
Optimisation de performance pour des systèmes temps … · tèmes temps réel (systèmes...
21
RECHERCHE Optimisation de performance pour des systèmes temps réel stricts à priorité fixe Joël Goossens * — Pascal Richard ** * Université Libre de Bruxelles CP 212 50, avenue Franklin D. Roosevelt B-1050 Bruxelles [email protected] ** LISI / ENSMA Téléport 2 - 1, avenue Clément Ader BP 40109 F-86961 Futuroscope Chasseneuil cedex [email protected] RÉSUMÉ. De nombreux systèmes temps réel doivent conjointement satisfaire des contraintes temps réel et assurer une qualité de service. Dans cette optique, nous présentons une méthode par séparation et d’évaluation dédiée aux systèmes temps réel stricts à priorité fixe. Notre mé- thode est basée sur un algorithme générique qui utilise des fonctions communes indépendam- ment du critère de performance utilisé. Seules quelques fonctions devront être spécialisées pour le critère de performance considéré. Nous présentons ensuite, une telle spécialisation de l’al- gorithme afin de minimiser le temps de réponse moyen pondéré de tâches. ABSTRACT. Many real-time systems must simultaneously handle hard real-time constraints and Quality of Service constraints. Thus, a performance criterion must be optimized for some tasks while meeting all deadlines for hard real-time tasks. For that purpose, we present a generic Branch & Bound method dedicated to hard real-time fixed-priority schedulers. Our approach is based on a generic algorithm that defines common functions to any performance criteria. Only few functions need to be specialized to deal with a specific criterion. We then present such a specialization for minimizing the weighted average response time of tasks. MOTS-CLÉS : ordonnancement, priorités fixes, optimisation de performance. KEYWORDS: scheduling, fixed-priority, performance optimization. RSTI - TSI – 24/2005. Ordonnancement temps réel, pages 991 à 1011
Transcript of Optimisation de performance pour des systèmes temps … · tèmes temps réel (systèmes...

RECHERCHE
Optimisation de performancepour des systèmes temps réel strictsà priorité fixe
Joël Goossens* — Pascal Richard**
* Université Libre de Bruxelles CP 21250, avenue Franklin D. RooseveltB-1050 Bruxelles
** LISI / ENSMATéléport 2 - 1, avenue Clément AderBP 40109F-86961 Futuroscope Chasseneuil cedex
RÉSUMÉ.De nombreux systèmes temps réel doivent conjointement satisfaire des contraintestemps réel et assurer une qualité de service. Dans cette optique, nous présentons une méthodepar séparation et d’évaluation dédiée aux systèmes temps réel stricts à priorité fixe. Notre mé-thode est basée sur un algorithme générique qui utilise des fonctions communes indépendam-ment du critère de performance utilisé. Seules quelques fonctions devront être spécialisées pourle critère de performance considéré. Nous présentons ensuite, une telle spécialisation de l’al-gorithme afin de minimiser le temps de réponse moyen pondéré de tâches.
ABSTRACT.Many real-time systems must simultaneously handle hard real-time constraints andQuality of Service constraints. Thus, a performance criterion must be optimized for some taskswhile meeting all deadlines for hard real-time tasks. For that purpose, we present a genericBranch & Bound method dedicated to hard real-time fixed-priority schedulers. Our approachis based on a generic algorithm that defines common functionsto any performance criteria.Only few functions need to be specialized to deal with a specific criterion. We then present sucha specialization for minimizing the weighted average response time of tasks.
MOTS-CLÉS :ordonnancement, priorités fixes, optimisation de performance.
KEYWORDS:scheduling, fixed-priority, performance optimization.
RSTI - TSI – 24/2005. Ordonnancement temps réel, pages 991 à 1011

992 RSTI - TSI – 24/2005. Ordonnancement temps réel
1. Introduction
L’utilisation d’ordinateurs pour le contrôle de systèmes critiques et temps réelconnaît un essor important ces dernières années. En conséquence de quoi, lessys-tèmes temps réel(systèmes informatiques dont la correction dépend des résultats descalculs et des instants auxquels ces résultats sont produits) sont devenus l’objet denombreuses études.
Puisque le concept detempsest si important dans les applications temps réel, etpuisque ces systèmes impliquent le partage d’une ou plusieurs ressources parmi diffé-rents processus concurrents, la question de l’ordonnancementdes tâches fait intégrale-ment partie de la conception et de l’analyse de ces systèmes.La théorie de l’ordonnan-cement, qui consiste à assigner les ressources disponiblesaux tâches, est un domainede recherche bien établi. Cependant, les tâches dans les environnements temps réelsont classiquement de nature récurrente. De tels systèmes sont typiquement modéliséspar une ensemble fini detâchesrépétitives, chaque tâche générant desinstancesde ma-nière prédictible. Pour chaque instance, nous disposons d’une borne supérieure pourson pire temps d’exécution et d’une échéance associée. Danscet article, nous considé-rons le cas de tâches périodiques qui réalisent des instances à intervalles périodiquesréguliers. Dans notre modèle de calcul, chaque tâcheτi périodique est caractérisée parle tuple(Ci, Di, Ti, wi), avec0 < Ci ≤ Di, Ci ≤ Ti etwi ≥ 0 (cette dernière hypo-thèse est importante pour améliorer les performances de notre méthode), c’est-à-dire,par une périodeTi, une échéance relative stricteDi, un pire temps d’exécutionCi
pour chaque instance, et un poidswi, indiquant l’importance vis-à-vis d’un critère dequalité de service ou de performance à optimiser. Les instances deτi sont séparées parTi unités de temps et apparaissent aux instants(k − 1)Ti (k = 1, 2, . . . ). L’exécutionde lak
e instance de la tâcheτi, qui débute après l’instant(k − 1)Ti, doit terminer sontravail avant ou à l’instant(k − 1)Ti + Di ; le non respect d’une échéance est fatalpour le système : les échéances sont supposées strictes. Tous les paramètres temporelsdans notre modèle de calcul sont supposés être des nombres naturels (cependant, lesgrandeurswi pourront être des nombres réels).
Des cas particuliers intéressants sont les systèmes àéchéance sur requête, oùl’échéance de chaque tâche coïncide avec la période (c’est-à-dire,Di = Ti ∀i, chaqueinstance doit se terminer avant l’occurrence de l’instancesuivante pour la mêmetâche), les systèmes àéchéances contraintes, où l’échéance n’est pas supérieure àla période (c’est-à-dire,Di ≤ Ti ∀i) et les systèmes àéchéances arbitraires, s’iln’y a pas de contraintes entre l’échéance et la période. Remarquons que si l’échéanceest supérieure à la période, il est parfaitement possible d’avoir plusieurs instances ac-tives1 simultanément pour une même tâche et un système ordonnançable. La théoriede l’ordonnancement pour les systèmes temps réel se focalise généralement sur lessolutions algorithmiques pour (i) l’analyse de faisabilité(déterminer s’il existe aumoins un ordonnancement pour lequel chaque instance respecte son échéance) et pour
1. Par définition, une instance est dite active entre son instant d’activation et son instant determinaison.

