
Un modèle de Case-Based Reasoning pour la détection d ...2004.pdf · l'apprentissage de nouvelles...
28
Nicolas Nobelis Septembre 2004 DEA RSD / ESSI3 SAR Un modèle de Case-Based Reasoning pour la détection d'intrusion Rapport de stage DEA RSD/ESSI3 SAR Stage effectué sous l'encadrement de M elle Karima Boudaoud pour le laboratoire I3S Avril – Septembre 2004
Transcript of Un modèle de Case-Based Reasoning pour la détection d ...2004.pdf · l'apprentissage de nouvelles...

Nicolas Nobelis Septembre 2004DEA RSD / ESSI3 SAR
Un modèle de Case-Based Reasoning pour ladétection d'intrusion
Rapport de stage DEA RSD/ESSI3 SAR
Stage effectué sous l'encadrement de Melle Karima Boudaoud pour le laboratoire I3S
Avril – Septembre 2004

1. Introduction
Les réseaux et systèmes informatiques sont devenus des outils indispensables au fonctionnement desentreprises. Ils sont aujourd’hui déployés dans tous les secteurs professionnels : la banque, les assurances, lamédecine ou encore le domaine militaire. Initialement isolés les uns des autres, ces réseaux sont à présentinterconnectés et le nombre de points d’accès ne cesse de croître. Ce développement phénoménal s’accompagne naturellement de l'augmentation du nombre d’utilisateurs.Ces utilisateurs, connus ou non, ne sont pas forcément pleins de bonnes intentions vis-à vis de ces réseaux.Ils peuvent exploiter les vulnérabilités des réseaux et systèmes pour essayer d’accéder à des informationssensibles dans le but de les lire, les modifier ou les détruire, pour porter atteinte au bon fonctionnement dusystème ou encore tout simplement par jeu.
Dès lors que ces réseaux sont apparus comme des cibles d’attaques potentielles, leur sécurisation estdevenue un enjeu incontournable. De nombreux outils et moyens sont disponibles, tels que firewalls,solutions matérielles, logiciels d'audits ou systèmes de détection d'intrusion (IDS). Les IDS sont une des pluspopulaires réponses au problème posé par :
● l'évolution continue des attaques,● l'apparition de nouvelles attaques,● la nécessité de pouvoir appliquer rapidement de nouvelles politiques de sécurité dans un réseau
afin de détecter et réagir le plus vite possible aux attaques survenant dans ce réseau.
Dans ce contexte, un IDS utilisant des politiques de sécurité et fondé sur un système multi-agents a étéproposé ([21]). Dans ce système, des agents intelligents coopèrent et communiquent pour détecterefficacement des attaques suivant des schémas d'attaque définis dans leur base de connaissances. Lescaractéristiques clés des agents intelligents (AI) utilisées dans ce système sont la délégation, la coopérationet la communication. Cependant, une propriété importante des AI, qui est leur capacité d'apprentissage, n'apas été utilisée. Cette caractéristique nous paraît idéale pour détecter de nouvelles attaques. C'est pour cetteraison que nous nous proposons d'étendre cet IDS multi-agents en lui ajoutant la fonction d'apprentissage denouveaux schémas d'attaque.
L'objectif de ce travail est donc de concevoir d'un modèle permettant la détection d'attaques inconnues pourle système à base d'agents existant.
Nous commencerons par un état de l'art sur la détection d'intrusions. Puis, nous présenterons une techniqueparticulière permettant l'extraction et la classification de données pertinentes, issues de fichiers d'audit, pourla détection d'intrusions : le Data Mining. Ensuite, nous étudierons une seconde technique, dite"Raisonnement à Base de Cas" ("Case Based Reasoning"), technique qui nous semble intéressante dansl'apprentissage de nouvelles attaques. Enfin, nous décrirons notre modèle fondé sur le CBR pour la détectiond'intrusions inconnues. Finalement, nous terminerons par une conclusion et quelques remarques sur lestravaux futurs.
2/28

2. État de l'art
Une intrusion peut être définie comme tout ensemble d'actions qui essaye de compromettre :
● la confidentialité des données,● l'intégrité des données,● la disponibilité d'une ressource ou d'un service.
En dépit des différentes formes d'intrusion, elles peuvent être regroupées dans deux classes :
● les intrusions connues● les intrusions inconnues ou anomalies.
Dans le cadre de ce travail, nous nous intéresserons à la détection de ces deux types d'intrusions.
2.1 La détection d'intrusions
La détection d'intrusions fait référence à la capacité d'un système informatique de déterminerautomatiquement, à partir d'événements relevant de la sécurité, qu'une violation de sécurité se produit ous'est produite dans le passé. Pour ce faire, la détection d'intrusions nécessite qu'un grand nombred'événements de sécurité soient collectés et enregistrés afin d'être analysés. On parle alors d'audit desécurité.Les systèmes de détection d'intrusion (IDS) actuels reposent sur des techniques diverses et variées. Danscette section, nous présentons une classification de haut niveau de ces techniques.
Les systèmes de détection d'intrusions sont divisés en deux catégories, suivant l'approche utilisée, qui peutêtre ([21]) :
● soit une approche par scénarios.● soit une approche comportementale.● soit hybride (i.e. un mixte des deux approches)
Les approches par scénarios se basent sur le fait que toute attaque connue produit une trace spécifique dansles enregistrements d'audit. Elles nécessitent une connaissance a priori des attaques à détecter : une alarmeest émise lorsque la trace d'une attaque connue est détectée. Les approches par scénarios utilisent destechniques différentes, dont les principales sont :
● les techniques à base de règle (i.e. les systèmes experts). La base de connaissances des systèmesexperts contient des règles concernant non seulement les scénarios d'attaque que l'on veutdétecter sur le système cible, mais aussi les vulnérabilités connues de ce système. La constructionde cette base repose entièrement sur l'expérience et le savoir faire de l'officier de sécurité.
● les approches fondées sur la signature des attaques essayent de représenter les attaques sousforme de signatures. Les données courantes sont alors comparées à ces signatures. S'il y a dessimilitudes, une alarme est déclenchée.
● et les algorithmes génétiques, utilisés afin d'optimiser la recherche de scénarios d'attaque dansdes fichiers d'audit ([20]). Leur utilisation permet d'éviter une recherche exhaustive ensélectionnant les meilleurs éléments d'une population (ici les scénarios d'attaque).
L'approche comportementale vise à modéliser ou à prédire le comportement normal : cette approchenécessite une phase d'apprentissage proprement dite durant laquelle les cas de références, représentant leprofil normal, sont construits. Une alarme est émise quand une déviation trop importante de ce profil estobservée.Pour modéliser le profil normal, les approches comportementales utilisent :
3/28

● soit des modèles statistiques qui consistent à utiliser des mesures statistiques pour modéliser unprofil de comportement et détecter ensuite des comportements intrusifs. Chacune des ces mesuresest associée à un seuil ou à un intervalle de valeurs, dans lequel une activité est considéréecomme normale. Tout dépassement de seuil ou situation de valeurs à l'extérieur des bornes del'intervalle indique une activité anormale,
● soit des systèmes experts. La différence majeure entre un système expert et un modèlestatistique est que ce dernier utilise des formules statistiques pour identifier des comportementsdans les données d'audit alors que le système expert utilise un ensemble de règles pourreprésenter ces comportements.
Les approches comportementale prédisant le profil normal peuvent, quant à elles, reposer sur :
● des générateurs de forme prédictive. Cette approche prédit les formes les plus probables en sebasant sur les formes observées. Durant la phase d'apprentissage, cette approche détermine desrègles temporelles qui caractérisent le comportement normal des utilisateurs.
● ou des réseaux de neurones. Un réseau de neurones est constitué de plusieurs éléments detraitement simples appelés unités et qui interagissent en utilisant des connections pondérées. Leréseau constitue le profil normal d'un utilisateur. Ainsi, après chaque commande utilisée par cetutilisateur, le réseau essaye de prédire la commande suivante, en tenant compte des n commandesantérieures. Si la commande réelle dévie de celle prédite, alors une alarme est envoyée.
Quelle que soit l'approche choisie (comportementale, par scénarios ou hybride), tous les IDS se trouventconfrontés au problème de la détection de nouvelles attaques, plus précisément à la détection d'attaquesinconnues. Les systèmes fondés sur une approche par scénarios, ne peuvent, a priori, détecter que desattaques connues : la détection de nouvelles attaques pour eux consiste en la mise à jour de leur base deconnaissance (à la manière des logiciels antivirus). L'approche comportementale, quant à elle, permeteffectivement de détecter des attaques inconnues, puisque toutes les attaques constituent une déviation vis àvis de leur comportement normale de référence.
Au delà du problème de la détection de nouvelles attaques, tous les IDS existants (encore une fois, quelleque soit l'approche sur laquelle ils reposent) sont soumis aux problèmes de l'extraction et surtout de laclassification de données pertinentes d'un large volume de donnée diverses ([13]). Ce volume et cette variétépeuvent se justifier par ([9]) :
● l'augmentation du nombre d'attaques ainsi que la taille des journaux d'audits manipulés (quicontiennent de plus en plus d'événements), augmentations liées à celle des débits des réseaux,
● l'éventail d'IDS (propriétaires ou non) utilisant chacun leurs techniques et données propres parmanque de standard reconnu.
Une des techniques les plus populaires à l'heure actuelle est celle du Data Mining, que nous allonsexpliciter dans la partie suivante.
2.2 Le Data Mining et la classification de données d'audit
D'après Dary Alexandra Pena Maldonado ([9]), le Data Mining (DM) est une technique permettant deretrouver des corrélations d'attributs entre éléments d'un même jeu de données, pour caractériser uncomportement spécifique, mais autorisant également la construction de règles à des fins de classification.Pour Wenke Lee & Al. ([18]), le DM est un processus chargé d'extraire automatiquement un modèle d'unlarge ensemble de données. Les auteurs distinguent différent types d'algorithmes de DM :
● Classification : permet de déterminer l'appartenance d'un élément à une catégorie prédéfinie.● Analyse de lien : permet de déterminer les relations entres différentes caractéristiques d'une base
de données, afin de conseiller le meilleur jeu de caractéristiques pour la détection d'intrusions.
4/28

