
Pratique du modèle linéaire (2) - lsta.upmc.fr · S´election de variables `0 Ridge et PCR Lasso...
35
Pratique du mod` ele lin´ eaire (2)
Transcript of Pratique du modèle linéaire (2) - lsta.upmc.fr · S´election de variables `0 Ridge et PCR Lasso...

Pratique du modele lineaire (2)

Selection de variables `0
Ridge et PCR Lasso et elastic-net
Avant de commencer :
Se connecter a ma page ici et recuperer les transparents ici.
Creer un repertoire
Faire pointer R vers ce repertoire
Charger les jeux de donnees dans le repertoire creehttp://www.lsta.upmc.fr/guilloux.php?main=enseignement
Charger les packages ’HH’ et ’car’ (sur ma page)Polycopies pour aller plus loin :
Philippe Besse (exemples en SAS)
Jean-Marc Aza
¨
ıs et Jean-Marc Bardet
Pratique du modele lineaire (2)

Selection de variables `0
Ridge et PCR Lasso et elastic-net
Tests du Student et de Fisher
On se place dans le modele
Y = X� + ✏
avec ✏ ⇠ N ((0, . . . , 0)>,�2In) et X� 2 V = vect(X 1, . . . ,X p).
On veut selectionner les variables qui ont une influence sur Y , i.e.determiner les indices k 2 {1, . . . , p} pour lesquels �k 6= 0.
Si on veut tester H0
: �k = 0, on peut utiliser le test du Student de niveau
PH0
��� �j � �j
�2(X>X )�1
jj
�� > F�1
T (n�p)(1� ↵/2)�= ↵
Pratique du modele lineaire (2)

Selection de variables `0
Ridge et PCR Lasso et elastic-net
Tests du Student et de Fisher
Si on veut tester H0
: �k1
= . . . = �kl = 0, on pourrait utiliser lesstatistiques du Student mais le niveau pour un seuil s est alors donne par :
PH0
(H0
) = P��� �k
1
�2(X>X )�1
k1
k1
�� > s [ . . . [�� �kl
�2(X>X )�1
kl kl
�� > s)
P��� �k
1
�2(X>X )�1
k1
k1
�� > s�+ . . .+ P
��� �kl
�2(X>X )�1
kl kl
�� > s).
Pour garantir un niveau ↵, il faut prendre s = F�1
T (n�p)(1� ↵/(2l)) pour avoir :
PH0
(H0
) ↵l+ . . .+
↵l= ↵.
Mais la puissance de chaque test est alors assez mauvaise car
F�1
T (n�p)(1� ↵/(2l)) >> F�1
T (n�p)(1� ↵/(2)) si l >> 1.
Pratique du modele lineaire (2)

Selection de variables `0
Ridge et PCR Lasso et elastic-net
Tests du Student et de Fisher
Pour tester H0
: �k1
= . . . = �kl = 0, on utilise le test de Fisher.
On note W = vect{(X1
, . . . ,Xp)/(Xk1
, . . . ,Xkl )} de dimension p � l .
On note X � = proj>W (Y ) et on a toujours X � = proj>V (Y ).
On ecrit
X � = proj?V (Y ) = proj?V (X� + ✏) = X� + proj?V (✏) et
X � = proj?W (Y ) = proj?W (X� + ✏) = proj?W (X�) + proj?W (✏)
= X� + proj?W (✏) seulement si H0
est vraie
Sous H0
, on a donc
Y � X � = ✏� proj?V (✏) = proj?V?(✏) et Y � X � = ✏� proj?W (✏) = proj?W?(✏).
On remarque que W ⇢ V et donc W? = V??LW?V et finalement
kY�X �k2�kY�X �k2 = k proj?W?(✏)k2�k proj?V?(✏)k2 = k proj?W?V (✏)k2.
Pratique du modele lineaire (2)
Selection de variables `0
Ridge et PCR Lasso et elastic-net
Tests du Student et de Fisher
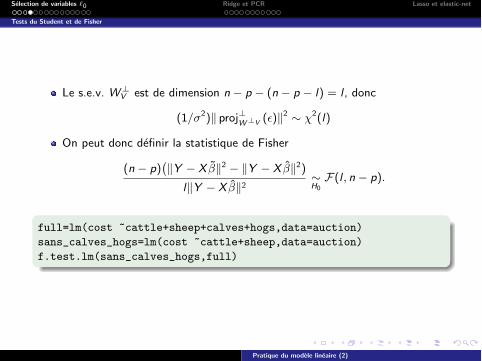
Le s.e.v. W?V est de dimension n � p � (n � p � l) = l , donc
(1/�2)k proj?W?V (✏)k2 ⇠ �2(l)
On peut donc definir la statistique de Fisher
(n � p)�kY � X �k2 � kY � X �k2)
lkY � X �k2⇠H0
F(l , n � p).
full=lm(cost ~cattle+sheep+calves+hogs,data=auction)
sans_calves_hogs=lm(cost ~cattle+sheep,data=auction)
f.test.lm(sans_calves_hogs,full)
Pratique du modele lineaire (2)

