
Portefeuilles répliquant et calcul du capital économique ...
125
Portefeuilles répliquant et calcul du capital économique en assurance vie: nouvelles approches de calibration TOUKOUROU Ademola Tuteur en entreprise: VISCUSO Jeremie Tuteur Pédagogique ISFA: Bienvenüe Alexis ISFA, Mars 2013
Transcript of Portefeuilles répliquant et calcul du capital économique ...

Portefeuilles répliquant et calcul du capital économiqueen assurance vie: nouvelles approches de calibration
TOUKOUROU Ademola
Tuteur en entreprise: VISCUSO Jeremie
Tuteur Pédagogique ISFA: Bienvenüe Alexis
ISFA, Mars 2013

Résumé
Dans le cadre de la mise en oeuvre sous Solvabilité 2 d’un modèle interne, les assureursvie sont très souvent limités dans le choix d’une méthode efficace d’obtention de la distri-bution des fonds propres économiques à 1 an. En effet la méthode des simulations dansles simulations s’avère couteuse en temps de calcul et ne constitue pas une solution pé-renne dans le cadre d’un processus de calcul trimestriel du SCR de marché. Le recoursà des proxy pour l’évaluation des passifs est donc indispensable. Parmi les alternativespossibles au SdS classique, la méthode des replicating portfolio s’avère très efficace pouraccélérer ces calculs et repose sur un principe assez simple : utiliser un portefeuille d’actifsfinanciers reproduisant la valeur économique des passifs. L’utilisation de cette méthodesoulève toutefois de nombreuses interrogations dont deux cruciales qui vont nous intéres-ser particulièrement dans ce mémoire :
– Comment choisit-t-on les actifs candidats qui vont composer le portefeuille connais-sant la structure du portefeuille ? Une automatisation ou au moins une accélérationde cette étape du processus est-t-elle possible ?
– Une fois les actifs candidats choisis, quelle est la méthode de calibration la plusefficace des poids du portefeuille pour une estimation la plus précise de la Value-at-risk à 99,5% ?
Nous présentons dans ce mémoire des pistes pour répondre à ces deux questions quenous avons développées dans le cadre de l’amélioration de la méhodologie d’AXA pour lecalcul de son Solvency Capital Requirement (SCR) de marché.
Mots clés : Solvabilité 2, modèle interne, régression PLS, régression LAR, OrthogonalMatching Pursuit, portefeuille répliquant, cashflow mismatch, simplexe, optimisation, gé-nérateur de scénario, modèle ALM, risque de marché, SCR.

Abstract
In the framework of the implementation of Solvency 2 internal model, life insurers areoften limited in choosing an effective method for obtaining the one-year time horizondistribution of own funds. Indeed the classical full nested method is expensive in compu-tation time and is not a permanent solution in the framework of calculating the marketSCR on a quarterly basis. The use of proxy for the valuation of liabilities is essential.Among the possible alternatives to traditional full nested solution, the method of re-plicating portfolio is very effective in accelerating these calculations based on a simpleconcept : use a portfolio of financial assets reproducing the economic value of liabilities.The use of this method, however, raises many questions which are both crucial and thatwill particularly interest us in this paper :
– How does one choose the candidates who will compose active portfolio knowing thestructure of the liabilities ? Is an Automation or at least acceleration of this stageof the process possible ?
– Once the assets candidates have been selected, what is the most efficient calibrationmethod of the portfolio weights that will be the most accurate estimate of the 99.5% value-at-risk ?
We present in this paper ways to answer these two questions that we developed in thecontext of improving the AXA’s mehodology for computing the market SCR.
Keywords : Solvency 2, internal model, Partial Least Square regression, Least AngleRegression, Orthogonal Matching Pursuit, portefeuille répliquant, cashflow mismatch,simplex method, optimisation, economic scenario generator, Asset Liability Manage-ment (ALM) model, market instruments, SCR.
2

Table des matières
Remerciements 4
Introduction 5
I La directive Solvabilité 2 7
1 Rappels sur Solvabilité 1 8
2 Focus sur Solvabilité 2 102.1 Pilier 1 : Exigences en capital . . . . . . . . . . . . . . . . . . . . . . . . 102.2 Pilier 2 : Activités de contrôle et de supervision . . . . . . . . . . . . . . 112.3 Pilier 3 : Discipline de marché . . . . . . . . . . . . . . . . . . . . . . . . 11
3 Modèle Interne vs Formule Standard 123.1 La formule standard . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143.2 Les approches par modèle interne . . . . . . . . . . . . . . . . . . . . . . 16
3.2.1 Les Simulations dans les simulations . . . . . . . . . . . . . . . . 163.2.2 L’accélérateur SdS . . . . . . . . . . . . . . . . . . . . . . . . . . 163.2.3 Le curve fitting . . . . . . . . . . . . . . . . . . . . . . . . . . . . 173.2.4 La méthode LSM . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
II La méthode des replicating portfolio 22
4 Généralités 234.1 Réplication parfaite à l’aide de Zéro-Coupons . . . . . . . . . . . . . . . 244.2 La participation aux bénéfices et les calls . . . . . . . . . . . . . . . . . . 24
5 Description de la méthode des replicating portfolio pour le calcul duSCR à 1 an 265.1 Actifs candidats à la réplication . . . . . . . . . . . . . . . . . . . . . . . 275.2 Résolution du programme d’optimisation . . . . . . . . . . . . . . . . . . 285.3 Validation du portefeuille répliquant . . . . . . . . . . . . . . . . . . . . 31
5.3.1 Validation statistique . . . . . . . . . . . . . . . . . . . . . . . . . 315.3.2 Analyse de la structure générale du portefeuille . . . . . . . . . . 315.3.3 Validation sur des sensibilités . . . . . . . . . . . . . . . . . . . . 32
5.4 Application du portefeuille répliquant . . . . . . . . . . . . . . . . . . . . 32
1

III Applications à un portefeuille d’épargne Euros 33
6 Description du portefeuille 346.1 Le Modèle ALM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
6.1.1 Modélisation du passif . . . . . . . . . . . . . . . . . . . . . . . . 356.1.2 Modélisation de l’actif . . . . . . . . . . . . . . . . . . . . . . . . 35
6.2 Le Générateur de scénario . . . . . . . . . . . . . . . . . . . . . . . . . . 366.2.1 Les univers monde réel et risque-neutre . . . . . . . . . . . . . . . 366.2.2 Le modèle Action . . . . . . . . . . . . . . . . . . . . . . . . . . . 376.2.3 Le modèle de taux . . . . . . . . . . . . . . . . . . . . . . . . . . 386.2.4 Discrétisation des processus . . . . . . . . . . . . . . . . . . . . . 406.2.5 Génération des déflateurs . . . . . . . . . . . . . . . . . . . . . . . 406.2.6 Test de martingalité . . . . . . . . . . . . . . . . . . . . . . . . . 40
6.3 Calibration des portefeuilles : Réplication de passifs ou de marges ? . . . 416.3.1 Portefeuille A . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 426.3.2 Portefeuille B . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 446.3.3 Portefeuille C . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 456.3.4 Calibration des portefeuilles : vision marges . . . . . . . . . . . . 46
7 Développements réalisés 487.1 La régression Partial Least Square (PLS) . . . . . . . . . . . . . . . . . . 48
7.1.1 Présentation de la méthode . . . . . . . . . . . . . . . . . . . . . 487.1.2 Présentation des résultats . . . . . . . . . . . . . . . . . . . . . . 55
7.2 CashFlow mismatch . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 587.2.1 Initialisation du problème . . . . . . . . . . . . . . . . . . . . . . 597.2.2 Absolute CashFlow mismatch . . . . . . . . . . . . . . . . . . . . 617.2.3 Conditional Value-at-risk mismatch . . . . . . . . . . . . . . . . . 657.2.4 Conditional Value-at-risk and Absolute mismatch . . . . . . . . . 677.2.5 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
7.3 Sélection automatique des instruments financiers . . . . . . . . . . . . . . 707.3.1 Least Angle Regression . . . . . . . . . . . . . . . . . . . . . . . . 717.3.2 Orthogonal matching pursuit . . . . . . . . . . . . . . . . . . . . 777.3.3 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
Conclusion 89
Annexe 91
Bibliographie 121
2

Notations et Acronymes
SCR Solvency Capital Requirement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1ALM Asset Liability Management . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2PLS Partial Least Square . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2LAR Least Angle Regression . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71OMP Orthogonal Matching Pursuit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77MCO Moindres Carrés Ordinaires . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59SdS Simulations dans les SimulationsLSMC Least Square Monte Carlo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19SVD Singular Value Decomposition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30VaR Value-at-Risk . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15CVaR Conditional Value-at-RiskESG Economic Scenario Generator . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34PRESS PRediction Error Sum of Squares . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52RSS Residual Sum of Square . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
3

Remerciements
Je tiens à remercier en premier lieu M. Jérémie VISCUSO, responsable de l’équipe por-tefeuille répliquant chez AXA, de m’avoir acceuilli au sein de son équipe et permis de meconsacrer en grande partie à la rédaction de ce mémoire. Je lui témoigne toute ma gratitudepour l’attention qu’il a pu porter à mon travail. Mes remerciements s’adressent également auxmembres de l’équipe pour leurs nombreux conseils et explications qui m’ont permis d’avancerdans ma réflexion sur les portefeuilles répliquants.
Je tiens également à remercier l’ensemble des professeurs de l’Institut de Sciences Finan-cières et d’Assurance (ISFA) pour ces enseignements qui m’ont conforté dans mon choix detravailler dans le monde de l’actuariat. Je remercie en particulier mon tuteur pédagogique M.Alexis BIENVENÜE pour ses conseils et sa relecture attentive de mon travail.
Enfin, the last but not least, je remercie ma famille, et tout particulièrement mes parentspour le soutien qu’ils m’ont apporté pendant toute ma scolarité.
4

Introduction
Dans le but de protéger les assurés et d’améliorer la gestion des risques dans le secteur del’assurance, l’Union Européenne a décidé de mettre en place une nouvelle réforme , Solvabilité2. Basée sur trois pilliers comme Bâle 2, cette réforme vise à garantir la solvabilité des assu-reurs. En effet, Solvabilité 2 impose aux compagnies d’assurance de détenir des fonds propresau moins supérieurs à la perte maximale possible sur un horizon de 1 an, avec un niveau deconfiance de 99,5%.
Ce calcul des fonds propres économiques s’avère souvent coûteux en temps de calcul no-tamment en assurance vie où les garanties proposées imposent aux compagnies de modéliserles interactions qui existent entre l’actif et le passif. La méthodologie des portefeuilles ré-pliquants utilisée par AXA est l’une des méthodologies de calcul du capital économique enmodèle interne qui se sont développées ces dernière années pour le calcul du SCR de marchénotamment. Le principe de cette méthode est de répliquer la valeur économique des passifspar une combinaison linéaire d’instruments financiers facilement valorisables (idéalement enformule fermée) en effectuant notamment une régression des moindres carrés.
L’objet de ce mémoire est de proposer des alternatives dans un premier temps à la réplicationdes passifs. Nous allons notamment nous intéresser directement aux flux de l’actionnaire, quisont la variable qui nous intéresse dans la détermination de notre portefeuille répliquant. Dansun deuxième temps nous allons proposer différentes méthodes de régression alternatives à larégression des moindres carrés ordinaires.
Dans la première partie du mémoire nous nous attacherons à présenter les enjeux règle-mentaires de la nouvelle directive, ainsi que les deux options principales dont disposent lesassureurs européens pour évaluer la charge en capital au titre du risque de marché. Il s’agitde la méthodologie formule standard et de la méthologie modèle interne. La formule standardde Solvabilité 2 a été mise en oeuvre par l’EIOPA au fur et à mesure des différents exercicesde QIS ( Quantitative Impact Study) qui ont permis d’affiner la calibration des chocs. De parsa simplicité, la formule standard est donc un des moyens proposés pour évaluer sa charge encapital. Elle présente l’inconvénient de s’appliquer de manière identique à toutes les compa-gnies d’assurance, et ne permet donc pas à l’assureur d’avoir une vision précise des risques.L’alternative à la formule standard que représente le développement d’un modèle interne per-met justement de palier à cette lacune. Nous présenterons donc dans cette première partiel’idée générale de la mise en oeuvre d’un modèle interne et mettrons en lumière la difficultéque représente cette approche dans le cas particulier de l’assurance vie et présenteront lessolutions principales qui sont aujourd’hui à la disposition des assureurs pour contourner cettedifficulté.
5

Dans la deuxième partie du mémoire nous présenterons plus en détail une des méthodesde calcul du capital économique : il s’agit de la méthode des portefeuilles répliquants. Uneprésentation sera faite des principales étapes qui sont nécessaires à la calibration d’un porte-feuille répliquant et les outils d’analyse de la qualité de ces portefeuilles.
Enfin la troisième partie présentera les développements qui ont été réalisés dans le cadrede cette étude. Ces développements concernent deux étapes cruciales dans la constructiond’un portefeuille répliquant de bonne qualité. L’une d’entre elles correspond à la calibrationdes poids des instruments financiers qui constituent le portefeuille. La régression des moindrescarrés classique présente certains inconvénients auxquels nous essaierons de remédier à tra-vers diverses méthodes alternatives. La deuxième étape importante dans la construction d’unportefeuille est le choix des instruments candidats. Comme nous le montrerons dans la suite,cette étape peut s’avérer fastidieuse pour des portefeuilles présentant de multiples facteursde risques. Nous allons présenter des méthodes qui vont permettre d’automatiser cette étapedu processus et qui vont s’avérer plutôt efficaces pour avoir une première liste d’intrumentsfinanciers qui pourra par la suite être modifiée à la marge pour arriver à un portefeuille finalsatisfaisant en terme de qualité.
6

Première partie
La directive Solvabilité 2
7

Chapitre 1
Rappels sur Solvabilité 1
La réforme Solvabilité 1 constitue le régime de solvabilité actuellement en vigueur. Elle adébuté par l’application de deux directives européennes, celle de 1973 pour l’assurance non-vieet celle de 1979 pour l’assurance vie. Elle impose aux compagnies d’assurance de détenir unmontant de fonds propres minimal. Solvabilité I repose sur trois notions :
– La marge de solvabilité qui est constituée par le patrimoine de l’organisme libre de toutengagement prévisible.
– L’exigence de marge de solvabilité ou marge de solvabilité règlementaire qui est le mon-tant en fonds propres que doit détenir une compagnie d’assurance.
– Le fonds de garantie qui est le second seuil pour les ressources dont doit disposer l’en-treprise.
Les règles établies par Solvabilité 1 fixent :– Une exigence de composition des actifs en couverture des engagements.– La présentation annuelle d’un rapport de solvabilité.– La détermination d’une marge de solvabilité règlementaire.– La détermination du Fonds de Garantie
Solvabilité I se caractérise par des méthodes simples de calcul et par sa robustesse, il offreaux sociétés d’assurance une vue d’ensemble sur le montant nécessaire des provisions et desméthodes pour comptabiliser les primes avec les provisions. Cependant ce projet présentequelques limites d’ordre qualitatives et quantitatives.
– Limites quantitatives : la principale critique adressée au projet solvabilité 1 est qu’iln’opère pas de distinction entre les risques et l’impact de leur volatilité à l’intérieur desbranches d’activités qui révèlent en réalité des profils de risque différents. En effet, lamarge de solvabilité est déterminée selon des facteurs représentant les engagements dela société ou le volume d’activité des sociétés sans tenir compte des risques assumés parces dernières.Les assureurs se trouvent donc dans l’obligation d’immobiliser plus de capitaux dans lesprovisions techniques ce qui peut freiner leurs projets d’investissement et anéantir leurmarge de bénéfice. Une autre critique qui a été adressée à ce projet est que les formes detransfert de risques et les conséquences des corrélations des actifs et des passifs n’étaientpas étudiées.
– Limites qualitatives : peuvent être résumées par l’absence de surveillance et de contrôleinternes. En effet, Schuckmann.S(2007) affirme que le premier objectif de l’assuranceest de réduire l’inconvénient informationnel. Selon le même auteur, les informations surla santé financière d’une société d’assurance seraient asymétriquement distribuées. Cesproblèmes résultant d’asymétrie antérieure de l’information pourraient être résolus par
8

la transparence croissante du marché ou en rassemblant des informations fiables surl’assureur.
9

Chapitre 2
Focus sur Solvabilité 2
Dans l’esprit de Bâle II régulant les activités bancaires, la Commission Européenne sou-haite améliorer l’évaluation et le contrôle des risques dans le secteur de l’assurance. Dans cecontexte, la directive Solvabilité II (Solvency II) est un projet de réglementation prudentielles’appliquant à l’ensemble des compagnies d’assurance de l’Union Européenne.Rappelons qu’une directive est une décision de droit communautaire visant à favoriser l’harmo-nisation des législations nationales des États membres de l’Union Européenne. Contrairementau règlement européen qui s’impose directement aux ressortissants de l’Union, la directive n’apas vocation à s’appliquer directement aux entreprises ou aux particuliers et nécessite unetransposition en droit national. Solvabilité II porte deux grands objectifs. Le premier est decréer un marché de l’assurance unique, compétitif et ouvert à la concurrence à l’échelle euro-péenne. Le second est de protéger davantage les assurés et les contreparties des compagnies.Le premier objectif découle du caractère européen de la réforme et de l’uniformisation descontraintes prudentielles au sein de chaque pays membre. L’harmonisation de la réglemen-tation supprime les inégalités de référentiels réglementaires et permet la construction d’unmarché unique et libre.Le second objectif est porté par l’idée qu’un assureur doit mieux gérer, connaître et évaluer sesrisques. Dans une logique similaire à Bâle II, Solvabilité II se construit autour de trois piliers.
2.1 Pilier 1 : Exigences en capital
Les assureurs et réassureurs européens devront disposer de fonds propres permettant decouvrir leur exposition aux risques assurantiels, de marché, de crédit et au risque opérationnel.Une approche standardisée à l’ensemble des acteurs européens a été développée à cet effet. Elleest communément appelée formule standard. Outre cette approche standardisée, les assureursont la possibilité de développer des modèles internes de façon à pouvoir quantifier au mieux leurexposition aux différents risques. Ces modèles doivent être validés par le régulateur européen,représenté en France par l’Autorité de Contrôle Prudentiel (ACP).L’ACP dispose donc pour ce faire de pouvoirs renforcés et peut en particulier imposer au caspar cas, des exigences en fonds propres différentes en fonction de la robustesse du modèleutilisé pour le calcul du besoin en fonds propres ou du niveau de fonds propres de l’entreprise.Le niveau de fonds propres requis équivaut à une Value-at-Risk à 99,5% sur un horizon de 1an.
10

2.2 Pilier 2 : Activités de contrôle et de supervision
Au sein de ce pilier seront fixées les normes qualitatives de suivi des risques en interne, ilindiquera comment l’autorité de contrôle va exercer ses pouvoir de contrôle dans le contextede Solvabilité 2. Le pilier 2 impose donc la mise en place de dispositif de gouvernance desrisques en se servant du modèle défini dans le pilier 1. Un des grands enjeux du piler 2 estdonc la mise en place du dispositif ORSA et la validation des modèles internes.
2.3 Pilier 3 : Discipline de marché
Ce dernier pilier a pour objectif de définir les obligations de publications des entreprisesd’assurance vis-à-vis des assurés, des investisseurs et des autorités de marché.
Tous ces piliers sont bien évidemment liés entre eux et nous nous intéresserons principale-ment dans ce mémoire au pilier 1.
Figure 2.1 – Structure de Solvabilité 2
11

Chapitre 3
Modèle Interne vs Formule Standard
La définition du capital économique dans l’environnement Solvabilité II repose sur unevision économique du bilan de la compagnie : les actifs sont évalués en valeur de marchéde façon market-consistent et les engagements c’est-à-dire que les provisions mathématiquesdoivent être calculées de façon best estimate : la valeur de ces engagements doit représenter lavaleur réelle à l’instant de calcul. En ce sens, la construction du bilan économique constitue lepilier de la nouvelle réforme. En effet, du bilan économique vont dépendre plusieurs processusinhérents à l’activité d’une compagnie d’assurance :
– le calcul du SCR et la détermination des fonds propres éligibles, qui représentent leséléments des fonds propres de la compagnie qui permettent de couvrir le capital desolvabilité SCR calculé en formule standard ou en modèle interne
– le calcul de la MCEV et de la new business value qui permettent d’évaluer la capacitédes contrats d’assurance vie à générer des profits futurs
A chaque date t, il est possible de construire le bilan économique suivant :
Bilan économique en tAt FPt
V EPt
Sous les notations :– At : valeur de marché de l’actif en t,– V EPt : valeur économique des passifs en t– FPt : fonds propres économiques en t.Le bilan étant équilibré, on a la relation : FPt = At − V EPt.
Désignons par Ft la filtration permettant de caractériser à chaque date l’information financièredisponible. La valeur de chacun des postes du bilan correspond à l’espérance sous la probabilitérisque-neutre Q des cash-flows futurs actualisés.Soient :
– δu le facteur d’actualisation s’exprimant ainsi : δu = e−∫ u0 rudu, ou ru désigne le taux
d’intérêt sans risque– Pt : les cashflows de passifs (prestations, commissions, etc) en t– Rt : le résultat de la compagnie en t.– P (s, t) : le prix en s d’une obligation zéro coupon de maturité t
12

Figure 3.1 – Structure du bilan économique sous Solvabilité 2
Avec ces notations on a alors :
V EP0 = EQ
[∑u≥1
δuPu|F0
](3.1)
et,
FP0 = EQ
[∑u≥1
δuRu|F0
](3.2)
En projetant donc le bilan en t = 1 on a :
V EP1 = EQ
[∑u≥2
δuPu|F1
](3.3)
et,
FP1 = EQ
[∑u≥2
δuRu|F1
](3.4)
Le capital économique, défini par Solvabilité II, est le niveau minimal de fonds propres endate initiale permettant de satisfaire la contrainte : P (FP1 ≤ 0) = 0, 5%. Il vient donc :
SCR = FP0 − P (0, 1).V aR99,5%(FP1) (3.5)
où P (0, 1) est le prix d’une obligation zéro coupon.La distribution de la variable FP1 est donc essentielle au calcul du capital économique. Maiscomme on l’a rappelé en introduction, cette distribution des fonds propres économiques est
13

très difficile à estimer puisqu’elle implique pour l’assureur un premier niveau de simulation quipermet de projeter la situation économique à l’horizon d’une année imposée par la directivepour l’estimation de la distribution des fonds propres. Un second niveau de simulation estnécessaire pour l’évaluation des engagements de l’assureur qui doivent comporter la valeurtemps des options inclues dans les contrats d’assurance vie. Les assureurs disposent commenous l’avons mentionné en introduction de deux principales options pour évaluer leur SCR :
– Mettre en place un modèle interne afin d’évaluer le SCR : simulations dans les simulations– Evaluer le SCR en formule standard
La mise en oeuvre de la formule standard ainsi que la calibration des chocs de marché notam-ment sont présentées dans la section suivante.Quant à la mise en place d’un modèle interne à proprement dit, les temps de calculs imposéspar l’approche "directe" présentée ci-dessus rendent difficile la mise en oeuvre opérationnelled’une telle méthodologie au sein des compagnies d’assurance. Les assureurs disposent de plu-sieurs alternatives pour mettre en oeuvre un modèle interne. En effet, depuis la mise en placede Solvabilité 2 plusieurs méthodes "simplifiées" ont été proposées notamment dans l’ap-proche modèle interne pour le calcul du SCR afin d’optimiser les temps de calcul. On retrouvedans la littérature plusieurs méthodes pour y arriver :
– la méthode de l’accélérateur SdS cf Devineau et Loisel– la méthode des portefeuilles répliquants– l’approche curve fitting– l’approche Least Square Monte Carlo
Nous développerons brièvement le principe de ces méthodes dans cette partie du mémoire. Laméthode des replicating portfolio qui fait l’objet de notre étude sera développée plus en détaildans la deuxième partie de ce mémoire.
3.1 La formule standard
La deuxième option est l’approche par formule standard qui repose sur le calcul du capitaléconomique par chocs instantanés sur chacun des risques pris en compte dans le cadre deSolvabilité 2. Les capitaux économiques ainsi obtenus sont agrégés via des matrices de corré-lation.Le principe de la formule standard est donc, pour un risque R, de réévaluer le bilan suite àun choc instantané sur ce risque. Le capital économique correspond à la différence entre lesfonds propres économiques en situation centrale et les fonds propres économiques en situationstressée.On a donc :
SCR = FP0 − FPR0 (3.6)
où– FP0 désigne les fonds propres économiques en situation centrale– FPR
0 désigne les fonds propres économiques suite au choc instantané sur le risque RComme on peut le constater sur le diagramme ci-dessus cette formule repose sur une
approche modulaire du risque. Les charges en capital sont calculées unitairement puis agrégéesà plusieurs niveaux suivant la formule suivante :
SCR = SCROp +BSCR + Adj
où– SCROp correspond au SCR opérationnel qui se calcule factoriellement
14

Figure 3.2 – Structure modulaire de la formule standard
– Adj représente l’ajustement pour la capacité d’absorption des pertes par les provisionstechniques
Enfin la composante principale de cette somme est le BSCR qui repose sur la formule suivante :
BSCR =√∑
i,j Corri,jSCRiSCRj + SCRIntangible
Le calibrage des chocs qui a été réalisé pour correspondre à une Value-at-Risk (VaR) à 99,5%a beaucoup évolué au cours des dernières années et n’est toujours pas fixé.Nous allons nous intéresser dans cette section au calcul du SCR en formule standard pour lerisque de marché. La contribution de ce module au SCR final est assez importante pour unassureur vie. Les risques pris en compte dans ce module sont les suivants :
– Risque action– Risque de taux– Risque de spread– Risque de change– Risque d’illiquidité– Risque immobilier– Risque de concentration
Les charges en capital calculées unitairement pour chacun des risques précédents sont ensuiteagrégées via la matrice de corrélation suivante : Le choix du paramètre A dépend du scénarioretenu dans le cadre du calcul de la charge en capital au titre du risque de taux :
– Si le scénario haussier est retenu alors A=0– Si le scénario baissier est retenu alors A=0.5
15

(i,j) Taux Action Immobilier Spread Concentration Change Prime contra-cycliqueTaux 1 A A A 0 0.25 0Action A 1 0.75 0.75 0 0.25 0
Immobilier A 0.75 1 0.5 0 0.25 0Spread A 0.75 0.5 1 0 0.25 0
Concentration 0 0 0 0 1 0 0Change 0.25 0.25 0.25 0.25 0 1 0
Prime contra-cyclique 0 0 0 0 0 0 1
Table 3.1 – Matrice de corrélation des risques de marché
3.2 Les approches par modèle interne
Le point commun des approches présentées ci-dessous en dehors de celle classique desSimulations dans les simulations est qu’elles essayent de réduire au maximum les temps decalcul qu’impliqueraient un calcul de SCR par l’approche simulations dans les simulations.Chacune de ces méthodes par des moyens divers permet de réduire les simulations nécessaireset donc les temps de calcul, ce qui s’avère relativement efficace pour les compagnies dansle cadre d’une mise en oeuvre opérationnelle de modèles à priori théoriques. Le point cléévidemment est de maîtriser l’erreur commise quand on utilise une méthode et de pouvoirs’assurer que cette erreur n’est pas trop grande.
3.2.1 Les Simulations dans les simulations
On rappelle que le but d’une évaluation du capital économique est de déteminer la dis-tribution des fonds propres à un an FP1 que nous avons défini par ailleurs dans la premièrepartie de ce mémoire. Le but final est donc de déterminer directement le quantile à 99,5% dela distribution à un an des fonds propres économiques. Cette méthode à l’avantage de fournirune estimation très précise du capital économique mais s’avère très coûteuse en temps decalcul et ne constitue donc pas une solution viable dans le cadre de processus à intégrer dansune compagnie d’assurance.
On peut résumer le principe de cette approche en trois étapes :– Etape 1 : Diffusion des valeurs financières sur un an (rendements action, courbe destaux, ...) calibrées en monde réel. Ils sont dits scénarios primaires
– Etape 2 : Estimation des richesses à horizon 1 an : plus ou moins value à 1 an, perted’actifs suite à des défauts,
– Etape 3 : Valorisation du bilan économique pour chacun des scénarios primaires d’aprèsdes scénarios économiques market consistent
3.2.2 L’accélérateur SdS
Comme son nom l’indique le principe de cette méthode est d’accélérer le calcul du SCR enprivilégiant les pires trajectoires dans la détermination de la queue de distribution des fondspropres. Cette sélection de trajectoire se calcule par rapport à des facteurs de risques et àl’aide d’une distance déterminée dans l’article de Loisel et Devineau. Cette méthode permet deréduire significativement les calculs en concentrant les simulations sur ces facteurs de risque.Pour résumer on peut dire que cette méthode repose sur les étapes suivantes :
– Déterminer les principaux facteurs de risques– Définir une norme permettant de quantifier le risque de chacune des simulations primaires
16

Figure 3.3 – Illustration de l’approche SdS
– Calculer la valeur des facteurs de risques pour chacune des simulations selon la normechoisie
– Définir une norme permettant de quantifier le risque de chacune des simulations primaires– Isoler selon l’algorithme d’itération les situations les plus adverses– Réaliser les calculs sur ces trajectoires
Toutefois l’ajout de facteurs de risque augmente la complexité de l’algorithme et donc aussiles temps de calculs.
3.2.3 Le curve fitting
Le Best Estimate, et donc par conséquent les fonds propres est soumis à un nombre limitéde risques. Le principe de l’approche curve fitting est, dans le même esprit que l’algorithmed’accélération présenté plus haut, d’interpoler la valeur du passif, sur un nombre limité depoints importants des scénarios en monde réel. La valeur du best estimate est en réalité unefonction complexe d’un nombre limité de risk drivers définis par les scénarios économiques enmonde réel. Dans ce cas, deux scénarios à peu près identiques vont conduire à la même valo-risation du Best Estimate. Le but de l’approche curve fittinge est justement d’éviter d’utiliserdeux fois les 1000 scénarios risque neutre pour avoir la même valeur de best estimate si onutilise l’approche simulation dans les simulations.
Dans une première étape, on va donc valoriser le best estimate sous un certains nombrede stress instantanés. Le choix des stress doit être réalisé afin qu’ils couvrent largement lesrisques pour lesquels on souhaite évaluer la charge en capital. On réalise ensuite une inter-polation à travers ce nombre limité de points. Une fois la méthode d’interpolation choisie
17

(polynomiale, par morceaux, etc) et mise en oeuvre on dispose d’une fonction qui nous donneune estimation rapide du best estimate en fonction d’un nombre de risks drivers limité. Onpeut donc facilement calculer la distribution des fonds propres qui va permettre d’évaluer lequantile à 99,5% .
18

2.png
Figure 3.4 – Illustration de l’approche Curve Fitting
3.2.4 La méthode LSM
Une façon de réduire le nombre de calculs en méthodologie modèle interne est de toujoursfaire des milliers de simulations en monde réel, mais de n’utiliser que quelques uns, ou mêmeune seule simulation secondaire pour l’évaluation du bilan économique. Évidemment, cela varéduire le temps d’exécution pour les calculs, mais il est tout aussi évident que cette évaluationdu bilan économique pour chaque scénario monde réel sera probablement inexacte. Toutefois,cette imprécision peut être efficacement corrigée par une régression relativement simple grâceà l’ensemble des évaluations inexactes dans tous les scénarios pour produire une courbe derégression. Cette courbe de régression est ensuite utilisée pour calculer la valeur du passif aulieu de simples évaluations inexactes. Ce procédé est connu sous le nom de «moindres carrésde Monte Carlo» (LSMC) en raison de la régression qui minimise la somme des carrés des er-reurs entre les valeurs des simulations simples et les simulations de Monte Carlo stochastiques.Assez curieusement, cette approche relativement simple, qui ne nécessite pas de ressourcesinformatiques massives, produit des résultats remarquablement précis.
Dans cette section on se propose d’exposer le principe de l’approche Least Square MonteCarlo (LSMC) pour le calcul du SCR. L’idée de la méthode est de réduire significativementles nombres de simulations secondaires pour l’estimation du best estimate en recourant à uneméthode de régression. En effet comme nous l’avons mentionné plus haut, la difficulté del’évaluation du SCR provient de l’estimation de la quantité suivante en (4.4) :
FP1 = EQ
[∑u≥2
δuRu|F1
](3.7)
Ici, l’espérance conditionnelle représente la principale difficulté pour développer une techniqueappropriée de Monte-Carlo. Ceci est analogue à la valorisation d’options Bermudéenne, oùles espérances conditionnelles impliquées dans les itérations de la programmation dynamiquereprésentent également la principale difficulté pour le développement des techniques de Monte-Carlo (cf. [8]). Une solution appropriée à ce problème a été proposée par [16], qui utilisentrégression des moindres carrés sur un ensemble fini de fonctions de base pour approcher l’es-pérance conditionnelle.
Comme l’a souligné [8], l’algorithme consiste plus précisément en deux différents types d’ap-
19

proximations. Dans la première étape d’approximation, l’espérance conditionnelle est rempla-cée par une combinaison linéaire finie de fonctions de base. Ici on va donc remplacer l’espéranceconditionnelle FP1 par une combinaison linéaire finie de fonctions de bases (ek(Y1))k=1,··· ,M :
FP1 ≈ FPM1 =
∑k=1
αk.ek(Y1) (3.8)
en supposant que la suite (ek(Y1))k≥1 est indépendante et complète dans l’espace de HilbertL2(Ω, σ(Y1),P).Les fonctions de bases (ek(Y1))k=1,··· ,M peuvent être par exemple les polyômes de Lagrange,les polynômes de Laguerre, polynômes de d’Hermite, les fonctions trigonométriques.[3] retient cette méthode mais en considérant que la base hilbertienne (ek(Y1))k=1,··· ,M estconstituée de polynômes à 4 inconnues :
– l’actif de la compagnie– la fonction de perte– le résultat de la première année– le taux court de la première année
FP1 est une variable aléatoire dans l’espace de Hilbert L2(Ω, σ(Y1),P) et on peut doncdécomposer cette variable aléatoire sur une base de cet espace :
FP1 =+∞∑k=1
αkek(Y1) ≈M∑k=1
αkek(Y1) = FPM1 (Y1) (3.9)
Il faut donc déterminer les coefficients αk. Pour cela on s’appuie sur la simulation de trajec-toires des variables d’état, i = 1, · · · , n :
(Y it )t=1,··· ,T
Le long de chacune de ces trajectoires , on calcule
PVi =∑
j≥2 δi1(j)×X i
j,
On peut alors construire un estimateur de α en posant :
αN = argminN∑i=1
(PVi −
M∑k=1
αkek(Yi
1 )
)2
On obtient finalement l’approximation suivante :
FP1 ≈ FP(M,N)1 (Y1) =
M∑k=1
αNk ek(Y1) (3.10)
La seconde étape d’approximation plus classique correspond à l’utilisation de scénarios deMonte Carlo pour évaluer la distribution des fonds propres qui va nous permettre d’évaluer lequantile à 99,5%.
20