● Analyse de séquence : autorise la recherche, dans une séquence d'événements, de schémascaractéristiques, afin de définir le comportement normal.
Le DM peut être utilisé quelque soit le type de stratégie sur lequel repose le système de détectiond'intrusions, comme nous allons le voir dans les paragraphes ci-dessous.
2.2.1 Le Data Mining dans les approches par scénarios
Le protocole utilisé dans cette approche est le suivant :Il faut tout d'abord prendre un vaste jeu de données dont les entrées sont étiquetées comme étant desactivités normales ou anormales. Le Data Mining intervient à travers l'utilisation d'un logiciel de création derègles comme RIPPER ([19]) : A partir du jeu de données, des règles précises sont générées permettant decaractériser une activité, caractérisation normale ou anormale.Deux exemples populaires d'une telle approche sont :
● Le projet "Automated Discovery of Concise Predictive Rules for Intrusion détection" de Helmer& Al ([12] plus agents [10] [11]), qui utilise la technique suivante : RIPPER est lancé sur un jeude données d'entraînement étiqueté (i.e. les attaques sont identifiées). Cet algorithme génèreensuite des règles de classification pour la classe comprenant le moins d'éléments. Illustrons celapar un exemple. Soit V un vecteur d'événements inconnus à classifier. Si dans le jeud'entraînement, il y a moins d'attaques que d'événements normaux, les règles généréesressemblent à :
Si caractéristique no1 de V > xalors V est une attaque
Si (caractéristique no2 de V > y et caractéristique no5 de V <> 3)alors V est une attaque
...Sinon
V n'est pas une attaque.
Illustration 1: Un exemple de règles générées par RIPPER
Ceci reste une utilisation classique de RIPPER, mais ce projet est néanmoins très intéressant de parl'utilisation de plusieurs techniques conjointes (tel que RIPPER et les algorithmes génétiques parexemple).
● Le projet JAM – Java Agent For Metalearning ([18][17][16]), qui utilise une approchenécessitant le calcul d'un profil issu de données étiquetées durant une phase d'apprentissage. Unalgorithme d'apprentissage est ensuite utilisé pour classifier des événements inconnus. Ce projetprésente un caractère original car le système JAM est indépendant de l'algorithmed'apprentissage. Les algorithme RIPPER, Bayes et Wpebls sont inclus nativement dans lesystème, mais n'importe quel autre algorithme peut être utilisé via un système de plugin. Pourplus de détails sur les résultats de ce projet, voir [15].
2.2.2 Le Data Mining dans les approches comportementales
Dans les approches comportementales, le DM est utilisé sur un jeu de données enregistrées durant uneutilisation normale du système lors d'une phase dédiée d'apprentissage (contrairement à l'approcheprécédente, les données ne sont pas étiquetées suivant leur nature - normale ou anormale - ) . L'utilisation duDM permet de construire le profil normal utilisé pour l'observation de déviations par rapport à ce profil, afinde caractériser les attaques.
5/28

Deux exemples d'une telle approche sont :
● Le projet ADAM – Audit Data Analysis and Meaning ([8]) qui utilise une combinaison de règlesd'association et de classification pour découvrir des attaques dans des fichiers d'audit du logicielTCPdump. ADAM construit tout d'abord un profil normal à partir de ces fichiers d'auditenregistrés durant une période ne comprenant pas d'attaques. Ensuite, un algorithme est lancé surun jeu de données à tester afin de retirer toutes les traces d'un comportement normal, ceci à l'aidedu profil normal construit précédemment. Finalement, un dernier algorithme spécialemententraîné à la classification des attaques est lancé sur les données restantes, les classifiant enattaques connues, attaques inconnues et fausses alarmes.
● Le projet "Intrusion Detection with Unlabeled Data Using Clustering" de Leonid Portnoy ([14])qui définit un framework permettant de détecter des attaques inconnues nécessitant uniquementun jeu de données non étiqueté durant la phase d'apprentissage. Les données brutes nonidentifiées sont agrégées en clusters, puis le cluster contenant le plus d'éléments est étiqueté"normal", les autres clusters étant étiquetés "anormaux". Lorsqu'un événement inconnu estsoumis au système, un algorithme détermine à quel cluster appartient l'événement avec descalculs de distance euclidienne.
2.2.3 La nécessité d'une autre approche
Pour conclure, le Data Mining est une approche très performante dans le domaine de la détectiond'intrusions, et sa popularité caractérise bien l'engouement que les chercheurs ont eu pour lui. Néanmoins,deux points importants peuvent entraver son utilisation :
● Dans une approche par scénarios, l'obligation de posséder un jeu de données comprenant à la foisdes attaques (true positive) et à la fois des événements normaux (true negative).
● Dans une approche comportementale, la nécessité de consacrer une phase d'apprentissage dédiéeà la création d'un profil normal.
Ces deux points nous ont poussé a chercher une autre approche que le Data Mining, recherche qui nous aconduit aux Modèles de Raisonnement à Base de Cas, dit "Case-Based Reasoning Models", que nousdécrivons dans la section suivante.
2.3 Le Case-Based Reasoning
Comme le définissent Aamodt & Plaza ([3]), "Le Case-Based Reasonning (CBR), est une approche capabled'utiliser la connaissance spécifique de problèmes (cas) s'étant déjà produits dans le passé pour répondre àde nouveaux problèmes. Un nouveau problème est résolu en cherchant un cas passé similaire, et enréutilisant sa solution dans le problème présent."
Cette définition montre que le CBR est un algorithme très naturel : en tant qu'être humain, lorsqu'unproblème se pose, l'idée première est de rechercher si ce problème (ou un cas similaire) s'est déjà produit, et,le cas échéant, reprendre la solution passée pour essayer de l'adapter au problème présent.
6/28

De part la généralité de son algorithme, le Case-Based Reasoning a été utilisé dans des domaines variés, etnombreux sont les systèmes se fondant sur cette technique : CASEY, PROTOS, PATDEX ([7]), CREEK etCHROMA ([6]) pour ne citer que les plus connus.
● PROTOS est un système de CBR développé pour aider au diagnostique des malentendants. Unproblème est présenté à PROTOS comme un vecteur de caractéristiques, et la tâche du systèmeest de retrouver le cas passé qui correspond le plus au vecteur. La solution d'un problème passéest proposée comme solution au problème présent, sans adaptation (pas de REVISE). Si lasolution est refusée par l'utilisateur, une étape d'apprentissage commence : PROTOS peut alorsrechercher une autre solution, ou accepter une solution de l'utilisateur. Dans ce cas, l'utilisateurest obligé de définir les termes entrés dans le système qui sont inconnus de PROTOS, endécrivant leur relation avec les termes existants. Cette phase permet de construire laconnaissance générale du système. Si le problème a été résolu tout de suite, le système renforce(par pondération) les caractéristiques ayant permit la résolution. Parallèlement, si le problèmen'est résolu qu'en seconde étape, PROTOS affaiblit les caractéristiques fautives. L'originalité dePROTOS tient au fait que son apprentissage repose sur l'utilisateur.
● CASEY est un système de CBR développé pour aider au diagnostique de problèmes cardiaques.Un problème présenté à ce système est résolu en recherchant un cas, et, contrairement àPROTOS, en adaptant la solution passée au problème présent. Chaque cas contient uneexplication causale qui lie les caractéristiques au diagnostique (i.e. la solution). CASEY apprendtoujours de la résolution d'un problème : le nouveau cas est enregistré s'il possède descaractéristiques suffisamment différentes du cas de référence recherché. Si le cas de référence estidentique au problème présent, les informations définissant l'importance de ses caractéristiquessont mises à jour. Le problème majeur de CASEY est son absence d'interaction avec l'utilisateur(c'est, en quelque sorte, un monde fermé).
● CHROMA est un système utilisé pour choisir les techniques de chromatographie utilisées dans lapurification de protéines issues de cultures. Ce système se focalise plus précisément sur lacoopération dans un CBR distribué. Chaque agent dispose de connaissances propres sur les caspassés. Les auteurs identifient deux formes de CBR : le Distributed CBR (DistCBR) et leCollective CBR (ColCBR). Dans le premier cas, le problème posé à un agent A est transmit par
7/28
Illustration 2: Les principales étapes d'unalgorithme de CBR

