LIVRE DES RESUMES - roadef 2009
431
ROADEF 2009 Nancy, 10-12 février 2009 10ème Congrès de la Société Française de Recherche Opérationnelle et d'Aide à la Décision LIVRE DES RESUMES
Transcript of LIVRE DES RESUMES - roadef 2009

ROADEF 2009
Nancy, 10-12 février 2009
10ème Congrès de la Société
Française de Recherche
Opérationnelle et
d'Aide à la Décision
LIVRE DES RESUMES

Liste des Sponsors

Avant-propos
La 10ème conférence de la Société Française de Recherche Opérationnelle et d’Aide à la Déci-sion (ROADEF 2009) est organisée à Nancy par l’INRIA Nancy Grand Est en collaborationavec le LORIA et l’ensemble des Universités Lorraine.Nous sommes heureux que les légendaires grands frimas du Nord Est de la France n’aient pase!rayés les nombreux participants (environ 300) qui participent à cette conférence et nousespérons qu’ils trouveront à Nancy un accueil chaleureux et qu’ils sauront consacrer un peude temps pour apprécier la ville.Comme à chaque édition, tous les domaines de la Recherche Opérationnelle et de l’Aide à laDécision sont bien représentés et découpés en une soixantaine de sessions sur les trois jours.Les vainqueurs du « Challenge ROADEF » proposés cette année par AMADEUS recevrontleur prix au dîner de Gala, mais il y aura également à cette occasion la remise du prix RobertFAURE de Recherche Opérationnelle.La Recherche Opérationnelle, par nature pluridisciplinaire, trouve sa place à Nancy dans lecadre de la nouvelle Fédération Charles Hermite (créée le 1er janvier 2009) qui regroupe leschercheurs mathématiciens, informaticiens et automaticiens lorrains issus de quatre UMR deNancy et de Metz (CRAN, IECN, LORIA et LMAM). Cette fédération a non seulement pourobjectifs de renforcer la visibilité de chaque secteur, mais également de jouer un rôle centralpour dynamiser les recherches transverses.De nombreuses entreprises et organismes ont accepté de soutenir l’organisation de cette confé-rence et nous les remercions :• 1POINT2, AIMMS, ATEJI, CORA, EURODECISION, GO FIRST, IBM-ILOG, KLS-
OPTIM,• Agence Universitaire de la Francophonie, GDR MACS, GDR RO,• CNRS, INRIA, LORIA, CRAN, Nancy Université, Université Paul Verlaine de Metz,• Communauté Urbaine du Grand Nancy, Département de Meurthe et Moselle et la région
LORRAINE.Le comité d’organisation est composé de membres issus de nombreux organismes lorrains(Epinal, Metz et Nancy) : du CRAN, de l’INRIA Grand Est, du LGIMP, du LITA et duLORIA. Tous ont fait de leur mieux. Nous tenons tout particulièrement à remercier Anne-Lise Charbonnier et Nicolas Alcaraz, du service colloques de l’INRIA Grand Est, qui ontcouvert tous les aspects administratifs et une grande partie des aspects matériels.Nous remercions également tous les re-lecteurs que nous avons sollicité, en particulier pour lasélection des articles longs.En vous souhaitons une très bonne conférence ROADEF 2009 à Nancy.
Ammar OulamaraMarie-Claude Portmann
Février 2009

Organisation
La conférence ROADEF 2009 est organisée par l’INRIA Nancy Grand Est en collaborationavec le LORIA.
Comité d’organisation
H. Amet A. Aubry A. BellangerS. Belmokhtar S. Carriera J. CohenL. Cucu-Grosjean E. Jeannot A. NagihN. Navet M. Oughdi A. OulamaraM.C. Portmann W. Ramdane cherif N. Sauer
Comité scientifique
AIDER.M (Algérie) BAPTISTE. Ph (France) BAPTISTE. P (Canada)BENABDELAZIZ. F (Tunisie) BENSHAKROUN. A (Canada) BERMOND. J. CBILLIONNET. F (France) BOUYSSOU. D (France) BOUZGARROU. E (France)BUI. M (France) CAMINADA. A (France) CARLIER. J (France)CAZEAU. Y (France) CHRETIENNE. P (France) CHU. C (France)CORNUEJOLS. G (France) COSTA. M. C (France) CRAMA. Y (Belgique)DAUZERE PERES. S (France) De BACKER. B (France) DEJAX. P (France)DE WERRA. D (Suisse) DEMANGE. M (France) DOLGUI. A (France)DUPONT.L (France) FORTZ. B (Belgique) FOTSO. L-P (Cameroun)FREVILLE. A (France) GANDIBLEUX. X (France) GENDREAU. M (Canada)GOURDIN. E (France) GOURGAND. M (France) HAO. J (France)HANAFI. S (France) HAOUARI. M (Tunisie) HERTZ. A (Canada)JACQUET LAGREZE. E JAUMARD. B (Canada) LABBE. M (Belgique)LAMURE. M (France) LEMARECHAL. C (France) LE THI. A (France)LOPEZ. P (France) MACULAN. N (Brésil) MARCOTTE. P (Canada)MARTEL. J. M (Canada) MARTELLO. S (Italie) MAURAS. J. F (France)MICHELON. Ph (France) MINOUX. M (France) MOUKRIM. A (France)MUNIER. A (France) NADDEF. D (France) OSMAN. I. H (Liban)PASCHOS. V (France) PHAM DINH. T (France) PIERREVAL. H (France)PINSON. E (France) PIRLOT. M (Belgique) PLATEAU. G (France)PORTMAN. M. C (France) PRINS. C (France) QUEYRANNE. M (France)RIBEIRO. C (Brésil) ROUCAIROL. C (France) SEBO. A (France)SBIHI. N (France) SEMET. F (France) SIARRY. P (France)SLOWINSKI. R (Pologne) SOUBEIGA. E (GB) TAILLARD. E (Suisse)TALBI. E (France) TEGHEM. J (Belgique) TSOUKIAS. A (France)VANDERBECK. F (France) WIDMER. M (Suisse)

Table des matières
Conférence ROADEF 09
Résumés invitésSmith’s Ratio Rule in Scheduling . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1Maurice Queyranne
Théorie de la décision algorithmique et optimisation dans les graphes . . . . . . . . . . . . . . . 2Patrice Perny
Récentes innovations sur les solveurs et outils de développement d’applications . . . . . . . 3Sofiane Oussedik
La complexité de l’a!ectation de flotte d’une compagnie aérienne avec gestion desitineraires passagers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4Semi Gabteni
Résumés acceptésProblème de tournées de véhicules avec routes multiples pour réaliser des traitementsphytosanitaires . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5F. Hernandez, D. Feillet, R. Giroudeau, O. Naud, J.C. Konig
Optimisation des tournées d’inspection des voies ferrées . . . . . . . . . . . . . . . . . . . . . . . . . . . 7S. Lannez, C. Artigues, J. Damay, M. Gendreau, N. Marcos, P. Pouligny
Optimisation de la planification de tournées de cars . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9A. Huart, F. Semet
Conception de Tournées de Véhicules Régulières . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11D. Feillet, T. Garaix, F. Lehuédé, O. Péton, D. Quadri
Une heuristique duale pour le sac à dos quadratique avec contrainte de cardinalité . . . 13L. Létocart, M-C. Plateau, G. Plateau
Comparaison entre di!érentes relaxations pour des problèmes de coloration de graphes 15Ph. Meurdesoif.
Une approche par moindres carrés semidéfinis pour le problème k-cluster . . . . . . . . . . . . 17Jérôme Malick, Frédéric Roupin
Applying the T-Linearization to the Quadratic Knapsack Problem . . . . . . . . . . . . . . . . . 19C.D. Rodrigues, D. Quadri, P. Michelon, S. Gueye, M. Leblond

IV
Chainage des sommets d’un graphe pour le test des circuits intégrés . . . . . . . . . . . . . . . . 22Y. Kie!er, L. Zaourar
Vers une notion de compromis en optimisation multidisciplinaire multiobjectif . . . . . . . 24B. Guédas, P. Dépincé, X. Gandibleux
Profils de performance pour le paramétrage et la validation de métaheuristiquesstochastiques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26Johann Dréo
Segmentation optimale d’image par optimisation multiobjectif . . . . . . . . . . . . . . . . . . . . . 28A. Nakib, H. Oulhadj, P. Siarry
Sélection du portefeuille de projets d’exploration production en utilisant la méthodede Markowitz . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31Fateh BELAID, Daniel DE WOLF
Construction d’un modèle de simulation par le biais de données de localisation desproduits . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33A. Véjar, P. Charpentier
Solving of waiting lines models in the airport using queuing theory model and linearprogramming . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35Houda Mehri, Taoufik Djemel
Evaluation de projets d’investissement pétrolier en utilisant la simulation de MonteCarlo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37Fateh BELAID, Daniel DE WOLF
Softening Gcc with preferences . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39J-Ph. Métivier, P. Boizumault, S. Loudni
Impact des modes de comptage sur les méthodes à base de divergences . . . . . . . . . . . . . 41W. Karoui, M.-J. Huguet, P. Lopez
Relaxation lagrangienne pour le filtrage d’une contrainte-automate à coûts multiples . 43Julien Menana, Sophie Demassey, Narendra Jussien
Satisfaction de contraintes pondérées et séparation de contraintes de capacités pourle problème CVRP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45M. Hifi, M.O.I. Khemmoudj, S. Negre
Recherche locale haute performance pour l’optimisation de la distribution de gazindustriels par camions-citernes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49Thierry Benoist, Bertrand Estellon, Frédéric Gardi, Antoine Jeanjean
Elaboration d’un outil de chargement de camion pour l’approvisionnement en piècesdes usines Renault . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51Jean-Philippe Brenaut

V
Optimisation du réseau d’acheminement du courrier . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53A. JARDIN, E. PINSON, B. LEMARIE
Aide à l’élaboration de la carte militaire. La recherche adaptative pour uneoptimisation multicritères. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56Commandant S. Sécherre
Optimisation de l’utilité espérée dépendant du rang dans les diagrammes d’influence . 59G. Jeantet, O. Spanjaard
Une méthode de génération de colonnes basée sur un algorithme central de planscoupants . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61M. Trampont,, C. Destré,, A. Faye,
Programmation dynamique par blocs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63N. Touati, L. Létocart, A. Nagih
Un schéma de décomposition Dantzig-Wolfe pour les problèmes de tournées devéhicules sur arcs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65H.M. Afsar
Résolution du problème d’arbre couvrant quadratique de poids minimum via RBS . . . 67T. Garaix, F. Della Croce
Recherche Locale Guidée pour la Coloration de Graphes . . . . . . . . . . . . . . . . . . . . . . . . . 69Daniel Cosmin Porumbel, Jin Kao Hao, et Pascale Kuntz
Un algorithme génétique pour minimiser le makespan dans un flow shop hybrideavec périodes flexibles d’indisponibilité des machines . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72W. Besbes, J. Teghem, T. Loukil
Résolution d’un problème de Job-Shop avec contraintes financières . . . . . . . . . . . . . . . . . 75P. Féniès, P. Lacomme, A. Quilliot
Job-shop avec un seul robot de capacité non unitaire . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77P. Lacomme, M. Larabi,, N. Tchrnev
Méthode exacte pour le flowshop hybride avec machines à traitement par batches etcompatibilité entre les tâches. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79A. Bellanger, A. Oulamara
Composition optimale d’équipes d’athlétisme . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81Frédéric Gardi
Résolution d’un problème de Job-Shop intégrant des contraintes de RessourcesHumaines . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83O. Guyon, P. Lemaire, É. Pinson, D. Rivreau

VI
Etude de l’influence de l’algorithme de séparation et d’évaluation appliqué auxthématiques d’ordonnancement de bus et d’équipages. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85Clément Solau et Laure Thoma-Cosyns
Un modèle pour le calcul de plus court chemin multimodal en milieu urbain . . . . . . . . . 87Tristram Grabener, Alain Berro, Yves Duthen
Calcul de plus court chemin bicritére . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 90G. Sauvanet, E. Néron
Coupes valides pour le problème de minimisation de la somme pondérée de retard etde l’avance sur une machine unique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92Maher. Rebai, Imed. Kacem
Localisation de caches dans un réseau de distribution de contenu . . . . . . . . . . . . . . . . . . . 94Philippe Chrétienne, Pierre Fouilhoux, Eric Gourdin, Jean-Mathieu Segura
Un algorithme approché de facteur 2 log2(n) pour le problème du cycle de couverture . 96V.H. Nguyen
Construction des séries d’états dans l’algorithme Divide-and-Evolve . . . . . . . . . . . . . . . . 98Jacques BIBAI, Marc SCHOENAUER, Pierre SAVÉANT
The Multi-Period GAP Problem . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100X. CAO, A. JOUGLET, D. NACE
Heuristiques itératives basées sur des relaxations pour le problème du sac-à-dosmultidimensionnel à choix multiples . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102Christophe Wilbaut et Saïd Hanafi
Une formulation PLNE e"cace pour 1|rj |Lmax . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104C. Briand, S. Ourari
Amélioration de la borne préemptive pour le problème 1|ri|Lmax . . . . . . . . . . . . . . . . . . . 106F. Della Croce, V. T’kindt
Jackson’s Semi-Preemptive Schedule on One Machine with Heads and Tails . . . . . . . . . 108A. Gharbi,, M. Labidi
Minimisation des croisements de flux dans une plateforme de crossdocking . . . . . . . . . . 111O. Ozturk, G. Alpan, M.-L. Espinouse
Planification d’itinéraires en transport multimodal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113Fallou Gueye, Christian Artigues, Marie J. Huguet, Frédéric Schettini, LaurentDezou
Core Routing on Time-Dependent Networks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115G. Nannicini,, D. Delling

VII
Un modèle de Plan Directeur des Opérations pour une Supply Chain. Une étude decas dans l’Automobile. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 117J.P. Garcia-Sabater, J. Maheut
Un modèle MILP pour la Planification Globale. Etude de cas dans l’Automobile. . . . . . 119J.P. Garcia-Sabater, J. Maheut
Optimisation robuste pour la gestion court terme d’un portefeuille d’actifs gaziers . . . . 121R. Apparigliato, G. Erbs, S. Pedraza Morales, M.-C. Plateau
Approximation algorithms for minimizing the makespan on two parallel machineswith release dates . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123M. Hifi,, I. Kacem
Deux agents concurrents pour l’ordonnancement des travaux dans un flowshop avecétage commun . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 125A. Soukhal, N. Huynh Tuong, L. Miscopein
Aide à la Décision Collective : Vers une estimation dynamique de l’e"cacité desréunions de prise de décision collective . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 128G. Camilleri, P. Zarate
Mesurage additif conjoint pour la problématique du tri . . . . . . . . . . . . . . . . . . . . . . . . . . . 130D. Bouyssou, Th. Marchant
Aide à la décision pour l’optimisation des gares de triage . . . . . . . . . . . . . . . . . . . . . . . . . . 132H. Djellab,, C. Mocquillon, C. Weber
Heuristiques et metaheuristique pour le Multiproduct Parallel Assembly LinesBalancing Problem . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 135N. Grangeon, S. Norre
Un algorithme GRASP pour la résolution d’un TLBP avec des contraintes liées auxchoix d’équipements . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 137M. Essafi, X. Delorme, A. Dolgui
Gestion de l’autonomie des Robots Mobiles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 140Hassan BAALBAKI
Programmation linéaire en nombres entiers pour l’ordonnancement modulo souscontraintes de ressources . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142M. Ayala, C. Artigues
Formulation on-o! pour le RCPSP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 144O. Koné, C. Artigues, P. Lopez, M. Mongeau
Le Problème d’Ordonnancement avec Production et Consommation de Ressources . . . 146Jacques Carlier, Aziz Moukrim, Huang Xu

VIII
Extension du Contexte de Mise en Oeuvre des Ordonnancements PFAIR . . . . . . . . . . . . 148S. MALO, A. GENIET, M. BIKIENGA
Implémentation e!ective d’un ordonnanceur distribué . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 150M. Pérotin, P. Martineau, C. Esswein
Une heuristique e"cace pour l’ordonnancement périodique de tâches avec contraintesde stockage . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 152K. Deschinkel,, S.A.A Touati
Complexité de kSTSP, ou TSP multi-containers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 154S. Toulouse, R. Wolfler Calvo
Couverture d’un graphe à l’aide d’une forêt contrainte de poids minimal . . . . . . . . . . . . 156C. Bazgan,, B. Couëtoux
Approximation et algorithmes exponentiels : le cas de la couverture minimum . . . . . . . 157N. Bourgeois, B. Esco"er, V. Th. Paschos
Ordonnancement temps réel multiprocesseur partitionné et programmation parcontraintes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 159Anne-Marie Déplanche,, Pierre-Emmanuel Hladik
Problème d’acquisition de données par une torpille . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 161G. Simonin, A.-E. Baert, A. Jean-Marie, R. Giroudeau
T -coloration d’hypergraphe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 163A. Gondran, A. Caminada, O. Baala
Problème de la somme coloration d’un graphe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 165Yu Li, Corinne Lucet, Aziz Moukrim, Kaoutar Sghiouer
Tentative de caractérisation des colorations valides d’un graphe . . . . . . . . . . . . . . . . . . . . 167J.N. Martin,, A. Caminada
Les algorithmes évolutionnaires pour l’exploration de données par projectionsrévélatrices . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 169Souad Larabi Marie-Sainte, Alain Berro et Anne Ruiz-Gazen
Solving the Single Straddle Carrier Routing Problem using Genetic Algorithm . . . . . . . 171Khaled MILI, Khaled MELLOULI
Routage et a!ectation de longueurs d’onde dans les réseaux optiques WDM . . . . . . . . . 173L. Belgacem, I. Charon, O. Hudry
Génération d’emplois du temps pour les établissements à formation à "la carte" . . . . . 175H. Mabed,, H. Manier, M-A. Manier, O. Baala, S. Lamrous, C. Renaud
Optimisation de la planification de bourses d’échanges de technologies . . . . . . . . . . . . . . 177C. Guéret, O. Morineau, C. Pavageau, O. Péton, D. Poncelet

IX
Conception des horaires de bus (graphicage) et conception des horaires des chau!eursde bus (habillage) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 179T.Dereu, F.Lamer, D.Montaut, A.Schweitzer
Comment deviner le prix de réservation de son adversaire pour maximiser son revenu ? 181H. Le Cadre, M. Bouhtou
Résolution d’enchères sur réseau par décomposition de Benders . . . . . . . . . . . . . . . . . . . . 183S. Lannez, T. Crainic, M. Gendreau
Partage de ressources informatiques : Enchères combinatoires dans les grilles1 . . . . . . . 185L. Belgacem, E. Gourdin, R. Krishnaswamy, A. Ouorou
Application de MO-TRIBES au dimensionnement de circuits électroniques . . . . . . . . . . 187Y. Cooren, M. Fakhfakh, P. Siarry
Multiobjective dynamic optimization of a fed-batch copolymerization reactor . . . . . . . 189B. Benyahia, A. Latifi, C. Fonteix, F. Pla, S. Nacef
Optimiser sur les ensembles d’arêtes des graphes bipartis induits . . . . . . . . . . . . . . . . . . . 192D. Cornaz,, R. Mahjoub
Le problème de la grue préemptif asymétrique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 194H.L.M. Kerivin, M. Lacroix et A.R. Mahjoub
Le problème du voyageur de commerce asymétrique avec contraintes de saut . . . . . . . . . 196Laurent Alfandari, Sylvie Borne et Lucas Létocart
Problème de tournée du personnel de soins pour l’hospitalisation à domicile . . . . . . . . . 198Y. Kergosien, Ch. Lenté, et J-C. Billaut
Algorithme mémétique pour l’ordonnancement des blocs opératoire . . . . . . . . . . . . . . . . . 200M. SOUKI et A. REBAI,
Planification des blocs opératoires . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 203M. Souki, S. Ben Youcef et A. Rebai
Modélisation orientée objet avec OptimJ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 206Denis Debarbieux et Patrick Viry
ParadisEO-MO : une plate-forme pour le développement de métaheuristiques à basede solution unique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 208J-C. Boisson, S. Mesmoudi, L. Jourdan et E-G. Talbi
Outil de visualisation d’ordonnancements . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 210David Savourey1 Ce travail de recherche est en partie financé par le projet européen Grid4All [3].

X
Une procédure de séparation pour le meilleur des cas dans un ordonnancement degroupes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 212Guillaume Pinot
Politique de service optimal dans une file d’attente en temps discret avec impatiences . 214E. Hyon,, A. Jean-Marie
Problèmes de couverture généralisée en transport : combinaisons d’une heuristiquegloutonne et de la génération de colonnes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 216J. Sadki, L. Alfandari, A. Plateau, A. Nagih
Un outil d’aide à la décision pour l’optimisation du cantonnement de voie ferrée . . . . . 218J. Damay et H. Djellab
Restauration d’images par coupes minimales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 220N. Lermé, L. Létocart et F. Malgouyres
Un algorithme bi-objectif pour les systèmes d’assemblages bi-niveau avec incertitudede délais d’approvisionnement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 223F. Hnaien X. Delorme, A.Dolgui
Planification stratégique d’un réseau logistique international . . . . . . . . . . . . . . . . . . . . . . . 225M. Suon, N. Grangeon,, S. Norre,, O. Gourguechon,
Comparaison de trois heuristiques pour la planification stratégique de réseauxlogistiques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 227P.N. Thanh, N. Bostel, O. Péton
Une généralisation du problème du cycle Hamiltonien. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 229V. Jost,, G. Naves
Détermination des k arêtes les plus vitales pour le problème de l’arbre couvrant minimal 232C. Bazgan, S. Toubaline, D. Vanderpooten
Un algorithme générique pour le calcul d’arbres couvrants sous contraintes . . . . . . . . . . 234J. Brongniart, C. Dhaenens, El.G Talbi
Heuristique pour la résolution des problèmes d’ordonnancement de type FlowShopavec blocage RCb . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 236C. Sauvey,, N. Sauer
Flow shop à deux machines et moyen de transport intermédiaire . . . . . . . . . . . . . . . . . . . 239N. Chikhi, et M. Boudhar
An integrated approach for lot streaming and just in time scheduling . . . . . . . . . . . . . . . 241O.Hazir, S. Kedad Sidhoum
A hybrid genetic algorithm for the vehicle routing problem with private fleet andcommon carriers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 243J. Euchi,, H. Chabchoub,

XI
Un algorithme exact bi-objectif pour le problème du voyageur de commerce multi-modal 246Nicolas Jozefowiez, Gilbert Laporte, Frédéric Semet
Utilisation de la moyenne de Hölder dans une optimisation multi-critères dutransport à la demande . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 248Rémy CHEVRIER
Composition de services Web et équité vis-à-vis des utilisateurs finaux . . . . . . . . . . . . . . 251J. El Haddad, O. Spanjaard
Introduction au choix social computationnel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 253J. Lang
Dominance de Lorenz itérée et recherche de solutions équitables en optimisationcombinatoire multi-agents . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 254B. Golden, P. Perny
Allocation de ressources distribuée dans un contexte topologique . . . . . . . . . . . . . . . . . . . 255S. Estivie
Détermination du vainqueur d’une élection : complexité des procédures de Slater etde Condorcet-Kemeny . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 257O. Hudry
Apprentissage distribué d’états stables pour le routage . . . . . . . . . . . . . . . . . . . . . . . . . . . . 259D. Barth, O. Bournez, O. Boussaton, J. Cohen
Analyse de fiabilité des systèmes semicohérents et description par des polynômeslatticiels . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 261Alexander Dukhovny, Jean-Luc Marichal
Allocation de fréquences dans un système de communication satellitaire utilisant leSDMA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 263Laurent Houssin, Christian Artigues, Erwan Corbel
Optimisation de la collecte de données dans un champ de capteurs par VNS/VND . . . 265M. Sylla, B. Meden, C. Duhamel
Scalabilité pour le contrôle réparti : un problème d’agrégation d’informations . . . . . . . . 267T. Bernard, A. Bui, C. Rabat
Présentation d’une méthode de résolution pour les problèmes de placement 2D et 3D . 269G. Jacquenot, F. Bennis, J.-J. Maisonneuve, P. Wenger
Le problème de placement/chargement en trois-dimensions : calcul de bornes etméthodes approchées . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 271N.Cherfi, M.Hifi, I. Kacem

XII
Algorithme coopératif parallèle pour le problème de découpe contraint à deuxdimensions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 274Mhand Hifi, Rym M’Hallah, Toufik Saadi
Nouvelles Bornes Inférieures pour le Problème de Bin Packing avec Conflits . . . . . . . . . 277Ali Khanafer, François Clautiaux, El-Ghazali Talbi
Un algorithme coopératif pour le problème de découpe circulaire non-contraint . . . . . . 279H. Akeb M. Hifi, S. Nègre
X-hyperarbres . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 281F. Brucker, A. Gély
Recent Results on the Discretizable Molecular Distance Geometry Problem . . . . . . . . . . 283C. Lavor, L. Liberti, A. Mucherino, N. Maculan
Analyse combinatoire de données et temps de survie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 285J. Darlay, L.-P. Kronek, N. Brauner
Modèles et heuristiques pour un problème de biclustering . . . . . . . . . . . . . . . . . . . . . . . . . 287D. Perrin, C. Duhamel, H. J. Ruskin
Aide à la décision pour la massification des flux du fret SNCF . . . . . . . . . . . . . . . . . . . . . 289Housni Djellab, Yann Guillemot, Christian Weber
Gestion du revenu pour le transport de containers par voies ferrées . . . . . . . . . . . . . . . . . 292I.C. Bilegan, L. Brotcorne, D. Feillet, Y. Hayel
Ordonnancement des trains sur une voie unique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 294F. Sourd,, Ch. Weber
Problème de lot-sizing à capacité finie avec fenêtres de temps et contraintes de services 296S. Kedad-Sidhoum, C. Rodríguez-Getán, N. Absi, S. Dauzère-Pérès
On the discrete lot-sizing and scheduling problem with parallel resources . . . . . . . . . . . . 298C. Gicquel, M. Minoux, Y. Dallery
Un système d’agents pour la planification et l’ordonnancement multi-produits,multi-modes avec approvisionnements . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 300K. Belkhelladi, P. Chauvet, L. Péridy, A. Schaal
Dimensionnement et ordonnancement de livraisons de repas . . . . . . . . . . . . . . . . . . . . . . . 302V. André, N. Grangeon, S. Norre,
Utilisation de problèmes d’ordonnancement pour la conception de systèmes flexiblesde production . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 304L. Deroussi,
Borne inférieure et coupes pour le problème d’optimisation des changements de séries . 306C. Pessan, E. Néron

XIII
Minimisation du nombre de processeurs pour les systèmes temps réel multiprocesseurs 308François DORIN, Michael RICHARD, Emmanuel GROLLEAU, Pascal RICHARD
Ordonnancement de tâches synchrones multipériodiques . . . . . . . . . . . . . . . . . . . . . . . . . . 310Mikel Cordovilla, Julien Forget, Claire Pagetti, Frédéric Boniol
d-bloqueurs et d-transversaux . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 312C. Bentz, M.-C. Costa, D. de Werra, C. Picouleau, B. Ries, R. Zenklusen
Un algorithme polynomial pour calculer le stable maximum (pondéré) dans uneclasse de graphes sans P5 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 314F. Ma!ray, G. Morel
Une nouvelle classe de graphes : les hypotriangulés . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 316M.-C. Costa, C. Picouleau, H. Topart
Gestion de production électrique en contexte incertain . . . . . . . . . . . . . . . . . . . . . . . . . . . . 318Sinda Ben Salem,, Michel Minoux
Amélioration des solutions intermédiaires pour la résolution exacte du sac à dosmultidimensionnel en 0–1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 320S. Boussier, M. Vasquez et Y. Vimont
Recherche à grands voisinages pour l’a!ection d’activités dans un contextemulti-activités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 322Quentin Lequy, Mathieu Bouchard, Guy Desaulniers, François Soumis
Un algorithme augmenté pour le problème du knapsack disjonctif . . . . . . . . . . . . . . . . . . 324M. Hifi, M. Ould Ahmed Mounir
Routage de guides d’ondes dans un satellite de télécommunications . . . . . . . . . . . . . . . . . 326F. Bessaih, B.Cabon, D. Feillet, Ph.Michelon, D.Quadri
Méthode hybride PPC/PLNE pour le réordonnancement de plan de circulationferroviaire en cas d’incident . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 328R. Acuna-Agost, P. Michelon, D. Feillet, S. Gueye
Recherche de zone de blocage dans un graphe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 330Jun HU, Mohammad DIB, Alexandre CAMINADA, Hakim MABED
Etude comparative de recherche locale et de propagation de contraintes en CSP n-aire 332M. Dib, I. Devarenne, H. Mabed, A. Caminada
Reformulations between structured global optimization problems and algorithms . . . . . 334S. Cafieri, P. Hansen, L. Liberti
Gestion des symétries dans une résolution exacte de l’a!ectation quadratique à troisdimensions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 336B. Le Cun, F. Galea

XIV
The symmetry group of a mathematical program . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 338L. Liberti
Non Linear Mathematical Programming Approaches to the Classification Problem :A Comparative Study . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 341Soulef Smaoui, Habib Chabchoub,, Belaid Aouni
Using Stochastic Goal Programming to rearrange Beds inside Habib Bourguiba Hospital 343A. Badreddine Jerbi, B. Hichem Kammoun,
Symétrie et préférences des ressources dans la planification des blocs opératoires . . . . . 346B. Roland,, F. Riane
Approche mathématique pour la programmation des rendez-vous de mises au pointmédicales en ambulatoire . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 348J.-P. Cordier, F. Riane, H. Aghezzaf
Un algorithme exact pour la sélection et l’ordonnancement de tâches sur une machine 350F. Talla Nobibon, J. Herbots, R. Leus
Lotissement et séquencement sur une machine imparfaite avec temps de changementde série . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 352A. Dolgui, M.Y. Kovalyov, K. Shchamialiova
On maximizing the profit of a satellite launcher : selecting and scheduling taskswith time windows and setups . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 354P. Baptiste, P. Chrétienne, J. Meng-Gérard, F. Sourd
Minimisation du retard des mesures dans la fabrication des semi-conducteurs . . . . . . . . 356B. Detienne, C. Yugma, S. Dauzère-Pérès
Le probléme de tournées de véhicules m-péripatétiques . . . . . . . . . . . . . . . . . . . . . . . . . . . 358Sandra U. NGUEVEU, Christian PRINS, Roberto WOLFLER-CALVO
Modèle de simulation pour l’évaluation des performances de tournées de véhiculesen conditions réelles de trafic . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 360M. Chabrol, M. Gourgand, P. Leclaire
Méthode de Branch & Price heuristique appliquée au problème de Tournées deVéhicules avec Contraintes de Chargement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 362Boris BONTOUX,, Christian ARTIGUES, Dominique FEILLET
Une méthode pour l’analyse de sensibilité à l’aide des réseaux de Petri stochastiques . . 365S. SAGGADI, K. LABADI,, L. AMODEO
Multiparametric programming to assess the completion time sensitivity ofmultipurpose parallel machines . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 367Minh Hoang LE, Alexis AUBRY, Mireille JACOMINO

XV
Comparaison d’algorithmes de décomposition Application à la gestion de production . 370Alice Chiche
Optimisation de placement de publicité internet par l’algorithme des bandits manchots 372Antoine Jeanjean, Bruno Martin
Trois jeux d’arbre couvrant pour agents individualistes . . . . . . . . . . . . . . . . . . . . . . . . . . . 374Laurent Gourvès et Jérôme Monnot
Reformulation du Problème du Sac à Dos Bi-Niveaux . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 376R. Mansi, S. Hanafi, L. Brotcorne
Problème d’a!ectation entre plusieurs organisations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 378Laurent Gourvès, Jérôme Monnot et Fanny Pascual
Convex relaxations for quadrilinear terms . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 380S. Cafieri, J. Lee, L. Liberti
About the direct support method in linear programming . . . . . . . . . . . . . . . . . . . . . . . . . . 382Sonia Radjef, Mohand Ouamer Bibi
Optimisation des réseaux de transport de gaz à l’aide de la méthode des Moments. . . . 384Dan GUGENHEIM,, Jean ANDRÉ, Frédéric BONNANS
Résumés du Challenge ROADEFChallenge ROADEF 2009 Gestion de perturbations dans le domaine aérien . . . . . . . . . . 386M. Boudia, O. Gerber, R. Layouni, M. Afsar, C. Artigues, E. Bourreau et O. Briant
Challenge ROADEF 2009. Statistical Analysis of Propagation of Incidents forrescheduling simultaneously flights and passengers under disturbed operations . . . . . . 389R. Acuna-Agost, P. Michelon, D. Feillet, S. Gueye
Challenge ROADEF 2009. Une méthode de recherche à grand voisinage pour lagestion des perturbations dans le domaine aérien . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 391S. Bisaillon, J.-F. Cordeau, G. Laporte, F. Pasin
Challenge ROADEF 2009. Stratgie d’oscillation pour la gestion de perturbationsdans le domaine arien . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 393Saïd Hanafi, Christophe Wilbaut, Raïd Mansi et Franois Clautiaux
Challenge ROADEF 2009. Approche heuristique pour la gestion de perturbationsdans le domaine aérien . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 395Nicolas Jozefowiez, Catherine Mancel, Félix Mora-Camino
Challenge ROADEF 2009. Use of a Simulated Annealing-based algorithm inDisruption Management for Commercial Aviation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 397J. Peekstok, E. Kuipers

XVI
Challenge ROADEF 2009. Une approche heuristique pour la gestion de perturbationdans le domaine aérien . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 399J. Darlay, L.-P. Kronek, S. Schrenk, L. Zaourar
Challenge ROADEF 2009. Disruption Management for Commercial Aviation, AMixed Integer Programming Approach . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 401Sophie Dickson, Olivia Smith, Wenkai Li
Challenge ROADEF 2009. Airline disruption recovery ROADEF Challenge 2009 . . . . . 403Niklaus Eggenberg, Matteo Salani
Challenge ROADEF 2009. Description of the TUe Solution Method . . . . . . . . . . . . . . . . 405Christian Eggermont, Murat Firat, Cor Hurkens, Maciej Modelski
Index des Auteurs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 408

Smith’s Ratio Rule in Scheduling
Maurice Queyranne
Centro de Modelamiento Matemático, Universidad de Chile, Santiago ; et Sauder School ofBusiness, University of British Columbia, Vancouver, Canada
In 1956, Wayne E. Smith proposed a simple sequencing rule, now known as Smith’s ratioor Weighted Shortest Processing Time (WSPT) rule : sequence the jobs in nondecreasingorder of their ratio of processing time to weight. This rule plays a central role in minsumscheduling, when the objective is to minimize a weighted sum of completion times. Smithproved its optimality for the simplest minsum scheduling problem, when all jobs are simulta-neously available for processing on a single machine. We review some of the many extensionsand related results in the past 53 years since Smith’s seminal result. The main themes ad-dressed in this talk include an interpretation of Smith’s rule as a greedy algorithm for certainsupermodular polyhedra ; a geometric representation using two-dimensional Gantt charts ;extensions to problems with release dates and parallel machines ; and recent results on theanalysis of on-line heuristics for deterministic and stochastic minsum scheduling.

Théorie de la décision algorithmique et optimisationdans les graphes
Patrice Perny
LIP6-Université Paris 6, 104, avenue du Président Kennedy, 75016 Paris, [email protected]
Les développements récents de la théorie de la décision ont fourni divers modèles de pré-férences sophistiqués pour la prise de décision en environnement complexe (décision dansl’incertain et le risque, décision multicritère, décision collective). Dans ce domaine, l’essentielde l’e!ort a porté sur l’accroissement du pouvoir descriptif des modèles pour rendre comptede la diversité des comportements observés, mais aussi sur l’analyse axiomatique et la justi-fication théorique des critères de décision employés.
Cependant, lorsqu’il s’agit de problèmes d’optimisation combinatoire, la définition d’unmodèle de préférences sur les solutions ne su"t plus pour déterminer le(s) meilleur(s) choixpuisque l’ensemble des alternatives (solutions réalisables) est défini en compréhension et sataille empêche toute énumération explicite. De plus les approches constructives simples de typeprogrammation dynamique ou algorithme glouton ne s’étendent pas naturellement en présencede préférences complexes et l’on a besoin d’algorithmiques spécifiques pour la recherche dessolutions préférées.
Dans ce contexte, l’objet de cette présentation est tout d’abord, en partant de problèmesd’optimisation classiques dans les graphes (chemins, arbres couvrants, a!ectation/transport)d’introduire des problèmes d’optimisation combinatoire à base de préférences complexes, etce dans divers contextes tels que l’optimisation robuste dans l’incertain ou le risque, l’op-timisation équitable en décision multiagent et l’optimisation multiobjectif. Nous évoqueronsensuite la complexité des problèmes introduits puis présenterons quelques voies possibles pourla résolution exacte et/ou approchée de tels problèmes. Les quelques thèmes abordés dans cetexposé illustrent en fait un programme de recherche plus vaste, au carrefour de la théorie dela décision et de l’algorithmique, que nous esquisserons en guise de conclusion.

Récentes innovations sur les solveurs et outils dedéveloppement d’applications
Sofiane Oussedik
ILOG, 3-5 Avenue Gallièni, 94253 Gentilly, [email protected]
Durant cette présentation, les dernières avancées techniques sur les produits d’optimisa-tion ILOG (société du groupe IBM) seront abordées. Nous parcourrons ainsi les outils o!ertspar la suite d’optimisation en vue de couvrir le processus de modélisation et de développe-ment applicatif, depuis le prototypage rapide, la mise au point des applications, jusqu’audéploiement et à la maintenance.
Les récents développements sur la suite d’optimisation permettent d’automatiser la créa-tion d’applications d’optimisation personnalisées tout en o!rant aux utilisateurs la possibilitéde configurer et modifier eux-mêmes les applications qui guideront leurs décisions opéra-tionnelles. Ainsi, le développeur et l’utilisateur métier ont rapidement accès à des fonctionsprêtes à l’emploi d’analyse par simulation et de comparaison de scénarios. Les utilisateurspeuvent alors mesurer l’impact des modifications sur leur activité en ajustant des hypothèses,des contraintes opérationnelles et des objectifs de planification et d’ordonnancement des res-sources dans une terminologie métier familière et de définir ainsi la meilleure stratégie àadopter face à une multitude de problèmes.
Une innovation majeure ces dernières années a également été l’introduction de IBM ILOGCP Optimizer, nouveau moteur de programmation par contraintes, qui modifie la perceptionquant à l’utilisation de la programmation par contraintes pour la résolution de problèmesd’ordonnancement en apportant deux innovations majeures :
– Un Framework de modélisation basé sur des intervalles, ce qui réduit considérablementle nombre de concepts requis pour décrire les contraintes et les coûts d’un problèmed’ordonnancement.
– De plus, il inclut un solveur puissant et testé sur une large gamme de problèmes d’or-donnancement di!érents
La combinaison de ces deux innovations permettent le développement d’applications en« model and run » en suivant les mêmes principes de développement qu’en programmationlinéaire en nombres entiers. IBM ILOG CP Optimizer permet de tester très rapidement si uneformulation ou une stratégie de décomposition fournit des résultats en un temps raisonnable.

La complexité de l’a!ectation de flotte d’une compagnieaérienne avec gestion des itineraires passagers
Semi Gabteni
Senior Manager, Operations Research & OptimizationAmadeus IT Group SA. [email protected]
Une des clés de la profitabilité d’une compagnie aérienne est son programme de vols. Laconstruction de ce dernier requiert une compréhension fine des revenus et des couts qui endécoulent. Cette compréhension repose aujourd’hui, chez nombre de compagnies aériennessur la modélisation et la résolution du problème d’a!ectation de flotte, plus connu sous lenom de Fleet Assignment. . Ce modèle est centré sur les vols et ne prend pas en compte lesitinéraires passagers qui combinent plusieurs vols. Depuis les années quatre-vingt-dix, quelquestravaux se sont penchés sur cette di"culté, sans pour autant qu’une solution de référence aitémergé a ce jour. A notre connaissance, la grande majorité des compagnies aériennes qui ontimplémenté un modèle de Fleet Assignment, ne s’en sont pas a!ranchi. Entre autres raisons,citons la granularité de la gestion des itinéraires, ainsi que les limites, voire la complexité, desapproches proposées. Nous nous consacrerons d’abord à la présentation du problème, puisnous passerons les approches proposées en revue, en essayant de dégager des composants derésolution majeurs, et en evaluant leurs forces et faiblesses

Problème de tournées de véhicules avec routes multiplespour réaliser des traitements phytosanitaires
F. Hernandez1,2, D. Feillet3, R. Giroudeau2, O. Naud1, and J.C. Konig2
1 Cemagref UMR ITAP, 361 rue JF Breton, [email protected]
2 LIRMM UMR 5506 équipe APR, 161 rue Ada 34392 [email protected]
3 Ecole des Mines de Saint-Etienne CMP Georges Charpak, Gardanne [email protected]
1 Problème de planification de traitements phytosanitaires
L’objectif de ce travail est de réduire le temps de travail au sein d’une exploitation viti-cole, composé de n parcelles, d’un dépôt et disposant de u opérateurs. Pour cela nous devonsdéterminer l’ordre dans lequel e!ectuer une opération sur les parcelles i, et grouper ces par-celles dans des lots de travail rk. Dans le cas d’opérations de pulvérisation pour le traitementphytosanitaire, la taille maximale d’un lot dépend de la capacité de la cuve du pulvérisateur.
Le traitement est caractérisé, sur la parcelle i, par une consommation de ressource di etune durée d’exécution sti. Ces dernières di!èrent en fonction de la parcelle i traitée. Chaqueparcelle doit être traitée durant une fenêtre temporelle, qui est caractérisée par une borneinférieure ai et une borne supérieure bi. Le coût de déplacement cij entre deux parcelles estdéfini par la durée de déplacement entre ces deux parcelles. Nous supposons que ces duréesde déplacement respectent l’inégalité triangulaire.
A l’issue du calcul, chaque lot de travail rk sera caractérisé par une durée et une quantité deressource (produit de traitement) nécessaire à sa réalisation dk. Il sera également caractérisépar une fenêtre temporelle [ak, bk] durant laquelle il devra être e!ectué. Une fois tous les lotsde travail e!ectués, toutes les parcelles devront avoir été traitées une et une seule fois. Laquantité de ressource nécessaire à chaque lot de travail ne devra pas dépasser une certainelimite Q correspondant à la capacité maximale de la cuve utilisée par l’opérateur e!ectuantles traitements de ce lot. De plus après chaque lot de travail l’opérateur devra revenir audépôt (remplir sa cuve ou terminer sa journée).
Dans cet article nous considérons le cas, que nous noterons !1, d’un opérateur uniqueavec un seul équipement de traitement. Nous pouvons formaliser !1 comme suit :
Données : Un graphe G = (V,A), V = {v0, · · · , vn} avec v0 représentant le dépôt etv1, · · · , vn les clients (parcelles), un coût cij pour tout arc (vi, vj) ! A, une capacité dechargement Q et pour tout client vi ! {v1, · · · , vn} une demande di, une fenêtre temporelle[ai, bi] avec ai, bi ! IN et un temps de service sti.
Question : Trouver un ensemble de routes de coût minimum visitant tous les clients,respectant les contraintes de capacité et de fenêtre temporelle, et tel que deux routes n’aientpas lieu en même temps.

6 Hernandez, Feillet, Giroudeau, Naud, Konig
2 Méthode proposée : Génération de colonnes
Nous proposons de modéliser le problème en associant à chaque route une variable etd’utiliser pour sa résolution une méthode basée sur la génération de colonnes. Le principe,rappelé dans D. Feillet [Fei07], consiste à décomposer le problème en un problème de couver-ture (problème maître) et un problème de recherche de routes améliorantes (sous-problème)qui s’apparente à un problème de recherche de plus court chemin élémentaire (ESPPRC).Notre problème di!ère du VRPTW du fait que deux routes parcourues par un même véhiculene doivent pas avoir d’intersection temporelle. Pour cela, il est nécessaire de situer les routesdans le temps. Pour la génération d’une route améliorante, nous devons prendre en comptela date à laquelle la route commence et celle à laquelle elle finit. Le sous-problème consiste àrechercher les routes rk qui violent les contraintes du dual du problème maître, car seules cesroutes peuvent améliorer la solution courante. Nous utilisons l’algorithme de programmationdynamique décrit dans [FDGG04] pour résoudre notre sous-problème. L’algorithme (et enparticulier la règle de dominance) est adapté afin de gérer e"cacement la liberté sur l’heurede démarrage des routes. L’ensemble est inclus dans un schéma de Branch and Price, afind’obtenir des solutions entières. Les branchements sont e!ectués sur le flot des arcs du grapheG.
3 Conclusion
Nous avons implémenté cette méthode en c++ en utilisant le solver Glpk. Nous testonsactuellement cette méthode sur certaines instances de Solomon.
Une étude a été mené par N. Azi et al. [AGP07] dans le cas du transport de denréespérissables où la durée des routes était limitée. Dans notre approche, la durée maximaled’une route n’est pas fixée à priori.
Nous comptons améliorer notre schéma de Branch and Price en branchant sur les fenêtrestemporelles associées aux sommets ainsi que sur le flot des arcs du graphe G. Nous avonsétudié ce problème dans le cadre d’un seul véhicule. Notre méthode nous permet égalementd’étendre la résolution de tounées au cas multi-véhicules.
Nous prévoyons de mettre en place une méthode de réordonnancement en ligne dans lecas où une ou plusieurs fenêtres temporelles changeraient.
Références
[AGP07] N. Azi, M. Gendreau, and J. Y. Potvin. An exact algorithm for a single-vehicle rou-ting problem with time windows and multiple routes. European Journal of OperationalResearch, 178(3) :755–766, 2007.
[FDGG04] D. Feillet, P. Dejax, M. Gendreau, and C. Gueguen. An exact algorithm for the elementaryshortest path problem with resource constraints : Application to some vehicle routingproblems. Networks, 44(3) :216–229, 2004.
[Fei07] D. Feillet. Solution of vehicle routing problem with Branch and Price. Habilitation àdiriger des recherches, Université d’Avignon et des Pays de Vaucluse, 2007.

Optimisation des tournées d’inspection des voies ferrées
S. Lannez1,3, C. Artigues3, J. Damay1, M. Gendreau4, N. Marcos1, and P. Pouligny2
1 SNCF I&R/GDA, 45 rue de Londres, 75008 Paris, France{sebastien.lannez,jean.damay,nicolas.marcos}@sncf.fr2 SNCF IMT/IM-2, 45 rue de Londres, 75008 Paris, France
[email protected] LAAS-CNRS, 7 avenue du Colonel Roche 31077 Toulouse Cedex 4, France
[email protected] Université de Montréal, C.P. 6128, succursale Centre-ville, Montréal (Québec), H3C 3J7 Canada
Résumé Le problème que nous considérons est l’optimisation de la planification an-nuelle des tournées de surveillance des rails par les engins d’auscultation ultrasonore dela SNCF. La modélisation retenue pour le réseau ferré induit un graphe de grande tailleet impose l’utilisation d’heuristiques de résolution. Nous décrivons dans ce résumé, laproblématique, le modèle mathématique et l’algorithme retenu.
1 Introduction
Dans ce résumé, nous présentons le modèle d’optimisation qui accompagnera l’Établisse-ment Logistique National de la SNCF (ELOGN) dans sa réorganisation de la programmationdes tournées de surveillance du réseau ferroviaire français. L’ELOGN, avec l’aide des établis-sements régionaux, e!ectue certaines maintenances préventives sur le réseau à l’aide de trainsspécifiquement conçus pour chaque type d’inspection. L’une de ces tâches est la détection defissures internes du rail. Lorsque cela est possible, ces défauts sont détectés par des enginsmobiles qui auscultent le champignon du rail grâce aux ultrasons. Les fréquences d’ausculta-tion varient de 6 mois à 10 ans en fonction principalement du tonnage annuel qui les traverse.Pour réaliser cette maintenance préventive, la SNCF dispose aujourd’hui de trois engins quiréalisent annuellement plus de 50.000 km d’auscultation. Ces engins ne sont pas autorisés àausculter tout le réseau. Pour des raisons techniques, certaines parties sont auscultées parl’établissement régional qui en est responsable. L’outil que nous développons s’intègre dansle cadre d’une réorganisation du processus de programmation des tournées d’auscultation quientrera en vigueur en 2010. Ce nouveau processus centralise, au sein de l’ELOGN, la priseen charge de 2/3 des auscultations annuelles par ultrasons. Cette centralisation faciliterala coordination des régions qui pourront articuler leur planning autour de celui de l’entitécentrale.
2 Modélisation
Le problème présenté s’apparente aux problèmes d’optimisation de tournées périodiquesà cause des cycles d’auscultation. La prise en compte des auscultations passées ainsi que lanécessité de pouvoir garder le contrôle sur les dates de passages nous ont orienté vers un

8 S. Lannez, C. Artigues, J. Damay, M. Gendreau, N. Marcos, P. Pouligny
modèle d’optimisation de tournées sur arcs avec fenêtres de temps. L’horizon de planificationd’un an et les nombreux travaux sur voies (non cycliques sur un an) nous ont fait écarter lamodélisation sous forme de tournées cycliques. Nous avons opté pour un modèle dans lequelles tâches d’auscultations sont représentées sous la forme de passages obligés d’une durée fixéedans une fenêtre de temps fixée. Ces passages obligés sont aussi utilisés pour modéliser lesdemandes de mises à disposition des engins pour les régions, ainsi que pour les maintenancesdes engins. Les travaux, ou fermetures de voies, sont décrits à l’aide de périodes pendantlesquelles il est impossible de circuler sur la voie. Le lecteur intéressé par une introductionaux problèmes de tournées sur arcs et aux tournées de véhicules pourra se documenter dansles livres de [1] et [2].
Le modèle de tournées sur arcs est augmenté de contraintes spécifiques dont les deuxprincipales sont l’autonomie de couplant et l’unicité de l’expert. La première stipule qu’unengin possède une autonomie de 120 km d’auscultation. Cette autonomie est due au besoinde maintenir la voie couplée aux capteurs à l’aide d’une pellicule d’eau. La seconde contrainteimpose qu’il ne peut pas y avoir plus d’un engin en auscultation au sein d’une même région.Cette contrainte résulte du fait qu’il n’y a qu’un seul agent pas région autorisé à valider àbord la réalisation des auscultations.
3 Résolution
Dans un premier temps, un ensemble de tronçons de tournées d’une durée d’une journéeet assurant la réalisation de toutes les auscultations est généré. Ensuite, la coordination de laréalisation de ces tronçons est faites par un problème d’ordonnancement sur machine paral-lèle. Le premier problème est résolu par génération de colonnes tandis que le second est résolupar programmation par contraintes. Le sous problème dans la génération de colonnes est unplus court chemin élémentaire avec des contraintes de ressources (distance maximale et duréemaximale d’auscultation journalière). Le problème maître est un problème de couverture avecdes contraintes additionnelles pour favoriser la sélection de tronçons de tournées potentielle-ment faciles à ordonnancer. Le second problème consiste à ordonnancer un ensemble de tâchessur di!érentes machines. Ces tâches peuvent ne pas être compatibles avec toutes les machineset posséder des durées de préparation dépendant de la machine d’exécution et de la tâcheprécédemment réalisée.
Références
1. Dror M., editor : Arc Routing : Theory, Solutions and Applications. Springer, 2000.2. Golden, B. and Raghavan S. and Wasil E., editors : The Vehicle Routing Problem : Latest Advances
and New Challenges. Springer, 2008.

Optimisation de la planification de tournées de cars
A. Huart1 and F. Semet2
1 LAMIH - UMR CNRS 8530, Université de Valenciennes - Le Mont Houy 59313 - ValenciennesCedex 9 France.
[email protected] LAGIS - UMR CNRS 8146, Ecole Centrale de Lille, Avenue Paul Langevin, BP 48 59651
Villeneuve d’ascq Cedex [email protected]
1 Introduction
Dans cette présentation, nous nous intéressons à un problème de tournées de véhicules(PTV)avec contrainte horaire dont un survol complet est fait dans le livre de Toth et Vigo [1]. Leproblème ici traité est celui auquel doit faire face une entreprise de transport de voyageurs.Il s’agit d’e!ectuer un ensemble de transports de personnes. Chacun d’eux étant caractérisépar un lieu de départ, une heure de départ, un lieu d’arrivée, une heure d’arrivée. Les heuresde début et de fin de transport étant imposées, nous avons donc une contrainte plus fortequ’une fenêtre de temps traditionnelle décrite dans le PTV avec fenêtre de temps. Le but dutransporteur étant de trouver l’ordre de parcours des clients qui, pour un nombre minimalde véhicules, minimisera le coût de transport tout en respectant l’ensemble des contraintesimposées par la convention collective nationale des transports routiers et des activités auxi-liaires du transport. La législation impose dans notre cas que chaque tournée démarre dansun dépôt et finisse dans ce même dépôt, une tournée ne devant violer les contraintes de tempsde conduite. De plus, cet ensemble de tournées est limité par la taille de la flotte de véhicules.Le meilleur ensemble de tournées est celui qui génère un minimum de transport à vide et detemps d’attente. Nous avons modélisé ce problème sous la forme d’un problème d’élaborationde tournée sur les noeuds d’un graphe. Chaque sommet correspond à un transport demandépar un client. Les informations rattachées à chaque sommet sont les caractéristiques du trans-port décrites précédemment. Les arcs de ce graphe sont pondérés et orientés. Un arc entre aet b peut être interprété par la possibilité d’enchaîner les transports a et b. La pondérationassociée à l’arc correspond au coût d’enchaînement de ces deux transports. D’un point de vuedu graphe, le problème consiste à trouver un ensemble de circuits permettant la visite de tousles noeuds une et une seule fois à l’exception du noeud associé au dépôt.
2 Méthode de résolution
Dans leur article, Crainic et Semet [2] exposent di!érentes modélisations possibles pourla résolution de ce type de problème. Certaines de ces modélisations ont amené des méthodesfaisant partie des plus e"caces pour résoudre exactement la plupart des PTV dont la géné-ration de colonnes. Celle-ci repose sur une formulation du PTVFT basée sur le modèle departitionnement d’ensemble. Dans cette formulation introduite par Balinski et Quandt [3] lesvariables sont des tournées, c’est pourquoi cette formulation est aussi appelée " formulation

10 A. Huart, F. Semet
chemin ". D’après Feillet [4], une approche exacte basée sur la génération de colonnes permetde résoudre à l’optimum et en des temps acceptables des problèmes de PTVFT consistantà la visite d’environ cent clients. Pour résoudre des problèmes de taille moyenne et élevée,une nouvelle classe d’heuristiques à base de génération de colonnes permet d’obtenir de bonsrésultats. Ainsi Taillard [5] a développé une heuristique de cette classe permettant de ré-soudre un problème d’élaboration de tournées avec flotte hétérogène. Les résultats obtenusmontrent la robustesse et l’e"cacité de la méthode pour des instances de tailles réelles. Nousproposons ici une heuristique de cette classe adaptée au transport de voyageurs. On définitle problème maître comme étant le problème de partitionnement d’ensemble défini pour unsous-ensemble T’ de tournées de T. A une itération donnée, la relaxation linéaire du pro-blème maître est résolue, puis étant donné les valeurs des variables duales, des tournées decoût réduit négatif sont recherchées. L’identification d’une telle tournée se fait au travers dela résolution du sous-problème qui est, dans ce cas, un problème de plus court chemin élé-mentaire avec contraintes de temps. Nous rappelons que le problème du Plus Court CheminContraint(PCCC) est NP-dur, même en ne considérant qu’une seule ressource. Cependant,l’impact de la contrainte horaire sur le graphe rend le sous problème polynômial. En e!et,un graphe étant acyclique, un algorithme basé sur le tri topologique permet de détecter deschemins de coût négatif et ainsi de résoudre nos sous-problèmes. Généralement, lors de l’uti-lisation d’algorithmes basés sur la génération de colonnes, lorsqu’il n’y a plus de tournée decoût réduit négatif où lorsque la solution du problème maître n’est pas entière, une règle debranchement est appliquée. Le processus de génération de colonnes reprend sur chacune deces deux branches. Le fonctionnement de notre algorithme est di!érent. A chaque itération,nous ajoutons des colonnes de coût réduit négatif au problème maître. Finalement, lorsqu’aucune de ces tournées n’est identifiée, le problème maître en nombre entier est résolu . C’estpour cela que notre algorithme est heuristique. Nous avons évalué notre heuristique sur desinstances réelles comportant plus de trois cents clients. Nos résultats ont été comparés à ceuxobtenus par une adaptation de l’heuristique de Clarke&Wright [6] ainsi qu’a ceux obtenu parconfection manuelle des tournées. Les résultats obtenus montrent l’e"cacité de l’approche pargénération de colonnes pour le problème considéré.
Références
1. P. Toth and D. Vigo, editors. The Vehicle Routing Problem, volume 9 of SIAM Monographs onDiscrete Mathematics and Applications. SIAM, 2002.
2. T. Crainic, F. Semet, Recherche opérationnelle et transport de marchandises, Optimisation Com-binatoire 3, V. Paschos, éditeur, Hermès (2005).
3. M. Balinski and R. Quandt, On an integer program for a delivery problem. Operations Research,12, 1964.
4. D. Feillet, Résolution de problèmes de tournée par Branch and Price. Ecole de jeunes chercheurs.Avignon 2008.
5. E.D Taillard, A heuristic column generation method for the heterogeneous fleet VRP. OperationsResearch – Recherche opérationnelle 33 (1), 1999, 1-14.
6. G. Clarke and J.W.Wright, Scheduling of Vehicles from a Central Depot to a number of DeliveryPoints. Operations Research, 12 :568-581, 1964.

Conception de Tournées de Véhicules Régulières
D. Feillet1, T. Garaix2, F. Lehuédé3, O. Péton3, and D. Quadri4
1 École des Mines de Saint-Etienne, CMP Georges Charpak, 880 avenue de Mimet, F-13541GARDANNE
[email protected] Politecnico di Torino - Corso Duca degli Abruzzi, 24 - I-10129 Torino.
[email protected] IRCCyN, Ecole des Mines de Nantes, 4 rue Alfred Kastler, F-44307 NANTES.
fabien.lehuede, [email protected] Laboratoire Informatique d’Avignon (LIA), Université d’Avignon et des Pays du Vaucluse, 339
chemin des Meinajaries Agroparc, F-84911 [email protected]
L’optimisation de problèmes de tournées de véhicules se concentre généralement sur laminimisation de la distance parcourue ou du temps de parcours. Optimiser la qualité deservice est un critère au moins aussi important dans de nombreux contextes (Paquette et al.[1]). En particulier, dans le cas de clients servis de manière répétitive au cours du temps,maintenir une certaine régularité dans le service peut être grandement apprécié.
Un cas très représentatif est celui des grandes sociétés de messagerie (type UPS, DHL...)pour la livraison de colis auprès de grands comptes industriels (Groër et al [2]). Du faitde l’importance de l’activité des entreprises clientes, les réceptions de colis se répètent surune base presque quotidienne. Être capable de proposer à la fois un horaire de livraison etun chau!eur réguliers à chaque livraison procure un vrai confort pour le client, facilite laréception des livraisons et a!ermit la confiance entre transporteur et client (Day et al. [3],Haughton [4]).
Un autre cas emblématique est celui du transport de personnes handicapées vers et àpartir d’établissements médico-sociaux (CAT, IME). Du fait de leur manque d’autonomie, laplupart des personnes qui se rendent dans ces établissements ne peuvent le faire par leurspropres moyens. Les établissements ont donc recours à des sociétés de transport pour orga-niser ces trajets quotidiens. Dans de nombreux cas, la demande des clients est connue, maisprésente de légères variations au niveau des conditions de prise en charge (par exemple unepersonne qui n’émet pas de demande de transport pour le mercredi après-midi, ou une per-sonne souhaitant être déposée à une autre adresse le vendredi). De plus, ce type de passagersest particulièrement sensible aux changements de planning. Il est alors primordial d’essayer demaintenir un horaire de service aussi régulier que possible malgré les variations de la demande(Lehuédé et al. [5]).
Dans cette présentation, nous nous intéressons à la planification de tournées en prenantcompte la régularité des horaires. Le projet se décline en plusieurs sous-objectifs :
– Nous cherchons à donner une ou plusieurs définitions de la notion de la régularité etdiscuter des liens de cette notion avec d’autres concepts proches (robustesse, distanceentre solutions, analyse de sensibilité...). Pour chaque client, on définit une classe horairecomme un ensemble de dates de service considérées comme identiques. Par exemple, unclient livré à 10h20 le lundi et 10h23 le mardi ne percevra aucune di!érence entre ceshoraires, qui peuvent donc être considérés comme appartenant à la même classe. La

12 D. Feillet, T. Garaix, F. Lehuédé, O. Péton, D. Quadri
notion de régularité est étroitement liée au nombre de classes horaires pour chaqueclient.
– Nous examinons plusieurs manières d’inclure la régularité dans les modèles d’optimisa-tion de tournées. Une première approche consiste à minimiser uniquement le nombre declasses sans se préoccuper du coût des tournées). La solution optimale peut aboutir à destournées aberrantes du point de vue logistique. Cette approche peut présenter un intérêtlorsque la régularité du service prime sur la performance logistique, ce qui est parfois lecas dans les activités de service à la personne. En pratique, on cherchera à minimiserle nombre de classes en s’assurant que les tournées soient simplement acceptables d’unpoint de vue logistique.Une autre approche consiste à fixer a priori un nombre de classes acceptable pourchaque client. Le modèle recherche les tournées de longueur minimale, en limitant lenombre de classes à cette valeur maximale pour tout client. Ce modèle est voisin decelui présenté dans [2], la principale di!érence réside dans la définition de la régularité.Une optimisation bi-objectif peut être réalisée assez facilement faisant varier le nombrede classes acceptables entre 1 et le nombre de périodes de l’horizon de planification.
– Nous évaluons quantitativement l’impact de la régularité sur la résolution des problèmesainsi définis. La résolution des modèles évoqués précédemment par le solveur Xpress-MPnécessite des heures de calcul pour des problèmes de taille très réduite (de l’ordre de 10clients pour 3 véhicules sur un horizon de 5 jours).Nous proposons donc l’heuristique suivante. Considérons une journée particulière j etl’ensemble des tournées de cette journée. Les clients de cette journée ont déjà un certainnombre de classes sur les autres journées. Leur attribuer un nouvel horaire de passageau jour j permet soit de conserver le nombre de classes, soit de l’augmenter de 1 unitéen cas d’incompatibilité. Pour chaque client, on peut facilement déterminer la ou lesfenêtres horaires permettant de ne pas augmenter le nombre de classes. Trouver lesmeilleures tournées de la journée j consiste donc à résoudre un VRP en respectant desfenêtres horaires multiples et sans temps d’attente entre clients. Partant d’une solutiondonnée, une solution voisine peut être construite en e!açant une journée et en résolvantle VRP à fenêtres multiples associé.
Références1. Paquette J., J.-F. Cordeau and G. Laporte : Quality of Service in Dial-a-ride Operations, à
paraitre dans Computers and Industrial Engineering (2008).2. Groër C., B. Golden and E. Wasil : The Consistent Vehicle Routing Problem, Vehicle Routing
in Practice conference (VIP’2008), Oslo, Norvège (2008).3. Day J.M., P. D. Wright, T. Schoenherr, M. Venkataramanan and K. Gaudette : Improving
routing and scheduling decisions at a distributor of industrial gasses, Omega, Volume 37, 1,227–237 (2009).
4. Haughton M.A. : Assigning delivery routes to drivers under variable customer demands, Trans-portation Research Part E : Logistics and Transportation Review, 43, 2, 157–172 (2007).
5. Lehuédé F., C. Pavageau and O. Péton, Un système d’aide à la décision pour planifier les trans-ports vers les établissements médico-sociaux, Conférence Handicap 2008, Paris, (2008).

Une heuristique duale pour le sac à dos quadratique aveccontrainte de cardinalité
L. Létocart1, M-C. Plateau2, and G. Plateau1
1 LIPN UMR CNRS 7030, Institut Galilée, Université Paris 13, 99, avenue J-B. Clément, 93430Villetaneuse France.
{lucas.letocart,gerard.plateau}@lipn.fr2 GDF SUEZ, Direction de la Recherche, 361, avenue du Président Wilson, BP 33, 93210
Saint-Denis La Plaine [email protected]
1 Introduction
Le problème du sac à dos quadratique avec contrainte de cardinalité (E-kQKP) consiste àmaximiser une fonction quadratique à coe"cients positifs soumise à deux contraintes linéaires,l’une portant sur la capacité du sac et l’autre imposant le nombre d’objets à mettre dans lesac. Ce problème NP-di"cile est une extension du problème du sac à dos quadratique danslequel le nombre d’objets à mettre dans le sac est fixé à k. La modélisation mathématique dece problème est la suivante :
(E-kQKP)
!"""""""#
"""""""$
max f(x) =n%
i=1
n%
j=1cijxixj
s.c.&nj=1 ajxj " b (1)&nj=1 xj = k (2)xj ! {0, 1} j = 1, . . . , n
Une heuristique duale, exploitant une relaxation agrégée du problème, est proposée afind’obtenir rapidement des solutions de très bonne qualité.
2 L’heuristique duale
L’heuristique classique pour le sac à dos quadratique [1] combine un algorithme gloutonet une procédure de remplissage et d’échanges. Elle peut être facilement adaptée pour larésolution de (E-kQKP). Cependant, les résultats ainsi obtenus ne sont pas aussi satisfaisantsque ceux dévolus au sac à dos quadratique standard.
Pour pallier cette perte de qualité, nous proposons une nouvelle heuristique basée sur unerelaxation agrégée de (E-kQKP). Cette relaxation agrégée consiste ‡ transformer la contraintede cardinalité en une contrainte d’inégalité, puis à agréger les deux contraintes (de capacité etde cardinalité maximale) à l’aide d’un multiplicateur dual. Le problème ainsi relâché devientdonc un sac à dos quadratique dont les données des contraintes ne sont plus entières.
Une résolution approchée du dual agrégé de ce problème relâché est réalisée par un algo-rithme de sous-gradients inspiré de [3]. À chaque itération de cet algorithme, nous adaptons

14 L. Létocart, M-C. Plateau, G. Plateau
le branch-and-bound et la relaxation lagrangienne proposés dans [2] pour résoudre le sac àdos quadratique. De manière standard, notre heuristique duale consiste à sauvegarder lesmeilleures solutions réalisables de (E-kQKP) au cours de l’algorithme de sous-gradients. Plusprécisément, cette procédure de sauvegarde est déclenchée à chaque itération, donc pourchaque résolution de problèmes de sac à dos quadratique, lors de l’exploration de l’arbre derecherche. D’autre part, dans le but de limiter à quelques minutes les temps de résolutionpour les instances de grande taille (e.g. 200 objets), nous admettons une mise à jour anticipéedu multiplicateur agrégé sans que chaque problème de sac à dos quadratique ne soit résoluexactement.
De nombreux résultats expérimentaux valident cette appproche en réduisant significative-ment (jusqu’à moins de 1%) les écarts relatifs entre les valeurs obtenues par cette heuristiqueduale et les valeurs des meilleurs majorants connus.
Références
1. A. Billionnet et F. Calmels : Linear programming for the 0-1 knapsack problem. European Journalof Operational Research 92, pp 310–325 (1996).
2. A. Caprara, D. Pisinger et P. Toth : Exact solution of the quadratic knapsak problem. INFORMSJournal on Computing 11, pp 125–137 (1999).
3. A. Fréville et G. Plateau : An exact search for the solution of the surrogate dual of the 0-1 bidi-mensional knapsack problem. European Journal of Operational Research 68, pp 413–421 (1993).

Comparaison entre di!érentes relaxations pour desproblèmes de coloration de graphes
Ph. Meurdesoif.1
Université Bordeaux 1 – INRIA Bordeaux Sud Ouest, Projet ReAlOpt, 351 cours de la Libération,33405 Talence
1 IntroductionLes problèmes de coloration de graphes apparaissent dès lors qu’on veut regrouper des
objets sous des contraintes d’exclusion de paires incompatibles : ces incompatibilités sontmodélisées par les arêtes d’un graphe G(V,E) non dirigé et on veut attribuer une couleurà chaque sommet en évitant de colorier de la même couleur les extrémités d’une arête. Leproblème le plus simple consiste à minimiser le nombre de couleurs utilisées : le nombrechromatique, noté "(G). Il est clair qu’une clique de k sommets tous reliés entre eux imposed’utiliser k couleurs, aussi la taille de la clique maximum, #(G) est-elle un minorant de "(G)et on a l’égalité pour de nombreux graphes. Mais que se passe-t-il entre ces bornes pour lesgraphes tels que #(G) < "(G) ?
2 Quelques relaxations du nombre chromatiqueDeux bornes "classiques" existent, le nombre $ de Lovász et le nombre chromatique frac-
tionnaire "F (G). La première, calculable polynômialement par la programmation semidéfinie,est historiquement un majorant de la taille maximum d’un stable d’un graphe, noté %(G)[3] ;or, il est vite apparu que $(G) est prise en "sandwich" entre #(G) et "(G). La seconde borneest en fait la relaxation continue d’un programme linéaire en nombres entiers à variablesindicées sur les stables du graphe, et exprimant que tout sommet doit être couvert par (aumoins) un stable ; elle est NP-di"cile, mais calculable par la génération de colonnes avecpour sous-problème, l’obtention d’un stable de poids maximum[4] ; il a été prouvé qu’aucuneborne polynômiale B ne pouvait vérifier "F (G) " B(G) " "(G) pour tout graphe G, sauf siP=NP.[2]
Dans un article récent[1], D. Cornaz et V. Jost ont montré que pour tout graphe G, munid’une numérotation o des sommets, on pouvait construire un graphe auxiliaire H tel que"(G) = |V |#%(H). En fait, il y a même b#ection entre les stables de H et les colorations deG. Les auteurs ont suggéré de remplacer %(H) par sa relaxation SDP $(G) pour obtenir uneborne inférieure intéressante sur ", que nous noterons &(G).
Des expérimentations dont nous présentons les résultats montrent que :– H est construit à partir de la numérotation o ; or, si %(H) est indépendant de o, il n’en
va pas de même pour $(H) et donc de &(G).– Des idées algorithmiques pour trouver une numérotation induisant une "bonne" valeur
pour &(G) sont en général lourdes ou imprécises, et il est souvent plus pratique deprendre la meilleure valeur trouvée avec plusieurs numérotations choisies alátoirement.

16 Meurdesoif
– Quelque soit la numérotation des sommets, la borne &(G) est de meilleure qualité que$(G) et parfois aussi que "F (G).
3 Relaxations d’autres problèmes de coloration
Nous présenterons également des résultats comparatifs sur d’autres problèmes de colora-tion. Selon les problèmes, l’une ou l’autre des formulations SDP sera plus adaptée à la varianteconsidérée.
3.1 Coloration "Max"
Dans cette variante, les sommets du graphe sont munis d’un poids positif. Le poids d’uneclasse de couleur est le poids maximum d’un de ses sommets. On cherche à minimiser lasomme des poids des classes de couleur. D. Cornaz et V. Jost ont montré que cette varianteétait équivalente à résoudre un problème de stable de poids max sur le graphe auxiliaire H ,pourvu que celui-ci soit construit avec une numérotation des sommets dans un ordre des poidsdécroissant.
Nous avons également étudié la borne par génération de colonnes, où le sous-problèmeconsiste en plusieurs stables max. successifs. Enfin, aucune formulation de type "$(G)" n’a pourl’instant été trouvée. Sans surprise, la borne par génération de colonnes est la plus puissante,mais la borne utilisant H est compétitive, d’autant que la question de la numérotation ne sepose plus.
3.2 Coloration avec préférences
Dans cette variante, il s’agit toujours de trouver une coloration en k couleurs, mais uncoût vient sanctionner le fait d’associer dans la même couleur certaines paires de sommets.Les bornes que l’on comparera ici sont une borne de type "$(G)" et une borne par générationde colonnes : le coût d’un stable est la somme des coûts des paires de sommets qui se trouventtous deux dans le stable. Le sous-problème revient alors à rechercher un stable maximisantune fonction de coût quadratique, et est résolu par énumération.
Références
1. Denis Cornaz, Vincent Jost : A one-to-one correspondence between colorings and stable sets.Operations Research Letters, Volume 36, Issue 6, pp 673-676 (2008).
2. Neboj!a Gvozdenovi" and Monique Laurent : The Operator ! for the Chromatic Number of aGraph, SIAM J. Optim. Volume 19, Issue 2, pp. 572-591 (2008).
3. L. Lovász : On the Shannon capacity of a graph, IEEE Transactions on Information Theory, vol25, issue 1, pp. 1-7 (1979).
4. Anuj Mehrotra, Michael A. Trick : A column generation approach for graph coloring, INFORMSJournal on Computing, Vol. 8, pp. 344 - 354 (1996).

Une approche par moindres carrés semidéfinispour le problème k-cluster
Jérôme Malick1 and Frédéric Roupin2
1 CNRS, Laboratoire J. Kunztmann, 51 rue des Mathématiques, 38400 Grenoble, [email protected]
2 CEDRIC-CNAM, 292 rue Saint-Martin, 75141 Paris Cedex [email protected]
Nous présentons une application au problème k-cluster d’une nouvelle approche de typeoptimisation semidéfinie : une approche par “moindres carrés semidéfinis” [4,5].
Le problème k-cluster est un problème d’optimisation combinatoire NP-di"cile (mêmedans les graphes bipartis). Soient un graphe non orienté de n sommets G = (V,E) et unentier 1 " k " n ; on cherche un sous-graphe de G de k sommets avec un nombre maximald’arètes. Ce problème peut se formuler comme un programme quadratique en variables 0-1 :
(k-cluster)
!#
$
max y!Aye!y = ky ! {0, 1}n,
avec e = (1, . . . , 1) ! Rn et A la matrice d’adjacence de G. Plusieurs approches par pro-grammation mathématique ont été proposées pour résoudre ce problème - en particulier parprogrammation linéaire [2], semidéfinie [3,6] ou quadratique convexe [1].
Pour obtenir une relaxation par moindres carrés semidéfinis, nous utilisons une reformu-lation des contraintes binaires par une contrainte dite "sphérique" [4]. Voici schématiquementl’idée de cette reformulation. La première étape consiste à opérer un changement de variablepour écrire la contrainte de bivalence sous la forme x ! {#1, 1}n, puis à homogénéiser lesformes quadratiques en ajoutant une variable pour finalement obtenir un problème d’optimi-sation purement quadratique en x ! Rn+1 :
(QP)
!#
$
max x!Q1 xx!Q2 x = 2k # nx ! {#1, 1}n+1,
avecQ1 et Q2 dépendant de A et e (plus précisement, Q2 = [0, e!; e, zeros(n, n)]). On appliqueensuite le classique “lifting” dans l’espace des matrices symétriques que l’on munit du produitscalaire
$X,Y % = trace(XY ) pour X,Y matrices symétriques.Ceci consiste à introduire la matrice symétrique de rang 1 de taille n+ 1 qui s’écrit X = xx!pour réécrire de manière équivalente le problème de k-cluster comme :
(SDP)
!""""#
""""$
max $Q1, X%$Q2, X% = 2k # ndiag(X) = erang(X) = 1X & 0

18 Malick, Roupin
La dernière contrainte signifie que la matrice X est semi-définie positive (SDP). L’étape finale- c’est ici le point clé et original de la formulation - consiste alors à remarquer que dans cettesituation la contrainte de rang 1 est précisement équivalente à la contrainte 'X'2 = (n+ 1)2,que l’on appelle contrainte sphérique.
Nous montrons que la dualisation de la contrainte sphérique conduit alors à un programmesemidéfini de moindres carrés. Le calcul d’une borne duale revient essentiellement à résoudre
!""#
""$
min 'X #Q1/%'2$Q2, X% = 2k # ndiag(X) = eX & 0
Un problème de ce type peut être résolu numÈriquement par des méthodes e"caces mÍmepour de grandes tailles (voir [5]). Un avantage majeur de cette approche est la réductionpossible du temps de résolution de la relaxation en échange d’une dégradation de la qualitéde la borne (en fixant la valeur du paramètre %). Cette possibilité est particulièrement appré-ciable dans le contexte d’une résolution exacte (de type Branch&Bound par exemple). Nouscomparons notre approche avec les di!érentes relaxations proposées (en particulier les liensde dominance théorique), et nous donnons de premiers résultats numériques e!ectués sur desinstances classiques du problème k-cluster.
Références
1. Billionnet A., Elloumi S., et Plateau M.-C. : Improving the performance of standard solvers forquadratic 0-1 programs by a tight convex reformulation : the QCR method. A paraître dansDiscrete Applied Mathematics, 2009.
2. Billionnet A. : Di#erent formulations for solving the heaviest k-subgraph problem. InformationSystems and Operational Res., 43(3), 171-186, 2005.
3. Jäger G., et Srivastav A. : Improved approximation algorithms for maximum graph partitioningproblems. Journal of combinatorial optimization 10(2), 133-167, 2005.
4. Malick, J. : The spherical constraint in Boolean quadratic programs. Journal of Global Optimiza-tion 39(4), 609-622, 2007.
5. Malick, J. : A dual approach to semidefinite least-squares problems. SIAM Journal on MatrixAnalysis and Applications 26(1), 272-284, 2004.
6. Roupin, F. : From linear to semidefinite programming : an algorithm to obtain semidefinite re-laxations for bivalent quadratic problems. Journal of Combinatorial Optimization, 8(4), 2004.

Applying the T-Linearization to the Quadratic KnapsackProblem
C.D. Rodrigues1,2, D. Quadri1, P. Michelon1, S. Gueye3, and M. Leblond1
1 Université d’Avignon et Pays du Vaucluse, Laboratoire d’Infomatique d’Avignon, France.2 Universidade Federal do Ceará, Campus do Pici, Fortaleza, Brésil.
3 Université du Havre LMAH, 25 rue Philippe Lebon,BP 540, 76058 Le Havre{carlos-diego.rodrigues, dominique.quadri, philippe.michelon}@univ-avignon.fr
[email protected]@etd.univ-avignon.fr
1 Introduction
Knapsack problems are among the most studied problems in Operations Research, due totheir simplicity in definition, hardness in solving and broadly aplicability in both practicaland theoretical problems. The 01-Knapsack problem can be defined as {max cTx : ax "b, x ! {0, 1}n}, where the inclusion of the object in the knapsack is defined by the x anda, b, c ( 0 ! )n.
When modeling the cases where the combinations of objects are more important than theirindividual inclusion in the knapsack, researchers usually consider the quadratic knapsackproblem (QKP ) = {max cTx + xQx : ax " b, x ! {0, 1}n} and a, b, c ( 0 ! )n andQ ( 0 ! )n *)n.
The quadratic summation is nonlinear and can not be treated easily though. In order tosolve the problem, a common approach is to proceed with a linearization of the objectivefunction. In this work we will apply an original linearization to the (QKP ). Contrasting totraditional linearization schemes, our approach only adds one extra variable, that we nameT .
2 The T-linearization
The T-linearization consists in substituting the quadratic term by an additional variable,T , and modeling its behavior by means of constraints. This linearization was first introducedby Gueye and Michelon [3] to the (QP ) = {max cTx + xQx : x ! {0, 1}n}, c ( 0 ! )n andQ ( 0 ! )n * )n. The authors demonstrated that the (QP ) convex hull and the followingpolyhedra are equivalent :
P(x,T ) =
'(x, T ) ! "n+1 : T #
n%
1!i<j!n
q!(i)!(j)x!(j),$" ! Sn
((1)
This result leads us immeadiately to a relaxation for (QP ), which we denote by T-relaxation.Consequently, knowing that (QKP ) can be seen as (QP ) with the knapsack constraint, therelaxation can be extended to the (QKP ) case :

20 C.D. Rodrigues, D. Quadri, P. Michelon, S. Gueye, M. Leblond
(QKP ) max&ni=0 cixi + T
s.t.&ni=0 aixi # b
T #&n
1!i<j!n q!(i)!(j)x!(j), $" ! Snx ! [0, 1]n
The equivalent linear formulation is still di"cult to be solved, due to the number ofconstraints over the variable T . It immeaditely implies a constraint generation method,though. Given a permutation ' of the variables, we generate the suitable constraint andtest whether it is violated or not. If so, we add it to the linearized model and resolve themodel. This process should be repeated until we can not find a permutation that gives aviolated constraint.
Gueye and Michelon [3] showed that for the (QP ) the separation problem is polynomial,and more than that, its deterministic algorithm is very simple. It is su"cient to order thevariables in a non-increasing order, using their optimal values obtained by the linear relaxationas the key to the order. This algorithm is certainly not optimal to the (QKP ) but remainsas our separation heuristic of choice.
3 Preliminary computational results and Perspectives
We applied the presented relaxation and the implied constraint generation algorithm to aset of benchmark instances (Soutif [5]) for witch the optimum value is known. These are 100variables randomly generated instances where the amount of correlation between the variablesis fixed to 25%.
Table 1 shows a comparision between the upper bound given by our relaxation and thelagrangean relaxation method implemented by Billionnet and Soutif [1]. We see that thequality of the bound obtained by our method is slightly inferior to the compared one, butstill the average is less than 1% to the optimum. On the other hand, our method outperformsin CPU time.
The other test we made, also stated in table 1, concerns the quality of the relaxationincluding the integrality constraints on the variables at the end of the constraint generationalgorithm. We measured the optimal value obtained when considering only the constraintsgenerated on the root node of a possible branch-and-bound method. In this case we see thathalf of the problems reached the optimum value, so that we have a completely satisfactorydescription of the polyhedra, while the others remained at less than 2%, giving an average of0.26%. Also, the number of generated constraints (NGC) is given for each instance and muchinferior to the maximum (|Sn| = n!).
There’s still a lot to investigate in this beginning project. First, the generated constraintscould be strenghtened in the (QKP ) compared for the (QP ) case. Then, it is essential tomeasure how the constraint generation performs on a complete branch-and-bound algorithmand compare to other results in the field [4].
Références
1. Billionnet, A., Soutif, E. An exact method for the 0-1 Quadratic Knapsack Problem based onLagrangian Decomposition. European J. of Operational Research vol. 157(3) : 565-575 (2004).

Applying the T-Linearization to the Quadratic Knapsack Problem 21
Tab. 1. T-relaxation vs. Lagrangean relaxation upper bounds
Method Opt Lagrangean T-Relaxation Integral T-RelaxationInstance UB Gap(%) Time(s) UB Gap(%) Time(s) UB Gap(%) NGC
1 18558 18910.56 1.90 9.24 19124.1 3.05 0.14 18865 1.65 1092 56525 56574.63 0.09 7.57 56576 0.09 0.02 56525 0.00 323 3752 3807.68 1.48 9.13 3900.53 3.96 0.9 3785 0.88 3124 50382 50448.08 0.13 9.29 51064.5 1.35 11.37 50589 0.41 5805 61494 61623.22 0.21 8.4 61621 0.21 0.01 61494 0.00 66 36360 36464.87 0.29 8.94 36654.9 0.81 0.73 36399 0.11 2837 14657 14749.58 0.63 10.18 14853.5 1.34 1.05 14657 0.00 4458 20452 20525.15 0.36 8.17 20528.5 0.37 0.05 20452 0.00 469 35438 35485.16 0.13 15.19 35487 0.14 1.55 35438 0.00 36110 24930 25191.5 1.05 10.43 25496.9 2.27 3.04 20190 1.04 401
Average 32255 32378.04 0.63 9.65 32530.7 0.85 1.89 32339.6 0.26 257.5
2. Gueye, S. Linéarisation et relaxation lagrangienne pour problèmes quadratiques en variables bi-naires. PhD. Thesis, UniversitÈ d’Avignon et Pays du Vaucluse (2002).
3. Gueye, S., Michelon, P. : On the Convex Hull of a Quadric Polytope. Technical report of LIA(2005)
4. Pissinger, D., Rasmussen, A.B., Sandvik, R. Solution of Large-sized Quadratic Knapsack ProblemsThrough Aggressive Reduction. INFORMS Journal on Computing (2006).
5. Soutif, E. : (QKP) Instances http ://cedric.cnam.fr/ soutif/QKP/QKP.html

Chainage des sommets d’un graphe pour le test descircuits intégrés
Y. Kie!er and L. Zaourar1
G-SCOP, 46 avenue Félix Viallet, Grenoble-INP, 38031 Grenoble Cedex France.{Yann.Kieffer, Lilia.Zaourar}@g-scop.inpg.fr
1 Contexte
De la médecine aux loisirs, du fond des océans jusqu’aux confins du système solaire,les puces électroniques sont présentes à chaque pas de notre vie quotidienne. En e!et, leniveau d’investissement consacré en permanence à l’industrie de la micro-électronique montrel’importance grandissante des circuits intégrés (CI).
Le flot de conception d’un CI, c’est-à-dire la suite d’applications logicielles qui permetau concepteur d’un CI de passer de sa spécification à sa réalisation concrète, met en jeu àde nombreux stades des problématiques d’optimisation [3]. En e!et, la réalisation d’un CIest une opération très coûteuse en temps et en argent et qui nécessite de grands moyensaussi bien humains qu’industriels. En plus des progrès technologiques, qui améliorent conti-nuellement l’e"cacité des techniques de fabrication des CI (finesse de gravures sur silicium),l’augmentation en continu de la puissance de calcul des ordinateurs o!re de grandes possibi-lités d’amélioration du processus de fabrication d’un CI.
Mais à une époque oô la concurrence dans l’industrie de la micro-électronique est parti-culièrement féroce, les paramètres de temps de mise sur le marché et la qualité du produitdeviennent prépondérants. Le circuit doit répondre sans faille aux attentes du client en termesde fonctionnalité, rapidité, qualité, fiabilité et coût. Pourtant, lors du test final (test de fa-brication), plus de 60% des CI sont rejetés, parce que non fonctionnels. Dans ce contexteéconomique exigeant, et compte tenu du niveau de complexité important atteint par les CI,le test est plus que jamais une donnée importante du problème de conception. Il doit être àla fois court, e"cace et le moins coûteux possible.
Aujourd’hui, beaucoup de recherches fondamentales et appliquées ayant pour objectifl’amélioration de la testabilité des circuits intégrés sont poursuivies de manière très activetant au niveau universitaire qu’industriel [4]. Alors, pour améliorer et faciliter le test des CI,di!érentes techniques de conception en vue du test dites DFT (pour Design For Test) sontcouramment utilisées et cela très tôt dans le flot de conception. C’est sur l’optimisation deces techniques que portent nos travaux [1].
2 Description du problème industriel
A l’heure actuelle, le Scan path est une des méthodes les plus utilisées dans l’industrie dela micro-éléctronique. Il s’agit d’un ensemble de composants et de connexions électroniquesqu’on rajoute au CI afin de faciliter l’étape de test post fabrication. Les principaux inconvé-nients de cette méthode sont : la surface additionnelle, la surconsommation et la dégradation

Chainage de sommets pour le test de circuits intégrés 23
des performances du CI après l’insertion de ces éléments [4]. Dans ce contexte, le problèmeindustriel auquel il faut faire face est le suivant : il s’agit de chaîner les éléments mémoires ducircuit les uns aux autres pour former des chaînes de scan. Ces dernières doivent couvrir tousles éléments mémoires du circuit afin de vérifier leur bon fonctionnement. Mais, si le chaînageest fait de manière aléatoire, en particulier si on réalise des connexions entre éléments mé-moires trop éloignés dans le CI, on crée des contraintes supplémentaires pour les outils quiinterviennent plus tard dans le processus de conception. Le problème est qu’à cette étape deconception on ne connait pas encore le futur emplacement des éléments mémoires dans le CI.
3 Contributions
L’objectif de notre travail est de développer un outil permettant la génération de solu-tions optimales pour l’insertion du Scan path dans un CI tout en respectant l’ensemble descontraintes électroniques liées au problème (fréquence d’horloge, temps de test, consommationdu circuit...). Nous avons modélisé ce problème comme la recherche de plus courtes chaînesdans un graphe dont les sommets sont les éléments mémoire du circuit, et les arêtes, lesconnexions électroniques entre eux, avec un poids sur les arêtes traduisant l’ensembles descontraintes électroniques liées au problème. Une étape importante de notre travail a consistéen la clarification des critères d’optimisations. En e!et, le problème semblait au départ multi-objectif. Mais après une analyse fine du problème, nous avons pu passer à un problèmemonocritère qui est la minimisation de la longueur totale des interconnexions.
Le problème est que ce critère ne peut être mesuré qu’à la sortie du flot de conception etpas au moment de notre optimisation. Nous l’avons alors formalisé pour être accessible à notreniveau. Ainsi, nous avons pu proposer des méthodes de résolutions. Elles sont basées sur larecherche de chaînes hamiltoniennes de longueur minimale. Nous avons ramené ce problèmeà la résolution du célèbre problème du voyageur de commerce [2].
Références
1. Chouki Aktouf. Test en ligne et aide à la conception testable de systèmes électroniques complexes.Mémoire d’habilitation, LCIS, Valence, 2001.
2. William J. Cook, William H. Cunningham, William R. Pulleyblank, and Alexander Schr$ver.Combinatorial optimization. John Wiley & Sons, Inc., New York, NY, USA, 1998.
3. Bernhard Korte, Laszlo Lovasz, Hans Jurgen Promel, and Alexander Schr$ver. Paths, Flows, andVLSI-Layout. Springer-Verlag New York, Inc., Secaucus, NJ, USA, 1990.
4. Christian Landrault. Test de circuits et de systèmes intégrés. Hermès, 2004.

Vers une notion de compromis en optimisationmultidisciplinaire multiobjectif
B. Guédas1, P. Dépincé1, and X. Gandibleux2
1 IRCCyN, 1, rue de la Noe - BP 92 101 - F 44321 Nantes Cedex 03, [email protected]
[email protected] LINA, 2, rue de la Houssinière - BP 92208 - F 44322 Nantes Cedex 03, France.
1 Introduction
Les problèmes de conception complexes rencontrés dans les domaines de l’aéronautique,du naval ou de l’automobile sont généralement organisés en plusieurs disciplines qui doiventcollaborer pour aboutir à des solutions de compromis satisfaisant chacune des disciplinessimultanément. De plus chaque discipline a généralement plusieurs objectifs à atteindre surun ensemble de variables qui est en partie commun à plusieurs autres disciplines et en partiepropre à chaque discipline.
Dans ce travail, nous nous limiterons au cas où chaque discipline doit résoudre un pro-blème d’optimisation multiobjectif sur un ensemble commun de variables de conception. Nousproposons une méthode de compromis entre les disciplines telle que s’il existe un ensemble desolutions satisfaisant les critères d’optimalité de toutes les disciplines, alors cet ensemble estl’ensemble des solutions du problème de conception global.
2 Compromis entre disciplines
Dans la suite, une solution e"cace désigne une solution dont l’image n’est pas dominéeau sens de Pareto dans l’espace des objectifs. Nous notons (Rn,!n) l’ordre produit qui cor-respond à l’ordre large associé à la relation de dominance (") pour n objectifs à valeur dans R.
Une manière de considérer le compromis entre plusieurs disciplines qui ont chacune plu-sieurs objectifs est de le définir comme un seul problème d’optimisation multiobjectif regrou-pant tous les objectifs des disciplines. Ceci revient à chercher le produit des ordres de chaquediscipline. Par exemple, pour deux disciplines ayant respectivement p et q objectifs, l’ensembleordonné représentant le problème regroupant les p+ q objectifs noté (Rp+q,!p+q) est égal auproduit des ordres disciplinaires à p et q objectifs noté (Rp,!p)* (Rq,!q).
En terme de compromis, cette définition n’est pas satisfaisante car des informations re-latives à l’e"cacité des solutions sont perdues lors du produit. En e!et, on peut considérerque les points non-dominés de chaque discipline sont meilleurs que les autres. Or, un pointnon-dominé n’est pas toujours comparable à tous les points dominés. En conséquence, lorsdu produit si un point non-dominé et un point dominé ne sont pas comparables, ils sont

vers une notion de compromis en optimisation multidisciplinaire multiobjectif 25
potentiellement tous deux sur le front de Pareto global s’ils sont également incomparablesdans les autres disciplines.
Pour remédier à ce problème, nous proposont une extension de l’ordre produit (Rn,!n) quenous noterons (Rn,!"n). Soient Y l’espace des objectifs d’une discipline, YN + Y l’ensembledes points non-dominés et YD := Y\YN l’ensemble des points dominés. Nous ajoutons lapropriété suivante : ,(y1, y2) ! YN *YD, y1 !" y2. Il s’agit de l’extension la plus simple, maiselle peut encore être étendue.
3 Utilisation du rang
L’extension proposée ci-dessus est une extension particulière de l’ordre produit. Elle peutde plus être décrite comme la somme ordinale [4] de deux sous-ensembles ordonnées de(Rn,!n ) : (Rn,!"n) = (YN ,!n|YN )- (YD,!n|YD ).
Une manière de partitionner plus finement l’espace des objectifs de chaque discipline Yest d’utiliser le rang [4] qui est une application de Y dans N. L’ordre global est alors définicomme le produit des sommes ordinales des ensembles disciplinaires partionnés suivant leurrang. Nous pouvons définir l’ordre !""n de la façon suivante : a !""n b./ r(a) < r(b).
Une application de rang étant utilisée dans certains algorithmes génétiques multiobjectifs[1,2], une méthode d’optimisation multidisciplinaire utilisant de tels algorithmes peut tirerpartie de cette information pour converger plus rapidement.
4 Implémentation et perspectives
Nos définitions de compromis ont été intégrées à COSMOS [3], qui est une méthoded’optimisation multidisciplinaire multiobjectif. Elle calcule les solutions e"caces du problèmeregroupant tous les objectifs en utilisant un algorithme génétique mutiobjectif dans chaquediscipline. Une expérimentation numérique sera réalisée à l’aide de fonctions d’évaluationfondées sur plusieurs objectifs [1]. Les solutions de la littérature seront comparées à cellestrouvées avec la méthode COSMOS originale et celles modifiées intégrant l’extension simpleet l’extension sur les rangs. Les di!érents résultats seront discutés lors de la communication.
Références
1. Deb (Kalyanmoy), Multi-objective optimization using evolutionary algorithms, coll. « Wiley-Intersciences series in systems and optimization ». Wiley, juin 2001.
2. Goldberg (David E.), Genetic Algorithms in Search, Optimization and Machine Learning, ».Addison-Wesley, 1989.
3. Rabeau (Sébastien), Optimisation Multi-objectif en conception collaborative. PhD thesis, ÉcoleCentrale de Nantes, Nantes, France, 2007.
4. Schröder (Bernd S. W.), Ordered Sets : An introduction. Birkhäuser, December 2002.

Profils de performance pour le paramétrage et lavalidation de métaheuristiques stochastiques
Johann Dréo
Decision Technologies & Mathematics LaboratoryTHALES Research & [email protected]
1 Introduction
La facilité d’utilisation apparente d’algorithmes stochastiques pour l’optimisation ne doitpas cacher le fait qu’elles doivent être conçues et validées rigoureusement [1]. Trois principauxproblèmes apparaissent alors : (a) comment estimer les performances ? (b) comment régler lesparamètres ? (c) comment valider l’e"cacité de l’algorithme en pratique ?
Les métaheuristiques peuvent être utilisées pour diverses raisons, divisables en deux classes :e"cacité ou e"cience.Suivant cette classification, l’e"cacité est relié à la robustesse (le com-portement attendu face à une large gamme de problèmes) et l’e"cience à la mesure de laqualité des solutions [1].
Concernant le réglage des paramètres de métaheuristiques stochastiques, il existe plusieursapproches automatiques [3]. Ces méthodes utilisent soit une étape de réglage préliminaire,soit un contrôle pendant l’exécution. Le contrôle de paramètre nécessitant un supplémentde calculs, il peut a!ecter l’e"cience, là où le réglage préalable peut entrainer une perted’e"cacité [2]. Les méthodes de paramétrage les plus connues sont le racing, l’optimisationséquentielle et le méta-paramétrage mono-objectif (parfois nommé “méta-algorithmes”).
Dans ce travail, nous considérons un méta-paramétrage bi-objectif de métaheuristiquesstochastiques, utilisées sur des problèmes mono-objectifs.
2 Méthode
La plupart des méthodes de réglage de paramètre essayent de résoudre un problème d’op-timisation, où l’objectif est de trouver la configuration la plus e"ciente [1]. Nous proposonsdans ce travail de considérer que le réglage de paramètre est plus utilement considéré commeun problème avec plusieurs objectifs. En e!et, pour une métaheuristique utilisée pour ré-soudre un problème de “conception”, on peut préférer un algorithme trouvant des solutionsoptimales, mais dans une utilisation en “production”, on peut préférer une méthode renvoyantrapidement une bonne approximation. Cependant, avec les métaheuristiques stochastiques,ces deux objectifs sont contradictoires : pour des problèmes su"samment di"ciles, il est enpratique impossible d’avoir une méthode rapide et précise. Ainsi, pour une instance de méta-heuristique donnée, sur une instance de problème donné, il existe une collection de réglagesnon-dominés, qui satisfons à la fois des objectifs de précision et de rapidité. Nous appeleronscet ensemble le profil de performance, qu’il soit projeté dans l’espace des objectifs ou danscelui des paramètres. Nous proposons donc une approche Pareto pour résoudre ce problème.