Figure 3.5 – Illustration de l’approche Least Square Monte Carlo
21

Deuxième partie
La méthode des replicating portfolio
22

Chapitre 4
Généralités
Les techniques de réplications sont à la base des méthodes qui ont contribué à l’essor desmarchés à travers notamment la formule d’évaluation de Black et Scholes qui repose sur ceprincipe et plus généralement le problème de la valorisation market-consistent d’autres actifs.Rappelons ici brièvement le principe de la réplication.Notons (Ft)t≥0 la filtration qui caractérise l’information financière disponible à la date t etconsidérons Z une variable aléatoire FT -mesurable. On suppose également que l’économie estcomposée de d+1 actifs financiers de prix Xt = (X0
t , X1t , · · · , Xd
t ) à la date t et où X0t est
diffusé comme suit :
dX0t = X0
t rtdt, X0t = 1,
où rt désigne le taux sans risque.Sous certaines hypothèses on peut construire un processus adapté wt = (w0
t , w1t , · · · , wdt ) qui
permet de répliquer la variable aléatoire Z satisfaisant les propriétés suivantes :
wtXt = w0X0 +
∫ t0wsdXs ∀t ≤ T, p.s
wTXT = Z p.s
Les composantes du processus wt représentent les poids de chacun des actifs dans un porte-feuille auto-finançant répliquant la variable aléatoire Z.La valorisation par arbitrage permet donc de définir le prix de l’instrument financier ayantcomme cashflow la variable Z comme suit : πt = wtXt = e−
∫ Tt rsdsZ|Ft.
Finalement, on peut retrouver la formule de Black et Scholes permettant de déterminer leprix d’un call de maturité T, de strike K et de sous-jacent X1
t en valorisant le portefeuillerépliquant les cashflows de la variable aléatoire Z = (X1
T −K)+.Supposons que le taux sans risque est constant égal à r, et que sous la probabilité risque-neutreQ on a :
dX1t
X1t
= rdt+ σdWt,
où (Wt) est un mouvement brownien sous Q. Alors la composition du portefeuille répliquantà tout instant t est le suivant :
w0t = −Ke−rTN(dt2)
et,
23

w1t = N(dt1),
où,
dt1 = 1σ√T−t
(ln(X1t
K
)+(r + 1
2σ2
).(T − t)
), dt2 = dt1 − σ
√T − t
N(.) est la fonction de répartition d’une loi normale centrée réduite.
Le principe des portefeuilles répliquants repose principalement sur cette idée, à la seule diffé-rence qu’on s’intéresse dans ce cas à répliquer des flux liés à des passifs d’assurance.La réplication dépendra de la garantie proposée et notamment de la complexité des passifs dela compagnie d’assurance. Nous allons présenter quelques situations basiques dans lesquellesla réplication peut être effectuée parfaitement.
4.1 Réplication parfaite à l’aide de Zéro-Coupons
Dans certains cas, notamment en assurance non-vie, on travaille sur des cash flows futursgarantis, c’est-à-dire qu’on connait exactement les montants qui devront être payés. Dans cecas on a une indépendance entre la perfomance de l’actif et le passif de l’assureur. Il n’estdonc pas nécessaire d’avoir un modèle ALM pour simuler sous plusieurs scénarios les cashflow futurs.Dans ce cas, le portefeuille sera constitué de zéro-coupons avec des nominaux et des maturitéscorrespondant aux dates de paiement des flux futurs. Un seul scénario sera nécessaire pourfournir une réplication parfaite des passifs.
4.2 La participation aux bénéfices et les calls
Certains contrats d’assurance-vie comportant des options peuvent se lire de manière op-tionnelle et donc faciliter la réplication à l’aide d’instruments financiers simples.Considérons par exemple un contrat d’assurance avec un taux garanti et une participationaux bénéfices. Dans ce contrat, l’assuré confie une prime à l’assureur et reçoit à maturité ducontrat cette prime capitalisée au taux garanti ainsi qu’une participation aux bénéfices fixéeà l’avance dans le contrat.Les caractéristiques du contrat sont les suivantes :
– Maturité : 6 ans– Prime : 10 000 euros– Taux minimum garanti : 2%– Taux de participation aux bénéfices : 75%– Allocation d’actif :– 20% d’actions– 80% d’obligations à un taux de 3%
Ce contrat très simplifié peut être parfaitement répliqué par un portefeuille d’actifs comprenantdes zéro coupons et des options de type Call.En établissant la valeur à maturité du fonds ainsi que le montant minimum garanti,
FondsValue =10000×[0.2× ST
S0+ 0.8× (1 + 0.03)6
]Guarantee = 10000× (1 + 0.02)6
24

on a le payoff à maturité du contrat qui est défini comme suit :
PayOff = Guarantee+ 0.75×max [FondsV alue−Guarantee; 0]
= Guarantee+ 0.75×max
[10000× 0.2× ST
S0
+ 10000× 0.8× (1 + 0.03)6 − 10000× (1 + 0.02)6; 0
]= Guarantee+ 0.75× 10000× 0.2×max
[STS0
−[
(1 + 0.02)6 − 0.8× (1 + 0.03)6
0.2
]; 0
]= α× ZC + β × Call
En faisant l’application, on trouve α= 11 261.62 et β = 1500 , où ZC est un zéro couponde maturité 6 ans avec un taux de 2% et Call représente la valeur d’un call de maturité 6 anset de strike 85.5%.On voit donc que sur exemple assez simplifié, la réplication d’un contrat d’assurance peutse faire parfaitement à l’aide d’instruments financiers simples. Dans le cadre de contratsplus complexes avec des clauses de sortie anticipée par rachats ou mortalité par exemple,l’approche que nous avons employée ne sera plus possible. L’utilisation des simulations seradonc nécessaire pour trouver un portefeuille qui approche les passifs qu’on souhaite répliquer.
25

Chapitre 5
Description de la méthode desreplicating portfolio pour le calcul duSCR à 1 an
Un portefeuille répliquant d’un passif d’assurance est un portefeuille d’instruments finan-ciers standards qui a la même valeur de marché "Market Consistent Value" et la mêmesensibilité aux différents facteurs de risque que le passif.
Comme la méthode des simulations dans les simulations est très fastidieuse en raison desa complexité (Cf première partie), la technique des portefeuilles répliquants est donc utiliséecomme une approche alternative pour accélérer le calcul du capital économique au titre durisque de marché. L’évaluation des passifs est rendue possible en réduisant le passif d’assuranceà des instruments financiers pour lesquels les informations de marché sont disponibles et desformules fermées existent 1. Ainsi, la technique des portefeuilles répliquants permet un calculopérationnel des exigences en capital de risque de marché.
Une fois le portefeuille répliquant obtenu, il est utilisé pour obtenir la distribution des fondspropres économiques au titre des risques de marché au temps t= 1 année 2. Dans ce contexte,les simulations monde réel sont réalisées au moyen d’un modèle VaR. Ensuite, chaque simu-lation risque neutre est utilisée pour évaluer la valeur de marché du portefeuille de réplicationsur la base de formules fermées. La figure ci-dessous donne une explication graphique surl’approche qui est utilisée dans l’évaluation du passif et de valeur pour les actionnaires enutilisant les portefeuilles répliquants.
Pour créer un portefeuille répliquant il faut disposer d’un jeu de K instruments financierscandidats à la réplication. Le but est d’écrire la valeur présente des flux de passifs commeune combinaison linéaire de plusieurs instruments financiers. Il faut donc trouver des poidsw = (w1, w2, · · · , wK) qui représentent le minimum d’un programme d’optimisation. Laconstruction d’un portefeuille répliquant se fait donc en trois étapes :
– Etape 1 : Choix des instruments de réplication– Etape 2 : Résolution du programme d’optimisation
1. Selon cette approche, l’évaluation du passif est presque instantanée. Ceci permet l’introduction de techniques sophis-tiquées pour calculer le capital économique couvrant le risque de marché
2. Suite aux directives de l’EIOPA sur la construction des modèles internes qui vise à assurer une approche harmoniséede l’utilisation des modèles internes et à améliorer l’évaluation du profil de risque de l’entreprise d’assurance, le capital derisque de marché exigence correspond à une mesure de la VaR, avec un niveau de confiance de 99,5% sur une période d’unan calibré de façon à s’assurer que tous les les risques quantifiables auxquels les sociétés d’assurance-vie sont exposés sontpris en compte
26

Figure 5.1 – Illustration de l’approche RP
– Etape 3 : Validation de la qualité du portefeuille
5.1 Actifs candidats à la réplication
Le choix des actifs candidats à la réplication est la première étape dans la construction duportefeuille répliquant. Idéalement on s’intéresse à des actifs simples et disposant de formulesfermées afin d’éviter le recours à des méthodes de type Monte Carlo 3 pour la valorisation.On choisira également des actifs qui sont exposés aux même risques que les passifs d’assurance.
Cependant, la complexité des passifs d’assurance vie sont parfois difficilement réplicables àl’aide d’instruments financiers trop simples. En effet, l’usage d’instruments pas suffisamentcomplexes peut conduire à une mauvaise réplication. Une solution serait ainsi de créer desactifs financiers spécifiques aux garanties qui nous intéressent.
Nous verrons dans la suite du mémoire comment on peut essayer d’automatiser cette étapedu processus de réplication. Des travaux pour automatiser cette étape de la construction duportefeuille répliquant ont été réalisés par Devineau et Chauvigny [9]. Les auteurs utilisent desformes paramétriques pour valoriser le passif et vont donc créer dans un premier temps dessous portefeuilles répliquant pour chaque terme de la forme paramétrique. Ensuite, tous lessous-portefeuilles sont agrégés en un seul pour obtenir le portefeuille répliquant final.
En pratique, pour obtenir un portefeuille de qualité acceptable, on commence par calibrer unportefeuille composé uniquement de zéro coupon. Ensuite on ajoute des swaptions payeuses etreceveuses pour capter la sensibilité des garanties aux rachats. Enfin on peut également rajou-ter des Indices equity ainsi que des Call et des Puts. La structure du passif et les particularitésde chaque garantie peuvent conduire à utiliser des instruments financiers différents.
3. La méthode de Monte Carlo est un nom assez général pour toute approche de mesure du risque qui comportedes modèles de simulations stochastiques pour les changements des principaux facteurs de risque. La mise en oeuvredes simulations de Monte Carlo impliquent la création d’un grand nombre de scénarios possibles et la réévaluation desinstruments financiers sous ces scénarios
27

5.2 Résolution du programme d’optimisation
Grâce aux simulations des différentes variables économiques (obtenues via un générateurde scénarios économiques), il est possible par le biais d’un modèle ALM, de déterminer lavaleur des flux de passif pour un scénario donné à un instant donné.La valeur actuelle de ce passif correspond à la somme actualisée des flux futurs, l’objectifétant de répliquer cette valeur présente.Soit L un passif d’assurance caractérisé par ses cash flows à la date t pour le scénario i :L.CF(i, t) où i = 1, · · · , n, t = 1, · · · , T.Si FI est un instrument financier candidat, FI.CF(i, t) ses flux et D(i, t) où i = 1, · · ·n, t =1, · · ·T son déflateur. Formellement, construire un portefeuille répliquant c’est trouver lacombinaison d’instruments financier FIk, k = 1, · · · , K avec les poids respectifs wk, k =1, · · · , K qui minimisent la norme : ‖ FI.W − L ‖2.La norme 4 ‖‖2 utilisée ci-dessus est définie sur l’espace des cash flows qui sont modélisésmathématiquement par un vecteur de taille l’horizon T du passif d’assurance que l’on souhaiterépliquer. Cette norme est appliquée à la valeur présente 5 des cashflows.
Les flux du portefeuille répliquant s’écrivent :
RP.CF(i, t) =∑
k wkFIk.CF(i, t), i = 1, · · ·n, t = 1, · · ·TAvec les notations suivantes :
W=
w1
w2...wK
, qui désigne le vecteur des poids de chacun des instruments dans le portefeuille,
L=
L.CF1
L.CF2...
L.CFn
qui désigne le vecteur des valeurs présentes des cash flows de passifs qu’on
souhaite répliquer,
FI=
FI1,1 · · · FI1,K... . . . ...
FIn,1 · · · FIn,K
qui désigne la matrice dont les colonnes représentent les valeurs
présentes des cash-flows liés à un instrument donné sur les n scénarios. On considère égalementque ∆ = (FITFI) et µ = FITL.Alors, la détermination du portefeuille répliquant revient à résoudre le problème d’optimisationsuivant :
W ∗ = minW‖ FI.W − L ‖2 (5.2)
En réalité la résolution de ce problème d’optimisation revient à faire une régression desmoindres carrés du vecteur L sur les données de la matrice FI.La solution de ce système est donc la suivante :
w∗ = (FITFI)−1FITL = ∆−1µ (5.3)4. La métrique naturelle pour définir cette norme est la distance euclidienne.5. Nous avons décidé d’utilisé dans notre mémoire la métrique basée sur les valeurs présente en utilisant les déflateurs.
Si L représente un passif d’assurance alors la valeur présente est définie comme suit :
L = EQ
[∑t
L.CF(t)D(t)
]=
1
n
∑i
∑t
L.CF(i, t)D(i, t), i = 1, · · ·n, t = 1, · · ·T (5.1)
Une alternative peut être d’utiliser la valeur terminale des cashflows.
28

En effet les poids optimaux sont obtenus en minimisant la somme des carrés des résidus. Laforme quadratique en le vecteur des poids w est définie par la fonction q suivante :
q(w) =K∑
k,l=1
wk.wl. < FIk, F Il > −2K∑k=1
wk. < FIk, L > + < L,L > (5.4)
En utilisant les notations matricielles, la fonction q peut donc se réécrire comme suit :
q(w) = wT∆w − 2wµ+ < L,L > (5.5)
La matrice ∆ est symétrique et définie positive et la forme quadratique q est définie-positiveen raison de la linéarité du produit scalaire . Le minimum de la fonction q est donc obtenu endérivant simplement par rapport à w et en égalisant la dérivée à 0. On a donc :
∂wq(w) = 2∆.w − 2µ = 0⇐⇒ w∗ = ∆−1µ (5.6)
Comme on peut le constater, la solution optimale est conditionnée par l’inversibilité de lamatrice (FITFI). Cette matrice peut s’avérer non inversible dans les cas où on a de fortescorrélations entre les cash flows des instruments, notamment de la colinéarité. Nous verronsdans la suite du mémoire comment détecter cette colinéarité et analyser l’impact que cela peutavoir sur l’estimation des poids des instruments financiers. La complexité du calcul dépenddonc uniquement 6 du nombre K des instruments financiers choisis puisque w est expriméecomme la solution d’équations linéaires en dimension K.
Dans le cadre de la calibration d’un portefeuille répliquant, il peut s’avérer nécessaired’imposer certaines contraintes que doit avoir le portefeuille. Une contrainte souvent imposéeest la valeur de marché à l’instant initial du portefeuille répliquant qui doit être égale à lavaleur initiale des passifs que l’on souhaite répliquer. On peut également vouloir imposer lavaleur de marché du portefeuille répliquant dans le cas de situations de stress de marchés afinde rendre la calibration plus robuste.Un ensemble de p contraintes sera définie par une matrice B de dimensions p × n où ndésigne le nombre d’instruments utilisés lors de la réplication ainsi qu’un vecteur colonne d.Chaque ligne de la matrice B représente la valeur de chacun des instruments financiers dans lasituation de stress concernée. La ligne correspondante du vecteur d représente donc la valeurqu’on souhaite imposer pour l’instrument financier.La calibration du portefeuille revient donc à résoudre le problème d’optimisation suivant :
W ∗ = minBW=d
‖ FI.W − L ‖2 (5.7)
La résolution de ce programme d’optimisation sous contraintes dans le cadre de la décomposi-tion en valeur singulière se fait en utilisant les multiplicateurs de Lagrange. Afin de minimiserla fonction q des coefficients de pondération, les multiplicateur de Lagrange sont utilisés avecle modèle des moindres carrés ordinaires puisque les multiplicateurs de Lagrange fournissentune stratégie pour trouver les minima d’un système soumis à des contraintes et peuvent éga-lement être utilisés avec de multiples contraintes.On sait déjà que la solution des moindres carrés ordinaires avec contraintes est obtenue enminimisant la fonction q suivante :
q(w) = wT∆w − 2wµ+ < L,L >
6. La solution ne dépend pas du nombre de scénarios ni de l’horizon temporel.
29

En introduisant les multiplicateurs de Lagrange on cherche finalement à minimiser la fonctionQ suivante :
Q(w, λ) = q(w) + λ(wTBT − dT )
La solution de ce système revient à dériver Q par rapport à w et λ qui doit être égal à 0 :
∂(w, λ)Q(w, λ) = ∆′w′ − µ′ = 0 (5.8)
où on a,
∆′=(
∆ BT
B 0
)w′=(wλ
)µ′=(
µdT
)La solution w′ est donc définie telle que :
w′= (∆
′)−1µ
′
L’ajout d’un ensemble de contraintes α tel que présenté ci-dessus conduit à un ensemblede K + α d’équations linéaires qui doivent être résolues. L’inclusion de plusieurs contraintesne signifie pas que toutes les contraintes seront exactement remplies en raison du faiblenombre d’instruments et de leurs caractéristiques. Dans une certaine mesure, les contraintesqui sont respectées dans la réplication fournissent une indication de la qualité du portefeuillede réplication.
L’ajustement Singular Value Decomposition (SVD)
Afin d’augmenter la stabilité numérique, la méthode des MCO a été enrichie avec la dé-composition en valeurs singulières. Cette méthode pose que la matrice ∆ est diagonalisablede la manière suivante :
∆ = U.L.V
où L est une matrice diagonale, et U et V sont deux matrices orthogonales.Cette approche fonctionne même si la matrice ∆ est singulière (c’est à dire qu’elle possèdeune ou plusieurs valeurs propres nulles). En outre, l’instabilité numérique créée par des valeurspropres très petites peut être améliorée en mettant à zéro les valeurs correspondantes avantinversion de la matrice. Le choix du seuil pour fixer la valeur propre à zéro est un choix critiquepour l’équilibre entre la perte potentielle d’informations par rapport à la stabilité des résultats.Cette opération s’effectue en remplaçant L par L′ , définie par :
L′i,i = Li,i
si Li,i < MaxLi,iseuil
alors L′i,i = 0
La matrice inversée est donc la suivante :
∆−1 = V (L′)−1U
30

Il est important de noter que le SVD aura une incidence sur le calcul du poids des instrumentsfinanciers dans les portefeuilles de réplication. En conséquence, l’utilisation d’un seuil trèsélevé (en ignorant un grand nombre de dimensions) va détériorer la qualité du portefeuillealors que l’utilisation d’un seuil trop bas (sans élimination de dimensions) pourrait conduire àune instabilité numérique. Le choix du seuil est donc une question critique, et est laissé à ladiscrétion de l’utilisateur. La recommandation est de commencer avec un seuil plutôt bas etde l’augmenter seulement si nécessaire.
5.3 Validation du portefeuille répliquant
Plusieurs éléments vont nous permettre d’analyser la qualité du portefeuille :– Validation statistique de la régression– Analyse de la structure générale du portefeuille– Evaluation du pouvoir de prédiction à travers des tests de sensibilité du portefeuille àdes chocs de marché
5.3.1 Validation statistique
Plusieurs tests statistiques tels que le test de Kolmogorov Smirnov, peuvent servir à étudierla normalité de la distribution de l’erreur. Un indicateur utile est également le R2 qui représenteun indicateur de la qualité d’une régression linéaire simple ou multiple. Il mesure l’adéquationentre le modèle et les données observées grâce à l’indicateur suivant :
R2 = 1− ‖Y−Y ‖2
‖Y−Y ‖2
où– Y représente les valeurs estimées– Y représente les valeurs observées– Y représente le vecteur dont les composantes sont toutes égales et correspondent à lamoyenne des valeurs observées
Un seuil de R2 supérieur à 90% est imposé pour valider un modèle, au moins sur la qualitéde la régression. En effet il faut rappeler que le R2 n’est qu’un indicateur de l’adéquation dumodèle aux observations. Il ne nous indique donc pas les qualités prédictives du portefeuillerépliquant qui sont celles qui nous intéressent dans ce mémoire. Pour cette raison la validationstatistique du portefeuille doit être complétée par un test d’adéquation des prédictions dansdes scénarios standards ou extrêmes.Un autre indicateur intéressant de la bonne qualité du portefeuille est l’analyse des résidus.Le modèle de régression étant basé sur l’hypothèse de normalité des résidus, il convient doncde tester la normalité des résidus à travers une analyse empirique de la distribution ou unQQ-plot.
5.3.2 Analyse de la structure générale du portefeuille
L’idée ici est de vérifier que le portefeuille obtenu est facilement interprétable en termesde passifs d’assurance c’est à dire :
– composé de zéro coupon et/ou de swaps liés au primes encaissées et aux engagements– composé de dérivés de taux tels que les swaptions ou les cap/floor qui reflètent lecomportement dynamique des assurés
31

– composé d’expositions (directes ou via des dérivés) aux sous-jacents pour prendre encompte la sensibilité aux décisions d’allocation stratégique du portefeuille d’actifs enreprésentation des engagements du passif
5.3.3 Validation sur des sensibilités
Il peut arriver qu’on obtienne un portefeuille présentant d’excellentes qualités statistiquesen terme d’ajustement mais que la qualité de prédiction dans des situations différentes decelles qui ont prévalu lors de la calibration ne soit pas satisfaisante. Il est donc très importantde tester la sensiblilité du portefeuille sur des chocs clés.
En fonction des riques sous-jacents aux portefeuilles une liste de chocs peut être définiepar la compagnie. On pourra notamment s’inspirer des chocs de la formule standard.
5.4 Application du portefeuille répliquant
Les applications du portefeuille répliquant sont nombreuses pour un assureur :– Compréhension de la structure des passifs :Les portefeuilles répliquant, en ré-exprimant les passifs en termes d’instruments finan-ciers, permettant d’améliorer la compréhension et la communication notamment avecles gestionnaires d’actif.De plus, les portefeuilles répliquant en mettant sur un pied d’égalité actif et passif,facilitent ainsi la gestion actif-passif.
– Evaluation plus rapide des impacts de choc des marchés :Avant l’utilisation du portefeuille répliquant, le calcul des sensibilités du passif impliquaitla génération de scénarios stochastiques ce qui est très coûteux en termes de puissancede calcul. Désormais, le portefeuille répliquant nous fournit les sensibilités avec beau-coup moins de calcul. En effet, un portefeuille répliquant est composé des instrumentsfinanciers standards dont les sensibilités peuvent se calculer grâce à des formules fermées.
– Calcul de la distribution des fonds propres économiques :De même qu’il est possible d’obtenir à moindre coût des sensibilités, les calculs pourobtenir la distribution des fonds propres économiques, en particulier le calcul de SCR,peuvent se faire relativement rapidement par raport à une approche Simulations dans lesSimulations.
Cependant, il faut aussi noter que l’utilisation des portefeuilles répliquant reste limitée car lavaleur et la dynamique du passif dépendent de l’allocation d ?actifs qui couvre ce passif. Dansce cas, le portefeuille répliquant ne représente que le portefeuille sous-jacent pour les actifs quisont pris en compte dans la réplication. Tout changement dans l’allocation d’actifs nécessitele calcul d’un nouveau portefeuille répliquant.
32

Troisième partie
Applications à un portefeuilled’épargne Euros
33

Chapitre 6
Description du portefeuille
Dans le cadre de cette étude nous avons dans un premier temps réalisé une implémentationde la méthodologie des simulations dans les simulations à l’aide d’un modèle ALM certessimplifié, mais qui comporte les caractéristiques principales d’un portefeuille Euros moyend’une compagnie d’assurance vie. Les résultats obtenus nous permettront de pouvoir ainsiévaluer l’efficacité des différentes alternatives de modélisation présentées dans ce mémoire.Le modèle ALM comprend donc les caractéristiques qui assurent d’avoir l’optionnalité liée àun portefeuille classique d’euros en assurance vie. Il est également relié à un générateur descénario économique qui va nous permettre de faire des projections aussi bien en univers risqueneutre qu’en univers monde réel.
6.1 Le Modèle ALM
Le modèle ALM est un outil de gestion actif/passif. La gestion actif/passif a été définie en2002 par Piermay, Mathoulin et Cohen :
La gestion actif/passif consiste d’une part à analyser la couverture des engagements d’unassureur ou d’un investisseur institutionnel par les actifs dans une perpective de déroulementdans le temps. Elle recouvre d’autre part l’ensemble des actions visant à piloter le bilan del’institution. L’absence de de gestion actif-passif aussi bien au sens de l’analyse que de l’actionest pour beaucoup dans les difficultés rencontrées par les assureurs et les fonds de pension aucours des quinze dernières années dans différents pays : couverture d’engagement certains pardes espoirs de plus-values, prolongation de la tendance passée, absence d’examen de scénariosd’évolution des actifs et du passif.
Le modèle ALM permet donc de modéliser l’actif et le passif ainsi que les différentesinteractions qui peuvent exister entre ces deux derniers. IL permet aussi de prendre en compteles "management rule" qui peuvent être par exemple l’allocation d’actifs, la participation auxbénéfices ou encore la réalisation de plus ou moins values.
On obtient alors sur un scénario de l’Economic Scenario Generator (ESG) l’ensemble desflux liés au portefeuille :
– Produits financiers– Frais de gestion– Impôts– Prestations liées aux décès, rachats, etc.– Charges financières
A partir de ces flux on obtient pour chaque scénario le résultat futur de l’assureur. Cela
34

constitue donc un outil de décision indispensable pour les assureur dans le cadre par exemblede lancement d’un nouveau produit ou de l’étude de la rentabilité des produits existants.
Nous présentons dans la suite un modèle ALM simplifié qui a servi à la réalisation de cemémoire.
6.1.1 Modélisation du passif
Le passif a été modélisé de façon agrégée et le modèle prend en compte à la fois le nombrede polices et le montant des provisions mathématiques.
Primes Futures : Les primes futures unitaires sont définies arbitrairement. Le montant dela prime future ainsi arbitrairement défini est ajusté en fonction du nombre de polices en cours.
Les rachats : Les rachats sont modélisés annuellement et dépendent du montant des provi-sions techniques et du nombre de polices en cours en début de période.
Les frais : Les frais ont été modélisés et dépendent du nombre de polices en cours.
Taux minimum garanti : Un taux minimum garanti de 1% a été modélisé
Taux de marché et comportement dynamique : Un taux de marché a été modéliséet correspond au taux zéro coupon à 5 ans et représente le taux attendu par les assurés.
Par ailleurs un comportement dynamique des assurés a été modélisé. En fonction de ladifférence entre le taux servi et le taux attendu par les assurés, un taux de rachat conjoncturelest appliqué et varie entre -50% et +50%.
Provisions techniques : Les provisions techniques sont calculées comme la valeur actualiséedes flux futurs.
6.1.2 Modélisation de l’actif
Deux types d’actifs sont modélisés : les actions et les obligations.
Obligations : Le modèle ALM permet d’investir en cours de projection sur des obligationsdont la maturité restante varie entre 1 et 10 ans. A chaque étape de la projection, la valeurde marché des obligations est calculée en utilisant la courbe des taux issue du générateur descénario.La valeur comptable est calculée en fonction du montant acheté et vendu, et amortie selonune méthode actuarielle. La réserve de capitalisation n’a pas été modélisée.
Les actions : La valeur de marché des actions est projetée dans le modèle en fonction dumodèle action total return issu du générateur économique de scénario, en prenant en compteun taux de dividende de 2%. Enfin, 75% des plus ou moins values sont réalisées.
Allocation de l’actif : L’allocationd’actif est fixe pendant toute la durée de la projection etbasée sur la valeur de marché des actifs. Les actifs sont rebalancés à la fin de chaque périodeafin de respecter l’allocation suivante :
35

Catégorie d’actif % de la valeur de marché totale de l’actifObligations 80%Actions 20%Total 100%
6.2 Le Générateur de scénario
Le génération de scénarios représente avec le modèle ALM un pilier du modèle interneen assurance vie. L’ESG est un outil de simulation stochastique permettant comme son noml’indique de généreur des scénarios économiques.
Plus précisément il va permettre de simuler différentes variables économiques qui vontalimenter le modèle ALM :
– Courbe des taux– Inflation– Rendement des indices actions– Immobiler– etc.La définition des modèles ainsi que le calibrage revêtent donc un caractère très important
dans le processus de calibrage des portefeuilles répliquants. En effet du générateur de scénariovont dépendre les flux à répliquer. Le générateur de scénario joue donc un rôle central dans lecalcul du SCR dans le sens où la directive Solvabilité 2 impose une logique de cohérence avecles valeurs de marché. La mise en oeuvre du générateur de scénarios constitue donc une étapecruciale et des test de market-consistency ( test de martingalité, reproduction de la courbedes taux sans risques, reproduction des paramètres de calibrage, etc.) doivent notamment êtreréalisés sur les scénarios générés afin de garantir leur qualité. On pourra se référer à [10] pourplus de détails sur l’importance du générateur de scénarios économiques.L’objet de ce mémoire étant principalement axé sur le processus de calibration des portefeuillesrépliquants nous n’entrerons pas dans les détails de la mise en oeuvre du générateur de scénarioqui a servi dans le cadre de notre étude. Nous présentons donc brièvement dans cette partieles modèles utilisés.
6.2.1 Les univers monde réel et risque-neutre
La génération des scénarios économiques en assurance vie peut se faire sous deux proba-bilités distinctes en fonction de l’étude qui est menée :
– L’univers monde réel correspond à une probabilité utilisée pour choquer ou prédire leniveau de richesse à un an. Il s’agit d’une probabilité subjective reposant sur la vue del’évolution future des conditions de marché ; elle est souvent estimée à partir de donnéeshistoriques des variables financières étudiées et permet notamment l’études de quantilesdes variables d’intérêts.Sous la probabilité monde réel (ou historique) les rendements des actifs in-cluent une prime de risque
– La probabilité risque neutre est une probabilité utilisée pour valoriser les postes du bilan :elle a la propriété d’assurer l’absence d’opportunité d’arbitrage.Sous la probabilité risque-neutre, tous les processus de prix évoluent enmoyenne au taux sans risque
Le générateur de scénarios économiques décrit dans cette section et qui a servi lors de cetteétude permet de générer les variables économiques suivantes dans des scénarios monde réel
36

et risque neutres :– Les taux zéro coupon sur l’horizon de projection c’est-à-dire 25 ans– Les déflateurs ou facteurs d’actualisation stochastique– Le rendement de l’indice action sur la période
Les scénarios sont donc générés sous certaines hypothèses sur les facteurs de risques suivants :– Le taux zéro-coupon 1 an– Le taux zéro-coupon 5 ans– Le taux zéro-coupon 15 ans– Le rendement annuel de l’action sur la période de projection– Le taux de rendement instantané rt
Les hypothèses concernant les modèles utilisés en monde réels sont les suivants :– Les taux de rendements instantanés suivent une loi normale N (0, σsr)– Les taux 1 an, 5 ans et 15 ans suivent respectivement des lois normales N (0, σyc1),N (0, σyc5) et N (0, σyc15)
– Le rendement de l’action suit une loi normale N (1, σsh)– la courbe des taux initiale est flat
Concernant les projections en risque neutre l’hypothèse d’absence d’opportunité d’arbitrageest garantie par la martingalité des actifs actualisés du marché. Les actions suivent un modèlede Black et Scholes et les taux sont diffusés selon le modèle de Hull et White.
6.2.2 Le modèle Action
Pour le modèle action on choisit le modèle classique de Black et Scholes qui présentel’avantage d’être simple et permet d’avoir des formules fermées relativement facilement. Ondéfinit (St)t≥0 le processus qui définit l’évolution de l’indice action en univers historique quivérifie l’équation différentielle stochastique suivante :
dSt = µStdt+ σStdWt (6.1)
où :– µ représent la moyenne des rendements– σ la volatilité– W un mouvement brownien standard
On peut alors montrer que :St = S0e
(µ− 12σ2)t+σWt (6.2)
Sous la mesure risque-neutre P∗, on a :
dSt = St(rtdt+ σSdW∗t ), 0 ≤ t ≤ T. (6.3)
où (W ∗t )0≤t≤T est un mouvement brownien standard sous P∗ et rt représente le processus de
taux simulé par l’ESG. En l’occurrence rt est diffusé selon le modèle de Hull et White. On adonc les équations stochastiques suivantes :
dStSt
= rtdt+ σshdWt,1
drt = (1− art)dt+ σdWt,2
< dWt,1, dWt,2 > = φdt
où σsh et φ sont respectivenment la volatilité de l’indice action et le coefficient de corrélationentre les taux courts et l’indice action.
37

