
Programmation Logique Inductive à partir de la … · Programmation Logique Inductive à partir de...
64
Programmation Logique Inductive à partir de la simulation d’un modèle qualitatif Yannick Sannier, étudiant en DEA Informatique IFSIC Université de Rennes I encadrement : Marie-Odile Cordier et Véronique Masson, équipe DREAM, IRISA 23 juin 2003
Transcript of Programmation Logique Inductive à partir de la … · Programmation Logique Inductive à partir de...

Programmation Logique Inductive à partir dela simulation d’un modèle qualitatif
Yannick Sannier, étudiant en DEA Informatique
IFSICUniversité de Rennes I
encadrement : Marie-Odile Cordier et Véronique Masson, équipe DREAM, IRISA
23 juin 2003

1

Remerciements
Je tiens à remercier Marie-Odile Cordier et Véronique Masson pour leur enca-drement ; Chantal Gascuel et Florent Tortrat de l’INRA Rennes pour leurs exper-tises et leurs nombreux conseils ; Élisa Fromont, Alban Grastien, François Portetet Axel Caillard pour toute l’aide apportée sur ICL, JAVA, Perl,...Un grand merci à Oliver Brobecker pour awk et les coups de mains en LATEX.Enfin, merci aux membres des équipes Symbiose et Dream de l’Irisa, pour les bonsmoments passés avec vous.
2

3

Table des matières
1 Introduction 6
2 Introduction à la Programmation Logique Inductive 82.1 Petits rappels sur la logique du premier ordre . . . . . . . . . . . 8
2.1.1 Notions et vocabulaire de base . . . . . . . . . . . . . . . 82.1.2 Bases des systèmes de preuves . . . . . . . . . . . . . . . 102.1.3 Sémantiques normales et définies . . . . . . . . . . . . . 12
2.2 Cadre général de la Programmation Logique Inductive . . . . . . 142.2.1 La relation de couverture en logique du premier ordre . . . 142.2.2 La subsomption en logique du prédicat du premier ordre . 152.2.3 Structuration de l’espace des hypothèses en logique du 1er
ordre . . . . . . . . . . . . . . . . . . . . . . . . . . . . 172.3 Exploration de l’espace des solutions . . . . . . . . . . . . . . . . 20
2.3.1 Recherche d’une solution par des algorithmes de PLI . . . 202.3.2 Les biais de recherche . . . . . . . . . . . . . . . . . . . 22
2.4 La PLI sur des environnements dynamiques : un exemple d’ap-prentissage de chroniques . . . . . . . . . . . . . . . . . . . . . . 252.4.1 Modélisation de l’activité cardiaque : de l’ECG à la repré-
sentation symbolique . . . . . . . . . . . . . . . . . . . . 252.4.2 L’apprentissage . . . . . . . . . . . . . . . . . . . . . . . 26
2.5 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
3 L’organisation du projet SACADEAU 293.1 Les termes agronomiques essentiels . . . . . . . . . . . . . . . . 293.2 La place de l’outil informatique . . . . . . . . . . . . . . . . . . 303.3 Les étapes nécessaires à l’inférence de règles . . . . . . . . . . . 32
4 Le modèle biophysique 344.1 Ce que l’on doit modéliser . . . . . . . . . . . . . . . . . . . . . 34
4.1.1 La rétention et la persistance d’un pesticide . . . . . . . . 344.1.2 Ruissellement, lessivage et bande enherbée . . . . . . . . 354.1.3 Le sol . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
4.2 La maquette de simulation . . . . . . . . . . . . . . . . . . . . . 37
4

4.2.1 Fonctionnement global . . . . . . . . . . . . . . . . . . . 374.2.2 Les modifications apportées . . . . . . . . . . . . . . . . 39
5 Constitution de la base d’apprentissage 405.1 Traitement des données . . . . . . . . . . . . . . . . . . . . . . . 40
5.1.1 Données climatiques . . . . . . . . . . . . . . . . . . . . 405.1.2 Données sur les parcelles . . . . . . . . . . . . . . . . . . 425.1.3 Données sur le bassin . . . . . . . . . . . . . . . . . . . . 45
5.2 Résultats : scénarios et sorties de simulation . . . . . . . . . . . . 465.2.1 Les scénarios . . . . . . . . . . . . . . . . . . . . . . . . 475.2.2 Présentation et classification des résultats des simulations . 48
5.3 L’apprentissage par PLI . . . . . . . . . . . . . . . . . . . . . . . 495.3.1 Formalisation sous forme de clauses logiques . . . . . . . 495.3.2 Le biais d’apprentissage . . . . . . . . . . . . . . . . . . 50
6 Conclusion 52
A Les tableaux d’évaluation du seuil d’infiltrabilité (original et modifié) 57
B Les équations de ruissellement 59B.1 Détermination si une pluie est ruisselante et calcul des quantités
d’eaux ruisselées et lessivées . . . . . . . . . . . . . . . . . . . . 59B.2 Calcul du stock de pesticide avant une pluie ruisselante . . . . . . 60B.3 Calcul des flux de pesticide ruisselant et lessivant . . . . . . . . . 60
C Détails sur les stratégies d’application des pesticides 62
5

Chapitre 1
Introduction
L’apprentissage artificiel est l’un des axes majeurs de recherche en intelligenceartificielle. Pourquoi ? Tout simplement parce que la plupart des systèmes dits « in-telligents » possèdent un module d’apprentissage. le système qui nous intèresseici, est un outil d’aide à la décision pour des gestionnaires de bassins versants agri-coles1. Cet outil est développé au sein du projet SACADEAU (Système d’Acqui-sition de Connaissances et d’Aide à la Décision pour la qualité de l’EAU) et a pourbut de développer un logiciel de simulation des activités agricoles de désherbagesur des parcelles de maïs à l’échelle d’un bassin versant, du transfert de pesticidesrésultant de ces pratiques et ses impacts sur la qualité de l’eau à l’exutoire du bas-sin.
Le logiciel devra :– pouvoir simuler et analyser différents scénarios structurés : types de climat,
aléas climatiques, topolologie du bassin versant, stratégies de désherbagedes agriculteurs (parcelle par parcelle ou de façon plus générale),... Il s’agitdonc de pouvoir simuler et analyser la dynamique d’un bassin versant.
– extraire automatiquement des relations par simulations. L’analyse des sor-ties du simulateur peut être faite manuellement dans le cas où le nombrede simulations reste faible. Cependant, cela rend plus difficile la mise enévidence de relations entre les différents paramètres du simulateur et leursconséquences sur la qualité de l’eau. La découverte de parcelles « critiques »suivant les stratégies des agriculteurs, les aléas climatiques, la topologie dubassin,etc., la recherche de seuils conduisant à des effets différents sur laqualité de l’eau en terme de stratégie d’application d’une molécule (dose,dates) ou, au contraire, l’absence d’influence de certains paramètres : toutceci est encore mal connu et nécessite une analyse sur un grand nombre dedonnées issues de simulations ou de données historiques et donc l’emploiede techniques d’apprentissage ou de fouilles de données.
1un bassin versant agricole est un ensemble de parcelles agricoles dont les eaux de ruissellements’écoulent dans un même cours d’eau
6

Qui dit « analyse », dit « modélisation ». Dans le cadre du stage de DEA,il s’agissait de modéliser les éléments constitutifs de la simulation : le climat, lebassin versant et les « stratégies » de désherbage des agriculteurs. Par la suite,les scénarios intéressants pour le problème du ruissellement devaient être définis.Enfin, les simulations par le modèle biophysique des scénarios fourniraient les en-trées d’un système d’apprentissage par Programmation Logique Inductive (PLI),système qui permet d’induire à partir d’observations, des hypothèses expliquantces observations.
7

Chapitre 2
Introduction à la ProgrammationLogique Inductive
Notre étude s’oriente ici vers une technique d’apprentissage symbolique super-visé : symbolique par opposition à numérique (issu des statistiques) et supervisé ausens où l’on fournira une assistance extérieure au système, une sorte d’expert oude professeur, pour l’aider dans son apprentissage. Dans un cadre non-supervisé,le système se débrouille seul de l’extraction de la connaissance à la proposition demodèles, c’est ce que l’on retrouve en fouille de données. Nous nous intéressons icià une technique d’apprentissage qui se situe entre la programmation logique et l’in-telligence artificielle : la programmation logique inductive (PLI). On peut dire quela PLI se situe à l’intersection de ces deux domaines scientifiques puisqu’elle uti-lise des techniques propres à ces deux thèmes. En PLI, il s’agit de faire apprendredes concepts sous forme de clauses logiques, à partir d’exemples de ces conceptset de connaissances a priori sur ce que l’on souhaite induire. Le fait d’utiliser la lo-gique du premier ordre comme langage de description, fait que les systèmes de PLIpeuvent modéliser des concepts très complexes et trouvent donc des applicationsdans des domaines très variés : la biologie, la médecine, le traitement du langagenaturel...
2.1 Petits rappels sur la logique du premier ordre
Cette première partie est là avant tout pour passer en revue le langage de des-cription des concepts que nous allons chercher à apprendre : la logique du premierordre (ou des prédicats du premier ordre). Certaines notions élémentaires sont sup-posées connues : variables, constantes, connecteurs, prédicats, quantificateurs, etc.
2.1.1 Notions et vocabulaire de base
Nous allons donner ici les définitions de concepts logiques que nous allonsréutiliser par la suite.
8

Le langage de la logique du premier ordre
Définition 1 (Terme) un terme se définit récursivement comme étant :� soit une constante ;� soit une variable ;� soit une fonction appliquée à des termes.
Définition 2 (Littéral) Un littéral est un prédicat appliqué à des termes, éventuel-lement précédé du symbole de négation ���
Définition 3 (Atome) Un atome est un littéral positif (non précédé du signe � ).Un littéral qui ne contient pas de variable, est dit clos ou complètement instancié.
Définition 4 (Formule) une formule se définit récursivement ainsi :� un littéral est une formule ;� si a et b sont des formules alors�a � b ��� � a b ��� � � b ��� � a b � et
�a �� b �
sont des formules ;� si v est une variable et α est une formule alors� ���
v � α � et� ���
v � α � sont desformules.
Définition 5 (Sous-formule) une sous-formule est une suite de symboles d’uneformule qui est elle même une formule.
Définition 6 (Variable libre ou liée) une variable X est dite liée dans une formuleφ s’il existe dans φ une sous-formule commençant par
���X � ou
���X � . Dans le cas
contraire, elle est dite libre.
Le langage des clauses et des programmes logiques
Définition 7 (Clause) Une clause est une disjonction finie de littéraux dans la-quelle toutes les variables sont quantifiées universellement. En général, on sim-plifie son écriture en se passant des quantificateurs puisque toutes les variablesdoivent être interprétées comme quantifiées universellement.
Définition 8 (Clause de Horn) Une clause de Horn est une clause ayant au plusun littéral positif.
Définition 9 (Clause définie) Une clause définie est une clause de Horn qui aexactement un littéral positif.
Lorsque l’on a supprimé les quantificateurs d’une clause définie, on peut latransformer de la façon suivante :
9

A � B1 � � � � Bn
se transforme en :
B1 � � � � � Bn A
puis en introduisant un nouveau connecteur et en changeant la notation de la conjonc-tion on obtient :
A � B1 � � � � � Bn
où le connecteur « � » représente simplement l’implication de la droite vers lagauche. C’est cette notation qui est utilisée dans les programmes prolog.
Définition 10 (Tête et corps de clause) le seul littéral positif d’une clause définieest appelé la tête de la clause tandis que la conjonction des littéraux B1,. . ., Bn estle corps de la clause.
Définition 11 (Clause unitaire, clause but) Une clause définie ne possédant queson seul littéral positif est appelée une clause unitaire. Une clause but est uneclause de Horn n’ayant pas de littéral positif. On la note � B1 � � � � � Bn.
Définition 12 (Programme logique) Un programme logique défini, ou pour sim-plifier un programme logique, est un ensemble fini de clauses définies.
2.1.2 Bases des systèmes de preuves
Étant donné un programme logique P, le but est maintenant de raisonner à partirde ce programme et d’obtenir des résultats en prouvant des propriétés. En pratique,la preuve dans un programme logique se fait en utilisant une règle d’inférence lo-gique dite de modus ponens. Informellement, elle s’énonce ainsi :
si (a) et (a implique b) sont vrais alors (b) est vrai.On le note généralement :
a � �a b �b
L’algorithme de résolution (Robinson,[24]) est souvent employé pour cettepreuve. Nous allons le présenter après avoir défini les notions de substitution etd’unification.
10

La substitution
Définition 13 (Substitution) Une substitution est une liste de paires Xi / ti où Xi
est une variable et ti un terme. Si σ est la substitution X1�t1 � � � � � Xn
�tn, l’ensemble
des variables Xi est noté dom(σ). Appliquer une substitution σ à une formule Fconsiste à remplacer chaque occurrence des variables de dom(σ) par le termecorrespondant. On note Fσ le résultat de la substitution.
L’unification
Définition 14 (Unificateur) Si (si � ti) est une paire de termes, un unificateur estune substitution σ telle que pour tout i : siσ � tiσ.
Si un tel unificateur existe, alors on dit que les termes si et ti sont unifiables.Un unificateur de deux littéraux p(s1 � � � � � sn) et p(t1 � � � � � tn) est un unificateur
de l’ensemble des paires {(s1 � t1 ��� � � � ��sn � tn � }.
L’unificateur le plus général (noté upg) est une substitution σ telle que pourtout unificateur Θ, il existe une substitutionϒ telle que σϒ � Θ. Il est montré qu’àun renommage de variables près, l’upg de deux clauses est unique.
La résolution
La résolution d’un programme logique consiste en une suite d’étapes. à chaqueétape, on cherche à construire une clause à partir de deux autres clauses. Dans lecas de programmes prolog (ce qui est souvent le cas en PLI) où l’on utilise desclauses définies, on peut appliquer une méthode de résolution particulière : la réso-lution SLD 1. Une étape de résolution SLD est définie comme suit.
Soit deux clauses définies :
C1 : H1� A � a et C2 : H2
� boù H1, a et b sont des conjonctions d’atomes (éventuellement vides). A est un
littéral quelconque du corps de C1 et a est le reste du corps de C1.
Définition 15 (Résolution) Une paire de clauses (C1 � C2) est dite résoluble (ouencore C1 peut être résolue avec C2) si H2 et A s’unifient avec un upg Θ (on a doncAΘ � H2Θ � .
Le résultat de l’étape, appelé résolvante, est Res�C1 � C2 � : H1Θ � bΘ � a.
Par cette définition, on impose que le littéral résolu s’unifie avec la tête de C2
et avec un littéral du corps de C1.
Par exemple les clauses : parent(claire,marie) et fille(X,Y)�
parent(Y,X) se ré-solvent assez facilement en donnant fille(marie,claire) avec l’upg Θ = {X / marie ,Y / claire}.
1Résolution SLD pour résolution linéaire avec fonction de sélection pour clauses définies.
11

