Simulations de séismes sur grappes de machines ...numasis.gforge.inria.fr/doc/numasis_stic.pdf ·...
29
Simulations de séismes sur grappes de machines multiprocesseurs NUMA Raymond Namyst Professeur, Université Bordeaux 1 Projet INRIA Runtime ANR-05-CIGC-002
Transcript of Simulations de séismes sur grappes de machines ...numasis.gforge.inria.fr/doc/numasis_stic.pdf ·...

Simulations de séismessur grappes de machinesmultiprocesseurs NUMA
Raymond NamystProfesseur, Université Bordeaux 1
Projet INRIA Runtime
ANR-05-CIGC-002

Présentation
• Projet ANR CIGC 2005 Coordinateur : Jean-François Méhaut (UJF, Grenoble)
• Partenaires Géophysique, sismologie
BRGM, CEA, Total MAGIQUE3D (INRIA, Pau)
Algorithmique, couplage Scalapplix (INRIA, Bordeaux), PARIS (IRISA)
Architectures et supports d’exécution Bull Mescal/Moais (INRIA, Grenoble), Runtime (INRIA, Bordeaux)

Plan
• Enjeux et défis en simulation sismique Amélioration de la prédiction des conséquences des séismes Couplage de modèles numériques
• L’évolution des architectures parallèles contemporaines Processeurs multicœurs Architectures NUMA
• Comment programmer de telles architectures efficacement Axes de travail Quels modèles de programmation/supports d’exécution ?

