
UNIVERSITÉ CLAUDE BERNARD LYON 1 INSTITUT DE …docs.isfa.fr/labo/PATARD Pierre-Alain.pdf ·...
335
UNIVERSIT CLAUDE BERNARD LYON 1 INSTITUT DE SCIENCE FINANCI¨RE ET DASSURANCES INGNIERIE DES PRODUITS STRUCTURS. Essais sur les mØthodes de simulation numØrique et sur la modØlisation des donnØes de marchØ. Pierre-Alain Patard Directeur de thLse : M. le professeur Jean-Claude Augros Version : 11 juillet 2008
-
Upload
phungxuyen -
Category
Documents
-
view
231 -
download
0
Transcript of UNIVERSITÉ CLAUDE BERNARD LYON 1 INSTITUT DE …docs.isfa.fr/labo/PATARD Pierre-Alain.pdf ·...

UNIVERSITÉ CLAUDE BERNARD LYON 1INSTITUT DE SCIENCE FINANCIÈRE ET
D�ASSURANCES
INGÉNIERIE DES PRODUITS STRUCTURÉS.Essais sur les méthodes de simulation numériqueet sur la modélisation des données de marché.
Pierre-Alain Patard
Directeur de thèse :M. le professeur Jean-Claude Augros
Version :11 juillet 2008


Résumé
Cette thèse regroupe un ensemble de travaux sur les problématiques de simu-lation numérique et de modélisation des données de marché rencontrées lors dudéveloppement d�un système d�évaluation des produits dérivés actions.La première partie porte sur l�utilisation des méthodes de simulation MonteCarlo et Quasi-Monte Carlo pour évaluer des produits dérivés. Elle insiste plusparticulièrement sur le choix et sur l�implémentation des générateurs uniformes,sur les techniques de simulation des variables gaussiennes et sur l�utilisation desméthodes de réduction de variance pour accélérer la convergence des estima-teurs.La seconde partie porte sur la modélisation des paramètres de marché qui inter-viennent dans la dynamique des prix d�une action. Elle aborde successivementla construction des courbes zéro-coupon et des surfaces de volatilité implicite enabsence d�arbitrage puis l�évaluation d�une option Européenne en présence dedividendes discrets dont les montants sont connus à l�avance.
Mots-Clefs : [à dé�nir]
Abstract
This thesis gathers a set of studies dealing with the problematic of numericalprocedures and with the problematic of market data modelling met during thedevelopment of an equity derivatives valuation tool.The �rst part relates to the use of Monte Carlo and Quasi-Monte Carlo simu-lations in order to price derivatives. It insists more particularly on the choiceand the implementation of uniform generators, on the techniques employed tosimulate Gaussian variables and on the variance reduction procedures that canbe applied to improve the convergence rate of the estimators.The second part relates to the modelling of the market parameters, which in-�uence the stock price dynamic. The �rst two chapters deal successively with thezero curve construction and the implied volatility surface �tting under the no-arbitrage assumption. The third chapter resolves the European option-pricingproblem in the presence of discrete cash dividends.
Keywords : [to be de�ned]
i

ii

iii

Table des matières
Introduction Générale 1
I Méthodes de simulation numérique 16
1 Intégration probabiliste Monte Carlo 191.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 191.2 Générateurs pseudo-aléatoires . . . . . . . . . . . . . . . . . . . . 211.3 Simulation de la loi normale unidimensionnelle . . . . . . . . . . 391.4 Simulation de la loi normale multidimensionnelle . . . . . . . . . 481.5 Méthode de Monte Carlo . . . . . . . . . . . . . . . . . . . . . . 551.6 Evaluation d�options par simulation . . . . . . . . . . . . . . . . 601.7 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66A Méthode de Schrage . . . . . . . . . . . . . . . . . . . . . . . . . 69B Méthode de Box-Muller . . . . . . . . . . . . . . . . . . . . . . . 70C Factorisation de Cholesky . . . . . . . . . . . . . . . . . . . . . . 71Références . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
2 Intégration déterministe Quasi-Monte Carlo 772.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 772.2 Intégration Quasi-Monte Carlo . . . . . . . . . . . . . . . . . . . 812.3 Suites de Weyl . . . . . . . . . . . . . . . . . . . . . . . . . . . . 932.4 Suites de Halton . . . . . . . . . . . . . . . . . . . . . . . . . . . 1052.5 Comparaison des temps de calcul . . . . . . . . . . . . . . . . . . 1232.6 Quasi-Monte Carlo dans la pratique . . . . . . . . . . . . . . . . 1252.7 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133A Quadratures déterministes classiques . . . . . . . . . . . . . . . . 136B Démonstration du théorème 2.8 . . . . . . . . . . . . . . . . . . . 137C Démonstration du théorème 2.16 . . . . . . . . . . . . . . . . . . 138D Démonstration du lemme 2.19 . . . . . . . . . . . . . . . . . . . 141Références . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142
iv

II Modélisation des données de marché 146
3 Construction de la gamme des taux zéro-coupon en l�absenced�opportunité d�arbitrage 1493.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1493.2 Eléments de théorie . . . . . . . . . . . . . . . . . . . . . . . . . 1513.3 Conventions de marchés . . . . . . . . . . . . . . . . . . . . . . . 1563.4 Choix des instruments de calibration . . . . . . . . . . . . . . . . 1593.5 Extraction des facteurs d�actualisation . . . . . . . . . . . . . . . 1633.6 Interpolation non-arbitrable de la courbe des taux . . . . . . . . 1733.7 Comparaison des méthodes proposées . . . . . . . . . . . . . . . 1863.8 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 191A Démonstration de la proposition 3.1 . . . . . . . . . . . . . . . . 192B Caractéristiques des taux IBOR . . . . . . . . . . . . . . . . . . 192C Démonstration de la formule (3.64) . . . . . . . . . . . . . . . . . 193D Calculs du paragraphe 3.6.3 . . . . . . . . . . . . . . . . . . . . . 194Références . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 196
4 Construction de la surface de volatilité implicite en l�absenced�opportunité d�arbitrage 1994.1 La volatilité implicite : un enjeu stratégique . . . . . . . . . . . . 2004.2 Normalisation du marché . . . . . . . . . . . . . . . . . . . . . . 2094.3 Contraintes de non-arbitrage . . . . . . . . . . . . . . . . . . . . 2124.4 Données utilisées dans le chapitre . . . . . . . . . . . . . . . . . . 2184.5 Modélisations possibles pour la surface de volatilité implicite . . 2294.6 Construction d�une surface de volatilité non-arbitrable . . . . . . 2434.7 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 263A Démonstrations du paragraphe 4.3 . . . . . . . . . . . . . . . . . 265B Prix normalisé d�un call dans le modèle de Merton . . . . . . . . 270C Démonstrations du paragraphe 4.6.3 . . . . . . . . . . . . . . . . 272Références . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 275
5 Evaluation d�un call Européen en présence de dividendes dis-crets. 2795.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2795.2 Approximations comonotones d�une somme de variables aléatoires
lognormales dépendantes . . . . . . . . . . . . . . . . . . . . . . . 2825.3 Approximations comonotones du prix d�un call Européen . . . . 2885.4 Applications numériques . . . . . . . . . . . . . . . . . . . . . . . 2935.5 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 297A Approximations du prix d�un call Européen . . . . . . . . . . . . 300Références . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 303
v

Conclusion Générale 304
Bibliographie 308
vi

Introduction Générale
L�émergence de la gestion collective
Avant les années 70, l�accès aux marchés �nanciers était réservé aux personnespossédant un patrimoine important et une certaine connaissance des mécanismesboursiers. L�épargnant au patrimoine plus modeste devait s�orienter vers desplacements tels que le Livret A ou les emprunts d�Etat.Vers la �n des années 70, le développement des Organismes de Placements Col-lectifs en Valeurs Mobilières (OPCVM) a largement modi�é cette situation :l�accès aux marchés �nanciers s�est démocratisé par le biais de gestionnairesprofessionnels auxquels on con�e son épargne.
Un OPCVM est un instrument qui permet de mutualiser d�importantes sommescollectées auprès de personnes physiques ou morales pour en con�er l�investisse-ment et la gestion à des professionnels. Il existe en France deux types d�OPCVMdont la nature juridique est di¤érente : les SICAV (Société d�Investissement àCapital Variable), créées par une ordonnance de 1945 et les FCP (Fonds Com-mun de Placement), créés en 1979, qui sont des copropriétés de valeurs mobi-lières.
Par dé�nition, une SICAV possède la personnalité morale (il s�agit d�une sociétéanonyme) et elle émet des actions. Tout investisseur devient actionnaire et peuts�exprimer par son vote au sein des assemblées générales. Une SICAV peutassurer elle-même la gestion de ses investissements ou con�er cette fonction àune société de gestion de portefeuilles1 française agréée par l�AMF2 (Autoritédes Marchés Financiers).Un FCP n�a pas de personnalité morale. Il n�émet donc pas des actions, mais desparts. En achetant des parts, l�investisseur devient membre d�une copropriété devaleurs mobilières mais ne dispose d�aucun droit de vote. Un FCP est représentéet géré, sur les plans administratif, �nancier et comptable, par une société degestion de portefeuilles agréée par l�AMF.
1Une société de gestion de portefeuilles est une société d�investissement dont le but estd�assurer la gestion d�organismes de placements collectifs. La plupart des sociétés de gestionsont des �liales de grands groupes bancaires et sont généralistes, mais il existe aussi des sociétésde gestion indépendantes, souvent spécialisées dans certaines stratégies d�investissements.
2Site Internet de l�AMF : http://www.amf-france.org.
1

Les FCP sont des instruments �nanciers plus �exibles que les SICAV. En e¤et,pour créer un FCP (copropriété), il faut réunir au moins 2 porteurs qui apportentun actif minimal de 300 000 euros. En comparaison, la création d�une SICAV(société anonyme) représente un engagement plus lourd : il faut réunir au moins7 actionnaires qui apportent un actif minimal de 4 000 000 d�euros3 .
Pour cette raison, la plupart des sociétés de gestion préfèrent monter des FCPplutôt que des SICAV, d�autant plus que les deux supports fonctionnent d�unemanière très similaire. Ils permettent aux investisseurs (particuliers ou institu-tionnels) de pro�ter de la rentabilité des marchés �nanciers français ou inter-nationaux au travers d�une large gamme de produits qui couvre la plupart desmarchés (marchés actions, marchés monétaires, marchés obligataires, marchésémergents. . .) au travers de di¤érentes stratégies (performance absolue, répli-cation indicielle, stratégies diversi�ées ou garanties, produits dérivés et struc-turés, stratégies alternatives. . .). Les OPCVM constituent donc une alternativeattractive pour l�épargnant ou l�institutionnel qui ne dispose pas des moyens,des compétences ou des habilitations nécessaires pour investir en direct sur lesmarchés �nanciers.
Le marché de la gestion collective a connu un essor sans précédent au coursdes quarante dernières années, comme en attestent les chi¤res suivants. Ondénombrait en France 53 OPCVM pour un actif d�environ 13 milliards de francsen 1970 (Vitrac 2002). A la �n de l�année 2007, l�AMF recensait 8243 OPCVMpour un actif total d�environ 1350 milliards d�Euros4 . La France est considéréecomme l�un des leaders mondiaux de la gestion collective.
Une activité très réglementée
Compte tenu des encours gérés, l�activité de gestion collective joue un rôle depremier plan dans l�économie du pays. Tout d�abord, elle mobilise de manière ac-crue l�épargne des particuliers et se positionne comme une alternative sérieuse àdes placements plus classiques tels que les livrets d�épargne. Ensuite elle permetà un nombre croissant d�institutionnels (associations ou entreprises) de gérerleur trésorerie. En�n, l�ensemble des fonds de la place détiennent des parts trèsimportantes du capital ou de la dette de nombreuses entreprises françaises ouétrangères, ce qui met les sociétés de gestion en position d�in�uencer la stratégiedes dirigeants de ces entreprises. Pour ces raisons, les pouvoirs publics ont misen place un appareil législatif étendu qui permet de garantir la déontologie, latransparence et la sécurité des investissements �nanciers et de s�assurer que lesorganismes gestionnaires agissent dans le seul intérêt des porteurs de parts.La surveillance des activités de gestion collective par les autorités s�exerce àtrois niveaux.
3Voir l�article 411-14 du Livre IV du Règlement Général de l�AMF (AMF 2007a).4Document disponible sur le site de l�AMF à la rubrique : OPCVM & produits d�épargne
> Liste des encours.
2

Surveillance au niveau de l�Etat français avec l�AMF
L�AMF5 , est un organisme public indépendant, doté de la personnalité moraleet disposant d�une autonomie �nancière, qui a pour mission de veiller :� à la protection de l�épargne investie dans les instruments �nanciers et toutautre placement donnant lieu à appel public à l�épargne,
� à l�information des investisseurs,� au bon fonctionnement des marchés d�instruments �nanciers.Elle apporte aussi son concours à la régulation des marchés européens et inter-nationaux.
L�AMF réglemente et contrôle l�ensemble des activités de gestion collective.
1. Elle délivre les agréments et autorise les sociétés de gestion à exercer leuractivité. Elle veille au respect des règles de déontologie en vigueur. Elleimpose des pratiques de marché visant à privilégier l�intérêt des porteurs.Elle s�assure que les sociétés de gestion mettent en �uvre les moyens �nan-ciers, juridiques, techniques et humains nécessaires au bon déroulement deleur activité, de manière à o¤rir une sécurité et une transparence maxi-male aux investisseurs. Elle peut restreindre ou retirer les agréments demanière temporaire ou, le cas échéant, de manière dé�nitive.
2. Elle délivre les agréments pour la création et la dissolution des OPCVMet procède à des véri�cations au cours de la durée de vie de ces fonds.Dans un souci d�information et de protection des porteurs, elle imposedepuis 2004 aux sociétés de gestion d�établir un prospectus pour chaquefonds créé, véritable carte d�identité de l�OPCVM (AMF 2004). Le pros-pectus présente en particulier : l�objectif de gestion du fonds décrit demanière claire et précise, les règles d�investissement et d�évaluation desactifs, les conditions de souscription et de rachat, les frais de gestion, lesdroits d�entrée et de sortie6 .
3. Elle s�assure que les sociétés de gestion opèrent en parfaite indépendancepar rapport à leurs contreparties �nancières et par rapport à leurs action-naires. En particulier, dans le cas des sociétés de gestion attachées à unebanque, elle s�assure que les intérêts de la maison mère (la banque ou lasociété d�assurance) ne soient pas confondus avec les intérêts des clients.
4. Elle joue un rôle consultatif auprès des sociétés et des épargnants. En par-ticulier, elle peut être interrogée par les sociétés de gestion concernant desquestions réglementaires ou d�habilitation à exercer certains types d�opé-rations ou à réaliser certains types de montages.
5L�AMF a été créée en août 2003 par la loi n� 2003-706 de sécurité �nancière. Elle estissue de la fusion de la Commission des opérations de bourse créée en 1967 (COB), du Conseildes marchés �nanciers créé en 1996 (CMF) et du Conseil de discipline de la gestion �nancière(CDGF). L�objectif de ce rapprochement était de renforcer l�e¢ cacité et la visibilité de larégulation de la place �nancière française.
6Pour une présentation du contenu et de l�élaboration du prospectus, on pourra se référerau document d�information AMF (2007b).
3

En outre, l�AMF dispose de cinq pouvoirs : elle peut réglementer, elle peutordonner à tout agent économique de mettre �n à des pratiques qu�elle juge né-fastes pour le marché, elle peut enquêter (sur un délit d�initié éventuellement),elle peut saisir la justice pour mettre �n à des irrégularités portant atteinteaux droits des épargnants, elle peut prononcer des sanctions �nancières à l�en-contre de personnes physiques ou morales ayant enfreint la réglementation oula déontologie du marché.
Surveillance au niveau de la profession avec l�AFG
L�Association Française de la Gestion Financière ou AFG7 est l�organisationprofessionnelle de la gestion pour compte de tiers. Elle réunit tous les acteurs dumétier de la gestion, qu�elle soit collective ou individualisée sous mandat. L�AFGassure la représentation des intérêts économiques, �nanciers et moraux de sesmembres, des organismes qu�ils gèrent et de leurs clients. Elle est l�interlocuteurdes pouvoirs publics français et européens et contribue activement à l�évolutionde la réglementation.
L�AFG joue également un rôle important au niveau de la déontologie et elle veilleà ce que les sociétés d�investissement agissent dans le seul intérêt des porteurs departs. En�n, l�AFG a un rôle consultatif : les sociétés de gestion peuvent prendredes avis ou faire part de problèmes rencontrés dus, par exemple, à l�évolutionde la réglementation et aux di¢ cultés soulevées par la mise en application d�unnouveau règlement.
Surveillance au niveau européen avec la MIFID
La directive MIFID (Market In Financial Instruments Directive, en anglais)dé�nit le nouveau cadre réglementaire d�exercice des activités de marché dansl�ensemble de l�Union Européenne. Elle poursuit trois objectifs : l�ouvertureà la concurrence des lieux de négociations, l�harmonisation des réglementationsnationales, une meilleure protection des investisseurs et une transparence accruedes négociations sur actions. La directive MIF est en vigueur en France depuisle 1er novembre 2007, ainsi que dans la plupart des pays de l�Union Européenne.Toutefois, certains états, comme la Hollande ou l�Espagne, ont pris du retarddans la transposition de règles et ne seront prêts que l�année prochaine.
La MIFID introduit de nouvelles règles pour renforcer le devoir d�informationet formaliser les obligations de "meilleure exécution" des ordres sur instruments�nanciers. Elle responsabilise davantage l�ensemble des acteurs (établissementsbancaires, intermédiaires �nanciers, clients) en �xant clairement les droits etdevoirs de chacun :� pour les intermédiaires �nanciers, des règles de bonne conduite et de trans-parence,
7Site Internet de l�AFG : http://www.afg.asso.fr/.
4

� pour les clients, l�information sur leur situation patrimoniale et �nancière a�nde béné�cier pleinement de l�ensemble des protections qu�elle peut o¤rir.
La directive distingue trois catégories de clients :� les "Contreparties Eligibles", qui sont essentiellement les établissements decrédit, les compagnies d�assurance, les sociétés de gestion,
� les "Clients Professionnels", regroupant les grandes entreprises qui remplissentcertains critères en terme de taille de bilan,
� les "Clients non Professionnels", c�est-à-dire tous les autres clients.A chaque catégorie correspond un niveau de traitement et d�information spéci-�ques.Ainsi, les Clients Professionnels (et à fortiori les Contreparties Eligibles)sont présumés avoir l�expérience et la connaissance des instruments �nancierscomplexes et disposer d�une situation �nancière leur permettant de faire faceaux risques �nanciers liés aux transactions sur ces instruments �nanciers ; ilsbéné�cient d�une protection moindre. Les épargnants, en tant que clients nonprofessionnels, béné�cient d�un niveau de conseil et d�information accru. D�unemanière générale, l�intermédiaire �nancier doit être en mesure de prouver qu�ila agi dans l�intérêt de l�épargnant, en privilégiant le choix des meilleures contre-parties ou qu�il a traité aux coûts les plus bas.
L�activité de gestion est donc particulièrement contrôlée en France. Les di¤é-rentes normes réglementaires au niveau français (AMF) et au niveau européen(MIFID) militent en faveur d�une plus grande sécurité �nancière pour les épar-gnants et elles incitent les sociétés de gestion à se doter d�outils performantspour mesurer et gérer les risques qu�elles prennent et qu�elles font prendre àleurs clients.
Le marché des fonds à formule
Le besoin de concilier sécurité et performance
Après les krachs boursiers de la �n des années 80, les épargnants recherchentdes placements sécuritaires. Ils se détournent alors des fonds investis en actionset en obligations dont les rendements sont jugés trop incertains pour aller versdes supports de type monétaire. Mais la faiblesse des taux d�intérêt a rendules fonds monétaires traditionnels moins rentables qu�auparavant, donc moinsattractifs pour les clients.
A�n de conserver leur clientèle dans cette conjoncture économique di¢ cile, decontinuer d�attirer de nouveaux investisseurs et de préserver leurs marges, lesbanques ont commencé de proposer des OPCVM dont le capital est garanti àun certain horizon et qui o¤rent une perspective de performance attrayante, engénéral indexée sur les marchés boursiers8 . Ces fonds répondent aux attentes desparticuliers qui recherchent à la fois la sécurité (par l�intermédiaire de la garantie
8Les premiers fonds de ce type furent lancés au début des années 90 par La Poste, devenueaujourd�hui La Banque Postale.
5

en capital totale ou partielle) et le rendement potentiel (lié à l�exposition auxmarchés boursiers). Ils constituent une catégorie AMF à part entière : les fondsà formule.
Caractéristiques des fonds à formule
Un fonds à formule a pour objectif9 d�o¤rir au souscripteur qui investit à la datede création du fonds :� une garantie totale ou partielle du capital à l�échéance du fonds,� la performance d�un payo¤ exotique portant sur l�évolution d�un ou de plu-sieurs sous-jacents (actions ou indices actions dans la majorité des cas).
Ces garanties s�appliquent uniquement à l�échéance du produit.En d�autres termes on peut schématiquement écrire :
Fonds à formule = Zéro-Coupon+ Payo¤ Exotique (1)
Dans le cas des fonds destinés aux particuliers, la garantie en capital est le plussouvent totale, de sorte que, à l�échéance du fonds, l�investisseur est assuré derécupérer au minimum la somme investie. Il existe toutefois des fonds plus dy-namiques qui ne garantissent qu�une fraction du capital initial ou qui protègentle capital tant que le marché n�est pas descendu en dessous d�un certain seuil.Ces fonds o¤rent une espérance de rendement supérieure en compensation del�augmentation de la prise de risque.
Le payo¤ exotique (ou structuré) est acheté par l�OPCVM auprès de la salledes marchés d�une banque d�investissement. Sa nature (option à cliquets, op-tion sur maximum, option sur moyenne, option sur panier de valeurs. . .) estdéterminée par la société de gestion en fonction du type de clientèle ciblé et sescaractéristiques (nombre de points dans la moyenne, fréquence d�observation dessous-jacents, niveau de barrière. . .) sont déterminées en fonction des conditionsde marché.
La combinaison (1) est synthétisée par le gestionnaire qui négocie un swap struc-turé dans lequel l�OPCVM échange les �ux associés au rendement total d�uncertain portefeuille investi en actions ou en obligations10 contre les �ux généréspar la structure optionnelle et qui constituent la rémunération promise au client.Pour une étude approfondie des techniques de montage et de gestion des fondsà formule, on pourra consulter Patard (2001).Soulignons en�n que, les fonds à formule permettent de pro�ter pleinementde la �scalité avantageuse o¤erte par le PEA (Plan d�Epargne en Actions) ou
9Une dé�nition o¢ cielle des fonds à formule est donnée à l�article R214-27 du code moné-taire et �nancier.10Ce portefeuille constitue l�actif physique du fonds et n�est en aucun cas lié aux sous-jacents
du payo¤ structuré qui représente la performance o¤erte au client.
6
Fonds à Formule
0
10
20
30
40
50
60
70
80
1994 1995 1996 1997 1998 1999 2000 2001 2002 2003 2004 2005 2006 2007
Act
if G
éré
(Mds
EU
R)
Fonds à Vocation Générale
0
200
400
600
800
1000
1200
1400
1600
1994 1995 1996 1997 1998 1999 2000 2001 2002 2003 2004 2005 2006 2007
Act
if G
éré
(Mds
EU
R)
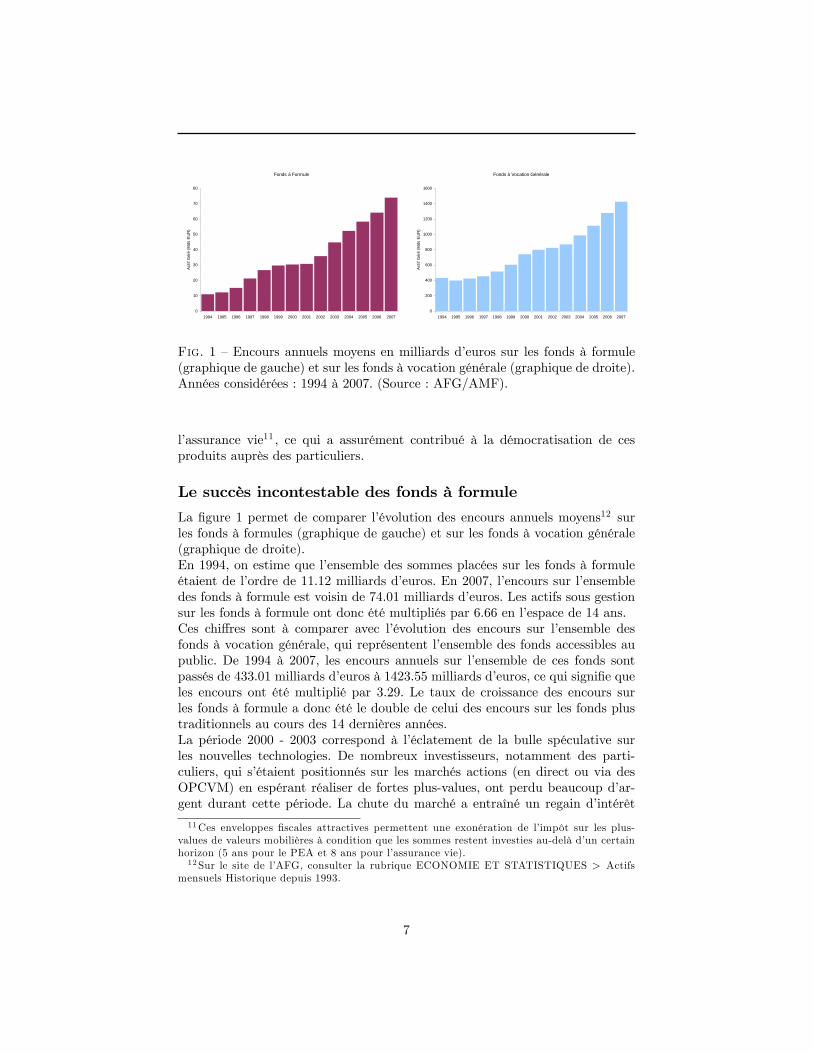
Fig. 1 �Encours annuels moyens en milliards d�euros sur les fonds à formule(graphique de gauche) et sur les fonds à vocation générale (graphique de droite).Années considérées : 1994 à 2007. (Source : AFG/AMF).
l�assurance vie11 , ce qui a assurément contribué à la démocratisation de cesproduits auprès des particuliers.
Le succès incontestable des fonds à formule
La �gure 1 permet de comparer l�évolution des encours annuels moyens12 surles fonds à formules (graphique de gauche) et sur les fonds à vocation générale(graphique de droite).En 1994, on estime que l�ensemble des sommes placées sur les fonds à formuleétaient de l�ordre de 11:12 milliards d�euros. En 2007, l�encours sur l�ensembledes fonds à formule est voisin de 74:01 milliards d�euros. Les actifs sous gestionsur les fonds à formule ont donc été multipliés par 6:66 en l�espace de 14 ans.Ces chi¤res sont à comparer avec l�évolution des encours sur l�ensemble desfonds à vocation générale, qui représentent l�ensemble des fonds accessibles aupublic. De 1994 à 2007, les encours annuels sur l�ensemble de ces fonds sontpassés de 433:01 milliards d�euros à 1423:55 milliards d�euros, ce qui signi�e queles encours ont été multiplié par 3:29. Le taux de croissance des encours surles fonds à formule a donc été le double de celui des encours sur les fonds plustraditionnels au cours des 14 dernières années.La période 2000 - 2003 correspond à l�éclatement de la bulle spéculative surles nouvelles technologies. De nombreux investisseurs, notamment des parti-culiers, qui s�étaient positionnés sur les marchés actions (en direct ou via desOPCVM) en espérant réaliser de fortes plus-values, ont perdu beaucoup d�ar-gent durant cette période. La chute du marché a entraîné un regain d�intérêt
11Ces enveloppes �scales attractives permettent une exonération de l�impôt sur les plus-values de valeurs mobilières à condition que les sommes restent investies au-delà d�un certainhorizon (5 ans pour le PEA et 8 ans pour l�assurance vie).12Sur le site de l�AFG, consulter la rubrique ECONOMIE ET STATISTIQUES > Actifs
mensuels Historique depuis 1993.
7

pour des supports d�épargne sécurisés, représentés entre autres par les fonds àformule à capital garanti. A partir de cette période, les entreprises d�investis-sement (banques et assurances) ont proposé de manière quasi systématique desproduits garantis à leurs clients particuliers, devenus spécialement désireux deprotéger leur épargne contre les aléas des marchés actions13 .
Une réglementation spéci�que et renforcée pourles fonds à formule
Les fonds à formule représentent depuis quelques années une part signi�cativedes nouveaux agréments d�OPCVM et de la collecte, notamment auprès desparticuliers.L�AMF a adopté une réglementation spéci�que pour ces fonds a�n de protégerles intérêts des investisseurs, très attirés par ce type de produits et mis encon�ance par le sentiment de sécurité qu�ils inspirent.
Prévenir les risques de dérive commerciale
Les fonds à formule peuvent attirer une clientèle nouvelle, non initiée aux pro-duits �nanciers. Ces produits peuvent être facilement présentés par les réseauxcommerciaux comme des produits sans risque avec des perspectives de rende-ments très intéressants ayant toutes chances de se réaliser.
S�il est vrai que les fonds à formule ont des avantages indéniables (avec la garan-tie totale ou partielle du capital investi et de belles perspectives de rendement)et peuvent séduire une clientèle aux moyens �nanciers limités, désireuse de faireprospérer son épargne sans prendre de risque sur son capital, ils ont, commetout produit �nancier, leurs inconvénients et c�est de ceux-là, qu�à l�égal de leursavantages, l�AMF entend que les réseaux commerciaux avertissent clairement lesouscripteur a�n d�éviter d�éventuelles déconvenues. En e¤et :� Les frais d�entrée compris entre 1% et 3% du capital investi réduisent d�autantle montant du capital apporté par le souscripteur.
� Les fonds investis ne sont pas bloqués mais, en cas de sortie anticipée, desfrais s�élevant entre 2% et 6% de la valeur liquidative sont pénalisants. Lesouscripteur doit être conscient qu�il ne doit placer que les fonds dont il estsûr de ne pas avoir l�usage pendant la durée du contrat.
� A l�échéance, le client retrouve bien le montant du capital garanti. Mais lagarantie totale du capital n�est pas systématique. Dans le cas où le capitaln�est pas garanti ou garanti partiellement, le client doit savoir que la partienon garantie, si elle peut lui apporter une forte plus value, peut aussi perdrede sa valeur selon l�évolution des marchés.13A ce sujet, on pourra consulter le dossier du magazine Capital de mars 2008 (No. 198),
intitulé : "les fonds garantis, une bonne réponse à la crise boursière".
8

Un prospectus étendu
A�n de prévenir toute dérive commerciale, comme cela a quelquefois pu se pro-duire, l�AMF impose dorénavant aux établissements �nanciers d�établir, dans lecas des fonds à formule, un prospectus spéci�que, qui donne plus d�informationsque celui des fonds traditionnels.
Le prospectus doit insister sur la durée de l�investissement recommandée et surle fait que la valeur liquidative14 du fonds pourra évoluer di¤éremment des in-dices sous-jacents. Il contient aussi quatre rubriques permettant au souscripteurd�appréhender le produit et les espérances de gains a�n de faire un choix entoute connaissance (AMF 2002) :� une description détaillée du payo¤ exotique, des objectifs du produit, de sesavantages et inconvénients,
� une présentation et une analyse des scénarios de marché favorables et défavo-rables au fonds,
� un back-testing du fonds qui illustre les rendements que l�on aurait obtenuss�il avait été lancé dans le passé,
� une comparaison, pour la même période, avec les rendements d�autres place-ments (placement sur le sous-jacent du payo¤ exotique et placement au tauxsans risque).
Prévenir les risques de con�it d�intérêt
La structuration �nancière des fonds à formule repose exclusivement sur l�utili-sation de payo¤ structurés qui sont vendus et couverts par les salles des marchésdes banques d�investissement. Cela conduit à deux risques potentiels.
1. Un risque de con�it d�intérêts entre la société de gestion, qui agit au nomet pour le compte des porteurs de parts, et les salles des marchés quiagissent pour le compte propre des banques. Il faut éviter que la sociétéde gestion privilégie une contrepartie pour des raisons autres que le prixdu produit ou la qualité de service.
2. Un risque �nancier pour les porteurs de parts. En e¤et, les salles des mar-chés ont un savoir-faire en matière d�évaluation, de couverture et d�analysedes risques sur les produits dérivés que les sociétés de gestion ne possèdentpas. Il faut éviter qu�une société de gestion engage, sur les conseils d�unecontrepartie bancaire, ses clients sur un produit structuré "novateur" dontelle maîtrise mal les di¤érents aspects.
A�n de garantir l�autonomie des sociétés de gestion par rapport à leurs contre-parties bancaires et dans le souci de protéger les intérêts des investisseurs, l�AMFimpose aux sociétés de gestion de pouvoir réévaluer à tout instant et de manièreautonome les positions sur les produits structurés détenus par les OPCVM.Les principes et les obligations de cette contrainte réglementaire sont dé�nisà l�article R214-13 du code monétaire et �nancier dont nous reproduisons unextrait ci-dessous.14La valeur liquidative désigne la valeur d�une part du fonds.
9

"Un organisme de placement collectif en valeurs mobilières peutconclure des contrats constituant des instruments �nanciers à termeen vue de protéger ses actifs ou de réaliser son objectif de gestion[. . . ]Ils font l�objet d�une valorisation e¤ectuée par l�organisme de pla-
cement collectif en valeurs mobilières, qui ne se fonde pas uniquementsur des prix de marché donnés par la contrepartie et satisfait auxcritères suivants :1) La valorisation se fonde sur une valeur de marché actuelle,
qui a été établie de manière �able pour l�instrument ou, si une tellevaleur n�est pas disponible, sur un modèle de valorisation utilisantune méthode reconnue et appropriée ;2) Cette valorisation est véri�ée soit par un tiers indépendant
du cocontractant, de façon régulière et selon des modalités tellesque l�organisme de placement collectif en valeurs mobilières puissela contrôler, soit par un service de l�organisme de placement collectifen valeurs mobilières indépendant des fonctions opérationnelles eten mesure de procéder à cette véri�cation."
La société de gestion ne peut donc pas se contenter de négocier les produitsstructurés puis d�utiliser les prix qui lui sont communiqués par ses contrepartiespour déterminer la valeur de l�actif du fonds :� elle doit véri�er ces prix à l�aide d�un modèle de marché adapté, ce qui sous-entend qu�elle ne peut pas utiliser un modèle aux hypothèses trop simples etqu�elle doit disposer des équipes compétentes pour implémenter et comprendredes modèles complexes,
� cette véri�cation doit être e¤ectuée en toute indépendance par rapport auxservices de gestion, a�n de limiter d�éventuels con�its d�intérêts, ce qui sous-entend qu�elle doit disposer d�un service capable d�évaluer les produits com-plexes ou bien qu�elle doit sous-traiter cette tâche.
Des contraintes opérationnelles fortes
Les exigences de l�article R214-13 se traduisent par deux contraintes opération-nelles fortes pour les sociétés de gestion qui souhaitent monter et commercialiserdes fonds à formule.
La première contrainte pour la société de gestion est d�obtenir un agrémentde l�AMF qui l�autorise à traiter des produits structurés. Pour cela, elle doitprésenter un programme d�activité qui décrit les produits sur lesquels elle in-terviendra ainsi que les moyens humains et techniques qu�elle entend mettreen �uvre pour gérer ces produits dans les meilleures conditions. Ce documentdoit être particulièrement précis, notamment en ce qui concerne les modèles demarché utilisés AMF (2003a, 2003b).
1. La société de gestion doit justi�er le choix et la pertinence des modèlesde marché qui seront mis en �uvre. Pour cela, elle présente les tests qui
10

ont été menés pour valider les modèles et elle communique les CurriculumVitae des personnes qui ont pris les di¤érentes décisions.
2. Elle doit présenter les méthodes numériques retenues pour la mise en�uvre des modèles (méthode de Monte-Carlo, formules fermées, EDP. . .)et justi�er ses choix.
3. Elle doit présenter les hypothèses retenues pour la calibration des modèlesainsi que la manière dont les paramètres de marché nécessaires à sa miseen �uvre seront construits et justi�er ses choix.
L�obtention de l�agrément n�est pas systématique et, dans la pratique, seules lessociétés de gestion qui disposent de moyens importants sont capables de �nancerles équipes de recherche, de gestion et de contrôle ainsi que les outils informa-tiques indispensables à l�exercice de ce genre d�activité. Les sociétés de gestionqui n�obtiennent pas l�agrément n�ont pas d�autre choix que de sous-traiter lemontage de fonds à formule auprès des sociétés habilitées à les monter. Lorsquel�agrément est accordé, le programme d�activité doit être remis à jour au fur et àmesure que la société de gestion fait évoluer les technologies qu�elle utilise ou lagamme des produits qu�elle négocie. L�AMF se réserve la possibilité d�e¤ectuerà tout moment des contrôles approfondis a�n de s�assurer que les engagementspris dans le programme d�activité sont bien tenus. A cette occasion, elle peutrestreindre ou supprimer, de manière temporaire ou dé�nitive, l�agrément de lasociété de gestion sur les produits structurés.
La seconde contrainte porte sur la négociation des opérations de swaps struc-turés des fonds à formule qui doit reposer sur le principe de concurrence (AMF2002). Cela signi�e que la société de gestion doit procéder à un appel d�o¤resentre les di¤érentes contreparties bancaires susceptibles de réaliser l�opération.L�objectif étant de rechercher les meilleures conditions de prix et de respecterle principe fondamental de la primauté de l�intérêt des porteurs. L�AMF re-commande de retenir plusieurs contreparties à l�issu de l�appel d�o¤res a�n dediversi�er les risques de marché. Toutefois, la société de gestion a la possibilitéde contracter avec une contrepartie unique ou avec une contrepartie liée (parexemple la salle des marchés de la banque dont elle est �liale). Dans ce cas, elleengage directement sa responsabilité si elle n�a pas obtenu pour ses clients desconditions similaires à celles du marché.
La nécessité de diversi�er les contreparties pour une même opération impliqueque le nombre de swaps structurés gérés par la société de gestion est nettementplus important que le nombre de fonds commercialisés (il y a en moyenne 3swaps par fonds15). Cette stratégie limite assurément les risques �nanciers et lesrisques de contrepartie. En revanche, elle augmente considérablement la chargede travail qui pèse sur l�organe de contrôle des prix des opérations et elle induitdes risques opérationnels importants16 et peut ralentir sévèrement le processusde publication de la valeur liquidative du fonds.15L�opération de swap structuré est systématiquement divisée entre plusieurs contreparties.
Le nombre de contreparties est déterminé par le montant nominal du swap.16En multipliant les contreparties sur une opération, on augmente mécaniquement les risques
11

Industrialisation des processus de gestion des fondsà formule
L�augmentation considérable du nombre de fonds sous gestion et les contraintesréglementaires particulièrement fortes auxquelles sont soumises les sociétés degestion militent en faveur du développement de systèmes de gestion très auto-matisés. Autrement dit, on assiste aujourd�hui à une industrialisation accéléréedes processus de gestion des fonds à formule.
Industrialisation du montage des fonds
Le marché des fonds à formule est rémunérateur pour les réseaux placeurs, maisil est fortement concurrentiel, car ce sont des produits qui permettent d�attirerde nouveaux clients. Il est donc fondamental que la société de gestion soit enmesure d�innover rapidement en ce qui concerne les payo¤ exotiques pour sedistinguer des concurrents et pour entretenir l�intérêt des clients potentiels pources produits. En�n, l�élaboration du prospectus d�un fonds à formule nécessite derenseigner di¤érentes rubriques dont le contenu est similaire d�un fonds à l�autre.Ces di¤érents points incitent à mettre en place des outils automatisés pourconstruire et pour tester les payo¤ et pour réaliser les simulations numériquesdu prospectus.Dans la phase de structuration, le gérant recherche des pro�ls de payo¤ pré-sentant un couple rendement/risque optimal. Cela peut se faire sur la base desimulations numériques des distributions de rendement des produits, à conditiontoutefois de disposer d�un modèle de marché réaliste (Argou 2003).
Industrialisation des systèmes d�évaluation des produits struc-turés
Pour permettre les entrées et les sorties des clients durant la vie du fonds17 ,la société de gestion publie périodiquement la valeur de la part du fonds (ouvaleur liquidative), déterminée sur la base des cours d�ouverture ou des coursde clôture des sous-jacents du produit. La fréquence de valorisation et le typede cours utilisé sont des données du prospectus18 .
En principe, la valeur liquidative doit être calculée le jour prévu et une accu-mulation des retards de publication des valeurs liquidatives peut entraîner desrappels à l�ordre de l�AMF.
suivants : (i) ne pas recevoir l�ensemble des réévaluations des positions pour calculer la valeurliquidative en temps voulu, (ii) ne pas avoir des réévaluations e¤ectuées sur les bons niveaux demarché (clôture veille au lieu d�ouverture par exemple), (iii) ne pas recevoir de réévaluationssuite à un problème informatique de l�une des contreparties.17Dans le cas des fonds à formule, cette opération n�est pas conseillée, car les frais de sortie
anticipée sont pénalisants.18En général, la fréquence est quotidienne ou hebdomadaire. Dans de rares cas, elle est
bimensuelle.
12

Dans le cas d�un fonds à formule, publier la valeur liquidative implique deréévaluer l�ensemble des swaps structurés qui composent le portefeuille et deconfronter les valorisations obtenues à celles envoyées par les contreparties. Ilest fréquent que les contreparties envoient des valorisations éloignées de cellestrouvées par la société de gestion. Dans ce cas, la �abilité de l�outil interne joueun rôle essentiel comme en témoignent les analyses des cas suivants.
1. Le plus souvent, la di¤érence de valorisation réside dans des choix di¤é-rents pour la modélisation des paramètres de marché inobservables telsque la volatilité des sous-jacents ou la structure par terme de dividendes.Après avoir identi�é la cause des écarts, l�organe de valorisation de la so-ciété de gestion donne son accord pour la prise en compte du prix proposépar la contrepartie. Cela suppose que la société de gestion sache modéliserles paramètres de manière consistante.
2. Dans les périodes de krach boursier comme celui du début de l�année2008, il n�est pas rare que des contreparties se trouvent dans l�impossibilitéd�envoyer une valorisation de l�opération dans les délais impartis ou queles écarts de valorisation ne trouvent pas une explication mathématiqueou �nancière19 . Dans ce cas, il faut parfois plusieurs jours avant que leproblème ne soit résolu. En pratique, la société de gestion, ne peut pas sepermettre de retarder le processus de publication de la valeur liquidativeau-delà d�une journée. Elle peut alors prendre la décision de valoriser elle-même le produit concerné, ce qui suppose qu�elle ait toute con�ance enses systèmes de valorisation.
Ces di¤érents cas démontrent tout d�abord que l�autonomie imposée par l�AMFn�est pas uniquement une contrainte réglementaire, c�est aussi et surtout unecontrainte opérationnelle. Ensuite, ils signi�ent qu�il faut penser l�architecturedu processus de valorisation dans son ensemble (modèle de marché, données demarché et méthodes numériques) de manière à disposer d�un système automa-tique, homogène et robuste (Overhaus, Rerraris et al. 2002).
Soulignons que les OPCVM sont structurellement acheteurs des payo¤ exo-tiques, ce qui signi�e qu�ils n�ont pas de risque lié à la couverture du produit,contrairement à leurs contreparties. En conséquence, la société de gestion nefait pas la même utilisation des modèles de valorisation que les salles de mar-ché. Dans le cas des sociétés de gestion, c�est la recherche du compromis entrela �abilité des résultats et la rapidité des calculs qui doit guider le choix desmodèles.
Mise en place d�une veille technologique
Les salles de marché font évoluer leurs technologies en permanence, tant au ni-veau du service o¤ert qu�au niveau des modèles utilisés, ce qui leur permet de
19En général, ces écarts proviennent du fait que les contreparties choisissent des niveauxtrès prudentiels pour les paramètres qui sont alors très éloignés de ceux que l�on peut estimeren observant le marché.
13

proposer constamment de nouveaux payo¤ exotiques. Par ailleurs, la réglemen-tation AMF impose aux sociétés de gestion de savoir réévaluer l�ensemble despayo¤ traités de manière consistante. En�n, l�industrie des fonds à formule estbasée sur le caractère innovant des produits commercialisés.
En conséquence, les sociétés de gestion qui désirent occuper une place de premierplan sur le marché des fonds à formule doivent innover dans les technologies devalorisation, a�n de pouvoir traiter les nouveaux payo¤ sans di¢ culté. Cela im-plique la mise en place et le �nancement d�une veille technologique permanentea�n de faire évoluer ou de remplacer les systèmes existants.
L�apparition depuis quelques années de sociétés telles que Reech Capital20 , Nu-merix21 ou Pricing Partners22 qui proposent des services de valorisation in-dépendante et qui éditent des logiciels de valorisation de produits exotiquesdémontrent qu�il existe aujourd�hui un véritable marché des problématiques devalorisation (Benhamou 2007). En faisant l�acquisition d�un outil de valorisationexterne, une société de gestion s�a¤ranchit des problèmes de recherche théoriqueet d�implémentation des modèles de marché et elle peut concentrer les e¤ortsde ses équipes sur la modélisation des données de marché utilisées pour fairefonctionner les modèles et sur l�innovation produit.
Périmètre de l�étude
Les problématiques de modélisation quantitative peuvent être réparties en troiscatégories :� la construction et/ou l�étude de modèles de marché mathématiques,� l�étude et l�implémentation de méthode numériques pour évaluer les actifsconditionnels,
� la construction des paramètres qui servent d�inputs aux modèles d�évaluationà partir des données de marché.
Le périmètre de notre étude concerne la mise en �uvre des méthodes numériqueset la modélisation des paramètres de marché. Ces deux points constituent unpartie importante du travail des praticiens. L�objectif est de mettre en �uvre,de tester et de faire évoluer les modèles de la littérature pour les adapter auxcontraintes opérationnelles telles que la nécessité d�e¤ectuer les calculs dans unintervalle de temps réduit et avec le maximum de précision ou la nécessité depréparer et de modéliser des données de marché incomplètes ou arbitrables pourprocéder à la calibration des modèles.
Cette thèse regroupe un ensemble de travaux qui ont été menés sur les probléma-tiques de simulation numérique et de modélisation des données de marché dansle cadre d�une activité de gestion et de recherche quantitative au sein du pôle de
20Site Internet : www.sungard.com/reech.21Site Internet : www.numerix.com.22Site Internet : www.pricingpartners.com.
14

gestion quantitative de CM-CIC Asset Management, la société de gestion pourcompte de tiers du groupe Crédit Mutuel CIC.
Notre travail s�organise en deux parties.
La première partie montre comment le praticien peut mettre en �uvre les tech-niques de simulation Monte Carlo et Quasi-Monte Carlo, pour implémenter unoutil d�évaluation des produits dérivés. On y insiste plus particulièrement surle choix et l�implémentation des générateurs de nombres uniformes et sur lasimulation gaussienne.
La seconde partie est consacrée à la modélisation des paramètres de marchénécessaires à l�évaluation des produits dérivés sur les actions et sur les indices :les courbes de taux zéro-coupon, la volatilité implicite et les dividendes. Elle meten évidence les problèmes pratiques rencontrés lors de l�extraction des donnéesde marché et propose des solutions permettant de surmonter ces di¢ cultés.
15

Première partie
Méthodes de simulationnumérique
16

Depuis quelques années, on assiste à un développement très important de l�in-dustrie des produits dérivés qui se traduit par une augmentation considérabledes volumes de transactions, une complexi�cation notoire des stratégies (pro-duits hybrides portant sur plusieurs classes d�actifs, options sur CPPI23 . . . ) etune diversi�cation des sous-jacents (actions et indices, taux, crédit, in�ation,matières premières, fonds. . . ).Ce phénomène s�explique principalement par une concurrence accrue entre lesbanques d�investissement qui souhaitent préserver leurs marges et par les exi-gences croissantes de clients de plus en plus avertis, informés et désireux depro�ter de toutes les opportunités o¤ertes par les marchés mondiaux.
Pour mesurer et analyser les risques qu�implique cette intensi�cation des échanges,les intervenants (salles de marché, sociétés de gestion, fonds d�investissement)doivent développer des modèles de marché probabilistes qui capturent les carac-téristiques comportementales des sous-jacents de manière toujours plus réaliste.Par exemple, on peut remplacer la volatilité constante de la di¤usion lognormaledu modèle de Black et Scholes (1973) par une volatilité stochastique (Hull etWhite 1987, Heston 1993) ou bien combiner le mouvement Brownien qui per-turbe l�évolution des rendements avec un processus à sauts (Merton 1976, Kou2002). Mais ces modèles ne conduisent plus à des formules analytiques telles quela formule de Black et Scholes (1973).
Les méthodes de simulation numérique du type Monte Carlo ou Quasi-MonteCarlo deviennent alors un outil incontournable pour estimer la valeur des pro-duits dérivés complexes (Bouleau et Lépingle 1993, Jäckel 2002, Glasserman2004).
Cette partie s�organise en deux chapitres.
Le premier chapitre24 porte sur la méthode d�intégration numérique probabilisteMonte Carlo. Nous nous attachons à identi�er un générateur pseudo-aléatoirede nombres uniformes rapide et robuste. Nous proposons une technique d�échan-tillonnage de la loi normale scalaire et vectorielle adaptée aux contraintes cal-culatoires de la simulation numérique intensive. Nous présentons les techniquesde simulation Monte Carlo et deux solutions pour accélérer la convergence del�estimateur et nous montrons comment ces méthodes peuvent être appliquéespour évaluer une option dont le prix dépend du chemin suivi par le sous-jacent.
Le second chapitre porte sur la méthode de Quasi-Monte Carlo, fréquemmentconsidérée comme une version déterministe de la méthode de Monte Carlo, car
23CPPI signi�e Constant Proportion Portfolio Insurance. Stratégie de gestion dynamiqueconsistant à allouer dynamiquement un portefeuille composé schématiquement d�une pocherisquée et d�une poche sans risque, a�n de maintenir un e¤et de levier constant sur l�actifrisqué, tout en sécurisant les performances déjà réalisées par le portefeuille.24Une version de ce chapitre a été publiée dans le Bulletin Français d�Actuariat Bulletin,
Vol. 8, No. 14, juillet - décembre 2007, sous le nom �Outils numériques pour la simulationMonte Carlo des produits dérivés complexes�.
17

elle repose sur l�utilisation de suites déterministes qui présentent un très hautdegré d�uniformité, appelées suites à discrépance faible. Nous menons une étudecomplète (propriétés théoriques et implémentation) de deux familles de suitesà discrépance faible classiques et nous proposons une solution pour améliorerleurs propriétés en grande dimension. Par ailleurs, en procédant à des tests nu-mériques, nous montrons comment implémenter la méthode de Quasi-MonteCarlo pour obtenir une réduction de l�erreur signi�cative par rapport à la mé-thode de Monte Carlo.
Les méthodes présentées nécessitant des calculs intensifs et répétitifs, nous avonsaccordé une importance particulière à la manière dont il faut implémenter lesgénérateurs de nombres uniformes de manière à réduire les temps d�échantillon-nage.
18

Chapitre 1
Intégration probabilisteMonte Carlo
1.1 Introduction
La simulation aléatoire consiste d�une part à produire des échantillons indépen-dants, identiquement distribués (i.i.d.) de loi uniforme U (0; 1) par un procédédéterministe (L�Ecuyer 2004a) �il convient donc de porter une attention particu-lière sur les générateurs pseudo-aléatoires utilisés, car ce sont eux qui permettentd�échantillonner les lois de probabilité sous-jacentes du modèle théorique �etd�autre part à déterminer une transformation de la loi uniforme pour engendrerla loi de probabilité souhaitée, sachant que la plupart des lois de probabilitése déduisent de la loi uniforme par des transformations plus ou moins triviales(Devroye 1986, Niederreiter 1992).
1.1.1 Origines de la méthode de Monte Carlo
Une application majeure de la simulation de systèmes stochastiques complexesest la méthode de Monte Carlo. C�est un outil d�inférence statistique qui permetd�approcher une quantité déterministe, telle que l�espérance d�une variable aléa-toire. Le principe consiste (i) à simuler un grand nombre de réalisations de lavariable aléatoire considérée puis (ii) à approcher l�espérance de cette variablepar la moyenne empirique de l�échantillon ainsi construit. L�utilisation systéma-tique de la méthode de Monte Carlo pour résoudre des problèmes complexescoïncide avec l�apparition des premiers ordinateurs au milieu des années 1940.On peut considérer que John von Neumann et Stanislaw Ulam sont les premiersà avoir eu l�idée d�utiliser des nombres aléatoires générés par un ordinateur.Leur objectif était de résoudre les problèmes rencontrés lors de la mise au pointde la bombe atomique (Lemieux 2008). Le terme Monte Carlo, utilisé par Me-tropolis et Ulam (1949), fait référence au célèbre casino de la principauté deMonaco où l�on peut pratiquer le jeu de roulette qui peut être assimilé à une
19

succession d�épreuves aléatoires. La méthode de Monte Carlo a connu un essorconsidérable dans la période 1950-1980. Parmi les auteurs ayant contribué à sondéveloppement, nous pouvons citer Hammersley et Morton (1956), Hammersleyet Handscomb (1964), Haber (1966), Kuipers et Niederreiter (1974) et Nieder-reiter (1978). Cette liste non exhaustive donne les principales références sur lesujet.
Boyle (1977) est, à notre connaissance, le premier à avoir proposé d�appliquerla méthode de Monte Carlo pour évaluer des produits optionnels. L�idée sous-jacente consiste à remarquer que la valeur d�une option est égale à l�espérance deson payo¤ actualisé. On peut alors mettre en oeuvre la méthode de Monte Carloen simulant un grand nombre de réalisation du payo¤ considéré. L�approcheMonte Carlo est aujourd�hui utilisée dans presque tous les domaines de la �nancequantitative pour simuler la dynamique des variables de marché. L�objectif étantd�e¤ectuer des calculs de risques, de déterminer des allocations optimales deportefeuilles et d�évaluer les contrats optionnels aux caractéristiques complexes(Jäckel 2002, Glasserman 2004).
1.1.2 Organisation du chapitre
Ce chapitre s�inscrit dans un contexte où les méthodes de simulation numériquesont devenues un outil indispensable pour la modélisation et la quanti�cationdes risques de nature �nancière. Il s�attache à montrer comment le praticienpeut utiliser les résultats théoriques de la littérature spécialisée pour répondreau problème de l�évaluation des produits dérivés par la méthode de Monte Carlo.Les sections 2, 3 et 4 sont consacrées au choix fondamental des outils de simula-tion, tandis que les sections 5 et 6 présentent la méthode de Monte Carlo, deuxméthodes systématiques pour réduire la variance ainsi que leur implémentationpour évaluer un produit dérivé.
La section 2 pose le problème de l�imitation du hasard sur un ordinateur, i.e.par un procédé déterministe. A ce titre, nous comparons di¤érents générateursaléatoires. En particulier, nous présentons une technologie récente dite "Mer-senne Twister" (Matsumoto et Nishimura 1998) et montrons qu�elle constitueune solution rapide et robuste pour simuler la loi uniforme U (0; 1). La section3 est consacrée à la simulation de la loi normale, car cette loi de probabilité esttrès fréquemment utilisée pour modéliser l�évolution des facteurs de risque dumarché. Nous envisageons successivement deux approches pour échantillonnerla loi gaussienne : la transformation non linéaire d�un jeu de variables uniformes(méthode de Box-Muller), puis la méthode d�inversion de la fonction de répar-tition (Beasley et Springer 1977, Moro 1995, Acklam 2000). Les tests pratiquéss�inspirent des travaux de Neave (1973) et montrent que la première solution in-duit des biais d�échantillonnage non négligeables, tandis que la seconde solutionpermet de supprimer ces biais. Dans la section 4, nous abordons le problèmede la simulation de la loi normale multidimensionnelle à partir de la loi nor-male scalaire. Nous discutons le problème de la décomposition de la matrice de
20

covariance et nous proposons un algorithme e¢ cace et rapide pour simuler desvariables suivant une loi de Gauss multivariée. Dans la section 5, nous rappelonsles principes et les propriétés de la méthode de Monte Carlo, puis nous présen-tons ensuite deux techniques pour réduire systématiquement la variance de l�es-timateur quelle que soit la forme initiale du problème : la méthode "classique"des variables antithétiques et une méthode dite "adaptative", plus récente etplus �exible que la méthode antithétique (Arouna 2004, Bouchard 2006). Dansla section 6, nous appliquons les méthodes étudiées précédemment pour évaluerdes produits dérivés complexes. Nous prenons comme exemple le cas d�une op-tion asiatique géométrique mono sous-jacent, pour laquelle le prix est connu sousune forme explicite1 . Nous montrons comment les méthodes de réduction de va-riance permettent de contrôler l�incertitude sur le prix simulé et nous procédonsà une analyse numérique du comportement des estimateurs mis en oeuvre. Nousdonnons la conclusion du chapitre dans la section 7.
1.2 Générateurs pseudo-aléatoires
En raison de leur simplicité et parce qu�elles nécessitent des calculs intensifset répétitifs, les méthodes de simulation se prêtent bien à une implémentationinformatique. Cela suppose que l�on soit capable de produire rapidement desnombres au hasard par un procédé déterministe. Nous discutons ce point dansla suite.
1.2.1 Considérations générales sur les nombres aléatoires
Choix d�une source de hasard
Sources de hasard réel On connaît aujourd�hui une seule méthode pourobtenir des nombres véritablement aléatoires. Elle consiste à mesurer des phé-nomènes physiques intrinsèquement aléatoires, comme le bruit thermique dansles semi-conducteurs ou les émissions d�une source radioactive (Lachaud etLeclanche 2003). Cette approche semble particulièrement prometteuse dans ledomaine de la cryptographie. Ainsi, on sait obtenir des clés de chi¤rementuniques et imprédictibles en exploitant les propriétés quantiques de photonspolarisés (Langlois 1999). Cependant, elle nécessite des équipements spéciauxparticulièrement onéreux, ce qui la rend impropre à la simulation numérique surles systèmes courants.
Sources de hasard virtuel Les spécialistes préfèrent exploiter d�autres tech-niques, dont l�objectif est d�imiter le hasard le mieux possible. Pour cela, onutilise des algorithmes purement déterministes, appelés générateurs pseudo-aléatoires. Les séquences construites par un tel générateur sont sensées repro-duire �dèlement les propriétés statistiques de suites de nombres véritablement
1Etant donné que le prix "réel" du produit est connu, nous serons en mesure d�apprécierla convergence de la méthode numérique vers son objectif théorique.
21

aléatoires. On démontre qu�il ne su¢ t pas de juxtaposer "au hasard" des ins-tructions machine pour obtenir un bon générateur. Cette démarche peut s�avérerdésastreuse. En conséquence, l�élaboration d�un générateur doit reposer sur desfondements théoriques solides.
Architecture d�un générateur pseudo-aléatoire La plupart des généra-teurs pseudo-aléatoires fabriquent des nombres Uk apparemment i.i.d. de loiU (0; 1) selon un schéma récurrent et déterministe de la forme suivante :
Uk = g (sk) , où sk = f (sk�1) et s0 2 S: (1.1)
Les fonctions f : S ! S (fonction de transfert) et g : S ! (0; 1) (fonction desortie) sont déterministes. L�espace des états S est un ensemble �ni de symbolesreprésentables en machine. Le symbole produit à la k-ième itération, sk, estl�état interne du générateur. Cette présentation formelle des générateurs pseudo-aléatoires est due à L�Ecuyer (2004a).
Choix de l�état initial L�état initial s0, qui permet d�amorcer la récurrence,est aussi appelé la graine ou encore le germe du générateur (seed en anglais).Lorsqu�il est �xé une fois pour toutes, on obtient invariablement la même sé-quence. Cela facilite le développement et la mise au point des modèles et permetde reproduire une expérience virtuelle avec les mêmes conditions initiales. Endehors de ces besoins particuliers, il est recommandé d�amorcer le générateuravec des graines uniformément i.i.d. dans l�espace des états, ce qui permet d�en-visager, équitablement et sans biais, l�ensemble des évolutions possibles pourle modèle. Comme l�objectif visé est l�analyse d�un phénomène simulé et nonpas la sécurité d�un système, on peut engendrer les graines successives avec ungénérateur pseudo-aléatoire auxiliaire (plus facile à exploiter qu�une source dehasard physique).
Propriétés indésirables et propriétés recherchées
Défauts structurels des algorithmes pseudo-aléatoires Comme l�espacedes états est �ni, l�algorithme ne peut renvoyer qu�un nombre �ni de valeursdistinctes et, comme la dynamique (1.1) est déterministe, le générateur retrouvele même état interne au bout d�un certain nombre d�itérations. Ensuite, lesmêmes séquences sont à nouveau générées. En d�autres termes, les générateurspseudo-aléatoires sont périodiques. Ces propriétés des séquences simulées nesont pas en accord avec le fait qu�une séquence véritablement aléatoire de loiU (0; 1) est par nature non-périodique et qu�elle prend une in�nité de valeurs.
En pratique, on exige que la période T du générateur (déterminée par f etcard (S)) soit largement supérieure à la longueur de toutes les séquences envi-sageables et que l�échantillonnage du segment unité (déterminé par S et g) soitle plus �n possible. Il est communément admis que pour un bon générateur ondoit avoir
T ' card (S) et, si possible, T � 260 ' 1:15� 1018: (1.2)
22

Pour cela, on peut choisir f comme une permutation imprédictible des élémentsde S et construire g de façon à transformer les états internes successifs en unesuite de valeurs discrètes bien équidistribuées.
Propriétés statistiques recherchées Le critère (1.2) ne su¢ t pas à dé�nirun bon générateur (L�Ecuyer 2004a, p. 4). Il faut aussi véri�er les propriétésstatistiques des séquences générées (uniformité, équidistribution, indépendance,imprédictibilité) par des tests exigeants qui permettent d�identi�er les algo-rithmes les plus e¢ caces. De tels tests sont présentés de manière approfondiedans Knuth (1998), L�Ecuyer (1998a, 1998b), Niederreiter (1992) ou Klimasaus-kas (2003b). Malgré tout, chaque générateur pseudo-aléatoire a des caractéris-tiques intrinsèques qui le rendent impropre à certains types d�applications. C�estpourquoi, il est recommandé d�utiliser exclusivement des générateurs dont lespropriétés théoriques ont été établies par des spécialistes, puis validées par unjeu de tests connus comme DIEHARD (Marsaglia 1996) ou TestU01 (L�Ecuyer etSimard 2005).
Propriétés non statistiques souhaitables Lorsque le générateur est utilisépour la simulation numérique intensive, certaines propriétés, de nature non sta-tistique, comme la rapidité des calculs, la reproductibilité des séquences (qui per-met de recommencer une expérience virtuelle dans des conditions identiques) etla portabilité du code (pour la mise en oeuvre sur di¤érentes machines) s�avèrentparticulièrement intéressantes.
Evolution de la technologie
Les algorithmes pseudo-aléatoires les plus anciens (les plus simples aussi) sont lesgénérateurs à congruences linéaires (Niederreiter 1978, Knuth 1998). Bien qu�ilséquipent la plupart des systèmes de calcul standards, leurs propriétés s�avèrentsouvent décevantes (L�Ecuyer (2001) ou Klimasauskas (2003a, 2003b)).Les spécialistes ont su faire évoluer les techniques (Gentle 2003) parallèlement àl�évolution de la puissance de calcul des ordinateurs, d�abord en combinant desgénérateurs connus (Wichmann et Hill 1982, L�Ecuyer 1988), puis en explorantdes solutions nouvelles. Aussi, les générateurs récents sont-ils conçus autour del�architecture binaire des ordinateurs (L�Ecuyer et Panneton 2000, Panneton2004).
1.2.2 Générateurs linéaires congruentiels
La plupart des logiciels de calcul ou de développement disposent d�un générateurde nombres aléatoires. Pour des raisons principalement historiques, celui-là estsouvent de type linéaire congruentiel. La méthode des congruences linéaires futintroduite par Lehmer en 1949. Elle est particulièrement bien présentée dansl�ouvrage de Knuth (1998, p. 10).
23

Approche théorique
Dynamique linéaire congruentielle La dynamique d�un générateur linéairecongruentiel (LCG) est donnée par :
Xk = (aXk�1 + c)modm et X0 2 N; (1.3)
avec m 2 N� (le module), a 2 N� (le multiplicateur), c 2 N (l�incrément).
La récurrence (1.3) est appelée suite de Lehmer et son comportement est entière-ment déterminé par le triplet (m;a; c) et X0 (L�Ecuyer 2004a). Par construction,l�espace des états et la période d�un générateur congruentiel véri�ent :
S � Nmdef= f0; : : : ;m� 1g ; T � m:
En distinguant le cas c = 0 (générateurs congruentiels multiplicatifs) du casc > 0 (générateurs purement a¢ nes) on sait trouver des jeux de paramètres quipermettent de maximiser la période.
Obtenir des nombres uniformes dans (0; 1) Comme 0 � Xk � m � 1, ily a trois possibilités pour construire un nombre uniforme Uk entre 0 et 1 :
Uk =Xk
mou Uk =
Xk
m� 1 ou Uk =Xk + 0:5
m=Xk
m+
1
2m:
La première (resp. la seconde) solution conduit à des nombres dans l�intervallesemi-ouvert [0; 1[ (resp. l�intervalle fermé [0; 1]), tandis que la troisième solutiongénère des nombres dans l�intervalle ouvert ]0; 1[. Nous recommandons cettedernière approche, car elle présente deux avantages : (i) il n�est pas possibled�obtenir 0 ou 1 (intéressant lorsqu�on applique l�inverse d�une fonction de ré-partition aux sorties du générateur), (ii) les valeurs possibles pour Uk sont dansl�ensemble f1=(2m); : : : ; 1� 1=(2m)g, qui est symétrique autour de 1=2.
Générateurs congruentiels multiplicatifs (c = 0)
Dé�nition et propriété Lorsque c = 0, on parle de générateur linéairecongruentiel multiplicatif (MLCG) et la récurrence (1.3) devient :
8k 2 N�; Xk = (aXk�1)modm: (1.4)
Dans ce cas, l�état 0 est absorbant : si Xk = 0, alors les termes suivants dans lasuite seront tous nuls. Le générateur doit donc prendre ses valeurs dans Nmn f0g,de cardinal m� 1. Knuth (1998, p. 20) démontre le théorème suivant.
Théorème 1.1 Soit X un MLCG dé�ni par (m;a) et X0.� Si m est premier, la période maximale vaut m � 1. Elle est atteinte si etseulement si X0 ^m = 1 et a est primitif 2 modulo m.
2Un entier a est primitif modulo m si et seulement si am�1modm = 1 et ak�1modm 6= 1pour k = 1; : : : ;m� 1.
24

� Si m = 2n (n � 4), la période maximale vaut m=4. Elle est atteinte si etseulement si X0mod8 = 1 et amod8 = �3.
Une implémentation naïve de la dynamique (1.4) suppose que le produit aXk�1soit représentable en machine, ce qui est rarement le cas. En e¤et, les générateursacceptables ont un module m voisin du plus grand entier représentable et unmultiplicateur a élevé. Lorsque a2 < m, Schrage (1979) propose une méthodee¢ cace pour calculer axmodm sans dépassement de capacité (voir Annexe A).
Générateur Ran0 (Park et Miller, 1988) Park et Miller (1988) considèrentle générateur suivant :
Uk =Xk
231 � 1 avec Xk = (16807Xk�1)mod�231 � 1
�: (1.5)
Selon les auteurs, ce générateur constitue le standard minimal utilisable parles non-spécialistes. En e¤et, l�algorithme est convenablement testé, le code estportable sur tous les systèmes et la période (TRan0 = 231 � 2 ' 2:15 � 109) estmaximale au sens du théorème 1.1. Soulignons toutefois que la période de Ran0semble un peu courte pour des simulations intensives.
Générateurs congruentiels a¢ nes (c > 0)
Dé�nition et propriété Lorsque c > 0, Knuth (1998, p. 17) démontre quel�on peut espérer construire des générateurs de période m.
Théorème 1.2 La période maximale d�un générateur purement a¢ ne vaut m.Elle est atteinte si, et seulement si :� c et m sont premiers entre eux,� a = 1mod d, pour tout nombre premier d tel que mmod d = 0,� a = 1mod 4, si mmod4 = 0.Dans ce cas, pour tout choix de X0, chaque valeur de Nm sera atteinte pour uncertain k. Il n�existe pas de choix privilégié pour X0.
Nous donnons ci-dessous deux exemples de générateurs congruentiels a¢ nes.
Générateur Rnd (Microsoft Visual Basic) La fonction Rnd, disponibledans Microsoft Visual Basic (Microsoft 2004, Microsoft 2005), est un générateurlinéaire congruentiel dé�ni par :
Uk =Xk
224avec Xk = (16598013Xk�1 + 12820163)mod 2
24: (1.6)
Par construction, les Uk sont à valeurs dans l�intervalle semi-ouvert [0; 1[ et lafonction s�annule une seule fois au cours d�un cycle complet, lorsque Xk�1 =13497921. Selon L�Ecuyer (2001), ce générateur a de mauvaises propriétés sta-tistiques et une période un peu courte (TRnd = 224 ' 1:68� 107) pour envisagerde l�utiliser dans des applications numériques lourdes.
25

Générateur Rand (Microsoft Visual C++) La fonction Rand, implémen-tée dans le compilateur C de Microsoft depuis 1985, renvoie des nombres Ykuniformément distribués dans l�ensemble
�0; : : : ; 215 � 1
selon l�équation :
Yk =
�Xk
216
�mod215 où Xk = (214013Xk�1 + 2531011)mod 2
31; (1.7)
La suite (Xk) est un générateur congruentiel a¢ ne à valeurs dans�0; : : : ; 231 � 1
et de période maximale : TRand = 231 ' 2:15� 109. La suite (Yk) est formée enisolant, à chaque itération, les 16 bits les plus signi�catifs du générateur X. Elleprend donc 32768 valeurs distinctes dans l�ensemble
�0; : : : ; 215 � 1
et l�on peut
montrer qu�elle s�annule 7 fois au cours d�un cycle complet de X.Si la longueur de la période peut être considérée comme acceptable, le cardinalde l�espace des états est notoirement insu¢ sant (card (S) = 215 = TRand=65536).Le générateur Rand ne respecte pas le critère (1.2) et n�est pas adapté au calculnumérique intensif.
1.2.3 Générateurs linéaires combinés
Une solution simple pour construire des générateurs de période longue avec debonnes propriétés statistiques consiste à combiner plusieurs générateurs congruen-tiels multiplicatifs de la forme Xi;k = (aiXi;k�1)modmi, où i = 1; : : : ; I et mi
premier. Il existe deux techniques pour combiner des générateurs linéaires, lapremière est due à Wichmann et Hill (1982) et la seconde à L�Ecuyer (1988,1996, 1999).
Approche théorique
Combinaison de Wichmann et Hill La combinaison de Wichmann et Hill(1982) admet la forme générale suivante :
Uk =
IXi=1
Xi;k
mi
!mod1; (1.8)
où l�opérateur "mod1" signi�e que l�algorithme retourne la partie décimale dela somme des quotients.
Combinaison de L�Ecuyer Lorsquem1 = max fmi : i � 1g, L�Ecuyer (1988,1996, 1999) propose une dynamique voisine de la précédente :
Uk =Xk
m1et Xk =
IXi=1
(�1)i�1Xi;k
!modm1. (1.9)
26

Période d�un générateur combiné Si chaque générateur élémentaire estchoisi de période maximale (soitmi�1) et si les termes (mi � 1) =2 sont premiersentre eux, on peut démontrer que la période maximale d�un générateur dé�nipar (1.8) ou par (1.9) est donnée par la formule :
T =
QIi=1 (mi � 1)2I�1
: (1.10)
Le lecteur trouvera une preuve de ce résultat dans L�Ecuyer (1988, 1996) oudans Sakamoto et Morito (1995).
Générateur RWH (Wichmann et Hill, 1982)
Le générateur de (Wichmann et Hill 1982) est dé�ni par :
Xk = (171Xk�1)mod 30269;
Yk = (172Yk�1)mod 30307;
Zk = (170Zk�1)mod 30323;
et
Uk =
�Xk
30269+
Yk30307
+Zk30323
�mod1:
Il franchit les tests DIEHARD de Marsaglia et la période est donnée par (1.10) :
TRWH =(mX � 1) (mY � 1) (mZ � 1)
4' 6:95� 1012:
Ce générateur est donc utilisable pour la plupart des applications courantes. Enparticulier, il est implémenté dans la fonction ALEA() du tableur Excel depuis laversion 2003 (Microsoft 2006). Cela est un gage de �abilité pour les utilisateursqui souhaitent manipuler des nombres aléatoires dans les feuilles de calcul.
Générateur Ran2 (L�Ecuyer, 1988)
L�Ecuyer (1988) considère deux générateurs multiplicatifs, X et Y , de para-mètres :
(mX ; aX) =�231 � 85; 40014
�; (mY ; aY ) =
�231 � 249; 40692
�qu�il combine selon la convention (1.9) :
Uk =ZkmX
, avec Zk =�Xk � Yk si Xk > YkXk � Yk +mX � 1 si Xk � Yk
:
Les paramètres permettent d�atteindre une période maximale au sens de laformule (1.10) :
TRan2 =(mX � 1) (mY � 1)
2' 2:31� 1018;
27

ce qui est environ 1 milliard de fois la période de chaque générateur pris indé-pendamment.
Press et al. (2002) soulignent les excellentes propriétés statistiques de ce généra-teur et proposent d�augmenter l�imprédictibilité de l�algorithme en appliquantun mélange de Bays-Durham : il s�agit d�un petit algorithme qui perturbe l�ordrede la suite (Xk), ce qui permet de briser les corrélations sérielles entre les sortiessuccessives du générateur.
1.2.4 Générateurs Mersenne Twister
Fondements de l�approche Mersenne Twister (MT)
Les Mersenne Twister sont des générateurs récents3 , proposés pour la premièrefois par Matsumoto et Nishimura (1998). L�idée originale des auteurs est dedé�nir la récurrence du générateur, non pas à partir des opérations arithmétiquesclassiques sur les entiers (comme pour la plupart des générateurs courants), maisà partir des opérations d�arithmétique matricielle dans le corps �ni N2 = f0; 1g.
Cette approche nouvelle présente quatre avantages majeurs : (i) on peut écrirel�algorithme avec les opérateurs de bits présentés dans le paragraphe suivant(L�Ecuyer et Panneton 2000), de sorte que le générateur exploite pleinementl�architecture binaire de l�ordinateur (Panneton 2004), (ii) les temps de calculsont considérablement réduits (les opérateurs de bits sont très rapides), (iii) onpeut obtenir des générateurs de période arbitrairement longue (les bits allouésà la mémoire du générateur sont mélangés à chaque itération, ce qui accroîtl�espace des états du générateur), et (iv) on améliore l�équidistribution multi-dimensionnelle du générateur en appliquant un ultime mélange des bits avantrenvoi d�un nouveau nombre uniforme (Matsumoto et Kurita 1992, 1994).
Opérateurs de bits
Représentation des entiers en machine L�ensemble des entiers représen-tables en machine est de la forme N2! , où ! désigne le nombre de bits del�ordinateur4 . Tout entier X 2 N2! , de décomposition binaire
P!�1i=0 xi2
i, eststocké sous la forme d�un "vecteur de bits" : X � (x!�1; x!�2; : : : ; x0).
Décalage de bits Soit 0 � v � !. On note "� v" le décalage de v bits versla droite (lire v bits right shift) dé�ni par :
X � vdef= (0; : : : ; 0; x!�1; : : : ; xv+1) = bX=2vc :
De manière symétrique, le décalage de v bits vers la gauche (v bits left shift)est noté "� v" et correspond à l�opération :
X � vdef= (x!�v�1; : : : ; x0; 0; : : : ; 0) = (2
vX)mod 2!:
3http://www.math.sci.hiroshima-u.ac.jp/~m-mat/eindex.html4! = 32 sur une machine 32 bits et ! = 64 sur une machine 64 bits.
28

Les opérateurs de décalage de bits sont donc des raccourcis pour la division (resp.la multiplication) par une puissance de 2. Ils sont particulièrement rapides, carils agissent directement sur les bits de l�entier X.
Arithmétique bit à bit Soit Y =Pi<! yi2
i 2 N2! , on dé�nit les opérateurs"bit à bit" :
X � Y def=
!�1Xi=0
(xi � yi) 2i et X Ydef=
!�1Xi=0
(xi yi) 2i;
avec la convention xi � yi = (xi + yi)mod 2 et xi yi = (xi � yi)mod 2.
La dynamique Mersenne Twister
Paramètres du Mersenne Twister Soit 0 � r � !� 1. On note Mr (resp.Mr) l�entier dont les r bits d�ordre inférieur (resp. les !�r bits d�ordre supérieur)sont égaux à 1, les autres bits étant nuls : Mr = 2
r � 1 et Mr = 2! � 2r. Ces
entiers sont appelés masques de bits du générateur.
Par ailleurs, on dé�nit une fonction sur l�ensemble des entiers machine par
A (x) = (x� 1)��0 si xmod2 = 0a si xmod2 = 1
;
où a 2 N2! est une constante entière "bien choisie". Cette fonction, appeléeperturbation du générateur, décale les bits de l�entier x de 1 rang vers la droiteet, lorsque x est impair, mélange le résultat avec les bits de la constante a.
Récurrence du générateur La dynamique Mersenne Twister est basée surun schéma récurrent d�ordre n dans l�ensemble des entiers machine. Pour k � 0,le terme Xk+n est construit à partir de Xk, Xk+1 et Xk+m (0 � m < n) de lamanière suivante :
Xk+n = Xk+m �A�(Xk+1 Mr)� (Xk Mr)
�:
L�entier (Xk+1 Mr)� (Xk Mr) est formé en concaténant les r bits d�ordreinférieur de Xk+1 avec les ! � r bits d�ordre supérieur de Xk+1, puis il estmélangé par la fonction A. Le nouvel entier ainsi obtenu est additionné (bit àbit) avec Xk+m. Ces mélanges successifs augmentent l�imprédictibilité du géné-rateur. Notons que la séquence est initialisée en choisissant n entiers machine(X0; : : : ; Xn�1) 2 Nn2! .
Opération de tempering A�n d�améliorer l�équidistribution multidimen-sionnelle des sorties du générateur, les concepteurs proposent de mélanger lesbits de Xk+n selon l�algorithme suivant :
29

Algorithme 1 Tempering de Matsumoto et Kurita (1998)Y Xk+n
Y Y � (Y � u)Y Y � ((Y � s) b)Y Y � ((Y � t) c)Y Y � (Y � l)
Cette opération, appelée tempering, intervient avant de renvoyer un nouveauréel dans le segment unité. Di¤érentes techniques de tempering sont discutéesdans la thèse de Panneton (2004, pp. 34-37).
Sorties du générateur Le k-ième réel uniforme dans ]0; 1[ est donné par
Uk =Y + 0; 5
2!2�
1
2!+1;3
2!+1; : : : ; 1� 1
2!+1
�et la période maximale théorique vaut :
TMT = 2!n�r � 1:
Pour certains choix de !, n et r, la période est un nombre de Mersenne (i.e. unnombre premier de la forme 2i � 1), ce qui justi�e, à posteriori, le nom de cettefamille de générateurs.
Générateur MT19937 (Matsumoto et Nishimura, 1998)
Paramètres de récurrence Les paramètres de récurrence du générateurMT19937 sont les suivants :
! = 32; n = 624; r = 31; m = 397; a = 2567483615:
Ce choix permet de maximiser la période :
TMT19937 = 2!n�r � 1 = 219937 � 1 ' 4:32� 106001:
La période obtenue est un nombre premier de Mersenne comportant environ6000 chi¤res, ce qui est colossal.
Paramètres de tempering Les paramètres de tempering sont :
u = 11; s = 7; t = 15; l = 18; b = 2636928640 et c = 4022730752:
Ils assurent à MT19937 une équidistribution optimale dans 623 dimensions5 .
5Pour une présentation théorique de la notion d�équidistribution, nous invitons le lecteurà consulter Niederreiter (1992) ou Tezuka (1995).
30

Procédure d�initialisation Soulignons que le générateur MT19937 est trèssensible au choix de l�état initial. S�il contient trop de bits nuls, la suite géné-rée conservera cette tendance sur plus de 10000 simulations (Panneton 2004).Depuis 2002, les auteurs proposent de construire (X0; : : : ; Xn�1) selon une ré-currence qui assure une bonne di¤usion des bits du registre :
Xi = 1812433253� ((Xi�1 �Xi�1 � 30) + i) ; i = 1; : : : ; n� 1;
où X0 2 N2! est �xé arbitrairement.
1.2.5 Choix d�un générateur
Le choix d�un générateur pseudo-aléatoire dépend de ses propriétés intrinsèques(longueur de la période et comportement statistique) ainsi que de la machineutilisée (vitesse d�exécution), l�objectif étant de trouver l�algorithme réalisant lemeilleur compromis entre ces critères et les besoins réels de l�utilisateur.
Caractéristiques intrinsèques des générateurs présentés
Longueur de la période Dans le tableau ci-dessous nous avons classé lesgénérateurs étudiés en fonction de leur période, dont l�ordre de grandeur estdonné sous la forme d�une puissance de 10.
Générateur Rnd Ran0 & Rand RWH Ran2 MT19937Période 1:68E7 2:15E9 6:95E12 2:31E18 4:32E6001
La période du générateur MT19937 est "in�niment" plus grande que celle desautres générateurs étudiés. Par exemple, la période de Ran0 représente une frac-tion in�nitésimale de la période de MT19937 :
TRan0TMT19937
' 2:15� 1094:32� 106001 ' 4; 97� 10
�5993:
Pour les applications pratiques, on considèrera que la période du MersenneTwister est in�nie.
Propriétés statistiques des séquences L�objectif de ce travail est d�o¤rirau lecteur une présentation synthétique de di¤érentes techniques permettant deproduire des nombres au hasard et non pas de procéder à des tests statistiquesexhaustifs sur les di¤érents algorithmes. En e¤et, il existe pour cela des logicielsbien spéci�ques (cf. paragraphe 1.2.1), développés et utilisés par les spécialistesqui ont, par ailleurs, déjà publié ce type de tests comparatifs (L�Ecuyer et Simard2005).
Nous retiendrons simplement que les générateurs combinés RWH et Ran2 ainsi quele générateur à opérations binaires MT19937 passent sans di¢ culté les tests sta-tistiques les plus exigeants, tandis que Rnd, Rand et Ran0 échouent certains testsplus élémentaires (L�Ecuyer 2001). De ce point de vue, RWH, Ran2 et MT19937surclassent les générateurs linéaires congruentiels.
31

Equidistribution multidimensionnelle
Pour simuler des vecteurs i.i.d. selon la loi uniforme sur l�hypercube unité ]0; 1[s
à partir des sorties successives d�un générateur pseudo-aléatoire, il su¢ t deconsidérer la suite de terme général :
Ukdef=�U(k�1)s+1; U(k�1)s+2; : : : ; Uks
�0; k � 1: (1.11)
D�un point de vue théorique, les points construits selon la formule (1.11) doiventoccuper le cube "au hasard" et, par conséquent, leur disposition ne doit présenteraucune structure déterministe apparente. Dans la suite, nous proposons deuxtests utilisant des échantillons de la forme (1.11) et qui permettent de révéler ledéterminisme sous-jacent des générateurs Rnd, Rand et Ran0.
Examen des projections bidimensionnelles Une manière simple de mettreen évidence le déterminisme sous-jacent des générateurs Rnd et Rand consiste àreprésenter les projections des points de la suite dé�nie par la relation (1.11) surdi¤érents plans du cube ]0; 1[s. Pour les besoins de l�expérience, nous avons choisiles plans de coordonnées (1; 2), (8; 9), (29; 30), (62; 63), (96; 97) et (117; 118). Lesquatre premiers plans sont issus de Jäckel (2002) et nous avons choisi les deuxderniers au hasard. Dans tous les cas, nous avons généré 5000 points. La �-gure 1.1 représente les projections obtenues avec le générateur Rnd (dimensions = 256) et la �gure 1.2 représente les projections obtenues avec le générateursRand (dimension s = 214). A titre de comparaison, nous avons représenté lesprojections obtenues avec le générateur Ran0 (�gure 1.3) et avec le générateurMT19937 (�gure 1.4).� Sur la �gure 1.1, sur chaque plan de projection, les nuages de points com-posent des formes géométriques régulières. Cela est en contradiction avec lefait que les points sont sensés se répartir dans tout le plan sans privilégierdes regroupements reconnaissables comme les arcs de cercles que l�on voit ici.Le générateur Rnd n�a pas été capble d�imiter une répartition des points auhasard.
� Sur la �gure 1.2, les projections obtenues sont di¤érentes de celles de la �gure1.1, mais présentent encore des formes géométriques très régulières, ce quimontre que le générateur Rand n�est pas su¢ samment performant pour imiterune distribution des points au hasard.
Dans la mesure où les générateurs Rnd et Rand ont échoué ce test empiriquetrès simple, nous recommandons de ne pas les utiliser pour les applicationsnumériques lourdes telle que la simulation de processus stochastiques complexes.� Les �gures 1.3 et 1.4 obtenues avec les générateurs Ran0 et MT19937 ne pré-sentent aucune structure déterministe apparente6 . Les points se répartissentde manière imprédictible et uniforme, conformément à ce que l�on peut at-tendre d�un jeu de points véritablement aléatoires.
6Nous avons choisi de ne pas faire �gurer les projections obtenues avec les générateurs Ran2et RWH, car elles sont semblables aux �gures 1.3 et 1.4.
32

Le résultat est surprenant pour le générateur Ran0 qui appartient à la mêmefamille de générateurs linéaires congruentiels que Rnd et Rand. On peut penserque cela provient du choix des paramètres.
Le test graphique suivant permet de distinguer nettement les générateurs Ran0et MT19937.
Structure latticielle Etant donné que les générateurs Ran0 et MT19937 ontdonné des résultats semblables lors du test des projections, nous réalisons unenouvelle expérience destinée à mettre en évidence le déterminisme de l�algo-rithme Ran0. L�idée est d�étudier le comportement des points générés à uneéchelle miniature. Pour cela, nous avons réalisé l�expérience suivante avec cha-cun des deux générateurs :
1. simulation de 625 millions de points "aléatoires" dans le cube unité ]0; 1[3,
2. observation du comportement des points dans le "petit" cube ]0; 0:02[3.
La �gure ci-dessous permet de comparer les résultats obtenus selon que le gé-nérateur utilisé est Ran0 (cube de gauche) ou MT19937 (cube de droite).
Les points construits avec Ran0 se répartissent sur des plans parallèles, ce quiest en contradiction avec le fait que le générateur est sensé imiter des nombres"au hasard". Cette con�guration spatiale particulière est caractéristique desgénérateurs linéaires congruentiels (Ran0, Rnd, Rand) : elle est appelée struc-ture latticielle (Knuth 1998). En revanche, les points simulés avec le MersenneTwister ne présentent pas de structure déterministe à l�échelle miniature, cequi con�rme la qualité de ce générateur. Soulignons que des �gures tout à faitsimilaires auraient été obtenues si nous avions remplacé MT19937 par l�un desgénérateurs combinés RWH ou Ran2. Les générateurs combinés ne présentent au-cune structure latticielle patente.
33

Fig. 1.1 �Projections de 5000 points de la suite vectorielle (Uk), dé�nie par(1.11), sur 6 plans engendrés par des couples de coordonnées consécutives. Legénérateur utilisé est Rnd et la dimension de simulation est s = 256.
34

Fig. 1.2 �Projections de 5000 points de la suite vectorielle (Uk), dé�nie par(1.11), sur 6 plans engendrés par des couples de coordonnées consécutives. Legénérateur utilisé est Rand et la dimension de simulation est s = 214 = 16384.
35

Fig. 1.3 �Projections de 5000 points de la suite vectorielle (Uk), dé�nie par(1.11), sur 6 plans engendrés par des couples de coordonnées consécutives. Legénérateur utilisé est Ran0 et la dimension de simulation est s = 214 = 16384.
36

Fig. 1.4 �Projections de 5000 points de la suite vectorielle (Uk), dé�nie par(1.11), sur 6 plans engendrés par des couples de coordonnées consécutives. Legénérateur utilisé est MT19937 et la dimension de simulation est s = 214 = 16384.
37

Conclusion Le Mersenne Twister est le seul générateur de ce comparatif quipermette de produire des points en dimension multiple sans qu�aucune structuredéterministe ne soit décelable, ni en examinant les projections bidimensionnelles,ni en examinant la con�guration des points à l�échelle miniature. Ces résultatsincitent à utiliser le Mersenne Twister pour la simulation numérique multidi-mensionnelle.
Considérations d�implémentation
Choix d�un langage de programmation La simulation numérique néces-site des calculs intensifs, répétitifs et précis. C�est pourquoi, les spécialistesrecommandent de coder les générateurs pseudo-aléatoires dans un langage deprogrammation puissant, typiquement le C ou le C++. Ces langages sont dits"compilés", car le code d�un programme est traduit une fois pour toutes eninstructions machine qui s�exécutent très rapidement. Toutefois, pour des testsponctuels, il est possible d�utiliser un langage interprété, comme Visual BasicApplication. Dans ce cas, les lignes de code sont contrôlées puis converties eninstructions machine au fur et à mesure de leur appel, ce qui ralentit l�exécutionmais n�a¤ecte en rien la précision des calculs.
Vitesse de calcul Nous avons procédé à un test comparatif consistant à gé-nérer 1 milliard de nombres pseudo-aléatoires sur un PC équipé d�un processeurIntel Pentium IV cadencé à 3.20GhZ, de 1Go de RAM et de Microsoft WindowsXP Professionnel. Le compilateur utilisé est Microsoft Visual C++ 6.0.
Générateur Ran0 Rnd Rand RWH Ran2 MT19937
temps d�exécution (s) 62:8 45:9 31:2 232:6 119:7 48:2temps d�exécution relatif 100% 73% 50% 370% 191% 77%
Le générateur minimal standard (Ran0) est pris comme référence ; il met 62:8secondes pour achever la simulation, ce qui signi�e qu�il produit environ 16millions de nombres par seconde.Avec des temps d�exécution respectifs de 232:6 et 119:7 secondes, les générateurscombinés RWH et Ran2 sont les plus lents de ce comparatif. Notons que le rapportentre la vitesse d�un générateur combiné et la vitesse du générateur de référenceest approximativement égal au nombre de générateurs formant la combinaison.Ainsi, RWH (resp. Ran2) est trois fois (resp. deux fois) plus lent que Ran0.Rand et Rnd sont les générateurs les plus rapides de ce comparatif avec des tempsd�exécution respectifs de 31:2 secondes et 45:9 secondes. Les di¤érences de tempsde calcul par rapport au générateur minimal (qui repose pourtant sur un algo-rithme similaire) s�expliquent essentiellement par le fait que les modules de Randet Rnd sont des puissances de 2, ce qui accélère considérablement l�exécution enlangage binaire.MT19937 se classe en troisième position du comparatif : il met 48:2 secondespour achever la simulation, ce qui correspond à un temps d�exécution 30% pluscourt que celui du générateur de référence. Une explication est que l�algorithme
38

Mersenne Twister pro�te pleinement de l�architecture binaire de la machineet s�exécute particulièrement rapidement : il produit environ 21 millions denombres par seconde.
Conclusion
Les générateurs RWH, Ran2 et MT19937 présentent des propriétés statistiquesmeilleures et des périodes respectives plus longues que les générateurs linéairescongruentiels. De plus, MT19937 possède une période quasi-in�nie et sa vitesse decalcul est particulièrement élevée. Il est implémenté, en versions 32 et 64 bits,dans la très sérieuse bibliothèque de calcul numérique IMSL7 (InternationalMathematical and Statistical Library), ce qui est un signe de son e¢ cacité. Legénérateur MT19937 semble donc répondre parfaitement aux contraintes de lasimulation numérique intensive.
Nous allons maintenant montrer comment utiliser les générateurs aléatoires deloi uniforme pour simuler des réalisations de la loi de Gauss.
1.3 Simulation de la loi normale unidimension-nelle
La loi gaussienne est particulièrement utilisée dans les applications �nancièrespour représenter l�aléa des variables de marché (Lamberton et Lapeyre 1997,Björk 2004). Nous allons envisager deux techniques pour simuler cette loi deprobabilité : la transformation non linéaire d�un jeu de variables uniformes (mé-thode de Box-Muller) puis l�inversion de la fonction de répartition (méthode deMoro et méthode de Acklam).
1.3.1 Loi normale unidimensionnelle : rappels
SoitG une variable aléatoire dé�nie sur un espace probabilisé (; T ; P ), à valeursdans (R;BR), où BR désigne la tribu borélienne. On dit que G suit une loinormale ou gaussienne de paramètres � 2 R et � 2 R�+, si elle admet unedensité par rapport à la mesure de Lebesgue de la forme suivante :
'�;� (x) =1
�p2�exp
� (x� �)
2
2�2
!; x 2 R:
On peut démontrer que E [G] = � et Var [G] = �2 : la loi normale est entièrementdéterminée par son espérance et sa variance et l�on note indi¤éremment G �N (�; �) ou N
��; �2
�.
La loi N (0; 1) est appelée loi normale centrée réduite ou encore loi normalestandard et sa densité sera notée '. Le théorème suivant nous montre qu�il su¢ t
7Cette bibliothèque est éditée par Visual Numerics : http://www.visualnumerics.com/.
39
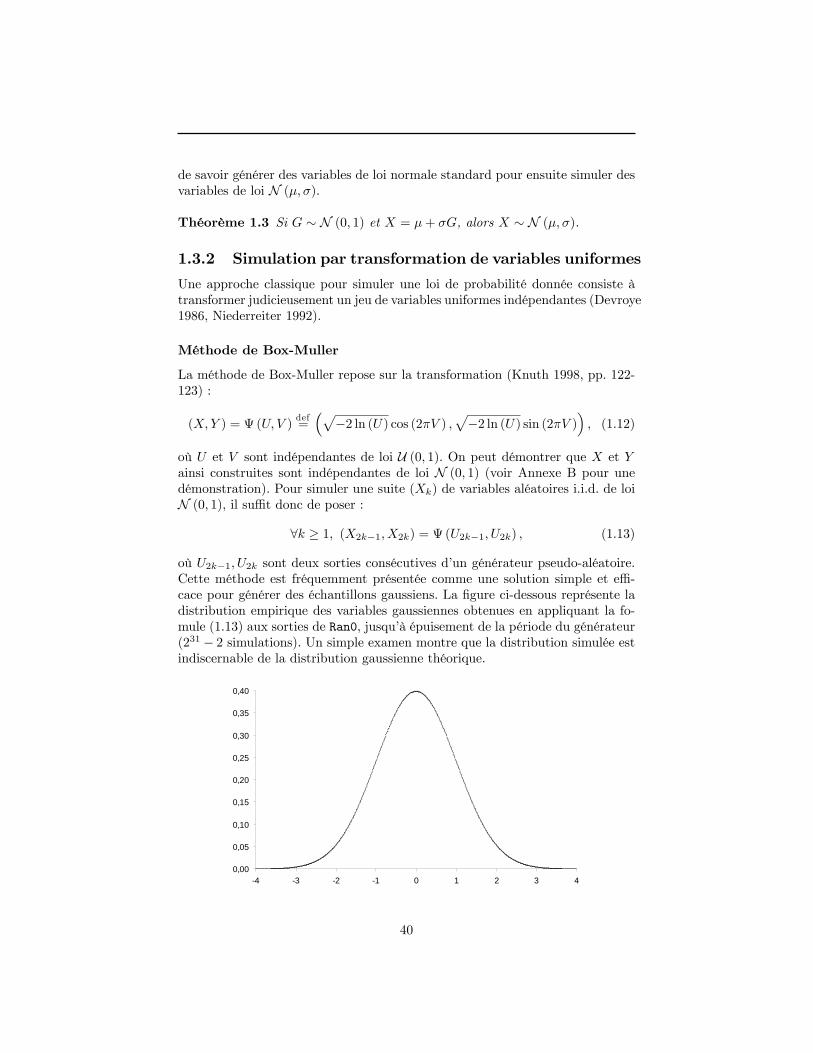
de savoir générer des variables de loi normale standard pour ensuite simuler desvariables de loi N (�; �).
Théorème 1.3 Si G � N (0; 1) et X = �+ �G, alors X � N (�; �).
1.3.2 Simulation par transformation de variables uniformes
Une approche classique pour simuler une loi de probabilité donnée consiste àtransformer judicieusement un jeu de variables uniformes indépendantes (Devroye1986, Niederreiter 1992).
Méthode de Box-Muller
La méthode de Box-Muller repose sur la transformation (Knuth 1998, pp. 122-123) :
(X;Y ) = (U; V )def=�p�2 ln (U) cos (2�V ) ;
p�2 ln (U) sin (2�V )
�; (1.12)
où U et V sont indépendantes de loi U (0; 1). On peut démontrer que X et Yainsi construites sont indépendantes de loi N (0; 1) (voir Annexe B pour unedémonstration). Pour simuler une suite (Xk) de variables aléatoires i.i.d. de loiN (0; 1), il su¢ t donc de poser :
8k � 1; (X2k�1; X2k) = (U2k�1; U2k) ; (1.13)
où U2k�1; U2k sont deux sorties consécutives d�un générateur pseudo-aléatoire.Cette méthode est fréquemment présentée comme une solution simple et e¢ -cace pour générer des échantillons gaussiens. La �gure ci-dessous représente ladistribution empirique des variables gaussiennes obtenues en appliquant la fo-mule (1.13) aux sorties de Ran0, jusqu�à épuisement de la période du générateur(231 � 2 simulations). Un simple examen montre que la distribution simulée estindiscernable de la distribution gaussienne théorique.
0,00
0,05
0,10
0,15
0,20
0,25
0,30
0,35
0,40
4 3 2 1 0 1 2 3 4
40

