
Rapport de “Projet de fin d’étude” Ecole MatMécacfdbib/repository/WN_CFD_01_12.pdf · 3...
25
1 RAFFARD Annick Promo 2001 Rapport de “Projet de fin d’étude” Ecole MatMéca réf. : WN CFD 01 12 EADS-Airbus SA
Transcript of Rapport de “Projet de fin d’étude” Ecole MatMécacfdbib/repository/WN_CFD_01_12.pdf · 3...

1
RAFFARD Annick Promo 2001
Rapport de “Projet de fin d’étude” Ecole MatMéca
réf. : WN CFD 01 12
EADS-Airbus SA

2
AMR “Adaptive Mesh Refinement”
Sommaire Remerciements
1. Présentation de EADS-Airbus SA et du CERFACS
2. Qu’est que l’A.M.R. ?
3. Etat des lieux
Equations résolues Approche Multigrille local Le code NSMB
4. Les étapes du couplage Réorganisation par niveau Mise en place de la correction déficitaire Mise en place de la remontée de l’incrément en temps Mise en place du “postsmoothing”
5. Validations et résultats
Code existant AMR multigrille
6. Perspectives et conclusions

3
Remerciements
Je tiens à remercier Loïc Tourrette de m’avoir permis d’effectuer mon stage au sein d’EADS-Airbus et d’avoir pris l’initiative de me confier aux bons soins de Jean-Christophe Jouhaud au CERFACS. Je remercie Jean-Christophe Jouhaud pour sa disponibilité, sa gentillesse et sa bonne humeur ainsi que pour la qualité de l’encadrement qu’il m’a procuré. Je remercie également Denis Darracq pour ses encouragements ainsi que tous les membres de l’équipe CFD du CERFACS pour leur naturel et leur joie de vivre. Je remercie également M. Jean-Paul Caltagirone d’avoir accepté d’être mon tuteur universitaire. Enfin, une petite pensée spéciale pour tous les militaires du site de Météo-France qui auront contribué au bon déroulement de mon séjour à Toulouse.

4
1. Présentation de EADS-Airbus SA et du CERFACS EADS-Airbus SA http://www.airbus.com Airbus est un avionneur européen qui est la propriété de deux compagnies européennes leader dans le domaine de l’aéronautique : EADS ( European Aeronautic Defence and Space Company), née de la fusion entre Airbus consortium et ses partenaires Aérospatiale-Matra (France), Daimler-Chrysler Aerospace (Allemagne) et CASA (Espagne); et BAE SYSTEMS (Grande-Bretagne). En juin 2000, EADS et BAE SYSTEMS ont annoncé la création de “Airbus Integrated Company”, destiné à consolider les ressources d’Airbus et le “savoir- faire” des différents sites européens en une seule entité. Ainsi, tous les sites européens d’Airbus company (et tous leurs employés) sont maintenant dirigés par une équipe unique. La firme emploie aujourd’hui quelques 40.000 personnes partout en Europe, et va continuer à travailler avec plus de 1.500 sous-traitants ce qui représente approximativement 100.000 employés dans le monde. La production des avions Airbus a lieu dans différents sites de EADS et BAE SYSTEMS à travers l’Europe, chacun desquels produit une section complète de l’avion. Puis les sections ainsi terminées sont acheminées vers l’un des deux sites de montage final Airbus, sur les chaînes d’assemblages (Toulouse et Hambourg). EADS-Airbus SA contribue par le savoir-faire de son bureau des méthodes à la réalisation d’outils numériques et à la conception des avions. CERFACS (Centre Européen de Recherche et Formation Avancée en Calcul Scientifique) http://www.cerfacs.fr Situé à Toulouse sur le site de Météo-France, le CERFACS qui emploie 65 chercheurs de toutes nationalités, est l’un des leaders mondiaux parmi les instituts de recherche travaillant sur l’efficacité des algorithmes pour résoudre les problèmes scientifiques à grande échelle. Il prend part à de nombreux projets européens. L’organisation scientifique du CERFACS est principalement basée sur deux types d’activités : Un noyau central, qui concerne surtout les activités de recherche fondamentale et qui permet au CERFACS d’être présent à la fois sur la scène internationale au titre d’un établissement de recherche reconnu et de procurer un soutien aux équipes plus appliquées du groupe. Les deux équipes concernées sont : “Parallel algorithms” et “Image and signal processing”. Une autre série des activités est plus appliquée et concerne l’organisation du transfert du savoir et des technologies. Ces activités s’appuient principalement sur les orientations souhaitées par les quatre actionnaires (EADS, CNES, Electricité de France et Météo-France). Elles concernent donc : “Climate Modelling and Global Change”, “Computational Fluid Dynamics” et “Electromagnetism and Control”. C’est au sein de l’équipe CFD que ce stage a été effectué pour le compte du bureau des méthodes de EADS-Airbus SA.

5
2. Qu’est que l’A.M.R. ? La simulation numérique prend une part de plus en plus importante dans le monde industriel et notamment dans le domaine de la conception. Les méthodes de calcul pouvant amener de meilleurs compromis entre les contraintes de mémoire, le temps de calcul et la précision sont étudiées avec le plus grand soin. C’est dans ce cadre que EADS s’intéresse à l’AMR. A.M.R. signifie “ Adaptive Mesh Refinement ”. C’est une technique d’enrichissement local en structures hiérarchisées (cf. figure 1) permettant par le biais d’un calcul multi-blocs étagé d’améliorer la précision en économisant le nombre de points de calcul. Le but de l’AMR est de diminuer les coûts de calculs tout en conservant une bonne précision.
Enrichissement d’un maillage unique
Intégration d’un maillage non-structuré
Enrichissement en structure hiérarchisée
Résolution composite
Figure 1: Stratégies de raffinement local
Dans un premier temps il est utile de préciser quelques termes de vocabulaire spécifique à l’AMR ou bien utilisé par abus de langage dans le code de calcul NSMB.
Multi-Bloc : découpage d’un domaine à mailler en plusieurs sous domaines (ou blocs). Ce découpage est imposé par la génération d’un maillage structuré autour d’une géométrie complexe. Ceci permet également le calcul en parallèle.
Raffinement : action de diviser (en général par 2) les cellules d’un bloc. Le raffinement peut s’effectuer simultanément dans les trois directions de l’espace ou bien uniquement dans une ou deux.
Sous-blocs : Blocs obtenus par raffinement local d’une partie d’un bloc existant. Les sous-blocs sont superposés aux blocs dont ils sont issus.

