Traitement et analyse de données biologiques - Accueil · ... de production ou de marketing...
31
Objectifs - Redonner le sens pratique à des étudiants gavés de théorie (« je connais mais ne sais pas l’appliquer »); c’est pourquoi cette UE est très accèe sur la pratique. - Savoir se débrouiller seul (passer à la pratique, repérer la situation, travailler vite et bien). Etre capable d’analyser ses propres données expérimentales, de production ou de marketing (contexte stage, labo, bureau d’étude, entreprise, …) - Parler un langage de base en statistique (et éviter les excès : « l’inférence de l’ inféron ») permettant de faire appel aux spécialistes lorsque cela est nécessaire - Ne pas confondre bioinformatique et biostatistique! - Essayer de mieux décrypter notre monde - Prendre des responsabilités (et des risques mesurés) - En faire profiter le CV Traitement et analyse de données biologiques 1
Transcript of Traitement et analyse de données biologiques - Accueil · ... de production ou de marketing...

Objectifs
- Redonner le sens pratique à des étudiants gavés de théorie (« je connais mais ne
sais pas l’appliquer »); c’est pourquoi cette UE est très accèe sur la pratique.
- Savoir se débrouiller seul (passer à la pratique, repérer la situation, travailler vite
et bien). Etre capable d’analyser ses propres données expérimentales, de
production ou de marketing (contexte stage, labo, bureau d’étude, entreprise, …)
- Parler un langage de base en statistique (et éviter les excès : « l’inférence de
l’inféron ») permettant de faire appel aux spécialistes lorsque cela est nécessaire
- Ne pas confondre bioinformatique et biostatistique!
- Essayer de mieux décrypter notre monde
- Prendre des responsabilités (et des risques mesurés)
- En faire profiter le CV
Traitement et analyse de données biologiques
1

Plan de travail
- Traitement et analyse de données, le contexte spécifique de la biologie
(Tout ce que vous avez toujours voulu savoir sur les Biostats, le Big Data,
les Data Scientist et autres mots sympathiques)
- L’essentiel sur les statistiques descriptives
- Les graphiques de qualité professionnelle
- Analyse univariée
- Analyse multivariée : analyse factorielle, régression linéaire et ANOVA
Et nous disposons de seulement 25 heures pour tout cela !
Traitement et analyse de données biologiques
2

Méthode de travail
Nous allons travailler (si possible) en salle de la façon suivante :
Travail en groupe
- Analyse et résolution d’un problème en utilisant les fiches de cours
(qui peuvent être données en live au tableau)
- Travailler par groupe de 3 étudiants avec 2 ordinateurs, un pour la
recherche (utiliser internet et forum) l’autre pour le calcul
- Résoudre une problématique et rendre 1 fiche d’analyse en fin de séance
- Quizz intervenant n’importe quand (y répondre le plus vite possible)
Salle informatique
- Logiciels à disposition
- Site web de soutien (et vidéos de résumé ?)
Synthèses
- Débriefing
- Corrections faites par l’enseignant
Traitement et analyse de données biologiques
3

- Rapide historique
Statistique provient du latin status signifiant état.
Depuis les temps les plus reculés (Babylone, Égypte, Chine, Grèce,
Rome,…), les États voulaient disposer d'informations sur leurs sujets
(recensements de population) et sur les ressources qu'ils produisaient ou les
biens possédaient (cf rouleaux de papyrus, colonne ou tablettes d’argile au
musée du Louvre). Les statistiques étaient alors purement descriptives.
A partir du 17ème siècle s'est développé le calcul des probabilités et des
méthodes statistiques sont apparues en Allemagne, en Angleterre et en
France. De nombreux scientifiques y ont apporté leur contribution, dont vous
avez surement entendu parler : Pascal, Bernoulli, Moivre, Laplace, Gauss,
Mendel, Pearson, Fischer, Student, Wilcoxon, …
L’une des missions assignées aux premiers ordinateurs (années 1950) étaient
de faciliter le recensement de la population américaine…
Il n’est actuellement pas un domaine ou une discipline, scientifique ou non, qui
puisse se passer de l’outil statistique. Où nous mènera le Big Data?
Statistique / Analyse des données
4

Univac - 1951

Système de Gestion de Base de Données (SGBD) Quelques définitions
- Une base de données c’est essentiellement une collection structurée
d’informations non nécessairement du même type (format)
- Une base de données est usuellement localisée en un seul lieu et un seul
support (dupliqué en fait) qui est généralement informatique (numérique)
- Pièce centrale des dispositifs informatiques qui servent à la collecte, le
stockage et l’utilisation des informations
- SGBDR, acronyme de Système de Gestion de Base de Données
Relationnelles : logiciel moteur qui pilote la base et en permet la
manipulation et l’exploitation (interrogation).
- Toutes les secondes le volume d’information ne cesse d’augmenter
contribuant au Big Data. Mais sans analyse et sans base de données
(contribuant à préparer les données à leur analyse), le Big Data n’est rien.

