Reconstruction monoculaire du mouvement humain et...
57
Reconstruction monoculaire du mouvement humain et autres travaux 2000-2004 Bill Triggs Habilitation à diriger des recherches INRIA Montbonnot, 07 janvier 2005
Transcript of Reconstruction monoculaire du mouvement humain et...

Reconstruction monoculaire du mouvement humain
et autres travaux 2000-2004
Bill TriggsHabilitation à diriger des recherches
INRIA Montbonnot, 07 janvier 2005

Plan de l'exposé
Capture du mouvement humainContexte et motivation
Approche 3-D par modélisation explicite
Approches 2-D
Approche 3-D par apprentissage
Autres travaux 2000-2004Vision de bas niveau
Vision géométrique et reconstruction de scène
Modélisation statistique et reconnaissance de formes
Encadrements, autres activités, bilan

Capture du mouvement – Contexte
Reconstruction de la pose, du mouvement articulaire du corps humain, pour :
les effets spéciaux (film, TV, jeux)
l'analyse médicale et sportive
Systèmes actuelsmulti-caméra + vêtements spéciaux + illumination stroboscopique + pre-calibrage métrique
chèr (50-300 kEu) et encombrant (4-30 caméras)
hors du “pipeline” – les effets spéciaux nécessitent un traitement en 2 fois + reintegration
ne s'applique pas aux films quotidiens, historiques
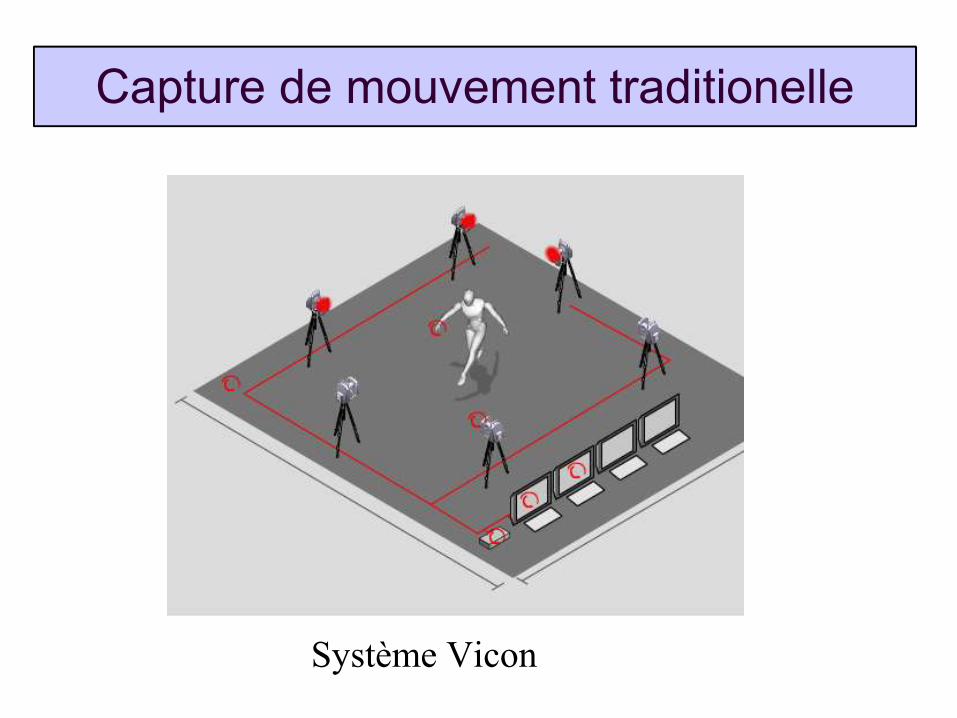
Capture de mouvement traditionelle
Système Vicon

Capture du mouvement monoculaire et non-instrumenté ?
On voudrait travailler avec une seule caméra, sur scène réelle / à partir de films existents, sous l'illumination naturelle, sans vêtements spéciaux, sans pre-calibrage, au moindre coût, en temps réel ...
Une baisse de précision est inévitable10 cm à la place de plusieurs millimètres
Mais le domaine d'applications sera plus large effets ... + interfaces homme-machine, surveillance

Difficultés de la capture monoculaire
Non-instrumentée – les correspondances modèle-image sont très ambiguées
Monoculaire – les erreurs en profondeur sont quasi-inobservables => 1000's de solutions cinématiques pour chaque image, qui se mélangent
Modèle imparfait, dimension élevée, contraintes complexes

Défi – rattrapper les décrochages
Ambiguïté de correspondance + solutions 3-D qui se mélangent
=> le suivi se décroche très souvent ! (< 0.5 secondes)
Nous avons dévelopé 3 classes d’approches :
Approche 3-D à base de modèle explicitecombine les difficultés 2-D et 3-D – pour y faire face il faut améliorer la recherche de solutions alternatives voisines
Approche 2-D à base de modèleévite les problèmes du 3-D – nos contributions sont en détection initiale et en modélisation dynamique
Approche 3-D à base d'apprentissagesimplifie le problème 3-D en se penchent sur les mouvements typiques
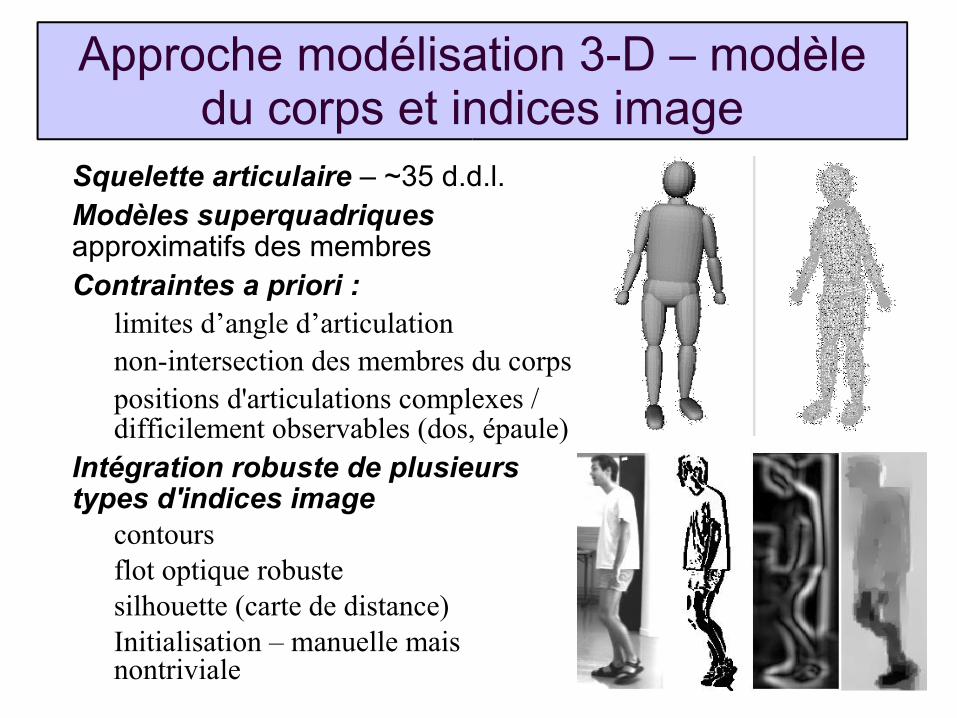
Approche modélisation 3-D – modèle du corps et indices image
Squelette articulaire – ~35 d.d.l.Modèles superquadriques approximatifs des membresContraintes a priori :
limites d’angle d’articulationnon-intersection des membres du corpspositions d'articulations complexes / difficilement observables (dos, épaule)
Intégration robuste de plusieurs types d'indices image
contoursflot optique robustesilhouette (carte de distance)Initialisation – manuelle mais nontriviale

