
Apprentissage Statistique, Modélisation, Prévision, Data Mining

Knowl Inf SystDOI 10.1007/s10115-013-0660-8
REGULAR PAPER
Mining non-derivable hypercliques
Anna Koufakou
Received: 16 October 2012 / Revised: 1 March 2013 / Accepted: 6 April 2013© Springer-Verlag London 2013
Abstract A hyperclique (Xiong et al. in Proceedings of the IEEE international conferenceon data mining, pp 387–394, 2003) is an itemset containing items that are strongly corre-lated with each other, based on a user-specified threshold. Hypercliques (HCs) have beensuccessfully used in a number of applications, for example, clustering (Xiong et al. in Pro-ceedings of the 4th SIAM international conference on data mining, pp 279–290, 2004) andnoise removal (Xiong et al. in IEEE Trans Knowl Data Eng 18(3):304–319, 2006). Eventhough HC has been shown to respond well to datasets with skewed support distribution andlow support threshold, it may still grow very large for dense datasets and lower h-confidencethreshold. In this paper, we propose a new pruning method based on combining HCs andnon-derivable itemsets (NDIs) (Calders and Goethals in Proceedings of the PKDD interna-tional conference on principles of data mining and knowledge discovery, pp 74–85, 2002)in order to substantially reduce the amount of generated HCs. Specifically, we propose anew collection of HCs, called non-derivable hypercliques (NDHCs). The NDHC collectionis a lossless representation of HCs, that is, given the itemsets in NDHCs, we can generatethe complete HC collection and their support, without additional scanning of the dataset.We present an efficient algorithm to mine all NDHC sets, NDHCMiner, and an algorithmto derive all HC sets and their support from NDHCs, NDHCDeriveAll. We experimentallycompare our collection, NDHC with HC, with respect to runtime performance as well astotal number of generated sets, using real and artificial data. We also show comparisonswith another condensed representation of HCs, maximal hyperclique patterns (MHPs). Ourexperiments show that the NDHC collection offers substantial advantages over HCs, andeven MHPs, especially for dense datasets and lower h-confidence values.
Keywords Hyperclique · Non-derivable itemset · Frequent itemset mining · Dense data ·Skewed support distribution
A. KoufakouU.A. Whitaker College of Engineering, Florida Gulf Coast University, Fort Myers, FL, USAe-mail: [email protected]
123

A. Koufakou
1 Introduction
Frequent itemset mining (FIM) has attracted substantial attention since the seminal paperby Agrawal and Srikant [1] introduced the Apriori algorithm, which is recognized today asone of the ten most influential data mining algorithms [20]. FIM aims to extract patternsor itemsets, sets of items that co-occur frequently in the dataset, based on a user-enteredthreshold of support, σ .
As discussed in [26], the frequent itemsets generated by an FIM algorithm may con-tain items that are weakly related to each other. Furthermore, there might be many spu-rious combinations of items if a low σ threshold is used and the frequency distributionof items is skewed. Finally, when the σ threshold is set to a high value, strong affin-ity itemsets involving items with low support levels are missed. To address these issues,a hyperclique pattern [26] was proposed as a new type of association pattern that con-tains items that are highly affiliated with each other. Specifically, the presence of anitem in one transaction strongly implies the presence of every other item that belongs tothe same hyperclique. The h-confidence measure captures the strength of this associationand is defined as the minimum confidence of all association rules containing an item-set.
An itemset is a hyperclique HC if the h-confidence of this itemset is greater thanhc, a user-specified threshold. A hyperclique pattern is a maximal hyperclique if nosuperset of this pattern is a hyperclique [11]. HCs can be generated at extremely lowlevels of support in dense datasets and have been shown to be useful in a num-ber of applications. For example, the authors in [22] used hypercliques to filter outnoisy objects, in order to improve performance of clustering as well as association rulemining.
Hypercliques have been shown to work well for large data and low support threshold;however, they might still face problems for dense datasets, e.g. census data, especially as hc
decreases. For example, for the Pumsb dataset, with σ = 0 and hc = 0.7, over 3 million HCsare generated (see Sect. 5). Dense datasets contain many strong correlations and are typicallycharacterized by long transactions and many items with high frequency [29]. Usually, densedatasets result in very long frequent itemsets even for large support thresholds; conversely,datasets such as market basket data, are defined as sparse, with relatively short transactions,and not highly correlated items [16].
This is a known problem for FIM algorithms, which perform well with sparse datasets,such as market basket data, but face problems for dense data [29]. To solve this issue, muchwork has been done toward obtaining condensed representations of frequent itemsets (CFIs).The goal of these methods is to generate a smaller collection of representative sets, fromwhich all FIs can be deduced. Many CFIs have been proposed, e.g. maximal, closed, δ-free,non-derivable (see [5] for a CFI survey).
The purpose of this paper is to propose a way to reduce the size of HC. Specifically, in thispaper, we propose a new collection of itemsets, non-derivable hypercliques (NDHCs). Thiscollection is a condensed representation of hypercliques based on a well-known condensedrepresentation of frequent itemsets, non-derivable itemsets (NDIs) proposed in [2]. NDIs havebeen shown to lead to large performance gains over FIs [4] and have recently been appliedsuccessfully to Outlier Detection [14,15]. Similar to NDIs that are a lossless representationof all FIs, our proposed collection, NDHC, is a lossless representation of HCs: that is, allHCs and their individual support can be generated given NDHC, without additional scans ofthe dataset.
123

Mining non-derivable hypercliques
We summarize the contribution of our work as follows:
– We propose a lossless condensed representation of hypercliques [26], which has notbeen proposed before to the best of our knowledge. Our proposed representation, callednon-derivable hypercliques (NDHCs), is based on non-derivable itemsets (NDIs) [2].
– We compare our proposed representation, NDHC, with the original HC [26] with respectto runtime performance and total generated sets, using real and artificial datasets andvarious parameter values. Additionally, we present runtime results for deriving all HCsand their support from the NDHC collection. Our experimental results show that theNDHC collection is significantly smaller than the HC collection. The gains of using theNDHC collection over the HC collection become more significant for dense datasets,such as census data, and lower hc values.
– We also compare our proposed representation, NDHC, with maximal hyperclique patterns(MHPs), an existing condensed representation of HCs [11]. The NDHC collection growsmuch slower than MHP for dense data as hc decreases. Moreover, the sets in HC andtheir support can be generated from our proposed collection, NDHC, but only the sets inHC, not their support, can be generated from MHP.
Preliminary results of our work were presented in [13]. The current paper contains exten-sive discussion including properties of NDHC, a detailed description of our proposed algo-rithms, NDHCMiner and NDHCDeriveAll, as well as further experimentation, with additionaldatasets.
The organization of this paper is as follows: Sect. 2 summarizes previous relatedwork. Section 3 describes hypercliques (HCs) and non-derivable itemsets (NDIs). Section 4describes our proposed collection, non-derivable hypercliques (NDHCs) and its properties, aswell as an efficient algorithm to mine all NDHC sets, NDHCMiner, and an algorithm that gen-erates all hypercliques and their individual support from the sets in NDHC, NDHCDeriveAll.Section 5 contains our experiments and results, and Sect. 6 summarizes our work and providesconcluding remarks.
2 Related work
Hyperclique patterns were introduced in [26], and their properties and applications werediscussed in detail in [27]. The authors in [18] showed how to extend hyperclique patternsfor continuous data by using a generalized notion of support. A hybrid approach for min-ing maximal hyperclique patterns (MHPs) was presented in [11]. An algorithm for miningmaximal hyperclique patterns in datasets containing quantitative attributes was presented in[10].
An algorithm for hierarchical clustering using hypercliques, called Hierarchical Clusteringwith pAttern Preservation (HICAP), was proposed in [25]. A data cleaning method basedon hypercliques, HCleaner, was proposed in [22] in order to remove noise with the goal toproduce better clustering performance and higher quality associations; noise was defined asirrelevant or weakly relevant objects to be removed before data analysis. An unsupervisedclustering algorithm that selects constraints automatically based on hyperclique patternscalled HP-KMEANS was presented in [6].
The authors in [21] applied hypercliques to the identification of functional modules in pro-tein complexes. Hyperclique-based transformations of biological data were presented in [17]with the aim to enhance the performance of standard protein function prediction algorithms.The authors in [23] proposed a hyperclique pattern based semi-supervised learning (HPSL)
123