2.1.3 Sémantiques normales et définies
Nous allons maintenant décrire les éléments logiques impliqués dans l’infé-rence inductive, ainsi que les liens existants entre ces éléments. Globalement, ils’agit ici de reformuler les contraintes qui existent (conditions de complétude et decorrection) entre les différents éléments qui vont constituer les données d’appren-tissage, et les hypothèses à inférer. Ces contraintes portent le nom de sémantiquenormale.
Rappel sur la sémantique du premier ordre
On revoit ici des notions concernant la sémantique du langage du premier ordre.
Définition 16 (Interprétation) On appelle interprétation I du langage des prédi-cats du premier ordre la donnée :� d’un domaine d’interprétation (ou base d’interprétation) D qui est un en-
semble non vide de valeurs que peuvent prendre les variables.� d’une application qui :- à toute constante c associe un élément cI de D ;- à toute fonction f d’arité n associe une application fI telle que fI : Dn � D ;- à tout prédicat P d’arité n associe une application PI : Dn ��� V RAI � FAUX � .
Définition 17 (Valuation) Pour une interprétation I de base D, on appelle valua-tion ou assignation toute application v = v(I) de l’ensemble des variables à valeursdans D.
Définition 18 (Conséquence sémantique) On dit qu’une formule B (d’un ensemblede formules bien formées F) est conséquence sémantique d’un ensemble de for-mules bien formées Γ inclus dans F, si pour toute interprétation I et toute assigna-tion v telles que :�
A � Γ : (I,v � A) pour chaque I et v, avec en même temps, (I,v) � B.On écrit alors Γ � B.
Définition 19 (Satisfiabilité) On dit qu’un ensemble de formules Γ est satisfiable(ou consistant ou non contradictoire) s’il existe une interprétation I et une assi-gnation v telles que pour tout A � Γ, on ait (I,v) � A. Un tel couple (I,v) est appelémodèle de Γ. Dans le cas contraire, Γ est dit insatisfaisant, inconsistant ou contra-dictoire.
La sémantique normale
Étant donné une théorie du domaine T 2, c’est-à-dire un ensemble de clausesdécrivant la connaissance a priori sur le domaine du problème, et un ensemble E
2aussi noté B dans la littérature pour Background knowledge
12

d’exemples (décomposé en deux sous-ensembles disjoints E � et E � d’exemplesrespectivement positifs et négatifs), la programmation logique inductive cherche àinduire une hypothèse H, composée d’un ensemble de clauses, telle que les quatreconditions suivantes sont respectées :
� Satisfiabilité a priori : T � E ����
. (notation :�
= faux)� Satisfiabilité a posteriori(consistance) : T � H � E ����
.� Nécessité a priori : T�
E � .� Condition a posteriori (complétude): T � H � E � .
Ces quatre conditions définissent la sémantique normale.La condition de satisfiabilité a priori permet de s’assurer qu’aucun exemple
négatif ne peut être déduit des connaissances a priori du modèle.La condition de consistance permet de vérifier qu’on ne peut déduire aucun
exemple négatif de l’hypothèse induite et de la connaissance initiale.La condition de nécessité a priori nous assure qu’on ne peut pas déduire tous
les exemples positifs de la connaissance initiale (sinon, il n’y a rien à induire).Enfin la condition de complétude a posteriori nous indique que l’on peut dé-
duire les exemples positifs grâce à l’hypothèse induite.
Dans la plupart des systèmes de PLI, les exemples et la théorie du modèle sontécrits sous la forme de clauses définies. Dans ce cas, on se place dans un cas parti-culier de la sémantique normale qui est la sémantique définie.
Définition 20 (Sémantique définie) Si T est une théorie et M � son plus petit mo-dèle de Herbrand, alors on a :
� Satisfiabilité a priori :�
e � E � , e est faux dans M ��T � .� Satisfiabilité a posteriori (consistance) :
�e � E � , e est faux dans M �
�T �
H � .� Nécessité a priori :�
e � E � , tel que e est faux dans M ��T � .� Condition a posteriori (complétude):
�e in E � , e est vrai dans M �
�T � H � .
Ici, M ��T � représente le modèle de Herbrandt minimal 3 (ou plus petit modèle
de Herbrandt) de T.
En fait, pour simplifier et couvrir les cas pratiques, la plupart des systèmes dePLI sont majoritairement basés sur la sémantique définie dans laquelle tous lesexemples sont des faits liés.
3Chaque clause définie possède une fermeture syntaxique (le plus petit modèle de Herbrandt)dans lequel toute formule est soit vraie soit fausse.
13

2.2 Cadre général de la Programmation Logique Induc-tive
L’objectif de la programmation logique inductive est de construire des pro-grammes logiques à partir d’un ensemble d’exemples E de leur comportement(souhaité ou non). La complexité de l’induction dépend du langage dans lequelon désire exprimer les hypothèses : plus le langage est simple, moins il est ex-pressif mais moins la complexité de l’apprentissage est grande. Le langage despropositions se révèle vite manquer d’expressivité pour des domaines un tant soitpeu complexes à décrire. C’est pourquoi on est tenté de faire de l’induction avec lalogique du premier ordre. Ce gain en expressivité a un certain coût car ce que l’onsait faire avec une relative aisance dans le cadre de la logique propositionnelle, serévèle plus compliqué à réaliser dans un ordre supérieur.
On peut commencer par distinguer deux grandes familles d’approches en PLI :� l’apprentissage incrémental ou interactif, dans lequel on cherche à adapterune description (ou théorie) du domaine en fonction de nouveaux exempleset contre-exemples fournis au fur et à mesure de l’avancement de l’appren-tissage. On fait ce que l’on appelle de la révision de connaissances.� l’apprentissage classique dans lequel on dispose de nombreux exemples etcontre-exemples donnés au tout début du processus, pour apprendre un nou-veau concept. On cherche à apprendre un concept qui va permettre de dé-duire (on dit aussi couvrir) tous les exemples positifs et aucun exemple né-gatif.
Dans le cadre du stage de DEA, nous nous intéressons à une étude de l’ap-proche classique.
2.2.1 La relation de couverture en logique du premier ordre
La notion de couverture logique est celle de la généralité ou subsomption. Dé-terminer qu’une clause est plus générale qu’une autre revient, dans le cadre de lalogique propositionnelle à tester la subsomption (la couverture) de deux expres-sions en contrôlant simplement que toute proposition apparaissant dans l’expres-sion la plus générale, apparaît aussi dans l’expression la plus spécifique. Lorsquel’on veut généraliser une formule, il s’agit alors simplement de supprimer un termed’une formule conjonctive ou d’en ajouter un dans une formule disjonctive.
Si l’on veut ré-exprimer la même chose en logique du prédicat du premier ordre(également appelée logique du premier ordre), il est nécessaire de revoir quelquepeu la notion de subsomption qui va définir la hiérarchie de généralité entre clausesà cause de la présence des variables dans les littéraux.
14

2.2.2 La subsomption en logique du prédicat du premier ordre
On cherche ici à définir la notion de subsomption (ou généralité) entre clauses.Le cas commun de subsomption est le suivant (assez proche de la subsomption dela logique propositionnelle) :
Forme(X) :- rouge(X), cercle(X).
Forme(X) :- rouge(X),petit(X),cercle(X).
Les termes commencant par une majuscule sont des varaiables, ceux commen-cant par des minuscules (cf. exemple suivant) sont des constantes (syntaxe Prolog).Intuitivement, la première clause, qui définit les cercles rouges, est plus générale(subsume) que la seconde clause qui définit les petits cercles rouges.
Par contre, il faut aussi pouvoir exprimer la généralité entre deux clauses dansle cas suivant :
Forme2(X) :- carré(X), triangle(Y), memecouleur(X,Y).
Forme2(X) :- carré(X), triangle(t), memecouleur(X,t).
La première clause décrit les carrés de même couleur que les triangles existants.La seconde, plus spécifique, décrit les carrés de la même couleur qu’un certain
triangle. Il faudra pouvoir là aussi exprimer la généralité entre clauses.
La Θ-subsomption
Si l’on combine les deux cas précédents, on arrive au modèle de déduction leplus simple pour la PLI : la Θ-subsomption, définie par Plotkin [19].
Définition 21 (Subsomption) Une clause c1 Θ-subsume une clause c2 si et seule-ment si il existe une substitution Θ tel que c1Θ � c2 (où � dénote l’inclusion en-sembliste entre c1Θ et c2). c1 est une généralisation de c2 sous la Θ-subsomptionet, respectivement, c2 est une spécialisation de c1.
On peut remarquer que si c1 Θ-subsume c2, alors on a aussi : c1 � c2. La réci-proque n’est pas toujours vrai comme le montre l’exemple qui suit :
liste([V � W ]) :- liste(W).
liste([X � Y � Z]) :- liste (Z).
Si on part de la liste vide, la première clause permet de construire des listesde n’importe quelle longueur, tandis que la seconde ne permet de construire que
15

des listes de longueur paire. La première clause est plus générale que la secondepuisqu’on peut construire toutes les listes déduites de la seconde forme avec lapremière clause. Et pourtant, il n’existe pas de substitutions permettant à partir dela première clause, d’obtenir la seconde. La Θ-subsomption est donc plus faibleque l’implication et elle a des limites dès lors que l’on veut apprendre des clausesrécursives (incapacité de prendre en compte des clauses qui peuvent être résoluesavec elles-mêmes).
L’implication
On pourrait envisager de réutiliser, comme pour la logique des propositions,l’implication logique comme relation de généralité entre deux clauses. On auraitalors :
�clauses C1, C2 : C1 subsume C2 si C1 � C2 �
Cette idée pose ici un grand problème : on a ici une définition sémantique del’implication mais il faut encore prouver logiquement que C1 implique C2. Il fautdonc préciser la procédure effective de la preuve de la subsomption ainsi que laprocédure permettant de généraliser une clause.
La subsomption relative à une théorie
Jusqu’à présent, nous n’avons considéré que la relation de généralité entre deuxclauses. Toutefois, nombre de cas intéressants se situent là où il est nécessaire deconsidérer, non des clauses, mais des ensembles de clauses formant des théories.
C1 : concept(X) :- petit(X),triangle(X).
C2 : polygone(X) :- triangle(X).
C3 : concept(X) :- polygone(X).
C4 : polygone(X) :- triangle(X).
Sur l’exemple ci-dessus, C3 � C4 C1 � C2. Par contre, si l’on considèreuniquement C3 et C1, on n’a pas C3 C1.
On a alors recours à la subsomption entre clauses, relativement à une théorie,car la subsomption entre clauses ne suffit clairement plus.
Définition 22 (Subsomption relativement à une théorie) Une clause C1 subsumeune clause C2 relativement à une théorie T si (T � C1) � C2.
16

Conclusion
Des trois types de relation de subsomption, la Θ-subsomption est la plus fa-cile à mettre en œuvre mais elle est la plus faible des relations de généralité. Elleest décidable mais NP-complète... Quant à l’implication, elle n’est même pas dé-cidable 4[4], même si l’on ne considère que des clauses de Horn. La subsomptionpar rapport à une théorie est elle aussi indécidable. Par rapport à l’implication, ellenécessite en plus de prendre en compte la théorie relativement à laquelle on vaétablir la subsomption (et donc de faire du calcul en plus). De toute façon, qu’unethéorie T soit présente ou pas, il faut que l’on puisse calculer la généralisation lamoins générale (lgg pour least general generalization) de deux clauses, ainsi queleur spécialisation maximale (mgs pour most general specialization). Encore unefois, la complexité du langage de représentation joue sur la capacité de raisonne-ment que l’on peut avoir. Il est à noter que l’utilisation d’un langage de clausesgénérales sans symbole de fonctions conduit à avoir un espace de recherche desolutions ayant une structure de treillis. C’est pourquoi la plupart des systèmes dePLI se placent dans ce cadre-là pour pouvoir profiter de cet ordonnancement.
2.2.3 Structuration de l’espace des hypothèses en logique du 1er ordre
Grâce à l’une des relations de subsomption (on dit aussi couverture) entreclauses décrites ci-dessus, on va pouvoir structurer l’espace de recherche des hy-pothèses. Il est alors possible de considérer l’induction d’une hypothèse commeune recherche dans l’espace de toutes les hypothèses possibles (dit aussi espacede représentation) en se guidant avec les relations de subsomptions. Le fait deconsidérer les lggs (respectivement les mgs) vient de l’hypothèse que l’on fait,qu’en généralisant (respectivement spécialisant) minimalement, on limite le risquede surgénéralisation (respectivement de surspécialisation).
Calcul de la lgg pour la Θ-subsomption
Dans le cadre de la Θ-subsomption introduite par Plotkin [20], le calcul de lagénéralisation la moins générale se définit avec les règles suivantes :
La lgg de deux termes t1 et t2 (et l’on note lgg(t1 � t2) ce nouveau terme) est unevariable si :� l’un des deux termes est une constante, et t1 �� t2 ;� au moins un des deux termes est déjà une variable ;� t1 et t2 sont deux termes fonctionnels construit à partir de symboles fonction-
nels différents.
On doit, au passage, prendre la précaution suivante :4Church (1932) a malheureusement montré qu’il ne peut y avoir d’algorithme pouvant décider en
un temps fini si une inférence est logiquement valide ou non en logique du premier ordre.
17

Soit Θ1 et Θ2 les deux substitutions telles que lgg�t1 � t2 � Θi � ti 5 (i � 1 � 2 �
alors il ne doit pas exister de variables distinctes X et Y telles que XΘ1 = Y Θ1 etXΘ2 = Y Θ2.
La lgg de deux termes construits sur le même symbole de prédicat est donnépar la formule suivante :
lgg�p�t1 � � � � � tn ��� p � s1 � � � � � sn � � � p
�lgg
�t1 � s1 ��� � � ��� lgg
�tn � sn � �
Enfin, la lgg de deux clauses l0� l1 � � � � � ln et m0
� m1 � � � � � mn est donnée parla formule :
lgg�l0 � m0 � � � lgg
�li � mi � � � i ��� 0 � n � telle que li et mi sont des littéraux de même
signe et de même symbole de prédicat}.
rlgg et Θ-subsomption relative
On définit la plus petite généralisation relative (rlgg pour relative least généralgeneralization) de deux clauses en utilisant la Θ-subsomption relative, de manièreanalogue à ce que l’on vient de voir pour la lgg.
On rappelle qu’une clause c1 Θ-subsume une clause c2 relativement à un pro-gramme logique P si il existe une substitution Θ telle que P � c1Θ � c2.
Ainsi on a pour deux atomes e1 et e2 :
rlgg�e1 � e2 � � lgg
�e1
� T � e2� T � .
Il faut ici faire attention à ce que les atomes de T, e1 et e2 soient liés. À cause decela, la théorie du domaine T doit être donnée en extension, ce qui n’est pas conce-vable de faire dans la majorité des problèmes. Pour remédier à cette contrainte,Buntime [3] a proposé en 1988 de n’exprimer en extension, que la définition dudomaine que l’on peut calculer à partir du plus petit modèle de Herbrandt de laconnaissance initiale (donnée en intention). Plotkin [21] en 1971 avait, quant à lui,proposé de supprimer les littéraux logiquement redondant dans les clauses pour di-minuer leur taille. Ces deux solutions ne sont pas très satisfaisantes : celle de Plot-kin est très coûteuse puisqu’elle demande d’utiliser des prouveurs de théorèmes ;celle de Buntime restreint trop l’espace de recherche des hypothèses et on risquealors de ne pas considérer toutes les instances des hypothèses et, ainsi, de fausserle résultat de l’algorithme d’apprentissage.
Calcul de la lgg pour la résolution inverse
Plutôt que de se baser sur la sémantique pour définir la subsomption, Muggle-ton [5] a proposé une définition à partir de la technique de preuve (en logique desprédicats, c’est le principe de résolution de Robinson). Ici, on dira qu’une clause
5Si c est la lgg de c1 et c2 alors il existe par définition deux substitutions Θ1 et Θ2 telles quecΘ1 = c1 et cΘ2 = c2.
18

