
SPLEX Statistiques pour la classi cation et fouille de...
16
SPLEX Statistiques pour la classification et fouille de donn´ ees en g´ enomique Apprentissage statistique Pierre-Henri WUILLEMIN DEcision, Syst` eme Intelligent et Recherche op´ erationnelle LIP6 [email protected] http://webia.lip6.fr/~phw/splex Quelques points d’organisation • Intervenants : Nataliya Sokolovska, Pierre-Henri Wuillemin • TME en python (Nataliya Sokolovska) • Cours (23-24 201) – TME (14-15 406) • ´ Evaluation : 2 examens r´ epartis (70%=35%+35%), une note de TME (30%) SPLEX Statistiques pour la classification et fouille de donn´ ees en g´ enomique Apprentissage statistique 2 / 47 Un (tout petit) peu d’histoire La classification est un th` eme majeur de l’histoire de la biologie. Andreas Caesalpinus (C´ esalpin), De plantis libri XVI, Florence, 1583 : Premi` ere taxonomie. Buffon, 1749 Le seul moyen de faire une m´ ethode instructive et naturelle est de mettre ensemble les choses qui se ressemblent et de s´ eparer celles qui diff` erent les unes des autres. XIX ` eme si` ecle : Th´ eorie statistique Qu´ etelet (1796–1874) Recensement am´ ericain, 1890 (utilisation de la carte perfor´ ee). XX ` eme si` ecle : Analyse de donn´ ees, apprentissage statistique SPLEX Statistiques pour la classification et fouille de donn´ ees en g´ enomique Apprentissage statistique 3 / 47
Transcript of SPLEX Statistiques pour la classi cation et fouille de...

SPLEXStatistiques pour la classification et fouille de donnees en
genomiqueApprentissage statistique
Pierre-Henri WUILLEMIN
DEcision, Systeme Intelligent et Recherche operationnelleLIP6
[email protected]://webia.lip6.fr/~phw/splex
Quelques points d’organisation
• Intervenants : Nataliya Sokolovska, Pierre-Henri Wuillemin
• TME en python (Nataliya Sokolovska)
• Cours (23-24 201) – TME (14-15 406)
• Evaluation : 2 examens repartis (70%=35%+35%), une note de TME (30%)
SPLEX Statistiques pour la classification et fouille de donnees en genomique Apprentissage statistique 2 / 47
Un (tout petit) peu d’histoire
La classification est un theme majeur de l’histoire de la biologie.
Andreas Caesalpinus (Cesalpin),De plantis libri XVI, Florence, 1583 : Premiere taxonomie.
Buffon, 1749� Le seul moyen de faire une methode instructive et naturelle estde mettre ensemble les choses qui se ressemblent et de separercelles qui different les unes des autres. �
XIXeme siecle : Theorie statistiqueQuetelet (1796–1874)
Recensement americain, 1890 (utilisation de la carte perforee).
XXeme siecle : Analyse de donnees, apprentissage statistique
SPLEX Statistiques pour la classification et fouille de donnees en genomique Apprentissage statistique 3 / 47

Quel est le probleme ?
Description de la tache de classification
Identifier la classe d’appartenance des objets a partir de certains de leursattributs (features),
Attribuer une classe a un objet a partir de ces attributs.
Buts de la classification
Connaissance (apprentissage) de la structure des ensembles d’objets
Processus de decisions automatiques
ApplicationsDiagnostic medical
Pret bancaire, Marketing(profiling)
Fusion de senseurs
Controle de process
Reconnaissance de formes(pattern recognition)
etc.
SPLEX Statistiques pour la classification et fouille de donnees en genomique Apprentissage statistique 4 / 47
Analyse de donnees et Data Mining
ý Definition (Analyse de donnees)
Ensemble de methodes d’explorations de donnees considerees comme des pointsdans un espace vectoriel multi-dimensionnel.
Par exemple : Analyse en Composantes Principales (ACP), regression lineaire, etc.
