
Time is data - 10h11.com · un lieu d’émergence de nouveaux problèmes techniques, sociaux et...
64
Time is data Livre blanc proposé par la société 10h11 - Mars 2015 #datavisualisation @10h11
Transcript of Time is data - 10h11.com · un lieu d’émergence de nouveaux problèmes techniques, sociaux et...

Timeis
data
Livre blanc proposé par la société 10h11 - Mars 2015#datavisualisation @10h11


3

Ce livre blanc a pour vocation d’offrir un regard différent sur la datavisualisation, en portant un intérêt particulier aux problématiques qui nous entourent, que celles-ci proviennent de nouveaux comportements et usages de la data, ou encore de modèles de communication inédits.
Nous nous interrogerons sur les liens unissant datavisualisation et comportements humains : comment ces derniers ont-ils fait émerger un rapport différent à la « data-information » au sein de nos sociétés contemporaines ? Quelles données sont générées, échangées et pourquoi ? Comment répondre positivement à ce nuage de flux qui nous entoure ?
Ce paysage créateur de données multiples est un champ d’exploration inédit, mais également un lieu d’émergence de nouveaux problèmes techniques, sociaux et d’usage. Questionner les data et leurs processus de fabrication, c’est décrire
PRÉLUDE_
4

et analyser des comportements sociaux et biologiques naissants. En parcourant ce livre blanc, vous vous apercevrez que l’esthétisme est primordial dans la datavisualisation et que son objectif premier « est de rendre certains phénomènes plus compréhensibles »1. Vous découvrirez également une méthodologie et une technique, permettant d’appréhender la visualisation de données de manière structurée, afin qu’elle devienne un levier d’action pertinent et nécessaire dans notre quotidien numérique et hyperconnecté.La datavisualisation est autant une histoire qu’une définition complexe que nous vous proposons d’explorer en interrogeant nos besoins et nos spécificités cognitives.La datavisualisation est enfin un ensemble de particularités scénaristiques, graphiques et techniques propres à chaque cas. Nous vous ferons découvrir un exemple concret de visualisation de données, de sa création à son exploitation.
5
6
SOMMAIRE_
p.8 p.9p.10
p.11p.12
p.13
p.14
p.15
p.16
p.17
p.18
p.19
p.20
p.21
p.22
p.23
p.24
p.25
p.26
p.27
p.28
p.29
p.30
p.31
p.32p.33
p.34p.35p.36p.37p.38p.39
p.40p.41
p.42
p.43
p.44
p.45
p.46
p.47
p.48
p.49
p.50
p.51
p.52
p.53
p.54
p.55
p.56
p.57
p.58
p.59
p.60p.61
p.623 000 700 100
01_
02_03_
04_
05_ 06_
lettres par page
mots par page
lignes par page
chapitres

7
La datavisualisation : une science à la croisée de la donnée et de l’image
01_ p.8
L’étude de la donnée dans notre société hyperconnectée
02_ p.14
La datavisualisation : la réponse aux besoins émergents
03_ p.24
Méthodologie :Design de service et UX design appliqués aux données
04_ p.34
Sources
05_ p.60
Contact
06_ p.62
lettres par chapitre
mots par chapitre
lignes par chapitre
pages chapitres
moyenne par chapitre : > 9 477 lettres> 1 440 mots
> 263 lignes> 10,6 pages

8

01_
La datavisualisation,une science à la croisée de la donnée et de l’image
A. Un art historique
B. Une assise mathématique
C. Un savoir exploitable
D. Une représentation graphique
E. Une réponse aux 3V
9

Cartographie : A New and Acceurat Map of the World, 1961.
LA DATAVISUALISATION :UNE SCIENCE À LA CROISÉE DE LA DONNÉE ET DE L’IMAGE_
01_
10
© D
R

Un art historiqueLa visualisation de données peut sembler être un phénomène récent, souvent associé dans l’imaginaire collectif à la naissance du Big Data. Pourtant, synthétiser et représenter des données est un savoir-faire historique.
Dès le XIVe siècle, les penseurs ont mis en image sous forme d’arbre les systèmes de pensées des érudits. De grandes personnalités scientifiques comme William Playflair, créateur de l’histogramme au XIXe siècle, ont eu recours à de nombreuses représentations graphiques telles que les arbres de science, les arbres généalogiques, les tableaux accomplis et les tables des matières, dans le but de diffuser des informations.
Il est ainsi bien plus juste de dire que l’âge d’or de la datavisualisation ne s’inscrit pas dans une époque contemporaine, mais bien entre 1850 et 1900.
Une assise mathématiqueLa théorisation des statistiques, notamment par Euler au XIXe siècle, et l’utilisation importante des graphes ont contribué
à associer la visualisation de données à ce domaine mathématique.C’est pour cette raison qu’aujourd’hui encore, lorsque nous cherchons à définir la datavisualisation, notre première hypothèse est celle d’une représentation graphique de données statistiques.
De nombreux chercheurs du XXe siècle ont participé à faire perdurer la fausse idée que de la donnée statistique était la seule véritable base de la représentation graphique. Ainsi, d’éminentes personnalités comme John Turkey (créateur de l’interactive graphic) ou encore Jacques Bertin (précurseur de théories mathématiques sur la datavisualisation dans les années 60) ont pensé la donnée et l’esthétique graphique avant tout comme une data mathématique. Leurs travaux ont cependant été capitaux pour la réalisation future de programmes d’exploitations permettant l’élaboration graphique d’une visualisation de données.
Un savoir exploitableIl y a encore quelques années, la communauté dataviz s’accordait sur une définition universelle de la visualisation de données
« Synthétiser et représenter des données est un savoir-faire historique »
11

Représentation des flux de données par la technique du light painting.
comme étant la mise en forme de data brutes en un langage esthétique permettant la transmission, la compréhension et une rapidité d’appropriation d’une information. Mais lorsqu’on pense mise en image des données, il faut aussi penser mouvement des données. L’arrivée massive de l’Open Data a en effet permis d’élargir la définition de la visualisation de données : aujourd’hui, réaliser une datavisualisation c’est penser une data qu’elle soit aussi bien statistique, picturale, sémantique, ou encore linguistique. Une visualisation de données est une modélisation de la pensée humaine, une transformation de data en informations et en savoirs exploitables. Pour rendre ce phénomène possible, la datavisualisation passe en grande partie par la simplification de la donnée brute et sa scénarisation en image : une expérience à la croisée du design et de l’analyse.
Une représentation graphiqueDes scientifiques comme Paivio et Clark2 se sont intéressés à la modélisation mnésique de l’image dans notre cerveau. Ils ont découvert que l’image est traitée et encodée deux fois : dans le système verbal et dans le système visuel. L’image facilite donc la
compréhension. Même si notre cerveau semble mieux comprendre et retenir une image qu’un texte, il n’en demeure pas moins que comme un mot, l’image est un signe. Cependant, le mot relève du symbole tandis que l’image s’apparente à l’icône, ce qui la soumet aux interprétations individuelles, collectives et culturelles. Une représentation graphique est donc toujours en lien avec un contexte de création, d’analyse et d’observation. Suivant la culture, un chat noir est associé à un bon ou mauvais présage. Il en est de même pour les couleurs, les formes et les textures3. Comme le souligne Roland Barthes4, l’image et les mots sont toujours en lien, car ils contribuent à la contextualisation. Le chercheur Éric Jamet5 confirme que pour mieux comprendre une image, notre cerveau a besoin de mots pour contextualiser l’information et lui donner un sens. Par l’analyse, la datavisualisation va donc contextualiser les données et leur donner un sens iconique par le design. La visualisation de données n’a de nouveau que sa terminologie et non son concept. Pourtant, dans le contexte actuel du Big Data, le nombre de personnes connectées et notre rapport aux nouvelles technologies ont fait
12
© K
evin
Do
ole
y

émerger des problématiques inédites. Il est important de les décrire et de les analyser afin de comprendre l’importance des données dans notre quotidien et la nécessité de la datavisualisation dans nos échanges et prises de décision.
Une réponse aux 3VLa datavisualisation répond à trois difficultés engendrées par le Big Data et communément appelées « les 3V » :— Volume des données — Variabilité des données— Vitesse des données Les data sont créatrices d’un nouvel espace complexe. En effet, la masse de données présente et indexée sur internet n’est rien en comparaison du « web invisible » ou « web profond », autrement dit les data non indexées par les moteurs de recherche. Selon le géant américain Google, le « web profond », estimé à un trilliard de pages, serait 500 fois plus volumineux que le « web visible » et donc seule 0,2 % des données seraient indexées sur le web.Il y a aujourd’hui une véritable « digitalisation du quotidien »6. Chaque jour, nous produisons une grande quantité de nouvelles données. Nous sommes liés à la data à chaque instant de notre vie : au travail, en vacances, pendant notre sommeil, avant notre naissance ou même après notre mort…
Les individus et les entreprises sont ainsi de plus en plus en confrontation directe avec de véritables problématiques de data : comment contrôler les données que nous produisons ? À qui appartiennent-elles une fois émises ? Comment se transmettent-elles ? Quels impacts peuvent-elles avoir sur nos interactions sociales ? Les data sont au cœur des échanges humains : nous les créons, les enrichissons et les diffusons. Par conséquent, nos actions et nos comportements individuels et collectifs peuvent être la source d’une démarche créative autour de la donnée.
De quels comportements s’agit-il ? Quels nouveaux besoins s’en dégagent ? Quelles sont les évolutions présentes et futures de la « data-information » ? Comment va-t-elle impacter sur notre quotidien ? Nous vous proposons de découvrir ensemble ces comportements, de les questionner et de mettre en avant ces nouveaux besoins du quotidien, vecteurs d’interrogations et de solutions novatrices.
La nouvelle génération numérique, de nouveaux comportements.
13
© B
rad
Flic
kin
ger

14

02_
L’étude de la donnée dans notre société hyperconnectée.
A. La donnée produite
B. La donnée synthétique
C. La donnée instantanée
D. La compréhension de la donnée
15

L’ÉTUDE DE LA DONNÉE DANS NOTRE SOCIÉTÉ HYPERCONNECTÉE_
02_
Surconnexion des usagers due à l’accès facile à internet et à la démocratisation des smartphones et tablettes.
16
© P
at (C
letc
h) W
illia
ms
© G
esa
Hen
selm
ans

