
NOSE: a Nomadic, Modular, Scalable IT Platform for Pervasive Sensing

RainbowFS:Modular Consistency and Co-designed Massive File
systemCohérence modulaire et conception conjointe d’un système de fichiers
massif
Appel à projets générique ANR 2016PRCE (Projet de recherche collaborative — Entreprises)
Défi 7. Société de l’information et de la communicationAxe 7 : Infrastructures de communication, de traitement et de stockage
Axe 3 : Sciences et technologies logiciellesAxe 5 : Données, Connaissances, Données massives (Big Data)
Orientations de la SNR concernant le Défi 7 :26 : 5è génération des infrastructures réseau (déploiement à grande échelle de l’internet des objets) ;
27 : objets connectés (architectures logicielles distribuées) ;28 : Exploitation des grandes masses de données (stockage).
12 April 2016
Abstract
RainbowFS proposes a “just-right” approach to storage and consistency, for developingdistributed, cloud-scale applications. Existing approaches shoehorn the application design tosome predefined consistency model, but no single model is appropriate for all uses. Instead,we propose tools to co-design the application and its consistency protocol. Our approachreconciles the conflicting requirements of availability vs. safety: common-case operations aredesigned to be asynchronous; synchronisation is used only when strictly necessary to satisfythe application’s integrity invariants. Furthermore, we deconstruct classical consistencymodels into orthogonal primitives that the developer can compose efficiently, and provide anumber of tools for quick, efficient and correct cloud-scale deployment and execution. Usingthis methodology, we will develop an entreprise-grade, highly-scalable file system, exploringthe rainbow of possible semantics, which we will demonstrate in a massive experiment.
Keywords: Cloud Computing; Consistency; File Systems; Storage; Geo-Replication; StaticVerification; Distributed Application Software Engineering; Big Data.
1

CONTENTS
I Administrative information / Informationsadministratives 3
I.1 Table of people involved in the project/ Tableau récapitulatif des personnesimpliquées dans le projet . . . . . . . 3
I.2 Changes from the pre-proposal /Évolutions éventuelles par rapport àla pré-proposition . . . . . . . . . . . 3
II Context, positioning and objectives ofthe detailed proposal / Contexte, position-nement et objectif de la proposition dé-taillée 3
II.1 Objectives and challenges . . . . . . . 3
II.2 Context . . . . . . . . . . . . . . . . 5
II.3 Project outcomes, results, and products 6
II.4 Related work and partners’ previouscontributions . . . . . . . . . . . . . 7
II.4.1 Strong consistency . . . . . . 7
II.4.2 Availability and weak consist-ency . . . . . . . . . . . . . . 8
II.4.3 Hybrid consistency . . . . . . 8
II.4.4 Modular consistency . . . . . 8
II.4.5 File systems . . . . . . . . . . 9
II.5 Relation with ANR and Europeanwork programmes . . . . . . . . . . . 9
II.6 Feasibility, risks and risk mitigation . 9
III Scientific and technological programme,project organisation / Programme scienti-fique et technique, organisation du projet 10
III.1 Decomposition into tasks . . . . . . . 10
Task 1: Application co-design . . . 12
Task 2: Modular geo-replication . 14
Task 3: Geo-replicated massive filesystem . . . . . . . . . . . . 16
III.2 Project organisation . . . . . . . . . 19
III.3 Scientific explanation of funding request 19
III.4 Project partners . . . . . . . . . . . . 21
III.4.1 Consortium as a whole . . . . 21
III.4.2 Principal Investigator . . . . . 21
III.4.3 Inria Paris (Projet Regal) . . . 21
III.4.4 CNRS Laboratoire d’Informatiquede Grenoble (LIG) . . . . . . 22
III.4.5 Télécom SudParis . . . . . . 22
III.4.6 Scality S.A. . . . . . . . . . . 22
IV Impact of project, strategy for take-up, pro-tection and exploitation of results / Impactdu projet, stratégie de valorisation, de pro-tection et d’exploitation des résultats 22
IV.1 Impact . . . . . . . . . . . . . . . . . 22
IV.1.1 Economic Impact . . . . . . . 22
IV.1.2 Practical Impact . . . . . . . 23
IV.1.3 Scientific Impact . . . . . . . 23
IV.2 How the project addresses the challenges 23
IV.3 Scientific communication and uptake . 23
IV.4 Intellectual property and exploitationof results . . . . . . . . . . . . . . . . 24
IV.5 Industrial exploitation . . . . . . . . . 24
2

I ADMINISTRATIVE INFORMATION / INFORMATIONS ADMINISTRATIVES
I.1 Table of people involved in the project/ Tableau récapitulatif des personnes im-pliquées dans le projet
Table 1 summarises the people involved in the project.
Table 2 shows how the manpower is distributed, firstby partner and task, second by partner and type.
I.2 Changes from the pre-proposal / Évolu-tions éventuelles par rapport à la pré-proposition
The major change with respect to the first-phase sum-mary is the requested duration of the funding period.
ANR plans to announce the funding decision in July2016. As this is a very unfavourable period for re-cruiting the best PhD students, we are requesting a48-month duration of the funding period to cope withuncertainty. The workplan itself takes 36 months, withM 01 starting when the project students and staff ishired.
The budget has increased slightly, because our initialestimate ignored the institutional overheads.
II CONTEXT, POSITIONING AND OBJECTIVES OF THE DETAILED PROPOSAL / CONTEXTE,POSITIONNEMENT ET OBJECTIF DE LA PROPOSITION DÉTAILLÉE
II.1 Objectives and challenges
RainbowFS proposes a “Just-Right Consistency”approach to developing geo-distributed applica-tions, whereby an application pays only the con-sistency price that it strictly requires. The toolscontributed by the project will prove that the ap-plication is safe, while at the same time ensuringthat it is highly available and scalable. Other toolswill contribute to the rapid deployment and to themonitoring and analysis of system behaviour andperformance. The project applies this approach tothe design of a high performance, highly scalable,tunable geo-replicated file system.Current cloud storage offerings are divided between op-posing, monolithic, one-size-fits-all consistency mod-els. The RainbowFS partners believe that this thinkingis obsolete. We turn the monolithic, predefined modelon its head, and propose a methodology by which thesystem is as weakly consistent as possible, yet suffi-ciently consistent to be safe. Thus, the application paysthe consistency price it strictly requires, and no more.We call this approach “Just-Right Consistency.”
Our first challenge towards this vision is to guide thedeveloper, and help her make correct choices in thesafety-vs.-availability trade-off. Availability is an es-sential enabler for performance and scalability, since,to be always available, a replica must avoid synchron-ising with others [1, 16]. We aim to develop a co-design methodology that reconciles correct applica-tion development with high availability. The co-designapproach is enabled by a logic that was previously de-
veloped by the academic partners [12, 31, 54–56]. Thelogic enables verifying formally that the application’sintegrity invariants are satisfied by a given (weak) con-sistency protocol. If not, a tool implementing the logicwill provide a counter-example, which helps the de-veloper diagnose and fix the problem. Then, to restorecorrectness, the developer has two choices: either toweaken the specification, at the risk of anomalous beha-viour, or to strengthen the synchronisation, decreasingavailability. Which direction to take is a design de-cision, but in either case, the tool verifies that the fixactually restores correctness. In this way, the developerco-designs the application specification and the associ-ated consistency protocol. Our approach avoids minim-ises synchronisation, thus enabling availability, to whatis strictly needed, while proving that the application isnonetheless correct.
Our second challenge is to translate the resulting spe-cification into a running, efficient, deployable applica-tion. We deconstruct consistency models into compos-able primitives along three dimensions that structurethe consistency design space. Correspondingly, wewill develop a library of components that the applica-tion developer can combine into a functional applica-tion skeleton, paying only for what is strictly needed.These components are bound together by a compos-ition framework that ensures that the composition ishighly efficient, for instance by consolidating togetherany redundant messages or waits. Finally, this taskprovides a set of deployment, monitoring, analysis anddebugging tools to aid the programmer achieve the
3
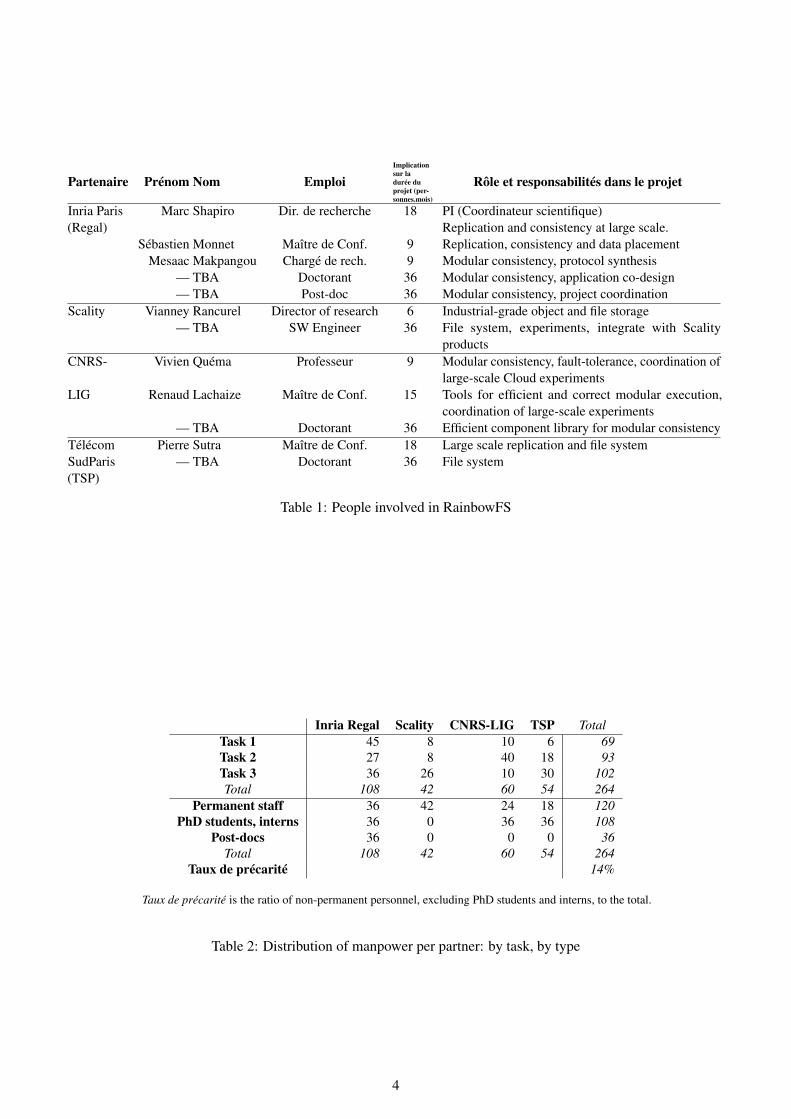
Partenaire Prénom Nom EmploiImplicationsur ladurée duprojet (per-sonnes.mois)
Rôle et responsabilités dans le projet
Inria Paris(Regal)
Marc Shapiro Dir. de recherche 18 PI (Coordinateur scientifique)Replication and consistency at large scale.
Sébastien Monnet Maître de Conf. 9 Replication, consistency and data placementMesaac Makpangou Chargé de rech. 9 Modular consistency, protocol synthesis
— TBA Doctorant 36 Modular consistency, application co-design— TBA Post-doc 36 Modular consistency, project coordination
Scality Vianney Rancurel Director of research 6 Industrial-grade object and file storage— TBA SW Engineer 36 File system, experiments, integrate with Scality
productsCNRS- Vivien Quéma Professeur 9 Modular consistency, fault-tolerance, coordination of
large-scale Cloud experimentsLIG Renaud Lachaize Maître de Conf. 15 Tools for efficient and correct modular execution,
coordination of large-scale experiments— TBA Doctorant 36 Efficient component library for modular consistency
Télécom Pierre Sutra Maître de Conf. 18 Large scale replication and file systemSudParis(TSP)
— TBA Doctorant 36 File system
Table 1: People involved in RainbowFS
Inria Regal Scality CNRS-LIG TSP TotalTask 1 45 8 10 6 69Task 2 27 8 40 18 93Task 3 36 26 10 30 102Total 108 42 60 54 264
Permanent staff 36 42 24 18 120PhD students, interns 36 0 36 36 108
Post-docs 36 0 0 0 36Total 108 42 60 54 264
Taux de précarité 14%
Taux de précarité is the ratio of non-permanent personnel, excluding PhD students and interns, to the total.
Table 2: Distribution of manpower per partner: by task, by type
4