celui-ci à un autre agent B. Ainsi, la méthode de CBR utilisée sera celle de B. De manièregénérale, un problème soumis au CBR est distribué à tous les agents qui utilisent ensuite leurspropres méthodes pour sa résolution. Dans le cas du ColCBR, lorsque A transmet le problème, iltransmet également sa méthode à B (ainsi, la méthode de A sera utilisée avec la connaissance deB). Autrement dit, l'émetteur utilise les mémoires de cas des autres agents : il s'agit, en quelquesorte, d'une mémoire collective.
Il existe de nombreux documents traitant des optimisations de l'algorithme et plus particulièrement :
● de l'organisation des données dans la base de cas ([2] et [3]).● de l'algorithme de similarité utilisé dans le meilleur cas ([5] et [4])● de l'utilisation de connaissances pour effectuer une analyse sémantique lors du RETRIEVE et du
RETAIN (voir l'Illustration 2) au lieu de l'analyse syntaxique traditionnellement utilisée [1].
2.4 Conclusion
Pour conclure, le Case-Based Reasoning est un modèle d'apprentissage qui pourrait se substituer au DataMining dans notre domaine de recherche, et, à notre connaissance, cette approche n'a jamais été appliquéedans la détection d'intrusions. Dans le cadre de ce travail nous nous proposons d'intégrer dans un IDS à based'agents intelligents existant (décrit dans la section suivante) un modèle fondé sur le CBR pour la détectiond'attaques inconnues. Ce modèle est décrit dans la section 4.
8/28

3. Système de détections d'intrusion base d'agentsintelligents.
Le système multi-agents existant est complètement décrit dans [21], mais nous allons cependant présenterles principales caractéristiques ayant un rapport avec notre modèle. En particulier, nous décrirons le modèleorganisationnel du système multi-agents, ainsi que son modèle événementiel.
3.1 Le modèle organisationnel
Les caractéristiques clés de ce système de détection d’intrusions à base d’agents sont : l’autonomie, ladistribution, la coopération, l’adaptabilité et la flexibilité. Dans ce système, les agents intelligents, localisésdans des entités spécifiques du réseau, sont organisés de manière hiérarchique (voir Illustration 3) dans deuxcouches : une couche gestionnaire et une couche locale.
La couche gestionnaire gère la sécurité globale d’un réseau. Dans cette couche, il existe trois niveauxd’agents : l’agent gestionnaire de politiques de sécurité, l’agent gestionnaire extranet et des agentsgestionnaires intranet.
L'agent gestionnaire de politique de sécurité à pour rôle d'assurer les fonctions suivantes :● dialogue avec l'administrateur pour la spécification des politiques de sécurité.● gestion des politiques de sécurité (création, mise à jour, activation, ...).● instanciation des schémas d'attaque et transmission des buts aux entités du niveau inférieur, i.e
les agents gestionnaires extranet.
Le gestionnaire extranet a une vue globale du réseau d'entreprise, et remplit les fonctions suivantes :● réception des buts du niveau supérieur.● détection des attaques globales et coordonnées.● distribution des attaques aux entités distribuées du niveau inférieur.
Le gestionnaire intranet remplit la même fonction que le gestionnaire extranet, mais du point de vue localdu réseau d'entreprise.
La couche locale gère la sécurité d’un domaine, composé d’un sous-ensemble de machines dans un réseaulocal. Cette couche contient un seul niveau d’agents qui sont les agents surveillants locaux et qui ont pourfonction la détection des schémas d’attaque.
9/28
Illustration 3: Le modèle organisationnel du système existant
Surveillant local
Gestionnaire intranet
Administrateur Gestionnaire de politiquede sécurité
Gestionnaire extranet
Dépendance hiérarchiqueReports

Dans ce modèle multi-agents hiérarchique, chaque agent gestionnaire a la capacité de contrôler des agentsspécifiques et d’analyser des données, alors que les agents surveillants locaux ont pour mission de surveillerdes activités spécifiques. A chaque niveau, les agents communiquent et s’échangent leurs connaissances etanalyses afin de détecter les activités intrusives de manière coopérative.
3.2 Le modèle événementiel.
Dans cette section, nous décrivons le modèle événementiel du système existant, i.e. la manière dont lesévénements sont filtrés suivant les schémas d'attaques reçus par les agents.
Le modèle événementiel se décompose en trois étapes simples :
● filtrer les événements à l'aide de critères définis par les schémas d'attaques,● regrouper les événements filtrés à partir des schémas d'attaque pour construire des suites d'événements
corrélés, i.e. agréger les événements identiques avec des opérateurs d'occurrence par exemple,● analyser les suites d'événements corrélés pour identifier des schémas d'attaque.
3.3 Conclusion sur le système existant.
Le système que nous venons de décrire ne permet de détecter que des attaques connues. L'objectif de cetravail est donc d'enrichir ce système avec un modèle fondé sur le CBR pour :
● obtenir de nouveaux événements à analyser,● détecter à partir de ces événements des attaques inconnues,● mettre à jour automatiquement les politiques de sécurité pour prendre en compte les nouvelles
attaques détectées.
Ce modèle est décrit dans la section suivante.
10/28
Illustration 4: Le modèle événementiel du système existant
Suite S1
E1 E2…………………………………………………………...…….…Em
Filtres d ’événements
Fenêtre temporelle d ’observation
M1 M2…………………………………………………………………Mn
Messages
Evénements
Suites d ’événementsSuite S2 Suite SpSuite Si
Filtrage
Regroupement
……….
Schémas d ’attaque
Modèle conceptuel de données
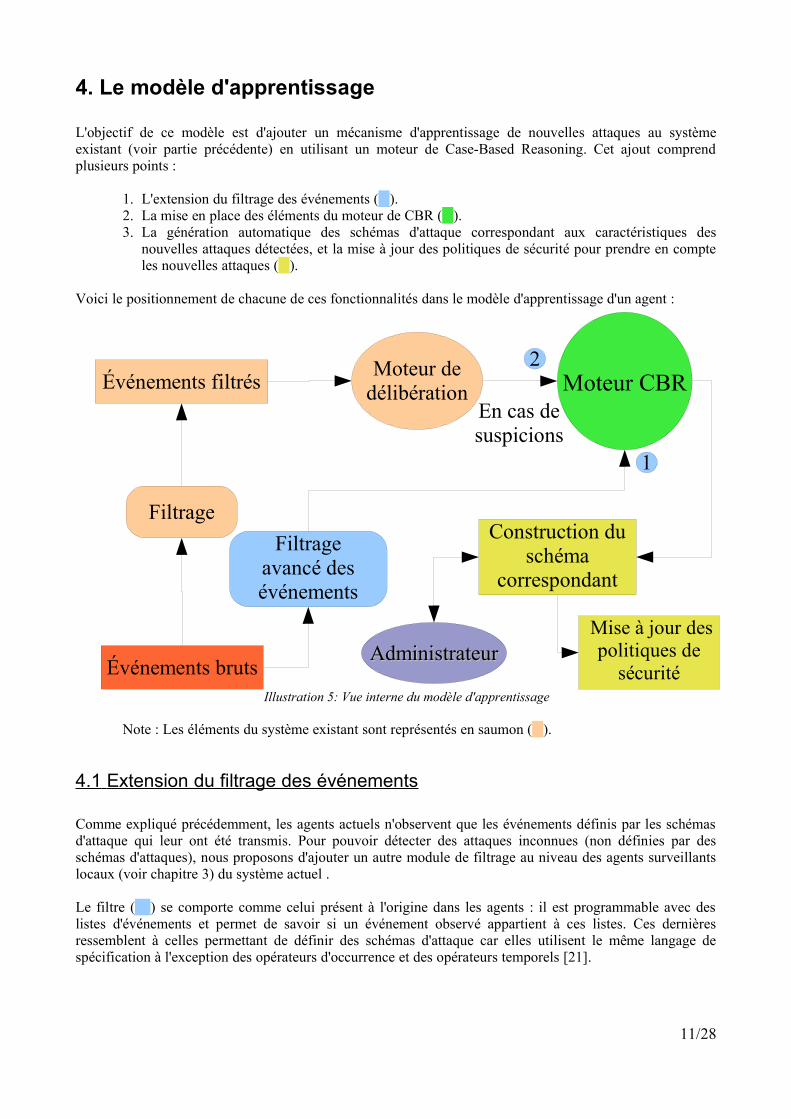
4. Le modèle d'apprentissage
L'objectif de ce modèle est d'ajouter un mécanisme d'apprentissage de nouvelles attaques au systèmeexistant (voir partie précédente) en utilisant un moteur de Case-Based Reasoning. Cet ajout comprendplusieurs points :
1. L'extension du filtrage des événements ( ).2. La mise en place des éléments du moteur de CBR ( ).3. La génération automatique des schémas d'attaque correspondant aux caractéristiques des
nouvelles attaques détectées, et la mise à jour des politiques de sécurité pour prendre en compteles nouvelles attaques ( ).
Voici le positionnement de chacune de ces fonctionnalités dans le modèle d'apprentissage d'un agent :
Note : Les éléments du système existant sont représentés en saumon ( ).
4.1 Extension du filtrage des événements
Comme expliqué précédemment, les agents actuels n'observent que les événements définis par les schémasd'attaque qui leur ont été transmis. Pour pouvoir détecter des attaques inconnues (non définies par desschémas d'attaques), nous proposons d'ajouter un autre module de filtrage au niveau des agents surveillantslocaux (voir chapitre 3) du système actuel .
Le filtre ( ) se comporte comme celui présent à l'origine dans les agents : il est programmable avec deslistes d'événements et permet de savoir si un événement observé appartient à ces listes. Ces dernièresressemblent à celles permettant de définir des schémas d'attaque car elles utilisent le même langage despécification à l'exception des opérateurs d'occurrence et des opérateurs temporels [21].
11/28
Illustration 5: Vue interne du modèle d'apprentissage
Filtrage avancé des événements
Événements filtrés
Événements bruts
Filtrage
Moteur de délibération
En cas de suspicions
Moteur CBR
1
2
AdministrateurAdministrateur Mise à jour des
politiques de sécurité
Construction du schéma
correspondant