Définition
Ensembles de données tellement volumineux qu'ils deviennent difficiles à manipuler et à analyser
avec des outils classiques de gestion de base de données ou de gestion de l'information. L’outil
statistique doit être repensé pour eux (data mining = fouille de données; techniques
d’apprentissage,…). On ne sait pas vraiment ce que l’on va y chercher. On essaye de trouver un
sens à cette masse considérable d’information (en Zétaoctets).
Synonymes
Mégadonnées, données massives, datamasse
Analyse du Big Data
Stockage : l’accès se fait via le réseau (cloud computing). Le Big Data s'accompagne du
développement d'applications à visée analytique, qui traitent les données pour en tirer du sens.
Ces analyses sont appelées Big Analytics («broyage de données»).
Historique
BIG DATA
7
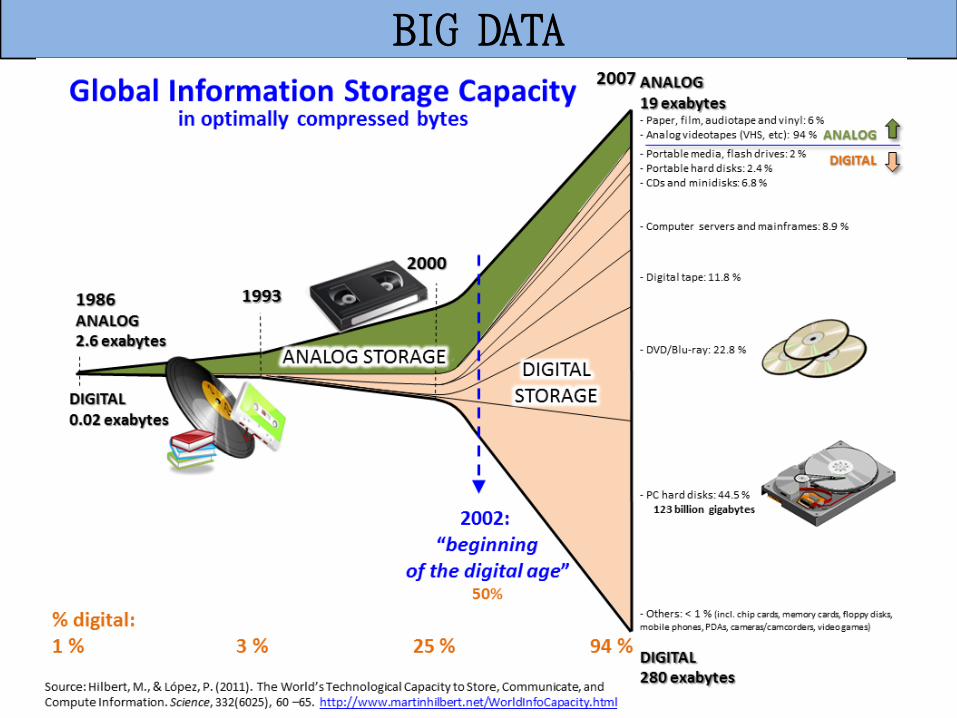
BIG DATA
8

Les 3 V
Croissance des données « tri-dimensionnelle » :
les analyses complexes répondent à la règle dite «des 3V»
Volume, Vitesse et Variété
Volume Le volume des données stockées aujourd’hui est en pleine expansion
Environ 4 zettaoctets en 2015
Vélocité
Fréquence à laquelle les données sont générées, capturées et partagées! Elles doivent être
analysées en temps réel (Data Stream Mining). Risque pour l'Homme de perdre une grande partie
de la maîtrise du système >>> Trading haute fréquence : des "robots" sont capables de lancer des
ordres d'achat ou de vente de l'ordre de la nanoseconde.
Variété
Les data centers sont devant un véritable défi : la variété des données. Il ne s'agit pas de données
relationnelles traditionnelles, elles sont brutes, semi-structurées, non structurées >>> analyses
d’autant plus complexes qu’elles portent sur les liens entre des données de natures différentes.
BIG DATA
9