Retrouver les minima locaux voisins
Ambiguïtés image + minima qui se mélangent => décrochage
Notre contribution principale : 4 méthodes de recherche de minima locaux voisins, pour mieux rattrapper le suivi
Covariance scaled sampling – échantillonner mieux
Recherche des regions de transition (“cols de montagne”)
par minimisation locale modifiée : suivi de vecteur propre, balayage de hyper-surface
par évolution chaine de Markov : balade hyperdynamique
Les sautes cinématiques – exploiter la structure des minima cinématiques

Contexte – suivi probabiliste particulaire
Le suivi probabiliste propage une distribution de probabilités dans l'éspace de paramètres
Les méthodes particulaires approximent la séquence de distributions par une arbre d'hypothèses ponctuelles
On garde les branches les plus probables
La méthode permet de bien gérer les ambiguïtés visuelles
… mais seulement en basse dimension

Proprietés de la fonction du coût
Augmentation rapide du volume en fonction du rayon en haute diménsion
=> on tombe rarement dans l'or – les centres des minima sont très petits par rapport aux environs
=> échantillonner ne suffit pas, il faut ensuite optimiser localement pour arriver aux bas coûts
Mauvaise conditionnement (103-104)
=> forme allongée des minima – l'échantillonnage sphèrique est très inefficace (vol(ellipsoïde)/vol(sphère englobante) ~ 10-50)
=> il faut épouser la forme locale de la fonction
Les minima sont bien écartés (101-102 écartes standards)
=> l'échantillonnage aux queues longues
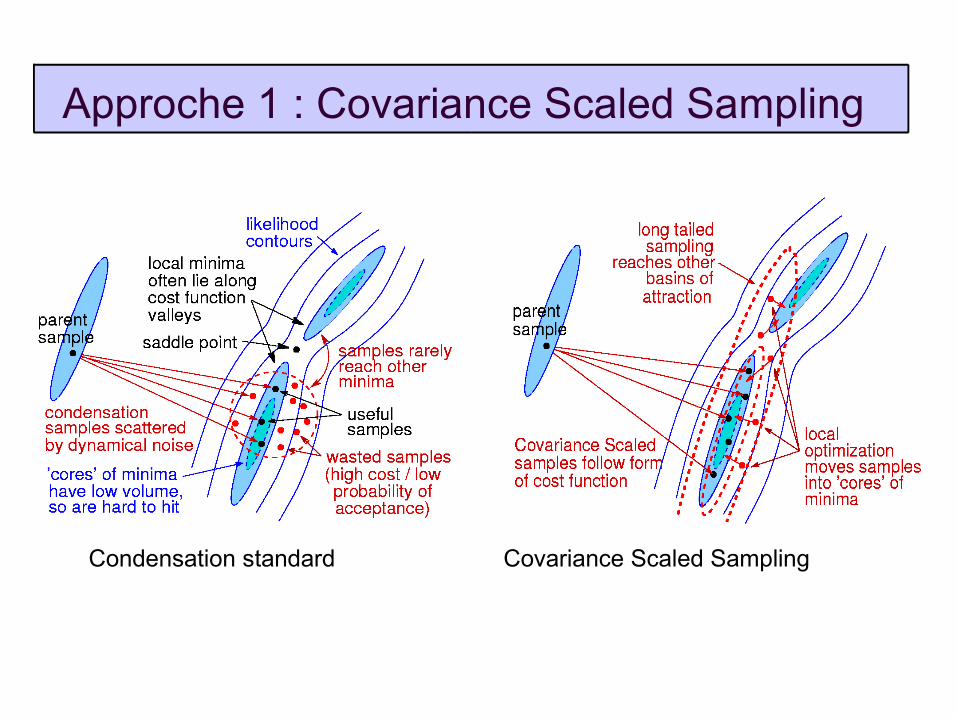
Condensation standard Covariance Scaled Sampling
Approche 1 : Covariance Scaled Sampling

Suivi Covariance Scaled Sampling

CSS sur une séquence réelle

Approche 2 : Retrouver les “zones de transition”
Retrouver les minima voisins en retrouvant les “cols de montagne” qui ménent à eux
Methodes numériques pour retrouver les zones de transition :
Minimisation locale Newton modifiée – retrouve le point selle au sommet du trajectoire : suivi de vecteur propre, balayage de hyper-surface
‘Hyperdynamique’ : balade chaîne de Markov dans un potentiel modifié concentre les échantillons sur les zones de transition

Balayage de hyper-surface
Suivre un minimum local dans un hyper-surface qui balaie l’espace, jusqu’à un maximum – souvent un point selle

Suivi de vecteur propre
Retrouve les points selle par une série de minimisations locaux virtuelles

Recherche hyperdynamique
petit – raideur – grand
faible
fort
Balade aléatoire chaîne de Markov alterne entre la recherche des zones de transition et des minima

