
présentation du Big data
38
Encadré par: Réalisé par: Mme. F. Nader Kouicem Amine Zeggari Nabil Ministère de l’Enseignement Supérieur et de la Recherche Scientif Ecole Nationale Supérieure D’informatique Master de Recherche Thème : Les technologies Big da Option: SI 20/03/2013
-
Upload
zeggarinabil -
Category
Documents
-
view
237 -
download
15
Transcript of présentation du Big data

Encadré par:Réalisé par:
Mme. F. Nader Kouicem Amine Zeggari Nabil
Ministère de l’Enseignement Supérieur et de la Recherche Scientifique
Ecole Nationale Supérieure D’informatique
Master de Recherche
Thème : Les technologies Big dataOption: SI
20/03/2013

2 Table de matière:
1. Introduction ……………………………………………………………….……….03
2. Le concept Big data………………………………………………………………06
3. La technologie NoSQL/ NewSQL………………………………..…………13
4. La technologie Hadoop ……… ………..........................................22
5. Architecture du Big data…………………………………………….…………27
6. Les approches du Big Data……………………………………………………28
7. Perspective de recherche……..…………………………………….………..34
8. Références bibliographiques…………………………………………………35

3 1. Introduction
La masse des données dans le monde augmente de jour en jour:
– 1800 exaoctets en 2011. (Gartner, 2011)
– 35 000 exaoctets en 2020 (Prévision par IBM)
– 250 Milliards d’e-mails envoyés/jour. (Radicati Group, 2009)
– 80% de l’information est «non-structurée » (Forrester, 2011)
– 95% de l’information est « non-exploitée » (Forrester, 2011)

4
Dans les réseaux sociaux:Facebook:
‒ 900 millions d’utilisateurs.‒ 250 millions de photos uploadées/jour.‒ 2,7 milliards de « Like » /jour.
Twitter:– Plus de 465 millions de comptes.– 175 millions de tweets/jour.
Youtube:– 2 milliards de vues/jour.– 72h de vidéos déposées/ minute.
1. Introduction
http://tepbigdata.blogspot.fr/ 2012 consulté le 17/02/2013
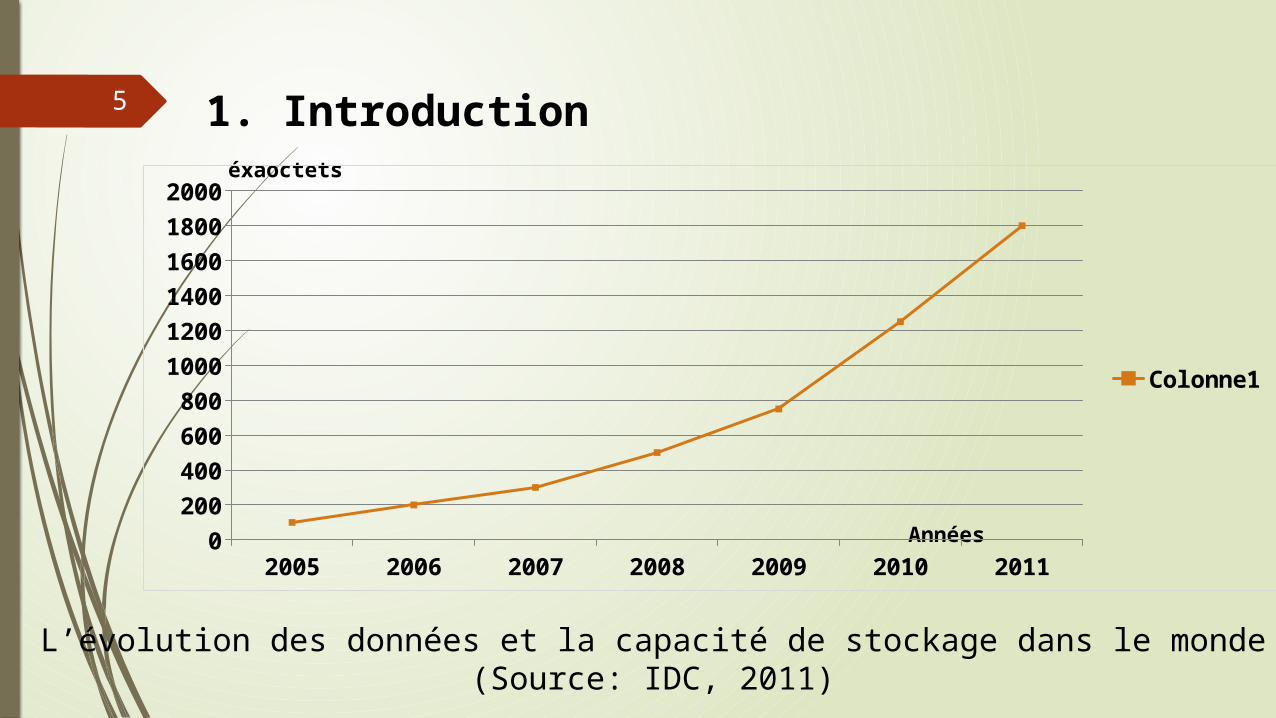
5 1. Introduction
L’évolution des données et la capacité de stockage dans le monde (Source: IDC, 2011)
éxaoctets
Années
2005 2006 2007 2008 2009 2010 20110
200
400
600
800
1000
1200
1400
1600
1800
2000
Volume des données

6 2. Le concept Big data 2.1 Définition du Big data (partie 1)
« le concept Big Data fait référence aux ensembles de données dont la
taille dépasse celle des ensembles de données que les outils de bases de
données traditionnels peuvent collecter, gérer et traiter dans un délai
acceptable ».
http://www.mckinsey.com/ consulté le 17/01/2013

7 2. Le concept Big data 2.1 Définition du Big data (partie 2)
« Les technologies Big data décrivent une nouvelle génération de technologies
et d'architectures dans la gestion de données, conçu pour extraire de la valeur
économique à partir de très grands volumes et variétés de données, en
capturant, en traitant et en analysant à grande vitesse ».
http://www.idc.com/ consulté le 20/01/2013