A. Koufakou
with the goal to predict privacy leakage in multi-relational databases. Hyperclique patternswere used in [9] to detect unauthorized access to off-topic documents. The HICAP algorithmfrom [25] was compared with the bisecting K-means Clustering with pAttern Preservation(K-CAP) algorithm in [24].
Much work has been conducted toward condensed representations of frequent itemsets(CFIs). The goal of these methods is to generate a smaller collection of representative sets,from which all frequent itemsets can be deduced. Many CFIs have been proposed, e.g.maximal, closed, δ-free, non-derivable (see [5] for a CFI survey). In this paper, we usenon-derivable itemsets (NDIs) proposed in [2] and discussed in detail in [4]. A depth-fistalgorithm was also presented in [3]. An approximation of NDIs and non-almost-derivableitemsets (NADIs) based on a δ parameter was proposed in [28]. Algorithms that use NDIsand NADIs to detect outliers in categorical data were proposed in [14,15].
Besides condensed representations, other types of techniques have been proposed andused as a step prior to data mining tasks, such as clustering. For example, Summary sets [19]are proposed to summarize categorical data for clustering, while a support approximationand clustering method is presented in [12].
3 Background
Please see Table 1 for the notation and abbreviations used in this paper. We consider a datasetD which contains n records or transactions (rows). Let I = {i1, i2, . . . , ir } be a set of r itemsin D. Each transaction (row) T in D is a set of items such that T ⊆ I. Given X , a set of someitems in I, we say that T contains X if X ⊆ T . We often denote an itemset by the sequenceof its items; for example, {a, b, c} is denoted abc. The support of X , supp(X ), is the numberof transactions in D that contain X , divided by n. We say that X is frequent if it appears atleast in σ % of the transactions in D, where σ is a user-defined threshold. The collection of
Table 1 Notation andabbreviations used in this paper
Term Definition
D Dataset
n Number of transactions in DI Set of items in Dr Number of items in II, J, X An itemset
|I | Length of itemset I
ik The kth item in itemset I
supp(I ) Support of itemset I
hcon f (I ) h-confidence of itemset I
σ Minimum support
hc Minimum h-confidence threshold
FI The collection of frequent itemsets
HC The collection of hypercliques
NDI The collection of non-derivable itemsets
NDHC The collection of non-derivable hypercliques
MHP The collection of maximal hyperclique patterns
123

Mining non-derivable hypercliques
frequent itemsets is denoted by FI:
FI = {X ⊆ I|supp(X) ≥ σ }3.1 Hypercliques (HCs) and maximal hyperclique patterns (MHP)
In this section, we present background information on hypercliques from [26] and on maximalhypercliques from [11].
The h-confidence of an itemset I = {i1i2 . . . im} is defined as:
hcon f (I ) = min{con f (i1 → i2 . . . im),
con f (i2 → i1i3 . . . im), . . . , con f (im → i1 . . . im−1)}where con f is the association rule confidence [1]. As shown in [26], the hcon f above isequivalent to:
hcon f (I ) = supp(I )
maxi∈I
supp({i})Given user-defined thresholds for support, σ , and h-confidence, hc, itemset X is a
hyperclique if it is frequent (i.e., supp(X) ≥ σ ) and its h-confidence is at least hc (i.e.,hcon f (X) ≥ hc). The collection of hypercliques HC is defined as:
HC = {X ⊆ I | supp(X) ≥ σ ∧ hcon f (X) ≥ hc}Example 3.1 Given the example dataset in Table 2 with 10 transactions and four sin-gle items a, b, c, d; let support σ = 0.2, and h-confidence hc = 0.3. Itemset acdis a hyperclique with supp(acd) = 0.3 > σ , and hcon f (acd) = supp(acd) ÷max{supp(a), supp(c), supp(d)} = 3/7 = 0.43 > hc.
H-confidence has three important properties, specifically the anti-monotone property, thecross-support property, and the strong affinity property (see [27] for details). We briefly statethe first two properties as they are used in this paper.
The anti-monotone property states that if itemset I has h-confidence below the hc thresh-old, so does every superset of I . This implies that, if I is not a hyperclique, none of itssupersets can be a hyperclique. Additionally, if I is a hyperclique, then all subsets of I arealso hypercliques.
Table 2 Example dataset(σ = 0.2, hc = 0.3)
TID Items
1 a, b
2 b
3 c, d
4 a, b
5 a, c, d
6 a, b, c
7 a
8 a, c, d
9 b
10 a, b, c, d
123

A. Koufakou
The cross-support property states that given a single item J , all itemsets that contain Jand at least one other single item X such that supp(X) < hc × supp(J ) are cross-supportpatterns, guaranteed to have h-confidence less than hc, and therefore cannot be hypercliques.In other words, if we combine two or more single items with widely differing supports intoan itemset, the resulting itemset cannot be a hyperclique.
Mining HC can easily be implemented using an Apriori-like algorithm for mining FI (allfrequent itemsets). When hc = 0, the HC collection is the same as the FI collection. Duringcandidate generation, based on the anti-monotone property of the h-confidence measure,we can prune a candidate itemset of length m if any of its (m − 1)-length subsets is not ahyperclique pattern. Finally, after computing exact support and h-confidence for all candidateitemsets, we then prune candidates using the thresholds σ and hc.
A hyperclique P is a maximal hyperclique pattern (MHP) if none of its supersets is ahyperclique pattern. The collection of MHP is defined below:
M H P = {X ⊆ I | X ∈ HC ∧ ∀Y ⊃ X, Y /∈ HC}
The MHP collection is a condensed representation of the HC collection. This means thatthe entire HC collection can be derived given the MHP collection. Even though maximalsets are typically orders of magnitude fewer than the original collection, they lead to a lossof information; specifically, it is not possible to derive the support of each hyperclique inHCs from the MHP collection. In this paper, we used the implementation provided by Huanget al. [11] to mine the MHP collection in order to compare it with our proposed collection,NDHC.
3.2 Non-derivable itemsets (NDIs)
In the following, we present background on the NDI representation from [4]. Calders et al.[4] showed that itemsets whose support can be deduced or derived from their subsets, i.e.derivable sets, can be pruned; this can dramatically reduce the total amount of sets generated.
Let a general itemset, G, be a set of items and negations of items, e.g. G = {abc}. Thesupport of G in this case is the percent of transactions where items a and b are present, whileitem c is not present. We say that a general itemset G = X ∪ Y is based on itemset I ifI = X ∪ Y . The deduction rules in [4] are based on the inclusion-exclusion (IE) principle[7]. For example, using the IE principle we write the following for the support of anothergeneral itemset {abc}:
supp(abc) = supp(a)− supp(ab)− supp(ac)+ supp(abc).
Based on supp(abc) ≥ 0, we can write the following:
supp(abc) ≥ supp(ab)+ supp(ac)− supp(a).
The above is a lower bound on the support of set abc. Calders and Goethals [4] extendedthis concept to compute rules in order to derive the upper and lower bounds on the supportof itemset I based on its subsets.
Let L B(I ) and U B(I ) be the lower and upper bounds on the support of itemset I :
L B(I ) = max{δX (I ), |I\X |odd}U B(I ) = min{δX (I ), |I\X |even}
123

Mining non-derivable hypercliques
where δX (I ) denotes the summation shown below:
δX (I ) =∑
X⊆J⊂I
(−1)|I\J |+1supp(J ).
Given a database D and threshold σ , the NDI algorithm produces the condensed repre-sentation non-derivable itemsets NDIs defined below, which contains only the non-derivablefrequent itemsets:
N DI = {X ⊆ I | supp(X) ≥ σ ∧ L B(X) �= U B(X)}Example 3.2 Given the 10 transaction dataset in Table 2 and σ = 0.2. Itemset acd is deriv-able, because its lower and upper support bounds are equal to 3 (out of 10), as shown below.
supp(acd) ≥ 0
≤ supp(ac) = 4, supp(ad) = 3, supp(cd) = 3
≥ supp(ad)+ supp(ac)− supp(a) = 0
≥ supp(ac)+ supp(cd)− supp(c) = 3
≥ supp(ad)+ supp(cd)− supp(d) = 3
≤ supp(ac)+ supp(ad)+ supp(cd)
−supp(a)− supp(c)− supp(d)
+supp(∅) = 5.
In order to find the frequent itemsets, the NDI algorithm uses Apriori-Gen, the candidategeneration step of Apriori to generate candidate sets and then prune infrequent candidates.If the lower and upper support bounds are equal, then the itemset is derivable. If a set X isNDI, i.e. L B(X) �= U B(X), the algorithm needs to count the support of X ; if it is found thatsupp(X) = L B(X) or supp(X) = U B(X), all strict supersets of X are derivable and theycan be pruned. This process is repeated until candidate sets cannot be generated further.
Several properties of the NDIs were presented in [4], some of which we briefly summarizebelow.
Monotonicity: Let itemsets J ⊆ I . If J is derivable, then its superset I is derivable.The NDI collection cannot be very large, because the width of the support intervals,
W (I ) = U B(I ) − L B(I ), decreases exponentially with the cardinality of itemset I . Also,every set I with cardinality larger than the logarithm of the size of database, i.e. |I | >
log2(n)+ 1, must be derivable.Finally, the N DI collection is a condensed representation of FI, i.e. all sets in FI and
their support can be generated given N DI s, without additional data scanning.
4 Mining non-derivable hypercliques (NDHCs)
We propose to use the techniques described for non-derivable itemsets (NDIs) in [4] toconsiderably prune the HC collection. Specifically, we propose to compute bounds on thesupport of each HC set, similarly to the bounds in the NDIs context, and then prune thoseHC sets that are derivable.
The following describe our proposed itemset collection, NDHC, as well as related algo-rithms. Specifically, Sect. 4.1 defines and describes properties of the NDHC collection.
123

