
Univers BO WinCRApprentissage - Cv Joachim …j.pellicioli.free.fr/download/Memoire.docx · Web...
174
CONSERVATOIRE NATIONAL DES ARTS ET METIERS CENTRE REGIONAL ASSOCIE DE BOURGOGNE MEMOIRE présenté en vue d'obtenir le DIPLOME D'INGENIEUR C.N.A.M. SPECIALITE : INFORMATIQUE OPTION : SYSTEMES D’INFORMATION par Joachim PELLICIOLI ______ Conception d’un entrepôt de données corrélant les effectifs en apprentissage et le suivi financier des centres de formation au sein des Conseils régionaux Soutenu le 28 juin 2010 _______ Président : Jacky AKOKA C.N.A.M. Paris
Transcript of Univers BO WinCRApprentissage - Cv Joachim …j.pellicioli.free.fr/download/Memoire.docx · Web...

CONSERVATOIRE NATIONAL DES ARTS ET METIERS
CENTRE REGIONAL ASSOCIE DE
BOURGOGNE
MEMOIRE
présenté en vue d'obtenir le
DIPLOME D'INGENIEUR C.N.A.M.
SPECIALITE : INFORMATIQUE
OPTION : SYSTEMES D’INFORMATION
par
Joachim PELLICIOLI
______
Conception d’un entrepôt de données corrélant les effectifs en apprentissage et le suivi financier des centres de formation
au sein des Conseils régionaux
Soutenu le 28 juin 2010
_______
Président : Jacky AKOKA C.N.A.M. ParisEncadrant : Christophe NICOLLE Université de BourgogneMembres : Christophe CRUZ Université de Bourgogne
Didier MACKE Société YmagEric JACQUIN Société Ymag

44 L’entrepôt de données en pratique
Remerciements
Je tiens à remercier toutes les personnes qui ont donné de leur temps, talent et
expérience tout au long de ce projet et durant mes huit années d’études au C.N.A.M.
Je souhaite notamment remercier Monsieur Christophe Nicolle, maitre de conférences,
pour ses remarques pertinentes et ses précieux conseils pour l’élaboration de mon mémoire. Je
remercie messieurs Jacky Akoka et Christophe Cruz qui ont accepté de faire partie de mon
jury.
Je tiens également à remercier mon entreprise qui a su me faire confiance et me laisser
gérer un dossier aussi important et sensible. Je remercie tout particulièrement Messieurs
Didier Macke et Eric Jacquin qui ont accepté d’être présents à mon jury.
Bien entendu, je n’aurais probablement pas réalisé tout cela sans le soutien de mon
épouse Mélanie. Une page ne suffirait pas pour lui témoigner toute ma gratitude.
Joachim PELLICIOLI 1

44 L’entrepôt de données en pratique
Glossaire
AFPI : Association de formation professionnelle de l’industrie. Centre de
formation continue pour l’industrie.
BI : Business intelligence : Ensemble de données consolidées qui permet la
prise de décision.
BO : Business Objects, solution de la société SAP.
CAP : Certificat d’aptitude professionnelle, diplôme de niveau 5 reconnu par
l’éducation nationale.
CCI : Chambre du commerce et de l’industrie. Ce sont des organismes chargés
de représenter les intérêts des entreprises commerciales, industrielles et de service [WIK2].
CFA : Centre de formation d’apprentis. Ce sont des établissements
d’enseignement en alternance accueillant des apprenants âgés de 16 à 25 ans.
CFAI : Centre de formation d’apprentis industriels. Idem qu’un CFA, mais
pour les techniques industrielles.
CIF : Contrainte d’intégrité fonctionnelle ou dépendance fonctionnelle. Une
CIF fait référence à une notion mathématique entre ensemble.
CPA : Classe préparatoire à l’apprentissage pour les apprenants de moins de 16
ans.
Cube : Structure matricielle à trois dimensions.
DARES : Direction de l’animation de la recherche, des études et des
statistiques. C’est une direction du ministère du travail français.
Data warehouse : Entrepôt de données. Concept de stockage de données.
Data mart : Magasin de données. C’est un sous ensemble de l’entrepôt de
données.
DLL : Dynamic Link Library : Bibliothèque de codes pouvant être exploitée
par plusieurs applications.
DSI : Direction des systèmes d’information. Elle régit l’intégralité du parc
informatique, du réseau et de l’information.
Joachim PELLICIOLI 2

44 L’entrepôt de données en pratique
ETL : Extract Transfort Load ou datadumping. Processus ayant pour but de
récupérer les données des bases de production pour les injecter dans le data warehouse après
avoir effectué des transformations.
ETP : Equivalence temps plein. Permet de comparer les charges salariales sur
l’équivalence d’un emploi en temps plein.
Hypercube : Structure matricielle à quatre dimensions ou plus.
MCD : Modèle conceptuel des données. Représentation graphique de la
structure de données d’une entité à analyser.
Merise : Méthode d’analyse et de conception d’un système d’information.
NAF : Nomenclature d’activités française.
OLAP : On-Line Analytical Processing : Concept permettant de traiter des
données multidimensionnelles à des fins d’analyse.
OLTP : On-Line Transactional Processing : Concept permettant de traiter des
données transactionnelles.
SGBD : Système de gestion de base de données.
SGBDR : Système de gestion de base de données relationnelle.
SGBDM : Système de gestion de base de données multidimensionnelle.
SI : Système d’information. Il représente l’ensemble des éléments participant à
la gestion, au stockage, au traitement, au transport et à la diffusion de l’information au sein
d'une organisation.
SID : Système d’information décisionnelle.
SIG : Système d’information géographique. Outil informatique de restitution
de carte géographique.
SIO : Système d’information opérationnelle.
SQL : Structured query language permet l’interrogation des bases de données
relationnelles afin d’en extraire des données tout en les restreignant en fonction de critères.
THR : Transport Hébergement Restauration. C’est un abrégé fréquemment
utilisé pour parler des aides fournies aux apprentis pour leur permettre d’assister aux cours.
XML Schema : ou XSD : Document permettant de définir la structure d’un
document XML.
XML : Extend Markup Language : Langage de balisage, servant à stocker et
transférer des données.
Joachim PELLICIOLI 3

44 L’entrepôt de données en pratique
Tables des matières
REMERCIEMENTS............................................................................................................................ 1
GLOSSAIRE......................................................................................................................................... 2
TABLES DES MATIÈRES................................................................................................................. 4
1 INTRODUCTION........................................................................................................................ 7
2 CONTEXTE DU PROJET........................................................................................................ 102.1 Le groupe YMAG SAS.............................................................................................................. 102.2 L’équipe région....................................................................................................................... 12
2.2.1 Objectifs.............................................................................................................................122.2.2 Organisation......................................................................................................................12
2.3 Les Conseils régionaux............................................................................................................ 122.3.1 Objectifs.............................................................................................................................122.3.2 Organisation......................................................................................................................132.3.3 Centre de formation d’apprentis.......................................................................................132.3.4 Ymag dans les Conseils régionaux......................................................................................142.3.5 Interlocuteurs principaux...................................................................................................14
2.4 Les solutions d’Ymag...............................................................................................................152.5 Définition du besoin............................................................................................................... 16
2.5.1 Contexte du projet.............................................................................................................162.5.2 Comment définir le besoin................................................................................................162.5.3 Analyse du besoin..............................................................................................................182.5.4 Périmètre de l’étude..........................................................................................................18
2.6 Synthèse................................................................................................................................. 19
3 L’ENTREPÔT DE DONNÉES EN THÉORIE........................................................................203.1 Le data warehouse................................................................................................................. 21
3.1.1 Définition...........................................................................................................................213.1.2 Objectifs.............................................................................................................................22
3.2 Le data mart........................................................................................................................... 233.2.1 Définition...........................................................................................................................233.2.2 Avantages..........................................................................................................................253.2.3 Inconvénients....................................................................................................................25
3.3 Modélisation d’un data mart..................................................................................................253.3.1 Les composants.................................................................................................................25
3.3.1.1 Les « faits » ou « indicateurs ».............................................................................253.3.1.2 Les « dimensions »...............................................................................................263.3.1.3 Exemple de table des faits et dimensions............................................................26
3.3.2 Modélisation en étoile.......................................................................................................273.3.3 Modélisation en flocon de neige........................................................................................283.3.4 Modélisation en constellation...........................................................................................29
3.4 Concept OLAP......................................................................................................................... 303.4.1 Définition...........................................................................................................................303.4.2 Comparaison entre OLAP et OLTP......................................................................................33
3.4.2.1 Définition de OLTP...............................................................................................333.4.2.2 Tableau comparatif..............................................................................................33
3.4.3 Fonctions liées à OLAP.......................................................................................................343.4.3.1 Définition.............................................................................................................343.4.3.2 Exemples.............................................................................................................34
Joachim PELLICIOLI 4

44 L’entrepôt de données en pratique
3.5 Processus d’alimentation du data warehouse.........................................................................373.5.1 Sous processus de l’ETL.....................................................................................................37
3.5.1.1 Extraction............................................................................................................373.5.1.2 Transformation....................................................................................................383.5.1.3 Chargement.........................................................................................................38
3.5.2 Type d’ETL..........................................................................................................................383.5.3 Stratégie de chargement...................................................................................................39
3.5.3.1 Extraction complète.............................................................................................393.5.3.2 Extraction incrémentale......................................................................................39
3.6 Synthèse................................................................................................................................. 41
4 L’ENTREPÔT DE DONNÉES EN PRATIQUE.....................................................................424.1 Définition des phases du projet...............................................................................................42
4.1.1 Contexte............................................................................................................................424.1.2 Identification des différentes phases du projet.................................................................424.1.3 Calendrier de réalisation des phases.................................................................................43
4.2 Phase d’étude......................................................................................................................... 444.2.1 Méthodologie....................................................................................................................454.2.2 Généralités sur l’existant...................................................................................................464.2.3 Objectifs.............................................................................................................................484.2.4 Risques...............................................................................................................................504.2.5 Choix technologiques.........................................................................................................504.2.6 Détail des tâches à réaliser................................................................................................544.2.7 Synthèse............................................................................................................................56
4.3 Phase ETL............................................................................................................................... 574.3.1 Analyse..............................................................................................................................574.3.2 Réalisation.........................................................................................................................594.3.1 Synthèse............................................................................................................................64
4.4 Méthodologie de conception d’un data mart..........................................................................654.4.1 Axes d’analyses..................................................................................................................654.4.2 Portefeuille d’indicateurs...................................................................................................674.4.3 Modélisation......................................................................................................................684.4.4 Synthèse de la méthode....................................................................................................69
4.5 Phase effectifs........................................................................................................................ 704.5.1 Objectifs.............................................................................................................................704.5.2 Axes d’analyse...................................................................................................................704.5.3 Portefeuille d’indicateurs effectifs.....................................................................................754.5.4 Schématisation..................................................................................................................774.5.5 Réalisation.........................................................................................................................784.5.6 Synthèse............................................................................................................................79
4.6 Phase financier....................................................................................................................... 804.6.1 Comptes généraux.............................................................................................................81
4.6.1.1 Objectifs...............................................................................................................814.6.1.2 Axes d’analyse.....................................................................................................814.6.1.3 Portefeuille d’indicateurs....................................................................................834.6.1.4 Schématisation et volumétrie..............................................................................854.6.1.5 Réalisation...........................................................................................................86
4.6.2 Frais de personnel..............................................................................................................884.6.2.1 Objectifs...............................................................................................................884.6.2.2 Axes d’analyse.....................................................................................................884.6.2.3 Portefeuille d’indicateurs....................................................................................904.6.2.4 Schématisation....................................................................................................924.6.2.5 Réalisation...........................................................................................................93
4.6.3 Taxe d’apprentissage.........................................................................................................944.6.3.1 Objectifs...............................................................................................................944.6.3.2 Axes d’analyse.....................................................................................................944.6.3.3 Portefeuille d’indicateurs....................................................................................95
Joachim PELLICIOLI 5

44 L’entrepôt de données en pratique
4.6.3.4 Schématisation....................................................................................................974.6.3.5 Réalisation...........................................................................................................97
4.6.4 Dépense théorique............................................................................................................994.6.4.1 Objectifs...............................................................................................................994.6.4.2 Axes d’analyse.....................................................................................................994.6.4.3 Portefeuille d’indicateurs..................................................................................1004.6.4.4 Schématisation..................................................................................................1024.6.4.5 Réalisation.........................................................................................................103
4.6.5 Synthèse..........................................................................................................................1044.7 Phase de finalisation............................................................................................................. 106
4.7.1 Business Objects..............................................................................................................1064.7.2 Documentation................................................................................................................1084.7.3 Formation........................................................................................................................1084.7.4 Synthèse..........................................................................................................................110
5 CONCLUSION........................................................................................................................ 111
TABLE DES ILLUSTRATIONS................................................................................................... 114Listes des figures............................................................................................................................. 114Listes des tableaux.......................................................................................................................... 115
RÉFÉRENCES BIBLIOGRAPHIQUES....................................................................................... 116Livres.............................................................................................................................................. 116Livres blancs.................................................................................................................................... 116Sites internet................................................................................................................................... 116
Joachim PELLICIOLI 6

44 L’entrepôt de données en pratique
1 Introduction
L’informatique décisionnelle ou « business intelligence » (BI) est depuis quelques
années un fort pôle d’attraction pour l’entreprise. Beaucoup de salons, de revues ou de livres
font les éloges de ces technologies. Tous les grands acteurs ont apporté leurs solutions
(Oracle, Microsoft, SAP, …). Toujours le même but recherché par les consommateurs de BI,
celui d’optimiser les coûts de production, de rentabiliser, de corréler les données ou plus
simplement d’interroger des systèmes d’informations. Au cours des deux dernières décennies,
les entreprises ont acquis beaucoup de solutions pour gérer chaque activité de leur
organisation. Elles estiment que les logiciels spécifiques augmentent la performance du
service géré. De nos jours, les dirigeants souhaitent avoir une vue globale de leur activité afin
de prendre les décisions en fonction d’indicateurs précis. C’est pour cela que les entreprises
sont demandeuses d’outils d’aide à la décision qui vont leur permettre de mettre en évidence
les données importantes.
En France et plus particulièrement dans les Conseils régionaux, la tendance est
identique. Avec la politique de réduction des coûts, il devient très important pour les élus de
contrôler et trouver les incohérences présentes dans leur système d’information. L’activité des
Conseils régionaux est très variée. La Région participe à l’éducation, la formation, l’emploi et
est active sur le plan économique et social, sans oublier les transports qu’elle gère (trains entre
région, bus scolaire, …). Dernièrement le Conseil régional s’est engagé sur le développement
durable. Cette diversité en fait un modèle complexe à modéliser et à analyser en un seul
ensemble.
La société dans laquelle je travaille (Ymag) a, depuis de nombreuses années, aidé et
apporté un soutien informatique aux services de la formation et de l’apprentissage des
Conseils régionaux. Ymag a acquis une grande expertise depuis les années 1990 en travaillant
avec les centres de formation d’apprentis (CFA). Ainsi au début des années 2000, lorsque les
Régions ont eu besoin de nouveaux logiciels, nous avons su nous démarquer de nos
concurrents grâce à notre expertise sur les métiers de la formation. C’est donc tout
Joachim PELLICIOLI 7

44 L’entrepôt de données en pratique
naturellement que nous avons été sollicités afin de concevoir leur base de données
décisionnelle.
Ma société n’avait aucune expérience en base de données décisionnelle, elle devait donc
répondre à un besoin sans avoir les compétences requises. C’est alors que la direction m’a
proposé de changer de service en intégrant l’équipe région pour réaliser ce projet (avant mon
stage je travaillais sur le logiciel Ypareo destiné aux CFA). J’ai accepté ce défi qui offre un
double avantage : le premier, professionnel, qui permet à mon entreprise d’évoluer et
d’acquérir de nouvelles compétences en répondant ainsi positivement à une demande client.
Et le second, plus personnel, qui conclut ma formation d’ingénieur C.N.A.M. avec la
réalisation de mon stage.
L’organisation de la Région étant complexe, mon stage prendra en charge l’étude et à la
réalisation d’une base de données décisionnelle pour le service de la formation et de
l’apprentissage. Par abus de langage dans la suite de ce rapport, nous parlerons parfois du
Conseil régional pour le service de la formation et de l’apprentissage.
Dans ce mémoire nous commencerons par décrire le contexte du projet. Puis nous
présenterons les différents participants ainsi que leurs rôles. Ensuite nous définirons l’objectif
de ce travail ainsi que le périmètre de l’étude.
Dans un second temps, nous nous attarderons sur les notions théoriques des entrepôts de
données. Comme je viens de l’indiquer, pour mon entreprise et pour moi-même au début du
projet, l’informatique décisionnelle était une notion abstraite. Il est important de bien
comprendre la théorie afin de déterminer les principaux éléments. L’informatique
décisionnelle fait partie d’un effet de mode, il est parfois difficile de discerner une vision
marketing d’un fondement mathématique. L’étude théorique permet de répondre à de
nombreuses questions. Elle permettra également d’augmenter la connaissance de l’entreprise
avec des axes de recherches établis pour ce projet et ceux à venir.
En dernière partie, nous étudierons la mise en place de l’entrepôt de données pour les
Conseils régionaux. Celle-ci va mettre en valeur plusieurs étapes, dont la planification,
l’analyse et la réalisation. Nous pouvons dès à présent découper la réalisation en deux grandes
familles. La première porte sur l’analyse des effectifs d’apprentis des CFA. Ceux-ci
Joachim PELLICIOLI 8

44 L’entrepôt de données en pratique
transmettent régulièrement aux Conseils régionaux des données sur les effectifs qui sont
contenues dans leur système d’information. La deuxième porte sur l’étude financière des
CFA. Elle peut se sous diviser en plusieurs parties. La première concernera l’étude des
comptes financiers des CFA, puis l’étude des frais de personnel. Nous aurons également une
partie sur la taxe d’apprentissage et enfin sur la dépense théorique des CFA. Bien entendu,
une corrélation entre les effectifs et les données financières sera effectuée afin d’obtenir des
données financières par effectifs.
Enfin nous terminerons ce chapitre en donnant quelques informations sur la finalisation
de ce projet. Nous verrons l’exploitation de l’entrepôt de données par les outils utilisés par les
agents des Conseils régionaux. Nous évoquerons les notions de documentations réalisées. Et
pour finir nous expliquerons comment se déroule les formations.
Joachim PELLICIOLI 9

44 L’entrepôt de données en pratique
2 Contexte du projet
2.1 Le groupe YMAG SAS
Ymag est une société de service en ingénierie informatique dijonnaise. Son domaine
d’activité se concentre sur la création de logiciels dédiés à la formation. Sa zone d’activité
s’étend sur la France et les départements d’Outre Mer, avec trois types de clients principaux :
La formation initiale (CFA, CFAI, …).
La formation continue (CCI, AFPI, ….).
Les Conseils régionaux.
La société Ymag s’est spécialisée dans la formation et accompagne les centres de
formation en apprentissage dans leur informatisation. Ce partenariat nous a permis de
comprendre le « métier de la formation ». Grâce à cette expérience et à l’évolution des centres
de formation, nous avons étendu nos compétences à la formation continue. Par la suite nous
avons offert nos compétences aux services de formation des Conseils régionaux qui sont en
contacts permanent avec les CFA.
Ymag a su se positionner sur le marché de la formation grâce à son expertise du besoin.
Actuellement forte de ses 30 années d’écoute et de collaboration avec les clients, elle est
capable de répondre aux besoins du marché. Nous travaillons avec nos clients, dans un même
contexte et sur un processus métier bien maitrisé.
Quelques chiffres sur la société :
Création : 1979.
Salariés : 50.
Age moyen : 30 ans.
90% d’homme et 10% de femme.
Quelques chiffres sur l’activité :
5.2 millions d’euro de chiffre d’affaire en 2009.
Joachim PELLICIOLI 10

44 L’entrepôt de données en pratique
663 CFA sur 1049 équipés par une solution informatique Ymag.
1 110 Clients.
14 Conseils régionaux équipés d’une solution informatique Ymag.
Ymag soutient depuis quelques années une forte croissance. Elle trouve son origine
dans la demande importante des centres de formation : demande en logiciels, en évolution des
produits ou en modules complémentaires.
Voici deux schémas qui montrent l’évolution au cours des cinq dernières années du
chiffre d’affaire et du nombre de salariés.
Figure 1 Ymag nombre de salariés et chiffre d'affaire
L’organigramme de la société Ymag est le suivant :
Figure 2 Ymag organigramme
Joachim PELLICIOLI 11
1 PDG
1 Directeur général
1 Directeur commercial
4 Chefs de projets
25 Développeurs 15 Formateurs
2 Secrétaires / 1 comptable

44 L’entrepôt de données en pratique
Au sein de cet organigramme, la société se divise en deux équipes :
La première étant rattachée aux logiciels qui équipent les centres de formation.
La deuxième est rattachée aux logiciels qui équipent les Conseils régionaux.
2.2 L’équipe région
2.2.1 Objectifs
L’équipe région a pour objectif de répondre aux besoins concernant le suivi
d’apprentissage par le Conseil régional. Elle prend en compte les demandes et les évolutions
de la législation française et fait évoluer ses solutions. Elle accompagne les projets des
Conseils régionaux dans le domaine de la formation. Elle fait part de son expérience et surtout
de l’expérience des autres Conseils régionaux. Elle a pour but également de consolider le
dialogue entre les CFA et les Régions. Une grande partie du travail des Conseils régionaux est
issue des données que leur transmettent les CFA.
2.2.2 Organisation
L’équipe région est constituée de six analystes programmeurs encadrés par un chef de
projet.
Les analystes programmeurs ont en charge l’analyse du besoin, la mise en place de la
solution et le suivi évolutif du produit. Ce suivi peut se faire via une assistance téléphonique
ou au cours de réunions avec le Conseil régional.
2.3 Les Conseils régionaux
2.3.1 Objectifs
La Région a la responsabilité des CFA ainsi que des établissements du domaine
sanitaire et social (paramédical, sage-femme, travail social, …). Elle centralise les besoins des
professionnels sur son territoire et adapte ses sections de formation pour y répondre (elle
Joachim PELLICIOLI 12

44 L’entrepôt de données en pratique
ouvre et ferme les différentes formations.). Par exemple les chantiers de Saint Nazaire
peuvent demander plus de soudeurs à la Région. Elle cofinance les centres de formation. Elle
impose en retour une information détaillée des comptes des CFA. Grâce à ces informations
financières elle organise le budget de chacun des centres.
2.3.2 Organisation
Les décisions sont prises par le président du Conseil régional, puis mises en accord avec
les Conseillers régionaux.
Dans notre cas nous travaillons avec le service nommé « Direction de la formation et de
l’apprentissage » ainsi qu’avec le service « Direction des systèmes d’information » (DSI). Ces
deux services sont très importants pour la Région comme en réfère le budget 2010 du Conseil
régional Centre :
Figure 3 Budget 2010 Région Centre [REG1]
2.3.3 Centre de formation d’apprentis
Le centre de formation d’apprentis dispense aux apprentis une formation générale et
technique ; il assure la coordination entre la formation qu’il dispense et celle que réalise
l’entreprise dans le cadre du contrat d’apprentissage. La Région cofinance les CFA et finance
les aides individuelles aux apprentis : aide à l’achat du premier équipement professionnel, au
transport, à l'hébergement, à la restauration et gratuité des manuels scolaires. La Région a
Joachim PELLICIOLI 13

44 L’entrepôt de données en pratique
aussi décidé de favoriser l’embauche de jeunes en difficulté scolaire ou sociale en modulant
les primes versées aux entreprises.
Les CFA sont soumis à des conventions régionales de fonctionnement. Les deux
sources de revenus principaux d’un centre de formation sont [LAP1] :
Les subventions de la région.
La taxe d’apprentissage.
2.3.4 Ymag dans les Conseils régionaux
Nous apportons trois solutions :
Première solution : Le recueil d’informations sur les effectifs et leurs descriptifs
au sein des différentes formations des CFA. Ces données permettent d’orienter
les choix du Conseil régional dans l’ouverture ou la fermeture des formations.
Deuxième solution : Le recueil et l’analyse des données financières des centres.
Elle permet d’allouer les fonds à la formation et de calculer le budget
prévisionnel. Cela permet d’instruire les dossiers utilisés lors des négociations.
La troisième solution est liée aux primes versées aux employeurs. Pour soutenir
l’effort de formation des maîtres d’apprentissage, chaque région a mis en place
un système d’attribution d’aide à l’employeur.
2.3.5 Interlocuteurs principaux
Nos applications actuelles sont utilisées par le personnel de production des services
apprentissages. Ces services sont constitués de huit à dix-huit personnes, gérants l’information
échangée avec les CFA sur les formations et les effectifs, les contrats d’apprentissage, mais
aussi les données financières. Nous collaborons avec ces personnes afin de collecter leurs
difficultés et leurs besoins pour faire évoluer nos solutions. Nous sommes également à leur
écoute afin de répondre à des problèmes ponctuels (difficulté sur l’application, changement de
législation, question sur un CFA, …).
Ces agents sont encadrés par le directeur du service de la formation et de
l’apprentissage. Il est l’interlocuteur entre son service et les élus. Il nous donne les grandes
Joachim PELLICIOLI 14