E¤et Neave
L�interaction entre des systèmes non-linéaires complexes, comme les générateurspseudo-aléatoires (Herring et Palmore 1989) et la méthode de Box-Muller, pro-duit parfois des e¤ets de bord imprévisibles et indésirables. Neave (1973) a misen évidence une déformation systématique des queues de distribution de la loinormale quand l�algorithme de Box-Muller est associé avec un générateur li-néaire congruentiel.
Distorsion de la densité de probabilité Les résultats présentés dans lasuite ont été obtenus en appliquant la formule (1.13) aux sorties de Ran0 jusqu�àépuisement de la période du générateur, soit 231 � 2 simulations.
Sur la �gure 1.5, on observe un échantillonnage irrégulier (en "dents de scie")au niveau des queues de distribution. Cette déviation entre la distribution théo-rique et la distribution empirique ne peut être imputée ni au générateur, car ilpasse les tests standards, ni à la longueur de l�échantillon, car elle correspondà la période de Ran0. Ce phénomène est donc la conséquence d�une interactionnon souhaitée entre l�algorithme de Box-Muller et le générateur. A�n de con�r-
0,0000
0,0001
0,0001
0,0002
0,0002
0,0003
0,0003
0,0004
0,0004
0,0005
0,0005
4,5 4,4 4,3 4,2 4,1 4,0 3,9 3,8 3,7
distribution empirique distribution théorique
0,0000
0,0001
0,0001
0,0002
0,0002
0,0003
0,0003
0,0004
0,0004
0,0005
3,7 3,8 3,9 4,0 4,1 4,2 4,3 4,4 4,5
distribution empirique distribution théorique
Fig. 1.5 �Queues de distribution (Box-Muller + Ran0).
mer les observations précédentes, nous nous proposons d�analyser les fréquencesde la distribution empirique de X1; : : : ; Xn sur des intervalles [a; b[ arbitraire-ment petits. On note n[a;b[ le nombre de réalisations dans l�intervalle [a; b[. Sousl�hypothèse H0 : "les Xk sont i.i.d. de loi N (0; 1)", on doit avoir
E�n[a;b[
�= np
[a;b[et Var
�n[a;b[
�= np
[a;b[
�1� p
[a;b[
�;
où p[a;b[
= �(b) � � (a) et � est la fonction de répartition de la loi N (0; 1).Lorsque n est su¢ samment grand, on a l�approximation gaussienne pour le
41
biais d�échantillonnage sur l�intervalle [a; b[ :
d[a;b[ =n[a;b[ � E
�n[a;b[
�qVar
�n[a;b[
� �n!1
N (0; 1) :
La p-value du test s�écrit :
�[a;b[ = 2�1� �
���d[a;b[����et on rejette l�hypothèseH0 pour tous les seuils � inférieurs à �(n)a;b . Le tableau ci-dessous donne les résultats obtenus pour di¤érents intervalles lorsque n = 231�2.
intervalle observé attendu déviation p-value[a; b[ n[a;b[ np
[a;b[d[a;b[ �[a;b[
�3:77 : �3:76 6929 7157 �2:70 6:93E� 03�3:76 : �3:75 7794 7432 4:20 2:67E� 05�3:75 : �3:74 7200 7716 �5:87 4:36E� 09�3:74 : �3:73 8516 8010 5:65 1:60E� 08�3:73 : �3:72 7812 8314 �5:51 3:59E� 083:72 : 3:73 8868 8314 6:08 1:20E� 093:73 : 3:74 7357 8010 �7:30 2:88E� 133:74 : 3:75 8156 7716 5:01 5:44E� 073:75 : 3:76 7064 7432 �4:27 1:95E� 053:76 : 3:77 7405 7157 2:93 3:39E� 03
L�hypothèse d�adéquation à la loi gaussienne est rejetée sur tous les intervallestestés (les p-values sont toutes voisines de zéro) : on en déduit que l�e¤et Neavese traduit par une distorsion non négligeable de la densité de probabilité de laloi gaussienne.
Distorsion de la fonction de répartitition Nous allons à présent montrerque les déformations identi�ées dans l�analyse précédente induisent un biais lorsde l�estimation de probabilités cumulées (fonction de répartition et fonction desurvie) au niveau des extrêmes de la distribution. Nous reprenons les raison-nements du paragraphe 1.3.2 en travaillant sur les fréquences (et non plus surle nombre d�observations) et en remplaçant a par �1 (resp. b par +1) pourles intervalles situés dans la partie négative (resp. dans la partie positive) de ladistribution. Les résultats obtenus sont présentés dans le tableau suivant.
42
probabilité probabilité probabilité déviation p-valueà estimer mesurée attendue
P fX < �3:8g 0:00704% 0:00723% �10:36 3:79E� 25P fX < �3:9g 0:00461% 0:00481% �13:41 5:40E� 41P fX < �4:0g 0:00298% 0:00317% �15:14 8:27E� 52P fX < �4:1g 0:00189% 0:00207% �17:83 4:39E� 71P fX < �4:2g 0:00112% 0:00133% �27:03 6:73E� 161P fX � 3:8g 99:99259% 99:99277% �9:75 1:76E� 22P fX � 3:9g 99:99501% 99:99519% �12:20 2:98E� 34P fX � 4:0g 99:99666% 99:99683% �14:50 1:28E� 47P fX � 4:1g 99:99778% 99:99793% �15:91 5:66E� 57P fX � 4:2g 99:99849% 99:99867% �22:60 4:79E� 113
Les déviations mesurées sont signi�cativement plus élevées que celles observéesdans le test de déformation de la densité. Cela suggère que les e¤ets des distor-sions locales observées sur des intervalles d�amplitude faible se cumulent lors del�estimation du poids des queues de distribution dans les régions extrêmes. Onne peut donc pas retenir l�hypothèse d�adéquation gaussienne pour l�échantillongénéré.
L�e¤et Neave avec le Mersenne Twister Tezuka (1991, 1995) observe unphénomène semblable à l�e¤et Neave lorsque la méthode de Box-Muller est com-binée avec un générateur de Tausworthe, un précurseur du Mersenne Twister.On peut donc se demander si l�e¤et Neave se produit aussi lorsque MT19937 estassocié à la méthode Box-Muller. Etant donné la longueur de la période de cegénérateur (4:32� 106001), on ne peut évidemment pas reproduire l�expérienceréalisée avec le générateur Ran0. En e¤et, il n�est pas envisageable d�épuiser lapériode de MT19937 dans un temps raisonnable. Ainsi, l�ordinateur décrit auparagraphe 1.2.5 produit 107 nombres par seconde. Lorsque le soleil disparaîtradans 5 milliards d�années, la machine aura simulé environ 1024 nombres "gaus-siens", ce qui représente une fraction de l�ordre de 10�5977 de la période duMersenne Twister.
Cependant, nous avons pu constater la présence de l�e¤et Neave (parfois atténué)sur di¤érents jeux de 231 � 2 simulations gaussiennes (comme dans le cas del�expérience faite avec Ran0) obtenus en choisissant di¤érentes valeurs de lagraine pour amorcer le générateur MT19937. Les statistiques déterminées sur lestests menés avec le Mersenne Twister étant très similaires à celles présentéeslors de l�étude de l�e¤et Neave avec Ran0, nous avons choisi de ne pas les faire�gurer.
Du rôle des queues de distribution
Les queues de distribution jouent un rôle fondamental dans les applications �-nancières, car elles représentent les scénarios les plus extrêmes, donc les plusrisqués et les plus redoutés par les opérateurs (krachs boursiers). Il est donc
43

fondamental de mettre en oeuvre une méthode numérique qui ne conduise pasà sous-estimer la probabilité d�un scénario catastrophe. Les déviations calcu-lées dans l�étude du paragraphe 1.3.2 sont toutes négatives, ce qui prouve queles probabilités empiriques déterminées à partir de l�échantillon sous-estimentsystématiquement les poids des queues de distribution calculés en évaluant lafonction de répartition (ou la fonction de survie) de la loi normale. En consé-quence, l�algorithme de Box-Muller ne constitue pas la meilleure alternativepour simuler l�aléa de la dynamique des cours de bourse. Dans le paragraphesuivant, nous étudions une méthode plus performante pour échantillonner la loigaussienne à partir d�un générateur aléatoire.
1.3.3 Simulation par inversion de la fonction de réparti-tion
Fonction inverse gaussienne
Soit � la fonction de répartition de la loi normale standard. Elle est dé�nie par :
� (x) = P fG � xg =Z x
�1' (z) dz; x 2 R:
L�application � est clairement bijective (continue et strictement croissante) deR vers ]0; 1[. La fonction inverse gaussienne ��1 étant dé�nie sur ]0; 1[, on peutconstruire une variable aléatoire réelle G à valeurs dans R en posant :
G = ��1 (U) ; U � U (0; 1) :
On véri�e que G suit une loi normale standard, i.e. G admet � pour fonctionde répartition :
8x 2 R; P fG � xg = P���1 (U) � x
= P fU � � (x)g = �(x) :
On en déduit que, pour simuler des réalisations i.i.d. de la loi N (0; 1), il su¢ tde poser :
Gk = ��1 (Uk) ; Uk i.i.d. U (0; 1) : (1.14)
Cette technique est appelée méthode de simulation par inversion de la fonctionde répartition8 . Sa mise en oeuvre suppose que l�on soit capable d�approchernumériquement ��1, car cette fonction n�admet pas d�expression analytique.
Méthode d�inversion de Beasley, Springer (1977) et Moro (1995)
Beasley et Springer (1977) proposent d�approcher ��1 sur l�intervalle [0:5; 1[puis de considérer la symétrie de la loi normale standard, soit
��1 (u) = ���1 (1� u) ; 0 < u < 1; (1.15)
8Notons que la méthode d�inversion de la fonction de répartition peut être utilisée poursimuler n�importe quelle loi de probabilité.
44

pour étendre l�approximation à l�intervalle complémentaire ]0; 0:5[ en conservantla même précision.
Pour 0:5 < u � 0:92, les auteurs modélisent ��1 par une fonction rationnelleen u :
��1 (u) 'P3k=0 ak (u� 1=2)
2k+1
1 +P3k=0 bk (u� 1=2)
2k: (1.16)
Pour 0:92 < u < 1, la queue de distribution droite est modélisée par une fonctionrationnelle de (ln (1� u))1=2.
Moro (1995) propose de remplacer la quadrature de Beasley et Springer auniveau de la queue de distribution par une approximation basée sur un dévelop-pement en série de Chebyshev tronqué :
��1 (u) '8Xk=0
ck [ln (� ln (1� u))]k ; 0:92 � u < 1: (1.17)
Cette modi�cation améliore considérablement la précision de l�algorithme ori-ginal au niveau des queues de distribution. Les coe¢ cients ak, bk et ck sontdonnés ci-dessous :
a0 = 2:50662823884 c0 = 0:3374754822726147a1 = �18:61500062529 c1 = 0:9761690190917186a2 = 41:39119773534 c2 = 0:1607979714918209a3 = �25:44106049637 c3 = 0:0276438810333863
c4 = 0:0038405729373609b0 = �8:47351093090 c5 = 0:0003951896511919b1 = 23:08336743743 c6 = 0:0000321767881768b2 = �21:06224101826 c7 = 0:0000002888167364b3 = 3:13082909833 c8 = 0:0000003960315187
Méthode d�inversion de Acklam (2000)
Acklam (2000) propose d�approcher ��1 sur l�intervalle ]0; 0:5]. La quadratureest étendue à l�intervalle unité ouvert en appliquant la formule (1.15).
Pour 0:02425 < u � 0:5 l�auteur modélise la fonction inverse gaussienne par unefonction rationnelle de q = u� 1=2 et r = q2 :
��1 (u) ' q � a1r5 + a2r
4 + a3r3 + a4r
2 + a5r + a6b1r5 + b2r4 + b3r3 + b4r2 + b5r + 1
:
Pour 0 < u < 0:02425 (queue de distribution gauche), l�approximation est baséesur une fonction rationnelle de q = (�2 lnu)1=2 :
��1 (u) ' c1q5 + c2q
4 + c3q3 + c4q
2 + c5q + c6d1q4 + d2q3 + d3q2 + d4q + 1
:
Les jeux de coe¢ cients ak, bk, ck et dk sont donnés ci-dessous :
45

a1 = �3:969683028665376E+ 01 c1 = �7:784894002430293E� 03a2 = 2:209460984245205E+ 02 c2 = �3:223964580411365E� 01a3 = �2:759285104469687E+ 02 c3 = �2:400758277161838E+ 00a4 = 1:383577518672690E+ 02 c4 = �2:549732539343734E+ 00a5 = �3:066479806614716E+ 01 c5 = 4:374664141464968E+ 00a6 = 2:506628277459239E+ 00 c6 = 2:938163982698783E+ 00
b1 = �5:447609879822406E+ 01 d1 = 7:784695709041462E� 03b2 = 1:615858368580409E+ 02 d2 = 3:224671290700398E� 01b3 = �1:556989798598866E+ 02 d3 = 2:445134137142996E+ 00b4 = 6:680131188771972E+ 01 d4 = 3:754408661907416E+ 00b5 = �1:328068155288572E+ 01
Rapidité et précision des méthodes présentées
Test de rapidité Nous avons évalué9 chacune des deux fonctions sur un en-semble de 109 points, équidistribués dans le segment unité et dé�nis par :
u0 = 0 et 8k � 1; uk = uk�1 + 10�9:
L�algorithme de Acklam a e¤ectué l�ensemble des calculs en 375 secondes etl�algorithme de Moro en 388 secondes. Les deux algorithmes ont donc des tempsd�exécution comparables avec un léger avantage calculatoire pour l�algorithmede Acklam.
Test de précision Supposons que ��1 constitue une approximation précisede la fonction inverse gaussienne, alors � � ��1 est "pratiquement" la fonctionidentité et l�on doit avoir :
e1def= max
k=1;:::;109
(��� � ��1 (uk)� uk��uk
)' 0:
Comme la fonction de répartition gaussienne n�admet pas d�expression ana-lytique, on remplace � par l�excellente approximation de West (2005) et l�onobtient :
eMoro1 ' eAcklam1 = 2:48� 10�15:
En conséquence les deux méthodes sont extrêmement précises et elles donnentdes résultats identiques. Cela con�rme les conclusions de Jäckel (2002, p. 11).
Pour les tests pratiqués dans la suite, nous avons retenu la méthode de Acklamcar elle s�avère (très légèrement) plus rapide que l�algorithme de Moro tout eno¤rant le même degré de précision.
9La machine utilisée est décrite au paragraphe 1.2.5.
46

Atténuation de l�e¤et Neave
La simulation par inversion de la fonction de répartition est une méthode plusnaturelle que la méthode de Box-Muller. Une conséquence de cela est l�atté-nuation considérable des phénomènes pathologiques identi�és au paragrapheprécédent (e¤et Neave). Nous avons reproduit l�expérience du paragraphe 1.3.2en combinant l�inversion de Acklam et le générateur Ran0. Sur la �gure 1.6, on
0,0000
0,0001
0,0001
0,0002
0,0002
0,0003
0,0003
0,0004
0,0004
0,0005
0,0005
4,5 4,4 4,3 4,2 4,1 4,0 3,9 3,8 3,7
distribution empirique distribution théorique
0,0000
0,0001
0,0001
0,0002
0,0002
0,0003
0,0003
0,0004
0,0004
0,0005
3,7 3,8 3,9 4,0 4,1 4,2 4,3 4,4 4,5
distribution empirique distribution théorique
Fig. 1.6 �Queues de distribution (Acklam + Ran0).
remarque que l�histogramme s�ajuste parfaitement avec la distribution théoriquede la loi normale standard au niveau des queues de distribution.
Disparition du biais d�échantillonnage de la densité A�n de con�rmercette observation graphique, nous donnons ci-dessous un tableau d�analyse desfréquences de l�échantillon.
intervalle observé attendu déviation p-value[a; b[ n[a;b[ np
[a;b[d[a;b[ �[a;b[
�3:77 : �3:76 7157 7157 0:00 100:00%�3:76 : �3:75 7432 7432 0:00 100:00%�3:75 : �3:74 7715 7716 �0:01 99:20%�3:74 : �3:73 8010 8010 0:00 100:00%�3:73 : �3:72 8314 8314 0:00 100:00%
3:72 : 3:73 8314 8314 0:00 100:00%3:73 : 3:74 8010 8010 0:00 100:00%3:74 : 3:75 7715 7716 �0:01 99:20%3:75 : 3:76 7432 7432 0:00 100:00%3:76 : 3:77 7157 7157 0:00 100:00%
47

L�hypothèse d�adéquation à la loi gaussienne est largement retenue pour tousles intervalles testés (les p-values sont toutes voisines de 100%), ce qui prouveque le biais d�échantillonnage est à présent négligeable.
Disparition du biais d�échantillonnage des probabilités cumulées Nouscomplétons notre étude en mesurant les biais d�échantillonnage au niveau desprobabilités cumulées dans les extrêmes des queues de distribution. Les résultatsobtenus sont présentés dans le tableau ci-après.
probabilité probabilité probabilité déviation p-valueà estimer mesurée attendue
P fX < �3:8g 0:00723475% 0:00723480% �3:15E� 03 99:75%P fX < �3:9g 0:00480958% 0:00480963% �3:46E� 03 99:72%P fX < �4:0g 0:00316706% 0:00316712% �5:65E� 03 99:55%P fX < �4:1g 0:00206572% 0:00206575% �3:13E� 03 99:75%P fX < �4:2g 0:00133454% 0:00133457% �4:59E� 03 99:63%
P fX � 3:8g 99:99276521% 99:99276520% 6:12E� 04 99:95%P fX � 3:9g 99:99519037% 99:99519037% 3:49E� 04 99:97%P fX � 4:0g 99:99683290% 99:99683288% 1:82E� 03 99:86%P fX � 4:1g 99:99793423% 99:99793425% �1:62E� 03 99:87%P fX � 4:2g 99:99866541% 99:99866543% �1:31E� 03 99:90%
Les p-values calculées pour chaque intervalle testé sont toutes supérieures à99:5% (alors qu�elles sont presque nulles dans le cas de la méthode de Box-Muller), ce qui prouve que l�algorithme de Acklam permet de simuler les queuesde distribution avec une grande précision.
Choix d�une méthode de simulation La méthode d�inversion de la fonc-tion de répartition de Acklam supprime les biais d�échantillonnage observés avecl�algorithme de Box-Muller, ce qui est particulièrement intéressant pour les ap-plications �nancières (cf. paragraphe 1.3.2). Dans la suite, nous simulerons lesvariables gaussiennes scalaires en appliquant cette technique qui ne perturbepas les queues de distribution. Nous allons à présent montrer comment générerdes vecteurs gaussiens.
1.4 Simulation de la loi normale multidimen-sionnelle
Les vecteurs gaussiens permettent de modéliser l�évolution simultanée des nom-breux facteurs de risque qui gouvernent le comportement d�un panier de titres(Korn et Korn 2001, Björk 2004). Nous en présentons les principales propriétésci-dessous.
48

1.4.1 Vecteurs gaussiens : rappels
Dans ce paragraphe, nous adoptons les notations suivantes :� X désigne une variable aléatoire réelle, tandis que X désigne un vecteuraléatoire,
� le symbole " 0 " désigne la transposée d�une matrice ou d�un vecteur.
Dé�nition et premières propriétés
Le concept de vecteur gaussien permet d�étendre de manière consistante la loigaussienne univariée aux dimensions s � 1. On dit qu�un vecteur aléatoireX = (X1; : : : ; Xs)
0 2 Rs, est un vecteur gaussien si et seulement si sa fonc-tion caractéristique est de la forme :
8� 2 Rs; �X (�)def= E
�exp
�i�0X
��= exp
�i�0�� 1
2�0��
�; (1.18)
où � = (�i)1�i�s est un vecteur de Rs et � = (�ij)1�i;j�s est une matricecarrée d�ordre s, symétrique (i.e. � = �0). Pour que (1.18) dé�nisse bien unefonction caractéristique, il faut que j�X (�)j � 1 ce qui implique �0�� � 0 pourtout � 2 Rs. Donc � est nécessairement semi-dé�nie positive. Plus précisément,on peut montrer que � et � sont respectivement le vecteur moyen et la matricede covariance de X (Jacod et Protter 2003) :
�i = E [Xi] ; �ij = Cov [Xi; Xj ] :
La loi d�un vecteur gaussien est donc entièrement déterminée par la connaissancede son vecteur moyen et de sa matrice de covariance. C�est pourquoi on noteX � N (�;�).
Lorsque � est inversible (i.e. symétrique dé�nie positive), on dit que X est unvecteur gaussien non dégénéré et l�on peut montrer que la loi de X admet unedensité par rapport à la mesure de Lebesgue de la forme :
'�;� (x) =1
(2�)s=2det (�)
1=2exp
��12(x� �)0 ��1 (x� �)
�; x 2 Rs:
Inversement lorsque � est singulière (i.e. ker� 6= ;), la mesure image de Xn�admet pas de densité, elle est même étrangère à la mesure de Lebesgue sur Rset X prend ses valeurs dans le sous-espace a¢ ne � + Im (�). On dit alors quela loi de X est dégénérée.
Loi des composantes
Chaque composante d�un vecteur gaussien suit une loi gaussienne univariée. Ene¤et, on remarque que Xk = e0kX où ek est le ki�eme vecteur de la base canonique
49

de Rs. Il vient :
8� 2 R; �Xk(�) = E [exp (i�Xk)] = E [exp (i�e
0kX)]
= �X (�ek) = exp
�i��k �
�2�kk2
�;
ce qui prouve que Xk � N (�k;�kk) pour k = 1; : : : ; s. Dans ces conditions, a�nd�adopter des notations cohérentes avec celles utilisées pour la loi gaussienneunivariée, on pose :
�2kdef= �kk = Var [Xk] ; 1 � k � s:
Notons cependant que la réciproque est fausse : il existe des vecteurs à compo-santes gaussiennes qui ne sont pas des vecteurs gaussiens au sens de la dé�ni-tion précédente. Pour s�en persuader, il su¢ t de considérer le vecteur (X; "X)où X � N (0; 1) et " est une loi de Bernoulli symétrique, indépendante de X,telle que P (" = 1) = P (" = �1) = 1=2. La fonction caractéristique du couples�écrit :
8� = (�1; �2)0 2 R2; �(X;"X) (�) = cosh (�1�2) exp���
21 + �
22
2
�;
ce qui prouve que ce n�est pas un vecteur gaussien. Pourtant on véri�e facilementque "X � N (0; 1), i.e. (X; "X) est bien un vecteur à composantes gaussiennes.
Indépendance dans le cas gaussien
Toute l�information sur la dépendance entre les composantes d�un vecteur gaus-sien est contenue dans la matrice de covariance. Plus précisément on a le résultatsuivant.
Proposition 1.4 Les composantes de X sont mutuellement indépendantes siet seulement si la matrice de variance-covariance est diagonale.
Proof. Si les composantes de � sont indépendantes, alors leurs covariances sontnulles et la matrice � est diagonale. Réciproquement, si � = diag
��21; : : : ; �
2s
�,
un simple calcul permet de véri�er que :
�X (�) =sYi=1
exp
�i�k�k �
�2k�2k
2
�:
La fonction caractéristique de X s�écrit donc comme le produit des fonctionscaractéristiques des Xk, ce qui prouve l�indépendance des composantes.
Lorsque � = 0 et � = Is (matrice identité d�ordre s), les composantes deX sonti.i.d. de loi N (0; 1). On dit que X suit une loi gaussienne multidimensionnellestandard (ou centrée réduite) et l�on noteX � N (0; Is). Il est donc assez simplede simuler des variables Xk i.i.d. de loi N (0; Is), en posant :
50

Xkdef=�X(k�1)s; : : : ; Xks�1
�0; k � 1; (1.19)
où les variables scalaires Xn sont i.i.d. de loi N (0; 1) et obtenues par l�une desméthodes étudiées au paragraphe 1.3.
1.4.2 Simulation d�un vecteur gaussien
Nous étudions dans ce qui suit la simulation d�un vecteur gaussien quelconque.
Stabilité par transformation linéaire
On sait que si G est une variable aléatoire réelle de loi N (0; 1), alors �+ �G �N��; �2
�. Cette propriété, appelée invariance par transformation linéaire, peut
être étendue au cas des vecteurs gaussiens de la manière suivante. Soit � 2 Rs,� une matrice carrée d�ordre s et G � N (0; Is), alors :1. ��0 est symétrique, semi-dé�nie positive,
2. la variable �+ �G suit la loi N (�;��0).En e¤et, il su¢ t de remarquer que :
��+�G (�) = exp�i�0�
��G (�
0�) = exp
�i�0�� 1
2�0��0�
�:
D�après la formule (1.19), la simulation de la loi gaussienne standardN (0; Is) estaisée. En conséquence, la principale di¢ culté rencontrée lors de la simulationd�un vecteur gaussien de loi N (�;�) est de trouver une matrice � telle que� = ��0. Il s�agit là d�un problème d�algèbre linéaire.
Décomposition de Cholesky
Lorsque la loi de X est non dégénérée (i.e. lorsque � est inversible), le théo-rème de Cholesky (cf. Annexe C) assure l�existence d�une unique matrice �,triangulaire inférieure à diagonale strictement positive, telle que � = ��0.
Comme � est triangulaire inférieure, cette identité se traduit par la relationsuivante :
�ij =
jXk=1
�ik�jk; 1 � j � i � s:
Alors, pour tout 1 � j � s on a :
�jj =
�jj �
j�1Xk=1
�2jk
!1=2; (1.20)
�ij =�ij �
Pj�1k=1 �ik�jk�jj
; i > j: (1.21)
51

Nous en déduisons un algorithme itératif pour construire la matrice � colonneaprès colonne.
Algorithme 2 Factorisation de CholeskyDonnées : une matrice �[ ][ ], symétrique dé�nie positive.Résultat : �[ ][ ], triangulaire inférieure, telle que � = ��0.
for j = 1 to s dofor i = j to s do
{calcul de s = �ij �Pj�1k=1 �ik�jk}
s �[i][j]for k = 1 to j � 1 dos s� �[i][k]� �[j][k]
end for
if j = i then�[j][j]
ps {calcul de �jj selon la formule (1.20)}
else�[i][j] s=�[j][j] {calcul de �ij selon la formule (1.21)}
end if
end forend for
La factorisation de Cholesky présente un avantage calculatoire évident, surtoutsi la dimension s est élevée. En e¤et, comme la matrice � est triangulaire in-férieure, la i-ième composante du vecteur est donnée par �i +
Pij=1 ijXj , ce
qui nécessite 2i opérations élémentaires (i additions et i multiplications). Pourconstruire une réalisation du vecteur gaussien, il faut donc réaliser
Psi=1 2i =
s (s+ 1) opérations élémentaires. Le temps de simulation est donc divisé quasi-ment par 2 par rapport au cas où la matrice � serait quelconque (2s2 opérations).
Vecteur gaussien dégénéré
Lorsque la loi deX est dégénérée (i.e. � est "simplement" semi-dé�nie positive),on ne peut plus utiliser l�algorithme de Cholesky et il faut utiliser une autreméthode pour construire une matrice �.
Comme � est symétrique (donc diagonalisable dans une base orthonormée) etsemi-dé�nie positive (donc ses valeurs propres �i sont positives ou nulles), ilexiste une matrice orthonormale A (i.e. AA0 = Is) telle que :
� = A�A0 où � = diag (�1; : : : ; �s) :
On dé�nit alors la matrice � par :
� = A�1=2 où �1=2 = diag��1=21 ; : : : ; �
1=2S
�: (1.22)
52

Par construction, cette matrice est solution du problème posé. Il n�existe pas deméthode théorique systématique pour diagonaliser une matrice, mais on connaîtd�excellents algorithmes permettant d�approcher la matrice � et la matrice Aavec le degré de précision souhaité (Press et al. 2002, p. 459).
Notons que la technique présentée dans ce paragraphe est tout à fait générale. Enparticulier elle s�applique aussi lorsque la matrice � est inversible. Cependant,par souci d�optimisation des temps de calcul, nous recommandons d�utiliser ladécomposition de Cholesky dès que cela est possible. En e¤et, la matrice �donnée par la formule (1.22) ne possède pas de forme particulière, ce qui signi�eque la simulation d�un vecteur gaussien requiert 2s2 opérations (contre s (s+ 1)opérations avec la décomposition de Cholesky).
1.4.3 Mise en oeuvre opérationnelle
Matrice de corrélation
Sachant que la seule forme de dépendance "autorisée" dans le monde des vec-teurs gaussiens est la dépendance linéaire, la totalité de l�information sur ladépendance entre les composantes est contenue dans la matrice de corrélationR de terme général :
�ij = Cor [Xi; Xj ] =Cov [Xi; Xj ]pVar [Xi] Var [Xj ]
=�ij�i�j
: (1.23)
D�une part, on peut montrer que :
�1 � �ij � 1 pour i 6= j et �ii = 1:
D�autre part, la dé�nition (1.23) implique que la matrice de covariance s�écrit :
� = �R� avec � def= diag (�1; : : : ; �s) : (1.24)
La matrice de corrélation hérite donc de l�ensemble des propriétés algébriques dela matrice de covariance : elle est symétrique, semi-dé�nie positive et inversiblelorsque � est inversible.
La décomposition (1.24) montre qu�il est équivalent de se donner une matricede covariance � ou de se donner une matrice d�écarts-types � et une matrice decorrélation R, qui modélisent respectivement l�incertitude et la structure de dé-pendance du vecteur gaussien. Cela permet de contrôler séparément les "risquesindividuels" et la dépendance des composantes du vecteur. La loi gaussiennemultidimensionnelle est donc entièrement déterminée par la donnée de � 2 Rs(vecteur moyen), de � 2 Rs (vecteur d�incertitude) et d�une matrice de corréla-tion R (matrice de dépendance).
53

Retour sur la simulation d�un vecteur gaussien
Pour simuler un vecteur gaussien dé�ni par le triplet (�; �;R), il su¢ t d�adap-ter légèrement les techniques présentées au paragraphe précédent. Soit L une"racine carrée" de R (i.e. R = LL0). Comme � est une matrice diagonale, on a�0 = �, puis :
� = �R� = � (LL0)� = (�L) (�L)0:
En conséquence, on a : � = �L et �+ �G = �+ � (LG) où G � N (0; Is).
En pratique, on commence par trouver L telle que R = LL0 en appliquant laméthode de Cholesky (R dé�nie positive) ou la méthode de diagonalisation (Rsemi-dé�nie positive). Puis, autant de fois que nécessaire, on répète les étapessuivantes :
1. Simuler un vecteur standard à composantes indépendantes :G � N (0; Is).2. Corréler les composantes du vecteur simulé : X(R) = LG,
3. Appliquer la matrice de risques individuels : X(�) = �X(R).
4. Ajuster sur la moyenne souhaitée : X = �+X(�).
Cette méthode, qui consiste à corréler les variables, avant de les ajuster surleur niveau de risque individuel, peut être mise en oeuvre dans la plupart dessimulations �nancières.
Simulation d�un vecteur gaussien en dimension 2
Lorsque s = 2, la dépendance entre les composantes du vecteur est déterminéepar la donnée d�un unique réel �1 � � � 1. Dans ce cas, la matrice de corrélationR et sa décomposée de Cholesky L s�écrivent :
R =
�1 �� 1
�; L =
�1 0
�p1� �2
�:
Pour simuler un vecteur gaussien standard X = (X1; X2)0 à composantes cor-
rélées, il su¢ t donc de poser :
X1 = G; X2 = �G+p1� �2G?; (1.25)
où G et G? sont deux variables indépendantes de loi N (0; 1).
Nous allons à présent montrer comment le coe¢ cient de corrélation in�uencela distribution jointe d�un couple de variables gaussiennes. D�abord, nous choi-sissons trois valeurs de �, qui correspondent à des con�gurations spéci�ques :� = 0 (indépendance), � = 0:75 (corrélation positive) et � = �0:90 (forte corré-lation négative aussi appelée anticorrélation). Ensuite, nous simulons n = 5000réalisations du couple
�Gk; G
?k
�en posant :
Gk = ��1 (U2k�1) ; G?k = �
�1 (U2k) ;
54

où U2k�1 et U2k sont les sorties successives du générateur MT19937 et ��1 dé-signe la fonction inverse gaussienne de Acklam. En�n, pour chaque valeur duparamètre �, nous construisons des copies indépendantes du vecteur X en ap-pliquant la formule (1.25) à l�échantillon précédent :
Xk;1 = Gk; Xk;2 = �Gk +p1� �2G?k ; k � 1:
Le fait d�utiliser les mêmes points�Gk; G
?k
�pour produire les trois jeux de
données permet d�isoler l�e¤et de la corrélation sur le comportement du nuagede points. Les résultats obtenus sont représentés dans les graphiques suivants,ce qui nous permet d�illustrer la manière dont la corrélation linéaire contrôle lecomportement d�un jeu de variables gaussiennes.
La �gure de gauche représente le nuage de points obtenu lorsque � = 0, c�est-à-dire lorsque les composantes du vecteur sont indépendantes. La �gure du milieu(cas � > 0) et la �gure de droite (cas � < 0) montrent comment le nuage sedéforme lorsque l�on introduit une corrélation non nulle. Dans le cas � = 0 (�-gure de gauche), le nuage de points est isotrope, centré sur l�origine. La densitédes points décroît au fur et à mesure que l�on s�éloigne du centre du repère, cequi re�ète le caractère gaussien centré des composantes. Dans le cas � = 0:75(composantes corrélées positivement), les deux variables évoluent statistique-ment dans le même sens et le nuage de points se concentre sur l�axe d�équationy = 0:75x. Dans le cas � = �0:90 (composantes corrélées négativement), les deuxvariables évoluent clairement dans des sens contraires et le nuage de points estconcentré sur la droite d�équation y = �0:90x. D�une manière générale, lorsquej�j �! 1 (relation linéaire parfaite), la formule (1.25) nous donne l�approxima-tion X2 ' �G = �X1 : le nuage de points se contracte pour former un agrégattrès dense qui �nit par se confondre localement avec la droite d�équation y = �x.C�est ce phénomène que nous avons observé en comparant la �gure du milieuavec la �gure de droite.
Nous possédons maintenant tous les éléments nécessaires pour présenter la mé-thode de Monte Carlo et la mettre en oeuvre.
55

1.5 Méthode de Monte Carlo
Soit (; T ; P ) un espace probabilisé, X une variable aléatoire à valeurs dans Rsmuni de la tribu borélienne BRs et h : Rs ! R une application mesurable. Leproblème est d�évaluer numériquement l�intégrale :
Idef= E [h (X)] =
Z
h (X) dP; (1.26)
lorsque h (X) est P -intégrable, i.e. h (X) 2 L1 (; T ; P ).
1.5.1 Calcul d�espérance par simulation
La méthode de Monte Carlo consiste à générer N copies indépendantes de X(notées X1; : : : ; XN ) puis à former l�approximation :
I 'N!1
IN ; INdef=
1
N
NXn=1
h(Xn): (1.27)
Un simple calcul d�espérance montre que IN est un estimateur sans biais deI et la loi forte des grands nombres garantit que cet estimateur est fortementconsistant (i.e. IN converge presque sûrement vers I lorsque N !1).
Construction d�un intervalle de con�ance pour le résultat
Majoration probabiliste de l�erreur d�intégration Dès que h (X) 2 L2 (; T ; P ),le théorème de la limite centrale s�applique :
pN�IN � I
�loi!
N!1N�0; �2
�où �2 def= Var [h (X)] :
On peut alors construire un intervalle de con�ance au niveau 1� � :
P
����IN � I��� < q1��=2�pN
�=
N!11� �; (1.28)
où q1��=2 désigne le quantile d�ordre 1��=2 de la loi normale standard. L�erreurd�intégration est donc majorée par la quantité :
"N = q1��=2�pN
(1.29)
avec une probabilité de 1��. Il subsiste un risque � que l�erreur soit supérieureau seuil "N .
Estimation de l�erreur d�intégration Dans la plupart des cas pratiques, �2
est inconnue. On calcule alors la variance empirique modi�ée de l�échantillon :
�2N =1
N � 1
NXn=1
�h(Xn)� IN
�2: (1.30)
56

Cette quantité est un estimateur fortement consistant de la variance de h (X)et, dès que N est su¢ samment grand, on estime l�erreur d�intégration (1.29) enremplaçant � par �N :
"N = q1��=2�NpN: (1.31)
Cette quantité permet de mesurer la qualité de l�approximation de I.
Avantages et inconvénients de l�approche Monte Carlo
La méthode de Monte Carlo possède trois avantages : (i) elle est très facile àimplémenter pour peu que l�on sache simuler la loi de X, (ii) elle permet d�inté-grer des fonctions irrégulières et de construire une estimation réaliste de l�erreurcommise, (iii) elle converge en O
�N�1=2� indépendamment de la dimension s
du problème, ce qui constitue un atout incontestable par rapport aux quadra-tures classiques qui convergent en O
�N�2=s� et deviennent impraticables dès
que s � 5.
Toutefois, cette approche présente deux défauts majeurs : (i) la majoration del�erreur est probabiliste, de sorte qu�il subsiste toujours une incertitude (faible)quant à la valeur exacte de l�intégrale et (ii) la vitesse de convergence en N�1=2
s�avère "relativement lente". En e¤et, si l�on souhaite une précision de l�ordre de10�2, on doit choisir N ' 104 et pour espérer réduire l�erreur d�un facteur 10, ilfaut multiplier la taille de l�échantillon par 100, ce qui induit un accroissementdes temps de calcul signi�catif, inacceptable pour nos applications �nancières.
1.5.2 Techniques de réduction de variance
E¢ cacité d�un estimateur
Supposons que l�on dispose de deux fonctions h et g telles que E [h (X)] =E [g (X)] = I. Nous allons répondre à la question suivante : est-il préférabled�utiliser des copies de h (X) (méthode H) ou des copies de g (X) (méthode G)pour construire l�estimateur Monte Carlo de I ? Intuitivement, la méthode Gsera préférée à la méthode H si G conduit systématiquement à une erreur plusfaible que H dans le temps T (�xé arbitrairement).
Soit ch le temps de calcul pour générer une seule copie de h (X), alors dansl�intervalle de temps T , on peut simuler Nh (T ) = T=ch exemplaires de h (X).De la même manière, Ng (T ) = T=cg.
On dit que G est plus e¢ cace que H si :
8T > 0; "Ng(T ) < "Nh(T ); (1.32)
où "Ng(T ) et "Nh(T ) sont obtenus en remplaçant N par Nh (T ) ou Ng (T ) dansla formule (1.29) :
"Nh(T ) =q1��=2p
T�hpch; "Ng(T ) =
q1��=2pT
�gpcg:
57

Alors, le critère d�e¢ cacité (1.32) est équivalent à :
cg�2g < ch�
2h: (1.33)
La quantité ch�2h est donc une mesure de la qualité de la méthode H. La relation(1.33) montre que l�on ne peut pas conclure que la méthode G est meilleure que laméthodeH sur le simple critère �2g < �2h, car on doit aussi tenir compte du tempsde calcul nécessaire pour simuler une copie de chaque variable. Cependant, dansla majorité des cas où deux méthodes d�estimation H et G seront envisagées,on aura cg ' ch et �2g << �2h ou bien �2g >> �2h. Il est clair qu�il faudramettre en oeuvre l�estimateur de faible variance pour améliorer la convergencede l�algorithme.
L�objectif des méthodes dites de réduction de variance (Glasserman 2004) estprécisément de déterminer un autre estimateur de I, plus e¢ cace que l�esti-mateur naturel au sens du critère (1.33). Si l�on considère que l�accroissementdu temps de calcul induit par le choix d�un autre estimateur est marginal, leproblème revient à déterminer une fonction g telle que :
E [g (X)] = I et Var [g (X)] < Var [h (X)] : (1.34)
La plupart des techniques de réduction de variance sont étroitement liées àl�expression analytique de h et à la loi de X, de sorte que chaque intégrale doitêtre traitée comme un cas particulier et il n�est pas possible d�envisager uneapproche universelle pour réduire la variance de façon systématique.
Nous présentons la méthode des variables antithétiques et la méthode adap-tative, car elles reposent sur des hypothèses su¢ samment générales pour êtremises en oeuvre de manière quasi-systématique, en particulier lorsque le vecteurX est à composantes gaussiennes.
Méthode des variables antithétiques
Description de la méthode Cette technique, due à Hammersley et Morton(1956), consiste à exploiter les symétries de la loi de X pour réduire la variance.L�idée est de trouver une transformation � : Rs ! Rs telle que : (i) � (X) aitmême loi que X et (ii) h (X) et h (� (X)) soient négativement corrélées, i.e.Cor [h (X) ; h (� (X))] < 0 (on parle de variables antithétiques).
Dans ces conditions, l�estimateur Monte Carlo basé sur l�application g : Rs ! Rdé�nie par :
g (x) =h (x) + h (� (x))
2; x 2 Rs;
est un estimateur sans biais et fortement consistant de l�intégrale (1.26) et savariance est plus faible que celle de l�estimateur naturel (1.27). En e¤et, commeX � � (X) on a :
E [g (X)] =1
2E [h (X) + h (� (X))] = I
58

et
�2g =1 + Cor [h (X) ; h (� (X))]
2�2h: (1.35)
Etant donné que la corrélation est inférieure à 1, on a �2g � �2h, de sorte quela variance de l�estimateur antithétique sera toujours inférieure à la variance del�estimateur naturel. Comme Cor [h (X) ; h (� (X))] < 0, on a �2g < �2h=2. Dansce cas, le gain sur la variance est au moins égal à 50%.
Variables antithétiques dans le cas gaussien Si les composantes de Xsont des variables gaussiennes centrées, alors �X � X et l�on peut poser � (X) =�X. Si de plus h est une fonction monotone en chacun de ses arguments, alorsh (�X) est décroissante lorsque h (X) est croissante et inversement. Les deuxvariables �uctuent dans des sens opposés et elles forment une paire antithétique(Glasserman 2004, p. 207). Pour une généralisation de la méthode des variablesantithétiques à des lois non gaussiennes, le lecteur pourra consulter Fishman etHuang (1983).
Méthode de Monte Carlo adaptative
On suppose que X est un vecteur centré. Sous cette hypothèse, les variablesaléatoires de la forme g (�;X) = h (X)�h�;Xi avec � 2 Rs sont des estimateurssans biais de I. La notation h�; �i désigne le produit scalaire euclidien sur Rs.
Un problème d�optimisation Parmi les candidats de la forme précédente,l�idée est de retenir celui qui minimise la variance de g (�;X). On doit doncdéterminer :
�� = argmin fVar [g (�;X)] : � 2 Rsg (1.36)
en espérant que Var [g (��; X)] < �2h. Si tel est le cas, il devient intéressantd�intégrer g (��; X) plutôt que h (X).
On note X1; : : : ; Xs (resp. �1; : : : ; �s) les composantes de X (resp. de �) etl�on pose H (�) = Var [g (�;X)]. La condition du premier ordre du problème deminimisation (1.36) s�écrit :
@H
@�i= 2 (�i � E [Xih (X)]) = 0; i = 1; : : : ; s:
Alors, les coe¢ cients du vecteur �� sont donnés par :
��i = E [Xih (X)] ; i = 1; : : : ; s:
Les ��i s�exprimant sous la forme d�une espérance, ils peuvent être approchéspar la méthode de Monte Carlo classique : si Xn = (X1;n; : : : ; Xs;n)
0 est unesuite de variables i.i.d. selon la loi de X, alors :
��i;N =1
N
NXn=1
Xi;nh (Xn) (1.37)
est un estimateur sans biais et fortement consistant de ��i .
59

Construction de l�estimateur adaptatif La mise en oeuvre naturelle de laméthode adaptative consiste à lancer deux simulations Monte Carlo : (i) la pre-mière simulation permet d�approcher le vecteur �� par ��N =
���1;N ; : : : ; �
�s;N
�0,
(ii) la seconde simulation consiste à former l�approximation I ' 1N
PNn=1 g (�
�N ; Xn).
Cela n�est pas envisageable dans la mesure où l�on souhaite conserver des tempsde calcul raisonnables.
Bouchard (2006) propose de contourner ce problème, en estimant simultanémentl�intégrale et le vecteur optimal ��. Pour cela, il considère l�estimateur adaptatifdé�ni par :
IADNdef=
1
N
NXn=1
g���n�1; Xn
�; (1.38)
où l�on a pris la convention ��0 = 0. L�idée est d�utiliser le vecteur optimal obtenuà l�étape n � 1 (i.e. ��n�1) pour simuler le terme
��n�1; Xn
�à l�étape n puis
d�estimer une nouvelle approximation ��n qui servira aux calculs de l�étape n+1et ainsi de suite. Cette approche est adaptative, dans le sens où les paramètresde l�estimateur sont modi�és d�une étape à l�autre en fonction des simulations.Notons que la suite de terme général g
���n�1; Xn
�n�est plus i.i.d. car ��n�1
dépend de toutes les simulations précédentes. On ne peut donc plus appliquerdirectement la loi forte des grands nombres pour justi�er la convergence del�estimateur (1.38) et le théorème de la limite centrale pour mesurer l�erreurd�intégration.
Justi�cation de la convergence Lorsque h est au plus à croissance expo-nentielle, Arouna (2004) démontre le résultat suivant.
Proposition 1.5 La suite de terme général IADN est un estimateur sans biaiset fortement consistant de I. De plus, on a un résultat équivalent au théorèmede la limite centrale :
pN�IADN � I
�loi!
N!1N (0;Var [g (��; X)]) :
En�n, la "variance empirique" dé�nie par
��ADN
�2 def=
1
N � 1
NXn=1
�g���n�1; Xn
�� IADN
�2(1.39)
est un estimateur fortement consistant de Var [g (!�;X)].
Cette proposition montre que l�on peut construire un intervalle de con�ancepour I comme dans la méthode de Monte Carlo classique et procéder ainsi àune analyse pertinente de l�erreur d�estimation.
60

1.6 Evaluation d�options par simulation
Dans cette dernière partie nous appliquons les outils de simulation présentésdans les sections précédentes pour évaluer une option exotique portant sur latrajectoire d�un sous-jacent de type action ou indice.
1.6.1 Présentation du problème
L�approche risque-neutre
On se place dans le cadre d�analyse de Black et Scholes (1973). Le sous-jacentne détache pas de dividende et sa dynamique dans l�univers risque-neutre estdonnée par :
St = S0 exp
��r � �2
2
�t+ �Wt
�; t � 0; (1.40)
où S0 (le cours de l�actif observé à l�instant 0), r (le taux sans risque de l�éco-nomie) et � (la volatilité de l�actif) sont des constantes positives. fWt : t � 0gest un mouvement Brownien standard sous la mesure risque-neutre.
On considère le problème de l�évaluation d�un call européen de type asiatiquegéométrique :
C = E�e�rT �T
�où �T = max
��ST �K; 0
�: (1.41)
T et K désignent respectivement la date d�expiration et le prix d�exercice del�option, �ST = (
Qmk=1 Stk)
1=m est la moyenne géométrique des cours du sous-jacent aux dates d�observation 0 � t1 < � � � < tm � T . Notre objectif estd�estimer C en appliquant les méthodes de simulation présentées dans ce travail.
Formule analytique pour l�option asiatique géométrique
Lorsque le sous-jacent suit une loi lognormale (ce qui est le cas dans le mo-dèle retenu), le prix d�une option asiatique géométrique peut être déterminé demanière analytique (Bruno 1991) :
C = e�rT�S0e
a+b2=2�
�a� lnK
b+ b
��K�
�a� lnK
b
��; (1.42)
où
a =
�r � �2
2
� mXk=1
�1� k � 1
m
�hk; b = �
vuut mXi=1
�1� k � 1
m
�2hk:
Les termes hk sont dé�nis par hk = tk�tk�1. Etant donné que nous connaissonsle prix de l�option sous une forme explicite, nous pouvons quanti�er l�erreurd�estimation et ainsi comparer les performances des méthodes proposées.
61

1.6.2 Simulation du sous-jacent
Simulation incrémentale
A partir de la formule (1.40) on obtient très facilement la relation suivante :
Stk = Stk�1 exp
��r � �2
2
�(tk � tk�1) + �
�Wtk �Wtk�1
��; k = 1; : : : ;m:
(1.43)On rappelle que les incréments du mouvement Brownien sont mutuellementindépendants et queWtk�Wtk�1 � N (0;
ptk � tk�1). On peut donc les simuler
en posantWtk �Wtk�1 =
ptk � tk�1Gk; k = 1; : : : ;m; (1.44)
où G1; : : : ; Gm sont i.i.d. de loi N (0; 1).
En injectant la formule (1.44) dans la relation (1.43), on obtient une procédurerécursive pour simuler le cours du sous-jacent aux dates t1; : : : ; tm :
~S0 = S0; ~Sk = ~Sk�1 exp
��r � �2
2
�hk + �
phkGk
�; (1.45)
où hk = tk � tk�1. Ce schéma de simulation est exact dans la mesure où le
m-uplet�~S1; : : : ; ~Sm
�suit la même loi de probabilité que (St1 ; : : : ; Stm). L�es-
timateur Monte Carlo naturel est simplement dé�ni comme le payo¤ actualisé :
XMC = e�rT �T ( ~S1; : : : ; ~Sm):
Simulation antithétique
Pour obtenir une trajectoire antithétique, on remplace Gk par �Gk dans laformule (1.45) :
~S�0 = S0; ~S�k =~S�k�1 exp
��r � �2
2
�hk � �
phkGk
�: (1.46)
Il est donc facile d�obtenir une trajectoire antithétique du sous-jacent en réuti-lisant les points déjà simulés. L�estimateur Monte Carlo antithétique s�écrit
XMC�AV = e�rT �T (
~S1; : : : ; ~Sm) + �T ( ~S�1 ; : : : ;
~S�m)
2=XMC +XAV
2;
où XAVdef= e�rT �T ( ~S
�1 ; : : : ;
~S�m) désigne le payo¤ actualisé obtenu à partir dela trajectoire antithétique.
62

Simulation adaptative
L�estimateur Monte Carlo adaptatif est de la forme suivante :
XMC�AD = e�rT �T ( ~S1; : : : ; ~Sm)�
mXk=1
��k�1Gk = XMC �XAD;
où XADdef=Pmk=1 �
�k�1Gk représente le terme de correction adaptative. Les
poids optimaux ��k�1 est réestimé à chaque itération selon le processus décritau paragraphe 1.5.2.
1.6.3 Tests comparatifs
Mise en oeuvre des tests
Les paramètres retenus pour les applications numériques sont les suivants : r =4%, � = 20%, T = 10 et S0 = K = 100. Les dates t1; : : : ; tm sont dé�niespar tk = kT=m avec m = 120, ce qui correspond à une fréquence d�observationmensuelle. La formule analytique (1.42) nous donne C ' 17:8958.
Nous avons mis en oeuvre la méthode de Monte Carlo classique (MC), la mé-thode antithétique (MC-AV) et la méthode adaptative (MC-AD) pour les va-leurs de N suivantes : 5000n, n = 1; : : : ; 50. Les variables gaussiennes ont étésimulées en appliquant la méthode d�inversion de Acklam aux sorties du généra-teur Mersenne Twister. La �gure 1.7 présente deux graphes de convergence desestimateurs obtenus pour deux choix di¤érents de l�état initial. Une simple com-
16,80
17,00
17,20
17,40
17,60
17,80
18,00
18,20
0 25 50 75 100 125 150 175 200 225 250
N (x 103)
prix
estim
é
prix th. MC MCAV MCAD
17,70
17,80
17,90
18,00
18,10
18,20
18,30
18,40
18,50
18,60
18,70
0 25 50 75 100 125 150 175 200 225 250
N (x 103)
prix
estim
é
prix th. MC MCAV MCAD
Fig. 1.7 �Diagrammes de convergence des estimateurs vers le prix théoriqueC ' 17:8958. Les deux �gures ont été construites à partir de deux grainesdi¤érentes.
paraison de la �gure de gauche et de la �gure de droite montre que deux graines
63

distinctes peuvent conduire à des courbes d�approximation très di¤érentes (lescourbes de gauche présentent une tendance croissante, tandis que les courbesde droite ont une tendance globalement décroissante). Par ailleurs, sur la �gurede gauche, les estimateurs MC-AV et MC-AD convergent vers le prix cherchéau bout de 70000 itérations environ, tandis que la convergence de ces mêmesestimateurs a lieu au bout de 160000 simulations sur la �gure de droite. Celamontre que la vitesse de convergence observée dépend fortement de l�amorce dugénérateur. En pratique, il existe deux solutions équivalentes pour s�a¤ranchirdu "risque d�amorce" : (i) choisir une seule graine mais augmenter le nombred�itérations ou (ii) lancer di¤érents jeux de simulations à partir de graines dis-tinctes10 et prendre la moyenne des résultats obtenus comme approximation dela valeur cherchée.
Remarque 1.6.1 Dans les deux exemples présentés, l�estimateur naturel (MC)converge plus lentement vers la solution du problème que les deux autres esti-mateurs. Soulignons également que les courbes de convergence des estimateursMC-AV et MC-AD ont la même forme, quel que soit l�état initial choisi. Cephénomène s�explique par le fait que ces méthodes d�estimation reposent toutesdeux sur l�utilisation d�une variable auxiliaire anticorrélée avec l�estimateur na-turel (voir paragraphe suivant).
Explication de la réduction de variance par la corrélation entre lesestimateurs
En utilisant les di¤érentes réalisations des variables XMC, XAV et XAD obtenueslors des simulations qui ont permis de générer le graphique de droite, nous avonsestimé les coe¢ cients de corrélation empiriques suivants :
�MC�AV = Cor [XMC; XAV] = �0:5026;�MC�AD = Cor [XMC; XAD] = 0:8634:
En appliquant la formule (1.35) on obtient
�2MC�AV =1 + �MC�AV
2�2MC ' 0; 249 �2MC ' �2MC=4;
où �2MC désigne la variance de l�estimateur naturel XMC. La méthode antithé-tique doit donc diviser la variance par 4 environ.
De même en considérant que les estimateurs XMC et XAD ont des variancescomparables (i.e. �2MC ' �2AD), on peut écrire :
�2MC�AD = �2MC + �2AD � 2 �MC �AD �MC�AD
' 2 �2MC�1� �MC�AD
�' 0; 273 �2MC ' �2MC=4:
10Pour une discussion sur le choix de la graine dans les applications scienti�ques, le lecteurpourra consulter l�article de (Marsaglia 2003).
64

Ce second résultat montre que l�estimateur adaptatif doit réduire la varianced�un facteur voisin de 4 (dans l�exemple choisi). Nous con�rmons cette analysepréliminaire en étudiant le comportement des intervalles de con�ance, dans leparagraphe suivant.
E¤et de la réduction de variance sur la précision asymptotique
On désigne par CN et �2N le prix estimé et la variance empirique de l�estimateur
au bout de N itérations. Alors, l�intervalle de con�ance pour le prix au seuil de95% est dé�ni par :
IN =
�CN � 1:96�
�NpN; CN + 1:96�
�NpN
�:
Comme nous l�avons exposé au paragraphe 1.5.1, le prix théorique appartientà cet intervalle avec une probabilité de 95% et l�amplitude de l�intervalle decon�ance, i.e. l�incertitude autour du prix cherché, diminue proportionnellementà 1=pN . La �gure 1.8 illustre ce phénomène pour les trois estimateurs11 .
17,00
17,25
17,50
17,75
18,00
18,25
18,50
18,75
19,00
19,25
19,50
0 25 50 75 100 125 150 175 200 225 250
N (x 103 )
prix
est
imé
& in
terv
alle
de c
onfia
nce
pr ix th. MC
17,00
17,25
17,50
17,75
18,00
18,25
18,50
18,75
19,00
19,25
19,50
0 25 50 75 100 125 150 175 200 225 250
N (x 103 )
prix
est
imé
& in
terv
alle
de c
onfia
nce
pr ix th. MCAV
17,00
17,25
17,50
17,75
18,00
18,25
18,50
18,75
19,00
19,25
19,50
0 25 50 75 100 125 150 175 200 225 250
N (x 103 )
prix
est
imé
& in
terv
alle
de c
onfia
nce
prix th. MCAD
Fig. 1.8 �Réduction de l�amplitude de l�intervalle de con�ance (donc de l�in-certitude) sur le prix cherché pour l�estimateur naturel (à gauche), l�estimateurantithétique (au milieu) et l�estimateur adaptatif (à droite).
Comme attendu, lorsque N augmente, les bornes de l�intervalle de con�ancede chacun des estimateurs se resserrent. Les e¤ets de la réduction de variancesont particulièrement nets sur les deux derniers graphiques où les intervallesde con�ance sont environ moitié moins larges que sur le premier graphique quireprésente l�estimateur naturel MC. A�n d�appréhender l�impact des méthodesde réduction de variance proposées, nous donnons ci-dessous les prix estimés,
11Les courbes de convergence utilisées sont celles du graphique de droite dans la �gure 1.7.
65
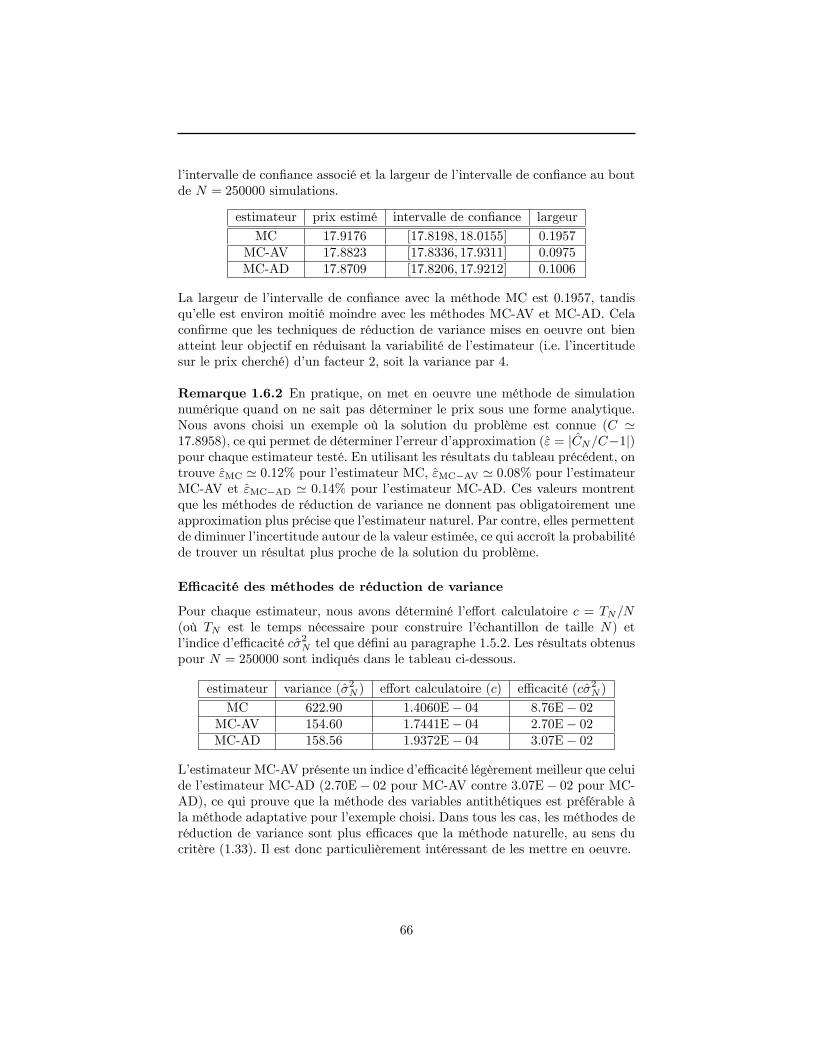
l�intervalle de con�ance associé et la largeur de l�intervalle de con�ance au boutde N = 250000 simulations.
estimateur prix estimé intervalle de con�ance largeur
MC 17:9176 [17:8198; 18:0155] 0:1957MC-AV 17:8823 [17:8336; 17:9311] 0:0975MC-AD 17:8709 [17:8206; 17:9212] 0:1006
La largeur de l�intervalle de con�ance avec la méthode MC est 0:1957, tandisqu�elle est environ moitié moindre avec les méthodes MC-AV et MC-AD. Celacon�rme que les techniques de réduction de variance mises en oeuvre ont bienatteint leur objectif en réduisant la variabilité de l�estimateur (i.e. l�incertitudesur le prix cherché) d�un facteur 2, soit la variance par 4.
Remarque 1.6.2 En pratique, on met en oeuvre une méthode de simulationnumérique quand on ne sait pas déterminer le prix sous une forme analytique.Nous avons choisi un exemple où la solution du problème est connue (C '17:8958), ce qui permet de déterminer l�erreur d�approximation (" = jCN=C�1j)pour chaque estimateur testé. En utilisant les résultats du tableau précédent, ontrouve "MC ' 0:12% pour l�estimateur MC, "MC�AV ' 0:08% pour l�estimateurMC-AV et "MC�AD ' 0:14% pour l�estimateur MC-AD. Ces valeurs montrentque les méthodes de réduction de variance ne donnent pas obligatoirement uneapproximation plus précise que l�estimateur naturel. Par contre, elles permettentde diminuer l�incertitude autour de la valeur estimée, ce qui accroît la probabilitéde trouver un résultat plus proche de la solution du problème.
E¢ cacité des méthodes de réduction de variance
Pour chaque estimateur, nous avons déterminé l�e¤ort calculatoire c = TN=N(où TN est le temps nécessaire pour construire l�échantillon de taille N) etl�indice d�e¢ cacité c�2N tel que dé�ni au paragraphe 1.5.2. Les résultats obtenuspour N = 250000 sont indiqués dans le tableau ci-dessous.
estimateur variance (�2N ) e¤ort calculatoire (c) e¢ cacité (c�2N )
MC 622:90 1:4060E� 04 8:76E� 02MC-AV 154:60 1:7441E� 04 2:70E� 02MC-AD 158:56 1:9372E� 04 3:07E� 02
L�estimateur MC-AV présente un indice d�e¢ cacité légèrement meilleur que celuide l�estimateur MC-AD (2:70E� 02 pour MC-AV contre 3:07E� 02 pour MC-AD), ce qui prouve que la méthode des variables antithétiques est préférable àla méthode adaptative pour l�exemple choisi. Dans tous les cas, les méthodes deréduction de variance sont plus e¢ caces que la méthode naturelle, au sens ducritère (1.33). Il est donc particulièrement intéressant de les mettre en oeuvre.
66

1.7 Conclusion
Les profondes modi�cations de l�environnement �nancier au cours des dernièresannées (explosion des marchés de produits dérivés de toutes natures, entrée envigueur de nouvelles normes comptables et réglementaires) ont fait des méthodesde simulation numérique un outil incontournable pour la gestion des risques.Dans ce contexte, nous nous sommes attachés à montrer comment élaborer unesolution complète pour évaluer des produits dérivés par la méthode de MonteCarlo à partir des solutions théoriques proposées dans la littérature.
Dans la seconde section, nous avons envisagé le problème de la simulation duhasard par des moyens déterministes en comparant trois familles de générateurspseudo-aléatoires uniformes, les générateurs linéaires congruentiels, les géné-rateurs linéaires combinés et les générateurs Mersenne Twister, plus récentset conçus pour exploiter l�architecture binaire des ordinateurs. Notre étude acon�rmé que cette nouvelle famille de générateurs présentait de solides atoutspour la simulation numérique intensive : le Mersenne Twister MT19937 possèdeune période in�nie (à l�échelle informatique), il produit des séquences bien équi-distribuées que l�on obtient rapidement sur les machines standards.
Dans la troisième section, nous avons étudié les méthodes de simulation de la loigaussienne unidimensionnelle. Nous avons montré comment les transformationsnon-linéaires d�un jeu de variables uniformes (Box-Muller) pouvaient conduireà des e¤ets de bord indésirables (e¤et Neave). C�est pourquoi nous avons choiside simuler la loi normale standard en inversant la fonction de répartition. Celanécessite d�approcher la fonction inverse gaussienne par un algorithme robuste.Nous avons présenté la méthode proposée par Beasley et Springer (1977) et Moro(1995), puis nous l�avons comparée avec la méthode proposée par Acklam (2000).Les deux approches atténuent considérablement les artefacts de simulations etelles se sont avérées aussi précises l�une que l�autre. Pour une mise en oeuvreopérationnelle, c�est l�inversion de Acklam que nous avons retenue, car elle s�estmontrée légèrement plus rapide que l�inversion de Beasley et Springer et Moro.
La quatrième section est consacrée à l�étude de la loi normale multidimension-nelle. Nous avons montré comment utiliser les algorithmes de simulation de laloi normale univariée pour simuler un vecteur gaussien quelconque. L�élémentfondamental lors de la simulation d�un vecteur gaussien consiste à déterminerune racine carrée de la matrice de covariance. Pour e¤ectuer cette tâche, l�al-gorithme de Cholesky s�avère particulièrement e¢ cace. En e¤et, il construitune matrice triangulaire et nous avons démontré que cela permettait de réduired�un facteur 2 le nombre de calculs nécessaires pour générer les composantes duvecteur gaussien considéré.
Dans la cinquième section, nous avons présenté la méthode de Monte Carlo qui,en raison de sa simplicité et parce qu�elle nécessite des calculs intensifs et répé-titifs, se prête particulièrement bien à une implémentation informatique. Nous
67

avons par ailleurs étudié la technique des variables antithétiques et la techniqueadaptative. Ces deux méthodes de réduction de variance reposent sur des hypo-thèses très générales et peuvent être mises en oeuvre de manière systématique.Cela est un atout considérable lorsqu�on envisage d�évaluer des produits dérivésaux payo¤s très di¤érents, car il n�est pas nécessaire de modi�er l�algorithme desimulation pour l�adapter aux caractéristiques de chaque produit.
L�application �nancière de la section 6 a permis de mettre en oeuvre les di¤érentsalgorithmes étudiés dans ce travail pour évaluer une option exotique en simulantl�évolution des cours boursiers dans le cadre du modèle de Black et Scholes.Les tests réalisés ont montré comment les méthodes de réduction de variancepermettent (i) de contrôler l�incertitude sur l�erreur commise, (ii) d�accélérerla convergence de l�algorithme vers la valeur cherchée. Soulignons en�n que laméthode adaptative, qui permet d�ajuster les caractéristiques de l�estimateur enfonction des simulations réalisées, est une technique avantageuse. En e¤et, ellerepose sur des hypothèses moins contraignantes que la technique antithétique.Ces résultats dans le cadre de notre étude se sont révélés très satisfaisants etprometteurs.
Les recherches dans le domaine de la simulation numérique sur ordinateur res-tent ouvertes, car l�accroissement de la puissance de calcul des machines permetd�envisager des solutions toujours plus performantes, comme la simulation en pa-rallèle. Une solution consiste à générer simultanément plusieurs trajectoires dusous-jacent sur di¤érents processeurs pour multiplier le nombre de réplicationsdu payo¤ par le nombre de processeurs sur la grille de calcul (Pauletto 2001).Une autre solution plus récente est de générer plusieurs nombres aléatoires si-multanément sur un seul processeur "multi-coeurs" avec la technologie SIMD(Single Instruction Multiple Data). En utilisant cette technologie, Saito (2007)a développé une version optimisée du Mersenne Twister, deux fois plus rapideque l�algorithme original, MT19937.
68

A Méthode de Schrage
L�ensemble des entiers représentables sur une machine à "! bits" est N2! . L�ob-jectif est de calculer axmodm pour a 2 N2! , m 2 N2! et x 2 N2! . Commeaxmodm = a (xmodm)modm, on peut se limiter aux x 2 Nm.
Une implémentation directe de la fonction x ! axmodm sera très instablepour les couples (a; x) tels que ax > 2!. Certains compilateurs renvoient uneerreur, tandis que d�autres évaluent la quantité axmod2!. Dans le premier cas,il y a dépassement de capacité et le programme s�arrête. Dans le second cas, lecalcul se poursuit et le résultat �nal est (axmod2!)modm, à priori di¤érent deaxmodm, sauf pour m = 2� avec � < !. Tout semble fonctionner normalement,mais le résultat �nal est faux. Schrage (1979) démontre la proposition ci-dessousqui permet de contourner ce problème.
Proposition 1.6 Soient a et m deux entiers tels que :
0 < a2 < m et m = aq + r avec r 2 Na:Alors, pour tout x 2 Nm, on a :
axmodm =
�a (xmod q)� r bx=qc si a (xmod q) � r bx=qca (xmod q)� r bx=qc+m si a (xmod q) < r bx=qc :
Proof. En utilisant l�identité x = q bx=qc+ (xmod q), on a :ax = aq bx=qc+ a (xmod q) = (m� r) bx=qc+ a (xmod q) :
Regroupons les termes :
ax = m bx=qc+ (a (xmod q)� r bx=qc) ;puis
axmodm = (a (xmod q)� r bx=qc)modm: (1.47)
Comme xmod q < q, on a
0 � a (xmod q) < aq � m: (1.48)
De plus, 0 � x < m et a2 < m, donc
0 � bx=qc r < bm=qc r = ar < a2 < m: (1.49)
En retranchant (1.48) et (1.49) membre à membre, il vient :
�m < a (xmod q)� r bx=qc < m: (1.50)
Si a (xmod q) � r bx=qc, l�inégalité (1.50) devient 0 � a (xmod q)�r bx=qc < m,ce qui implique :
(a (xmod q)� r bx=qc)modm = a (xmod q)� r bx=qc :Dans le cas contraire, on remarque que 0 < a (xmod q)� r bx=qc+m < m, d�oùl�on déduit :
(a (xmod q)� r bx=qc)modm = a (xmod q)� r bx=qc+m;ce qui établit la formule annoncée.
69

B Méthode de Box-Muller
Soit (X;Y ) un couple de variables aléatoires indépendantes, de loi N (0; 1). Ondé�nit un changement de variables en coordonnées polaires ' : (x; y) �! (r; �)en posant :
r =�x2 + y2
�1=2et � = � � 2 arctan
y
(x2 + y2)1=2 � x
!:
Par construction, ' est un C1-di¤éomorphisme de R2 nf(x; 0) : x � 0g vers R�+�]0; 2�[ (qui sont des ouverts) et, de plus,
PX;Y�R2 nf(x; 0) : x � 0g
= PX;Y
�R2= 1:
Alors, par le théorème de changement de variables, le couple (R;�) = ' (X;Y )admet une densité fR;� par rapport à la mesure de Lebesgue sur R2 :
fR;� (r; �) = fX;Y (r cos �; r sin �)���det J'�1 (r; �)��� 1]0;1[ (r)� 1]0;2�[ (�) ;
où J'�1 (r; �) est la matrice jacobienne de '�1 (r; �) = (r cos �; r sin �). On a
J'�1 (r; �) =
�cos � �r sin �sin � r cos �
�;
ce qui implique det J'�1 (r; �) = r > 0 puis :
fR;� (r; �) = re�r2=21]0;1[ (r)�
1
2�1]0;2�[ (�) :
La densité du couple (R;�) s�écrit comme le produit d�une fonction de r etd�une fonction de �, donc R et � sont indépendantes (ce qui n�était pas évidentà priori) et l�on peut voir que � suit une loi uniforme sur ]0; 2�[ et que R suitune loi de Rayleigh.
On dé�nit un C1-di¤éomorphisme , de R�+ � ]0; 2�[ dans ]0; 1[2, en posant :
u = e�r2=2; v = �=2�:
Le couple (U; V ) = (R;�) admet une densité par rapport à la mesure deLebesgue sur R2 dé�nie par :
fU;V (u; v) = fR;�
�p�2 lnu; 2�v
����det J �1 (u; v)��� 1]0;1[2 (u; v) ;
où
�1 (u; v) =�p�2 lnu; 2�v
�et J �1 (u; v) =
�1=�up�2 lnu
�0
0 2�
�:
70

Alors, det J �1 (u; v) = 2�=�up�2 lnu
�> 0 puis, après calcul,
fU;V (u; v) = 1]0;1[ (u)� 1]0;1[ (v)
ce qui prouve que (U; V ) est un couple de variables uniformes indépendantes.On achève la démonstration en remarquant que :
(X;Y ) = '�1 (R;�) = '�1 � �1 (U; V )
=�p�2 lnU cos (2�V ) ;
p�2 lnU sin (2�V )
�:
C Factorisation de Cholesky
Théorème 1.7 (Cholesky) Soit � une matrice carrée d�ordre s, symétriquedé�nie positive. Il existe une unique matrice �, triangulaire inférieure à coe¢ -cients diagonaux strictement positifs, telle que � = ��0. La matrice � est appeléeracine carrée de Cholesky de �.
Proof. L�unicité et l�existence se démontrent simultanément par récurrence surla dimension s. Si s = 1 alors, � = [�11] avec �11 > 0, car � est dé�nie positive.Alors la seule solution du problème est � =
�p�11�. Supposons l�hypothèse vraie
au rang s � 1 et considérons �, une matrice carrée symétrique dé�nie positived�ordre s+ 1 qui s�écrit :
� =
��s R0sRs �
�;
où �s est la sous-matrice principale d�ordre s de � (elle aussi symétrique dé�-nie positive), Rs est un vecteur ligne de taille s et � est le coe¢ cient d�ordre(s+ 1; s+ 1) de �. Il faut montrer l�existence et l�unicité de �, triangulaire in-férieure à coe¢ cients diagonaux strictement positifs, telle que � = ��0. On doitdonc chercher � sous la forme :
� =
��s 0Ts
�;
où �s est la sous-matrice principale d�ordre s de �, Ts est un vecteur ligne detaille s et est le coe¢ cient d�ordre (s+ 1; s+ 1) de �. L�égalité � = ��0 estvéri�ée si et seulement si :
�s = �s�0s; (1.51)
Rs = Ts�0s; (1.52)
� = TsT0s +
2; (1.53)
En appliquant l�hypothèse de récurrence à la matrice �s (symétrique dé�niepositive d�ordre s), on déduit qu�il existe une unique matrice �s, triangulaireinférieure à diagonale strictement positive, solution de (1.51). En remarquantque �s est inversible (le déterminant d�une matrice triangulaire est égal auproduit des éléments diagonaux, tous strictement positifs dans le cas présent)
71

l�égalité (1.52) admet une unique solution Ts = Rs (�0s)�1. En�n, l�égalité (1.53)
implique 2 = � � TsT 0s (Ts est à présent connu). Alors est nécessairementl�une des racines carrées du scalaire � � TsT
0s (on ne connaît pas le signe de
� � TsT 0s, donc est éventuellement complexe). La matrice � ainsi construitevéri�e bien � = ��0. Il ne reste qu�à prouver que peut être choisi strictementpositif pour conclure. � est triangulaire par blocs, donc
det � = det �0 = det �s ) det� = det ��0 = (det �)2= 2 (det �s)
2:
Or det� > 0 (� est dé�nie positive) et det �s > 0 (�s est à diagonale strictementpositive) donc 2 = ��TsT 0s est strictement positif. On peut donc choisir > 0ce qui achève la récurrence.
Remarque C.1 La condition � dé�nie positive est une condition su¢ sante(mais non nécessaire) pour garantir l�existence d�une racine carrée de Cholesky.En e¤et, il existe des matrices non dé�nies positives admettant une factorisationde Cholesky. Par exemple la matrice � de terme général �ij = 1 (1 � i; j � s)s�écrit ��0 où � est dé�nie par :
�ij =
�1 si j = 10 si j > 1
:
Mais on observe, dans la pratique, que lorsque � n�est pas dé�nie positive, ladécomposition de Cholesky échoue presque toujours.
72

Références
Acklam P.J. (2000). �An algorithm for computing the inverse normal cumulativedistribution function�, Technical Paper, http://home.online.no/~pjacklam/notes/invnorm/.Arouna B. (2004). �Adaptative Monte Carlo Method, A Variance ReductionTechnique�, Monte Carlo Methods and Applications, Vol. 10, No. 1, pp. 1-24.Beasley J.D., Springer S.G. (1977). �Algorithm AS 111. The percentage pointsof the normal distribution�, Applied Statistics, 26, pp. 118-121.Björk T. (2004). Arbitrage Theory in Continuous Time, Second Edition, OxfordUniversity Press.Black F., Scholes M. (1973). �The Pricing of Options And Corporate Liabilities�,Journal of Political Economy, Vol. 81, pp. 36-72.Bouchard-Denize B. (2006). Méthodes de Monte Carlo en Finance, Notes decours, Université de Paris VI.Boyle P.P. (1977). �Option : a Monte Carlo approach�, Journal of FinancialEconomics, Vol. 4, pp. 323-338.Bruno M.G. (1991). �Calculation methods for evaluating asian options�, Wor-king Paper.Devroye L. (1986). Non-Uniform Random Variate Generation, Springer-Verlag,New York.Fishman G.S., Huang B.D. (1983). �Antithetic Variates Revisited�, Communi-cations of the ACM, 26, pp. 964-971.Gentle J.E. (2003). Random Number Generation and Monte Carlo Methods,Second Edition, Springer-Verlag.Glasserman P. (2004). Monte Carlo methods in �nancial engineering, Springer.Haber S. (1966). �A Modi�ed Monte-Carlo Quadrature�, Mathematics of Com-putation, Vol. 20, No. 95, pp. 361-368.Hammersley J. M., Handscomb D.C. (1964). Monte Carlo Methods, Methuen,London.Hammersley J.M., Morton K.W. (1956). �A New Monte Carlo Technique : An-tithetic Variates�, Proceedings of the Cambridge Philosophical Society, 52, pp.449-475.Herring C., Palmore J.I. (1989). �Random Number Generators Are Chaotic�,Communications of the ACM, 38, pp. 121-127.Jäckel P. (2002). Monte Carlo methods in �nance, John Wiley & Sons.Jacod J., Protter P. (2003). L�essentiel en théorie des probabilités, Cassini.Klimasauskas C. (2003a). �Not Knowing Your Random Number GeneratorCould Be Costly : Random Generators - Why Are They Important�, InformationArticle, Advanced Technology For Developers Group, http://www.klimasauskas.com/pub_rng.php.Klimasauskas C. (2003b). �Testing Your Random Number Generator�, Informa-tion Article, Advanced Technology For Developers Group, http://www.klimasauskas.com/pub_rng.php.Knuth D.E. (1998). The Art of Computer Programming, Volume 2 : Seminu-merical Algorithms, Third edition, Addison-Wesley.
73

Korn R., Korn E. (2001). Option Pricing and Portfolio Optimization : ModernMethods of Financial Mathematics, Graduate Studies in Mathematics, Vol. 31,American Mathematical Society.Kuipers L., Niederreiter H. (1974). Uniform Distribution of Sequences, JohnWiley & Sons.Lachaud A., Leclanche G. (2003). �Génération de nombres aléatoires par numé-risation d�impulsions radiatives�, Rapport de �n d�études, Maîtrise d�Electro-nique, Université de Limoges.Lamberton D., Lapeyre B. (1997). Introduction au calcul stochastique appliquéà la �nance, Ellipse.Langlois M. (1999). �Cryptographie quantique - solution au problème de distri-bution de clefs secrètes�, Papier de recherche, Université d�Ottawa.Lemieux C. (2008). Monte Carlo and Quasi-Monte Carlo Sampling, Springer(to appear).L�Ecuyer P. (1988). �E¢ cient and Portable Combined Random Number Gene-rators�, Communications of the ACM, 31, pp. 742-749 and 774.L�Ecuyer P. (1996). �Combined Multiple Recursive Generators�, Operations Re-search, Vol. 44, No. 5, pp. 816-822.L�Ecuyer P. (1998a). �Random Number Generators and Empirical Tests�, Lec-ture Notes in Statistics 127, Springer-Verlag, pp. 124-138.L�Ecuyer P. (1998b). �Uniform Random Number Generators�, Proceedings ofthe 1998 Winter Simulation Conference, IEEE Press, pp. 97-104.L�Ecuyer P. (1999). �Good parameters and implementations for combined mul-tiple recursive random number generators�, Research Paper, Université de Mont-réal - DIRO.L�Ecuyer P. (2001). �Software for uniform random number generation : distin-guishing the good and the bad�, Proceedings of the 2001 Winter SimulationConference, IEEE Press, pp. 95-105.L�Ecuyer P. (2004a). �Random Number Generation�, Chapter 2 of the Hand-book of Computational Statistics, (J.E. Gentle, W. Haerdle, and Y. Mori Eds.),Springer-Verlag, pp. 35-70.L�Ecuyer P., Panneton F. (2000). �A New Class of Linear Feedback Shift Re-gister Generators�, Proceedings of the 2000 Winter Simulation Conference, pp.690-696.L�Ecuyer P., Simard R. (2005). �TestU01 - A software Library in ANSI C for Em-pirical Testing of Random Number Generators, User�s guide (compact version)�,Université de Montréal - DIRO, http://www.iro.umontreal.ca/~simardr/.Marsaglia G. (1996). �DIEHARD, a battery of tests of randomness�, http://www.stat.fsu.edu/pub/DIEHARD/.Marsaglia G. (2003). �Seeds for random number generators�, Communicationsof the ACM, 46, pp. 90-93.Matsumoto M., Kurita Y. (1992). �Twisted GFSR generators�, ACM Transac-tions on Modeling and Computer Simulation, 2, pp. 179-194.Matsumoto M., Kurita Y. (1994). �Twisted GFSR generators II�, ACM Tran-sactions on Modeling and Computer Simulation, 4, pp. 254-266.
74

Matsumoto M., Nishimura T. (1998). �Mersenne Twister : A 623-dimensionallyequidistributed uniform pseudorandom number generator�, ACM Transactionson Modeling and Computer Simulation, 8, pp. 3-30.Metropolis N., Ulam S.M. (1949). �The Monte Carlo method�, Journal of theAmerican Statistical Association, Vol. 44, No. 247, pp. 335-341.Microsoft (2004). �How Visual Basic Generates Pseudo-Random Numbers forthe Rnd Function�, Knowledge Base Article 231847, http://support.microsoft.com/default.aspx?scid=kb;en-us;231847.Microsoft (2005). �Rnd and Randomize Alternatives for Generating RandomNumbers�, Knowledge Base Article 28150, http://support.microsoft.com/default.aspx?scid=kb;en-us;28150.Microsoft (2006). �Description of the RAND function in Excel 2003�, Know-ledge Base Article 828795, http://support.microsoft.com/default.aspx?scid=kb;en-us;828795.Moro B. (1995). �The Full Monte�, Risk Magazine, Vol. 8, pp. 57-58.Neave H.R. (1973). �On using the Box-Muller tranformation with multiplicativecongruential pseudo-random number generators�, Applied Statistics, 22, pp. 92-97.Niederreiter H. (1978). �Quasi-Monte Carlo methods and pseudo-random num-bers�, Bulletin of the American Mathematical Society, Vol. 84, No. 6, pp. 957-1041.Niederreiter H. (1992). Random Number Generation and Quasi-Monte CarloMethods, SIAM-CBMS Lecture Notes 63.Panneton F. (2004). �Construction d�ensembles de points basée sur des récur-rences linéaires dans un corps �ni de caractéristique 2 pour la simulation MonteCarlo et l�intégration quasi-Monte Carlo�, Thèse de Doctorat, Université deMontréal.Park S.K., Miller K.W. (1988). �Random Number Generators : Good Ones AreHard To Find�, Communications of the ACM, 31, pp. 1192-1201.Pauletto P. (2001). �Parallel Monte Carlo Methods for Derivative Security Pri-cing�, in Numerical Analysis and Its Applications (L. Vulkov, J. Wasnievskiand P. Yalamov Eds.), Lecture Notes in Computer Science, Vol. 1988, Springer-Verlag, pp. 650-657.Press W.H., Teukolsky S.A., Vetterling W.T., Flannery B.P. (2002). NumericalRecipes in C++, the art of scienti�c computing, Second Edition, CambridgeUniversity Press.Saito M. (2007). �An Application of Finite Field : Design and Implementationof 128-bit Instruction-Based Fast Pseudorandom Number Generator�, ResearchPaper, Department of Mathematics, Graduate School of Science, Hiroshima Uni-versity, http://www.math.sci.hiroshima-u.ac.jp/~m-mat/JSPS-CoreToCore/index.html.Sakamoto M., Morito S. (1995). �Combination of Multiplicative CongruentialRandom-Number Generators With Safe Prime Modulus�, Proceedings of the1995 Winter Simulation Conference (C. Alexopoulos, K. Kang, W. R. Lilegdon,and D. Goldsman Eds.), pp. 309-315.
75

Schrage L. (1979). �A More Portable Fortran Random Number Generator�,ACM Transactions on Mathematical Software, 5, pp. 132-138.Tezuka S. (1991). �Neave E¤ect Also Occurs With Tausworthe Sequences�, Pro-ceedings of the 1991 Winter Simulation Conference, pp. 1030-1034.Tezuka S. (1995). Uniform Random Numbers : Theory and Practice, KluwerAcademics Publishers.West G. (2005). �Better approximations to cumulative normal functions�, Wil-mott Magazine, pp. 70-76.Wichmann B., Hill I. (1982). �Algorithm AS 183. An E¢ cient and PortablePseudo-random Number Generator�, Applied Statistics, 31, pp. 188-190.
76

Chapitre 2
Intégration déterministeQuasi-Monte Carlo
2.1 Introduction
La méthode de Monte Carlo présentée dans le chapitre précédent permet d�es-timer la valeur d�une espérance en formant l�approximation :
I = E [h (X)] 'N!+1
1
N
NXn=1
h(Xn);
où les Xn sont des variables aléatoires i.i.d. de même loi que X. Pour échan-tillonner la loi de X, on utilise le fait que la plupart des lois de probabilités sedéduisent de la loi uniforme par des transformations plus où moins complexes(voir Devroye 1986 et Niederreiter 1992). On note C le segment unité ouvert]0; 1[, de sorte que Cs désigne le cube unité ouvert ]0; 1[s. Si T est une trans-formation telle que X = T (U) avec U � UCs , alors l�espérance I peut être vue
comme l�intégrale de la fonction f def= h � T sur le cube unité :
I = E [h (X)] = E [h � T (U)] = E [f (U)] =ZCs
f(u)du
et l�estimateur Monte Carlo se réécrit :
IN =1
N
NXn=1
f(Un); (2.1)
où les Un sont des variables aléatoires mutuellement indépendantes de loi uni-forme UIs . A�n de simpli�er les raisonnements, nous ne considérerons doréna-vant que des espérances (ou des intégrales) dé�nies sur le cube unité Cs.
La méthode de Monte Carlo est particulièrement simple à mettre en oeuvre dèsque l�on s�est doté d�un bon générateur de variables uniformes. Elle s�applique
77

à une large classe de fonctions (l�ensemble des fonctions Lebesgue intégrables)et elle permet d�obtenir facilement une estimation probabiliste de l�erreur d�in-tégration lorsque f est de carré intégrable. La vitesse de convergence de l�algo-rithme, de l�ordre de N�1=2 où N désigne le nombre de points de l�échantillon,est indépendante de la dimension, ce qui est un atout incontestable par rap-port aux quadratures déterministes dont la qualité d�approximation de l�ordrede O
�N�2=s� se dégrade considérablement lorsque la dimension du problème
augmente et qui deviennent impraticables1 pour s � 5.
2.1.1 Idée sous-jacente de l�approche Quasi-Monte Carlo
La vitesse de convergence en N�1=2 est une caractéristique intrinsèque des mé-thodes d�échantillonnage probabilistes du type Monte Carlo. Elle provient de lanature stochastique de l�échantillon utilisé. En e¤et, chaque point est construitindépendamment des points déjà générés, de sorte que l�on observe la forma-tion d�agrégats dans certaines régions du domaine d�intégration (phénomènede sur-échantillonnage), tandis que d�autres régions restent entièrement vides(phénomène de sous-échantillonnage). En d�autres termes, les points aléatoiresn�échantillonnent pas le domaine d�intégration de manière optimale et un grandnombre d�itérations est nécessaire avant d�obtenir une couverture "uniforme"du domaine d�intégration. Cependant, on connaît des suites complètement dé-terministes, appelées suites équiréparties, dont les points se distribuent dans lecube unité avec une plus grande régularité que des points aléatoires. La �gureci-dessous permet d�illustrer nos propos : nous avons représenté 5000 pointsbidimensionnels obtenus avec le générateur pseudo-aléatoire Mersenne TwisterMT19937 (plan de gauche) et avec la suite équirépartie de Halton (�gure dedroite) dont les propriétés seront étudiées en détail dans la suite du chapitre.
1Voir Annexe A pour une présentation succincte de tels algorithmes.
78

Une simple comparaison des deux jeux de points soulève la question suivante :quelle serait la nature de la convergence obtenue si l�on remplaçait les pointsaléatoires dans l�estimateur (2.1) par les points d�une suite équirépartie telleque la suite de Halton ? Cette démarche est envisageable dans la mesure où cen�est pas le caractère imprédictible de la suite échantillonnante que l�on cherche àexploiter dans l�intégration Monte Carlo, mais sa capacité à recouvrir le domained�intégration de la fonction étudiée2 . C�est précisément sur cette observation querepose la méthode d�intégration déterministe dite de Quasi-Monte Carlo.
2.1.2 Approximation Quasi-Monte Carlo
L�idée est de remplacer les points aléatoires Un dans la quadrature Monte Carlo(2.1) par les points d�une suite équirépartie déterministe. On obtient alors l�es-timateur Quasi-Monte Carlo de l�intégrale I :
QN =1
N
NXn=1
f(un); (2.2)
où u1; : : : ; uN désignent les N premiers points d�une suite équirépartie. Etantdonné que les un réalisent un échantillonnage hautement uniforme du domained�intégration, on peut espérer que l�estimateur Quasi-Monte Carlo QN conver-gera plus rapidement que l�estimateur Monte Carlo IN .
L�échantillon que nous envisageons d�utiliser ayant perdu toute caractéristiquealéatoire, il n�est plus possible de justi�er l�approche Quasi-Monte Carlo à par-tir des théorèmes fondamentaux des probabilités comme c�est le cas dans l�ap-proche Monte Carlo. En conséquence, nous devrons introduire de nouveaux ou-tils mathématiques a�n d�apporter une réponse théorique solide aux questionssuivantes.
1. Comment mesurer l�équirépartition d�une suite et comment identi�er lessuites équiréparties candidates à l�intégration Quasi-Monte Carlo ?
2. Sous quelles hypothèses sur la fonction f et sur la suite (un) l�estimateurQN converge-t-il vers l�intégrale I ?
3. Dispose-t-on encore d�un outil e¢ cace pour estimer l�erreur d�intégration
"N =���QN � I��� ?
4. Quelle est la vitesse de convergence de la quadrature Quasi-Monte Carlo ?En particulier, est-elle meilleure que la vitesse de convergence de l�inté-gration Monte Carlo ?
2Dans l�intégration Monte Carlo, la nature stochastique de l�échantillon ne nous intéresseque dans la mesure où elle conduit au remplissage asymptotique du domaine d�intégrationet qu�elle permet d�appliquer les théorèmes de probabilité pour justi�er la convergence del�estimateur et pour majorer l�erreur commise.
79

2.1.3 Origine et intérêt de la méthode Quasi-Monte Carlo
Les méthodes de Monte Carlo ont été développées puis utilisées pour des projetssecrets de la défense américaine à partir du milieu du 20i�eme siècle. Le terme"Quasi-Monte Carlo" est apparu pour la première fois dans un rapport de Richt-myer (1951). A l�origine, les méthodes de Quasi-Monte Carlo devaient permettred�accélérer les simulations numériques sur des ordinateurs dont la puissance decalcul était relativement limitée. Les fondements théoriques de cette approche,jugée très prometteuse, ont été développés à partir des années 1960 jusqu�à la �ndes années 1980, notamment grâce aux travaux de Halton (1960), Hammersleyet Handscomb (1964), Haber (1966, 1970), Niederreiter (1972, 1978), Kuiperset Niederreiter (1974), Cranley et Patterson (1976), Faure (1981, 1982) ou Zin-terhof (1987). Cette liste n�est pas exhaustive, mais elle donne les référencesmajeures sur le sujet.
Le principal avantage de la méthode de Quasi-Monte Carlo est qu�elle convergeplus rapidement que la méthode de Monte Carlo (cf. Finschi 1996, Pagès et Xiao1997, Tu¢ n 1997). Par contre, elle comporte deux inconvénients qui n�existentpas avec la méthode de Monte Carlo : la vitesse de convergence dépend de la di-mension du problème (i.e. la méthode perd de son e¢ cacité lorsque la dimensionaugmente) et surtout il est di¢ cile, voire impossible, de produire e¢ cacementune estimation de l�erreur d�intégration (Thiémard 2000a, 2000b). La plupartdes travaux menés depuis les années 1990 ont eu pour objectif de proposer des so-lutions a�n d�améliorer l�équidistribution des suites utilisées (Tu¢ n 1996a, Kociset Whiten 1997, Wang et Hickernell 2000) ou de proposer une mesure e¢ cace del�erreur commise (Moroko¤ et Ca�isch 1994, Snyder 2000, Warnock 2001). De-puis le début des années 2000, la solution privilégiée par les spécialistes consisteà randomiser la méthode de Quasi-Monte Carlo a�n de pouvoir estimer l�er-reur d�intégration par des moyens probabilistes. A ce sujet, le lecteur pourraconsulter Ökten (1997), Tu¢ n (1996b, 2005), L�Ecuyer (2004b), Ökten, Tu¢ net Burago (2005) ou Lemieux (2008).
L�utilisation des méthodes de Quasi-Monte Carlo en �nance est relativementrécente. En e¤et, les travaux de Paskov (1994), Boyle, Broadie et Glasserman(1995), Papageorgiou et Traub (1996, 1997), Galanti et Jung (1997) ou Boyle etTan (1997), qui peuvent être considérés comme les premières publications surle sujet, datent du milieu des années 1990. Les problèmes rencontrés en �nancequantitative sont extrêmement variés (calculs d�espérance, calculs de quantiles,simulation de processus stochastiques, etc.) et les modèles sous-jacents sontparticulièrement complexes et de grande dimension (Da Silva et Barbe 2005).Dans ce contexte, les méthodes de simulation numérique sont devenues aujour-d�hui un outil incontournable pour les spécialistes de la �nance quantitative(Jäckel 2002, Glasserman 2004).
80

2.1.4 Organisation du chapitre
L�objectif de ce chapitre est de montrer comment le praticien peut mettre enoeuvre la méthode de Quasi-Monte Carlo pour évaluer des produits dérivés com-plexes avec une précision accrue par rapport à la méthode de Monte Carlo. Dansla seconde section, nous introduisons les outils théoriques nécessaires à la bonnecompréhension des mécanismes de l�intégration Quasi-Monte Carlo en insistantsur les di¤érences fondamentales avec la méthode de Monte Carlo, notamment ladi¢ culté à mesurer l�erreur d�intégration. Dans les sections 3 et 4, nous étudionsles suites de Weyl et les suites de Halton, deux familles de suites équirépartiesperformantes. Nous montrons comment améliorer les propriétés de ces suites envue d�une intégration numérique en grande dimension et nous proposons desalgorithmes extrêmement rapides pour les générer. Dans la cinquième section,nous discutons le problème des temps de calcul, qui sont un élément détermi-nant dans le choix d�une méthode numérique. Dans la sixième section, nousappliquons la méthode de Quasi-Monte Carlo pour évaluer des produits op-tionnels : nous commençons par véri�er que la méthode de Quasi-Monte Carloconverge plus rapidement que la méthode de Monte Carlo sur une intégrale test,puis nous montrons comment combiner l�approche Monte Carlo avec l�approcheQuasi-Monte Carlo pour obtenir une estimation de l�erreur systématique et uneréduction de variance importante. La conclusion du chapitre est donnée dans lasection 7.
2.2 Intégration Quasi-Monte Carlo
La méthode de Quasi-Monte Carlo est parfois considérée comme une versiondéterministe de la quadrature Monte Carlo. Cette a¢ rmation peut prêter àconfusion car, s�il est vrai que les estimateurs (2.1) et (2.2) ont la même formeet qu�ils s�implémentent de manière identique, les fondements théoriques desdeux approches sont fondamentalement di¤érents. Notons cependant, qu�il estpossible d�établir certaines analogies entre les deux méthodes : en e¤et, chaqueconcept ou résultat de nature probabiliste développé pour les besoins de l�analyseMonte Carlo possède un "équivalent de nature déterministe" dans le cadre del�analyse Quasi-Monte Carlo.
Dans cette section, nous présentons les principaux résultats mathématiques surlesquels repose l�intégration Quasi-Monte Carlo et nous discutons les pointsdélicats liés à cette approche. Dans le premier paragraphe, nous formalisonsle concept de suite équirépartie, nous énonçons un théorème fondamental quipermet d�identi�er les classes de fonctions pour lesquelles l�estimateur (2.2)converge, puis nous dé�nissons la discrépance qui est un outil statistique pourmesurer la non-uniformité des suites (plus la discrépance d�une suite est faible,plus elle est uniformément répartie). Dans le second paragraphe, nous intro-duisons une généralisation déterministe de la notion de variance, appelée varia-tion d�une fonction au sens de Hardy et Krause ; nous énonçons l�inégalité deKoksma-Hlawka qui est une majoration de l�erreur d�intégration par le produit
81

de la discrépance de la suite échantillonnante et de la variation de la fonction in-tégrée. Ce résultat incite à rechercher les meilleures suites uniformes au sens de ladiscrépance. Dans le dernier paragraphe, nous montrons que la discrépance dessuites est bornée inférieurement et qu�il existe des suites équiréparties, appeléessuites à discrépance faible, pour lesquelles la discrépance asymptotique coïn-cide avec cette borne inférieure. Ces suites présentent un intérêt évident pourl�intégration Quasi-Monte Carlo, car leur très haut degré d�uniformité est lagarantie d�une convergence rapide pour l�estimateur (2.2). Pour une démonstra-tion des résultats énoncés, nous renvoyons le lecteur à Niederreiter (1978, 1992)et Drmota et Tichy (1997).
2.2.1 Suites équiréparties, intégration numérique, discré-pance
L�objectif de ce paragraphe est : (i) de traduire en termes mathématiques lespropriétés "visuelles" des suites équiréparties (ce sont des suites dont les pointsse distribuent dans le cube unité de manière homogène et uniforme), (ii) d�iden-ti�er les fonctions intégrables à l�aide de telles suites et (iii) de proposer un"instrument" pour mesurer et comparer l�équirépartition des suites : la discré-pance.
Dé�nition d�une suite équirépartie
Dans cette section, (un)n�1 désigne une suite à valeurs dans le cube unité fermé�Cs = [0; 1]
s. La mesure de probabilité empirique induite par les N premierspoints de u est dé�nie par �uN =
1N
PNn=1 �un , où �un est la mesure de Dirac au
point un. Pour tout A � Rs on a :
�uN (A) =1
N
NXn=1
1A (un) =Card fn 2 f1; : : : ; Ng : un 2 Ag
N;
où 1A (:) est la fonction indicatrice de l�ensemble A dé�nie par :
8x 2 Rs; 1A (x) =�1 si x 2 A0 si x =2 A :
Par construction, �uN (A) est la proportion de points appartenant à A parmifu1; : : : ; uNg.
Pour tout x 2 �Cs, on désigne par J�x le pavé semi-ouvert, d�extrémité x, ancréen 0 :
J�xdef= [0; x[ =
sYi=1
[0; xi[ ; x = (x1; : : : xs)0 avec 0 � xi � 1:
Nous donnons ci-dessous la dé�nition d�une suite équirépartie (Kuipers et Niederreiter1974).
82