Le Big Data et la recherche scientifique
Parmi les plus gros pourvoyeurs de données. Les approches massives basées sur une logique
d’exploration des données et de recherche d’induction sont complémentaires des approches
classiques basées sur l'hypothèse initiale formulée (Ouf! On respire!)
Les approches massives en biologie
- Génomique et toutes les « omiques » >>> Décoder le génome humain a originellement pris 10 ans,
cela peut désormais être fait en moins d'une semaine : les séquenceurs d'ADN ont progressé d'un facteur
10 000 les dix dernières années, soit 100 fois la loi de Moore (caractérisée par un facteur 100 sur 10 ans)
- Environnement
- Epidémiologie
- Big Brain
- Drug Design …
Autres
- Physique : Large Hadron Collider; Astronomie; Climat et Météo
- Gestion du temps réel
- Banques
- Réseaux sociaux (Facebook : , Twitter,…) et autres monstres (Google, Yahoo, …)
- Assurances …
Big Data
10

Dans cette perspective:
- je vous propose d’apprendre à travailler conjointement avec différents types
d’informations
- vous allez pouvoir appliquer (enfin) vos connaissance ;
- acquérir de la méthode et de la rigueur;
- devenir progressivement autonomes dans l’analyse de vos propres données;
- vous préparer à l’étape 1 du traitement massif des données…
- Il va y avoir beaucoup de travail, mais ça en vaut la peine
Analyse Multivariée
11

Les outils
Nous allons utiliser quelques connaissances indispensables pour nous mener en
douceur vers l’analyse multivariée.
Statistiques
- Types de variables
- Loi normale
- Risque a et Pvalue
- Proportion, moyenne et notion de variance (indispensable pour l’AF)
- Test du Chi-deux et de Fisher exact (rappels)
- L’analyse factorielle (AFC,ACP,AMF)
Logiciels
- L’outil graphique
- Une petite connaissance du logiciel R et d’EXCEL
Autres
Une certaine logique d’interprétation
Analyse Multivariée
12

- Collection/recueil des données (data collection)
L'origine des données est multiple (homme, machines, automates, ordinateurs,
capteurs, satellites, serveurs,….), mais l'information collectée en biologie transite
toujours par des fichiers, très souvent texte non formatés (ASCII, universels)
pour permettre un échange aisé (portabilité).
- Traitement des données (data processing)
Consiste en la préparation des données (filtre, tri, regroupement, mise à
l’échelle, normalisation, organisation en tableaux…) afin qu’elles soient
analysables.
- Analyse des données (data analysis)
C'est surtout dans cette étape qu’intervient l'outil statistique. On interprète les
résultats, on les compare avec ceux déduits de la théorie des probabilités.
Si certains logiciels sont dédiés à l'acquisition et au traitement des données d’un
domaine précis de la biologie, on utilise les mêmes outils statistiques, donc les
mêmes logiciels d'analyse de données quelque soit la discipline impliquée.
Fichiers, support de l'information
13
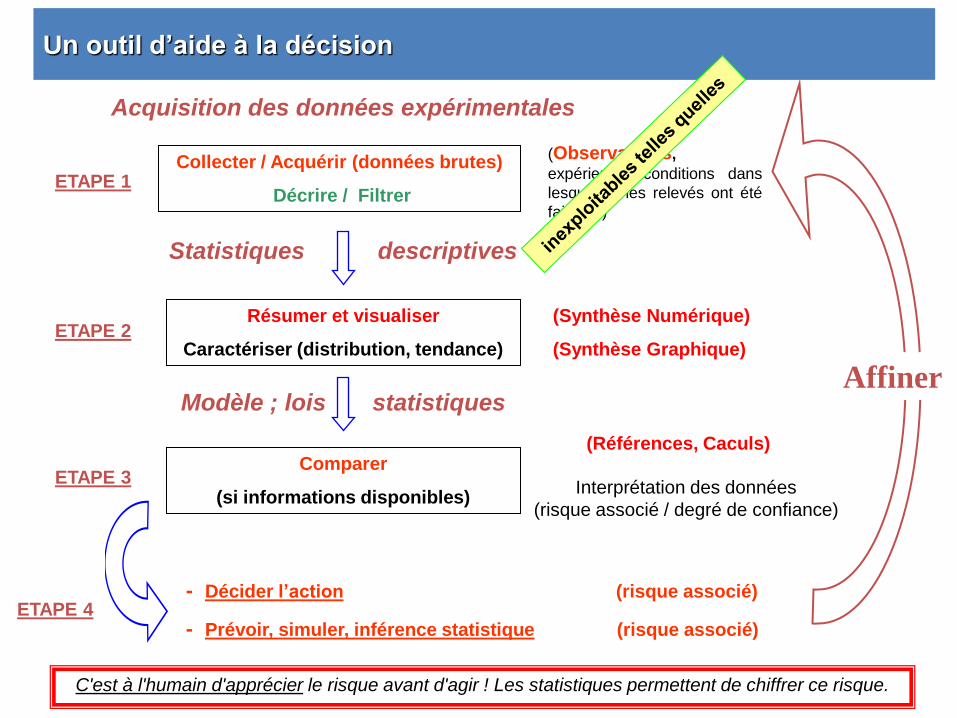
Un outil d’aide à la décision
Affiner
Collecter / Acquérir (données brutes)
Décrire / Filtrer
(Observations,
expérience, conditions dans
lesquelles les relevés ont été
faits !…)
ETAPE 1
Acquisition des données expérimentales
- Décider l’action (risque associé)
- Prévoir, simuler, inférence statistique (risque associé) ETAPE 4
(Synthèse Numérique)
(Synthèse Graphique)
Résumer et visualiser
Caractériser (distribution, tendance) ETAPE 2
Statistiques descriptives
Modèle ; lois statistiques
Comparer
(si informations disponibles) ETAPE 3
(Références, Caculs)
Interprétation des données
(risque associé / degré de confiance)
C'est à l'humain d'apprécier le risque avant d'agir ! Les statistiques permettent de chiffrer ce risque.