4.2 Mise en place des éléments du moteur de CBR.
A présent, nous disposons de nouveaux événements à analyser, et nous désirons les soumettre au moteur deCase-Based Reasoning. Pour cela, il faut identifier tous les éléments intervenant dans l'algorithme ainsi quetoutes les étapes de cet algorithme.
4.2.1 Notre algorithme de Case-Based Reasoning
Voici les étapes effectuées par le moteur de délibération du CBR (en ( ) sur l'Illustration 5) lors de lasoumission d'une suite suspicieuse d'événements :
● La suite est traitée par un préprocesseur (non présenté sur le schéma) qui va positionner lesopérateurs d'occurrence sur les éléments de la suite (i.e. agréger les événements identiques)
● A l'aide d'une fonction de similarité, le cas le plus similaire est recherché dans une base de cas(appelée mémoire dans la terminologie du Case-Based Reasoning), contenant des attaques (i.e.des suites d'événements passés, identifiées comme attaques) : c'est le Retrieve.
● Si le taux de similarité est trop faible entre le meilleur cas et la suite suspicieuse, lesystème peut : soit ignorer la suite, soit demander l'avis de l'administrateur (choisir lemeilleur cas tout seul, ignorer la suite ou certifier que la suite est une attaque – et passerà l'étape suivante – ).
● Si la suite suspicieuse est une attaque, un nouveau cas correspondant à cette attaque est ajoutédans la mémoire et la suite d'événements est passée au module suivant qui va générer le schémad'attaque correspondant.
Nous devons à présent définir le coeur du système, i.e. La fonction de similarité qui va nousrenvoyer le meilleur cas.
12/28
Illustration 6: Le moteur de délibération du CBR
Suite suspicieuse d'événements
Recherche du meilleur cas (Retrieve)
Enregistrement du nouveau cas (Retain)
AdministrateurAdministrateur Mémoire des cas

4.2.2 La Fonction de similarité
L'objectif de cette fonction est, à partir d'une suite d'événements suspicieuse et d'une base de cas contenantdes attaques (sous forme de suite d'événements), de trouver l'attaque ressemblant le plus à la séquenceobservée. Cette recherche va évaluer la ressemblance entre la séquence à tester et chaque séquence deréférence. Toutes ces séquences sont sous la forme d'une suite d'événements, forme comprenant en plus lesopérateurs d'occurrence et de séquence utilisés de la manière suivante :
• l'opérateur d'occurrence permet d'agréger plusieurs éléments identiques consécutifs.• l'opérateur de séquence permet de définir si l'ordre temporel des événements est
caractéristique de ces derniers.Pour plus d'informations sur ces opérateurs, ainsi que sur le langage permettant de les décrire, consulter[21], page 74, section 4.3.1.2.
Avant de commencer à décrire la fonction de similarité, regardons les classes définissant les événements desécurité :
Nous nous rendons compte qu'un événement peut être vu à plusieurs niveaux : • Le niveau 0, le plus élevé, où l'événement est vu comme un GenericSecurityEvent.
13/28
Illustration 7: Les classes d'événements de sécurité

• Le niveau 1, où l'événement est considéré, suivant sa nature, comme un AuditEvent ou unNetworkEvent.
• Le niveau 2, dernier niveau, où l'on s'intéresse aux sous-classes des éléments de niveau 1.
De part la nature des objets à comparer, nous allons subdiviser le problème de l'étude de la similarité dedeux suites d'événements en plusieurs étapes :
• Le calcul de la similarité de deux classes de niveau 0, appelé "comparaison de base".• La prise en compte de la similarité des classes de niveau 1 et 2, qui sera analysée lors de la
"comparaison avancée".• Puis le calcul final de la similarité des deux suites d'événements, i.e. "la comparaison
finale".
4.2.2.1 Les bases de la fonction de similarité
L'algorithme que nous nous proposons d'utiliser, pour écrire cette fonction, est l'algorithme le plus simplepossible existant dans le Case-Based Reasoning : CBL1 (Case-Based Learning) [4] [5]. Cet algorithme esttrès basique et il existe de nombreuses améliorations dont nous ne discuterons pas ici (mais qui constituentdes possibilités d'extension du système).Voici CBL1, définissant la similarité des cas C1 et C2 :
avec P un vecteur de caractéristiques et
Ainsi, la similarité de deux cas correspond à l'inverse de la distance euclidienne des caractéristiquesnumériques et utilise un simple test de correspondance pour les caractéristiques discrètes. Pour éviter que lescaractéristiques numériques prennent plus d'importance que les autres caractéristiques, nous avons lapossibilité :
● de normaliser linéairement toutes les caractéristiques numériques (via l'utilisation d'unpréprocesseur)
● ou alors, de pondérer chaque caractéristique à l'aide d'un coefficient.
En utilisant la deuxième solution, notre fonction de calcul de la similarité devient :
4.2.2.1.a Espace de valeur de la fonction de similarité
Nous nous intéressons maintenant aux valeurs que peut prendre la fonction de similarité, si toutes lescaractéristiques sont discrètes. Pourquoi considérer seulement ce cas ? La majorité des caractéristiquesdes nos suites d'événements sont discrètes (à une ou deux exception près), et dans la mesure du possible,
14/28
Feature _ dissimilarity C1i,C 2i
= {C1i−C 21
2 Si la caractéristique i est numérique0 Si la caractéristique i est discrète et C1i
=C 2i
1 Sinon2
Similarity C1, C 2, P = 1
∑i∈Pw i⋅Feature _ dissimilarity C 1i
,C 2i
3
avec ∑i∈P
wi = 1, 0wi≤1
SimilarityCBL1C1, C 2, P = 1
∑i∈PFeature _ dissimilarity C1i
,C 21
1