6
Fin/grossier ou Fils/père : un bloc fin est un bloc obtenu par raffinement, le bloc grossier est le bloc ayant servi de base au raffinement, celui-ci est également appelé père, et le bloc raffiné fils. Un bloc père peut avoir plusieurs fils et des petits- fils (sous-blocs de niveau 2).
Niveau : (ou niveau de raffinement) les blocs du maillage de base (les plus grossiers) sont dits de niveau 0. Leurs fils sont dits de niveau 1, etc. Ainsi un calcul à trois niveaux possède des blocs de niveau 0, 1 et 2.
Structure hiérarchisée : Dans notre cas la structure choisie est appelée STRUCTURE HIÉRARCHISÉE “PROPERLY-NESTED”, c’est à dire qu’elle respecte les trois conditions suivantes :
• inclusion de l’union des sous-blocs dans les parents • pas de recouvrement des sous-blocs d’un même niveau • Les mailles adjacentes à un niveau l doivent appartenir au niveau l-1, sauf
éventuellement aux frontières du domaine (conditions limites) . De plus, pour faciliter la programmation nous avons interdit qu’un sous-bloc puisse avoir deux pères, c’est à dire que tout sous-bloc est strictement inclus dans son père, il ne peut pas être à cheval sur deux blocs. Le raffinement s’effectue généralement par l’intermédiaire d’un senseur judicieusement choisi, permettant de déterminer les régions du maillage où sont calculées les structures caractéristiques (choc, couche limite, tourbillons, …). Typiquement, en régime stationnaire, en transsonique, fluide parfait (cadre actuel d’application de l’AMR dans NSMB), les senseurs détectent les chocs. Ils permettent d’identifier les cellules qui seront raffinées dans un sous-bloc. S’il est en théorie possible de créer autant de niveaux que l’on souhaite, en pratique, on se limite souvent à deux ou trois niveaux.
L’intérêt de l ‘AMR est un gain important en espace mémoire (car il y a un gain important en nombre de points de calcul), un gain important en temps de calcul en conservant toutefois une précision comparable. (Les résultats de l’AMR sont comparés avec les résultats obtenus à solveur équivalent sur un maillage raffiné sur la totalité du domaine.)
Il est également important de souligner que l’AMR allège la phase initiale de création du maillage dans la mesure où l’AMR est une technique automatique de raffinement local. Dans le cas étudié, l’AMR est appelé par une chaîne de calcul : GAME (Grid Adaptation by Mesh Enrichment). Cette chaîne de calcul comprend le code de calcul ainsi que des outils permettant l’adaptation du maillage (outils de raffinement, de grouping/clustering, de projection). Son fonctionnement est le suivant :
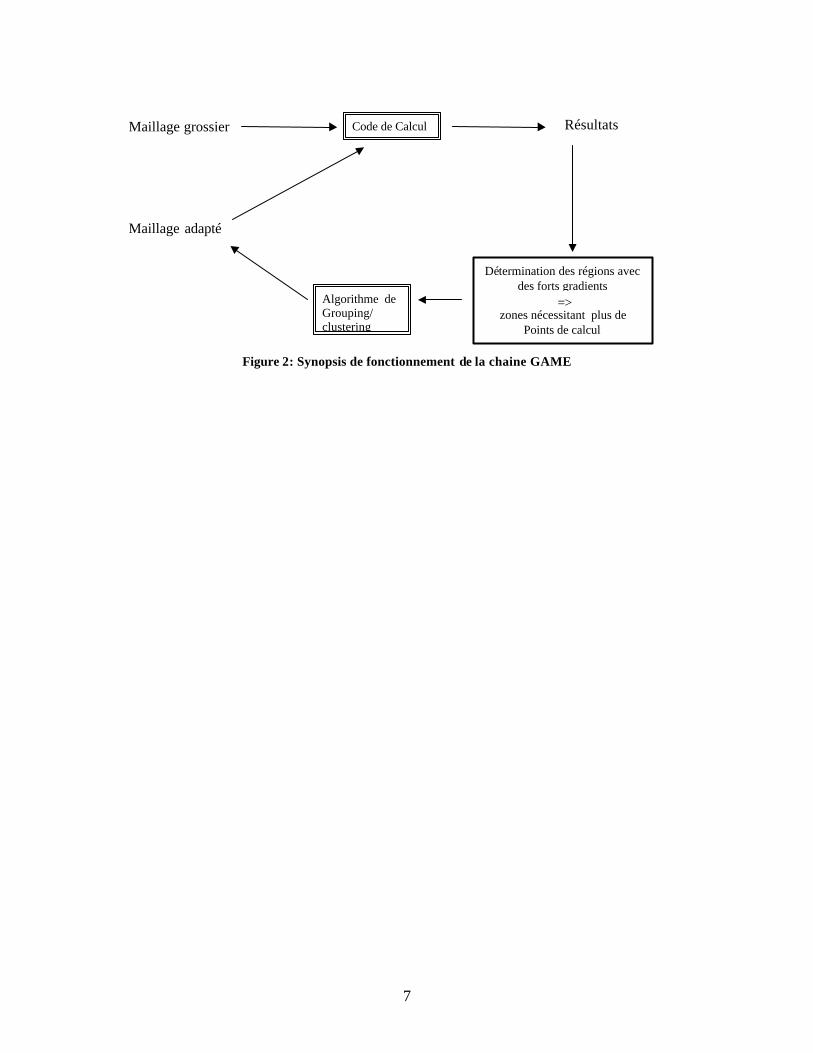
7
Figure 2: Synopsis de fonctionnement de la chaine GAME
Maillage grossier Maillage adapté
Code de Calcul Résultats
D é ter mination des régions avec des forts gradients
zones nécessitant plus de Points de calcul
Algorithme de Grouping/ clustering
=>