8
1995-2000 2000-2005 2005-2010 2010-2015 2015-2020
Phénomène Big data (internet)
Genèse Développement Dissémination Démocratisation
Innovation
technique
Phase
Google PageRank
(1996)
Google Adwords (2000)
Google MapReduce
(2004)
Criteo 2005 launch 2008
Couch Base (2011) ?
Stockage et traitement distribué et dissémination de recherche effectuées
par Google et consorts
Les grands acteurs de la toile développent des outils de traitement et l’analyse des données
massives non structurées
Développement d’un système de solution dédiéesApplication dans d’autres secteurs
Algorithme d’apprentissage
statistique et modèles de prédiction tirant
parti des architectures distribué
2. Le concept Big data 2.2. un peu d’historique.
Chronologie du Phénomène Big data. [E. Bellity, 2012]
Apache Hadoop (2007)
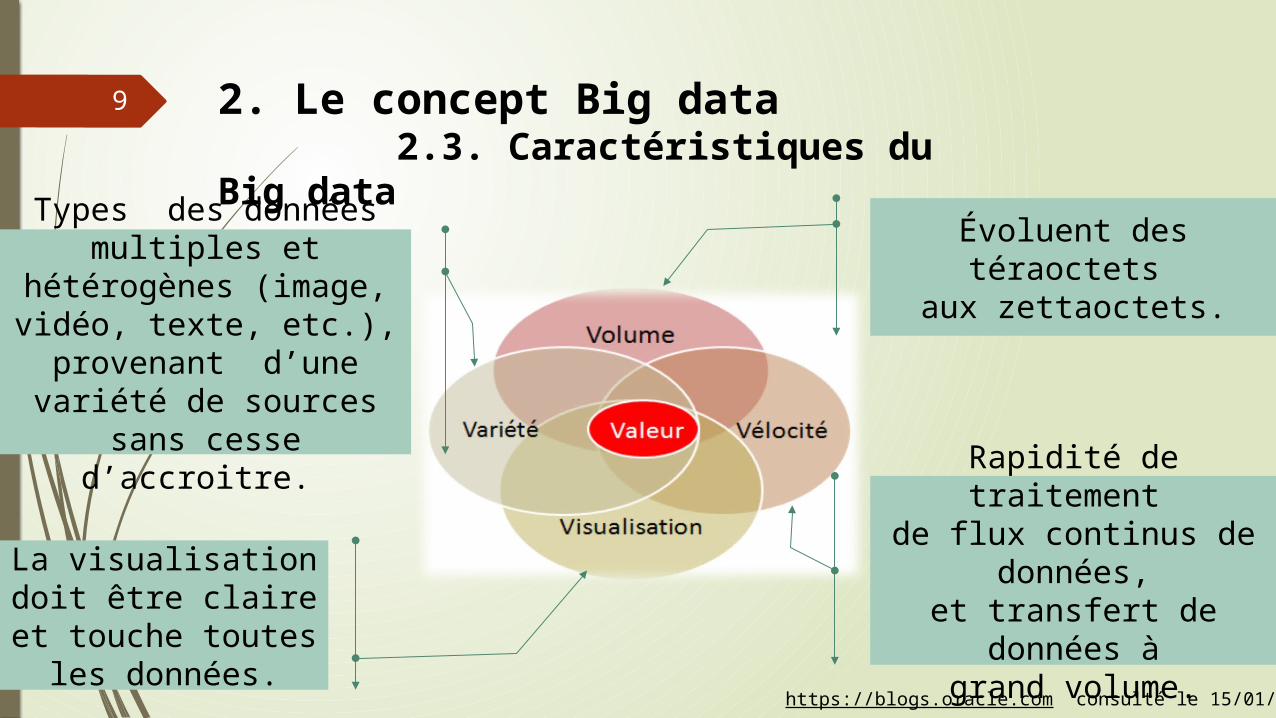
9 2. Le concept Big data 2.3. Caractéristiques du Big data
Évoluent des téraoctets aux zettaoctets.
Rapidité de traitement de flux continus de données,
et transfert de données àgrand volume.
Types des données multiples et hétérogènes (image, vidéo, texte, etc.), provenant d’une variété de sources sans cesse
d’accroitre.
La visualisation doit être claire et touche toutes les données.
https://blogs.oracle.com consulté le 15/01/2013

10
Les avancements technologiques L’automatisation des systèmes Les exigences réglementaires La multiplication des machines Les solutions de Business Intelligence Les centres de recherche
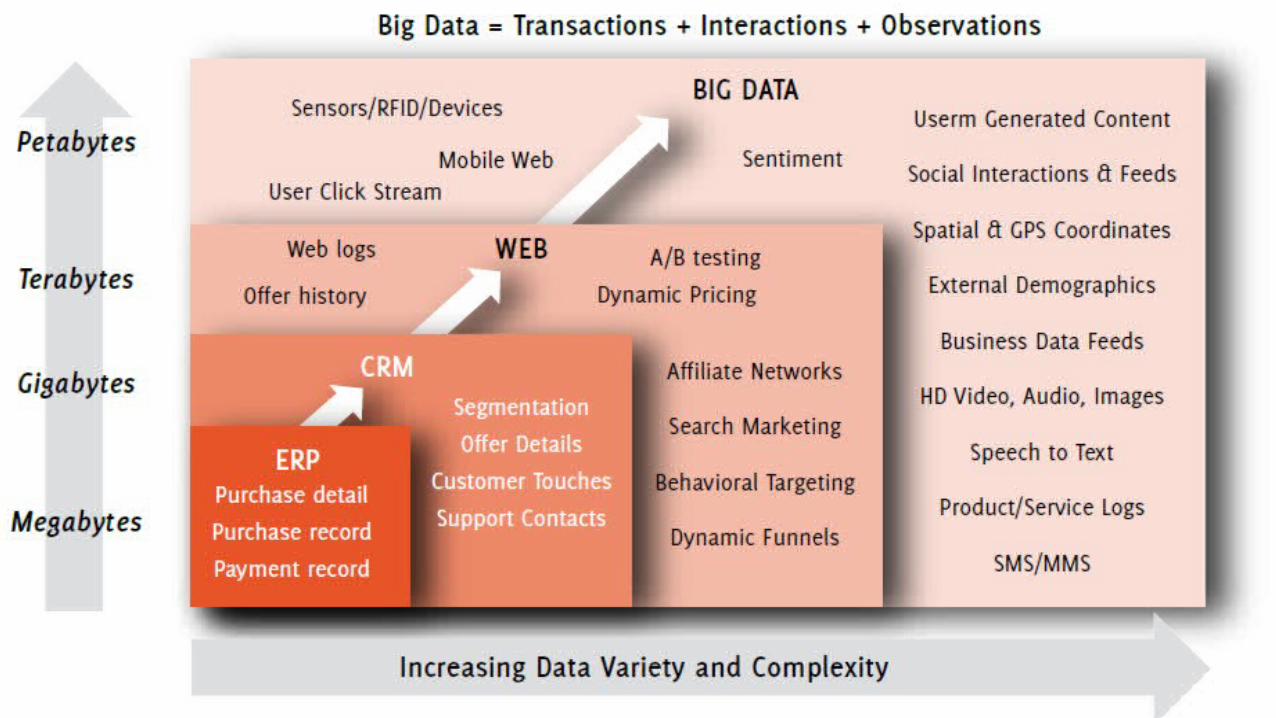
2. Le concept Big data 2.4. l’origine des données du Big data (partie 1)
http://www.journaldunet.com consulté le 14/02/2013.
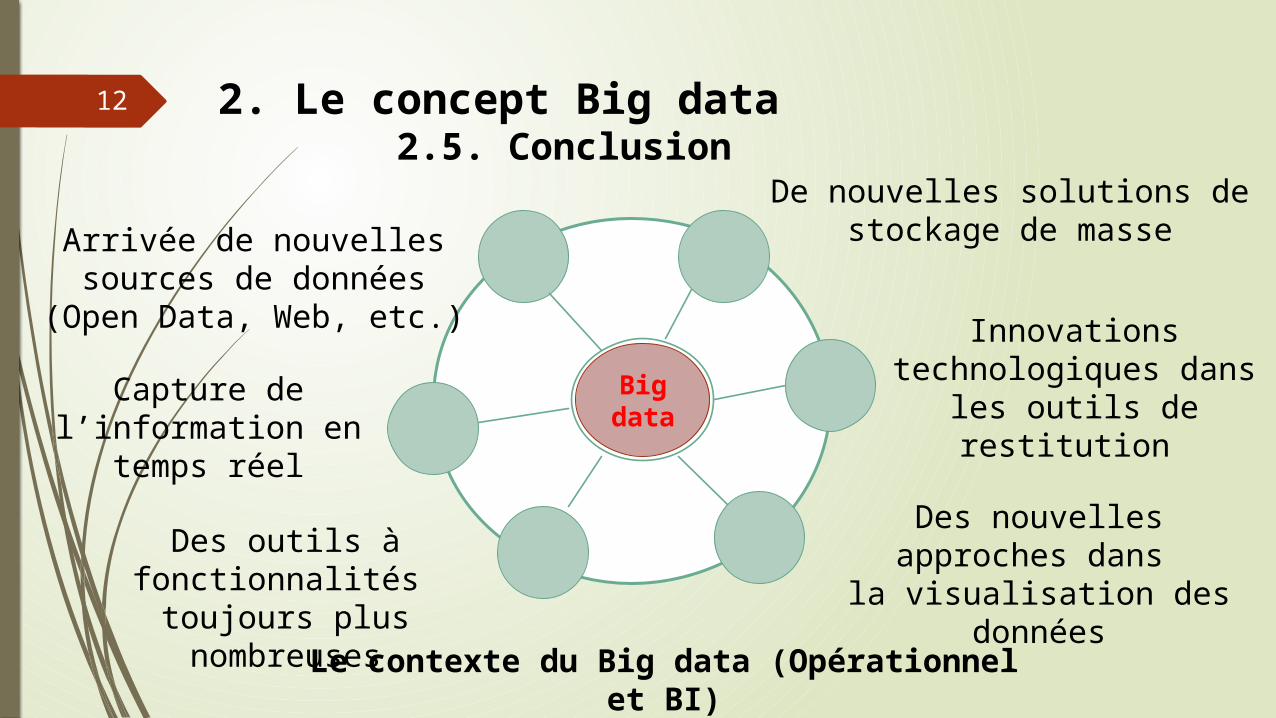
11 2. Le concept Big data 2.4. l’origine des données du Big data (partie 2)
BDDExploiter
& Analyser
Résu
ltats
d’a
naly
se p
ou
r le
décis
ion
nel
DW
Les données et les résultats attendue du Big data
12 2. Le concept Big data 2.5. Conclusion
Le contexte du Big data (Opérationnel et BI)
Big data
De nouvelles solutions de stockage de masse
Innovations technologiques dans les outils de restitution
Arrivée de nouvelles sources de données (Open Data, Web, etc.)
Capture de l’information en temps réel
Des nouvelles approches dans la visualisation des donnéesDes outils à fonctionnalités
toujours plus nombreuses