dual goals of safety and availability.
The third challenge is to apply our approach to areal, useful and challenging application, and to val-idate experimentally that our goals have been met.Given the market demand for structured storage (dis-cussed later in this document), we target the develop-ment of an entreprise-grade, highly available, perform-ant and scalable file system. The file system will beco-designed and proved correct according to the Just-Right Consistency approach. It will be implementedand deployed using the tools of modular consistency.
Because client needs vary, RainbowFS will study thefull rainbow of reasonable storage semantics. At thislevel too, users should pay only for what they need.Applications will be able to count on a Posix-like nam-ing tree and powerful synchronous commands, suchas rename. An application that manages a flat hier-archy of unique, write-once files, should enjoy similarperformance to an object store, but remains confid-ent (thanks to the tools of Task 1) that the applicationremains correct under these weaker guarantees. Anapplication with extreme latency requirements (e.g.,an interactive game) should be able to request replicasvery close to the end-user; this requires the file systemto hundreds or thousands of partial replicas. The scaleand correctness of this file system will be validated ina massive-scale geo-distributed experiment.
II.2 Context
Cloud computing and innovation. Cloud comput-ing is motivated by the potential of economies of scale,resource consolidation, access to unlimited resources,and service automation. The cloud market has beenso far captured by a few oligopolies, each running asmall number of vast data centres, essentially based inthe USA. The appeal of the cloud is likely to continueand to capture an increasing fraction of demand forcomputing.
However, current cloud architectures do not satisfyemerging client requirements for millisecond response,security and privacy, and integration of private re-sources into the cloud. Especially in Europe, com-munities and governments provide local resources, and5G networks will deploy mini-datacentres at the edge.Social networks, open data, electronic commerce, sci-entific experiments, the Internet of Things will con-tinue to feed an explosion of data sources and needsfor ever-greater amounts of computation and storage.
According to this so-called “Fog Computing” vision,cloud resources will grow in number and variety. Fu-ture clouds will collect high numbers of diverse andgeographically distributed data centres. Future cloud
stores will consist of hundreds or even thousands ofgeo-distributed sites [17].
The cloud is an area of rapid innovation, calling fora close cooperation between academic research andentrepreneurship. It raises deep research questions, forinstance in the area of distributed computing, whichcall for concrete solutions that pass the test of reality.The French innovation ecosystem is well positioned,with very active and successful SMEs, feeding on arich soil of academic research in distributed computingand related areas.
The RainbowFS proposal grows out from previous col-laboration between an SME and academia. It aims toaddress the difficulty of developing applications thatare both correct and make good use (from both aneconomic and performance perspective) of large-scaledistributed resources at Fog-computing scale.
Replication and consistency models. Today, pro-gramming a distributed application remains somethingof a black art. Programming requires to be able topredict what the machine will be doing, but a distrib-uted system has many independent moving parts, andis subject to unpredictable additions and removals ofresources, due to upgrades, failures, or flash load vari-ations. Furthermore, the requirements themselves areoften ill-defined and change over time. This requiresa fast development path that ensures that the applica-tion requirements are met, within a changing executionenvironment.
For performance and fault-tolerance reasons, inevit-ably, the same information is duplicated. For instance,a given data item may have many redundant copies,e.g., across a RAID, backed-up on tape, cached inmemory, and replicated in multiple data centres Fur-thermore, different data items are logically related: forinstance, accounting rules require that the balance ofall accounts be a constant, therefore, increasing oneaccount requires decreasing another.
This raises the issue of consistency. Any update needsto be validated against integrity rules (such as the con-stant balance rule above) and propagated to all copiesof the data item and to the related data items. Thisis not instantaneous; measured intercontinental round-trip times are in the order of hundreds of milliseconds(France-US East Coast: 90–120 ms; France-New Zea-land 300–600 ms). Therefore, perfect consistency isnot practical, and an application runs above a less-than-perfect consistency model provided by the system.
A so-called strong model, one that performs updatesin a total sequential order is easy to understand fordevelopers. However, when network failure occurs
5

(which is inevitable), the strongly-consistent modelblocks rather than risk returning a wrong answer, andeverything grinds to a halt. Thus, the strong modelinherently sacrifices availability (and thus performanceand scalability) to maintain a high standard of con-sistency. The cost and difficulty of strong consistencyincreases with latency and number of sites; in a FogComputing set-up with thousands of sites, is is just notpossible.
Alternatively the system can remain available, i.e.,continue to accept updates, at the risk of returninganomalous results [30]. Such a weaker consistencymodel admits more parallelism and enjoys better per-formance, but exposes the application to anomalies,which confuse the programmer and may lead to dataloss or violation of integrity.
The performance difference is substantial. In con-trolled benchmarks, we measured a 13.5× perform-ance improvement (3× lower latency and 4.5× bet-ter throughput) between the strongest and the weak-est model in a small-size cloud [6]. These numbersmean that synchronisation wastes enormous amountsof money and energy costs due to synchronisation. Pro-jecting the above numbers, under weak consistency,the same workload might cost up to 13.5 times less,in hardware and energy resources, than under strongconsistency.
On the other hand, because of the need to cope withanomalies at the application level, the developmentcost is much higher.
This inherent trade-off between safety on the one hand,and availability on the other has sparked the devel-opment of many competing consistency models, ap-proaches, and acronyms: SQL, NoSQL, NewSQL, AP,CP, KVS, object storage, file systems, databases, etc.Application developers must make a bet in advance ofwhich model to chose, that will be most appropriate totheir needs. Some systems provide strength parameters[10, 13, 15, 48, 73, 81], but all lack tools and guidanceto ensure that their application will behave as intendedover the model provided.
Storage systems. The need for data storage is ex-panding at a high rate. User-generated data, such associal networks and videos, is already radically push-ing requirements, to the order of petabytes. This isdwarfed by the volume to be generated by IoT devices,or by scientific experiments such as LHC at CERN.As a result, there is demand for efficient, dependable,geo-aware and low-cost storage systems.
Increasingly, storage is software defined, i.e., is built asa logical network of commodity components. Data is
sharded and replicated within data-centres for parallel-ism fault tolerance, and geo-replicated for availabilityand access latency. In fact, a cloud-scale storage sys-tem such as Amazon S3, Cassandra or HDFS oftenforms the bottom layer of internet-scale services.
Data storage systems are currently divided, based onhow they address replication and consistency. Beforeeven starting to store their internet-scale data and todevelop applications to exploit it, developers are forcedto choose upfront between antagonistic solutions.
Traditional file systems are a hierarchy of folders andfiles. Files are updated in place, i.e., an update over-writes the previous state. File systems are often con-sidered slow and non-scalable. Indeed, because of itscomplex transactional semantics (e.g., rename), ex-isting systems all require strong consistency to somedegree. File systems are here to stay, because legacyapplications (e.g., databases, custom software, or CADsoftware) rely on their structure, and because theirhierarchy provides an intuitive way to organise and tosecure information.
Nonetheless, for reasons of scalability and perform-ance, a current trend is towards low-level object stor-age systems, similarly to the NoSQL trend in data-bases. This approach forgoes the file system tree infavour of buckets, which are similar to very large, flatfolders. Furthermore, each update of an object createsa new version. In this way, complex synchronisation isavoided in the common case. These are widely usedin modern applications (e.g., Web 2.0 and edge net-works).
II.3 Project outcomes, results, and products
This project advances both the principles and the prac-tice of distributed computing in general, and of Fog-scale storage in particular.
RainbowFS will expand and apply the new Just-RightConsistency approach to the design of distributedcomputing and storage systems. This turns the tra-ditional model-oriented approach on its head. So far,consistency models have been designed in a generic,application-independent way. This has been product-ive in better understanding the design space. However,no single consistency model is uniformly better thanthe other, due to the contradictory imperatives of safetyand availability. Shoehorning an application to con-form to a model that was predefined in a vacuum, isnot a productive use of developers’ skills. Just-RightConsistency instead is an approach that co-designsthe application and its consistency protocol, thus en-abling the developer to semi-automatically identify the
6

strict minimum of synchronisation that her applicationneeds.
To support the Just-Right Consistency approach, theRainbowFS project will develop tools to preciselyidentify the problematic concurrency patterns, to helpwith rapid development and deployment, and to mon-itor, analyse and understand the behaviour of applica-tions. One such tool is a static analysis engine, basedon the CISE logic [12, 31, 54–56], which proves, withpolynomial complexity, whether a given applicationrunning above a given consistency protocol maintainsa given invariant. If not, other tools will leverage thecounter-examples returned by the CISE tool to pre-cisely identify the problem and to suggest solutions,such as a weakening of the application specification,or a strengthening of synchronisation. The static toolswill be complemented by dynamic ones, for deploy-ing and controlling the distributed application, whilemonitoring its performance and correctness. Anothertool is a library of consistency primitives that can becombined efficiently, leveraging ongoing research bythe partners that organises the consistency design spaceinto three logical dimensions.
Using the tools described above, the project will tacklea real and demanding use-case. We will analyse,design, prove correct, build, deploy and experimentwith a new distributed file system. The file systemhas several important objectives: (i) to support theextreme data sizes (hundreds of petabytes) required bymodern big-data applications, (ii) to support the thou-sands of sites, of heterogeneous size and computingpower, foreseen for future Fog-computing networks,(iii) to converge the file-system and object-storage ap-proaches, and (iv) to support a Just-Right Consistencyapproach for the file system’s users themselves, allow-ing them to safely parameterise its semantics to min-imise cost while guaranteeing higher-level correctness.The industrial partner, Scality SA, plans to integratethis file system into its commercial offerings withinthe timeframe of the project.
Many companies are reluctant to make the move toobject storage, because a many existing applicationsrely on the Posix file system interface. Our designlayers the file system above Scality’s object store. Aswe discuss later, a file system actually requires syn-chronisation only in very limited circumstances, andtherefore our design can reconcile the performance ofobject storage with the safety requirements of legacyapplications. Our system will offer the full rainbow offile system semantics, from linearisable to fully asyn-chronous; applications that require the availability ofobject stores can have it, and those that require highly-structured file system trees with atomic rename can
have it too.
Some systems, such as HDFS, take the approachof force-fitting the file system into an eventual-consistency model that breaks the Posix requirements.The originality of our approach is to start from therequirements of the application that runs on top ofthe file system, and to tailor the consistency modelsaccordingly; hence the “Rainbow” model.
II.4 Related work and partners’ previouscontributions
The design of efficient and robust large scale distrib-uted storage systems is a very active R&D field, at thecore of the cloud revolution. As explained earlier,the market is split between strongly- and weakly-consistent system designs. We hope to help heal thissplit with our Just-Right Consistency and modular con-sisistency approaches, and to reconcile them in our filesystem application.
II.4.1 Strong consistency Strong consistencyprovides familiar guarantees and decreases the effortto make applications correct, but entails frequent syn-chronisation; each consensus requires two round-trips[47], i.e., several hundred milliseconds in a wide-areanetwork. Strong consistency comes at a high hard-ware cost; for instance, the very strong guarantees ofGoogle’s Spanner require specific hardware clocksand high-quality dedicated fibre network links [21].Recent research has aimed to decrease the cost ofstrong consistency, in several ways, such as enforcingtotal order writes but weakening guarantees on reads[14, 73], or increased internal parallelism throughsharding, disjoint-access parallelism, and genuine par-tial replication [26, 63, 72]. Few practical systemsenforce the strongest consistency; even commercialcentralised databases do not ensure serialisability bydefault [9]; the resulting anomalies are consideredacceptable with respect to the improved performance.However, the Jepsen experiments [41] highlightedthat many production systems suffer from ill-definedguarantees and/or incorrect implementation thereof.
The partners have contributed efficient strong con-sistency designs. Sutra and Shapiro [77] designed alatency-optimal consensus protocol that parallelisescommuting updates. Saeida Ardekani et al. [62] im-proved snapshot isolation [73] to support genuine par-tial replication and to improve internal parallelism.Partners designed a throughput-optimal uniform totalorder broadcast protocol for state machine replicationwithin a cluster of machines [34]. Aublin et al. [8] de-signed protocols for efficient Byzantine fault-tolerant
7

state machine replication, as well as a framework tocompose such protocols, in order to efficiently supportvarious operating conditions.
II.4.2 Availability and weak consistency To beavailable despite network partitions, the system mustaccept concurrent updates without remote synchron-isation. This enables good performance, thanks toimmediate local response, spreading load in parallelover available resources, and a greater range of imple-mentation choices.
In return, these systems can promise only weak con-sistency [92]. Such models exhibit anomalies, whichrequire extra effort by the application programmer toensure safety, increasing the development cost. Ex-ample commercial systems include Cassandra [83],Amazon S3 [15], Dynamo [25] or Riak [43].
The partners of this proposal have been strong con-tributors to research on available storage systems. Wehave designed and implemented systems that guaranteeCausal Consistency and highly-available transactions[9]. Zawirski et al. [93] implemented SwiftCloud, ahighly-available, widely-geo-replicated cloud databasedesigned for Fog environments. Akkoorath et al. [4]designed and implemented Antidote, a geo-replicatedcloud database designed for high internal parallelismand modularity. Previously, Shapiro et al. [68, 69] in-vented CRDTs, high-level data types that provide con-vergence and correctness guarantees to applicationsabove a causally-consistent system. Scality and Inriatogether designed and implemented a geo-replicatedfile system featuring CRDT semantics [80].
II.4.3 Hybrid consistency Some designs allow theuser to specify a different level of consistency and/oravailability on a case-by-case basis [45, 73, 90]. Com-mercial examples include Cassandra or Riak. Red-Blue Consistency classifies each operation as eitherblue, commutative with all others and executed asyn-chronously, or red, non-commuting with and synchron-ised with other red operations. At a higher level ofabstraction, the Pileus key-value store [81] supportsflexible and dynamically adjustable consistency-basedservice level agreements.
However, more consistency options only complicatethe developer’s task, in the absence of tools to guidethe developer and to ensure that the result is correct.Previous static analysis tools include Bloom [5], whichidentifies points of non-commutativity, Homeostasis[61] which considers conflicts between assignments,and Sieve [49], which helps automate Red-Blue con-sistency. All three have limited scope and lack theoret-ical grounding.
The tools previously contributed by the project part-ners constitute a breakthrough in this respect. Our firstmajor result was Explicit Consistency [10], later im-proved with the CISE logic [31] and the associated tool[55, 56]. CISE boils down to three correctness condi-tions: (i) Effector safety verifies that every update inisolation maintains the invariant, (ii) effector commut-ativity verifies that concurrent updates commute, and(iii) precondition stability checks whether the precon-dition of one update (required by the first rule) is stableunder concurrent updates. The CISE logic supportsgeneral properties expressable in first-order logic andwas shown to be sound. It is able to prove, with poly-nomial complexity, that a given application maintainsa given invariant above a given consistency protocol.Conversely, it enables to tailor a consistency protocol,such that has enough synchronisation to ensure theapplication’s safety, but no more.
Task 1 aims to build upon and improve the state of theart of hybrid consistency; the other two tasks will buildupon this.
II.4.4 Modular consistency The distributed al-gorithms community has formalised the different con-sistency models, both for transactional [2] and non-transactional systems [91]. However, previous workhas classified the models informally along a singlestrong-to-weak axis. This linear view is clearly inad-equate, since, for instance, Snapshot Isolation and Seri-alisability are incomparable. Similarly, although twopapers claim that causal consistency is “the strongestpossible” model compatible with availability in thelinear classification [7, 50], both Bailis et al. [9] andourselves [4, 93] have strengthened causal consistencywith transactional guarantees.
The RainbowFS partners have previously contributedto improving the conceptual and practical toolkit ofapplication designers with a modular decompositionof consistency. Aublin et al. [8] show how to decom-pose Byzantine fault-tolerant state machine replicationinto modular protocols. Similarly, Ardekani et al. [6]decompose transactional protocols into composableprimitives. In this proposal, we plan to scientificallydeconstruct consistency models along three (mostly-)orthogonal dimensions: guarantees related to a totalorder of writes, those related to the causal order ofreads, and those on the transactional composition ofmultiple operations. A model may be stronger thananother on one dimension and weaker on another. Webelieve that this new classification scheme is both scien-tifically sound and has good explicative value. Task 2will leverage this decomposition.
8