Dé�nition 2.1 Une suite u à valeurs dans �Cs est équirépartie (ou uniformé-ment distribuée) si et seulement si :
8x 2 �Cs; limN!+1
�uN (J�x) = �s (J
�x) ; (2.3)
où �s désigne la mesure de loi uniforme sur �Cs de densité de probabilité d�s (x) =1 �Cs (x) dx.
Cette dé�nition signi�e que la suite des mesures empiriques �uN "converge" versla mesure de loi uniforme sur tous les sous-pavés du cube unité ancrés à l�origine.Une conséquence de la relation (2.3) est que les suites équiréparties intègrent lesfonctions en escalier sur �Cs, donc les fonctions Riemann-intégrables (car toutefonction Riemann-intégrable est limite d�une suite de fonctions en escalier). Nousdétaillons ce point ci-dessous.
Classes de fonctions intégrables
Dans la méthode de Monte Carlo, l�estimateur (2.1) converge dès que f estLebesgue-intégrable sur le cube unité. Cela est une conséquence directe de laloi des grands nombres. L�approche Quasi-Monte Carlo étant basée sur dessuites déterministes, il n�est plus possible d�appliquer ce résultat pour justi�erla convergence de l�estimateur :
QN �!N!+1
Z�Cs
f (u) du: (2.4)
Le théorème suivant donne les familles de fonctions intégrables à l�aide des suiteséquiréparties (voir Drmota et Tichy (1997) pour une démonstration).
Théorème 2.1 Les propositions suivantes sont équivalentes :
1. la suite u est équirépartie,2. (2.4) est véri�ée pour toute fonction f continue sur �Cs,3. (2.4) est véri�ée pour toute fonction f Riemann-intégrable sur �Cs.
L�approche Quasi-Monte Carlo est donc limitée aux fonctions Riemann-intégrables.L�exemple suivant montre qu�il n�est pas possible d�étendre (2.4) à l�ensemble des
fonctions Lebesgue-intégrables sur �Cs. Posons U def= fun : n 2 N�g l�ensemble
des points de la suite u et considérons la fonction 1U. Cette fonction est inté-grable sur le cube unité au sens de Lebesgue, mais pas au sens de Riemann etson intégrale est nulle. Etant donné que 1
N
PNn=1 1U (un) = 1 pour tout N 2 N�,
on en déduit que limN!+1 QN = 1. En conséquence, la moyenne empirique del�échantillon ne converge pas vers la moyenne théorique de la fonction.
Remarque 2.2.1 Le point 2 du théorème 2.1 signi�e que la suite (�uN )N2N�converge étroitement vers la mesure de loi uniforme �Cs. Il permet d�étendre leconcept de suites équiréparties aux espaces topologiques compacts, alors que ladé�nition 2.1 ne peut pas être directement transposée. Sur ce sujet, le lecteurest invité à consulter Drmota et Tichy (1997).
83

Nous énonçons à présent un théorème de Weyl (1916) qui est aussi connu sousle nom de "critère de Weyl" (Kuipers et Niederreiter 1974). Ce théorème estfondamental, car il montre que pour établir qu�une suite est équirépartie, ilsu¢ t de véri�er qu�elle permet d�intégrer une classe de fonctions particulièresde la forme x! e2�ihm;xi avec m 2 Zsn f0g.
Théorème 2.2 La suite u à valeurs dans �Cs est équirépartie si et seulement sipour tout m 2 Zsn f0g on a :
1
N
NXn=1
e2�ihm;uni �!N!+1
0; (2.5)
où hx; yi =Psk=1 xkyk désigne le produit scalaire euclidien sur Rs.
La démonstration de la formule (2.5) repose sur le théorème de Fejér multi-dimensionnel (Bachman, Narici et Beckenstein 2000, p. 259) qui montre quetoute fonction continue sur �Cs peut être approchée uniformément par une suitede polynômes trigonométriques, c�est-à-dire par des combinaisons linéaires defonctions de la forme x ! e2�ihm;xi avec m 2 Zsn f0g. L�idée est de considé-rer une suite qui véri�e (2.5). Elle intègre donc les polynômes trigonométriquespuis, par "passage à la limite", on en déduit qu�elle intègre les fonctions conti-nues (point 2 du théorème 2.1). Cela prouve que toute suite qui véri�e (2.5) estéquirépartie. Réciproquement, pour montrer que toute suite équirépartie véri�e(2.5), il su¢ t de remarquer que les fonctions x ! e2�ihm;xi avec m 2 Zsn f0gsont continues sur �Cs, d�intégrale nulle et l�on conclut avec le point 2 du théo-rème 2.1. Nous renvoyons le lecteur à Kuipers et Niederreiter (1974) ou Drmotaet Tichy (1997) pour les détails de la démonstration.
Discrépance d�une suite
Les suites de points éligibles à l�intégration Monte Carlo doivent passer unebatterie de tests statistiques d�indépendance et d�uniformité plus ou moins exi-geants. Dans le cas de l�intégration Quasi-Monte Carlo, c�est uniquement lahaute uniformité multidimensionnelle des points de la suite échantillonnantequi nous intéresse, car plus les points sont uniformément distribués, plus l�onespère obtenir une convergence rapide dans la relation (2.4). Pour mesurer l�uni-formité des suites en dimensions multiples, l�idée est de généraliser la distancede Kolmogorov-Smirnov qui est utilisée en statistiques pour tester l�adéquationde la loi empirique d�un échantillon à valeurs dans R avec une loi de probabilitédonnée. Cette distance de Kolmogorov généralisée est appelée la discrépance :elle mesure la déviation de la distribution empirique des points de la suite can-didate par rapport à la mesure de la loi uniforme sur le cube unité. Le mot"discrépance" dérive du verbe latin "discrepare" qui signi�e "être di¤érent de".La discrépance est donc une mesure de non-uniformité, ce qui signi�e que plusla discrépance d�une suite est faible, plus la suite est uniforme. Dans ce qui suit,u1; : : : ; uN désignent les N premiers points de la suite u.
84

Dé�nition 2.2 Pour tout x 2 �Cs, la quantité
DN (J�x ; u)
def= j�uN (J�x)� �s (J�x)j (2.6)
est appelée discrépance locale de u1; : : : ; uN relativement au pavé J�x .
La discrépance locale mesure l�écart entre la mesure uniforme (i.e. le volume)d�un pavé ancré à l�origine et la proportion de points de la suite qui se situentdans le même pavé. Notons que, d�après la dé�nition 2.1, la suite u est équiré-partie si et seulement si limN!+1DN (J
�x ; u) = 0 pour tout x 2 �Cs.
On montre facilement3 que DN (J�x ; u) prend ses valeurs dans [0; 1]. En consé-
quence, l�application x �! DN (J�x ; u) appartient à L
1 � �Cs�. En prenant lanorme L1 de la discrépance locale, on dé�nit une mesure globale de l�écart entrela distribution induite par le positionnement u1; : : : ; uN dans le cube unité et ladistribution uniforme (voir Drmota et Tichy 1997).
Dé�nition 2.3 On appelle discrépance à l�origine de u1; : : : ; uN la quantité :
D�N (u) = sup
x2 �Cs
DN (J�x ; u) = sup
x2 �Cs
j�uN (J�x)� �s (J�x)j : (2.7)
La détermination de cette grandeur revient à identi�er l�intervalle ancré à l�ori-gine qui contient la proportion de points la plus anormalement faible ou la plusanormalement dense relativement à son volume. Etant donné que la discrépancelocale est majorée par 1, on a :
8N 2 N�; 0 < D�N (u) � 1 (2.8)
Par ailleurs, il est clair que plus la discrépance est petite, plus la séquenceformée par u1; : : : ; uN est uniforme. La proposition ci-dessous montre que lessuites équiréparties sont les suites dont la discrépance est asymptotiquementnulle.
Proposition 2.3 La suite u est équirépartie si et seulement si :
D�N (u) �!
N!+10: (2.9)
La discrépance à l�origine est une généralisation de la distance de Kolmogorov-Smirnov aux suites multidimensionnelles : en e¤et, lorsque s = 1, on a la formule(Niederreiter 1992) :
D�N (u) = max
1�n�Nmax
����u(n) � n
N
��� ; ����u(n) � n� 1N
�����=
1
2N+ max1�n�N
����u(n) � 2n� 1N
���� ;3D�une part, 0 � �uN (J
�x) � 1, d�autre part 0 � �s (J�x) � 1, donc �1 � �uN (J
�x) �
�s (J�x) � 1.
85

où u(1) < : : : < u(N) sont les N premières valeurs de la suite classées dansl�ordre croissant.
Le calcul de la discrépance à l�origine dans le cas s = 1 ne pose donc aucunproblème particulier. En revanche, dès que s � 2, l�estimation de D�
N (u) devientparticulièrement délicate (Thiémard 2000a, 2000b). Montrons maintenant que ladiscrépance conditionne la vitesse de convergence de la quadrature Quasi-MonteCarlo.
2.2.2 Majoration de l�erreur d�intégration
Dans l�approche Monte Carlo, l�erreur d�intégration est proportionnelle à laquantité Var [f(U)], la variance de f(U), qui constitue une mesure du degré devariabilité de la fonction que l�on intègre. Pour analyser l�erreur d�intégration dela quadrature Quasi-Monte Carlo, considérer la variance de la fonction est d�unintérêt limité, car cette grandeur est de nature probabiliste. Pour cette raison,nous devons introduire une nouvelle mesure d�irrégularité pour la fonction f ,appelée variation au sens de Hardy et Krause. Ce nouvel outil étant dé�ni,nous pourrons énoncer l�inégalité de Koksma-Hlawka, qui est l�une des seulesformules connues pour la majoration de l�erreur d�intégration dans l�approcheQuasi-Monte Carlo. Nous suivons la démarche de Niederreiter (1992).
Inégalité de Koksma-Hlawka
Soit Is l�ensemble des sous-pavés de �Cs de la formeQsi=1
ha(i)1 ; a
(i)2
iavec 0 �
a(i)1 < a
(i)2 � 1. Pour tout A 2 Is on note :
�(f;A) =
2Xl1=1
2Xl2=1
: : :
2Xls=1
h(�1)l1+���+ls f
�a(1)l1; : : : ; a
(s)ls
�i: (2.10)
Soit P l�ensemble des partitions de �Cs constituées d�éléments de Is.
Dé�nition 2.4 (Variation au sens de Vitali) La variation au sens de Vi-tali d�une fonction f : �Cs ! R est dé�nie par :
V (s) [f ] = supP2P
XA2Pj�(f;A)j : (2.11)
Lorsque��V (s)(f)�� < +1, on dit que f est à variation bornée au sens de Vitali.
Lorsque la dérivée partielle @sf@u1:::@us
existe et est continue, Niederreiter (1992)démontre la relation suivante :
V (s) [f ] =
Z�Cs
���� @sf
@u1 : : : @us
���� du1 : : : dus:
86

Soulignons qu�une fonction peut être à variation bornée au sens de Vitali sanspour autant être di¤érentiable.
Pour tout 1 � k � s et pour tout jeu d�indices 1 � i1 < i2 < � � � < ik �s, on dé�nit une fonction sur �Ck = [0; 1]
k en considérant la restriction de faux points (u1; : : : ; us) 2 �Cs tels que uj = 1 pour j =2 fi1; : : : ; ikg. On noteV (k) [f ; i1; : : : ; ik] la variation au sens de Vitali de cette nouvelle fonction. Cettequantité est appelée variation k-dimensionnelle de f au sens de Vitali.
Dé�nition 2.5 (Variation au sens de Hardy et Krause) La variation ausens de Hardy et Krause d�une fonction f : �Cs ! R est dé�nie par :
VHK [f ] =sX
k=1
X1�i1<:::<is�s
V (k) [f ; i1; : : : ; ik] : (2.12)
Lorsque jVHK [f ]j < +1, on dit que f est à variation bornée au sens de Hardyet Krause.
Nous disposons de tous les éléments pour énoncer le théorème de Koksma-Hlawka.
Théorème 2.4 (Inégalité de Koksma-Hlawka) Si f : �Cs ! R est à varia-tion bornée au sens de Hardy et Krause alors, pour toute suite (un)n�1 à valeursdans �Cs, on a la relation :����� 1N
NXn=1
f (un)�Z�Cs
f (u) du
����� � VHK [f ]D�N (u) ; (2.13)
où D�N (u) désigne la discrépance à l�origine de fu1; : : : ; uNg dé�nie par (2.7).
L�inégalité (2.13) est fondamentale, car elle nous donne une indication précisesur le rôle essentiel de la discrépance des suites échantillonnantes dans l�approcheQuasi-Monte Carlo. Plus précisément, il ressort que la vitesse de convergence dela méthode de Quasi-Monte Carlo dépend exclusivement des propriétés d�unifor-mité (i.e. de la discrépance) de la suite échantillonnante utilisée. Cet argumentnous incite à rechercher parmi les suites équiréparties, celles dont la discrépanceest arbitrairement faible. De telles suites, si elles existent, devraient permettred�obtenir une vitesse de convergence élevée pour la quadrature (2.4). Cette ques-tion sera abordée dans le dernier paragraphe.
Auparavant, nous discutons la portée opérationnelle de l�inégalité de Koksma-Hlawka en la comparant avec la majoration de l�erreur disponible dans la qua-drature Monte Carlo.
87

Comparaison avec l�approche Monte Carlo
Dans la méthode de Monte Carlo, la majoration de l�erreur obtenue en appli-quant le théorème de la limite centrale :����� 1N
NXn=1
f (Un)�Z�Cs
f (u) du
����� � q1��=2 � [f ]pN; (2.14)
où Un est une suite de points i.i.d. de loi U �Cs et � [f ]def=pVar [f(U)] désigne
l�écart-type de la fonction f , q1��=2 étant le quantile d�ordre 1� �=2 de la loinormale standard.
En comparant les formules (2.13) et (2.14) on s�aperçoit que les deux inégalitésont la même structure mathématique, dans le sens où les propriétés de la fonc-tion à intégrer et les propriétés de la suite échantillonnante sont séparées. Ene¤et, l�erreur d�approximation donnée par (2.13) est le produit de VHK [f ], quimesure l�irrégularité de la fonction f , par D�
N (u), qui mesure l�irrégularité de lasuite échantillonnante. De manière analogue, l�erreur d�intégration donnée par(2.14) est le produit de � [f ] qui mesure l�écart-type (donc l�irrégularité dansun sens probabiliste) de la fonction f par q1��=2=
pN qui mesure la vitesse de
convergence d�un échantillonnage basé sur une suite aléatoire.
Supériorité théorique de l�approche Quasi-Monte Carlo D�un pointde vue théorique, la majoration de l�erreur fournie par l�inégalité de Koksma-Hlawka présente deux avantages incontestables sur la formule (2.14) :� La formule (2.13) constitue une majoration à priori de l�erreur commise qui este¤ective et déterministe, tandis que (2.14) est une majoration probabiliste,vraie avec une probabilité 1 � � seulement. En d�autres termes, il subsistetoujours une incertitude quant à l�erreur commise dans l�approche MonteCarlo, alors que l�erreur est connue de manière certaine dans l�approche Quasi-Monte Carlo.
� La vitesse de convergence de la quadrature Monte-Carlo est voisine de 1=pN
quelle que soit la qualité du générateur pseudo-aléatoire choisi pour e¤ectuerles calculs, tandis que la vitesse de convergence de la quadrature Quasi-MonteCarlo dépend de la qualité de la suite échantillonnante utilisée. Cela signi�eque l�on peut espérer "accélérer" la quadrature Quasi-Monte Carlo en utilisantdes suites toujours mieux équiréparties.
Cependant, l�intérêt de l�inégalité (2.13) reste essentiellement théorique commenous le discutons ci-après.
De la di¢ culté opérationnelle pour estimer l�erreur d�intégration Dé-terminer l�erreur commise dans l�intégration Quasi-Monte Carlo revient à cal-culer le produit VHK [f ]D�
N (u). En pratique, il s�avère que cette estimation de
88

la variation d�une fonction4 et le calcul de la discrépance à l�origine d�une suitesont des tâches impossibles à réaliser avec des temps de calcul raisonnables. Celaest un désavantage par rapport à la méthode de Monte Carlo dans laquelle l�es-timation de l�erreur est rapide et systématique (il su¢ t de calculer la varianceempirique de la fonction f à partir de l�échantillon simulé).Par ailleurs, l�expérience montre que la majoration (2.13) surestime fortementl�erreur commise (cf. Ökten 1997), tandis que la relation (2.14) donne une esti-mation pertinente de l�erreur d�intégration de la quadrature Monte Carlo.En�n, la condition jVHK (f)j < +1 est restrictive, car elle impose en particulierque f soit bornée. Owen (2004) montre que cette condition est rarement véri�éepar les fonctions qui interviennent dans l�évaluation des produits optionnels.On déduit de ces observations que, contrairement à la méthode Monte Carlo,on ne sait pas calculer e¢ cacement l�erreur commise dans une quadrature detype Quasi-Monte Carlo (Snyder 2000, Warnock 2001, Owen 2005). Ce pro-blème constitue le principal obstacle à la mise en oeuvre opérationnelle de laméthode de Quasi-Monte Carlo. Toutefois, comme nous le verrons dans la der-nière section, il est possible d�utiliser l�approche Quasi-Monte Carlo comme uneméthode de réduction de variance dans l�approche Monte Carlo, ce qui permetde combiner les avantages théoriques et opérationnels des deux méthodes et, enparticulier, de calculer l�erreur d�intégration.
2.2.3 Suites à discrépance faible
Comme nous l�avons souligné, la discrépance correspond au taux de convergencethéorique de la méthode de Quasi-Monte Carlo. Dans ce paragraphe, nous en-visageons la possibilité de construire des suites de discrépance arbitrairementfaible.
Dé�nition
Pour espèrer "battre" la quadrature Monte Carlo, il nous faut rechercher dessuites de points déterministes dont la discrépance soit au moins inférieure à ladiscrépance d�une suite aléatoire (Un)n�1 de loi uniforme sur le cube unité. Ladiscrépance d�une telle suite véri�e ce que l�on appelle "la loi du logarithmeitéré" (cf. Tezuka 1995, p. 52) :
lim supN!+1
r2N
ln lnND�N (U)
p:s:= 1) D�
N (U)p:s:= O
rln lnN
N
!: (2.15)
La relation (2.15) prouve que les suites aléatoires uniformes sont équirépartiespresque-sûrement, ce qui nous permet de proposer une première dé�nition (em-pirique) du concept de suite à discrépance faible.
4Pour une ré�exion approfondie sur le calcul de la variation d�une fonction multidimen-sionnelle, le lecteur pourra consulter Bouleau et Lépingle (1993), Owen (2004) ou Tu¢ n(1997, 2005).
89

Dé�nition 2.6 On dit qu�une suite équirépartie est à discrépance faible si sadiscrépance est asymptotiquement meilleure que la discrépance d�une suite aléa-toire.
La dé�nition précédente donne un premier critère pour sélectionner les suiteséquiréparties susceptibles de donner satisfaction dans la quadrature Quasi-MonteCarlo. En revanche, elle n�indique pas s�il existe des suites dont la discrépanceest inférieure à
pN�1 ln lnN . Le résultat suivant, démontré par Halton (1960),
répond à cette interrogation.
Théorème 2.5 Pour toute dimension s � 1, il existe une suite u à valeursdans �Cs telle que :
D�N (u) = O
�(lnN)
s
N
�: (2.16)
Notons que le théorème précédent repose sur une preuve constructive : l�auteura explicité une famille de suites multidimensionnelles véri�ant (2.16). Ces suitessont appelées les suites de Halton et elles seront présentées en détail dans lasection 2.4. On connaît aujourd�hui d�autres suites équiréparties dont la discré-pance est de l�ordre de O ((lnN)s =N). Elles portent généralement le nom deleur auteur. Les plus connues sont les suites de Faure, les suites de Sobol etles suites de Niederreiter. Pour une analyse détaillée de la construction de cessuites, nous renvoyons le lecteur à Faure (1982), Niederreiter (1992), Thiémard(2000a), Jäckel (2002) et Glasserman (2004).
La conjecture suivante montre que la relation (2.16) dé�nit un ordre de grandeuroptimal pour la discrépance d�une suite équirépartie (Drmota et Tichy 1997, p.40).
Conjecture 2.6 Pour toute dimension s � 1, il existe une constante Cs > 0,telle que pour toute suite u à valeurs dans �Cs on a l�inégalité :
D�N (u) � Cs
(lnN)s
Npour une in�nité de valeurs de N . (2.17)
Cette conjecture a été prouvée dans le cas s = 1. Il est communément admispar les spécialistes qu�elle est vraie pour s � 2. Cela nous amène à proposer uneseconde dé�nition pour la notion de suite à discrépance faible, plus précise quela dé�nition 2.6.
Dé�nition 2.7 Une suite u à valeurs dans �Cs est dite à discrépance faible, siD�N (u) = O
�(lnN)s
N
�.
Etant donné que la discrépance mesure la vitesse de convergence de la quadra-ture (2.4), les suites à discrépance faible (au sens de la dé�nition précédente)sont les meilleures suites équiréparties envisageables pour réaliser l�approxima-tion Quasi-Monte Carlo. Pour cette raison et a�n de souligner les analogies entre
90

l�approche Monte Carlo et l�approche Quasi-Monte Carlo, elles sont fréquem-ment appelées "générateurs quasi-aléatoires" par les spécialistes. Dans la suitede ce travail, nous emploierons indi¤éremment les termes "suites à discrépancefaible" et "générateurs quasi-aléatoires" bien que cette désignation puisse prê-ter à confusion : en e¤et, les suites à discrépance faible n�ont absolument riend�aléatoire. Elles reposent sur des schémas de construction déterministes quivisent à optimiser la distribution hautement uniforme des points dans le cubeunité.
Malédiction de la dimension La borne optimale (2.16) pour la vitesse deconvergence est une fonction croissante de la dimension s du problème par la pré-sence du terme (lnN)s. Cela suggère que la quadrature Quasi-Monte Carlo perdde son e¢ cacité lorsque la dimension du problème augmente. En conséquence, ilfaut augmenter le nombre de simulations pour maintenir l�erreur d�intégrationau-dessous d�un certain seuil lorsque la dimension augmente.
Il est communément admis que pour les dimensions supérieures à 20, la supé-riorité de l�approche Quasi-Monte Carlo sur l�approche Monte Carlo devientdiscutable (cf. Tu¢ n 1996b, Snyder 2000). Ce phénomène bien connu des spé-cialistes de l�analyse numérique est appelé la "malédiction de la dimension"(Judd 2006). Il s�explique par le fait que le schéma de construction déterministedes points hautement uniformes des suites à discrépance faible perd de son ef-�cacité dans les dimensions élevées, ce qui ralentit l�obtention de la propriétéd�équirépartition lorsque s devient arbitrairement grand. Nous reviendrons surce point lorsque nous mettrons en oeuvre les générateurs quasi-aléatoires présen-tés dans les sections 2.3 et 2.4. En particulier, nous montrerons comment utiliserl�intégration Quasi-Monte Carlo pour traiter des problèmes en dimension élevée.
De l�intérêt pratique de la borne optimale
L�équation (2.16) donne un ordre de grandeur asymptotique pour la discrépance,c�est-à-dire valide lorsque N ! +1. En pratique, elle n�a aucune utilité pourles valeurs de N utilisées qui sont tout au plus de l�ordre quelques dizaines demilliers. La �gure 2.1 représente le comportement de la fonction D�
QMC : N �!(lnN)
s=N pour di¤érentes valeurs de s. A�n de faciliter les comparaisons, nous
avons fait �gurer sur le même graphique la courbe d�équation D�MC : N �!p
N�1 ln lnN qui correspond à la discrépance d�une suite aléatoire uniforme.La comparaison des di¤érentes courbes amène plusieurs remarques : (i) la fonc-tion D�
QMC est croissante dans un premier temps, puis elle décroît vers 0 deplus en plus lentement quand la dimension augmente, (ii) elle peut atteindredes valeurs très élevées (de l�ordre de 1011 pour s = 15 au point maximum dela courbe rouge) et (iii) pour les valeurs de N raisonnables (inférieures à 106),D�QMC est presque toujours supérieure à la discrépance d�une suite aléatoire sauf
pour s = 1 et s = 2.
Concernant le point (i), un calcul de@D�
QMC
@N = (lnN)s�1
N (s� lnN) con�rme la
91

1,0E21
1,0E17
1,0E13
1,0E09
1,0E05
1,0E01
1,0E+03
1,0E+07
1,0E+11
1,0E+15
1,0E+00 1,0E+02 1,0E+04 1,0E+06 1,0E+08 1,0E+10 1,0E+12 1,0E+14 1,0E+16 1,0E+18 1,0E+20 1,0E+22
Nombre de simulations = N
Dis
crép
ance
Opt
imal
e
s=1
s=2
s=5
s=7
s=10
s=15
rand
Fig. 2.1 �Discrépance optimale d�un générateur quasi-aléatoire D�QMC =
(lnN)s
Npour s = 1; 2; 5; 7; 10 et 15. A comparer avec la discrépance d�une suite aléatoire
D�MC =
qln lnNN (courbe noire intitulée rand).
forme observée pour les courbes (croissante puis décroissance) et montre queD�QMC est maximale pour N ' es qui augmente très rapidement avec s. Concer-
nant le point (ii), en appliquant la formule de Stirling (i.e. s! � sse�sp2�s
lorsque s! +1) on obtient un équivalent du maximum atteint par D�QMC :
D�QMC (e
s) =ss
es� s!p
2�s�!s!+1
+1:
Le maximum de la borne optimale pour la discrépance devient très rapide-ment in�niment grand. En�n le point (iii) montre que, pour des valeurs de Nraisonnables les générateurs aléatoires ont un meilleur comportement que lesgénérateurs quasi-aléatoires dès que la dimension est supérieure à 2.
Ces di¤érentes remarques montrent que la borne D�QMC n�a aucune utilité pour
les valeurs raisonnables de N , car d�après la formule (2.8), la discrépance doittoujours être inférieure à 1. En conséquence, une comparaison des générateursquasi-aléatoires basée exclusivement sur l�ordre de grandeur asymptotique deleur discrépance n�a qu�un intérêt théorique. En e¤et, la plupart des applicationspratiques exigent des temps de calculs relativement courts (quelques minutes àquelques heures), ce qui impose de travailler dans un régime non-asymptotique
92

et avec des valeurs de N de l�ordre O�106�. Pour de telles valeurs de N , on
ne dispose aujourd�hui d�aucun résultat théorique permettant d�appréhender lecomportement des suites équiréparties.
On connaît aussi des suites, telles que la suite SQRT de Richtmyer, dont ladiscrépance asymptotique ne satisfait pas la dé�nition 2.7 et qui permettentcependant d�obtenir une convergence très rapide de la quadrature Quasi-MonteCarlo (Pagès et Xiao 1997, Takhtamyshev, Vandewoestyne et Cools 2007), cequi soulève le problème de la mesure de la discrépance dans les régimes non-asymptotiques.
Mesure de la discrépance en régime non-asymptotique
Les études empiriques menées par Schlier (2004a, 2004b) puis Takhtamyshev etal. (2007) ont montré que l�ordre de grandeur moyen de la discrépance dans lesrégimes non-asymptotiques est de l�ordre de :
D�N = O
�1
N�
�; 0:6 � � � 1; (2.18)
y compris pour les grandes valeurs de s. Ces résultats montrent que l�approcheQuasi-Monte Carlo conduit rapidement à des taux de convergence meilleurs quel�approche Monte Carlo dans de nombreux cas. Ils illustrent le fait que : (i) lesoutils disponibles actuellement ne sont pas adaptés pour décrire le comporte-ment de la discrépance pour les "petites" valeurs deN et (ii) qu�ils ne permettentpas d�expliquer les bonnes performances de l�approche Quasi-Monte Carlo. Onpeut penser que la recherche mathématique donnera des résultats théoriques quiviendront éclairer les résultats obtenus dans les travaux cités précédemment.
Dans les deux sections suivantes nous présentons deux familles de générateursquasi-aléatoires dont nous discutons les propriétés. Ces générateurs seront testésdans l�avant dernière section, ce qui permettra d�en évaluer les performances.
2.3 Suites de Weyl
Les suites de Weyl sont vraisemblablement les plus anciennes suites équirépar-ties connues. Leur construction a été proposée par Weyl (1916) dans le mêmeessai que celui où il donne une démonstration du théorème 2.2. Ces suites in-terviennent dans de nombreuses applications autres que l�intégration numérique(Chen, Bhatia et Sinha 2003). Elles existent sous d�autres noms dans la litté-rature : suites de Kronecker (Larcher 1988, Drmota et Tichy 1997), suites deTranslations Irrationnelles du Tore (Bouleau et Lépingle 1993, Patard 2001),suites fn�g (lire "n alpha modulo 1") (Coulibaly 1997), suites SQRT (Pagèset Xiao 1997, Tu¢ n 1997, Lebrere et al. 2001) ou encore suites de Richtmyer(James, Hoogland et Kleiss 1997, Takhtamyshev et al. 2007). Notons que la
93

suite de Richtmyer et la suite SQRT sont une seule et même suite particulière deWeyl que nous étudierons ultérieurement.
Les suites de Weyl sont des suites à discrépance faible au sens de la dé�nition2.6 : en e¤et, leur discrépance est nettement meilleure que celle d�une suite denombres aléatoires sans pour autant atteindre la borne optimale O ((lnN)s =N).Leur construction repose sur certaines propriétés des nombres irrationnels. Ellesont suscité beaucoup d�attention dans la littérature spécialisée des années 1960-1980 (Haber 1966, 1970, Niederreiter 1972, 1978, Kuipers et Niederreiter 1974).Depuis le début des années 1980, les spécialistes, en utilisant les propriétés desnombres rationnels, ont développé de nouvelles suites ou amélioré celles quiexistaient, obtenant ainsi des suites à discrépance encore plus faible comme lessuites de Halton, de Sobol ou de Faure. Cette démarche peut s�expliquer par lefait que :� les nombres irrationnels ne peuvent pas être représentés exactement sur lesordinateurs5 , ce qui a sans doute dissuadé certains spécialistes d�utiliser lessuites de Weyl pour résoudre des problèmes numériques,
� il est délicat de trouver des jeux de paramètres optimaux pour les suites deWeyl, de sorte que la découverte de "bonnes" suites tient essentiellement àl�intuition du chercheur,
� certaines suites de Weyl sont impliquées dans l�élaboration de générateurspseudo-aléatoires (Haber 1966, Heng, Qinghua et Fengshan 2005), ce qui peutintroduire une confusion dans l�esprit des utilisateurs potentiels qui ne saventplus vraiment si les suites de Weyl sont déterministes ou aléatoires.
Cependant, les suites de Weyl possèdent plusieurs atouts incontestables :
1. elles sont faciles à implémenter et s�exécutent rapidement sur les machinesactuelles,
2. elles se prêtent particulièrement bien au calcul parallèle (Hofbauer, Uhl etZinterhof 2006a, 2006b),
3. elles sont équiréparties pour presque tous les jeux de paramètres (au sensde la mesure de Lebesgue), ce qui signi�e qu�il n�existe pas de "mauvaises"suites de Weyl, alors qu�il existe de mauvais générateurs aléatoires oude mauvaises suites à discrépance faible (Pagès et Xiao 1997, Lebrere etal. 2001),
4. certaines d�entre elles (la suite de Richtmyer par exemple) ont une excel-lente équidistribution multidimensionnelle (James et al. 1997). Les testsdémontrent qu�elles rivalisent sans di¢ culté avec les meilleures suites connues,telle que la suite de Sobol, pour intégrer des fonctions en dimension trèsélevée (Pagès et Xiao 1997, Takhtamyshev et al. 2007).
Les points énoncés précédemment expliquent le regain d�intérêt, que l�on constatedans la littérature depuis la moitié des années 1990, pour ce type de suites équi-répartie. Nous commençons par présenter les suites de Weyl de manière générale,
5La précision est de l�ordre de 15 chi¤res signi�catifs sur les machines actuelles.
94

puis nous proposons une étude comparative inédite basée sur les projections bi-dimensionnelles de quelques suites citées dans la littérature. Nous terminonscette section en présentant un algorithme original qui permet de générer trèsrapidement, sur une machine standard, les termes successifs d�une suite de Weyl.
2.3.1 Eléments de théorie des nombres
Partie entière, partie décimale
On rappelle que pour tout x 2 R, il existe un unique entier relatif, appelé partieentière de x et noté bxc, tel que bxc � x < bxc + 1. On peut alors dé�nirfxg def= x � bxc 2 [0; 1[, la partie décimale de x. On étend ces dé�nitions auxvecteurs x = (x1; : : : ; xs) avec s � 2 en posant :
bxc = (bx1c ; : : : ; bxsc) 2 Zs;fxg = (fx1g ; : : : ; fxsg) 2 [0; 1[s ;
de sorte que la décomposition x = bxc+ fxg soit maintenue.
Comme x = bxc � 1 + fxg avec 0 � fxg < 1, on peut considérer que fxg est lereste de la division euclidienne (étendue aux réels ou aux vecteurs) de x par 1.
C�est pourquoi, on trouve dans la littérature la notation : fxg def= xmod1. Nousutiliserons indi¤éremment l�une ou l�autre des deux notations a�n de faciliter lalecture en fonction du contexte.
Rationnels, Irrationnels, Indépendance
On rappelle qu�un nombre réel x est rationnel s�il peut s�écrire sous la formex = p
q avec p 2 Z et q 2 N�. On dit que x est irrationnel, si x n�est pasrationnel, i.e. si pour tout m 2 Z� on a mx =2 Z. On note Q l�ensemble desnombres rationnels et RnQ l�ensemble des nombres irrationnels. Le concept denombre rationnel ou irrationnel s�étend sans di¢ culté aux vecteurs : on dit quele vecteur x = (x1; : : : ; xs)
0 2 Rs est rationnel, si x1; : : : ; xs sont tous rationnelset qu�il est irrationnel dans le cas contraire. La proposition suivante se démontreaisément.
Proposition 2.7 x 2 Rs est irrationnel si et seulement si pour tout m 2Zsn f0g on a hm;xi =2 Z.
Nous attirons l�attention du lecteur sur le fait que les vecteurs irrationnels sontles vecteurs dont au moins l�une des coordonnées est un nombre irrationnel. Ladé�nition suivante nous servira dans la suite.
Dé�nition 2.8 On dit que les nombres 1; x1; : : : ; xs sont linéairement indépen-dants sur Q si pour tout (r0; � � � ; rs) 2 Qs+1 on a :
r0 +sXi=1
rixi = 0) (r0; � � � ; rs) = 0Rs+1 :
95

Dé�nition 2.9 On dit qu�un nombre x 2 R est algébrique s�il est racine d�unpolynôme à coe¢ cients dans Q.
D�après la dé�nition précédente, les nombres rationnels sont algébriques (si x =pq 2 Q alors x est solution de l�équation x � p=q = 0) et les nombres de laforme x =
pp avec p 2 N sont algébriques (si x =
pp alors x est solution
de l�équation x2 � p = 0). Pour une discussion approfondie sur les nombresrationnels, irrationnels et sur leurs propriétés, nous invitons le lecteur à consulterl�ouvrage de Niven (1956). Nous disposons à présent des outils nécessaires pourprésenter les suites de Weyl.
2.3.2 Dé�nition et premières propriétés
D�une manière générale, on appelle suite de Weyl toute suite à valeurs dans[0; 1]
s dont le terme général un (n � 1) est donné par une relation de la forme :
un = fn�+ �g = (fn�1 + �1g; : : : ; fn�s + �sg) ; (2.19)
où le multiplicateur � def= (�1; : : : ; �s) et l�incrément �
def= (�1; : : : ; �s) sont deux
vecteurs de Rs.
C�est exclusivement le choix de � qui conditionne la propriété d�équirépartitionde la suite. Plus précisément, Weyl (1916) établit le résultat ci-dessous (voirdémonstration en Annexe B).
Théorème 2.8 Les propositions suivantes sont équivalentes :
1. la suite dé�nie par (2.19) est équirépartie,
2. le multiplicateur � est irrationnel dans Rs,3. les nombres 1; �1; : : : ; �s sont linéairement indépendants sur Q.
Il découle de ce théorème que les suites de Weyl à multiplicateur rationnelne sont pas équiréparties. Or, l�ensemble des vecteurs rationnels est Lebesgue-négligeable. On peut donc supposer que pour presque tout � 2 Rs la suite deWeyl de multiplicateur � sera équirépartie. Le résultat suivant con�rme cettehypothèse (Coulibaly 1997, Niederreiter 1978).
Théorème 2.9 Pour tout " > 0, la discrépance de la suite dé�nie par (2.19)est de l�ordre de :
D�N (u) = O
(lnN)
s+1+"
N
!(2.20)
pour presque tout � 2 Rs au sens de la mesure de Lebesgue sur Rs.
D�après ce théorème presque toutes les suites de Weyl sont à discrépance faibleau sens de la dé�nition 2.6. On pense qu�il n�existe pas de suite de Weyl à discré-pance faible au sens de la dé�nition 2.7. Toutefois, comme nous l�avons souligné
96

dans la discussion du paragraphe 2.2.3, l�ordre de grandeur asymptotique de ladiscrépance n�est qu�une indication sur la qualité d�une suite équirépartie.
En pratique, on ne connaît pas de vecteur irrationnel pour lequel la discrépancede la suite est donnée par la formule (2.20). La proposition suivante donne ladiscrépance des suites de Weyl pour certaines familles de nombres irrationnelsque l�on sait construire (Niederreiter 1978, pp. 995-996). Toutefois, l�ordre degrandeur obtenu est moins bon que (2.20).
Théorème 2.10 La discrépance d�une suite de Weyl est de l�ordre de :
D�N (u) = O
�1
N1�"
�(2.21)
pour tout " > 0, dès que les nombres �1; : : : ; �s véri�ent l�une ou l�autre desconditions suivantes :
1. les �i sont des nombres irrationnels algébriques,
2. les �i s�écrivent �i = eri avec r1; : : : ; rs rationnels distincts non nuls.
La borne dé�nie par (2.21) est asymptotiquement moins bonne que (2.20). Ce-pendant, la fonction N �! 1=N1�" décroît plus vite que la fonction N �!pN�1 ln lnN qui dé�nit la discrépance d�une suite aléatoire. Cela con�rme que
les suites de Weyl dé�nies par le théorème 2.10 sont de bonnes candidates pourl�intégration Quasi-Monte Carlo. Nous étudions ci-dessous quelques exemples desuites de Weyl construites sur la base du théorème 2.10.
2.3.3 Exemples de suites de Weyl
Dans ce paragraphe, nous présentons di¤érents jeux de paramètres proposésdans la littérature. Nous analysons le comportement des suites associées en exa-minant l�uniformité des projections de di¤érents couples de coordonnées choisisau hasard. Soulignons que toutes les suites évoquées ici ont une discrépance dontl�ordre de grandeur asymptotique est D�
N (u) = O�1=N1�"�.
Suites basées sur une famille d�irrationnels algébriques
Nous nous intéressons ici aux suites qui véri�ent la condition 1 du théorème2.10.
Suite SQRT (Richtmyer, 1951) Richtmyer (1951) propose de choisir :
� = (pp1; : : : ;
pps) ; (2.22)
où p1 < � � � < ps sont les s premiers nombres premiers. Cette suite est parfoisappelée suite SQRT à cause de la forme de son multiplicateur (Tu¢ n 1997). Lesnombres
ppi sont algébriques (
ppi est solution de l�équation x2 = pi) et l�on
peut démontrer qu�ils sont linéairement indépendants sur Q.
97

La �gure 2.2 représente les projections des 5000 premiers points de la suitede Richtmyer en dimension s = 120 sur les plans de coordonnées (1; 2), (8; 9),(29; 30), (62; 63), (96; 97) et (117; 118). Les quatre premiers plans sont issus deJäckel (2002) et nous avons choisi les deux derniers au hasard.Un examen des di¤érents plans de projection montre que la suite de Richtmyera un comportement tout à fait satisfaisant : les points sont distribués avec unegrande uniformité quelle que soit les coordonnées considérées. Cela con�rmeles très bonnes propriétés de ce générateur, soulignées par di¤érents auteurs(Haber 1970, James et al. 1997). La suite de Richtmyer est même considéréepar certains auteurs comme la suite de Weyl la plus performante connue à cejour (Pagès et Xiao 1997), notamment pour l�intégration Quasi-Monte Carlo engrande dimension (Takhtamyshev et al. 2007).
Suite NDR2 (Niederreiter, 1972) Niederreiter (1972) démontre que pourminimiser l�erreur d�intégration de certaines classes de fonctions dont les coe¢ -cients de Fourier sont bornés dans un sens dé�ni par l�auteur, il est souhaitablede choisir le vecteur � de sorte que les nombres 1; �1; : : : ; �s forment la based�une extension de corps de degré s + 1 sur Q. En considérant ce critère, lemultiplicateur dé�ni par (2.22) n�est pas optimal, car le corps Q[pp1; : : : ;
pps]
est de dimension 2s sur Q. C�est pourquoi il propose de choisir le multiplicateursuivant :
� =�21=(1+s); : : : ; 2s=(1+s)
�: (2.23)
Par construction, Q[21=(1+s); : : : ; 2s=(1+s)] est bien un corps de degré s+1 sur Qet les composantes de � sont indépendantes sur Q. Notons que l�on peut étendrece raisonnement à tout multiplicateur de la forme :
� =�p1=(1+s); : : : ; ps=(1+s)
�; (2.24)
où p est un nombre premier (Niederreiter 1978). Le choix p = 2 facilite l�im-plémentation en langage binaire. La �gure 2.3 représente di¤érentes projectionsbi-dimensionnelles de la suite de Niederreiter en base 2. Les plans de projec-tion sont les mêmes que ceux utilisés pour la suite de Richtmyer, ce qui permetde comparer le comportement des deux suites. La dimension s utilisée pour lasimulation est 120.Sur le premier plan de projection (plan (1; 2)) on observe de larges bandes pa-rallèles. Notons que les bandes seraient plus étroites si nous avions considéré lesdeux premières coordonnées de la suite de Niederreiter en dimension plus élevée(par exemple s = 500 ou s = 1000 ), ce qui s�explique de la manière suivante : lescoe¢ cients des deux premières coordonnées sont �1 = 21=(1+s) et �2 = 22=(1+s).Lorsque s devient arbitrairement grand, on peut former l�approximation :
�1 ' 1 +ln 2
s+ 1; �2 ' 1 +
2 ln 2
s+ 1;
de sorte que les premiers termes de la suite sont donnés (pour n <�s+12 ln 2
�) par :
un;1 = fn�1g 'ln 2
s+ 1n; un;2 = fn�2g '
2 ln 2
s+ 1n:
98

Fig. 2.2 �Projections des 5000 premiers points de la suite de Richtmyer sur 6plans engendrés par di¤érents couples d�irrationnels (�i; �i+1) donnés ci-après :premier plan (�1 =
p2; �2 =
p3), second plan (�8 =
p19; �9 =
p23), troisième
plan (�29 =p109; �30 =
p113), quatrième plan (�62 =
p293; �63 =
p307),
cinquième plan (�96 =p503; �97 =
p509), sixième plan (�117 =
p643; �118 =p
647).
99

Fig. 2.3 �Projections des 5000 premiers points de la suite de Niederreiter enbase 2 sur 6 plans correspondant à di¤érents couples d�irrationnels (�i; �i+1) :premier plan (�1 = 21=121; �2 = 22=121), second plan (�8 = 28=121; �9 =29=121), troisième plan (�29 = 229=121; �30 = 230=121), quatrième plan (�62 =262=121; �63 = 263=121), cinquième plan (�96 = 296=121; �97 = 297=121), sixièmeplan (�117 = 2117=121; �118 = 2118=121).
100

Cela implique une relation de la forme un;2 ' 2un;1, où un;i désigne la ii�eme
coordonnée du point un. La pente des bandes observées est donc de l�ordrede 2. Cette disposition est assez fréquente avec les suites équiréparties dontles paramètres "optimaux" dépendent de la dimension du problème. Dans lecas de la suite de Niederreiter, cela ne constitue pas un handicap majeur, carl�expérience montre que les coordonnées sont très rapidement uniformémentdistribuées.
Suites basées sur une famille d�exponentielles
Les suites présentées ici véri�ent la condition 2 du théorème 2.10. Leur mul-tiplicateur s�écrit � = (er1 ; : : : ; ers) où r1; : : : ; rs sont des nombres rationnelsdistincts et non nuls. Elles sont connues sous le nom de suites de Baker, depuisque A. Baker en a établi les propriétés théoriques (Niederreiter 1978, p. 993).
Zinterhof (1987) propose di¤érents choix pour les coe¢ cients ri selon la dimen-sion du problème.� Lorsque s est inférieur à 8, il pose :
ri = i; (2.25)
� Lorsque s est supérieur à 8 les coe¢ cients ri sont :
ri =pips+1
; i = 1; : : : ; s; (2.26)
où pi désigne le ii�eme nombre premier. Ces familles de coe¢ cients sont trèssimples à construire.
On peut toutefois choisir d�autres valeurs pour les ri. Zinterhof (1994) proposeune famille de coe¢ cients qui se prêtent bien à une parallélisation des calculs :
r(k)i = k +
i
s; k 2 N; i = 1; : : : ; s: (2.27)
L�entier k dé�nit le numéro du processeur utilisé. Les projections obtenues avecles suites (2.26) et (2.27) ressemblent fortement aux projections de la �gure 2.3,ce qui nous a conduit à ne pas les présenter. La raison en est que les coe¢ cientsdu multiplicateur dépendent de la dimension du problème.
Judd (1998) propose de choisir :
ri =1
pi; i = 1; : : : ; s; (2.28)
où pi désigne le ii�eme nombre premier. Plus récemment, Hofbauer, Uhl et Zin-terhof (2006a, 2006b) utilisent la suite dé�nie par :
ri =1
i; i = 1; : : : ; s: (2.29)
101

Selon les auteurs, cette suite se prête elle aussi particulièrement bien au calculdistribué. Ces deux suites ont un comportement très similaire : les projectionsen dimension élevée ont tendance à former des bandes de plus en plus denses,parallèles entre elles. Cela provient du fait que ri ! 0 lorsque i! +1. Prenonsl�exemple de la suite dé�nie par (2.28) : pour i su¢ samment grand, on peutformer l�approximation :
�i ' 1 +1
pi; �i+1 ' 1 +
1
pi+1:
Alors, pour toutes les valeurs de n < pi on obtient :
un;i 'n
pi; un;i+1 '
n
pi+1) un;i+1 '
pipi+1
un;i:
Cela signi�e que les jeux de coordonnées consécutives tendent à s�ajuster surdes droites parallèles de pente pi
pi+1. A�n de véri�er cette analyse, nous donnons
sur la �gure 2.4 les plans de projection de la suite de Judd pour les couples decoordonnées utilisés dans les exemples précédents. Le lecteur remarquera que laqualité des projections se dégrade très rapidement lorsque i augmente.
Nous avons remarqué au cours de di¤érents tests que nous ne présentons pasici, que la performance des suites basées sur des coe¢ cients de la forme eri avecri 2 Q� était moins bonne en comparaison des performances des suites SQRT etNDR2. Plus généralement, le comportement des suites de Weyl est très sensibleau choix des coe¢ cients du multiplicateur.
Nous discutons dans la suite les problèmes liés à l�implémentation des suites deWeyl.
2.3.4 Implémentation des suites de Weyl
Considérons la suite réelle de terme général :
vn = fna+ bg = (na+ b)mod 1; (2.30)
où a est un nombre irrationnel et b est un réel quelconque. Une implémentationnaïve de cette suite consiste à calculer directement les termes fna+ bg ce quiimplique une multiplication par n (cette opération peut être assez lente lorsquel�on opère sur des variables de type double) et un appel à l�opérateur partieentière b:c (noté floor(.) en langage C/C++) qui est, lui aussi, assez lent. Deplus, étant donné que les nombres sont représentés avec une précision �nie (15chi¤res signi�catifs pour le type double en langage C/C++), il y a une perte deprécision dans les calculs lorsque n devient arbitrairement grand. Nous allonsmontrer ci-dessous qu�il est possible de générer les termes successifs de manièreextrêmement rapide et en minimisant la perte de précision. A�n de faciliter lalecture on utilise la notation xmod1 pour fxg.
102

Fig. 2.4 �Projections des 5000 premiers points de la suite dé�nie par (2.28)sur 6 plans engendrés par di¤érents couples d�irrationnels (�i; �i+1) donnés ci-après : premier plan (�1 = e1=2; �2 = e1=3), second plan (�8 = e1=19; �9 =e1=23), troisième plan (�29 = e1=109; �30 = e1=113), quatrième plan (�62 =e1=293; �63 = e
1=307), cinquième plan (�96 = e1=503; �97 = e1=509), sixième plan(�117 = e
1=643; �118 = e1=647).
103

Proposition 2.11 Soit x et y deux réels, alors
(x+ y)mod 1 = (xmod1 + ymod1)mod 1: (2.31)
Proof. Ecrivons
x+ y = bxc+ byc+ xmod1 + ymod1= bxc+ byc+ bxmod1 + ymod1c| {z }
2Z
+ (xmod1 + ymod1)mod 1| {z }2[0;1[
:
Par unicité de la partie décimale, on déduit le résultat annoncé.Tout d�abord, en faisant n = 0 dans (2.30) on obtient :
v0 = bmod1;
ce qui prouve que b n�intervient que par l�intermédiaire de sa partie décimale.Par ailleurs, pour n � 1, la relation (2.31) nous permet d�écrire :
vn = (na+ b)mod 1
= ((n� 1) a+ b+ a)mod 1= (((n� 1) a+ b)mod 1 + amod1)mod 1= (vn�1 + amod1)mod 1: (2.32)
Nous remarquons que le coe¢ cient a n�intervient, lui aussi, que par l�intermé-diaire de sa partie décimale dans (2.32). Donc, la suite de terme général vnest entièrement déterminée par les parties décimales de a et de b. Par ailleurs,on déduit de (2.30) et (2.32) que les termes successifs de la suite véri�ent larécurrence suivante :
v0 = ~b; vn = (vn�1 + ~a)mod 1; (2.33)
où l�on a posé ~a def= amod1 2 ]0; 1[ et ~b def= bmod1 2 [0; 1[. Notons que la partiedécimale de a est strictement positive, car a est irrationnel. On comprend à pré-sent pourquoi les suites de Weyl portent le nom de "translations irrationnelles" :en e¤et, le terme de rang n se déduit du terme de rang n�1 par une translationdont le paramètre (le nombre ~a dans le cas considéré) est un irrationnel.
La récurrence obtenue permet de construire les termes de la suite de procheen proche en utilisant une seule addition pour chaque terme et non plus unemultiplication et une addition, ce qui accélère un peu l�algorithme. En revanche,(2.33) fait appel à la fonction partie décimale à chaque étape. Le lemme suivantmontre qu�il est encore possible d�accélérer les calculs.
Lemme 2.12 Soit 0 � x < 1 et 0 � y < 1, alors :
(x+ y)mod 1 =
�x+ y si x < 1� yx+ y � 1 si x � 1� y : (2.34)
104

Proof. Il su¢ t de distinguer des cas. Si 0 � x < 1 � y, donc 0 � x + y < 1 =(x+ y)mod 1 par unicité de la partie décimale. Si maintenant on a 1�y � x < 1,alors 1 � x+ y < 1+ y, puis 0 � x+ y� 1 < y < 1, ce qui prouve que x+ y� 1est bien la partie décimale de x+ y.On peut formuler une récurrence sur les termes de la suite qui ne fait plusintervenir la fonction partie décimale :
v0 = ~b; vn =
�vn�1 + ~a si un�1 < �avn�1 � �a si un�1 � �a
; (2.35)
où l�on a posé �a def= 1� ~a 2 ]0; 1[.
A�n d�illustrer la réduction du temps de calcul obtenue grâce aux transfor-mations proposées auparavant, nous donnons ci-dessous les temps d�exécutionrelatifs des méthodes (2.30), (2.33) et (2.35). Le nombre de simulations est 109.
Méthode (2.30) (2.33) (2.35)
Temps d�exécution relatif 100:00% 73:00% 68:62%Réduction de temps �27:00% �31:38%
Par rapport à une implémentation naïve de la formule (2.30), le gain en terme detemps de calcul est voisin de 27% avec la méthode (2.33) et de l�ordre de 32%,lorsque l�on utilise la récurrence (2.35). Ces résultats valident l�étude menéedans le paragraphe.
Nous donnons ci-dessous un algorithme basé sur la récurrence (2.35) permettantde générer de proche en proche les termes d�une suite de Weyl vectorielle dé�niepar (2.19).
Algorithme 3 Construction par récurrence d�une suite de WeylDonnées : les tableaux a[ ], aa[ ] et u[ ] dé�nis par :
a[i] = �imod1; aa[i] = 1� a[i]; u[i] = un�1;i; i = 1; : : : ; s:
Résultat : le tableau u[ ] mis à jour.
for i = 1 to s doif (u[i] < aa[i]) thenu[i] u[i] + a[i]
elseu[i] u[i]� aa[i]
end ifend for
105

Conclusion
Comme le soulignent James et al. (1997), les générateurs quasi-aléatoires deWeyl ne semblent pas avoir suscité beaucoup d�attention dans la littérature �-nancière. Bien souvent, les auteurs préfèrent utiliser des suites à discrépancefaible telles que les suites de Halton, de Sobol ou de Faure. Cela provient sansdoute du fait que certains spécialistes se sont détournés de ce type de géné-rateurs, redoutant des problèmes d�arrondis ou de propagation d�erreurs. Uneautre explication à ce manque d�intérêt pour l�échantillonnage de Weyl est peut-être la di¢ culté pour déterminer des familles d�irrationnels permettant d�obtenirune excellente équidistribution dans toutes les dimensions. En cela, le générateurSQRT de Richtmyer est remarquable.
2.4 Suites de Halton
La famille de suites étudiées dans cette section a été proposée par Halton (1960).Ce sont les plus anciennes suites à discrépance faible connues et elles sont encoretrès utilisées. Dans leur forme originale, elles donnent des résultats très satis-faisants lorsqu�il s�agit d�évaluer des intégrales en dimension modérée (s � 20).Par contre, leur performance se dégrade signi�cativement lorsque s augmente(Moroko¤ et Ca�isch 1994, Tu¢ n 1996a, Kocis et Whiten 1997). Ce phéno-mène est dû à une corrélation indésirable entre les coordonnées d�indices élevés(Chi 2004). Pour cette raison, certains praticiens préfèrent utiliser d�autres suitesà discrépance faible, telles que les suites de Sobol, réputées pour leur capacité àintégrer des fonctions en dimension élevée (Jäckel 2002, Da Silva et Barbe 2005).Toutefois, il est possible d�améliorer considérablement la perfomance des suitesde Halton en perturbant judicieusement le processus de construction des termesde la suite. A ce sujet Faure et Lemieux (2007) donnent une présentation ex-haustive des techniques de perturbation proposées depuis une trentaine d�annéeset ils procèdent à des comparaisons entre les di¤érentes solutions. Certains ré-sultats obtenus sont très encourageants et ils montrent que l�on sait aujourd�huiconstruire des suites de Halton, dites généralisées, dont la performance rivaliseavec celle des meilleures suites à discrépance faible connues. Dans un premiertemps, nous présentons les suites de Halton dans leur forme originale, puis nousprésentons une généralisation possible de ces suites, basée sur un procédé pro-posé par Chi, Mascagni et Warnock (2005), qui permet d�accroître considéra-blement leurs performances. En�n, dans le dernier paragraphe, nous abordonsles problèmes d�implémentation : en e¤et, il ne faudrait pas que les temps decalcul soient un frein à l�utilisation de ces suites. Nous présentons un algorithmeparticulièrement rapide pour générer les suites de Halton originales, basé sur lestravaux de Struckmeier (1995), puis nous démontrons un résultat original quipermet d�étendre le résultat précédent aux suites de Halton généralisées. Lesgains en terme de performance, de l�ordre de 65%, sont considérables.
106

2.4.1 Préliminaires : écritures b-adique
Dans ce paragraphe, nous �xons un entier b � 2. Nous commençons par dé�nirle développement b-adique d�un entier comme son écriture dans le système denumération en base b, puis nous considérons l�opération de renversement dunombre par rapport à la virgule décimale, appelée opération radicale inverse.
On pose Nbdef= f0; 1; : : : ; b� 1g l�ensemble des entiers strictement inférieurs à b
et Sb l�ensemble des suites à valeurs dans Nb, nulles à partir d�un certain rang.
Développement b-adique d�un entier
On rappelle que tout entier n 2 N peut s�écrire sous la forme :
n =
+1Xi=0
aibi; ai 2 Nb: (2.36)
Cette écriture est unique et on l�appelle le développement (ou la décomposition)b-adique de n. Les ai sont appelés les chi¤res (digits en anglais) de n en base b.L�égalité (2.36) suppose que le terme de droite ait une valeur �nie, ce qui signi�e
que les ai sont tous nuls à partir d�un certain rang !def= min fi : ai = 0g.
Lorsque n est strictement positif, ! véri�e :
b!�1 � k < b! , ! = 1 + bln k= ln bc ;
de sorte que (2.36) se réécrit :
n =
!�1Xi=0
aibi: (2.37)
On dit que (a0; : : : ; a!�1) sont les chi¤res signi�catifs de l�écriture de n en baseb et l�on note :
n � (a!�1 : : : a1a0)b :
Cette écriture est l�expression de n dans le système de numération en base b.
Remarque 2.4.1 Les nombres 0 et 1 sont les seuls nombres qui ont la mêmeécriture dans n�importe quelle base :
8b � 2; (0)b = 0; (1)b = 1:
En toute rigueur, il faudrait noter ai � ai (n; b) et ! � ! (n; b), pour marquer ladépendance des coe¢ cients de la décomposition par rapport à n et b. Cependant,la base b étant implicitement �xée dans ce paragraphe, nous décidons d�allégerles notations.
107

Détermination des ai
Si l�on note qidef=�n=bi
�, on peut démontrer que les ai sont donnés par la
formule suivante :
ai = qi � bqi+1 = qimod b; i 2 N: (2.38)
En remarquant que les qi véri�ent la récurrence
q0 = n; qi = bqi�1=bc ; (2.39)
on en déduit un algorithme simple pour déterminer les ai de proche en proche :étant donné un entier n � 0 et une base b � 2, l�algorithme calcule les ai et lesstocke dans un tableau a[ ]. On suppose que n < b� (partiquement � = 32 surune machine 32 bits), de sorte qu�il su¢ t de prendre a[ ] de taille � + 1 pourstocker tous les chi¤res signi�catifs.
Algorithme 4 Construction des ai de proche en procheDonnées : n � 0, b � 2, le tableau a[ ] initialisé à 0.Résultat : le tableau a[ ] avec a[i] = ai, pour 0 � i � �.
{Obtention des coe¢ cients par divisions euclidiennes successives}i 0; q kwhile q > 0 doa[i] qmod bi i+ 1q bq=bc
end while
On passe ! (n) = 1 + blnn= ln bc dans la boucle, donc la complexité de cetalgorithme est O (lnn).
Fonction radical-inverse
On appelle fonction radical-inverse en base b l�application b dé�nie par :
b (n) =
1Xi=0
aibi+1
; n 2 N; (2.40)
où les ai sont les chi¤res de n dans la base b. On note :
Ubdef= f b (n) : n 2 Ng (2.41)
l�image de N par b. Par construction, Ub � Q\ [0; 1[. L�application b réaliseune bijection de N vers Ub.
Remarque 2.4.2 Si l�on écrit n � (a!�1; : : : ; a0)b, alors on voit que b (n)est le nombre obtenu en renversant les chi¤res de n par rapport à la virguledécimale. On écrit b (n) � (0; a0a1a2 : : : a!�1)b.
108

L�algorithme présenté ci-dessous évalue b (n) enO (lnn) opérations. Il construitles ai de proche en proche (selon le principe de l�algorithme 4) et en les recombinesimultanément pour former b (n).
Algorithme 5 Evaluation directe de b(k)Données : n � 0; b � 2Résultat : u = b (n)
q k; u 0; invb 1=bwhile q > 0 dou u+ (qmod b)� invbinvb invb=bq bq=bc
end while
Nous disposons à présent de tous les éléments nécessaires à la bonne compré-hension des mécanismes des suites de Halton.
2.4.2 Suites de Halton originales
Dé�nition
On appelle suite de Van Der Corput en base b, la suite réelle dont le termegénéral est donné par
un = b (n) ; n 2 N: (2.42)
Les suites de Van Der Corput sont des suites à discrépance faible D�N (u) =
O (lnN=N) (voir Faure (1981) pour une discussion à ce sujet). Les suites deHalton généralisent les suites de Van Der Corput pour les dimensions s � 2.L�idée est de considérer simultanément plusieurs suites de Van Der Corput 2.42dans des bases di¤érentes.
Soit b1; : : : ; bs des entiers positifs premiers entre eux deux à deux. La suite deHalton de bases b1; : : : ; bs a pour terme général (Halton 1960) :
un =� b1 (n) ; : : : ; bs (n)
�; n � 1: (2.43)
Par construction, cette suite prend ses valeurs dans l�ensemble Ub1 � � � � �Ubs ,où Ubi � Q\ [0; 1[ désigne l�image de N par la fonction bi . Notons que dansnotre dé�nition nous avons supposé n � 1, de sorte que les composantes de (un)ne prennent que des valeurs strictement positives.
Proposition 2.13 Pour tout N � 1, la discrépance d�une suite de Halton vé-ri�e :
D�N (u) <
s
N+1
N
sYi=1
�bi � 12 ln bi
lnN +bi + 1
2
�= O
�(lnN)
s
N
�: (2.44)
109

Nous renvoyons à Niederreiter (1992) pour une démonstration de ce résultat. Lessuites de Halton sont donc des suites à discrépance faible et l�on peut démontrerque le choix optimal pour b1; : : : ; bs consiste à poser bi = pi où p1 < � � � < ps dé-signent les s premiers nombres premiers. En e¤et, ce choix est celui qui minimisela constante
Qsi=1
bi�12 ln bi
devant le terme (lnN)s =N . Souligons que le coe¢ cient
du terme dominantQsi=1
bi�12 ln bi
tend vers l�in�ni quand la dimension augmente.Cela incite à étudier le comportement des suites de Halton en dimension élevée.Nous discutons ce point dans le paragraphe suivant.
De la nécessité d�optimiser les suites de Halton
Examen des projections bidimensionnelles Pour illustrer le comporte-ment de la suite dé�nie par (2.43), nous considérons les projections des 5000 pre-miers points générés sur les plans de coordonnées (1; 2), (8; 9), (29; 30), (62; 63),(96; 97) et (117; 118) (voir �gure 2.5). En examinant successivement les di¤érentsplans, on observe une dégradation notable de la qualité des projections.� Sur les deux premiers plans (coordonnées (1; 2) et (8; 9)), la couverture ducarré unité est homogène et uniforme, ce qui est conforme à ce que l�on attendd�un générateur quasi-aléatoire.
� Les plans intermédiaires (coordonnées (29; 30) et (62; 63)) font apparaître desstries parallèles à la diagonale du carré. En particulier, sur le plan de coordon-nées (62; 63) on observe une dégradation substentielle de l�échantillonnage, carcertaines zones du plan (bandes blanches parallèles à la diagonale du carré)ne contiennent aucun point.
� Sur les plans de coordonnées (96; 97) et (117; 118), le phénomène identiféauparavant s�accentue : la totalité des points est concentrée sur deux bandesétroites et parallèles à la diagonale du carré. La majorité du plan de projectionest vide, ce qui signi�e que l�échantillonnage est de très mauvaise qualité.
La qualité d�un générateur quasi-aléatoire réside dans sa capacité à engendrerdes points dans le cube unité dont la distribution soit la plus uniforme et laplus homogène possible. Dans le cas de la suite de Halton, nous constatonsque, lorsque la dimension augmente, l�échantillonnage du cube unité est de plusen plus mauvais (au niveau des coordonnées élevées), ce qui rend cette suiteimpropre à intégrer e¢ cacement des fonctions comportant un grand nombre devariables. C�est la malédiction de la dimension évoquée en introduction. Notonstoutefois que, la suite de Halton étant équirépartie, nous sommes certains qu�enaugmentant le nombre de simulations, les points de la suite �niraient par couvrirl�intégralité des plans de projections quel que soit le couple de coordonnéesconsidéré. Pour une analyse approfondie des projections bidimensionnelles de lasuite de Halton, nous invitons le lecteur à se reporter aux travaux de Moroko¤et Ca�isch (1994) ou de Kocis et Whiten (1997).
Analyse des corrélations intra-coordonnées Pour expliquer l�apparitionde bandes parallèles à la diagonale du carré de pente 1 lorsque la dimensionaugmente, nous procédons à une analyse succincte des corrélations entre lescoordonnées des points projetés. Notre raisonnement s�inspire des travaux de
110

Fig. 2.5 �Projections des 5000 premiers points de la suite de Halton sur les 6plans engendrés par les couples de bases (bi; bi+1) donnés ci-après : premier plan(b1 = 2; b2 = 3), second plan (b8 = 19; b9 = 23), troisième plan (b29 = 109; b30 =113), quatrième plan (b62 = 293; b63 = 307), cinquième plan (b96 = 503; b97 =509), sixième plan (b117 = 643; b118 = 647).
111

Chi (2004) repris par Chi et al. (2005). Soit bi < bi+1 les bases associées auplan de projection (i; i + 1). On suppose i su¢ samment grand pour que bi lesoit aussi (par exemple bi � 100). On note un;i (resp. un;i+1) la ii�eme (resp.la (i+ 1)i�eme) coordonnée du point un. L�idée est de calculer la corrélation
entre les suites u�;idef= (un;i)n�1 et u�;i+1
def= (un;i+1)n�1 lorsque n parcourt
l�ensemble f1; : : : ; bi � 1g. Comme bi est su¢ samment grand, ce calcul a unsens. On remarque sans di¢ culté que pour 1 � n � bi � 1 on a :
un;i = bi (n) =n
bi; un;i+1 = bi+1 (n) =
n
bi+1: (2.45)
Donc, les suites u�;i; u�;i+1 sont liées par la relation :
u�;i+1 =bibi+1
u�;i; 1 � n � bi � 1: (2.46)
En utilisant (2.46) il vient :
Cov[u�;i; u�;i+1] =bibi+1
Var[u�;i]; Var[u�;i+1] =
�bibi+1
�2Var[u�;i]: (2.47)
Alors, le coe¢ cient de corrélation linéaire entre u�;i et u�;i+1 est donné par :
Cor[u�;i; u�;i+1] =Cov[u�;i; u�;i+1]
(Var[u�;i+1]Var[u�;i])1=2
=
bibi+1
Var[u�;i]��bibi+1
�2Var[u�;i]�Var[u�;i]
�1=2= 1: (2.48)
Ce résultat montre que sur un jeu de bi � 1 simulations, les coordonnées u�;iet u�;i+1 sont parfaitement corrélées, ce qui explique que les premiers pointssimulés s�alignent sur une bande de pente 1 (voir �gure 2.5, sixième projection).La raison pour laquelle plusieurs bandes parallèles apparaissent provient dufait que chaque coordonnée est translatée chaque fois que n atteint une valeurmultiple de bi (pour la coordonnée u�;i) ou de bi+1 (pour la coordonnée u�;i+1).Une analyse approfondie de ce phénomène est proposée par Chi (2004, pp. 21-23).
2.4.3 Suites de Halton généralisées
Les résultats du paragraphe précédent nous donnent une indication sur la ma-nière dont on peut procéder pour améliorer la distribution multidimensionnelledes suites de Halton. L�idée est de briser les corrélations entre les fonctionsradical-inverses qui déterminent les di¤érentes coordonnées. Nous présentonsquelques solutions ci-dessous avant de choisir celle qui nous paraît la plus e¢ -cace.
112

Quelques solutions envisagées dans la littérature
Depuis une trentaine d�années, di¤érents auteurs ont imaginé des techniquesplus ou moins complexes ou faciles à mettre en oeuvre.
1. Faure (1981) considère une suite de Van Der Corput généralisée, dé�niepar un =
P+1i=0 � (ai (n)) =b
i+1 où les ai sont les chi¤res de n en base b et� est une permutation de f0; 1; : : : ; b� 1g. En choisissant judicieusementla permutation, il parvient à réduire sensiblement discrépance de la suitede Van Der Corput.
2. Tu¢ n (1996a) considère une suite de Halton dont chaque composanteest une suite de Van Der Corput généralisée (au sens du point 1). Lespermutations sont choisies de manière à minimiser la discrépance de lasuite dimension par dimension. L�auteur ne fournit pas les permutationsutilisées, il donne simplement les résultats obtenus en terme de discrépancejusqu�à la dimension 16.
3. Kocis et Whiten (1997) proposent de remplacer l�indice de simulation ndans (2.43), par mL, où L est un nombre premier distinct de b1; : : : ; bs etm décrit N. Cela revient à ne considérer que les termes d�ordre mL de lasuite originale et, lorsque L est bien choisi, cela permet aussi de réduire lacorrélation entre les di¤érentes composantes de la suite. Ce type de suiteest appelé suite de Halton à sauts (Leaped-Halton sequence en anglais).Les auteurs déterminent la valeur de L optimale en minimisant l�erreurd�intégration sur un jeu de fonctions tests. Cette technique présente selonnous un inconvénient : en e¤et, il est toujours possible d�optimiser unesuite de points de manière à ce qu�elle "intègre" une fonction bien choisie.Mais il reste un doute sur la capacité de la suite à intégrer d�autres famillesde fonctions.
4. Wang et Hickernell (2000) proposent de choisir le point de départ de lasuite de Halton au hasard, ce qui revient à considérer la suite de termegénéral :
un =� b1(n+N1); : : : ; bs(n+Ns
�);
où N1; : : : ; Ns sont des entiers choisis au hasard. Une telle suite est appeléesuite de Halton à départ aléatoire (Random-Start Halton Sequence enanglais). Cette méthode ne permet pas de briser la corrélation entre lescomposantes de la suite (Chi 2004), mais elle performe mieux que la suitede Halton originale.
5. Chi (2004), puis Chi et al. (2005) considèrent des suites de Halton géné-ralisées au sens du point 1. avec des permutations de la forme �i(k) =!ikmod bi, où les !i sont choisis de manière à minimiser la discrépanced�un générateur linéaire congruentiel multiplicatif. Le critère utilisé pourla détermination de !i est une majoration de la discrépance bidimension-nelle d�un générateur congruentiel établie par Niederreiter (1978, p. 1025).Les tests numériques pratiqués par Faure et Lemieux (2007) montrent quecette suite est très performante.
113

6. Vandewoestyne et Cools (2006) discutent les di¤érentes techniques exis-tantes et proposent d�utiliser la permutation �i(k) = (bi � k)mod bi. Ilsmontrent que cette nouvelle suite présente une discrépance meilleure quela suite de Halton originale. Selon les tests pratiqués par Faure et Lemieux(2007), cette suite ne performe pas mieux que la suite originale, ce qui tendà prouver que la discrépance n�est pas un indicateur su¢ sant pour mesurerla qualité d�une suite équirépartie.
7. Faure et Lemieux (2007) ont proposé d�utiliser des permutations de laforme �i(k) = !ikmod bi, où les !i sont choisis de manière à optimisertoutes les projections bidimensionnelles de la suite. Ils procèdent selon uneméthode itérative pour déterminer les paramètres optimaux : le multipli-cateur sélectionné pour la ji�eme coordonnée (soit !j) est celui qui minimisela discrépance des suites bidimensionnelles (u�;i; u�;j) pour i = 1; : : : ; j�1.Lorsque le multiplicateur optimal !j est trouvé, on passe au rang j + 1.La suite ainsi obtenue donne des résultats très prometteurs selon les testspratiqués par les auteurs.
Les solutions envisagées peuvent être regroupées principalement en deux caté-gories : (i) celles qui consistent à introduire une permutation des chi¤res del�indice de simulation dans les di¤érentes bases et (ii) celles qui consistent àrandomiser la suite originale. Les résultats obtenus par Chi (2004), Chi et al.(2005) ou Faure et Lemieux (2007) incitent à choisir l�approche (i). Ci-dessous,nous présentons en détail la solution de Chi et al. (2005).
Fonction radical-inverse généralisée
Soit b � 2 et � une permutation de Nb = f0; 1; : : : ; b� 1g. On dé�nit la fonctionradical-inverse généralisée �(�)b en posant :
�(�)b (n) = b (� (n)) =
+1Xi=0
� (ai (n))
bi+1: (2.49)
Une permutation � étant choisie, on appelle suite de Van Der Corput généraliséeen base b la suite de terme général �(�)b (n) . Nous pouvons à présent dé�nir lessuites de Halton généralisées comme étant les suites dont le terme général estdé�ni par :
un =��(�1)b1
(n) ; : : : ; �(�s)bs
(n)�; n � 1; (2.50)
où �1; : : : ; �s sont des permutations opérant sur les ensembles Nb1 ; : : : ;Nbs etb1; : : : ; bs sont des entiers premiers entre eux. Lorsque chaque permutation estl�identité on retrouve la suite de Halton dans sa forme originale (2.43).
Choix de la forme des permutations
Il existe b! permutations de l�ensemble Nb. Parmi ces permutations, on ne consi-dère que celles qui laissent 0 invariant. La raison de ce choix est que les per-mutations qui ne laissent pas 0 invariant introduisent un biais dans la suite de
114

Halton (Chi 2004, Vandewoestyne et Cools 2006). Un choix commode consisteà retenir les permutations linéaires de la forme :
�b(k) = !kmod b;
où ! est une racine primitive de l�unité6 . Dans ce cas, �b est un générateurlinéaire congruentiel multiplicatif (de multiplicateur ! et de module b) de pé-riode maximale b�1. A présent, il nous faut déterminer un jeu de multiplicateursoptimaux !�1; : : : ; !
�s pour l�ensemble des coordonnées de la suite de Halton gé-
néralisée.
Détermination du multiplicateur optimal par minimisation de la dis-crépance Chi (2004) propose de choisir le multiplicateur optimal !� associéà la base b en optimisant un critère donné par Niederreiter (1978, p. 1025). Leprincipe est le suivant. Soit v la suite bidimensionnelle de terme général :
vk =
�k
b;!kmod b
b
�; 0 � k � b� 1;
où ! est une racine primitive de l�unité. Niederreiter montre que la discrépancede (v0; : : : ; vb�1) véri�e :
(b� 1)D�b�1 (v) � 2 +
lXj=1
qj ; (2.51)
où q1; : : : ; ql sont les quotients partiels du développement du rationel !=b enfraction continue7 . Chi recherche parmi toutes les racines primitives de l�unitémodulo b, celle dont la somme des quotients partiels est minimale. On la note !�.Il fournit un tableau des racines trouvées jusqu�en dimension 40. Les résultatsobtenus sur une intégrale test particulièrement délicate sont très encourageants.Toutefois, cette approche présente un inconvénient car, au niveau de certainescoordonnées, les multiplicateurs optimaux ne sont pas su¢ samment éloignés desorte qu�il subsiste des corrélations indésirables. Par exemple, pour les dimen-sions 13 et 14, les bases sont b13 = 41, b14 = 43 et les multiplicateurs trouvéssont !�13 = 17, !
�14 = 18 (Chi 2004, p. 29).
Détermination du multiplicateur par hybridation avec la suite deRichtmyer Selon Vandewoestyne et Cools (2006), une idée proposée par T.T.Warnock est de combiner le comportement initial de la suite de Richtmyer dé-�nie par (2.22) avec le comportement asymptotique de la suite de Halton. Lamotivation de l�auteur provient du fait que la suite de Richtmyer présente unebonne équidistribution dans toutes les dimensions (�gure 2.2). Le raisonnement
6Un entier ! est primitif modulo b si et seulement si !b�1mod b = 1 et ak�1mod b 6= 1pour k = 1; : : : ; b� 1.
7On rappelle que les qj sont des entiers supérieurs ou égaux à 1 et que, pour des raisonsd�unicité du développement, ql = 1 (Niederreiter 1992, p. 219).
115

est le suivant. Soit �b(k) = !kmod b l�image de l�entier k par la permutation�b. Lorsque k décrit 0; 1; : : : ; b� 1, la division euclidienne de !k par b s�écrit :
!k = bqk;b + !kmod b)!k
b= qk;b +
!kmod b
b;
où qk;b 2 N désigne le quotient de la division. Alors,
!k
bmod1 =
!kmod b
b; 0 � k � b� 1:
La suite de terme général !kb mod1 se comporte comme la suite de Richtmyerde base
pb dès que :
!k
bmod1 ' (k
pb)mod 1 0 � k � b� 1:
En faisant k = 1 dans l�approximation précédente, on obtient :
!
b'pbmod1 = f
pbg ) ! ' bf
pbg:
Comme ! doit être un nombre entier, il su¢ t de choisir l�une ou l�autre des deuxvaleurs suivantes :
!�def=jbfpbgk; !+
def=lbfpbgm; (2.52)
où dxe def= 1+bxc est le plus petit entier strictement supérieur à x. Pour e¤ectuerle choix, les auteurs proposent : (i) de déterminer les développements en fractioncontinue de !�=b = [q�1 ; : : : ; q
�l� ] et !
+=b = [q+1 ; : : : ; q+l+ ], (ii) de calculer les
sommes :
Q� =l�Xj=1
q�j ; Q+ =l+Xj=1
q+j
et (iii) de retenir la racine associée à la plus petite des deux sommes. En d�autrestermes, on choisit ! = !� si Q� < Q+ et sinon ! = !+. En appliquantcet algorithme pour chaque dimension, on obtient ainsi un jeu de coe¢ cientsoptimaux qui confèrent à la suite de Halton des propriétés d�équirépartition dela suite de Richtmyer. Dans cette approche, on ne teste pas si le multiplicateur! trouvé est une racine primitive de l�unité.
Construction d�une suite de Halton optimale Chi et al. (2005) proposentde mélanger les deux approches décrites auparavant. Le processus de sélectiondu multiplicateur associé à chaque dimension est le suivant : pour chaque basebi, on détermine le mutiplicateur !richt:i qui confère à la suite les propriétés dela suite de Richtmyer selon le procédé précédent. Ensuite deux cas peuvent seprésenter :� si !richt:i est une racine primitive de l�unité modulo bi, on pose !�i = !richt:i ,
116
� si !richt:i n�est pas une racine primitive de l�unité modulo bi, on détermine laracine primitive de l�unité modulo bi la plus proche de !richt:i selon le critère(2.51).
Cette technique présente deux atouts majeurs : (i) elle nous assure que lespermutations utilisées forment toutes des cycles de longueur maximal (car lemultiplicateur est une racine de l�unité) et (ii) la suite obtenue doit avoir uncomportement voisin de la suite de Richtmyer, c�est-à-dire une bonne équi-distribution multidimensionnelle. Nous donnons dans le tableau ci-dessous lescoe¢ cients optimaux pour les dimensions 1 � i � 50.
i bi !�i i bi !�i i bi !�i i bi !�i i bi !�i1 2 1 11 31 17 21 73 40 31 127 39 41 179 69
2 3 2 12 37 5 22 79 70 32 131 57 42 181 83
3 5 2 13 41 17 23 83 8 33 137 97 43 191 157
4 7 5 14 43 26 24 89 38 34 139 109 44 193 174
5 11 6 15 47 40 25 97 82 35 149 32 45 197 8
6 13 7 16 53 14 26 101 7 36 151 48 46 199 22
7 17 3 17 59 42 27 103 20 37 157 84 47 211 112
8 19 10 18 61 51 28 107 38 38 163 124 48 223 205
9 23 19 19 67 12 29 109 47 39 167 155 49 227 17
10 29 11 20 71 31 30 113 70 40 173 27 50 229 31
Notons que certains des multiplicateurs indiqués par Chi et al. (2005, p. 18) nesont pas des racines primitives de l�unité modulo la base correspondante. Nousen avons recensés trois qui sont consignés dans le tableau ci-dessous. La colonneintulée CMW contient les nombres originaux proposés par les auteurs.
i bi CMW !�i5 11 3 69 23 18 1946 199 32 22
Examen des projections bidimensionnelles
Pour conclure ce paragraphe, nous avons représenté (�gure 2.6) les projectionsbidimensionnelles de la suite de Halton optimale obtenue selon le procédé duparagraphe précédent. Les plans de projection sont identiques à ceux de la �gure2.5. Pour l�ensemble des plans considérés, la couverture du carré unité est ho-mogène et uniforme. On observe sur les plans de coordonnées (62; 63), (96; 97)et (117; 118) que les bandes parallèles à la diagonale principale du carré ontdisparu. Cela con�rme que nous avons brisé les corrélations intra-coordonnées.Le comportement de la suite est conforme à ce que l�on attend d�un générateurquasi-aléatoire. On peut donc considérer que l�optimisation a réussi. Des testscalculatoires viendront con�rmer ce que nous avons constaté visuellement.
117

Fig. 2.6 �Projections des 5000 premiers points de la suite de Halton optimale.Les 6 plans sont les suivants : premier plan (b1 = 2; b2 = 3), second plan(b8 = 19; b9 = 23), troisième plan (b29 = 109; b30 = 113), quatrième plan (b62 =293; b63 = 307), cinquième plan (b96 = 503; b97 = 509), sixième plan (b117 =643; b118 = 647).
118

2.4.4 Implémentation des suites de Halton
Une solution simple pour implémenter les suites de Halton consiste à mettre enoeuvre l�algorithme 5 pour déterminer la valeur de chacune des coordonnées.Notons que cet algorithme peut s�avérer assez lent (environ deux fois plus lentque le Mersenne Twister MT19937), ce qui incite à rechercher une implémen-tation plus e¢ cace. Struckmeier (1995) propose d�utiliser une transformationdite de Van-Neumann-Kakutani pour construire la suite de Van Der Corput parrécurrence. Nous en présentons une variante dans ce paragraphe.
Récurrence sur les écritures b-adiques
La proposition suivante nous montre comment déduire les chi¤res de l�écritureb-adique de n+ 1 à partir des chi¤res de l�écriture b-adique de n.
Proposition 2.14 Soit n 2 N, de développement b-adiqueP+1i=0 ai (n) b
i avec(ai (n))i2N 2 Sb. On pose :
qn = min fi : ai (n) < b� 1g ; (2.53)
l�indice du premier chi¤re strictement inférieur à b� 1 dans l�écriture de n.Les chi¤res de l�écriture b-adique de n+ 1 sont donnés par
ai (n+ 1) =
8<: 0 pour i < qn1 + aqn (n) pour i = qnai (n) pour i > qn
(2.54)
Proof. Comme (ai (n))i2N est nulle à partir d�un certain rang, alors qn tel quedé�ni dans (2.53) existe et est �ni. Ecrivons :
n =
qn�1Xi=0
ai (n) bi + aqn (n) b
qn ++1Xi>qn
ai (n) bi:
Par dé�nition de qn, on aPqn�1i=0 ai (n) b
i =Pqn�1i=0 (b� 1) bi = bqn�1. Injectons
ce résultat dans l�écriture précédente et simpli�ons, il vient :
n+ 1 = (1 + aqn (n)) bqn +
+1Xi>qn
ai (n) bi:
Comme 1+ aqn (n) < b, l�égalité précédente est l�écriture de n+1 en base b. Enidenti�ant les coe¢ cients ci-dessus avec les ai (n+ 1) on obtient (2.54).
Nous donnons ci-dessous un algorithme qui met à jour les ai (n), par détermina-tion de qn. Comme pour l�algorithme 4, les ai (n) sont stockés dans un tableaua[ ] de taille � + 1. Donc l�algorithme fonctionne pour les entiers n < b�.
119

Algorithme 6 Mise à jour des ai par détermination de qnDonnées : b � 2 et le tableau a[ ] avec a[i] = ai(n), pour 0 � i � �.Résultat : q = qn, a[i] = ai (n+ 1) pour 0 � i � �.q 0; bb b� 1while a[q] = bb doa[q] 0; q q + 1
end while
Lorsque n est �xé, on teste a[0]; : : : ; a[qn] en entrée de boucle : un calcul naïf de lacomplexité de l�algorithme n�est pas pertinent, car le résultat dépend du choix dek. En revanche, lorsque n parcourt f0; : : : ; b� � 1g, on peut évaluer la complexitémoyenne qui dépend de b et de b�. Pour 0 � i � �� 1, l�élément a[i] du tableauest testé en entrée de boucle si, et seulement si, a[0] = � � � = a[i� 1] = b� 1 et(a[i]; : : : ; a[� � 1]) 2 N��i
b . Donc, il existe b��i con�gurations possibles. Lorsquek prend les valeurs 0; : : : ; b� � 1, le nombre total de tests e¤ectués en entrée deboucle est donc :
��1Xi=0
b��i = b��1 +
1
b� 1
�� b
b� 1 ;
et la complexité moyenne sur b� appels consécutifs vaut :
Cb;� =
�1 +
1
b� 1
�� b
b� 1b�� = O
�1 +
1
b� 1
�:
La procédure présentée est donc en temps constant à b �xé.
Implémentation de la suite de Halton originale
Notre objectif est de construire directement b (n+ 1) connaissant b (n). Enutilisant la proposition 2.14, on montre que les termes successifs de la suite deVan Der Corput véri�ent une relation linéaire.
Proposition 2.15 Soit n 2 N, de développement b-adiqueP+1i=0 ai (n) b
i et qndé�ni par la relation (2.53). Alors, b (n+ 1) se déduit de b (n) selon la relationde récurrence :
b (n+ 1) = b (n) +1 + b
b1+qn� 1: (2.55)
120

Proof. Avec (2.54) et par dé�nition de b, on a :
b (n+ 1) =+1Xi=0
ai (n) =bi+1
= (1 + aqn (n)) =b1+qn +
+1Xi=1+qn
ai (n) =bi+1
= 1=b1+qn ++1Xi=qn
ai (n) =bi+1
= 1=b1+qn + b (n)�qn�1Xi=0
(b� 1)=bi+1
= b (n) + 1=b1+qn � (1� 1=bqn)
= b (n) + (b+ 1) =b1+qn � 1:
Ce qui établit la formule (2.55).
De ce résultat, nous déduisons un algorithme très simple qui détermine b (n+ 1)connaissant b (n) et le tableau a[ ]. Le tableau a[ ] est mis à jour par l�algorithme6. Le tableau auxiliaire b[ ] est a¤ecté une fois pour toute :
b[q] =b+ 1
bq+1; q = 0; : : : ; �:
Algorithme 7 Evaluation de b (n+ 1) après mise à jour des aiDonnées : b � 2, le tableau a[ ] avec a[i] = ai(n), pour 0 � i � � et u = b (n).Résultat : q = qn, a[i] = ai (n+ 1) pour 0 � i � � et u = b (n+ 1).
{Recherche de l�indice qn}bb b� 1; q 0while a[q] = bb doa[q] 0; q q + 1
end while
{Calcul de aqn (n+ 1) puis de b (n+ 1)}a[q] 1 + a[q]; u u+ b[q]
La complexité totale sur b� appels consécutifs estO (b�). A titre de comparaison,b� appels consécutifs de l�algorithme 5 ont une complexité en O (b� ln b�), ce quiest nettement moins bon.
Remarque 2.4.3 Les calculs sont e¤ectués en virgule �ottante, ce qui entraîneimmanquablement des erreurs d�arrondi à chaque étape. Celles-ci se propagentet s�ampli�ent puisque la variable u est réutilisée pour calculer chaque nouvelle
121

sortie. En conséquence, il est important de mesurer l�erreur commise par rapportà un calcul direct en fonction du compilateur utilisé. Nous recommandons detravailler avec des variables de type double, dès que le compilateur le permet.Sinon, une bibliothèque multiprécision permettra de résoudre ce problème audétriment de la rapidité de calcul.
A�n d�illustrer la réduction du temps de calcul obtenue grâce à l�algorithmeprésenté ci-dessus, nous donnons les temps d�exécution relatifs des algorithmes5 et 7. Le nombre de simulations est 109.
Algorithme 5 7
Complexité sur N appels O (N lnN) O (N)Temps d�exécution relatif 100:00% 4:55%Réduction de temps �95:45%
Par rapport à l�algorithme naïf 5, le gain de temps de calcul est voisin de 95%,ce qui est considérable. Ces résultats valident l�étude menée dans le paragraphe.Nous allons tenter de les étendre pour optimiser de manière similaire la suite deHalton généralisée.
Implémentation de la suite de Halton généralisée
A présent, nous montrons comment modi�er l�algorithme précédent pour générere¢ cacement les termes successifs d�une suite de Van Der Corput généraliséedé�nie par (2.49). La permutation utilisée est de la forme �b (k) = !kmod b où! est une racine primitive de l�unité modulo b.
Une solution immédiate pour implémenter les suites de Halton généraliséesconsiste à modi�er légèrement l�algorithme 5. On obtient l�algorithme ci-dessousqui évalue �(�b)b (n) en O (lnn) opérations. Il construit les ai de proche en procheet applique la permutation �b à chacun d�entre eux. Il recombine simultanémentles coe¢ cients pour former �(�b)b (n).
Algorithme 8 Evaluation directe de �(�b)b (n)
Données : n � 0; b � 2; 1 � ! < b
Résultat : u = �(�b)b (n)
q k; u 0; invb 1=bwhile q > 0 dou u+ (! � (qmod b))mod b� invbinvb invb=bq bq=bc
end while
Etant donné le gain de temps considérable obtenu lorsque nous avons décidéd�implémenter la suite de Halton par récurrence, il est intéressant de chercher
122

à mettre en oeuvre la même technique avec la suite de Halton généralisée. Pourcela, nous utilisons le résultat original ci-dessous : il donne la relation de ré-currence entre �(�b)b (n+ 1) et �(�b)b (n). Nous donnons une démonstration de laformule (2.56) en Annexe C.
Théorème 2.16 Soit n 2 N, alors �(�b)b (n+ 1) et �(�b)b (n) sont liées par larelation suivante :
�(�b)b (n+ 1) = �
(�b)b (n) +
b� !b� 1
�1
bqn+1� 1�+1f~aqn (n)<b�!g
bqn; (2.56)
où qn est dé�ni par (2.53) et où l�on a posé ~ai (n)def= �b (ai (n)).
Supposons à présent que les coe¢ cients ~ai (n) soient connus. Pour appliquer larécurrence (2.56) il nous faut : (i) déterminer qn à partir des ~ai (n), puis (ii)calculer les ~ai (n+ 1) à partir des ~ai (n). Les résultats suivants nous permettentde traiter ces deux points.
Proposition 2.17 Soit qn dé�ni par (2.53), alors :
qn = min fi : ~ai (n) 6= b� !g : (2.57)
Proof. �b est bijective de Nb = f0; 1; : : : ; b� 1g dans lui-même, donc :
ai (n) = b� 1, ~ai (n) = �b (b� 1) :
Pour conclure, il ne reste qu�à remarquer que �b (b� 1) = b�! (formule (2.86)établie en Annexe au paragraphe C).
Proposition 2.18 Les termes ~ai (n+ 1) sont donnés par la relation :
~ai (n+ 1) =
8<:0 pour i < qn(! � b+ ~aqn (n)) + b1f~aqn (n)<b�!g pour i = qn~ai (n) pour i > qn
: (2.58)
Proof. La relation (2.58) est une reformulation des résultats (2.87) et (2.91).
Les résultats précédents permettent d�écrire un algorithme qui calcule �(�b)b (n+ 1)
à partir de �(�b)b (n). L�algorithme utilise un tableau auxiliaire b[ ][ ], a¤ecté unefois pour toutes et dé�ni par :
b[q][1] =b� !b� 1
�1
bq+1� 1�+1
bq; b[q][2] = b[q][1]� 1
bq; q = 0; : : : ; �:
123

Algorithme 9 Evaluation de �(�b)b (n+ 1) et mise à jour des ~ai (n+ 1)
Données : b � 2, 1 � ! < b, le tableau a[ ] avec a[i] = ~ai(n), pour 0 � i � �
et u = �(�b)b (n).
Résultat : q = qn, a[i] = ~ai (n+ 1) et u = �(�b)b (n+ 1).
{Recherche de l�indice qn}bb b� !; q 0while a[q] = bb doa[q] 0; q q + 1
end while
{Calcul de �(�b)b (n+ 1) puis de ~aqn (n+ 1)}if a[q] < bb thenu u+ b[q][1]; a[q] a[q] + !
elseu u+ b[q][2]; a[q] a[q]� bb
end if
La complexité de cet algorithme sur b� appels consécutifs est O (b�), ce qui estéquivalent à la complexité de l�algorithme 7. Comme pour les suites de Haltonoriginales, on constate que l�algorithme 9 apporte un gain de temps signi�catifpar rapport à l�algorithme direct 8. Nous donnons dans le tableau suivant lestemps d�exécution relatifs des deux algorithmes. Le nombre de simulations est109.
Algorithme 8 9
Complexité sur N appels O (N lnN) O (N)Temps d�exécution relatif 100:00% 4:17%
Ecart de temps �95:83%
L�algorithme 9 est considérablement plus rapide que l�algorithme naïf 8 puisquela réduction du temps de calcul est de l�ordre de 96%. Notons que la réductiondes temps de calcul est du même ordre de grandeur que celle obtenue avec lasuite de Halton originale. Nous avons donc atteint notre objectif : les tempsde calcul ne constituent plus un obstable à l�utilisation de la suite de Haltongénéralisée.
2.5 Comparaison des temps de calcul
Nous disposons à présent de tous les éléments nécessaires pour tester l�e¢ cacitéopérationnelle de la méthode de Quasi-Monte Carlo. Dans cette section, nouscomparons les temps de calcul des générateurs étudiés dans ce chapitre à celuidu Mersenne Twister MT19937 qui est l�un des générateurs pseudo-aléatoires lesplus rapides. En e¤et, le temps de calcul est un élément déterminant lorsquel�on envisage la mise en oeuvre opérationnelle d�une méthode numérique et il
124

ne faudrait pas que le gain en terme d�uniformité soit obtenu au prix d�unedégradation importante de la vitesse de simulation.Les générateurs utilisés dans les tests ont été codés en C++ (compilateur :Microsoft Visual C++ 6.0) et la machine utilisée est la même que celle quia permis de réaliser les tests sur les générateurs pseudo-aléatoires (PC équipéd�un processeur Intel Pentium IV cadencé à 3:20GhZ, de 1Go de RAM et deMicrosoft Windows XP).
Les valeurs de N (nombre d�itérations) et de s (dimension du problème) sontles suivantes :
N = 2� 106; s = 500:
Pour ces valeurs des paramètres, les di¤érents générateurs produisent Ns = 109
nombres uniformes au total. Les générateurs testés sont la suite SQRT de Richt-myer, la suite de Halton originale (notée HALT) et la suite de Halton généraliséede Chi, Mascagni et Warnock (notée HCMW). Les deux suites de Halton sontimplémentées à l�aide des algorithmes rapides 7 et 9 obtenus auparavant. Lesrésultats sont donnés ci-dessous.
Générateur MT19937 SQRT HALT HCMW
temps d�exécution (s) 48:6 58:2 46:0 65:8temps d�exécution relatif 100% 119:7% 94:7% 135:3%
Le générateur MT19937 est pris comme référence dans ce comparatif : il met48:6 secondes pour e¤ectuer l�ensemble des simulations8 . Un rapide examen desrésultats obtenus montre que toutes les suites considérées (à l�exception de lasuite HALT) ont des temps de calcul légèrement supérieurs à ceux du générateurde référence. D�une manière générale, les résultats obtenus pour l�ensemble dessuites testées sont très encourageants, car les temps de calcul sont très prochesde ceux du générateur de référence qui est l�un des générateurs pseudo-aléatoiresles plus rapides.Avec un temps d�exécution de l�ordre de 46 secondes (inférieur d�environ 5:3%au temps de calcul du générateur de référence), le générateur de Halton (HALT)est le plus rapide du comparatif. La suite HCMW est la plus lente du comparatif :elle réalise les simulations en 65:8 secondes, ce qui correspond à un temps d�exé-cution environ 35% supérieur à celui du générateur de référence et environ 42%supérieur à la suite de Halton. Ce phénomène provient du fait que l�algorithmede la suite HCMW nécessite plus de calculs que celui de la suite de Halton. No-tons que cette performance ne constitue cependant pas un frein à l�utilisationde cette suite pour les applications opérationnelles.La suite SQRT prend la seconde position du comparatif : elle est environ 19:7%plus lente que le générateur de référence. Cela s�explique par le fait que l�algo-rithme 3 opère directement sur des variables réelles en double précision (type
8Nous avions trouvé 48:2 secondes dans le test comparatif entre les générateurs pseudo-aléatoires. L�écart observé provient du fait que les deux séries de tests n�ont pas été réaliséessimultanément. En e¤et, les temps de calcul d�une machine non spéci�quement dédiée aux testssont susceptibles de �uctuer légèrement d�une utilisation à l�autre en fonction des processuslancés sur la machine.
125

double dans la plupart des langages), ce qui "ralentit" les calculs. Si l�on tientcompte du fait que la suite de Halton n�est pas adaptée aux calculs en grandedimension, alors la suite SQRT est la meilleure du comparatif.
2.6 Quasi-Monte Carlo dans la pratique
D�un point de vue théorique, la méthode de Quasi-Monte Carlo est plus e¢ caceque la méthode de Monte Carlo, car son taux de convergence est asymptotique-ment meilleur que le taux de convergence obtenu en réalisant un échantillonnagealéatoire du domaine d�intégration. Cependant, cette "supériorité" reste essen-tiellement théorique car, en pratique, on rencontre deux di¢ cultés lorsque l�onmet en oeuvre la méthode de Quasi-Monte Carlo : (i) on ne dispose pas d�uneméthode systématique et pertinente pour estimer l�erreur commise (voir la dis-cussion du paragraphe 2.2.2) et (ii) on est conduit à réaliser un nombre desimulations toujours plus grand pour que la quadrature reste précise quand ladimension augmente (voir paragraphe 2.2.3).
Dans cette dernière partie, nous discutons ces deux di¢ cultés et nous mon-trons comment résoudre les problèmes soulevés précédemment en combinantl�approche Monte Carlo avec l�approche Quasi-Monte Carlo. L�idée est d�in-troduire une perturbation aléatoire dans la suite à discrépance faible que l�onenvisage d�utiliser, sans en changer les propriétés de haute uniformité (Tu¢ n1996b, 2005). Cela permet de pro�ter de la convergence rapide de la méthode deQuasi-Monte Carlo (car la qualité de l�échantillonnage reste inchangée) et d�esti-mer l�erreur d�intégration comme dans la méthode de Monte Carlo (car les suitessont devenues aléatoires). Cette approche est appelée méthode de Quasi-MonteCarlo Randomisée (RQMC). Pour une discussion approfondie sur les techniquesRQMC, on peut se reporter à Ökten (1997), Ökten et al. (2005) ou Lemieux(2008).
2.6.1 Randomisation des générateurs quasi-aléatoires
La randomisation d�une suite à discrépance faible est une tâche délicate : ene¤et il ne faut pas changer les propriétés de la suite en introduisant la pertur-bation aléatoire. Nous présentons ci-dessous deux méthodes de randomisation.La première méthode, due à Cranley et Patterson (1976), s�applique à tous lesgénérateurs quasi-aléatoires, tandis que la seconde est spéci�que aux suites deHalton (Wang et Hickernell 2000). Dans tous les cas, la technique de randomi-sation proposée est choisie de manière à ne pas dégrader les temps de calcul desgénérateurs.
126