Optimisation de performance 993
(ii) l’ ordonnancement en-ligne(ordonnancer l’exécution des instances pendant la viedu système).
Dans certaines applications temps réel, les tâches doiventrespecter leurs échéanceset optimiser un critère de performance. Typiquement, de telles applications consi-dèrent une notion de qualité de service, par exemple en se basant sur les temps deréponse, les gigues, etc. Dans un tel environnement temps réel, l’objectif est doncd’optimiser un indice de performance tout en respectant leséchéances des instances.Le paramètrewi traduit l’importance que joue la tâcheτi dans le critère de perfor-mance. Si par exemple la tâcheτi ne doit pas être considérée dans le critère nouschoisironswi = 0, dans ce cas.
Dans la littérature, on distingue en général, deux types d’algorithme d’ordonnan-cement : les algorithmes àpriorité fixe (aussi appelés àpriorité statique) et ceux àpriorité dynamique. Les algorithmes à priorité fixe, assignent des priorités aux tâcheslors de la conception du système ; de plus, pendant l’exécution du système, chaqueinstancehérite de la priorité de sa tâche. Un exemple d’algorithme à priorité fixepopulaire, pour des tâches périodiques, estRM (Rate Monotonic (Liuet al., 1973)).Les algorithmes à priorité dynamique, assignent pendant l’exécution du système, despriorités aux instances.EDF (Earliest Deadline First (Liuet al., 1973)) est un telalgorithme.
Cette recherche. Dans cet article, nous nous intéressons à l’ordonnancementdetâches périodiques utilisant une assignation de priorité statique de manière à respectertoutes les échéances (si c’est possible) et optimiser (minimiser ou maximiser) un cri-tère de performance. Notons que la majorité des systèmes temps réel mis en œuvre re-pose sur une affectation de priorités statiques aux tâches.Notre contribution est triple :(i) nous proposons une procédure par séparation et d’évaluation (Branch and Bound)qui est générique dans la mesure où elle n’est pas dédiée à un critère de performanceparticulier, ni à un sous-modèle de tâches particulier (échéance sur requête, échéancecontrainte, etc.), ce problème est NP-difficile au sens fort(Richard, 2002), (ii) nousrésolvons un problème spécifique : la minimisation du temps de réponse moyen pourdes tâches périodiques à échéances contraintes. Ce critèrede performance permet deminimiser le travail en cours du système (Pan, 2003). En particulier, nous proposonsune borne inférieure basée sur les travaux de Redell (Redellet al., 2002), (iii) nousavons également complété le processus itératif, considérédans (Redellet al., 2002),afin de calculer le meilleur temps de réponse.
Organisation du document. La suite du document est organisée de la manièresuivante. Dans le paragraphe 2, nous présentons notre procédure générique par sépa-ration et d’évaluation. Dans le paragraphe 3, nous appliquons notre algorithme dansun cas spécifique : la minimisation du temps de réponse moyen pour des tâches pé-riodiques à échéances contraintes. Nous présentons également une évaluation expéri-mentale de notre technique dans le paragraphe 3.5 avant de conclure paragraphe 4.

994 RSTI - TSI – 24/2005. Ordonnancement temps réel
2. Méthode générique par séparation et d’évaluation
Les procédures par séparation et d’évaluation sont très utilisées pour résoudre desproblèmes combinatoires. Ces algorithmes sont basés sur l’idée d’énumérer « intelli-gemment » les solutions réalisables (Brucker, 2001). De tels algorithmes sont aussiutilisés pour ordonnancer des tâches sujettes à des contraintes temps réel strictes.Dans (Jonssonet al., 1997) une procédure par séparation et d’évaluation paramétrableordonnance des tâches soumises à des contraintes de précédence sur une plate-formemultiprocesseur afin de minimiser la plus grande latence destâches. Récemment,Pan (Pan, 2003), propose une procédure par séparation et d’évaluation qui ordonnancedes tâches non récurrentes et non préemptives afin de minimiser la somme totale pon-dérée des temps d’exécution des tâches.
Dans ce travail, nous nous concentrons sur l’affectation depriorités statiques (aussiappelées priorités fixes). Une solution partielle est une assignation partielle de prio-rités (c’est-à-dire, qu’il existe des tâches ayant reçues une priorité et des tâches sanspriorité). Le principe de l’énumération est basée sur l’exploration d’un arbre de re-cherche. Le nombre de façons différentes d’affecter des priorités fixes àn tâches estn!.
Chaque sommet de l’arbre de recherche correspond à une assignation de priorité.Les sommets sont des assignations partielles (à l’exception des feuilles) et sont sto-ckées dans l’arbre de recherche. La racine de l’arbre de recherche est un sommet fictifqui précède tous les autres sommets de l’arbre. Chaque sommet, autre que la racine,est associé à une tâche. Le niveau du sommet dans l’arbre de recherche correspondau niveau de priorité de la tâche correspondante. Ainsi, la tâche associée à un sommetde niveauk est affectée au niveau de prioriték. Le niveau 1 dans l’arbre de recherchecorrespond au niveau de priorité 1, qui est le plus élevé. Unefeuille de l’arbre est auniveaun de l’arbre de recherche et correspond au niveau de priorité le plus faible.Avec cette représentation de l’assignation des priorités,l’arbre de recherche énumèretoutes les façons d’affecter les priorités aux tâches. Chaque branche de la racine à unefeuille correspond à une solution du problème d’assignation des priorités aux tâches.
Puisque le problème d’optimisation est NP-difficile, la seule manière de trouverune solution en un temps acceptable est de détecter au plus tôt qu’un sommet ne peutpas mener à une amélioration par rapport à la meilleure solution déjà connue pourle critère de performance considéré. Sans nuire à la généralité, nous pouvons nousrestreindre à la minimisation d’un critère de performance (puisque maximiser unefonction objectiff est équivalent à minimiser−f ).
Une étape préliminaire à l’invocation de la procédure par séparation et d’évalua-tion consiste à estimer (par une heuristique) uneborne supérieurede notre fonctionobjectif. La mise en œuvre des procédures par séparation et d’évaluation se base gé-néralement sur un ensemble de sommets non visités, nous l’appelleronsl’ensembleactif. A chaque étape de la boucle principale de la procédure par séparation et d’éva-luation, le sommet exploré est séparé, autrement dit, ses sommets fils sont définis enassignant le niveau de priorité suivant à chacune des tâchescorrespondantes. Pour

Optimisation de performance 995
Algorithme 1. Méthode générique par séparation et d’évaluation
Calculer laborne supérieure ;Initialiser l’ensemble actifA avec les sommets1 . . . n (le premier niveau del’arbre) ;while A 6= ∅ do
Choisir un sommet deA avec larègle de sélection des sommets ;if c’est une feuille et le critère est amélioré (utilisantborne inférieure)then
mettre à jour la meilleure solution ;endelse ifce n’est pas une feuillethen
Générer l’ensembleB des fils du sommet en utilisant lastratégie deparcours;Calculer la borne inférieure pour chaque sommet deB (utilisantborneinférieure) ; Eliminer les sommets deB en utilisant larègled’élimination ;Trier les sommets deB de manière non décroissante par rapport à larègle de sélection des sommets ;Déplacer les sommets restants deB versA ;
endSupprimer le sommet sélectionné deA ;
end
chaque fils, uneborne inférieuredu critère est calculée. Ces sommets sont suppriméssi la borne inférieure du critère n’est pas plus petite que lameilleure solution connue(la borne dite supérieure) ou si les contraintes du problèmene sont pas satisfaites.L’algorithme 1 présente le pseudo-code de la méthode générique par séparation etd’évaluation.
La procédure par séparation et d’évaluation est basée sur les caractéristiques sui-vantes :
– règle de sélection des sommets : cette règle choisit le prochain sommet can-didat dans l’ensemble actif ; ce sommet est alorsséparé, c’est-à-dire que ses sommetsfils sont construits et évalués ;
– stratégie de parcours : il s’agit de la stratégie de parcours dans l’arbre derecherche ;
– borne supérieure : il s’agit d’une borne supérieure de la fonction objectif, cal-culée de manière préliminaire, afin d’obtenir une valeur atteignable pour le critèretout en respectant les contraintes du problème. La borne supérieure est ensuite miseà jour durant la recherche lorsqu’une feuille mène à une amélioration de la meilleuresolution connue ;