nous souhaitons éviter les caractéristiques numériques, notamment à cause de leur variation importante encas de dissimilarité.Nous remarquons tout d'abord que si les cas sont similaires en tout point, la fonction de similarité tendravers l'infini. Laissons ce cas quelque peu spécial de côté, et intéressons nous aux extremums de la fonction.
Proposition : la valeur de retour de la fonction de similarité est comprise entre :
Démonstration : la similarité entre deux cas augmente lorsque la distance entre ceux-ci diminue. Lorsque lesdeux cas sont totalement différents, (2) vaut 1 pour toutes les caractéristiques des cas, (3) devient :
d'où la borne inférieure de l'intervalle. Lorsque deux cas, sont très très similaires ("i.e. le plus similaire possible sans être égaux"), cela revient àdire que seule la caractéristique ayant le moins d'importance est différente. La caractéristique la plus faiblecorrespond au coefficient w minimal (noté wmin). (3) devient :
CQFD.
Néanmoins, un problème reste posé : cette espace de valeur n'est pas fixe, i.e. la borne supérieure dépend ducoefficient de pondération le plus faible. Pour cela, nous définissons une nouvelle fonction, qui ramène lesvaleurs de l'intervalle (4), dans [1, 2]. Pour cela, nous appliquons une simple fonction linéaire :
Pourquoi avoir choisit [1, 2] ? Ces valeurs sont totalement arbitraires mais il était nécessaire de fixer unordre de grandeur comme nous le verrons plus tard. Nous verrons également pourquoi cet intervalle nepouvait pas être [0, 1].
4.2.2.1.b Comparaison de base
La comparaison de base se charge de calculer la similarité entre deux événements en considérant cesévénements comme des GenericSecurityEvent. Pour cela, il faut tout d'abord identifier quellecaractéristiques de cette classe vont servir à la comparaison. Voici les membres de cette classe que nousavons retenu (voir Illustration 7: Les classes d'événements de sécurité) :
● EventType qui indique s'il s'agit d'un message réseau, d'une commande système, d'uneconnection ou d'un fichier.
● EventName qui contient le nom de la commande ou du service UDP/TCP utilisé.● EventSource qui précise la source de l'événement sous la forme d'une adresse IP.● EventDestination parallèlement concerne la cible de l'événement.● EventResult, qui permet de savoir le résultat de l'événement (en terme de succès/échec, mais
aussi en terme de légitimité de l'action).
Maintenant que ces caractéristiques ont été isolées, il faut à présent leur accorder un poids : pour cela, nous
15/28
1
∑i∈Pwi
=3 1
1 wmin
car wi = 0 pour tout wi≠wmin
[1, 1 wmin ] où wmin = Min wi 4
Nouvel _ Intervalle N , wmin = N⋅ wmin
1 −wmin
1−2 ⋅wmin
1−wmin
5
où N est une valeur dans [1, 1 wmin
]

devons garder à l'esprit que ce poids sanctionne la non similarité des caractéristiques. Ainsi, EventType etEventName sont pour nous des attributs très importants pour définir la dissimilarité de deux cas.Parallèlement, la différence des adresses sources ou destinations n'as pas réellement de poids dans lacomparaison : ces données ne permettent pas de définir une attaque (puisque l'attaque peut survenirdepuis/vers n'importe quel poste). Si les adresses sont identiques, la comparaison "récompensera" cetteattribut en renvoyant 0 (via la fonction (2)), dans le cas contraire, le score final ne sera pas affecté par cettedifférence.
Voici le vecteur de poids w que nous proposons pour les caractéristiques respectives {EventType,EventName, EventSource, EventDest, EventResult} :
Tous les paramètres de la comparaison de base sont à présent définis : deux GenericSecurityEvent, C1 et C2sont comparés grâce à la fonction Similarity (voir (3)), suivant les caractéristiques énoncées plus haut et lapondération w (6). Le résultat est un nombre décimal à ramener dans l'intervalle [1, 2], via la fonctionNouvel_Intervalle (voir (5)).
4.2.2.2 Comparaison avancée.
La comparaison avancée rajoute l'information des classes de niveaux 1 et 2 à la comparaison de base. L'idéeprincipale ici est de descendre dans la hiérarchie des classes et d'ajuster la similarité suivant la nature desobjets comparés.
Voici donc la fonction effectuant la comparaison avancée :
La moyenne harmonique de deux valeurs étant définit ainsi :
L'utilisation de la moyenne harmonique se justifie par le fait que les fonctions de calcul de similaritérenvoient des inverses de distance. Si nous avions utilisé une moyenne arithmétique, quel sens donner à unemoyenne d'inverse de distance ? La moyenne harmonique calcule la moyenne des distances, puis renvoil'inverse de cette moyenne : c'est un inverse de moyenne de distance, dont la signification paraît plusnaturelle. Néanmoins, l'utilisation de cette fonction nous empêche d'autoriser les fonctions de calcul desimilarité à renvoyer une valeur nulle, d'où l'intervalle choisit : [1, 2].
Avant de définir Similarity2, remarquons tout d'abord que les classes de niveau 1 (AuditEvent etNetworkEvent) n'ont toutes deux qu'une seule caractéristique, respectivement UserName et ProtocolType(voir Illustration 7: Les classes d'événements de sécurité). Nous arrivons donc à cette définition :Soit
16/28
w={1 3
, 1 3
, 1 12
, 1 12
, 1 6} 6
MoyHarmoniqueA , B = 1
MoyArithmétique 1 A
, 1 B
9
Similarity Avancée C 1, C 2 = MoyHarmoniqueSimilarity1C 1, C 2, P , Similarity2C 1, C 2, P ' 7
avec Similarity1C1, C 2, P = Nouvel _ Intervalle Similarity C 1, C 2, P , wmin 8

Nous remarquons que Similarity2 est une fonction récursive à deux niveaux : au premier (resp. deuxième)niveau elle compare des classes de niveau 1 (resp. 2). Quel que soit le niveau, si les cas ne sont pas de mêmeclasse, alors ils n'ont certainement pas des caractéristiques similaires, d'où la valeur la plus faible surl'intervalle [1, 2].
Lorsque Similarity2 compare des classes de niveau 2, elle effectue juste un simple calcul de similarité, enramenant la valeur de retour sur [1, 2] (via (8)), en lui ajoutant une constante P3 et en majorant le résultat parla valeur maximale de similarité, 2. Voici les caractéristiques retenues pour les classes de niveau 2, ainsi que leur pondérations (voir (3))proposées respectives :
La comparaison de niveau 1 est un peu spéciale parce que, comme expliqué précédemment, les classes deniveau 1 n'ont qu'une seule caractéristique. Suivant la similarité de cette caractéristique, une constante d'unecertaine valeur est ajoutée, et un appel récursif est effectué pour calculer la similarité des cas C1 et C2 en lesconsidérant comme des instances de classe de niveau 2.
Les constantes Pi sont présentes pour rappeler le fait que les objets comparés sont de classes identiques(donc que leur similarité est un peu plus élevée), même si leurs caractéristiques ne sont pas similaires. Voiciune proposition pour les Pi :
Notons que P1 est plus élevé car il doit refléter que la caractéristique de niveau 2 est similaire pour les deuxcas.
Avant de conclure sur le calcul de la similarité de suite d'événements, intéressons nous au cas où, à
17/28
P i∈[1, 2]avec P1 P2 ~ P3
Sc A=Avue comme une sous - classe de niveau 2
[FileEvent={FileName 0.375 , FileType 0.25 , FileAccessType 0.375}FileSystem={UsedCPURate 0.5 , MemOccupationRate 0.5}ConnectionEvent={Endtime 0.5 , Duration 0.5}ICMPEvent={ICMPType 0.5 , ICMPCode 0.5}TCPEvent={TCPSquenceNumber 0.5 , AcknowledgeNumber 0.5}UDPEvent {SourcePort 0.25 , DestinationPort 0.75}
] 11
P={0.5, 0 .15, 0 .15} 12
Similarity2C 1i,C 2i
= {1 si C1 et C 2 ne sont pas de la même classe (de niveau 1 ou 2)
Si C1 et C 2 sont de niveau 1 :
Max [2, P1 Similarity2 Sc C1 , Sc C 2] , si C1 . cara=C 2 .caraMax [2, P2 Similarity2 Sc C 1 , Sc C 2] , si C1 . cara≠C 2 . cara
Si C1 et C 2 sont de niveau 2 :
Max [2, P3 Similarity1 C 1, C 2]
10

n'importe quel niveau de la comparaison, deux cas parfaitement identiques sont découverts. Dans cettesituation, la fonction (3) diverge vers l'infini et donc toute la récursivité de la fonction (9) est écrasée parcette valeur, même si en amont, les cas ne sont pas similaires. Pour cela, nous considérons que si unesimilarité parfaite est découverte, nous remplaçons l'infini par la valeur maximal sur l'intervalle [1, 2], i.e. 2(ce remplacement ne figure pas dans la définition de la fonction, afin d'alléger la notation). Cela revient àfaire une approximation, puisque nous "oublions" qu'une telle similarité a été découverte, mais cetteapproximation est négligeable devant les autres paramètres du système (tels que les coefficients depondération ou les Pi).
A ce point de l'étude de la fonction de similarité, nous pouvons parfaitement comparer deux événements etcalculer leur similarité sur l'intervalle [1, 2]. Nous nous intéressons maintenant à la comparaison finale.
4.2.2.3 Comparaison finale.
Comme expliqué précédemment, la comparaison finale permet, à partir d'une base de cas contenant desattaques (sous la forme d'une suite d'événements) de chercher le cas de référence le plus similaire à une suited'événements suspicieuse donnée. Cette recherche doit prendre en compte deux opérateurs présents dans lesdeux suites :
• l'opérateur d'occurrence qui permet d'agréger plusieurs éléments identiques consécutifs.• l'opérateur de séquence qui permet de définir si l'ordre temporel des événements est
caractéristique de ces derniers.
4.2.2.3.a Algorithme de base.
Avant d'effectuer la comparaison finale, nous devons tout d'abord définir la comparaison de deux suitesd'événements. Soit C2 le cas de référence. Subdivisons les cas ainsi :
4.2.2.3.b Cas où l'ordre temporel n'est pas présent
18/28
ComparaisonsuiteC1, C 2 = {Comparaisonsuite _ atemporelle C1, C 2 Si l'ordre temporel n'est pas présent dans C 2
Comparaisonsuite _ temporelle C1, C 2 Si l'ordre temporel est présent dans C 2
13
Notons A la suite d'événements suspicieuse, Ai étant les événements de cette suite i∈[1, N A]Soit B la base des cas de référence, B j étant un cas j∈[1, M ] ,B jk étant un événement de ce cas k∈[1, N B j
]
Comparaisonsuite _ atemporelle A , B j = {Pour chaque B jk (événement) :
Pour chaque Ai (événement) : Calculer S i k = Similaritéavancée _ occAi ,B jk
Pour chaque B jk (évènement) :Calculer SMAX k = Distribuer _ les _ similarités S , k
Calculer STotal = MoyHarmoniqueSMAX k
14