Depuis les années 1990 et l’expansion d’Internet, notre environnement hyperconnecté a progressivement modifié notre relation à l’information. De nouvelles typologies de comportements ont émergé aussi bien lors des phases de production que d’échange ou de lecture de la donnée, produisant des besoins sociaux, physiologiques, et économiques inédits.Une grande partie de la population est aujourd’hui surconnectée, notamment grâce à la simplification de l’accès à Internet, à la démocratisation des smartphones et tablettes ou encore l’émergence des objets connectés.En ce sens, l’agence de marketing numérique Tecmark7 a publié une étude qui nous apprend que l’on consulte notre smartphone
en moyenne 221 fois par jour, ce qui correspondrait à 3h16 de notre temps. À titre de comparaison, l’opérateur britannique O28 précise dans une autre étude que nous n’interagissons que 97 minutes par jour avec notre compagnon. Sergueï Brin, cofondateur de Google, prédit que l’hyperconnexion dont nous sommes sujets pourrait être créatrice « d’un troisième hémisphère dans notre cerveau »9. Les nouveaux usages sur le web, comme les likes ou les tweets1 , sont désormais assimilés à des modes de communication à part entière. Les réseaux sociaux, lieux d’échanges, deviennent hétérogènes et plus que jamais un canal entre le virtuel et le réel. À ce stade, il est nécessaire d’analyser les comportements que nous pouvons observer dans les phases de production, de consommation et d’échange de la donnée.
La donnée produite> La production naturelle Comme nous l’avons évoqué précédemment, nous sommes devenus des producteurs de données par le biais de la démocratisation du numérique dans notre quotidien. Nous produisons de l’information, parfois sans y prêter attention, sous forme de données brutes. Même si 80 % des Français sont conscients qu’ils génèrent une trace numérique, 70 % n’envisagent pas de modifier leurs comportements et leurs usages des outils numériques10. À première vue, nous pourrions penser que ce type d’usages témoigne d’une gestion et d’une production non maitrisées des données personnelles. À titre d’exemple, la géolocalisation, les paiements par carte bancaire et l’utilisation des moteurs de recherche sont des comportements générateurs de données
17
« De nouvelles typologies de comportements ont émergé aussi bien lors des phases de production que d’échange ou de lecture de la donnée »

sur nos modes de vie. Cependant, certains développent une production maitrisée et réfléchie de leurs données. Elles deviennent alors un moyen de communiquer sur soi. > La production personnelleNous n’avions pas idée de compter notre nombre d’amis, Facebook nous a appris à le faire. Nous ne mesurions pas le nombre de kilomètres parcourus dans la journée, Fitbit le fait pour nous. Cette méthode de production de la donnée n’est pas seulement un effet de mode, c’est l’émergence et l’ancrage d’un nouveau type de comportement humain. Quels intérêts avons-nous à être créateur d’un « moi » numérique ? 11
La pratique du quantifiedself peut être vue comme un besoin de se connaître soi-même et une nécessité de maîtriser ses données personnelles de leur fabrication à leur diffusion. Ces données sont un moyen de créer son identité virtuelle pour soi-même et
à destination des autres. C’est la réalisation d’un autoportrait chiffré : les données deviennent notre miroir numérique. Ainsi, certains tentent de mieux maîtriser leur identité numérique. Une étude du Pew Institute14 révèle qu’un adolescent américain sur deux désactiverait la géolocalisation de son smartphone pour un meilleur contrôle de ses données. Un équilibre peut-il être trouvé dans la production de nos données personnelles ?La production de data fait appel à de nouveaux besoins et usages : la compréhension, le savoir, la comparaison et la compétition. Non seulement nous sommes créateurs de nos données, mais nous sommes aussi lecteurs de celles des autres. Nos attentes et besoins en terme de lectures numériques se sont considérablement transformés. Aujourd’hui, nous souhaitons davantage de la data rapide et synthétique afin d’en lire le plus possible. L’émergence
Bracelet connecté FuelBand de la marque Nike.
« Les données deviennent notre miroir numérique »
18
© N
ike

du datajournalisme au sein des plus grands quotidiens français, conjugué avec une utilisation plus importante des infographies pour décrire une situation politique ou économique, nous interroge sur nos comportements de lecture et d’analyse des médias. La consommation de l’information mute vers une consommation de la donnée. Le datajournaliste britannique David McCandless mesure toute l’importance de prendre du recul par rapport aux données brutes pour en réaliser des datavisualisations. « On change d’échelle, il y a toujours des informations, mais elles sont davantage liées entre elles. Le savoir, c’est cela : c’est la connexion des informations entre elles ».12
Demain, il est possible que nous cherchions à apprivoiser ce qui n’est pas mesurable aujourd’hui, comme l’humeur, la conviction ou la motivation.13 Déjà, certains Curriculum Vitæ prennent la forme d’infographies regroupant et croisant l’ensemble des données brutes maîtrisables et exploitables sur soi-même.
La donnée synthétiqueL’utilisation des smartphones et tablettes a transformé notre rapport à la lecture et à la recherche d’informations15. En effet, le besoin d’une donnée synthétique et compréhensible est devenu un nouveau mode de consommation de la data.
Par l’intermédiaire des brèves informatives, les lecteurs d’aujourd’hui sont devenus de véritables experts en veille informationnelle. Cette dernière se définit comme l’ensemble des stratégies mises en place pour rester informé tout en y consacrant le moins de temps possible et en utilisant des processus de signalements automatisés16. Parler de veille informationnelle pour l’utilisateur mobile est encore récent. En réalité, elle s’est démocratisée jusqu’à devenir un comportement social quotidien notamment par le biais du smartphone. En tant que consommateur de la donnée, l’utilisateur d’interfaces mobiles a presque ritualisé son rapport à l’information. De par cette activité continue et itérative, il réalise aussi bien une veille passive, permettant la récolte de données de manière massive (notamment par le biais des notifications), qu’une veille active, favorisant la recherche précise d’informations. Il est possible d’envisager un tel comportement avec d’autres TIC
Séance de sport qui permet de générer de la donnée personnelle.
La donnée synthétique est plus rapide-ment accessible via les appareils mobiles.
19
© D
R
© k
ris
krü
g

(Technologies de l’Information et de la Communication) comme l’ordinateur ou les objets connectés. Ce type de comportements n’est donc pas spécifique au smartphone : il est simplement plus visible dans notre quotidien. Le besoin d’une donnée synthétique est inhérent à cette nouvelle consommation de l’information.
Toutefois, cela ne nous empêche pas de créer une quantité particulièrement importante de data. À tel point qu’aujourd’hui, les scientifiques tendent à reconsidérer les fonctions de l’ADN humain non plus comme une simple mémoire de notre patrimoine génétique, mais comme une mémoire de nos données numériques. Selon Kenneth Cukier et Viktor Mayer-Schönberger, respectivement journaliste et professeur à l’université d’Oxford, « la masse d’informations disponibles est telle que, si on la répartissait entre tous les Terriens, chacun en recevrait une quantité 320 fois supérieure à la collection d’Alexandrie : en tout, 1200 exaoctets (millions de téraoctets). Si on enregistrait le tout sur des CD, ceux-ci formeraient cinq piles capables chacune de relier la Terre à la Lune »17. Le théoricien
Russel L. Ackoff avait lui remarqué qu’à partir d’une certaine masse de données, la quantité d’information baisse et devient mathématiquement nulle. C’est la traduction algébrique de l’adage « trop d’informations détruit l’information »18. Cette réflexion arithmétique se vérifie dans la sélection et le traitement numérique de la donnée. Elle est d’autant plus complexe et aléatoire lorsqu’il s’agit de l’humain, car l’information devient alors tributaire de l’attention, ainsi que de l’ensemble des facteurs affectifs et émotionnels. Par conséquent, chez l’homme, l’information devient d’abord une raison puis une motivation. Une information dénuée de sens est inutile pour le récepteur humain, même si elle est acceptable pour un robot. De même, une information chargée de sens, mais non animée par une énergie psychologique est stérile.
Dans le processus qui mène de la donnée à l’action chez l’homme (données > information > connaissance > sens > motivation), seules les deux premières étapes sont prises en compte dans la formulation de la théorie de l’information classique.
L’ADN : nouvelle mémoire des données humaines.
20
© E
stit
xu C
arto
n

Comme le confirme le théoricien de l’information Kevin Bronstein, l’ordinateur ne définit l’information que selon deux valeurs : le nombre de bits et l’organisation des sèmes (unité minimale de signification en linguistique). À contrario, le psychisme fait intervenir des facteurs dynamiques tels que la passion, la motivation, le désir ou encore la répulsion, qui donnent vie à l’information psychologique.19
Le besoin croissant de comprendre la donnée en un instant provoque l’apparition massive d’une nouvelle attente : la rapidité, à la fois d’un point de vue technologique, mais également vis-à-vis de la donnée.
La donnée instantanéeIl n’est pas rare de voir des personnes perdre leur self-control face à un ordinateur trop peu réactif. Une étude réalisée par Crucial, agence spécialisée dans les problématiques de stockage et mémoire numérique, indique que près d’un Français sur deux avoue avoir déjà agressé physiquement ou verbalement son ordinateur au cours des six derniers mois.
Par ailleurs, 62,4 % des Français se sentent énervés lorsque leur ordinateur fonctionne mal et 26,4 % se sentent impuissants20. D’autres études tendent à démontrer que nous sommes autant impatients vis-à-vis de l’accès à l’information que lors de la lecture de la donnée elle-même.Il est aujourd’hui primordial d’appréhender l’immédiateté de la data. L’étude de Phocuswright pour Travel Site Performance révèle que 8% des visiteurs d’un site de voyage abandonneront leur navigation si une page met entre 1 et 2 secondes à s’afficher. Si le chargement de la page persiste une seconde de plus, ce chiffre grimpe à 16%, puis à 31 % entre 3 et 4 secondes et enfin à 43 % lorsque le temps d’attente dépasse les 4 secondes21. L’analyse de l’expérience utilisateur démontre donc qu’aujourd’hui, le temps de réponse est devenu une donnée ergonomique essentielle. Jean-François Nogier22, spécialiste en ergonomie et webdesign, indique que « le temps de réponse influe sur l’utilisabilité du logiciel de deux manières. D’une part, c’est un facteur de stress. L’anxiété de l’utilisation augmente lorsque le temps de réponse s’allonge et qu’aucun affichage ne l’informe des traitements en cours. [...] D’autre part, le temps de réponse alourdit la charge de travail, car il oblige l’utilisateur à faire des efforts pour conserver en mémoire les informations nécessaires pour continuer sa tâche ». Jakob Nielsen23, également spécialiste dans l’ergonomie informatique, ajoute que « la réactivité d’une interface optimise les performances de l’utilisateur qui n’a pas à faire d’effort de mémorisation, tout en lui donnant la sensation d’avoir le contrôle. Après une seconde, l’utilisateur a l’impression d’attendre. Un temps de chargement
Un temps de chargement trop long fait abandonner la navigation d’un site internet.
21
© M
arti
n A
beg
glen