996 RSTI - TSI – 24/2005. Ordonnancement temps réel
– borne inférieure : cette borne est utilisée pour évaluer une solution partielle.Chaque fois que la borne inférieure de la fonction objectif n’est pas plus petite quela meilleure solution connue (borne supérieure), le sommet candidat est supprimé(par exemple ses fils ne sont pas crées dans l’arbre de recherche). Lorsqu’une feuilleest atteinte, la fonction objectif est calculée exactement, par exemple, en construisantl’ordonnancement en utilisant un simulateur d’algorithmeà priorité fixe ;
– règle d’élimination : cette règle vérifie que les sommets fils générés mènentà une solution réalisable (c’est-à-dire, que les contraintes d’échéances strictes sontsatisfaites). De plus, la règle vérifie que laborne inférieure n’est pas plus petite quela meilleure solution connue (borne supérieure). Chaque fois que ce n’est pas le cas,ces sommets et leurs fils ne seront pas considérés dans la recherche (ils sont supprimésde l’arbre de recherche).
Notons que l’optimalité de la méthode sera garantie si deux conditions sont res-pectées :
– la borne inférieure de la fonction objectif est non-décroissante,
– les règles d’élimination n’éliminent que des solutions pour lesquelles deséchéances strictes ne sont pas respectées.
Nous allons à présent détailler les caractéristiques des fonctions génériques. Avantcela nous définissons les principales notations utilisées dans la suite de l’article :
τ : configuration de tâchesn : nombre de tâches dans la configurationττj : tâche d’indicejTj : période de la tâcheτj
Dj : échéance relative de la tâcheτj
Cj : pire durée d’exécution de la tâcheτj
wj : nombre réel mesurant l’importance deτj
[i] : indice de la tâche affectée au niveau de priorité numéroiRj : pire temps de réponse de la tâchej
Rj(`) : borne inférieure du pire temps de réponse de la tâchej pour lesommet̀ de l’arbre de recherche
Rjk : temps de réponse de lake instance deτj
Rjk(`) : borne inférieure du pire temps de réponse de lake instance deτj
pour le sommet̀ de l’arbre de rechercheR̄j : temps de réponse moyen de la tâchej en considérant toutes ses instances
R̄(`) : borne inférieure du temps de réponse moyen pondérépour le sommet̀ de l’arbre de recherche
A : ensemble des sommets de l’arbre de recherche restant à explorer

Optimisation de performance 997
2.1. Règle de sélection des sommets
La règle de sélection des sommets définit le prochain sommet àséparer à partir del’ensemble actif. Des règles classiques sontFIFO (First-In First-Out), LIFO (Last-InFirst-Out) et LLB (Least Lower Bound).
2.2. Stratégie de parcours
La stratégie de parcours définit l’ordre dans lequel les sommets de l’ensembleactif seront traités. Différentes techniques mènent à différents parcours de l’arbre. Lesparcours en profondeur ou en largeur sont des exemples classiques. D’un point de vuealgorithmique, un parcours en profondeur revient à considérer l’ensemble actif commeune pile, alors qu’un parcours en largeur revient à considérer l’ensemble actif commeune file. Pour plus de commodité pour présenter la méthode, nous considérons dans lasuite disposer d’un arbre de recherche plutôt que d’une liste de sommets non explorésavec les assignations de priorités partielles correspondantes à chaque sommet.
Etant donné notre problème d’assignation de priorité, un sommet est caractérisépar un numéro de tâche. Le niveau d’un sommet dans l’arbre correspond à son niveaude priorité. Le premier niveau de l’arbre correspond aux tâches les plus prioritaires,et de la même manière, les feuilles de l’arbre correspondentaux tâches les moinsprioritaires. Le nombre de sommets de l’arbre de recherche est clairement exponentieldans la taille du problème. Puisque le nombre de sommets au niveauk est le nombre depermutations dek éléments parmin, le nombre de sommets au niveauk vaut n!
(n−k)! .
Dès lors, le nombre total de sommets de l’arbre de recherche vaut∑n−1
i=0
∏ik=0(n−k).
La stratégie de parcours a un impact important sur la taille maximale que peut at-teindre l’ensemble actif. La plus couramment utilisée est la stratégie en profondeur.L’intérêt principal de cette dernière est que la taille de l’ensemble actif est borné demanière polynomiale en fonction de la taille du problème. (Remarquons que ce n’estpas le cas des autres stratégies, en particulier pour le parcours en largeur). De cette ma-nière, le nombre maximum de sommets stockés simultanément dans l’ensemble actifestn(n + 1)/2. Cette valeur est toujours atteinte durant la recherche de la premièrefeuille dans l’arbre de recherche. La complexité en espace de notre méthode est doncΘ(n2). Afin de mettre en œuvre le parcours en profondeur, nous considérons que larègle de sélection estLIFO.
2.3. La borne supérieure
La première étape de la procédure par séparation et d’évaluation, consiste à ap-pliquer une méthode heuristique pour déterminer une première assignation de prioritéconduisant à un ordonnancement faisable. La valeur correspondante du critère de per-formance définira une borne supérieure.

998 RSTI - TSI – 24/2005. Ordonnancement temps réel
Les performances de l’algorithme dépendent de manière évidente de la précisionde la borne supérieure, cette dernière doit être la plus serrée possible. Sinon, la quasitotalité des sommets seront explorés. Pour cette raison, lechoix de la borne supérieure,et par conséquent l’efficacité de l’algorithme, est dépendante de la fonction objectif.
2.4. La borne inférieure
Une fonction objectif spécifique sera détaillée pour le temps de réponse moyenpondéré dans le paragraphe 3. La qualité de la borne inférieure a des conséquences trèsimportantes sur l’efficacité de l’algorithme pour prouver l’optimalité de la meilleuresolution connue. Par conséquent, sa définition dépend étroitement de la fonction ob-jectif.
Lorsqu’une feuille est atteinte, afin de calculer la valeur correspondante de lafonction objectif, un ordonnancement est construit sur l’intervalle[0, ppcmi=1...nTi),puisque nous savons que l’ordonnancement est périodique, de période ppcm{Ti|i =1, . . . , n} (consultez par exemple (Goossens, 1999), Corollaire 2.49,p. 47 pour unepreuve). La complexité de ce calcul est exponentielle.
2.5. La règle d’élimination
La règle d’élimination est capitale pour réduire significativement l’espace de re-cherche et éliminer des sommets dans l’arbre. Nous allons détailler dans la suite troisconditions génériques afin d’éliminer un sommet.
– la sélection immédiate ;
– la vérification des échéances ;
– la borne inférieure est plus grande que la meilleure solution connue (la bornesupérieure).
2.5.1. La sélection immédiate
La règle de sélection immédiate identifie les fils qui ne conduisent pas à une solu-tion ordonnançable, le résultat suivant définit une telle règle :
Théorème 1 (Richard, 2002) Pour toutes pairesτi, τj de tâches, si :⌈
Ti
Tj
⌉
× Cj + Ci > Di [1]
alors la condition : la priorité deτi est plus grande que celle deτj , est une conditionnécessaire pour l’ordonnançabilité du système.
Etant donné ce résultat, nous pouvons définir un ensemble de contraintes quidoivent être satisfaites durant chaque étape de sélection.Par exemple, si l’on identifie