13 3. La technologie NoSQL/ NewSQL3.1. Le théorème CAP (Éric Brewer en 2000 )
Consistency
Ce théorème est démontré par Seth Gilbert et Nancy Lych en 2002., montre qu'il est impossible pour un système de données distribué de garantir les trois propriétés suivantes simultanément:
Cohérence: tous les clients du système voient les mêmes données au même instant.
Disponibilité: désigne qu’un système est dit disponible si toute requête reçue par un nœud retourne un résultat.
Tolérance à la partition: les données peuvent être partitionnées.
A
PC
Cassandra,CoucheDB,etc.
BigTable,Neo4J,MongoDB,Redis, etc.
SGBDR: Oracle, MS SQL Server, MySQL, etc.
Availibility
Partition tolerance [M. Dimaglie, 2012]

14 3. La technologie NoSQL/ NewSQL3.2. Définition du NoSQL
Le NoSQL (Not Only SQL) est un terme utilisé pour décrire une classe de systèmes de
gestion de base de données qui se distinguent aux SGBD relationnelles :
Elle n’utilise pas SQL comme moyen d’interroger les données.
La base de données repose sur une architecture distribuée.
Elle permet le traitement d’un gros volume de données.
Elle a une meilleure résistance aux pannes.
[J. Hamelin, 2012]

15 3. La technologie NoSQL/NewSQL3.3. Définition du NewSQL
Les bases de données NewSQL ont vu le jour en 2012 et se caractérisent par:
Respecter le modèle de bases de données relationnelles.
Les bases NewSQL respectent le modèle ACID et utilisent SQL.
La plupart sont optimisées pour effectuer de grands nombres de
transactions et pour effectuer des requêtes répétitives et proposent
souvent un système d’indexation optimisé.
[M. Bérard.,al , 2012] [S. Fermigier, 2012]

16 3. La technologie NoSQL/ NewSQL3.4. Les types de bases de données NoSQL (partie 1)
Dans le sphère du NoSQL, il existe une
diversité d’approches classées en quatre
catégories: les bases de données clé-valeur,
orientées colonne, orientées document, et
les bases de données orientées graphes.
Clé-Valeur
Colonne
Document
Graphe
Les différents types de bases NoSQL. [M. Bérard., al, 2012]
Complexités des données
Volu
me
des
donn
ées

17 3. La technologie NoSQL/ NewSQL3.4. Les types de bases de données NoSQL (partie 2)
3.4.1. Base des données Clé-Valeur: C’est le
modèle le plus simple qui associe une clé a une seule valeur
de type BLOB, La clé peut être aussi une adresse, un lien vers
une ressource. Il est particulièrement adapté au système de
cache et offre un accès très rapide aux données.
Exemple: Redis (REmote DIctionary Server).
Valeur 2
Valeur 1Clé 1
Clé 2
.
.
.
Clé n BDD Clé-Valeur[M. Bérard., al, 2012]