Statistique descriptive
L'objectif de la statistique descriptive est de décrire, c'est-à-dire de résumer et représenter en un
minimum de chiffres, de graphes et de mots les données, observations synchrones, récoltées ou
disponibles (terrain, labo, entreprise, usine, satellite, réseaux, clientèle, …) qui sont associées à
des distributions d’échantillons (ou de populations, notamment dans le cas du Big Data).
Statistique inférentielle
Consiste à induire, avec une certaine marge d'erreur, les caractéristiques inconnues d'une
population à partir d'un échantillon issu de cette population.
Trois grandes phases de développement :
1 - A la fin du 19e siècle, avec les travaux de Fisher, Pearson, Neyman, …
conduisant aux notions fondamentales de vraisemblance, test d'hypothèse, intervalle de
confiance.
2 - Dans un second temps, l'informatique a permis l'explosion des techniques de simulation par
application des techniques de rééchantillonnage :
méthode de Monte Carlo, bootstrap, …
3 - Depuis une dizaine d’années, le saut vers l’inconnu : Le Big Data …
Statistique – Analyse des données
15
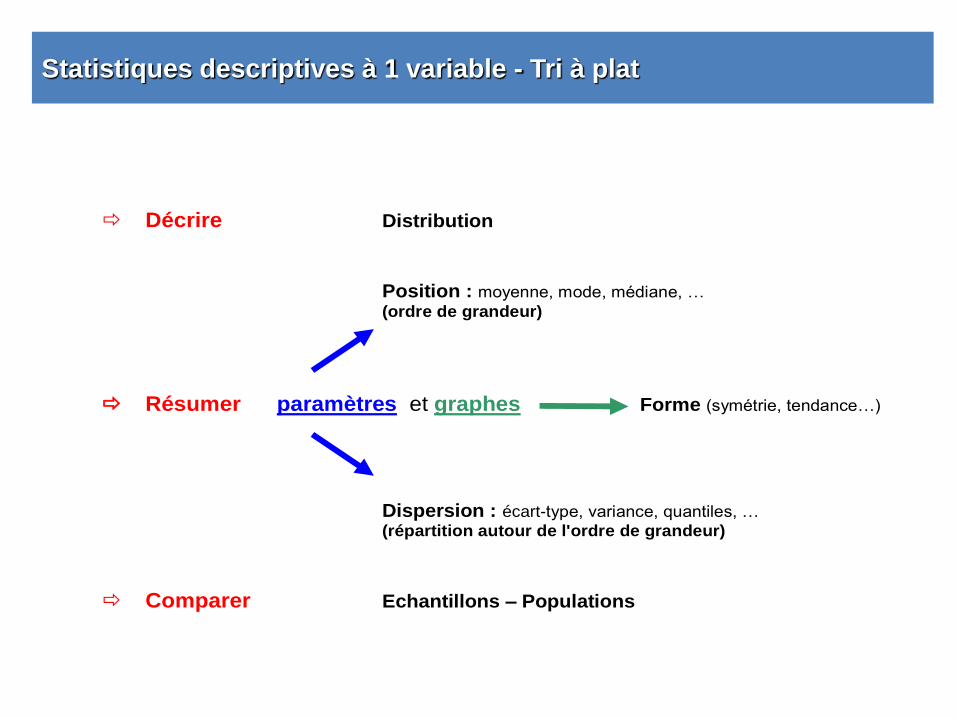
Statistiques descriptives à 1 variable - Tri à plat
Décrire Distribution Position : moyenne, mode, médiane, … (ordre de grandeur)
Résumer paramètres et graphes Forme (symétrie, tendance…)
Dispersion : écart-type, variance, quantiles, … (répartition autour de l'ordre de grandeur)
Comparer Echantillons – Populations