de quelques secondes sur un site suffit donc à lui donner une mauvaise impression. Si l’attente se répète, l’utilisateur risque de quitter le site ».Selon le psychiatre Jean Cottraux24, « nous vivons dans une culture de l’impulsivité de la génération zapping ». L’impatience est donc aujourd’hui un phénomène à prendre en compte lors de la diffusion de la donnée. Nous consommons de la data à tout moment, n’importe où, rapidement et en grande quantité. L’ensemble de ces comportements oblige les entreprises à repenser les contenus, les outils et les services liés au numérique. La datavisualisation fait partie de ces nouveaux moyens pouvant répondre à ces besoins sociaux émergents : la rapidité et l’accessibilité.
La compréhension de la donnéeDans son ouvrage « Internet rend-il bête ? »25, l’auteur américain Nicholas Carr questionne l’impact de l’environnement électronique sur notre état mental et notre comportement
social. Notre cerveau, extrêmement façonnable, se familiarise très vite aux nouvelles technologies26. Avant la révolution numérique, il s’est ainsi adapté à la naissance de l’écriture puis de l’imprimerie. Notre activité cérébrale s’est peu à peu transformée. Nous ne sommes pas moins intelligents, nous pensons différemment . En 2009, Gary Small, chercheur à l’Université de Californie, a comparé l’activité cérébrale d’internautes novices à celle d’internautes chevronnés lorsqu’ils utilisent un moteur de recherche. Il s’est ainsi aperçu que les plus expérimentés stimulaient plus de zones de leur cerveau27.La numérisation de notre quotidien a transformé notre cerveau de plusieurs manières. En 2011, le professeur Betsy Sparrow28 et son équipe de psychologues de l’Université de Colombia ont démontré que notre cerveau enregistre plus facilement le chemin pour aller chercher une information que l’information elle-même, ce qui prouve que notre mémoire visiospatiale (capacité à se
La data à tout moment, n’importe où.
22
« Il est en effet difficile pour notre cerveau de faire la différence entre ce qui est important et ce qui ne l’est pas »
© B
rad
Flic
kin
ger
© D
R

souvenir du chemin emprunté dans l’espace) a été améliorée. Cependant, il ne faut pas négliger que la modélisation cognitive d’une information mnésique reste plus difficile à construire. En effet, l’usage d’Internet rend la mémorisation à long terme plus délicate. La multiplication des tâches simultanées est en passe de devenir une pratique cognitive puissante dans cet environnement digital. Néanmoins, plusieurs études ont démontré que notre cerveau n’est pas totalement prêt à gérer le multitâche.On peut alors s’interroger sur le rôle d’Internet dans l’amélioration de nos capacités cognitives. Les travaux de Jérôme Dinet29, professeur en psychologie, montrent que les individus les plus connectés seraient les plus aptes à modifier leurs mécanismes mentaux et leurs connaissances afin de s’adapter à des situations nouvelles. Francis Eustache, directeur de recherche à l’INSERM, se demande si « les internautes ne vont pas développer de nouvelles compétences leur permettant de
rendre plus performante leur mémoire de travail dans ce type de situation. Ce n’est pas du tout impossible, notamment en développant des stratégies rapides qui leur permettent d’ordonner l’importance des informations à mémoriser ».
La transmission et la mémorisation des connaissances sont elles aussi bouleversées à cause de la masse de data accessible en ligne. « La profusion d’informations sur Internet peut être un leurre, car la connaissance a besoin d’être appropriée et pas simplement disponible. Avoir à portée de souris des bibliothèques ou des sites remplis de théorèmes de mathématiques ne se substituent pas à la connaissance acquise » souligne Emmanuel Sander30, professeur en psychologie. Or, Internet ne semble pas favoriser pas cette acquisition. Au contraire, les nouvelles technologies occasionnent un problème nouveau à l’attention, processus cognitif indispensable à l’apprentissage. Il est en effet difficile pour notre cerveau de faire la différence entre ce qui est important et ce qui ne l’est pas. Il est particulièrement compliqué de fixer son attention durant un processus d’apprentissage. Pour qu’Internet puisse être bénéfique à l’apprentissage, des chercheurs comme Nicole Boubée de l’université de Toulouse, ou encore Jean-François Rouet, Directeur de recherche au CNRS, pensent qu’il est nécessaire de prodiguer une éducation et une pédagogie du web31. La datavisualisation peut ainsi être envisagée comme une solution permettant la transmission et l’apprentissage des données importantes.
23
Il est nécessaire de prodiguer une éducation et une pédagogie du web.

24

03_
La datavisualisation : une solution aux besoins émergents.
A. Une réponse positive à nos spécificités cognitives
B. Un moyen de rendre plus accessible la donnée brute
C. Un moyen de s’adapter à chaque individu
25

Nous savons désormais que notre comportement vis-à-vis de l’information a été bousculé. À la fois créateurs, médiateurs et consommateurs de data, nous devons faire face à de nouveaux besoins. Sur plusieurs points, la datavisualisation s’apparente à une alliée de choix pour y répondre efficacement.
Une réponse positive à nos spécificités cognitivesComme nous l’avons constaté auparavant, Internet a un impact important sur la transformation de nos processus mentaux : mémoire, concentration, multitâche et
apprentissage sont autant de capacités cognitives redéfinies pour notre environnement numérique.Une étude réalisée par Mindlab International démontre que lors d’une prise de décision multitâche, nous utilisons 20 % de ressources cognitives en moins lorsque le support est visuel32. La perception visuelle, gérée par le cortex visuel qui analyse le stimulus reçu par la rétine, est extrêmement rapide dans le traitement de la donnée picturale. Le MIT appuie cette théorie grâce à une étude réalisée par le professeur Mary Potter en 2014.
LA DATAVISUALISATION :UNE SOLUTION AUX BESOINS ÉMERGENTS_
« Lire une image revient donc à faire le choix de la rentabilité cognitive »
03_
26

Dashboard de données Crédit AgricoleSociété 10h11, 2014.
Il a confirmé la capacité du cerveau humain à comprendre promptement une image en démontrant qu’une analyse picturale ne nécessite que 13 millisecondes de calcul33. Selon ce même test, les ordinateurs n’ont pas encore une capacité d’analyse d’image aussi rapide. Par conséquent, nous comprenons un visuel en un minimum d’effort : lire une image revient donc à faire le choix de la rentabilité cognitive. À contrario, l’analyse d’un texte ou d’une situation n’est pas gérée par le cortex visuel, mais par le cortex cérébral gauche. En 2007, le professeur Stanislas Dehaene34 démontre qu’il est beaucoup plus lent et qu’il a besoin d’une demi-seconde pour trouver la signification d’un terme. L’un des avantages majeurs de la datavisualisation
est de faire appel en priorité à ses capacités visuelles et ainsi augmenter la rapidité de captation de l’information.Elle permet de mettre en évidence les informations essentielles des données brutes et de les scénariser pour une meilleure transmission et mémorisation. Elle devient une solution pour aider notre cerveau à exploiter une masse importante de données.Le professeur Dehaene35 souligne également que la visualisation de données est à la fois un processus de mise en image, une analyse et une gestion de la donnée. Il est essentiel que ces trois éléments fonctionnent en parallèle pour que le lecteur, devenu spectateur, puisse bénéficier de la plus-value d’une
27
© 10h11

datavisualisation. C’est d’ailleurs la principale difficulté de l’élaboration d’une visualisation de données : elle ne se résume pas à un travail visuel, mais en un travail pluridisciplinaire, intégrant à la fois une problématique technique, une conception graphique et une analyse de la donnée intelligible.Cependant, choisir un bon dispositif visuel peut s’avérer complexe, surtout dans un contexte multidimensionnel comme le Big Data. Selon Antal E. Fekete, professeur de mathématiques et de statistiques, la visualisation de données permet d’envisager les data sous un angle nouveau : l’évident est mis en lumière et des interprétations cachées apparaissent. Son propos a notamment été illustré par John Tukey, l’un de ses confrères, qui a déclaré : « La plus grande valeur d’une image, c’est quand elle nous oblige à remarquer ce que nous ne nous serions jamais attendus à voir»36.Comme nous l’avons vu précédemment, le contexte de consommation de la donnée répond à une demande exponentielle de rapidité. Le besoin de comprendre et de transmettre une information rapidement est au cœur des attentes de chaque individu. Par l’infographie et l’analyse des données, la datavisualisation permet de maintenir un lien de diffusion simple
et rapide de la donnée et devient, par exemple, un moyen de réduire le temps passé sur les écrans.Elle est une ressource favorisant la communication entre l’entreprise et ses clients, entre les membres d’une même structure ou entre les institutions et les citoyens. Elle est créatrice d’interaction entre les individus et une solution pour répondre aux besoins de communication et de prise de décision rapide. Elle également est un atout à la data lui conférant un pouvoir opérationnel et permettant une prise de décision intelligente en simplifiant une donnée complexe.
« Un pouvoir opérationnel et une prise de décision intelligente »
Hiérarchisation des infor-mations afin de les rendre accessibles et inattendus.
28
Fête des Lumières, LyonSociété 10h11, 2014.
© 1
0h
11
© T
he
New
Yo
rk T
imes