La solution du système d’équation précédent est donc :
St = S0 exp(rtt−1
2σ2sht+ σwt) (6.4)
6.2.3 Le modèle de taux
Le modèle de taux utilsé dans le cadre de notre générateur de scénario appartient à laclasse des modèles dits HJM (Heath Jarrow Morton).Cette classe de modèle de taux admet que sous la probabilité risque neutre les zéros couponssuivent la dynamique suivante :
dB(t, T ) = B(t, T )(rtdt+ Γ(t, T )dwt
où B(t, T ) est le prix d’une obligation zéro coupon, Γ(t, T ) une fonction de volatilité et wtun mouvement brownien.La solution de cette équation différentielle stochastique est donnée par :
B(t, T ) = B(0, T )e∫ t0 rsds+int
t0Γ(s,T )dws− 1
2
∫ t0 Γ(s,T )2ds
En prenant T = t, et en utilisant le fait que B(t, t) = 1, on a :
1 = B(0, t)e∫ t0 rsds+int
t0Γ(s,t)dws− 1
2
∫ t0 Γ(s,t)2ds
En divisant les deux équations précédentes on obtient la relation finale suivante pour un zérocoupon :
B(t, T ) =B(0, T )
B(0, t)e∫ t0 rsds+int
t0(Γ(s,T )−Γ(s,t))dws− 1
2
∫ t0 (Γ(s,T )2−Γ(s,t)2)ds (6.5)
Les taux forward continus R(t, T ) entre T et T + θ à la date t est défini par :
eθR(t,T ) = 1B(T,T+θ)
où B(T, T + θ) est la valeur d’un zéro coupon forward qui satisfait par absence d’opportunitéd’arbitrage :
B(T, T + θ) = B(t,T+θ)B(t,T )
En particulier, les taux courts s’écrivent :
rt = f(0, t)−∫ t
0γ(s, t)dws +
∫ t0γ(s, t)Γ(s, T )ds
Le modèle Hull et White suppose que sous la probabilité risque neutre, le taux court rt vérifiel’équation :
drt = (1− art)dt+ σrdWt
où :– Wt est un mouvement brownien– a est la vitesse de retour à la moyenne– σr est la volatilité des taux courts
Le modèle Hull et White ainsi défini correspond à un cas particulier du modèle HJM où on a :
γ(s, T ) = −σ(s) exp(−a(t− s))
En effet dans ce cas on :
38

Γ(s, T ) = −σ(s)1−exp(−a(t−s))a
Cela implique que la valeur du taux court rt dans le modèle HJM est donnée par :
rt =f(0, t) + exp(−at)∫ t
0
σ(s) exp(as)dWs +1
aexp(−at)
∫ t
0
σ2(s) exp(as)ds
− 1
aexp(−2at)
∫ t
0
σ2(s) exp(2as)ds
En différenciant l’équation précédente on a donc :
drt =∂f(0, t)
∂tdt+ σ(t)dwt− a exp(−at)
(∫ t
0
σ(s) exp(as)dWs
)dt−
exp(−at)(∫ t
0
σ2(s) exp(as)ds
)+ 2 exp(−2at)
(∫ t
0
σ2(s) exp(2as)
)d’où :
drt + artdt = af(0, t)dt+ ∂f(0,t)∂t
dt+(∫ t
0γ(s, t)2ds
)dt+ σ(t)dWt
On en déduit que si la condition suivante est satisfaite, le modèle de Hull et White appartientà la classe des modèles HJM :
θ(t) = af(0, t) + ∂f(0,t)∂t
+∫ t
0γ(s, t)2ds
Nous venons donc de démontrer qu’avec un choix adapté de γ(s, t), le modèle de Hull et Whitefait partie de la classe des modèles dits HJM. En tant que tel il s’ajuste mécaniquement àla courbe des taux initiale qui est déduite par interpolation linéaire des taux en entrée dumodèle (les taux 1 ans, 5 ans et 15 ans) et constitue donc un input au modèle. C’est unecaractéristique qui sera essentielle lorsqu’il faudra valoriser le portefeuille répliquant.Le modèle ainsi défini, on peut maintenant évaluer le prix des zéro-coupons. En effet l’équationdifférentielle stochastique suivante :
drt =∂f(0, t)
∂tdt+ σ(t)dwt− a exp(−at)
(∫ t
0
σ(s) exp(as)dWs
)dt−
exp(−at)(∫ t
0
σ2(s) exp(as)ds
)+ 2 exp(−2at)
(∫ t
0
σ2(s) exp(2as)
)admet une unique solution donnée par :
– rt = exp(−at)r0 + 1a(1− exp(at)) + (σ − exp(−at))
(∫ t0
exp(as)dWs
)– rt suit une loi normale : N (exp(−at)r0 + 1
a(1− exp(−at)), σ2
2a(1− exp(−2at)))
En utilisant la définition du prix d’un zéro coupon dans le modèle HJM, on obtient la distri-bution suivante pour les déflateurs
P (s, t) = A(s, t) exp(−B(s, t)r(s))
où :– B(s, t) = 1−exp(−a(t−s))
a
– A(s, t) = P (0,t)P (0,s)
exp(−B(s, t)∂ log(P (0,S)
∂s− σ2(exp(−a(t−s)))2(exp(2as)−1)
4a3
)
39

6.2.4 Discrétisation des processus
Sous la probabilité risque neutre le cours des actions est solution de l’équation de Black etScholes qui admet pour unique solution :
St = St−1 exp(rt − 12σ2sh)
En utilisant le schéma de discrétisation d’Euler on obtient les équations suivantes qui vontnous permettre de simuler l’évolution des taux courts et de l’indice action :
rt = rt−1(1− a) + σsr.W1
St = St−1 exp(σsh.W1 + σsh√
1− ψ2N (0, 1))− 12σ2sh
St est actualisée à l’étape t+ 1 afin de garantir la martingalité des prix.
6.2.5 Génération des déflateurs
Les déflateurs sont des coefficients d’actualisation stochastiques qui permettent la modéli-sation stochastique de certains facteurs économiques tout en travaillant en probabilité risqueneutre.Pour chaque scénario monde réel s, le déflateur à l’instant t est donné par la formule suivante :
D(s, t) = ZC(t, T )−1T − 1
où ZC(t,T) est le prix à l’instant t d’un zéro coupon de maturité T, avec le modèle de Hullet White.Les prix des zéro coupons sont calculés à partir des données de chaque scénario monde réel.
6.2.6 Test de martingalité
Le but de l’ESG dans le cadre de notre étude est de générer des scénarios qui permettrontde valoriser le bilan économique de la compagnie. Ils serviront également à la création desportefeuilles répliquants pour le calcul du capital règlementaire. Il est donc indispensable dejustifier la robustesse du modèle pour le faire valider dans le cadre de Solvabilité 2.Un contexte risque neutre est indispensable à la validité des modèles de diffusion et dans cecadre la martingalité des prix actualisés de chacun des facteurs de risque garantit l’unicité de laprobabilité risque neutre. Cette unicité garantit la complétude des marchés et donc l’absenced’opportunité d’arbitrage.Afin de garantir ces caractéristiques essentielles de l’ESG, des tests de martingalité sont donceffectués :
1N
∑iD
i(t)Si(t) ≈ S(0)
où– Di(t) est le déflateur du scénario i à l’instant t– Si(t) est la valeur de l’action à l’instant t
1N
∑iD
i(t)CF i(t) ≈ V (0)
où– CF i(t) est le cashflow du scénario i à l’instant t– V (0) est la valeur du passif à l’instant 0
40

6.3 Calibration des portefeuilles : Réplication de passifs ou demarges ?
On s’interroge dans cette section sur la variable d’intérêt à utilser pour la calibration desportefeuilles. L’assureur dispose pour ce faire soit des cash flows du passifs c’est à dire lescash flows liés à l’assuré, soit des cash flows de marges qui sont liés à l’actionnaire. Pourrépondre à cette problématique nous allons calibre diffférents portefeuilles en utilisant cesdeux méthodologies. Cela nous permettra de valider le choix de la variable à utiliser pour lasuite du mémoire.
Avant de calibrer les portefeuilles répliquants nous allons calculer dans un premier temps lecapital économique en utilisant une approche Simulations dans les Simulations. La simplicitédu passif et donc du modèle ALM utilisé nous permet en effet de faire ce calcul et d’obtenirégalement la distribution des fonds propres économiques.
Les simulations ont été réalisées avec le modèle ALM que nous venons de présenter. 5000scénarios en monde réel ont été générés pour calculer la distribution des fonds propres. Pourchacun de ces 5000 scénarios, 1000 scénarios risque neutres ont été utilisés pour valoriser lebilan économique sur un horizon de 25 ans. En outre le modèle a également été utilisé pourévaluer le passif dans les situations de marché suivante :
– Choc taux +100bps– Choc taux +100bps– Choc action -30%– Choc action +30%– Choc combiné +100bps/-30%– Choc combiné -100bps/-30%
Ces sensibilités vont nous permettre de rendre plus robuste la calibration des portefeuillesrépliquants. En effet on a les quatre premières sensibilités (action et taux) qui sont des sen-sibilités classiques dans le sens où on essaye de s’assurer que la sensibilité des portefeuillesobtenus aux principaux facteurs de risques soient identiques aux sensibilités du passif. Lesdeux dernières sensibilités quant à elle résultent de l’analyse des scénarios qui conduisent àdes NAV extrêmes parmi les 5000 scénarios monde réel. Les résultats obtenus vont nous servirde référence afin d’évaluer l’efficacité des méthodologies développées dans la suite du mémoire.
Valeur de marché de l’actif Best Estimate NAVSituation initiale 100,4 77,6 22,9
Choc taux +100bps 96,7 63,2 22,9Choc de taux -100bps 104,5 96,8 33,4Choc action +30% 107,0 82,0 7,7Choc action -30% 93,8 75,2 25,0
Choc combiné +100bps/-30% 90,1 60,2 29,8Choc combiné -100bps/-30% 97,9 93,7 4,1
Table 6.1 – Valorisation du bilan
Le graphique suivant nous permet de visualiser la distribution des fonds propres qui meten exergue l’optionnalité du portefeuille ainsi que l’asymétrie entre la queue de distribution
41
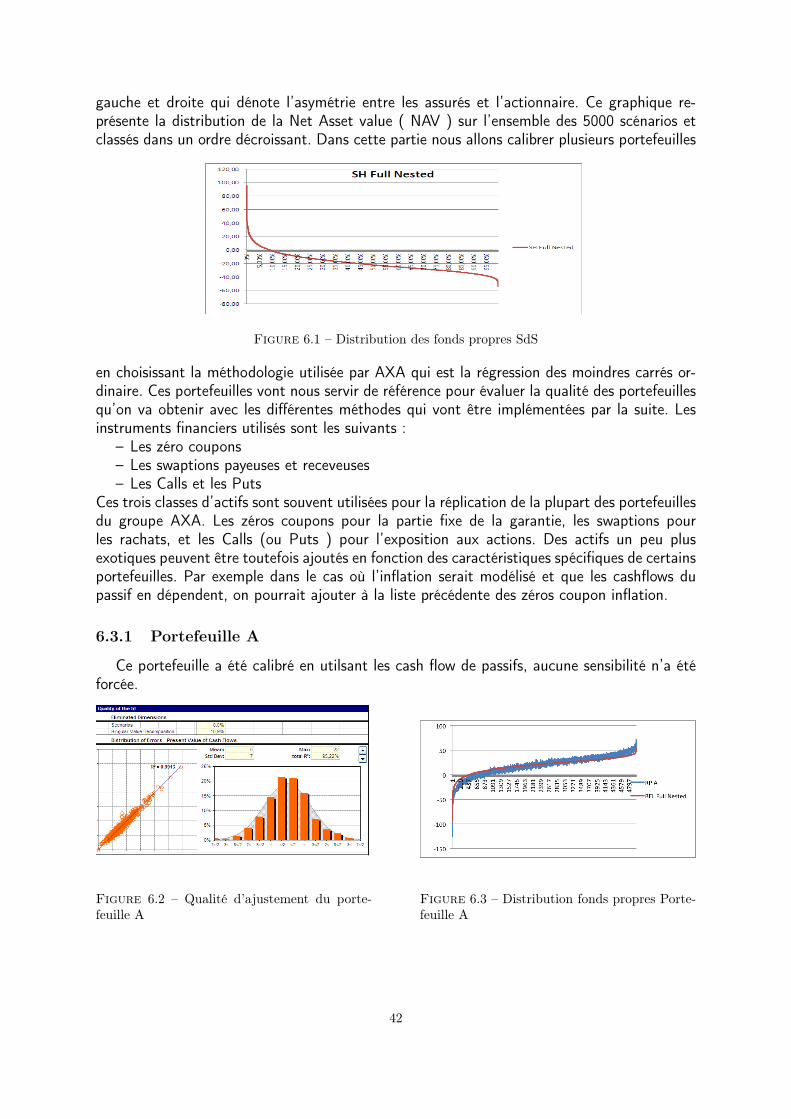
gauche et droite qui dénote l’asymétrie entre les assurés et l’actionnaire. Ce graphique re-présente la distribution de la Net Asset value ( NAV ) sur l’ensemble des 5000 scénarios etclassés dans un ordre décroissant. Dans cette partie nous allons calibrer plusieurs portefeuilles
Figure 6.1 – Distribution des fonds propres SdS
en choisissant la méthodologie utilisée par AXA qui est la régression des moindres carrés or-dinaire. Ces portefeuilles vont nous servir de référence pour évaluer la qualité des portefeuillesqu’on va obtenir avec les différentes méthodes qui vont être implémentées par la suite. Lesinstruments financiers utilisés sont les suivants :
– Les zéro coupons– Les swaptions payeuses et receveuses– Les Calls et les Puts
Ces trois classes d’actifs sont souvent utilisées pour la réplication de la plupart des portefeuillesdu groupe AXA. Les zéros coupons pour la partie fixe de la garantie, les swaptions pourles rachats, et les Calls (ou Puts ) pour l’exposition aux actions. Des actifs un peu plusexotiques peuvent être toutefois ajoutés en fonction des caractéristiques spécifiques de certainsportefeuilles. Par exemple dans le cas où l’inflation serait modélisé et que les cashflows dupassif en dépendent, on pourrait ajouter à la liste précédente des zéros coupon inflation.
6.3.1 Portefeuille A
Ce portefeuille a été calibré en utilsant les cash flow de passifs, aucune sensibilité n’a étéforcée.
Figure 6.2 – Qualité d’ajustement du porte-feuille A
Figure 6.3 – Distribution fonds propres Porte-feuille A
42

BE DFA RP A DifférenceSituation initiale 77,6 77,6 0
Choc taux +100bps -14,3 -14,4 0Choc de taux -100bps 19,2 19,1 +0,15Choc action +30% 4,4 4,4 0Choc action -30% -2,4 -3,4 +1,0
Choc combiné +100bps/+30% -17,3 -17,5 +0,13Choc combiné -100bps/-30% 16,2 15,2 +0,9
Table 6.2 – Sensibilités Portefeuille A
Quantile SdS RP A Différence99,5% -35,2 -53,1 17,999% -24,8 -41,1 16,395% -6,9 -18,3 11,490% 1,2 -7,5 8,770% 14,7 11,3 3,350% 22,2 22,3 030% 28,1 30,9 -2,810% 35,2 41,5 -6,35% 38,2 46,3 -8,21% 43,2 54,6 -11,40,5% 44,7 57 -12,3
Table 6.3 – Ecarts Portefeuille A
La table 6.2 représente pour la situation de marché initiale et les différents chocs de marchéla valeur du passif obtenue via le modèle ALM ainsi que la valeur du portefeuille répliquant.La troisième colonne représente la différence entre les deux valeurs précédentes. Ce tableaupermet d’évaluer la robustesse de la calibration obtenue. En effet les écarts entre les sensibilitésdu portefeuille et les valeurs de marchés du passif pour ces sensibilités peuvent être considéréescomme un critère de qualité.La figure 6.2 comporte deux figures. Celle de gauche représente un nuage de points composéen abcisse des 1000 valeurs présentes des cash flows du passif dans les 1000 scénarios utiliséspour la calibration du portefeuille et en ordonnées des 1000 valeurs présentes des cash flow duportefeuilles répliquant. Une réplication parfaite donnerait des points alignés sur la premièrebissectrice et nous permet donc d’évaluer la qualité de la réplication en observant l’alignementdu nuage de points par rapport à cette première bissectrice. Il comporte notamment uneindication sur le coefficient R2 de la régression. La figure de gauche est un histogramme dela distribution des erreurs de la réplication.La figure 6.3 représente deux graphiques. Le graphique rouge est la distribution des fondspropres ordonnée de la plus petite à la plus grande pour les 5000 scénarios monde réel utilisés.Le graphique bleu représente les valeurs du portefeuille A dans l’ordre des 5000 scénariosmonde réel du graphique rouge.Enfin la table 6.3 représente dans le même esprit que la figure 6.1 les différents quantilesde la distribution des fonds propres selon une vision simulation dans les simulations et uneseconde vision en utilisant le portefeuille A. La dernière colonne est la différence entre les deuxvaleurs précédentes. Notre attention se portera tout au long du mémoire particulièrement surle quantile à 99,5%.
Ici on a pour le portefeuille A une différence de 17,9 sur l’estimation du quantile à 99,5%, cequi représente un écart assez conséquent. Cela est du essentiellement aux différentes sensibilités
43

qui ne sont pas consistantes comme on peut le voir dans le tableau 6.2.
6.3.2 Portefeuille B
Le portefeuille B a été calibré en deux temps. Une première phase pendant laquelle oncalibre le portefeuille sur des cashflows de passif obtenus via un jeu de scénarios orthogonaux.Les scénarios orthogonaux consistent en 500 scénarios monde réel. Les scénarios monde réelsont les sorties de l’ESG que nous avons présentées plus haut. Pour chacun de ces scénariosmonde réel on projette le passif à des fins de valorisation sur 100 scénarios risque neutre. Lescorrélations entre les facteurs de risque sont fixés à 0 sur l’ensemble des scenarios. Cela vanous permettre d’augmenter le budget d’information dans les cashflows utilisés en input del’algorithme de calibration des poids du portefeuille répliquant. Ce procédé revient à faire duLSMC dans le sens où on réduit le nombre de simulations risque neutre avec un nombre desimulations monde réel plus important.Les poids obtenus pour chacun des instruments sur les scénarios orthogonaux sont utilisésdans un second temps pour calibrer le portefeuille sur les cash flows de passifs initiaux.
Figure 6.4 – Qualité d’ajustement du porte-feuille B
Figure 6.5 – Distribution fonds propres Porte-feuille B
BE DFA RP B DifférenceSituation initiale 77,6 77,6 0
Choc taux +100bps -14,3 -15,8 +1,5Choc de taux -100bps 19,2 19,4 -0,16Choc action +30% 4,4 4,4 0Choc action -30% -2,4 -5,3 +2,87
Choc combiné +100bps/+30% -17,3 -20,7 +3,39Choc combiné -100bps/-30% 16,2 13,7 +2,51
Table 6.4 – Sensibilités Portefeuille B
44

Quantile SdS RP B Différence99,5% -35,2 -40,6 5,499% -24,8 -30,6 5,895% -6,9 -12,2 5,390% 1,2 -3,2 4,470% 14,7 12,9 1,750% 22,2 23 -0,830% 28,1 31,7 -3,610% 35,2 42,5 -7,35% 38,2 47 -8,81% 43,2 55,5 -12,40,5% 44,7 58,6 -13,9
Table 6.5 – Ecart Portefeuille B
6.3.3 Portefeuille C
Le portefeuilles A et B ont de très bonnes propriétés statistiques, avec notamment descoefficients R2 plutôt satisfaisants mais ils présentent deux principaux défauts :
– Leur pouvoir de prédiction n’est pas très satisfaisant au vu des valeurs des portefeuillessur les différentes sensibilités
– On remarque également au niveau de la queue de la distribution un mauvais ajustementLe portefeuille C a été calibré sur les cash flow de passif comme le portefeuille A, mais on a
forcé ici les 5 premières sensibilités. On constate un R2 plus dégradé que celui du portefeuilleA mais un ajustement à la distribution des fonds propres plutôt satisfaisant.
Figure 6.6 – Qualité d’ajustement du porte-feuille C
Figure 6.7 – Distribution fonds propres Porte-feuille C
BE DFA RP C DifférenceSituation initiale 77,6 77,6 0
Choc taux +100bps -14,3 -14,4 0Choc de taux -100bps 19,2 19,2 0Choc action +30% 4,4 4,4 0Choc action -30% -2,4 -2,4 0
Choc combiné +100bps/+30% -17,3 -17,3 0Choc combiné -100bps/-30% 16,2 17,5 -1,32
Table 6.6 – Sensibilités Portefeuille C
45

Quantile SdS RP C Différence99,5% -35,2 -39,4 4,299% -24,8 -34,7 9,995% -6,9 -13,3 6,490% 1,2 -4,3 5,670% 14,7 13,1 1,650% 22,2 22,6 -0,430% 28,1 30,5 -2,410% 35,2 40,9 -5,75% 38,2 45,4 -7,21% 43,2 53,8 -10,60,5% 44,7 57,6 -12,9
Table 6.7 – Ecarts Portefeuille C
On constate néanmoins, malgré la qualité d’ajustement à la distribution des fonds propres,une augmentation significative de la volatilité par rapport aux deux portefeuilles précédents.Cela est essentiellement dû au fait qu’on ait forcé certaines sensibilités.
6.3.4 Calibration des portefeuilles : vision marges
Comme nous l’avons détaillé dans la première partie de ce mémoire, AXA utilise la techniquedes portefeuilles répliquants pour le calcul du capital économique basée sur une réplicationdes passifs.On peut néanmoins s’interroger sur ce choix de modélisation car la variable d’intérêt dansle calcul du capital économique est la marge de la compagnie. Il est donc plus judicieux decalibrer directement les portefeuilles sur les cashflow de marge plutôt que sur les passifs. Eneffet cette méthode permet de mieux maîtriser l’erreur commise dans l’estimation du capitaléconomique. On suppose que l’ordre de grandeur du BE des passifs étant supérieur à celuides fonds propres, un écart dans l’estimation du passif produirait une erreur dans l’estimationdu capital plus élevée que l’erreur qu’on obtiendrait si le même écart était constaté dansl’estimation des fonds propres.Devineau et Chauvigny démontrent bien ce raisonnement et en arrivent à la conclusion qu’uneerreur de 1% dans l’estimation du passif peut conduire à plus de 20% d’erreur dans l’estima-tion du capital économique. Nous avons donc testé cette approche afin de pouvoir comparerles résultats qu’on obtient en terme de composition de portefeuilles mais également en termed’estimation de certains quantiles de la distribution des fonds propres. Nous avons gardé lesmêmes instruments financiers que ceux utilisés pour calibrer les portefeuilles sur les cashflowsde passifs. En effet les fonds propres étants obtenus par différence entre la valeur de marchédes actifs et le BE de passif, les instruments ayant servis à calibrer les passifs devraient êtreles mêmes.Les résultats sont détaillés en annexe pour chacun des portefeuilles. Une analyse de la distri-bution des portfeuilles calibrés sur les marges démontrent dans l’ensemble une qualité assezsatisfisante. Néanmoins on ne constate pas une amélioration significative dans l’estimation duquantile à 99,5% notamment. On remarque que contrairement à la régression sur les cashflows de passif, la régression sur les marges tend à sous-estimer la charge en capital. Cela sevoit très bien sur les graphiques où on note que la courbe rouge se situe en dessous de lacourbe bleue au niveau de la queue de la distribution. On s’en rend compte sur les résultatsobtenus avec le portefeuille A notamment (Cf Annexe).
46

Conclusion : La calibration d’un portefeuille en utilisant les cash flows de margesplûtôt que les cash flows de passifs n’améliore pas significativement la qualité dela préplication. En effet les résultats sur les sensibilités ainsi que la qualité derégression des portefeuilles ne montre pas une différence majeure entre ces deuxméthodologies. Nous avons donc fait le choix pour la suite du mémoire d’utiliserles cash flows de passifs qui permettent une lecture plus intuitive des instrumentsfinanciers en termes de passifs d’assurance.
47

Chapitre 7
Développements réalisés
7.1 La régression PLS
La méthode PLS est une méthode de régression linéaire de c variables réponses sur pvariable explicatives toutes mesurées sur les même individus. Les tableaux des observationsnotés respectivement Y et X, de dimensions n× c et n× p.L’intérêt de la méthode comparée à la régression des moindres carrés ou la régression surcomposantes principales, réside dans le fait que les composantes PLS sur les X, notées t, sontcalculées dans le même temps que des régressions partielles sont exécutées. Cette simultanéitédevrait leur conférer un meilleur pouvoir prédictif que cellui obtenu en utilisant la régressionclassique des moindres carrés ou une régression en composantes principales par exemple.Nous décrivons dans la suite les différentes étapes de calcul des coefficients de régression. Lesrésultats obtenus via cette méthode en la testant sur les portefeuilles A, B et C.
7.1.1 Présentation de la méthode
Principe de l’algorithme et passage à l’écriture matricielle
On considère que les vecteurs xj des variables explicatives et que le vecteur y de la variableà expliquer sont centrés. On note X la matrice individus × variables de dimension n×p. Dansle cadre des portefeuilles n représente donc le nombre de scénarios utilisés lors de la réplicationet p le nombre d’instruments qui représentent ici nos variables explicatives. On va donc cher-cher le vecteur ah = (ah1, · · · , ahp) des coefficients du modèle de régression à h composantes.
Première étape : On construit la première composante t1 comme une combinaison li-néaire des p variables explicatives xj. Les coefficients w′h = (w11, · · · , w1J , · · · , a1p) de cettecombinaison linéaire cherchent à résumer le mieux possible les variables explicatives xj et àexpliquer au mieux la variable y :
t1 = w11x1 + · · ·+ w1pxp
w1j =cov(xj ,y)√∑pj=1 cov
2(xj ,y)
On effectue ensuite une régression simple de y sur t1 :
y = c1t1 + y1
où y1 est le vecteur des résidus et c1 est le coefficient de régression :
48

c1 = cov(y,t1)
σ2t1
On en déduit donc une première équation de régression :
y = c1w11︸ ︷︷ ︸a11
x1 + · · ·+ c1w1p︸ ︷︷ ︸a1p
xp + y1
On peut passer à l’écriture matricielle sachant que les vecteurs xj et y sont centrés :
cov(xj, y) =∑n
i=1 xijyi = x′jy
cov(y, t1) =∑n
i=1 yit1i = y′t1
σ2t1
=∑n
i=1 t1it1i = t′1t1
d’où
w1 = X′y
‖X′y‖
t1 = Xw1
c1 = y′t1
t′1t1
a1 = c1w1
Deuxième étape : On construit une deuxième composante t2, non corrélée à t1 et expli-quant bien le résidu y1. Cette composante t2 sera une combinaion linéaire des résidus x1j desrégressions simples des variables xj sur t1 :
t2 = w21x11 + · · ·+ w2px1p
w2j =cov(x1j ,y1)√∑pj=1 cov
2(x1j ,y1)
Pour calculer les résidus x1j, on réalise une régression linéaire de toutes les variables xj surt1 :
xj = p1jt1 + x1j
où x1j est le vecteur des résidus et p1j est le coefficient de régression :
p1j =cov(xj ,t1)
σ2t1
d’où,
x1j = xj − p1jt1
On effectue ensuite une régression de y sur t1 et t2 :
y = c1t1 + c2t2 + y2
où c1 est le coefficient de régression de la première étape et c2 est le coefficient de la régressionsimple de y1 sur t2 et y2 est le vecteur des résidus de cette régression :
y1 = c2t2 + y2
d’où
49

c2 = cov(y1,t2)
σ2t2
Nous verrons dans la suite comment calculer le vecteur a2 des coefficients de l’équation derégression :
y = a21x1 + · · ·+ a2pxp + y2
En passant à l’écriture matricielle, et en sachant que les x1j ety1 sont centrés et en notantX1 = (x11, · · · , x1p) la matrice des résidus x1j :
p1 = X′t1
‖t′1t1‖
X1 = X − t1p′1
y1 = y − c1t1
w2 =X′1y1
‖X′1y1‖
t2 = X1w2
c2 =y′1t2
t′2t2
Etapes suivantes : Cette procédure itérative peut se poursuivre en utilisant de la mêmemanière les résidus y2 et x21, · · · , x2p. Le nombre de composantes t1, · · · , tH à retenir peutêtre déterminé en utilisant un critère de validation croisée qui sera présenté dans la suite decette section.L’utilisation de cette méthode de régression requiert donc un critère d’arrêt de la boucle ensachant que nombre de variables latentes final ne doit évidemment pas dépasser le rang de lamatrice A. L’idéal est de ne pas avoir un surajustement afin de ne pas dégrader le pouvoir deprédiction du modèle, ce qui est l’objectif du portefeuille répliquant.
L’algorithme
L’algorithme suivant décrit dans [23] a donc été implémenté dans l’outil de calibration :Etape 1 : X0 = Xet y0 = yEtape 2 : Pour h = 1, · · · , H :Etape 2.1 : Calcul du vecteur wh = (wh1, · · · , whj, · · · , whp)
wh =X′
h−1yh−1
‖ X ′h−1yh−1 ‖(7.1)
Etape 2.2 : Calcul de la composante th
th = Xh−1wh (7.2)
Etape 2.3 : Calcul du coefficient de régression ch de yh−1 sur th
ch =y′
h−1th
t′hth
(7.3)
Etape 2.4 : Calcul du vecteur yh des résidus de la régression de yh−1 sur th
yh = yh−1 − chth (7.4)
50

Etape 2.5 : Calcul du vecteur ph des coefficients des régressions de xhj sur th
ph =X′
h−1th
‖ t′hth ‖(7.5)
Etape 2.6 : Calcul de la matrice Xh des vecteurs des résidus des régressions de xhjsur th
Xh = Xh−1 − thp′
h (7.6)
Calcul des coefficients de régression
Comme on peut le constater, l’algorithme présenté ci-dessus ne calcule pas de manièreexplicite les coefficients de régression ah du modèle à h composantes :
y = ah1x1 + · · ·+ ahpxp + yh = Xah + yh
En effet on peut monter que :
ah = c1w∗1 + · · ·+ chw
∗h (7.7)
où C ′h = (c1, · · · , ch) est le vecteur des coefficients des régressions linéaires sur les h compo-santes, et W ∗
h = (w∗1, · · · , w∗h) est la matrice des h vecteurs w∗h vérifiant :
th = w∗h1x1 + · · ·+ w∗hpxp = Xw∗h (7.8)
On peut montrer que le vecteur w∗h est défini par la formule de récurrence suivante :
w∗h = wh −h−1∑k=1
w∗k(p′
kwh) (7.9)
Il suffit alors de rajouter à l’étape 2 de l’algoritme présenté plus haut les étapes 2.7 et 2.8suivantes :
Etape 2.7 : w∗h = whPour k = 1, · · · , hw∗h = wh − w∗k(p
′
kwh)Etape 2.8 : ah = W ∗
hChPour retrouver la formule [4] à partir de [5], on sait que : y = c1t1 + · · ·+ chth + yhth = Xw∗hd’où
y = c1Xw∗1 + · · ·+ chXw
∗h + yh
= X (c1w∗1 + · · ·+ chw
∗h)︸ ︷︷ ︸
ah
+yh
Pour retrouver la formule de récurrence 7.9 on procède comme suit :
– Le calcul de w∗1 est immédiat cart1 = X w1︸︷︷︸w∗1
51

– Pour trouver w∗2, on cherche w∗2 tel que t2 = Xw∗2. On a :
t2 = X1w2
= (X − t1p′
1)w2
= (X −Xw1p′
1)w2
= X(w2 − w1p′
1w2︸ ︷︷ ︸w∗2
)
– Pour trouver w∗3, on procède de la même manière :
t2 = X2w3
= (X1 − t2p′
2)w3
= (X − t1p′
1 − t2p′
2)w3
= X(w3 − w1(p′
1w3)− w∗2(p′
2w3)︸ ︷︷ ︸w∗3
)
Donc en généralisant à une étape h quelconque de l’algorthme on retrouve facilement 7.9.
Choix du nombre de composantes par validation croisée (PRediction Error Sum of Squares(PRESS))
La procédure de validation croisée pour le choix du nombre de composantes présentée par[23] est la suivante. A chaque étape h et donc pour chaque nouvelle composante th on calculele critère suivant :
Q2h = 1− PRESSh
RSSh−1
Pour h = 1, on a RSS0 =∑n
i=1(yi − yi)2. Une nouvelle composante th est significative
et donc conservée si Q2h ≥ 0.0975 . Ce seuil peut être également fixé à 0.05 si la taille de
l’échantillon est inférieur à 100 et 0 si la taille de l’échantillon est supérieure à 100. On définitdonc les critères RSSh et PRESSh qui sont calculés en utilisant le modèle de régression dey sur les h composantes suivant,
y = c1t1 + · · ·+ cht∗h︸ ︷︷ ︸
yh
+yh (7.10)
pour calculer la prédiction yh = y − yh. Donc pour chaque observation i :– on calcule la prédiction yhi deyi à l’aide du modèle 7.10 obtenu en utilisant toutes lesobservations
– on calcule la prédiction yh(−i) de yi à l’aide du modèle 7.10 obtenu sans utiliser l’obser-vation i
Les critères RSSh ( Residual Sum of Square) et PRESSh (PRediction Error Sum of Squares)sont alors définis par :
RSSh =∑n
i=1(yi − yhi)2
et,
PRESSh =∑n
i=1(yi − yh(−i))2
52

Régression PLS avec contraintes linéaires
Comme nous l’avons rappellé dans la première partie de ce mémoire, le programme d’opti-misation que nous essayons de résoudre peut présenter des contraintes linéaires. Nous allonsdécrire dans les lignes qui suivent une méthode qui va nous permettre de nous ramener à unprogramme d’optimisation classique auquel on pourra appliquer la régression PLS définie plushaut.Avec les notations décrites dans la première partie, on souhaite résoudre une programmed’optimisation de la forme suivante :
W ∗ = minBW=d
‖ FI.W − L ‖
Si on applique la décomposition QR (Cf Sectioin suivante ) à la matrice BT telle que :
QTBT =
[R0
]pn-p
et on définit les matrices A1, A2, les vecteurs Y et Z tels que :
FI.Q =[A1 A2
]p n-p
et QTW =
[YZ
]pn-p
On a alors B = RTQT et BW = RTQTW = RTT ; et (FI.Q)(QTW ) = FI.W = A1Y +A2Z.Avec ces notations notre problème initial peut être reformulé comme suit :
minRTY=d
‖ A1Y + A2Z − L ‖
L’équation RTY = d permet de trouver la solution Y et Z est obtenu en se ramenant à unproblème d’optimisation classique sans contraintes :
minz‖ A2Z − (L− A1Y ) ‖
La solution de notre problème initial avec contraintes est donc défini comme suit :
W ∗ = Q
[YZ
]La décomposition QR
Il existe plusieurs moyens de décomposer une matrice quelconque ( décomposition SVD,LU, etc...) et l’une des plus utilisée est la décomposition QR.
Théorème 1 Soit A une matrice orthogonale quelconque de Mn,m(C).Alors,∃Q ∈ Mm,m une matrice orthogonale, ∃M ∈ Mn,m(C) une matrice triangulaire supé-
rieure telles que
A=QR
53

