑋3+⋯+𝛽𝑗𝑋𝑗
La régression logistique repose sur l’hypothèse fondamentale notée ci-dessous. Dans ce cas, nous
avons pu utiliser la fonction de logarithme népérien puisqu’il s’agit d’une probabilité logistique et
encore ln(x) = ϵ [0,1]
Ln 𝑃(𝑌=1|𝑋=𝑥)
𝑃(𝑌=0|𝑋=𝑥) = β0 + β1 X1 + β 2 X2 + β 3 X3 + … + βj Xj (3)
Autrement,
Ln Π (x)
1−Π (x) = β0 + β1 X1 + β 2 X2 + β 3 X3 + … + βj Xj (4)
L’expression mentionnée ci-dessus est appelée Logit. Cette dernière prouve qu’il s’agit bien
d’une régression logistique. En effet, la loi de probabilité est spécifiée à partir d’une « loi
logistique ». Elle prouve d’autre part « la régression » car son but principal est de montrer une
relation de dépendance entre une variable à expliquer et une série de variables explicatives.
a) Méthode de maximum de vraisemblance
Afin d’utiliser le modèle pour la description de relations entre les variables ou bien pour une
prédiction préalable, nous avons besoin d’estimer les paramètres β0, β1, β2, β3, …, βj relatifs
au modèle approprié. Dans cette perspective, les logiciels statistiques utilisent la méthode de
vraisemblance afin estimer β0, β1, β2, β3, …, βj. . C’est l’équivalent de la méthode de moindre
carré pour la régression linéaire.
L’idée majeure de cette méthode est de calculer les probabilités et d’observer les valeurs
X1…Xn de la fonction avec des paramètres inconnus et des données connues. La meilleure
façon d’estimer les paramètres est de voir l’estimateur, celui qui va maximiser la probabilité

16
considérée. Évidemment, cela sera bien proche de la réalité. Nous aurons donc les paramètres
en fonction des données. Donc, la vraisemblance dépend essentiellement de deux choses :
Les paramètres qu’on veut estimer
L’échantillon considéré
Après avoir introduit le principe général de la méthode de maximum de vraisemblance, nous
allons présenter quelques étapes pour appliquer ce principe.
On a Π (x) = 𝑃(𝑌=1)
𝑃(𝑋=𝑥)
Π (xi) ; yi = 1 (5)
1- Π (xi) ; yi = 0
= Π (xi) yi
. [1- Π (xi)] 1-yi
Nous avons la possibilité de passer par le produit, car les échantillons sont indépendants les
uns des autres (aléatoires). Nous aurons alors :
L (Y, β) = Πn i=0 [Π (xi)
yi. [1- Π (xi)]
1-yi] (6)
L’objectif suivant sera de maximiser cette expression (max [L (Y, β)]).
Une application d’un logarithme népérien peut vraiment être une bonne solution. En effet,
comme nous le savons, la fonction logarithmique est une fonction strictement croissante
(certes, elle n’influera pas sur notre maximisation). Nous obtenons donc :
H (Y, β) = ln [L (Y, β)]
Par conséquent, maximiser L (Y, β) revient à maximiser H (Y, β). Donc, pour obtenir les
valeurs des β0, β1 … βj qui maximisent la fonction de log-vraisemblance, il faut effectuer le
dérivée de H (Y, β) = ln [L (Y, β)] en fonction de ses paramètres β0, β1 … βj, et égaliser les
résultats à zéro. Deux équations appelées « équations de vraisemblance » sont obtenues après
un certain développement mathématique et nous obtiendrons :