Enjeux et défis ensimulation sismique
Mieux comprendre lesphénomènes sismiques
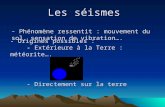
Simulation de séismes
• Propagation des ondes sismiques dans les différentes couchesgéologiques Modélisation de la croûte et du manteau terrestres Effets de site
• Applications Évaluation des risques/conséquences de séismes Découverte de réservoirs d’hydrocarbures
source
Earthquake!
site
propagation des ondes
Caractéritiques géomécaniques
Structure géologique
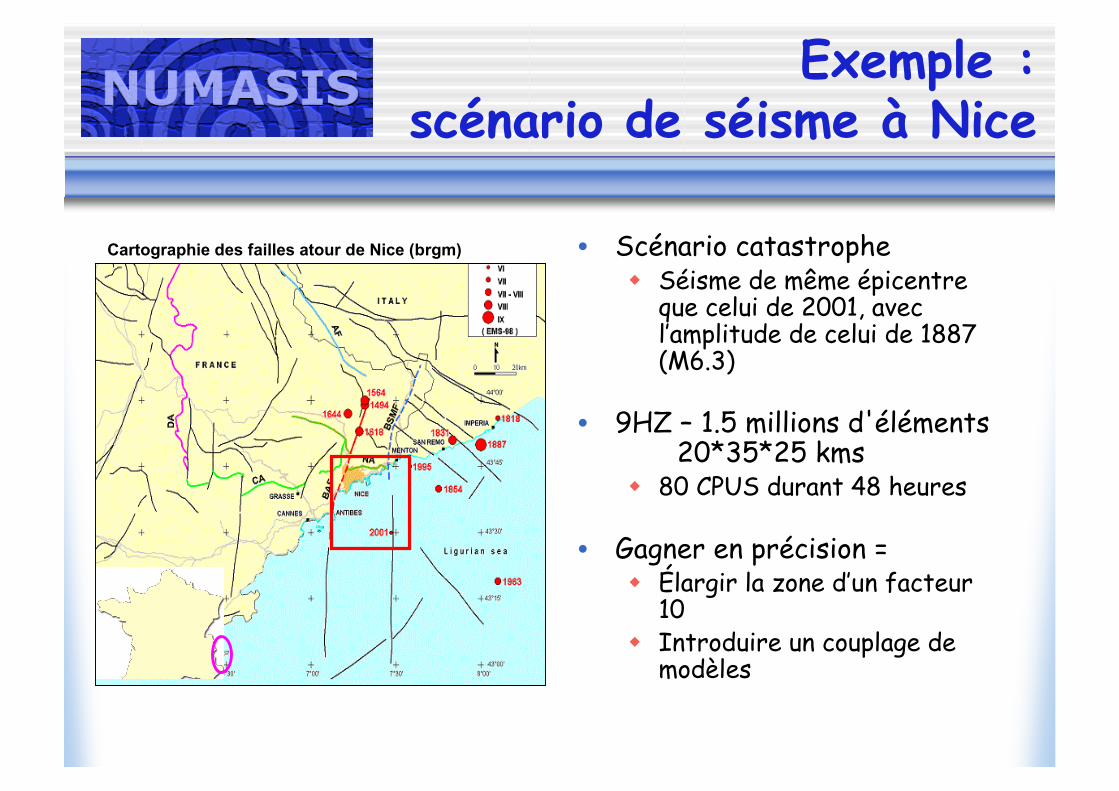
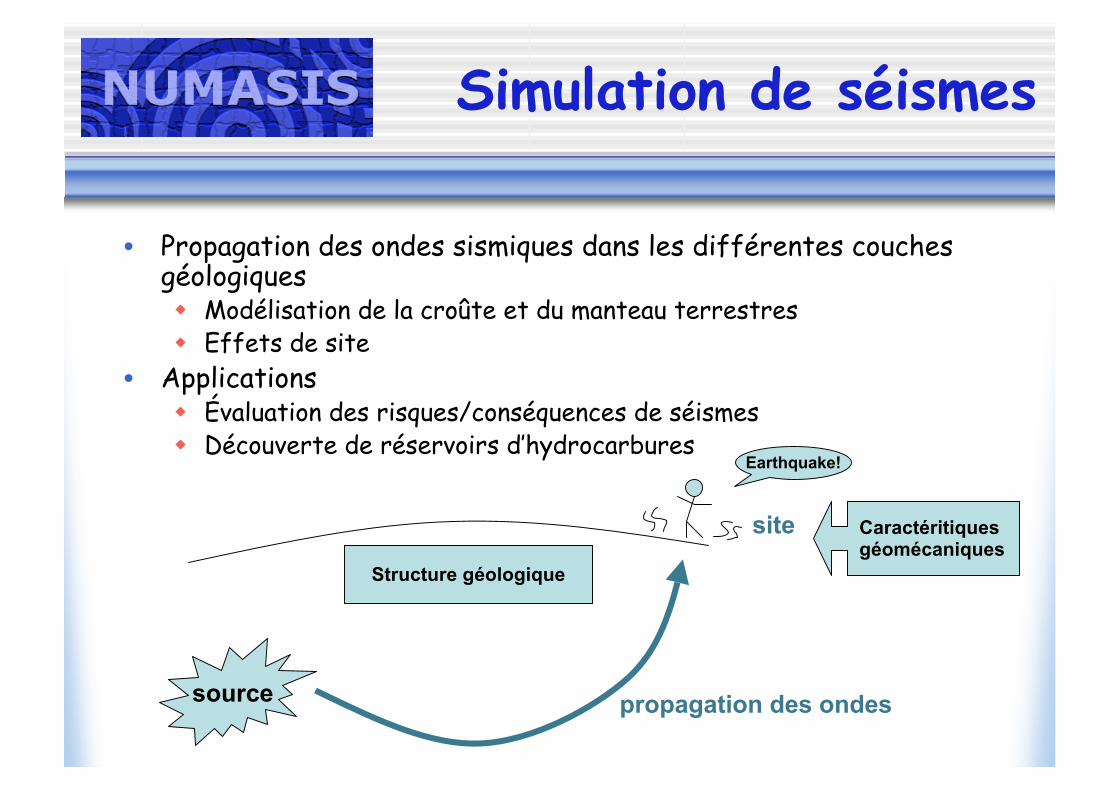
Exemple :scénario de séisme à Nice
• Scénario catastrophe Séisme de même épicentre
que celui de 2001, avecl’amplitude de celui de 1887(M6.3)
• 9HZ – 1.5 millions d'éléments20*35*25 kms
80 CPUS durant 48 heures
• Gagner en précision = Élargir la zone d’un facteur
10 Introduire un couplage de
modèles
Cartographie des failles atour de Nice (brgm)
Exemple :scénario de séisme à Nice