18 3. La technologie NoSQL/ NewSQL3.4. Les types de bases de données NoSQL (partie 3)
3.4.2. Base des données orienté
colonne: La valeur est décomposée en colonne et
s’apparente d’avantage à une liste. les colonnes
peuvent être différentes d’une ligne à l’autre.
Exemple: Cassandra développée par Facebook pour
la messagerie des utilisateurs, depuis 2008 elle est
devenue open-source.
Colonne 1: valeur
Colonne 1: valeur
Clé
Colonne 1: valeur
BDD orientée colonne[M. Bérard., al, 2012]
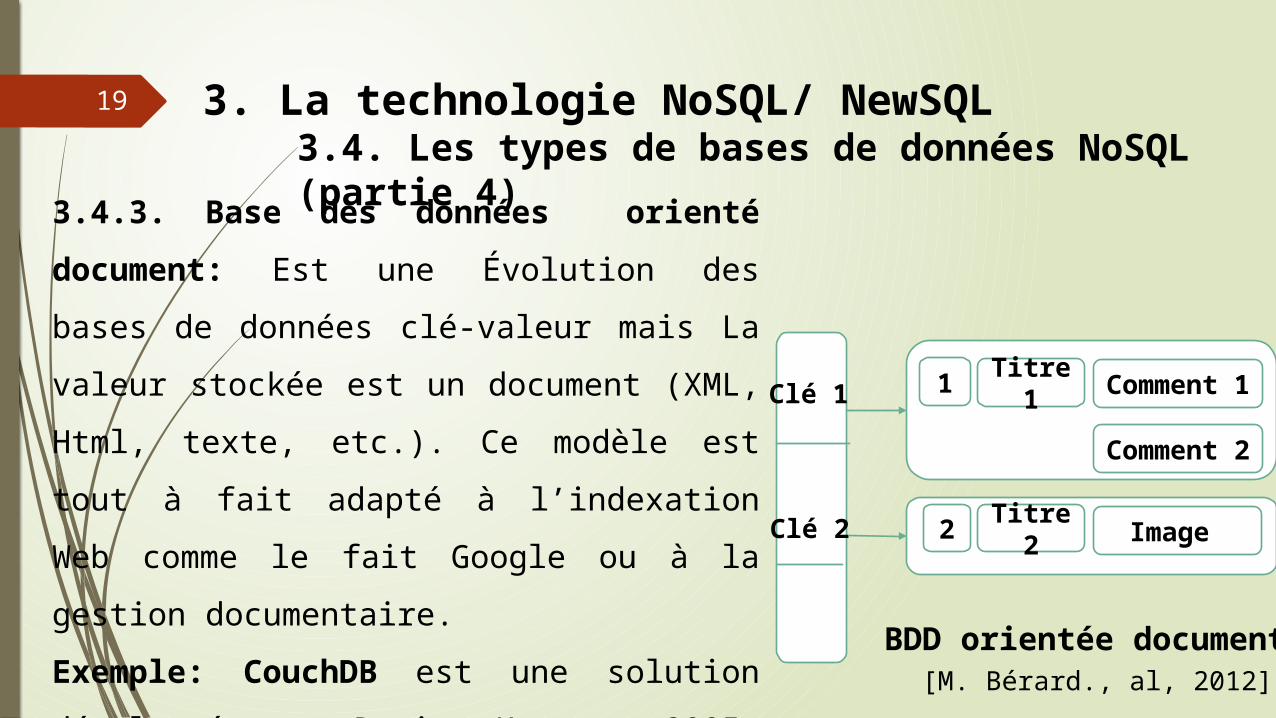
19 3. La technologie NoSQL/ NewSQL3.4. Les types de bases de données NoSQL (partie 4)3.4.3. Base des données orienté
document: Est une Évolution des bases de
données clé-valeur mais La valeur stockée est un
document (XML, Html, texte, etc.). Ce modèle est tout
à fait adapté à l’indexation Web comme le fait Google
ou à la gestion documentaire.
Exemple: CouchDB est une solution développée par
Damien Katz en 2005. Depuis 2008, ce dernier l'a
transformée en projet Apache.
1
Comment 2
Titre1 Comment 1
2 Titre 2 Image Clé 2
Clé 1
BDD orientée document[M. Bérard., al, 2012]

20 3. La technologie NoSQL/ NewSQL3.4. Les types de bases de données NoSQL (partie 5)
3.4.4. Base des données graphe: Les bases orientés graph sont
conçues pour manipuler des données liées par des relations plus ou moins
complexes. Elles trouvent leur application en général dans les réseaux sociaux.
BDD orientée graphe[M. Bérard., al, 2012]
Exemple: Neo4J est développée par NeoTechnology.
La première version est sortie en 2010.

21 3. La technologie NoSQL/ NewSQL3.5. Conclusion
Redis CouchDB Cassandra Neo4JType Clé-Valeur Document Colonne Graphe
Licence BSD Apache Apache GPL
Architecture Maître / Esclave Nœuds indépendants
Nœuds indépendants
Maître / Esclave
Développé en C/C++ Erlang Java Java
Avantage Base de données en Mémoire
Visualisation des documents
Evolutivité facile Permet d'avoir des données avec beaucoup de relationsRespect des propriétés ACID
Inconvénient Taille de la mémoire
Se complexifie avec son évolution
Intégrité gérée depuis le client
Impossible de partager les données entre plusieurs serveurs.
Exemple d’utilisation
Collecte de données en temps réel
CRM / CMS Collecte de données en temps réel
Réseau social
Repense au CAP
CP AP AP CPTableau comparatif entre les quatre types de base NoSQL [L. Heinrich, 2012]

Hadoop est un projet de Apache incluant des implémentations open source
d’un système de fichiers distribués et du modèle MapReduce. Il a été inspiré
des projets de Google: GFS et MapReduce. L’écosystème Hadoop inclut aussi
des projets comme Apache Pig, Hbase et ZooKeeper.
4.La Technologie Hadoop4.2. Définition
22
[D. Borthakur.,al, 2011]

C’est un système spécialisé dans la sauvegarde de grosse masses de données à
travers des systèmes d’ordinateurs distribués avec un grand débit et de multiples
réplications dans un cluster. Il tolère beaucoup d’erreurs et bâtie pour être
déployé dans des machines à cout réduit.
4.La Technologie Hadoop4.3. HDFS -Hadoop Distributed File System-(Partie 1)
[D. Borthakur.,al, 2011] [J. Nilsson, 2011] [A.S. Talwalkar, 2011]
23
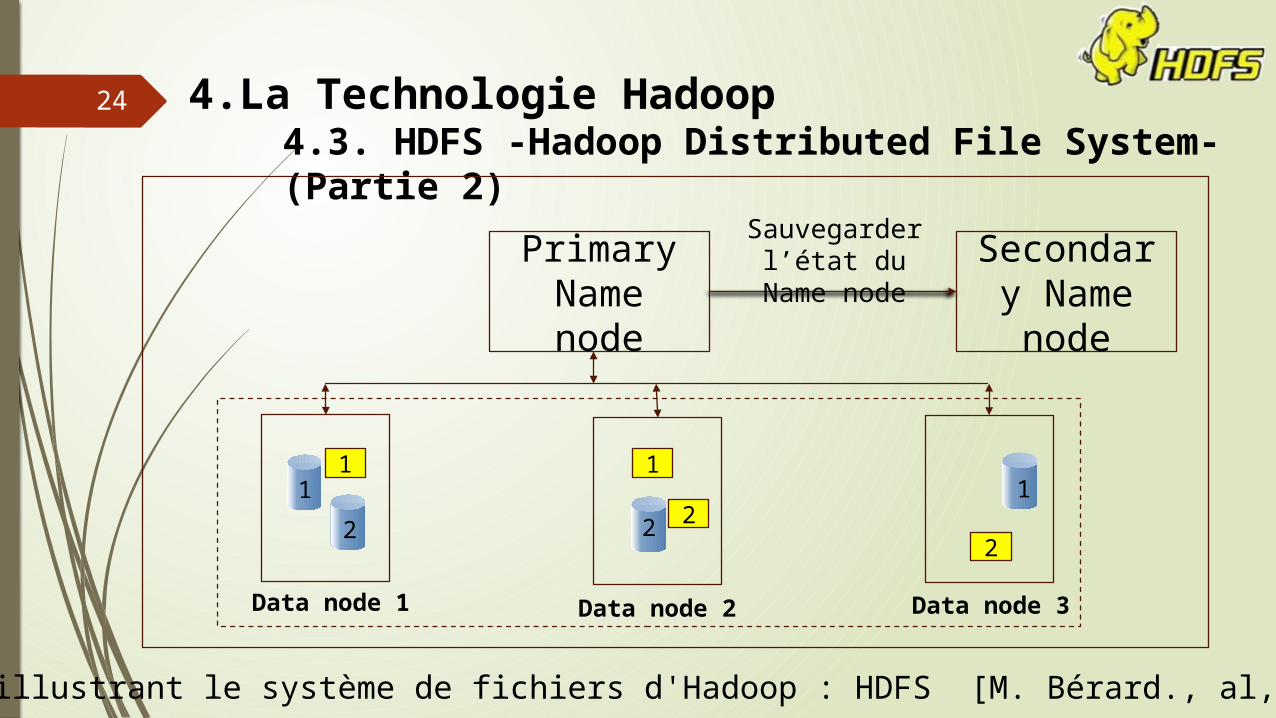
Sauvegarder l’état du Name node
illustrant le système de fichiers d'Hadoop : HDFS [M. Bérard., al, 2012]
Data node 1
1 1
22
1
2
1
2
Primary Name node
Secondary Name node
Data node 2 Data node 3
4.La Technologie Hadoop4.3. HDFS -Hadoop Distributed File System-(Partie 2)
24