II.4.5 File systems File systems have been the sub-ject of much research and implementation. RelaxingPosix semantics, AFS [36] introduces caching andclose-to-open semantics. Lustre, GoogleFS and HDFS[29, 64, 70, 82] improve parallelism by storing dataseparately from metadata; however they rely on a cent-ral metadata server. GoogleFS and HDFS improvereliability by storing data blocks in a quorum of serv-ers.
The above systems are designed for a single datacenter.Systems designed for geo-scale, such as GlusterFS [24]XtreemFS [37], do not deliver convincing performance.Google has announced the design of a planet-scale filesystem, Collossus [21], but technical information islacking.
A recent promising geo-distributed approach is Calv-inFS [84], layered above a key-value store [27]. Calv-inFS splits the metadata server into shards; each sharduses Paxos consensus [46] to synchronise its opera-tions. A file operation is implemented as a transactionacross one or more logical shards. CalvinFS outper-forms HDFS in both volume and I/O performance.
Commercial cloud-based file-systems designed forcollaboration, such as Google Drive and MicrosoftOneDrive, are limited to a small number of concurrentusers. Furthermore, they are unsafe: for instance, inthe presence of concurrent rename operations, theycan lose data [57, 80].
The project partners are active in the area of distributedfile systems. Scality is one of the major providersof high-volume, high-throughput, high-distributionsoftware-defined storage. Scality and Inria Regaltogether have designed and implemented a highly-available file system, geoFS [65, 80]. Currently, theyare working together on proving its specification cor-rect and on measuring its performance. Télécom Sud-Paris have proposed FlexiFS [88], a framework to com-pare file system design and consistency choices.
In RainbowFS, Task 3 aims at designing an efficientand correct file system for Fog-scale computing. Tothis end, it will apply the co-design approach de-veloped in Task 1, and will rely on the geo-replicationmodules created in Task 2.
II.5 Relation with ANR and European workprogrammes
Within the ANR programme’s Challenge 7 “In-formation and Communication Society” (Société del’information et de la communication), this proposalfits into Axis 7 “Communication, computation andstorage infrastructures” (Infrastructures de communi-cation, de traitement et de stockage).
As we propose to verify formally that applications cor-rectly enforce their invariants, this eases the productionof safely operating software; thus, our proposal relatesto Axis 3 “Software science and technology” (Scienceset technologies logicielles). Finally, RainbowFS is alsolinked to Axis 5 “Big Data” (Données, Connaissances,Données massives), as it designed for the petabytescale.
This proposal builds upon the results of previous col-laborations. ANR project ConcoRDanT, “Consistencywithout concurrency control, in Cloud and P2P sys-tems” (ANR Blanc 2010–2014) was the first to studythe concept of CRDTs (Conflict-free Replicated DataTypes). CRDTs encapsulate replication and concur-rency resolution, and ensure convergence by construc-tion [67–69]. CRDTs are a first stab at ensuring thecorrectness of applications running above asynchron-ous replication, and are one of the building blocks ofthe RainbowFS proposal. In particular, the RainbowFSfile system will be developed in Task 3 using CRDTdata types.
European FP7 project SyncFree (2013–2016) is ex-ploring large-scale computation without (or with min-imal) synchronisation. SyncFree supports a highly-available cloud database that scales to extreme num-bers of widely geo-distributed replicas, yet ensures thesafety of applications executing at the edge. Extreme-scale distributed and consistency protocols, the insightof strengthening causal consistency, and its formalisa-tion with the CISE analysis, to be carried out in Task 1,are outcomes of SyncFree.
Finally, the main ideas underlying the massively-distributed file system design, to be studied in depthand implemented in Task 3, are the outcome of pre-vious joint work (a CIFRE industrial PhD thesis)between Scality and Inria Regal.
II.6 Feasibility, risks and risk mitigation
This project is ambitious but feasible. In fact, thepartners have already proof-of-concept designs or pro-totypes for several of the contributions targeted in thisproject.
Regarding Task 1, the CISE logic and its proof ofsoundness have been published at POPL, the premiervenue in language and verification [31]. A prototypeCISE analysis tool has been developed [55, 56] anddemonstrated on some proof-of-concept examples, in-cluding a simplified model of the file system [54].However, it is only a restricted research prototype,which is too complex and low-level for general use.
Similarly, the partners have experience towards thestudies of Task 2. They have published preliminary
9

deconstructions of consensus protocols [8] and of trans-actional protocols [6]. They have accumulated exper-ience in tools for deployment and monitoring distrib-uted systems [59, 60].
The industrial and academic partners are very experi-enced in cloud-scale storage systems and consistency[3, 10–12, 28, 35, 40, 62, 77, 89, 93]. The work pro-posed for Task 3 builds upon a previous collabora-tion between Scality and one of the academic part-ners to design a geo-scale, highly-available file system[65, 80].
We describe some risks specific to the tasks of the pro-ject in the corresponding sections (see Section III.1).Furthermore, we identify some overall risks for theproject:
1. Unfavourable timing of the announcement of thefunding decision (planned for July 2016). At thistime of the year, the best PhD students have typic-ally already committed to a project. To manage thisrisk, we request a project duration of 48 months,
which will give us extra hiring flexibility. Withinthose 48 months, the workplan takes 36 months,numbered M 01 to M 36, starting from when thestaff is hired.
2. Failure to develop programs that reconcile avail-ability and safety. This may be, either becauseapplication semantics turns out to be too difficult tospecify, or because any useful semantics requiresa lot of synchronisation. Given recent advancesin the state of the art, we think this is unlikely[12, 31, 48, 49, 55, 56, 61]. To manage this risk,we can always use a stronger consistency model, atthe expense of availability.
3. Given the many difficulties of developing, configur-ing and deploying a distributed system, we mightfail to scale to the targeted metrics. We mitigatethis risk by using state-of-the-art development anddeployment technology, and by developing furthertools for deployment, monitoring, debugging andanalysis in our Task 2.
III SCIENTIFIC AND TECHNOLOGICAL PROGRAMME, PROJECT ORGANISATION/ PROGRAMME SCIENTIFIQUE ET TECHNIQUE, ORGANISATION DU PROJET
The aim of RainbowFS is to develop and validate anovel approach to the design of distributed applica-tions.
Today, the developer must start by choosing a spe-cific consistency model, and bet in advance that it willprovide the safety-vs.-availability tradeoff that is rightfor her application. Although, as explained earlier,some platforms support selecting different guaranteesat runtime, they do not help to ensure that the result iscorrect. In the application area, a number of distributedfile systems exist, but they are monolithic, and are notdesigned for geo-replicated operation at large scale.
In contrast, RainbowFS aims for Just-Right Consist-ency, adjusting the application semantics and the con-sistency protocol together. As a result the system is asavailable as possible, yet sufficiently consistent to besafe; the application pays only the price that it strictlyneeds. This approach is supported by static and dy-namic tools that verify that the resulting applicationis correct and efficient. It is served by a library andAPI that deconstructs classical consistency models intoindependent primitives, from which the developer cancombine the minimal set that is necessary. A composi-tion framework ensures that the combination remainshighly efficient. This comes with deployment, monit-oring, analysis and debugging tools. The approach willbe used in practice on a demanding and useful applica-
tion: an entreprise-grade file system, tunable accordingto the needs of its users, designed to be deployed onlarge numbers of geo-distributed sites. It will be valid-ated in a large-scale experiment, to be deployed acrossseveral continents.
III.1 Decomposition into tasks
Table 3 summarises the tasks, their timing and depend-encies, and the milestones of the project.
Table 4 lists all the deliverables.
We count the first month of the project, designatedM 01, when the PhD students are hired. The projectterminates 36 months thereafter at M 36. However werequest ANR funding duration of 48 months in orderto have the flexibility to hire the best PhD students (seeRisks, Section II.6).
Recalling Section II.1, the challenges addressed by theRainbowFS proposal are:
1. Design-time tools and guidance to the developer inthe co-design of the application and its associatedconsistency protocol. This challenge is addressedby Task 1.
2. Transforming an application specification, verifiedin the previous task, into an efficient applicationskeleton, leveraging composable consistency prim-
10

Task 1: Application co-design Task 2: Modulargeo-replication
Task 3: Geo-distributedmassive file system
M01–M12 User-friendly, robust CISE tool.
Domain-Specific Language todescribe operations andinvariants.
Consider extracting informationfrom source.
Basic consistency componentlibrary.
Decompose to fine-grainmodularity, along threedimensions.
Deployment, profiling andmonitoring tools.
Single-DC prototype of filesystem.
MS1 Basic co-design and toolsM13–M24 Programming patterns.
Generate advice to developer forfixing conflicts.
Heuristics deriving high-levelinformation fromcounter-example.
Efficient component library.
Composition framework.
Analysis and validation tools.
Initial evaluation of single-DCprototype.
Geo-distributed file systemprototype.
MS2 Functional prototypesM25–M36 Synchronisation protocol
generation, taking into accountworkload and faults.
Co-design and proof of filesystem and other applications.
Apply component library to filesystem and other applications.
Large-scale evaluation of library.
Running large-scale experiments,using our deployment andmonitoring tools.
Large-scale evaluation evaluationof file system, based on realworkloads.
MS3 Large-scale evaluation
Table 3: Table of tasks
Month Task TitleM12 1 User-friendly co-design tool
2 Consistency components; deployment, profiling & monitoring tools3 Single-DC file system prototype
M24 1 Synchronisation protocol generator2 Efficient composition; analysis & validation tools.3 Geo-distributed massive file system prototype
M36 1 Co-design and proof of complete file system and other applications.2 Large-scale experimental validation of the component library & tools3 Large-scale evaluation report
Table 4: Table of deliverables
11

itives and tools. This challenge is addressed inTask 2.
3. Experimental and market validation by applyingthis to a challenging, demanding application. Thisis the work of Task 3.
The following paragraphs describe each task in detail.
Task 1 : Application co-design
This task is summarised in Table 5.
Objectives of the task: To ensure that an applica-tion is correct without incurring more synchronisationthan necessary, thus maximising availability, and en-abling scalability and performance.
Instead of imposing a pre-defined consistency model,we propose to co-design the application functionalityand its consistency protocol. The basic insight is that,even within an application, consistency requirementsvary depending on the specific operation [48]. Someoperations can safely run asynchronously in parallel,while others require synchronisation. A recent break-through is the CISE static analysis [12, 31, 54–56],which verifies statically (in polynomial time) whethera program has sufficient synchronisation.
The challenge of this task is to provide design-timeand run-time tools to guide the developer in the co-design of the application and its associated consist-ency protocol. The tools shall verify that the combina-tion is safe, i.e., updates have the intended semanticsand verify the system’s integrity invariants. When thetools detect an anomaly, they should provide at leasta counter-example, and better still, suggest ways toremove the anomaly.
Our co-design approach uses (low latency, available)asynchronous operations by default, ensuring conver-gence by using Conflict-Free Replicated Data Types(CRDTs) [68]. Using a tool that automatically dis-charges the CISE proof obligations (the “CISE Tool”),the developer verifies whether the application satisfiesits invariants under these conditions. If not, the toolreturns a counter-example, which serves as a guide toeither weaken the invariants (possibly at the cost ofunfamiliar semantics) or to strengthen the synchronisa-tion (at the cost of reduced availability). The analysis-design cycle repeats until verification succeeds. Thus,the developer co-designs the application and the pro-tocol, minimising synchronisation to what is strictlyrequired by its invariants, with the assurance that theresult is correct [10].
For instance, consider the invariant that a file systemforms a tree. The CISE analysis tells us that concur-rent rename operations may violate the tree invari-ant. Therefore, the developer must either change thesemantics of rename,1 or ensure that rename opera-tions are mutually synchronised. With these changes,the CISE analysis succeeds, thus proving that the filesystem maintains the tree invariant. The CISE analysisalso tells us that the other file system operations do notinherently require synchronisation and that mergingsemantics is possibe [80].
Methods and technical decisionsApplication co-design. We have applied the abovemethodology successfully to some small examples,including a simplified model of the file system. Ulti-mately, we wish to achieve the co-design and completecorrectness proof of the widely-replicated file systemof Task 3. We also plan to co-design other applications,including some that make use of the file system itself.
The specification will model, initially, the Posix filesystem API [38]. From the invariant that the file sys-tem structure must be shaped as a tree, it will derive,for instance, the sequential precondition to rename,which forbids to move a directory underneath itself.Furthermore, the Posix specification disallows manyconcurrent updates, e.g., writes to the same file, andit therefore requires a lot of synchronisation. Usingthe co-design approach, we will carefully remove syn-chronisation on most operations while retaining a se-mantics reasonably similar to Posix. However, ourpreliminary CISE analysis shows that, in some cornercases, rename conflicts with concurrent rename op-erations. It follows that, either rename must be syn-chronised, or anomalies are unavoidable, such as lossor duplication of whole directories.
User-friendly, robust analysis tool. Our prototypeCISE Tool is sufficiently advanced to prove the concept.It already checks the CISE Rules to prove the safety ofthe application. If not, it reports a counter-example thatthe developer can inspect to fix the problem [55, 56].However, it is only a prototype and remains difficultto use. For instance, it requires writing a model ofthe application in the Z3 internal format. It is up tothe developer to understand the counter-example, todeduce the issue, and to correct the application.
A short-term improvement will be to develop a trans-lator from some high-level Domain-Specific Language(DSL) to Z3. Longer term, we would like the toolto leverage the application source code itself, eitherautomatically or semi-automatically.
1 For instance, replacing the atomic rename with a non-atomic copy to the new location, followed by deleting the source location.
12