Un moyen de rendre plus accessible la donnée bruteLa donnée est peut-être difficile à comprendre de par, sa quantité mais également de par sa qualité. Il peut être difficile de rendre compréhensible une donnée technique. En effet, un flux d’informations trop pointues peut entraîner le même type de processus cognitif chez l’homme que lorsqu’il est confronté à une masse d’informations importante. La datavisualisation par l’étude de la donnée va engendrer un processus de vulgarisation de l’information par l’image permettant à l’individu une meilleure compréhension, mémorisation et concentration lors de la réception de la data. La scénarisation de la donnée et son analyse vont permettre d’atténuer les deux principales difficultés liées à la data : la quantité et la complexité.À ce jour, il est même possible d’aller plus loin et de se servir de la datavisualisation
pour concevoir des services qualitatifs par la création d’interfaces numériques. Par exemple, au Canada37, des chercheurs ont pu localiser les infections chez les bébés prématurés avant que les symptômes visibles n’apparaissent. Pour y parvenir, ils ont généré un flux de plus de 1000 données/s, combinant seize indicateurs, parmi lesquels le pouls, la tension, la respiration et le niveau d’oxygène dans le sang. En réalisant une datavisualisation des données issues de ces indicateurs, ils sont parvenus à établir des corrélations entre des dérèglements mineurs et des maux plus sérieux. Michael Bloomberg, entrepreneur à succès dans l’industrie des données numériques et maire de New-York, utilise la visualisation de données pour renforcer l’efficacité des services publics et en diminuer le coût. Il a notamment amélioré la stratégie de prévention de la ville contre les incendies en enregistrant chaque année 25 000 plaintes pour des habitations
À New-York, la visualis-ation de données renforce l’efficacité des services publics.
29
© T
rain
Ph
oto
s

surpeuplées. La mairie a également créé une banque de données recensant les 9 000 bâtiments de la ville, complétée par les indicateurs de 19 agences municipales : liste des exemptions fiscales, coupures d’eau ou d’électricité, loyers impayés, etc. Il est important de préciser qu’aucune des caractéristiques retenues par les analystes ne peut être considérée en soi comme une cause d’incendie, mais mises bout à bouts, elles sont pourtant étroitement corrélées avec un risque accru de départ de feu. Cette expérience a facilité le travail des inspecteurs New-Yorkais. En effet, par le passé, 13% seulement de leurs visites donnaient lieu à un ordre d’évacuation. Cette proportion a grimpé à 70% après l’adoption de la nouvelle méthode.
Un moyen de s’adapter à chaque individuConcevoir une datavisualisation répond à un besoin de plus en plus important d’innovation sociale.Chaque collaborateur ou citoyen est remis au cœur des échanges et des prises de décisions : il est reconnu à la fois comme créateur de la data, mais aussi comme lecteur actif des données.
Ainsi, la visualisation de données est une solution pour répondre au besoin de recentrage sur l’humain et ses interactions. C’est un outil de mise en responsabilité des utilisateurs au sein d’un processus de décision. La réalisation d’une datavisualisation passe nécessairement par une analyse contextuelle et intelligente de la data. Il y a une prise de conscience que cette data est issue d’interactions humaines et que lui donner de la valeur, c’est aussi de lui offrir du sens social.Tout comme le neuromarketing, la datavisualisation peut se baser sur des particularités humaines et cognitives pour orienter positivement nos actions. Aujourd’hui, même si peu d’études sur l’impact de la datavisualisation dans notre quotidien ont été réalisées, il serait intéressant de porter la visualisation de données vers un objectif d’amélioration de la société et de prise de conscience. Les dérives numériques que nous avons pu relever : la perte de la sociabilité réelle, la baisse de la créativité ou encore l’information trop simplificatrice pourraient être rééquilibrées par la datavisualisation. Cette dernière est un
Une solution entre les data et les usagers.
30
© D
R
© Ia
n S
ane

Dette du gouvernement central en europe. Société 10h11, 2015.
moyen efficace permettant de répondre à l’ensemble des nouveaux besoins énumérés dans cette étude, à chacun ensuite, de choisir comment en faire l’usage. Elle est l’outil de référence en matière d’analyse, d’interprétation, de communication et d’exploration de la donnée.La représentation graphique est moteur d’innovation et porteuse de connaissances. Elle évolue naturellement comme une réponse logique aux comportements et besoins de la société connectée. Pour aller plus loin dans notre réflexion, 10h11 et son pôle Recherche & Développement contribuent à l’émergence d’études
scientifiques et de recherches centrées sur les nouveaux usages liés à la datavisualisation, ainsi que son efficacité et sa nécessité dans notre monde connecté. La visualisation de données contribue à améliorer notre rapport à la donnée pour modérer sa densité et sa complexité. C’est une pratique émergente qui s’harmonise avec les phénomènes sociaux et cognitifs de la data dans notre société. Cependant, il est indispensable de s’appuyer sur des méthodologies et des techniques existantes pour la mise en place de datavisualisations efficaces.
31
© 1
0h
11

32
Datavisualisation de la récurrence d’utilisation d’un mot dans le contenu du livre blanc. L’épaisseur et la taille des cercles varient en fonction du nombre d’utilisations.
CONVERGENCE RADIALESEGMENTÉE_ algorithme par Boris Muller
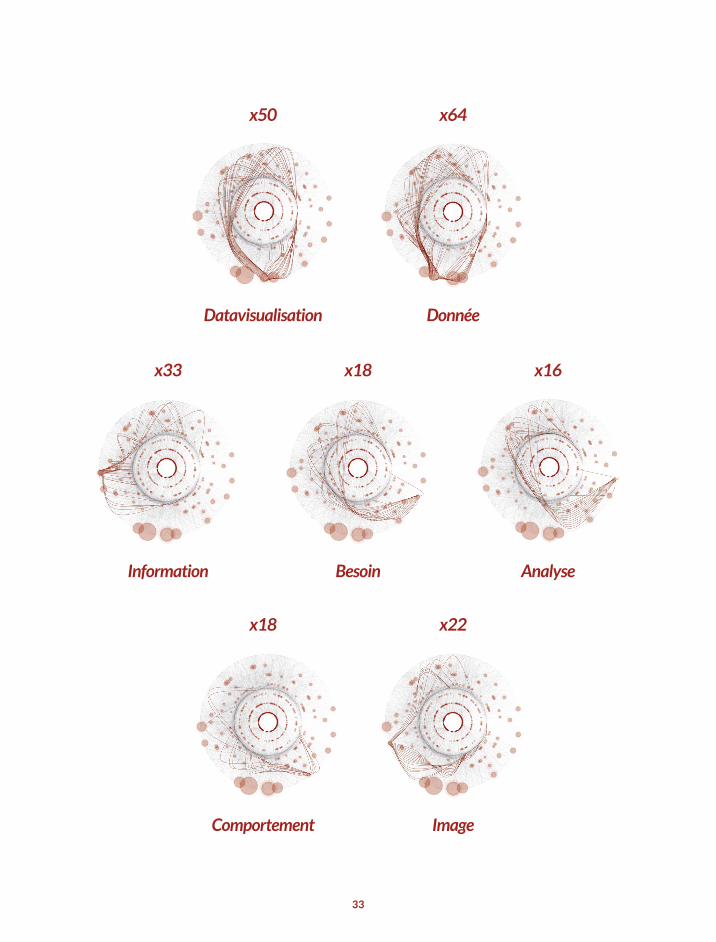
33
Datavisualisation Donnée
Comportement Image
Information Besoin Analyse
x50 x64
x18 x22
x33 x18 x16

34

04_
Méthodologie : Design de services et UX design appliqués aux données
35

04_
MÉTHODOLOGIE :DESIGN DE SERVICES ET UX DESIGN APPLIQUÉS AUX DONNÉES_
Nous avons constaté que de plus en plus d’entreprises souhaitent travailler avec leurs données et ont pris conscience que la datavisualisation peut les aider à produire un rendu plus compréhensible et plus accessible.
Cependant, lorsqu’elles démarrent en interne une réflexion à ce sujet, de nombreuses questions émergent : quel set de données dois-je utiliser ? Comment puis-je innover dans le rendu visuel ? Dois-je choisir une solution existante ou imaginer un outil sur mesure ?
L’équipe de 10h11 est confrontée au quotidien à ces problématiques. Pour y répondre, nous avons décidé de construire une méthodologie de travail pour aider les entreprises à structurer leur réflexion autour de la donnée.
Phase de récolte, aucune piste n’est à écarter.
36

PROBLÉMATIQUE
DONNÉES CLIENTS
OPEN DATA
DONNÉES PARTENAIRES
2 3 41Création LivraisonDécouverte
Idéation / Croquis / Recherches Itération / Prototypes / Conception
Définition
Méthodologie en double diamand
Quatre grandes étapes distinctes se succèdent de façon logique.La démarche va de la plus abstraite à la plus concrète et vise à appréhender au départ la complexité inhérente au projet, à ouvrir ensuite sur
toutes les solutions possibles, puis à resserrer pour sélectionner la solution la plus prometteuse et l’affiner au fur et à mesure au moyen des tests et de la co-création.
_
/ DÉMARCHE
37
Mettre l’accent sur le service et l’ergonomieLa visualisation de données est un savoir-faire qui demande un design de service personnalisé ainsi que sur une expérience utilisateur en adéquation avec les spécificités des sets de données.
Le design de services est l’application de la démarche et des compétences issues du design au développement des services. Il s’agit d’une approche pratique et créative pour améliorer les services existants et en créer de nouveaux. Le design d’expérience utilisateur (UX design) est une façon nouvelle et radicalement différente de penser les dispositifs numériques. Il modifie profondément les méthodes de travail, l’organisation et les compétences des équipes de projet. Le design d’expérience utilisateur est une démarche pragmatique, pluridisciplinaire, orientée vers la résolution des problèmes et résolument tournée vers l’innovation.
Le double diamant au service de la donnéePour construire notre méthodologie, nous nous sommes naturellement appuyés sur le principe du double diamant.
Le principe du «Double Diamond» a été développé au Design Council (Royaume-Uni) en 2005 en tant que moyen graphique simple pour décrire le processus de conception. Divisé en quatre étapes distinctes (la découverte, la définition, la création et la livraison) le schéma met en lumière les différents modes de penser que les concepteurs utilisent.
Adapté à la problématique de traitement de la donnée, le schéma devient un guide pratique pour envisager la conception un outil de visualisation de données.