Exemples d'ambiguïté cinématique
• Mèthode suivie de vecteur propre
• Fonction de coût “positions image connues” – sans ambiguïté image
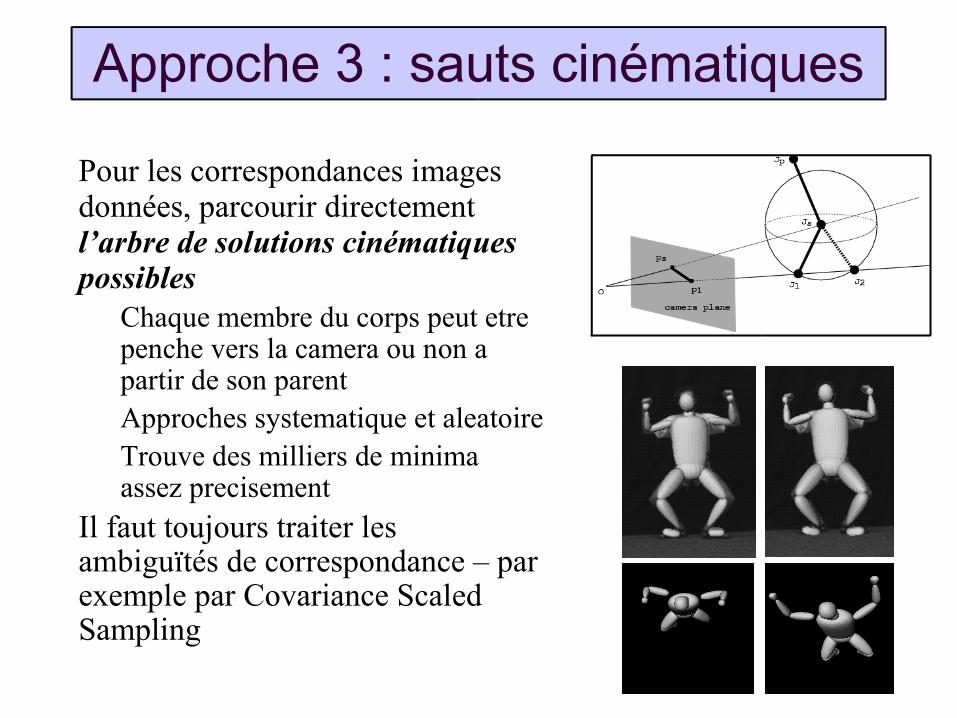
Pour les correspondances images données, parcourir directement l’arbre de solutions cinématiques possibles
Chaque membre du corps peut etre penche vers la camera ou non a partir de son parentApproches systematique et aleatoireTrouve des milliers de minima assez precisement
Il faut toujours traiter les ambiguïtés de correspondance – par exemple par Covariance Scaled Sampling
Approche 3 : sauts cinématiques
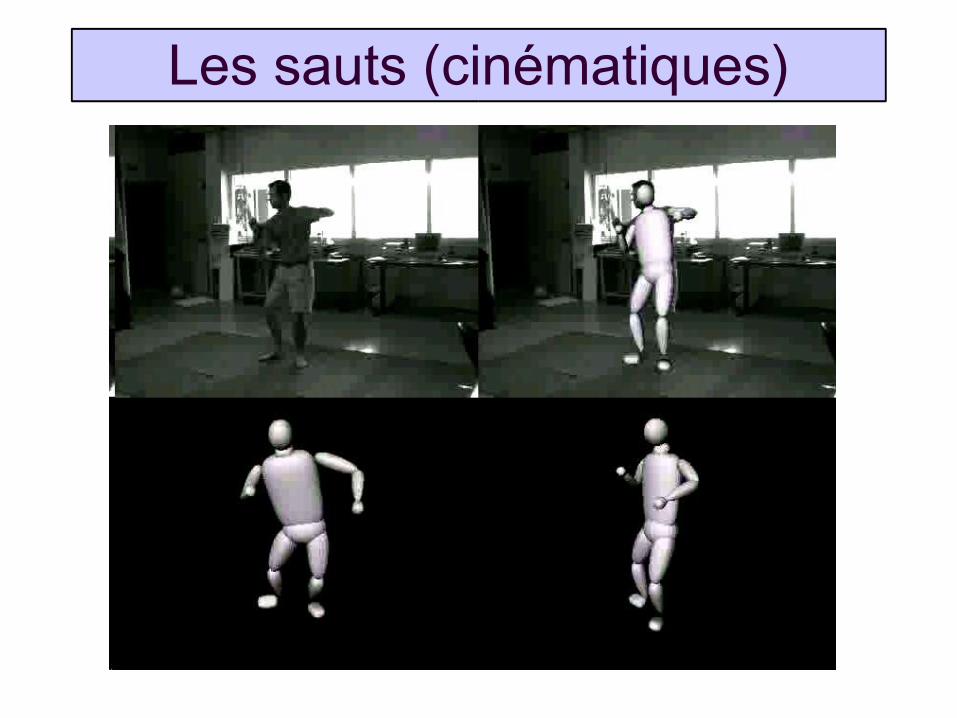
Les sauts (cinématiques)

Performance des approches modèle 3-D
Performances pratiques – temps entre décrochages :
CONDENSATION traditionelle, mouvements simples : < 0.5 secondesCovariance Scaled Sampling, mouvements simples : 1-2 secondes
Recherche suivi de vecteur propre / balayage de hyper-surface, mouvements un peu plus complexes : 3-4 secondes
Sauts cinématiques + CSS, mouvements complexes mais lisses : – 5-10 secondes

Faiblesses des approches modele 3-D
Mèthode souple et complète en principe, mais :
Initialisation complexe, donc à la main : délicate, pas de rattrapage apres décrochage
Assez lourde – complexe a implanter, jusqu’à plusieurs minutes de calcul par trame
N’incorpore pas de l’information à priori sur les poses, les mouvements typiques
passe beaucoup de temps a investiguer les configurations qui sont possibles en principe, mais inutiles en pratique

Approche modèle 2-DAvantages
Simple, près de l'image, suivi par correlation de gabarit
Pas de minima locaux cinématiques
Une représentation intermediaire utile, même si on veut du 3-D à la fin
Limitations
Modèle non-rigide – un lien plus faible avec le 3-D
L'apparence du modèle dépende du point de vue – il faut suivre à travers des “changements d'aspect”
Détecteur articulaire d'humains Modélisation dynamique pour la capture du
mouvement 2-D
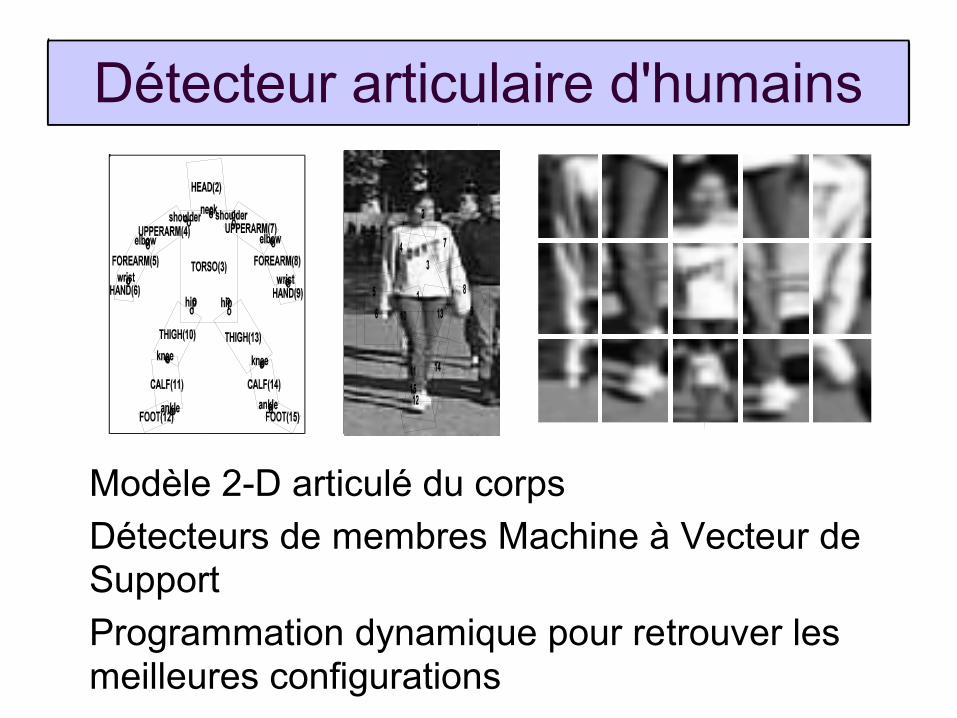
Détecteur articulaire d'humains
Modèle 2-D articulé du corps
Détecteurs de membres Machine à Vecteur de Support
Programmation dynamique pour retrouver les meilleures configurations