Profils de performance pour métaheuristiques 27
Dans nos expériences, nous avons utilisé l’algorithme NSGA-II, optimisant en variablesréelles, avec un taux de mutation de 0.01, une probabilité de croisement à 0.25, une probabilitéde mutation à 0.35 (paramètres opérateurs le plus souvent proposés dans la littérature), unepopulation de 10 individus et un critère d’arrêt stoppant la recherche après 5 itérations sansamélioration (paramètres permettant un temps d’exécution raisonnable). Nous avons d’abordparamétré plusieurs métaheuristiques stochastiques sur des problèmes d’optimisation conti-nue. Dans un second problème, la métaheuristique est une méthode hybridant un algorithmeévolutionniste de décomposition avec un solveur en programmation par contrainte (“Divideand Evolve” [4]), utilisé sur des problèmes de planification temporelle issus de la compétitioninternationale de planification.
3 ConclusionNos résultats suggèrent que le choix du critère d’arrêt a une influence drastique sur l’intérêt
du profil de performance, il doit donc être choisi avec soin. De même, la méthode ne permetpas naturellement de trouver un unique profil de performance pour un jeu de test complet,mais n’est rigoureusement valable que pour une instance d’un problème donnée. Enfin, nousconstatons que les profils de performances sont souvent convexes dans l’espace des objectifs,ce qui pourrait indiquer qu’une agrégation des objectifs est envisageable.
La méthode proposée permet d’agréger l’ensemble des paramètres en un seul, déterminantla position au sein du profil de performance, depuis un comportement fortement orienté versla production (rapide, peu précis) jusqu’à un comportement de conception (peu rapide, plusprécis). La projection du profil dans l’espace des paramètres permet également de refléterl’impact des paramètres sur les performances, ou la dépendance entre paramètres. Ces indi-cations peuvent être très pertinentes pour mieux comprendre le comportement de certainesmétaheuristiques complexes. Il devient également possible de comparer plus rigoureusementplusieurs métaheuristiques, sur l’instance d’un problème donné, en reportant les profils deperformance sur la même échelle. La validation statistique bénéficie également de dimensionsde discriminations supplémentaires.
En perspectives, il reste à réduire la demande en calculs du méta-optimiseur, en employantdes méthodes dédiées (SPO, racing, etc.). Il est également possible d’étendre la méthode enprenant en compte des mesures de robustesses comme objectif et en vérifiant la possibilité dereconstruire des corrélations sur un jeu d’instances.
Références1. Thomas Bartz-Beielstein. Experimental Research in Evolutionary Computation : The New Expe-
rimentalism. Natural Computing Series. Springer, 2006.2. Je# Clune, Sheni Goings, Bill Punch, and Eric Goodman. Investigations in meta-gas : panaceas
or pipe dreams ? In GECCO ’05 : Proceedings of the 2005 workshops on Genetic and evolutionarycomputation, pages 235–241, New York, NY, USA, 2005. ACM.
3. Fernando G. Lobo, Cláudio F. Lima, and Zbigniew Michalewicz, editors. Parameter Setting inEvolutionary Algorithms, volume 54 of Studies in Computational Intelligence. Springer, 2007.
4. Marc Schoenauer, Pierre Savéant, and Vincent Vidal. Divide-and-evolve : A new memetic schemefor domain-independent temporal planning. pages 247–260. 2006.

Segmentation optimale d’image par optimisationmultiobjectif
A. Nakib, H. Oulhadj, and P. Siarry
Laboratoire Images, Signaux et Systèmes Intelligents (LISSI, E.A. 3956)61 avenue du Général de Gaulle, 94010 Créteil, France
1 Introduction
La segmentation d’une image consiste à extraire les éléments les plus importants présentsdans cette image. Un recueil des méthodes courantes figure dans [1]. Le seuillage d’imagepar analyse d’histogramme est certainement l’approche la plus utilisée. Dans le cas d’unhistogramme en N classes, le seuillage consiste à déterminer N#1 seuils tels que chaque classesoit associée à un intervalle de niveaux de gris distinct. Malheureusement, cette technique, quiest basée sur l’optimisation d’un seul critère, ne produit pas de bons résultats sur tous typesd’images. Pour améliorer le processus de segmentation, nous proposons dans cet article derecourir à l’optimisation multiobjectif, qui permet la prise en compte simultanée de plusieurscritères.
2 Méthode proposée
Nous nous plaçons dans le cas simplifié d’une image à deux classes, dont l’histogramme estnoté h(i), avec i ! G, où G = 0, 1, 2, ..., 255 est l’ensemble des niveaux de gris. Le problèmeconsiste à déterminer le seuil optimal qui sépare les deux classes de l’image (objets et fond).La méthode de segmentation proposée est basée sur l’optimisation multiobjectif selon uneapproche Pareto. Le principe consiste à optimiser plusieurs critères de segmentation en paral-lèle, et à rechercher les solutions qui représentent un compromis entre les di!érents critères.A cet e!et, nous utilisons l’algorithme de référence NSGA-II [6].Les critères utilisés sont la variance interclasse biaisée et l’entropie totale de l’image. La va-riance interclasse biaisée [3] s’écrit :
MV ar (t1, ..., tN#1) = %.N&j=1
)j .(
2Bet(j) + )j
*(1) t$ =ArgMax MV ar(t) (2)
0 < t < Loù (2
Bet(j) est la variance interclasse de l’image [1], L est le nombre total de niveaux de gris,N est le nombre de classes dans l’image à segmenter (supposé connu a priori), % est égal à(1000 *M)#10NR, où M est le nombre total de pixels dans l’image et NR le nombre derégions. 
j = (1 + logNj), avec Nj le nombre de pixels dans la classe j. )j = (C(Nj)/Nj),où C(Nj) est le nombre de régions dont le cardinal est égal à Nj [3]. Le problème de la seg-mentation est alors exprimé sous la forme définie dans (2). L’entropie totale de l’image est lasomme des entropies des di!érentes classes. Le seuillage entropique [3], basé sur le principe de

Segmentation optimale d’image par optimisation multiobjectif 29
la maximisation de l’entropie totale de l’image, peut être exprimé sous la forme d’un problèmed’optimisation :
t$ = ArgMin(#HT (t)) (3)0 < t < L
où t le vecteur de seuils de segmentation et HT est l’entropie totale définie dans [3].
3 Exemples de résultats
La figure 1 présente les résultats de la segmentation des images test maison et avion (fig.1 (a) et (d)). Les segmentations en deux classes de ces images sont présentées respectivementsur les figures 1 (b) et (e). D’un point de vue visuel, la segmentation de l’image maison estde bonne qualité. De plus, les contours de la maison sont bien préservés. Pour la deuxièmeimage test, on constate également que l’objet avion est globalement bien séparé du fond. Lesrésultats de la segmentation en trois classes sont présentés sur les figures 1 (c) et (f). Dansce cas aussi, la segmentation de l’image maison est visuellement d’assez bonne qualité. Pourl’image avion, en revanche, la segmentation est de moindre qualité : davantage de pointscensés appartenir au fond, au coin gauche de l’image, sont rangés dans la même classe queles pixels qui composent l’avion. Le résultat présenté est obtenu en moyennant les résultatsde 20 exécutions de notre algorithme.
4 Conclusion
Dans cet article, nous avons proposé l’optimisation multiobjectif pour segmenter di!érentstypes d’images. Nous avons utilisé l’algorithme NSGA-II pour rechercher le front de Pareto.Les résultats de segmentation obtenus sont de qualité satisfaisante. En perspective à ce tra-vail, nous proposons d’intégrer davantage de critères et de mettre en oeuvre une techniqued’optimisation dynamique, pour segmenter des séquences d’images.
(a) (b) (c) (d) (e) (f)
Fig. 1. Exemples de résultats. (a) image maison originale, (b) segmentation en 2 classes, avec t = 185,(c) segmentation en 3 classes, avec t = (125; 185), (d) image avion originale, (e) segmentation en 2classes, avec t = 67, (f) segmentation en 3 classes, avec t = (77; 124).

30 Nakib, Oulhadj, Siarry
Références
1. R. C. Gonzales, R. E. Woods. Digital image processing. Prentice Hall, Upper Sadler River, NJ,USA, 2002.
2. K. Deb, S. Agrawal, A. Pratap, T. Meyarivan. A fast elitist non-dominated sorting genetic algo-rithm for multiobjective optimization : NSGA II. IEEE Transactions on Evolutionary computation,Vol. 5, 3, pp. 115-148, 2002.
3. A. Nakib, H. Oulhadj, P. Siarry, Non-supervised image segmentation based on multiobjectiveoptimization, Pattern Recognition Letters, Vol. 29, 2, pp. 161-172, 2008.

Sélection du portefeuille de projets d’explorationproduction en utilisant la méthode de Markowitz
Fateh BELAID and Daniel DE WOLF
Institut des Mers du Nord,Université du Littoral,
49/79 Place du Général de Gaulle, B.P. 5529,59 383 Dunkerque Cedex 1, [email protected]@univ-littoral.fr
1 La problématique considérée
L’objet de cet article est une étude quantitative du risque, en ce qui concerne la prise dedécision dans l’amont pétrolier. L’objectif principal de ce travail est de fournir un outil d’aide àla décision qui va permettre aux compagnies pétrolières de choisir prudemment leurs stratégiesd’investissement et de réduire les risques d’échec. En e!et, d’une part, le forage d’explorationcoûte très cher, et d’autre part, le processus de prise de décision d’investissement pétrolier esttributaire de risques importants principalement d’ordres géologique, économique et politique.
La problématique qui s’impose alors est celle de la détermination de méthodes destinéesà améliorer le processus décisionnel en matière de sélection de projets d’investissement enamont pétrolier.
2 Insu"sance des méthodes classiques
Au cours de ces dernières années, le processus décisionnel des compagnies pétrolièress’est fortement complexifié. En e!et, les compagnies pétrolières sont amenées à sélectionnerun ensemble de projets sur la base de variables incertaines, notamment le prix du brut,et l’étendue des ressources disponibles. Les indicateurs classiques utilisés dans le processusdécisionnel, notamment la valeur actuelle nette, le taux de rendement interne et l’indice deprofitabilité, se révèlent insu"sants, à cause d’une faible prise en compte de la notion durisque qui est un élément essentiel de l’industrie pétrolière. D’autre part, ces indicateurs nepermettent pas de tenir compte des interactions entre les di!érents projets.
Dès lors, afin de tenter de pallier aux insu"sances de l’approche traditionnelle, s’est poséela question de l’opportunité de recours à une variante de la méthode de Markowitz, méthodejusqu’à présent peu utilisée par les pétroliers. Plus précisément, il s’agit de savoir si la dé-termination du portefeuille optimal de projets d’exploration-production améliore le processusdécisionnel en assurant le meilleur compromis “risque minimum-valeur maximale” en tenantcompte des diverses contraintes auxquelles l’entreprise est confrontée.

32 Fateh BELAID, Daniel DE WOLF
3 Application à un cas pratique
Un cas pratique d’application à la sélection de projets d’exploitation pétrolière en Mer duNord est présenté. Nous avons essayé de présenter sur ce cas la méthode de manière simple etconcrète, afin de la rendre compréhensible et facile à appliquer par les décideurs de compagniespétrolières.
4 Modélisation de l’incertitude sur le prix du brut
Pour notre cas, nous utilisons trois scénarios de prix di!érents, que nous avons essayéde justifier par l’analyse des facteurs de la conjoncture économique actuelle, et les éventuelschangements futurs, par exemple, l’accroissement continu de la demande mondiale, l’épuise-ment éventuel des réserves, la découverte de nouveaux gisements, ou une éventuelle arrivéed’une énergie nouvelle, etc.
A partir de ces scénarios, nous construisons quatre modèles :Modèle 1 : nous imaginons un prix bas à 25 $/baril, en supposons que la croissance de
la demande pétrolière mondiale ralentit fortement suite à la transition vers des énergiesalternatives ;
Modèle 2 : nous imaginons un prix moyen à 100 $/baril, en tablant sur une continuité desapprovisionnements de brut, avec une demande qui reste soutenue mais qui commence àralentir ;
Modèle 3 : nous imaginons un prix élevé à 200 $/baril, ce scénario de crise prévoit quel’o!re sera perturbée par des attentats ou des troubles politiques ;
Modèle 4 : un modèle mixte, où l’on assigne une probabilité d’occurrence de chaque scénariode prix afin qu’on puisse calculer une espérance de valeur actuelle nette :– un prix à 25 $/baril avec une probabilité de 0,2 ;– un prix à 100 $/baril avec une probabilité de 0,4 ;– un prix à 200 $/baril avec une probabilité de 0,4.
5 Conclusions
Les résultats de cette application permettent de tirer les conclusions suivantes :– La méthode de sélection traditionnelle ignore les interactions et corrélations qui existent
entre les projets. Elle représente la valeur la plus importante pour la VAN et le risquele plus élevé du portefeuille e"cient de la méthode du Markowitz.
– La méthode de Markowitz contrairement aux méthodes classiques permet, d’analyserles projets en prenant en considération les di!érentes facettes du risque et les di!érentescorrélations qui existent entre les di!érents projets ;
– Le recours à la semi-variance est plus opportun que le recours à la variance, car elle nese concentre que sur le risque au-dessous de la moyenne.

Construction d’un modèle de simulation par le biais dedonnées de localisation des produits
A. Véjar and P. Charpentier
Centre de Recherche en Automatique de Nancy (CRAN), Nancy Université, Faculté des Sciences etTechniques, BP 239, 54506 Vandœuvre Cedex, France
[email protected],[email protected]
1 IntroductionNotre travail consiste à étudier les avantages potentiels liés à l’exploitation d’informations
de localisation de produits au fil du temps dans le contexte de systémes manufacturiers.Ce papier présente ici un cas d’application possible : la génération automatique de code desimulation de flux sur la base des données de localisation des produits, durant leur passage surle système de production. Ces données constituent un flux d’information pouvant être assimiléá la trace ou trajectoire des produits. Si, depuis quelques années, la simulation de flux estdevenue incontournable pour l’évaluation de la dynamique des systèmes manufacturiers [1], iln’en demeure pas moins que les phases de modélisation, puis de maintenance, de ces modéles,restent des opérations délicates et chronophages [2]. Ces raisons expliquent, à elles seules, lechoix de nous intéresser à cette problématique. L’idée est de remplacer la plus grosse partiedes interventions des experts humains lors de la construction du modèle, lors des phases demaintenance ou de reconfiguration, par un générateur automatique. La figure (1) montre leprincipe retenu. Le générateur y est alimenté par un flux de données en provenance du systèmeréel. Ce système quelconque, peut être de type flow-shop ou job-shop. Les produits peuventy être assemblés, transformés ou désassemblés. L’hypothèse principale est de considérer quetous les objets élémentaires d’un système de production manufacturier peuvent être localisés.Les données observées seront considérées comme fiables et non entachées d’erreur.
Fig. 1. Le «génerateur» dans son environnement
2 Formalisation du problèmeL’information de localisation accessible est définie par le 3-tuple (I, R, T ) où I est l’en-
semble des identifiants des objets. Un identifiant est assigné à chacun des objets de façonunique. R 1 R2 est l’ensemble de positions, et T représente le temps. Chaque (i, r, t), est unélément dans le flux f . Cette information est la seule qui sera utilisée pour la génération ducode de simulation. Notre problème consiste à concevoir un générateur de modèle de simula-tion en ligne *, capable d’élaborer un modèle m à partir d’un flux de données réelles F . Ce

34 A. Véjar, P. Charpentier
générateur * doit être capable d’adapterm en fonction de l’évolution du flux F dans le temps.De façon plus formelle nous pouvons noter : F = {f1, f2, f3, . . .}, où fk représente un flux àun instant donné, il est alors l’un des composants du flux F . On considérera que le modèle estinitialement vide. L’arrivée d’un nouveau flux au générateur lui permet une mise à jour dumodèle m. Le problème consiste à définir * pour obtenir m à chaque instant d’arrivée d’unnouveau flux. Cette manière de procéder permet d’adapter le modèle aux modifications éma-nant du système réel : le modèle en est le reflet instantané. Ainsi nous proposons une forme deprésentation récursive du processus d’obtention du modèle m : m0 = 2 ; mk = *(fk,mk#1).
3 PropositionsLe suivi de la trajectoire d’un objet nous permet d’en déterminer la vitesse v : soit celle-ci
est nulle, soit celle-ci est positive. Le produit est en mouvement ou il est arrêté : cette dernièrepropriété étant le signe d’une attente... d’où le choix de construire un modèle de simulationbasé sur un réseau de files d’attente. L’information v = 0, situe un point particulier à labase de la construction de notre modèle. Pour chacun de ces points il est possible d’obtenirun histogramme représentatif du temps de «service» par type de produit. Avant la sortie duproduit du système de production, aucune information sur sa composition n’est disponible.Les objets (initiaux et intermédiaires) constituants ce produit ne fournissent en e!et, durantleur passage dans le système, aucune information quant à leur destination finale. C’est à ladisparition du produit final que sa composition est découverte (de par les mouvements jointsde chacun de ses composants). Il est alors possible de retracer l’ensemble des parcours de sesconstituants jusqu’à leur naissance, et ainsi de mettre à jour les histogrammes des temps deservices d’un constituant destiné à un produit final sur un point v = 0.
4 Algorithme et résultatsL’algorithme proposé est composé de trois parties principales. La première partie génère
les positions des machines et les chemins suivis par les produits, sur la base des flux de donnéestemps réel qui l’alimentent. La seconde partie traite la problématique de sortie des produitsdu système. La sortie des produits est en e!et le moment où il est possible de savoir si ouiou non ce produit existait ou pas. S’il existait on met à jour ses données, sinon on le créé. Latroisième partie sert à modéliser les lois de comportement pour le modèle ainsi généré. Deslois statistiques sont proposées pour représenter les temps d’inter-arrivées et de services pourchaque type de produit et chaque machine. Des tests ont été menés sur des systèmes de taillesdi!érentes (nombre de machines, de pièces et d’opérations variables). Ils ont tous montré queles temps d’interarrivées des pièces, et les temps de services sur les machines entre le systèmeréel et le modèle obtenu par notre générateur étaient totalement cohérents.
Références1. Cassandras, C.G., Lafortune, S. : Introduction to Discrete Events Systems. Kluwer Academic
Publishers, Dordrecht (1999)2. Park, K.J., Lee, Y.H. : A On-line Simulation Approach to Search E%cient Values of Decision
Variables in Stochastic Systems. Int J Adv Manuf Technol (2005)

Solving of waiting lines models in the airport usingqueuing theory model and linear programming
Houda Mehri and Taoufik Djemel
Laboratoire GIAD-FSEG-Sfax B.P.1081-3018 [email protected], [email protected]
1 Introduction
In the air travel system, the bulk of delays are caused by excessive demand on limitedfacilities, causing queues to form for service, and forcing those who must wait in the queuesto incur delay costs. The demand comes from arriving and departing planes, and the servicethey are demanding is usage of the airport runways, terminals, and other facilities. Thedemand level is often uncertain due to the even more unpredictable arrival and departureof unscheduled general aviation flights. The capacity of the service facility (i.e. runways andairspace) is also often uncertain due to weather conditions, non optimal controller behavior,and equipment failure. There are two branches of modeling theory that can be useful inapproaching this problem, Queuing theory and simulation. Queuing theory is concerned withthe mathematical analysis of highly abstracted queuing systems. Simulation is concerned withanalyzing systems of arbitrary complexity by generating repeated random trials over manydi!erent scenarios. The goal of this work is to explore some of the models that these twodisciplines provide that might be useful in understanding airport delays. The characteristics ofthe models with respect to depth of analysis, cost, and applicability will be used to determinetheir desirability.
2 Queuing theory
This section is meant as a short summary of the notation and results of queuing theory.Queuing theory is oriented toward analytical investigation of service systems, their demandcharacteristics, and the delays they produce. In order to provide analytical results, simpli-fying assumptions are often made with regard to the important aspects of the system. Theseassumptions can limit the applicability of the results.
3 Sensitivity to service and demand Rates
The first tests which were run investigated the delays over a whole day with respect tochanges in the utilization ratio, that is, the ratio of demand rate to service rate. The Kivestuapproximation of a third order Erlang service queue with time varying Poisson demand wasused as the airport model. The solutions are plotted below. Note that operations include onlylandings. Arrivals were not considered customers of the landing server.

36 Mehri, Djemel
3.1 Sensitivity to service Rate Variance
In this study the delays induced by a Poisson and a high order Erlang queue were gene-rated for various combinations of average service rate and total operations using the Kivestuapproximation program. The solutions for the average delay over the whole day are plotted astwo curves, one for the various demand rates using a Poisson server, and the other using the30-order Erlang server. The Erlang curve is the lower one in all cases. The two curves forma region in which systems with server time variance between Poisson and order 30 Erlangwould fall.
3.2 Accuracy of Poisson Arrival Assumption
To test the accuracy of the Poisson arrivals assumption, the actual airport schedule forarriving flights was used to generate randomized arrival patterns that incorporated an un-certain deviation from the scheduled arrival time for each flight. A large number of theserandomized patterns were compared to what one would have expected from a Poisson gene-rating process. This amounted to testing whether a Monte Carlo simulation of arrivals, meantto be close approximation to the actual process governing arrivals, was distinguishable fromPoisson generated arrivals.
Finally, some simulation tests of the accuracy of the Poisson arrivals process were executedfor the scheduled arrival profile at airport. The Poisson was found to be fairly accurate, withsome reservations. The simulation distribution of interarrival times was found to have greatervariance than would be predicted by the Poisson, but this could be attributed to clumpingover the day in the schedule. The variance of interarrival times was found to be remarkablyinsensitive to the variance of the lateness distribution used in the simulation, implying thatwhatever the process generating arrivals is, it is robust to changes in the lateness variance..
Références
1. Bertsimas, Dimitris J, and Nakazato, Daisuke. Transient and Busy Period Analysis of the GI/G/1Queue : Part 1, The Method of stages. Part II. Solution as a Hilbert Problem. 1989.
2. Brown, T.H. A Comparaison of Runway Capacity and Delay Using Computer Simulation andAnalytic Models. M.S. Thesis C.E. 9/76.
3. Conolly, Brian. Lecture Notes on Queuing System. John wikey and Sons, 1975.4. Hengsbash, Gerd and Odoni, Amedeo R. Time Dependent Estimates of Delays and Delay Costs
at Major Airports. FTL Report R75-4, 1/1975.5. Kivestu, Peeter. Alternative Methods of Investigation the Time Dependent M/G/k Queue. M.S.
Thesis Aero 1976.6. Koopman, Bernard O. "Air Terminal Queues under Time Dependent Conditions". , Operations
Research 20, 1089-1114(1972).7. Klienrock, L. Queuing Systems V1. 1975.8. Odoni, A.R., and Kiivestu, P. A Handbook for the Estimation of Airside Delays at Major Air-
ports, FTL Report

Evaluation de projets d’investissement pétrolier enutilisant la simulation de Monte Carlo
Fateh BELAID, Daniel DE WOLF
Institut des Mers du Nord,Université du Littoral,
49/79 Place du Général de Gaulle, B.P. 5529,59 383 Dunkerque Cedex 1, [email protected]@univ-littoral.fr
1 Introduction
L’exploration et le développement d’un champ pétrolier font face à de nombreuses incer-titudes liées aux rendements et aux coûts tout au long du cycle de vie du projet. A titred’exemple les réserves potentielles, les coûts d’investissement (Capex), les coûts opératoires(Opex), la production, et le prix du pétrole, sont souvent incertains. En conséquence, Il estdi"cile de prévoir les cash-flows même pour les projets les plus simples.
Di!érentes méthodes sont disponibles pour aider les décideurs à évaluer les incertitudes,et réduire le risque des opportunités d’investissement en amont pétrolier.
La simulation a été reconnue comme un outil d’analyse de risque et de prise de décision enévaluation de projets d’investissement en amont pétrolier au début des années 60. Aujourd’huipratiquement toutes les grandes compagnies pétrolières ont incorporé la simulation dans leursétudes de projets.
2 La problématique
Dans cet article, nous essayons d’expliquer les critères d’évaluation et d’analyse du risquede projets d’investissement en amont pétrolier basés sur les cash-flows, et de montrer commentla simulation de Monte Carlo peut être utile dans ce cadre.
3 La méthode
Le préalable à l’évaluation d’un projet consiste à mettre en place un scénario de la situationde base et de calculer sa valeur actuelle nette. Ceci suppose que les valeurs des paramètresd’entrée sont connues : la production par année, le prix de pétrole pour chaque année, les coûtsd’investissement, les coûts opératoires de chaque année, le taux d’actualisation, la structurefiscale, etc.
La Valeur Actuelle Nette (VAN) sera alors calculée comme la di!érence entre les fluxnets de trésorerie actualisés générés par un investissement et le montant initial de celui-ci. Elle indique l’enrichissement net de l’entreprise qui découlerait de la réalisation de cetinvestissement.

38 Fateh BELAID, Daniel DE WOLF
La simulation permet ensuite aux analystes de décrire le risque et l’incertitude des va-riables qui influencent la rentabilité du projet par des distributions de probabilité. Le premierobjectif de l’utilisation de la simulation dans l’évaluation de projet en amont pétrolier est dedéterminer la distribution de la VAN à partir des variables qui influent sur le rendement duprojet, d’où l’on pourra déduire sa moyenne ou la valeur actuelle espérée.
On peut résumer le processus de la simulation de Monte Carlo e!ectué en trois étapesprincipales, comme suit :1. Création d’une distribution de probabilité pour chaque paramètre d’entrée : nous considé-
rons trois principaux facteurs de risque : la production, les Opex, les Capex. Leurs distri-butions de probabilité sont évaluées en utilisant les valeurs historiques et les jugementsd’experts :– pour la production, on utilise une distribution log-normale,– pour les Opex, une distribution triangulaire,– pour les Capex, une distribution triangulaire.
2. Génération de 5 000 itérations pour la simulation de Monte Carlo .3. Enregistrement des résultats de la simulation :
– la distribution de VAN espérée,– la moyenne de la VAN,– sa variance,et enfin on récupère les données de la simulation qui vont être utilisées pour le calcul dela matrice des variances-covariances des valeurs espérées de la VAN et celle des semi-covariances.
Pour tout le processus, on a utilisé la dernière version d’évaluation de logiciel Crystal Ball(Version 7.3).
4 Conclusions
La simulation de Monte Carlo que nous avons utilisé pour la simulation des VAN desprojets est une méthode d’estimation générale, flexible et souvent simple à implanter.
La comparaison des valeurs obtenues par l’approche de Monte Carlo aux valeurs détermi-niste nous éclaire sur la validité de la méthode Monte Carlo. En e!et, les valeurs des di!érentesvariables utilisées dans cette méthode sont "correctement" estimées.
La simulation de Monte Carlo n’est qu’une prolongation normale de la situation de basede la VAN standard, en tenant compte du fait que les variables ne sont pas connues aveccertitude. Les distributions statistiques standards telles que la loi normal, la loi log-normal,la loi uniforme et les distributions triangulaires sont employées pour décrire les paramètresd’entrée.

Softening Gcc with preferences
J-Ph. Métivier, P. Boizumault, and S. Loudni
GREYC (UMR 6072), Université de Caen, Bd du Maréchal juin, 14032 Caen Cedex France.{jmetivie,patrice.boizumault}@info.unicaen.fr,[email protected]
In this abstract, we propose the global constraint +-Gcc which is a soft version of theGlobal Cardinality Constraint (Gcc) taking account preferences. We have used +-Gcc forsolving over-constrained timetabling problems (http://www.cs.nott.ac.uk/\~\\hspace{-0.75ex}tec/NRP/).
1 The Global Cardinality Constraint
Gcc [3] is defined on a set of n variables and specifies, for each value in the union of theirdomains (Doms), bounds on the maximal (uj) and minimal (lj) number of times, value vjcan occur in a solution. Gcc can be considered as a meta-constraint and decomposed into aset of Atleast (resp. Atmost) constraints enforcing the lower bound (resp. upper bound) foreach vj!Doms :
Definition 1. Let X be a set of n variables, Di be the domain of the variable Xi andDoms=3i%XDi. Let vj ! Doms, lj and uj their lower and upper bounds,
Atleast(X , vj , lj) 4 |{Xi ! X | Xi = vj}| ( ljAtmost(X , vj , uj) 4 |{Xi ! X | Xi = vj}| " uj
Gcc(X , l, u) 4+vj%Doms(Atleast(X , vj , lj) 5 Atmost(X , vj , uj))
Theorem 1. (Consistency-Check [3]) Gcc (X , l, u) is hyperarc consistent i! there exits afeasible s–t flow of value n (where n=|X |) in the network N={V ,A} with :
V = X 3Doms 3 {s, t}A = As 3AX 3AtAs = {(s,Xi) | i ! {1, . . . , n}},AX = {(Xi, vj) | vj ! Di, i ! {1, . . . , n}},At = {(vj , t) | vj ! Doms},
demand and capacity functions :,a ! As, d(a) = 1 and c(a) = 1,a ! AX , d(a) = 0 and c(a) = 1,a ! Ap, d(a) = lj and c(a) = uj
Consistency-check can be performed in O(n*m) (where m=|A|). To maintain hyperarcconsistency, all arcs (and then values) which do not belong to any feasible flow are removedthanks to computation of strongly connected components in O(n+m).
2 Relaxing Gcc
In many real-life situations, lower or upper bounds may be too restrictive to get a solution.To each value vj!Doms, are associated a shortage function (s(X , vj)) measuring the numberof missing assignments of vj to satisfy Atleast(X , vj , lj), and an excess function (e(X , vj))measuring the number of assignments of vj in excess to satisfy Atmost(X , vj , uj) [4] :
s(X , vj) = max(0, lj # |{Xi | Xi = vj}|)e(X , vj) = max(0, |{Xi | Xi = vj}| # uj)

40 J-Ph. Métivier, P. Boizumault, S. Loudni
To express preferences on the minimal/maximal requirements on each value vj , to each lj(resp. uj) we associate a weight ,atleastj (resp. ,atmostj ) denoting the amount of violation to payif the requirement is not satisfied. We define violation cost for constraints Atleast(X , vj , lj)and Atmost(X , vj , uj) as follows :
weight(Atleast(X , vj , lj)) = ,atleastj * s(X , vj)weight(Atmost(X , vj , uj)) = ,atmostj * e(X , vj)
3 Soft Global Constraint !-GccWe propose a new soft global constraint +-Gcc, the soft version with preferences of the
Gcc constraint. For this constraint, we introduce a new violation based semantic which takesinto account preferences between violations.
Let Cdec be the decomposition of a Gcc constraint into a set of Atleast and Atmostconstraints. The decomposition based semantic µdec computes the weighted sum of Atleast(X , vj , lj)and Atmost(X , vj , uj) constraints in Cdec that are violated :
µdec(X ) =%
vj%Doms,atleastj * s(X , vj) + ,atmostj * e(X , vj)
As for Gcc , +-Gcc can be modeled by a network N! . Violation arcs are added in orderto model shortage and excess functions :
- Shortage violation arcs,Ashortage={(s, vj) | vj!Doms}, are used to model Atleast(X , vj , lj)constraints. For each shortage violation arc a=(s, vj), its demand d(a)=0, its capacityc(a)=lj, and its weight w(a) = ,atleastj .
- Excess violations arcs,Aexcess={(vj , p) | vj!Doms}, are used to model Atmost(X , vj , uj)constraints. For each excess violation arc a = (vj , t), its demand d(a)=0, its capacityc(a) =6, and its weight w(a) = ,atmostj .
Let z be a cost variable that represents the allowed amount of violation for a +-Gcc constraint.Corollary 1. (Consistency-Check [2]) The constraint +-Gcc(X , l, u, z, µdec) is hyperarc consistentif and only if there exists an integer s–t flow f of value n in N! with weight(f) " max(Dz).Corollary 2. (Filtering [2]) The constraint +-Gcc is hyperarc consistent if and only if forevery arc a ! AX there exists an integer s–t flow f of value max(n,
&vj%Doms lj) in N! with
f(a) = 1 and weight(f) " max(Dz).Consistency-Check can be performed thanks to a Ford and Fulkerson algorithm inO(max(n
,&vj%Doms lj)*(m+n*log(n))) [1]. Filtering can be performed inO((n+d)*(m+n*log(n))).
Références1. L.R. Ford and D.R. Fulkerson. Flow in Networks. Princeton University Press, 1962.2. J.P. Métivier, P. Boizumault, and S. Loudni. Softening Gcc and Regular with Preferences. In
ACM SAC2009, pages 484–488, 2009.3. J.C. Régin. Generalized arc consistency for global cardinality constraint. In AAAI/IAAI, Vol. 1,
pages 209–215, 1996.4. W.J. van Hoeve, G. Pesant, and L.M. Rousseau. On global warming : Flow-based soft global
constraints. J. Heuristics, 12(4-5) :347–373, 2006.

Impact des modes de comptage sur les méthodes à basede divergences
W. Karoui1,2, M.-J. Huguet1,3, and P. Lopez1
1 CNRS ; LAAS ; 7 avenue du colonel Roche, F-31077 Toulouse, France2 Université de Toulouse ; UPS, INSA, INP, ISAE ; LAAS ; F-31077 Toulouse, France
3 Unité de recherche ROI ; Ecole Polytechnique de Tunisie, 2078 La Marsa, Tunisie{wakaroui, huguet, lopez}@laas.fr
1 Introduction
Un problème de satisfaction de contraintes (CSP) est défini par un triplet (X,D,C) où :X = {X1, . . . , Xn} est un ensemble fini de variables ; D = {D1, . . . , Dn} est un ensemble dedomaines des variables, chaque Di est un ensemble de valeurs discrètes pour la variable Xi ;C = {C1, . . . , Cm} est un ensemble de contraintes.
Dans le cadre de la résolution des CSP, plusieurs axes d’amélioration des méthodes derecherche ont été envisagés. Ce travail s’intéresse ainsi à l’intégration de di!érentes techniquespour rendre plus e"caces des méthodes arborescentes basées sur les divergences. Le conceptde divergence a été introduit par Harvey et Ginsberg [?] ; il correspond à une déviation parrapport au choix de la valeur sélectionnée prioritairement par une heuristique d’ordre sur lesvaleurs (heuristique de référence).
LDS est à la base d’une méthode de recherche complète. Etant donné l’heuristique dechoix des valeurs ne peut éviter de mauvais choix, LDS remédie à ce problème en augmentantprogressivement le nombre d’erreurs tolérées de la part de l’heuristique : les divergences. Ceprincipe nous mène à un parcours très particulier de l’arborescence. Plusieurs travaux ontamélioré ce principe en proposant des variantes plus e"caces comme ILDS, DDS et Yet Im-provEd Limited Discrepancy Search (YIELDS) [?]. Vu la particularité de ce principe, plusieurspistes d’améliorations sont encore à exploiter. Dans ce travail, nous étudions spécifiquementle mode de comptage des divergences.
2 Comptage des divergences
Le comptage des divergences présente deux possibilités pour les arbres non-binaires.– Le comptage binaire. Le parcours de la branche associée à la meilleure valeur selon
l’heuristique de référence correspond à 0 divergence. Le parcours de toutes les autresbranches possibles pour la variable considérée implique une et une seule divergence.
– Le comptage non-binaire. Les valeurs d’une variable donnée sont ordonnées selon uneheuristique d’ordre sur les valeurs de telle sorte que la meilleure valeur a le rang 1.Choisir une valeur de rang k > 1 conduit à k # 1 divergences.
La figure 1 présente le nombre de divergences obtenues pour chaque feuille dans le cas d’unCSP à trois variables Xi, i = 1, . . . , 3 avec |Di| = 3, ,i.

42 Karoui et al.
1 2 1 2 2 31 1 2 1 2 2 2 3 2 3 3 1 2 2 2 3 3 2 3 300 1 2 1 2 3 2 3 4 1 2 3 2 3 4 3 4 5 2 3 4 3 4 5 4 5 6
X1
X2
X3
Comptage Binaire :Comptage Non-binaire :
Fig. 1. Comptage binaire et non binaire pour les divergences
Le principe d’une méthode à base de divergences peut être associé à un comptage binaire ounon-binaire [?]. Nous pouvons remarquer que le comptage binaire correspond à une rechercheà “forte granularité” et que le comptage non-binaire correspond à une recherche à “faiblegranularité”. On peut ainsi identifier des niveaux dans l’arbre où une recherche de faiblegranularité sera utile, alors que d’autres niveaux, jugés moins déterminants pour l’orientationdu parcours, feront l’objet d’une recherche à forte granularité, plus rapide. On peut mêmeimaginer un mélange des deux modes de comptage décrits ci-dessus, pour obtenir ainsi uncomptage mixte. Quelques paramètres sont à introduire, comme la profondeur dans l’arbrede recherche, pour distinguer les di!érentes zones de comptage. A partir de cette profondeur,on peut changer le mode de comptage adopté. On peut a"ner le paramètre qui contribue àla délimitation des zones à explorer di!éremment par des mécanismes d’apprentissage.
3 Evaluation des di!érents modes de comptage des divergences
L’évaluation des di!érents modes de comptage proposés est faite dans la méthode YIELDSen comparaison d’un Backtrack Chronologique et d’un ILDS classique. Les tests portent surdes problèmes aléatoires de diverses tailles, des problèmes d’ordonnancement de type job-shop et des problèmes de Car Sequencing de la CSPLib. Pour la variante YIELDS utilisantun comptage mixte, nous adoptons des profondeurs de 1
3 et de 23 de la hauteur de l’arbre
de recherche. Les performances sont évaluées en termes de temps et de nombre de nœudsdéveloppés dans l’arbre ainsi qu’en fonction du taux de résolution dans un temps d’exécutionlimité à 200 secondes.
Les premiers résultats obtenus sont globalement en faveur du comptage non-binaire pourla plupart des problèmes considérés. Le comptage mixte s’avère meilleur que le comptagenon-binaire si l’on adapte l’heuristique au mode de comptage en même temps que l’on adaptele comptage à la zone ciblée dans l’espace de recherche. Ceci nous incite à a"ner l’étude ducomptage mixte dans YIELDS : les paramètres délimitateurs doivent profiter de l’apprentis-sage et s’adapter à la nature du problème.

Relaxation lagrangienne pour le filtrage d’unecontrainte-automate à coûts multiples
Julien Menana, Sophie Demassey and Narendra Jussien
Ecole des Mines de Nantes - LINA CNRS UMR 62414 rue Alfred Kastler - BP 20722F-44307 Nantes Cedex3, France
{julien.menana, sophie.demassey, narendra.jussien}@emn.fr
La programmation par contraintes est un paradigme de résolution approprié dans le do-maine de la planification d’horaires. Elle o!re une modélisation concise et évolutive des nom-breuses conditions, hétérogènes et versatiles, qui définissent typiquement un emploi du tempsvalide. La contrainte globale regular [1] permet dans ce contexte de spécifier sous la formed’un automate fini déterministe, les séquences d’activités qui correspondent à un horaire réali-sable, et de forcer cette condition de réalisabilité par filtrage des séquences non-reconnues parl’automate. La variante cost-regular [2] prend en compte des coûts d’a!ection des activités.Traiter les coûts au sein de la contrainte-automate améliore considérablement la profondeurdu filtrage sans augmenter la complexité temporelle – cubique en la taille de la séquence – del’algorithme.
L’algorithme de filtrage de cost-regular repose sur la recherche dans le graphe acycliqueobtenu par le déploiement de l’automate des plus courts (resp. longs) chemins. Les informa-tions fournies permettent non seulement de déterminer le coût minimal (resp. maximal) del’a!ectation d’une séquence d’activités réalisable, mais aussi de retirer les a!ectations quimèneraient à un coût supérieur (resp. inférieur) aux bornes fournies.
Si l’utilisation de cost-regular permet une modélisation encore plus fonctionnelle quecelle proposée par regular, il est possible de pointer quelques lacunes pour la modélisationde planifications d’horaires. En e!et, il est quasiment obligatoire lorsque l’on souhaite parexemple borner le temps passé sur chacune des activités d’utiliser de manière transversaledes contraintes de cardinalité. L’utilisation de cette contrainte transversale n’exploite pas lastructure du graphe déduit de l’automate. On peut aisément penser que gérer simultanémenttous les coûts au sein de l’automate permet d’extraire plus d’informations pour réduire l’espacede recherche, mais aussi d’éviter de lourds échanges d’informations entre deux contraintesstructurellement orthogonales.
Afin de répondre à ces problématiques, nous proposons de définir une nouvelle contraintemulti-cost-regular qui étant donnés : ! = (S,+, -, s, A) un automate fini déterministe(DFA) ;X = (x1, x2, ..., xn) une suite de variables de domaines finisD = (dom(x1), ..., dom(xn)) ;Z = (z0, ..., zr) un ensemble de variables de domaines bornés et C une matrice de coûts telleque ,i ! [[1, n]], ,j ! dom(xi) , cij est le vecteur de coût de dimension r correspondant àl’a!ectation de j à xi, assure
X ! L(!) et, ,k ! [[0, r]],n%
i=1ckixi = zk
La puissance de modélisation d’une telle contrainte n’est pas gratuite car le problème sous-jacent à cette contrainte, un plus court chemin sous contraintes de ressources RCSPP, est

44 Julien Menana, Sophie Demassey and Narendra Jussien
NP-complet [3]. Il est donc nécessaire de bien calibrer l’e!ort fourni lors de la résolution afinde trouver le bon compromis entre coût et e"cacité.
Le problème de plus court chemin sous contraintes de ressources RCSPP est le problème detrouver le plus court chemin dans un graphe orienté et valué G = (V,E, c) entre une sources et un puits t de manière à ce que la quantité totale de ressources consommées sur chaquearc ne dépasse pas une limite donnée.
Afin de résoudre ce type de problème, deux grandes classes de solutions existent : lesalgorithmes d’étiquetage de graphes et les algorithmes fondés sur une relaxation lagrangiennedes contraintes de ressources. [3]. Pour des raisons de mémoire, nous nous sommes tournésvers la seconde classe d’algorithmes où le problème est relâché en intégrant les contraintes deressources au sein de la fonction objectif. L’intégration d’une relaxation lagrangienne au seind’un algorithme de filtrage a été introduite par Sellmann [4], suivant le principe établi parFoccaci, Lodi et Milano [5] de filtrage des variables de décision à partir d’un calcul de coût. Lepoint important est le théorème qui dit qu’une valeur n’appartenant pas à une solution dansun sous problème lagrangien ne peut appartenir à une solution dans le problème principal.Nous avons étendu ce théorème au niveau de la structure même du graphe, montrant qu’unarc ne pouvant appartenir à une solution d’un sous problème, n’appartiendra pas à un cheminsolution du RCSPP.
La relaxation lagrangienne associée consiste à résoudre une série de sous problèmes lagran-giens qui prennent la forme de simples plus courts chemins. Chacun de ses sous-problèmespermet de retirer des valeurs qui n’appartiennent à aucune solution. La suite de ses plus courtschemins, converge vers une borne inférieure du RCSPP. De manière similaire à la contraintecost-regular, le calcul de la borne supérieure permet également, à travers une suite de pluslongs chemins, de réduire la taille des domaines. Selon les sous-problèmes que l’on résout, leurnombre et la qualité des bornes que l’on calcule, il est possible d’augmenter la puissance dufiltrage ou de limiter le nombre de calculs e!ectués.
La contrainte multi-cost-regular permet donc de mutualiser les contraintes de séquen-cement et de cardinalité dans de nombreux problèmes de planifications d’horaires. En outre,l’existence dans le catalogue de contraintes globales [6] de contraintes modélisables par unautomate à tableau de compteurs permet également d’imaginer dériver automatiquement lesalgorithmes de filtrage de ces contraintes à partir de leur représentation.
Références1. G. Pesant, “A regular language membership constraint for finite sequences of variables,” in CP,
pp. 482–495, 2004.2. S. Demassey, G. Pesant, and L.-M. Rousseau, “A cost-regular based hybrid column generation
approach,” Constraints, vol. 11, no. 4, pp. 315–333, 2006.3. G. Handler and I. Zang, “A Dual Algorithm for the Restricted Shortest Path Problem,” Networks,
vol. 10, pp. 293–310, 1980.4. M. Sellmann, “Theoretical foundations of cp-based lagrangian relaxation,” Principles and Practice
of Constraint Programming –CP 2004, pp. 634–647, 2004.5. F. Focacci, A. Lodi, and M. Milano, “Cost-based domain filtering,” Principles and Practice of
Constraint Programming –CP’99, pp. 189–203, 1999.6. N. Beldiceanu, M. Carlsson, and J. Rampon, “Global Constraint Catalog,” tech. rep., EMN, 2008.

Satisfaction de contraintes pondérées et séparation decontraintes de capacités pour le problème CVRP
M. Hifi, M.O.I. Khemmoudj, S. Negre
Université de Picardie Jules Verne, AmiensUFR des Sciences, Laboratoire MIS, Axe Optimisation Discrète et réoptimisation
33, rue Saint Leu 80039 Amiense-mails : {hifi, idir.Khemmoudj, stephane.negre}@u-picardie.fr
1 Introduction
Un modèle couramment utilisé pour le problème de tournées de véhicules contraint, notéCVRP [1,5], est la formulation à deux indices. Dans ce modËle, une variable zij est associée àchaque arête (i, j). Elle reprÈsente le nombre de fois que cette arête est empruntée. Le modèleest le suivant :
min%
(i,j)%Edijzij (1)
s.c.
z(-(i)) = 2 1 " i " n (2)
z(-(0)) = 2K (3)z(-(S)) ( 2r(S) ,S + Vc (4)zij ! {0, 1} 1 " i < j " n (5)z0i ! {0, 1, 2} 1 " i " n (6)
où di est le le coût de l’emprunt de l’arête (i, j), le sommet 0 représente le dépôt contenantk véhicules de capacité homogène Q, Vc = {1, ..., n} est l’ensemble des clients auxquels unequantité qi doit Ítre acheminée. Pour chaque ensemble S + Vc, -(Vc) dénote l’ensemble desarêtes qui ont exactement une extrémité dans S (l’autre est dans V \ S). La notation -({i})est remplacée par -(i). Pour un sous-ensemble F + E, la notation z(F ) désigne la quantité&
(i,j)%F zij . Pour S + Vc, r(S) est le nombre minimum de véhicules nécessaires pour desservirles clients dans S. Ce dernier est un problème NP-di"cile puisque cela revient à résoudre unproblème de placement (“Bin Packing"). Les contraintes de type (4) expriment des restrictionsrelatives aux capacités des véhicules et au fait que chaque route doit contenir le dépôt. Leprincipal inconvénient de cette formulation est que le nombre de ces contraintes varie de ma-nière exponentielle en fonction de n, le nombre de clients. Cependant, en adoptant un principede résolution du type branch-and-cut, un nombre restreint d’inégalités valides peuvent su"repour exprimer ou bien approcher l’enveloppe convexe de ce problème. Une inégalité valideest une inégalité que doit satisfaire toute solution du CVRP. Dans la littérature, di!érentesclasses de ces inégalités ont été proposées et un grand nombre de travaux ont porté sur la

46 M. Hifi, M.O.I. Khemmoudj, S. Negre
classe des inégalités de capacité arrondie (RCI pour Rounded Capacity Inequalities). Pour unS + Vc donné, l’inégalité RCI associée s’écrit comme suit :
z(-(S)) ( 27q(S)8 (7)
où q(S) = 1Q
&i%Sqi. Dans cet exposé, nous proposons un modèle de génération de certaines in-
égalités valides. Ce travail est basé sur la formulation des inégalités de type (7) sous forme d’unWCSP (Weighted Constraint Satisfaction Problem) pour lequel est associé un programme li-néaire.
Le problème de tournées de véhicules contraint, noté CVRP [1,5], est un problème del’optimisation combinatoire. Une instance du CVRP peut être définie par un graphe completG = (V,E), où V = {i | 0 " i " n} est un ensemble de sommets et E = {(i, j) | 0 " i < j " n}un ensemble d’arêtes. Dans ce cas, le sommet 0 représente un dépôt contenant K véhiculesde capacité homogène Q. Par ailleurs, chaque sommet i 9= 0 représente un client pour lequelune quantité qi d’un produit donné doit être acheminée par exactement un des véhicules.Il s’agit de déterminer pour chaque véhicule un itinéraire (route admissible) pour partir dudépôt, servir un sous-ensemble de clients, puis revenir au dépôt. La somme des demandesde l’ensemble des clients visités, par un même véhicule, est bornée par la capacité Q (duvéhicule). De plus, à chaque arÍte (i, j) ! E est associé un coût dij qui correspond ‡ un co˚tà payer si cette arÍte (i, j) est empruntée. Le but du probème est donc de trouver les K routesadmissibles réalisant le moindre coût.
D’une façon formelle, étant donnée la variable zij associée à chaque arÍte (i, j) représentantle nombre de fois que cette arÍte est utilisée, alors le problème peut être écrit sous sa formehabituelle suivante (appelée formulation à deux indices) :
min%
(i,j)%Edijzij (8)
s.c.
z(-(i)) = 2 1 " i " n (9)
z(-(0)) = 2K (10)z(-(S)) ( 2r(S) ,S + Vc (11)zij ! {0, 1} 1 " i < j " n (12)z0i ! {0, 1, 2} 1 " i " n (13)
où Vc = V \ {0}. Pour chaque ensemble S + Vc, -(Vc) dénote l’ensemble des arêtes qui ontexactement une extrémité dans S (l’autre est dans V \S). La notation -({i}) est remplacée par-(i). Pour un sous-ensemble F + E, la notation z(F ) désigne la quantité
&(i,j)%F zij . Pour
S + Vc, r(S) est le nombre minimum de véhicules nécessaires pour desservir les clients dansS. Le calcul de r(S) est un problème NP-di"cile puisque celà revient à résoudre un problèmede placement (“Bin Packing"). Les contraintes de type (4) expriment des restrictions relativesaux capacités des véhicules et au fait que chaque route doit contenir le dépôt. Le nombre deces contraintes varie de manière exponentielle en fonction de n, le nombre de clients. Cela

Title Suppressed Due to Excessive Length 47
constitue le principal inconvénient de cette formulation. Cependant, en adoptant le principede résolution du type branch-and-cut, un nombre restreint d’inégalités valides peuvent su"repour exprimer ou bien approcher l’enveloppe convexe de ce problème. Une inégalité valide estune inégalité que doit satisfaire toute solution du CVRP. Dans la literature, di!érentes classesde ces inégalités ont été proposées et un grand nombre de travaux ont porté sur la classe desinégalités de capacité arrondie (RCI pour Rounded Capacity Inequalities). Pour un S + Vcdonné, l’inégalité RCI associée s’écrit comme suit : z(-(S)) ( 27q(S)8 où q(S) = 1
Q
&i%Sqi.
Dans cet exposé, nous proposons un modèle de génération de certaines inégalités valides.Ce travail est principalement basé sur la formulation des inégalités RCI sous forme d’unWCSP (Weighted Constraint Satisfaction Problem) pour lequel est associé un programmelinéaire.
2 Problème de séparation des inégalités de capacité arrondie sousforme d’un WCSP
Il existe une inÈgalitÈ RCI violÈe par une solution z si le problème P : minS&Vc
)z(-(S)) #
27q(S)8*
est de valeur négative. La quantité z(-(S))#27q(S)8 peut se réécrire sous forme d’unesomme de deux parties : [z(-(S))# 2q(S)] + [2q(S)# 27q(S)8] . Nous formulons la premièrepartie sous forme d’un WCSP binaire (c.f. [2] pour plus de détails sur la description duWCSP et les méthodes de résolution utilisées) : pour chaque i ! Vc est associée une variablexi ! {0, 1} et une contrainte unaire pondérée ci représantant une fonction coût, où ci(0) = 0et ci(1) = z0i # 2qi/Q. Nous introduisons également pour chaque (i, j) ! E : zij 9= 0 unecontrainte binaire pondérée cij avec cij(0, 0) = cij(1, 1) = 0 et cij(0, 1) = cij(1, 0) = zij . Ladeuxième partie peut être considérée comme une contrainte pondérée qui associe le coût #2.1à chaque S + Vc avec 0 " .1 = 7q(S)8# q(S) " 1# 1/Q. En exploitant la formulation PLNEproposée dans [3] pour les WCSP binaires, nous proposons un PLNE pour le WCSP associéà P. Cette formulation peut s’écrire comme suit :
minn&i=1
(z0i # 2qi/Q)xi(1)+&cij%C
zij(xij(0, 1) + xij(1, 0))# 2.1
s.c.xi(k) = xij(k, 0) + xij(k, 1) ,(i, j, k) : zij 9= 0, k ! {0, 1} (i)xj(l) = xij(0, l) + xij(1, l) ,(i, j, l) : zij 9= 0, l ! {0, 1} (ii)xi(0) + xi(1) = 1 ,i : 1 " i " n (iii)1Q
n&i=1qixi(1) + .1 = .2 (iv)
0 " .1 " Q#1Q (v)
xi(k) ! {0, 1}, ,(i, k) : 1 " i " n, k ! {0, 1}(vi).2 ! N (vii)
Dans ce modèle, une variable xi(1) prend la valeur 1 si et seulement si xi prend la valeur1 (si i ! S). Sinon (i /! S), c’est la variable xi(0) qui prend la valeur 1 (contraintes (iii)et (vi)). Pour toute arête (i, j) ! E, zij 9= 0, et toute paire (k, l) ! {0, 1}2, ce modèle

48 M. Hifi, M.O.I. Khemmoudj, S. Negre
introduit la variable xij(k, l) contrainte à prendre la valeur 1 lorsque xi(k) et xj(l) prennenttoutes les deux la valeur 1, 0 sinon (contraintes (i) et (ii)). Ce modèle introduit égalementles variables .1 et .2 pour représenter les quantités 7q(S)8 # q(S) et 7q(S)8 respectivement(contraintes (iv), (v) et (vii)). On peut facilement vérifier qu’à tout S + Vc, ce modèlefait correspondre une solution de coût z(-(S)) # 27q(S)8. Sa résolution permet de séparerde manière exacte les inégalités RCI. Nos expérimentations ont montré que cette méthodepermet d’améliorer les bornes inférieures calculées grace à la séparation par des heuristiques,proposées par Lysgaard et al. [4].
Ce travail ouvre la voie à l’exploitation des techniques de la programmation par contraintes(PPC) pour la génération d’inégalités valides. Dans le futur, nous comptons exploiter des mé-thodes exactes et approchées de la PPC pour résoudre le WCSP proposé dans ce travailpour la séparation des inégalités RCI. Nous comptons également étendre ce travail à d’autresclasses d’inégalités valides et au cas des CVRP avec contraintes sur les chargements et dé-chargements.
Références
1. Dantzing, G.B., Ramser, R.H. : The truck dispatching problem. Management Science, 6 (1959)80-91.
2. Khemmoudj, M.O.I. : Modélisation et résolution de systèmes de contraintes : Application au pro-blème de placement des arrêts et de la production des réacteurs nucléaires d’EDF, Université Paris13, Institut Galilée, Laboratoire d’Informatique Paris Nord (LIPN), 2007.
3. Koster, A. : Frequency Assignment : Models and Algorithms. PhD Thesis. UM (Maastricht, TheNetherlands) (1999).
4. Lysgaard. J., A. N. Letchford., R. W. Eglese. : A New Branch-and-Cut Algorithm for the Capa-citated Vehicle Routing Problem, Mathematical Programming, 141 (2) (2004) 223-445.
5. Toth. P., Vigo. D. : An overview of vehicle routing problems. In P. Toth, D. Vigo (Eds.). TheVehicle Routing Problem, SIAM Monographs on Discrete Mathematics and Applications, Phila-delphia, 1–26.

Recherche locale haute performance pour l’optimisationde la distribution de gaz industriels par camions-citernes
Thierry Benoist1, Bertrand Estellon2, Frédéric Gardi1, Antoine Jeanjean1
1 Bouygues e-lab, Paris.{tbenoist,fgardi,ajeanjean}@bouygues.com
2 Laboratoire d’Informatique Fondamentale, Faculté des Sciences de Luminy, [email protected]
Dans cette note, nous abordons un problème réel d’optimisation de la logistique de distri-bution de gaz industriels par camions-citernes. Le problème de logistique traité ici généraliseune problématique connue sous son nom anglophone "inventory routing problem", que l’onpourrait traduire en français par problème d’optimisation de tournées de véhicules avec ges-tion des stocks (le lecteur est renvoyé à [3] pour un état de l’art sur le sujet). Une di!érencemajeure avec le “vehicle routing problem” est qu’ici les stocks des clients sont gérés par lefournisseur.
Nous avons, éparpillés sur une zone géographique, des clients qui consomment du gaz etdes sources qui en produisent. Chaque client est équipé d’un stockage possédant une certainecapacité ; de même, chaque source (correspondant à une usine) possède un stockage duquelpeut être prélevé le gaz. Les prévisions de production des sources sont connues sur un certainhorizon. Côté client, nous gérons deux types d’approvisionnement. Le premier type, dit “à laprévision”, correspond aux clients pour lesquels on possède les prévisions de consommationsur un certain horizon. Les stocks de ces clients doivent être alimentés par camions-citernesde façon à ne jamais descendre en dessous d’un niveau de sécurité. Le second type, dit "àla commande", correspond aux clients qui passent des commandes comprenant la quantitéà livrer et la fenêtre de temps dans laquelle la livraison doit être e!ectuée. Certains clientspeuvent appartenir aux deux types à la fois : leur stock est géré de façon prévisionnelle maisils peuvent passer commande lorsqu’ils le souhaitent (pour faire face à une augmentationimprévue de leur consommation, par exemple). Les contraintes de maintien des niveaux destocks et de satisfaction des commandes sont définies comme molles, l’existence d’une solutionn’étant pas assurée.
Les livraisons sont e!ectuées à l’aide de trois types de ressources : les chau!eurs, lestracteurs, les remorques. Chaque ressource est attachée à une base. Un véhicule correspond àl’association d’un chau!eur, d’un tracteur et d’une remorque. Tous les triplets de ressources nesont pas admissibles. Chaque ressource possède des fenêtres de disponibilité pendant lesquellescelle-ci peut être utilisée. Chaque site (source ou client) n’est accessible qu’à un sous-ensembledes ressources. Ainsi, planifier la tournée d’un véhicule consiste à définir : une base, un tripletde ressources (chau!eur, tracteur, remorque), et un ensemble d’opérations définies chacunepar un triplet (site, date, quantité) correspondant aux livraisons/chargements e!ectués surla tournée. Une tournée doit donc démarrer depuis une base où toutes les ressources sontprésentes et se clore par un retour à cette même base. Les temps de travail et de conduitedes chau!eurs sont limités ; dès qu’un maximum est atteint, le chau!eur doit prendre unepause d’une durée minimale. Les sites visités (sources, clients) durant la tournée doivent êtreaccessibles aux ressources composant le véhicule. L’intervalle de temps pendant lequel est

50 T. Benoist, B. Estellon, F. Gardi, A. Jeanjean
utilisée une ressource doit être contenu dans une fenêtre de disponibilité de celle-ci. La datede livraison/chargement doit être contenu dans une des fenêtres d’ouverture du site. Enfin,les équations de dynamique des stocks, qui s’apparentent à des équations de flux, doiventêtre respectées à chaque pas de temps, pour chaque stockage (sources et clients) et chaqueremorque ; en particulier, la somme des livraisons (resp. des chargements) e!ectuées chez unclient (resp. une source) doit être inférieure (resp. supérieure) à la capacité de stockage duclient (resp. à zéro).
La planification des tournées est réalisée jour après jour de façon déterministe sur un hori-zon glissant de 15 jours. Le premier objectif de la planification est, à long terme, de satisfaireles contraintes molles évoquées précédemment (maintien des niveaux de sécurité, satisfactiondes commandes). En pratique, les cas où ces contraintes ne peuvent être respectées sont extrê-mement rares. L’objectif second est donc, à long terme, de minimiser un ratio logistique définicomme la somme des coûts des tournées (composés de di!érents coûts d’utilisation des res-sources a!ectées à la tournée) divisé par la somme des quantité livrée aux clients. Autrementdit, ce ratio logistique correspond au coût payé par unité de quantité livrée. Pour donner unordre d’idée de l’échelle des instances réelles, une zone géographique peut comporter jusqu’à500 clients, 5 sources, 5 bases, 50 chau!eurs, 50 tracteurs, 50 remorques. Toutes les dates etles durées sont exprimées en minutes (au total, l’horizon de planification comporte donc 21600minutes) ; seule la dynamique des stocks des sources et des clients est réalisée à l’heure (lesprévisions étant données à l’heure près). Le temps d’exécution est limité à 5 minutes (sansparallélisation) sur des serveurs classiques (CPU 3 GHz, RAM 4 Go, cache L2 4 Mo).
Nous avons conçu une heuristique à base de recherche locale pour résoudre ce problème.La conception de notre algorithme s’appuie sur les travaux récents de Estellon et al. [1,2].La stratégie de recherche se limite à une méthode de descente avec choix stochastique desmouvements, à partir d’une solution initiale obtenue par une heuristique gloutonne. Nousutilisons un pool d’une cinquantaine de mouvements, que l’on peut regrouper en une dizainede types (sur les opérations : insertion, suppression, éjection, déplacement, échange ; sur lestournées : insertion, suppression, déplacement, échange, décalage). L’évaluation des mouve-ments est réalisée en deux temps : calcul des dates de livraison/chargement, puis a!ectationdes quantités. Pour chacun de ces sous-problèmes, des algorithmes en temps et espace linéaire(non optimaux mais e!ectifs en pratique) ont été conçus afin que l’évaluation soit la plus ra-pide possible. En moyenne, notre recherche locale tente 50000 mouvements par seconde, letaux d’acceptation des mouvements étant de quelques %.
Les tests que nous avons e!ectués montrent des gains de près de 20% sur des horizonsdépassant la centaine de jours. Ces gains sont obtenus sur des solutions construites manuelle-ment par des planificateurs experts. Notre logiciel est aujourd’hui exploité par un des leadersmondiaux des gaz industriels et médicaux pour planifier sa distribution en Amérique du Nord.
Références1. B. Estellon, F. Gardi, K. Nouioua (2008). Two local search approaches for solving real-life car
sequencing problems. European Journal of Operational Research 191(3), pp. 928–944.2. B. Estellon, F. Gardi, K. Nouioua (2008). Recherche locale haute performance pour la planification
des interventions à France Télécom. In Actes des JFPC 2008. Nantes, France.3. M.W.P. Savelsbergh, J.-H. Song (2008). An optimization algorithm for the inventory routing with
continuous moves. Computers and Operations Research 35, pp. 2266–2282.

Elaboration d’un outil de chargement de camion pourl’approvisionnement en pièces des usines Renault
Jean-Philippe Brenaut
RENAULT / Pôle d’Expertise d’Optimisation des Flux13, Avenue Paul Langevin 92359 LE PLESSIS ROBINSON CEDEX
1 Description du problème
Afin d’avoir une meilleure maîtrise des approvisionnements en pièces de ses usines, et deréduire ses coûts logistiques, Renault a été amené à développer un outil de calcul de plans dechargement de camions.Pour chaque camion dont on doit calculer le plan de chargement, on connait la liste des piècesà transporter ainsi que les emballages dans lesquels les pièces doivent être conditionnées. Ausein d’un camion, il peut y avoir des pièces provenant d’expéditeurs di!érents et destinéesà des sites de déchargement di!érents. Les règles métier imposent que les piles d’emballagessoient mono-expéditeur et mono-destinataire, et que les piles soient placées dans le camionen respectant l’ordre de passage chez les di!érents expéditeurs, et pour un expéditeur donnédans l’ordre inverse de passage chez les di!érents destinataires. Le but est de placer toutesles piles en minimisant la distance entre l’avant du camion et l’extrémité de la pile la pluséloignée (on veut "tasser" vers l’avant au maximum). D’un point de vue théorique, il s’agitd’un problème de type bin-packing 3D, pour lequel diverses méthodes de résolutions ont faitl’objet de publications [1]. Dans la pratique, les nombreuses contraintes métier à prendre encompte et di"ciles à modéliser nous ont conduits à séparer le problème en deux phases :la construction des piles, puis le placement de ces piles dans le camion. Seule cette dernièrephase qui garde un caractère algorithmique complexe, de type bin-packing 2D ou placementde rectangles sur une surface [2], va être décrite.
2 Méthodes de résolution
La première méthode développée est une heuristique, consistant à placer les piles les unesaprès les autres, après les avoir classées par groupes expéditeur/destinataire. Pour chaquepile, les choix possibles sont : le côté de placement (à gauche, à droite ou "au milieu"), etl’orientation (en long ou en large). Dans cette heuristique simple, l’orientation est décidée apriori en choisissant la dimension (longueur, largeur) de plus petit modulo par rapport à lalargeur du camion. Le côté de placement est choisi de manière à équilibrer en permanenceles 3 choix possibles (droite, gauche, milieu). Concernant la zone milieu, on placera la pilecourante le plus au fond possible dans l’espace laissé vacant par les piles déjà placées, en lacalant (à gauche ou à droite) contre une de ces piles. La seconde méthode consiste à utilisercette heuristique simple en mode "look-ahead" : lors du placement d’une pile, on exploretoutes les combinaisons possibles d’orientation et de placement pour la pile courante et les N

52 Jean-Philippe Brenaut
suivantes. N est appelé profondeur du look-ahead. C’est une recherche arborescente partielleavec back-track. On choisit pour la pile courante le placement qui donne la meilleure solutionpour l’ensemble des N+1 piles. La qualité de chaque solution est mesurée selon le tassement etla "compacité" du résultat (c’est-à-dire la meilleure utilisation de la surface occupée, y comprisles petits morceaux de "surface perdue", comme dans un problème de découpe de tissu). Labonne mise en oeuvre de cet indicateur est déterminante pour la qualité finale de la solution.Il est toutefois à noter que cette méthode n’étant pas optimale, il n’y a pas de garantie que lerésultat d’un look-ahead de profondeur N soit meilleur que celui d’une profondeur inférieure,ni que celui de l’heuristique de base, même si cela s’avère souvent vrai. Une grande partiede la mise au point du look-ahead a été consacrée à l’élimination le plus tôt possible desbranches sous-optimales de l’arbre de recherche, et de manière générale à l’implémentationinformatique. Un facteur 10 en temps de calcul a ainsi pu être gagné entre la version initialede l’algorithme et sa version actuelle. De plus, ce travail sur l’implémentation a permis depasser d’une croissance exponentielle des temps de calcul en fonction du nombre de piles àune croissance quasi-linéaire. Pour donner un ordre de grandeur, un calcul de chargementde 5600 camions prend 26 secondes en mode heuristique et 600 secondes en mode look-ahead de profondeur 5. La figure 1 ci-dessous illustre les di!érences de choix de placement etd’orientation entre l’heuristique de base et le look-ahead.
Fig. 1.
3 Méthodes alternativesDes essais ont été réalisés, en employant une modélisation en PLNE, ainsi qu’une approche
basée sur l’utilisation d’un outil de Programmation Par Contraintes (PPC). La piste de laPLNE s’est avérée très décevante (au-delà de 6 ou 7 piles les temps de calcul sont prohibitifs).La piste de la PPC a donné des résultats nettement meilleurs qu’avec la PLNE, mais moinsbons que l’heuristique, pour des temps de traitement plus longs, et moyennant la mise enoeuvre de stratégies de branchement assez complexes.
Références1. Boschetti M. : New lower bounds for the three dimensional finite bin-packing problem.
Computers & Operations Research 2003.2. El Hayek J.,Moukrim A.,Nègre S. : New resolution algorithm and pretreatments for the two-
dimensional bin-packing problem. Computers & Operations Research 2008

Optimisation du réseau d’acheminement du courrier
A. JARDIN1,2, E. PINSON2, and B. LEMARIE1
1 La Poste - Direction Technique du Courier,10 rue de l’île mabon, BP 86 334, 44 263 Nantes CEDEX 2, France.
[email protected], [email protected] Institut de Mathématiques Appliquées - LISA,
44 rue Rabelais, BP 10 808, 49 008 Angers CEDEX 1, [email protected]
Mots-Clefs : Dimensionnement de réseau de transport, Multiflots à fortes contraintes couplantes,Planification de véhicules, Génération de coupes valides.
1 Introduction
Cette étude porte sur l’optimisation du réseau de transport postal national. Le problèmed’acheminement du courrier consiste d’une part à concevoir et dimensionner le réseau entre lessites logistiques, en proposant un plan de transport intermodal et d’autre part à router les fluxcourrier sur ce réseau. L’intégration des capacités de transport et de traitement des flux sur lessites où ils transbordent avec les délais d’acheminement tendus induisent une synchronisationcomplexe des moyens de transport. L’objectif est double : réduire les coûts inhérents autransport tout en améliorant la qualité de service en terme de délais de distribution.
2 Présentation du modèle
Le réseau national postal est composé de centres de traitements, appelés Plates-formesIndustrielles du Courrier et de hubs. A partir de ces PIC, des flux courriers sont acheminésvers des PIC destination où ils subissent un tri pour être distribués à leur destinataire. Pourmassifier les flux sur le réseau, des hubs ont été positionnés dans une étude stratégique préa-lable. Les flux transitent (ou non) par un ou plusieurs hubs. L’ensemble des sites composantce réseau est noté S et partitionné en PIC (PC) et hubs (PF) : S = PC 3 PF .Deux types de flux sont considérés : des flux Urgents qui doivent être livrés en J+1 et des fluxNon Urgents. Pour l’acheminement, l’horizon temporel $ retenu part de 13h00 le jour J et setermine à 17h le lendemain. Le pas de temps est le 1/4 heure : $ est discrétisé en périodes.Les flux sont banalisés sous la notion de produits. Un produit est caractérisé par un 6-uplet[s(p), t(p), qt(p), es(p), lc(p), u(p)], s(p) désignant sa PIC origine, t(p) sa PIC destination,qt(p) la quantité de courrier, es(p) la date de disponibilité au plus tùt sur sa PIC origine,lc(p) la date au plus tard de fin de traitement sur la PIC destination et u(p) son urgence.A noter, toutes les données temporelles sont retranscrites en périodes et toutes les quantitéstransitant sur le réseau sont exprimées en CE30, unité de conditionnement du courrier.La flotte de véhicules considérée VR est hétérogène et illimitée. Chaque moyen v ! VR estcaractérisé par les attributs [cp(v), cf(v), pf(v)], où cp(v) désigne la capacité du véhicule,cf(v) son coût fixe kilométrique et pf(v) son profil vitesse.Nous considérons en outre des traitements des flux sur les sites logistiques : un tri concernant

54 A. JARDIN, E. PINSON, B. LEMARIE
tous les flux arrivant sur leur PIC destination et un traitement de "cross dock" pour les pro-duits transitant par hub. Pour chaque période t de l’horizon, une capacité de traitement .tsest spécifiée pour chaque site s ! S .
3 Formalisation et technique de résolution
Pour chaque produit, nous définissons un unique routage primaire, correspondant à uneséquence ordonnée de sites allant de sa PIC origine à sa PIC destination via un transit éven-tuel par un ou plsuieurs hubs. On distingue deux types de routages primaires : les routages"1-hub" et "2-hubs" transitant respectivement par un ou deux hub(s) (limitations opération-nelles). Quant aux routages reliant directement deux PIC origine et destination, ils ne sontpas traités car ils ne posent aucune di"culté majeure de synchronisation des moyens de trans-port.Nous introduisons une formalisation originale reposant sur les notions de segments et d’opéra-tions de transport. Un segment transport / ! ST correspond à une séquence ordonnée de PICà visiter aboutissant à un hub (segment collecte type PC#PF) ou partant d’un hub (segmentdispersion de type PF # PC) ou une liaison inter-hubs (type PF # PF). Une Opération deTransport # ! 0 correspond au "calage" temporel d’un moyen de transport de type tp(#) surun segment transport référent /(#). Une Opération de Transport est, de plus, caractériséepar st(#) et ct(#) ses dates de départ du site origine et d’arrivée au site destination de /(#).Pour résoudre ce problème, nous développons une stratégie globale de résolution faisant in-teragir trois modules de décision. Le 1er palier permet de déterminer les routages primairesdes produits ; on en déduit une base de segments transport permettant de construire une based’Opérations de Transports admissibles au regard des contraintes temporelles. Cette based’OT 0 est soumise en input au 2ème niveau dans lequel une sélection d’OT est réalisée parun Programme Maître [PM ]. Cette sélection 0 est transmise à son tour à un 3ème module oùun Programme Satellite [PS] construit une base de routages admissibles (synchronisation desmoyens de transport) sur laquelle il tente une a!ectation des produits intégrant un contrôlede traitement des produits sur les sites du réseau. Ce dernier module interagit avec l’étagemaître supérieur au travers de coupes valides. De même, une révision des routages primairespermettrait d’exécuter la rétroaction avec le premier niveau du processus. Dans cette étudenous nous focalisons sur l’interaction des modules de planification et d’a!ectation des pro-duits (paliers 2 et 3).En considérant la base de segments transport issus du 1er module du processus de décision,il est possible de partitionner les PIC origine (resp. destination) en groupes (composantesconnexes) relativement à une relation d’équivalence spécifique. Chaque composante connexedéfinit un sous-réseau collecte (resp. dispersion). Les sous-réseaux inter-hubs s’obtiennent,quant à eux, en considérant toutes les paires de hubs interconnectés dans le réseau physique.Ces sous-réseaux spatiaux bien qu’interconnectés au travers des contraintes de traitement surles hubs, vont faire l’objet d’une résolution en deux niveaux, tels que décrits ci-dessus.Nous avons développé une méthode de résolution globale (sous-optimale) de générations decoupes. Cette méthode réalise, dans une 1ère phase, la décomposition spatiale et résout lessous-problèmes en collecte, puis en dispersion en suivant le processus de résolution en deuxniveaux. La base d’OT activées est injectée dans le réseau global intégrant aussi les liaisons

Optimisation du réseau d’acheminement du courrier 55
inter-hubs. Le processus de générations de coupes est à nouveau appliqué pour obtenir unplan de transport et l’acheminement de tous les flux sur le réseau étendu.
4 Expérimentations numériques
Après diverses tentatives de résolution avec di!érentes méthodes, cette approche est lapremière qui nous permet de résoudre le problème d’acheminement du courrier sur le réseaucible à dimension réelle. Le dimensionnement du problème est important car atteint près de70 sites logistiques (PIC et hubs confondus) sur lequel quelques 5 000 produits circulent. Cesrésultats expérimentaux s’avèrent très probants et nous encouragent à intégrer davantage despécificités opérationnelles liées à la production particulière des flux postaux.
Références
1. C. Barnhart, S. Shen, "Logistics Service Network Design for Time-Critical Delivery", PA-TAT’04 Proceedings of the 5! International Conference on the Practise and Theory of AutomatedTimetabling. (2004)
2. V. Gabrel, A. Knippel, M. Minoux, "A comparison of heuristics for the discrete cost multi-commodity network optimization problem", (2002)
3. T. Gr¸nert, H.J. Sebastian and M. Tharigen, "The design of a Letter-Mail TransportationNetwork by Intelligent Techniques", In R. Sprague, editor, Proceedings of the Hawaii InternationalConference on System Sciences 32. (1999)

Aide à l’élaboration de la carte militaire.La recherche adaptative pour une optimisation
multicritères.
Commandant S. Sécherre
Centre de Doctrine d’Emploi des Forces. Division Simulation et Recherche Opé[email protected]
1 Introduction
Afin d’élaborer la nouvelle carte militaire, l’état-major de l’armée de terre (EMAT) a cher-ché à optimiser le positionnement des formations1 de l’armée de Terre (AT) au sein de basesde défenses2(BDD). La définition des objectifs et la récolte des données par le bureau station-nement infrastructure de l’EMAT a permis la mise en œuvre d’un algorithme de recherchelocale [1] après son adaptation aux besoins du problème.
2 La nouvelle carte militaire
Le problème :Il s’agit de positionner au mieux 200 formations de l’armée de Terre dans 80 BDD (ordres degrandeur). Sept objectifs ont été retenus :1. positionner les organismes dans les meilleures BDD selon 31 critères,2. accroître la stabilité des militaires au sein des BDD,3. maximiser les possibilités de changer de spécialité au sein de chaque BDD,4. privilégier les BDD situées dans les zones à forte densité de population,5. minimiser les coûts (constructions, aménagements, acquisitions foncières, immobilières),6. limiter le nombre de déplacements des formations,7. limiter la dispersion géographique des formations de chaque brigade.
Si le premier objectif concentre les formations dans la BDD la mieux notée, le quatrième tendà les répartir dans toute la France. Les objectifs deux et trois déterminent les regroupementsde formations au sein de chaque BDD. Les autres objectifs peuvent être considérés commedes contraintes "molles".
Les contraintes :Le déplacement d’une formation dans une BDD peut être imposé. Une BDD peut être ferméeet ne comptera plus de formation à l’issue du calcul. Enfin certaines formations ont des besoins1 Ensemble des unités de l’armée de Terre : les régiments, les états-majors, les écoles, etc.2 Aire géographique de 30km environ autour d’un site pouvant accueillir plusieurs formations de la
Défense.

Aide à l’élaboration de la carte militaire 57
spécifiques. par exemple une unité "montagne" ne pourra être a!ectée que dans un nombrerestreint de BDD.
Les données :Le premier objectif tient compte de la somme pondérée de l’évaluation d’une trentaine decritères, ce qui fournit une note pour chaque BDD et pour chaque type de formation. Lesobjectifs deux et trois utilisent une base de données fournissant les e!ectifs de l’AT par for-mation et par domaine de spécialité. Les objectifs quatre et cinq ont besoins d’informationsstatistiques civiles ou militaires, ainsi que de données issues d’une seconde base de l’EMAT.Enfin le septième objectif ne tient compte que de l’organisation hiérarchique de l’AT et de ladistance entre les BDD.
3 RésolutionL’algorithme "recherche adaptative" [1] :
L’algorithme "recherche adaptative" est une recherche locale taboue mise au point par l’IN-RIA. Le voisinage permute les valeurs de deux variables. Le choix de ces variables est réaliséen deux étapes :1. Sélection de la variable primaire satisfaisant le moins les contraintes du problème.2. Sélection de la variable secondaire pour laquelle la permutation apporte le meilleur gain
pour la fonction objectif.La détermination de la variable primaire nécessite la définition d’une fonction d’erreur
pour chaque contrainte. Une combinaison linéaire des valeurs de ces fonctions donne le niveaud’insatisfaction de chaque variable. La fonction objectif peut alors être la somme des niveauxd’insatisfaction des variables, ce qui est le cas de l’étude présentée ici.
L’initialisation de l’algorithme a!ecte à chaque variable une valeur unique. Si la premièreinitialisation peut correspondre à l’état initial du système à optimiser, la diversification estassurée par un mécanisme de restart qui a!ecte aléatoirement les valeurs aux variables.
Adaptation de l’algorithme :Pour le problème étudié, chaque BDD peut recevoir plusieurs formations. Certaines variablesde décision peuvent donc avoir les mêmes valeurs. Inversement, certaines valeurs ne sont nepas attribuées aux variables si les BDD correspondantes sont désertées. Il a donc fallu adapterl’algorithme pour traiter ce problème particulier. On ne cherche plus seulement la meilleurepermutation mais également le meilleur changement de valeur possible pour la variable pri-maire.Du fait de l’optimisation multicritères, une dernière adaptation consiste à ne plus faire cor-respondre les fonctions d’erreur aux contraintes du problème mais aux objectifs à atteindre.
L’optimisation multicritères :La fonction objectif du problème est une combinaison linéaire des sept fonctions d’erreur. Lescoe"cients fixent l’importance relative des critères. Les fonctions d’erreur ont été normaliséespour que leurs images soient identiques, afin que leurs influences soient similaires. Toutefoisl’étude montre que si elles sont monotones elles ne sont pas linéaires. De fait, une fonctiond’erreur normalisée n’a pas la même influence qu’une autre à coe"cient égal. Un jeu decoe"cients o!rant un bon équilibre des critères a donc été déterminé par un plan d’expériencepuis fourni au bénéficiaire de l’étude.

58 CDT S. Sécherre
4 Résultats
L’outil développé fournit quatre solutions en moins de vingt secondes avec un processeurIntel T7250 à 2 GHz, toutes les variables étant taboues à la fin de chaque restart. Aucuneétude comparative avec un autre algorithme n’a été faite en raison des délais de l’étude.Les gains les plus significatifs sont obtenus en initialisant la variable de décision avec la cartemilitaire actuelle, dont la cohérence est ainsi soulignée. Cette propriété semble indiquer qu’elletient déjà compte des objectifs établis.
5 Conclusion
Cette étude a conduit à la réalisation d’un outil permettant le lancement de l’optimisa-tion, la visualisation et l’analyse des résultats. Il facilite la simulation et l’étude de plans destationnement, ce qui en fait un outil d’aide à la décision intéressant.Par ailleurs l’approche méthodologique "recherche opérationnelle" a aidé le bénéficiaire dansson analyse de la problématique générale.
Références
1. P. Codognet and D. Diaz : Yet another local search method for constraint solving. In AAAI FallSymposium on Using Uncertainty within Computation, Cape Cod. (2001)

Optimisation de l’utilité espérée dépendant du rang dansles diagrammes d’influence
G. Jeantet and O. Spanjaard
LIP6, 104, avenue du président Kennedy, 75016 Paris France.{gildas.jeantet, olivier.spanjaard}@lip6.fr
On appelle décision dans l’incertain les situations de choix où les conséquences des actionsd’un agent ne sont pas connues avec certitude. Lorsque cette incertitude est probabilisée, au-trement dit lorsque le résultat obtenu ne dépend que de la réalisation d’événements dont onconnaît les probabilités, on parle alors de décision dans le risque [2]. De nombreux modèlesde décision dans le risque existent dans la littérature. Le plus connu et le plus utilisé est lemodèle de l’espérance d’utilité (EU), pour sa simplicité et son attrait sur le plan normatif[8]. Néanmoins, la mise en cause de la capacité du modèle EU à modéliser certains com-portements rationnels (paradoxe d’Allais, paradoxe d’Ellsberg...) a conduit à l’émergence demodèles non-linéaires plus sophistiqués. A ce titre, nous nous intéressons ici plus particulière-ment au modèle de l’utilité espérée dépendant du rang (RDU) qui étend le pouvoir descriptifdu modèle EU grâce à une modélisation plus fine de l’attitude du décideur vis-à-vis du risque[5]. Néanmoins la di"culté de mise en œuvre opérationnelle du modèle RDU ea freiné sonutilisation jusqu’à aujourd’hui.
En e!et, dans la pratique, il est fréquent de rencontrer des problèmes de décision séquen-tielle dans le risque, c’est-à-dire des problèmes où l’on ne suit pas une unique décision, maisune stratégie (i.e. une séquence de décisions conditionnellement à des événements incertains)conduisant à une conséquence finale incertaine. De tels problèmes peuvent se représenter àl’aide de plusieurs outils formels, parmi lesquels on peut mentionner en particulier les arbresde décision-hasard [6], les diagrammes d’influence [7] et les processus décisionnels markoviens[1]. Dans un tel contexte, il est important de noter que l’ensemble des stratégies potentiellesest combinatoire. La recherche d’une stratégie optimale pour une représentation et un critèrede décision donnés est alors un problème algorithmique en soi. La non-linéarité du critèreRDU induit de nouvelles di"cultés algorithmiques, qui ne se posaient pas avec le critère EU.Ceci fait précisément l’objet de notre travail.
Nous nous intéressons ici à l’optimisation de RDU dans le cadre des diagrammes d’in-fluence. Les diagrammes d’influence sont des modèles graphiques qui permettent une repré-sentation particulièrement compacte des problèmes de décision séquentielle dans l’incertain,en exploitant les dépendances probabilistes du problème pour factoriser certaines données.La détermination d’une stratégie EU-optimale dans un diagramme d’influence est déjà unproblème NP-di"cile. Néanmoins des algorithmes performants utilisant des techniques im-portées des réseaux bayésiens existent pour le résoudre [4]. Ces algorithmes ne s’étendent paspour l’optimisation du critère RDU. De plus, une di"culté supplémentaire survient lorsqu’onutilise ce dernier critère : contrairement à une stratégie EU-optimale, une stratégie RDU-optimale n’est pas nécessairement conséquentialiste. Nous appelons ici conséquentialiste unestratégie où chaque décision prise ne dépend que du futur et non du passé. Autrement dit,

60 G. Jeantet, O. Spanjaard
face à deux situations identiques, et quels que soient les événements antérieurs, une stratégieconséquentialiste conduira à prendre les mÍmes décisions. Dans les diagrammes d’influence,cette propriété est cruciale car la description de telles stratégies reste alors linéaire dans lataille du diagramme, ce qui n’est plus le cas pour les stratégies non-conséquentialistes. Ladescription d’une stratégie RDU-optimale peut ainsi nécessiter un espace mémoire exponen-tiel dans la taille de l’instance, ce qui rend la t‚che d’optimisation singulièrement ardue. Celanous a conduit à envisager deux approches pour l’utilisation de RDU dans les diagrammesd’influence :
– Recherche d’une stratégie RDU-optimale parmi l’ensemble des stratégies potentielles.Nous procédons pour cela en deux phases : 1) générer un arbre de décision-hasard équi-valent au diagramme d’influence, puis 2) e!ectuer les calculs directement dans l’arbrede décision-hasard ainsi construit, à l’aide d’un algorithme dédié à l’optimisation deRDU dans les arbres de décision-hasard [3].
– Recherche d’une stratégie RDU-optimale parmi l’ensemble des stratégies conséquentia-listes. Pour ce faire, nous proposons un algorithme par séparation et évaluation dont lescalculs s’e!ectuent dans un arbre de jonction déduit du diagramme d’influence.
Ces deux méthodes ont été implantées et testées numériquement. Nous présenterons lesrésultats numériques obtenus, en mettant en avant la qualité des stratégies retournées par laseconde méthode au regard de leur valeur RDU comparativement à la valeur RDU-optimale(valeur de la stratégie retournée par la première méthode).
Références
1. Dean, T. and al. : Planning with deadlines in stochastic domains. In Proc. of the 11th AAAI,574-579 (1993)
2. Gayant, J-P. : Risque et décision. Vuilbert (2001)3. Jeantet, G. and Spanjaard, O. : Rank-Dependent Probability Weighting in Sequential Decision
Problems under Uncertainty. ICAPS 2008 :148-1554. Jensen, F. V. and al. : From Influence Diagrams to junction Trees. UAI 1994 :367-373 (1994)5. Quiggin, J. : Generalized Expected Utility Theory : The Rank-Dependent Model. Kluwer (1993)6. Rai#a, H. : Decision Analysis : Introductory Lectures on Choices under Uncertainty. Addison-
Wesley (1968)7. Shachter, R. : Evaluating influence diagrams. Operations Research 34 :871-882 (1986)8. von Neuman, J. and Morgenstern, O. : Theory of games and economic behaviour. Princeton
University Press (1947)

Une méthode de génération de colonnes basée sur unalgorithme central de plans coupants
M. Trampont,1, C. Destré,1, and A. Faye,2
1 Orange Labs, 38-40 rue du Général Leclerc, 92740 ISSY-LES-MOULINEAUX, [email protected]@orange-ftgroup.com
2 ENSIIE, 18 allée Jean Rostand, 91000 EVRY, [email protected]
Résumé Nous présentons ici une variante de génération de colonnes basée sur unalgorithme de plan coupant central développé par Betro dans [5] pour la programmationlinéaire semi-infinie. Nous verrons le fonctionnement général de cet algorithme et sonutilisation dans une méthode de génération de colonnes. Des techniques usuelles destabilisation, comme le boxstep ou la méthode de stabilisation par point intérieur deRousseau et al. [6], peuvent être adaptées pour fonctionner avec cette méthode. Pourjuger de l’e%cacité de cette méthode, ses résultats sur un problème de conception deréseau seront comparés à ceux d’une génération de colonnes classique avec boxstep etstabilisation par point intérieur.
Mots-Clefs. Génération de colonnes ; Algorithme de plans coupants.
1 Un algorithme central de plans coupants stabilisé
Les problèmes de stabilité que l’on voit apparaître dans la génération de colonnes ou dansles algorithmes de plans coupants, peuvent venir d’une dégénérescence (i.e. d’une infinitéde solutions duales optimales), mais aussi du fait que les informations contenues dans lesvariables ou coupes rajoutées ne sont bonnes qu’à proximité du points du dual pour lesquelselles ont été obtenues. Ce point est appelé point de séparation. Se pose alors la question desavoir si la solution duale optimale du problème maître est bien le meilleur point de séparationpossible.
Plusieurs alternatives ont été proposées pour le choix du point de séparation. Les algo-rithmes centraux de plans coupants proposent de prendre un point central de l’ensemble dessolutions admissibles du dual, plutôt que d’en obtenir un point extrême en résolvant le pro-blème maître. Ce centre peut être analytique, ou géométrique comme dans l’algorithme deBetro [5]. Le principe de cet algorithme est de choisir comme point de séparation le centre dela plus grande sphère contenue dans le polyèdre formé par les contraintes du dual. A ce poly-èdre on ajoute une information sur une borne inférieure. La résolution du problème maître estremplacée par le problème (DRQ), qui cherche à maximiser le rayon ( de la sphère, où 1 estune combinaison convexe d’une borne inférieure LB et d’une borne supérieure UB. Chaquecontrainte (??) s’assure que tout point de la sphère respecte la contrainte correspondante dudual du problème maître. La contrainte (??) est celle contenant l’information sur la borne

62 Trampont, Destré, Faye
inférieure. Elle s’assure que tout point de la sphère est compris entre le plan de la fonctionobjectif du dual du problème maître et le plan de la borne 1 .
(DRQ)
!"""""""""""""#
"""""""""""""$
max",u
(
s.c.n%
j=1bij .uj + (.
,--.n%
j=1bij " ci ,i = 1 . . . |I| (1)
n%
j=1uj # (.(1 +
0n+ 1) ( 1 (2)
uj ( 01 agit comme une borne inférieure test. Pendant le déroulement de la génération de co-
lonnes, deux choses peuvent se produire : le sous-problème (SP) ne retourne pas de colonneset 1 se révèle être une borne inférieure, ou (DRQ) devient infaisable et 1 se révèle être uneborne supérieure. Les valeurs des bornes et de 1 sont alors mises à jour en conséquence, etl’encadrement de la valeur optimale est réduit. L’algorithme s’arrête lorsque la di!érence re-lative entre borne supérieure et borne inférieure vaut moins qu’un 2 choisi. Périodiquement,lorsque (SP) ne retourne rien, nous résolvons le problème maître. Cela peut permettre demettre à jour UB et d’accélérer la terminaison de l’algorithme.
Tout comme le problème maître, (DRQ) peut présenter une infinité de solutions optimales.Nous avons donc implémenté les mêmes techniques de stabilisation que pour la génération decolonnes classique. L’adaptation de la stabilisation par point intérieur [6] se fait naturellement.Au lieu de chercher un point à l’intérieur du polyèdre des solutions optimales du dual duproblème maître, nous le cherchons à l’intérieur de celui de (DRQ) en suivant les principes de[6]. En revanche, l’adaptation du boxstep complique un peu l’algorithme. Le boxstep consisteà imposer des bornes aux variables duales de faÁon à rester dans les environs d’un point dudual appelé centre de stabilité. Il faut bien prendre garde en cas d’infaisabilité de (DRQ),à déterminer si cela est d˚ aux contraintes du boxstep ou à la valeur de 1 . Pour cela, encas d’infaisabilité, nous rel‚chons le boxstep. Si (DRQ) devient faisable, nous remettons leboxstep et augmentons la taille de la boîte jusqu’à ce que le problème devienne faisable.
Une fois ces techniques implémentées, nous avons comparé cette nouvelle génération decolonnes avec une génération de colonnes classique sur un problème de conception de réseau.Les tests sont e!ectués sur deux séries de dix instances générées aléatoirement. Le temps decalcul pour la nouvelle méthode est trois fois inférieur en moyenne sur la première série etpresque six fois sur la deuxième. On peut également observer que les temps de calcul varientbeaucoup moins au sein d’une même série qu’avec la génération de colonnes classique. Cettenouvelle génération de colonnes se montre donc plus stable.
Références1. B. Betro, An accelerated central cutting plane algorithm for linear semi-infinite programming,
Mathematical Programming, Vol.101, 479-495, 2004.2. L-M. Rousseau, M. Gendreau, D. Feillet, Interior point stabilization for column generation,
Operations Research Letters, Vol. 35, 660-668, 2007

Programmation dynamique par blocs
N. Touati1, L. Létocart1 and A. Nagih2
1 LIPN, UMR 7030 CNRS, Université Paris 13, 99 avenue Jean-Baptiste Clément 93430,Villetaneuse, France.
{nora.touati,lucas.letocart}@lipn.fr2 LITA, Université Paul Verlaine, Ile du Saulcy 57045 Metz Cedex 1, France.
Mots-clés : Programmation dynamique, problème de plus court chemin avec fenêtres detemps.
1 Introduction
La Programmation Dynamique est particulièrement adaptée aux problèmes satisfaisant leprincipe d’optimalité de Bellman [1] : Toute politique optimale est composée de sous-politiquesoptimales. Elle a été appliquée e"cacement pour résoudre plusieurs problèmes d’optimisationcombinatoire, et permet d’élaborer des algorithmes pseudo-polynomiaux pour la résolutionde problèmes NP-di"ciles [2], on cite par exemple le problème de plus court chemin aveccontraintes de ressources. Nous l’appliquons dans ce travail pour la résolution du Problèmede Plus Court Chemin avec Fenêtres de Temps et Contraintes de Capacité (PPCCFTCC),et proposeons une amélioration basée sur une réduction de l’espace de recherche de nouvellesétiquettes e"caces.
2 Problème de plus court chemin avec fenêtres de temps etcontraintes de capacité
Le PPCCFTCC est défini par un graphe orienté G = (N,A), où N = {0, ..., n = |N |} estl’ensemble des sommets (représentant des clients, des sites, ...), avec 0 et n les sommets sourceet destination respectivement. Chaque sommet est caractérisé par une demande et doit êtrevisité au cours d’une fenêtre de temps donnée. A est l’ensemble des arcs qui interconnectentles sommets, chaque arc est caractérisé par un coût et une durée de parcours.
Le problème PPCCFTCC consiste à trouver un chemin de la source à la destination demoindre coût, tel que, la demande cumulée sur ce chemin n’excède pas une capacité maximaletolérée, et chaque sommet est visité au cours de la fenêtre de temps associée. Le PPCCFTCCfigure généralement comme sous-problème du problème de tournées de véhicules avec fenêtresde temps et contraintes de capacité résolu avec la génération de colonnes.
3 Programmation dynamique
Pour chaque chemin réalisable du PPCCFTCC, on associe une étiquette, définie par untriplet (coût, temps, demande) correspondant respectivement au coût, à la durée et à lademande cumulées sur ce chemin. Le calcul de toutes les étiquettes correspond à l’énumération

64 Touati, Létocart et Nagih
de tous les chemins réalisables, i.e. respectant les fenêtres de temps et les contraintes decapacité. Les algorithmes basés sur la programmation dynamique consistent à énumérer unsous-ensemble de ces étiquettes dites e"caces en utilisant des procédures de dominance. Uneétiquette E est dite e"cace s’il n’existe aucune étiquette meilleure que E par rapport auxcritères : coût, temps et demande. Les procédures de dominance permettent d’élaguer lesétiquettes dont les prolongements n’aboutissent pas à une solution optimale. Elles peuventêtre coûteuses en temps de calcul, leur complexité dépend fortement du nombre d’étiquettestraitées.
Nous étudions les performances de l’algorithme de programmation dynamique avec cor-rection d’étiquettes pour la résolution du PPCCFTCC dans le cas de graphes acycliques etproposerons une méthode visant à diminuer le nombre total d’étiquettes traitées pendant larésolution.
4 Programmation dynamique par blocs
Dans ce travail [4], nous nous sommes fixés comme objectif la réduction de l’espace derecherche de nouvelles étiquettes e"caces. Le principe de base est de construire des blocsqui représentent des espaces susceptibles de contenir des étiquettes e"caces. Initialement cesespaces sont les domaines réalisables relativement aux fenêtres de temps et aux contraintesde capacité. Lorsqu’une nouvelle étiquette e"cace E est trouvée, on peut définir un espace(bloc) qui ne pourra contenir dans la suite de la résolution que des étiquettes qui domineraientE. Notre objectif est de caractériser ces blocs pour chaque nouvelle étiquette calculée afin deréduire l’espace de recherche de nouvelles étiquettes e"caces.
Notre objectif consiste également à appliquer la dominance uniquement sur les étiquettesdominées afin de ne pas faire de tests inutiles. Cela est possible en établissant un ordre surles durées des étiquettes e"caces de chaque sommet.
Les résultats expérimentaux sur des instances du PPCCFTCC, ont montré l’e"cacité decette méthode. Le nombre d’étiquettes traitées a considérablement diminué. La programma-tion dynamique par blocs a été utilisée pour la résolution des sous-problèmes dans un schémade génération de colonnes pour la résolution du problème de tournées de véhicules avec fe-nêtres de temps. Cette approche a permis de diminuer nettement les temps de résolution dessous-problèmes.
Références
1. Bellman, B. : Dynamic programming. Princeton university press, NJ, USA (1957)2. Laurière, J. L. : Éléments de programmation dynamique. Collection programmation, Gauthiers-
Villars (1979)3. Desrosiers, J. et Soumis, F. : A generalized permanent labelling algorithm for the schortest path
problem with time window. Centre de recherche sur les transports, Montreal 17 (1985)4. Touati, N. : Amélioration des performances du schéma de la génération de colonnes : Applica-
tion aux problèmes de tournées de véhicules. Thèse, Laboratoire d’Informatique de Paris Nord,Université paris 13 (2008)

Un schéma de décomposition Dantzig-Wolfe pour lesproblèmes de tournées de véhicules sur arcs
H.M. Afsar
LAAS-CNRS; Université de Toulouse ; 7 avenue du Colonel Roche - 31077 Toulouse Cedex 4 FranceNovacom Services ; 8, rue Hermès, Parc Technologique du Canal 31520 Ramonville St Agne France
1 Introduction
Le problème de tournées de véhicules consiste à déterminer l’a!ectation des clients auxvéhicules d’une flotte et l’ordre de service de ces clients. Si les clients sont localisés sur despoints précis du réseau, nous sommes face à un problème de tournées sur les sommets. D’autrepart, si les clients sont sur les liens de ce réseau, il s’agit du problème de tournées sur arcs(“Capacitated Arc Routing Problem” ou CARP).
Dans ce travail, nous nous intéressons aux problèmes du second type : le problème detournées de véhicules sur arcs. Les applications réelles modélisées par ce type de problèmesont, par exemple, la collecte des déchets, le déneigement des routes, la distribution de courrieret l’inspection de lignes à haute tension [1].
Le CARP peut être défini de la façon suivante : Soit G(V,E) un graphe non orienté etEr 1 E l’ensemble des arêtes requises (correspondant à des demandes clients) et v0 ! V ledépôt. Chaque arête a un coût de passage ce > 0 et chaque arête requise a une demandeqe. Un certain nombre de véhicules de capacité Q sont disponibles. Le but est de trouverun ensemble de tournées, de coût total minimal, qui satisfont toute la demande en servantchaque arête une fois et qui commence et se termine au dépôt.
La première formulation du problème de tournées sur les arcs est donnée par Golden etWong [2]. Plus tard, trois autres formulations sont apparues. Ces formulations, proposées parWelz [3] et par Belenguer et Benavent [4], [5] considèrent, les graphes peu et très peu denses.Plusieurs bornes inférieures du problème de tournées sur les arcs utilisent la relaxation dela contrainte de capacité pour tomber sur le problème du postier chinois non orienté. Ellesra"nent la qualité en considérant que d’autres arêtes non requises doivent être ajoutées pourformer les tournées de véhicules [6].
2 Décomposition de Dantzig-Wolfe
Nous transformons le graphe non orienté G = (V,E) en un graphe orienté G"(V,A) telque pour chaque arête e = (i, j), nous ajoutons deux arcs a = (i, j) et ainv = (j, i). Nouspouvons donc dire que, si un arc a est servi par un véhicule, son inverse (ainv) ne doit pasêtre servi. La fonction objectif (1) minimise la distance totale parcourue. Le service d’une rueà double sens est assurée par la contrainte (3). Les variables duales ('0,'ar) sont associées

66 H.M. Afsar
avec les contraintes (2) et (3), respectivement. Afin d’éviter d’écrire la même contrainte deuxfois, nous définissons :
Ainvr = {ar = (i, j)|ainvr = (j, i) ! Ar et i < j}z$ = min
%
p%Pcp3p (1)
'0 #:%
p%P3p = K (2)
'ar #:%
p%P)arp 3p +
%
p%P)ainvrp 3p = 1 ,ar ! Ainvr (3)
3p ( 0 ,p ! P - l’ensemble des tournées réalisables (4)
3 Sous-ProblèmeTrouver une tournée p de plus petit coût réduit c tel que chaque arête requise est servie
au plus une fois et la demande totale servie ne dépasse pas la capacité du véhicule
cp = cp #%
ar%Ainvr
)arp 'invar # '0
Le sous-problème est résolu par une approche heuristique et par un modèle de program-mation dynamique basée sur la méthode proposée par Gueguen et al. [7] en considérant lesplus courts chemins entre les arcs requis.
f(Aa!r , Qa!r , a"r) = min f(Aa!r # a
"r, Qa!r # qa!r , a) + car,a!r + ca!r # 'a!r
où Aa!r est l’ensemble des arcs requis utilisés jusqu’à l’arc a"r, Qa!r est la demande totale serviepar le chemin, car ,a!r est le coût du plus court chemin entre l’arc ar et a"r.
Les résultats numériques ainsi que les détails des méthodes de résolution seront présentéslors de la Conférence Roadef 2009.
Références1. Ramdane-Chérif, W., 2002, Problèmes d’optimisation en tournées sur les arcs, UTT, Thèse de
doctorat, Troyes2. Golden B.L., Wong R.T.,1981 Capacitated arc routing problems. Networks, 11, 305-3153. Welz S.A., 1994, Optimal solution for the capacitated arc routing problem using integer program-
ming. PhD Dissertation, Dept of QT and OM, University of Cincinnati4. Belenguer J.M., Benavent E., 1998, The capacitated arc routing problem : valid inequalities and
facets. Computational Optimization and Applications, 10, 165-1875. Belenguer J.M., Benavent E.,2003, A cutting plane algorithm for the capacitated arc routing
problem. Computers and Operations Research, 30(5), 705-7286. Labadi N., 2003, Problèmes tactiques et stratégiques en tournées sur arc, UTT, Thèse de doctorat,
Troyes7. Gueguen C., Dejax P., Dror M., Feillet D., Gendreau M., 2000 An Exact Algorithm for the Ele-
mentary Shortest Path Problem with Resource Constraints : Application to some Vehicle RoutingProblems, Research Report 2000-15, CRT

Résolution du problème d’arbre couvrant quadratique depoids minimum via RBS
T. Garaix1 and F. Della Croce2
Politecnico di Torino, 24, corso Duca Degli Abruzzi, 10121 Torino, [email protected]
1 IntroductionLe problème d’arbre couvrant de poids minimum est un problème classique d’optimisation
combinatoire. Il est défini par Boruvka en 1926 [5], afin de trouver le schéma le plus écono-mique pour un réseau électrique. Étant donné un graphe connexe, il s’agit de trouver un arbrecouvrant tous les sommets et minimisant la somme des poids (coûts) des arêtes le composant.De nombreuses variantes de ce problème existent, ajoutant des contraintes sur les degrés dessommets dans l’arbre ou attribuant des poids stochastiques aux arêtes. Dans sa version qua-dratique, récemment définie par Xu en 1984 [6], des coûts – quadratiques – sont associés àchaque paire d’arêtes. Ce coût quadratique représente les interactions possibles entre arêtessélectionnées. Ce type de problème se rencontre dans le transport d’hydrocarbures ou dans lesréseaux de communication. Les coûts quadratiques sont alors issus de l’utilisation de sectionsde tuyaux ou de technologies di!érentes.
Nous résolvons le problème d’arbre couvrant quadratique de coût minimum (QMSTP) viaune metaheuristique appelée Recovery Beam Search (RBS) dont le nom est traduisible par :recherche arborescente par faisceau avec réparations.
2 Revue de la littératureÀ notre connaissance, peu de chercheurs se sont intéressés à cette variante du MSTP.
La première définition en est donnée par Xu [6,7]. Il propose des heuristiques gloutonnes etune méthode exacte. La résolution exacte du problème est peu approfondie ; en grande partieà cause de la di"culté du calcul d’une borne inférieure de bonne qualité [1]. Ainsi, Zhouet Gen [8] proposent un algorithme génétique en 1998 et obtiennent de meilleurs résultatsqu’avec les approches gloutonnes. Notons aussi les travaux de Gao et al. [4] qui portent surdes adaptations du QMSTP basées sur de la logique floue.
Enfin, plus récemment, Cordone et Passeri [2] comparent trois algorithmes gloutons etune recherche tabou sur des instances générées aléatoirement. Ces instances comptent de 10à 30 sommets avec des densités prenant les valeurs 1/3, 2/3 ou 1. Par l’utilisation d’uneborne inférieure dans une recherche arborescente, ils donnent les solutions optimales pour lesinstances à 10 et 15 sommets.
3 Recovery Beam Search pour le QMSTPDéjà utilisé avec succès pour d’autres problèmes d’optimisation combinatoire [3], le RBS
se présente comme une recherche arborescente classique faite en largeur et où à chaque niveau

68 Garaix, Della Croce
de l’arbre de recherche, on ne conserve qu’un nombre limité de nœuds à explorer. Le nombrede nœuds sélectionnés, après évaluation, correspond au faisceau (ou beam). Avant d’être ex-ploré, chaque nœud sélectionné subit une phase de réparation. Cette phase consiste en laconstruction d’un nœud de même niveau, en autorisant la remise en cause de décisions prisesà des niveaux supérieurs de l’arbre. Si la réparation améliore le nœud courant, ce dernierest remplacé par le nœud réparé. La taille du faisceau étant constant, la complexité du RBSdépend donc de la hauteur de l’arbre de recherche qui est généralement racine d’un polynomed’ordre un de la taille des données.
Dans le cas du QMSTP, les décisions de branchement prises à chaque nœud consistent enla sélection ou non d’arêtes dans la solution courante. On dit que ces arêtes sont fixées à 1 ouà 0. Nous proposons deux nouvelles bornes inférieures pour le QMSTP. Ces bornes inférieuressont données par des arbres couvrants qui correspondent à des solutions réalisables. Nousappliquons une procédure de recherche locale à cet arbre, afin d’obtenir une borne supérieure.À chaque itération, nous e!ectuons le meilleur remplacement d’une arête non fixée à 1 del’arbre courant, par une arête extérieure à l’arbre non fixée à 0. La procédure s’arrête dèsqu’un optimum local est atteint.
La phase de réparation est similaire à celle décrite ci-dessus, en inversant le rôle des arêtesde l’arbre couvrant fixées à 1 avec les autres, et en autorisant des arêtes fixées à 0 à “rentrer”dans l’arbre. Le niveau de l’arbre est conservé en fixant à 1 les nouvelles arêtes de l’arbreréparé et en fixant à 0 celles qui n’y sont plus.
Plusieurs fonctions d’évaluation et stratégies de branchement sont testées.Pour un paramétrage donné, nous obtenons des résultats comparables (meilleurs en moyenne)
à ceux obtenus par les algorithmes proposés par Cordone et Passeri, avec des temps de calculsproches (moins d’une minute).
Cependant, nous envisageons d’étudier des instances de plus grande taille afin de mieuxcomparer les di!érentes approches.
Références1. Assad, A. A. and Xu, W. : On lower bounds for a class of quadratic 0-1 problems. Operation
Research Letters, (1985), 4 : 175-180.2. Cordone, R. and Passeri, G. : Heuristic and exact approaches to the Quadratic Minimum Spanning
Tree Problem. Rapport technique, Università degli Studi di Milano, Italie (2008).3. Della Croce, F., Ghirardi, M. and Tadei, R. : Recovering Beam Search : Enhancing the beam
search approach for combinatorial optimisation problems. Journal of Heuristics (2004), 10 : 89-04.4. Gao, J., and Lu, M. : Fuzzy quadratic minimum spanning tree problem. Applied Mathematics
and Computation (2005), 164 : 773-788.5. Graham, R. L. and Hell, P. : On the history of the minimum spanning tree problem. Annals of
the History of Computing, (1985), 7 : 43-57.6. Xu, W. : Quadratic minimum spanning tree problems and related topics. Thèse, University of
Maryland, (1984).7. Xu, W. : On the quadratic minimum spanning tree problem. Thèse, Acte de 1995 Japan-China
International Workshops on Information Systems, eds. M. Gen and W. Xu. Ashikaga, (1995),141-148.
8. Zhou, G. and Gen, M. : An e#ective genetic algorithm approach to the quadratic minimumspanning tree problem. Computers & Operations Research (1998), 25(3) : 229-237.