q A p q, B
p A, B
FIG. 2.1 – l’opérateur d’absorption
subsume une autre clause si la première permet la déduction de la seconde parrésolution SLD. On voit ainsi l’induction comme étant l’inverse de la résolution.
Définition 23 (généralité) Soient un programme logique P, deux clauses C et D.C est plus générale que D au sens de la SLD-subsomption si et seulement siC � P � SLD D.
Comme la Θ-subsomption, la SLD-subsomption induit des opérations syn-taxiques sur les programmes, qui sont les bases de l’apprentissage par inversionde la résolution. Comme on a aussi que (C � P � SLD D) (C � P � D), à cause de lajustesse de la résolution SLD, on a ici un cas particulier de l’implication relativeà une théorie. Dans le cadre de la PLI, Muggleton et Buntime [15] ont introduitquatre règles de résolution inverse6 :
Règle d’absorption (opérateur V) :q � A p � A � Bq � A p � q � B
Règle d’identification (opérateur V) :p � A � B p � A � qq � B p � A � q
Règle d’intra-construction (opérateur W) :p � A � B p � A � C
q � B p � A � q q � C
Règle d’inter-construction (opérateur W) :p � A � B q � A � C
p � r� B r � A q � r� C
Dans ces règles, les lettres majuscules représentent des conjonctions d’atomeset les minuscules des atomes. Les règles d’absorption et d’identification inversentune étape de résolution. La figure 2.1 montre comment on inverse la résolutionavec un opérateur V.
Les opérateurs d’intra-construction et d’inter-construction (appelés aussi opé-rateurs W) résultent de la combinaison de deux opérateurs en V qui représententchacun une étape de résolution inverse. On remarque qu’on introduit un nouveauprédicat dans ces règles : on fait de l’invention de prédicat.
L’inversion de la résolution est une opération non-déterministe puisqu’à chaqueétape on a à choisir la génération de clauses à réaliser. Pour pallier ce non-déterminisme,Muggleton a proposé que ce soit l’inversion de résolution la plus spécifique qui soit
6Notation : AB se lit « on peut induire A de B ».
19

choisie dans le processus de généralisation. On utilisera donc la substitution inversela plus spécifique à chaque étape de la résolution.
2.3 Exploration de l’espace des solutions
Le formalisme logique que nous venons de passer en revue permet de détermi-ner l’espace des versions (défini globalement par Mitchell [12] comme l’ensembledes hypothèses cohérentes avec les données d’apprentissage). Les programmes dePLI recherchent une solution dans cet espace des versions. La taille importante dece dernier implique l’utilisation de techniques d’élagage et de biais d’apprentis-sage. Ces programmes s’imposent souvent de respecter des contraintes que l’onvient de décrire dans ce que l’on appelle la sémantique normale, ce qui est globa-lement une reformulation correcte et complète d’une hypothèse avec les exemples.
2.3.1 Recherche d’une solution par des algorithmes de PLI
Algorithme général de la PLI
Globalement, les programmes de PLI cherchent à induire une hypothèse H àpartir d’un ensemble d’exemples E � , d’un ensemble de contre-exemples E � dis-joint de E � , et d’un ensemble de connaissances a priori sur le théorie à apprendre,telle que l’on puisse déduire tous les exemples positifs (on dit aussi courammentcouvrir les exemples positifs) sans pouvoir déduire les exemples négatifs. Les pro-grammes de PLI cherchent aussi à respecter ce que nous avons défini comme lasémantique normale, ou un cas particulier : la sémantique définie qui s’appliquemieux dans un cadre opérationnel et simplifie la tache d’apprentissage.
Algorithme générique de la PLI
Initialiser HTant que la condition d’arrêt de l’apprentissage n’est pas remplie faire
Effacer un élément h de HChoisir des règles d’inférences r1 � � � � � rk à appliquer à hAppliquer r1 � � � � � rk à h pour obtenir h1 � � � � � hn
Ajouter h1 � � � � � hn à Hélaguer H
Fin tant que
L’algotithme fonctionne comme suit. On prend un ensemble d’hypothèses can-didates H. De façon répétitive, on supprime une hypothèse h de H. On applique à hdes règles d’inférences r1 � � � � � rk qui produisent des nouvelles hypothèses h1 � � � ��� hn
que l’on rajoute à H. On élague H et on recommence jusqu’a ce que l’on rem-plisse la condition d’arrêt. Cette condition d’arrêt est souvent le simple fait d’avoirtrouver une solution i.e. une hypothèse qui couvre les exemples positifs et aucun
20

exemple négatif.
L’algorithme général de la PLI utilise deux fonctions :� la fonction effacer influence la stratégie de recherche qui peut alors s’effec-tuer en largeur d’abord, en profondeur d’abord ou avec une autre stratégie,� la fonction choisir détermine les règles d’inférence à appliquer à l’hypothèsechoisie.
On peut classer les règles d’inférences en deux catégories : les règles induc-tives et les règles déductives.
Définition 24 (Règle d’inférence déductive r) Elle fait correspondre une conjonc-tion de clauses S à une autre conjonction de clauses G telle que G � S. r est unerègle de spécialisation.
Définition 25 (Règle d’inférence inductive r) Elle fait correspondre une conjonc-tion de clauses G à une conjonction de clauses S telle que G � S. r est une règle degénéralisation.
Stratégie de recherche de solutions
Lors de la conception d’un système de PLI, le choix de la stratégie de rechercheest fondamental. C’est à ce moment que l’on décide de l’approche que l’on vaadopter :� partir des exemples et de la théorie du modèle, et les généraliser pour in-
duire une hypothèse en appliquant des règles d’inférence inductive de façonitérative (systèmes CIGOL, CLINT, GOLEM, PROGOL [13]). Les contre-exemples ne doivent pas être couverts ce qui limite la généralisation. Ce sontdes systèmes dits ascendants.� partir d’une hypothèse très générale et chercher à la spécialiser pour qu’ellene couvre plus (ou le moins possibles dans le cas où l’on a des connaissances« bruitées ») d’exemples négatifs. On doit encore couvrir les exemples posi-tifs, ce qui limite la spécialisation. Ce sont ce que l’on nomme des systèmesdescendants (systèmes FOIL et ses multiples dérivés [23], MOBAL, CLAU-DIEN).
Il est de plus notable qu’il existe des systèmes hybrides tel CHILIN [26] quiutilise les deux stratégies pour combler les lacunes de chacune.
Élagage de l’espace de recherche des hypothèses
Dans l’algorithme général, la fonction élaguer détermine quelles hypothèsesdoivent être enlevées de l’ensemble H des hypothèses. On peut distinguer deux casd’élagages distincts : l’un dû à la spécialisation et l’autre à la généralisation.
21

� Si B et H n’implique pas logiquement un exemple positif e, c’est-à-dire siB � H
�e, alors aucune spécialisation de H ne pourra impliquer e, et toutes
les spécialisations de H peuvent donc être élaguées de l’espace de recherchedes solutions.
� Si un exemple négatif e est couvert, c’est-à-dire si B � H � e�
c, alors toutesles généralisations de H peuvent être élaguées puisqu’elles seront trop géné-rales et inconsistantes avec B � E .
Si par exemple, on possédait la base de connaissance B suivante :
pere(gaston,francois)�
pere(gaston,laurent) �
pere(laurent,julien)�
Et que l’ensemble des exemples positifs contienne l’exemple :
oncle(francois,julien)�
Alors on peut d’ores et déjà élaguer toutes les clauses plus spécifiques que laclause oncle(A,B)
�pere(A,B). On est ici dans le premier cas d’élagage puisque B
� oncle(A,B)�
pere(A,B) ne couvre pas l’exemple positif oncle(francois,julien).Même si ces propriétés d’élagage (qui découlent directement de la relation
de subsomption entre hypothèses) se révèlent très utiles, l’espace de recherche serévèle encore beaucoup trop grand. Il est donc nécessaire d’avoir recours à desbiais supplémentaires.
2.3.2 Les biais de recherche
L’espace de recherche en PLI est très grand, voire infini. Il est donc logique devouloir le restreindre à l’aide de biais. Le rôle de ceux-ci est double :� réduire la taille de l’espace de recherche pour diminuer le temps de réponse
du système,� garantir une certaine qualité d’apprentissage en évitant au système de consi-dérer des hypothèses inutiles.
On distingue deux classes de biais : les biais syntaxiques ou biais de langage,et les biais sémantiques.
Les biais syntaxiques
Un biais syntaxique permet de définir l’ensemble des hypothèses envisageablesen spécifiant explicitement leur syntaxe. Plus formellement, les biais de langagedéfinissent l’ensemble des hypothèses bien formées. On distingue quatre grands
22

types de biais syntaxiques en PLI [18]: le langage de Bergadano, les grammairesde description d’antécédents de Cohen, les schémas de l’équipe BLIP-MOBAL etles variantes de cette dernière.
� Le langage de programmation logique inductive de Bergadano est en faitune sorte d’extension du langage prolog dans laquelle on a ajouté les no-tions d’ensembles de prédicats et d’ensembles de clauses. Cela donne surl’exemple suivant :
{pere(X,Y) :- {homme(X),femme(X)},parent(X,Y) ;mere(X,Y) :- {homme(X),femme(X)},parent(X,Y)}
Le prédicat pere/2 est constitué d’un sous-ensemble de prédicats de l’en-semble {homme(X), femme(X)} suivis du prédicat parent(X,Y). De mêmepour mere/2. Qui plus est, la solution globale comprendra un sous-ensemblede l’ensemble constituant notre exemple dans sa définition.
� Grâce à des sortes de grammaires de clauses définies, Cohen décrit l’en-semble des clauses bien formées. On obtient alors ce genre de formalisme :
formule-but(pere(X,Y)).formule-but(mere(X,Y)).corps(pere(X,Y) � h(X),f(X),[parent(X,Y)]corps(mere(X,Y � � h(X),f(X),[parent(X,Y)]h(X) � []h(X) � [homme(X)]f(X) � []f(X) � [femme(X)]
Dans cette notation, on a formule-but qui définit les prédicats à apprendre,corps(P) est l’axiome pour apprendre les clauses dont la tête est P. Les cro-chets entourent les symboles terminaux.
� Dans le système MOBAL, le formalisme de biais introduit par Emde, Ha-bel et Rollinger est une sorte de schéma du second ordre. Un schéma dusecond ordre est une clause où certains noms de prédicats sont des variablesde prédicats quantifiées de façon existentielle. Par exemple, si on considèrele schéma :
S ��
P� Q � R : P�X � Y � � Q
�X � XW ��� Q �
YW � Y ��� R �XW � YW �
Et la substitution : Θ={P=connecte, Q=partie-de, R=touche}, alors on a leschéma instancié suivant :
SΘ=connecte(X,Y) � partie-de(X,XW), partie-de(YW,Y),touche(XW,YW)
23

Ces trois approches ont l’avantage d’avoir une spécification très proche de lastructure de l’espace de recherche sous la Θ-subsomption et d’être aisément uti-lisable dans des approches générale-vers-spécifique sous la Θ-subsomption. L’ap-proche de Cohen est la plus puissante mais la moins utilisable tandis que celle deBergadano et celle de MOBAL sont complémentaires au sens où le formalisme deBergadano peut s’abstraire facilement du nombre de littéraux dans les clauses tan-dis qu’un langage de biais ayant un nombre fixe de littéraux provoquera un grandnombre d’expressions.
D’autres méthodes de réduction de l’espace sont aussi envisagées, par exemple :� limiter le nombre de littéraux des clauses induites ;� limiter le nombre de variables apparaissant dans les clauses ;� limiter la profondeur de la récursivité dans les termes ;� n’autoriser que les clauses range restricted, c’est-à-dire celles dont l’en-semble des variables se trouvant en tête de clause est inclus dans celui desvariables du corps.
Les biais sémantiques
À l’opposé des biais de langage, les biais sémantiques imposent des restrictionssur le sens des hypothèses. La définition de types et de modes pour les variables estutilisée depuis longtemps en programmation logique pour permettre une meilleureanalyse statique des programmes et, ainsi, accroître leur efficacité. Depuis leurintroduction dans le système MIS en 1983, il est devenu courant de les utiliseren programmation logique inductive. Les types et les modes constituent alors unbon moyen pour définir des biais sémantiques. En effet, si un littéral contient unevariable V de type t, toutes les occurrences de V dans la même clause devront êtredu même type t. Ceci permet déjà d’élaguer de l’espace de recherche toutes lesclauses incorrectement typées. De même les déclarations de modes permettent deréduire la taille de l’espace des solutions. Si, par exemple, on utilise le prédicatconcat/3 avec la déclaration de mode suivante :
concat(+L1,+L2,-L)où les variables précédées d’un « + » doivent être données en entrée et celle
précédée du « - » est un argument de sortie calculé par concat/3. On peut alorséliminer toutes les clauses utilisant concat/3 avec un mauvais mode, par exemple :
concat(L1,L2,[a,b,c])
puisque l’on utilise ici le prédicat en mode � ��� � � au lieu de� � � ��� .
On a ici quelques moyens d’utiliser les modes sur les variables des prédicats :� Toutes les variables en entrée en tête de clause doivent être utilisées dans lecorps de la clause (si on choisit pas de variables inutiles).� Les variables en sortie dans la tête doivent être présente dans le corps de laclause (on s’assure que les résultats sont bien calculés dans le corps de la
24

clause).� On peut obliger toutes les variables en sortie dans le corps d’une clause, soità servir en entrée d’un autre prédicat (résultat intermédiaire), soit à servir desortie pour le prédicat de la tête de clause (apparaître en sortie dans la têtede clause).� Il est envisageable d’interdire à une même variable d’apparaître plusieursfois en sortie de prédicat du corps (une variable est calculée une fois pourtoute en un seul endroit).
Dans le système PROGOL de Muggleton [13], par exemple, il est possiblede déclarer des modes sur les variables des littéraux pour restreindre l’espace derecherche. PROGOL différencie les prédicats qui peuvent se trouver en tête et encorps de clause, ce qui permet d’élaguer encore plus l’espace des hypothèses enutilisant un principe de « clause bien formée ».
2.4 La PLI sur des environnements dynamiques : un exempled’apprentissage de chroniques
Jusque-là, nous n’avons observé que l’apprentissage d’exemples jouets. Deplus, la dimension temporelle n’intervenait jamais. Or, beaucoup des systèmesayant un module d’apprentissage, travaillent dans un cadre dynamique ou doiventrespecter des contraintes temporelles.
L’apprentissage de chroniques sert essentiellement dans le diagnostic et la sur-veillance de système. Avec un apprentissage par des techniques de PLI, on a lapossibilité d’avoir un système qui ne fonctionne qu’avec un seul langage pour re-présenter les exemples d’apprentissage et les concepts modélisés. C’est toujoursavec ce même langage que le système effectue la tâche de diagnostic ou de sur-veillance, et c’est encore dans le langage de la logique du premier ordre qu’il four-nit les explications aux utilisateurs. De plus, le fait d’apprendre les concepts sousforme de formules du premier ordre les rend plus abstraits que si on les avait apprissous forme de propositions : on a gagné en expressivité.
Dans une activité proche de celle du stage, l’équipe travaille sur l’apprentis-sage d’arythmies cardiaques à partir d’électrocardiogrammes (ECG) [22] [25] enutilisant le système de PLI ICL (pour Inductive Constraint Logic) de De Raedt etVan Laer [5]. Par la suite, nous verrons où se situe la démarche d’apprentissage parrapport au reste du projet SACADEAU.
2.4.1 Modélisation de l’activité cardiaque : de l’ECG à la représenta-tion symbolique
Sans rentrer dans des détails médicaux, on peut remarquer qu’une activité car-diaque normale se résume à des cycles de successions d’onde P—complexe QRS—onde T. Ces oscillations sont séparées par des intervalles de temps que l’on notera
25