Optimisation de performance 999
queτi doit avoir une priorité plus grande queτj suivant le théorème 1, alors la tâcheτi
doit être générée avantτj dans l’arbre de recherche. De plus,τj peut recevoir une prio-rité, si et seulement si,τi a déjà reçu une priorité. En pratique, une matrice est définieavant l’exécution de la procédure par séparation et d’évaluation proprement dit, quireprésente les contraintes de précédence définies par le théorème 1. Ces contraintesde précédence vont guider la génération des sommets lors du parcours de l’arbre derecherche. Il est facile de voir que ces contraintes peuventêtre calculées avant le débutde la phase d’optimisation et que la vérification du respect des contraintes de précé-dence à la séparation d’un sommet peuvent se faire en temps polynomial.
2.5.2. La vérification des échéances
Nous détaillons à présent la manière dont nous allons vérifier les échéances pour lesommet courant. La stratégie de parcours génère les sommetsfils à partir du sommetcourant tout en respectant la règle de sélection immédiate.Si le sommet de niveaui − 1 est séparé, alors tous ses fils seront associés au niveau de priorité i. La premièreétape est de vérifier que les tâches une fois assignées à ce niveau de priorité respectentleurs échéances. Puisque le sommet vient d’être séparé, nous savons que les tâches desniveaux de priorités1 . . . i−1 sont ordonnançables. Les autres tâches n’interfèrent pasavec l’exécution deτ[i]. Nous pouvons vérifier la faisabilité deτ[i] par le calcul du piretemps de réponse de chaque tâche.
Le pire temps de réponse d’une tâche peut être calculé en un temps pseudo-poly-nomial en utilisant la méthode présentée dans (Josephet al., 1986) pour des systèmesà échéances contraintes. Dans la partie générique de ce travail, nous considérons dessystèmes à échéances arbitraires. Une extension a été proposée pour calculer les piretemps de réponse pour ce type de tâche dans (Lehoczky, 1990; Tindell, 1994). Cetteméthode prend également un temps pseudo-polynomial puisqu’il dépend de la lon-gueur de la période d’activité du processeur de niveaui (c’est-à-dire, un intervalledurant lequel le processeur est occupé seulement par des tâches de priorité supérieureou égale ài). Notons que, à notre connaissance, la faisabilité pour uneassignationde priorité donnée ne peut pas être vérifiée en un temps polynomial (c’est-à-dire, lacomplexité en temps de ce problème est ouvert). Le pire tempsde réponse de la tâcheτ[i] dépend de la charge de travail induite par les tâches plus prioritaires. La demandedes tâches ayant une priorité plus grande quei à l’instantt dans une période d’activitécontenantq instances deτ[i] estW (t) :
W (t) = (q + 1)C[i] +
i−1∑
j=1
⌈
t
T[j]
⌉
C[j] [2]
Le pire temps de réponse deτ[i] est obtenu en considérantq = 1, 2 . . . et pourchaque valeur deq l’équation récurrentet = W (t) est résolue en recherchant defaçon itérative le plus petit point fixe de cette équation, plus formellement :

1000 RSTI - TSI – 24/2005. Ordonnancement temps réel
{
R(0)[i] = C[i]
R(k)[i] = W (R
(k−1)[i] )
[3]
R[i] = R(k)[i] = R
(k−1)[i] [4]
Les calculs s’arrêtent lorsque l’inégalité suivante est satisfaite :R[i] ≤ (q +1)T[i].
Pour résumer, nous utilisons la règle suivante :
Si R[i] > D[i] pour un sommet, alors il est supprimé, ainsi ses descendantsdansl’arbre de recherche ne seront pas construits et évalués.
Nous devons à présent considérer le cas des tâches qui n’ont pas reçu une priorité.Quelle que soit l’assignation de priorité des tâches qui ontdéjà une priorité, l’inter-férence de ces dernières est toujours identique pour les tâches « sans priorité ». Nousévaluons leur pire temps de réponse en les assignant au premier niveau de priorité dis-ponible (c’est-à-dire, le suivant puisque nous assignons les priorités de la plus grandeà la plus petite).
2.5.3. La borne inférieure
La dernière manière d’éliminer un sommet est de vérifier si lameilleure solutionconnue (c’est-à-dire la borne supérieure) est plus petite que la borne inférieure dusommet courant (pour un problème de minimisation). Puisquela génération de sesfils ne pourra qu’accroître la borne inférieure, alors continuer la recherche dans cettebranche ne permettra pas d’améliorer la meilleure solutionconnue.
Pour conclure, nous pouvons remarquer que tous ces tests peuvent être réalisésen temps pseudo-polynomial. Cette complexité est due au calcul du pire temps deréponse.
3. Le cas spécifique de la minimisation du temps de réponse moyen
Dans ce paragraphe, nous allons appliquer notre technique pour le cas suivant :nous considérons l’ordonnancement de tâches périodiques àéchéances contraintes etnous souhaitons minimiser le temps de réponse moyen, pondéré par le coefficientwi mesurant l’importance de la tâche vis-à-vis du critère. A notre connaissance, cecritère pondéré n’a jamais été étudié dans la littérature. Dans un article précédent, nousavons étudié le problème de minimisation de la somme des piretemps de réponses destâches (Richard, 2002). Ce critère capture seulement les performances moyennes despirestemps de réponse. Dans la suite, nous calculonsexactementle temps de réponsemoyen des tâches (c’est-à-dire, que nous considéronstoutesles instances de tâches).
Comme précisé dans l’introduction, ce critère de performance permet de minimi-ser le travail en cours dans le système (Pan, 2003). Minimiser le temps de réponse