ý Definition (Data Mining)
Organisation et exploration de donnees considerees comme des points dans unespace vectoriel multi-dimensionnel dans le but d’apprendre une structure oud’apprendre a predire.
Predire : apprentissage par l’exemple afin de mimer un comportement.
Discrimination,Regression,Classification supervisee, etc.
Apprendre une structure : extraire de l’information.
Classification non supervisee,Detection de motifs, etc.
SPLEX Statistiques pour la classification et fouille de donnees en genomique Apprentissage statistique 5 / 47
Formalisation
Soit Π une population (un ensemble d’objets),
chaque element de Π est determine par d attributs (supposementquantitatifs). On nomme D ⊆ Rd l’espace descriptif,
chaque element de Π appartient a une classe de C.
Autrement dit,
Relations fonctionnelles
∃D : Π→ D et C : Π→ C telles que ∀π ∈ Π,D(π) est le vecteur des attributs determinant π,
C (π) est la classe de π. D C
Π
D(.) C(.)
On ne connait en fait un objet π que par l’intermediaire de sa description D(π).
Tache de classification
Trouver C : D → C telle que∀π, C (D(π)) ≈ C (π) avec “le moins d’erreur possible”
C est appele le classifieur. D C
Π
D(.) C(.)
C(.)
SPLEX Statistiques pour la classification et fouille de donnees en genomique Apprentissage statistique 6 / 47

Trouver C : methodologie en mode supervise
D C
Π
D(.) C(.)
C(.)On suppose que D, C et D sont parfaitement connus mais pas C .
1 Apprentissage sur un base d’exemples
Soit Πa ⊂ Π pour lequel on connait parfaitement la restriction C|Πa,
on peut alors estimer C sur Πa.
2 Validation sur un base d’exemples
Soit Πv ⊂ Π \ Πa pour lequel on connait parfaitement la restriction C|Πv,
On peut alors evaluer C sur Πv et construire des indicateurs de qualite.
3 Prediction
∀π ∈ Π \ (Πa ∪ Πv ), on ne connait pas C (π) : on le predit par C (D(π)).
Nature des donneesChaque donnee (D, Πa, C|Πa , Πv , C|Πv ,) peut etre fausse, bruitee,incomplete, non independante, etc.
L’estimation est une approximation et la construction de l’estimateur peut
etre une heuristique !
SPLEX Statistiques pour la classification et fouille de donnees en genomique Apprentissage statistique 7 / 47
Simplifier les notations
Generalement, le probleme de classification prendra la forme suivante :
Soit une v.a. X (de dimension d) a valeurs dans R (D = Rd),
Soit une v.a. Y (de dimension 1)discrete (classification : C ⊂ Z)
continue (regression : C ⊆ R).
Πa ∪ Πv est une base de N observations (Xi ,Yi ) de ces variables.
X2
X1
X1
X2
XN
D C
Π
D(.) C(.)
D(π) C(π)
π1 X 11 X 2
1 Y1
π2 X 12 X 2
2 Y2
π3 X 13 X 2
3 Y3
· · · · · · · · ·πn X 1
N X 2N YN
Le probleme de la classification (et de la regression)
Soit x une instantiation de X , quelle valeur prendrait y = C (x) ?
SPLEX Statistiques pour la classification et fouille de donnees en genomique Apprentissage statistique 8 / 47
Deux approches de la classification supervisee
Approches non parametriques
Pas d’hypothese sur le modele des donnees,
Seuls les exemples menent vers C .
Exemple : methode des k plus proches voisins, fenetre de Parzen.
Approches parametriques
A partir de l’hypothese forte de l’existence d’un modele,
Phase d’estimation des parametres du modele : Θ,
C est alors CΘ
.
Exemple : Regression, Classification bayesienne
Pour la suite du cours (sauf si precise), on simplifiera la tache de classification a ladiscrimination entre 2 classes seulement : Y peut prendre les valeurs −1 et 1.
Le classifieur C se decompose alors en 2 fonctions : g : Rd → R et C = σ(g).