PR, QT et RR représentant respectivement les intervalles de temps entre un signalP et le signal QRS suivant, entre deux ondes QRS et entre une onde QRS et l’ondeT suivante. Les arythmies cardiaques sont, quant à elles, des pathologies à l’originede désordres dans l’organisation du cycle cardiaque. Un ECG permet d’avoir unereprésentation visuelle de l’activité cardiaque d’un patient et permet à des expertsde la décoder, en fonction de la forme du signal de l’ECG.
Ici, on cherche à apprendre à déterminer des signaux issus d’ECGs pour diffé-rencier les comportements normaux des pathologies cardiaques (et celles-ci entreelles).
Grâce à des experts, on a à disposition des ECGs montrant des fonctionnementsnormaux et des fonctionnements arythmiques. Une arythmie de type Bigeminy sedécrit par exemple ainsi :
� Des séquences d’ondes : où QRS’ dénote une ondulation QRS de formeanormale.� Des contraintes temporelles : PR normal, RR court et RR long (avec R re-présentant QRS).
Il est très simple de formuler ceci dans le cadre de la logique du premier ordrepuisque la clause prolog suivante exprime exactement la définition précédente :
bigeminy : � qrs�R0 � normale � P0 � _ ��� qrs
�R � anormale � P1 � R0 ��� rr1
�R0 � R1 � short �
D’ailleurs, les exemples d’apprentissage décrivant des arythmies de type Bige-miny ne sont rien d’autres que des instanciations de cette formule.
On cherche à induire des formules ressemblant à celle-ci et la PLI (qui induitles concepts sous forme de clause du premier ordre) est bien adaptée pour le faire.
2.4.2 L’apprentissage
L’apprentissage a été réalisé en utilisant le système ICL [5] qui emploie le lan-gage DLAB [6] pour la description de biais syntaxiques. ICL est un système quicherche à induire des hypothèses complètes (couvrant tous les exemples positifsfournis) et correctes (ne couvrant aucun contre-exemple). DLAB est un langagede spécification de concepts d’assez haut niveau qui permet de définir la syntaxedu langage des hypothèses. ICL permet de faire de l’apprentissage multi-classe ausens où l’on peut avoir plusieurs concepts à induire en même temps. L’apprentis-sage s’est fait sur cent ECGs de dix secondes chacun décrivant quatre arythmies etun cœur normal (vingt ECGs pour chaque classe). La grammaire de DLAB a étéutilisée pour décrire un langage de biais lors de l’apprentissage. Elle est composéede modèles de règles permettant de définir la forme des clauses devant représen-ter le concept à apprendre. Ces règles sont de la forme tête � corps où tête et
26

corps sont des termes de DLAB. Un terme est soit une formule atomique, soit unensemble de spécifications de la forme : 1-h[elt1,. . .,eltn].
Une telle expression s’interprète comme : choisissez de 1 à h termes de cetensemble. Ces expressions sont utilisées pour produire toutes les combinaisons surles éléments satisfaisant les gabarits.
Les résultats provenant de ce travail (près de 99% de précision pendant l’ap-prentissage et pendant la phase de test) montrent bien qu’il est possible d’induiredes définitions très précises d’informations complexes structurées dans le temps.Ceci étant dit, ce résultat plus que probant, est en partie dû à des spécificationsde cycles cardiaques très restrictives : des descriptions plus permissives mènentà des caractérisations de mauvaise qualité ou conduisent à des temps d’exécutiontrès (trop) long. De plus, il arrive que certains résultats (et ce fût le cas ici), bienque corrects, ne correspondent pas à la définition généralement employée par lesspécialistes.
2.5 Conclusion
Comme nous venons de le voir, la programmation logique inductive (PLI) esttournée vers l’apprentissage supervisé de concepts exprimés sous la forme de pro-grammes logiques. L’apprentissage est ici guidé par une relation de généralité dansl’espace des hypothèses et consiste à trouver une hypothèse H cohérente (correcteet complète) avec les exemples d’apprentissages. Étant donné la taille de l’espacede recherche, nous avons vu qu’il était nécessaire d’avoir des biais syntaxiquesou/et sémantiques pour l’élaguer et faciliter ainsi le travail du cœur de tout systèmede PLI : le démonstrateur de théorèmes logiques. Même alors, tout n’est qu’unequestion de compromis entre complexité des descriptions recherchées et efficacitéalgorithmique.
Il existe d’autre techniques d’apprentissages et la fouille de données en est une.C’est un sujet de recherche relativement récent et, en particulier, la recherche deséquences fréquentes dans de grandes bases de données est un thème important àl’heure actuelle. Jusqu’alors, la plupart des algorithmes de recherche s’inspiraientd’algorithmes assez classiques de recherche par niveau et cherchaient à découvrirdes règles d’association entre les éléments. L’utilisation de contraintes dans les al-gorithmes de fouille s’est tout d’abord imposée, mais les algorithmes conçus decette façon ne s’intéressaient qu’à des données exprimées en logique proposition-nelle ou dans une logique attribut-valeur. Or, il s’est vite avéré que l’on avait besoind’une plus grande expressivité dès que l’on a eu à modéliser des gabarits un peucomplexes. En se tournant vers des modèles de données proches de la logique dupremier ordre, la fouille de données s’est rapprochée de la programmation logiqueinductive.
Si l’on considère le langage SeqLog de Dan Lee et De Raedt [8], ou le sys-tème SPIRIT-LOG de Masson et Jacquenet [10] qui sont utilisés pour faire de larecherche de données séquentielles et plus particulièrement de la recherche de sé-
27

quences fréquentes dans des bases de données, on s’aperçoit qu’ils sont fondéssur la logique du premier ordre. On y retrouve les notions de subsomption de sé-quences, de caractérisation de séquences à partir de contraintes monotones et nonmonotones (ce qui rappelle en PLI les « exemples » et « contre-exemples »). Ony retrouve un algorithme pour trouver les gabarits maximaux (« hypothèse la plusgénérale ») proche des algorithmes de PLI, et des techniques d’optimisation quel’on retrouve aussi en programmation logique inductive.
28

Chapitre 3
L’organisation du projetSACADEAU
Le but du projet SACADEAU (Système d’Acquisition de Connaissances pourl’Aide à la Décision pour la qualité de l’EAU) est de développer une plateforme desimulation des activités agricoles de désherbage sur culture maïs à l’échelle d’unbassin versant, et d’observer les conséquences en terme de qualité de l’eau à lasortie du bassin. Ce logiciel a deux vocations : d’une part simuler des scénariosstructurés (écrit dans un langage très précis) et ainsi permettre l’analyse au cas parcas d’exemples de fonctionnement du bassin ; et d’autres part d’extraire automati-quement des connaissances des simulations. Étant étrangers au domaine de l’agro-nomie, nous sommes tout d’abord passés par une nécessaire phase d’apprentissagede vocabulaire pour pouvoir discuter avec les experts.
3.1 Les termes agronomiques essentiels
Dans la suite de ce rapport, il sera souvent question de bassin versant, d’exu-toire, de ruissellement,... Autant de termes qui n’évoquent que peu de choses àtoute personne extérieure au domaine de l’agriculture ou de l’agronomie. Nousdonnons ici une définition de ces termes.
Un terme que nous avons utilisé plusieurs fois est « bassin versant ». Ce termedésigne un ensemble de parcelles agricoles se trouvant sur un territoire drainé parun cours d’eau principal et ses affluents. De l’extrémité supérieure (l’amont) à labase d’un bassin versant (l’aval), l’eau se déplace et se jette dans des cours d’eau.Tout au long de son parcours, la composition de l’eau est modifiée par les caracté-ristiques naturelles du bassin et par les activités humaines qui s’y déroulent. C’estdonc l’unité territoriale la plus appropriée pour travailler sur la qualité de l’eau.
L’exutoire d’un bassin versant est la sortie hydrographique des eaux du bassin.C’est globalement la partie du cours d’eau principal où toutes les eaux issues des
29

cours d’eau secondaires ont été récupérées.
Nous nous attachons à la pollution des cours d’eau par des pesticides. Ceci nousamène à redéfinir ce qu’est le transfert des pesticides dans un bassin, autrementdit, quel est le devenir des pesticides une fois qu’on les a épandus :
1. Lors de l’application ou rapidement après, les processus mis en jeu sont– la dérive : une partie des produits est entraînée par le vent.– l’interception par le couvert végétal (s’il y en a) : les végétaux captent une
partie des pesticides qui n’atteindra donc pas le sol.– la volatilisation du produit, qui entraîne une partie des pesticides dans
l’atmosphère.
2. Au niveau du sol :– une partie des pesticides est minéralisée (transformation complète du car-
bone organique en CO2) ;– une partie reste telle quel dans le sol ;– le reste est transféré lors de pluies : plus profondément dans le sol par les-
sivage du sol ou vers les cours d’eau par ruissellement.
Le devenir des pesticides est représenté sur le shéma suivant (cf. 3.1). On adonc globalement une distribution des pesticides en trois phases :
– une phase solide : elle représente la partie adsorbée par les particules du sol.Comme elle est peu mobile, cette phase est peu susceptible de contaminerles eaux.
– les phases liquide et gazeuse : c’est la partie encore mobile des pesticidesqui est donc la plus susceptible de provoquer des pollutions.
Pour lutter contre les pollutions, les agriculteurs peuvent placer sur leurs par-celles des dispositifs tampons. Ils prennent la forme de haies, de talus, de fossés,de bandes herbeuses,... et ils servent à capter une partie des eaux
3.2 La place de l’outil informatique
L’utilité d’un simulateur est évidente : pouvoir tester le rôle des haies, des fos-sés, la rotation des cultures,... à l’échelle d’un bassin versant dans sa globalité estessentiel si l’on veut à terme, faire de la recommandation sur les actions à menerpour améliorer la qualité de l’eau. L’extraction de connaissances est un pas de plusdans ce sens. Devant la quantité de critères explicatifs, le nombre de façons dont onpeut les combiner, leur complexité, les possibilités d’évolution,... un raisonnementhumain n’est généralement plus assez efficace pour pouvoir faire ressortir des re-lations nettes entre les différents paramètres qu’il faut analyser. Actuellement, onconnaît peu ou approximativement ces relations. Par contre, l’analyse d’un grandnombre de données et leurs mises en relation est une tâche réalisable par un outilinformatique. Il permet d’aller au-delà de ce qui se fait déjà en terme de conseils et
30

FIG. 3.1 – Processus impliqués dans le devenir des pesticides
de connaissances sur le sujet, comme des classements de parcelles à risques évo-luables suivant les conditions, au lieu de fixes comme maintenant. De plus, pourpouvoir faire de l’induction, il faut un nombre suffisamment important d’exemplesde situations. Or, le nombre d’exemples de situations réelles est faible et il doncnécessaire de créer des exemples via l’utilisation de simulateurs (et donc la créa-tion de modèles qui vont servir à les construire).
L’idée de base de l’apprentissage à partir de simulations peut être illustréecomme suit. L’utilisateur part avec ses connaissances sur un sujet et simule unscénario en ayant une idée préconçue du résultat. Comme les résultats ne corres-pondent pas toujours avec ce qu’il sait, il analyse les résultats et découvre la raisonde cette différence. Il émet de nouvelles hypothèses et les met à l’épreuve sur denouvelles simulations. En tirant partie de ses essais successifs, l’utilisateur amé-liore sa connaissance du sujet. Nous venons de le voir, il y a trop de données pourque l’homme puisse faire de l’apprentissage dans de bonnes conditions. Il est doncnécessaire d’utiliser un système d’apprentissage automatique pour aider l’expert.La PLI (cf chap. 2) est la technique que nous nous proposons d’utiliser pour réali-ser cette phase.
Tout système d’apprentissage a besoin d’exemples des situations considéréespour pouvoir apprendre. Nous pouvons obtenir ces exemples de deux façons com-
31

plémentaires : nous pouvons travailler sur des données historiques ou nous pouvonssimuler ces données. L’avantage de données historiques est qu’elles sont « vraies »,au sens où elles sont issues d’observations et n’ont pas eu besoin d’être créées.Dans notre cas, elles sont malheureusement en nombre trop insuffisants pour pou-voir constituer une partie de la base d’apprentissage, c’est-à-dire l’ensemble desexemples qui vont nous permettre d’induire des théories (ici des relations entrevariables explicatives). La base d’apprentissage que nous allons créer sera doncintégralement constituée d’exemples issus de la simulation. Quels scénarios géné-rer ? Comment spécifier les paramètres d’une simulation ? Comment synthétiser etregrouper les informations ? Tout ceci dépend de la base que l’on crée.
Le fait de faire de l’apprentissage nécessite que nous passions par une premièrephase de classification des données. Comme nous souhaitons faire de l’apprentis-sage via la PLI, il est nécessaire de passer en plus par une phase de modélisationsous forme logique des concepts que nous allons chercher à apprendre. On peutglobalement découper la tâche de modélisation en trois :
– on doit simuler les transfert de polluants et apprendre sur les résultats fournis(concentrations de pesticides), ce qui nécessite une modélisation ;
– on doit modéliser les climats sur lequels nous allons travailler ;– on doit modéliser les activités humaines ;– on doit enfin modéliser la topologie globale du bassin versant (répartition
des parcelles de maïs dans le bassin selon la pente de la parcelle, la distanceà l’exutoire ,...)
L’avantage de la PLI est qu’une fois ce premier effort de modélisdation effectué,on aura peu de problèmes pour passer à une représentation sous forme de clauseslogiques de nos scénarios.
Des quatre modèles nécessaires, un est associé à un simulateur : nous les dé-crivons dans le chapitre suivant ; les deux autres n’ont pas encore été simulé maisdevraient l’être dans la suite du projet.
3.3 Les étapes nécessaires à l’inférence de règles
Nous devons passer par une succession d’étapes pour arriver à inférer des règlesde corrélation entre variables concernant la qualité de l’eau :
1. Construire la base d’exemples et de contre-exemples (donner pour chaqueclasse à apprendre, un nombre suffisamment important d’exemples pour pou-voir induire des relations).
2. Définir un biais d’apprentissage efficace (i.e. trouver un bon compromisentre l’efficacité du moteur d’inférence et la puissance du langage de des-cription des scénarios).
3. Inférer les règles i.e. identifier les variables explicatives et des relations entreces variables.
32