Task 1 Application co-designTask Leader Marc Shapiro, Inria Regal
Deliverables M12 User-friendly co-design toolM24 Synchronisation Protocol GeneratorM36 Co-design and proof of complete file system and other applications
Participant Inria Paris Scality CNRS-LIG Télécom SP TotalPerson×months 45 8 10 6 69
Table 5: Summary of Task 1
An important objective is to automatically analyse thecounter-examples, identifying conflicting pairs of op-erations.
Finally, we plan to work on extending the CISE lo-gic. First, we wish to remove the assumption of causalconsistency, and detect cases where causality is notrequired, in order to decrease overhead and increaseparallelism. Second, we plan to extend CISE to relaxedforms of transactions such as Snapshot Isolation [14],PSI [73] or NMSI [62]. Finally, we wish to addresstesting. Tools such as symbolic execution [19] cansystematically generate test cases from the source codeitself, but suffer combinatorial explosion with paral-lel code. Our intuition is that an approach similar toCISE can make this quadratic, which would be a majorbreakthrough.
Automating protocol generation. The set of conflictingpairs from the previous step still needs to be translatedinto an efficient concrete protocol. An advanced toolwould suggest efficient concurrency control protocolsand/or weakenings of effect or invariant. The developeris still free to follow the suggestion, or to devise herown fix.
Operations that conflict must execute one after theother. For a given set of conflicting pairs, there aremany possible implementations of this order. Theseimplementations vary in efficiency and liveness. Oneextreme is to ensure simple mutual exclusion (e.g., en-suring each operation in a pair contains a read-modify-write instruction, or acquires and releases a lock). Thisis safe and live, but repeated synchronisation is unlikelyto perform well. At the other extreme, we might allowonly one process to execute conflicting operations (e.g.,acquiring locks at the beginning of execution and neverreleasing them); this is safe, and much more efficientin terms of concurrency-control traffic; but it’s unlikelyto be live.
The best approach in terms of efficiency is often some-where in the middle. The choice depends highly onthe workload: for instance, if operations that conflictare always called by a single process, the “lock before-hand and never release” approach works well. A lazy
approach, acquiring a lock on first use, and releasing itonly when required by a different process, will prob-ably give good results in many cases. Furthermore,there are more efficient alternatives to locking in somesituations, e.g., leveraging causality or using escrow.
We envisage a tool based on heuristics to generate anefficient protocol, and to compare protocol behaviourunder benchmark workloads or fault injection scen-arios. The choice shall be guided by energy savings,latency, throughput, fault tolerance and other perform-ance considerations, which depend on the workloadand on the environment. The tool’s heuristics shouldavoid deadlock, and the tool should verify liveness.
Detailed work programme
Subtask 1.1 User-friendly, robust CISE Tool. Weplan to develop a front-end that parsesthe specification in a convenient Domain-Specific Language syntax (for instance,Z3lib or TLA+) before discharging theCISE Rules to the Z3 SMT solver. Later,we will consider methods for extractingthe information directly from the sourcecode of the application, either automatic-ally or with assistance from the developer.
Subtask 1.2 Generation of fixes for CISE violations.This task will identify standard program-ming patterns that correct common sub-classes of CISE violations. It will developa heuristic tool that examines the counter-examples returned by the tool and willsuggest fixes, either by weakening the ap-plication specification or by strengthen-ing synchronisation.
Subtask 1.3 Synchronisation protocol generation. Anumber of standard concrete synchronisa-tion protocols to avoid conflicts will beidentified. We will compare their beha-viours under benchmark workloads andfault scenarios. We will develop a toolto propose a suitable concrete protocol,according to runtime and environment
13

characteristics. Thanks to run-time mon-itoring and a feedback loop, the tool willbe able to learn from experimental dataand propose changes to the protocol whenconditions change.
Success indicators Our current proof-of-conceptCISE tool has been applied to few test cases. In Rain-bowFS, we aim to make it accessible to ordinary pro-grammers, to leverage source code directly, to extendit to run-time testing and verification, and to apply it tothe challenging file-system design described hereafter.
Therefore, we identify the following success indicat-ors (i) The ability for ordinary programmers to effi-ciently use CISE tool thanks to a high-level DSL toco-design their applications and the suitable consist-ency guarentees. (ii) The characterization of most con-crete synchronization protocols and their performancein application-specific workloads and faults scenarios.(iii) Identifying common patterns of CISE violationsand guidelines on how to fix them.
Deliverables
M 12: User-friendly CISE co-design tool, trans-lating a model written in a high-level lan-guage to the solver’s format, discharging theproof obligations, and returning any counter-example in a high-level language.
M 24: Semi-automated synchronisation protocolgeneration. This tool will consider a limitedset of synchronisation protocols and a numberof well-specified workloads and scenarios.
M 36: Co-design and correctness proof of completefile-system design and an application usingthe file system.
Risks and risk mitigation The work proposed inTask 1 is ambitious but feasible. Indeed, the CISE logicand its proof of soundness have been published [31];a prototype CISE analysis tool has been developed[55, 56] and demonstrated on some proof-of-conceptexamples, including a simplified model of the file sys-tem [54]. However, it is only a restricted research pro-totype, which is too complex and low-level for generaluse.
We see two main risks for this task. First, identifyingstandard programming patterns and heuristics to fixCISE violations might turn out to be too specific toapplications. In this case, instead of the generationof fixes of CISE violation, we will provide a suite ofuse cases to help developers. Second, the perform-ance of a concrete synchronisation protcol depends
on workloads characteristics and fault scenarios. Bothworkloads and fault scenarios are dynamic. Hence,it might turn out to be difficult to devise benchmarkworkloads that are representative of real situations. Inthis case, we will at least provide guidelines for choos-ing synchronisation protocols, according to workloadand runtime characteristics.
Task 2 : Modular geo-replication This task is sum-marised in Table 6.
Objectives of the task: To provide the buildingblocks allowing developers to quickly implement an ef-ficient and sound geo-replicated storage system/servicewith flexible (just-right) consistency semantics.
The present task aims to help the developer transforman application specification, proved correct in the pre-vious task, into a functional application skeleton. Askeleton comprises the core communication and dataprocessing infrastructure. In particular, this includesthe code that manages message transmission, receptionand delivery, and enforces consistency invariants. Thisalso includes the code that reacts to dynamic eventssuch as faults or changing workloads; such events re-quire to create or move replicas, in order to guaranteelong-term availability and performance. Note that theconsistency specification must define the behavior ofthe system in the presence of faults such as disconnec-tion or crashes.
This task has two main challenges: (i) To providelean and efficient primitive consistency componentsthat can be combined to implement the application’scommunication and consistency requirements quickly.(ii) To provide a composition framework that ensuresthat the composition is as efficient as a monolithic im-plementation, in terms of message delays, number ofmessages, size of message, synchronisation steps, etc.To comply with the Just-Right Consistency approach,which is to “pay only for what you need,” our modularapproach should not impose any synchronisation orabstraction overhead not strictly required by the spe-cification, and must use hardware resources efficiently.
In particular, the composed components should notimpose any redundant steps, metadata, or spurious syn-chronisation. For instance, if two components bothsend a message with the same source and destination,the composition framework should consolidate theminto a single message. In addition to protocol effi-ciency, the component model should make good useof the resources modern hardware, such as multicoreCPUs and high-speed network interfaces.
14

Task 2 Modular geo-replicationTask Leader Vivien Quéma, CNRS LIG
Deliverables M12 Consistency components; deployment, profiling & monitoring toolsM24 Efficient composition; analysis & validation tools.M36 Large-scale experimental validation of the component library & tools
Participant Inria Paris Scality CNRS-LIG Télécom SP TotalPerson×months 27 8 40 18 93
Table 6: Summary of Task 2
Methods and technical decisions The key aspectsof this tasks’s approach is summarized as follows.
Modular decomposition of consistency and fault man-agement. We propose to deconstruct consistency mod-els along three (mostly-)orthogonal axes: (i) total or-der of operations relative to a single object; (ii) causalordering of reads with respect to writes; and (iii) atom-icity of transactions combining multiple operations. Aconsistency protocol can be strong along one axis andweak along another. Each axis corresponds a specificclass of guaranteed invariants, respectively: constraintson the value of a single data item; partial order betweenevents or data items; and equivalence between dataitems. Only total-order requires mutual synchronisa-tion, and thus only the first axis is subject to the CAPtrade-off. In contrast, atomicity and causality can beimplemented with high availability.
Therefore, in order to improve the efficiency of applica-tion developers (time of development and safety of theresulting code), we will implement a library of consist-ency components. More precisely, there will be threeclasses of consistency components: one class for eachof the three above-discussed axes, with several variantsin each class (according to the chosen strength for thecorresponding consistency dimension). To the bestof our knowledge, the above-described “3-D” decom-position is new. We believe that it represents a goodcompromise between completeness and intelligibility.
This task will also study how modularity can be appliedto fault-tolerance code. The idea is to design protocolabstractions enabling reuse, as much as possible, ofthe same fault-tolerance building blocks for differentapplication-level consistency specifications. This isimportant because the fault-tolerance code is critical toboth safety and performance, for instance, when oper-ating in degraded mode or while rebuilding of a replica.Therefore, the design and implementation of correctand efficient fault-tolerant code is complex and timeconsuming and would strongly benefit from code reuseand simplified incremental development. To achievethis goal, we will build on our experience with theAbstract framework [8], for designing modular statemachine replication protocols.
The design of the framework will be guided by (i) theopportunities of semi-automatic code/template genera-tion from the toolchain of Task 1 and (ii) the require-ments of the tools designed in this task. For thesereasons, we plan to consider a clean-slate approachfor the APIs of the framework, but we nonetheless in-tend to facilitate the development of many componentsby borrowing and adapting code from existing open-source projects. For example, we intend to borrowcode from the G-DUR framework [6] (developed bytwo of the partners) and from CockroachDB [44] (anopen-source clone of Google Spanner [21]).
Tools. This task will design and implement tools toassess the correctness and the efficiency of a skeletonbuilt by composing library components. We envisiontwo kinds of tools: (i) Checking correctness, i.e., thatthe application’s safety and liveness; (ii) Check effi-ciency, i.e., that the implementation does not introduceunnecessary synchronisation or redundant steps. Thesetools will rely on a combination of static and dynamicapproaches, leveraging the uniform design and API ofthe components.
We plan to leverage existing model-checking tools(e.g., CADP [39]) to assess the correctness of our im-plementations in fault-free cases. Similarly, we willextend existing stress-test tools, such as Jepsen [42],to assess our implementations when faults occur. Fi-nally, we will develop simple tools to monitor the per-formance of the consistency protocols developed usingour component library, collecting performance metricssuch as message latency and throughput or space andtime overheads.
Detailed work programme
Subtask 2.1 Component library. We will develop amodular library of consistency compon-ents and fault-tolerance components, withan efficient composition framework. Thecomponents offer fine grained modularitywith respect to consistency and fault tol-erance guarantees. Associated are toolsto assess the soundness of the individual
15

components, the library glue code, andthe resulting component assemblies.
Subtask 2.2 Efficient composition framework. Thissubtask will support the component lib-rary, both at the design level (i.e., theassembly of micro-protocols for consist-ency and fault-tolerance), and at the im-plementation level. For each componentcomposition, our goal here it to reach theperformance and resource footprint of amonolithic implementation. This will besupported by developing monitoring andprofiling tools that spot performance bot-tlenecks.
Subtask 2.3 Evaluation. We will assess the benefitsof Just-Right Consistency compared toexisting monolithic approaches. This as-sessment feeds back iteratively into thedesign. Each iteration consists of anexperimental campaign followed by thedesign and implementation of new optim-izations. This feedback loop will makeuse of three kinds of workloads: (i) syn-thetic micro-benchmarks; (ii) existing ap-plications (adapted from existing code);(iii) the file-system use case from Task 3.
Success indicators We see the following success cri-teria for this task: (i) The ability to reimplementexisting geo-storage application designs (from the lit-terature) with low effort. (ii) For a given applicationdesign, the ability to achieve at least comparable per-formance with respect to a monolithic implementation.(iii) The ability to demonstrate that an implementationderived from the Just-Right-Consistency approach canyield tangible performance gains.
Deliverables
M 12: Library of consistency components; deploy-ment, profiling and monitoring tools.
M 24: Efficient composition framework of consist-ency components; analysis and validationtools.
M 36: Large-scale experimental validation of thecomponent library and tools.
Risks and risk mitigation The partners have pre-liminary experience towards this task. They have pub-lished preliminary deconstructions of consensus proto-cols [8] and of transactional protocols [6]. They have
accumulated experience in tools for deployment andmonitoring distributed systems [59, 60].
We see two main risks for this task. First, the degree ofmodularity that we envision for the components mayturn out to introduce excessive complexity and/or asubstantial performance overhead. In this case, we willrestrict the modularity of the framework and consideronly the consistency configurations that most useful forthe file system use case studied in Task 3. Second, themonitoring and analysis that we envision may prove tobe challenging to design and implement (e.g., due toheavy resource requirements). In this case, we mightfall back on testing in a controlled environment.
Task 3 : Geo-replicated massive file system Thistask is summarised in Table 7.
Objectives of the task: To design an entreprise-grade geo-replicated file system with consistency guar-antees, and to demonstrate it at massive scale.
The data storage market shows a growing demand forfile and object based storage. This demand comes fromthe legacy use of file systems as one-size-fits-all stor-age solutions, together with a growing appetite for bigdata infrastructures (e.g., HDFS in Hadoop). Analystfirm IDC predicts the global file and object storagemarket will continue to gain momentum and reach $38billion by 2017 [58]. Scality regularly gets requestsfor file systems up to hundred of petabytes.
Jointly to this demand for raw performance, compag-nies are getting more and more de-centralised, oper-ating at the geographical scale. However, as pointedout in II.4.5, existing file systems designs are not yetready for Fog computing and geo-distribution. Theyeither do not deliver convincing performance at thatscale, or they still rely on a central metadata server.To bridge this technological gap and target a prom-ising market, our flagship application in RainbowFSis a geo-replicated massive file system.2 To build thisfile system in Task 3, we will address the followingchallenges:
• Elastic Geo-distribution. We provide a Fog-computing experience to the end-user. In par-ticular, we target large-scale infrastructures thatconsist of dozens of large data centres (DCs) andpossibly hundreds of smaller point-of-presencecentres, scattered around the globe. This scale ofinfrastructure is required by today’s digital busi-nesses, which need distributed, always-on ser-vice; applications with extreme latency require-ments will leverage replicas located very close to
2 We also plan to apply it to several other real-world applications, for instance big-data analytics and indexing, outside of RainbowFSfunding.
16