Méthode du décalage aléatoire
Soit (un)n�1 une suite à discrépance faible dans le cube unité [0; 1]s. L�idée est
de considérer les suites (~un) dont le terme général est de la forme :
~un = fun + V g = (un + V )mod 1 2 [0; 1[s ; (2.59)
où V est une variable aléatoire de loi uniforme sur le cube unité et fxg = xmod1désigne la partie fractionnaire du vecteur x 2 Rs. Ce procédé est appelé laméthode du décalage aléatoire (random shift en anglais). On peut démontrerque la méthode du décalage aléatoire possède les deux propriétés suivantes.
1. Pour chaque réalisation v du vecteur aléatoire V , la suite (fun + vg)n�1est une suite à discrépance faible (voir Tu¢ n 1996b). Autrement dit, laméthode du décalage aléatoire permet de construire une in�nité de suitesà discrépance faible à partir d�une suite à discrépance faible donnée.
2. Comme V � U[0;1[s , chaque terme ~un de la suite randomisée suit la loiuniforme sur [0; 1[s, soit ~un � U[0;1[s (Lemieux 2008). Cette propriété nesigni�e pas que les termes successifs de la suite sont des réalisations mu-tuellement indépendantes de la loi uniforme sur le cube unité, elle signi�esimplement que chaque terme est une réalisation de la loi uniforme.
Dégradation des temps de calcul Considérons que le calcul de la fonctionx ! fx+ yg (x et y réels) se décompose en trois opérations élémentaires :l�addition a x + y, le calcul de b bac et la soustraction c a � b. Alors,pour générer le terme ~un de la suite randomisée, il faut ajouter 3s opérations aunombre d�opérations nécessaires pour générer le point un de la suite originale.En conséquence, si CN;s est la complexité de l�algorithme permettant de généreru1; : : : ; uN , alors la complexité de l�algorithme permettant de générer ~u1; : : : ; ~uNest donnée par :
~CN;s = CN;s + 3Ns:
En pratique, cela se traduit par une dégradation des temps de calcul lorsque ladimension et le nombre de simulations augmentent : par exemple, simuler N =105 termes de la suite randomisée en dimension s = 100, implique de réaliser30 millions d�opérations supplémentaires. La durée des calculs supplémentairessera d�autant plus évidente que les temps de calcul des générateurs avec lesquelsnous travaillons sont très faibles (i.e. CN;s << 3Ns).
Suites de Weyl à départ aléatoire
Dans le cas des suites de Weyl, la méthode du décalage aléatoire est particu-lièrement facile à implémenter et elle n�entraîne aucun temps de calcul sup-plémentaire. Cela provient du fait que les suites de Weyl sont dé�nies par descongruences modulo 1. Considérons le lemme suivant, dont nous donnons ladémonstration dans l�Annexe D.
Lemme 2.19 Pour tout x 2 Rs et V � U[0;1[s on a (x+ V )mod 1 � U[0;1[s .
127

Soit V � U[0;1[s et (un)n�1 une suite de Weyl dé�nie par un = (n�+ �)mod 1avec (�; �) 2 Rs. Alors, en appliquant la formule (2.31) il vient :
~un = (un + V )mod 1
= ((n�+ �)mod 1 + V )mod 1
= (n�+ � + V )mod 1
= (n�+ (� + V )mod 1)mod 1
= (n�+ Y )mod 1;
où l�on a posé Y def= (� + V )mod 1. D�après le lemme précédent, Y suit une loi
uniforme sur le cube unité. En conséquence, pour randomiser une suite de Weylde paramètres (�; �) 2 Rs, il su¢ t :1. de remplacer l�incrément � 2 Rs par une variable aléatoire Y de loi uni-forme sur [0; 1[s,
2. de générer les termes successifs de la suite randomisée à l�aide de l�algo-rithme rapide 3.
On remarque que les suites ainsi obtenues sont des suites de Weyl à incrémentaléatoire ou encore à départ aléatoire (par construction, ~u0 = Y ). Par ailleurs,nous avons obtenu le résultat annoncé en début de paragraphe : la méthode dudécalage aléatoire n�induit aucun calcul supplémentaire dans le cas de ces suites.
Suites de Halton à départ aléatoire
Dans le cas des suites de Halton, il n�est pas possible d�implémenter la méthodedu décalage aléatoire aussi e¢ cacement que pour les suites de Weyl. Si l�onsouhaite réduire les temps de calcul au maximum, il faut envisager une autreapproche. Wang et Hickernell (2000) proposent de choisir au hasard l�indice dedépart de chaque coordonnée de la suite : ils obtiennent ainsi une famille desuites de Halton randomisées dont le terme général est de la forme :
~un = ( b1(n+N1); : : : ; bs(n+Ns)); (2.60)
où N1; : : : ; Ns sont des entiers choisis au hasard. Les suites de Halton obtenuespar ce procédé sont appelées suites de Halton à départ aléatoire. Cette méthodeprésente un double intérêt : (i) elle ne modi�e pas les propriétés intrinsèques dela suite originale (Bouleau et Lépingle 1993) et (ii) elle ne dégrade pas les tempsde calcul, car on peut encore appliquer l�algorithme rapide 7 pour générer lestermes de la suite de proche en proche. Un autre aspect positif est qu�elle setranspose facilement aux suites de Halton généralisées en considérant :
~un = (�(�1)b1
(n+N1); : : : ; �(�s)bs
(n+Ns)); (2.61)
avec N1; : : : ; Ns aléatoires. Dans ce cas également, on peut continuer d�utiliserl�algorithme rapide 9 pour construire les points de la suite.
128

2.6.2 Méthode de Quasi-Monte Carlo Randomisée
Dans ce paragraphe, nous montrons comment utiliser les générateurs quasi-aléatoires randomisés pour déterminer l�erreur d�intégration dans l�approcheQuasi-Monte Carlo.
Construction de l�estimateur
L�idée est de construire des réalisations aléatoires et indépendantes de l�esti-mateur Quasi-Monte Carlo. Plus précisément, on considère la variable aléatoiresuivante :
QN (X)def=
1
N
NXn=1
f (~un(X)) ; (2.62)
où (~un(X)) désigne un générateur quasi-aléatoire randomisé par le vecteur X.Dans le cas où le générateur est une suite de Weyl, les termes ~un(X) sont donnéspar la formule (2.59) et X � U[0;1[s . Dans le cas des suites de Halton, ils sontdonnés par l�une ou l�autre des formules (2.60) ou (2.61) et X = (N1; : : : ; Ns)
0
où les Ni sont des entiers aléatoires et indépendants. Dans tous les cas,
~un(X) � U[0;1[s ; n = 1; : : : ; N: (2.63)
La variable QN (X) est appelée estimateur Quasi-Monte Carlo Randomisé (RQMC)de l�intégrale de f . Par construction, cet estimateur est sans biais :
E[QN (X)] =1
N
NXn=1
E[f (~un(X))] =
ZCs
f (u) du = I:
L�avant-dernière égalité provient du fait que, d�après la relation (2.63), on aE[f (~un(X))] =
RCs f (u) du.
On peut alors former l�estimateur Monte Carlo de l�intégrale cherchée en posant :
QL;Ndef=1
L
LXl=1
QN (Xl); (2.64)
où X1; : : : ; XL sont des copies i.i.d. de la variable X. Par construction, QL;Nest un estimateur sans biais et fortement consistant de I.
Estimation de l�erreur d�intégration
Dans la pratique, on approche la variance de QN (X), qui est une quantitéinconnue du problème, par son estimateur sans biais :
�2L[QN (X)] =1
L� 1
LXl=1
(QN (Xl)� QL;N )2: (2.65)
129

On peut alors construire un intervalle de con�ance de l�intégrale cherchée auniveau 1� � :
P
(���QL;N � I��� < q1��=2�2L[QN (X)]p
L
)=
M!11� �; (2.66)
où q1��=2 désigne le quantile d�ordre 1��=2 de la loi normale standard. L�erreurd�intégration est donc majorée par la quantité :
"M;N = q1��=2�2L[QN (X)]p
L: (2.67)
Comme la suite (~un(X)) possède les propriétés de haute uniformité de la suite(un), l�estimateur QN (X) prend des valeurs aléatoires très proches de l�inté-grale cherchée dès que N est su¢ samment grand. Cela signi�e que la variancede QN (X) doit être particulièrement faible. On peut donc espérer obtenir uneréduction de variance signi�cative par rapport à l�estimateur Monte Carlo clas-sique basé sur LN réalisations i.i.d. de la variable f (U), où U � U[0;1[s .
E¢ cacité de l�estimateur
Nous pouvons déterminer l�e¢ cacité de l�estimateur RQMC de la même manièreque nous l�avons fait pour l�estimateur Monte Carlo dans le Chapitre 1. L�indiced�e¢ cacité de l�estimateur est donné par :
E� (X;N) = Var[QN (X)]� ~cN ; (2.68)
où Var[QN (X)] désigne la variance de QN (X) et ~cN est le temps nécessaire pourcalculer QN (X).
En pratique, pour déterminer le temps de calcul ~cN , on peut procéder de lamanière suivante. Soit ~TLN le temps total nécessaire pour déterminer QL;N . Enremarquant que ~TLN correspond au temps qu�il faut pour construire L réalisa-tions i.i.d. de l�estimateur QN (X) on déduit :
~cN =~TLNL
: (2.69)
En conséquence, pour estimer l�e¢ cacité de l�estimateur Quasi-Monte CarloRandomisé sur un jeu de simulations, on applique la formule suivante :
cE� (X;N) ' �2L[QN (X)] ~TLNL : (2.70)
A titre de comparaison, l�e¢ cacité de l�estimateur Monte Carlo classique basésur LN réalisations i.i.d. de la variable f (U) est donnée par la formule :
cE�MC ' �2LN [f ]TLNLN;
130

où �2LN [f ] désigne la variance empirique de f (U) et TLN est le temps nécessairepour calculer l�estimation Monte Carlo de l�intégrale.
Les temps de calcul sont donc une composante à part entière de l�e¢ cacité desestimateurs. Cela justi�e à posteriori que nous ayons cherché à améliorer lavitesse d�exécution des générateurs quasi-aléatoires.
Dans le paragraphe suivant, nous mettons en oeuvre la méthode RQMC pourestimer le prix de l�option asiatique géométrique étudiée au Chapitre 1.
2.6.3 Evaluation d�un call asiatique géométrique
Les hypothèses sur la dynamique du sous-jacent et les caractéristiques de l�op-tion étudiée sont les mêmes que celles du Chapitre 1. Le problème est de déter-miner la quantité suivante :
C = E�e�rT �T
�où �T = max
��ST �K; 0
�; (2.71)
où r est le taux sans risque instantané, T et K désignent respectivement ladate d�expiration et le prix d�exercice de l�option, �ST = (
Qmk=1 Stk)
1=m est lamoyenne géométrique des cours du sous-jacent aux dates d�observation 0 � t1 <� � � < tm � T .
Dans un premier temps, nous montrons comment construire un estimateurQuasi-Monte Carlo de la valeur de l�option. Dans un second temps, nous testonsla méthode de Quasi-Monte Carlo Randomisée pour évaluer l�option considérée.
Ecriture du prix de l�option sous la forme d�une intégrale
On note hk = tk � tk�1 et Sk le cours du sous-jacent à la date tk. D�après lesrésultats obtenus au Chapitre 1, on sait que les cours aux dates d�observationvéri�ent le schéma récurrent suivant :
Sk = Sk�1 exp((r � �2=2)hk + �phkGk); k = 1; : : : ;m; (2.72)
où les variables G1; : : : ; Gm sont i.i.d. de loi N (0; 1).En appliquant cette formule de proche en proche à partir de S0 on obtientimmédiatement :
Sk = S0 exp
(r � �2=2)tk + �
mXk=1
phkGk
!def= k (G1; : : : ; Gk) : (2.73)
En d�autres termes, le cours à la date tk est une fonction de G1; � � � ; Gk.
En utilisant la formule (2.73) on a :
�T = �T (S1; : : : ; Sm)
= �T (1 (G1) ; : : : ;m (G1; : : : ; Gm))
= � (G1; : : : ; Gm) : (2.74)
131

Notons que la relation obtenue est indépendante de la formule mathématiquedu payo¤.Posons Uk = �(Gk) où � est la fonction de répartition de la loi normale stan-dard. Alors Uk � U (0; 1). La formule (2.74) se réécrit :
�T = ����1 (U1) ; : : : ;�
�1 (Um)�; (2.75)
où U1; : : : ; Um sont i.i.d. de loi U (0; 1).En injectant la formule (2.75) dans (2.71) on obtient :
C = E�e�rT �
���1 (U1) ; : : : ;�
�1 (Um)��
=
ZCm
e�rT����1 (u1) ; : : : ;�
�1 (um)�du1 : : : dum: (2.76)
Donc la valeur de l�option peut s�exprimer comme une intégrale sur le cube unitéCm que l�on peut approcher par la méthode de Quasi-Monte Carlo :
C ' e�rT
N
NXn=1
����1 (un;1) ; : : : ;�
�1 (un;m)�; (2.77)
où (un) est un générateur quasi-aléatoire.
Tests comparatifs
Les paramètres du modèle sont les mêmes que ceux utilisés au Chapitre 1 :r = 4%, � = 20%, T = 10 et S0 = K = 100. Les dates t1; : : : ; tm sont dé�niespar tk = kT=m avec m = 120, ce qui correspond à une fréquence d�observationmensuelle. La valeur théorique de l�option est C ' 17:8958.Nous utilisons ci-dessous la méthode de Quasi-Monte Carlo Randomisée pourapprocher la valeur de l�option avec les trois générateurs suivants : SQRT, HALT,HCMW. A�n de comparer l�e¢ cacité de l�approche RQMC avec celle de l�approcheMonte Carlo, nous faisons �gurer les résultats obtenus avec les estimateursMonte Carlo (MC), Monte Carlo Antithétique (MC-AV) et Monte Carlo Adap-tatif (MC-AD) étudiés au Chapitre 1. Le générateur pseudo-aléatoire est leMersenne Twister MT19937.Pour l�ensemble des simulations réalisées, nous avons utilisé la fonction inversegaussienne de Acklam.
Résultats obtenus Les valeurs de N (nombre de termes de l�estimateurRQMC) et de L (nombre de randomisations) sont les suivantes :
N = 5� 104; L = 10:
Pour ces valeurs des paramètres, les di¤érents générateurs produisent NL =5� 105 nombres uniformes au total.
Dans les deux tableaux ci-dessous, la colonne intitulée Err% donne l�erreur rela-tive d�approximation, donnée par la formule Err%= jC=C � 1j où C est le prix
132

estimé par simulation. La colonne intitulée Variance donne la variance empi-rique de l�estimateur calculée sur les simulations. La colonne intitulée E¢ cacitéfournit l�e¢ cacité de l�estimateur, calculée selon les règles du paragraphe 2.6.2.En�n, la colonne intitulée Gain donne le ratio E¢ cacité MC
E¢ cacité XX où XX désigne l�unedes autres méthodes envisagées. Ce ratio mesure le gain en terme d�e¢ cacité dela méthode XX par rapport à la méthode de Monte Carlo.
Monte Carlo (LN=500000)
Estimateur Prix Est. Int. Con�ance Err% Variance E¢ cacité Gain
MC 17.8842 [17.8149,17.9534] 0.065% 624.27 6.64E-02
MC-AV 17.9268 [17.8922,17.9613] 0.173% 155.38 2.33E-02 2.86
MC-AD 17.9250 [17.8897,17.9602] 0.163% 161.53 2.53E-02 2.62
Quasi-Monte Carlo Randomisé (L=10, N=50000)
Générateur Prix Est. Int. Con�ance Err% Variance E¢ cacité Gain
SQRT 17.8812 [17.8624,17.9000] 0.081% 9.225E-04 4.64E-03 14.32
HALT 17.8822 [17.8535,17.9108] 0.076% 2.140E-03 1.08E-02 6.18
HCMW 17.8937 [17.8862,17.9013] 0.011% 1.471E-04 7.46E-04 89.11
Les méthodes testées ont toutes un indice d�e¢ cacité plus faible que celui de laméthode de Monte Carlo classique. Le gain d�e¢ cacité apporté par les méthodesde réduction de variance classiques (MC-AV et MC-AD) se situe entre 2:6 et 2:9.En comparaison, le gain d�e¢ cacité apporté par la méthode RQMC est supérieurà 6:1, quel que soit le générateur quasi-aléatoire employé. La méthode RQMCest donc plus e¢ cace que les méthodes de réduction de variance classiques et lefacteur d�amélioration est supérieur à 2(' 6:18
2:86 ). Nous comparons ci-dessous lesindices d�e¢ cacité des générateurs quasi-aléatoires.Le générateur de Halton (HALT) s�avère le moins performant, puisque le gaind�e¢ cacité par rapport à la méthode MC est "seulement" de 6:18.Le générateur SQRT prend la seconde place du comparatif avec un gain de l�ordrede 14:32 par rapport à la méthode MC. Ce qui représente une amélioration del�e¢ cacité de l�ordre de 2:32(' 14:32
6:18 ) par rapport au générateur HALT.En�n, le générateur HCMW est le plus performant, car le gain en e¢ cacité est del�ordre de 89:11 par rapport à la méthode MC. Cela correspond à une multiplica-tion de l�e¢ cacité par un facteur égal à 6:22(' 89:11
14:32 ) par rapport au générateurSQRT et par un facteur égal à 14:42(' 89:11
6:18 ) par rapport au générateur de Haltonclassique.Par ailleurs, l�erreur relative est inférieure à 0:1% pour l�ensemble des généra-teurs quasi-aléatoires testés, alors qu�elle est supérieure à 0:1% avec les méthodesde réduction de variance MC-AV et MC-AD. Cela prouve que la méthode RQMCest non seulement plus e¢ cace que l�approche Monte Carlo mais aussi plus pré-cise. L�erreur minimale est égale à 0:011%. Elle est atteinte avec le générateurHCMW, ce qui con�rme la grande qualité de ce générateur quasi-aléatoire.Cette étude démontre que l�approche RQMC constitue une méthode d�intégra-tion numérique e¢ cace qui permet de déterminer la valeur d�une option avec unegrande précision. Par ailleurs, les temps de calcul avec la méthode RQMC sont
133

légèrement inférieurs à ceux des méthodes MC-AV et MC-AD. La méthode deQuasi-Monte Carlo Randomisée constitue donc une alternative intéressante auxméthodes de réduction de variance classiques pour évaluer des produits dérivéscomplexes.
Choix optimal de L et N Dans la pratique, le nombre maximal de simula-tions réalisables, i.e. le produit L�N , dépend exclusivement du temps de calcultotal que l�on peut allouer à l�évaluation du produit. Ainsi, dans l�exemple pré-cédent, nous avons réalisé 5 � 105 simulations au total et nous avons choisiL = 10 et N = 5 � 104. On peut toutefois se demander s�il existe une manièreoptimale de choisir L et N , pour obtenir une réduction de variance maximale,sachant le nombre total de simulations que l�on peut réaliser. Cette question estun problème ouvert et il n�existe pas de méthode systématique pour choisir Let N (Tu¢ n 2005). Les analyses suivantes permettent d�apporter un éclairagesur l�in�uence exercée par chacun des paramètres.Lorsque N augmente, on privilégie l�échantillonnage quasi-aléatoire ce qui per-met d�obtenir une estimation plus précise de l�intégrale à chaque randomisation.En conséquence, L diminue, de sorte que l�intervalle de con�ance estimé n�estpas signi�catif. Pour cette raison, on recommande de choisir L � 10.Inversement, lorsque L augmente, on privilégie la composante Monte Carlo del�approche. L�estimation de l�intervalle de con�ance est plus pertinente, car ellerepose sur un "grand" nombre de randomisations. En contrepartie, l�estimateurRQMC comporte moins de termes (N diminue), donc sa variance augmente etl�on perd en précision de calcul.L�utilisateur doit donc procéder à di¤érents tests, jusqu�à ce qu�il trouve uncouple (L;N) qui permette de minimiser l�intervalle de con�ance autour duprix cherché.
2.7 Conclusion
Dans ce chapitre, nous avons étudié la méthode d�intégration numérique deQuasi-Monte Carlo (QMC), qui peut être considérée comme une version déter-ministe de la méthode de Monte Carlo et nous avons montré comment mettreen oeuvre cette approche pour évaluer des produits dérivés.
Dans la seconde section, nous avons donné les fondements et propriétés théo-riques de l�approche Quasi-Monte Carlo. Elle repose sur un échantillonnage dé-terministe du domaine d�intégration de la fonction étudiée par des suites depoints hautement uniformes, appelées suites à discrépance faible ou généra-teurs quasi-aléatoires. L�utilisation de ces suites garantit un taux de convergenceasymptotique théorique de l�ordre de O((lnN)s=N) où s est la dimension duproblème et N est le nombre de simulations e¤ectuées, ce qui est nettementmeilleur que le taux de convergence de la méthode de Monte Carlo qui est del�ordre de O(1=
pN). Le principal inconvénient de la méthode de Quasi-Monte
134

Carlo est qu�il n�est pas possible d�estimer l�erreur d�intégration commise à par-tir des simulations réalisées, comme c�est le cas dans la méthode de Monte Carlo.La raison en est que les points utilisés sont déterministes et l�on ne dispose plusd�un outil tel que le théorème de la limite centrale pour construire un intervallede con�ance autour de la valeur de l�intégrale cherchée. Par ailleurs, la mé-thode QMC perd de son e¢ cacité lorsque la dimension du problème augmente,contrairement à la méthode de Monte Carlo dont la vitesse de convergence nedépend que du nombre de simulations réalisées.
Dans la troisième section, nous avons étudié la famille des suites de Weyl (1916),encore appelées suites de translations irrationnelles du Tore, qui reposent surles propriétés des nombres irrationnels. Nous avons présenté di¤érentes suites deWeyl proposées dans la littérature et nous avons comparé leur comportement enprojetant les points qu�elles génèrent sur di¤érentes faces du cube unité. La suiteSQRT de Richtmyer (1951) présente de très bonnes propriétés d�équidistributiony compris en dimension élevée. En�n, nous avons proposé un algorithme originalpour générer les termes successifs d�une suite de Weyl par récurrence. Les testspratiqués montrent qu�il réduit les temps de calcul d�environ 30% par rapportà une implémentation naïve du générateur.
Dans la quatrième section, nous avons étudié la famille des suites de Halton(1960), dont la construction repose sur les propriétés des nombres rationnels. Enétudiant les projections des points de ces suites sur di¤érents plans, nous avonsobservé qu�elles avaient une mauvaise équidistribution en dimension élevée. Nousavons alors envisagé di¤érentes approches pour améliorer leur équidistribution.Le générateur HCMW proposé par Chi et al. (2005), qui combine les propriétés dela suite SQRT de Richtmyer avec les propriétés des suites de Halton, donne desrésultats particulièrement satisfaisants. En�n, nous avons proposé deux algo-rithmes originaux pour générer par récurrence les suites de Halton classiques etgénéralisées. Ces algorithmes permettent de réduire les temps de calcul d�environ95% par rapport à une implémentation naïve de ces générateurs.
Dans la cinquième section, nous avons comparé les temps de calcul des di¤érentsgénérateurs étudiés en utilisant comme référence ceux du générateur pseudo-aléatoire Mersenne Twister MT19937. Les résultats obtenus montrent que lasuite de Halton est légèrement plus rapide que le Mersenne Twister, tandis quela suite SQRT et la suite HCMW sont légèrement plus lentes. Dans tous les cas, lestemps de calcul des générateurs sont du même ordre de grandeur que celui duMersenne Twister, donc ils peuvent être utilisés pour les simulations numériquesintensives.
Dans la sixième section, nous avons présenté la méthode dite de Quasi-MonteCarlo Randomisée (RQMC). Cette approche consiste à initialiser aléatoirementune suite à discrépance faible pour construire une série d�estimateurs Quasi-Monte Carlo aléatoires. En calculant la moyenne empirique de ces estimateurs,
135

on obtient une approximation non biaisée de l�intégrale cherchée. Le princi-pal avantage de la méthode RQMC est qu�elle converge rapidement comme laméthode de Quasi-Monte Carlo et que l�on peut construire un intervalle decon�ance pour le résultat obtenu comme dans la méthode de Monte Carlo.Nous avons appliqué la méthode RQMC au problème consistant à évaluer l�op-tion asiatique géométrique étudiée dans les tests du Chapitre 1. Les résultatsobtenus ont montré que cette nouvelle approche est nettement plus e¢ cace queles méthodes de réduction de variance classiques : elle permet de construire desintervalles de con�ance étroits autour du prix cherché et l�erreur d�intégrationest particulièrement faible.
136

A Quadratures déterministes classiques
En dimension 1, les quadratures classiques consistent à approcher I en calculantla moyenne pondérée des valeurs prises par la fonction aux n+1 points uk = k=npour k = 0; : : : ; n. On fait alors l�approximation :Z 1
0
f(u)du 'nXk=0
�kf (uk)
et l�erreur commise est :
"n =
Z 1
0
f(u)du�nXk=0
�kf (uk) :
Dans la méthode des rectangles, on prend �k = 1=n pour k = 0; : : : ; n � 1 et�n = 0. Si f est de classe C1 sur [0; 1], alors
j"nj �kf 0k1n
, où kf 0k1 = sup fjf 0(x)j : x 2 [0; 1]g :
Dans la méthode des trapèzes, on prend �0 = �n = 1=2n et �k = 1=n pourk = 1; : : : ; n� 1. Si f est de classe C2 sur [0; 1], alors
j"nj �kf 00k112n2
, où kf 00k1 = sup fjf 00(x)j : x 2 [0; 1]g :
L�extension des quadratures précédentes aux dimensions s � 2 implique d�éva-luer f aux n = (m+ 1)
s points uk1;:::;ks =�k1m ; : : : ;
ksm
�où chaque kd décrit
f0; : : : ;mg. Ensuite, on construit une approximation de la forme :Z�Cs
f(u)du 'mX
k1=0
� � �mX
ks=0
!k1 � � �!ksf (uk1;:::;ks) :
En dimension s, dès que la fonction f admet des dérivées partielles d�ordre 2,l�erreur d�approximation avec la méthode des trapèzes devient O
�n�2=s
�, ce qui
restreint considérablement la portée de la quadrature. Le nombre de n�uds croîtexponentiellement avec la dimension et la méthode atteint vite ses limites quands augmente : si 100 noeuds sont nécessaires pour obtenir le seuil de précisionsouhaité en dimension 1, alors pour maintenir le même degré de précision surl�estimation d�une intégrale en dimension s = 5, il faudra évaluer la fonction en1005 = 1010 points (soit dix milliards de points à calculer). Ce phénomène estappelé la "malédiction de la dimension". Il rend ces méthodes de quadratureimpraticables en dimension élevée.
137

B Démonstration du théorème 2.8
La démonstration repose sur l�utilisation du théorème 2.2. A�n de simpli�er lesraisonnements, nous e¤ectuons un calcul préliminaire :
hm;uni = hm; fn�+ �gi= hm;n�+ � � bn�+ �ci= hm;n�+ �i � hm; bn�+ �ci= n hm;�i+ hm;�i � hm; bn�+ �ci :
En utilisant le fait que :
m 2 Zsn f0g ) hm; bn�+ �ci 2 Z) e2�ihm;bn�+�ci = 1;
il vient :e2�ihm;uni = e2�ihm;�ine2�ihm;�i; m 2 Zsn f0g :
Alors, la somme de Weyl associée à u1; : : : ; uN (cf. théorème 2.2) s�écrit :
SN (�; �;m)def=
1
N
NXn=1
e2�ihm;uni =e2�ihm;�i
N
NXn=1
e2�ihm;�in: (2.78)
Nous pouvons à présent établir l�équivalence. L�ordre de la démonstration est lesuivant : (1))(2))(3))(1).
(1))(2) : supposons la suite u équirépartie. Si � n�est pas irrationnel, alors ilexiste m 2 Zsn f0g tel que hm;�i 2 Z. Dans ce cas, on a e2�ihm;�in = 1 pourtoute valeur de n 2 N�, de sorte que :
8N 2 N�; SN (�; �;m) = e2�ihm;�i 6= 0:
Par ailleurs, la suite étant équirépartie, elle véri�e (2.5), i.e. limN!+1 SN (�; �;m) =0. Il y a contradiction, donc � est nécessairement irrationnel.
(2))(3) : supposons � irrationnel. Soit r0; r1; : : : ; rs 2 Qs+1 tels que r0 +Psi=1 ri�i = 0. Notons ri = pi=qi avec qi 2 N� et posons R =
sQi=0
qi 2 N�,
~r0 = Rr0 et ~r = (Rr1; � � � ; Rrs)0. Par construction, on a ~r0 2 Z et ~r 2 Zs eth~r; �i = �~r0. Si ~r 6= 0, alors h~r; xi =2 Z car � est irrationnel. Ce cas est excluétant donné que �~r0 2 Z. Donc ~r est le vecteur nul puis ~r0 = �h~r; �i = 0.
(3))(1) : supposons 1; �1; : : : ; �s linéairement indépendants sur Q. Soit m 2Zsn f0g, alors hm;�i 6= 0 (sinon, on aurait trouvé une combinaison linéaire nullede 1; �1; : : : ; �s avec des coe¢ cients non tous nuls). Dans ce cas, les termese2�ihm;�in dans (2.78) forment une suite géométrique de raison e2�ihm;�i 6= 1 etl�on peut simpli�er l�expression de SN (�; �;m). On obtient tous calculs faits :
SN (�; �;m) =e2�ihm;�+�i
N
1� e2�ihm;�iN1� e2�ihm;�i : (2.79)
138

En prenant la norme de chaque membre de (2.79) et en remarquant que��e2�ihm;�+�i�� =
1 et que��1� e2�ihm;�iN �� � 1 + ��e2�ihm;�iN �� = 2, il vient :
jSN (�; �;m)j =��e2�ihm;�+�i��
N
����1� e2�ihm;�iN1� e2�ihm;�i
���� � 1
N
2��1� e2�ihm;�i�� : (2.80)
En passant à la limite dans (2.80) il vient limN!+1 SN (�; �;m) = 0. Donc lasuite u véri�e (2.5), ce qui prouve qu�elle est équirépartie.
C Démonstration du théorème 2.16
Nous commençons par énoncer une série de propositions qui simpli�eront ladémonstration. On rappelle que �b est une permutation de Nb dé�nie par larelation :
�b (k) = !kmod b; 0 � k � b� 1; (2.81)
où ! est une racine primitive de l�unité di¤érente de 1, ce qui impose :
1 � ! � b� 1: (2.82)
Proposition 2.20 Pour 0 � k � b� 1, on a la relation suivante :
(! + k)mod b = (! + k � b) + b1fk<b�!g: (2.83)
Proof. Comme 0 � k � b� 1 et avec (2.82) on a :
1 � ! + k � 2b� 2:
Il su¢ t alors de distinguer des cas.� si k < b� !, alors 0 � ! + k � b� 1, puis (! + k)mod b = ! + k.� si k � b � !, alors b � ! + k � 2b � 2, puis 0 � ! + k � b � b � 2, i.e.(! + k)mod b = ! + k � b.
Alors, on a :
(! + k)mod b = (! + k)1fk<b�!g + (! + k � b)1fk�b�!g= (! + k � b) + b1fk<b�!g:
Proposition 2.21 Pour 1 � k � b� 1, on a la relation suivante :
�b (k + 1) = (! + �b (k))mod b (2.84)
= (! � b+ �b (k)) + b1f�b(k)<b�!g (2.85)
139

Proof. Il su¢ t d�écrire :
�b (k + 1) = (! (k + 1))mod b
= (! + !k)mod b
= (! + �b (k))mod b:
On conclut en remarquant que 1 � �b (k) � b � 1 et en appliquant la formule(2.83).
Proposition 2.22 On a la formule suivante :
�b (b� 1) = b� !: (2.86)
Proof. Ecrivons :
�b (b� 1) = (! (b� 1))mod b= ((! � 1) b+ (b� !))mod b= (b� !)mod b:
Avec (2.82) il vient 1 � b� ! � b� 1, ce qui prouve que b� ! = (b� !)mod bpuis (2.86).
Proposition 2.23 Les chi¤res ~ai (n+ 1) sont donnés par la règle suivante :
~ai (n+ 1) =
8<: 0 pour i < qn(! + ~aqn (n))mod b pour i = qn~ai (n) pour i > qn
; (2.87)
où qn est dé�ni par (2.53).
Proof. Pour i < qn alors, ai (n+ 1) = 0 puis
~ai (n+ 1) = �b (ai (n+ 1)) = � (0) = 0:
Pour i > qn alors, ai (n+ 1) = ai (n) d�où
~ai (n+ 1) = �b (ai (n+ 1)) = �b (ai (n)) = ~ai (n) :
Pour i = qn, en appliquant (2.84) il vient :
~aqn (n+ 1) = �b (aqn (n+ 1))
= �b (1 + aqn (n))
= (! + ~aqn (n))mod b:
140

La formule (2.87) nous permet d�écrire la relation liant �(�b)b (n+ 1) et �(�b)b (n) :
�(�b)b (n+ 1) =
+1Xi=0
~ai (n+ 1)
bi+1
=~aqn (n+ 1)
bqn+1+
+1Xi>qn
~ai (n+ 1)
bi+1
=~aqn (n+ 1)
bqn+1+
+1Xi>qn
~ai (n)
bi+1
= �(�b)b (n) +
~aqn (n+ 1)� ~aqn (n)bqn+1
�qn�1Xi=0
~ai (n)
bi+1: (2.88)
Or, pour tout i < qn en utilisant (2.86) on a :
ai (n) = b� 1, ~ai (n) = �b (b� 1) = b� !:
Alors :qn�1Xi=0
~ai (n)
bi+1= (b� !)
qn�1Xi=0
1
bi+1=b� !b� 1
�1� 1
bqn
�: (2.89)
En injectant (2.89) dans (2.88), il vient :
�(�b)b (n+ 1) = �
(�b)b (n) +
~aqn (n+ 1)� ~aqn (n)bqn+1
� b� !b� 1
�1� 1
bqn
�: (2.90)
D�après (2.87) et avec (2.85) on a :
~aqn (n+ 1) = (~aqn (n) + !)mod b
= (! � b+ ~aqn (n)) + b1f~aqn (n)<b�!g: (2.91)
Alors,
~aqn (n+ 1)� ~aqn (n)bqn+1
=(! � b) + b1f~aqn (n)<b�!g
bqn+1
=1f~aqn (n)<b�!g
bqn� b� !bqn+1
: (2.92)
En injectant cette relation dans (2.90) on obtient :
�(�b)b (n+ 1) = �
(�b)b (n) +
1f~aqn (n)<b�!g
bqn� b� !bqn+1
� b� !b� 1
�1� 1
bqn
�= �
(�b)b (n) +
b� !b� 1
�1
bqn� 1� b� 1
bqn+1
�+1f~aqn (n)<b�!g
bqn
= �(�b)b (n) +
b� !b� 1
�1
bqn+1� 1�+1f~aqn (n)<b�!g
bqn: (2.93)
Ce dernier point établit la formule annoncée.
141

D Démonstration du lemme 2.19
On pose Y = (x+ V )mod 1. Il su¢ t de prouver la relation :
P = fY1 � y1; : : : ; Ys � ysg =sYi=1
yi; y 2 [0; 1]s :
Etant donné que les coordonnées de V sont mutuellement indépendantes, on adéjà :
P = fY1 � y1; : : : ; Ys � ysg =sYi=1
P fYi � yig :
En appliquant le résultat (2.31), on peut écrire Yi = (~xi + Vi)mod 1, où ~xidef=
ximod1 2 [0; 1[. On peut alors appliquer la formule (2.34) en remplaçant xi par~xi :
P fYi � yig = P f(~xi + Vi)mod 1 � yig= P
�~xi + Vi � 1fVi�1�xig � yi
= P (f~xi + Vi � yig \ fVi < 1� ~xig)
+P (f~xi + Vi � 1 � yig \ fVi � 1� ~xig)= P fVi � yi � ~xig+ P f1� ~xi � Vi � 1g= yi � ~xi + 1� (1� ~xi) = yi:
Ce dernier point achève la démonstration.
142

Références
Bachman G., Narici L., Beckenstein E. (2000). Fourier and Wavelet Analysis,Springer-Verlag, New York.Bouleau N., Lépingle D. (1993). Numerical methods for stochastic processes,John Wiley & Sons Ltd.Boyle P.P., Broadie M., Glasserman P. (1995). �Recent Advances in SimulationFor Security Pricing�, Proceedings of the 1995 Winter Simulation Conference.Boyle P.P., Tan K.S. (1997). �Quasi-Monte Carlo Methods�, Proceeding ofAFIR Conference in Cairns, Australia.Chen C.-M., Bhatia R., Sinha R.K. (2003). �Multidimensional DeclusteringSchemes using Golden Ratio and Kronecker Sequences�, IEEE Transactionson Knowledge and Data Engineering, pp. 659-670.Chi H. (2004). �Scrambled Quasirandom Sequences And Their Applications�,PhD Thesis, The Florida State University.Chi H., Mascagni M., Warnock T. (2005). �On the optimal Halton sequence�,Mathematics and Computers in Simulation 70, pp. 9-21.Coulibaly I. (1997). �Contributions à l�analyse numérique des méthodes quasi-Monte Carlo�, Thèse de Doctorat, Université Joseph Fourier-Grenoble 1.Cranley R., Patterson T.N.L. (1976). �Randomization of Number TheoreticMethods for Multiple Integration�, SIAM Journal on Numerical Analysis, Vol.13, No. 6, pp. 904-914.Da Silva M.E., Barbe T. (2005). �Quasi Monte Carlo in Finance : Extending forHigh Dimensional Problems�, Economia Aplicada, Vol. 9, No. 4, pp. 577-594.Devroye L. (1986). Non-Uniform Random Variate Generation, Springer-Verlag,New York.Drmota M., Tichy R.F. (1997). Sequences, Discrepancies, and Applications, Lec-ture Notes in Mathematics 1651, Springer-Verlag.Faure H. (1981). �Discrépance de suites associées à un système de numération(en dimension 1)�, Bulletin de la S.M.F., Tome 109, pp. 143-182.Faure H. (1982). �Discrépance de suites associées à un système de numération(en dimension s)�, Acta Arithmetica, Vol. 41, pp. 337-351.Faure H., Lemieux C. (2007). �Generalized Halton Sequences in 2007 : A Com-parative Study�, Papier de Recherche, Institut Mathématique de Luminy, http://iml.univ-mrs.fr/editions/preprint2007/files/faure_HFL.pdf.Finschi L. (1996). �Quasi-Monte Carlo : An Empirical Study on Low-DiscrepancySequences�, Working Paper, Eidgenössische Technische Hochschule Zürich.Galanti S., Jung L. (1997). �Low Discrepancy Sequences : Monte Carlo Simu-lation of Option Prices�, The Journal Of Derivatives, pp. 63-83.Glasserman P. (2004). Monte Carlo methods in �nancial engineering, Springer.Haber S. (1966). �A Modi�ed Monte-Carlo Quadrature�, Mathematics of Com-putation, Vol. 20, No. 95, pp. 361-368.Haber S. (1970). �Numerical Evaluation of Multiple Integrals�, SIAM Review,Vol. 12, No. 4, pp. 481-526.Halton J.H. (1960). �On the e¢ ciency of certain quasi-random sequences ofpoints in evaluating multi-dimensional integrals�, Numerische Mathematik 2,
143

pp. 84-90.Hammersley J.M., Handscomb D.C. (1964). Monte Carlo Methods, Methuen,London.Heng L., Qinghua L., Fengshan B. (2005). �A Class of Random Number Ge-nerators Based on Weyl Sequence�, Applied Mathematics-A Journal of ChineseUniversities, Vol. 20, No. 4, pp. 483-490.Hofbauer H., Uhl A., Zinterhof P. (2006a). �Zinterhof Sequences in GRID-BasedNumerical Integration�,Monte Carlo and Quasi-Monte Carlo Methods 2006 (A.Keller, S. Heinrich, H. Niederreiter Eds.), Springer, pp. 495-510.Hofbauer H., Uhl A., Zinterhof P. (2006b). �A Pragmatic View on NumericalIntegration of Unbounded Functions�, Monte Carlo and Quasi-Monte CarloMethods 2006 (A. Keller, S. Heinrich, H. Niederreiter Eds.), Springer, pp. 511-528.Jäckel P. (2002). Monte Carlo methods in �nance, John Wiley & Sons.James F., Hoogland, J., Kleiss R. (1997). �Multidimensional sampling for simu-lation and integration : measures, discrepancies, and quasi-random numbers�,Computer Physics Communications, Vol. 99, No. 2, pp-180-220.Judd K.L. (1998). Numerical Methods in Economics, The MIT Press.Judd K.L. (2006). �O�Curse of Dimensionality, Where is Thy Sting ?�, Procee-dings of CEF2006, Cyprus.Kocis L. , WhitenW.J. (1997). �Computational investigations of low-discrepancysequences�, ACM Transactions on Mathematical Software 23, No. 2, pp. 266-294.Kuipers L., Niederreiter H. (1974). Uniform Distribution of Sequences, JohnWiley & Sons.Larcher G. (1988). �On the distribution of s-dimensional Kronecker sequences�,Acta Arithmetica, Vol. 51, pp. 335-347.Lebrere A., Talhi R., Tripathy M., Pyée M. (2001). �A quick and easy impro-vement of Monte Carlo codes for simulation�, Proceedings of ISSS-6.L�Ecuyer P. (2004b). �Quasi-Monte Carlo Methods in Finance�, Proceedings ofthe 2004 Winter Simulation Conference.Lemieux C. (2008). Monte Carlo and Quasi-Monte Carlo Sampling, Springer(to appear).Moroko¤ W.J., Ca�isch R.E. (1994). �Quasi-random sequences and their dis-crepancies�, SIAM Journal on Scienti�c Computing, Vol. 15, pp. 1251-1279.Niederreiter H. (1972). �On a number-theoretical integration method�, Aequa-tiones Mathematicae 8, pp. 304-311.Niederreiter H. (1978). �Quasi-Monte Carlo methods and pseudo-random num-bers�, Bulletin of the American Mathematical Society, Vol. 84, No. 6, pp. 957-1041.Niederreiter H. (1992). Random Number Generation and Quasi-Monte CarloMethods, SIAM-CBMS Lecture Notes 63.Niven I. (1956). Irrational Numbers, The Mathematical Association of America.Ökten G. (1997). �Contributions to the Theory of Monte Carlo and Quasi-MonteCarlo Methods�, PhD Thesis, Claremont Graduate University.
144

Ökten G.,Tu¢ n B., Burago V. (2005). �A Central Limit Theorem and improvederror bounds for a hybrid-Monte Carlo sequence with applications in computa-tional �nance�, Inria, Rapport de recherche No. 5600.Owen A.B. (2004). �Multidimensional variation for quasi-Monte Carlo�, Re-search Paper, http://www-stat.stanford.edu/~owen/reports/.Owen A.B. (2005). �On the Warnock-Halton quasi-standard error�, ResearchPaper, http://www-stat.stanford.edu/~owen/reports/.Pagès G., Xiao Y.-J. (1997). �Sequences with low discrepancy and pseudo-random numbers : theoretical results and numerical tests�, Journal of StatisticalComputation and Simulation, Vol. 56, pp. 163-188.Papageorgiou A., Traub J.F. (1996). �Beating Monte Carlo�, Risk Magazine,Vol. 9, pp. 63-65.Papageorgiou A., Traub J.F. (1997). �Faster Evaluation of MultidimensionalIntegrals�, Working Paper, Department of Computer Science, Columbia Uni-versity New-York.Paskov S.H. (1994). �Computing High Dimensional Integrals with Applicationsto Finance�, Technical Report CUCS-023-94, Department of Computer ScienceColumbia University.Patard P.-A. (2001). �Evaluation de Swaps Structurés sur Actions et Indices�,Mémoire d�actuaire, Institut de Science Financière et d�Assurances, UniversitéClaude Bernard Lyon 1.Richtmyer R.D. (1951). �On the evaluation of de�nite integrals and a quasi-Monte Carlo method based on properties of algebraic numbers�, Report LA-1342, Los Alamos Scienti�c Laboratories.Schlier C. (2004a). �Discrepancy behaviour in the non-asymptotic regime�, Ap-plied Numerical Mathematics 50, pp. 227-238.Schlier C. (2004b). �Error trends in Quasi-Monte Carlo integration�, ComputerPhysics Communications 159, pp. 93-105.Snyder W.C. (2000). �Accuracy estimation for quasi-Monte Carlo simulations�,Mathematics and Computers in Simulation 54, pp. 131-143.Struckmeier J. (1995). �Fast generation of low-discrepancy sequences�, Journalof Computational and Applied Mathematics, Vol. 91, pp. 29-41.Takhtamyshev G., Vandewoestyne B., Cools R. (2007). �Quasi-random integra-tion in high dimensions�, Mathematics and Computers in Simulation 73, pp.309-319.Tezuka S. (1995). Uniform Random Numbers : Theory and Practice, KluwerAcademics Publishers.Thiémard E. (2000a). �Sur le calcul et la majoration de la discrépance à l�ori-gine�, Thèse de Doctorat, EPFL.Thiémard E. (2000b). �An algorithm to compute bounds for the star discre-pancy�, Research Paper, EPFL.Tu¢ n B. (1996a). �Improvement of Halton Sequences distribution�, Irisa, Pu-blication interne 998.Tu¢ n B. (1996b). �On the Use of low discrepancy sequences in Monte-Carlomethods�, Irisa, Publication interne 1060.
145

Tu¢ n B. (1997). �Simulation accélérée par les méthodes de Monte Carlo etquasi-Monte Carlo : théorie et applications�, Thèse de Doctorat, UniversitéRennes 1.Tu¢ n B. (2005). �Randomization of Quasi-Monte Carlo Methods for Error Es-timation Survey and Normal Approximation�, Irisa-Inria, Research Paper.Vandewoestyne B., Cools R. (2006). �Good permutations for deterministic scram-bled Halton sequences in terms of L2�discrepancy�, Journal of Computationaland Applied Mathematics, Vol. 189, pp. 341-361.Wang X., Hickernell F.J. (2000). �Randomized Halton sequences�,Mathematicaland Computer Modelling, Vol. 32, pp. 887-899.Warnock T.T. (2001). �E¤ective error estimates for quasi-Monte Carlo compu-tations�, Technical Report LA-UR-01-1950, Los Alamos National Labs, http://lib-www.lanl.gov/la-pubs/00367143.pdf.Weyl H. (1916). �Über die Gleichverteilung von Zahlen mod. Eins�, Mathema-tische Annalen 77, pp. 313-352.Zinterhof P. (1987). �Gratis Lattice Points for Multidimensional Integration�,Computing, Vol. 38, No. 4, pp347-353.Zinterhof P. (1994). �Parallel Generation and Evaluation of Weyl Sequences�,Report R5Z-4, PACT Project.
146

Deuxième partie
Modélisation des donnéesde marché
147

Le principal avantage des modèles de marché mathématiques est qu�ils per-mettent d�attribuer une valeur à un produit dérivé qui soit consistante avec lesprix des actifs observés sur le marché à l�instant de l�évaluation. Cela supposetoutefois de choisir les paramètres du modèle de manière à ce que celui-là re-trouve (ou approche avec une grande précision) les prix des actifs utilisés pourla couverture du produit considéré à un instant donné. C�est ce que l�on appellela calibration du modèle.
Elaborer un procédé de calibration est une tâche délicate, qui soulève de nom-breuses di¢ cultés opérationnelles. La première di¢ culté est le choix des ins-truments utilisés pour la calibration, car les valeurs des paramètres dépendentcomplètement de cette sélection. La seconde di¢ culté provient du fait que lesmarchés "réels" ne sont pas parfaits : les données observées (prix d�options,taux cotés...) sont en général incomplètes, bruitées et présentent des oppor-tunités d�arbitrage (McIntyre 2001). Si l�utilisateur ne prend pas garde à leurappliquer un retraitement préliminaire pour les régulariser, il risque d�obtenirdes paramètres inconsistants pour le modèle, ce qui peut induire des problèmesde convergence des algorithmes et des prix faux ou arbitrables pour les produitsdérivés considérés.
Par ailleurs, les modèles de marché existants ne sont pas su¢ samment perfor-mants pour que l�on puisse se contenter de les calibrer une fois pour toutes.En pratique, les paramètres du modèle doivent être réestimés périodiquement,de manière à prendre en compte l�évolution de la con�guration du marché de-puis la dernière date d�évaluation du produit. L�expérience montre que le faitde travailler sur des données non-arbitrables permet d�accroître la stabilité desparamètres estimés au cours du temps (Bekker et Bouwman 2007).
Etant donné que la calibration est une tâche répétitive, il faut accorder uneimportance particulière à l�automatisation du traitement des données de marché,de manière à réduire l�intervention de l�utilisateur. On peut alors envisager decalibrer les modèles pendant la nuit ce qui permet de gagner du temps pourprocéder à la valorisation des di¤érents produits dérivés dès le lendemain matin.
La qualité des prix et des paramètres de couverture des produits dérivés dé-pend étroitement de la manière dont les données de marché sont modélisées etde l�implémentation des procédures de calibration. Pour cette raison, les entre-prises d�investissement entretiennent la plus grande con�dentialité autour destechnologies qu�elles ont développées dans ce domaine. On ne peut donc pasconsidérer qu�il existe une pratique de place pour la modélisation des donnéesde marché, chaque institution ayant développé des solutions qui lui sont propres.
Cette partie est consacrée à la modélisation des données de marché qui inter-viennent dans les modèles de type action : les taux d�intérêt, les dividendes etla volatilité implicite. Les deux premiers paramètres sont des variables écono-miques que l�on peut observer directement. Le troisième paramètre est inobser-vable et il faut l�estimer à partir des prix des options cotées.
148

La partie est constituée de trois chapitres.
Dans le premier chapitre nous étudions la construction d�une courbe de tauxzéro-coupon sous l�hypothèse d�absence d�opportunité d�arbitrage. Nous discu-tons le choix des instruments de calibration et nous présentons une méthode pourextraire les facteurs d�actualisation associés aux maturités des instruments choi-sis. En�n, nous proposons deux méthodes d�interpolation des taux zéro-coupon(dont une nouvelle) qui permettent d�obtenir une courbe non-arbitrable.
Dans le second chapitre, nous proposons une étude complète des problématiquesopérationnelles soulevées par la construction d�une surface de volatilité impli-cite non-arbitrable. Nous envisageons di¤érentes modélisations de la surface devolatilité et nous montrons qu�elles ne parviennent pas à capturer correctementla forme des données ou qu�elles ne permettent pas d�extrapoler les volatilitésimplicites manquantes. Nous présentons alors une nouvelle méthode qui permetd�interpoler et d�extrapoler la surface de volatilité implicite avec précision et desupprimer les arbitrages de manière systématique.
Dans le troisième chapitre9 , nous envisageons la problématique de l�évaluationd�une option Européenne en présence de dividendes discrets dont les montantssont connus à l�avance. Nous appliquons les résultats de la théorie actuarielle desrisques comonotones pour construire une formule fermée qui permet d�approcherle prix de l�option avec une précision accrue par rapport aux approximationsexistantes.
9Une version de ce chapitre a été publiée dans les Cahiers de Recherche de l�ISFA (février2008) et a été soumise à la revue Banque et Marchés sous le titre �Approximations comono-tones pour la valeur d�une option d�achat Européenne en présence de dividendes discrets�.
149

Chapitre 3
Construction de la gammedes taux zéro-coupon enl�absence d�opportunitéd�arbitrage
3.1 Introduction
La construction des gammes de taux zéro-coupon est une étape préliminaireindispensable du processus d�évaluation des produits dérivés, quelle que soit lanature des sous-jacents utilisés1 . Les deux principales raisons sont les suivantes :� le processus de taux sans risque instantané, noté (rt)t�0, contrôle la tendancede la dynamique des prix dans l�univers risque-neutre,
� les facteurs d�actualisationB (t; T ) = exp��R Ttrsds
�, permettent de "conver-
tir" tout �ux payé à une date T > t, en un �ux équivalent à la date t.
Formellement, la gamme (ou courbe) des taux zéro-coupon à la date t est lafonction R (t; �) qui à toute date T > t associe le taux continu zéro-couponR (t; T ) tel que :
B (t; T ) = exp (�R (t; T ) � (t; T )) ;
où � (t; T ) désigne le nombre d�années entre la date t et la date T . Le choix detravailler avec des taux continus est une convention standard lorsque l�on s�in-téresse à l�évaluation des produits dérivés, car la plupart des modèles classiquessupposent une dynamique des prix en temps continu. La fonction T ! R (t; T )
1Dans le cadre de ce travail, nous nous intéressons à l�évaluation des produits dérivés écritssur des actifs de type action. Dans ce cas précis, l�usage veut que l�on néglige la volatilité destaux par rapport à la volatilité de l�actif risqué. Cela signi�e que l�on travaille avec des tauxdéterministes.
150

n�est pas un paramètre de marché directement observable : en pratique on doitl�estimer à partir des prix d�un panier d�instruments de marché bien choisis.
Principe de la construction d�une courbe zéro-coupon La constructionde la courbe en tant que telle comporte quelques di¢ cultés mathématiques mais,ce sont surtout le choix et le retraitement des données à partir desquelles serontmenés les calculs, qui peuvent s�avérer particulièrement délicats. En e¤et, sil�on n�est pas assez attentif à la qualité des données et aux conventions demarché utilisées, le risque est d�obtenir des inconsistances dans la gamme detaux estimée, ce qui pourrait introduire des biais lors de l�évaluation des produitsdérivés.
Les di¤érentes étapes de la construction d�une courbe de taux sont les suivantes.
1. Choix d�une famille d�instruments de calibration liquides, dont les datesd�échéances couvrent une plage de maturité allant de quelques jours à aumoins dix ans.
2. Extraction de taux zéro-coupon R (t; T1) ; : : : ; R (t; Tn) à partir des prixobservés pour les instruments du panier. En général, T1 � : : : � Tn cor-respondent aux dates d�échéances des instruments considérés.
3. Choix d�une famille de fonctions d�interpolation ou de lissage su¢ sammentrégulières qui permettent de calculer la valeur du taux zéro-coupon R (t; T )pour toute date t � T � Tn.
4. Calibration de la fonction choisie sur les taux zéro-coupon obtenus àl�étape 2 du processus.
Observations Au niveau des étapes 1 et 2 du processus précédent, les deuxprincipales di¢ cultés rencontrées par le praticien sont (i) de sélectionner desinstruments de calibration liquides, appartenant à une classe de risques homo-gènes et (ii) d�intégrer dans les calculs les conventions de marché associées auxproduits du panier de calibration qui dépendent de la devise considérée et de lanature de l�instrument utilisé.Les étapes 3 et 4 soulèvent des problématiques de nature mathématique. On peutchoisir d�interpoler ou bien de lisser les taux zéro-coupon obtenus. Il n�existe pasd�approche optimale, les deux solutions comportant des avantages et des incon-vénients que nous discuterons dans la suite. La dernière étape est un problèmed�optimisation : il s�agit d�ajuster une fonction paramétrique ou non paramé-trique sur un ensemble de points discrets.
L�objectif de ce chapitre est de proposer une méthodologie robuste pour construirela gamme de taux zéro-coupon dans n�importe quelle économie. Notre travailest organisé selon le schéma suivant : dans la seconde section, nous donnonsles principaux résultats théoriques sur les courbes zéro-coupon et nous démon-trons les contraintes que doit véri�er une telle courbe en l�absence d�opportunitéd�arbitrage. Dans la troisième section, nous présentons les conventions de mar-ché utilisées pour gérer les dates et les échéanciers de �ux. Dans la quatrième
151

section, nous posons le problème de la reconstruction de la courbe des tauxd�intérêts dans le cadre de l�évaluation de produits optionnels et nous discu-tons le choix des instruments de calibration. Dans la cinquième section, nousmontrons comment extraire les facteurs d�actualisation associés aux maturitésdes instruments du panier de calibration. Dans la sixième section, nous répon-dons à la question : est-il préférable de lisser ou d�interpoler les taux obtenuslors de l�estimation des facteurs d�actualisation, puis nous proposons deux mé-thodes robustes et simples à mettre en oeuvre pour obtenir des courbes de tauxzéro-coupon non-arbitrables ; la seconde méthode, basée sur les splines cubiquescontraints, est inédite. Dans la septième section, nous démontrons l�e¢ cacitédes méthodes proposées sur un exemple pour lequel les approches classiques nepermettent pas d�obtenir une courbe non-arbitrable. La conclusion est donnéedans la huitième section.
3.2 Eléments de théorie
Dans cette section, nous donnons les concepts théoriques qui seront utilisés lorsde la construction de la courbe zéro-coupon et nous démontrons que l�hypothèsed�absence d�opportunité d�arbitrage (AOA) induit des contraintes sur la formede la courbe des taux, qu�il faut impérativement prendre en compte lors de laprocédure de reconstruction. La lettre t désigne la date courante (aujourd�hui).
3.2.1 Autour de la notion de zéro-coupon
Obligation zéro-coupon
On appelle obligation zéro-coupon (ou plus simplement zéro-coupon) d�échéanceT un instrument �nancier qui paye une unité monétaire (u.m.) à la date T etqui ne détache aucun �ux avant la date T . On note B (t; T ) le prix en date t del�obligation d�échéance T :
B (t; T ) = prix en date t de 1 u.m. payée en date T .
Par dé�nition, on a B (t; t) = 1.
Lorsque les taux sont déterministes, la quantité B (t; T ) est appelée facteur d�ac-tualisation à la date t et la fonction T ! B (t; T ) est appelée fonction d�actua-lisation à la date t. Dans la suite, nous emploierons indi¤éremment l�expression"facteur d�actualisation" ou "zéro-coupon".
Taux zéro-coupon
Il existe plusieurs manières de dé�nir le taux de rendement d�un zéro-coupon.
152

Taux zéro-coupon annuel continu Le taux zéro-coupon annuel continu quiprévaut entre les dates t et T , noté R (t; T ), est dé�ni par la relation :
B (t; T ) = exp (�R (t; T ) � (t; T )), R (t; T ) = � lnB (t; T )� (t; T )
; (3.1)
où � (t; T ) désigne le nombre d�années entre la date t et la date T , c�est-à-direla maturité du zéro-coupon. La fonction T ! R (t; T ) est appelée la gamme(ou courbe ou structure par terme) des taux zéro-coupon à la date t. C�estprécisément cette fonction que nous cherchons à obtenir.
Taux zéro-coupon continu �at On appelle taux zéro-coupon continu �atou, plus simplement, taux zéro-coupon �at la quantité dé�nie par :
~R (t; T ) = R (t; T ) � (t; T ) = � lnB (t; T ) : (3.2)
Etant donné que B (t; t) = 1, on a ~R (t; t) = 0.
Taux zéro-coupon annuel linéaire Le taux zéro-coupon annuel linéaire quiprévaut entre les dates t et T , noté L (t; T ), est dé�ni par la relation :
B (t; T ) =1
1 + L (t; T ) �L (t; T ), L (t; T ) =
1
�L (t; T )
�1
B (t; T )� 1�: (3.3)
La quantité �L (t; T ) désigne le nombre d�années entre la date t et la date T .L�indice "L" signi�e simplement que l�on ne mesure pas nécessairement les an-nées de la même manière lorsque le taux considéré est linéaire et lorsque le tauxconsidéré est continu. Ce point sera discuté dans la suite.
Nous pouvons maintenant introduire la notion de taux forward.
3.2.2 Taux forward
D�une manière générale, le terme "forward" désigne tout instrument ou toutegrandeur �nancière relative à une période dont la date de départ T est supérieureà la date courante t.
Zéro-coupon forward-start
Un zéro-coupon forward-start est un zéro coupon dont la date de départ T estsupérieure à la date t. On note B (T;U) le prix qu�il faudra payer à la date Tpour détenir le zéro-coupon forward-start d�échéance U � T :
B (T;U) = prix en date T de 1 u.m. payée en date U .
Il est possible de �xer à la date t le prix futur B (T;U). Le principe est d�acheterle zéro-coupon d�échéance U et de vendre simultanément B (t; U) =B (t; T ) zéro-coupons d�échéance T . La stratégie donne lieu à deux �ux : un �ux sortant à la
153

date T (égal à B (t; U) =B (t; T )) et un �ux entrant à la date U (égal à 1 u.m.).On reconnaît un zéro-coupon synthétique de départ T et d�échéance U dont leprix est donné par la formule :
Bt (T;U)def=
B (t; U)
B (t; T ); T � U: (3.4)
L�indice "t" signi�e qu�il s�agit d�une quantité "vue de t". En faisant T = t etU = T dans la formule ci-dessus on retrouve le prix d�un zéro-coupon départ t :i.e. Bt (t; T ) = B (t; T ). Donc la dé�nition (3.4) est consistante.
Taux zéro-coupon forward
Comme dans le cas des opérations départ t, il existe plusieurs manières de dé�nirle taux de rendement associé à un zéro-coupon forward-start.
Taux zéro-coupon forward annuel continu Le taux de rendement associéau zéro-coupon forward-start est noté Rt (T;U) et dé�ni par :
Rt (T;U) = �lnBt (T;U)
� (T;U)=lnB (t; T )� lnB (t; U)
� (T;U); (3.5)
où � (T;U) est le nombre d�années entre la date T et la date U , c�est-à-dire lamaturité de l�obligation.
Taux zéro-coupon forward continu �at Le taux de rendement associé auzéro-coupon forward-start est noté ~Rt (T;U) et dé�ni par :
~Rt (T;U) = � lnBt (T;U) = lnB (t; T )� lnB (t; U) : (3.6)
Taux zéro-coupon forward annuel linéaire Le taux de rendement forwardlinéaire entre la date T et la date U est dé�ni par la relation :
Bt (T;U) =1
1 + Lt (T;U) �L (T;U): (3.7)
Un simple calcul nous donne :
Lt (T;U) =1
�L (t; T )
�B (t; U)
B (t; T )� 1�: (3.8)
Nous disposons de tous les éléments pour dé�nir le concept de taux instantané.
154

3.2.3 Taux instantané
Taux forward instantané
On suppose que la fonction U ! Rt (T;U) est continue. On peut alors dé�nirpour chaque date T la quantité :
rt (T )def= lim
U!T+Rt (T;U) : (3.9)
rt (T ) est appelé taux forward implicite instantané ou plus simplement tauxforward instantané. Il s�agit du taux court qui prévaudra entre les dates futuresT et T+dT , vu de t. Nous en donnons une interprétation au paragraphe suivant.
En remplaçant Rt (T;U) par son expression (3.5) on véri�e facilement que :
rt (T ) = �@ lnBt (T;U)
@U
����U=T
= � @ lnB (t; U)
@U
����U=T
: (3.10)
D�après (3.2), on peut remplacer � lnB (t; U) par ~R (t; U) dans la formule pré-cédente, ce qui nous donne une troisième expression pour le taux forward ins-tantané :
rt (T ) =@ ~R (t; U)
@U
�����U=T
: (3.11)
A partir de (3.10), on peut exprimer très simplement les prix zéro-coupon enfonction du taux forward instantané :
B (t; T ) = exp
�Z T
t
rt (s) ds
!, Bt (T;U) = exp
�Z U
T
rt (s) ds
!: (3.12)
Nous donnons ci-dessous une interprétation simple du taux forward instantanélorsque l�économie est stochastique.
Interprétation du taux forward instantané
On suppose que, en plus des zéro-coupons, il est possible d�investir dans un actifmonétaire "sans risque", dont les intérêts sont capitalisés continûment au tauxcourt de l�économie rt, supposé stochastique. Soit �t;T , la valeur à la date T , de1 u.m. investie dans l�actif monétaire à la date t. On a clairement :
�t;T = exp
Z T
t
rsds
!: (3.13)
A�n d�éviter toute opportunité d�arbitrage entre l�actif monétaire et le zéro-coupon, il faut imposer la condition suivante : un investissement de B (t; T )u.m. dans le zéro-coupon d�échéance T et un investissement de B (t; T ) u.m.dans l�actif monétaire doivent tous deux générer 1 u.m. à la date T . Etant donné
155

que le taux court évolue de manière stochastique, cette condition se traduit parla relation (Rebonato 2002) :
B (t; T ) = EQ
"exp
�Z T
t
rsds
!jFt
#; (3.14)
où EQ [� jFt ] est l�opérateur "espérance sous Q conditionnellement à l�infor-mation disponible en t" et Q désigne une mesure de probabilité risque-neutre(Harrison et Kreps 1979, Harrison et Pliska 1981). Par un raisonnement ana-logue, on démontre aussi la relation :
Bt (T;U) = EQ
"exp
�Z U
T
rsds
!jFt
#: (3.15)
En nous basant sur (3.15), on peut écrire2 :
�@ lnBt (T;U)@U
= �@Bt (T;U) =@UBt (T;U)
=�1
Bt (T;U)EQ
"@ exp
�Z U
T
rsds
!=@U jFt
#
=1
Bt (T;U)EQ
"rU exp
�Z U
T
rsds
!jFt
#: (3.16)
En faisant U = T dans (3.16) on obtient :
�@ lnBt (T;U)@U
= EQ [rT jFt ] : (3.17)
En identi�ant le résultat obtenu avec (3.10) il vient :
rt (T ) = EQ [rT jFt ] ; T � t: (3.18)
La relation précédente montre que, lorsque les taux sont stochastiques, le tauxforward instantané est la meilleure estimation possible du taux court futur.Lorsque l�on suppose que les taux sont déterministes, on peut supprimer l�opé-rateur espérance dans la formule (3.18) qui s�écrit alors :
rt (T ) = rT : (3.19)
Dans ce cas, le taux forward instantané est égal au taux court qui prévaudradans le futur.
Les concepts introduits jusqu�ici reposent implicitement sur l�hypothèse d�ab-sence d�opportunité d�arbitrage (ou AOA) dont nous analysons les conséquencesci-dessous.
2Pour une présentation détaillée, le lecteur pourra consulter Muselia et Rutkowski (1997).
156

3.2.4 Courbe de taux admissible
L�AOA induit des contraintes sur la forme de la courbe des taux, qu�il fautimpérativement prendre en compte lors de la procédure de construction. Nousénonçons ces contraintes ci-dessous (voir démonstration en Annexe A).
Proposition 3.1 Lorsque la courbe des taux ne présente pas d�opportunité d�ar-bitrage, alors les trois propositions équivalentes suivantes sont véri�ées :
1. la fonction d�actualisation est décroissante,
2. les taux continus �ats sont croissants,
3. les taux forwards instantanés sont positifs.
Nous donnons ci-dessous la dé�nition d�une courbe de taux admissible, au sensde l�AOA.
Dé�nition 3.1 On dit que la courbe des taux zéro-coupon est admissible si etseulement si l�un des trois points de la proposition (3.1) est véri�é.
Pour pouvoir mettre en oeuvre les outils théoriques introduits dans cette section,il est indispensable de connaître les conventions et les termes techniques utiliséspar les intervenants qui opèrent sur les marchés de taux. Cela fait l�objet de lasection suivante.
3.3 Conventions de marchés
Dans un premier temps, nous présentons les conventions de calcul permettantde déterminer le nombre d�années entre deux dates. Ensuite, nous donnons lestermes techniques utilisés pour la gestion des échéanciers. En�n nous présentonsles placements dits "au jour-le-jour" dont les caractéristiques sont standardiséessur tous les marchés.
3.3.1 Mesure du nombre d�années entre deux dates
Dans le paragraphe précédent, nous avons introduit les quantités � (t; T ) et�L (t; T ) qui sont des mesures du nombre d�années entre les dates t et T . Lamesure du nombre d�années séparant deux dates peut dans certains cas s�avérerproblématique, car l�année est une unité de mesure non constante (365 jours ou366 jours lorsque l�année est bissextile). Pour répondre à ce problème, les inter-venants qui opèrent sur les marchés de taux ont dé�ni di¤érentes conventions,appelées bases de calcul, pour mesurer le nombre d�années d�un placement. Lesconventions utilisées varient en fonction des instruments et des zones géogra-phiques considérées.
Nous présentons ci-dessous les bases de calcul qui seront mentionnées ou utili-sées dans ce travail. Cette liste n�est pas exhaustive et pour une présentation
157

complète des conventions en vigueur sur les marchés de taux, nous invitons lelecteur à consulter Christie (2003) et ISDA (2006).
Nombre de jours d�un placement
Soit t et T deux dates avec t � T . On rappelle qu�un placement entre t et Test supposé inclure la date t et exclure la date T . Cette convention provientdu fait que le dernier jour de placement (i.e. la date T ) est consacré au calculdes intérêts à payer ou à recevoir et au règlement des �ux. Durant ce dernierjour, les sommes investies ne peuvent donc pas porter intérêt. Dans la suite, onnote n (t; T ) le nombre de jours calendaires entre la date t (incluse) et la dateT (exclue).
Bases de calcul
Base Act/360 Cette base est utilisée pour les opérations de courte durée(maturité inférieure à un an). Le nombre d�années du placement est donné par :
� (t; T ) =n (t; T )
360: (3.20)
La formule (3.20) suppose implicitement que le nombre de jours dans une annéepleine est égal à 360. Ainsi, un placement du 06=04=2006 au 06=04=2007 (365jours) a une durée égale à 365=360 ' 1:01389 années dans la base "Act/360".
Base Act/365 Le nombre d�années du placement est donné par la formule :
� (t; T ) =n (t; T )
365: (3.21)
Cette base est utilisée pour les deposits libellés en Livre Sterling (GBP) et pourles swaps contre LIBOR libellés en Yen (JPY).
Base Act/365.25 Etant donné qu�une année normale comporte 365 jours etqu�une année sur 4 comporte 366 jours, on peut considérer que le nombre moyende jours dans une année est égal à :
3� 365 + 3664
= 365:25:
La convention Act/365.25 revient donc à supposer que la longueur de l�annéeest 365:25 jours, de sorte que le nombre d�années entre la date t et la date T estdonné par la formule :
� (t; T ) =n (t; T )
365:25: (3.22)
Nous avons retenu cette base pour exprimer les durées associées aux taux zéro-coupon continus.
158

Base 30/360 Cette base est utilisée principalement sur les marchés obliga-taires. Les mois entiers sont supposés avoir une durée de 30 jours. Une annéecomplète comporte donc 12 mois de 30 jours, soit 360 jours. Cette base estparfois appelée Bond Basis ou Annual Bond Basis. On note T1 = D1:M1:Y1 etT2 = D2:M2:Y2, où 1 � Di � 31 désigne le jour du mois (Day), 1 �Mi � 12 estle mois de l�année (Month) et Yi � 0 représente l�année (Year). Le nombre d�an-nées entre T1 et T2 (T1 � T2) est donné par la formule (Brigo et Mercurio 2006) :
� (T1; T2) =min (D2; 30)�min (D1; 30) + 30 (M2 �M1) + 360 (Y2 � Y1)
360(3.23)
La base 30/360 admet de nombreuses variantes en fonction des zones géogra-phiques (ISDA 2006).
3.3.2 Termes techniques relatifs aux échéanciers
Désignation des dates
Jour Ouvré Pour un marché donné, ce terme désigne toute date où la boursede référence est ouverte, c�est-à-dire toute date à laquelle des transactions et deséchanges de �ux ont lieu. Le calendrier des jours ouvrés est di¤érent en fonctiondes devises considérées.
Date de Négociation La date de négociation (encore appelée date de tran-saction) d�une opération est la date à laquelle les modalités de l�opération (tauxapplicables, échéanciers. . . ) sont �xées par les parties.
Date de Départ/Date de Valeur On appelle indi¤éremment date de départou date de valeur ("value date" en anglais) la date du commencement e¤ectifd�une opération. La date de départ coïncide rarement avec la date de négociationde l�opération : elle est en général située entre un et trois jours ouvrés (le plussouvent deux jours ouvrés) après la date de négociation.
Date de Fixing On appelle date de �xing ("�xing date" en anglais) toutedate à laquelle on observe un des paramètres d�une opération �nancière (engénéral, le niveau d�un taux variable).
Date de Paiement Le terme date de paiement ("payment date" en anglais),désigne toute date à laquelle un �ux ou plusieurs �ux d�une opération �nancièresont payés.
Date Spot On appelle date spot ("spot date" en anglais) la date située deuxjours ouvrés après la date courante.
159

Gestion des jours non-ouvrés
Tous les produits de taux d�intérêt (obligations, swaps, deposits. . . ) comportentun échéancier d�intérêts, c�est-à-dire un ensemble de dates auxquelles inter-viennent des paiements intermédiaires. La fréquence des dates de paiement des�ux est souvent régulière et multiple d�un nombre entier de mois3 . Lorsque l�ondétermine l�échéancier, il faut s�assurer que chaque date de paiement ou de �xingsoit un jour ouvré. Lorsque la date théorique tombe un jour non-ouvré, il estconvenu d�ajuster la date au jour ouvré le plus proche, selon l�une des troisconventions suivantes (ISDA 2006) :� convention "Following" : la date théorique est ajustée au premier jour ouvrésuivant dans le calendrier,
� convention "Preceding" : la date est ajustée au premier jour ouvré précédentdans le calendrier,
� convention "Modi�ed Following" ou "Modi�ed" : la date théorique est ajustéeselon la convention Following, sauf si cet ajustement fait changer de moiscalendaire, auquel cas la date est ajustée selon la convention Preceding.
La convention "Modi�ed Following" est la plus utilisée.
Dans la section suivante, nous nous intéressons au choix des instruments utiliséspour l�extraction de la courbe de taux sans risque.
3.4 Choix des instruments de calibration
Dans le premier paragraphe, nous montrons que dans le contexte de l�évaluationdes produits dérivés, la notion de taux sans risque fait référence aux transac-tions interbancaires. Dans le second paragraphe, nous donnons les principalescaractéristiques des références de taux interbancaires utilisées en Europe. Dansle troisième paragraphe, nous présentons les trois sortes d�opérations interban-caires les plus courantes, les plus standardisés et les plus liquides : les deposits,les futures de taux et les swaps vanilles.
3.4.1 Notion de taux sans risque
Une dé�nition imprécise Le concept de taux sans risque est imprécis. Ene¤et, les taux d�intérêt �uctuent aléatoirement en fonction de l�o¤re et de la de-mande, en fonction des anticipations économiques, en fonction des annonces oudes interventions des banques centrales (Cherif 2000). Ainsi, quels que soient lesinstruments de taux considérés (obligations d�états, taux interbancaires, obliga-tions corporates. . . ), il n�existe pas d�investissement présentant un risque nul.Par ailleurs, le taux sans risque est associé à une zone économique donnée : dansla zone Euro, il correspond à des opérations libellées en Euros (EUR), tandis quedans la zone Dollar, il correspond à des opérations libellées en Dollars (USD) etainsi de suite.
3Les fréquences les plus utilisées sont les fréquences trimestrielles, semestrielles et annuelles.
160

Les taux d�états comme taux sans risque L�idée première conduirait àchoisir comme taux sans risque le taux instantané associé aux obligations d�étatdans une économie donnée, celles-là étant réputées présenter le risque de défautle plus faible parmi tous les produits de taux existants sur le marché. Dans unezone géographique telle que la zone Euro, cette approche soulève la question duchoix des "meilleures" obligations d�états dans la mesure où plusieurs pays (parexemple l�Allemagne et la France) sont des émetteurs de qualité.
Les taux interbancaires comme taux sans risque Lorsque l�on s�intéresseà l�évaluation des produits dérivés, l�utilisation d�une courbe de taux d�étatcomme courbe de taux sans risque n�est sans doute pas la solution la mieuxadaptée. Nous le démontrons ci-après. Le principe fondamental d�évaluation desproduits dérivés repose sur le fait que le prix d�un actif optionnel est égal àla valeur de son portefeuille de couverture à chaque instant. Le portefeuille decouverture d�une option Européenne portant sur une action ou sur un indiceboursier, est composé schématiquement d�une position longue (ou courte) surl�actif risqué qui est �nancée par un emprunt (ou qui �nance un prêt) rémunéréau taux sans risque. En d�autres termes, la gamme de taux sans risque cor-respond à la gamme de taux sur laquelle les traders peuvent intervenir, ce quisigni�e qu�elle doit être construite à partir d�instruments indexés sur les tauxde référence interbancaires.
3.4.2 Produits de taux interbancaires
La sélection des instruments de calibration repose principalement sur des cri-tères de liquidité4 . En e¤et, les marchés liquides sont biens arbitrés et les tauxdes instruments que l�on peut négocier n�incluent ni prime de risque, ni primede liquidité. En utilisant des instruments de calibration liquides nous sommesdonc assurés d�obtenir une courbe de taux sans risque consistante qui re�ètevéritablement le niveau des taux sous-jacents. Les trois familles d�instrumentsles plus liquides sur le marché interbancaire sont : les deposits, les futures detaux et les swaps de taux vanilles. Nous présentons ces produits ci-dessous.
Deposits
Un deposit (ou dépôt en français) est une opération de prêt ou d�emprunt in �nedont la maturité est comprise entre 1 jour et 1 an. Les deux parties s�engagentsur un taux d�intérêt, sur une durée et sur un montant notionnel dans une devisedonnée. L�emprunteur reçoit le montant notionnel à la date de départ et, à la�n, il le restitue majoré des intérêts calculés sur la période. Un deposit peutdonc être assimilé à un zéro-coupon.
4Un marché liquide peut être décrit comme un marché où les transactions de taille im-portante sont exécutées rapidement avec un impact négligeable sur les prix. Les trois carac-téristiques d�un marché liquide sont les suivantes : (i) des fourchettes de prix serrées, (ii) desvolumes de transaction élevés et (iii) la vitesse à laquelle les prix reviennent à la normale aprèsdes ordres déséquilibrants.
161

Mode de cotation Les deposits sont cotés en taux et non pas en prix. Parconvention, les taux de deposits sont des taux linéaires dé�nis par les formules(3.3) et (3.7).
Deposits au jour-le-jour Les deposits au jour-le-jour sont des opérations deprêt/emprunt in �ne d�un jour ouvré au jour ouvré suivant. Il existe trois typesde deposits au jour-le-jour dont les caractéristiques sont normalisées :� le deposit "OverNight" (noté ON) qui correspond à un prêt/emprunt entreaujourd�hui et demain ouvré,
� le deposit "Tom-Next" (noté TN) qui correspond à un prêt/emprunt entredemain ouvré (Tomorrow) et après-demain ouvré (Next),
� le deposit "Spot-Next" (noté SN) qui correspond à un prêt/emprunt entreaprès-demain ouvré et le jour ouvré suivant.
Notons que le terme "après-demain ouvré" désigne la date spot : les placementsON et TN correspondent aux opérations que l�on peut réaliser avant la datespot. Par ailleurs, le placement SN est le placement de maturité la plus courtecommençant à la date spot.
Taux IBOR Les deposits de maturité supérieure à 1 semaine sont fondamen-taux, car ils permettent de calculer les taux IBOR, qui sont les taux de référencedu marché interbancaire sur les places Européennes. Le terme IBOR signi�e In-terBank O¤ered Rate (en français, Taux Interbancaire O¤ert) et désigne unensemble de taux de référence pour les opérations de deposits entre banques,publiés pour 15 maturités standardisées allant de 1 semaine à 1 an et appelées"ténors" :� 1 semaine (1W), 2 semaines (2W), 3 semaines (3W),� 1 mois (1M), 2 mois (2M), 3 mois (3M), . . . , 12 mois (12M).
Le taux IBOR de maturité � dans la devise X correspond à la moyenne des tauxde deposits de maturité � , libellés dans la devise X, pratiqués par un échantillond�établissements bancaires de première catégorie. Les taux les plus extrêmessont écartés des calculs, a�n de protéger les indices d�éventuelles erreurs oud�une crise de liquidité qui pourrait a¤ecter certaines banques de l�échantillon.La composition de l�échantillon est stable et connue à l�avance.
Les principaux taux IBOR sont :� les taux LIBOR5 (London InterBank O¤ered Rate), qui couvrent plusieursdevises,
� l�EURIBOR (EURo InterBank O¤ered Rate) qui correspond à des depositslibellés en Euros uniquement6 .
Les taux LIBOR sont calculés et publiés par la British Bankers�Association(BBA) en collaboration avec Reuters à 12H (GMT) à partir des contributionsfournies par des banques établies à Londres. Les taux EURIBOR sont calculés
5Site o¢ cel de la BBA : http://www.bba.org.uk/bba/6Site o¢ cel de l�EURIBOR : http://www.euribor.org
162

et publiés par Reuters à 11H (CET) à partir des contributions fournies parles banques (non nécessairement situées à Londres) considérées comme les plusreprésentatives sur le marché de l�Euro. Les caractéristiques des taux IBOR sontdonnées en Annexe B.
Contrats Futures
Les futures de taux sont des contrats standardisés écrits sur des références inter-bancaires de type IBOR, négociés sur des marchés organisés. Ce type de contratpermet de garantir un niveau de taux d�intérêt dans le futur. L�avantage prin-cipal de ces produits est assurément leur grande liquidité. Ils permettent decouvrir une plage de maturités allant de quelques semaines à 2 ans, c�est-à-direles maturités moyennes. Les principaux contrats futures sur taux IBOR sont :� le contrat USD-LIBOR3M, coté sur le CME7 et sur le LIFFE8 ,� le contrat EURIBOR3M, coté sur le LIFFE,� le contrat GBP-LIBOR3M, coté sur le LIFFE.
Swaps de taux vanilles
Un swap de taux vanille est une opération de gré-à-gré dans laquelle deux contre-parties conviennent d�échanger une série de �ux à taux �xe contre une série de�ux indexés sur un taux variable de type IBOR, les deux séries de �ux étantlibellées dans la même devise. Les �ux d�intérêts sont calculés en appliquantd�une part le taux �xe, et d�autre part, le taux variable sur un montant nominalidentique. Il n�y a pas d�échange de nominal, ni au début, ni au terme de l�opé-ration, seuls les intérêts sur le nominal sont échangés. Lors de sa mise en place,l�opération d�échange doit être �nancièrement équitable pour les deux parties.En d�autres termes, à la date départ, les deux chroniques de �ux ont la mêmevaleur de marché. Les swaps de taux vanilles couvrent une plage de maturitésallant de 1 an à 30 ans9 , c�est-à-dire les maturités moyennes et longues. Ils sontcotés en fourchette de taux Bid/Ask, le taux coté correspondant au taux �xede l�opération. Le taux Bid (resp. le taux Ask) représente le taux �xe qui serapayé (resp. reçu) par le market-maker qui recevra (resp. payera) en échange les�ux variables.
De l�utilisation des futures de taux
Certains auteurs recommandent d�utiliser les cotations des futures de tauxpour extraire les taux zéro-coupon sur la partie court-terme/moyen-terme dela gamme des taux (Martellini et Priaulet 2004). Nous considérons que ce choix
7CME est l�abréviation de Chicago Mercantile Exchange. Site du CME : http://www.cme.com/.
8LIFFE signi�e London International Financial Futures and options Exchange. Site duLIFFE : http://www.euronext.com/landing/liffeLanding-12601-EN.html.
9Notons que sur certains marchés, comme celui de l�EURIBOR, les swaps sont cotés pourdes maturités allant jusqu�à 50 ans.
163

est discutable et nous expliquons notre position dans la suite. Les contrats fu-tures ne sont pas de même nature que les dépôts ou les swaps. Tout d�abord, lanégociation des contrats futures est essentiellement électronique (à l�exceptiondu marché de Chicago), donc très rapide, ce qui n�est pas le cas des dépôts et desswaps qui se négocient par téléphone. Ensuite, la vente ou l�achat d�un contratfuture n�entraîne aucun paiement immédiat (à l�exception du paiement d�un dé-pôt de garantie) contrairement aux deposits qui entraînent le décaissement dela somme empruntée. En�n, la négociation des futures ne nécessite pas la miseen place d�un contrat de gré à gré comme les opérations de swaps. En d�autrestermes, la négociation des contrats futures est très souple (pas de contrat) et peucoûteuse (pas de décaissement d�argent à la mise en place). Pour ces di¤érentesraisons, les contrats futures sont les instruments privilégiés des arbitragistes etdes spéculateurs qui peuvent ainsi prendre une position sur le marché et l�an-nuler dans un intervalle de temps très court. Une conséquence en est que lescotations des contrats futures peuvent être très instables : il n�est pas rare devoir le prix d�un contrat donné s�écarter brusquement de son niveau d�équi-libre simplement parce que des opérateurs viennent d�intervenir sur ce contratpour des tailles importantes. Dans ces conditions, on ne peut pas considérer queles cotations des contrats futures re�ètent le niveau intrinsèque des taux, carelles incluent une prime spéculative non négligeable. Pour les di¤érentes raisonsque nous venons d�évoquer, nous proposons de construire la courbe zéro-couponseulement à partir des taux de deposits et des taux de swaps.
Dans la section suivante, nous montrons comment utiliser les deposits et lesswaps de taux vanilles pour extraire les facteurs d�actualisation aux maturitésdiscrètes pour lesquelles nous avons une cotation.
3.5 Extraction des facteurs d�actualisation
Les marchés des deposits et des swaps sont des marchés de gré à gré. Cela signi�eque les parties à l�opération doivent s�entendre au préalable sur les modalités ducalendrier des �ux et sur les conventions de calcul à appliquer. A�n de rendreles transactions plus e¢ caces et plus rapides, les intervenants se sont attachésà normaliser les caractéristiques des opérations les plus courantes, notammenten ce qui concerne : (i) les règles de détermination des dates de commencementet d�échéance, (ii) la construction des échéanciers d�intérêts et (iii) les règlesde calcul des coupons. Une conséquence de cette standardisation est que denombreuses clauses sont implicitement contenues dans les cotations des produitsstandards. La principale di¢ culté rencontrée par le praticien est donc d�inclureles conventions de marché implicites dans le processus d�extraction des tauxzéro-coupon. Ces conventions varient non seulement en fonction de la deviseconsidérée, mais aussi en fonction de la nature de l�instrument (deposit ou swap).
Les deposits couvrent une plage de maturités allant de 1 jour à 1 an (maturitéscourtes) et les swaps couvrent une plage de maturités allant de 2 ans à 30 ans
164

(maturités moyennes et longues). Dans un premier temps, nous démontronsles formules qu�il faut appliquer pour reconstruire les facteurs d�actualisationà partir des deposits. Dans un second temps, nous proposons un algorithmerécursif qui permet de déterminer les facteurs d�actualisation pour les swaps.
3.5.1 Facteurs d�actualisation associés aux deposits
Préliminaires
Données disponibles On utilise 11 maturités représentatives, appelées lesténors de la courbe.� Deposits de maturité 1 jour ouvré : ON, TN, SN (voir paragraphe 3.4.2 pourune description de ces taux particuliers).
� Deposits de maturité inférieure à 1 mois : 1W, 2W, 3W.� Deposits de maturité inférieure à 1 an : 1M, 3M, 6M, 9M, 12M.Quelle que soit la devise considérée, les deposits ON (OverNight) et TN (Tom-
Next) couvrent respectivement les périodes t ! tONdef= t � 1 et tON ! tSN
def=
t � 2, où la notation �i signi�e que l�on ajoute i jours ouvrés à la date t. Ledépôt SN (Spot-Next) couvre la période tSN ! t� 3.
Pour toutes les devises, sauf pour la devise GBP (Livre Sterling), les depositsde maturité supérieure à une semaine commencent à la date spot tSN, qui estsituée deux jours ouvrés après la date t (voir Annexe B). Pour la devise GBP,les deposits commencent en t.
Taux cotés Les deposits sont cotés en fourchette de taux Bid/Ask. Etantdonné que nous ne souhaitons pas privilégier un sens pour les opérations, nousraisonnons sur les taux milieu de fourchette (ou taux "Mid") dé�nis par :
xMiddef=
xBid + xAsk2
:
Le taux xMid peut être vu comme le taux théorique d�équilibre de l�opérationconsidérée et l�intervalle [xBid; xAsk] comme l�intervalle de con�ance appliquépar le market-maker autour du taux xMid. La di¤érence xAsk � xBid, appeléeBid/Ask spread, mesure le degré d�incertitude autour du prix théorique. Sur lesdeposits, le Bid/Ask spread est en moyenne de l�ordre de 0:05%, ce qui traduitla con�ance des market-makers dans les prix proposés.
Correction des facteurs d�actualisation Notre objectif est d�obtenir unecourbe de taux zéro-coupon dont la date de départ est égale à t (la date decalibration). Cela signi�e que, lorsque les ténors cotés ont pour date de départtSN = t� 2, il faut apporter une correction aux facteurs d�actualisation trouvésa�n de les convertir en facteurs d�actualisation dont la date de départ est égaleà t. Le terme correcteur est déterminé en combinant les facteurs d�actualisationON et TN qui couvrent respectivement les périodes t ! tON et tON ! tSN.Le graphique ci-dessous illustre le fonctionnement de l�ajustement proposé dans
165

le cas du deposit 1M. Les notations sont les suivantes : BON est le facteurd�actualisation ON, BTN est le facteur d�actualisation TN et B1M est le facteurd�actualisation associé au ténor 1M.
tSpot+1MtSpottONt
BON BTN B1M
tSpot+1MtSpottONt
BON BTN B1M
L�idée est de multiplier le facteur B1M par BON et BTN a�n d�obtenir un facteurd�actualisation qui couvre la période comprise entre la date courante t (incluse)et la date d�échéance correspondant au ténor 1M (exclue). Nous justi�erons cescalculs dans la suite.
Facteur d�actualisation associé à un ténor quelconque
Formule générale Un deposit est un zéro-coupon, donc son prix est donnépar la formule :
Bt (tVal; T ) =1
1 + xT �Dep (tVal; T ); (3.24)
où tVal est la date de départ du dépôt, T sa date d�échéance, �Dep (tVal; T )désigne le nombre d�années entre la date tVal (incluse) et la date T (exclue) dansla base de calcul du dépôt considéré et xT est le taux milieu de fourchette coté10 .Cette formule générale permet d�obtenir le facteur d�actualisation correspondantà chaque ténor.
Détermination de la date d�échéance La date T est obtenue en ajoutantla maturité du deposit considéré (1 jour ouvré, 1W, 2W, 3W, 1M, 3M,. . . ) à ladate de valeur tVal. Quand la date ainsi obtenue ne correspond pas à un jourouvré, elle est ajustée selon la convention Modi�ed Following.
Facteur d�actualisation Pré-Spot
Ténor OverNight Le ténor ON correspond à un placement sur un jour ouvréentre la date t et la date tON. Le facteur d�actualisation associé au dépôt ONest obtenu en remplaçant tVal par t et T par tON dans la formule (3.24) :
B (t; tON) =1
1 + xON �ON (t; tON); (3.25)
où xON est le taux OverNight milieu de fourchette et �ON (t; tON) est le nombred�années entre la date t et la date tON.
10On rappelle que pour toutes les devises, le taux coté est un taux linéaire annualisé.
166

Ténor Tom-Next Le ténor TN correspond à un placement sur un jour ouvréentre la date tON et la date tSN. Le facteur d�actualisation associé au dépôt ONest obtenu en remplaçant tVal par tON et T par tSN dans la formule (3.24) :
Bt (tON; tSN) =1
1 + xTN �TN (tON; tSN); (3.26)
où xTN est le taux Tom-Next milieu de fourchette et �TN (tON; tSN) est le nombred�années entre la date tON et la date tSN.
Obtention d�un facteur d�actualisation en départ t
Lorsque la date de départ d�un deposit quelconque (i.e. tVal) est égale à la datespot, il faut corriger le facteur d�actualisation donné par (3.24) en le multi-pliant par B (t; tON) et Bt (tON; tSN). Soit T > tSN la date d�échéance du ténorconsidéré, alors en utilisant la formule (3.4) on a :
B (t; T ) = B (t; tSN)Bt (tSN; T )
= B (t; tON)Bt (tON; tSN)Bt (tSN; T ) :
La quantité :
B (t; tSN)def= B (t; tON)Bt (tON; tSN) ; (3.27)
est appelée facteur d�actualisation pré-spot. Elle correspond au facteur d�actua-lisation entre la date t et la date tSN.
3.5.2 Facteurs d�actualisation associés aux swaps
Préliminaires
La construction de la courbe zéro-coupon est e¤ectuée selon un processus ité-ratif, appelé méthode du "bootstrap" : chaque nouveau point de la courbe estcalculé à partir des points précédemment construits. Comme nous le verronsdans la suite, cette approche suppose que nous disposons d�une cotation pourtoutes les maturités multiples de la fréquence des paiements de la jambe �xedu swap. Lorsque ce n�est pas le cas, nous proposons une solution nouvellequi permet d�extraire les facteurs d�actualisation isolés sans interpoler les tauxmanquants.
Hypothèses de travail Les hypothèses sur lesquelles reposent nos raisonne-ments sont les suivantes.
1. Les swaps cotés obéissent aux mêmes conventions de marché. En parti-culier, la période entre deux paiements de la jambe �xe (notée PF) et lapériode entre deux paiements de la jambe variable (notée PV) sont lesmêmes pour tous les swaps.
2. Tous les swaps cotés ont la même date de départ.
167

3. La date de départ de chaque jambe coïncide avec la date de départ duswap.
4. Les dates d�échéance des deux jambes sont les mêmes.
5. On dispose d�un taux coté pour toutes les maturités de la forme Tndef=
n� PF avec 1 � n � N .La première hypothèse est vraie pour presque toutes les devises. En général, lafréquence de paiement de la jambe �xe est semestrielle (PF = 6M) ou annuelle(PF = 1Y). La fréquence de la jambe variable est toujours inférieure ou égale àla fréquence de paiement de la jambe �xe : PV = 3M, 6M ou 1Y.L�hypothèse 2 est toujours vraie. En général, la date de départ est la datecourante t ou la date spot tSN = t� 2.Les hypothèses 3 et 4 sont toujours véri�ées en pratique.L�hypothèse 5 n�est pas toujours véri�ée, car les cotations sont espacées irrégu-lièrement. On doit donc interpoler les cotations manquantes. Le procédé utiliséest décrit au paragraphe 3.5.2.
Démarche générale La démarche générale est la suivante. Le premier fac-teur d�actualisation T1 est connu : il s�agit du facteur d�actualisation 6M ou 1Yobtenu à partir des taux de dépôt. Ensuite, on construit les facteurs d�actualisa-tion de proche en proche, le facteur d�actualisation d�échéance Ti étant obtenuà partir du facteur d�actualisation d�échéance Ti�1.
Evaluation d�un swap quelconque
Par dé�nition, une opération de swap est équitable, ce qui signi�e que les deuxjambes du swap ont la même valeur de marché lors de la mise en place. Dansce qui suit nous démontrons la formule d�évaluation de la jambe variable.
Notations On note ftj : j = 1; : : : ;mg les dates de paiement de la jambe va-riable du swap et fTi : i = 1; : : : ; ng les dates de paiement de la jambe �xe. Soitt0 (resp. T0), la date de départ de la jambe variable (resp. de la jambe �xe).D�après les hypothèses 2 et 3,
tVal = t0 = T0: (3.28)
Soit T la date d�échéance du swap, d�après l�hypothèse 4, on a :
T = tm = Tn: (3.29)
On pose :
�j = �V (tj�1; tj) ; j = 1; : : : ;m; (3.30)
�i = �F (Ti�1; Ti) ; i = 1; : : : ; n: (3.31)
Les notations �V et �F indiquent que les bases de calcul sont propres à chaquejambe. En�n, le taux variable (EURIBOR ou LIBOR) payé en date tj est noté
168