4. Vérifier la cohérence des règles induites avec des experts.
Construire la base d’apprentissage est la partie la plus importante, et était le butpremier du stage, pour préparer dans de bonnes conditions les phases 2 et 3.. Pourpouvoir le faire, il faut créer des exemples à partir d’un simulateur : nos donnéeshistoriques sont trop peu nombreuses.
La création d’un modèle biophysique de transferts de polluants est une dé-marche nécessaire si l’on veut pouvoir simuler notre problématique. Ce modèle estle cœur de la future application qui prendra en entrée des données topologique surle bassin, un type de climat et des données sur les pratiques agricoles. Il décrit, enfait, ce qui se passe entre l’application d’un produit et le moment où on le retrouvedans un cours d’eau. Nous revenons sur celui-ci dans le chapitre suivant.
Nous devons simuler les pratiques des agriculteurs : quelles molécules utilisent-ils, avec quelles doses, quand, sous quelles conditions,... ? Le modèle décisionnelissu du dépouillement de questionnaires de ce type doit permettre la simulationsdes actes techniques des agriculteurs, en fonction de ce qui peux influencer leurdécision. Ce modèle peut être très complexe, aussi nous nous sommes restreintdans une première approche à ne modéliser que les applications de pesticides etpas ce qu’il y a autour. Par contre, une modélisation « complète » sera faite dans lasuite du projet.
Un modèle climatique est nécessaire à la simulation puisque ce sont les aléasclimatiques qui sont à l’origine des problèmes de ruissellement de pesticides. Àcôté de cela, une modélisation des climats pour la problématique du ruissellementservira pour la création d’un générateur de climats pour la suite du projet.
Enfin, il faut fournir à l’application des données topologiques sur le bassin enlui-même. Il s’agit ici de décrire l’emplacement et les proportions des parcelles quinous intéresse sur le bassin.
On peut donc découper notre première phase de construction de base d’appren-tissage comme suit :
– Construction du modèle de simulation (modèle biophysique, modèle déci-sionnel, modèle climatique et couplage des trois modèles) ;
– Élaboration d’un langage de scénario permettant de décrire de manière qua-litative les jeux de données en entrées (nos « scénarios ») et les sorties dessimulations (classification des sorties) ;
– Génération d’exemples.
33

Chapitre 4
Le modèle biophysique
Nous allons décrire ici le modèle biophysique à définir (et la maquette associée)qui va nous servir lors de la simulation des transferts de pesticides dans un bassinversant. La construction de ce modèle est l’un des éléments importants du projetSACADEAU. Pour l’instant, nous travaillons sur un modèle dynamique simplifiéqui utilise en entrée différents paramètres que nous allons décrire, et en sortie nousrenvoie des chroniques temporelles de la qualité de l’eau sous forme d’une suite deconcentrations et de flux de pesticides datée.
4.1 Ce que l’on doit modéliser
La pollution par les pesticides est principalement perçue par leur présence dansles eaux (de rivière ou des nappes phréatiques) et les aliments. Pour réduire lescontaminations par pesticides, il est nécessaire de bien comprendre les processusauxquels sont soumis les pesticides dans le sol, soit globalement leur dégradation,persistance, rétention et transfert. Les facteurs importants qui donnent son caractèrepolluant à un pesticide sont sa rétention et sa persistance.
4.1.1 La rétention et la persistance d’un pesticide
La rétention est un facteur qui montre la disponibilité d’un pesticide dans lesol. Elle est caractérisée par des coefficients de partage du polluant entre les phasessolides et liquides. Plus particulièrement, on retient pour chaque pesticide son Koc,ou coefficient de partage carbone organique-eau. Comme la rétention est propor-tionnelle à l’augmentation de la teneur en carbone organique, et que celle-ci estrelativement indépendante du sol, le Koc permet de distinguer les pesticides entreeux et intervient dans la phase de calcul sur le devenir d’un pesticides dans le sol.
La persistance d’un produit dans le sol est un indicateur de l’évolution de saconcentration au fil du temps alors qu’il se dégrade (de façon naturelle par desmicro-organismes). Si l’on considère que la vitesse de dégradation est proportion-
34

nelle à la concentration du pesticide dans le sol, alors on peut exprimer la per-sistance d’un pesticide par une durée dite de demi-vie (DT50) ou temps moyennécessaire à la disparition de la moitié de la quantité initialement épandue. Cettedurée dépend fortement du produit actif, du type de sol et des conditions clima-tiques : 2 à 6 jours pour du sulcotrione, de 18 à 119 jours pour de l’atrazine (lescaractéristiques des produits simulés sont regroupées dans le tableau C.1 en an-nexe) et est prise en compte dans les caculs de stocks résiduels des pesticides dansle sol.
4.1.2 Ruissellement, lessivage et bande enherbée
Le ruissellement (écoulement d’eau en surface) et le lessivage des sols (écou-lement d’eau sous la surface vers la nappe phréatique) sont des phénomènes com-plexes mais relativement bien connus. On a donc à disposition des séries d’équa-tions relativement simples pour les simuler. Il en va de même pour les bandes en-herbées (il existe d’autres dispositifs tampons mais le but n’étant pas de faire unemesure comparative de l’efficacité des dispositifs, nous avons choisis de ne conser-ver que celui-ci, quitte à donner les équivalents en bande enherbées pour les autrestypes de dispositifs). Les équations qui controlent le ruissellement, le lessivage etles abattements provoqués par les bandes enherbées sont données en annexe B.
4.1.3 Le sol
L’état de surface est une caractéristique d’une parcelle, au même titre que sacomposition ou son occupation. Il est nécessaire de le connaître pour pouvoir dé-terminer l’infiltrabilité d’un sol, et donc savoir si une pluie va être ruissellante oupas, et l’importance du ruissellement s’il y a lieu. Il est défini comme la combinai-son du faciès du sol (la morphologie de la surface), de sa rugosité et de son couvertvégétal1 . Le modèle que nous utilisons, est inspiré des travaux d’Y. Le Bissonnaiset autres de l’INRA Orléans qui ont mis au point un système de règles expertesfondés sur ces trois paramètres pour fixer le seuil d’infiltrabilité du sol.
Le schéma suivant illustre les phases d’évolution du faciès d’un sol depuis ledernier travail (état très fragmenté donc très poreux : F0) jusqu’à un état plus com-pact dû aux précipitations (dès qu’un excès d’eau se forme sur le sol, des particulesse détachent des mottes et créent des micro-strates quasi-imperméables et doncdiminue la porosité du sol : phase F2).
En parallèle à la dégradation du faciès, on note aussi une diminution de larugosité du sol. La rugosité est évaluée en mesurant l’écart type des hauteurs dedénivellation D entre cols et dépressions du sol et peut être classée en cinq catégo-ries :
1il est admis qu’un couvert végétal bien développé protège le sol de l’action des pluies. Évidem-ment, sur des parcelles cultivées, le couvert végétal évolue beaucoup tout au long de l’année
35

F0 Tous les fragments sont parfaitement distinctsF1 F11 Fragments soudés mais contours encore reconnaissables
F12 Fragments soudés, contours disparusF2 Continuité totale avec signes de dispersion
TAB. 4.1 – Catégories de faciès
FIG. 4.1 – Évolution de l’état de surface d’un sol
R0 D � 1 cm Surface très affinée ou très battueR1 1 � D � 2 cm Existence de barrages discontinus et de petits
bourrelets entourant de petites dépressionsR2 2 � D � 5 cm Fort pourcentage de mottes � 2cmR3 5 � D � 10 cm Nombreux massifs entourant des dépressionsR4 D � 10 cm État très motteux, relief serré, forte discontinuité
TAB. 4.2 – Catégories de rugosité
36

Comme le couvert végétal (CV) intervient au niveau du « type » d’une parcelle,il faut aussi le modéliser. Avec les experts, il a été décidé de le classer en troisgrandes catégories représentant le pourcentage de sol recouvert par des végétaux :
CV1 0 à 30%CV2 31 à 60%CV3 61 à 100%
TAB. 4.3 – Catégories de couvert végétal
La combinaison des trois facteurs cités ci-dessus a permis d’assigner une valeurrelative de sensibilité au ruissellement allant de 0 à 4 (4 étant la valeur assignéeaux combinaisons les plus susceptibles de produire un ruissellement). Le tableauqui donne le seuil d’infiltrabilité d’un sol en fonction de son faciès de sa rugositéet de son couvert est reproduit en annexe A.1.
4.2 La maquette de simulation
Au début du projet SACADEAU, nous disposions d’une maquette assez in-complète capable de simuler les transferts de pesticides à l’échelle de l’hectarepour une parcelle isolée. Cette maquette a été conçue en 1999 lors d’un stage deDESS CCI par T. Courgeon. La maquette originale ne convenait que modérémentà nos besoins : notre échelle de travail est le bassin versant, pas la parcelle, et, bienque les calculs de ruissellement en eux-mêmes correspondent à ce que l’on peuttrouver dans la littérature, les approximations faites autour de ces équations ren-daient les résultats de la maquette très peu réalistes 2. Il a donc fallu améliorer lamaquette existante.
4.2.1 Fonctionnement global
Globalement, la maquette fonctionne au pas de temps journalier. Après l’initia-lisation (pesticides employés, doses, dates, types de sols, bandes enherbées, fichiermétéo...), la maquette cherche successivement les journées où il y a eu des pluiesruisselantes et lessivantes. À partir de là, elle calcule les flux de pesticides ruisse-lants et lessivants, et les stocks résiduels. La phase de simulation se déroule commele montre la figure 4.2.
Les équations sur lesquelles se basent les calculs de flux ruisselant ou lessivant,les concentrations, etc. sont reportées en annexe. On peut ajouter qu’à chaque pluie,on regarde s’il est nécessaire ou pas de faire évoluer le seuil d’infiltrabilité du sol,puisque c’est lui qui détermine si (et combien) l’eau va ruisseler.
2Pour la suite du projet, la maquette de simulation ne sera pas qu’un simple simulateur numérique,mais elle se basera sur un modèle hydrologique d’écoulement des eaux en surface et en subsurfaceet gagnera donc en précision.
37

DeriveInterception par le CV
i = i+1Jour i
non
oui
Pluie ?
Calcul des quantites de puieruisselante et lessivante
Fichier des pluies
Parametres en relation avec : la parcellela matiere activele modele
Calcul du stock initial de pesticidesdans le sol
non
oui
Calcul des flux ruisselant et lessivantDegradation et retention
apres la pluie
Ruissellement et lessivage Pluie ruisselante et lessivante ?
Calcul du stock residuel de pesticides
FIG. 4.2 – Schéma global de fonctionnement
38

4.2.2 Les modifications apportées
Le simulateur dont nous avions besoin devait être capable de simuler le de-venir des pesticides sur tout un bassin et la maquette originale ne le pouvait pas.Reprendre la maquette et l’augmenter pour pouvoir faire des simulations à plusgrande échelle aurait nécessité d’en refaire quasiment une nouvelle : écrite en JAVAmais pas conçue orienté objet, nous avons fait face à un code très soudé et peu dé-composable avec, qui plus est, une interface graphique totalement imbriquée dansle reste du code.
L’intérêt d’une IHM est discutable dans notre cas. Certes, cela donne un côtéplus convivial à l’application (surtout pour les non-informaticiens) mais, ceci dit,celle que nous avions sous la main n’était pas satisfaisante pour analyser les résul-tats que nous avions. De plus, une interface homme-machine est loin d’être ce qu’ilfaut pour analyser des données en nombre très important. À part pour la configu-ration de la maquette, une IHM n’avait pas réellement d’utilité. Nous l’avons doncsupprimée.
Plutôt que de repartir de zéro, nous avons choisi de rajouter une surcoucheen Perl destinée à compléter le travail original. Nous avons donc court-circuitél’interface graphique pour ne garder qu’un « noyau » de simulation. Puis nousavons créé la surcouche pour s’occuper du paramétrage du simulateur (à l’échelledu bassin versant et non plus de la parcelle), pour générer les données, les regrouperet les analyser. En plus de cela, nous avons amélioré la maquette en rendant plusde choses paramétrables, en permettant par exemple, des applications simultanéesou non de plusieurs pesticides différents (ce qui n’était pas possible avant) ou enlui ajoutant la possibilité de générer des exemples par série et non plus un par un,à la main.
39

Chapitre 5
Constitution de la based’apprentissage
La constitution d’une base d’apprentissage passe par une première phase d’abs-traction de ce que l’on veut modéliser. Il s’agit en fait de classer, nettoyer et traiterles données de façon à les rendre utilisables par le système d’apprentissage. Ici,nous avions des données de types différents : climatique, topologique et « agri-cole » (qui concerne l’activité agricole à l’échelle d’une parcelle). Puis il s’agissaitde trouver les scénarios intéressants et de constituer la base en elle même.
5.1 Traitement des données
Elles sont de trois types : météorologique (description des conditions météoen terme de précipitations et de température), topologique (description de l’orga-nisation du bassin versant) et parcellaire (le type de stratégie de désherbage quel’agriculteur emploit sur sa parcelle, le type de la parcelle).
5.1.1 Données climatiques
Grâce à l’INRA Rennes, nous avons à disposition les précipitations au pas detemps horaire ces neufs dernières années sur les communes du Rheu (bassin deRennes) et de Naizin (commune proche du bassin versant du Frémeur : le bassintest du projet SACADEAU), et des dix dernières années sur Quimper. On disposeégalement des températures moyennes sur une journée de ces mêmes années.
Mise en forme des données
Comme nous l’avons vu, le modèle biophysique fonctionne au pas de tempsjournalier. Or, nous disposons de données météorologiques à l’échelle de l’heure.Il a donc fallu traiter une première fois ces données pour qu’elles soient utilisables,tout en gardant les informations importantes qui sont les quantités d’eau tombées
40

supérieures à certains seuils de précipitations horaires (quantité journalière des pré-cipitations supérieures à 2, 4, 6... mm/h). En effet, ce sont ces quantités d’eau qui,en fonction du seuil d’infiltrabilité du sol (SI), détermine la quantité d’eau ruisse-lée, et donc la quantité de pesticide qui sort de la parcelle : 2 mm si le SI est de 10mm/h et qu’il a plu 12 mm sur une heure.
Pour que la maquette simulant notre modèle fonctionne, nos fichiers météocontiennent donc pour tous les jours d’une année :
– le cumul de précipitation sur une journée ;– la valeur moyenne des températures de la journée ;– le cumul de précipitations supérieures à 2, 4, 6, 8, 10, 12, 15 et 20 mm/h,
seuils qui correspondent aux différents seuils d’infiltrabilité du sol dans lemodèle (cf A.2 en annexe).
Classification des données
L’autre travail nécessaire à l’utilisation des données climatiques est leur clas-sification. La difficulté la plus importante vient du fait qu’une classification desclimats, même de façon grossière, dépend beaucoup du point de vue dont on re-garde les données météo : une « bonne » année pour le ruissellement peut être une« mauvaise » année pour un agriculteur, tout en étant « moyenne » pour un tou-riste par exemple. Ceci impose presque de passer par un expert du domaine (ici desproblèmes de ruissellement) pour identifier les variables qui semblent importantesvis à vis du problème, trouver des valeurs seuils et conjuguer ces paramètres pourclasser les données. L’utilisation de techniques de classification non supervisé au-rait éventuellement pu servir dans le cadre d’une vérification des critères retenuspar les experts. L’intérêt premier de regrouper les années climatiques par classe estévident : on limite la combinatoire lors de la géneration de la base d’apprentissage.
En discutant des causes du ruissellement avec des experts, on peut voir se dé-gager une hiérarchie de critères, mais surtout une synergie de facteurs : il n’y aruissellement que si la conjonction de certains critères est réunie. Globalement, il ya ruissellement au printemps1 si l’averse est de forte intensité et que l’infiltrabilitédes sols est faible. Si le sol est humide, le ruissellement est plus important. Troiscritères ont été retenus parmi ceux qui concernent ce problème :
1. le cumul de pluie du 1er mai au 31 juillet (on ne s’occupe que des parcellesde maïs, sinon on ne travaillerait pas sur cette période : septembre-mars pourle blé par exemple)
2. la fréquence des cumuls de pluies supérieurs à 10 mm sur 24 heures,
3. la fréquence des cumuls de pluies supérieurs à 15 mm sur 48 heures.
1c’est la saison qui nous intéresse pour la culture du maïs
41