QUIZZ n°1
Q1 - Pouvez vous citer une contribution de Laplace ?
Q2 - Pouvez vous citer une contribution de Mendel ?
Q3 - Pouvez vous citer une contribution de Pearson ?
Q4 - Définissez (le plus simplement/synthétiquement possible) la loi de Bernoulli
Statistique – Analyse des données
17

De l’Analyse Univariée à l’Analyse Multivariée
On commence par analyser séparément les variables avant de les traiter
conjointement (par paires). Le regroupement des colonnes apparaissant dans les
fichiers de données s’effectue au travers d'un tableau récapitulatif de leurs
caractéristiques. Il s’agit d'une démarche progressive : on effectue les calculs en
dimension 1 (analyse univariée) avant de passer a la dimension 2 (analyse
bivariée).
Les calculs en dimensions supérieures font appel a des calculs plus généraux,
souvent vectoriels (matrices), regroupés sous le terme d'analyse multivariée.
On est ainsi amené à comparer les résultats de ces analyses à une, deux
dimensions ou plus et à quantifier le degré de confiance qu'on peut accorder a
ces résultats en réalisant des intervalles de confiance et des tests statistiques.
L'utilisation de logiciels ne dispense pas de connaitre, de reconnaître et de savoir
interpréter les formules qui en découlent. Tout au plus, ceci nous libère t-il de
devoir les apprendre par cœur.
Statistique – Analyse des données
18

L’aspect logiciel
Quelque soit la discipline impliquée, biologie, psychologie, économétrie,
physique…, on utilise souvent les mêmes logiciels d'analyse de données.
Parmi ces logiciels : R (libre, gratuit, universel, GNU) qui ne cesse de
prendre de l'importance (y compris dans les traitements de gros volumes de
données : RevolutionR), STATA, CCSS, SAS, S, EXCEL, etc…
Nous allons apprendre à nous servir de deux logiciels pour analyser les
données : R et EXCEL (sans faire de programmation car il faut bien faire un
choix stratégique).
Analyse des données
19

Le logiciel R
R est avant tout un logiciel entièrement dédié à l’analyse statistique
Il offre une grande souplesse d'utilisation, il est compatible avec de très nombreux
formats d'entrée et il dispose d'une importante et sans cesse croissante, bibliothèque
de modules dédiés à des applications spécifiques (évolution, protéine, plans
d'expérience, traitement cartographique, brain, génomique, biologie structurale,
environnement, graphisme,….).
Il est, en outre, doté d'un langage de programmation et est interfaçable avec des
bases de données. Seul limite : R est très rapide mais il dépend de la mémoire vive
de l'ordinateur sous laquelle il fonctionne (les capacités de la mémoire vive ne
cessant d'augmenter on peut s'attendre à ce que cela ne soit plus une limite
Enfin, dans ses dernières versions, le logiciel peut fonctionner en cluster (réseau
d'ordinateur partageant le temps de calcul).
Analyse des données
20
Notre premier apprentissage
Suivre les instructions au tableau
Analyse des données
21