Cette décomposition est souvent utilisée pour résoudre des problèmes linéaires de la forme :
Ax=B
En effet, Ax = B ⇐⇒ QRx = B ⇐⇒ Rx = QT b. Cette dernière équation est beaucoupplus facile à résoudre du fait de la triangularité de la matrice R.Plusieurs méthodes existent pour réaliser cette décomposition :
– L’orthogonalisation de Gram-shimdt– Les matrices de HouseHolder– La méthode de Givens
Nous avons choisi la méthode de Householder qui permet de décomposer notre matrice origi-nale par des itérations sucessives où on multiplie à chaque fois la matrice A par une matricede Householder Hi. Une matrice de Householder est une matrice orthogonale qui appliquel’opération suivante sur un vecteur quelconque :
H
xxxx
=
x000
L’algorithme suivant permet de réaliser cette opération élémentaire qui servira à la décompo-sition QR :
Soit x ∈ Rn, la fonction suivante calcule le vecteur v ∈ Rn tel que v(1) = 1 et β ∈ R telque P = In − βvvT est orthogonal et Px =‖ x ‖2 e1
Fonction : [v,β] = house (x) n = longueur(x)σ = x(2 : n)
′x(2 : n)
v =
[1
x(2 :n)
]si σ = 0
β = 0sinon
µ =√x(1)2 + σ
si x(1) <= 0v(1) = x(1)− µ
sinonv(1) = −σ
x(1)+mu
fin Siβ = 2v(1)2
σ+v(1)2
v = vv(1)
fin SiGrâce à cet algorithme on peut maintenant définir l’algorithme de la décomposition QR :Pour j = 1, · · · ;n
[v, β] = house(A(j : m, j))A(j : m, j : n) = (Im−j+1 − βvv
′)A(j : m, j : n)
si j < mA(j + 1 : m, j) = v(2 : m− j + 1)
fin Sifin For
54

7.1.2 Présentation des résultats
La méthode PLS a été implémentée 1 dans l’outil de calibration afin de comparer les résul-tas qu’on obtient en termes de qualité de portefeuilles. Dans un premier temps on a utilisé lesmêmes portefeuilles que ceux utilisés au début de cette partie. On ne constate pas une amé-lioration significative des résultats par rapport à l’ancienne méthode sur le quantile spécifiqueà 99,5%. Les résultats peuvent être qualifiés d’identiques sur l’ensemble de la distribution. Eneffet, cela s’explique par le fait que la méthode PLS converge quasiment vers la solution desmoindres carrés.Cependant on remarque que la méthode PLS gère relativement bien la colinéarité qui peutexister entre les cash flow des actifs du portefeuille répliquant. En effet, la méthodologie ac-tuelle utilisée par AXA gère les problèmes de colinéarité en utilisant la décomposition SVDet, avec la régression PLS, on arrive sans aucun ajustement à avoir des résultats presqueidentiques et même meilleurs pour certains portefeuilles.
Portefeuille A
Les inputs qui ont servi à calibrer ce portefeuille sont identiques à ceux du précédentportefeuille A décrit au début de cette partie. 15 variables latentes ont été nécessaires àl’algorithme PLS sur un nombre initial de 45 instruments.
Figure 7.1 – Qualité d’ajustement du porte-feuille A
Figure 7.2 – Distribution fonds propres Porte-feuille A
BE DFA RP A DifférenceSituation initiale 77,6 77,6 0
Choc taux +100bps -14,3 -14,25 -0,07Choc de taux -100bps 19,2 19,11 +0,09Choc action +30% 4,4 4,38 +0,04Choc action -30% -2,4 -3,23 +0,83
Choc combiné +100bps/+30% -17,3 -17,17 -0,15Choc combiné -100bps/-30% 16,2 15,50 +0,68
Table 7.1 – Sensibilités Portefeuille A
Les résultats obtenus sont quasiment identiques sur l’ensemble de la distribution par rapportaux résultats obtenus par la régression des moindres carrés avec l’ajustement SVD utilisépour prendre en compte les effets de colinéarité entre les différents instruments financiers. Lequantile à 99,5% notamment est légèrement plus élevé.
1. La régression PLS ainsi que toutes les méthodes présentées dans ce chapitre ont été implémentées sous VBA Excel.Les codes VBA correspondants sont retranscrits en annexe.
55

Quantile SdS RP A Différence99,5% -35,2 -57,4 22,299% -24,8 -44,8 2095% -6,9 -20,4 13,590% 1,2 -9,1 10,470% 14,7 10,6 4,150% 22,2 21,8 0,430% 28,1 30,6 -2,510% 35,2 41,2 -5,95% 38,2 46,1 -7,91% 43,2 54,1 -110,5% 44,7 56,5 -11,8
Table 7.2 – Ecarts Portefeuille A
Portefeuille B
La composition du portefeuille B ainsi que le mode de calibration sont identiques à ceuxutilisés pour la calibration du pourtefeuille B de référence. 13 variables latentes ont été utiliséespar l’algorithme PLS sur un nombre initial de 39 instruments. L’estimation du quantile à 99,5%est meilleure par rapport à la méthodologie basée sur la régression des moindres carrés avecajustement SVD.
Figure 7.3 – Qualité d’ajustement du porte-feuille B
Figure 7.4 – Distribution fonds propres Porte-feuille B
BE DFA RP B DifférenceSituation initiale 77,6 77,6 0
Choc taux +100bps -14,3 -13,76 -0,56Choc de taux -100bps 19,2 18,29 +0,91Choc action +30% 4,4 4,46 -0,03Choc action -30% -2,4 -4,9 +2,51
Choc combiné +100bps/+30% -17,3 -18,3 +0,97Choc combiné -100bps/-30% 16,2 12,94 +3,23
Table 7.3 – Sensibilités Portefeuille B
Portefeuille C
Le portefeuille C a été calibré sur les cash flow de passif comme le portefeuille A, maison a forcé ici les 5 premières sensibilités en utilisant une version de la régression PLS aveccontraintes. On constate un R2 plus dégradé que celui du portefeuille A mais un ajustement
56

Quantile SdS RP B Différence99,5% -35,2 -37,6 2,499% -24,8 -28,4 3,695% -6,9 -9,6 2,790% 1,2 -1 2,270% 14,7 14,7 -0,150% 22,2 23,9 -1,730% 28,1 30,9 -2,810% 35,2 38,4 -3,25% 38,2 41,8 -3,61% 43,2 46,5 -3,30,5% 44,7 48,9 -4,2
Table 7.4 – Ecarts Portefeuille B
à la distribution des fonds propres plutôt satisfaisant avec une estimation de la VaR à 99,5%très bonne et identique à la méthode des moindres carrés avec l’ajustement SVD.
Figure 7.5 – Qualité d’ajustement du porte-feuille C
Figure 7.6 – Distribution fonds propres Porte-feuille C
BE DFA RP C DifférenceSituation initiale 77,6 77,6 0
Choc taux +100bps -14,3 -14 0Choc de taux -100bps 19,2 19,2 0Choc action +30% 4,4 4,4 0Choc action -30% -2,3 -2 0
Choc combiné +100bps/+30% -17,3 -17 0Choc combiné -100bps/-30% 16,1 17,5 -1,3
Table 7.5 – Sensibilités Portefeuille C
On constate néanmoins, malgré la qualité d’ajustement à la distribution des fonds propres,une augmentation significative de la volatilité. Cela est essentiellement dû au fait qu’on aitforcé certaines sensibilités.
Choix du nombre de variables latentes
Le choix du nombre de variables latentes des portefeuilles présentés ci-dessus a été réalisésur la base du critère Q2
h présenté plus haut. Un des inconvénients majeurs de cette approcheest le temps de calibration en utilisant ce critère. En effet le calcul du PRESS à chaque étapede l’algorithme augmente significativement le temps de calcul. Une alternative à ce critèred’arrêt serait de se baser soit sur le RSS ou le R2. On constate que le critère Q2
h est à peu
57

Quantile SdS RP C Différence99,5% -35,2 -39,5 4,399% -24,8 -35,3 10,595% -6,9 -13,2 6,390% 1,2 -4,3 5,570% 14,7 12,7 2,050% 22,2 21,7 0,530% 28,1 29,4 -1,310% 35,2 39,4 -4,25% 38,2 43,7 -5,51% 43,2 52,2 -9,00,5% 44,7 56,4 -11,7
Table 7.6 – Ecarts Portefeuille C
près équivalent à celui du R2 car, dès que Q2h passe en dessous de 0, les valeurs du Residual
Sum of Square (RSS) et du R2 se stabilise. Une alternative acceptable serait donc de définirun critère d’arrêt sur le R2 ou le RSS dès qu’il se stabilise à un niveau, i.e, la différence devaleur de ces indicateurs entre deux étapes dépasse un certain seuil défini par l’utilisateur. Ceraisonnement se justifie heuristiquement par l’analyse de l’évolution du PRESSh, du RSSh,du R2 et du Q2
h en fonction du nombre de variables latentes. Les graphes suivants illustrentnotre propos pour le portefeuille A par exemple.
Figure 7.7 – Evolution du PRESSh et duRSSh en fonction du nombre de variables la-tentes
Figure 7.8 – Evolution du R2 et du Q2h en fonc-
tion du nombre de variables latentes
7.2 CashFlow mismatch
La méthodologie développée dans cette partie est fortement inspirée de [7] qui propose uneapproche différente dans la calibration des poids d’un portefeuille répliquant dans un cadreplus général que celui de l’assurance. Nous avons donc adapté le modèle proposé à celui ducalibrage des portefeuilles répliquants dans le cadre de l’étude qui nous intéresse. En effet,jusqu’ici les méthodes de réplication que nous avons implémentée ont toujours cherché àminimiser l’écart entre les cashflows du portefeuille et les passifs qu’on souhaite répliquer. Defait, cette approche qu’on pourrait qualifier de "classique" présente certains inconvenients :
– On n’a aucun moyen de contrôler à quel point le portefeuille doit matcher les cashflows de passif. Cette approche de l’optimisation va donc fournir uniquement le meilleur
58

portefeuille qu’on peut avoir étant donné les instruments fournis en entrée du programmede minimisation.
– Le processus de réplication utilisant une régression Moindres Carrés Ordinaires (MCO)classique ne permet pas de de vérifier a priori si les instruments financiers utilisés sont debons candidats pour le portefeuille de passifs qu’on souhaite répliquer, même si l’écartminimum est atteint en termes d’erreur de réplication. On peut imaginer que l’écartminimum atteint demeure à un niveau très élevé.
– La valorisation du portefeuille est faite séparément du processus de réplication. En effetle processus de calibration classique qui utilise la régression des moindres carrés ordi-naires ne prend pas en compte le coût du portefeuille de réplication. Cette situation estproblématique, car si il y a plusieurs portefeuilles d’actifs qui sont en mesure de répliquerles passifs, alors, du point de vue des prix, on préférerait le portefeuille le moins couteux.
[7] propose donc une nouvelle approche pour calibrer le portefeuille de réplication en imposantdes contraintes sur les écarts de cashflows. Cette méthode permet de pallier aux inconvénientsde l’approche "classique" de calibration utilisée jusque là. Nous allons d’abord présenter leprogramme proposé par [7] et dans un second temps exposer comment nous l’avons adapté àla réplication des passifs en assurance vie.
7.2.1 Initialisation du problème
Bien que nous ayons obtenu le portefeuille de réplication en utilisant un critère de mi-nimisation de la fonction objectif, on propose ici d’imposer les contraintes sur les écarts decashflows afin de trouver le portefeuille avec le coût minimal de réplication. Cela donne leproblème d’optimisation suivant :
argminx
E
[∑t∈T
∑i∈A
xiCkt,id
kt
](7.11)
sous les contraintes suivantes pour chaque time bucket t :
f
[ ∑i∈A,j∈L
(xiCkt,i − Ck
t,j)
]≤ σt (7.12)
avec les notations suivantes :– x représente le vecteur des poids des instruments financiers dans le portefeuille– A représente l’ensemble de nos instruments financiers– Ct,i représente les cashflow de l’instrument financier i– dt représente le facteur d’actualisation– f est une fonction qui indique comment on souhaite que le matching des cashflows soitréalisé. Nous verrons plus loin des exemples de fonction qui peuvent être utilisées.
L’interprétation économique de ce modèle est de trouver le portefeuille d’actifs le moins coû-teux parmi l’ensemble des solutions possibles qui réplique au mieux les passifs en conformitéavec les contraintes de faisabilité (σ)Tt=1 définies par l’utilisateur. Contrairement à l’optimisa-tion classique basée sur les moindres carrés ordinaires, l’exigence sur la qualité de l’ajustementdu portefeuille de réplication est contrôlée explicitement ici en réglant le niveau de tolérancedéfini par les (σ)Tt=1. En outre, en raison des contraintes 7.12 qui constituent la région defaisabilité du problème, un problème avec un ensemble de solutions vide indique simplementsoit un mauvais choix de portefeuille de réplication soit un choix inapproprié du niveau de
59

tolérance. Puisque l’un des principaux problèmes de réplication des passifs est la sélection desinstruments appropriés pour la réplication, cette caractéristique du modèle est plutôt appré-ciable. En effet, dans ce modèle d’optimisation, le contrôle de faisabilité est intégré dans leprocessus de calibration à la différence de l’optimisation basée sur la régression des moindrescarrés ordinaires, où le niveau de tolérance du portefeuille optimum ne peut être découvertqu’après avoir calibré le portefeuille.Pour résoudre le problème d’optimisation défini par 7.11 et 7.12, nous utilisons une ap-proche par scénarios. En remplaçant l’espérance 7.11 par la moyenne empirique sur les 1000scénarios, nous pouvons représenter le problème d’optimisation comme suit :
argminx
1
n
n∑k=1
[∑t∈T
∑i∈A
xiCkt,id
kt
](7.13)
sous les contraintes :1
n
n∑k=1
f(ukt (x)) ≤ σt (7.14)
où pour chaque time bucket t on a :
ukt (x) =∑
i∈A,j∈L
(xiCkt,i − Ck
t,j) (7.15)
pour t ∈ T , et k = 1, · · · , n.Dans le cadre de notre étude et afin de pouvoir comparer les résultats obtenus ici avec
ceux obtenus précédemment, nous allons travailler ici avec les cashfows en present value :cela revient à se limiter à une unique time bucket. On peut donc reformuler le problème deminimisation de la manière suivante :
argminx
1
n
n∑k=1
[∑i∈A
xiPVki
](7.16)
sous les contraintes :1
n
n∑k=1
f(uk(x)) ≤ σ (7.17)
où pour k = 1, · · · , n on a :
uk(x) =∑i∈A
(xiPVki − Lk) (7.18)
avec les notations suivantes :– n représente le nombre de scénarios utilisés pour la calibration– A représente l’ensemble de nos instruments financiers– σ représente le seuil de tolérance– PV k
i représente la valeur présente des cashflow de l’instrument i dans le scénario kLe choix de la fonction f sera bien sûr l’élément déterminant du programme d’optimisation.Le but sera de choisir une fonction f qui permette d’écrire le programme sous une formelinéaire. En effet, la particularité ici va être le fait qu’on va résoudre le problème en utilisantla programmation linéaire, notamment la méthode du simplexe (Cf [21]).
60
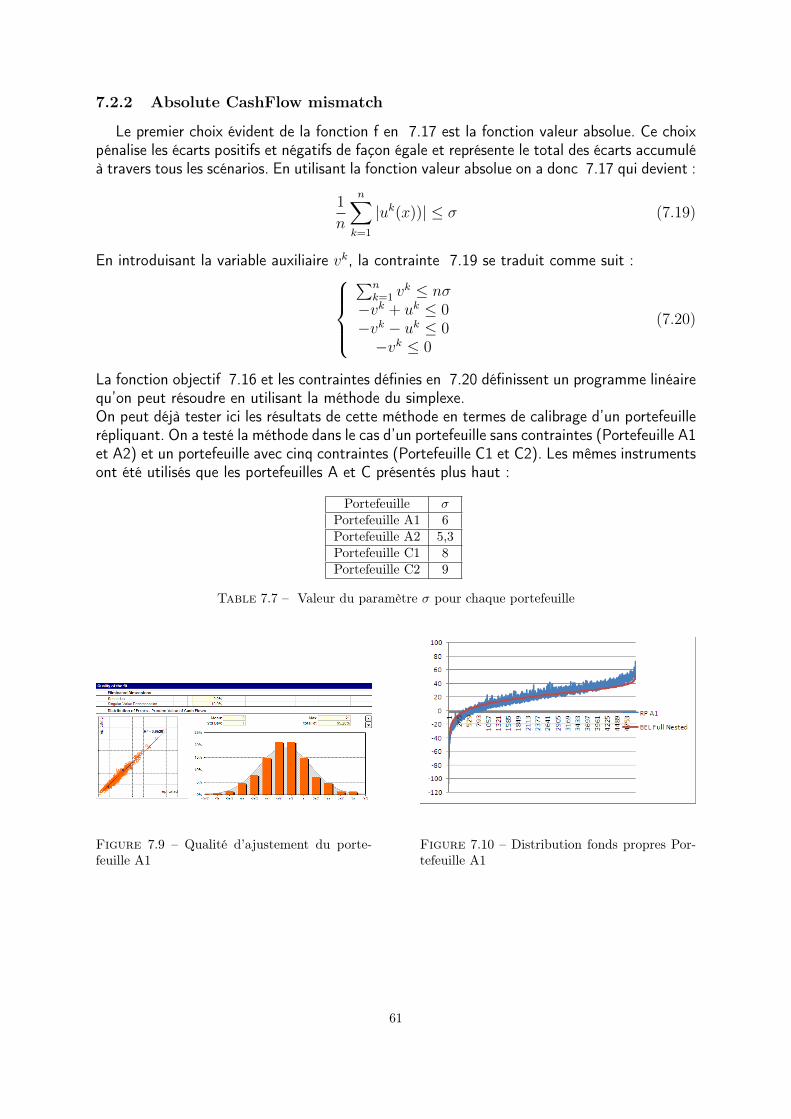
7.2.2 Absolute CashFlow mismatch
Le premier choix évident de la fonction f en 7.17 est la fonction valeur absolue. Ce choixpénalise les écarts positifs et négatifs de façon égale et représente le total des écarts accumuléà travers tous les scénarios. En utilisant la fonction valeur absolue on a donc 7.17 qui devient :
1
n
n∑k=1
|uk(x))| ≤ σ (7.19)
En introduisant la variable auxiliaire vk, la contrainte 7.19 se traduit comme suit :∑n
k=1 vk ≤ nσ
−vk + uk ≤ 0−vk − uk ≤ 0−vk ≤ 0
(7.20)
La fonction objectif 7.16 et les contraintes définies en 7.20 définissent un programme linéairequ’on peut résoudre en utilisant la méthode du simplexe.On peut déjà tester ici les résultats de cette méthode en termes de calibrage d’un portefeuillerépliquant. On a testé la méthode dans le cas d’un portefeuille sans contraintes (Portefeuille A1et A2) et un portefeuille avec cinq contraintes (Portefeuille C1 et C2). Les mêmes instrumentsont été utilisés que les portefeuilles A et C présentés plus haut :
Portefeuille σPortefeuille A1 6Portefeuille A2 5,3Portefeuille C1 8Portefeuille C2 9
Table 7.7 – Valeur du paramètre σ pour chaque portefeuille
Figure 7.9 – Qualité d’ajustement du porte-feuille A1
Figure 7.10 – Distribution fonds propres Por-tefeuille A1
61

BE DFA RP A1 DifférenceSituation initiale 77,6 77,6 0
Choc taux +100bps -14,3 -15,51 +1,18Choc de taux -100bps 19,2 19,1 +0,10Choc action +30% 4,42 4,17 0,24Choc action -30% -2,39 -4,36 +1,96
Choc combiné +100bps/+30% -17,33 -19,61 +2,27Choc combiné -100bps/-30% 16,2 14,41 +1,76
Table 7.8 – Sensibilités Portefeuille A1
Quantile SdS RP A1 Différence99,5% -35,2 -43,9 8,799% -24,8 -33,5 8,795% -6,9 -13,9 7,090% 1,2 -4,3 5,570% 14,7 12,7 2,050% 22,2 23,0 -0,730% 28,1 31,4 -3,310% 35,2 41,8 -6,65% 38,2 46,5 -8,31% 43,2 55,0 -11,80,5% 44,7 57,3 -12,6
Table 7.9 – Ecarts Portefeuille A1
Figure 7.11 – Qualité d’ajustement du porte-feuille A2
Figure 7.12 – Distribution fonds propres Por-tefeuille A2
62

BE DFA RP A2 DifférenceSituation initiale 77,6 77,6 0
Choc taux +100bps -14,3 -14,65 +0,32Choc de taux -100bps 19,11 19,1 +0,09Choc action +30% 4,42 5,06 -0,63Choc action -30% -2,39 -3,55 +1,15
Choc combiné +100bps/+30% -17,33 -17,95 +0,62Choc combiné -100bps/-30% 16,2 15,25 +0,92
Table 7.10 – Sensibilités Portefeuille A2
Les résultats sont plutôt satisfaisants sur les deux portefeuilles avec des coefficients R2
plutôt élevés. On remarque également des poids nuls pour certains instruments en comparai-son de la valeur qu’ils avaient pour le cas initial. Cela laisse supposer que cette méthodologieopère en quelque sorte une sélection des instruments. Les sensibilités sont meilleures et onobtient des résultats très satisfaisants sur la queue de la distribution pour le portefeuille A1.Malgré un coefficient σ moins élevé pour le portefeuille A2 par rapport au portefeuille A1, lesrésultats du portefeuille A1 sont beaucoup plus satisfaisants.Un coefficient σ trop bas peut donc conduire à des écarts très importants en termes d’esti-mation du quantile à 99,5%.
Quantile SdS RP A2 Différence99,5% -35,2 -57,9 22,799% -24,8 -45,8 21,095% -6,9 -20,8 13,990% 1,2 -9,6 10,870% 14,7 10,3 4,450% 22,2 21,9 0,330% 28,1 31,2 -3,110% 35,2 42,4 -7,25% 38,2 47,4 -9,21% 43,2 55,9 -12,70,5% 44,7 58,1 -13,4
Table 7.11 – Ecarts Portefeuille A2
Figure 7.13 – Qualité d’ajustement du porte-feuille C1
Figure 7.14 – Distribution fonds propres Por-tefeuille C1
63

BE DFA RP C1 DifférenceSituation initiale 77,6 77,6 0
Choc taux +100bps -14,3 -14,3 0Choc de taux -100bps 19,2 19,2 0Choc action +30% 4,42 4,42 0Choc action -30% -2,39 -2,39 0
Choc combiné +100bps/+30% -17,33 -17,33 0Choc combiné -100bps/-30% 16,2 17,51 -1,3
Table 7.12 – Sensibilités Portefeuille C1
Quantile SdS RP C1 Différence99,5% -35,2 -36,8 1,699% -24,8 -30,8 695% -6,9 -11,3 4,490% 1,2 -3,1 4,370% 14,7 12,9 1,850% 22,2 21,8 0,430% 28,1 29,4 -1,310% 35,2 39,2 -45% 38,2 43,3 -5,11% 43,2 50,6 -7,40,5% 44,7 54,0 -9,3
Table 7.13 – Ecarts Portefeuille C1
Figure 7.15 – Qualité d’ajustement du porte-feuille C2
Figure 7.16 – Distribution fonds propres Por-tefeuille C2
64

BE DFA RP C2 DifférenceSituation initiale 77,6 77,6 0
Choc taux +100bps -14,3 -14,3 0Choc de taux -100bps 19,2 19,2 0Choc action +30% 4,42 4,42 0Choc action -30% -2,39 -2,39 0
Choc combiné +100bps/+30% -17,33 -17,33 0Choc combiné -100bps/-30% 16,2 17,50 -1,3
Table 7.14 – Sensibilités Portefeuille C2
Quantile SdS RP C2 Différence99,5% -35,2 -39,9 4,799% -24,8 -34,1 9,395% -6,9 -13,2 6,390% 1,2 -4,4 5,670% 14,7 12,6 2,150% 22,2 22 0,230% 28,1 29,9 -1,810% 35,2 40,3 -5,15% 38,2 44,6 -6,41% 43,2 52,9 -9,70,5% 44,7 55,9 -11,2
Table 7.15 – Ecarts Portefeuille C2
La méthode du simplexe étant optimisée pour les contraintes linéaires, l’ajout des contraintesde sensibilité se fait assez naturellement en rajoutant des contraintes d’égalité au programmed’optimisation représenté par 7.16 et 7.20. Il faut également noter que le programme d’opti-misation permet de rajouter des contrainte moins coercitives sur les coefficients en définissantdes seuils de tolérance pour le niveau d’erreur que l’utilisateur peut accepter sur les différentessensibilités.Comme dans les sections précédentes l’ajout des contraintes dégrade le coefficient R2 maisdonne des résultats très satisfaisants en améliorant l’estimation du quantile à 99,5%. Commeremarqué précédemment le coefficient σ lorqu’il est trop bas donne de moins bons résultatssur la distribution et plus particlièrement dans l’estimation du quantile à 99,5%.
7.2.3 Conditional Value-at-risk mismatch
Les contraintes basées sur la somme de la valeur absolue des écarts ne capturent pas lesécarts importants dans la queue de la distribution des erreurs. En effet, ce type de contraintes’applique sur l’ensemble de la distribution, ce qui n’empêche pas d’avoir des écarts importants(aussi bien positifs que négatifs) dans certains scénarios.On peut illustrer ce type d’écart en réalisant un QQ-plot de l’erreur de réplication des porte-feuilles A1 et C2 par exemple :
On peut remarquer pour le portefeuille A1 un écartement de la bissectrice dans la queuegauche de la distribution des erreurs tandis que pour le portefeuille C2 cet écartement estencore plus accentué des deux côtés de la distribution. Du fait de l’utilisation qui est faitedes portefeuilles répliquants, c’est-à-dire un proxy pour le calcul de la distribution des fondspropres économiques, ce type d’écart peut dégrader l’estimation de la VaR. Le but de cettepartie est de pallier justement à ce type de problématiques.
65

Figure 7.17 – QQ-Plot Distribution des erreursdu portefeuille C2 (sans CVaR Mismatch)
Figure 7.18 – QQ-Plot Distribution des erreursdu portefeuille A1 (sans CVaR Mismatch)
Pour mesurer les écarts de cashflow dans la queue de la distribution, nous considérons laConditional Value-At-Risk. La CVaR est une mesure de risque généralement utilisée dans lesecteur financier et souvent préférée à la VaR par les gestionnaires de risques en raison desa cohérence intrinsèque (voir Artzner et al (1997)). Une mesure de risque cohérente estégalement une mesure de risque convexe, ce qui est une propriété importante dans le cadrede problèmes d’optimisation.
Soit β1 et β2 les deux paramètres qui définissent à combien de scénarios vont s’appliquer lacontrainte pour chacun des côtés de la distribution des écarts de cashflows. Puis, comme pourla VaR, nous définissons deux percentiles correspondants α1(x, β1) et α2(x, β2) tels que :
α1(x, β1) = sup u|P [−u(x, y) ≥ u] ≤ β1
α2(x, β2) = sup u|P [u(x, y) ≥ u] ≤ β2
où x est le vecteur des poids de nos instruments financiers et y représente l’aléa dont dépendla fonction u qui correspond aux écarts de cashflow.
En supposant que le vecteur y a une fonction de densité de probabilité conjointe p(y), nouspouvons maintenant définir la VaR conditionnelle des écarts de cashflow comme suit :
g(β1) =∫−u(x,y)≥α1(x,β1)
u(x, y)p(y)dy
g(β2) =∫u(x,y)≥α2(x,β2)
u(x, y)p(y)dy
En utilisant la même technique que Rockafellar et Uryasev (2000) [22] et Krokhmal et al(2002) [15], la VaR conditionnelle peut être approchée à l’aide d’un ensemble de n scénariosde simulation comme suit :
g(x, γ1) = γ1 + 1(1−β1)n
∑nk=1[−uk − γ1]+
g(xγ2) = γ2 + 1(1−β2)n
∑nk=1[uk − γ2]+
où la fonction [.]+ est définie comme suit :
[x]+ =
x si x ≥ 00 sinon
66

La VaR conditionnelle des écarts de cashflow peut donc être controlée en rajoutant descontraintes au problème initial 7.16 :
g(β1) ≤ σ1
g(β2) ≤ σ2
Ces contraintes se traduisent donc comme suit en rajoutant des variables auxiliaires zki pourk = 1, · · · , n et i = 1, 2 :
zk1 ≥ −uk − γ1
zk1 ≥ 0−γ1 − 1
(1−β1)n
∑nk=1 z
k1 ≥ σ1
zk2 ≥ uk − γ2
zk2 ≥ 0−γ2 − 1
(1−β2)n
∑nk=1 z
k2 ≥ σ2
(7.21)
7.2.4 Conditional Value-at-risk and Absolute mismatch
On a vu dans la section précédente que les contraintes que nous avons définies ne peuventêtre utiles qu’une fois combinées avec les contraintes sur les écarts de cashflow absolu.Nous allons donc tester dans cette dernière partie un programme d’optimisation regroupanttoutes les contraintes qu’on a définies précédemment :
argminx
E
[∑t∈T
∑i∈A
xiCkt,id
kt
](7.22)
sous les contraintes :
∑nk=1 v
k ≤ nσvk + uk ≤ 0vk − uk ≤ 0−vk ≤ 0zk1 ≥ −uk − γ1
zk1 ≥ 0−γ1 − 1
(1−β1)n
∑nk=1 z
k1 ≥ σ1
zk2 ≥ uk − γ2
zk2 ≥ 0−γ2 − 1
(1−β2)n
∑nk=1 z
k2 ≥ σ2
(7.23)
La difficulté dans cette partie a été de trouver les coefficients σ1 et σ2 adaptés au problème.En effet, une contrainte pas assez forte va fausser le programme d’optimisation dans le sens oùles VaR solutions du programme ne correspondent pas aux VaR réelles des écarts. A contrario,avec une contrainte trop forte, l’algorithme du simplexe ne trouve pas de solution ce qui peutêtre une conséquence du choix de la contrainte ou du choix des instruments candidats. Onpeut le constater dans le tableau où nous avons testé plusieurs valeurs pour σ1 et σ2. Nousn’allons pas présenter ici les résultats des différents tests qui ont été réalisés. On réussit aufinal à améliorer les deux portefeuilles précédents tout en améliorant également l’erreur auniveau des queues de la distribution. Les paramètres du programme d’optimisation pour cesdeux portefeuilles sont les suivants :
67

– β1 = β2 = 99, 5%, on impose ainsi des contraintes sur les deux côtés de la distributiondes erreurs.
– On garde les valeurs de σ identiques à celles des portefeuilles obtenus pour les contraintesabsolues uniquement : donc σ = 6 pour le portefeuille sans contraintes de sensibilité etσ = 9 pour le portefeuille avec contraintes
– Pour le portefeuille sans contraintes, on a σ1 = 29, 97 et σ2 = 67– Pour le portefeuille avec contraintes, on a σ1 = σ2 = 38.Premièrement, on a une amélioration des QQ-plot qui se traduit par un écartement moins
significatif dans la queue de la distribution :
Figure 7.19 – QQ-Plot Distribution des erreursdu portefeuille C2 (avec CVaR Mismatch)
Figure 7.20 – QQ-Plot Distribution des erreursdu portefeuille A1 (avec CVaR Mismatch)
Ensuite en faisant une analyse plus classique des deux portefeuilles, on a une améliorationà la fois sur les sensibilités pour le portefeuille sans contraintes et sur la distribution des fondspropres économiques :
Figure 7.21 – Qualité d’ajustement du porte-feuille A1 (avec CVaR Mismatch)
Figure 7.22 – Distribution fonds propres Por-tefeuille A1 (avec CVaR Mismatch)
68

BE DFA RP A1 DifférenceSituation initiale 77,6 77,6 0
Choc taux +100bps -14,3 -15,18 +0,85Choc de taux -100bps 19,2 18,92 +0,29Choc action +30% 4,42 4,77 -0,34Choc action -30% -2,39 -4,27 +1,87
Choc combiné +100bps/+30% -17,33 -19,20 +1,87Choc combiné -100bps/-30% 16,2 14,33 +1,84
Table 7.16 – Sensibilités Portefeuille A1 (avec CVaR Mismatch)
Quantile SdS RP A1 Différence99,5% -35,2 -43,5 8,399% -24,8 -33,5 8,595% -6,9 -14,3 7,490% 1,2 -4,7 5,970% 14,7 12,3 2,450% 22,2 22,7 -0,530% 28,1 31,4 -3,310% 35,2 42,3 -7,15% 38,2 47,0 -8,81% 43,2 55,3 -12,20,5% 44,7 58,2 -13,5
Table 7.17 – Ecarts Portefeuille A1 (avec CVaR Mismatch)
Figure 7.23 – Qualité d’ajustement du porte-feuille C2 (avec CVaR Mismatch)
Figure 7.24 – Distribution fonds propres Por-tefeuille C2 (avec CVaR Mismatch)
7.2.5 Conclusion
Pour conclure avec cette partie, on peut remarquer au travers des différents résultats quel’approche de calibration basée sur une optimisation du coût du portefeuille répliquant avecdes contraintes présente plusieurs avantages. En effet, la forme du programme d’optimisationpermet à l’utilisateur d’imposer toutes sortes de contraintes linéaires (égalités ou inégalités) auprogramme. Cela constitue un avantage dans le sens où on gagne en termes de flexibilité et onpeut notamment rendre la calibration plus robuste. Ensuite le programme présente égalementun avantage par rapport à la régression MCO classique qui réside dans les problèmes que l’onpeut rencontrer sur la colinéarité qui peut exister entre les différents instruments financiers
69