SPLEX Statistiques pour la classification et fouille de donnees en genomique Apprentissage statistique 9 / 47
Evaluations et Comparaisons de Classifieurs
Evaluations et Comparaisons de Classifieurs 10 / 47
Evaluation d’un classifieur
Quelles proprietes peut-on demander pour C ?
Critere : precision
Un classifieur doit minimiser le taux d’erreur lors de son utilisation. ( ?)
Critere : comprehensibiliteUn classifieur representant une base doit etre intelligible :
expliquable (et donc exploitable),
comprehensible (par un expert),
parametrable (par un expert).
Critere : rapiditeLes operations sur le classifieur doivent etre facilitees.
Construction aisee,
Mise a jour aisee (incrementale),
Critere de classification rapide.
Evaluations et Comparaisons de Classifieurs 11 / 47
Methodologie
Πa
ΠvValidation
Evaluation
Bas
e
Tes
t
App
rent
issa
ge
C ∗
Ci
algo i
Evaluations et Comparaisons de Classifieurs 12 / 47

Evaluation de C
D C
Π
D(.) C(.)
C(.)
Ce qu’on voudrait connaıtre, c’est l’erreur que l’on fera en utilisant C au lieu de C .
Erreur en generalisation
e(C ) = Ex
(C (x) 6= C (x)
)
En regression, on utilisera plutot la distance quadratique :
e(C) = Ex
(C(x) − C(x)
)2
Toutefois, cette erreur en generalisation n’est pas atteignable. Il faut donc l’estimer.
Erreur en apprentissage, erreur en validation
ea(C ) = 1‖Πa‖
∑x∈Πa
δ(C (x) − C (x)
)ev (C ) = 1
‖Πv‖∑
x∈Πvδ(C (x) − C (x)
)
ou δ(x) =
{1 si x 6= 0
0 si x = 0
Mais ces erreurs experimentales n’indiquent a priori rien d’autres que des hypotheses sur e(C).
Evaluations et Comparaisons de Classifieurs 13 / 47
Erreurs des erreurs de classification
erreur d’apprentissage
Sur la base Πa =⋃Na
i=1{x(a)i } :
εa =1
Na
Na∑
i=1
δ(C (x
(a)i ) − C (x
(a)i ))
On peut rendre εa = 0.
erreur de test de validation
Sur la base Πv =⋃Nv
i=1{x(v)i } :
εv =1
Nv
Nv∑
i=1
δ(C (x
(v)i ) − C (x
(v)i )
)
εv = 0 est tres dependant de Πv
(biais, approximation, etc.).
C peut se sur-adapter a Πa :
sur-apprentissage
εa
εv
Sur-apprentissage
Evaluations et Comparaisons de Classifieurs 14 / 47
Estimation du taux d’erreur de C
Estimation sur Πa
+O Estimation aisee !
-O Sous-estimation evidente
-O Favorise le surapprentissage
Estimation sur Πv
+O Estimation aisee !
-O Gachis d’une partie des donnees classees
-O Donnees issues de la meme base que Πa ⇒ risque de biais
Cross-Validation, Leave-one-out, bootstrap
Avec C (Π∗) bien connu, construire plusieurs Πv differents et apprendre surΠa = Π
∗ \ Πv ...
+O Plus de perte de donnees,
+O Une certaine robustesse de l’evaluation,
-O Cher et lent ! !Evaluations et Comparaisons de Classifieurs 15 / 47

LOOCV : Leave-One-Out Cross Validation
LOOCV est un algorithme qui permet de se passer de Πv en contre-partie d’un temps de calcul beaucoup plusimportant.
LOOCV
Data : Πa
1 for each π ∈ Πa do
2 Calculer C−π en apprenant sur Πa \ {π}
3 eπ = |C−π(π) − C (π)|
4 Calculer C en apprenant sur Πa
5 alors
eLOOCV(C ) =1
‖Πa‖∑
π∈Πa
eπ
Il existe bien evidemment des variantes de cet algorithme, moins gourmands carutilisant une partition en k sous-ensembles de Πa plutot que d’en isoler chaquesingleton : k-fold Cross Validation.