Exemples de détections

Modelisation dynamique du suivi 2-D
Les actions / les mouvements humains sont compliqués mais suivent des comportements typiques
En 2-D on perd les contraintes de rigidité et l’invariance de point de vue
le suivi est moins stable, il faut suivre à travers les changements “d’aspect”
On voudrait classer les actions
=> Apprendre un modele dynamique pour améliorer le suivi
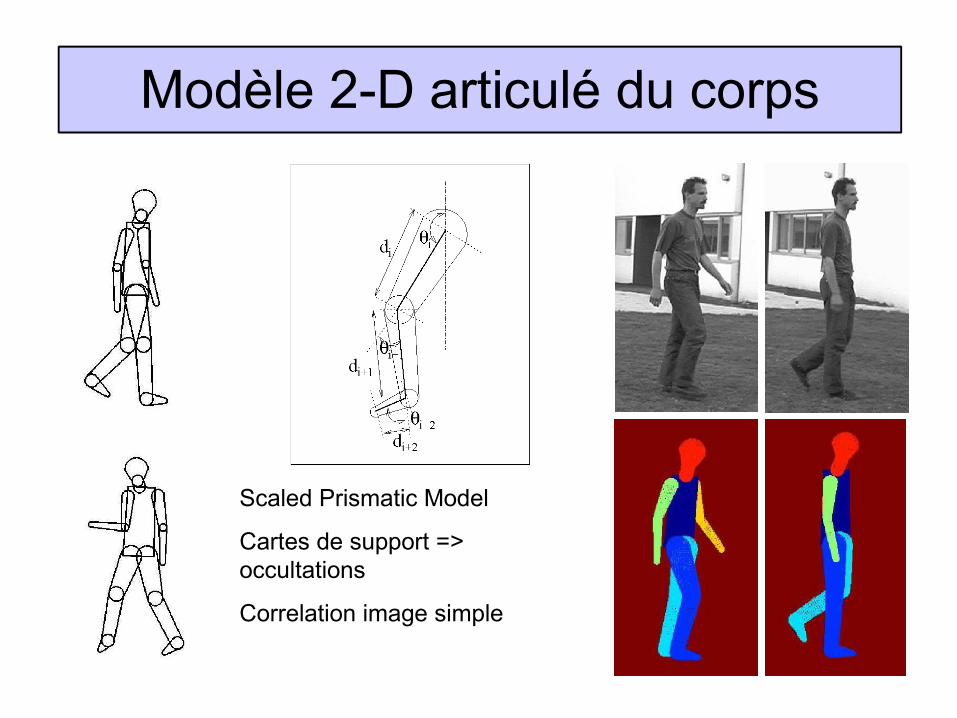
Modèle 2-D articulé du corps
Scaled Prismatic Model
Cartes de support => occultations
Correlation image simple
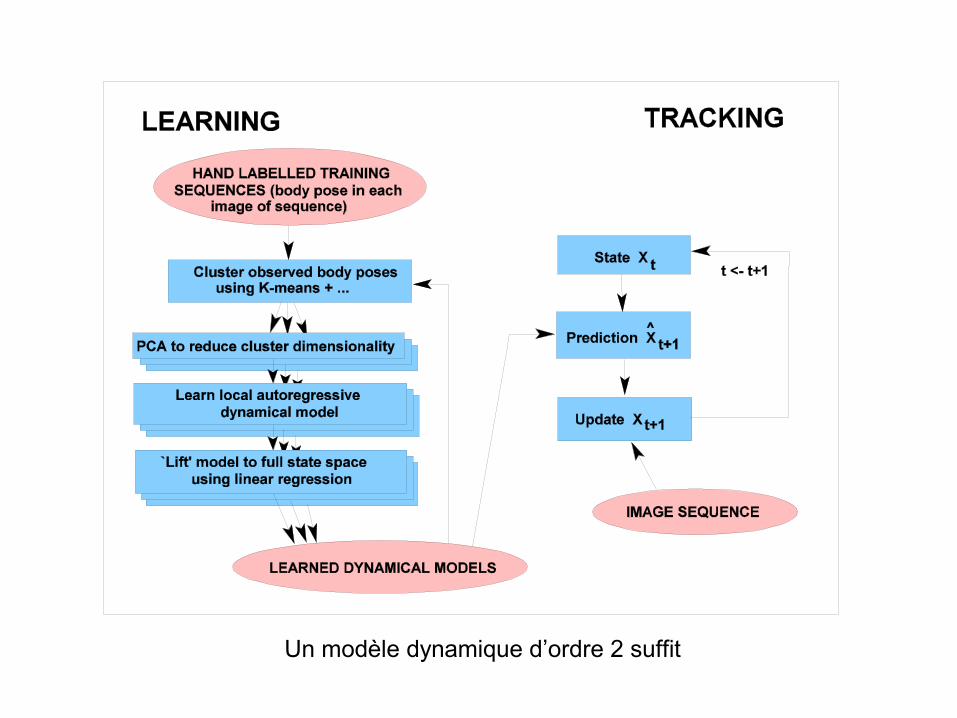
Un modèle dynamique d’ordre 2 suffit

Suivi de la course
Athlète d’apprentissage Athlète de teste

Suivi d'un changement d’aspect

Bilan du suivi 2-D
Résultats intéressants mais préliminaires
Pas d’initialisation automatique
Mise en correspondence image simpliste
Gamme de mouvements limitée, modèle dynamique à raffiner
Il faut renforcer les liens avec le 3-D (reconstruction – rigidite)