Il a fallu trouver par la suite, différentes valeurs seuils de chacune de ces va-riables, et trouver un moyen de les combiner efficacement pour obtenir une classi-fication homogène et sensée : il ne sert à rien de créer une classe si aucune donnéene peut y être classer. Pour faire simple (dans le but de limiter la combinatoire),nous avons pu en collaboration avec des experts, « isoler » trois classes de climats.La combinaison des critères se fait par une moyenne des classements pour chaquecritère.
Période mai-juillet Classe 1 Classe 2 Classe 3
critère 1 � 100 mm 100 � 150 mm � 150 mmcritère 2 � 3 3 � 6 � 6critère 3 � 4 4 � 7 � 7
TAB. 5.1 – Typologie des climats
Les critères et les seuils ont évolué au cours du temps, au vu des résultats declassifications des données. Finalement, on peut qualifier les trois classes commesuit :
– classe 1 : « printemps » plutôt sec avec peu de fortes précipitations– classe 2 : « printemps » moyennement humide (classe intermédiaire)– classe 3 : « printemps » plutôt humide avec des fortes pluies
Cette classification est issue du travail avec les experts. On peut remarquer quel’on ne couvre pas tous les cas possibles, comme les saisons humides avec despluies faibles mais régulières, mais il est plus judicieux de perdre en représenta-tivité pour gagner sur la combinatoire : à vouloir être exhaustif, on aurait pu seretrouver avec une classe de climat par année météorologique étudiée !
5.1.2 Données sur les parcelles
Il s’agit ici de déterminer les paramètres qui peuvent jouer pour le ruissellementà l’échelle d’une parcelle agricole. Indubitablement, la stratégie de désherbage del’agriculteur entre dans cette catégorie. Entre aussi dans cette catégorie la richessedu sol en matière organique et la vitesse d’évolution de ce dernier. On a donc icides paramètres qui dépendent intégralement de l’homme et d’autres pas.
Modes de décision de l’agriculteur
De tous les paramètres que nous venons de citer, la stratégie utilisée est celuiqui est le plus complexe à aborder. L’agriculteur a plusieurs choix à faire lorsqu’ilveut désherber sa parcelle :
– choisir une stratégie globale : va-t-il traiter en une ou deux fois, à quel stadede croissance de la culture (avant ou après la levée du semis) ?
– choisir un produit.
42

– choisir les doses qu’il va appliquer.
Ces choix qu’il doit faire se font en fonction (dans le désordre):– des conseils des techniciens agricoles et des revendeurs ;– de la disponibilité des produits ou de ses stocks ;– coût des produits (et donc santé financière de son exploitation) ;– de sa formation, de son expérience (quel produit s’est révélé plus efficace
qu’un autre, quelle stratégie s’est montrée moins coûteuse,...), de ce que faitson voisinage...
– éventuellement de sa préoccupation à protéger son environnement (choix demolécules moins aggressives, création de dispositifs tampons).
Ces choix sont plus de nature culturelle que technique, et un technicien qui sechargerait de réaliser le désherbage aurait sans aucun doute choisi d’autre critèresplus physique :
– prévision météo,– hygrométrie de l’air,– nature et état de croissance des adventices (« mauvaises herbes »),– concurrence des adventices avec la culture en place,– sélectivité du produit vis à vis de la culture,– ...
Notre modélisation
Après consultation des experts, nous avons choisi de ne considérer que les stra-tégies d’application de pesticides en elles-mêmes, ainsi que les différents types desol et la qualité des dispositifs tampons sur la parcelle. Par type de sol, nous en-tendons sa capacité à évoluer et sa teneur en matière organique (MO) : un solqui évolue « vite » ruissellera plus qu’un sol qui évolue lentement. Là encore,nous avons fait l’hypothèse qu’une parcelle avait un sol uniforme sur son intégra-lité. Cette approximation est due au choix des experts de considérer les parcellescomme homogènes.
Types de sols : Nous avons choisi d’utiliser deux sols bien distincts dans le mo-dèle (sols que l’on retrouve sur le bassin versant du Frémeur qui est notre bassinde références):
%MO seuil F0F11 seuil F11F12 seuil F12F2 seuil R3R2 seuil R2R1 seuil R1R0
sol 1 3% 50 mm 150 mm 250 mm 30 mm 170 mm 250 mm
sol 2 6% 65 mm 200 mm 450 mm 40 mm 210 mm 325 mm
TAB. 5.2 – Types de sols
43

Par seuil FiFi+1 (resp. seuil RiRi-1), nous entendons ici le cumul de précipita-tion nécessaire pour faire passer le sol d’un faciès (resp. d’une rugosité) Fi à Fi+1(resp. Ri à Ri-1).
Initialement, nous avons considéré que la parcelle se trouvait dans l’état :– faciès du sol : F0 (état après travail du sol)– rugosité : R3 (dénivellation entre cols et creux des sillons entre 5 et 10 cm)– couvert végétal nul (on vient de semer).
Ceci nous permet de calculer le seuil d’infiltrabilité initial du sol (via des règlesexpertes) et, sachant son type et les précipitations, nous permet de calculer sonévolution future (faciès, rugosité, seuil d’infiltrabilité)2 .
Stratégies de désherbage : On peut dégager trois grandes stratégies d’applica-tion de pesticides. Pour chaque stratégies, un agriculteur a le choix entre plusieursproduits ou combinaisons de ces produits. Globalement, les agriculteurs suiventles conseils des techniciens et cela simplifie grandement le regroupement des typesd’applications en stratégies globales. Ces stratégies se distinguent par leur périoded’application :
– traitement avant la levée des cultures (stratégie d’assurance).– traitement après la levée des cultures (stratégie d’adaptation puisqu’elle
consiste à différer les applications et/ou à diminuer les doses).– traitement fractionné en deux temps avant et après la levée.
Les applications se font à partir d’observations directes de l’état de la parcelle,mais le plus souvent en fonction de l’état attendu de la parcelle en fonction de sonhistorique.
Dispositifs tampon : Il est reconnu que des dispositifs tels que des bandes enher-bées, des talus ou des fossés, sont des moyens de réduire la sortie de pesticides desparcelles. Il est par exemple supposé qu’une bande enherbée d’une largeur de 12mètres est capable de retenir 50% des pesticides qui ruissellent (l’efficacité n’estpas linéaire et il faut plus de 24 m de bandes enherbées pour capter « 100% » despesticides). Nous avons choisi de simuler des dispositifs plus ou moins efficaces :
– efficace à 0% : pas de dispositifs tampons,– efficace à 50%– efficace à 90%.
La présence de tels dispositifs sur une parcelle dépend entièrement de son proprié-taire : il n’y a, par exemple, pas d’obligation légale d’en mettre sur les parcelles àrisque fort.
2pour ce qui est du couvert, il évolue en fonction du cumul de température : au bout d’un certaincumul de température, on gagne une classe de CV, jusqu’à la récolte où le couvert retombe à 0%.
44

Ce qui en ressort : Nous avons choisi de retenir deux types de sols, trois types dedispositifs tampons et les deux premières stratégies. Comme nous n’avons pas demodèles de prédiction de l’évolution des adventices sur les parcelles, nous avonsdonc fixé les dates d’applications en fonction seulement des pratiques des agri-culteurs : le plus tôt possible après le semis pour la stratégie en pré-levée (soit2equinzaine d’avril) et pendant la 2equinzaine de juin pour la stratégie en post-levée. Nous avons en plus, une période intermédiaire (2equinzaine de mai) pourdes applications en post levée plus précoce : au stade où la culture a développéentre 3 et 5 feuilles. Encore une fois, cette limitation vient de la nécessité de limiterl’explosion combinatoire, donc de trouver un compromis entre la représentativitédu langage et l’efficacité algorithmique. Dans un premier temps, nous avons choiside réduire les problèmes de combinatoire en jouant sur la complexité du langage,pour nous permettre d’avoir un biais simple. Ceci dit, pour le futur outil d’aide à ladécision du projet SACADEAU, il est clair qu’un modèle décisionnel assez poussésera nécessaire pour avoir un outil plus opérationnel ou plus réaliste. Dans ce cas,il faudra utiliser un biais plus restrictif.
5.1.3 Données sur le bassin
Le troisième type de données que nous avions à traiter concernait le bassinversant dans sa globalité. Il s’agissait ici de décrire la topologie du bassin. Nousavons fait plusieurs simplifications :
– on a choisit de ne s’occuper que des parcelles de maïs (les pesticides pour lesautres cultures, et leurs périodes d’application, étant différents, on ne risquaitpas de « mélanger » les produits).
– on ne classifie les parcelles qu’en fonction de leur pente (inférieure ou supé-rieure à 3%3) et de leur distance à l’exutoire (en fait, c’est la distance entrela sortie hydrographique de la parcelle et le cours d’eau). On ne considèreque ces deux types de pentes : il n’y a pas de différence au niveau du ruis-sellement de la parcelle (par contre, il y en a pour son érosion, mais celaest pris en compte lors du typage du sol des parcelles au niveau des vitessesd’évolution du faciès et de la rugosité).
Nous avons retenu trois types de bassins. Ces types se définissent en fonctionde la proportion de parcelles de maïs se trouvant à une certaine distance du coursd’eau et ayant une certaine pente. Notre bassin de type 1 a la configuration suivantedécrite par le tableau 5.3.
Par exemple, on a ici 25% des parcelles de maïs qui ont moins de 3% de penteet qui se situent à moins de 20 mètres du cours d’eau.
Ces pourcentages représentent non seulement la répartition topologique desparcelles de maïs sur le bassin, mais nous donnent aussi partiellement la fonctionde combinaison des parcelles entre elles. En effet, nous voulons des exemples à
3il a été montré qu’une parcelle ayant moins de 3% de pente ruisselait très peu
45

��
��
��
��
��
�pentedistance
<20 m 20-200 m >200 m
<3% 25% 20% 30%>3% 5% 20% 0%
TAB. 5.3 – Un type de bassin
l’échelle d’un bassin mais que le cœur du simulateur fonctionne à l’échelle d’uneparcelle : il est donc nécessaire d’assembler les flux de pesticides concernant lesparcelles pour ne former qu’une seule sortie concernant l’intégralité du bassin.
On suppose que plus une parcelle est loin d’un cours d’eau et moins elle estsusceptible de le polluer : avec l’accroissement de la distance, les pesticides ontplus de chances d’être filtrés et de partir avec les eaux de lessivage vers la nappe,ou de s’arrêter sur une autre parcelle. On prend donc en compte la distance desparcelles au cours d’eau dans la combinaison. Nous avons donc des abattementsproportionnelles à l’éloignement de la parcelle (0% pour les parcelles à moins de20 m, 70% pour les parcelles de 20 à 200 m et 95% pour celles éloignées de plus de200 m). Nous avons de plus choisi de « faire ruisseler » les parcelles ayant moinsde 3% de pente, tout en abattant leurs rejets de 90% pour avoir une meilleure si-mulation.
On a donc les abattements suivant à opérer (à ces abattements viennent encorese greffer ceux dus aux bandes enherbées) :
��
��
��
��
��
�pentedistance
<20m 20-200m >200m
<3% 90% 97% 99,99%>3% 0 70% 95%
TAB. 5.4 – Abattement
5.2 Résultats : scénarios et sorties de simulation
Pour créer les exemples d’apprentissage, nous sommes partis des scénarios (en-semble des paramétrages du bassin versant : son type, son climat, la/les stratégie(s)appliquée(s) sur le bassin, le type de sol sur les parcelles du bassin) et avons classéleurs résultats. Malgré les restrictions que nous avons prises, nous verrons par lasuite que nous avons un langage de scénarios riche.
46

5.2.1 Les scénarios
Pour avoir des scénarios réalistes, il fallait que nos scénarios correspondent àce qu’il se fait en matière de désherbage. Notre bassin test est celui du Frémeur,et nos scénarios se basent sur l’activité agricole se situant sur ce bassin (Résultatsd’une enquête INRA sur les pratiques agricoles).
Pour classer les résultats, nous utilisons les concentrations des pesticides dansle cours d’eau. Il faut donc en plus de tout ce que l’on a déjà fait, simuler les coursd’eau, ce qui revient en fait à simuler leurs débits pour avoir de « bonnes » dilu-tions des pesticides. Là encore, peu de données historiques étaient disponibles surles débits de rivières : à peine les débits de l’Evel (le cours d’eau qui passe dansle bassin du Frémeur) pour les années 98 à 2001. Il a donc fallu recréer des débitscohérents pour les autres années de simulation, travail essentiellement réalisé parles experts.
Une fois tout ceci pris en compte, il faut s’intéresser aux réelles capacités desimulation de notre maquette. Autrement dit, quelle est la puissance de notre lan-gage de description ?Nous pouvons simuler :
– 3 types de climats,– 3 types de bassins,– 6 « super parcelles » qui peuvent être de 4 types différents (2 possibilités de
types de sols * 2 stratégies d’application de pesticides différentes)– 3 catégories de dispositifs tampons.
Nous avons donc à disposition un langage assurément très riche malgré lenombre restreint de classes par paramètres : pas plus de quatre classes différentes àchaque fois. Ceci dit, une rapide multiplication montre que l’on peut quand mêmegénérer 110 592 bassins différents, et si l’on entre dans les détails des classes,on a actuellement la possibilité de générer (3 bassins * 3 dispostifs tampons * 2types de sols * 7 applications différentes sur 6 zones * 28 années climatiques)28 � 3 � 3 � 2 � 76 � 59 295 096 bassins versants différents.
Pour ce qui est des scénarios à réaliser, notre choix s’est porté dans un premiertemps sur la simulation de combinaisons :
– des trois types de bassins ;– des trois types de climats : on se restreint sur les dates d’applications des
pesticides pour simuler des épandages « réalistes » vis à vis des conditionsmétéo ;
– des stratégies de types pré-levée et post-levée ;– des deux types de sols ;– les bandes enherbées ne sont présentes que sur les parcelles proches du cours
d’eau (<20 m) : si il y en a, elles sont efficaces à 90%. On simule des bassins
47