A. Koufakou
Fig. 1 Generated itemsets for the data in Table 2, σ = 0.2, and hc = 0.3: non-derivable itemsets (NDIs),hypercliques (HCs), and non-derivable hypercliques (NDHCs)—shading denotes a frequent itemset
Section 4.2 presents NDHCMiner, an efficient algorithm to mine all NDHC sets, and Sect. 4.3describes NDHCDeriveAll, an algorithm to generate all sets in HCs and their exact supportfrom NDHCs.
4.1 Non-derivable hypercliques (NDHCs)
Definition 4.1 An itemset X is a non-derivable hyperclique (NDHC) if X is frequent(supp(X) ≥ σ ), and X is a hyperclique (hcon f (X) ≥ hc), and X is non-derivable(L B(X) �= U B(X)).
Given a dataset D, support σ , and h-confidence hc, the collection of non-derivable hyper-cliques (NDHCs) is defined below:
N DHC =de f {X ⊆ I | supp(X) ≥ σ ∧ hcon f (X) ≥ hc ∧ L B(X) �= U B(X)}Example 4.1 Given the ten transactions in Table 2, support σ = 0.2, and h-confidencehc = 0.3.
Itemset I = {acd} is derivable as shown in Example 3.2 and a hyperclique as shownin Example 3.1, and therefore, it is a derivable hyperclique. On the other hand, J = {abc}is non-derivable with support bounds [2, 3] (out of 10), but it is not a hyperclique, withhcon f (J ) = 2/7 = 0.29 < hc. Finally, Y = {ac} is a non-derivable hyperclique because it isnon-derivable with support bounds [0, 5] (out of 10), and it is a hyperclique with hcon f (Y ) =4/7 = 0.57 > hc.
Figure 1 depicts the sets in NDIs, HCs, and NDHCs for the example dataset in Table 2,with σ = 0.2, and hc = 0.3. In summary, the collections shown in Fig. 1 for the exampledataset are:
FI = {a, b, c, d, ab, ac, bc, ad, cd, abc, acd}NDI = {a, b, c, d, ab, ac, bc, ad, cd, abc}HC = {a, b, c, d, ab, ac, bc, ad, cd, acd}
NDHC = {a, b, c, d, ab, ac, bc, ad, cd}
Based on Definition 4.1, and the definitions and properties of NDIs from [4], and those ofHC from [27] (also summarized in Sects. 3.1 and 3.2), we present the following.
123

Mining non-derivable hypercliques
Theorem 4.1 (Antimonotonicity) Let itemsets J ⊆ I . If I ∈ NDHC, then J ∈ NDHC.
Proof Per Definition 4.1, if itemset I ∈ NDHC, L B(I ) �= U B(I ), therefore I ∈ NDI. Then,each subset J ⊂ I is also NDI (antimonotonicity of NDIs [2]). Also, per the same definition,if itemset I ∈ NDHC, hcon f (I ) ≥ hc, therefore I ∈ HC . Then, each subset J ⊂ I is alsoHC (antimonotonicity of HC [26]).
Therefore, each itemset, J , subset of a non-derivable hyperclique, I , is also a non-derivablehyperclique. ��
It follows that, given itemsets J ⊂ I , if itemset J /∈ N DHC , then I /∈ N DHC .
Theorem 4.2 The cardinality of the NDHC collection is smaller than or equal to the cardi-nality of the NDI collection: |NDHC| ≤ |NDI|.Proof For hc = 0: it holds that∀X ∈ NDHC : hcon f (X) ≥ 0. Removing this condition fromDefinition 4.1, what remains is the definition of NDI. Therefore, for hc = 0, the collectionof NDHC is identical to the collection of NDI : |NDHC| = |N DI |.
For hc > 0: per Definition 4.1, NDHC contains only those itemsets X ∈ N DI such thathcon f ≥ hc. Then, as NDHC ⊆ NDI, it follows that the cardinality of the NDHC collectionis smaller or equal to NDI, or |NDHC| ≤ |N DI |.
We note that the portion of itemsets that are contained in the NDI collection but not in theNDHC collection varies depending on the value of the h-confidence threshold hc, as well asthe dataset (see experimental results in Sect. 5). As the purpose of the paper is to reduce thenumber of HCs, not the number of NDIs, we do not compare the NDHC collection with theNDI collection, therefore we do not show results for hc = 0 in Sect. 5. Even though we donot show results for hc = 0, it is apparent in the experimental results that as the hc valuedecreases, the NDHC collection increases in size.
Theorem 4.3 The cardinality of the NDHC collection is smaller than or equal to the cardi-nality of the HC collection: |NDHC| ≤ |HC |.Proof Per Definition 4.1, NDHC contains only those hypercliques X that are not derivable, oritemsets X ∈ HC such that L B(X) �= U B(X). Therefore, NDHC ⊆ HC , thus |NDHC | ≤|HC |. ��
Additionally, the itemsets Y ∈ HC such that Y /∈ NDHC are the derivable hypercliques:Y ∈ HC ∧ L B(Y ) = U B(Y ). Based on the monotonicity principle, every superset of Ywill also be derivable and thus also not included in the NDHC collection. Finally, as shownin [4], longer itemsets are more likely to be derivable, so the NDHC collection will containhypercliques of smaller length, while the derivable hyperclique collection will contain longerhypercliques.
The experiments in Sect. 5 confirm the above and show that the reduction by NDHC issignificant in comparison to the original HC collection, especially for low hc values anddense datasets.
4.2 NDHCMiner algorithm to mine all sets in NDHC
A naïve method to mine non-derivable hypercliques NDHCs is to first mine all non-derivableitemsets NDI and, in a second step, prune those sets in NDIs whose h-confidence is lessthan hc. However, there are some datasets for which a high number of NDIs are generatedas shown in [15].
123