Statistiques descriptives à 1 variable - Tri à plat
Présentation des acteurs, exemples concrets et règles de calculs
Le centre de recherche d'une société spécialisée dans les biotechnologies a récemment mis
au point une nouvelle variété céréalière.
Le rendement en quintaux de cette nouvelle variété a été relevé dans la région Centre sur un
échantillon de parcelles témoin (1 ha chacune) en condition de culture « bio ».
On a demandé à une jeune stagiaire d'exploiter rapidement et au mieux ces résultats.
Rendements mesurés :
102 ; 104,5 ; 121,63 ; 122,5 ; 103,23 ; 106 ; 107,25 ; 106,44 ; 110 ; 111,3 ; 112,23 ; 96,6 ; 120
; 102 ; 103,2 ; 104 ; 127,56 ; 113,5 ; 95 ; 101,125 ; 125 ; 96 ; 114 ; 109 ; 92,3 ; 106,65 ; 107,7 ;
113,8 ; 115 ; 109,3 ; 123,325 ; 124,1 ; 113,5 ; 112,21 ; 111,56 ; 110 ; 112,22 ; 129 ; 133,25 ;
102 ; 114,5 ; 94,25 ; 116 ; 115,2 ; 125 ; 109,4 ; 108,55 ; 96,2 ; 116,6 ; 117,3 ; 97,5 ; 117,66 ;
117,8 ; 117,5 ; 118,22 ; 118 ; 117,5 ; 119 ; 114,3 ; 90 ; 96,2 ; 116,6 ; 123,56 ; 115 ; 120,23
Commentaires …

QUIZZ n°2
Q1 - Echantillon ou population?
Q2 - Combien de variables peut-on identifier ?
Q3 - Quel type de graphique peut-on réaliser avec ces données ?
Q4 - Peut-on faire ce graphique avec n’importe quel logiciel ?
Q5 - Y-a-t-il une loi de probabilité qui peut être invoquée?
Q6 - A quoi pourait-on comparer ces données?
Statistique – Analyse des données
23

Les quatre types de variables
Qualitative
Nominale
Ordinale
Quantitative
Discrète
Continue
Variables, lois de probabilités et tests associés
24

Les graphiques
Variable Qualitative : on utilise des diagrammes à secteurs circulaires (pies, camemberts),
des diagrammes en tuyaux d'orgue ou encore des diagrammes en bandes. Il s’agit de
représenter des aires proportionnelles aux fréquences des modalités prises par la variable.
Variable Quantitative discrète : On utilise un diagramme en bâtons, complété du diagramme
des fréquences cumulées (diagramme cumulatif) qui est la représentation graphique de la
fonction de répartition de la variable.
Variable Quantitative discrète : le diagramme représentant la série est un histogramme
composé des rectangles juxtaposés dont chacune des bases est égale à l’intervalle de chaque
classe et dont la hauteur est telle que l’aire de chaque rectangle soit proportionnelle aux
effectifs (histogramme des effectifs) ou aux fréquences de la classe correspondante
(histogramme des fréquences). On peut aussi utiliser en ordonnées la densité de probabilité
(aire totale égale à 1, facilitant les comparaisons avec une distribution théorique).
Variables, lois de probabilités et tests associés
25