Los Angeles,sept. 2001
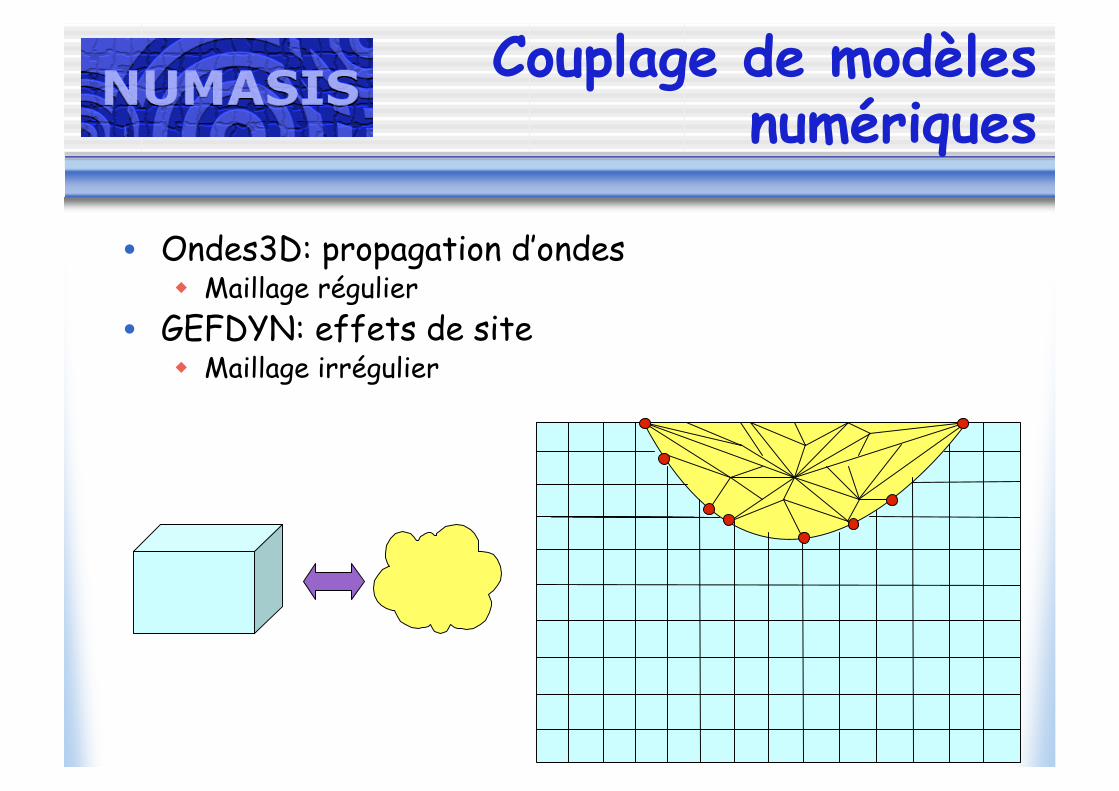
Couplage de modèlesnumériques
• Ondes3D: propagation d’ondes Maillage régulier
• GEFDYN: effets de site Maillage irrégulier

Calculs à l’échelle duglobe terrestre
Problème : très haute résolution requise, donctrès gros calculs en parallèle avec le logicielSPECFEM3D (Fortran90 + MPI)
But : calculer l’effet sur les ondes sismiques dela structure interne du noyau terrestre, etconfronter les résultats aux donnéesenregistrées autour de la Terre lors de vraistremblements de terre afin de valider lesmodèles

Calculs à l’échelle duglobe terrestre
• Découpage de la Terre en P tranches (= 6 blocs de N x N tranches)• Le maillage est densifié géométriquement à la surface, qui est la région où setrouvent les stations d’enregistrement sismique• Le maillage contient 126 milliards de points (~ 5000 x 5000 x 5000 points)• Durée du calcul : 50600 pas de temps en 60 heures de CPU sur 2166processeurs