A. Koufakou
We propose an algorithm that takes advantage of the fact that both hypercliques and non-derivable itemsets use the monotonicity principle. This way, we are able to prune a candidateitemset I if any of its subsets J ⊂ I are either (a) derivable, i.e. L B(J ) = U B(J ), or (b)non-hypercliques, i.e. hcon f (J ) < hc. Furthermore, using the support bounds of a set, toextend the cross-support property of HC [27], we can make use of the following property toprune additional non-derivable itemsets, because they cannot be hypercliques.
Given non-derivable itemset I = {i1i2 . . . im} with support bounds L B(I ) and U B(I ).
Property 4.1 Support Bound Pruning If U B(I ) < Maxi∈I
supp({i}) × hc, itemset I has h-
confidence less than hc, i.e. hcon f (I ) < hc, I cannot be a hyperclique, therefore set I canbe pruned.
In other words, if the upper support bound of the Non-Derivable Itemset I, U B(I ), isless than the maximum support over all single items i contained in set I multiplied by theh-confidence threshold hc, then I cannot be a hyperclique.
Proof From the definition of hcon f in Sect. 3.1, we have the following:
hcon f (I ) = supp(I )
maxi∈I
supp({i}) ≤U B(I )
maxi∈I
supp({i})because the upper support bound, U B(I ), as defined in [4], is the least upper bound on theactual support of I : supp(I ) ≤ U B(I ).
Therefore, if the last term in the above inequality is less than the h-confidence hc, we canwrite the equation above as:
U B(I ) < Maxi∈I
supp({i})× hc
then hcon f (I ) < hc, and I is not a hyperclique. ��Based on this property, itemsets can be pruned earlier based on support bounds, which
means that we avoid counting support or computing h-confidence for these itemsets.Additionally, the upper support bound of itemset I , U B(I ), is bounded by the support of
its subsets J ⊂ I . Therefore, we can prune itemsets even before we compute their supportbounds. Specifically, we can replace the upper support bound of itemset I term, U B(I ), inProperty 4.1 with the minimum support of its subsets: min{supp(J |J ⊂ I )}.
The algorithm for mining the sets in the non-derivable hyperclique NDHC collection,NDHCMiner, is shown in Algorithm 1.
NDHCMiner first counts the support of single items in the dataset, and keeps only thefrequent single items (lines 1–2). Then, the NDHCMiner algorithm generates candidates oflength k > 2, and computes their support bounds (lines 3–6), exactly as in the Non-DerivableItemset NDI algorithm presented in [4].
Then, a candidate set I , is non-derivable, if its upper bound U B(I ) is larger than thesupport threshold, σ , and its bounds L B(I ) and U B(I ) are not equal to each other (line7). Additionally, in line 9, we only keep non-derivable itemsets that can be hypercliquesaccording to the Support Bound Pruning property (see Property 4.1 above). In line 18, weprune candidates that do not pass the conditions in lines 7–9.
For each set I that was not pruned, we count its support supp(I ) (line 10); then, usingthis support, we calculate its h-confidence hcon f (I ) per Sect. 3.1 (line 11). As a result, theNDHC collection includes the frequent non-derivable itemsets with hcon f not less than hc
(line 12). Otherwise, non-derivable itemsets with hcon f less than hc are excluded from the
123

Mining non-derivable hypercliques
Input : Database D, support threshold σ , h-confidence threshold hcOutput: N DHC collection
1 Count support of single items;2 NDHC← single items with support ≥ σ ;3 foreach itemset length k ← 2..K do
4 Ck = Generate non-derivable candidates of length k using Apriori-Gen;5 foreach candidate I ∈ Ck do
6 Compute support bounds, L B(I ) and U B(I ), based on NDI rules;7 if L B(I ) �= U B(I ) and U B(I ) ≥ σ // Non-Derivable8 and9 U B(I ) ≥ Max
i ∈ Isupp({i})× hc // Support Bound Pruning then
10 Count supp(I );11 Compute hcon f (I );
12 if supp(I ) ≥ σ and hcon f (I ) ≥ hc then13 NDHC← NDHC ∪ I ;14 else15 Prune candidate I ; // infrequent or non-HC16 end17 else18 Prune candidate I ; // infrequent,derivable,or non-HC19 end20 end21 end
Algorithm 1: NDHCMiner Algorithm
NDHC collection at the same time as non-derivable itemsets that were found to be infrequent(line 15).
Finally, the algorithm terminates when no more candidate sets can be generated in line 4.
4.3 NDHCDeriveAll algorithm to derive HC sets and their support from NDHC
The complete HC collection as well as the support of each hyperclique can be generatedgiven the NDHC collection. The process for deriving all hypercliques from NDHC is similarto generating all frequent itemsets, FI, and their support from the NDI collection presentedin [4].
In our case, an itemset I is pruned in NDHCMiner (see Algorithm 1) because it iseither infrequent (supp(I ) < σ ), or derivable (L B(I ) = U B(I )), or not a hyperclique(hcon f (I ) < hc). The itemsets that we wish to generate to obtain the complete HC collec-tion are those sets which are not contained in NDHC but are contained in HC, which are thederivable hypercliques. In other words, we still wish to exclude itemset I if it is infrequentor not a hyperclique.
The algorithm for deriving all HCs and their support from NDHC, NDHCDeriveAll, isdescribed below, and shown in detail in Algorithm 2.
Given non-derivable hyperclique X in the NDHC collection, we generate a superset itemsetI by adding a new item a to itemset X : I = {Xa} (line 6). In order to avoid regenerating allsets in the NDHC collection, we start from the sets on the border of the NDHC collection,B+(NDHC) (see lines 3–4). The border of NDHC consists of all itemsets that are in NDHCwhose supersets are not in NDHC. The formal definition is shown below:
B+(NDHC) = {X ⊆ I | ∀X ⊂ Y : X ∈ NDHC ∧ Y /∈ NDHC}
123

A. Koufakou
Input : NDHC, support threshold σ , h-confidence threshold hcOutput: HC collection
1 Checked← {};2 HC← NDHC;3 G ← B+(NDHC);
4 foreach itemset X ∈ G do5 foreach single item a /∈ X do
6 I = {Xa} such that I /∈ Checked;7 Compute support bounds, L B(I ) and U B(I ), based on NDI rules;8 if L B(I ) ≥ σ then
9 Compute hcon f (I ) using L B(I ) as supp(I );10 if hcon f (I ) ≥ hc then
11 HC← HC ∪ I ;12 G ← G ∪ I ;13 end14 end15 Checked = Checked ∪ I ;16 end17 end
Algorithm 2: NDHCDeriveAll Algorithm
For each itemset I = {Xa} , we calculate its support bounds, L B(I ) and U B(I ), usingthe same deduction rules as in generating NDIs (line 7). As in [4], we exclude itemset I ifL B(I ) < σ , i.e. I is infrequent. On the other hand, if I is frequent (line 8), it is either aderivable itemset, or a non-derivable itemset that is not a hyperclique, otherwise it wouldhave been included in the NDHC collection. If it is derivable, its support equals the lowerand upper support bounds, i.e. supp(I ) = L B(I ) = U B(I ).
The next step is to compute the h-confidence hcon f (I ) per Sect. 3.1 using L B(I ) as thesupport (line 9). If this value is equal to the threshold hc or larger, we add itemset I to theHC collection (lines 10–11). We also use this set to generate more hypercliques in the nextiteration (line 12). The algorithm also keeps track of all itemsets already checked to avoidduplicating work for the same itemset (line 15). Finally, the complete HC collection ends upas the union of all sets in NDHC (line 2), and the derivable hypercliques in line 11.
In summary, the itemsets I that are added to HC in this algorithm are the derivablehypercliques, and their support supp(I ) is by definition equal to the support bounds calculatedbased on the NDI deduction rules [4]. This also means that the algorithm only uses the NDHCcollection and not the data itself; this leads to large computational savings as shown in Sect. 5,because the algorithm avoids scanning the data in order to count the support of an itemset.
5 Experiments
5.1 Experimental setup
We conducted all experiments on a PC Intel(R) Core(TM) i5 2.50GHz processor with 8GBRAM. We used the NDI code available online,1 and implemented the rest of the algorithmsin C++. For the algorithm to mine all hypercliques, we completed an Apriori-like algorithmbased on the NDI code (i.e., we removed those parts of the NDI code that calculate or use
1 http://www.adrem.ua.ac.be/goethals/software.
123
Mining non-derivable hypercliques
Table 3 Dataset details: numberof transactions (rows), averagetransaction length, total numberof single distinct items
Dataset Transactions Avg. transaction Items
Mushroom 8,124 23 119
Chess 3,196 37 76
Pumsb 49,046 74 2,113
Pumsb∗ 49,046 51.48 2,089
Connect 67,557 43 129
Accidents 340,183 33.8 468
Kosarak 990,002 8.1 41,270
T40I10D100K 100,000 40.61 942
support bounds, for example to prune sets). We note that our implementations do not includethe cross-support pruning technique exactly as shown in [26]. For the maximal hypercliquepatterns (MHPs), we executed the MHP code, exactly as provided from the authors of [9].
Our experiments were conducted using seven real datasets (Mushroom, Chess, Pumsb,Pumsb*, Connect, Accidents, and Kosarak), and one artificially generated dataset(T40I10D100K). All datasets were obtained from the FIMI repository2 (see Table 3 fordataset details). The Mushroom dataset contains characteristics from different species ofmushrooms. The Pumsb dataset is based on census data and is a benchmark set for evalu-ating the performance of FIM algorithms on dense datasets. One of its characteristics is theskewed support distribution, e.g. 81.5 % of the items in this set have support less than 1 %,while 0.95 % of them have support greater than 90 %. Pumsb∗ is the same dataset as Pumsb,except all items of 80 % support or more have been removed, making it less dense. TheAccidents dataset [8] contains (anonymized) traffic accident data. The Kosarak dataset con-tains (anonymized) click-stream data of a Hungarian on-line news portal. Finally, the Chessand Connect datasets are derived from the steps of the respective games. The benchmarkdense datasets are mushroom, pumsb, connect, and chess (see further discussion on denseand sparse data in [16,29]).
5.2 Results
We ran several experiments with various values for thresholds, σ and hc, to compare ourproposed collection with HC and with MHP and to show results for deriving HC fromNDHC.
5.2.1 Comparison with hypercliques (HCs)
Table 4 contains the number of generated sets for HC and NDHC for all datasets and variousσ and hc combinations. Table 5 contains runtime in seconds for the mining of hypercliquesversus the NDHCMiner. A ‘−’ symbol indicates that we had to stop execution of the corre-sponding algorithm due to the large number of itemsets generated and high execution timeof the corresponding algorithm.
As Table 4 shows, the NDHC collection is much smaller than the HC collection, especiallyfor lower hc values. The collections are close in number of sets for the artificial dataset,T40I10D100K, except for the lowest hc value of 0.1 (see Table 4a). This is not surprising as
2 http://fimi.ua.ac.be/data/.
123