Task 3 Geo-replicated massive file systemTask Leader Vianney Rancurel, Scality
Deliverables M12 Single DC File System PrototypeM24 Geo-distributed Massive File System PrototypeM36 Large-scale Evaluation Report
Participant Inria Paris Scality CNRS-LIG Télécom SP TotalPerson×months 36 26 10 30 102
Table 7: Summary of Task 3
their end users. The system shall support elasticscalability, dynamically and seamlessly addingand removing servers, or even whole DCs.
• Massive Performance. To achieve massiveperformance, we plan to leverage the fully-decentralized nature of the large-scale underly-ing infrastructure. Our file system will aggreg-ate network bandwidth where possible, and willsupport massively parallel distributed operations.To ensure scalable geo-distribution, it will sup-port partial replication.
• Consistency, Security & Fault-tolerance. Ourfile system must be dependable, ensuring consist-ency (as described under Task 1) and toleratingfailures such as machine crashes, disconnection,or whole-DC failure. It shall be secure thanksto state-of-the-art cryptography techniques, andensure integrity using erasure codes. An ap-plication should be able to have its own dataplacement policy, e.g., placing replicas in dis-tinct locations to cope with the possibility of aDC being compromised, or ensuring that all itsreplicas remain within a given jurisdiction.
Methods and technical decisions Our technical de-cisions build upon our rich experience in designingand evaluating distributed data storage systems.
Synchronisation-free Operations Where Possible. Weensure our file system is both scalable and correct us-ing the co-design approach developed in Task 1. Thesystem maintains the invariant that both the director-ies and the internal (inode and block) data structuresform a tree. We know from Task 1 that there is noneed for strong synchronisation to implement the addand remove operations. However, the Posix standardcontains additional operations that make it difficult toscale geographically and/or to high numbers of usersand high update rates. We plan to make as many oper-ations as possible synchronisation-free, without viol-ating user-defined expectations, and to boost perform-ance using techniques such as caching or close-to-opensemantics [36]. For instance the referential-integrity in-variant (every node is referenced from some directory)
does not require synchronisation, only causal deliveryof create and delete operations.
This methodology builds upon the CISE analysis andupon our previous geoFS design, a proof-of-conceptgeo-replicated file system [80]. In geoFS, all opera-tions are asynchronous ( concurrent rename suffersonly a minor anomaly, i.e., duplication of a sub-tree,and concurrent updates to a file result in two renamedfiles).
Tailorable Data Consistency. Historically, file sys-tems focused on the strong Posix model. More re-cent designs have shifted to ensuring availability un-der weaker consistency, because of the need for geo-distributed, planetary-scale and always-available ser-vices. However, existing file systems offer the sameconsistency level for all end-users and applications,and are often incorrect. RainbowFS departs from thismonolithic vision of the file system, and explores fine-grained consistency, parameterised according to usage,while still ensuring correctness. Users may choosetheir semantics at the granularity of a sub-tree or evenof a single file, thus supporting the rainbow of allreasonable consistency/available trade-offs. For in-stance, by user option, concurrent writes to a samefile can either be disallowed as in NTFS, arbitratedby last-writer-wins as in NFS, or be merged simil-arly to SVN or git, if the file content is a CRDT, orcause the creation of two files side-by-side as in Mi-crosoft OneDrive or geoFS. For rename, the user willhave a choice of either occasional unavailability as instrongly-consistent systems, or occasional anomaliesas in geoFS. Even if an application running above thetailorable file system chooses the more liberal optionsfor availability and performance, it will remain safe,because it can itself be verified thanks to the tools fromTask 1.
All the above options can be supported above a single,asynchronous codebase. To disallow a specific anom-aly requires only some extra synchronisation, whichcan be added on top. In the limit, if all operationsare made synchronous, the system exhibits the strongPosix semantics.
17

Object Store Everywhere. We build our file system atopan object store, currently being developed by Scality,code-named IrM hereafter. This object store is elastic,dependable and geo-distributed. It also supports dataplacement policies. RainbowFS implements all high-level file system calls as transactions of IrM-level oper-ations. We cleanly separate data objects (file content)from metadata objects (inodes). The data store is op-timised for write-once objects, and the metadata storefor highly-mutable objects. Metadata forms a virtu-alisation layer above the object store to avoid update-in-place. This approach converges the file- and theobject-based storage designs, which we believe is aworthwhile research topic on its own merit.
Fully-distributed Architecture. Current industrial-grade file systems [29, 70, 75] are built around a centralmetadata server. As the metadata server is a serial-isation bottleneck, this design does not scale beyondthe petabyte [71]. To support future sizes and geo-distributed Fog computing, our approach instead dis-tributes metadata management across geo-distributedDCs. To support synchronisation when necessary in-side the file system, the object store will support prim-itives such as read-modify-write (rmw) or compare-and-swap (cas). For instance, in the Posix semantics,creating a file is an atomic transaction that first createsan inode block, then adds the file to the parent direct-ory with rmw. Only the latter operation needs strongconsistency to ensures that two clients don’t create the“same” file concurrently. Synchronisation and commu-nication use the library of components developed inTask 2.
Experimental validation. As a reality check, weare planning a massive experimental deployment andbenchmarking of the file system. It must be of suffi-cient scale to be credible and to be competitive withscientific publications in the best conferences, cur-rently dominated by the American cloud giants suchas Google and Amazon.
Our performance target aims for 105 servers over sev-eral DCs, supporting petabytes of data, and an updatebandwidth exceeding 10 GB/s. However, a petabyte-scale experiment would be prohibitively expensiveand would make sense only with real client data. Toremain feasible within the budget of an ANR pro-posal, we aim for a terabyte-scale experiment, with103 physical nodes and 10 servers per node, across fivegeographically-distributed DCs. The experiment planis developed in more detail in Table 8 and Section III.3.
The experiment will initially use the French na-tional Grid’5000 national experimentation facility [33],which can be accessed for free. Once the system hasbeen thoroughly debugged on Grid’5000, and to ex-
pand beyond the Grid’5000 capacity, we will add re-sources rented from a commercial cloud provider. Weexpect to be able to execute essentially the same codeon both platforms. Although only terabyte-scale, thissetup should still enable us to draw meaningful conclu-sions on the way to the petabyte.
Detailed work programme
Subtask 3.1 File System. We design and implementa distributed file system with support forfile replication, data redundancy and en-cryption, multi-scale fault-tolerance, anda rainbow of consistency levels. It islayered above the IrM object store. In-titially, it will support a single DC and asingle level of consistency; later it will beextended to available geo-replication andtailorable consistency.
Subtask 3.2 Evaluation. This subtask is devoted to theextensive evaluation of our file system de-scribed above.
Success indicators We evaluate the success ofTask 3 in terms of functionality and performance. Thismeans that (i) We deliver a fully functional file sys-tem interface that can run industrial-grade benchmarks(e.g., IOzone, SPECsfs or FileBench [20, 52, 74])as well as synthetic traces [86, 87]; (ii) the degreeof consistency required by the user is satisfied at alltime by the file system, from fully asynchronous as ingeoFS, to fully-synchronous Posix semantics, whileremaining correct; and (iii) the evaluation assessesthat we reach the competitive performance in termsof throughput, latency, fault-tolerance, parallelism andgeo-distribution.
Deliverables
M 12: Initial version of the prototype with base objectand file operations at the level of a single DC.We use separate instances of the IrM object storeto store data and metadata objects. The CISEtool verifies safety of the file system specifica-tion.
M 24: A more evolved prototype including the fullsupport of file system operations in a single DC,and base operations across them. The under-lying geo-distributed data block storage shouldsupport erasure coding, data locality as well asput/get/rmw operations.
M 36: Full geo-distributed evaluation of the Rain-bowFS prototype. This evaluation leverages re-sources taken from both Grid’5000 and commer-cial clouds.
18