Optimisation de performance 1001
moyen des instances est équivalent à minimiser la somme pondérée des dates d’achè-vement des tâches, puisque ces deux critères ne différent que d’un terme additif : lasomme des instants d’arrivé des instances. De plus, minimiser le temps de réponsemoyen a pour effet de minimiser le nombre moyen d’instances non achevées dansle système ainsi que le délai moyen d’attente avant qu’une instance débute son exé-cution (Baker, 1974). En d’autres termes, l’optimisation de ce critère permet d’avoirun système le plusréactif possible. Ce critère est notamment utilisé dans le contextedes bases de données temps réel. Les exécutions des transactions sont assujetties àdes échéances strictes. Une transaction peut être exécutéepar des utilisateurs ou defaçon automatique afin de mémoriser des valeurs acquises automatiquement via descapteurs. Outre le respect des échéances, le critère utilisé pour évaluer la qualité de ser-vice d’un système exploitant une base de données temps réel est le temps de réponsemoyen. Ce critère minimise la quantité de mémoire centrale simultanément utiliséepar les exécutions concurrentes des transactions (Aldarmiet al., 1998).
Lorsque les instances ne sont pas sujettes à des échéances strictes, minimiser letemps de réponse des instances pour un système mono-processeur est obtenu en ap-pliquant la stratégiesSRPT : Shortest Remaining Processing Time(Baker, 1974).Notons que de manière évidente, cette règle est loin d’être optimale si nous devonsrespecter des échéances. Enfin, notons aussi qu’il n’y aucunintérêt à ajouter destemps creux dans l’ordonnancement si nous souhaitons minimiser le temps de réponsemoyen (Baker, 1974).
Dans le paragraphe 3.1 nous présentons notre indice de performance, dans le para-graphe 3.2, l’assignation de priorités, dans le paragraphe3.3, la borne supérieure, dansle paragraphe 3.4 la borne inférieure afin d’éliminer des sommets, et nous présentonsdans le paragraphe 3.5 nos résultats expérimentaux.
3.1. Le critère d’optimisation
Dans la suite,Ri,k dénote le temps de réponse de lake instance deτi, R̄i désigne le
temps de réponse moyen des instances de la tâcheτi. Dans ce paragraphe, nous allonsappliquer notre technique afin de minimiser le temps de réponse moyen pondéré avecla définition suivante :
R̄def= lim
f→∞
1
f
n∑
i=1
f∑
j=1
wi · Ri,j [5]
Premièrement, nous simplifions l’équation 5. Puisque les tâches sont périodiques,
nous savons que l’ordonnancement lui-même est périodique,sa période vautHdef=
ppcm{Ti | i = 1, . . . , n}. De plus, puisque nous considérons un système à départsimultané, le comportement périodiques de l’ordonnancement débute à l’instant0. Parconséquent, pour̄Ri (le temps de réponse moyen des instances deτi), nous obtenons :

1002 RSTI - TSI – 24/2005. Ordonnancement temps réel
R̄i = limk→∞
Ti
k · H
k·H/Ti∑
j=1
Ri,j =Ti
H
H/Ti∑
j=1
Ri,j [6]
Dès lors, notre critère d’optimisation est :
R̄ =
n∑
i=1
wi · Ti
H
H/Ti∑
j=1
Ri,j
[7]
3.2. L’assignation de priorités
Notre algorithme, assigne les priorités du plus prioritaire au moins prioritaire. Unsommet dans l’arbre de recherche correspond à une tâche, sonniveau correspond à sapriorité. Pour chaque sommet (exception faite des feuilles) nous évaluons une borneinférieure du critère (avec un algorithme pseudo-polynomial). Pour les feuilles, nouscalculons exactement la valeur du critère (c’est-à-dire, nous réalisons un calcul exactdu temps de réponse de chaque instance en construisant l’ordonnancement par simu-lation).
3.3. La borne supérieure
Nous considérons des tâches à départ simultané et échéancescontraintes pour les-quellesDM (deadline monotonic algorithm) est une assignation de priorités optimalepour le respect des échéances. Mais cette assignation de priorités n’est évidemmentpas optimale pour optimiser le temps de réponse moyen. Cependant, cette assignationde priorités mène à un ordonnancement faisable (s’il en existe un), et peut être utiliséepour calculer la borne supérieure.
Une meilleure approche, est l’utilisation de l’algorithmedéfini dans (Audsley,1991). Nous allons proposer un algorithme qui fournira toujours une solutionmeilleure que l’ordonnancementDM, vis-à-vis du critère optimisé. Nous assignonsles priorités dans l’ordre inverse, se basant sur la propriété suivante :
Lemme 1 (Audsley, 1991) Si une tâcheτi estordonnançable au niveau de priorité leplus faible(c’est-à-dire que si l’on donne la plus basse priorité àτi, et une prioritéplus élevée aux autres tâches dans une ordre quelconque, toutes les instances deτi
respectent leur échéance) alors il existe une assignation faisable de priorité pourτssi il existe une assignation faisable de priorité pourτ \ {τi}.
L’heuristique assigne les priorités aux tâches de la moins prioritaire jusqu’à laplus prioritaire et choisit à chaque étape, une tâche qui augmente le moins possible

Optimisation de performance 1003
le critère de performance parmi les tâches ordonnançables àce niveau de priorité. Aune étape donnée, l’algorithme choisit la tâche ayant le plus petit poids (et n’ayantpas encore reçu de priorité) parmi les tâches ordonnançables à ce niveau de priorité.Une conséquence directe du Lemme 1 est que l’heuristique trouvera toujours une as-signation faisable (s’il en existe une conduisant à un ordonnancement faisable). Dansl’algorithme 2, nous donnons le pseudo-code de l’heuristique, déterminant une bornesupérieure du critère. Le calcul des tâches ordonnançablesà un niveau de priorité estpseudo-polynomial puisque les temps de réponses des tâchesdoivent être calculés.
Algorithme 2. Calcul de la borne supérieureSoitX l’ensemble des tâches etn le nombre de tâches ;while X 6= ∅ do
SoitX ′ les tâches ordonnançables au niveau de prioritén parmi celles del’ensembleX ;Soita la tâche avec le plus petit poids de l’ensembleX ′ ;Assigner la prioritén àa ;n = n − 1;X = X \ {a} ;
endCalculer la fonction objectif pour l’assignation de priorité obtenue ;
3.4. La borne inférieure
Dans ce paragraphe, nous allons caractériser la borne inférieure (et un processusitératif pour son évaluation) de notre critère. Nous allonsdistinguer le cas des tâchesqui ont déjà reçu une priorité (tâches avec priorités) et celles qui n’ont pas encore reçuune priorité (tâches sans priorités).
3.4.1. Tâches avec priorités
Nous considérons la tâcheτ[i] et supposons que cette tâche a déjà reçu une priorité(le niveaui par définition).
Définissons, dans l’intervalle[0, H) :
– Rmax[i] le plus grand temps de réponse parmi les instances deτi ;
– Rmin[i] le plus petit temps de réponse parmi les instances deτi.
Théorème 2 Le temps de réponse moyen d’une tâche affectée au niveau de priorité i(c’est-à-dire,τ[i]) vérifie l’inéquation suivante :
R̄[i] ≥T[i]
H
(
(H
T[i]− 1) · Rmin
[i] + Rmax[i]
)
De plus, cette borne est serrée.