44 L’entrepôt de données en pratique
orientations pour nos applications et nous tient informés des changements politique et
législatif. C’est également avec cette personne que nous organisons des rencontres avec les
CFA. Elles ont pour but d’expliquer les choix du Conseil régional aux centres de formation
afin de les aider à appréhender les échanges d’informations (Région <=> CFA).
La partie technique et l’orientation physique des systèmes d’information (SI) sont
traitées avec la direction des systèmes d’information (DSI). Cette branche gère l’intégralité
des ressources informatiques du Conseil régional. Elle encadre le changement technique et
fonctionnel lié aux systèmes d’informations et elle se charge de la formation du personnel sur
les nouvelles technologies, … . Elle influence sur le plan technique l’évolution de nos
logiciels. Par exemple nous sommes à l’étude sur l’implémentation de nos applications en
« Full Web ».
2.4 Les solutions d’Ymag
Comme évoqué dans le paragraphe 2.3.4 Ymag dans les Conseils régionaux, nous allons
décrire les deux solutions mises à disposition par Ymag afin de satisfaire la demande des
clients :
WinCRApprentissage : Logiciel permettant de gérer les conventions de
formation et avenants entre les CFA et la Région. La convention définit un seuil
mini et maxi d’apprentis pour les ouvertures et fermetures de chaque formation
d’un CFA. Pour cela WinCRApprentissage intègre un module d’enquête qui est
diffusé dans tous les CFA. Cette enquête est standardisée et permet une
remontée nationale.
Une autre fonctionnalité importante est la collecte des données financières du
CFA. Le centre doit justifier ses coûts de fonctionnement. Nous entendons par
coût de fonctionnement, tout ce qui gravite autour de la formation (salaire des
formateurs, frais de fonctionnement des infrastructures, …). Après avoir collecté
ces informations, les Conseils régionaux peuvent établir des budgets
prévisionnels pour allouer les subventions aux différents CFA. Ils régularisent
également les comptes financiers en fonction des comptes réels.
Joachim PELLICIOLI 15

44 L’entrepôt de données en pratique
WinCRPrimes : Logiciel permettant de gérer les contrats d’apprentissage. Ces
contrats donnent lieu à des primes versées aux employeurs. Historiquement,
cette compétence était gouvernementale. Pour suivre les mesures de
décentralisation cette compétence a été transmise aux Régions en 2003. Les
Conseils régionaux ont donc personnalisé les types d’aides (aide à l’embauche,
aide favorisant l’égalité entre les sexes, …). Les Régions favorisent ainsi la
formation des apprentis et leurs emplois à leur sortie de formation. La Région a
plus de visibilité sur les entreprises de son secteur, elle a donc la possibilité
d’adapter ses aides afin d’optimiser le dynamisme d’apprentissage sur son
territoire.
2.5 Définition du besoin
2.5.1 Contexte du projet
Ce projet a débuté avec un ex-collaborateur d’Ymag, qui nous a quittés en pleine phase
d’étude. Ma Direction a cherché la personne qui pouvait s’adapter le plus rapidement afin de
reprendre ce projet et le mener à bien. Ils m’ont donc proposé la gestion de ce dossier. J’ai
changé de service pour intégrer l’équipe de développement pour les Conseils Régionaux.
Dans un premier temps j’ai été formé sur les solutions Ymag leur étant destinées. Pour
augmenter mes connaissances j’ai effectué de la maintenance évolutive. Ensuite j’ai pu
m’impliquer dans le projet avec une meilleure vision du travail de la Région. Mon ex-collègue
n’ayant laissé que très peu de notes sur l’avancement du projet, ma direction m’a autorisé à
reprendre contact avec notre Région pilote afin d’établir le besoin.
2.5.2 Comment définir le besoin
Pour établir le besoin je me suis basé sur un système d’interview ciblé pour chaque type
d’interlocuteur :
Les élus : Les élus ont un rôle décisionnel. Ils votent les modifications et les
grandes orientations qui leur sont soumises. Dans notre cas, ils peuvent valider
ou non un budget ; ouvrir ou fermer des CFA. Ils ont besoin de croiser leurs
Joachim PELLICIOLI 16

44 L’entrepôt de données en pratique
informations afin d’obtenir des cartes géographiques chiffrées. Ces cartes
doivent être claires afin d’être présentées aux administrés. Ils ont besoin de
chiffres globaux sur le nombre d’apprentis, sur les budgets ainsi que sur les
comptes financiers.
Le directeur de la formation et de l’apprentissage : Il est l’interlocuteur
principal des élus, c’est lui qui va rendre compte de l’état actuel de l’information
et de l’analyse effectuée. Il propose les orientations aux élus.
Le directeur a donc besoin d’avoir des tableaux de bord précis afin de donner
très rapidement les valeurs globales aux élus. Il a également besoin de chiffres
précis pour un CFA donné afin d’ouvrir ou fermer les formations, adapter le
budget, …
Le personnel de la formation et de l’apprentissage : Ce sont les agents de
production, ils ont un besoin de requêtes ponctuelles sur des données variées
afin de trouver des solutions à des attentes bien particulières. Ils ont besoin de
requêtes sur les effectifs et sur la gestion financière des CFA. Leurs attentes
peuvent varier en fonction du commanditaire (CFA, directeur, organisme
gestionnaire,…).
La direction des systèmes d’information : Elle a une vision globale du
fonctionnement de la Région ; elle coordonne les différentes applications et donc
les différentes branches d’activités de la Région. C’est elle qui accorde la
cartographie des logiciels. Elle est décisionnaire dans les choix techniques et
oriente les choix fonctionnels.
Leur besoin est de croiser les informations des différentes solutions afin de
déceler des anomalies de fonctionnement. Elle souhaite ainsi rapprocher les
données de différents services.
Joachim PELLICIOLI 17

44 L’entrepôt de données en pratique
2.5.3 Analyse du besoin
Compte tenu des informations collectées durant ces entretiens, j’ai cherché quelles
solutions s’offraient à nous. En premier lieu, essayons de comprendre ce que souhaitent les
différentes personnes travaillant pour le Conseil régional.
Besoin d’exécuter des requêtes dynamiques : il faut avoir accès à des données
quantifiables mises en valeur par diverses informations.
Besoin de tableaux de bord : il faut obtenir des tableaux de bord de vue globale afin
d’aider à la décision et de planifier l’avenir.
Besoin de croiser les données de différentes applications : il faut pouvoir combiner les
données de différentes bases de production afin de contrôler la cohérence des données.
Grâce à ces informations, j’ai proposé la création d’une base de données décisionnelle
(ou data warehouse). Cette base de données a pour but de répondre à nos trois besoins
principaux.
2.5.4 Périmètre de l’étude
Après concertation avec les Conseils régionaux, j’ai décidé de cibler notre projet sur la
mise en place d’une base de données décisionnelle, orientée sur le service formation et
apprentissage. Ceci est la première brique mise en place pour la création d’une base de
données décisionnelle. Mes choix seront faits en concertation avec la Région pour que les
données puissent s’intégrer facilement dans une vision de base de données décisionnelle
régionale. Nous intervenons pour le compte des Régions en tant que prestataire. Il ne nous est
pas demandé de créer l’entrepôt de données de la région, mais uniquement celui du service
d’apprentissage et de la formation. Il faudra bien évidemment être à l’écoute et influer pour
obtenir suffisamment d’information sur les données qui seront communes à d’autres services.
Mon rôle sera de traiter les données situées dans la base de production du logiciel
fournie par Ymag. Puis de les mettre à disposition dans une base de données décisionnelle. Le
projet portera le nom de « WinCRAnalyse ». Deux orientations se dessinent :
Gestion des effectifs : Module de comptage des effectifs.
Joachim PELLICIOLI 18

44 L’entrepôt de données en pratique
Gestion financière : Module regroupant plusieurs sous modèles (compte
financier, taxe d’apprentissage, …).
Joachim PELLICIOLI 19

44 L’entrepôt de données en pratique
2.6 Synthèse
Dans ce chapitre de présentation, nous venons de définir les différents acteurs concernés
par le projet. Nous avons d’un côté la société Ymag dans laquelle je suis salarié dans le
service dédié aux logiciels « Région ». D’un autre côté nous avons les Conseils régionaux
avec leurs divers services. Nous retiendrons le service de l’apprentissage et de la formation
ainsi que la direction des systèmes d’information.
J’ai défini les deux solutions de production mises à disposition par Ymag pour les
Conseils régionaux (WinCRApprentissage et WinCRPrimes).
Nous avons établi le besoin des Régions en termes d’informatique décisionnelle, nous
venons de définir leurs attentes et leurs besoins. Deux orientations sont à réaliser, une pour la
gestion des effectifs et l’autre pour la gestion financière.
Nous allons maintenant voir en détails les différents concepts de l’informatique
décisionnelle, avant de pouvoir concevoir une base de données répondant aux attentes du
client.
Joachim PELLICIOLI 20

44 L’entrepôt de données en pratique
3 L’entrepôt de données en théorie
Dans ce chapitre nous allons expliquer les concepts des systèmes d’information
décisionnels (SID) avant de donner des détails sur la réalisation du projet décisionnel des
Conseils régionaux. Les SID sont les pendants décisionnels des systèmes d’information
opérationnels (SIO).
Voici un schéma qui offre une visibilité sur les différents flux de l’entrepôt de données
(data warehouse). Nous définirons tous ces composants afin de comprendre le principe
global.
Figure 4 Flux du data warehouse
Nous allons définir ce qu’est un entrepôt de données, puis nous aborderons les concepts
de data mart et d’OLAP. Ensuite nous expliquerons comment les données sont intégrées dans
l’entrepôt.
Joachim PELLICIOLI 21

44 L’entrepôt de données en pratique
3.1 Le data warehouse
3.1.1 Définition
Un data warehouse ou entrepôt de données est utilisé pour collecter et stocker de
manière définitive des informations provenant d’autres bases de données.
D’après Ralph Kimball, le data warehouse se représente ainsi [KIM1] :
Figure 5 Composants de base du data warehouse
Sa définition du data warehouse est assez large et englobe tout le processus de cette
conception.
Il prend en premier lieu les systèmes sources. D’après son modèle les systèmes sources
sont comparables aux systèmes de production. Nous y retrouvons les données liées à
l’activité.
En seconde partie nous trouvons la « zone de préparation de données ». Il définit ainsi
tout un processus qui a pour but de nettoyer (purge, suppression de doublon, ….) les données
provenant des systèmes sources. Ce nettoyage permet d’alimenter la phase suivante.
Joachim PELLICIOLI 22

44 L’entrepôt de données en pratique
En troisième plan nous avons le « serveur de présentation du data warehouse ». Celui-ci
est découpé en sous parties, elles-mêmes alimentées par la « zone de préparation des
données ».
Enfin la partie « portail de restitution » correspond à la partie utilisateur. Elle permet
l’accès aux données contenues dans le « serveur de présentation du data warehouse ».
Reprenons le cœur de ce que l’on appelle communément le data warehouse. Bill Inmon
définit le data warehouse de cette manière: « A warehouse is a subject-oriented, integrated,
time-variant and non-volatile collection of data in support of management's decision making
process » [INM1]. Nous pouvons traduire cette phrase ainsi : « Un entrepôt de données est
une collection de données orientées sujet, intégrées, non volatiles, historisées, résumées,
organisées pour le support d’un processus d’aide à la décision. ».
Reprenons les termes utilisés dans sa situation afin de les expliquer :
Orientées sujet : Les données sont regroupées en familles, afin de définir des
thèmes.
Intégrées : Les données peuvent provenir de sources différentes, il faut donc les
manipuler afin de déterminer les données identiques.
Non volatiles : Les données ne sont ni modifiées ni supprimées, afin de garantir
l’intégrité dans le temps.
Historisées : Les données ont une notion de temps afin de conserver leur
évolution dans le temps.
Résumées : Les données peuvent être agrégées dans certains cas, pour optimiser
la prise de décision.
Processus d’aide à la décision : Les utilisateurs doivent avoir accès aux données
qui leur sont autorisées.
3.1.2 Objectifs
Le data warehouse permet de séparer des informations identiques mais qui n’ont pas la
même utilité. D’un côté nous avons les systèmes d’information opérationnels qui collectent
l’information (création, mise à jour et suppression). De l’autre nous avons les systèmes
d’information décisionnels qui restituent l’information (uniquement de la lecture). Il ne faut
pas oublier que l’information est essentielle pour l’entreprise, c’est une richesse importante. Il
Joachim PELLICIOLI 23

44 L’entrepôt de données en pratique
faut absolument que ces données soient fiables et traitées afin d’atteindre des objectifs
concrets.
Nous pouvons définir trois points que l’entrepôt de données doit prendre en compte :
Il doit restituer l’information de l’entreprise d’une manière cohérente. Le but
premier de l’entrepôt est l’accès aux données. Celles-ci doivent être cohérentes
dans leur ensemble. De plus certaines données peuvent provenir de différents
services, avoir des noms différents mais être identiques en termes de contenu. Il
faut donc rendre cohérentes toutes ces données.
Les données doivent êtres souples et adaptables. Un entrepôt de données n’est
jamais vraiment terminé, il doit pouvoir accueillir de nouvelles données,
répondre à de nouvelles questions, sans pour autant remettre en cause son
existence.
L’entrepôt constitue la base décisionnelle de l’entreprise. Grâce à cette
centralisation d’informations, l’accès aux données est simplifié. L’entrepôt
facilite la prise de décision.
3.2 Le data mart
3.2.1 Définition
Nous retrouvons encore une fois plusieurs définitions. Nous allons étudier deux des plus
importantes définitions [WIK1] :
Inmon : « Le data mart est issu d’un flux de données provenant du data
warehouse. Contrairement à ce dernier qui présente le détail des données pour
toute l’entreprise, il a vocation à présenter la donnée de manière spécialisée,
agrégée et regroupée fonctionnellement. »
Kimball : « Le data mart est un sous-ensemble du data warehouse, constitué de
tables au niveau détaillé et à des niveaux plus agrégés, permettant de restituer
tout le spectre d’une activité métier. L’ensemble des data marts de l’entreprise
constitue le data warehouse. »
Joachim PELLICIOLI 24

44 L’entrepôt de données en pratique
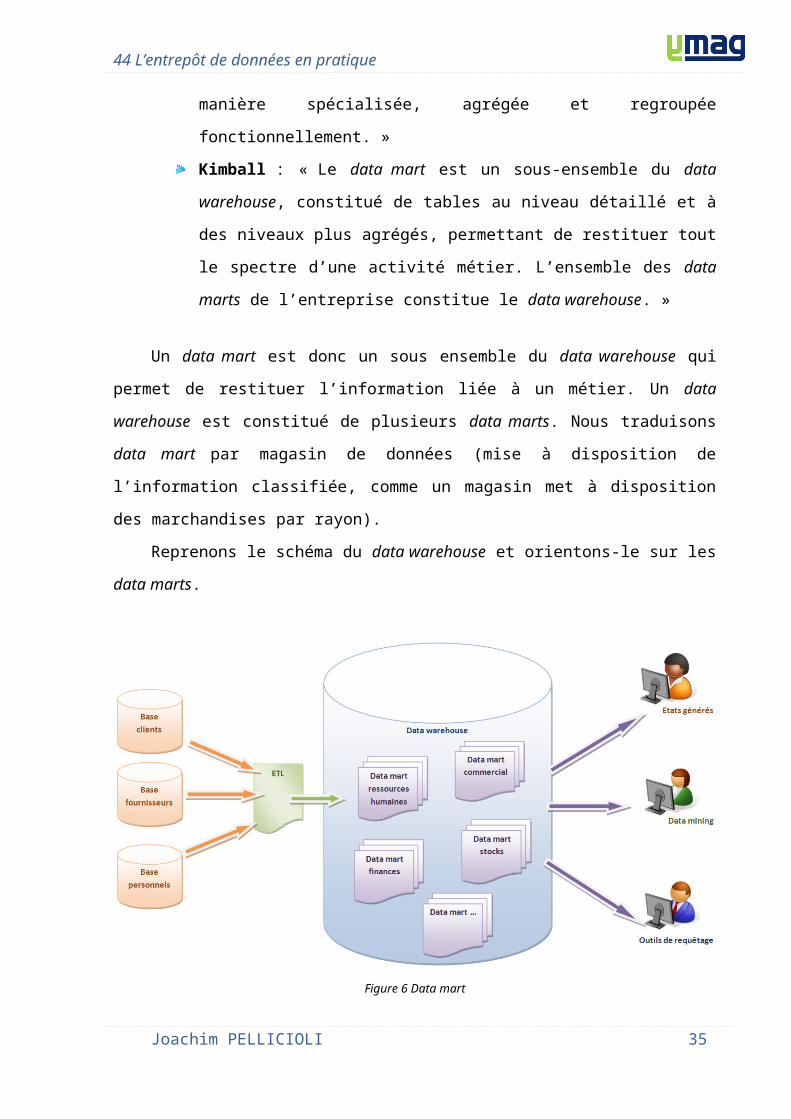
Un data mart est donc un sous ensemble du data warehouse qui permet de restituer
l’information liée à un métier. Un data warehouse est constitué de plusieurs data marts. Nous
traduisons data mart par magasin de données (mise à disposition de l’information classifiée,
comme un magasin met à disposition des marchandises par rayon).
Reprenons le schéma du data warehouse et orientons-le sur les data marts.
Figure 6 Data mart
Notre data warehouse contient plusieurs data marts. Nous pouvons découper les data
marts de différentes manières :
Découpage par service : Nous recherchons les fonctions de l’entreprise et créons
un data mart par service, par exemple un data mart pour les ressources
humaines, un pour les ventes, un pour les commandes, …
Découpage par sous-ensemble organisationnel : En fonction de l’organisation de
l’entreprise nous créons des data marts, par exemple un data mart par
succursale, filière, …..
Mais quels sont les avantages et les inconvénients des data marts ?
Joachim PELLICIOLI 25

44 L’entrepôt de données en pratique
3.2.2 Avantages
Processus de conception simplifié.
Données ciblées à un métier.
Gain de temps sur la recherche d’information.
Données classifiées et clarifiées.
Maintenance simplifiée.
Lisibilité par des non informaticiens.
3.2.3 Inconvénients
Moins de flexibilité.
Impossible d’extraire une information qui sort du cadre habituel défini dans le
data mart.
Augmentation des coûts pour obtenir une requête complexe.
Difficultés de conception des liens entre data marts.
3.3 Modélisation d’un data mart
Nous venons de présenter le cœur de la base de données décisionnelle. Le projet global
peut se nommer data warehouse. Au sein de celui-ci nous retrouvons les data marts.
Maintenant nous allons expliquer comment sont organisées les données au sein d’un data
mart.
3.3.1 Les composants
La base de données décisionnelle a pour but de restituer des données quantifiées mises
en valeur par des libellés.
Joachim PELLICIOLI 26

44 L’entrepôt de données en pratique
3.3.1.1 Les « faits » ou « indicateurs »
Les faits représentent les informations quantifiées de l’entreprise. Nous pouvons les
nommer faits, indicateurs ou encore mesures. Ce sont les données à analyser qui
correspondent à l’activité de l’entreprise. Les indicateurs ont la particularité d’être additifs. Ils
sont contenus dans une table physique de la base de données décisionnelle. Nous nommerons
« portefeuille d’indicateurs », « table des faits » ou « table des mesures » le regroupement de
plusieurs indicateurs.
Les indicateurs n’ont d’intérêt que s’ils sont mis en valeur par des informations. Une
ligne de faits correspond aux valeurs de l’intersection des tables des dimensions. Grâce aux
dimensions, nous déterminons le grain (la finesse) des résultats contenus dans la table des
faits.
3.3.1.2 Les « dimensions »
Tout comme les faits, les dimensions sont contenues dans des tables physiques de la
base de données. Ce sont des informations qui vont mettre en évidence les données contenues
dans les tables des faits. Lorsque nous parlons de dimension nous parlons également « d’axe
d’analyse ». Une dimension regroupe les valeurs de même type. Par exemple dans la
dimension géographique nous pourrions avoir : le continent, pays, région, ville, quartier, rue,
bâtiment, étage, porte. Grâce à cet exemple nous comprenons mieux le sens d’« axe
d’analyse », puisque nous distinguons tout de suite une hiérarchie au sein de la dimension.
Nous nous apercevons immédiatement de la corrélation entre les tables des faits et les
tables des dimensions.
La dimension a deux rôles principaux.
Afficher les données : Ce seront les entêtes des lignes ou des colonnes pour
regrouper les faits. Nous caractérisons ainsi la donnée brute contenue dans la
table des faits.
Filtrer les données : Nous allons choisir telle ou telle valeur de dimension afin
d’obtenir un tableau correspondant à nos attentes.
3.3.1.3 Exemple de table des faits et dimensions
Voici un exemple représentant l’interaction entre les tables des faits et les tables des
dimensions. Prenons une quantité d’un produit vendu pour remplir notre table des faits
Joachim PELLICIOLI 27

44 L’entrepôt de données en pratique
(élément de mesure). Pour mettre en valeur cette quantité nous prenons deux dimensions qui
sont la situation géographique du point de vente (commune) et la gamme du produit vendu.
Nous pouvons répondre à plusieurs requêtes avec ces données :
Quelle est la quantité de produit vendue par commune ?
Quelle est la quantité de produit vendue par gamme ?
Quelle est la quantité de produit vendue par commune et par gamme ?
Quelle est la commune qui vend le plus de produit de la gamme « x » ?
Voici la modélisation correspondant à notre exemple :
Figure 7 Exemple de table des faits et dimensions
Nous venons de voir les concepts de table des dimensions et table des faits. Celles-ci
peuvent se structurer de différentes façons. Nous allons étudier deux techniques de
modélisation multidimensionnelle :
La modélisation en étoile.
La modélisation en flocon de neige.
3.3.2 Modélisation en étoile
La modélisation en étoile (ou star join schema) doit son nom à sa forme. Au cœur de ce
modèle se trouve la table des faits. Autour nous retrouvons des satellites qui donnent chacun
un axe d’analyse différent. Ces satellites correspondent aux dimensions. Cette modélisation ne
tient pas compte des formes normales, car elle a uniquement une préoccupation, celle de
Joachim PELLICIOLI 28

44 L’entrepôt de données en pratique
l’analyse (lecture des données). La table des faits est la seule table à contenir des jointures
avec les dimensions.
Ce schéma est très performant pour la restitution de données, mais il est plus gourmand
en espace de stockage.
Voici une représentation d’un modèle en étoile sur un exemple très simple de gestion
des ventes avec analyse du lieu, de la période de vente et du produit :
Figure 8 Modélisation en étoile
3.3.3 Modélisation en flocon de neige
Le modèle en flocon de neige (ou snowflake schema) est constitué d’une table des faits
au centre et des tables des dimensions autour, comme pour le modèle en étoile. La différence
se situe au niveau des tables des dimensions, qui peuvent également se diviser en plusieurs
branches différentes. Ces branches sont souvent utilisées pour modéliser des hiérarchies.
Cependant d’après Ralph Kimball, elles peuvent engendrer un certain nombre de points
négatifs [KIM2] :
Difficulté de compréhension par des non informaticiens.
Requêtes alourdies par un nombre grandissant de jointure.
Joachim PELLICIOLI 29

44 L’entrepôt de données en pratique
Il estime même que l’argument du gain de place n’est pas forcement fondé, lorsqu’il est
comparé à la table des faits qui est très volumineuse.
Reprenons l’exemple cité dans le paragraphe 3.3.2 Modélisation en étoile. Nous allons
éclater la dimension produit, afin de créer une hiérarchie :
Figure 9 Modélisation en flocon
3.3.4 Modélisation en constellation
Les modèles en étoile ou en flocon ne gèrent qu’une seule table des faits. Par contre, il
est très fréquent pour décrire une activité d’entreprise que nous ayons plusieurs tables des
faits, donc plusieurs étoiles. Ces différentes étoiles auront peut être des dimensions
communes. Si nous relions ces dimensions ensemble nous obtenons une constellation.
Joachim PELLICIOLI 30

44 L’entrepôt de données en pratique
Reprenons l’exemple cité dans le paragraphe 3.3.2 Modélisation en étoile. Nous allons
ajouter la table des faits « achat » et la dimension « fournisseur », la dimension « produit » est
commune aux deux tables des faits. Nous obtenons la constellation suivante :
Figure 10 Modélisation en constellation
3.4 Concept OLAP
3.4.1 Définition
On Line Analytical Processing est un système d’accès aux données en lecture
uniquement. Les programmes accédant aux informations travaillent sur de très grandes
quantités de données, ce qui permet de réaliser des analyses complexes. Le système OLAP
regroupe l’information provenant de diverses sources. Il les regroupe, les intègre, les stocke,
tout ceci afin de donner une vue métier à l’utilisateur. Cette vue métier va l’aider à retrouver
Joachim PELLICIOLI 31