A. Koufakou
Table 4 Hypercliques (HCs) versus non-derivable hypercliques (NDHCs)
hc σ = 0.0025 σ = 0.005 σ = 0.01
HCs NDHCs HCs NDHCs HCs NDHCs
(a) T40I10D100K
0.30 1,084 1,084 1,008 1,008 860 860
0.20 2,186 2,144 2,019 1,978 1,564 1,524
0.15 6,551 6,183 6,140 5,773 4,215 3,967
0.10 55,186 34,353 52,784 32,048 17,254 14,524
hc σ = 0 σ = 0.1 σ = 0.2
HCs NDHCs HCs NDHCs HCs NDHCs
(b) Mushroom
0.70 197 160 103 83 88 68
0.50 485 327 375 236 335 208
0.30 5,506 1,316 5,264 1,122 4,610 818
0.20 59,274 3,228 58,302 2,663 53,624 1,143
0.10 619,693 9,781 574,473 4,347 53,664 1,143
hc σ = 0 σ = 0.2 σ = 0.5
HCs NDHCs HCs NDHCs HCs NDHCs
(c) Pumsb
0.95 2,617 2,399 553 337 413 244
0.90 6,500 3,112 4,430 1,044 3, 709 910
0.80 179,905 6,821 177,819 4,737 174,753 4,484
0.70 −− 11,948 −− 9,831 −− 9,378
0.50 −− 62,340 −− 6,0029 −− 47,764
hc σ = 0.02 σ = 0.04 σ = 0.06
HCs NDHCs HCs NDHCs HCs NDHCs
(d) Pumsb∗0.90 1,021 377 927 283 902 258
0.70 17,339 878 17,238 777 17,213 752
0.60 38,336 1,806 38,234 1,704 38,200 1,675
0.50 441,645 4,820 441,543 4,718 441,507 4,687
0.30 −− 42,251 −− 42,129 −− 42,086
hc σ = 0.2 σ = 0.5 σ = 0.8
HCs NDHCs HCs NDHCs HCs NDHCs
(e) Connect
0.95 2,579 197 2,558 176 2,548 166
0.90 28,839 274 28, 818 253 28,808 243
0.80 553,838 452 553,817 431 534,232 348
0.70 −− 689 −− 668 −− 348
0.20 −− 7,574 −− 1,397 −− 348
123

Mining non-derivable hypercliques
Table 4 continued
hc σ = 0.02 σ = 0.05 σ = 0.10
HCs NDHCs HCs NDHCs HCs NDHCs
(f) Accidents
0.70 756 501 719 464 687 432
0.50 8,966 3,739 8,929 3,702 8,895 3,668
0.40 35,104 11,119 35,065 11,080 35,025 11,040
0.30 158,403 36,174 158,359 36,130 158,295 36,066
hc σ = 0.2 σ = 0.4 σ = 0.5
HCs NDHCs HCs NDHCs HCs NDHCs
(g) Chess
0.70 51,336 976 51,322 962 51,315 955
0.60 265,580 2,209 265,559 2,188 265,489 2,122
0.50 1,311,723 4,531 1,311,629 4,439 1,272,933 3,425
0.40 6,631,269 9,307 6,472,981 7,185 1,272,933 3,425
0.30 −− 19,205 −− 7,185 −− 3,425
hc σ = 0.001 σ = 0.002 σ = 0.005
HCs NDHCs HCs NDHCs HCs NDHCs
(h) Kosarak
0.90 20,636 20,609 15,776 15,749 9,859 9,832
0.85 24,765 22,941 19,899 18,075 13,948 12,130
0.80 794,245 36,510 789,245 31,575 783,041 25,530
0.75 −− 123,022 −− 117,805 −− 111,688
0.70 −− 514,622 −− 509,157 −− 502,976
synthetic datasets tend to be sparse [29], and thus, they will not generate as many derivableitemsets, which is also observed in [4].
Differences in number of sets are larger for the real datasets, as hc decreases. For example,for the Mushroom dataset (see Tables 4b, 5a), σ = 0, and hc = 0.1, there are more than 600thousand HC sets generated in about 75 s versus less than 10 thousand NDHC sets generatedin less than a second.
The gains become more pronounced for larger dense datasets and for relatively high hc
values. For example, for the Pumsb dataset (see Tables 4c, 5b), σ = 0 and hc = 0.8, the HCcollection contains almost 180 thousand sets generated in 11 min versus less than 7 thousandNDHC sets generated in 19 s. As hc becomes 0.7, there are more than 3 million HCs, andHC mining was terminated, versus less than 12 thousand NDHCs generated in only 25 s. ThePumsb∗ dataset is a less dense version of the Pumsb dataset; nevertheless, we observe thatfor hc equal to 0.5, there are more than 440 thousand HC sets versus less than 5000 NDHCsets, and, for values lower than 0.5, the HC mining was terminated as shown in Table 4d.
We make similar observations for other dense datasets, for example, Connect (see Tables4e, 5c). For example, for σ = hc = 0.8, HC mining takes 47 min to generate more than 530thousand HC sets versus 2 s for the NDHCMiner to generate 348 NDHC sets. For the third
123
A. Koufakou
Table 5 Runtime comparison (seconds)—HC mining versus NDHCMiner
hc σ = 0 σ = 0.1 σ = 0.2
HCs NDHCs HCs NDHCs HCs NDHCs
(a) Mushroom
0.7 1 1 1 1 1 1
0.5 1 1 1 1 1 1
0.3 1 1 1 1 1 1
0.2 6 1 6 1 5 1
0.1 75 1 69 1 5 1
hc σ = 0 σ = 0.2 σ = 0.5
HCs NDHCs HCs NDHCs HCs NDHCs
(b) Pumsb
0.95 17 13 10 8 7 5
0.90 27 14 19 8 14 6
0.80 643 19 576 13 563 10
0.70 −− 25 −− 19 −− 15
0.50 −− 95 −− 76 −− 54
hc σ = 0.2 σ = 0.5 σ = 0.8
HCs NDHCs HCs NDHCs HCs NDHCs
(c) Connect
0.95 11 3 11 2 10 2
0.90 78 3 79 2 78 2
0.80 2,951 3 2,945 3 2,808 2
0.70 −− 3 −− 3 −− 2
0.20 −− 7 −− 3 −− 2
hc σ = 0.02 σ = 0.05 σ = 0.10
HCs NDHCs HCs NDHCs HCs NDHCs
(d) Accidents
0.70 33 23 32 22 29 20
0.50 96 43 93 42 91 39
0.40 324 79 319 78 319 75
0.30 1,939 191 1,930 190 1,862 183
hc σ = 0.2 σ = 0.4 σ = 0.5
HCs NDHCs HCs NDHCs HCs NDHCs
(e) Chess
0.70 9 1 9 1 9 1
0.60 57 1 57 1 57 1
0.50 262 1 262 1 261 1
0.40 1,137 1 1,102 1 251 1
0.30 −− 1 −− 1 −− 1
123