Risks and risk mitigation While clustered file sys-tems, such as NFS, Lustre or HDFS are widely de-ployed, peer-to-peer file systems [23, 53] never gainedmomentum. As a consequence, it is possible that in therainbow of colors, very weakly consistent file systemsseem risky to the end-user. To mitigate this problem,our insight is to avoid lost updates under weak con-sistency with the help of CRDT-like file operations.Another possible risk is related to the large-scale evalu-ation of our file system. Synthetic benchmarks shouldbe as close as possible to realistic scenario. However,when a massive number of users concurrently use afile system, the number of reasonable scenarios to eval-uate is too large. To avoid this problem, we plan toleverage public traces of personal cloud storages, e.g.,Ubuntu One [32], as well as tools employed in theHPC community [66] to model I/O-intensive distrib-uted applications.
III.2 Project organisation
The consortium and partners will be described in Sec-tion III.4.
The Project Leader is Marc Shapiro of Inria Regal. Hewill receive support for technical coordination fromthe post-doc, acting as coordinator.
The Management Board has the responsibility of gen-eral circulation of information, and technical and non-technical decisions that require coordination betweenthe partners. This board includes the project leader,the coordinator, one representative per partner, and onerepresentative per task. The same person can attendin multiple capacities. The board meets physically, bytelephone or similar means, at least once a month.
Each partner names its representative in the Manage-ment Board at the start of the project. At the time ofsubmitting the proposal, these are identified as MarcShapiro of Inria, Vianney Rancurel of Scality, VivienQuéma of CNRS-LIG, and Pierre Sutra of TSP.
The technical work described will be carried out by thedifferent partners, organised in Tasks, under the lead-ership of a Task Leader, as described in Section III.1.A Task Leader may take the decisions required in thetask. He shall inform in advance other tasks of anyissues that impact them, and will take their input andrequirements into account.
The project will use modern development tools, such asgithub, which support a distributed design and develop-ment team. Nonetheless, real communication requiresphysical meetings. There will be general meeting of allthe project participants, at least once every six months.Smaller working groups will meet as required, either
physically or electronically. Any of these meetingsmay invite outside expertise as required, as long as allthe partners agree.
In case the Project Leader or one of the members ofthe Management Board does not wish to, or cannotfulfill his/her duties, the corresponding partner shall re-place him or her, with the agreement of the remainingmembers of the Management Board. A Task Leadercan be replaced, in similar circumstances, by a jointdecision of the partners working on the task and of theManagement Board.
In case of a conflict between partners, the ProjectLeader will endeavour to resolve the problem by con-sensus. For this task, he/she may consult outside ex-perts. If consensus cannot be found, a special manage-ment board is called to vote on the issue; each partnerinstitution has one vote; in addition the project leaderhas one vote and can resolve a tie.
III.3 Scientific explanation of funding re-quest
The budget plan and funding request will be found inthe administrative submission document. More detailfollows.
We request funding for three PhD students, one post-doctoral researcher, and one junior engineer, all fulltime. The students are involved in all the tasks, but oneis more specifically responsible of the co-design task,one of the modular consistency task, and one of the filesystem task. Although the post-doc is assigned to theInria budget, he or she will be serving the whole pro-ject. He or she will focus on the modular consistencychallenge, and will also coordinate the research acrossthe different areas of the project. The engineer willwork on connecting the file system with the underlyinglocal storage and replication substrate, contribute to themassive file system experiment, and help integrate theproject’s results into Scality’s products. The partnerswill also bring in other students and engineers, fundedfrom other sources, who will help with the project.
Publication on experimental research in distributed sys-tems is currently dominated by large American cloudoperators. European academia generally does not havethe means to compete. To regain the research lead, ourworkplan includes an ambitious massive-scale experi-ment. It will leverage both Grid’5000 and commercialcloud resources, which would be impossible withoutthe requested ANR funding.
Its target is to experiment with 1 100 nodes, 10 serversper node, across five geographically-distributed datacentres (DCs). Preparation and ramp-up will be done
19
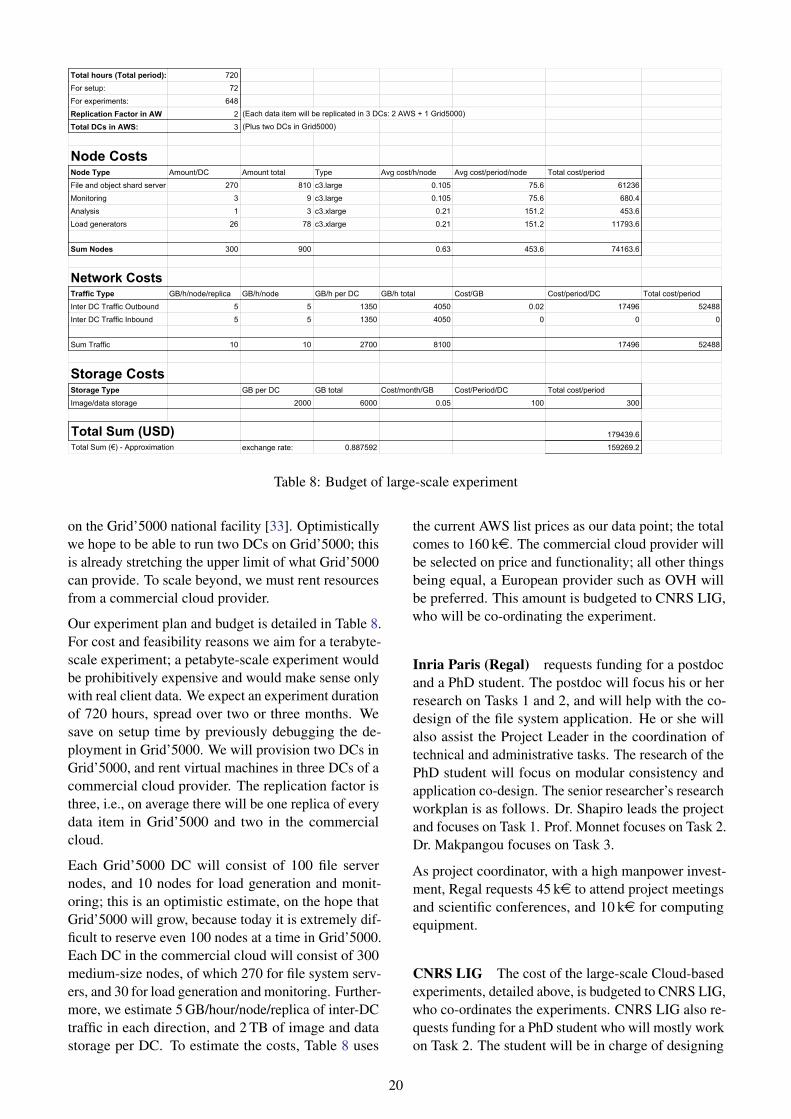
Total hours (Total period): 720
For setup: 72
For experiments: 648
Replication Factor in AW 2
Total DCs in AWS: 3
Node CostsNode Type Amount/DC Amount total Type Avg cost/h/node Avg cost/period/node Total cost/period
File and object shard server 270 810 c3.large 0.105 75.6 61236
Monitoring 3 9 c3.large 0.105 75.6 680.4
Analysis 1 3 c3.xlarge 0.21 151.2 453.6
Load generators 26 78 c3.xlarge 0.21 151.2 11793.6
Sum Nodes 300 900 0.63 453.6 74163.6
Network CostsTraffic Type GB/h/node/replica GB/h/node GB/h per DC GB/h total Cost/GB Cost/period/DC Total cost/period
Inter DC Traffic Outbound 5 5 1350 4050 0.02 17496 52488
Inter DC Traffic Inbound 5 5 1350 4050 0 0 0
Sum Traffic 10 10 2700 8100 17496 52488
Storage CostsStorage Type GB per DC GB total Cost/month/GB Cost/Period/DC Total cost/period
Image/data storage 2000 6000 0.05 100 300
179439.6
exchange rate: 0.887592 159269.2
(Each data item will be replicated in 3 DCs: 2 AWS + 1 Grid5000)
(Plus two DCs in Grid5000)
Total Sum (USD)Total Sum (€) - Approximation
Table 8: Budget of large-scale experiment
on the Grid’5000 national facility [33]. Optimisticallywe hope to be able to run two DCs on Grid’5000; thisis already stretching the upper limit of what Grid’5000can provide. To scale beyond, we must rent resourcesfrom a commercial cloud provider.
Our experiment plan and budget is detailed in Table 8.For cost and feasibility reasons we aim for a terabyte-scale experiment; a petabyte-scale experiment wouldbe prohibitively expensive and would make sense onlywith real client data. We expect an experiment durationof 720 hours, spread over two or three months. Wesave on setup time by previously debugging the de-ployment in Grid’5000. We will provision two DCs inGrid’5000, and rent virtual machines in three DCs of acommercial cloud provider. The replication factor isthree, i.e., on average there will be one replica of everydata item in Grid’5000 and two in the commercialcloud.
Each Grid’5000 DC will consist of 100 file servernodes, and 10 nodes for load generation and monit-oring; this is an optimistic estimate, on the hope thatGrid’5000 will grow, because today it is extremely dif-ficult to reserve even 100 nodes at a time in Grid’5000.Each DC in the commercial cloud will consist of 300medium-size nodes, of which 270 for file system serv-ers, and 30 for load generation and monitoring. Further-more, we estimate 5 GB/hour/node/replica of inter-DCtraffic in each direction, and 2 TB of image and datastorage per DC. To estimate the costs, Table 8 uses
the current AWS list prices as our data point; the totalcomes to 160 ke. The commercial cloud provider willbe selected on price and functionality; all other thingsbeing equal, a European provider such as OVH willbe preferred. This amount is budgeted to CNRS LIG,who will be co-ordinating the experiment.
Inria Paris (Regal) requests funding for a postdocand a PhD student. The postdoc will focus his or herresearch on Tasks 1 and 2, and will help with the co-design of the file system application. He or she willalso assist the Project Leader in the coordination oftechnical and administrative tasks. The research of thePhD student will focus on modular consistency andapplication co-design. The senior researcher’s researchworkplan is as follows. Dr. Shapiro leads the projectand focuses on Task 1. Prof. Monnet focuses on Task 2.Dr. Makpangou focuses on Task 3.
As project coordinator, with a high manpower invest-ment, Regal requests 45 ke to attend project meetingsand scientific conferences, and 10 ke for computingequipment.
CNRS LIG The cost of the large-scale Cloud-basedexperiments, detailed above, is budgeted to CNRS LIG,who co-ordinates the experiments. CNRS LIG also re-quests funding for a PhD student who will mostly workon Task 2. The student will be in charge of designing
20

the component library and its associated monitoringtools. He will also contribute to Task 3.
In addition, CNRS LIG requests 20 ke for travel (toattend project meetings and scientific conferences) and5 ke to acquire laptops for the design and developmentwork. The slightly higher travel budget (compared toother partners with similar manpower) is explained bythe fact that CNRS LIG is the only partner locatedoutside the Paris area (where most project meetingswill be held).
Télécom SudParis (TSP) will work mostly on thedevelopment and evaluation of the geo-distributedmassive file system. To help in the coding of the filesystem and the large-scale evaluation, TSP requeststhe funding of a PhD student. Besides that, the fund-ing demand of TSP also includes 15 ke for travel toproject meetings and scientific conferences, as well as5 ke to be spent in small equipment.
Scality In order to participate to the scientific re-search and to prototype the scientific results of Rain-bowFS into their product line, Scality will take theopportunity of this project to hire a permanent-staff(CDI) research engineer. The engineer will participatein the design and development of the geo-distributedfile system (Task 3) above Scality’s object storage sys-tem. He or she will also help to develop and put to usethe modular consistency, deployment, monitoring andanalysis components studied in Task 2. (Regarding theco-design tools studied in Task 1, Scality acts mostly asusers.) This is important, because practical implement-ation research serves to validate the scientific model,and can provide unanticipated insights. This is alsobeneficial for the usefulness of the project since it willbe integrated into Scality’s product.
III.4 Project partners
III.4.1 Consortium as a whole The partners to-gether have the expertise and the critical mass neces-sary for this project. They already have a history ofcollaboration, including design and development of ahighly-available file system [65, 80] and of advancedconsistency protocols [6, 62, 76–78].
Scality is world leader in massive distributed storageon commodity system architectures. Inria Regal bringsexpertise in large-scale replication, different consist-ency models, and CRDTs. CNRS LIG are recognisedexperts in fault-tolerance in distributed systems us-ing replication protocols (both within a datacenter andacross datacenters). Télécom SudParis are experts in
consistency protocols and distributed storage systems;they contributed to the design and implementation ofInfinispan [51], the flagship distributed key-value storedevelopped by RedHat.
III.4.2 Principal Investigator The Principal In-vestigator is Marc Shapiro, a Senior Researcher (Dir-ecteur de recherche) at Inria and LIP6. He is a leadingEuropean expert in distributed computing. He led theSOS group (Systèmes d’objets répartis) at Inria for 13years, then the Cambridge Distributed Systems Groupat Microsoft Research Cambridge for 6.5 years.
He has participated in numerous cooperative projects,with both academic and industrial partners. He was theleader of the recent ANR project ConcoRDanT. He iscurrently (until Sept. 2016) the Principal Investigatorfor the SyncFree FP7 project on ultra-scalable tech-niques for sharing mutable data in wide-area end-userapplication scenarios. The outcome of both projectswill be used in RainbowFS.
He authored 89 international publications, 35 invitedtalks, 18 recognised software systems, and five pat-ents. Recent relevant publications include POPL 2016[31], EuroSys 2015 [10], PaPoC 2015 [22, 85], Systor2015 [80], SRDS 2015 [11], Middleware 2014 and2015 [6, 93], SIGACT News 2014 [40], OPODIS 2014[3], SRDS 2013 [62], and SSS 2011 [68], all availableonline.
III.4.3 Inria Paris (Projet Regal) Dr. Makpangou,Prof. Monnet and Dr. Shapiro are members of Regal,a joint research group of Inria Paris with CNRS andUniversité Pierre et Marie Curie (Paris 6) through theLaboratoire d’Informatique de Paris 6, LIP6 (UMR7606).
The research of the Regal team addresses the theoryand practice of Computer Systems, including multicorecomputers, clusters, networks, peer-to-peer systems,cloud computing systems, and other communicatingentities such as swarms of robots. It addresses the chal-lenges of communicating, sharing information, andcomputing correctly in such large-scale, highly dy-namic computer systems. This includes addressingthe core problems of communication, consensus andfault detection, scalability, replication and consistencyof shared data, information sharing in collaborativegroups, dynamic content distribution, and multi- andmany-core concurrent algorithms.
Regal has developed a number of systems, such asSwiftCloud [93], G-DUR [6], NMSI [62], CRDTs[68, 69], and the CISE Tool [31, 56] that are relev-ant to this proposal.
21

III.4.4 CNRS Laboratoire d’Informatique deGrenoble (LIG) The Erods team at LIG is workingin the domains of operating systems and distributedsystems from both a practical and theoretical perspect-ive. Recent works of the team include efficient proto-cols for the design of fault-tolerant distributed systems(e.g. state-machine replication protocols), optimiza-tion techniques for systems executed on NUMA mul-ticore machines (e.g. thread and memory placementalgorithms), as well as profiling and monitoring toolsfor both centralized and distributed systems (e.g. theMemProf memory profiler).
Vivien Quéma will be the technical leader for theCNRS-LIG partner. He is Professor of Computer Sci-ence at Grenoble INP. He has been a visiting researcherat the University of Rome 1 “La Sapienza,” at EPFL, atUT Austin, and at LIP6 (Paris 6). He has been workingfor ten years on the design and optimization of com-plex systems of various scales, including multicoreoperating systems, replicated servers and large-scalepeer-to-peer systems. He has co-authored research pa-pers in venues such as ACM TOCS, OSDI, ASPLOS,EuroSys, USENIX ATC, DSN, Middleware, ICDCSand SRDS. He received a best paper award at EuroSys2010 for his work on modular fault-tolerant replicationprotocols and a best paper award at USENIX 2015for his work on performance optimization of NUMAmulticore systems.
III.4.5 Télécom SudParis The ACMES team ofTélécom SudParis focuses on the design of algorithms,components and services for distributed systems, fromsmall to large scale. The team is part of the SAMO-VAR Laboratory (UMR 5157). Recent advances in theteam include a multiscale framework for the IoT, con-currency control algorithms for multicore architectures,
as well as a middleware of distributed objects.
Pierre Sutra (assistant professor) will be in charge ofthe Télécom SudParis partner. Recently, Pierre was ajunior researcher at the University of Neuchâtel, anda post-doc at INRIA. Pierre received his PhD fromUPMC in 2010. He is interested in both the theory andpractice of distributed systems, with an emphasis ondata consistency and concurrency. His recent publica-tions on the topic of data storage systems and concur-rency control include DISC 2015 [18], CLOUD 2015[59], Middleware 2014 [93], SRDS 2014 [28, 35] andOPODIS 2014 [79].
III.4.6 Scality S.A. Founded in 2009, Scality is aFrench company with headquarters in San Franciscoand subsidiaries in Japan and France. Most of theR&D and engineering is done in France, where Scalityemploys 102 people. Scality is an industry leader insoftware-defined storage at petabyte scale. Scality’scustomers include four of the top ten cable operatorsin the US, the second largest telco in France, leadingoperators in Japan, leading television network in Ger-many, and the second largest online video site in theworld.
Scality deploys software-based storage solutions thatdeliver billions of files to more than two hundred mil-lion users daily, with 100% availability. At petabytescale, hardware-based scale-up approaches are veryexpensive and also very hard to scale and operate.Scality’s answer is a 100% software-based, scale-outapproach, using a cluster of commodity servers ab-stracted by a logical layer that handles data access,data durability, data availability and data movement. Itsupports a Posix-compliant distributed filesystem withhigh-level APIs (FUSE, NFS, CIFS and CDMI), ontop of a Distributed Hash Table (DHT).
IV IMPACT OF PROJECT, STRATEGY FOR TAKE-UP, PROTECTION AND EXPLOITATION OFRESULTS / IMPACT DU PROJET, STRATÉGIE DE VALORISATION, DE PROTECTION ET
D’EXPLOITATION DES RÉSULTATS
IV.1 Impact
The project will have scientific, practical and economicimpact. Let’s consider them in reverse order.
IV.1.1 Economic Impact In a cloud-scale system,the choice of the consistency model is a difficult andvexing choice. Strongly-consistent storage shields thedeveloper from the complexities of parallelism and dis-tribution, but comes at a stiff price. A highly available
system can be faster and cheaper, but early adopterslearned the hard way that the anomalies of weak con-sistency are error-prone. Pragmatically, in real-worlddistributed systems, weak and strong consistency co-exist, but this combination is hard to understand.
Our approach enables the developer to identify theweakest, most available and most efficient synchronisa-tion pattern that supports her application. This gives aneconomic advantage, because weak consistency con-sumes considerably less resources and responds more
22