8
3. Etat des lieux La méthode de AMR est fondée sur une résolution composite des équations sur un maillage multi-blocs étagé. C’est-à-dire que l’on résout les équations sur chaque niveau et que la solution finale est la solution sur la structure hiérarchisée. Pour assurer la cohésion de des solutions fines et grossières, il est nécessaire de coupler les solutions obtenues sur les blocs fins avec les solutions sur les blocs plus grossiers : cela constitue les fondements de l’AMR. Dans ce paragraphe sera présenté un couplage relativement complet et basé sur le principe d’une technique multigrille. C’est ce couplage qui sera implémenté dans NSMB pour calculer des écoulements transsoniques stationnaires.
Equations résolues
Equation de Navier-Stokes :
∂W∂t
+ ∂(f-fv)
∂x +
∂(g-gv)∂y
+ ∂(h-hv)
∂z =0
Equation 1
soit
∂t
ρ ρu ρv ρw ρE
+ ∂x
ρu ρu2+p+τxx
ρuv-τxy
ρuw-τxz
u(ρE+p)-(τU)x+qx
+∂y
ρv ρvu-τxy
ρv2+p+τyy
ρvw-τyz
v(ρE+p)-(τU)y+qy
+∂z
ρw ρwu-τxz
ρwv -τyz
ρw2+p+τzz
w(ρE+p)-(τU)z+qz
= 0
Equation 2
où τ est le tenseur des contraintes visqueuses. qx est le flux de chaleur calculé en utilisant la loi de Fourrier. En intégrant les équations à l’aide une méthode volume-fini et une méthode implicite en temps, cela revient à résoudre :
Vol∆t
I + ∂R∂W
∆Wn+1= -R(Wn)
Equation 3
où R est le résidu et W le vecteur d’état. Dans le cadre de l’application de l’AMR dans NSMB, on utilise un schéma centré en espace de type Jameson et une méthode LU-SGS implicite pour l’intégration en temps.

9
Approche multigrille local : De par la similitude du traitement pouvant être réalisé en stationnaire, l’AMR peut se rapprocher des méthodes multigrilles. Il est alors appelé AMR multigrille local car les grilles de niveau 1 et 2 ne recouvrent pas l’ensemble du domaine de calcul. L’approche multigrille classique réside dans le fait de superposer au maillage des grilles dé-raffinées (typiquement en structuré: on garde un point de maillage sur 2) afin de mieux éliminer les basses fréquences du schéma. En effet, tous les schémas ont la propriété d’éliminer les hautes fréquences du résidu, cependant certains, appelés lisseurs (IRS, LU, LU-SGS, …), les éliminent plus efficacement. Or, en dé-raffinant, ce qui étaient des basses fréquences par rapport au maillage précédent deviennent alors des hautes fréquences pour ce nouveau maillage, le lisseur est donc plus apte à les éliminer.
L’intérêt de cette technique est d’augmenter la vitesse de convergence en utilisant un bon lisseur.
La principale différence est qu’en AMR on part d’un maillage relativement grossier et que l’on ne raffine qu’aux endroits supposés des structures caractéristiques. Cela permet de travailler sur un nombre de point de calcul moins important.
Par contre cela pose de nouveaux problèmes d’implémentation : Alors qu’en multigrille, toute grille fine possède une grille grossière correspondante de même dimension géométrique, en AMR seule une partie des grilles grossières est recouverte. Une autre différence est que chaque bloc multigrille n’appartenant pas au niveau de base (fin) a toujours exactement un fils alors qu’un bloc AMR peut en avoir plusieurs ou au contraire aucun. De ce fait, il peut exister des lieux de maillage où la grille de départ n’a pas été raffinée et se retrouve donc être en même temps du niveau le plus grossier et localement aussi le plus fin. Il y a aussi des problèmes spécifiques liés aux traitements aux limites des sous-blocs. C’est pour cette raison essentiellement que l’algorithme de traitement multigrille ne peux être directement utilisé pour l’AMR et doit être adapté.
Figure 3: Effet multigrille

10
Le code NSMB : “A Navier Stokes Multi Block Finite Vo lume Flow Solver Using Dynamic Memory Allocation and the MEMCOM data base” NSMB est un solveur RANS (Reynolds Average Navier-Stokes Equation), possédant plusieurs schémas et plusieurs équation de turbulence. L’étendu des outils qui y sont codés (LES, ALE, Patch-grid,… ) en fait un solveur performant et relativement complet. NSMB est codé en FORTRAN 77, compilé en FORTRAN 90, et utilise des routines C (pour l’allocation dynamique) et MPI (pour le parallèle). La version 1.0 du solveur a été développé by J.B. Vos à l’IMHEF-EPFL (Ecole Polytechnique de Lausanne) puis la version 2.0 et les suivantes ont été développées conjointement au sein du projet NSMB. Le consortium NSBM réunit EADS (Toulouse), C2M2-NADA-KTH ( Stockholm), CERFACS (Toulouse), SAAB ( Linköping), IMHEF-EPF (Lausanne), ENSAM (Paris) et CFS Engineering (Lausanne). La dernière version en date est la version 5.2 datant du 1er - mai – 2001. La version 5.2 du code NSMB a la fonctionnalité de l’AMR. Ce codage de l’AMR donne des résultats très satisfaisants : à niveau convergence égale et à précision pratiquement égale, l’AMR permet en un nombre sensiblement égal d’itérations, de gagner en moyenne un facteur 3 en terme de nœuds de maillage et un facteur 4 en terme de temps CPU. Cependant, dans ce codage le couplage y est basique afin de permettre une première démonstration de l’efficacité de cet outil : c’est une première ébauche pour fournir rapidement à EADS un outil satisfaisant. Ainsi, le couplage se fait par recopie des résidus des grilles fines sur les grilles grossières pour la descente et la remontée n’y est pas implémentée. De plus le transfert des résidus s’effectue en une fois, ceci pour tous les blocs : on ne profite pas pleinement des dernières avancées en temps.

11
4. Les étapes du couplage :
L’objectif de ce stage a consisté à mettre en place un couplage plus efficace en terme de convergence, c’est à dire à coder le multigrille local avec sa descente et sa remontée. Mon travail a été découpé en étapes avec des validations successives. Les quatre étapes principales ont été :
• Réorganisation par niveau • Mise en place de la correction déficitaire • Mise en place de la remontée de l’incrément en temps • Mise en place du “postsmoothing”
Il a été décidé de d’abord avancer la programmation sur un cas Euler puis d’adapter au cas visqueux en rajoutant le couplage des termes de turbulence et de viscosité. Par analogie avec le multigrille, on peut parler de cycles de grille (V, W, etc), de descentes et de remontées. Toutes les opérations de restrictions sont conservatives. Réorganisation par niveau Dans un tout premier temps, afin d’optimiser le codage de l’AMR déjà présent dans NSMB, le traitement des blocs a été réorganisé par niveaux. Ainsi, cela a permit de transmettre le dernier calcul de résidu des blocs fins à leur pères. Si cette modification a amené une amélioration, elle n’est toutefois pas significative, son but étant avant tout de préparer le terrain pour un couplage plus évolué. Cette nouvelle structuration a de plus amené une meilleure lisibilité du code du point de vue de l’AMR. Mise en place de la correction déficitaire Cette étape correspond à la descente du cycle. Le calcul est en premier lieu effectué sur les blocs les plus fins (ou niveau fin ou niveau L), puis sur leurs pères et les autres blocs d’un niveau de raffinement inférieur (L-1) et ainsi de suite jusqu’aux blocs les plus grossiers (niveau 0). Les résidus et les variables d’état calculés sur les grilles les plus fines servent à coupler la résolution sur les grilles plus grossières. Ils sont transférés des blocs fins vers leur père. Le terme transféré est aussi appelé correction déficitaire car il provient de la non-linéarité des équations et s’apparente à l’erreur de troncature entre les deux maillages. Comme il existe plusieurs formulations, il a été décidé de coder la correction telle qu’elle avait déjà été choisie pour le multigrille classique dans NSMB. Dans notre cas, l’opérateur de restriction est de deux types selon qu’il s’agisse des flux ou du vecteur d’état. Pour le vecteur d’état, l’opérateur impose dans la cellule grossière la moyenne des valeurs des cellules fines du dessus et recalcule la pression. Pour les flux, l’opérateur ajoute au membre de droite de l’équation un terme correspondant au transfert des résidus fins. Si on prend pour convention de mettre en exposant le temps et en indice le niveau de raffinement, l’algorithme de la correction déficitaire s’écrit comme suit :