C’est un langage de programmation pour l'analyse des ensembles de masses
de données extrêmement importantes d'une manière rapide, évolutive et
distribuée. il a été adapté d'une manière à pouvoir fonctionner sur un cluster
de machines à faible coût.
4.La Technologie Hadoop4.4. MapReduce (partie 1)
[J. Nilsson, 2011] [A.S. Talwalkar, 2011]
25
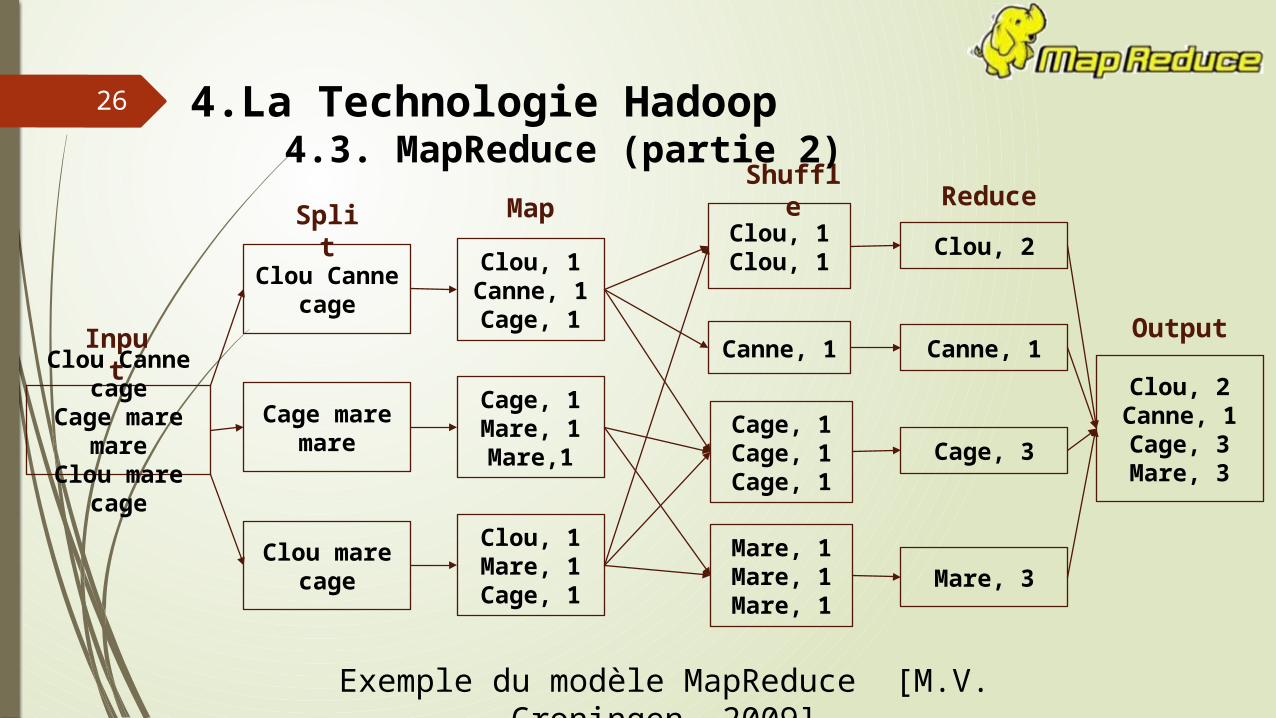
Exemple du modèle MapReduce [M.V. Groningen, 2009]
Clou Canne cageCage mare mareClou mare cage
Cage mare mare
Clou mare cage
Clou Canne cage
Cage, 1Mare, 1Mare,1
Clou, 1Mare, 1Cage, 1
Clou, 1Canne, 1Cage, 1
Clou, 2Canne, 1Cage, 3Mare, 3
Cage, 1Cage, 1Cage, 1
Clou, 1Clou, 1
Canne, 1
Cage, 3
Clou, 2
Mare, 3
Canne, 1
Mare, 1Mare, 1Mare, 1
Input
Split
MapShuffl
e Reduce
Output
4.La Technologie Hadoop4.3. MapReduce (partie 2)
26
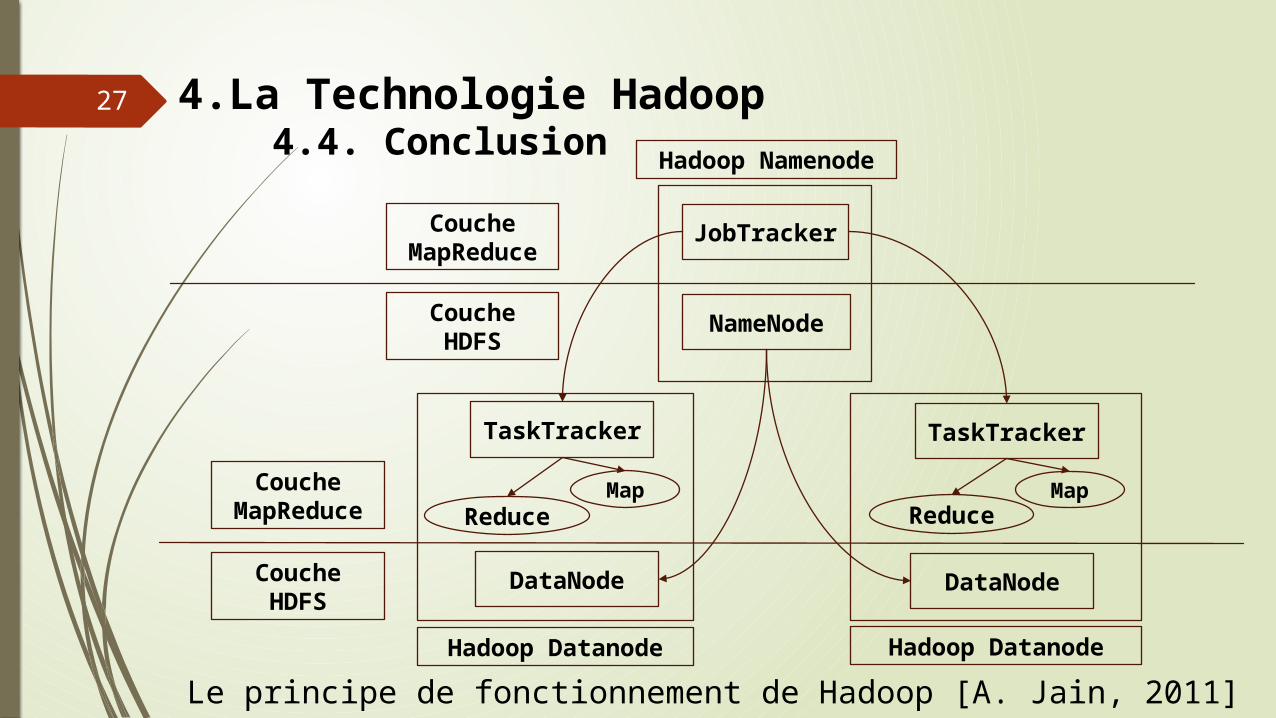
Couche MapReduc
eCoucheHDFS
Couche MapReduc
eCoucheHDFS
JobTracker
NameNode
TaskTracker
DataNodeDataNode
MapReduce
TaskTracker
MapReduce
Hadoop Namenode
Hadoop Datanode Hadoop Datanode
4.La Technologie Hadoop4.4. Conclusion
Le principe de fonctionnement de Hadoop [A. Jain, 2011]
27
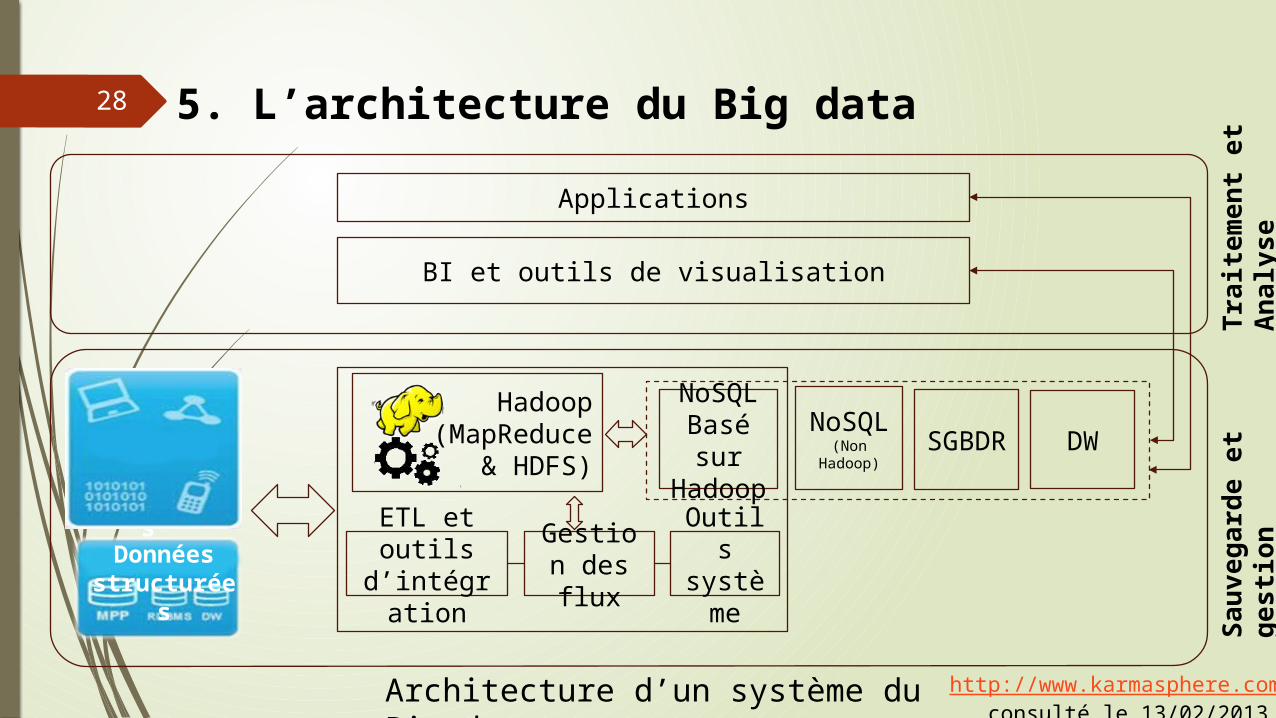
5. L’architecture du Big data
Hadoop(MapReduce
& HDFS)
ETL et outils d’intégration
Gestion des flux