Mining non-derivable hypercliques
Table 5 continued
hc σ = 0.001 σ = 0.002 σ = 0.005
HCs NDHCs HCs NDHCs HCs NDHCs
(f) Kosarak
0.90 56 54 57 53 51 46
0.85 76 61 73 62 70 56
0.80 144 63 139 62 136 58
0.75 −− 72 −− 71 −− 62
0.70 −− 86 −− 87 −− 79
dense dataset, Chess (see Tables 4g, 5e), for σ = 0.2 and hc = 0.4, there are more than 6.5million HC sets generated at 19 min versus 9307 NDHC sets generated in under a second.
For the Kosarak set (see Tables 4h, 5f), for σ = 0.001 and hc = 0.8, we have a littleless than 800 thousand HC sets generated in 2 min versus less than 40 thousand NDHC setsgenerated in 1 min. Additionally, the HC algorithm had to be terminated for hc values lowerthan 0.8 due to “out of memory” error. For this particular dataset, the issues are that of a largenumber of single items (more than 40 thousand) and of transactions (about 990 thousand)(see Table 3).
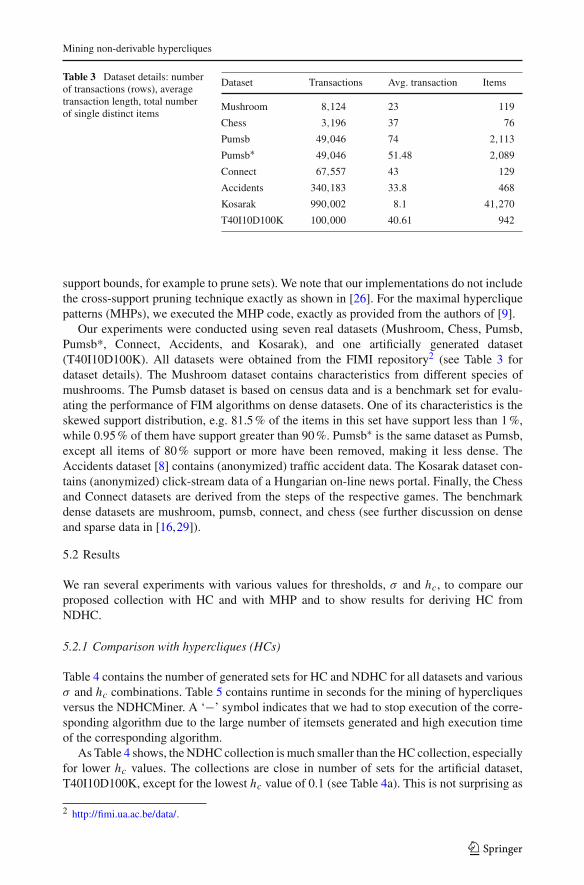
Figure 2 contains a pictorial representation of generated sets in the NDHC collectionversus the HC collection (logarithmic scale) for the Mushroom, Pumsb, Connect, Acci-dents, Chess, and Kosarak datasets, as hc decreases for two different σ values. As thesefigures also show, the HC collection grows much faster than the NDHC collection as hc
decreases, especially for the dense datasets (pumsb, connect, chess) and the larger dataset(Kosarak).
For the Accidents dataset (see Fig. 2d) we observe smaller differences between thetwo collections for high hc values. As this dataset is not dense, there are not as manyderivable hypercliques generated as for the dense datasets (e.g. pumsb or chess). Nev-ertheless, for hc lower than 0.4, there is a large difference in the number of sets gen-erated for the two collections, as seen in Table 4f: for example, for hc = 0.3 andσ = 0.02, there are about 36 thousand NDHC sets versus more than 158 thousandHC sets.
5.2.2 Comparison with maximal hyperclique patterns (MHPs)
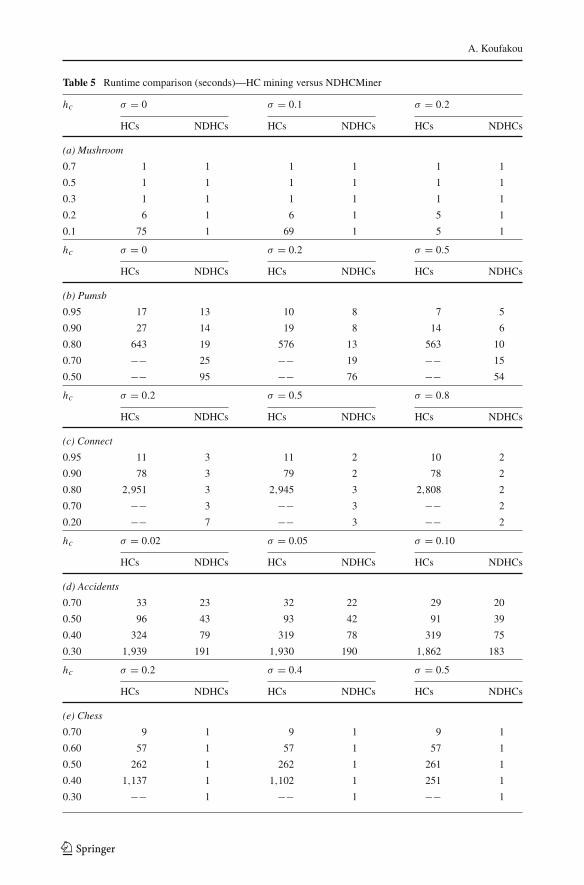
Figure 3 depicts the number of NDHC versus the number of MHP for three dense datasets(Pumsb, Connect, and Chess), and a non-dense dataset, Accidents, as h-confidence hc
decreases (support σ = 0). As can be seen in Figs. 3a–c which correspond to the threedense datasets (Pumsb, Connect, Chess respectively), the MHP collection increases in sizemuch faster than the NDHC collection. For example, for the Pumsb dataset (see Fig. 3a) andhc = 0.5, there are more than 290 thousand MHPs versus a little over 60 thousand NDHCsets. The collections grow slower for the Connect data, but the difference between NDHCand MHP becomes larger as hc decreases (see Fig. 3b): for this dataset and hc = 0.1, thereare a little over 36 thousand NDHC and more than 240 thousand MHP. Thirdly, for the Chessdataset (see Fig. 3c) and hc = 0.3, there are less than 20 thousand NDHCs versus a little lessthan 300 thousand MHPs.
123
A. Koufakou
0.10.20.30.50.7
102
105
hc
Set
sNDHC σ=0NDHC σ=0.2HC σ=0.2HC σ=0
(a)
0.50.70.80.90.95
103
105
Set
s
hc
NDHC σ=0NDHC σ=0.2HC σ=0HC σ=0.2
0.20.70.80.90.95
103
106
Set
s
NDHC σ=0.2NDHC σ=0.5HC σ=0.2HC σ=0.5
hc
0.30.40.50.60.7
103
105
hc
Set
s
NDHC σ=0.02NDHC σ=0.05HC σ=0.02HC σ=0.05
0.30.40.50.60.7
104
106
hc
Set
s
NDHC σ=0.2NDHC σ=0.4HC σ=0.2HC σ=0.4
0.70.750.80.850.910
4
106
hc
Set
s
NDHC σ=0.001NDHC σ=0.002HC σ=0.001HC σ=0.002
(b)
(c) (d)
(e) (f)
Fig. 2 Generated sets (Log Scale): NDHCs versus HCs for a Mushroom, b Pumsb, c Connect, d Accidents,e Chess, and f Kosarak as hc decreases (σ values on each figure)
The situation we just described does not apply to the Accidents dataset, which is not adense dataset (see Fig. 3d). In contrast to the results for the dense datasets, here the MHPcollection grows slower than the NDHC collection. For example, for hc = 0.3, there are36551 NDHCs versus 7407 MHPs. These results strengthen our observation that the NDHCcollection leads to more significant gains if the dataset is dense.
123