Recherche Locale Guidée pour la Coloration de Graphes
Daniel Cosmin Porumbel,1,2 Jin Kao Hao,1 et Pascale Kuntz2
1 Leria, Université d’Angers, 2, Boulevard Lavoisier, 49045 Angers Cedex 01 – [email protected],[email protected]
2 Lina, Polytech’Nantes, rue Christian Pauc, BP 50609, 44306 Nantes Cedex 3 – [email protected]
1 Introduction
L’évolution de tout processus de recherche locale est étroitement liée à la structure de l’es-pace de recherche. Une heuristique e"cace tient compte—implicitement ou explicitement—del’arrangement des optima locaux dans cet espace. Une des plus grandes di"cultés pour lesrecherches locales est de sortir des bassins d’attraction des optima locaux. Cette situation estd’autant plus contraignante lorsque la taille des ces bassins est grande.
Dans cette communication, nous considérons le cas où le processus de recherche, mêmes’il est capable de sortir d’un bassin d’attraction, cycle sur un sous-ensemble restreint debassins d’attraction. La situation concrète considérée ici est le problème classique de colorationde graphe et notre recherche locale est Tabucol[2], un algorithme Tabou classique pour ceproblème. Notons les bassins d’attraction Bi, avec i ! 1, 2, 3, . . . .Lors d’expérimentationsnumériques nous avons observé qu’il y a un nombre restreint de bassins d’attractions trèscontraignants (notés B1, B2, . . . Bn, avec n < 100 généralement) qui attirent très fréquemmentle processus de recherche. En fonction de la position initiale, l’algorithme atteint un bassinBi, puis, dès qu’il en sort, atteint un autre bassin Bj similaire ; d’où un exemple d’évolutionclassique : B1 : B2 : B3 : B2 : B4 : B1 : B4 : B2 : B1 : B3, etc.
La recherche Tabou (TS) classique ne propose aucun mécanisme pour résoudre cette situa-tion problématique, car elle utilise seulement une mémoire à court terme. Nous introduisonsune distance dans l’espace de recherche pour pouvoir identifier et stocker les plus importantsbassins d’attractions (Section 2)—nous avons expérimentalement montré que les meilleurescolorations d’un bassin d’attraction forment des clusters de points dans l’espace. Puis (Section3), nous introduisons deux algorithmes : (i) TS-Div—un algorithme de diversification pourassurer que chaque Bi n’est visité qu’une seule fois et, (ii) TS-Int—un algorithme d’intensifi-cation qui n’explore que le voisinage des meilleures colorations fournies par TS-Div.
2 Arrangements des meilleures colorations
Pour étudier l’arrangement des colorations, on définit une distance dans l’espace de re-cherche. On considère deux colorations CA et CB comme deux partitions de l’ensemble V dessommets et on utilise une distance classique entre partitions. Plus exactement, la distancede transfert entre CA et CB est le nombre minimum de transferts d’un élément d’une classedans une autre nécessaires pour transformer CA en CB [1].

70 Daniel Porumbel, Jin Kao Hao, Pascale Kuntz
3D MDS ( 350 configurations)
0 X Axis 200
0Z
Axi
s20
0
0
Y Axis
200
Nu
mb
er o
f D
istan
ces
L’arrangement des minima locaux est illustré dans l’illustration ci-contre pour un grapheavec |V | = 250. On a utilisé une procédure de type "Muldimensional Scaling" ; les distancesentre les points 3D tentent de préserver au mieux la distance entre les colorations de l’espace|V |-dimensionnel. On observe que les minima locaux se regroupent en quelques clusters quicorrespondent à des bassins d’attractions dans l’espace. Après avoir fait plusieurs tests, nousavons observé que le rayon approximatif des clusters est 0.1* |V | pour n’importe quel graphe.On définit la sphère SC de la coloration C comme l’ensemble des colorations situées à unedistance inférieure à 0.1 * |V | de C. Comme l’algorithme Tabou passe d’une coloration àl’autre en changeant la couleur d’un sommet, il doit changer la couleur de 0.1* |V | sommetspour sortir d’une sphère SC (s’il part de C, qui est son centre).
3 Algorithme de Diversification et d’IntensificationL’idée principale de l’algorithme TS-Div est d’empêcher le processus de recherche de reve-
nir dans la sphère d’une coloration déjà visitée. TS-Div est basé sur un processus de rechercheTabou auquel est ajouté un processus d’apprentissage avec deux objectifs : (i) il enregistretoutes les sphères S(C1), S(C2), S(C3), . . . visitées (telles que Ci 9! S(Cj), ,i 9= j) et (ii) si lacoloration à l’itération courante fait partie d’une sphère S(Ci) déjà visitée, il déclenche unephase de diversification. Le mécanisme pour cela est la longueur de la liste Tabou : chaquefois que le processus retourne dans une sphère déjà visitée, la longueur de la liste tabou estincrémentée d’une unité, et ce, jusqu’au moment où la recherche découvre une nouvelle sphère.
Cet algorithme assure la diversification car une liste tabou très longue contraint le pro-cessus TS à e!ectuer une exploration plus large. Mais il a aussi un inconvénient : il explorechaque sphère qu’une seule fois et cela peut être insu"sant. Pour cela, on a ajouté un nouvelalgorithme d’intensification qui explore en profondeur l’intérieur des sphères.
4 ConclusionNous avons présenté les idées principales d’une recherche locale qui mémorise les régions
(sphères) visitées pour ne pas les re-visiter inutilement (TS-Div). En combinaison avec unalgorithme d’intensification, nous obtenons une méthode de recherche qui gère très e"cace-ment les bassins d’attraction des optima locaux. Les comparaisons expérimentales confirmentcette propriété. Nous obtenons sur les graphes DIMACS les meilleures colorations connues etmême une nouvelle coloration légale pour dsjc1000.9 avec 223 couleurs. Le principe présentépourrait être retenu pour d’autres problèmes d’optimisation pour lesquels on peut calculer,avec une complexité calculatoire restreinte, une distance entre les solutions potentielles.

Recherche Locale Guidée 71
Références
1. I. Charon, L. Denoeud, A. Guenoche, and O. Hudry. Maximum Transfer Distance Between Par-titions. Journal of Classification, 23(1) :103–121, 2006.
2. A. Hertz and D. Werra. Using tabu search techniques for graph coloring. Computing, 39(4), 1987.

Un algorithme génétique pour minimiser le makespandans un flow shop hybride avec périodes flexibles
d’indisponibilité des machines
W. Besbes1, J. Teghem2 and T. Loukil3
1 GIAD, Faculté des Sciences Economiques et de Gestion, Route l’aérodrome km 4, BP 1088, 3018Sfax, Tunisie.
[email protected] MathRO, Faculté Polytechnique de Mons, 9 Rue de Houdain, Mons 7000, Belgique.
[email protected] LOGIQ, Institut Supérieur de Gestion Industrielle B.P. 954 - 3018, Sfax, Tunisie.
Mots-clés : flow shop hybride, algorithme génétique, indisponibilité, flexibilité
1 Introduction
Dans la majorité des travaux proposés dans la littérature relative à l’ordonnancement de laproduction d’une façon générale, les auteurs supposent que les machines sont continuellementdisponibles durant l’horizon de travail. Cependant, dans le contexte industriel, les machinespeuvent ne pas être disponibles d’une façon continue. Cette indisponibilité peut être due àdes raisons déterministes (maintenance préventive, etc.) ou stochastiques (une machine quitombe en panne, etc.).
Plus particulièrement, en ce qui concerne le problème de flow shop hybride, appelé aussiflow shop flexible, peu de travaux ont été proposés pour le résoudre sous contraintes d’indis-ponibilité des machines [1], [2] et [3]. De plus dans ces quelques travaux, les auteurs traitentle problème à 2 étages seulement et quand les dates de début des périodes de maintenance(PM) sont préfixées. Dans ce travail, nous proposons une nouvelle approche pour minimiserle makespan (Cmax) dans un flow shop hybride à k étages, sous contraintes d’indisponibilitédes machines due à des périodes de maintenance préventive (le cas déterministe). De plus,les dates de début des PM sont flexibles et seront déterminées au sein d’une fenêtre de tempsdurant l’horizon de travail.
Vu la complexité du problème traité, une méthode approchée basée sur l’algorithme gé-nétique est proposée pour minimiser le makespan. Les résultats des expérimentations menéesmontrent bien l’e"cience de l’approche flexible par rapport à l’approche fixe souvent utili-sée dans la littérature. Ils soulèvent aussi une remarque importante par rapport l’approcheproposée.
2 Flexibilité des dates de début des périodes de maintenance
Dans la plupart des études proposées dans la littérature relative à l’ordonnancement deproduction sous contraintes d’indisponibilité des machines, les auteurs considèrent des dates

Un GA pour minimiser le makespan dans un flow shop hybride 73
de début fixes des PM [4] et [5]. Cependant, il est plus intéressant d’intégrer un degré deflexibilité au niveau des dates de début des PM [6]. Contrairement à [6], nous pouvons soitavancer soit reculer la PM, par rapport au job qui a été sélectionné, à l’intérieur de la fenêtrede temps allouée à l’exécution de la tâche de maintenance lorsque nous nous situons dans le cassuivant : Ci,j > em et Ci,j +dm " fm où Ci,j est la date de fin du job j sur l’étage i, em(resp.fm) est la date de début (resp. de fin) de la fenêtre de temps allouée à la PM et dm est ladurée e!ective de la tâche de maintenance. En nous basant sur les trois paramètres suivants :t#m (la date de disponibilité de la machine avant la PM), em et Ci#1,j , nous avons analysé les6 sous cas possibles pour le rangement de ces trois dates. Pour trouver la meilleure alternativeà entreprendre entre l’avancement de la PM(A) et son recul (R) dans chaque sous cas défini,nous avons conduit une étude axée sur la minimisation des temps morts sur les machines. Atravers cette étude, nous concluons que si Ci#1,j > max {t#m, em}, la meilleure alternative àappliquer est (A). Il est plus intéressant d’appliquer (R) dans le cas où em ( max {t#m, Ci#1,j}.Dans le cas où t#m ( max {em, Ci#1,j}, nous pouvons appliquer soit (A) soit (R) étant donnéles mêmes valeurs des temps morts sur les machines pour les deux alternatives. Cette étudeest intégrée à l’algorithme génétique décrit dans [7].
3 ExpérimentationsEtant donné l’inexistence de benchmark concernant ce problème, nous avons généré aléa-
toirement les données. Nous avons conduit trois plans d’expériences. Le premier est unevalidation de l’étude développée pour choisir la meilleure alternative à appliquer dans chaquesous cas. Dans le deuxième, nous comparons l’approche fixe et l’approche flexible proposéeoù dm = 15 et fm # em = 15 (approche fixe), 25, 30, 45 ou 50. Le dernier plan d’expériencesest similaire au second si ce n’est que dm = 30 et fm # em = 30 (approche fixe), 50, 60,90 ou 100. Au total, nous avons mené 2700 évaluations du makespan : 75 (instances) *12(versions de l’algorithme génétique) * 3 (essais pour chaque instance et pour chaque versionde l’algorithme).
Les résultats de ces expérimentations montrent bien l’e"cacité de l’approche proposéepour minimiser le makespan. De plus, nous avons remarqué que l’e"cacité de la flexibilité dé-pend de la di!érente entre l’approche fixe (dm = fm#em) et le cas standard (sans contraintesd’indisponibilité des machines) en terme de Cmax. Tout d’abord, lorsque cette di!érence - quiest toujours supérieure ou égale à dm - est proche de dm, l’apport de l’approche flexible sur laqualité de la fonction objectif par rapport à l’approche fixe est moins important que lorsquecette di!érence est supérieure à dm. Pour vérifier cette importante remarque, nous avons faitun calcul de corrélation entre (GAfi (approche fixe) - GAspm (le cas standard sans contraintesd’indisponibilité des machines) - dm) et (GAfi#GAfl (approche flexible)) suivi d’une analysede régression. Les résultats obtenus consolident la pertinence de la remarque.
Références1. Allaoui H. and Artiba A. : Integrating simulation and optimization to schedule a hybrid flow shop
with maintenance constraints. Computers & Industrial Engineering, 47, 431-450 (2004).2. Xie J. and Wang X. : Complexity and algorithms for two-stage flexible flowshops scheduling with
limited machine availability constraints. Computers and Mathematics Applications, 50, 1629-1638(2005).

74 Besbes, Teghem, Loukil
3. Allaoui H. and Artiba A. Scheduling two-stage hybrid flow shop with availability constraints.Computers & Operations Research, 33, 1399-1419 (2006).
4. Lee C.Y. : Minimizing the makespan in two-machine flowshop scheduling problem an availabilityconstraints. Operations Research Letters, 20, 129-139 (1997).
5. Kubiak W., Blazewicz J., Formanowicz P., Breit J. and Schmidt G. : Two-machine flow shop withlimited machine availability. European Journal of Operational Research, 136, 528-540 (2002).
6. Aggoune R. : Minimizing the makespan for the flow shop scheduling problem with availabilityconstraints. European Journal of Operational Research, 153, 534-543 (2004).
7. Besbes W., Teghem J. and Loukil T. : A genetic algorithm to minimize the makespan in the k-stage hybrid flow shop scheduling problem. Soumis pour publication à International Transactionsin Operational Research.

Résolution d’un problème de Job-Shop avec contraintesfinancières
P. Féniès1, P. Lacomme2, and A. Quilliot1 Université de Clermont 1, IUP de Management, 63177 Aubière Cedex
[email protected] Université Blaise Pascal, LIMOS-ISIMA, 63177 Aubière Cedex.
1 Introduction
.Ce papier propose une approche de résolution d’un problème d’ordonnancement de type
Job-Shop et de gestion de trésorerie dans une optique de Supply Chain Management. Auniveau opérationnel comme au niveau tactique, peu de travaux proposent de lier flux physiqueset flux financiers au niveau de la planification alors que l’intérêt managérial pour des solutionsopérationnelles est évident (Vickery et al., 2003).
Le modèle du Job-Shop dans le cadre de la modélisation de la chaîne logistique est évident,il est possible de considérer qu’une " business unit " de la Supply Chain peut être modéliséecomme une machine, et une commande client par un job. L’intéret principal du modèle dejob-shop est de permettre la modélisation qu’un client d’une " business unit " pour un produitdonné peut tout à fait devenir fournisseur de cette même " business unit " pour un autre typede produit.
Bien souvent, on ne considère pour le job-shop que des critères liés au flux physiques(Cmax, Tmax, Lmax) pour évaluer la qualité d’un ordonnancement. Pour appréhender lejob-shop avec flux financiers, il faut itnroduire la notion de trésorerie initiale (en AnglaisInitial Cash Position) qui représente le montant financier initialement disponible en débutd’ordonnancement et une fonction Cash(t) donnant la position de trésorie à un instant t.Par rapport à un problème de job-shop classique, un problème de job-shop avec contraintesfinancière (Job# Shop/FC) peut se définir par :
– un ensemble F de fournisseurs avec lequel la chaîne logistique à des relations contrac-tuelles ;
– des opérations i reliées par des relations de précédence ;– un temps de traitement pi de l’opération i ;– un délais de paiement di,j pour l’opération i envers le fournisseur j ;– un cout financier ci,j pour l’opération i envers le fournisseur j ;– un gain financier si pour l’opération i (seule la dernière opération de la gamme possède
un gain financier positif) ;– un montant financier r0 disponible en début d’ordonnancement.
En gestion stratégique, les plan de production ou le plan industriel et commercial (PDP etPIC) sont établis selon la règle financière simple suivante : "une opération n’est commencéeque si les ressources financières disponibles permettent de s’assuser que l’opération peut être

76 Fénies P., Lacomme P.
menée à terme". La résolution du problème de job-shop avec flux financier peut se faire enconsidérant la somme des couts financiers de chaque opération et ne prenant pas en compteles délais de paiement des fournisseurs. Le problème de job-shop avec contraintes financièresest un problème connexe des problèmes de RCPSP et proches des problèmes de ResourceInvestment Problem (RIP).
2 FrameworkNous proposons un schéma d’optimisation (figure 1) qui permet d’inclure dans le graphe
disjonctif du job-shop des arcs supplémentaires disjonctifs qui sont calculées grace à la réso-lution d’un problème de flow dans un graphe auxiliaire de calcul. Ce schéma d’optimisation
Fig. 1. Le Schéma d’optimisation et deux courbes financières d’une solution du Job-Shop et duJob % Shop/FC
permet de traiter à la fois des instances de job-shop "classiques" et des instances de job-shopavec flux financiers. Les expérimentations portent sur environ 50 instances et montrent :
– que les solutions obtenues en résolvant le job-shop avec flux financiers sont financière-ment acceptables et respectent la disponibilité financière disponibles ;
– que les solutions du job-shop sont financières des solutions non acceptables. Ceci estmis en évidence avec des découverts bancaires correspondant à un ordonnancement neprenant pas en compte l’aspect financier.
Les instances sont téléchargeables à l’adresse suivante : http : //www.isima.fr/lacomme/JSCF/.
Références1. P. Fenies, P. Lacomme, A. Quilliot : Le modèle théorique du job-shop comme outil d’évaluation
des flux physiques et financiers de la supply chain. MOSIM’08, 7ème Conférence Internationalede Modélisation et Simulation, 31 mars - 2 avril 2008.

Job-shop avec un seul robot de capacité non unitaire
P. Lacomme, M. Larabi, and N. Tchrnev
Université Blaise Pascal, LIMOS, Campus des Cézeaux, BP 10125, 63177 Aubière Cedex, [email protected] ; [email protected],[email protected]
1 Introduction
Le problème du job-shop avec transport consiste à ordonnancer un ensemble n jobsJ = {J1, J2, .., Jn} sur un ensemble de m machines M = {M1,M2, ..,Mm}. Ces jobs sonttransportés par un seul robot avec une capacité limitée supérieure à 1. Chaque job Ji estensemble ordonné de ni opérations notées Oi,1, Oi,2, .., Oi,ni . A chaque opération machineOi,j est associé un temps de traitement Pi,j . Une machine ne peut exécuter sans préemp-tion qu’un job à la fois, de même chaque job ne peut s’exécuter que sur une seule et uniquemachine à la fois. Le robot peut charger des jobs tant que la capacité maximale n’est pasatteinte. Les temps de déplacement du robot de la machine µi vers la machine µj sont dé-terministes et peuvent être égaux ou croissants selon que le robot transporte une charge dek jobs, k = {0, 1, ..MAXcapa}. On suppose aussi que les stocks d’entrée/sortie des machinessont de capacité infinie comme dans le job-shop classique. L’objectif est de trouver un or-donnancement faisable qui minimise le makespan Cmax = Max {Cj} o˘ Cj représente la find’exécution de la dernière opération du job j.
2 Modélisation du problème
Dans le graphe disjonctif-conjonctif les sommets modélisent d’une part, les opérationsmachine, et d’autre part les opérations transport à charge et à vide. Les arrêtes sont de troistypes : (i) les arrêtes conjonctives qui relient les di!érentes opérations de chaque job et quiexpriment les contraintes de précédences ; (ii) les arrêtes disjonctives machine qui exprimentl’ordre de passage des jobs sur les di!érentes machines ; (iii) les arrêtes disjonctives transportqui définissent l’ordre des opérations transport. Une solution du problème consiste à définirles dates de début de toutes les opérations machines et de toutes les opérations transport endéfinissant :
– les disjonctions machine qui décrivent l’ordre de passage des jobs sur les machines ;– les disjonctions transport qui décrivent les mouvements du robot.La figure 1 donne un exemple de graph disjonctif orienté. Les temps de transport sont
consants est égaux à 2. La solution représentée sous forme d’un diagramme du gantt estmontrée dans la figure 2. Les flèches expriment les mouvements du robot.3 Schéma d’optimisation
Nous proposons un schéma d’optimisation de type algorithme génétique hybride avec unerecherche locale basée sur les propriétés des blocs [1] et [2]. Ce schéma est fondé sur :
– une modélisation du problème sous la forme d’un graphe disjonctif non orienté ;

78 P. Lacomme, M. Larabi, N. Tchernev
Fig. 1. Graphe disjonctif orienté représentant la solution du problème
Fig. 2. Diagramme de gantt représentant la solution du graphe de la figure 1
– un algorithme génétique hybride générant les ordres des opérations transport ;– l’obtention d’un graphe disjonctif orienté modélisant une solution à partir de l’ordre
fourni par l’algorithme génétique hybride ;– l’obtention d’un critère de performance (makespan) par un algorithme de plus long
chemin.Cet algorithme est basé sur une généralisation des séquences de Bierwirth. Cette géné-
ralisation nous permet de traiter simultanément les disjonctions machine et les disjonctionstransport. Nous avons repris les instances introduites par Hurink et Knust dans [2] afin de secomparer au cas o˘ la capacité du robot est égale à 1. Les résultats obtenus montrent que laméthode est compétitive avec celle de Hurink et Knust sur le cas particulier d’un seul robotde capacité unitaire.
Références1. P. Lacomme, M. Larabi, N. Tchernev : A Disjunctive Graph for the Job-Shop with several ro-
bots. MISTA 2007,The 3rd Multidisciplinary International Scheduling Conference : Theory andApplications August 28-31, Paris, 2007
2. J. Hurink and S. Knust : A tabu search algorithm for scheduling a single robot in a job-shopenvironment. European Journal of Operational Research,vol 119, pages 181-203, 2002

Méthode exacte pour le flowshop hybride avec machinesà traitement par batches et compatibilité entre les
tâches.
A. Bellanger and A. Oulamara
Laboratoire LORIA, École des Mines de Nancy, Parc de Saurupt, 54042, [email protected] [email protected]
1 Introduction
Dans ce papier, nous nous intéressons au problème de minimisation de la durée totale del’ordonnancement de n tâches dans un flowshop hybride constitué de deux étages. Le premierétage est composé de m1 machines identiques en parallèle et le second étage contient m2machines parallèles à traitement par batches. Chaque machine du premier étage traite uneseule tâche à la fois, alors que chaque machine du second étage peut traiter jusqu’à k (k < n)tâches simultanément dans un même batch. Les tâches sont exécutées sur le premier étagepuis sur le second étage. La durée opératoire d’une tâche j sur le premier étage est donnée parpj (j = 1, . . . , n), et sur le deuxième étage sa durée opératoire est donnée par un intervalle detemps [aj , bj]. Sur le second étage, les tâches peuvent être exécutées dans un même batch sielles sont compatibles entre elles. Autrement dit, si l’intersection de leurs intervalles de duréeopératoire n’est pas vide (i.e., ,i, j [ai, bi]; [aj , bj ] 9= 2). La durée d’exécution d’un batch surle second étage correspond à la plus grande valeur initiale aj des tâches qui le composent.Bellanger et Oulamara [1] présentent une application de ce problème dans l’industrie depneumatiques. Nous notons le problème (P ).
Le problème de flowshop hybride avec machines classiques sur chaque étage est largementétudié dans la littérature de l’ordonnancement (voir Kis et al. [3] pour un état-de-l’art),mais pas en présence de machines à traitement par batches. Dans [1] nous avons considéré leproblème (P ) et nous avons proposé des approches de résolution basées sur des heuristiquesavec garantie de performance.
2 Approche de Résolution
Nous proposons ici une méthode exacte de type séparation et évaluation (PSE) pourminimiser la durée totale de l’ordonnancement. Comme la minimisation du makespan dans unflowshop hybride est symétrique, c’est-à-dire qu’il est possible d’obtenir une solution optimalede notre problème en inversant les deux étages, nous nous intéressons ici à la fois au problèmeinitial et à son problème inverse où le premier étage est composé de machines à traitementpar batches et le second étage est composé de machines classiques.
La méthode que nous utilisons est inspirée par les travaux de Carlier et al. [2]. Elle énu-mère les ordonnancements de l’étage critique en relaxant le second étage, ensuite elle fournitpour chacun des ordonnancements du premier étage un ordonnancement optimal du second

80 Bellanger, A., Oulamara, A.
étage. Comme l’étage critique varie, nous avons développé une méthode commençant parl’ordonnancement de l’étage composé des machines classiques (méthode directe), et une mé-thode commençant par ordonnancer l’étage composé des machines à traitement par batches(méthode inverse). Chaque méthode se décompose en deux étapes, la première étape énumèretous les ordonnancements du premier étage ; puis la seconde étape fournit, pour chaque ordon-nancement du premier étage, la solution optimale du problème de flowshop hybride respectantl’ordonnancement du premier étage. Pour un ordonnancement donné du premier étage, noustransformons les dates de fin des tâches sur le premier étage en dates de disponibilité pourle second étage. La deuxième étape, résout un problème de machines parallèles (du secondétage) pour chaque ensemble de dates de disponibilité. Ainsi la première étape de la méthodedirecte énumère tous les ordonnancements non-dominés du problème P (m1)|d = UB|#, puischacun de ces ordonnancements nécessite la résolution d’un problème de machines parallèlesà traitement par batches avec dates de disponibilité des tâches. Dans la méthode inverse,la première étape énumère tous les ordonnancements non-dominés du problème de machinesparallèles à traitement par batches puis chacun de ces ordonnancements entraîne la résolutiond’un problème de type P (m1)|ri, d = UB|Cmax.
Pour la méthode directe, l’énumération des ordonnancements du premier étage utilise unarbre de recherche dans lequel un nœud correspond à l’ajout d’une tâche à la liste des tâchesdéjà ordonnancées. L’ordonnancement de cette liste se fait en plaçant chaque tâche sur lapremière machine disponible. La seconde étape résout le problème de machines parallèles àtraitement par batches en énumérant les ordonnancements réalisables du second étage. Cetteénumération s’e!ectue à l’aide d’arbres de recherche dans lesquels un nœud correspond àl’ajout d’un batch à la liste de batches déjà ordonnancés. Pour la méthode inverse les nœudsdu premier étage correspondent à l’ajout de batches, alors que la second étape utilise deuxméthodes de résolution, une procédure par séparation et évaluation et une méthode utilisantla programmation dynamique.
3 Résultats expérimentaux
Dans le but d’évaluer la performance de notre méthode par séparation évaluation, nousavons e!ectué une série d’expériences. Nos instances de test sont composées de 2 ou 5 machinessur chaque étage avec une capacité des batches égale à 2. Les expériences menées, nous ontpermis de résoudre des instances de 15 tâches en quelques secondes. Nous avons constaté quemalgré la programmation dynamique du second étage, la méthode inverse n’a pas toujourstrouvé de solutions plus rapidement que la méthode directe.
Références
1. Bellanger A, Oulamara A. Scheduling hybrid flowshop with parallel batching machines and com-patibilities. Computers and Operations Research available online (2008)
2. J. Carlier and E. Néron. (2000) An exact method for solving the multiprocessor flowshop.RAIRO-Oper Res. 78 : 146-161.
3. T. Kis, et E. Pesch. A review of exact solution methods for the non-preemptive multiprocessorflowshop problem. European Journal of Operational Research 164 : 592-608 (2005)

Composition optimale d’équipes d’athlétisme
Frédéric Gardi
Bouygues e-lab, 32 avenue Hoche, 75008 Paris, France.
Dans cette note, nous présentons un problème d’optimisation combinatoire que l’on peutqualifier de “problème du quotidien”. Celui-ci, bien qu’aux enjeux modestes, fait un excellentexercice de recherche opérationnelle pour les étudiants, ainsi qu’un sujet de vulgarisation àdestination du grand public.
En 2003, Martin et Rottembourg [2] présentaient au colloque ROADEF l’approche qu’ilsavaient mise en œuvre pour résoudre un problème de constitution d’équipes de natation.Ils concluaient leur présentation en mentionnant qu’un problème similaire se posait pour laconstitution d’équipes d’athlétisme. En e!et, chaque année les clubs d’athlétisme franÁais seréunissent à di!érents niveaux pour une compétition appelée “interclubs”. Le principe de lacompétition est le suivant. Chaque club doit constituer une équipe masculine et une équipeféminine. Les équipes masculines s’a!rontent sur 21 épreuves réparties en quatre groupes :les courses (100 m, 200 m, 400 m, 110 m haies, 400 m haies, 800 m, 1500 m, 3000 m, 5000 m,3000 m steeple, 5000 m marche), les sauts (longueur, hauteur, triple saut, perche), les lancers(poids, disque, javelot, marteau), les relais (4 * 100 m, 4 * 400 m). De la mÍme manière, leséquipes féminines s’a!rontent sur 19 épreuves semblables aux épreuves masculines (seuls le5000 m et le 3000 m steeple n’ont pas d’équivalent chez les femmes).
Chaque club peut aligner au plus deux athlètes par épreuve (bien entendu, hommes etfemmes concourent séparément). Chaque athlète peut concourir sur deux épreuves au plusappartenant à des groupes di!érents parmi courses, sauts et lancers. Chaque athlète peutparticiper en sus à une des deux épreuves de relais, ceux-ci se déroulant en toute fin decompétition. Les performances des athlètes sur chaque épreuve sont convertis en points àl’aide de tables (celles-ci, appelées “tables hongroises”, sont établies par application d’uneformule du type p(x) = <ax2 + bx+ c= pour chaque épreuve, o˘ p(x) est le nombre de pointsobtenus pour une performance x exprimée dans l’unité adéquate). Ainsi, l’objectif pour unclub est de maximiser son nombre total de points à l’issu de la compétition.
Les interclubs se jouent en deux rencontres. A l’issu de ces deux tours, les clubs sontclassés à l’échelon national en fonction de leur performance (classement qui est regardé pourl’octroi de subventions). Cela en fait un rendez-vous crucial dans la vie des clubs d’athlétismefrançais, petits ou grands. De par notre expérience, nous pouvons a"rmer que la compositiondes équipes d’interclubs est un casse-tête pour les entraÓneurs d’athlétisme. Au-delà de lacomplexité mÍme du problème d’optimisation qu’ils ont à résoudre (une cinquantaine d’ath-lètes à a!ecter à 21 + 19 épreuves), ils doivent faire face à des impondérables, jusqu’au jourmÍme de la compétition (absences, blessures). Un outil informatique d’aide à la décision leurpermettant de composer, et surtout de recomposer, leur équipe de faÁon optimale en fonctionde la disponibilité des athlètes, de leurs performances du moment, ou encore du planning dela compétition (par exemple, il est préférable de ne pas aligner un athlète sur 400 m, s’il a lesaut à la perche à réaliser en mÍme temps) serait donc le bienvenu.

82 Gardi F.
Pour le chercheur opérationnel, la résolution du problème en question ne pose vraimentpas de di"culté, une fois observé que celui-ci peutêtre formulé comme un problème de flotde co˚t maximum lorsque la question des relais, qui n’est pas décisive, est laissée de cÙté.En e!et, soit A l’ensemble des athlètes, G les di!érents groupes d’épreuves et E l’ensembledes épreuves hors relais. Le réseau est construit de la faÁon suivante. ¿ chaque athlète, ainsiqu’à chaque épreuve, est associé un nœud. Le nœud origine est relié à chaque nœud “athlète”par un arc de capacité 2 et chaque nœud “épreuve” est reliée au nœud destination par unarc de capacité 2. Ensuite, à chaque athlète est associé |G| nœuds représentant les groupesd’épreuves. Tout nœud “athlète” est relié à chacun de ses noeuds “groupe” par un arc decapacité 1 et tout nœud “groupe” associé à un athlète est relié à chaque nœud “épreuve”qui lui appartient par un arc de capacité 1 et de co˚t Pa,e égal au nombre de points espérési cette épreuve est a!ecté à l’athlète. Le réseau obtenu comporte |A|(|G| + 1) + |E| nœudset (|A| + |E|)(|G| + 1) arcs. Essentiellement deux types d’algorithme ont été proposés pourcalculer un flot maximum de co˚t minimum dans un réseau [4] : la méthode d’augmentationdu flot (augmenter le flot le long de chemins de co˚t minimum) et la méthode de réductiondu co˚t (calculer un flot maximum puis éliminer les circuits de co˚ts négatifs). Ces méthodesseront ici toutes deux e"caces tant en théorie (puisque la valeur du flot maximum est bornéepar 2 max{|A|, |E|}, les co˚ts sont positifs et le réseau est acyclique) qu’en pratique (puisque|A| " 100, |G| = 3, |E| = 40).
Toutefois, afin d’anticiper d’éventuelles évolutions rendant une modélisation par les flotsimpossible (par exemple, si l’on considère les contraintes d’exclusion mutuelle entre épreuvesdues au planning de la compétition), nous avons opté pour une approche par programmationlinéaire en nombres entiers. Le programme peutêtre écrit comme suit, o˘ xa,e est égal à 1 sil’athlète a ! A est a!ecté à l’épreuve e ! E et à 0 sinon : maximiser
&a,e Pa,exa,e pour tout
a ! A et e ! E, sujet à&a xa,e " 2 pour tout e ! E (au plus deux athlètes par épreuve),&
e xa,e " 2 pour tout a ! A (au plus deux épreuves par athlète),&e%g xa,e " 1 pour tout
a ! A et g ! G (au plus une épreuve de chaque groupe par athlète). On peut montrer que lamatrice de ce programme est totalement unimodulaire, impliquant que toute base optimale desa relaxation linéaire est entière [3]. En pratique, la résolution de ce programme linéaire parl’algorithme du simplexe implémenté dans la librairie GLPK [1] est instantanée (une centained’itérations de simplexe), d’autant plus qu’il est facile de lui fournir une bonne base réalisable(à partir d’une a!ectation heuristique des athlètes aux épreuves).
Notre logiciel, qui se présente sous la forme d’un classeur Excel accompagné d’une DLLdédiée à la résolution du problème d’optimisation, a été utilisé en 2008 pour composer leséquipes d’interclubs homme et femme du BCI Athlétisme (Isle-sur-la-Sorgue, Vaucluse).
Références1. A. Makhorin (2007). GLPK : Gnu Linear Programming Kit, version 4.24.
http://www.gnu.org/software/glpk/2. B. Martin, B. Rottembourg (2003). Constitution optimale d’équipes de natation. In ROADEF
2003. Avignon, France.3. A. Schr$ver (2003). Combinatorial Optimization : Polyhedra and E%ciency. Algorithms and
Combinatorics 24, Vol. A, Springer-Verlag, Berlin, Allemagne.4. R.E. Tarjan (1983). Data Structures and Network Algorithms. CBMS-NSF Regional Conference
Series in Applied Mathematics 44, SIAM Publications, Philadelphie, PA.

Résolution d’un problème de Job-Shop intégrant descontraintes de Ressources Humaines
O. Guyon1,2, P. Lemaire2, É. Pinson1, and D. Rivreau1
1 LISA-IMA, 44 rue Rabelais, 49008 Angers Cedex 1 France{olivier.guyon, eric.pinson, david.rivreau}@uco.fr
2 IRCCyN, CNRS ; École des Mines de Nantes, 4 rue Alfred Kastler, 44307 Nantes Cedex [email protected]
1 IntroductionNous nous plaçons dans le cadre d’un atelier de type job-shop à haute technicité qui fait in-
tervenir des contraintes de qualification pour les opérateurs a!ectés au pilotage des machines.Plus précisément, nous considérons une unité manufacturière dans laquelle la production defaible volume à réaliser requiert divers types de machines dans des séquences variées. Chaquemachine nécessite pour son utilisation la présence d’un agent spécialement qualifié à son pilo-tage. Les ressources humaines sont également assujetties à des contraintes légales restreignantleur disponibilité. Nous considérons un critère d’optimisation lexicographique pour lequel laminimisation de la durée de production constitue le premier objectif et la minimisation descoûts salariaux le second. Ce problème coïncide avec le cas particulier d’instance "correspon-dance activité-resource" de C. Artigues et al. [1]. Pour faciliter la comparaison, nous nouse!orcerons d’utiliser les mÍmes notations par la suite.
2 Formalisation du problèmeFormellement, nous considérons la production d’un ensemble J de n jobs sur m machines.
Chaque job i est caractérisé par une séquence d’opérations {Oi,j}j=1,...,m. L’opération Oijs’e!ectue sur une machine mij donnée et sa durée d’exécution est notée pij . Pour plus decommodités, nous utiliserons 4ik pour désigner la durée de l’opération du job i qui s’exécutesur la machine k. Les tâches ne sont pas interruptibles et requièrent la présence d’un opérateurqualifié sur la machine au moment de leur exécution. Nous noterons {Ee}e=1,...,µ l’ensembledes µ opérateurs et Ae représentera l’ensemble des machines sur lequel l’opérateur e peutintervenir. L’atelier fonctionne suivant une logique de type 3*8 et l’horizon de planifications’étend ainsi sur un ensemble {s}s=0,...,"#1 de ( tranches horaires consécutives. La duréee!ective d’une tranche horaire est fixe et notée ' pour un horizon H = ( * '. Le coûtd’a!ectation de l’agent e sur la machine k durant la tranche s est désigné par ceks, étantentendu que l’opérateur ne change pas de machine en cours de poste. Chaque opérateur e estdisponible sur un sous-ensemble de tranches horaires Te. Par ailleurs, un agent ne peut Ítreactif qu’au maximum une fois parmi trois tranches horaires consécutives (contrainte légale).
Nous proposons ci-dessous une formalisation sous forme de PL-01 de ce problème. Lesvariables binaires xeks et yikt valent respectivement 1 si l’opérateur e est a!ecté à la machinek sur la tranche s et si le job i démarre à l’instant t sur la machine k.
minLex/Cmax,
µ%
e=1
%
k%Ae
%
s%Te
ceksxeks
0(1)

84 Guyon, Lemaire, Pinson, Rivreau
&Ht=0 t · yikt + #ik # Cmax i = 1, . . . , n k = mim (2)&Ht=0 yikt = 1 i = 1, . . . , n k = 1, . . . ,m (3)
&tu="ik
yilu %&t""iku=0 yiku # 0 i = 1, . . . , n j = 1, . . . ,m% 1
k = mij l = mi(j+1) t = #ik, . . . ,H % #il (4)&ni=1&tu=t""ik+1 yiku # min(1,
&µe=1 xeks) k = 1, . . . , m t = 0, . . . ,H s = &t/"' (5)
&k/#Ae
&#s=0 xeks = 0 e = 1, . . . , µ (6)
&k#Ae
&s/#Texeks = 0 e = 1, . . . , µ (7)
&k#Ae
(xeks + xek(s+1) + xek(s+2)) # 1 e = 1, . . . , µ s = 0, . . . ,$ % 2 (8)
La première contrainte exprime la date de fin de l’ordonnancement en fonction de ladernière opération de chaque job. La contrainte (2) spécifie que toute opération doit Ítreexécutée. Les contraintes (3) et (4) correspondent respectivement aux séquences job et auxcontraintes de disponibilité machine (au plus une opération en cours à un instant donné, sousréserve de la présence d’un opérateur). Les équations (6) et (7) précisent qu’un opérateur nepeut Ítre a!ecté que sur une machine sur laquelle il est qualifié et qu’il doit Ítre disponiblepour la tranche horaire concernée. Finalement, la contrainte légale est exprimée par (8).
3 Résolution
Di!érentes techniques de résolution ont été appliquées sur ce problème : résolution directepar solveur de MIP, utilisation de relaxation lagrangienne, relaxation et génération de coupes(cf. [3], [4]). Nous avons en outre intégré les méthodes propres à l’optimisation de problèmede job-shop, et en particulier les règles d’éliminations classiques et le shaving (cf., e.g., [2]).Ces méthodes s’avèrent extrÍmement utiles pour l’accélération de la résolution du problèmecomplet, comme le montrent les expérimentations réalisées tant sur des instances généréesaléatoirement que sur celles d’Artigues et al.
Références
1. Artigues, C. ; Gendreau, M. ; Rousseau, L.-M. & Vergnaud, A. : Solving an integrated employeeand job-shop scheduling problem via hybrid branch-and-bound, To appear in Computers andOperations Research (Available online 28 August 2008)
2. Carlier, J. & Pinson, . . .. : Adjustment of heads and tails for the job-shop problem, EuropeanJournal of Operational Research 78, pp146-161 (1994)
3. Detienne, B. ; Péridy, L. ; Pinson, . . .. & Rivreau, D. : Cut generation for an employee timetablingproblem, To appear in European Journal of Operational Research (Available online 1 April 2008)
4. Guyon, O. ; Lemaire, P. ; Pinson, . . .. & Rivreau, D. : Couplage planification/ordonnancement :une approche par décomposition et génération de coupes, Actes de la 7e Conférence Internationalede Modélisation et Simulation, pp. 1376-1385 (2008)

Etude de l’influence de l’algorithme de séparation etd’évaluation appliqué aux thématiques
d’ordonnancement de bus et d’équipages.
Clément Solau1 et Laure Thoma-Cosyns2
1 ESIEE, 14 Quai de la Somme, 80082 Amiens Cedex [email protected]
2 ESIEE, 14 Quai de la Somme, 80082 Amiens Cedex [email protected]
1 Introduction et problématique
L’ordonnancement de véhicules et d’équipages sont deux problèmes émergeants spéciale-ment dans les transports en commun. [1] et [2] ont montré l’intérêt d’utiliser une approchede type intégrée par rapport à une approche séquentielle (ou séparée). Nous proposons unalgorithme exact basé sur la méthode de génération de colonnes et du Branch-and-Boundrésolvant le problème d’ordonnancement de bus et d’équipages. Cet article vise à comparer enterme de coût l’écart entre un résultat fourni par un algorithme basé sur le Branch-and-Boundavec une solution où la contrainte binaire est relaxée.Le problème est de trouver un ordonnancement respectant certaines contraintes tel que chaqueservice est couvert par exactement un chau!eur et un véhicule. Les hypothèses retenues sontles suivantes :- Contrainte de relève : on dit qu’il y a relève lorsqu’un chau!eur change de véhicule lors desa pause. Dans notre cas, les relèves (i.e. changeovers) ne seront pas prises en compte.- Contrainte géographique : dans notre cas, nous supposons que le chau!eur a!ecté à unecertaine séquence de services devra retourner au démarrage du premier service qui lui a étéa!ecté une fois sa séquence e!ectuée.- Fonction de coût : La fonction de coût est le résultat de la somme des coûts liés aux véhiculeset de ceux liés aux équipages.Par conséquent, les chau!eurs et les véhicules exécuteront une séquence de services faisableappelée généralement combined duty.
2 Modélisation Mathématique
Soit N = {1, 2, ..i, j, .., n} l’ensemble des n services où le service i commence à la dateai et termine à la date bi. Soit tij la durée de trajet (appelée aussi haut le pied) entrela localité de fin de i et la localité de départ du service j. Deux services i et j sont ditcompatibles s’ils satisfont la relation bi + tij " aj .Par conséquent, une séquence de ser-vices est dite faisable si elle ne contient pas de services incompatibles entre eux. Soit E ={(i, j) |i, j compatibles, i ! N, j ! N} l’ensemble de tous les hauts le pied entre services com-patibles. Ces deux ensembles définissent un graphe noté G = (N,E).Le problème global peut

86 Solau, Thoma-Cosyns
être défini comme un problème de partition d’ensemble.Nous définirons xk comme étant uneséquence de services (i.e. combined duty). En e!et, d’après [3], il est possible de modéliser laséquence de services a!ectée aux bus et aux chau!eurs sous une même variable . La variablede décision xk est associée à son coût ck. Par conséquent, le problème d’ordonnancement devéhicules et d’équipages peut, dans notre cas, se représenter comme suivant :
min&|K|k=1 ckxk
(1)&k%K ajkxk = 1 j = 1, 2, ...., n
(2)xk !{0, 1} pour tout k ! K
(3)xk indique si la séquence de services est sélectionnée dans la solution. ajk ! {0, 1} est unevariable égale à 1 si la variable de décision xk couvre le service j.
3 Strucure de l’algorithmeLa structure élaborée est la suivante : La résolution du sous-problème (i.e. pricing problem)
est e!ectuée via l’algorithme de D#kstra. Enfin, l’algorithme du Branch-and-Bound intervientune fois que toutes les colonnes intéressantes ont été générées.
4 ConclusionNous avons remarqué que les résultats fournis par le Branch-and-Bound étaient similaires
à ceux fournis par un algorithme de type simplexe après avoir appliqué une procédure d’ar-rondi. C’est pourquoi, avec un jeu de données comme celui là (300 services), nous pouvonsnous passer de l’utilisation du Branch-and-Bound. Cependant, afin de pouvoir mieux juger lerésultat il faudrait tester sur un plus grand nombre de services.
Références1. Freling R., Huisman D., Wagelmans A.P.M : Models and algorithms for integration of vehicle and
crew scheduling. J. Scheduling 63-85 (2003)2. Freling R., Wagelmans P.M., Paixao : An Overview of Models and Techniques for Integrating
Vehicle and Crew Scheduling. Computer-Aided Transit Scheduling (1999)3. Huisman : A note on model VCSP1 (2002)

Un modèle pour le calcul de plus court cheminmultimodal en milieu urbain
Tristram Grabener, Alain Berro, and Yves Duthen
IRIT-UT1, UMR 5505, CNRS — Université de Toulouse2 rue du doyen Gabriel Marty 31042 Toulouse Cedex 9, France{tristram.grabener, alain.berro, yves.duthen}@irit.fr
Mots-Clefs. Transport multimodal urbain ; Plus court chemin dynamique
Introduction
Le transport multimodal1 consiste à combiner plusieurs moyens de transport pour arriverà destination. Calculer un plus court chemin multimodal présente plusieurs di"cultés. D’unepart le graphe modélisant le réseau est dynamique : la valeur des arcs change en fonction dutemps (embouteillages) et la topologie également (métro fermé). D’autre part la contraintedite FIFO[4] n’est généralement pas respectée : il peut être plus intéressant de laisser passerun train omnibus pour prendre un direct permettant d’arriver plus rapidement à destination.
Nous proposons un modèle permettant de calculer e"cacement le plus court chemin mul-timodal lorsque l’objectif à minimiser est le temps. Il repose sur la création d’une couche parmoyen de transport et sur l’intégration du temps d’attente dans le coût des arc.
1 Algorithmes existants
Modélisation Un réseau routier ou de transports en commun se modélise naturellement sous laforme d’un graphe valué. Il est important de noter que le poids des arcs est traditionnellementune constante (longueur ou temps), mais qu’il est parfaitement possible d’utiliser une fonctionarbitraire. La longueur d’un chemin c = (ci)i%1,...,l est alors calculé en appliquant les fonctionsde coût correspondantes à chaque arc traversé : F (c) = Fc1c2 > ... > Fcl"1cl(t0) où t0 la valeurinitiale. Il est donc possible de modéliser les variations de trafic en fonction de l’heure.
Plus court chemin unimodal Afin de calculer le plus court chemin dans un graphe, l’algorithmele plus connu est probablement celui de D#kstra qui calcule le plus court chemin d’un noeudvers tous les autres en O(m+n logn) (avec n noeuds et m arcs). Il existe d’autres algorithmesplus spécialisés pour le monde du transport. Le lecteur s’y intéressant pourra se référer à [5].Dans le cas de poids constants, l’algorithme de D#kstra est applicable si tous les poids sontpositifs. Dans le cas de fonctions, il faut que celles-ci soient croissantes [2].
1 le terme intermodal est parfois utilisé [1], tandis que [3] utilise multimodal

88 T. Grabener, A. Berro, Y. Duthen
Approches existantes L’approche habituelle consiste à discrétiser le temps en q intervalles,pour construire un graphe espace-temps où un noeud est associé à chaque couple (noeud,temps). Les arcs modélisent les transitions possibles, et permettent de prendre en compte letemps d’attente à un noeud. L’algorithme Chrono-SPT [4] calcule le plus court chemin engénérant implicitement ce graphe en O(q · m). Les approches [6] et [1] sont basées sur unemodification de cet algorithme pour prendre en compte la multimodalité.
2 Modèle proposé
Duplication des noeuds par mode Pour chaque mode de transport une couche est générée.Ainsi un réseau avec n noeuds est modélisé par un graphe à 3n noeuds si l’on prend encompte le vélo, la voiture et la marche. Chaque ligne de transports en communs est modéliséepar une couche séparée. Das le cas où sur une même ligne un train peu en dépasser un autre,la ligne est dédoublée. Les noeuds entre deux couches sont reliés s’il est possible de passerd’un mode à l’autre, prenant en compte le temps nécessaire pour cela.
Gestion du temps d’attente La nature multi-couches permet de garantir qu’il n’est pas possibled’avoir un dépassement sur un arc. Il ne sert donc à rien d’attendre plus longtemps sur unnoeud avant d’emprunter un arc. On intègre donc ce temps dans la fonction de coût de l’arc.
Propriétés Ce modèle respecte les contraintes d’optimalité de l’algorithme de D#kstra. Deplus il o!re une grande flexibilité de modélisation : il est possible de prendre en compte lapossibilité « d’abandonner » son véhicule (Parking-relai), les vélos en libre service ainsi queles temps de changements entre chaque mode. Le fait de ne pas discrétiser le temps permetd’avoir une meilleur précision qu’avec les approches habituelles.
Limitations La principale limitation est que cette approche n’est valable que si l’on désireminimiser le temps de parcours. En voulant minimiser le coût ou les émissions de CO2, letemps d’attente ne peut plus être incorporé dans la fonction de coût. La multiplication descouches entraîne une plus grande consommation de mémoire ; cependant cette augmentationest linéaire en fonction des modes de transports considérés et ne doit pas en pratique poserde problèmes.
Résultats Sur un carré des 100 km de coté centré sur Toulouse (60000 noeuds), en prenanten compte la marche et le Vélo-Toulouse (qui n’est accessible qu’à certains moments de lajournée), nous avons e!ectué 1000 calculs entre deux noeuds2. Le temps moyen était 40 ms etle pire cas 250 ms. Utiliser des fonction de coût arbitraires permet donc de conserver de trèsbonnes performances. De plus le temps de calcul évolue de manière quasi-linéaire en fonctiondu nombre de noeuds (en temps moyen et dans le pire cas), permettant un passage à l’échelle.
2 l’implémentation de D$kstra est classique, la recherche est simplement arrêtée en arrivant à des-tination

Plus court chemin multimodal 89
Références
1. M. Boussedjra, C. Bloch, and A. El Moudni. Solution optimale pour la recherche du meilleurchemin intermodal. MOSIM, 2003.
2. M. Gondran and M. Minoux. Graphes, Dioıdes et semi-anneaux. TEC & DOC, Paris, 2002.3. S. Hoogendoorn-Lanser, R. van Nes, and P. Bovy. Path Size Modeling in Multimodal Route Choice
Analysis. Transportation Research Record, 1921(-1) :27–34, 2005.4. S. Pallottino and M. Scutella. Shortest path algorithms in transportation models : classical and
innovative aspects. Kluwer Academic Publishers, 1998.5. F. Zhan and C. Noon. Shortest Path Algorithms : An Evaluation using Real Road Networks.
TRANSPORTATION SCIENCE, 32 :65–73, 1998.6. A. Ziliaskopoulos and W. Wardell. An intermodal optimum path algorithm for multimodal net-
works with dynamic arc travel times and switching delays. European Journal of OperationalResearch, 125(3) :486–502, 2000.

Calcul de plus court chemin bicritére
G. Sauvanet and E. Néron
Université François Rabelais Tours — Laboratoire d’Informatique{gael.sauvanet|emmanuel.neron}@univ-tours.fr
1 Introduction
L’objectif de ce papier est de faire une présentation générale du probléme de plus courtchemin bicritére et de proposer une méthode de résolution exacte avec prétraitements. Iciles deux critéres considérés sont la distance et la sécurité. En e!et l’application cible vise àcalculer des itinéraires cyclistes à l’echelle d’un département. Cette étude se fait dans le cadred’une convention CIFRE1.
2 Présentation du probléme
Considérons le graphe orienté G=(V,A) composé de n nœuds et dem arcs. Dans ce graphe,les nœuds s, t ! N correspondent aux nœuds initial et terminal. Une fonction c : A : R+
associe un coût à chaque arc du graphe. Dans le cas du probléme bicritére, il y a deux fonctionsde coûts c1 et c2 correspondant aux deux critéres.
Un chemin de i vers j (i, j ! V ) est une séquence de o arcs p = (a1, a2, ..., ao) contigus. Leplus court chemin p d’une instance (un graphe G et un couple de nœuds s; t) est le cheminqui minimise la fonction de coût : mina%p
&c(a).
3 Probléme monocritére
L’algorithme de D#kstra[1] permet de résoudre le probléme monocritére en temps polyno-mial. Le principe est de maintenir une étiquette contenant la distance entre chaque nœud etle nœud source et de garder une liste des nœuds restants à explorer. Cette méthode permetde garantir que chaque nœud ne sera exploré qu’une fois.
Il existe de nombreuses variantes de cet algorithme permettant d’accélérer le calcul[5].Dans la recherche bidirectionnelle, deux recherches de plus court chemin sont lancées en mÍmetemps, l’une partant de s vers t et l’autre de t vers s, et la méthode prend fin lorsque les deuxrecherches se rencontrent. La méthode A*[2] quant à elle, modifie la priorité d’explorationdes nœuds afin d’orienter la recherche vers les nœuds potentiellement plus proches du nœudterminal. Enfin, les méthodes à base de prétraitements sont généralement les plus e"caces.Par exemple, la méthode ALT[2] est une extension de A* qui utilise les distances précalculéesentre un sous ensemble de noeuds L ! V et la totalité des noeuds V .1 Thése CIFRE n 1097/2007, association Autour du Train

Calcul de plus court chemin bicritére 91
4 Probléme bicritéreDans le probléme bicritére, il n’existe pas une solution optimale, mais un ensemble de
solutions non dominées où chacune d’entre elles correspond à un couple de valeur des deuxcritéres. Une solution (x", y") est dite dominée par une autre (x, y) si x " x" et y " y" avecau moins une inégalité stricte. L’ensemble de ces solutions de compromis peut Ítre représentédans l’espace des deux critéres et constitue ce que l’on appelle le front de Pareto. Il s’agitd’un probléme NP-complet[3].
Un état de l’art récent sur les problémes de plus court chemin multicritéres est dispo-nible dans [4]. Les méthodes de résolution peuvent Ítre regroupées en plusieurs catégories enfonction de leur objectif : trouver une solution de compromis, trouver l’ensemble du front dePareto, trouver une approximation du front de Pareto, etc.
5 Méthode de résolution exacte avec prétraitementsLes méthodes de résolutions classiques permettant de trouver l’ensemble des solutions non
dominées sont des adaptations de méthodes monocritéres (D#kstra ou méthode des k pluscourts chemins). Nous proposons ici d’adapter une des méthodes avec prétraitements pouraccélerer le calcul.
En e!et, étant donné que le graphe ne change pas d’une instance à l’autre, il est possible desélectionner un sous ensemble de nœuds L ! V et de précalculer l’ensemble des chemins nondominés entre chacun de ces nœuds. Ces prétraitements permettent de calculer rapidementune approximation du front de Pareto pour une instance donnée et ainsi réduisent le nombrede nœuds à explorer.
6 ConclusionNous venons de montrer un aperçu du probléme de plus court chemin bicritére. La méthode
présentée permet de réduire le temps de calcul de l’ensemble des solutions non dominées parrapport à une méthode classique. Les résultats seront détaillés lors de la présentation.
Références1. E.W. D$kstra. A note on two problems in connection with graphs. Numerische Mathematik,
(1) :269–271, 1959.2. Harrelson C. Goldberg, A. Computing the shortest path : A* meets graph theory. Proceedings
of the 16th Annual ACM-SIAM Symposium on Discrete Algorithms (SODA 2005), SIAM (2005),2005.
3. P Serafini. Some considerations about computational complexity for multiobjective combinatorialproblems. In Lecture Notes in Economics and Mathematical Systems, pages 222–232. Springer-Verlag, 1987.
4. Z. Tarapata. Selected multicriteria shortest path problems : An analysis of complexity, models andadaptation of standard algorithms. Iinternational Journal Of Applied Mathematics And ComputerScience, 17 :269–287, 2007.
5. D. Wagner, T. Willhalm. Speed-Up Techniques for Shortest-Path Computations. STACS, pages23-36, 2007.

Coupes valides pour le problème de minimisation de lasomme pondérée de retard et de l’avance sur une
machine unique
Maher. Rebai1 and Imed. Kacem2
ICD-LOSI CNRS FRE 2848. Université de technologie de Troyes, [email protected]@utt.fr
Ce travail concerne le problème d’ordonnancement d’un certain nombre de tâches indé-pendantes sur une seule machine. L’objectif est de minimiser la somme pondérée des retardset des avances. Ce problème peut être formulé comme suit :
MinN%
i=1wid
+i + hid#i
Sous les contraintes :Ci # d+i + d#i = di ,i = 1 . . .N (1)&Ni=1 xij = 1 ,j = 1 . . .N (2)&Nj=1 xij = 1 ,i = 1 . . .N (3)Ci + P (1# xij) (
&jk=1&Nt=1 ptxtk ,i = 1 . . .N, j = 1 . . .N (4)
Ci # P (1# xij) "&jk=1&Nt=1 ptxtk ,i = 1 . . .N, j = 1 . . .N (5)
xij ! {0, 1} Ci, d+i , d
#i ! N P =
&Ni=1 pi #mini%Npi
d#i : désigne la déviation négative de la tâche i ou également l’avance.d+i : désigne la déviation positive de la tâche i ou également le retard.Ci : désigne le temps d’achèvement de la tâche i dans la séquence optimale.xij =
11 si la tâche i est a!ectée à la position j.0 sinon.
Données : wi : pénalité de retard de la tâche i ; hi : pénalité d’avance de la tâche i ; di : datedue de la tâche i ; pi : temps opératoire de la tâche i.
(1) exprime que chaque tâche doit dévier positivement ou négativement par rapport à sadate due. (2) et (3) sont des contraintes d’a!ectation : Chaque tâche occupe une seule po-sition et chaque position ne peut contenir qu’une seule tâche. (4) permet de déterminer unevaleur de temps d’achèvement optimal de la tâche i quand cette dernière est en retard, sinonelle est redondante. (5) permet de déterminer une valeur de temps d’achèvement optimal dela tâche i quand cette dernière est en avance, sinon elle est redondante.Pour améliorer la qualité de la solution relaxée du modèle nous avons proposé plusieurs coupesvalides.La première coupe consiste à minorer la valeur de la somme pondérée des temps d’achèvementdes tâches dans la séquence optimale par la somme du flowtime pondéré (WF1(p, w))de laséquence obtenue en appliquant la règle WSPT à l’ensemble des tâches (en utilisant des poids

Coupes valides pour le problème d’ordonnancement 93
fictifs et en les associant aux tâches). La deuxième famille de contraintes de cette premièrecoupe consiste à majorer la valeur de la somme pondérée des temps d’achèvement des tâchesdans la séquence optimale par une valeur obtenue en calculant la somme du flowtime pon-déré de la séquence obtenue en appliquant la règle WSPT et en e!ectuant un changement derepère.&Ni=1 wiCi (WF1(p, w)&Ni=1 w
"iCi "
&Ni=1 w
"i(P + pi)#WF1(p, w")
En appliquant le même principe et en utilisant la règle WLPT nous obtenons les contraintessuivantes :&Ni=1 wiCi "WF2(p, w)&Ni=1 w
"iCi (
&Ni=1 w
"i(P + pi)#WF2(p, w")
La deuxième coupe consiste à encadrer le temps d’achèvement de chaque tâche i dans chaqueposition j par deux valeurs : Il s’agit donc de déterminer une borne inférieure et une bornesupérieure pour la date de fin de la tâche i si elle est ordonnancée à la position j.&Nj=1 Cijxij "Ci "
&Nj=1 Cijxij ,i = 1 . . .N
avec Cij = max(C1ij , C
2ij)
où'C1ij =&jk=1 p[k] k ! {[1], [2], . . . , [j]}
C2ij =&j#1k=1 p[k] + pi, k ! {[1], [2], . . . , [j]}
[k] est la kème tâche de la séquence S obtenue en appliquant la règle SPT à l’ensemble destâches.et Cij = min(C1
ij , C2ij)
où'C
1ij =&jk=1 p[k] k ! {[N ], [N # 1], . . . , [N # j + 1]}
C2ij =&j#1k=1 p[k] + pi, k ! {[N ], [N # 1], . . . , [N # j + 1]}
L’idée de la troisième coupe est similaire à celle de la premiere coupe. Il su"t de prendredes poids égaux aux temps opératoires des tâches pour avoir une contrainte du type égalité.&Ni=1 piCi =WF1(p, p)
Références1. Baker KR, Scudder GD. : Sequencing with earliness and tardiness penalties : a review. Operations
Research (1990)2. Kacem I. : Lower bounds for tardiness minimization on a single machine with family setup times.
International journal of Operations Research (2007)3. Sourd F, Keded-Sidhoum S, Rio Solis Y. : Lower bounds for the earliness-tardiness scheduling
problem on parallel machines with distinct due dates. European Journal of Operational Research(2007)

Localisation de cachesdans un réseau de distribution de contenu
Philippe Chrétienne2, Pierre Fouilhoux2, Eric Gourdin1, and Jean-Mathieu Segura1,2
1 Orange Labs, 38-40 rue du Général Leclerc, 92794 Issy-Les-Moulineaux.{eric.gourdin,jeanmathieu.segura}@orange-ftgroup.com
2 LIP6, 104 avenue du Président Kennedy, 75016 Paris.{philippe.chretienne,pierre.fouilhoux,jean-mathieu.segura}@lip6.fr
Mots-Clefs : VoD, télécommunications, caches, localisation, a!ectation
Nous nous intéressons au problème de localisation d’équipements dans un réseau lorsque l’ondésire a!ecter des produits et des clients à ces équipements.Ce problème intervient dans la distribution de contenu, comme celle d’un catalogue de filmsdans le service de vidéo à la demande (VoD) destinés à des utilisateurs de ce service et àtravers le réseau d’un opérateur internet. Les équipements à positionner dans le réseau sontdes disques durs, appelés des caches, où l’on peut stocker un nombre limité de films. Lescaches doivent être répartis dans le réseau de manière à permettre un accès rapide lors de ladistribution des films aux clients. La solution de ce problème consiste donc, tout à la fois, àplacer les caches, ainsi qu’a!ecter les films sur ces caches, de sorte à ce que chaque client aitaccès à la totalité des films du catalogue.Dans ce contexte de distribution de films, le coût de raccordement des clients aux caches sontplus important pour des films dits "populaires" que pour les films peu demandés. Dès lors, lesobjectifs sont de minimiser le coût de raccordement des clients aux caches, ainsi que le coûtd’installation de ces caches.
1 ModélisationOn dispose d’un ensemble de sites V = {1, ..., n} pour installer les caches. Ce sont les clients,les concentrateurs du réseaux, un système de Peer-to-Peer ou le serveur central de distributiondes films. Les sites sont rassemblés dans un réseau R = (V,E) où E est l’ensemble des liaisonsdu réseaux. L’ensemble des films est noté F = {1, ...,m}. Le coût de raccordement d’un clienti ! V à un équipement situé en j ! V pour le film f ! F est noté cijf . Ce coût dépendà la fois de la valeur d’un plus court chemin entre i et j et de la popularité du film f . Onnotera µi la capacité en nombre de film que l’on peut placer sur le cache placé sur le sitei ! V . La capacité des disques est di!érente selon que le disque est placé sur un site client,concentrateur ou selon le principe de Peer-to-Peer.Le problème consiste alors à décider de positionner un cache sur chaque site d’un multi-ensemble S 1 V tel que chaque film soit a!ecté à au moins un cache : on note alors Sfl’ensemble des chaches contenant le film f . Il faut également décider une a!ectation de chaqueclient à un et un seul site j de Sf , pour chaque film f ! F . Cette double a!ectation doitrespecter la contrainte de capacité interdisant de placer plus de µi films par cache.L’objectif du problème doit réaliser un compromis entre minimiser le nombre de caches etminimiser la somme des coûts d’accès à chaque film pour tous les clients. En pratique, le

Localisation de caches dans un réseau de distribution de contenu 95
nombre de caches est souvent fixé à l’avance (contrainte budgétaire). On note alors p = |S|le nombre de caches à positionner.Le problème tel qu’il est défini est NP-di"cile dans le cas d’un graphe quelconque, puisqu’ilest une généralisation du problème p-médian qui a été montré NP-di"cile, même dans le casd’un graphe planaire de degré maximum 3 [1] (en revanche, le problème du p-median a étémontré polynomial dans le cas d’un arbre [1].)
2 Formulation PLNENous supposons ici que tous les sites sont des clients potentiels et que chaque disque a la mêmecapacité µ. Une modélisation mathématique possible sous forme de programme linéaire ennombre entier est alors la suivante :
minn&i=1
n&j=1
m&f=1cijf * xijf
s.t.n&i=1xijf = 1, ,j, ,f (1)
xijf " xjjf , ,i, j, ,f (2)m&f=1xjjf " µ* zj, ,j (3)
n&j=1zj = p, (4)
xijf ! {0, 1}, zj ! N (5)
La contrainte (1) implique que chaque client i est a!ecté à un site j pour chaque film f . Lacontrainte (2) exprime que si le client i est a!ecté à un site j pour le film f , alors un cachedoit être installé sur le site j et le film f y être e!ectivement stocké. La contrainte (3) imposeque le nombre de films stockés sur les caches situés en j est bien inférieur à leurs capacités.Enfin, la contrainte (4) impose le nombre de caches à placer, tandis que les contraintes (5)expriment l’intégrité des variables.
3 RésultatsUne étude expérimentale préliminaire a démontré que, même pour n et p petits, les instancesdu problème sous cette modélisation sont di"cilement résolues par CPLEX. Nous étudieronsalors une approche polyédrale pour ce problème dont les premiers résultats seront présentés.Nous présenterons également des résultats algorithmiques exactes ou approchées sur des casde graphes simples (étoile, arbres) qui sont fréquemment utilisés pour modéliser les réseauxd’opérateurs internet.
Références1. O. Kariv and S. L. Hakimi An Algorithmic Approach to Network Location Problems. II : Thep-Medians SIAM Journal on Applied Mathematics (1979)

Un algorithme approché de facteur 2 log2(n) pour leproblème du cycle de couverture
V.H. Nguyen1
LIP6, Université Pierre et Marie Curie Paris 6, 4 place Jussieu, 75252 Paris Cedex [email protected]
1 Introduction
Soit G = (V,A) un graphe orienté où |V | = n et |A| = m. Les arcs de A sont pondérées parune fonction c : A/ Q+. Un cycle de couverture T est un sous-graphe T = (U,F ) tel que– Pour toute e ! A, il existe au moins f ! F intersectant e, i.e. f a au moins une extrémité
communne avec e.– T est un cycle (qui n’est pas forcément simple).Nous considérons le problème du cycle de couverture de poids minimum (DToCP abbréviationen anglais pour Directed Tour Cover Problem). Appelons T $ le cycle de couverture de poidsminimum cherché. Puisque T $ peut ne pas être simple, nous pouvons supposer sans perte degénéralité que chaque arc dans T $ représente le plus court chemin de son extrémité initiale àson extrémité terminale, i.e. les coûts définis par c satisfont l’inégalité triangulaire. La versionnon-orientée où on cherche un circuit de couverture de poids minimum (ToCP) a été étudiédans la littérature. Ce problème est introduit initialement dans un papier de Arkin et al. [1].Ils démontrent que ToCP est NP -di"cle et proposent un algorithme d’approximation pure-ment combinatoire avec un facteur d’approximation de 5,5. Plus tard, Konemann et al. [2]utilisent une formulation linéaire 0/1 du ToCP pour améliorer le facteur d’approximation en 3.
2 Un algorithme approché de facteur 2 log2(n)
On peut démontrer que DtoCP est NP -di"cile par une reduction d’un cas particulier pro-blème du Voyageur de Commerce Assymétrique où les coût satisfont l’inégalité triangulaire(noté MATSP pour Metric Assymmetric Travelling Salesman Problem). La preuve est assezsimilaire à la preuve pour ToCP donnée par Arkin et al. dans [1]. Étant donné une instanceG = (V,A) et c du MATSP où c est la fonction de coût sur les arcs, la reduction peut êtredécrite comme suit. Pour chaque sommet i ! V , on crée un nouveau sommet i" et ajoute unarc (i, i") de coût +6 dans G. Appelons G" le nouveau graphe obtenu. Considérons le DToCPdans G", comme les coûts sont métriques, on peut se limiter à considérer seulement des cyclesde couverture de G" qui sont simples. De plus, par la structure particulière de G", ces cyclessont les cycles hamiltoniens de G. On a donc une correspondance entre les cycles de couver-ture de G" et les cycle hamiltoniens de G. Cette réduction préserve en plus l’approximation,i.e. si on a un algorithme d’approximation de facteur % pour DToCP alors on aura le mêmefacteur d’approximation pour MATSP. À notre connaissance, le meilleur facteur actuel pourMATSP est 0.824 log2(n) obtenu par Kaplan et al. [3]. Il sera donc très di"cile de concevoir

Cycle de couverture 97
un algorithme de facteur constant pour DToCP. Ce serait alors plus réaliste d’approcher lefacteur 0.824 log2(n) pour MATSP.Dans ce papier, nous allons présenter un algorithme d’approximation de facteur 2 log2(n) pourDToCP. Ce facteur est un peu plus 2 fois que le meilleur facteur d’approximation pour ATSP.On peut l’expliquer par le fait que notre algorithme est inspiré de celui de Konneman et al.pour ToCP. Leur algorithme est basé sur la borne donnée par la relaxation de Held-Karppour le metric TSP alors que le notre est basé sur la borne donnée par la relaxation de Held-Karp pour le MATSP. Il est prouvé respectivement que le coût du voyageur de commercenon-orienté est au plus 3
2 fois la solution optimale de la relaxation Held-Karp pour le metricTSP et le coût du voyageur de commerce orienté est au plus log2(n) fois la solution optimalede la relaxation Held-Karp pour le MATSP. Notre facteur 2 log2(n) suit logiquement 3 quiest égal à 2* 3
2 , le meilleur facteur pour ToCP.
Références
1. Arkin, E. M., Halldórsson, M. M. and Hassin R. : Approximating the tree and tour covers of agraph. Information Processing Letters, vol.47, pp. 275-282 (1993)
2. Könemann, J., Konjevod, G. and Sinha, A. : Improved Approximations for Tour and Tree Covers.Algorithmica, vol. 38, pp. 441-449 (2003)
3. Kaplan, H., Lewenstein, M. , Shafrir, N. and Sviridenko, M. Approximation algorithms for asym-metric TSP by decomposing directed regular multigraphs. Journal of the ACM, vol. 52, pp. 602-626, (2005)

Construction des séries d’états dans l’algorithmeDivide-and-Evolve
Jacques BIBAI12, Marc SCHOENAUER1, and Pierre SAVÉANT2
1 Projet TAO, INRIA Saclay & LRI, Université Paris Sud, Orsay, [email protected]
2 Thales Research & Technology, Palaiseau, [email protected]
1 L’approche Divide-and-Evolve
Nous nous intéressons à la résolution générique des problèmes de planification temporelle detype STRIPS, telle qu’elle est définie par le formalisme PDDL2.1 [5]. Plusieurs approches ontété proposées pour la résolution de problèmes de planification temporelle, combinant des tech-niques de recherche heuristique de résolution des problèmes de planification classique (consi-dérant que toutes les actions ont la même durée) aux techniques issues de la recherche opé-rationnelle [1,2]. Mais ces techniques de résolution, certes e"caces, ne passent pas à l’échellelorsque la taille de l’espace des états et/ou le nombre d’actions possibles augmentent. Afinde surmonter cette di"culté, plusieurs méthodes sub-optimales ont été proposées. Certainesd’entre elles permettent de produire rapidement des solutions, mais souvent au prix d’unemauvaise qualité du plan généré [9].L’approche Divide-and-Evolve (DAE) [3] est basée sur l’hypothèse de l’existence de séquencesd’états intermédiaires E0 = I, E1, . . . , En = G "faciles à atteindre". Dans un premier temps, leproblème initial de planification temporelle PD(I,G) est décomposé par évolution artificielle[4] en une séquence de sous-problèmes PD(Ei, Ei+1) qui sont sous-traités à un planificateurtemporel existant. Si tous les sous-problèmes sont résolus, les solutions partielles ainsi trouvéessont ensuite recomposées pour obtenir une solution (sub-optimale) du problème initial. Dansson implantation actuelle, chaque sous-problème PD(Ei, Ei+1) est résolu par le planificateurexact CPT (Constraint Programming Temporal) [2].Nous nous intéresserons ici, au sein de l’approche DAE, à l’étape particulière que constituela construction des séquences d’états que l’on espère faciles à résoudre. Le lecteur intéressépar le détail de l’algorithme Divide-and-Evolve pourra se reporter à [7] et à [6].
2 Construction des états
La construction d’états est un des points critiques de l’algorithme DAE qui intervient dans lesphases d’initialisation et génération de nouvelles solutions candidates à l’aide des opérateursde variations. La phase d’initialisation consiste à une construction stochastique d’un ensemblede séries d’états potentiel, qui est le point de départ de l’optimisation. A chaque génération,les séries d’états possédant les meilleures évaluations seront modifiées par des opérateurs devariation pour la production de nouvelles solutions.

Séries d’états dans DAE 99
Deux aspects principaux guideront la conception de l’algorithme : essayer de respecter lacohérence des états Ei, et restreindre au maximum la taille de l’espace de recherche en utilisantdes connaissances a priori que l’on peut déduire du problème. Deux points de vue vont êtreenvisagés, di!érant par le degré de prise en compte des relations entre atomes constituant unétat donné. Ainsi, dans la construction aveugle, nous nous intéresserons à la constructiondes séries d’états E0 = I, E1, . . . , En = G grâce à des choix uniformes des atomes dansl’ensemble des atomes tout en garantissant la cohérence 2 à 2 des atomes dans chaque Ei. Laconstruction orientée quant à elle utilisera en plus une estimation du temps au plus tôtd’apparition d’un atome dans toute solution du problème lors de la construction de la séried’états E0 = I, E1, . . . , En = G.
3 Expérimentations
Le choix des atomes permettant la description des états étant un problème ouvert [7], nousavons implémenté en deux versions la construction aveugle des séries d’états. La premièreversion (1) utilise les atomes de l’état final et leurs voisins pour la construction des sériesd’états et la seconde construit ces séries d’états grâce aux atomes issus de la règle définiedans [6]. Cette règle permet de restreindre l’ensemble des atomes de base utilisé pour laconstruction des séries d’états aux atomes construits à partir d’un nombre de prédicats fixé.L’implémentation de la construction orientée des séries d’états est obtenue à partir de (1) enremplaçant ces opérateurs de variation et son initialisation par ceux implémentant la méthodeorientée. L’heuristique h2 définie dans [10] a été utilisée pour l’estimation des dates.Nos expériences sur 4 domaines des benchmarks l’Internationnal Planning Competition (IPC)ont montré qu’aucune méthode n’est meilleure (en proportion d’optima trouvée) que les autressur les 4 domaines. Lors de notre présentation, nous exposerons ces di!érentes méthodes deconstruction des séries d’états ainsi que des résultats de comparaisons.
Références1. Steven A. Wolfman and Daniel S. Weld. Combining linear programming and satisfiability solving for resource
planning. The Knowledge Engineering Review, 16, Cambridge University Press, New York (2001)2. V. Vidal and H. Ge!ner. Branching and Pruning : An Optimal Temporal POCL Planner based on Constraint
Programming. Artificial Intelligence, 170,pages 298-335, (2006)3. Marc Schoenauer and Pierre Savéant and Vincent Vidal. Divide-and-Evolve : a Sequential Hybridization Strategy
using Evolutionary Algorithms. Advances in Metaheuristics for Hard Optimization, Z. Michalewicz and P. Siarry,Springer, pages 179-198 (2007)
4. A.E. Eiben and J.E. Smith. Introduction to Evolutionary Computing, Springer Verlag (2003).5. M. Fox and D. Long. PDDL2.1 : An extension to PDDL for expressing temporal planning domains. JAIR, 20 :61-
124, 2003.6. J. Bibai and M. Schoenauer and P. Savéant and V. Vidal. DAE : Planning as Artificial Evolution (Deterministic
part). In 6th International Planning Competition Booklet (IPC-2008).7. J. Bibai and M. Schoenauer and P. Savéant and V. Vidal. Planification Evolutionnaire par Décomposition. INRIA
research report NRT-0355 (2008). URL : http ://hal.inria.fr/inria-00322880/en/8. T. Bylander. The Computational Complexity of Propositional STRIPS planning. Artificial Intelligence, 69(1-2) :
165-204 (1994)9. S. Edelkamp and M. Helmert. Mips - The Model Checking Integrated Planning System. AI Magazine Volume 22
Number 3 (2001).10. P. Haslum and H. Ge!ner. Heuristic planning with time and resources. European Conference of Planning (ECP-
01), 121-132 (2001)

The Multi-Period GAP Problem
X. CAO, A. JOUGLET and D. NACE
Université de Technologie de Compiè[email protected], [email protected], [email protected]
1 IntroductionWe focus in this article to the Multi-Period Generalized Assignment Problem(MPGAP). Thiskind of problem is inspired from di!erent real-life situations, especially when one needs tomanage a set of equipments by determining their replacement dates given a budget over a timehorizon [5]. MPGAP can be seen as a combination of the multi-period knapsack problem andthe Generalized Assignment Problem(GAP). In literature, there are a few works dealing withsome multi-period variants of knapsack problems, but, to the best of our knowledge, there areno studies directly concerned with the problem considered in this paper. More specifically, in[3] the author deals with the simple multi-period knapsack problem and in [4], the authorsstudy the multi-period multiple-choice knapsack problem.
2 Mathematical formulationLet us begin first with some notations :J gives the set of items j.T gives the time horizon. It is composed of consecutive periods t.xj,t is the decision variable with respect to choose item j at some period t.wj,t gives the weitht for item j at the period t.pj,t gives the profit associated to decision of choosing the item j at the period t.Bt gives the total capacity available for the first t periods.
max%
j%J,t%Tpj,txj,t (1)
t%
p=1
%
j%Jwj,pxj,p " Bt, ,t ! T, (2)
%
t%Txj,t " 1, ,j ! J, (3)
xj,t ! {0, 1}, ,j ! J, t ! T, (4)where B1 " B2 " B3, ...," BT .
This formulation is a general case. In fact, the problem that we deal is a special case. In ourcase, the pj,t values are non-increasing during the time horizon for a j given. And the wj,tremains no changed during the time horizon for a j given. Thus, wj,t = wj .
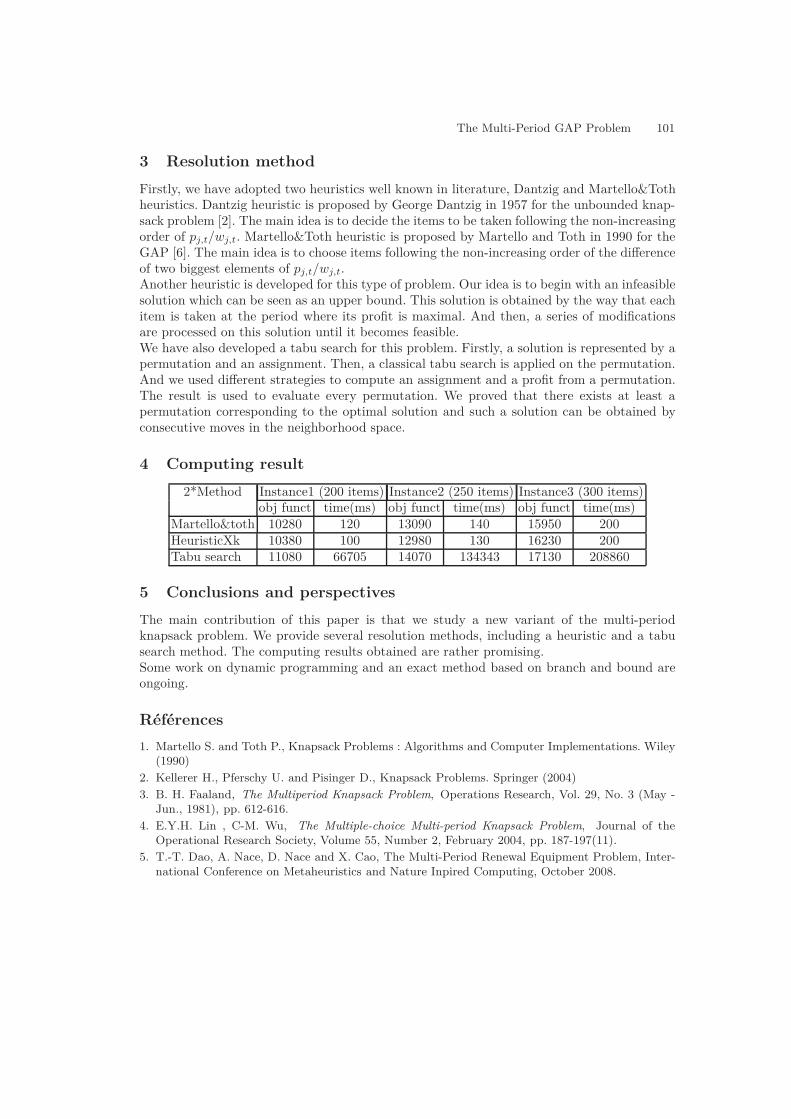
The Multi-Period GAP Problem 101
3 Resolution methodFirstly, we have adopted two heuristics well known in literature, Dantzig and Martello&Tothheuristics. Dantzig heuristic is proposed by George Dantzig in 1957 for the unbounded knap-sack problem [2]. The main idea is to decide the items to be taken following the non-increasingorder of pj,t/wj,t. Martello&Toth heuristic is proposed by Martello and Toth in 1990 for theGAP [6]. The main idea is to choose items following the non-increasing order of the di!erenceof two biggest elements of pj,t/wj,t.Another heuristic is developed for this type of problem. Our idea is to begin with an infeasiblesolution which can be seen as an upper bound. This solution is obtained by the way that eachitem is taken at the period where its profit is maximal. And then, a series of modificationsare processed on this solution until it becomes feasible.We have also developed a tabu search for this problem. Firstly, a solution is represented by apermutation and an assignment. Then, a classical tabu search is applied on the permutation.And we used di!erent strategies to compute an assignment and a profit from a permutation.The result is used to evaluate every permutation. We proved that there exists at least apermutation corresponding to the optimal solution and such a solution can be obtained byconsecutive moves in the neighborhood space.
4 Computing result2*Method Instance1 (200 items) Instance2 (250 items) Instance3 (300 items)
obj funct time(ms) obj funct time(ms) obj funct time(ms)Martello&toth 10280 120 13090 140 15950 200HeuristicXk 10380 100 12980 130 16230 200Tabu search 11080 66705 14070 134343 17130 208860
5 Conclusions and perspectivesThe main contribution of this paper is that we study a new variant of the multi-periodknapsack problem. We provide several resolution methods, including a heuristic and a tabusearch method. The computing results obtained are rather promising.Some work on dynamic programming and an exact method based on branch and bound areongoing.
Références1. Martello S. and Toth P., Knapsack Problems : Algorithms and Computer Implementations. Wiley
(1990)2. Kellerer H., Pferschy U. and Pisinger D., Knapsack Problems. Springer (2004)3. B. H. Faaland, The Multiperiod Knapsack Problem, Operations Research, Vol. 29, No. 3 (May -
Jun., 1981), pp. 612-616.4. E.Y.H. Lin , C-M. Wu, The Multiple-choice Multi-period Knapsack Problem, Journal of the
Operational Research Society, Volume 55, Number 2, February 2004, pp. 187-197(11).5. T.-T. Dao, A. Nace, D. Nace and X. Cao, The Multi-Period Renewal Equipment Problem, Inter-
national Conference on Metaheuristics and Nature Inpired Computing, October 2008.