Outils système
Applications
BI et outils de visualisation
NoSQLBasé sur Hadoop
NoSQL(Non Hadoop)
SGBDR DW
Sauv
egar
de e
t ges
tion
Trai
tem
ent e
t Ana
lyse28
Architecture d’un système du Big data http://www.karmasphere.com/ consulté le 13/02/2013
Données non structurées
Données structurées
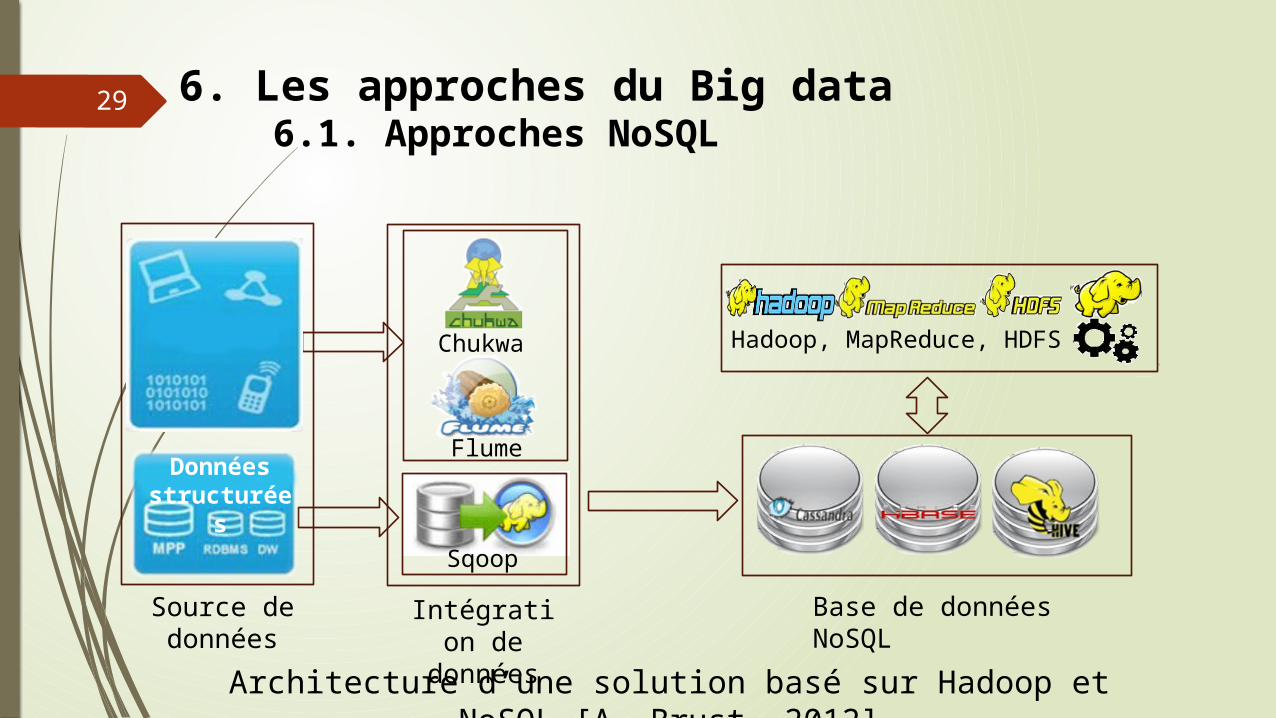
Base de données NoSQL
Hadoop, MapReduce, HDFS
6. Les approches du Big data6.1. Approches NoSQL
29
Architecture d’une solution basé sur Hadoop et NoSQL [A. Brust, 2012]
Chukwa
Flume
Sqoop
Données non structurées
Données structurées
Intégration de données
Source de données
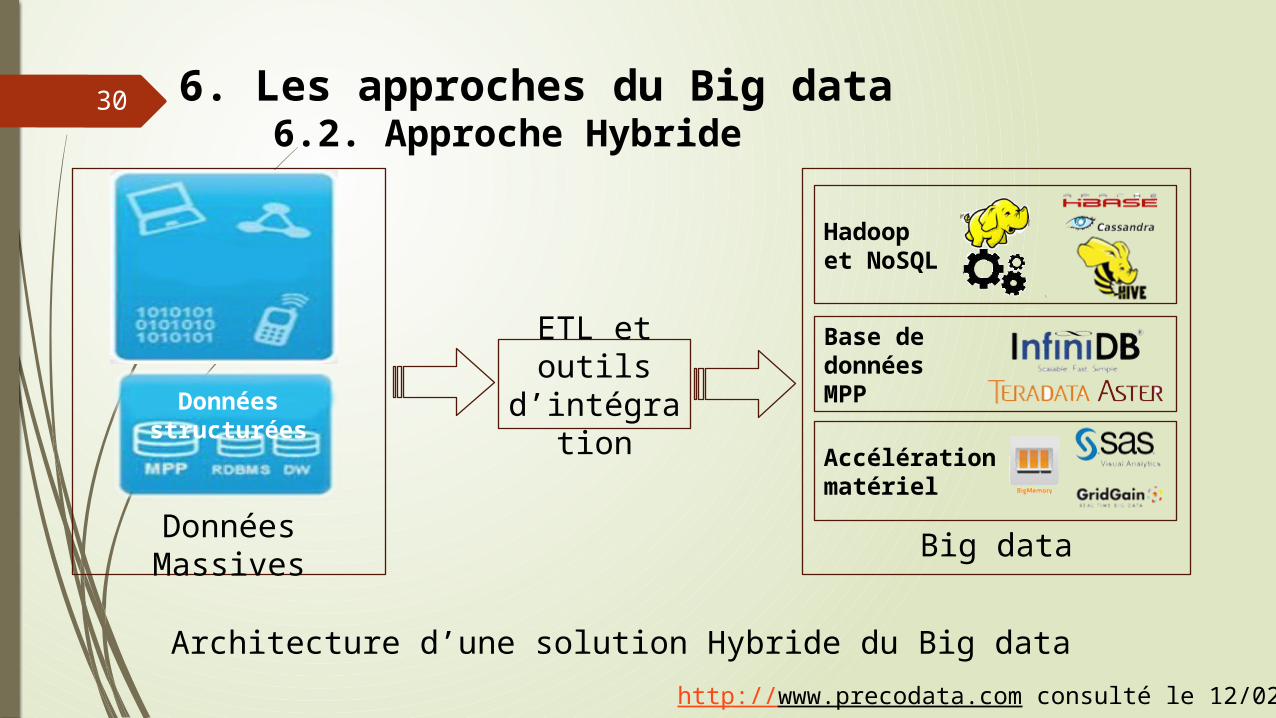
30
Données Massives
6. Les approches du Big data6.2. Approche Hybride
ETL et outils d’intégration
Big data
Hadoopet NoSQL
Base dedonnées MPP
Accélération matériel
Architecture d’une solution Hybride du Big data
Données non structurées
Données structurées
http://www.precodata.com consulté le 12/02/2013
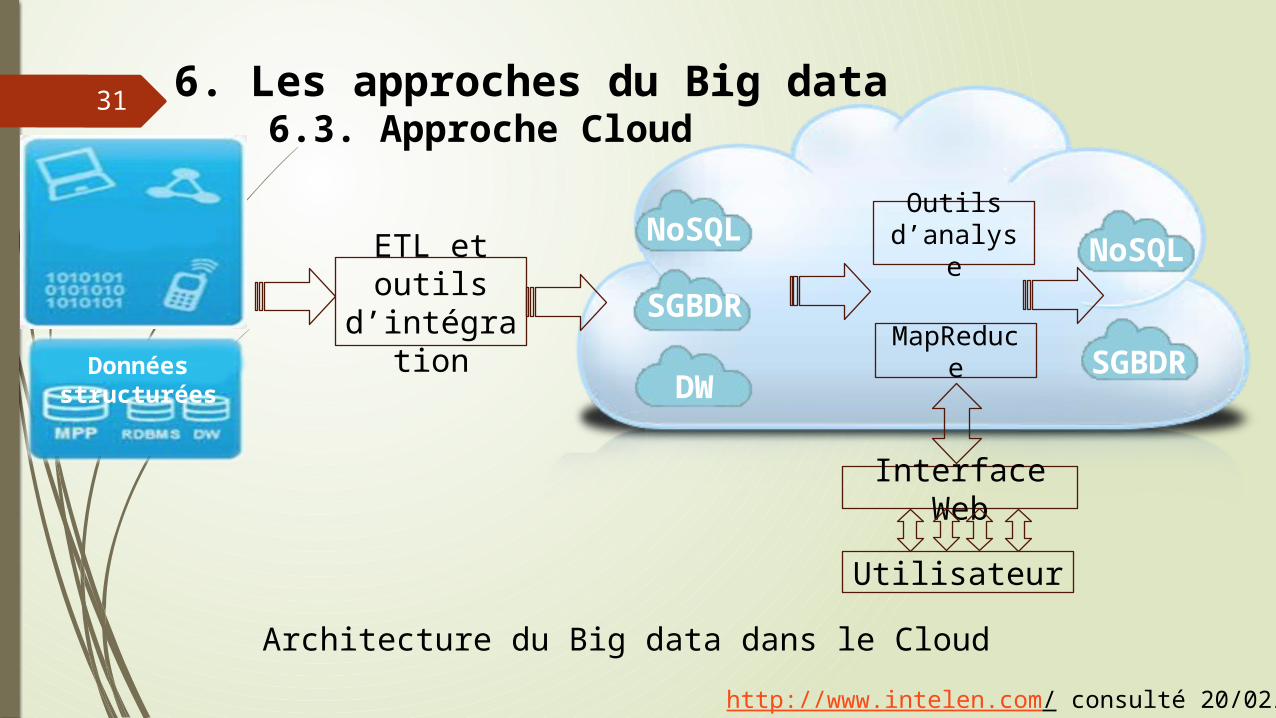
6. Les approches du Big data6.3. Approche Cloud
31
ETL et outils d’intégration
Outils d’analyse
MapReduce
NoSQL
SGBDR
DW
NoSQL
SGBDR
Utilisateur
Interface Web
Architecture du Big data dans le Cloud
http://www.intelen.com/ consulté 20/02/2013
Données non structurées
Données structurées