Mining non-derivable hypercliques
0.50.70.80.95
50
250
hc
Set
sNDHCMHP
0.10.20.30.50.70.9
50
200
hc
Set
s
NDHCMHP
0.30.40.50.6
50
300
hc
Set
s
NDHCMHP
0.30.40.50.7
10
350
hc
Set
sNDHCMHP
(a) (b)
(c) (d)
Fig. 3 Generated sets (in thousands): NDHC versus MHP for a Pumsb, b Connect, c Chess, and d Accidentsas hc decreases (σ = 0)
Finally, it is, once more, important to note that it is possible to derive all HC sets andtheir individual support from the NDHC collection, while only HC sets, not their support,can be generated from the MHP collection. Therefore, NDHC is useful even in cases whenit is larger than MHP.
5.2.3 Deriving all HCs and their support from NDHC
Figure 4 shows a runtime comparison between mining all HC sets versus mining theNDHC collection using NDHCMiner and then deriving the complete HC collection (usingNDHCDeriveAll), including hypercliques and their supports, for the Pumsb, Connect, Chess,and the Accidents datasets, with σ = 0. The time to run NDHCMiner in order to mine allsets in NDHC is included in the times shown in these figures.
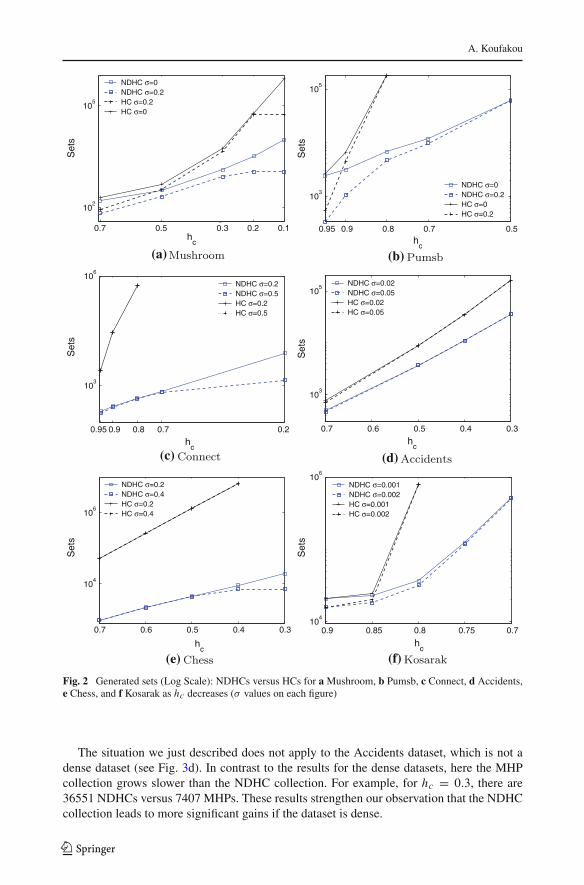
In Fig. 4a, both algorithms have similar runtime for the Pumsb dataset and hc values higherthan 0.85. As hc decreases to 0.8, the runtime difference between the two algorithms becomeslarger: 11 min for HC mining versus less than 1 min for deriving all HC from NDHC. Wehad to stop execution of the HC mining algorithm for hc = 0.75, while the NDHCDeriveAllalgorithm finishes in less than 1 min, then finishes in 7 min for hc = 0.7. It is noteworthythat the NDHCMiner algorithm generates all NDHC sets in 95 s for the same dataset andhc = 0.7. As noted earlier, there are over 3 million HC sets versus under 12 thousand NDHC
123
A. Koufakou
0.95 0.9 0.85 0.8 0.75 0.7
100
500
hc
Tim
e (s
ec)
NDHCDeriveAllHC
0.70.750.80.850.9
1000
3000
hc
Tim
e (s
ec)
HCNDHCDeriveAll
0.40.50.60.7
100
500
1000
hc
Tim
e (s
ec)
HCNDHCDeriveAll
0.30.40.50.7
100
500
2000
hc
Tim
e (s
ec)
HCNDHCDeriveAll
(a) (b)
(c) (d)
Fig. 4 Runtime (in seconds) to mine NDHC and derive all HCs from NDHC (NDHCDeriveAll) versushyperclique mining (HC) for a Pumsb, b Connect, c Chess, and d Accidents (σ = 0)
sets for the Pumsb dataset, σ = 0, and hc = 0.7 (see Table 4c). The large gains in runtime isbecause we avoid additional scans of the dataset that would be needed to count the supportof over 3 million derivable hypercliques; instead, we calculate the support of the derivableitemsets directly from their subsets using the NDI rules presented in [4].
Similar observations can be made for the Connect dataset in Fig. 4b. For hc = 0.8,NDHCDeriveAll takes 23 s for 554 thousand HCs, while HC mining takes 50 min. Forhc = 0.75, NDHCMiner finishes in 4 s, NDHCDeriveAll generates more than 1.6 millionHC sets and their support in less than 2 min, while HC mining had to be terminated. Forhc = 0.7, execution of the NDHCDeriveAll algorithm took about 8 min; more than 4.2million HCs were generated versus 759 NDHCs. Finally, results shown for the Connectand Accidents datasets (Fig. 4c, d) follow the same trend, though, we did not have to stopexecution of the HC mining program. Nevertheless, for these datasets as well, HC mining ismuch slower than NDHCDeriveAll; for example, for Accidents (see Fig. 4d) and hc = 0.3,NDHCDeriveAll finishes in about 3 versus 33 min for HC mining.
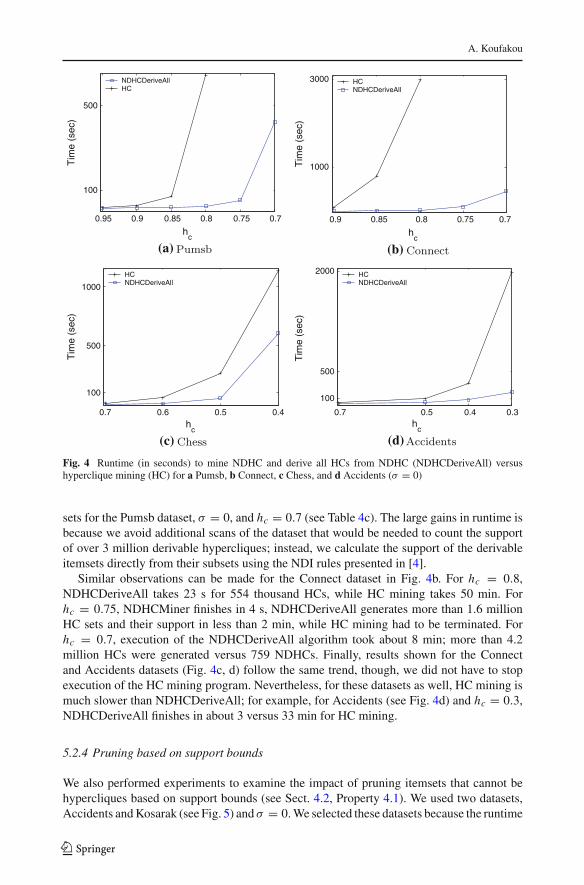
5.2.4 Pruning based on support bounds
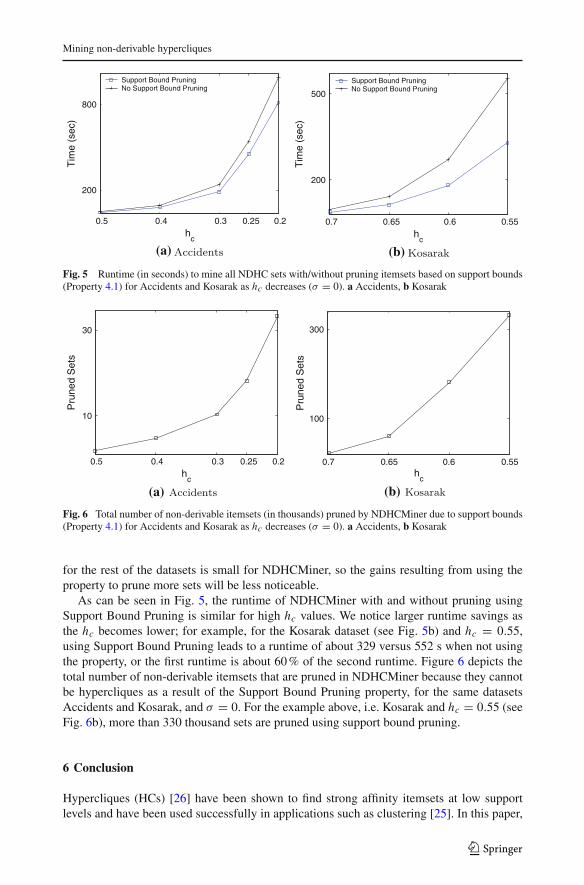
We also performed experiments to examine the impact of pruning itemsets that cannot behypercliques based on support bounds (see Sect. 4.2, Property 4.1). We used two datasets,Accidents and Kosarak (see Fig. 5) and σ = 0. We selected these datasets because the runtime
123
Mining non-derivable hypercliques
0.20.250.30.40.5
200
800
hc
Tim
e (s
ec)
Support Bound PruningNo Support Bound Pruning
0.550.60.650.7
200
500
hc
Tim
e (s
ec)
Support Bound PruningNo Support Bound Pruning
(a) (b)
Fig. 5 Runtime (in seconds) to mine all NDHC sets with/without pruning itemsets based on support bounds(Property 4.1) for Accidents and Kosarak as hc decreases (σ = 0). a Accidents, b Kosarak
0.20.250.30.40.5
10
30
hc
Pru
ned
Set
s
0.550.60.650.7
100
300
hc
Pru
ned
Set
s
(a) (b)
Fig. 6 Total number of non-derivable itemsets (in thousands) pruned by NDHCMiner due to support bounds(Property 4.1) for Accidents and Kosarak as hc decreases (σ = 0). a Accidents, b Kosarak
for the rest of the datasets is small for NDHCMiner, so the gains resulting from using theproperty to prune more sets will be less noticeable.
As can be seen in Fig. 5, the runtime of NDHCMiner with and without pruning usingSupport Bound Pruning is similar for high hc values. We notice larger runtime savings asthe hc becomes lower; for example, for the Kosarak dataset (see Fig. 5b) and hc = 0.55,using Support Bound Pruning leads to a runtime of about 329 versus 552 s when not usingthe property, or the first runtime is about 60 % of the second runtime. Figure 6 depicts thetotal number of non-derivable itemsets that are pruned in NDHCMiner because they cannotbe hypercliques as a result of the Support Bound Pruning property, for the same datasetsAccidents and Kosarak, and σ = 0. For the example above, i.e. Kosarak and hc = 0.55 (seeFig. 6b), more than 330 thousand sets are pruned using support bound pruning.
6 Conclusion
Hypercliques (HCs) [26] have been shown to find strong affinity itemsets at low supportlevels and have been used successfully in applications such as clustering [25]. In this paper,
123