DONNÉES CLIENTS
OPEN DATA
DONNÉES PARTENAIRES
21Découverte Définition
38
Le premier diamant est l’étape où l’ensemble du matériel récolté va servir de base à la génération des idées. Désignée par le néologisme « idéation », elle consiste à ouvrir le champ des possibles et à disposer du plus grand nombre de candidats (set de données
dans notre cas) pour sélectionner la meilleure solution en fonction du contexte du projet. Il est nécessaire de préciser que l’idéation est ici une phase rationnelle basée sur l’analyse de l’ensemble des sets de données à disposition.
UTILISATEURL’utilisateur, c’est-à-dire ses motivations, ses comportements, ses attentes et ses contextes d’utilisation.
CONTENUComprend l’information
et les services ; l’information recouvre tous les médias (textes,
images, sons, vidéos, données, fichiers...), les métadonnées
(mots-clés, catégories, dates, auteur…) et le contenu généré
par les utilisateurs ;
PROJET
CONTEXTELes objectifs du projet, la culture d’entreprise du commanditaire et les ressources dédiées au projet.
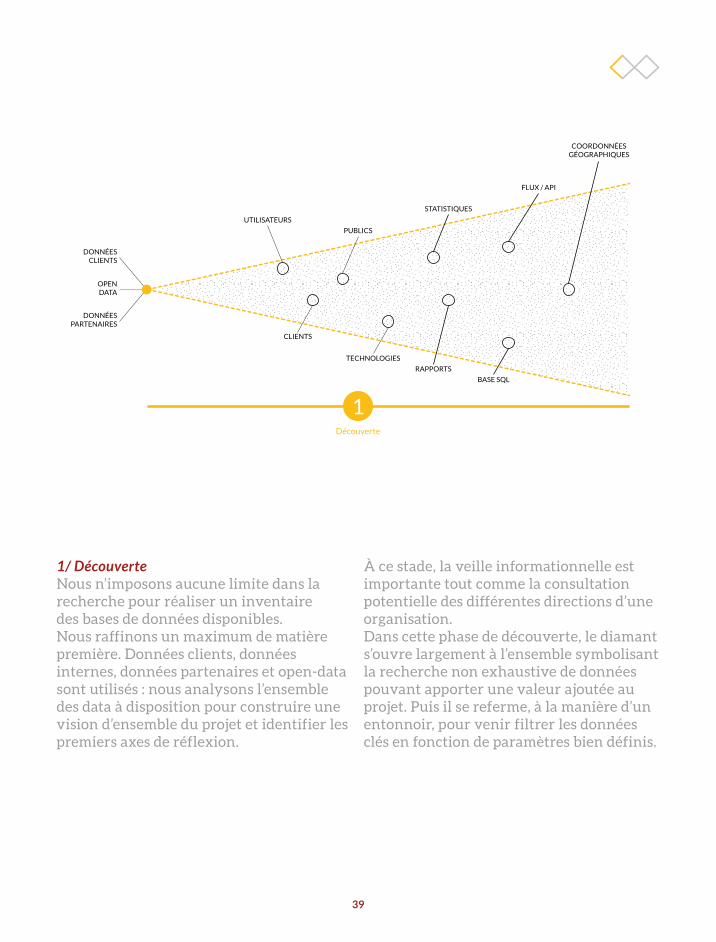
DONNÉES CLIENTS
UTILISATEURS
PUBLICS
TECHNOLOGIES
BASE SQL
RAPPORTS
CLIENTS
COORDONNÉESGÉOGRAPHIQUES
FLUX / API
STATISTIQUES
OPEN DATA
DONNÉES PARTENAIRES
1Découverte
La phase de découverte, qui combine la définition de lastratégie, la recherche sur les utilisateurs, l’inventaire du contenu et des données.
Cetteétape de démarrage vise à collecter toutes les informations nécessaires pourétablir la vision d’ensemble du projet et identifier les problèmes à résoudre.
_
/ DÉMARCHE
1/ DécouverteNous n’imposons aucune limite dans la recherche pour réaliser un inventaire des bases de données disponibles. Nous raffinons un maximum de matière première. Données clients, données internes, données partenaires et open-data sont utilisés : nous analysons l’ensemble des data à disposition pour construire une vision d’ensemble du projet et identifier les premiers axes de réflexion.
À ce stade, la veille informationnelle est importante tout comme la consultation potentielle des différentes directions d’une organisation.Dans cette phase de découverte, le diamant s’ouvre largement à l’ensemble symbolisant la recherche non exhaustive de données pouvant apporter une valeur ajoutée au projet. Puis il se referme, à la manière d’un entonnoir, pour venir filtrer les données clés en fonction de paramètres bien définis.
39

PROBLÉMATIQUE
2Définition
La phase de définition, qui va fixer le périmètre du projet (la portée du dispositif, les fonctionnalités et le contenu) à l’issue des séances d’idéation qui concernent tous les aspects du dispositif : structuration de l’information (catégorisation du contenu, qualification des données), design d’interaction
(comportement des éléments interactifs, parcours, tunnels d’inscription ou d’achat…), systèmes de navigation (menus, liens), design d’interface (mise en forme de l’écran) et design d’information (représentation, ordre et hiérarchie visuelle des éléments à l’intérieur de l’écran).
_
FLUX / API
UTILISATEURS
CLIENTS
STATISTIQUES
TECHNOLOGIES
/ DÉMARCHE
Définition : le choix du bouquetDans cette seconde étape, l’objectif est de choisir les grappes de données que nous allons conserver pour le projet. Il est rare de garder l’ensemble des données pertinentes identifiées. Les données conservées doivent nous amener à dégager une problématique globale à laquelle le futur outil devra répondre. Pour chaque étape à venir, nous veillerons à garder en tête la problématique que nous devrons résoudre. En effet, les projets de visualisation de données nous amènent souvent à sortir du cadre, à penser des interfaces singulières, mais cela ne doit pas se faire au détriment du sujet de départ et du besoin du commanditaire.
40
2/ Les marqueurs de sélection de la donnéeOutre la valeur ajoutée intrinsèque de chaque set, la question est : comment choisir la bonne donnée ? Nous avons défini 5 grands indicateurs à surveiller pour faciliter la conception du futur outil de visualisation : la responsabilité, la sécurité, le format, la mise à jour et l’historicité. ResponsabilitéIl est pertinent de connaître le responsable de chaque jeu de données ainsi que les interlocuteurs pour accéder à la donnée et pourvoir la monitorer rapidement. L’intérêt est de pouvoir lever des doutes sur l’exploitation de la donnée lors de la création des scénarios comme de l’outil.FormatLe format est prépondérant pour la partie analyse, mais également pour la partie

DONNÉES
2Autour de la donnée
SÉCURITÉRESPONSABILITÉ
HISTORICITÉ
FORMAT
MISE À JOUR
production. La donnée est-elle industrialisable ? Pouvons-nous facilement construire une base complète sous un unique format ? L’enjeu de l’exploitation réside en partie dans le format que nous allons devoir traiter. Mise à jourLa fréquence de mise à jour est essentielle pour bien choisir les sets de data. La donnée est-elle mise à jour de manière journalière, mensuelle, annuelle ? Par quel moyen ? Nous devons être en mesure d’anticiper la péremption comme le renouvellement de notre matière première. Si nous sommes amenés à comparer deux sets de données en temps réel qui n’ont pas la même fréquence de mise à jour, nous pouvons faire des erreurs involontaires d’interprétation.SécuritéLes données ne sont pas toutes ouvertes au
public. Certaines demandent un hébergement sur serveur protégé par mot de passe, mais d’autres ne peuvent simplement pas être maintenues sur un serveur externe au commanditaire. Ces protocoles de sécurité demandent à être identifiés en amont afin de limiter les mauvais choix technologiques. HistoricitéNous aimons à dire que la donnée est comme le bon vin, le temps nous permet de l’appréhender et de la comprendre avec une plus grande finesse. Pouvoir analyser une tendance en l’examinant dans le temps nous permettra de construire des hypothèses d’interprétation plus pertinentes. Toujours en relation avec le contexte de départ, le niveau d’historicité est à mesurer sur l’ensemble des sets disponibles.
41
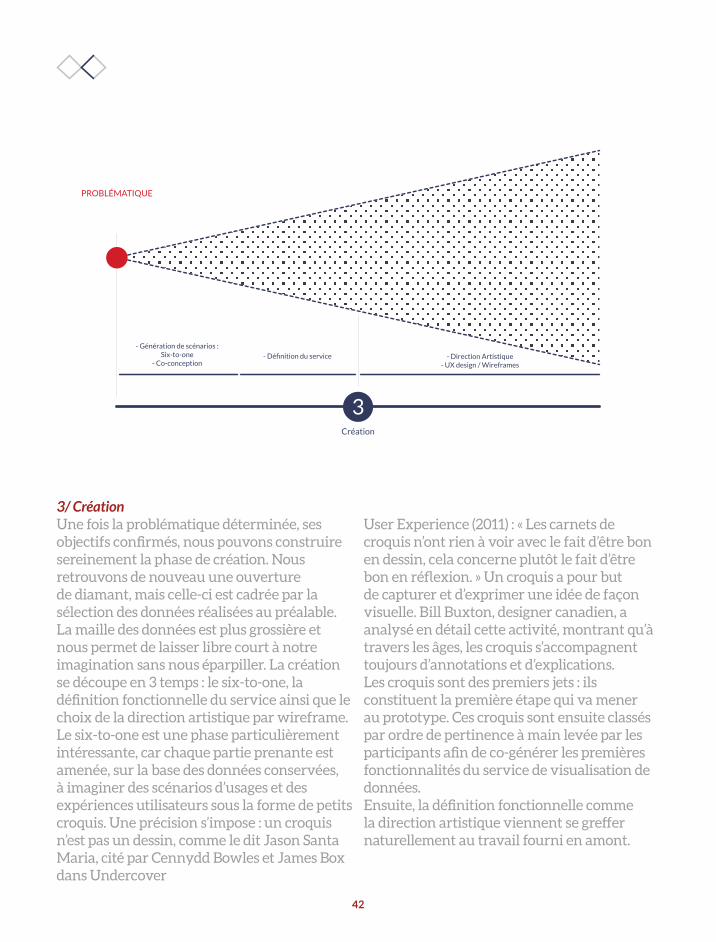
3Création
La phase de prototypage qui sert à réaliser, sous forme de maquettes, les solutions retenues à l’issue de la phase précédente ;
c’est une phase d’itération dédiée aux tests des prototypes et à leurs modifications successives en fonction des retours des utilisateurs.
—
- Génération de scénarios : Six-to-one
- Co-conception- Direction Artistique
- UX design / Wireframes
PROBLÉMATIQUE
- Définition du service
/ DÉMARCHE
3/ CréationUne fois la problématique déterminée, ses objectifs confirmés, nous pouvons construire sereinement la phase de création. Nous retrouvons de nouveau une ouverture de diamant, mais celle-ci est cadrée par la sélection des données réalisées au préalable. La maille des données est plus grossière et nous permet de laisser libre court à notre imagination sans nous éparpiller. La création se découpe en 3 temps : le six-to-one, la définition fonctionnelle du service ainsi que le choix de la direction artistique par wireframe.Le six-to-one est une phase particulièrement intéressante, car chaque partie prenante est amenée, sur la base des données conservées, à imaginer des scénarios d’usages et des expériences utilisateurs sous la forme de petits croquis. Une précision s’impose : un croquis n’est pas un dessin, comme le dit Jason Santa Maria, cité par Cennydd Bowles et James Box dans Undercover
User Experience (2011) : « Les carnets de croquis n’ont rien à voir avec le fait d’être bon en dessin, cela concerne plutôt le fait d’être bon en réflexion. » Un croquis a pour but de capturer et d’exprimer une idée de façon visuelle. Bill Buxton, designer canadien, a analysé en détail cette activité, montrant qu’à travers les âges, les croquis s’accompagnent toujours d’annotations et d’explications. Les croquis sont des premiers jets : ils constituent la première étape qui va mener au prototype. Ces croquis sont ensuite classés par ordre de pertinence à main levée par les participants afin de co-générer les premières fonctionnalités du service de visualisation de données. Ensuite, la définition fonctionnelle comme la direction artistique viennent se greffer naturellement au travail fourni en amont.
42