Approche 3 : 3-D par apprentissage
Les modeles du corps sont complexes / inexactes / difficiles a initialiser / n’encodent pas le comportement typique
– est-ce qu’on peut travailler sans modele explicite ?
=> Approche “boîte noire” diagnostique
Apprendre à estimer la pose / le mouvement directement à partir de l’image
Régression non-lineaire, appris sur un ensemble d’exemples réels – pose 3-D (système capture de mouvement classique) + image correspondante
Indices image => silhouettes sans modèle 3-D, on ne peut pas génerer les images / vérifier les hypothèses
pour simplifier, on suppose la soustraction préalable du fond

Reconstruction de pose par régression
Représente la silhouette par un vecteur de déscripteurs z, et la pose par un vecteur d’angles d’articulation xApprend une régression directe x = x(z)
Méthodes moindre carrés regularisé, Machine à Vecteur de Pertinence (RVM), MVS, …
Limitation : la relation z → x n’est pas en effet fonctionelle (valeurs multiples)

Descripteur robuste de silhouette
Encoder la forme de la silhouette, mais rester robuste aux occultations / à la segmentation inexacte
Éviter les descripteurs globaux (moments, …)
Utiliser les histogrammes de “shape contexts” – distributions de “clichés locaux quantifiées” de la silhouette

Résultats intermédiaires – images statiques
• Erreur moyen par d.d.l. : 6.0o
• Mais ~ 15% d’erreurs grossières en raison des ambiguïtés de la représentation silhouette – par exemple confonder les deux jambes
Séquence de teste – marche spirale synthétique

Méthode images statiques

Ambiguïté de la silhouette
Plusieurs poses 3-D ont la meme silhouette
=> le comportement de la régression silhouette-pose mono-valeur est irregulière …
Solution 1: apprendre une régression multi-valeur – un mélange de régressions
Solution 2: désambïguer avec de l’information temporelle – approche suivi

Régression multi-valeur
Éstimer un mélange de Gaussiens dans l’éspace conjointe (descripteur,pose)
Conditionner pour éstimer les poses possibles à partir d’un descripteur
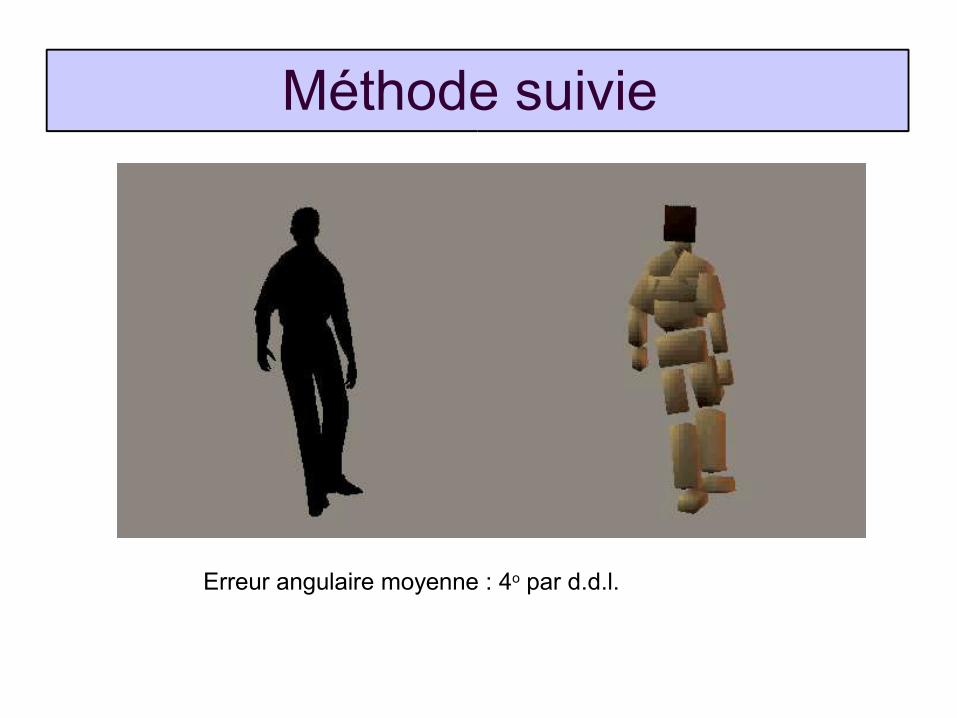
Méthode suivie
Erreur angulaire moyenne : 4o par d.d.l.
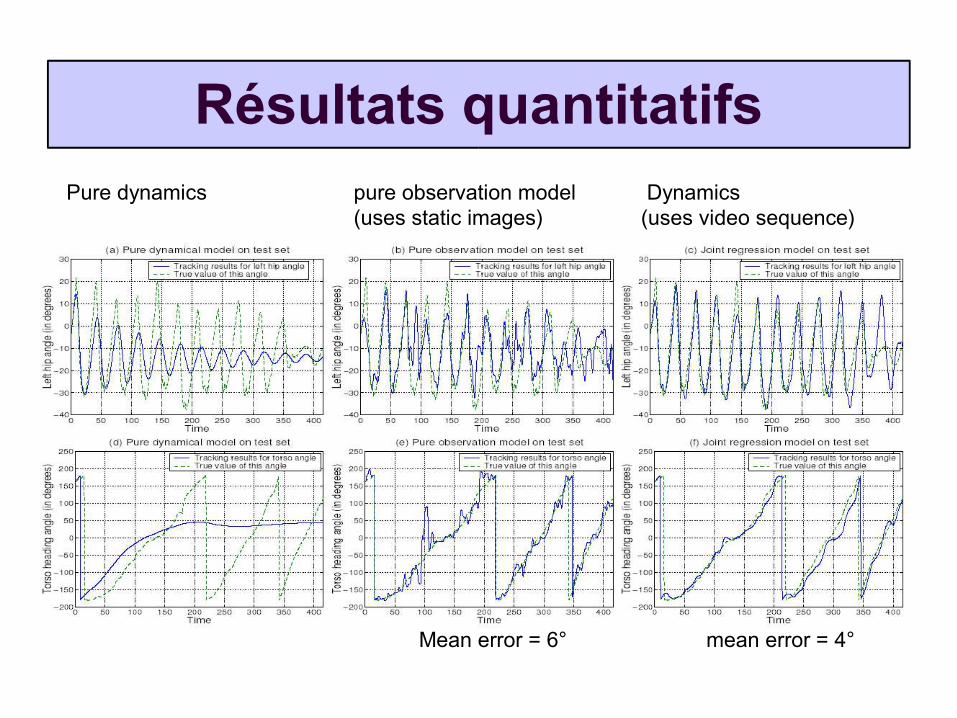
Résultats quantitatifsPure dynamics pure observation model Dynamics
(uses static images) (uses video sequence)
Mean error = 6° mean error = 4°