12
Equation 4 où T est l’opérateur de restriction conservatif du fils vers le père. Suite au transfert du vecteur d’état, un calcul de la pression est effectué. Cette formulation est valable en Euler. Pour traiter des cas visqueux turbulents, il faut de plus transférer les variables visqueuses et turbulentes telles que la viscosité turbulente. Ce transfert s’effectue de façon identique au transfert du vecteur d’état. Mise en place de la remontée de l’incrément en temps L’étape suivante correspond à la remonté. On effectue une sauvegarde du vecteur d’état au début de l’itération en temps afin de pouvoir calculer l’avancé ∆W. C’est ce ∆W qui est appelé incrément en temps car le W calculé à la fin de l’itération a profité des avancées en temps des autres grilles : Le nouveau W est donc W(n+qqch.). Le fait de prolonger cet incrément sur les grilles plus fines permet d’augmenter la vitesse de convergence, c’est l’effet multigrille. Les incréments en temps sont transférés aux blocs fils ou plus exactement, les ∆W sont prolongés des blocs pères vers leurs fils (du niveau L à L+1). L’opérateur de prolongement peut être de plusieurs sortes : un ajout pondéré de la valeur du ∆W de la cellule du père au vecteur d’état dans toutes les cellules du fils correspondantes ou bien un prolongement à l’ordre 1 (prolongement trilinéaire) avec ou sans métrique. Cette remontée a une conséquence bénéfique sur la convergence de la solution fine. Les basses fréquences sont en effet mieux lissées par cette technique que par le schéma. Remonter l’incrément de temps a donc pour effet d’accélérer la convergence de la solution (effet multigrille). Ainsi on modifie le vecteur d’état W des blocs fils. Il est alors préférable de “postsmoother” la solution c’est à dire de refaire quelques itérations de Gauss-Seidel pour lisser la solution. Mise en place du “postsmoothing” Lorsqu’on remonte l’incrément de temps de grille en grille, on introduit des hautes fréquences de l’erreur : on perturbe la solution sur les grilles fines. Pour améliorer cela, on introduit le “postsmoothing” c’est à dire qu’on re-calcul une avancée en temps pour le vecteur d’état en tenant compte de sa nouvelle valeur introduite par le prolongement de
11
12
11
21
21
11
1
121
1
221
22
2
)(
0])([)(
)(
0
fWRWA
recouvertnonrecouvertfWRTWR
f
recouvertnonWrecouvertTW
W
fWRWA
f
nn
nn
n
nn
nn
−=∆
−−−
=
−=
−=∆
=
++
++
++
+