1004 RSTI - TSI – 24/2005. Ordonnancement temps réel
Démonstration : nous considérons le cas optimiste où( HT[i]
− 1) instances deτ[i] ont
un temps de réponse égal àRmin[i] et une seule instance a un temps de réponse égal à
Rmax[i] .
Puisque les tâches sont à départ simultané et à échéance contrainte, la premièreinstance deτ[i] est activée à un instant critique conduisant exactement au temps deréponseRmax
[i] . Toutes les autres exécutions ne peuvent pas avoir un temps de réponse
plus petit queRmin[i] . En conséquence, l’inégalité est vérifiée sur une hyperpériode et
donc de façon équivalente sur toute la durée de l’ordonnancement.
Nous montrons maintenant que la borne proposée est serrée, c’est-à-dire que l’in-égalité devient alors une égalité. Pour cela il suffit de considérer un exemple avecdeux tâches à échéance sur requête et à départs simultanésτ[1] etτ[2] avec les caracté-ristiques suivantes :
C[1] = C[2] = 1
T[1] = 2T[2]
La longueur de l’hyperpériode estH = T[1]. Dans l’ordonnancement, la premièreinstance deτ[2] obtient la valeurRmax
[2] = 2, puisqu’elle est réveillée en même tantqueτ[1] qui est plus prioritaire, tandis que la seconde instance deτ[2] s’exécute sansinterférence avecτ[1], et en conséquence obtient un temps de réponseRmin
[2] = C[2] =1. Nous avons donc :
R̄[2] =T[2]
H
(
(H
T[2]− 1) · Rmin
[2] + Rmax[2]
)
La borne est donc serrée.
Notons que puisque nous connaissons les tâches plus prioritaires queτ[i], Rmax[i]
est la plus petite solution positive de l’équation (consulter (Josephet al., 1986) pourune preuve) :
Rmax[i] = C[i] +
i−1∑
j=1
⌈
Rmax[i]
T[j]
⌉
· C[j] [8]
Le calcul deRmax[i] est un calcul exact puisque les tâches sont à départ simultané
et à échéance contrainte. Cela ne sera pas le cas pour évaluerRmin[i] , comme nous le
montrons maintenant. Le calcul deRmin[i] est plus complexe, à partir de (Redellet
al., 2002) nous définissons une borne inférieure pour le meilleur temps de réponse(une borne plus précise que de considérerC[i]), nous désignons parRlb
[i] cette borneinférieure, qui est la plus grande solution positive de l’équation
Rmin[i] = C[i] +
i−1∑
j=1
⌈
max{Rmin[i] − T[j], 0}
T[j]
⌉
· C[j] [9]

Optimisation de performance 1005
Un processus itératif peut être défini pour calculer le plus petit point fixe :
Rmin,(0)[i] = init
Rmin,(k)[i] = C[i] +
i−1∑
j=1
max{Rmin,(k−1)[i] − T[j], 0}
T[j]
· C[j]
Dans les travaux de Redell (Redellet al., 2002), aucune valeur n’est donnée pourinit, nous complétons à présent le résultat. La suite définit ci-dessus doit impérative-ment être initialisée par une borne supérieure du meilleuretemps de réponse afin d’as-surer la convergence vers une borne inférieure du meilleur temps de réponse (Redellet al., 2002). Nous obtenons une telle borne de la façon suivante :
Rmin,(k)[i] = C[i] +
i−1∑
j=1
max{Rmin,(k−1)[i] − T[j], 0}
T[j]
· C[j]
≤ C[i] +
i−1∑
j=1
max{Rmin,(k−1)[i] − T[j], 0}
T[j]
· C[j]
≤ C[i] +
i−1∑
j=1
Rmin,(k−1)[i]
T[j]
· C[j]
≤C[i]
1 −∑i−1
j=1C[j]
T[j]
Par conséquent, nous proposons le processus itératif complet :
Rmin,(0)[i] =
C[i]
1 −∑i−1
j=1C[j]
T[j]
Rmin,(k)[i] = Ci +
i−1∑
j=1
max{Rmin,(k−1)[i] − T[j], 0}
T[j]
· C[j]
Afin, de garantir que le calcul de cette borne inférieure respecte bien les conditionsd’optimalité de la méthode, nous vérifions que :

1006 RSTI - TSI – 24/2005. Ordonnancement temps réel
Lemme 2 Pour tout couple de sommetsa et b de l’arbre de recherche tels quea ≺ b,nous vérifions pour toute tâche assignée au niveau de priorité [i] :
Rmin[i] (a) ≤ Rmin
[i] (b)
La preuve résulte de la définition de l’équation 9 et du principe itératif de la re-cherche du plus petit point fixe de cette équation.
3.4.2. Tâches sans priorité
Nous considérons à présent le cas oùτi n’a pas encore reçu une priorité pour unsommet de l’arbre de recherche. Soit` ce sommet oùp tâches possèdent une prio-rité. Alors les temps de réponses des tâches sans priorités sont évalués en supposantqu’elles sont affectées au niveau de prioritép + 1. Nous vérifions donc :
Lemme 3 Pour tout couple de sommeta et b de l’arbre de recherche tel quea ≺ b etpour toute tâcheτi sans priorité pour le sommeta nous avons :
Rmin[i] (a) ≤ Rmin
[i] (b)
Rmax[i] (a) ≤ Rmax
[i] (b)
(Remarquons que la tâcheτi peut avoir une priorité pour le sommetb ou non).
La preuve résulte du calcul itératif du temps de réponse dansles équations 8 et 9.
La borne inférieure évaluée pour chaque sommet` non feuille de l’arbre de re-cherche (c’est-à-dire, toutes les tâches ne sont pas assignées à des niveaux des priori-tés) est calculée par l’équation suivante :
R̄(`) =
n∑
i=1
wi · Ti
H
(
(H
Ti− 1) · Rmin
i (`) + Rmaxi (`)
)
[10]
Le calcul de la borne inférieure du pire temps de réponse, lorsque les tâches nesont pas toutes assignées à des niveaux de priorité, est pseudo-polynomial. Cette com-plexité résulte du calcul du plus petit point fixe pour déterminerRmax
[i] etRmin[i] .
Nous montrons maintenant que la condition d’optimalité de méthode sur le critèrede performance optimisé est respectée :
Théorème 3 Soienta et b deux sommets de l’arbre de recherche tels quea ≺ b,alors l’évaluation de la borne inférieure du temps de réponse moyen pondéré vérifiela propriété suivante :
a < b ⇒ R̄i(a) ≤ R̄i(b)
Démonstration : ce résultat découle directement des lemmes 2 et 3.