Évolutions des machinesparallèles contemporaines
Vers des architectureshiérarchiques non uniformes…
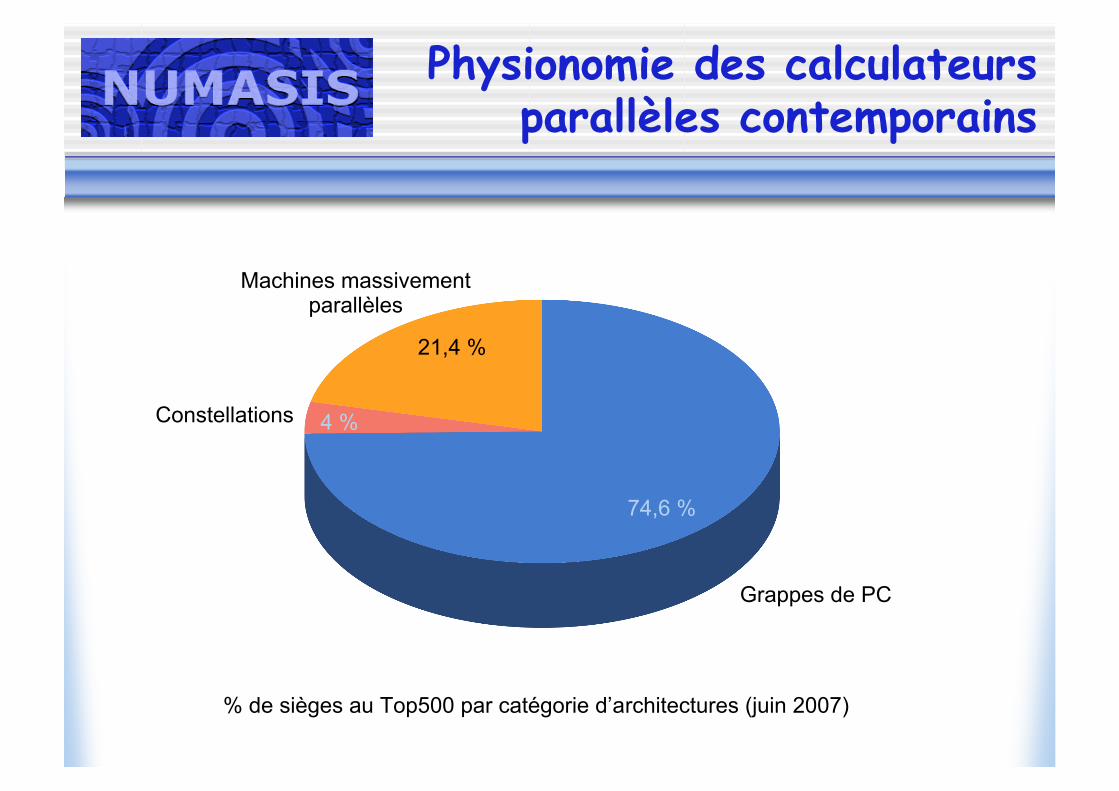
Physionomie des calculateursparallèles contemporains
Constellations
Grappes de PC
Machines massivementparallèles
% de sièges au Top500 par catégorie d’architectures (juin 2007)
4 %
74,6 %
21,4 %

Les grappes de calcul
• Ordinateurs interconnectés par un réseaurapide Myrinet, Infiniband, Quadrics, …
• Ces ordinateurs sont légèrement survitaminés Beaucoup de mémoire, plusieurs processeurs
Les processeurs sont « ordinaires » Intel, AMD, IBM, Sun
C’est dans ce domaine que les évolutions sont lesplus spectaculaires

Évolution desmicroprocesseurs
• La fréquence augmente En tout cas, c’était vrai jusqu’à il y a peu…
• Mais surtout, il y a constamment de la placepour de nouveaux circuits Caches Exécution dans le désordre
Analyse de dépendances (renommage des registres) Prédicteurs en tous genres
Exécution spéculative (branchements, préchargements) Unités de calcul supplémentaires
Procs superscalaires, multiprogrammés, et… multicœurs