13
l’incrément en temps. Cela permet de lisser la solution, de ne pas prolonger brutalement le ∆W de la grille la plus fine vers les grilles les plus grossières. Pour cela, il faut faire appel à la routine de calcul de l’avancée en temps après avoir ajouter le ∆W. Ainsi si on considère les trois blocs de la figure suivante, le bloc 1 est au niveau de raffinement 0, le bloc 2 est au 1 et le bloc 3 au niveau 2.
1
2
3
Figure 4: exemple de sous-blocs
La séquence de couplage s’écrit alors :
1) Calcul de 13
+nW 2) Restriction du résidu de 3 vers 2 3) Calcul de ε+nW2 4) Restriction du résidu de 2 vers 1 5) Calcul de δ+nW1 6) Prolongement de ∆W1 vers 2 7) Calcul de '
2ε+nW
8) Prolongement de ∆W2 vers 3 9) Calcul de '1
3+nW
N iveau fin
1 3 3 3
+ = ∆ + n n W W W )) ( (
1 2 3 3 ' 1
3 W P W P W W W n n ∆ + ∆ + ∆ + = +
T P
ε + = ∆ + n n W W W 2 2 2 ) (
1 2 2 '
2 W P W W W n n ∆ + ∆ + = + ε
T P
N iveau grossier δ + = ∆ + n n W W W 1 1 1 ∆ W 1
Figure 5: Cycle en V
14
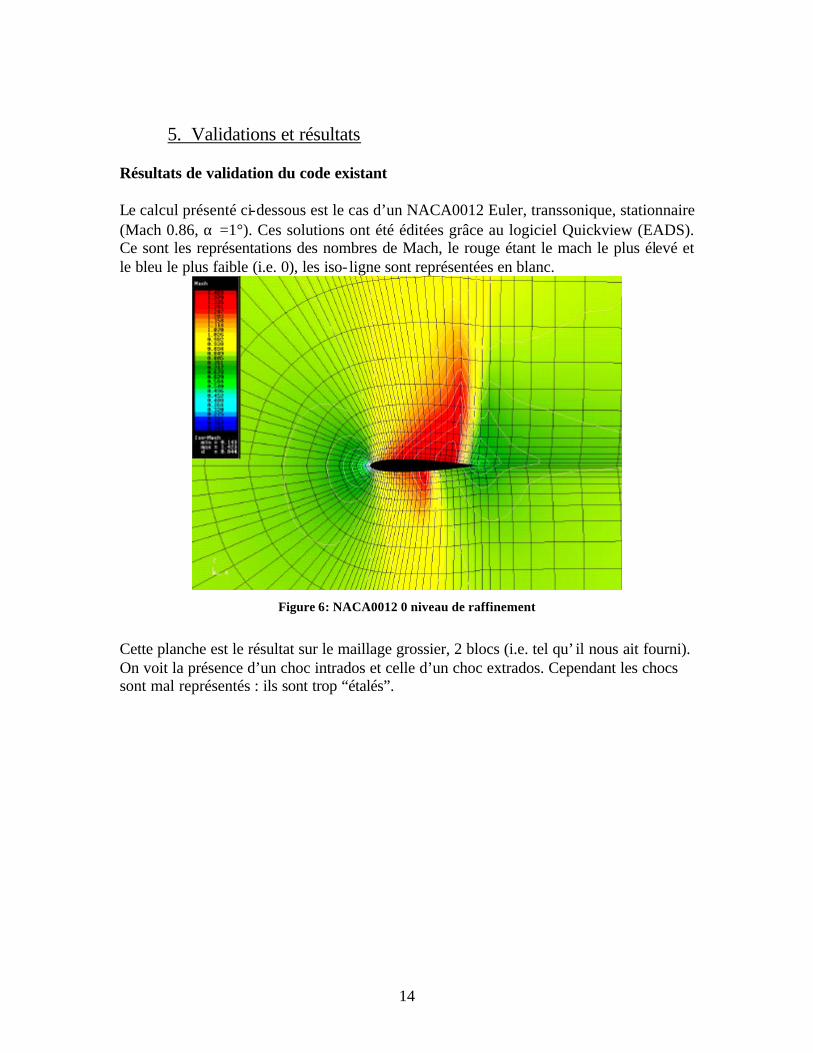
5. Validations et résultats Résultats de validation du code existant Le calcul présenté ci-dessous est le cas d’un NACA0012 Euler, transsonique, stationnaire (Mach 0.86, α =1°). Ces solutions ont été éditées grâce au logiciel Quickview (EADS). Ce sont les représentations des nombres de Mach, le rouge étant le mach le plus élevé et le bleu le plus faible (i.e. 0), les iso- ligne sont représentées en blanc.
Figure 6: NACA0012 0 niveau de raffinement
Cette planche est le résultat sur le maillage grossier, 2 blocs (i.e. tel qu’ il nous ait fourni). On voit la présence d’un choc intrados et celle d’un choc extrados. Cependant les chocs sont mal représentés : ils sont trop “étalés”.
15
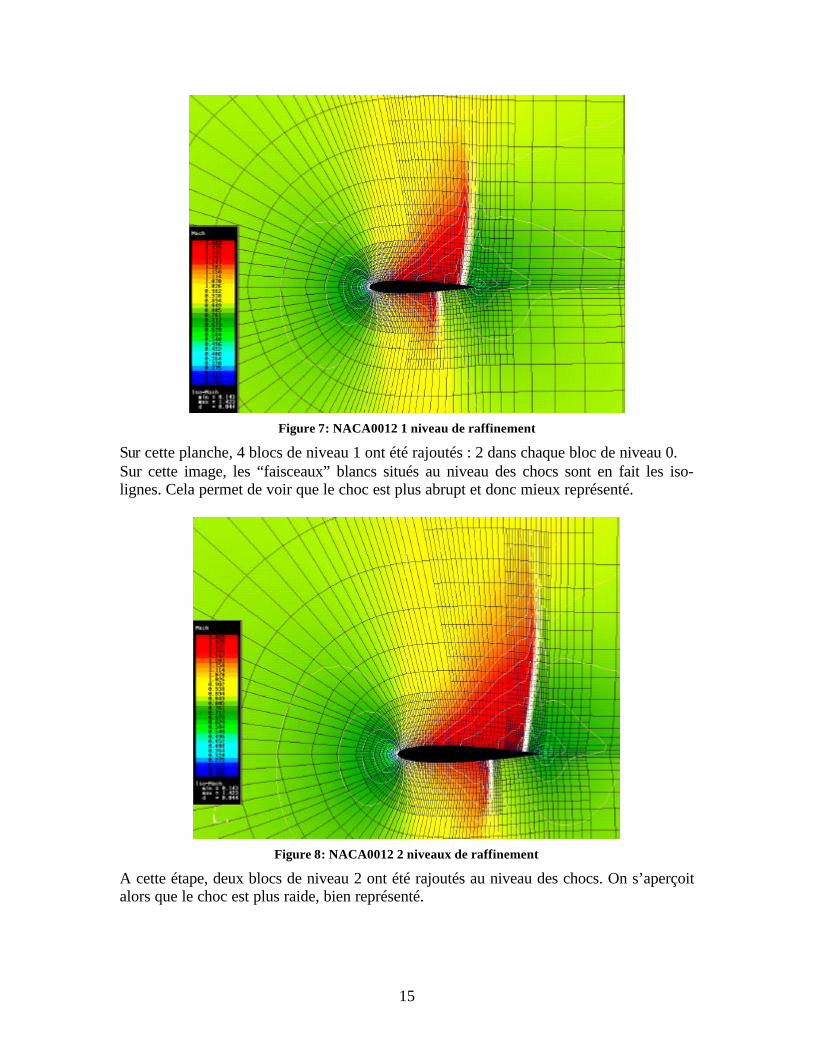
Figure 7: NACA0012 1 niveau de raffinement
Sur cette planche, 4 blocs de niveau 1 ont été rajoutés : 2 dans chaque bloc de niveau 0. Sur cette image, les “faisceaux” blancs situés au niveau des chocs sont en fait les iso-lignes. Cela permet de voir que le choc est plus abrupt et donc mieux représenté.
Figure 8: NACA0012 2 niveaux de raffinement
A cette étape, deux blocs de niveau 2 ont été rajoutés au niveau des chocs. On s’aperçoit alors que le choc est plus raide, bien représenté.