7. Perspectives de recherche 32
Comment exploiter des données externes (semi-
structurées et non-structurées) présentes dans le web
notamment dans les réseaux sociaux pour enrichir les
données internes afin d’augmenter la performance de la
gestion de relation client.

33 8. Références (partie 1)
[E. Bellity, 2006] Emmanuel Bellity., al. Big Data, la matière première du Data Scientist. 2006. 47page. Rapport de recherche disponible sur le site (http://www.ENSAE.fr ) consulté le 14/01/2013.[J. Hamelin, 2012] JEAN-FRANÇOIS HAMELIN. Base de données distribuée appliquée à la génétique dans le cadre de l’analyse du séquençage génomique. Rapport Technique. Université de Montréal. Département de génie logiciel. 2012. 70pages. [L. Heinrich, 2012] Lionel HEINRICH. Not only SQL. Travail de Bachelor réalisé en vue de l’obtention du Bachelor HES en Informatique de Gestion. École supérieure de Gestion de Genève (HEG-GE). 2012. 61p.[M. Dimaglie, 2012] Matteo DI MAGLIE. Adoption d’une solution NoSQL dans l’entreprise. Mémoire réalisé en vue de l’obtention du Bachelor HES en Informatique de Gestion. École supérieure de Gestion de Genève (HEG-GE). 2012. 68p.[M. Bérard., al, 2012] Maxime Bérard., al . Big Data et NoSQL : de l’explosion des volumes de données liée à l’essor du Web à l’émergence de nouvelles architectures de stockage et d’interrogation de données. Support de cours .université de Nice.2012. 25p.[S. Fermigier, 2012] Stefane Fermigier. Big data et open source : une convergence inévitable?. Livre blanc. 2012. 21p. Disponible sur le site (http://www.fermigier.com) consulté le 23/1/2013.