17
∑ yi − Π (xi) = 0𝑛𝑖=0 (7)
Et
∑ xi [yi − Π (xi)] = 0𝑛𝑖=0 (8)
La résolution de ces dernières équations exige l’utilisation d’une méthode itérative, citons par
exemple la méthode de Newton-Raphson, celle de Walker et Duncan, et l’algorithme de
Gauss-Newton. Ces méthodes sont utilisées dans les logiciels informatiques et ces derniers se
chargeront de tous les calculs nécessaires. Effectivement, les solutions obtenues sont appelées
les estimations de vraisemblance notées β0, β1, β2, β3, …, βj.
Après avoir estimé les paramètres notés β0, β1, β2, β3, …, βj, il faut tester évidement leurs
significativités. À cet égard, trois méthodes ayant le même principe se présentent : le test du
rapport de maximum de vraisemblance, le test de Wald et le test de Score. En effet, elles se
basent sur une comparaison entre les valeurs observées de la variable dépendante et celles
prédites par le modèle avec ou sans les variables en question.
Les hypothèses à tester seront : H0 : β 1 = 0, H1 : β 1 < > 0.
Étant donnée : Π (x) = P (Y=1 /X=x) = 𝑒𝛽0+𝛽1𝑋1
1+𝑒𝛽0+𝛽1𝑋1
H0: β1 = 0 H1: β1 # 0
𝑒𝛽0+𝛽1𝑋1
1+𝑒𝛽0+𝛽1𝑋1
𝑒𝛽0+𝛽1𝑋1
1+𝑒𝛽0+𝛽1𝑋1
x n’a pas aucun effet x est pertinent
Qu’est-ce qu’un « p-value » ?
« Dans un test statistique, la valeur p (en anglais : p-value) est le plus petit niveau auquel on
rejette l'hypothèse nulle. En d'autres termes, la valeur p est la probabilité de commettre une

18
erreur de type I, c'est à dire de rejeter à tort l'hypothèse nulle et donc d'obtenir un faux positif.
» (Wikipédia)
Dans la pratique, les tests statistiques, en général, conduisent à deux types d'erreurs :
Rejet à tort de l'hypothèse H0 : erreur de première espèce.
Acceptation à tort de l'hypothèse H0 : erreur de seconde espèce.
Il est alors possible de contrôler α, le taux d'erreur de première espèce :
Si p-value < α : On rejette H0
Si p-value > α : On accepte H0
Remarque : Dans les livres statistiques, l’hypothèse nulle H0 est rejetée si et seulement si p-
value < α.
D'après Gujarati, la p-value est le plus bas niveau de significativité ; c’est la valeur maximal
pour laquelle l’hypothèse H0 peut être rejetée (j’ai essayé de traduire le sens général de la
définition qui ne peut pas être textuel) [34].
Si l'on retient α = 5%.
D’une façon générale, les variables prédictives indépendantes dites significatives sont celles
qui possèdent une p-value inférieure au seuil de significativité fixé souvent à 0.05.
Définition d’une signification statistique : Un résultat est dit généralement significatif
lorsqu’il n’y a pas plus de 5 chances sur 100 que ce même résultat ait été produit par les
fluctuations du hasard ; ce qui correspond à une probabilité p de 5 % soit p = 0,05 (on utilise
aussi parfois un seuil de significativité à 1 % soit p = 0,01).
4. Exemple de Modèle Probabiliste basé sur la Régression Logistique (Étude de Cas
de la gestion des risques de crédit en Micro finance) :
a) Introduction à la régression logistique :
La régression logistique est une technique statistique qui consiste à produire un modèle
permettant de prédire les valeurs prises par une variable catégorielle, le plus souvent binaire, à
partir d'une série de variables explicatives continues ou binaires.

19
b) Principe de la régression logistique :
Par rapport aux autres techniques de régression, en particulier la régression linéaire, la
régression logistique se distingue essentiellement par le fait que la variable à expliquer est
discrète (catégorielle).
c) Présentation de l’exemple et de la Modélisation de l’équation avec explication de
chaque variable :
Nous supposons que Pi = P (Yi = 1) représente la probabilité que l'individu i réalise un retard
de remboursement,
On définit une fonction score Y*= ß0 + ßnX+ åi
Si Yi*=< 0 alors Yi =0
Si Yi*> 0 alors Yi =1
Avec :
Y représente le vecteur Dummy retard
ß0 représente le vecteur de la constante
X représente le vecteur des variables explicatives
ß représente le vecteur des coefficients à estimer
å représente le terme d'erreur qui suit une loi double exponentielle
ce qui se traduit par : Pi = P (Yi = 1) = P (Yi* > 0) et P (Yi = 0) = P (Yi
*=< 0)
Pi est compris entre 0 et 1, d'où, elle peut être assimilée à une fonction de répartition F, elle
s'écrit alors :
Pi = F (ß0 +ß X)
P (Yi* =< 0) = P (ß0 + ßnXi + åi =< 0)