Evaluations et Comparaisons de Classifieurs 16 / 47
Autres indicateurs sur Πv
Matrice de confusionSur une base de test :
C (x) = -O C (x) = +O
C (x) = -O VN FN VN + FN
C (x) = +O FP VP VP + FP
VN + FP FN + VP N
Indicateurs
Taux d’erreur : ev (C ) = FP+FNN
Accuracy (taux de bon classement) : VP+VNN
Specificite (taux de vrai negatifs) : VNVN+FP
1−Specificite (taux de faux positifs) : FPVN+FP
Sensibilite,Rappel (taux de vrai positifs) : VPVP+FN
Precision : VPVP+FP
Evaluations et Comparaisons de Classifieurs 17 / 47
Couts d’affectation
Il peut etre interessant de briser la symetrie entre FP et FN.
Matrice d’affectation
C (x) = -O C (x) = +O
C (x) = -O 0 γFN
C (x) = +O γFP 0
Generalement, on privilegie les erreurs de premiere espece : γFP � γFN
On peut alors definir un cout d’un classifieur :
Indicateur de cout
cout(C ) =FP · γFP + FN · γFN
N
Evaluations et Comparaisons de Classifieurs 18 / 47

Limite des indicateurs issus de la matrice de confusion
Comment comparer
C1 -O +O
-O 40 10
+O 10 40
et
C2 -O +O
-O 45 5
+O 20 30
?
eV (C1) = 0.2 et eV (C2) = 0.25
⇒ C1 � C2
Avec la matrice de cout :
-O +O
-O 0 10
+O 1 0
, cout(C1) = 1.1 et cout(C2) = 0.7
⇒ C1 ≺ C2
PS : Comparer eV revient a utiliser une matrice de cout avec γFP = γFN = 1.
Doit-on tester pour toutes les matrices de cout possible ?Comment comparer globalement les modeles sans cout ?
Evaluations et Comparaisons de Classifieurs 19 / 47
Cas de classes desequilibrees
Matrice de confusion – COIL’00 – Challenge police d’assurance
Sur une base de test :
C -O +O
-O 3731 31
+O 229 9
eV (C ) = 229+314000
eV (Toujours -O) = 31+94000 C ≺ Toujours -O
Au lieu de se limiter a des criteres sur l’affectation proposee, il s’agirait de mesurer la propension a etre dansune classe.Un classifieur est souvent compose de :
Une fonction g : D −→ RUne fonction σ : R −→ C (fonction signe si classificateur binaire)
Quand Ci (x) = σ(gi (x)), il faudrait comparer g1 et g2 ! ! !
Evaluations et Comparaisons de Classifieurs 20 / 47
Courbe de ROC
Courbe de ROC : Receiver Operating Characteristic
Outil d’evaluation et de comparaison de classifieurs,
Outil graphique (aisement lisible),
Independant des matrices de couts,
Utilisable dans le cas de classes desequilibrees,
Indicateur synthetique associe (aisement interpretable).
Evaluations et Comparaisons de Classifieurs 21 / 47

Construction de la courbe de ROC
Soit C (x) = σ(g(x)).Soit B> la base des x ∈ Πa, classes par valeur croissante de g(x).
On construit alors une famille de classifieurs Ck , k ∈ {0, · · · , |Πa|}, definis ainsi :
∀k ∈ {0, · · · , |Πa|} , Ck = {classer -O les x de rang≤k dans B>}
Rappel :
1−Specificite (TFP) : FPVN+FP
Sensibilite (TVP) : VPVP+FN
C0 : sensibilite=1 et specificite=0
C|Πa| : sensibilite=0 et specificite=1
Construction de la courbe de ROC
∀k ∈ {0, · · · , |Πa|}, afficher le point(1−specificite(Ck),sensibilite(Ck))
Evaluations et Comparaisons de Classifieurs 22 / 47
construction de la courbe de ROC (1)
From : Ricco RAKOTOMALALA – Laboratoire ERIC
Evaluations et Comparaisons de Classifieurs 23 / 47
construction de la courbe de ROC (2)
From : Ricco RAKOTOMALALA – Laboratoire ERIC
Evaluations et Comparaisons de Classifieurs 24 / 47

Utilisation de la courbe de ROC (1)
1 Tout classifieur est un point dans l’espace ROC.(0, 1) : Classifieur parfait.
(1, 1) : Classifieur “toujours +O”.