Lj (ce taux est �xé en tj�1). Le taux �xe du swap (taux milieu de fourchette) estnoté xn. Le graphique ci-dessous illustre le fonctionnement du swap présenté (lapériode des paiements de la jambe �xe est le double de la période des paiementsde la jambe variable).
xn ∆1
L1 δ1
xn ∆2 xn ∆3
L2 δ2 L3 δ3 L4 δ4 L5 δ5 L6 δ6
t6t1 t2 t3 t4 t5
Branche Fixe
Branche Variable
T1 T2 T3
xn ∆1
L1 δ1
xn ∆2 xn ∆3
L2 δ2 L3 δ3 L4 δ4 L5 δ5 L6 δ6
t6t1 t2 t3 t4 t5
Branche Fixe
Branche Variable
T1 T2 T3
Evaluation de la jambe variable Soit JVn0 la valeur de marché de la jambevariable à la date de départ t0 > t. En AOA, elle est égale à la somme des �uxvariables actualisés sur la courbe de taux sans risque :
JVn0 =mXj=1
Lj�jBt (t0; tj) : (3.32)
Les taux forwards Lj sont donnés par la formule (3.8) :
Lj =1
�j
�Bt (t0; tj�1)
Bt (t0; tj)� 1�: (3.33)
En injectant (3.33) dans (3.32) et en utilisant la relation Bt (t0; t0) = 1, on peutécrire :
JVn0 =mXj=1
�Bt (t0; tj�1)
Bt (t0; tj)� 1�Bt (t0; tj)
=mXj=1
(Bt (t0; tj�1)�Bt (t0; tj))
= 1�Bt (t0; tm) : (3.34)
D�après (3.29) on a :JVn0 = 1�Bt (t0; Tn) : (3.35)
169

Evaluation de la jambe �xe Soit JFn0 , la valeur de marché de la branche�xe à la date de départ t0. Un simple calcul d�actualisation permet d�écrire :
JFn0 =nXi=1
xn�iBt (t0; Ti) = xn�nBt (t0; Tn)+ xn
n�1Xi=1
�iBt (t0; Ti)
!: (3.36)
D�après l�hypothèse 4, les dates T0; T1; : : : ; Tn�1 sont communes aux échéanciersdes swaps d�échéance Tn�1 et d�échéance Tn. Alors on a :
JFn�10 =n�1Xi=1
xn�1�iBt (t0; Ti),n�1Xi=1
�iBt (t0; Ti) =JFn�10
xn�1: (3.37)
En injectant (3.37) dans (3.36) il vient :
JFn0 = xn�nBt (t0; Tn) +xnxn�1
JFn�10 : (3.38)
Nous disposons à présent de tous les éléments pour établir la formule de récur-rence entre les facteurs d�actualisation.
Détermination des facteurs d�actualisation par récurrence
Les deux branches du swap ont la même valeur à la date t0. En appliquant cerésultat aux swaps d�échéances Tn�1 et Tn il vient :
JFn0 = JVn0 ; JFn�10 = JVn�10 : (3.39)
Alors, en injectant ces relations dans (3.38) on peut écrire :
JVn0 = xn�nBt (t0; Tn) +xnxn�1
JVn�10 : (3.40)
En appliquant la relation (3.35) avec les dates Tn�1 et Tn on a :
JVn0 = 1�Bt (t0; Tn) ; JVn�10 = 1�Bt (t0; Tn�1) : (3.41)
On remplace JVn0 et JVn�10 par leur valeur respective dans (3.40) et l�on obtient
tous calculs faits :
Bt (t0; Tn) =1� xn
xn�1(1�Bt (t0; Tn�1))1 + xn�n
: (3.42)
Cette formule permet de déterminer le facteur d�actualisation entre t0 et Tnà partir du facteur d�actualisation d�échéance Tn�1. Le facteur d�actualisationd�échéance T1 étant connu, on peut alors déterminer tous les facteurs d�actuali-sation de proche en proche jusqu�à la dernière maturité TN . Contrairement auxformules habituellement proposées dans la littérature qui sont valables unique-ment pour une fréquence de coupon �xe égale à 1Y, la formule établie ici estcomplètement indépendante de la fréquence des paiements de la jambe �xe etelle s�applique à tous les swaps rencontrés sur le marché.
170

Obtention de facteurs d�actualisation en départ t Comme dans le casdes facteurs d�actualisation associés aux opérations de dépôt, si la date t0 estégale à la date spot, on corrige les facteurs d�actualisation trouvés en les mul-tipliant par le facteur pré-spot B (t; tSN). Dans le cas où t0 est égale à la datecourante, aucun ajustement n�est nécessaire.
Détermination des facteurs d�actualisation isolés
La méthode décrite au paragraphe précédent permet de déterminer très rapide-ment les facteurs d�actualisation, à condition (hypothèse 5) que l�on connaisse letaux de swap associé à chaque maturité de la forme Tn = n�PF. Par exemple,pour les swaps contre EURIBOR, cette propriété est véri�ée jusqu�au ténor15Y. Au-delà de cette maturité, on dispose d�un taux coté tous les 5 ans (20Y,25Y, 30Y), de sorte qu�il n�est plus possible d�appliquer la formule récursive(3.42) pour construire les facteurs d�actualisation cherchés. Une approche fré-quemment utilisée par les praticiens consiste à interpoler linéairement les tauxde swap cotés pour les maturités non disponibles. On dispose ainsi d�un jeude données complet et l�on applique la méthode précédente. Cette approchetrès simple donne en général de bons résultats, mais elle revient à ajouter del�information arti�cielle, là où il n�y en avait pas (Hagan et West 2006). Nousproposons ci-dessous une méthode qui permet de déterminer directement le tauxzéro-coupon cherché sans procéder à une construction des taux aux maturitésmanquantes.
Transformation du problème On suppose que l�on cherche à déterminer lefacteur d�actualisation du ténor Tn, dont le taux de swap coté est xn. Le dernierténor coté est Tn�k (taux de swap xn�k). Les taux des dates Tn�k+1; : : : ; Tn�1sont inconnus. Les notations sont les mêmes que celles du paragraphe précédent.L�égalité de la jambe �xe et de la jambe variable du swap d�échéance Tn s�écrit :
1�Bt (t0; Tn) = xn
nXi=1
�iBt (t0; Ti)
= xn
n�kXi=1
�iBt (t0; Ti) +
nXi=n�k+1
�iBt (t0; Ti)
!
=xnxn�k
JFn�k0 + xn
nXi=n�k+1
�iBt (t0; Ti) : (3.43)
La dernière égalité provient du fait que les swaps de maturités Tn�k et Tnpartagent le même échéancier jusqu�à la date Tn�k. En utilisant les identités(3.39) et (3.35) au rang n� k, il vient :
JFn�k0 = JVn�k0 = 1�Bt (t0; Tn�k) : (3.44)
171

Injectons (3.44) dans (3.43) :
1�Bt (t0; Tn) =xnxn�k
(1�Bt (t0; Tn�k)) + xnnX
i=n�k+1�iBt (t0; Ti) : (3.45)
Par ailleurs, la relation (3.4) entre les zéro-coupons forward-starts nous donne :
Bt (t0; Ti) = Bt (t0; Tn�k)Bt (Tn�k; Ti) ; n� k + 1 � i � n: (3.46)
En convenant de noter Bn�k à la place de Bt (t0; Tn�k) et Bn�k;i à la place deBt (Tn�k; Ti), l�égalité (3.45) devient :
1�Bn�kBn�k;n =xnxn�k
(1�Bn�k) + xnBn�knX
i=n�k+1�iBn�k;i: (3.47)
En regroupant les termes connus à droite et les termes inconnus Bn�k;i à gaucheon a :
xn
nXi=n�k+1
�iBn�k;i +Bn�k;n =1� xn
xn�k(1�Bn�k)
Bn�k: (3.48)
Ci-dessous, nous utilisons l�expression obtenue pour déterminer le facteur d�ac-tualisation manquant.
Calcul du facteur d�actualisation à la date Tn L�idée est d�exploiterles propriétés de la méthode d�interpolation RT-Linéaire des taux zéro-couponqui est présentée en détail au paragraphe 3.6.3. Dans cette approche, les tauxcontinus �ats sont interpolés linéairement entre deux dates d�observation consé-cutives :
~R (t; T ) = a� � (Tn�k; T ) + b; Tn�k � T � Tn; (3.49)
où � (Tn�k; T ) est le nombre d�années entre Tn�k et T dé�ni par (3.58). Lescoe¢ cients a et b sont déterminés en imposant la continuité en Tn�k et Tn :
b = ~R (t; Tn�k) ; (3.50)
a =~R (t; Tn)� ~R (t; Tn�k)
� (Tn�k; Tn): (3.51)
Le coe¢ cient a dépend du taux ~R (t; Tn) qui est inconnu. En l�absence d�oppor-tunité d�arbitrage, les taux ~R (t; T ) sont croissants, donc on doit avoir a � 0.
En appliquant (3.2), il vient :
B (t; T ) = e�~R(t;T )
= e�(~R(t;Tn�k)+a��(Tn�k;T ))
= B (t; Tn�k) e�a��(Tn�k;T ): (3.52)
172

En divisant par B (t; Tn�k) les deux membres de l�égalité on a :
Bt (Tn�k; T ) = e�a��(Tn�k;T ) Tn�k � T � Tn: (3.53)
En réécrivant (3.53) aux dates Ti (i = n� k; : : : ; n) on obtient :
Bn�k;i = e�a��(Tn�k;Ti) = e�a� i ; (3.54)
où l�on a posé � idef= � (Tn�k; Ti).
Remplaçons les termes Bn�k;i par (3.54) dans (3.48) :
xn
nXi=n�k+1
�ie�a� i + e�a�n =
1� xnxn�k
(1�Bn�k)Bn�k
: (3.55)
La fonction f : a ! xnPni=n�k+1�ie
�a� i + e�a�n est continue, strictementdécroissante de R+ dans lui-même, donc l�équation (3.55) admet une uniquesolution, notée a�, que l�on peut déterminer par la méthode de Newton (Judd1998). Une manière d�initialiser l�algorithme est de choisir :
a�0 =� (t; Tn)xn � ~R (t; Tn�k)
� (Tn�k; Tn); (3.56)
où xn est le taux de swap associé au ténor Tn. En l�absence d�opportunitéd�arbitrage, l�algorithme converge en quelques itérations vers la valeur cherchéea� � 0.Si la convergence n�a pas lieu dans R+, c�est que la courbe présente un arbitrageen Tn et, dans ce cas, on pose :
a� =� (t; Tn)R (t; Tn�k)� ~R (t; Tn�k)
� (Tn�k; Tn):
Cela revient à cristalliser le dernier taux zéro-coupon connu R (t; Tn�k). Lorsquea� est estimé, il ne reste qu�à écrire la relation (3.52) avec T = Tn pour obtenirle facteur d�actualisation cherché :
B (t; Tn) = B (t; Tn�k) e�a��n :
En procédant ainsi avec tous les ténors "isolés", on obtient des facteurs d�ac-tualisation consistants, sans introduire de l�information au niveau des donnéesobservées.
3.5.3 Calcul des taux zéro-coupon associés aux di¤érentsténors
Nous calculons les taux zéro-coupon annualisés associés aux di¤érents facteursd�actualisation en appliquant la relation (3.1). Les taux cherchés sont exprimésen base Act/365.25 et sont donnés par les formules suivantes :
R (t; T ) = � 365:25n (t; T )
lnB (t; T ) ; (3.57)
173

où n (t; T ) désigne le nombre de jours calendaires entre la date courante t (in-cluse) et la date T (exclue).
On dispose à présent des facteurs d�actualisation et des taux zéro-coupon auxdates d�échéances T1 � � � � � TN des instruments de calibration. On supposeque les données sont non-arbitrables11 , ce qui signi�e que la suite des facteursd�actualisation est décroissante ou que la suite des taux continus �ats est crois-sante (voir proposition 3.1). Dans la suite, nous montrons comment reconstituerune courbe de taux zéro-coupons continus à partir des points observés.
3.6 Interpolation non-arbitrable de la courbe destaux
Il existe principalement deux approches pour ajuster une courbe sur des don-nées. La première approche consiste à procéder à un lissage. Ce qui revient àdéterminer une courbe régulière passant le plus près possible des points obser-vés (au sens d�une distance à dé�nir). La seconde approche consiste à interpolerles données : on recherche une courbe régulière qui passe par tous les pointsobservés. Dans le cas de la construction des courbes de taux, les deux approchessont, à priori, envisageables. Il n�existe pas de méthode optimale, tout dépenddes besoins de l�utilisateur (Ron 2000).
Après avoir posé le problème en termes mathématiques, nous discutons les avan-tages et les inconvénients de pratiquer un lissage sur les données. Nous en arri-vons à la conclusion que cette solution n�est pas pleinement satisfaisante, lorsquel�on souhaite utiliser la courbe des taux pour évaluer des produits dérivés. Nousprésentons alors deux méthodes d�interpolation qui permettent d�obtenir unecourbe zéro-coupon non-arbitrable, l�une classique l�autre originale, dont l�im-plémentation est aisée.
3.6.1 Position du problème
Pour pouvoir mettre en oeuvre un algorithme numérique, nous devons convertirles dates en maturités. On pose donc :
� i =n (t; Ti)
365:25; i = 1; : : : ; N; (3.58)
où n (t; Ti) est le nombre de jours calendaires entre la date t (incluse) et la dateTi (exclue). Notre objectif est de déterminer le taux R (�) pour � 2 [�1; �N ].
Dans la suite, nous notons Bi le facteur d�actualisation de maturité � i.Ri = � lnBi=� i et ~Ri = Ri� i désignent respectivement le taux zéro-couponannualisé et le taux �at de maturité � i. Les données ne sont pas arbitrables11Le marché interbancaire est très bien arbitré ; il est donc rare que les facteurs d�actuali-
sation associés aux di¤érents ténors présentent des opportunités d�arbitrage.
174

donc les Bi forment une suite décroissante et les ~Ri forment une suite crois-sante. La méthode retenue (lissage ou interpolation) doit garantir que la courbereconstituée présente les mêmes propriétés.
3.6.2 Lissages de la courbe zéro-coupon
L�avantage principal des méthodes de lissage est qu�elles permettent de capturerla forme de la courbe des taux sans pour autant passer par des points quipourraient être jugés comme aberrants. On distingue les méthodes de lissageparamétriques et les méthodes de lissage non-paramétriques. Nous en présentonsci-dessous les avantages et les inconvénients.
Lissage paramétrique de type Nelson-Siegel
Principe Le lissage paramétrique consiste : (i) à postuler une famille decourbes qui dépendent d�un certain nombre de paramètres en général interpré-tables (paramètre de niveau, paramètre de pente, paramètre de courbure. . . ) et(ii) à trouver le jeu de paramètres qui minimisent la distance entre les pointsobservés et la courbe théorique. Nelson et Siegel (1987) ont proposé une fonctionde lissage paramétrique pour les courbes de taux, qui est une combinaison defonctions polynomiales pondérées par des coe¢ cients à décroissance exponen-tielle. La fonctionnelle de Nelson-Siegel peut se mettre sous la forme :
R (�) = �1 + �2
�1� e��=��=�
�+ �3
�1� e��=��=�
� e��=��; � � 0: (3.59)
Le paramètre � est un paramètre de retour à la moyenne. Les paramètres�1; �2; �3 contrôlent respectivement le comportement de la courbe sur le long-terme, sur le moyen-terme et sur le court-terme. Le modèle est calibré auxdonnées observées en résolvant un problème de minimisation non linéaire :
(��1; ��2; �
�3; �
�) = argmin
(NXn=1
(R (�n)�Rn)2 : (�1; �2; �3; �) 2 R4): (3.60)
A�n de simpli�er la procédure de calibration, certains auteurs proposent de �xerla valeur de � à priori et, dans ce cas, le problème (3.60) devient un problèmed�optimisation linéaire (Martellini et Priaulet 2004, Diebold et Li 2006).
Propriétés On peut montrer que cette famille de fonctions permet d�obte-nir les quatre formes de courbes classiques (ascendante, descendante, plate etinversée). En revanche, elle présente deux inconvénients majeurs.
1. Elle ne permet pas de capturer les formes de courbes plus complexes quel�on peut rencontrer dans certaines con�gurations de marché, notammentles courbes possédant un creux et une bosse (Martellini et Priaulet 2004).
2. Elle peut introduire des opportunités d�arbitrage sur la courbe (Bekker etBouwman 2007).
175

Concernant la première observation, certains auteurs ont proposé des variantesde la fonctionnelle (3.59) qui o¤rent un ajustement de meilleure qualité surles données (Svensson 1994, Bliss 1997, Björk et Christensen 1999). Le gainen �exibilité est obtenu en augmentant le nombre de paramètres du modèle,mais cela se fait au détriment de la procédure de calibration qui devient alorsfortement non linéaire (Geyer et Mader 1999, Ramponi et Lucca 2003). Pourune étude comparative détaillée des propriétés de la fonctionnelle (3.59) et deses variantes, le lecteur pourra consulter Kalev (2004) ou De Pooter (2007).Concernant la seconde observation, Bekker et Bouwman (2007) proposent uneméthode pour calibrer le modèle en intégrant des contraintes de non-arbitragesur les paramètres. Coroneo, Nyholm et Vidova-Koleva (2008) montrent quele modèle (3.59) est statistiquement non-arbitrable. Les paramètres obtenus ene¤ectuant l�optimisation classique (3.60), conduisent dans la plupart des con�-gurations à une courbe de taux non-arbitrable.
Discussion L�avantage principal des approches paramétriques du type Nelson-Siegel est que les paramètres sont interprétables12 et qu�ils sont relativementstables dans le temps. C�est pourquoi ces modèles sont utilisés : (i) par lesbanques centrales pour reconstruire les courbes de taux d�états étalons (Ricartet Sicsic 1995, BIS 2005, Diebold, Li et Yue 2006, ECB 2007) et (ii) par les ana-lystes économiques pour prédire l�évolution des taux dans le futur (Bernadell,Coche et Nyholm 2005, Diebold et Li 2006, Almeida et Vicente 2007, De Pooter,Ravazzolo et Van Dijk 2007).
En revanche, leur incapacité à restituer �dèlement certaines formes de courbesles rend impropres à lisser les courbes de taux qui interviennent dans l�évaluationet la couverture des produits dérivés. En e¤et, les opérateurs cherchent avanttout à obtenir des prix qui re�ètent le coût de leur portefeuille de couvertureavec exactitude. On comprend dès lors que, si l�on utilise un modèle qui donneune approximation imprécise de la courbe zéro-coupon, le risque est d�introduiredes biais lors de l�évaluation du produit dérivé et des paramètres de risques.
Lissage non-paramétrique par splines cubiques
Les méthodes de lissage paramétrique manquent de �exibilité et elles ne per-mettent pas de reconstituer toutes les formes de courbes rencontrées en pratique.Pour résoudre ce problème, on peut alors envisager d�utiliser une méthode non-paramétrique basée sur des fonctions splines. McCulloch (1971, 1975) proposed�utiliser des splines cubiques polynomiaux. Smirnov et Zakharov (2003) étu-dient la possibilité de reconstruire la courbe des taux en utilisant des splinesexponentiels. Ils montrent comment tenir compte explicitement des contraintes
12Plus précisément, les paramètres peuvent être identi�és aux facteurs de risque quicontrôlent les déformations de la courbe des taux. Ce résultat peut être mis en évidence enprocédant à une Analyse en Composantes Principales de l�évolution de la courbe (Martelliniet Priaulet 2004, pp. 57-63).
176

de non-arbitrage lors de la calibration. Cette seconde approche est particulière-ment délicate à mettre en oeuvre, car elle nécessite de résoudre des problèmesd�optimisation fortement non-linéaires.
Nous présentons ci-dessous le lissage par splines cubiques de McCulloch.
Principe Le principe est de diviser le segment [�1; �N ] en di¤érents sous-intervalles et d�approcher la fonction cherchée par un polynôme de degré 3 surchacun des intervalles. Les coe¢ cients de chaque polynôme sont déterminés enimposant des conditions de continuité de la fonction et de ses dérivées d�ordres1 et 2 aux extrémités de chaque sous-intervalle. Soit �1 = �1 � � � � � �k = �Nle partage de l�intervalle [�1; �N ]. Les �i sont appelés les noeuds de la fonctionspline. L�approximation par splines cubiques consiste à écrire la fonction R sousla forme suivante :
R (�) =n�1Xi=1
fi (�)1f�i����i+1g; (3.61)
où les fi sont des polynômes de degré 3 dé�nis par :
fi (�) = ai�3 + bi�
2 + ci� + di: (3.62)
A�n de garantir un maximum de régularité, on impose les conditions suivantesen chaque noeud :
fi (�i) = fi�1 (�i) (continuité)f 0i (�i) = f 0i�1 (�i) (continuité de la dérivée première)f 00i (�i) = f 00i�1 (�i) (continuité de la dérivée seconde)
(3.63)
En écrivant les relations (3.63) on obtient des relations linéaires entre les coe¢ -cients des polynômes sur chaque intervalle
��i; �i+1
�, ce qui réduit la dimension
du problème. Plus précisément, lorsque les contraintes (3.63) sont véri�ées, lafonction cherchée peut se réécrire sous la forme (voir Annexe C pour une dé-monstration) :
R (�) = �0 + �1 (� � �1)+ + �2 (� � �1)2+ +
k�1Xi=1
�i+2 (� � �i)3+ ; (3.64)
où x+def= max (x; 0) et � def= (�0; : : : ; �k+1)
0 2 Rk+2 sont des coe¢ cients à déter-miner. Le vecteur de coe¢ cients optimaux, noté ��, est solution du problèmede minimisation quadratique :
�� = argmin
(NXn=1
(R� (�n)�Rn)2 : � 2 Rk+2): (3.65)
La résolution de (3.65) est un problème d�algèbre linéaire qui ne pose aucune dif-�culté. Pour une présentation approfondie des fonctions splines, on peut consul-ter Lyche et Mørken (2006).
177

Choix de la position des noeuds La principale di¢ culté avec cette méthodeest de choisir le nombre de noeuds k et les valeurs des coe¢ cients (�i)1�i�k. Pours�en convaincre, il su¢ t de tenir le raisonnement suivant :� en augmentant le nombre de noeuds on améliore mécaniquement la qualité del�ajustement, le risque étant que la fonction obtenue oscille entre les noeuds,
� inversement, en diminuant le nombre de noeuds, on obtient un e¤et de lissageplus important, le risque étant que la fonction obtenue représente mal lesdonnées.
Il n�existe pas de méthode systématique pour choisir les noeuds. McCullochsuggère de choisir k comme l�entier le plus proche de
pN et de dé�nir les
coe¢ cients �i en posant :
�i = �hi + �i (�1+hi � �hi) ; (3.66)
où hi = biN=kc (le symbole b�c désigne l�opérateur partie entière) et �i =iN=k � hi. Martellini et Priaulet (2004) proposent de placer les noeuds auxmaturités remarquables de la courbe : par exemple 1 an, 5 ans, 10 ans, 20 ans etainsi de suite. Dans ces conditions, on peut considérer que les di¤érents segments��i; �i+1
�correspondent aux parties court-terme, moyen-terme et long-terme de
la courbe.
Discussion Les méthodes de lissage par splines sont utilisées par de nom-breuses institutions pour reconstruire les courbes de taux zéro-coupon sur lemarché interbancaire (Waggoner 1997, Ron 2000, Bolder et Gusba 2002). Mais,nous avons pu observer que dans les périodes où les marchés sont perturbés(krach), ce type d�approche ne donnait pas des résultats totalement satisfai-sants. En e¤et, dans de telles périodes, la courbe des taux peut prendre desformes particulièrement complexes (double creux, double bosse) qui traduisentle manque de sérénité des intervenants. La position des noeuds prend alors uneimportance considérable et il devient très di¢ cile d�obtenir une courbe qui res-titue �dèlement la forme des données observées, notamment sur les maturitéscourtes (inférieures à un an). De plus, les lissages par splines cubiques ne per-mettent pas de garantir que la courbe sera non-arbitrable, même si les donnéesobservées ne sont pas arbitrables (Hagan et West 2006).
Conclusion
Les méthodes de lissage permettent d�obtenir des courbes de taux lisses et ré-gulières. Toutefois elles soulèvent deux problèmes.
1. Il se peut que les données observées ne soient pas restituées �dèlement,ce qui est particulièrement le cas pour les méthodes paramétriques. Lesméthodes de lissage par splines cubiques corrigent ce défaut dans la me-sure où elles n�imposent pas une forme déterminée pour la courbe. Encontrepartie, elles sont très sensibles au choix des noeuds qui relient lespolynômes entre eux.
178

2. Il n�existe pas de méthode de lissage qui soit à la fois simple à mettre enoeuvre et qui donne des courbes de taux non-arbitrables. En pratique lescontraintes de non-arbitrage doivent être intégrées explicitement dans leproblème de calibration qui devient alors non-linéaire.
Compte tenu de l�analyse précédente et dans la mesure où l�objectif du modèlen�est pas d�imposer une forme théorique "idéale" à la courbe des taux, mais deproduire une courbe non-arbitrable qui soit cohérente avec les données observées,nous allons montrer qu�il est préférable d�interpoler les données observées, plutôtque de procéder à un lissage.
3.6.3 Interpolations de la courbe zéro-coupon
Nous commençons par discuter di¤érentes solutions proposées dans la littéra-ture. Ensuite, nous présentons deux méthodes d�interpolation "classiques" de lacourbe zéro-coupon et nous introduisons une nouvelle méthode qui permet decorriger les inconvénients des deux méthodes précédentes.
Quelques solutions présentées dans la littérature
Il n�existe pas de méthode optimale pour l�interpolation de la courbe des taux.En pratique, il faut choisir une solution qui réalise un compromis entre facilité demise en oeuvre et robustesse des résultats. Chazot et Claude (1995) proposentde travailler avec les taux zéro-coupon annualisés et de procéder soit à une in-terpolation linéaire, soit à une interpolation par splines cubiques naturels. Ron(2000) souligne que, lorsque la courbe des taux présente des changements depente fréquents et/ou importants, l�interpolation linéaire produit des cassuresinacceptables au niveau des di¤érents noeuds de la courbe, ce qui conduit à évi-ter cette approche. Par ailleurs, Kruger (2003) démontre que l�interpolation parsplines cubiques naturels produit des courbes qui oscillent entre les données,ce qui n�est pas souhaitable quand on doit reconstituer des courbes de taux.Adams (2001) modélise la fonction de taux instantané par des splines quar-tiques (polynômes d�ordre 4). Cette méthode permet d�obtenir la fonction detaux instantané la plus régulière possible, mais elle présente deux inconvénients :(i) le nombre de contraintes à prendre en compte lors de la calibration est trèsimportant et surtout (ii) elle ne permet pas de garantir la positivité des tauxforwards instantanés. Hagan et West (2006) procèdent à une étude compara-tive exhaustive des méthodes d�interpolation envisageables pour la constructionde la courbe des taux. Ils distinguent les méthodes d�interpolation simples, quiconsistent à interpoler linéairement une quantité à préciser (taux zéro-coupon,facteurs d�actualisation, taux �ats. . . ), des méthodes d�interpolation complexes,qui sont essentiellement des variantes de l�interpolation par splines cubiques(splines cubiques contraints). Les auteurs démontrent sur un exemple que laplupart des méthodes étudiées ne permettent pas d�obtenir systématiquementune courbe non-arbitrable. Ils proposent alors deux nouvelles méthodes d�inter-polation pour résoudre ce problème. Mais elles sont particulièrement lourdes à
179

mettre en oeuvre, car il faut tenir compte, lors de la calibration, d�un grandnombre de contraintes.
Nous exposons ci-dessous les trois méthodes suivantes.
1. L�interpolation par splines cubiques naturels sur les taux zéro-coupon : lacourbe obtenue est régulière (de classe C2), mais elle peut présenter desopportunités d�arbitrage.
2. L�interpolation RT-Linéaire (RTL), employée par de nombreux praticiens.Elle garantit l�obtention d�une courbe non-arbitrable, mais elle présenteun inconvénient : les taux forwards sont discontinus.
3. L�interpolation RT-Cubique-Monotone (RTCM). C�est une méthode ori-ginale dont nous proposons l�utilisation. Elle combine les avantages desdeux méthodes précédentes : la courbe zéro-coupon est systématiquementnon-arbitrable et les taux forwards instantanés sont continus.
Interpolation par splines cubiques naturels
L�interpolation par splines cubiques naturels est un cas particulier de la mé-thode de lissage du paragraphe 3.6.2 dans lequel on fait coïncider les points deraccordement des splines avec les dates d�observations :
k = N; �i = � i: (3.67)
La fonction de taux zéro-coupon est dé�nie par la formule (3.64) :
R (�) = �0 + �1 (� � �1)+ + �2 (� � �1)2+ +
N�1Xi=1
�i+2 (� � � i)3+ : (3.68)
Pour déterminer les inconnues du problème (�0; : : : ; �N+1) 2 RN+1, on imposeà la fonction de passer par les taux observés R1; : : : ; RN :
R (� i) = Ri; i = 1; : : : ; N: (3.69)
La relation (3.69) nous donne N contraintes, or il y a N + 2 inconnues à dé-terminer. Il faut donc introduire deux contraintes supplémentaires. La méthodedite des splines cubiques naturels consiste à poser :
R00 (�1) = R00 (�N ) = 0: (3.70)
Dans ce cas, la convexité de la courbe est minimale aux extrémités13 . En écri-vant les di¤érentes contraintes, on peut déterminer un système linéaire dont lasolution correspond aux coe¢ cients cherchés.
13Une autre solution, appelée splines cubiques �nanciers, consiste à remplacer la contrainte(3.70) par la relation R0 (�1) = R0 (�N ) = 0. Cette condition impose que la courbe soit plateaux points extrêmes, ce qui permet d�extrapoler les données au-delà de la maturité la plusgrande. Hagan et West (2006) discutent de nombreuses variantes de l�interpolation par splinescubiques.
180

Discussion La courbe obtenue est de classe C2, ce qui est un avantage cer-tain. Par contre, l�interpolation par splines cubiques présente deux inconvénientsmajeurs14 :� elle peut produire des courbes de taux arbitrables, alors que les données d�en-trée ne sont pas arbitrables,
� l�interpolation est globale, ce qui signi�e qu�en modi�ant un point d�entrée,on déforme toute la courbe.
La méthode s�avère malgré tout relativement performante lorsque l�on disposed�un grand nombre de points observés. Dans ce cas, la courbe obtenue est lisseet régulière. En revanche, dès que le nombre de points est peu important (5 ou6 points), la courbe obtenue ampli�e les tendances que l�on peut observer auniveau des données.
Interpolation RT-Linéaire (RTL)
Cette méthode est fréquemment utilisée par les opérateurs de marché. L�idéeest de procéder à une interpolation linéaire, non pas sur les taux zéro-couponannualisés Ri, mais sur les taux �ats ~Ri = Ri� i (appelés "taux RT" dans lapratique). Cette méthode est très simple à implémenter, elle est très stable (lafonction de taux forwards instantanés est peu sensible à une modi�cation del�un des taux observés) et surtout, elle garantit que la courbe obtenue sera non-arbitrable (Hagan et West 2006, West 2006).
Taux zéro-coupon Sur chaque intervalle [� i; � i+1], le taux continu �at estdé�ni par :
~R (�) = ai� + bi; (3.71)
où ai et bi sont donnés par les formules :
ai =� i+1Ri+1 � � iRi
� i+1 � � i; (3.72)
bi =� i� i+1� i+1 � � i
(Ri �Ri+1) : (3.73)
La relation (3.2) nous donne l�expression du taux annualisé :
R (�) = ai +bi�: (3.74)
Etant donné que l�on a la relation ~R (�) = � ln B (�), où B (�) est le facteurd�actualisation de maturité � , cette méthode est parfois appelée interpolationlog-linéaire.
14On retrouve ces inconvénients pour les splines cubiques dits "�nanciers", qui reposent surle même principe d�interpolation.
181

Taux forward instantané Les taux forwards instantanés, notés r (�), sontdonnés par la formule (3.11) :
r (�) = ~R0 (�) = ai; � i � � � � i+1: (3.75)
La fonction � ! r (�) est donc en escalier.
Une conséquence intéressante de (3.75) est la suivante :
r (�) > 0, ai > 0, ~Ri+1 > ~Ri: (3.76)
Autrement dit, les taux forwards instantanés sont positifs, dès que les taux�ats observés sont croissants (ce qui est le cas par hypothèse, car les donnéesobservées ne présentent pas d�opportunité d�arbitrage).
Localité de l�interpolation Les formules (3.72) et (3.73) montrent que si l�onchange la valeur d�entrée Ri alors la fonction � ! R (�) n�est modi�ée que surles intervalles [� i�1; � i] et [� i; � i+1], le reste de la courbe est inchangé. En termesmathématiques, on dit que l�interpolation est locale, car les déformations sur lesdonnées observées ne sont répercutées que localement (Hagan et West 2006).
Stabilité de l�interpolation En dérivant successivement la formule (3.75)par rapport à Ri et Ri+1 il vient :
@r
@Ri=
�� i� i+1 � � i
= Cste; (3.77)
@r
@Ri+1=
� i+1� i+1 � � i
= Cste0: (3.78)
La méthode d�interpolation est particulièrement stable, car la sensibilité de lafonction r aux taux observés ne dépend que de la position initiale des maturitésobservées.
Commentaires La méthode RTL est une méthode d�interpolation particuliè-rement attractive pour plusieurs raisons :� la courbe obtenue est, par construction, non-arbitrable,� l�interpolation est locale (la courbe ne se déforme que localement),� l�interpolation est stable (les sensibilités du taux instantané aux données d�en-trée sont constantes).
Cette méthode présente cependant un inconvénient : les taux forwards instan-tanés sont discontinus (West 2006). C�est pourquoi nous envisageons une autreapproche qui permet de construire une fonction interpolante de classe C1.
Interpolation RT-Cubique-Monotone (RTCM)
Nous souhaitons construire une fonction interpolante continûment dérivable, desorte que les taux forwards instantanés soient continus. A�n de préserver les
182

propriétés de non-arbitrage de la courbe, nous imposons la contrainte r (�) � 0,pour 0 � � � �N . Une solution envisagée par Hagan et West (2006) consisteà modéliser la fonction r en imposant de nombreuses contraintes de positivité.Cette méthode conduit à des calculs particulièrement lourds, c�est pourquoi nousenvisageons une autre approche, plus simple à mettre en oeuvre et dont nousexposons la démarche ci-dessous.
Interpoler en préservant la monotonie On sait que les taux instantanéssont toujours positifs si et seulement si la fonction � ! ~R (�) est croissante avecla maturité. Or, nous avons supposé que les taux �ats observés ~Ri formaientune suite croissante. L�idée est donc d�interpoler les ~Ri par une fonction declasse C1 qui préserve la monotonie du jeu de données. La fonction ~R ainsireconstituée sera dérivable et sa dérivée sera positive et continue. Fritsch etCarslon (1980) proposent d�utiliser des splines cubiques contraints pour e¤ectuerce type d�interpolation. Le principe est de remplacer l�hypothèse de continuité dela dérivée seconde par une hypothèse de monotonie sur chaque segment [� i; � i+1].Les auteurs démontrent que la monotonie sur chaque segment est entièrementdéterminée par les valeurs des dérivées ~R0i = ri et ~R0i+1 = ri+1 aux extrémités � iet � i+1. Ils proposent un algorithme qui permet de construire les ri à partir del�ensemble des données observées, ce qui signi�e que l�interpolation est globale.En d�autres termes, toute modi�cation sur une seule valeur d�entrée, par exemple~Ri, est répercutée sur toute la courbe. Nous utilisons une variante de l�algorithmede Fritsch et Carslon, due à Fritsch et Butland (1984), dans laquelle le calculdes dérivées est immédiat et qui produit une interpolation locale. L�algorithmeretenu est présenté dans la suite15 .
Interpolation de Hermite Le principe est d�écrire la fonction cherchée ~Rde la manière suivante :
~R (�) =
n�1Xi=1
fi (�)1f� i���� i+1g; �1 � � � �n; (3.79)
où chaque fi est un polynôme de degré 3 dé�ni par l�équation :
fi (�) = ai (� � � i)3 + bi (� � � i)2 + ci (� � � i) + di; � i � � � � i+1: (3.80)
Dans l�interpolation dite de Hermite, les coe¢ cients (ai; bi; ci; di) sont détermi-nés par les quatre conditions suivantes :
� le polynôme fi passe par les points observés�� i; ~Ri
�et�� i+1; ~Ri+1
�:
�fi (� i) = ~Ri (interpolation à gauche)fi (� i+1) = ~Ri+1 (interpolation à droite)
; (3.81)
15 Il existe d�autres approches pour construire des splines cubiques monotones interpolants,mais leur mise en oeuvre nécessite d�introduire des points de contrôle intermédiaires pour"corriger" la forme de la courbe, ce qui complexi�e les calculs (Gasparo et Morandi 1991).
183

� la dérivée du polynôme fi interpole le taux forward instantané à chaqueborne : �
f 0i (� i) = ri (interpolation à gauche)f 0i (� i+1) = ri+1 (interpolation à droite)
; (3.82)
où ri et ri+1 désignent les valeurs du taux forward instantané aux points � iet � i+1.
Les coe¢ cients cherchés sont donnés par les formules suivantes :
ai =1
h2i(ri + ri+1 � 2mi) ; (3.83)
bi =1
hi(3mi � 2ri � ri+1) ; (3.84)
ci = ri; (3.85)
di = ~Ri; (3.86)
oùmidef= ( ~Ri+1� ~Ri)=hi désigne la pente entre les points (� i; ~Ri) et (� i+1; ~Ri+1).
Les calculs �gurent en Annexe D.1.
Garantir la monotonie de la courbe Par construction, la fonction dé�nieprécédemment est de classe C1 sur l�intervalle [�1; �n] et sa forme est entièrementdéterminée par les triplets (� i; ~Ri; ri). Dans notre problème, les seules donnéesobservées sont les couples (� i; ~Ri). L�idée est de �xer les inconnues r1; : : : ; rn, quireprésentent les valeurs du taux forward instantané aux dates d�observations,de manière à ce que le polynôme fi soit monotone sur l�intervalle [� i; � i+1].
Fritsch et Carslon (1980) considèrent la dérivée de fi qui est donnée par laformule :
f 0i (�) = 3ai (� � � i)2+ 2bi (� � � i) + ci; (3.87)
puis ils étudient son signe en fonction des coe¢ cients.
A�n de simpli�er les raisonnements, ils posent :
�i =rimi
; �i =ri+1mi
: (3.88)
Une condition nécessaire (mais non su¢ sante) pour que la courbe soit monotonesur l�intervalle [� i; � i+1] est que les dérivées aux bornes de l�intervalle soient demême signe que la pente entre les points (� i; ~Ri) et (� i+1; ~Ri+1). Cela impliqueune première condition :
�i � 0; �i � 0: (3.89)
Les coe¢ cients ai, bi et ci se réécrivent sous la forme suivante :
ai =mi
h2i(�i + �i � 2) ; (3.90)
bi =mi
hi(3� 2�i � �i) ; (3.91)
ci = mi�i: (3.92)
184

En injectant ces formules dans (3.87) on obtient :
f 0i (�) = mi
�3 (�i + �i � 2)x2� + 2 (3� 2�i � �i)x� + �i
�;
où l�on a posé x�def= (� � � i) =hi 2 [0; 1]. En conséquence, pour connaître le
signe de f 0i (�), il su¢ t d�étudier le polynôme dé�ni par :
g(x) = 3 (�i + �i � 2)x2 + 2 (3� 2�i � �i)x+ �i; 0 � x � 1:
Pour le détail des calculs, on peut consulter Fritsch et Carslon (1980).
Les contraintes de monotonie sont données par les règles ci-dessous.
1. Si �i + �i � 2 � 0, alors fi est monotone si et seulement si la condition(3.89) est réalisée.
2. Si �i + �i � 2 > 0, alors fi est monotone si et seulement si la condition(3.89) est réalisée et si l�une des conditions suivantes est véri�ée :
(a) 2�i + �i � 3 � 0;(b) �i + 2�i � 3 � 0;(c) �2i + �i (�i � 6) + (�i � 3)
2< 0:
Fritsch et Carslon (1980) donnent un algorithme pour construire les dérivées rià partir de l�ensemble des points de la courbe, ce qui signi�e que l�interpola-tion qu�ils proposent est globale. Nous montrons ci-dessous comment choisir lesdérivées de manière à ce que l�interpolation soit la plus locale possible.
Choix des dérivées Fritsch et Carslon démontrent que les règles précédentesdé�nissent une région D du plan dont la forme est relativement complexe et quele plus grand carré contenu dans D est le pavé [0; 3]� [0; 3]. Pour cette raison etpar soucis de simplicité, Fritsch et Butland (1984) proposent de restreindre larecherche des coe¢ cients (ri; ri+1) à l�ensemble des couples tels que (�i; �i) 2[0; 3]� [0; 3]. Ils proposent aussi de calculer les dérivées cherchées avec la formulesuivante :
ri =
� mi�1mi
�imi+(1��i)mi�1si mi�1mi > 0
0 si mi�1mi � 0; 2 � i � n� 1; (3.93)
où �i est dé�ni par :
�i =hi + 2hi+13 (hi + hi+1)
2�1
3; 1
�: (3.94)
Véri�ons que (�i; �i) 2 [0; 3]� [0; 3] :
�i =rimi
=1
�imi=mi�1 + (1� �i)� 1
(1� �i)< 3;
�i =ri+1mi
=1
�i+1 + (1� �i+1)mi=mi+1� 1
�i+1< 3:
185

Donc ce choix des dérivées convient.
Il ne reste qu�à �xer les dérivées aux points extrêmes �1 et �N pour que lacourbe soit entièrement paramétrée. Pour cela, nous imposons que la dérivéeseconde de la fonction soit nulle aux extrémités du segment [�1; �N ] :
f 001 (�1) = f 00N�1 (�N ) = 0: (3.95)
On obtient alors (voir calcul en Annexe D.2) :
r1 =3m1 � r2
2; (3.96)
rN =3mN�1 � rN�1
2: (3.97)
On véri�e sans di¢ culté que (3.96) implique 2�1+�1�3 = 0, donc la condition2(a) est véri�ée. Par ailleurs, (3.97) implique 2�N�1 + �N�1 � 3 = 0, donc lacondition 2(b) est véri�ée. En conséquence, la fonction interpolante est mono-tone sur le premier et sur le dernier segment.
Taux zéro-coupon Sur chaque intervalle [� i; � i+1], le taux zéro-coupon an-nualisé est dé�ni par :
R (�) =ai (� � � i)3 + bi (� � � i)2 + ri (� � � i) + ~Ri
�; �1 � � � �n: (3.98)
Taux forward instantané La fonction de taux forwards instantanés est ob-tenue en dérivant l�expression (3.80) membre à membre :
r (�) = 3ai (� � � i)2 + 2bi (� � � i) + ri; �1 � � � �n: (3.99)
Par construction, elle est continue et toujours positive.
Localité de l�interpolation Les quantités mi�1;mi; ri; ri+1 dépendent dutaux ~Ri. Alors, si l�on change la valeur de ~Ri les coe¢ cients des polynômesfi�1; fi et fi+1 sont modi�és. Cela signi�e que toute modi�cation du taux ~Riinduit une déformation de la fonction ~R sur l�intervalle [� i; � i+1] et sur les deuxintervalles adjacents : [� i�1; � i] et [� i+1; � i+2]. On en conclut que l�interpolationRTCM est locale.
Stabilité de l�interpolation L�étude de la stabilité de l�interpolation RTCMest plus délicate que dans le modèle RTL car, au travers des formules (3.93),(3.96) et (3.97), les coe¢ cients du polynôme interpolant dépendent de manièrenon-linéaire des données observées. Toutefois, il est possible d�encadrer la dé-formation des taux forwards instantanés en calculant les dérivées de r (�) parrapport aux données d�entrée mi, ri et ri+1.
@r
@mi= 3
@ai@mi
(� � � i)2 + 2@bi@mi
(� � � i) = 6x (1� x) ;
186

où x def= (� � � i) =hi 2 [0; 1]. La fonction x ! 6x (1� x) est bornée sur [0; 1],
minorée par 0 et majorée par 1=3. On en déduit que :
0 � @r
@mi� 13: (3.100)
Calculons :
@r
@ri= 3
@ai@ri
(� � � i)2 + 2@bi@ri
(� � � i) + 1 = 3x2 � 4x+ 1;
où x est dé�ni comme précédemment. La fonction sur x! 3x2�4x+1 est bornéesur l�intervalle [0; 1], minorée par �1=3 et majorée par 1. Alors, on obtient :
�13� @r
@ri� 1: (3.101)
En�n, on a :
@r
@ri+1= 3
@ai@ri+1
(� � � i)2 + 2@bi@ri+1
(� � � i) + 1 = 3x2 � 2x:
La fonction sur x! 3x2�2x est bornée sur l�intervalle [0; 1], minorée par �1=3et majorée par 1, d�où l�on déduit :
�13� @r
@ri+1� 1: (3.102)
Les formules (3.100), (3.101) et (3.102) signi�ent que les déformations de lafonction r sont bornées, donc l�interpolation RTCM est stable.
Commentaire L�interpolation RTCM présente les mêmes atouts que l�inter-polation RTL mais, en plus, elle garantit la continuité des taux forwards instan-tanés.
3.7 Comparaison des méthodes proposées
Dans cette section, nous illustrons les performances des méthodes d�interpola-tion RTL et RTCM que nous comparons à l�interpolation par splines cubiquesnaturels. Nous prenons deux exemples : le premier établit la nécessité d�uti-liser une méthode d�interpolation qui garantit la positivité des taux forwardsinstantanés, le second montre comment les méthodes proposées permettent deconstruire la courbe zéro-coupon EURIBOR.
3.7.1 Splines cubiques naturels et taux instantanés néga-tifs
L�exemple présenté est issu de Hagan et West (2006). On considère la courbede taux zéro-coupon donnée dans le tableau ci-dessous.
187

� R(�) ~R(�) B (�)
0:1 8:10% 0:81% 0:991931:0 7:00% 7:00% 0:932394:0 4:40% 17:60% 0:838629:0 7:00% 63:00% 0:5325920:0 4:00% 80:00% 0:4493330:0 3:00% 90:00% 0:40657
Les taux �ats observés sont croissants (3i�eme colonne), donc la courbe ne devraitpas présenter d�opportunité d�arbitrage.Pourtant, comme l�illustre la �gure 3.1, les taux forwards instantanés obtenusavec l�interpolation par splines cubiques naturels sont négatifs dans certainesrégions. En comparaison, les méthodes d�interpolation RTL et RTCM préserventla structure non-arbitrable des données observées.Le graphique du haut représente les courbes zéro-coupon (en vert) et de tauxforward instantané (en pointillé rouge) lorsque les données sont interpolées parla méthode des splines cubiques naturels. Le graphique du milieu donne lesmêmes courbes obtenues avec l�interpolation RTL et le graphique du bas avecl�interpolation RTCM.La courbe des taux zéro-coupon est très régulière avec les splines cubiques natu-rels, mais elle présente des opportunités d�arbitrage. En e¤et, les taux forwardsinstantanés sont négatifs dans l�intervalle de maturités [15; 25] avec un taux for-ward minimal d�environ �5:10%. Ce résultat démontre que l�interpolation parsplines cubiques naturels peut s�avérer décevante lorsqu�il s�agit de reconstruireles courbes des taux à partir de peu de points. En revanche, les taux forwardsinstantanés restent positifs avec les méthodes RTL et RTCM, ce qui con�rmeque ces deux approches préservent la structure non-arbitrable des données ob-servées. Sur cet exemple, l�interpolation RTCM se montre la plus performantepour deux raisons : (i) la courbe de taux zéro-coupon est parfaitement régulièreet elle n�accentue pas les tendances entre les données, (ii) la courbe des taux for-wards est, elle aussi, très régulière, alors qu�elle est discontinue avec la méthodeRTL.
Nous allons maintenant appliquer les méthodes proposées à des données réelles.
3.7.2 Construction de la courbe EURIBOR
Les données utilisées sont celles du vendredi 09 mai 2008 et la courbe recons-tituée est la courbe EURIBOR. Les jours ouvrés sont gérés selon le calendrierTARGET16 et les dates de départ des di¤érentes opérations sont les suivantes :
t = 09=05=2008;
tON = 12=05=2008;
tSN = 13=05=2008:
16Voir Annexe B.
188
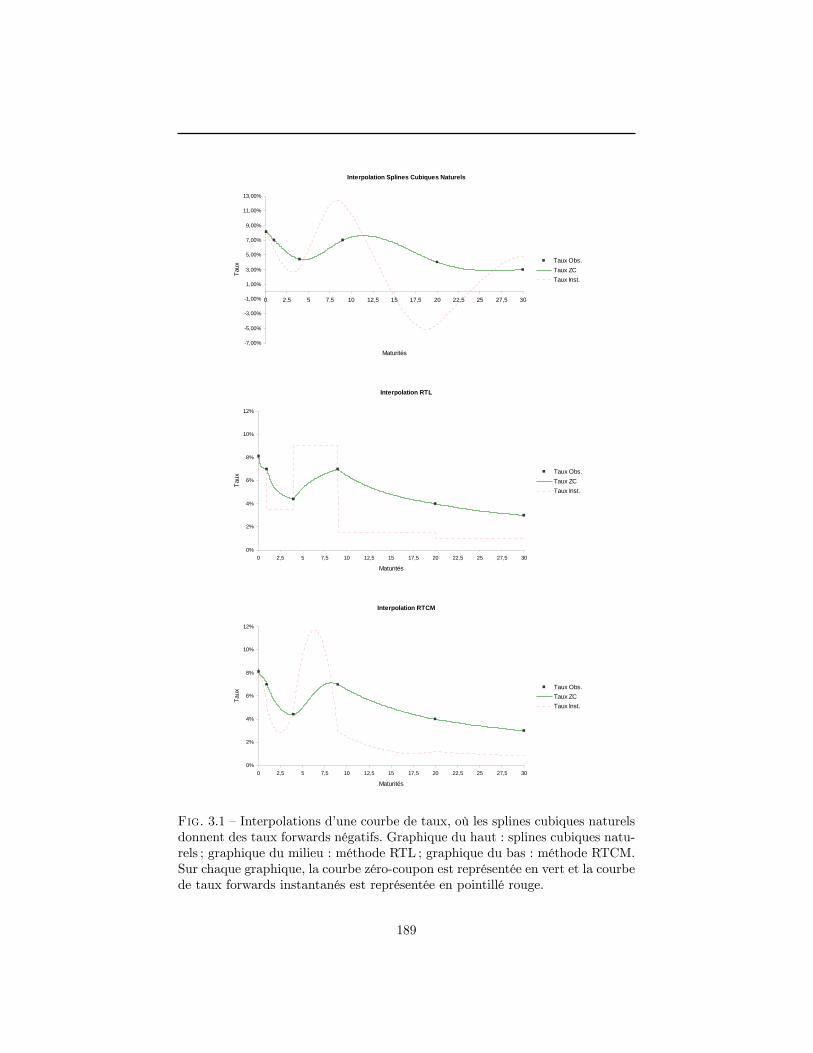
Interpolation Splines Cubiques Naturels
7,00%
5,00%
3,00%
1,00%
1,00%
3,00%
5,00%
7,00%
9,00%
11,00%
13,00%
0 2,5 5 7,5 10 12,5 15 17,5 20 22,5 25 27,5 30
Maturités
Taux
Taux Obs.Taux ZCTaux Inst.
Interpolation RTL
0%
2%
4%
6%
8%
10%
12%
0 2,5 5 7,5 10 12,5 15 17,5 20 22,5 25 27,5 30
Maturités
Taux
Taux Obs.Taux ZCTaux Inst.
Interpolation RTCM
0%
2%
4%
6%
8%
10%
12%
0 2,5 5 7,5 10 12,5 15 17,5 20 22,5 25 27,5 30
Maturités
Taux
Taux Obs.Taux ZCTaux Inst.
Fig. 3.1 �Interpolations d�une courbe de taux, où les splines cubiques naturelsdonnent des taux forwards négatifs. Graphique du haut : splines cubiques natu-rels ; graphique du milieu : méthode RTL ; graphique du bas : méthode RTCM.Sur chaque graphique, la courbe zéro-coupon est représentée en vert et la courbede taux forwards instantanés est représentée en pointillé rouge.
189

Les deposits couvrent la plage des maturités allant de 1 jour ouvré (ON) à 1 an.Les swaps couvrent les maturités allant de 2 ans à 30 ans. Il existe deux types deswaps sur le marché de l�EURIBOR : les swaps contre EURIBOR 3 mois et lesswaps contre EURIBOR 6mois qui sont les plus liquides et que nous utilisons ici.Par convention, tous les swaps contre EURIBOR sont en départ Spot. Les datesd�échéances sont ajustées suivant la convention Modi�ed Following. La base decalcul de la jambe �xe est 30/360 et la base de calcul de la jambe variable estAct/360. La méthode utilisée pour l�extraction des facteurs d�actualisation estcelle décrite dans la section 3.5. Les facteurs d�actualisation et les taux zéro-coupon associés aux di¤érents ténors sont donnés dans le tableau ci-dessous.
Inst. Type Tenor Bid Ask Mid Start End DF ZC rateD ON 3,660 3,780 3,720 09/05/08 12/05/08 0,999690 3,774D TN 3,770 3,890 3,830 12/05/08 13/05/08 0,999584 3,802D SN 3,790 3,910 3,850 13/05/08 14/05/08 0,999477 3,823D 1W 3,980 4,100 4,040 13/05/08 20/05/08 0,998799 3,990D 2W 4,200 4,320 4,260 13/05/08 27/05/08 0,997931 4,204D 3W 4,225 4,345 4,285 13/05/08 03/06/08 0,997091 4,256D 1M 4,270 4,390 4,330 13/05/08 13/06/08 0,995871 4,318D 3M 4,740 4,860 4,800 13/05/08 13/08/08 0,987471 4,797D 6M 4,820 4,940 4,880 13/05/08 13/11/08 0,975259 4,867D 9M 4,810 4,930 4,870 13/05/08 13/02/09 0,963606 4,836D 1Y 4,701 4,821 4,761 13/05/08 13/05/09 0,954156 4,645S 2Y 4,407 4,437 4,422 13/05/08 13/05/10 0,916848 4,320S 3Y 4,297 4,327 4,312 13/05/08 13/05/11 0,880921 4,214S 4Y 4,256 4,286 4,271 13/05/08 14/05/12 0,845824 4,172S 5Y 4,248 4,278 4,263 13/05/08 13/05/13 0,811609 4,166S 6Y 4,269 4,299 4,284 13/05/08 13/05/14 0,777380 4,190S 7Y 4,309 4,339 4,324 13/05/08 13/05/15 0,743170 4,235S 8Y 4,356 4,386 4,371 13/05/08 13/05/16 0,709376 4,286S 9Y 4,409 4,439 4,424 13/05/08 15/05/17 0,675794 4,346S 10Y 4,462 4,492 4,477 13/05/08 14/05/18 0,643199 4,408S 11Y 4,510 4,540 4,525 13/05/08 13/05/19 0,611773 4,464S 12Y 4,555 4,585 4,570 13/05/08 13/05/20 0,581348 4,516S 13Y 4,594 4,624 4,609 13/05/08 13/05/21 0,552322 4,563S 14Y 4,627 4,657 4,642 13/05/08 13/05/22 0,524761 4,603S 15Y 4,655 4,685 4,670 13/05/08 15/05/23 0,498488 4,637S 20Y 4,721 4,751 4,736 13/05/08 15/05/28 0,389372 4,712S 25Y 4,716 4,746 4,731 13/05/08 13/05/33 0,309659 4,687S 30Y 4,689 4,719 4,704 13/05/08 13/05/38 0,249501 4,626
La �gure 3.2 représente les courbes de taux zéro-coupon (en vert) et les courbesde taux forwards instantanés (en pointillé rouge) obtenues avec les trois mé-thodes d�interpolation : splines cubiques naturels (graphique du haut), RTL(graphique du milieu) et RTCM (graphique du bas). On constate que l�interpo-lation par splines cubiques naturels ne conduit pas à des taux forwards négatifs.La raison en est que le jeu de points utilisé est su¢ samment dense pour queles splines cubiques opèrent une reconstruction des données manquantes �dèleaux données observées. Comme attendu, la courbe de taux forwards instantanésest en escalier dans l�interpolation RTL, tandis qu�elle est continue et régulière
190

Interpolation Splines Cubiques Naturels
3,00%
3,50%
4,00%
4,50%
5,00%
5,50%
0 2,5 5 7,5 10 12,5 15 17,5 20 22,5 25 27,5 30
Maturités
Taux
Taux Obs.Taux ZCTaux Inst.
Interpolation RTL
3,0%
3,5%
4,0%
4,5%
5,0%
5,5%
0 2,5 5 7,5 10 12,5 15 17,5 20 22,5 25 27,5 30
Maturités
Taux
Taux Obs.Taux ZCTaux Inst.
Interpolation RTCM
3,0%
3,5%
4,0%
4,5%
5,0%
5,5%
0 2,5 5 7,5 10 12,5 15 17,5 20 22,5 25 27,5 30
Maturités
Taux
Taux Obs.Taux ZCTaux Inst.
Fig. 3.2 � Courbe de taux EURIBOR au 09/05/2008 construite selon troisméthodes : la méthode des splines cubiques naturels (graphique du haut), laméthode RTL (graphique du milieu) et la méthode RTCM (graphique du bas).Sur chaque graphique, la courbe zéro-coupon est représentée en vert et la courbede taux forwards instantanés est représentée en pointillé rouge.
191

dans l�interpolation RTCM. En particulier, la courbe de taux forwards est plusrégulière avec la méthode RTCM qu�avec l�interpolation par splines cubiquesnaturels sur le court-terme (maturités inférieures à 2:5 ans).Ces résultats sont très encourageants et nous conseillons d�utiliser systémati-quement les méthodes RTL ou RTCM. Le choix d�utiliser une méthode plutôtque l�autre dépend du type d�application que l�on envisage et du nombre dedonnées disponibles. Si l�on souhaite privilégier la régularité de la courbe detaux forwards instantanés, il faut mettre en oeuvre la méthode RTCM.
3.8 Conclusion
Les courbes zéro-coupon sont les piliers sur lesquels reposent les systèmes d�éva-luation des actifs dérivés complexes actuels. Il faut donc les construire avecsoin, en tenant compte des conventions de marché et en veillant à ce qu�elles neprésentent pas d�opportunité d�arbitrage.
Dans la seconde section, nous avons donné les principaux concepts théoriquessur lesquels repose la construction d�une courbe de taux zéro-coupon et nousavons démontré les propriétés qu�une telle courbe doit véri�er lorsque le mar-ché fonctionne en l�absence d�opportunité d�arbitrage. Dans la troisième section,nous avons présenté les conventions en vigueur sur les marchés de taux d�intérêtpour calculer les dates et pour gérer les échéanciers de �ux. Dans la quatrièmesection, nous avons montré que, pour construire les courbes de taux destinéesà l�évaluation des produits �nanciers, il fallait utiliser des instruments du mar-ché interbancaire et nous avons présenté les di¤érents types d�instruments pourlesquels on dispose de cotations �ables. Dans la section cinq, nous avons dé-montré comment extraire les facteurs d�actualisation zéro-coupon à partir destaux de deposits et des taux de swaps vanilles en tenant compte des conventionsde marché. Dans la sixième section, nous avons envisagé deux approches pourreconstituer une courbe de taux complète et non-arbitrable : le lissage ou l�in-terpolation. Après avoir écarté les techniques de lissage (qui ne donnent pas unereconstitution �dèle des données), nous avons présenté la méthode des splinescubiques naturels (qui ne permet pas de préserver les propriétés de non-arbitragede la courbe), ainsi que deux méthodes d�interpolation très e¢ caces, l�interpola-tion RT-Linéaire (RTL) et l�interpolation RT-Cubique-Monotone (RTCM) aveclesquelles on obtient systématiquement une courbe non-arbitrable. Dans la sec-tion sept, nous avons comparé les méthodes proposées, d�abord sur un jeu dedonnées spécialement choisi, puis sur des données réelles (courbe EURIBOR).L�étude a montré que la méthode des splines cubiques naturels pouvait engen-drer des taux forwards négatifs, tandis que les deux autres méthodes donnenttoujours des taux forwards positifs.
L�interpolation RTCM combine les avantages de l�interpolation par splines cu-biques (la courbe obtenue est de classe C1, donc lisse) avec les avantages del�interpolation RTL (localité, stabilité, positivité des taux forwards instanta-nés). Pour les applications pratiques, nous recommandons d�utiliser la méthode
192

RTL lorsque la continuité des taux forwards n�est pas indispensable et la mé-thode RTCM dès que le problème nécessite de travailler avec des taux forwardscontinus. Une extension possible de l�approche RTCM est d�imposer la conti-nuité de la dérivée seconde de la courbe zéro-coupon a�n d�obtenir une courbede taux forwards encore plus régulière. Dans ce cas, déterminer la courbe destaux devient un problème d�optimisation sous contraintes dont la calibrationpeut être arbitrairement longue (Turlach 1997, Wolberg et Itzik 1999).
193

A Démonstration de la proposition 3.1
L�équivalence entre les points 1 et 2 est une conséquence directe de la dé�nition(3.2). L�équivalence entre les points 2 et 3 provient de la formule (3.11). Il su¢ tdonc d�établir le point 1. Supposons qu�il existe un zéro-coupon d�échéance U telque : B (t; T ) < B (t; U) et T < U . Alors, à la date t, on met en place la stratégiesuivante : vente du zéro-coupon d�échéance U et achat de B (t; U) =B (t; T ) zéro-coupons d�échéance T . Par construction, la mise en place de l�opération ne donnelieu à aucun �ux. A la date T , on reçoit un �ux égal à B (t; U) =B (t; T ) et à ladate U , on décaisse un �ux égal à 1. En supposant que l�on ne fasse rien entre ladate T et la date U , on réalise un gain systématique égal à B (t; U) =B (t; T )�1 > 0. Donc la stratégie proposée constitue un arbitrage, ce qui est exclu parhypothèse.
B Caractéristiques des taux IBOR
Nous donnons dans le tableau ci-dessous les devises pour lesquelles il existe destaux IBOR. Pour chaque devise, nous faisons �gurer la base, la date de Valeuret le calendrier des taux associés.
Référence Devise Base Date de Valeur Calendrier
LIBOR USD Act/360 Spot GBP+USDJPY Act/360 Spot GBP+JPYGBP Act/365 Jour GBPCHF Act/360 Spot GBP+CHFCAD Act/360 Spot GBP+CADAUD Act/360 Spot GBP+AUDDKK Act/360 Spot GBP+DKKSEK Act/360 Spot GBP+SEKNZD Act/360 Spot GBP+NZDEUR Act/360 Spot TARGET
EURIBOR EUR Act/360 Spot TARGET
A l�exception des taux GBP-LIBOR, qui sont en date de Valeur "Jour" (ledépart a lieu le jour de publication), tous les taux de la famille IBOR sont endate de Valeur "Spot" (le départ a lieu 2 jours ouvrés après la publication).
Les taux EUR-LIBOR sont très peu utilisés et il ne faut pas les confondre avecles taux EURIBOR. Ces deux taux partagent le calendrier TARGET (Trans-european Automated Real-time Gross settlement Express Tranfer). Les joursnon-ouvrés du système TARGET sont : les week-ends, le jour de l�An, le vendrediSaint, le lundi de Pâques, le premier mai (fête du travail), le 25 décembre (jourde Noël) et le 26 décembre.Pour les taux, dont la devise n�est pas l�Euro, le calendrier est de la formeGBP+XXX, ce qui signi�e que l�on considère les dates qui sont des jours ouvréspour la place de Londres et pour la principale place de cotation de la deviseXXX.
194

C Démonstration de la formule (3.64)
Les conditions (3.63) s�écrivent :
di + ci�i + bi�i + ai�3i = di�1 + ci�1�i + bi�1�
2i + ai�1�
3i ; (3.103)
ci + 2bi�i + 3ai�2i = ci�1 + 2bi�1�i + 3ai�1�
2i ; (3.104)
2bi + 6ai�i = 2bi�1 + 6ai�1�i: (3.105)
La relation (3.105) se réécrit :
�bidef= bi � bi�1 = �3�ai�i; (3.106)
où �aidef= ai � ai�1. En combinant (3.106) et (3.104) il vient :
�cidef= ci � ci�1 = �2�bi�i � 3�ai�2i
= 3�ai�2i : (3.107)
En injectant (3.106) et (3.107) dans (3.103) on a :
�didef= di � di�1 = ��ai�3i ��bi�2i ��ci�i
= ��ai�3i : (3.108)
Soit � 2 R, avec les relations précédentes, on peut écrire :
fi (�)� fi�1 (�) = �ai�3 +�bi�
2 +�ci� +�di
= �ai�3 � 3�ai�i�2 + 3�ai�2i � ��ai�3i
= �ai (� � �i)3: (3.109)
En sommant l�égalité (3.109) membre à membre pour i = 2; : : : ; l, on obtient :
fl (�) = f1 (�) +lXi=2
�ai (� � �i)3; � 2 R: (3.110)
195

Alors, pour tout � 2 R, on a :
R (�) =k�1Xl=1
fl (�)1f�l����l+1g
= f1 (�)1f�1����2g +k�1Xl=2
f1 (�) +
lXi=2
�ai (� � �i)3
!1f�l����l+1g
= f1 (�)k�1Xl=1
1f�l����l+1g +k�1Xl=2
lXi=2
�ai (� � �i)31f�l����l+1g
= f1 (�)1f�1����kg +k�1Xi=2
k�1Xl=i
�ai (� � �i)31f�l����l+1g
= f1 (�)1f�1����kg +
k�1Xi=2
�ai (� � �i)3
k�1Xl=i
1f�l����l+1g
!
= f1 (�)1f�1����kg +k�1Xi=2
�ai (� � �i)31f�i����kg
=
f1 (�)1f���1g +
k�1Xi=2
�ai (� � �i)31f���ig
!1f0����kg: (3.111)
Le premier polynôme f1 peut toujours s�écrire sous la forme :
f1 (�) = �0 + �1 (� � �1) + �2 (� � �1)2+ �3 (� � �1)
3; (3.112)
où les coe¢ cients (�0; �1; �2; �3) sont obtenus en e¤ectuant un développementlimité à l�ordre 3 au voisinage de �1. On pose alors :
�ai = �i+2; i = 2; : : : ; k � 1: (3.113)
En injectant les formules (3.112) et (3.113) dans (3.111) et en posant
x+def= max (x; 0) = x1fx�0g
on obtient l�expression cherchée :
R (�) =
�0 + �1 (� � �1)+ + �2 (� � �1)
2+ +
k�1Xi=1
�i+2 (� � �i)3+
!1f0����kg:
(3.114)
D Calculs du paragraphe 3.6.3
D.1 Calcul des coe¢ cients du polynôme de Hermite
Commençons par écrire fi et sa dérivée f 0i :
fi (�) = ai (� � � i)3 + bi (� � � i)2 + ci (� � � i) + di; (3.115)
f 0i (�) = 3ai (� � � i)2 + 2bi (� � � i) + ci: (3.116)
196

En faisant � = � i dans l�équation (3.115) il vient :
~Ri = fi (� i) = di: (3.117)
De manière analogue, on obtient ci en faisant � = � i dans l�équation (3.116) :
ri = f 0i (� i) = ci: (3.118)
Les coe¢ cients ai et bi sont obtenus en écrivant les condition d�interpolation en� i+1 :
~Ri+1 = fi (� i+1) = aih3i + bih
2i + rihi + ~Ri; (3.119)
ri+1 = f 0i (� i+1) = 3aih2i + 2bihi + ri; (3.120)
En résolvant le système d�équations (3.119) et (3.120) on obtient :
ai =ri + ri+1 � 2mi
h2i; (3.121)
bi =3mi � 2ri � ri+1
hi; (3.122)
où l�on a posé mi = ( ~Ri+1 � ~Ri)=hi.
D.2 Calcul des dérivées aux points extrêmes
En dérivant l�expression (3.116) membre à membre, il vient :
f 00i (�) = 6ai (� � � i) + 2bi: (3.123)
La condition f 001 (�1) = 0 nous donne :
b1 = 0 =3m1 � 2r1 � r2
h1, r1 =
3m1 � r22
: (3.124)
La condition f 00n�1 (�n) = 0 nous donne :
6an�1hn�1 + 2bn�1 = 0, rn�1 =3mn�1 � rn�1
2: (3.125)
197

Références
Adams K. (2001). �Smooth Interpolation of Zero Curves�, Algo Research Quar-terly, Vol. 4, pp. 11-22.Almeida C., Vicente J. (2007). �The Role of No-Arbitrage on Forecasting Les-sons from a Parametric Term Structure Model�, Working Paper, No. 657, Gra-duate School of Economics, Rio de Janeiro.Bekker P.A., Bouwman K.E. (2007). �Arbitrage Smoothing in Fitting a Se-quence of Yield Curves�, Working Paper, Department of Economics, Universityof Groningen.Bernadell C., Coche J., Nyholm K. (2005). �Yield Curve Prediction for TheStrategic Investor�, ECB Working Paper Series, No. 472, European CentralBank, Frankfurt am Main.BIS (2005). �Zero-Coupon Yield Curves : Technical Documentation�, Bank forInternational Settlements, Basle.Björk T., Christensen B. (1999). �Interest Rate Dynamics and Consistent For-ward Rate Curves�, Mathematical Finance, pp. 323-348.Bliss R.R. (1997). �Testing Term Structure Estimation Methods�, Advances inFutures and Options Research, Vol. 9, pp. 197-231.Bolder D.J., Gusba S. (2002). �Exponentials, Polynomials, and Fourier Series :More Yield Curve Modelling at the Bank of Canada�, Working Paper 2002-29,Bank of Canada.Brigo D., Mercurio F. (2006). Interest Rate Models - Theory and Practice, WithSmile, In�ation and Credit, Springer.Chazot C., Claude P. (1995). Les swaps, Concepts et Applications, SecondeEdition, Economica.Cherif M. (2000). Les taux d�intérêt, Banqueéditeur.Christie D. (2003). �Accrued Interest & Yield Calculations and Determinationof Holiday Calendars�, Technical Document, SWX Swiss Exchange.Coroneo L., Nyholm K., Vidova-Koleva R. (2008). �How Arbitrage-Free Is TheNelson-Siegel Model ?�, ECB Working Paper Series, No. 874, European CentralBank, Frankfurt am Main.De Pooter M. (2007). �Examining the Nelson-Siegel Class of Term StructureModels�, Tinbergen Institute Discussion Paper, Faculty of Economics, ErasmusUniversity, Rotterdam.De Pooter M., Ravazzolo F., Van Dijk D. (2007). �Predicting the Term Struc-ture of Interest Rates�, Working Paper, Econometric Institute and TinbergenInstitute, Erasmus University, Rotterdam.Diebold F., Li C. (2006). �Forecasting the term structure of government bondyields�, Journal of Econometrics 130, pp. 337-364.Diebold F., Li C., Yue V.Z. (2006). �Global Yield Curve Dynamics and In-teractions : A Generalized Nelson-Siegel Approach�, Working Paper, http://www.ssc.upenn.edu/~fdiebold.ECB (2007). �General description of ECB yield curve methodology�, EuropeanCentral Bank, Frankfurt am Main.
198

Fritsch F.N., Butland J. (1984). �A Method For Constructing Local MonotonePiecewise Cubic Interpolation�, SIAM Journal on Scienti�c Computing, Vol. 5,No. 2, pp. 300-304.Fritsch F.N., Carslon R.E. (1980). �Monotone Piecewise Cubic Interpolation�,SIAM Journal on Numerical Analysis, Vol. 17, No. 2, pp. 238-246.Gasparo M.G., Morandi R. (1991). �Piecewise Cubic Monotone Interpolationwith Assigned Slopes�, Computing, Vol. 46, pp. 355-365.Geyer A., Mader R. (1999). �Estimation of the Term Structure of Interest Rates :A Parametric Approach�, OeNB Working Paper Series, No. 37, OesterreichischeNationalbank.Hagan P.S., West G. (2006). �Interpolation Methods For Curve Construction�,Applied Mathematical Finance, Vol. 13, No. 2, pp. 89-129.Harrison J., Kreps D. (1979). �Martingales and arbitrage in multiperiod secu-rities markets�, Journal of Economic Theory, Vol. 20, pp. 381-408.Harrison J., Pliska S. (1981). �Martingales and stochastic integral in the theoryof continuous trading�, Stochastic Processes and their Applications, Vol. 11, pp.215-260.ISDA (2006). �2006 ISDA De�nitions�, International Swaps And DerivativesAssociation, http://www.isda.org/.Judd K.L. (1998). Numerical Methods in Economics, The MIT Press.Kalev P. (2004). �Estimating and Interpreting Zero Coupon and Forward Rates :Australia 1992-2001�, Working Paper, Department of Accounting and Finance,Monash University.Kruger C.J.C. (2003). �Constrained Cubic Spline Interpolation for ChemicalEngineering Applications�, http://www.korf.co.uk/spline.pdf.Lyche T., Mørken K. (2006). �Spline Methods, Lecture Notes�, Department ofInformatics, University of Oslo http://home.ifi.uio.no/tom.Martellini L., Priaulet P. (2004). Produits de taux d�intérêt, Méthodes dyna-miques d�évaluation et de couverture, Seconde Edition, Economica.McCulloch J.H. (1971). �Measuring the term structure of interest rates�, TheJournal of Business, Vol. 44, pp. 19-31.McCulloch J.H. (1975). �The tax-adjusted yield curve�, The Journal of Finance,Vol. 30, pp. 811-830.Muselia M., Rutkowski M. (1997). �Continuous-time term structure models :Forward measure approach�, Finance and Stochastics, Vol. 1, No. 4, pp. 261-291.Nelson C.R., Siegel A.F. (1987). �A parsimonious modeling of yield curve�,Journal of Business, Vol. 60, No. 4, pp. 473-489.Ramponi A., Lucca K. (2003). �On a generalized Vasicek-Svensson model forthe estimation of the term structure of interest rates�, IV Workshop FinanzaQuantitativa, Torino.Rebonato R. (2002). Modern Pricing of Interest-Rate Derivatives : The LIBORMarket Model and Beyond, Princeton University Press.Ricart R., Sicsic P. (1995). �Estimation d�une Structure par Terme des Tauxd�Intérêt sur Données Françaises�, Bulletin de la Banque De France, No. 22, pp.117-129.
199

Ron U. (2000). �A Practical Guide to Swap Curve Construction�, WorkingPaper 2000-17, Bank of Canada.Smirnov S.N., Zakharov A.V. (2003). �A Liquidity-Based Robust Spline Fittingof Spot Yield Curve Providing Positive Forward Rates�, Working Paper, De-partment of Risk Management and Insurance, State University - Higher Schoolof Economics, Moscow.Svensson L.E.O. (1994). �Estimating and Interpreting Forward Interest Rates :Sweden 1992-1994�, Centre for Economic Policy Research, Discussion Paper,No. 1051.Turlach B.A. (1997). �Constrained Smoothing Splines Revisited�, Technical Re-port, Australian National University, Canberra.Waggoner D.F. (1997). �Spline Methods for Extracting Interest Rate Curvesfrom Coupon Bond Prices�, Working Paper 97-10, Federal Reserve Bank ofAtlanta.West G. (2006). �A Brief Comparison of Interpolation Methods For Yield CurveConstruction�, Working Paper, Financial Modelling Agency, http://www.finmod.co.za/interpolationsummary.pdf.Wolberg G., Itzik A. (1999). �Monotonic Cubic Spline Interpolation�, Procee-dings of the International Conference on Computer Graphics, pp. 188-195.
200

Chapitre 4
Construction de la surfacede volatilité implicite enl�absence d�opportunitéd�arbitrage
Ce chapitre traite de la construction des surfaces de volatilité implicite desgrands indices boursiers à partir des prix d�options disponibles sur les marchéslistés.Notre objectif est de proposer une méthodologie pour construire une surfacede volatilité implicite complète et non-arbitrable à partir des prix des optionsobservées.Ce travail est organisé selon le schéma suivant. Dans la première section, nousmontrons que la construction de la surface de volatilité implicite est un enjeustratégique pour les acteurs des marchés de produits dérivés. Dans la secondesection, nous proposons une méthode pour simpli�er le problème de la construc-tion de la surface de volatilité implicite en transformant les données de manièreà travailler dans un espace de prix normalisés où les taux d�intérêt sont nuls etles actifs ne détachent pas de dividende. Dans la troisième section nous donnonsles contraintes imposées par l�hypothèse d�absence d�opportunité d�arbitragesur les prix des calls Européens et sur les volatilités implicites. Dans la qua-trième section nous présentons les données de marché (les options Européennessur l�indice DJ EuroStoxx 50 cotées sur l�Eurex) qui seront utilisées pour lestests de calibration et nous proposons une procédure pour retraiter les prix desoptions cotées a�n d�éliminer les données fausses ou non-signi�catives. Dans lacinquième section, nous mettons en oeuvre deux méthodes proposées dans la lit-térature et utilisées par certains praticiens pour contruire la surface de volatilitéet nous montrons qu�elles ne donnent pas des résultats tout à fait satisfaisants.Dans la sixième section nous proposons un procédé original pour construire une
201

surface de volatilité lisse et non-arbitrable de manière systématique. L�approcheenvisagée combine des techniques de modélisation paramétrique du smile, pourextrapoler les volatilités manquantes au niveau des strikes extrêmes, avec desméthodes d�interpolation et de lissage non-paramétrique, pour générer une sur-face de volatilité complète et éliminer les arbitrages éventuels. La conclusion estdonnée dans la septième section. Les démonstrations des résultats sont donnéesen Annexe.
4.1 La volatilité implicite : un enjeu stratégique
4.1.1 Contrats Européens
Options Européennes
Un call Européen est un contrat qui donne le droit à son détenteur d�acheterune unité d�un certain actif S (l�actif sous-jacent), à un prix prédé�ni K (lestrike ou prix d�exercice), à une date prédé�nie T (la date d�échéance ou dated�expiration).Le payo¤ d�un call Européen correspond à la somme encaissée par le détenteurdu contrat lorsqu�il exerce son droit :
�C(ST ) = (ST �K)+; (4.1)
où (x)+ def= max(x; 0).
Un put Européen est un contrat qui donne le droit de vendre le sous-jacent etson payo¤ est donné par :
�P (ST ) = (K � ST )+: (4.2)
Contrat forward
Un contrat forward est un contrat qui donne l�obligation à son détenteur d�ache-ter une unité d�un certain actif S (l�actif sous-jacent), à un prix prédé�ni K (lestrike ou prix d�exercice de l�option), à une date prédé�nie T (la date d�échéanceou date d�expiration du contrat). Le payo¤ d�un contrat forward est donné par :
�F (ST ) = ST �K: (4.3)
Relation de parité call-put
Sous l�hypothèse d�absence d�opportunité d�arbitrage, les prix d�un call et d�unput Européens de même strike K et de même date d�échéance T sont liés par larelation suivante :
Ct (K;T )� Pt (K;T ) = Ft (K;T ) ; (4.4)
202

où Ct (K;T ), Pt (K;T ) et Ft (K;T ) désignent respectivement le prix du call,le prix du put et le prix du contrat forward d�échéance T et de strike K à ladate t. Cette relation est indépendante du modèle retenu pour la dynamique dusous-jacent.
4.1.2 Le modèle de Black-Scholes-Merton (1973)
Dynamique des prix
Dans le modèle de Black et Scholes (1973) étendu par Merton (1973), le coursde l�actif sous-jacent est modélisé par un mouvement Brownien géométrique dela forme :
dStSt
= (rt � qt)dt+ �tdWt; S0 > 0; (4.5)
où S0 est le cours de l�actif à l�instant de l�évaluation, rt � 0 est le taux court(déterministe) de l�économie, qt � 0 est le taux de dividende instantané (déter-ministe) de l�actif et fWt : t � 0g est un mouvement Brownien standard sous lamesure de probabilité risque-neutre Q.
La fonction �t, appelée volatilité instantanée de l�actif, est déterministe et àvaleurs strictement positives. La volatilité module l�amplitude des variations decours : lorsque �t augmente, elles deviennent de plus en plus fortes et imprédic-tibles ; lorsque �t diminue, elles deviennent de plus en plus faibles ; dans le casextrême où �t = 0, il n�y a plus aucune incertitude quant à l�évolution des prix.La volatilité est donc le paramètre de risque du modèle.
L�équation (4.5) implique que les rendements instantanés de l�actif suivent uneloi gaussienne de paramètres :
E[dSt=St] = (rt � qt)dt; Var[dSt=St] = �2tdt: (4.6)
Par ailleurs, on peut démontrer que le cours du sous-jacent à une date T quel-conque suit une loi lognormale de la forme :
ST = S0exp
Z T
0
(rt � qt ��2t2)dt+
Z T
0
�tdWt
!: (4.7)
Prix des contrats Européens
L�un des principaux avantages du modèle de Black-Scholes-Merton (BSM enabrégé)1 est que l�on peut déterminer analytiquement la valeur des options Eu-ropéennes. Plus précisément, si CBS désigne la valeur d�un call et PBS celle d�unput, on a :
CBS (K;T; S0; r; q; �) = S0e��qTT�
�D+��Ke��rTT�
�D�� ; (4.8)
PBS (K;T; S0; r; q; �) = Ke��rTT���D��� S0e��qTT� ��D+
�; (4.9)
1Dans la pratique, les opérateurs omettant souvent Merton, parlent du modèle Black-Scholes, d�où l�abréviation BS ou lieu de BSM.
203

où K et T sont le strike et la date d�échéance de l�option. � (�) est la fonctionde répartition de la loi normale standard.Les quantités �rT et �qT désignent respectivement le taux zéro-coupon annualiséde l�économie du produit et le taux de dividende annualisé du sous-jacent quiprévalent entre 0 et T . Elles sont dé�nies par :
�rTdef=1
T
Z T
0
rtdt; �qTdef=1
T
Z T
0
qtdt: (4.10)
Les coe¢ cients D+ et D� sont donnés par les formules :
D� =ln (S0=K) + (�rT � �qT )T
��TpT
� ��TpT
2; (4.11)
où ��T ,qui représente le niveau moyen de la volatilité instantanée sur la période[0; T ], est dé�ni de la manière suivante2 :
��Tdef=
s1
T
Z T
0
�2tdt: (4.12)
L�ensemble des paramètres nécessaires à l�évaluation des formules (4.8) et (4.9)- le strike K, la maturité T , le cours spot S0, le taux zéro-coupon �rT , le tauxde dividende �qT - sont observables directement sur le marché, à l�exception duparamètre de volatilité ��T qui doit être estimé.
Le succès du modèle BSM
Ce n�est pas l�existence de formules analytiques pour les contrats Européens quiest à l�origine du succès du modèle Black-Scholes-Merton (ces formules avaientété proposées quelques années auparavant par Samuelson (1965)), mais c�estplutôt la façon dont les auteurs sont parvenus à les obtenir qui a rendu lemodèle si important.Black et Scholes (1973) démontrent par des raisonnements d�arbitrage que l�onpeut répliquer un payo¤ conditionnel avec un portefeuille auto�nancé, composédu sous-jacent et d�un zéro-coupon, et rebalancé continûment. En l�absence d�op-portunité d�arbitrage, la valeur d�une option doit coïncider à tout instant avecla valeur de son portefeuille de couverture.Le risque lié à la vente d�une option peut donc être annulé en totalité enconstituant un portefeuille de couverture que l�on gère dynamiquement jusqu�àl�échéance du contrat. Cette approche, appelée principe de réplication, permetde synthétiser le contrat optionnel tout en lui attribuant une valeur de marché.Elle est, dans une large mesure, à l�origine du développement sans précédent del�industrie des produits dérivés.
2En anglais, ��T est appelé Root-Mean-Square Volatility.
204

4.1.3 La volatilité implicite
Dé�nition
Comme les fonctions CBS et PBS sont continues et strictement croissantes parrapport au paramètre de volatilité (les autres paramètres étant �xés), on endéduit qu�il existe une bijection entre le prix d�une option et la volatilité dusous-jacent ��T > 0.En conséquence, à chaque prix d�option observé sur le marché, CobsK;T ou P
obsK;T ,
correspond une unique valeur du paramètre de volatilité que l�on appelle vola-tilité implicite et que l�on note �. Cela signi�e que les marchés d�options sonten fait des marchés de volatilité.
La relation de parité call-put implique que le call et le put de même strike et demême maturité ont la même volatilité implicite. Elle est obtenue en résolvantl�une ou l�autre des deux équations suivantes :
CBS (K;T; S0; r; q; �) = CobsK;T ; (4.13)
PBS (K;T; S0; r; q; �) = P obsK;T : (4.14)
Smile et structure par terme
Dans la pratique, on observe que la volatilité implicite dépend (fortement) dustrike à maturité �xée. Ce phénomène est appelé le smile (ou skew ou smirk)de volatilité3 . Parallèlement, on constate que la forme du smile se modi�e d�unematurité sur l�autre. Plus précisément, le smile tend à s�aplatir lorsque la ma-turité augmente. Ce phénomène est illustré à la �gure 4.1.
La dépendance au temps de la volatilité implicite n�est pas vraiment problé-matique, puisque le modèle BSM suppose que la volatilité instantanée est unefonction du temps.En revanche, l�existence du smile de volatilité souligne les limites de l�hypothèsed�une di¤usion lognormale pour les cours du sous-jacent. En e¤et, si cette hy-pothèse était exacte, la volatilité implicite devrait être identique pour toutes lesoptions de même maturité.Cela doit inciter à rechercher des modèles de marché plus e¢ caces qui per-mettent :� de trouver des prix d�options vanilles consistants avec les volatilités implicitesobservées,
� d�évaluer et de mettre en place des stratégies de couverture e¢ caces pour lesproduits dérivés complexes qui font intervenir le sous-jacent considéré.
3Lorsque la volatilité implicite est monotone en fonction du strike, on parle de skew oude smirk (sourire grimaçant en anglais). Lorsqu�elle prend la forme d�une courbe en "U",semblable à un "sourire", on parle de smile. Dans la suite de ce chapitre, nous emploieronsindi¤éremment les di¤érentes terminologies en gardant à l�esprit que "skew" est le terme leplus adapté dans le cas des indices boursiers.
205
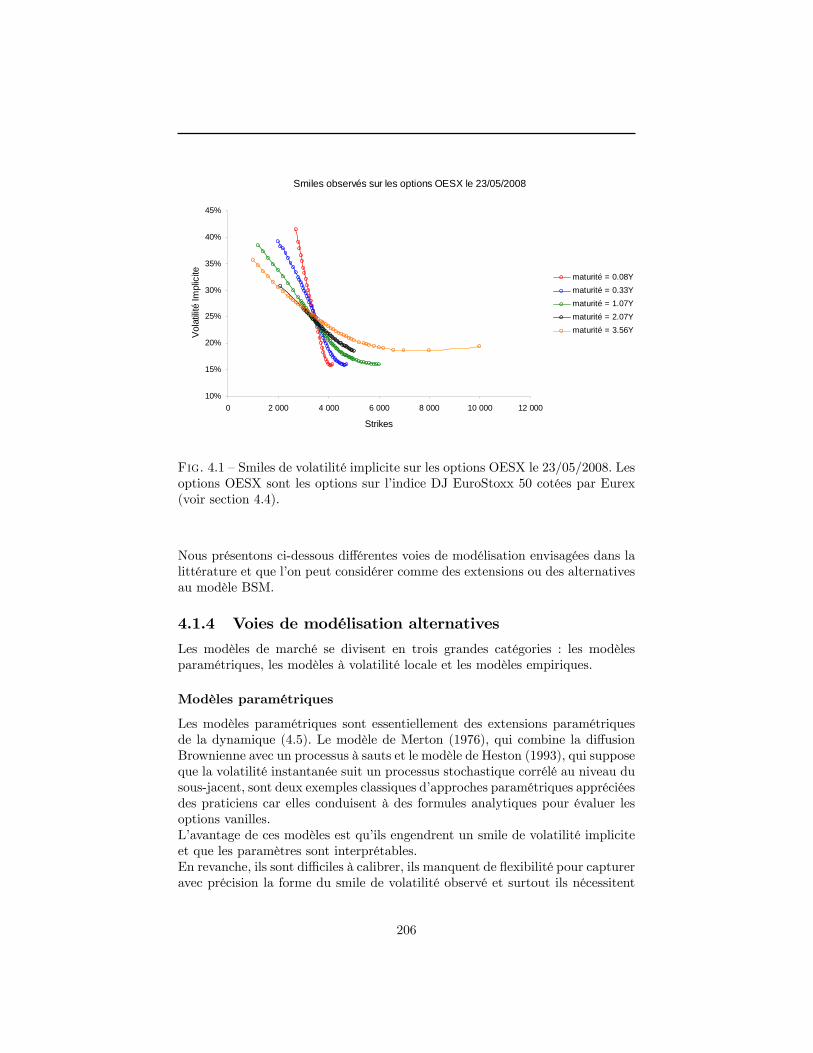
Smiles observés sur les options OESX le 23/05/2008
10%
15%
20%
25%
30%
35%
40%
45%
0 2 000 4 000 6 000 8 000 10 000 12 000
Strikes
Vola
tilité
Impl
icite maturité = 0.08Y
maturité = 0.33Ymaturité = 1.07Ymaturité = 2.07Ymaturité = 3.56Y
Fig. 4.1 �Smiles de volatilité implicite sur les options OESX le 23/05/2008. Lesoptions OESX sont les options sur l�indice DJ EuroStoxx 50 cotées par Eurex(voir section 4.4).
Nous présentons ci-dessous di¤érentes voies de modélisation envisagées dans lalittérature et que l�on peut considérer comme des extensions ou des alternativesau modèle BSM.
4.1.4 Voies de modélisation alternatives
Les modèles de marché se divisent en trois grandes catégories : les modèlesparamétriques, les modèles à volatilité locale et les modèles empiriques.
Modèles paramétriques
Les modèles paramétriques sont essentiellement des extensions paramétriquesde la dynamique (4.5). Le modèle de Merton (1976), qui combine la di¤usionBrownienne avec un processus à sauts et le modèle de Heston (1993), qui supposeque la volatilité instantanée suit un processus stochastique corrélé au niveau dusous-jacent, sont deux exemples classiques d�approches paramétriques appréciéesdes praticiens car elles conduisent à des formules analytiques pour évaluer lesoptions vanilles.L�avantage de ces modèles est qu�ils engendrent un smile de volatilité impliciteet que les paramètres sont interprétables.En revanche, ils sont di¢ ciles à calibrer, ils manquent de �exibilité pour captureravec précision la forme du smile de volatilité observé et surtout ils nécessitent
206

d�introduire une ou plusieurs sources de risques que l�on ne peut pas couvrir(risque de sauts, risque sur la volatilité). Cela signi�e que l�on sort du cadre desmarchés complets : la mesure de probabilité risque-neutre n�est plus unique etil existe plusieurs stratégies de couverture envisageables pour une même option.
Modèles à volatilité locale
Les modèles à volatilité locale, aussi appelés modèles de di¤usion implicite, ontété introduits simultanément par Dupire (1994), Derman et Kani (1994a, 1994b)et Rubinstein (1994). L�idée est de considérer la volatilité instantanée commeune fonction déterministe du temps et du prix du sous-jacent. Ainsi la volatilitéest-elle stochastique par nature (elle dépend du sous-jacent qui est aléatoire),mais déterministe conditionnellement au niveau du sous-jacent.La dynamique du sous-jacent dans l�univers risque-neutre est régie par une équa-tion di¤érentielle stochastique de la forme :
dStSt
= (rt � qt)dt+ � (t; St) dWt; S0 > 0: (4.15)
Les modèles à volatilité locale présentent deux avantages certains.
1. Ils permettent de préserver l�hypothèse de marché complet. En e¤et, l�évo-lution de l�actif ne dépend que d�une seule source d�incertitude, le mou-vement Brownien (Wt). Cela signi�e qu�il existe une unique stratégie decouverture et donc un unique prix de marché pour un payo¤ donné.
2. Ils permettent de reproduire exactement la surface de volatilité impliciteobservée. En e¤et, on peut démontrer que la fonction de volatilité locale� se déduit de la volatilité implicite � par la formule (Fengler 2005a, p.56) :
� (T;K) =�T + 2
@�@T + 2K(�rT � �qT )
@�@K
K2�
1K2�T +
2D+
K~�pT@�@K +
D+D�
~�
�@�@K
�2+ @2�
@K2
� ; (4.16)
où D+ et D� sont donnés par (4.11).
Pour les raisons que nous venons d�évoquer, ces modèles sont très utilisés parles praticiens.Notons cependant qu�ils présentent certains inconvénients.
1. Contrairement aux modèles paramétriques, ils n�expliquent pas l�existencedu smile de volatilité. Ils se limitent à le reproduire.
2. La surface de volatilité locale est très instable au cours du temps, elledépend étroitement de la qualité des données utilisées pour la calibration.
3. La procédure de calibration est particulièrement délicate à implémenter(Andersen et Brotherton-Ratcli¤e 1997).
A�n de lisser la surface de volatilité locale, certains auteurs choisissent une formeparamétrique pour la fonction � (t; St), puis ils procédent à la calibration. Brown
207

et Randall (1999) combinent des fonctions de trigonométrie hyperbolique pourcapturer les e¤ets de skew, de smile et la structure par terme des volatilités.Dumas, Fleming et Whaley (1998) modélisent la surface de volatilité locale pardes polynômes de degré au plus égal à 2 par rapport St et dont les coe¢ cientsdépendent linéairement du temps. Coleman, Li et Verma (1999) utilisent dessplines cubiques bi-dimensionnels. McIntyre (2001) modélise la surface de vola-tilité locale avec des polynômes de Hermite.
Modèles empiriques
Les modèles à volatilité locale supposent que l�actif suit une di¤usion de Itôdont la volatilité n�est pas spéci�ée : elle est ajustée de manière à retrouver lesprix des options cotées. Une généralisation de ces modèles consiste à supprimerl�hypothèse d�une di¤usion de Itô pour le processus de prix du sous-jacent. Cesont les modèles de marché empiriques.L�idée est d�inférer la dynamique du sous-jacent anticipée par le marché à partirdes prix d�options observés.En e¤et, on sait que, sous l�hypothèse d�absence d�opportunité d�arbitrage etlorsque les marchés sont complets, il existe une unique mesure risque-neutre souslaquelle les prix des actifs sont des martingales (Harrison et Kreps 1979, Harrisonet Pliska 1981).Le problème est donc le suivant : on observe un jeu de prix d�options qui neprésente pas d�opportunité d�arbitrage et l�on cherche à déterminer une martin-gale à valeurs positives qui réévalue simultanément toutes les options observées(Laurent et Leisen 1998, Buehler 2006).Cette approche permet de s�a¤ranchir complètement des contraintes imposéespar un modèle (semi-)paramétrique et, par construction, elle garantit une ca-libration extrêmement précise du modèle sur les données. En contrepartie, lepraticien ne peut plus s�appuyer sur des paramètres interprétables pour analy-ser et expliquer le comportement du modèle de marché.
Les exemples donnés auparavant montrent qu�il existe des alternatives intéres-santes au modèle de di¤usion lognormale à coe¢ cients déterministes. On peutdonc se demander dans quelle mesure la connaissance de la surface de volatilitéimplicite, qui est intrinséquement liée au modèle BSM, est fondamentale pourles spécialistes des marchés de produits dérivés. Nous répondons à cette questiondans le paragraphe suivant.
4.1.5 Utilisations de la volatilité implicite
La volatilité implicite est un langage
Les relations (4.13) et (4.14) établissent une correspondance non-linéaire entrele prix d�une option et la volatilité implicite. En d�autres termes, la volatilitéimplicite peut être vue comme un langage pour exprimer les prix des options.D�ailleurs, les opérateurs qui interviennent sur les marchés d�options négocientles transactions en terme de volatilité implicite et non pas en terme de prix.
208