Heuristiques itératives basées sur des relaxations pour leproblème du sac-à-dos multidimensionnel à choix
multiples
Christophe Wilbaut et Saïd Hanafi
Laboratoire d’Automatique, de Mécanique et d’Informatique industrielles et Humaines deValenciennes, Équipe SIADE, UMR CNRS 8530
Le Mont Houy, 59313 Valenciennes Cedex 9(christophe.wilbaut, said.hanafi)@univ-valenciennes.fr
Le problème du sac-à-dos multidimensionnel à choix multiples (MMKP pour Multi-choiceMultidimensional Knapsack Problem) est une variante du problème de sac-à-dos [3,6]. LeMMKP est défini par un ensemble N d’objets, divisé en n groupes disjoints G = (G1 3G2 3... 3 Gn), oô chaque groupe Gi(i = 1, ..., n) a ni = |Gi| objets. À chaque objet (j = 1, ..., ni)du groupe Gi est associé un profit cij et un ensemble de poids Aij = (a1
ij , a2ij , ..., a
mij ) relatifs
aux m contraintes de sac-à-dos (ou de ressources) b = (b1, b2, ..., bm). L’objectif du problèmeest de choisir exactement un objet de chaque groupe de manière à maximiser le profit totalet en respectant les contraintes de capacité. Plus formellement, le MMKP peut être définicomme suit :
(MMKP)
2
33333334
maxn&i=1
&j%Gicijxij
sous les contraintes :n&i=1
&j%Giakijxij " bk ,k = 1, . . . ,m
&j%Gixij = 1 i = 1, . . . , n
xij ! {0, 1} i = 1, . . . , n, j ! Gioô xij = 1 si l’objet j du groupe Gi est choisi, 0 sinon.Plusieurs applications pratiques du MMKP peuvent être recencées dans la litérature telle quedans les systèmes multimédias adaptatifs [3].En raison de sa di"culté, la plupart des approches proposées pour résoudre ce problèmesont basées sur des heuristiques. Moser et al. [4] furent parmi les premiers à s’intéresser àla résolution de ce problème à l’aide d’un algorithme basé sur la relaxation Lagrangienne.Finalement, les papiers de Hifi et al. [2] et de Cherfi et Hifi [1] basés sur une méthode derecherche locale guidée et sur une génération de colonnes ont permis d’obtenir des réultatstrès intéressants sur un ensemble d’instances existantes.Plusieurs approches hybrides proposées récemment pour résoudre des problèmes d’optimi-zation di"ciles sont basées sur l’exploration de petits voisinages (voir références dans [5]).L’approche que nous proposons repose sur ce même principe, et consiste à résoudre une sériede problèmes réduits de petite taille générés à partir de l’information fournie par une série desolutions optimales de relaxations du problème. A chaque itération, une ou plusieurs pseudo-coupes sont ajoutées dans le problème de manière à restreindre l’espace de recherche et assurerla convergence de la méthode vers une solution optimale. La convergence de l’algorithme est

Heuristiques itératives basées sur des relaxations pour le MMKP 103
cependant di"cile à obtenir en pratique, nous l’utilisons plutôt comme une heuristique enfixant à l’avance le nombre d’itérations ou le temps total d’exécution. Plusieurs élémentspeuvent facilement être intégrés à la méthode pour en améliorer le fonctionnement tels quedes techniques de dominance permettant de diminuer le nombre de problèmes réduits à ré-soudre, ou encore l’utilisation d’une recherche locale pour a"ner la valeur de la meilleureborne inférieure obtenue [5]. Dans ce travail nous proposons l’utilisation de la méthode pourrésoudre le MMKP. Quelques composants particuliers sont ajoutés et l’approche est validéesur un ensemble de 33 instances existantes. Le tableau 1 récapitule les résultats obtenus. Nousprécisons dans ce tableau pour chaque instance la meilleure valeur reportée dans [1], la valeurobtenue par notre approche et le temps d’exécution en secondes. Globalement les résultatsreportés dans ce tableau montrent l’e"cacité de l’approche pour ce problème.
Tab. 1. Synthèse des résultats
Instance Best cx CPU Instance Best cx CPU Instance Best cx CPUI01 173 173 0 Ins01 10732 10712 56 Ins14 32870 32869 477I02 364 364 0 Ins02 13598 13596 53 Ins15 39157 39160 562I03 1602 1602 5 Ins03 10943 10934 41 Ins16 43361 43363 660I04 3597 3597 9 Ins04 14440 14442 167 Ins17 54349 54355 954I05 3905.7 3905.7 0 Ins05 17053 17041 134 Ins18 60460 60462 816I06 4799.3 4799.3 0 Ins06 16825 16823 327 Ins19 64923 64928 979I07 24587 24585 60 Ins07 16435 16420 173 Ins20 75611 75606 564I08 36892 36862 111 Ins08 17510 17503 203I09 49176 49146 76 Ins09 17760 17744 101I10 61461 61442 68 Ins10 19314 19306 378I11 73775 73752 122 Ins11 19434 19418 63I12 86078 86091 525 Ins12 21731 21720 80I13 98431 98425 732 Ins13 21575 21576 595
Références1. Cherfi, N. et M. Hifi. A column generation method for the multiple-choice multi-dimensional
knapsack problem, Computational Optimization and Applications, DOI 10.1007/s10589-008-9184-7, 2008.
2. Hifi, M., M. Michrafy and A. Sbihi. Heuristic algorithms for the multiple-choice multidimensionalknapsack problem, Journal of the Operational Research Society, 55, pp. 1323–1332, 2004.
3. Khan, S., K. F. Li and E. G. Manning. The Utility Model for Adaptive Multimedia System. In :International Workshop on Multimedia Modeling, pp. 111–126, 1997.
4. Moser, M., D. P. Jokanovic and N. Shiratori. An algorithm for the multidimensional multiple-choice knapsack problem, IEICE Transactions, A(E80), pp. 582–589, 1997.
5. Wilbaut, C. and S. Hanafi. New convergent heuristics for 0-1 mixed integer programming. Euro-pean Journal of Operational Research, DOI 10.1016/j.ejor.2008.01.044, 2008.
6. Wilbaut, C., S. Hanafi and S. Salhi. A survey of e#ective heuristics and their application toa variety of knapsack problems, IMA Journal of Management Mathematics, DOI 10.1093/ima-man/dpn004, 2008.

Une formulation PLNE e"cace pour 1|rj|Lmax
C. Briand and S. Ourari
LAAS-CNRS ; Université de Toulouse ; 7, avenue du Colonel Roche, F-31077 Toulouse, France.{briand,sourari}@laas.fr
1 IntroductionCet article s’intéresse au problème d’ordonnancement à 1 machine. Il s’agit de déterminerune séquence de n travaux , chaque travail j étant caractérisé par une date de début au plustôt rj , une date de fin au plus tard dj et une durée opératoire pj , de sorte à minimiser leplus grand retard algébrique (problème classiquement noté 1|ri|Lmax). En l’absence d’hypo-thèse supplémentaire, ce problème est NP-di"cile au sens fort. Néanmoins, on sait que laméthode branch-and-bound de Carlier (voir [2]) est capable de résoudre très e"cacementdes instances comptant plusieurs milliers de travaux. Cet article propose une formulationde ce problème sous forme d’un Programme Linéaire en Nombres Entiers (PLNE). Cetteformulation est doublement intéressante. Tout d’abord, elle o!re une méthode de résolutionalternative puisque, grâce à l’utilisation d’un solveur du marché, elle permet de résoudree"cacement des instances comptant plusieurs milliers de travaux. Ensuite, une formulationPLNE étant par essence générique, d’autres critères ou contraintes peuvent être envisagés.La formulation PLNE est fondée sur un théorème de dominance qui permet de restreindrel’espace de recherche à un sous ensemble de séquences de travaux ayant une forme particulière.Ce théorème est présenté dans la première partie.
2 Un théorème de dominanceDans les années 80, un nouveau théorème est proposé dans [3] pour la caractérisation d’unensemble de séquences dominantes pour le problème à une machine. Ce théorème est basésur une analyse de structure d’intervalles. Un intervalle [rj ,dj ] est associé à chaque travail j.On s’intéresse dans ce qui suit aux sommets de la structure d’intervalles et aux pyramidesqu’ils caractérisent. Un travail t est dit sommet s’il n’existe pas de travail j 9= t tel querj > rt 5 dj < dt (i.e., l’intervalle de t n’est pas inclus strictement dans un autre intervalle).Étant donné un sommet t, la pyramide Pt relative à t est l’ensemble des travaux j tels querj < rt 5 dj > dt (i.e., l’ensemble des travaux dont l’intervalle d’exécution inclut strictementcelui de t). Pour la détermination des sommets et pyramides, seul l’ordre relatif défini par lesdates de début au plus tôt rj et de fin au plus tard dj des n travaux est considéré (i.e., lesdurées opératoires pj et les valeurs numériques de rj et dj ne sont pas utilisées).On suppose que les m sommets de la structure d’intervalles sont indicés par rj croissants (pardj croissants en cas d’égalité de rj). La pyramide notée P# désigne la pyramide caractérisée parle sommet t#. On note u(j) (resp. v(j)) l’indice de la première pyramide à laquelle le travailj appartient (resp. l’indice de la dernière pyramide à laquelle le travail j appartient). Unensemble dominant de séquences peut alors être caractérisé ainsi que décrit dans le théorèmesuivant.

Une formulation PLNE e%cace pour 1|rj |Lmax 105
Theorème 1 L’ensemble des séquences de travaux de la forme ( = %1 ? t1 ? &1 ? · · · ?%k ? tk ? &k ? · · · ? %m ? tm ? &m, où :- tk est le sommet de la pyramide Pk, ,k = 1 . . .m ;- %k et &k sont deux sous-séquences de travaux situées respectivement à la gauche et à la
droite du sommet tk, telles que les travaux de la sous-séquence %k sont ordonnés selonl’ordre croissant de leur rj, et ceux appartenant à &k, selon l’ordre croissant de leur dj ;
- tout travail non sommet j est a!ecté soit à %k, soit à &k, pour un certain k tel que u(j) "k " v(j) ;
est dominant pour le problème de recherche d’une solution admissible.
3 Détermination du plus grand retard algébriqueConsidérant une séquence dominante de la forme ( = %1 ? t1 ? &1 ? · · · ? %k ? tk ?&k ? · · · ? %m ? tm ? &m, il est possible d’associer à chaque sous-séquence %k ? tk ? &kles grandeurs numériques Rk et Dk. Rk correspond à la date de fin au plus tôt de la sous-séquence %k et peut être calculée par l’équation 1 ; où eftk#1 est la date de fin au plus tôt dela sous-séquence &k#1 , définie par l’égalité : eftk#1 = Rk#1 + ptk"1 +
&j%$k"1
pj .
Rk = maxi%#k
(rtk ,max(ri, eftk#1) +%
{j%#k|i'j}
pj + pi) (1)
De façon similaire, la variable Dk, correspondant à la date de début au plus tard de la sous-séquence &k, peut être calculée par l’équation 2 ; où lstk+1, correspondant à la date de débutau plus tard de la sous-séquence %k+1, est calculée par la formule : lstk+1 = Dk+1 # ptk+1 #&j%#k+1
pj.
Dk = mini%$k
(dtk ,min(di, lstk+1)#%
{j%$k|j'i}
pj # pi) (2)
Dans [1], il est alors montré que le plus grand retard algébrique des travaux appartenant à lasous-séquence %k ? tk ? &k est exactement égal à Rk #Dk + ptk . Par conséquent, minimiserla fonction z = maxk=1...m(Rk # Dk + ptk) est équivalent à minimiser le plus grand retardalgébrique.Sur la base de ce résultat, nous proposons un PLNE en variables mixtes (entières et binaires)pour résoudre le problème 1|rj |Lmax. Ce PLNE sera décrit lors de la conférence et nousdiscuterons de son e"cacité, de ses limites et de ses possibles extensions pour résoudre d’autresproblèmes à une machine.
Références1. Briand C., Ourari S., Bouzouia B. “An e%cient ILP formulation for the single machine scheduling
problem", submitted to RAIRO - Operations Research, 2008.2. Carlier, J., “The one-machine sequencing problem", 1982, European Journal of Operational Re-
search, 11, 42-47.3. Erschler, J., Fontan, G., Merce, C., Roubellat, F.,“A New Dominance Concept in Schedulingn Jobs on a Single Machine with Ready Times and Due Dates", Operations Research, Vol. 31,pp114-127, 1983.

Amélioration de la borne préemptive pour le problème1|ri|Lmax
F. Della Croce1 and V. T’kindt2
1 D.A.I. Politecnico di Torino, Torino, [email protected]
2 Laboratoire d’Informatique de l’Université François-Rabelais Tours, 64 avenue Jean Portalis,37200 Tours, France.
1 Introduction
Dans ce papier nous considérons le problème d’ordonnancement à une machine où tous lestravaux disposent d’une date de début au plus tôt et d’une date de fin souhaitée. Le problèmepeut être établi comme suit. Un ensemble de n travaux doit être exécuté sur une machinedisponible sans interruption. Chaque travail i a un temps opératoire pi, une date de débutau plus tôt ri et une date due di. La machine peut traiter un seul travail à la fois et aucuntravail ne peut débuter avant sa date de début au plus tôt. La préemption n’est pas autorisée.L’objectif est de minimiser le plus grand retard algébrique Lmax = maxi Li = maxi(Ci # di),avec Ci la date de fin du travail i. Ce problème, qui peut être noté 1|ri|Lmax, est NP-di"cileau sens fort.
Lorsque la préemption des travaux est autorisée, le problème devient résoluble en O(n log(n))en calculant l’ordonnancement préemptif de Jackson ([3]) : “Ordonnancer à chaque instant t letravail de plus petite date due parmi les travaux disponibles à cette date”. La valeur du critèreLmax pour ce problème constitue une borne inférieure, très e"cace, pour le problème non pré-emptif. La résolution exacte du problème 1|ri|Lmax peut être réalisée à l’aide des algorithmesproposés par Carlier ([1]) et Pan et Shi ([4]). D’ailleurs, Pan et Shi proposent également uneborne inférieure, notée SLB, qui améliore la borne préemptive d’approximativement 31%sur des instances non triviales où cette dernière ne donne pas la solution optimale. Dans cepapier, nous proposons une amélioration de la borne préemptive qui est fortement basée surl’analyse des conséquences de la préemption. Il est intéressant de noter que cette améliora-tion conserve la même complexité algorithmique dans le pire des cas que celle du calcule dela borne préemptive. Ce travail s’inscrit dans la lignée de l’amélioration déjà réalisée pourla borne préemptive sur le problème 1|ri|
&iCi ([2]). Des résultats expérimentaux montrent
que non seulement nous améliorons significativement la borne préemptive, mais également laborne SLB.
2 Amélioration de la borne préemptive
Supposons que les n travaux i soient numérotés selon leur date de fin dans l’ordonnancement,noté JPS, obtenu en appliquant la règle de Jackson. Soit j le travail critique, i.e. celui qui

Amélioration de la borne préemptive pour le problème 1|ri|Lmax 107
donne la valeur du Lmax dans JPS. Autrement dit, Lj est la valeur de la borne inférieurepréemptive. Soit OPT une solution optimale au problème non préemptif. Nous allons, enétudiant le travail j, essayer d’améliorer la valeur de la borne préemptive. Pour cela nousconsidérons les quatres cas, exhaustifs, suivants :1. Dans OPT , les travaux 1, ..., j précèdent les travaux j+1, ..., n avec le travail j en position
[j].2. Dans OPT , les travaux 1, ..., j précèdent les travaux j+1, ..., n avec le travail j en position
[h] < [j].3. Dans OPT , le travail j est précédé des travaux 1, ..., j# 1 et d’au moins un travail k > j.4. Dans OPT , un travail h < j est précédé des travaux 1, ..., h#1, h+1, ..., j et par au moins
un travail k > j.Pour chaque cas, nous dérivons une borne inférieure sur l’augmentation deLmax(JPS) et nousretenons la plus petite augmentation au final comme amélioration de la borne préemptive.
3 Résultats expérimentauxNous avons évalué expérimentalement notre borne, notée LBDCT , sur des instances généréesaléatoirement suivant le protocole décrit dans [4]. Nous avons comparé notre borne à la bornepréemptive, notée Lmax(JPS), et à la borne SLB. Nous nous sommes intéressés à la réduc-tion, par LBDCT et SLB, de l’écart à l’optimum de la borne préemptive.
Les résultats que nous avons obtenus, pour des tailles de problème allant de 50 à 1000 travaux,montrent qu’en moyenne, sur les instances sur lesquelles Lmax(JPS) 9= Lmax(OPT ), la borneLBDCT réduit au minimum l’écart à l’optimum de 73%. Cela signifie que lorsque l’écartentre Lmax(JPS) et Lmax(OPT ) est de 100, LBDCT est en moyenne inférieure de 27 àLmax(OPT ). De plus, LBDCT améliore Lmax(JPS) pour 69% des instances sur lesquellesLmax(JPS) 9= Lmax(OPT ). Et au minimum pour 62% de ces instances, LBDCT retrouve lavaleur de Lmax(OPT ).Les résultats obtenus par SLB sont moins bons que ceux obtenus par LBDCT : au mieux,SLB réduit l’écart à l’optimum de 58% mais dans ce cas LBDCT le réduit de 93%. Dernierélément de comparaison : sur les 1665 instances pour lesquelles Lmax(JPS) 9= Lmax(OPT ),LBDCT améliore Lmax(JPS) pour 1334 instances tandis que SLB n’améliore Lmax(JPS)que pour 681 instances.
Références1. Carlier J. (1982), “The one-machine sequencing problem”, European Journal of Operational Re-
search 11, 42-47.2. Della Croce F. and T’Kindt V. (2003), “Improving the preemptive bound for the one-machine
dynamic total completion time scheduling problem”, Operations Research Letters 31, 142-148.3. Jackson J.R. (1955), “Scheduling a Production Line to Minimize Maximum Tardiness”, Research
Report 43, Management Science Research Project, University of California, Los Angeles.4. Pan Y. and Shi L. (2006), “Branch-and-bound algorithms for solving hard instances of the one-
machine sequencing problem”, European Journal of Operational Research 168, 1030-1039.

Jackson’s Semi-Preemptive Schedule on One Machinewith Heads and Tails
A. Gharbi,1 and M. Labidi2
1 Industrial Engineering Department, College of Engineering, King Saud University, Saudi [email protected]
2 ROI-Recherche OpÈrationnelle pour l’Industrie, Ecole Polytechnique de Tunisie, Tunisia [email protected]
1 Introduction
We consider the scheduling problem of minimizing the makespan on a single machine whereeach job j(j = 1, .., n) has a release date (or head) rj , a nonpreemptive processing time pj ,and a delivery time (or tail) qj . This strongly NP-hard problem, denoted by 1|rj , qj |Cmax,plays a central role in solving more complex scheduling problems. This is probably due toits e"cient resolution by the clever branch-and-bound algorithm of Carlier [1]. Actually, oneof the major factors which are responsible of the impressive e"ciency of Carlier’s algorithmis the implementation of a tight lower bound. This bound is based on the optimal solutionof the preemptive relaxation of the problem which is computed using the so called Jackson’sPreemptive Schedule (JPS). It consists in scheduling the first available job with largest tailwhen either the machine becomes available, or the currently scheduled job has a smaller tail(this job is preempted and resumed later). The JPS-based lower bound had been consideredas the best one in the literature for the 1|rj , qj |Cmax until the very recent development ofan enhanced lower bounding procedure for the equivalent 1|rj |Lmax problem [2]. Again, thisenhanced bound is based on structural properties of JPS. Moreover, JPS has the additionalinteresting feature to be useful in adjusting heads and tails for the job shop problem. Inthis paper, we propose an e!ective improvement of JPS, baptized Jackson’s Semi-PreemptiveSchedule (JSPS). It roughly consists in reducing the preemption impact by constraining someparticular job parts to be processed in fixed time intervals. An immediate consequence is thatan optimal semi-preemptive schedule yields a lower bound which dominates the preemptiveone. Furthermore, it enables more e!ective adjustments of the heads and tails. Our expe-rimental study reveals that embedding JSPS in Carlier’s algorithm makes feasible to solve88.39% of the hard instances which could not be solved by its original variant.
2 Jackson’s Semi-Preemptive Schedule
Consider the decision variant of the 1|rj , qj |Cmax which consists in checking the existenceof a schedule with makespan less than or equal to a trial value C. A deadline dj = C # qj isassociated to each job j. As introduced in [3], the semi-preemptive scheduling concept is basedon the observation that, in a non-preemptive schedule, any job j with rj + pj > dj # pj hasa fixed part which has to be nonpreemptively processed during the interval [dj # pj , rj + pj ]for 2pj # dj + rj units of time. The remaining part, referred to as its free part, has to be

Jackson’s Semi-Preemptive Scheduling on One Machine 109
processed in [rj , dj # pj ] 3 [rj + pj , dj ] for dj # rj # pj units of time, and is allowed to bepreempted. Interestingly, the semi-preemptive concept can be extended by also consideringthose jobs which do not satisfy rj + pj > dj # pj . Indeed, based on the mandatory partintroduced by Lahrichi [4], we can derive the following observation : In a non-preemptiveschedule, any job j has to be processed for at least xj units of time within the interval[rj + pj # xj , dj # pj + xj ]. Therefore, any job j can be replaced by two jobs j! and j!! whichare allowed to be preempted and such that rj! = rj +pj#xj ; pj! = xj ; dj! = dj #pj+xj ; andrj!! = rj ; pj!! = pj # xj ; dj!! = dj . After performing extensive computational experiments, wefound that a good performance is achieved through setting xj = 2pj#dj+rj if rj+pj > dj#pjand xj = 1 otherwise. In order to check the existence of a feasible semi-preemptive schedule, itsu"ces to construct JPS on the modified instance (here the priority is given to the available jobwith minimum dj). Indeed, JPS minimizes the maximal deviation of the job completion timeswith respect to their respective deadlines when preemption is allowed. Consequently, if thereis a job which finishes processing after its corresponding deadline, then there is no feasiblesemi-preemptive schedule. The obtained schedule is referred to as Jackson’s Semi-PreemptiveSchedule (JSPS). The optimal semi-preemptive makespan can be computed using a bisectionsearch on the interval [PLB,UB], where PLB denotes the preemptive lower bound and UBdenotes the makespan of Schrage schedule [1].
3 Preliminary Experimental Results
The performance of the JSPS-based proposed lower bound has been assessed on a set of 224hard instances randomly generated in a similar way as in [1]. All of these instances could notbe solved within 2 minutes by Carlier’s branch-and-bound algorithm and have been obtainedafter generating 500,000 instances. Table 1 shows the performance of Carlier’s algorithmafter embedding the semi-preemptive lower bound. For each number of jobs n, we provide thepercentage number of solved instances (Solved) and the average required CPU time (Time)on a Core 2 Duo 1.83 GHz laptop with 1 GB RAM. Table 1 provides strong evidence ofthe worth of implementing JSPS. Indeed, this makes feasible to solve 88.39% of these hardinstances within an average CPU time of 1.4 seconds. Moreover, preliminary comparison withthe recent lower bound proposed in [2] exhibits promising performance of JSPS, while beingmuch easier to implement.
Tab. 1. Performance of Carlier’s algorithm with JSPS-based lower bound
n 50 100 150 200 250 300 350 400 450 500
Solved 83.33 83.78 72.73 88.89 80 100 87.50 100 100 100Time 0.01 0.02 0.04 0.08 0.14 0.28 0.41 0.97 1.03 0.95
n 550 600 650 700 750 800 850 900 950 1000Solved 66.67 100 100 100 100 100 100 100 100 100Time 1.13 1.62 1.89 1.92 2.52 2.78 2.61 3.88 4.37 1.30

110 Anis Gharbi et Mohamed Labidi
Références
1. Carlier, J. : The one-machine sequencing problem. European Journal of Operational Research 11,42-47 (1982)
2. Della Croce, F., T’Kindt, V. : Improving the Preemptive Bound for the Single Machine Min-MaxLateness Problem Subject to Release Times. Proceedings of the Eleventh International Workshopon Project Management and Scheduling, Istanbul, 52-55 (2008)
3. Haouari, H., Gharbi, A. : An Improved Max-Flow Based lower Bound for Minimizing MaximumLateness on Identical Parallel machines. Operations Research Letters 31, 49-52 (2003)
4. Lahrichi, A. : Ordonnancements : La Notion de "Parties Obligatoires" et son Application auxProblËmes Cumulatifs. RAIRO-RO 16, 241-262 (1982)

Minimisation des croisements de flux dans uneplateforme de crossdocking
O. Ozturk, G. Alpan, and M.-L. Espinouse
Laboratoire G-SCOP, Grenoble INP-UJF-CNRS 46 Ave. Félix Viallet, 38031 [email protected]
1 Introduction
Le crossdocking a pour but de minimiser le temps et le coût de stockage et de transport encréant un point de consolidation pour les marchandises vers une même destination et desorigines diverses. Un produit arrivant dans une plateforme de crossdock est, soit directementconsolidé avec d’autres produits vers une même destination, soit stocké pour une très courtedurée, puis chargé sur un camion de sa destination. Dans ce travail, nous traitons le problèmed’a!ectation des camions aux portes d’une plateforme de crossdocking. La plupart des tra-vaux sur l’a!ectation des camions se focalisent sur la minimisation de la distance parcouruepar des transpallettes [2]. Gue et Bartholdi [1] montrent que ce critère n’est pas toujours leplus pertinent et ils proposent une a!ectation pour minimiser la congestion au sein du cross-dock. D’autres critères ont été considérés dans la littérature , tels la minimisation des coûtsengendrés par le nombre de marchandises déposées au sol, la minimisation du nombre de chan-gements de camions aux portes ou encore la minimisation de la durée entre les opérations dedéchargement et chargement sont considérés [3]. Dans [1] les auteurs définissent la congestionen termes de quantité de frets déposés au sol. Notons que la congestion peut être égalementdues aux croisements des transpalettes. A chaque croisement entre deux transpalettes, l’und’eux doit attendre pour que l’autre passe. Cette attente peut être plus ou moins importanteselon l’agencement du crossdock. Dans cette étude, le but est de trouver une a!ectation descamions aux portes d’entrée et de sortie telle que les croisements de flux soit minimisé. Pourrésoudre ce problème, nous proposons un programme linéaire.
2 Hypothèses
Nous prenons les hypothèses suivantes :1. La quantité de marchandises dans un camion d’entrée et sa destination sont connues. Grâceà cette hypothèse, nous pouvons déduire le flux entre les portes d’entrée et de sortie pour unea!ectation donnée. Ces flux sont exprimés en nombre de tours de transpallettes nécessairespour transférer les marchandises2. Aucune marchandise n’est déposée au sol. Tout produit entrant est directement transférévers un camion de sortie.3. Les séquences des camions en entrée et en sortie sont connues.4. Les portes ne sont pas prédéfinies en tant que portes de type "entrée" ou de type "sortie".5. Les croisements peuvent être de 2 types (voir figure 1) : Les croisement par un point (parexemple entre les portes 1-6 et 2-5) seront appelés les croisements de type 0 et les croisements

112 Ozturk, Alpan, Espinouse
Fig. 1. figure 1
de type chevauchement de flux (par exemple entre les portes 8-6 et 7-5) seront appelés lescroisements de type 1. Cette classification facilite l’expression mathématique des croisementsdans notre programme linéaire.6. Pour un flux de marchandises donné au sein du crossdock, le nombre de croisements estdéfini par le nombre de tours de transpalettes. Par exemple, dans l’exemple en figure 1,supposons qu’il y ait 5 tours de transpalettes sur l’axe (7-5) et 3 tours sur l’axe (8-6). Lenombre de croisements est donc 3.
3 Modélisation et limites de la résolution
Pour déterminer l’a!ectation des camions aux portes du crossdock qui permet de minimiser lenombre de croisements de flux de type 0 et de type 1, nous proposons un programme linéaire.Ce programme linéaire permet d’obtenir la solution optimale en quelques secondes pour desproblèmes avec 6 portes. A partir de 8 portes, la durée de résolution devient extrêmementimportante.La performance de notre méthode est similaire aux méthodes d’a!ectation optimale quicherchent à minimiser la distance parcourue au sein d’un crossdock.
4 Perspectives
Une perspective à cette étude est de proposer des heuristiques performantes pour pouvoirrésoudre des problèmes de plus grande taille.
Références
1. Gue, K.R. , and Bartholdi., J.J. : "Reducing Labor Costs in an LTL Crossdocking Terminal."Operations Research, 48 (6) : 823-832, 2000.
2. Iris, F., Vis A. and Roodbergen, K. J. : "Positioning of goods in a cross docking environment",Computers and Industrial Engineering Volume 54, Issue 3 Pages 677-689, 2008.
3. Yu, W. and Egbelu, P.J. : "Scheduling of inbound and outbound trucks in cross docking systemswith temporary storage", European Journal of Operational Research, Volume (Year) : 184 (2008),Pages : 377-396.

Planification d’itinéraires en transport multimodal
Fallou Gueye1,2, Christian Artigues1, Marie J. Huguet1, Frédéric Schettini2, Laurent Dezou2
1 CNRS ; LAAS ; 7 avenue du colonel Roche, F-31077 Toulouse, France Université de Toulouse ;UPS, INSA, INP, ISAE ; LAAS ; F-31077 Toulouse, France.
2 MobiGIS ; ZAC Proxima,rue de Lannoux, 31310 Grenade Cedex [email protected] ; [email protected] ; [email protected] ; [email protected]
1 Présentation du problème
Dans le contexte du développement de modes de transport alternatif au véhicule individuelpour l’organisation des déplacements de passagers via les modes de transports combinés,nous cherchons à evaluer et proposer des informations de plus en plus élaborées afin d’aiderles voyageurs à choisir le ou les modes de transport les plus appropriés (voiture, transporten commun, transport à la demande, marche à pied, vélo, modes, etc.) par rapport à leursbesoins de déplacements.Le problème central de ce travail est celui de la recherche de plus courts chemins point à pointsur des réseaux de transport multimodaux. Cette caractéristique de multimodalité induit uncertain nombre de contraintes supplémentaires (fréquences et horaire de passage des bus etmétro, vitesses de la circulation fluctuantes en fonction des conditions de trafic, restrictionspropres à chaque mode). Ansi, généralement, le problème multimodal est dépendant du temps.Dans ce contexte de calcul d’itinéraires multimodaux, on peut avoir besoin de rechercher unchemin ou les k meilleurs chemins avec un seul critère (le coût) ou plusieurs (coût et nombrede changement de modes etc.). Le problème considéré dans cet article est celui de la recherchede plus courts chemins origine-destination(s) tout en limitant le nombre de changement demodes de transport.
2 Etat de l’art des algorithmes de recherche d’itinéraires
Les problèmes de calcul d’itinéraires dits statiques, se basent sur des graphes dans lesquelsles valuations des arcs sont fixes et n’évoluent pas dans le temps. Les algorithmes de calculd’itinéraires origine-destination(s) sont de complexité polynomiale et on les répartit classi-quement en deux familles : celle à fixation d’étiquettes (algorithme de D#kstra) et celle àcorrection d’étiquettes (algorithme de Bellman). Dans un réseau de transport dépendant dutemps, la di!érence principale avec un problème statique réside dans le fait que la valuationassociée à chaque arc est liée au temps. On peut trouver aussi des temps d’attente associéaux sommets du graphe [1,6,3]. Ces réseaux de transport, dits dynamiques, sont classés selonqu’ils respectent ou non la propriété FIFO : partir plus tôt d’un point i permet d’arriver plustôt en un point j. Les problémes de plus court chemin dans un graphe dépendant du tempsont été largement étudié dans la littérature. Dans [3], les auteurs proposent des extensionsde l’algorithme de D#kstra dans le cas FIFO ou non FIFO. L’article de Pallattino et al. [6]présente une extension d’un algorithme de D#kstra basé sur les buckets en se basant sur unereprésentation du probléme par un graphe espace-temps acyclique.

114 C. Artigues, L. Dezou, F. Gueye, M.J. Huguet, F. Schettini
Dans un réseau de transport multimodal, les noeuds et les arcs du graphe sont liés aux modes.Les arcs du graphe sont valués par leur coût et par le mode utilisé (le transfert étant un modeparticulier). Le problème de calcul de chemin multimodal revient à déterminer un cheminde coût minimal tout en respectant des contraintes sur la composition des trajets (nombremaximum de transferts ou la viabilité du chemin parcouru en raison des préférences de l’uti-lisateur). Febbraro et Sacone [4] considèrent un problème de plus court chemin classique oùle critère à minimiser est le temps de trajet sans prendre en compte de contraintes addition-nelles sur la composition des trajets. Ils proposent un algorithme adapté de celui de D#kstraet le valide sur un graphe de petite taille (80 arcs et 66 noeuds). Lozano et Storchi [5] s’in-téressent à la recherche de plus court chemin multimodal viable et respectant une contraintesur le nombre maximum de transferts. Ils proposent pour cela un algorithme incrémental surle nombre de modes utilisés basé sur [6]. La validation expérimentale est limitée à un petitgraphe (21 noeuds et 51 arcs). Les évaluations d’algorithmes multimodaux et dépendant dutemps de [2,7] proposées par Bielli et Ziliaskopoulos vont jusqu’aux graphes de 1000 noeudset de moins 3000 arcs.
3 Evaluation experimentale d’algorithmesLes performances des algorithmes de calcul de recherche d’itinéraires sur des réseaux multimo-daux et dependant du temps de taille conséquente ne sont pas à notre connaissance clairementétablies. Nous proposons donc de comparer les performances de di!érents algorithmes de cal-cul d’itinéraires multimodaux viables et respectant une limite sur un nombre de changementde modes sur un réseau de transport réel (cas de Toulouse) plus grand que celui de [2] et [7],et utilisant les modes de transport suivants (bus, métro, voiture, marche). Les algorithmesauxquels nous nous intéressont sont : (a) une extension au cas multimodal d’un algorithme deD#kstra dépendant du temps ; (b) une extension de l’algorithme de Lozano [5]multimodal aucas dépendant du temps ; (c) une variante de A$. Cette etude experimentale nous permettrad’adapter ces algorithmes sur des réseaux réels de transports multimodaux.
Références1. Ahuja, R. K. Orlin, J. B. Pallotino, S. et M.G. Scutella, 1998. Minimum time cost problems in
street networks with tra%c lights, Transportation Science 36(3)p.326-336.2. Bielli,M., Boulmakoul, et A.,Mouncif, H. Object modeling and path computation for multimodal
travel systems.European Journal of Operational Research 175 p. 1705-1730.3. Chabini, I. 1997. A new short path algorithm for discrete dynamic networks. In the proceeding of
the 8th IFAC symposium on transport system, p. 551-556.4. Di. Febbraro, A. et S. Sacone, 1995. An on-line information system to balance tra%c flows urban
areas. Proceeding of the 36th IEEE conference on decision and control, 5, p.4772-4773, 1995.5. Lozano, A. et Storchi, G., 2001. Shortest viable path Algorithm in multimodal network. Trans-
portation Research Part A 35, p. 225-2416. Pallottino, S. et M. G. Scutellà, 1998. Shortest path algorithms in aransportation models : Classical
and Innovative Aspects. Equilibrium and Advanced Transportation Modelling, Kluwer, p.245-2817. Ziliaskopoulos, A. et W. Wardell. 2000. An intermodal optimum path algorithm for multimodal
networks with dynamic arc travel times and switching delays. Elsevier Science, European Journalof Operational Research, 125 : p. 486-502.

Core Routing on Time-Dependent Networks
G. Nannicini,1 and D. Delling2
1 LIX, Ecole Polytechnique, 91128 Palaiseau Cedex, [email protected]
2 Universität Karlsruhe (TH), 76128 Karlsruhe, [email protected]
1 Introduction
We consider the Time-Dependent Shortest Path Problem (TDSPP) : given a directedgraph G = (V,A), a source node s ! V , a destination node t ! V , an interval of time instantsT , a departure time 10 ! T and a time-dependent arc cost function c : A * T : R+, find apath p = (s = v1, . . . , vk = t) in G such that its time-dependent cost )%0(p), defined recursivelyas follows :
)%0(v1, v2) = c(v1, v2, 10) (1))%0(v1, . . . , vi) = )%0(v1, . . . , vi#1) + c(vi#1, vi, 10 + )%0 (v1, . . . , vi#1)) (2)
for all 2 " i " k, is minimum. Throughout the rest of this paper we will consider a function3 : A : R+ such that ,(u, v) ! A, 1 ! T we have 3(u, v) " c(u, v, 1). We assume that thecost function has the FIFO property, so that the TDSPP is polynomially solvable [2].Several practical applications (e.g. route planners on web sites) motivate the study of al-gorithms that can solve the TDSPP in a few milliseconds at most. In a recent work [3],we proposed a point-to-point shortest paths algorithm which applies bidirectional search ontime-dependent road networks. By extending the algorithm with a hierarchical approach [1],we have been able to obtain the smallest average search space reported in the literature fortime-dependent shortest paths computations between random points. In this paper we surveyour recent research.
2 Algorithm
Bidirectional search is a commonly used speedup technique for shortest paths computationson static (i.e. non time-dependent) graphs. However, bidirectional search cannot be directlyapplied on time-dependent graphs, the optimal arrival time at the destination being unknown.In a recent work [3], we proposed a time-dependent bidirectional ALT algorithm (TDALT).The algorithm is based on restricting the scope of a time-dependent A$ search from thesource using a set of nodes defined by a time-independent A$ search from the destination.The backward search is a reverse search on the graph G weighted by 3.Core routing is a hierarchical approach which has been widely used for shortest paths algo-rithms on static graphs. The main idea is to use contraction : a routine iteratively removesnodes and adds edges to preserve correct distances between the remaining nodes, so that wehave a smaller network where most of the search can be carried out. When the contracted

116 Nannicini, Delling
Tab. 1. Performance of time-dependent D$kstra, TDALT and TDCALT.
Preproc. Querytime space # settled time
technique [min] [B/n] nodes [ms]D$kstra 0 0 8 877 158 5 757.4TDALT 28 256 2 931 080 2 953.3TDCALT 60 61 60 961 121.4
graph GC = (VC , AC) has been computed, it is merged with the original graph to obtainGF = (V,A3AC). In other words, we build a 2-levels hierarchy, adding a smaller network ontop of the original graph. In [1], we proposed the following query algorithm.1. Initialization phase : start a D#kstra search from both the source and the destination node
on GF , using the time-dependent costs for the forward search and the time-independentcosts 3 for the backward search, pruning the search (i.e. not relaxing outgoing arcs) atnodes ! VC . Add each node settled by the forward search to a set S, and each node settledby the backward search to a set T . Iterate between the two searches until : (i) S ; T 9= 2or (ii) the priority queues are empty.
2. Main phase : (i) If S;T 9= 2, then start an unidirectional D#kstra search from the sourceon GF until the target is settled. (ii) If the priority queues are empty and we still haveS ; T = 2, then start TDALT on the graph GC , initializing the forward search queuewith all leaves of S and the backward search queue with all leaves of T , using the distancelabels computed during the initialization phase. The forward search is also allowed toexplore any node v ! T . Stop when t is settled by the foward search.
In other words, the forward search “hops on” the core when it reaches a node u ! S ; VC ,and “hops o!” at all nodes v ! T ;VC . We call this algorithm TDCALT = Core + TDALT.
3 Experiments
We tested our algorithm on the road network of Western Europe provided by PTV AG forscientific use, which has approximately 18 million vertices and 42.6 million arcs, on one coreof an AMD Opteron 2218 clocked at 2.6 GHz. In Table 1 we report preprocessing time andspace, as well as average number of settled nodes and query times over 10 000 random queries.We can observe that TDCALT yield a reduction of the search space of a factor @ 150 withrespect to D#kstra’s algorithm.
Références1. D. Delling and G. Nannicini. Bidirectional Core-Based Routing in Dynamic Time-Dependent
Road Networks. In Proceedings of ISAAC 08, LNCS. Springer, Dec. 2008. to appear.2. D. E. Kaufman and R. L. Smith. Fastest paths in time-dependent networks for intelligent vehicle-
highway systems application. Journal of Intelligent Transportation Systems, 1(1) :1–11, 1993.3. G. Nannicini, D. Delling, L. Liberti, and D. Schultes. Bidirectional A$ search for time-dependent
fast paths. In Proceedings of WEA 08, volume 5038 of LNCS, pages 334–346.

Un modèle de Plan Directeur des Opérations pour uneSupply Chain. Une étude de cas dans l’Automobile.
J.P. Garcia-Sabater1 and J. Maheut2
1 Dpto. de Organizacion de Empresas, Universidad Politécnica de Valencia, Camino de Vera s/n,46022 Valencia, Espana.
2 Dpto. de Organizacion de Empresas, Universidad Politécnica de Valencia, Camino de Vera s/n,46022 Valencia, Espana.
[email protected], [email protected]
1 Contexte de l’étude
Comme département directement impliqué dans la Supply Chain, le département de Pro-duction est généralement chargé de fixer le rythme de production journalier, de signaler lesnécessités en matières premières au département « Achats », mais aussi d’assurer la produc-tion nécessaire afin d’assurer les envois à la charge du département logistique. La plupart dutemps, les entreprises disposent d’un outil informatique puissant standard, un MPS/MRP.Son objectif est de planifier les besoins en produits afin de satisfaire la demande finale. Il éta-blit également un échéancier de la production pour satisfaire le plan industriel et commercial(PIC).
Dans le cadre de la redistribution de sa production au niveau mondial, l’usine de fabricationde moteurs d’Almussafes (Espagne) s’est trouvée dans le besoin de disposer d’un outil capablede planifier toute sa chaîne logistique et de planifier à court terme sa production. Ceci afind’augmenter sa rentabilité et la satisfaction de ses clients. Traitant d’une usine qui fournit denombreux clients en moteurs tout comme en composants, la gestion des envois, de la produc-tion et des achats est très lourde. Cette usine produit non seulement di!érents moteurs pourdi!érents clients sur une même ligne de montage mais aussi des composants de hautes valeursajoutées. Pour cela, il existe cinq lignes de fabrication appelées 5Cs (Bloque-moteur, Bielle,Arbre à came, Culasse, Vilebrequin) qui sont des parties intégrantes d’un moteur assemblé.
En fonction des commandes, il s’établit un plan d’envoi de produits (moteurs et composants)par camions ou bateaux à ses clients. A partir de ce plan, il s’établit un mix de productionjournalier en moteurs et un plan de nécessité en matériaux de second niveau. Ensuite, il seplanifie les di!érentes lignes de composants qui possèdent, elles aussi, des clients diverses etvariés et des contraintes d’envois importantes. Il se planifie alors un plan de nécessités detroisième niveau (matière première). Ces deux plans de fabrication doivent être cohérentsavec la politique de stocks de l’entreprise mais aussi respecter les séquences de production desdi!érentes pièces.Le projet qui a permit l’écriture de cet article traite de la conception d’un outil flexible ete"cient avec des modèles mathématiques intéressants. Mais aussi, l’intérêt de cette étude est lacomplexité de la modélisation de la situation réelle. Il s’est avéré qu’un modèle compact tenanten compte les trois niveaux de planification avec trois niveaux de produits peut collapser. Il

118 Garcia-Sabater, Maheut
s’est donc crée di!érentes alternatives de modèles mathématiques pour obtenir un outil o!rantdes résultats impressionnants dans un temps de calcul faible grâce à un software gratuit. Cemodèle est au cur d’un outil basé sur une interface très fonctionnelle permettant la possibilitéde comparer diverses solutions.
2 Description brève du modèle mathématique
Le modèle MILP en question est multi-objectifs. L’outil permet de : Optimiser les coûts detransports des produits ; Minimiser les niveaux de stocks des produits, que ce soit des moteursou des composants des 5Cs ; Augmenter la satisfaction des clients en diminuant les backlogsdes envois de produits ; Stabiliser les plans de production afin d’optimiser la politique d’achatsde matières premières.
Les di!érentes contraintes sont relatives : Aux caractéristiques des di!érentes lignes de pro-ductions ; A la politique de gestion de stocks de l’entreprise ; Aux commandes clients ; Auxcontraintes des di!érents moyens de transport ; Aux limitations physiques et matérielles del’entreprise ; A la stabilité de production requise par la direction.
L’outil s’est montré compétitif avec l’obtention d’un plan intégral tenant en compte les troisniveaux de planification et en o!rant à l’utilisateur une interface simple et confortable. Cemodèle a été implanté avec succès dans le centre de Logistique et gère actuellement toute laSupply Chain de l’usine en question du constructeur automobile.

Un modèle MILP pour la Planification Globale. Etudede cas dans l’Automobile.
J.P. Garcia-Sabater1 and J. Maheut2
1 Dpto. de Organizacion de Empresas, Universidad Politécnica de Valencia, Camino de Vera s/n,46022 Valencia, Espana.
2 Dpto. de Organizacion de Empresas, Universidad Politécnica de Valencia, Camino de Vera s/n,46022 Valencia, Espana.
[email protected], [email protected]
1 Contexte de l’étude
Face à la récente instabilité du marché, les Supply Chain dans l’automobile doivent faire faceà des nouvelles nécessités dans la Gestion de leurs Opérations et de leurs Planifications. Leprésent projet traite d’un cas réel d’implantation d’un outil de planification de la production.La programmation mathématique linéaire utilisée se distingue par de nouvelles considérationsprises en compte. Ce cas d’étude fut destiné à une usine de fabrication de moteurs. Il s’est tenucompte de toutes les nécessités de l’entreprise comme de ses clients internationaux (demandesvariables, calendriers di!érents,...).L’automobile a toujours été caractérisée par des ventes relativement stables d’où une pro-duction JIT avec des calendriers de production figés. Suite à la chute des ventes, la majoritédes constructeurs n’ont su réadapter leur capacité car la Supply Chain n’a pu ajuster leurproduction par le manque de flexibilité de la Planification de Production. Ceci s’est aussitôttraduit par des stocks importants et des fermetures temporaires de sites.La Planification de Production à six mois de l’usine en question se gère en deux parties, laligne de moteurs et cinq lignes de production de pièces 5Cs (Bloques-moteur, Bielles, Arbres àcames, Culasses, Vilebrequins) qui sont indépendantes dans leur fonctionnement les unes desautres. De plus, à cause du niveau d’automatisation des lignes de fabrication et des coûts defonctionnement, la gestion de l’usine est atypique. La direction cherche à stopper la productiondès qu’elle le peut car ce sont des économies et le personnel s’occupe de tâches annexes ou vaen formation. D’autre part, la gestion de la capacité de production des lignes est singulièrecar elle peut être modifiée mais avec des contraintes de calendrier importantes et des pertesde productivité à tenir en compte.L’usine gère donc ses Opérations di!éremment. A la di!érence d’un « Aggregated Plan »traditionnel, le constructeur ne constitue pas de familles di!érentes mais réalise directementun plan du mix de production. De plus, le modèle est utilisé comme générateur pour lesPlans Directeurs de Production car la continuelle introduction de nouveaux modèles le rendnécessaire. Le fonctionnement actuel connait de nombreuses limitations et, de plus, l’usine vadoubler les variantes de ses di!érents produits avec l’arrivée de nouveaux clients et avec unedemande qui change constamment.Il s’est donc implanté un outil complet et personnalisé incluant une base de données spéci-fique, un système de fenêtres de capture de données et de visualisation avec au cur de cetoutil, un modèle MILP sujet de cette étude. Le modèle mathématique qui se présentera n’est

120 Garcia-Sabater, Maheut
pas courant dans la littérature. Afin d’introduire les nécessités et spécificités de ce système degestion de production général, de nouvelles contraintes ont été prises en compte. Le modèle,qui est développé, a été conçu et calibré via un processus itératif de prototypage/approbation.Le système complet implanté se fait grâce à l’usage d’un software gratuit et les di!érentesinterfaces ont été conçues afin de nécessiter le moins possible d’interactions entre elles. L’op-timisation des coûts de fonctionnement du système avec l’usage de ce software a été évaluée.
2 Description brève du modèle établi
La résolution globale de la planification se base sur un problème multi-objectif :Minimisationdes coûts de fonctionnement de la ligne considérant le calendrier, les configurations des di!é-rentes lignes ; Optimisation des inventaires des produits en tenant compte les contraintes de lademande et de la politique de l’entreprise ; Variabilité minimum des prévisions établies. Dansce projet, la résolution est multi-objective via la génération de scénarios et de leurs analyses.Les di!érentes contraintes sont relatives : Aux caractéristiques des di!érentes lignes de pro-duction ; A la politique de stock de l’entreprise et ses nécessités pour satisfaire les commande ;Aux contraintes calendaires imposées par les di!érents clients ; A la politique de l’entreprisequi peut imposer de travailler des jours féries ou des demi-journées et même de stopper laproduction un jour ouvrable ; A la dépendance de nécessités entre la ligne de moteurs et leslignes de production des composants principaux.L’implantation a été ajustée afin de minimiser les temps de calculs et optimiser le panel desolutions proposées. De plus, grâce à une analyse de scénarios permis grâce à la flexibilité desparamètres d’entrée, il en résulte une faible variabilité de la production réelle avec celle prévue.Ceci a amélioré le flux d’informations de la chaîne logistique avec comme résultats : Meilleurvisibilité pour les fournisseurs afin d’éviter les risques de rupture de stocks ; Diminution descoûts de transport ; Flexibilité et Capacité d’ajuster au mieux la planification face à n’importequelle situation du marché.

Optimisation robuste pour la gestion court terme d’unportefeuille d’actifs gaziers
R. Apparigliato1, G. Erbs1, S. Pedraza Morales1, and M.-C. Plateau1
GDF SUEZ, 361 avenue du Président Wilson, 93211 Saint-Denis La Plaine, [email protected]
[email protected]@gmail.com
1 La gestion court terme des approvisionnements de gaz naturel
Nous considérons les activités d’un négociant en gaz naturel. Il possède un portefeuille decontrats avec des producteurs de gaz, des gestionnaires d’infrastructures (réseaux, stockages),ainsi que des contrats de vente avec des clients. Il a aussi la possibilité de recourir à desmarchés d’échange de gaz. Son objectif est de gérer au mieux ce portefeuille de contrats, afind’assurer la continuité de l’approvisionnement de ses clients, maîtriser les risques financiers,et minimiser ses coûts de gestion.Nous nous plaçons ici dans une vision court terme : afin de répondre à la demande, le négociantdoit gérer chaque jour l’ensemble des actifs de son portefeuille (enlèvements sur les contrats,transit, etc.), et doit planifier les décisions à prendre sur le reste du mois courant. Les décisionsprises à court terme doivent, de plus, s’articuler avec les orientations données par la gestionà plus long terme (sous forme de cibles à atteindre en fin de mois).La planification des décisions à prendre est sujette à di!érents aléas : climat (dont la consom-mation dépend), prix de marché, défaillance d’actifs... Nous considérons dans la suite unique-ment l’aléa climatique, car les objectifs de gestion mettent la priorité sur la satisfaction de lademande.
2 Optimisation robuste du portefeuille d’actifs gaziers
L’optimisation de la planification des décisions à prendre sur un horizon de court termedoit prendre en compte l’aléa de consommation afin de produire des décisions permettantde s’adapter à la réalisation de l’aléa chaque jour. L’optimisation robuste [2,3,1] fait partiedes méthodes adaptées à ce type de problématiques d’optimisation dans l’incertain. Cettetechnique consiste à choisir un sous-ensemble des réalisations possibles de l’aléa (l’ensembled’incertitude) et à reformuler le problème (contrepartie robuste) de manière à ce que lesdécisions prises soient valides pour toute réalisation de l’aléa dans ce sous-ensemble.L’objectif principal du problème est de produire un planning de décisions équilibrant exacte-ment le portefeuille, c’est-à-dire satisfaisant exactement la demande à l’aide des flux transitantdans le réseau. Ne pas avoir assez de gaz, ou en avoir trop, par rapport à la demande, expose lenégociant à des risques financiers (pénalités à payer, ou obligation de revendre sur le marché

122 Apparigliato, Erbs, Pedraza Morales, Plateau
à des prix peu intéressants). On voit ici la di"culté du problème : la réalisation de l’aléa necorrespondra jamais exactement à la prévision que l’on a pu en faire pour l’optimisation.Ouorou et Vial [4] proposent une méthode permettant de traiter ce cas dans le cadre deréseaux de télécommunications. L’idée est de décomposer les variables du problème en deuxparties, l’une représentant une décision nominale et l’autre représentant son adaptation à laréalisation de l’aléa.Nous étudions l’application de cette méthode au problème de gestion de portefeuille d’actifsgaziers, et fournissons des résultats numériques permettant de montrer ses apports.
Références
1. R. Apparigliato. Règles de décision pour la gestion du risque : Application à la gestion hebdoma-daire de la production électrique. PhD thesis, Ecole Polytechnique, Palaiseau, 2008.
2. A. Ben Tal and A. Nemirovski. Robust optimization – methodology and applications. Mathema-tical Programming, Series B, 92(3) :453–480, 2002.
3. D. Bertsimas and M. Sim. The Price of Robustness. Operations Research, 52(1) :35–53, 2004.4. A. Ouorou and J.-P. Vial. A model for robust capacity planning for telecommunications networks
under demand uncertainty. In Proceedings of the 6th International Workshop on Design of ReliableCommunication Networks (DRCN 2007). IEEE, 2007.

Approximation algorithms for minimizing the makespanon two parallel machines with release dates
M. Hifi,1 and I. Kacem2
1 MIS-ODR, UniversitÈ Picardie Jules-Verne d’Amiens, [email protected]
2 ICD-LOSI, Université de Technologie de Troyes, [email protected]
We consider the two-machine scheduling problem with release dates, with the aim of mi-nimizing the makespan. Formally, the problem is defined in the following way. We have toschedule a set J of n jobs on two identical machines. Each job j ! J has a processing time pj ,a release date rj . Each machine can only perform one job at a given time. The preemption isnot permitted. The machines are available at time t = 0. The problem is to find a sequenceof jobs, with the objective of minimizing the makespan Cmax = max1(j(n {Cj (S)} whereCj (S) is the completion time of job j in sequence S. We also define tj (S) as the starting timeof job j (i.e., Cj (S) = tj (S) + pj). Without loss of generality, we assume that the jobs areindexed in the nondecreasing order of their release dates : r1 " r2 " ... " rn (i.e., accordingto the FIFO rule). Note that due to the dominance of the FIFO order, an optimal solutionis composed of two sequences (each of them is on a one of the machines) of jobs scheduled innondecreasing order of their indices. The problem is denoted as (P). In the remainder of thispaper, C$max(Q) denotes the minimal makespan for problem Q and CSmax(Q) is the makespanof schedule S for problem Q.In this paper, we propose some approximation algorithms for the studied problem. Weshow the existence of an FPTAS for the problem. Moreover, 2-approximation and 3/2-approximation algorithms, based on the FIFO rules, are presented. We believe that thisanalysis constitutes a first step toward the investigation of more sophisticated approximationalgorithms, which will be considered in a future work.The first heuristic is very simple ! We schedule all the jobs on one of the machines accor-ding to the FIFO rule. It is denoted as H . However, this simple heuristic has a worst-caseperformance ratio of 2 and this bound is tight.Lemma 1. Heuristic H is a 2-approximation for problem P and this bound is tight.The second heuristic schedules the jobs in the same order as their indexes on the two machines(at each step, we schedule the job having the smallest release date on the first availablemachine). It is denoted as H ". The algorithm is described as follows :Algorithm H"(i). Set t = r1 ; j = 1 ; z1 = 0 ; z2 = 0 ; k = 1 ; S = ! ;(ii). At time t, schedule job j on machine k.(iii). Set S = S 3 {j} ;tj (H ") = t ; zk = tj (H ") + pj ;If |S| = n, then STOP ;If z1 < z2 then k = 1, else k = 2 ; zk = max {zk; rj+1} ; t = zk ; j = j + 1 ;Go to step (ii).

124 Hifi M., Kacem I.
Lemma 2. Heuristic H " is a 3/2-approximation for problem P and this bound is tight.Our FPTAS is based on two steps. First, we use Algorithm H ". In the second step of ourFPTAS, we apply a new trimmed algorithm A& in order to reduce the running time.Given an arbitrary 5 > 0, we define LB = 2CH!max(P)
3 , & =53n
2&6
and ) = CH!
max(P)$ . We split
the interval70, Cmax
8into & equal subintervals Ih = [(h# 1)), h)]1(h($ of length ) (where
Cmax = CH!max (P)). Our algorithm A& generates reduced sets O#j . It can be described as
follows :Algorithm A&
(i). Set O#0 = {[0, 0]}.
(ii). For k ! {1, 2, 3, ..., n},For every state [u, v] in O#
j#1 :1) Put [max(u, rj) + pj , v] in O#
j
2) Put [u,max(v, rj) + pj ] in O#j
Remove O#j#1
Let [u, v]h be the state in O#j such that u ! Ih with the smallest possible u (ties are
broken by choosing the state of the smallest v). Set O#j = {[u, v]h |1 " h " &}.
(iii). CA!max (P) = min[u,v]%O#
n{max(u, v)}.
Theorem 1. Given an arbitrary 5 > 0, algorithm A& yields an output CA!max (P) such that
CA!max(P)C#max(P) " (1 + 5).
Lemma 3. Given an arbitrary 5 > 0, algorithm A (5) can be implemented in O)n2/5*
time.Corollary 1. Algorithm A& is an FPTAS for the studied problem.
Références1. Dessouky, M.I., Margenthaler, C.R., 1972. The one-machine sequencing problem with early starts
and due dates. AIIE Transactions 4(3), 214–222.2. Gens, G.V., Levner, E.V., 1981. Fast approximation algorithms for job sequencing with deadlines.
Discrete Applied Mathematics 3, 313–318.3. Hall, L.A., Shmoys, D.B., 1992. Jackson’s rule for single machine scheduling : making a good
heuristic better. Mathematics of Operations Research 17, 22-35.4. Kacem I (2007) Approximation algorithms for the makespan minimization with positive tails on
a single machine with a fixed non-availability interval, Journal of Combinatorial Optimization,doi :10.1007/s10878-007-9102-4.
5. Kellerer, H., Strusevich, V.A., Fully polynomial approximation schemes for a symmetric quadraticknapsack problem and its scheduling applications. Algorithmica.
6. Kovalyov, M.Y., Kubiak, W., 1999. A fully polynomial approximation scheme for weightedearliness-tardiness problem. Operations Research 47, 757-761.
7. Potts, C.N., 1980. Analysis of a heuristic for one machine sequencing with release dates anddelivery times. Operations Research 28, 1436-1441.
8. Sahni, S., 1976. Algorithms for scheduling independent tasks. Journal of the ACM 23, 116–127.ValenSciences 5, 191-206.

Deux agents concurrents pour l’ordonnancement destravaux dans un flowshop avec étage commun
A. Soukhal, N. Huynh Tuong, and L. Miscopein
Laboratoire d’Informatique de l’université François Rabelais Tours, 64, av. Jean Portalis 37200Tours.
[email protected], {nguyen.huynh,laurent.miscopein}@etu.univ-tours.fr
1 Introduction
Généralement, la qualité d’une solution est donnée par une mesure appliquée à l’ensembledes travaux. En e!et, les modèles classiques considèrent soit tous les travaux équivalents soitdi!érents dans la mesure où des poids sont ajoutés pour les di!érencier. Ainsi, la qualitéde l’ordonnancement global est quantifiée en appliquant la même mesure à ces travaux sansdistinction (la mesure peut être la minimisation de la date de fin d’exécution du dernier travail(makespan), par exemple).Il arrive dans certains cas que l’application de la même mesure à tous les travaux ne soit paspertinente. En e!et, il est possible d’envisager un atelier où les travaux ont la particularitésuivante : les travaux d’un premier sous-ensemble peuvent avoir une date de fin souhaitéeavec une permission de retard (à être réduite au minimum), ceux du second sous-ensemblepeuvent avoir des dates de fin impératives et les travaux du troisième sous-ensemble n’ont pasde date d’échéance (produire pour le stock). Pour le premier type de travaux, le décideur veutréduire au maximum les retards ; pour le deuxième type, il ne tolère aucun retard ; cependantpour le dernier type de travaux, il veut réduire la valeur totale (ou la moyenne) des tempsde traitement. L’ordonnancement de chaque sous-ensemble des travaux est évalué en fonctionde di!érents objectifs, mais ces travaux sont en concurrence avec l’usage des machines. Ils’agit d’un problème d’ordonnancement multicritères où un nouveau type de compromis doitêtre obtenu. Ces problèmes d’ordonnancement sont appelés dans la littérature “Ordonnance-ment multi-agent" ou bien “Ordonnancement avec agents concurrents" [Agnetis et al., 2000],[Agnetis et al., 2004], [Cheng et al., 2006], [Agnetis et al., 2007]. Chaque agent avec sa fonc-tion objectif, dispose d’un ensemble de travaux à ordonnancer.Dans cette étude, il s’agit d’ordonnancer l’ensemble N de travaux répartis en deux sous-ensembles disjoints dans un atelier de type flowshop à trois machines. On suppose que tousles travaux sont disponibles à la dates zéro et doivent être exécutés sans préemption surexactement deux machines, i.e. chaque travail est constitué de deux opérations. Nous avonsdonc deux types de produits à réaliser. Notons par N1 et N2 les deux sous-ensembles enquestion avec N1 ; N2 = 2 et N1 3N2 = N . Soit n1 (resp. n2 le nombre de travaux de N1(resp. N2). Sans perte de généralité, on suppose que les travaux de N1 sont numérotés de1 à n1 et ceux de N2 sont numérotés de n1 + 1 à n. Chaque sous-ensemble lui est associéun objectif. L’objectif du chef d’atelier est de trouver un ordonnancement qui permet deminimiser à la fois la date d’achèvement du dernier travail de chaque sous-ensemble. Selon lanotation en trois champs et celle proposée dans [Oguz et al., 1997], le problème étudié est noté

126 A. Soukhal, N. Huynh Tuong, and L. Miscopein
F3|T = 2|Cmax(N1) : Cmax(N2) (T = 2 signifie que chaque travail est constitué d’exactementde deux opérations). L’approche 5-contrainte est considérée dans notre étude.Dans le cas monocritère, le problème F3|T = 2|Cmax(N ) a été étudié en particulier par[Oguz et al., 1997] et [Bertrand, 1999] où quelques résultats de complexité et propriétés ontété élaborés.
2 Problèmes étudiés et résultats
2.1 F3|T = 2, (M1 !"M2;M1 !"M3)|Cmax(N1) : Cmax(N2)
Dans cette section, on s’intéresse au cas où les travaux du premier agent doivent être exécutésd’abord sur la machineM1 puis la machine M2. Quant à ceux du deuxième agent, ils doiventpasser sur M1 puis M3 dans cet ordre. Dans ce cas nous avons le théorème suivant.
Théorème 1 : Le problème F3|T = 2, (M1 A: M2;M1 A: M3)|Cmax(N1) : Cmax(N2) estNP-di"cile au sens fort.Preuve : La preuve est donnée par la réduction du problème de décision 3-partition connuNP-di"cile au sens fort [Garey and Johnson, 1979].
2.2 F3|T = 2, (M1 !"M3;M2 !"M3)|Cmax(N1) : Cmax(N2)
Dans cette section, on s’intéresse au cas où les travaux du premier agent doivent être exécutésd’abord sur la machineM1 puis la machine M3. Quant à ceux du deuxième agent, ils doiventpasser sur M2 puis M3 dans cet ordre. Dans ce cas nous avons le théorème suivant.
Théorème 2 : Le problème F3|T = 2, (M1 A: M3;M2 A: M3)|Cmax(N1) : Cmax(N2) estNP-di"cile au sens fort.Preuve : Déduite des travaux de Bertrand [Bertrand, 1999] pour le cas monocritère.
2.3 F3|T = 2, (M1 !"M2;M2 !"M3)|Cmax(N1) : Cmax(N2)
On s’intéresse ici au cas où les travaux du premier agent doivent être exécutés d’abord sur lamachine M1 puis la machine M2. Quant à ceux du deuxième agent, ils doivent passer sur M2puis M3 dans cet ordre. Dans ce cas nous avons le théorème suivant.
Théorème 3 : Le problème F3|T = 2, (M1 A: M2;M2 A: M3)|Cmax(N1) : Cmax(N2) estNP-di"cile au sens ordinaire.Preuve : La preuve est donnée par la réduction du problème de Partition connu NP-di"cileau sens faible [Garey and Johnson, 1979]. Pour calculer une solution optimale, nous proposonsun algorithme pseudo-polynomial en O(n252P3) avec P3 =
&ni=n1+1 p3,i où p3,i est la durée
opératoires du travail Ti,n1+1(i(n ! N2 sur la troisième machine.

Title Suppressed Due to Excessive Length 127
Références
[Agnetis et al., 2000] Agnetis A., Mirchandani P.B., Pacciarelli D., et Pacifici A. (2000). Nondo-minated schedules for a job-shop with two competing users. Computational & MathematicalOrganization Theory 6, pp. 191–217.
[Agnetis et al., 2004] Agnetis A., Mirchandani P.B., Pacciarelli D., et Pacifici A. (2004). Schedulingproblems with two competing agents. Operations Research 52, pages 229–242.
[Agnetis et al., 2007] Agnetis A., Pacciarelli D., and Pacifici A. (2007). Multi-agent single machinescheduling. Annals of Operations Research 150, pages 3–15.
[Bertrand, 1999] Bertrand M.T.L (1999). The strong NP-hardness of two-stage flowshop schedulingwith a common second-stage machine. Computers & Operations Research 26, pages 695–698.
[Cheng et al., 2006] Cheng T.C.E., Ng C.T., and Yuan J.J. (2006). Multi-agent scheduling on a singlemachine to minimize total weighted number of tardy jobs. Theoretical Computer Science 362,pages 273–281.
[Garey and Johnson, 1979] Garey M.R. et Johnson D.S. (1979). Computers and Intractability : AGuide to the Theory of NP-Completeness. W.H. Freeman & Company, San Francisco.
[Oguz et al., 1997] Oguz C., Bertrand M.T.L, Cheng, T.C.E (1997). Two-stage flowshop schedulingwith a common second-stage machine. Computers & Operations Research 24, pages 1169–1174.

Aide à la Décision Collective : Vers une estimationdynamique de l’e"cacité des réunions de prise de
décision collective
G. Camilleri1 and P. Zarate1
IRIT -IC3-, Université Paul Sabatier, 118 Route de Narbonne, F-31062 TOULOUSE CEDEX 9France
[email protected], [email protected]
Encore aujourd’hui, l’outil principal de prise de décision collective reste la réunion face à face.Cependant, il n’est pas rare que les réunions soient perçues comme improductives en termesd’utilisation e"cace du temps, et d’accomplissement des objectifs attendus. Par conséquent,la tenue de réunions «e"caces» est un enjeu important pour les organisations.De nombreux travaux visent à améliorer l’e"cacité des réunions de décision collective enintroduisant des technologies comme les systèmes d’aide à la décision de groupe (GDSS),en développant des méthodes facilitant le processus de réunion (comme le Brainstorming,NGP, etc.) ou plus simplement, en formulant des recommandations. Une question centraleà toutes ces études est : «Une réunion donnée est-elle e"cace ?». Pour répondre de manièresatisfaisante à cette interrogation, il paraît nécessaire de définir la notion d’e"cacité et d’êtreen mesure de l’estimer.Cet article propose un cadre de travail générique permettant de définir et d’estimer dynami-quement l’e"cacité des réunions de prise de décision de groupe. Pour simplifier notre étude,nous segmentons le processus de prise de décision collective en six phases : 1) la phase depréparation de la réunion, 2) la phase de compréhension collective des objectifs, 3) la phasede génération des solutions, 4) la phase de choix, 5) la phase de formalisation de la décisionet 6) la phase clôture de la réunion.L’évaluation de l’e"cacité des réunions de ce type nécessite de déterminer les variables in-fluençant le déroulement des réunions. Les contraintes ayant guidé notre travail sont :– Les variables doivent être su"samment abstraites pour pouvoir être utilisées dans le plus
grand nombre de décisions (tâches) dans di!érents contextes (cas des décisions non pro-grammées),
– elles doivent être clairement définies et,– il doit être possible de les mesurer quantitativement.Afin de satisfaire la première contrainte (généricité), nous nous sommes intéressés aux travaux(sur les organisations et en psychologie sociale [2]) portant plus généralement sur le travail enéquipe, en considérant la prise de décision collective (réunion de décision) comme un travaild’équipe. L’étude de Ross, Jones et Adams dans [3] s’appuie sur ces travaux pour développerun modèle mathématique estimant l’e"cacité des équipes. Ils proposent d’utiliser ce modèlepour prédire l’e"cacité du travail en équipe dans sa globalité.Notre approche d’estimation de l’e"cacité se base sur le modèle de Ross, Jones et Adams enréduisant la couverture du modèle aux réunions de prise de décision de groupe. Comme Ross,Jones et Adams, nous utilisons les variables globales suivantes : La performance P estime dansquelle mesure les résultats sont conformes aux standards de quantité, de qualité, et de temps

Papier soumis à ROADEF 09 129
des organisations. Le comportement B estime dans quelle mesure les membres d’une équipeagissent et réagissent entre eux. L’attitude A détermine comment les sensations de sécuritépsychologique, de volonté à coopérer, etc. des membres influencent l’e"cacité de l’équipe. Lescaractéristiques individuelles des membres M déterminent l’impact qu’ont les caractéristiquesindividuelles sur l’e"cacité du groupe. La culture d’entreprise C estime l’influence du climatde l’organisation dans lequel les équipes opèrent.Dans ce cadre, l’e"cacité E est mesurée sur une échelle à cinq niveaux (1=le plus faibleet 5=optimal). Comme de nombreuses variables en sciences humaines et sociales, l’e"cacitéest supposée suivre une distribution normale permettant de définir les intervalles suivants :4.3 < E " 5.0 (Opimale), 3.7 < E " 4.3 (E"cace), 2.3 < E " 3.7 (Moyenne), 1.7 < E " 2.3(Ine"cace) et 1.0 < E " 1.7 (Défectueuse).L’e"cacité de réunion E est définie comme une fonction de ces cinq variables (groupe de nparticipants) :E = 3 +
11n [&n
i=1(Pi#3)+0.5
&n
i=1(Bi#3)+0.15
&n
i=1(Ai#3)+1.65
&n
i=1(Mi#3)]+0.05(C#3)
3.35
9
Nous proposons au travers de la segmentation en phases, de caractériser plus précisémentle processus de réunion employé. Cette spécialisation a principalement deux avantages : Ellepermet de réduire les processus de groupe considérés, et de faciliter le développement d’unmodèle dynamique. Pour construire notre approche, nous nous sommes intéressés au mo-dèle dynamique du brainstorming présenté par Brown et Paulus dans [1]. Ce modèle utilisedes équations di!érentielles pour représenter la production d’idées de la manière suivante :o"i(t) = #aioi(t) # bi
&i)=j oj(t) + mi
:1n#1&j )=i oj(t)# oi(t)
;avec oi(t) le taux d’idées gé-
nérées pour le participant i, ai le coe"cient d’épuisement, bi le coe"cient de blocage, mila tendance à s’harmoniser, et n la taille du groupe. Dans notre cadre, il permet de me-surer la productivité de l’activité de Brainstorming comme composante de la performance
Pi =aXoc+bXbc+cXcr+dfp(
< tbtaoi(t)dt)
a+b+c+d avec a,b,c et d les valeurs de corrélation de l’objectif com-mun (Xoc), des buts clairement définis (Xoc), de la clarté des rôles (Xcr) et de la fonctiond’évaluation de la production fp sur l’intervalle [ta, tb].Ce travail est un point de départ pour la construction d’un modèle dynamique de l’estimationde l’e"cacité des réunions de prise de décision collective. Nous nous sommes intéressés ici à laphase de génération des solutions au travers du processus de brainstorming. L’intérêt majeurd’un tel modèle dynamique est de donner des indications sur l’évolution de l’e"cacité duprocessus en cours. Il peut alors servir de critère de gestion dans le cadre d’un système d’aideà l’animation de réunion, en aidant par exemple le facilitateur à déterminer l’arrêt de la phasede génération des solutions.
Références1. Brown, V. and Paulus, P. : A Simple Dynamic Model of Social Factors in Group Brainstorming
dans Small Group Research, 27, p91-114 (1996).2. Mathieu J., Maynard, Rapp and Gilson : Team E#ectiveness 1997-2007 : A Review of Recent
Advancements and a Glimpse Into the Future, dans Journal of Management, 34 :3, p410–476(2008).
3. Ross, Jones and Adams : Can team e#ectiveness be predicted ?, dans Team Performance Mana-gement, 14 :5/6, p248 - 268 (2008).

Mesurage additif conjoint pour la problématique du tri
D. Bouyssou1 and Th. Marchant2
1 CNRS–LAMSADE & Université Paris DauphinePlace du Maréchal de Lattre de Tassigny, F-75 775 Paris Cedex 16, France.
[email protected] Universiteit Gent
Department of Data Analysis, H. Dunantlaan, 1, B-9000 Gent, [email protected]
1 Introduction et motivation
Un problème central en analyse multicritère est de bâtir une relation de préférence sur unensemble d’actions évaluées sur plusieurs attributs, sur la base de préférences exprimées auniveau de chaque attribut et d’informations inter-attributs (par exemple, des poids). La ma-nière classique de procéder consiste à bâtir une fonction de valeur. Ceci revient à construireune fonction v associant un nombre v(x) à chaque action x et à déclarer que l’action x est« au moins aussi bonne »que l’action y si et seulement si v(x) ( v(y).Une relation de préférence conduit, en général, à un modèle d’évaluation relative des actions.Il n’est pas toujours pertinent de vouloir élaborer une recommendation sur la base d’un telmodèle d’évaluation. Celui-ci n’ayant qu’un caractère relatif, les « meilleures »actions peuventse révéler bien peu désirables. Ceci amène à l’étude de modèles d’évaluation ayant un carac-tère plus absolu. Ces modèles se rattachent à ce que l’on appelle la problématique de tri.Supposons, par exemple, qu’une institution académique souhaite bâtir un modèle aidant uncomité à sélectionner des candidats à un certain programme. On recherchera plutôt un modèlepermettant d’isoler les candidats qui semblent répondre aux standards de ce qui définit un« bon »candidat qu’un modèle comparant les candidats entre eux.Les méthodes multicritères conçues pour faire face à ce type de problème amènent à bâtir unepartition ordonnée de l’ensemble des actions, par comparaison des actions à des « normes »oupar l’analyse d’exemples typiques. Ce type de méthodes a récemment été l’objet de nombreusesétudes [2,8]. Diverses technique ont été proposées pour y faire face telle que UTADIS [3] ouELECTRE TRI [5].Le but de cette présentation sera de contribuer à une tendance récente dans la littératurevisant à analyser les fondement théoriques de ce type de méthodes [1,6].Avec la méthode UTADIS en tête, nous nous concentrerons ici sur la question de l’analyse desméthodes reposant sur une agrégation additive, complétant et étendant les résultats présentés[7]. Notre stratégie sera de montrer qu’il est possible d’adapter les résultats classique dumesurage conjoint additif [4] pour traiter du cas de partitions et de couvertures ordonnées.
2 Le modèle
Soit n ( 2 un entier et X = X1 *X2 * · · ·*Xn un ensemble d’objects que l’on interpréteracomme un ensemble d’actions évaluées sur un ensemble N = {1, 2, . . . , n} d’attributs.

Mesurage additif conjoint 131
Nos primitives consisteront dans une couverture ordonnée de X , c’est à dire par la donnéesde deux ensembles A$ and U$ tels que A$ 3U$ = X , A$ 9= ! et U$ 9= !. Les éléments de A$(resp. U$) sont interprétés comme l’ensemble des actions « acceptables »(resp. inacceptables).Les éléments de A$ ; U$ = F sont à la « frontière »entre les deux catégories et modélisentune situation d’hésitation.Notre tâche principale sera de montrer sous quelles conditions, il existe des fonctions de valeurvi sur Xi telles que, ,x ! X ,
x ! A$ ./n%
i=1vi(xi) ( 0,
x ! U$ ./n%
i=1vi(xi) " 0.
On présentera des conditions su"santes garantissant l’existence de telles fonctions. On gé-néralisera ensuite ce résultat au cas de partitions et au cas de plus de deux catégories. Lesrésultats obtenus peuvent être vus comme une tentative de donner une base axiomatiquesolide à la méthode UTADIS.
Références
1. D. Bouyssou and Th. Marchant. An axiomatic approach to noncompensatory sorting methods inMCDM, I : The case of two categories. European Journal of Operational Research, 178(1) :217–245, 2007.
2. S. Greco, B. Matarazzo, and R. S&owi'ski. Decision rule approach. In J. Figueira, S. Greco, andM. Ehrgott, editors, Multiple Criteria Decision Analysis : State of the Art Surveys, pages 507–562.Springer-Verlag, Boston, 2005.
3. É. Jacquet-Lagrèze. An application of the UTA discriminant model for the evaluation of R&Dprojects. In P. Pardalos, Y. Siskos, and C. Zopounidis, editors, Advances in Multicriteria Analysis,pages 203–211. Kluwer, Dordrecht, 1995.
4. D. H. Krantz, R. D. Luce, P. Suppes, and A. Tversky. Foundations of measurement, vol. 1 :Additive and polynomial representations. Academic Press, New York, 1971.
5. B. Roy and D. Bouyssou. Aide multicritère à la décision : méthodes et cas. Economica, Paris,1993.
6. R. S&owi'ski, S. Greco, and B. Matarazzo. Axiomatization of utility, outranking and decision-rulepreference models for multiple-criteria classification problems under partial inconsistency with thedominance principle. Control and Cybernetics, 31(4) :1005–1035, 2002.
7. K. Vind. Independent preferences. Journal of Mathematical Economics, 20 :119–135, 1991.8. C. Zopounidis and M. Doumpos. Intelligent decision aiding systems based on multiple criteria for
financial engineering. Kluwer, Dordrecht, 2000.

Aide à la décision pour l’optimisation des gares de triage
H. Djellab,1, C. Mocquillon2, and C. Weber1
1 SNCF - I&R-AAD, 45 rue de Londres, 75000 Paris Cedex France.2 EURODECISION, 9A, rue de la Porte de Buc, 78000 Versailles Cedex France.
1 IntroductionUne gare de triage est une installation ferroviaire permettant l’acheminement de wagons demarchandise de leur origine vers leur destination finale. Pour optimiser le coût de transportdes wagons à travers le réseau, les flux origine/destination sont massifiés :1. les commandes d’une zone géographique sont regroupées au niveau d’une gare de type
« plateforme »,2. les flux de di!érentes plateformes sont regroupés et traités au niveau des gares de type
« hub »3. les flux des hub sont redéployés vers les plateformes qui acheminent enfin les wagons au
niveau de leurs destinations finales.L’architecture globale du réseau et les interactions possibles entre les hubs et les plateformessont présentés à la figure 1.
Fig. 1. Structure du réseau
Le routage des wagons est e!ectué lors d’un phase stratégique en amont de notre étude,l’objectif des gares de triage est alors de maximiser la qualité de service client en minimisantle nombre de correspondances ratées entre les wagons réceptionnés et les trains au départde la gare tout en assurant le respect des contraintes de ressources (personnels et engins demanoeuvre).Une gare de triage est composée de quatre chantiers distincts : le chantier de réception, lechantier de débranchement, le chantier de formation et le chantier de départ. Les trains àl’arrivée de la gare sont réceptionnés puis inspectés sur le faisceau de voies du chantier deréception. A l’aide d’un engin de manoeuvre, ils sont ensuite refoulés (poussés) sur la bosse(chantier de débranchement) d’où les wagons descendent en roulant par gravité et sont orientés

Optimisation des gares de triage 133
vers les di!érentes voies du faisceau de formation. Lorsque l’ensemble des wagons d’un mêmetrain au départ est présent sur le faisceau de formation, il est trié avant de subir une opérationd’inspection.Une fois les wagons inspectés et triés, ils sont acheminés au niveau du chantier de départ oùils subissent une dernière opération de préparation à l’expédition. La figure 2 présente uneversion schématisée d’une gare de triage à une bosse.
Fig. 2. Représentation schématique d’une gare de triage
L’objectif de la gare de triage est donc de minimiser le nombre de correspondances ratées touten respectant les di!érentes contraintes de capacités de chaque chantier : nombre de voies,disponibilités des voies, nombre d’équipes disponibles pour réaliser les opérations, ...La figure ci-dessous décrit la méthodologie de description de notre problème suivant la mé-thodologie CHIC-2 ([9]).
Fig. 3. Méthodologie de modélisation du problème
2 Etude bibliographiqueLe problème d’optimisation des gares de triage n’a pas suscité beaucoup de recherche. Onpeut catégoriser les études réalisées (cf. bibliographie) en deux groupes :Le premier groupe est focalisé sur l’analyse des performances des opérations des gares detriage. La gare de triage est considérée comme un système de production [3,4] et on peut donc

134 Djellab, Mocquillon, Weber
appliquer les di!érentes techniques de gestion de production pour améliorer ses performances :identifier le goulot d’étranglement, analyser l’hétérogénéité des arrivées et des départs destrains, etc.Le second groupe d’étude est concentré sur l’optimisation des opérations dans les di!érentschantiers. La quasi-totalité des méthodes d’optimisation proposées dans ce groupe sont desméthodes approximatives : simulation à base de règles [5], heuristique [6,3], programma-tion dynamique avec décomposition du problème, programmation mathématique [1,2,5](pourl’ordre de débranchement), ...C’est un problème très di"cile au sens mathématique du terme (NP-Hard). Une instance dece problème peut être amené à un problème de flow shop hybride à 4 étages où chaque étagecorrespondants à un chantier et chaque machine à une voie.3 Méthodes de résolutionNous avons développé une approche basée sur une méthode d’améliorations itératives [4].La première phase consiste à déterminer une solution initiale la meilleure possible en tenantcompte de caractéristiques du problème. En suite à l’aide d’un processus guidé ou aléatoireon perturbe la solution on vue d’améliorer la solution.Nous avons comparé et orienté notre approche heuristique à l’aide des résultats obtenus parune approche PLNE sur des jeux de données fictifs de tailles moyennes. La validation de notreapproche sur des jeux de données réelles des sites pilotes retenus est en cours.Nous présenterons en détail le problème avec les di!érentes contraintes et notamment lestechniques mises en oeuvre pour trier les wagons lors de la formation des trains au départ.Nous présenterons aussi les résultats sur des jeux de données réels des sites pilotes retenus.Références1. Edwin R. Kraft, Priority car sorting in railroad classification yards using a continuous multi-stage
method, United States Patent, 20022. Edwin E. R. and M. Guignard Spielberg, A mixed integer optimization model to improve freight
car classification in railroad yards, Report 93-06-06, University Pennsylvania 19933. Jeremiah R. Dirnberger, Development and application of lean railroading to improve classification
terminal performance, Thesis, degree of Masters of Science in Civil Engineering in the GraduateCollege of the University of Illinois at Urbana-Champaign, 2006
4. Jeremiah R. Dirnberger, Christopher P.L. Barkan, Improving Railroad Classification Yard Per-formance Through Bottleneck Management Methods, Proceedings of the AREMA 2006 AnnualConference, Louisville, KY, 2006
5. Larry Shughart, Ravindra Ahuja, Arvind Kumar, and Saurabh Mehta, Nikhil Dang and GüvençSahin. A Comprehensive Decision Support System for Hump Yard Management Using Simulationand Optimization, 2006
6. R. Ha$ema. Train shunting : A practical heuristic inspired by dynamic Programming, Universityof Amsterdam, Master Thesis in operational Research, 2001
7. R. Ha$ema, C.W. Duin, and N.M. van D$k. Train shunting : A practical heuristic inspired by dy-namic programming. In W. van Wezel, R. Jorna, and A. Meystel (editors), Planning in intelligentsystems, pages 437-477. Wiley, New York, United States, 2006.
8. Rapport interne « Optimisation des gares de triage »(Février 2008).9. CHIC-2 Methodology for Combinatorial Application (European Esprit Project 22165).

Heuristiques et metaheuristique pour le MultiproductParallel Assembly Lines Balancing Problem
N. Grangeon and S. Norre
LIMOS, CNRS UMR 6158, IUT de MontluçonAv. Aristide Briand, 03100 Montluçon
[email protected], [email protected]
1 Présentation du problème
Le Simple Assembly Line Balancing Problem (SALBP) consiste à a!ecter des tâches à desstations tout en respectant des contraintes de précédence entre les tâches et des contraintesde temps de cycle. Il a été abondamment étudié et a fait l’objet d’un grand nombre de pu-blications. La classe Generalized Assembly Line Balancing Problems (GALBP) est très largeet contient toutes les extensions qui peuvent être intéressantes dans la pratique, incluant lasélection d’équipement, les contraintes d’a!ectation, ... Récemment, le problème du Multi-product Parallel Assembly Lines Balancing Problem (MPALBP) a été proposé par [2]. Ceproblème s’intéresse à des lignes d’assemblage en parallèle et à la possibilité qu’un opérateurpuisse travailler sur deux lignes adjacentes.Nous considérons un atelier de fabrication constitué de L lignes d’assemblage, placées l’une àcôté de l’autre, en parallèle. Chaque ligne d’assemblage est dédiée à la production d’un type deproduit. Toutes les lignes ont le même temps de cycle. Le processus de production de chaquetype de produit est modélisé par un graphe de précédence où les tâches sont les noeuds, lesdurées des tâches sont les poids des noeuds et les relations de précédentce entre les tâches sontles arcs. A un instant donné, une tâche est réalisée par, au plus, un opérateur. Les lignes sontdécoupées en stations, de même longueur quelle que soit la ligne. Le principe du MPALBPconsiste à considérer qu’un opérateur peut être partagé entre deux lignes adjacentes, ce quisignifie qu’un opérateur travaille sur deux stations en vis-à-vis pendant un même cycle, enpartageant son temps entre les tâches a!ectées à la station j de la ligne k et celles a!ectées àla station j de la ligne k+ 1. Le fait d’a!ecter un opérateur à deux lignes permet de diminuerle nombre d’opérateurs mais sous-entend que des stations peuvent être inutilisées. La plupartdes problèmes d’équilibrage de lignes provient de l’industrie automobile et traite de lignesd’assemblage de véhicules. Le MPALBP considère des lignes d’assemblage de produits depetite taille tels les produits électroniques, les téléphones portables, ...A notre connaissance, trois articles ont été publiés sur cette problématique. [2] ont proposé unmodèle mathématique pour un nombre quelconque de lignes, tout en indiquant qu’il ne permetde résoudre que des instances de petite taille, ainsi que deux heuristiques. [1] proposent demodéliser le problème sous la forme d’un réseau représentant les a!ectations possibles d’unetâche à un opérateur. Aucun résultat n’est donné, les auteurs indiquent que leur objectifest de donner une nouvelle vision du problème. L’article le plus récent a été proposé par[4] et présente une analyse du MPALBP. Le problème est décrit en détail en définissant lestermes employés par rapport au SALBP, les avantages sont présentés à l’aide d’exemples

136 Grangeon, Norre
numériques. Ils proposent un modèle mathématique qui prend en compte le problème del’a!ectation des types de produits aux lignes et une méthode exacte qui combine un algorithmede branch-bound ABSALOM initialement proposé pour le ARALBP (Assignment RestrictedAssembly Line Balancing Problem) et une méthode d’énumération pour l’a!ectation des typesde produit au lignes.
2 PropositionsComme le mentionne [4], les méthodes exactes ne permettent pas de résoudre des instancesde grande taille. Or, le problème, de par sa définition, concerne un grand nombre de tâches.Nous proposons donc d’utiliser des méthodes approchées (heuristiques et métaheuristiques)basées sur les méthodes que nous avons proposées dans [3] et qui se sont montrées e"cacessur les instances de SALBP-1 de la littérature. Dans un premier temps, il nous est apparuintéressant de distinguer deux cas :cas 1 : l’atelier est composé de deux lignes d’assemblage et chaque ligne traite un type de
produits. Nous avons deux graphes de précédence. Ce problème peut être modélisé parun SALBP-1 avec un graphe de précédence composé des deux graphes de précédencereliés entre eux par une tâche fictive de début de durée 0. Les méthodes proposées dans[3] peuvent être appliquées directement. A partir de la liste des tâches a!ectées à unopérateur, l’a!ectation de l’opérateur à une ou deux stations adjacentes peut facilementêtre déduite. Les résultats obtenus permettent d’améliorer les résultats de la littérature :sur les 20 instances pour lesquelles la solution otimale n’est pas connue, nous obtenonsune meilleure solution que les solutions de la littérature et pour 9 instances, nous obtenonsune valeur identique à la borne inférieure.
cas 2 : l’atelier est composé de L > 2 lignes d’assemblage et chaque ligne traite un typede produits. Nous avons L > 2 graphes de précédence. Ce problème peut être modélisépar un ARALBP-1, extension du SALBP-1 avec un graphe de précédence composé des Lgraphes de précédence reliés entre eux par une tâche fictive de début de durée 0 et descontraintes d’a!ectation (les tâches a!ectées à un opérateur doivent être réalisées soit surla même ligne, soit sur au maximum deux lignes adjacentes). Nous proposons d’étendre lesméthodes utilisées dans le cas précédent pour prendre en compte cette contrainte. Aucunrésultat n’a été publié dans ce cas, mais les résultats obtenus semblent intéressants.
Les perspectives de ce travail portent sur un troisième cas où l’atelier est composé de L > 2lignes d’assemblage et l’a!ectation des types de produits aux lignes est à déterminer.
Références1. Benzer, R. and Gökçen, H. and Çetinyokus, T. and Çercioglu, H : A Network Model for Parallel
Line Balancing Problem. Mathematical Problems in Engineering, Article ID 10106, (2007)2. Gökçen, H. and Agpak, K. and Benzer, R. : Balancing of parallel assembly lines. International
Journal of Production Economics, 103 (2), p.600-609, (2006)3. M. Gourgand and N. Grangeon and S. Norre : Metaheuristics based on bin packing for the line
balancing problem. RAIRO Operational Research, 41, p.193-211, (2007)4. Scholl, A. and Boysen, N. : The multiproduct parallel assembly lines balancing problem : model
and optimization procedure. Jena Research Papers in Business and Economics, 13, (2008)

Un algorithme GRASP pour la résolution d’un TLBPavec des contraintes liées aux choix d’équipements
M. Essafi, X. Delorme and A. Dolgui
Département Génie Industriel et Informatique, Ecole des Mines de Saint-Etienne, 158 CoursFauriel, 42023, Saint-Etienne, France.(essafi,delorme,dolgui)@emse.fr
1 Introduction
Nous traitons le problème d’équilibrage de ligne d’usinage connu sous le nom de TLBP (Trans-fer Lines Balancing Problem) avec des contraintes liées aux choix d’équipements. Les lignesétudiées sont sérielles, i.e. la pièce à usiner traverse une séquence de stations en passant d’uneà l’autre en respectant une cadence imposée : le temps de cycle de la ligne. Les stations sontcomposées des machines d’usinage à commandes numériques (ou machines CNC : Compu-ter Numerical Controller). Une machine à commandes numériques est mono-broche et peututiliser séquentiellement plusieurs outils d’usinage et faire tourner la pièce sur un plateaurotatif afin d’exécuter plusieurs opérations d’usinage sur des faces di!érentes de la pièce. Plu-sieurs machines peuvent être installées sur une seule station, elles e!ectuent alors les mêmesopérations sur des unités de produits di!érentes, ainsi le temps de cycle local de la stationest égal au temps de cycle de la ligne multiplié par le nombre de machines de la station. Leproblème d’équilibrage étudiée intègre les contraintes classiques de précédence, d’exclusionet d’inclusion. En plus de cela, le temps de chargement d’une station dépend de la séquenced’opérations a!ectées. En e!et, un temps inter-opératoires doit être pris en compte entredeux opérations, ce temps est lié aux temps nécessaires pour le changement d’outils, rotationde la pièce, etc. Des contraintes d’accessibilité sont également traitées, en e!et, suivant laposition de la pièce dans la machine et le type de la machine utilisée, nous avons un ensemblede faces accessibles (et donc les opérations d’usinage situées sur ces faces sont accessibles)[1]. Deux types de machines avec des caractéristiques di!érentes peuvent être utilisées dansla conception d’une telle ligne. Ainsi, plusieurs opérations nécessitent l’utilisation d’un typeparticulier de machine. Le problème d’équilibrage consiste à déterminer, pour un temps decycle donné, le nombre de stations à installer ainsi que le nombre et le type des machines surchaque station, la séquence d’opérations à a!ecter à la station, tout en tenant compte descontraintes du problème. L’objectif de l’équilibrage consiste à minimiser le co˚t total de laligne à installer.
2 Algorithme
Nous proposons un algorithme de résolution basée sur GRASP [2]. L’algorithme est composéde deux phases :– Une première phase qui consiste à construire une solution admissible à l’aide d’un algo-
rithme glouton aléatoire (semi-glouton) (Fig.1) ;
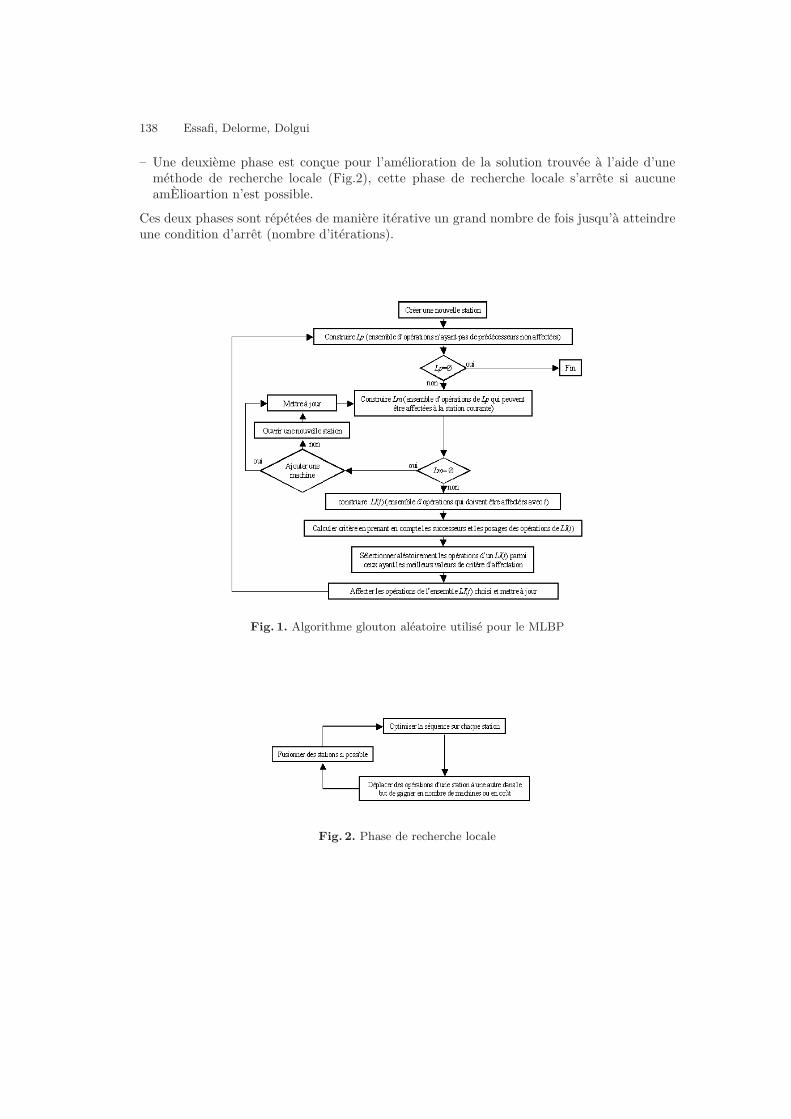
138 Essafi, Delorme, Dolgui
– Une deuxième phase est conçue pour l’amélioration de la solution trouvée à l’aide d’uneméthode de recherche locale (Fig.2), cette phase de recherche locale s’arrête si aucuneamÈlioartion n’est possible.
Ces deux phases sont répétées de manière itérative un grand nombre de fois jusqu’à atteindreune condition d’arrêt (nombre d’itérations).
Fig. 1. Algorithme glouton aléatoire utilisé pour le MLBP
Fig. 2. Phase de recherche locale

Title Suppressed Due to Excessive Length 139
Références
1. Delorme X., A. Dolgui, M. Essafi, L. Linxe and D. Poyard : Automatic Machining Lines : Designand Optimization. Chapter in : Handbook of Automation, S. Nof (Ed.). Springer Verlag (2008)
2. Feo, T.A. and M.G.C. Resende : A probalistic heuristic for a computationally di%cult set coveringproblem. Operations Research Letters, Vol. 8, p. 97-71 (1989)

Gestion de l’autonomie des Robots Mobiles
Hassan BAALBAKI
CIS, Ecole Nationale Superieur des Mines de Saint Etienne, 42023 St. Etienne Cedex [email protected]
1 Introduction
L’étude suivante consiste à gérer l’autonomie d’un ensemble de robots mobiles dotés de bat-teries ayant une capacité limitée et nécessitants un temps de rechargement assez considérableNotre objectif est d’assurer la continuité du travail, de garantir la disponibilité d’un des ro-bots et de s’assurer que tous les robots ne se rechargent pas en même temps. Pour réalisercet objectif, les demandes des journées précédentes sont analysées afin de prévoir les futuresdemandes et d’estimer les besoins, et en fonction de ces besoins un planning de rechargementpour chaque robot est établi.Cette étude s’inscrit dans le cadre du projet européen IWARD dont le but est de développerun ensemble de robots intelligents capables d’assister le cadre médical dans les hôpitaux auquotidien en e!ectuant a leur place les tâches logistiques comme le transport, le nettoyage,la tournées de chambre, la surveillance, la téléconférence entre le patient et le médecin et ladétection des situations anormales.Ce problème fait parti de la module de gestion centralisée des robots qui décompose de 3 sousparties fortement reliés : (i) La localisation des zones de stationnement de chaque robot (ii)La configuration et reconfiguration des robots (iii) La gestion de l’autonomie des robots. Les2 premiers sous problèmes ont été largement étudiés dans [1] et [2].Dans ce présent papieron étudie le dernier sous problème et on le modélise comme un système de programmationlinéaire.La formulation du problème proposée consiste à décomposer la journée en plusieurs périodest ! T équivalantes à une période de rechargement, à chacune de ces périodes est associé unensemble de missionsm !Mt qui doivent être exécutées avant la fine de cette période. Chaquerobot n ! {1...N} est muni d’une batterie dont le niveau initial est de Cn,0 et Cn,t représentele niveau d’énergie à la fin de la période t . On symbolise par an la quantité d’énergie minimaleconsommée pendant la totalité d’une période par le robot n en état d’attente. La quantitéd’énergie supplémentaire pour exécuter la mission m est représentée par en,m et gn,t est laquantité d’énergie rechargée durant la période t.
1.1 FormulationAfin de formuler le problème en un P.L., ces variables de décision sont utilisées :
Xn,t =1
1 si le robot n est active durant la période t0 sinon le robot est en train de se recharger
Zn,m =1
1 si la mission m est a!ectée au robot n0 sinon

Gestion de l’autonomie des Robots Mobiles 141
Le problème est formulé ainsi :
La fonction objective (1) maximise le nombre total des robot actifs. La contrainte (2) garantieque chaque mission est a!ectée a un et un seul robot. La contrainte (3) assure que le nombre derobots actifs soit toujours au dessus d’un seuil Lt prédéfini pour chaque période. La contrainte(4) a"rme qu’ une mission ne peut être a!ectée qu’à un robot actif . La contrainte (5) établitla continuée du niveau d’énergie des batteries, et que le niveau actuelle dépend du niveauprécédant et des activités accomplit durant la période. La contrainte (6) certifie que le niveaud’énergie ne dépasse pas les capacités physiques de la batterie. La contrainte (7) assure quela quantité d’énergie rechargé gn,t ne dépasse pas un certain seuil Rn qui est relié à la vitessemaximale de rechargement et la durée de rechargement. Les contraintes (8) sont les contraintesd’intégrité des variables de décisions.
2 ConclusionLe modèle présenté ci-dessus à été programmé en utilsant le solver MIP de CPLEX. Lesrésultats obtenus sont satisfaisants pour des problèmes de petite et moyenne tailles dont larésolution prend quelque secondes, mais en ajoutant plus de périodes et en augmentant lataille de l’instance à 100 robots et 1000 tâches la résolution du système devient de plus enplus complexe et nécessite plusieurs heures de calcul.
Références1. Baalbaki, H., Lamiri, M., Xie,X. : Joint location and configuration of mobile service robots for
hospitals. The 4th IEEE Conf. on Automation Science and Engineering (CASE 2008)2. Baalbaki, H., Lamiri, M., Xie,X. : A two-phase approach for configuration and location of mobile
robots in a hospital setting. The I*PROMS Conference on Innovative Production Machines andSystems(2008)

Programmation linéaire en nombres entiers pourl’ordonnancement modulo sous contraintes de ressources
M. Ayala, C. Artigues
LAAS-CNRS; Université de ToulouseAvenue du Colonel Roche, F-31077 Toulouse, France.
[email protected]@laas.fr
Beaucoup d’études dans le domaine de la compilation pour les processeurs superscalairesmodernes et architectures VLIW (Very Large Instruction Word) sont focalisées sur le pro-blème d’ordonnancement d’instructions. Ce problème est défini par un ensemble d’opérationsà ordonnancer, un ensemble de dépendances entre ces opérations et la micro architecturedu processeur cible qui définit des contraintes des ressources complexes. Une opération estconsidérée comme une instance d’une instruction dans un programme. L’ordonnancementd’instructions par boucles internes est connu sous le nom de pipeline logiciel. Le pipelinelogiciel est une méthode e"case pour l’optimisation de boucles qui permet la réalisation enparallèle des opérations des di!érentes itérations de la boucle. Aujourd’hui, les compilateurscommerciaux utilisent des méthodes basées sur les algorithmes d’ordonnancement modulo.L’ordonnancement modulo est une structure d’ordonnancements cycliques 1-périodiques avecpériode entière. Cela rend le modèle plus simple que le modèle classique d’ordonnancementcyclique et aussi plus facilement implémentable. Le modulo-ordonnancement est une tech-nique qui crée des liens entre les itérations successives d’une boucle. Le but est de trouverun ordonnancement valide pour une boucle pour qu’elle puisse se superposer plusieurs foisdans un intervalle constant, que nous appelons intervalle d’initiation ou période (3). L’algo-rithme d’ordonnancement modulo doit prendre en compte les contraintes de dépendances desopérations, les contraintes de ressources (et la taille des registres qui sont ignorés dans cetteétude). Il doit aussi considérer les critères d’optimisation tels que la minimisation de l’inter-valle d’initiation de l’ordonnancement 3 ou la minimisation de la durée de l’ordonnancementd’une itération de la boucle.Le problème d’ordonnancement modulo consiste à trouver les dates de début d’un ensembled’opérations génériques de telle sorte que dans le contexte cyclique, les instances des opéra-tions génériques sont répétées toutes les 3 unités de temps. La date de début d’une instanced’opération est donc définie par deux valeur : la date de début (i dans une période générique,variant de 0 à 3 # 1 et le numéro ki de la période. L’aspect modulo permet de limiter lenombre d’opérations à considérer aux seules opérations génériques. Les ressources sont dis-ponibles en quantités limitées et chaque opération demande une quantité positive ou nullede chaque ressource. Les demandes cumulées des opérations en cours d’exécution à chaqueinstant modulo 3 sur chaque ressource ne doivent pas dépasser sa limitation. Les contraintesde dépendances sont définies relativement aux dates de début "e!ectives" (i + ki3.Dans ce travail, nous considérons le problème de minimisation de la somme pondérée des datesd’exécution des opérations à durées unitaires pour un intervalle d’initiation donné. Dans lecontexte de la programmation linéaire en nombres entiers (PLNE) pour l’ordonnancement mo-dulo avec contrainte de ressources, di!érentes formulations ont été proposées, basées sur des

Title Suppressed Due to Excessive Length 143
généralisation de la formulation classique non préemptive et indexée par le temps de Pritskeret al. [3] pour le RCPSP (Resource Constrained Project Scheduling Problem). Eichenbergeret Davidson [1] proposent une formulation comportant deux ensembles de variables : unevariable binaire yi% donnant la date de début de l’opération i dans la période générique (telleque (i =
&'#1%=0 1yi% ) et la variable entière ki. Dupont-de-Dinechin et al. [2] donnent une
formulation comportant un seul type de variable binaire xit tel que yi% =&K#1k=0 xi,%+k'
et ki =&K#1k=1&K'#1t=k' xit avec K et 3 donnés. Dans les deux cas, suivant l’approche de
Christofides et al. [5], des contraintes de précédence structurées et non structurées sont pré-sentées. Mingozzi et al. [4] présentent une formulation 0-1 pour le RCPSP qui nécessite ungrand nombre de variables correspondant à des sous-ensembles d’activités qui peuvent êtreexécutées simultanément sans violer les contraintes de ressources ou de précédence. Dans cetravail, nous proposons des extensions de la formulation de Mingozzi pour RCMSP. Danscette extension l’ordonnancement se fait sur la période générique alors que dans le modèle deMingozzi l’ordonnancement se fait pour tout l’horizon de temps. Nous proposons un schémade génération de colonnes pour résoudre la relaxation du PLNE. Nous avons trouvé que lesous-problème correspond à 3 problèmes du sac-à-dos multidimensionnel. Ces extensions sontproposées pour les PLNE présentés précédemment. Les résultats expérimentaux pour com-parer les di!erents formulations proposées sont réalisés en utilisant des instances de RCMSPprovenant du compilateur commercial ST200.
Références[1] A Eichenberger, E. S. Davidson .E"cient Formulation for Optimal Modulo Schedulers.SIGPLAN Conference on Programming Language Design and Implementation - PLDI’97(1997).[2] B.Dupont-De-Dinechin. C. Artigues. S. Azem. Resource Constrained Modulo Scheduling.In C. Artigues, S. Demassey and E. Néron. Resource-Constrained Project Scheduling Models,algorithms, extensions and applications. November (2007).[3]A. Pritsker, L.Watters and P. Wolfe. Multi-project scheduling with limited resources : azero-one programming approach. Management Science 16, 93-108, (1969).[4] A. Mingozzi and V. Maniezzo. An Exact Algorithm For The Resource Constrained ProjectScheduling Problem Based on a New Mathematical Formulation. Management Science 44,714-729, (1998).[5] N. Christofides , R. Alvarez-Valdés and J. Tamarit. Project scheduling with resourceconstraints : a branch and bound approach. European Journal of Operational Research 29(3),262-273, (1987).