20
= P (åi =< - (ß0 + ßnXi))
= F (- (ß0 + ßnXi))
Etant donné qu'il s'agit d'une loi symétrique, F(x) + F (-x) = 1, alors
P (Yi = 1) = F (ß0 + ßnXi) = 1 – F (- (ß0 + ßnXi))
Puisque le terme d'erreur suit une loi double exponentielle alors :
F (åi) = exp (- exp (åi)) d'où P (Yi = 1) = F (ß0 + ß1Xi+...... +ßnXi)
Pi= exp(0+1𝑋𝑖+⋯+𝑛𝑋𝑖)
1+exp(0+1𝑋𝑖+⋯+𝑛𝑋𝑖) (9)
Et P (Yi = 0) = 1- P (Yi = 1) = 1
1+exp(0+1𝑋𝑖+⋯+𝑛𝑋𝑖) (10)
Logodds = log 𝑃(𝑌𝑖=1)
𝑃(𝑌𝑖=0) = ß0 + ß1Xi+...... +ßnXi (11)
Donc, après la présentation des attaques qui pourraient y avoir sur le réseau VANET au
chapitre précédant ainsi que le modèle de régression qu’on utilisera pour l’optimisation du
protocole de détection d’intrusions, le chapitre qui suit détaillera la problématique à traiter
dans le cadre de ce mémoire.

CHAPITRE 5
PROBLEMATIQUE
Comme nous l’avons dit au début, pour améliorer la méthode de corroboration des attaques,
nous proposons un modèle probabiliste innovant basé sur la régression logistique. Cette
méthode permettra d'estimer la survenance d'un événement (dans notre cas, une attaque). La
méthode est basée sur un historique d'une base de connaissances qui estime les occurrences de
l'attaque. Lorsque le modèle de régression est validé, il sera utilisé pour estimer la probabilité
d'une attaque et si elle dépasse le seuil défini à l'avance, l'attaque est alors confirmée.
Dans ce chapitre, nous présentons notre modèle probabiliste pour prédire l’occurrence d'une
attaque: le modèle de régression logistique.
Une régression logistique est une technique prédictive. Elle vise à renforcer un modèle pour
prédire / expliquer les valeurs prises par une variable non catégorique (généralement binaire,
elle est appelée régression logistique binaire et si elle a plus de deux variables, elle est appelé
régression logistique multinomiale) à partir d'un ensemble de variables qualitatives ou
quantitatives (l’encodage est nécessaire dans ce cas).
1. Description du modèle logistique utilisé
Pour prédire l'occurrence d'une attaque, nous avons utilisé le Logit modèle ci-dessous. Ce
modèle est une régression logistique multinomiale. Dans notre cas:
P [Y=1] =𝒆(𝑵𝑽𝑨𝟏𝒙𝟏+𝑵𝑽𝑨𝟐𝒙𝟐+𝑵𝑽𝑨𝟑𝒙𝟑)
𝟏 + 𝒆(𝑵𝑽𝑨𝟏𝒙𝟏+𝑵𝑽𝑨𝟐𝒙𝟐+𝑵𝑽𝑨𝟑𝒙𝟑)⁄ (12)
sera l'équation de régression logistique pour les prédictions d'attaques, où