16
Ces trois figures, permettent de se rendre compte du gain de précision au niveau du choc, obtenu par l’ajout d’un sous-bloc. Toutefois, il est important de souligner que l’AMR ne permet pas d’obtenir des résultats plus précis que ceux obtenus sur un maillage fin complet.
Figure 9: CP a la paroi dans les différents blocs
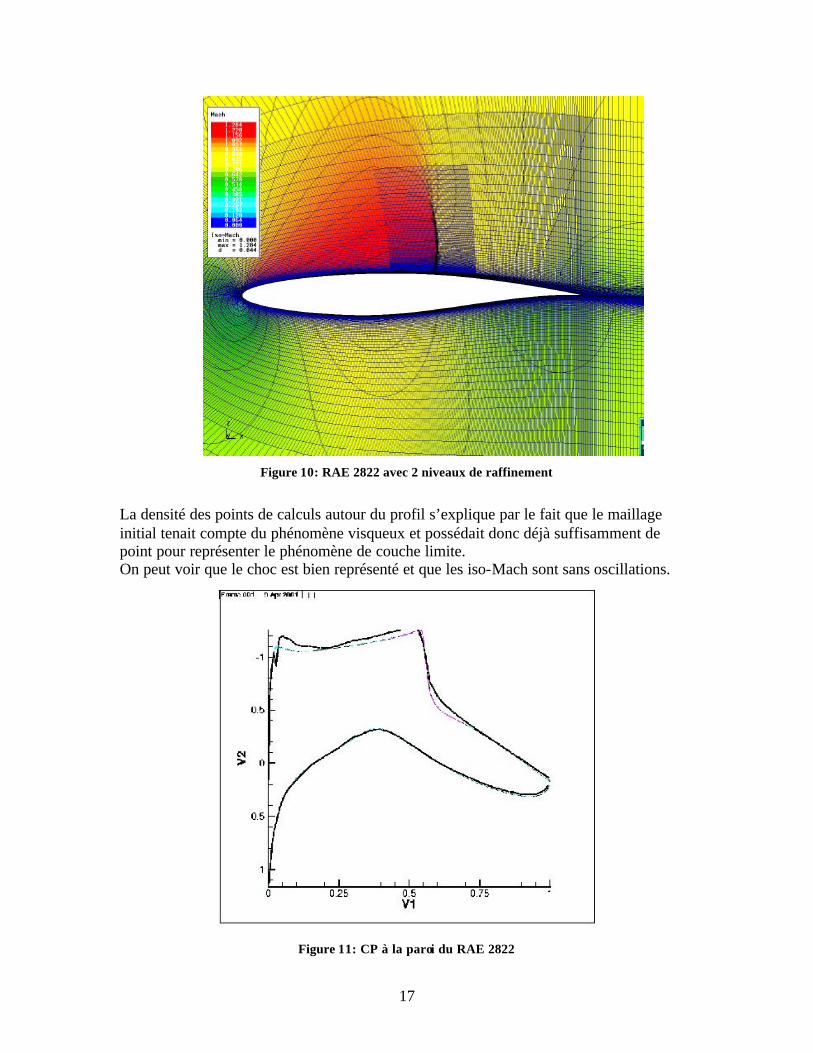
Ce graphe permet de visualiser que plus un bloc appartient à un niveau élevé plus le choc y est bien représenté. Ce calcul a été effectué avec 22.488 cellules de calcul, pour représenter le même niveau de raffinement sur l’ensemble du maillage, il nous aurait fallu 262.656 cellules : l’AMR permet une réelle économie en terme de mémoire. Le calcul présenté ci-dessous est le cas d’un RAE2822 visqueux (Spalart-Almaras), transsonique, stationnaire (Mach 0.73, Re.m-1 : 6.5E+6, α =2.79°). Ces solutions ont été éditées grâce au logiciel Quickview (EADS). Ce sont les représentations des nombres de Mach, le rouge étant le mach le plus élevé et le bleu le plus faible (i.e. 0), les iso-lignes sont représentées en noir tout comme le maillage utilisé.
17
Figure 10: RAE 2822 avec 2 niveaux de raffinement
La densité des points de calculs autour du profil s’explique par le fait que le maillage initial tenait compte du phénomène visqueux et possédait donc déjà suffisamment de point pour représenter le phénomène de couche limite. On peut voir que le choc est bien représenté et que les iso-Mach sont sans oscillations.
Figure 11: CP à la paroi du RAE 2822
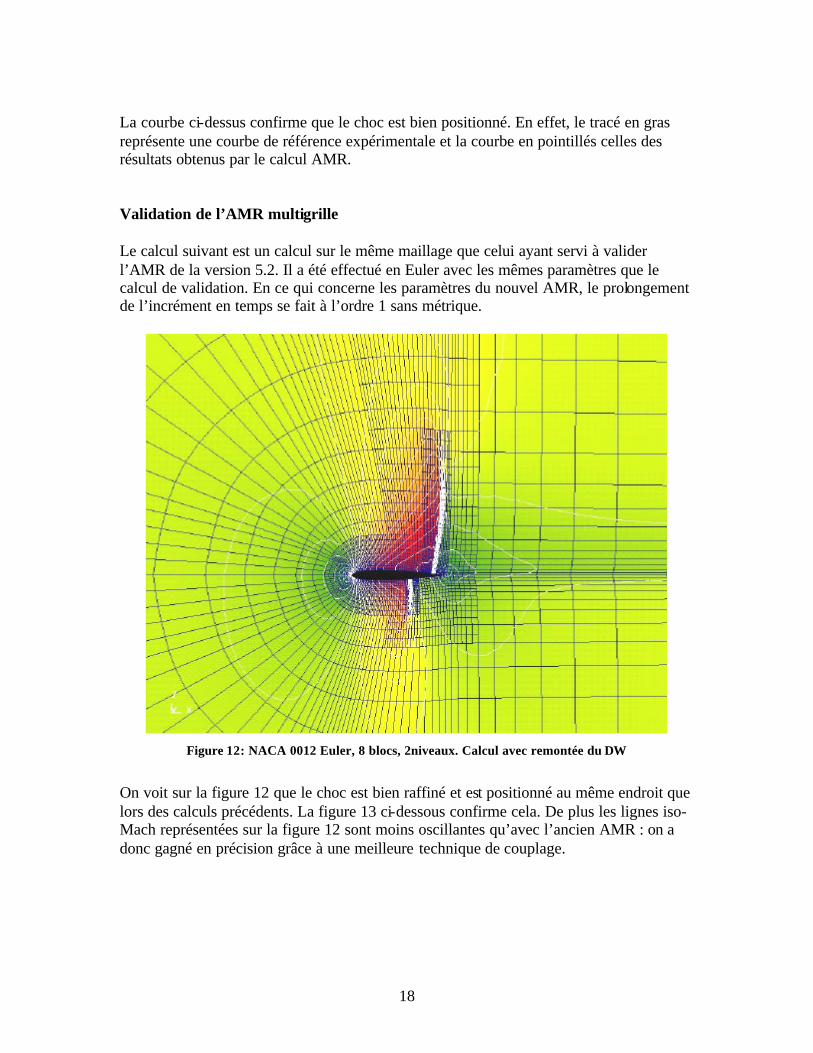
18
La courbe ci-dessus confirme que le choc est bien positionné. En effet, le tracé en gras représente une courbe de référence expérimentale et la courbe en pointillés celles des résultats obtenus par le calcul AMR. Validation de l’AMR multigrille Le calcul suivant est un calcul sur le même maillage que celui ayant servi à valider l’AMR de la version 5.2. Il a été effectué en Euler avec les mêmes paramètres que le calcul de validation. En ce qui concerne les paramètres du nouvel AMR, le prolongement de l’incrément en temps se fait à l’ordre 1 sans métrique.
Figure 12: NACA 0012 Euler, 8 blocs, 2niveaux. Calcul avec remontée du ∆W
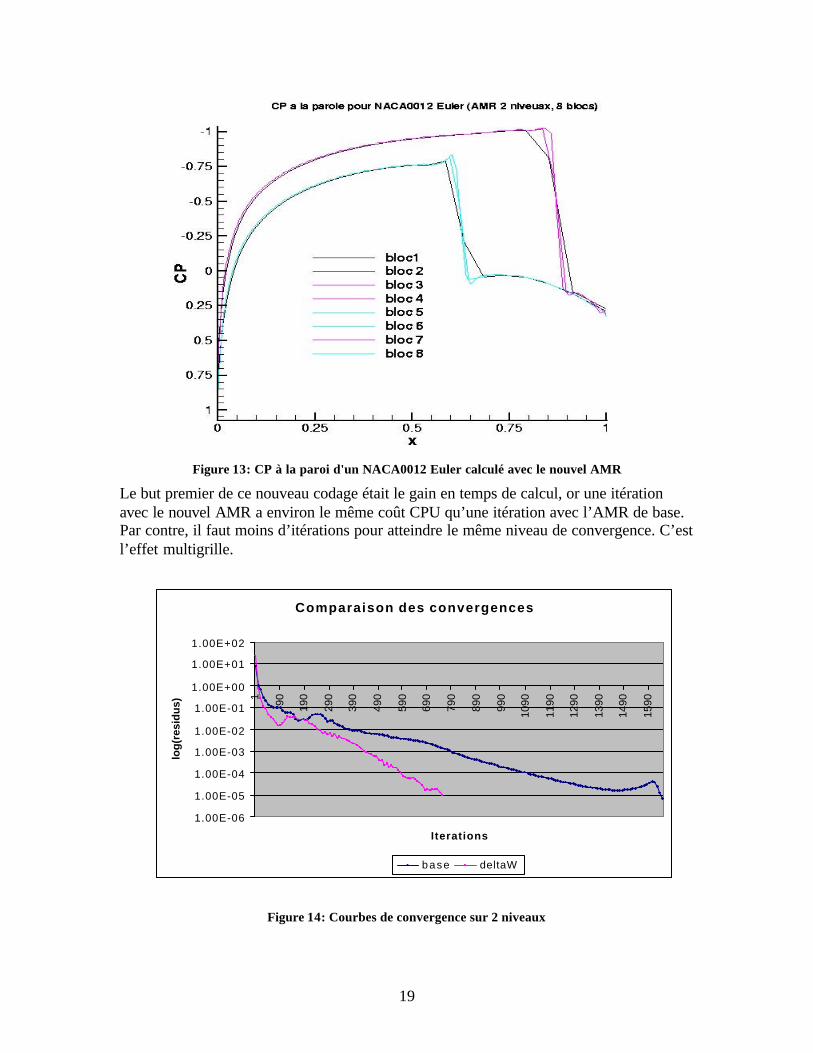
On voit sur la figure 12 que le choc est bien raffiné et est positionné au même endroit que lors des calculs précédents. La figure 13 ci-dessous confirme cela. De plus les lignes iso-Mach représentées sur la figure 12 sont moins oscillantes qu’avec l’ancien AMR : on a donc gagné en précision grâce à une meilleure technique de couplage.
19
Figure 13: CP à la paroi d'un NACA0012 Euler calculé avec le nouvel AMR
Le but premier de ce nouveau codage était le gain en temps de calcul, or une itération avec le nouvel AMR a environ le même coût CPU qu’une itération avec l’AMR de base. Par contre, il faut moins d’itérations pour atteindre le même niveau de convergence. C’est l’effet multigrille.
Figure 14: Courbes de convergence sur 2 niveaux
Comparaison des convergences
1.00E-06
1.00E-05
1.00E-04
1.00E-03
1.00E-02
1.00E-01
1.00E+00
1.00E+01
1.00E+02
1 90 190
290
390
490
590
690
790
890
990
1090
1190
1290
1390
1490
1590
Iterations
log
(res
idu
s)
base deltaW