Formulation on-o! pour le RCPSP
O. Koné1, C. Artigues1, P. Lopez1, and M. Mongeau2
1 LAAS-CNRS ; Université de Toulouse ; 7 avenue du Colonel Roche, F-31077 Toulouse cedex [email protected], [email protected], [email protected]
2 Université de Toulouse, UPS, Institut de Mathématiques, 31062 Toulouse cedex [email protected]
Le RCPSP est un problème d’ordonnancement cumulatif qui consiste à organiser l’exécutiond’un ensemble d’activités soumises à des contraintes de temps et de ressources. Inspirée destravaux sur les problèmes d’atelier [3] et d’une formulation basée sur les événements [1], nousproposons ici une nouvelle formulation de ce problème basée non seulement sur le conceptd’événement mais aussi sur l’idée de fixer une variable binaire à 1 sur toute la durée d’exécutiond’une activité. On rappelle que le RCPSP se caractérise formellement par un ensemble T =0, ..., n# 1 de n activités. Chaque activité i, de durée opératoire pi, est à ordonnancer surun horizon de temps H . Les activités sont liées entre elles par des contraintes de précédence.Ainsi, il existe un ensemble de précédences U tel que pour toute paire d’activités (i, j) ! U ,l’activité j ne peut débuter qu’après l’achèvement de l’activité i. Nous disposons égalementd’un ensemble R de K ressources, disponibles en quantité constante Rk, k ! R, sur toutl’horizon H , et chaque activité consomme rik unités de la ressource k.
1 Formulation on-o! basée sur les événements
A la di!érence des formulations classiques [2] utilisant des variables de décision indexéespar le temps sur un horizon d’ordonnancement discrétisé à intervalle constant (exemple :xit = 1 signifie que l’activité i démarre à la date t), on considère ici deux types de variables(zie et te) avec les variables zie indexées par des événements. Un événement se produit audébut de l’exécution d’une activité. La variable zie = 1 si l’activité i débute ou est en coursd’exécution immédiatement après l’événement e. Ainsi, cette variable zie reste égale à 1 surtoute la durée d’exécution de l’activité i. Les variables te désignent la date de l’événemente. Un ordonnancement optimal ne comporte pas plus d’événements de début d’activité qued’activités. Ce modèle semble donc prometteur du point de vue du nombre de variablesbinaires, contrairement aux formulations classiques qui ont un nombre de variables qui exploseavec une augmentation de l’horizon d’ordonnancement. En e!et, le nombre d’événementsétant borné par n, le nombre de variables de notre formulation est inférieur ou égal à n2 +n.Tout comme la formulation basée sur les événements [1], il présente l’avantage de prendreen compte des durées non-entières (exemple : pi = 3, 8). Il présente également l’avantage dereprésenter de façon simple les contraintes de ressources, tout en ayant beaucoup moins devariables (2n2 + n).L’objectif est de minimiser la durée totale qui correspond à la date du dernier événement. Unecontrainte fixe la date de l’événement 0 au temps 0. Une inéquation permet de lier les variablesbinaires d’optimisation zie aux variables continues d’optimisation te, tout en assurant quela durée d’exécution d’une activité soit égale à la durée opératoire de cette activité. Desinéquations, dites inéquations de contiguïté, assurent que les événements pendant lesquels

Formulation on-o" pour le RCPSP 145
une activité est en cours d’exécution sont contigus. Une inéquation assure que chaque activitéest exécutée au moins une fois pendant tout l’horizon d’ordonnancement du projet. A celas’ajoutent les contraintes de précédence et les contraintes de ressource.
2 Résultats expérimentaux
Nous avons testé cette formulation sur des instances particulières. Ces instances de 15 ac-tivités sont caractérisées par la valeur des durées opératoires pi des activités qui varient desimples unités (exemple : pi = 5) à des centaines d’unités (exemple : pi = 259). Ces instancess’apparentent aux jeux de données rencontrés dans certains problèmes de pétrochimie. Lesrésultats que nous avons obtenus montrent que la formulation on-o! présente de meilleuresperformances pour la résolution de ce type de problème par rapport aux formulations clas-siques de la littérature. On remarque aussi que, contrairement aux résultats sur les instancesclassiques et parfois critiquées de la PSPLIB [6], la formulation de Christofides [4] conduit àde moins bons résultats que celle de Pritsker [5].
En conclusion, nous avons introduit une nouvelle formulation PLNE basée sur les événementsqui semble particulièrement adaptée pour la résolution des problèmes d’ordonnancement s’ap-parentant aux problèmes rencontrés dans certains problèmes de pétrochimie, caractérisés pardes durées entières et non entières, de valeurs très disproportionnées.
Références
1. O. Koné, C. Artigues, P. Lopez and M. Mongeau, Programmation linéaire en nombres entiers(PLNE) pour le problème de gestion de projet avec contraintes de ressources (RCPSP) : Lesformulations basées sur les événements et comparaisons expérimentales, Présentation au congrèsROADEF 2008.
2. S. Demassey, C. Artigues and P. Michelon. Constraint propagation-based cutting planes : An appli-cation to the resource-constrained project scheduling problem. INFORMS Journal on computing,17(1) :52-65, 2005.
3. S. Dauzère-Pérès and J.B. Lasserre, A new mixed-integer formulation of the flow-shop sequen-cing problem, 2nd workshop on models and algorithms for planning and scheduling problems,Wernigerode, Allemagne, May 1995.
4. N. Christofides, R. Alvarez-Valdès and J. M. Tamarit, Project scheduling with resourceconstraints : A branch and bound approach, European Journal of Operational Research,29(3) :262–273, 1987.
5. A. Pritsker, L. Watters and P. Wolfe, Multi-project scheduling with limited resources : A zero-oneprogramming approach, Management Science, 16, 1969.
6. PSPLIB. //129.187.106.231/psplib/

Le Problème d’Ordonnancement avec Production etConsommation de Ressources
Jacques Carlier, Aziz Moukrim, and Huang Xu
Université de Technologie de CompiègneHEUDIASYC, UMR CNRS 6599
BP 20529, 60205 Compiègne cedex, France{jacques.carlier, aziz.moukrim, huang.xu}@hds.utc.fr
1 Introduction
La plupart des modèles d’ordonnancement considèrent des contraintes potentielles classiqueset des ressources renouvelables, c’est-à-dire que celles-ci sont exigées au début de l’exécutionde chaque tâche et sont restituées en fin d’exécution. Peu de travaux traitent de ressourcesconsommables, c’est-à-dire qui ne sont pas restituées à la fin de l’exécution des tâches. Nousétudions dans cet article un modèle d’ordonnancement avec production et consommation deressources. Ce modèle inclut donc ressources renouvelables et consommables. Dans la section2, nous déclarons le modèle. Puis nous présentons des méthodes approchées dans la section3, et une méthode exacte dans la section 4.
2 Un Modèle Comprenant la Consommation et la Production deRessources
Dans ce modèle, chaque évènement i requiert une certaine quantité ai de ressource pour com-mencer son exécution. La quantité ai > 0 (resp. ai < 0) signifie que l’évènement i consomme(resp. produit) une quantité |ai| de la ressource. vij représente le décalage de temps entrel’évènement i et l’évènement j. Ce modèle peut représenter les ressources renouvelables etnon-renouvelables. Dans le cas de ressource renouvelable (RCPSP), une tâche i de durée piqui requiert une quantité ai de ressource peut-être représentée, dans notre modèle, en intro-duisant deux évènements i" et i"" où l’évènement i" consomme une quantité |ai| de ressource,et où l’évènement i"" produit une quantité |ai| de la ressource avec vi!i!! = pi et vi!!i! = #pi.Dans le graphe conjonctif G de notre modèle, ceci est exprimé par un arc (i", i"") valué parpi et un arc (i"", i") valué par #pi. Le problème consiste à trouver une solution minimisant lemakespan d’un problème d’ordonnancement avec production et consommation de ressources.Ce problème, par extension du RCPSP, est NP-Complet.
3 Méthodes approchées
Pour résoudre ce problème, nous proposons une méthode basée sur l’algorithme du RecuitSimulé [4] et une méthode basée sur les algorithmes mémétiques [8].

Le Problème d’Ordonnancement avec Production et Consommation de Ressources 147
Pour ces deux méthodes, nous utilisons le même codage d’une solution. Dans notre mo-dèle, nous considérons un arbitrage complet [1], c’est-à-dire comprenant tous les évènementsi1, i2, ..., in du projet, de consommation comme de production de ressource, que nous ex-primons par l’ensemble d’arcs conjonctifs % = {(i1, i2), (i2, i3), ..., (in#1, in)}. Nous associonscet ensemble à la permutation !# = (i1, i2, ..., in) correspondant aux relations induites par%. Nous utilisons ces permutations pour représenter les solutions, dans la mesure où l’Algo-rithme de l’Arbitrage Complet [2] permet de déterminer une solution optimale compte tenudes contraintes exprimées par un arbitrage complet donné. Nous avons montré qu’il est égale-ment possible, lorsqu’il n’existe aucun arc vij de coût négatif, d’obtenir une solution optimaleen considérant des arbitrages de consommation, c’est-à-dire ne faisant apparaître que des arcsentre évènements de consommation, avec l’Algorithme de l’Arbitrage de Consommation.Les deux méthodes proposées ont été testées sur les instances de référence PSPLIB pourle RCPSP J30, J60 et J90 [7]. Ces instances sont employées par défaut, aucun benchmarkn’existant pour notre modèle et le RCPSP constituant un cas particulier de celui-ci. Notre al-gorithme mémétique donne de bons résultats selon les critères établis par Kolisch et Hartmann[5]. L’algorithme de recuit simulé est moins performant.
4 Une méthode exacte
Nous proposons aussi une méthode exacte de type arborescent. Dans la méthode exacte,afin de calculer une borne inférieure, nous adaptons la borne inférieure de JPPS [3] à notreproblème par relaxation à un problème à ressources renouvelables. Nous utilisons aussi l’al-gorithme de décalage [1] par relaxation à un problème à ressources consommables. Chaquenoeud dans l’arbre de recherche représente un ensemble d’arcs qui sépare l’espace de recherche.Nous rapporterons des résultats préliminaires de calcul.
Références
1. J. Carlier, "Problèmes d’Ordonnancements à Contraintes de Ressources : Algorithmes et Com-plexité". Thèse d’état, Université Pierre et Marie Curie (Paris VI), 1984.
2. J. Carlier, A. Moukrim and H. Xu, "The Project Scheduling Problem with Production andConsumption of Resources : a list-scheduling based algorithm", soumis à Discrete Applied Math-matics en révision.
3. J. Carlier, E. Pinson, "Jackson’s pseudo-preemptive schedule and cumulative scheduling problems",EJOR 145(2004), p80-94.
4. S. Kirkpatrick, C. D. Gelatt and M. P. Vecchi, "Optimization by Simulated Annealing", Science,1983/220/4598, p671-680.
5. R. Kolisch and S. Hartmann, "Experimental Investigation of Heuristics for Resource-ConstrainedProject Scheduling : An Update", EJOR 174(2006), p23-37.
6. R. Ruiz and T. Stützle, "A simple and e#ective iterated greedy algorithm for the permutationflowshop scheduling problem", EJOR, 177(2007), p2033-2049.
7. R. Kolisch and A. Sprecher,"PSPLIB–A project scheduling library", EJOR 1996, p205-216.8. P.Moscato, "On Evolution, Search, Optimization, Genetic Algorithms and Martial Arts : Towards
Memetic Algorithms", Caltech Concurrent Computation Program, Report, 1989, p7904.

Extension du Contexte de Mise en Oeuvre desOrdonnancements PFAIR
S. MALO1, A. GENIET1, and M. BIKIENGA2
1 1. Av Clément Ader BP 40109-86961 Futuroscope [email protected],[email protected]
2 Université Polytechnique de Bobo Dioulasso. 01 BP 1091 Bobo Dioulasso [email protected]
1 Introduction
Dans ce papier nous nous intéressons au problème de l’ordonnançabilité des tâches tempsréel sur des architectures multiprocesseurs centralisées. Nous allons plus particulièrementétudier l’ordonnançabilité des tâches périodiques asynchrones à échéances contraintes sousPFAIR. Les algorithmes d’ordonnancement PFAIR sont les seuls algorithmes d’ordonnance-ment pouvant garantir le respect des échéances tâches indépendantes périodiques synchroneset à échéances sur requêtes sur une plateforme multiprocesseur suivant une stratégie globale.Mais la restriction aux tâches synchrones et à échéances sur requêtes limite sévèrement l’uti-lisation de ses algorithmes. Nous nous intéressons dans ce papier à la possibilité d’étendre cerésultat d’ordonnançabilité aux tâches asynchrones et à échéances contraintes sur une pla-teforme multiprocesseur suivant toujours une stratégie globale. Nous montrons à travers dessimulations que le résultat d’ordonnançabilité établi pour les tâches synchrones à échéancessur requêtes peut s’étendre aux tâches asynchrones et à échéances contraintes.
2 Les ordonnancements PFAIR
Nous utilisons le formalisme de Liu et Layland [3] pour modéliser les tâches. Une tâcheest donc dénotée 1i (ri, Ci, Di, Ti) avec Ci " Di " Tiet une configuration de n tâches 1 ={11, 12, ..., 1n}. L’hyperpériode d’une configuration de tâches est notée T et T = PPCMi=1..n (Ti).L’architecture matérielle est composée de m processeurs identiques partageant une mémoirecommune. Les tâches sont préemptibles mais non parallèlisables. La migration est possiblerendant ainsi l’ordonnancement global. Formellement, un ordonnancement sur une plateformede m processeurs est une fonction S : 1 * B : {0, 1} telle que : ,t ! B :
&%i%% S(1i, t) " m
avec S(1i, t) = 1 si la tâche 1i a été ordonnancée sur le slot [t, t+ 1) et S(1i, t) = 0 sinon. Lorsd’un ordonnancement idéal, chaque tâche 1i doit recevoir exactement Ui.t unités de tempsprocesseur dans l’intervalle [0, t). Cependant, un tel ordonnancement n’est pas possible dansle cas discret. En revanche, PFAIR tente à chaque instant de répliquer le plus fidèlementpossible cet ordonnancement idéal. La di!érence entre l’ordonnancement idéal et l’ordonnan-cement construit est formalisée par la notion de retard. Formellement, le retard d’une tâche1i à l’instant t, dénoté retard(S, 1i, t), est défini par : retard(S, 1i, t) = Ui.t#
&j=t#1j=0 S(1i, j).
Un ordonnancement est alors dit PFAIR si et seulement si ,1i, t : #1 < retard(S, 1i, t) < 1.Dans [2], Baruah et Al. ont montré la condition d’existence d’un ordonnancement PFAIR

Extension du Contexte de Mise en Oeuvre des Ordonnancement P-équitables 149
pour une configuration de tâches synchrone à échéances sur requête. Cette condition s’énoncecomme suit :Theorem 1. Soit 1 une configuration de n tâches synchrÙnes à échéance sur requête, il existeun ordonnancement PFAIR sur une plateforme de m processeurs identiques si et seulementsi&i=ni=1
CiTi" m.
3 Extension de la propriété d’équité aux configurations de tâchespériodiques indépendantes
Notre objectif dans cette étude est d’étendre la condition d’existence d’ordonnancementPFAIR à toute configuration de tâches périodiques indépendantes. Pour cela nous avons pro-cédé dans une première phase à des simulations. Le simulateur met en oeuvre un générateuraléatoire d’applications temps réel et un d’ordonnancement suivant algorithme d’ordonnance-ment PFAIR. L’olgorithme utilisé est PF. Nous avons tout d’abord adapté les conditions demise en oeuvre de cet algorithme à notre contexte afin que l’équité soit maintenue.Le tempsprocesseur #i(t) idéalement reçu par une tâche 1i dans un intervalle de temps [0, t) est definicomme suit :
%i(t) =
!"""#
"""$
0 si t ! [0, ri)
k.Ci + CiDi.(t% k.Ti % ri) si t ! [k.Ti + ri, k.Ti +Di + ri)
(k + 1).Ci si t ! [k.Ti +Di + ri, (k + 1).Ti + ri).
o˘ k ==tTi
>. Les résultats des simulations nous ont conduit à énoncer les conjectures suivantes :
Conjecture 1. Pour une configuration de n tâches périodiques indépendantes & , si&i=ni=1
CiDi# m,
alors il existe pour & un ordonnancement PFAIR valide sur une plateforme de m processeurs iden-tiques.Conjecture 2. L’ordonnancement PF est cyclique et l’entrée dans le cycle se produit au plus tard àla date max {ri}i=...n + P .En e#et, à notre connaissance aucun résultat sur la cyclicité des ordonnancements temps réel n’existedans un contexte d’ordonnancement PFAIR sur une plateforme multiprocesseur hors mis les travauxde [1] et [4]. D’autre part, une étude plus poussée peut permettre de connaître l’incidence du facteurd’utilisation U et du facteur de charge CH sur l’ordonnançabilité des configuration tâches à échéancecontrainte.
Références1. Annie Choquet-Geniet and Emmanuel Grolleau. Minimal schedulability interval for real time
systems of periodic tasks with o#sets .Theoretical of Computer Sciences, vol. 310, 2004, pp. 117-134.
2. BARUAH S., COHEN N., PLAXTON C. G., VARVEL D., Proportionate progress : notion offairness in resource allocation , Algorithmica. vol. 15, p. 600-625, 1996.
3. Liu C. and Layland J.W.,Scheduling algorithms for multiprogramming in a hard real-time envi-ronment. Journal of ACM, vol.20,p.46-61,1973.
4. L. Cucu,J. Goossens, Feasibility Intervals for Fixed-Priority Real-Rime Scheduling on UniformMultiprocessors. ETFA. IEEE Conference,20-22 Sep. 2006 Pages :397-404

Implémentation e!ective d’un ordonnanceur distribué
M. Pérotin, P. Martineau, and C. Esswein1
LI Tours, 64 avenue Jean Portalis, 37200 Toursmatthieu.perotin,patrick.martineau,[email protected]
1 IntroductionUn double constat motive ce travail : la demande en calcul haute performance formulée par leschercheurs et la faible utilisation moyenne de la puissance de calcul des ressources pédagogiquesorganisées en salles de travaux pratiques. La problématique a été de répondre à cette demande quiémane de chercheurs qui ne sont pas spécialistes du parallélisme et de l’ordonnancement, tout enpréservant les ressources pédagogiques pour les enseignements.Ce résumé présente une solution permettant d’utiliser cette puissance résiduelle en satisfaisant descontraintes imposées par les utilisateurs du système. Il présentera tout d’abord des éléments de modé-lisation du système et montrera que le problème clé à résoudre est un problème d’ordonnancement. Unsimulateur sera présenté afin de comparer diverses heuristiques. Enfin des résultats d’implémentatione#ective seront donnés.
2 Élements de modélisationDi#érents acteurs sont ammenés à interagir autour d’un système permettant l’exécution de calculsparallèles sur un réseau universitaire :– L’utilisateur interactif : qui correspond à une personne travaillant physiquement sur un ordinateur,
par exemple un étudiant pendant une scéance de travaux pratiques.– L’utilisateur de calcul haute performance : il s’agit d’une personne qui souhaite concevoir et exécuter
des processus de calcul intensif.Ces acteurs ont des attentes di#érentes vis à vis du système. Typiquement l’utilisateur interactif nesouhaite pas être pénalisé par l’exécution des processus lourds lancés par l’utilisateur de calcul hauteperformance. Ce dernier souhaite que ses processus soient exécutés le plus rapidement possible etsouhaite que leur soumission soit facile.La plupart des contraintes modélisant les souhaits des utilisateurs peuvent être satisfaites par l’uti-lisation d’un certain nombre de solutions techniques existantes. D’autres, en revanche, n’admettentpas de solution toute prête.Ces contraintes sont relatives à l’encombrement mémoire des processus, l’hétérogénéité des ordina-teurs et l’utilisation des ordinateurs par les di#érents acteurs. Un nouveau problème d’ordonnance-ment a été obtenu en les incorporant à un problème de rééquilibrage de charge ([1]). Dans ce typede problème, il s’agit, partant d’une a#ectation initiale des processus sur les processeurs, de déplacerle moins de tâches possible dans le but d’obtenir une charge similaire sur l’ensemble des processeurs.Une nouvelle métrique de charge a été définie. Le problème obtenu est en-ligne et bi-critère ([2]). Ilest, dans sa variante décisionnelle NP-Complet ([3]).
3 Simulation et ImplémentationPlusieurs heuristiques ont été étudiées et comparées à l’aide d’un simulateur basé sur SimGrid ([4]).Le simulateur a permis l’étude de diverses heuristiques et de comparer leurs performances. Cette
Implémentation e#ective d’un ordonnanceur distribué 151
première phase a mené au choix de l’une d’entre elle pour une implémentation e#ective du mécanismeau sein de Kerrighed. Les résultats obtenus sont très proches de ceux fournis par la simulation. Lafigure 1 montre la convergence d’un système réel composé de 14 ordinateurs vers un état équilibré.
Fig. 1. Charges des ordinateurs, situation initiale et finale
4 Conclusion
Une nouvelle solution s’articulant à la fois autour de solutions techniques existantes et de la résolutiond’un problème d’ordonnancement a été proposée afin de permettre la mise en place de calcul hauteperformance dans les universités en utilisant les équipements déjà présents.À cet e#et, un nouveau problème d’ordonnancement a été défini et étudié, plusieurs heuristiques ontété proposées pour le résoudre et comparées à l’aide d’un simulateur. Une plateforme expérimentalea été déployée afin de vérifier que la solution proposée satisfait l’ensemble des contraintes.
Références
1. Aggarwal (G.), Motwani (R.) et Zhu (A.). – The load rebalancing problem. Proc. ACM SPAA,2003, 2003.
2. Perotin, M., Martineau P. et Esswein C. : Rééquilibrage de charge en-ligne bi-critère RENPAR2008, Fribourg.
3. Perotin, M., Martineau P. et Esswein C. : Équilibrage de charge pour la grille. MOSIM 2008,Paris.
4. Casanova (Henri), Legrand (Arnaud) et Marchal (Loris). – Scheduling distributed applications :the simgrid simulation framework. Proceedings of the third IEEE International Symposium onCluster Computing and the Grid (CCGrid’03), 2003.

Une heuristique e"cace pour l’ordonnancementpériodique de tâches avec contraintes de stockage
K. Deschinkel, and S.A.A Touati
PRiSM, Université de Versailles Saint-Quentin en Yvelines, 45 avenue des Etats-Unis, 78035Versailles
[email protected]@prism.uvsq.fr
1 Description du problèmeCet article traite du problème d’optimisation du besoin en stockage dans les graphes de tâches pé-riodiques. En pratique, notre problème tend à minimiser le besoin en registres dans les programmesembarqués, où les instructions d’une boucle sont représentées par un graphe de dépendances de don-nées cyclique (GDD). Dans cet article, nous supposons une exécution parallèle des instructions sansaucun modèle de ressources - la parallélisme étant borné par les contraintes de stockage uniquement.Notre but est d’analyser le compromis entre le besoin en registres et le parallélisme dans un problèmed’ordonnancement périodique de tâche.Les techniques existantes d’allocation périodique de registres appliquent généralement un ordonnance-ment périodique d’instructions sous contraintes de ressources, tout en étant sensible aux contraintesde registres. Plusieurs travaux proposent des algorithmes d’ordonnancement d’instructions d’uneboucle (sous contraintes de ressources et de période) tel que le code résultant ne crée pas plus de Rvariables simultanément en vie. Or, en pratique, de tels algorithmes n’engendrent pas toujours descodes rapides, car les contraintes de registres sont plus critiques que les contraintes de performances :ceci car les accès mémoire coûtent plus de 100 unités de temps (cycles processeur) alors que les latencesdes instructions sont inférieures à 10 cycles. Dans cet article, nous garantissons les contraintes desregistres avant la phase d’ordonnancement d’instructions sous contraintes de ressources : nous analy-sons et modifions le GDD afin de garantir que tout ordonnancement d’instructions sous contraintesde ressources ne crée pas plus de R variables simultanément en vie. Notre modification du GDDessaie de ne pas altérer l’extraction du parallélisme si possible en prenant comme métrique la valeurdu circuit critique du graphe. Cette idée a déjà été abordée dans [1].
2 Une heuristique en deux phasesLe problème d’ordonnancement périodique de tâches (instructions) cycliques avec minimisation dunombre de registres, dans sa forme la plus générale, peut se formuler sous forme d’un programmelinéaire en nombre entiers où les variables de décision sont les dates de début de chacune des tâches,des variables binaires indiquant une réutilisation ou non de registres entre deux tâches (non né-cessairement distinctes), et les distances de réutilisation. Ce problème étant NP-complet [2], unerésolution exacte s’avère trop coûteuse en pratique. Ici, nous avons exploité le fait que le problèmeen question fait apparaître un problème sous-jacent d’a#ectation pour lequel nous connaissons unalgorithme en temps polynomial (méthode Hongroise) pour proposer une heuristique appropriée ap-pelée SIRALINA [3]. Cette heuristique, en deux phases, nécessite dans un premier temps la résolutiond’un programme linéaire entier avec une matrice des contraintes totallement unimodulaire, puis larésolution d’un problème d’a#ectation linéaire.

Une heuristique pour l’ordonnancement périodique de tâches avec contraintes de stockage 153
3 Résultats
Nous avons testé SIRALINA sur un ensemble de benchmarks, issus de la communauté d’optimisationde codes, et correspondants à des codes de calcul haute performance pour l’embarqué (LAO, MEDIA-BENCH, SPEC2000-CINT, SPEC200-CFP, SPEC2006). Nos expériences montrent que SIRALINAproduit des solutions très satisfaisantes en très peu de temps. Par conséquent, cette méthode est entrain d’être incluse dans un compilateur pour l’embarqué chez STMicroelectronics.
4 Perspectives
Nous devons étudier la manière de prendre en compte dans notre modélisation des spécificités duproblème liées à l’architecture matérielle ou à la réalisabilité de l’ordonnancement sous contraintesde ressources. Par exemple, l’utilisation de banc de registres rotatifs force l’existence d’un seul cir-cuit hamiltonien dans le graphe de réutilisation. Le graphe de réutilisation est ordonnançable souscontraintes de ressources à condition que tout circuit dans ce graphe ait une distance positive. Letraitement de ces di#érentes spécificités constitue des pistes de travail supplémentaires.
Références
1. S-A-A Touati et C. Eisenbeis : Early Periodic Register Allocation on ILP Processors. ParallelProcessing Letters, 14(2), Juin 2004. World Scientific.
2. S-A-A Touati : Register Pressure in Instruction Level Parallelisme. Thèse, Université de Versailles,France, Juin 2002. ftp.inria.fr/INRIA/Projects/a3/touati/thesis.
3. K. Deschinkel et S-A-A Touati : E%cient Method for Periodic Task Scheduling with StorageRequirement Minimisation, Lecture Notes in Computer Science (COCOA 2008), Canada, Août2008.

Complexité de kSTSP, ou TSP multi-containers
S. Toulouse and R. Wolfler Calvo1
LIPN (UMR CNRS 7030) - Institut Galilée, Université Paris 13, [email protected], [email protected]
1 IntroductionLe problème du voyageur de commerce multi-containers, kSTSP, considère un nombre constant decontainers dans lesquels n objets sont à empiler lors d’un tour de collecte, puis à dépiler lors d’un tourde livraison. Outre quelques tentatives de résolution approchée, [2,1], kSTSP fait partie des variantesles moins explorées du TSP. S’il s’agit d’un problème NP% h (à partir de TSP, considérer deux fonc-tions distance identiques à l’orientation des arcs près), nous nous intéressons plus particulèrement àl’impact des containers dans la complexité du problème. Notamment, à l’instar des travaux accom-plis sur les PQ-arbres, [3], nous proposons un algorithme polynomial de programmation dynamiquepermettant de résoudre certains TSP avec contraintes de précédence.
2 Présentation du problèmeUne instance I de kSTSP est la donnée d’un nombre n de colis et de deux fonctions distance d1, d2 :E(Kn+1) ( N, où Kn+1 désigne le graphe complet d’ordre n + 1 (orienté ou non). Le sommet 1représente le dépôt, tandis que les sommets 2, . . . , n + 1 représentent les lieux de chargement et delivraison. On définit un partionnement ordonné comme un ensemble P = {P 1, . . . , P k} de q$-upletsP $ = (v$1, . . . , v$q" ) formant une partition de {2, . . . , n+ 1}. Une solution est un triplet (T 1, T 2, P),où T 1 (collecte) et T 2 (livraison) sont des tours sur [n+ 1] ; une solution est réalisable si pour toutepile P $ ! P , T 1 collecte ses objets dans l’ordre v$1 < . . . < v$q" , tandis que T 2 les livre dans l’ordrev$1 > . . . > v
$q" ; une solution est optimale si elle est de moindre coût, oû le coût est donné par la
somme des coûts des deux tournées.
3 Déterminer P (resp., T 2) sachant (T 1, T 2) (resp., T 1)Lemme 1 Soient deux tours T 1 et T 2, décider s’il existe P compatible se ramène au problème de lak-coloration dans un graphe d’ordre n, qui est NP% c pour k ) 3.
Lemme 2 Si I2STSP désigne l’ensemble des instances de 2STSP et opt2STSP (I) la valeur opti-male sur I ! I2STSP , alors la valeur opt2STSP |T1,# (resp. opt2STSP |T2,#) de la meilleure solution(T 1, T 2,P) sachant T 1,$ (resp., sachant T 2,$) vérifie :
infI#I2STSP
opt2STSP |T1
(I)/ opt2STSP
(I) = infI#I2STSP
opt2STSP |T2
(I)/ opt2STSP
(I) = +*
Démonstration. 1. Si G%=(W,E) désigne le graphe défini par W = [n + 1]\{1} et {i, j} ! E ssi icollecté et livré avant j dans T 1 et T 2, alors il existe P compatible ssi G%= est k-colorable : unecouleur est une pile, et i peut être conjointement collecté et livré avant j ssi i et j appartiennent àdeux piles distinctes. 2. Pour le cas orienté : considérer d1 et d2 tq. d1(i, i+ 1) = d2(i, i + 1) = 1 $iet d1(i, j) = 1 + ', d2(i, j) = n partout ailleurs.

Résolution du kSTSP 155
4 Déterminer (T 1, T 2) sachant P
Lemme 3 Pour P fixé, déterminer les tournées optimales est polynomial.
Démonstration. (Tour de collecte.) On propose un algorithme de programmation dynamique dontles états sont les vecteurs non nuls e = (e1, . . . , ek) de +k$=1[0, q$] correspondant à l’empilement des e$premiers éléments v$1, . . . , v$e" de chaque pile P $ ; pour un état e et une pile (, l’étiquette E(e, () désignele coût d’une collecte optimale des objets de e, finissant par v$e" . Conditions initiales : E(e, () = +*, àl’exception des (èmes vecteurs canoniques e$ pour lesquels E(e$, () = d1(1, v$1). Optimalité : la valeuroptimale opt est donnée par mink$=1{E((q1, . . . , qk), () + d1(v$q" , 1)}. Relation de récurrence : pourréaliser l’état e en finissant par l’objet v$e" (si e$ ) 1), le seul état prédécesseur possible est l’étatp(e, () = (e1, . . . , e$"1, e$ % 1, e$+1 . . . , ek) ; l’étiquette E(e, () est alors donnée par le meilleur coûtparmi E(p(e, (), (&) + d1(v$!
p(e,$)"! , v$e" ), pour (& tq. p(e, ()$! ) 1. Le calcul de opt par programmation
dynamique s’e#ectue en complexité temporelle d’ordre k2"k(n+ k)k.
Théorème 4 TSP/sp_graph(k)! P, où TSP/sp_graph(k) désigne le TSP avec contraintes de pré-cédence de type graphe couvrant série-parallèle de largeur au plus k. Les problèmes d’ordonnancement(1/sp_graph(k),p,STsd/Cmax ,TST) et (1/sp_graph(k),p,SCsd/TSC) sont et lui sont équivalents(les notations pour la classification )/*/+, [5] des problèmes d’ordonnancement sont reprises de [4]).
Démonstration. À partir des piles, construire le graphe de source 1, de puits n + 2 (duplication dudépôt) et de chemins (1, v$1, . . . , v$q" , n+ 2). Généralisation à sp_graph(k) : dupliquer les sommets desorte à obtenir (au plus) k chemins deux-à-deux disjoints de la source au puits (au pire, kn sommetsajoutés).
Références
1. Petersen H.L., Madsen O.B.G. : The double travelling salesman problem with multiple stacks -Formulation and heuristic solution approaches. EJOR (2008, article in press)
2. Felipe A., Ortuño M., Tirado G. : Neighborhood structures to solve the double TSP with multiplestacks using local search. in Proc. of FLINS 2008 (2008).
3. Burkard R.E., Deineko V.G., Woeginger G.J. : The Travelling Salesman and the PQ-Tree. In Proc.5th Internat. IPCO Conference, LNCS 1084 :490-504 (1996).
4. Allahverdi A., Gupta J.N.D., Aldowaisan T. : A review of scheduling research involving setupconsiderations. Omega 27(2) :219-239 (1999)
5. Graham R.L., Lawler E.L., Lenstra J.K., Rinnooy Kan A.H.G. : Optimization and approximationin deterministic sequencing and scheduling : a survey. Ann. of Discrete Math. 5 :287-326 (1979).

Couverture d’un graphe à l’aide d’une forêt contraintede poids minimal
C. Bazgan, and B. Couëtoux
Université Paris Dauphine, LAMSADE, Place du Maréchal de Lattre de Tassigny 75775 ParisCedex 16
bazgan,[email protected]
Des nombreux problèmes de localisation visent à trouver dans un graphe un sous-ensemble de sous-graphes satisfaisant certaines contraintes. Nous nous interessons dans la suite au problème Min CF(p)consistant à trouver une couverture par une forêt du graphe de coût minimal, on appelle couvertureun sous-ensemble d’arête. Plus précisement, étant donné un graphe avec des coûts positifs sur lesarêtes, le problème Min CF(p) consiste à chercher une forêt couvrante de coût minimal telle quechacune de ses composantes connexes contient au moins p sommets.Min CF(p) pour p ) 4 a été montré NP-di%cile par Imielinska et al. [2]. Ces auteurs ont égalementétabli un algorithme d’approximation à un facteur 2 près en utilisant une méthode gloutonne. Laszloand Mukherjee [3] proposent une heuristique plus ra%née que la précédente, qui fournit une solutionau moins aussi bonne que la solution fournie par l’algorithme précédent, mais qui reste cependant uneapproximation à 2 près. L’application de la méthode de Goemans et Williamson [1] pour Min CF(p)donne un algorithme d’approximation à un facteur 2% 1/n près, où n est le nombre des sommets dugraphe.
Dans la suite nous exposons les résultats que nous avons obtenus sur ce problème. Min CF(p) resteNP-di%cile pour p = 3 ainsi que dans le cas sans coùts. Min CF(p), p ) 3, est aussi APX-di%ciledans le cas général, et il le reste aussi dans le cas de graphes bipartis. Si on se restreint aux graphesde largeur d’arbre bornée, c’est à dire les graphes qui acceptent une représentation sous forme d’arbretelle que chaque noeud de l’abre contiennent un nombre borné de sommets du graphe, le problèmedevient polynomial. Min CF(p) sur les graphes planaires reste NP-di%cile mais admet un schémad’approximation polynomial e%cace.
Références
1. Goemans M. and Williamson D. : A general approximation technique for constrained forest pro-blems. SIAM Journal on Computing 24 (1995), 296-317.
2. Imielinska. C, Kalantari B., and Khachiyan L. : A greedy heuristic for a minimum-weight forestproblem. Operations Research Letters 14 (1993), 65-71.
3. Laszlo M. and Mukherjee S. : Another greedy heuristic for the constrained forest problem. Ope-rations Research Letters 33 (2005), 629-633.

Approximation et algorithmes exponentiels : le cas de lacouverture minimum
N. Bourgeois1, B. Esco%er1, and V. Th. Paschos1
LAMSADE, Université Paris Dauphie, Place du Maréchal de Lattre de Tassigny, 75775 Paris Cédex16 France.
{bourgeois,escoffier,paschos}@lamsade.dauphine.fr
Pour faire face à l’existence de problèmes NP-complets, il existe principalement deux approches clas-siques, à savoir la résolution exacte (au prix d’une complexité élevée) et la recherche d’heuristiques,autrement dit d’algorithmes plus rapides susceptibles de produire des solutions ‘proches’ de l’optimal.La branche principale en ce dernier domaine est ce qu’on appelle l’approximation polynomiale, quivise à proposer des algorithmes polynomiaux permettant de déterminer des solutions admissibles, etdont la proximité à l’optimal est garantie par un rapport d’approximation.
Ce sont là deux champs de recherche très actifs tant en optimisation combinatoire qu’en informatiquethéorique. En ce qui concerne la résolution exacte, de nombreux et récents travaux se sont consacrésau développement d’algorithmes garantissant une complexité au pire de cas la plus faible possible.En considérant par exemple le très classique Max Independent Set, il est facile de voir qu’unalgorithme examinant successivement tous les sous-ensembles de V et conservant chaque fois le plusgrand produira la solution optimale en un temps O$(2n), où n est le cardinal de V - la notationf = O$(g) signifiant que l’on néglige un éventuel facteur polynomial. La question qui se pose alorsest de savoir si l’on peut concevoir un algorithme produisant un stable de cardinal maximal en untemps n’excédant pas O$(+n), avec + < 2. La réponse est oui, et une série d’articles récents s’estattachée à abaisser toujours davantage la valeur de cette constante (voir [8,7] par exemple).L’approximation polynomiale, de son côté, s’est considérablement développée depuis les années 70,établissant à la fois des résultats positifs (c’est à dire des algorithmes garantissant de bons rapports),mais également des limites structurelles à son action ([1]) : sous certaines hypothèses communémentadmises (typiquement, P -= NP), certains problèmes ne peuvent être approximés en-deça d’un cer-tain ratio. Ainsi pour Max Independent Set ne peut-on espérer obtenir un rapport n1"%, quel quesoit , > 0 ([5]).
Récemment, nous avons proposé une approche mêlant les deux précédentes, en essayant de répondreà la question suivante : peut-on trouver des algorithmes garantissant un rapport d’approximation quine peut être obtenu en temps polynomial, et ce au prix d’une complexité certes super-polynomiale,mais très inférieure à celle d’un algorithme exact ? C’est ce que nous avons appelé approximatione#ciente. Nous avons appliqué cette approche aux problèmes Max Independent Set et Min Ver-tex Cover, obtenant n’importe quel rapport r -= 1 en un temps meilleur que celui de la résolutionexacte ([3]).
Dans cet exposé, nous présenterons de nouveaux résultats obtenus sur cette problématique pourle problème Min Set Cover. En notant m le nombre d’ensembles et n le nombre d’éléments àcouvrir, il existe bien sûr un algorithme trivial en O$(2m) (consistant à énumérer tous les choixpossibles), et un algorithme en O$(2n) ([2]). Par ailleurs, Min Set Cover est approximable à rapportlogarithmique, mais aucun rapport meilleur (en particulier constant) ne peut être obtenu (à moins queNP . DTIME(nlogn)) [4]. Nous montrerons comment adapter la technique d’élagage de l’arbre derecherche, puis comment combiner des techniques gloutonnes et de résolution exacte, pour obtenir des

158 Bourgeois, N., Esco%er, B., Paschos, V.
algorithmes approchés pour Min Set Cover garantissant de très bons rapports d’approximation endes temps faiblement exponentiels. Par exemple, nous pouvons obtenir un rapport d’approximation5 en un temps O$(1.005m).
Références
1. G. Ausiello, P. Crescenzi, G. Gambosi, V. Kann, A. Marchetti-Spaccamela, and M. Protasi.Complexity and approximation. Combinatorial optimization problems and their approximabilityproperties. Springer-Verlag, Berlin, 1999.
2. A. Björklund and T. Husfeldt. Inclusion-exclusion algorithms for counting set partitions. InProc. FOCS’06, pages 575–582, 2006.
3. N. Bourgeois, B. Esco%er, and V. Th. Paschos. E%cient approximation by “low-complexity”exponential algorithms. Cahier du LAMSADE 271, LAMSADE, Université Paris-Dauphine,2008. Available at http ://www.lamsade.dauphine.fr/cahiers/PDF/cahierLamsade271.pdf
4. U. Feige. A threshold of lnn for approximating set cover. J. Assoc. Comput. Mach., 45 :634–652,1998.
5. J. Håstad. Clique is hard to approximate within n1"%. Acta Mathematica, 182 :105–142, 1999.6. D. S. Johnson. Approximation algorithms for combinatorial problems. J. Comput. System Sci.,
9 :256–278, 1974.7. J. M. Robson. Finding a maximum independent set in time O(2n/4). Tecnical Report 1251-01,
LaBRI, Université de Bordeaux I, 2001.8. G. J. Wœginger. Exact algorithms for NP-hard problems : a survey. In M. Juenger, G. Reinelt,
and G. Rinaldi, editors, Combinatorial Optimization - Eureka ! You shrink !, volume 2570 ofLecture Notes in Computer Science, pages 185–207. Springer-Verlag, 2003.

Ordonnancement temps réel multiprocesseur partitionnéet programmation par contraintes
Anne-Marie Déplanche1, and Pierre-Emmanuel Hladik2
1 IRCCyN (UMR CNRS 6597) Université de Nantes, Nantes, France .2 CNRS ; LAAS ; 7 avenue du colonel Roche, F-31077 Toulouse, France
Université de Toulouse ; UPS, INSA, INP, ISAE ; LAAS ; F-31077 Toulouse, [email protected], [email protected]
Problématique. En matière d’ordonnancement temps réel dans le contexte de systèmes multipro-cesseurs, des techniques dites de partitionnement peuvent être mises en oeuvre. Chaque processeurest alors doté d’un ordonnanceur local qui, de manière indépendante, ordonnance les tâches depuissa propre liste de tâches prêtes. L’ordonnancement multiprocesseur se ramène dans ce cas à un pro-blème d’a#ectation des tâches aux processeurs (le partitionnement proprement dit) et à un problèmed’ordonnancement monoprocesseur. L’avantage de l’ordonnancement multiprocesseur partitionné estqu’il aborde ces problèmes de manière découplée et qu’il permet ainsi d’exploiter pleinement lesrésultats connus en matière d’ordonnancement et d’analyse d’ordonnançabilité monoprocesseur.Nos travaux s’intéressent à l’ordonnancement temps réel multiprocesseur partitionné. Ils considèrentplus particulièrement des tâches indépendantes, périodiques et à échéances inférieures ou égales auxpériodes. Le système multiprocesseur est homogène — les temps de traitement d’une tâche sont iden-tiques sur tous les processeurs — et l’ordonnancement local est dynamique, préemptif et à prioritésfixes pour les tâches. La figure 1 illustre le principe de cette approche.
Fig. 1. Schéma de partitionnement avec ordonnancement à priorités fixes
La recherche d’un partitionnement, c’est-à-dire d’une application qui associe à chaque tâche un pro-cesseur pour son exécution, doit être conduite de sorte que pour chaque processeur, l’ordonnançabilitédes tâches qui lui sont allouées, c’est-à-dire le respect de leurs contraintes temporelles, soit assurée.On doit pour cela se référer aux conditions disponibles en analyse d’ordonnançabilité monoprocesseur.Le problème est NP-di%cile au sens fort.Nos travaux utilise la programmation par contraintes (ppc) pour la recherche d’un partitionnement.Dans notre contexte d’ordonnanceurs locaux, nous disposons d’une condition nécessaire et su%sante

160 Déplanche, Hladik
d’ordonnançabilité portant sur les pires temps de réponse des tâches [1], c.-à-d. la plus grande duréeséparant le moment où la tâche demande à s’exécuter et le moment où elle se termine. Son calcul passepar une évaluation itérative d’une expression analytique combinant durées d’exécution et périodesdes tâches plus prioritaires. La condition vérifie, pour chaque tâche, que son pire temps de réponseest inférieur à son échéance.Résolution du problème. La démarche que nous évoquons ici est une extension du travail présentédans [2]. Dans un premier temps, nous avons modélisé le problème sous la forme d’un problème desatisfaction de contraintes pour pouvoir ensuite y appliquer les algorithmes de la ppc. La di%cultémajeure de cette approche a été d’introduire le test d’ordonnançabilité par le calcul du pire tempsde réponse dans le processus de recherche d’une solution.Pour pallier cette di%culté, deux voies ont été étudiées. La première consiste à utiliser le test d’or-donnançabilité pour apprendre progressivement un ensemble de contraintes qui traduisent l’existenced’un ordonnancement valide. Cette approche a pour cadre théorique la décomposition de Benders[3]. La seconde étude à consister à construire une contrainte globale dédiée embarquant le calcul depire temps de réponse.Chacune de ces méthodes utilise les expressions analytiques du calcul du pire temps de réponse afind’optimiser les algorithmes - d’apprentissage pour le cas de la décomposition et de filtrage pour lacontrainte globale -.L’implémentation, puis l’expérimentation de ces méthodes ont montré leur e%cacité en terme detemps de calcul pour résoudre le problème du partitionnement ; l’approche globale étant plus e%cace.Conclusion. Par ces travaux, nous montrons que la programmation par contraintes est un paradigmesimple et e%cace pour résoudre le problème du partitionnement avec une politique d’ordonnancementà priorités fixes. De plus, l’approche que nous avons développée est optimale dans le sens où, s’il existeun partitionnement ordonnançable une solution sera produite. En général, les approches utiliséesne sont pas optimales pour deux raisons : (i) les méthodes de recherche ne sont pas complètesmais seulement heuristiques ; (ii) l’évaluation de l’ordonnançabilité est uniquement faite à l’aide deconditions su%santes. Ici, l’utilisation de la ppc couplée avec un test basé sur le pire temps de réponsenous assure une recherche complète et une condition nécessaire et su%sante d’ordonnançabilité.La continuité de ces travaux sera d’étudier l’adaptation de la démarche à des modèles de tâches plusétendus (partage de ressource, non-préemption, etc.) et d’ordonnanceurs plus évolués (FP-FIFO,OSEK, EDF, etc.).
Références
1. J. P. Lehoczky : Fixed priority scheduling of periodic task sets with arbitrary deadlines, In proc.of 11th IEEE Real-Time Systems Symposium, 1990
2. P.-E. Hladik, H. Cambazard, A.-M. Déplanche and N. Jussien : Solving a real-time allocationproblem with constraint programming, Journal of Systems and Software, 81(1), 2008
3. J. F. Benders : Partitionning procedures for solving mixed-variables programming problems, Nu-merische Mathematik, 4 :238–252, 1962.

Problème d’acquisition de données par une torpille
G. Simonin, A.-E. Baert, A. Jean-Marie and R. Giroudeau
LIRMM, CNRS, Université Montpellier 2161, rue Ada, 34392 Montpellier Cedex 5 - France.
Auteur à contacter : [email protected]
1 IntroductionCe papier traite du problème d’ordonnancement stochastique de tâche-couplées, introduites par Sha-piro [1], qui sont soumises à des contraintes de précédence avec des tâches dîtes de traitement surun monoprocesseur. Le problème que nous proposons ici est celui de l’acquisition de données parune torpille autonome sous-marine. Cette torpille a comme objectif d’e#ectuer di#érents relevés,d’analyser la topologie du fond sous-marin, ou encore faire de la cartographie. Une fois la torpilleen immersion, elle va recevoir de manière aléatoire di#érents groupes de tâches à réaliser dans uncertain ordre sur son monoprocesseur. Ces tâches vont devoir être réalisées de manière périodiquejusqu’à la fin de l’expérience. Afin d’acquérir les données demandées, puis de pouvoir les traiter, latorpille possède des capteurs qui permettent soit d’envoyer des échos qui reviennent après un certaintemps d’inactivité, soit de faire des relevés en moyenne (moyenne entre deux relevés, ce qui revientà une tâche-couplée). Le problème, qui sera noté T P, consiste à décider si, pour certain groupes detâches à réaliser, la torpille peut exécuter périodiquement toutes les tâches dans le temps imparti, etce jusqu’à l’arrivée des dernières tâches à e#ectuer. La problématique définie ci-dessus etant typique-ment un problème d’ordonnancement stochastique sur un monoprocesseur, nous allons modéliser ceproblème puis conclure en présentant de manière synthétique l’approche utilisée pour le résoudre.
2 Modélisation du problèmeLa modélisation du problème d’acquisition de données par une torpille en immersion T P est lasuivante.Soit S = {S1, S2, . . . , Sm} l’ensemble des composantes connexes, chaque composante connexe Si(1 # i # m) forme un graphe de précédence orienté entre certaines tâches d’acquisition et certainestâches de traitement (voir Figure 1(a)). Dans un premier temps et pour simplifier cette premièreétude, chaque Si possède une date périodique Pi = P à la fin de laquelle toutes les tâches d’acquisitiondoivent être re-exécutées. Enfin, les composantes connexes possèdent chacune une date d’arrivée dansle système de manière aléatoire en suivant une loi uniforme (voir Figure 1(c)).Soit A = {A1, A2, . . . , An1} l’ensemble des tâches d’acquisition, semblables aux tâches-couplées in-troduites par Shapiro [1]. Chaque tâche d’acquisition Aj (1# j # n1) consiste en deux sous-tâchesaj et bj de durée d’exécution respectives paj et pbj . Elles sont séparées par un délai d’inactivitéincompressible Lj , i.e., la sous-tâche bj doit démarrer son exécution exactement Lj unités de tempsaprès l’exécution de la sous-tâche aj (voir Figure 1(b)). Les tâches d’acquisition seront toujours dessources dans le graphe de précédence des composantes connexes. Enfin, chaque tâche d’acquisitionAj possède une date d’arrivée notée rAj constante à chaque période et attribuée aléatoirement selonune loi uniforme (voir Figure 1(d)).Soit T = {T1, T2, . . . Tn2} l’ensemble des tâches de traitement. Ces tâches ont la propriété d’êtrepréemptibles et sont toujours précédées par au moins une tâche dans les graphes de précédence.Chaque tâche de traitement Tk (1 #k# n2) possède une longueur d’exécution variable notée pTk .

162 Simonin, Baert, Jean-Marie, Giroudeau
A1
A2
A3
A4
A5
A6
T4
T5
T6
(S1, RS1 )
(S2, RS2 )
r4
r5
r6
T1
T2
T3
r1
r2
r3
(a) Graphes de précédence formés par les composantesconnexes
aj bjLj
paj pbj
(b) Tâche d’acquisition
RS1 RS2RS3 RS4 RS5
0 P 2P 3P 4P 5P 6P 7P. . .
(c) Arrivées aléatoires des compo-santes connexes
0 P
a1 a2 a3b1 b2 b3T1 T2 T3
r1 r2 r3
(d) Arrivées aléatoires des ri durant une période
Fig. 1. Modélisation du problème T P
3 Résultats
Dans ce résumé, nous présentons un nouveau type de problème d’ordonnancement en temps réel. Dans[3], nous avons montré que le même problème déterministe était NP-complet. Afin de décider de lafaisabilité du problème, nous cherchons di#érents ordonnancements utilisant des règles de prioritéproche de celle utilisée dans [2]. L’ordonnancement le plus intéressant est d’utiliser les graphes deprécédence disponibles par la torpille entre deux périodes. En e#et, à chaque période, nous appliquonsune règle de priorité en fonction des arrivées aléatoires rj des tâches d’acquisition Aj dans les graphesde précédence, qui permet de calculer l’ordre d’exécution des tâches contenues dans les composantesconnexes déjà arrivées.
Références
1. R.D. Shapiro : Scheduling coupled tasks, Naval Research Logistics Quarterly, 27, 1980, 477-481.2. M. Pinedo : Scheduling, Theory, Algorithms, and Systems, Second Edition, Prentice Hall, 2006.3. G. Simonin : Étude de la complexité de problèmes d’ordonnancement avec tâches-couplées sur
monoprocesseur, Majecstic ’08, 2008.

T-coloration d’hypergraphe
A. Gondran, A. Caminada and O. Baala
SeT, UTBM, 90010 Belfort Cedex France.[Alexandre.Gondran,Alexandre.Caminada,Oumaya.Baala]@utbm.fr
1 Introduction
Les problèmes d’a#ectation de ressources sont souvent modélisés par des problèmes de T -coloration degraphe. Cependant, la notion de graphe est restrictive car elle correspond à des relations binaires surdes ensembles. Or les relations entre les ensembles sont souvent multiples ; c’est le cas des interférencesdans les problèmes de planification de fréquences par exemple. Une modélisation par hypergraphepermet de représenter les influences multiples et donne alors une représentation plus réaliste desphénomènes étudiés. Nous introduisons donc un nouveau problème, la T -coloration d’hypergrapheafin de rendre compte de ces influences multiples. Les hyperarêtes de l’hypergraphe auront pourfonction de représenter les contraintes n-aires qui lient plus de deux variables à la fois.Nous montrons ensuite l’intérêt d’une telle modélisation pour des problèmes réels issus de la planifi-cation de fréquences de réseaux locaux sans fil. Di#érents algorithmes d’optimisation sont testés surun benchmark.
2 T-coloration d’hypergraphe
Rappelons d’abord la définition d’une T -coloration du graphe [1]. Une T -coloration du grapheG(V,E) associée à la matrice symétrique de diagonale nulle T = (tij)i,j#V , tij ! IN, est une co-loration ci de chaque sommet vi de V qui respecte les contraintes suivantes :
$(vi, vj) ! E, |ci % cj | ) tij
Un hypergrapheH = (V,E) est dit orienté si chaque hyperarêteEk est un couple de deux parties nonvides disjointes de V de la forme Ek = (E+
k , E"k ) où E+
k sont les sommets sortantes de l’hyperarêteet E"k les sommets entrantes dans l’hyperarête. Si de plus $k, |E+
k | = 1, l’hypergraphe est ditpointé et on dit que l’hyperarête Ek pointe vers un sommet noté vik , appelé pointe de l’arête(E+k = {vik}). Pour chaque hyperarête Ek d’un hypergraphe pointé, nous adoptons la notation
suivante : Ek = (vik ,-k) avec -k = E"k = {vk1 , ..., vkq}. Nous notons V = {vi1 , ..., vim} l’ensembledes pointes des arêtes E = {E1, ..., Em} et H = (V, V, E) l’hypergraphe pointé.On définit maintenant le problème de T-coloration d’hypergrapheSoit un hypergraphe pointé H = (V, V,E), avec V = {v1, ..., vn} les sommets, V = {vi1 , ..., vim}l’ensemble des pointes des arêtes E = {E1, ..., Em}.A chaque arête Ek = (vik ,-k) de l’hypergraphe on associe une contrainte n-aire linéaire Cnairek =(c, ik,"k) avec "k = {)k1 , ...,)kq} et $i = 1, ..., q, )ki ! IR+ :
%
'i%=ik
)ki|cik % ci| ) )kik
Soit T = {Cnaire1 = (c, i1,"1), ..., Cnairem = (c, im,"m)} la collection de ces contraintes n-aireslinéaires.

164 Gondran, Caminada, Baala
Une T -coloration de l’hypergraphe H associée à la collection de contraintes n-aires linéaires T estune coloration ci de chaque sommet vi de V qui respecte ces contraintes Cnairek . Un problème deT -coloration d’hypergraphe est défini par le triplet (H = (V, V,E), F, T ).La T -coloration d’hypergraphe est bien une généralisation de la T -coloration de graphe dans le casoù les arêtes relient uniquement 2 sommets.
3 Expérimentations
Lorsque l’ensemble des couleurs disponibles est fixe, le problème est un problème de décision. Ils’agit de répondre par oui ou non à la question : "Existe-il une coloration qui satisfasse toutes lescontraintes ?" Dans les problèmes réels, il n’existe souvent pas de solutions réalisables. Dans notrecas nous avons transformé le problème de décision en un problème d’optimisation : une pénalité estassociée à chaque groupe de contraintes non satisfaites et l’objectif est de rechercher une solution quiminimise la somme des pénalités.Nous appliquons ce problème à des exemples réels issus de la planification de réseaux radio sansfils [2]. Les sommets sont des antennes, les couleurs sont des fréquences à attribuer à chaque antenneet les arêtes représentent les contraintes d’écart de fréquences à respecter. Dans cet article nouschoisissons de minimiser le nombre d’usagers non satisfaits. Un usager u, u ! U est satisfait si ungroupe de contraintes gu = {Cu1 , ..., Cun} sont respectées. Soit c = (ci)i#V une solution du problèmede coloration qui alloue la couleur ci au sommet vi.La formulation de problème de minimisation du nombre de clients non satisfaits est :
trouver c qui minimise%
u
?
@1%A
Cj#gu
.Cj
B
C (1)
avec .Cj =1
1 si la contrainte Cj est respectée par la solution c0 sinon . Il su%t qu’une seule contrainte
du groupe gu soit non satisfaite pour que l’usager u soit non satisfait.Nous avons validé l’approche en testant sur un benchmark de 7 instances le problème d’optimisationde T -coloration d’hypergraphe. Cette approche donne de meilleurs résultats qu’une approche par T -coloration de graphe. Di#érents types d’algorithmes (plusieurs Recherches Tabou et algorithmes évo-lutionnaires) ont été testés. Les instances du benchmark ont été créées à partir de bâtiments réels enutilisant le modèle de propagation d’Orange Labs. Il est disponible sur : http ://alexandre.gondran.free.fr/benchmaks/h
Références
1. Dorne, R. and Hao, J.-K. : Tabu Search for graph coloring, T -coloring and Set T -colorings. inMeta-heuristics : Advances and Trends in Local Search Paradigms for Optimization de S. Voss,S. Martello, I.H. Osman and C. Roucairol, chap. 3, pp.33-48, Kluwer, 1998.
2. Gondran A., Baala O., Caminada A. and Mabed H : Hypergraph T-Coloring for AutomaticFrequency Planning problem in Wireless LAN. 19th IEEE International Symposium on Personal,Indoor and Mobile Radio Communications 2008 (PIMRC 2008), Cannes, France, September 15-18,2008.

Problème de la somme coloration d’un graphe
Yu Li1, Corinne Lucet1, Aziz Moukrim2, Kaoutar Sghiouer2
1 Laboratoire MIS/Pôle Sciences, 33 rue St Leu, 80000 Amiens{Yu.Li, Corinne.Lucet}@u-picardie.fr
2 Université de Technologie de Compiègne, Laboratoire HEUDIASYC UMR CNRS 6599,BP 20529, 60205 Compiègne
{Aziz.Moukrim, Kaoutar.Sghiouer}@hds.utc.fr
1 Introduction
Le problème de la coloration de graphe (GCP) est l’un des problèmes NP-di%ciles en optimisationcombinatoire. Il existe plusieurs problèmes dérivés du GCP ou constituant une généralisation du GCP,nous nous sommes intéressés plus particulièrement au problème de la somme coloration minimale degraphe (MCS). Les algorithmes gloutons jouent un rôle important dans la pratique : d’une part,ils peuvent être utilisés pour obtenir une solution dans le cas où l’exigence du temps de calcul estbeaucoup plus importante que celle de la qualité de la solution et d’autre part, ils peuvent égalementêtre intégrés dans des méthodes exactes ou approchées. Nous procédons à l’élaboration d’une nouvellefamille d’algorithmes gloutons pour MCS.Dans la section 2, nous rappelons le problème de la coloration de graphe ainsi que le problème de lasomme coloration minimale de graphe, puis nous introduisons dans la section 3 des bornes inférieurespour MCS. Enfin nous étudions une nouvelle variante des heuristiques DSATUR [2] et RLF [3] pourtraiter ces problèmes.
2 Définition
2.1 Problème de la coloration de graphe
Une coloration valide d’un graphe G = (V,E) est une fonction c : v /( c(v) associant à tout sommetv ! V une couleur c(v), en s’assurant que c(v) -= c(u) pour toute arête [u, v] ! E. Le nombrechromatique /(G) d’un graphe G est le nombre minimum de couleurs à utiliser pour colorier G. Larésolution du problème de la coloration de graphe consiste à trouver une coloration valide utilisant/(G) couleurs.
2.2 Problème de la somme coloration d’un graphe
Soit G = (V,E) un graphe, le problème de la somme coloration minimale de G (MCS) consiste àtrouver une coloration valide telle que
&v#V c(v) soit minimale. Cette somme coloration minimale est
notée&
(G). Le plus petit nombre de couleurs utilisées pour colorier le graphe G dans une solutionoptimale pour MCS est appelé force du graphe, et noté s(G).

166 Yu Li, Corinne Lucet, Aziz Moukrim, Kaoutar Sghiouer
3 Bornes Inférieures
Nous considérons une clique de taille k, il existe une façon unique de la colorier qui nécessite k couleurset la somme associée est
&k1 i = k(k + 1)/2. Nous nous sommes basés sur cette observation pour
fournir une borne inférieure issue de la décomposition du grapheG en cliques. Dans un premier temps,nous avons utilisé un algorithme glouton qui fournit une clique Xi, la supprime du graphe initial Get recherche une autre clique dans le nouveau graphe G \Xi et ainsi de suite jusqu’à l’éliminationde tous les sommets de G. Cet algorithme simple est basé sur un ordre de traitement des sommetsdans la construction des cliques (degrés croissants, degrés décroissants, etc.) Nous avons améliorécette approche en considérant le graphe plus globalement : en construisant le graphe complémentaireG& du graphe d’origine G, puis en le coloriant par un algorithme glouton qui fournit des stables deG&, on obtient alors une décomposition du graphe G en cliques. Le problème de coloration associéne consiste plus alors à minimiser le nombre chromatique, ni à minimiser la somme associée, mais àmaximiser
&ki(ki + 1)/2, avec ki la taille du stable de couleur i, fourni par la coloration de G&.
4 Nouvelle variante de DSATUR et RLF
Le problème MCS a été introduit par Kubicka et Schwenk [1]. Depuis, plusieurs travaux théoriquesont été réalisés. Le seul travail à notre connaissance qui présente des résultats numériques date de2007 [4]. Nous proposons une nouvelle variante de DSATUR et RLF. Ces algorithmes gloutons sontles plus cités dans la littérature, ils ont été élaborés par Brélaz [2] et Leighton [3] en 1979.Le principe de cette variante est similaire à celui de DSATUR ou RLF au sens où à chaque itération,on a#ecte la plus petite couleur disponible au sommet vérifiant un certain critère. Cette varianteprend en compte l’influence de la coloration d’un sommet sur son voisinage avant une colorationdéfinitive.Les résultats numériques montrent que cette nouvelle variante est plus e%cace à la fois pour la bornesupérieure et la borne inférieure de MCS. La complexité de cette variante est en O(n3).
Références
1. Kubicka, E. and Schwenk, A. : An introduction to chromatics sum. Proc.17th Annual ACMComputer Science Conf (1989)
2. Brélaz, D. : New methods to color the vertices of a graph. ACM, Volume 22, Number 4 (1979)3. Leighton, FT. : A graph Coloring Algorithm for Large Scheduling Problems. Journal of research
of the national institute of standards and technology, Volume 84, Number 6 (1979)4. Kokosinski, Z. and Kwarciany, K. : On Sum Coloring of Graphs with Parallel Genetic Algorithms.
ICANNGA 2007, Part I, LNCS 4431, pp. 211-219 (2007)

Tentative de caractérisation des colorations valides d’ungraphe
J.N. Martin, and A. Caminada
Laboratoire SET, UTBM, 90010 Belfort CedexJean-noel.martin,[email protected]
1 Introduction
Nous annonçons, dans ces deux pages de résumé, une communication destinée à proposer les grandeslignes d’analyse d’un graphe menant à une caractérisation de ses colorations valides. Les résultatsdéjà obtenus, encore partiels, les di%cultés rencontrées puis solutionnées, mettent en évidence lapertinence d’une approche globale du problème à résoudre : il ne s’agit pas seulement de traiterle graphe particulier étudié mais aussi ses ’composantes’ comme le laissent nettement entendre lesthéorèmes du No Free Lunch. Voir [1].
2 Une démarche de caractérisation des colorations valides
Etant donné un graphe simple, non orienté G comportant n sommets, on considère l’ensemble F detoutes les colorations à k couleurs, valides pour G, s’il en existe ; le nombre k des couleurs disponiblesdoit bien sûr être su%sant pour assurer cette existence. Grâce à l’outil central de clique maximale,on analyse le graphe G donné quelconque dans l’optique de sa coloration. Voir [4]. La méthodedéveloppée permet de caractériser relativement simplement ce qu’est une coloration valide de G.On échappe réellement, mais hélas pas totalement ..., à une part inutile d’explosion combinatoireen isolant au plus juste les responsabilités des défauts de coloration. On comprend en particuliercomment le nombre n des sommets, s’il est en pratique lié à la probabilité de di%culté d’obtenir unecoloration valide, n’en est pas un véritable critère tout comme le concept de degré ; ils représententseulement des accompagnateurs ordinaires de la résistance à l’obtention facile de colorations licites.Voir [7]. En découle la nécessité de faire le deuil de l’espoir de trouver un algorithme capable de traiteravec le même bonheur, toutes les instances d’un problème donné ! Par suite, on met en évidence aussiles colorations qui présentent un, deux ou plusieurs défauts ; cette question confronte à des problèmessérieux de combinatoire, comme on peut s’y attendre. Par contre il est possible de définir des classesde colorations aboutissant aux mêmes types de défauts. En ce sens, est confirmée l’inutilité de visiterdes colorations de même classe dans une heuristique, par exemple. Sont ainsi mises en évidence desparties des espaces de recherche, invariantes sous certaines permutations, véritables trous noirs desalgorithmes de recherche. Voir [2] et [3]. On en pressent la cause, en plus de constater le phénomène.Il est alors possible d’établir un lien entre le graphe initial donné, mais aussi certaines de ses com-posantes, avec des ensembles de k-colorations d’un ensemble de n sommets. Ce lien fait apparaîtredes zones de stabilité troublantes dans la présence des propriétés de coloration ; il est trop tôt pour-tant pour a%rmer qu’il s’agirait d’une véritable détermination de leur cause. Voir [5]. L’ensembledes outils mis en place, des méthodes développées, permet d’associer au graphe G un polynôme decoloration qui décompte et fournit des renseignements sur la nature des k-colorations valides pour legraphe étudié. Un certain nombre de résultats abstraits se voient confirmés expérimentalement ; biensûr, ces expérimentations sont menées dans le cadre d’étude de graphes dont le nombre de sommets

168 J.N. Martin, A. Caminada
n est réduit. La portée de cette étude est dans le principe même limitée, en termes de taille ; pourtantl’enjeu est d’importance puisqu’il apparaît que des lois semblent décrire des comportements qui sereproduisent dans divers types de graphes. En particulier, l’existence du polynôme de coloration, etla possibilité de son évaluation pour un entier k donné , fournit le nombre minimal de couleurs né-cessaires à la coloration d’un graphe G donné, respectant toutefois les contraintes de taille précitées.L’étude de la confrontation des outils développés avec le comportement de diverses heuristiques surun certain nombre d’instances de tailles convenables (donc réduites par principe même), devrait per-mettre d’obtenir des enseignements sur le pourquoi de leur excellence ou celui des di%cultés qu’ellesrencontrent. Inversement, la compréhension encore partielle des phénomènes, doit permettre de piégerdéjà certaines heuristiques, dès lors qu’on sait comment elles travaillent. Voir [6]. Des prolongementsmultiples se présentent, dont spécialement celui d’études locales de sous-parties de graphes donnésou de leurs partitionnements sous quelques hypothèses limitatives.
Références
1. D.H. Wolpert and W.G. Macready. : No Free Lunch Theorems for Optimization. IEEE Transac-tions on Evolutionary Computation, 67-82. (1997)
2. C. Schumacher, M.D. Vose, and D. Whitley. : The No Free Lunch and Problem DescriptionLength. In L. Spector, and alter, editors, Proceedings of the Genetic and Evolutionary Computa-tion Conference (GECCO 2001), 565-570, San Francisco, California, USA, 7-11. Morgan KaufmannPublishers. (2001)
3. C. Igel, and M. Toussaint. : On Classes of Functions for which No Free Lunch Results Hold.Technical Report, Institut für Neuroinformatik, Ruhr-Universität Bochum, ND 04 44780 BochumGermany. (2001)
4. C. Berge : Graphes Gauthiers-Villars (1971)5. B. Weinberg. : Analyse et résolution approchée de problèmes d’optimisation combinatoire : appli-
cation au problème de coloration de graphe. Thèse, UST de Lille, 42-50. (2004).6. S. Droste, T. Jansen, and I. Wegener. : Optimization with Randomized Search Heuristics - The
(A)NFL Theorem, Realistic Scenarios, and Di%cult Functions. Theoritical Computer Science,287(1) : 131-144, september 2002. (2002).
7. J.N. Martin, and A. Caminada. : Champs de validité du No Free Lunch : quelques pistes d’utili-sation en coloration. Roadef’08, 311-312, Clermont-Ferrand. (2008).

Les algorithmes évolutionnaires pour l’exploration dedonnées par projections révélatrices
Souad Larabi Marie-Sainte1, Alain Berro1 et Anne Ruiz-Gazen2
1 IRIT-UT1, UMR 5505, CNRS , Université de Toulouse, 2 rue du doyen Gabriel Marty 31042Toulouse Cedex 9, France.
[email protected], [email protected] Toulouse school of economics (Gremaq et IMT), Université de Toulouse, 2, rue du
Doyen-Gabriel-Marty, 31042 Toulouse Cedex 9 [email protected]
1 Introduction
Nous présentons dans cet article des travaux de recherche qui consistent à analyser l’apport desalgorithmes évolutionnaires pour aider le statisticien dans sa recherche de structures telles que laprésence d’observations atypiques ou de groupes homogènes dans des ensembles de données volumi-neux et multidimensionnels, à l’aide de projections révélatrices.Parmi les techniques de vie artificielle, nous avons considéré les algorithmes génétiques (AG) ainsique l’optimisation par essaim particulaire (l’OEP).Les méthodes de projections révélatrices sont des méthodes d’analyse exploratoire qui permettent dedétecter et d’analyser d’éventuelles structures d’intêret présentes mais cachées au sein des données.La détection de telles structures dans des ensembles de données multidimensionnels passe générale-ment par l’analyse de représentations graphiques obtenues par projection des données. Ces méthodessont basées sur la définition et l’optimisation d’un indice associé à chaque direction ou espace deprojection. Les directions ou espaces de projection associés à des optima locaux d’un indice corres-pondent potentiellement à des représentations graphiques intéressantes dans des espaces de faiblesdimensions. De nombreux indices de projection ont été proposés dans la littérature mais le problèmed’optimisation de ces indices est toujours complexe et couteux en temps de calcul et les solutions pro-posées pour maximiser ces indices ne sont pas toujours convaincantes. Par conséquent, ces méthodesde projection sont peu utilisées et absentes dans les principaux logiciels de statistique.
2 Indices de projection et Méthodes d’optimisation
Nous avons choisi 4 indices de projection : l’indice de Friedman-Tukey (Friedman et Tukey, 1974),l’indice de Friedman (Friedman, 1987), l’indice du Kurtosis (Penã et Prieto, 2001) et l’indice dit dis-criminant que nous introduisons dans un article (Berro, Larabi Marie-Sainte et Ruiz-Gazen, 2008).Les deux premiers indices sont définis à partir d’un estimateur de la densité des données proje-tées et cherchent des projections qui s’éloignent d’une distribution spécifiée comme la loi Normalepour l’indice de Friedman. Les deux autres indices sont basés sur des notions de moment d’ordre 4.Chaque indice a un comportement spécifique (indices dédiés à la détection des groupes et d’autresà la recherche d’observations atypiques). L’objectif est d’appliquer l’OEP et les AG pour maximiserces indices. L’OEP est facile à programmer mais possède beaucoup de paramètres à régler avec no-tamment le voisinage que nous avons développé en 3 versions ; une version où nous avons considérél’OEP sans voisinage, une deuxième avec un voisinage global (chaque particule est voisine de toutes

170 Souâd Larabi Marie-Sainte, Alain Berro, Anne Ruiz-Gazen
les autres) et la dernière que nous appelons voisinage limité (une particule étant représentée par unvecteur appelé "vecteur de projection", on choisit 3 voisins qui forment un angle ne dépassant pas 60degrés).Ainsi, nous proposons de comparer deux méthodes d’optimisation, dont une possède trois versions,et d’utiliser quatre indices de projection uni et bidimensionnels.
3 Resultats et conclusion
Les AG et l’OEP, en version voisinage limité, donnent des résultats satisfaisants atestés par le com-portement de chaque indice sur des exemples simulés ou réels où la structure d’intérêt est connue.Notre conclusion est qu’il est intéressant d’utiliser plusieurs indices de projection et d’examiner lesdi#érents résultats obtenus par application de diverses méthodes d’optimisation afin de guider lestatisticien dans sa recherche et son analyse de structures. Nous pouvons dire aussi que la méthodedes AG, grâce à sa propriété d’évolution, est meilleure que la méthode d’OEP classique, un résultatqui nous incite à diriger notre étude vers l’OEP évolutionnaire (Clerc, 2005).
Références
1. Berro. A, Larabi Marie-Sainte. S, Ruiz-Gazen. A : Particle Swarm Optimization for ExploratoryProjection Pursuit, in revision in Journal of Machine Learning, (2008).
2. Clerc, M. : L’optimisation par essaims particulaires, Lavoisier ISBN 2-7462-0991-8, Frane (2005).3. Friedman. J.H. : Exploratory Projection Pursuit. Journal of the American Statistical Association,
82(1), 249-266, (1987).4. Friedman. J.H., and Tukey. J. W. : A Projection Pursuit Algorithm for Exploratory Data Analysis,
IEEE Trans. Comput., C-23, 881-889., (1974).5. Pena. D., and Prieto. F.J. : Cluster Identification Using Projections, Journal of American Statis-
tical Association, Vol. 96, No. 456, (2001).

Solving the Single Straddle Carrier Routing Problemusing Genetic Algorithm
Khaled MILI and Khaled MELLOULI
Institute of the High Commercial Studies, LARODEC, Tunisia
The success of a seaport container terminal resides in a fast transhipment process with reducedcosts and it is measured by many performance indicators such as the productivity and the customersatisfaction. Because containerships are highly capitalized and their operating costs are very high,it is very important that their turn-around time in container terminals is as short as possible. Theturn-around time of a containership implies the sum of the queue time and service time which is thesum of time for berthing, unloading, loading and departing.Since inbound containers are usually unloaded into a designated open space, the yard handlingequipment (i.e. Straddle Carrier) does not have to travel much during the unloading operation.However, the time for loading depends on the loading sequence of containers as well as the numberof loaded containers. The Straddle Carrier Routing Problem (SCRP) has a great e#ect on the timeservice and the performance of the container terminal. In this paper our objective is to minimize thetotal travel time of the Straddle Carrier (SC) for loading outbound containers.Operational decision problems on seaport terminals have received increasing attention by researchers.Some of them evoked the SCRP as Kim and Kim in 1999 ; they present in their paper a mathematicalformulation for the single SCRP where their objective is to minimize the distance between yard-baysin the storage area during the SC tour. They propose a solution procedure based on beam searchheuristic method that its principle is to select the nearest yard-bay to visit by a SC.However, they suggest that the times spend by the SC inside yard bays are constant. In reality wenote that these times vary and significantly a#ect the SC routing tour. It can happen that the timespent inside the selected yard bay in the solution of Kim and Kim is bigger than the time spentby SC to visit other yard bay. Hence, we will estimate the time spent between initial position andall destinations yard bays in addition to the time cost inside each one and we select the least ofthem. Therefore, in our paper we solve the Single SCRP by considering this time (intra-yard bay)as variable. In fact, we judge that the reshu(ing and the unproductive movements inside a yard baydepend on the positions of required containers into stacks and levels.To solve this problem, we reformulate it by adding two variables : one for the position of the requiredcontainer inside the stack and other between stacks.Similar problem to the SCRP is Traveling Salesman Problem (TSP). We know that TSP is a NP-complete problem. If we consider the yard-bays (SCRP) as cities (TSP) and the distances betweenblocks or yard-bays (SCRP) as the distances between the cities (TSP), we can visualize a TSP toSCRP conversion. Therefore a solution for the SCRP is also a solution for TSP what means that, ifa polynomial solution could be found for SCRP, a polynomial solution for TSP could be found aswell. As no polynomial solution has ever been found for TSP, the same is true for SCRP. Since nopolynomial-time solution for SCPR can found, heuristics are a good alternative.The most of our model’s constraints are as equality form and, therefore, obtaining feasible solutionsis a hard task. In this case, the probability of reaching infeasible solutions is more than feasiblesolutions and therefore we need a population-based approach such as Genetic Algorithm (GA) tobetter exploration of the solution routing. GA is a well-known meta-heuristic that its e%ciency isverified for many problems in the literature.They are general search and numerical optimization algorithms inspired by natural selection pro-cesses. For our problem, individuals represent candidate solutions. A candidate solution to an ins-

172 MILI, MELLOULI
tance of the SCRP specify the number of required containers, the possible visited yard bays, thepartition of the demands and also the delivery order for each route. Each chromosome represents afeasible solution defining a possible route. It is composed by a set of genes. Each gene represents acontainer that can be picked up by a SC to perform a Quay Crane (QC) work schedule.For example a QC demands r containers type A to load them into a containership, SC has to movetoward the yard bays that include this type of containers, and transports them to the QC. Eachcontainer is characterized by its position and its type. It has a transportation cost depends on itsposition inside the storage yard (yard bay, stack and level) and especially in its chromosome’s orderand the cost of the SC’s tour will be the sum of transportation costs of the picked up containers.We use a GA which starts with initializing population with chromosomes composed of rt genes chosenfrom n available required containers. For each individual at this initial generation, a fitness value isdetermined. As a result of many previous tests in the literature, many researchers suggest that sigmoidand exponential functions are found to be better. So we adopt this type of fitness function. Since theSCRP is a minimization problem ; thus, the smaller the objective function is, the higher the fitnessvalue must be.We obtain a population of feasible solutions in which the reproduction loops then takes place throughrandomized exchange. It is a process in which chromosomes with a higher fitness value would havemore of their copies at the next generation. After reproduced chromosomes constitute a new popu-lation, crossover is performed to introduce new chromosomes (or children) by recombining currentgenes. In our algorithm, we use the 2-point crossover to give rise to better individuals. Diversity is ad-ded to the population by changing randomly some genes from the resulting children through mutationoperators applying (insertion, swap, or inversion) operators to each chromosome with equal proba-bilities. These genetic operators are repeated until the population converges. And the final solutionwill be the route having the least cost among all feasible solutions from the generated chromosomes.We propose GA as a solution approach and we develop a heuristic procedure representing di#erentcases that can be found in real QC work schedule such as single tour where containers of the sametype are required, select one container from particular set, select more than one container from aspecific set, and sub-tours where more groups are required. Each case is solved by a GA procedure.To prove the e%ciency of our solution and its improvement, we run it with real instances where anumber of containers in the storage yard will be picked up. For example, comparing with previouswork, we found that our method gives a path reaching a gain equal to 354.08 seconds to pick up 7containers of the same type and 651.92s to pick up 3 containers type B and 4 containers type A. Thegain will increase with the number of the required containers.In a container terminal there is more than one quay crane, with their respective work schedules,and many SCs. Several SCs must complete their routing, by sharing the same yard-map. This newscenario introduces a few complications to the single SCRP, increasing significantly its complexity.Our future work aims to solve the multiple straddle carrier routing problem in a container terminal.

Routage et a!ectation de longueurs d’onde dans lesréseaux optiques WDM
L. Belgacem1 , I. Charon2, O. Hudry2
1 Orange Labs FT R&D, 38-40, rue du Général Leclerc, 92794 Issy-les-Moulineaux Cedex [email protected]
2 École nationale supérieure des télécommunications, 46, rue Barrault, 75634 Paris Cedex 13.Irè[email protected], [email protected]
1 Introduction
Nous considérons ici deux problèmes relatifs au routage et à l’a#ectation de longueurs d’onde (pro-blème appelé RWA dans la littérature anglo-saxonne, pour Routing and Wavelength Assignment) dansles réseaux optiques à multiplexage en longueurs d’onde (WDM dans la littérature anglo-saxonne,pour Wavelength Division Multiplexing).Plus précisément, on dispose d’un réseau WDM, représenté par un graphe non orienté G, et onsouhaite établir un certain nombre de connexions dans ce réseau. Une demande de connexion dest caractérisée par un quadruplet de la forme d = (x, y,),*), où x et y sont des sommets de G(les sommets entre lesquels on doit établir la connexion) et où [), *] désigne l’intervalle de tempspendant lequel la connexion doit être établie. Le routage de d = (x, y,), *) consiste à déterminer unchemin optique, représenté par une chaîne C de G d’extrémités x et y, grâce auquel la connexion estétablie pendant la fenêtre horaire [), *]. Il faut par ailleurs attribuer une longueur d’onde à C poursatisfaire la demande d. On cherche donc à déterminer simultanément comment router les demandesdans le réseau optique et comment attribuer les longueurs d’onde. Les contraintes techniques liées àl’utilisation d’un réseau optique sont les suivantes :– une même longueur d’onde doit être utilisée le long des arêtes consituant un chemin optique donné ;– à tout instant donné et pour toute arête a de G, une longueur d’onde ne peut être utilisée que
pour sastisfaire une seule demande passant par a ; autrement dit, si deux demandes ont des fenêtreshoraires non disjointes, on ne peut les router à l’aide d’une même longueur d’onde que si les cheminsoptiques qui leur sont associés n’ont aucune arête en commun.
Le premier problème que nous considérons consiste à déterminer le nombre minimum de longueursd’onde nécessaires pour satisfaire toutes les demandes, tout en respectant les contraintes précédentes.Dans le second problème, le nombre de longueurs d’onde est fixé et on cherche à maximiser le nombrede demandes que l’on peut satisfaire sans dépasser le nombre de longueurs d’onde disponibles tout enrespectant, là encore, les contraintes précédentes. Ces deux problèmes sont NP-di%ciles (voir [2]) etont fait l’objet de nombreuses études, ainsi que certaines de leurs variantes (voir par exemple [1], [3] etles références qui se trouvent dans ces deux articles). On notera en particulier la méthode développéepar N. Skorin-Kapov dans [3], qui fournit habituellement d’excellents résultats et qui nous sert deréférence dans notre étude.
2 Modélisation et méthodes de résolution
Pour résoudre ces problèmes, on construit un graphe de conflit H défini de la façon suivante. Pourchaque demande d = (x, y,), *), on calcule un certain nombre k fixé (par exemple, k = 5) de chaînes

174 Belgacem, Charon, Hudry
entre x et y dans G : C1d , C2
d , ..., Ckd . On associe un sommet de H à chacune de ces chaînes. Ainsi,si . désigne le nombre de demandes à satisfaire, le nombre de sommets de H vaut k.. Les arêtes deH sont de deux natures :– d’une part, on met toutes les arêtes reliant deux sommets issus d’une même demande, c’est-à-dire,
pour chaque demande d, les k(k% 1)/2 arêtes de la forme {Cid, Cjd} pour 1 # i < j # k ; ces arêtesdéfinissent donc, pour chaque demande d, une clique sur l’ensemble des sommets de la forme Cidpour 1 # i # k ;
– d’autre part, on met une arête de la forme {Cid, Cje} (avec 1 # i # k et 1 # j # k), où d =(x, y,),*) et e = (z, t, +, ,) sont deux demandes, si les fenêtres horaires de d et e se chevauchent([), *] 0 [+, ,] -= 1) et si les chaînes Cid et Cje ont en commun au moins une arête. Ces arêtes{Cid, Cje} représentent un conflit entre d et e au sens où on ne pourra pas attribuer une mêmelongueur d’onde à d et à e si on décide de router d à l’aide du chemin optique Cid et e à l’aide duchemin optique Cje .
Un ensemble stable de H définit alors un ensemble de demandes que l’on peut router à l’aide d’unemême longueur d’onde, en indiquant de plus quels chemins optiques on peut adopter pour routerces demandes. La méthode de résolution que nous adoptons consiste alors à chercher, à l’aide d’uneméthode de descente, un stable S de cardinal maximum dans H : ce stable permettra de satisfaire |S|demandes à l’aide de la première longueur d’onde. Si l’on dispose d’autres longueurs d’onde, on retirede H toutes les cliques associées aux demandes satisfaites, et on recommence à chercher un stablemaximum dans le graphe restant. On obtient ainsi une suite de stables S1, S2, S3... Si un sommetCid de H appartient au stable Sq, on route d à l’aide du chemin optique Cid auquel on attribue laqe longueur d’onde. On procède ainsi jusqu’à avoir satisfait toutes les demandes pour le premierproblème, ou tant qu’il existe encore une longueur d’onde disponible et une demande non satisfaitepour le second problème.On étudie ici, d’une part, l’apport de la modélisation du problème sous la forme de la recherched’une suite de stables de cardinal maximum dans le graphe de conflit, d’autre part, l’apport d’uneméthode de post-optimisation permettant d’améliorer les résultats obtenus par la descente ou parla méthode développée par N. Skorin-Kapov. Les résultats expérimentaux montrent que, à tempsde calcul identique, la modélisation par le graphe de conflit pour le problème 2 et la méthode depost-optimisation pour les deux problèmes fournissent des solutions significativement meilleures quecelles obtenues par la méthode de N. Skorin-Kapov.
Références
1. Belgacem, L., Puech, N. : Solving Large Size Instances of the RWA Problem Using Graph Parti-tioning. Proceedings of 12th Conference on Optical Network Design and Modelling, Vilanova i laGeltrú, Espagne, 2008.
2. Chlamtac I., Ganz, A., Karmi, G. : Lightpath communications : an approach to high-bandwidthoptical WANs. IEEE Trans. Commun. 40, 1171–1182, 1992.
3. Skorin-Kapov, N. : Heuristic Algorithms for the Routing and Wavelength Assignment of ScheduledLightpath Demands in Optical Networks. IEEE J. of Selected Areas in Com. 24 (8), 2–15, 2006.