A. Koufakou
we propose a new method to substantially reduce the size of HCs, based on non-derivableitemsets (NDIs) [2].
Our proposed HC representation, non-derivable hypercliques (NDHCs), is a lossless rep-resentation of HC: that is, all HC sets and their individual support can be generated givenNDHC, without additional data scans. We present an algorithm to efficiently mine all NDHCsets, NDHCMiner, and an algorithm to generate all HCs and their support from the NDHCcollection, NDHCDeriveAll. We present experiments with several datasets and for variousparameter values. Our experiments show that the NDHC collection presents significant advan-tages compared to HCs. The gains in collection size and runtime performance grow signif-icantly for dense datasets and lower h-confidence threshold hc values. Secondly, we showthat we are able to derive all sets in HCs and their support using NDHCs, much faster thanmining all HC sets. Finally, for dense data, such as census data, NDHC grows much slowerthan another HC representation, maximal hyperclique patterns (MHPs) [11], as hc decreases.We also note that the support of all sets in HCs cannot be deduced from MHPs, while this ispossible for the NDHC collection.
Future directions include utilizing NDHC in applications such as clustering, and furtherreducing the size of the HC collection.
References
1. Agrawal R, Srikant R (1994) Fast algorithms for mining association rules in large databases. In: Proceed-ings of the international conference on very large data bases VLDB, pp 487–499
2. Calders T, Goethals B (2002) Mining all non-derivable frequent itemsets. In: Proceedings of the PKDDinternational conference on principles of data mining and knowledge discovery, pp 74–85
3. Calders T, Goethals B (2005) Depth-first non-derivable itemset mining. In: Proceedings of the SIAMinternational conference on data mining, pp 250–261
4. Calders T, Goethals B (2007) Non-derivable itemset mining. Data Min Knowl Discov 14(1):171–2065. Calders T, Rigotti C, Boulicaut J (2004) A survey on condensed representations for frequent sets. In:
LNCS constraint-based mining and inductive databases, vol 3848, pp 64–806. Chang Y, Lee D, Archibald J, Hong Y (2008) Unsupervised clustering using hyperclique pattern con-
straints. In: Proceedings of the international conference on pattern recognition, ICPR, pp 1–47. Ganter B, Wille R (1999) Formal concept analysis. Springer, Berlin8. Geurts K, Wets G, Brijs T, Vanhoof K (2003) Profiling high frequency accident locations using association
rules. In: Proceedings of the 82nd annual transportation research board, p 189. Hu T, Xu Q, Yuan H, Hou J, Qu C (2007) Hyperclique pattern based off-topic detection. In: Lecture notes
in computer science APWeb/WAIM, vol 4505, pp 374–38110. Huang Y, Xiong H, Wu W, Sung S (2006) Mining quantitative maximal hyperclique patterns: a summary
of results. In: Proceedings of the 10th Pacific-Asia conference on advances in knowledge discovery anddata mining PAKDD’ 06, pp 552–556
11. Huang Y, Xiong H, Wu W, Zhang Z (2004) A hybrid approach for mining maximal hyperclique patterns.In: Proceedings of the international conference on tools with artificial intelligence ICTAI, pp 354–361
12. Jea K, Chang M (2008) Discovering frequent itemsets by support approximation and itemset clustering.Data Knowl Eng 65(1):90–107
13. Koufakou A, Ragothaman P (2011) Mining non-derivable hypercliques. In: Proceedings of the interna-tional conference on tools with artificial intelligence, ICTAI, pp 489–496
14. Koufakou A, Secretan J, Fox M, Gramajo G, Anagnostopoulos GC, Georgiopoulos M (2009) Outlierdetection for large high-dimensional categorical data using non-derivable and non-almost-derivable sets.In: Proceedings of the international conference on data mining DMIN, pp 505–511
15. Koufakou A, Secretan J, Georgiopoulos M (2011) Non-derivable itemsets for fast outlier detection inlarge high-dimensional categorical data. Knowl Inf Syst 29(3):697–725
16. Lucchese C, Orlando S, Perego R (2006) Fast and memory efficient mining of frequent closed itemsets.IEEE Trans Knowl Data Eng 18(1):21–36
17. Pandey G, Steinbach M, Gupta R, Garg T, Kumar V (2007) Association analysis-based transformationsfor protein interaction networks: a function prediction case study. In: Proceedings of the ACM SIGKDDinternational conference on knowledge discovery and data mining, pp 540–549
123

Mining non-derivable hypercliques
18. Steinbach M, Tan P-N, Xiong H, Kumar V (2004) Generalizing the notion of support. In: Proceedings ofthe ACM international conference on knowledge discovery and data mining, pp 689–694
19. Wang J, Karypis G (2006) On efficiently summarizing categorical databases. Knowl Inf Syst 9(1):19–3720. Wu X, Kumar V, Ghosh J, Yang Q, Motoda H, McLachlan G, Ng A, Liu B, Yu P, Zhou Z, Steinbach M,
Hand D, Steinberg D (2008) Top 10 algorithms in data mining. Knowl Inf Syst 14(1):1–3721. Xiong H, He X, Ding C, Zhang Y, Kumar V, Holbrook S (2005) Identification of functional modules in
protein complexes via hyperclique pattern discovery. In: Pacific symposium on biocomputing, p 22122. Xiong H, Pandey G, Steinbach M, Kumar V (2006) Enhancing data analysis with noise removal. IEEE
Trans Knowl Data Eng 18(3):304–31923. Xiong H, Steinbach M, Kumar V (2005b) Privacy leakage in multi-relational databases via pattern based
semi-supervised learning. In: Proceedings of th ACM international conference on information and knowl-edge management, pp 355–356
24. Xiong H, Steinbach M, Ruslim A, Kumar V (2009) Characterizing pattern preserving clustering. KnowlInf Syst 19:311–336
25. Xiong H, Steinbach M, Tan P, Kumar V (2004) Hicap: hierarchical clustering with pattern preservation.In: Proceedings of the 4th SIAM international conference on data mining, pp 279–290
26. Xiong H, Tan P, Kumar V (2003) Mining strong affinity association patterns in data sets with skewedsupport distribution. In: Proceedings of the IEEE international conference on data mining, pp 387–394
27. Xiong H, Tan P, Kumar V (2006b) Hyperclique pattern discovery. Data Min Knowl Discov 13(2):219–24228. Yang X, Wang Z, Bing L, Shouzhi Z, Wei W, Bole S (2005) Non-almost-derivable frequent itemsets
mining. In: Proceedings of the international conference on computer and information technology, pp157–161
29. Zaki M, Hsiao C (2005) Efficient algorithms for mining closed itemsets and their lattice structure. IEEETrans Knowl Data Eng 17(4):462–478
Author Biography
Anna Koufakou received a B.Sc. in Computer Informatics at theAthens University of Economics and Business in Athens, Greece, anda M.Sc. and a Ph.D. in Computer Engineering at the University of Cen-tral Florida, Orlando, Florida. Her research interests include Mining ofLarge Datasets, Distributed Data Mining, Outlier Detection, and Fre-quent Itemset Mining. She is currently an Assistant Professor in Soft-ware Engineering at the U.A. Whitaker College of Engineering, FloridaGulf Coast University, Fort Myers, Florida.
123


