20
La figure 14 met nettement en évidence l’effet multigrille. En effet, la courbe appelée “base” correspond à l’AMR tel qu’il est codé dans la version 5.2 de NSMB et la courbe appelée “DeltaW” représente la courbe de convergence du nouvel AMR avec descente et remontée de l’incrément en temps. Ce graphe permet donc de visualiser le gain de l’ordre d’un facteur 2 (facteur 2,2 en itération et 1,9 en temps CPU) obtenu grâce au nouvel AMR.

21
6. Perspectives et conclusions L’objectif, lorsqu’il a été envisagé de coder la technique de couplage selon l’approche multigrille local pour AMR, était d’améliorer la convergence de l’AMR existant. Les résultats obtenus en Euler sur les trois premières étapes sont satisfaisants et encourageants et l’objectif est d’ores et déjà atteints grâce aux trois premières étapes puisqu’on constate un gain de l’ordre 50% en nombre d’itérations pour la nouvelle version de l’AMR comparée à l’AMR de base. Le codage du postsmoothing a commencé, cependant les résultats obtenus laissent penser qu’il subsiste une erreur non corrigée puisque les calculs n’atteignent pas le niveau de convergence requis (résidus <10E-5). En effet, on assiste à une stagnation en plateau des résidus. Cela dit, l’objectif ayant été atteint grâce aux trois premières étapes, la priorité à été donné par EADS-Airbus à l’adaptation aux calculs visqueux. Cette adaptation a donc commencé selon les mêmes étapes que les cas Euler. Elle consiste notamment à rajouter des transferts, dans un premier temps, puis des prolongements des variables de turbulences.