Génération d’emplois du temps pour les établissements àformation à "la carte"
H. Mabed,1, H. Manier2, M-A. Manier2, O. Baala2, S. Lamrous2, C. Renaud2
1 UFC, LIFC, 25200 Montbé[email protected]
2 UTBM, Laboratoire SET, 90000 Belfort.marie-ange.manier, herve.manier, oumaya.baala, claude.renaud, [email protected]
Cette proposition traite de la conception d’un outil d’aide à la décision pour l’élaboration des emploisdu temps dans le cadre d’une formation dans l’enseignement supérieur. Ce travail s’inscrit dans lecadre d’un projet pédagogique réalisé au sein de l’Université de Technologie de Belfort-Montbéliard,avec pour objectif le remplacement et l’amélioration des outils existants. Ce projet, baptisé Chronos,est actuellement en cours.Par rapport à d’autres écoles d’ingénieurs, l’Université de Technologie de Belfort-Montbéliard sedistingue par une formation à « à la carte » compliquant ainsi la problématique de l’élaborationdes emplois du temps des étudiants et des enseignants. En e#et, chaque étudiant a la possibilité deconstruire sa formation en choisissant chaque semestre les modules (UVs) qu’il souhaiterait suivre,parmi un ensemble de modules possibles. Dans les di#érentes matières enseignées, on ne retrouvedonc pas le même groupe d’étudiants pour une même promotion. Ceci augmente évidemment lacomplexité de ce type de problème, qui comporte par ailleurs des contraintes de di#érents types :capacité des ressources (salles, enseignants), calendrier, contraintes pédagogiques d’enchaînements desenseignements, nombre limité d’étudiants par groupe, . A ces contraintes classiques viennent encores’ajouter des contraintes molles telles que les souhaits des enseignants (1/2 journée de disponibilitépeut être demandée), ou le souhait de lisser la répartition des étudiants sur les groupes. De plus,la répartition sur trois sites géographiques des enseignements rend nécessaire la prise en compte decontraintes sur les déplacements des étudiants et des enseignant entre les sites (regrouper tous lesenseignements d’une demi-journée d’un étudiant ou d’un enseignant sur un même site).La première phase du travail e#ectué a été d’élaborer un modèle par programmation linéaire à partirdes données et contraintes recensées pour ce problème. Toutefois, compte tenu de la taille des donnéeset des contraintes du modèle (2000 étudiants, 1800 séances à programmer, 1200 groupes à constituer),une approche heuristique a été adoptée pour la résolution.L’algorithme de recherche fait évoluer une solution unique générée à partir d’une heuristique construc-tive moyennant trois opérateurs de mouvement simples : (a) changement de groupe à un étudiant,(b) changement de créneau à une séance et (c) changement de salle à une séance. Après chaquemouvement, la qualité de la nouvelle solution est réévaluée en utilisant une procédure d’évaluationincrémentale ou delta-évaluation. La procédure de réévaluation dépend du type de mouvement réa-lisé. Pour éviter des dégradations conséquentes de la solution courante di%cilement récupérables, unmécanisme de contrôle de la dégradation est implémenté. Sont rôle est de réguler la fréquence etl’amplitude des dégradations produites après chaque mouvement en rejetant certains mouvementsdégradants. A ce mécanisme s’ajoute une procédure de liste tabou utilisée pour empêcher les cyclesde recherche faisant rétablir précipitamment un choix précédent récemment modifié. Ce cycle estréitéré jusqu’à ce qu’un nombre limite d’itérations paramétrable soit atteint ou qu’un flag (valeurdans un fichier) soit activé par l’utilisateur de l’interface graphique.La génération de la solution initiale est réalisée en trois étapes chacune a pour objectif de répondre àl’une des dimensions du problème : l’a#ectation des créneaux, l’a#ectation des salles et la constitutiondes groupes. La procédure d’a#ectation des créneaux commence par les séances se rapportant aux

176 Mabed, Manier, Baala, Lamrou, Renaud
UVs les plus demandées en terme d’e#ectif. Pour chaque UV prise dans cet ordre, on balaye l’ensemblede tous les créneaux possibles à la recherche de celui qui cause le moins de conflits avec les UVs déjàplanifiées. A ce niveau uniquement le potentiel de conflits entre UVs est considéré. Ce potentiel estévalué à partir du nombre d’e#ectifs en commun entre les UVs (UV à planifier et UVs déjà planifiées)et le nombre de groupes de chaque UV. Deuxièmement, pour chaque inscription d’un étudiant à uneUV, nous recherchons le meilleur groupe de cours, de TD et de TP pour l’étudiant. La notion de« meilleure » est déterminée à partir de la planification horaire de chacun des groupes possibles.Rappelons que cette planification est réalisée lors de l’étape précédente d’a#ectation des créneaux.La troisième étape de la constitution de la solution initiale consiste à l’a#ectation des salles auxséances. A chaque séance nous choisissons la salle dont la capacité, le site et le type conviennent etqui provoque le moins de conflits. Rappelons que les di#érentes séances sont déjà planifiées dans letemps et les groupes déjà constitués.Les premiers résultats obtenus par la méthode sur les données issues du semestre d’automne 2006montrent que le nombre de conflits résiduels est très faible. Au bout de 2 heures de calcul sur un PCIntel 2.20GHz avec 2Go de RAM, l’algorithme de recherche obtient une solution avec 3 conflits surles étudiants, 3 conflits sur les salles, 0 violation de l’indisponibilité des enseignants. Ces résultatsrestent améliorables avec des temps d’exécution plus conséquent.L’un des points centraux de l’étude porte sur l’impact de la non-périodicité sur les performancesde l’emploi du temps. En e#et l’analyse faite, montre que le système de périodicité sur 2 semainesadoptée par l’UTBM limite la qualité des solutions trouvées.
Références
1. Abdullah S., Burke K.E., McCollum B. : A hybrid evolutionary approach to the university coursetimetabling problem. Congress on Evolutionary Computation, 1764-1768 (2007)
2. Rahoual M., Mabed M. : Hybridation des algorithmes génétiques et recherche taboue pour lesproblèmes d’emploi du temps. Procedings of Evolutionary Algorithms Conference EA99 (1999)
3. A survey of metaheuristic-based techniques for University Timetabling problems. Revue OR Spec-trum, Springer, pp 167-190 (2007)

Optimisation de la planification de bourses d’échangesde technologies
C. Guéret1, O. Morineau1, C. Pavageau1, O. Péton1, and D. Poncelet2
1 IRCCyN - École des Mines de Nantes, La Chantrerie, BP 20722 F-44307 Nantes, cedex 3 - France,{Christelle.Gueret,Odile.Morineau,Claire.Pavageau,Olivier.Peton}@emn.fr
2 GEPEA - École Nationale d’Ingénieurs des Techniques des Industries Agricoles et Alimentaires,Route de la Géraudière, BP 82225, F-44322 Nantes CEDEX 03 - France.
1 Description du problèmeLors de certaines conférences scientifiques ou congrès professionnels sont organisées des boursesd’échanges de technologies, c’est à dire des réunions entre participants ayant émis le souhait dese rencontrer. En pratique, nous considérons une conférence qui rassemble 100 à 200 personnes (aca-démiques et industriels) durant trois jours. Chacun dispose de la liste des participants et exprime desvoeux sur les individus qu’il souhaite rencontrer, classés par ordre de préférence. Environ cinq sessionssont organisées pendant la durée de la conférence pour permettre ces rencontres. Une session com-porte cinq ou six rencontres de 30 minutes. Une rencontre ne regroupe que deux interlocuteurs autourd’une table. Plusieurs salles peuvent être réservées pour l’organisation de ces bourses d’échange.Les di%cultés d’une telle organisation sont multiples : il faut satisfaire au mieux l’ensemble desvoeux exprimés par les participants, chercher à minimiser le coût de location des salles, limiter lesdéplacements des personnes entre salles, et si possible entre tables d’une même salle. Le planning derencontres doit respecter un ensemble de contraintes plus ou moins fortes, par exemple :1. On ne peut pas planifier plus d’une rencontre par participant dans une même plage horaire.2. Une rencontre n’est planifiée que sur une seule plage horaire.3. Il faut que chaque participant ait un nombre minimal donné de rencontres assurées sur la totalité
des rencontres dans lesquelles il est impliqué.4. Il est souhaité de laisser des plages libres pour des pauses et des discussions informelles. Il est
donc préférable que chaque participant n’ait pas plus de deux rencontres à la suite au sein dechaque session.
5. Les rencontres de chaque participant doivent être planifiées de manière équilibrée sur la duréede la manifestation.
6. Il faut autant que possible planifier au moins 66% des 6 premiers choix de chaque participant.Des premiers travaux sur ce problème ont été présentés lors de la conférence ROADEF’06 [1], maisils ne tiennent pas compte de l’ensemble des contraintes, le problème ayant évolué entre-temps.
2 Méthode de résolution proposéeNous proposons de résoudre le problème en trois temps : dans un premier temps nous définissons lesrencontres et les a#ectons à une période de façon à maximiser le nombre de rencontres planifiées. Lenombre de rencontres étant conséquent, ce problème est résolu en deux étapes : dans une premièreétape, un programme linéaire en nombres entiers est utilisé pour planifier les rencontres correspondant

178 Guéret C., Morineau O., Pavageau C., Péton O., D. Poncelet
aux 6 premiers choix de chaque participant. Le planning obtenu est ensuite complété en résolvantun autre programme linéaire en nombres entiers dont l’objectif est de planifier les autres rencontres.Ces deux problèmes sont résolus à l’aide d’un logiciel libre de Programmation Linéaire en NombresEntiers (GLPK).La deuxième étape a pour objectif de déterminer les salles nécessaires pour réaliser le planningde rencontres calculé à l’étape précédente, de façon à minimiser le coût de location des salles. Lecoût des salles étant supposé proportionnel à leur capacité, le problème à résoudre est un problèmed’empilement de capacité maximale B égale au nombre maximal de rencontres ayant lieu en mêmetemps, et composé de n objets (salles) ayant une taille donnée (capacité). Ce problème est résolu parun algorithme de programmation dynamique en O(nB).Enfin la dernière étape consiste à a#ecter à chaque rencontre une salle parmi celles sélectionnées àl’étape précédente, et une table dans cette salle. L’objectif est de minimiser le nombre de déplacementsdes participants entre salles et entre tables à l’intérieur d’une même salle. La méthode utilisée pourrésoudre ce dernier problème est une recherche tabou. Le voisinage utilisé consiste à permuter lestables de deux rencontres.Cette approche considère donc que l’objectif prioritaire est de planifier un maximum de rencontres.Nous considérons ensuite qu’il est plus important de minimiser le nombre de salles utilisées que lenombre de déplacements des participants entre tables.
3 Résultats
Lors des éditions précédentes de la conférence, auxquelles ont assisté une centaine de participants, laplanification des sessions avait occupé deux personnes pendant une journée complète. Notre approcherésout en quelques minutes seulement des instances générées aléatoirement de 200 participants. Lesjeux de données des éditions précédentes n’étant pas disponibles, nous ne pouvons comparer les solu-tions obtenues avec notre approche aux solutions manuelles. Nous présentons cependant les résultatsobtenus sur les données réelles d’une conférence ayant lieu en février 2009 [2].Cette première approche est rapide et satisfaisante. Nous explorons actuellement d’autres approchesbasées sur la programmation par contraintes.
Références
1. X. Gandibleux, B. Pajot et D. Poncelet, Modèle en variables 01 et système d’aide pour l’optimi-sation de l’organisation de bourses d’échanges de technologies, ROADEF’06, Lille, France
2. Industrial Symposium and Trade Fair on Applied Microencapsulation Brussels, Belgium, February3-5, 2009

Conception des horaires de bus (graphicage) etconception des horaires des chau!eurs de bus (habillage)
T.Dereu, F.Lamer, D.Montaut, and A.Schweitzer
EURODECISION, 9A, rue de la porte de BUC, 78000 [email protected] [email protected]
[email protected] [email protected]
1 Problématique
La construction d’une o#re de transport dans le domaine du bus comprend :– La conception des horaires des bus (graphicage)– puis la conception des horaires des chau#eurs (habillage)
Dans un premier temps nous présentons un module d’optimisation de l’habillage urbain. Ce moduled’habillage construit les horaires des chau#eurs de bus qui couvrent l’ensemble des tâches desvéhicules (graphique), respectent les conditions de travail et minimisent le nombre de chau#eurs. Cemodule est basé sur de la génération de colonnes.
Dans un deuxième temps nous nous intéressons à la problématique d’habillage interurbain. Cetteproblématique a plusieurs spécificités par rapport à l’urbain :– Les courses commerciales sont très dispersées géographiquement et les enchaînements possibles
entre ces courses sont nombreux.– Les planificateurs construisent manuellement le graphique et l’habillage ensemble car ces deux
problèmes sont très liés. La qualité de l’habillage dépend beaucoup de celle du graphique.– En automatique, il faut donc construire un graphique et un habillage.
C’est pour ces raisons que nous avons développé deux modules pour résoudre la problématique dutransport interurbain :– Un module de graphicage :
– construisant les horaires des bus– minimisant le nombre de véhicules.– intégrant plusieurs contraintes d’habillage.Ce module est basé sur de la génération de colonnes.
– Un module d’habillage automatique très proche du module d’habillage urbain.
2 Formulation mathématique du problème
Voici brièvement les principaux éléments du modèle mathématique du problème de graphicage puisdu problème d’habillage.

180 T.Dereu, F.Lamer, D.Montaut, A.Schweitzer
2.1 Graphicage
Fonction objectif : minimiser le nombre de services voiture et leur durée totale.Variables de décision : variables binaires de choix ou non des services voiture.Contraintes :Principales contraintes voiture :Toutes les tâches doivent Ítre couvertes une et une seule fois par les services voitureLe nombre de véhicules disponibles par type de véhicule et par dépÙt doit Ítre respecté
Principales contraintes agent anticipées pour le module d’habillage :Respecter le temps de travail maximum d’un agentRespecter le temps de conduite continue maximum d’un agent
2.2 Habillage
Fonction objectif : minimiser le nombre de services agent et le temps total de travail.Variables de décision : variables binaires de choix ou non des services agent.Contraintes :Toutes les tâches doivent Ítre couvertes une et une seule fois par les services agentTout service agent doit respecter les conditions de travail (temps de travail maximum, nombre mini-mum de pauses . . . )
3 Résolution
3.1 Graphicage
La méthode choisie est une méthode de génération de colonnes basée sur un problème de plus courtchemin contraint. Le problème maître est un problème de partitionnement : chaque tâche doit Ítrecouverte une et une seule fois par les services voiture. Le problème esclave est un problème de pluscourt chemin avec ressources.
3.2 Habillage
A partir du planning des bus et compte tenu de la complexité du sous-problème, un ensemble ex-plicite de services agent candidats est généré. Cet ensemble est susceptible d’évoluer au cours de larésolution. Chaque service agent correspond à une colonne dans la modélisation. Le problème maîtreest un problème de partitionnement : chaque tâche doit Ítre couverte une et une seule fois par lesservices agent. Le problème esclave met à jour le coût réduit de chaque colonne à partir d’informa-tions (les duales) fournies par le problème maître et envoie un ensemble de colonnes intéressantes auproblème maître.

Comment deviner le prix de réservation de sonadversaire pour maximiser son revenu ?
H. Le Cadre and M. Bouhtou
Orange Labs, rue du Général Leclerc, 92794 Issy-les-Moulineaux Cedex 9 France.{helene.lecadre ;mustapha.bouhtou}@orange-ftgroup.com
Les stratégies dites de reinforcement learning visent à trouver un compromis entre une stratégie d’ex-ploration et une stratégie d’exploitation, i.e. elles déterminent un équilibre entre explorer l’environ-ment afin de déterminer les actions optimales et sélectionner l’action la meilleure empiriquement aussisouvent que possible. L’un des exemples les plus simples du dilemne entre exploration/exploitationest le problème des bandits à plusieurs bras. Dans ce problème orginellement proposé par Robbins(cf Auer et al. [2]), un joueur dans un casino doit choisir de joueur sur une des K machines à sousprésentes dans la salle. A chaque pas de temps, il actionne le bras de l’une des machines dite banditmanchot, et reçoit une récompense. Le but du joueur est de maximiser son gain total en actionnantà chaque instant un bandit. Puisque chaque bandit génère une récompense distribuée suivant unecertaine distribution, le but du joueur est de déterminer le plus rapidement possible, le bandit gé-nérant la meilleure récompense espérée, puis de continuer à actionner cette machine. La nécessitéde trouver un compromis entre exploration et exploitation résulte de l’observation suivante. D’uncôté, si le joueur choisit exclusivement la machine qu’il pense être la meilleure (exploitation), il peutpasser à côté d’une machine qui lui aurait rapporté plus encore. D’un autre côté, s’il passe trop detemps à tester toutes les machines et à collectionner des statistiques, il ne peut pas se concentrer surle bandit qui lui aurait rapporté le plus. Il a été démontré que la statégie optimale est de choisir àchaque instant le bandit ayant l’indice de Gittins le plus élevé (cf Ross [4]). Dans le passé, le pro-blème des bandits avait presque toujours été étudié sous des hypothèses statistiques sur le processusgénérant les revenus associés à chaque bandit. Or, dans nombre de problème concrets d’allocation deressource, il est impossible de déterminer les bonnes hypothèses statistiques. Cesa-Bianchi et Lugosi[1], Auer et al. [2] considèrent une variante du problème où aucune hypothèse statistique n’est faitesur la génération des revenus. On parle alors de suite individuelle, car le gain associé à chaque ban-dit est déterminé à chaque étape par un adversaire suceptible d’anticiper les actions du joueur. Laperformance du joueur est mesurée par son regret, i.e. la di#érence entre le revenu total perçu parle joueur et le revenu total généré par le meilleur bandit. Piccolboni et Schindelhauer [3] étendent leproblème de prédiction de suite individuelle à un cas d’allocation séquentielle de bande passante où lefeedback est partiel et dépend des actions choisies. Cesa-Bianchi et Lugosi [1] introduisent la notiond’experts qui proposent diverses stratégies prédisant la suite individuelle, au joueur, sous informationincomplète (feedback partiel).Nous considérons trois opérateurs mobile ; deux d’entre eux disposent de capacités limitées. Nous lesnoterons MNO 1 et MNO 2 (MNO signifie Mobile Network Operator). Le troisième est un opérateurvirtuel (dit MVNO, pour Mobile Virtual Network Operator), i.e. il ne possède pas de réseau en propreet doit négocier l’accès aux réseaux des autres opérateurs. Les MNOs contrôlent le partage de leursressources avec l’opérateur virtuel ainsi que la charge d’accès unitaire. Le MVNO est initialementinconnu sur le marché. Pour séduire les clients, il investit dans la publicité. Les MNOs peuventpartager une partie de ses investissement, i.e. faire de la publicité coopérative.Le problème est que les MNOs disposent d’une information incomplète ; en e#et, le MVNO définitun prix maximum qu’il est prêt à payer à chaque instant ; en-dessus de cette valeur il refuse touteinterconnexion. Les MNOs veulent déterminer les coûts de partage de la publicité minimisant leurspertes, i.e. la di#érence entre ce qu’ils auraient pu gagner s’ils avaient connu le prix de réservation

182 H. Le Cadre, M. Bouhtou
du MVNO et ce qu’ils reçoivent. En e#et si les coût de partage de la publicité sont trop faibles leMVNO risque de ne pas s’interconnecter. Donc de la bande passante sera inutilisée sur les réseaux desMNOs ; ce qui représente une perte financière. Par contre, si les coûts de partage de la publicité sonttrop élevés, les MNOs perdent de l’argent car le MVNO était prêt à s’interconnecter pour moins cher.Chaque MNO va donc chercher à apprendre la stratégie du MVNO. Notre objectif est de comprendrece qui influence la vitesse d’apprentissage et comment cela se traduit dans l’évolution des revenusdes MNOs.
Description du jeu dynamique avec feedback– Premier niveau : partage des coûts de la publicité
(1) Le MVNO choisit secrètement son prix de réservation.(2) Chaque MNO détermine son coe%cient de partage des coûts de la publicité du MVNO.
– Second niveau : jeux sur les capacités(3) Les MNOs partagent leurs bande passante et définissent leurs charges d’accès.
– Troisième niveau : jeux sur les prix(4) Les opérateurs (MNOs, MVNO) fixent leurs prix de vente et niveaux d’investissement dans lapublicité. Les clients choisissent leurs fournisseurs.(5) Les MNOs reçoivent des feedbacks partiels qui correspondent à leurs revenus.
Plusieurs types de stratégies sont évaluées (fictitious play, minimisation du regret externe, minimisa-tion du regret interne [1]). On démontre l’existence d’un équilibre corrélé à notre modèle seulementdans le cas de la minimisation du regret interne [1]. Ce qui signifie qu’aucun des MNO n’a inérêt àdévier en moyenne des coûts de partage recommandés par cet équilibre. Par simulation nous mettonsen évidence deux phases au cours du jeu dynamique : d’abord le MNO fait varier ses prix pour devinerla stratégie du MVNO (exploration) puis il maximse son revenu une fois qu’il a appris la stratégiede l’opérateur virtuel (exploitation). En fait, c’est le MNO qui accepte de perdre le plus au débutqui apprend le plus vite et maximise son revenu au final. Donc pour apprendre le plus vite, il fautaccepter de perdre de l’argent au départ.
Références
1. Cesa-Bianchi N., Lugosi G. : Predicition, Learning, And Games. Cambridge University Press(2006)
2. Auer P., Cesa-Bianchi N., Freund Y., Schapire R. : Gambling in a rigged casino : The adversialmulti-armed bandit problem. 36th Annual Symposium on Foundations of Computer Science (1995)
3. Piccolboni A., Schindelhauer C. : Discrete Predicition Games with Arbitrary Feedback and Loss.14th Annual Conference on Computational Learning Theory (2001)
4. Ross S. : Introduction to Stochastic Dynamic Programming. Academic Press (1995)

Résolution d’enchères sur réseau par décomposition deBenders
S. Lannez,1 T. Crainic2 and M. Gendreau1
1 Université de Montréal, C.P. 6128, succursale Centre-Ville Montréal (Québec) H3C 3J7, [email protected],[email protected]
2 UQAM, 315 Ste-Catherine est, Montréal (Québec) H2X 3X2 [email protected]
1 Introduction
L’enchère de Vickrey[1] di#érencie l’allocation du bien du calcul des paiements. L’allocation estréalisée en satisfaisant la meilleure o#re. Ensuite, le calcul du paiement du gagnant est réalisé defaçon à prendre en compte le manque à gagner imposé aux perdants. Cette enchère, initialementproposée pour l’allocation d’un unique bien non divisible, a été généralisée par les mécanismes deVickrey-Clarke-Groves[2,3] à l’allocation de plusieurs biens.L’enchère que nous proposons est une enchère à enveloppe scellée mettant en relation un vendeur etplusieurs acheteurs. Le vendeur possède un réseau dont les arcs ont une capacité finie. Ce sera un plande transport si le vendeur est un transporteur, un ensemble de sillons pour un gérant d’infrastructureferroviaire ou un réseau de télécommunication pour un opérateur de télécommunication. Les ache-teurs veulent acquérir un chemin de capacité donnée entre deux nœuds du réseau du vendeur. Cechemin peut représenter le transport d’une quantité de marchandise, la circulation d’un train ou latransmission d’une quantité d’information.Nous verrons que la recherche des gagnants de l’enchère et le calcule des paiements nécessitent larésolution répétitive de problèmes en nombres entiers qui sont numériquement très proches. Pouraccélérer la résolution de l’enchère, nous avons utilisé la décomposition de Benders et réutilisonsles coupes générées. Nous montrerons par l’analyse de tests numériques que cette approche devientintéressante dès que le problème de routage dans le réseau devient non trivial et que le nombre deconflits entre les mises augmentent.
2 Mécanismes VCG
Enchères de Vickrey : Chaque participant propose dans une « enveloppe scellée » le prix maximumqu’il est prêt à payer pour le bien. Le commissaire-priseur ouvre toutes les « enveloppes » et allouele bien au plus o#rant. Le paiement de ce dernier sera équivalent à la deuxième meilleure o#re. Ceprincipe simple assure que s’il n’y a pas collusion entre les participants, personne n’a intérêt à sur ousous évaluer sa mise.
Mécanisme de Clarke : L’idée du mécanisme de Clarke[2] est de généraliser l’enchère de Vickrey àplusieurs biens. Soit M(I,K, c) un mécanisme qui alloue les objets k ! K aux participants i ! I enfonction de la valeur cik de chaque objet pour chaque participant. Soit z(I,K, c) la valeur totale del’allocation M(I,K, c). "i est le prix que paiera le participant i si sa mise est acceptée. Il est définipar : "i =M(I,K, c)%M(I \ i, K, c).

184 S. Lannez, T. Crainic, M. Gendreau
3 Modèle mathématique
La détermination des gagnants est réalisée à l’aide d’un programme en nombres entiers. Ce programmemathématique est un modèle de multiflot avec des variables additionnelles.
Détermination des gagnants : Soit G = (V,A) le graphe sur lequel à lieu l’enchère. V est l’ensembledes nœuds et A l’ensemble des arcs. I est l’ensemble des participants de l’enchère. Le paramètre piest la valeur de la mise du participant i. Le paramètre di est la capacité demandée par i entre lesnœuds origi et desti. cia est le coût supporté par le vendeur pour une unité de flot traversant l’arca. bvi vaut di (resp. %di) si v est le nœud origi (resp. desti) de la mise du participant i. La variableyi vaut 1 si la mise du participant i est acceptée, 0 sinon. xia est la quantité de flot du participant iqui traverse l’arc a.
(M) : max%
i#I
piyi %%
i#I
%
a#Ai
ciaxia (1)
s.c.%
a#Ai+(v)
xia %%
a#Ai"(v)
xia % bvi yi = 0, $i ! I,$v ! V (2)
%
i#I
xia # ua,$a ! A (3)
xia ) 0, $i ! I, a ! A (4)yi ! {0, 1}, $i ! I. (5)
Détermination des paiements : Soit I$ l’ensemble des gagnants élus pendant la résolution deM(I).Pour calculer le paiement de chaque gagnant i ! I$, il faut résoudreM(I \ i). Ces problèmes peuventêtre obtenus en retirant de M(I) la colonne correspondant à la variable yi.
4 Décomposition de Benders
Nous montrerons ensuite la validité des coupes générées pendant la résolution deM(I) pour les sousproblèmes. Les jeux de tests ont été réalisés en faisant varier la densité d’un graphe de 40 nœudset 400 arcs, le nombre de participants, le nombre de mises conflictuelles et la taille des sous réseauxadmissibles de chaque participant.
Références
1. Vickrey, W. : Counterspeculation, auctions, and competitive sealed tenders. Journal of Finance,16(1) :8-37, 1961
2. Clarke, E. H. : Multipart pricing of public goods. Public Choice, 2 :19-33, 19713. Groves, T. : Incentives in teams. Econometrica, 413 :617-31, 19734. Lannez, S. : Mise en oeuvre des mécanismes de Vickrey-Clarke-Groves sur des réseaux. Université
de Montréal, M. Sc. Thesis, 2007

Partage de ressources informatiques :Enchères combinatoires dans les grilles#
L. Belgacem, E. Gourdin, R. Krishnaswamy, and A. Ouorou1
Orange Labs, 38-40 rue du Général Leclerc, 92794 Issy les Moulineaux Cedex 9, France.[lucile.belgacem, eric.gourdin, ruby.krishnaswamy, adam.ouorou]@orange-ftgroup.com
1 Introduction
Initialement réservées à la communauté académique ou à certaines entreprises dans le cadre de projetsscientifiques de grande ampleur, les grilles sont des infrastructures virtuelles constituées d’un ensemblede ressources informatiques (tout élément qui permet l’exécution d’une tâche ou le stockage d’unedonnée numérique) potentiellement partagées, distribuées, hétérogénes, et autonomes (voir [2]). Lepartage de ces ressources permet de résoudre d’importants problèmes de calcul nécessitant des tempsd’exécution trés longs en environnement classique, mais aussi d’optimiser l’utilisation des ressources.La prochaine étape consiste naturellement à démocratiser cette technologie pour permettre à touteorganisation virtuelle (utilisateurs domestiques, écoles ou universités, administrations, associations,entreprises...) d’obtenir des ressources informatiques sur l’Internet sans devoir investir individuelle-ment dans l’achat et l’administration de telles ressources. La majeur partie des protocoles proposésdans la littérature pour l’allocation de ressources dans les grilles est fondée sur des négociations bila-térales séquentielles ou simultanées entre un consommateur et plusieurs fournisseurs éventuels, qu’ilfaut donc ensuite coordonner. Ces protocoles ne permettent pas d’exprimer la complémentarité desressources, or l’exécution d’une tâche peut souvent nécessiter plusieurs types de ressources di#érents(par exemple du CPU et de l’espace mémoire). Le participant doit donc dans ce cas tenter d’évalueret d’acquérir ces deux ressources séparément, en prenant le risque de n’en obtenir qu’une.Afin de contourner ces di%cultés, des travaux plus récents (voir par exemple [4], [5] et [6]) proposentd’utiliser les enchères combinatoires dont la spécificité est de permettre aux participants d’enchérirsur des ensembles d’objets plutÙt que sur des objets individuels (voir [1]). En outre il est possiblede traiter globalement des négociations faisant intervenir plusieurs vendeurs et plusieurs acheteurs.Notre contribution s’inscrit dans la continuité de ces travaux.
2 Spécifications du mécanisme d’enchères combinatoires
Nous proposons tout d’abord un langage de description riche et adapté qui permet aux participantsde formuler précisément les requêtes qu’ils soumettent au marché. De façon trés simplifiée, les besoinsdes consommateurs peuvent être représentés par les quantités aq des ressources q souhaitées (q ! Q),un intervalle de temps [e, l] durant lequel les ressources sont demandées, et une valuation v . Demême, les o#res des fournisseurs sont caractérisées par des quantités dq, (q ! Q), par un intervallede temps [c, f ] de disponibilité des ressources, et par un prix de réserve r (la somme minimumque l’agent est prêt à accepter : le coût de revient des ressources). Dans le modéle proposé, unconsommateur peut soumettre au marché un ensemble de tâches exclusives, elles-mêmes subdiviséesen un ensemble de tâches complémentaires, alors que chaque fournisseur peut soumettre un ensembled’o#res indépendantes.! Ce travail de recherche est en partie financé par le projet européen Grid4All [3].

186 L. Belgacem et al.
Comme tout mécanisme de marché, les enchères combinatoires consistent en deux phases. Il s’agitd’abord de déterminer le plan d’allocation des ressources, et donc de décider quelles enchères sontgagnantes. Ce problème d’optimisation combinatoire NP-di%cile est appelé Winner DeterminationProblem. De façon classique, l’objectif de ce problème est de maximiser le social welfare, défini commele surplus global généré par l’allocation :
%
cons. gagnantsv %
%
fourn. gagnantsr.
Les contraintes du problème doivent naturellement décrire les di#érentes requêtes des négociateurs(caractéristiques des ressources recherchées, intervalle de disponibilité des ressources, valuations etprix de réserve, etc). Nous spécifions de plus quelques régles d’allocation spécifiques au modéle, commel’exclusivité des tâches soumises par un consommateur, ou leur parallélisation, et des contraintesportant sur l’éclatement possible des ressources d’un fournisseur entre plusieurs tâches.Aprés avoir établi l’allocation optimale des ressources, il faut déterminer les prix à payer pour lesenchères gagnantes. Nous nous plaçons dans une optique de tarification par commodité : des prix sontétablis pour chaque commodité échangée sur le marché (ex : 1 unité de CPU par unité de temps). Lesprix obtenus doivent aboutir à un marché équilibré (budget-balance), et respecter les contraintes devaluations et prix de réserve des agents (individual rationality). De plus on souhaite obtenir des prixvérifiant la propriété de market clearing : les consommateurs perdants constatent que leur valuationest trop faible et les fournisseurs perdants que leur prix de réserve est trop élevé. Malheureusement,dans le cas d’enchères combinatoires, cette propriété est rarement réalisable. Nous proposons doncune variante de la méthode décrite dans [4] qui consiste en la résolution d’une série de problèmes deprogrammation linéaire dont l’objectif est de se rapprocher le plus possible de la propriété de marketclearing.
Références
1. Cramton P., Shoham Y. and Steinberg R. Combinatorial Auctions, MIT Press, 2006.2. Foster I. « The Grid : A New Infrastructure for 21st Century Science », Physics Today, 2002.3. Krishnaswamy R., Navarro L., Brunner R., LeÛn X. and Vilajosana X., Grid4All : Open Mar-
ket Places for Democratic Grids. Proceedings of the 5th Int. Workshop on Grid Economics andBusiness Models (GECON 2008), Spain, August 2008, LNCS 5206, pp. 197-207, Springer, 2008.
4. Kwasnica A., Ledyard J., Porter D. and DeMartini C. « A new and improved Design for Multi-Object Iterative Auctions », Management Science, 51, 3, pp. 419-434, 2005.
5. Schnizler B., Neumann, D., Veit D., and Weinhardt C. « Trading Grid Services - A Multi-attributeCombinatorial Approach », European Journal of Operation Research, 187, pp. 943-961, 2006.
6. Stoesser J., Neumann D. « GREEDEX - A Scalable Clearing Mechanism for Utility Computing »,Networking and Electronic Commerce Research Conference (NAEC), Riva Del Garda, Italy, 2007.

Application de MO-TRIBES au dimensionnement decircuits électroniques
Y. Cooren1, M. Fakhfakh2, P. Siarry1
1 Laboratoire Images, Signaux et Systèmes Intelligents, LiSSi (E.A. 3956)61 avenue du Général de Gaulle, 94010, Créteil.
{cooren,siarry}@univ-paris12.fr2 Université de Sfax, [email protected]
1 Introduction
La conception des circuits intégrés analogiques a toujours été entravée par le procédé technologique,principalement parce que la technologie a été optimisée pour les circuits numériques. En e#et, la partieanalogique des circuits intégrés mixtes requiert plus de temps pour sa conception. La conceptionassistée par ordinateur est devenue une étape indispensable pour réduire le coût et le temps deconception d’un circuit analogique.Le processus de conception repose en grande partie sur l’expérience du concepteur. Cependant,vu la complexité de l’opération, les concepteurs ont tendance à se satisfaire d’une approximationgrossière [1]. En e#et, un système, même d’apparence simple, peut être très complexe à optimiser,principalement du fait que les variables de décision sont liées à des objectifs antagonistes.Si l’on aborde la conception du point de vue, non de l’électronique, mais de la recherche opérationnelle,le dimensionnement peut être considéré comme un problème d’optimisation à variables continues,soumis à des contraintes. Les variables de décision sont alors les valeurs des composants du circuit(dimensions des transistors MOS, etc.), les contraintes étant imposées aussi bien par le fonctionnementdu circuit (régime de fonctionnement des transistors) que par le cahier des charges du circuit (gain,slewrate, etc.). Les convoyeurs de courant (CCII) forment les circuits de base dans le domaine defonctionnement en mode courant.Dans ce travail, on cherche à optimiser les performances d’un convoyeur de courant de secondegénération (CCII) en fonction des dimensions des transistors MOS qui le constituent. La figure 1(a)représente le CCII réalisé en technologie CMOS. Le but est de minimiser la résistance parasite (RX)du port X du CCII, et de maximiser la fréquence de coupure haute (fchi) du transfert en courantentre les ports X et Z du CCII. Le problème a été résolu à l’aide de MO-TRIBES, un algorithmed’optimisation par essaim particulaire multiobjectif, sans paramètre de contrôle.
2 MO-TRIBES
MO-TRIBES est un algorithme d’optimisation par essaim particulaire multiobjectif sans paramètrede contrôle. Il reprend les principaux éléments de TRIBES [2], auxquels sont ajoutés de nouveauxmécanismes destinés à traiter des problèmes multiobjectif.Notre objectif est de trouver des solutions non-dominées. On considère qu’un essaim a atteint unétat de quasi-équilibre s’il n’arrive plus à trouver de nouvelles solutions non-dominées. L’essaim seradonc réinitialisé si, entre deux itérations successives de MO-TRIBES, l’algorithme n’a pas trouvé denouvelles solutions non-dominées.

188 Y. Cooren, M. Fakhfakh, P. Siarry
Comme MO-TRIBES se veut un algorithme sans paramètre de contrôle, il est imposé d’adapterla taille de l’archive en fonction du comportement de l’algorithme. Tout d’abord, on admet que lataille de l’archive dépend du nombre d’objectifs. Plus le nombre d’objectifs est important, plus il estnécessaire de disposer de beaucoup de solutions non-dominées pour approcher le front de Pareto.Ensuite, à chaque nouvelle adaptation, la taille de l’archive est mise à jour, en fonction du nombrede solutions non-dominées trouvées depuis l’adaptation précédente.
3 Exemple de résultat
La figure 1(b) montre les fronts de Pareto (RX = f(%fchi)) obtenus pour di#érentes valeurs ducourant de polarisation I0 du CCII.
(a) (b)
Fig. 1. (a) Convoyeur de courant de seconde génération à boucle translinéaire, (b) Front de Paretoen fonction du courant de polarisation I0.
Le CCII ainsi optimisé a été simulé à l’aide du logiciel SPICE en utilisant la technologie AMS 0.35µm.Les résultats de la simulation concordent avec ceux obtenus en appliquant l’algorithme proposé.
Références
[1] R. Conn et al.. (1996). ”Optimization of custom MOS circuits by transistor sizing”, Proceedingsof the International Conference on Computer-Aided Design ICCAD’96, pp. 174-190, 1996, IEEEPress.
[2] Y. Cooren. (2008). ”Perfectionnement d’un algorithme adaptatif d’Optimisation par Essaim Par-ticulaire. Applications en génie médical et en électronique”, Thèse de doctorat, Université de Paris12, Créteil.

Multiobjective dynamic optimization of a fed-batchcopolymerization reactor
B. Benyahia1,2, A. Latifi1, C. Fonteix1, F. Pla1, S. Nacef3
1 Laboratoire des Sciences du GÈnie Chimique, CNRS-ENSIC1 rue Grandville, BP 451, 54001 Nancy Cedex, France
[email protected] DÈpartement de Chimie, FacultÈ des Sciences et Sciences de l’IngÈnieur, UniversitÈ Mohamed
Boudiaf , M’sila, Algerie3 DÈpartement de GÈnie des ProcÈdÈs, UniversitÈ Ferhat Abbas, SÈtif, Algerie
1 IntroductionMultiobjective optimization problems are encountered in most real-world applications and more re-cently in chemical processes ([1], [2], [3], [4]). Since such problems involve several objective functionswith conflicting nature, the final optimum is not unique but a set of non dominated solutions (thePareto front) which show a trade-o# among the whole objectives. A decision support approach isthen used to rank the Pareto solutions according to the decision maker’s preferences.
Emulsion polymerization is an important industrial process used to produce a great variety of po-lymers of multiple uses (e.g. paints, adhesives, coatings, varnishes). More over, it has significantadvantages over bulk and solution polymerization processes such as heat removal capacity and vis-cosity control. These advantages result mostly from the multiphase and compartmentalized natureof the emulsion polymerization which allows the production of polymers of high molecular weight athigh polymerization rates, delivering a high versatility to product qualities. However, the complexityof emulsion polymerization systems arising from factors such as the multiphase nature, nonlinearbehaviour and sensitivity to disturbances induce more intense di%culties on modelling and makethe development of optimization procedures of emulsion polymerization reactions a very challengingtask.Molecular weight distribution (MWD), polymer microstructure, glass transition temperature (Tg)and particle size distribution (PSD) and morphology are the main parameters witch strongly governthe end-use properties of the products (latex and polymer).The present paper deals with a multiobjective dynamic optimization of an emulsion copolymeriza-tion fed-batch reactor. The aim is to produce core-shell particles with specific end-use properties byusing two criteria subject to a set of tight operational constraints and the mathematical model ofthe system. The nondominated zone (Pareto’s domain) is obtained by using evolutionary algorithm.The ranking is therefore obtained by decision making support.
2 Formulation and resultsThe process model was developed and validated for the batch and fed-batch emulsion copolymeriza-tion of styrene and butyl acrylate in the presence of n-C12 mercaptan as chain transfer agent ([5]).The objective of the model is to predict di#erent variables including overall monomers conversion,number and weight average molecular weights, particle size distribution and residual monomer frac-tions. The objective of the process is to produce core-shell particles with a specific end-use properties
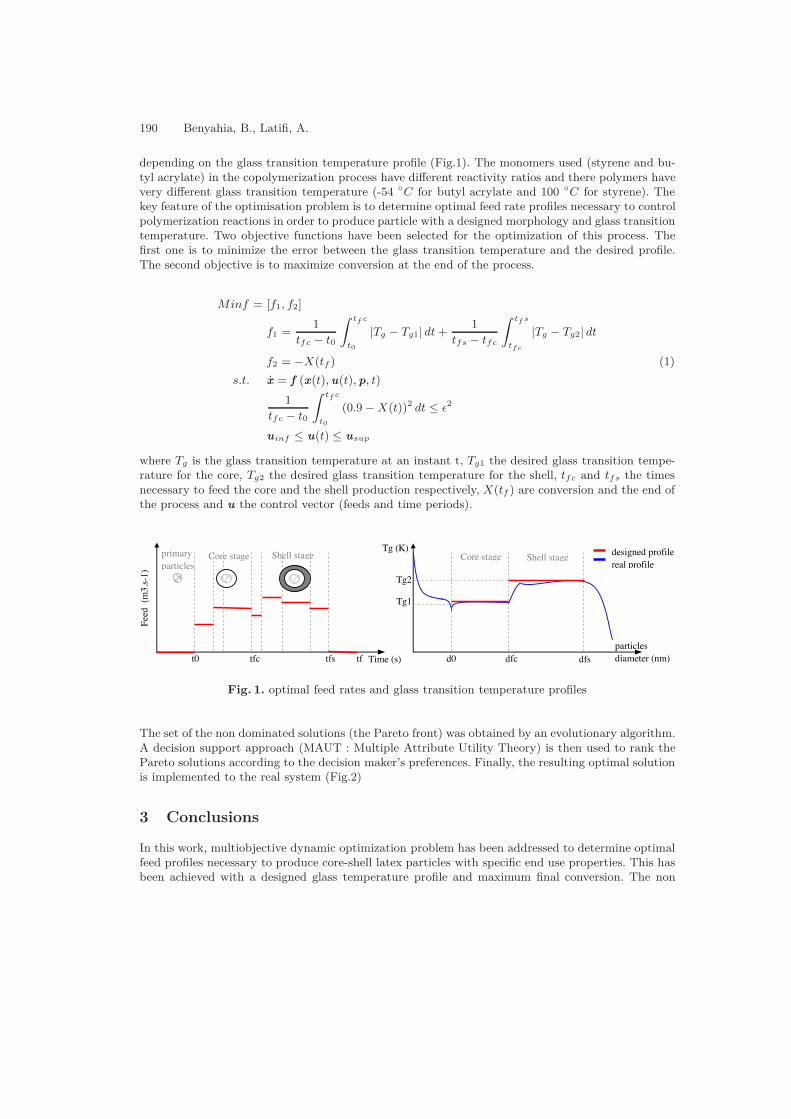
190 Benyahia, B., Latifi, A.
depending on the glass transition temperature profile (Fig.1). The monomers used (styrene and bu-tyl acrylate) in the copolymerization process have di#erent reactivity ratios and there polymers havevery di#erent glass transition temperature (-54 (C for butyl acrylate and 100 (C for styrene). Thekey feature of the optimisation problem is to determine optimal feed rate profiles necessary to controlpolymerization reactions in order to produce particle with a designed morphology and glass transitiontemperature. Two objective functions have been selected for the optimization of this process. Thefirst one is to minimize the error between the glass transition temperature and the desired profile.The second objective is to maximize conversion at the end of the process.
Minf = [f1, f2]
f1 = 1tfc % t0
D tf c
t0
|Tg % Tg1| dt+1
tfs % tfc
D tfs
tfc
|Tg % Tg2| dt
f2 = %X(tf ) (1)s.t. x = f (x(t),u(t),p, t)
1tfc % t0
D tf c
t0
(0.9%X(t))2 dt # ,2
uinf # u(t) # usup
where Tg is the glass transition temperature at an instant t, Tg1 the desired glass transition tempe-rature for the core, Tg2 the desired glass transition temperature for the shell, tfc and tfs the timesnecessary to feed the core and the shell production respectively, X(tf ) are conversion and the end ofthe process and u the control vector (feeds and time periods).
t0 tfc tftfs Time (s)
primary particles
Core stage Shell stageTg (K) designed profile
real profileTg2
Tg1
dfc dfsparticles diameter (nm)
Feed
(m
3.s-
1)
d0
Core stage Shell stage
Fig. 1. optimal feed rates and glass transition temperature profiles
The set of the non dominated solutions (the Pareto front) was obtained by an evolutionary algorithm.A decision support approach (MAUT : Multiple Attribute Utility Theory) is then used to rank thePareto solutions according to the decision maker’s preferences. Finally, the resulting optimal solutionis implemented to the real system (Fig.2)
3 ConclusionsIn this work, multiobjective dynamic optimization problem has been addressed to determine optimalfeed profiles necessary to produce core-shell latex particles with specific end use properties. This hasbeen achieved with a designed glass temperature profile and maximum final conversion. The non

Papier soumis à ROADEF 09 191
dominated solutions were obtained and ranked by using MAUT strategy. The simulations of the bestsolution showed a good agreement with the desired profiles.
-9,5E-01
-9,5E-01
-9,4E-01
-9,4E-01
-9,3E-01
-9,3E-010,0E+00 1,0E+01 2,0E+01 3,0E+01 4,0E+01
Critiria 1
Criti
ria 2 Tg(°C)
-1,6E+01
-1,1E+01
-6,0E+00
-1,0E+00
4,0E+00
9,0E+00
1,4E+01
2,0E-08 4,0E-08 6,0E-08 8,0E-08 1,0E-07dp(nm)
0,0E+00
2,0E-01
4,0E-01
6,0E-01
8,0E-01
1,0E+00
0,0E+00 3,0E+03 6,0E+03 9,0E+03 1,2E+04 1,5E+04
Time [s]
Con
vers
ion
0,0E+00
2,0E-08
4,0E-08
6,0E-08
8,0E-08
1,0E-07
1,2E-07
0,0E+00 3,0E+03 6,0E+03 9,0E+03 1,2E+04 1,5E+04
Time [s]
Ave
rage
dia
met
er (m
)
Pareto’s front
Fig. 2. Pareto’s front and the main results related to the optimum solution (glass temperature profile,the overall conversion and the average particles diameter)
Références
1. Fonteix C., Massebeuf S., Pla F., Nandor Kiss L, Multicriteria optimization of an emsulsionpolymerization process, Eur. J. Oper. Res., 153, 350-359 (2004)
2. Garg S., Gupta S. K., Multiobjective optimization of a free radical bulk polymerization reactorusing gentic algorithm, Macromol. The. Simul. 8, 46-53 (1999)
3. Mitra K., Majundar S., Raha S., Multiobjective optimization of a semibatch epoxy polymerizationprocess usinbg the eliptic gentic algorithm, Ind. Eng. Chem., 43, 6055-6063(2004)
4. Sakar D., Rohani S., Jutan A., Multiobjective optimization of semibatch reactive crystallizationprocesses, AIChE J., 53, 5, 1164-1174 (2007)
5. Benyahia B., Latifi A., Fonteix, C., Pla, F., Nacef, S., Elaboration of a tendency model anddetermination of optimal feed rate profiles for styrene/butyl acrylate semi-batch emulsion copo-lymerization reactor, CHISA 2008, Praha (2008)

Optimiser sur les ensembles d’arêtes des graphes bipartisinduits
D. Cornaz,1 and R. Mahjoub2
1 LIMOS, Complexe scientifique des Cézeaux, 63173 AUBIERE cedex, [email protected]
2 Laboratoire LAMSADE Université Paris Dauphine Place du Maréchal de Lattre de Tassigny75775 Paris CEDEX 16.
Soit G = (V,E) un graphe simple non-orienté avec un poids we pour chaque arête e de G. Lesous-graphe de G induit par un sous-ensemble de sommets W . V est le graphe H = (W,F ) avecF = {e ! E : e = uv, u, v ! W}. Le sous-graphe induit H est biparti si il existe une bipartition{W1,W2} de W telle que F = {e ! E : e = uv, u ! W1, v ! W2} ; ou de manière équivalente si Hn’a pas de cycle impair.Dans ce travail, un sous-ensemble d’arête F . E sera dit réalisable si il existe un sous-ensemble desommets W . V induisant un graphe biparti (W,F ). Nous considérerons le problème d’optimisationcombinatoire consistant à maximiser
&e#F we sur les F . E réalisables. Le vecteur caractéristique
d’un sous-ensemble d’arête F . E est le vecteur x ! {0, 1}E tel que xe = 1 si et seulement si e ! F .Soit R = {x ! {0, 1}E : x est le vecteur caractéristique d’un F . E réalisable}. Le problèmed’optimisation combinatoire est équivalent à optimiser sur R, i.e. maximiser
&e#E wexe sur les
x ! R. Une formulation pour R est un polyèdre P tel que R = P 0 {0, 1}E . Optimiser sur R estNP-di%cile, toutefois, lorsque que l’on peut optimiser sur P en temps polynomial (i.e. résoudrerapidement max{
&e#E wexe : x ! P}), la méthode Branch-and-bound permet de restreindre l’arbre
d’exploration. Dans ce contexte on s’intéresse aux formulations (polyèdres) P les plus proches deconv.hull(R). Nous proposons une formulation de R (décrite ci-dessous) dont nous montrerons qu’elleest plus proche de conv.hull(R) que (la projection) d’une formulation utlisant des variables sur lessommets et les arêtes. Cette formulation est
xe ) 0 pour toute arête e, (1)%
e#C
xe # |C|% 2 pour tout cycle impair C, (2)
xsu % xuv + xvt # 1 pour tout triplet d’arêtes su, uv, vt ! E (3)
(avec éventuellement s = t) que l’on renforcera par
%
e#D
xe # |D|% 1 pour tout D ! D (4)
où D est l’ensemble des D . E qui ne sont pas contenus dans un F . E réalisable, mais dont tousles sous-ensembles stricts sont contenus dans un F . E réalisable.

Arêtes des bipartis induits 193
54
6
1
23
Fig. 1. Un graphe G = (V,E) avec E = {1, 2, 3, 4, 5, 6}
Par-exemple, si G est le graphe de la figure 1, (1)-(3) est :
x1, x2, x3, x4, x5, x6 ) 0x4 +x5 +x6 # 1
x1 +x2 %x4 # 1x1 +x3 %x5 # 1x2 +x3 %x6 # 1
x1 %x4 +x6 # 1x1 %x5 +x6 # 1x2 %x4 +x5 # 1x2 +x5 %x6 # 1x3 +x4 %x6 # 1x3 +x4 %x5 # 1
Ici (1, 0, 0, 13 ,
13 ,
13 ) !(1)-(3)\conv.hull(R) mais ne satisfait pas la contrainte x1 + x6 # 1 du type (4).
Nous décrirons complètement D et donnerons un algorithme polynomial pour optimiser sur (1)-(4).
Références
1. Cornaz, D. et Fonlupt J. : Chromatic characterization of biclique covers. Discrete Mathematics306(5) : 495-507 (2006)
2. Cornaz, D. et Mahjoub, A.R. : The Maximum Induced Bipartite Subgraph Problem with EdgeWeights. SIAM J. Discrete Math. 21(3) : 662-675 (2007)
3. Fouilhoux P. et Mahjoub, A.R. : Polyhedral results for the bipartite induced subgraph problem.Discrete Applied Mathematics (DAM) 154(15) :2128-2149 (2006)

Le problème de la grue préemptif asymétrique
H.L.M. Kerivin,1 M. Lacroix2 et A.R. Mahjoub2
1 Department of Mathematical Sciences, Clemson University, O-326 Martin Hall, Clemson, SC29634, USA.
[email protected] Laboratoire LAMSADE, Université Paris Dauphine, Place du Maréchal de Lattre de Tassigny,
75775 Paris cedex 16 [email protected],[email protected]
Dans ce travail, nous nous intéressons au problème de la grue préemptif asymétrique, introduit parAtallah et Kosaraju [1] (pour le cas symétrique). Ce problème peut être défini de la manière suivante.Soit D = (V,A) un graphe orienté et v0 un sommet particulier de V appelé dépôt. Les autres sommetsdu graphe sont appelés arrêts. À chaque arc a du graphe est associé un coût positif ca. Un ensembleP de demandes de transport est également donné. Chaque demande p de P est définie par un arrêtorigine op et un arrêt destination dp et peut donc être représentée par l’arc (op, dp). Nous notonspar 0 le graphe induit par l’ensemble des arcs associés aux demandes de P . Pour transporter cesdemandes, nous disposons d’un véhicule (ou grue) qui commence et termine sa tournée au dépôt etne peut transporter qu’une seule demande à la fois. Le coût de la tournée du véhicule correspond àla somme des coûts des arcs de cette tournée. Le terme préemptif indique que durant son transport,une demande peut être déchargée à n’importe quel arrêt di#érent de sa destination et être rechargéepar la suite. Dans ce travail, nous ne considérons aucune contrainte ni aucun coût additionnel surle nombre de rechargements. Le problème de la grue préemptif asymétrique consiste à déterminerla tournée du véhicule et les chemins des demandes tel que les demandes sont transportées de leurorigine à leur destination à l’aide du véhicule et le coût de la tournée du véhicule est minimum.Kerivin et al. [2] ont montré que si le graphe D est complet, les coûts c vérifient les inégalitéstriangulaires et chaque arrêt est l’origine ou la destination d’au plus une demande, alors il existeune solution optimale telle que chaque arc est traversé au maximum une fois par le véhicule, etchaque demande est transportée sur un chemin élémentaire. Nous définissons alors les solutions parl’ensemble des arcs traversés par le véhicule et les demandes respectivement. Nous utilisons ainsi lesvariables x ! R(|A|"2|V |+3))|P | telles que
xpa =1
1 si la demande p est transportée sur l’arc a,0 sinon,
pour tout arc a ! A \ {.in(op) 2 .out(dp)} et pour toute demande p ! P , et les variables y ! R|A|telles que
ya =1
1 si le véhicule traverse l’arc a,0 sinon,
pour tout arc a ! A. Ici, .in(v) (respectivement .out(v)) pour un sommet v ! V désigne l’ensembledes arcs entrant dans v (respectivement sortant de v). Tout vecteur (x, y) associé à une solution

Le problème de la grue préemptif asymétrique 195
réalisable du problème satisfait les contraintes%
a#&out(v)
ya %%
a#&in(v)
ya = 0 $ v ! V, (1)
%
a#&out(v)
xpa %%
a#&in(v)
xpa = bpv $ p ! P, $ v ! V, (2)
%
a#&out(v)
xpa # 1 $ p ! P, $ v ! V, (3)
ya %%
p#P
xpa ) 0 $ a ! A, (4)
où le nombre bpv représente la production/demande associée au sommet v ! V par rapport à lademande p ! P . En e#et, les contraintes (1) sont les contraintes de conservation de flot associées auxarcs traversés par le véhicule. Les contraintes (2) et (3) imposent que les arcs traversés par chaquedemande correspondent à un chemin élémentaire. Les contraintes (4) sont les contraintes de capacité.Elles imposent qu’au maximum une demande soit transportée en même temps sur un arc traversépar le véhicule. Bien que ces contraintes soient valides, tout vecteur (x, y) satisfaisant les contraintes(1)-(4) ne correspond pas obligatoirement à une solution réalisable. Pour restreindre les vecteurs àceux correspondant à une solution réalisable, il faut également que chaque vecteur (x, y) vérifientles contraintes valides suivantes, appelées contraintes de vulnérabilité relaxées et définies pour toutsous-ensemble non vide W de V tel que v0 !W , A'(W ) -= 1 et .'(W ) = 1,
%
a#&out(W )
ya %%
p#A#(W )
%
a#&out(W )
xpa +M%
p#A#(W )
%
a#&out(W )
xpa ) 1, (5)
où M est une constante su%samment grande et A'(W ) correspond à l’ensemble des demandes de Pdont les arrêts origine et destination appartiennent à l’ensemble V \W .Kerivin et al. [3] ont montré que le polytope défini par les variables (x, y) et les contraintes (1)-(5) estéquivalent à l’ensemble des solutions du problème de la grue préemptif asymétrique et ont montré quetoutes les contraintes sont séparables en temps polynomial. Nous prolongeons ce travail en donnantdes conditions nécessaires et su%santes pour que les inégalités triviales et les contraintes (3)-(5)définissent des facettes. Nous développons par la suite un algorithme de coupes et branchementspour résoudre le problème et donnons quelques résultats expérimentaux.
Références
1. Atallah, M.J. and Kosaraju, S.R. : E%cient Solutions to Some Transportation Problems withApplications to Minimizing Robot Arm Travel. SIAM Journal on Computing, vol 17, pp. 849-869(1988)
2. Kerivin, H.L.M., Lacroix, M., Mahjoub, A.R. : The Eulerian closed walk with precedence pathconstraints problem. Rapport technique LIMOS/RR-08-03 (soumis pour publication) (2007)
3. Kerivin, H.L.M., Lacroix, M., Mahjoub, A.R. : Models for the single-vehicle preemptive pickupand delivery problem. (Soumis pour publication) (2007)

Le problème du voyageur de commerce asymétrique aveccontraintes de saut
Laurent Alfandari1, Sylvie Borne2 et Lucas Létocart2
1 ESSEC, Av. Bernard Hirsch, B.P. 50105 95105 Cergy, Franceet LIPN - UMR CNRS 7030, Université Paris 13.
[email protected] LIPN - UMR CNRS 7030,
Institut Galilée, Université Paris 1399 Avenue J-B. Clément 93430 Villetaneuse.{sylvie.borne,lucas.letocart}@lipn.fr
1 Introduction
Le problème du voyageur de commerce asymétrique (ATSP ) est un problème classique de l’optimi-sation combinatoire. Il consiste à trouver le circuit hamiltonien de coût minimal contenu dans ungraphe orienté sans boucle G = (V,A) où V = {1, . . . n} et les coûts cij sont associés à chaquearc (i, j) ! A. Dans le cas asymétrique, les coûts cij et cji peuvent être di#érents pour tout couple{i ! V, j ! V }. Ce problème est connu pour être NP-di%cile et a été trés étudié dans la littérature[2,7,3,4,5,1,9,8,6].Mais qu’en est-il si certaines villes doivent être éloignées d’au moins s liens dans le tour ? Soit Sl’ensemble des villes soumises à la condition de saut (i.e., dont la distance en nombre d’arêtes entrechacune de ces villes est d’au moins s). Le problème du voyageur de commerce asymétrique aveccontraintes de saut ((hop-ATSP), hop Asymmetric Traveling Salesman Problem) consiste alors àtrouver un circuit hamiltonien de coût minimal qui respecte l’éloignement entre les villes de S.
2 Formulations et résolution
Nous présentons deux formulations originales pour ce problème sous la forme de programmes linéairesen nombres entiers. Nous utilisons notamment des variables de décision indiquant la position dechaque ville dans le tour ou des variables permettant de prendre en compte le nombre de sauts entreles villes dans le tour.Nous discutons de résultats théoriques intéressants concernant ces formulations. Nous adaptons éga-lement des contraintes valides pour le problème (ATSP) présentes dans la littérature [8,2]. Nousdiscutons de la qualité des bornes inférieures obtenues par la résolution des relaxations linéaires.Nous étudions également la structure faciale des polytopes associés au problème. En particulier, nousidentifions de nouvelles inégalités valides. En utilisant ces résultats, nous présentons un algorithmede coupes et branchements pour le problème. Nous discutons de certains résultats expérimentaux.
Références
1. R.D. Carr et G. Lancia : Compact vs. exponential-size LP relaxations. Operations Research Let-ters, 30 :57-65 (2002)

Le problème hop-ATSP 197
2. G. Dantzig, D. Fulkerson et S. Johnson : Solution of a large scale traveling salesman problem.Operations Research, 2 : 393-410 (1954)
3. M. Desrochers et G. Laporte : Improvements and extensions to the Miller-Tucker-Zemlin subtourelimination constraints. Operations Research Letters, 10 : 27-36 (1991)
4. L. Gouveia et J. Pires : The asymmetric traveling salesman problem and a reformulation of theMiller-Tucker-Zemlin constraints. European Journal of Operational Research, 112 : 134-146 (1999)
5. L. Gouveia et J. Pires : The asymmetric traveling salesman problem : on generalizations of disag-gregated Miller-Tucker-Zemlin constraints. Discrete Applied Mathematics, 112 : 129-145 (2001)
6. L. Létocart, L. Alfandari et S. Borne : Modéles linéaires et quadratiques pour le problème duvoyageur de commerce asymétrique. 9éme congrés de la Société FranÁaise de Recherche Opéra-tionnelle et d’Aide à la Décision (ROADEF2008), Clermont-Ferrand, France : pp. 295-296 (Février2008)
7. C. Miller, A. Tucker et R. Zemlin : Integer programming formulation of traveling salesman pro-blems. Journal of ACM, 7 : 326-329 (1960)
8. S.C. Sarin, H.D. Sherali et A. Bhootra : New tighter polynomial length formulations for the asym-metric traveling salesman problem with and without precedence constraints. Operations ResearchLetters, 33 : 62-70 (2005)
9. H.D. Sherali et P.J. Driscoll : On tightening the relaxations of Miller-Tucker-Zemlin formulationsfor asymmetric traveling salesman problems. Operations Research, 4 : 134-146 (2002)

Problème de tournée du personnel de soins pourl’hospitalisation à domicile
Y. Kergosien, Ch. Lenté, et J-C. Billaut
Université François Rabelais Tours,Laboratoire Informatique, 64, av. Jean Portalis, 37200 Tours.
{yannick.kergosien|christophe.lente|jean-charles.billaut}@univ-tours.fr
1 IntroductionL’hospitalisation à domicile (HAD) se développe un peu partout. Elle consiste à amener les soins auxpatients à domicile. Ce développement est essentiellement dû à des facteurs économiques, d’engorge-ment des hôpitaux, de vieillissement de la population... L’HAD a pour objectif d’améliorer la qualitédes soins et de diminuer les coûts. De nombreux articles traitent de l’HAD et de ses avantages. Unnouveau problème d’organisation dans le domaine de la santé apparaît, celui de la coordination etde la qualité des soins hors des murs de l’hôpital. Nous nous intéresserons ici au problème de pla-nification des tournées du personnel de soins, et à leur coordination au domicile des patients. Nousramenons ce problème à une extension du problème du voyageur de commerce (PVC) et proposonsun programme linéaire en nombre entier (PLNE) pour le résoudre. De nombreux travaux ont étéréalisés au niveau de la planification des tournées d’infirmières ([2,3,1]).L’approche proposée tente deprendre en compte le plus de contraintes possibles.
2 Présentation du problèmeEtant donné un ensemble d’intervenants, chaque intervenant k ayant un ensemble de compétences Ck(médecin, infirmière, aide soignante,...), nous devons a#ecter à chaque intervenant une liste ordonnéede soins à dispenser à des patients. Chaque intervenant k doit partir et revenir à son propre ’dépôt’Dk.Les horaires de travail d’un intervenant sont définis par une fenêtre de temps [eDk , (Dk ]. Un ensemblede patients doit recevoir des soins à domicile par un ou plusieurs intervenants. Un service est un soinà apporter à un patient par un intervenant, et un service i est caractérisé par une compétence requiseQi, une fenêtre de temps [ei, (i] durant laquelle le service doit commencer et une durée de servicepi. Certains services doivent être réalisés simultanément, d’autres au contraire ne le doivent surtoutpas, certains services doivent être réalisés par un même intervenant, et d’autres peuvent déjà êtrepré a#ectés à un intervenant. Pour les ensembles de services à e#ectuer simultanément, un décalagetemporel est toutefois possible, un service j peut débuter 1i,j unités de temps après i.Ce problème est similaire à un m-PVC avec fenêtres de temps et quelques contraintes spécifiques. [8]étudie ce problème avec des extensions (fenêtres de temps, nombre non fixé de voyageurs, nombremaximal ou minimal de sommets à visiter,...), ses applications pratiques, certaines formulations enprogrammation linéaire, et certaines heuristiques ou méthodes exactes pour résoudre ces problèmes.Notons que vérifier si un m-PVC avec fenêtre de temps est réalisable est NP-complet [6].
3 Modèle de programmation linéaireL’une des premières modélisations en PLNE pour le PVC a été formulée par [5]. Cette formulationa été étendue par [7] à plusieurs voyageurs. Dans [4], les auteurs proposent d’étendre ces modèles en

Problème de tournée du personnel de soins pour l’HAD 199
intégrant un nombre minimum et maximum de sommets à visiter pour chaque voyageur aussi biendans le cas d’un seul dépôt que de dépôts multiples.Les variables du PLNE sont xki,j qui vaut 1 si l’intervenant k e#ectue le service i puis le service j ;yi,j qui vaut 1 si le service i est e#ectué avant j ; et ti la date de début du service i.Les contraintes expriment le fait que tous les sommets j doivent être traversés exactement une fois (unservice est traité par un seul intervenant) ; la continuité des circuits ; une seule sortie d’un intervenantk de son dépôt Dk ; respect des horaires de travail ; temps de trajets entre deux sommets ; retourau dépôt avant la date de fin de travail ; services e#ectués en même temps ou avec un décalage ;services non e#ectués en même temps ou par le même intervenant ; pré-a#ectation des services à unintervenant ; compétences entre services et intervenants.La fonction objectif consiste à minimiser le coût total des trajets des intervenants
4 Conlusion et perspectives
Nous avons proposé un PLNE pour résoudre le problème qui peut s’étendre à la plupart des problèmesHAD. Ce PLNE obtient de bons résultats avec CPLEX, mais malgré des techniques de pré-processinget des coupes, le temps de résolution pour des instances réelles reste trop important. Nous envisa-geons d’essayer d’autres méthodes (génération de colonnes), ou des méthodes approchées comme larecherche Tabou ou les algorithmes génétiques.
Références
1. Akjiratikarl C., Yenradee P., Drake P.R. : PSO-based algorithm for home care worker schedulingin the UK. Computers & Industrial Engineering 53, 559-583, (2007).
2. Bertels S., Fahle T. : A hybrid setup for a hybrid scenario : combining heuristics for the homehealth care problem Computers & Operations Research 33, 2866-2890, (2006).
3. Eveborn P., Flisberg P., Ronnqvist M. : LAPS CARE-an operational system for sta# planning ofhome care European Journal of Operational Research 171, 962-976, (2006).
4. Kara I., Tolga B. : Integer linear programming formulations of multiple salesman problems andits variations. European Journal of Operational Research, 174, 1449-1458, (2006).
5. Miller C.E., Tucker A.W., Zemlin R.A. : Integer programming formulation of travelling salesmanproblems. J. Assoc. Comput. Mach., 7, 326-329, (1960).
6. Savelsbergh M.W.P. : Local search in routing problems with time windows. Ann. Oper. Res., 4,285-305, (1985).
7. Svetska J.A., Huckfeldt V.E. : Computational experience with an m-salesman travelling salesmanalgorithm. Management Sci., 19, 790-799, (1973).
8. Tolga B. : The multiple traveling salesman problem : an overview of formulations and solutionprocedures. Omega, 34, 209-219, (2006).

Algorithme mémétique pour l’ordonnancement des blocsopératoire
M. SOUKI et A. REBAI,
FSEGS, route de l’aéroport km 4, Sfax 3018 [email protected]
La versatilité et les incertitudes qui règnent sur les hôpitaux, rendent leurs gestionnaires soucieuxde la réduction de leurs coûts et de la recherche d’une meilleure optimisation de leurs ressources.Le bloc opératoire constitue la ressource la plus critique dans l’hôpital et constitue le centre de laplupart des cas hospitalisés. Ces dernières années, un certain nombre de travaux [1] [2] [3] [5] [7] [8]ont été e#ectués sur la planification des blocs opératoires, mais, les travaux sur la planification etl’ordonnancement avec la stratégie "Block Scheduling" restent limités.Dans un autre travail, nous avons proposé une approche pour la planification et l’ordonnancementdes blocs opératoires avec la stratégie "Block Scheduling". Notre approche est décomposée de deuxniveaux de planification : La planification des admissions et l’ordonnancement des plages horaires. Leproblème de planification des admissions consiste à a#ecter les interventions des patients aux plageshoraires. L’a#ectation doit permettre de maximiser le nombre d’interventions a#ectées en minimisantles temps inexploités dans les plages horaires avec respect de la disponibilité des lits d’hospitalisationet de la date limite des interventions.Le modèle de planification des admissions ne précise pas l’ordre d’exécution des interventions ni desplages horaires. Par ailleurs, l’ordonnancement des plages horaires consiste à préciser pour chaqueplage horaire et pour chaque intervention une date de début et une date de fin. En e#et, ce problèmepeut être identifié par un problème de Flow-Shop Hybride à deux étages avec la contrainte no-idledans la salle d’opération pour les interventions d’une même plage horaire et la contrainte no-waitentre la salle d’opération et le lit de réveil pour chaque patient.Nous avons proposé une formulation mathématique du problème. Le problème d’ordonnancement desplages horaires est modélisé par un programme linéaire mixte ayant pour objectif la minimisationdes horaires d’ouvertures du bloc et de minimisation de la valeur de la fonction pénalisante sur ladétérioration de la contrainte no-idle.Le problème du Flow-Shop Hybride à deux étages est réputé NP-di%cile [4]. Par conséquent, nousavons proposé dans un premier temps, treize heuristiques qui se décomposent deux étapes. La pre-mière étape qui consiste à trier les interventions en se basant sur les règles de priorité (SPT, LPT,MWR et LWR) appliquées sur les plages horaires et sur les interventions dans les plages horaires etl’algorithme de Johnson. La deuxième étape consiste à a#ecter les interventions aux salles d’opéra-tions et aux lits de réveil suivant l’ordre pré-établi dans la première étape. L’a#ectation prend enconsidération la contrainte no-wait entre la salle d’opération et la salle de réveil et une a#ectationsuccessive des interventions d’une même plage horaire dans une même salle d’opération minimisantainsi, la valeur de la fonction pénalisante sur la détérioration de la contrainte no-idle.Dans un deuxième lieu, nous avons proposé un algorithme mémétique (MA) pour l’ordonnancementdes plages horaires. Suivant Moscato [10], MA constitue un mariage entre une recherche globale àbase de population et une heuristique de recherche locale appelée pour chaque solution initiale et pourchaque individu obtenu par application des opérateurs génétiques. L’algorithme mémétique proposéconstitue une combinaison de l’algorithme génétique (GA) avec VNS (Variable Neighborhood Search)[9] pour améliorer la qualité de la solution.

MA pour l’ordonnancement des blocs opératoires 201
Dans l’algorithme mémétique, chaque solution est encodée par un chromosome qui représente sespropriétés. Chaque solution est évaluée par la valeur de sa force fitness. La recherche locale estappelée pour améliorer la population initiale. Les opérateurs génétiques sont appelés aléatoirementpour générer des nouvelles solutions. Une évaluation est e#ectuée sur les solutions obtenues. Larecherche locale est appelée pour améliorer les bonnes solutions. Ce processus est répété jusqu’à lasatisfaction des conditions d’arrêt. Les conditions d’arrêt sont décrites généralement par l’atteinte dunombre maximal d’itération et/ou du temps maximal d’exécution qui sont en relation avec la tailledu problème.L’heuristique proposée MAORS se décompose de trois étapes. La première étape consiste à générerla population initiale en appliquant treize heuristiques basées sur des règles de priorité qui sont dé-crites précédemment. La deuxième phase consiste à appliquer aléatoirement six types d’opérateursgénétiques que nous avons adoptés aux plages horaires et aux interventions : le croisement à un pointnormal et inversé, le croisement à deux points normal et inversé et le croisement à de carte normalet inversé.
La troisième étape se résume à la recherche locale. Nous avons utilisé VND (Variable NeighborhoodDescent) une variante de VNS [9]. Deux structures de voisinage sont appelées. Le voisinage parpermutation (swap-moves) qui consiste à sélectionner deux positions aléatoirement et modifier lesinterventions correspondantes. Le voisinage par insertion (insert-moves) qui consiste à sélectionneraléatoirement une position et le réinsérer dans une autre position aléatoire, les interventions entre ledeux position seront déplacées. Ce processus est répété jusqu’à la satisfaction d’une condition d’arrêt(amélioration de la solution ou arriver au nombre maximal d’itération).Nous adoptons le concept d’Agenda pour conserver les bonnes solutions dans un ordre croissant deleur fitness. La sélection (Le même principe utilisé par Reeves [11]) se fait d’une part, sur le calcule dela force fitness de l’individus (en fonction du Cmax et de la fonction pénalisante sur la détériorationde la contrainte no-idle). Et d’autre part, sur le calcule de la probabilité de distribution dans l’Agenda.
Enfin, pour évaluer la performance de notre algorithme, nous avons utilisé quinze problèmes degrande taille avec des données générées aléatoirement suivant des distributions statistiques Log-Normale [12]. L’implémentation des heuristiques et de l’algorithme génétique a été e#ectuée avecVisual C++ utilisant un PC Pentium 4, 3.2 GHz avec 512MB de RAM. L’algorithme a donné desrésultats encourageants au niveau du temps de calcul et par une comparaison avec les solutionsdonnées par les heuristiques et avec la borne inferieure donnée dans [6] et avec la solution trouvéepar ILOG/Cplex.
Références
1. F. Dexter, A. Macario, R. D. Traub, M. Hopwood, D. A. Lubarsky, An operating room schedulingstrategy to maximize the use of operating room bloc time : computer simulation of patientscheduling and survey of patients preferences for surgical waiting time, Anesthesia & Analgesia,89, 7-20, 1999.
2. H. Fei, C. Chu, N. Meskens, A. Artiba, Solving surgical cases assignment problem by a branch-and-prise approach, International Journal of Production Economics, 2007.
3. A. Guinet, S. Chaabane, Operating theatre planning, International Journal of Production Eco-nomics, 85, 69-81, 2003.
4. J. N. D. Gupta, E. A. Tunc, Scheduling a two-stage Hybrid Flow-Shop with separable setup andremoval time, European Journal of Operation Research, 77, 415-428, 1994.

202 M. SOUKI et A. REBAI
5. S. Hammami, Thèse Aide à la décision dans le pilotage des flux matériels et patients d’un plateaumédico-technique, Institute national polytechnique de Grenoble, 2006.
6. M. Haouari, R. M’Hallah, Heuristic algorithms for the two-Stage hybrid flowshop problem, Ope-rations Research Letters, 21, 43-53, 1997.
7. A. Jebali, A. Hadj Alouane, P. Ladet, Operating room scheduling, International Journal of Pro-ductions Economics, 99, 52-62, 2006.
8. S. Kharraja, Thèse Outils d’aide à la planification et l’ordonnancement des plateaux-médico-techniques, Université Jean-Monnet, Saint-Etienne, 2003.
9. N. Mladenovic, P. Hansen, Variable neighbourhood search. Computers and Operations Research,24,1097-1100, 1997.
10. P. Moscato, Memetic algorithms : a short introduction, In : D. Corne, M. Dorigo and F. Glover,Editors, New Ideas in Optimization, McGraw-Hill, 219-234, 1999.
11. C. R. Reeves, A genetic algorithm for flowshop sequencing, Computers and Operations Research,22, 5-13, 1995.
12. J. Zhou, F. Dexter, Method to assist in the scheduling of add-on surgical case : Upper predictionbounds for surgical case durations based on the log-normal distribution, Anesthesiology, 89, 5,1228-1232, 1998.

Planification des blocs opératoires
M. Souki, S. Ben Youcef et A. Rebai
FSEGS, route de l’aéroport km 4, Sfax 3018 [email protected]
Ces dernières années, un certain nombre de travaux [1] [2] [3] [4] [6] [7] ont été e#ectués sur laplanification des blocs opératoires, mais, les travaux sur la planification et l’ordonnancement avec lastratégie "Block Scheduling" restent limités. Dans ce travail, nous allons proposer une approche pourla planification et l’ordonnancement des blocs opératoires avec la stratégie "Block Scheduling".La planification des blocs opératoires doit répondre à un double objectif. En fait, elle doit permettreaussi bien l’optimisation de l’utilisation des ressources critiques à capacité finie que la satisfactiond’une demande des interventions des patients. Ce double objectif nous impose d’adopter une planifi-cation à deux niveaux.Le premier niveau qui se résume à la planification des admissions qui consiste à a#ecter les inter-ventions des patients dans les plages horaires d’une même spécialité avec objectif la minimisation detemps inexploités des plages par la minimisation du nombre des plages horaires utilisées et le respectde la date limite des interventions. Ce niveau prend en considération la disponibilité des lits d’hos-pitalisation et des plages horaires. Le modèle de planification des admissions ne précise pas l’ordred’exécution des interventions des patients ni des plages horaires des chirurgiens. Ceci fera l’objet dudeuxième niveau de l’ordonnancement des plages horaires.Le deuxième niveau qui se résume à l’ordonnancement des plages horaires. Il permet d’a#ecter lesplages horaires des chirurgiens aux salles d’opérations ainsi que l’a#ectation d’une date de début etd’une date de fin dont l’objectif est la minimisation des durées d’ouvertures des salles d’opérations.Ce niveau prend en considération la disponibilité des salles d’opération et des lits de réveil.Dans un premier temps, nous avons utilisé la modélisation mathématique pour donner une descriptionformelle à ces deux problèmes. La planification des admissions est modélisée par un programmelinéaire en nombres entiers et ayant pour objectif la minimisation du nombre des plages horairesutilisées et la minimisation de la valeur de la fonction pénalisante sur la détérioration du non respectde la date limite des interventions.L’ordonnancement des plages horaires est modélisé par un programme non linéaire en nombres entiersmixtes et ayant pour objectif la minimisation du durée d’ouvertures des salles d’opération et laminimisation de la valeur de la fonction pénalisante sur la détérioration du non respect de la contrainteno-idle. Les deux modèles ont été implémentés avec ILOG/Cplex.Dans un deuxième temps, nous avons proposé quatre heuristiques à deux niveaux pour le problèmede planification des admissions qui se basent sur des règles de gestion. Le premier niveau consisteà ordonner les interventions des patients dans un premier temps, suivant la date limite de l’inter-vention et dans un deuxième temps, suivant les règles de gestions SPT (Shortest Processing Time)et LPT (Longest Processing Time) appliquées sur les durées d’interventions et sur les durées d’hos-pitalisation. Le deuxième niveau, consiste à a#ecter les interventions dans les plages horaires parordre chronologique avec respect de la disponibilité de la plage choisie et de la disponibilité des litsd’hospitalisation durant le séjour des patients (voir algorithme 1 : A#ectation). L’implémentation desheuristiques nous a permit d’obtenir quatre solutions. L’évaluation de chaque solution a été e#ectuéesur la fitness de la solution qui est égale au nombre de plages utilisées avec la valeur de la fonctionpénalisante sur la détérioration du non respect de la date limite de l’intervention.
Algorithme 1 A#ectationDébut

204 Souki, Ben Youcef et Rebai
Initialisation du nombre des interventions a#ectéesInitialisation du nombre de plages utilisées et de la valeur de la fonction pénalisante
Exist3 fauxTant que (Existe des interventions dans le problème)
DébutTant que ((Existe des plages horaires) && (exist ! =vrai))Début
Chercher la plage horaire la plus adéquate par ordre chronologiqueTest la disponibilité des lits d’hospitalisation durant le séjour du patientSi (trouve == vrai)AlorsA#ecter l’intervention dans la plage horaire choisieMAJ de la disponibilité de la plage horaire et des lits d’hospitalisationMAJ de la fonction pénalisanteExist3 vrai
SinonExist3fauxAller à la plage suivante
Fin tant queFin tant queCalcule de la fitness de la solutionFin
Dans un troisième temps, nous avons proposé treize heuristiques à deux niveaux pour le problèmed’ordonnancement des plages horaires. Le premier niveau consiste à ordonner les interventions despatients suivant les règles de gestions SPT (Shortest Processing Time), LPT (Longest ProcessingTime), MWR (Most Work Remaining) et la règle de Johnson appliquées sur les durées d’interven-tions et sur les durées de réveil des interventions et des plages horaires. Le deuxième niveau, consisteà mettre les interventions d’une même plage horaire dans une liste d’attente pour S (nombre de salled’opération) plages horaires. L’a#ectation sera à partir de la liste d’attente avec l’intervention quiminimise le temps du blocage. Si le nombre de plages dans la liste d’attente diminue, on ajoute lesinterventions de la plage suivante jusqu’à l’a#ectation de toutes les interventions (voir algorithme 2 :ORDPH). L’implémentation des heuristiques, nous a permit d’obtenir treize solutions. L’évaluationde chaque solution a été e#ectuée sur la fitness de la solution qui est égale à la durée d’ouverture dessalles d’opération avec la valeur de la fonction pénalisante sur la détérioration du non respect de lacontrainte no-idle.
Algorithme 2 : ORDPHDébut
Initialisation de la liste des interventions a#ectées et de la liste d’attenteInitialisation de la valeur de la fonction pénalisanteTant que (existe des interventions dans le problème ou dans la liste d’attente)
DébutSi (Nombre des plages horaire dans la liste d’attente < nombre de salle d’opération)Alors
Chercher une salle d’opération videInsérer les interventions de la plage horaire dans la liste d’attente etconserver la salle d’opération sélectionnée
SinonChercher dans les premières interventions des plages horaires dans la liste

Planification des blocs opératoires 205
d’attente l’intervention qui minimise le blocage de la salle d’opérationChercher un lit de réveil libreCalculer la date début de l’intervention choisieDstart = Max (datelibsalleopération , dateliblitréveil - durée intervention)A#ecter l’intervention choisie dans la salle d’opérationA#ecter l’intervention choisie dans le lit de réveilSupprimer l’intervention a#ectée de la liste d’attenteMAJ de la disponibilité de la salle d’opération et du lit de réveilMAJ de la valeur de la fonction pénalisante
Fin tant queCalculer la fitness de la solution
Fin
Enfin, pour valider nos modèles et pour évaluer la performance des heuristiques, nous avons utilisévingt problèmes de taille di#érente avec des données générées aléatoirement suivant des distribu-tions statistiques Log-Normale [8]. L’implémentation des modèles linéaire mixte a été e#ectuée surILOG/Cplex 10.0. L’implémentation des heuristiques a été e#ectuée avec Visual C++ utilisant unPC Pentium 4, 3.2 GHz avec 512MB de RAM, une comparaison a été e#ectuée avec les solutionsdonnées par les heuristiques et avec la transformation de la borne inferieure donnée dans [5] et avecla solution trouvée par ILOG/Cplex.
Références
1. F. Dexter, A. Macario, R. D. Traub, M. Hopwood, D. A. Lubarsky, An operating room schedulingstrategy to maximize the use of operating room bloc time : computer simulation of patientscheduling and survey of patients preferences for surgical waiting time, Anesthesia & Analgesia,89, 1999, 7-20.
2. H. Fei, C. Chu, N. Meskens, A. Artiba, Solving surgical cases assignment problem by a branch-and-prise approach, International Journal of Production Economics, 2007.
3. A. Guinet, S. Chaabane, Operating theatre planning, International Journal of Production Eco-nomics, 85, 2003, 69-81.
4. S. Hammami, Thèse Aide à la décision dans le pilotage des flux matériels et patients d’un plateaumédico-technique, Institute national polytechnique de Grenoble, 2006.
5. M. Haouari, R. M’Hallah, Heuristic algorithms for the two-Stage hybrid flowshop problem, Ope-rations Research Letters, 21, 1997, 43-53.
6. A. Jebali, A. Hadj Alouane, P. Ladet, Operating room scheduling, International Journal of Pro-ductions Economics, 99, 2006, 52-62.
7. S. Kharraja, Thèse Outils d’aide à la planification et l’ordonnancement des plateaux-médico-techniques, UniversitéJean-Monnet, Saint-Etienne, 2003.
8. J. Zhou, F. Dexter, Method to assist in the scheduling of add-on surgical case : Upper predictionbounds for surgical case durations based on the log-normal distribution, Anesthesiology, 89 (5),1228-1232.

Modélisation orientée objet avec OptimJ
Denis Debarbieux et Patrick Viry
Ateji - BL 14 - 14/16 rue Soleillet - 75020 Paris - Francehttp ://www.ateji.com/{prenom.nom}@ateji.com
La modélisation de données est un aspect souvent sous-estimé de la modélisation mathématique. Ellea pourtant un impact essentiel sur le temps de mise au point, la qualité du résultat et l’intégrationà des applications.Plusieurs études [1,3] montrent que sur un projet typique de consultants en recherche opérationnelle,l’e#ort consacré à la modélisation mathématique représente seulement 10% à 20% du temps dedéveloppement. L’intégration concerne quant à elle 50% de ce temps, le reste étant consacré à desaspects tels que interfaces graphiques ou entrées/sorties.Nous présentons ici un langage de modélisation prenant en compte ces aspects de modélisation dedonnées et d’intégration. OptimJTM est une extension de JavaTM permettant l’écriture de modèlesd’optimisation sous une forme algébrique intuitive et concise. Un modèle OptimJ est une classe Javapouvant contenir, en plus des champs et des méthodes, des variables de décision, des contraintes etune fonction objectif.Considérons le modèle diet qui vise à concevoir un menu équilibré à un coût minimal. Dans unpremier temps, comparons deux modélisations possibles de la notion de vitamine :- Dans l’expression traditionnelle de diet, le concept de vitamine n’est pas explicité et les propriétésd’une vitamine sont réparties dans di#érents tableaux sans relation entre eux.
set VTM ;param minAmount { VTM } ;param maxAmount { VTM } ;
- Dans une approche orientée objet, le concept de vitamine est identifié de façon explicite et définipar ses propriétés. En Java, cela s’exprime par une interface :
interface Vitamin {String name() ;float minAmount() ; // Quantité minimum recomandée par repasfloat maxAmount() ; // Quantité maximum recomandée par repas
}Le modèle OptimJ s’écrit alors tout naturellement en fonction de ses interfaces :
// variables de décisions : quelle quantité d’aliments faut-il acheter ?var double[Food] Buy[Food f : foods] in f.minQuantity() .. f.maxQuantity() ;// fonction objectif : minimiser le coûtminimize
sum {Food f : foods} {f.cost() * Buy[f ] } ;// contrainte : concevoir un menu équilibréconstraints {
forall(Vitamin v : vitamins) {v.minAmount() <= sum {Food f : foods} {f.amount(v) * Buy[f]} ;sum {Food f : foods} {f.amount(v) * Buy[f]} <= v.maxAmount() ;
}}

Modélisation orientée objet avec OptimJ 207
Comme pour une classe Java, les paramètres du modèle sont passés via un constructeur :
public DietModel(Set<Food> foods, Set<Vitamin> vitamins){. . . }Les paramètres peuvent être construits par des API standards telles que JDBC pour accéder à unebase de données SQL, HSSF pour une feuille Excel, SAX pour un document XML, ou toute autreAPI maison [4]. Il est possible de changer la source des données sans modifier le modèle.En comparaison, les approches disponibles précédemment sont de deux types :- API Java d’un solver : l’intégration est immédiate, mais l’expression du modèle est verbeuse et peuintuitive.- langage spécialisé tel que AMPLTM, GAMSTM, OPLTM : le modèle s’écrit de façon concise etintuitive, mais l’intégration nécessite un travail de programmation lourd, ennuyeux et source debugs.Par ailleurs la modélisation orientée-objet basée sur un langage répandu rend accessibles à l’expert enoptimisation les outils de développement, de productivité et de qualité du langage de base. L’expertpeut alors bénéficier par exemple de supports à l’édition (Eclipse), de documentations automatiques(JavaDoc) ou de tests unitaires (JUnit).Les autres langages de modélisation conçus et réalisés avec des techniques d’extension de langagesont MSF pour les langages de la famille .NET [5] et CoJava [2].
En conclusion, écrire un modèle en OptimJ permet de réduire la part de travail liée à l’intégrationet de se concentrer sur le code à haute valeur ajoutée.
Références
1. Application Development with the CHIP System. Cosytec whitepaper (1997)2. CoJava : a unified language for simulation and optimization. Alex Brodsky et Hadon Nash,
OOPSLA (2005)3. Is there a future for modeling systems ? Jan J. Bisschop, GAMS Workshop (2003)4. Object-Oriented Modeling with OptimJ. Ateji whitepaper. http ://www.ateji.com/optimj.html
(2007)5. Microsoft Solver Foundation, http ://code.msdn.microsoft.com/solverfoundation (2008)

ParadisEO-MO : une plate-forme pour le développementde métaheuristiques à base de solution unique
J-C. Boisson, S. Mesmoudi, L. Jourdan et E-G. Talbi
LIFL-Equipe projet INRIA DOLPHIN, INRIA Lille-Nord Europe40 Avenue Halley - 59650 Villeneuve d’Ascq Cedex
{jean-charles.boisson, laetitia.jourdan, el-ghazali.talbi}@lifl.fr,[email protected]
Mots-Clefs. Métaheuristiques, recherches locales, ParadisEO-MO, hybridation
1 Historique de ParadisEOParadisEO est à l’origine une plate-forme pour la conception et le déploiement de métaheuristiquesparallèles hybrides sur clusters et grilles ; fruit du travail de thèse de Sébastien Cahon [1,2]. En e#et,elle permettait la parallélisation des méthodes développées sur la plate-forme Evolving Objects (EO).EO était une plate-forme C++ sous licence GPL (General Public Licence) dédiée à la conceptiond’applications à base d’algorithmes évolutionnaires. Elle était définie comme libre de tout paradigmeet couvrant les di#érentes familles d’algorithmes à base de population de solutions : les algorithmesgénétiques, les stratégies évolutionnistes, la programmation évolutionnaire et génétique. La plate-forme EO fournissait la plupart des représentations classiques ainsi que les mécanismes de variationsassociés. Le but de cette plate-forme était de fournir un environnement de développement générique etmodulaire pour faire évoluer des objets pouvant avoir un indicateur de qualité. Sur ce même principede modularité et dans le but de faciliter le travail de l’utilisateur, ParadisEO est devenue aujourd’huiune plate-forme dédiée au développement de métaheuristiques au sens large. Cette plate-forme estconstituée de : ParadisEO-EO qui représente la plate-forme EO originelle dédiée aux algorithmesà base de population de solution, ParadisEO-MO dédiée aux métaheuristiques à base de solutionunique, ParadisEO-MOEO dédiée aux métaheuristiques multi-objectif et ParadisEO-PEO qui permetde paralléliser de manière invisible pour l’utilisateur tous les algorithmes développés avec les autresparties de ParadisEO.
2 ParadisEO-MOCette partie de la plate-forme ParadisEO est dédiée au développement de métaheuristiques à basede solution unique plus communément appelées recherches locales. Appliquer une recherche localesur une solution donnée correspond à lui appliquer des modifications successives afin d’améliorer saqualité. Au sein de ParadisEO-MO, ces modifications sont vu comme des mouvements d’où les lettresMO pour Moving Object. Quelque soit la recherche locale développée, il est toujours nécessaire deparcourir un (ou plusieurs) voisinage(s) donné(s). Par conséquent, un ensemble de questions géné-riques est lié à cette génération de voisinage : comment générer un voisin à partir d’une solutioncourante, comment l’évaluer, comment parcourir le voisinage, quand doit-on arrêter de générer desvoisins, quel voisin doit-on choisir, . . .. ParadisEO-MO propose de construire des recherches locales endonnant des réponses à chacune de ces questions de manière indépendante. Dans cette construction,le travail de l’utilisateur se limite aux détails que sont dépendants du problème comme la repré-sentation d’une solution, son évaluation, . . .. Pour tout le reste, ParadisEO-MO propose des objets

ParadisEO-MO 209
utilisables directement. Ainsi, la version actuelle (1.1) propose quatre algorithmes qui sont : la mé-thode par descente (Hill Climbing, objet moHC), la Recherche Tabou (Tabu search, objet moTS),le recuit simulé (Simulated Annealing, objet moSA) et la recherche locale itérative (Iterative LocalSearch, objet moILS). Pour chacun de ces algorithmes, le tableau 1 détaille le nombre d’objet quel’utilisateur doit implémenter quand il part de zéro ou quand il a déjà utilisé la méthode par descentede ParadisEO-MO ainsi que le nombre d’objets génériques nécessaires à chaque algorithme.
Tab. 1. Nombre d’objets dédiés que l’utilisateur doit implémenter quand il part de zéro (NOI) ouquand il a déjà utilisé un objet moHC (NOIHC) pour utiliser les algorithmes de ParadisEO-MO.NOG correspond au nombre d’objets génériques utilisés.
moHC moTS moSA moILSNOI 4 4 3 1
NOIHC 0 0 1 0NOG 1 3 2 3
Celui-ci montre qu’après un e#ort de la part de l’utilisateur pour la mise en place d’une premièrerecherche locale, la plate-forme permet d’accéder de manière quasi-instantanée à tous les autresrecherches locales. De plus, il est possible d’utiliser une recherche locale de ParadisEO-MO dans lesalgorithmes de ParadisEO-EO pour obtenir des schémas d’hybridation méta/méta dont l’hybridationalgorithmes génétiques/méthode par descente est un exemple classique. Enfin ParadisEO-MO est déjàutilisé aussi bien sur des problèmes classiques comme le TSP que réels [3].La version 1.1 de la plate-forme ainsi que des tutoriels pour chacun des algorithmes proposés parcelle-ci sont disponibles sur le site o%ciel de ParadisEO à l’adresse suivante :
http : //paradiseo.gforge.inria.fr
La version 1.2 proposera en plus la recherche à voisinage variable (Variable Neighborhood Search) etle Threshold accepting qui est un dérivé du recuit simulé.
Références
1. S. Cahon. ParadisEO : Une plate-forme pour la conception et le déploiement de métaheuristiquesparallèles hybrides sur clusters et grilles, PhD thesis, Université des Sciences et Technologie deLille, 2005.
2. S. Cahon, N. Melab and E-G. Talbi. ParadisEO : A Framework for the Reusable Design of Paralleland Distributed Metaheuristics, Journal of Heuristics, 10(3) :357-380,2004.
3. J-C. Boisson. Modélisation et résolution par métaheuristiques coopératives : de l’atome à la sé-quence protéique, PhD thesis, Université des Sciences et Technologie de Lille, 2008.