(0, 0) : Classifieur “toujours -O”.
(q, q) : Classifieur “proba(C(x) = +O) = q”.
2 Une famille de classifieurs Ck doit avoir sacourbe de ROC au dessus de la premiere diagonale(x = y).Puisque cette premiere diagonale correspond aux classifieuraleatoires.
3 critere AUC Area Under Curve
Pour la diagonale : AUC = 12
Pour le test ideal, AUC = 1
Pour un test quelconque, 12 ≤ AUC ≤ 1. Plus
il est grand, mieux c’est.
AUC indique la probabilite pour que C interclasse un positif et unnegatif.
Evaluations et Comparaisons de Classifieurs 25 / 47
Utilisation de ROC (2) : comparaison de classifieurs
1 DominanceSi ROCM1 � ROCM2 alors il ne peut pas existerde situation (quelque soit le cout) ou M2 seraitun meilleur classifieur que M1.
2 Enveloppe convexeLes classifieurs ne participant jamais al’enveloppe convexe sont domines et peuventetre elimines.
M1 domine
M4 domine par max(M2,M3)
Evaluations et Comparaisons de Classifieurs 26 / 47
Aggregations de Classifieurs
Aggregations de Classifieurs 27 / 47

Introduction au bootstrap
PrincipeProbleme : Quelle est la distribution d’un estimateur calcule a partir d’un echantillon L ?
Si on connait la distribution de l’echantillon ou si on peut faire l’hypothese d’une
distribution gaussienne, pas de problemes. Mais sinon ?
But du bootstrap : Remplacer des hypotheses probabilistes pas toujours verifieesou meme inverifiables par des simulations et donc beaucoup de calcul.
Exemple : L = {x1, · · · , xn} suffit a calculer x , estimateur de µ.Comment estimer sa precision (son ecart-type) ? son biais ?
1 iid + TCL ⇒ X ∼ N (µ, σ2
n ).
2 Soit (Lj)j∈J une famille d’echantillons.⇒ on peut estimer ces statisiques a partir des (xj)j∈J .
3 Soit L l’unique echantillon utilisable ⇒ calculer un echantillon bootstrap.
Aggregations de Classifieurs 28 / 47
Bootstrap : points de reperes
Bradeley Erfon, 1979. Erfon & Tibshirani, 1993.
Origine du nom : Inspiree du baron de Munchausen(Rudolph Erich Raspe) qui se sortit de sables mouvantspar traction sur ses tirants de bottes.
Popularise avec la montee en puissance de l’ordinateur dans les calculsstatistiques.
Base sur une theorie mathematique bien rodee.
Aggregations de Classifieurs 29 / 47
Echantillon bootstrap
General Bootstrap Algorithm
Data : L echantillon,θ parametre a estimer sur L,1 for b ∈ {1, · · · ,B} do2 Tirer aleatoirement Lb, un echantillon avec remise dans L
3 Estimer θb sur l’echantillon Lb
4 L ={θ1, · · · , θB
}est un echantillon bootstrap issu de L.
On peut alors utiliser L pour estimer desstatistiques de la distribution del’estimateur de θ :
σ2θ≈ σ2
B = 1B−1
∑Bb=1
(θb −
1B
∑Bb=1 θb
)2
Intervalle de confiance, biais, quantiles,
tests d’hypotheses, etc.
Aggregations de Classifieurs 30 / 47

Considerations sur le bootstrap
L ne remplace pas L.
L est utilise pour estimer des parametres d’un estimateur base sur L ! !
Le bootstrap ne peut pas s’appliquer si :
Echantillon L trop faible
Donnees trop bruitees
Dans le cas de dependances structurelles dans L (par exemple, series
temporelles, problemes 2D,etc.)