22
- Y: L'attaque à prédire (variable dépendante);
- NVA1, NVA2, NVA3: paramètres de l’estimation;
- Xj: Les variables prédictives (autrement Xj est assimilé respectivement aux trois attaques
utilisées dans la simulation, le déni de service, l’attaque sur la vie privée ainsi que le Black
Hole, avec j € [1, 2,3]).
Notre cadre expérimentale est basé sur la régression logistique binaire, Y est la valeur de la
variable dichotomique qui peut prendre la valeur de «0» zéro pour montrer l'absence, ou le
«pas existence » d'une attaque, ou «1» dans le cas de l’occurrence d’une attaque, tandis que X
représente les valeurs des différents attributs prédictifs liés à chaque échantillon ou participant
qui peut avoir des valeurs discrètes ou continues. Ces attributs prédictifs seront dans notre cas
les nombres de véhicules attaqués respectivement pour chaque attaque, les nombres de
paquets de données transmis et perdus.
Enfin, pour obtenir les résultats de prédiction, nous devons d'abord mettre en œuvre la base de
données que nous recevons de la simulation dans notre Modèle Logit. Ensuite, avec l'aide d'un
logiciel statistique "R statistique "nous pouvons prévoir si oui ou non nous avons la présence
d'une attaque sur notre réseau.
2. Description de la base de données
Dans cette section, nous présentons trois types d'attaques (Denial of Service, Attaque sur la
vie privée, Black Hole) et leurs algorithmes que nous allons mettre en œuvre pour avoir les
connaissances dans la base de données.
- La génération de base de données:
Nous allons mettre en œuvre trois types d'attaques en simulant respectivement les trois
comportements de ces derniers sur une combinaison de véhicules. Par la suite, nous aurons un
tableau de données dans lequel nous aurons l’occurrence du nombre d’attaques et d'autres
paramètres relatif à ces derniers tels que le taux de paquets délivré (PDR), le nombre de
véhicules attaqués, le nombre de véhicules attaquants,...
- Une fois la base de données extraite, nous allons la mettre en œuvre dans notre modèle de
régression qui est, comme dit auparavant, reconnu comme un modèle de prédiction donnant

23
un résultat binaire {0, 1}. Alors pour prédire l’occurrence d’une attaque on a « 1 » pour la
présence et « 0 » pour l’absence.
3. Description des trois attaques simulées et des algorithmes
Afin de construire notre base de données qui sera implémentée ultérieurement dans le modèle
logistique, nous allons simuler le comportement de trois types d’attaques sur notre réseau. Ci-
dessous, on explique en quoi consistent ces dernières ainsi que leurs comportements sous
forme d’algorithmes.
a) Déni de service : l’attaque de déni de service consiste à rendre le réseau non-
fonctionnel et ainsi notre réseau sera plus fonctionnel. Un attaquant peut mettre en
place ce type d’attaque en inondant le réseau par des informations non utiles aux
utilisateurs ou en perturbant les connexions entre différent machines.
Pour notre simulation, l’attaquant perturbera toute communication et échange de données
entre tout véhicule se trouvant à un saut de lui (sachant que 1 saut équivaut à la différence
entre deux entités qui est égale à 1, autrement dit [‘Position-based’ du Vi – ‘Position-based’
du Vj = 1]. L’algorithme relatif à ce comportement est le suivant:
Début
“Gen”: Nombre aléatoire généré entre 1 et 100
Vi: Tous les véhicules générés dans la simulation
Va: Le véhicule attaquant
X==Vi (Gen)
Si X € [1...10] alors
Vi est considéré comme attaquant;
Va == Vi;
et
Tous les Vi qui sont à 1 saut de Va ne seront pas capable de communiquer avec
leurs voisins
Fin
"Vi" sont tous les véhicules générés;
"Va" sont les véhicules attaquants.
Dès que, nous détectons un véhicule attaquant, nous adoptons le comportement suivant:

24
• Tous les "Vi" autour du "Va" ne peuvent ni émettre ni recevoir des messages. Cette
technique de blocage de communication sera illustrée dans le simulateur en désactivant tout
droits de communication aux véhicules qui sont à une distance de 1 saut du véhicule attaquant
(Becaon message = OFF, Data message = OFF).
• Toutes les communications des "Vi" autour du nœud "Va" sont arrêtées.
b) L’écoute de message : Les inférences sur les données personnelles du conducteur
pourraient être accomplies, et c’est une violation de sa vie privée. La vulnérabilité
réside dans le trafic périodique et fréquent du réseau véhiculaire.
Pour notre simulation, l’attaquant écoutera toute communication et échange de données
entre les véhicules. L’algorithme relatif à ce comportement est :
Début
Ecoute des paquets
Décapsuler les paquets
Si (Paquet == paquet de données) alors
Decrypt=Généré un nombre aléatoire entre 1et 100
Si (Decrypt > 75) alors
Décripter le paquet de données
Ecouter la transmission de données actuelle
Sinon
Décryptage échoué
Ignorer le paquet
Fin si
Fin si
Fin
c) L’attaque du Trou noir (Black hole) : le nœud malveillant utilise son protocole
de routage afin d’annoncer qu’il possède le plus court chemin vers le nœud de
destination. Lorsque la route est établie, l’attaquant à la totale possession du
paquet envoyée et ainsi il pourra le détruire ou le réacheminer vers une adresse
inconnu. Le paquet sera complètement perdu, d’où le nom du Trou noir.