Les processeursmulticœurs
= plusieurs processeurs gravés sur une mêmepuce
Caches externes parfois partagés• Tendance nette chez les constructeurs
Intel , AMD, IBM, Sun
SMT
cache
SMT
cache
Puce bi-cœurs avec SMT 4 voies
Gordon Moorea toujours raison…
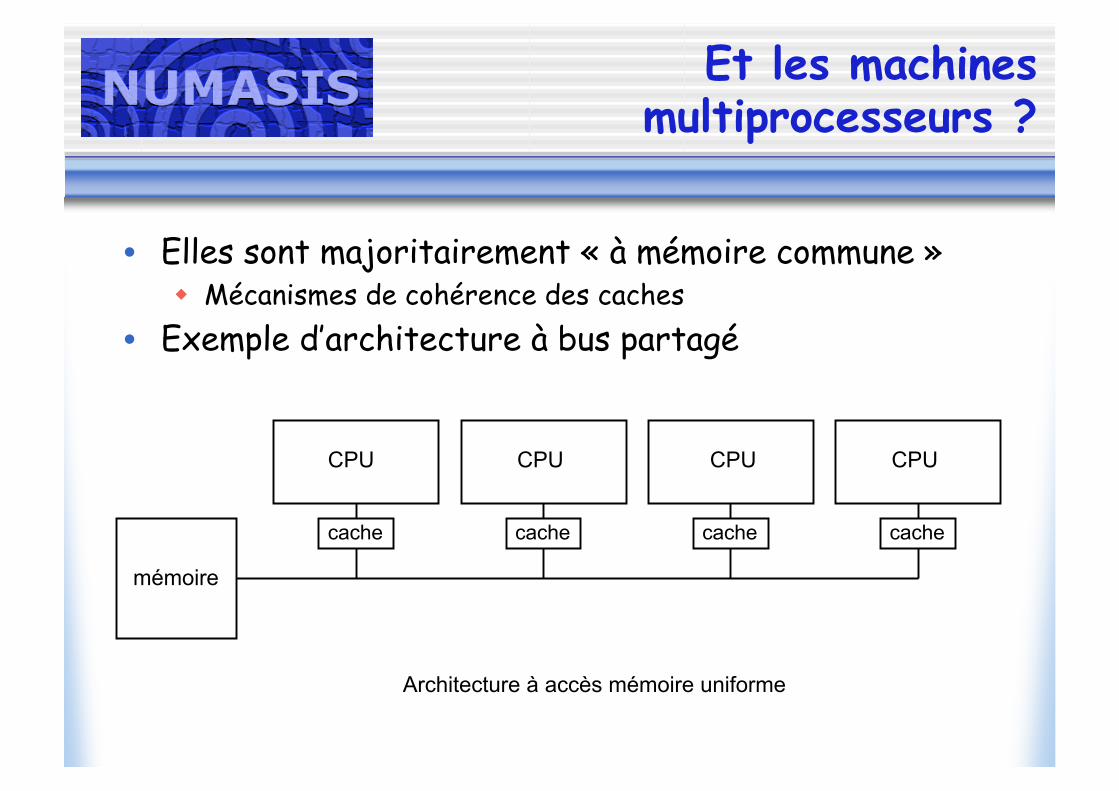
Et les machinesmultiprocesseurs ?
• Elles sont majoritairement « à mémoire commune » Mécanismes de cohérence des caches
• Exemple d’architecture à bus partagé
mémoire
Architecture à accès mémoire uniforme
cache cache cache cache
CPU CPU CPU CPU