Selection de variables `0
Ridge et PCR Lasso et elastic-net
Selection pas a pas a partir du test de Fisher
Si le modele de depart a p variables, il y a #P{1, . . . , p} = 2p sous-modeles aexplorer. Il faut des algorithmes e�caces :
forward : on part du modele avec seulement l’intercept et on ajoute lesvariables une a une. A chaque pas, on ajoute celle qui a la plus grandestatistique de Fisher. On s’arrete quand la p-value associee devient > 0.5
backward : on part du modele avec toutes les variables et on retire lesvariables une a une. A chaque pas, on ajoute celle qui a la plus petitestatistique de Fisher. On s’arrete quand la p-value associee devient < 0.1
stepwise mixte des deux premieres (on ajoute, puis on permet uneelimination, etc)
Exercice : Coder une selection backward basee sur la statistique de Fisher pourle jeu de donnees Auction
Pratique du modele lineaire (2)

Selection de variables `0
Ridge et PCR Lasso et elastic-net
Selection de variable par minimisation de critere penalise
Modeles, vrai modele
On se donne une famille de modeles M, par exemple M = P{1, . . . , p}. Onsuppose qu’il existe un vrai modele m⇤ 2 M tel que :
Y = X (m⇤)�(m⇤
) + ✏⇤ avec ✏⇤ ⇠ N ((0, . . . , 0)>, (�m⇤)2In).
On veut retrouver m⇤.
Attention : le R2 n’est pas un bon critere pour ce probleme car il choisiratoujours le modele complet (avec toutes les covariables)
On note mtot le modele complet.
Pratique du modele lineaire (2)

Selection de variables `0
Ridge et PCR Lasso et elastic-net
Selection de variable par minimisation de critere penalise
Estimation dans le modele m
Dans le modele m, on note |m| le nombre de covariables qu’il contient et
�(m) =�(X (m))>X (m)
��1
(X (m))>Y
Y (m) = X (m)�(m)
\(�m)2 =kY � Y (m)k2
2
n � |m|
Pratique du modele lineaire (2)

Selection de variables `0
Ridge et PCR Lasso et elastic-net
Selection de variable par minimisation de critere penalise
Risque quadratique
Le risque quadratique de Y (m) pour l’estimation de X ⇤�⇤ est donne par
E(kY (m) � X ⇤�⇤k2) = E(kY (m) � X (m)�(m)k2)| {z }
variance
+ kX (m)�(m) � X ⇤�⇤k2| {z }
biais
2
= �2|m|+ kX (m)�(m) � X ⇤�⇤k2
ou X (m)�(m) est la projection de X ⇤�⇤ sur vect(X (m)).
PROBLEME : le terme de biais est inconnu.
Pratique du modele lineaire (2)