BE DFA RP C2 DifférenceSituation initiale 77,6 77,6 0
Choc taux +100bps -14,3 -14,3 0Choc de taux -100bps 19,2 19,2 0Choc action +30% 4,42 4,42 0Choc action -30% -2,39 -2,39 0
Choc combiné +100bps/+30% -17,33 -17,33 0Choc combiné -100bps/-30% 16,2 17,50 -1,34
Table 7.18 – Sensibilités Portefeuille C2 (avec CVaR Mismatch)
Quantile SdS RP C2 Différence99,5% -35,2 -35,4 0,299% -24,8 -29,8 5,095% -6,9 -10,7 3,890% 1,2 -2,6 3,870% 14,7 12,9 1,850% 22,2 22,0 0,330% 28,1 29,7 -1,610% 35,2 39,9 -4,75% 38,2 44,3 -6,11% 43,2 51,9 -8,70,5% 44,7 55,5 -10,8
Table 7.19 – Ecarts Portefeuille C2 (avec CVaR Mismatch)
essentiellement due au fait qu’on travaille en present value. En effet quand on analyse lesdifférents portefeuilles obtenus avec cette méthodologie, on s’aperçoit que la composition desportefeuilles est la même mais les poids de plusieurs instruments financiers sont nuls. De plusl’hypothèse d’indépendance entre les instruments candidats qui est très souhaitable lorsqu’onfait une régression des MCO classique, n’est plus une contrainte ici. Enfin cette méthodede calibration présente l’avantage de permettre à l’utilisateur d’avoir un contrôle sur l’erreurqu’il commet aussi bien sur l’ensemble de la distribution des erreurs que dans la queue de ladistribution pour les écarts anormaux.Toutefois, cette méthode peut s’avérer coûteuse en temps de calcul si on souhaite calibrerdes portefeuilles qui ont été simulés sur plus de 1000 scénarios car comme on a pu le voir lenombre de contraintes dépend du nombre de scénarios utilisés pour la calibration. La méthodedu simplexe peut donc présenter une réelle limite à ce niveau là. Une solution pourrait êtred’utiliser au lieu de l’algorithme du simplexe, un algorithme de type point intérieur plus adaptéà des données de grande taille.
7.3 Sélection automatique des instruments financiers
Comme nous pouvons le constater dans la théorie de portefeuille de réplication, la qualitéde l’ajustement de la réplication dépend fortement de l’ensemble sélectionné des instrumentsfinanciers.Théoriquement, il est possible de répliquer parfaitement un flux en utilisant un très grandnombre d’instruments financiers. En effet la structure linéaire du système nous permet detrouver les poids si le nombre d’instruments est plus grand ou égal au nombre de scénarios.En pratique, cela est impossible car pour chaque portefeuille d’assurance, le nombre de scé-
70

narios utilisés pour calculer la valeur de marché est souvent très grand (1000 dans le cadre denotre étude). Donc trouver plus de 1000 instruments financiers simples et indépendants estquasiment impossible. L’enjeu de la calibration est donc de sélectionner les bons instrumentsfinanciers pour trouver un portefeuille répliquant de bonne qualité.Afin de faire une bonne sélection, une bonne connaissance du passif est essentielle. Cepen-dant, le comportement du passif ou des marges est souvent très complexe ce qui oblige àfaire plusieurs essais avant d’obtenir un portefeuille approprié. Jusqu’à présent, ces tests ontété effectués manuellement et ils ralentissent la création d’un portefeuille de réplication. Eneffet certaines entités du groupe AXA qui utilisent les portefeuilles répliquants se plaignent dedevoir en moyenne consacrer une journée à la calibration d’un portefeuille donné. Et une entitédispose en moyenne d’une dizaine de portefeuilles. Le but de cette partie est de proposer unalgorithme de sélection qui permette d’accélérer cette étape du processus de création d’unportefeuille répliquant en s’inspirant des méthodes de sélection de variables.
L’objet de cette partie sera donc de définir un algorithme qui permette de classifier nosinstruments financiers, afin d’identifier lesquels sont les plus importants pour une qualité derégression optimale de nos cashflows.
En utilisant deux procédures différentes de sélection de variables nous allons automatiserle choix des portefeuilles répliquant en suivant les différentes étapes suivantes :
– Définition des intruments financiers pouvant répliquer le passif– Génération d’une pré-liste d’instruments à partir de la liste des catégories définies préala-blement. L’avantage de la méthode se situe là : en effet on a pas ici à préciser exactementles caractéristiques des instruments mais seulement des intervalles auxquels les strikespeuvent appartenir.
– Vérification de la cohérence de l’algorithme dans des situations de réplication parfaite,de surréplication ou de sous réplication
– Mise en oeuvre de l’algorithme de sélection : les variables ici sont nos instruments finan-ciers
La procédure ainsi définie sera appliquée pour deux algorithmes de sélection différents maispeut s’appliquer avec n’importe quel algorithme de sélection de variable. Nous allons nousintéresser dans ce mémoire à deux de ces algorithmes.
7.3.1 Least Angle Regression
Nous allons présenter d’abord les principes de l’algorithme Least Angle Regression (LAR)qui est une généralisation de plusieurs méthodes de sélection. En effet, on peut montrerqu’une modification de l’algorithme LAR conduit à la méthode LASSO ainsi qu’à la méthodeStepWise. Après avoir présenté comment cela a été implémenté au sein de l’outil de réplicationnous présenterons les résultas des différentes méthodes sur le portefeuille qui fait l’objet denotre étude.
Principe de l’algorithme
En se basant sur la théorie de la sélection, une sélection itérative pourrait être utiliséepour automatiser la création d’un portefeuille répliquant. Une méthode très classique est laForward Selection. Il s’agit d’une méthode qui procède également étape par étape : à chaqueétape, l’algorithme choisit la variable la plus corrélée avec le résidu et définit le nouveau résidu
71

orthogonalement à l’ensemble des variables sélectionnées. Cette méthode est efficace maistrop agressive et élimine certaines variables utiles. Afin de rendre la sélection plus robuste,nous avons utilisé une autre méthode itérative, dérivée de la méthode Forward Selection, àsavoir la régression LAR ( Least Angle Regression).La méthode LAR est une méthode de sélection des variables qui procède étape par étape.Soit Y la variable qu’on veut régresser (dans notre cas les cash flow de passif ou de marge),et x1, · · · , xp un ensemble de variables prédictives ( dans notre cas cela correspond à nosp instruments financiers ). Les prédicteurs seront sélectionnés un à un suivant la procéduredécrite dans les lignes qui suivent.Nous allons traiter un exemple pour le cas de deux prédicteurs. Notons µ la réponse, ona µ = β1x1 + β2x2 . L’algorithme commence par β1 = β2 = 0 et µ0 = 0. On choisitx1 car sa corrélation avec y est plus grande que celle de x2 . Posons µ1 = µ0 + γ1x1
avec γ1 qui est choisi tel que Corr(y − µ1, x1) = Corr(y − µ1, x2) . Soit u2 le vecteurunitaire équiangulaire (la bissectrice) entre x1 et x2 et posons µ2 = µ1 + γ2x2, pour cetexemple, γ2 est choisi tel que µ2 soit égal à la projection y de y sur le plan formé parx1 et x2 (Figure 7.25). Pour le cas avec plus de deux prédicteurs, γ2 doit être la pluspetite valeur tel qu’il existe x3 ayant la même corrélation avec y − µ2 que x1 et x2 , soitCorr(y−µ2, x1) = Corr(y−µ2, x2) = Corr(y−µ2, x3). Nous allons décrire plus précisément
Figure 7.25 – Description géométrique de l’algorithme LAR pour p=2 prédicteurs
l’algorithme dans la section suivante.
Description de l’algorithme
Avec les notations de la section précédente, on suppose dans cette partie que les p pré-dicteurs sont linéairement indépendants. Le vecteur β = (β1, · · · , βp) définit un vecteur µ deprédiction.Soit A un sous-ensemble de l’ensemble 1, · · · , p des indices de nos prédicteurs, qui repré-sente l’ensemble des prédicteurs choisis à une étape de l’algorithme.
c = X′(y − µA) représente le vecteur des corrélations entre les résidus et les prédicteurs ap-
partenant à l’ensemble A. Pour tout j ∈ A, on a |cj| = maxl|cl| = C, et |sj| = signcj,
sj désignant si le j prédicteur sélectionné est positivement ou négativement corrélé au résidu.On définit alors les matrices suivantes :
XA = (· · · , sjxj, · · · )j∈A
GA = X′AXA
AA = (1′AG−1A 1A)−1/2
72

où 1A est un vecteur de 1 dont la longueur est le cardinal de l’ensemble A.Alors le vecteur équiangulaire uA est défini comme suit :
uA = XAwA
où wA = AAG−1A 1A.
Ce vecteur est l’unique vecteur formant des angles égaux avec les prédicteurs appartenant àl’ensemble A.On définit enfin la matrice suivante :
(· · · , ai, · · · )1≤i≤p = a = X′uA
On peut alors décrire l’algorithme LAR.Supposons qu’on est à l’étape k et que k variables aient déjà été sélectionnées, on a alorscardinal(A) = k. On calcule alors c, C,GA, AA, uA et a comme décrits précédemment.
L’étape suivante de l’algorithme LAR met le vecteur de prédiction à jour tel que :
µA+ = µA + γuA
où,
γ :+
minj∈Ac C − cjAA − aj
,C + cjAA + aj
et la fonction min+(.) est défini comme suit :
min+(a, b) =
min(a, b) si a ≥ 0 et b ≥ 0
a si b < 0 et a ≥ 0b si a < 0 et b ≥ 00 si a < 0 et b < 0
En fait, si on définit µ(γ) = µA + γuA pour γ > 0, le vecteur des corrélations du j prédicteurest :
cj(γ) = x′j(y − µ(γ)) = x
′j(y − µA − γuA) = cj − γaj
Pour j ∈ A , on a :
|cj(γ)| = C − γAA
Pour j ∈ Ac , on sait que cj(γ) atteint sa valeur maximale pour γ =C−cjAA−aj
ou γ =C+cjAA+aj
.On choisit alors la plus petite valeur positive des deux qui nous permet d’identifier la nouvellevariable j qui rejoint l’ensemble A. On a alors : A = A ∪ j et C = C − γAA. On passealors à l’étape suivante de l’algorithme.
Présentation des résultats LAR
La question qui se pose maintenant est comment appliquer cet algorithme à la sélectiondes instruments financiers pour un portefeuille répliquant. Comme nous pouvons constaterqu’après m étapes, LAR retrouve exactement la solution des moindres carrés ordinaires. Nousn’avons pas intérêt à prendre tous les instruments. L’idée est donc d’introduire une conditiond’arrêt. Lorsque cette condition est satisfaite, la procédure s’arrête.
73

Instrument Base Index Curr Term1 Term2 Strike Poids InitialZero Coupon EUR 3 12248Zero Coupon EUR 5 3934Zero Coupon EUR 6 48664Zero Coupon EUR 13 3327Zero Coupon EUR 16 11825
Floor EUR-05Y EUR 7 5 2% 1254Cap EUR-05Y EUR 10 5 5% 11812
Receiver Swaption EUR-05Y EUR 20 5 2, 10% 4041Payer Swaption EUR-05Y EUR 1 5 3, 75% 1793Equity Index Call EUR-Eq EUR 1 130% 791
Table 7.20 – Composition de l’indice de CashFlows
Avant de tester LAR sur le portefeuille de passifs nous avons voulu tester l’efficacité del’algorithme dans des cas très simples. Pour cela on a créé un indice de cashflows à partird’une dizaine d’instruments financiers avec des poids différents définis dans le tableau ci-dessous :
Etape de réplication parfaiteIci, on propose en entrée de l’algorithme les instruments financiers qui ont servi à la com-position de l’indice. LAR retrouve bien les poids initiaux de chacun des instruments en lessélectionnant dans l’ordre suivant :
Etape Instrument Base Index Curr Term1 Term2 Strike Poids Trouvé R2
1 Zero Coupon EUR 3 12248 0,272 Zero Coupon EUR 16 11825 0,293 Zero Coupon EUR 13 3327 0,814 Zero Coupon EUR 6 48664 0,9965 Receiver Swaption EUR-05Y EUR 20 5 2, 10% 4041 0,996 Equity Index Call EUR-Eq EUR 1 130% 791 0,997 Cap EUR-05Y EUR 10 5 5% 11812 0,998 Zero Coupon EUR 5 3934 0,999 Floor EUR-05Y EUR 7 5 2% 1254 0,9910 Payer Swaption EUR-05Y EUR 1 5 3, 75% 1793 1
Table 7.21 – Instruments sélectionnés dans l’ordre de LAR
Etape de sur-réplicationNous avons montré ainsi qu’on pouvait répliquer de manière exacte un indice créé à partird’un nombre donné d’instruments financiers par ces mêmes instuments financiers. Nous allonsà présent tester l’efficacité de LAR en mettant en entrée de l’algorithme les instrumentsfinanciers ayant servi à la composition de l’indice ainsi que des instruments financiers parasites.L’efficacité de l’algorithme se mesurera au nombre d’instruments financiers parasites ayant étésélectionnés qui devra être très bas. Même si ces instruments étaient sélectionnés une qualitéappréciable de l’algorithme serait de trouver des poids nuls pour ces instruments. On rajouteaux instruments candidats des instruments financiers parasites qui dans notre exemple sontdes Floor de différents strikes.Ci-dessous les instruments sélectionnés par LAR dans l’ordre :
On peut constater au vu de ces résultats que LAR sélectionne assez bien les instrumentstant qu’on a pas atteint une réplication parfaite en terme de R2. Cependant les instrumentsfinanciers n’appartenant pas à l’indice de départ même s’ils sont sélectionnés avant d’atteindre
74

Etape Instrument Base Index Curr Term1 Term2 Strike Poids Trouvé R2
1 Zero Coupon EUR 3 12248 0,272 Zero Coupon EUR 16 11825 0,293 Zero Coupon EUR 13 3327 0,814 Zero Coupon EUR 6 48664 0,9965 Receiver Swaption EUR-05Y EUR 20 5 2, 10% 4041 0,9976 Equity Index Call EUR-Eq EUR 1 130% 791 0,997 Floor EUR-05Y EUR 10 5 2% 11812 0,998 Cap EUR-05Y EUR 10 5 5% 11812 0,999 Zero Coupon EUR 5 3934 0,9910 Floor EUR-05Y EUR 7 5 2% 1254 0,9911 Floor EUR-05Y EUR 4 5 3% 0 0,9912 Payer Swaption EUR-05Y EUR 1 5 3, 75% 0 113 Floor EUR-05Y EUR 13 5 2% 0 114 Floor EUR-05Y EUR 2 5 3% 0 115 Floor EUR-05Y EUR 15 5 2% 0 116 Floor EUR-05Y EUR 1 5 2% 0 117 Floor EUR-05Y EUR 4 5 2% 0 118 Floor EUR-05Y EUR 3 5 2% 0 1
Table 7.22 – Instruments sélectionnés dans l’ordre de LAR
un coefficient R2 de 1, ont de toute façon un poids de 0 dans le portefeuille calibré. Nousavons effectué d’autre tests avec un nombre plus important d’instruments financiers parasites.Les résultats montrent que LAR sélectionne toujours les bons instruments et affecte des poidsde 0 aux instruments financiers qui ne composent pas l’indice de départ.
Etape de sous-réplicationLes deux précedentes étapes de réplication parfaite et de surréplication ont permis de validerl’efficacité de LAR uniquement en termes de sélection d’instruments financiers dans des universparfaits i.e l’indice de cash flow qu’on a créé correspond à une combinaison linéaire parfaitedes cash flows d’instruments financiers connus. Dans la suite nous allons nous placer dans ununivers non parfait dans le sens où l’indice cible ( dans la pratique les cashflows de passif d’unassureur) n’est plus une combinaison parfaite des instruments servant à la réplication. Pource faire on a bruité l’indice de cashflows précédent à l’aide d’une variable aléatoire qui dansce cas est une loi normale centrée de variance 10. La procédure de sélection avec un indicede cashflow ainsi bruité a été testée en utilisant LAR :
On remarque que malgré le bruitage, l’ordre de sélection des instruments est le même.Seul le calibrage des poids est différent. L’analyse des poids finaux sur plusieurs calibrationsmontre des résultats légèrement différents en termes de poids des instruments financiers debase ayant servi à la composition de l’indice. Mais globalement l’écart entre les poids trouvéset les poids initiaux du portefeuille n’est pas très siginificatif. En outre on constate que avecdes niveaux de variance plus élevés la précision des poids trouvés se dégrade encore plus, cequi semble assez logique.Nous avons ainsi montré l’efficacité de l’algorithme en termes de sélection d’instruments. Nousallons donc tester LAR sur le portefeuille de passif qui fait l’objet de notre étude.
Nous avons mis à l’entrée de LAR les instruments suivants :– Des Zéro Coupon pour répliquer le taux garanti– Des swaptions dont le strike va varier autour du taux garanti pour représenter la parti-
75
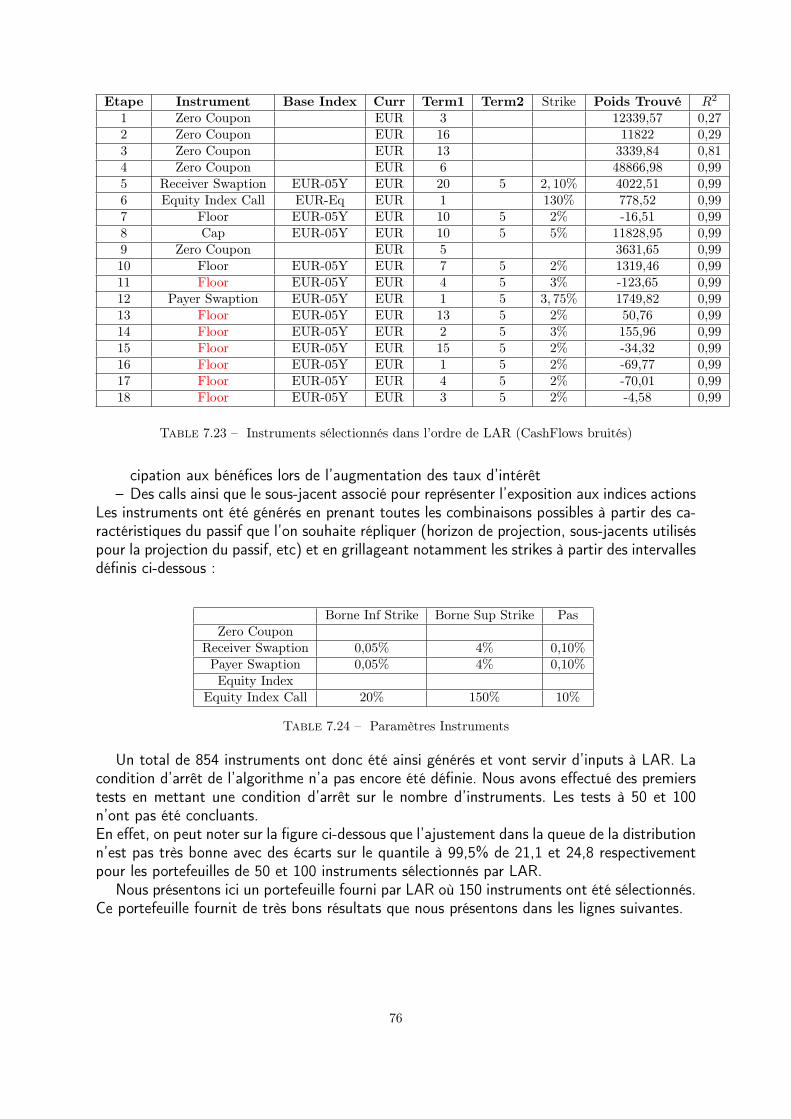
Etape Instrument Base Index Curr Term1 Term2 Strike Poids Trouvé R2
1 Zero Coupon EUR 3 12339,57 0,272 Zero Coupon EUR 16 11822 0,293 Zero Coupon EUR 13 3339,84 0,814 Zero Coupon EUR 6 48866,98 0,995 Receiver Swaption EUR-05Y EUR 20 5 2, 10% 4022,51 0,996 Equity Index Call EUR-Eq EUR 1 130% 778,52 0,997 Floor EUR-05Y EUR 10 5 2% -16,51 0,998 Cap EUR-05Y EUR 10 5 5% 11828,95 0,999 Zero Coupon EUR 5 3631,65 0,9910 Floor EUR-05Y EUR 7 5 2% 1319,46 0,9911 Floor EUR-05Y EUR 4 5 3% -123,65 0,9912 Payer Swaption EUR-05Y EUR 1 5 3, 75% 1749,82 0,9913 Floor EUR-05Y EUR 13 5 2% 50,76 0,9914 Floor EUR-05Y EUR 2 5 3% 155,96 0,9915 Floor EUR-05Y EUR 15 5 2% -34,32 0,9916 Floor EUR-05Y EUR 1 5 2% -69,77 0,9917 Floor EUR-05Y EUR 4 5 2% -70,01 0,9918 Floor EUR-05Y EUR 3 5 2% -4,58 0,99
Table 7.23 – Instruments sélectionnés dans l’ordre de LAR (CashFlows bruités)
cipation aux bénéfices lors de l’augmentation des taux d’intérêt– Des calls ainsi que le sous-jacent associé pour représenter l’exposition aux indices actions
Les instruments ont été générés en prenant toutes les combinaisons possibles à partir des ca-ractéristiques du passif que l’on souhaite répliquer (horizon de projection, sous-jacents utiliséspour la projection du passif, etc) et en grillageant notamment les strikes à partir des intervallesdéfinis ci-dessous :
Borne Inf Strike Borne Sup Strike PasZero Coupon
Receiver Swaption 0,05% 4% 0,10%Payer Swaption 0,05% 4% 0,10%Equity Index
Equity Index Call 20% 150% 10%
Table 7.24 – Paramètres Instruments
Un total de 854 instruments ont donc été ainsi générés et vont servir d’inputs à LAR. Lacondition d’arrêt de l’algorithme n’a pas encore été définie. Nous avons effectué des premierstests en mettant une condition d’arrêt sur le nombre d’instruments. Les tests à 50 et 100n’ont pas été concluants.En effet, on peut noter sur la figure ci-dessous que l’ajustement dans la queue de la distributionn’est pas très bonne avec des écarts sur le quantile à 99,5% de 21,1 et 24,8 respectivementpour les portefeuilles de 50 et 100 instruments sélectionnés par LAR.
Nous présentons ici un portefeuille fourni par LAR où 150 instruments ont été sélectionnés.Ce portefeuille fournit de très bons résultats que nous présentons dans les lignes suivantes.
76

Figure 7.26 – Distribution fonds propres Por-tefeuille LAR (50 Ins)
Figure 7.27 – Distribution fonds propres Por-tefeuille LAR (100 Ins)
Figure 7.28 – Qualité d’ajustement du porte-feuille LAR
Figure 7.29 – Distribution fonds propres Por-tefeuille LAR
Aucune contrainte n’a été forcée et la qualité du portefeuille en termes d’ajustement dela distribution est meilleure que tous les portefeuilles obtenus jusque là dans notre mémoire.En effet, on remarque un très bon ajustement de la distribution. En testant LAR avec plusd’instruments on constate une dégradation de la qualité du portefeuille à 250 instruments parexemple. Cela nous suggère qu’il existe un nombre d’instruments optimal qui doit être définià l’aide d’un critère d’arrêt pertinent.
7.3.2 Orthogonal matching pursuit
Le Matching Pursuit et sa variante orthogonale , le Matching Pursuit Orthogonal (OrthogonalMatching Pursuit (OMP)) sont deux méthodes classiques largement utilisées dans différentsdomaines du traitement du signal : approximation, débruitage, problèmes inverses, détections,séparation de sources, etc.Le problème de base où apparaissent ces deux algorithmes est le suivant : On dispose d’unsignal Y et d’un dictionnaire de signaux X=(Xi)0≤i≤p de la taille de Y et on souhaite écrire Ycomme une combinaison linéaire d’éléments Xi de X ou au moins approcher Y par une tellecombinaison linéaire.Le MP propose une approche simple : on estime l’atome Xi0 le plus corrélé à Y, on soustraità Y sa projection sur Xi0 , et on recommence l’opération sur le résidu Y − λXi0 tant qu’unecertaine condition d’arrêt n’est pas respectée. Un des inconvénients de cette méthode résidedans le fait que l’algrithme MP peut sélectionner plusieurs fois le même atome Xi0 . OMP
77

BE DFA RP LAR DifférenceSituation initiale 77,6 77,6 0
Choc taux +100bps -14,3 -14,41 0,09Choc de taux -100bps 19,2 19,75 -0,55Choc action +30% 4,42 4,71 -0,29Choc action -30% -2,39 -3,31 +0,92
Choc combiné +100bps/+30% -17,33 -17,39 0,06Choc combiné -100bps/-30% 16,2 16,06 +0,11
Table 7.25 – Sensibilités Portefeuille LAR
Quantile SdS RP LAR Différence99,5% -35,2 -38,6 3,499% -24,8 -32,4 7,695% -6,9 -13,7 6,890% 1,2 -5,8 7,070% 14,7 10,8 3,950% 22,2 22,1 0,130% 28,1 31,9 -3,810% 35,2 44,2 -9,05% 38,2 49,8 -11,61% 43,2 59,1 -15,90,5% 44,7 62,5 -17,8
Table 7.26 – Ecarts Portefeuille LAR
répond à cette limite en sélectionnant également un à un les atomes Xi , mais la projections’effectue cette fois sur l’ensemble des atomes sélectionnés. Quand Y s’écrit comme une com-binaison linéaire des atomes Xi c’est-à-dire dans un cas non aléatoire, OMP peut convergerassez rapidement vers une erreur nulle.Il convient de rappeler que cette catégorie d’algorithme s’applique à des problèmes sous déter-minés, c’est à dire quand le nombre de signaux est plus important que le nombre d’observations.On se propose dans cette section d’adapter cet algorithme au cas des portefeuilles répliquants.Les signaux élémentaires correspondent dans ce cas aux instruments financiers et le signal àreconstituer est représenté par le vecteur des cashflows. Dans un premier temps nous allonsgénérer un nombre très importants d’instruments financiers qui serviront d’input à OMP etl’algorithme nous permettra de sélectionner les instruments appropriés et d’obtenir les poidsassociés.
Principe de l’algorithme
Soit Γn l’ensemble qui définit les éléments non nuls du vecteur poids des instrumentsfinanciers, c’est à dire que Γn = i : wi 6= 0 où wi est le i élément du vecteur w. L’ensembleΓn va nous permettre de définir la matrice ΦΓn qui est une sous-matrice de la matrice descashs-flows initiaux Φ. De même wΓn va représenter un sous-vecteur de w. Les colonnes de Φsont notées φi, et on suppose que ‖ φi ‖= 1.Avec les notations définies précédemment on peut décrire l’algorithme OMP qui consiste àconstruire itération par itération l’ensemble Γn en rajoutant à chaque étape un nouvel indice.Après une mise à jour de Γn, l’erreur de réplication est évaluée comme suit :
ε ≈ εn ≈ ΦΓnwnΓn = ΦΓnΦ†Γnε (7.24)
78

où Φ†Γn est la pseudo-inverse de Monroe ΦΓn .La pseudo-inverse de Monroe est une façon générique de trouver les ou la solution(s) d’uneéquation linéaire du type :
Ay = b
où b ∈ Rm, y ∈ Rn et A ∈ Rm×n La matrice A† permet de trouver la solution y = A†b etpossède certaines propriétés :
– AA†A = A– A†AA† = A†
– (AA†)T = AA†
– (A†A)T = A†ADans le cadre de l’algorithme OMP, les propriété qui vont nous intéresser sont celles de la
solution y. En effet :– si m=n alors A† = A−1
– si m>n la solution y minimise l’écart des distances :‖ Ay − b ‖
et correspond donc à la solution des moindres carrés.– si m<n, il existe en général une infinité de solutions. La solution y sera celle qui minimisela quantité suivante :
‖ y ‖En effet ΦΓnΦ†Γnε est l’approximation de x en utilisant des combinaisons linéaires des colonnesde ΦΓn . La procédure de sélection des instruments est fortement inspirée de l’algorithme Mat-ching Pursuit présentée dans [5].A chaque itération, OMP calcule une nouvelle approximation du signal xn. L’erreur d’approxi-mation rn = x−xn est alors utilisée à la prochaine itération pour déterminer le nouvel élémentà ajouter. La sélection est basée sur les produits scalaires entre les résidus rn et les vecteursdes colonnes φi de Φ. En effet, on a :
αni = φTi rn (7.25)
Le nouvel élément est celui pour lequel αni est le plus grand :
inmax = argi max |αni | (7.26)
et donc,Γn+1 = Γn ∪ inmax (7.27)
On notera ici la similitude de l’algorithme avec celui du LAR. On peut donc résumer OMPsuivant les étapes suivantes :Etape 1 : r0 = x, z0 = 0, γ0 = Etape 2 : Pour n = 1, · · · , nIns et tant que la condition d’arrêt n’est pas satisfaite :Etape 2.1 : Calcul du vecteur des scalaires αi
αi = φTi rn−1 pour tout i ∈ Γn−1 (7.28)
Etape 2.2 : Détermination du nouvel élément imax à ajouter
imax = argi max |αni | (7.29)
Γn = Γn−1 ∪ inmax (7.30)
79

Etape 2.3 : Mise à jour de QΓn et RΓn tel que QΓnRΓn = ΦΓn , QTΓnQΓn = I et RΓn
est une matrice triangulaire supérieure.Etape 2.4 : Mise à jour du vecteur z : on suppose que q est la nouvelle colonne ajoutée à lamatrice QΓn
zΓn =[zΓn ; qTx
](7.31)
Etape 2.5 : Mise à jour du vecteur rn des erreurs de réplication
rn = rn−1 − qTxq (7.32)
Etape 3 :wΓn = R−1
ΓnzΓn (7.33)
Présentation des résultats OMP
Afin de tester l’efficacité de l’algorithme, nous avons effectué des opérations similaires quecelles effectuées avec l’algorithme LAR c’est-à-dire tester l’algorithme dans les trois situationssuivantes :
– Etape de réplication parfaite– Etape de sur-réplication– Etape de sous-réplicationRéplication parfaite
Ici on propose en entrée de l’algorithme les instruments financiers qui ont servi à la compositionde l’indice. OMP retrouve bien les poids initiaux de chacun des instruments en les sélectionnantdans l’ordre suivant :
Etape Instrument Base Index Curr Term1 Term2 Strike Poids Trouvé R2
1 Zero Coupon EUR 3 12248 43,15%2 Zero Coupon EUR 16 11825 94,35%3 Zero Coupon EUR 6 48664 99,61%4 Receiver Swaption EUR-05Y EUR 20 5 2, 10% 4041 99,81%5 Equity Index Call EUR-Eq EUR 1 130% 791 99,84%6 Cap EUR-05Y EUR 10 5 5% 11812 99,98%7 Zero Coupon EUR 13 3327 99,99%8 Floor EUR-05Y EUR 7 5 2% 1254 99,99%9 Payer Swaption EUR-05Y EUR 1 5 3, 75% 1793 99,99%10 Zero Coupon EUR 5 3934 100%
Table 7.27 – Instruments sélectionnés dans l’ordre de OMP
Sur RéplicationNous avons montré qu’on pouvait répliquer de manière exacte un indice créé à partir d’unnombre donné d’instruments financiers par ces mêmes instuments financiers. Nous allons àprésent tester l’efficacité de OMP en mettant en entrée de l’algorithme non seulement lesinstruments financiers ayant servi à la composition de l’indice mais également des instrumentsfinanciers parasites. L’efficacité de l’algorithme se mesurera au nombre d’instruments financiersparasites ayant été sélectionnés qui devra être très bas. Même si ces instruments étaientsélectionnés une qualité appréciable de l’algorithme serait de trouver des poids nuls pour cesinstruments.On rajoute aux instruments candidats des instruments parasites (qui ne composent pas l’indicede départ) qui sont ici des Floor de différentes caractéristiques. On retrouve ci-dessous lesinstruments sélectionnés par OMP dans l’ordre :
80