Outil de visualisation d’ordonnancements
David Savourey
Lix, École Polytechnique, 91128 [email protected]
1 PrésentationCet exposé aura pour but de présenter brièvement le projet “ScheViz”, initié en janvier 2008, etdéveloppé au sein du laboratoire Lix. Il vise à fournir un outil de visualisation graphique d’ordon-nancements divers et variés. Le public ciblé est celui de la recherche académique qui travaille souventsur des traces textuelles.ScheViz est capable de modéliser un grand nombre de problèmes d’ordonnancement (pas tous quandmême). Pour citer quelques exemples, les problèmes à une machine, à machines parallèles, les pro-blèmes d’atelier, les ressources cumulatives, les relations de précédence, les compatibilités machines/opérations,les opérations multi-modes, etc. sont modélisables. Un problème est défini par une fonction objectif(pas de multi-objectifs pour l’instant) et un ensemble de contraintes. Un ordonnancement est associéà une instance, elle-même associée à un problème. Un ordonnancement est simplement défini commeun ensemble d’exécutions. Cela permet de représenter des ordonnancements partiels ou complets,violant ou non les contraintes du problème associé. Comme un problème est défini à partir d’unefonction objectif et d’un ensemble de contrainte, ScheViz est capable de calculer le coût d’un or-donnancement, et de vérifier les contraintes du problème associé à un ordonnancement. Le modèle,agrémenté d’exemples, sera présenté plus en détail lors de la présentation.
2 Utilisabilité et fonctionnalitéNous souhaitons que cet outil soit rapide à appréhender et qu’il puisse être utilisé sur les principauxsystèmes d’exploitation. ScheViz est développé en Java, il est documenté et sera open-source. Parailleurs, une interface graphique permettra une utilisation stand-alone, tandis que des appels externesdepuis un code appartenant à l’utilisateur sont également possibles.La principale fonction de ScheViz est la visualisation graphique d’ordonnancement. Nous souhaitonségalement que ScheViz soit en mesure d’exporter une visualisation dans un format utilisable dans undocument (article, présentation, poster, page web, etc.).
3 Cas d’usage envisageables– visualisation simple d’un ordonnancement ;– création de figures réutilisables ;– débuggage ;– déroulement visuel d’un algortihme ;– etc.On peut envisager plusieurs “aides graphiques” : faire apparaitre les violations de contraintes, faireapparaitres les opérations en retard, faire apparaitre les di#érences entre deux ordonnancements, etc.Un problème semble relativement facile à définir, une fois les fonctions objectif et les contraintesclassiques intégrées au moteur. En revanche, l’importation de données, en particulier les instances,

Visualisation d’ordos 211
nous semble plus délicate. Nous n’avons pas fait le choix d’imposer un format aux utilisateurs. Desprimitives de lecture sont intégrées à ScheViz. Elles permettent de créer, facilement nous l’espérons,un lecteur ad hoc aux instances à importer. Cela permet à chacun de conserver les instances surlesquelles il travaille.
4 Objectifs
Nous souhaitons sortir une première version le plus rapidement possible. Nous aurons ensuite besoinde retours d’expérience afin de faire évoluer le projet. Toutes les idées sont déjà les bienvenues ! Notonspour terminer que lors de la construction de la couche graphique de ScheViz, nous envisageons dèsmaintenant la possibilité future de modifier un ordonnancement “à la souris”, ce qui soulèvera desproblèmes de réordonnancement.

Une procédure de séparation pour le meilleur des casdans un ordonnancement de groupes
Guillaume Pinot
IRCCyN, 1 rue de la Noé, BP 92101, 44321 Nantes Cedex 3, [email protected]
1 Introduction
L’ordonnancement de groupes permet d’introduire une flexibilité séquentielle importante tout engarantissant une certaine qualité dans le pire des cas. Une évaluation du meilleur des cas d’unordonnancement de groupes pourrait également être utile.[1] expose une méthode exacte pour trouver le meilleur des cas dans un ordonnancement de groupesbasée sur l’énumération des ordonnancements actifs. Cet article propose une nouvelle procédure deséparation pour ce problème.
2 Ordonnancement de groupes
L’ordonnancement de groupes fut créé au LAAS il y a plus de 30 ans ([2,3,4]). Il est également connusous le nom ORABAID (ORdonnancement d’Atelier Basé sur l’AIde à la Décision) et est implémentédans le progiciel ORDO 1. Cette méthode est décrite dans [5].Un groupe d’opérations permutables est un ensemble d’opérations qui seront exécutées successive-ment sur une même machine, dans un ordre qui n’est pas fixé à l’avance. Un ordonnancement degroupes est défini par une séquence de groupes (d’opérations permutables) sur chaque machine. Il estdit réalisable si toute permutation des opérations au sein de chaque groupe conduit à un ordonnance-ment qui satisfait les contraintes du problème. Un ordonnancement de groupes définit ainsi plusieursordonnancements réalisables de manière implicite.
3 Méthode exacte existante
[1] présente une borne inférieure pour la date de début (2i) et la date de fin (/i) d’une opérationdans un ordonnancement de groupes. Ces outils sont utilisés pour générer des bornes inférieures pourtout objectif régulier, et plus particulièrement pour le makespan.La méthode exacte exposée dans [1] se base sur l’énumération des ordonnancements actifs. Pourréduire l’espace de recherche, elle utilise une condition su%sante permettant de séquencer un groupe.La date de fin d’une opération interfère avec tout objectif régulier de deux manières :– la date en elle-même, car la fonction objectif est une fonction des dates de fin des opérations ;– en interférant avec les dates de fin des autres opérations, à cause des contraintes de précédences
ou de ressources.Partant de cette constatation, une condition su%sante au séquencement d’un groupe courant complettout en conservant la solution optimale est proposée. Lorsque cette condition est validée, elle permetde séquencer un groupe sans énumérer les ordonnancements actifs correspondant.1 http://www.ordosoftware.com/

Une procédure de séparation pour l’ordonnancement de groupes 213
4 Nouvelle procédure de séparation
Pour diminuer encore l’espace de recherche, nous proposons d’utiliser cette constatation de façon pluse%cace en l’intégrant à la procédure de séparation.La procédure de séparation se présente alors comme un problème à une machine multiobjectif sur lesopérations du groupe à séquencer. Les solutions Pareto optimales de ce problème correspondent auxnouveaux nœuds. Le problème est composé de n+ 1 objectifs, n étant le nombre d’opérations dansle groupe. Le premier objectif correspond à la fonction objectif sur le problème à une machine. Pourchaque opération, un objectif est généré, correspondant à son influence sur les autres opérations.Cette procédure de séparation est utilisable pour tout objectif régulier. Dans le pire des cas, cette pro-cédure de séparation revient à énumérer les ordonnancements actifs. Cette procédure inclut égalementla condition su%sante proposée par [1]. Ainsi, par définition, l’espace de recherche correspondant àcette procédure de séparation sera plus petit que celui de la méthode exacte exposée dans [1].
5 Conclusion
Dans cet article, nous proposons une nouvelle méthode de séparation pour le meilleur des cas dansun ordonnancement de groupes. Cette méthode de séparation est adaptée à tout objectif régulier.Par définition, elle permet de diminuer l’espace de recherche par rapport à la méthode exposée dans[1].Pour évaluer l’e%cacité de cette procédure de séparation, des expérimentations comparant la méthodeexacte de [1] et cette nouvelle procédure de séparation devront être réalisées.
Références
1. Pinot (G.), Coopération homme-machine pour l’ordonnancement sous incertitudes. Thèse dedoctorat, Université de Nantes, 2008.
2. Erschler (J.), Analyse sous contraintes et aide à la décision pour certains problèmes d’ordon-nancement. Thèse de doctorat, Université Paul Sabatier, Toulouse, 1976.
3. Demmou (R.), Étude de familles remarquables d’ordonnancements en vue d’une aide à la décision.Thèse de doctorat, Université Paul Sabatier, Toulouse, 1977.
4. Thomas (V.), Aide à la décision pour l’ordonnancement d’atelier en temps réel. Thèse de doctorat,Université Paul Sabatier, Toulouse, 1980.
5. Artigues (C.), Billaut (J.-C.) et Esswein (C.), « Maximization of solution flexibility for robustshop scheduling », European Journal of Operational Research, vol. 165, no 2, septembre 2005,p. 314–328.

Politique de service optimal dans une file d’attente entemps discret avec impatiences
E. Hyon,12 and A. Jean-Marie3
1 LIP6, UPMC 4 place Jussieu, F-75252 Paris Cedex2 Université Paris Ouest Nanterre la Défense
[email protected] INRIA et LIRMM, CNRS/Université Montpellier 2, 161 Rue Ada, F-34392 Montpellier
Mots-clés : Ordonnancement Optimal, Processus de Décision Markovien, Politique à seuil.
1 Introduction
On s’intéresse ici à l’ordonnancement (scheduling) optimal de clients dans une unité de traitement,dans le cas où les clients qui attendent sont impatients (l’impatience modélise aussi des clients soumis àdes échéances). Le démarrage d’un service (set-up) aussi bien que le départ de clients avant leur service(que nous nommerons pertes) impliquent des coûts, et il s’agit de décider quand servir les clients pourminimiser ces coûts. Nous nous plaçons dans le cas où l’évolution du système est déterminée par desparamètres stochastiques.De tels modèles, aussi bien déterministes que stochastiques, ont été largement étudiés dans la litté-rature de par leur large champ d’applications qui va des réseaux à des problèmes tels que l’allocationde ressources ou les politiques de réservations (voir [1,4] et références incluses). Néanmoins la plupartde ces travaux ne considère pas que les clients sont impatients, alors que c’est un phénomène nonnégligeable dans certaines situations. Ainsi, le problème incluant coûts de type holding et set-up, avectraitement par lots mais sans pertes, est résolu dans la littérature grâce à des techniques de contrôleoptimal [2]. La politique optimale est une politique à seuil. Pour ce même modèle de coûts, [3] utilisedes Processus de Décisions Markoviens (MDP) et s’attache à montrer des propriétés structurellesde la fonction de valeur et de l’opérateur de programmation dynamique qui permettent de déduirecertaines propriétés de la politique optimale.Dans cet article, nous reprenons le problème et la méthode pour un modèle à une seule machine età temps discret et nous utilisons un MDP à horizon infini et à coûts actualisés. Nous établissons lespropriétés structurelles de l’opérateur de programmation dynamique stochastique, et nous déduisonsque la politique optimale est à seuil. Par ailleurs, grâce à une analyse trajectorielle comparative dedeux politiques à seuil, nous calculons la valeur de ce seuil en fonction des paramètres du problème.
2 Le modèle de MDP
Nous considérons un modèle à temps discret dans lequel durant un intervalle de temps (slot), uncertain nombre d’arrivées aléatoires se produisent. Une fois arrivés les clients sont stockés dans unefile d’attente de taille infinie en attendant d’être admis pour traitement. La décision d’admission estprise par un contrôleur et un seul client peut être traité à la fois. On suppose le traitement a unedurée de un slot et occasionne un coût cB . Les clients dans la file sont soumis à des impatienceset peuvent quitter la file avec probabilité ) dans chaque slot, ce qui signifie que le temps passé par

Papier soumis à ROADEF 09 215
un client dans la file suit une loi géométrique. Une perte occasionne alors un coût cL. L’équationd’évolution du système est donc
xn+1 = [xn % qn]+ % Ln([xn % qn]+) + An+1,
où xn, qn sont respectivement le nombre de clients et la décision (dans {0, 1}) au slot n, An+1 lenombre d’arrivées, et L(y) le nombre de pertes sachant qu’il y a y clients. Le coût instantané vautalors c(xn, qn) = qncB + )[xn % qn]+cL.On cherche à calculer "$ définie, pour une actualisation 2 ! [0, 1[, par
v!#
( (x) = min{q0,q1,...}
Ex
E*%
n=0
2n c(xn, qn)
F.
De [5], on sait que v!#( est la solution de l’équation de point fixe v(x) = minq Tv(x, q) où
Tv (x, q) = c(x, q) + 2%
y#
p (y|(x, q)) v(y) ,
avec p (y|(x, q)) la probabilité d’une transition en y sachant que l’état est x et que la décision est q.
3 Propriétés structurelles et politiques à seuil
Nous montrons que la fonction Tv(x, q) est sous-modulaire sur +{0, 1} (voir définition de la sous-modularité dans [5]) si v(x) est croissante convexe. De plus si v est croissante convexe alors la fonctionv1 définie par v1(x) = minq Tv(x, q) est aussi croissante convexe. Nous en déduisons que la politiqueoptimale est une politique à seuil (il est optimal de servir un client si et seulement si x dépasse unecertaine valeur). Nous comparons ensuite les trajectoires du système opérant sous deux seuils di#érantd’une unité. Nous déduisons que le seuil optimal vaut 1 ou +*, selon que le nombre cB(1% (1%))2)est inférieur ou supérieur à cL).
Références
1. E. Altman. Handbook of Markov Decision Processes Methods and Applications, chapter Applica-tions of Markov Decision Processes in Communication Networks : a survey. Kluwer, 2001.
2. R.K. Deb and R.F. Serfozo. Optimal control of batch service queues. Advances in Applied Proba-bility, 5(2) :340–361, 1973.
3. K. P. Papadaki and W.B. Powell. Exploiting structure in adaptative dynamic programmingalgorithms for a stochastic batch service problem. European Journal of Operational Research,142 :108–127, 2002.
4. J. D. Papastavrou, S. Rajagopalan, and A. J. Kleywegt. The dynamic and stochastic knapsackproblem with deadlines. Management Science, 42(12) :1706–1718, 1996.
5. M. Puterman. Markov Decision Processes Discrete Stochastic Dynamic Programming. Wiley,2005.

Problèmes de couverture généralisée en transport :combinaisons d’une heuristique gloutonne et de la
génération de colonnes
J. Sadki1, L. Alfandari1,2, A. Plateau3, and A. Nagih4
1 LIPN, UMR-CNRS 7030, Université Paris 13, 99 Av. J-B Clément 93430 [email protected]
2 ESSEC, Av. Bernard Hirsch B.P. 50105 95105 [email protected]
3 CEDRIC, CNAM, 292 Rue Saint-Martin 75141 Paris Cedex [email protected]
4 LITA, Université Paul Verlaine-Metz, Ile du Saulcy 57045 Metz Cedex [email protected]
1 IntroductionLe problème classique de couverture généralisée (CIP pour Covering Integer Programming) modélisede nombreux problèmes d’optimisation industriels. Il apparaît également comme problème maîtredans d’autres problèmes plus complexes qui se prêtent à une décomposition de type Dantzig-Wolfe.Nous nous intéressons au problème dit de couverture généralisée en transport où le problème (CIP)est le problème maître. Nous proposons pour ce problème NP-di%cile, une approche de résolutioncombinant heuristique gloutonne et méthode de génération de colonnes.
2 Problème de couverture généralisée en transport (PCGT)Le problème (PCGT) consiste à construire des plannings pour des ressources de transport (eg. lo-comotives, avions, équipages) afin de couvrir un certain nombre de tâches (eg. trains, vols). Cesressources sont soumises à des contraintes de parcours de type chemin et peuvent être distinguéespar type selon leurs caractéristiques techniques. L’objectif du problème est de minimiser une fonctionde coût liée à l’utilisation des ressources. Notons K l’ensemble des types de ressources, P k l’ensembledes plannings réalisables pour le type k ! K, ckp le coût associé au planning p ! P k et N l’ensembledes tâches à couvrir. Nous considérons une généralisation de la notion de couverture où plusieursressources peuvent être nécessaires pour couvrir une tâche. Ainsi, on munit chaque tâche i d’un poidsbi représentant le nombre d’unités requises pour sa couverture, et chaque couple formé d’une tâchei et d’un planning p, d’un poids akip désignant le nombre d’unités de couverture de la tâche i par leplanning p.Dans une approche de décomposition de type Dantzig-Wolfe, le problème maître obtenu est donnépar le programme linéaire en nombres entiers suivant :
min&k#K&p#Pk c
kpykp
s.c&k#K&p#Pk a
kipykp ) bi $i ! N
ykp ! N $p ! P k, $k ! KL’énumération complète des plannings réalisables (ie. l’énumération de P k) est non envisa-geable vu leur nombre exponentiel. Nous utilisons à cet e!et la méthode de génération decolonnes, qui consiste à résoudre ce problème maître avec un ensemble restreint de plan-nings dont la génération est assurée par un problème auxiliaire de type plus court chemincontraint ou non. Notre objectif est de combiner la méthode de génération de colonnes avecune heuristique gloutonne décrite dans la section suivante.

Combinaison d’une heuristique gloutonne et de la génération de colonnes pour (PCGT) 217
3 Notre approche de résolutionL’heuristique gloutonne de Dobson [1] à rapport d’approximation logarithmique pour le (CIP),consiste à sélectionner à chaque itération une colonne p de ratio ckp&
i$Nakip
minimal, de mettre àjour les données du problème en fonction de la colonne sélectionnée et de réitérer ce processusjusqu’à ce que l’ensemble des colonnes sélectionnées forme une solution réalisable.Cette heuristique est adaptée au (PCGT) au niveau de la procédure de sélection des colonnesen choisissant des plannings de meilleurs ratios coût/couverture. Ceci revient à résoudre, pourchaque type k ! K, des problèmes de plus court chemin (dans notre cas non contraints) àobjectif fractionnaire, dans des graphes Gk = (Nk 3{sk}3{ tk}, Ak) où Nk est l’ensemble destâches associées au type k avec sk et tk respectivement la source et le puits, et Ak l’ensembledes arcs tel que chacun d’eux modélise un enchaînement de deux tâches par le même type.Ces problèmes sont définis comme suit :
min&
(i,j)$Akckijx
kij&
(i,j)$Ak :i$Nkmin(akij ,bi)xkij
s.c&
(i,j)%Ak:i%Nk xkij =&
(j,l)%Ak:l%Nk xkjl ,j ! Nk&
j%Nk xkskj =
&i%Nk x
kitk = 1
xkij ! {0, 1} ,(i, j) ! Ak
où la variable xkij vaut 1 si l’arc (i, j) ! Ak est sélectionné dans le planning et 0 sinon. Larésolution de ce problème fractionnaire revient à celle d’une suite de programmes linéairesparamétrés en variables 0-1 définis sur le même ensemble de contraintes et dont la fonctionobjectif est : z(3) : min
&(i,j)%Ak c
kijxkij # 3
&(i,j)%Ak:i%Nk min(akij , bi)xkij
où 3 est un paramètre réel que l’on fait varier par la méthode dite de Dinkelbach [3] jusqu’àtrouver un paramètre 30 vérifiant l’équation z(30) = 0. La solution optimale x0 = (xij)(i,j)%Akainsi obtenue est aussi solution optimale du problème fractionnaire associé [2].Des résultats préliminaires de notre approche, basée sur l’heuristique gloutonne, montrentqu’on obtient un bon compromis entre le temps de résolution et la qualité des solutionsobtenues. En e!et, la méthode de Dinkelbach pour la résolution des problèmes fractionnairesconverge très rapidement, et les solutions engendrées sont souvent de bonne qualité comparéesà celles obtenues par une résolution exacte du modèle explicite du problème de transporttraité. Un atout supplémentaire de cette approche est la diversité des chemins composantles solutions obtenues. Pour tirer profit des avantages de cette heuristique gloutonne et dela méthode de génération de colonnes, deux types de combinaisons sont mises en oeuvre.D’une part, nous adaptons cette heuristique pour la construction d’un ensemble de colonnesdiversifiées afin d’alimenter le problème maître restreint de la génération de colonnes, etd’autre part, nous exploitons la solution continue obtenue par la génération de colonnes pourinitialiser une procédure de type multistart sur l’heuristique gloutonne. Ces deux coopérationstendent à guider la résolution vers des solutions entières de meilleure qualité.Références1. G. Dobson, Worst-case analysis of greedy heuristics for integer programming with non-negative
data. Mathematics for Operations Research 7 :4 (1982) 515-531.2. A. Nagih, G. Plateau, Problèmes fractionnaires : Tour d’horizon sur les applications et méthodes
de résolutions. RAIRO Operations Research. 33 (1999) 383-419.3. W. Dinkelbach, On Nonlinear Fractional Programming. Management Science 13 (1967) 392-400.

Un outil d’aide à la décision pour l’optimisation ducantonnement de voie ferrée
J. Damay1 et H. Djellab1
SNCF I&R/GDA, 45 rue de Londres, 75008 Paris, France.{jean.damay, housni.djellab}@sncf.fr
1 Problématique métier
Le cantonnement d’une ligne de chemin de fer est le processus qui consiste à définir la positiondes signaux régulant la circulation sur les di!érentes voies composant la ligne. Des distances desécurité entre tous couples de signaux consécutifs doivent être respectées. Elles correspondent,pour un schéma de signalisation classique, à la distance minimale d’arrêt des trains circulantsur la voie considérée à leur vitesse maximale imposée – ces vitesses-limites, ainsi que le profil(déclivités), varient naturellement le long de la voie. En e!et, la présence d’un train sur uncanton (délimité par deux signaux) agit sur les indications portées par le signal d’entrée ducanton et le signal amont précédent, de sorte que le conducteur d’un éventuel train circulantderrière le premier soit averti et ne pénètre pas ce canton. Si ces distances de sécurité nesont pas respectées, un autre type de circulation spécifique est mis en place, de manièreponctuelle ou sur des zones spécifiques, mais ceci n’est pas à prioriser. En outre, des contraintesd’infrastructure viennent d’une part interdire l’implantation de signaux dans des zones bienprécises (autour d’appareils de voie, dans des tunnels...) et d’autre part imposer la présencede signaux sur d’autres zones (en amont de postes d’aiguillage, de passages à niveau...) à desdistances spécifiées par la réglementation en vigueur.Une fois toutes ces contraintes prises en compte, il s’agit de positionner les signaux sur la voiede manière à optimiser certains critères, tels que l’« ergonomie de conduite » ou le débit d’untype de train circulant. Un critère unique est spécifié pour une étude donnée. Le premier deces deux critères est lié à l’homogénisation des temps de parcours du train sur les di!érentscantons. Le second dépend de la fréquence maximale à laquelle on peut faire circuler destrains identiques, et donc du temps de parcours sur chaque canton et du temps d’espacementnécessaire entre deux trains. L’appel à un module de calcul de « marche » du train rend plusprécises les estimations des valeurs de ces critères.
2 Composantes Recherche
Les calculs de distance d’arrêt et les calculs de marche des trains ont fait l’objet d’activités derecherche à part entière. Nous nous concentrons ici sur la partie optimisation de cantonnement,à savoir le modèle mathématique et l’algorithme retenus et implémentés dans un outil logicield’aide au cantonnement optimisé, déployé dans les groupes « programmes et consignes » ensignalisation des plateformes régionales d’ingénierie de la SNCF. Cet outil propose trois modesde cantonnement : manuel, semi-automatique et automatique.

Un outil d’aide à l’optimisation du cantonnement 219
Dans notre description du problème, les vitesses imposées aux trains sont des données d’en-trée d’une étude. Certaines approches de la littérature ([3] [4]) tentent de les modifier pouroptimiser le débit des trains. Le choix ici a été de laisser cette possibilité à l’expert via l’in-terface de l’outil, mais de n’intervenir dans le cadre de l’optimisation d’une étude que surle positionnement des signaux. Il existe quelques approches pour ce problème, citons cellesutilisant les algorithmes génétiques ([1] [2]).Nous avons fourni une modélisation qui met clairement en évidence son caractère non li-néaire, ce qui la rend di"cilement exploitable. Des approches basées sur la programmationpar contraintes ou sur la programmation dynamique ont été proposées, mais nous avons optépour l’adaptation de la métaheuristique de voisinage appelée « recuit simulé », qui consiste àparcourir l’espace des solutions de notre problème :– en partant d’une solution initiale correspondant à un cantonnement « serré » construit de
manière itérative gloutonne ;– grâce à un opérateur de voisinage qui consiste à répartir un pourcentage de la longueur
excédentaire du canton péjorant le plus le critère d’optimisation, sur un ou plusieurs cantonsvoisins ;
– en paramétrant cet opérateur et l’acceptation de solution dégradante par un ensemble deparamètres évoluant au fur et à mesure des itérations (la « température »).
Références
1. Mao, B., Liu, H., Liu, J., Ho, T., and Ding, Y. : Signalling Layout for Fixed-block Railway Lineswith Real-Coded Genetic Algorithms. HKIE Transactions, Vol. 13 No. 12 (2006)
2. Chang, C.S. and Du, D. : Improved optimisation method using genetic algorithms for mass transitsignalling block-layout design. IEE Proc-Electr. Power Appl., Vol. 145 No. 3 (1998)
3. Gill, D.C. and Goodman C.J. : Computer-based optimisation techniques for mass transit railwaysignalling design. IEE Proc-B, Vol. 139, No. 3 (1992)
4. Landex, A. and Kaas, A.H. : Planning the most suitable travel speed for high frequency railwaylines. Proc. of the 1st International Seminar on Railway Operations Modelling and Analysis,ISBN : 90-9019596-3, TU Delft (2005)

Restauration d’images par coupes minimales
N. Lermé1, L. Létocart2 et F. Malgouyres3
1 LAGA UMR CNRS 7539 et LIPN UMR CNRS 7030, Université Paris 13, 99 avenue J.B.Clément, 93430 Villetaneuse, France.
[email protected],2 LIPN UMR CNRS 7030, Université Paris 13, 99 avenue J.B. Clément, 93430 Villetaneuse, France.
[email protected],3 LAGA UMR CNRS 7539 et L2TI, Université Paris 13, 99 avenue J.B. Clément, 93430
Villetaneuse, [email protected]
1 Présentation du problème
On considère le problème de restauration d’images appliqué à des images discrètes de RNdéfinies sur un ensemble 0 borné où N représente la taille de l’image. La restauration d’uneimage est définie comme l’estimation d’un objet u$ à partir d’une version dégradée de l’objetu. La dégradation est modélisée par
vk = uk + bk, ,k ! {0, . . . , N # 1} (1)
où v ! RN est l’image dégradée, u ! RN est l’image idéale et b correspond à un bruitimpulsionnel de densité db indépendant et identiquement distribué (i.i.d.) ou bien à un bruitgaussien i.i.d. de loi normale N (0,(2
b ).L’approche par minimisation d’énergie est un cadre abstrait élégant qui se prête bien à lamodélisation du problème de restauration. À l’instar des autres problèmes de Vision parOrdinateur (VO), ce problème est dit mal-posé (au sens de Hadamard) et est source d’insta-bilités numériques face au bruit. L’introduction d’une connaissance a priori sur la solutionest une astuce classique qui se caractérise par l’ajout d’une contrainte supplémentaire dans laformulation de l’énergie. La résolution de (1) consiste alors à minimiser la fonction d’énergie
E(u, v) =%
p%(Ep(up, vp)
G HI JTerme d’attache aux données
+ &%
{p,q}%N
Ep,q(up, uq)
G HI JTerme de régularisation
avec & ! R+$ , (2)
où N est un système de voisinage (4, 8 ou 16 connexités). Le premier terme mesure l’écartentre les étiquettes up et vp au pixel p et force la solution à être proche des données initiales.L’écart augmente avec la distance entre up et vp. Le second terme mesure le coût lorsque l’ona!ecte respectivement les étiquettes up et uq aux pixels p et q voisins dans l’image u. Ce coûtaugmente avec la distance entre up et uq.La minimisation de (2) est un problème d’optimisation combinatoire NP-Di"cile. Les mé-thodes de minimisation globales classiques (recuit simulé, descente de gradient, etc.) ontl’avantage de pouvoir minimiser n’importe quelle fonction de la forme (2) mais o!rent cepen-dant peu de garanties de convergence et d’optimalité sur la solution. En pratique, les fonctions

Restauration d’images par coupes minimales 221
d’énergie non-convexes sont plus courantes en VO mais plus di"cilement minimisables de parl’existence de plusieurs minima locaux. Néanmoins, l’obtention d’une solution optimale entemps polynomial est envisageable pour des classes d’énergies plus restreintes pour lesquellesil existe d’autres techniques plus adaptées comme les graph-cuts.
2 Minimisation d’énergie par graph-cuts
Les graph-cuts sont une technique de minimisation d’énergie basée sur le calcul de coupesminimales dans des graphes peu denses à la topologie régulière. Leur e"cacité et leur poly-valence en font un outil de choix qui a déjà fait ses preuves dans de nombreuses applicationsde VO comme la reconstruction 3D ou la segmentation.Considérons un graphe G = (V , E) orienté et pondéré où V = {1, . . . , n} 3{ s} 3{ t} désigneles sommets (pixels de l’image) et E = {1, . . . ,m} désigne les arcs. On désigne V # {s, t} parV+ et l’on distingue deux sommets particuliers de V où s est la source et t le puit. On scindel’ensemble E en deux tel que E = En 3 Et et Et ; En = 2– Les n-links : En = {(i, j) | i, j ! V+ et (i, j) ! E}– Les t-links : Et = {(s, i) | i ! V+ et (s, i) ! E} 3 {(i, t) | i ! V+ et (i, t) ! E}Initialement décrits dans [5] en 1989, Greig et al. établissent un résultat important : ilsmontrent que les graph-cuts sont capables de résoudre exactement un problème d’étiquetagebinaire en temps polynomial, en calculant une coupe minimale dans un graphe. La valeur dela coupe correspond alors à une énergie minimum modélisée par une fonction d’énergie (2), àune constante près. On obtient ensuite une partition du graphe en deux ensembles S, T 1 Vcorrespondant à un étiquettage optimal tel que V = S 3 T et S ; T = 2.Oubliés pendant une dizaine d’années, les graph-cuts ont connu un essor considérable depuis1999 avec l’apport de résultats importants dans le cas multi-étiquettes [2], [6], [7], [10] etl’avènement d’un nouvel algorithme de flot maximum mieux adapté aux graphes à « grille » [1].Ces nouveaux résultats ont notamment permis de caractériser plus précisément les classesd’énergie minimisables par graph-cuts. Par exemple, Kolmogorov et al. ont montré dans lecas binaire que ces énergies doivent respecter une condition de sous-modularité sur le termede régularisation [7].Dans le cas multi-étiquettes, Ishikawa montre que la convexité de ce terme est une conditionnécessaire et su"sante pour qu’une fonction d’énergie soit minimisable par graph-cuts [6].Dans le cas contraire, plusieurs heuristiques ont été proposées lorsque le terme Ep,q est unemétrique (%-expansion) ou une semi-métrique (%-& swap) [10], [2].
3 Schémas de minimisation des modèles TV
Récemment, [3] et [4] ont proposé de nouveaux schémas de minimisation exacts pour desclasses de fonctions d’énergies restreintes où les termes Ep et Ep,q sont des fonctions convexes.Plus précisément, les auteurs proposent de résoudre les deux modèles
u$ = minu%
p%(wp,q|up # uq|
G HI JV ariation Totale
+&'u# v'#L$ avec % ! {1, 2}, (3)

222 N. Lermé, L. Létocart, F. Malgouyres
où wp,q représente le poids selon la connexité du voisinage et '.' la norme euclidienne sur RN .L’utilisation de la variation totale (TV) comme mesure permet de lisser les zones homogènestout en préservant les bords nets dans la solution. Le modèle ROF ou TV + L2 (% = 2),introduit par Rudin Osher et Fatemi en 1992 [9] est strictement convexe et entraîne uneperte de contraste dans la reconstruction. À l’opposé, le modèle TV + L1 (% = 1) proposépar Nikolova [8], n’est pas strictement convexe mais n’entraîne pas de perte de contraste.On dédie généralement le modèle TV + L1 au traitement du bruit impulsionnel et le modèleTV + L2 au traitement du bruit gaussien.Le principe décrit dans [3] et [4] est de reformuler l’énergie totale (3) en une somme d’énergiesbinaires. L’objectif est alors de résoudre exactement une succession de problèmes d’optimisa-tion en variables 0-1 par coupes minimales dont les solutions sont des ensembles de niveauxde u$, le minimiseur de (3). Les auteurs proposent plusieurs algorithmes qui battent assezlargement les algorithmes existants à la fois en terme de garantie de convergence et de tempsde calcul.Dans ce travail, un algorithme dyadique de complexité O(log2(2d)) (où d est la profondeurde l’image) est étudié pour la restauration d’images 2D et 3D. Dans le cas d’images 3D, lataille des graphes générés augmente rapidement. Nous proposons donc un moyen exact deréduire ces graphes pour réduire le temps de résolution de la coupe minimale. Le principeest de construire partiellement le graphe en supprimant les noeuds qui constituent des zones« homogènes » dans v. Nous présenterons les temps de calcul ainsi que quelques résultatsnumériques pertinents pour des images 2D et 3D.
Références1. Y. Boykov and V. Kolmogorov : An experimental comparison of min-cut/max-flow algorithms
for energy minimization in vision. In EMMCVPR’01, pages 359–374, Ithaca, NY, USA, 2001.Cornell University.
2. Y. Boykov, O. Veksler, and R. Zabih : Markov random fields with e%cient approximations. InCVPR’98, page 648, Ithaca, NY, USA, 1998. Cornell University.
3. A. Chambolle : Total variation minimization and a class of binary mrf models. In EMMCVPR05,pages 136–152, 2005.
4. J. Darbon and M. Sigelle : A fast and exact algorithm for total variation minimization. InIbPRIA05, page I :351, 2005.
5. D. M. Greig, B. T. Porteous, and A. H. Seheult : Exact maximum a posteriori estimation forbinary images. In J. Royal Statistical Soc., 51 :271–279, 1989.
6. H. Ishikawa : Exact optimization for markov random fields with convex priors. In PAMI,25(10) :1333–1336, Octobre 2003.
7. V. Kolmogorov and R. Zabih : What energy functions can be minimized via graph cuts ? pages65–81, 2002.
8. M. Nikolova : Minimizers of cost-functions involving nonsmooth data-fidelity terms. Applicationto the processing of outliers. In SIAM J. Numer. Anal., 40(3) :965–994, 2002.
9. L. I. Rudin, S. Osher, and E. Fatemi : Nonlinear total variation based noise removal algorithms.In Phys. D, 60(1-4) :259–268, 1992.
10. O. Veksler : E%cient Graph-Based Energy Minimization Methods in Computer Vision. In PhDthesis, 2005.

Un algorithme bi-objectif pour les systèmesd’assemblages bi-niveau avec incertitude de délais
d’approvisionnement
F. Hnaien1 X. Delorme and A.Dolgui2
1 LIMOS, UMR CNRS 6158, Institut Français de Mécanique Avancée, Campus de ClermontFerrand, Complexe scientifique des Cézeaux, 63173 Aubière Cedex France.
[email protected] Centre Génie Industriel et Informatique (G2I), École Nationale Supérieure des Mines de Saint-
Étienne, 158, cours Fauriel, 42023 Saint-Étienne cedex 2, France.{delorme,dolgui}@emse.fr
1 Problématique
Nous nous intéressons ici à la gestion des stocks en présence d’aléas qui est un problèmeclassique pour les entreprises industrielles. Di!érentes sources d’aléas existent le long de lachaîne logistique notamment la demande en produit fini et les délais d’approvisionnement encomposants. Les modèles qui prennent en compte la variabilité des délais d’approvisionnementsont rares. Pourtant, ces délais sont rarement constants, di!érents évenements plus au moinsprévisibles le long de la chaîne logistique peuvent causer des perturbations (panne de machine,problème de transport, qualité,...). Les études se limitent soit au problème de planification dessystèmes d’assemblage à un seul niveau (en ne tenant pas compte de l’interdépendance entreles niveaux), soit au problème de planification des chaînes logistiques dont la nomenclaturedes produits finis est à structure linéaire à plusieurs niveaux (en ne tenant pas compte del’interdépendance entre les délais des composants nécessaires pour l’assemblage d’un mêmetype de produit). Sur ces problèmes, nous pouvons citer respectivement les travaux de [1], [2],et ceux de [3] et [4].
Dans nos récents travaux [5], nous nous sommes intéressés à la planification des réapprovi-sionnements d’un système d’assemblage bi-niveaux en prenant en compte les aléas des délaisd’approvisionnements. Notre objectif était de minimiser les coûts de stockage des composantset les coûts de rupture en produits finis par un algorithme génétique mono-objectif. Cepen-dant, il est souvent, en pratique, di"cile de mesurer le coût de rupture unitaire. Ainsi, nousconsidérons ici un niveau de service. Notre étude porte sur l’assemblage d’un seul type deproduit fini et nous supposons que sa demande et sa date de livraison sont connues. Noussupposons aussi que le délai d’approvisionnement de chaque type de composants à chaqueniveau est une variable aléatoire discrète qui suit une loi quelconque, cette loi étant supposéeconnue d’avance. L’objectif est donc de trouver un compromis entre les coûts de stockage descomposants et le niveau de service.

224 Hnaien, F., Délorme, X., Dolgui, A.
2 Optimisation multi-objectif par un algorithme NSGA-II
Le but de notre étude est donc la résolution d’un problème d’optimisation bi-objectif (mi-nimiser le coût de stockage et maximiser le niveau de service). Nous proposons ici un algo-rithme génétique multi-objectif pour obtenir une approximation de l’ensemble des compromise"caces. Cet algorithme reprend le schéma de base de NSGA-II (A Fast and Elitist Muti-objective Gentic Algorithm, proposé par [6]).
L’algorithme NSGA-II proposé commence par la création d’une population initiale. Ensuite,à partir des parents Pi de la génération i, il utilise les opérateurs de reproduction (croisementet mutation) pour créer les descendants Di. Ensuite les populations Pi et Di sont réunies dansle même ensemble Ui. La population suivante Pi+1 est crée à partir des n premiers fronts detelle sorte que le nombre d’individus contenus dans ces n premiers fronts soit inférieur ou égala N . Cette population Pi+1 est alors complétée par les meilleurs individus du front n+ 1 ausens de la distance de Crowding.
Les premiers tests e!ectués montrent l’é"cacité de l’algorithme proposé pour di!érentes taillesde problèmes et l’algorithme converge dans un temps de calcul raisonnable. Les résultats sontcomparés à ceux obtenus en utilisant un algorithme mono-objectif et permettent d’identifierun ensemble des compromis d’un point de vue théorique. Enfin, nous comptons de comparernotre algorithme avec une autre méthode d’optimisation multi-objectif telle que l’algorithmeSPEA2 (Improving the Strength Pareto Evolutionary Algorithm, proposée par [7]), et aussiétendre l’étude pour le cas des systèmes d’assemblage á plus de deux niveaux.
Références
1. Chu, C., Proth, J.M., Xie, X. : Supply management in assembly systems. Naval Research Logistics,40, 933-949 (1993)
2. Ould Louly, M.-A., Dolgui, A., Hnaien, F. : Optimal Supply Planning in MRP Environmentsfor Assembly Systems with Random Component Procurement Times. International Journal ofProduction Research, 46(19), 5441-5467 (2008)
3. Hnaien, F., Dolgui, A., Marian, H., Ould Louly M.-A. : Planning order release dates for multilevellinear supply chain with random lead times, Systems Science, 31, 19-25 (2007)
4. Yano, C.A. : Setting planned leadtimes in serial production systems with tardiness costs. Mana-gement Science, 33, 95-106 (1987)
5. Hnaien, F., Delorme, X., Dolgui, A. : Genetic algorithm for supply planning in two-level assemblysystems with random lead times, Engineering Applications of Artificial Intelligence, (accepted)(2008)
6. Deb, K., Pratap A., Agarwal S., Meyarivan T. : A fast and elitist multi-objective genetic algorithm :NSGA-II. IEEE Transactions on Evolutionary Computation, 6(2), 182-197 (2002)
7. Zitzler, E., Laumanns,M. Thiele,L. : SPEA2 : Improving the Strength Pareto Evolutionary Al-gorithm for Multiobjective Optimization in Evolutionary Methods for Design, Optimisation, andControl, pp. 19-26 (2002)

Planification stratégique d’un réseau logistiqueinternational
M. Suon1,2, N. Grangeon,1, S. Norre,1, and O. Gourguechon,2
1 LIMOS, CNRS UMR 6158, IUT de MontluçonAv. Aristide Briand, 03100 Montluçon
[email protected], [email protected] PSA Peugeot Citroën, 57 avenue du Général Leclerc, 25600 Sochaux
[email protected], [email protected]
1 Présentation du problème
Dans cet article, nous nous intéressons à un problème de planification stratégique d’un ré-seau logistique dans le cas de l’industrie automobile. Nous considérons un réseau logistiqueconstitué de zones de commercialisation (ZC) où sont vendus di!érents types de véhicules (re-groupés en familles de véhicules), de zones de production (ZP) où les véhicules sont assemblésà partir de di!érents types de pièces (regroupés en familles de pièces) et de zone d’approvi-sionnement (ZA) où sont achetées les pièces. Ces zones peuvent être reliées entre elles pardes routes d’approvisionnement (entre une ZA et une ZP) et par des routes de distribution(entre une ZP et une ZC). Sur les ZP, di!érentes technologies de production peuvent êtredisponibles pour réaliser les activités de production nécessaires à la fabrication des famillesde véhicules.L’objectif est de définir, pour une période donnée, les quantités de familles de véhicules pro-duites sur chaque ZP et les quantités de familles de pièces achetées sur chaque ZA - ce quirevient à définir les quantités de familles de pièces transportées sur les routes d’approvision-nement et les quantités de familles de véhicules transportées sur les routes de distribution -en minimisant le coût d’exploitation du réseau logistique tout en respectant les contraintessuivantes :– Pour chaque ZA et chaque famille de pièces, les capacités minimum et maximum d’appro-
visionnement doivent être respectées,– Pour chaque technologie de production et chaque ZP, les capacités minimum et maximum
de production doivent être respectées,– Pour chaque ZC et chaque famille de véhicules, la demande prévisionnelle doit être satisfaite,– Pour chaque ZP et chaque famille de véhicule, les quantités de familles de pièces appro-
visionnées et les quantités de familles de véhicules produites doivent respecter les liens denomenclature.
Le coût d’exploitation du réseau logistique intègre :– les coûts d’achat des familles de pièces auprès des ZA,– les coûts de transport d’approvisionnement,– les coûts de production qui englobent à la fois les coûts liés à la main d’oeuvre et ceux liés
à l’amortissement de l’installation des technologies de production,– les coûts de transport de distribution.

226 Gourguechon, Grangeon, Norre, Suon
Le cadre de l’étude étant international, une spécificité du problème est l’intégration de ladouane dans le coût de transport. Ce coût de douane, qui est généralement modélisé commefixe pour un produit (famille de pièces ou famille de véhicules) dans la littérature, est calculé,dans notre cas, à partir de la valeur en douane des produits à la frontière et du taux de douane.De plus, cette valeur en douane est fonction du prix de revient de fabrication intégrant lesfrais d’amortissement qui dépendent des quantités de production.Le problème de planification étudié est donc un problème monopériode, multi-niveau, multi-produit avec nomenclature, dans un contexte international et intégrant une économie d’échelleen production.
2 Approche proposée
Dans un premier temps, nous nous sommes attachés à construire le modèle de connaissancedu système étudié. Une part importante de ce travail a concerné la définition du coût d’exploi-tation du réseau logistique qui, en raison des spécificités expliquées ci-dessus, est non-linéaire.Nous nous sommes ensuite intéressés à la résolution du problème de planification. La premièrepartie de ce travail a concerné l’étude du problème en considérant que le prix de revient defabrication est estimé a priori. Cette hypothèse simplificatrice permet de se ramener à unmodèle linéaire, proche de ceux rencontrés dans la littérature [1], [3]. Ce modèle a permis deproposer une borne inférieure.L’étude du problème dans son intégralité a conduit à la proposition de plusieurs systèmes devoisinage implantés dans des metaheuristiques à base de recuit simulé [2]Enfin, des tests sont en cours sur une instance industrielle et sur di!érentes instances généréesen accord avec les spécificités du problème industriel.
Références
1. Arntzen B. C., Brown G. G., Harrison T. P., Trafton L. L., "Global supply chain management atDigital Equipment Corporation". Interfaces, 25, pp. 69 - 93, 1995.
2. Jayaraman V.,Ross A. "A simulated annealing methodology to distribution network design andmanagement”, European Journal Of Operational Research, 144, 629-645, 2003
3. Fleischmann B., Feber S., Henrich, P., "Strategic Planning of BMW’s Global Production Network",Interfaces, 36, pp. 194- 208, 2006.

Comparaison de trois heuristiques pour la planificationstratégique de réseaux logistiques
P.N. Thanh1, N. Bostel2, and O. Péton1
1 IRCCyN, Ecole des Mines de Nantes, 4, rue Alfred Kastler, 44307 Nantes, [email protected], [email protected]
2 IRCCyN, IUT de Saint-Nazaire, 58 rue Michel Ange, 44606 Saint-Nazaire, [email protected]
Nous présentons trois méthodes heuristiques de résolution d’un problème de conception etde planification stratégique de la chaîne logistique. L’objectif est de planifier l’évolution phy-sique de la chaîne logistique et des flux sur un horizon stratégique de plusieurs années. Nousdécrivons un modèle mathématique de programmation linéaire en variables mixtes (MILP).Les variables de décision concernent la localisation de sites, l’ouverture, la fermeture ou l’ex-tension de ces sites ainsi que les flux physiques le long de la chaîne logistique. L’objectif estde définir une structure optimale du réseau logistique sur la globalité de l’horizon considéré.Notre travail porte essentiellement sur les aspects stratégiques. Quelques aspects tactiques,comme les stocks saisonniers et cycliques, sont pris en compte [1].Les trois méthodes heuristiques présentées visent à obtenir des résultats quasi-optimaux enun temps de calcul acceptable. Pour évaluer ces méthodes, nous avons généré un ensemble de450 instances de test, divisées en 15 familles. Les résultats sont comparés à ceux obtenus parle solveur Xpress-MP.L’heuristique 1 est basée sur la relaxation linéaire et des règles d’arrondi pour recouvrer unesolution réalisable. Elle repose sur les résolutions successives de la relaxation continue duMILP d’origine, en fixant 0 ou 1 les variables de décision proche de 0 ou 1 dans la solution duproblème relaxé. La mise en œuvre de cette heuristique nécessite quelques règles pour arrondirles valeurs à 0 ou 1, et également pour corriger les solutions non réalisables engendrées parla relaxation. L’heuristique s’arrête lorsque plus aucun arrondi n’est réalisable, il ne restequ’à résoudre par un solveur le MILP résiduel. Cette méthode permet en moyenne un gainde temps appréciable par rapport au solveur. Néanmoins, quelques instances de grande taillene peuvent être résolues dans le temps imparti car le MILP résiduel reste intrinsèquementdi"cile.L’heuristique 2 utilise la programmation D.C. (Di!erence of Convex functions) et l’algorithmeD.C.A [2] comme une méthode de recherche locale e"cace pour fournir de bonnes bornessupérieures. Cette méthode apporte des progrès notables par rapport à la précédente. Toutd’abord, une solution est obtenue pour l’ensemble des instances. Le gain de temps par rapportau solveur est impressionnant (jusqu’à 20 fois plus rapide). Les solutions obtenues sont enmoyenne très proches de celles obtenues avec le solveur, parfois mêmes meilleures dans le cas oùle solveur a été arrêté après trois heures de calcul. Malheureusement, pour certaines instancesnous obtenons un saut d’optimalité jugé trop important, ce qui nous amène à rechercher uneméthode plus robuste.Dans l’heuristique 3, la relaxation linéaire est remplacée par une relaxation Lagrangienne.Cette méthode s’inspire des travaux de Hinojosa et al. pour un problème voisin [3]. Nousrelaxons 4 groupes de contraintes sur les 26 que comporte le modèle mathématique. Nous

228 Thanh, Bostel, Péton
procédons à une décomposition par niveau de nomenclature, puis par site, puis par période.À chaque étape, une borne inférieure peut être calculée par inspection, une borne supérieureest fournie par l’algorithme D.C.A. Cette heuristique permet d’obtenir à coup sûr une solutionde très bonne qualité pour l’ensemble des instances. Le seul bémol vient du temps de calcul,plus long que pour l’heuristique 2.Nous présenterons une comparaison détaillée des résultats numériques, qui montrent quechaque méthode convient à un certain type d’instances [4]. Nous énonçons finalement lespistes d’améliorations et les perspectives de recherche à l’issue de ce travail.
Références
1. Thanh P.N., N. Bostel and O. Péton, A dynamic model for facility location in the design ofcomplex supply chains, International Journal of Production Economics, 113(2) 678–693. (2008)
2. Le Thi H.A. and T. Pham Dinh, A continuous approach for the concave cost supply problem viaDC programming and DCA, Discrete Applied Mathematics, 156(3), 325–338. (2008)
3. Hinojosa Y., J. Kalcsics, S. Nickel, J. Puerto and S. Velten, Dynamic supply chain design withinventory, Computers and Operations Research, 35, 373–391. (2008)
4. Thanh P.N., Conception et planification stratégique des réseaux logistiques, Thèse de doctoratde l’Université de Nantes (2008).

Une généralisation du problème du cycle Hamiltonien.
V. Jost,1 and G. Naves2
1 LIX, École Polytechnique, 91128 Palaiseau [email protected]
2 G-SCOP, 46, avenue Félix Viallet, 38031 Grenoble Cedex [email protected]
1 Hamiltonicité
Soit G un graphe non-orienté connexe. Un tour de G est une marche fermée de G passantpar chaque sommet. On appelle cycle Hamiltonien ou tour Hamiltonien un tour de G passantpar chaque sommet une et une seule fois. Un graphe possèdant un cycle hamiltonien est ditHamiltonien.Un ensemble éclatant d’un graphe G est un ensemble U + V (G) de sommets tels que lenombre de composantes de G # U est supérieur à la cardinalité de U . Autrement dit, si cest la fonction qui à un ensemble de sommets associe le nombre de composantes connexesde son complémentaire, c(U) # |U | > 0. Remarquons qu’un graphe admettant un ensembleéclatant ne peut pas être Hamiltonien. Un graphe est dit k-tough si min*)=U+V |U|
c(U) ( k. Lesgraphes sans ensemble éclatant sont exactement les graphes 1-tough. La Figure 1 présentedeux graphes non-Hamiltoniens et sans ensemble éclatant. Notons que calculer la toughnessd’un graphe ou décider l’existence d’un ensemble éclatant sont des problèmes NP-di"ciles.
Fig. 1. Deux graphes non-Hamiltonien et ne possédant pas d’ensemble éclatant.
La question de trouver des classes de graphes qui vérifient que tout graphe k-tough dans laclasse est Hamiltonien est un problème classique de théorie des graphes, en particulier dans lecas k = 1. L’un des principaux résultats dans ce sens est que les graphes de co-comparabilité1-tough sont Hamiltoniens (Deogun, Kratsch, Steiner)[1].

230 Jost, Naves
2 Plus court tour visitant chaque sommet
La version graphique du problème du voyageur de commerce consiste à trouver un plus petittour dans un graphe quelconque. Une solution peut passer plusieurs fois par le même sommet,contrairement au problème du cycle Hamiltonien. On appelle tour graphique un tel tour. Denouveau se pose la question de savoir si les ensembles éclatants peuvent certifier la non-existence de bonnes solutions.On considère le problème avec une fonction de poids sur les sommets, qui est une restrictiondu cas général, dans lequel les poids sont sur les arêtes. La longueur d’un tour est alors lasomme sur tous les sommets du poids multiplié par le nombre de passages par le sommet.Pour tout ensemble éclatant U , on sait que n’importe quel tour doit passer c(U) fois par Uau minimum. On pose donc le programme linéaire suivant, et son dual :
min wx s.t. (P)x(U) ( c(U) (U + V )
max%
U&VyUc(U) s.t. (D)
%
U,vyU = wv (x ! V )
Il n’y a pas nécessairement égalité entre l’optimum de ce polyèdre et le tour graphique mi-nimum, par exemple les graphes présenté Figure 1 ne sont pas Hamiltoniens, et acceptentpourtant le vecteur constamment égal à 1 comme solution minimale de (P) (puisqu’ils n’ontpas d’ensemble éclatant).La version duale est en fait packing d’ensembles éclatants. On s’intéresse au problème consis-tant à trouver des classes de graphes pour lesquelles les optima des deux programmes précé-dents ont même valeur que la longueur minimum d’un tour graphique. En particulier, si west constamment égal à 1, on démontre le résulat suivant :
Theorem 1. Soit G un graphe d’intervalle connexe. La longueur du plus court tour passantau moins une fois par chaque sommet est égale à maxP
&U%P c(U), où P décrit les partitions
de V (G).
Et dans le cas d’une fonction de poids plus générale :
Theorem 2. Soit G un cographe, et soit w : V (G) : N une fonction de poids. Alors lalongueur du plus court tour passant par chaque sommet est égale au maximum de (D).
Enfin, on appelle chaise le graphe à 5 sommets obtenu en ajoutant un sommet de degré 1adjacent à un sommet de degré 1 de la gri!e K1,3.
Theorem 3. Si G est un graphe sans chaise induite, alors le systême d’inéquations (P) estTDI.
3 Perspectives
On espère pouvoir généraliser le résultat des graphes d’intervalles pour le cas pondéré. D’autresclasses de graphes plus générales pourraient aussi avoir ces propriétés, en particulier lesgraphes de co-comparabilité. La classe des graphes sans triplet astéroïdal généralise la classedes graphes de co-comparabilité. Un triplet astéroïdal est un triplet (u, v, w) de sommets d’un

Une généralisation du problème du cycle Hamiltonien. 231
graphe, tel que pour toute paire de sommets parmi ces trois, il existe un chemin joignant cettepaire qui n’intersecte pas le voisinage du troisième sommet. On ose entre autres la conjecturesuivante :
Conjecture 1. Tout graphe sans triplet astéroïdal 1-tough est Hamiltonien.
Références
1. Deogun, J.S., Kratsch, D., Steiner, G. : 1-tough cocmoparability graphs are hamiltonian. DiscreteMathematics, Vol. 170, No. 1-3, pp.99-106, (1997)

Détermination des k arêtes les plus vitales pour leproblème de l’arbre couvrant minimal
C. Bazgan, S. Toubaline, and D. Vanderpooten
Université Paris-Dauphine, LAMSADE, Place du Maréchal de Lattre de Tassigny,75775 Paris Cedex 16, France.
Cristina.Bazgan, Sonia.Toubaline, [email protected]
Dans de nombreux contextes, il est parfois utile d’appréhender la vulnérabilité d’un réseau decommunication en identifiant les infrastructures critiques. Nous entendons par infrastructurecritique, un ensemble de liens dont la défaillance engendre la plus grande augmentation ducoût associé à ce réseau. En modélisant ce réseau par un graphe pondéré, l’identification desinfrastructures critiques revient à déterminer un ensemble d’arêtes dont la suppression per-turbe le plus possible une propriété particulière du graphe. Ce type de problème est référencédans la littérature sous le nom de k Most Vital Edges. Nous nous intéressons à ce pro-blème dans le cas particulier de l’arbre couvrant de valeur minimale (MST), problème appelédans la suite k Most Vital Edges MST. Il s’agit alors de déterminer un sous ensemblede k arêtes dont la suppression engendre la plus grande augmentation de valeur d’un arbrecouvrant minimal dans le graphe partiel correspondant.Soit G = (V,E) un graphe pondéré, non orienté, connexe où |V | = n et |E| = m. Le problèmek Most Vital Edges MST consiste à trouver un sous ensemble d’arêtes S$ + E avec|S$| = k qui maximise la valeur de l’arbre couvrant minimal dans le graphe G(V,E # S$).Frederickson et al. [1] montrent que ce problème est NP-di"cile et proposent une log k-approximation. Shen [5] présente un algorithme approché aléatoire à 2 près. Pour k fixé, leproblème est évidemment polynomial. Le problème de l’arête la plus vitale (k = 1) a étélargement étudié dans la littérature. Le meilleur algorithme déterministe connu à ce jourest en O(m log%(m,n)) [2,4], où % est l’inverse de la fonction d’Ackermann. Pour k ( 2,plusieurs algorithmes exacts fondés sur l’énumération explicite de toutes les solutions pos-sibles ont été proposés. Le meilleur est celui proposé par Liang [3], dont la complexité est enO(nk%((k+1)(n#1), n)). En utilisant le résultat plus récent de Pettie [4], cette borne devientO(nk log%((k + 1)(n# 1), n)).Nous proposons, pour résoudre le problème k Most Vital Edges MST, un nouvel al-gorithme exact, également fondé sur une énumération explicite des solutions possibles. Sacomplexité, en O(nk log%(2(n # 1), n)), est théoriquement légèrement inférieure à celle del’algorithme proposé par Liang [3]. Néanmoins, compte tenu du fait que %(m,n) est toujoursen pratique inférieur à 4, la complexité des deux algorithmes peut être considérée commeéquivalente. En revanche, le grand intérêt de notre algorithme est que, à la di!érence des al-gorithmes précédemment proposés, il peut facilement être adapté pour établir un algorithmeexact d’énumération implicite selon le schéma d’une procédure par séparation et évaluation.Pour ce faire, nous utilisons une borne supérieure fondée sur la résolution approchée d’unproblème de sac à dos. Nous exploitons également une borne inférieure construite en éten-dant la forêt, correspondant au noeud d’exploration considéré, en un arbre couvrant minimalparticulier.

k Most Vital Edges(Nodes) 233
Nous avons implémenté et testé ces deux algorithmes en utilisant, pour l’algorithme d’énu-mération implicite, di!érentes stratégies de séparation et évaluation. Les résultats montrentque ce dernier est beaucoup plus rapide que l’algorithme d’énumération explicite et que sonutilisation de l’espace mémoire permet de traiter des instances de taille sensiblement plusgrande.En conclusion, nous discutons quelques variantes et extensions du problème k Most VitalEdges MST notamment la variante où les éléments vitaux sont les sommets et non pas lesarêtes.
Références
1. Frederickson, G.N. and Solis-Oba, R. : Increasing the weight of minimum spanning trees, Procee-dings of the seventh Annual ACM-SIAM Symposium on Discrete Algorithms, 539-546, (1996).
2. Iwano, K. and Katoh, N. : E%cient algorithms for finding the most vital edge of a minimumspanning tree, Information Processing Letters, 48 : 211-213, (1993).
3. Liang, W. : Finding the k most vital edges with respect to minimum spanning trees for fixed k,Discrete Applied Mathematics, 113 : 319-327, (2001).
4. Pettie, S. : Sensitivity Analysis of Minimum Spanning Tree in Sub-Inverse-Ackermann Time,Proceeding of 16th international symposium, ISAAC 2005, Sanya, Hainan, China , 964-973, (2005).
5. Shen, H. : Finding the kmost vital edges with respect to minimum spanning tree, Acta Informatica,36 : 405-424, (1999).
ACPMArbre Couvrant de Poids Minimum

Un algorithme générique pour le calcul d’arbrescouvrants sous contraintes
J. Brongniart, C. Dhaenens, and El.G Talbi
INRIA Lille-Nord Europe, 59650 Villeneuve d’Ascq - [email protected]
1 ProblématiqueSoit un graphe G = {E, V,C}, où C associe un coût à chaque arête de G. Un arbre couvrantde G est un sous-graphe acyclique et connexe. Parmi l’ensemble des arbres couvrants de G, l’ACPM est un arbre couvrant minimisant la somme des coûts de ses arêtes (
&e%T C(e)). Le
calcul d’un tel arbre couvrant est très facilement résoluble par un algorithme glouton tel quecelui de Kruskal [3].Mais les problèmes réels se traduisent souvent par des problèmes d’ACPM contraints, oùdes restrictions supplémentaires doivent être considérées. La plupart de ces contraintes ad-ditionnelles transforment les problèmes résultants en problèmes -di"ciles et rendent délicatel’évaluation de la faisabilité d’une solution. Ce travail présente un algorithme dynamique per-mettant de calculer un voisinage générique prenant en compte les contraintes additionnelles.
2 Échange d’arête et arbre couvrantLa figure 1(a) donne un exemple d’arbre couvrant T de G, où les arêtes épaisses sont lesarêtes de l’arbre et les arêtes fines les arêtes du reste du graphe. Une restriction possible,utilisée pour les problèmes de réseaux d’accès, peut être la mesure du diamètre de l’arbre,correspondant au plus long chemin dans T (l’un de ces plus long chemins est représenté pardes arêtes hachurées).
(a) Un arbre couvrant (b) Arêtes de remplace-ment pour {2, 4}
Fig. 1. Échange d’arêtes et arbre couvrant sous contraintes
La figure 1(b) illustre le voisinage étudié. Le retrait de l’arête {2, 4} déconnecte l’arbre endeux composantes {1, 2, 3, 5} et {4, 6, 7, 8}. Seules les arêtes appartenant à la coupe formée par

Un algorithme générique pour le calcul d’arbres couvrants sous contraintes 235
ces deux composantes peuvent reconstruire un arbre valide, et définissent donc un voisinagevalide pour {2, 4}. Ces arêtes sont représentées sur la figure par des hachures et sont appeléesarêtes de remplacement. Si une contrainte est ajoutée au problème, seule une petite partiede ces arêtes de remplacement peuvent conduire à une solution réalisable. En supposant unecontrainte de diamètre de 4, les seules arêtes de remplacement possible pour l’arête {2, 4}sont les arêtes {2, 7} et {5, 7}.Calculer la valeur des contraintes (par exemple, le diamètre) de l’arbre formé par l’échangede deux arêtes peut nécessiter un calcul très lourd (O(|V |) pour le diamètre), rendant l’ex-ploration des voisinages extrêmement coûteux (O(|V |2|E|) dans le cas du diamètre [1]).
3 Calcul des arêtes de remplacement
Ce voisinage par remplacement est le plus simple et le plus générique pour les problèmesd’ACPM sous contraintes. Cependant, les méthodes actuelles doivent explorer l’ensemble Epour distinguer les arêtes d’une coupe, ce qui entraîne un parcours du voisinage en O(|E||V |),en plus de la vérification des contraintes.Nous proposons d’employer une nouvelle méthode dynamique pour le calcul de ce voisinage.Nous avons conçu cet algorithme pour le problème dynamique de l’ACPM, où l’ACPM doitêtre mis à jour pendant des changements au niveau du graphe (càd. ajout, retrait ou chan-gement du coût d’une arête). Cet algorithme permet de trouver le meilleur échange pourle cas sans contrainte en O(|V | C log(|V |)) chaque fois que le ACPM change. De plus, cetteméthode s’appuie sur une structure originalement employée [2] pour mettre à jour sur desarbres des mesures telles que d’excentricité en O(log(|V |)). Grâce au cela, l’ensemble desarêtes de la coupe et les informations nécessaires pour la vérifications des contraintes peuventêtre trouvées en O(|V | log(|V |)).
4 Applications
Dans ce travail, nous présenterons des applications de cet algorithme aux contraintes de flotet de diamètre, classiques dans le domaines des télécommunications, pour mettre en valeurla généricité de cette méthodes par rapport aux contraintes qu’elle permet de prendre encompte. Ainsi, nous étudierons plusieurs méthodes de résolutions, exactes ou heuristiques,montrant la généricité du voisinage choisi.
Références
1. Ayman Abdalla and Narsingh Deo. Random-tree diameter and the diameter-constrained mst.International Journal of Computer Mathematics, 79 :651–663, 2002.
2. Stephen Alstrup, Jacob Holm, Kristian De Lichtenberg, and Mikkel Thorup. Maintaining diame-ter, center, and median of fully-dynamic trees with top trees. Unpublished, 2003.
3. Joseph B Kruskal. On the shortest spanning subtree of a graph and the traveling salesmanproblem. Proceedings of the American Mathematical Society, 7 :48–50, 1956.

Heuristique pour la résolution des problèmesd’ordonnancement de type FlowShop avec blocage RCb
C. Sauvey,1 and N. Sauer2
1 LGIPM, Université Paul Verlaine-Metz, Ile du Saulcy, 57045 Metz Cedex [email protected]
2 LGIPM, Université Paul Verlaine-Metz, INRIA Nancy-Grand Est Metz, [email protected]
1 Introduction
Dans ce travail, nous étudions des problèmes d’ordonnancement de type flow-shop, caracté-risés par un ensemble de jobs comportant un enchaînement identique d’opérations sur di!é-rentes machines. Ces problèmes sont largement répandus dans l’industrie et leur résolutionrapide représente un enjeu stratégique de taille en vue de la réduction des coûts de produc-tion. Même s’il est possible et utile de donner des solutions de bonne qualité à ces problèmesavec des méta-heuristiques [1][2], leur résolution avec des heuristiques présente un intérêt im-médiat, car elles sont obtenues avec des temps de calcul très courts et servent de point dedépart à une résolution plus complexe [3].Nous nous intéressons à la minimisation du makespan d’un flowshop avec un blocage parti-culier que l’on rencontre dans certaines situations industrielles [4]. Lors d’un blocage de typeRCb [5], le job bloque une machine jusqu’à ce que son traitement sur la machine suivante soitterminé et qu’il quitte cette machine (Fig.1). La complexité du problème d’ordonnancementd’un flowshop avec blocage RCb a été prouvée polynomiale pour 3 machines et NP-Di"cile àpartir de 5 machines [6]. Il a été résolu avec un recuit simulé [4] et une métaheuristique baséesur "Electromagnétism-like method" [7].
Ji
Ji
Ji
Ji
Jj
Jj
Jj
Jj
Jk
Jk
Jk
Jk
M1
M2
M3
M4
tempsTemps de blocage
Temps mort
Temps de blocagedifférentiel « avant »Temps de blocage différentiel « après »
Fig. 1. Problème à 4 machines avec blocage particulier RC.
Par rapport aux problèmes d’ordonnancement de flowshop classiques, le blocageRCb impliqueun temps de blocage supplémentaire, que nous avons défini comme temps de blocage di!é-rentiel. En fonction du fait que ce temps de blocage apparaisse avant ou après la réalisationdu job sur une machine, nous parlerons de temps de blocage di!érentiel "avant" ou "après".

Heuristique pour les problèmes de type FlowShop avec blocage RCb. 237
Ainsi, sur l’exemple de la figure 1, le job Jj sur M2 induit un temps de blocage di!érentiel"avant" sur M1 dû à une durée de Jj sur M1 inférieure à celle de Ji sur M3. De même, le jobJj sur M2 induit un temps de blocage di!érentiel "après" sur M3 dû à une durée de Jj surM2 supérieure à celle de Ji sur M4.L’heuristique proposée construit une solution en plaçant, parmi les jobs non encore placés,celui qui présente le moins de temps de blocage di!érentiel avec la solution partielle existante.Une séquence débutant par chacun des jobs est construite et la meilleure des séquences estchoisie pour l’étape suivante. Ensuite, on procède à une amélioration locale. Le job qui, danscette séquence, présente le temps de blocage di!érentiel le plus élevé, est permuté avec tousles autres jobs de la séquence et la meilleure solution est retenue. On continue tant que lespermutations améliorent le makespan.Le tableau 1 compare les résultats de cette heuristique (HCS2) à ceux donnés par MNEH[4]. Les résultats obtenus sont du même ordre de grandeur. HCS2 devient plus performante àmesure que le nombre de jobs à ordonnancer augmente.
Tab. 1. Comparaison des résultats des heuristiques MNEH et HCS2
Jobs 5 5 5 10 10 10 20 20 20 50 50 50Machines 5 10 20 5 10 20 5 10 20 5 10 20
MNEH 0.99 0.69 0.38 2.64 2.38 2.61 9.19 14.73 16.29 9.48 19.45 24.71HCS2 0.66 0.77 0.61 1.64 2.7 2.95 7.47 16.17 21.17 6.82 16.82 23.51
2 Conclusion
En nous appuyant sur la définition du blocage di!érentiel, nous avons proposé une heuris-tique e"cace dédiée aux problèmes d’ordonnancement de flowshop avec blocage RCb. Dansla suite, nous allons considérer cette heuristique comme point de départ d’une optimisationplus poussée avec des méta-heuristiques du type algorithmes génétiques, par exemple. Noustravaillerons également au développement d’autres heuristiques pour résoudre les mêmes pro-blèmes et ainsi profiter de temps de calcul quasi-immédiats.
Références1. Fink, A., et Voss, S. : Solving the continuous flow-shop scheduling problem by metaheuristics,
European Journal of Operational Research, 151, pp. 400-414 (2003).2. Framinan, J.M., Gupta, J.N.D. et Leisten, R. : A review and classification of heuristics for per-
mutation flow-shop scheduling with makespan objective, JORS, 55(12), pp. 1243-55 (2004).3. Nawaz,M. and Enscore,E. et Ham,I. : A heuristic algorithm for the m-machine, n-job flowshop
sequencing problem, OMEGA, The International Journal of Management Science, 11(1), pp. 91-95(1983).
4. Martinez., S. : Ordonnancement de systèmes de production avec contraintes de blocage, Thèse deDoctorat de l’Université de Nantes (2005).

238 Sauvey, Sauer
5. Dauzère-Pérès, S., Pavageau, C. et Sauer, N. : Modélisation et résolution par PLNE d’un problèmeréel d’ordonnancement avec contraintes de blocage, ROADEF’2000, pp. 216-217, Nantes (2000).
6. Martinez, S., Dauzère-Pérès, S., Guéret, C., Mati, Y. et Sauer, N. : Complexity of flowshop sche-duling problems with a new blocking constraint. EJOR, 169(3), pp.855-864 (2006).
7. Yuan, K. et Sauer, N. : Application of EM algorithm to flowshop sheduling problems with a specialblocking, IESM’07, Chine (2007).

Flow shop à deux machines et moyen de transportintermédiaire
N. Chikhi, et M. Boudhar
Faculté de Mathématiques, USTHB, BP 32, 16111 El Alia, Bab-Ezzouar, Algiers, [email protected]
1 Introduction
Ce travail traite du problème de l’ordonnancement de type flow shop à deux machines en in-troduisant un système de transport de tâches (robot ou convoyeur) entre les deux machines.Ce système de transport de tâches semi-finies est également impliqué dans le chargementet le déchargement des machines. Ce modèle peut être illustré par l’exemple d’un atelier detraitement de surface de galvanoplastie dont le procédé consiste à déposer une fine couche demétal sur des pièces. Le déplacement des pièces est principalement e!ectué par un chariotde manutention circulant le long d’un axe. Il peut être illustré aussi dans le cas des ateliersà cellules robotiques qui se trouvent, typiquement, dans les usines de fabrication des semi-conducteurs ou de textiles, dans lesquels un véhicule auto-guidé est chargé de déplacer lestâches. Les tâches venant d’être exécutées sur la première machine attendent le convoyeurpour être transportées vers la deuxième machine. L’objectif est de construire un ordonnance-ment minimisant la date de fin de traitement de l’ensemble des tâches. Le problème généralest NP-di"cile. Nous donnons une formulation mathématique, nous montrons que deux casparticuliers de ce problème sont polynomiaux et nous donnons deux algorithmes optimauxpour les résoudre. Nous présentons également des heuristiques pour la résolution du problèmegénéral avec des expérimentations numériques.
2 Principaux résultats
Soit le problème qui consiste à ordonnacer n tâches indépendantes T1, ...Tn sur deux machinesM1 et M2 dans un atelier de type flow shop. Chaque tâche Ti (i = 1, ..., n) est composée dedeux opérations, la première està exécuter sur la machine M1 et la deuxième sur la machineM2 et est caractérisée par des temps de traitement pi1 et pi2, respectivement sur les deuxmachines et ne possède pas de dates de disponibilité ni de dates échues. Le transport d’unetâche de la machine M1 à la machine M2 s’e!ectue grâce à un véhicule autoguidé ou unchariot et nécessite un temps de transport égal à t (l’aller-retour nécessite 2t). La capacitédu chariot peut être limitée (au maximum c pièces ) ou illimitée. Le problème ainsi défini estnoté TF2/6 = 1, c ( 1/Cmax ( 6 est le nombre de convoyeurs).Nous proposons une modélisation mathématique du problème sous forme d’un programmelinéaire en variables entières et bivalentes. Ce modèle mathématique a été testé en utilisantles solveurs LINGO et CPLEX. Nous avons obtenu de bons résultats pour des instances detaille réduite.

240 Chikhi, Boudhar
Nous proposons aussi des bornes inférieures pour la fonction objectif. Nous étudions quelquessous problèmes du problème général. On cite essentiellement les cas : TF2/pi1 = p, 6 = 1, c (1/Cmax et TF2/pi2 = p, 6 = 1, c ( 1/Cmax.Etant montré que le problème général TF2/6 = 1, c ( 1/Cmax est NP-di"cile, nous propo-sons des heuristiques pour le résoudre. Ces heuristiques sont basées sur la règle de Johnsonou sur de nouvelles règles de priorité que nous avons défini et sur d’autres règles de prio-rité connues, ainsi que sur une procédure que nous avons réalisé qui permet la constructiondes di!érents batchs. Ces heuristiques sont testées en utilisant plusieurs instances généréesaléatoirement.Les résultats obtenus sur les di!érents tests ont révélé que les heuristiques basées sur lerangement des tâches selon la règle LPT (Longuest Processing Time) par rapport aux tempsd’exécution sur la deuxième machine et sur la procédure de construction des batchs conduisentgénéralement à de très bonnes solutions qui sont optimales dans la majorité des cas.
Références
1. Brucker, P., and Knust, S. (2004) : Complexity results for flow-shop and open-shop schedulingproblems with transportation delays, Annals of Operations Research, vol. 129, pp. 81–106.
2. Chen, ZL., and Lee, CY. (2001) : Machine scheduling with transportation considerations. Journalof scheduling, vol. 4, pp. 3–24.
3. Hurink, J., and Kunst, S. (1998) : Flow-shop problems with transportation times and a singlerobot. Université Osnabrack.
4. Kise, H. (1991) : On an automated two-machine flowshop scheduling problem with infinite bu#er.Journal of the Operations Research Society of Japan, vol. 34, pp. 354–361.
5. Panwalker, S.S. (1991) : Scheduling of a two machine flow shop with travel time between machines.J. Opl. Res. Soc, vol. 42, No 7, pp. 609–613.
6. Soukhal, A., Oulamara, A., and Martineau, P. (2005) : Complexity of flow shop scheduling pro-blems with transportation constraints. European Journal of Operational Research, vol. 161, pp.32–41.

An integrated approach for lot streaming and just intime scheduling
O.Hazir1 and S. Kedad Sidhoum1
Laboratoire d’Informatique de Paris 6, 104 Avenue du President Kennedy, 75016 Paris, France.{oncu.hazir,safia.kedad-sidhoum}@lip6.fr
1 Introduction
Production planning and control decisions are traditionally categorized into three : the strate-gic level, the tactical level and the operational level. In this research, we focus on the tacticaland operational levels, and concentrate on lot sizing, lot streaming and scheduling problems.Lot sizing decision, which is at tactical level, identifies when and how much to produce so thattotal cost is minimized. On the other hand, lot streaming decisions deal with splitting theproduction into batches with respect to the quantities planned. By the use of lot streaming,lead times and work in process (WIP) inventories - control of which is crucial in just in time(JIT) production- could be reduced. Furthermore, integration of a pegging and a schedulingmodule that assigns lots to demands and sets the starting time of the lots minimizing timeor cost based criterion is valuable to generate globally optimal plans.Integrated lot sizing and scheduling problems has been a research topic with practical im-plications [1]. In scheduling, models with both earliness and tardiness penalties cope withthe JIT requirement of lower lead times and WIP. These models have been investigated byvarious researchers (see [5] for non-preemptive models and [2] for preemptive case). In ma-chine scheduling models, either job processing times are usually assumed to be fixed ; or insome cases they are assumed to be controllable [3]. When lot streaming is incorporated, earlycompletion of the lots is possible. Recently [4] combined lot-streaming and pegging, whichaddresses transfer of materials between stocks and users, and used linear programming soft-ware to solve their model. In addition, she proposed a dynamic programming model thatminimizes the sum of production costs and weighted tardiness cost. But, early release of thebatches have not been penalized in this study. Addressing the just in time scheduling systems,we incorporate the earliness costs as well.
2 Problem Definition
We consider a single production system which can handle at most one customer order ata time. Each customer order k has a distinct due date dk. Demand is deterministic and allorders are ready to be processed at time zero. For each order, individual earliness and tardinesscompletion time penalties, %k and &k, are given. There exits upper and lower bounds, b andB, on the size of batch i, and two pegging conditions are considered : in mono-pegging it isrequired that each customer order is met from a single batch, on the contrary in multi-peggingorders could be satisfied from di!erent batches. Batch availability is assumed, meaning thatproducts could not be released before its batch is completely processed. The goal is to split

242 O.Hazir, S. Kedad Sidhoum
the production into batches and schedule them so that the sum of earliness and tardinesscosts is minimized. These costs are computed per unit time and per unit material. Therefore,we minimize the absolute deviation between the completion time of a batch and the due dateof the order satisfied by the batch multiplied with the quantity delivered by the batch. Todefine formally, let qki represent the quantity of order k processed in batch i and Ci be thecompletion time of batch i. A production schedule S could be defined with the set of thesedecision variables. We can formulate the total cost of the optimal schedule as follows :
f$(q, C) =Min'%
k
%
i
7%kq
ki (dk # Ci)+ + &kq
ki (Ci # dk)+8 : b "
%
k
qki " B ,i(
3 Structural PropertiesRobert [2007] investigated the total tardiness problem and defined the following dominancecriteria :1. Processing the batches in a left justified single block without idle times is dominant.2. When b = 1, creating batches of size 1 in multi-pegging and a batch for each order in
mono pegging is dominant.3. In multi-pegging, with unitary weights, i.e. &k = 1 ,k, earliest due date (EDD) schedules
are dominant.4. In multi-pegging, the batches with sizes in between b and 2b# 1 are dominant.
When earliness costs are incorporated, we can list some of the properties for multi-peggingcase with demand independent weights, i.e. %k = %, &k = & ,k as follows :1. Earliest due date (EDD) schedules are dominant.2. When b = 1, there exists an optimal schedule in which each order is processed within a
single block, which is a group of batches that contains no idle time.3. The batches with sizes in between b and 2b#1 are dominant for the tardy batches, which
consist of only tardy orders.We will present some other structural properties of the optimal solution and develop ane"cient dynamic programming algorithm that uses these properties.
Références1. Dauzère-Pérès S. and Lasserre J.B. On the importance of sequencing decisions in production plan-
ning and scheduling. International Transactions in Operational Research, 9(6) : 779-793,(2002).2. Hendel Y, Runge N., Sourd F. : The one-machine just-in-time scheduling problem with preemp-
tions Discrete Optimization (article in press)3. Jozefowska J. Just-in-Time Scheduling Models and Algorithms for Computer and Manufacturing
Systems 1st ed. Springer. New York,U.S. (2007)4. Robert A. Optimization des batches de production. PhD thesis, Université Pierre et Marie Curie
(Paris 6)(2007).5. Sourd F., Kedad-Sidhoum S. A faster branch-and-bound algorithm for the earliness-tardiness
scheduling problem. Journal of Scheduling 11(1) : 49-58 (2008).

A hybrid genetic algorithm for the vehicle routingproblem with private fleet and common carriers
J. Euchi, and H. Chabchoub,
FSEGS, route de l’aÈroport km 4, Sfax 3018 [email protected]
1 IntroductionDespite its wealth and abundance of work that are devoted to it, the Vehicle Routing Problemwith Private fleet and common Carrier (VRPPC) represent only a subset of a larger familyknown as "Vehicle Routing problem- VRP". The VRP is one of the optimization problemsmost studied.This problem holds the attention of several researchers for many years, and everywhere inthe world. Several authors have made a literature review that deal with vehicle routing theseinclude those of Bodin et al. [2], Laporte [8,], and Toth and Vigo [11]. More specifically,two types of problems have been addressed in literature : the vehicle routing problem withlimited fleet and the vehicle routing problem with private fleet and common carrier. Someauthors have studied the problem of vehicle routing with limited fleet include Gendreau etal. [7], Taillard [10] and Li et al. [9]. All these items using a mixed fleet limited but su"cientcapacity to serve all customers.At the level of routing problem with external carrier are Volgenant and Jonker [12], whichdemonstrated that the problem involving a fleet of one single vehicle and external carrierscan be rewritten as Traveling Salesman Problem - TSP. This problem also have been studiedby Diaby and Ramesh [6] whose objective was to decide that customers visited with externalcarrier and optimize the tour of remaining customers.Several approaches have been used to solve the classical VRP, exact methods, heuristicsand metaheuristics solution principally are proposed. To our knowledge, the VRPPC wasintroduced by Ball et al. [1], Chu [5] and Bolduc et al. [3, 4].Under this extended abstract, we are studying the vehicle Routing Problem with Private fleetand Common carrier- VRPPC. The network studied consists of a depot and several customers.One or more products are distributed. Each customer must be served one and only once by theprivate fleet either by a common carrier. The internal fleet is composed of a limited numberof vehicles. The capacity of vehicles is determined in terms of units produced. The vehicleshave both a fixed cost of use and a variable cost depending on the distance travelled. Thecosts of external transport are set for each customer depending on its geographical locationand quantities required.
2 Problem definitionOne of the most general version of the vehicle routing problem is the vehicle routing problemwith private fleet and common carrier (VRPPC), which can be formally described in the

244 Euchi, Chabchoub
following way. Let G = (V,A) be a graph where V = {0, 1, ..., n} is the vertex set andA = {(i, j) : i, j ! V, i 9= j} is the arc set. Vertex 0 is a depot, while the remaining verticesrepresent customers. A private fleet of m vehicles is available at the depot. The fixed cost ofvehicle k is denoted by fk, its capacity by Qk, and the demand of customer i is denoted byqi. A travel cost matrix (cij) is defined on A . If travel costs are vehicle dependent, then cijcan be replaced with cijk, where k ! 1, ...,m . Each customer i can be served by a vehicle ofthe private fleet, in which case it is called an internal customer or by a common carrier at acost equal to ei , in which case it is called an external customer.
3 A hybrid genetic algorithm to solve the VRPPC
We propose a hybrid genetic algorithm to solve the VRPPC. To improve the solution genera-ted with a genetic algorithm, it is recommended to hybridize it with a variable neighbourhoodsearch. In this section we discuss the step of our proposal algorithm to solve the vehicle routingwith limited fleet and common carrier.Genetic algorithm in the initialization phase may be started from heuristic created solution.In the first step we consider that all vehicles are at the depot. Second, for every step we selectrandomly a customer and we insert it in the best position that minimizes the total cost andthat satisfy the capacity constraint.A selection mechanism is necessary when selecting individuals for both reproducing and sur-viving. We select at randomly 2 solutions from 25% of the best solutions. Then we apply thecrossover, a simple crossover starts with two parent solution and chooses a random cut, whichis used to divide both parents into two parts. It generates one o!spring’s that is obtained byputting together customers in first vector in front of the cut and we choose the customers inorder of position in second vector.After the selection and crossover, we use the tournament replacement. A subset of individualsis selected at random, and the worst one is selected for replacement.Finally to improve the solution generated with genetic algorithm, we propose to apply theVNS algorithm. The VNS algorithm start with the initial solution obtained with the geneticalgorithm, and then shaking is performed. We use a permutation move, it consists of replacingall possible swaps of pairs of di!erent positions. If the swap moves improve the solution, weapply the insertion local search.We use a maximum number of iteration as a stopping criterion.
4 Computational results
In order to evaluate and to compare the performance of the our proposed algorithm wecompare it with the results presented in the literature.A hybrid genetic algorithm were tested on a set of benchmark problems of Bolduc et al.[3].The results shows the proposed genetic algorithm framework with variable neighbourhoodsearch could provide reasonably good solutions. Also the computational time for all instancesis reasonable.

A hybrid genetic algorithm for the VRPPC 245
Références
1. Ball MO, Golden A, Assad A, Bodin LD. : Planning for truck fleet size in the presence of acommon-carrier option. Decision Sciences 14, 103-120 (1983)
2. Bodin, L. D., B. L. Golden, A. A. Assad, and M. O. Ball. : Routing and scheduling of Vehiclesand crews. The state of the Art, Computers and operations research, 10, 69-211 (1983)
3. Bolduc M.-C., Renaud J., Boctor F.F. : A heuristic for the routing and carrier selection problem.Short communication. European Journal of Operational Research 183, 926-932(2007)
4. Bolduc M.-C., Renaud J. Boctor F.F., Laporte G. : A perturbation metaheuristic for the vehiclerouting problem with private fleet and common carriers. Journal of the Operational ResearchSociety (200) 59, 776-787.
5. Chu C-W. : A heuristic algorithm for the truckload and less-than-truckload problem. EuropeanJournal of Operational Research 165, 657-667(2005)
6. Diaby M, Ramesh R. : The Distribution Problem with Carrier Service : A Dual Based PenaltyApproach. ORSA Journal on Computing 7, 24-35(1995)
7. Gendreau M., Laporte G., Musaraganyi C., Taillard . . ..D. : A tabu search heuristic for the hetero-geneous fleet vehicle routing problem. Computers and Operations Research 26, 1153-1173(1999)
8. Laporte, G. : The Vehicle Routing Problem : An overview of exact and approximate algorithms.European Journal of Operational Research, 59 (3), 345-358 (1992)
9. Li F., Golden B.L., Wasil E.A. : A record-to-record travel algorithm for solving the heterogeneousfleet vehicle routing problem. Computers and Operations Research, 34 2734-2742(2007)
10. Taillard ED. : A heuristic column generation method for the heterogeneous fleet VRP. RAIRO33 (1), 1-14 (1999)
11. Toth P., Vigo D. : Models, relaxations and exact approaches for the capacitated vehicle routingproblem. Discrete Applied Mathematics, 123, 487-512 (2002)
12. Volgenant T., Jonker R. : On some generalizations of the travelling-salesman problem. Journalof the Operational Research Society 38,1073-1079(1987)

Un algorithme exact bi-objectif pour le problème duvoyageur de commerce multi-modal
Nicolas Jozefowiez1,2, Gilbert Laporte3, and Frédéric Semet4
1 CNRS ; LAAS ; 7 avenue du colonel Roche, F-31077 Toulouse, [email protected]
2 Université de Toulouse ; UPS, INSA, INP, ISAE ; LAAS ; F-31077 Toulouse, France.3 CIRRELT, HEC-Montréal, 3000 Chemin de la Côte-Sainte-Catherine, Montréal, QC, Canada
4 LAGIS, Ecole Centrale de Lille - Cité Scientifique - BP48 - 59651 Villeneuve d’Ascq Cedex,France.
1 Problème
Dans cet article, nous nous intéressons à la résolution d’un problème de tournées bi-objectif :le problème du voyageur de commerce multi-modal. Les données du problème consistent enun graphe non orienté valué G = (V,E) et d’un ensemble de couleurs C. Chaque arête e ! Ea une couleur -(e) ! C. Les couleurs peuvent être vues comme des moyens de transport, desmoyens de production ... Le but du problème est de générer une tournée en minimisant salongueur et le nombre de couleurs qu’elle utilise. Une couleur k ! C est dite utilisée si unearête e ! 7(k) est empruntée pendant la tournée avec 7(k) = {e ! E|-(e) = k}. Le problèmepeut être modélisé de la manière suivante :
min (%
e%Ecexe,
%
k%Cuk) (1)
%
e%)({i})xe=2 ,i ! V (2)
%
e%)(S)xe(2 ,S 1 V, 3 " |S| " |V |# 3 (3)
xe"u*(e) ,e ! E (4)xe ! {0, 1} ,e ! E (5)uk ! {0, 1} ,k ! C (6)
où #(S) = {e = (i, j) ! E|i ! S et j ! V \ S}, ce est le coût de l’arête e ! E, xe vaut 1 si eest utilisée, 0 sinon, uk vaut 1 si k ! C est utilisée, 0 sinon. On peut ajouter au modèle lescontraintes valides suivantes :
uk"%
e%+(k)xe ,k ! C (7)
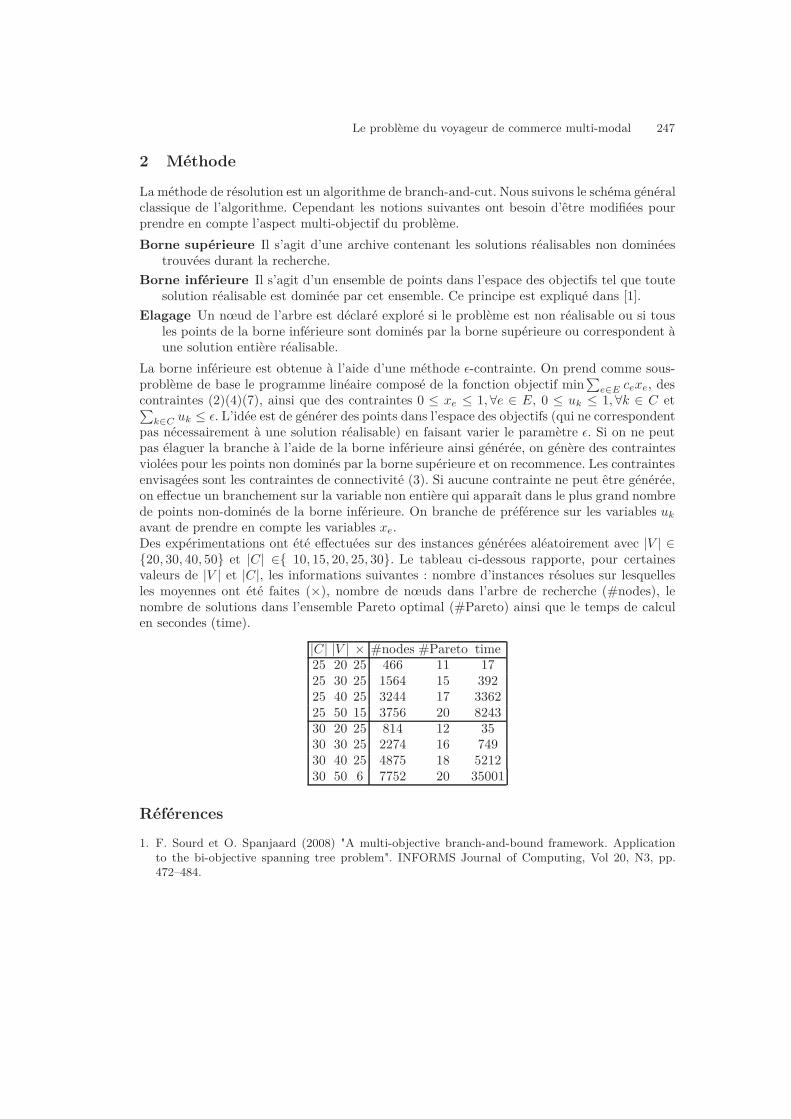
Le problème du voyageur de commerce multi-modal 247
2 MéthodeLa méthode de résolution est un algorithme de branch-and-cut. Nous suivons le schéma généralclassique de l’algorithme. Cependant les notions suivantes ont besoin d’être modifiées pourprendre en compte l’aspect multi-objectif du problème.Borne supérieure Il s’agit d’une archive contenant les solutions réalisables non dominées
trouvées durant la recherche.Borne inférieure Il s’agit d’un ensemble de points dans l’espace des objectifs tel que toute
solution réalisable est dominée par cet ensemble. Ce principe est expliqué dans [1].Elagage Un nœud de l’arbre est déclaré exploré si le problème est non réalisable ou si tous
les points de la borne inférieure sont dominés par la borne supérieure ou correspondent àune solution entière réalisable.
La borne inférieure est obtenue à l’aide d’une méthode 2-contrainte. On prend comme sous-problème de base le programme linéaire composé de la fonction objectif min
&e%E cexe, des
contraintes (2)(4)(7), ainsi que des contraintes 0 " xe " 1, ,e ! E, 0 " uk " 1, ,k ! C et&k%C uk " 2. L’idée est de générer des points dans l’espace des objectifs (qui ne correspondent
pas nécessairement à une solution réalisable) en faisant varier le paramètre 2. Si on ne peutpas élaguer la branche à l’aide de la borne inférieure ainsi générée, on génère des contraintesviolées pour les points non dominés par la borne supérieure et on recommence. Les contraintesenvisagées sont les contraintes de connectivité (3). Si aucune contrainte ne peut être générée,on e!ectue un branchement sur la variable non entière qui apparaît dans le plus grand nombrede points non-dominés de la borne inférieure. On branche de préférence sur les variables ukavant de prendre en compte les variables xe.Des expérimentations ont été e!ectuées sur des instances générées aléatoirement avec |V | !{20, 30, 40, 50} et |C| !{ 10, 15, 20, 25, 30}. Le tableau ci-dessous rapporte, pour certainesvaleurs de |V | et |C|, les informations suivantes : nombre d’instances résolues sur lesquellesles moyennes ont été faites (*), nombre de nœuds dans l’arbre de recherche (#nodes), lenombre de solutions dans l’ensemble Pareto optimal (#Pareto) ainsi que le temps de calculen secondes (time).
|C| |V | * #nodes #Pareto time25 20 25 466 11 1725 30 25 1564 15 39225 40 25 3244 17 336225 50 15 3756 20 824330 20 25 814 12 3530 30 25 2274 16 74930 40 25 4875 18 521230 50 6 7752 20 35001
Références1. F. Sourd et O. Spanjaard (2008) "A multi-objective branch-and-bound framework. Application
to the bi-objective spanning tree problem". INFORMS Journal of Computing, Vol 20, N3, pp.472–484.

Utilisation de la moyenne de Hölder dans uneoptimisation multi-critères du transport à la demande
Rémy CHEVRIER
LIFL (UMR USTL/CNRS 8022) / INRIA Projet DOLPHIN,40 avenue Halley, 59650 Villeneuve d’Ascq Cedex France.
1 Introduction
Le Transport à la Demande (TAD) est une forme de transport public collectif terrestre à mi-chemin entre le taxi et le bus. Ce type de service o!re aux usagers une haute qualité de servicequi se traduit notamment par la possiblité de choisir les points de départ et de destinationainsi que les horaires. Le TAD est un service flexible activé seulement à la demande et iln’est pas, dans sa forme idéale [2], sujet à une ligne fixe qu’il devrait suivre en respectant deshoraires prédéfinis.Face au transport en commun classique, le TAD o!re un ensemble d’avantages comme larationalisation des coûts du service et nécessite donc un ensemble d’optimisations. En cela, ilest en lien direct avec les problèmes de tournées de véhicules tels que le Dial-a-Ride Problem(DARP) pour lequel un ensemble de travaux ont déjà été consacrés [4]. Cependant, les solu-tions proposées s’intéressent aux instances de la littérature et ne sont pas forcément adaptéesà des situations concrètes de demandes de service. À cette fin, nous exploitons des jeux d’ins-tances de TAD basés sur des données réalistes relatives au territoire du Pays de Montbéliard.L’optimisation des tournées est réalisée à l’aide d’un algorithme génétique multi-objectifs :NSGA-II [5]. Nous proposons ici d’analyser les e!ets de la moyenne de Hölder sur le calcul dutemps de parcours dans l’optimisation multi-critères d’un service de TAD. Nous souhaitonsmontrer les di!érences qualitatives des fronts de solutions obtenus selon la moyenne appliquéeà la réduction des temps de parcours.
2 Modèle d’optimisation
La rationalisation des coûts peut être vue sous plusieurs angles. Dans notre modèle, nousminimisons :– le nombre de véhicules (ensemble V ), i.e. coût économique : min |V | ;– les retards (qualité de service aux clients) en utilisant la distance de Minkowski (cf. [3]) ;– les temps de parcours en utilisant la moyenne de Hölder (minimisation du coût environne-
mental en réduisant les émissions de polluants), objectif ,.La moyenne de Hölder (power mean) généralise les moyennes [1] et se définit ainsi :Xq =
) 1n
&ni=1 x
qi
* 1q , i, n ! N, q ! R.
Dans le cas du DARP, la réduction des temps de parcours consiste généralement à minimiserla somme des temps de chaque véhicule [4], ce qui correspond à une moyenne arithmétique des

Une approche multi-critères dans le TAD 249
temps de parcours à un coe"cient 1n près. Nous proposons donc de comparer trois moyennes,
chacune étant un cas particulier de la moyenne de Hölder, appliquées à l’objectif , sur unedistribution de temps T = (t0, ..., tn) :– arithmétique : T q=1 = 1
n
&ni=1 ti ;
– harmonique : T q=#1 = n&n
i=11ti
;
– géométrique : T q-0 =)Kni=1 ti* 1n .
3 Résultats
Les figures 1(a,b) représentent des distributions de solutions obtenues avec trois configurationsd’optimisation (moy. géométrique, harmonique et arithmétique) pour une même instance à100 requêtes et sont représentatives des comportements di!érents des trois moyennes. Nousdisposons d’une trentaine d’instances générées à partir de données géographiques du Paysde Montbéliard [3]. Nous remarquons d’emblée les formes di!érentes des distributions, cequi montre clairement les di!érences de comportement de ces moyennes et leurs aptitudesà optimiser certains objectifs au détriment d’autres. La moyenne harmonique se révèle pluse"cace pour réduire les retards que la moyenne arithmétique, qui elle-même semble meilleuredans la diminution des temps de parcours.
40000
45000
50000
55000
60000
65000
20 30 40 50 60 70 80 90 100
Cum
ul d
es te
mps
de
parc
ours
(s)
Nombre de vehicules
P,G,L1P,H,L1
P,M1,L1
0
1000
2000
3000
4000
5000
6000
7000
8000
9000
10000
20 30 40 50 60 70 80 90 100
Cum
ul d
es re
tard
s (s
)
Nombre de vehicules
P,G,L1P,H,L1
P,M1,L1
Fig. 1. Fronts des solutions (a. gauche : véhicules/temps V/T, b. droite : véhicules/retards V/R)issues de trois configurations d’optimisation : G moy. géométrique, H moy. harmonique , M1 moy.arithmétique. Les flèches représentent les meilleurs compromis V/T et V/R.
Références
1. Bullen, P. : Handbook of Means and their Inequalities. 2nd edn. Springer (2003)2. Castex, É. : Le Transport à la Demande en France : de l’état des lieux à l’anticipation. Thèse de
Doctorat. Université d’Avignon et des Pays de Vaucluse (2007)3. Chevrier, R. : Optimisation de transport à la demande dans des territoires polarisés. ThËse de
Doctorat. Université d’Avignon et des Pays de Vaucluse (2008)

250 Rémy CHEVRIER
4. Cordeau, J.-F. et Laporte, G. : The Dial-a-Ride Problem : models and algorithms in Annals ofOperations Research, 153(1) 29–46 (2007)
5. Deb, K. : Multi-Objective Optimization using Evolutionary Algorithms. Wiley (2001)

Composition de services Webet équité vis-à-vis des utilisateurs finaux
J. El Haddad1 and O. Spanjaard2
1 LAMSADE, Université Paris Dauphine, Place du Maréchal de Lattre de Tassigny, 75775 ParisCedex 16 France.
[email protected] LIP6, Université Pierre et Marie Curie, 104 avenue du Président Kennedy, 75016 Paris France.
1 Composition de services Web
La migration des systèmes d’information des entreprises vers un schéma orienté Business toBusiness (i.e., des entreprises mettant leurs services à disposition d’autres entreprises sousforme de composants logiciels) a favorisé l’émergence des services Web depuis le début desannées 2000 [1]. Par exemple, une compagnie aérienne peut mettre en ligne à disposition desagences de voyage un service logiciel de réservation de vols. Pour fournir une valeur ajoutéeà l’utilisateur final, une agence de voyage peut décider de composer plusieurs services Webafin de faciliter l’organisation d’un séjour. Par exemple, une agence peut proposer un pack"déplacement" comportant d’une part la réservation d’un billet pour un événement sportif,d’autre part une réservation de billet de train ou d’avion. On parle alors de composition deservices Web [3]. Ce type de composition peut être représentée à l’aide d’un graphe de tâches,comme celui indiqué sur la Figure 1. Les tâches t1, t2 et t3 représentent respectivement uneréservation de place, une réservation de train ou de vol. Dans ce graphe, certains utilisateursemprunteront le chemin d’exécution $t1, t2% (ceux réservant un billet de train) et d’autres lechemin d’exécution $t1, t3% (ceux réservant un billet d’avion). Il arrive très fréquemment queplusieurs services répondent à un même ensemble de besoins fonctionnels. Par exemple, pourréaliser la réservation d’une place au stade, un utilisateur peut mettre en concurrence plusieursservices de billeterie. Une sélection de services Web consiste alors à assigner un service Web àchaque tâche. Cette a!ectation est appelée plan d’exécution. L’ensemble des plans d’exécutionpossibles est combinatoire : pour n tâches avec un choix parmi m services pour chacune, ily a mn compositions possibles. Afin de discriminer parmi ces plans d’exécution, on utilise lanotion de qualité de service. En e!et, les services Web simples asurant les mêmes propriétésfonctionnelles se distinguent les uns des autres par des critères de qualité de service, tels queréputation, coût, durée d’exécution etc. Etant donné un chemin d’exécution, la qualité deservice assurée par un service Web composite (résultant d’un plan d’exécution) sur un critèrepeut être calculée selon une règle d’agrégation propre à chaque critère. Le vecteur de qualitésde service ainsi obtenu est ensuite lui-même scalarisé en un indicateur unique de qualité viaune fonction d’agrégation. Le problème combinatoire qui se pose alors est de déterminer unplan d’exécution optimisant cet indicateur. Néanmoins, pour un même plan d’exécution, laqualité de service di!ère selon le chemin d’exécution emprunté par l’utilisateur final.