Méthode suivie – séquence réelle
1. Étape de pretraitement
a) Soustraire le fond b) Enlever les ombres c) Éstimer la silhouette d) Evaluer le descripteur

Méthode suivie – séquence réelle
2. Étape de régression
a) éstimer les angles d’articulation (méthode RVM) b) synthètiser de nouvelles images

Bilan de capture du mouvement
Approche modèlisation 3-D explicitecomplète et flexible, mais lourde et delicate à mettre en oeuvre
Approche 2-Dune bonne voie intermédiaire, mais ne fournit pas directement du 3-D, et peut manquer de stabilité (pas de contrainte de rigidité 3-D)
Approche 3-D par apprentissagelégère, de bons résultats visuels, mais limitée aux mouvements connus, difficile de mettre en oeuvre sans silhouettes (pas de modèle explicite)
A faire : combiner les avantages des différentes méthodesextraction de descripteur 2-D => estimation 3-D par apprentissage => optimisation de modèle explicite

Autres travaux 2000-2004Vision de bas niveau
Interpolation optimale d'image
Détection de points clé stables
Mise en correspondance probabiliste
Vision géométrique et reconstruction de scèneÉtudes algébriques – configurations critiques, pose de caméra
Approches plan + parallaxe et projective-tensorielle
Ajustement des faisceaux
Modélisation statistique et reconnaissance de formesModélisation générative – diagnostique
Reconnaissance visuelle par hiérarchie de parts
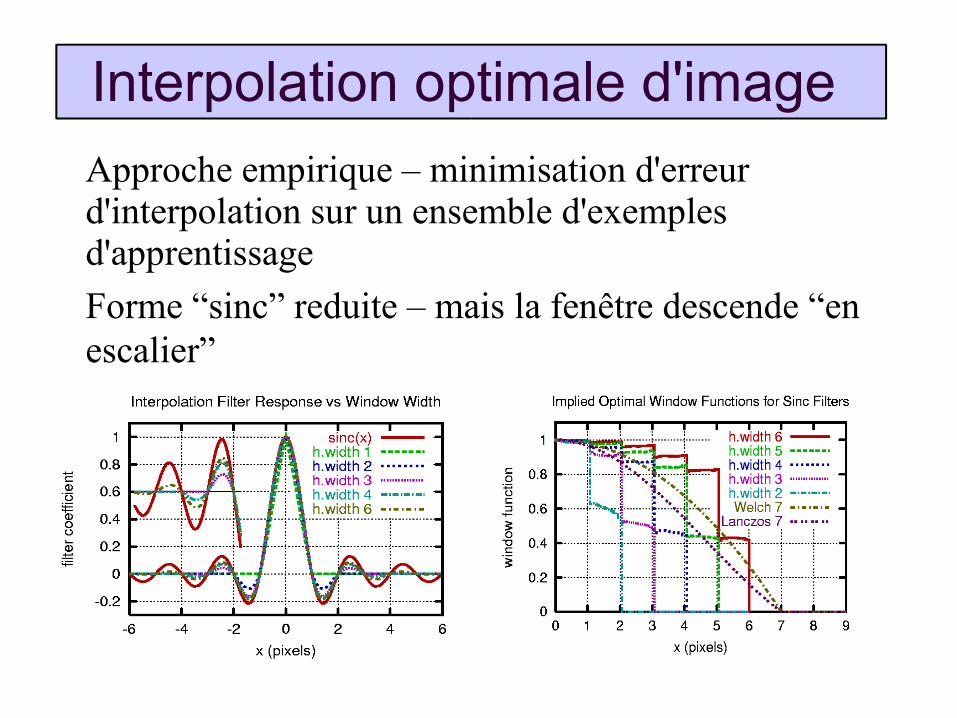
Interpolation optimale d'image
Approche empirique – minimisation d'erreur d'interpolation sur un ensemble d'exemples d'apprentissage
Forme “sinc” reduite – mais la fenêtre descende “en escalier”

Détection de points clé stables
translation + échelle
translation
affinesimilaritétranslation
translation + rotation
similarité