Etape Instrument Base Index Curr Term1 Term2 Strike Poids Trouvé R2
1 Zero Coupon EUR 3 12248 43,15%2 Zero Coupon EUR 16 11825 94,35%3 Zero Coupon EUR 6 48664 99,61%4 Receiver Swaption EUR-05Y EUR 20 5 2, 10% 4041 99,81%5 Equity Index Call EUR-Eq EUR 1 130% 791 99,84%6 Cap EUR-05Y EUR 10 5 5% 11812 99,98%7 Zero Coupon EUR 13 3327 99,99%8 Floor EUR-05Y EUR 7 5 2% 1254 99,99%9 Payer Swaption EUR-05Y EUR 1 5 3, 75% 1793 99,99%10 Zero Coupon EUR 5 3934 100%11 Floor EUR-05Y EUR 13 5 2% 0 100%12 Floor EUR-05Y EUR 2 5 3% 0 100%13 Floor EUR-05Y EUR 4 5 3% 0 100%14 Floor EUR-05Y EUR 4 5 2% 0 100%15 Floor EUR-05Y EUR 15 5 2% 0 100%16 Floor EUR-05Y EUR 1 5 2% 0 100%17 Floor EUR-05Y EUR 10 5 2% 0 100%18 Floor EUR-05Y EUR 3 5 2% 0 100%
Table 7.28 – Instruments sélectionnés dans l’ordre de OMP
On peut constater au vu de ces résultats que OMP sélectionne assez bien les instrumentstant qu’on n’a pas atteint une réplication parfaite en termes de R2, mais par contre les ins-truments financiers n’appartenant pas à l’indice de départ même s’ils sont sélectionnés avantd’atteindre un coefficient R2 de 1 ont de toute façon un poids de 0 dans le portefeuille calibré.En outre, comparé à LAR, l’OMP sélectionne mieux les instruments financiers. En effet, lestests effectués avec un nombre plus important d’instruments financiers nous montrent que lesdix premiers instruments sélectionnés par OMP sont toujours ceux qui composent l’indice dedépart contrairement à LAR qui ne sélectionne pas toujours les dix instruments financiers debase au bout des dix premières itérations de l’algorithme.
Sous RéplicationLes deux précedentes étapes de réplication parfaite et de surréplication ont permis de validerl’efficacité de OMP dans un univers parfait. Dans la suite, nous allons nous placer dans ununivers non parfait dans le sens où l’indice cible ( dans la pratique les cashflows de passif d’unassureur) n’est plus une combinaison linéaire parfaite des instruments servant à la réplication.Pour ce faire on a créé des indices de cashflow bruités avec lesquels nous avons testé OMP(comme précédemment avec LAR) :
Le bruitage a été réalisé à l’aide d’une loi normale centrée de variance 10. On remarqueque malgré le bruitage, OMP sélectionne d’abord les instruments ayant servi à créer l’indiceavant les instruments parasites. Seul le calibrage des poids est différent. L’analyse des poidsfinaux sur plusieurs calibrations ( avec des variances plus importantes de la loi normale ayantservi à bruiter les casflows) montre des résultats légèrement différents en termes de poids desinstruments financiers de base ayant servi à la composition de l’indice. Plus la variance dela variable ayant servi à bruiter les cashflows est élevée, plus on remarque une déviation despoids finaux par rapport aux poids initiaux ayant servi à la création de l’indice.OMP a été testé avec la même liste d’instruments que celle utilisée pour LAR. Nous avonstesté l’algorithme comme avec LAR pour une sélection de 50 puis de 100 instruments. Lesrésultats sont les mêmes au niveau de l’estimation de la VaR à 99,5% avec des écarts assez
81
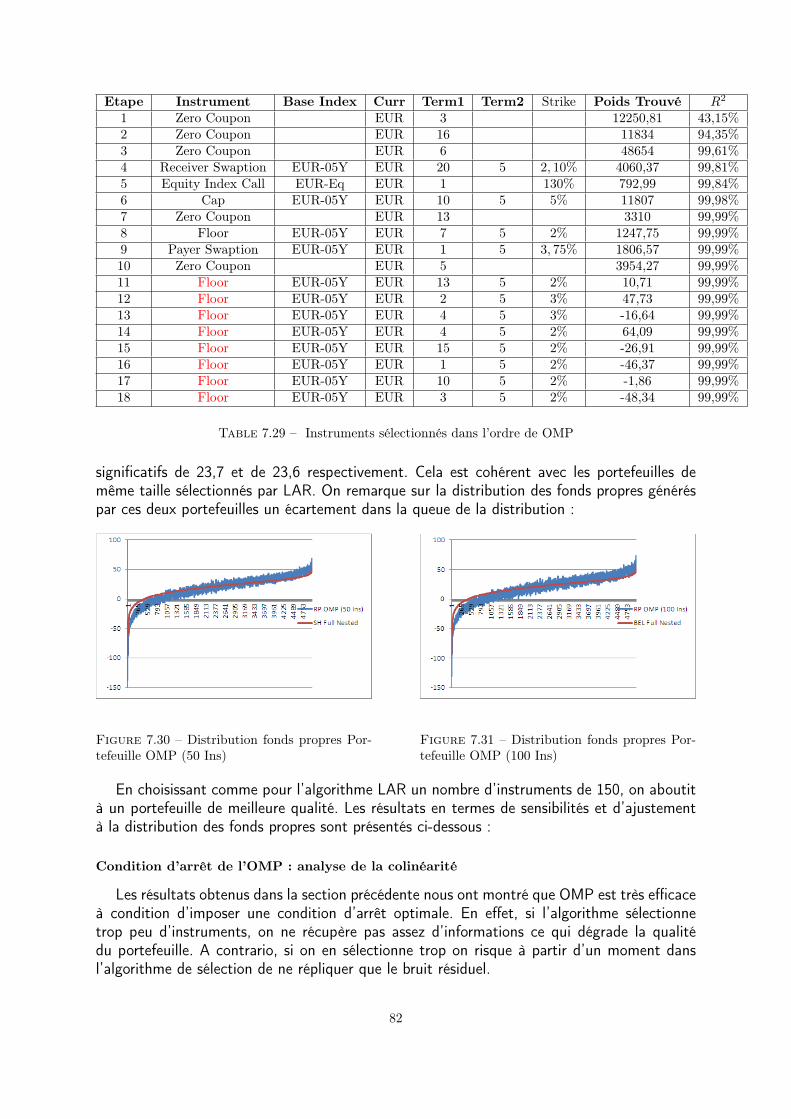
Etape Instrument Base Index Curr Term1 Term2 Strike Poids Trouvé R2
1 Zero Coupon EUR 3 12250,81 43,15%2 Zero Coupon EUR 16 11834 94,35%3 Zero Coupon EUR 6 48654 99,61%4 Receiver Swaption EUR-05Y EUR 20 5 2, 10% 4060,37 99,81%5 Equity Index Call EUR-Eq EUR 1 130% 792,99 99,84%6 Cap EUR-05Y EUR 10 5 5% 11807 99,98%7 Zero Coupon EUR 13 3310 99,99%8 Floor EUR-05Y EUR 7 5 2% 1247,75 99,99%9 Payer Swaption EUR-05Y EUR 1 5 3, 75% 1806,57 99,99%10 Zero Coupon EUR 5 3954,27 99,99%11 Floor EUR-05Y EUR 13 5 2% 10,71 99,99%12 Floor EUR-05Y EUR 2 5 3% 47,73 99,99%13 Floor EUR-05Y EUR 4 5 3% -16,64 99,99%14 Floor EUR-05Y EUR 4 5 2% 64,09 99,99%15 Floor EUR-05Y EUR 15 5 2% -26,91 99,99%16 Floor EUR-05Y EUR 1 5 2% -46,37 99,99%17 Floor EUR-05Y EUR 10 5 2% -1,86 99,99%18 Floor EUR-05Y EUR 3 5 2% -48,34 99,99%
Table 7.29 – Instruments sélectionnés dans l’ordre de OMP
significatifs de 23,7 et de 23,6 respectivement. Cela est cohérent avec les portefeuilles demême taille sélectionnés par LAR. On remarque sur la distribution des fonds propres généréspar ces deux portefeuilles un écartement dans la queue de la distribution :
Figure 7.30 – Distribution fonds propres Por-tefeuille OMP (50 Ins)
Figure 7.31 – Distribution fonds propres Por-tefeuille OMP (100 Ins)
En choisissant comme pour l’algorithme LAR un nombre d’instruments de 150, on aboutità un portefeuille de meilleure qualité. Les résultats en termes de sensibilités et d’ajustementà la distribution des fonds propres sont présentés ci-dessous :
Condition d’arrêt de l’OMP : analyse de la colinéarité
Les résultats obtenus dans la section précédente nous ont montré que OMP est très efficaceà condition d’imposer une condition d’arrêt optimale. En effet, si l’algorithme sélectionnetrop peu d’instruments, on ne récupère pas assez d’informations ce qui dégrade la qualitédu portefeuille. A contrario, si on en sélectionne trop on risque à partir d’un moment dansl’algorithme de sélection de ne répliquer que le bruit résiduel.
82

Figure 7.32 – Qualité d’ajustement du porte-feuille OMP
Figure 7.33 – Distribution fonds propres Por-tefeuille OMP
BE DFA RP OMP DifférenceSituation initiale 77,6 77,6 0
Choc taux +100bps -14,3 -14,47 0,14Choc de taux -100bps 19,2 21,02 -1,8Choc action +30% 4,42 4,58 -0,16Choc action -30% -2,39 -3,41 +1,02
Choc combiné +100bps/+30% -17,33 -17,52 0,19Choc combiné -100bps/-30% 16,2 17,22 -1,04
Table 7.30 – Sensibilités Portefeuille OMP
L’analyse des itérations des différents algorithmes montre une forte colinéarité des nouveauxinstruments ajoutés par rapport à ceux déjà sélectionnés. L’idée de la condition d’arrêt qui aété développée est justement d’arrêter l’algorithme dès qu’on atteint un niveau trop importantde colinéarité. Nous allons définir dans la suite ce qu’on entend par là.Sur le plan statistique auquel on se limite ici, l’existence d’une colinéarité approximative,appelée colinéarité statistique, peut pertuber les estimations des poids de nos instruments.Plusieurs conséquences peuvent découler d’une telle colinéarité statistique :
– les coefficients de régression peuvent être élevés en valeur absolue– les signes peuvent être contraires à l’intuition, ce qui peut être assez problématique dansle cadre de l’usage qu’on fait des portefeuilles répliquants
– les variances des estimateurs peuvent être élevéesLa colinéarité statistique crée donc des difficultés importantes dans l’interprétation des ré-
sultats. Il convient donc de pouvoir mesurer cette colinéarité statistique. Une première mesurede cette colinéarité statistique est le facteur d’inflation fj défini par :
fj = 11−R2
j
où R2j est le coefficient de corrélation multiple obtenu en effectuant la régression d’une variable
Xj par le reste des variables explicatives. Le facteur d’inflation fj est donc d’autant plus grandque la la variable Xj est corrélée à une combinaison linéaire des autres variables explicatives.Cependant la difficulté majeure pour l’utilisation de cette mesure est de déterminer le seuil àpartir duquel on estime que cet indicateur est élevé ou pas.Le coefficient de corrélation multiple peut toutefois permettre de définir un critère d’arrêt.En effet, ce critère serait basé sur le calcul à chaque étape de l’algorithme du coefficient decorrélation multiple du nouvel instrument financier par rapport aux instruments déjà choisis àchaque itération de l’OMP.
83

Quantile SdS RP OMP Différence99,5% -35,2 -31,5 -3,799% -24,8 -28,2 3,495% -6,9 -15,9 9,090% 1,2 -9,1 10,370% 14,7 8,6 6,050% 22,2 22,2 030% 28,1 33,6 -5,510% 35,2 46,8 -11,65% 38,2 51,6 -13,41% 43,2 59,4 -16,20,5% 44,7 61,5 -16,8
Table 7.31 – Ecarts Portefeuille OMP
L’algorithme OMP peut donc être modifié de la façon suivante afin d’introduire un critèred’arrêt lié à la colinéraité des instruments choisis avec comme indicateur de la colinéarité lecoefficient de corrélation multiple :
– à chaque ajout d’un nouvel instrument, on effectue une régression des CashFLows dunouvel instrument par rapport aux instruments déjà choisis
– Un seuil de x% sur le R2 de cette régression (équivalent au coefficient de corrélationmultiple) permet de définir si le nouvel instrument est colinéaire aux instruments déjàsélectionnés. Les instruments ayant été identifiés comme colinéaires ne seront pas prisen compte dans la liste finale des instruments sélectionnés
– L’algorithme s’arrête si à partir d’un moment il sélectionne un nombre NbN d’instrumentscolinéaires à la suite
Plusieurs combinaisons ont été testées pour le couple (x,NbN), et les résultats démontrent unebonne estimation de la VaR à 99,5% et plus généralement un bon ajustement à la distributiondes fonds propres pour le couple (99%,5). Toutefois on peut constater que la définition d’uncritère d’arrêt s’avère très difficile car les paramètres (x, NbN) qu’on a défini ici pourraient nepas être concluants pour d’autre type de portefeuilles. L’algorithme OMP doit donc être utiliséavec précaution et necéssite de la part de l’utilisateur une bonne connaissance du portefeuille.
Pour compléter cette analyse de la colinéarité statistique nous allons nous inspirer de [4] quipropose deux principaux outils d’analyse et de détection de la colinéarité. Le premier consisteà utiliser la décomposition SVD de la matrice X, et le second consiste en la décomposition dela variance des coefficients estimés grâce notamment à la décomposition SVD.
La décomposition SVD
Toute matrice X ∈ M(n, p) de n observations et de p variables peut être décomposéecomme suit :
X = UDV T
où UTU = V TV = Ip, et D est la matrice diagonale dont les éléments tous positifs µk, k =1, · · · , p, sont appelés valeurs singulières de X. Pour les besoins de l’analyse de la colinéarité,on suppose que la matrice X est réduite. Les auteurs démontrent que les très petites de valeursµk, indiquent une dépendance de cette varable par rapport à une autre. Le degré de cette
84

Valeur singulière Proportions deV ar(b1) V ar(b2) · · · V ar(bp)
µ1 π11 π12 · · · π1pµ2 π21 π22 · · · π2p...
......
......
µp πp1 πp2 · · · πpp
Table 7.32 – Décomposition de la variance
dépendance sera donc déterminé par rapport à la valeur maximale µmax. On définit donc :
ηk =µmaxµk
(7.34)
Les résultats dans [4] indiquent que les faibles dépendances correspondent à des valeurs de ηkentre 0 et 10, quand les dépendances moyennes et fortes correspondent à des valeurs de ηkentre 30 et 100.
La décomposition de la variance des coefficients de régression
Comme on a vu précédemment, une valeur singulière trop petite par rapport à la valeur sin-gulière maximum indique une certaine dépendance. Dans cette partie on se propose d’établirà quel point cette dépendance influe sur l’estimation des poids des instruments dans l’hy-pothèse où ces poids ont été estimés selon la méthode des moindres carrés. Cela est le caspour l’algoritme OMP dans le sens où la solution finale (une fois les instruments candidatschoisis) est la solution des MCO. Cette décomposition peut être considérée comme un bonoutil d’analyse de la qualité de l’estimation des poids.La matrice de variance-covariance de l’estimateur des moindres carrés b = (XTX)−1XT estσ2(XTX)−1, où σ2 est la variance de l’erreur ε du modèle y = Xβ + ε. En utilisant ladécomposition SVD, X = UDV T , la matrice de variance-covariance s’écrit donc :
V (b) = σ2(XTX)−1 = σ2V D−2V T (7.35)
où la part de la variance due à la composant k est :
var(bk) = σ2∑j
v2kj
µ2j
(7.36)
avec V ≡ (vij).L’équation précédente décompose la variance de l’estimateur bk en une somme de com-
posantes associées chacune à une valeur singulière µj. On peut donc décomposer la variancetotale de l’estimateur bk en définissant pour chaque valeur singulière une proportion qui cor-respond à sa contribution à la variance totale de l’estimateur. On définit donc les coefficientsde décomposition de la variance comme suit :
πjk ≡φkjφk, k, j = 1, · · · , p (7.37)
où φkj ≡v2kjµ2j
et φk ≡∑p
j=1 φkj, k = 1, · · · , pCette décomposition de la variance est mieux résumée dans le tableau suivant : Ce tableau
peut être un outil complémentaire à l’analyse de la qualité d’un portefeuille et permet ainsi de
85
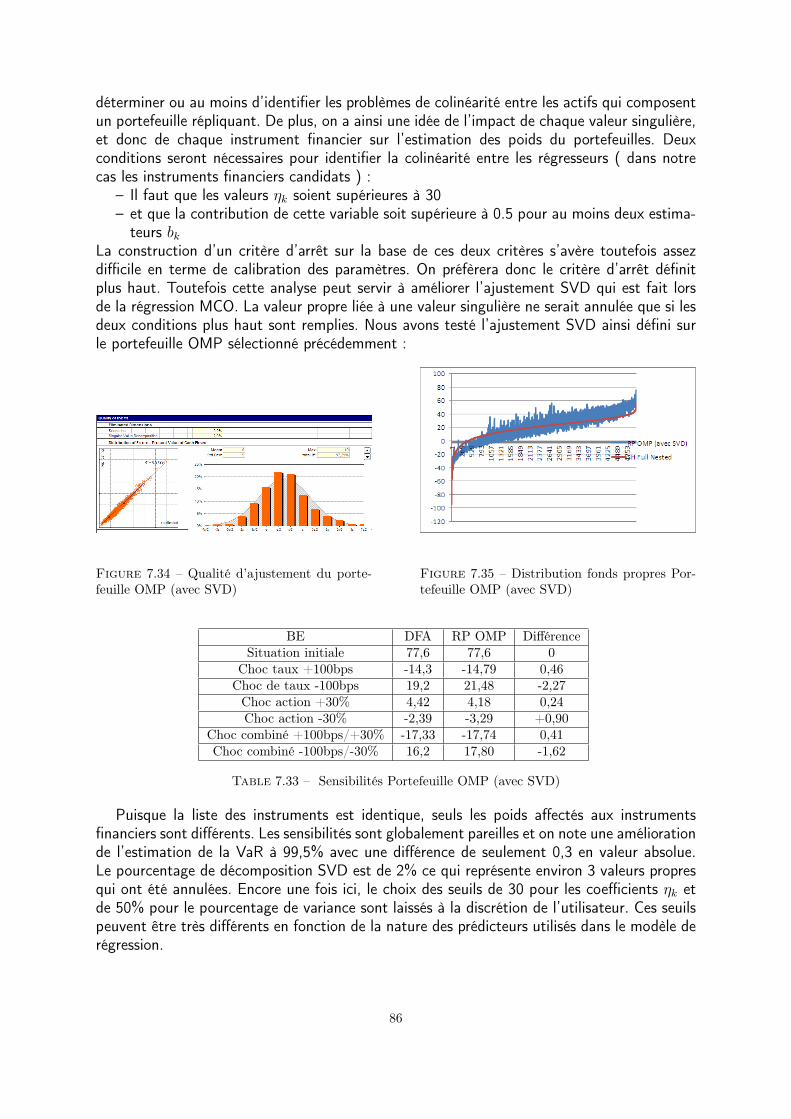
déterminer ou au moins d’identifier les problèmes de colinéarité entre les actifs qui composentun portefeuille répliquant. De plus, on a ainsi une idée de l’impact de chaque valeur singulière,et donc de chaque instrument financier sur l’estimation des poids du portefeuilles. Deuxconditions seront nécessaires pour identifier la colinéarité entre les régresseurs ( dans notrecas les instruments financiers candidats ) :
– Il faut que les valeurs ηk soient supérieures à 30– et que la contribution de cette variable soit supérieure à 0.5 pour au moins deux estima-teurs bk
La construction d’un critère d’arrêt sur la base de ces deux critères s’avère toutefois assezdifficile en terme de calibration des paramètres. On préfèrera donc le critère d’arrêt définitplus haut. Toutefois cette analyse peut servir à améliorer l’ajustement SVD qui est fait lorsde la régression MCO. La valeur propre liée à une valeur singulière ne serait annulée que si lesdeux conditions plus haut sont remplies. Nous avons testé l’ajustement SVD ainsi défini surle portefeuille OMP sélectionné précédemment :
Figure 7.34 – Qualité d’ajustement du porte-feuille OMP (avec SVD)
Figure 7.35 – Distribution fonds propres Por-tefeuille OMP (avec SVD)
BE DFA RP OMP DifférenceSituation initiale 77,6 77,6 0
Choc taux +100bps -14,3 -14,79 0,46Choc de taux -100bps 19,2 21,48 -2,27Choc action +30% 4,42 4,18 0,24Choc action -30% -2,39 -3,29 +0,90
Choc combiné +100bps/+30% -17,33 -17,74 0,41Choc combiné -100bps/-30% 16,2 17,80 -1,62
Table 7.33 – Sensibilités Portefeuille OMP (avec SVD)
Puisque la liste des instruments est identique, seuls les poids affectés aux instrumentsfinanciers sont différents. Les sensibilités sont globalement pareilles et on note une améliorationde l’estimation de la VaR à 99,5% avec une différence de seulement 0,3 en valeur absolue.Le pourcentage de décomposition SVD est de 2% ce qui représente environ 3 valeurs propresqui ont été annulées. Encore une fois ici, le choix des seuils de 30 pour les coefficients ηk etde 50% pour le pourcentage de variance sont laissés à la discrétion de l’utilisateur. Ces seuilspeuvent être très différents en fonction de la nature des prédicteurs utilisés dans le modèle derégression.
86

Quantile SdS RP OMP Différence99,5% -35,2 -34,8 -0,399% -24,8 -31,0 6,295% -6,9 -17,9 11,090% 1,2 -10,3 11,570% 14,7 8,0 6,750% 22,2 22,3 -0,130% 28,1 34,1 -6,010% 35,2 47,5 -12,35% 38,2 52,2 -14,01% 43,2 59,4 -16,30,5% 44,7 61,4 -16,7
Table 7.34 – Ecarts Portefeuille OMP (avec SVD)
7.3.3 Conclusion
Pour conclure avec cette partie, on voit que les indicateurs de qualité sont assez bons pourles deux portefeuilles sélectionnés par OMP et LAR. En effet, les coefficients R2 sont trèsbons, et les différentes sensibilités sont également très bonnes.Cependant, le résultat nous fournit des informations très intéressantes au niveau des élémentssélectionnés.
– D’abord, on a tout les zéro coupons qui servent à répliquer le taux garanti.– Ensuite, les deux algorithmes de sélection choisissent des calls dans la monnaie ( ayantun strike entre 50% et 100%). Le choix des calls dans la monnaie correspond à nosattentes car on veut des instruments permettant à la fois une protection contre unebaisse importante des indices boursiers et une sensibilité assez linéaire au mouvementdes actions en cas de hausse.
– En ce qui concerne les swaptions, les deux algorithmes ont sélectionné des instrumentsqui nous permettent de fixer l’exposition au taux d’intérêt.– Dans le cas d’une baisse des taux, l’assuré va avoir la possiblité d’investir dans soncontrat d’assurance vie en maintenant son taux garanti élevé. Il bénéficie de la baissedes taux, ceci est reflété par les receiver swaptions.
– Dans le cas d’une hausse de taux au dessus de 1%, nous pouvons utiliser des payerswaption pour pouvoir répliquer la participation aux bénéfices de l’assuré.
Donc, on constate que LAR et OMP choisissent exactement les instruments financiers dontle strike correspond à ce que l’on attend avec notamment des receiver swaption de strike baset des payer swaption de strike élevé.Il apparait ainsi, à la suite de ce travail, qu’il est possible d’utiliser une sélection itérative parl’algorithme LAR ou OMP pour construire un portefeuille répliquant satisfaisant les critères dequalité. De ce point de vue, nous pouvons envisager une amélioration au niveau des procéduresde construction des portefeuilles répliquants.Par ailleurs, les deux algorithmes reposent quasiment sur la corrélation des instruments avec lepassif : on peut très bien avoir des instruments financiers très corrélés au passif mais qui n’ontpas d’explications cohérentes. Il est donc indispensable de s’appuyer sur les connaissances del’utilisateur pour sélectionner les instruments financiers convenables.En outre, les algorithmes tels que LAR et OMP possèdent une autre limite liée au critèrede sélection basée sur la corrélation : comme l’algorithme fait la sélection sur un critèrecorrélation, il n’est pas évident que les sensibilités soient bien répliquées. Alors, il reste àtrouver un moyen pour tenir compte des contraintes, au moins des contraintes linéaires, dans
87

la procédure de sélection de l’algorithme.
88

Conclusion
Suite au développement du nouveau cadre réglementaire Solvabilité II, les techniques deréplication de portefeuilles connaissent un véritable essor en assurance vie.
En effet, ces techniques permettent de traduire dans un même langage les actifs et les passifsdu bilan d’un assureur, ainsi que leurs risques. Ces techniques de réplication, relativementcomplexes, font l’appel à l’expertise et à la connaissance des engagements de l’assureur. Laméthode de sélection des instruments financier développée dans ce mémoire, basée sur lesalgoritmes Least Angle Regression et Orthogonal Matching Pursuit peut se révéler être uneaide précieuse de la réplication. Elle permet d’identifier en amont les instruments financierssimples qui permettent d’obtenir un bon portefeuille répliquant. De ce fait, elle accélère sen-siblement le processus de réplication de portefeuille. De plus la méthode étant itérative, il estpossible pour l’utilisateur de sélectionner dès le départ un très grand nombre d’instruments,200 sur 1000 par exemple et pour calibrer le portefeuille de n’utiliser que les 50 premiers ou100 premiers. Cela permet de ne pas perdre du temps à relancer l’algorithme plusieurs fois. Ilfaut noter toutefois certaines limites à cette méthodologie notamment sur la liste des instru-ments. Il faut rappeller que le jugement de l’utilisateur sera toujours nécessaire pour analyserles sorties de l’algorithme et ajuster éventuellement les résultats obtenus.
Néanmoins, il est important de noter que ces techniques (LAR et OMP) doivent être utiliséesavec précaution et les résultats finaux doivent s’appuyer non seulement sur ces techniquesmais aussi sur la connaissance et l’expertise de l’utilisateur.On s’est également intéressé dans ce mémoire à la calibration des portefeuilles à proprementparler. Les deux méthodologies qui ont été testées (régression PLS et CashFlow mismatch)nous ont permis de pallier à certains aspects qui pouvaient rendre la régression classique desmoindres carrés pas assez robuste.
On a vu que la régression PLS était efficace pour traiter la colinéarité. On a pu vérifiercela en constatant que les résultats en termes de sensibilité et d’ajustement à la distributiondes fonds propres sont plutôt équivalents à la méthode classique avec ajustement des valeurspropres via la décomposition SVD. En outre, la régression par minimisation des écarts de ca-shflows par scénarios nous a fournis de très bons résultats et permet notamment à l’utilsateurune meilleure compréhension du processus de calibration en lui permettant de choisir des seuilsde tolérance pour contrôler l’erreur de régression. Cette méthode de calibration permet parailleurs de valider la liste des actifs candidats fournis en entrée.
Enfin, le travail de comparaison qui a été fait dans l’estimation de la VaR à 99,5% parrapport à une VaR SdS calculée avec un modèle ALM simplifié nous a permis d’évaluer l’ef-ficacité de ces différentes méthodes. Cependant, dans la réalité ce type de comparaison n’est
89

pas possible. Une suite au travail qui a été réalisé dans ce mémoire pourrait donc être deréfléchir à l’estimation de l’erreur que l’on commet dans le calcul du SCR lorsqu’on utilisecomme proxy de passif les portefeuilles répliquants, et plus généralement les deux autres proxyque sont le curve fitting et le Least Square Monte Carlo.
En effet pour chacun de ces proxy on est confronté à deux principales erreurs :– la première concerne l’hypothèse de "complétude" selon laquelle la valeur de marchédes passifs peut être exprimée comme une combinaison linéaire des fonctions de basechoisies lors de la régression. Cette erreur pourrait être qualifiée d’erreur d’incomplétudecar dans la pratique une telle combinaison linéaire n’existe pas. En principe, l’erreurd’incomplétude peut être définie comme un ajustement théorique construit à partir desfonctions de base moins la valeur de marché du passif calculé via le proxy.
– La deuxière erreur est un type d’erreur plus classique dans le cadre de simulations etconcerne les simulations. Cette erreur qu’on pourrait qualifier d’erreur d’échantillonnagese produit parce que l’estimation des coefficients du portefeuille répliquant ( et plusgénéralement les coefficients de régression qui sont calculés dans le cas du Curve Fittingou du Least Square Monte Carlo) sont effectués à l’aide de simulations de Monte Carlo.Cela introduit de l’incertitude pour les résultats. L’erreur d’échantillonnage peut êtredéfinie comme la différence entre l’estimation théorique du meilleur ajustement à partirdes instruments de base et l’ajustement estimé en utilisant un nombre fini de scénarios.
Une suite logique aux travaux qui ont été présentés dans ce mémoire serait de mesurer cesdeux types d’erreurs et d’évaluer l’impact qu’elles ont sur l’estimation du capital économique.
90

Annexe
Composition des portefeuilles et poids associés
91

Idx
Instrument
BaseIndex
Curr
Term1
Term2
Strike
OLS
OLSMarge
PLS
RP
A1
RP
A2
RP
A1(avecCvar)
1Ze
roCou
pon
EUR
1-10,69
98,03
-2,91
-27,28
0-25,09
2Ze
roCou
pon
EUR
3-0,66
-8,5
-14,09
00
03
ZeroCou
pon
EUR
5-5,26
-11,37
-14,4
0-41,31
04
ZeroCou
pon
EUR
7-9,98
-5,4
-5,56
-17,77
00
5Ze
roCou
pon
EUR
10-13,75
2,95
2,67
00
1,85
6Ze
roCou
pon
EUR
139,86
-23,5
8,63
054,09
07
ZeroCou
pon
EUR
1518,72
-41,45
24,36
00
08
ZeroCou
pon
EUR
1752,11
-22,31
50,06
164,16
00
9Ze
roCou
pon
EUR
2066,38
19,87
55,6
0107,51
187,94
10Ze
roCou
pon
EUR
2335,13
16,75
36,09
00
011
ZeroCou
pon
EUR
258,93
-16,02
10,48
35,93
28,04
-12,13
12ReceiverSw
aption
EUR-05Y
EUR
15
0,021
15,42
-47,15
6,54
00
013
ReceiverSw
aption
EUR-05Y
EUR
45
0,021
33,54
-17,61
36,72
029,01
014
ReceiverSw
aption
EUR-05Y
EUR
75
0,021
68,38
-60,31
59,98
063,72
015
ReceiverSw
aption
EUR-05Y
EUR
105
0,021
47,01
0,95
41,71
040,16
016
ReceiverSw
aption
EUR-05Y
EUR
135
0,021
38,18
-15,99
32,97
055,78
107,67
17ReceiverSw
aption
EUR-05Y
EUR
155
0,021
2,77
-8,99
12,51
78,47
00
18ReceiverSw
aption
EUR-05Y
EUR
205
0,021
28,92
-20,19
36,61
030,59
019
Payer
Swap
tion
EUR-05Y
EUR
15
0,0375
40,14
61,03
13,68
00
020
Payer
Swap
tion
EUR-05Y
EUR
45
0,0375
12,13
-18,09
21,33
00
021
Payer
Swap
tion
EUR-05Y
EUR
75
0,0375
-18,05
-4,32
-3,85
00
022
Payer
Swap
tion
EUR-05Y
EUR
105
0,0375
-22,28
-29
-12,87
00
023
Payer
Swap
tion
EUR-05Y
EUR
135
0,0375
21,4
-36,94
15,33
00
024
Payer
Swap
tion
EUR-05Y
EUR
155
0,0375
7,75
5,06
1,39
00
025
Payer
Swap
tion
EUR-05Y
EUR
205
0,038
31,4
10,93
22,48
00
026
Equ
ityInd
exCall
EUR-E
qEUR
11,08
-0,09
-3,75
0,22
-2,99
1,26
0,75
27Equ
ityInd
exCall
EUR-E
qEUR
31,08
-1,44
-2,32
-1,59
-2,85
-1,74
0,32
28Equ
ityInd
exCall
EUR-E
qEUR
51,08
1,84
1,09
1,84
21,56
0,29
29Equ
ityInd
exCall
EUR-E
qEUR
71,08
0,9
0,08
0,88
2,18
1,71
0,06
30Equ
ityInd
exCall
EUR-E
qEUR
101,08
3,12
2,24
3,08
2,74
3,01
2,65
31Equ
ityInd
exCall
EUR-E
qEUR
131,08
0,77
0,85
0,81
1,38
2,06
3,44
32Equ
ityInd
exCall
EUR-E
qEUR
151,08
4,56
2,62
4,58
3,53
2,94
2,06
33Equ
ityInd
exCall
EUR-E
qEUR
171,08
0,01
0,13
-0,07
1,4
23,31
34Equ
ityInd
exCall
EUR-E
qEUR
201,08
2,86
2,5
2,87
3,1
0,75
2,96
35Equ
ityInd
exCall
EUR-E
qEUR
221,08
-1,06
-0,95
-1,05
0,43
1,37
-1,57
36Equ
ityInd
exPut
EUR-E
qEUR
10,75
18,91
2,86
20,45
022,81
037
Equ
ityInd
exPut
EUR-E
qEUR
30,75
15,29
13,51
14,34
18,16
10,79
21,08
38Equ
ityInd
exPut
EUR-E
qEUR
50,75
0,57
-2,52
0,79
04,38
039
Equ
ityInd
exPut
EUR-E
qEUR
70,75
-7,69
4,36
-8,01
-3,65
-8,39
-5,54
40Equ
ityInd
exPut
EUR-E
qEUR
100,75
-5,8
-14,82
-6,43
3,58
-4,34
1,07
41Equ
ityInd
exPut
EUR-E
qEUR
130,75
-10,18
-10,71
-9,42
0-10,99
042
Equ
ityInd
exPut
EUR-E
qEUR
150,75
-18,52
-10,15
-17,82
-31,29
-11,13
-34,82
43Equ
ityInd
exPut
EUR-E
qEUR
170,75
-0,27
-23,75
0,65
-19,85
-5,46
044
Equ
ityInd
exPut
EUR-E
qEUR
200,75
-26,99
-26,3
-26,95
0-26,2
-27,75
45Equ
ityInd
exPut
EUR-E
qEUR
220,75
-7,16
-25,93
-9,01
-15,01
-7,32
0
Tabl
e7.35
–Com
position
etPoids
dupo
rtefeuilleA
92