4Livraison
La phase de réalisation du dispositif à partir des prototypes finaux de laphase précédente. Cette phase correspond au design graphique, ainsi qu’au
travail de développement pour aboutir à la livraison finale.—
- Design graphique- Spécifications fonctionnelles détaillées
- Développement- Livraison
/ DÉMARCHE
4/ LivraisonLe second diamant se referme par la validation d’un cahier de spécifications fonctionnelles, validé par le commanditaire après plusieurs itérations, qui décrit, avec beaucoup de précisions, le futur outil imaginé. Le contexte projet, les sets de données avec la sélection effectuée, les choix technologiques, les maquettes graphiques et les explications d’ergonomie détaillées y sont rappelés afin que le commanditaire obtienne un rapport complet sur l’exploitation de sa donnée.Ce document est un rapport exploitable en interne dans l’entreprise comme au niveau des développeurs pour une mise en production.
Nous appelons audit de données l’ensemble du travail fourni sur le double diamant jusqu’à la livraison du cahier des spécifications fonctionnelles.
Pour confronter la méthodologie à un cas concret, nous avons choisi le projet Goria, un service de visualisation de données d’objets connectés. Afin de ne pas avoir de limite sur le plan de la confidentialité comme de la propriété intellectuelle, nous avons sélectionné volontairement un projet de R&D interne à l’entreprise.
43

GORIA :SUJET D’APPLICATION DE LA MÉTHODOLOGIE_
L’aventure commence maintenant.
44
L’équipe de 10h11 a travaillé en interne sur la thématique des objets connectés. Nous souhaitions créer un outil de visualisation des données d’objets connectés qui soit plus facilement compréhensible par ses usagers et qui apporte une valeur ajoutée dans ses fonctionnalités.
Nous vous proposons de découvrir l’ensemble du processus de création de manière synthétique. Il vous permettra de naviguer de manière concrète dans chaque phase du double diamant.

ContexteAlors que 9 milliards d’objets et de capteurs seraient déjà reliés aujourd’hui à Internet, ce nombre devrait être multiplié par cinq d’ici à 2020. 85% du marché sera représenté par des objets connectés directement à Internet ou via un terminal intermédiaire (données sont stockées dans le cloud). Le rythme de croissance des objets connectés va rapidement dépasser celui des PC, tablettes et smartphones, dont l e nombre est estimé par Gartner à 7,3 milliards d’unités actives en 2020. Partant de ce constat, nous avons répertorié l’ensemble des objets connectés disponibles aujourd’hui sur le marché et vérifié les paramètres suivants : La donnée est-elle sécurisée et accessible de manière automatique ?
Quel est le protocole d’accès disponible à la donnée ?Quelle est la fréquence de mise à jour d’appel de la donnée pour chaque objet connecté ?Quel est le format disponible pour monitorer la donnée ?Ces questions nous ont amenés à faire le tri sur l’ensemble des objets connectés pour choisir, sur notre première itération, qu’un seul type de données ayant les caractéristiques suivantes : Les données appartiennent à un provider leader du marché actuel permettant d’envisager une taille critique d’utilisateur ;Une donnée est sécurisée par identifiant / mot de passe et nous pouvons la rapatrier via un protocole API afin de sécuriser son transfert et automatiser son traitement.
GORIA : PHASE 01 >LA DÉCOUVERTE : ANALYSE DE LA DONNÉE DISPONIBLE_
45

Nous avons observé que les utilisateurs des objets connectés dits « wearable », sont intéressés par leurs performances personnelles. Au-delà du phénomène de quantification de vie, le « quantified self », les services actuels ne permettent pas d’avoir une vision d’ensemble, structurée, optimisée des différentes pratiques physiques, sociales et géographiques des usagers. De plus, ils ne prennent pas en compte la grande infidélité des utilisateurs qui changent de marques d’objets connectés à chaque nouvelle vague technologique.Nous avons décidé, sur la base des données disponibles que nous possédions,
GORIA : PHASE 02 > DÉFINITION DU PRODUIT_
46
de positionner notre produit comme catalyseur de données des objets connectés leaders sur le marché. Nous avons aussi pris conscience de l’importance de la géolocalisation dans notre service par l’émancipation des apps de tracking sportives sur le marché. Sans être un objet, les apps deviennent des providers de data intéressants à relier à notre produit. Runkeeper, par exemple, est alors apparu comme le service indispensable à rajouter étant donné qu’il était leader sur son marché et qu’il répondait aux critères précédemment choisis en phase de découverte.Nous avons sélectionné les grappes de data suivantes en fonction des providers :
Sommeil
Social
GéolocalisationSanté
Météo
Sport

Croisement des données récoltées afin d’en dégager une problématique pertinente et innovante.
Problématique :
Comment créer un nouveau service proposant une visualisation des données issues de différents objets connectés, qui soit à la fois pédagogique et monitorable pour l’utilisateur ?
47

GORIA :PHASE 03 > CRÉATION_
scénario 04
scénario 05
scénario 06
scénario 01
scénario02
scénario03
48
Le six-to-oneLe Six-to-One est une méthode collective que Cennydd Bowles et James Box ont mise en place à partir des exercices créés par Leah Buley et Brandon Schauer d’Adaptive Path. Chaque participant reçoit un gabarit de six formes simples, appelé le « six-up », dans lequel il doit dessiner six versions de scénario dans un temps limité (cinq à dix minutes). Le six-to-one est la partie créative de la méthodologie. En effet, nous sommes une nouvelle fois dans l’ouverture puisque, sur la base des données et providers sélectionnés, nous devons imaginer le service potentiel que fournit l’outil de visualisation. Nous vous proposons de consulter certains des scénarios créés par notre équipe au cours de ce travail. Étant donné que chaque participant réalise six planches, nous avons généralement une trentaine de planches à étudier à la fin de ce brainstorming d’usage.

Scénario 1Je cours avec mon bracelet Nike et je dors avec mon bracelet Jawbone. Je ne peux pas comparer mes courses et mon sommeil sur un dashboard unique. Je me connecte au nouveau service et je peux croiser visuellement mes données afin de mieux comprendre mes comportements.
Scénario 2J’ai perdu les identifiants des dashboards qui me permettent d’aller voir mes données des providers. De ce fait, je ne vais que sur un seul dashboard, mais je ne vois que mes activités cardiaques et mon nombre de pas. Le nouveau service centralise les données en un seul lieu avec un accès rapide et simple par un unique identifiant / mot de passe.
Scénario 3J’ai l’impression d’avoir fait les mêmes activités que d’habitude, je me sens fatiguée, mais je ne comprends pas pourquoi. Je me connecte au nouveau service et je vois qu’en réalité j’ai marché 3 fois plus que d’habitude. De plus, la géolocalisation me rappelle que je viens d’effectuer sur les 3 derniers mois plusieurs déplacements à l’étranger. Je suis en mesure d’appréhender mon temps de récupération moyen par rapport à un décalage horaire.
Scénario 4J’ai changé d’objet et de provider, mais je ne peux pas lier les données de l’ancien objet avec mon nouveau. Je n’ai pas de suivi historique de mes données ! Avec le nouveau service, je peux changer d’objet et sa source de données sera ajoutée à l’ancienne base.
Scénario 5J’ai reçu une montre connectée à Noël, mais je ne comprends pas l’intérêt de mes données si elles ne m’apprennent rien. Le nouveau service permet de croiser les données et de développer une intelligence artificielle simple par la prise en compte du contexte pour valoriser le temps des activités.
Scénario 6Cela fait 2 ans que j’utilise mon bracelet connecté. Ces derniers mois, j’ai perdu plusieurs kilos, mais je n’arrive pas à comprendre pourquoi. Le nouveau service permet de visualiser par planche les différentes données d’activités, de santé, de sommeil, de météo et de géolocalisation pour m’aider à comparer et visualiser les indicateurs m’ayant permis de perdre du poids.
49
La conclusion synthétique du six-to-oneLe six-to-one fournit ci-dessus n’est qu’une fine partie de l’ensemble du travail mené en scénarisation sur Goria. Cependant, il permet d’appréhender de manière plus concrète cette phase de travail. Retenons que les scénarios d’usages doivent nous aider à choisir les fonc-tionnalités principales de notre outil.

GORIA :PHASE 03 > DÉFINITION DU SERVICE_
Suite à la récolte des six to one, le service est défini afin de construire une ligne directrice pour les étapes suivantes.
50

Goria vous propose de retrouver l’ensemble de vos données liées aux objets connectés et applications de tracking sur un seul dashboard unique. La compilation des données permet de fournir à l’utilisateur une intelligence artificielle permettant d’améliorer son quotidien.
CentralisationLes utilisateurs possèdent plusieurs objets ou Apps de tracking. Ils n’ont pas d’endroit où centraliser et visualiser leur donnée.Goria propose un Dashboard de l’ensemble des données personnelles.
CroisementLes utilisateurs possèdent plusieurs objets ou Apps de tracking. Ils désirent pouvoir croiser leurs données pour mieux les interpréter et mieux comprendre leurs habitudes.Goria propose un Dashboard croisé de l’ensemble des données personnelles.
IntelligenceLes utilisateurs possèdent plusieurs objets ou Apps de tracking. Ils souhaitent améliorer leur vie avec ses données, mais aucun service ne propose un algorithme basé sur les
données personnelles.Goria propose l’intelligence artificielle la plus puissante du marché.
Récupération / ConservationLes utilisateurs changent régulièrement d’objets ou d’Apps de tracking. Leurs données ne sont pas récupérées ni conservées lorsqu’ils changent d’appareil.Goria propose plusieurs connexions d’appareils simultanément.
Habitude / DépendanceLes utilisateurs ont des habitudes d’usage sur certaines plateformes liées au lien social ou encore à la confidentialité qui freinent cette migration complète.Goria propose plusieurs connexions d’appareils simultanément pour accueillir ces utilisateurs.
51