Cet algorithme va balayer tous les événements d'un cas de référence Bj et chercher le meilleur accordpossible, entre les événements d'un suite suspicieuse et les siens. Ce meilleur accord s'effectue via lafonction Distribuer_les_similarités qui permet de chercher l'évènement Ai le plus similaire à un événement(Bj)k seulement si aucun autre événement de Bj n'est plus similaire à Ai . Voici un exemple d'exécution de cetalgorithme sur le tableau des S(i k) suivant :
Soit B (resp. A) les colonnes (resp. lignes) de S. Regardons :• Distribuer_les_similarités(S, B1) : le maximum de la colonne est en A3, mais (B1, A3) n'est
pas le maximum de la ligne A3. Nous prenons le second maximum, A1 (et nous marquons laligne A1). D'où la réponse 1.2.
• Distribuer_les_similarités(S, B2) : le maximum de la colonne est en A1, mais la ligne A1est marqué. Nous prenons donc le second maximum et nous marquons la ligne A2. D'où laréponse 1.
• Distribuer_les_similarités(S, B3) : le maximum de la colonne est en A3, qui n'est pas prise,et (B3, A3) est le maximum de la ligne A3. Nous prenons donc le maximum et nousmarquons la ligne A3. D'où la réponse 1.7.
•Note : Une situation bloquante peut survenir si une colonne n'a que des minimums :
Ici, lors du choix de B2, A3 est déjà marqué par B1 et aucune valeur ne peut être prise par A2 . Solution :effectuer auparavant tous les autres passages, ici celui de B3, et effectuer à nouveau celui de B2, enl'autorisant à prendre une ligne libre, même si il n'est pas maximum sur cette ligne. Cette situation n'est pasprésente dans l'algorithme pour alléger la notation.
19/28
avec Similaritéavancée _ occC1, C 2 = {Similarité Avancée C1, C 2 si C 1. occ=1 et C 2. occ=1Max [2, Q1 Similarité Avancée C1, C 2] si C 1. occ=C 2. occMax [2, Q2 Similarité Avancée C1, C 2] si C 1. occC 2. occMax [2, Q1 Similarité Avancée C1, C 2] si C 1. occC 2. occ
avec Distribuer _ les _ similarités S , k n = {Chercher imax tel que S imax k n
=Max S i k , pour k∈[1, N B j]
si imax n'est pas marqué etsi S imax k n
=Max S i k , pour i∈[1, N A] , i non marquémarquer i et renvoyer S imax k n
sinon recommencer en cherchant imax−1 , etc...
soit S = [1.2 1.1 11 1 1
1.5 1 1.7]
soit S = [1.2 1 1.11.1 1 1.21.5 1 1 ]

La fonction Similaritéavancée_occ permet de prendre en compte les occurrences des événements lors du calculde la similarité : si les événements n'ont pas d'occurrence multiple, leur similarité n'est pas modifiée. Aucontraire, si leur occurrence est égale, un bonus leur est accordé. Ce bonus est identique si le nombred'occurrence de la suite d'événements suspicieuse est supérieure à celui du cas référence. En effet, nouspouvons considérer que l'attaque est reconnue même si des événements en plus sont observés. En revanche,si moins d'événements ont été observés que dans le cas de référence, le bonus est moins important. Voici unordre de grandeur des bonus accordés :
Note : Nous pourrions pondérer le bonus Q2 par le nombre d'occurrences manquantes, c'est une possibilitéqui ne figure pas dans notre modèle, afin de l'alléger quelque peu, mais tout à fait envisageable.
Une fois que le meilleur accord possible a été déterminé, via la fonction Distribuer_les_similarités,l'algorithme effectue une moyenne harmonique (voir (8)) sur toutes les similarités entre événements, pourdéterminer la similarité globale entre deux suites d'événements.
4.2.2.3.c Cas où l'ordre temporel est présent
L'idée de cet algorithme est de prendre un par un les événements du cas de référence et de chercher à quelmoment le cas le plus similaire est survenu dans la suite suspicieuse (en cherchant la similarité maximale).Une fois que la position est trouvée, nous retenons son index (c'est le couple (imax, k)), et nous créons unsous-ensemble V, qui comprend les événements de la suite suspicieuse, de l'élément suivant l'index jusqu'à lafin de la suite. Lorsque nous effectuerons la recherche suivante, avec l'événement suivant du cas deréférence, nous travaillerons seulement sur l'ensemble V.
20/28
Q={0.3, 0 .1} 15
Comparaisonsuite _ temporelle A , B j = {première _ comparaison
Pour chaque B jk (événement) :Soit V le sous intervalle de [imax1, k−1 , N A]Si V =∅
S imax k =1Sinon
Pour chaque Ai (événement), i∈VCalculer S i k = Similaritéavancée _ occAi ,B jk
Chercher imax , k tel que S imax k = Max S i k pour i∈VSi S imax k Tmin
imax , k =imax , k−1 et S imax k =1Calculer STotal = MoyHarmoniqueS imax k , pour k∈[1, N B j
]
16

La fonction première_comparaison effectue un passage pour le premier événement du cas de référence :cette fonction distincte est nécessaire pour initialiser l'espace V au début de l'algorithme.Le fait de toujours réduire l'ensemble de recherche permet de garantir l'ordre temporel : ainsi, tous lesévénements redondants de la suite suspicieuse sont écartés (et donc ne baissent pas la similarité). Si à unmoment donné l'ensemble V est vide, cela signifie qu'il manque des événements à la suite suspicieuse, etdonc nous pénalisons le calcul de la similarité avec 1 (pas de similarité).
Un problème peut survenir si, à n'importe quel moment de l'algorithme, nous ne trouvons pas un événementdu cas de référence dans la séquence suspicieuse : toutes les notes de similarité seraient alors médiocres etl'espace V pourrait se réduire considérablement en effaçant des événements importants. Pour cela, nousutilisons une constante (Tmin) garantissant un taux minimal de similarité avant d'entamer la réduction del'espace. Si, par exemple, à un moment donné un événement est absent de la suite suspicieuse, le tauxmaximal de cet événement sera exécrable, nous le remplacerons par 1 (pas de similarité) puis nous passons àl'événement suivant sans réduction de l'espace V. Voici un ordre de grandeur de ce seuil :
A présent, nous avons complètement défini la fonction Comparaisonsuite (voir (13)), que ce soit dans le castemporel et atemporel. Nous pouvons donc très simplement, définir la comparaison finale, qui, rappelons le,permet de trouver le cas le plus similaire à une attaque potentielle. Ses paramètres sont une suite suspicieuseC et une base de cas B :
4.2.2.4 Cas d'indécisions
Ces cas se produisent lorsque :● plusieurs cas de la mémoire sont candidats à l'élection pour le cas de référence et que leurs taux
de similarité sont trop proches les uns des autres pour les départager,● un cas de référence est trouvé, mais son taux de similarité est très légèrement inférieur au taux
minimal requis (Tmin ) : nous souhaitons quand même minimiser le taux d'échecs lors de larecherche du cas de référence.
Nous proposons donc des critères de comparaison avancés effectués lors de tests de rattrapage pour réglerces cas. Cependant, nous ne développerons pas plus en avant ces critères, l'objectif de ce rapport étant justela démonstration de notre modèle d'apprentissage de base.
4.2.2.4.a Prise en compte de la durée entre deux événements
21/28
avec première _ comparaison = {Pour B j1,
Pour chaque Ai (événement) : Calculer S i 1 = Similaritéavancée _ occAi ,B j1
Chercher imax , 1 tel que S imax 1 = Max S i 1 pour i∈[1, N A]Si S imax 1T min
imax , 1=1, 1 et S imax 1=1
Comparaison finale C , B = {Pour chaque B j , calculer S j = Comparaisonsuite C , B j
Le meilleur cas est Bmeilleur , tel que S meilleur = Max S j , j∈[1, N B]17
T min=1.1 16