Optimisation de performance 1007
3.4.3. Evaluation des feuilles
Pour terminer, le principe d’évaluation des feuilles de l’arbre ne repose pas sur descalculs de bornes inférieures du meilleur et du pire temps deréponse. Alors̄Ri, ∀i, 1 ≤i ≤ n, est obtenu en construisant l’ordonnancement par simulation de l’ordonnanceurà priorité fixe de l’exécutif temps réel. Ce calcul est donc exact, mais le volume descalculs est exponentiel puisqu’il est proportionnel au ppcm des périodes des tâches.
L’évaluation de chaque feuille de l’arbre de recherche permet de mettre à jour laborne supérieure du critère (c’est-à-dire, la valeur de la meilleure solution connue).A chaque séparation d’un sommet, les bornes inférieures du temps de réponse moyensont calculés et comparés à la valeur courante de la borne supérieure.
3.5. Résultats expérimentaux
Nous avons évalué notre technique sur des ensembles de tâches périodiques àéchéance sur requête générés de manière (pseudo-)aléatoire. Pour un nombre de tâchesdonné, nous avons évalué 25 instances du problème. Les problèmes comportent entre7 et 29 tâches. Nous avons constaté expérimentalement que lorsque la charge proces-seur est forte alors il existe peu d’ordonnancements faisables et l’algorithme déter-mine rapidement l’absence de solution ; lorsque la charge processeur est faible alorsles contraintes temporelles sont faibles et les techniquesde coupes sur ces critères nesont pas sollicitées. Ceci nous a amené à fixer le facteur d’utilisation du processeur àenviron 50 % pour toutes les instances de problèmes générés aléatoirement.
Nous avons utilisé une loi uniforme pour notre générateur pseudo-aléatoire et lesparamètres de génération des instances sontCi ∈ [1, 10], Di = Ti sont calculés demanière à avoir une utilisation proche d’un demi, etwi ∈ [0, 20]. L’expérimentation aété réalisée sur un Pentium IV/3,2 GHz. Nous avons fixé un temps limite d’une heurepour la résolution de chaque instance.
La figure 1 illustre le temps moyen de résolution pour chaque taille du problèmepour les instances résolues et pour toutes les instances (pour les instances résolues ounon). Pour les instances résolues le temps moyen de résolution est très court puisqu’iln’excède pas 600 secondes. Par contre, pour des instances composées de 25 tâches, letemps limite a été atteint pour chaque instance, sans jamaisprouver l’optimalité de lasolution atteinte.
La figure 2 illustre le pourcentage d’instances résolues contre le pourcentage d’ins-tances non résolues. Nous pouvons remarquer que toutes les instances de moins de 15tâches ont été résolues à l’optimum, mais par contre, aucunede plus de 25 tâches n’apu être résolue de manière optimale dans la limite de temps imposée. On constatede plus que le nombre d’instances non résolues dans l’intervalle augmente très ra-pidement puisqu’au delà de 20 tâches moins de 20 % des instances sont résolues àl’optimum.
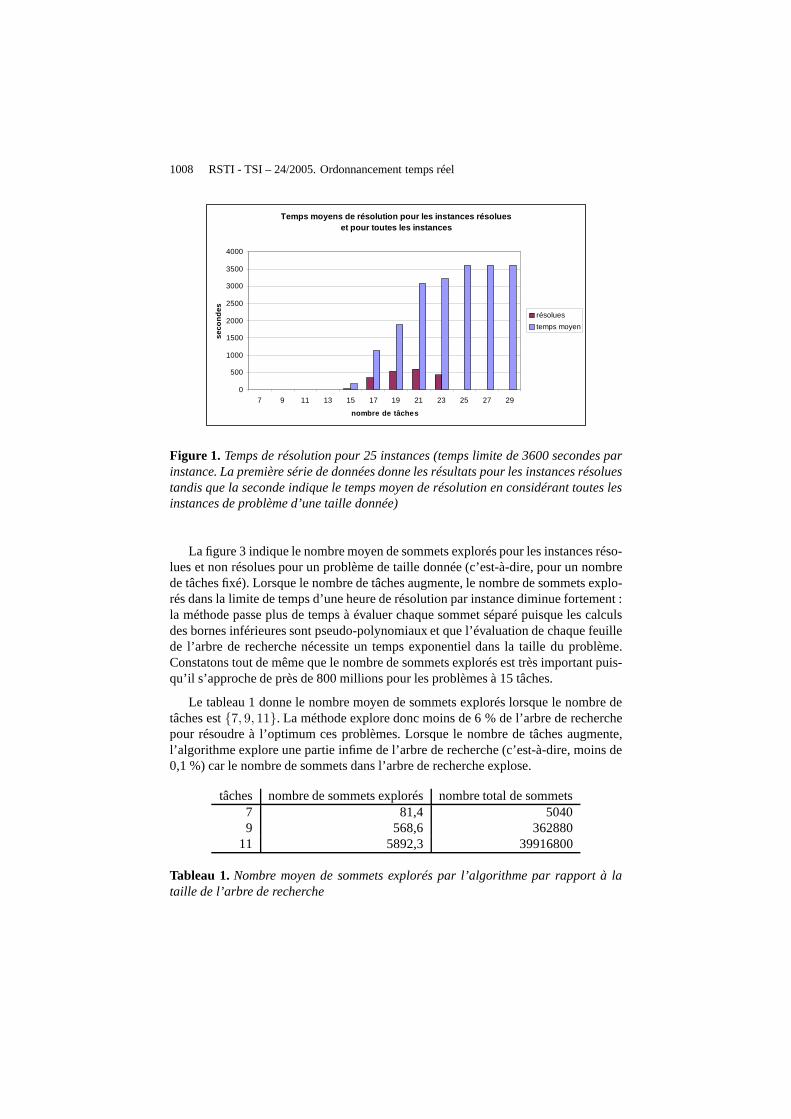
1008 RSTI - TSI – 24/2005. Ordonnancement temps réel
Temps moyens de résolution pour les instances résol ues et pour toutes les instances
0
500
1000
1500
2000
2500
3000
3500
4000
7 9 11 13 15 17 19 21 23 25 27 29
nombre de tâches
seco
ndes résolues
temps moyen
Figure 1. Temps de résolution pour 25 instances (temps limite de 3600 secondes parinstance. La première série de données donne les résultats pour les instances résoluestandis que la seconde indique le temps moyen de résolution enconsidérant toutes lesinstances de problème d’une taille donnée)
La figure 3 indique le nombre moyen de sommets explorés pour les instances réso-lues et non résolues pour un problème de taille donnée (c’est-à-dire, pour un nombrede tâches fixé). Lorsque le nombre de tâches augmente, le nombre de sommets explo-rés dans la limite de temps d’une heure de résolution par instance diminue fortement :la méthode passe plus de temps à évaluer chaque sommet séparépuisque les calculsdes bornes inférieures sont pseudo-polynomiaux et que l’évaluation de chaque feuillede l’arbre de recherche nécessite un temps exponentiel dansla taille du problème.Constatons tout de même que le nombre de sommets explorés esttrès important puis-qu’il s’approche de près de 800 millions pour les problèmes à15 tâches.
Le tableau 1 donne le nombre moyen de sommets explorés lorsque le nombre detâches est{7, 9, 11}. La méthode explore donc moins de 6 % de l’arbre de recherchepour résoudre à l’optimum ces problèmes. Lorsque le nombre de tâches augmente,l’algorithme explore une partie infime de l’arbre de recherche (c’est-à-dire, moins de0,1 %) car le nombre de sommets dans l’arbre de recherche explose.
tâches nombre de sommets explorésnombre total de sommets7 81,4 50409 568,6 362880
11 5892,3 39916800
Tableau 1.Nombre moyen de sommets explorés par l’algorithme par rapport à lataille de l’arbre de recherche
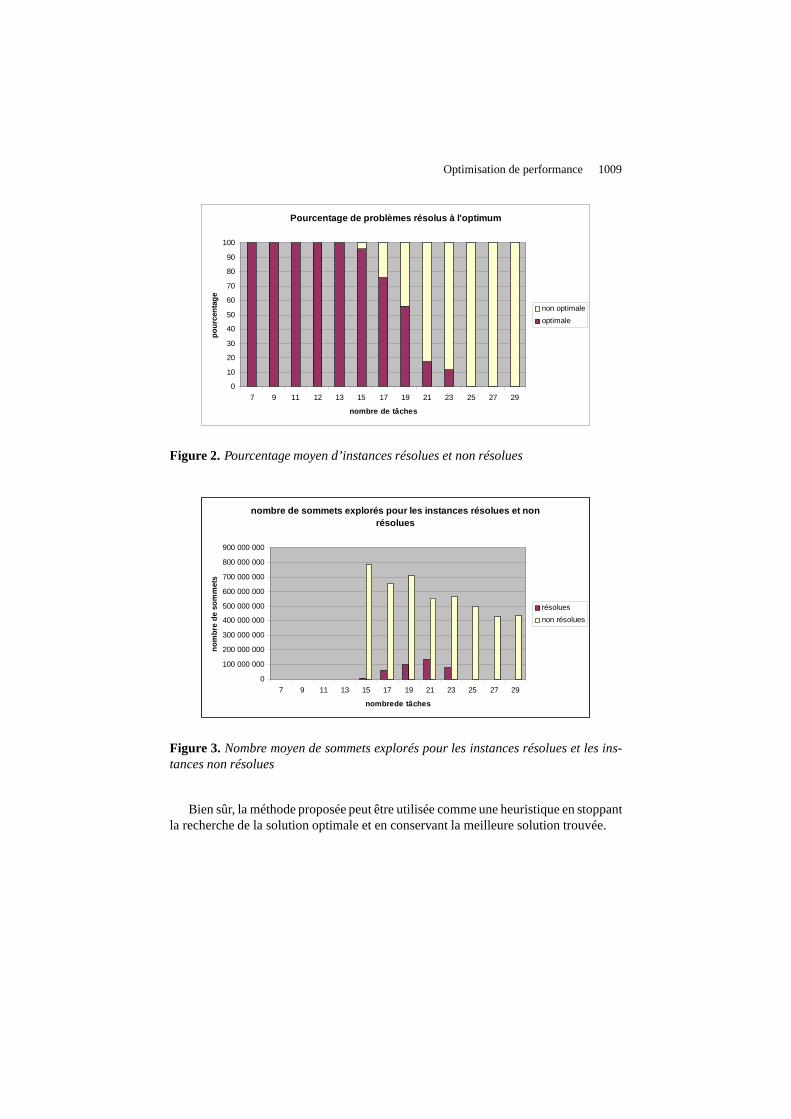
Optimisation de performance 1009
Pourcentage de problèmes résolus à l'optimum
0
10
20
30
40
50
60
70
80
90
100
7 9 11 12 13 15 17 19 21 23 25 27 29
nombre de tâches
pour
cent
age
non optimale
optimale
Figure 2. Pourcentage moyen d’instances résolues et non résolues
nombre de sommets explorés pour les instances résol ues et non résolues
0
100 000 000
200 000 000
300 000 000
400 000 000
500 000 000
600 000 000
700 000 000
800 000 000
900 000 000
7 9 11 13 15 17 19 21 23 25 27 29
nombrede tâches
nom
bre
de s
omm
ets
résolues
non résolues
Figure 3. Nombre moyen de sommets explorés pour les instances résolues et les ins-tances non résolues
Bien sûr, la méthode proposée peut être utilisée comme une heuristique en stoppantla recherche de la solution optimale et en conservant la meilleure solution trouvée.