Idx
Instrument
BaseIndex
Curr
Term1
Term2
Strike
OLS
OLSMarge
PLS
PLSMarge
1Ze
roCou
pon
EUR
1-17,52
43,76
-0,77
28,79
2Ze
roCou
pon
EUR
3-13,22
26,48
-123,23
16,9
3Ze
roCou
pon
EUR
5-6,95
8,73
77,5
13,22
4Ze
roCou
pon
EUR
70,25
-2,6
4,56
-11,03
5Ze
roCou
pon
EUR
1011,41
-13,09
-4,15
-22,87
6Ze
roCou
pon
EUR
1321,33
-16,24
16,47
-10,21
7Ze
roCou
pon
EUR
1526,58
-14,84
16,46
0,14
8Ze
roCou
pon
EUR
1730,61
-11,16
49,5
8,46
9Ze
roCou
pon
EUR
2034,32
-5,58
85,92
20,02
10Ze
roCou
pon
EUR
2335,8
-2,6
74,12
8,73
11Ze
roCou
pon
EUR
2535,85
-4,2
-34,04
-28,39
12ReceiverSw
aption
EUR-05Y
EUR
45
0,023
3,97
-15,8
-42,05
-77,97
13ReceiverSw
aption
EUR-05Y
EUR
75
0,023
5,86
-27,9
2,85
-98,11
14ReceiverSw
aption
EUR-05Y
EUR
105
0,023
6,46
-36,74
12,81
-85,08
15ReceiverSw
aption
EUR-05Y
EUR
135
0,023
5,95
-41,94
9,24
-55,6
16ReceiverSw
aption
EUR-05Y
EUR
155
0,023
5,09
-42,16
-6,8
-44,43
17ReceiverSw
aption
EUR-05Y
EUR
205
0,023
2,38
-39,73
27,13
-25,27
18Payer
Swap
tion
EUR-05Y
EUR
45
0,05
-1,16
0,24
121,71
14,99
19Payer
Swap
tion
EUR-05Y
EUR
75
0,05
-2,93
-4,34
59,94
21,65
20Payer
Swap
tion
EUR-05Y
EUR
105
0,05
-4,13
-10,47
27,19
23,21
21Payer
Swap
tion
EUR-05Y
EUR
135
0,05
-4,5
-16,28
18,34
28,04
22Payer
Swap
tion
EUR-05Y
EUR
155
0,05
-4,23
-18,63
41,8
34,7
23Payer
Swap
tion
EUR-05Y
EUR
205
0,05
-2,88
-18,94
77,1
46,31
24Equ
ityInd
exCall
EUR-E
qEUR
71,2
1,5
-1,06
1,7
-1,1
25Equ
ityInd
exCall
EUR-E
qEUR
101,2
2,44
1,37
2,48
1,43
26Equ
ityInd
exCall
EUR-E
qEUR
131,2
1,98
1,41
2,05
1,42
27Equ
ityInd
exCall
EUR-E
qEUR
151,2
1,33
1,01
1,33
1,03
28Equ
ityInd
exCall
EUR-E
qEUR
171,2
1,97
1,66
1,98
1,59
29Equ
ityInd
exCall
EUR-E
qEUR
201,2
0,94
0,92
0,97
130
Equ
ityInd
exCall
EUR-E
qEUR
221,2
1,73
1,85
1,59
1,83
31Equ
ityInd
exPut
EUR-E
qEUR
50,68
-7,42
10,49
14,2
8,83
32Equ
ityInd
exPut
EUR-E
qEUR
70,68
-7,77
-6,79
-3,57
-9,07
33Equ
ityInd
exPut
EUR-E
qEUR
100,68
-7,22
-13,16
-16,51
-12,92
34Equ
ityInd
exPut
EUR-E
qEUR
130,68
-6,5
-14,49
-14,94
-12,95
35Equ
ityInd
exPut
EUR-E
qEUR
150,68
-6,54
-15,36
-12,94
-8,85
36Equ
ityInd
exPut
EUR-E
qEUR
170,68
-7,04
-16,79
-14,31
-18,23
37Equ
ityInd
exPut
EUR-E
qEUR
200,68
-8,85
-20,6
-11,41
-21,36
38Equ
ityInd
exPut
EUR-E
qEUR
220,68
-10
-17,87
-10,68
-23,49
39Equ
ityInd
exPut
EUR-E
qEUR
250,68
-11,32
-14,6
3,4
-12,04
Tabl
e7.36
–Com
position
etPoids
dupo
rtefeuilleB
93

Idx
Instrument
BaseIndex
Curr
Term1
Term2
Strike
OLS
OLSMarge
PLS
RP
C1
RP
C2
RP
C2(A
vecCvar)
1Ze
roCou
pon
EUR
1-42,79
88,48
-15,36
-96,11
-80,63
-85,11
2Ze
roCou
pon
EUR
3-14,47
-30,38
-51,56
00
03
ZeroCou
pon
EUR
5-30,54
-53,3
-38,04
00
04
ZeroCou
pon
EUR
7-41,54
-76,46
-40,5
00
05
ZeroCou
pon
EUR
102,73
-30,89
-4,25
00
06
ZeroCou
pon
EUR
1329,92
-0,48
8,59
00
07
ZeroCou
pon
EUR
1510,46
-10,39
23,88
00
08
ZeroCou
pon
EUR
1730,55
10,52
54,07
93,08
87,58
87,95
9Ze
roCou
pon
EUR
2068,75
48,6
60,18
00
010
ZeroCou
pon
EUR
2338,13
5,01
40,97
00
011
ZeroCou
pon
EUR
25-14,01
-60,72
-11,58
40,87
31,81
35,49
12ReceiverSw
aption
EUR-05Y
EUR
15
0,04
208,06
190,47
130,62
143,99
110,73
105,66
13ReceiverSw
aption
EUR-05Y
EUR
45
0,04
-53,49
-159,16
-15,43
-49,74
00
14ReceiverSw
aption
EUR-05Y
EUR
75
0,04
-12,2
-112,21
-23,46
00
015
ReceiverSw
aption
EUR-05Y
EUR
105
0,04
16,48
-66,57
5,16
00
016
ReceiverSw
aption
EUR-05Y
EUR
135
0,04
33,63
-2,96
44,83
00
017
ReceiverSw
aption
EUR-05Y
EUR
155
0,04
-16
-108,13
-36,16
00
018
Payer
Swap
tion
EUR-05Y
EUR
15
0,015
14,91
180,42
86,57
134,18
105,88
125,12
19Payer
Swap
tion
EUR-05Y
EUR
45
0,015
-12,74
-174,08
-16,07
00
020
Payer
Swap
tion
EUR-05Y
EUR
75
0,015
8,23
-60,8
1,1
00
021
Payer
Swap
tion
EUR-05Y
EUR
105
0,015
17,72
-31,62
13,53
00
022
Payer
Swap
tion
EUR-05Y
EUR
135
0,015
30,28
38,27
49,74
00
023
Payer
Swap
tion
EUR-05Y
EUR
155
0,015
28,51
35,15
47,28
7,6
00
24Equ
ityInd
exEUR-E
qEUR
11
3565,71
36,89
27,66
24,8
21,05
25Equ
ityInd
exEUR-E
qEUR
51
10,2
14,32
10,03
8,27
11,26
7,2
26Equ
ityInd
exEUR-E
qEUR
101
17,68
15,66
17,52
13,49
8,88
17,8
27Equ
ityInd
exEUR-E
qEUR
151
19,76
4,27
13,72
24,32
24,26
24,35
28Equ
ityInd
exEUR-E
qEUR
201
18,01
7,68
23,81
17,76
14,62
15,95
29Equ
ityInd
exCall
EUR-E
qEUR
11,3
-80,51
-154,32
-84,11
-62,09
-49,71
-43,16
30Equ
ityInd
exCall
EUR-E
qEUR
31,3
6,08
11,96
4,84
3,22
3,43
3,61
31Equ
ityInd
exCall
EUR-E
qEUR
51,3
-7,21
-9,24
-7,12
-6,02
-2,79
-3,42
32Equ
ityInd
exCall
EUR-E
qEUR
71,3
0,55
0,21
0,21
2,31
-3,24
1,73
33Equ
ityInd
exCall
EUR-E
qEUR
101,3
-14,73
-12,64
-14,31
-10,56
-10,08
-17,48
34Equ
ityInd
exCall
EUR-E
qEUR
131,3
1,66
1,62
1,6
2,13
3,23
2,31
35Equ
ityInd
exCall
EUR-E
qEUR
151,3
-17,2
-3,27
-11,17
-22,18
-16,69
-18,83
36Equ
ityInd
exCall
EUR-E
qEUR
171,3
0,36
1,08
0,55
2,05
-3,58
-5,09
37Equ
ityInd
exCall
EUR-E
qEUR
201,3
-14,28
-3,01
-20,24
-14,94
-11,8
-8,77
38Equ
ityInd
exCall
EUR-E
qEUR
221,3
-1,07
-1,86
-0,91
-2,91
-1,18
-1,99
39Equ
ityInd
exCall
EUR-E
qEUR
251,3
-0,5
-0,66
-0,57
1,45
0,35
-0,33
40Equ
ityInd
exPut
EUR-E
qEUR
10,8
73,14
109,83
78,07
51,98
28,46
39,33
41Equ
ityInd
exPut
EUR-E
qEUR
30,8
40,61
72,2
40,18
41,46
63,39
25,24
42Equ
ityInd
exPut
EUR-E
qEUR
50,8
2440,37
23,45
21,35
00
43Equ
ityInd
exPut
EUR-E
qEUR
70,8
6,33
20,05
8,4
7,41
33,36
28,72
44Equ
ityInd
exPut
EUR-E
qEUR
100,8
21,3
16,27
20,64
19,72
036,9
45Equ
ityInd
exPut
EUR-E
qEUR
130,8
1,2
-3,29
-3,51
016,4
046
Equ
ityInd
exPut
EUR-E
qEUR
150,8
8,37
7,92
7,87
16,69
00
47Equ
ityInd
exPut
EUR-E
qEUR
170,8
8,57
-4,12
50
034,1
48Equ
ityInd
exPut
EUR-E
qEUR
200,8
16,08
10,98
26,22
27,01
00
49Equ
ityInd
exPut
EUR-E
qEUR
220,8
-15,91
-40,19
-22,19
-22,9
00
50Equ
ityInd
exPut
EUR-E
qEUR
250,8
21,98
27,67
22,93
24,74
33,04
11,91
Tabl
e7.37
–Com
position
etPoids
dupo
rtefeuilleC
94

Résultats de la régression OLS sur les marges
Portefeuille A
Figure 7.36 – Distribution Portefeuille A
Figure 7.37 – Qualité d’ajustement du portefeuille A
Portefeuille B
Figure 7.38 – Distribution Portefeuille B
Portefeuille C
95
Figure 7.39 – Qualité d’ajustement du portefeuille B
Figure 7.40 – Distribution Portefeuille C
Figure 7.41 – Qualité d’ajustement du portefeuille C
96

Qua
ntile
SdS
RP
ADifférence
RP
BDifférence
RP
CDifférence
99,5%
-43,5
-16,1
-27,3
-42,9
-0,6
-37,4
-6,1
99%
-32,8
-11,3
-21,5
-33,4
0,6
-28,9
-3,9
95%
-12,2
1,1
-13,3
-12,6
0,4
-10
-2,2
90%
-3,3
6,3
-9,6
-40,7
-2,2
-1,1
70%
11,5
15,1
-3,6
10,4
1,0
12,7
-1,2
50%
19,9
19,9
0,0
17,6
2,3
20,6
-0,7
30%
26,4
23,7
2,7
22,8
3,5
26,4
0,0
10%
33,9
28,4
5,6
28,9
5,0
33,0
0,9
5%37
30,4
6,7
31,3
5,8
36,3
0,7
1%42,4
33,7
8,7
35,0
7,4
57,0
-14,6
0,5%
44,4
34,9
9,5
36,6
7,8
66,6
-22,3
Tabl
e7.38
–Récap
itulatifde
ladistribu
tion
despo
rtefeuilles
DFA
RP
ADifférence
RP
BDifférence
RP
CDifférence
Situationinitiale
19,5
19,5
019,5
019,5
0Cho
ctaux
+100b
ps10,42
9,68
+0,74
8,55
+1,86
10,42
0Cho
cde
taux
-100bp
s-14,21
-12,41
-1,80
-12,12
-2,09
-14,21
0Cho
caction
+30%
3,9
3,27
+0,63
4,16
-0,25
3,9
0Cho
caction
-30%
-2,44
-4,41
+1,97
-5,3
+2,85
-2,44
0Cho
ccombiné
+100b
ps/+
30%
6,88
5,96
+0,91
3,94
+2,93
6,88
0Cho
ccombiné
-100bp
s/-30%
-17,74
9-17,66
-0,09
-18,24
+0,49
-15,48
-2,27
Tabl
e7.39
–SensibilitésdesPortefeuillescalib
réssurlesmarges
97

Code VBA
Algorithme Régression PLS
Public Sub PLSAlgorithm_sansPRESS_avec_contraintesv1(x, y, Bc, dc, scn , nIns , nbc , a, w)’ PLS Algorithm without stopping condition: user have to precise number of Latent variablesApplication.ScreenUpdating = FalseDim i, j, l, m, n As Integer’Dim scn , nIns , nbc , a, wDim val1 , val2 , Rss , Press As DoubleDim tmp , tmp1 , tmp2 , tmp3 , tmp4 , tmp5 , tmpQ , tmpY , A1 , A2Dim tX, tY, wh, wb, q, qb, qbb , B, C, wbis , ttbis , tbis , qbis , tXbis , tYbis , u, p
m = 0
’’’’ Construction du èproblme sans contraintes
Call trsp(Bc, nbc , nIns , tmp1)Call fullqrdcp(tmp1 , nIns , nbc , tmpQ , tmp4 , tmp5)Call trsp(tmp5 , nbc , nbc , tmp2)Call TriResolve(tmp2 , nbc , nbc , dc, tmpY)
Call prod(x, scn , nIns , tmpQ , nIns , nIns , tmp5)ReDim A1(1 To scn , 1 To nbc)ReDim A2(1 To scn , 1 To nIns - nbc)For i = 1 To scn
For j = 1 To nInsIf j <= nbc Then A1(i, j) = tmp5(i, j)If j > nbc Then A2(i, j - nbc) = tmp5(i, j)
Next jNext iCall prod(A1, scn , nbc , tmpY , nbc , 1, tmp2)
nIns = nIns - nbc
ReDim x(1 To scn , 1 To nIns)
For i = 1 To scnFor j = 1 To nIns
x(i, j) = A2(i, j)Next j
Next i
For i = 1 To scny(i, 1) = y(i, 1) - tmp2(i, 1)
Next i
ReDim wb(1 To nIns , 1 To a)ReDim wh(1 To nIns , 1 To a)
ReDim qb(1 To a)ReDim qbb(1 To a, 1)
ReDim pb(1 To nIns , 1 To a)
’’’’’’’’’’’’’’’’’’’’ DEBUT ALGORITHME PLS ’’’’’’’’’’’’’’’’’’’’’’’’’’’
For k = 1 To a
’ Calcul du RSSIf k - 1 = 0 Then
Rss = (std(y, scn) ^ 2) * scnElse
Rss = norm(y, scn) ^ 2End If
’ Calcul de wkCall trsp(x, scn , nIns , tX)Call trsp(y, scn , 1, tY)Call prod(tX, nIns , scn , y, scn , 1, tmp1)
98

tmp = norm(tmp1 , nIns)Call scalprod(tmp1 , nIns , 1, 1 / tmp , w)
’’’’ Mise à jour de la matrice WFor i = 1 To nInswb(i, k) = w(i, 1)Next i
’’’’ Calcul de la nouvelle composante tk
Call prod(x, scn , nIns , w, nIns , 1, T)
’’’’ Mettre à jour la matrice T
’’’’ Calcul de pk: vecteur des coefficients de érgression de X sur tkCall prod(tX, nIns , scn , T, scn , 1, tmp1)Call trsp(T, scn , 1, tt)Call prod(tt, 1, scn , T, scn , 1, tmp2)Call scalprod(tmp1 , nIns , 1, 1 / tmp2(1, 1), p)
’’’’ Mettre à jour la matrice PFor i = 1 To nIns
pb(i, k) = p(i, 1)Next i
’’’’ Mise à jour de la matrice des érsidus X
Call trsp(p, nIns , 1, tmp1)
Call prod(T, scn , 1, tmp1 , 1, nIns , tmp2)For i = 1 To scn
For j = 1 To nInsx(i, j) = x(i, j) - tmp2(i, j)
Next jNext i
’’’’ Calcul de qk: coefficient de érgression de y sur tkCall prod(tY, 1, scn , T, scn , 1, tmp1)Call prod(tt, 1, scn , T, scn , 1, tmp2)q = tmp1(1, 1) / tmp2(1, 1)
’’’’ Mettre à jour le vecteur Qqb(k) = qqbb(k, 1) = q
’’’’ Calcul de ukCall scalprod(y, scn , 1, 1 / q, u)
’’’’ Mise à jour de YCall scalprod(T, scn , 1, q, tmp1)For i = 1 To scny(i, 1) = y(i, 1) - tmp1(i, 1)Next i
’’’’ calcul de wh: sert à avoir les coefficients ah de érgression élis aux composantes de xFor i = 1 To nIns
wh(i, k) = w(i, 1)Next i
For i = 1 To k - 1ReDim tmp1(1 To nIns , 1)For j = 1 To nIns
tmp1(j, 1) = pb(j, i)Next jCall trsp(tmp1 , nIns , 1, tmp3)Call prod(tmp3 , 1, nIns , w, nIns , 1, tmp1)
ReDim tmp2(1 To nIns , 1)For j = 1 To nIns
99

tmp2(j, 1) = wh(j, i)Next j
Call scalprod(tmp2 , nIns , 1, tmp1(1, 1), tmp4)
For j = 1 To nInswh(j, k) = wh(j, k) - tmp4(j, 1)
Next j
Next i
Next k
’’’’’’’’’’’’’’’’’’’’ FIN ALGORITHME PLS ’’’’’’’’’’’’’’’’’’’’’’’’’’’’’
’’’’ Calcul du vecteur des coefficients de la érgressionCall prod(wh, nIns , a, qbb , n, 1, tmp2)
’’’’ Construction de la solution du èproblme avec contraintesReDim tmp1(1 To nIns + nbc , 1)For i = 1 To nbctmp1(i, 1) = tmpY(i, 1)Next iFor i = nbc + 1 To nIns + nbctmp1(i, 1) = tmp2(i - nbc , 1)Next iCall prod(tmpQ , nIns + nbc , nIns + nbc , tmp1 , nIns + nbc , 1, tmp2)
ReDim w(1 To nIns + nbc)
’’’’ Construction du vecteur des poids wFor i = 1 To nIns + nbcWorksheets("éDonnes").Cells (2 + i, 1).Value = tmp2(i, 1)w(i) = tmp2(i, 1)Next i
nIns = nIns + nbcApplication.ScreenUpdating = TrueEnd Sub
Algorithme Cash Flow Mismatch
Public Sub simplx(a, m, n, m1, m2, m3, icase , izrov , iposv)Dim i, ip, i_s , k, kh, kp, nl1 As IntegerDim l1, l3Dim q1, bmax As DoubleDim EPSEPS = 1e-06
If (m <> m1 + m2 + m3) Then GoTo err1ReDim l1(1 To n + 1)ReDim l3(1 To m)’ReDim l3(0 To m)
’l1 = ivector(1, n + 1)’l3 = ivector(1, m)nl1 = nFor k = 1 To n
l1(k) = kizrov(k) = k
Next kFor i = 1 To m
If a(i + 1, 1) < 0 Then GoTo err2iposv(i) = n + i
Next i
If (m2 + m3) Then
100

For i = 1 To m2l3(i) = 1
Next iFor k = 1 To n + 1
q1 = 0For i = m1 + 1 To m
q1 = q1 + a(i + 1, k)Next ia(m + 2, k) = -q1
Next kDo While 0 = 0
Call simp1(a, m + 1, l1, nl1 , 0, kp , bmax)If (bmax <= EPS And a(m + 2, 1) < -EPS) Then
icase = -1Exit Sub ’’’’ A REFORMULER
ElseIf (bmax <= EPS And a(m + 2, 1) <= EPS) Then
For ip = m1 + m2 + 1 To mIf iposv(ip) = ip + n Then
Call simp1(a, ip, l1 , nl1 , 1, kp, bmax)If bmax > EPS Then GoTo one
End IfNext ipFor i = m1 + 1 To m1 + m2
If l3(i - m1) = 1 ThenFor k = 1 To n + 1
a(i + 1, k) = -a(i + 1, k)Next k
End IfNext iExit Do
End IfEnd IfCall simp2(a, m, n, ip, kp)If ip = 0 Then
icase = -1Exit Sub
End Ifone: Call simp3(a, m + 1, n, ip, kp)
If iposv(ip) >= n + m1 + m2 + 1 ThenFor k = 1 To nl1
If l1(k) = kp Then Exit ForNext knl1 = nl1 - 1For i_s = k To nl1
l1(i_s) = l1(i_s + 1)Next i_s
Elsekh = iposv(ip) - m1 - nIf kh >= 1 Then
If l3(kh) Thenl3(kh) = 0a(m + 2, kp + 1) = a(m + 2, kp + 1) + 1For i = 1 To m + 2
a(i, kp + 1) = -a(i, kp + 1)Next i
End IfEnd If
End Ifi_s = izrov(kp)izrov(kp) = iposv(ip)iposv(ip) = i_s
LoopEnd If
While 0 = 0Call simp1(a, 0, l1, nl1 , 0, kp , bmax)If bmax <= EPS Then
icase = 0Exit Sub
End IfCall simp2(a, m, n, ip, kp)
101

If ip = 0 Thenicase = 1Exit Sub
End IfCall simp3(a, m, n, ip, kp)i_s = izrov(kp)izrov(kp) = iposv(ip)iposv(ip) = i_s
Wenderr1:
MsgBox "Bad input constraints counts in simplx"err2:
MsgBox "Bad input table in simplx"End Sub
Public Sub simp1(a, mm, ll, nll , iabf , kp, bmax)Dim k As IntegerDim test As DoubleDim EPSEPS = 1e-06If nll <= 0 Then
bmax = 0Else
kp = ll(1)bmax = a(mm + 1, kp + 1)For k = 2 To nll
If iabf = 0 Thentest = a(mm + 1, ll(k) + 1) - bmax
Elsetest = Abs(a(mm + 1, ll(k) + 1)) - Abs(bmax)
End IfIf (test > 0) Then
bmax = a(mm + 1, ll(k) + 1)kp = ll(k)
End IfNext k
End IfEnd Sub
Public Sub simp2(a, m, n, ip , kp)Dim k, i As IntegerDim qp, q0, q, q1 As DoubleDim EPSEPS = 1e-06
ip = 0For i = 1 To m
If a(i + 1, kp + 1) < -EPS Then Exit ForNext iIf i > m Then Exit Subq1 = -a(i + 1, 1) / a(i + 1, kp + 1)ip = iFor i = ip + 1 To m
If a(i + 1, kp + 1) < -EPS Thenq = -a(i + 1, 1) / a(i + 1, kp + 1)If q < q1 Then
ip = iq1 = q
ElseIf q = q1 Then
For k = 1 To nqp = -a(ip + 1, k + 1) / a(ip + 1, kp + 1)q0 = -a(i + 1, k + 1) / a(i + 1, kp + 1)If q0 <> qp Then Exit For
Next kIf q0 < qp Then ip = i
End IfEnd If
End IfNext iEnd Sub
102

Public Sub simp3(a, i1, k1, ip, kp)Dim kk, ii As IntegerDim piv As Double
piv = 1 / a(ip + 1, kp + 1)For ii = 1 To i1 + 1
If ii - 1 <> ip Thena(ii, kp + 1) = a(ii , kp + 1) * pivFor kk = 1 To k1 + 1
If kk - 1 <> kp Then a(ii, kk) = a(ii , kk) - a(ip + 1, kk) * a(ii , kp + 1)Next kk
End IfNext iiFor kk = 1 To k1 + 1
If kk - 1 <> kp Then a(ip + 1, kk) = -a(ip + 1, kk) * pivNext kka(ip + 1, kp + 1) = pivEnd Sub
Public Sub PortC_absoluteMismatch ()Application.ScreenUpdating = FalseDim a, m, n, m1 , m2 , m3 , icase , sum , sigma , liab , cfl , Bc, dc, nbcscn = 1000nIns = 50nbc = 6ReDim liab(1 To scn)ReDim cfl(1 To scn , 1 To nIns)ReDim Bc(1 To nbc , 1 To nIns)ReDim dc(1 To nbc , 1)
If nbc <> 0 ThenFor i = 1 To nbc
For j = 1 To nInsBc(i, j) = Worksheets("Contraintes").Cells(1 + i, j).Value
Next jdc(i, 1) = Worksheets("Contraintes").Cells (30 + i, 1).Value
Next iEnd If
n = scn + nIns * 2m1 = 1 + scnm2 = scnm3 = nbcFor i = 1 To scn
For j = 1 To nInscfl(i, j) = Worksheets("éDonnes").Cells(2 + i, 3 + j).Value
Next jliab(i) = Worksheets("éDonnes").Cells(2 + i, 2).Value
Next i
sigma = 9m = m1 + m2 + m3
ReDim a(1 To m + 2, 1 To n + 1)For i = 1 To m + 2
For j = 1 To n + 1a(i, j) = 0
Next jNext i
’’’’’ Objective functiona(1, 1) = 0For i = 2 To nIns + 1
sum = 0For j = 1 To scn
sum = sum + cfl(j, i - 1)Next ja(1, i) = -sum / scna(1, i + nIns) = sum / scn
Next i
103

For i = 2 * nIns + 2 To scn + 2 * nIns + 1a(1, i) = 0
Next i
’’’’’’ First inequalitya(2, 1) = scn * sigmaFor i = 2 To nIns + 1
a(2, i) = 0a(2, i + nIns) = 0
Next iFor i = 2 * nIns + 2 To scn + 2 * nIns + 1
a(2, i) = -1Next i
For k = 1 To scnIf liab(k) >= 0 Then
’ inferior inequalitya(2 + k, 1) = liab(k)For i = 2 To nIns + 1
a(2 + k, i) = -cfl(k, i - 1)a(2 + k, i + nIns) = cfl(k, i - 1)
Next ia(2 + k, 2 * nIns + 1 + k) = 1
’ superior inequalitya(2 + k + scn , 1) = liab(k)For i = 2 To nIns + 1
a(2 + k + scn , i) = -cfl(k, i - 1)a(2 + k + scn , i + nIns) = cfl(k, i - 1)
Next ia(2 + k + scn , 2 * nIns + 1 + k) = -1
Else’ inferior inequalitya(2 + k, 1) = -liab(k)For i = 2 To nIns + 1
a(2 + k, i) = cfl(k, i - 1)a(2 + k, i + nIns) = -cfl(k, i - 1)
Next ia(2 + k, 2 * nIns + 1 + k) = 1 ’’’’’’’ attention
’superior inequalitya(2 + k + scn , 1) = -liab(k)For i = 2 To nIns + 1
a(2 + k + scn , i) = cfl(k, i - 1)a(2 + k + scn , i + nIns) = -cfl(k, i - 1)
Next ia(2 + k + scn , 2 * nIns + 1 + k) = -1
End IfNext k
For j = 1 To nbcIf dc(j, 1) >= 0 Then
a(2 + 2 * scn + j, 1) = dc(j, 1)For i = 2 To nIns + 1
a(2 + 2 * scn + j, i) = -Bc(j, i - 1)a(2 + 2 * scn + j, i + nIns) = Bc(j, i - 1)
Next iFor i = 2 * nIns + 2 To scn + 2 * nIns + 1
’a(2 + 2 * scn + 1, i) = 0a(2 + 2 * scn + j, i) = 0
Next iElse
a(2 + 2 * scn + j, 1) = -dc(j, 1)For i = 2 To nIns + 1
a(2 + 2 * scn + j, i) = Bc(j, i - 1)a(2 + 2 * scn + j, i + nIns) = -Bc(j, i - 1)
Next iFor i = 2 * nIns + 2 To scn + 2 * nIns + 1
’a(2 + 2 * scn + 1, i) = 0a(2 + 2 * scn + j, i) = 0
Next i
104

End IfNext j
ReDim izrov(1 To n)ReDim iposv(1 To m)
Call simplx(a, m, n, m1, m2, m3 , icase , izrov , iposv)
Worksheets("Simplexe").ActivateRange("B3:D3000").ClearContentsIf icase = 0 Then
For i = 1 To m + 2Worksheets("Simplexe").Cells(2 + i, 2).Value = iIf i <= m Then Worksheets("Simplexe").Cells(2 + i, 3).Value = iposv(i)Worksheets("Simplexe").Cells(2 + i, 4).Value = a(i, 1)Next i
End If
Application.ScreenUpdating = True
End Sub
Public Sub PortC_CVar_AbsoluteMismatch ()Application.ScreenUpdating = FalseDim a, m, n, m1 , m2 , m3 , icase , sum , sigma , liab , cfl , Bc, dc, nbcscn = 1000nIns = 50nbc = 6ReDim liab(1 To scn)ReDim cfl(1 To scn , 1 To nIns)ReDim Bc(1 To nbc , 1 To nIns)ReDim dc(1 To nbc , 1)
If nbc <> 0 ThenFor i = 1 To nbc
For j = 1 To nInsBc(i, j) = Worksheets("Contraintes").Cells(1 + i, j).Value
Next jdc(i, 1) = Worksheets("Contraintes").Cells (30 + i, 1).Value
Next iEnd If
n = scn + nIns * 2 + 2 * scn + 2
m1 = 1 + scnm2 = scnm3 = nbc
m1_bis = 2 + scnm2_bis = scn
For i = 1 To scnFor j = 1 To nIns
cfl(i, j) = Worksheets("éDonnes").Cells(2 + i, 3 + j).ValueNext jliab(i) = Worksheets("éDonnes").Cells(2 + i, 2).Value
Next i
sigma = 9sigma_1 = 38sigma_2 = 38beta_1 = 0.995beta_2 = 0.995m = m1 + m1_bis + m2 + m2_bis + m3
’one:
105

ReDim a(1 To m + 2, 1 To n + 1)For i = 1 To m + 2
For j = 1 To n + 1a(i, j) = 0
Next jNext i
’’’’’ Objective functiona(1, 1) = 0For i = 2 To nIns + 1
sum = 0For j = 1 To scn
sum = sum + cfl(j, i - 1)Next ja(1, i) = -sum / scna(1, i + nIns) = sum / scn
Next iFor i = 2 * nIns + 2 To scn + 2 * nIns + 1
a(1, i) = 0Next i
’’’’’’ 2 First inequalities: CVar mismatcha(2, 1) = sigma_1’a(2, 2 * nIns + 2) = 1a(2, 2 * nIns + 2) = -1a(2, 2 * nIns + 3) = 0For i = 2 * nIns + 4 To 2 * nIns + 3 + scn
a(2, i) = -1 / ((1 - beta_1) * scn)’a(2, i) = -1 / ( beta_1 * scn)
Next i
a(3, 1) = sigma_2a(3, 2 * nIns + 2) = 0a(3, 2 * nIns + 3) = -1For i = 2 * nIns + 3 + scn + 1 To 2 * nIns + 3 + 2 * scn
a(3, i) = -1 / ((1 - beta_2) * scn)Next i’’’’’’’’’’’’’’’’’’
’’’’’’ Third Inequality: Absolute mismatcha(4, 1) = scn * sigmaFor i = 2 To nIns + 1
a(4, i) = 0a(4, i + nIns) = 0
Next iFor i = 2 * nIns + 3 + 2 * scn + 1 To 2 * nIns + 3 + 3 * scn
a(4, i) = -1Next i
’’’’’’’ Absolute Mismatch linked InequalitiesFor k = 1 To scn
If liab(k) >= 0 Then’ inferior inequalitya(4 + k, 1) = liab(k)For i = 2 To nIns + 1
a(4 + k, i) = -cfl(k, i - 1)a(4 + k, i + nIns) = cfl(k, i - 1)
Next ia(4 + k, 2 * nIns + 3 + 2 * scn + k) = 1
’ superior inequalitya(4 + k + 2 * scn , 1) = liab(k)For i = 2 To nIns + 1
a(4 + k + 2 * scn , i) = -cfl(k, i - 1)a(4 + k + 2 * scn , i + nIns) = cfl(k, i - 1)
Next ia(4 + k + 2 * scn , 2 * nIns + 3 + 2 * scn + k) = -1
Else’ inferior inequalitya(4 + k, 1) = -liab(k)
106

For i = 2 To nIns + 1a(4 + k, i) = cfl(k, i - 1)a(4 + k, i + nIns) = -cfl(k, i - 1)
Next ia(4 + k, 2 * nIns + 3 + 2 * scn + k) = 1
’superior inequalitya(4 + k + 2 * scn , 1) = -liab(k)For i = 2 To nIns + 1
a(4 + k + 2 * scn , i) = cfl(k, i - 1)a(4 + k + 2 * scn , i + nIns) = -cfl(k, i - 1)
Next ia(4 + k + 2 * scn , 2 * nIns + 3 + 2 * scn + k) = -1
End IfNext k
’’’’’’’ CVAr Mismatch linked Inequalities
For k = 1 To scnIf liab(k) >= 0 Then
’ inferior inequalitya(3 + m1 + k, 1) = liab(k)For i = 2 To nIns + 1
a(3 + m1 + k, i) = -cfl(k, i - 1)a(3 + m1 + k, i + nIns) = cfl(k, i - 1)
Next ia(3 + m1 + k, 2 * nIns + 1 + 1) = 0a(3 + m1 + k, 2 * nIns + 1 + 2) = 1a(3 + m1 + k, 2 * nIns + 3 + k + scn) = 1
’ superior inequalitya(4 + k + 3 * scn , 1) = liab(k)For i = 2 To nIns + 1
a(4 + k + 3 * scn , i) = -cfl(k, i - 1)a(4 + k + 3 * scn , i + nIns) = cfl(k, i - 1)
Next ia(4 + k + 3 * scn , 2 * nIns + 1 + 1) = -1a(4 + k + 3 * scn , 2 * nIns + 1 + 2) = 0a(4 + k + 3 * scn , 2 * nIns + 3 + k) = -1
Else’ inferior inequalitya(3 + m1 + k, 1) = -liab(k)For i = 2 To nIns + 1
a(3 + m1 + k, i) = cfl(k, i - 1)a(3 + m1 + k, i + nIns) = -cfl(k, i - 1)
Next ia(3 + m1 + k, 2 * nIns + 1 + 1) = 1a(3 + m1 + k, 2 * nIns + 1 + 2) = 0a(3 + m1 + k, 2 * nIns + 3 + k) = 1’superior inequality
a(4 + k + 3 * scn , 1) = -liab(k)For i = 2 To nIns + 1
a(4 + k + 3 * scn , i) = cfl(k, i - 1)a(4 + k + 3 * scn , i + nIns) = -cfl(k, i - 1)
Next ia(4 + k + 3 * scn , 2 * nIns + 1 + 1) = 0a(4 + k + 3 * scn , 2 * nIns + 1 + 2) = -1a(4 + k + 3 * scn , 2 * nIns + 3 + k + scn) = -1
End IfNext k
If nbc <> 0 ThenFor j = 1 To nbc
If dc(j, 1) >= 0 Then’a(2 + 2 * scn + 1, 1) = Worksheets (" Contraintes ").Cells(31, 1).Valuea(4 + m1 + m1_bis + m2 + m2_bis - 3 + j, 1) = dc(j, 1)For i = 2 To nIns + 1
’a(2 + 2 * scn + 1, i) = -Worksheets (" Contraintes ").Cells(2, i - 1).Value’a(2 + 2 * scn + 1, i + nIns) = Worksheets (" Contraintes ").Cells(2, i - 1).Valuea(4 + m1 + m1_bis + m2 + m2_bis - 3 + j, i) = -Bc(j, i - 1)a(4 + m1 + m1_bis + m2 + m2_bis - 3 + j, i + nIns) = Bc(j, i - 1)
107