44 L’entrepôt de données en pratique
l’information rapidement. Une notion importante est l’historisation des données au sein des
bases OLAP. Ceci entraine, avec une architecture différente, une grandeur de base de données
supérieure aux bases de données classiques.
En 1993 E.F. Codd a définit dans « Providing OLAP to user-analyst » le concept de
OLAP. Il a mit en évidence 12 règles [COD1] que doivent respecter les bases pour être
OLAP :
1. Multidimensional Conceptual View (Vue conceptuelle multidimensionnelle)
Permet d'avoir une vision multidimensionnelle des données. L’inverse se nomme les
tables unidimensionnelles.
2. Transparency (Transparence)
L'utilisateur ne doit pas se rendre compte de la provenance des données si celles-ci
proviennent de sources hétérogènes. Ces sources peuvent provenir des bases de
données de production, de fichiers à plats, … .
3. Accessibility (Accessibilité)
L’utilisateur doit disposer d’un accès aux données provenant de sources multiples en
faisant abstraction des conversions et extractions de celles-ci.
4. Consistence Reporting Performance (Performance continue dans les rapports)
Les performances ne doivent pas être diminuées lors de l'augmentation du nombre de
dimensions ou lors de l’augmentation la taille de la base de données, mais doivent être
proportionnelles à la taille des réponses retournées.
5. Client-Server Architecture (Architecture client-serveur)
Il est essentiel que le produit soit client-serveur. Le serveur stocke les données et le
client les restitue.
6. Generic Dimensionality (Dimensionnement générique)
Chaque dimension doit être équivalente par rapport à sa structure et à ses capacités
opérationnelles pour ne pas fausser les analyses.
7. Dynamic Sparse Matrix Handling (Gestion dynamique des matrices creuses)
Certaines cellules de l’hypercube peuvent êtres vides. Elles doivent être stockées de
manières à ne pas détériorer les temps d’accès.
8. Multi-User support (Support multi-utilisateurs)
Les outils OLAP doivent fournir des accès concurrents, l'intégrité, la sécurité et la
gestion des mises à jour.
Joachim PELLICIOLI 32

44 L’entrepôt de données en pratique
9. Unrestricted Cross-dimensional Operations (Opération non restrictive entre les
dimensions)
Les calculs doivent être possibles à travers toutes les dimensions qui sont régies par
les règles de gestion. Toutes les tranches de cube doivent être visualisées.
10. Intuitive Data Manipulation (Manipulation intuitive des données)
La manipulation des données se fait directement à travers les cellules d'une feuille de
calcul, sans recourir aux menus ou aux actions multiples. Au final, il doit permettre
l'analyse intuitive dans plusieurs dimensions.
11. Flexible Reporting (Flexibilité dans la création des rapports)
La création des rapports ou des graphiques se doit d’être simple et efficace pour les
utilisateurs.
12. Unlimited Dimensions & Aggregation Levels (Nombre illimité de niveaux
d’agrégation et de dimensions)
Dimensions et niveaux d'agrégation illimités, afin d’autoriser les analyses les plus
pointues.
Ces 12 règles ont pour but de normaliser une base de données décisionnelle. Cette base
de données peut être un système de gestion de base de données relationnelle ou
multidimensionnelle, respectivement SGBDR et SGBDM.
Dans les SGBDM, le stockage des données se base sur le principe des hypercubes. Un
hypercube est une matrice décisionnelle avec au minimum quatre dimensions d’analyse. Nous
parlons également du cube, qui est une matrice décisionnelle avec trois dimensions.
Le concept d’OLAP est décliné en plusieurs « sous concepts » qui orientent la structure
physique des données ou les techniques de traitements.
M-OLAP : Multidimensional on line analytical processing. M-OLAP est la forme la
plus classique. Elle utilise les tables multidimensionnelles pour sauver les informations et
réaliser les opérations. Les données sont stockées dans une base de données
multidimensionnelle.
R-OLAP : Relationnal on line analytical processing. R-OLAP utilise une structure de
base de données relationnelle. Son avantage réside en la simplicité de mise en place
puisqu’elle ne nécessite aucun investissement dans une base multidimensionnelle.
Joachim PELLICIOLI 33

44 L’entrepôt de données en pratique
H-OLAP : Hybrid on line analytical processing. H-OLAP utilise R-OLAP et M-OLAP
en fonction des données qu’il traite. Sur les données agrégées il utilise M-OLAP, par contre
sur les données plus détaillées, il utilise R-OLAP.
S-OLAP : Spatial on line analytical processing. S-OLAP est une plateforme visuelle
pour l’exploration et l’analyse spatio-temporelle. Ceci dans le but de présenter les données
sous une autre forme que celle tabulaire.
D-OLAP : Desktop on line analytical processing. D-OLAP les données sont récupérées
sur le poste du client. Ensuite un moteur OLAP local traite ces données.
3.4.2 Comparaison entre OLAP et OLTP
3.4.2.1 Définition de OLTP
On Line Transaction Processing est le modèle utilisé dans les bases de données de
production. Il utilise un mode de travail transactionnel. Son rôle principal est l’interaction sur
les données avec les actions suivantes : ajout, suppression et mise à jour. Il permet également
l’interrogation des données avec des requêtes simples. OLTP permet l’accès à ces données et
ces traitements à un grand nombre d’utilisateurs simultanés. Les transactions ainsi générées
travaillent sur de petits ensembles de données.
3.4.2.2 Tableau comparatif
Tableau I Comparaison OLAP vs OLTP
Caractéristiques OLAP OLTP
Orientation Multidimensionnelle Ligne
Utilisateur Base décisionnelle Base de production
Nombre d’utilisateurs Réduit Elevé
Accès Lecture Lecture et écriture
Type d’opération Analyse Mise à jour
Granularité d’analyse Globale Elémentaire
Quantité d’information échangée Importante Faible
Quantité d’information stockée Importante Faible
Longévité des données Historique En cours
Joachim PELLICIOLI 34
44 L’entrepôt de données en pratique
Joachim PELLICIOLI 35

44 L’entrepôt de données en pratique
3.4.3 Fonctions liées à OLAP
3.4.3.1 Définition
Dans l’analyse OLAP nous retrouvons plusieurs fonctions qui permettent l’analyse et la
restitution des données contenues dans le cube d’informations. Ces fonctions donnent un
accès précis et rapide aux données et permettent le changement de vue d’analyse.
Voyons les fonctions un peu plus en détail :
Drill up (Monter) : Parcours vers le sommet d’une hiérarchie (obtention de
données de plus en plus agrégées).
Drill down (Descendre) : L’inverse du drill up, permet de plonger dans la
hiérarchie afin d’avoir plus de détails.
Drill through (Entrer) : Possibilité d’obtenir des valeurs sur une donnée
agrégée. Cette fonction n’est valable que sur certain mode OLAP tel qu’H-
OLAP qui change automatiquement entre la base de données relationnelle et
multidimensionnelle.
Rotate (Rotation) : Sélectionne un couple de dimensions à analyser, en conserve
un et fait évoluer l’autre.
Slicing (Couper « en tranche ») : Extraction d’une tranche d’information.
Scoping (Couper « un morceau ») : Extraction d’un bloc de données, sur le
principe du slicing mais plus généraliste.
3.4.3.2 Exemples
Pour mieux appréhender ces notions nous allons voir quelques exemples. Nous allons
les illustrer par des tableaux d’informations ainsi que par une représentation graphique du
cube. La vision d’un cube aide à la compréhension de la structure de données, elle augmente
la vision et l’interprétation des fonctions que nous allons voir. En exemple nous travaillerons
sur les véhicules vendus durant trois années. Nous distinguons les ventes de voitures
d’occasions et neuves ainsi que la marque du constructeur.
Drill : Grâce au drill, nous plongeons dans le détail des données ou à l'inverse
nous remontons pour avoir une vue globale. La dimension temps au départ de
Joachim PELLICIOLI 36

44 L’entrepôt de données en pratique
notre exemple est très agrégée, elle donne une vue globale sur deux années
"2007-2009". Puis nous plongeons dans les données mises en valeur par la
dimension temps afin d'obtenir plus de détails. Nous passons à une vue par
année pour finir par une vue par trimestre de l'année "2009". En ce qui concerne
la dimension "produit", nous partons d'une donnée agrégée "Voiture" puis nous
descendons dans le détail entre les voitures neuves et d'occasions, pour enfin
voir la répartition des voitures d'occasions par marque.
Figure 11 OLAP Drill up et drill down
Rotate : Cette vue nous montre deux dimensions qui sont le temps et le type de
vente. Grâce à la fonction rotate, nous allons intervertir une dimension afin
d’obtenir une vue par région à la place du type de vente.
Joachim PELLICIOLI 37

44 L’entrepôt de données en pratique
Figure 12 OLAP Rotate
Slicing : Nous prenons les données d’une dimension complète ou par tranche
d’information. Dans notre exemple nous souhaitons voir les ventes de 2008 tout
en gardant le détail des ventes de voitures neuves ou d’occasions ainsi que le
lieu de vente.
Figure 13 OLAP Slicing
Scoping : Nous allons cibler notre recherche d’informations en limitant les
données de plusieurs dimensions, nous extrayons un bloc d’information. Nous
voulons dans ce cas limiter notre analyse aux années 2008-2009 et pour les
véhicules neufs, tout en gardant la précision sur le lieu de vente.
Joachim PELLICIOLI 38

44 L’entrepôt de données en pratique
Figure 14 OLAP Scoping
3.5 Processus d’alimentation du data warehouse
Figure 15 ETL
Ce processus est connu sous le nom de « Extract Transform Load » (ETL) qui signifie
littéralement extraire transformer charger (ou data dumping). Pour alimenter le data
warehouse il faut collecter les données dans les bases de données de production pour les
injecter dans la base de données décisionnelle. L’ETL récupère les données de production
historiées et ceci d’une manière cyclique.
Etudions les sous processus que sont l’extraction, la transformation et le chargement des
données.
3.5.1 Sous processus de l’ETL
Joachim PELLICIOLI 39

44 L’entrepôt de données en pratique
3.5.1.1 Extraction
Le but de ce processus est de récupérer les données de production. Attention ces
données ne sont pas forcément stockées dans une seule base de données. Les données
pourront être issues de structures propriétaires, de logiciels, de systèmes de fichier, … . De
plus, elles ne sont pas obligatoirement stockées au même endroit géographiquement (ex :
siège social à Paris et succursale à Madrid). En partant de ce constat, il est important de ne pas
minimiser cette étape. Elle implique une très bonne connaissance des sources de données, afin
de connaître la structure et la sémantique de chaque information.
Toutes les données sources n’ont pas systématiquement de l’intérêt pour la base de
données décisionnelle. Le processus d’extraction aura également pour mission de filtrer les
données utiles.
3.5.1.2 Transformation
Ce sous processus travaille sur les données provenant de l’extraction. Il a pour but de
transformer les données afin de répondre à des contraintes d’ordre techniques ou
fonctionnelles. Les transformations les plus fréquentes sont le changement de monnaie ou la
correction de casse sur un libellé. Nous pouvons aussi transformer des informations afin de
correspondre à une nomenclature, ce qui aura pour effet d’uniformiser les dimensions dans
l’entrepôt de données. Lors de la transformation nous pouvons scinder ou consolider des
données afin d’optimiser les futures requêtes.
La liste des tâches liées à ce sous processus n’est pas exhaustive, elle dépend de la
qualité des données sources et de l’objectif du data warehouse.
3.5.1.3 Chargement
Ce sous processus est la troisième phase du processus d’alimentation. Il intègre les
données au data warehouse en récupérant le résultat du processus de transformation. Il
contrôle également l’intégrité des données. Il pourra, le cas échéant, ajouter des données afin
de respecter toutes les contraintes d’intégrité du modèle décisionnel. Par exemple si pour une
vente nous n’avons pas la dimension géographique nous indiquerons « inconnue ». Le
chargement est le garant de l’évolution des données. Lors de celui-ci, deux possibilités
s’offrent à nous : soit historiser les changements des données, soit conserver les dernières
modifications.
Joachim PELLICIOLI 40

44 L’entrepôt de données en pratique
3.5.2 Type d’ETL
Les ETL se regroupent en trois familles, en fonction de leur mode de fonctionnement et
plus particulièrement en fonction des traitements effectués [SYS1] :
Engine-based : Les transformations sont effectuées par le moteur de l’ETL en
fonction d’un référentiel. Il offre l’avantage de pouvoir effectuer des
transformations multi-base.
Database-embedded : Les transformations sont réalisées par la base de données
sources. Il offre l’avantage d’avoir un accès complet au traitement.
Code-generators : Un code est généré en fonction des transformations à
apporter. Il offre l’avantage d’être complètement indépendant de la source de
données.
3.5.3 Stratégie de chargement
Il y a plusieurs façons d’extraire et de charger les données pour un ETL. Les critères tels
que l’architecture physique, la taille des données ou la disponibilité des serveurs vont
permettre de choisir le mode de chargement.
Le chargement des données peut se faire de deux façons distinctes au sein d’un ETL :
complète ou incrémentale.
3.5.3.1 Extraction complète
Le chargement complet consiste à vider la table de destination avant de réintégrer les
données de la table source. Elle est intéressante pour les structures de données simples et de
taille modeste.
Avantages :
Simplicité de mise en œuvre.
Aucune différence de traitement entre les anciennes et les nouvelles données.
Inconvénients
Besoin de beaucoup de ressources surtout si la source de données est importante
ou que les traitements sont lourds.
Joachim PELLICIOLI 41

44 L’entrepôt de données en pratique
Gestion de l’historique impossible, car nous perdons la trace de l’existant.
3.5.3.2 Extraction incrémentale
La mise à jour incrémentale consiste à comparer la précédente remontée d’informations
vis-à-vis de la nouvelle remontée. Toutes les modifications seront intégrées. Il existe plusieurs
solutions afin de trouver les différences entre les remontées :
Comparaison des remontées.
Marquer les modifications au niveau de la source de données.
Analyser les fichiers de log des moteurs de base de données.
L’extraction incrémentale apporte la possibilité d’historiser les données. Par contre son
implémentation s’avère plus compliquée que l’extraction complète.
Avantages :
Rapidité sur de gros ensembles.
Historisation des données possible.
Inconvénients :
Difficulté de mise en œuvre.
Historique difficile à rechercher.
Joachim PELLICIOLI 42

44 L’entrepôt de données en pratique
3.6 Synthèse
Dans ce chapitre nous venons de poser les briques qui nous permettent d’appréhender
les notions liées aux bases de données décisionnelles et au business intelligence (BI).
Le projet data warehouse englobe un certain nombre de notions. En amont de ce
processus, nous avons l’ETL qui va récupérer les données dans les bases de données de
production afin de les restituer à l’entrepôt de données. Le rôle de l’ETL est important, car il
est le garant des données, il les travaille, les nettoie, vérifie leur intégrité puis les fournit à
l’entrepôt.
Ensuite le data warehouse peut se décomposer en plusieurs data marts, qui représente
une partie des données stockées ciblée. Nous parlons de data mart des ressources humaines,
de la paie, de la production, …. Les data marts sont composés de tables des dimensions ainsi
que de tables des faits. Les éléments quantifiables de l’organisme géré sont contenus dans la
table des faits. Les dimensions sont des axes d’analyse. Elles regroupent les notions de même
famille, par exemple la dimension temporelle peut être constituée d’un siècle, d’une décennie,
d’une année, d’un semestre, d’un mois, d’une semaine, d’un jour, d’une heure et d’une
minute. Nous remarquerons qu’il y a souvent une hiérarchie au sein d’une dimension. Les
faits n’ont aucune valeur sans la mise en évidence par une dimension.
Une fois cette structure mise en place, elle peut être exploitée par des mécanismes tels
que le drill, scoping,… que nous venons de définir. Ces mécanismes sont des outils mis à
disposition pour les logiciels de restitutions des données.
Joachim PELLICIOLI 43
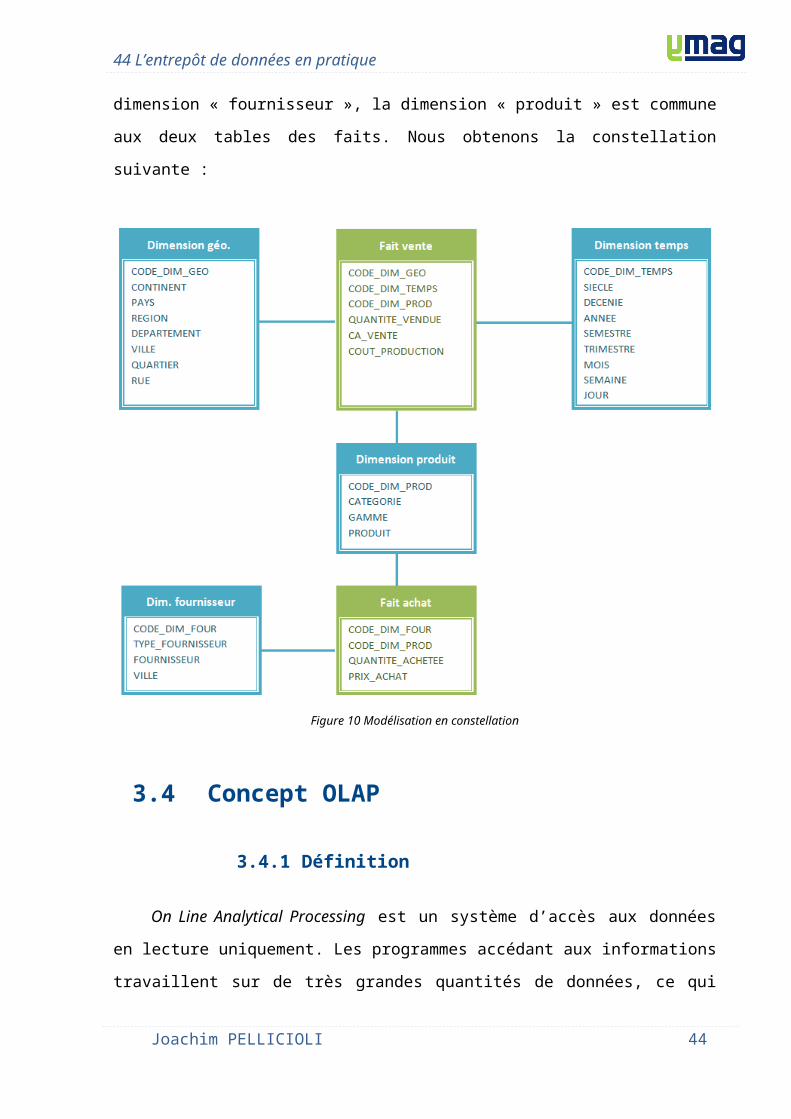
44 L’entrepôt de données en pratique
4 L’entrepôt de données en pratique
Ce chapitre traite de l’étude et de la réalisation du projet décisionnel. Nous nommons ce
projet WinCRAnalyse et il se découpe en deux modules :
WinCRAnalyseEffectifs le data mart des effectifs.
WinCRAnalyseFinancier le data mart financier.
4.1 Définition des phases du projet
4.1.1 Contexte
Nous avons défini au chapitre 2.5 Définition du besoin le périmètre de notre projet.
Nous avons vu comment nous avons extrait les informations liées au besoin et le résultat vers
lequel nous voulons tendre. A partir de cette étude préliminaire nous allons mettre en place un
calendrier prévisionnel afin de planifier les différentes tâches à exécuter, ainsi que l’ordre
dans lesquelles elles doivent l’être.
4.1.2 Identification des différentes phases du projet
Ce projet se découpe en cinq grandes phases :
Phase d’étude : Elle se divise en deux sous parties. La première recense le
besoin. A partir de celui-ci, nous allons établir le but du projet et les moyens
techniques et humains à mettre en œuvre dans un temps restreint afin de
l’atteindre. La deuxième consiste à créer un cahier des charges qui fera office de
contrat de réalisation entre la Région et Ymag.
Phase ETL : Celle-ci se décompose également en deux sous parties. Tout
d’abord nous allons concevoir un ETL, qui permettra l’échange et la
transformation des données des bases de production au data warehouse. Ensuite
Joachim PELLICIOLI 44

44 L’entrepôt de données en pratique
nous réaliserons une interface de pilotage de l’ETL. Celle-ci aura pour but de
paramétrer et programmer l’exécution de l’ETL, ainsi que le contrôle de
l’exécution.
Phase effectifs : Conception de la structure de base de données du data mart
effectifs. Réalisation des transformations à apporter avec l’ETL pour obtenir les
données traitées. Création de l’univers dans le logiciel choisi ainsi que les
documents associés. Une fois le data mart réalisé nous entrerons dans une phase
de test de recette avec la Région pilote.
Phase financière : Nous allons nous appuyer sur l’expertise du data mart
effectifs pour réaliser le data mart financier. Les points à réaliser restant
identiques d’un data mart à l’autre.
Phase de finalisation : Dernière étape de ce projet, avec la finalisation des
phases précédentes. Après validation par la Région pilote des data marts nous
pouvons les déployer dans les autres Conseils régionaux. Nous aurons à installer
l’ETL et le data warehouse sur les serveurs. Dans un deuxième temps nous
aurons la formation des utilisateurs.
4.1.3 Calendrier de réalisation des phases
Il est important dans un projet de définir un calendrier de réalisation. Ce calendrier
apporte plusieurs points intéressants. Tout d’abord il permet de communiquer avec les
intervenants du projet. Communication avec la hiérarchie de l’entreprise qui a besoin d’une
vue d’ensemble sur ses activités. Communication avec l’équipe projet, pour se donner des
objectifs et se donner une trame d’organisation de travail. Communication avec le client pour
justifier des grandes étapes du projet et rendre compte de l’avancement de celui-ci.
Le calendrier permet également de définir l’ordre mais aussi les synchronisations entre
nos différentes tâches. Reprenons nos cinq étapes principales du projet, voici le calendrier
donnant une vue synthétique de la réalisation :
Joachim PELLICIOLI 45

44 L’entrepôt de données en pratique
Tableau II Calendrier des phases
Mars 2009Etude
Avril 2009
Mai 2009
ETLJuin 2009
Juillet 2009
EffectifsAoût 2009
Septembre 2009
Financier
Octobre 2009
Novembre 2009
FinalisationDécembre 2009
Janvier 2010
Février 2010
Dans notre contexte le calendrier précis n’est pas évident à mettre en œuvre. Ymag ne
possède aucune expérience en termes de conception de base de données décisionnelle. C’est
pour cela qu’il faudra dans chacune des étapes prévoir un temps de sécurité plus important
que sur d’autres projets informatiques. Cela étant, ce projet doit servir d’élément de référence
pour les projets décisionnels à venir.
4.2 Phase d’étude
Suite à l’étude préliminaire, nous avons obtenu une vision plus globale des projets
menés par les Conseils régionaux. Actuellement tributaires de nombreux prestataires, ils
mènent des campagnes de création de data marts pour chaque prestataire. Leur projet a pour
but de créer un immense data warehouse. Chaque Conseil régional fonctionne d’une manière
autonome. Cela signifie qu’il n’y a pas forcément de concertation au niveau de la création de
ces entrepôts. La DSI aura pour rôle de coordonner ces différents data marts.
Nous travaillons avec le service de l’apprentissage et de la formation, nous
considérerons celui-ci comme une entité autonome et indépendante. Nous aurons à
harmoniser les besoins des différentes Régions pilotes afin d’obtenir un entrepôt cohérent
dans les différentes Régions clientes. Notre objectif est de fournir des data marts métiers
correspondant parfaitement aux attentes des utilisateurs. Si nous atteignons cet objectif, ces
Joachim PELLICIOLI 46

44 L’entrepôt de données en pratique
data marts pourront être exploités par les différents services de l’apprentissage et de la
formation de toutes les Régions puisqu’ils fonctionnent de la même manière (même métier).
Au sein du service de l’apprentissage et de la formation, nous avons également vu en
étude préliminaire qu’il y avait deux orientations pour notre base de données décisionnelle.
Nous parlerons dès à présent de data mart effectifs et de data mart financier. Ces deux data
marts pourraient être considérés comme deux projets, nous verrons par la suite comment l’un
et l’autre vont se croiser afin d’améliorer le résultat global.
Dans ce mémoire nous n’aborderons pas l’aspect mercatique (devis, chiffrage, marge,
….), ceci fait partie d’une stratégie menée par la direction.
Dans un premier temps nous allons expliquer la méthodologie mise en œuvre, nous
allons ensuite déterminer les objectifs du projet. Ensuite nous définirons l’environnement
technique. Tout ceci nous permettra d’établir la liste des tâches du projet et en créer le
calendrier global.
4.2.1 Méthodologie
La société Ymag a fortement évoluée ces quelques dernières années. En passant de 20 à
50 salariés, l’organisation générale de l’entreprise doit être remise en cause. Nous sommes en
pleine réflexion sur la méthodologie à adopter. Il n’y a donc pas réellement de schéma de
conduite de projet au sein de ma société. La réalisation de chaque projet est laissée au bon
soin de la personne responsable du module. Je ne peux donc pas me baser sur une
méthodologie d’entreprise. C’est également le premier projet de ce type, je ne peux donc pas
me référer à l’expérience des chefs de projets actuels.
Dans mon cas, j’ai souhaité mettre en application les méthodes et outils découverts dans
les cours du C.N.A.M. tels que « management de projet, management social ». Ensuite j’ai
essayé de rechercher ce qui devait, dans le cas d’un projet de base de données décisionnelle,
être amplifié pour atteindre nos objectifs. J’ai donc placé le client au centre du projet. Bien
souvent, ses considérations sont prises en compte au début du projet, puis durant les phases de
réalisation il est mis de côté. Dans un projet décisionnel, il est la clé de voute, il est le seul à
avoir l’information sur « son métier ». C’est pour cela que tout au long des phases du projet,
celui-ci sera sollicité, pour valider, s’exprimer ou modifier chacune des étapes.
Joachim PELLICIOLI 47