Selection de variables `0
Ridge et PCR Lasso et elastic-net
Selection de variable par minimisation de critere penalise
Calcul du terme de biais
On montre que
E(kY (m) � Y k2) = (n � |m|)�2 + kX (m)�(m) � X ⇤�⇤k2.
Finalement
E(kY (m) � X ⇤�⇤k2) = �2|m|� (n � |m|)�2 + E(kY (m) � Y k2)
= 2�2|m|+ E(kY (m) � Y k2)� n�2.
On approxime E(kY (m) � Y k2) par
kY (m) � Y k2 = (n � |m|)\(�m)2.
Pratique du modele lineaire (2)

Selection de variables `0
Ridge et PCR Lasso et elastic-net
Selection de variable par minimisation de critere penalise
Cp de Mallows
On choisit mCp 2 M tel que :
mCp = argminm2M
Cp(m),
avec
Cp(m) =\(�m)2
\(�mtot )2
+ 2|m|n
Pratique du modele lineaire (2)

Selection de variables `0
Ridge et PCR Lasso et elastic-net
Selection de variable par minimisation de critere penalise
Cp de Mallows - risque quadratique
On choisit mCp 2 M tel que :
mCp = argminm2M
Cp(m),
avec
Cp(m) =\(�m)2
\(�mtot )2
+ 2|m|n
Pratique du modele lineaire (2)

Selection de variables `0
Ridge et PCR Lasso et elastic-net
Selection de variable par minimisation de critere penalise
AIC/BIC - distance de Kullback
On choisit mAIC 2 M et mBIC 2 Mtel que :
mAIC = argminm2M
AIC(m),
mBIC = argminm2M
BIC(m),
avec
AIC(m) = log⇣\(�m)2
⌘+
2|m|+ 1n
BIC(m) = log⇣\(�m)2
⌘+
log(n)|m|n
Pratique du modele lineaire (2)

Selection de variables `0
Ridge et PCR Lasso et elastic-net
Selection de variable par minimisation de critere penalise
Illustration d’apres Aza
¨
ıs et Bardet
0 50 100 150
-400
-300
-200
-100
0
id
5 - 0
.03
* id
^2 +
2e-
04 *
id^3
- 3
* lo
g(id
)
Comparaison des prédictions : modèle total, backward par Fisher, AIC, BIC
---
VraieTotalBackwardAICBIC
Pratique du modele lineaire (2)

Selection de variables `0
Ridge et PCR Lasso et elastic-net
Selection de variable par minimisation de critere penalise
Illustration d’apres Aza
¨
ıs et Bardet
0 50 100 150
-400
-300
-200
-100
0
id
5 - 0
.03
* id
^2 +
2e-
04 *
id^3
- 3
* lo
g(id
)
Comparaison des prédictions : modèle total, backward par Fisher, AIC, BIC
---
VraieTotalBackwardAICBIC
Pratique du modele lineaire (2)

Selection de variables `0
Ridge et PCR Lasso et elastic-net
Introduction aux regressions penalisees et sur variables synthetiques
On observe Y et X de dimension n ⇥ p. On fait l’hypothese qu’il existe un vraimodele m⇤ tel que
Y = Xm⇤�m⇤
+ ✏m⇤= X ⇤�⇤ + ✏⇤,
et que |m⇤| est petit devant p et n.Quand p devient grand par rapport a n, il y a trois problemes potentiels :
� = (X>X )�1X>Y peut ne pas etre defini car X>X n’est alors plusinversible (c’est aussi le cas si des colonnes de X sont colineaires)
La variance d’estimation a partir de X devient trop grande. En e↵et, on adeja montre que
E(kX � � X ⇤�⇤k2) = p�2 + kX (m)�(m) � X ⇤�⇤k2 = p�2.
Les algorithmes de selection de variables `0
ne peuvent plus etre appliquesa cause des 2p modeles a comparer.
Pratique du modele lineaire (2)

Selection de variables `0
Ridge et PCR Lasso et elastic-net
Introduction
La regression ridge et PCR (principal components regression) s’attaquent auxdeux premiers problemes :
la premiere en regularisant le probleme des moindres carres
la seconde en travaillant sur des variables synthetiques issues d’une PCA(APC).
Les deux ont de bonnes performances en prediction mais ont l’inconvenient deproduire des modeles di�cilement interpretables.
Pratique du modele lineaire (2)