GORIA :PHASE 03 > RECHERCHES ET WIREFRAMES_
Goria V1 :Pour imaginer la visualisation de données Goria, nous avons souhaité mettre l’accent sur l’accessibilité et la hiérarchisation des flux de données afin de répondre à notre besoin de pédagogie dans la navigation ainsi que de monitoring rapide.Nous avons construit un tableau de bord par planche de couleur full screen dédié à chaque typologie de données. Ce choix graphique nous permet d’obtenir une ergonomie qui respecte la lisibilité des données en accord avec la ligne de flottaison d’un ordinateur. Ce design permet aussi une identification rapide des jeux de données et permet d’envisager différentes versions mobiles reponsive par blocs de couleurs. Enfin, chaque utilisateur peut jouer avec ses données en choisissant un affichage annuel, mensuel, hebdomadaire ou encore journalier dans chaque partie inférieure de chaque bloc de couleur.
52

GORIA :PHASE 04 > MAQUETTAGE_
Maquettage Il y a toujours un écart entre les wireframes et les écrans graphiques. Logo, couleurs, polices de caractères et vocabulaire graphique (pictogrammes, icônes, filets, ombres...) vont donner de la personnalité à l’interface. Le choix des visuels et des cadrages va aussi transformer l’aspect général, avec une part d’interprétation et de création qui tient à la personne qui en est chargée.
Partition colorimétrique des différentes parties du dashboard. Exemple ci-contre : santé.
Maquettage sur différents écrans afin de rendre accessible le service sur tous les supports digitaux : fixes ou portables.
53

GORIA :PHASE 04 > DÉVELOPPEMENT & LIVRAISON_
pas stockées sur nos serveurs, mais captées en temps réel. Elles sont cependant mises en cache pour des raisons de performances. Les données cachées ne sont pas exploitables telles quelles et le cache expire au bout d’une courte période.
Les données sont obtenues par le protocole Oauth (oauth 1 ou 2 selon les fournisseurs).Ce protocole permet à l’utilisateur et à son fournisseur de garder un contrôle total sur l’accès aux données par Goria. Lors de la phase de connexion, l’utilisateur ne transmet jamais à la plateforme ses identifiants de connexion, mais un « jeton » qui peut être expiré par le fournisseur selon sa politique interne. Même si les API de chaque fournisseur utilisent le protocole Oauth, chacune d’entre elles fournit ses données selon son propre modèle. La difficulté principale de l’agrégation de data reste la renormalisation des données reçues.
Si nous sommes amenés à développer le moteur d’intelligence artificielle, les données seront agrégées et stockées afin d’être analysées. Cependant, même une fois stockées, l’utilisation de ses données répond à l’acceptation des conditions d’utilisation de chaque fournisseur. Goria s’engage, dans sa propre police de confidentialité, à respecter ces conditions.
54
Choix technologiques : Opensource et réactivitéNous avons fait le choix d’utiliser une structure back/front communiquant via une API privée.
1er choix, le backend : Nous utilisons le framework Ruby on Rails. Un framework solide, qui a fait ses preuves, activement soutenu par une communauté open source très impliquée.2d choix, le frontend : Nous utilisons le framework Angular. Un framework JS en pleine expansion, activement soutenu par Google. Il permet une organisation rigoureuse du front et une gestion des données dynamiques.3e choix, l’hébergement : l’application est actuellement hébergée sur Heroku, un Paas qui nous permet de nous concentrer sur le développement plutôt que sur la plateforme. Ce service délivre par ailleurs une montée en charge très rapide si la plateforme enregistre un pic de connexion.
Sécurité et temps réel pour gérer la donnéeComme mentionné au préalable, toutes les données proviennent des APIs des différents fournisseurs que sont Withings, Jawbone ou encore Facebook et Runkeeper.Pour assurer une sécurité et une confidentialité dans le traitement des données, celles-ci ne sont
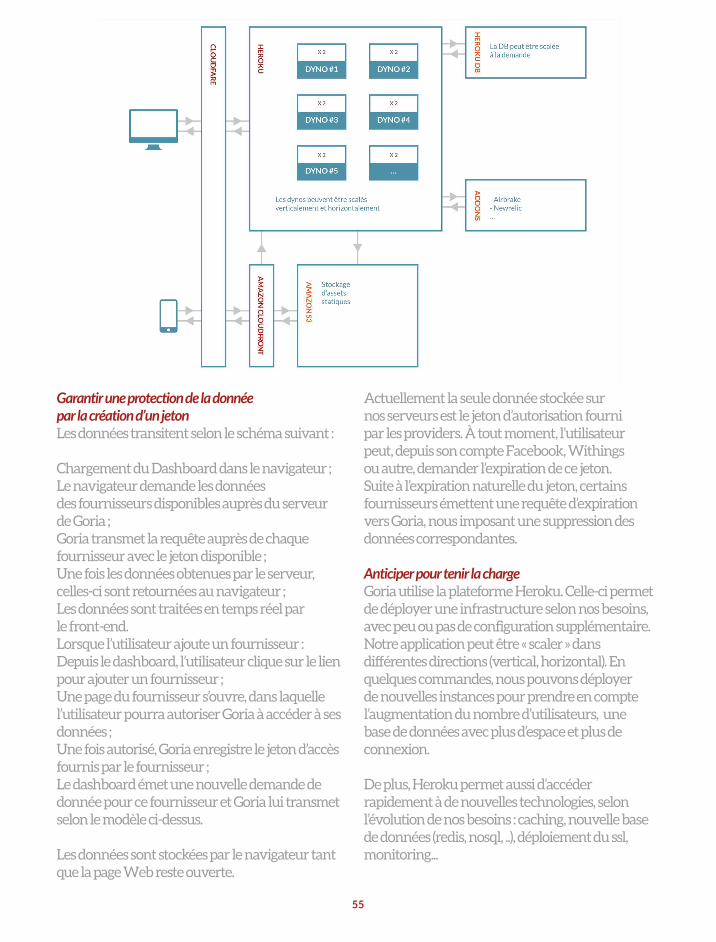
Garantir une protection de la donnée par la création d’un jetonLes données transitent selon le schéma suivant :
Chargement du Dashboard dans le navigateur ;Le navigateur demande les données des fournisseurs disponibles auprès du serveur de Goria ;Goria transmet la requête auprès de chaque fournisseur avec le jeton disponible ;Une fois les données obtenues par le serveur, celles-ci sont retournées au navigateur ;Les données sont traitées en temps réel par le front-end.Lorsque l’utilisateur ajoute un fournisseur :Depuis le dashboard, l’utilisateur clique sur le lien pour ajouter un fournisseur ;Une page du fournisseur s’ouvre, dans laquelle l’utilisateur pourra autoriser Goria à accéder à ses données ;Une fois autorisé, Goria enregistre le jeton d’accès fournis par le fournisseur ;Le dashboard émet une nouvelle demande de donnée pour ce fournisseur et Goria lui transmet selon le modèle ci-dessus.
Les données sont stockées par le navigateur tant que la page Web reste ouverte.
55
Actuellement la seule donnée stockée sur nos serveurs est le jeton d’autorisation fourni par les providers. À tout moment, l’utilisateur peut, depuis son compte Facebook, Withings ou autre, demander l’expiration de ce jeton. Suite à l’expiration naturelle du jeton, certains fournisseurs émettent une requête d’expiration vers Goria, nous imposant une suppression des données correspondantes.
Anticiper pour tenir la chargeGoria utilise la plateforme Heroku. Celle-ci permet de déployer une infrastructure selon nos besoins, avec peu ou pas de configuration supplémentaire. Notre application peut être « scaler » dans différentes directions (vertical, horizontal). En quelques commandes, nous pouvons déployer de nouvelles instances pour prendre en compte l’augmentation du nombre d’utilisateurs, une base de données avec plus d’espace et plus de connexion.
De plus, Heroku permet aussi d’accéder rapidement à de nouvelles technologies, selon l’évolution de nos besoins : caching, nouvelle base de données (redis, nosql, ..), déploiement du ssl, monitoring...

GORIA V1.1 :RETOURS EXPÉRIENCES UTILISATEURS > IDÉATION & ITÉRATION_
56

Retours expériences utilisateursL’expérience utilisateur pour améliorer le produit. Suite à la sortie de la version 1 du projet Goria, le service a été soumis à des expériences utilisateurs tant dans le service lui-même que dans l’interface. L’expérience utilisateur est un terme qui tente de qualifier le résultat (bénéfice) et le ressenti de l’utilisateur (expérience) lors d’une manipulation (utilisation provisoire ou récurrente) d’un objet fonctionnel ou d’une interface homme-machine. Il sous-entend un impact émotionnel cumulé à un bénéfice rationnel.Ces retours sont primordiaux pour le projet tant pour l’utilisateur du produit que pour le commanditaire. Cela permet une compréhension et une optimisation du service de visualisation. Les retours expériences utilisateurs sont réalisés grâce à différents indicateurs : feedback par mail des utilisateurs, visualisation des zones d’utilisation du produit, KPIs de données analytics, veille et adaptation aux nouvelles interfaces ( montres connectées, applications mobiles...), récupération des billets d’humeurs de l’utilisateur par l’interface ou encore questionnaire de satisfaction.
L’itération pour l’optimisationAfin de rendre compte visuellement des itérations possibles lors de l’optimisation du service Goria, nous avons repris le schéma
57
du double diamant pour y apporter, dans chacune de ces étapes, une phase d’itération. Le principe est simple, sur la base des retours utilisateurs, nous avons repris chacune des phases du projet afin de revenir sur nos travaux et les questionner. L’itération demande un bon archivage de l’ensemble des livrables remis à chaque étape du double diamant afin de revenir rapidement sur la première pensée et la remettre en question.L’objectif n’est pas de détruire ce qui a été fait, mais bien au contraire de bâtir de nouvelles propositions à partir de l’existant. Pour Goria, la reprise de l’ensemble des datas disponibles nous a permis de constater que nous devions devenir fournisseur d’une donnée personnelle afin de fidéliser plus facilement nos utilisateurs et développer une intelligence artificielle propre à notre service : une donnée d’humeur. Au regard des retours utilisateurs, la visualisation de données devait devenir plus précise et mobile. Nous avons fait le choix de repenser l’entrée à la donnée par l’insertion d’une navigation par calendrier ainsi qu’un déploiement sur mobile et montre connectée du service.