Lee (2005) établit une analogie intéressante entre la notion de volatilité impliciteet la notion de taux de rendement actuariel, utilisée par les opérateurs desmarchés obligataires.Le taux de rendement actuariel d�un placement est le taux constant auquel il fautactualiser tous les �ux du placement pour retrouver son prix de marché. Cela nesigni�e pas pour autant que les taux d�intérêt sont plats ou constants. Il s�agitd�une manière d�exprimer le prix d�une obligation, qui permet notamment decomparer entre elles plusieurs obligations dont les coupons, les montants faciauxet les échéanciers sont di¤érents.De manière analogue, la volatilité implicite permet de comparer entre elles desoptions de strike, de maturité et de sous-jacents di¤érents. Elle donne égalementune information sur la manière dont est perçu le risque du sous-jacent.
Evaluer et couvrir un payo¤ Européen non-vanille
On suppose dans ce paragraphe que nous connaissons l�ensemble du smile devolatilité pour une maturité donnée, par exemple T . Alors, les formules (4.8) et(4.9) nous donnent les prix de marché de toutes les options Européennes vanillesde maturité T .
On peut démontrer que toute fonction f : R+ ! R qui est deux fois di¤érentiablepeut s�écrire sous la forme suivante (Overhaus, Bermúdez et al. 2007) :
f(x) = f(x�) + f 0(x�)(x� x�)
+
Z x�
0
f 00(u)(u� x)+du
+
Z +1
x�f 00(u)(x� u)+du;
où x� 2 R+ est un réel quelconque.
Considérons une option Européenne non-vanille d�échéance T , c�est-à-dire uneoption dont le payo¤�nal� ne dépend que de ST . Si� est deux fois di¤érentiablepar rapport à ST , on peut écrire le payo¤ de l�option considérée en appliquantla relation précédente :
�(ST ) = �(K�) + �0(K�)(ST �K�)
+
Z K�
0
�00(K)(K � ST )+dK
+
Z +1
K��00(K)(ST �K)+dK;
où K� est choisi arbitrairement.
Un examen de la formule obtenue montre que le payo¤ de l�option se compose :
209

� d�une position longue de �(K�) zéro-coupons,� d�une position longue de �0(K�) contrats forwards de strike K�,� d�une position longue de �00(K) puts Européens pour tous les strikes comprisentre 0 et K�,
� d�une position longue de �00(K) calls Européens pour tous les strikes comprisentre K� et +1.
En prenant l�espérance de chaque membre et en actualisant les �ux avec lefacteur zéro-coupon noté Bt;T , on obtient la valeur de l�option à l�instant t quel�on note �t :
�t = �(K�)Bt;T +�0(K�)Ft (K
�; T )
+
Z K�
0
�00(K)Pt (K;T ) dK
+
Z +1
K��00(K)Ct (K;T ) dK;
où Ft (K�; T ), Pt (K;T ) et Ct (K;T ) sont dé�nis comme au paragraphe 4.1.1.Cette technique est utilisée pour évaluer et pour construire la couverture statiquedes variances swaps (Demeter�, Derman, Kamal et Zou 1999).
Si l�on connaît le smile de volatilité implicite pour la maturité T : K ! � (K;T ),on peut déterminer la valeur des options qui composent le portefeuille de couver-ture et donc attribuer un prix au produit. La connaissance du smile de volatilitéimplicite permet donc d�évaluer et de couvrir tout payo¤ Européen non-vanille,mais su¢ samment régulier.
Déterminer la distribution des rendements du sous-jacent
Breeden et Litzenberger (1978) ont démontré que la densité de probabilitérisque-neutre du sous-jacent à l�horizon T , notée hT , est liée à la dérivée se-conde des prix de calls par l�égalité suivante :
hT (K jS0 ) = e�rTT@2C
@K2: (4.17)
Supposons que la fonction K ! ~� (K;T ) soit deux fois dérivable par rapport àK. En partant de la relation C (K;T ) = CBS (K;T; � (K;T )) on peut déterminer@2C=@K2 en utilisant la règle de la di¤érenciation en chaîne.Dérivons une première fois par rapport à K, il vient :
@C
@K=@CBS@K
+@�
@K
@C
@~�; (4.18)
dérivons de nouveau par rapport à K :
@2C
@K2=@2CBS@K2
+ 2@2CBS@K@~�
@�
@K+@2CBS
@~�2
�@�
@K
�2+@CBS@~�
@2�
@K2: (4.19)
210

En remplaçant les dérivées partielles de CBS par rapport à K et par rapport à� on obtient le résultat suivant (Fengler 2005b) :
hT (K jS0 ) = S0e��qTT
pT'(D+)
1
K2�T +2D+
K�pT@�@K
+D+D�
�
�@�@K
�2+ @2�
@K2
!;
où ' est la densité de la loi normale standard. Le terme devant la parenthèseest appelé "véga" de l�option. Il correspond à la sensibilité du prix BSM parrapport à la volatilité implicite.
Calibrer un modèle de marché
Supposons en�n que l�on connaisse la surface de volatilité implicite complète,pour tous les strikes et pour toutes les maturités.On peut appliquer la formule (4.16) pour déterminer la surface de volatilitélocale. Cela suppose que la volatilité implicite dont nous disposons soit de classeC2 par rapport à K et de classe C1 par rapport à T .Plus généralement, si l�on connaît la surface de volatilité implicite, on peutreconstruire la surface des prix d�options et calibrer un modèle de marché para-métrique ou empirique sur les prix observés.
Nous terminons cette section en discutant la nécessité d�éliminer systématique-ment les arbitrages lors de la construction de la surface de volatilité.
4.1.6 Prévenir les arbitrages lors du processus de construc-tion
Construire une surface de volatilité implicite est ce que l�on a coutume d�ap-peler un problème inverse "mal-posé", car on ne dispose que de quelques prixd�options, répartis irrégulièrement sur une grille de strikes et de maturités, quipeuvent présenter des opportunités d�arbitrage. A partir de ces données on doitgénérer une surface de volatilité implicite, continue, si possible di¤érentiable etqui ne présente pas d�opportunité d�arbitrage.En e¤et, si la surface de volatilité implicite présente des opportunités d�arbitrage,on risque d�obtenir des densités de probabilité ou des volatilités locales négativespour le sous-jacent. Cette situation fâcheuse introduit des biais systématiquesdans les prix des produits dérivés portant sur le sous-jacent (Fengler 2005b,Laurini 2007).De plus, il est recommandé d�utiliser des données non-arbitrables pour calibrerles modèles paramétriques. L�expérience montre que les paramètres ainsi obtenussont plus stables dans le temps que lorsque le modèle est calibré sur des donnéesprésentant des arbitrages.
Les discussions et les di¤érents exemples d�utilisation présentés dans cette sec-tion illustrent l�importance stratégique de la surface de volatilité implicite pour
211

les acteurs des marchés de produits dérivés. Dans la section suivante, nous mon-trons comment simpli�er le problème de la modélisation des volatilités implicitesen l�absence d�opportunité d�arbitrage.
4.2 Normalisation du marché
Nous démontrons qu�il est possible, tout en préservant la généralité des résultats,de nous placer dans une économie normalisée dans laquelle l�actif ne détache nitaux d�intérêt, ni dividende (Buehler 2006).
4.2.1 Hypothèses de travail
Dans l�ensemble de ce chapitre, on suppose que le taux sans risque instantanéet le taux de dividende instantané sont des fonctions déterministes du temps.La première hypothèse peut être justi�ée de la manière suivante : la volatilitédes taux d�intérêt étant négligeable par rapport à la volatilité des actions, onpeut la considérer comme nulle.D�un point de vue théorique, les dividendes anticipés sont aléatoires : ils dé-pendent en e¤et de nombreux paramètres di¢ ciles à appréhender tels que lesrésultats futurs ou la politique de distribution des dividendes de la société.Toutefois, on observe que leurs �uctuations sont négligeables par rapport à lavolatilité de l�actif risqué, ce qui justi�e la seconde hypothèse (Patard 2003).
On note Bt le prix d�un zéro-coupon d�échéance t. Comme le taux instantanéest déterministe, Bt coïncide avec le facteur d�actualisation de l�économie :
Bt = e�R t0rudu: (4.20)
De plus, comme les dividendes sont déterministes, on peut calculer explicitementle prix forward du sous-jacent, noté Ft :
Ftdef= EQ [St] = S0e
R t0(ru�qu)du; (4.21)
où EQ [�] est l�opérateur "espérance sous Q" et Q la mesure risque-neutre.
4.2.2 Normalisation du sous-jacent
Sous l�hypothèse d�absence d�opportunité d�arbitrage, le processus de gain nor-malisé de l�actif S, noté (Mt), est une martingale sous la mesure risque-neutre(Björk 2004). En supposant des dividendes déterministes, proportionnels aucours du sous-jacent, on a :
Mtdef= BtSte
R t0qudu =
StFt: (4.22)
Par construction, M véri�e :
M0 = 1 = EQ [Mt] ; t � 0: (4.23)
212

Le processus (Mt) s�interprète comme le processus de prix d�un actif de valeurinitiale égale à 1 qui ne détache pas de dividende, dans une économie sans tauxd�intérêt. Pour cette raison, nous l�appelons processus de prix normalisé.
Nous montrons ci-dessous qu�il existe une correspondance entre les options surle sous-jacent S et les options sur le sous-jacent M .
4.2.3 Normalisation des prix d�options
En remplaçant ST par le produit FTMT on peut réécrire le payo¤ d�un calld�échéance T et de strike K de la manière suivante :
(ST �K)+ = FT (MT � �T )+ ; �Tdef=
K
FT: (4.24)
La quantité �T est appelée la moneyness-forward ou encore le strike relatif del�option. Elle indique dans quelle mesure l�option est à la monnaie forward à ladate d�évaluation.
En prenant l�espérance de chaque membre de l�égalité (4.24) et en actualisant,il vient :
C (K;T ) = BTFT c (�T ; T ), c (�T ; T ) =C (K;T )
BTFT; (4.25)
où C (K;T ) est la valeur d�un call de strike K et d�échéance T sur le sous-jacent S et c (�T ; T ) est la valeur d�un call de strike �T et d�échéance T sur lesous-jacent M . La quantité c (�T ; T ) est appelée prix de call normalisé.
L�équivalence (4.25) montre qu�il existe une correspondance bijective entre lesprix des calls sur S et les prix des calls sur M , lorsque les prix zéro-coupon etles prix forwards sont déterministes. On peut donc, en préservant la généralitédes résultats, étudier les options sur le sous-jacent normalisé M .
4.2.4 Application au modèle BSM
Dans le cas du modèle BSM, l�évolution des prix du sous-jacent est décrite parl�équation (4.7), de sorte que le processus de prix normalisé est donné par :
Mt = S0exp
��Z t
0
�2u2du+
Z t
0
�udWu
�; t � 0: (4.26)
Le processus (Mt) ne dépend que de la volatilité qui est précisément le paramètreque nous cherchons à modéliser.
Pour obtenir le prix d�un call normalisé, noté cBS, il su¢ t de transformer la
formule (4.8) pour faire apparaître le prix forward FT , le prix zéro-coupon BT
213

et la moneyness �T , puis de diviser par le produit BTFT . On obtient tous calculsfaits :
cBS = ��D+�� �T�
�D�� ; D� = � ln�T
�TpT� �T
pT
2: (4.27)
Notons que cBS dépend uniquement de la moneyness de l�option, de la maturitéet de la volatilité du sous-jacent.
4.2.5 Observations
Travailler avec un modèle de marché normalisé présente plusieurs avantages.
1. Les prix des options ne dépendent que de la volatilité qui est le paramètreque nous souhaitons modéliser.
2. La dépendance aux taux d�intérêt et aux taux de dividende a disparue, cequi limite le risque d�introduire des biais lors de l�estimation de la volatilitéimplicite.
3. Les calculs et les raisonnements sont facilités, car les fonctions manipuléesne font intervenir que trois paramètres : le temps T , la volatilité impliciteet la moneyness.
Pour les raisons que nous venons d�évoquer, nous nous plaçons dans le modèlede marché normalisé. Nous pourrons à tout moment revenir sous le modèle demarché réel en utilisant la formule (4.22) et l�équivalence (4.25).
Dans la section suivante, nous étudions les contraintes imposées par l�hypothèsed�absence d�opportunité d�arbitrage sur les prix d�options et sur les volatilitésimplicites.
4.3 Contraintes de non-arbitrage
L�hypothèse d�absence d�opportunité d�arbitrage (AOA) induit des contraintessur les prix des options Européennes et, par conséquent, sur la forme de la nappede volatilité implicite. Toute modélisation consistante des volatilités implicitesdoit tenir compte de ces contraintes pour aboutir à une surface de volatiliténon-arbitrable. Notons que les résultats obtenus sont indépendants du modèlechoisi pour le sous-jacent, car ils reposent sur des raisonnements d�arbitragegénéraux.
4.3.1 Formalisation du problème
Marché normalisé non-arbitrable
Dans cette section, nous travaillons avec le modèle de marché normalisé dé�nipar les 3 hypothèses suivantes.
214

1. Le marché est représenté par un espace probabilisé complet (; T ; Q),muni de la �ltration (Ft)t�0 de l�information des prix. Q est l�uniquemesure de probabilité risque-neutre.
2. Il n�y a pas de taux d�intérêt et pas de dividende.
3. Le processus de prix de l�actif risqué (Mt)t�0 est une Ft-martingale stric-tement positive d�espérance égale à 1.
Les hypothèses 1,2,3 dé�nissent ce que l�on appelle un modèle de marché stric-tement non-arbitrable (Buehler 2006, Overhaus, Bermúdez et al. 2007). Dansla suite, nous supprimerons le terme "strictement" et non dirons simplementque le marché est non-arbitrable ou qu�il fonctionne en l�absence d�opportunitéd�arbitrage.
Options sur l�actif normalisé
Le prix à l�instant t d�un call (resp. d�un put) Européen écrit sur l�actif M , demoneyness � et d�échéance T , est noté ct (�; T ) (resp. pt (�; T )). En l�absenced�opportunité d�arbitrage, on a (Augros et Moreno 2002) :
ct (�; T ) = EQ[(MT � �)+ jFt ]; pt (�; T ) = EQ[(��MT )+ jFt ]: (4.28)
Lorsque t = 0, on ne fait plus apparaître l�indice t et l�on note simplementc (�; T ) et p (�; T ). Les applications c : (�; T ) 2 R+ � R+ ! c (�; T ) et p :(�; T ) 2 R+ � R+ ! p (�; T ) sont appelées respectivement fonctions de pricingdes calls et fonction de pricing des puts à la date 0. Leurs représentations gra-phiques respectives sont appelées surface de prix de calls et surface de prix deputs.
Identités remarquables
Lorsque t = T , le prix de l�option coïncide avec son payo¤ :
cT (�; T ) = (MT � �)+ ; pT (�; T ) = (��MT )+; (4.29)
Le prix d�une option d�échéance T = 0 coïncide avec son payo¤ :
c (�; 0) = (1� �)+ ; p (�; 0) = (�� 1)+ : (4.30)
Ces quantités sont appelées valeur intrinsèque du call et valeur intrinsèque duput.
Les prix d�un call et d�un put de moneyness � = 0 et d�échéance T quelconquevéri�ent :
c (0; T ) = 1; p (0; T ) = 0: (4.31)
Notons que les formules présentées dans ce paragraphe sont indépendantes dumodèle choisi pour représenter la dynamique des prix.
215

La proposition 4.1 ci-dessous montre qu�il est possible de raisonner uniquementsur les prix des calls. Elle est suivie de la proposition 4.2 qui donne un enca-drement du prix d�un call Européen. On trouvera une démonstration de cespropositions en Annexe A.
Proposition 4.1 (Parité call-put) En l�absence d�opportunité d�arbitrage, ona :
ct (�; T )� pt (�; T ) =Mt � �; t � T: (4.32)
La formule (4.32), appelée relation de parité call-put, est indépendante du mo-dèle choisi pour la dynamique du sous-jacent. Elle montre que lorsque l�onconnaît le prix d�un call, on peut en déduire le prix du put associé et inversement.Pour cette raison, nous pouvons nous contenter de travailler exclusivement surles prix des calls Européens.
Proposition 4.2 En l�absence d�opportunité d�arbitrage, le prix d�un call Eu-ropéen est minoré par sa valeur intrinsèque et majoré par 1 :
0 � (1� �)+ � c (�; T ) � 1: (4.33)
Dans le paragraphe suivant, nous démontrons l�existence d�une unique surfacede volatilité implicite.
4.3.2 Existence de la surface de volatilité implicite
La volatilité implicite de moneyness � et de maturité T , notée � (�; T ), estdé�nie comme l�unique solution positive de l�équation :
cBS(�; T; � (�; T )) = c (�; T ) : (4.34)
L�application (�; T )! � (�; T ) est appelée surface (ou nappe) de volatilité im-plicite.La proposition suivante est démontrée en Annexe A.
Proposition 4.3 L�encadrement (4.33) garantit l�existence d�une unique vola-tilité implicite � (�; T ) > 0 pour tout couple (�; T ) 2 R+ � R+.
En d�autres termes, sous les hypothèses 1-2-3, la surface de volatilité impliciteexiste et elle est unique.Nous pouvons à présent établir les contraintes induites par les hypothèses 1, 2et 3 sur les prix d�options et sur les volatilités implicites.
4.3.3 Conditions de non-arbitrage
La proposition suivante est fondamentale : elle donne les propriétés des prixde calls Européens lorsque le marché est non-arbitrable. Nous donnons une dé-monstration de cette proposition en Annexe A, basée sur les propriétés ma-thématiques de la dynamique des prix. Pour une démonstration fondée sur desraisonnements d�arbitrages, le lecteur pourra consulter Crozet (2007).
216

Proposition 4.4 En l�absence d�opportunité d�arbitrage, les prix des calls Eu-ropéens véri�ent les trois propriétés suivantes.
1. La fonction � ! c (�; T ) est strictement décroissante par rapport à lamoneyness ; la dérivée partielle de c par rapport à � est bornée et véri�e :
�1 � @c
@�� 0: (4.35)
2. La fonction �! c (�; T ) est convexe par rapport à la moneyness ; la dérivéepartielle d�ordre 2 de c par rapport à � est donnée par la formule :
@2c
@�2= hT (�) � 0; (4.36)
où hT (�) désigne la densité de probabilité de MT sous la mesure risque-neutre Q :
hT (�)def= Q f� �MT < �+ d�g ; � � 0: (4.37)
3. La fonction T ! c (�; T ) est croissante par rapport à la maturité :
c (�; T1) � c (�; T2) ; 0 � T1 � T2: (4.38)
La relation (4.36) est connue sous le nom de formule de Breeden et Litzenberger(1978). Ce résultat remarquable montre que la densité de probabilité risque-neutre de la partie martingale des cours est égale à la dérivée seconde des prixréduits par rapport à la moneyness (la maturité étant �xée). De plus, il estvalable quel que soit le modèle retenu pour le sous-jacent. La formule (4.38)est, à notre connaissance, la seule condition établie qui concerne l�absence d�op-portunité d�arbitrage entre des options de di¤érentes maturités encore appeléeabsence d�opportunité d�arbitrage calendaire (Rebonato 2004, Fengler 2005b).
Etant donné qu�il existe une bijection entre la surface de prix des calls Européenset la surface de volatilité implicite, il est possible d�exprimer les conditionsde non-arbitrage de la proposition précédente en terme de volatilité implicite(démonstration en Annexe A).
Proposition 4.5 En l�absence d�opportunité d�arbitrage, les volatilités impli-cites véri�ent les trois propriétés suivantes.
1. La dérivée de la fonction � ! � (�; T ), appelée skew de volatilité, véri�el�encadrement :
�� (�D+)
�pT' (D+)
� @�
@�� � (D�)
�pT' (D�)
; (4.39)
où D+ et D� sont dé�nis à la relation (4.27) et ' est la densité de la loinormale standard.
217

2. La dérivée partielle d�ordre 2 de � par rapport à � véri�e l�inégalité non-linéaire :
1
�2�T+
2D+
K�pT
@�
@�+D�D+
�
�@�
@�
�2+@2�
@�2� 0: (4.40)
3. La fonction T ! �2 (�; T )def= �2 (�; T )T , appelée variance totale, est
croissante par rapport à la maturité :
�2 (�; T1) � �2 (�; T2) ; 0 � T1 � T2: (4.41)
Comme le souligne Fengler (2005a, 2005b), les contraintes d�absence d�oppor-tunité d�arbitrage en moneyness (contraintes 1 et 2) se traduisent simplementlorsque l�on raisonne sur les prix de calls et elles deviennent fortement non li-néaires lorsque l�on raisonne sur les volatilités implicites.Seule la contrainte d�arbitrage calendaire (contrainte 3) s�exprime simplement,que l�on raisonne sur les prix d�options ou sur les volatilités implicites.Pour ces raisons, nous utiliserons les contraintes sur les prix d�options (propo-sition 4.4) pour éliminer les arbitrages lors de la construction de la surface devolatilité implicite.
Les deux propositions précédentes sont de bons outils pour véri�er qu�une sur-face de prix d�options (ou de volatilité) ne présente pas d�opportunité d�arbi-trage. En revanche, elles ne donnent aucune information directement exploitablesur la forme du smile de volatilité implicite en fonction de la moneyness, ce quipeut être problématique quand on travaille sur des données réelles. En e¤et, lesprix observés sont concentrés autour de la monnaie (� ' 1), de sorte qu�il est in-dispensable d�extrapoler la surface de volatilité vers les strikes faibles (�! 0+)et vers les strikes élevés (�! +1) de manière à obtenir une surface de volatilitéimplicite complète. Le paragraphe suivant est consacré à l�analyse du smile auniveau des moneyness extrêmes.
4.3.4 Smile de volatilité aux moneyness extrêmes
Nous énonçons ci-dessous deux résultats démontrés par Lee (2004). Ils éta-blissent un lien entre les moments de la loi du sous-jacent et la forme asympto-tique du smile aux moneyness extrêmes. Nous introduisons la log-moneyness :
~�def= ln� (4.42)
et l�on note abusivement � (~�; T ) la volatilité implicite en fonction de la log-moneyness. Les zones de moneyness extrêmes sont appelées les ailes de la vo-latilité (ou de la variance) implicite. L�aile gauche correspond aux moneynessnulles (� ! 0+ , ~� ! �1) et l�aile droite correspond aux moneyness in�nies(�! +1, ~�! +1).
218

Théorème 4.6 (Smile lorsque �! +1) On pose :
p� = supfp : EQ[M1+pT ] <1g; �� = lim sup
~�!+1
�2 (~�; T )T
j~�j : (4.43)
Alors0 � �� � 2 (4.44)
et
p� =1
2
�1p���p��
2
�2, �� = 2� 4(
pp�2 + p� � p�); (4.45)
où l�on a pris la convention �� = 0, p� = +1.
Théorème 4.7 (Smile lorsque �! 0+) On pose :
q� = supfq : EQ[M�qT ] < +1g; �� = lim sup
~�!�1
�2 (~�; T )T
j~�j : (4.46)
Alors0 � �� � 2 (4.47)
et
q� =1
2
1p���p��
2
!2, �� = 2� 4(
pq�2 + q� � q�); (4.48)
où l�on a pris la convention �� = 0, q� = +1.
Dans sa démonstration, Lee ne fait aucune hypothèse sur la loi de probabilitédu sous-jacent : les résultats sont donc complètement indépendants du modèleretenu pour la dynamique des prix.
Les formules de Lee sont appelées formules des moments car elles relient l�ordremaximal des moments de la loi du sous-jacent avec les quantités �� et �� quel�on peut interpréter comme les pentes des asymptotes de la variance implicite,prise comme fonction de la log-moneyness ~�. Les théorèmes que nous venonsd�énoncer montrent que ces pentes sont �nies, ce qui signi�e que la varianceimplicite est linéaire aux ailes.Plus précisément, quand la moneyness devient arbitrairement grande (aile droite),le théorème 4.6 donne une relation de la forme :
�2 (~�; T ) � ��
T~�; 0 � �� � 2;
et, quand la moneyness devient arbitrairement faible (aile gauche), le théorème4.7 donne une relation de la forme :
�2 (~�; T ) � ���
T~�; 0 � �� � 2;
219

où �� = 0 (resp. �� = 0) lorsque le prix (resp. l�inverse du prix) du sous-jacentadmet des moments de tous ordres.
Lorsque T ! +1, on a ��=T ! 0 et ��=T ! 0, donc les variances implicites ontdes asymptotes horizontales lorsque la maturité devient arbitrairement élevée.Cela signi�e que le smile de volatilité s�aplatit au niveau des maturités lointaines.Ce résultat peut être démontré par des considérations purement mathématiques(Rogers et Tehranchi 2008).
On trouve fréquemment dans la littérature des méthodes de reconstruction dusmile de volatilité implicite basées sur des polynômes. D�après les théorèmesprécédents, il ne faut en aucun cas les utiliser pour extrapoler la volatilité auniveau des ailes. Plus précisément, la variance implicite doit être extrapoléelinéairement par rapport à la log-moneyness. Ce point sera étudié au paragraphe4.5.2.
Pour conclure ce paragraphe, rappelons que dans le cas du modèle BSM, leprix de l�actif risqué suit une loi lognormale, donc p� = q� = +1. D�après lesthéorèmes précédents, les asymptotes de la variance implicite sont horizontalesau niveau des deux ailes : on retrouve le fait que la volatilité est constante dansce modèle.
Pour pouvoir mettre en oeuvre les résultats théoriques présentés dans cettesection, il faut, au préalable, analyser et éventuellement préparer les données demarché. Ce point est discuté dans la section suivante.
4.4 Données utilisées dans le chapitre
Pour les besoins de ce chapitre, nous utilisons les prix des options Européennessur l�indice DJ EuroStoxx 50, cotées sur l�Eurex. Dans cette section, nous pro-cédons à une analyse des données disponibles. Ensuite, nous proposons uneprocédure qui permet de les retraiter a�n de nous placer dans le cadre du mo-dèle de marché normalisé décrit précédemment. Cela nous donne une indicationsur la manière dont il faut procéder pour reconstruire la surface de volatilitéimplicite.
4.4.1 Les options sur l�indice DJ EuroStoxx 50
L�indice DJ EuroStoxx 50
L�indice DJ EuroStoxx 50 (abréviation de Dow Jones EURO STOXX 50) estcomposé des 50 actions les plus représentatives de la zone Euro. Les actionsentrant dans la composition de l�indice sont sélectionnées sur des critères decapitalisation et de liquidité. Le poids de chaque action est déterminé en fonc-tion de sa capitalisation boursière �ottante et il est plafonné à 10%. L�indice estcalculé et publié par Stoxx Limited, une société conjointe entre Deutsche Börse
220

AG (bourse Allemande), Dow Jones & Company (fournisseur de données �nan-cières) et SWX group (bourse Suisse). Le système de cotation est entièrementélectronique et le cours de l�indice est recalculé toutes les 15 secondes4 .
La plateforme électronique Eurex
L�Eurex (EURopean EXchange) est l�un des plus grands marchés électroniquesde produits dérivés au monde, géré par Deutsche Börse AG et SWX group. Ilo¤re aux investisseurs un grand choix de produits dérivés sur les taux d�inté-rêt, sur les actions et sur les indices actions, sur l�in�ation et sur le carbone5 .Nous nous intéressons plus particulièrement aux options portant sur l�indice DJEuroStoxx 50.
Les options OESX
OESX est le code des options sur l�indice DJ EuroStoxx 50 cotées par l�Eurex.Le marché des options OESX est très actif : les volumes de transaction sontélevés et les contrats sont très liquides. Les options, de type Européen, sontnégociables pour des maturités standardisées allant jusqu�à 119 mois (soit 10ans environ). Le dernier jour de négociation est le troisième vendredi du moisd�expiration du contrat. Les options sont cotées en points d�indice avec un chi¤reaprès la virgule et l�échelon de cotation ou tick6 est de 0:1 point d�indice7 .
4.4.2 Choix des données
Nous pouvons envisager de travailler sur des cours "en temps réel", relevés àun instant donné durant une journée de bourse, ou bien à partir des coursde compensation, publiés après la clôture du marché. Nous discutons ces deuxpossibilités ci-dessous.
Cours en "temps réel"
Le principal avantage lorsque l�on utilise des données en "temps réel" est queles prix observés correspondent à des transactions qui ont eu lieu. On peuts�attendre à ce qu�ils correspondent parfaitement aux anticipations de marchédes investisseurs mais ce serait sans tenir compte des inconvénients suivants.� Les prix observés résultent de l�o¤re et de la demande, donc ils ne re�ètent pasnécessairement le niveau intrinsèque de la volatilité, mais plutôt les intérêtsponctuels de certains investisseurs.
4Pour obtenir des informations détaillées sur la constitution et sur le calcul de l�indice, onpourra consulter le site internet de Stoxx Limited : http://www.stoxx.com.
5Site internet : www.eurexchange.com.6L�échelon de cotation est la plus petite unité de cotation d�un contrat sur les marchés de
produits dérivés standardisés.7Pour les caractéristiques détaillées des contrats OESX voir : http://www.eurexchange.
com>Trading>Products>EquityIndexDerivatives>DowsJonesSTOXX>BlueChip.
221

� Les prix observés présentent des asynchronicités : certaines options sont cotéesavec un prix ancien, car elles n�ont pas été traitées à l�instant de l�observation.
� Les fourchettes Bid/Ask des options cotées traduisent l�incertitude autour duprix "théorique" et peuvent biaiser l�estimation de la "vraie" valeur de lavolatilité implicite.
� Une analyse des volumes de transactions montre que les options de maturitéscourtes sont plus liquides que les options de maturités lointaines, ce qui signi�eque la qualité de l�information disponible se dégrade avec la maturité descontrats.
� Les options les plus liquides et les plus négociées sont les options à la monnaieet les options en dehors de la monnaie, car elles o¤rent un e¤et de leviersupérieur pour la spéculation et un moindre coût de couverture.
Hentschel (2003) propose une analyse approfondie des sources d�incertitude etdes distorsions induites par le choix du jeu de données.
Cours de compensation
Les cours de compensation sont calculés en �n de séance par l�organisateur dumarché (Eurex) selon le procédé ci-dessous.� Des market-makers d�options vanilles fournissent des fourchettes Bid/Ask surles calls et les puts qu�ils sont prêts à traiter pour chaque maturité Ti.
� A partir des fourchettes de prix fournies par les market-makers, l�organisa-teur de marché calibre un modèle interne décrivant le skew de volatilité pourchaque échéance, puis il publie l�ensemble des cours de compensation.
L�utilisation des prix de compensation permet d�obtenir des prix d�options pourla plupart des strikes ouverts à la négociation, toutes maturités confondues.
L�utilisation des cours de compensation présente di¤érents avantages :� la matrice des prix de compensation contient plus de données que la matricedes prix en "temps réel" que l�on pourrait obtenir durant une scéance debourse ; en particulier pour couple (K;T ) coté, on dispose systématiquementdu prix de call et du prix du put associé,
� les prix ont été donnés et contrôlés par des market-makers, donc ils re�ètentvéritablement les anticipations des opérateurs à la clôture du marché,
� les prix sont synchrones puisqu�ils sont calculés sur la base du cours de clôturedu sous-jacent.
Les inconvénients liés à cette approche sont :� le processus détaillé de construction des cours de compensation est tenu secret,� la surface de volatilité implicite obtenue dépend du modèle utilisé par lasociété organisant le marché8 .
8Au sujet de la modélisation des volatilités implicites, Eurex propose de télécharger letravail de Weizmann (2007), réalisé en partenariat avec Eurex. Il s�agit d�une étude approfondiedu modèle Vanna-Volga et de sa mise en oeuvre pour modéliser les volatilités implicites surl�indice DJ EuroStoxx 50. On peut donc penser que Eurex utilise une méthode voisine de celledécrite dans le document.
222
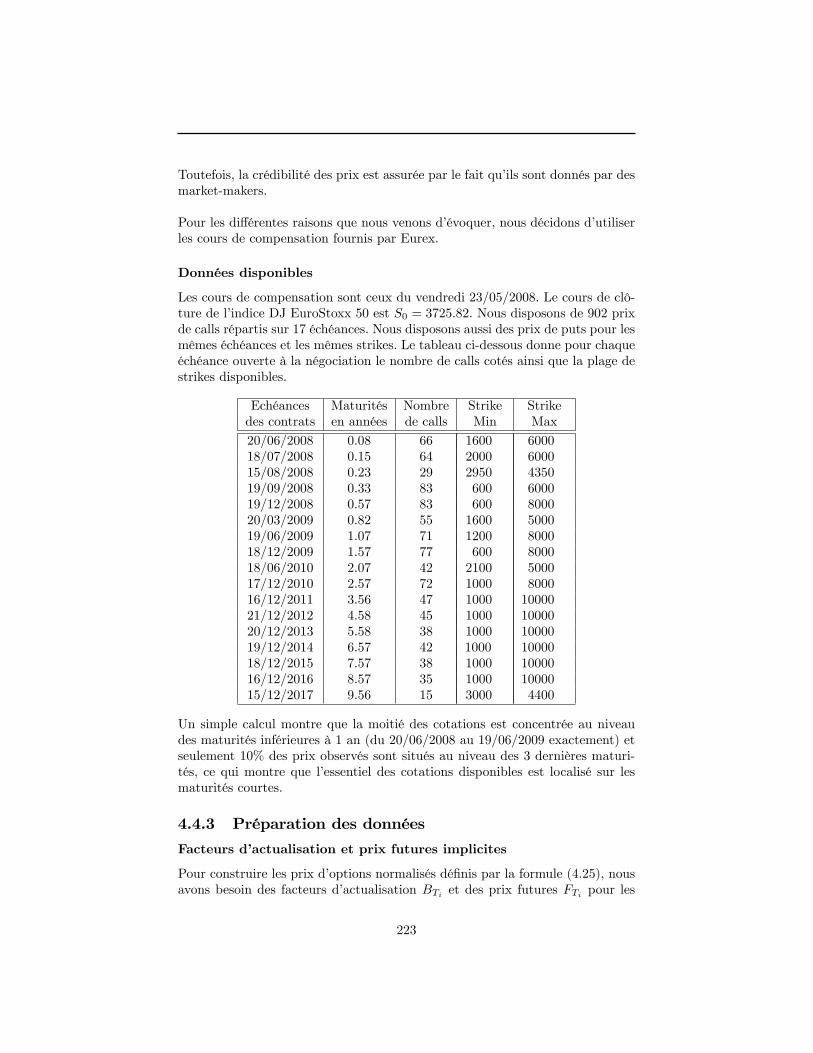
Toutefois, la crédibilité des prix est assurée par le fait qu�ils sont donnés par desmarket-makers.
Pour les di¤érentes raisons que nous venons d�évoquer, nous décidons d�utiliserles cours de compensation fournis par Eurex.
Données disponibles
Les cours de compensation sont ceux du vendredi 23/05/2008. Le cours de clô-ture de l�indice DJ EuroStoxx 50 est S0 = 3725:82. Nous disposons de 902 prixde calls répartis sur 17 échéances. Nous disposons aussi des prix de puts pour lesmêmes échéances et les mêmes strikes. Le tableau ci-dessous donne pour chaqueéchéance ouverte à la négociation le nombre de calls cotés ainsi que la plage destrikes disponibles.
Echéances Maturités Nombre Strike Strikedes contrats en années de calls Min Max
20=06=2008 0:08 66 1600 600018=07=2008 0:15 64 2000 600015=08=2008 0:23 29 2950 435019=09=2008 0:33 83 600 600019=12=2008 0:57 83 600 800020=03=2009 0:82 55 1600 500019=06=2009 1:07 71 1200 800018=12=2009 1:57 77 600 800018=06=2010 2:07 42 2100 500017=12=2010 2:57 72 1000 800016=12=2011 3:56 47 1000 1000021=12=2012 4:58 45 1000 1000020=12=2013 5:58 38 1000 1000019=12=2014 6:57 42 1000 1000018=12=2015 7:57 38 1000 1000016=12=2016 8:57 35 1000 1000015=12=2017 9:56 15 3000 4400
Un simple calcul montre que la moitié des cotations est concentrée au niveaudes maturités inférieures à 1 an (du 20=06=2008 au 19=06=2009 exactement) etseulement 10% des prix observés sont situés au niveau des 3 dernières maturi-tés, ce qui montre que l�essentiel des cotations disponibles est localisé sur lesmaturités courtes.
4.4.3 Préparation des données
Facteurs d�actualisation et prix futures implicites
Pour construire les prix d�options normalisés dé�nis par la formule (4.25), nousavons besoin des facteurs d�actualisation BTi et des prix futures FTi pour les
223

échéances cotées T1 � � � � � Tn. Une première solution consiste à calculer cesquantités avec un modèle interne mais, dans ce cas, les valeurs obtenues serontvraissemblablement di¤érentes de celles utilisées par l�organisateur du marchépour déterminer les cours de compensation des options. Pour cette raison, ilest préférable d�extraire BTi et FTi par une inférence statistique sur les prixobservés. On parle alors de facteurs d�actualisation et de prix futures implicites.
Soit K1 < � � � < Kmiles strikes des options cotées pour la ii�eme échéance. On
note :
Cobsm;idef= C (Km; Ti) ; P obsm;i
def= P (Km; Ti) ; 1 � m � mi: (4.49)
En appliquant la relation de parité call-put aux options observées, il vient :
Cobsm;i � P obsm;i = BTi (FTi �Km) = �i + �iKm: (4.50)
où l�on a posé :
�idef= BTiFTi ; �i
def= �BTi : (4.51)
Il su¢ t alors d�e¤ectuer une régression linéaire de Cobsm;i � P obsm;i par rapport aux
strikes Km pour obtenir les estimations �i et �i des coe¢ cients �i et �i. Lefacteur d�actualisation et le prix forward estimés pour l�échéance Ti sont donnéspar :
BTi = ��i; FTi = ��i
�i: (4.52)
Nous présentons dans le tableau ci-dessous les facteurs d�actualisation et les prixfutures obtenus à partir des données du 23=05=2008, ainsi que le coe¢ cient dedétermination R2 de la régression linéaire.
i Echéances Maturités Ti BTi FTi R2
1 20=06=2008 0:08 0:99676 3722:94 0:9999999999771672 18=07=2008 0:15 0:99323 3730:33 0:9999999999987683 15=08=2008 0:23 0:98936 3735:91 0:9999999999178124 19=09=2008 0:33 0:98492 3751:88 0:9999999999933745 19=12=2008 0:57 0:97311 3779:03 0:9999999999265106 20=03=2009 0:82 0:96132 3816:26 0:9999999996755577 19=06=2009 1:07 0:95001 3748:21 0:9999999998773218 18=12=2009 1:57 0:92862 3806:2 0:9999999999671629 18=06=2010 2:07 0:90857 3775:91 0:99999999999566410 17=12=2010 2:57 0:88938 3824:65 0:99999999999816511 16=12=2011 3:56 0:85275 3838:91 0:99999999994016712 21=12=2012 4:58 0:81713 3856:63 0:99999999997336413 20=12=2013 5:58 0:78318 3869:79 0:99999999952126714 19=12=2014 6:57 0:74901 3889:29 0:99999999913456415 18=12=2015 7:57 0:71409 3916:38 0:99999999956176116 16=12=2016 8:57 0:67855 3951:44 0:99999999913516217 15=12=2017 9:56 0:64286 3993:96 0:999999999947164
224

Le coe¢ cient R2 est quasiment égal à 1 pour chaque échéance traitée, ce quitraduit la qualité de la régression. D�une manière générale la méthode que nousproposons s�avère particulièrement robuste et elle permet de s�a¤ranchir desproblèmes liés à l�incertitude sur les taux d�intérêt et sur les dividendes.
A�n de limiter au maximum les distorsions lors de l�extraction des volatilitésimplicites, nous procédons à un retraitement préliminaire des cours de compen-sation a�n d�éliminer les prix faux ou non-signi�catifs.
Filtrage des prix faux et des prix non-signi�catifs
Elimination des prix faux Pour chaque maturité Ti, nous supprimons lesoptions pour lesquelles il n�est pas possible de calculer une volatilité implicite.D�après la proposition 4.3, cela revient à ne conserver que les prix Cobsm;i quivéri�ent :
BTi(FTi �Km)+ � Cobsm;i � BTi FTi ; 1 � m � mi: (4.53)
Elimination des prix non-signi�catifs Le tick de cotation représente laprécision avec laquelle les prix d�options sont exprimés (0:1 point d�indice dansle cas présent). Donc, on ne peut tirer aucune information pertinente des prixd�options situés à 1 tick de cotation des bornes de l�encadrement (4.53) et nousconsidérons qu�il ne faut pas en tenir compte.En pratique, nous appliquons un �ltre plus restrictif qui consiste à éliminer lesprix situés à moins de 2 ticks de cotation9 des bornes de l�inégalité (4.53). Celarevient à conserver les cours de compensation qui vérifent l�encadrement :
BTi(FTi �Km)+ + 2 ticks < Cobsm;i < BTi FTi � 2 ticks: (4.54)
Allure de la matrice des cours de compensation La �gure 4.2 illustre lamatrice des prix de compensation et elle permet d�identi�er les options éliminéespar les deux �ltres décrits précédemment.Un examen de cette �gure montre que les options dont les prix (représentés enrouge) ne respectent pas l�encadrement (4.53), se situent au niveau des premièresmaturités et des strikes les plus faibles. Les options dont les prix (représentés enbleu) ne respectent pas l�encadrement (4.54), se situent au niveau des premièresmaturités et des strikes les plus élevés. A partir de la 9i�eme maturité (2 ansenviron) tous les prix d�options sont considérés comme valides au sens des deux�ltres proposés. Nous donnons ci-dessous un tableau qui permet de quanti�er le�ltrage que nous avons pratiqué sur les données initiales.
Nb. Options PourcentageTotal 902 100:00%Filtre 1 19 2:11%Filtre 2 116 12:86%Restant 767 85:03%
9Kermiche (2007) applique un �ltre similaire, mais moins restrictif, puisqu�elle élimineuniquement les options dont le prix est inférieur à un échelon de cotation.
225

Strikes600 1 1 2
800 1 1 2
1 000 1 1 3 3 3 3 3 3 3 3
1 200 1 1 3 3 3 3 3 3 3
1 400 1 1 3 3 3 3 3 3 3
1 500 1 2
1 600 1 1 3 3 3 3 3 3 3 3 3
1 700 1 3 3 3
1 800 1 2 3 3 3 3 3 3 3 3 3 3 3
1 900 2 3 3 3 3
2 000 2 1 3 3 3 3 3 3 3 3 3 3 3 3
2 100 3 3 3 3 3 3
2 200 1 1 3 3 3 3 3 3 3 3 3 3 3 3
2 300 3 3 3 3 3 3 3
2 400 2 2 3 3 3 3 3 3 3 3 3 3 3 3
2 500 2 3 3 3 3 3 3 3 3 3 3
2 600 2 3 3 3 3 3 3 3 3 3 3 3 3 3
2 700 3 3 3 3 3 3 3 3 3 3 3
2 800 3 3 3 3 3 3 3 3 3 3 3 3 3 3
2 850 3 3 3 3
2 900 3 3 3 3 3 3 3 3 3 3 3 3
2 950 3 3 1 3 3 3
3 000 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3
3 050 3 3 3 3 3 3 3 3 3 3
3 100 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3
3 150 3 3 3 3 3 3 3 3 3 3
3 200 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3
3 250 3 3 3 3 3 3 3 3 3 3
3 300 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3
3 350 3 3 3 3 3 3 3 3 3 3 3
3 400 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3
3 450 3 3 3 3 3 3 3 3 3 3
3 500 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3
3 550 3 3 3 3 3 3 3 3 3 3
3 600 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3
3 650 3 3 3 3 3 3 3 3 3 3 3
3 700 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3
3 750 3 3 3 3 3 3 3 3 3 3 3
3 800 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3
3 850 3 3 3 3 3 3 3 3 3 3
3 900 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3
3 950 3 3 3 3 3 3 3 3 3 3
4 000 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3
4 050 3 3 3 3 3 3 3 3 3 3
4 100 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3
4 150 3 3 3 3 3 3 3 3 3 3
4 200 2 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3
4 250 2 3 3 3 3 3 3 3 3 3
4 300 2 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3
4 350 2 3 3 3 3 3 3 3 3 3
4 400 2 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3
4 450 2 2 3 3 3 3 3 3 3
4 500 2 2 3 3 3 3 3 3 3 3 3 3 3 3 3
4 550 2 2 3 3 3 3 3 3 3
4 600 2 2 3 3 3 3 3 3 3 3 3 3 3 3 3
4 650 2 2 3 3 3 3 3 3 3
4 700 2 2 3 3 3 3 3 3 3 3 3 3 3 3 3
4 750 2 2 3 3 3 3 3 3 3
4 800 2 2 3 3 3 3 3 3 3 3 3 3 3 3 3
4 850 2 2 2 3 3 3 3 3 3
4 900 2 2 2 3 3 3 3 3 3 3 3 3 3 3 3
4 950 2 2 2 3 3 3 3 3
5 000 2 2 2 3 3 3 3 3 3 3 3 3 3 3 3
5 050 2 2 2
5 100 2 2 2 3 3 3
5 150 2 2 2
5 200 2 2 2 3 3 3 3 3 3 3 3
5 250 2 2 2
5 300 2 2 2 3 3 3
5 350 2
5 400 2 2 2 3 3 3 3 3 3 3 3 3
5 450 2
5 500 2 2 2 2 3 3 3
5 550 2
5 600 2 2 2 2 3 3 3 3 3 3 3
5 650 2
5 700 2 2 2 2 3 3
5 750 2
5 800 2 2 2 2 3 3 3 3 3 3 3
5 850 2
5 900 2 2 2 2 3 3
5 950 2
6 000 2 2 2 2 3 3 3 3 3 3 3 3 3
6 200 2 2 3 3 3
6 400 2 2 3 3
6 600 2 3 3 3 3 3
6 800 2 2 3 3
7 000 2 2 3 3 3 3 3 3 3 3
7 200 2 2 3 3
7 400 2 2 3 3
7 600 2 2 3 3
7 800 2 2 2 3
8 000 2 2 2 3 3 3 3 3 3 3
10 000 3 3 3 3 3 3
Maturités : 0,08 0,15 0,23 0,33 0,57 0,82 1,07 1,57 2,07 2,57 3,56 4,58 5,58 6,57 7,57 8,57 9,56
Fig. 4.2 �Illustration de la matrice des cours de compensation du 23=05=2008sur les options OESX. Gris clair : prix non renseignés ; gris sombre : prix valides ;bleu : prix non-signi�catifs ne respectant pas l�encadrement (4.54) ; rouge : prixfaux ne respectant pas l�encadrement (4.53).
226

0,00
0,50
1,00
1,50
2,00
2,50
3,000 1 2 3 4 5 6 7 8 9 10
Maturités (Y)
Mon
eyne
ss
Fig. 4.3 �Moneyness des options cotées en fonction de la maturité. Pointillébleu : moneyness ; droite rouge : monnaie forward ; losanges jaunes : arbitragesen moneyness.
Le premier �ltre a supprimé environ 2% des données et le second �ltre environ13%. Cela signi�e que 85% des données initiales contiennent une informationutilisable pour modéliser la surface de volatilité implicite. Nous avons pu véri�erque ces proportions étaient relativement stables au cours du temps.
Pour conclure cette section, nous analysons la con�guration des données �ltrées.
Répartition des cotations
Pour chaque échéance, nous pouvons calculer la moneyness forward des options
retenues après le �ltrage à partir du prix future estimé soit �obsm;idef= Km=FTi .
La �gure 4.3 représente (pointillé bleu) les moneyness des options en fonctiondes échéances de contrats. La droite horizontale rouge correspond aux optionsà la monnaie forward (� = 1) et les losanges jaunes représentent les prix arbi-trables10 . Un simple examen des données montre qu�il y a pratiquement autantd�options dont la moneyness est inférieure à 1 que d�options dont la moneynessest supérieure à 1. Sur les premières maturités les prix observés sont associés à
10Voir le paragraphe 4.4.3 pour la détection des prix arbitrables.
227

des niveaux de moneyness compris entre 0:50 et 1:50. A partir de la 7i�eme matu-rité, les prix disponibles sont associés à des niveaux de moneyness compris entre0:25 et 2:5 environ. Le tableau ci-dessous donne la proportion d�options danschaque intervalle de moneyness, toutes maturités confondues (il y a ntotal = 767options).
Intervalles Nb. Options Proportion� 2 [a; b[ n[a;b[ n[a;b[=ntotal
0:00 : 0:50 48 6:37%0:50 : 0:75 98 13:01%0:75 : 1:00 249 33:07%1:00 : 1:25 231 30:68%1:25 : 1:50 84 11:16%1:50 : 2:00 43 5:71%2:00 : 2:50 8 1:06%2:50 : 3:00 6 0:80%
On constate qu�environ 63:75%(' 33:07% + 30:68%) des options sont situéesdans l�intervalle de moneyness [0:75; 1:25[, ce qui signi�e que l�essentiel de l�in-formation disponible est concentrée autour de la monnaie. Les options de money-ness inférieure à 0:75 représentent environ 19:38%(' 6:37% + 13:01%) des prixdisponibles et les options de moneyness supérieure à 1:25 représentent environ18:73%(' 11:16% + 5:71% + 1:06% + 0:80%) des prix disponibles. On disposedonc d�une quantité d�information non négligeable au niveau des moneynessextrêmes dont il faudra tenir compte lors de la construction de la surface devolatilité implicite.
Détection des arbitrages en moneyness
Nous terminons l�analyse des données disponibles en présentant une méthodesimple pour détecter la présence d�arbitrages entre les prix cotés pour une mêmeéchéance11 . Les données �ltrées véri�ent la proposition 4.2. Pour contrôler laprésence d�arbitrages en moneyness, il nous su¢ t de véri�er les points 1 et 2 de laproposition 4.4. Etant donné que l�on dispose de données discrètes, nous devonstraduire les formules (4.35) et (4.36) en leurs équivalents discrets. Les prix decalls normalisés observés sont donnés par la formule cobsm;i = Cobsm;i=(BTi FTi).
La formule (4.35) signi�e que la pente des prix de calls normalisés est compriseentre �1 et 0, de sorte que son équivalent discret s�écrit :
�1 �cobsm;i � cobsm�1;i
�obsm;i � �obsm�1;i� 0: (4.55)
11La détection des arbitrages calendaires suppose que l�on dispose des prix d�options pourles mêmes moneyness à chaque maturité, ce qui n�est pas le cas lorsque l�on considère les prixd�options observés.
228

La formule (4.36) signi�e que la pente entre les prix observés doit être croissanteà maturité �xée. On en déduit que l�équivalent de (4.36) s�écrit :
cobsm+1;i � cobsm;i
�obsm+1;i � �obsm;i
�cobsm;i � cobsm�1;i
�obsm;i � �obsm�1;i: (4.56)
On retrouve les conditions de non-arbitrage démontrées par Carr et Madan(2005).
Nous avons détecté 4 violations de la relation (4.56) sur les données observées.La moneyness des options associées est représentée par des losanges jaunes surla �gure 4.3. En revanche, la relation (4.55) a toujours été respectée. Les prixobservés présentent peu d�opportunités d�arbitrage. Cela con�rme le fait que lemarché des options listées sur le DJ EuroStoxx 50 est bien arbitré.
Surface de prix, surface de volatilité implicite
Pour conclure cette section, nous présentons les prix de calls normalisés cobsm;i
(�gure 4.4, graphique du haut) ainsi que les volatilités implicites �obsm;i (�gure4.4, graphique du bas), obtenues en résolvant l�équation suivante12 :
cBS(�obsm;i; Ti; �
obsm;i) = cobsm;i: (4.57)
Un examen du graphique supérieur de la �gure 4.4 montre que les prix normali-sés semblent véri�er les hypothèses de non-arbitrage (décroissance et convexitépar rapport à la moneyness, croissance par rapport à la maturité). On constatequ�il n�y a pas de prix pour les options de moneyness arbitrairement faible ou ar-bitrairement élevée au niveau des premières échéances et à la dernière échéance.Cette con�guration des données rend l�inférence statistique particulièrement dif-�cile, car il faut extrapoler les prix qui n�existent pas de manière cohérente parrapport à l�information disponible aux maturités intermédiaires.Sur le graphique inférieur de la �gure 4.4, on retrouve les principales carac-téristiques de la volatilité sur les marchés actions : le skew est plus prononcépour la première échéance (appelée échéance front) et il s�aplatit au niveau desmaturités longues.
Pour construire la surface de volatilité implicite, on peut choisir de travailler surles prix normalisés ou sur les volatilités. Nous considérons qu�il est préférablede modéliser les volatilités pour les deux raisons suivantes.� Les prix normalisés peuvent prendre des valeurs très proches de zéro (del�ordre de 1:0E�07). Etant donné que les ordinateurs représentent les nombresavec une précision �nie, il n�est pas souhaitable de travailler sur des quantitésarbitrairement faibles qui deviennent rapidement indiscernables.12Nous déterminons les volatilités implicites par dichotomie. Cette méthode simple permet
d�obtenir les volatilités avec le degré de précision désiré. Son principal inconvénient est le tempsde calcul nécessaire. A ce sujet, on pourra consulter Jäckel (2006) qui discute les problèmesliés à l�inversion numérique de la fonction cbs, considérée comme une fonction de la volatilitéimplicite.
229
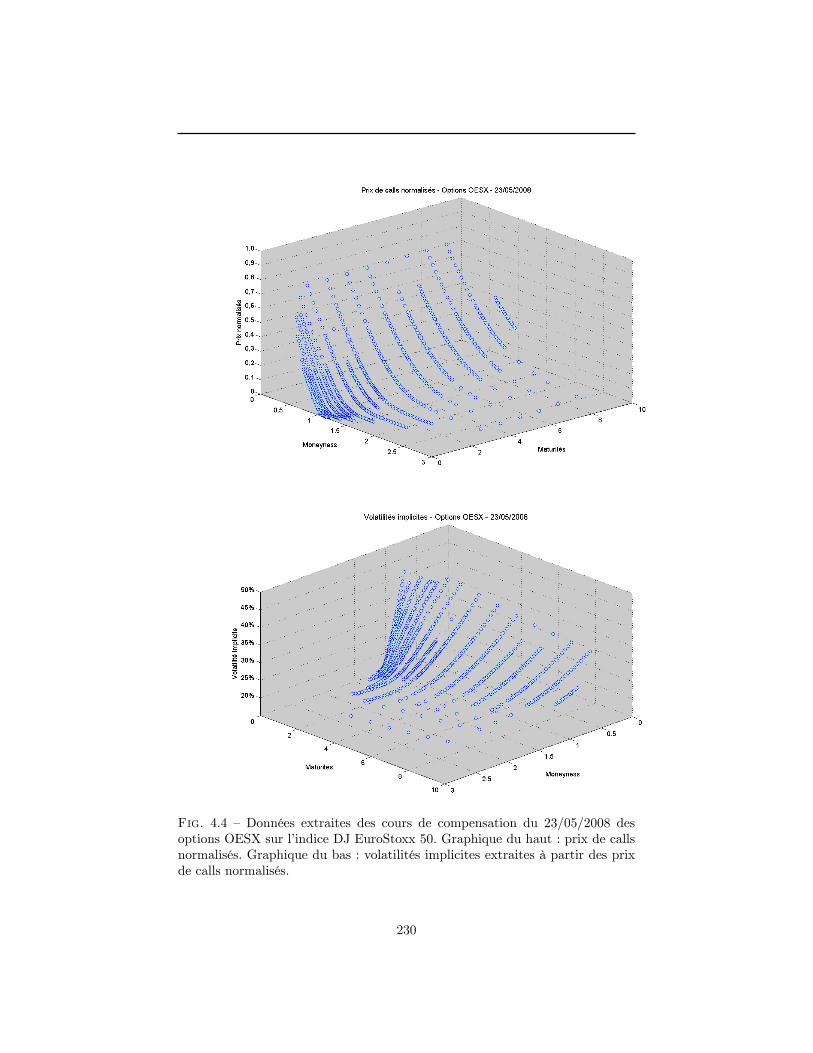
Fig. 4.4 � Données extraites des cours de compensation du 23/05/2008 desoptions OESX sur l�indice DJ EuroStoxx 50. Graphique du haut : prix de callsnormalisés. Graphique du bas : volatilités implicites extraites à partir des prixde calls normalisés.
230

� Les volatilités au contraire ont un ordre de grandeur voisin de 1:0E�01, cequi permet de les traiter avec précision sur l�ordinateur.
Dans la section suivante, nous présentons quelques voies de modélisation dessurfaces de volatilité envisagées dans la littérature et fréquemment utilisées parles praticiens.
4.5 Modélisations possibles pour la surface devolatilité implicite
Nous envisageons successivement deux approches pour construire la surface devolatilité implicite et nous montrons pourquoi elles ne donnent pas des résultatspleinement satisfaisants. La première approche consiste à calibrer sur les prixd�options observés un modèle de marché consistant qui "explique" l�existencedu smile de volatilité en tenant compte, par exemple, de la nature stochastiquede la volatilité ou de la présence de sauts dans la dynamique du sous-jacent. Laseconde approche, dite descriptive, consiste à modéliser les volatilités observéespar une méthode paramétrique ou non-paramétrique. Dans ce cas, l�idée n�estpas d�expliquer l�existence du smile de volatilité, mais plutôt de reproduire saforme.
4.5.1 Modèles de marchés explicatifs du smile
Le modèle de Black et Scholes (1973) suppose que le prix de l�actif risqué suitun mouvement Brownien géométrique : la volatilité des rendements est détermi-niste, les trajectoires du sous-jacent sont continues presque-sûrement et les prixsuivent une loi lognormale. Or les études empiriques montrent que : (i) la volati-lité évolue de manière aléatoire au cours du temps et qu�elle est corrélée au coursdu sous-jacent, (ii) les cours boursiers sont soumis à des variations violentes, desorte que les rendements sont discontinus (présence de sauts). L�existence dusmile de volatilité est une conséquence du fait que le modèle de di¤usion lo-gnormale de Black et Scholes n�est pas su¢ samment réaliste, car il ne tient pascompte des phénomènes évoqués ci-dessus. Les spécialistes ont donc tenté d�en-richir le modèle original de manière à lui donner les caractéristiques (volatilitéstochastique et/ou sauts) mises en évidence par l�expérience, l�objectif étantd�expliquer et d�analyser le smile de volatilité (Aboura 2005).
Quelques solutions envisagées dans la littérature
Modèles à volatilité stochastique Certains auteurs ont fait le choix deremplacer la volatilité constante de la di¤usion lognormale par une volatilitéstochastique qui peut être une fonction du sous-jacent, comme dans le modèleCEV (Cox et Ross 1976, Cox 1996), ou un processus stochastique corrélé àl�évolution du sous-jacent (Hull et White 1987, Scott 1987, Heston 1993). Parnature, les modèles à volatilité stochastique tiennent compte du caractère hété-roscédastique de la volatilité du sous-jacent. L�expérience montre qu�ils peuvent
231

reproduire les di¤érentes formes de smiles observées dans la réalité et qu�ils en-gendrent une structure par terme de volatilité implicite consistante (Corrado etSu 1998, Lewis 2000). En revanche, ils ne parviennent pas à restituer �dèlementle smile de volatilité sur les maturités courtes. Ce phénomène provient du faitque les prix des options d�échéances courtes sont expliqués essentiellement parla présence de sauts dans la dynamique du sous-jacent (Gatheral 2006).
Modèles de di¤usion à sauts Une autre alternative envisagée par Merton(1976) ou Cox et Ross (1976) consiste à combiner la dynamique Brownienneavec un processus de Poisson composé. On parle alors de di¤usion à sauts(jump-di¤usion en anglais). Les sauts peuvent avoir une amplitude constanteou suivre une loi de probabilité spéci�que. Merton travaille avec des sauts de loilognormale, Kou (2002) modélise l�amplitude des sauts par une loi de Laplaceasymétrique, Zhu et Hanson (2005) supposent que les sauts suivent une loi uni-forme. Comme les modèles à volatilité stochastique, les modèles de di¤usion àsauts permettent d�engendrer un smile et une structure par terme de volatilitéimplicite. Gatheral (2006) démontre que ce type de processus est capable decapturer le smile de volatilité sur les maturités courtes, mais que la structurepar terme des volatilités s�aplatit beaucoup trop rapidement par rapport à ceque l�on observe dans la réalité.
Modèles hybrides Dans la réalité des marchés �nanciers, les �uctuationsdes prix résultent de la combinaison du caractère hétéroscédastique de la vola-tilité et de la présence de sauts dans les rendements. Pour cette raison, certainsauteurs ont proposé d�intégrer des processus à sauts dans les modèles à volati-lité stochastique (Bates 1996, 2000). On obtient ainsi une dynamique des prixréaliste. La surface de volatilité implicite obtenue par cette méthode combineles caractéristiques des modèles à volatilité stochastique (structure par termeconsistante et bonne représentation du smile sur le long terme) avec les carac-téristiques des modèles à sauts (bonne représentation du smile sur les maturitéscourtes) ; elle est relativement proche de celle observée empiriquement (Bakshi,Cao et Chen 1997, Gatheral 2006). Toutefois, ce type de modèle est particu-lièrement di¢ cile à calibrer et les paramètres sont très instables dans le temps(Lempereur 2004). Pour une discussion approfondie sur les modèles à volatilitéstochastique et sauts, on pourra consulter la thèse de Sy (2003).
Avantages et inconvénients des modèles explicatifs Les modèles expli-catifs présentent plusieurs avantages :� la dynamique de l�actif risqué possède des caractéristiques statistiques prochesde celles des rentabilités boursières,
� ils expliquent simultanément le smile et la structure par terme de la surfacede volatilité implicite,
� ils o¤rent un cadre d�analyse consistant pour évaluer et couvrir les produitsdérivés complexes.
232

On peut donc les utiliser pour reconstruire une surface de volatilité implicitecomplète à partir des prix d�options observés à un instant donné. En particulier,ils permettent d�extrapoler les données manquantes en préservant la surfaced�éventuelles opportunités d�arbitrage (Randjiou 2002).
Toutefois, ce type d�approche sou¤re des inconvénients communs à toutes lesméthodes paramétriques :� la calibration, particulièrement complexe, induit des résolutions numérique-ment très lourdes (problèmes non-linéaires d�optimisation multidimension-nelle sous contraintes),
� le modèle est capable d�imiter les formes de surfaces de volatilité rencontréesdans la pratique, mais la qualité de l�ajustement sur les données réelles estdiscutable. Par exemple, les modèles combinant une volatilité stochastique etdes sauts surévaluent systématiquement les options à la monnaie (Sy 2003).
Ce dernier point provient du fait que l�on cherche à imposer, par des considéra-tions empiriques, une forme prédé�nie aux données observées (Kermiche 2007).
Pour les raisons que nous venons d�évoquer, nous conseillons d�utiliser une ap-proche paramétrique lorsque l�on travaille avec peu de données : une fois lesparamètres estimés, on reconstruit l�ensemble des données manquantes à l�aidedu modèle. En revanche, lorsque nous disposons d�un grand nombre de données,ce qui est le cas sur le marché de l�indice DJ EuroStoxx 50, il est préférabled�envisager une autre approche, plus �exible, qui sera à même de capturer l�en-semble de l�information contenue dans les prix observés. Avant de présenter lesméthodes de capture du smile de volatilité implicite, nous donnons les résultatsobtenus en calibrant le modèle de Merton (1976) sur les données utilisées dansle chapitre.
Volatilités implicites engendrées par le modèle M76 de Merton
L�intérêt du modèle de Merton est que l�on dispose d�une formule analytiquepour évaluer les options Européennes et qu�il est consistant avec l�hypothèsed�absence d�opportunité d�arbitrage.
Hypothèses du modèle Nous travaillons avec le processus de prix normalisés(Mt) qui est une martingale positive d�espérance égale à 1. Nous supposons quele processus (Mt) présente des sauts aléatoires (Yi)i�1 à des instants aléatoiresdiscrets (� i)i�1 qui sont les instants de sauts d�un processus de Poisson homo-gène (Nt), d�intensité � > 0. Entre deux sauts consécutifs, les prix Mt évoluentselon un mouvement Brownien géométrique de volatilité � > 0. On suppose deplus que les processus (Wt)t�0, (Nt)t�0 et la suite de variables aléatoires (Yi)i�1sont mutuellement indépendants.
A�n de simpli�er les calculs, Merton (1976) impose que les variables Yi soientidentiquement distribuées selon une loi lognormale de paramètres " 2 R et� > 0 :
lnYi � N�"; �2
�: (4.58)
233

La dynamique des prix est régie par l�équation di¤érentielle stochastique sui-vante :
dMt
Mt�= �dWt + (Yt � 1) dNt � ��dt; (4.59)
où � def= E[Yi] � 1 = exp(" + �2=2) � 1 et Mt� désigne le prix normalisé immé-diatement avant la date t.
Sous ces hypothèses, le cours du sous-jacent à une date t quelconque est de laforme (Matsuda 2004) :
Mt =MBt M
Pt ;
où (MBt ) est une martingale Brownienne dé�nie par :
MBt = exp
���
2
2t+ �Wt
�(4.60)
et (MPt ) est une martingale Poissonienne dé�nie par :
MBt = exp
���t+
NtXi=1
lnYi
!: (4.61)
Prix d�un call Européen Le prix normalisé d�un call Européen de moneyness� et d�échéance T , noté cM76(�; T ), est donné par la formule (démonstration enAnnexe B) :
cM76(�; T ) =+1Xn=0
e���T (
��T )n
n!cBS(�n; T; �n) ; (4.62)
où cBS(�n; T; �n) est le prix Black et Scholes normalisé d�un call de moneyness
�n, d�échéance T , de volatilité �n et
�� = � (1 + �) ; �n =�
(1 + �)ne���T
; �2n = �2 +�2n
T: (4.63)
Calibration Avec la formule fermée pour les prix de calls normalisés (4.62),nous pouvons calibrer le modèle sur les prix d�options observés en résolvant leproblème de minimisation non-linéaire ci-dessous :
(��; ��; "�; ��) = argminnXi=1
miXm=1
�cM76(�m; Ti; �; �; "; �)� cobsm;i
�2: (4.64)
Les paramètres obtenus sont les suivants :
�� ' 0:15646; �� ' 0:08749; "� ' �0:80288; �� ' 0:41170: (4.65)
On remarque que l�espérance de la taille des sauts, "�, est voisine de �80%,alors qu�elle devrait être comprise entre �5% et �15%. Ce résultat, surprenant,
234

s�explique par le fait que nous avons cherché un jeu de paramètres qui expliquesimultanément les prix des options de maturité courte (1 mois) et des options dematurité longue (9:5 ans environ). La valeur trouvée pour "� signi�e que nousavons utilisé le modèle au-delà de sa capacité explicative en cherchant à lui fairereproduire la forme du smile long-terme. Ce résultat con�rme les modèles dedi¤usion à sauts, comme celui présenté ici, ne permettent pas de reproduireavec précision une surface de volatilité implicite complète.
Qualité de l�ajustement La �gure 4.5 représente, en rouge, les volatilitésimplicites obtenues avec le modèle M76 lorsque les paramètres sont donnés par(4.65) et avec des cercles noirs les volatilités observées.Un examen des cinq premiers graphiques (maturités inférieures à 1 an) montreque le smile court-terme est particulièrement mal représenté. En revanche, lesmile moyen/long-terme est mieux représenté (cinq derniers graphiques). Laqualité d�ajustement augmente avec la maturité, ce qui tend à con�rmer le faitque ce sont les prix des options long-termes qui ont in�uencé la calibration dumodèle.
Quanti�cation des erreurs de calibration A�n de con�rmer les observa-tions faites à partir des graphiques, nous calculons pour chaque maturité Ti :� la moyenne des écarts entre les volatilités implicites données par le modèle etles volatilités observées, notée ErrV,
� la moyenne des écarts relatifs entre les prix donnés par le modèle et les prixobservés, notée ErrC.
Dans les deux cas, les écarts sont pris en valeur absolue, ce qui évite les phé-nomènes de compensation. Les quantités ErrV et ErrC sont dé�nies par lesformules suivantes :
ErrV (Ti) =1
mi
miXm=1
����M76 (~�m; Ti)� �obsm;i
��� ; (4.66)
ErrC (Ti) =1
mi
miXm=1
�����cM76 (~�m; Ti)cobsm;i
� 1����� : (4.67)
Les résultats des calculs sont donnés dans le tableau ci-dessous.
235
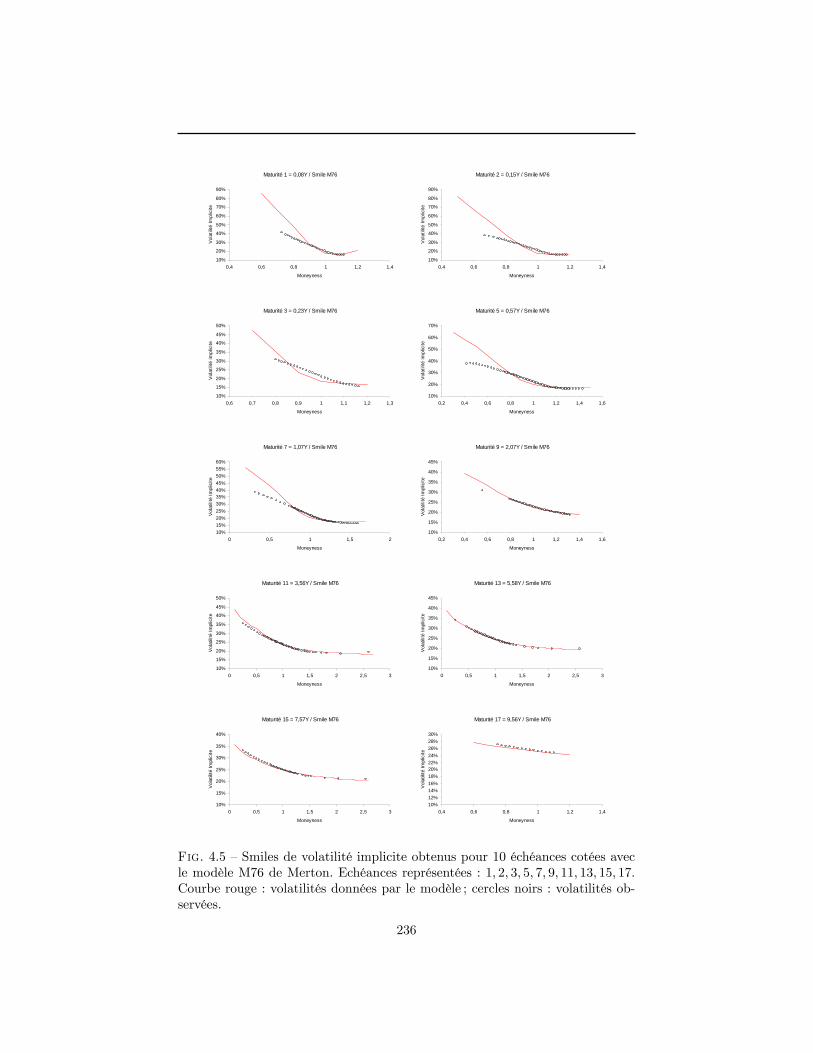
Maturité 1 = 0,08Y / Smile M76
10%
20%
30%
40%
50%
60%
70%
80%
90%
0,4 0,6 0,8 1 1,2 1,4
Moneyness
Vol
atili
té Im
plic
ite
Maturité 2 = 0,15Y / Smile M76
10%
20%
30%
40%
50%
60%
70%
80%
90%
0,4 0,6 0,8 1 1,2 1,4
Moneyness
Vol
atili
té Im
plic
ite
Maturité 3 = 0,23Y / Smile M76
10%
15%
20%
25%
30%
35%
40%
45%
50%
0,6 0,7 0,8 0,9 1 1,1 1,2 1,3
Moneyness
Vol
atili
té Im
plic
ite
Maturité 5 = 0,57Y / Smile M76
10%
20%
30%
40%
50%
60%
70%
0,2 0,4 0,6 0,8 1 1,2 1,4 1,6
Moneyness
Vol
atili
té Im
plic
ite
Maturité 7 = 1,07Y / Smile M76
10%15%20%25%30%35%40%45%50%55%60%
0 0,5 1 1,5 2
Moneyness
Vol
atili
té Im
plic
ite
Maturité 9 = 2,07Y / Smile M76
10%
15%
20%
25%
30%
35%
40%
45%
0,2 0,4 0,6 0,8 1 1,2 1,4 1,6
Moneyness
Vol
atili
té Im
plic
ite
Maturité 11 = 3,56Y / Smile M76
10%
15%
20%
25%
30%
35%
40%
45%
50%
0 0,5 1 1,5 2 2,5 3
Moneyness
Vol
atili
té Im
plic
ite
Maturité 13 = 5,58Y / Smile M76
10%
15%
20%
25%
30%
35%
40%
45%
0 0,5 1 1,5 2 2,5 3
Moneyness
Vol
atili
té Im
plic
ite
Maturité 15 = 7,57Y / Smile M76
10%
15%
20%
25%
30%
35%
40%
0 0,5 1 1,5 2 2,5 3
Moneyness
Vol
atili
té Im
plic
ite
Maturité 17 = 9,56Y / Smile M76
10%12%14%16%18%20%22%24%26%28%30%
0,4 0,6 0,8 1 1,2 1,4
Moneyness
Vol
atili
té Im
plic
ite
Fig. 4.5 �Smiles de volatilité implicite obtenus pour 10 échéances cotées avecle modèle M76 de Merton. Echéances représentées : 1; 2; 3; 5; 7; 9; 11; 13; 15; 17.Courbe rouge : volatilités données par le modèle ; cercles noirs : volatilités ob-servées.
236

i Ti ErrV (Ti) ErrC (Ti)
1 0:08 5:55% 5:69%2 0:15 4:15% 11:24%3 0:23 1:97% 10:61%4 0:33 3:85% 13:15%5 0:57 3:39% 12:56%6 0:82 2:63% 6:47%7 1:07 1:83% 17:86%8 1:57 1:33% 8:08%9 2:07 0:42% 2:86%10 2:57 0:84% 4:65%11 3:56 0:56% 3:93%12 4:58 0:25% 1:86%13 5:58 0:21% 1:97%14 6:57 0:31% 1:81%15 7:57 0:36% 1:58%16 8:57 0:36% 1:10%17 9:56 0:25% 0:72%Moyenne : 1:66% 6:24%
Dans la troisième colonne, on voit que la moyenne des écarts, entre les volatilitésobservées et les volatilités modélisées, diminue globalement lorsque la maturitéaugmente.De même, dans la quatrième colonne, on voit que la moyenne des écarts relatifs,entre les prix donnés par le modèle et les prix observés, présente une tendanceglobalement décroissante.La quantité ErrV est nettement inférieure à 1% à partir de la 9i�eme échéance(2 ans) : on peut donc considérer que les volatilités moyen/long-termes sontcorrectement représentées. En revanche, les volatilités des options de maturitéinférieure à 2 ans (1 � i � 8) sont mal représentées. Pour ces échéances, ErrVest supérieure à 1:3% et elle atteint même 5:55% pour la première maturité.Les écarts sur les volatilités expliquent le comportement des écarts de prix rela-tifs mesurés par la quantité ErrC. Entre la 1�ere et la 8i�eme échéance, les écartsde prix ont un ordre de grandeur voisin de 10% et, à partir de la 9i�eme échéance,ils sont voisins de 2%.La 9i�eme échéance constitue donc une frontière à partir de laquelle on peutconsidérer que le modèle explique correctement les prix observés. Toutefois, cerésultat n�est pas acceptable car, le modèle devrait reproduire �dèlement lesprix des options de maturités courtes pour lesquelles on dispose d�un maximumd�information.Pour terminer cette analyse, soulignons que la moyenne des écarts en volatilité,toutes échéances confondues, est voisine est de 1:66% et que la moyenne desécarts de prix relatifs sur l�ensemble des données observées est de 6:24%. Ceschi¤res démontrent que le modèle ne permet pas d�expliquer correctement lesprix d�options observés et par conséquent la forme de la surface de volatilitéimplicite associée.
237

Etant donné que les modèles de marché paramétriques ne sont pas su¢ samment�exibles pour reproduire �dèlement les volatilités implicites observées, certainsauteurs proposent de modéliser les volatilités implicites, sans chercher à expli-quer les mécanismes de formation du smile et de la structure par terme desvolatilités implicites.
4.5.2 Modèles descriptifs du smile
Nous cherchons à déterminer une fonction qui serait capable de reproduire lesdi¤érentes formes de smiles et de structures par termes que l�on peut observerdans la réalité. Construire une telle fonction revient à trouver une modélisationparamétrique d�une variable à deux dimensions (la surface de volatilité implicitevue comme une fonction de la moneyness et de la maturité). Cette tâche estparticulièrement délicate et elle repose essentiellement sur un examen minutieuxde la forme du smile de volatilité, vu comme une fonction de la moneyness oucomme une fonction de la log-moneyness (Hafner et Wallmeier 2001).Au voisinage de la monnaie (~� ' 0), on observe que le smile de volatilité a uneforme convexe que l�on peut assimiler à une portion de parabole ou, plus géné-ralement, à une portion de courbe polynomiale. Partant de cette constatation,di¤érents auteurs ont proposé de représenter le smile à une maturité donnée parun polynôme de degré inférieur ou égal à 4.
Dans un premier temps, nous présentons di¤érentes modélisations des volatilitésimplicites basées sur des polynômes et proposées dans la littérature. Dans unsecond temps, nous testons un modèle dans lequel la variance implicite est unefonction quadratique de la log-moneyness.
Modélisations du smile par des polynômes
Modèles de Sepp (2002) Sepp (2002) envisage deux paramétrisations de lasurface de volatilité dans lesquelles le smile est un polynôme de degré 3 ou 4par rapport à la log-moneyness :
�1 (~�; T ) =�a0 + a1T + a2T
2�+ (a3 + a4T )~�+ a5~�
2 + a6~�3 (4.68)
et�2 (~�; T ) =
�a0 + a1e
�a2T�+ a3~�+ a4~�
2 + a5~�3 + a6~�
4: (4.69)
Selon l�auteur, le modèle (4.69) est plus réaliste que le modèle (4.68), car lescoe¢ cients ont une interprétation �nancière : a0 représente la volatilité à lamonnaie lorsque T ! +1, a1 mesure l�écart entre la volatilité à la monnaie dematurité T et la volatilité à l�in�ni, a2 > 0 représente la vitesse de convergencedes volatilités à la monnaie vers la volatilité limite a0. Les paramètres a3; : : : ; a6contrôlent la forme du smile de volatilité au voisinage de la monnaie.
238

Modèle de Alentorn (2004) Alentorn (2004) propose de modéliser le smilede volatilité comme une fonction quadratique de la log-moneyness dont les co-e¢ cients se déforment avec la maturité :
� (~�; T ) = (a0 + a1T ) +
�a3pT+ a4pT
�~�+
a5pT~�2: (4.70)
La fonction a0 + a1T représente la structure par terme des volatilités à la mon-naie, la fonction a3=
pT +a4
pT représente la pente de la volatilité à la monnaie
(encore appelée skewness) et le coe¢ cient a5=pT représente la convexité de la
volatilité à la monnaie (encore appelée smileness). Selon les tests pratiqués parl�auteur, le modèle (4.70) permet de capturer correctement la forme de la surfacede volatilité implicite. Soulignons que l�équation choisie pour dé�nir le skewnessn�est pas conforme à ce que l�on observe dans la réalité : lorsque T ! +1, on aa3=pT + a4
pT ! �1 selon le signe de a4, ce qui contredit le fait que le smile
tend à s�aplatir au niveau des maturités lointaines.
Modélisations de Daglish, Hull et Suo (2007) Daglish, Hull et Suo (2007)analysent di¤érents modèles de volatilité fréquemment utilisés par les traders suroptions. Ils envisagent tout d�abord un modèle inspiré des travaux de Dumas,Fleming et Whaley (1998) :
� (~�; T ) = � (0; T ) +�a0 + a1T + a2T
2�+ (a3 + a4T )~�+ a5~�
2: (4.71)
Les auteurs testent aussi le modèle suivant, dans lequel les coe¢ cients des termesen ~� sont des puissances de T�1=2 :
� (~�; T ) = � (0; T ) +a1T 1=2
~�+a2T~�2 +
a3T 3=2
~�3 +a4T 2~�4: (4.72)
En�n, ils généralisent le modèle (4.72) en remplaçant les puissances successivesde T�1=2 par des termes de la forme T�k� où � > 0 est di¤érent de 1=2 :
� (~�; T ) = � (0; T ) +a1T�~�+
a2T 2�
~�2 +a3T 3�
~�3 +a4T 4�
~�4: (4.73)
Les di¤érents tests de calibration montrent que � est voisin de 0:44.
Modèle de Zhang et Xiang (2008) Zhang et Xiang (2008) considèrent unevolatilité implicite quadratique de la forme suivante :
� (~�; T ) = �0
�1 +
1pT~�+
2T~�2�; (4.74)
où �0 représente la volatilité à la monnaie, 1 contrôle la pente de la volatilité àla monnaie et 2 contrôle la convexité de la volatilité à la monnaie. Les auteursdémontrent que ces paramètres sont reliés aux moments d�ordre 3 (skewness) et4 (kurtosis) de la loi de probabilité des rendements du sous-jacent. Ils calibrentle modèle sur les prix d�options sur l�indice S&P 500 en minimisant la distance
239

entre les volatilités observées et les volatilités données par (4.74), mais en pondé-rant les observations en fonction des volumes des transactions sur les di¤érentesoptions. En procédant ainsi, ils démontrent que la fonctionnelle (4.74) permet decapturer les caractéristiques intrinsèques de la forme de la surface de volatilitéimplicite.
Avantages et inconvénients des modèles polynomiaux Les modèles pré-sentés ci-dessus donnent une équation paramétrique simple pour la surface devolatilité et il est aisé de les calibrer sur les données observées, ce qui les rendattractifs. Ils présentent toutefois deux inconvénients majeurs :� ils ne garantissent pas que la surface obtenue sera non-arbitrable,� les théorèmes 4.6 et 4.7 montrent qu�il ne faut en aucun cas les utiliser pourextrapoler les volatilités implicites au niveau des moneyness extrêmes (j~�j !+1), car la variance implicite est asymptotiquement une fonction linéaire dela log-moneyness.
Nous présentons dans la suite les résultats obtenus en calibrant un modèle desmile polynomial sur les volatilités implicites des options OESX au 23/05/2008.
Volatilités implicites engendrées à partir d�une variance quartique
Les modèles de smile quadratiques sont des approximations de la surface devolatilité au voisinage de la monnaie (~� ' 0) dont la qualité se dégrade trèsrapidement dès que l�on sort de l�intervalle 0:9 � � � 1:1 (Argou 2006). Or,pour certaines maturités, on dispose de volatilités implicites pour des moneynesscomprises entre 0:25 et 2:6, comme on peut le voir sur la �gure 4.3 avec la 11i�eme
maturité qui correspond aux options d�échéance 3:56 ans.En représentant le smile par un polynôme de degré 4 (smile quartique) quio¤re deux degrés de liberté supplémentaires par rapport à une représentationquadratique, on a un gain de �exibilité permettant d�obtenir un lissage précisquelle que soit la largeur de l�intervalle des moneyness cotées.Nous pouvons encore améliorer un peu la qualité de la régression en modélisantla variance et non pas la volatilité par un polynôme de degré 4. C�est ce que nousavons pu observer en reconstruisant les surfaces de volatilité implicite utiliséesdans le cadre de notre activité de gestion sur les produits structurés.
Variance implicite quartique La variance implicite �2 (~�; T ) est un poly-nôme de degré 4 par rapport à la log-moneyness ~� dé�ni par :
�2 (~�; T ) = aT ~�4 + bT ~�
3 + cT ~�2 + dT ~�+ eT ; (4.75)
où eT représente la variance implicite à la monnaie (eT > 0 etpeT = � (0; T )),
dT représente la pente de la variance implicite à la monnaie et cT contrôlela convexité de la variance implicite à la monnaie. Les paramètres aT et bTpermettent de capturer la forme du smile au niveau des volatilités éloignées dela monnaie.
240

La volatilité implicite de maturité T est obtenue en prenant la racine carrée del�expression précédente :
� (~�; T ) =�aT ~�
4 + bT ~�3 + cT ~�
2 + dT ~�+ eT�1=2
: (4.76)
Qualité de l�ajustement Pour chaque maturité, nous avons calibré la fonc-tion (4.75) sur les variances implicites cotées. Les smiles de volatilité implicite,donnés par la formule (4.76), sont présentés à la �gure 4.6. Un examen desdi¤érentes courbes montre que le modèle s�ajuste parfaitement aux donnéesobservées pour toutes les maturités. Une simple comparaison entre les smilesobtenus à partir des variances quartiques et les smiles obtenus avec le modèlede Merton M76 (�gure 4.5) con�rme la supériorité du modèle descriptif sur lemodèle explicatif, qui ne restitue pas �dèlement la forme des volatilités obser-vées. Nous poursuivons l�analyse en étudiant les écarts entre les volatilités etles prix d�options donnés par le modèle et les volatilités et les prix d�optionsobservés.
Quanti�cation des erreurs de calibration Dans le tableau ci-dessous, nousfournissons pour chacune des 17 maturités cotées, le coe¢ cient R2 de la régres-sion de la fonction (4.75) sur les variances observées, la moyenne des écarts entreles volatilités implicites estimées et les volatilités observées (ErrV) et la moyennedes écarts relatifs entre les prix donnés par le modèle et les prix observés (ErrC).
i Ti R2 ErrV (Ti) ErrC (Ti)
1 0:08 0:999816 0:09% 0:57%2 0:15 0:999912 0:06% 1:16%3 0:23 0:999935 0:04% 0:63%4 0:33 0:999716 0:12% 2:29%5 0:57 0:999458 0:17% 3:11%6 0:82 0:999987 0:02% 0:24%7 1:07 0:999575 0:13% 3:29%8 1:57 0:998732 0:21% 5:40%9 2:07 0:999987 0:01% 0:08%10 2:57 0:999659 0:09% 1:61%11 3:56 0:999524 0:10% 1:37%12 4:58 0:999771 0:06% 0:67%13 5:58 0:999546 0:07% 0:64%14 6:57 0:999726 0:05% 0:39%15 7:57 0:999864 0:03% 0:26%16 8:57 0:999920 0:02% 0:15%17 9:56 0:999981 0:00% 0:01%Moyenne : 0:999712 0:07% 1:29%
Le coe¢ cient R2 est quasiment égal à 1 pour chaque échéance traitée, ce quitraduit la qualité de la régression et con�rme le choix du modèle.
241

Maturité 1 = 0,08Y / Smile Quartic
10%
20%
30%
40%
50%
60%
70%
0,4 0,6 0,8 1 1,2 1,4
Moneyness
Vol
atili
té Im
plic
ite
Maturité 2 = 0,15Y / Smile Quartic
10%15%20%25%30%35%40%45%50%55%
0,4 0,6 0,8 1 1,2 1,4
Moneyness
Vol
atili
té Im
plic
ite
Maturité 3 = 0,23Y / Smile Quartic
10%
15%
20%
25%
30%
35%
40%
0,6 0,7 0,8 0,9 1 1,1 1,2 1,3
Moneyness
Vol
atili
té Im
plic
ite
Maturité 5 = 0,57Y / Smile Quartic
10%
15%
20%
25%
30%
35%
40%
45%
0,2 0,4 0,6 0,8 1 1,2 1,4 1,6
Moneyness
Vol
atili
té Im
plic
ite
Maturité 7 = 1,07Y / Smile Quartic
10%
15%
20%
25%
30%
35%
40%
45%
50%
0 0,5 1 1,5 2
Moneyness
Vol
atili
té Im
plic
ite
Maturité 9 = 2,07Y / Smile Quartic
10%
15%
20%
25%
30%
35%
40%
0,2 0,4 0,6 0,8 1 1,2 1,4 1,6
Moneyness
Vol
atili
té Im
plic
ite
Maturité 11 = 3,56Y / Smile Quartic
10%
15%
20%
25%
30%
35%
40%
45%
0 0,5 1 1,5 2 2,5 3
Moneyness
Vol
atili
té Im
plic
ite
Maturité 13 = 5,58Y / Smile Quartic
10%
15%
20%
25%
30%
35%
40%
0 0,5 1 1,5 2 2,5 3
Moneyness
Vol
atili
té Im
plic
ite
Maturité 15 = 7,57Y / Smile Quartic
10%
15%
20%
25%
30%
35%
40%
0 0,5 1 1,5 2 2,5 3
Moneyness
Vol
atili
té Im
plic
ite
Maturité 17 = 9,56Y / Smile Quartic
10%12%14%16%18%20%22%24%26%28%30%
0,4 0,6 0,8 1 1,2 1,4
Moneyness
Vol
atili
té Im
plic
ite
Fig. 4.6 �Smiles de volatilité implicite obtenus pour 10 échéances cotées avec lemodèle de variance quartique dé�ni par (4.75) et (4.76). Echéances représentées :1; 2; 3; 5; 7; 9; 11; 13; 15; 17. Courbe rouge : volatilités données par le modèle ;cercles noirs : volatilités observées.
242

Les écarts entre volatilités estimées et volatilités observées évoluent dans l�inter-valle [0:00%; 0:21%] et leur niveau moyen est voisin de 0:07%, ce qui correspondà une réduction de l�erreur d�approximation de l�ordre de 23:71(' 1:66%
0:07% ) parrapport au modèle M76. Ce résultat très satisfaisant est complètement cohérentavec les conclusions de l�examen de la �gure 4.6.L�écart le plus important (0:21%) est observé au niveau de la 8i�eme échéance,pour laquelle le coe¢ cient R2 est le plus "faible" (R2 ' 0:998732). A titrede comparaison, les écarts ErrV (Ti) sont toujours supérieurs à 0:21% avec lemodèle M76. Autrement dit, les erreurs de calibration avec le modèle de variancequartique sont toujours inférieures aux erreurs de calibration observées avec lemodèle de M76.La réduction de l�erreur d�approximation sur les volatilités s�accompagne d�uneréduction de la moyenne des écarts relatifs entre prix estimés et prix observéspour chaque maturité. Les écarts de prix relatifs sont compris entre 0:01% pourla dernière maturité et 5:40% pour la 8i�eme maturité. La moyenne des écartsde prix relatifs sur l�ensemble des données ressort à 1:29%, soit une réductionde l�erreur de l�ordre de 4:84(' 6:24%
1:29% ) par rapport au modèle M76. Notons quele facteur de réduction de l�erreur est moins important lorsque l�on raisonnesur les prix d�options, car ils dépendent de la volatilité implicite d�une manièrefortement non-linéaire.
Conclusion L�étude précédente établit la supériorité des modèles descriptifsdu smile sur les modèles explicatifs, lorsqu�il s�agit de construire la surface devolatilité implicite.Les modèles explicatifs parviennent à saisir les caractéristiques principales de ladynamique des cours, mais ne permettent pas d�intégrer les contraintes secon-daires, ce qui explique que la forme de la surface de volatilité observée di¤èrede la forme théorique "parfaite" imposée par le modèle.Les modèles descriptifs du smile tentent de reproduire le plus �dèlement possibleles données observées, sans chercher à les expliquer. Dans ce cadre, le modèlede smile à quartique que nous avons proposé s�avère particulièrement e¢ cacepour lisser et interpoler les volatilités manquantes. Il s�implémente facilementet il donne des résultats très satisfaisants, y compris lorsque l�on travaille avecdes volatilités très éloignées de la monnaie.
Cette dernière modélisation présente toutefois deux désavantages :� elle ne préserve pas des opportunités d�arbitrage,� elle ne permet pas d�extrapoler correctement les volatilités en dehors de l�in-tervalle des moneyness cotées pour une maturité donnée (voir �gure 4.7).
En ce qui concerne le premier point, au cours de notre expérience, nous avonsobservé que le modèle n�introduit en général pas d�arbitrage lorsque les donnéessont issues de marchés liquides et bien arbitrés.Le second point signi�e que pour construire une surface de volatilité implicitecomplète, non-arbitrable et qui soit su¢ samment lisse il faut envisager une autreapproche que celles présentées jusqu�ici.
243
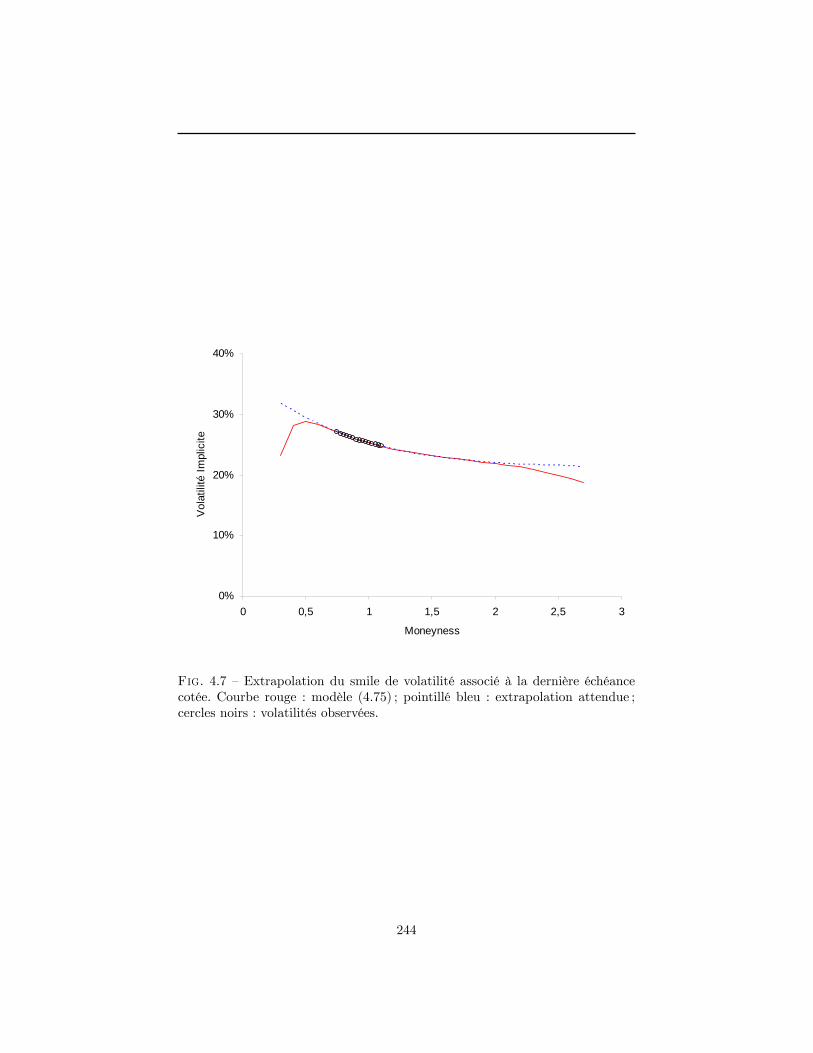
0%
10%
20%
30%
40%
0 0,5 1 1,5 2 2,5 3
Moneyness
Vol
atili
té Im
plic
ite
Fig. 4.7 �Extrapolation du smile de volatilité associé à la dernière échéancecotée. Courbe rouge : modèle (4.75) ; pointillé bleu : extrapolation attendue ;cercles noirs : volatilités observées.
244

Dans la section suivante, nous proposons une méthodologie qui permet de construirela surface de volatilité en intégrant l�ensemble des contraintes évoquées.
4.6 Construction d�une surface de volatilité non-arbitrable
Dans un premier temps, nous étudions une méthode paramétrique pour lisser etextrapoler au niveau des moneyness extrêmes le smile de la première maturité.Dans un second temps, nous mettons en oeuvre une méthode non-paramétriquepour reconstruire l�ensemble de la surface de volatilité implicite. Dans un troi-sième temps, nous présentons un algorithme non-paramétrique qui permet d�im-poser les contraintes de non-arbitrage de la proposition (4.4). Dans un quatrièmetemps, les algorithmes sont appliqués au jeu de données utilisé dans ce chapitre(voir section 4.4) et nous comparons les résultats avec les méthodes proposéesà la section précédente.
4.6.1 Le modèle de smile paramétrique SVI
Les résultats du paragraphe 4.3.4 montrent que le smile de variance impliciteest approximativement une fonction a¢ ne de la log-moneyness au niveau desmoneyness extrêmes. En analysant le comportement du smile engendré par lemodèle à volatilité stochastique de Heston, Gatheral(2004, 2006) est parvenu àconstruire une fonction paramétrique du smile, appelée modèle SVI (Stochas-tic Volatility Inspired), qui intègre la contrainte de linéarité aux ailes. Nousprésentons ce modèle ci-dessous et nous montrons comment l�utiliser.
Dé�nition du modèle
Dans le modèle SVI, la variance implicite �2 (~�; T ) est dé�nie par la fonctionsuivante qui dépend de 5 paramètres :
�2 (~�; T ) = #T (~�)def= aT + bT
��T (~��mT ) +
q(~��mT )2 + �
2T
�; (4.77)
où ~� représente la log-moneyness. Dans la suite, pour alléger les notations, nousne ferons plus �gurer la dépendance en T des paramètres du modèle.
Linéarité aux ailes Le principal avantage du modèle SVI réside dans soncomportement au niveau des strikes extrêmes. En e¤et, la fonction #T présentedeux asymptotes linéaires #�T (à gauche) et #
+T (à droite) dont les équations sont
les suivantes :
#�T (~�) = b (�� 1) (~��m); ~�! �1; (4.78)
#+T (~�) = b (�+ 1) (~��m); ~�! +1: (4.79)
245