[J. Stuhler, 2011] Julian Stuhler. Data in Memory. Disponible sur le site (http://www.databasejournal.com) publié le 28/01/2011 consulté le 02/ 03/2013.
[A. Jain, 2011] Ankit Jain. Installation of hadoop in the cluster - A complete step by step tutorial. Tutoriel disponible sur: (http://ankitasblogger.blogspot.com) publié le 04/01/2011 consulté le 04/03/2013.
[M.V. Groningen, 2009] Martijn van Groningen. Introduction to Hadoop. Article disponible sur : (http://blog.jteam.nl ) publié le 04/08/2009 consulté le 04/03/2013.
[D. Borthakur.,al, 2011] Dhruba Borthakur et al. Apache Hadoop Goes Realtime at Facebook. SIGMOD ’11. 2011, pp. 1071-1080. ISSN: 978-1-4503-0661-4 Disponible sur le site: http://oss.csie.fju.edu.tw.
[T. White, 2012] Tom White. Hadoop the Denitive Guide. Edition O'Reilly Media, 3ième edition, 2012. 647pages. ISBN: 9781449311520.
[Gartner, 2012] Gartner. Concevoir sa plateforme Big data. Article disponible sur le site (http://www.precodata.com ) Publié en 2012 consulté le 11/02/2013.
[A. Brust, 2012] Andrew Brust. MapReduce and MPP: Two sides of the Big Data coin?. Disponible sur le site (www.znet.com) publié le 02/03/2102 consulté le 18/02/2012.
8. Références (partie 2)34

35
Merci Pour Votre
Attention

36
37
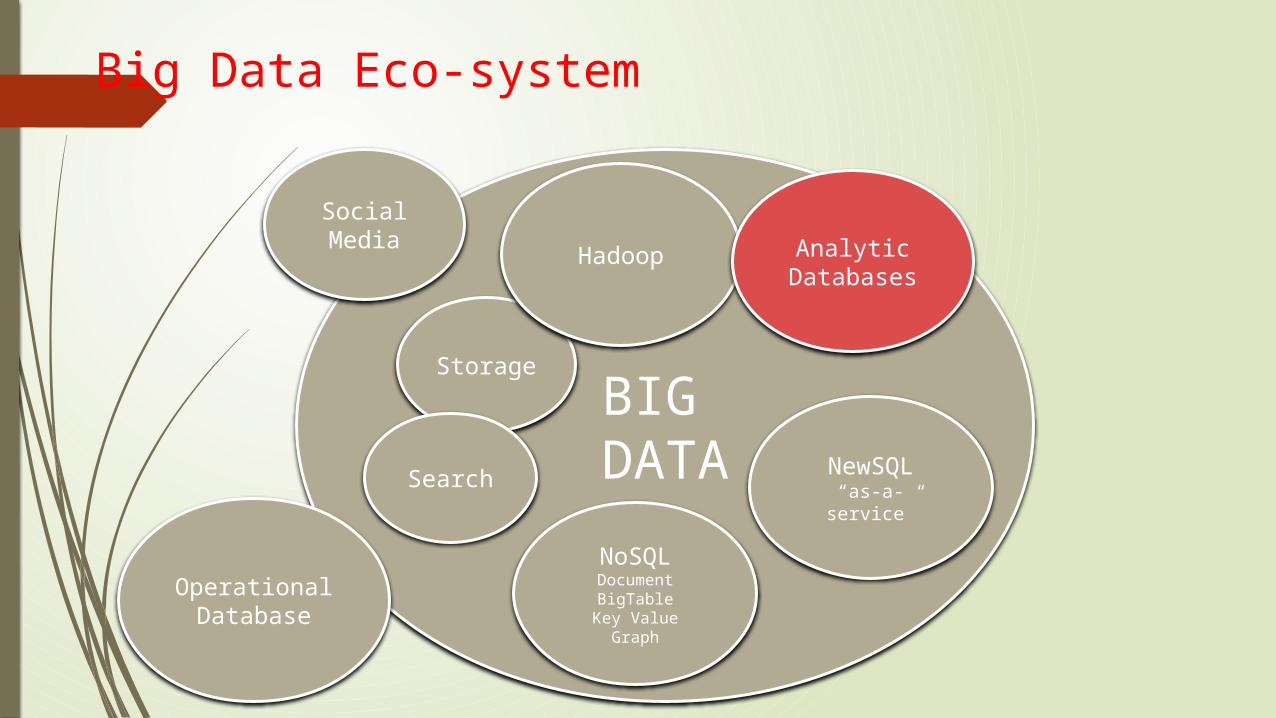
Big Data Eco-system
BIG DATA
OperationalDatabase
NewSQL“as-a-service”
NoSQLDocumentBigTable
Key ValueGraph
Social Media
Storage
Search
Hadoop AnalyticDatabases


