44 L’entrepôt de données en pratique
Pour simplifier ce dialogue et ne pas réunir les douze Régions clientes à chaque phase
du projet, j’ai décidé de choisir deux Régions pilotes. Comment c’est fait ce choix ? Il m’a
paru judicieux d’en prendre deux, une pour le data mart effectifs et une autre pour le data
mart financier. Chacune ayant son rôle défini avec une vision globale du projet. Ainsi les
parties communes auront un double point de vue. Les parties spécifiques seront pilotées par
une Région et validées par une autre. Grâce à ce fonctionnement je pourrai garantir l’adhésion
des autres Régions au produit, une fois celui-ci terminé. Le data mart effectifs sera développé
avec la Région Centre et le data mart financier avec la Région Lorraine.
4.2.2 Généralités sur l’existant
Au sein du logiciel WinCRApprentissage, nous retrouvons les deux grandes parties qui
sont les effectifs et le financier. Je vais donner quelques éléments sur le fonctionnement de
l’application actuelle, cela permettra de donner un contexte sur le métier de l’apprentissage et
de la formation.
Effectifs et conventions
Le CFA signe une convention qui régit l’ouverture des formations au sein de son
établissement. Cette convention a une durée de vie de cinq ans et définit le seuil minimal et
maximal d’effectifs dans chaque formation. Par exemple le lycée X de Dijon a signé une
convention pour l’ouverture d’une formation de soudeur au niveau de certificat d’aptitude
professionnelle (CAP). La Région Bourgogne estime que le besoin en soudure est important
et accepte cette ouverture. Ensuite elle va définir le seuil minimal pour lequel la formation à
lieu d’ouvrir. Elle fera de même pour le seuil maximal, auquel cas une nouvelle formation
sera ouverte. Toute cette démarche fait partie de négociation entre la Région et le CFA.
La convention une fois signée fait office de contrat. Pour contrôler le respect de ces
seuils, la Région demande au CFA de lui transmettre les effectifs par classe. Pour s’exécuter
le centre de formation extrait les informations de son logiciel administratif et les transfère sur
le site de la Région : ce traitement est communément appelé « une remontée d’effectifs ».
Cette enquête permet de vérifier le respect de la convention. Si les seuils sont approchés ou
franchis, la Région contactera le CFA afin de réguler la formation. Cette régulation se
Joachim PELLICIOLI 48
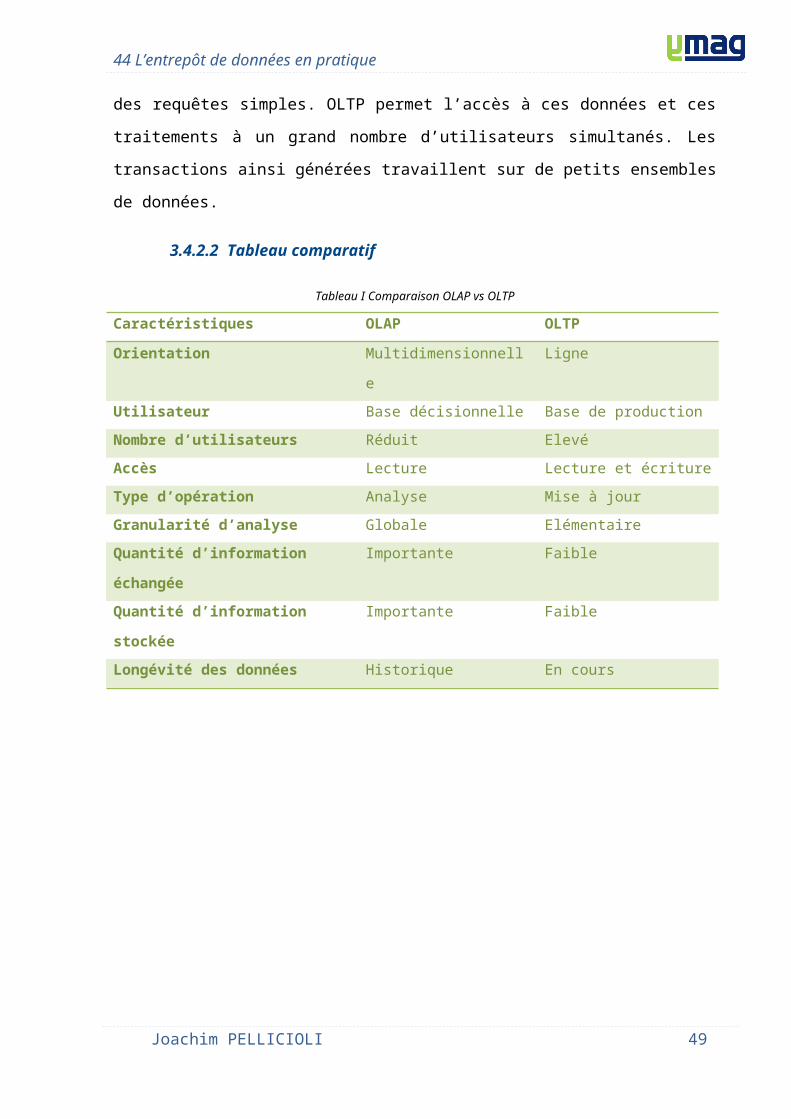
44 L’entrepôt de données en pratique
concrétise par un avenant à la convention. La Région peut demander autant de remontée
d’effectifs qu’elle le souhaite. Ainsi il n’est pas rare de voir une remontée d’effectifs tous les
mois en début d’année scolaire pour contrôler l’évolution des formations.
Au niveau des traitements, l’intégralité de cette gestion est effectuée via l’application
WinCRApprentissage. Au fur et à mesure des demandes, nous avons sorti de nouveaux
tableaux de bord répondant aux besoins. Ces tableaux sont fixes et accessibles depuis
l’application. Nous avons créé quelques exports dans un tableur afin que les utilisateurs
opèrent les modifications souhaitées aux résultats.
Financier
La Région doit subvenir financièrement aux besoins du CFA. Pour cela elle doit
contrôler l’intégralité de la comptabilité du centre de formation. Pour rappel, un CFA
bénéficie de deux types de ressources, la première étant la taxe d’apprentissage que versent
les entreprises et la deuxième est la subvention versée par la Région. Nous comprenons bien
pourquoi il est important que la Région régule l’ouverture et la fermeture des formations
comme nous l’avons évoqué dans le paragraphe précédent. La Région prend en charge des
coûts tels que l’amortissement des locaux et des machines, le personnel et les frais de
fonctionnement. La Région finance également les aides versées aux apprentis aux titres du
transport et de l’hébergement. Ces aides sont données aux CFA qui les reversent aux
apprentis.
Le module financier s’articule en deux grandes notions :
Le prévisionnel : La région, en fonction de la convention et d’autres paramètres
tels que le nombre d’heures de cours, les infrastructures, les investissements, les
transports, l’hébergement, va définir un budget prévisionnel. Ce budget va
concerner l’année à venir. Il permettra de faire des paiements par avance pour le
fonctionnement du CFA. Attention dans la partie financière, une année est
considérée comme une année civile, alors que dans la partie sur les effectifs une
année est considérée comme une année scolaire.
Le réalisé : Le réalisé correspond à la comptabilité saisie par le CFA. Grâce à
ces données ayant un impact réel, la Région pourra effectuer des corrections vis-
Joachim PELLICIOLI 49

44 L’entrepôt de données en pratique
à-vis du prévisionnel et combler ou récupérer des fonds alloués. Ces comptes
seront étudiés afin d’adapter le prochain budget prévisionnel du CFA.
De même que pour la partie sur les effectifs de WinCRApprentissage, nous avons mis
en place des états accessibles depuis l’application.
4.2.3 Objectifs
Je pense qu’il est important de fixer les objectifs à réaliser. Ceux-ci ont un double
intérêt. Ils permettent de définir le but du projet et également de le qualifier en fin de phase de
conception. Ils nous donnent les cibles à atteindre pour pouvoir justifier de la réussite du
projet. Les objectifs sont également le pivot de la communication avec le client.
L’étude des objectifs ne se fera pas data mart par data mart. Nous avons opté pour une
analyse globale des buts à atteindre, nous les présenterons en deux parties différentes : les
optimisations et les évolutions.
Optimisations
L’application actuelle ne fournit pas toutes les garanties sur les données pour réaliser
une analyse performante. WinCRApprentissage véhicule un lourd historique, qui a conduit à
des erreurs d’analyse et de conception. Ce point empêche certaines requêtes dans la version
actuelle de la structure. Les Régions et les CFA travaillent avec de nombreuses
nomenclatures, parfois communes, parfois différentes. Il faudra prendre en compte tous ces
points afin d’unifier et d’optimiser les informations de notre SID.
Ensuite certaines données sont particulièrement longues à obtenir. Par exemple sur les
effectifs, chacune des enquêtes traitent plusieurs dizaines de milliers de lignes : les requêtes
en sont alourdies. Il faudra que le SID puisse ressortir des informations sur de gros ensembles
de données.
Evolutions
Les autres types de demande sont les évolutions des possibilités actuelles. Il n’est pas
rare que les Régions appellent pour savoir comment ressortir les effectifs par formation et par
Joachim PELLICIOLI 50

44 L’entrepôt de données en pratique
sexe en fonction de tel ou tel critère. L’implication croissante des Régions dans la vie locale,
les oblige à rendre davantage de comptes. C’est pour cela que les demandes sont de plus en
plus fréquentes et variées. Il faut donc donner la possibilité aux utilisateurs d’exécuter des
requêtes ponctuelles d’une manière autonome, sans faire appel à société Ymag.
Dans l’application actuelle, les deux modules effectifs et financiers sont indépendants.
Nous avons beaucoup de demandes afin de croiser les deux. Les Régions ont besoin de
connaitre le coût de formation par apprenti. Les élus souhaitent aller plus loin et utiliser leur
système d’information géographique (SIG) afin de créer des cartes qui mettent en valeur les
données du service de l’apprentissage et de la formation. Ces cartes ont une forte valeur
ajoutée en termes de communication pour les Régions. Elles permettent une communication
visuelle avec tous les administrés (entreprise, parent, CFA, formateur, …).
Un autre objectif serait de pouvoir mettre en corrélation certaines informations afin de
mieux organiser le service de l’apprentissage et de la formation. Actuellement la Région ne
peut pas contrôler toutes ses données, ce qui peut entrainer des erreurs très difficiles à déceler.
Ces erreurs peuvent avoir un impact financier important. Grâce à un entrepôt de données, la
Région pourra mettre en comparaison deux formations dans deux CFA différents et vérifier
qu’il n’y ait pas d’écart trop important sur le budget. La Région aura ainsi un outil de
contrôle.
Pour finir, chaque Région a besoin de tableaux de bord pour le pilotage qui lui est
propre. Il est difficile de gérer ce point dans les applications actuelles.
Synthèse des objectifs
Tableau III Objectifs synthèse
Type Objectifs
OptimisationAnalyser des données fiables.
Améliorer les temps de réponse des requêtes.
Evolution
Pouvoir faire de l’analyse à la demande (ad hoc).
Croiser les données sur les effectifs et le financier.
Croiser avec les données SIG.
Mettre en corrélation certaines informations difficilement comparables.
Joachim PELLICIOLI 51
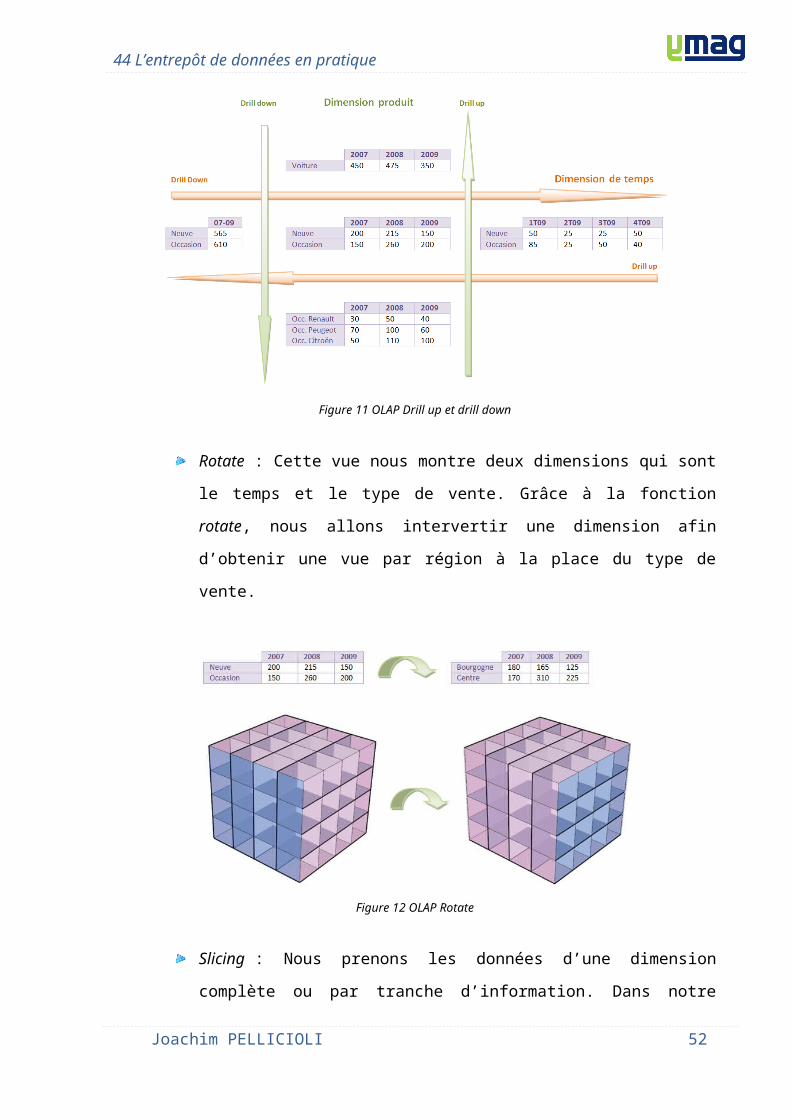
44 L’entrepôt de données en pratique
4.2.4 Risques
L’enjeu le plus important dans ce projet est de bien faire comprendre l’intérêt et les
objectifs de celui-ci. Il intègre des acteurs très variés avec des besoins différents. Pour les
élus, le SID donnera des réponses à des questions auxquelles ils n’arrivent pas à avoir
actuellement de réponse. Par contre pour les opérationnels, il est difficile de ne pas vouloir la
même chose que dans les logiciels de production (données détaillées, rapports déjà existants,
…). L’enjeu lors de cette phase d’étude et durant toute les autres et de bien définir l’objectif
de l’informatique décisionnelle.
Les présidents de Régions ainsi que les DSI ont choisi de créer des SID. Ils ont
communiqué sur ce sujet et ont expliqué aux différents intervenants les objectifs d’une telle
technologie. Nous devons, en tant que prestataire, suivre cet objectif d’information.
4.2.5 Choix technologiques
Les choix technologiques sont multiples dans la création d’un SID. Tout d’abord il faut
choisir une technologie pour l’ETL, pour le stockage de l’entrepôt de données et pour les
outils d’analyse, de conception de requête et de reporting.
ETL
Le marché offre différents outils pour extraire les données des SIO. Comme nous
l’avons vu dans le chapitre 3.5 Processus d’alimentation du data warehouse, les ETL sont
multiples. Ils peuvent fonctionner en automatique ou sur la base de données sources. Il existe
beaucoup d’ETL sur le marché, certains payants et d’autres libres.
Voici quelques exemples d’ETL du marché :
Offre commerciale : SAP Business Objects Data Integrator, Informatica
PowerCenter, ...
Offre libre : Talend Open Studio, KETL, …
Joachim PELLICIOLI 52

44 L’entrepôt de données en pratique
Pour la réalisation du projet, nous pouvons également créer notre propre ETL. Nous
allons essayer de donner quelques critères permettant d’évaluer les avantages et les
inconvénients d’un ETL développé en interne ou d’un ETL du marché. Voici les avantages de
chacun :
ETL du marché
Développement simplifié. Ce qui donne un gain au niveau du coût et du temps.
De nombreux connecteurs sont intégrés afin d’extraire et de charger dans des
sources diverses.
Optimisé pour les grandes structures de données.
Outil permettant de faire des analyses d’impact lors de modification.
Utilisable par des personnes ayant une connaissance métier et non informaticien.
Génération automatique de documentation, en fonction de la description des
données (métadonnées).
ETL développé en interne
Contrôle total sur les traitements effectués dans l’ETL.
Grande souplesse sur les traitements et les métadonnées.
Aucune limitation liée au fournisseur.
Possibilité de créer des outils de test unitaire.
Indépendant de toute structure commerciale.
Attention ce choix est à faire en fonction du projet et de l’environnement de travail.
Compte tenu de la situation de ce projet, nous sommes en train de traiter des données
hétéroclites provenant des bases de production de la société Ymag. L’ETL aura un rôle limité
en termes de connectivité. Nous avons la maîtrise des données provenant de la source.
Nous avons décidé de créer notre propre ETL pour les raisons suivantes :
Autonomie dans la conception, l’évolution et la maintenance de l’ETL.
Type de source quasi unique.
Excellente connaissance de la source de données.
Simplicité du déploiement dans les Régions.
Joachim PELLICIOLI 53

44 L’entrepôt de données en pratique
Pour réaliser cet ETL nous travaillerons avec l’environnement DELPHI 7, certaines
données pourront provenir de fichiers XML et nous récupérerons les données de production
dans les bases en SQL Server 2000.
Entrepôt de données
Pour gérer l’entrepôt de données nous avons la possibilité de le faire dans des SGBD
classiques ou d’autres orientés sur l’analyse dimensionnelle.
Par rapport à nos données et à la méthodologie à mettre en œuvre, j’ai choisi d’utiliser
une base relationnelle avec une méthodologie OLAP. Nous n’avons pas de données
conséquentes, ainsi les traitements de restitution ne devraient pas être pénalisés.
Compte tenu du fait que nous avons ciblé une base de données de type relationnel, il
reste un nombre important d’éditeurs. Nous pouvons citer Oracle, Interbase, SQL Server,
MySQL, PostgreSQL, … Pour choisir entre ces différents éditeurs, nous avons fait appel à
nos clients. Certains travaillent déjà avec un éditeur pour un produit ou ont déjà commencé la
création de data mart. Il s’avère que pour des raisons de coût d’investissement, les Régions
préfèrent travailler avec les produits actuels acquis. Tous les services de l’apprentissage et de
la formation ayant répondu à notre questionnaire travaillent avec le moteur SQL Server 2000
de Microsoft.
Nous avons décidé de stocker l’entrepôt de données dans une base SQL Server en
fonction de ces raisons :
Coût diminué par mutualisation pour nos clients.
Coût diminué pour ma société car nous travaillons déjà avec SQL Server.
Outil adapté au traitement par SQL standard.
Outils de construction de requête et reporting
L’application retenue devra avoir des caractéristiques de :
Générateur de rapport ou Reporting.
L’analyse multidimensionnelle : navigation dans les données (drill up, drill
down, scoping, …).
Analyse à la demande ou ad hoc.
Joachim PELLICIOLI 54

44 L’entrepôt de données en pratique
Plusieurs éditeurs sont sur le marché du reporting et de l’analyse dimensionnelle. Nous
pouvons citer par exemple les produits suivants [SMI1] :
Business Object de SAP.
Reporting Services de Microsoft.
Cognos d’IBM.
JasperReports de Jasper.
….
Tous ces logiciels sont des suites d’outils permettant les traitements spécifiés. Les outils
de restitutions sont à la charge des DSI, ce sont eux qui décident des outils les mieux adaptés
à leurs besoins. Les Régions (Centre, Lorraine, Rhône-Alpes, …) ont investit dans le produits
Business Object XI R2 de la société SAP (BO).
Cette suite logicielle comprend :
Business Object Desktop Intelligence pour la création de rapport et la navigation
dans les données ainsi que pour gérer les requêtes à la demande.
Business Object WebIntelligence offre les mêmes possibilités que BO Deskop
Intelligence, mais via un navigateur web. WebIntelligence repose sur la
technologie D-OLAP (cf 3.4.1 Définition).
Toutefois il faut garder à l’esprit que ce produit ne sera pas utilisé par toutes les
Régions. Nous nous sommes engagés à réaliser la mise en place ainsi que les développements
sur la suite Business Object XI R2 puisque cette solution est globalement utilisée par les
Régions. Néanmoins nous inclurons la quasi-totalité des traitements sur les données dans
l’entrepôt. Comme par exemple la concaténation de deux champs pour en créer un troisième.
Ainsi les Régions comme la Région Bretagne qui utilise une technologie différente ne perd
pas, ou que très peu, de fonctionnalité vis-à-vis des Régions utilisant BO.
Synthèse des choix technologiques
Tableau IV Synthèse des choix technologiques
Domaine Choix
ETL ETL développé en Delphi par Ymag
Entrepôt de données SQL Server 2000
Reporting, navigation et requête ad hoc Business Object XI R2
Joachim PELLICIOLI 55

44 L’entrepôt de données en pratique
4.2.6 Détail des tâches à réaliser
Compte tenu de l’analyse qui vient d’être expliquée, nous allons déterminer les
différentes tâches du projet. En amont, nous avons défini les phases qui correspondent aux
briques de celui-ci, nous allons maintenant détailler plus finement.
La gestion du planning s’est révélée complexe. J’ai pris l’initiative de mettre le client au
centre du projet pour améliorer la qualité de l’entrepôt de données. Cela a entrainé beaucoup
de réunions : réunions de validations techniques, fonctionnelles ou encore de présentations.
Chacune d’entre elles a réuni un public différent, voir croisé. Nous avons eu des réunions
avec la DSI, le chef de service de l’apprentissage et de la formation, mais aussi avec les
agents de terrain. Parfois les réunions étaient organisées avec un panaché de ces personnes.
Cela a compliqué l’organisation du projet puisqu’il est très difficile de réunir toutes les
personnes concernées.
Nous allons voir mois par mois les réalisations effectuées :
Mars :
Réunion de projet entre Ymag et les Régions pilotes.
Définition des objectifs.
Avril :
Recherche sur les différents ETL.
Recherche sur les différents outils de reporting, de création de requête et de
navigation dans les données.
Validation des choix techniques.
Définition du planning.
Mai :
Formation reçue sur SQL Server.
Formation reçue sur WinCRApprentissage module effectifs.
Formation reçue sur Business Object XI R2 création d’univers.
Joachim PELLICIOLI 56

44 L’entrepôt de données en pratique
Analyse de l’ETL.
Analyse de la structure du data mart effectifs.
Juin :
Validation de l’ETL.
Conception de l’ETL.
Conception de l’interface de pilotage de l’ETL.
Juillet :
Validation du data mart effectifs.
Réalisation du data mart effectifs.
Tests et recettes de l’ETL.
Août :
Création d’un programme d’installation pour le projet WinCRAnalyse.
Création de la documentation sur l’ETL.
Création de la documentation sur l’installation du projet WinCRAnalyse.
Création de la documentation sur les transformations de l’ETL pour le data mart
effectifs.
Début des tests et recettes de WinCRAnalyseEffectifs à Ymag.
Septembre :
Formation reçue sur Business Object XI R2 WebIntelligence.
Formation reçue sur WinCRApprentissage module financier.
Début de l’analyse de la structure du data mart financier.
Octobre :
Validation de WinCRAnalyseEffectifs à Ymag.
Création de la documentation sur l’univers data mart effectifs.
Installation de WinCRAnalyseEffectifs à la Région pilote.
Formation des personnels à l’univers effectifs.
Début des tests par le site pilote sur l’univers effectifs.
Analyse de la structure du data mart financier.
Joachim PELLICIOLI 57

44 L’entrepôt de données en pratique
Novembre :
Analyse de la structure du data mart financier.
Validation du data mart financier.
Début de la réalisation du data mart financier.
Validation WinCRAnalyseEffectifs par la Région pilote.
Décembre :
Réalisation du data mart financier.
Début des tests et recettes de WinCRAnalyseFinancier à Ymag.
Janvier :
Validation de WinCRAnalyseFinancier à Ymag.
Création de la documentation sur l’univers data mart financier.
Installation de WinCRAnalyseFinancier à la Région pilote.
Formation des personnels à l’univers financier.
Début des tests par le site pilote sur l’univers financier.
Février :
Validation WinCRAnalyseFinancier par la Région pilote.
Sortie officielle sur le marché de WinCRAnalyse.
4.2.7 Synthèse
Durant cette partie nous avons décrit le projet. Nous avons présenté l’existant, ce qui
avec les demandes de nos clients, nous a permis de définir les objectifs du projet. Les deux
plus importants sont l’amélioration des temps de réponse lors de l’interrogation des données
ainsi que la corrélation des données financières avec les effectifs.
Nous avons évalué un certain nombre de risques et nous avons choisi les technologies à
mettre en œuvre dans ce projet. Le contexte et les objectifs ayant été définis, nous avons
dressé un planning précis sur les tâches à accomplir.
Nous allons dans les prochaines parties décrire les principales phases du projet.
Joachim PELLICIOLI 58