avec 10%, 50% ou 90% de parcelles ayant des bandes enherbées efficaces.
En plus de cela, nous nous limitons au cas où on applique la même stratégied’application sur l’intégralité du bassin, ce qui ne nous laisse plus que 108 com-binaisons différentes, avec la possibilité de générer plus d’une dizaine d’exemplesdifférents de chaque scénarios.
5.2.2 Présentation et classification des résultats des simulations
Chaque simulation produit une chronique temporelle de la concentration depesticide dans le cours d’eau. Pour chaque jour à partir de l’application, nous avonsdonc le flux ruisselant en µg et la concentration des différents pesticides en µg/l. Enthéorie, on ne peux pas mélanger ou additionner les concentrations des pesticidesentre elles. Ceci dit, lorsque l’on contrôle la qualité de l’eau, on ne cherche pas àsavoir qui est le responsable de la pollution. On se contente simplement de montrerle problème. Aussi, même si nous faisons la distinction entre chaque pesticide,nous classifions nos sorties en fonction de la concentration globale des pesticides.
Les données historiques que nous avons à disposition concernent essentielle-ment l’atrazine. Ce pesticide a été très utilisé par le passé mais est maintenant« interdit » à cause de sa dangerosité pour l’homme et pour l’environnement en casde pollution. Sa dynamique est donc bien connue et c’est ce pesticide qui va servirà étalonner la maquette, puis à valider nos résultats.
Le cadre légal concernant la potabilité de l’eau existe. Au sujet de la présencede pesticides dans les cours d’eau, les normes sont des seuils de concentrations :
– pas plus de 0,1 µg/l par molécule ;– pas plus de 0,5 µg/l en cumulé sur toutes les molécules.
Le travail de classification des résultats s’est, là encore, déroulé en collabo-ration avec les experts de l’INRA Rennes. Pour qualifier nos sorties, nous avonschoisit de retenir les critères suivants :
– on classe nos résultats sur la période mai-juillet ;– on prend en compte la somme des concentrations en pesticides suivant les
critères définis dans le tableau 5.5– on ajoute des pénalités (changement de classe) si il y a un nombre de pics
supérieur aux seuils réglementaires (0,1 et 0,5 µg/l).
Finalement, nos classes de résultats sont au nombre de cinq :– classe 0 : non contaminé ;– classe 1 : contamination faible ;– classe 2 : contamination moyenne (mais pas catastrophique)– classe 3 : contamination forte ;– classe 4 : contamination très forte.
48
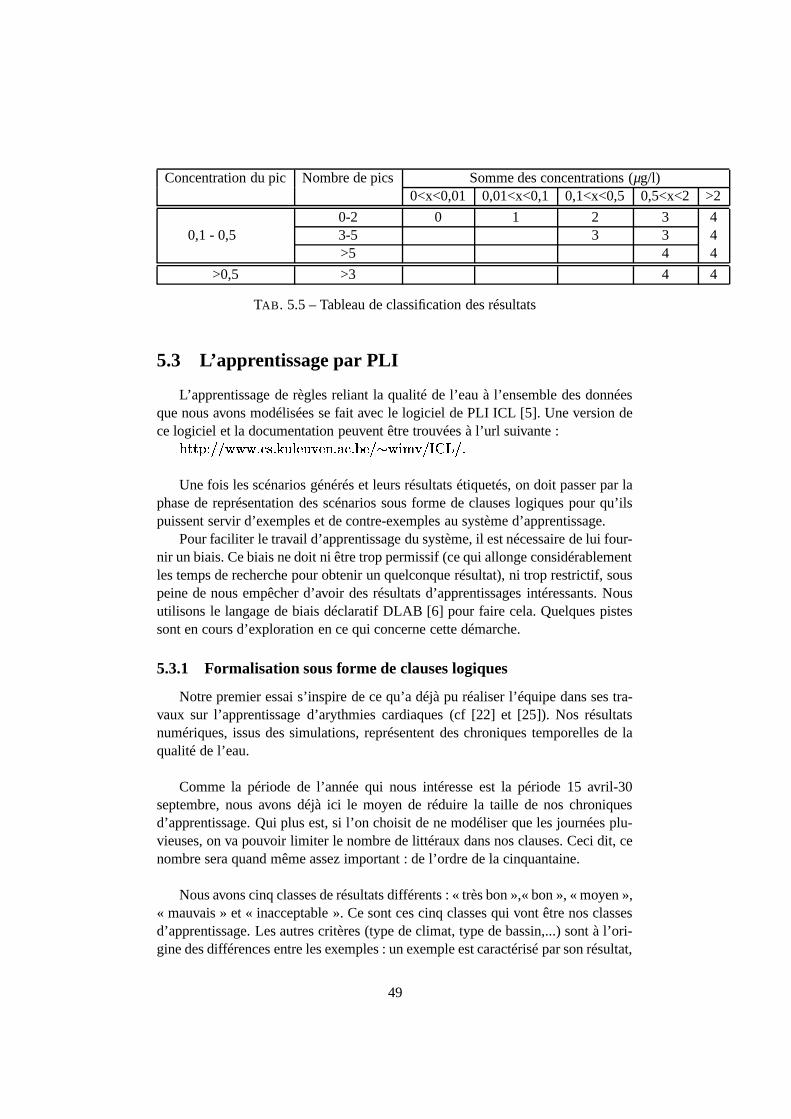
Concentration du pic Nombre de pics Somme des concentrations (µg/l)0<x<0,01 0,01<x<0,1 0,1<x<0,5 0,5<x<2 >2
0,1 - 0,50-2 0 1 2 3 43-5 3 3 4>5 4 4
>0,5 >3 4 4
TAB. 5.5 – Tableau de classification des résultats
5.3 L’apprentissage par PLI
L’apprentissage de règles reliant la qualité de l’eau à l’ensemble des donnéesque nous avons modélisées se fait avec le logiciel de PLI ICL [5]. Une version dece logiciel et la documentation peuvent être trouvées à l’url suivante :���������������� ����� ����������������� ��� �!"���#$&%(')����*,+.-/�0
Une fois les scénarios générés et leurs résultats étiquetés, on doit passer par laphase de représentation des scénarios sous forme de clauses logiques pour qu’ilspuissent servir d’exemples et de contre-exemples au système d’apprentissage.
Pour faciliter le travail d’apprentissage du système, il est nécessaire de lui four-nir un biais. Ce biais ne doit ni être trop permissif (ce qui allonge considérablementles temps de recherche pour obtenir un quelconque résultat), ni trop restrictif, souspeine de nous empêcher d’avoir des résultats d’apprentissages intéressants. Nousutilisons le langage de biais déclaratif DLAB [6] pour faire cela. Quelques pistessont en cours d’exploration en ce qui concerne cette démarche.
5.3.1 Formalisation sous forme de clauses logiques
Notre premier essai s’inspire de ce qu’a déjà pu réaliser l’équipe dans ses tra-vaux sur l’apprentissage d’arythmies cardiaques (cf [22] et [25]). Nos résultatsnumériques, issus des simulations, représentent des chroniques temporelles de laqualité de l’eau.
Comme la période de l’année qui nous intéresse est la période 15 avril-30septembre, nous avons déjà ici le moyen de réduire la taille de nos chroniquesd’apprentissage. Qui plus est, si l’on choisit de ne modéliser que les journées plu-vieuses, on va pouvoir limiter le nombre de littéraux dans nos clauses. Ceci dit, cenombre sera quand même assez important : de l’ordre de la cinquantaine.
Nous avons cinq classes de résultats différents : « très bon »,« bon », « moyen »,« mauvais » et « inacceptable ». Ce sont ces cinq classes qui vont être nos classesd’apprentissage. Les autres critères (type de climat, type de bassin,...) sont à l’ori-gine des différences entre les exemples : un exemple est caractérisé par son résultat,
49

bien entendue, mais aussi par ses paramètres d’entrée.
Un exemple d’une classe quelconque aura donc la forme :
exemple(Num,Clim,Bassin,Parc,BE):–journee(Date1 ,Cat1,Ruiss1),journee(Date2 ,Cat2,Ruiss2),
...journee(Date f in ,Cat f in,Ruiss f in).
avec :– Num : numéro de l’exemple– Clim : classe de climat– Bassin : type de bassin– Parc : type de parcelle (stratégie et sol)– BE : qualité des bandes enherbées
– Datei : date de la pluie– Cati : type de pluie– Ruissi : type du ruissellement
Ceci est la représentation « ICL » d’un exemple d’une certaine classe. On peutnoter qu’en plus de ce que l’on pouvait attendre, on a rajouté des types de pluies etdes types de ruissellement pour la journée. On essaye ici de rajouter un peu d’infor-mation pour pouvoir distinguer les différents cas de ruissellement : ceux qui sontdus à des pluies importantes et ceux dus à des pluies plus faibles ; et dans tous lescas, on rajoute l’importance du ruissellement. On fait ainsi la différence entre des« mauvaises » années dues à de nombreux petits ruissellement et des « mauvaises »années dues à des ruissellements importants mais peu fréquents.
On pourrait envisager de considérer plus d’information dans les clauses :– écart de temps avec la dernière pluie– temps passé depuis la dernière pluie de même type– cumul de précipitations sur 48, 72, 96,... heures– ...Ces critères seraient bien sûr plus qualitatifs que numériques: on parlerait, par
exemple, de pluies faibles dans les dernières 72 heures.
5.3.2 Le biais d’apprentissage
Construire un biais d’apprentissage n’est pas une chose facile (exemple en[22]). Construisez le de manière trop précise, vous obtiendrez des résultats quicolleront beaucoup aux exemples. Construisez le de façon trop permissive et vous
50

obtiendrez peu de résultats intéressants (après beaucoup de temps de calcul). Lelangage de biais que nous utilisons est DLAB que nous avons rapidement décrit ensection 2.4.
Pour le moment, nous pensons écrire un biais obligeant ICL à trouver des ré-sultats contenant certains de nos critères d’entrées. Le biais pourrait s’écrire de lafaçon suivante :
��� �������������� ��� ���(% ' � ��� +.�(% ' � � ��������� ��� ! ��,�,% ������ �� �,% ����������� ��� � ��� � ��� �������� ��� � ��� ������������� ��� ! �����������.����������
�où :– TClimat représente un type de climat ;– TBassin représente un type de bassin ;– ...
On inférerait des règles qui seraient des conjonctions des paramètres d’entrées :on pourrait imaginer obtenir des règles disant, par exemple, que quelque soit leclimat, avec tel type de bassin et tel type de dispositifs tampons, on obtient desrésultats de la classe « bon ».
Ceci dit, on pourrait imaginer avoir deux exemples ayant le même paramétrage(même type de climat, de bassin, ...) et obtenir deux classifications différentes pources exemples : une année bonne et une année moyenne par exemple. Le fait qu’ICLconsidère les exemples des autres classes comme étant des contre-exemples pourla classe apprise, n’est pas encore gênant : on a la possibilité de fixer un taux decouverture des exemples positifs et négatifs (concrètement, on s’autorise à ne pascouvrir certains exemples positifs et à couvrir quelques exemples négatifs). Encontre partie, il faudra fournir plus d’exemples au système. Cela pourrait devenirembêtant si jamais ce cas de figure apparaissait trop souvent, et il faudrait doncrajouter plus d’informations dans le biais. Il est raisonnable de penser que deuxexemples ayant les mêmes paramètres et les mêmes caractéristiques de ruisselle-ment (en termes de classe de nombres de pics de certaines catégories : « peu degrand pics » ou « un nombre moyen de petits pics ») se trouvent dans la mêmeclasse de résultat. Comme, notre classification des résultats se base entre autres surla fréquence des pics de concentration de pesticides, il serait donc naturel de fairefigurer cette information dans le biais.
Un autre point de vue qui n’a pas encore été abordé dans la constitution dubiais est le fait que nos exemples soient des chroniques temporelles. Avec le biaisque nous avons proposé plus haut, nous perdons cette information.
51

Chapitre 6
Conclusion
L’objectif principal de ce stage fût de créer une base d’apprentissage pour in-férer des règles reliant qualité de l’eau et pratiques agricoles. Ceci a demandé unimportant travail de traitement et de modélisation de données très diverses, en col-laboration avec des experts. Cette activité a pris beaucoup de temps, ce qui a réduitle temps consacré à la phase d’apprentissage en elle même : la formalisation sousforme de clauses logiques et la construction du biais d’apprentissage sont en cours,mais les premières pistes que nous avons sont encore en cours de tests. Ceci dit,c’est ce qui a donné à ce stage son côté pluridisciplinaire et appliqué.
La constitution de la base en elle même est en voie d’achèvement. Nous nesommes pas loin de pouvoir réaliser une démarche complète de simulation et d’ana-lyse de résultats : le simulateur fonctionne et n’a pas eu besoin de subir d’impor-tants réglages ; l’analyse automatique des résultats du simulateur est quasiment in-tégré et la transcription automatique des exemples sous formes de clauses logiquesdevrait bientôt être achevée. Une fois ceci terminé, il ne restera plus qu’à définir unbiais de bonne qualité et lancer la phase d’apprentissage et d’analyse des résultatsappris. Bien sûr il faudra passer par des phases d’adaptation du biais, mais ceci ne« coûte » pas grand chose par rapport à la constitution de la base en elle-même.Pour SACADEAU même, il faudra simplement passer à une maquette plus précise(qui vient d’être terminée par le doctorant F. Tortrat de l’INRA). Comme le langagede scénarios et la modélisation des résultats ne changent pas ou peu, ce qui a étéfait durant le stage pourra être réutilisé facilement.
S’il a été un peu frustrant de ne pas aller plus loin dans l’utilisation de la PLI,il y a eu un travail méthodologique important de réalisé et celui-ci pourra êtreréutilisé dans des situations avec des problématiques proches (globalement : l’in-duction de règles explicatives dans un domaine où il existe un simulateur capablede reproduire les processus mis en jeu et donc de fournir des résultats en fonc-tion de données d’entrées). Ces situations peuvent très bien sortir du domaine del’agro-alimentaire puisqu’il est envisageable d’utiliser la même approche dans le
52

cadre d’acquisition de connaissances à partir de données médicales ou de donnéesissues de la simulation de réseaux à très hauts débits (p. ex.les projets CEPICA,sur les nouvelles sondes cardiaques Ela-Medical, et MAGDA2, avec les donnéesMib-Qos sur le réseau VTHD, développés au sein de l’équipe).
53

Bibliographie
[1] E. Barriusio, R. Calvet, M. Schiavon, and G. Soulas. Les pesticides et lespolluants organiques du sol. Étude et gestion des sols, 3-4:279–295, 1996.
[2] Y. Le Bissonnais. Analyse des mécanismes de désagrégation et de la mobi-lisation des particules de terre sous l’action des pluies. Thèse doctorale descience de la terre, Université d’Orléans, 1988.
[3] W. Buntime. Generalised subsmption and its application to induction andredundancy. Artificial Intelligence, 36(2):149–176, 1988.
[4] A. Church. A set of postulates for the foundation of logic. Ann. of Math.,33:346–366, 1932. Second paper with same title in Vol. 33, pages 839–864,of same journal.
[5] L. De Raedt and W. Van Laer. Inductive constraint logic. Lecture Notes inComputer Science, 997:80–??, 1995.
[6] L. Dehaspe and L. De Raedt. DLAB: a declarative language bias forma-lism. In Zbigniew W. Rás and Maciek Michalewicz, editors, Proceedingsof the Ninth International Symposium on Foundations of Intelligent Systems,volume 1079 of LNAI, pages 613–622, Berlin, June 9–13 1996. Springer.
[7] W. Van Laer, L. De Raedt, and S. Džroski. On multi-class problems anddiscretization in inductive logic programming. In Zbigniew W. Ras and An-drzej Skowron, editors, Proceedings of the 10th International Symposium onFoundations of Intelligent Systems (ISMIS-97), volume 1325 of LNAI, pages277–286, Berlin, October 15–18 1997. Springer.
[8] S. Dan Lee and L. de Raedt. Constraint based mining of first order sequencesin seqlog. In First International Workshop on Knowledge Discovery in In-ductive Databases (KDID02). In conjunction with ECML’02 and PKDD’02,2002.
[9] R. A. Leonard, G. W. Langdale, and W. G. Fleming. Herbicides losses fromupland Piedmont watersheds - data and implications for modeling pesticidetransport. Journal of Environment Quality, 8:223–229, 1979.
[10] C. Masson and F. Jacquenet. Découverte de séquences logiques fréquentessous contraintes. In Actes du 13e Congrès Francophone AFRIF-AFIA deReconnaissance des Formes et Intelligence Artificielle. RFIA’02, pages 673–684, janvier 2002.
54