1010 RSTI - TSI – 24/2005. Ordonnancement temps réel
4. Conclusion
De nombreux systèmes temps réel doivent conjointement respecter des contraintestemporelles et assurer une certaine qualité de service. Dèslors, un critère de per-formance doit être optimisé et les échéances doivent être respectées. Dans cette op-tique, nous avons présenté une méthode par séparation et d’évaluation dédiée pourles systèmes temps réel stricts à priorité fixe. Notre approche est basée sur un algo-rithme générique qui utilise des fonctions communes quel que soit le critère de perfor-mance visé. Nous avons présenté une spécialisation de la méthode, afin de minimiserle temps de réponse moyen pondéré des tâches périodiques à activations simultanéeset à échéances contraintes.
Dans des travaux futurs, nous souhaitons :
– mettre en œuvre deux modules : une boîte à outils, permettant aux développeursd’ajouter des fonctions spécifiques pour ses indices de performance; une interfacegraphique afin qu’un utilisateur puisse, spécifier son problème, intégrer ses fonctionsspécifiques, définir des expérimentations numériques, et ceci de manière indépendantedu critère d’optimisation considéré ;
– étendre la méthode pour tenir compte des ressources partagées, des contraintesde précédence. . .
Remerciements
Les auteurs tiennent à remercier les lecteurs anonymes pourleurs remarquesconstructives et leurs encouragements.
5. Bibliographie
Aldarmi S. A., Burns A., Real-Time Database Systems : Concepts and Design, Technical Reportn˚ YCS 303, Department of Computer Science, University of York, 1998.
Audsley N., Optimal priority assignment and feasibility ofstatic priority assignment with arbi-trary start times, Technical Report n˚ YCS 164, Department of Computer Science, Univer-sity of York, 1991.
Baker K.,Introduction to sequencing and scheduling, John Wiley and Sons, 1974.
Brucker P.,Scheduling algorithms, Springer Verlag, 2001.
Goossens J., Scheduling of Hard Real-Time Periodic Systemswith Various Kinds of Deadlineand Offset Constraints, PhD thesis, Université Libre de Bruxelles, Belgique, 1999.
Jonsson J., Shin K., « A parametrized Branch and Bound strategy for scheduling precedence-constrained tasks on a multiprocessor system »,proc. Int. Conf. on Parallel Processing,p. 158-165, 1997.
Joseph M., Pandya P., « Finding Response Times in a Real-TimeSystem »,The ComputerJournal, vol. 29, n˚ 5, p. 390-395, October, 1986.

Optimisation de performance 1011
Lehoczky J. P., « Fixed Priority Scheduling of Periodic TaskSets with Arbitrary Deadlines »,IEEE Real-Time System Symposium, 1990.
Liu C., Layland J., « Scheduling Algorithms for Multiprogramming in a Hard Real-Time Envi-ronment »,Journal of the ACM, vol. 20, n˚ 1, p. 46-61, 1973.
Pan Y., « An improved branch and bound algorithm for single machine scheduling with dead-lines to minimize total weighted completion time »,Operations Reseach Letters, vol. 31,p. 492-496, 2003.
Redell O., Sanfridson M., « Exact best-case response time analysis of fixed-priority scheduledtasks »,Euromicro Real-Time Systems, 2002.
Richard P., « Controlling response time in real-time systems »,Computer Performance Evalua-tion : Modelling Techniques and Tools, LNCS 2324, Springer Verlag, p. 339-348, 2002.
Tindell K., Fixed-Priority Scheduling of Hard Real-Time Systems, PhD thesis, University ofYork, UK, 1994.
Article reçu le 16 juin 2004Version révisée le 12 avril 2005
Joël Goossensest chargé d’enseignement à l’Université Libre de Bruxelles. Il enseigne l’algo-rithmique, la programmation, les bases de données, les compilateurs et la gestion des processusdans les systèmes d’exploitation. Ses travaux de rechercheconcernent la théorie de l’ordonnan-cement pour les systèmes temps réel et les performances des grilles de calcul.
Pascal Richardest maître de conférences à l’IUT de Poitiers. Ses travaux derecherche s’ef-fectuent au sein de l’équipe Analyse et Modélisation des Systèmes Temps Réel du Laboratoired’Informatique Scientifique et Industrielle (LISI) de Poitiers et portent sur l’ordonnancementdes tâches dans les systèmes temps réel.


