44 L’entrepôt de données en pratique
4.3 Phase ETL
4.3.1 Analyse
Sources et destination des données :
L’ETL doit être capable de lire les données dans la base de production de
WinCRApprentissage ; celle-ci utilise SQL Server. Il devra également insérer les données
dans l’entrepôt qui sera également en SQL Server. L’ETL devra pouvoir traiter des données
en extraction et en chargement sur des serveurs différents.
Nous aurons besoin d’insérer de nouvelles données dans l’entrepôt. Par exemple nous
devrons intégrer la liste des communes, départements et régions suivant la nomenclature de
l’INSEE. Pour l’ajout de données diverses, j’ai décidé d’utiliser un import par fichier XML.
Celui-ci a l’avantage d’être souple, standardisé, évolutif et d’une manière générale facilement
compris.
Référentiel des données :
Pour l’appairage des données sources avec les données destinations, j’ai décidé
d’utiliser un référentiel en XML. Grâce à ce fichier, nous garderons une dépendance entre le
référentiel et l’ETL. Ainsi si par la suite nous décidons de développer un nouvel ETL, le
référentiel resterait inchangé. Il apporte un autre avantage, celui d’être déployé facilement en
clientèle pour apporter une modification, suite à une demande d’évolution urgente.
Pour faciliter le développement de ce fichier, j’ai décidé de le coupler à une grammaire
XML Schema. La grammaire apporte une vérification sur la structure du fichier XML. Elle
permet également de définir des listes de possibilités ou des règles de saisies. Par exemple
pour définir un type de champ, nous pouvons définir une liste comme suit : Int, varchar, date,
datetime, …
Chargement des données dans l’entrepôt :
Joachim PELLICIOLI 59

44 L’entrepôt de données en pratique
L’ETL apportera des modifications directes sur les données. Par exemple en tronquant à
vingt caractères une chaine ou en supprimant des espaces mal positionnés. L’ETL pourra
également corriger par procédure stockée l’information pré-chargée dans l’entrepôt de
données. Il effectuera certains calculs sur les tables des faits (agrégation, moyenne, ….). Il est
le garant de la cohérence des données. Il doit ainsi charger un ensemble de données ayant un
lien entre elles, sans le rompre. En cas d’erreur ou d’anomalie l’ETL doit informer
l’utilisateur qu’il est en train de travailler sur des données partielles chargées à un instant
« t ».
Modification de la structure physique de l’entrepôt de données :
Outre les données, la structure de l’entrepôt peut changer. Nous pouvons ajouter,
modifier ou supprimer une colonne d’une table. L’ETL devra être en mesure de mettre en
phase la structure de données physique. Pour réaliser cette opération, l’entrepôt doit connaitre
son numéro de version. L’ETL aura pour mission de vérifier la cohérence du numéro du
référentiel avec le numéro de l’entrepôt.
Dans la société Ymag nous utilisons déjà une dynamic link library (DLL) pour réaliser
ce type de manipulation. Elle utilise des fichiers de description de la structure (tables, champs,
déclencheurs, contraintes, …) de la base de données et applique les modifications sur la base
traitée. J’ai décidé d’utiliser cette DLL afin de mutualiser ce concept. Grâce à elle, nous
éviterons la duplication du code et nous gagnerons du temps en réalisation et en maintenance.
Interface de gestion de l’ETL :
L’ETL sera piloté par une interface graphique qui aura pour rôle principal de gérer la
planification. Elle permettra également le lancement du chargement des données ou la
modification de la structure. Cette interface sera utilisée pour le paramétrage global de l’ETL
lors de la phase d’installation par Ymag. Par ailleurs elle sera accessible par les agents de la
DSI pour interagir avec l’ETL.
L’ETL devra tracer les actions qu’il produit au sein d’un fichier de log. Ce fichier sera
placé sur la machine contenant l’ETL et sera visible depuis l’interface de gestion. J’ai choisi
de ne pas placer cette trace en base de données pour pouvoir loguer les problèmes de
connexion à celle-ci.
Joachim PELLICIOLI 60

44 L’entrepôt de données en pratique
La planification se fera à l’aide d’un service Windows, qui vérifiera les heures de
déclenchement et soumettra le travail à l’ETL.
Schéma de la structure physique de l’ETL :
Figure 16 Graphique des interactions de l'ETL
4.3.2 Réalisation
Référentiel :
Le concept est de pouvoir faire un appairage d’un champ source vers un champ
destination. Pour cela il faut indiquer les tables sources et destinations. Voici un exemple
simple qui illustre ce concept. Pour la table « statut_cfa_2 » de la source, je souhaite extraire
le « lib_statut_cfa » et l’envoyer dans la table destination « categorie_centre » et le champ
« lib_categorie_centre ».<table src="STATUT_CFA_2" dest="CATEGORIE_CENTRE">
<col src="LIB_STATUT_CFA_2" dest="LIB_CATEGORIE_CENTRE"/></table>
Joachim PELLICIOLI 61

44 L’entrepôt de données en pratique
Pour construire une table destination (une dimension), nous aurons besoin de plusieurs
tables sources. Nous rappelons que les dimensions ne suivent pas les mêmes règles de
normalisation que les tables d’une base de données relationnelle. Dans la base de données
source, les données sont éclatées dans plusieurs tables afin de répondre à la troisième forme
normale (3FN).
De même il est impératif de pouvoir joindre deux tables de destination afin de recréer
les clés étrangères qui lient les deux tables ensemble.
Voici un exemple dans lequel nous allons extraire la table source « examen » pour la
charger dans la table destination « examen ». Ici nous allons joindre la table « secteur_pro » à
la base de données décisionnelle afin de récupérer la clé qui correspond à l’enregistrement du
« secteur_pro » de la table source.<table src="EXAMEN" dest="EXAMEN" >
<col src="CODE_EXAMEN" dest="EXAMEN" /><col src="LIBELLE" dest="LIB_EXAMEN" /><col src="SECTEUR_PRO" dest="CODE_SECTEUR_PROFESSIONNEL">
<join table="SECTEUR_PROFESSIONNEL" joinCol="SECTEUR_PROFESSIONNEL" selCol="CODE_SECTEUR_PROFESSIONNEL" oblig="1"/>
</col></table>
Pour nettoyer certaines données, j’ai créé des fonctions SQLServer. Dans le référentiel
nous pouvons indiquer si une donnée à besoin d’un traitement. Dans l’exemple ci-dessous,
nous contrôlons la taille du libellé des nomenclatures d’activités française (NAF) à 100
caractères maximum.<table src="NAF" dest="NAF">
<col src="CODE_NAF" dest="NAF" /><col src="LIBELLE" dest="LIB_NAF" fonctionDestination="left(%s,
100)"/></table>
De la même manière nous pouvons donner une valeur par défaut à un champ vide, pour
répondre à une contrainte fixée sur une dimension.<table src="EXAMEN" dest="EXAMEN" >
<col src="CODE_EXAMEN" dest="EXAMEN" /><col src="LIBELLE" dest="LIB_EXAMEN" fonctionSource="dbo.ConvertVarcharInNotNull(%s, 'Non renseigné')"/>
</table>
Le référentiel détermine le type de chacun des champs (int, varchar, date, ….). J’ai mis
en place la collecte d’un certain nombre d’informations ; pour faire la distinction entre un
champ classique et un identifiant ; la mise à jour de données, le type de jointure, …
Joachim PELLICIOLI 62

44 L’entrepôt de données en pratique
Enfin dans certaines situations, nous avons besoin de faire une mise à jour d’un
ensemble de données inséré dans l’entrepôt. Par exemple, nous avons un état qui permet de
savoir si le site de formation est ouvert, fermé ou en projet d’ouverture. Dans
WinCRApprentissage cette notion est le résultat de plusieurs champs différents. Nous allons
ajouter notre état après insertion des données dans l’entrepôt. <update col="ETAT_SITE" value="En projet" type="varchar">
<clause col="CREAT_EFFECTIVE" value="N" type="varchar"/><clause col="FERMETURE" value="N" type="varchar"/>
</update><update col="ETAT_SITE" value="Fermé" type="varchar">
<clause col="CREAT_EFFECTIVE" value="O" type="varchar"/><clause col="FERMETURE" value="O" type="varchar"/>
</update>
Afin de traiter les ensembles de données complexes, il nous a fallu exécuter des
procédures stockées, soit du côté de l’entrepôt de données soit dans la base d’origine. En
reprenant l’exemple ci-dessus sur les NAF, l’application WinCrApprentissage a conservé les
NAF rev. 1 et les NAF rev. 2 qui ont fait leur apparition en février 2008 [INS1]. Du côté de
l’entrepôt de données, nous allons fusionner les deux révisions de NAF afin d’obtenir un
ensemble homogène de NAF rev. 2.<procedure name="Maj_Naf"/>
Ci-dessous, nous avons un graphique représentant le XML Schema du référentiel. Il
permet de distinguer toutes les possibilités offertes par le référentiel. J’ai décidé de joindre
aux documents XML une grammaire afin de contrôler la cohérence du document qui est à la
base de la création du data warehouse. Nous pouvons séparer en deux la grammaire, d’un
côté l’exécution des procédures, de l’autre la sélection et la mise à jour des données.
Joachim PELLICIOLI 63

44 L’entrepôt de données en pratique
Exécution des procédures :
Figure 17 XML Schéma - procédure de l'ETL
Sélection et mise à jour des données :
Figure 18 XML Schéma - table de l'ETL
Joachim PELLICIOLI 64

44 L’entrepôt de données en pratique
ETL :
J’ai choisi comme nom de programme « YmagETL ». Je suis resté neutre sur ce nom
afin que l’ETL soit adapté et amélioré le jour où d’autres projets d’Ymag auront besoin de
transférer des données.
J’ai développé l’ETL dans le langage Delphi, qui est le langage de référence dans ma
société. Nos applications sont classiquement programmées en événementiel. Pour ce projet
j’ai décidé de le développer en orientation objet. Ceci pour les raisons suivantes :
Des concepts objets ressortent de la modélisation du référentiel.
Réutilisabilité d’une ou plusieurs classes.
Tests facilités.
L’ETL comporte un certain nombre d’options qui lui permettent de savoir comment il
doit s’exécuter. Certaines options sont facultatives comme par exemple le lancement « en
mode trace complète » ou chaque action même sans incidence va être tracée dans le fichier de
log.
En parallèle à ce développement j’ai créé un service Windows, développé également en
objet avec Delphi. Ce projet a pour nom YmagService. Il a en charge la lecture du fichier de
configuration fourni par l’interface de paramétrage de l’ETL et le déclenchement du
processus le moment voulu. Il est garant également de la non superposition de deux tâches.
L’interface de pilotage :
Le projet de l’interface graphique se nomme « ServiceManager ». L’interface graphique
a également été conçue en Delphi.
Le ServiceManager permet :
De configurer l’accès au serveur de production.
De configurer l’accès au serveur décisionnel.
De gérer le compte servant à faire les requêtes.
De gérer le compte ayant les droits pour faire migrer la structure.
De configurer les horaires de déclenchement de l’ETL.
Joachim PELLICIOLI 65

44 L’entrepôt de données en pratique
D’interagir avec le service Windows (Arrêt, démarrage, redémarrage).
De charger les données en direct.
De modifier les données en direct (réservé à un usage de maintenance).
C’est le centre de configuration et de pilotage de l’ETL. Nous avons donné la possibilité
de mémoriser deux configurations différentes, une pour la production et l’autre pour le test.
Ainsi la DSI pourra, à la livraison d’une nouvelle version, passer en mode de test avant de
basculer en production. Bien évidemment cette étape aura déjà été réalisée par Ymag avant la
livraison d’une nouvelle version aux Régions.
Voici l’interface développée pour piloter l’ETL :
Figure 19 Interface de gestion de l'ETL
4.3.1 Synthèse
J’ai créé l’ETL en gardant à l’esprit qu’il devait évoluer. C’est pour cela qu’il a été
développé en langage objet. Sur chacune des décisions prises durant sa réalisation, j’ai pris
soin de rester générique et ouvert sur l’avenir. Nous gardons à l’esprit, compte tenu du plan
Joachim PELLICIOLI 66

44 L’entrepôt de données en pratique
d’urbanisation décisionnelle des Régions, qu’elles pourront nous demander la création de data
mart pour d’autres solutions proposées par Ymag (WinCRPrimes, …).
L’interface de gestion ainsi que le service permettent de manipuler l’ETL facilement
pour des tâches d’administration. L’interface a été pensée pour les utilisateurs des Régions,
afin qu’ils n’aient besoin que de quelques explications pour la prendre en main.
4.4 Méthodologie de conception d’un data mart
Afin de concevoir les data marts j’ai mis en place une méthodologie de construction
que nous allons présenter dans cette partie.
Tout d’abord il est impératif de travailler sur un ensemble restreint afin de concevoir un
modèle simple. Un modèle simple se représente par une activité précise à analyser. Une fois
une activité choisie, la méthode consiste à définir les grandes parties qu’il faut mettre en
œuvre :
Gestion des dimensions : axes d’analyses.
Gestion des faits : portefeuille d’indicateurs.
Représentation graphique : modélisation.
Encore une fois l’objectif est d’inclure le client au cœur du projet. Dans ce sens nous
allons voir comment j’ai articulé le travail afin de faire participer les non informaticiens à la
conception des différents data marts.
4.4.1 Axes d’analyses
Suite aux différents entretiens menés, nous pouvons recenser les axes d’analyse liés à
l’activité que nous voulons représenter. Reste alors à regrouper ces notions en famille
« métiers » afin de créer nos dimensions. Ces familles sont le résultat de croisement entre les
données que nous avons dans les bases sources et les différents points relevés durant les
entretiens dans les Conseils régionaux. C’est également le moment d’entrevoir les hiérarchies
contenues dans les informations. Une hiérarchie se caractérise par une structure d’éléments
allant d’un état généraliste à un état spécifique. Elles ont un réel intérêt pour les changements
d’échelle (drill down, drill up).
Joachim PELLICIOLI 67

44 L’entrepôt de données en pratique
Il est important de repréciser que cette recherche de dimension passe par une dé-
normalisation de la structure de données. Voici un petit exemple pour illustrer cette dé-
normalisation :
Le schéma de base de données est représenté par un modèle conceptuel des données
(MCD) tiré de la méthode Merise. La table groupe_secteur_pro a une clé primaire
(code_groupe_secteur_pro) ainsi qu’un libellé (lib_groupe_secteur_pro), idem pour les tables
secteur_pro et formation. La table groupe_secteur_pro est reliée à la table secteur_pro par une
relation de type contrainte d’intégrité fonctionnelle (CIF) ce qui veut dire qu’un secteur_pro a
un et un seul groupe_secteur_pro (idem pour le table formation). La dé-normalisation entraine
la création d’une seule table composée d’une nouvelle clé primaire ainsi que les trois champs
« libellé » des tables précédentes.
Figure 20 Dé-normalisation
Afin de bien préciser le travail, que ce soit avec le client ou le reste de l’équipe, il est
important de définir quels sont nos axes d’analyse, quels attributs les constituent et à quoi
correspondent chacun de ces attributs. Pour réaliser cela, j’ai utilisé des grilles qui permettent
de détailler chacun des axes d’analyse.
Grille de description des dimensions :
Tableau V Grille de description des dimensions
Axe d’analyse : Nom de l’axe d’analyse
Description Description détaillée de l’axe d’analyse. Nous le replaçons dans le
contexte et nous précisons le rôle de celui-ci.
Comptage Estimation ou nombre réel d’occurrences chargées dans la dimension.
Attributs
Joachim PELLICIOLI 68

44 L’entrepôt de données en pratique
Nom de l’attribut 1 Description : Description de l’attribut, explication métier.
Source de données : Définition de l’emplacement d’origine de
cette information.
Type de données : Type de données de l’attribut (entier, chaine
de caractères, …).
Règle de calcul : Règle de calcul pour créer l’attribut de la
dimension (condition, concaténation, …).
Contrainte : Contrainte imposée au chargement de
l’attribut dans la dimension.
Nom de l’attribut 2 Description : Description de l’attribut, explication métier.
Source de données : Définition de l’emplacement d’origine de
cette information.
Type de données : Type de données de l’attribut (entier, chaine
de caractères, …).
Règle de calcul : Règle de calcul pour créer l’attribut de la
dimension (condition, concaténation, …).
Contrainte : Contrainte imposée lors du chargement de
l’attribut dans la dimension.
Nom de l’attribut … …
4.4.2 Portefeuille d’indicateurs
Comme nous venons de le voir, nous devons cibler notre analyse sur une activité
particulière. Le portefeuille d’indicateurs porte sur les éléments quantifiables de cette activité.
Les faits ont pour but de répondre aux questions relevées durant les entretiens. Par exemple
les utilisateurs veulent savoir si les effectifs en BAC PRO comptabilité ont évolué durant les 3
dernières années et si cette hausse est supérieure à 2% par année.
Les faits représentent l’activité à analyser et très souvent nous aurons à les modifier afin
de les rendre cohérents à notre ensemble de restitution. Ces modifications seront plus
particulièrement des mises à échelle afin d’agréger ou de faire un prorata d’une valeur
numérique.
Comme pour les axes d’analyse j’ai décrit dans une grille les différents indicateurs.
Toujours en gardant à l’esprit le double impact de ces grilles : l’un sur les utilisateurs, l’autre
sur l’équipe en charge du data warehouse.
Grille de description des indicateurs :
Joachim PELLICIOLI 69

44 L’entrepôt de données en pratique
Tableau VI Grille de description des indicateurs
Indicateur : Nom de l’indicateur
Description Nous décrivons précisément à quoi correspond notre indicateur. Nous
donnons également son contexte et la notion qu’il véhicule, l’échelle
de grandeur utilisée….
Règles de calcul Dans cette partie nous détaillons la formule de calcul qui a permis
d’obtenir notre indicateur (agrégation, prorata, ….).
Type de données Type de données de l’indicateur. En règle générale un fait est un
élément numérique. Nous pourrons préciser si nous travaillons en
entier, en réel et avec quelle précision.
Fonction d’agrégation Fonction utilisée pour restituer notre indicateur (rappel : un indicateur
est un fait additif, nous pourrons par exemple l’indiquer par la
commande SQL « SUM »).
Unité de mesure Quelle est l’unité de mesure de notre indicateur (métrique, monétaire,
nombre, ….).
Source de données Indique la provenance de l’information source qui nous a permis de
créer l’indicateur du data warehouse.
Contraintes Contrainte imposée lors du chargement de l’indicateur dans la table
des faits.
4.4.3 Modélisation
Une fois la collecte et l’organisation de l’information effectuées, nous pouvons
organiser les informations dans un modèle en étoile. Ce modèle se veut simple pour permettre
le dialogue avec les personnes qui ne sont pas familières avec les méthodes de conception
informatique.
Le modèle met en évidence les relations entre les dimensions et les tables des faits. Pour
rappel dans un modèle en étoile nous avons la table des faits au centre et les tables des
dimensions qui gravitent autour. Ainsi nous pouvons recenser les interactions entre une table
des faits et toutes les dimensions qui mettent en valeur les indicateurs. Ces interactions sont
maquettées (création de rapports ou de tableaux de bord) pour donner une vue sur les
possibilités du modèle aux futurs utilisateurs.
Joachim PELLICIOLI 70

44 L’entrepôt de données en pratique
4.4.4 Synthèse de la méthode
Comme nous venons de le voir durant cette description de la méthodologie que j’ai mise
en œuvre pour la réalisation des data marts effectifs et financier, tous les modèles et
descriptifs ont un double intérêt :
Aide à la conception et validation des data marts. Les modèles vont être utilisés
durant les réunions pour contrôler les possibilités ainsi que les limites du data
mart.
Aide à la réalisation des data marts. Ils offriront une aide précieuse pour la
maintenance évolutive.
Le tableau ci-dessous résume la méthodologie de conception d’un data mart :
Tableau VII Méthodologie de conception
Etapes
- Sélection d’une activité à analyser.
- Collecte des informations de dimensions et création des axes d’analyse.
- Recherche des hiérarchies et formalisation.
- Création du portefeuille d’indicateurs.
- Création d’un modèle en étoile mettant en relation les dimensions avec les faits.
- Maquettage (rapports et tableaux de bord)
- Présentation aux clients pour validation.
Une fois ces étapes conceptuelles réalisées, nous réaliserons l’implémentation du
transfert et des modifications dans l’ETL.
Joachim PELLICIOLI 71

44 L’entrepôt de données en pratique
4.5 Phase effectifs
4.5.1 Objectifs
La priorité de ce data mart consiste à analyser l’enquête des effectifs collectée par la
Région. Cette enquête est déjà exploitée dans l’application WinCRApprentissage, mais elle
n’offre pas assez de souplesse. Les Régions souhaitent pouvoir créer des rapports plus
poussés avec des évolutions sur plusieurs années pour une formation. Ils souhaitent également
pouvoir répondre à des questions ponctuelles que leur posent les élus.
Nous rappelons que les données liées aux effectifs sont remontées des CFA vers le
Conseil régional par un système informatisé. C’est une enquête anonyme. Elle permet de
déterminer les effectifs par formation dans un centre de formation. Le CFA envoie une ligne
d’information par apprenant (sexe, âge, département, année de formation, diplôme, CFA,
effectifs de l’entreprise, ….).
Le data mart effectifs doit principalement permettre l’analyse des effectifs et les
différentes évolutions par formation. Nous allons créer la première brique qui nous permettra
de travailler avec le data mart financier que nous verrons dans le prochain paragraphe.
La table des faits et les tables des dimensions stockées en mémoire ne dépassent pas la
centaine de méga-octets. Les disques durs ainsi que les moteurs de base de données actuels
gèrent sans difficulté des giga-octets de données. C’est pour cela que nous n’établirons pas de
chiffrage dans ce data mart.
4.5.2 Axes d’analyse
Nous déterminons les différents axes d’analyse qui seront en relation avec notre table
des faits.
Formation
L’axe d’analyse sur la formation regroupe toutes les notions de celle-ci. Prenons un
intitulé afin de bien comprendre tous les termes faisant partie de cette dimension :
Joachim PELLICIOLI 72

44 L’entrepôt de données en pratique
1er année BAC PRO commerce en 3 ans.
La première notion est l’année de formation que nous associons au nombre total
d’années de formation (1ère année sur 3 ans).
La deuxième notion se situe au niveau du diplôme préparé (baccalauréat professionnel).
La troisième notion est le métier (commerce). Ce métier fait partie d’une hiérarchie
définie par une nomenclature des spécialités de formation (NSF) :
3- Domaines technico-professionnels des services.
31 - Echanges et gestion.
312 - Commerce, vente.
Cette dimension possède des informations propres à la formation ainsi qu’à l’année dans
laquelle est l’apprenant. Afin de concevoir des dimensions communes au data mart financier,
nous avons décidé de séparer en une dimension l’année de formation et en une sous
dimension la formation. Afin d’éviter le modèle en flocon (optimisation des requêtes), nous
n’allons pas relier la « formation » à « l’année de formation » mais conserver deux
dimensions indépendantes :
Formation.
Année de formation.
Pour ne pas surcharger ce document, nous décrirons à titre d’exemple, quelques
dimensions comme définies dans la méthodologie :
Tableau VIII Axe d’analyse : Formation
Axe d’analyse : Formation
Nom Formation
Description Description des formations dispensées dans les centres. Nous retrouvons les
informations sur l’examen, le niveau du diplôme, …
Comptage Environ 800.
Attributs
Code Examen Description : Code de l'examen (ex : 51321302, ....).
Source de données : Examen.Code_Examen
Destination : Examen
Type de données : Varchar(10)
Règle de calcul : Aucune
Contrainte : Aucune
Lib_Examen Description : Libellé de l'examen (ex : Coiffure, ...).
Joachim PELLICIOLI 73

44 L’entrepôt de données en pratique
Source de données : Examen.Lib_Examen
Destination : Lib_Examen
Type de données : Varchar(50)
Règle de calcul : Aucune
Contrainte : Aucune
Niveau Diplome Description : Niveau du diplôme suivant la nomenclature des
diplômes (ex : 1, 2, ...).
Source de données : Dip_Form.Niveau
Destination : Niveau_Diplome_Examen
Type de données : Integer
Règle de calcul : Aucune
Contrainte : Aucune
Nb Total Annee Formation Description : Nombre d'année total de la formation.
Source de données : Dip_Form.Niveau
Destination : Nb_Annee_Diplome_Examen
Type de données : Integer
Règle de calcul : Aucune
Contrainte : Aucune
Code GFE Description : Code regroupant des examens. Groupe Formation
Emploi (GFE2).
Source de données : GFE2.Code_GFE2
Destination : GFE
Type de données : Varchar(6)
Règle de calcul :
Si (GFE2.Code_GFE2= ‘’) alors ‘ ?’
Sinon GFE2.Code_GFE2
Contrainte : Aucune
Lib GFE Description : Libellé regroupant des examens. Groupe Formation
Emploi (GFE2).
Source de données : GFE2.Libelle_GFE2
Destination : Lib_GFE
Type de données : Varchar(50)
Règle de calcul :
Si (GFE2.Libelle_GFE2 = ‘’) alors ‘Non renseigné’
Sinon GFE2.Libelle_GFE2
Contrainte : Aucune
Lib Groupe Secteur Pro Description : Libellé du regroupement de secteur professionnel de
l'examen (ou GFE = Groupe Formation Emploi).
Source de données : Groupe_Secpro.Libelle
Destination : Lib_Groupe_Secteur_Pro
Type de données : Varchar(50)
Règle de calcul :
Si (Groupe_Secpro.Libelle = ‘’) alors ‘Non renseigné’
Joachim PELLICIOLI 74