La durée entre deux événements dans une suite suspicieuse n'est pas présente dans le système existant. Pourcela, nous nous proposons de rajouter un champ EventTime dans la suite EventSeriesFeatures (voir [21]) quicomprendrait deux séries de deux index, ΔT et Δt. Voici la définition de ces index :
Ces durées peuvent donc être utilisées dans la comparaison de deux suites d'événements afin d'affiner lecalcul de leur similarité.
4.2.2.4.b Blacklistes et connaissances de l'agent.
Dans le système existant, l'agent dispose de connaissances à caractère permanents tels que ([21]) : ● les informations de configuration du réseau (équipements, utilisateurs, applications);● la liste des utilisateurs connus/ groupes d’utilisateurs;● la liste des machines connues;● a liste des adresses connues (internes/externes, local/intranet/extranet), adresses interdites,
réservées, impossibles;● la liste des utilisateurs ayant la fonction d'administrateur et liste des administrateurs par
machine;● la liste des utilisateurs suspects/ attaquants : Ce sont les blacklistes.● la liste des adresses suspicieuses/ attaquantes : Ce sont les adresses à surveiller ou à interdire
l’accès;● la liste des utilisateurs autorisés à se connecter de l’extérieur du réseau distribué.● la liste des utilisateurs absents : ce sont les utilisateurs en congé, en mission ou en arrêt maladie.
Si un cas d'indécision se produisait, il serait possible d'utiliser ces connaissances à caractère permanent afinde définir une attaque.
4.2.2.4.c Reconstruction temporelle.
Il faut remarquer que les événements issus du filtrage avancé ne sont pas les seuls à être soumis au moteurde délibération du CBR : comme nous pouvons le voir sur l'Illustration 5, les suites d'événementssuspicieuses non reconnues dans le système de base sont elles aussi soumises au CBR (cercle ( ) numéroté2). Si un cas d'indécision se produit, nous pourrions utiliser l'algorithme suivant :
● si une suite issue du filtrage avancé est reconnue par le CBR comme un cas de référence avec unecertaine similarité S
● alors, nous pouvons chercher, en reconstruisant la suite temporelle 1 + 2, des événementssupplémentaires dans 1 permettant d'obtenir une similarité plus élevée.
L'inverse est aussi vrai (i.e. reconstruire 1 + 2 pour chercher dans 2 des événements manquants àl'identification de 1).
22/28
Soit une suite E i d'événements . Soit {E0, ... , En} ces événements .Soit {TE0, ... ,TEn} les temps où ces événements se sont produits.Nous définissons T i = TE i−TE0 le temps entre le premier événement et l'événement E i . Nous définissons t i = TE i−TE i−1 le temps entre les événements E i et E i−1 , avec t0 = 0 .
Soit E0, E1, E2 t2
T 2
, ... avec TE i = {1, 2 , 4} ,
Nous avons donc T i = {0, 1 , 3} et t i = {0, 1 , 2}.

Note : cette reconstruction temporelle n'est obligatoire que si le cas de référence nécessite un ordretemporel. Si ce n'est pas le cas, cette reconstruction n'est pas effectuée et la recherche est tout de suitelancée.
4.2.2.5 Performance et améliorations
Intéressons nous à présent à la complexité des trois fonctions, avec n le nombre d'événements dans la suitesuspicieuse, m le nombre moyen d'événements dans un cas de référence et M le nombre de cas de référence :
● Comparaisonsuite_atemporelle : environ o(2.m.n).● Comparaisonsuite_temporelle : environ o(2.m.n) au pire des cas (i.e. V ne diminue que d'un élément à
la fois).● Comparaisonfinale : environ o(2.m.n.M) + o(M) (pour le calcul du maximum).
Voici un ordre de grandeur des entités utilisées par la fonction de similarité :● Nombre d'événements de A (i.e. NA) : 10.● Nombre moyen d'événements dans une attaque de référence : 10.● Nombre de cas de référence dans la base : 1000.
Nous nous apercevons que la complexité du système augmente quadratiquement quand la taille des donnéesaugmente linéairement, ce qui n'est pas bon.
Il existe de nombreuses améliorations disponibles pour CBL1, portant sur des éléments divers tels quel'organisation des structures de données de la base des cas, le pré-traitement des données ou une approcheprobabilitiste (voir [4] et [3]). Sans rentrer dans des améliorations complexes, nous proposons de diminuerle nombre de calculs de similarité inutiles grâce à cet algorithme :
● Avant qu'une suite suspicieuse soit analysée, nous construisons une table d'index contenant lesEventName (de la classe GenericSecurityEvent) ainsi que leur numéro d'événement :
Ainsi, au lieu de parcourir tous les événements de la suite A (par exemple dans Comparaisonsuite_temporelle),pour calculer leur similarité avec un événement Bi, nous ne parcourons que les événements de A qui ont lemême EventName que celui de Bi. Cela revient à faire une approximation, puisque nous ne testons que les cas susceptibles d'offrir unesimilarité élevée, mais cela nous permet de diminuer la complexité du système : en considérant que nous nebalayons plus que 10% des événements de A, et en utilisant l'ordre de valeur énoncé plus haut, la complexitédes fonctions devient :
● Comparaisonsuite_atemporelle : environ o(2.m) + o(n).● Comparaisonsuite_temporelle : environ o(2.m) + o(n).● Comparaisonfinale : environ o(2.m.M) + o(M) + o(n)
Note : les o(n) dans les Comparaisonsuite proviennent de la construction de la table d'index, qui se fait entemps linéaire.
La complexité de l'algorithme reste quadratique, mais dans la comparaison de deux suites devient linéaire.Une mise en pratique de ces tables d'index à un niveau plus haut (i.e. pour comparer la suite suspicieuseavec seulement les cas intéressants) serait intéressante pour obtenir une complexité logarithmique sur toutl'algorithme. Cette optimisation, ainsi que toutes les autres, ouvre la possibilité à de nombreux travauxfuturs.
23/28
Par exemple la suite suivante :
[Evénement 1 EventName=TelnetEvénement 2 EventName=SSHEvénement 3 EventName=Telnet] entraîne la table d'index : [EventName=Telnet [1, 3]
EventName=SSH [2] ]

4.2.2.6 Le peuplement initial de la base des cas.
Jusqu'à présent, nous avons supposé que la base des cas était peuplée. Le problème qui se pose à présent estcomment remplir cette base. Nous ne pouvons partir d'une mémoire vierge, car l'administrateur serait alorsactivement sollicité pour identifier les suites suspicieuses (et cela reviendrait à effectuer une phased'apprentissage ce dont nous désirons nous passer).Pour répondre à ce problème, nous supposons que la base des cas est importée à partir d'une sourcesécurisée et certifiée, un serveur ftp universitaire regroupant toutes les bases de cas de référence. Cesmémoires de référence peuvent êtres :
● Écrites à la main par des experts.● L'oeuvre de contribution des utilisateurs du système.● En provenance d'un autre système/logiciel. Dans ce cas, les mémoires de référence seraient
converties dans le bon format.
A présent, le moteur de CBR ainsi que tous ses éléments sont totalement définis. Nous pouvons passer à ladernière étape, la mise à jour des politiques.
4.2.3 Génération du schéma d'attaque et mise à jour des politiques.
Nous supposons qu'une attaque (ou une variante) a été détectée : nous allons nous intéresser au moduleconstruction du schéma correspondant + mise à jour des politiques de sécurité (en ( ) sur l'Illustration 5).Bien que cette partie du système n'ait pas été finalisée, nous proposons le protocole général suivant :
● Le schéma d'attaque correspondant à la suite d'événements est généré : lors de cette génération,un algorithme doit déterminer quels événements sont caractéristiques de l'attaque, quels attributs(par exemple la source de l'attaque) peuvent être omis, si le temps entre deux événements estsignificatif, si l'ordre temporel est nécessaire, etc... Cet algorithme abouti à un schéma d'attaquedont certains attributs sont positionnés (i.e. ont une valeur), et d'autres sont laissés génériques.
● Sur la confirmation de l'administrateur, les politiques de sécurité sont modifiées pour prendreen compte la nouvelle attaque découverte, attaque qui sera ensuite transmise aux agentsultérieurement. Nous considérons que la génération des schémas d'attaque est un point tropcritique pour être réalisé de manière entièrement automatisée, et que, par conséquent, uneintervention humaine est nécessaire avant la mise à jour de la base des schémas d'attaque. Sil'administrateur refuse de reconnaître une attaque, la suite d'événements est aussi retirée de lamémoire des cas.
4.2.4 Conclusion sur le modèle
Dans cette section, nous avons décrit notre modèle fondé sur le CBR pour la détection d'intrusionsinconnues. Ce modèle est constitué de trois sous-modèles : un modèle pour l'extension du filtrage desévénements, un modèle pour le moteur de CBR et enfin un dernier modèle pour la génération automatiquedes schémas d'attaque ainsi que la mise à jour des politiques de sécurité. Bien que la fonction de générationde schéma et de mise à jour des politiques de sécurité ne soit pas complètement spécifiée, le coeur de notremodèle (filtrage et moteur de CBR) l'est. En effet, nous avons défini la fonction de similarité qui est lecomposant essentiel du moteur CBR et qui permet d'identifier des attaques inconnues. Cette fonction qui aété construite à partir d'un algorithme générique simple (CBL1) et qui a fortement enrichi cet algorithme,nous permet de calculer la similarité de deux objets complexes.
24/28