25
Début
1. Un nœud malveillant détecte l'itinéraire actif et note l'adresse de destination.
2. Un nœud malveillant envoie un message RREP (une requête de données), dans lequel il
met une adresse d’une destination usurpé. Dans la requête (RREP) afin de fausser la
voiture ciblée, l’attaquant prétend que le nombre de sauts est le plus faible (afin de gagner
la confiance de la cible).
3. Un nœud malveillant envoie un RREP au nœud le plus proche qui appartient à
l'itinéraire actif.
4. Le RREP reçu par le nœud le plus proche à travers le nœud malveillant sera relayé de la
route inverse établie au nœud source.
5. La nouvelle information reçue dans la requête RREP permettra au nœud source de
mettre à jour sa table de routage.
6. Un nouvel itinéraire est choisi par le nœud source pour sélectionner les données.
7. Le nœud malveillant va laisser tomber maintenant toutes les données qui appartiennent
à la route.
Fin.
Pour ce faire, nous ferons appel à deux simulateurs: le simulateur de trafic routier et le
simulateur réseau. Le simulateur de trafic routier qui sera Sumo 0.15 permet de générer la
mobilité des véhicules sur une carte. Le simulateur réseau qui est OMNET++ modélise le
comportement des différentes entités du réseau; c'est-à-dire qu'il permet de gérer les
interactions entre les différents nœuds du réseau.
Dans le chapitre qui suit, on présentera l’étude mené sur notre problématique, les simulations
des comportements des attaques et de leurs niveaux de danger sur le réseau sous forme d’un
article qui a été accepté à la conférence “7th IEEE International Workshop on Performance
Evaluation of Communications in Distributed Systems and Web based Service Architectures”
PEDISWESA’2015.

CHAPITRE 6
L’ARTICLE
A probalistic model to corroborate three attacks in Vehicular Ad Hoc
Networks
Accepté à la conference “7th IEEE International Workshop on Performance
Evaluation of Communications in Distributed Systems and Web based Service
Architectures” PEDISWESA’2015
Numéro papier: 1570116985.
ISBN: 978-1-4673-7194-0/15/$31.00 ©2015 IEEE.