22
Annexes
Algorithme du codage de la correction déficitaire : Calcul ∆t Do level = amr_level_max, 0, -1 Do nb= 1, nb_block_max Si (niveau (nb) = = level) Calcul Résidu (nb) Si( level ? amr_level_max) Ffunc=Résidu(nb)+Ffunc Résidu (nb)= Résidu (nb)- rfpc(nb) Is Do itérations de Gauss-Seidel Calcul W(nb) Si (dernière it.) Calcul pression, température et célérité Vérifie conditions aux limites du domaine is Od Si (niveau(nb)>0) Calcul Résidu(nb) Ffunc = - Résidu (nb) Résidu (nb)= Résidu (nb)- rfpc(nb) Ffunc=Résidu(nb)+Ffunc rfpc =Transfert du Ffunc(nb) à son père Transfert de W(nb) à son père Re-calcul de p Is Is Od Od Algorithme du codage de la remontée de l’incrément en temps : (suite á la correction déficitaire) Calcul ∆t Do level = amr_level_max, 0, -1 Do nb= 1, nb_block_max Si (niveau (nb) = = level) Calcul Résidu (nb) Si( level ? amr_level_max) Ffunc=Résidu(nb)+Ffunc Résidu (nb)= Résidu (nb)- rfpc(nb)
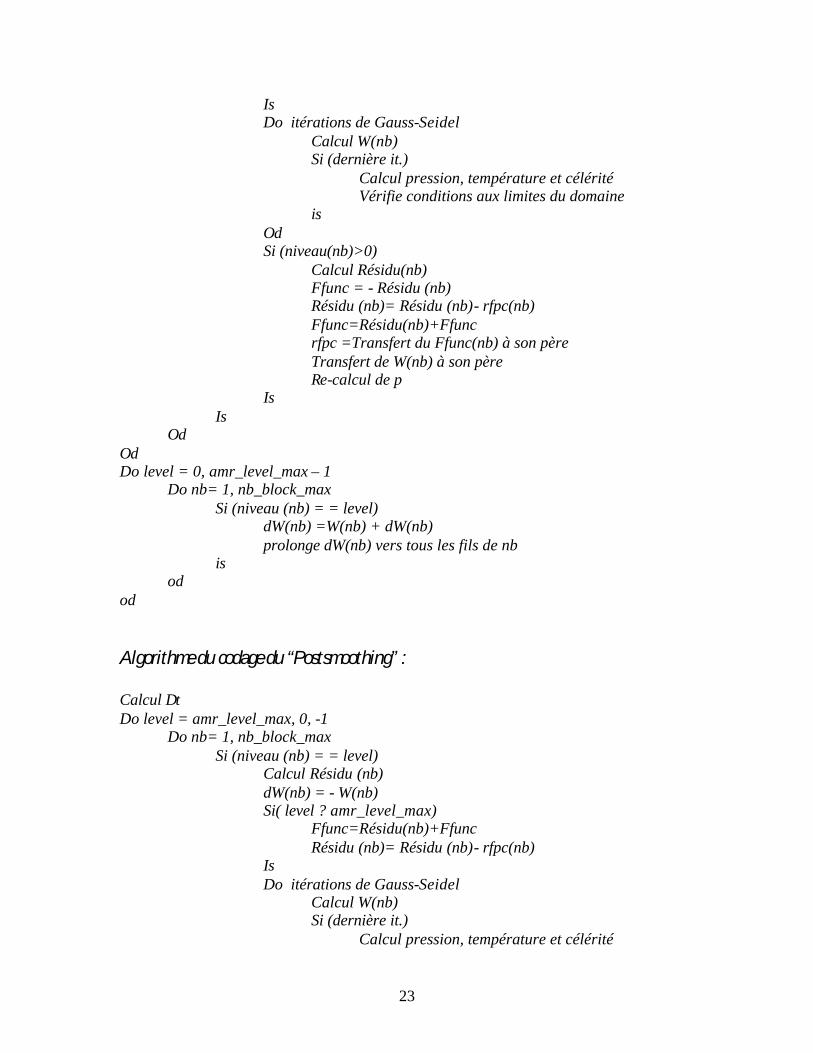
23
Is Do itérations de Gauss-Seidel Calcul W(nb) Si (dernière it.) Calcul pression, température et célérité Vérifie conditions aux limites du domaine is Od Si (niveau(nb)>0) Calcul Résidu(nb) Ffunc = - Résidu (nb) Résidu (nb)= Résidu (nb)- rfpc(nb) Ffunc=Résidu(nb)+Ffunc rfpc =Transfert du Ffunc(nb) à son père Transfert de W(nb) à son père Re-calcul de p Is Is Od Od Do level = 0, amr_level_max – 1 Do nb= 1, nb_block_max Si (niveau (nb) = = level) dW(nb) =W(nb) + dW(nb) prolonge dW(nb) vers tous les fils de nb is od od Algorithme du codage du “Postsmoothing” : Calcul ∆t Do level = amr_level_max, 0, -1 Do nb= 1, nb_block_max Si (niveau (nb) = = level) Calcul Résidu (nb) dW(nb) = - W(nb) Si( level ? amr_level_max) Ffunc=Résidu(nb)+Ffunc Résidu (nb)= Résidu (nb)- rfpc(nb) Is Do itérations de Gauss-Seidel Calcul W(nb) Si (dernière it.) Calcul pression, température et célérité

24
Vérifie conditions aux limites du domaine is Od Si (niveau(nb)>0) Calcul Résidu(nb) Ffunc = - Résidu (nb) Résidu (nb)= Résidu (nb)- rfpc(nb) Ffunc=Résidu(nb)+Ffunc rfpc =Transfert du Ffunc(nb) à son père Transfert de W(nb) à son père Is Is Od Od Do level = 0, amr_level_max – 1 Do nb= 1, nb_block_max Si (niveau (nb) = = level) dW(nb) =W(nb) + dW(nb) Si ( level ? amr_level_max) Calcul Résidu (nb) Résidu (nb)= Résidu (nb)- rfpc(nb) Do itérations de Gauss-Seidel Calcul W(nb) Si (dernière it.) Calcul pression, température et célérité Vérifie conditions aux limites du domaine is Od is Do sur tous les fils de nb prolonge dW(nb) Calcul pression, température et célérité Vérifie conditions aux limites du domaine Calcul ∆t od is od od

25
Bibliographie
« Méthodes d’adaptation de maillages structurés par enrichissement » J-C Jouhaud, Thèse de Doctorat (Université Bordeaux I), 1997 « Chaîne de calcul Navier-Stokes “GAME ” » F Crampé, Rapport de Stage, 1997 « Intégration d’une méthode d’adaptation de maillage par raffinement local dans le code NSMB » S Champeaux, Rapport de stage, 2000 « NSMB 5.0 User Guide » Consortium NSMB, Manuel d’utilisation, 2000 « NSMB Hand book 4.5 » Consortium NSMB, Manuel technique, 1999


