Cette propriété signi�e que l�on pourra utiliser le modèle SVI pour extrapolerles volatilités au niveau des ailes, car #T est approximativement linéaire lorsque~�! �1.
Interprétation des paramètres Les paramètres de la fonction #T sont ai-sément interprétables et ils ont chacun une in�uence bien précise sur la formedu smile obtenu. Une illustration du rôle de chaque paramètre est donnée à la�gure 4.8. Les graphiques se lisent de gauche à droite. Chaque graphique illustrel�in�uence de l�un des paramètres. La courbe rouge représente le smile de va-riance implicite pour les valeurs des paramètres suivants : a = 0:04, b = 0:4,� = �0:4, m = 0, � = 0:1. La courbe en pointillé vert représente le smile devariance obtenu en modi�ant l�un des paramètres concernés (a; b; �;m ou �) eten laissant les autres inchangés.
a donne le niveau général de la variance implicite : une augmentation de atranslate la courbe vers le haut, une diminution de a translate la courbe vers lebas (�gure 4.8, graphique en haut à gauche).b contrôle l�angle entre les asymptotes gauche et droite : une augmentation de bréduit l�angle entre les asymptotes, une diminution de b augmente l�angle entreles asymptotes (�gure 4.8, graphique en haut à droite).� contrôle l�orientation générale du smile : augmenter � fait pivoter la courbe versla droite, diminuer � fait pivoter la courbe vers la gauche (�gure 4.8, graphiquedu milieu à gauche).m contrôle la position horizontale de la courbe : augmenterm translate la courbevers la droite, diminuer m translate la courbe vers la gauche (�gure 4.8, gra-phique du milieu à droite).� contrôle la convexité du smile autour du minimum observé : plus � est élevé,plus le raccordement entre les ailes est lisse (�gure 4.8, graphique du bas).
A�n de mieux appréhender le comportement du modèle, nous établissons desbornes pour les paramètres.
Bornes pour les paramètres
Bornes pour le paramètre � Le paramètre � est le plus simple à étudier. Ene¤et, il apparaît par l�intermédiaire de son carré dans la formule (4.77). Donc,changer � en �� ne modi�e pas la fonction #T . On peut donc supposer � > 0sans perte de généralité. Par ailleurs, l�expérience montre que � est presquetoujours inférieur à 1, d�où l�on déduit :
0 < � < 1: (4.80)
Bornes pour le paramètre � On note �+ et �� les pentes des asymptotesdroite (~�! +1) et gauche (~�! �1). D�après les formules (4.78) et (4.79) ona :
�+ = b (�+ 1) ; �� = b (�� 1) : (4.81)
246

Influence de a (paramètre de niveau)
0
0,2
0,4
0,6
1 0,5 0 0,5 1
LogMoneyness
Var
ianc
e Im
plic
ite
a=0.04a=0.12
Influence de b (angle entre les asymptotes)
0
0,2
0,4
0,6
0,8
1
1 0,5 0 0,5 1
LogMoneyness
Var
ianc
e Im
plic
ite
b=0.4b=1.2
Influence de ρ (rotation du graphe)
0
0,2
0,4
0,6
1 0,5 0 0,5 1
LogMoneyness
Var
ianc
e Im
plic
ite
ρ=−0.4ρ=−0.8
Influence de m (translation du graphe)
0
0,2
0,4
0,6
1 0,5 0 0,5 1
LogMoneyness
Var
ianc
e Im
plic
ite
m=0m=0.25
Influence de λ (lissage du raccordement entre les asymptotes)
0
0,2
0,4
0,6
1 0,5 0 0,5 1
LogMoneyness
Var
ianc
e Im
plic
ite
λ=0.1λ=0.3
Fig. 4.8 � In�uence des paramètres du modèle SVI. Courbe rouge : smile deréférence correspondant aux paramètres a = 0:04, b = 0:4, � = �0:4, m = 0,� = 0:1. Courbe en pointillé vert : smile obtenu en modi�ant la valeur de l�undes paramètres, les autres restant �xes.
247

Les deux asymptotes doivent avoir des pentes de signes opposés, i.e. ���+ < 0.On en déduit :
b2��2 � 1
�< 0) � 2 ]�1; 1[ : (4.82)
De plus, les smiles de variance implicite sur les "actions" sont en général asymé-triques (on parle de smirk), ce qui signi�e, en raisonnant en valeur absolue, quela pente de l�asymptote gauche est plus importante que la pente de l�asymptotedroite. Cette condition s�écrit :������ � ���+��, jbj (1� �) � jbj (1 + �), � � 0: (4.83)
En combinant les deux inégalités précédentes, on a :
�1 < � � 0: (4.84)
Bornes pour le paramètre b La pente �� de l�asymptote gauche doit êtrenégative. Avec (4.84), on en déduit que la seule possibilité est d�avoir :
b > 0: (4.85)
Les formules (4.44) et (4.47) des théorèmes des moments impliquent j��j < 2=Tet j�+j < 2=T . En combinant ces deux relations il vient :
b <2
Tmin
�1
1� � ;1
1 + �
�: (4.86)
Comme �1 < � � 0, on a min�(1� �)�1 ; (1 + �)�1
�= (1� �)�1. Donc b
véri�e l�encadrement :
0 < b <2
T (1� �) : (4.87)
Les autres conditions sur les paramètres sont obtenues en étudiant le minimumde #T .
Minimum de la variance implicite dans le modèle SVI On véri�e que#T est deux fois dérivable par rapport à ~� et ses dérivées sont données par lesformules :
#0T (~�) = b
0@�+ ~��mq(~��m)2 + �2
1A ; #00T (~�) = b�2�
(~��m)2 + �2�3=2 : (4.88)
Etant donné que b > 0, la fonction #00T est strictement positive. Cela impliqueque #0T est strictement croissante. Un simple calcul montre que :
lim~�!�1
#0T (~�) = b (�� 1) < 0; lim~�!+1
#0T (~�) = b (�+ 1) > 0: (4.89)
248

Comme de plus #0T est continue, on en déduit que #T admet un unique minimum#�T sur R. Soit ~�
� la valeur de la log-moneyness pour laquelle le minimum estatteint, alors #0T (~�
�) = 0. Après calculs on obtient :
~�� = m� ��p1� �2
; #�T = a+ b�p1� �2: (4.90)
Bornes pour le paramètre m D�une manière générale, les smiles de varianceimplicite sur les actions présentent un minimum qui est atteint à droite de lamonnaie forward, donc ~�� � 0. On en déduit :
m � ��p1� �2
: (4.91)
Par ailleurs, l�expérience montre que l�on a m < 1. En combinant les deuxinégalités trouvées, on obtient l�encadrement suivant pour m :
��p1� �2
� m < 1: (4.92)
Bornes sur le paramètre a Le paramètre a contrôle le niveau global pour lacourbe. On pourrait penser qu�il doit être du même signe que la variance, c�est-à-dire positif. Cela n�est pas le cas en général. Dans la pratique, on s�aperçoitqu�il est préférable de laisser le signe de a quelconque. Mais, on peut établir desbornes pour a.En e¤et, le minimum de #T doit être strictement positif (pour que la volatilitéimplicite soit bien dé�nie) et inférieur à la variance à la monnaie �2ATM. Donc,0 < #�T � �2ATM. Cet encadrement entraîne :
�b�p1� �2 < a � �2ATM � b�
p1� �2: (4.93)
Nous avons obtenu les inégalités permettant de quanti�er les paramètres, nouspouvons maintenant proposer une procédure de calibration.
Calibration du modèle SVI
La procédure d�ajustement consiste à déterminer le vecteur des paramètres op-timaux, noté (a�; b�; ��;m�; ��), qui minimise la distance quadratique entre lesvariances observées et la fonction paramétrique #T . Il s�agit d�un problème d�op-timisation non-linéaire que l�on peut écrire sous la forme :
(a�; b�; ��;m�; ��) = argmin
(MXm=1
�#T�~�obsm
�� (�obsm;T )
2�2)
; (4.94)
où (a; b; �;m; �) 2 D, D étant le domaine dé�ni par les encadrements (4.93),(4.87), (4.84), (4.92) et (4.80).
249

Détermination des coe¢ cients optimaux Pour résoudre le problème (4.94),on peut utiliser l�algorithme de Levenberg-Marquardt ou tout autre algorithmed�optimisation non-linéaire tels que ceux proposés dans les logiciels de calculnumérique standards (Judd 1998). La principale di¢ culté étant, avec ce typed�algorithme, de choisir un point de départ pertinent, sinon le risque de conver-gence vers un minimum local est très élevé.
Pour déterminer le point de départ de l�algorithme de minimisation, on meten oeuvre un algorithme de localisation quasi-aléatoire13 . L�idée est de balayeruniformément le domaine D avec une suite à discrépance faible pour obtenir ungrand nombre de jeux de paramètres candidats. On calcule alors, pour chaquecandidat, la distance quadratique entre la fonction et les points observés et l�onchoisit le jeu de paramètres pour lequel cette distance est minimale. Une façone¢ cace de procéder est de répéter cette optimisation plusieurs fois en réduisant àchaque itération la taille des intervalles autour des paramètres optimaux trouvés.Nous obtenons ainsi un jeu de paramètres qui est utilisé comme point de départdans l�algorithme des moindres carrés.
En pratique, le modèle SVI se calibre facilement lorsque le minimum des va-riances implicites est observable. Il est donc bien adapté au lissage et à l�ex-trapolation du smile sur les premières maturités. En e¤et, les smiles observéssur les maturités courtes présentent généralement un minimum observable, alorsque ce n�est pas le cas pour les smiles long-termes14 .
Calibration sur la première maturité La �gure 4.9 illustre le comporte-ment du modèle SVI. Elle représente le smile de volatilité obtenu en calibrantla fonctionnelle (4.77) sur les données de la première maturité. Le graphiquedu haut montre de quelle manière le modèle capture la forme des données ob-servées (lissage) et la �gure du bas montre comment il permet d�extrapoler lesvolatilités au niveau des ailes.La moyenne des écarts entre les volatilités observées et les volatilité données parle modèle est ErrV (T1) ' 0:20%. Le résultat est donc légèrement moins précisque la régression quartique. Cela s�explique par le fait que le modèle SVI est basésur une fonction paramétrique, ce qui signi�e qu�il est moins "�exible" qu�unpolynôme. Cependant, il permet d�extrapoler les données de manière consistante(linéarité de la variance au niveau des ailes), ce que ne permet pas le modèle desmile polynomial.
La méthode SVI nous a permis de lisser et d�extrapoler le smile de volatilitéimplicite au niveau de la première maturité. Pour reconstituer la surface devolatilité complète, Gatheral (2006) propose d�ajuster la fonctionnelle SVI surles autres maturités cotées, puis d�interpoler les di¤érents smiles obtenus. On
13Pour une présentation approfondie des méthodes d�optimisation quasi-aléatoire, on pourraconsulter Niederreiter (1992).14Lorsque le minimum n�est pas observable, on peut au préalable préparer les données en
ajustant le modèle quartique (4.75) présenté dans la section précédente.
250
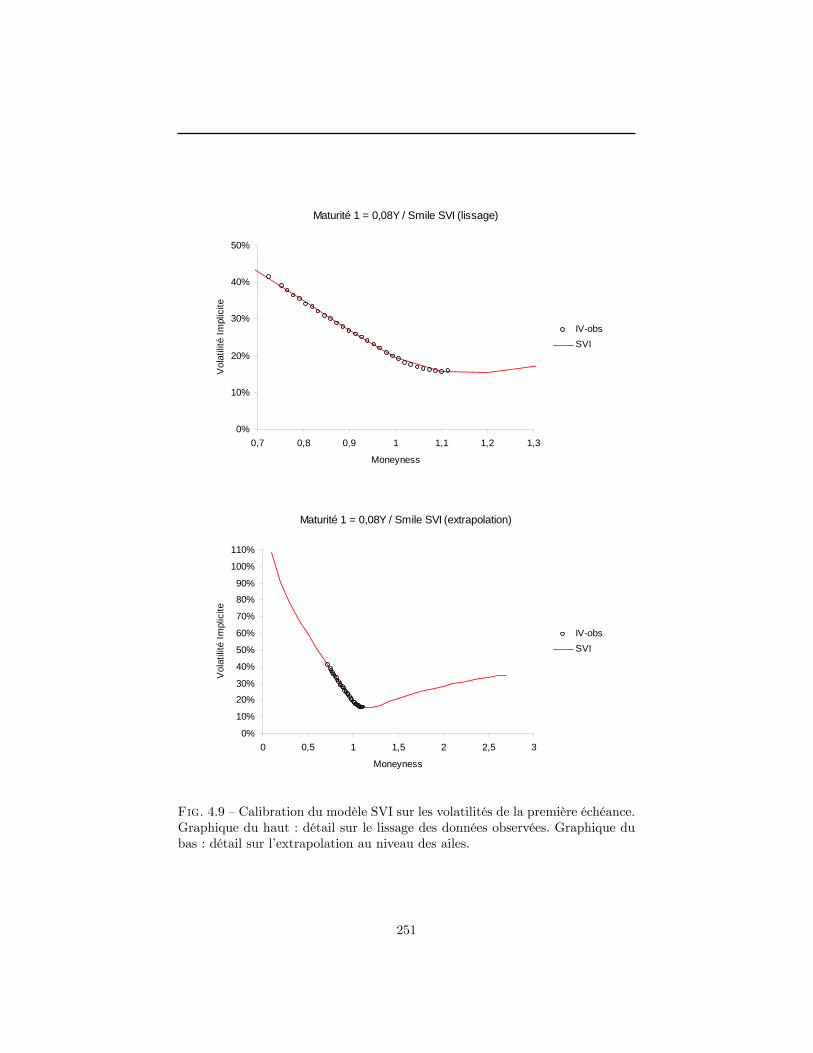
Maturité 1 = 0,08Y / Smile SVI (lissage)
0%
10%
20%
30%
40%
50%
0,7 0,8 0,9 1 1,1 1,2 1,3
Moneyness
Vol
atili
té Im
plic
ite
IVobsSVI
Maturité 1 = 0,08Y / Smile SVI (extrapolation)
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
110%
0 0,5 1 1,5 2 2,5 3
Moneyness
Vol
atili
té Im
plic
ite
IVobsSVI
Fig. 4.9 �Calibration du modèle SVI sur les volatilités de la première échéance.Graphique du haut : détail sur le lissage des données observées. Graphique dubas : détail sur l�extrapolation au niveau des ailes.
251

s�aperçoit à l�usage que cette approche ne donne pas des résultats satisfaisants.En e¤et, le modèle SVI permet de bien reconstituer le smile de volatilité corres-pondant à une maturité donnée, mais il n�est pas assez �exible pour capturerla déformation du smile d�une maturité sur l�autre, de sorte que l�on introduitdes arbitrages inter-maturités. Pour cette raison, nous proposons de construirele reste de la surface de volatilité par une méthode non-paramétrique que nousprésentons ci-dessous.
4.6.2 Construction d�une pré-surface de volatilité impli-cite par les Thin Plate Splines (TPS)
Nous disposons d�un smile complet pour la première maturité (obtenu avecle modèle SVI) et des volatilités implicites observées aux maturités suivantes.Notre objectif est de générer une surface de volatilité complète et régulière àpartir de ces données (�gure 4.10, graphique du haut). La méthode utilisée doitpermettre de "propager" le smile de la première maturité aux maturités sui-vantes en l�atténuant progressivement (phénomène d�évanouissement du smile),tout en préservant la propriété de linéarité au niveau des ailes.Nous pourrions envisager de réaliser une interpolation avec des splines bicu-biques (Planchet et Winter 2007) mais, étant donné la con�guration irrégulièredes observations15 , il est préférable d�utiliser les Thin Plate Splines, car cessplines sont spécialement conçus pour modéliser des données disposées de ma-nière quelconque (Eberly 2002).
Les Thin Plate Splines (TPS) ont été introduits par Duchon (1976) dans lebut de traiter des problèmes soulevés par le reconstruction de surfaces ou devolumes incomplets. Les TPS sont fréquemment considérés comme la généra-lisation bidimensionnelle des splines cubiques naturels en dimension 1, car ilsdé�nissent la surface de courbure minimale qui interpole un ensemble de pointsbidimensionnels16 .Une manière commode d�appréhender le comportement d�un TPS est de consi-dérer qu�il s�agit d�une feuille métallique qui passerait par les points observés.Cela signi�e en particulier que les TPS possèdent un e¤et de "mémoire" qui vanous permettre de propager le smile de la première maturité à toutes les autresmaturités cotées de manière consistante.
Nous donnons ci-dessous le schéma général de l�interpolation TPS. Pour uneprésentation détaillée, on pourra consulter Wahba (1990).
15Nous disposons de quelques volatilités observées par maturité et les moneyness associéesà ces volatilités sont di¤érentes d�une maturité à l�autre. Pour procéder à une interpolationbicubique, il serait préférable que les données soient réparties sur une grille régulière.16Rappelons une particularité des splines cubiques naturels : le spline cubique naturel est
la courbe de convexité minimale qui interpole un jeu de données en dimension 1.
252

Interpolation TPS (Thin Plate Splines)
On note (xi; yi; zi)i=1;:::;n le jeu de données que l�on souhaite interpoler. Le prin-cipe de l�interpolation TPS est de déterminer une fonction (x; y)! f(x; y) quipasse par les points observés, i.e. f(xi; yi) = zi, et dont l�énergie est minimale.L�énergie d�une surface est dé�nie par 17 :
Ifdef=
ZR2
�f2xx + 2f
2xy + f
2yy
�dxdy; (4.95)
où fxx, fyy et fxy désignent les dérivées partielles secondes de f .
On peut démontrer qu�il existe une unique fonction solution du problème pré-cédent et qu�elle s�écrit sous la forme :
f(x; y) =
nXj=1
aj(kx� xj ; y � yjk) + b0 + b1x+ b2y; (4.96)
où est la fonction dé�nie par (r) = r2 ln(r2) et k�k désigne la normeeuclidienne d�un vecteur, i.e. ku; vk =
pu2 + v2. La fonction est appelée
fonction radiale.
Détermination des coe¢ cients
Les coe¢ cients aj et bj sont déterminés en imposant que la fonction passe parles points observés. Cette condition s�écrit :
zi =
nXj=1
ijaj + b0 + b1xi + b2yi; i = 1; : : : ; n; (4.97)
où l�on a posé ijdef= (kxi � xj ; yi � yjk).
Soit a = (a1; : : : ; an)| et b = (b0; b1; b2)
| les vecteurs des coe¢ cients cherchés(le symbole "|" désigne l�opérateur de transposition).En termes matriciels, l�équation (4.97) devient :
Aa+Bb = z; (4.98)
où A def= [ij ] est une matrice carrée n � n et B est la matrice n � 3 dont les
lignes sont [1; xi; yi].Pour calculer les coe¢ cients, il nous faut introduire une contrainte supplémen-taire, car le système dé�ni par (4.98) est sous-déterminé (nous avons n + 3inconnues et seulement n équations). La contrainte manquante est donnée parla condition suivante (Duchon 1976) :
B|a = 0: (4.99)
17La quantité (4.95) est appelée énergie de courbure de la surface (bending energy) par lesphysiciens.
253

On peut démontrer que la matrice A est inversible, ce qui nous permet d�endéduire les vecteurs a et b :
a = A�1 (z �Bb) ; b =�B|A�1B
��1B|A�1z: (4.100)
La détermination des coe¢ cients du TPS requiert la manipulation de matricesde taille importante. Dans l�exemple traité ici, nous avons n ' 1000. Poure¤ectuer des calculs précis et rapides avec des matrices aussi volumineuses, nousrecommandons d�utiliser un logiciel de calcul numérique tel que MATLAB18 oula suite IMSL19 .
L�interpolation par les TPS nous a permis de construire une surface de volati-lité implicite complète (�gure 4.10, graphique du bas). Cependant, nous n�avonsintroduit aucune contrainte de non-arbitrage au cours du processus de construc-tion, ce qui signi�e que la surface est susceptible de présenter des opportunitésd�arbitrage. Dans le paragraphe suivant, nous proposons une méthode pour éli-miner ces arbitrages de manière systématique.
4.6.3 Lissage non-arbitrable des prix d�options avec le mo-dèle de Fengler (2005)
L�algorithme que nous présentons ici est dû à Fengler (2005b). Il consiste à lisserles prix normalisés avec des splines cubiques en introduisant les contraintes dela proposition 4.4. Il présente deux avantages.� L�estimation des splines se résume en une procédure d�optimisation quadra-tique, dont la solution est unique. Les conditions d�absence d�opportunitéd�arbitrage se traduisent par des contraintes linéaires sur les coe¢ cients quel�on cherche à estimer. Le problème peut être résolu facilement avec la routined�optimisation quadratique sous contraintes linéaires d�un package statistiquestandard (par exemple, la procédure quadprog en MATLAB).
� Les courbes obtenues sont, par construction, de classe C2, de sorte que l�onpourra déterminer la densité de probabilité du sous-jacent.
Pour une étude approfondie des méthodes de lissage par splines cubiques contraints,on pourra consulter Turlach (1997).
Dans un premier temps, nous présentons le problème de lissage des prix d�optionspour une même maturité sans contrainte d�arbitrage. Ensuite nous montronscomment modi�er l�algorithme de lissage pour intégrer les contraintes de non-arbitrage en moneyness. En�n, nous étendons les résultats pour tenir comptedes contraintes d�arbitrage intertemporel.
Préparation des données
Nous avons vu au paragraphe 4.3.3 que les contraintes de non-arbitrage surles volatilités implicites sont fortement non-linéaires (proposition 4.5), tandis
18http://www.mathworks.com/.19http://www.visualnumerics.com/.
254

Fig. 4.10 �Lissage des volatilités implicites avec les TPS. Graphique du haut :données utilisées pour la calibration des TPS. (points bleus : volatilités obser-vées ; ligne rouge : smile SVI). Graphique du bas : surface de volatilité impliciteobtenue avec les TPS.
255

qu�elles s�expriment de manière simple lorsque l�on raisonne sur les prix norma-lisés (proposition 4.4). Pour cette raison, nous décidons de travailler sur les prixd�options normalisés.
Soit [�min; �max] l�intervalle de moneyness sur lequel est dé�nie la surface devolatilité obtenue avec les TPS. En pratique, on a �min = 0:1 et �max = 2:7. On
divise cet intervalle en m sous-intervalles de longueur h def= (�max � �min)=m et
l�on pose :
�idef= �min + (i� 1)h; i = 1; : : : ;m: (4.101)
On peut alors calculer les prix de calls normalisés sur une grille régulière (�gure4.11, graphique du haut) :
ci;jdef= cBS(�i; Tj ; �(�i; Tj)); 1 � i � m; 1 � j � n; (4.102)
où T1; : : : ; Tn sont les maturités des options cotées. Prix de calls normaliséscalculés à partir de la surface de volatilité implicite obtenue avec l�interpolationpar les TPS.A�n de simpli�er les raisonnements, on ne fait pas apparaître l�indice j lorsquel�on s�intéresse aux prix d�options pour une seule maturité.
Modélisation des prix à maturité �xée
Le principe du lissage par splines cubiques consiste à approcher les donnéesobservées (ici les prix normalisés) par une fonction de la forme suivante :
g (�) =m�1Xi=1
gi (�)1f�i����i+1g; (4.103)
où les gi sont des polynômes de degré 3 dé�nis par :
gi (�) = �i(�� �i)3 + �i(�� �i)2 + �i(�� �i) + �i; �i � � � �i+1: (4.104)
A�n de garantir un maximum de régularité à la fonction g, on impose les condi-tions de continuité de la fonction et de ses dérivées première et seconde à chaquenoeud :
gi (�i+1) = gi+1 (�i+1) ; (4.105)
g0i (�i+1) = g0i+1 (�i+1) ; (4.106)
g00i (�i+1) = g00i+1 (�i+1) ; (4.107)
où i = 1; : : : ;m� 1.
Nous travaillons avec des splines cubiques naturels, donc la dérivée secondede g est nulle aux extrémités de l�intervalle de travail. Cela nous donne deuxconditions supplémentaires :
g00(�1) = 0; (4.108)
g00(�m) = 0: (4.109)
Cela garantit que la courbe présente une convexité minimale aux extrémités.
256

Représentation valeurs-dérivées secondes Selon Fengler (2005b), la re-présentation (4.104) n�est pas la plus adéquate pour résoudre le problème quenous avons à traiter. C�est pourquoi, il suggère d�utiliser une autre formulationde la fonction spline, dans laquelle les coe¢ cients (�i; �i; �i; �i) sont exprimés
en fonction de gidef= g(�i), i
def= g00(�i) avec 1 � i � m � 1, qui sont respecti-
vement la valeur du polynôme et la valeur de sa dérivée seconde au noeud �i.Cette autre représentation du spline cubique est appelée représentation valeurs-dérivées secondes.
En utilisant les relations (4.105) et (4.107), on démontre (voir Annexe C) queles coe¢ cients du ii�eme polynôme sont donnés par :
�i = i+1 � i6h
; �i = i2; �i =
gi+1 � gih
�( i+1 + 2 i)h
6; �i = gi:
(4.110)Le spline cubique naturel g est donc complètement dé�ni par les deux vecteurssuivants :
gdef= (g1; : : : ; gm)
|;
def=� 2; : : : ; m�1
�|: (4.111)
A�n de faciliter la lecture des raisonnements, nous avons volontairement employéle symbole "g" pour désigner la fonction spline et le vecteur de coe¢ cients gi.Les coe¢ cients 1 et m n�apparaissent pas dans la dé�nition du vecteur car,d�après (4.108) et (4.109), on a 1 = m = 0. Le spline est donc caractérisé par2m� 2 paramètres.
Splines cubiques valides Pour déterminer la forme des coe¢ cients des po-lynômes en fonction de gi et i, nous n�avons utilisé que les conditions (4.105) et(4.107), qui imposent la continuité de la fonction et la continuité de sa dérivéeseconde. En conséquence, les formules (4.110) dé�nissent une fonction polyno-miale par morceaux, continue, dont la dérivée seconde est continue. Mais rienne garantit que cette fonction possède une dérivée première continue, car nousn�avons pas utilisé la condition de continuité de la dérivée première (4.106). Au-trement dit, la donnée de g, de et de (4.110) ne su¢ t pas à dé�nir un splinecubique naturel valide.
En écrivant la condition de continuité de la dérivée première (4.106) on obtientla relation (voir démonstration en Annexe C) :
Q|g = R ; (4.112)
où Q et R sont les matrices dé�nies ci-dessous.
La matrice Q, de taille m� (m� 2), a pour terme général :
Qj�1;j =1
h; Qj;j =
�2h; Qj+1;j =
1
h; 2 � j � m� 1; (4.113)
et Qi;j = 0 pour ji� jj � 2.
257

La matrice R, de taille (m�2)�(m�2) est tridiagonale et a pour terme général :
Ri;i =2h
3; Ri;i+1 = Ri+1;i =
h
6; 2 � i � m� 1; (4.114)
et Ri;j = 0 pour ji� jj � 2.Soulignons que les matrices Q et R ne sont pas indicées de manière standard,comme le vecteur . Ce choix facilite la présentation des raisonnements.
Nous disposons à présent de tous les éléments pour présenter le problème dulissage de prix par un spline cubique naturel.
Lissage simple des prix de calls normalisés
Dans ce paragraphe, nous montrons que la détermination des coe¢ cients duspline qui lisse les prix d�options est un problème de minimisation quadratique.
Lissage simple, sans contrainte d�arbitrage Lisser les prix d�options ob-servés par un spline cubique naturel revient à déterminer les vecteurs g� et �,solutions du problème suivant :
(g�; �) = argmin
(mXi=1
(ci � g(�i))2 + �Z �m
�1
(g00(�))2d�
); (4.115)
où � est le coe¢ cient de lissage que l�on doit choisir pour équilibrer l�erreurd�approximation, représentée par la quantité
Pmi=1(ci�g(�i))2 et la rugosité de
la courbe, représentée par la quantitéR �m�1(g00(�))2d�.
Lorsque �! 0, le spline obtenu interpole les points observés. Lorsque �! +1,le spline coïncide avec la droite de régression linéaire des prix de calls normaliséssur les moneyness.
Formulation du problème sous forme matricielle Les résultats obtenusdans le paragraphe précédent permettent d�exprimer le problème (4.115) sousforme matricielle.
La forme matricielle de la rugosité d�un spline cubique est donnée par la formule(voir Annexe C) : Z �m
�1
(g00(�))2d� = |R : (4.116)
Considèrons les vecteurs de taille 2m� 2 dé�nis par :
x = (g|; |)| ; y = (c1; : : : ; cm; 0; : : : ; 0)|; (4.117)
et les matrices suivantes :
A =
�Q�R|
�; B =
�Im 00 �R
�; (4.118)
258

où Im est la matrice identité d�ordre m.
En utilisant (4.116), (4.117) et (4.118), le problème de lissage (4.115) se réécrit :
minx�y|x+ 1
2x|Bx sous la contrainte A|x = 0: (4.119)
On peut montrer que B est une matrice dé�nie positive, ce qui implique que(4.119) admet une unique solution.En résolvant le problème (4.119), on obtient un spline cubique naturel qui lisseles prix d�options observés pour une maturité donnée, mais ceux-là peuventprésenter des opportunités d�arbitrage en moneyness. Nous discutons ci-dessousla prise en compte des contraintes de non-arbitrage en moneyness.
Elimination des arbitrages en moneyness
On rappelle les contraintes d�arbitrage en moneyness données au paragraphe4.3.3 :� les prix de calls sont bornés : (1� �)+ � g � 1,� les prix de calls sont décroissants par rapport à la moneyness et leur dérivéeest bornée : �1 � g0 � 0,
� les prix de calls sont convexes : g00 � 0.Tout d�abord, nous explicitons la contrainte de convexité. Cela nous permetde dé�nir facilement les contraintes portant sur la dérivée première des prix.En�n, nous utilisons ces deux contraintes pour établir les contraintes sur lesprix eux-mêmes.
Convexité en moneyness Lorsque l�on travaille avec les splines cubiquesnaturels, la convexité est une condition facile à imposer. En e¤et, il su¢ t deremarquer que g00 est une fonction linéaire par morceaux :
g00 (�) = 6�i(�� �i) + 2�i; �i � � � �i+1: (4.120)
Par conséquent, g00 est positive sur l�intervalle [�i; �i+1] si et seulement si g00 (�i) �0 et g00 (�i+1) � 0. Autrement dit, on obtient la convexité de la fonction g enimposant :
i � 0; 2 � i � m� 1: (4.121)
On rappelle que 1 = m = 0, donc la fonction est bien convexe sur tout lesegment [�1; �m].
Décroissance par rapport à la moneyness Comme g00 est positive, ladérivée première du spline est croissante. Donc, pour imposer la condition �1 �g0 � 0 sur tout l�intervalle [�1; �m], il su¢ t d�avoir g0(�1) � �1 et g0(�m) � 0:En dérivant (4.104) par rapport à � on a :
g0 (�) = 3�i(�� �i)2 + �i(�� �i) + �i; �i � � � �i+1: (4.122)
259

En faisant i = m� 1 dans la relation précédente, en remplaçant les coe¢ cients�m�1; �m�1 et �m�1 par leurs expressions valeurs-dérivées secondes et en utili-sant le fait que m = 0, on obtient tous calculs faits :
g0 (�m) = 3�m�1h2 + �m�1h+ �m�1 =
m�16
h+gm � gm�1
h: (4.123)
On en déduit que la condition g0 (�m) � 0 est équivalente à :
gm � gm�1 � �h2
6 m�1: (4.124)
Par ailleurs, en faisant i = 1 dans (4.122) et en utilisant le fait que 1 = 0, ilvient :
g01 (�1) = �1 =g2 � g1h
� 26h: (4.125)
On en déduit que la condition g01 (�1) � �1 est équivalente à :
g2 � g1 �h2
6 2 � h: (4.126)
Positivité des prix On a maintenant une fonction convexe et décroissante.Il reste à imposer les contraintes de niveau de manière à garantir que g véri�e(1� �)+ � g � 1.Nous imposons :
1� �1 � g1: (4.127)
La convexité du spline su¢ t à garantir qu�il reste au-dessus de la droite d�équa-tion y = 1� x.
Pour assurer la majoration du spline on impose :
g1 � 1: (4.128)
La décroissance du spline assure qu�il reste inférieur à 1.
Pour assurer la positivité, on impose :
gm � 0: (4.129)
Le spline étant décroissant, il reste positif.
Résoudre le problème (4.119) sous les contraintes (4.121), (4.124), (4.126), (4.127),(4.128) et (4.129) permet d�obtenir, pour � �xé, le spline optimal respectantles conditions de non-arbitrage en moneyness. Il reste alors à introduire lescontraintes de non-arbitrage calendaires. C�est l�objet du paragraphe suivant.
260

Elimination des arbitrages calendaires
Nous considérons à présent qu�il y a plusieurs maturités T1 � � � � � Tn. L�ab-sence d�arbitrage calendaire impose que le prix des calls, à moneyness constante,soit une fonction croissante du temps :
cij � cij+1; j = 1; : : : ;m� 1:
Cette condition se traduit immédiatement en terme de spline par :
g(j) � g(j+1);
où l�on a noté g(j) le spline estimé à la maturité Tj .
On en déduit la méthode suivante pour éliminer les arbitrages calendaires.
1. A la maturité Tn, estimer le spline solution de (4.119) sous les contraintes(4.121), (4.124), (4.126), (4.127), (4.128) et (4.129).
2. Pour chaque maturité Tj , j = n � 1; : : : ; 1, estimer le spline solution de(4.119) sous les contraintes (4.121), (4.124), (4.126), (4.127) et (4.129). Lamajoration (4.128) étant remplacée par :
g(j)i � g
(j+1)i ; i = 1; : : : ;m: (4.130)
La contrainte (4.130) revient à imposer que le spline de la maturité Tj soitinférieur au spline de la maturité Tj+1 pour toutes les moneyness.
Le spline à la maturité Tj se déduit par récurrence du spline à la maturité Tj+1.Autrement dit, nous avons choisi un schéma d�itération backward (l�algorithmeopère de la plus grande maturité vers la plus petite maturité). La raison de cechoix est que les prix court-termes ont une plus forte probabilité de présenterdes arbitrages calendaires que les prix long-termes. En choisissant une itéra-tion forward (l�algorithme opère de la plus petite maturité vers la plus grandematurité), on risque de propager ces arbitrages à toute la surface de prix.
Pour conclure ce parapgraphe, nous présentons les résultats obtenus après miseen oeuvre des di¤érentes techniques qui viennent d�être exposées.
4.6.4 Volatilités implicites obtenues en combinant les al-gorithmes étudiés
Nous rappelons brièvement la démarche retenue. La construction de la surfacede volatilité implicite se déroule en 3 étapes.
1. Lissage et extrapolation du smile de volatilité au niveau de la premièrematurité avec le modèle SVI de Gatheral (2004). Cette étape donne laforme globale du smile.
261

2. Interpolation des volatilités observées et extrapolation des volatilités man-quantes au niveau des ailes avec des Thin Plate Splines qui "propagent"le smile SVI à l�ensemble des maturités.
3. Elimination des arbitrages en moneyness et des arbitrages calendaires parun lissage sous contraintes des prix de calls normalisés obtenus à partirde la surface de volatilité précédente en utilisant l�algorithme de Fengler(2005b).
Etant donné que le procédé combine di¤érentes méthodes proposées dans lalittérature, nous l�appelons algorithme GSF pour Gatheral, Splines, Fengler.Cet acronyme rappelle les di¤érentes étapes de la construction de la surface devolatilité implicite.Le graphique inférieur de la �gure 4.11 représente la surface de volatilité im-plicite obtenue en appliquant cet l�algorithme aux données du 23/05/2008. Enexaminant le graphique, on observe que la surface construite est ajustée sur lespoints observés.
Qualité de l�ajustement
Les smiles de volatilité implicite, obtenus avec l�algorithme GSF sont présentésà la �gure 4.12. L�algorithme permet de reconstituer parfaitement les smilesobservés pour toutes les maturités. Une simple comparaison avec les smiles ob-tenus avec le modèle quartique (�gure 4.6) ne permet pas de distinguer les deuxapproches. Nous analysons ci-dessous les écarts entre les volatilités et les prixd�options donnés par l�algorithme GSF et les volatilités et les prix d�optionsobservés.
Quanti�cation des erreurs de calibration
Dans le tableau ci-dessous, nous fournissons pour chacune des 17 maturitéscotées, la moyenne des écarts entre les volatilités implicites estimées et les vo-latilités observées (ErrV) ainsi que la moyenne des écarts relatifs entre les prixdonnés par le modèle et les prix observés (ErrC).
262
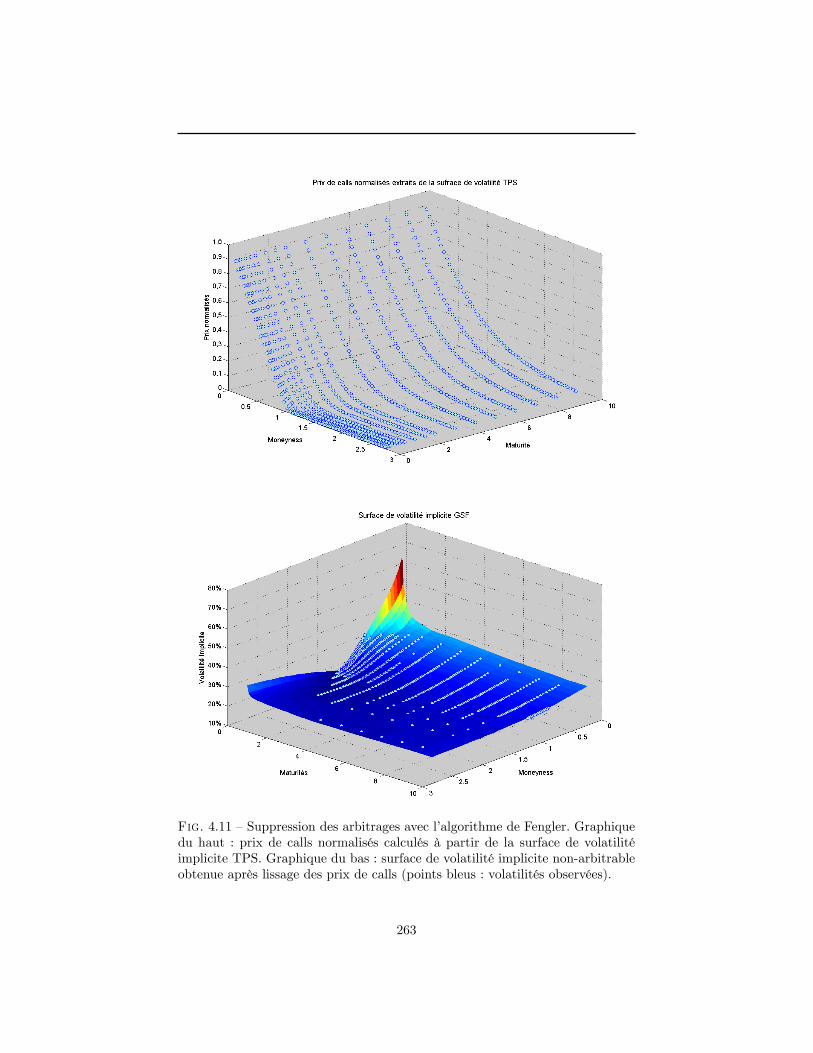
Fig. 4.11 �Suppression des arbitrages avec l�algorithme de Fengler. Graphiquedu haut : prix de calls normalisés calculés à partir de la surface de volatilitéimplicite TPS. Graphique du bas : surface de volatilité implicite non-arbitrableobtenue après lissage des prix de calls (points bleus : volatilités observées).
263
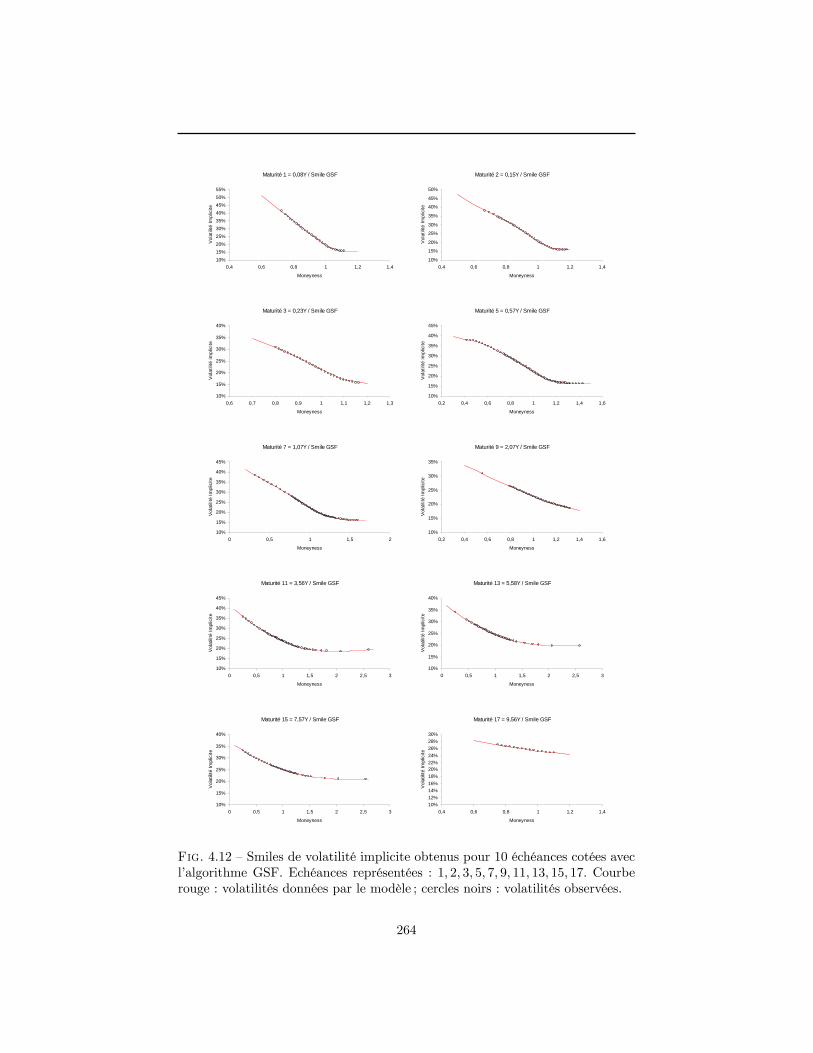
Maturité 1 = 0,08Y / Smile GSF
10%15%20%25%30%35%40%45%50%55%
0,4 0,6 0,8 1 1,2 1,4
Moneyness
Vol
atili
té Im
plic
ite
Maturité 2 = 0,15Y / Smile GSF
10%
15%
20%
25%
30%
35%
40%
45%
50%
0,4 0,6 0,8 1 1,2 1,4
Moneyness
Vol
atili
té Im
plic
ite
Maturité 3 = 0,23Y / Smile GSF
10%
15%
20%
25%
30%
35%
40%
0,6 0,7 0,8 0,9 1 1,1 1,2 1,3
Moneyness
Vol
atili
té Im
plic
ite
Maturité 5 = 0,57Y / Smile GSF
10%
15%
20%
25%
30%
35%
40%
45%
0,2 0,4 0,6 0,8 1 1,2 1,4 1,6
Moneyness
Vol
atili
té Im
plic
ite
Maturité 7 = 1,07Y / Smile GSF
10%
15%
20%
25%
30%
35%
40%
45%
0 0,5 1 1,5 2
Moneyness
Vol
atili
té Im
plic
ite
Maturité 9 = 2,07Y / Smile GSF
10%
15%
20%
25%
30%
35%
0,2 0,4 0,6 0,8 1 1,2 1,4 1,6
Moneyness
Vol
atili
té Im
plic
ite
Maturité 11 = 3,56Y / Smile GSF
10%
15%
20%
25%
30%
35%
40%
45%
0 0,5 1 1,5 2 2,5 3
Moneyness
Vol
atili
té Im
plic
ite
Maturité 13 = 5,58Y / Smile GSF
10%
15%
20%
25%
30%
35%
40%
0 0,5 1 1,5 2 2,5 3
Moneyness
Vol
atili
té Im
plic
ite
Maturité 15 = 7,57Y / Smile GSF
10%
15%
20%
25%
30%
35%
40%
0 0,5 1 1,5 2 2,5 3
Moneyness
Vol
atili
té Im
plic
ite
Maturité 17 = 9,56Y / Smile GSF
10%12%14%16%18%20%22%24%26%28%30%
0,4 0,6 0,8 1 1,2 1,4
Moneyness
Vol
atili
té Im
plic
ite
Fig. 4.12 �Smiles de volatilité implicite obtenus pour 10 échéances cotées avecl�algorithme GSF. Echéances représentées : 1; 2; 3; 5; 7; 9; 11; 13; 15; 17. Courberouge : volatilités données par le modèle ; cercles noirs : volatilités observées.
264

i Ti ErrV (Ti) ErrC (Ti)
1 0:08 0:20% 1:68%2 0:15 0:09% 1:56%3 0:23 0:03% 0:56%4 0:33 0:04% 0:68%5 0:57 0:05% 0:62%6 0:82 0:02% 0:20%7 1:07 0:02% 0:42%8 1:57 0:02% 0:55%9 2:07 0:01% 0:12%10 2:57 0:01% 0:10%11 3:56 0:01% 0:15%12 4:58 0:01% 0:08%13 5:58 0:01% 0:08%14 6:57 0:01% 0:05%15 7:57 0:01% 0:05%16 8:57 0:01% 0:05%17 9:56 0:00% 0:01%Moyenne : 0:03% 0:41%
Les écarts entre volatilités estimées et volatilités observées évoluent dans l�in-tervalle [0:00%; 0:20%] et leur niveau moyen est 0:03%, ce qui correspond à uneréduction de l�erreur d�approximation de l�ordre de 2:33(' 0:07%
0:03% ) par rapportau modèle à variance quartique et de l�ordre de 55:33(' 1:66%
0:03% ) par rapport aumodèle M76. Ce résultat très satisfaisant montre que le modèle capture avecune grande précision la forme des volatilités implicites observées.L�écart le plus important (0:20%) est observé au niveau de la 1�ere échéance,pour laquelle nous avons utilisé le modèle de smile paramétrique SVI. Cet écartprovient du fait qu�à l�instar de nombreux modèles paramétriques, le modèleSVI n�est pas su¢ samment �exible pour reproduire la courbe observée. Il fauttoutefois noter que l�ordre de grandeur de l�écart est tout à fait acceptable.Les écarts de prix relatifs sont compris entre 0:01%, pour la dernière maturité,et 1:68% pour la première maturité. La moyenne des écarts de prix relatifssur l�ensemble des données ressort à 0:41%, soit une réduction de l�erreur del�ordre de 3:15(' 1:29%
0:41% ) par rapport au modèle à variance quartique et del�ordre de 15:22(' 6:24%:
0:41% ) par rapport au modèle M76. Le modèle GSF apportedonc une amélioration considérable de la qualité de l�ajustement. Comme nousl�avons déjà observé lors de l�étude du modèle à variance quartique, le facteur deréduction de l�erreur est plus faible lorsque l�on raisonne sur les prix d�optionsque lorsque l�on raisonne sur les volatilités. La raison en est que les prix d�optionset les volatilités sont liés de manière fortement non-linéaire.L�algorithme GSF permet donc de lisser les volatilités observées avec une grandeprécision. Si l�on tient compte du fait qu�il permet aussi d�extrapoler les vola-tilités au niveau des moneyness extrêmes puis d�éliminer les arbitrages, on endéduit qu�il constitue une alternative extrêmement intéressante par rapport auxapproches classiques envisagées dans la littérature.
265

4.7 Conclusion
L�objectif de ce chapitre a été de proposer une méthode permettant de construireune surface de volatilité implicite lisse et non-arbitrable.Dans la première section, nous avons montré que la connaissance de la surfacede volatilité implicite est un enjeu stratégique pour les spécialistes des marchésde produits dérivés, car elle donne une information précieuse sur la dynamiquedu sous-jacent qui est anticipée par le marché. En particulier, elle permet dedéterminer la densité risque-neutre de l�actif et la surface de volatilité locale.Dans la seconde section, nous avons simpli�é le problème de la modélisation dela surface de volatilité implicite en nous plaçant dans une économie normaliséeoù les taux d�intérêt sont nuls et dans laquelle l�actif risqué ne détache pas dedividende.Dans la troisième section, nous avons établi que l�hypothèse d�absence d�oppor-tunité d�arbitrage impose des contraintes sur la forme de la surface des prixd�options et sur la forme de la surface de volatilité implicite. Par ailleurs, nousavons énoncé un résultat important qui montre que le smile de volatilité impli-cite est une fonction approximativement linéaire de la log-moneyness au niveaudes moneyness extrêmes.Dans la quatrième section, nous avons présenté les données de marché utiliséespour les tests de calibration e¤ectués dans le chapitre. Il s�agit des cours decompensation des options Européennes OESX sur l�indice DJ EuroStoxx 50,cotées sur l�Eurex. Nous avons montré comment retraiter ces données pour éli-miner les prix faux ou non-signi�catifs. Un examen des données a con�rmé quedéterminer la surface de volatilité implicite est un problème "mal-posé", dansla mesure où l�on cherche à construire une surface à partir d�un jeu de prixd�options incomplet, bruité et qui présente des opportunités d�arbitrage.Dans la cinquième section, nous avons envisagé successivement deux approchesfréquemment utilisées par les praticiens pour construire la surface de volatilité.La première consiste à calibrer un modèle de marché paramétrique qui expliquel�existence du smile de volatilité sur les prix observés. Les tests pratiqués avecle modèle de Merton (1976) ont démontré que ce type de modèle n�était passu¢ samment �exible pour capturer avec précision la con�guration des volatili-tés cotées. La seconde approche ne cherche pas à expliquer l�existence du smile,mais à le reproduire avec précision. Le principe est d�ajuster une fonction poly-nomiale sur le smile observé à chaque maturité. Nous avons proposé puis testé unmodèle dans lequel la variance implicite est un polynôme de degré 4 (variancequartique). Les résultats obtenus sont nettement meilleurs qu�avec le modèleparamétrique. En revanche, le modèle ne permet pas d�extrapoler linéairementles volatilités au niveau des ailes.Dans la sixième section, nous avons proposé une méthode nouvelle qui permetd�obtenir une surface de volatilité complète, non-arbitrable et qui s�ajuste sur lesdonnées observées avec une grande précision. Le procédé envisagé, appelé mé-thode GSF, combine trois méthodes de la littérature qui sont mises en oeuvredans un certain ordre. La première étape consiste à construire un smile de vo-latilité complet au niveau de la première maturité avec le modèle paramétrique
266

SVI de Gatheral (2004). La seconde étape repose sur l�utilisation des Thin PlateSplines pour générer une surface de volatilité complète à partir du smile SVI dela première maturité et des volatilités observées aux autres maturités. La der-nière étape consiste à appliquer le lissage non-paramétrique de Fengler (2005b)qui permet de supprimer les opportunités d�arbitrage et de lisser les prix d�op-tions. Les résultats obtenus sont particulièrement satisfaisants : l�ajustementsur les données observées est plus précis qu�avec les deux méthodes envisagéesauparavant et l�extrapolation des volatilités implicites au niveau des ailes estconsistante avec ce que prédit la théorie. De surcroît, cette méthode est facile àmettre en oeuvre avec n�importe quel logiciel de calcul numérique.
267

A Démonstrations du paragraphe 4.3
A.1 Démonstration de la proposition 4.1
Il su¢ t de remarquer que :
(MT � �)+ � (��MT )+=MT � �: (4.131)
En appliquant l�opérateur EQ [� jFt ] à chaque membre de (4.131) il vient :
ct(�; T )� pt(�; T ) = EQ [MT � � jFt ] =Mt � �: (4.132)
A.2 Démonstration de la proposition 4.2
La fonction x ! (x� �)+ est convexe et positive. En appliquant l�inégalité deJensen, il vient :
0 � (1� �)+ = (EQ [MT ]� �)+ � EQ[(MT � �)+] = c(�; T ): (4.133)
Cela établit la borne inférieure de l�encadrement. Par ailleurs, le payo¤ �nald�un call est toujours inférieur au cours du sous-jacent à l�échéance :
(MT � �)+ �MT =) c(�; T ) = EQ[(MT � �)+] � EQ [MT ] = 1; (4.134)
ce qui achève la démonstration.
A.3 Démonstration de la proposition 4.3
Considérons la fonction cBScomme une fonction de uniquement � (� et T sont
�xés). En dérivant par rapport à � l�expression (4.27) on obtient le véga du call :
@cBS
@�=pT'�D+�> 0; (4.135)
où ' est la densité de la loi normale standard. De plus, on a :
lim�!0+
cBS= (1� �)+ ; lim
�!+1cBS= 1: (4.136)
On déduit de (4.135) et (4.136) que cBSest bijective de R�+ dans l�intervalle
] (1� �)+ ; 1[. Donc l�équation (4.34) admet une solution unique si et seulementsi c(�; T ) 2] (1� �)+ ; 1[, ce qui est toujours le cas en AOA (d�après la proposi-tion 4.2).
A.4 Démonstration de la proposition 4.4
Démonstration des points 1 et 2 (arbitrage en moneyness) Soit hT ladensité de probabilité de MT dé�nie par (4.37). Alors le prix du call Européen
268

de moneyness � et d�échéance T est donné par la formule :
c(�; T ) = EQ[(MT � �)+]
=
ZR+(x� �)+ hT (x) dx
=
Z +1
�
xhT (x) dx� �Z +1
�
hT (x) dx: (4.137)
En dérivant (4.137) par rapport à � il vient :
@c
@�= �
Z +1
�
hT (x) dx = �Q fMT � �g : (4.138)
Or,0 � Q fMT � �g � 1:
Avec (4.138) on établit (4.35) :
�1 � @c
@�� 0: (4.139)
En dérivant (4.138) par rapport à �, on obtient (4.36) :
@2c
@�2= hT (�) � 0: (4.140)
Démonstration du point 3 (arbitrage calendaire) Comme Mt est uneFt-martingale sous Q on peut écrire :
MT1 = EQ[MT2 jFT1 ]; (4.141)
puis(MT1 � �)
+= (EQ[MT2 jFT1 ]� �)
+: (4.142)
La fonction x! (x� �)+ est convexe alors, d�après l�inégalité de Jensen condi-tionnelle, on a :
(EQ [MT2 jFT1 ]� �)+ � EQ[(MT2 � �)
+ jFT1 ]: (4.143)
En injectant (4.143) dans (4.142), il vient :
(MT1 � �)+ � EQ[(MT2 � �)
+ jFT1 ]: (4.144)
En appliquant l�opérateur EQ[�] aux deux membres de l�inégalité précédente eten utilisant le théorème des espérances itérées, on obtient :
c(�; T1) = EQ[(MT1 � �)+]
� EQ[EQ[(MT2 � �)+ jFT1 ]]
= EQ[(MT2 � �)+]
= c(�; T2): (4.145)
269

A.5 Démonstration de la proposition 4.5
Résultats préliminaires La dérivée par rapport à la moneyness (encore ap-pelée dual-delta) et le véga de cBS sont donnés par les formules :
@cBS@�
= ���D�� ; (4.146)
@cBS@�
=pT'�D+�: (4.147)
Les quantités ' (D+) et ' (D�) sont liées par la relation :
'�D+�= �'
�D�� : (4.148)
Les dérivées partielles de D+ et D� par rapport à � sont égales :
@D+
@�=@D�
@�=�1
��pT: (4.149)
Les dérivées partielles de D+ et D� par rapport à � véri�ent :
@D+
@�=
ln�
�2pT+1
2
pT = �D
�
�(4.150)
@D�
@�=
ln�
�2pT� 12
pT = �D
+
�: (4.151)
Démonstration du point 1 En admettant la dépendance explicite de lavolatilité par rapport à la moneyness et en utilisant la règle de la di¤érenciationen chaîne, on a :
@c
@�=@c
BS
@�+@c
BS
@�
@�
@�= ��
�D��+pT' �D+
� @�@�: (4.152)
Avec (4.148), la formule précédente devient :
@c
@�= ��
�D��+ �pT' �D�� @�
@�: (4.153)
D�après la formule (4.35), on a @c=@� � 0 d�où l�on déduit :
@�
@�� � (D�)
�pT' (D�)
; (4.154)
ce qui établit la borne supérieure de l�inégalité.
Pour établir la borne inférieure, nous utiliserons le lemme suivant.
Lemme 4.8 A maturité �xée, la fonction �! p (�; T ) =� est strictement crois-sante par rapport à la moneyness.
270

Proof. Il su¢ t d�écrire :
p (�; T )
�=
1
�EQ[(��MT )
+]
=1
�
ZR+(�� x)+ hT (x) dx
=
Z �
0
hT (x) dx�1
�
Z �
0
xhT (x) dx:
En dérivant cette égalité membre à membre on obtient tous calculs faits :
@p=�
@�=1
�2
Z �
0
xhT (x) dx � 0:
Nous pouvons procéder à la démonstration. En utilisant la relation de paritécall-put, on peut écrire :
p = c+ �� 1 =) p
�=c
�+ 1� 1
�: (4.155)
En dérivant membre à membre, il vient :
@p=�
@�= � c
�2+1
�
@c
@�+1
�2: (4.156)
D�après le lemme précédent, on a @p=�@� � 0 ; (4.156) conduit à l�inégalité :
�@c
@�� c� 1: (4.157)
On remarque que :
c� 1 = ��D+�� 1� ��
�D��
= ����D+
�� ��
�D�� (4.158)
En utilisant (4.152) on obtient :
�@c
@�= ���
�D��+ �pT' �D+
� @�@�; (4.159)
En injectant (4.158) et (4.159) dans (4.157) on observe que les termes en��� (D�)se simpli�ent et l�on trouve :
�pT'�D+� @�@�� ��
��D+
�() @�
@�� �� (�D
+)
�pT' (D+)
; (4.160)
ce qui établit la borne inférieure de l�inégalité annoncée.
271

Démonstration du point 2 Appliquons la règle de di¤érentiation en chaîneà (4.153) :
@2c
@�2= A+
pTB; (4.161)
avec
Adef= �
�@D�
@��0� +
@D�
@�
�'�D�� ; (4.162)
Bdef= �00�'
�D+�+ �0�
�@D+
@��0� +
@D+
@�
�'0�D+�; (4.163)
où l�on a posé
�0�def=
@�
@�; �00�
def=
@2�
@�2:
Détermination de A. Avec (4.149) et (4.151), l�égalité (4.162) devient :
A =
�1
��pT+D+�0��
�'�D�� : (4.164)
En combinant (4.148) et (4.147) on a :
'�D�� = ' (D+)
�=
1
�pT
@cBS@�
: (4.165)
En injectant (4.165) dans (4.164), on trouve tous calculs faits :
A =
�1
�2�T+D+�0���pT
�@cBS@�
: (4.166)
Détermination de B. Avec (4.149) et (4.150), l�égalité (4.163) s�écrit :
B = �00�'�D+���D�
�
��0��2+
�0���pT
�'0�D+�: (4.167)
Or '0 (x) = �x' (x), d�où l�on déduit :
B =
��00� +
D�D+
�
��0��2+D+�0���pT
�'�D+�: (4.168)
En remplaçant ' (D+) par 1pT
@cBS
@� dans (4.168), on trouve :
B =
��00� +
D�D+
�
��0��2+D+�0���pT
�1pT
@cBS
@�: (4.169)
272

Simpli�cation de (4.161) En injectant (4.166) et (4.169) dans (4.161) ilvient :
@2c
@�2=@cBS@�
�1
�2�T+D+�0���pT+ �00� +
D�D+
�
��0��2+D+�0���pT
�:
En simpli�ant et en regroupant les termes, on obtient :
@2c
@�2=@c
BS
@�
�1
�2�T+2D+
��pT�0� +
D�D+
�
��0��2+ �00�
�: (4.170)
Il ne reste qu�à rappeler que@c
BS
@� � 0 et @2c@�2 � 0 pour conclure que l�on a
nécessairement :
1
�2T �+2D+
��pT�0� +
D�D+
�
��0��2+ �00� � 0: (4.171)
Démonstration du point 3 Soit la fonction dé�nie sur R�+ par :
(x) = �
�� ln�p
x+
px
2
�� ��
�� ln�p
x�px
2
�: (4.172)
On véri�e sans di¢ culté que est strictement croissante de R�+ ! ]0; 1[ et que :
c (�; T ) = cBS(�; T; � (�; T )) =
��2 (�; T )
�; (4.173)
où �2 (�; T ) = �2 (�; T )T désigne la variance totale.
Soient T1 et T2 deux dates telles que T1 � T2. Supposons �2 (�; T1) > �2 (�; T2).Alors, comme est une fonction strictement croissante on a :
��2 (�; T1)
�>
��2 (�; T2)
�=) c (�; T1) > c (�; T2) ; (4.174)
ce qui contredit l�hypothèse d�absence d�opportunité d�arbitrage calendaire surles prix de calls. Donc, la seule possibilité est d�avoir �2 (�; T1) � �2 (�; T2).
B Prix normalisé d�un call dans le modèle deMerton
En utilisant le théorème des espérances itérées on peut écrire :
cM76(�; T ) = E[(MT � �)+] = E[E[(MT � �)+ jNT = n ]]; (4.175)
où E [�] est l�opérateur espérance sous Q et E [� jNT = n ] est l�opérateur espé-rance sous la mesure conditionnelle Q f� jNT = ng.
273

Conditionnellement à l�évènement fNT = ng, on a :
lnMT = ��2
2T + �WT � ��T +
nXi=1
lnYi: (4.176)
Comme les variables WT et lnYi sont gaussiennes, on en déduit que lnMT suitune loi gaussienne de paramètres :
�ndef= E [lnMT jNT = n ] ; �2n
def= Var [lnMT jNT = n ] :
En utilisant le fait que les variables considérées sont mutuellement indépen-dantes, on obtient tous calculs faits :
�n = n"� (�� + �2
2)T; (4.177)
�2n = �2T + �2n: (4.178)
On peut alors exprimer MT en fonction des paramètres �n et �n :
MT = exp(�n + �nG); (4.179)
où G � N (0; 1) sous la mesure Q f� jNT = ng.
Soit Fndef= E [MT jNT = n ]. En utilisant la relation (4.179), on a immédiate-
ment :
Fn = exp(�n + �2n=2)
= exp(�"+ �2=2
�n� ��T )
= (1 + �)nexp (���T ) : (4.180)
En injectant la formule (4.180) dans (4.179), on en déduit :
MT = FnMn;T ; Mn;Tdef= exp(��2n=2 + �nG): (4.181)
Posons :
�ndef=
�npT= �2 +
�2n
T: (4.182)
En faisant intervenir �n dans (4.181) il vient :
Mn;T = exp(��2nT=2 + �npTG): (4.183)
En remarquant quepTG � ZT , où ZT est la valeur en T d�un mouvement
Brownien standard (Zt)t�0 sous la probabilité conditionnelle Q f� jNT = ng onpeut écrire :
Mn;T = exp(��2nT=2 + �nZT ): (4.184)
274

La formule (4.184) montre que Mn;T peut être considéré comme la partie mar-tingale d�une di¤usion lognormale Black-Scholes sous la mesure risque-neutreconditionnelle Q f� jNT = ng, dont la volatilité serait �n. Par ailleurs, Fn s�in-terprète comme le prix forward de l�actifM . En utilisant cette analogie, on peutécrire :
E[(MT � �)+ jNT = n ] = E[(FnMn;T � �)+]= FnE[(Mn;T � �=Fn)+]= FncBS (�n; T; �n) ; (4.185)
où �ndef= �=Fn est la moneyness forward du call de strike � et
cBS(�n; T; �n) = �
�D+n
�� �n�
�D�n
�; (4.186)
D�n = � ln�n
�npT� 12�npT : (4.187)
En injectant (4.185) dans (4.175) il vient :
cM76(�; T ) =+1Xn=0
Q fNT = ngE[(MT � �)+ jNT = n ]
=+1Xn=0
e��T(�T )
n
n!FncBS (�n; T; �n) : (4.188)
La formule (4.180) nous permet d�écrire :
e��T(�T )
n
n!Fn = e��T
(�T )n
n!(1 + �)
nexp (���T )
= e��(1+�)T(� (1 + �)T )
n
n!
= e���T
���T�n
n!; (4.189)
où l�on a posé �� def= � (1 + �). En injectant (4.189) dans (4.188) on obtient la
formule annoncée :
cM76(�; T ) =+1Xn=0
e���T
���T�n
n!cBS(�n; T; �n) : (4.190)
C Démonstrations du paragraphe 4.6.3
C.1 Coe¢ cients valeurs-dérivées secondes
On pose gi = g(�i) et i = g00(�i) pour i = 1; : : : ;m.La dérivée seconde du spline sur l�intervalle [�i; �i+1] est donnée par :
g00 (�) = 6�i(�� �i) + 2�i: (4.191)
275

En faisant � = �i, il vient :�i = i=2: (4.192)
En utilisant la relation de continuité de la dérivée seconde (4.107) au noeud�i+1, il vient :
i+1 = 6�ih+ i , �i = i+1 � i6h
: (4.193)
Par ailleurs, en faisant � = �i dans la dé�nition de gi on a immédiatement :
�i = gi: (4.194)
En�n, en écrivant la condition de continuité de g (4.105) au noeud �i+1, onobtient :
gi+1 = �ih3 + �ih
2 + �ih+ �i
= i+1 � i6h
h3 + i2h+ �ih+ gi
= i+1 + 2 i
6h2 + �ih+ gi:
On en déduit :
�i =gi+1 � gi
h� i+1 + 2 i
6h; (4.195)
ce qui achève la démonstration.
C.2 Spline cubique valide
Ecrivons la condition de continuité de la dérivée première du spline au noeud�i, i = 2; : : : ;m� 1 :
3�i�1h2 + 2�i�1h+ �i�1 = �i: (4.196)
En remplaçant les coe¢ cients par leurs valeurs-dérivées secondes, on obtienttous calculs faits :
1
hgi�1 �
2
hgi +
1
hgi+1 =
h
6 i�1 +
2h
3 i +
h
6 i+1: (4.197)
On pose Q la matrice de terme général :
Qj�1;j =1
h; Qj;j =
�2h; Qj+1;j =
1
h; 2 � j � m� 1; (4.198)
et Qi;j = 0 sinon. Par construction, la matrice Q est de taille m� (m� 2).Le premier membre de l�égalité (4.197) s�écrit :
1
hgi�1 �
2
hgi +
1
hgi+1 = Qi�1;igi�1 +Qi;igi +Qi+1;igi+1
=mXj=1
Qj;igj =mXj=1
(Q|)i;j gj
= (Q|g)i : (4.199)
276

On pose R la matrice tridiagonale de terme général :
Ri;i =2h
3; Ri;i+1 = Ri+1;i =
h
6; 2 � i � m� 1; (4.200)
et Ri;j = 0 sinon.Alors, le second membre de l�égalité (4.197) s�écrit :
h
6 i�1 +
2h
3 i +
h
6 i+1 =
m�1Xj=2
Ri;j j = (R )i : (4.201)
En injectant (4.199) et (4.201) dans (4.197) on obtient : Q|g = R .
C.3 Expression matricielle de la rugosité
En élevant les deux membres de (4.191) au carré, il vient :
(g00 (�))2 = 36�2i (�� �i)2 + 24�i�i(�� �i) + 4�2i ; �i � � � �i+1 (4.202)
Intégrons membre à membre la relation (4.202) entre �i et �i+1 :Z �i+1
�i
(g00 (�))2d� = 12�2ih3 + 12�i�ih
2 + 4�2ih: (4.203)
où h = �i+1 � �i.En remplaçant �i et �i par les formules (4.110), on obtient tous calculs faits :Z �i+1
�i
(g00 (�))2d� =h
3 2i+1 +
h
3 2i +
h
3 i i+1: (4.204)
Alors, la rugosité du spline cubique est donnée par :Z �m
�1
(g00 (�))2d� =m�1Xi=1
Z �i+1
�i
(g00 (�))2d�
=2h
3
m�1Xi=2
2i +h
3
m�2Xi=2
i i+1: (4.205)
277

Par ailleurs, en utilisant la dé�nition de la matrice R on a :
|R =m�1Xi=2
i (R )i
= 2
�2h
3 2 +
h
6 3
�+m�2Xi=3
i
�h
6 i�1 +
2h
3 i +
h
6 i+1
�+ m�1
�h
6 m�2 +
2h
3 m�1
�=
2h
3 22 +
h
6 2 3 +
h
6
m�3Xi=2
i i+1 +2h
3
m�2Xi=3
2i
+h
6
m�2Xi=3
i i+1 +h
6 m�1 m�2 +
2h
3 2m�1
=2h
3
m�1Xi=2
2i +h
3
m�2Xi=2
i i+1: (4.206)
Il ne reste qu�à comparer les égalités (4.205) et (4.206) pour conclure :Z �m
�1
(g00 (�))2d� = |R : (4.207)
278

Références
Aboura S. (2005). Les Modèles de volatilité et d�options, Publibook.Alentorn A. (2004). �Modelling the implied volatility surface : an empiricalstudy for FTSE options�, Working Paper, Centre of Computational Financeand Economic Agents, University of Essex, http://privatewww.essex.ac.uk/~aalent/.Andersen L., Brotherton-Ratcli¤e R. (1997). �The equity option volatility smile :an implicit �nite-di¤erence approach�, Journal of Computational Finance, Vol.1, No. 2, pp. 5-38.Argou P. (2006). �Construction de Surfaces de Volatilité pour l�Evaluation deProduits Structurés Complexes et Introduction aux Nouveaux Instruments Dé-rivés de Volatilité�, Mémoire de DEA, Institut de Science Financière et d�Assu-rances, Université Claude Bernard Lyon 1.Augros J.-C., Moreno M. (2002). Les Dérivés Financiers et d�Assurance, Eco-nomica.Bates D.S. (1996). �Jumps and Stochastic Volatility : Exchange Rate ProcessImplicit in Deutsche Mark Option�, Review of Financial Studies, Vol.9, No. 1,pp. 69-107.Bates D.S. (2000). �Post-�87 crash fears in the S&P500 futures option market�,Journal of Econometrics, Vol. 94, pp. 181-238.Bakshi G., Cao C., Chen Z. (1997). �Empirical Performance of Alternative Op-tion Pricing Models�, Journal of Finance, Vol. 52, pp. 2003-2049.Benko M. (2006). �Functional Data Analysis with Applications in Finance�,Ph.D. Thesis, Humboldt-Universität, Berlin.Björk T. (2004). Arbitrage Theory in Continuous Time, Second Edition, OxfordUniversity Press.Black F., Scholes M. (1973). �The Pricing of Options And Corporate Liabilities�,Journal of Political Economy, Vol. 81, pp. 36-72.Breeden D.T., Litzenberger R.H. (1978). �Price of contingent claims implicit inoptions prices�, Journal of Business, Vol. 51, pp. 621-651.Brown G., Randall C. (1999).�If the skew �ts�, Risk Magazine, Vol. 12, pp.62-65.Buehler H. (2006). �Expensive Martingales�, Quantitative Finance, Vol. 6, No.2, pp. 207-218.Carr P., Madan D.P. (2005). �A note on su¢ cient conditions for no arbitrage�,Finance Research Letters, Vol. 2, No. 3, pp. 125-130.Coleman T.F., Li Y., Verma A. (1999). �Reconstructing The Unknown LocalVolatility Function�, Journal of Computational Finance, Vol. 2, No. 3, pp. 77-102.Corrado C.J., Su T. (1998). �An Empirical Test of Hull-White Option PricingModel�, Journal of Futures Markets, Vol. 4, pp. 363-378.Cox J.C., Ross S.A. (1976). �The valuation of options for alternative stochasticprocesses�, Journal of Financial Economics, Vol. 3, Issues 1-2, pp. 145-166.Cox J.C. (1996). �The constant elasticity of variance option pricing model�,Journal of Portfolio Management, pp. 15-17.
279

Crozet M. (2007). �Reconstruction de nappes de volatilité implicite�, Mémoired�Actuariat, Université Paris Dauphine.Daglish T., Hull J.C., Suo W. (2007). �Volatility Surfaces : Theory, Rules ofThumb, and Empirical Evidence�, Quantitative Finance, Vol. 7, No. 5, pp. 507-524.Demeter� K., Derman E., Kamal M., Zou J. (1999). �More Than You EverWanted To Know About Volatility Swaps�, Quantitative Strategies ResearchNotes, Goldman Sachs.Derman E., Kani I. (1994a). �The Volatility Smile and Its Implied Tree�, Quan-titative Strategies Research Notes, Goldman Sachs.Derman E., Kani I. (1994b). �Riding On a Smile�, Risk Magazine, Vol. 7, pp.32-39.Duchon J. (1976). �Splines Mimizing Rotation-Invariant Semi-Norms In SobolevSpaces�, Constructive Theory of Functions of Several Variables, Vol. 1, pp. 85-100.Dumas B., Fleming J., Whaley R.E. (1998). �Implied volatility functions : em-pirical tests�, Journal of Finance, Vol. 53, No. 6, pp. 2059-2106.Dupire B. (1994). �Pricing with a smile�, Risk Magazine, Vol. 7, pp. 18-20.Eberly D. (2002). �Thin Plate Splines�, Technical Paper, Geometric Tools, Inc.,http://www.geometrictools.com.Fengler M.R. (2005a). Semiparametric Modeling of Implied Volatility, Springer-Verlag.Fengler M.R. (2005b). �Arbitrage-Free Smoothing of the Implied Volatility Sur-face�, SFB 649 Discussion Paper 2005-019, Humboldt-Universität, Berlin.Gatheral J. (2004). �A parsimonious arbitrage-free implied volatility parame-terisation with application to the valuation of volatility derivatives�. In TDTFDerivatives Day, Amsterdam.Gatheral J. (2006). The Volatility Surface : A Practitioner�s Guide, Wiley Fi-nance.Hafner R., Wallmeier M. (2001). �The Dynamics of DAX Implied Volatilities�,International Quarterly Journal of Finance, Vol. 1, No. 1, pp. 1-27.Harrison J., Kreps D. (1979). �Martingales and arbitrage in multiperiod secu-rities markets�, Journal of Economic Theory, Vol. 20, pp. 381-408.Harrison J., Pliska S. (1981). �Martingales and stochastic integral in the theoryof continuous trading�, Stochastic Processes and their Applications, Vol. 11, pp.215-260.Hentschel L. (2003). �Errors in Implied Volatility Estimation�, Journal of Fi-nancial and Quantitative Analysis, Vol. 38, Issue 4, pp. 779-810.Heston S. (1993). �A Closed-Form Solution for Options with Stochastic Volati-lity with Applications to Bond and Currency Options�, The Review of FinancialStudies, Vol. 6, No. 2, pp. 327-343.Hofstetter E., Selby M.J.P. (2001). �The Logistic Function and Implied Volati-lity : Quadratic Approximation and Beyond�, Working Paper, Warwick BusinessSchool, University of Warwick, United Kingdom.Hull J., White A. (1987). �The Pricing of Options on Assets with StochasticVolatilities�, The Journal of Finance, Vol. 42, pp. 281-300.
280

Jäckel P. (2006). �By Implication�, Working Paper, http://www.jaeckel.org/ByImplication.pdf.Judd K.L. (1998). Numerical Methods in Economics, The MIT Press.Kermiche L. (2007). �Une modélisation de la surface de volatilité implicite parprocessus à sauts�, Communication, AFFI 2007.Kou S. (2002). �A jump di¤usion model for option pricing�,Management Science,Vol. 48, pp. 1086-1101.Laurent J.-P., Leisen D. (1998). �Building a Consistent Pricing Model fromObserved Option Prices�, Stanford University, Hoover Institution, DiscussionPaper No. B-443.Laurini M.P. (2007). �Imposing No-Arbitrage Conditions In Implied Volati-lity Surfaces Using Constrained Smoothing Splines�, Ibmec Working Paper,wpe_87, Ibmec São Paulo.Lee R.W. (2004). �The Moment Formula for Implied Volatility at ExtremeStrikes�, Mathematical Finance, Vol. 14, No. 3, pp. 469-480.Lee R.W. (2005). �Implied Volatility : Statics, Dynamics, and Probabilistic In-terpretation�, Recent Advances in Applied Probability (R. Baeza-Yates, J. Glaz,H. H. Gzyl, J. Hüsler, J.L. Palacios Eds.), Springer, pp. 241-268.Lempereur P. (2004). �Pricing et couverture dans un modèle de Bates�, Mémoired�Actuariat, Ecole Nationale de la Statistique et de l�Administration Econo-mique.Lewis A. (2000). Option Valuation under stochastic Volatility (With Mathema-tica Code), Finance Press, Newport Beach, Califormia, USA.Matsuda K. (2004). �Introduction to Merton Jump Di¤usion Model�, WorkingPaper, Department of Economics, The Graduate Center, New York, http://www.maxmatsuda.com/.McIntyre M.L. (2001). �Performance of Dupire�s implied di¤usion approach un-der sparse and incomplete data�, Journal of Computational Finance, Vol 4., No.4, pp. 33-84.Merton R.C. (1973). �Theory of Rational Option Pricing�, Bell Journal OfEconomics and Management Science, Vol. 4, pp. 141-183.Merton R.C. (1976). �Option pricing when underlying stock returns are discon-tinuous�, Journal of Financial Economics, Vol. 3, pp. 125-144.Niederreiter H. (1992). Random Number Generation and Quasi-Monte CarloMethods, SIAM-CBMS Lecture Notes 63.Overhaus M., Bermúdez A., Buehler H., Ferraris A., Jordinson C., LamnouarA. (2007). Equity hybrid derivatives, Wiley Finance.Patard P.-A. (2003). �Modélisation des Dividendes sur Actions et Indices�, Mé-moire de DEA, Institut de Science Financière et d�Assurances, Université ClaudeBernard Lyon 1.Planchet F., Winter J. (2007). �L�utilisation des splines bidimensionnels pourl�estimation de lois de maintien en arrêt de travail�, Bulletin Français d�Actua-riat, Vol. 7, No. 13, pp. 83-106.Randjiou Y. (2002). �Jump Di¤usion Processes Applied to Exotics Pricing andthe Market Model�, Présentation, Séminaire Bachelier, Global Quantitative Re-search, Deutsche Bank Global Equities.
281

Rebonato R. (2004). Volatility and Correlation : The Perfect Hedger and theFox, Second edition, Wiley Finance.Rogers L.C.G., Tehranchi M.R. (2008). �The Implied Volatility Surface DoesNot Move By Parallel Shifts�, Working Paper, University Of Cambridge, http://www.statlab.cam.ac.uk/~mike/implied-vol.pdf.Rubinstein M. (1994). �Implied binomial trees�, The Journal of Finance, Vol.49 , pp. 771-818.Samuelson P. (1965). �Rational theory of warrant pricing�, Industrial Manage-ment Review, Vol. 6, pp. 13-31.Scott L.O. (1987). �Option Pricing when the Variance Changes Randomly :Theory, Estimation, and an Application�, The Journal of Financial and Quan-titative Analysis, Vol. 22, No. 4, pp. 419-438.Sepp A. (2002). �Pricing Barrier Options under Local Volatility�, PrePrint,http://math.ut.ee/~spartak/papers/locvols.pdf.Sy A.S. (2003). �La volatilité stochastiques des marchés �nanciers : une ap-plication aux modèles d�évaluation d�instruments en temps continu�, Thèse dedoctorat, Université d�Aix-Marseille.Turlach B.A. (1997). �Constrained Smoothing Splines Revisited�, Technical Re-port, Australian National University, Canberra.Wahba G. (1990). Spline Functions for Observational Data, CBMS-NSF Regio-nal Conference series, SIAM, Philadelphia.Weizmann A. (2007). �Construction Of the Implied Volatility Smile�, Thesis,Goethe University, Frankfurt am Main.Zhang J.E., Xiang Y. (2008). �Implied Volatility Smirk�, Quantitative Finance,Vol. 8, No. 3, pp. 263-284.Zhu Z., Hanson F.B. (2005). �Risk-neutral option pricing for log-uniform jump-amplitude jump-di¤usion model�, Working Paper, University of Illinois, Chi-cago.
282

Chapitre 5
Evaluation d�un callEuropéen en présence dedividendes discrets.
5.1 Introduction
Les actions procurent deux types de revenus à leurs détenteurs : la plus-value,matérialisée par la di¤érence positive entre l�achat et la vente de titres, et le divi-dende qui représente la part des béné�ces (ou des réserves) de l�entreprise verséeavec une certaine fréquence (trimestrielle, semestrielle, annuelle ou irrégulière)aux actionnaires. Le dividende est un moyen pour une société de rémunérer etde �déliser les investisseurs qui ont pris le risque de participer au capital sur lelong terme. Lors de la distribution d�un dividende, le cours de bourse de l�actionchute d�un montant égal au dividende unitaire mis en paiement par la société,et l�actionnaire est crédité de ce même montant. En conséquence, le versementd�un dividende ne modi�e pas la richesse globale de l�actionnaire. En revanche,le prix d�une option sur action est modi�é par les versements de dividendes aucours de la vie du produit, car son payo¤ �nal ne dépend que de l�évolution(ou du niveau) du cours de bourse. Il est donc nécessaire de tenir compte desdividendes dans les modèles de marché utilisés pour évaluer les produits dérivésécrits sur des actions ou des indices boursiers.Dans la littérature académique, la question des dividendes est généralement ré-solue en introduisant un taux de dividende déterministe, continu (Merton 1973)ou discret (Björk 2004), dans le terme de dérive du processus de prix du sous-jacent, ce qui revient à considérer que les montants de dividendes futurs sontproportionnels au cours de l�actif. Cette approche, initiée par Merton simul-tanément aux travaux de Black et Scholes (1973), était à l�origine un arti�cecalculatoire permettant d�incorporer les dividendes futurs dans le modèle deBlack et Scholes tout en préservant l�hypothèse d�une di¤usion lognormale des
283

prix futurs du sous-jacent, hypothèse fondamentale sur laquelle repose l�exis-tence des formules analytiques pour le prix et les paramètres de couverture desoptions Européennes.Dans la réalité des marchés �nanciers, les dates de distribution et les montantsde dividendes futurs sont connus plusieurs mois à l�avance, de sorte que les in-tervenants (traders, market-makers, gérants de fonds) préfèrent raisonner, nonpas en termes de taux de dividende, mais plutôt en termes de montants de divi-dende distribués à des dates discrètes, ce qui revient à introduire des sauts dé-terministes dans le processus de prix, chaque saut représentant une distributionde dividende. Supposons que l�actif détache m dividendes (notés D1; : : : ; Dm)aux dates discrètes t1 < � � � < tm dans la période ]0; T [. Une méthode natu-relle pour incorporer cette chronique de dividendes discrets dans l�évolution descours consiste à supposer que le processus de prix chute d�un montant égal audividende mis en paiement aux dates ti et qu�il suit un mouvement Browniengéométrique entre deux dividendes consécutifs. Autrement dit, les prix futurs del�actif évoluent sous la probabilité risque-neutre Q selon l�équation di¤érentiellestochastique suivante (Frishling 2002) :
dSt = rStdt+ �StdWt �mXi=1
Di� (t� ti) ; S0 > 0; (5.1)
où r � 0 et � > 0 désignent respectivement le taux sans risque dans l�économiedu produit et la volatilité du sous-jacent (supposés constants), (Wt) est unmouvement Brownien standard sous la mesure Q et � (t� ti) est la mesure deDirac en ti. Ce modèle donne une représentation réaliste du comportement desprix ; par contre, il ne permet pas d�évaluer facilement les options vanilles detype Européen. En e¤et, on démontre que le cours de l�actif à la date d�échéancede l�option T est une combinaison linéaire de variables aléatoires lognormales(Frishling 2002) :
ST = S0e(r��2=2)T+�WT �
mXi=1
Die(r��2=2)(T�ti)+�(WT�Wti): (5.2)
La loi lognormale ne possédant aucune propriété d�additivité, la distribution deST n�admet pas de forme explicite et, dans ces conditions, on ne sait pas résoudreanalytiquement la formule générale du prix d�un call Européen d�échéance T etde strike K :
C = e�rTEh(ST �K)+
i; (x)
+ def= max (x; 0) ; (5.3)
où E [:] désigne l�opérateur espérance sous la mesure risque-neutre Q. Dans cecas, le prix de l�option doit être estimé par une méthode d�intégration numé-rique telle que la méthode de Monte Carlo, qui nécessite un temps de calculd�autant plus important que l�on souhaite obtenir un résultat précis. Malgré cetinconvénient, le modèle dé�ni par (5.1) reste un choix privilégié pour les pra-ticiens. C�est pourquoi les spécialistes ont développé di¤érentes formules pour
284

approcher le prix des options vanilles sans devoir implémenter une résolutionnumérique lourde.
La plupart des approximations proposées dans les publications consistent à ap-pliquer la formule de Black et Scholes (1973) et Merton (1973) pour les optionsEuropéennes en l�absence de dividende1 , mais en modi�ant certains paramètresen fonction de la chronique des dividendes futurs. Black (1975, p. 41) suggèred�appliquer la formule (5.52) en corrigeant le cours initial S0 d�un montant égalà la valeur actuelle des dividendes futurs. Cette approche a l�avantage d�êtresimple, mais elle sous-estime les prix des calls Européens de manière systéma-tique et conduit à des erreurs signi�catives (voir Frishling 2002, Haug 2007).Dans une série de publications datant du début des années 2000, certains au-teurs ont envisagé la possibilité d�améliorer l�approche de Black jugée insatisfai-sante. Beneder et Vorst (2001) puis Bos, Gairat et Shepeleva (2003) combinentl�ajustement proposé par Black avec une correction du paramètre de volatilité�, tandis que Bos et Vandermark (2002) corrigent simultanément le cours ini-tial S0 et le prix d�exercice K par des sommes pondérées des dividendes futursactualisés. Dans l�ensemble, les formules obtenues par ces di¤érents procédés2
donnent des résultats plus précis que l�ajustement envisagé par Black, mais étantdonné qu�elles reposent essentiellement sur des considérations empiriques, ellespeuvent conduire à des prix arbitrables ou trop éloignés des prix observés et nepermettent pas de contrôler l�erreur commise (voir Haug, Haug et Lewis (2003)pour une discussion sur ce sujet). Partant de cette observation, Haug et al.(2003) ont proposé un cadre d�analyse rigoureux pour le traitement des optionsen présence de dividendes discrets. Leur approche repose sur une modélisationconsistante de la dynamique des cours qui intègre la politique de dividende de la�rme. Cependant, elle ne permet pas d�obtenir des formules analytiques ferméespour les options Européennes et les auteurs donnent un algorithme permet-tant d�approcher le prix cherché par des intégrations numériques successives.Ce point restreint, selon nous, la portée opérationnelle du modèle.
Ce chapitre s�inscrit dans un contexte où les approximations existantes ne consti-tuent que des solutions partiellement satisfaisantes du traitement des optionsEuropéennes en présence de dividendes discrets et notre objectif est d�obtenir,par des raisonnements mathématiques rigoureux, une formule fermée qui per-mette (i) d�approcher le prix de l�option avec une précision accrue par rapportaux méthodes discutées auparavant et (ii) de déterminer les sensibilités de l�op-tion par rapport au sous-jacent (i.e. le Delta et le Gamma) sous une formeexplicite, ce dernier point n�étant pratiquement jamais abordé par les concep-teurs des modèles existants. Nous supposons que la dynamique du sous-jacentest dé�nie par (5.1), ce qui implique que le cours à l�échéance ST est donné parla formule (5.2) et, sous cette hypothèse, nous montrons que le problème initialconsistant à résoudre l�équation (5.3) revient à calculer la transformée stop-lossd�une somme de variables aléatoires lognormales dépendantes. Nous pouvons
1Voir annexe A, paragraphe A.1.2Voir annexe A pour une description détaillée des formules.
285

alors appliquer les résultats de la théorie actuarielle des risques comonotonespour établir des bornes déterministes qui encadrent le prix de l�option (voirDhaene, Denuit, Goovaerts, Kaas et Vyncke 2000a, 2000b ou Vandu¤el 2005)puis, en combinant ces bornes selon un procédé suggéré par Vyncke, Goovaertset Dhaene (2004), nous obtenons une nouvelle approximation particulièrementprécise.Le chapitre est organisé selon le schéma suivant : dans la section 2, nous rappe-lons quelques résultats de la théorie des risques comonotones nécessaires pourmener notre étude, puis nous les utilisons pour approcher les transformées stop-loss d�une somme de variables aléatoires lognormales dépendantes. Dans la sec-tion 3, nous transformons le problème initial pour pouvoir appliquer les formulesde la section précédente et obtenir ainsi trois approximations analytiques pourle prix du call Européen. Nous en déduisons par ailleurs les expressions du Deltaet du Gamma associés à chacune des approximations proposées. Dans la section4, nous e¤ectuons des tests numériques pour mesurer la qualité des approxima-tions construites dans la section précédente, puis nous comparons les résultatsobtenus avec les autres méthodes de la littérature. La conclusion du chapitre estdonnée dans la section 5.
5.2 Approximations comonotones d�une sommede variables aléatoires lognormales dépen-dantes
Dans ce paragraphe nous montrons comment approcher la loi de probabilitéd�une somme de variables aléatoires lognormales dépendantes.
5.2.1 Ordre convexe sur les variables aléatoires
Soit X une variable aléatoire réelle intégrable (i.e. E [jXj] < +1). On appelletransformées stop-loss de X au seuil d les quantités suivantes :
SLcX (d) = Eh(X � d)+
iet SLpX (d) = E
h(d�X)+
i; d 2 R:
Les exposants "c" et "p" signi�ent respectivement que la transformation estde type "call" ou de type "put". En e¤ectuant une intégration par parties (cf.Dhaene et al. 2000a), on peut établir les formules suivantes :
SLcX (d) =
Z +1
d
FX (x) dx; SLpX (d) =
Z d
�1FX (x) dx; (5.4)
où FX et FX = 1 � FX désignent respectivement la fonction de répartition etla fonction de survie de X. Ces formules prouvent que SLcX et SLpX quanti�entrespectivement les poids des queues de distribution droite et gauche de X, c�est-à-dire les risques associés à X. Une conséquence de cela est qu�il est possible decomparer des variables entre elles par l�intermédiaire des transformées stop-loss.
286

Dé�nition 5.1 Soit X et Y deux variables aléatoires réelles. On dit que X estinférieure à Y au sens de l�ordre convexe et l�on note X �cx Y , si et seulementsi pour tout d 2 R on a :
SLcX (d) � SLcY (d) et SLpX (d) � SL
pY (d) : (5.5)
D�après cette dé�nition, X �cx Y signi�e que X présente des queues de distri-bution moins épaisses que Y , i.e. X est moins "risquée" que Y .
On peut montrer que la relation (5.5) implique E [X] = E [Y ] ; en revanche, ellen�implique pas l�égalité des moments du second ordre (voir Dhaene et al. 2000a).Plus précisément, on a le résultat suivant (cf. Kaas, Dhaene et Goovaerts 2000) :X �cx Y si et seulement si E [h (X)] � E [h (Y )] pour toute fonction convexe htelle que h (X) et h (Y ) soient intégrables. En appliquant cette proposition à lafonction convexe x! x2, on en déduit que si X �cx Y , alors E
�X2�� E
�Y 2�.
Comme E [X] = E [Y ], il vient Var [X] � Var [Y ].
5.2.2 Sommes comonotones
Dé�nition 5.2 Des variables aléatoires réelles X1; : : : ; Xs de fonctions de ré-partitions respectives F1; : : : ; Fs sont dites comonotones si et seulement si
(X1; : : : ; Xs)0 �
�F�11 (U) ; : : : ; F�1s (U)
�0avec U � U (0; 1) : (5.6)
Le symbole "�" signi�e "a même loi que" et F�1i désigne la fonction quantile deXi. Dans ce cas, la somme X = X1 + � � �+Xs est appelée somme comonotone.
La comonotonie est une structure d�extrême dépendance positive entre des va-riables. En e¤et, les risques individuels des composantes sont contrôlés par unesource de hasard unique (la variable uniforme U) et les marginales F�1i (U) va-rient dans le même sens lorsque U est modi�ée, ce qui explique le sens du termecomonotone (monotonie commune).
Les sommes comonotones possèdent des propriétés intéressantes que nous don-nons ci-dessous et dont on peut trouver les démonstrations dans les travauxde Dhaene et al. (2000a) ou de Vandu¤el (2005). Dans ce qui suit, X est unesomme comonotone de fonctions de répartition marginales Fi.
Proposition 5.1 La fonction quantile de X est donnée par la formule :
F�1X (u) =sXi=1
F�1i (u) ; 0 < u < 1: (5.7)
De plus, lorsque les Fi sont bijectives, alors F�1X est bijective et, dans ce cas, la
fonction de répartition de X est entièrement déterminée par la relation :
F�1X (FX (x)) = x()sXi=1
F�1i (FX (x)) = x; x 2 R: (5.8)
287

Etant donné que la fonction x! max (x; 0) n�est pas une fonction linéaire de x,la transformée stop-loss (SLc ou SLp) n�est pas un opérateur linéaire sur l�en-semble des variables aléatoires. Toutefois, dans le cas des sommes comonotones,on a le résultat suivant :
Proposition 5.2 Lorsque les fonctions de répartition marginales Fi sont bijec-tives, les transformées stop-loss de X sont données par les formules suivantes :
SLcX (d) =sXi=1
SLcF�1i (U)
(di) ; SLpX (d) =sXi=1
SLpF�1i (U)
(di) ; (5.9)
où di = F�1i (FX (d)), i = 1; : : : ; s.
La transformée stop-loss d�une somme comonotone est donc égale à la somme destransformées stop-loss de ses composantes évaluées en des seuils di spéci�ques.Notons que la formule (5.8) implique la relation suivante :
sXi=1
di =sXi=1
F�1i (FX (d)) = d: (5.10)
5.2.3 Approximations au sens de l�ordre convexe
Encadrements comonotones
La proposition suivante montre comment encadrer les transformées stop-lossd�une somme de variables aléatoires quelconques. Le lecteur en trouvera unedémonstration dans Kaas et al. (2000), Dhaene et al. (2000a) ou Vandu¤el(2005).
Proposition 5.3 Soit X =Psi=1Xi une somme de variables aléatoires éven-
tuellement dépendantes et dé�nies par leurs fonctions de répartition marginalesFi. On pose3 :
Xub =
sXi=1
F�1i (U) ; Xlb =
sXi=1
E [XijZ] ; (5.11)
où U � U (0; 1) et Z est une variable aléatoire quelconque, indépendante de U .Alors on a les encadrements suivants :
Xlb �cx X �cx Xub () SLc=plb (d) � SLc=pX (d) � SLc=pub (d) ;
où la notation "c=p" signi�e que l�encadrement s�applique aux transformées detype "c" et de type "p" et SLc=plb et SLc=pub sont des notations abrégées pour SLc=pXlb
et SLc=pXub.
3Les indices "lb" et "ub" signi�ent respectivement "lower bound" et "upper bound".
288

Par construction, Xub est une somme comonotone, donc ses transformées stop-loss sont déterminées par (5.9). Par contre, Xlb n�est pas nécessairement unesomme comonotone mais, dans certains cas, on peut identi�er des variables Zqui permettent d�obtenir la propriété de comonotonie pour cette borne et ildevient alors très facile d�évaluer SLc=plb .
Approximation convexe basée sur les moments
Vyncke et al. (2004) proposent de construire une nouvelle approximation de Xen posant4 :
Fmb = �Flb + (1� �)Fub; � 2 [0; 1] ;où Flb et Fub sont les fonctions de répartition des bornes Xlb et Xub. Parconstruction, la variable aléatoire Xmb de fonction de répartition Fmb véri�e :
E [Xmb] = E [X] et SLc=pmb (d) = � SL
c=plb (d) + (1� �) SLc=pub (d) : (5.12)
Une conséquence de (5.12) est que les transformées stop-loss de Xmb sont com-prises entre les transformées stop-loss de Xlb et de Xub, ce qui implique :���SLc=pX (d)� SLc=pmb (d)
��� � SLc=pub (d)� SLc=plb (d) :
Cela prouve que les quantités SLcmb (d) et SLpmb (d) sont de nouvelles approxi-
mations de SLcX (d) et SLpX (d).
L�approximation optimale est obtenue en imposant l�égalité des moments d�ordre2, i.e. Var [Xmb] = Var [X]. Vyncke et al. (2004) démontrent que la valeur de �(notée ��) qui réalise cette égalité est donnée par la formule :
�� =Var [X]�Var [Xlb]
Var [Xub]�Var [Xlb]: (5.13)
Par construction la variable X�mb (obtenue pour � = ��) a les mêmes premiers
moments que X, ce qui laisse entrevoir que les transformées stop-loss de X�mb
approcheront les transformées stop-loss de X avec une certaine précision.
5.2.4 Application aux sommes de variables lognormalesdépendantes
Nous considérons à présent que X est une somme de s variables lognormalesdépendantes telle que :
X =
sXi=1
eYi ; (5.14)
où (Y1; : : : ; Ys)0 est un vecteur gaussien multivarié dé�ni par �i = E [Yi] et
�ij = Cov [Yi; Yj ] � 0. Nous prenons la convention �2i = Var [Yi] = �ii. Etant
4L�indice "mb" signi�e "moment bound".
289

donné que la loi lognormale ne possède aucune propriété d�additivité, la fonctionde répartition de X ne peut pas être déterminée analytiquement. Toutefois, lesrésultats du paragraphe précédent sont applicables et nous pouvons établir desapproximations comonotones pour la loi de X. Pour une démonstration et uneétude approfondie des résultats énoncés dans la suite, nous invitons le lecteurà consulter Kaas et al. (2000), Vandu¤el, Hoedemakers et Dhaene (2005) ouVandu¤el, Chen et al. (2007).
Transformées stop-loss d�une variable aléatoire lognormale
Soit Y � N (�; �), on rappelle que la fonction de répartition et la fonctionquantile de eY sont données par :
FeY (x) = �
�lnx� �
�
�() F�1
eY(u) = e�+��
�1(u); (5.15)
où � et ��1 désignent respectivement la fonction de répartition et la fonctionquantile de la loi normale standard. De plus, un simple calcul d�espérancespermet d�obtenir les transformées stop-loss de eY (Dhaene et al. 2000a) :
SLceY (d) = e�+�2
2 �
�� +
�� ln d�
�� d�
��� ln d
�
�; (5.16)
SLpeY(d) = d�
�ln d� �
�
�� e�+�2
2 �
�ln d� �
�� �
�: (5.17)
Borne comonotone supérieure
Lorsque X est dé�nie par (5.14), la borne supérieure comonotone dé�nie à laproposition 5.3 s�écrit :
Xub =sXi=1
e�i+�i��1(U); U � U (0; 1) : (5.18)
Comme les Fi sont bijectives, la fonction de répartition Fub de Xub est donnéepar la formule (5.8) :
sXi=1
e�i+�i��1(Fub(x)) = x; x 2 R�+: (5.19)
En injectant (5.16) et (5.17) dans les formules de la proposition 5.2 et en posantFub = 1� Fub on obtient tous calculs faits :
SLcub (d) =sXi=1
e�i+�2i2 �
��i � ��1 � Fub (d)
�� dFub (d) ; (5.20)
SLpub (d) = dFub (d)�sXi=1
e�i+�2i2 �
���1 � Fub (d)� �i
�: (5.21)
290