Next iElse
’a(2 + 2 * scn + 1, 1) = Worksheets (" Contraintes ").Cells(31, 1).Valuea(4 + m1 + m1_bis + m2 + m2_bis - 3 + j, 1) = -dc(j, 1)For i = 2 To nIns + 1
’a(2 + 2 * scn + 1, i) = -Worksheets (" Contraintes ").Cells(2, i - 1).Value’a(2 + 2 * scn + 1, i + nIns) = Worksheets (" Contraintes ").Cells(2, i - 1).Valuea(4 + m1 + m1_bis + m2 + m2_bis - 3 + j, i) = Bc(j, i - 1)a(4 + m1 + m1_bis + m2 + m2_bis - 3 + j, i + nIns) = -Bc(j, i - 1)
Next iEnd If
Next jEnd If
ReDim izrov(1 To n)ReDim iposv(1 To m)
Call simplx(a, m, n, m1 + m1_bis , m2 + m2_bis , m3, icase , izrov , iposv)
Worksheets("Simplexe").ActivateRange("B3:D8000").ClearContentsIf icase = 0 Then
For i = 1 To m + 2Worksheets("Simplexe").Cells(2 + i, 2).Value = iIf i <= m Then Worksheets("Simplexe").Cells(2 + i, 3).Value = iposv(i)Worksheets("Simplexe").Cells(2 + i, 4).Value = a(i, 1)Next i
End If
Application.ScreenUpdating = True
End Sub
Algorithme LAR
Public Sub LARS_Proc(x, y, scn , nIns , cnt , w, Active)Application.ScreenUpdating = False
Dim i, ii, j, l, m, k, nVar , ind , addvar , min_i As Integer
Dim val1 , val2 , Rss , Press , min_plus , Cmax , Ctest , t_prev , t_now , sum As DoubleDim tmp , tmp1 , tmp2 , tmp3 , tmp4 , tmp5 , tmpQ , tmpY , A1 , A2 , gA, xA, xj, txA , wtemp , Replicating , cDim tX, tY, wa, a, aa, ua, mu, mu_old , beta , beta_t , beta_tmp , rup , r, tr, CActive , SignA , gamma ,
gamma_bisDim SignOK
ReDim mu(1 To scn , 1)ReDim mu_old (1 To scn , 1)
ReDim wtemp(1 To nIns , 1)’’’ Initialization
For i = 1 To scnmu(i, 1) = 0mu_old(i, 1) = 0
Next i
m = nInsIf m <= scn - 1 Then m = nIns
ReDim Active (1 To nIns)ReDim CActive (1 To nIns)ReDim SignA(1 To nIns)ReDim NotUsed (1 To nIns)
ReDim gamma(1 To nIns)ReDim beta(1 To nIns , 1 To nIns)ReDim beta_t (1 To nIns , 1 To nIns)’ReDim gamma(1 To nIns)
108

’ReDim beta(1 To nIns , 1 To nIns)
For i = 1 To nInsActive(i) = 0CActive(i) = 1For k = 1 To nIns
beta(i, k) = 0beta_t(i, k) = 0
Next kSignA(i) = 0
Next i
nVar = 0SignOK = 1i = 0Call trsp(x, scn , nIns , tX)Worksheets(wks_au_selec).ActivateRange("M8:S1000").ClearContents
’’’’ ********************** Main LARS loop
While nVar < mi = i + 1
ReDim tmp2(1 To scn , 1)For j = 1 To scn
tmp2(j, 1) = y(j, 1) - mu(j, 1)Next jCall prod(tX, nIns , scn , tmp2 , scn , 1, c) ’ Calculate current correlation
Call AbsoluteMax(c, nIns , Cmax , ind) ’ Find the maximum absolute current correlation’Worksheets ("éDonnes ").Cells (50 + i, 1).Value = Cmax
If i = 1 Then addvar = ind
If SignOK ThennVar = nVar + 1Active(nVar) = addvar ’ add the new variable to active setCActive(addvar) = 0 ’ remove the variable from the inactive setSignA(addvar) = Sgn(c(addvar , 1))
End If
If nVar = 1 ThenCall ExtractX(x, scn , nIns , Active , SignA , nVar , xA , xj)Call trsp(xA, scn , nVar , txA)Call prod(txA , nVar , scn , xA , scn , nVar , gA)ReDim r(1, 1)r(1, 1) = gA(1, 1) ^ 0.5aa = (1 / gA(1, 1)) ^ ( -0.5)ReDim wa(1 To nVar , 1)wa(1, 1) = aa * 1 / gA(1, 1)Call scalprod(xA, scn , nVar , wa(1, 1), ua)Call prod(tX, nIns , scn , ua, scn , nVar , a)
Else
Call ExtractX(x, scn , nIns , Active , SignA , nVar , xA , xj) ’ Extract the new XA matrixIf SignOK Then
Call cholupdate(r, nVar , scn , xA , rup) ’ Update the Cholesky matrix
Else
’Call downdate(r, nVar , scn , xA , rup , delete) ’ Downdate the Cholesky matrix’Call downdatebis(r, nVar , scn , xA, rup , delete) ’ Downdate the Cholesky matrix
End IfReDim r(1 To nVar , 1 To nVar)For k = 1 To nVar
109

For j = 1 To nVarr(k, j) = rup(k, j)
Next jNext k’If i = 10 Then scn = scn / 0’If SignOK = 0 Then scn = scn / 0ReDim tmp1(1 To nVar , 1)For j = 1 To nVar
tmp1(j, 1) = 1Next jCall trsp(tmp1 , nVar , 1, tmp2)Call trsp(r, nVar , nVar , tr)Call TriResolve(r, nVar , nVar , tmp1 , tmp3)Call TriResolveUp(tr, nVar , nVar , tmp3 , tmp)
Call prod(tmp2 , 1, nVar , tmp , nVar , 1, tmp4)aa = (1 / tmp4(1, 1)) ^ 0.5 ’ Computes A
Call scalprod(tmp , nVar , 1, aa, wa) ’ Computes wA vectorCall prod(xA, scn , nVar , wa, nVar , 1, ua) ’ Computes the equiangular vector uACall prod(tX, nIns , scn , ua, scn , 1, a)
End If
ReDim beta_tmp (1 To nIns , 1)For j = 1 To nIns
beta_tmp(j, 1) = 0Next j
’ Calcultes new gamma coeeficient and find the new variable to join the active setIf nVar = m Then
gamma(i) = Cmax / aaElse
’k = 0ReDim gamma_bis (1 To nIns , 1 To 2)For j = 1 To nIns
If CActive(j) = 1 ThenIf aa - a(j, 1) <> 0 Then gamma_bis(j, 1) = (Cmax - c(j, 1)) / (aa - a(j, 1))
’gamma_bis(j, 1) = (Cmax - c(j, 1)) / (aa - a(j, 1))gamma_bis(j, 2) = (Cmax + c(j, 1)) / (aa + a(j, 1))
’Else’gamma_bis(j, 1) = 1E+15’gamma_bis(j, 2) = 1E+15
End IfNext j
Call minplus(gamma_bis , nIns , CActive , min_plus , min_i)gamma(i) = min_plusaddvar = min_i
End If
’ update the coefficient estimatesCall scalprod(wa, nVar , 1, gamma(i), tmp1)For j = 1 To nVar
beta_tmp(j, 1) = tmp1(j, 1)Next j
’ update the predictor estimatesCall scalprod(ua, scn , 1, gamma(i), tmp1)For j = 1 To scn
mu_old(j, 1) = mu(j, 1)mu(j, 1) = mu_old(j, 1) + tmp1(j, 1)
Next j
110

For j = 1 To nInsbeta(i, j) = beta_tmp(j, 1)
Next j
’’’’’’’’’’ Historique des R2For k = 1 To nIns
’Worksheets ("éDonnes ").Cells(2 + k, 1).Value = 0wtemp(k, 1) = 0
Next k
For k = 1 To nInssum = 0For j = 1 To i
sum = sum + beta(j, k)Next jIf Active(k) <> 0 Then wtemp(Active(k), 1) = sum * SignA(Active(k))
Next kCall prod(x, scn , nIns , wtemp , nIns , 1, Replicating)Worksheets(wks_au_selec).Cells (7 + i, 13).Value = CalculateR2(y, Replicating , scn)Worksheets(wks_au_selec).Cells (7 + i, 12).Value = nVar
’’’’’’’’’’’’’’’’’’’’’’If nVar = cnt ThennVar = nVar + mEnd If
Wend
If nVar <> m Then nVar = nVar - m
ReDim w(1 To nIns)For k = 1 To nIns
w(k) = 0Next k
For k = 1 To nVarsum = 0For j = 1 To i
sum = sum + beta(j, k)Next j’Worksheets ("éDonnes ").Cells(2 + Active(k), 1).Value = sum * SignA(Active(k))w(Active(k)) = sum * SignA(Active(k))
Next k
Application.ScreenUpdating = TrueEnd Sub
Algorithme OMP
Public Sub OMP_Proc(x, y, scn , nIns , cnt , w, Activebis)Application.ScreenUpdating = FalseDim i, ii, j, l, m, n, nVar , k, ind As Integer
Dim val1 , val2 , Rss , Press , min_plus , Cmax , Ctest , t_prev , t_now , sumt , sumtt As DoubleDim tmp , tmp1 , tmp2 , tmp3 , tmp4 , tmp5 , xA, List_indDim r, Active , CActive , z, z_t , rn , qn , q, s, sbis
’’’ Initialization
ReDim CActive (1 To nIns)ReDim Active (1 To nIns)ReDim Activebis (1 To nIns)ReDim r(1 To scn , 1)ReDim z(1 To nIns)
111

nVar = nInsFor i = 1 To nIns
CActive(i) = iActive(i) = 0Activebis(i) = 0
Next iFor i = 1 To scn
r(i, 1) = y(i, 1)Next iWorksheets(wks_au_selec).ActivateRange("L8:S4000").ClearContents’’’’ ********************** Main OMP loop
While Not n >= nInsn = n + 1
Call ExtractXbis(x, scn , nIns , CActive , nVar , xA , List_ind)Call trsp(xA, scn , nVar , tmp1)Call prod(tmp1 , nVar , scn , r, scn , 1, tmp2)Call AbsoluteMaxbis(tmp2 , nVar , Cmax , ind , List_ind)
nVar = nVar - 1CActive(ind) = 0Active(ind) = 1Activebis(nIns - nVar) = ind
’’’’’’’’’’’’’’’’’’’’’’Call ExtractXter(x, scn , nIns , Activebis , nIns - nVar , xA)Call MGSqrdcp(xA, scn , nIns - nVar , qn, rn, q)
Call trsp(q, scn , 1, tmp1)Call prod(tmp1 , 1, scn , y, scn , 1, tmp)z(nIns - nVar) = tmp(1, 1)
Call scalprod(q, scn , 1, tmp(1, 1), tmp2)For i = 1 To scn
r(i, 1) = r(i, 1) - tmp2(i, 1)Next i
’’’’’’’’’’’’’’’ R2 calculation
ReDim z_t(1 To n, 1)For i = 1 To n
z_t(i, 1) = z(i)Next i
Call TriResolveUp(rn, n, n, z_t , s)
ReDim sbis(1 To nIns , 1)For i = 1 To nIns
sbis(i, 1) = 0Next i
For i = 1 To nsbis(Activebis(i), 1) = s(i, 1)
Next iCall prod(x, scn , nIns , sbis , nIns , 1, tmp)
Worksheets(wks_au_selec).Cells (7 + n, 13).Value = CalculateR2(y, tmp , scn)Worksheets(wks_au_selec).Cells (7 + n, 12).Value = n
If n = cnt Then n = n + nIns
Wend
If n <> nIns Then n = n - nIns
112

ReDim w(1 To nIns)ReDim z_t(1 To n, 1)For i = 1 To n
z_t(i, 1) = z(i)Next i
Call TriResolveUp(rn, n, n, z_t , s)
ReDim sbis(1 To nIns , 1)For i = 1 To nIns
sbis(i, 1) = 0w(i) = 0
Next i
For i = 1 To nsbis(Activebis(i), 1) = s(i, 1)w(Activebis(i)) = s(i, 1)
Next i
Application.ScreenUpdating = TrueEnd Sub
Instruments Financiers
Notations
On considère les notations suivantes :– R(t, T ) est le taux discrétisé d’un zéro coupon de maturité T à l’instant t– Rc(t, T ) est le taux continu d’un zéro coupon de maturité T à l’instant t– D(t, T ) = 1
1+R(t,T )− T le déflateur de maturité T à l’instant t
– Dc(t, T ) = e−Rc(t,T )T le déflateur de maturité T à l’instant t– Libor(T ) = D(0,T )
D(0,T+1)−1 le taux d’intérêt à court terme T dérivé de la courbe des taux
spot– N(.) est la fonction de répartition de la loi normale
Les volatilités sont déduites des trajectoires en sortie de l’ESG :
Zéro coupon
Le détenteur d’un zéro coupon de maturité t1 et de nominal 1 reçoit une unité dans lamonnaie du zéro coupon :
CF(t)= 1 si t = t1,CF(t)= 0 sinon
ValorisationSi t1 n’est pas un entier, on définit le taux d’intérêt d’un zéro coupon de maturité t1 est définicomme suit :
R(0, t1) = (1− (t1 − Ent(t1)))R(0, Ent(t1)) + (t1 − Ent(t1)R(0, Ent(t1) + 1)
où Ent(.) désigne la fonction partie entière.Le prix du zéro coupon est :
ZC(t1) = 11+R(0,t1)−t1
113

Forward swap
Le détenteur d’un forward swap de maturité t1 et de ténor t2 paye un un taux d’intérêtvariable et reçoit un taux d’intérêt fixe K à t1 + 1 et jusqu’à t1 + t2. Pour payer le taux courtle détenteur du forward swap peut entrer dans un forward swap et payer le le taux fixe partaux S(t1, t2) et recevoir le taux variable :
CF(t)= K − S(t1, t2) si t1 + 1 ≤ t ≤ t1 + t2,CF(t)= 0 sinon
ValorisationLe prix P est le suivant :
K.PV0 − ZC(t1) + ZC(t1 + t2)
oùPV0 =∑t1+t2
t1ZC(i)
Call/Put
Le détenteur d’un call Européen de maturité t1 et de strike K a le droit d’acheter lesous-jacent à la date de maturité t1 au prix K. Les cashflow sont donc définis comme suit :
CF(t)= max(0;S(t)−K) si t = t1,CF(t)= 0 sinon
ValorisationSi on désigne par S le prix du sous-jacent à l’instant 0 et σeq la volatilité implicite de d’uneoption de maturité t1, alors Le prix P est le suivant :
P = S.N(d1)−K.exp(−Rc(0, t1)t1).N(d2
où d1 =ln( S
K)+t1(Rc(0,t1)
σ2eq2
)
σsw√i
, d2 = d1 − σeq√t1.
Les options sur indices actions ou immobilier permettent de prendre en compte les flux liésau caractère optionnel de l’engagement de l’assureur avec le mécanisme de la participationaux bénéfices.
Put
Le détenteur d’un put Européen de maturité t1 et de strike K a le droit de vendre lesous-jacent à la date de maturité t1 au prix K. Les cashflow sont donc définis comme suit :
CF(t)= max(0;K − S(t)) si t = t1,CF(t)= 0 sinon
ValorisationSi on désigne par S le prix du sous-jacent à l’instant 0 et σeq la volatilité implicite de d’uneoption de maturité t1, alors Le prix P est le suivant :
P = −S.N(−d1) +K.exp(−Rc(0, t1)t1).N(−d2
où d1 =ln( S
K)+t1(Rc(0,t1)
σ2eq2
)
σsw√i
, d2 = d1 − σeq√t1.
Les options sur indices actions ou immobilier permettent de prendre en compte les flux liésau caractère optionnel de l’engagement de l’assureur avec le mécanisme de la participationaux bénéfices.
114

Floor
Le détenteur d’un floor de date de départ t1, de ténor t2 et de strike K recevra à partir det1 + 1 et ce jusqu’à t1 + t2 la différence positive entre le strike et taux swap. Les cashflowsont donc définis comme suit :
CF(t)= max(K − S(t, T ); 0) si t1 + 1 ≤ t ≤ t1 + t2,CF(t)= 0 sinon
ValorisationSi on désigne par σsw la volatilité implicite de la swaption, alors Le prix P est le suivant :
P =∑t1+t2
i=t1+1 ZC(i).[−FwdAdj(i).N(−d1,i) +K.N(−d2,i)]
où d1,i =ln(
FwdAdj(i)K
)+iσ2sw
2
σsw√i
, d2,i = d1,i − σsw√i.
FwdAdj(i) = Fwd(i) + ConvAdj(i),
ConvAdj(i) = − i2.σ
2sw.Fwd(i)2.Conv(i)
Dur(i),
Conv(i) = T. T+1(1+Fwd(i))T+2 +
∑Tj=1 Fwd(i).j. j+1
(1+Fwd(i))j+2 ,
Dur(i) = −T(1+Fwd(i))T+1 −
∑Tj=1 Fwd(i). j
(1+Fwd(i))j+1 ,
Fwd(i) = ZC(i)−ZC(i+T )∑i+Tj=i+1 ZC(j)
.
Ces instruments permettent de prendre en compte la sensibilité des rachats aux variations destaux de marché.
Cap
Le détenteur d’un floor de date de départ t1, de ténor t2 et de strike K recevra à partir det1 + 1 et ce jusqu’à t1 + t2 la différence positive entre le taux swap et le strike. Les cashflowsont donc définis comme suit :
CF(t)= max(S(t, T )−K; 0) si t1 + 1 ≤ t ≤ t1 + t2,CF(t)= 0 sinon
ValorisationSi on désigne par σsw la volatilité implicite de la swaption, alors Le prix P est le suivant :
P =∑t1+t2
i=t1+1 ZC(i).[FwdAdj(i).N(d1,i)−K.N(d2,i)]
avec les même notations que pour la valorisation des floorsCes instruments permettent de prendre en compte la sensibilité des rachats aux variations destaux de marché.
Swaption receveuse
Le détenteur d’une swaption receveuse de maturité t1 et de ténor t2 a le droit d’entrer à t1dans un contrat de swap receveur où il paierait un taux variable et percevrait le taux fixe K.Le détenteur de la swaption receveuse exercera l’option uniquement si les conditions garanties
115

sont plus attractives que les conditions prévalant à la date d’échéance de l’option. Dans ce casle détenteur de l’option entrerait dans un swap payeur à t1 où il paierait le taux fixe S(t1, t2)et recevrait le taux variable. Les flux de taux variable s’annulent et on a donc les cashflow quipeuvent être décrit comme suit :
CF(t)= max(K − S(t1, t2); 0) si t1 + 1 ≤ t ≤ t1 + t2,CF(t)= 0 sinon
ValorisationSi on désigne par σsw la volatilité implicite de la swaption, alors Le prix P est le suivant :
P = PV0[−S.N(d1) +K.N(−d2)]
où PV0 =∑t1+t2
t1ZC(i),
S = ZC(t1)−ZC(t1+t2)PV0
,
d1 =ln( S
K)+
t1σ2sw2
σsw√t1
, d2 = d1 − σsw√t1.
Ces instruments permettent de prendre en compte la sensibilité des rachats aux variations destaux de marché.
Swaption payeuse
Le détenteur d’une swaption payeuse de maturité t1 et de ténor t2 a le droit d’entrer à t1dans un contrat de swap payeur où il percevrait un taux variable et paierait le taux fixe K. Ledétenteur de la swaption payeuse exercera l’option uniquement si les conditions garanties sontplus attractives que les conditions prévalant à la date d’échéance de l’option. Dans ce cas ledétenteur de l’option entrerait dans un swap receveur à t1 où il percevrait le taux fixe S(t1, t2)et paierait le taux variable. Les flux de taux variable s’annulent et on a donc les cashflow quipeuvent être décrit comme suit :
CF(t)= max(S(t1, t2)−K; 0) si t1 + 1 ≤ t ≤ t1 + t2,CF(t)= 0 sinon
ValorisationSi on désigne par σsw la volatilité implicite de la swaption, alors Le prix P est le suivant :
P = PV0[S.N(d1)−K.N(d2)]
avec les même notations que dans le cas de la valorisation d’une swaption receveuse.Ces instruments permettent de prendre en compte la sensibilité des rachats aux variations destaux de marché.
116

Table des figures
2.1 Structure de Solvabilité 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
3.1 Structure du bilan économique sous Solvabilité 2 . . . . . . . . . . . . . . . 133.2 Structure modulaire de la formule standard . . . . . . . . . . . . . . . . . . 153.3 Illustration de l’approche SdS . . . . . . . . . . . . . . . . . . . . . . . . . 173.4 Illustration de l’approche Curve Fitting . . . . . . . . . . . . . . . . . . . . 193.5 Illustration de l’approche Least Square Monte Carlo . . . . . . . . . . . . . 21
5.1 Illustration de l’approche RP . . . . . . . . . . . . . . . . . . . . . . . . . . 27
6.1 Distribution des fonds propres SdS . . . . . . . . . . . . . . . . . . . . . . 426.2 Qualité d’ajustement du portefeuille A . . . . . . . . . . . . . . . . . . . . 426.3 Distribution fonds propres Portefeuille A . . . . . . . . . . . . . . . . . . . 426.4 Qualité d’ajustement du portefeuille B . . . . . . . . . . . . . . . . . . . . 446.5 Distribution fonds propres Portefeuille B . . . . . . . . . . . . . . . . . . . 446.6 Qualité d’ajustement du portefeuille C . . . . . . . . . . . . . . . . . . . . 456.7 Distribution fonds propres Portefeuille C . . . . . . . . . . . . . . . . . . . 45
7.1 Qualité d’ajustement du portefeuille A . . . . . . . . . . . . . . . . . . . . 557.2 Distribution fonds propres Portefeuille A . . . . . . . . . . . . . . . . . . . 557.3 Qualité d’ajustement du portefeuille B . . . . . . . . . . . . . . . . . . . . 567.4 Distribution fonds propres Portefeuille B . . . . . . . . . . . . . . . . . . . 567.5 Qualité d’ajustement du portefeuille C . . . . . . . . . . . . . . . . . . . . 577.6 Distribution fonds propres Portefeuille C . . . . . . . . . . . . . . . . . . . 577.7 Evolution du PRESSh et du RSSh en fonction du nombre de variables latentes 587.8 Evolution du R2 et du Q2
h en fonction du nombre de variables latentes . . . 587.9 Qualité d’ajustement du portefeuille A1 . . . . . . . . . . . . . . . . . . . 617.10 Distribution fonds propres Portefeuille A1 . . . . . . . . . . . . . . . . . . . 617.11 Qualité d’ajustement du portefeuille A2 . . . . . . . . . . . . . . . . . . . 627.12 Distribution fonds propres Portefeuille A2 . . . . . . . . . . . . . . . . . . . 627.13 Qualité d’ajustement du portefeuille C1 . . . . . . . . . . . . . . . . . . . 637.14 Distribution fonds propres Portefeuille C1 . . . . . . . . . . . . . . . . . . . 637.15 Qualité d’ajustement du portefeuille C2 . . . . . . . . . . . . . . . . . . . 647.16 Distribution fonds propres Portefeuille C2 . . . . . . . . . . . . . . . . . . 647.17 QQ-Plot Distribution des erreurs du portefeuille C2 (sans CVaR Mismatch) . 667.18 QQ-Plot Distribution des erreurs du portefeuille A1 (sans CVaR Mismatch) . 667.19 QQ-Plot Distribution des erreurs du portefeuille C2 (avec CVaR Mismatch) 687.20 QQ-Plot Distribution des erreurs du portefeuille A1 (avec CVaR Mismatch) 687.21 Qualité d’ajustement du portefeuille A1 (avec CVaR Mismatch) . . . . . . . 68
117

7.22 Distribution fonds propres Portefeuille A1 (avec CVaR Mismatch) . . . . . . 687.23 Qualité d’ajustement du portefeuille C2 (avec CVaR Mismatch) . . . . . . . 697.24 Distribution fonds propres Portefeuille C2 (avec CVaR Mismatch) . . . . . . 697.25 Description géométrique de l’algorithme LAR pour p=2 prédicteurs . . . . . 727.26 Distribution fonds propres Portefeuille LAR (50 Ins) . . . . . . . . . . . . . 777.27 Distribution fonds propres Portefeuille LAR (100 Ins) . . . . . . . . . . . . 777.28 Qualité d’ajustement du portefeuille LAR . . . . . . . . . . . . . . . . . . . 777.29 Distribution fonds propres Portefeuille LAR . . . . . . . . . . . . . . . . . . 777.30 Distribution fonds propres Portefeuille OMP (50 Ins) . . . . . . . . . . . . 827.31 Distribution fonds propres Portefeuille OMP (100 Ins) . . . . . . . . . . . . 827.32 Qualité d’ajustement du portefeuille OMP . . . . . . . . . . . . . . . . . . 837.33 Distribution fonds propres Portefeuille OMP . . . . . . . . . . . . . . . . . 837.34 Qualité d’ajustement du portefeuille OMP (avec SVD) . . . . . . . . . . . 867.35 Distribution fonds propres Portefeuille OMP (avec SVD) . . . . . . . . . . . 867.36 Distribution Portefeuille A . . . . . . . . . . . . . . . . . . . . . . . . . . . 957.37 Qualité d’ajustement du portefeuille A . . . . . . . . . . . . . . . . . . . . 957.38 Distribution Portefeuille B . . . . . . . . . . . . . . . . . . . . . . . . . . . 957.39 Qualité d’ajustement du portefeuille B . . . . . . . . . . . . . . . . . . . . 967.40 Distribution Portefeuille C . . . . . . . . . . . . . . . . . . . . . . . . . . . 967.41 Qualité d’ajustement du portefeuille C . . . . . . . . . . . . . . . . . . . . 96
118

Liste des tableaux
3.1 Matrice de corrélation des risques de marché . . . . . . . . . . . . . . . . . 16
6.1 Valorisation du bilan . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 416.2 Sensibilités Portefeuille A . . . . . . . . . . . . . . . . . . . . . . . . . . . 436.3 Ecarts Portefeuille A . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 436.4 Sensibilités Portefeuille B . . . . . . . . . . . . . . . . . . . . . . . . . . . 446.5 Ecart Portefeuille B . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 456.6 Sensibilités Portefeuille C . . . . . . . . . . . . . . . . . . . . . . . . . . . 456.7 Ecarts Portefeuille C . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
7.1 Sensibilités Portefeuille A . . . . . . . . . . . . . . . . . . . . . . . . . . . 557.2 Ecarts Portefeuille A . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 567.3 Sensibilités Portefeuille B . . . . . . . . . . . . . . . . . . . . . . . . . . . 567.4 Ecarts Portefeuille B . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 577.5 Sensibilités Portefeuille C . . . . . . . . . . . . . . . . . . . . . . . . . . . 577.6 Ecarts Portefeuille C . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 587.7 Valeur du paramètre σ pour chaque portefeuille . . . . . . . . . . . . . . . . 617.8 Sensibilités Portefeuille A1 . . . . . . . . . . . . . . . . . . . . . . . . . . . 627.9 Ecarts Portefeuille A1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 627.10 Sensibilités Portefeuille A2 . . . . . . . . . . . . . . . . . . . . . . . . . . . 637.11 Ecarts Portefeuille A2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 637.12 Sensibilités Portefeuille C1 . . . . . . . . . . . . . . . . . . . . . . . . . . . 647.13 Ecarts Portefeuille C1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 647.14 Sensibilités Portefeuille C2 . . . . . . . . . . . . . . . . . . . . . . . . . . . 657.15 Ecarts Portefeuille C2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 657.16 Sensibilités Portefeuille A1 (avec CVaR Mismatch) . . . . . . . . . . . . . . 697.17 Ecarts Portefeuille A1 (avec CVaR Mismatch) . . . . . . . . . . . . . . . . 697.18 Sensibilités Portefeuille C2 (avec CVaR Mismatch) . . . . . . . . . . . . . . 707.19 Ecarts Portefeuille C2 (avec CVaR Mismatch) . . . . . . . . . . . . . . . . 707.20 Composition de l’indice de CashFlows . . . . . . . . . . . . . . . . . . . . . 747.21 Instruments sélectionnés dans l’ordre de LAR . . . . . . . . . . . . . . . . . 747.22 Instruments sélectionnés dans l’ordre de LAR . . . . . . . . . . . . . . . . . 757.23 Instruments sélectionnés dans l’ordre de LAR (CashFlows bruités) . . . . . . 767.24 Paramètres Instruments . . . . . . . . . . . . . . . . . . . . . . . . . . . . 767.25 Sensibilités Portefeuille LAR . . . . . . . . . . . . . . . . . . . . . . . . . . 787.26 Ecarts Portefeuille LAR . . . . . . . . . . . . . . . . . . . . . . . . . . . . 787.27 Instruments sélectionnés dans l’ordre de OMP . . . . . . . . . . . . . . . . 807.28 Instruments sélectionnés dans l’ordre de OMP . . . . . . . . . . . . . . . . 81
119

7.29 Instruments sélectionnés dans l’ordre de OMP . . . . . . . . . . . . . . . . 827.30 Sensibilités Portefeuille OMP . . . . . . . . . . . . . . . . . . . . . . . . . 837.31 Ecarts Portefeuille OMP . . . . . . . . . . . . . . . . . . . . . . . . . . . . 847.32 Décomposition de la variance . . . . . . . . . . . . . . . . . . . . . . . . . 857.33 Sensibilités Portefeuille OMP (avec SVD) . . . . . . . . . . . . . . . . . . . 867.34 Ecarts Portefeuille OMP (avec SVD) . . . . . . . . . . . . . . . . . . . . . 877.35 Composition et Poids du portefeuille A . . . . . . . . . . . . . . . . . . . . 927.36 Composition et Poids du portefeuille B . . . . . . . . . . . . . . . . . . . . 937.37 Composition et Poids du portefeuille C . . . . . . . . . . . . . . . . . . . . 947.38 Récapitulatif de la distribution des portefeuilles . . . . . . . . . . . . . . . . 977.39 Sensibilités des Portefeuilles calibrés sur les marges . . . . . . . . . . . . . . 97
120

Bibliographie
[1] Natixis Assurances. Normes de calcul du scr de marche, document interne. 2011.
[2] Natixis Assurances. Specifications fonctionelles detaillees du modele de natixis assurances,document interne. 2011.
[3] D. Bauer, D. Bergmann, and A. Reuss. Solvency ii and nested simulation - a least-squaresmonte carlo approach. 2009.
[4] David A. Besley, E. Kuh, and R.E. Welsch. Regression diagnostics : identifying influentialdata and sources of collinearity. 1980.
[5] Thomas Blumensath and Mike E. Davies. On the difference between orthogonal matchingpursuit and orthogonal least squares, 2007.
[6] T. T. Cai and Lie Wang. Orthogonal Matching Pursuit for Sparse Signal Recovery WithNoise. Information Theory, IEEE Transactions on, 57(7) :4680–4688, July 2011.
[7] Wei Chen and Jimmy Skoglund. Cashflow replication with mismatch constraints. Journalof Risk, 14 :115–128, 2012.
[8] E. Clement, D. Lamberton, and P. Protter. An economic overview of risk-based capitalrequirements for the property-liability insurance industry. Journal of Insurance Regulation,11 :427-447, 1994.
[9] L. Devineau and M. Chauvigny. Replicating portfolios : techniques de calibrage pour lecalcul du capital economique solvabilite 2. 2009.
[10] Maxime Druais. Pourquoi et comment calibrer le risque de marche sous solvabilità c© 2 ?le role centrale du generateur de scenarios economiques. 2012.
[11] Bradley Efron, Trevor Hastie, Iain Johnstone, and Robert Tibshirani. Least angle regres-sion. Annals of Statistics, 32 :407–499, 2004.
[12] EIOPA. Qis 5 technical specifications. 2009.
[13] EIOPA. Draft technical implementing measures. 2011.
[14] Gene H. Golub and Charles F. Van Loan. Matrix computations (3rd ed.). Johns HopkinsUniversity Press, Baltimore, MD, USA, 1996.
[15] Pavlo Krokhmal, Jonas Palmquist, and Stanislav Uryasev. Portfolio optimization withconditional value-at-risk objective and constraints. JOURNAL OF RISK, 4 :11–27, 2002.
[16] F.A. Longstaff and E.S. Schwartz. Valuing american options by simulation : A simpleleast-squares approach. The Review of Financial Studies, 14 :113-147, 2001.
[17] Stephane Mallat and Zhifeng Zhang. Matching pursuit with time-frequency dictionaries.IEEE Transactions on Signal Processing, 41 :3397–3415, 1993.
[18] European Parliament. Directive 85/611/eec. 1985.
121

[19] European Parliament. Directive 2006/48/eec. 2006.
[20] European Parliament. Directive 2009/138/ec. 2009.
[21] William H. Press, Saul A. Teukolsky, William T. Vetterling, and Brian P. Flannery. Nu-merical Recipes 3rd Edition : The Art of Scientific Computing. Cambridge UniversityPress, New York, NY, USA, 3 edition, 2007.
[22] R. Tyrrell Rockafellar and Stanislav Uryasev. Optimization of conditional value-at-risk.Journal of Risk, 2 :21–41, 2000.
[23] M. Tenenhaus. La regression pls, theorie et pratique. 1998.
[24] Robert Tibshirani. Regression shrinkage and selection via the lasso. Journal of the RoyalStatistical Society, Series B, 58 :267–288, 1994.
122


