5. Conclusion
A travers ce travail, nous pouvons voir que tous les IDS existants sont confrontés aux problèmes del'extraction, la catégorisation et la prise de décision à partir d'un large volume de données, afin de détecterles attaques se produisant dans un système, en particulier les attaques inconnues. Différentes approches ontété définies pour répondre à certains de ces problèmes, en particulier une approche très populaire, le DataMining, qui a largement prouvé son efficacité pour l'extraction et la classification d'événements à partir d'unlarge volume de données. Cependant, cette approche, comme nous l'avons expliqué dans la section 2.2.3,présente certains inconvénients, qui nous ont poussé à nous orienter vers le Cased-Base Reasoning, unenouvelle approche qui n'a, jusqu'à présent, pas été appliquée dans le domaine de la détection d'intrusions.En nous basant sur cette approche, nous avons conçu un nouveau modèle pour la détection d'attaquesinconnues. Ce modèle a été intégré à un système de détection d'intrusions à base d'agents, qui ne détectaitque des attaques connues.La phase de conception étant terminée, nous prévoyons de valider notre modèle par une applicationlogicielle. D'autre part, en ce qui concerne le moteur CBR (le coeur de notre système), nous avons proposéplusieurs optimisations qu'une étude empirique permettra de confirmer.
25/28

6. Index des illustrationsIllustration 1: Un exemple de règles générées par RIPPER................................................................. 5Illustration 2: Les principales étapes d'un algorithme de CBR.............................................................6Illustration 3: Le modèle organisationnel du système existant.............................................................8Illustration 4: Le modèle événementiel du système existant................................................................ 9Illustration 5: Vue interne du modèle d'apprentissage........................................................................10Illustration 6: Le moteur de délibération du CBR.............................................................................. 11Illustration 7: Les classes d'événements de sécurité........................................................................... 12
26/28

7. Table des matières1. Introduction...................................................................................................................................... 22. État de l'art........................................................................................................................................3
2.1 La détection d'intrusions............................................................................................................ 32.2 Le Data Mining et la classification de données d'audit..............................................................4
2.2.1 Le Data Mining dans les approches par scénarios............................................................. 52.2.2 Le Data Mining dans les approches comportementales..................................................... 52.2.3 La nécessité d'une autre approche...................................................................................... 6
2.3 Le Case-Based Reasoning..........................................................................................................62.4 Conclusion................................................................................................................................. 7
3. Système de détections d'intrusion base d'agents intelligents............................................................ 83.1 Le modèle organisationnel.........................................................................................................83.2 Le modèle événementiel............................................................................................................ 93.3 Conclusion sur le système existant............................................................................................ 9
4. Le modèle d'apprentissage..............................................................................................................104.1 Extension du filtrage des événements......................................................................................104.2 Mise en place des éléments du moteur de CBR.......................................................................11
4.2.1 Notre algorithme de Case-Based Reasoning ...................................................................114.2.2 La Fonction de similarité................................................................................................. 11
4.2.2.1 Les bases de la fonction de similarité.......................................................................134.2.2.1.a Espace de valeur de la fonction de similarité....................................................134.2.2.1.b Comparaison de base........................................................................................ 14
4.2.2.2 Comparaison avancée...............................................................................................154.2.2.3 Comparaison finale...................................................................................................17
4.2.2.3.a Algorithme de base........................................................................................... 174.2.2.3.b Cas où l'ordre temporel n'est pas présent..........................................................174.2.2.3.c Cas où l'ordre temporel est présent................................................................... 19
4.2.2.4 Cas d'indécisions...................................................................................................... 204.2.2.4.a Prise en compte de la durée entre deux événements.........................................204.2.2.4.b Blacklistes et connaissances de l'agent............................................................. 214.2.2.4.c Reconstruction temporelle................................................................................ 21
4.2.2.5 Performance et améliorations................................................................................... 214.2.2.6 Le peuplement initial de la base des cas...................................................................22
4.2.3 Génération du schéma d'attaque et mise à jour des politiques......................................... 224.2.4 Conclusion sur le modèle.................................................................................................23
5. Conclusion......................................................................................................................................246. Index des illustrations.....................................................................................................................258. Bibliographie.................................................................................................................................. 27
27/28

8. Bibliographie1: Knowledge-Intensive Case-Based Reasoning and Sustained Learning, Agnar Aamodt,Proceedings of the 9th European Conference on Artificial Intelligence (ECAI-90), 1990.2: Explanation-Driven Retrieval, Reuse and Learning of Cases, Agnar Aamodt, Proceddings ofEWCBR-93, 1993.3: Case-Based Reasoning : Foundational Issues, Methodological Variations, and SystemApproaches, Agnar Aamodt & Enric Plaza, AI Communications Vol. 7 Nr. 1, 1994.4: Case-Based Learning Algorithms, David W. Aha, Proceeding of the 1991 DARPA Case-BasedReasonning Workshop, 1991.5: Weighting Features, Dietrich Wettschereck & David W. Aha, ICCBR-95, 1995.6: Cooperation Modes among Case-Based Reasoning Agents, Enric Plaza, Josep Lluis Arcos andFrancisco Martin, Proceeding of the ECAI'96 Workshop on Learning in Distributed AI Systems,1996.7: Similarity, Uncertainty and Case-Based Reasoning in PATDEX, Michael M. Richter, StefanWess, Automated reasoning, essays in honour of Woody Bledsoe, Kluwer, pp. 249-265, 1991.8: ADAM : Detecting Intrusions by Data Mining, Daniel Barbará, Julia Couto, Sushil Jajodia,Leonard Popyack & NingNing Wu, Proceedings of the 2001 IEEE Workshop on InformationAssurance and Security, 2001.9: Data Mining : A New Intrusion Detection Approach, Dary Alexandra Pena Maldonado, GIACSecurity Essentials Certification Practical Assignement [SANS Institute], June 2003.10: Intelligents Agents for Intrusion Detection, Guy G. Helmer, Johnny S. K. Wong, VasantHonavar & Les Miller, Proceedings, IEEE Information Technology Conference pp 121-124, 1998.11: Lightweight Agents for Intrusion Detection, Guy Helmer, Johnny S. K. Wong, Vasant Honavar& Les Miller, the Journal of Systems and Software, 2000.12: Automated Discovery of Concise Predictive Rules for Intrusion Detection, Guy Helmer, JohnnyS.K. Wong, Vasant Honavar & Les Miller, the Journal of Systems and Software 60, 2002.13: Artificial Intelligence and Intrusion Detection : Current and Future Directions, Jeremy Franck,Division of Computer Science, University of California at Davis, 1994.14: Intrusion Detection with Unlabeled Data Using Clustering, Leonid Portnoy, ACM Workshop onData Mining Applied to Security (DMSA 2001), 2001.15: Cost-Base Modeling for Fraud and Intrusion Detection : Results from the JAM Project,Salvatore J. Stolfo, Andreas Prodromidis, Wenke Lee, Wei Fan & Philip K. Chan, Proceedings ofthe DARPA Information Survivability Conference and Exposition, IEEE Computer Press pp. 130-144, 2000.16: Java Agents for Meta-Learning over Distributed Databases, Salvatore Stolfo, Andreas L.Prodromidis, Shelley Tselepis, Wenke Lee, Dave W. Fan & Philip K. Chan, American Associationfor Artificial Intelligence, 1997.17: Data Mining Approaches for Intrusion Detection, Wenke Lee & Salvatore J. Stolfo, Proceedingsof the 7th USENIX Security Symposium, 1998.18: A Data Mining Framework for Building Intrusion Detection Models, Wenke Lee, Salvatore J.Stolfo & Kui W. Mok, IEEE Symposium on Security and Privacy, 1999.19: Fast Effective Rule Induction, William W. Cohen, Machine Learning : Proceedings of theTwelfth International Conference (ML95), 1995.20: Feature Selection Using a Genetic Algorithm for Intrusion Detection, Guy Helmer, JohnnyWong, Vasant Honavar & Les Miller, Proceedings, Genetic and Evolutionary ComputationConference, Orlando, 1999.21: Détection d'intrusions : Une nouvelle approche par systèmes multi-agents, Karima Boudaoud,Ecole Polytechnique Fédérale de Lausanne, 2000.
28/28


