27

28

29
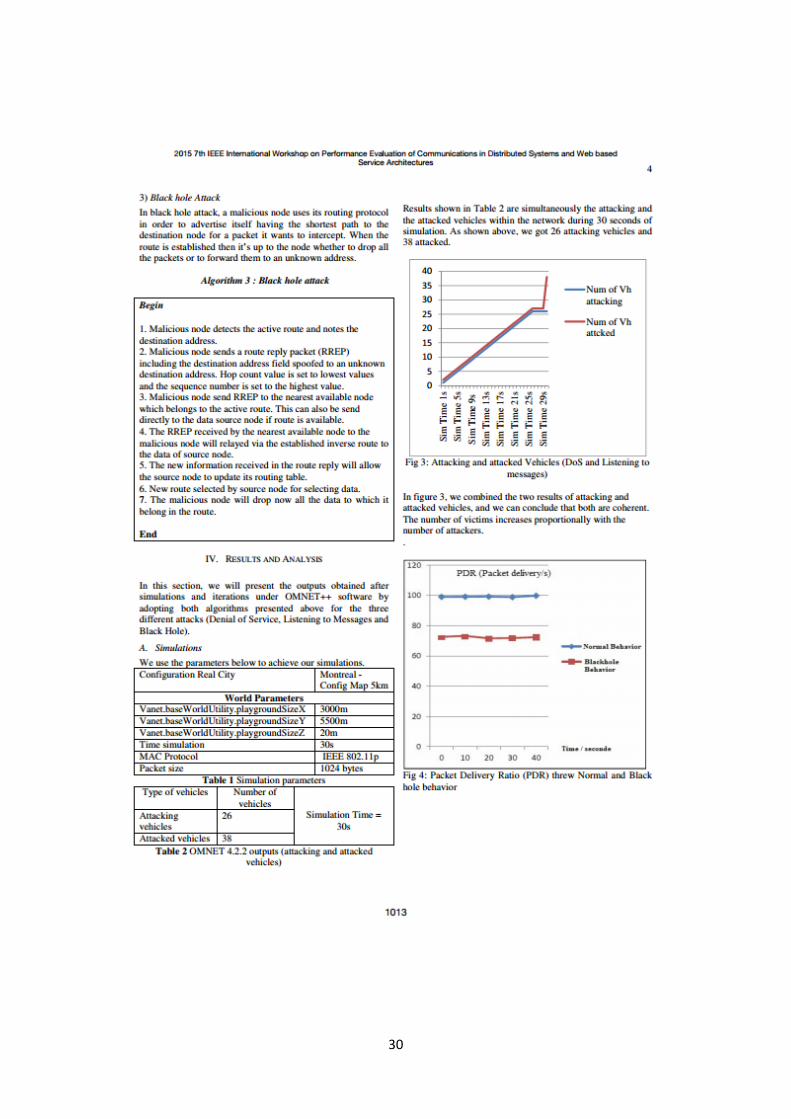
30

31

32

CHAPITRE 7
CONCLUSION ET PERSPECTIVES
De nos jours, les réseaux de véhicules sont développés et améliorés. Plusieurs nouvelles
applications sont utilisées par ce nouveau type de réseau de communication. Cependant,
comme ces dernières ont un impact sur la sécurité routière, des exigences de sécurité solides
doivent être atteints. De nouveaux mécanismes doivent être mis au point pour traiter les
caractéristiques inhérentes de ces réseaux (vitesse de nœuds, infrastructure décentralisée,
etc.).
Dans ce mémoire, nous avons présenté une méthode innovante de prévention d'attaques. Nous
avons utilisé un modèle mathématique basé sur une base de données de connaissances
acquises. Cette dernière est formée par trois types d'attaques, «déni de service», «l'écoute des
messages » et «trou noir». Nous étions en mesure de corroborer une attaque par
l'intermédiaire du modèle de régression logistique sur la base des résultats obtenu
statistiquement avec un taux équivalent à 82% de réussite. Nous avons prouvé que l'attaque
« écoute des messages » est fortement et hautement plus dangereuse sur le réseau que le «déni
de service » ou l’attaque du « trou noir ».
La sécurité dans VANET est un domaine émergent dans lequel plusieurs futurs axes de
recherche peuvent être soulignés. Bien que plusieurs mécanismes aient été proposés, quelques
problèmes doivent encore être abordés (par exemple les problèmes de la vie privée en raison
de la fréquence radio des empreintes digitales). En outre, puisque dans les protocoles
VANETs, les mécanismes et les applications sont basées sur des architectures différentes, un
cadre d'évaluation commun est nécessaire pour comparer les différentes contributions de la
recherche pour la sécurité. Les résultats de simulation sont souvent offerts à évaluer les
propositions actuelles. Cependant, il n'existe pas un scénario commun pour évaluer les
différentes alternatives. Enfin, la mise en œuvre matérielle cryptographique efficace est
nécessaire dans les véhicules.

Enfin et afin de valoriser ce travail, une étude menée sur d'autres d'attaques et de
comportements devrait être faite afin d’améliorer notre base de données et ainsi rajouter
d'autres variables et paramètres dans notre modèle Logit, ce qui donnera de meilleurs résultats
d’estimations et par la suite une prédiction de meilleure qualité. Plus notre base de données
sera élargie plus les prédictions seront meilleures. Aussi, il faudrait étudier d’autres modèles
et voir leurs pertinences en fonction du type d’attaques.