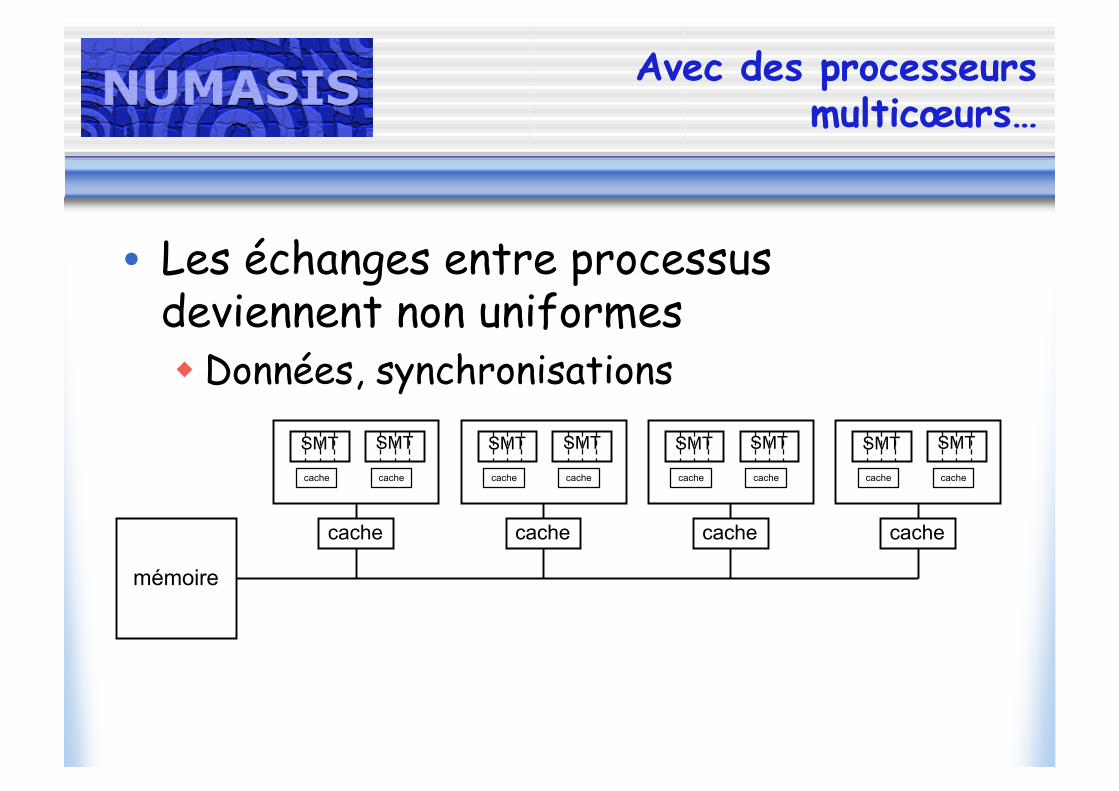
Avec des processeursmulticœurs…
• Les échanges entre processusdeviennent non uniformes Données, synchronisations
SMT
cache cache
SMT SMT
cache cache
SMT SMT
cache cache
SMT SMT
cache cache
SMT
mémoire
cache cache cache cache
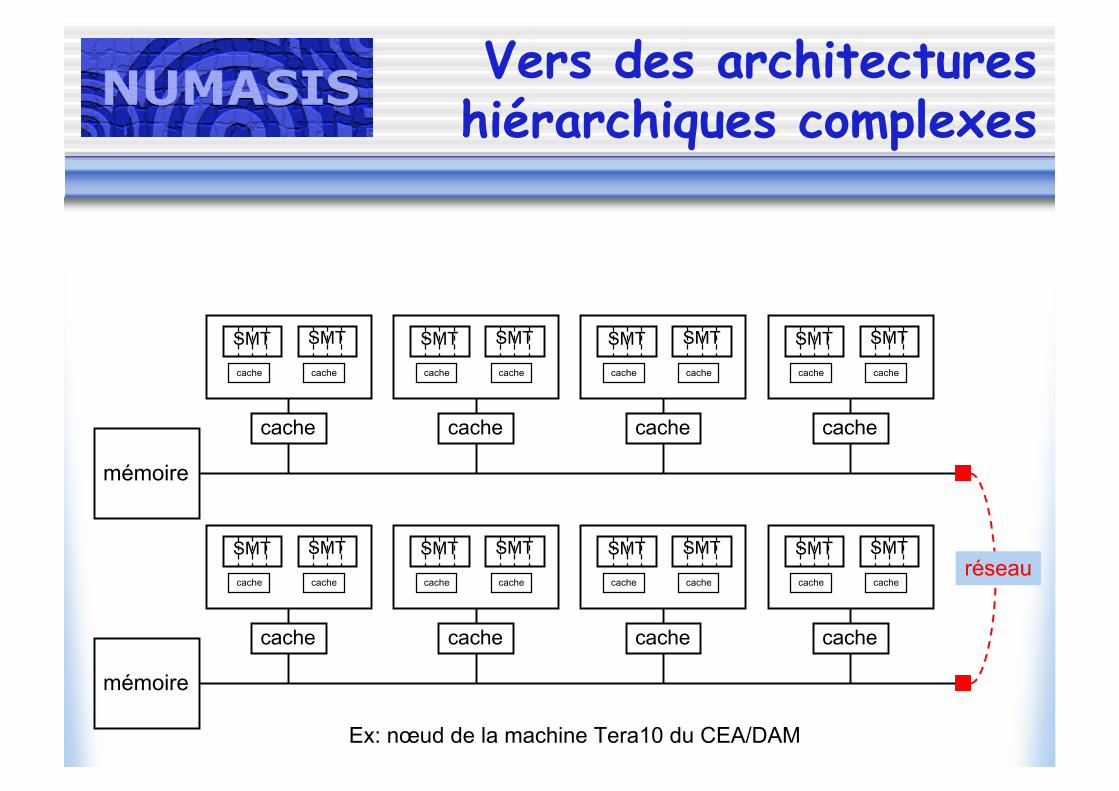
Vers des architectureshiérarchiques complexes
SMT
cache cache
SMT SMT
cache cache
SMT SMT
cache cache
SMT SMT
cache cache
SMT
mémoire
cache cache cache cache
SMT
cache cache
SMT SMT
cache cache
SMT SMT
cache cache
SMT SMT
cache cache
SMT
mémoire
cache cache cache cache