44 L’entrepôt de données en pratique
Sinon Groupe_Secpro.Libelle
Contrainte : Aucune
Code Secteur Professionnel Description : Code du secteur professionnel de l'examen.
Source de données : Secteur_Pro.Code_Sec_Pro
Destination : Secteur_Professionnel
Type de données : Varchar(6)
Règle de calcul :
Si (Secteur_Pro.Code_Sec_Pro = ‘’) alors ‘ ?’
Sinon Secteur_Pro.Code_Sec_Pro
Contrainte : Aucune
Lib Secteur Professionnel Description : Libellé du secteur professionnel de l'examen.
Source de données : Secteur_Pro.Libelle
Destination : Lib_Secteur_Professionnel
Type de données : Varchar(50)
Règle de calcul :
Si (Secteur_Pro.Libelle = ‘’) alors ‘Non renseigné’
Sinon Secteur_Pro.Libelle
Contrainte : Aucune
Code Groupe Diplome Description : Code de regroupement des diplômes.
Source de données : Groupe_diplome.Code_GDiplome
Destination : Groupe_Diplome
Type de données : Varchar(6)
Règle de calcul :
Si (Groupe_diplome.Code_GDiplome = ‘’) alors ‘ ?’
Sinon Groupe_diplome.Code_GDiplome
Contrainte : Aucune
Lib Groupe Diplome Description : Libellé de regroupement des diplômes.
Source de données : Groupe_diplome.Libelle_GDiplome
Destination : Lib_Groupe_Diplome
Type de données : Varchar(50)
Règle de calcul :
Si (Lib_Groupe_Diplome = ‘’) alors ‘Non renseigné’
Sinon Lib_Groupe_Diplome
Contrainte : Aucune
Code Diplome Description : Code du diplôme (ex : BP, ...).
Source de données : Diplome.Code_Dip
Destination : Diplome
Type de données : Varchar(10)
Règle de calcul :
Si (Diplome.Code_Dip = ‘’) alors ‘ ?’
Sinon Diplome.Code_Dip
Contrainte : Aucune
Lib Diplome Description : Libellé du diplôme (ex : Brevet professionnel, ...).
Joachim PELLICIOLI 75

44 L’entrepôt de données en pratique
Source de données : Diplome.Libelle
Destination : Lib_Diplome
Type de données : Varchar(50)
Règle de calcul :
Si (Diplome.Libelle = ‘’) alors ‘Non renseigné’
Sinon Diplome.Libelle
Contrainte : Aucune
Site de formation
Cet axe d’analyse correspond à la structure des centres de formation. Un CFA peut
posséder un ou plusieurs sites de formation. Ceux-ci sont des subdivisions du CFA, souvent
liés à des situations géographiques différentes. Le CFA est encadré par un organisme
gestionnaire. Un organisme peut gérer un ou plusieurs CFA.
Cela met en évidence la hiérarchie que nous allons citer en exemple :
Organisme gestionnaire.
Centre.
Site.
Cette hiérarchie permet de faire des études détaillées par centre mais également des
tableaux agrégés par organisme gestionnaire.
Nous pouvons regrouper les informations de cette dimension en grandes familles :
Statut : Date d’ouverture/fermeture, capacité d’accueil, identifiant, type de
structure (agricole, bâtiment, …).
Géographique : Adresse, bassin.
Campagne
La dimension campagne est notre dimension de temps (année et mois). Les Régions
collectent les effectifs par campagne. Par exemple la Région demande une remontée en
octobre pour contrôler le début de l’année scolaire, une remontée en décembre pour contrôler
les écarts liés aux ruptures de contrat et une remontée en mai pour vérifier les écarts liés aux
abandons. Dans cet exemple nous avons trois campagnes.
Apprenant
Nous pourrions nommer cet axe d’analyse « apprenant anonyme ». Comme nous
l’avons déjà souligné, la Région récupère certaines informations sur l’apprenant, mais rien qui
Joachim PELLICIOLI 76

44 L’entrepôt de données en pratique
permet de l’identifier (pas de nom prénom, ni numéro de téléphone, ni numéro de rue).
Uniquement des caractéristiques sur les apprenants sont mises en évidence dans cette
dimension. Nous retrouverons des notions sur le lieu d’habitation, la distance kilométrique
effectuée par l’apprenti, son âge, …. . Voici les grandes familles d’informations sur la
dimension apprenant :
Démographique : Age, sexe, nationalité.
Géographique : Département d’habitation, kilomètres parcourus entre le centre
et le domicile.
Antériorité : Qualité (interne, demi pensionnaire), origine scolaire avant CFA
(par exemple 3ème générale).
La particularité de cette dimension est qu’elle ne représente pas les apprenants
« physiques ». Nous stockerons un produit cartésien des différentes caractéristiques possibles.
Entreprise
L’apprentissage met en relation un apprenant avec une entreprise. De la même manière
que pour les apprenants, nous n’aurons pas d’information sur la raison sociale de l’entreprise
ou sur le nom du dirigeant, mais uniquement des informations de localisation et de
caractérisation de celle-ci. Nous pouvons citer en exemple, le secteur d’activité, l’effectif de
la société, la localisation géographique, …. . Représentons les grandes familles
d’informations :
Activité : Nomenclature d’activités française (NAF), nombre de salariés, origine
du contrat (agricole, commerce, …).
Géographique : Département de l’entreprise, kilomètres parcourus entre le
centre et l’entreprise.
4.5.3 Portefeuille d’indicateurs effectifs
Pour la Région l’objectif de ce data mart est l’exploitation de cette enquête, en
comptant des effectifs d’apprenants. Cela correspond à notre première table des faits que nous
nommerons « Fait_Effectif ». Cette table des faits a pour particularité de ne pas disposer
d’éléments calculés. Comme nous l’avons vu dans le chapitre 3.3.1.1 Les « faits » ou «
indicateurs », une table des faits reflète habituellement une activité calculée. Dans notre cas,
Joachim PELLICIOLI 77

44 L’entrepôt de données en pratique
les effectifs se matérialisent par un comptage du nombre d’occurrences. Ce type de table des
faits se nomme : « table des faits sans fait » [KIM2]. Nous n’avons pas d’indicateur
numérique contenu dans la table des faits, ce qui peut poser problème lors de la génération des
requêtes par le logiciel de restitution.
Nous allons essayer de déterminer l’impact de la table des faits sans fait sur notre
modèle à travers un exemple. Notre modèle comprendra la table des faits « effectif » et la
table des dimensions « entreprise ». La dimension entreprise sera simplifiée au maximum, elle
contiendra uniquement sa clé et la tranche d’effectif.
Figure 21 Table des faits sans fait effectifs
Voici la requête générée par un logiciel de restitution, pour obtenir les effectifs par âge :SELECT DA .Tranche_Effectif, COUNT(DISTINCT(FE.Code_Dim_Entreprise))FROM Fait_Effectif AS FEINNER JOIN Dim_Apprenant AS DA ON (FE.Code_Dim_Entreprise =
DA.Code_Dim_Entreprise)GROUP BY DA.Effectif_Entreprise
Nous sommes obligés de passer par une formule comptant le nombre d’occurrences
d’une valeur de la table des faits (cela correspond au nombre de lignes de la table des faits).
Afin d’optimiser la lisibilité des requêtes nous allons ajouter un champ nommé « effectif »
ayant pour valeur 1. Ceci nous permettra de standardiser les requêtes sur la table des faits
effectifs, en passant par l’instruction SQL : SUM.
Reprenons notre exemple avec ce nouveau champ.
Figure 22 Table des faits sans fait effectifs, avec champ effectifs
Nous pouvons modifier la requête afin de l’écrire ainsi :SELECT DA . Tranche_Effectif, SUM(FE.Effectif)FROM Fait_Effectif AS FE
Joachim PELLICIOLI 78

44 L’entrepôt de données en pratique
INNER JOIN Dim_Apprenant AS DA ON (FE.Code_Dim_Entreprise = DA.Code_Dim_Entreprise)
GROUP BY DA.Effectif_Entreprise
Nous pouvons donner le portefeuille d’indicateurs, qui dans notre cas ne correspond
qu’à un seul indicateur :
Tableau IX Indicateur "effectifs"
Indicateur : Effectif
Description Chaque ligne représente un apprenant.
Règles de calcul Si (Existe (une occurrence)) Alors 1
Type de données Boolean
Fonction d’agrégation SUM
Unité de mesure Nombre
Source de données Effectif.code_effectif
Contraintes Uniquement si une ligne existe dans la table source.
4.5.4 Schématisation
Afin d’appréhender les volumes échangés, étudions les données du data mart sur les
effectifs :
Campagne : 30 campagnes.
Site : 140 sites par Région.
Formation : 800 formations dispensées dans une Région.
Annee_formation : 2 500 années de formation (année par diplôme).
Apprenant : 300 lignes de caractéristiques apprenants.
Entreprise : 200 lignes de caractéristiques entreprises.
Fait_effectif : 450 000 faits.
Voici une représentation graphique des différentes dimensions et de la table des faits
que nous venons d’étudier :
Joachim PELLICIOLI 79

44 L’entrepôt de données en pratique
Figure 23 Modèle effectifs
4.5.5 Réalisation
Comme nous l’avons défini, l’objectif « primaire » de ce data mart des effectifs est de
gérer plus facilement l’analyse des effectifs des apprentis au sein des centres ou du moins
d’une manière plus globale.
Voici par exemple un document qui permet de ressortir l’évolution des effectifs par
niveau entre deux campagnes de collecte d’information. Est également mise en valeur la
répartition entre les effectifs féminins et masculins par niveau sur une année précise.
Joachim PELLICIOLI 80

44 L’entrepôt de données en pratique
Figure 24 Evolution des effectifs par niveau
Sans oublier que nous pouvons maintenant répondre à des questions ponctuelles, ce qui
étaient difficiles auparavant, voire infaisables. Voici quelques requêtes réalisées par les
Conseils régionaux :
Obtenir les noms des dix CFA ayant le plus gros pourcentage d’effectif féminin
dans les métiers du bois (technicien constructeur bois, charpentier, scieur, …).
Obtenir la répartition des apprentis handicapés par département.
Obtenir la liste des diplômes qui ont subi le plus fort taux de croissance durant
trois années consécutives.
4.5.6 Synthèse
Le data mart effectifs apporte des éléments de réponse aux différentes questions ad hoc
des utilisateurs régionaux. Il offre la possibilité de construire des documents de synthèse sur
les différentes formations ainsi que sur l’évolution. Il met en évidence les tendances de
l’apprentissage de la Région. Comme nous l’avons expliqué, certaines réponses étaient très
difficiles à obtenir, voire impossibles. Grâce à ce data mart les Conseils régionaux peuvent
maintenant y remédier.
Joachim PELLICIOLI 81

44 L’entrepôt de données en pratique
L’intérêt de ce data mart n’est pas uniquement la restitution de l’enquête et de son
analyse. Nous allons pouvoir, grâce aux effectifs, faire des corrélations entre les coûts de
fonctionnement et le nombre d’apprenants. Pour pouvoir réaliser ce type de tableau de bord
nous devons construire un data mart financier. Nous allons l’étudier dans la partie suivante.
4.6 Phase financier
Cette deuxième partie d’étude porte sur les éléments financiers. Les centres de
formation procèdent à diverses saisies de données sur le portail de la Région. Ces saisies
peuvent être plus ou moins riches en termes de contenu d’une Région à une autre. Pour le
Conseil régional, cette partie devra mettre en valeur certaines données pour l’instruction des
dossiers. Mais avant tout il devra permettre de contrôler les données en croisant les différentes
saisies des CFA.
Nous allons identifier les grandes familles qui donneront naissance aux différents data
marts financiers :
Comptes généraux : Ce data mart est orienté sur les comptes financiers.
C’est l’équivalent du plan comptable avec les valeurs financières des CFA. Il
gère également le budget en fonction de ces comptes.
Frais de personnel : Les frais de personnel sont une charge importante pour
les Régions. Elles demandent aux centres de justifier avec plus ou moins de
détail les salaires des différents agents, ainsi que la répartition horaire.
Taxe d’apprentissage : La taxe d’apprentissage est la deuxième source de
revenu d’un CFA. La Région souhaite être informée des montants que
perçoit le centre afin d’adapter la subvention allouée.
Dépense théorique : Data mart donnant des indicateurs sur les coûts réels
engagés par les CFA ainsi que sur les aides mises à disposition par la
Région. Nous avons également des indicateurs sur le transport,
l’hébergement et la restauration (THR).
Cette partie nécessite des compétences importantes dans la structure du modèle
WinCRApprentissage afin de récupérer, traiter et mettre en forme les données. Pour optimiser
Joachim PELLICIOLI 82

44 L’entrepôt de données en pratique
les temps de développement du projet, j’ai décidé d’impliquer un développeur de
WinCRApprentissage, ceci en accord avec la Direction.
Je lui ai affecté deux tâches importantes, qu’il a réalisées sur chaque data marts
financier :
Création de procédure en SQL afin de préparer les données pour les tables des
faits en fonction des règles de calcul.
Tests de cohérence des données entre le data warehouse et l’application
existante (phase de test unitaire et test d’intégration).
Comme pour le data mart sur les effectifs, nous ne réaliserons pas de chiffrage précis.
Nous allons donner une estimation du nombre de ligne des dimensions et des faits. Cette
estimation donnera un contexte sur les volumes globaux.
4.6.1 Comptes généraux
4.6.1.1 Objectifs
Ce premier data mart financier a pour but de restituer l’information des comptes
financiers. Nous utilisons la classification des comptes comptables de la Région. Toutes les
données sont représentées en deux notions :
Réalisé : Compte financier validé.
Budgétisé : Compte financier prévisionnel.
Grâce à ces notions, la Région souhaite ressortir des données afin de valider les dossiers
des centres (Le réalisé suit-il le budget ? Quelle est l’évolution d’un compte particulier sur les
cinq dernières années ? ….). Ce modèle donnera également accès à une vision plus globale de
la comptabilité, vision inter-centre. Ceci dans le but de croiser les données avec le service
financier et contrôler ainsi les dépenses publiques.
4.6.1.2 Axes d’analyse
Les comptes s’articulent autour de quatre grands axes d’analyse :
Comptes généraux.
Comptes analytiques.
Joachim PELLICIOLI 83

44 L’entrepôt de données en pratique
Période comptable.
Site de formation.
Comptes généraux
Cette dimension reprendra les comptes du plan comptable général. Pour chaque compte
la Région peut définir une famille ainsi qu’une sous famille. Ces deux notions permettent un
regroupement différent de ceux définis par l’arborescence du plan comptable. Nous pouvons
représenter ainsi les deux hiérarchies :
Famille
Sous famille
Compte du plan comptable général
Compte du plan comptable général sur une position
Compte du plan comptable général sur deux positions
…
Comptes analytiques
Les Régions ont mis en place une comptabilité analytique. Cette comptabilité est très
fréquemment utilisée pour différencier les types de formations et les types d’aides. Pour
formaliser ce besoin, les Régions utilisent une notion de centre d’activité. Dans la majorité
des cas, les centres d’activité se découperont de cette façon :
Apprentissage : Découpe la part financière liée à l’apprentissage.
Classe préparatoire à l’apprentissage (CPA) : Découpe la part liée aux classes
préparatoires à l’apprentissage.
Autre formation : Découpe la part de formation qui n’est pas prise en compte par
les deux premiers centres d’activités.
Hébergement : Découpe la part concernant l’hébergement (internat).
Restauration : Découpe la part concernant la restauration (demi-pension).
Transport : Découpe la part liée au transport (entre le centre et le lieu
d’habitation de l’apprenti).
Tous les centres d’activités peuvent être affinés avec des comptes analytiques choisis
par la Région.
Joachim PELLICIOLI 84

44 L’entrepôt de données en pratique
Période comptable
Nous avons créé une dimension pour la période comptable. Actuellement toutes les
Régions clientes travaillent en année civile, allant du 1er janvier au 31 décembre. La
dimension nous garantira une structure évolutive en cas de changement ou si une nouvelle
Région devient consommatrice de l’entrepôt de données.
La période comptable va permettre de séparer et comparer plusieurs années afin de
mettre en valeur les évolutions du data mart sur les comptes généraux, mais également tous
les autres data marts liés au financier.
Site de formation
Cette dimension est commune au data mart effectifs. Nous l’allons décrite dans le
paragraphe 4.5.2 Axes d’analyse.
4.6.1.3 Portefeuille d’indicateurs
Afin de travailler avec la granularité la plus fine, nous devons descendre au niveau
analytique les données de la table des faits. Pour un montant donné d’un centre de formation,
nous avons un montant ventilé en fonction des comptes analytiques.
Dans le schéma ci-dessous, nous allons montrer la granularité de notre table des faits.
Dans cet exemple nous travaillons sur les comptes d’un site en particulier. Pour le compte
« 606120 fourniture : eau » le solde débiteur est de 500€ : crédit de 200€ et débit de 700€.
Nous n’allons pas enregistrer cette valeur, puisque nous ne pourrions pas recréer de tableau
avec une précision « analytique ». Pour pallier à cette contrainte nous ajoutons deux lignes
dans notre table des faits, une pour l’analytique « apprentissage » avec le solde débiteur de
400€ et une seconde ligne avec le solde débiteur de 100€ pour les « CPA » (données
provenant de l’application). Grâce à cette répartition nous pouvons calculer les comptes
« débit » et « crédit » avec une précision analytique.
Joachim PELLICIOLI 85

44 L’entrepôt de données en pratique
Figure 25 Granularité de la table des faits : comptes généraux
Nous avons repris les indicateurs liés à la comptabilité :
Report au crédit, report au débit : Montant reporté de l’exercice comptable
précédent.
Crédit, débit : Montants saisis sur l’exercice comptable actuel.
Solde débiteur, solde créditeur : Différence calculée entre le débit et le crédit
ainsi que les reports.
Pour obtenir une granularité suffisante (dimension analytique), nous avons appliqué une
répartition des montants sur les différents comptes. Voici par exemple la description de
l’indicateur « crédit » :
Tableau X Indicateur "crédit"
Indicateur : Crédit (C)
Description Crédit de la période comptable en cours.
Règles de calcul MA = Montant Analytique
CS = Crédit Saisi
C=CS × MA∑ MA
Type de données Décimal(10,3)
Fonction d’agrégation SUM
Unité de mesure Euro
Source de données WinCRApprentissage.TEMP_BO_FIN_FAIT.MNT_CRE
Contraintes Aucune
Joachim PELLICIOLI 86

44 L’entrepôt de données en pratique
Pour faciliter les traitements j’ai ajouté un nouvel indicateur « solde signé » afin
d’obtenir une valeur positive ou négative en fonction du compte créditeur ou débiteur. Voici
la description de cet indicateur :
Tableau XI Indicateur "solde signé"
Indicateur : Solde signé (SS)
Description Solde positif ou négatif. Nous avons besoin de cette distinction puisque pour une
classe 6 le solde est débiteur, mais si nous avons un montant au crédit plus important
que le montant au débit, le solde va devenir créditeur. Dans la colonne signée nous
aurons un montant négatif.
Règles de calcul Rappel
SS = solde signé
RC = Report crédit => RD = Report débit
C = Crédit => D = Débit
Si (compte créditeur) alors
SS= (RC +C )−( RD+D )Sinon
SS= (RD+D )−( RC+C )
Type de données Décimal(10,3)
Fonction d’agrégation SUM
Unité de mesure Euro
Source de données WinCRApprentissage.TEMP_BO_FIN_FAIT.MNT_SIGN
Contraintes Aucune
Les Régions travaillent également sur des données typées « budget » pour préparer les
comptes et les dossiers des centres de formation pour l’année à venir. Ils ont la possibilité de
travailler sur plusieurs budgets à la fois. Il a été défini que dans l’entrepôt de données nous ne
travaillerons qu’avec deux budgets, le budget de référence ainsi que le budget retenu par la
Région.
4.6.1.4 Schématisation et volumétrie
Etudions les données volumétriques du data mart sur les comptes généraux :
Periode_comptable : 10 périodes comptables (année).
Site : 140 sites par Région.
Compte_general : 520 comptes généraux.
Joachim PELLICIOLI 87

44 L’entrepôt de données en pratique
Compte_analytique : 10 comptes analytiques.
Fait_cpt_g : 160 000 faits.
Figure 26 Modèle comptes généraux
4.6.1.5 Réalisation
Les Régions ont besoin d’obtenir des tableaux récapitulatifs sur les comptes. Dans notre
exemple, elles souhaitent obtenir une synthèse des évolutions des budgets des centres de
formation tous comptes confondus. Un alerteur leur permet de cibler les centres ayant un
budget en augmentation de plus de 10% (pourcentage en rouge). De la même façon elles
mettent en évidence les centres dont le budget diminue de la même proportion (pourcentage
en vert).
Joachim PELLICIOLI 88

44 L’entrepôt de données en pratique
Tableau XII Evolution du budget pour les centres
Joachim PELLICIOLI 89

44 L’entrepôt de données en pratique
4.6.2 Frais de personnel
4.6.2.1 Objectifs
Dans la partie précédente nous venons de décrire le data mart sur les comptes
financiers. Celui-ci ne suffit pas à la Région pour gérer un centre. Elle a besoin dans certains
cas de plus de détails, d’explications sur les chiffres et les montants fournis par les centres de
formation. C’est le cas des frais de personnel, qu’ils soient administratif ou formateur,
personnel de direction ou sur un emploi de service. La Région peut ensuite transposer les
chiffres par formation, par centre d’activité, …. . Un autre intérêt consiste à valider les
données saisies dans les comptes financiers et ainsi contrôler la bonne gestion des centres.
La Région a besoin de comparer les charges salariales sur une base commune pour le
personnel. Il est délicat de comparer plusieurs personnes car beaucoup de formateurs
travaillent sur des contrats particuliers qui diffèrent en termes d’horaire annuel. Pour pouvoir
effectuer les comparaisons, nous utilisons un système d’équivalence temps plein (ETP) par
catégorie de personnel (formateur, administratif, direction, …).
Les Régions ne travaillent pas toutes avec la même précision sur les données. Certaines
se contentent de données globales découpées par analytique uniquement. D’autres préfèrent
obtenir les valeurs en découpant les salaires des formateurs par formations enseignées.
Un autre objectif pour la Région est de travailler sur des données financières qui
proviennent de la saisie des centres, mais également de travailler sur des extrapolations afin
de préparer ou confirmer leur budget.
4.6.2.2 Axes d’analyse
Voici les axes d’analyse qui ont été relevés durant la phase d’analyse :
Période comptable.
Site de formation.
Compte analytique.
Formation.
Personnel.
Activité du personnel.
Joachim PELLICIOLI 90

44 L’entrepôt de données en pratique
Dans la liste ci-dessus certaines dimensions ont été définies dans d’autres data marts.
Les dimensions « période comptable », « site de formation », « compte analytique » ont été
décrites dans le data mart compte financier. La dimension formation l’a été dans le data mart
effectifs.
Personnel
Cette dimension est l’une des plus importantes de cette partie. C’est autour de celle-ci
que vont s’effectuer la majorité des analyses. Voici les grandes notions regroupées au sein de
cette dimension :
Etat civil : Nom, prénom, civilité, ….
Emploi : Catégorie professionnelle (enseignant, direction, administratif,
surveillant, …), fonction (directeur, directeur adjoint, …), statut (contractuel,
mise à disposition, titulaire, …).
Nous pourrons ainsi avoir accès aux informations financières avec une granularité de
l’ordre de l’individu à des niveaux d’agrégation bien supérieurs comme par catégorie
professionnelle ou encore par genre.
La dimension « personnel » est une dimension à évolution lente [SYS2], certaines
parties comme le nom peuvent changer (ex : en cas de mariage). Après concertation avec les
Conseils régionaux, il a été décidé de ne pas suivre l’évolution dans le temps ; nous garderons
uniquement la dernière valeur des bases de production.
Activité du personnel
Les activités des personnels correspondent aux différentes tâches que peut effectuer une
personne. Par exemple un formateur a comme activité l’enseignement, mais il peut également
prendre en charge la surveillance des devoirs, le soutien, … .
Certaines Régions, comme la Région Lorraine, souhaitent perfectionner leur analyse en
déterminant l’impact par formation de chaque activité du personnel.
Prenons l’exemple d’un formateur qui a réalisé 1 250 heures sur la période comptable,
ceci donne un coût global enregistré dans les comptes. Pour que la Région puisse définir
combien a coûté le soutien, nous devons récupérer les données correctement ventilées. Dans
notre cas nous aurions : 900 heures de formation et 350 heures de soutien (la ventilation des
heures va nous permettre de répartir les montants).
Joachim PELLICIOLI 91