REFERENCES
[1] M. Raya and J. P. Hubaux, “The security of vehicular ad hoc networks,” Proceedings of
the 3rd ACM workshop on Security of ad hoc and sensor networks - SASN’05, November 7,
2005, Alexandria, Virginia, USA. Copyright 2005 ACM 1-59593-227-5/05/00.
[2] Bing Wu, Jianmin Chen, Jie Wu, Mihaela Cardei “A Survey on Attacks and
Countermeasures in Mobile Ad Hoc Networks” in WIRELESS/MOBILE NETWORK
SECURITY, Chapter 12, 2006, ISBN 978-0-387-33112-6
[3] V. S. Yadav, S. Misra, and M. Afaque, "Security of self-organizing networks," ed, 2010.
Auerbach Publications is an imprint of Taylor & Francis Group, an Informa business, -13:
978-1-4398-1920-3 (Ebook-PDF), CRC Press, Taylor & Francis Group, USA.
[4] H.Hartenstein and Kenneth P. Laberteaux, "A tutorial survey on vehicular ad hoc
networks" 0163-6804/08/$25.00 © 2008 IEEE IEEE Communications Magazine • June 2008
IEEE Communications Magazine, 2008.
[5] M.Raya, P. Papadimitratos, and J. P. Hubaux, "Securing vehicular communications» 2006
Wireless Communications, IEEE, vol. 13, pp. 8-15, ISSN 1536-1284
[6] A. Stampoulis and C. Z., "Survey of security in vehicular networks" in Project CPSC,
2007.
[7] I. Aad, J. P. Hubaux, and E. W. Knightly, "Impact of Denial of Service Attacks on Ad Hoc
Networks" Networking, IEEE/ACM Transactions on, vol. 16, pp. 791-802, 2008.
[8] J.Blum and A. Eskandarian, "The threat of intelligent collisions" IT professional, vol. 6,
pp. 24-29, 2004, ISSN 1520-9202, IEEE
[9] N. Ben Salem and J. P. Hubaux, "Securing wireless mesh networks"2006, Wireless
Communications, IEEE, vol. 13, pp. 50-55, ISSN 1536-1284
[10] I. Ahmed Soomro, H. Hasbullah, and J.-l. Ab Manan, «Denial of Service (DOS) Attack
and Its Possible Solution in VANET,"2010. World Academy of Science, Engineering and
Technology Vol: 4 2010-05-25, International Science Index Vol: 4, No: 5, 2010
waset.org/Publication/1580
[11] J. M. d. Fuentes, A. I. González-Tablas, and A. Ribagorda, "Overview of security issues
in Vehicular Ad-hoc Networks," Handbook of Research on Mobility and Computing 2010.
ISBN 978-1609600426.
[12] D. Ren, S. Du, and H. Zhu, "A novel attack tree based risk assessment approach for
location privacy preservation in the VANETs" in Communications (ICC), 2011 IEEE
International Conference on, 2011, pp. 1-5. ISBN 978-1-61284-232-5.

[13] Q. Yi and N. Moayeri, "Design of secure and application-oriented VANETs," in
Vehicular Technology Conference, 2008. VTC Spring 2008. IEEE, 2008, pp. 2794-2799.
[14] T. W. Chim, S. Yiu, L. C. Hui, and V. O. Li, "Security and privacy issues for inter-
vehicle communications in vanets," in Sensor, Mesh and Ad Hoc Communications and
Networks Workshops, 2009. SECON Workshops' 09. 6th Annual IEEE Communications
Society Conference on, 2009, pp. 1-3. ISBN 978-1-4244-3938-6.
[15] C. Harsch, A. Festag, and P. Papadimitratos, "Secure Position-Based Routing for
VANETs," in Vehicular Technology Conference, 2007. VTC-2007 Fall. 2007 IEEE 66th,
2007, pp. 26-30. ISBN 978-1-4244-0263-2.
[16] C. Jung, C. Sur, Y. Park, and K.-H. Rhee, "A Robust Conditional Privacy-Preserving
Authentication Protocol in VANET," in Security and Privacy in Mobile Information and
Communication Systems. vol. 17, A. Schmidt and S. Lian, Eds., Ed: Springer Berlin
Heidelberg, 2009, pp. 35-45. ISBN 978-1-4244-0263-2.
[17] E. Fonseca and A. Festag, "A survey of existing approaches for secure ad hoc routing
and their applicability to VANETS," NEC network laboratories, 2006.
[18] L. Ertaul and S. Mullapudi, "The Security Problems of Vehicular Ad Hoc Networks
(VANETs) and Proposed Solutions in Securing their Operations," in The 2009 International
Conference on Wireless Networks ICWN, 2009.
[19] J. T. Issac, S.Zeadally, and J. S. Camara, "Security attacks and solutions for vehicular ad
hoc networks," 2010-04-30, IET Communication, vol. 4, pp. 894-903, ISSN 1751-8628.
[20] SU. Rahman,H.Falaki, ”Security & Privacy for DSRC-based automotive Collision
Reporting”, 2010 Second International Conference on Network Applications, Protocols and
Services, DOI 10.1109/NETAPPS.2010.17.
[21] B. Xiao, B. Yu, and C. Gao, "Detection and localization of sybil nodes in VANETs," in
International Conference on Mobile Computing and Networking: Proceedings of the 2006
workshop on Dependability issues in wireless ad hoc networks and sensor networks, 2006, pp.
1-8. ISBN: 1-59593-471-5
[22] B. Parno and A. Perrig, "Challenges in securing vehicular networks," in Workshop on
Hot Topics in Networks (HotNets-IV), 2005,
http://www.netsec.ethz.ch/publications/papers/cars.pdf.
[23] G. Samara, W. A. H. Al-Salihy, and R. Sures, "Security issues and challenges of
Vehicular Ad Hoc Networks (VANET)," in New Trends in Information Science and Service
Science (NISS), 2010 4th International Conference on, 2010, pp. 393-398. ISBN 978-1-4244-
6982-6.
[24] M. Koubek, S. Rea, and D. Pesch, "Event Suppression for Safety Message Dissemination
in VANETs," in Vehicular Technology Conference (VTC 2010-Spring), 2010 IEEE 71st,
2010, pp. 1-5. ISBN 978-1-4244-2518-1.