Distribution Conjointe de Features
Modèle probabiliste de mise en correspondance géométrique entre images – la distribution conjointe des positions d'indices correspondantes
Formes analytiques et méthodes d'estimation motivées par les contraintes de mise en correspondance classiques
Le modèle “epipolaire” reste stable pour les scènes planes – pas de selection de modèle...
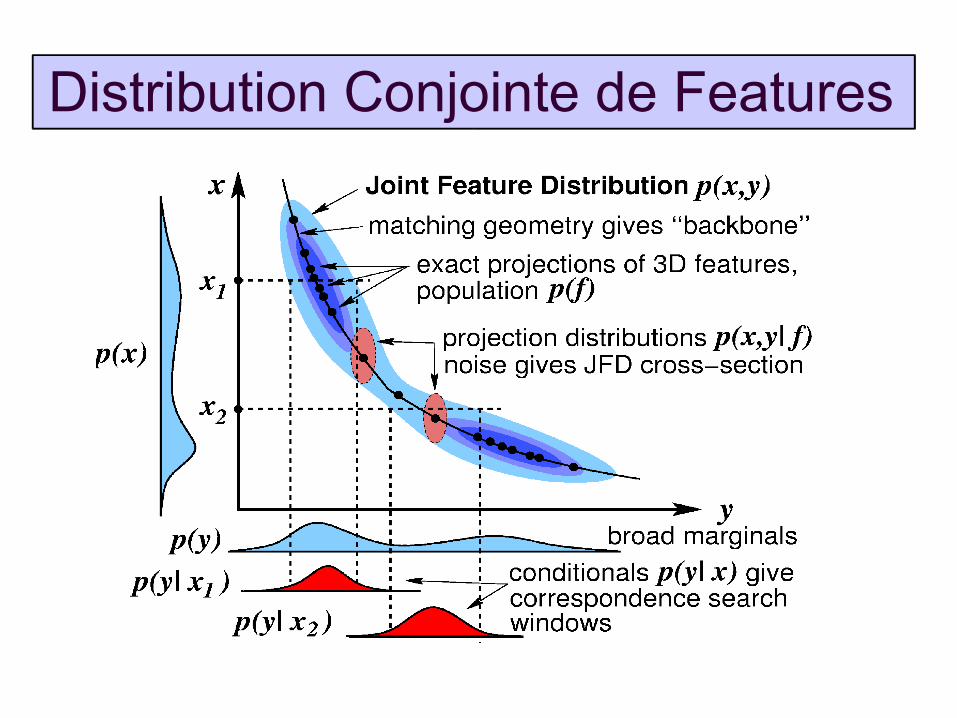
Distribution Conjointe de Features
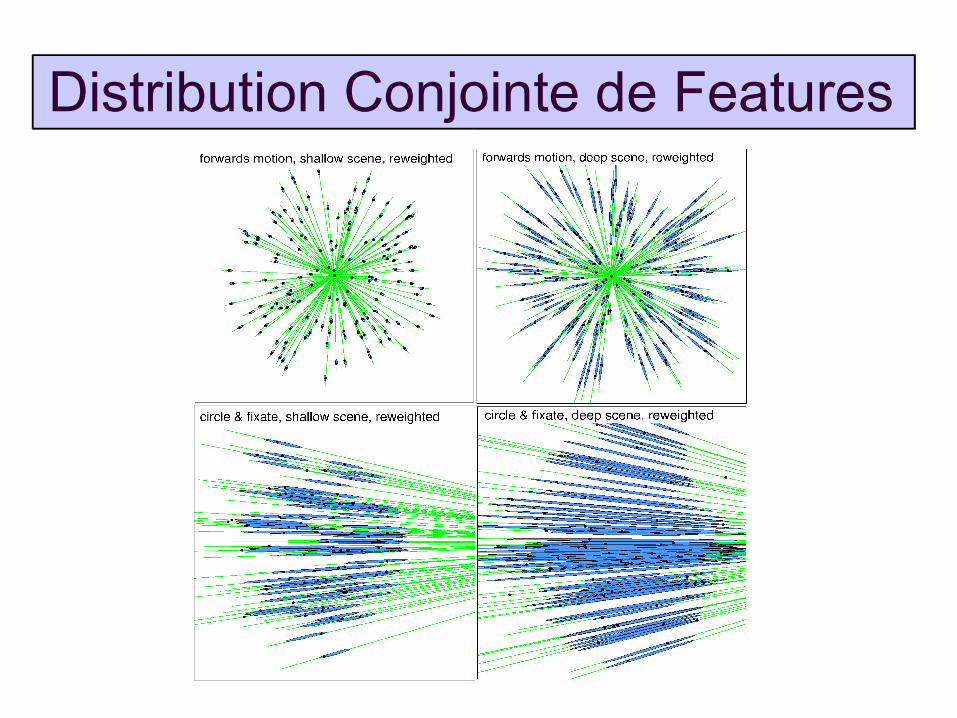
Distribution Conjointe de Features
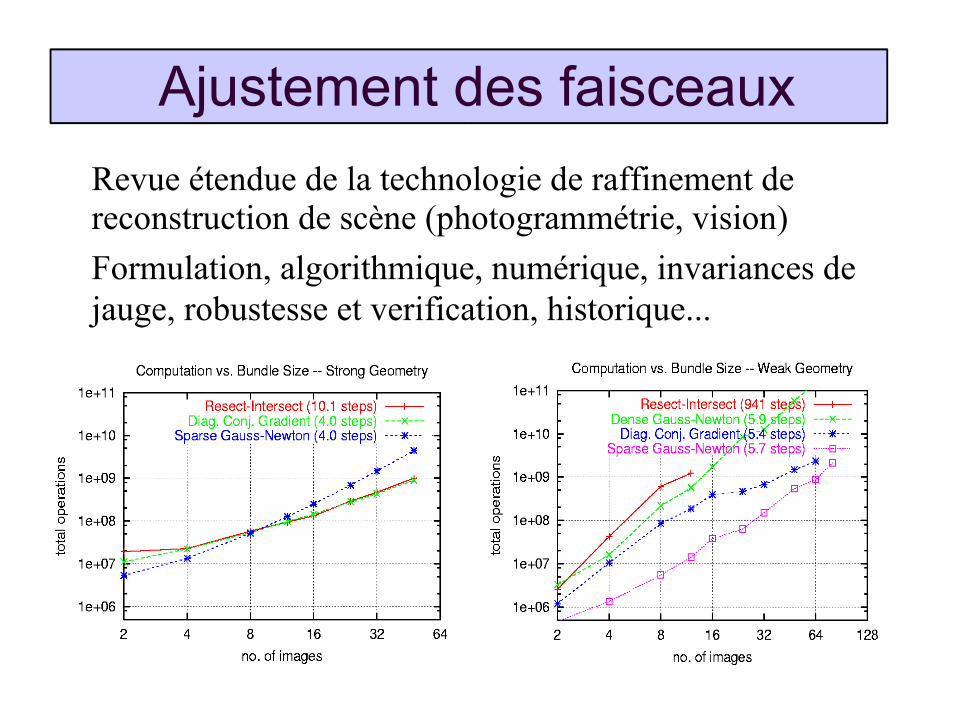
Ajustement des faisceaux
Revue étendue de la technologie de raffinement de reconstruction de scène (photogrammétrie, vision)
Formulation, algorithmique, numérique, invariances de jauge, robustesse et verification, historique...
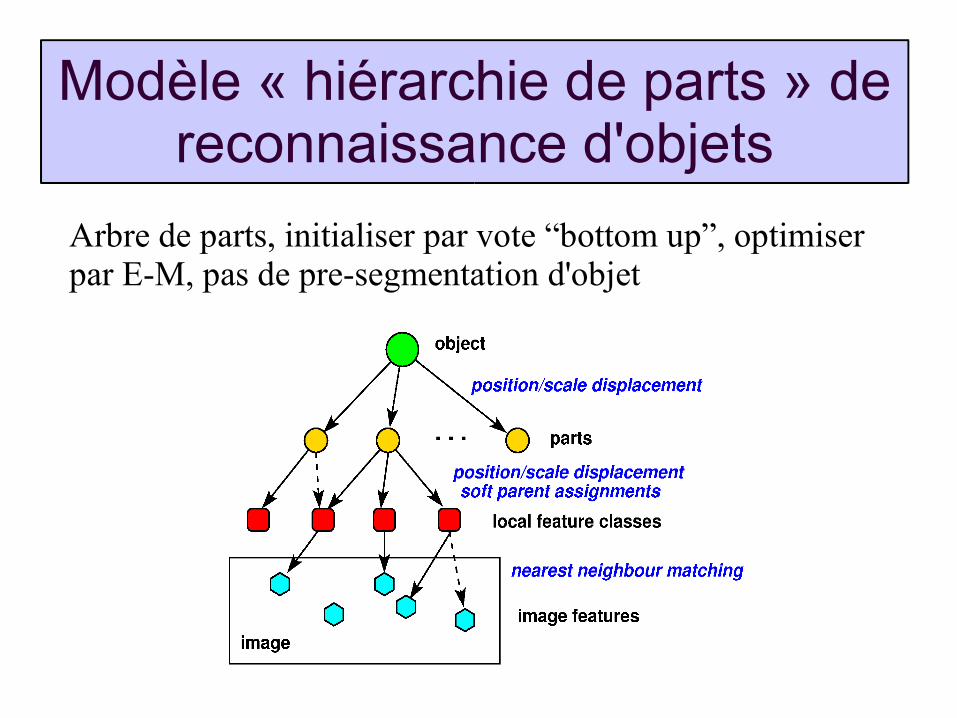
Modèle « hiérarchie de parts » de reconnaissance d'objets
Arbre de parts, initialiser par vote “bottom up”, optimiser par E-M, pas de pre-segmentation d'objet
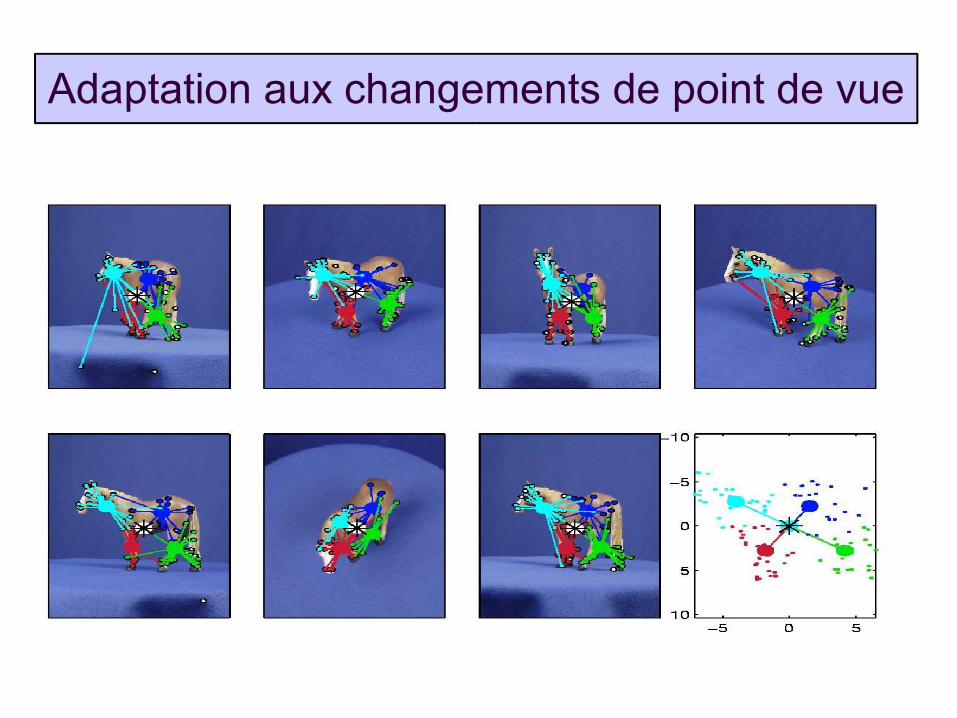
Adaptation aux changements de point de vue
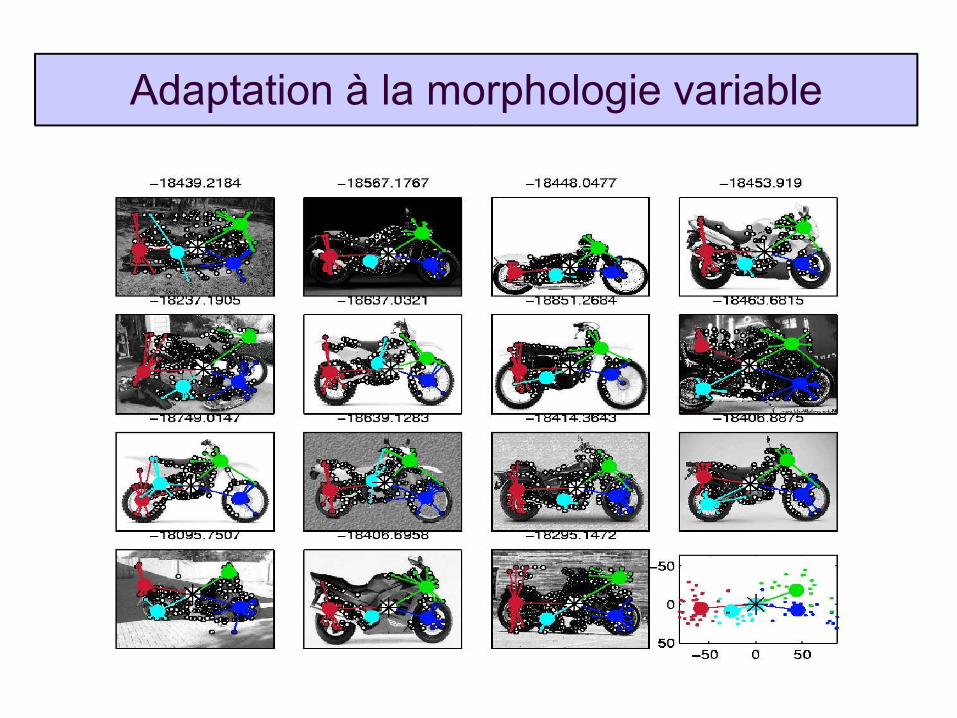