58
GORIA V2 :PORTABILITÉ ET OPTIMISATION DE LA NAVIGATION_
Suite au retour d’expériences utilisateurs, la version 1.1 de Goria propose une naviga-tion par date. Outre le fait de choisir plus aisément la période d’usage des données, le calendrier permet, en un coup d’oeil, de saisir la tendance de bien-être de l’utilisateur. En effet, par l’usage de simples pastilles visuelles de couleur rouge, grise ou verte, l’utilisateur peut constater si son humeur était négative ou positive pour chaque journée et saisir la tendance hebdomadaire ou mensuelle facilement.Lors du clic sur une pastille, l’utilisateur se retrouve plongé dans les données de la
Nouvelles navigations optimisées pour les différents écrans et choix de plages temporelles de visualisations.

59
Navigation optimisée pour les interfaces des objets connectés.
Application et wireframe.
journée concernée. Sur iPad, une barre de navigation fixe à droite est disponible pour le pouce de l’utilisateur. Cette navigation reprend les «charts» graphiques de chaque planche de couleur afin d’améliorer la rapidi-té et la fluidité de la navigation.
Une donnée d’humeurLa donnée d’humeur se comprend à la première lecture par l’utilisateur. Nous respectons le design mobile en « touch » en créant un système de pastille auquel nous associons un smiley ainsi qu’une couleur. En un « touch », l’utilisateur vient saisir sur ce
baromètre de sourire son ressenti personnel.L’application permet en complément d’obte-nir une visualisation par date, point fort de la V1.1, mais aussi en preview, un accès rapide à la donnée.
Adaptation à la dynamique du marchéDans la saisie de donnée d’humeur comme dans la consultation des données générales, les interfaces s’étendent désormais aux mon-tres connectées. La version 1.1 devrait être op-timisée pour ces nouveaux usages prometteurs.

05_
SOURCES_
1_ M.Lima, 2014, « La visualisation est un des grands défis de ce siècle »: Vidéo : http://digup.tv/video/ma-nuel-lima
2_ A.Paivio, E.Clark, 1973/1989, cité par N.J.T.T.Thomas, 2014, « Dual Coding and Common Coding Theories of memory », Stanford Encyclopedia of philosophy
3_ M.Karmes, 2014, « La datavisual-isation constitue-t-elle une réponse à l’amélioration du processus d’intelli-gibilité dans l’open-data ? », Mémoire de fin d’études, Master conception production écriture audiovisuelle et multimédia
4_ R.Barthes, 1964, « La rhétorique de l’image », in Communication, V4, N°4
5_ E. Jamet, 1998 « L’influence des formats de présentation sur la mémorisation », in Revue de Psy-chologie de l’éducation, N°1
6_ Data Sciences Sociales, 2014, « Analyse quantitative contenus 2.0 », article blog : http://data.hypotheses.org
7_ Teckmark, 2014, cité par Ouest-France, 2014, « Checky, l’appli qui mesure votre addiction aux smart-phones »
8_ Téléphonie Mobile 02, 2014, cité par TerraFemina, 2013, « On regarde plus notre smartphone que notre homme »
9_ S.Brin, 2013, cité par Libération, « Vie connectée - « l’âge de l’intuition technologique », 2013
10_ BVA, 2013, Etude sur la confi-dentialité des données sur internet : http://www.bva.fr/fr/sondages/la_confidentialite_des_donnees_sur_internet.html
11_ D.Cardon, 2012, « regardez les données », in Multitudes, 2012/2, N° 49
12_ D.McCandless, 2014, cité par Courrier International, 2014, « L’appétit pour le datajournalisme va encore grandir »
13_ J.E.G.Larsen, 2013, cité par Internet Actu.net , 2013, « La mise en scène de soi »
14_ V.Hollocou, 2012, « La gestion de l’identité numérique des adolescents sur le réseau social Facebook », Mémoire fin d’études, Master Information et communication de Toulouse
15_ Le Monde, 2014, « Lire sur smartphone est tellement addictif que j’ai arrêté les livres papier », article blog : http://www.lemonde.fr/livres/article/2014/02/19/lire-sur-smartphone-est-tellement-addic-tif-que-j-ai-arrete-les-livres-papi-er_4369688_3260.html
16_ Lardy J.-P, 2009, cité par Hay L., 2009, « La veille sur Internet en 5 étapes clés », in culturenum, Article blog : https://culturenum.info.uni-caen.fr/blogpost/wfylz84hi06/view
17_ K. Cukier, V. Mayer-Schön-berger, 2013, « Mise en données du monde, le déluge numérique », in Le monde diplomatique, article blog : http://www.monde-diplomatique.fr/2013/07/CUKIER/49318
18_ R.Ackoff, Théorie de l’informa-tion cité par Techno-Science.net, 2009, « La théorie de l’information », article blog : http://www.tech-no-science.net/?onglet=glossaire&-definition=10716
19_ K.Bronstein, Théorie de l’infor-mation, 2013, cité par C.Shannon, « Claude Shannon, painted por-trait – la théorie de l’information », article blog : http://www.mestechs.fr/claude-shannon-painted-por-trait-la-theorie-de-linforma-tion-_1010156.html
20_ Crucial, 2013, cité par Blog du modérateur, 2013 « Un français sur deux est agressif contre son ordi-nateur quand il rame », article blog : http://www.blogdumoderateur.com/un-francais-sur-deux-est-agressif-contre-son-ordinateur-quand-il-rame-concours/
21_ Phocuswright, 2010, cité par ergonomie-interface.com, 2010, « Vitesse de chargement des pages web: un critère ergonomique», article blog : http://www.ergonomie-in-terface.com/internet-web-site/vitesse-chargement-pag-es-web-critere-ergonomique/
22_ J.F.Nogier, 2011, « Ergonomie des interfaces - Guide pratique pour la conception des applications web...: Guide pratique pour la conception des applications web, logicielles, mobiles et tactiles», ed Dunod
23_ J.Nielsen, 2010, « Slow page rendering today is typically caused by server delays or overly fancy page widgets, not by big images. Users still hate slow sites and don’t hesitate tell-
60

ing us. », article blog : http://www.nngroup.com/articles/website-re-sponse-times/
24_ J.Cottraux, 2001, « Répétition des scénarios de vie : demain est une autre histoire », ed Odile Jacob
25_ N.Carr, 2011, « Internet rend-il bête ? », ed Robert Laffont
26_ O.Houdé, cité par D.Cedric, 2012, « L’impact du web en 4 ques-tions », in La recherche, article blog : http://www.larecherche.fr/savoirs/dossier/1-impact-du-web-4-ques-tions-01-09-2012-91553
27_ G. Small et al., 2009, in . J. Ger-iatric Psychiatry, V17, N°2, cité par D.Cedric, 2012, « L’impact du web en 4 questions », in La recherche, article blog : http://www.larecherche.fr/savoirs/dossier/1-impact-du-web-4-questions-01-09-2012-91553B. Sparrow et al. 2011, in , Science, N°772, cité par D.Cedric, 2012, « L’impact du web en 4 questions », in La recherche, article blog : http://www.larecherche.fr/savoirs/dossier/1-impact-du-web-4-ques-tions-01-09-2012-91553
28_ J. Dinet, 2003, in Psycholo-gie française, V48, N°3, cité par D.Cedric, 2012, « L’impact du web en 4 questions », in La recherche, article blog : http://www.larecherche.fr/savoirs/dossier/1-impact-du-web-4-questions-01-09-2012-91553
29_ E.Sander, cité par D.Cedric, 2012, « L’impact du web en 4 questions », in La recherche, article blog : http://www.la-recherche.fr/savoirs/dossier/1-impact-du-web-4-questions-01-09-2012-91553
30_ N.Boubée, 2011, « L’Activité in-formationnelle juvénile », ed Hermès Sciences Publications
31_ A.Wang, cité par tempsreel.nou-velobs.net, 2014, « La dépendance au smartphone, un mal croissant chez les jeunes », article blog : http://tempsreel.nouvelobs.com/topnews/20140615.AFP9649/la-de-pendance-au-smartphone-un-mal-croissant-chez-les-jeunes.html
32_ P. Bernanose, 2014, « PERCEP-TION VISUELLE: Un clin d’il de quelques millisecondes suffit – Atten-tion, Perception, and Psychophysics », in Santéblog, article blog : http://blog.santelog.com/2014/01/18/perception-visuelle-un-clin-d%C2%9Cil-de-quelques-millisecondes-suf-fit-attention-perception-and-psy-chophysics/
33_ B.Andrieu, 2010, « L’épistémiolo-gie du corps », ed Collége de France
34_ F.D.Fekete, 2013, « Software and Hardware Infrastructures for Visual Analytics », in Data Management to Exploration, V46, n°7
35_ B.Ourghanlian, 2013, « Big Data : visualiser pour donner du sens », in Les echos, article blog : http://www.lesechos.fr/idees-debats/cercle/cercle-92883-big-data-visualiser-pour-donner-du-sens-1002743.php?TWDzymqeFEJ3wd6W.99
36_ K. Cukier, V. Mayer-Schön-berger, 2013, « Mise en données du monde, le déluge numérique », in Le monde diplomatique, article blog : http://www.monde-diplomatique.fr/2013/07/CUKIER/49318
37_ P.Drucker, cité par D. Gysler, 2009, « Théorie critique du paradigme gestionnaire : une analyse de l’évolu-tion des modes gestionnaires au sein de la sphère du travail », Mémoire de fin d’études, Sociologie, UQUAM
61

06_
CONTACT_
Société 10h11
64 cours Clémenceau 33000 Bordeaux Tél. +33 (0)5 57 83 25 42@10h11 / [email protected] www.10h11.com
62
Livre blanc proposé par la société 10h11 - Mars 2015.
La couverture, seconde de couverture ainsi que les pages de garde de chapitre ont été réalisées par design génératif.
Direction de publication : Julien Daubert-Panasyuk
Rédaction : Maryne Cotty-Eslous, Pierrick Barnes, Jonathan Lalanne, Marius Ortiz, Sébastien Savater
Design graphique : Antoine Edel, Jonathan Lalanne
Méthodologie : Jonathan Lalanne, Marius Ortiz, Julien Daubert-Pa-nasyuk
Correction et relecture : Pierrick Barnes, Jonathan Lalanne, Marius Ortiz, Clément Boissy, Eliot Jacquin, Loic Triger
Impression : Sprint Copie, 82 Cours Georges Clemenceau, 33000 Bordeaux Papier issu des forêts gérées durablement (PEFC).


Livre blanc proposé par la société 10h11 - Mars 2015#datavisualisation @10h11


