Comment choisir B =∣∣∣L∣∣∣ ?
Un grand nombre de versions legerements differentes.Par exemple, Jackknife : extraire les n sous-liste de L de taille n − 1.
Aggregations de Classifieurs 31 / 47
Methodologie et aggregations
Πa
ΠvValidation
Evaluation
Bas
e
Tes
t
App
rent
issa
ge
C ∗
Ci
algo i
Est-ce choisir C∗ parmi les Ci a un sens ?Y a-t-il vraiment un ’meilleur’ ?
Aggregations de Classifieurs 32 / 47
Aggregations
Soit un certain nombre de classifieurs (Ci )i∈I pour une meme classification C .Chaque Ci est plus ou moins precis. Ils sont egalement plus ou moins stables.
Stabilite
Un classifieur C est instable quand de petites modifications dans Πa peuvent entraıner degrandes modifications dans la classification.
Les statistiques nous ont appris que moyenner les resultats est un bon moyen de reduirela variance (l’instabilite).
Est-il possible de combiner les (Ci )i∈I de maniere a obtenir un meilleur classifieur ?
Aggregation majoritaire
En considerant chaque Ci comme un ’expert’, une maniere d’aggreger leurs avis est deles faire voter et de choisir l’avis majoritaire :
Cmaj(x) = argmaxc∈{+O, -O}
∣∣∣{Ci (x) = c, i ∈ I
}∣∣∣
Aggregations de Classifieurs 33 / 47

Aggregations avec poids
On peut raffiner l’aggregation majoritaire en introduisant des poids associes al’expert.
Aggregation majoritaire avec poids
Pour chaque Ci , on note wi son poids associe,alors Cw(x) = argmaxc∈{+O, -O}
∑
( i∈ICi (x)=c)
wi
Pour fixer les poids, on s’attend a ce qu’un expert qui donne souvent la bonnereponse ait un poids ’eleve’.
Adaptation des poids
Data : β ∈ [0, 1)1 ∀i ,wi = 12 foreach π ∈ Πa do
3 if Ci (π) 6= C (π) then4 wi = β · wi
Si β = 0, algorithme dit de Halving.
Si β = 12, avec k le nbr minimal d’erreurs
faites par un Ci sur Πa, n le nombre de Ci ,et M le nombre d’erreurs faite par Cw,
M ≤ 2.4 (k + log2(n))
Aggregations de Classifieurs 34 / 47
Bagging
Pour le bagging, on considere qu’il faut constituer des ensembles Π(i)a specifiques
pour estimer chaque classifieur Ci (qui peuvent etre alors de meme type) etmoyenner les resultats : ca ressemble a du bootstrap.
Bootstrap aggregating
Soit(Π
(i)a
)i∈I
une famille d’echantillons bootstrap (avec remise), alors :
∀i ∈ I, Ci est estime sur Π(i)a et Cbagging(x) = Cmaj(x)
Si les Ci sont effectivement des classifieurs de meme type, heuristiquement, il doivent etre instable afin quechaque echantillon bootstrap fournisse un classifieur different.
Convergence et generalisation
Pas de preuve de convergence.
Pas de borne connue pour l’erreur de generalisation.
En pratique, bons resultats.
Aggregations de Classifieurs 35 / 47
Modeles additifs
Dans les classifieurs majoritaires a poids, la classification s’effecture commeesperance de plusieurs classifieurs, eventuellement ponderes.
Il s’agit donc de choisir chaque classifieur et son poids associe de maniere aameliorer le resultat global.
idee : au lieu de construire les classifieurs ’independamment’, il serait pertinentde construire incrementalement chaque classifieur afin qu’il s’interesseparticulierement aux points pour l’instant mal classes.
idee : ca pourrait marcher meme avec des classifieurs faibles.
ý Definition (Classifieur faible (weak classifier))
Un classifieur faible est un classifieur a peine plus precis que le classifieur aleatoire.
C’est le principe des algorithmes de boosting.