Selection de variables `0
Ridge et PCR Lasso et elastic-net
Ridge
Definition
Hoerl et Kennard (1970) ont l’idee d’ajouter a X>X une matrice diagonale�Idn pour retrouver l’inversibilite pour
X>X + �Idn = PDP�1 + �Idp = P(D + �Idn)P�1.
Montrons que c’est equivalent a considerer la forme penalisee des moindrescarres.
Penalite ridge
�ridge
� = argmin�2Rp
kY � X�k2 + �pX
j=1
�2
j .
Pratique du modele lineaire (2)

Selection de variables `0
Ridge et PCR Lasso et elastic-net
Ridge
Loi de l’estimateur ridge
On a alors
�ridge
� = (X>X+�Idp)�1X>Y = (X>X+�Idp)
�1X>X ⇤�⇤+(X>X+�Idp)�1X>✏⇤
donc sous l’hypothese gaussienne �ridge
� reste gaussien mais a pour moments
E�ridge
� = (X>X + �Idp)�1X>Y = (X>X + �Idp)
�1X>X ⇤�⇤
V�ridge
� = (X>X + �Idp)�1X>V(✏⇤)X (X>X + �Idp)
�1
= �2(X>X + �Idp)�1X>X (X>X + �Idp)
�1.
Il est donc biaise pour l’estimation de �⇤, de meme X �ridge
� est biaise pourl’estimation de X ⇤�⇤. On va montrer que meme si la regression ridge augmentele biais, elle peut diminuer le risque quadratique.
Pratique du modele lineaire (2)

Selection de variables `0
Ridge et PCR Lasso et elastic-net
Ridge
Propriete sur le risque quadratique
On connaıt le risque quadratique de l’estimateur des moindres carres
E(kX � � X ⇤�⇤k2) = p�2 + kX (m)�(m) � X ⇤�⇤k2 = p�2.
Calculons celui de pour la regression ridge
E(kX �ridge
� � X ⇤�⇤k2)
= E(kX (X>X + �Idp)�1X>X ⇤�⇤ + X (X>X + �Idp)
�1X>✏⇤ � X ⇤�⇤k2)
= E(kX (X>X + �Idp)�1X>X ⇤�⇤ � X ⇤�⇤k2) + E(kX (X>X + �Idp)
�1X>✏⇤k2)
Pratique du modele lineaire (2)

Selection de variables `0
Ridge et PCR Lasso et elastic-net
Ridge
Propriete sur le risque quadratique
0 2 4 6 8 10
0.55
0.60
0.65
0.70
grille_lambda
risque_quadratique
ridgeMC
Pratique du modele lineaire (2)

Selection de variables `0
Ridge et PCR Lasso et elastic-net
Ridge
Valeur des coe�cients
0 20 40 60 80 100
0.0
0.5
1.0
1.5
Coefficients
Pratique du modele lineaire (2)

Selection de variables `0
Ridge et PCR Lasso et elastic-net
Ridge
En pratique
Pour eviter les problemes d’echelle, on ajoute cette matrice diagonale �Idn a lamatrice X dont les colonnes ont ete au prealable renormalisees et pour unsignal Y recentre.
Exercice
On note
Y c = Y � Y
pour tout j = 2, . . . , p X j,S = Xj�¯
(Xj)
sd(Xj)
et X S = (X 2,S , . . . ,X p,S).
Ecrire la correspondance les moindres carres classiques argmin�2Rp
kY � X�k2 et les
moindres carres obtenus sur les variables renormalisees.
argmin�2Rp�1
kY c � X S�k2
Pratique du modele lineaire (2)

Selection de variables `0
Ridge et PCR Lasso et elastic-net
Ridge
Dans l’estimateur des moindres carres obtenus sur les variables renormalisees,on remplace (X S)>X S par ((X S)>X S + �Idn). Montrons que c’est equivalent aconsiderer
Penalite ridge
�ridge
� = argmin�2Rp
kY c � X S�k2 + �pX
j=2
�2
j .
Exercice
Coder la regression ridge sur l’exemple simule du code ”code penalisation.R”.
Pratique du modele lineaire (2)