quickly than strong consistency, and because the de-veloper will spend less time debugging than with amanual approach. This opens the market of cloud-scale applications to newcomers, enabling EuropeanSMEs to compete with the American giants.
Scality SA will be the first to benefit. They expectthat the file system designed in this project to bring insizeable revenue, thanks to its performance, scalabilityand novel features. It will also help Scality’s customersto transition smoothly from files to object storage.
IV.1.2 Practical Impact Our approach builds upona recent breakthrough, the CISE logic, which makesit possible to prove, with only polynomial complexity,that a given application specification satisfies givenintegrity invariants above a given consistency model.Furthermore, if the analysis shows the application to beincorrect, it returns a counter-example, which guidesthe developer towards a fix. She can either weaken theapplication specification or strengthen the consistency.
This is a complete change from current practices to dis-tributed software development. Classical approachesproceed from a predefined consistency model, andleave it to the developer to reason about applicationcorrectness. In contrast, our approach ensures that aspecific application, running on a specific consistencysemantics, is safe with respect to specific propertiesrelevant to the application. This lets the developer fo-cus on her problem, and gives greater confidence thatthe application is correct.
Debugging a distributed application is extremely com-plex, because of the combinatorics of parallel execu-tion, non-deterministic scheduling and messaging, andfailures. The current practice is mostly based on trialand error. Using the CISE logic, we are hopeful to beable to generate systematic test cases for distributedsystems with only quadratic complexity.
IV.1.3 Scientific Impact A successful RainbowFSproject will help disseminate knowledge about theCISE logic, a very recent breakthrough. Furthermore,our research aims to improve the existing tool and lo-gic in several directions, making them more widelyapplicable. These directions include adding a causalityanalysis, supporting common snapshot-based forms oftransactions, and applying the logic, not only to staticanalysis, but also to testing and debugging.
Currently, experimental research in distributed sys-tems is dominated by large American cloud operators.European academia generally does not have the meansto compete. To regain the research lead, our workplanincludes an ambitious massive experiment, leveraging
Grid’5000 and massive commercial cloud resources,which would be impossible without the requested ANRfunding.
IV.2 How the project addresses the chal-lenges
This section refers back to the challenges listed inSection II.5. Our agenda addresses scientific and tech-nical issues related to some of the hurdles identifiedfor Axis 7, namely: (i) issues regarding scaling up invarious dimensions, (ii) a far-reaching change to thearchitecture and operation of infrastructures, (iii) reli-ability and fault resilience. RainbowFS is completelyin line with the challenges put forth by ANR in Re-search Axis 7: “aim to avoid isolated infrastructuresgeared to just one type of application”, “using an agileapproach to comply with future, often unanticipated,developments”, “infrastructures must be capable ofachieving high levels of performance and efficiency,while being open and agile so that they can be adjus-ted to meet the diverse, dynamic requirements of thevarious application categories.”
By adapting consistency protocols to application needs,we provide the ability to offer efficient data access to awide variety of applications, on a large scale. Enablingsafe access to weak consistency has the potential toreduce substantially both the monetary and the energycost for large-scale distributed applications.
Beyond the concerns of the ANR Strategic Programmediscussed in Section II.5, the RainbowFS proposalsaddresses major concerns of the scientific communityand industry.
IV.3 Scientific communication and uptake
The members of the project plan to use the tools andthe library components (developed in Tasks 1 and 2of the project) as a teaching vehicle for lectures andhands-on sessions in distributed systems and distrib-uted algorithms (all the academic participants in theproject are already strongly involved in the teachingstaff of graduate-level classes related to distributedsystems and algorithms in several French universit-ies). The teaching material (source code, companiondocuments, problem sets and answers) will be madefreely available to the teaching community at large viaa dedicated website.
The project leader, Marc Shapiro, is a member ofACM’s Distinguished Speaker Program and will lever-age this opportunity to present the results of the projectto various (academic and industrial) audiences world-wide.
23

IV.4 Intellectual property and exploitationof results
All the partners, both academic and industrial, planto make the software and other artefacts developed inthis project available as open source. We plan to pub-lish scientific results in major conferences and journalsrelated to operating systems, distributed and parallelsystems, storage systems, and related areas.
In addition to the usual scientific papers, we also planto promote the results and the software produced bythe projects through additional channels: (i) We willpropose a tutorial session to a major international con-ference and/or a thematic school; (ii) We will posttutorial videos on YouTube or similar websites, simil-arly to the CISE demo already on YouTube [55].
IV.5 Industrial exploitation
The project follows on an existing scientific collabora-tion around geoFS between Regal and Scality [80], andwill help transfer the CISE tools developed by InriaRegal [12, 54–56] to Scality.
By ensuring guarantees, the RainbowFS approachhelps to develop novel applications easily without spe-cialised distributed systems expertise. This lowers thecost of entry and creates opportunities for the startupecosystem. By minimising synchronisation, this alsoenables applications to run efficiently in commodityclouds or clusters and achieve internet-size scalabilityand fast growth. With previous approaches, these twogoals conflict.
Our approach will be applied to the development of afile system, which has high economic value on its ownmerit. Scality, a French SME whose development andR&D teams are in France, is a world leader in massivestorage on commodity system architectures, an area ofgreat economic importance. The RainbowFS projectaims both to advance the scientific state of the art indistributed systems and to enlarge Scality’s offerings.Scality plans to include the file system in its offeringswithin the timeframe of the project.
The RainbowFS technology will allow Scality to builda file system on top of their object storage system. Itwill support legacy applications, because the specificconsistency requirements needed by the applicationwill be proven. In addition, its versatile consistencysemantics, tunable to application requirements, willappeal to a wider range of customers and market seg-ments. Furthermore, our verification tools will enablecustomers to check correctness. These features willprovide Scality with a significant competitive advant-age.
Scality believes that the file system will provide a veryinteresting offer, in line with current market demandfor storage technologies allowing a smooth transitionfrom a file-based storage model to an object-basedstorage model. Scality currently estimates that thistransition will last around ten years, and correspondingmarket to be approximately USD 100 billion. Thanksto the RainbowFS technology, Scality hopes to “un-lock” and lead this market, and strengthen its productoffer on top of the Scality object store, while comfort-ing its leader role in the object storage world.
REFERENCES / RÉFÉRENCES BIBLIOGRAPHIQUES
[1] D. J. Abadi. Consistency tradeoffs in modern distributeddatabase system design: CAP is only part of the story. IEEEComputer, 45(2):37–42, Feb. 2012.
[2] A. Adya. Weak Consistency: A Generalized Theory and Op-timistic Implementations for Distributed Transactions. PhDthesis, Mass. Institute of Technology, Cambridge, MA, USA,Mar. 1999.
[3] M. K. Aguilera, L. Querzoni, and M. Shapiro, editors. Prin-ciples of Distributed Systems, volume 8878 of Lecture Notesin Comp. Sc., Cortina d’Ampezzo, Italy, Dec. 2014.
[4] D. D. Akkoorath, A. Tomsic, M. Bravo, et al. Cure: Strong se-mantics meets high availability and low latency. In Int. Conf.on Distributed Comp. Sys. (ICDCS), Nara, Japan, 2016.
[5] P. Alvaro, N. Conway, J. Hellerstein, et al. Consistencyanalysis in Bloom: a CALM and collected approach. InBiennial Conf. on Innovative DataSystems Research (CIDR),Asilomar, CA, USA, Jan. 2011.
[6] M. S. Ardekani, P. Sutra, and M. Shapiro. G-DUR: A middle-ware for assembling, analyzing, and improving transactional
protocols. In Int. Conf. on Middleware (MIDDLEWARE), pp.13–24, Bordeaux, France, Dec. 2014.
[7] H. Attiya, F. Ellen, and A. Morrison. Limitations of highly-available eventually-consistent data stores. In Symp. on Prin-ciples of Dist. Comp. (PODC), pp. 385–394, Donostia-SanSebastián, Spain, July 2015.
[8] P.-L. Aublin, R. Guerraoui, N. Kneževic, et al. The next700 BFT protocols. Trans. on Computer Systems, 32(4):12:1–12:45, Jan. 2015. ISSN 0734-2071.
[9] P. Bailis, A. Davidson, A. Fekete, et al. Highly availabletransactions: Virtues and limitations. Proc. VLDB Endow., 7(3):181–192, Nov. 2013.
[10] V. Balegas, N. Preguiça, R. Rodrigues, et al. Putting con-sistency back into eventual consistency. In Euro. Conf. onComp. Sys. (EuroSys), pp. 6:1–6:16, Bordeaux, France, Apr.2015.
[11] V. Balegas, D. Serra, S. Duarte, et al. Extending eventuallyconsistent cloud databases for enforcing numeric invariants.In Symp. on Reliable Dist. Sys. (SRDS), pp. 31–36, Montréal,Canada, Sept. 2015.
24

[12] V. Balegas, C. Li, M. Najafzadeh, et al. Geo-replication: Fastif possible, consistent if necessary. IEEE Data EngineeringBulletin, 2016.
[13] Basho Inc. Riak distributed database. http://basho.com/riak/, 2016.
[14] H. Berenson, P. Bernstein, J. Gray, et al. A critique of ANSISQL isolation levels. SIGMOD Rec., 24(2):1–10, May 1995.ISSN 0163-5808.
[15] D. Bermbach and S. Tai. Eventual consistency: How soon iseventual? An evaluation of Amazon S3’s consistency beha-vior. In W. on Middleware for Service Oriented Computing,p. 1, Lisbon, Portugal, Dec. 2011.
[16] K. Birman, G. Chockler, and R. van Renesse. Toward aCloud Computing research agenda. ACM SIGACT News, 40(2):68–80, June 2009.
[17] F. Bonomi, R. Milito, J. Zhu, et al. Fog computing andits role in the internet of things. In W. on Mobile CloudComputing, pp. 13–16, Helsinki, Finland, 2012.
[18] Z. Bouzid, M. Raynal, and P. Sutra. Brief Announcement:Anonymous Obstruction-free (n, k)-Set Agreement withn − k + 1 Atomic Read/Write Registers. In DISC 2015,volume LNCS 9363 of 29th International Symposium onDistributed Computing, Tokyo, Japan, Oct. 2015.
[19] C. Cadar, D. Dunbar, and D. Engler. Klee: Unassisted andautomatic generation of high-coverage tests for complexsystems programs. In Symp. on Op. Sys. Design and Im-plementation (OSDI), pp. 209–224, San Diego, CA, USA,2008.
[20] D. Capps. IOzone filesystem benchmark. www.iozone.org,July Retrieved March 2016.
[21] J. C. Corbett, J. Dean, M. Epstein, et al. Spanner: Google’sglobally-distributed database. In Symp. on Op. Sys. Designand Implementation (OSDI), pp. 251–264, Hollywood, CA,USA, Oct. 2012.
[22] T. Crain and M. Shapiro. Designing a causally consistentprotocol for geo-distributed partial replication. In W. on Prin-ciples and Practice of Consistency for Distr. Data (PaPoC),co-located with EuroSys 2015, Bordeaux, France, Apr. 2015.
[23] F. Dabek, M. F. Kaashoek, D. Karger, et al. Wide-area co-operative storage with CFS. In Symp. on Op. Sys. Principles(SOSP), pp. 202–215, Banff, Alberta, Canada, 2001.
[24] A. Davies and A. Orsaria. Scale out with GlusterFS. LinuxJ., 2013(235), Nov. 2013. ISSN 1075-3583.
[25] G. DeCandia, D. Hastorun, M. Jampani, et al. Dynamo:Amazon’s highly available key-value store. In Symp. on Op.Sys. Principles (SOSP), volume 41 of Operating SystemsReview, pp. 205–220, Stevenson, Washington, USA, Oct.2007.
[26] J. Du, S. Elnikety, and W. Zwaenepoel. Clock-SI: Snapshotisolation for partitioned data stores using loosely synchron-ized clocks. In Symp. on Reliable Dist. Sys. (SRDS), pp.173–184, Braga, Portugal, Oct. 2013.
[27] R. Escriva, B. Wong, and E. G. Sirer. HyperDex: A distrib-uted, searchable key-value store. In SIGCOMM, pp. 25–36,Helsinki, Finland, 2012.
[28] P. Felber, M. Pasin, E. Rivière, et al. On the support ofversioning in distributed key-value stores. In 33rd IEEEInternational Symposium on Reliable Distributed Systems,SRDS 2014, Nara, Japan, October 6-9, 2014, pp. 95–104,2014.
[29] S. Ghemawat, H. Gobioff, and S.-T. Leung. The Google FileSystem. In Symp. on Op. Sys. Principles (SOSP), pp. 29–43,Bolton Landing, NY, USA, Oct. 2003.
[30] S. Gilbert and N. Lynch. Brewer’s conjecture and the feasib-ility of consistent, available, partition-tolerant web services.SIGACT News, 33(2):51–59, 2002. ISSN 0163-5700.
[31] A. Gotsman, H. Yang, C. Ferreira, et al. ’Cause I’m strongenough: Reasoning about consistency choices in distributedsystems. In Symp. on Principles of Prog. Lang. (POPL), pp.371–384, St. Petersburg, FL, USA, 2016.
[32] R. Gracia Tinedo, T. Yongchao, J. Sampe, et al. Dissect-ing ubuntuOne: Autopsy of a global-scale personal Cloudback-end. In IMC 2015, ACM Internet Measurement Confer-ence, October 28-30, 2015, Tokyo, Japan, Tokyo, JAPON,10 2015.
[33] Grid’5000. Grid’5000 Home. https://www.grid5000.fr/,retrieved March 2016.
[34] R. Guerraoui, R. R. Levy, B. Pochon, et al. Throughputoptimal total order broadcast for cluster environments. ACMTrans. Comput. Syst., 28(2):5:1–5:32, July 2010. ISSN 0734-2071.
[35] R. Halalai, P. Sutra, E. Rivière, et al. ZooFence: Principledservice partitioning and application to the ZooKeeper co-ordination service. In Symp. on Reliable Dist. Sys. (SRDS),pp. 67–78, Nara, Japan, Oct. 2014.
[36] J. H. Howard, M. L. Kazar, S. G. Menees, et al. Scale andperformance in a distributed file system. Trans. on ComputerSystems, 6(1):51–81, Feb. 1988.
[37] F. Hupfeld, T. Cortes, B. Kolbeck, et al. The XtreemFSarchitecture — a case for object-based file systems in grids.Concurr. Comput.: Pract. Exper., 20(17):2049–2060, Dec.2008. ISSN 1532-0626.
[38] IEEE and The Open Group. Standard for information tech-nology — Portable Operating System Interface — systeminterfaces, 2013.
[39] INRIA CONVECS team. CADP: Construction and analysisof distributed processes. http://cadp.inria.fr, 2016.
[40] B. Kemme, A. Schiper, G. Ramalingam, et al. Dagstuhl sem-inar review: Consistency in distributed systems. SIGACTNews, 45(1):67–89, Mar. 2014. ISSN 0163-5700.
[41] K. Kingsbury. Jepsen blog. https://aphyr.com/tags/Jepsen,2016.
[42] K. Kingsbury. Jepsen: Breaking distributed systems so youdon’t have to. https://github.com/aphyr/jepsen, 2016.
[43] R. Klophaus. Riak Core: building distributed applicationswithout shared state. In Commercial Users of FunctionalProgramming (CUFP), pp. 14:1–14:1, Baltimore, Maryland,2010.
[44] C. Labs. CockroachDB: A scalable, survivable, strongly-consistent SQL database.
[45] R. Ladin, B. Liskov, L. Shrira, et al. Providing high availab-ility using lazy replication. Trans. on Computer Systems, 10(4):360–391, 1992.
[46] L. Lamport. The part-time parliament. Trans. on ComputerSystems, 16(2):133–169, May 1998.
[47] L. Lamport. Lower bounds for asynchronous consensus.In Future Directions in Distributed Computing, pp. 22–23.Springer-Verlag, 2003.
[48] C. Li, D. Porto, A. Clement, et al. Making geo-replicated sys-tems fast as possible, consistent when necessary. In Symp. onOp. Sys. Design and Implementation (OSDI), pp. 265–278,Hollywood, CA, USA, Oct. 2012.
[49] C. Li, J. Leitão, A. Clement, et al. Automating the choice ofconsistency levels in replicated systems. In Usenix AnnualTech. Conf., pp. 281–292, Philadelphia, PA, USA, June 2014.
[50] P. Mahajan, L. Alvisi, and M. Dahlin. Consistency, availab-ility, and convergence. Technical Report UTCS TR-11-22,Dept. of Comp. Sc., The U. of Texas at Austin, Austin, TX,USA, 2011.
[51] F. Marchioni and M. Surtani. Infinispan Data Grid Platform.Packt Publishing Ltd, 2012.
25