réseau
Ex: nœud de la machine Tera10 du CEA/DAM
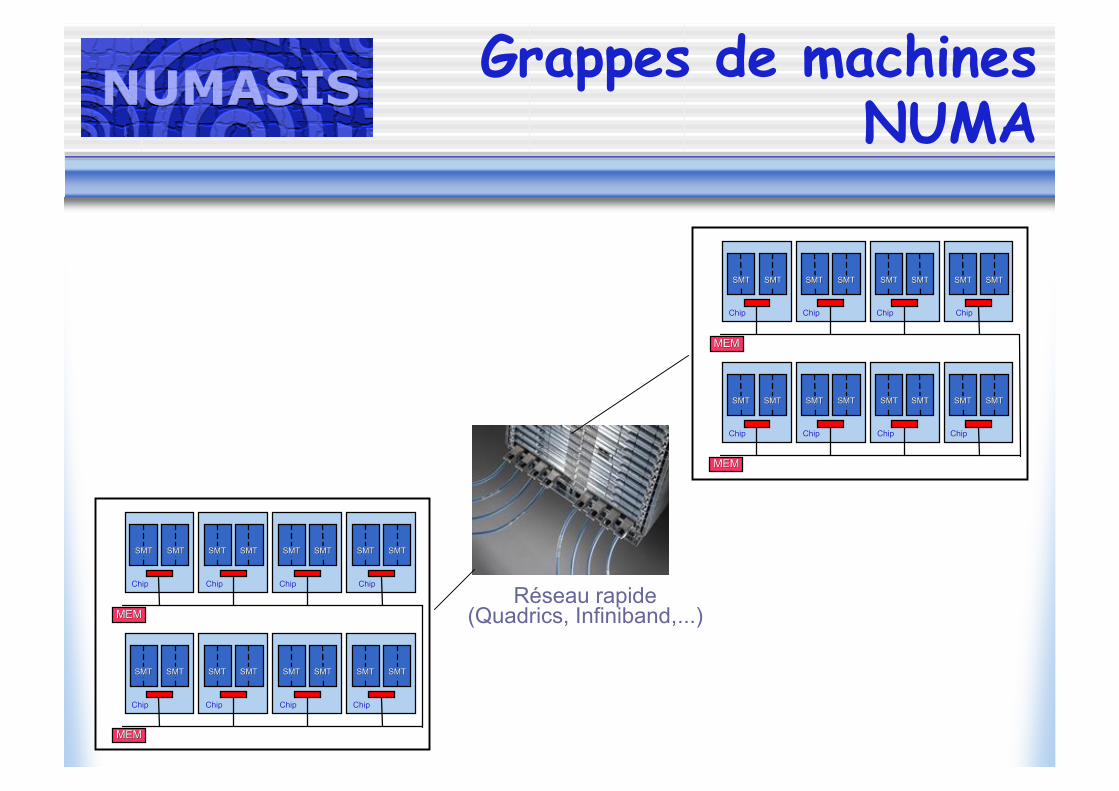
Grappes de machinesNUMA
Réseau rapide(Quadrics, Infiniband,...)
SMTSMT SMTSMT
ChipChip
SMTSMT SMTSMT
ChipChip
SMTSMT SMTSMT
ChipChip
SMTSMT SMTSMT
ChipChip
MEMMEM
SMTSMT SMTSMT
ChipChip
SMTSMT SMTSMT
ChipChip
SMTSMT SMTSMT
ChipChip
SMTSMT SMTSMT
ChipChip
MEMMEM
SMTSMT SMTSMT
ChipChip
SMTSMT SMTSMT
ChipChip
SMTSMT SMTSMT
ChipChip
SMTSMT SMTSMT
ChipChip
MEMMEM
SMTSMT SMTSMT
ChipChip
SMTSMT SMTSMT
ChipChip
SMTSMT SMTSMT
ChipChip
SMTSMT SMTSMT
ChipChip
MEMMEM