44 L’entrepôt de données en pratique
4.6.2.3 Portefeuille d’indicateurs
Afin de satisfaire toutes les Régions, nous devons utiliser la granularité la plus fine.
Dans ce data mart nous allons obtenir un découpage par personnel d’un centre puis par
analytique et enfin par activité et formation. Grâce à ce découpage les Régions travaillant sur
des données détaillées pourront ventiler leurs résultats. Les autres Régions travailleront sur
des données agrégées.
Prenons un exemple afin de mieux comprendre ce découpage qui caractérise notre table
des faits frais de personnel. Si le formateur « Franck » d’un CFA X enseigne 100h durant la
période comptable, nous répartirons les heures comme indiquées sur le schéma ci dessous :
Figure 27 Granularité de la table des faits : frais de personnel
Grâce à ce modèle nous pouvons répondre à des questions retournant un résultat
agrégé : « Combien d’heures ont été dispensées sur la période comptable ». Nous pouvons
également répondre à des questions retournant un résultat détaillé : « Quelle durée de
surveillance a été dispensée pour les CAP boulanger par des formateurs vacataires ? ».
Nous séparons les faits de notre table en trois catégories :
Heures : Nous avons plusieurs faits sur les heures afin de gérer le suivi. Par
exemple en heure classique, heure supplémentaire ou spéciale.
Charges : Toutes les charges liées aux personnels font parties de cette catégorie.
Charges horaires, charges sociales, …
Joachim PELLICIOLI 92
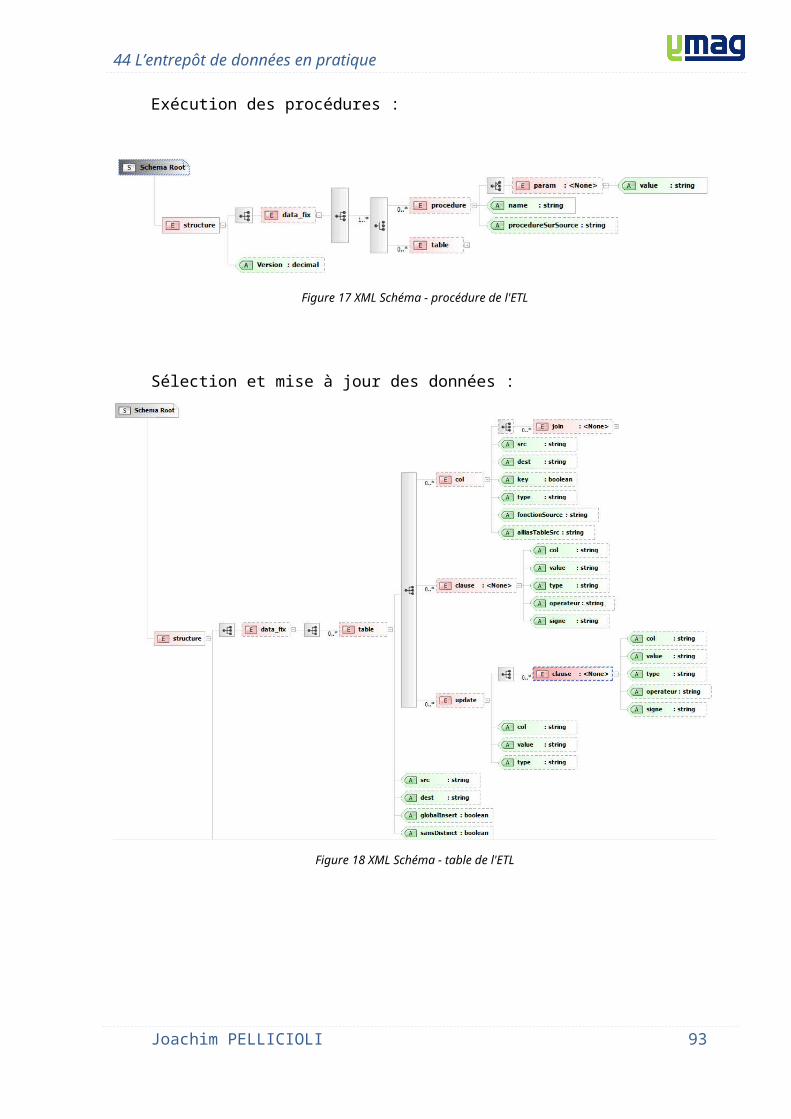
44 L’entrepôt de données en pratique
Masse salariale : Ce sont des indicateurs agrégés des différentes charges vues
précédemment.
ECT : Nombre d’heures, charges horaires et sociales des personnels calculés sur
une base commune de travail afin de comparer les personnels.
Afin de ne pas alourdir ce document, nous allons étudier un fait par catégorie évoquée.
Voici le nombre d’heures normales celui-ci correspond au nombre d’heures inscrites au
contrat et travaillées sur la période comptable.
Tableau XIII Indicateur "heures normales"
Indicateur : Heures normales (HN)
Description Nombre d’heures normales par personnel pour une année, un domaine analytique,
ainsi qu’une formation.
Règles de calcul HNSF = Heures Normales Saisies par Formation
MA = Montant Analytique
Si répartition par formation :
HN=HNSF × MA∑ MA
Type de données Décimal(10,3)
Fonction d’agrégation SUM
Unité de mesure Heure au centième
Source de données WinCRA.TEMP_BO_PERS_FAIT.NB_HEU_NO
Contraintes S’il n’existe pas de saisie du nombre d’heures par formation, on prend le nombre
d’heures globales.
Les « heures normales » étant calculées, nous allons pouvoir nous baser dessus afin
d’établir la charge liée aux heures normales.
Tableau XIV Indicateur "charges normales"
Indicateur : Charges normales (CN)
Description Coût du personnel pour les heures normales réalisées. Note les CN tiennent compte
de la répartition analytique et de la formation puisque les HN sont déjà ventilées. Les
charges normales sont également appelées « salaire brut ».
Règles de calcul CN=HN ×taux horaire normalType de données Décimal(10,3)
Fonction d’agrégation SUM
Unité de mesure Euro
Source de données WinCRA.TEMP_BO_PERS_FAIT.MNT_HEU_NO
Joachim PELLICIOLI 93

44 L’entrepôt de données en pratique
Contraintes Aucune
Voici le calcul de la masse salariale brute, elle correspond à la somme des charges
horaires et des charges sociales.
Tableau XV Indicateur "masse salariale brute"
Indicateur : Masse salariale brute (MSB)
Description Masse salariale brute payée pour le formateur, ventilée par analytique et formation.
Correspond à la charge liée aux heures de formation plus les charges.
Règles de calcul CN CS CSP : Charges Normales/Sociales/Spéciales
CISA CE CS IT : Charges ISA/Externes/Sociales/Impôts et taxes.
Pour un personnel et une année donnée :
MSB=(CN +CS+CSP)+(CISA+CE+CS+¿)
Type de données Décimal(10,3)
Fonction d’agrégation SUM
Unité de mesure Euro
Source de données WinCRA.TEMP_BO_PERS_FAIT.MASSE_SALARIALE_BRUT
Contraintes Aucune
Voici la charge horaire pour l’équivalence temps plein qui permettra la comparaison sur
une base commune des personnels :
Tableau XVI Indicateur "charges horaires équivalence temps plein"
Indicateur : Charges horaires équivalence temps plein (CHETP)
Description Correspond au coût horaire (coût lié aux heures sans les charges) pour un formateur
comme s’il avait eu un temps plein (temps plein = nombre d’heures HETP).
Règles de calcul CN CS CSP : Charges Normales/Sociales/Spéciales
HETP : Heure Equivalence Temps Plein
HC : Heures Cumulées
Pour un personnel et une année donnée :
CHETP=(CN +CS+CSP ) × HETP∑ HC
Type de données Décimal(10,3)
Fonction d’agrégation SUM
Unité de mesure Euro
Source de données WinCRA.TEMP_BO_PERS_FAIT. COUT_NO_TPS_PLEIN
Contraintes Aucune
Joachim PELLICIOLI 94

44 L’entrepôt de données en pratique
4.6.2.4 Schématisation
Examinons les données volumétriques du data mart sur les frais de personnel que nous
n’avons encore pas étudiées :
Personnel : 7 000 personnes travaillent dans les centres d’une
Région.
Activite_personnel : 15 activités différentes.
Formation : 800 formations dispensées dans une Région.
Fait_frais_perso : 50 000 faits.
Figure 28 Modèle frais de personnel
Joachim PELLICIOLI 95
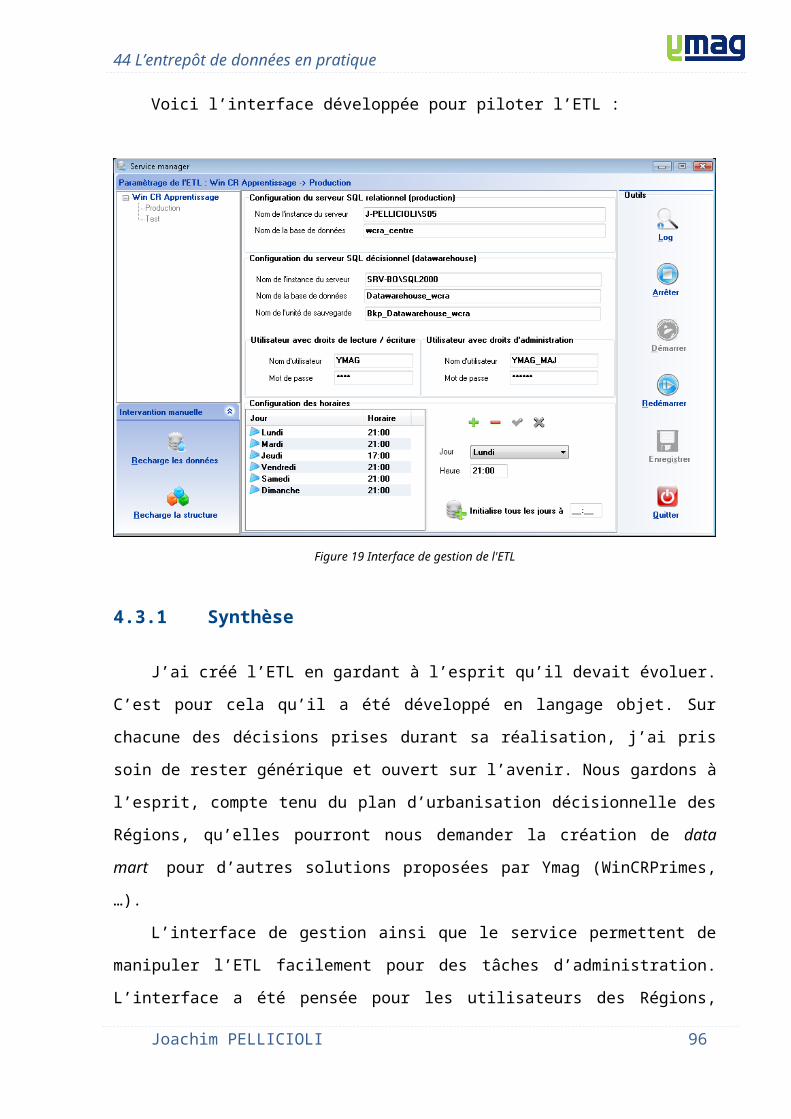
44 L’entrepôt de données en pratique
4.6.2.5 Réalisation
Voici un exemple livré aux Conseils régionaux, qui met en valeur le coût d’un
formateur, ainsi que son équivalence en temps plein afin de comparer les enseignants d’un
CFA.
Attention tous les chiffres présents dans les exemples sont des données issues de base de
test, il ne faut donc pas chercher à faire des corrélations ou des rapprochements avec le monde
réel.
Tableau XVII Exemple de rapport sur les frais de personnel
4.6.3 Taxe d’apprentissage
4.6.3.1 Objectifs
La taxe d’apprentissage est l’un des moyens de financement d’un CFA. La Région a
besoin de connaitre exactement les montants collectés par un centre afin d’adapter les
subventions qu’elle reverse à celui-ci. A des fins d’analyses plus précises, les données sont
réparties dans différentes catégories.
La Région veut pouvoir piloter un centre en particulier, mais aussi avoir des indicateurs
plus globaux afin de se rendre compte de l’utilisation de la taxe d’apprentissage. Par exemple
elle souhaite connaitre la répartition entre les coûts de fonctionnement et l’investissement.
Joachim PELLICIOLI 96

44 L’entrepôt de données en pratique
Comme pour le data mart sur les frais de personnel, la taxe d’apprentissage doit
permettre de confronter ces données avec les comptes financiers. Ce data mart délivre aussi
deux types de données, une sur les réalisations et une autre sur les budgets des centres de
formation.
4.6.3.2 Axes d’analyse
De la même manière que pour les autres data marts nous allons déterminer les axes
d’analyse de la taxe d’apprentissage :
Période comptable.
Site de formation.
Eclatement de la taxe.
Collecte de la taxe.
La dimension « période comptable » est commune au data mart sur les comptes
financiers. Celle de « site de formation » est commune avec le data mart sur les effectifs.
Eclatement de la taxe
Le montant de la taxe est un montant global récupéré par un centre de formation. A des
fins d’analyses nous le découpons en plusieurs familles :
La catégorie : Elle permet de faire une première distinction entre les différentes
sommes versées (ex : quota réservé à l’apprentissage).
La répartition : Autre éclatement permettant de déterminer la part de la taxe
utilisée pour une action particulière (ex : contribution aux dépenses des CPA).
La ventilation : Permet de diviser le montant de la taxe en investissement ou en
fonctionnement (ex : investissement : renouvellement normal de matériel).
Collecte de la taxe
Cette dimension offre des informations sur la provenance de la taxe d’apprentissage. La
Région a défini quelques notions pour créer des regroupements sur la collecte de la taxe.
Ainsi elle souhaite savoir si les fonds collectés proviennent d’entreprises extérieures à ses
départements administratifs, …. .
Joachim PELLICIOLI 97

44 L’entrepôt de données en pratique
4.6.3.3 Portefeuille d’indicateurs
Pour la taxe d’apprentissage, nous avons deux principaux indicateurs :
Montant prévu de la taxe : Le montant estimé de la taxe d’apprentissage versé
par les entreprises.
Montant versé de la taxe : Le montant effectivement versé par les entreprises.
Le schéma ci-dessous montre comment un montant agrégé peut être réparti en fonction
des informations sur la taxe d’apprentissage. Dans cet exemple nous prenons un versement de
100€ pour une entreprise X faisant partie de la catégorie « apprentissage » :
Figure 29 Granularité de la table des faits : taxe d'apprentissage
Comme dans nos autres data marts nous allons donner un exemple de fait. Ici nous
étudions le montant versé de taxe :
Tableau XVIII Indicateur "Montant taxe versé"
Indicateur : Montant taxe versé (MTV)
Description C’est le montant de la taxe saisi sur le compte financier.
Règles de calcul MC : Montant catégorie
MV : Montant ventilation
MR : Montant répartition
MCol : Montant collecte
Joachim PELLICIOLI 98

44 L’entrepôt de données en pratique
Si (∑k =1
4
MC k>0) Alors
Si (Répartition = « Contribution aux dépenses du C.F.A. »)
MTR= MC∑ MC
×Ventillation× MCol
∑k =1
4
MC k
Sinon
MTR= MC∑ MC
× Repartition× MCol
∑k=1
4
MC k
Sinon
Si (Répartition = « Contribution aux dépenses du C.F.A. »)
MTR= MC∑ MC
×Ventillation
Sinon
MTR= MC∑ MC
× Repartition
Type de données Décimal(10,2)
Fonction d’agrégation SUM
Unité de mesure Euro
Source de données WinCRA.TEMP_BO_TAXE_APP.MONTANT
Contraintes Aucun
4.6.3.4 Schématisation
Examinons les données volumétriques du data mart sur la taxe d’apprentissage que
nous n’avons pas encore étudiées dans les data marts précédents :
Eclatement_taxe : 40 éclatements différents.
Collecte_taxe : 10 types de collectes.
Fait_taxe : 155 000 faits.
Joachim PELLICIOLI 99

44 L’entrepôt de données en pratique
Figure 30 Modèle taxe d'apprentissage
4.6.3.5 Réalisation
Voici un exemple de réalisation à forte valeur ajoutée pour la Région. Comme nous
l’avons vu, les centres justifient la taxe d’apprentissage collectée en la répartissant dans
différentes rubriques. Le centre transmet également cette information via une écriture
comptable. Grâce au tableau ci-dessous nous pouvons afficher les valeurs comptables ainsi
que la saisie du centre, ce qui va nous permettre de mettre en évidence les différences. Nous
utilisons un alerteur visuel en trois couleurs ; vert : le compte et la saisie sont équilibrés ;
orange : un écart de moins de 20% est détecté ; rouge : pour les écarts de plus de 20%.
Tableau XIX Exemple de rapport sur la taxe d'apprentissage
Joachim PELLICIOLI 100

44 L’entrepôt de données en pratique
Joachim PELLICIOLI 101

44 L’entrepôt de données en pratique
4.6.4 Dépense théorique
4.6.4.1 Objectifs
La dépense théorique est un indicateur primordial pour la Région. Elle correspond aux
charges constatées ou estimées d’un centre de formation. Elle permet de se confronter à la
subvention régionale. Chaque Région a mis en place un système de calcul plus ou moins
compliqué de la subvention. Celle-ci, comme nous l’avons déjà vu, doit couvrir les frais des
CFA. La Région veille à compléter sous forme de subvention les fonds déjà collectés par la
taxe d’apprentissage pour couvrir les charges. Attention les Régions travaillent sur la période
comptable (majoritairement l’année civile) et elles subventionnent les formations qui se
déroulent par année scolaire. Pour arriver à des données cohérentes, de nombreuses Régions
utilisent des coefficients de pondération, qu’elles appliquent sur les effectifs du premier
semestre de la période comptable ainsi que sur le deuxième.
La Région demande aux centres de saisir les frais engagés par formation. Elle leur
demande également de remplir les charges liées au transport, à l’hébergement ainsi qu’à la
restauration. Nous parlons ici de transport puisque le CFA fait l’intermédiaire entre l’apprenti
et la Région qui subventionne ses déplacements.
La Région souhaite pouvoir obtenir des tableaux de bord comparant la subvention
versée d’un CFA à un autre pour une formation donnée. Ces indicateurs sont importants car
ils permettent de confronter les dossiers des centres à des moyennes « de terrain » et ainsi la
Région pourra mettre en œuvre une politique d’accompagnement pour réduire les écarts. Elle
souhaite avoir également des états donnant des indicateurs sur les coûts globaux de formation.
Ce que la Région définie par coûts globaux correspond à la dépense théorique de formation et
à la dépense liée aux THR.
4.6.4.2 Axes d’analyse
Nous concevrons la même méthodologie que pour les autres data marts et nous listons
les différents axes d’analyse :
Période comptable.
Site de formation.
Formation.
Joachim PELLICIOLI 102

44 L’entrepôt de données en pratique
Paramétrage de la formation.
Qualité de l’apprenti.
Les dimensions « période comptable », « site de formation » et « formation » ont déjà
été définies dans les autres data marts.
Paramétrage de la formation
Cette dimension donne un certain nombre d’informations sur la formation : date
d’ouverture de celle-ci, effectifs maximum et minimum autorisés dans une classe,
pourcentage de subvention de la Région, … . Dans notre modèle nous avons souhaité créer
une seule dimension avec ces informations. Nous avons ainsi créé le produit cartésien des
différentes possibilités de paramétrage des formations. Nous séparons ces différentes
informations en trois familles :
Formation : Nous retrouvons les informations sur les effectifs, les dates
d’ouverture et fermeture de la formation, l’année de formation, ….
Financière : Nous retrouvons les différents barèmes ou taux de prise en charge
de la formation par la Région.
Année de formation : Elle correspond à l’année de formation réalisée par les
apprentis.
Qualité
Cette dimension a une utilité pour les indicateurs liés aux transports, à l’hébergement
ainsi qu’aux repas. Nous la retrouvons dans les différentes qualités : interne, demi-
pensionnaire et externe. Certaines Régions travaillent avec d’autres qualités comme « interne-
externé ».
4.6.4.3 Portefeuille d’indicateurs
Nous avons plusieurs indicateurs pour gérer cette partie :
Effectifs : Nous retrouvons les effectifs par semestre, les effectifs pondérés,
redoublants ou encore d’enseignement spécialisé…
Heures : Nous avons des mesures sur les heures prévues à la convention, sur les
heures subventionnées, les heures par semestres, en enseignement spécialisé, …
Joachim PELLICIOLI 103

44 L’entrepôt de données en pratique
Montants : Nous retrouvons comme indicateurs les montants de dépense
théorique engagés par le centre de formation, les montants de subvention, les
montants pour l’enseignement spécialisé, ….
Transport : Nous regroupons toutes les mesures liées aux transports (nombre de
transports, montant de la charge, montant de la subvention).
Hébergement : Nous regroupons toutes les mesures liées à l’hébergement
(nombre de nuitées, montant de la charge, montant de la subvention).
Restauration : Nous regroupons toutes les mesures liées aux repas (nombre de
repas, montant de la charge, montant de la subvention).
Afin de bien comprendre la granularité mise en place dans ce data mart, prenons un
exemple. Nous avons une dépense théorique (DTO) de 100€ pour la formation BTS
Comptabilité d’un site X. La Région prend en charge 60% du montant de la dépense théorique
(Sub).
Figure 31 Granularité de la table des faits : dépense théorique
Voici quelques exemples de faits mis en œuvre dans ce data mart, nous commençons
par un fait sur les mesures des effectifs :
Joachim PELLICIOLI 104

44 L’entrepôt de données en pratique
Tableau XX Indicateur "effectifs pondérés"
Indicateur : Effectifs pondérés (EP)
Description Effectifs pondérés en fonction d’un coefficient entre les effectifs du 1er et du 2ème
semestre. Utiles pour le calcul de la subvention.
Règles de calcul ES1/ES2 : effectifs semestre 1 / effectifs semestre 2
EP=ES 1 ×CoefES 1+ES 2 ×Coef ES 2Exception pour CR Centrea = Année de formation
EP=∑a=1
x
ES 1 a×CoefES 1+∑a=1
x
ES 2a ×Coef ES 2
Type de données Réel
Fonction d’agrégation SUM
Unité de mesure Aucune
Source de données WinCRA.TEMP_BO_DTO_THR.EFF_PONDERE
Contraintes Aucune
Voici un autre indicateur, cette fois nous mesurons la subvention à verser :
Tableau XXI Indicateur "Montant subvention"
Indicateur : Montant subvention (MS)
Description Montant de subvention régionale attribué. Nous prenons un pourcentage du montant
de la dépense théorique.
Règles de calcul MDT : Montant de la dépense théorique
MS=MDT × Taux de prise en charge
Type de données Decimal(10,3)
Fonction d’agrégation SUM
Unité de mesure Euro
Source de données WinCRA.TEMP_BO_DTO_THR.MNT_SUBVEN
Contraintes Aucune
4.6.4.4 Schématisation
Comme pour les autres modèles nous allons examiner les données volumétriques du
data mart sur la dépense théorique que nous n’avons encore pas étudiée :
Formation_centre : 7500 paramétrages différents de formations.
Qualite : 4 qualités différentes.
Joachim PELLICIOLI 105

44 L’entrepôt de données en pratique
Fait_dto : 41 500 faits.
Figure 32 Modèle dépense théorique
4.6.4.5 Réalisation
Voici un exemple de tableau de bord comparant le coût de formation des « BEPA
travaux paysagers » d’un centre à un autre. La Région peut ainsi contrôler les divergences,
bien entendu ce tableau ne suffit pas à prendre une décision rationnelle. Il faut absolument
croiser les données avec d’autres indicateurs (investissements, charges de personnel, ….).
Comme dans de nombreux documents mis à disposition des Régions, nous avons un système
d’indicateur visuel. Dans cet exemple, il souligne les CFA ayant un écart de plus de 10%
entre la subvention versée et la moyenne des subventions pour la formation en question.
Joachim PELLICIOLI 106

44 L’entrepôt de données en pratique
Tableau XXII Exemple de rapport sur la dépense théorique
4.6.5 Synthèse
Cette partie vient de décrire l’analyse et la mise en place du data mart financier. Celui-
ci se découpe en plusieurs domaines. Chacun offrant un certain nombre d’indicateurs liés au
domaine analysé. Presque tous ces data marts ont une dimension commune : celle de la
formation. Grâce à celle-ci nous pouvons croiser l’information contenue dans chaque sous
ensemble. Par exemple nous pouvons afficher pour la formation X, le montant des charges
salariales provenant du data mart « frais de personnel », le montant de la subvention régionale
provenant du data mart « dépense théorique ».
Grâce au data mart sur les effectifs nous pouvons maintenant créer des tableaux de bord
avec des coûts par apprenti. Ceci a un fort impact pour les hommes politiques et pour la
gestion de l’éducation. Il ne faut pas oublier que l’entrepôt offre des données fiables et
corrigées, correspondant aux études actuelles (NAF homogénéisée, nomenclature, …). Enfin
la corrélation du data mart effectifs et financier se schématise par une constellation :
Joachim PELLICIOLI 107

44 L’entrepôt de données en pratique
Figure 33 Constellation WinCRAnalyse
Ces différents data marts apportent un support pour les requêtes des utilisateurs. De
nombreux croisements sont possibles afin d’analyser, voire d’extrapoler les données. Les
utilisateurs pourront ainsi prévoir avec plus de précisions les budgets. Les requêtes, grâce au
modèle en étoile, sont globalement rapides. Ceci offre un réel confort aux utilisateurs qui
sollicitent plus facilement l’outil.
Comme nous avons transposé les données dans l’entrepôt, nous offrons de nouvelles
perspectives à l’utilisateur, certaines données découpées en prorata pourront être agrégées et
mises en valeur par une dimension en particulier. Ces traitements étaient impossibles avec le
SIO actuel.
Joachim PELLICIOLI 108