Aggregations de Classifieurs 36 / 47

Boosting : principes
principe : un nouveau classifieur doit se concentrer sur les elements de Πa malclasses pour l’instant.
Boosting schematique1 Affecter un poids a chaque π ∈ Πa
2 Proposer un classifieur faible (“xi <...”, “regle d’or“, ”rule of thumb“)
3 Modifier les poids pour tenir compte de ce nouveau classifier
4 Recommencer T fois les 2 derniers points.
5 Combiner tous les classifieurs dans Cboosting
Deux questions (au moins) :
Comment mettre a jour les poids ?
Comment combiner correctement tous ces classifieurs ?
Aggregations de Classifieurs 37 / 47
Erreur en generalisation
On rappelle : eP(C ) = EP
(C (x) 6= C (x)
)ou P probabilite sur Π.
En particulier, si C est un classifieur faible, e(C) ≤ 12 − γ,γ > 0 : C est un peu meilleur que le classifieur
aleatoire qui se trompe une fois sur deux.Pour Πa = {x1, · · · , xn}, on notera D(xi) le poids associe a xi . D(.) probabilite (
∑i D(xi) = 1).
AdaBoost (Freund & Schapire, 1995)
1 ∀xi ,D1(x1) =1n
2 soit C1 un premier classifieur faible3 repeat
4 Calculer eDt (Ct) et βt =eDt (Ct)
1−eDt (Ct)< 1
5 Dt+1(xi ) ∝{Dt(xi ) si Ct(xi ) 6= C (xi )
βt · Dt(xi ) sinon
6 Estimer Ct+1 un classifieur faible minimisanteDt+1
7 until condition d’arret (T fois par exemple);
8 Cboosting(x) = σ
(∑tαt Ct(x)
)avec αt = log 1
βt
αt en fonction de eDt (Ct)
Aggregations de Classifieurs 38 / 47
AdaBoost : un exemple (”A Tutorial On Boosting“, Freung,Y. & Schapire,R.)
Aggregations de Classifieurs 39 / 47

AdaBoost : un exemple (”A Tutorial On Boosting“, Freung,Y. & Schapire,R.)
Aggregations de Classifieurs 40 / 47
AdaBoost : un exemple (”A Tutorial On Boosting“, Freung,Y. & Schapire,R.)
Aggregations de Classifieurs 41 / 47
AdaBoost : un exemple (”A Tutorial On Boosting“, Freung,Y. & Schapire,R.)
Aggregations de Classifieurs 42 / 47

AdaBoost : un exemple (”A Tutorial On Boosting“, Freung,Y. & Schapire,R.)
Aggregations de Classifieurs 43 / 47
bagging vs boosting
Les 2 methodes ont en commun une augmentation de la stabilite du classifieur, auprix d’un temps de calcul plus important. Voici quelques generalites a ne pasprendre pour verites absolues :
Bagging est souvent plus rapide que boosting.
A contrario, la reduction d’erreur est moindre pour bagging.
Bagging est une methode qui fonctionne avec des ensembles de classifieurs’raisonnables’ mais peu stables (arbres de decisions par exemple).
Boosting utilise des classifieurs tres simples et donc tres faibles.
AdaBoost n’a plus qu’un parametre : le nombre de classifieurs que l’on veutmettre.
Boosting est tres sensible au bruit i.e. a un grand nombre de donnees malclassees (puisqu’il va leur donner un grand poids).
Comme les classifieurs faibles ont un biais important, on peut considerer leboosting comme une methode de reduction du biais.
Aggregations de Classifieurs 44 / 47
Boosting : erreur en generalisation
Que se passe-t-il si on augmente beaucoup le nombre de classifieurs faibles ?
Generalement, on s’attend a :
Erreur d’apprentissage (sur Πa) quitend vers 0.
Erreur en generalisation quiremonte (sur-apprentissage,overfitting)
Comportement asymptotique des erreurs
Experimentalement, pour AdaBoost
L’erreur de test (meilleureapproximation de l’erreur engeneralisation) n’augmente pas !
Meme quand l’erreur d’apprentissageest nulle !