Construction de la borne inférieure
Lorsque les composantes de X sont lognormales, Vandu¤el et al. (2005) ou Van-du¤el, Chen et al. (2007) montrent que le choix optimal pour Z est le suivant :
Z =sXi=1
�iYi avec �i = e�i+�
2i =2 � 0: (5.22)
La variable Z ainsi construite suit une loi gaussienne5 ; donc l�espérance de eYi
conditionnellement à Z est donnée par :
E�eYi��Z� = eE[YijZ]+ 1
2Var[YijZ]): (5.23)
En posantZ = �Z + �Z�
�1 (V ) ; V � U (0; 1)et
�i = Cor [Yi; Z] =Cov [Yi; Z]
�i�Z=
Psj=1 �j�ij
�i�Z; (5.24)
on peut établir les formules suivantes (cf. Vandu¤el et al. 2005) :
E [YijZ] = �i + �i�i��1 (V ) ; Var [YijZ]) = �2i
�1� �2i
�:
On en déduit que la borne inférieure Xlb s�écrit :
Xlb =sXi=1
e�i+12 (1��
2i )�
2i+�i�i�
�1(V ): (5.25)
Les fonctions v ! e�i+12 (1��
2i )�
2i+�i�i�
�1(v) sont les fonctions quantiles de va-riables aléatoires lognormales de paramètres �i +
12 (1 � �
2i )�
2i et �i�i, ce qui
implique que Xlb est une somme comonotone. Pour obtenir la fonction de ré-partition et les transformées stop-loss de Xlb, on peut donc utiliser directementles résultats du paragraphe 5.2.4 en remplaçant �i par �i +
12 (1 � �
2i )�
2i et �i
par �i�i. En procédant ainsi, on obtient la fonction de répartition Flb à partirde l�équation (5.19) :
sXi=1
e�i+12 (1��
2i )�
2i+�i�i�
�1(Flb(x)) = x; x 2 R�+: (5.26)
Les transformées stop-loss de Xlb se déduisent des formules (5.20) et (5.21) etadmettent les expressions suivantes (on note F lb = 1� Flb) :
SLclb (d) =
sXi=1
e�i+�2i2 �
��i�i � ��1 � Flb (d)
�� dF lb (d) ; (5.27)
SLplb (d) = dFlb (d)�sXi=1
e�i+�2i2 �
���1 � Flb (d)� �i�i
�: (5.28)
5Toute combinaison linéaire des composantes d�un vecteur gaussien est une variable gaus-sienne.
291

Moments des bornes de l�encadrement convexe
Par propriété de la relation d�ordre convexe, les moments des variables X, Xlb
et Xub véri�ent :
E [X] = E [Xlb] = E [Xub] ; Var [Xlb] � Var [X] � Var [Xub] :
Vandu¤el et al. (2005) établissent les formules suivantes :
E [X] =sXi=1
e�i+�2i2 ; (5.29)
Var [X] =sXi=1
sXj=1
e�i+�j+12 (�
2i+�
2j ) (e�i�j�ij � 1) ; (5.30)
Var [Xlb] =
sXi=1
sXj=1
e�i+�j+12 (�
2i+�
2j ) (e�i�j�i�j � 1) ; (5.31)
Var [Xub] =
sXi=1
sXj=1
e�i+�j+12 (�
2i+�
2j ) (e�i�j � 1) : (5.32)
5.3 Approximations comonotones du prix d�uncall Européen
Dans cette section, nous appliquons les résultats des paragraphes 5.2.3 et 5.2.4pour approcher le prix d�un call Européen lorsque le sous-jacent suit la dyna-mique (5.1).
5.3.1 Transformations préliminaires
On remarque que la formule fondamentale d�évaluation (5.3), peut s�écrire comme
la transformée stop-loss de la variable �STdef= e�rTST au seuil �K
def= e�rTK :
C = e�rTEh(ST �K)+
i= E
h�e�rTST � e�rTK
�+i= SLc�ST
��K�:
La variable �ST est d�après (5.2) une combinaison linéaire de variables lognor-males à coe¢ cients positifs et négatifs. A�n de faire apparaître une somme de
termes à coe¢ cients tous positifs, on met �Tdef= e�WT��2T=2 en facteur commun
dans �ST � �K :
�ST � �K = S0e�WT��2T
2 �mXi=1
Die�(WT�Wti)�rti�
�2(T�ti)2 � e�rTK
= �T
S0 �
mXi=1
Die
��2
2 �r�ti��Wti �Ke
��2
2 �r�T��WT
!:
292

On dé�nit alors
~S =mXi=1
Die(�2=2�r)ti��Wti +Ke(�
2=2�r)T��WT ; (5.33)
de sorte que le prix du call devient :
C = E
��T
�S0 � ~S
�+�: (5.34)
La variable aléatoire �T est strictement positive et elle véri�e E [�T ] = 1, c�estdonc la densité de Radon-Nikodym d�une mesure ~Q équivalente à Q et l�on peutécrire :
d ~Q
dQ= �T = e
�WT��2T=2: (5.35)
La formule (5.34) devient :
C = E
"d ~Q
dQ
�S0 � ~S
�+#= ~E
��S0 � ~S
�+�= SLp~S (S0) : (5.36)
Le prix du call Européen C s�exprime donc comme la transformée stop-loss detype put au seuil S0 de la variable ~S sous la nouvelle mesure ~Q.
D�après le théorème de Girsanov, le processus de terme général ~Wtdef= Wt � �t
est un mouvement Brownien standard sous ~Q. Alors, en faisant apparaître ~Wdans (5.33), on obtient la loi de ~S sous ~Q :
~S =mXi=1
Die�(r+�2=2)ti�� ~Wti +Ke�(r+�
2=2)T�� ~WT : (5.37)
La variable alternative ~S est donc de la formePm+1i=1 e
Yi où (Y1; : : : ; Ym+1)0 est
un vecteur gaussien (sous ~Q) d�espérances :
�i =
�ln (Di)�
�r + �2=2
�ti si 1 � i � m
ln (K)��r + �2=2
�T si i = m+ 1
; (5.38)
et de covariances dé�nies par la relation (cf. Glasserman 2004) :
�ij = Cov [Yi; Yj ] = �2min (ti; tj) : (5.39)
Nous avons donc démontré que le prix du call est la transformée stop-loss d�unecombinaison linéaire à coe¢ cients tous positifs de m+ 1 variables lognormalesdépendantes, ce qui permet d�appliquer les résultats des paragraphes 5.2.3 et5.2.4.
293

5.3.2 Construction des bornes comonotones
D�après la proposition 5.3, on sait construire deux sommes comonotones notées~Sub et ~Slb, telles que :
~Slb �cx ~S �cx ~Sub =) SLplb (S0) � C � SLpub (S0) ;
où SLplb et SLpub sont obtenues en remplaçant �i et �ij par les expressions données
en (5.38) et (5.39) dans les formules des paragraphes 5.2.4 et 5.2.4.
Borne comonotone supérieure
En appliquant les résultats du paragraphe 5.2.4 on obtient tous calculs faits :
~Sub =
m+1Xi=1
�ie�i�
�1(U)��2i =2; U � U (0; 1) : (5.40)
Les paramètres �i et �i sont dé�nis par :
�i =
�Die
�rti si 1 � i � mKe�rT si i = m+ 1
; �i =
��pti si 1 � i � m
�pT si i = m+ 1
: (5.41)
La fonction de répartition associée (notée ~Fub) est solution de l�équation :
x =m+1Xi=1
�ie�i�
�1( ~Fub(x))��2i =2; x 2 R�+: (5.42)
En�n, la transformée stop-loss de ~Sub est donnée par :
SLpub(S0) = S0 ~Fub (S0)�m+1Xi=1
�i ����1 � ~Fub (S0)� �i
�: (5.43)
Borne comonotone inférieure
La borne inférieure est obtenue en injectant les paramètres de notre problèmedans la formule (5.25) :
~Slb =m+1Xi=1
�ie�i�i�
�1(V )��2i�2i =2; V � U (0; 1) : (5.44)
Les coe¢ cients �i sont dé�nis par :
�i =
Pm+1j=1 �j min (ti; tj)q
tiPm+1j;k=1 �j�kmin (tj ; tk)
; 1 � i � m+ 1:
La fonction de répartition ~Flb est solution de l�équation :
x =m+1Xi=1
�ie�i�i�
�1( ~Flb(x))��2i�2i =2; x 2 R�+: (5.45)
294

La borne inférieure étant comonotone, la transformée stop-loss ~Slb est obtenueen appliquant la formule (5.28) :
SLplb(S0) = S0 ~Flb (S0)�m+1Xi=1
�i ����1 � ~Flb (S0)� �i�i
�: (5.46)
Approximation basée sur les moments
Avec les notations introduites, l�espérance des variables considérées est
~E[ ~S] = ~E[ ~Sub] = ~E[ ~Slb] =m+1Xi=1
�i
et les formules (5.30), (5.31) et (5.32) deviennent :
Var[ ~S] =m+1Xi;j=1
�i�j
�e�
2ij � 1
�;
Var[ ~Slb] =m+1Xi;j=1
�i�j (e�i�j�i�j � 1) ;
Var[ ~Sub] =m+1Xi;j=1
�i�j (e�i�j � 1) :
Le raisonnement du paragraphe 5.2.3 permet de construire une approximationde ~S (notée ~Smb) basée sur l�identi�cation des deux premiers moments et dé�niepar sa fonction de répartition ~Fmb :
~Fmb = �� ~Flb + (1� ��) ~Fub avec �� =Var[ ~S]�Var[ ~Slb]Var[ ~Sub]�Var[ ~Slb]
: (5.47)
La transformée stop-loss de seuil S0 associée à ~Smb s�écrit :
C ' SLpmb (S0) = ��SLplb (S0) + (1� ��) SLpub (S0) : (5.48)
Par construction ~Smb et ~S ont la même espérance et la même variance. On peutdonc supposer que SLpmb (S0) constitue une bonne approximation du prix del�option.
Calcul du Delta et du Gamma
Les approximations proposées dans ce travail sont de la forme suivante C 'SLpxb (S0), où l�indice "xb" est une notation symbolique qui désigne indi¤érem-ment "lb", "ub" ou "mb". En conséquence, on peut obtenir une forme généralepour le Delta et le Gamma de l�option en utilisant la notation "xb" :
�xb = @S0C ' @S0SLpxb (S0) ; �xb = @2S0C ' @
2S0SL
pxb (S0) ;
295

où @S0 et @2S0désignent les dérivées partielles d�ordre 1 et 2 par rapport à S0.
Pour calculer ces dérivées, nous écrivons SLpxb (S0) en utilisant la formule (5.4) :
SLpxb (S0) =
Z S0
0
~Fxb (z) dz;
où ~Fxb est la fonction de répartition de la variable approchante ~Sxb.
Par construction, les variables ~Slb, ~Sub et ~Smb ne dépendent pas du cours àl�origine S0. Alors, la fonction ~Fxb est indépendante de S0 et l�on peut dériverl�intégrale précédente par rapport à sa borne supérieure :
�xb = @S0SLpxb (S0) =
~Fxb (S0) ; �xb = @2S0SLpxb (S0) =
~F 0xb (S0) ;
où ~F 0xb est la densité de probabilité de la variable ~Sxb.
Le calcul du Delta associé à chaque approximation ne comporte aucune di¢ -culté, car les équations (5.42), (5.45) et (5.47) permettent d�évaluer directementles fonctions de répartition des variables ~Sub, ~Slb et ~Smb.
Nous allons maintenant déterminer la densité de probabilité de ~F 0ub (donc leGamma) de la borne supérieure ~Sub. En dérivant les deux membres de l�équation(5.42) en x = S0 il vient :
1 =m+1Xi=1
�i�i~F 0ub (S0)
�0 � ��1�~Fub (S0)
�e�i��1( ~Fub(S0))��2i =2:En isolant le terme ~F 0ub (S0) et en remplaçant �
0 par ' (la densité de la loinormale standard) on obtient :
~F 0ub (S0) =' � ��1
�~Fub (S0)
�Pm+1i=1 �i�ie
�i��1( ~Fub(S0))��2i =2= �ub (S0) : (5.49)
Un raisonnement analogue nous permet de déterminer �lb à partir de (5.45) :
�lb (S0) =' � ��1
�~Flb (S0)
�Pm+1i=1 �i�i�ie
�i�i��1( ~Flb(S0))��2i�2i =2
: (5.50)
En�n, �mb (S0) est obtenu en dérivant (5.47) membre à membre :
�mb (S0) = �� �mb (S0) + (1� ��) �mb (S0) : (5.51)
Notons que, dans le cas où les dividendes sont tous nuls (i.e. �1 = �2 = � � � =�m = 0), les formules établies pour le prix et pour les Grecques sont identiquesaux formules de Black et Scholes (cf. annexe A.1).
296

Les trois approximations comonotones construites dans ce travail présentent unavantage calculatoire par rapport aux méthodes présentées dans l�annexe A. Ene¤et, nous avons non seulement obtenu des formules théoriques pour estimer leprix de l�option, mais nous avons aussi montré que ces formules permettaientde calculer le Delta et le Gamma sous une forme explicite.
5.4 Applications numériques
Dans cette dernière section, nous évaluons les performances des trois approxi-mations proposées. Elles sont notées CUB (Comonotonic Upper Bound) pourcelle basée sur la borne supérieure, CLB (Comonotonic Lower Bound) pour cellebasée sur la borne inférieure et MBA (Moment Based Approximation) pour cellebasée sur les moments. Les paramètres communs utilisés dans les tests numé-riques réalisés sont les suivants : r = 6%, T = 2 et S0 = 100. Par ailleurs, onsuppose que le titre détache quatre dividendes sur la période ; la chronique dedividendes est donnée dans le tableau ci-dessous :
Date 0:25 0:75 1:25 1:75Dividende 2:5 3:0 2:5 3:0
5.4.1 Test d�adéquation sur les fonctions de répartition
La volatilité et le strike retenus pour ce test sont � = 30% et K = 100. La�gure 5.1 représente les fonctions de répartition ~Fub, ~Flb, ~Fmb (à gauche) et lesdensités ~F 0ub, ~F
0lb, ~F
0mb (à droite). Les points de la fonction de répartition em-
pirique de ~S, notés MC, sont désignés par des losanges sur la �gure de gauche.Ils sont construits sur la base d�un échantillon comportant 105 réalisations in-dépendantes de la variable ~S obtenues par la méthode de Monte Carlo (cf.Glasserman 2004). Les fonctions de répartition comonotones s�ajustent parfai-tement sur la distribution empirique de ~S, ce qui laisse supposer que les variablesconstruites approchent la loi cherchée avec précision. Par ailleurs, on observe surla �gure de droite que (i) les densités CLB et MBA sont indiscernables et que (ii)la densité de la borne supérieure di¤ère légèrement des densités CLB et MBA auniveau du mode et de la queue de distribution gauche. En conséquence, on peutpenser que les distributions des variables ~Slb et ~Smb sont plus proches de la loithéorique de ~S que la distribution de la borne supérieure ~Sub. A�n de con�rmerces hypothèses faites à partir de l�observation des graphiques, nous appliquonsle test d�ajustement de Kolmogorov-Smirnov6 aux fonctions de répartition ~Fub,~Flb, ~Fmb, l�objectif étant de valider quantitativement l�adéquation à la loi ~S.
Le principe du test consiste à calculer la distance de la norme uniforme (notéeDn) entre la fonction de répartition empirique de l�échantillon (notée Fn) et lafonction de répartition théorique testée (notée ~Fxb comme au paragraphe 5.3.2).
6Le test de Kolmogorov-Smirnov est un test d�ajustement à une loi continue qui utilisetoute l�information disponible. A ce propos, on pourra se référer aux ouvrages de Saporta(1990) ou de Lecoutre (1998).
297

0,0
0,1
0,2
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1,0
25 50 75 100 125 150 175 200 225
x
cdf
CUB CLB MBA MC
0,000
0,002
0,004
0,006
0,008
0,010
0,012
25 50 75 100 125 150 175 200 225
x
Den
sity
CUB CLB MBA
Fig. 5.1 � Fonctions de répartition (�gure de gauche) et densités (�gure dedroite) des approximations comonotones.
Dn est donnée par Dn = supx2R
���Fn (x)� ~Fxb (x)���, où x(1) < : : : < x(n) sont
les observations classées dans l�ordre croissant. Sous l�hypothèse d�adéquationentre Fn et ~Fxb on démontre que la suite de variables aléatoires positives determe général
pnDn converge vers une variable aléatoire dont la fonction de
répartition est dé�nie par :
H (x) = 1� 2+1Xk=1
(�1)k+1 exp��2k2x2
�; x > 0:
Le test est rejeté pour tout seuil � supérieur à la p-value �ndef= 1�H
�pnDn
�.
Les résultats obtenus sont présentés dans le tableau ci-après.
borne CUB ( ~Fub) CLB ( ~Flb) MBA ( ~Fmb)
distance observée (Dn) 7:623E� 03 1:112E� 03 1:102E� 03statistique observée (
pnDn) 2:410615 0:351737 0:348385
p-value (�n) 0:00% 99:97% 99:97%
La p-value du test associé à la fonction de répartition ~Fub est nulle, ce qui signi�eque la borne supérieure ne constitue pas une bonne approximation de la variable~S. Par contre, les p-values calculées pour les fonctions de répartition ~Flb et ~Fmbsont égales à 99:97%, ce qui prouve que ~Slb et ~Smb constituent d�excellentesapproximations de la variable initiale ~S. Les prix d�options obtenus à partir desapproximations CLB et MBA seront donc plus précis que les prix obtenus àpartir de l�approximation CUB. Nous allons con�rmer cela dans le paragraphesuivant.
298
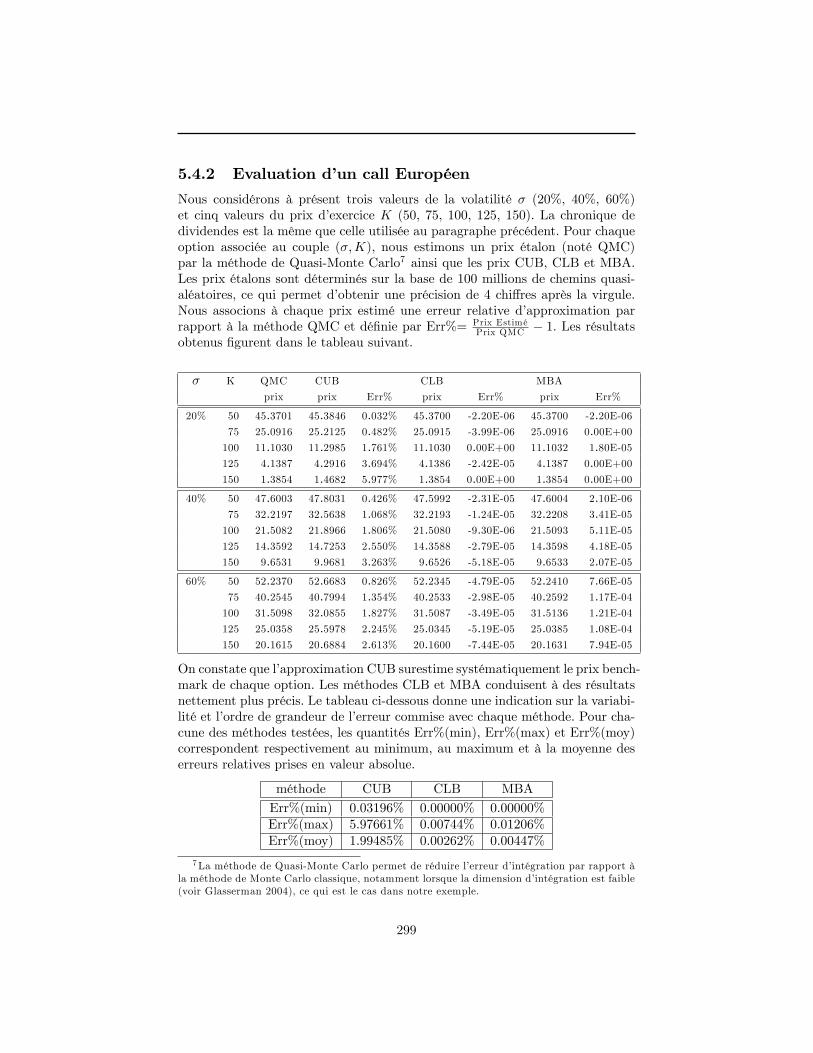
5.4.2 Evaluation d�un call Européen
Nous considérons à présent trois valeurs de la volatilité � (20%, 40%, 60%)et cinq valeurs du prix d�exercice K (50, 75, 100, 125, 150). La chronique dedividendes est la même que celle utilisée au paragraphe précédent. Pour chaqueoption associée au couple (�;K), nous estimons un prix étalon (noté QMC)par la méthode de Quasi-Monte Carlo7 ainsi que les prix CUB, CLB et MBA.Les prix étalons sont déterminés sur la base de 100 millions de chemins quasi-aléatoires, ce qui permet d�obtenir une précision de 4 chi¤res après la virgule.Nous associons à chaque prix estimé une erreur relative d�approximation parrapport à la méthode QMC et dé�nie par Err%= Prix Estimé
Prix QMC � 1. Les résultatsobtenus �gurent dans le tableau suivant.
� K QMC CUB CLB MBA
prix prix Err% prix Err% prix Err%
20% 50 45.3701 45.3846 0.032% 45.3700 -2.20E-06 45.3700 -2.20E-0675 25.0916 25.2125 0.482% 25.0915 -3.99E-06 25.0916 0.00E+00100 11.1030 11.2985 1.761% 11.1030 0.00E+00 11.1032 1.80E-05125 4.1387 4.2916 3.694% 4.1386 -2.42E-05 4.1387 0.00E+00150 1.3854 1.4682 5.977% 1.3854 0.00E+00 1.3854 0.00E+00
40% 50 47.6003 47.8031 0.426% 47.5992 -2.31E-05 47.6004 2.10E-0675 32.2197 32.5638 1.068% 32.2193 -1.24E-05 32.2208 3.41E-05100 21.5082 21.8966 1.806% 21.5080 -9.30E-06 21.5093 5.11E-05125 14.3592 14.7253 2.550% 14.3588 -2.79E-05 14.3598 4.18E-05150 9.6531 9.9681 3.263% 9.6526 -5.18E-05 9.6533 2.07E-05
60% 50 52.2370 52.6683 0.826% 52.2345 -4.79E-05 52.2410 7.66E-0575 40.2545 40.7994 1.354% 40.2533 -2.98E-05 40.2592 1.17E-04100 31.5098 32.0855 1.827% 31.5087 -3.49E-05 31.5136 1.21E-04125 25.0358 25.5978 2.245% 25.0345 -5.19E-05 25.0385 1.08E-04150 20.1615 20.6884 2.613% 20.1600 -7.44E-05 20.1631 7.94E-05
On constate que l�approximation CUB surestime systématiquement le prix bench-mark de chaque option. Les méthodes CLB et MBA conduisent à des résultatsnettement plus précis. Le tableau ci-dessous donne une indication sur la variabi-lité et l�ordre de grandeur de l�erreur commise avec chaque méthode. Pour cha-cune des méthodes testées, les quantités Err%(min), Err%(max) et Err%(moy)correspondent respectivement au minimum, au maximum et à la moyenne deserreurs relatives prises en valeur absolue.
méthode CUB CLB MBA
Err%(min) 0:03196% 0:00000% 0:00000%Err%(max) 5:97661% 0:00744% 0:01206%Err%(moy) 1:99485% 0:00262% 0:00447%
7La méthode de Quasi-Monte Carlo permet de réduire l�erreur d�intégration par rapport àla méthode de Monte Carlo classique, notamment lorsque la dimension d�intégration est faible(voir Glasserman 2004), ce qui est le cas dans notre exemple.
299

L�erreur moyenne avec l�approximation CUB est de l�ordre de 2%, tandis qu�elleressort autour de 0:002% avec la méthode CLB (soit une réduction de l�erreurd�un facteur 1000) et de 0:004% avec la méthode MBA (ce qui correspond àune réduction de l�erreur de l�ordre de 500). En conséquence, avec une erreurdont l�ordre de grandeur est le millième de pourcent, les méthodes CLB etMBA s�avèrent considérablement plus performantes que l�approximation CUBbasée sur la borne comonotone supérieure. Dans le paragraphe suivant, nouscomparons les approximations CLB et MBA aux méthodes présentées dans l�in-troduction.
5.4.3 Etude comparative avec d�autres approches courantes
La volatilité est à présent �xée à � = 30%. Le strike K varie de 50 à 150 commedans l�exemple numérique précédent. Pour chacune des méthodes testées, i.e.B75, BV01, BoV02, BGS03, HHL03 (cf. Annexe A pour les formules) et CLBet MBA dé�nies précédemment on désigne par Err% l�écart relatif entre le prixobtenu avec la méthode considérée et le prix obtenu par simulation Quasi-MonteCarlo (QMC). Les résultats ainsi que les erreurs commises sont présentés dansle tableau suivant. La dernière ligne du tableau donne pour chaque méthodele minimum, le maximum et la moyenne des erreurs relatives prises en valeurabsolue.
K QMC B75 BV01 BoV02 BGS03 HHL03 CLB MBA
50 46.0585 45.8341 45.9945 46.0844 46.0546 46.0668 46.05799 46.0582
-0.487% -0.139% 0.056% -0.008% 0.018% -0.001% -0.001%
75 28.3956 27.7255 28.2971 28.4204 28.3910 28.4056 28.3953 28.3959
-2.360% -0.347% 0.087% -0.016% 0.035% -0.001% 0.001%
100 16.3439 15.4634 16.2972 16.3361 16.3431 16.3465 16.3439 16.3444
-5.387% -0.286% -0.048% -0.005% 0.016% 0.000% 0.003%
125 9.0728 8.2623 9.0904 9.0386 9.0754 9.0686 9.0727 9.0731
-8.933% 0.194% -0.377% 0.029% -0.046% -0.001% 0.003%
150 4.9631 4.3389 5.0171 4.9200 4.9672 4.9560 4.9628 4.9631
-12.577% 1.088% -0.868% 0.083% -0.143% -0.006% 0.000%
Err%(min) 0.487% 0.139% 0.048% 0.005% 0.016% 0.000% 0.000%
Err%(max) 12.577% 1.088% 0.868% 0.083% 0.143% 0.006% 0.003%
Err%(moy) 5.949% 0.411% 0.287% 0.028% 0.052% 0.002% 0.002%
L�approximation de Black (B75) est la moins satisfaisante de ce comparatif :l�erreur relative varie de �0:487% pour les strikes les plus faibles à �12:577%pour les strikes les plus élevés et un simple calcul montre que la moyenne deserreurs relatives (en valeur absolue) est de l�ordre 5:949%. Notons par ailleursqu�elle sous-estime les prix de calls de manière systématique.L�ajustement de la volatilité proposé par Beneder et Vorst (BV01) permet d�ob-tenir une erreur moyenne de 0:411%, ce qui correspond à une réduction de
300

l�erreur d�un facteur 14:5(' 5:949%0:411% ) par rapport à la méthode B75. L�améliora-
tion porte essentiellement sur les options en dehors de la monnaie. Par ailleurs,le phénomène de sous-estimation systématique a disparu.La méthode de Bos et Vandermark (BoV02) est plus précise que les méthodesprécédemment analysées : l�erreur commise est inférieure au seuil de 1% en valeurabsolue (elle est comprise entre �0:868% et 0:087%) et la moyenne des erreursressort à 0:287%. Notons que les options en dehors de la monnaie sont cellespour lesquelles l�approximation est la moins performante (Err% = �0:868%).L�approximation de Bos et al. (BGS03) occupe la quatrième place de ce com-paratif : l�erreur prise en valeur absolue est inférieure à 0:083% sur l�ensembledes tests réalisés. La moyenne des erreurs est 0:028%, ce qui correspond à uneréduction de l�incertitude par rapport à la méthode de Bos et Vandermark d�unfacteur 10:2(' 0:287%
0:028% ).Le modèle de Haug et al. (HHL03) conduit lui aussi à des résultats précis :l�erreur varie entre �0:143% pour les options en dehors de la monnaie et 0:018%pour les options dans la monnaie. La moyenne des erreurs ressort à 0:052%. Unepartie des erreurs mesurées provient vraisemblablement du fait que la dynamique(5.62) utilisée par Haug et al. di¤ère légèrement de la dynamique (5.1) surlaquelle sont basées les autres approximations. Par ailleurs le prix de l�optiondevant être approché par des intégrations numériques successives, il subsiste uneincertitude quant à la précision des résultats obtenus.Les approximations comonotones CLB et MBA sont les plus précises de cecomparatif. Par ailleurs, les résultats obtenus avec les deux méthodes sont trèsproches. La moyenne des erreurs relatives (prises en valeur absolue) ressort à0:002% dans les deux cas, ce qui correspond à une amélioration d�un facteur14(' 0:028%
0:002% ) par rapport à la méthode BGS03 et d�un facteur 3000('5:949%0:002% )
par rapport à l�ajustement B75 de Black. Les méthodes CLB et MBA performentde manière identique pour les options dans la monnaie avec une erreur de l�ordrede 0:001% (en valeur absolue). Avec la méthode CLB l�erreur commise est voisinede zéro pour le call à la monnaie et elle est maximale pour les calls très en dehorsde la monnaie (�0:006%). Inversement, avec l�approximation MBA, l�erreur estmaximale pour les options à la monnaie (0:003%) et vaut zéro pour les optionsen dehors de la monnaie. On en déduit que l�approximation CLB sera plusperformante au voisinage de la monnaie, tandis que l�approximation MBA seraplus précise pour évaluer les calls très en dehors de la monnaie. En pratique,étant donné la grande précision des résultats obtenus (de l�ordre du millième depourcent), on pourra utiliser indi¤éremment l�une ou l�autre des deux méthodesproposées. Toutefois, si l�on tient compte de l�e¤ort calculatoire supplémentaireinduit pour évaluer la formule (5.48), on peut considérer que la méthode CLBest la solution la plus e¢ cace pour approcher le prix du call Européen.
5.5 Conclusion
L�intégration des dividendes dans les modèles de marché utilisés pour évaluer etcouvrir les produits optionnels sur action(s) est un problème particulièrement
301

délicat, notamment lorsque les dates et les montants des dividendes futurs sontconnus à l�avance. Dans ce cas, la dynamique du sous-jacent est un processus àsauts déterministes et il n�est plus possible d�obtenir des formules analytiquesfermées pour le prix et les paramètres de couverture des options Européennes,comme c�est le cas lorsque les dividendes sont supposés proportionnels au coursdu sous-jacent. Il faut alors traiter le problème par une méthode numériquetelle que la méthode de Monte Carlo. Une telle approche est particulièrementconsommatrice en temps de calcul, ce qui est di¢ cilement envisageable pour unemise en oeuvre opérationnelle. Les spécialistes ont donc développé di¤érentesformules d�approximation pour évaluer les options Européennes en présence dedividendes discrets. La plupart des solutions existantes sont construites à partirde considérations empiriques et consistent à modi�er en fonction de la chroniquedes dividendes futurs les paramètres de la formule originale de Black-Scholes-Merton (1973) pour les options Européennes en l�absence de dividende, maiselles conduisent à des résultats biaisés avec des niveaux d�erreur parfois élevés.
Dans ce chapitre, nous avons proposé trois nouvelles formules d�approximationdu prix d�un call Européen en présence de dividendes discrets en nous appuyantsur les résultats de la théorie actuarielle des risques comonotones. Cette ap-proche permet de remplacer la variable aléatoire considérée (dont on ne maîtrisepas la loi de probabilité) par une variable aléatoire "voisine" (au sens de l�ordreconvexe) à la structure interne plus simple et pour laquelle on sait déterminerla distribution et e¤ectuer les calculs. La méthode présentée dans ce chapitre sedécompose en trois étapes : (i) tout d�abord, nous avons écrit le prix de l�optioncomme la transformée stop-loss d�une somme de variables aléatoires lognormalesdépendantes, ensuite (ii) nous avons encadré (au sens de l�ordre convexe) la va-riable précédente par deux sommes comonotones de variables lognormales, en�n(iii) nous avons déterminé les primes stop-loss des deux bornes sous une formeexplicite. Par construction, les formules établies dans la dernière étape du rai-sonnement encadrent le prix de l�option. Nous les avons appelées approximationCLB (Comonotonic Lower Bound) et approximation CUB (Comonotonic UpperBound). Par ailleurs, en combinant les fonctions de répartition de ces bornes,nous avons construit une nouvelle approximation appelée MBA (Moment Ba-sed Approximation) qui possède la même espérance et la même variance que lavariable initiale.
Les approximations CLB et MBA conduisent à un niveau d�erreur relative voisinde 0:002% sur l�ensemble des tests réalisés, ce qui est nettement meilleur quel�ensemble des approximations existantes pour lesquelles l�ordre de grandeurde l�erreur est supérieur à 0:1%. De plus, l�erreur commise varie peu avec leniveau de strike de l�option considérée. Autrement dit, les approximations CLBet MBA permettent d�évaluer avec le même degré de précision les options dansla monnaie, les options à la monnaie et les options en dehors de la monnaie. Nousavons pu observer que ce n�était pas le cas avec les autres approches testées dansce travail.
302

En dérivant les formules d�approximation comonotones, nous avons pu détermi-ner le Delta et le Gamma de l�option sous une forme explicite. L�existence deformules fermées pour les paramètres de couverture de l�option permet d�envisa-ger l�utilisation des formules du chapitre non seulement pour évaluer, mais aussipour répliquer les payo¤s optionnels. Ce point constitue un avantage particuliè-rement intéressant de l�approche comonotone par rapport aux autres solutionsproposées dans la littérature : en e¤et, étant donné que les approximations exis-tantes reposent sur des considérations essentiellement empiriques et conduisentà des biais importants, on peut douter de leur capacité à restituer précisémentles sensibilités de l�option.
L�approche comonotone nous a donc permis d�évaluer le prix d�une optiond�achat Européenne avec une précision supérieure aux approximations exis-tantes. L�approximation basée sur l�identi�cation des moments (MBA) induitune erreur très similaire à l�erreur commise avec l�approximation basée sur laborne inférieure CLB. Si l�on tient compte de l�e¤ort calculatoire supplémentaireinduit pour évaluer la formule (5.48), on peut considérer que la méthode CLBest l�approximation analytique la plus e¢ cace pour déterminer le prix d�uneoption Européenne en présence de dividendes discrets.
303

A Approximations du prix d�un call Européen
A.1 Formules de Black-Scholes-Merton (1973)
Le prix d�un call Européen en l�absence de dividende est donné par la formulede Black et Scholes (1973) et Merton (1973) :
CBSM (S0; �; r;K; T ) = S0��D+��Ke�rT�
�D�� ; (5.52)
où � est la fonction de répartition de la loi normale standard et
D� =ln (S0=K) + rT
�pT
� 12�pT : (5.53)
En calculant les dérivées partielles de CBSM par rapport à S0 on obtient le Deltaet le Gamma de l�option (Hull 2003) :
�BSM = @S0CBSM = ��D+�; �BSM = @2S0CBSM =
' (D+)
S0�pT; (5.54)
où ' est la densité de la loi normale standard, dé�nie sur R par ' (x) =e�x
2=2=p2�.
A.2 Ajustements du cours spot et/ou du strike
Approximation "B75" (Black, 1975)
Black (1975) suggère d�évaluer le call Européen avec la formule (5.52) en rempla-
çant S0 par S0 � �D où �D def=Pmi=1Die
�rti est la valeur actuelle des dividendesfuturs :
CB75 (S0; �;K; r; T ) = CBSM�S0 � �D;�;K; r; T
�: (5.55)
Cette approche sous-estime les prix des calls de manière systématique.
Approximation "BoV02" (Bos et Vandermark, 2002)
Bos et Vandermark (2002) décomposent la valeur actuelle des dividendes futurs(i.e. �D =
Pmi=1Die
�rti) sous la forme �D = D+ �D, où D et �D sont des sommespondérées des dividendes futurs actualisés dé�nies par :
D =mXi=1
tiTDie
�rti ; �D =mXi=1
T � tiT
Die�rti : (5.56)
Par construction, D donne un poids plus important aux dividendes proches dela maturité T de l�option, tandis que �D surpondère les dividendes proches de ladate d�évaluation. Le prix d�un call Européen est obtenu à partir de la formule(5.52) en remplaçant S0 par S0 � �D et K par K + DerT :
CBoV02 (S0; �;K; r; T ) = CBSM
�S0 � �D;�;K + DerT ; r; T
�: (5.57)
304

Cette formule permet de réduire les biais d�évaluation de manière signi�cativepar rapport à la formule (5.55). Toutefois, lorsque les dividendes deviennentarbitrairement élevés elle peut conduire à des erreurs non négligeables.
A.3 Ajustements du cours spot et de la volatilité
Approximation "BV01" (Beneder et Vorst, 2001)
Beneder et Vorst (2001) ajustent le cours S0 selon le procédé de Black et rem-placent la volatilité � par une volatilité �, corrigée en fonction des dividendesattendus :
CBV01 (S0; �;K; r; T ) = CBSM�S0 � �D; �;K; r; T
�: (5.58)
La nouvelle volatilité est dé�nie par la relation suivante
�2 =1
T
0@ mXi=1
�S0
S0 �Pmj=iDje�rtj
!2(ti � ti�1) + �2 (T � tm)
1A : (5.59)
On constate que cette méthode est plus performante que la formule (5.55).Toutefois, cette solution repose sur des considérations empiriques, de sorte qu�iln�est pas possible de garantir la précision des résultats dans toutes les situationsque l�on peut rencontrer.
Approximation "BGS03" (Bos, Gairat et Shepeleva, 2003)
Cette approche repose sur le même principe que celle de Beneder et Vorst : l�idéeest de remplacer la volatilité � dans la formule (5.55) par une volatilité ~� quidépend des dividendes attendus et d�ajuster simultanément le cours initial :
CBGS03 (S0; �;K; r; T ) = CBSM�S0 � �D; ~�;K; r; T
�: (5.60)
La variance modi�ée ~�2 est obtenue par la méthode des perturbations et admetla forme suivante :
~�2 ' �2 + �r
�
2T
h4ea
2=2�s�1 (a) + eb2=2�2s�2 (b)
i; (5.61)
avec
a =ln�S0=
�Ke�rT
���pT
+�pT
2; b = a+
�pT
2:
Les termes �1 (a) et �2 (b) sont donnés par :
�1 (a) =
mXi=1
Die�rti
�� (a)� �
�a� �tip
T
��;
�2 (b) =mX
i;j=1
DiDje�r(ti+tj)
�� (b)� �
�b� 2�min (ti; tj)p
T
��:
305

Selon Haug et al. (2003), cette formule donne des résultats précis dans la plu-part des situations rencontrées. Par contre, elle peut conduire à des erreurssigni�catives lorsque les dividendes sont trop nombreux ou trop élevés.
A.4 Modèle "HHL03" (Haug, Haug et Lewis, 2003)
Les travaux de Haug et al. (2003) partent de l�observation suivante : la plupartdes approximations proposées dans la littérature sont obtenues à partir de consi-dérations essentiellement empiriques et elles peuvent, dans certains cas, conduireà des prix arbitrables ou trop éloignés des prix observés. Les auteurs proposentalors un cadre d�analyse rigoureux pour évaluer des options en présence de di-videndes discrets. Pour cela, ils introduisent des dividendes dynamiques de laforme Di = �(S�i ; Di), où S
�i est le cours avant le détachement, Di est le di-
vidende attendu à la date ti et � est une fonction qui dé�nit la politique dedividende de la �rme. La fonction � est construite de la manière suivante : sile cours avant le détachement est supérieur au dividende attendu Di, alors ledividende est payé en intégralité et, dans le cas contraire, le montant du divi-dende est "revu à la baisse" de manière à ce que le cours après détachementreste positif : �
�(x;Di) = Di si x > Di;�(x;Di) � Di si x � Di
:
La dynamique (5.1) doit être modi�ée pour tenir compte de la politique dedividende : les termes déterministes Di sont remplacés par la fonction aléatoire�(S�i ; Di) :
dSt =
rSt �
mXi=1
�(S�i ; Di)� (t� ti)!dt+ �StdWt: (5.62)
L�approche précédente garantit (par construction) la survie du processus de prixà chaque date de dividende, ce qui permet de modéliser la dynamique des courssur des horizons T arbitrairement longs. En contrepartie, elle rend la gestiondes dividendes discrets relativement délicate, car chaque dividende devient unefonction de la trajectoire de l�actif risqué. Ce modèle "benchmark" pour lesdividendes constitue une analyse pertinente du problème posé par la présencede dividendes discrets et peut être étendu à des processus de prix plus complexesincluant des sauts ou une volatilité stochastique.Les auteurs n�obtiennent pas de formule analytique pour le prix d�une optionEuropéenne, ce qui restreint la portée opérationnelle du modèle. Par contre,ils proposent un algorithme qui permet d�approcher le prix cherché par desintégrations numériques successives (cf. Haug et al. 2003, Haug 2007).
306

Références
Björk T. (2004). Arbitrage Theory in Continuous Time, Second Edition, OxfordUniversity Press.Black F. (1975). �Fact and Fantasy In The Use of Options�, Financial AnalystsJournal, pp. 36-72.Black F., Scholes M. (1973). �The Pricing of Options And Corporate Liabilities�,Journal of Political Economy, Vol. 81, pp. 36-72.Beneder R., Vorst T. (2001). �Options on Dividend Paying Stocks�, Proceedingsof the International Conference on Mathematical Finance, Shanghai.Bos M., Vandermark S. (2002). �Finessing �xed dividends�, Risk Magazine, Vol.9, pp. 157-158.Bos R., Gairat A., Shepeleva A. (2003). �Dealing with discrete dividends�, RiskMagazine, Vol. 1, pp. 109-112.Dhaene J., Denuit M., Goovaerts M.J., Kaas R., Vyncke D. (2000a). �Theconcept of comonotonicity in actuarial science and �nance : Theory�, Insurance :Mathematics And Economics, 31(1), pp. 3-33.Dhaene J., Denuit M., Goovaerts M.J., Kaas R., Vyncke D. (2000b). �Theconcept of comonotonicity in actuarial science and �nance : Applications�, In-surance : Mathematics And Economics, 31(2), pp. 133-161.Frishling V. (2002). �A discrete question�, Risk Magazine, Vol. 15, pp. 115-116.Glasserman P. (2004). Monte Carlo methods in �nancial engineering, Springer.Haug E.G., Haug J., Lewis A. (2003). �Back to Basics : a New Approach to theDiscrete Dividend Problem�, Wilmott Magazine, pp. 37-47.Haug E.G. (2007). The Complete Guide to Option Pricing Formulas, SecondEdition, McGraw-Hill.Hull J. (2003). Options, Futures, and Other Derivatives, Fifth Edition, PrenticeHall.Kaas R., Dhaene J., Goovaerts M.J. (2000). �Upper and lower bounds for sumsof random variables�, Insurance : Mathematics And Economics, 27, pp. 151-158.Lecoutre J.-P. (1998). Statistiques et probabilités, Dunod.Merton R.C. (1973). �Theory of Rational Option Pricing�, Bell Journal OfEconomics and Management Science, Vol. 4, pp. 141-183.Saporta G. (1990). Probabilités, Statistiques, Analyse des données, Technip.Vandu¤el S. (2005). �Comonotonicity : From risk measurement to risk manage-ment�, PhD Thesis, University of Amsterdam.Vandu¤el S., Chen X., Dhaene J., Goovaerts M., Henrard L., Kaas R. (2007).�Optimal Approximations for Risk Measures of Sums of Lognormals based onConditional Expectations�, Journal of Computational and Applied Mathema-tics, to be published.Vandu¤el S., Hoedemakers T., Dhaene J. (2005). �Comparing approximationsfor sums of non-independent lognormal random variables�, North American Ac-tuarial Journal, Vol. 9(4), pp. 71-82.Vyncke D., Goovaerts M., Dhaene J. (2004). �An accurate analytical approxi-mation for the price of a European-style arithmetic Asian option�, Finance, Vol.25, pp. 121-139.
307

Conclusion Générale
Dans cette thèse nous avons étudié deux problématiques rencontrées par le pra-ticien qui souhaite développer un système d�évaluation des produits dérivés suractions : la mise en �uvre des méthodes numériques et la modélisation desparamètres de marché.
La première partie, divisée en deux chapitres, est consacrée à la mise en oeuvredes méthodes de simulation numérique Monte Carlo et Quasi-Monte Carlo pourévaluer des produits dérivés complexes. Elle insiste plus particulièrement surle choix et sur l�implémentation des générateurs uniformes, sur les techniquesde simulation des variables gaussiennes scalaires et vectorielles et sur l�utilisa-tion des méthodes de réduction de variance pour accélérer la convergence desestimateurs.
La seconde partie porte sur la modélisation des paramètres de marché qui inter-viennent dans la dynamique des prix d�une action. Les deux premiers chapitresabordent respectivement la construction de la courbe des taux zéro-coupon et laconstruction de la surface de volatilité implicite sous l�hypothèse d�absence d�op-portunité d�arbitrage. Le troisième chapitre porte sur l�évaluation d�une optionEuropéenne en présence de dividendes discrets dont les montants sont connus àl�avance.
Synthèse des principaux résultats
Nous rappelons ci-dessous les principaux résultats obtenus dans cette étude.
Intégration probabiliste Monte Carlo
Le générateur à opérations binaires Mersenne Twister MT19937 est tout à faitadapté à la simulation numérique intensive (Matsumoto et Nishimura 1998). Enle combinant avec l�approximation de la fonction inverse gaussienne proposéepar Acklam (2000), on peut générer e¢ cacement des réalisations indépendantesde la loi normale standard. Pour simuler des vecteurs gaussiens à composantescorrélées, nous conseillons de décomposer la matrice des corrélations avec l�al-gorithme de triangulation de Cholesky. En�n, la technique des variables anti-
308

thétiques et la technique de Monte Carlo adaptative peuvent être utilisées demanière systématique pour réduire la variance de l�estimateur Monte Carlo.
Intégration déterministe Quasi-Monte Carlo
La suite de Richtmyer (1951) et la suite de Halton (1960) modi�ée par Chi et al.(2005) sont deux générateurs quasi-aléatoires e¢ caces qui permettent de traiterdes problèmes d�intégration numérique en dimension élevée. En randomisant cessuites à l�aide d�un générateur aléatoire, on peut mettre en �uvre la méthodedite de Quasi-Monte Carlo Randomisée, de pro�ter de la convergence rapidede la méthode de Quasi-Monte Carlo et d�estimer l�erreur d�intégration commedans la méthode de Monte Carlo.Cette approche utilisée comme technique pour réduire la variance de l�estimateurMonte Carlo s�avère largement plus e¢ cace que les méthodes de réduction devariance classiques.
Construction d�une courbe zéro-coupon
Les courbes de taux zéro-coupon utilisées pour l�évaluation des produits dérivéspeuvent être construites à partir des taux de deposits et des taux de swaps,indexés sur des références de taux interbancaires. Lorsque l�on interpole les tauxzéro-coupon, il faut veiller à ne pas introduire d�opportunité d�arbitrage dans lesdonnées. L�interpolation par splines cubiques naturels, fréquemment présentéedans la littérature, peut conduire à des courbes de taux arbitrables. Pour obtenirdes courbes de taux non-arbitrables de manière systématique, on peut utiliserla méthode d�interpolation RT-Linéaire (RTL) ou la méthode d�interpolationRT-Cubique-Monotone (RTCM). La méthode RTL, bien connue des praticiens,conduit à des taux forwards instantanés discontinus.La méthode RTCM est une approche nouvelle basée sur les splines cubiquescontraints. Elle permet d�obtenir des taux forwards continus.
Construction de la surface de volatilité implicite
La surface de volatilité implicite contient une information précieuse sur la dyna-mique du sous-jacent. Construire cette surface est un problème "mal-posé", caron dispose de quelques prix d�options pouvant présenter des arbitrages à partirdesquels on doit générer une surface de volatilité complète et non-arbitrable.La procédure GSF proposée dans le chapitre permet d�accomplir cette tâcheen trois étapes. La première étape consiste à lisser et à extrapoler le smile devolatilité sur la première maturité avec le modèle SVI de Gatheral (2004). Laseconde étape utilise les Thin Plate Splines (TPS) pour générer une surface devolatilité complète à partir du smile de la première maturité et des donnéesobservées aux autres maturités. La troisième étape permet de supprimer lesarbitrages en opérant un lissage sous contraintes des prix d�options (Fengler2005b).
309

Evaluation d�un call Européen en présence de dividendes discrets
Lorsque les montants des dividendes sont connus à l�avance, la détermination duprix d�une option Européenne revient à calculer la transformée stop-loss d�unesomme de variables aléatoires lognormales dépendantes.En appliquant les résultats de la théorie actuarielle des risques comonotonesnous avons obtenu une formule fermée qui permet : (i) d�approcher le prix del�option avec une précision accrue par rapport aux approximations existantes et(ii) de déterminer le Delta et le Gamma de l�option sous une forme explicite.La formule se généralise lorsque les montants de dividendes sont des fonctionsa¢ nes du sous-jacent.
Perspectives et ouvertures
Les produits dérivés comme source de diversi�cation des portefeuilles
Le montage de fonds à formule ne constitue pas la seule manière d�investir sur desproduits dérivés. On peut aussi envisager d�utiliser les produits dérivés commeune classe d�actifs à part entière permettant de diversi�er des portefeuilles plusconventionnels.
Une première façon consiste à investir sur des produits tels que les variance swapsou les correlation swaps. Ce qui revient à parier non pas sur l�évolution du coursd�un titre (action ou obligation), mais sur l�évolution d�un paramètre statistiquedu marché qui, par dé�nition, n�est pas un actif négociable. Dans les périodesoù les marchés ne présentent aucune tendance, les investissements classiques neprocurent que des rendements modestes, tandis que les investissements sur lavolatilité ou la corrélation peuvent s�avérer très rémunérateurs.
Une seconde façon consiste à intégrer les produits structurés sur action/indicedans les stratégies d�allocation de portefeuille. On peut alors chercher à déter-miner un portefeuille optimal composé de titres purs et de produits dérivés surces titres qui introduisent une exposition non-linéaire à l�évolution des marchés.Certaines banques d�investissement ont commencé à travailler sur les problé-matiques soulevées par ce type d�allocation hybride, notamment sur le choixde la mesure de risque (variance, Value-at-Risk. . . ) qui exerce une in�uenceconsidérable sur la composition du portefeuille optimal.
Les techniques de simulation numérique
L�augmentation de la puissance de calcul des ordinateurs (généralisation desprocesseurs multi-c�urs) milite en faveur d�un recours systématique aux tech-niques de simulation numérique. Cela va permettra aux spécialistes des produitsdérivés de travailler sur des modèles de marché toujours plus réalistes et d�éva-luer avec précision des payo¤ exotiques de plus en plus complexes.
310

On peut penser que les techniques de simulation aléatoire vont, elles aussi, évo-luer au cours des années à venir. Au sujet des générateurs de nombres aléatoires,deux évolutions semblent se dessiner. La première concerne la conception desgénérateurs qui sera de plus en plus élaborée autour de l�architecture internedes ordinateurs. La thèse de Panneton (2004) donne une idée de ce que serontles générateurs du futur. La seconde évolution se situe au niveau de la na-ture même des générateurs. Certains spécialistes envisagent en e¤et de réaliserles simulations numériques avec des générateurs cryptographiques, aujourd�huiutilisés pour sécuriser des données sensibles (Sugita 2004). Cela représente unvéritable dé�, car si ces générateurs sont plus imprédictibles que les générateurs"classiques", ils sont, pour l�instant, nettement plus lents.
Les modèles de marché
Les modèles de marché que l�on utilise aujourd�hui sont particulièrement com-plexes et pourtant ils ne parviennent pas à capturer certaines propriétés desséries �nancières telles que la présence de mémoire longue dans la volatilité(Cont 2001). A ce propos, les processus multifractals tels que le modèle MMAR(Multifractal Model of Asset Returns) proposé par Calvet et Fisher (2001, 2002)semblent donner des résultats très réalistes. Mais ces modèles ne permettent pasencore d�évaluer les produits optionnels.
Une autre voie de modélisation envisageable est celle des modèles à facteurs derisques. On sait que certains chi¤res économiques (taux de chômage, variationdes taux directeurs des banques centrales, taux d�in�ation. . . ) peuvent avoirun impact non négligeable sur l�évolution des taux d�intérêt ainsi que sur lescours boursiers. Intégrer de manière exhaustive l�ensemble de ces facteurs derisques dans un modèle de marché est une tâche irréalisable. En revanche, onpeut tenter d�isoler les principaux facteurs de risques qui in�uencent l�évolutionde la variable qui nous intéresse par une méthode statistique telle que l�Ana-lyse en Composantes Principales. Cette approche donne des résultats promet-teurs pour identi�er les facteurs de risques qui expliquent les déformations de lacourbe de taux (Martellini et Priaulet 2004) ou de la surface de volatilité impli-cite (Hafner 2004, Fengler 2005a). Les modèles de marché à facteurs de risquessemblent constituer une voie de modélisation intéressante, car ils permettent des�a¤ranchir des contraintes imposées par les modèles paramétriques.
311

Bibliographie
[1] Aboura S. (2005). Les Modèles de volatilité et d�options, Publibook.[2] Acklam P.J. (2000). �An algorithm for computing the inverse normal cu-
mulative distribution function�, Technical Paper, http://home.online.no/~pjacklam/notes/invnorm/.
[3] Adams K. (2001). �Smooth Interpolation of Zero Curves�, Algo ResearchQuarterly, Vol. 4, pp. 11-22.
[4] Alentorn A. (2004). �Modelling the implied volatility surface : an empi-rical study for FTSE options�, Working Paper, Centre of ComputationalFinance and Economic Agents, University of Essex, http://privatewww.essex.ac.uk/~aalent/.
[5] Almeida C., Vicente J. (2007). �The Role of No-Arbitrage on ForecastingLessons from a Parametric Term Structure Model�, Working Paper, No.657, Graduate School of Economics, Rio de Janeiro.
[6] AMF (2002). �La régulation des OPCVM à formule�, Bulletin MensuelCOB, No. 374, Décembre, http://www.amf-france.org/documents/general/4423_1.pdf.
[7] AMF (2003a). �Valorisation des instruments dérivés complexes utilisés engestion pour compte de tiers�, Bulletin Mensuel COB, No. 381, JuilletAoût, http://www.amf-france.org/documents/general/4755_1.pdf.
[8] AMF (2003b). �La valorisation des instruments dérivés complexes - Pointsur les moyens à mettre en �uvre �, Document d�Information, Auto-rité des Marchés Financiers, http://www.amf-france.org/documents/general/5078_1.pdf.
[9] AMF (2004). �Présentation règlement de l�AMF modi�ant le règlement dela COB n� 2003-08�, Revue Mensuelle de l�Autorité des Marchés Finan-ciers, No. 1, http://www.amf-france.org/documents/general/5311_1.pdf.
[10] AMF (2007a). �Règlement Général De l�Autorité des Marchés Financiers�Livre IV �Produits d�Epargne Collective�, Autorité des Marchés Finan-ciers, http://www.amf-france.org/documents/general/8091_1.pdf.
[11] AMF (2007b). �Le Prospectus�, Document d�Information, Auto-rité des Marchés Financiers, http://www.amf-france.org/documents/general/7709_1.pdf.
312

[12] Andersen L., Brotherton-Ratcli¤e R. (1997). �The equity option volatilitysmile : an implicit �nite-di¤erence approach�, Journal of ComputationalFinance, Vol. 1, No. 2, pp. 5-38.
[13] Argou P. (2003). �Construction des Distributions de Rendements de Pro-duits Structurés Complexes�, Mémoire d�actuaire, Institut de Science Fi-nancière et d�Assurances, Université Claude Bernard Lyon 1.
[14] Argou P. (2006). �Construction de Surfaces de Volatilité pour l�Evaluationde Produits Structurés Complexes et Introduction aux Nouveaux Instru-ments Dérivés de Volatilité�, Mémoire de DEA, Institut de Science Finan-cière et d�Assurances, Université Claude Bernard Lyon 1.
[15] Arouna B. (2004). �Adaptative Monte Carlo Method, A Variance Reduc-tion Technique�, Monte Carlo Methods and Applications, Vol. 10, No. 1,pp. 1-24.
[16] Augros J.-C., Moreno M. (2002). Les Dérivés Financiers et d�Assurance,Economica.
[17] Bachman G., Narici L., Beckenstein E. (2000). Fourier and Wavelet Ana-lysis, Springer-Verlag, New York.
[18] Bakshi G., Cao C., Chen Z. (1997). �Empirical Performance of AlternativeOption Pricing Models�, Journal of Finance, Vol. 52, pp. 2003-2049.
[19] Bates D.S. (1996). �Jumps and Stochastic Volatility : Exchange Rate Pro-cess Implicit in Deutsche Mark Option�, Review of Financial Studies,Vol.9, No. 1, pp. 69-107.
[20] Bates D.S. (2000). �Post-�87 crash fears in the S&P500 futures optionmarket�, Journal of Econometrics, Vol. 94, pp. 181-238.
[21] Beasley J.D., Springer S.G. (1977). �Algorithm AS 111. The percentagepoints of the normal distribution�, Applied Statistics, 26, pp. 118-121.
[22] Bekker P.A., Bouwman K.E. (2007). �Arbitrage Smoothing in Fitting aSequence of Yield Curves�, Working Paper, Department of Economics,University of Groningen.
[23] Beneder R., Vorst T. (2001). �Options on Dividend Paying Stocks�, Pro-ceedings of the International Conference on Mathematical Finance, Shan-ghai.
[24] Benhamou E. (2007). Global Derivatives �Products, Theory and Practice,World Scienti�c.
[25] Benko M. (2006). �Functional Data Analysis with Applications in Fi-nance�, Ph.D. Thesis, Humboldt-Universität, Berlin.
[26] Bernadell C., Coche J., Nyholm K. (2005). �Yield Curve Prediction forThe Strategic Investor�, ECB Working Paper Series, No. 472, EuropeanCentral Bank, Frankfurt am Main.
[27] BIS (2005). �Zero-Coupon Yield Curves : Technical Documentation�, Bankfor International Settlements, Basle.
313

[28] Björk T. (2004). Arbitrage Theory in Continuous Time, Second Edition,Oxford University Press.
[29] Björk T., Christensen B. (1999). �Interest Rate Dynamics and ConsistentForward Rate Curves�, Mathematical Finance, pp. 323-348.
[30] Black F. (1975). �Fact and Fantasy In The Use of Options�, FinancialAnalysts Journal, pp. 36-72.
[31] Black F., Scholes M. (1973). �The Pricing of Options And Corporate Lia-bilities�, Journal of Political Economy, Vol. 81, pp. 36-72.
[32] Bliss R.R. (1997). �Testing Term Structure Estimation Methods�, Ad-vances in Futures and Options Research, Vol. 9, pp. 197-231.
[33] Bolder D.J., Gusba S. (2002). �Exponentials, Polynomials, and FourierSeries : More Yield Curve Modelling at the Bank of Canada�, WorkingPaper 2002-29, Bank of Canada.
[34] Bos M., Vandermark S. (2002). �Finessing �xed dividends�, Risk Magazine,Vol. 9, pp. 157-158.
[35] Bos R., Gairat A., Shepeleva A. (2003). �Dealing with discrete dividends�,Risk Magazine, Vol. 1, pp. 109-112.
[36] Bouchard-Denize B. (2006). Méthodes de Monte Carlo en Finance, Notesde cours, Université de Paris VI.
[37] Bouleau N., Lépingle D. (1993). Numerical methods for stochastic pro-cesses, John Wiley & Sons Ltd.
[38] Boyle P.P. (1977). �Option : a Monte Carlo approach�, Journal of Finan-cial Economics, Vol. 4, pp. 323-338.
[39] Boyle P.P., Broadie M., Glasserman P. (1995). �Recent Advances in Simu-lation For Security Pricing�, Proceedings of the 1995 Winter SimulationConference.
[40] Boyle P.P., Tan K.S. (1997). �Quasi-Monte Carlo Methods�, Proceedingof AFIR Conference in Cairns, Australia.
[41] Breeden D.T., Litzenberger R.H. (1978). �Price of contingent claims im-plicit in options prices�, Journal of Business, Vol. 51, pp. 621-651.
[42] Brigo D., Mercurio F. (2006). Interest Rate Models - Theory and Practice,With Smile, In�ation and Credit, Springer.
[43] Brown G., Randall C. (1999).�If the skew �ts�, Risk Magazine, Vol. 12,pp. 62-65.
[44] Bruno M.G. (1991). �Calculation methods for evaluating asian options�,Working Paper.
[45] Buehler H. (2006). �Expensive Martingales�, Quantitative Finance, Vol.6, No. 2, pp. 207-218.
[46] Calvet L., Fisher A. (2001). �Forecasting multifractal volatility�, Journalof Econometrics 105 (1), pp. 27-58.
314

[47] Calvet L., Fisher A. (2002). �Multifractality in asset returns : Theory andevidence�, The Review of Economics and Statistics, Vol. 84, No. 3, pp.381-406.
[48] Carr P., Madan D.P. (2005). �A note on su¢ cient conditions for no arbi-trage�, Finance Research Letters, Vol. 2, No. 3, pp. 125-130.
[49] Chazot C., Claude P. (1995). Les swaps, Concepts et Applications, SecondeEdition, Economica.
[50] Chen C.-M., Bhatia R., Sinha R.K. (2003). �Multidimensional DeclusteringSchemes using Golden Ratio and Kronecker Sequences�, IEEE Transac-tions on Knowledge and Data Engineering, pp. 659-670.
[51] Cherif M. (2000). Les taux d�intérêt, Banqueéditeur.
[52] Chi H. (2004). �Scrambled Quasirandom Sequences And Their Applica-tions�, PhD Thesis, The Florida State University.
[53] Chi H., Mascagni M., Warnock T. (2005). �On the optimal Halton se-quence�, Mathematics and Computers in Simulation 70, pp. 9-21.
[54] Christie D. (2003). �Accrued Interest & Yield Calculations and Determina-tion of Holiday Calendars�, Technical Document, SWX Swiss Exchange.
[55] Coleman T.F., Li Y., Verma A. (1999). �Reconstructing The UnknownLocal Volatility Function�, Journal of Computational Finance, Vol. 2, No.3, pp. 77-102.
[56] Cont R. (2001). �Empirical properties of asset returns : Stylized facts andstatistical issues�, Quantitative Finance, Vol. 1, No. 2, pp. 223-236.
[57] Coroneo L., Nyholm K., Vidova-Koleva R. (2008). �How Arbitrage-Free IsThe Nelson-Siegel Model ?�, ECB Working Paper Series, No. 874, Euro-pean Central Bank, Frankfurt am Main.
[58] Corrado C.J., Su T. (1998). �An Empirical Test of Hull-White OptionPricing Model�, Journal of Futures Markets, Vol. 4, pp. 363-378.
[59] Coulibaly I. (1997). �Contributions à l�analyse numérique des méthodesquasi-Monte Carlo�, Thèse de Doctorat, Université Joseph Fourier-Grenoble 1.
[60] Cox J.C., Ross S.A. (1976). �The valuation of options for alternative sto-chastic processes�, Journal of Financial Economics, Vol. 3, Issues 1-2, pp.145-166.
[61] Cox J.C. (1996). �The constant elasticity of variance option pricing model�,Journal of Portfolio Management, pp. 15-17.
[62] Cranley R., Patterson T.N.L. (1976). �Randomization of Number Theore-tic Methods for Multiple Integration�, SIAM Journal on Numerical Ana-lysis, Vol. 13, No. 6, pp. 904-914.
[63] Crozet M. (2007). �Reconstruction de nappes de volatilité implicite�, Mé-moire d�Actuariat, Université Paris Dauphine.
315

[64] Daglish T., Hull J.C., Suo W. (2007). �Volatility Surfaces : Theory, Rulesof Thumb, and Empirical Evidence�, Quantitative Finance, Vol. 7, No. 5,pp. 507-524.
[65] Da Silva M.E., Barbe T. (2005). �Quasi Monte Carlo in Finance : Exten-ding for High Dimensional Problems�, Economia Aplicada, Vol. 9, No. 4,pp. 577-594.
[66] Demeter� K., Derman E., Kamal M., Zou J. (1999). �More Than YouEver Wanted To Know About Volatility Swaps�, Quantitative StrategiesResearch Notes, Goldman Sachs.
[67] De Pooter M. (2007). �Examining the Nelson-Siegel Class of Term Struc-ture Models�, Tinbergen Institute Discussion Paper, Faculty of Econo-mics, Erasmus University, Rotterdam.
[68] De Pooter M., Ravazzolo F., Van Dijk D. (2007). �Predicting the TermStructure of Interest Rates�, Working Paper, Econometric Institute andTinbergen Institute, Erasmus University, Rotterdam.
[69] Derman E., Kani I. (1994a). �The Volatility Smile and Its Implied Tree�,Quantitative Strategies Research Notes, Goldman Sachs.
[70] Derman E., Kani I. (1994b). �Riding On a Smile�, Risk Magazine, Vol. 7,pp. 32-39.
[71] Devroye L. (1986). Non-Uniform Random Variate Generation, Springer-Verlag, New York.
[72] Dhaene J., Denuit M., Goovaerts M.J., Kaas R., Vyncke D. (2000a). �Theconcept of comonotonicity in actuarial science and �nance : Theory�, In-surance : Mathematics And Economics, 31(1), pp. 3-33.
[73] Dhaene J., Denuit M., Goovaerts M.J., Kaas R., Vyncke D. (2000b). �Theconcept of comonotonicity in actuarial science and �nance : Applications�,Insurance : Mathematics And Economics, 31(2), pp. 133-161.
[74] Diebold F., Li C. (2006). �Forecasting the term structure of governmentbond yields�, Journal of Econometrics 130, pp. 337-364.
[75] Diebold F., Li C., Yue V.Z. (2006). �Global Yield Curve Dynamics andInteractions : A Generalized Nelson-Siegel Approach�, Working Paper,http://www.ssc.upenn.edu/~fdiebold.
[76] Drmota M., Tichy R.F. (1997). Sequences, Discrepancies, and Applica-tions, Lecture Notes in Mathematics 1651, Springer-Verlag.
[77] Duchon J. (1976). �Splines Mimizing Rotation-Invariant Semi-Norms InSobolev Spaces�, Constructive Theory of Functions of Several Variables,Vol. 1, pp. 85-100.
[78] Dumas B., Fleming J., Whaley R.E. (1998). �Implied volatility functions :empirical tests�, Journal of Finance, Vol. 53, No. 6, pp. 2059-2106.
[79] Dupire B. (1994). �Pricing with a smile�, Risk Magazine, Vol. 7, pp. 18-20.
[80] Eberly D. (2002). �Thin Plate Splines�, Technical Paper, Geometric Tools,Inc., http://www.geometrictools.com.
316

[81] ECB (2007). �General description of ECB yield curve methodology�, Eu-ropean Central Bank, Frankfurt am Main.
[82] Faure H. (1981). �Discrépance de suites associées à un système de numé-ration (en dimension 1)�, Bulletin de la S.M.F., Tome 109, pp. 143-182.
[83] Faure H. (1982). �Discrépance de suites associées à un système de numé-ration (en dimension s)�, Acta Arithmetica, Vol. 41, pp. 337-351.
[84] Faure H., Lemieux C. (2007). �Generalized Halton Sequences in 2007 :A Comparative Study�, Papier de Recherche, Institut Mathématiquede Luminy, http://iml.univ-mrs.fr/editions/preprint2007/files/faure_HFL.pdf.
[85] Fengler M.R. (2005a). Semiparametric Modeling of Implied Volatility,Springer-Verlag.
[86] Fengler M.R. (2005b). �Arbitrage-Free Smoothing of the Implied Volati-lity Surface�, SFB 649 Discussion Paper 2005-019, Humboldt-Universität,Berlin.
[87] Finschi L. (1996). �Quasi-Monte Carlo : An Empirical Study onLow-Discrepancy Sequences�, Working Paper, Eidgenössische TechnischeHochschule Zürich.
[88] Fishman G.S., Huang B.D. (1983). �Antithetic Variates Revisited�, Com-munications of the ACM, 26, pp. 964-971.
[89] Frishling V. (2002). �A discrete question�, Risk Magazine, Vol. 15, pp.115-116.
[90] Fritsch F.N., Butland J. (1984). �A Method For Constructing Local Mo-notone Piecewise Cubic Interpolation�, SIAM Journal on Scienti�c Com-puting, Vol. 5, No. 2, pp. 300-304.
[91] Fritsch F.N., Carslon R.E. (1980). �Monotone Piecewise Cubic Interpola-tion�, SIAM Journal on Numerical Analysis, Vol. 17, No. 2, pp. 238-246.
[92] Galanti S., Jung L. (1997). �Low Discrepancy Sequences : Monte CarloSimulation of Option Prices�, The Journal Of Derivatives, pp. 63-83.
[93] Gasparo M.G., Morandi R. (1991). �Piecewise Cubic Monotone Interpo-lation with Assigned Slopes�, Computing, Vol. 46, pp. 355-365.
[94] Gatheral J. (2004). �A parsimonious arbitrage-free implied volatility pa-rameterisation with application to the valuation of volatility derivatives�.In TDTF Derivatives Day, Amsterdam.
[95] Gatheral J. (2006). The Volatility Surface : A Practitioner�s Guide, WileyFinance.
[96] Gentle J.E. (2003). Random Number Generation and Monte Carlo Me-thods, Second Edition, Springer-Verlag.
[97] Geyer A., Mader R. (1999). �Estimation of the Term Structure of InterestRates : A Parametric Approach�, OeNB Working Paper Series, No. 37,Oesterreichische Nationalbank.
317

[98] Glasserman P. (2004). Monte Carlo methods in �nancial engineering,Springer.
[99] Haber S. (1966). �A Modi�ed Monte-Carlo Quadrature�, Mathematics ofComputation, Vol. 20, No. 95, pp. 361-368.
[100] Haber S. (1970). �Numerical Evaluation of Multiple Integrals�, SIAM Re-view, Vol. 12, No. 4, pp. 481-526.
[101] Hafner R. (2004). Stochastic Implied Volatility : A Factor-Based Model,Springer-Verlag.
[102] Hafner R., Wallmeier M. (2001). �The Dynamics of DAX Implied Vola-tilities�, International Quarterly Journal of Finance, Vol. 1, No. 1, pp.1-27.
[103] Hagan P.S., West G. (2006). �Interpolation Methods For Curve Construc-tion�, Applied Mathematical Finance, Vol. 13, No. 2, pp. 89-129.
[104] Halton J.H. (1960). �On the e¢ ciency of certain quasi-random sequences ofpoints in evaluating multi-dimensional integrals�, Numerische Mathematik2, pp. 84-90.
[105] Hammersley J.M., Handscomb D.C. (1964). Monte Carlo Methods, Me-thuen, London.
[106] Hammersley J.M., Morton K.W. (1956). �A New Monte Carlo Technique :Antithetic Variates�, Proceedings of the Cambridge Philosophical Society,52, pp. 449-475.
[107] Harrison J., Kreps D. (1979). �Martingales and arbitrage in multiperiodsecurities markets�, Journal of Economic Theory, Vol. 20, pp. 381-408.
[108] Harrison J., Pliska S. (1981). �Martingales and stochastic integral in thetheory of continuous trading�, Stochastic Processes and their Applications,Vol. 11, pp. 215-260.
[109] Haug E.G., Haug J., Lewis A. (2003). �Back to Basics : a New Approachto the Discrete Dividend Problem�, Wilmott Magazine, pp. 37-47.
[110] Haug E.G. (2007). The Complete Guide to Option Pricing Formulas, Se-cond Edition, McGraw-Hill.
[111] Heng L., Qinghua L., Fengshan B. (2005). �A Class of Random NumberGenerators Based on Weyl Sequence�, Applied Mathematics-A Journal ofChinese Universities, Vol. 20, No. 4, pp. 483-490.
[112] Hentschel L. (2003). �Errors in Implied Volatility Estimation�, Journal ofFinancial and Quantitative Analysis, Vol. 38, Issue 4, pp. 779-810.
[113] Herring C., Palmore J.I. (1989). �Random Number Generators Are Chao-tic�, Communications of the ACM, 38, pp. 121-127.
[114] Heston S. (1993). �A Closed-Form Solution for Options with StochasticVolatility with Applications to Bond and Currency Options�, The Reviewof Financial Studies, Vol. 6, No. 2, pp. 327-343.
318

[115] Hofbauer H., Uhl A., Zinterhof P. (2006a). �Zinterhof Sequences in GRID-Based Numerical Integration�, Monte Carlo and Quasi-Monte Carlo Me-thods 2006 (A. Keller, S. Heinrich, H. Niederreiter Eds.), Springer, pp.495-510.
[116] Hofbauer H., Uhl A., Zinterhof P. (2006b). �A Pragmatic View on Numeri-cal Integration of Unbounded Functions�, Monte Carlo and Quasi-MonteCarlo Methods 2006 (A. Keller, S. Heinrich, H. Niederreiter Eds.), Sprin-ger, pp. 511-528.
[117] Hofstetter E., Selby M.J.P. (2001). �The Logistic Function and ImpliedVolatility : Quadratic Approximation and Beyond�, Working Paper, War-wick Business School, University of Warwick, United Kingdom.
[118] Hull J. (2003). Options, Futures, and Other Derivatives, Fifth Edition,Prentice Hall.
[119]Hull J., White A. (1987). �The Pricing of Options on Assets with StochasticVolatilities�, The Journal of Finance, Vol. 42, pp. 281-300.
[120] ISDA (2006). �2006 ISDA De�nitions�, International Swaps And Deriva-tives Association, http://www.isda.org/.
[121] Jäckel P. (2002). Monte Carlo methods in �nance, John Wiley & Sons.[122] Jäckel P. (2006). �By Implication�, Working Paper, http://www.jaeckel.
org/ByImplication.pdf.[123] Jacod J., Protter P. (2003). L�essentiel en théorie des probabilités, Cassini.[124] James F., Hoogland, J., Kleiss R. (1997). �Multidimensional sampling for
simulation and integration : measures, discrepancies, and quasi-randomnumbers�, Computer Physics Communications, Vol. 99, No. 2, pp-180-220.
[125] Judd K.L. (1998). Numerical Methods in Economics, The MIT Press.[126] Judd K.L. (2006). �O�Curse of Dimensionality, Where is Thy Sting ?�,
Proceedings of CEF2006, Cyprus.[127] Kaas R., Dhaene J., Goovaerts M.J. (2000). �Upper and lower bounds for
sums of random variables�, Insurance : Mathematics And Economics, 27,pp. 151-158.
[128] Kalev P. (2004). �Estimating and Interpreting Zero Coupon and ForwardRates : Australia 1992-2001�, Working Paper, Department of Accountingand Finance, Monash University.
[129] Kermiche L. (2007). �Une modélisation de la surface de volatilité implicitepar processus à sauts�, Communication, AFFI 2007.
[130] Klimasauskas C. (2003a). �Not Knowing Your Random Number Gene-rator Could Be Costly : Random Generators - Why Are They Impor-tant�, Information Article, Advanced Technology For Developers Group,http://www.klimasauskas.com/pub_rng.php.
[131] Klimasauskas C. (2003b). �Testing Your Random Number Generator�,Information Article, Advanced Technology For Developers Group, http://www.klimasauskas.com/pub_rng.php.
319

[132] Knuth D.E. (1998). The Art of Computer Programming, Volume 2 : Se-minumerical Algorithms, Third edition, Addison-Wesley.
[133] Kocis L. , Whiten W.J. (1997). �Computational investigations of low-discrepancy sequences�, ACM Transactions on Mathematical Software 23,No. 2, pp. 266-294.
[134] Korn R., Korn E. (2001). Option Pricing and Portfolio Optimization :Modern Methods of Financial Mathematics, Graduate Studies in Mathe-matics, Vol. 31, American Mathematical Society.
[135] Kou S. (2002). �A jump di¤usion model for option pricing�, ManagementScience, Vol. 48, pp. 1086-1101.
[136] Kruger C.J.C. (2003). �Constrained Cubic Spline Interpolation for Che-mical Engineering Applications�, http://www.korf.co.uk/spline.pdf.
[137] Kuipers L., Niederreiter H. (1974). Uniform Distribution of Sequences,John Wiley & Sons.
[138] Lachaud A., Leclanche G. (2003). �Génération de nombres aléatoires parnumérisation d�impulsions radiatives�, Rapport de �n d�études, Maîtrised�Electronique, Université de Limoges.
[139] Lamberton D., Lapeyre B. (1997). Introduction au calcul stochastique ap-pliqué à la �nance, Ellipse.
[140] Langlois M. (1999). �Cryptographie quantique - solution au problème dedistribution de clefs secrètes�, Papier de recherche, Université d�Ottawa.
[141] Larcher G. (1988). �On the distribution of s-dimensional Kronecker se-quences�, Acta Arithmetica, Vol. 51, pp. 335-347.
[142] Laurent J.-P., Leisen D. (1998). �Building a Consistent Pricing Modelfrom Observed Option Prices�, Stanford University, Hoover Institution,Discussion Paper No. B-443.
[143] Laurini M.P. (2007). �Imposing No-Arbitrage Conditions In Implied Vo-latility Surfaces Using Constrained Smoothing Splines�, Ibmec WorkingPaper, wpe_87, Ibmec São Paulo.
[144] Lebrere A., Talhi R., Tripathy M., Pyée M. (2001). �A quick and easyimprovement of Monte Carlo codes for simulation�, Proceedings of ISSS-6.
[145] Lecoutre J.-P. (1998). Statistiques et probabilités, Dunod.
[146] Lee R.W. (2004). �The Moment Formula for Implied Volatility at ExtremeStrikes�, Mathematical Finance, Vol. 14, No. 3, pp. 469-480.
[147] Lee R.W. (2005). �Implied Volatility : Statics, Dynamics, and ProbabilisticInterpretation�, Recent Advances in Applied Probability (R. Baeza-Yates,J. Glaz, H. H. Gzyl, J. Hüsler, J.L. Palacios Eds.), Springer, pp. 241-268.
[148] Lemieux C. (2008). Monte Carlo and Quasi-Monte Carlo Sampling, Sprin-ger (to appear).
320

[149] Lempereur P. (2004). �Pricing et couverture dans un modèle de Bates�,Mémoire d�Actuariat, Ecole Nationale de la Statistique et de l�Adminis-tration Economique.
[150] Lewis A. (2000). Option Valuation under stochastic Volatility (With Ma-thematica Code), Finance Press, Newport Beach, Califormia, USA.
[151] L�Ecuyer P. (1988). �E¢ cient and Portable Combined Random NumberGenerators�, Communications of the ACM, 31, pp. 742-749 and 774.
[152] L�Ecuyer P. (1996). �Combined Multiple Recursive Generators�, Opera-tions Research, Vol. 44, No. 5, pp. 816-822.
[153] L�Ecuyer P. (1998a). �Random Number Generators and Empirical Tests�,Lecture Notes in Statistics 127, Springer-Verlag, pp. 124-138.
[154] L�Ecuyer P. (1998b). �Uniform Random Number Generators�, Proceedingsof the 1998 Winter Simulation Conference, IEEE Press, pp. 97-104.
[155] L�Ecuyer P. (1999). �Good parameters and implementations for combinedmultiple recursive random number generators�, Research Paper, Univer-sité de Montréal - DIRO.
[156] L�Ecuyer P. (2001). �Software for uniform random number generation :distinguishing the good and the bad�, Proceedings of the 2001 WinterSimulation Conference, IEEE Press, pp. 95-105.
[157] L�Ecuyer P. (2004a). �Random Number Generation�, Chapter 2 of theHandbook of Computational Statistics, (J.E. Gentle, W. Haerdle, and Y.Mori Eds.), Springer-Verlag, pp. 35-70.
[158] L�Ecuyer P. (2004b). �Quasi-Monte Carlo Methods in Finance�, Procee-dings of the 2004 Winter Simulation Conference.
[159] L�Ecuyer P., Panneton F. (2000). �A New Class of Linear Feedback ShiftRegister Generators�, Proceedings of the 2000 Winter Simulation Confe-rence, pp. 690-696.
[160] L�Ecuyer P., Simard R. (2005). �TestU01 - A software Library in ANSIC for Empirical Testing of Random Number Generators, User�s guide(compact version)�, Université de Montréal - DIRO, http://www.iro.umontreal.ca/~simardr/.
[161] Lyche T., Mørken K. (2006). �Spline Methods, Lecture Notes�, Depart-ment of Informatics, University of Oslo http://home.ifi.uio.no/tom.
[162] Martellini L., Priaulet P. (2004). Produits de taux d�intérêt, Méthodes dy-namiques d�évaluation et de couverture, Seconde Edition, Economica.
[163]Marsaglia G. (1996). �DIEHARD, a battery of tests of randomness�, http://www.stat.fsu.edu/pub/DIEHARD/.
[164] Marsaglia G. (2003). �Seeds for random number generators�, Communi-cations of the ACM, 46, pp. 90-93.
[165]Matsuda K. (2004). �Introduction to Merton Jump Di¤usion Model�, Wor-king Paper, Department of Economics, The Graduate Center, New York,http://www.maxmatsuda.com/.
321

[166] Matsumoto M., Kurita Y. (1992). �Twisted GFSR generators�, ACMTransactions on Modeling and Computer Simulation, 2, pp. 179-194.
[167] Matsumoto M., Kurita Y. (1994). �Twisted GFSR generators II�, ACMTransactions on Modeling and Computer Simulation, 4, pp. 254-266.
[168] Matsumoto M., Nishimura T. (1998). �Mersenne Twister : A 623-dimensionally equidistributed uniform pseudorandom number generator�,ACM Transactions on Modeling and Computer Simulation, 8, pp. 3-30.
[169] McCulloch J.H. (1971). �Measuring the term structure of interest rates�,The Journal of Business, Vol. 44, pp. 19-31.
[170] McCulloch J.H. (1975). �The tax-adjusted yield curve�, The Journal ofFinance, Vol. 30, pp. 811-830.
[171] McIntyre M.L. (2001). �Performance of Dupire�s implied di¤usion ap-proach under sparse and incomplete data�, Journal of Computational Fi-nance, Vol 4., No. 4, pp. 33-84.
[172] Merton R.C. (1973). �Theory of Rational Option Pricing�, Bell JournalOf Economics and Management Science, Vol. 4, pp. 141-183.
[173] Merton R.C. (1976). �Option pricing when underlying stock returns arediscontinuous�, Journal of Financial Economics, Vol. 3, pp. 125-144.
[174] Metropolis N., Ulam S.M. (1949). �The Monte Carlo method�, Journal ofthe American Statistical Association, Vol. 44, No. 247, pp. 335-341.
[175] Microsoft (2004). �How Visual Basic Generates Pseudo-Random Numbersfor the Rnd Function�, Knowledge Base Article 231847, http://support.microsoft.com/default.aspx?scid=kb;en-us;231847.
[176] Microsoft (2005). �Rnd and Randomize Alternatives for GeneratingRandom Numbers�, Knowledge Base Article 28150, http://support.microsoft.com/default.aspx?scid=kb;en-us;28150.
[177] Microsoft (2006). �Description of the RAND function in Excel2003�, Knowledge Base Article 828795, http://support.microsoft.com/default.aspx?scid=kb;en-us;828795.
[178] Moro B. (1995). �The Full Monte�, Risk Magazine, Vol. 8, pp. 57-58.
[179] Moroko¤ W.J., Ca�isch R.E. (1994). �Quasi-random sequences and theirdiscrepancies�, SIAM Journal on Scienti�c Computing, Vol. 15, pp. 1251-1279.
[180] Muselia M., Rutkowski M. (1997). �Continuous-time term structure mo-dels : Forward measure approach�, Finance and Stochastics, Vol. 1, No.4, pp. 261-291.
[181] Neave H.R. (1973). �On using the Box-Muller tranformation with mul-tiplicative congruential pseudo-random number generators�, Applied Sta-tistics, 22, pp. 92-97.
[182] Nelson C.R., Siegel A.F. (1987). �A parsimonious modeling of yield curve�,Journal of Business, Vol. 60, No. 4, pp. 473-489.
322

[183] Niederreiter H. (1972). �On a number-theoretical integration method�,Aequationes Mathematicae 8, pp. 304-311.
[184] Niederreiter H. (1978). �Quasi-Monte Carlo methods and pseudo-randomnumbers�, Bulletin of the American Mathematical Society, Vol. 84, No. 6,pp. 957-1041.
[185] Niederreiter H. (1992). Random Number Generation and Quasi-MonteCarlo Methods, SIAM-CBMS Lecture Notes 63.
[186] Niven I. (1956). Irrational Numbers, The Mathematical Association ofAmerica.
[187] Ökten G. (1997). �Contributions to the Theory of Monte Carlo and Quasi-Monte Carlo Methods�, PhD Thesis, Claremont Graduate University.
[188] Ökten G.,Tu¢ n B., Burago V. (2005). �A Central Limit Theorem and im-proved error bounds for a hybrid-Monte Carlo sequence with applicationsin computational �nance�, Inria, Rapport de recherche No. 5600.
[189] Overhaus M., Bermúdez A., Buehler H., Ferraris A., Jordinson C., Lam-nouar A. (2007). Equity hybrid derivatives, Wiley Finance.
[190] Overhaus M., Rerraris A., Knudsen T., Milward R., Nguyen-Ngoc L.,Schindlmayr G. (2002). Equity Derivatives � Theory and Applications,Wiley Finance.
[191] Owen A.B. (2004). �Multidimensional variation for quasi-Monte Carlo�,Research Paper, http://www-stat.stanford.edu/~owen/reports/.
[192] Owen A.B. (2005). �On the Warnock-Halton quasi-standard error�, Re-search Paper, http://www-stat.stanford.edu/~owen/reports/.
[193] Pagès G., Xiao Y.-J. (1997). �Sequences with low discrepancy and pseudo-random numbers : theoretical results and numerical tests�, Journal ofStatistical Computation and Simulation, Vol. 56, pp. 163-188.
[194] Panneton F. (2004). �Construction d�ensembles de points basée sur desrécurrences linéaires dans un corps �ni de caractéristique 2 pour la simula-tion Monte Carlo et l�intégration quasi-Monte Carlo�, Thèse de Doctorat,Université de Montréal.
[195] Papageorgiou A., Traub J.F. (1996). �Beating Monte Carlo�, Risk Maga-zine, Vol. 9, pp. 63-65.
[196] Papageorgiou A., Traub J.F. (1997). �Faster Evaluation of Multidimensio-nal Integrals�, Working Paper, Department of Computer Science, Colum-bia University New-York.
[197] Park S.K., Miller K.W. (1988). �Random Number Generators : Good OnesAre Hard To Find�, Communications of the ACM, 31, pp. 1192-1201.
[198] Paskov S.H. (1994). �Computing High Dimensional Integrals with Ap-plications to Finance�, Technical Report CUCS-023-94, Department ofComputer Science Columbia University.
[199] Patard P.-A. (2001). �Evaluation de Swaps Structurés sur Actions et In-dices�, Mémoire d�actuaire, Institut de Science Financière et d�Assurances,Université Claude Bernard Lyon 1.
323

[200] Patard P.-A. (2003). �Modélisation des Dividendes sur Actions et Indices�,Mémoire de DEA, Institut de Science Financière et d�Assurances, Univer-sité Claude Bernard Lyon 1.
[201] Pauletto P. (2001). �Parallel Monte Carlo Methods for Derivative SecurityPricing�, in Numerical Analysis and Its Applications (L. Vulkov, J. Was-nievski and P. Yalamov Eds.), Lecture Notes in Computer Science, Vol.1988, Springer-Verlag, pp. 650-657.
[202] Planchet F., Winter J. (2007). �L�utilisation des splines bidimensionnelspour l�estimation de lois de maintien en arrêt de travail�, Bulletin Françaisd�Actuariat, Vol. 7, No. 13, pp. 83-106.
[203] Press W.H., Teukolsky S.A., Vetterling W.T., Flannery B.P. (2002). Nu-merical Recipes in C++, the art of scienti�c computing, Second Edition,Cambridge University Press.
[204] Ramponi A., Lucca K. (2003). �On a generalized Vasicek-Svensson modelfor the estimation of the term structure of interest rates�, IV WorkshopFinanza Quantitativa, Torino.
[205] Randjiou Y. (2002). �Jump Di¤usion Processes Applied to Exotics Pri-cing and the Market Model�, Présentation, Séminaire Bachelier, GlobalQuantitative Research, Deutsche Bank Global Equities.
[206] Rebonato R. (2002). Modern Pricing of Interest-Rate Derivatives : TheLIBOR Market Model and Beyond, Princeton University Press.
[207] Rebonato R. (2004). Volatility and Correlation : The Perfect Hedger andthe Fox, Second edition, Wiley Finance.
[208] Ricart R., Sicsic P. (1995). �Estimation d�une Structure par Terme desTaux d�Intérêt sur Données Françaises�, Bulletin de la Banque De France,No. 22, pp. 117-129.
[209] Richtmyer R.D. (1951). �On the evaluation of de�nite integrals and a quasi-Monte Carlo method based on properties of algebraic numbers�, ReportLA-1342, Los Alamos Scienti�c Laboratories.
[210] Rogers L.C.G., Tehranchi M.R. (2008). �The Implied Volatility SurfaceDoes Not Move By Parallel Shifts�, Working Paper, University Of Cam-bridge, http://www.statlab.cam.ac.uk/~mike/implied-vol.pdf.
[211] Ron U. (2000). �A Practical Guide to Swap Curve Construction�, WorkingPaper 2000-17, Bank of Canada.
[212] Rubinstein M. (1994). �Implied binomial trees�, The Journal of Finance,Vol. 49 , pp. 771-818.
[213] Saito M. (2007). �An Application of Finite Field : Design and Implemen-tation of 128-bit Instruction-Based Fast Pseudorandom Number Genera-tor�, Research Paper, Department of Mathematics, Graduate School ofScience, Hiroshima University, http://www.math.sci.hiroshima-u.ac.jp/~m-mat/JSPS-CoreToCore/index.html.
324

[214] Sakamoto M., Morito S. (1995). �Combination of Multiplicative Congruen-tial Random-Number Generators With Safe Prime Modulus�, Proceedingsof the 1995 Winter Simulation Conference (C. Alexopoulos, K. Kang, W.R. Lilegdon, and D. Goldsman Eds.), pp. 309-315.
[215] Samuelson P. (1965). �Rational theory of warrant pricing�, Industrial Ma-nagement Review, Vol. 6, pp. 13-31.
[216] Saporta G. (1990). Probabilités, Statistiques, Analyse des données, Tech-nip.
[217] Schlier C. (2004a). �Discrepancy behaviour in the non-asymptotic regime�,Applied Numerical Mathematics 50, pp. 227-238.
[218] Schlier C. (2004b). �Error trends in Quasi-Monte Carlo integration�, Com-puter Physics Communications 159, pp. 93-105.
[219] Schrage L. (1979). �AMore Portable Fortran Random Number Generator�,ACM Transactions on Mathematical Software, 5, pp. 132-138.
[220] Scott L.O. (1987). �Option Pricing when the Variance Changes Randomly :Theory, Estimation, and an Application�, The Journal of Financial andQuantitative Analysis, Vol. 22, No. 4, pp. 419-438.
[221] Sepp A. (2002). �Pricing Barrier Options under Local Volatility�, PrePrint,http://math.ut.ee/~spartak/papers/locvols.pdf.
[222] Smirnov S.N., Zakharov A.V. (2003). �A Liquidity-Based Robust SplineFitting of Spot Yield Curve Providing Positive Forward Rates�, WorkingPaper, Department of Risk Management and Insurance, State University- Higher School of Economics, Moscow.
[223] Snyder W.C. (2000). �Accuracy estimation for quasi-Monte Carlo simula-tions�, Mathematics and Computers in Simulation 54, pp. 131-143.
[224] Struckmeier J. (1995). �Fast generation of low-discrepancy sequences�,Journal of Computational and Applied Mathematics, Vol. 91, pp. 29-41.
[225] Sugita H. (2004). �Security of Pseudo-random Generator and Monte-CarloMethod�, Monte Carlo Methods and Applications, Vol. 10, No. 3, pp. 609-615.
[226] Svensson L.E.O. (1994). �Estimating and Interpreting Forward InterestRates : Sweden 1992-1994�, Centre for Economic Policy Research, Dis-cussion Paper, No. 1051.
[227] Sy A.S. (2003). �La volatilité stochastiques des marchés �nanciers : uneapplication aux modèles d�évaluation d�instruments en temps continu�,Thèse de doctorat, Université d�Aix-Marseille.
[228] Takhtamyshev G., Vandewoestyne B., Cools R. (2007). �Quasi-random in-tegration in high dimensions�, Mathematics and Computers in Simulation73, pp. 309-319.
[229] Tezuka S. (1991). �Neave E¤ect Also Occurs With Tausworthe Sequences�,Proceedings of the 1991 Winter Simulation Conference, pp. 1030-1034.
325

[230] Tezuka S. (1995). Uniform Random Numbers : Theory and Practice, Klu-wer Academics Publishers.
[231] Thiémard E. (2000a). �Sur le calcul et la majoration de la discrépance àl�origine�, Thèse de Doctorat, EPFL.
[232] Thiémard E. (2000b). �An algorithm to compute bounds for the star dis-crepancy�, Research Paper, EPFL.
[233] Tu¢ n B. (1996a). �Improvement of Halton Sequences distribution�, Irisa,Publication interne 998.
[234] Tu¢ n B. (1996b). �On the Use of low discrepancy sequences in Monte-Carlo methods�, Irisa, Publication interne 1060.
[235] Tu¢ n B. (1997). �Simulation accélérée par les méthodes de Monte Carloet quasi-Monte Carlo : théorie et applications�, Thèse de Doctorat, Uni-versité Rennes 1.
[236] Tu¢ n B. (2005). �Randomization of Quasi-Monte Carlo Methods for Er-ror Estimation Survey and Normal Approximation�, Irisa-Inria, ResearchPaper.
[237] Turlach B.A. (1997). �Constrained Smoothing Splines Revisited�, Techni-cal Report, Australian National University, Canberra.
[238] Vandewoestyne B., Cools R. (2006). �Good permutations for determinis-tic scrambled Halton sequences in terms of L2�discrepancy�, Journal ofComputational and Applied Mathematics, Vol. 189, pp. 341-361.
[239] Vandu¤el S. (2005). �Comonotonicity : From risk measurement to riskmanagement�, PhD Thesis, University of Amsterdam.
[240] Vandu¤el S., Chen X., Dhaene J., Goovaerts M., Henrard L., Kaas R.(2007). �Optimal Approximations for Risk Measures of Sums of Lognor-mals based on Conditional Expectations�, Journal of Computational andApplied Mathematics, to be published.
[241] Vandu¤el S., Hoedemakers T., Dhaene J. (2005). �Comparing approxima-tions for sums of non-independent lognormal random variables�, NorthAmerican Actuarial Journal, Vol. 9(4), pp. 71-82.
[242] Vitrac D. (2002). Tout savoir sur la Bourse �Edition 2002/2003, GualinoEditeur.
[243] Vyncke D., Goovaerts M., Dhaene J. (2004). �An accurate analytical ap-proximation for the price of a European-style arithmetic Asian option�,Finance, Vol. 25, pp. 121-139.
[244] Waggoner D.F. (1997). �Spline Methods for Extracting Interest RateCurves from Coupon Bond Prices�, Working Paper 97-10, Federal Re-serve Bank of Atlanta.
[245] Wahba G. (1990). Spline Functions for Observational Data, CBMS-NSFRegional Conference series, SIAM, Philadelphia.
[246]Wang X., Hickernell F.J. (2000). �Randomized Halton sequences�, Mathe-matical and Computer Modelling, Vol. 32, pp. 887-899.
326

[247] Warnock T.T. (2001). �E¤ective error estimates for quasi-Monte Carlocomputations�, Technical Report LA-UR-01-1950, Los Alamos NationalLabs, http://lib-www.lanl.gov/la-pubs/00367143.pdf.
[248]Weizmann A. (2007). �Construction Of the Implied Volatility Smile�, The-sis, Goethe University, Frankfurt am Main.
[249]West G. (2005). �Better approximations to cumulative normal functions�,Wilmott Magazine, pp. 70-76.
[250] West G. (2006). �A Brief Comparison of Interpolation Methods For YieldCurve Construction�, Working Paper, Financial Modelling Agency, http://www.finmod.co.za/interpolationsummary.pdf.
[251] Weyl H. (1916). �Über die Gleichverteilung von Zahlen mod. Eins�, Ma-thematische Annalen 77, pp. 313-352.
[252]Wichmann B., Hill I. (1982). �Algorithm AS 183. An E¢ cient and PortablePseudo-random Number Generator�, Applied Statistics, 31, pp. 188-190.
[253]Wolberg G., Itzik A. (1999). �Monotonic Cubic Spline Interpolation�, Pro-ceedings of the International Conference on Computer Graphics, pp. 188-195.
[254] Zhang J.E., Xiang Y. (2008). �Implied Volatility Smirk�, QuantitativeFinance, Vol. 8, No. 3, pp. 263-284.
[255] Zhu Z., Hanson F.B. (2005). �Risk-neutral option pricing for log-uniformjump-amplitude jump-di¤usion model�, Working Paper, University of Illi-nois, Chicago.
[256] Zinterhof P. (1987). �Gratis Lattice Points for Multidimensional Integra-tion�, Computing, Vol. 38, No. 4, pp347-353.
[257] Zinterhof P. (1994). �Parallel Generation and Evaluation of Weyl Se-quences�, Report R5Z-4, PACT Project.
327


