[25] G. Guette and C. Bryce, "Using tpms to secure vehicular ad-hoc networks (vanets),"
IFIP International Federation for Information Processing 2008, Information Security Theory
and Practices. Smart Devices, Convergence and Next Generation Networks, pp. 106-116.
[26] G. Jyoti and M. S. Gaur, "Security of self-organizing networks MANET, WSN, WMN,
VANET," Auerbach ed: CRC Press, 2010, Auerbach Publications, CRC Press, Taylor &
Francis Group, USA. ISBN: 978-1-4398-1919-7.
[27] M. Schagrin. “Vehicle-to-Infrastructure (V2I) Communications for Safety” (2012, 2013-
17-01)
[28] "Trusted Platform Module (TPM) Specifications". Trusted Computing Group. Wikipedia
[29] M. A. Ramteke, "Realistic Simulation for Vehicular Ad-hoc Network Using ZigBee
Technology," International Journal of Engineering, e-ISSN: 2278-0181, vol. 1, 2012.
[30] MH Eiza, Q Ni, “A reliability-based routing scheme for vehicular ad hoc networks
(VANETs) on highways” 25–27 June 2012. IEEE 11th international conference on trust,
security, and privacy in computing and communications (TrustCom), Liverpool, UK, ISBN
1578–1585.
[31] J Kao, Research interests. http://www.cs.nthu.edu.tw/~jungchuk/research. Html.
Accessed (January 2015)
[32] Saleh Yousefi', MAhmoud Siadat MIousavi2 Mahmood Fathy', “Vehicular Ad Hoc
Networks (VANETs): Challenges and Perspectives”, 6th Intermational Coference on ITS
Teleconuiiic&ations Proceedingsn 0-7803-9586-7/06/$20.00 C2006 IEEE.
[33] TracNet System: http://www.kvh.com/ as of March 9th (2009).
http://www.kvh.com/Press-Room/Press-Release-Library/2006/TracNet-100-Mobile-Internet-
System-from-KVH-and-MSN-TV-Now-Available-Nationwide.aspx.
[34] D. N. Gujarati (2004) – Econometrics, fourth Edition.
[35] José María de Fuentes, Ana Isabel González-Tablas, Arturo Ribagorda, “Overview of
security issues in Vehicular Ad-hoc Networks”, Handbook of Research on Mobility and
Computing Copyright 2010, IGI Global, www.igi-global.com.
[36] Amar Bensaber Boucif, Karim Laroussi, Mhamed Mesfioui, Ismail Biskri, (2015), “A
Probabilistic Model to Corroborate Three Attacks in Vehicular Ad Hoc Networks”, 20th
IEEE Symposium on Computers and Communications (ISCC 2015), pp 1010-1015, ISBN:
978-1-4673-7194-0 ©2015 IEEE.

34
AFFICHE SCIENTIFIQUE PRESENTE DANS LE CADRE DU « NSERC DIVA 2014,
Ottawa »

35


