Comment programmer cesarchitectures efficacement ?
Vers des modèles deprogrammation et d’exécution
hiérarchiques…

Axes de travail
• Pour « coller » à la structure des machineshiérarchiques, il faut Intervenir à tous les maillons de la chaîne Associer les compétences
Modélisation• Maillage, couplage numérique
Algorithmique• Partitionneurs, solveurs
Support d’exécution• Outils pour l’ordonnancement, la gestion mémoire• Environnements de couplage• Exploitation des compteurs matériels

Couplage de modèles
• Nécessite une compréhension fine des phénomènesphysiques + capacités architecturales Interpolation + redistribution des données Agencement des communications sur grappes de NUMA
Ondes3D
GEFDYN

Supports d’exécution
• Utiliser MPI ? Communications explicites entre processus C’est le cas de la majorité des applications de simulation sismique ! Comment transmettre des directives d’ordonnancement
« portables » au support d’exécution sous-jacent ?
• Générer explicitement des processus légers (threads) Avec un compilateur OpenMP « NUMA-aware » Au travers d’une bibliothèque spécialisée (solveur, etc.)
• Transformer une application MPI en application multithread Environnement MPC du CEA/DAM

Ordonnancement de threads« NUMA-aware »
• Organisation récursive des threads Exprime les affinités entre threads Générée par une version modifiée de GNU OpenMP Performances souvent similaires à un placement manuel !

Composants logiciels (1)
• Système Extensions NUMA pour Linux (BULL)
• Exécutifs « bas niveau » Plateforme Marcel/BubbleSched (Runtime) Allocateurs mémoire (Mescal/Moais) Communication Madeleine (Runtime) Traçage (Mescal/Moais)
• Intergiciels MPI/SMP/NUMA (Bull) MPICH2/NEMESIS (Runtime) MPC (CEA) OpenMP/GOMP (Runtime) GridCCM (Paris)

Composants logiciels (2)
• Algorithmique scientifique Haute Performance Scotch (ScAlApplix) PaStiX (ScAlApplix)
• Applications sismiques ONDES3D (BRGM): C/MPI/OpenMP GEFDYN (BRGM): Fortran/MPI PRODIF (CEA): Fortran/MPI SPECFEM3D (Magique3D): Fortran/MPI
Partenariat avec Caltech/Los Angeles (J. Tromp)

Bilan
• Progression satisfaisante Collaboration multidisciplinaire enrichissante
Géophysique/Algorithmique/Supports d’exécution/Architecture Résultats préliminaires très encourageants
Masquage progressif des architectures sans perte deperformances• Vers la « portabilité des performances »…
Pile logicielle bientôt complète http://numasis.gforge.inria.fr/
• Mais Prochaine génération de machines
Accélérateurs de type GPU (projet ANR PARA) Cœurs hétérogènes ? Cohérence des caches ?