[52] J. Mauro, S. Shepler, and V. Tarasov. FileBench.sourceforge.net/projects/filebench, Retrieved March2016.
[53] A. Muthitacharoen, R. Morris, T. M. Gil, et al. Ivy: aread/write peer-to-peer file system. In Symp. on Op. Sys.Design and Implementation (OSDI), volume 36 of OperatingSystems Review, pp. 31–44, Boston, MA, USA, Dec. 2002.
[54] M. Najafzadeh. The Analysis and Co-design of Weakly-Consistent Applications. PhD thesis, Université Pierre etMarie Curie (UPMC), Paris, France, Apr. 2016.
[55] M. Najafzadeh and M. Shapiro. Demo of the CISE tool, Nov.2015. https://youtu.be/HJjWqNDh-GA.
[56] M. Najafzadeh, A. Gotsman, H. Yang, et al. The CISE tool:Proving weakly-consistent applications correct. Rapp. deRecherche RR-8870, Institut National de la Recherche enInformatique et Automatique (Inria), Rocquencourt, France,Feb. 2016.
[57] D. Perkins, N. Agrawal, A. Aranya, et al. Simba: Tunableend-to-end data consistency for mobile apps. In Euro. Conf.on Comp. Sys. (EuroSys), p. ???, Bordeaux, France, Apr.2015.
[58] A. Potnis, N. Yezhkova, and A. Nadkarni. Worldwide file-and object-based storage 2014–2018 forecast. Market Ana-lysis 251626, IDC, Framingham, MA, USA, oct 2014.
[59] D. L. Quoc, C. Fetzer, P. Felber, et al. Unicrawl: A practicalgeographically distributed web crawler. In 8th IEEE Inter-national Conference on Cloud Computing, CLOUD 2015,New York City, NY, USA, June 27 - July 2, 2015, pp. 389–396,2015.
[60] D. Reddy Malikireddy, M. Saeida Ardekani, and M. Shapiro.Emulating geo-replication on Grid’5000. Technical ReportRT-455, Institut National de la Recherche en Informatique etAutomatique (Inria), Paris and Rocquencourt, France, Aug.2014.
[61] S. Roy, L. Kot, G. Bender, et al. The Homeostasis protocol:Avoiding transaction coordination through program analysis.In Int. Conf. on the Mgt. of Data (SIGMOD), pp. 1311–1326,Melbourne, Victoria, Australia, 2015.
[62] M. Saeida Ardekani, P. Sutra, and M. Shapiro. Non-Monotonic Snapshot Isolation: scalable and strong consist-ency for geo-replicated transactional systems. In Symp. onReliable Dist. Sys. (SRDS), pp. 163–172, Braga, Portugal,Oct. 2013.
[63] N. Schiper, P. Sutra, and F. Pedone. P-Store: Genuine partialreplication in wide area networks. In Symp. on Reliable Dist.Sys. (SRDS), pp. 214–224, New Dehli, India, Oct. 2010.
[64] P. Schwan. Lustre: Building a File System for 1,000-nodeClusters. In Proceedings of the 2003 Linux Symposium, July2003.
[65] M. Segura, V. Rancurel, V. Tao, et al. Scality’s experiencewith a geo-distributed file system. In Posters & DemosSession, Int. Conf. on Middleware (MIDDLEWARE), Middle-ware Posters and Demos ’14, pp. 31–32, Bordeaux, France,Dec. 2014.
[66] H. Shan, K. Antypas, and J. Shalf. Characterizing and pre-dicting the i/o performance of hpc applications using a para-meterized synthetic benchmark. In Proceedings of the 2008ACM/IEEE Conference on Supercomputing, SC ’08, pp. 42:1–42:12, Piscataway, NJ, USA, 2008.
[67] M. Shapiro, N. Preguiça, C. Baquero, et al. A comprehens-ive study of Convergent and Commutative Replicated DataTypes. Rapp. de Recherche 7506, Institut National de laRecherche en Informatique et Automatique (Inria), Rocquen-court, France, Jan. 2011.
[68] M. Shapiro, N. Preguiça, C. Baquero, et al. Conflict-freereplicated data types. In Int. Symp. on Stabilization, Safety,
and Security of Distributed Systems (SSS), volume 6976 ofLecture Notes in Comp. Sc., pp. 386–400, Grenoble, France,Oct. 2011.
[69] M. Shapiro, N. Preguiça, C. Baquero, et al. Convergent andcommutative replicated data types. Bulletin of the EuropeanAssociation for Theoretical Computer Science (EATCS),(104):67–88, June 2011.
[70] K. Shvachko, H. Kuang, S. Radia, et al. The Hadoop Distrib-uted File System. In Mass Storage Systems and Technologies(MSST), 2010 IEEE 26th Symposium on, pp. 1–10, May2010.
[71] K. V. Shvachko. HDFS Scalability: The Limits to Growth.USENIX login, 35(2), Apr. 2010.
[72] A. Sousa, R. Oliveira, F. Moura, et al. Partial replication inthe database state machine. In Int. Symp. on Network Comp.and App. (NCA’01), pp. 298–309, Cambridge MA, USA,Oct. 2001.
[73] Y. Sovran, R. Power, M. K. Aguilera, et al. Transactionalstorage for geo-replicated systems. In Symp. on Op. Sys. Prin-ciples (SOSP), pp. 385–400, Cascais, Portugal, Oct. 2011.
[74] SPEC. SPECsfs2014. www.spec.org/sfs2014, RetrievedMarch 2016.
[75] Sun Microsystems, Inc. NFS: Network File System protocolspecification. RFC 1094, Network Information Center, SRIInternational, Mar. 1989.
[76] P. Sutra and M. Shapiro. Fault-tolerant partial replication inlarge-scale database systems. In Euro. Conf. on Parallel andDist. Comp. (Euro-Par), pp. 404–413, Las Palmas de GranCanaria, Spain, Aug. 2008.
[77] P. Sutra and M. Shapiro. Fast Genuine Generalized Con-sensus. In Symp. on Reliable Dist. Sys. (SRDS), pp. 255–264,Madrid, Spain, Oct. 2011.
[78] P. Sutra, J. Barreto, and M. Shapiro. Decentralised com-mitment for optimistic semantic replication. In Int. Conf.on Coop. Info. Sys. (CoopIS), Vilamoura, Algarve, Portugal,Nov. 2007.
[79] P. Sutra, E. Rivière, and P. Felber. A practical distributed uni-versal construction with unknown participants. In Int. Conf.on Principles of Dist. Sys. (OPODIS), volume 8878 of Lec-ture Notes in Comp. Sc., pp. 485–500, Cortina d’Ampezzo,Italy, Dec. 2014.
[80] V. Tao, M. Shapiro, and V. Rancurel. Merging semantics forconflict updates in geo-distributed file systems. In ACM Int.Systems and Storage Conf. (Systor), pp. 10.1–10.12, Haifa,Israel, May 2015.
[81] D. B. Terry, V. Prabhakaran, R. Kotla, et al. Consistency-based service level agreements for cloud storage. In Symp.on Op. Sys. Principles (SOSP), pp. 309–324, Farminton, PA,USA, 2013.
[82] The Apache Software Foundation. Hadoop. http://hadoop.apache.org. Retrieved Oct. 2015.
[83] The Apache Software Foundation. Cassandra. http://hadoop.apache.org/, Retrieved Oct. 2015.
[84] A. Thomson and D. J. Abadi. Calvinfs: Consistent wanreplication and scalable metadata management for distrib-uted file systems. In 13th USENIX Conference on File andStorage Technologies (FAST 15), pp. 1–14, Santa Clara, CA,Feb. 2015.
[85] A. Z. Tomsic, T. Crain, and M. Shapiro. An empirical per-spective on causal consistency. In W. on Principles andPractice of Consistency for Distr. Data (PaPoC), co-locatedwith EuroSys 2015, Bordeaux, France, Apr. 2015.
[86] A. Traeger, E. Zadok, N. Joukov, et al. A nine year study offile system and storage benchmarking. Trans. Storage, 4(2):5:1–5:56, May 2008. ISSN 1553-3077.
26

[87] A. Traeger, E. Zadok, E. L. Miller, et al. Findings from thefirst annual storage and file systems benchmarking workshop.;Login:, 33(5):113–117, Oct. 2008.
[88] J. Valerio, P. Sutra, E. Rivière, et al. Evaluating the price ofconsistency in distributed file storage services. In DistributedApplications and Interoperable Systems - 13th IFIP WG 6.1International Conference, DAIS 2013, Held as Part of the8th International Federated Conference on Distributed Com-puting Techniques, DisCoTec 2013, Florence, Italy, June 3-5,2013. Proceedings, pp. 141–154, 2013.
[89] J. Valerio, P. Sutra, E. Rivière, et al. Evaluating the price ofconsistency in distributed file storage services. In Distrib-uted Applications and Interoperable Systems, volume 7891of Lecture Notes in Comp. Sc., pp. 141–154. Springer-Verlag,2013. ISBN 978-3-642-38540-7.
[90] R. Van Renesse, K. P. Birman, and S. Maffeis. Horus: Aflexible group communication system. Communications ofthe ACM, 39(4):76–83, 1996.
[91] P. Viotti and M. Vukolic. Consistency in non-transactionaldistributed storage systems. ArXiv e-print 1512.00168,arXiv.org, Dec. 2015.
[92] H. Wada, A. Fekete, L. Zhao, et al. Data consistency prop-erties and the trade-offs in commercial cloud storage: theconsumers’ perspective. In Biennial Conf. on InnovativeDataSystems Research (CIDR), volume 11, pp. 134–143,2011.
[93] M. Zawirski, N. Preguiça, S. Duarte, et al. Write fast, readin the past: Causal consistency for client-side applications.In Int. Conf. on Middleware (MIDDLEWARE), pp. 75–87,Vancouver, BC, Canada, Dec. 2015.
27

















![ANNALES DE L INSTITUT OURIER - Centre Mersenne · OF HILBERT MODULAR FORMS by Volker DUNGER In 1973, Shimura [Sl] proved a striking connection between modular forms of half-integral](https://static.fdocuments.fr/doc/165x107/5edc7f8aad6a402d66672e6b/annales-de-l-institut-ourier-centre-mersenne-of-hilbert-modular-forms-by-volker.jpg)