Aggregations de Classifieurs 45 / 47
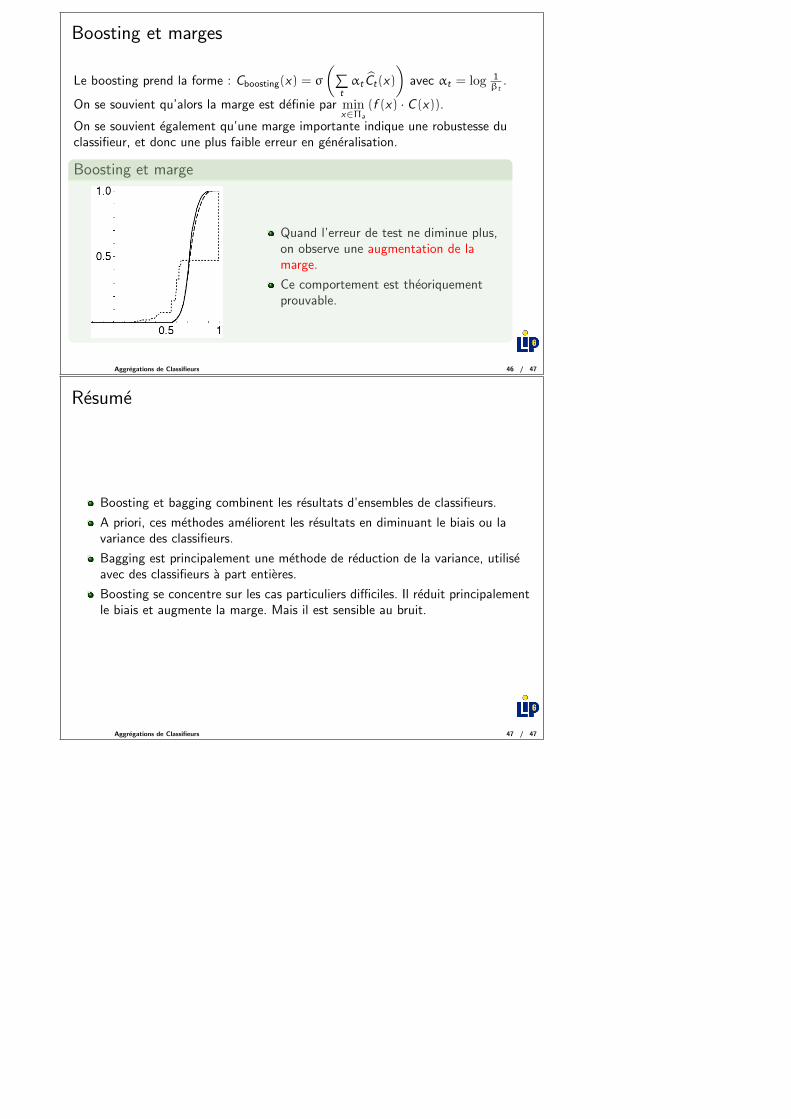
Boosting et marges
Le boosting prend la forme : Cboosting(x) = σ
(∑tαt Ct(x)
)avec αt = log 1
βt.
On se souvient qu’alors la marge est definie par minx∈Πa
(f (x) · C (x)).
On se souvient egalement qu’une marge importante indique une robustesse duclassifieur, et donc une plus faible erreur en generalisation.
Boosting et marge
Quand l’erreur de test ne diminue plus,on observe une augmentation de lamarge.
Ce comportement est theoriquementprouvable.
Aggregations de Classifieurs 46 / 47
Resume
Boosting et bagging combinent les resultats d’ensembles de classifieurs.
A priori, ces methodes ameliorent les resultats en diminuant le biais ou lavariance des classifieurs.
Bagging est principalement une methode de reduction de la variance, utiliseavec des classifieurs a part entieres.
Boosting se concentre sur les cas particuliers difficiles. Il reduit principalementle biais et augmente la marge. Mais il est sensible au bruit.
Aggregations de Classifieurs 47 / 47


