Selection de variables `0
Ridge et PCR Lasso et elastic-net
Ridge
Derniere chose : il faut choisir � par cross-validation.
Pratique du modele lineaire (2)

Selection de variables `0
Ridge et PCR Lasso et elastic-net
Ridge
Propriete sur les variables correlees
Theoreme (Zou (2010)
On suppose que toutes les variables ont ete renormalisees. Pour deux variablesX j et X j0 , on a
1kY k |�
j,ridge� � �j0,ridge
� | 1�
q2(1� cor(X j ,X j0)).
Preuve au tableau.
Pratique du modele lineaire (2)

Selection de variables `0
Ridge et PCR Lasso et elastic-net
Regression sur PC
En considerant X S , on peut decrire l’ACP via la formule
(X S)>X S = VD2V>
les colonnes de V sont les vecteurs propres de X S et egalement les composantesprincipales. La PCR consiste a regresser Y sur les m < p premierescomposantes principales.
Pratique du modele lineaire (2)

Selection de variables `0
Ridge et PCR Lasso et elastic-net
Introduction
La regression ridge consiste a resoudre
�ridge
� = argmin�2Rp
kY � X�k2 + �pX
j=1
�2
j .
ce qui est equivalent a
�ridge
� = argmin�2Rp
kY � X�k2 s.c.pX
j=1
�2
j < t.
Pratique du modele lineaire (2)
Selection de variables `0
Ridge et PCR Lasso et elastic-net
Introduction
-2 -1 0 1 2 3 4 5
-2-1
01
23
45
Pratique du modele lineaire (2)

Selection de variables `0
Ridge et PCR Lasso et elastic-net
Introduction
D’un autre cote, on peut voir la selection par Cp de Mallows
Cp(m) =\(�m)2
\(�mtot )2
+ 2|m|n
comme�Mallows
� = argmin�2Rp
kY � X�k2 + �k�k0
.
ce qui est equivalent a
�Mallows
� = argmin�2Rp
kY � X�k2 s.c. k�k0
< t.
Pratique du modele lineaire (2)
Selection de variables `0
Ridge et PCR Lasso et elastic-net
Le lasso
Introduit en 1996 par Tibshirani, la lasso peut etre vu comme un intermediaireentre la regression ridge et la selection `
0
.
Penalite lasso
� lasso
� = argmin�2Rp
kY � X�k2 + �pX
j=1
|�j |
= argmin�2Rp
kY � X�k2 + �k�k1
Pratique du modele lineaire (2)

Selection de variables `0
Ridge et PCR Lasso et elastic-net
Le lasso
Exercice
Sur un design orthogonal, ecrire la solution lasso.
Pratique du modele lineaire (2)

Selection de variables `0
Ridge et PCR Lasso et elastic-net
L’elastic net
Elastic net
�en
� = argmin�2Rp
kY � X�k2 + �1
k�k1
+ �2
k�k22
Pratique du modele lineaire (2)

Selection de variables `0
Ridge et PCR Lasso et elastic-net
Comparaison sur simulation
On utilise la librairie ”glmnet”. On veut comparer sur le modele
n=50
p=30
puis=c(0:9)
puis_petit=c(10:28)
beta=c(0.95^(puis),gamma^puis_petit)
X=cbind(matrix(rnorm(n*(p-1)),ncol=(p-1)))
epsilon=rnorm(n)
beta0=2
Y=beta0+X%*%beta+epsilon
les di↵erentes procedures d’estimation (Cp de Mallows, ridge, lasso, elastic net), en terme
de pouvoir de selection (taille du modele selectionne, sensibilite(TP/(TP+FN)), specificite (TN/(FP+TN)))
d’erreur d’estimation k� � �⇤kd’erreur de prevision kX � � X�⇤k
On peut faire varier la correlation entre les covaraibles via la fonction”covariates.matrix”.
Pratique du modele lineaire (2)


