[11] L. Miclet and A. Cornuéjols. Apprentissage artificiel : concepts et applica-tions, chapter 5, pages 157–192. Eyrolles, 2002.
[12] T. M. Mitchell. Machine Learning. McGraw-Hill, 1997.
[13] S. Muggleton. Inverse entailment and Progol. New Generation Computing,Special issue on Inductive Logic Programming, 13(3-4):245–286, 1995.
[14] S. Muggleton. Inductive logic programming : issues, results and the challengeof learning language in logic. Artificial Intelligence, (114 (1-2)):283–296,1999.
[15] S. Muggleton and W. Buntime. Machine invention of first order predicatesby inverting resolution. In Proceedings of the Fifth International Conferenceon Machine Learning, pages 339–352. Kaufmann, 1988.
[16] S. Muggleton and F. Cao. Efficient induction of logic programs. In Procee-dings of the Workshop on Algorithmic Learning Theory, Tokyo, 1990.
[17] S. Muggleton and L. De Raedt. Inductive logic programming: Theory andmethods. The Journal of Logic Programming, 19 & 20:629–680, May 1994.
[18] C. Nédellec, C. Rouveirol, H. Adé, F. Bergadano, and B. Tausend. Declarativebias in ILP. In L. De Raedt, editor, Advances in Inductive Logic Program-ming, pages 82–103. IOS Press, 1996.
[19] G. D. Plotkin. A note on inductive generalization. In B. Meltzer and D. Mi-chie, editors, Machine Intelligence 5, pages 153–163, Edinburgh, 1969. Edin-burgh University Press.
[20] G. D. Plotkin. A note on inductive generalization. In B. Meltzer and D. Mit-chie, editors, Machine Intelligence, pages 153–165, 1970.
[21] G. D. Plotkin. A further note on inductive generalization. In Machine Intelli-gence, volume 6, pages 101–124. Edinburgh University Press, 1971.
[22] R. Quiniou, M.-O. Cordier, G. Carrault, and F. Wang. Application of ILPto cardiac arrhythmia characterization for chronicle recognition. In CélineRouveirol and Michèle Sebag, editors, Proceedings of the 11th InternationalConference on Inductive Logic Programming, volume 2157 of Lecture Notesin Artificial Intelligence, pages 220–227. Springer-Verlag, 2001.
[23] J. R. Quinlan and R. M. Cameron-Jones. Induction of logic programs: FOILand related systems. New Generation Computing, Special issue on InductiveLogic Programming, 13(3-4):287–312, 1995.
[24] J. A. Robinson. A machine-oriented logic based on the resolution principle.Journal of the ACM, 12(1):23–41, January 1965.
[25] F. Wang, R. Quiniou, G. Carrault, and M.-O. Cordier. Learning structuralknowledge from the ECG. Lecture Notes in Computer Science, 2199:288–??,2001.
[26] J. M. Zelle, R. J. Mooney, and J. B. Konvisser. Combining top-down andbottom-up techniques in inductive logic programming. In W. W. Cohen and
55

H. Hirsh, editors, Proceedings of the 11th International Conference on Ma-chine Learning, pages 343–351. Morgan Kaufmann, 1994.
56

Annexe A
Les tableaux d’évaluation duseuil d’infiltrabilité (original etmodifié)
Nous présentons ici le tableau d’Y. Le Bissonnais qui permet l’évaluation duseuil d’infiltrabilité du sol en fonction de son faciès, de sa rugosité et de son cou-vert végétal. Entre parenthèses figurent les valeurs d’infiltrabilité (mm/h) qui cor-respondent à ces différents états de surface.
Rugosité Couvert Végétal FacièsF0 F11 F12 F2
> 10 cm>61% 0 (50) 0 (50) 0 (50) 2 (10)
31-61% 0 (50) 0 (50) 1 (20) 2 (10)<30% 0 (50) 1 (20) 1 (20) 2 (10)
5-10 cm>61% 0 (50) 0 (50) 0 (50) 2 (10)
31-61% 0 (50) 0 (50) 1 (20) 2 (10)<30% 0 (50) 1 (20) 2 (10) 3 (5)
2-5 cm>61% 0 (50) 0 (50) 1 (20) 2 (10)
31-61% 0 (50) 1 (20) 2 (10) 3 (5)<30% 0 (50) 1 (20) 2 (10) 3 (5)
1-2 cm>61% 0 (50) 1 (20) 2 (10) 3 (5)
31-61% 0 (50) 1 (20) 2 (10) 3 (5)<30% 1 (20) 2 (10) 3 (5) 4 (2)
< 1 cm>61% 0 (50) 1 (20) 2 (10) 3 (5)
31-61% 1 (20) 2 (20) 3 (5) 4 (2)<30% 2 (10) 2 (10) 3 (5) 4 (2)
TAB. A.1 – Évaluation du SI selon Y. Le Bissonnais
57

L’inconvénient majeur de ce tableau est qu’il n’est réaliste que si l’on consi-dère des intensités de pluies « instantanées ». Comme nous travaillons sur desprécipitations horaires, il a fallu adapter ce tableau car, typiquement, des valeursde précipitations horaires de l’ordre de 50 mm/h sont totalement exceptionnelles.Ce travail d’adaptation a été réalisé par F. Tortrat, thésard à l’INRA Rennes (UMRscience du sol) et membre du projet SACADEAU.
Dans le second tableau, les valeurs indiquées sont directement les seuils d’in-filtrabilité (en mm/h).
Rugosité Couvert Végétal FacièsF0 F11 F12 F2
> 10 cm>61% 20 20 15 12
31-61% 20 15 12 10<30% 15 12 10 10
5-10 cm>61% 20 15 12 10
31-61% 15 12 10 8<30% 15 12 8 8
2-5 cm>61% 15 12 10 8
31-61% 15 12 8 6<30% 12 10 6 4
1-2 cm>61% 15 12 10 6
31-61% 12 10 8 4<30% 10 10 6 2
< 1 cm>61% 12 12 8 4
31-61% 12 10 6 4<30% 8 6 4 2
TAB. A.2 – Évaluation du SI dans la maquette
58

Annexe B
Les équations de ruissellement
Nous présentons ici les équations et les approximations qui nous permettent decalculer les quantités et les concentrations de pesticides ruisselées.
B.1 Détermination si une pluie est ruisselante et calcul desquantités d’eaux ruisselées et lessivées
Un paramètre qui n’a pas été pris en compte lors du calcul du ruissellement,est de savoir au préalable si le sol est déjà saturé d’eau ou pas. En effet, un solsaturé ruisselle immédiatement tandis qu’un sol humide non saturé est encore ca-pable d’absorber de l’eau. La pluie d’imbibition (hauteur de pluie nécessaire pouramener la conductivité hydraulique du sol à saturation) n’a pas non plus été mo-délisée dans la maquette. Ceci aurait nécessité de fonctionner à deux échelles detemps différentes (journalière et horaire), et une refonte de la maquette.
Même si la maquette fonctionne au pas de temps journalier, nous avons besoinde certaines informations au plus au pas de temps horaire, puisque les seuils d’in-filtrabilité fournit par nos tableaux correspondent à des pluies instantanées (en faitles intensités maximum sur 6 minutes) ou en pluies horaires. Une pluie est doncruisselante ssi la quantité de pluies (Q) est supérieure au seuil d’infiltrabilité (SI).
Pour l’instant nous considérons simplement que la quantité d’eau ruisseléeQER sur une journée est égale au cumul de précipitations horaires sur la jour-née supérieur au seuil d’infiltrabilité SI du sol. La quantité d’eau lessivée QELest quand à elle égale à la différence entre la quantité totale des précipitations Qet QER. Comme on travaille ici à l’échelle de l’heure, on a en fait pour une heure i :
QER�i � � Q
�i � � SI QEL
�i � � Q
�i � � QER
�i �
59

Il ne reste plus qu’à faire la somme sur 24 heures pour avoir les quantités d’eauxlessivées et ruisselées pour une journée. pour d’autres calculs, on conserve le temps∆t passé depuis la dernière pluie ruisselante.
B.2 Calcul du stock de pesticide avant une pluie ruisse-lante
Le stock résiduel de pesticide SRiavant dans le 1ercm du sol à la date i est calculéen tenant compte du stock restant après la dernière pluie ruisselante SRi precedent ,auquel on applique un abattement prenant en compte la durée de demi-vie du pes-ticide.
Soit SR0 le stock initial de pesticide dans le sol.Si on se place dans le cas de la première pluie ruisselante, on a :
SRiavant � SR0� e �
∆t � ln�2 �
DT50 (kg/ha)
Sinon :
SRiavant � SRiprecedent� e �
∆t � ln�2 �
DT50 (kg/ha)
B.3 Calcul des flux de pesticide ruisselant et lessivant
Il s’agit, connaissant QER et QEL et le SRiavant de calculer la quantité de pesti-cide entraînée. On utilise l’équation de Léonard [9] qui donne l’équation de pesti-cides dans l’eau de ruissellement CPDER (en mg/l) en fonction de la concentrationde pesticides dans le stock résiduel CPDS (en mg/kg).
CPDS � K � CPDER1n soit : CPDER �
� CPDSK � n
avec K � Koc � %CO et %CO � %MO1 � 784 (%MO est un paramètre configu-
rable de la maquette et le Koc dépend du pesticide employée). Quant à n, il s’agitd’une constante appelée constante de Freundlich qui est proche de 1.
Par une première approximation (car n est proche de 1) on retiendra la formule :
CPDER � CPDSn
Koc � %CO
Comme on travaille sur le 1ercm du sol, et en supposant une densité apparentedes pesticides dans le sol de 1.3, alors la concentration dans le 1ercm vaut :
60

CPDS � SRiavant� 1 � 3 (µg/kg)
On en déduit donc le flux de pesticide ruisselant d’après la formule (et aprèsavoir fait les conversions dans les bonnes unités de mesure...) :
FPR � CPDER � QER � 104 (µg/ha)
Si on tient compte d’une bande enherbée, le flux sortant de la parcelle subit unabattement proportionnel à la largeur de la bande enherbée LBH. Sa valeur FPRbis
vaut :
FPRbis � FPR � e �LBH � ln
�2 �
LBHRA50 (µg/ha)
Le flux lessivant est calculé de la même façon :
CPDEL � CPDSn
Koc � %CO� FPL � CPDEL � QEL � 104 (µg/ha)
Enfin, le calcul du stock résiduel de pesticides après une pluie ruisselante est :
SRiprecedent � SRiavant �
�FPR � FPL �
109
�kg
�ha �
Pour obtenir les concentrations, il ne suffit plus que de savoir quelle est laquantité réelle de ce pesticide a ruisselée jusqu’au cours d’eau (via la combinaison)et de la diviser par la quantité d’eau se trouvant dans la rivière cette journée là viaQER et le fichier de débit. Cela nous donne une concentration moyenne sur unejournée.
61

Annexe C
Détails sur les stratégiesd’application des pesticides
Durant notre étude, nous avons travaillé sur un certain nombre de moléculesdifférentes, et que les agriculteurs utilisent actuellement. Nous exposons ici cesproduits, ainsi que leurs caractéristiques chimiques.
spécialitéscommer-ciales
molécule DT50 Koc Dose homo-loguée parha
Mikado sulcotrione(300 g/l)
2-6 j 1,08-8,98 1,5 l/ha
Milagro nicosulfuron(40 g/l)
5-15 j 4,6-29,9 1,5 l/ha
Frontière(Syntaxe)
diméthénamide(900 g/l)
4-35 j 90-474 1.6 l/ha
Diplômeflutiamide (60%) 13-54 j 113-696 1 kg/hamétolusane (2,5%) 6-47 j 51,5-264,7
Isard diméthenamide(720 g/l)
4-35 j 90-474 1,4 l/ha
Merlin isoxaflutole(750 g/kg)
2-7 j 93-165 0,133 kg/ha
Basamaïs(fighter)
bentazone (480 g/l) 4-21 j 13-176 2,5 l/ha
Callisto mésotrione(100 g/l)
3-7 j 29-186 1,5 l/ha
atrazine 18-119 j 38-170#
1000 g/ha
TAB. C.1 – Listes de pesticides pour les cultures de maïs
Comme on peut le constater, les caractéristiques des produits évoluent beau-
62

coup suivant le type de sol sur lequel on les a appliqués. Nous avons choisi detravailler sur les valeurs moyennes des caractéristiques des produits. Comparative-ment à l’atrazine, on peut noter que les molécules utilisées actuellement ont desDT50 plus faibles, et donc sont moins susceptibles de provoquer des pollutions surle long terme.
Voici les conditions d’applications pour les stratégies que nous avons retenues :– la stratégie d’assurance : (ou dite de pré-levée consolidée) elle vise en un
seul passage, le désherbage des graminés et des dicotylédones par des pro-duits ayant une action racinaire. Les bonnes conditions d’application sont :– tout de suite ou le plus tôt possible après le semi (pour être sûr d’avoir de
la pluie dans les quinzes jours) ;– un temps légèrement humide et pluvieux pour permettre aux produits d’at-
teindre les graines en germination ;– pas de fortes pluies, sinon les produits sont lessivés et tout est à refaire.L’application se fait en général durant la deuxième quinzaine d’avril. Unrattrapage éventuel peut se faire en post-levée durant la deuxième quinzainede juin.
– la stratégie d’adaptation : (stratégie en post-levée, en deux passages) plustechnique, cette stratégie réclame aussi un plus grand suivi des parcelles,mais est plus rentable financièrement. Les adventices sont déjà levés maisencore jeunes, et les produits utilisés ont une action au niveau des feuilles.Les applications sont faites durant les deuxièmes quinzaine de mai et de juin.Des conditions climatiques spécifiques doivent être réunies :– l’hygrométrie ne doit pas être trop basse ;– la température ne doit pas être doit élevée ;– il ne doit pas pleuvoir dans les deux à trois heures qui suivent l’application.Cette stratégie est moins consommatrice car mise en œuvre avec des dosesplus faibles.
Pour connaître les bonnes conditions climatiques, les agriculteurs se tiennentgénéralement au bulletin météo de la télévision, soit une prévision sur quatre joursassez moyenne.
Les informations qui sont réunies ici sont extraites d’enquêtes auprès d’agri-culteurs et devraient servir pour la constitution d’un modèle décisionnel sur lesactivités des agriculteurs.
63


