Schéma de synthèse
Variables, lois de probabilités et tests associés
26

27
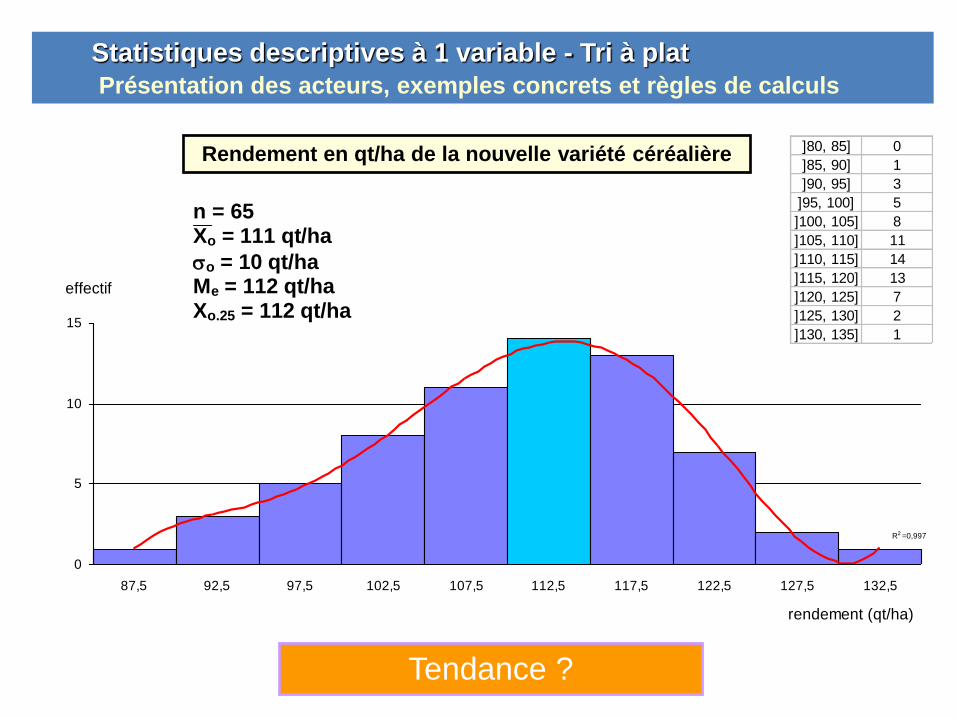
Statistiques descriptives à 1 variable - Tri à plat
Présentation des acteurs, exemples concrets et règles de calculs
R2 = 0,997
0
5
10
15
87,5 92,5 97,5 102,5 107,5 112,5 117,5 122,5 127,5 132,5
effectif
rendement (qt/ha)
Tendance ?
Rendement en qt/ha de la nouvelle variété céréalière ]80, 85] 0
]85, 90] 1
]90, 95] 3
]95, 100] 5
]100, 105] 8
]105, 110] 11
]110, 115] 14
]115, 120] 13
]120, 125] 7
]125, 130] 2
]130, 135] 1
n = 65 Xo = 111 qt/ha
o = 10 qt/ha Me = 112 qt/ha Xo.25 = 112 qt/ha
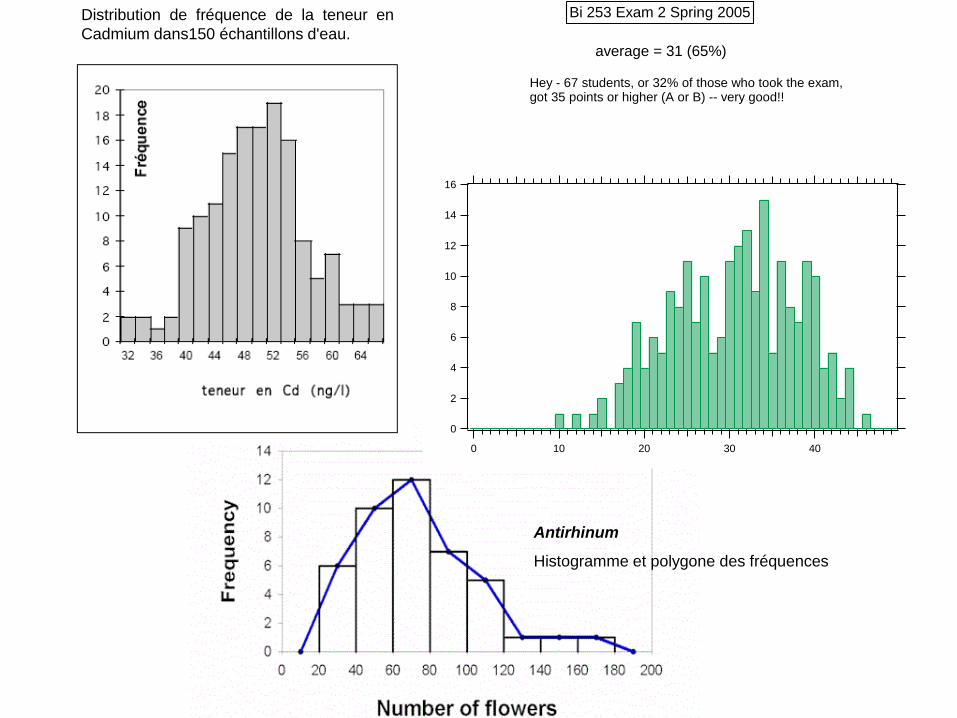
Distribution de fréquence de la teneur en
Cadmium dans150 échantillons d'eau.
16
14
12
10
8
6
4
2
0
403020100
Bi 253 Exam 2 Spring 2005
average = 31 (65%)
Hey - 67 students, or 32% of those who took the exam,got 35 points or higher (A or B) -- very good!!
Antirhinum
Histogramme et polygone des fréquences