Adaptation à la morphologie variable

Encadrements de thèse
C. Sminchisescu – approches modèle 3-D au capture du mouvement (INPG 1999-2002, encadrant unique)
M-A. Ameller – méthodes algébriques d'estimation de pose de caméra (INPG 1999-2002, co-encadré avec L. Quan)
G. Bouchard – apprentissage, modélisation statistique (UJF 2001-2005, co-encadré avec G. Celeux)
N. Dalal – détection de personnes (INPG 2003-, co-encadré avec C. Schmid)
A. Agarwal – approches apprentissage au capture de mouvement 2-D et 3-D (INPG 2004-, encadrant unique)
Autres encadrements4 ingénieurs / postdocs, 3 DEA / masters, 5 autres stages

Bilan d'activité, 2000-2004
15 articles congrès + 3 soumises, 4 articles journal + 2 soumises
2 thèses encadrées + 3 en cours, 12 autres stages
Rapporteur externe unique d'une thèse à Oxford
Participation au 4 projets européens + 1 national
Organisation du congrès principal de notre domaine – ICCV'03, Nice, France
Plusieurs autres workshops, area chairs, comités de congrès, etc

Questions ?
Remerciements à :
• Cristi, Ankur, Remi et Guillaume pour leurs transparents
• MOVI et LEAR pour être là