44 L’entrepôt de données en pratique
4.7 Phase de finalisation
La phase de finalisation est exécutée pour chacune des sous parties (ETL, effectifs,
financier, …). Nous allons la décrire globalement dans ce chapitre, en montrant le
développement effectué dans Business Objects (BO) ainsi que les diverses documentations
réalisées. Puis nous terminerons par ma méthodologie de formation préparée pour les agents
régionaux.
4.7.1 Business Objects
La solution retenue pour la restitution de données est la suite logicielle de Business
Objects XI R2. Nous travaillons avec deux des produits de la suite :
BO Designer.
BO WebIntelligence.
BO Designer
Afin de préparer les données, BO impose la création de ce qu’il appelle un « univers ».
Celui-ci a pour but de rassembler un certain nombre d’informations pour faciliter la création
des rapports, ainsi que pour optimiser la navigation dans les données. L’univers est le pendant
du data mart, il donne une vue métier sur des données ciblées pour un ensemble
d’informations à analyser.
BO Designer permet la création de différents objets qui seront utilisés par les agents.
Ces objets correspondent à la même notion que nous avons déjà vue. Nous retrouvons les
dimensions pour les champs d’informations et les indicateurs pour les champs calculés. Nous
avons également la possibilité de créer des classes d’informations afin d’engendrer une
arborescence fonctionnelle. Pour tous ces objets, nous pouvons ajouter des commentaires qui
compléteront la documentation pour les utilisateurs finaux.
Dans BO Designer nous préparerons également les hiérarchies contenues au sein de nos
dimensions afin de permettre les actions de drill down et drill up.
Enfin une autre fonctionnalité de BO Designer est de créer des filtres pré-paramétrés
afin de faciliter le travail des utilisateurs. Dans notre cas ces filtres ont été établis avec les
Joachim PELLICIOLI 109

44 L’entrepôt de données en pratique
agents du Conseil régional. Nous restons à leur disposition afin d’ajouter dans les versions
suivantes les nouveaux filtres.
Toute la partie de création d’univers, d’objet, de filtre, est réalisée par Ymag puis
fournie à la Région. Compte tenu de nos objectifs, nous avons limité au maximum les
interactions avec l’univers, afin de ne pas défavoriser les Régions n’ayant pas BO. Ainsi les
traitements sur les données, comme par exemple, la concaténation de deux champs, sont
déplacés dans l’entrepôt de données et sont traités par l’ETL.
BO WebIntelligence
C’est une solution permettant d’interroger l’entrepôt de données via l’univers créé dans
le BO Designer. Cette partie est utilisée par les agents du Conseil régional et permet :
De créer des rapports et des tableaux de bord.
De créer des requêtes dynamiques.
D’analyser des données (principe OLAP).
BO WebIntelligence est ce que nous appelons un client léger, il est accessible via un
navigateur internet et ne nécessite aucune installation sur les postes clients. BO
WebIntelligence exploite la technologie D-OLAP (cf. 3.4.1 Définition) et s’appuie sur les
informations qui ont été définies dans BO Designer (hiérarchie, indicateur, ….). Voici
comment se construit une requête utilisateur dans BO WebIntelligence :
Figure 34 BO WebIntelligence : requête
Joachim PELLICIOLI 110

44 L’entrepôt de données en pratique
4.7.2 Documentation
J’ai souhaité réalisé plusieurs documentations, pour répondre à des problématiques
internes de suivi de projet, mais également pour transmettre le maximum d’informations aux
clients. J’ai structuré la documentation en trois axes :
Documentation technique : Elle vise les différents collaborateurs d’Ymag qui
auront à travailler sur ce projet. Elle décrit les différentes phases de réalisation,
les choix techniques et les manipulations sur les données. Elle donne une
description de chaque champ de l’entrepôt de données, du type utilisé ainsi que
des informations sur la source de celui-ci. J’ai également écrit quelques normes
pour le nommage des tables et des champs pour la base de données, idem pour
objets créés dans BO.
Documentation fonctionnelle : Elle est conçue pour les utilisateurs. Elle
apporte des descriptions de chaque champ. Elle explique les différents
changements sur les données. Les faits sont également expliqués et des tableaux
avec des formules aident à comprendre la structure des données. Pour les
utilisateurs de la suite Business Object, nous donnons également des
informations sur les hiérarchies crées ainsi que sur les filtres prédéfinis.
Rapports types : Nous offrons avec notre solution un ensemble de rapports
types créés en BO WebIntelligent. Ceux-ci donnent aux utilisateurs un exemple
de requêtes plus ou moins complexes, ainsi que de résultat obtenu. Ces exemples
sont issus de cas concrets et apportent les premiers éléments de réponses aux
problématiques rencontrées par les agents (accessibilité de certaines données,
manque de souplesse, ….).
4.7.3 Formation
Dans cette phase de finalisation, j’ai préparé les formations pour les utilisateurs des
Conseils régionaux. Ces formations concernent un public varié avec des attentes différentes.
Dans tous les cas la même méthodologie est appliquée : utilisation des documents fournis,
explication théorique du fonctionnement, séances de questions-réponses et enfin mise en
Joachim PELLICIOLI 111

44 L’entrepôt de données en pratique
pratique des nouvelles notions acquises. Normalement les utilisateurs sont déjà formés aux
outils de création de requêtes et mise en forme des documents (BO WebIntelligence, ….).
J’ai découpé en deux familles le public visé par les formations :
Service informatique.
Service de la formation et de l’apprentissage.
Service informatique :
La formation du service informatique concerne les points techniques de notre solution.
La première partie consiste à sensibiliser ce service sur l’architecture que nous avons mise en
place (ETL, base de données, communication entre serveurs). Ensuite en fonction de leurs
besoins (souvent exprimés au cours d’une réunion téléphonique au préalable), nous adaptons
notre modèle et notre formation afin de correspondre à leur architecture. Une fois que tous ces
détails techniques sont résolus nous passons à la phase d’apprentissage sur l’installation des
différents composants de notre solution.
Ensuite nous voyons comment le service informatique devra réagir lors des mises à jour
que nous leur fournirons (changement de version de l’entrepôt de données). Ces changements
de version seront le résultat de la maintenance évolutive du produit.
En dernier point, nous travaillons sur le paramétrage et surtout sur le contrôle de
l’exécution de l’ETL. Cette partie leur permet de rester autonome et de pouvoir réagir en cas
de disfonctionnement du module ETL.
Service de la formation et de l’apprentissage
Cette partie s’adresse à l’ensemble des personnes du service de la formation et de
l’apprentissage, cela signifie que nous formons autant les chefs de service que les agents de
terrain. La formation dure 2 jours voici comment elle est structurée :
Rappel sur le principe de base de données décisionnelle : Explications sur les
objectifs et les attentes d’un tel outil. Nous donnons des exemples sur les
possibilités ainsi que les limites.
Présentation des univers effectifs et financiers : Explications sur les différents
concepts utilisés. Nous en profitons pour expliquer quelques transformations
apportées.
Manipulation des données : Dans cette partie nous étudions différentes
requêtes sur les données de notre entrepôt. Nous commençons par de petites
Joachim PELLICIOLI 112

44 L’entrepôt de données en pratique
requêtes simples et nous augmentons progressivement leurs complexités (filtre,
filtre complexe, multi requête). Une fois ces concepts maitrisés, nous passons au
requêtes multi data marts (ou univers pour BO). Ce qui leur permet d’entrevoir
les possibilités de l’outil mis à disposition. Un dernier point est abordé, celui de
la cohérence des données. Au sein de l’entrepôt, j’ai mis une table qui donne la
date et l’heure du dernier chargement des données ainsi que l’état des données
(données partiellement chargées, complètement chargées, ….). Grâce à cela les
agents pourront ajouter ces indicateurs qui justifieront la qualité des données du
document présenté (données récentes ou datant de plus de trois semaines, …).
4.7.4 Synthèse
Je suis persuadé que ces différentes étapes de documentation et de formation sont
primordiales au sein de ce projet. Nous offrons aux utilisateurs un outil très performant, qui
demande à être exploité. Si les personnes ne savent pas l’utiliser ou perdent trop de temps, le
projet est voué à l’échec. Durant la formation il n’est pas rare de côtoyer des personnes
réticentes vis-à-vis de l’outil, mais leur attitude change en voyant les solutions apparaitre à
leurs problèmes de tous les jours. De plus les différentes documentations leur permettent
d’évoluer d’une façon autonome et à leur vitesse.
J’ai également souhaité apporter beaucoup d’importance aux documentations, souvent
négligées dans les projets, afin de gagner en temps de maintenance. Il est important de laisser
une trace des différentes étapes du projet, ainsi que les explications techniques de façon à ce
qu’Ymag puisse affecter d’autres personnes sur ce projet.
Joachim PELLICIOLI 113

44 L’entrepôt de données en pratique
5 Conclusion
Le service de la formation et de l’apprentissage du Conseil régional a sollicité ma
société afin que nous les aidions à réaliser une base de données décisionnelle. Le Conseil
régional nous a fait part de ses contraintes et de ses attentes : tableaux de bord, requête à la
demande, analyse des données, recherche de solutions et tout ceci sur des données fiables.
Nous avons, au travers de ce mémoire, présenté la conception et la réalisation de ce projet.
Dans un premier temps, je me suis formé aux différentes technologies et concepts qu’il me
manquait afin de réaliser un entrepôt de données. Ensuite en me basant sur les acquis
théoriques, j’ai réalisé celui-ci.
Le data mart effectifs apporte de nouvelles perspectives aux Conseils régionaux. Le
service de la formation et de l’apprentissage devient autonome face aux requêtes ponctuelles
qui sont nécessaires à la réalisation de leurs travaux. Avec la vision globale qu’offre le data
mart effectifs, la Région peut effectuer des tableaux évolutifs sur X années et ainsi prévoir les
évolutions par centre de formation, mais aussi plus globalement par filière. Elle peut veiller
plus efficacement aux problèmes de mixité de certains métiers et agir en conséquence pour
diminuer les écarts. Ces données permettent de prévoir les coûts à longs termes (création d’un
nouveau CFA, …).
Le data mart financier quant à lui apporte un élément de contrôle et de création de
requête. Grâce à cet outil, les utilisateurs ressortent des données financières brutes afin
d’établir des documents propres à une instruction de dossier. Cet outil, au delà des possibilités
de reporting ou de création de requête à la demande, met en valeur des incohérences dans les
données financières. La Région peut contrôler la taxe collectée en la comparant aux comptes
financiers d’un CFA et réguler la prime versée en fonction de l’analyse. Avec le découpage
effectué lors de la réalisation des différents modules de ce data mart, nous arrivons à estimer
un coût de formation par apprenant (en croisant avec les données du data mart effectifs). Les
chiffres obtenus donnent la possibilité aux Conseils régionaux de comparer les CFA pour une
même formation. Toutes ces informations leur permettent de mieux gérer les finances
publiques. Comme nous l’avons vu, le poste de dépense de la formation est le plus important
d’un Conseil régional.
Joachim PELLICIOLI 114

44 L’entrepôt de données en pratique
Ce travail a apporté la connaissance de l’informatique décisionnelle à Ymag. Il nous
ouvre de nouvelles perspectives pour nos autres produits. Les Conseils régionaux ont la
solution qu’ils attendaient et peuvent continuer leur politique de contrôle des dépenses
publiques. Le développement de ce projet est terminé, les retours de la Région Centre sont
positifs, les autres Régions prennent rendez-vous pour l’installation et la formation. Nous
entrons progressivement dans une phase de maintenance évolutive, en fonction des futures
remontées des Conseils régionaux.
Actuellement la solution que j’ai réalisée durant ce stage est en production dans la
Région Centre : Région pilote. Je suis en train de déployer l’entrepôt en Région Rhône-Alpes
et Lorraine, suivront les séances de formations. Nous venons de recevoir des contacts de la
Région Bourgogne ainsi que de la Région Provence Alpes Côte d’Azur pour la mise en place
de l’entrepôt. La Région Bretagne quant à elle, a commandé uniquement le data warehouse
sans prendre l’univers Business Object que nous livrons.
Ce projet a été techniquement très riche pour moi. La Direction d’Ymag m’a offert une
grande liberté d’exécution. J’ai pu travailler sur une technologie inconnue de mon entreprise.
Rechercher l’information, la structurer, la valider et enfin créer l’entrepôt de données pour les
Conseil régionaux. Auparavant j’ai toujours évolué sur des bases de données relationnelles.
Structurer différemment ma logique pour travailler sur les bases de données décisionnelles
m’a ouvert l’esprit à d’autres conceptions. Passer par cette dé-normalisation afin de répondre
à une problématique de restitution a été très enrichissant. Ma vision a également évolué avec
la création du module d’intégration des données (ETL). Celui-ci doit répondre à de
nombreuses contraintes (données pré-chargées, clés externes, données calculées, ….), il doit
être robuste, rapide et sans faille. Il est le garant des données présentes dans l’entrepôt.
Malgré cette complexité, son interface de gestion est simplifiée au maximum pour les
utilisateurs. Afin de réaliser l’ETL, je me suis familiarisé avec la syntaxe SQL de Microsoft
SQL Server. En parallèle à l’entrepôt de données, mon entreprise m’a financé une formation
sur les outils de SAP, j’ai acquis les compétences en matière de création d’univers BO ainsi
que sur la création de document WebIntelligence.
Le travail d’investigation a été particulièrement captivant avec la Région Centre. Grâce
à la concertation avec les agents nous avons obtenu de nombreuses réponses conceptuelles qui
Joachim PELLICIOLI 115

44 L’entrepôt de données en pratique
ont amélioré la réalisation du projet. La diversité des personnes (assistantes, responsables,
chefs de service, élus) avec lesquelles j’ai travaillé en Région a compliqué la tâche. C’est
pourtant grâce à cette richesse que nous avons atteint nos objectifs.
Pour accélérer la réalisation du data mart financier, il était important que je fasse
participer un collègue à ce projet. Afin qu’il puisse travailler dans un environnement connu, je
l’ai formé à l’informatique décisionnelle, en le sensibilisant aux objectifs d’analyse et de
pilotage de l’entrepôt de données.
Il m’aurait été difficile de réaliser ce projet sans le soutien des cours que j’ai effectués
durant mes six années passées au C.N.A.M. Ma formation m’a permis de prendre de la
hauteur sur un tel projet. Des cours, tel que l’ingénieur au XXIème siècle, m’ont permis de
synthétiser les demandes des clients. D’autres cours comme la communication m’ont aidé à
prendre la parole avec des personnes ayants de nombreuses responsabilités, comme les chefs
de services.
Grâce à ma formation et à mon entreprise, j’ai réalisé un entrepôt de données qui répond
aux attentes des Conseils régionaux. Suite à celui-ci, un nouveau besoin est né et d’autres data
marts sont en projet à Ymag.
Joachim PELLICIOLI 116
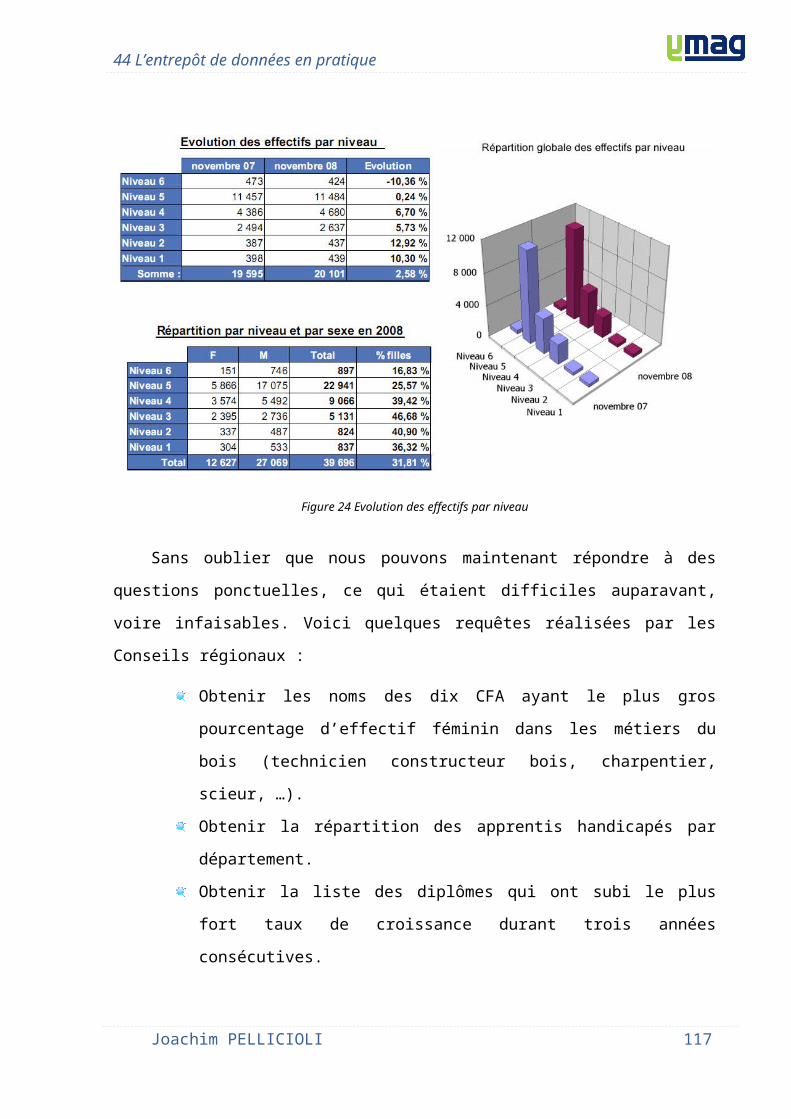
44 L’entrepôt de données en pratique
Table des illustrations
Listes des figures
Figure 1 Ymag nombre de salariés et chiffre d'affaire....................................................11
Figure 2 Ymag organigramme.........................................................................................11
Figure 3 Budget 2010 Région Centre [REG1]................................................................13
Figure 4 Flux du data warehouse.....................................................................................20
Figure 5 Composants de base du data warehouse...........................................................21
Figure 6 Data mart...........................................................................................................24
Figure 7 Exemple de table des faits et dimensions..........................................................27
Figure 8 Modélisation en étoile.......................................................................................28
Figure 9 Modélisation en flocon......................................................................................29
Figure 10 Modélisation en constellation.........................................................................30
Figure 11 OLAP Drill up et drill down...........................................................................35
Figure 12 OLAP Rotate...................................................................................................35
Figure 13 OLAP Slicing..................................................................................................36
Figure 14 OLAP Scoping................................................................................................36
Figure 15 ETL.................................................................................................................37
Figure 16 Graphique des interactions de l'ETL...............................................................59
Figure 17 XML Schéma - procédure de l'ETL................................................................62
Figure 18 XML Schéma - table de l'ETL........................................................................62
Figure 19 Interface de gestion de l'ETL..........................................................................64
Figure 20 Dé-normalisation.............................................................................................66
Figure 21 Table des faits sans fait effectifs.....................................................................76
Figure 22 Table des faits sans fait effectifs, avec champ effectifs..................................76
Figure 23 Modèle effectifs..............................................................................................78
Figure 24 Evolution des effectifs par niveau...................................................................79
Figure 25 Granularité de la table des faits : comptes généraux.......................................84
Figure 26 Modèle comptes généraux..............................................................................86
Figure 27 Granularité de la table des faits : frais de personnel.......................................90
Joachim PELLICIOLI 117

44 L’entrepôt de données en pratique
Figure 28 Modèle frais de personnel...............................................................................93
Figure 29 Granularité de la table des faits : taxe d'apprentissage....................................96
Figure 30 Modèle taxe d'apprentissage...........................................................................97
Figure 31 Granularité de la table des faits : dépense théorique.....................................101
Figure 32 Modèle dépense théorique............................................................................103
Figure 33 Constellation WinCRAnalyse.......................................................................105
Figure 34 BO WebIntelligence : requête.......................................................................107
Listes des tableaux
Tableau I Comparaison OLAP vs OLTP.........................................................................33
Tableau II Calendrier des phases.....................................................................................44
Tableau III Objectifs synthèse.........................................................................................49
Tableau IV Synthèse des choix technologiques..............................................................53
Tableau V Grille de description des dimensions.............................................................66
Tableau VI Grille de description des indicateurs............................................................68
Tableau VII Méthodologie de conception.......................................................................69
Tableau VIII Axe d’analyse : Formation.........................................................................71
Tableau IX Indicateur "effectifs"....................................................................................77
Tableau X Indicateur "crédit"..........................................................................................84
Tableau XI Indicateur "solde signé"................................................................................85
Tableau XII Evolution du budget pour les centres..........................................................87
Tableau XIII Indicateur "heures normales".....................................................................91
Tableau XIV Indicateur "charges normales"...................................................................91
Tableau XV Indicateur "masse salariale brute"...............................................................92
Tableau XVI Indicateur "charges horaires équivalence temps plein".............................92
Tableau XVII Exemple de rapport sur les frais de personnel.........................................94
Tableau XVIII Indicateur "Montant taxe versé".............................................................96
Tableau XIX Exemple de rapport sur la taxe d'apprentissage.........................................98
Tableau XX Indicateur "effectifs pondérés".................................................................102
Tableau XXI Indicateur "Montant subvention".............................................................102
Tableau XXII Exemple de rapport sur la dépense théorique........................................104
Joachim PELLICIOLI 118

44 L’entrepôt de données en pratique
Joachim PELLICIOLI 119

44 L’entrepôt de données en pratique
Références bibliographiques
Livres
[KIM1] KIMBALL (Ralph). REEVES (Laura). ROSS (Margy). THORNTHWAITE
(Warren). - Le data warehouse : Guide de conduit de projet. - Paris : Eyrolles, 2008.-
576 p.
[KIM2] KIMBALL (Ralph). – Entrepôt de données : Guide pratique de conception de « data
warehouse ». - Paris : International Thomson Publishing, 1997.- 368 p.
[CHA1] CHARTIER-KASTLER (Cyrille). - Précis de conduite de projet informatique. - Les
éditions d’organisation, 1997.
Livres blancs
[COD1] CODD (E.F.). CODD (S.B.). SALLEY (C.T.) - Providing OLAP to User-Analysts. –
E.F. CODD & Associate, 1993.- 20 p.
[SMI1] Smile open source solution - Providing OLAP to User-Analysts. – Smile open source
solution, 2010.- 78 p.
Sites internet
[INM1] « A definition of Data Warehousing ». In Intranet Journal [En ligne]
http://www.intranetjournal.com/features/datawarehousing.html (Page consultée le 29
septembre 2009).
[INS1] « Nomenclature d'activités française - NAF rév. 2, 2008 ». In INSEE [En ligne]
http://www.insee.fr/fr/methodes/default.asp?page=nomenclatures/naf2008/
naf2008.htm (Page consultée le 09 novembre 2009).
Joachim PELLICIOLI 120

44 L’entrepôt de données en pratique
[LAP1] « Le financement de l’apprentissage ». In lapprentis [En ligne]
http://www.lapprenti.com/html/cfa/financement.asp (Page consultée le 29 septembre
2009)
[REG1] « Budget 2010 » In Région Centre [En ligne]
http://www.regioncentre.fr/jahia/Jahia/site/portail/Budget-2010 (Page consultée le 15
février 2010).
[SYS1] « Le portail des systèmes ETL ». In systemetl [En ligne]
http://www.systemeetl.com/Portail_etl.htm (Page consultée le 01 octobre 2009)
[SYS2] « Dimensions- différents types ». In systemetl [En ligne]
http://www.systemeetl.com/types_dimensions.htm (Page consultée le 05 février
2010)
[WIK1] « Data mart ». In Wikipedia [En ligne] http://fr.wikipedia.org/wiki/Data mart (Page
consultée le 8 décembre 2009)
[WIK2] « Chambre du commerce et de l’industrie ». In Wikipedia [En ligne]
http://fr.wikipedia.org/wiki/Chambre_de_commerce_et_d%27industrie (Page
consultée le 30 septembre 2009)
Joachim PELLICIOLI 121

Conception d’un entrepôt de données corrélant les effectifs en apprentissage et le suivi financier des centres de formation. Mémoire d’ingénieur C.N.A.M., Dijon 2010.
Résumé
Les travaux présentés dans ce mémoire concernent la construction d’un entrepôt de données pour le service de la formation et de l’apprentissage des Conseils régionaux. Cette solution offre un outil d’aide à la décision sur les effectifs en apprentissage de la Région, ainsi que sur les données financières des centres de formation.
Mon travail s’est structuré en trois parties.La première concerne l’analyse théorique des différents composants qui constituent
l’informatique décisionnelle.La seconde s’attache à la mise en pratique des notions théoriques dans la mise en place
d’un magasin de données pour la gestion des effectifs et pour la gestion financière des centres de formation par alternance.
La troisième partie correspond à la mise en place de la solution chez nos clients : formations, documentations et maintenance évolutive.
Mots clés : Système d’information décisionnelle, ETL, entrepôt de données, magasin de données.
Summary
The project presented in this dissertation relates to the construction of a data-warehouse for the training and apprenticeship department of the Region councils. This solution offers a support tool to facilitate decisions concerning the apprentices in the Region as well as financial data in the training centres.
My dissertation is structured in three parts.The first part deals with the theoretical analysis of the different components which
factored in the decision support system.The second part concerns the application of the aforementioned theories in order to
create a data-mart to manage information regarding both personnel and finance in alternating training centres.
The third part looks at how to put a solution in place within our clients' companies; training, documentation and ongoing maintenance.
Key words: Decision support system, ETL, data-warehouse, data-mart.


![Frédéric Paulinpaulin/note...les formes différentielles, comme la formule de Kunneth (voir par exemple [BT, Hir, God]). Nous ne parlerons pas des variétés différentielles à](https://static.fdocuments.fr/doc/165x107/5e58e38f1750d93e2b490e85/frdric-paulin-paulinnote-les-formes-diirentielles-comme-la-formule.jpg)