252 El Haddad, Spanjaard
Fig. 1. Organisation d’un déplacement par composition de services Web
2 Equité vis-à-vis des utilisateurs finauxDans le contexte de la composition de services Web, l’équité [5] va désigner le soucis de nepas léser un utilisateur final vis-à-vis d’un autre dans le plan d’exécution utilisé pour assurerles di!érentes tâches. La méthode proposée par Zeng et al. [2] pour prendre en compte lamultiplicité des scénarios possibles d’utilisation (i.e., des chemins d’exécution) consiste à :1) déterminer indépendamment la sélection optimale pour chacun des chemins d’exécution,puis 2) “fusionner” ces sélections en un plan d’exécution unique. Pour ce faire, les auteurs as-signent à chaque tâche le service choisi dans le chemin d’exécution correspondant au hot pathde cette tâche. Le hot path d’une tâche désigne le chemin d’exécution le plus souvent empruntélors des exécutions de cette tâche. Cette manière de procéder peut néanmoins conduire à dessélections globalement peu satisfaisantes, comme nous l’illustrerons dans notre exposé. Pourpalier cet inconvénient, nous chercherons ici à prendre en compte explicitement les di!érentsscénarios possibles d’utilisation. Nous nous inspirerons pour cela des travaux menés en opti-misation robuste [4], cette dernière notion étant proche formellement de la notion d’équité.Nous viserons en particulier à minimiser le critère de regret maximum, classiquement utilisépour mesurer la robustesse d’une solution. Dans notre contexte, nous qualifierons d’équitableune solution optimale au sens de ce critère. Nous proposerons une formulation du problème derecherche d’un tel plan d’exécution équitable avec un programme linéaire en nombres entiers.Enfin, nous présenterons les résultats d’expérimentations numériques menées sur le sujet.
Références1. Austin, D., and Barbir, A., Ferris, C. and Garg, S. : Web Services Architecture Requirements.
W3C Working Draft, http ://www.w3c.org/TR/2002/WD-wsa-reqs-20020819 (2002).2. Zeng, L., Benatallah, B., Ngu, A.H.H., Dumas, M., Kalagnanam, J. and Chang, H. : QoS-Aware
Middleware for Web Services Composition. IEEE Transactions on Sofware Engineering, Vol. 30,No. 5, p. 311–327 (2004).
3. Dustdar, S. and Schreiner, W. : A survey on web services composition. International Journal ofWeb and Grid Services, Vol. 1, No. 1, p. 1–30 (2005).
4. Kouvelis, P. and Yu, G. : Robust discrete optimization and its applications. Kluwer AcademicPublisher (1997).
5. Moulin, H. : Axioms of Cooperative Decision Making. Monograph of the Econometric Society,Cambridge University Press (1988).

Introduction au choix social computationnel
J. Lang
LAMSADE, Université Paris-Dauphine, France. [email protected]
La théorie du choix social s’intéresse à la construction et à l’analyse de méthodes pour ladécision collective. Or, les informaticiens s’intéressent de plus en plus au choix social. Il ya deux raisons à cela, qui correspondent à deux lignes de recherche di!érentes. La premièreconsiste à importer des notions et des méthodes issues du choix social pour résoudre desproblèmes apparaissant dans des domaines d’applications relevant de l’informatique : c’est lecas, en particulier, pour la gestion de sociétés d’agents logiciels autonomes, qui nécessite lamise en oeuvre de procédures de vote et de négociation ; un autre exemple est l’applicationde techniques venant du choix social pour développer des systèmes de classement de pagespour les moteurs de recherche sur Internet. La seconde, qui est celle qui nous intéresse plusparticulièrement ici, consiste à importer des notions et des méthodes venant de l’informa-tique (en particulier la recherche opérationnelle et l’intellige ! nce artificielle) pour résoudredes questions venant à l’origine du choix social. Le point de départ de cette ligne de rechercheest le fait que l’essentiel des travaux existants en théorie du choix social s’est focalisée surl’obtention de résultats abstraits concernant l’existence (ou, plus souvent, la non-existence)de procédures vérifiant un certain ensemble de propriétés, mais ont jusqu’ici négligé les as-pects algorithmiques. C’est justement sur ce point que l’informatique (et en particulier laRO) a beaucoup à apporter. Il s’agit avant tout d’identifier la complexité des procédures dechoix social, en particulier les procédures de vote et de partage équitable de ressources, etde proposer des algorithmes pour leur calcul exact ou approché. Ce domaine de recherche,à la croisée de la theorie du choix social et de l’informatique, souvent appelé choix socialcomputationnel, est en pleine e!ervescence – en témoigne le nombre croissant d’articles surce sujet, sur ! tout depuis le début des années 2000, ainsi que la tenue, en 2 ! 006 puis en2008, du workshop international “Computational Social Choice”. Le but de cet exposé est dedonner un bref aperçu de quelques-uns des principaux thèmes de recherche en choix socialcomputationnel :– étude de règles de vote computationnellement di"ciles ;– procédures de vote sur des domaines combinatoires ;– la complexité algorithmique comme barrage aux comportements stratégiques ;– protocoles d’élicitation de préférences et décision collective avec préférences incomplètes ;– algorithmique du partage équitable de ressources.
Références
1. Y. Chevaleyre, U. Endriss, J. Lang and N. Maudet, An introduction to computational socialchoice, Proceedings of SOFSEM-07, Lecture Notes in Artificial Intelligence 4362, Springer Verlag,2007,

Dominance de Lorenz itérée et recherche de solutionséquitables en optimisation combinatoire multi-agents
B. Golden and P. Perny
LIP6 - UPMC, 104 avenue du président Kennedy, 75016 Paris, [email protected], [email protected]
La recherche de solutions équitables dans les problèmes d’optimisation combinatoires multi-agents est un sujet qui se situe au carrefour de la modélisation des préférences et de l’optimi-sation combinatoire multi-objectifs. On considère des problèmes combinatoires multi-agents(typiquement des problèmes d’optimisation dans les graphes) où chaque agent exprime sonpoint de vue sur les solutions à l’aide d’une fonction coût additive, à minimiser. Chaque solu-tion est donc caractérisée par un vecteur coût dont la ième composante représente le coût de lasolution selon l’agent i. On s’intéresse alors à déterminer, parmi les solutions Pareto-optimales,celles qui sont les plus équitables en un certain sens. Le nombre de solutions Pareto-optimalespouvant croître exponentiellement avec la taille du problème, on ne cherche généralement pasà réaliser une énumération préalable et exhaustive des solutions Pareto-optimales mais plutôtà déterminer directement les solutions jugées les plus équitables. Il s’agit donc d’abord, ens’appuyant sur les travaux menés en théorie de de la décision et en économie, de proposer desmodèles décisionnels facilement manipulables, su"sament discriminants, et permettant derendre compte de la notion d’équité dans la comparaison de solutions, afin de promouvoir dessolutions qui répartissent équitablement les coûts entre les agents. Il s’agit ensuite d’aborderles aspects algorithmiques et complexité de ces problèmes et de proposer des algorithmes derésolution e"caces.Dans ce contexte de travail, l’objet de la présentation est de s’intéresser plus particulièrementà l’utilisation de la dominance de Lorenz d’ordre infini pour discriminer finement entre lessolutions et à son utilisation pour la résolution de problèmes d’optimisation équitable dans lesgraphes. La dominance de Lorenz est un modèle classique développé en économie qui permetde ra"ner la dominance de Pareto en incluant une idée d’équité modélisée par le principede transfert de Pigou-Dalton (schématiquement ce principe dit qu’on améliore une solutionsi l’on transfert une masse de satisfaction d’un agent plus satisfait vers un moins satisfait).Au lieu de comparer directement deux vecteurs x et y à l’aide de la dominance de Pareto, onchoisit de comparer leur transformées de Lorenz L(x) et L(y). La dominance résultante ditedominance de Lorenz est compatible avec la dominance de Pareto qu’elle ra"ne mais resteparfois assez peu discriminante. C’est pourquoi on peut s’intéresser à itérer la transforméede Lorenz pour considérer des dominances d’ordre supérieur et, à la limite, la dominance deLorenz d’ordre infini qui ra"ne toute dominance de Lorenz d’ordre k.Dans l’exposé, nous présentons et étudions la dominance de Lorenz d’ordre infini et la struc-ture de préférences qu’elle induit sur les solutions. Nous établissons un résultat de représen-tation à l’aide d’une moyenne pondérée ordonnée. Nous montrons alors comment déterminerdes solutions équitables (optimales au sens de la dominance de Lorenz d’ordre infini) dansdes problèmes combinatoires mutliagents (a!ectation, chemins, arbres).

Allocation de ressources distribuée dans un contextetopologique
S. Estivie1
LAMIH, Le Mont Houy, 59313 Valenciennes Cedex 9 [email protected]
1 Résumé
1.1 Le problème de l’allocation de ressources
Le problème de l’allocation de ressources au sens large est un cadre très général qui recouvreun grand nombre d’applications (commerce, répartition et partage de ressources, etc..)[4]. Unensemble d’agents dispose de ressources réparties entre eux et chacun de ces agents va chercherà augmenter son bien-être individuel en échangeant ses ressources propres avec d’autres agents.
1.2 Négociation et Bien-être social
Les agents vont contracter ou non des transactions selon leurs propres critères et donc selonleur propre bien-être sans se soucier du bien-être de la société, menant le système d’uneallocation initiale à une allocation finale. Cependant, il arrive bien souvent que le bien-êtregénéral du système aille à l’encontre des préférences des agents qui le composent lorsque ceux-ci agissent de manière autonome. Or dans ces sociétés où chaque agent cherche à maximiser sonbien-être individuel sans se soucier du bien-être de la société, il apparaît nécessaire d’étudierd’une part, l’évolution du bien-être social au cours de ces négociations et d’autre part l’issuede ces négociations. Dans ce dernier point, il s’agit de déterminer si à la fin de la négociation,le bien-être social atteint sa valeur optimale. Dans le cas où l’optimalité n’est pas atteinte, ilest alors judicieux de s’intéresser à la distance entre l’allocation finale et l’allocation optimale.
1.3 Topologie
Les travaux existants sur le sujet [5,3] ont majoritairement fait abstraction de la topologie ensupposant que les agents avaient la possibilité de communiquer avec tous les autres agents sansaucune restriction ni préférence. Cependant, dans les domaines d’applications il arrive souventque les agents ne puissent communiquer qu’avec certains agents, et cela pour des raisonstrès diverses [9] . Par conséquent, dans ces cas, l’hypotèse d’un graphe de communicationtotalement connecté n’est plus possible.Dans un contexte présentant des restrictions sur les intéractions potentielles entre les agents,la question est de savoir quelles seront les conséquences de ces dernières sur le processus denégociation (atteinte de l’allocation optimale : convergence et complexité) puis de proposerdes solutions permettant d’optimiser l’issue de ces négociations contraintes.Pour celà, nous utiliserons le modèle de topologie pour la négociation proposé dans [2]. Danscelui-ci, la topologie et les restrictions qui en découlent sont modélisées sous forme de graphe

256 Estivie
dans lequel chaque noeud représente un agent et chaque arrête représente une communicationpossible entre deux agents. Afin de se rapprocher le plus possible des domaines d’applica-tion, nous ra"nerons ce modèle de topologie en utilisant plus particulièrement trois types degraphes : les graphes aléatoires [6,7], les scale-free [1] et les small-world[8].
Références
1. Caldarelli G. : Scale-free networks : complex webs in nature and technology. Oxford Univ. Press,Oxford (2007)
2. Chevaleyre Y., Endriss U.,Maudet N. : Allocating Goods on a Graph to Eliminate Envy. Procee-dings of the 22nd AAAI Conference on Artificial Intelligence (AAAI-2007), AAAI Press, 700–705,(2007)
3. Chevaleyre Y., Endriss U., Estivie S., Maudet N. : Multiagent Resource Allocation in k-additiveDomains : Preference Representation and Complexity. Annals of Operations Research, 163(1) :49–62, (2008)
4. Chevaleyre Y., Dunne P., Endriss U., Lang J., Lemaître M., Maudet N., Padget J., Phelps S.,Rodríguez-Aguilar J., Sousa P. : Issues in Multiagent Resource Allocation. Informatica, 30 :3–31,(2006)
5. Endriss U., Maudet N., Sadri F., Toni F. : Negotiating Socially Optimal Allocations of Resources.Journal of Artificial Intelligence Research, 25 :315–348, (2006)
6. Erdos P., Rényi A. : On random graphs. Publicationes Mathematicae Debrecen, 6 :290–297, (1959)7. Newman M. E. J. : The structure and function of complex networks. SIAM Review, 45 :167–256,
(2003)8. Watts D. J. : Networks, dynamics, and the small world phenomenon. Amer. J. Sociol., 105 :493–
592, (1999)9. Wilhite, A. : Bilateral trade and Ôsmall-worldÕ net- works. Computational Economics 18(1) :4964,
(2001).

Détermination du vainqueur d’une élection : complexitédes procédures de Slater et de Condorcet-Kemeny
O. Hudry
École nationale supérieure des télécommunications, 46, rue Barrault, 75634 Paris Cedex [email protected]
1 Introduction
On considère le problème de vote suivant : étant donnés un ensemble X de n candidats àune élection et un ensemble de m votants dont on connaît les préférences sur X , commentdéterminer le vainqueur de l’élection ?Plusieurs procédures ont été proposées pour résoudre ce problème (voir par exemple [?]). Àla fin du 18e siècle, Condorcet [2] proposait une méthode reposant sur des comparaisons parpaires. Dans une telle méthode, on suppose que les préférences des votants s’expriment sous laforme d’ordres totaux définis sur X . Cette collection d’ordres totaux constitue le profil associéà l’élection. Pour chaque couple (x, y) de candidats avec x 9= y, on calcule le nombre mxy devotants préférant x à y. On dit que x est majoritairement préféré à y si on a mxy ( myx(ou mxy > myx si on considère des préférences strictes). S’il n’y a pas d’ex æquo, ce quel’on supposera dans la suite, on peut alors définir le tournoi majoritaire T = (X,A) associéà l’élection de la façon suivante. Un tournoi est un graphe orienté complet antisymétrique :entre deux sommets distincts x et y, il existe un et un seul des deux arcs (x, y) ou (y, x).Ici, l’ensemble des sommets de T est l’ensemble X des candidats ; pour toute paire {x, y} desommets avec x 9= y, l’arc (x, y) appartient à A si on a mxy > myx. Si on veut tenir comptede l’intensité des préférences, on peut aussi pondérer l’arc (x, y) par mxy # myx (voir parexemple [?] pour une justification de ces poids).Il se peut que le tournoi obtenu T soit transitif. Dans ce cas, il représente un ordre total Oque l’on peut adopter comme préférence collective. On appellera vainqueur de O le candidatpréféré aux autres dans O. Mais il se peut aussi que T ne soit pas transitif, même si lespréférences individuelles sont des ordres totaux. Dans ce cas, la détermination d’une préférencecollective, ou même seulement d’un vainqueur, peut être délicate. Nous considérons deux desnombreuses procédures proposées pour résoudre ce problème (voir [4] pour des références surces deux procédures) : la procédure de Slater [11] et celle de Condorcet-Kemeny [10].
2 Description et complexité des deux procédures de vote
La méthode proposée par P. Slater consiste à déterminer un ordre à distance minimum deT , la distance entre T et un ordre total O étant donnée par le nombre d’arcs n’ayant pasla même orientation dans T et dans O. Le minimum de cette distance, noté i(T ), est appeléindice de Slater de T. Un ordre à distance de T égale à i(T ) est appelé ordre de Slater de T .Un vainqueur de Slater de T est le vainqueur d’un ordre de Slater de T .

258 Hudry
La méthode proposée vraisemblablement par Condorcet lui-même et retrouvée par d’autreschercheurs, dont J.G. Kemeny, consiste aussi à déterminer un ordre à distance minimum deT , mais la distance entre T et un ordre total O est ici donnée par la somme des poids des arcsn’ayant pas la même orientation dans T et dans O. On appellera indice de Condorcet-Kemenyle minimum de cette distance, minimum que l’on notera k(T ). Un ordre à distance de T égaleà k(T ) est appelé ordre de Condorcet-Kemeny de T . Un vainqueur de Condorcet-Kemeny deT est le vainqueur d’un ordre de Condorcet-Kemeny de T .Pour chacune de ces méthodes, on s’intéresse à la complexité des problèmes suivants, où Tdésigne le tournoi majoritaire (pondéré ou non) de l’élection :– déterminer un vainqueur de T selon la méthode considérée ;– déterminer tous les vainqueurs de T selon la méthode considérée ;– étant donné un élément x de X , déterminer si x est un vainqueur de T selon la méthode
considérée ;– calculer i(T ) et k(T ) ;– déterminer un ordre de Slater ou de Condorcet-Kemeny de T ;– étant donné un ordre total O défini sur X , déterminer si O est un ordre de Slater ou de
Condorcet-Kemeny de T .Des résultats récents ([1], [3], [5]) concernant le problème appelé Feedback Arc Set problemappliqué aux tournois permettent d’établir des transformations de Turing montrant que lesvariantes envisagées des problèmes de Slater et de Condorcet-Kemeny sont la plupart NP-di"ciles (voir [6] et [8]). On s’intéressera aussi à la localisation de ces problèmes dans lahiérarchie polynomiale et au rôle joué par le codage du profil dans la complexité de cesproblèmes.
Références1. Alon N. : Ranking tournaments. SIAM Journal on Discrete Mathematics 20 (1), 137–142, 2006.2. Caritat, M.J.A.N., marquis de Condorcet : Essai sur l’application de l’analyse à la probabilité des
décisions rendues à la pluralité des voix. Imprimerie royale, Paris, 1785.3. Charbit P., Thomassé, S., Yeo A. : The minimum feedback arc set problem is NP-hard for tour-
naments. Combinatorics, Probability and Computing 16 (1), 1–4, 2007.4. Charon, I., Hudry, O. : A survey on the linear ordering problem for weighted or unweighted
tournaments. 4OR 5 (1), 5–60, 2007.5. Conitzer V. : Computing Slater Rankings Using Similarities Among Candidates. In Proc. of the
21st National Conference on Artificial Intelligence (AAAI-06), Boston, MA, USA, 613–619, 2006.6. Hemaspaandra E., Spakowski H., Vogel J. : The complexity of Kemeny elections. Theor. Comput.
Sci. 349(3), 382–391, 2005.7. Hudry, O. : Complexity of voting procedures. In Encyclopedia of Complexity and Systems Science,
R. Meyers (éd.), Springer, New York, 2009.8. Hudry, O. : On the complexity of Slater’s problems. Soumis pour publication.9. Hudry, O., Leclerc, B., Monjardet, B., Barthélemy, J.-P. : Médianes métriques et laticielles. In
Concepts et méthodes pour l’aide à la décision, vol. 3 : analyse multicritère, sous la direction deD. Dubois, M. Pirlot, D. Bouyssou et H. Prade, Hermès, 271–316, 2006.
10. Kemeny J.G. : Mathematics without numbers. Daedalus 88, 577–591, 1959.11. Slater P. : Inconsistencies in a schedule of paired comparisons. Biometrika 48, 303–312, 1961.

Apprentissage distribué d’états stables pour le routage
D. Barth1, O. Bournez2, O. Boussaton3, and J. Cohen1
1 Laboratoire PRiSM, Université de Versailles. 45, avenue des Etats-Unis, 78000 Versailles, Francedominique.barth | [email protected]
2 Ecole Polytechnique - Laboratoire d’informatique. 91128 Palaiseau cedex, [email protected]
3 LORIA, 615, rue du Jardin Botanique, 54602 Villers les Nancy. [email protected]
Nous étudions un problème d’apprentissage d’équilibres dans un jeu de routage. Le jeu secompose d’un réseau dont la représentation comporte classiquement des noeuds et des arêtes.Les joueurs veulent transmettre de l’information entre deux noeuds du réseau tout en mini-misant le coût de la route utilisée. Ce jeu s’inspire des réseaux de Wardrop et des jeux decongestion (voir [2]). Le but de chacun est de minimiser son propre coût. Nous proposons iciun algorithme distribué d’apprentissage des équilibres.
1 ModèleChaque joueur i a pour objectif d’envoyer une quantité d’informations wi du sommet si versle sommet ti. Pour cela, il dispose un ensemble Si de chemins (actions) allant de si à ti.Le coût d’une route est la somme des coûts de toutes les arêtes qui la composent. Chaquearête e du réseau a une fonction de coût de la forme 8e(fe) = aefe + be avec ae et be ( 0 quifixe un coût, lors de chaque partie, en fonction de sa fréquentation, ou charge, fe.Les joueurs veulent minimiser leur coût. La notion d’équilibre de Nash capture cette notion :un équilibre de Nash correspond à un état où tout changement unilatéral de stratégie pourun seul joueur provoque une augmentation de son propre coût. Une stratégie est un vecteurde probabilité sur l’ensemble des chemins.Dans notre contexte, il existe toujours un équilibre de Nash pur [4] (dans le sens où la stra-tégie du joueur correspond à une action). Il est montré dans [2] que des systèmes centraliséspeuvent apprendre des états d’équilibres de Nash. Dans ce travail, nous considérons que lesjoueurs connaissent uniquement des informations les concernant (leurs propres stratégies etcoûts). Par la suite, nous notons qi le vecteur de stratégie du joueur i, qi est tel que , joueuri,&s%Si q
is = 1.
Nous décrivons maintenant le mécanisme d’apprentissage1. A chaque partie, chaque joueur i choisit un chemin (action) ai(t) en fonction de qi(t),2. Tous les joueurs connaissent leur coût ci(t) et lui associent une utilité ri(t) = 1 # ci(t)X ,
avec X su"sament grand pour que ri(t) soit toujours compris entre 0 et 1.3. Chaque joueur met à jour son vecteur de stratégies de la façon suivante :
,i, qi(t+ 1) = qi(t) + b* ri(t)* (eai(t) # qi(t)) i = 1, ..., N (1)où 0 < b < 1 est un paramètre de précision et eai(t) est un vecteur unitaire de dimensioncard(Si) avec la ai(t)eme composante qui vaut 1.

260 D. Barth, O. Bournez, O. Boussaton, J. Cohen
2 Raisonnement
L’état du jeu à la partie t est Q(t) = (q1(t), q2(t), ..., qN (t)) et l’évolution du jeu décrit ici estde la forme
Q[k + 1] = Q[k] + b ·G(Q[k], a[k], c[k]), (2)où a[k] et c[k] sont respectivement les actions et les coûts de tout le monde.On note hi,,(Q) l’espérance d’utilité du joueur i sachant lorsqu’il décide de jouer la stratégie8 et hi(Q) son espérance moyenne. On a hi(Q) =
&,! qi,,!(Q)hi,,!(Q). En exprimant les
espérances d’utilité pour les joueurs, on peut déterminer une équation de réplication selonlaquelle évolue le jeu en moyenne (plus b est petit, plus cette moyenne est fiable, on donneégalement en [1] des bornes sur l’erreur d’approximation).
dqi,ldt
= qi,l(hi,l(Q)# hi(Q)) (3)
A partir de là, on utilise la notion de fonction de potentiel.Theorem 1 (Extension of Theorem 3.3 from [3]). S’il existe une fonction non-négativeF telle que ,l, i, Q, il existe un certain ci positif tq. -F
-qi(Q) = ci * hi(Q) alors l’algorithme
d’apprentissage converge toujours vers un équilibre de Nash (EN).L’idée est de montrer que la fonction de potentiel est alors strictement croissante, ce quiimplique qu’elle ait une limite puisqu’elle est également bornée. On montre que la constanteci du théorème correspond au poids du joueur i, c’est à dire wi.On propose ensuite la fonction de potentiel suivante qui convient pour ce jeu.
F =%
e%E
Lae2 (%
i
Eprob(e)iwi)2 + be%
i
Eprob(e)iwi+ae%
i
w2iEprob(e)i*
)1# Eprob(e)i2
*M
(4)où Eprob(e)i est la probabilité pour le joueur i d’utiliser l’arête e.Nous avons introduit quelques aspects dynamiques dans un jeu de routage. Nous avons repriset adapté un algorithme d’apprentissage proposé par [3] et nous avons montré que le jeuconvergeait vers des équilibres de Nash si les joueurs l’utilisaient. Nous avons montré que cetagorithme est asymptotiquement équivalent à une équation di!érentielle qui tendra vers unéquilibre de Nash. Voir pour plus de détail [1].
Références1. Dominique Barth, Olivier Bournez, Octave Boussaton and Johanne Cohen. Distributed Learning
of Wardrop Equilibria Springer-Verlag - UC2008 - Vienna, Austria2. N. Nisan, T. Roughgarden, E. Tardos and V$ay V. Vazirani. Algorithmic Game Theory. Cam-
bridge University Press, 2007.3. P.S. Sastry, V.V. Phansalkar and M.A.L. Thathachar. Decentralized Learning of Nash Equilibria
in Multi-Person Stochastic Games With Incomplete information. IEEE transactions on system,man, and cybernetics - 1994.
4. J. Wardrop. Proceedings of the Institution of Civil Engineers, Part II - Some Theoretical Aspectsof Road Tra%c Research. 1952.

Analyse de fiabilité des systèmes semicohérents etdescription par des polynômes latticiels
Alexander Dukhovny1 and Jean-Luc Marichal2
1 Mathematics Department, San Francisco State University, San Francisco, CA 94132, USA.dukhovny[at]math.sfsu.edu
2 Mathematics Research Unit, University of Luxembourg, L-1511 Luxembourg, Luxembourg.jean-luc.marichal[at]uni.lu
Résumé
Considérons un système semicohérent consistant en un certain nombre de composants inter-connectés. Un tel système peut être décrit par sa fonction de structure qui exprime, à chaqueinstant, l’état du système en termes des états de ses composants. De manière équivalente, lesystème peut aussi être décrit au moyen d’un polynôme latticiel qui exprime la durée de viedu système en termes des durées de vie des composants. Par exemple, lorsque des composantssont connectés en série, la durée de vie du segment ainsi constitué est le minimum de duréesde vie des composants.
Dans notre présentation, nous mettons en évidence le parallélisme formel entre ces deuxdescriptions et nous montrons que les langages correspondants sont équivalents sur plusieursaspects. Nous montrons aussi que le langage des polynômes latticiels o!re des avantagessignificatifs. Par exemple, en exploitant la propriété de distributivité de la fonction indicatricepar rapport aux opérations latticielles, nous montrons que la description par les polynômeslatticiels constitue un outil très naturel pour mettre en relation la structure du système avecle treillis des événements typiques de fiabilité de la forme T " t, où T est une durée de viealéatoire. Cet outil met donc en relation l’objectif du système, qui est encodé dans le polynômelatticiel, avec l’équipement du système, qui est exprimé dans la distribution des durées de viedes composants.
Ensuite, nous établissons une liste de formules exactes pour le calcul de la fiabilité du système,aussi bien dans le cas où les durées de vie des composants sont indépendantes que dans lecas général dépendant. Ces formules permettent alors de fournir des expressions exactes decertains paramètres de fiabilité tels que la durée de vie moyenne du système.
Un autre avantage du langage des polynômes latticiels est qu’il nous permet d’étendre notreétude au cas plus général où nous considérons des bornes supérieures collectives sur la duréede vie de certains sous-ensembles de composants imposées par des conditions externes (tellesque des propriétés physiques de l’assemblage) ou même des bornes inférieures imposées parexemple par des dispositifs de sécurité ayant une durée de vie constante. En termes de duréesde vie, de tels systèmes peuvent être décrits par des polynômes latticiels pondérés. En termesde variables d’état, nous verrons qu’une “version pondérée” des fonctions de structure estalors requise. Nous en déduisons alors des formules exactes généralisées pour le calcul de la

262 Dukhovny, Marichal
fiabilité et de la durée de vie moyenne de ces systèmes ainsi dotés de bornes supérieures etinférieures.Finalement, nous montrons comment nos résultats peuvent fournir des formules exactes pourexprimer la fonction de répartition et les moments des polynômes latticiels pondérés de va-riables aléatoires.
Références
1. G. Birkho#. Lattice theory. Third edition. American Mathematical Society Colloquium Publica-tions, Vol. XXV. American Mathematical Society, Providence, R.I., 1967.
2. A. Dukhovny. Lattice polynomials of random variables. Statistics & Probability Letters,77(10) :989–994, 2007.
3. A. Dukhovny and J.-L. Marichal. System reliability and weighted lattice polynomials. Probabilityin the Engineering and Informational Sciences, 22(3) :373–388, 2008.
4. A. Dukhovny and J.-L. Marichal. Reliability analysis of semicoherent systems through theirlattice polynomial descriptions. Submitted. (http://arxiv.org/abs/0809.1332).
5. R. L. Goodstein. The solution of equations in a lattice. Proc. Roy. Soc. Edinburgh Sect. A,67 :231–242, 1965/1967.
6. M. Grabisch, J.-L. Marichal, and M. Roubens. Equivalent representations of set functions. Math.Oper. Res., 25(2) :157–178, 2000.
7. G. Grätzer. General lattice theory. Birkhäuser Verlag, Berlin, 2003. Second edition.8. P. Hammer and S. Rudeanu. Boolean methods in operations research and related areas. Berlin-
Heidelberg-New York : Springer-Verlag, 1968.9. J.-L. Marichal. Weighted lattice polynomials. Discrete Mathematics, to appear.
(http://arxiv.org/abs/0706.0570).10. J.-L. Marichal. On Sugeno integral as an aggregation function. Fuzzy Sets and Systems,
114(3) :347–365, 2000.11. J.-L. Marichal. Cumulative distribution functions and moments of lattice polynomials. Statistics
& Probability Letters, 76(12) :1273–1279, 2006.12. J.-L. Marichal. Weighted lattice polynomials of independent random variables. Discrete Applied
Mathematics, 156(5) :685–694, 2008.13. S. Ovchinnikov. Means on ordered sets. Math. Social Sci., 32(1) :39–56, 1996.14. G. Owen. Multilinear extensions of games. Management Sci., 18 :P64–P79, 1972.15. K. G. Ramamurthy. Coherent structures and simple games, volume 6 of Theory and Decision
Library. Series C : Game Theory, Mathematical Programming and Operations Research. KluwerAcademic Publishers Group, Dordrecht, 1990.
16. M. Rausand and A. Høyland. System reliability theory. Wiley Series in Probability and Statistics.Wiley-Interscience [John Wiley & Sons], Hoboken, NJ, second edition, 2004.
17. S. Rudeanu. Lattice functions and equations. Springer Series in Discrete Mathematics andTheoretical Computer Science. Springer-Verlag London Ltd., London, 2001.

Allocation de fréquences dans un système decommunication satellitaire utilisant le SDMA
Laurent Houssin1,2, Christian Artigues1, Erwan Corbel3
1 LAAS-CNRS; Université de Toulouse ; 7, avenue du Colonel Roche, 31077 Toulouse, France.2 Université de Toulouse ; UPS, France.
{houssin,artigues}@laas.fr3 Thales Alenia Space, Advanced Telecom & Navigation Systems Research, 26 av. J.F.
Champollion, 31037 Toulouse, [email protected]
L’évolution des systèmes de télécommunication satellitaires tend vers une plus grande capacitédes utilisateurs, une plus grand flexibilité (par rapport à la position des utilisateurs) et unemeilleure qualité. Plusieurs techniques permettent d’atteindre ces objectifs, notamment lemultiplexage fréquentiel et le multiplexage temporel. La plus récente et la plus prometteusede ces techniques est le SDMA (Spatial Division Multiple Access). Cette technique, qui peutêtre combinée avec les deux précédentes, consiste à dépointer les faisceaux formés par lesatellite et leur donner une forme qui va permettre de diminuer les interférences pour unutilisateur donné.Le système de télécommunication bidirectionnel que l’on étudie ici est constitué d’une passe-relle connectée au réseau terrestre, d’un satellite et d’une zone de service où des terminauxdisposés aléatoirement (distribution uniforme) demandent une fréquence. Dans le cadre decette étude, nous nous intéressons à la liaison retour, c’est-à-dire la liaison "utilisateurs àpasserelle" (voir figure 1).Les faisceaux formés par le satellite ont deux caractéristiques principales qui sont• la position du centre du faisceau sur la zone de service,• le diagramme de rayonnement de l’antenne.Une représentation analytique du diagramme de gain permet de calculer le niveau de gainreçu par un utilisateur donné. Cette valeur est une fonction non linéaire de la position del’utilisateur par rapport au centre du faisceau et de la position de l’utilisateur par rapport ausatellite.Le rapport signal sur bruit plus interférences C
N+I (qui met en jeu la fonction analytiquedécrivant le gain) d’un utilisateur doit être supérieur à un seuil
)CN
*RsModCod
(dépendant duschéma de modulation) pour permettre la communication :
C
N + I (NC
N
O
RsModCod
(1)
Ce rapport CN+I est calculé à travers un bilan de liaison qui met en jeu la fonction analytique
décrivant le gain, la position des interférants (i.e. les utilisateurs possédant la même fréquence)et la position de l’utilisateur.L’objectif est donc de maximiser le nombre d’utilisateurs servis sous la contrainte (1) pourchaque utilisateur et avec un nombre de fréquences limité.Afin de démontrer l’interêt du système SDMA, nous considérons deux scénarios représentatifsdes conditions réelles de fonctionnement. Un premier scénario où l’on considère que chaque

264 L. Houssin, C. Artigues, E. Corbel
utilisateur possède un faisceau centré sur lui (ce qui est rendu possible grâce au systèmeSDMA). Le second scénario est composé d’une allocation fixe et régulière des faisceaux,qui forment ainsi des "spots" sur la zone de service. Pour les deux scénarios, le nombre defréquences disponibles est limité à 8.Bien que le problème original mettent en jeu des contraintes non linéaires (notamment (1)) ,nous obtenons une formulation linéaire en nombres entiers du problème (pour une réalisationdonnée de la distribution des utilisateurs). En e!et, en tenant compte de l’e!et cumulatifdes interférences sur un utilisateur, nous ramenons le problème sous une forme linéaire. Plusprécisément, pour ces deux scénarios, on peut obtenir la contrainte suivante pour un utilisateuri : %
j%Interf(i)-ij " %i, (2)
où %i représente le niveau maximum d’interférences que peut recevoir l’utilisateur i et -ij leniveau d’interférence de l’utilisateur j sur l’utilisateur i si j a la même fréquence.En considérant l’aspect cumulatif des contraintes, nous présentons un programme linéaire ennombres entiers modélisant chaque scénario. Des algorithmes gloutons basés sur la représen-tation cumulative des contraintes sont également proposés pour résoudre chaque scénario.Enfin, nous concluons que l’analyse des performances des deux scénarios démontre tout l’in-térêt du système SDMA, à la fois pour les formulations de programme linéaire en nombresentiers où le temps d’exécution est limité à 1 minute et pour les algorithmes gloutons.
Fig. 1. communication utilisateurs à passerelle.
Références1. M. Palpant, C. Oliva, C. Artigues, P. Michelon and M. Didi Biha. Models and methods for
frequency allocation with cumulative interference constraints. Vol. 15, No. 3., pp. 307-324 Inter-national Transactions in Operational Research (2008).
2. J.C. Liberti and T.S. Rappaport. Smart Antennas for Wireless Communications (1999). PrenticeHall.

Optimisation de la collecte de données dans un champde capteurs par VNS/VND
M. Sylla1, B. Meden1, and C. Duhamel2
1 ISIMA, campus des Cézeaux, 63173 Aubière Cedex France.sylla,[email protected]
2 LIMOS, Université Clermont-Ferrand II, campus des Cézeaux, 63177 Aubière Cedex [email protected]
1 Introduction
Les réseaux de capteurs sans fil (WSN) sont composés d’un grand nombre de capteurs dissé-minés sur le terrain à étudier. Chaque capteur est une entité autonome possédant un senseur,une unité de traitement, une unité de communication et une batterie. Ainsi, un LiveNode estéquipé d’un ARM7TDMI à 55 MHz et de 64 Kb de SRAM [4]. Dans les WSN classiques,les capteurs sont capables de construire ex nihilo le réseau de communication de manière àacheminer leurs mesures vers un ou plusieurs points spéciaux : les puits. À la di!érence descapteurs, les puits ont davantage d’autonomie, de capacité de traitement et de stockage. Ilssont généralement plus volumineux.Au niveau énergétique, la part de consommation dédiée à la réception et à la transmissiondes données est prépondérante. Elle impacte fortement sur la durée de vie des senseurs et desprotocoles spécifiques sont mis en œuvre pour maximiser la durée de vie du réseau.Nous étudions ici un scénario alternatif dans lequel les capteurs n’établissent explicitement pasun réseau de communication vers les puits. Les informations sont stockées dans les capteursjusqu’au passage à proximité d’un agent chargé de la collecte. De ce fait, l’essentiel de l’énergiedu capteur est dédiée à la surveillance de son environnement proche augmentant d’autant ladurée de vie du système.Dans ce travail, nous proposons de modéliser le problème de la collecte des données stockéesdans les capteurs comme une variante du TSP puis nous présentons une métaheuritiquede type VNS/VND [1] permettant de trouver des solutions de bonne qualité en un tempsraisonnable.
1.1 Modélisation
On considère G = (N,A) le graphe orienté dans lequel N est l’ensemble des sommets (cap-teurs) et A est l’ensemble des arcs. Un arc (i, j) ! A représente la possibilité pour le capteuri de transmettre directement ses données au capteur j. On suppose que l’agent chargé dela collecte se situe initialement sur le sommet 0. Il doit e!ectuer une tournée permettant decollecter les données de chaque capteur. Pour simplifier, on suppose qu’il e!ectue ses collectesau-dessus des capteurs visités. Ainsi, s’il est sur le sommet i, il est capable de collecter sesdonnées, mais aussi les données des capteurs j tels que (j, i) ! A. Il n’est donc pas nécessairede passer par tous les capteurs et l’on recherche la tournée la plus courte.

266 Sylla, Meden, Duhamel
Ce problème est donc une variante du TSP : on ne doit pas passer par tous les sommetsmais tous les sommets doivent être couverts par la tournée. Il peut également être perçucomme la combinaison du TSP et du problème de p-médianes. Il est NP-di"cile. On noteraégalement des connexions avec le problème d’Orienteering [3] dans lequel on doit sélectionnerles sommets sur lesquels réaliser la tournée. À la di!érence de l’Orienteering, nous devonscouvrir tous les sommets. Récemment, Gulczynski et al. [2] ont proposé plusieurs heuristiquespour une variante du problème : des puces RFID sont disséminées dans un espace donné etil s’agit de déterminer la tournée minimale permettant de lire chaque puce. La tournée nepasse pas nécessairemnt par les sommets (les puces). Shuttleworth et al. [6] se sont égalementintéressés à ce problème dans un réseau urb ! ain.
1.2 VNS/VND
Nous proposons une métaheuristique VNS utilisant une VND pour la recherche locale. Pourla VND, quatre voisinages sont considérés : le 2-opt et le 3-opt [5], le transfert de sommetcouvert et la suppression de sommet visité. Les trois premiers voisinages travaillent à nombrede sommets visités fixe alors que le dernier voisinage vise à réduire de nombre de sommetsvisités. La solution initiale est générée par un algorithme glouton. À chaque itération, il insèredans la tournée partielle le sommet non lu qui permet de couvrir le plus de sommets non lus.La méthode de shaking de la VNS consiste à insérer aléatoirement dans la tournée un certainnombre de sommets non visités.Les résultats expérimentaux sur de petites instances permettent de comparer la qualité dela solution fournie par la VNS/VND par rapport à la solution optimale. Ils montrent quela méthode fournit des résultats de bonne qualité. Lorsque la taille des instances augmente,le temps de calcul augmente sensiblement et des stratégies de réduction de voisinage sontactuellement en cours d’étude.
Références1. N. Mladenovi", N. Hansen, P. : Variable neighborhood search. Computers and Operations Re-
search, Vol. 24(11), pp. 1097–1100 (1997)2. Gulczynski, D.J. Heath, J.W. Price, C.C. : The Close Enough TravelingSalesman Problem : A
Discussion of Several Heuristics. In Perspectives in Operations Research : Papers in Honor of SaulGass‚Äô 80th Birthday, F. Alt, M. Fu and B. Golden, eds, Springer Verlag, pp. 271–283 (2006)
3. Golden, B. Levy, L. Vohra, R. : The Orienteering Problem. Naval Research Logistocs, Vol. 34, pp.307–318 (1987)
4. Hou, K.-M. De Souza, J. Channet, J.-P. Zhou, H.-Y. Kara, M. Amamra, A. Diao, X. de Vaulx, C.Li, J.-J. Jacquot, A. : LiveNode : Limos versatile embedded wireless sensor node. In Proceedingsof 1st International Workshop on Wireless Sensor Networks, Marrakesh (2007)
5. S. Lin, S. Kernighan, B.W. : An E#ective Heuristic Algorithm for the Traveling-Salesman Problem.Operations Research, Vol. 21, pp. 498–516 (1973)
6. Shuttleworth, R. Golden, B.L. Smith, S. Wasil, E. : Advances in Meter Reading : Heuristic Solutionof the Close Enough Traveling Salesman Problem over a Street Network. In The Vehicle RoutingProblem : Latest Advances and New Challenges, B. Golden, S. Raghavan and E. Wasil, eds,Springer Verlag, pp. 487–501 (2008)

Scalabilité pour le contrôle réparti :un problème d’agrégation d’informations
T. Bernard1, A. Bui2, and C. Rabat1
1 SYSCOM CReSTIC, Université de Reims Champagne-Ardenne.{thibault.bernard , cyril.rabat}@univ-reims.fr
2 PRiSM, Université de Versailles [email protected]
Le cadre de notre étude concerne le développement d’outils et de méthodes pour permettre lecalcul réparti sur un ensemble d’entités de calculs autonomes interconnectées par un réseaude communication. Nous nous intéressons à la gestion des mécanismes permettant de mettreen œuvre ce type de système par l’étude de problèmes de contrôle et en particulier l’étudede problèmes de structuration au travers de la construction de structures topologiques cou-vrantes pour des systèmes répartis dynamiques sujet à des pannes transitoires. Nous avonsintroduit et utilisé la combinaison des concepts de mot circulant (jeton collecteur et di!useurd’informations) et de marche aléatoire comme outil de circulation des mots circulants. Parce biais, nous avons pu proposer des solutions pour construire des arbres couvrants adapta-tifs pour des systèmes dynamiques, même avec l’occurrence de pannes transitoires dans lesystème. Nous proposons ici une solution pour le passage à l’échelle de tels systèmes.
Un système réparti est constitué d’un ensemble d’entités autonomes qui e!ectuent un calculpar le biais d’échange de messages. Nous considérons des systèmes dynamiques : des entitéspeuvent s’y connecter ou s’en déconnecter de manière arbitraire. Pour gérer un tel système,il est nécessaire de construire une structure de contrôle sur l’ensemble des entités. Cettestructure doit en outre gérer le dynamisme du système. La gestion de cette structure impliquel’échange d’informations entre les entités du système : le volume d’informations échangéesaugmente lorsque le dynamisme du système augmente.Nous avons proposé dans [2], une solution à base de marche aléatoire pour gérer le dynamismed’un tel système. Nous exploitons les déplacements aléatoires d’un message particulier entreles entités du système (nous appelons ce message jeton). Ce jeton récolte les identifiants desentités rencontrées à l’aide d’un mot circulant (particule du jeton qui collecte de l’information,ici la liste des identifiants). Nous appliquons à cette liste un algorithme qui permet de main-tenir une arborescence couvrante capable de gérer la volatilité du système. Suivant le type decontexte, nous avons réussi à borner la taille du jeton à 2n# 1 pour des canaux symétriqueset à n2/4 pour des canaux asymétriques, où n est le nombre d’entités du système. La gestionà l’aide d’un mot circulant nous apporte l’adaptativité de la structure de contrôle : celle-ciest modifiée perpétuellement au fur et à mesure des déplacements du jeton et s’adaptant auxreconfigurations du système.Ce type de solutions fondées sur les marches aléatoires présente plusieurs avantages. A toutmoment, un seul message transite dans tout le système quel que soit le nombre de connexionsou déconnexions. Cela réduit le volume d’informations échangées entre les entités du système.De plus, les marches aléatoires n’utilisent que des informations locales, elles sont naturellementadaptatives au dynamisme des systèmes.

268 Bernard, Bui, Rabat
Par contre, le temps moyen de circulation (de l’ordre de O(n3) [3]) de ces marches peut s’avé-rer rédhibitoire lorsque le nombre de composants du système augmente, et constitue donc unfacteur limitatif pour concevoir des applications réparties à grande échelle. L’augmentation dunombre d’entités entraîne une baisse d’e"cacité de la maintenance de la structure de contrôle.Le temps de mise-à-jour nécessaire entre des pannes devient de plus en plus important, im-pliquant une latence de plus en plus importante. Suivant le temps de réponse souhaité parl’application exploitant le système, la taille peut atteindre une borne critique.De nombreuses solutions sont proposées dans la littérature pour gérer le passage à l’échelle.Le partitionnement est une solution envisagée. On décompose alors l’ensemble des entitésen partitions. Chaque partition s’auto-gère de manière indépendante et un protocole permetl’échange d’informations entre les partitions.A partir d’algorithmes de construction et de maintenance d’arbres couvrants fondés sur lemot circulant [2,1], nous utilisons cette structure pour décomposer le système de manièretotalement décentralisée. Cette solution conserve les propriétés d’adaptativité, de décentrali-sation et de tolérance aux pannes. Notre algorithme fonctionne en utilisant la maintenance dela structure de contrôle. Lorsque la taille de la structure devient trop importante (supérieureà M), nous divisons la structure en deux partitions. Afin de limiter le nombre de partitions,chacune a une taille bornée inférieurement parm. Lors de la division, une vague est envoyée lelong des deux structures de contrôle afin de mettre a jour les informations de partitionnement.Chacune des structures possède alors son propre jeton pour s’auto-gérer.Lors du déplacement du jeton, notre algorithme fonctionne en utilisant trois principes :Annexion Le jeton atteint une entité contenue dans aucune structure de contrôle. Celle-ci
est alors annexée à la structure du jeton en mettant à jour ses informations locales.Fusion Le jeton atteint une entité contenue dans une autre structure que celle que maintient
le jeton. Si la partition maintenue par le jeton est de taille insu"sante (i.e. inférieure à m), les deux structures sont fusionnées.
Division Le jeton annexe une nouvelle entité mais la taille de la structure est trop importante(i.e. supérieure à M). La structure est alors divisée en deux et chaque entité met à jour sesinformations locales de partitionnement.
Le choix de m et M dépend du dynamisme que l’on souhaite supporter. Le rapportM > 2mest impératif pour assurer le bon fonctionnement de l’algorithme. Plus le ratio M/m estimportant, plus le dynamisme accepté est grand, par contre la taille des structures de contrôlepeut être disparate et alors engendrer une variabilité dans la mise-à-jour de ces structures.Nos travaux futurs s’orientent donc dans une étude expérimentale de ces deux paramètres.
Références
1. T. Bernard, A. Bui, and O. Flauzac. Random distributed self-stabilizing structures maintenance.In ISADS’04, IEEE Internationnal Symposium on Advanced Distributed Systems Proccedings,volume 3061, pages 231–240. Springer Verlag, january 2004.
2. T. Bernard, A. Bui, O. Flauzac, and C. Rabat. Decentralized resources management for grid.In RDDS’06 International Workshop on Reliability in Decentralized Distributed systems, volumeLNCS 4278, pages 1530–1539. Springer, 2006.
3. L.Lovász. Random walks on graphs : A survey. In Combinatorics : Paul Erdos is Eighty (vol. 2),pages 353–398. János Bolyai Mathematical Society, 1993.

Présentation d’une méthode de résolution pour lesproblèmes de placement 2D et 3D
G. Jacquenot1,2, F. Bennis1, J.-J. Maisonneuve2, P. Wenger1
1 Ecole Centrale de Nantes, IRCCyN, UMR CNRS 6597, Nantes, France2 SIREHNA, Nantes, France
1 Introduction
Dans la littérature, les problèmes de découpe et de conditionnement (Cutting & Packingproblems) et les problèmes d’agencement (Layout problems) ont souvent été traités de manièresdistinctes. Toutefois, ils présentent de nombreuses similarités, qui nous permettent de lestraiter comme des problèmes, que nous appelons, problèmes de placement. Le problème dedécoupe de formes irrégulières et le problème d’agencement des composants d’un satellite fontpartie de cette famille.Etant donné un ensemble de composants et un contenant, un problème de placement consisteà trouver l’ensemble des variables de positionnement des composants afin de minimiser unensemble d’objectifs, tout en respectant certaines contraintes. Les problèmes de placementpeuvent alors être formulés comme des problèmes d’optimisation sous contraintes. Les contraintesde non chevauchement entre composants et les contraintes d’appartenance des composantsau contenant sont regroupées dans les contraintes de placement.Le développement d’une méthode de résolution adaptée de nombreux problèmes de placementrepose principalement sur deux constats :– Deux types de modélisation sont utilisables pour résoudre les problèmes de placement : les
méthodes de placement légal et les méthodes de placement relaxé. Bien que ne garantissantpas le respect des contraintes de placement, les méthodes de placement relaxé sont plussouples d’utilisation et adaptées à tout type de problème. Un algorithme de séparation peutalors utilisé pour faire respecter ces contraintes.
– La majorité des problèmes d’agencement ne sont pas réellement traités comme des pro-blèmes multi-objectifs : objectifs et contraintes sont agrégés dans une seule et même fonctionobjectif, qu’un optimiseur cherche à minimiser [1].
Notre objectif est de proposer une méthode de placement relaxé capable de traiter des com-posants de géométries complexes (polygones en 2D et polyèdres en 3D) pour la résolution deproblèmes de placement mono-objectifs et multi-objectifs.
2 Méthode proposée
La méthode proposée consiste en l’hybridation d’un algorithme d’optimisation global et d’unalgorithme de séparation. L’algorithme d’optimisation global génère des solutions en explorantde manière e"cace l’espace de recherche. L’algorithme de séparation a pour mission de rendreadmissibles autant que possible les solutions proposées par l’optimiseur global.

270 Jacquenot, Bennis, Maisonneuve, Wenger
L’algorithme génétique OmniOptimizer [2] est utilisé comme optimiseur global. Il est basésur la méthode NSGA-2 et est adapté à la résolution de problèmes mono-objectifs et multi-objectifs. Nous avons adapté les opérateurs de croisement et de mutation aux spécificitésdes problèmes de placement. Avant d’évaluer chaque solution, les contraintes de placementsont évaluées et si elles ne sont pas respectées, la solution est modifiée par l’algorithme deséparation afin de la rendre admissible.L’algorithme de séparation est chargé, à partir d’une solution initiale ne respectant pasles contraintes de placement, de déplacer localement les composants afin de minimiser unefonction traduisant le non-respect de ces contraintes. Cette fonction est choisie comme lasomme des profondeurs de pénétration entre composants. Un programme d’optimisation non-linéaire, pour lequel le gradient analytique de la fonction peut être facilement obtenu, estainsi construit. La méthode quasi-Newton BFGS est utilisée pour trouver le minimum decette fonction.En 2D, l’algorithme de séparation est basé sur l’utilisation de polygones de non recouvre-ment (No-fit polygon) et de polygones d’appartenance (Inner-fit polygon) [3]. En 3D, le calculdes polyèdres de non-recouvrement et d’appartenance est plus complexe, même dans le casde composants convexes (polytopes). Une méthode proposée consiste à transformer les com-posants en assemblages de sphères [4]. L’utilisation de tels assemblages présente plusieursavantages : simplicité de détection de collisions, invariance en rotation. De plus, cette modéli-sation permet de futures extensions, comme la modélisation de composants articulés ou encorel’introduction de composants déformables. Enfin, l’algorithme de séparation peut prendre encompte les cas spécifiques, où tous les composants ont une géométrie similaire et simple (rec-tangles, cercles en 2D, parallélépipèdes, ou sphères en 3D). Pour ces cas là, les méthodes derésolution ad-hoc seront toujours plus rapides que la méthode proposée, mais ne pourront pastraiter d’autres problèmes.
3 ConclusionLa méthode proposée se veut générique et adaptée à une large palette de problèmes de place-ment. Les simulations réalisées sur des exemples de la littérature permettent de s’approcherdes résultats de référence dans plusieurs disciplines. La modélisation actuelle est flexible etpermet de nombreuses extensions futures.
Références1. C. Aladahalli, J. Cagan, et K. Shimada, “Objective function e#ect based pattern search - an
implementation for 3D component layout,” Journal of Mechanical Design, vol. 129, pp. 255–265,2007.
2. K. Deb et S. Tiwari, “Omni-Optimizer : A generic Evolutionary Algorithm for single and multi-objective optimization,” European Journal of Operational Research, vol. 185, pp. 1062–1087, 2008.
3. T. Imamichi, M. Yagiura, et H. Nagamochi, “An iterated local search algorithm based on nonlinearprogramming for the irregular strip packing problem,” in Proceedings of the Third InternationalSymposium on Scheduling, Tokyo, Japan, no. 9, pp. 132–137, 2007.
4. T. Imamichi et H. Nagamochi, “A multi-sphere scheme for 2D and 3D packing problems,” in SLS,pp. 207–211, 2007.

Le problème de placement/chargement entrois-dimensions : calcul de bornes et méthodes
approchées
N.Cherfi1, M.Hifi2, and I. Kacem3
1 MSE, Université Paris 1, 106-112, Bd de l’Hôpital, 75013 Paris, [email protected]
2 MIS, UFR des Sciences, Université de Picardie Jules Verne, 33 rue Saint Leu, 80000 Amiens,France.
[email protected] LOSI, Université de Technologie de Troyes, 12 rue Marie Curie B.P 2060 Troyes 10010, France.
1 Introduction
Le problème de placement/chargement (bin-packing) en trois-dimensions est un problèmed’optimisation combinatoire. Ce problème apparaît dans plusieurs domaines d’application,comme le génie industriel, la logistique, la manutention ainsi que la production. Il consisteen général à placer/charger un ensemble de n objets dans un minimum de conteneurs (bins)identiques.À notre connaissance, peu d’articles concernant le problème de placement/chargement entrois-dimensions ont été publiés. En particulier, ce problème a été étudié par Martello etal. [3] qui ont proposé des bornes inférieures intéressantes et une méthode de résolutionexacte basée sur une procédure de branch-and-bound. Les auteurs ont montré, expérimenta-lement, que cette dernière méthode était e"cace pour des instances de petite taille. Dans unautre article, Lodi et al. [1] ont proposé une méthode approchée basée sur une recherche ta-bou employant une nouvelle heuristique constructive pour évaluer les voisinages. Finalement,Hifi [2] a proposé une autre méthode approchée qui s’appuie principalement sur la résolutiond’une série de problèmes de sac-à-dos unidimensionnels combinés ‡ une recherche tronquée.Cette dernière reste intéressante dans le sens où elle traite le cas guillotine et non-guillotinedu problème.
2 Le problème étudié
Dans cet article, nous étudions le problème de placement/chargement en trois dimensions quifait partie de la famille de "Découpe et Placement" (Cutting and Packing [6]). Une instancede ce problème est caractérisée par un ensemble de n objets (petits parallélépipèdes) etun ensemble de m support (grands parallélépipèdes ou des conteneurs). Chaque objet j !{1, . . . , n} est caractérisé par ses dimensions (lj , wj , hj) où lj représente sa longueur, wj salargeur et hj sa profondeur. De plus, comme il s’agit d’un problème lié au problème dechargement, des contraintes supplémentaires sont imposées sur chaque chargement : (i) éviter

272 Cherfi, Hifi, Kacem
le débordement et (ii) respecter le tonnage du support. Le problème revient alors à placertous les objets de sorte que :1. les objets ne se chevauchent pas ;2. le nombre de supports utilisé soit minimum.
Dans cet exposé, nous proposons trois méthodes de résolution approchée pour le problèmedu placement/chargement en trois-dimensions. La première méthode est caractérisée par denouvelles bornes obtenues en généralisant la procédure de Lodi et al. [1]. Les deux autresméthodes s’appuient principalement sur certaines techniques d’arrondi ainsi que la recherchelocale.
3 Méthodes de résolution
Nous nous intéressons à la résolution approchée du problème de placement/chargement entrois-dimensions en exploitant, d’un côté, une procédure proposée par Lodi et al. [1] et d’unautre côté les caractéristiques de la recherche locale et les techniques d’arrondi.Dans un premier temps, nous proposons une généralisation de l’approche proposée par Lodiet al. [1] par application de l’idée de la décomposition des objets j, j ! {1, . . . , n}. Par lasuite, en s’appuyant sur cette décomposition, nous proposons di!érentes bornes inférieures,selon l’axe choisi. Dans un deuxième temps, nous proposons deux nouvelles formulations duproblème sous forme de programmes linéaires mixtes (MIP).Vu l’importance des variables utilisées dans les deux modèles, nous nous sommes limités àla résolution exacte des instances de petite taille. Cependant, afin d’accroître l’intérêt desdeux modèles, nous avons étendu la résolution exacte vers une résolution heuristique, enparticulier pour des instances de taille plus importante. Pour ce faire, nous proposons unenouvelle méthode de résolution qui s’appuie sur les techniques d’arrondi. Cette dernière a pourbut d’approcher des solutions admissibles à partir de la relaxation en continue du problèmeoriginal. Cette approche peut se résumer comme suit :1. Résoudre la relaxation en continue du problème original, fixer et arrondir ensuite une
partie des variables binaires à leurs valeurs entières.2. Réitérer le procéssus jusqu’ à obtention d’une solution admissible.
Par la suite, cette méthode a été couplée avec une recherche locale, du type tabou, pour tenterl’amélioration des solutions obtenues. D’une façon générale, cette méthode consiste à appli-quer iterativement des modifications locales à la solution courante, tant qu’elles permettentd’améliorer la valeur de l’objectif.Ces di!érentes approches sont en cours de validation. Les premiers résultats expérimentauxsont encourageants.
Références
1. A. Lodi, S. Martello, D. Vigo, “Heuristic algorithms for the three-dimensional bin packing pro-blem" European Journal of Operational Research, vol. 141, pp.410–420, 2002.
2. M. Hifi, “Approximate algorithms for the container loading problem" International Transactionsin Operational Research, vol. 9, pp. 747–774, 2002.

Le problème de placement/chargement en trois-dimensions 273
3. S.Martello, D. Pisinger, D.Vigo, “The three-dimensional bin packing problem” Operations Re-search, vol. 48, pp.256–267, 2000.
4. G. Wäscher, H. Haussner and H. Schumann, “An improved typology of cutting and packingproblems" European Journal of Operational Research, vol. 183, pp. 1109–1130, 2007.

Algorithme coopératif parallèle pour le problème dedécoupe contraint à deux dimensions
Mhand Hifi1,3, Rym M’Hallah2, and Toufik Saadi3
1 LaRIA, Université de Picardie Jules Verne, 5 rue du Moulin Neuf, 80000 Amiens, France.2 Département de Statistique et de recherche opérationnelle, Kuwait University, P.O. Box 5969,
Safat 13060, Kuwait.3 CES, Equipe CERMSEM, MSE, Université Paris 1, 106-112, bd de l’Hôpital, 75647 Paris cedex
13, [email protected] ; [email protected] ;[email protected]
1 IntroductionNous proposons une application parallèle de la recherche par faisceaux pour résoudre le problèmede découpe contraint à deux dimensions et à deux niveaux. L’algorithme proposé exploite plusieursprocesseurs pour élargir l’espace de recherche et permet d’augmenter la largeur du faisceau. Parailleurs, L’algorithme fonctionne selon le paradigme maître/esclave et chaque type de processeurutilise une stratégie du meilleur d’abord dans ces développements. L’algorithme utilise le processeurmaître pour gérer les synchronisations et la diversification des chemins de recherche. Le caractèreirrégulier du problème traité, nous a poussé à définir une politique dynamique de régulation decharge. Les résultats obtenus sur deux groupes d’instante, réputés dans la littérature comme étant,très di%ciles, a donné des résultats encourageants et montre l’intérêt de l’utilisation du parallélismedans les méthodes approchées.
2 Analyse de l’algorithme séquentiel CGBSL’algorithme séquentiel combine l’algorithme GBS et la procédure de remplissage BFP. Le principede BFP est le suivant : Soit w, w # W , la hauteur du sous rectangle courant (L,w), r, r # n lenombre de bandes optimales de hauteur wj # w, Swj l’ensemble de pièces de la bande (L,wj), oùwj # w et fwj (L) la valeur de la solution associée à la bande (L,wj). Le plan de découpe associé ausous rectangle (L,w) de profit hL(w) est la solution optimale du programme linéaire suivant :
(IPL,w) =
!""""""""""#
""""""""""$
hL(W ) = maxr%
j=1
fw(L)yi
s.c.r%
j=1
wjyj # w
r%
j=1
xijyj # bi, i ! I
yj # aj , yj ! N, j = 1, ..., r,
où xij représente le nombre d’occurrences de la i ème pièce dans la j ème bande de dimension (L,wj)etaj = min
PQwpwj
R,mini#fwj
Qbixij
Ravec xij > 0
S

Algorithme coopératif parallèle pour FCTDC 275
Dans l’algorithme séquentiel SCGBS, un nœud u est représenté par deux sous rectangles ; (i) ((L,W%y), (L, y)), où (L,W % y) est la solution réalisable locale et (ii) (L, y) le sous rectangle à com-pléter. L’algorithme utilise une fonction d’évaluation qui combine trois solutions : Soit w une dé-coupe horizontale sur le sous rectangle complémentaire (L, y), avec w # Y et w ! w1, ..., wn. Soitv = ((L,W % y + w), (L, Y % w)) un des nœuds résultat de cette découpe. L’algorithme coopératifcombine les trois points suivants sur le nœud v :1. ZLocalv la valeur de la solution réalisable du sous rectangle (L,W % y + w).2. BFP(L,Y"w) une solution réalisable complémentaire du rectangle initial S.3. U (L,y) une borne supérieure du sous rectangle complémentaire (L, y %w).
L’examen de ces trois points permet de remarquer l’indépendance entre le calcul de la borne supérieureet l’obtention de la solution réalisable complémentaire. Le calcul en parallèle de ces deux pointsprésente un axe d’amélioration des performances de l’algorithme séquentiel.
3 L’algorithme coopératif parallèle
Les principales phases du traitement e#ectuées par le processeur maître sont les suivantes : Dansphase d’initialisation, l’algorithme calcul la borne supérieure complémentaireUK(L,W ); pour le couple(wj , fhorwj ), j ! J . Cette borne supérieure est calculée par programmation dynamique. La program-mation dynamique permet d’avoir toutes les bornes supérieures U(L,Y ), Y = 0, . . . ,W,. Le calcul dela borne inférieure complémentaire LB(L,W ); est réalisé par la procédure MFP qui est lancée paral-lèlement au calcul de la borne supérieure. Les deux bornes sont utilisées par la suite dans la phasede filtrage. Le filtrage est appliqué sur l’ensemble s. Cette phase consiste à mettre à jour la meilleuresolution réalisable courante z) par la résolution de max
j#J
TzLocalj
U.
Les phases principales de la procédure utilisée par les processeurs esclaves k, k = 1, . . . , 3, où 3présente le nombre de processeurs esclaves disponibles sont les suivantes :
La phase d’initialisation, est identique à la phase d’initialisation de l’algorithme SCGBS. En e#et, laprocédure MFP (voir Hifi et al[2]) est inutile dans cette phase. L’évaluation des nœuds et le calculde la solution complémentaire seront e#ectués dans la phase suivante.
La phase itérative commence par sélectionner le meilleur nœud, noté µ = ((L,W % Y ), (L, Y )), dela premier liste interne Bk et le supprime de celle-ci. Dans l’étape suivante, r (r # s # n) bandesgénérales sont crées par la résolution du problème BKgL,wr , où r = max
Pwr | wr ) wj , wj #
Wµ, j ! JS. L’algorithme calcul pour chaque bande (nœud) 4 les bornes inférieure (zLocal* ) et
supérieure complémentaire (U*). Ces deux bornes sont calculées en parallèle. L’algorithme continupar évaluer les nœuds pour les futures développements (zGlobal* ;). La borne inférieure complémentairezLocal* ) est obtenue par l’application de la procédure MFP décrite dans Hifi et al [2]. Dans l’étapesuivante, l’algorithme réalise une sélection sur les nœuds crées et les transfert à la deuxième listeinterne Bk et le filtrage est e#ectué sur Bk et retourne les meilleurs min{., |Bk|} nœuds qui réalisentla meilleure évaluation globale. L’algorithme vérifie le nombre de nœuds dans la première liste interne(Bk2Bk), cette étape concerne la régulation de charge entre les processeurs esclaves. La phase d’arrêtest composée de deux parties. Dans la première partie, le processeur esclave arrête la résolution, si laliste Bk est vide ou si la période de synchronisation T a écoulée. Dans le premier cas (liste Bk vide),le processeur esclave envoie la valeur de la solution réalisable locale courante au processeur maître.Si la période T a écoulée, le processeur esclave envoi, en plus de la valeur de la solution réalisablelocal courante, tous les nœuds des listes internes.

276 M.Hifi, Rym M’Hallah, Toufik Saadi
Références
1. M.Hifi, R.MHallah and T.Saadi, Algorithms for the Constrained Two%Staged Two%DimensionalCutting Problem, Informs Journal On Computing, Vol.20,pp.212 to 221,2008
2. M.Hifi and T.Saadi, A Cooperative Algorithm for Constrained Two%Staged Two%DimensionalCutting Problems, International Journal of Operational Research, à paraitre

Nouvelles Bornes Inférieures pour le Problème de BinPacking avec Conflits
Ali Khanafer, François Clautiaux and El-Ghazali Talbi
Université des Sciences et Technologies de Lille, LIFL CNRS UMR 8022, Inria Lille - Nord EuropeBâtiment INRIA, Parc De La Haute Borne, Villeneuve-D’ascq, France.
[email protected],[email protected],[email protected]
1 IntroductionNotre présentation traite du problème de bin packing avec conflits en une et deux dimensions. Ilconsiste à déterminer le nombre minimum de containers (bins) à utiliser pour ranger un ensembledonné d’objets, tout en prenant en compte des contraintes de compatibilité interdisant de placerensemble certaines paires d’objets.Une instance de bin packing avec conflits est composée d’un ensemble I fini d’articles, d’un nombreinfini de bins de type B et d’un graphe G = (I,E) de conflits, dans lequel l’arête [i, j] existe si i et jsont en conflit.Nous proposons des bornes inférieures basées sur le concept de fonctions dual-réalisables (DFF) et lenouveau concept de fonctions dual-réalisables dépendantes de la donnée généralisées (GDDFF) quenous proposons ici. Ce nouveau concept permet de prendre en considération le graphe de conflits enutilisant des techniques de triangulation de graphe et de décomposition arborescente.Nous proposons aussi une adaptation de prétraitements de la littérature, qui permettent de réduirela taille de l’instance initiale, ainsi que l’amélioration d’une méthode de calcule de bornes inférieuresbasé sur la résolution d’un problème de transport. Les résultats expérimentaux montrent l’e%cacitéde nos méthodes, et l’amélioration des résultats en comparaison avec la littérature.
2 Fonctions dual-réalisables dépendantes de la donnée généraliséesLes fonctions dual-réalisables ont été initialement proposées pour aider à la résolution du problèmede bin-packing en une dimension [1]. Les DFF ont la particularité suivante : si l’on applique une tellefonction aux tailles des articles et à la taille du bin d’une instance donnée de bin-packing, le problèmeobtenu est une relaxation du problème initial. L’objectif est d’obtenir une instance pour laquelle lesbornes simples vont être e%caces.Les DFF sont définies indépendamment de l’instance. La classe des DFF dépendantes de la donnée(DDFF), qui dépendent de la taille des objets dans l’instance considérée a été proposée par Carlier etal. [2]. Dans ce papier, nous généralisons ce concept au problème avec conflit, en prenant en comptel’information donnée par le graphe de conflits.Nous proposons deux fonctions de ce type, basées sur l’utilisation conjointe de techniques de trian-gulation de graphes et de décomposition arborescente, et de programmation dynamique.
3 Amélioration de la borne inférieure de Gendreau et al. [3]Pour le problème de bin packing non contraint, lorsque des DFF sont appliquées au problème, il su%ten général d’appliquer une borne simple reposant sur la somme des longueurs des articles. Pour le casavec conflits, même après application de GDDFF, des bornes plus complexes doivent être utilisées.

278 Ali Khanafer et al.
En pratique, nous avons utilisé une amélioration de la borne de [3], qui repose sur la résolutiond’un problème de transport entre des petits articles d’un côté, et des grands articles de l’autre. Notreamélioration consiste en l’ajout de sommets intermédiaires dans le réseau de transport afin de prendreen compte de manière partielle les conflits entre petits articles, qui ne sont pas considérés dans [3].
4 Résultats numériques
Tab. 1. R"ultats pour les instances de Berkey and Wang [4], Martello and Vigo [5]. Pour chaque classe d’instances,chaque ligne montre la densité d du graphe de conflit, le nombre d’instances sur 50 où la borne correspondante (notreborne KCT et celle de Gendreau et al. [3]) a strictement dépassé l’autre.
Classed% 1 3 5 7 8 9 10
KCT [3] KCT [3] KCT [3] KCT [3] KCT [3] KCT [3] KCT [3]0 24 0 29 0 41 0 43 0 44 0 43 0 9 010 24 0 29 0 41 0 43 0 44 0 43 0 7 020 26 0 5 10 38 0 43 0 44 0 43 0 3 1330 16 0 4 3 23 0 33 0 23 4 42 0 1 1140 14 7 11 0 28 0 12 3 3 4 42 0 6 350 26 0 15 0 40 0 21 0 14 0 42 0 8 160 26 0 19 0 15 0 14 0 10 0 42 0 4 270 20 0 15 0 24 0 2 2 5 0 41 0 11 080 18 0 11 0 9 0 6 0 7 0 39 0 13 090 24 0 5 0 14 0 3 0 13 0 34 0 4 0
Références
1. G. S. Lueker, Bin packing with items uniformly distributed over intervals [a,b], Proc. of the 24thAnnual Symposium on Foundations of Computer Science (FOCS 83), pp. 289-297 (1983)
2. J. Carlier and F. Clautiaux and A. Moukrim, New reduction procedures and lower bounds for thetwo-dimensional bin-packing problem with fixed orientation, Computers and Operations Research,34 (8), pp. 2223-2250, 2007
3. M. Gendreau, G. Laporte et F. Semet, Heuristics and lower bounds for the bin packing problemwith conflicts, Computers and Operations Research 31 (3) pp. 347-358 (2004)
4. J. O. Berkey and P. Y. Wang, Two dimensional finite bin packing algorithms, Journal of Opera-tional Research 38 pp. 423-429 (1987)
5. S. Martello and D. Vigo, Exact Solution of the Two-Dimensional Finite Bon Packing Problem,Manage. Sci. 44 (3) pp. 388-399 (1998)

Un algorithme coopératif pour le problème de découpecirculaire non-contraint
H. Akeb1,2 M. Hifi1 and S. Nègre1
1 UPJV Amiens, MIS, Axe Optimisation Discrète et Réoptimisation,33 rue Sait-Leu, 80039 Amiens Cedex 1, France
[email protected], [email protected], [email protected] ISC Paris, 22 bd du Fort de Vaux, 75017 Paris, France.
Mots clés : découpe et placement, beam search, algorithme coopératif, recherche en avant, distanceminimum.
1 IntroductionAujourd’hui, le gain de temps, de l’espace et la réduction des coûts de production sont devenus unenécessité pour les entreprises. Dans ce contexte, les problèmes de découpe et de placement peuventjouer un rôle important. Ces problèmes ont en e#et plusieurs domaines d’application comme legénie industriel, la logistique, la manutention ainsi que la production. Ils consistent généralement àplacer/découper un ensemble d’objets de dimensions connues dans un ou plusieurs supports dans lebut de minimiser l’espace inutilisé dans ces derniers.La plupart des travaux de la littérature, concernant le problème de la découpe circulaire, se sontfocalisés sur les cercles identiques. Ces méthodes sont alors influencées par cette caractéristique [4].À notre connaissance, peu d’articles concernant le problème de la découpe/placement de cercles non-identiques ont été publiés. Parmi ces méthodes de résolutions, un algorithme génétique a été utilisépar George et al. [3] ainsi que par Hifi et M’Hallah [2]. Stoyan et Yaskov ont proposé dans [5] unmodèle mathématique pour le problème. Enfin, plus récemment, Birgin et al. [1] se sont basés sur unmodèle non-linéaire pour la résolution du problème.
2 Le problème étudiéDans ce travail, nous étudions le problème de la découpe circulaire qui fait partie de la famille de“Découpe et Placement" (Cutting and Packing [6]). Une instance de ce problème peut être décritecomme suit. Soit R un support (bande) de largeur W fixée et de longueur infinie et S un ensemblefini de n pièces circulaires Ci de rayons connus ri, i ! N = {1, ..., n}. Le problème revient alors àplacer toutes les pièces dans R de sorte que :1. une pièce circulaire ne doit pas chevaucher une autre pièce et ne doit pas dépasser la limite de
la bande W .2. la largeur, que l’on notera L, de la bande soit minimum.
Ce problème est résolu par application d’un algorithme coopératif combinant une procédure construc-tive, une recherche par faisceaux (beam search) ainsi qu’une recherche en avant (looking-ahead) afind’améliorer les solutions obtenues. Une méthode de diversification est aussi utilisée, visant à s’échap-per des extema locaux.La recherche par faisceaux est une heuristique utilisant une recherche arborescente mais elle per-met d’éviter la recherche exhaustive. Pour cette dernière, à chaque niveau de l’arbre développé, unsous-ensemble de noeuds est sélectionné pour une exploration complète. Cet ensemble, de taille %,représente l’ensemble des noeuds élus et % représente la largeur du faisceau .

280 Akeb, Hifi &Nègre
3 Un algorithme coopératif
L’algorithme coopératif proposé combine la recherche par faisceau et la stratégie de recherche enavant. Un noeud de niveau ( de l’arbre de recherche du “beam" contient une solution partielle corres-pondant aux ( cercles déjà placés dans la bande (avec ( < n). Chaque noeud de ce niveau est alorsévalué en utilisant une stratégie de recherche en avant, basée sur l’heuristique de la distance minimumlocale, en plaçant les n% ( cercles restants. Les % noeuds conduisant aux meilleures solutions à partirdu niveau ( sont alors choisis pour une éventuelle extension dans l’arbre de recherche du beam, c-à-dpour passer au niveau ( + 1.Une stratégie de relance est aussi utilisée. Celle-ci consiste à modifier le premier cercle placé au débutdu placement. Le but de cette stratégie est de diversifier l’espace de recherche afin d’améliorer lessolutions obtenues.
4 Résultats expérimentaux
Plusieurs versions de l’algorithme ont été testées sur des instances de la littérature, notamment cellesde Stoyan et Yaskov [5] et Hifi et M’Hallah [2]. Nous avons constaté que les résultats obtenus parnos algorithmes amélioraient la plupart des meilleures solutions de la littérature.
Références
1. Birgin, E.G., Martinez, J.M. and Ronconi, D.P. : Optimizing the packing of cylinders into arectangular container : A nonlinear approach, European Journal of Operational Research, vol.160, 2005, pp. 19–33.
2. Hifi, M. and M’Hallah, R. : Approximate algorithms for the constrained circular cutting problem,Computers and Operations Research, vol. 31, 2004, pp. 675–694.
3. George, J.A., George, J.M. and Lamar, B.W. : Packing di#erent-sized circles into a rectangularcontainer, European Journal of Operational Research, vol. 84, 1995, pp. 693–712.
4. Graham, R.L. and Lubachesky, B.D. : Repeated patterns of dense packings of equal disks in asquare, The Electronic Journal of Combinatorics, vol. 3, #16, 17 pages.
5. Stoyan, Y.G. and Yaskov, G.N. : Mathematical model and solution method of optimization pro-blem of placement of rectangles and circles taking into account special constraints, InternationalTransactions in Operational Research, vol. 5, 1998, pp. 45–57.
6. Wäscher, G., Haussner, H. and Schumann, H. : An improved typology of cutting and packingproblems. European Journal of Operational Research, vol. 183, 2007, pp. 1109–1130.

X-hyperarbres
F. Brucker1 and A. Gély2
1 UFR MIM, Université Paul Verlaine, Ile du Saulcy BP 80794 57012 Metz cedex [email protected]
2 IUT de Metz, dpt STID, Ile du Saulcy 57045 Metz cedex 1 [email protected]
1 Introduction
Nous présentons dans cette communication un modèle qui étend à la classification les arbres phylo-génétiques (aussi appelés X-arbres). On a en e#et coutume de représenter l’évolution du vivant parun arbre dont les noeuds correspondent aux espèces (actuelles et les ancêtres disparus) et les arêtesaux liens de parentés.De façon mathématique, cet arbre est une extension du modèle hiérarchique (voir par exemple Wa-termann, 1995). Cependant, même si le modèle hiérarchique est plus simple que le modèle phylogé-nétique, un de ses intérêts fort est qu’il y a correspondance entre l’arbre et un système de classes : onpeut à la fois raisonner en terme d’ancêtre/descendant et en terme de classes d’individus (on raisonnealors en terme de proximité). Ceci est impossible en utilisant le modèle plus général qu’est l’arbrephylogénétique.Le modèle que que nous proposons – les X-hyperarbres – est une réponse possible à ce problème :c’est un modèle arboré, parcimonieux et dont les classes peuvent s’interpréter comme des ancêtres.En outre, il est en b$ection avec d’autres structures discrètes qui permettent de le manipuler aisément.En particulier :– produire les classes s’e#ectue grâce à la b$ection du modèle avec les quasi-ultramétriques cordées
(Brucker, 2001). On utilise pour cela un algorithme polynomial correspondant à la solution optimaled’un problème d’optimisation combinatoire (inférieures-maximales) ;
– on peut calculer rapidement ses classes car elles sont en b$ection avec les cliques maximales d’unefamille particulière de graphes triangulés (Gély et Nourine, 2007) ;
– les représenter se fait via un découpage en niveaux de leur treillis associé (le modèle est en b$ectionavec les treillis démantelables, Rival, 1974).
2 Exemple
L’exemple de la table 1 (matrice triangulaire inférieure) montre la distance d’évolution de six pri-mates. De façon usuelle on approxime cette distance pour produire une ultramétrique (figure 1(gauche)) ou une distance arborée (figure 1 (droite))), montrant l’évolution entre les di#érentesespèces. En utilisant la b$ection rendant équivalente les X-hyperarbres et les quasi-ultramétriquecordées, on peut produire des classes solution d’un problème d’optimisation combinatoire.En e#et, même si le problème général d’approximation d’une distance quelconque par une quasi-ultramétrique cordée est – tout comme pour les ultramétrique ou les distance d’arbres – NP-di%cile,en recherchant une solution plus petite que la distance originale (approximation par inférieure-maximale) on peut montrer que ce problème est – tout comme pour les ultramétrique – polynomialet admet de plus une solution unique (ce qui n’est pas le cas pour les distance arborées). La solutionpour la distance évolutive entre les primates est donnée table 1 (matrice triangulaire supérieure). La

282 Brucker, Gély
figure 1 (milieu) montre le diagramme de Venn des classes produites. On remarque que les classes dela hiérarchie sont conservées (les classes en gras) mais que ces classes sont a%nées par des liaisonssupplémentaires entre les classes (par exemple la classe contenant l’homme et le chimpanzé).
Tab. 1. Distance d’évolution entre six primates (matrice triangulaire inférieure), approximation parune quasi-ultramétrique cordée (matrice triangulaire supérieure)
homme bonobo chimpanzé gorille orang-outang gibbonhomme 0 0.19 0.18 0.24 0.36 0.51bonobo 0.19 0 0.07 0.23 0.37 0.51chimpanzé 0.18 0.07 0 0.21 0.37 0.51gorille 0.24 0.23 0.21 0 0.38 0.54orang-outang 0.36 0.37 0.37 0.38 0 0.51gibbon 0.52 0.56 0.51 0.54 0.51 0
Fig. 1. Une hiérarchie, un X-hyperabre et un X-arbre
Références
1. F. Brucker. Modèle de classification en classes empiétantes. Thèse, EHESS, Paris (2001).2. A. Gély and N. Nourine. Enumeration Aspects of Maximal Cliques and Bicliques. Discrete applied
mathematics, à paraître.3. I. Rival. Lattices with doubly irreducible elements. Canadian Mathematical bulletin, 17, 91–95
(1974).4. M. S. Watermann. Introduction to computational Biology. Chapmann and Hall (1995).

Recent Results on theDiscretizable Molecular Distance Geometry Problem
C. Lavor1, L. Liberti2, A. Mucherino2, and N. Maculan3
1 Dept. of Applied Mathematics, State University of Campinas, Campinas-SP, [email protected]
2 LIX, École Polytechnique, Palaiseau, France {liberti,mucherino}@lix.polytechnique.fr3 Systems Engineering, Federal University of Rio de Janeiro, Rio de Janeiro, Brazil
1 IntroductionThe Molecular Distance Geometry Problem (MDGP) is the problem of finding the positionsof the atoms of a molecular conformation when only some of the distances between such atoms areknown. This problem can be also seen as the problem of finding an immersion in "3 of a givenundirected and nonnegatively weighted graph G = (V,E, d). In the graph, the set V of verticesrepresents the set of atoms of the molecule, the set E of edges contains the couples of atoms whosedistance is known, and the weights d correspond to the known distances. In literature, di#erentapproaches for solving the MDGP have been proposed, and the reader is referred to [3] for a survey.The most common approach is the one in which the MDGP is formulated as a continuous nonconvexoptimization problem, where the function to be minimized is for example :
g(X) = 1|E|%
{u,v}#E
||x(u)% x(v)||% d(u, v)d(u, v) , (1)
where X = {x(v) : v ! V } is a molecular conformation specified through the three-dimensionalcoordinates of its atoms. Note that X is solution of the MDGP if and only if g(X) = 0.Instead of using a continuous formulation of the problem, we introduce the Discretizable Mole-cular Distance Geometry Problem (DMDGP) [3], which consists of a certain subset of MDGPinstances for which a discrete formulation can be supplied. The instances we take into account satisfytwo assumptions : 1) E contains all cliques on quadruplets of consecutive vertices ; 2) the strict trian-gular inequality d(vi"1, vi+1) < d(vi"1, vi) + d(vi, vi+1) holds for i = 2, . . . , n% 1 and vi ! V . If thesetwo assumptions are satisfied, each atom vi ! V can be located at most in two di#erent positions.In this way, we do not have to deal with continuous variables, but rather with binary variables. Thisallows to build a tree of possible solutions for a given instance of the DMDGP.
2 The Branch and Prune algorithmWe propose a Branch and Prune (BP) algorithm that, given an instance of the DMDGP, searchesthe solutions to the problem on the tree of atomic positions. If the aforementioned assumptions aresatisfied, each atom can be placed in only two possible positions. Moreover, these positions can beeither feasible or infeasible with respect to the known distances between the atoms in E. Therefore,if xi and x&i are the two possible positions for the atom i, three di#erent situations can be verified :1) both xi and x&i are feasible : we add two branches to the tree and both of them are explored ina depth-first fashion ; 2) only one of the positions is feasible : we continue the search on the branchdefined by this atomic position ; 3) both xi and x&i are infeasible : the current branch is pruned andthe search is backtracked. Details about the BP algorithm can be found in [3,4].

284 Lavor, Liberti, Mucherino, Maculan
3 Experiments
We developed a software procedure implementing the BP algorithm for solving instances of theDMDGP. Artificially generated instances and instances obtained by conformations of proteins areused in the experiments. In particular, we consider instances representing (real or simulated) back-bones of proteins, for which the aforementioned assumptions are satisfied most of the times. Ourcomputational experiments show that the BP algorithm is very competitive with respect to othermethods for MDGP based on a continuous formulation of the problem.We implemented two di#erent pruning tests for checking the feasibility of the atomic positions duringeach step of the BP algorithm. The first one (P1) checks if the known and computed distances betweenthe atoms of a conformations match. Another pruning test (P2) we use is based instead on the D$kstrashortest-path searches on Euclidean graphs. Our computational experiments show that the pruningtest P2 is able to identify infeasible atomic position much better than P1, but the computationaltime for performing P2 is usually larger than the one needed for P1. Some comparisons between thetwo pruning tests can be found in [2].We are also studying how the accuracy of the known distances can influence the accuracy of thefound solutions. Less accurate distances simulate real data that are usually a#ected by errors, and thepropagation of such errors during the algorithm need to be monitored and managed. For simulatinginstances having di#erent accuracies, we are collecting the distances smaller than 6Å between theatoms of known protein conformations, and we are storing them with di#erent degrees of accuracy.This procedure simulates data obtained by the NMR technique. An improved version of the BPalgorithm which is able to manage instances formed by distances a#ected by large errors is currentlyunder investigation.
Références
1. Lavor, C., Liberti, L., Maculan, N., Molecular distance geometry problem, In : Encyclopedia ofOptimization, Floudas, C., and Pardalos, P. (Eds.), 2nd edition, Springer, NY, 2305–2311 (2009).
2. Lavor, C., Liberti, L., Mucherino, A., Maculan, N., On a Discretizable Subclass of Instances ofthe Molecular Distance Geometry Problem, Proceedings of the Conference SAC09, Honolulu,Hawaii, March 8/12 (2009).
3. Liberti, L., Lavor, C., Maculan, N., A Branch-and-Prune Algorithm for the Molecular DistanceGeometry Problem, International Transactions in Operational Research 15 (1) : 1–17 (2008).
4. Liberti, L., Lavor, C., Maculan, N., Discretizable Molecular Distance Geometry Problem, Tech.Rep. q-bio.BM/0608012, arXiv (2006).

Analyse combinatoire de données et temps de survie
J. Darlay, L.-P. Kronek, and N. Brauner
Laboratoire G-SCOP, 46 avenue Félix Viallet, 38031 Grenoble, France.{nadia.brauner, julien.darlay, louis-philippe.kronek}@g-scop.inpg.fr
L’analyse de temps de survie [1] est une branche de l’analyse de données qui s’intéresse à la modé-lisation de la durée qui précède un événement. Dans le milieu médical, on cherchera par exemple àmodéliser le temps de rémission après un traitement.L’ACD pour Analyse Combinatoire de Données (logical analysis of data) est une méthode de fouille dedonnées (data mining) basée sur des méthodes de l’optimisation combinatoire. La fouille de donnéesconsiste à extraire de l’information à partir d’une base de données. Le point fort de l’ACD estde construire un modèle de prédiction simple, facilement interprétable par des non spécialistes del’analyse de données.Dans [2] les méthodes de l’ACD sont adaptées à l’analyse de temps de survie. Notre objectif estd’améliorer les résultats présentés dans [2] en explorant mieux l’espace des solutions dans un tempsraisonnable pour l’utilisateur.
1 Analyse de temps de survie
Dans un problème d’analyse de temps de survie [1] l’objectif est de prévoir le temps avant un événe-ment à l’aide des attributs de l’observation (‚ge, sexe, taille). Pour cela nous nous appuyons sur unebase de données contenant un grand nombre observations. Il se peut que, pour certaines observations,le temps avant l’événement n’ait pas pu être observé, par exemple, parce qu’il a eu lieu après la finde la période d’étude. On parlera alors d’observations censurées lorsqu’on ne connaît pas le tempsavant l’événement mais une borne inférieure sur ce temps.La fonction de survie s(t) donne la probabilité de survivre au moins jusqu’à la date t. Au lieu deprédire un temps de survie pour une nouvelle observation, nous allons lui attribuer une fonction desurvie à partir de ses attributs.
2 Analyse combinatoire de données
L’ACD est une méthode de fouille de données basée sur la combinatoire et l’optimisation présentéedans [3]. Elle a souvent été appliquée dans le cadre médical (voir par exemple [4]). Elle repose surle concept de motifs, c’est à dire une caractérisation d’observations homogènes pour les propriétésde survie. Par exemple, pour une base de données sur une maladie respiratoire, un motif pourraitêtre les personnes ayant moins de 50 ans et étant fumeuses. Il peut alors être représenté comme uneexpression booléenne : "fumeur = 1 4 age < 50".Le degré d’un motif est le nombre de termes dans son expression booléenne (2 dans l’exemple).L’intérêt d’avoir des motifs de faible degré est de pouvoir fournir des modèles simples, facilementinterprétables.Le support d’un motif est le nombre d’observations vérifiant les conditions du motif. La valeur dusupport permet de s’assurer que le motif ne représente pas un cas particulier.L’ACD repose sur deux étapes principales : la génération de motifs et la sélection de motif pourcomposer un modèle.

286 Brauner, Darlay, Kronek
Génération de motifs. Dans [2], les auteurs utilisent un algorithme de génération de motifs basésur les données. Cet algorithme ne parcourt qu’un ensemble réduit de motifs et ne donne aucunegarantie rien sur le degré et le support des motifs générés.Nous proposons de générer de façon exhaustive tout les motifs dont le support est supérieur à unseuil, et dont le degré est inférieur à un degré maximal. Cette génération est possible puisque le degrémaximal est généralement faible (3 ou 4).
Sélection du modèle. Un modèle consiste en un sous-ensemble, souvent minimal, de motifs. Dans[2], les auteurs utilisent un algorithme glouton sélectionnant les motifs un par un en maximisant laperformance du modèle.Nous proposons une méthode qui va parcourir plus e%cacement l’espace des motifs pour obtenirun modèle plus performant en terme d’interprétabilité et de prédiction. Dans les motifs générés,beaucoup sont redondants : ils couvrent les mêmes observations. Nous créons alors une mesure desimilarité entre les motifs. A l’aide d’éléments de la théorie des graphes, nous regroupons les motifssimilaires en familles, en résolvant un problème de partitions d’un graphe en cliques. La sélectiond’un sous-ensemble de familles minimal se ramène alors à un problème de couverture. Pour chaquefamille sélectionnée un motif représentant est élu. L’attribution de la fonction de survie se fait de lamême faÁon que dans [2].
3 Résultats expérimentaux
La méthode a été testée sur des données réelles, classiques pour des problèmes d’analyse de temps desurvie (GBSG-2 1, PBC 2). Les motifs ont été générés avec des outils de l’ACD [5]. Les performancessont proches de la méthode de [2] avec des modèles plus simples. La méthode a des performancesproches des forêts de survie avec une description du résultat plus compacte et plus lisible pour desutilisateurs.
Références
1. J.P. Klein, M.L. Moeschberger : Survival analysis, techniques for censored and truncated data.Springer, 2003.
2. L.-P. Kronek, A. Reddy : Logical analysis of survival data : prognostic survival models by detectinghigh-degree interactions in right-censored data. Bioinformatics 24, 248-253, 2008.
3. Y. Crama, P.L. Hammer, T. Ibaraki : Cause-e#ect relationships and partially defined booleanfunctions. Annals of Operations Research 16, 299-325, 1988.
4. P.L. Hammer, T. Bonates : Logical analysis of data : from combinatorial optimization to medicaloptimisation. Rutcor Research Report, 2005.
5. P. Lemaire : The ladoscope gang, utilitaires pour l’ACD. http://pit.kamick.free.fr/lemaire/lad/
1 http://www.blackwellpublishing.com/rss/Volumes/A162p1.htm2 http://lib.stat.cmu.edu/S/Harrell/data/descriptions/pbc.html

Modèles et heuristiques pour un problème debiclustering
D. Perrin1, C. Duhamel2, and H. J. Ruskin1
1 School of Computing, Dublin City University, Glasnevin, Dublin 9, [email protected]
2 LIMOS, Université Clermont-Ferrand II, campus des Cézeaux, 63177 Aubière Cedex [email protected]
1 Introduction
Les microarrays sont utilisés de manière intensive pour l’étude de l’implication des gènes dans lesdi#érents mécanismes physiologiques (par exemple immunitaire). Ils permettent de mesurer le ni-veau d’expression d’un ensemble de gènes par rapport à plusieurs conditions [3]. Typiquement, onconsidère des ensembles de plusieurs milliers de gènes dont on souhaite étudier la réponse par rap-port à une dizaine de conditions. Plusieurs techniques ont été développées pour analyser le résultatdes microarrays dans l’étude de l’expression des gènes (voir [6] pour une revue générale). Plusieursreposent sur la notion de clustering, que ce soit pour le regroupement de gènes en fonction de leurexpression face à plusieurs conditions ou pour le regroupement de conditions en fonction de l’expres-sion de plusieurs gènes [4,5]. Le biclustering a été introduit par Cheng et Church [1] et consiste àidentifier simultanément un sous-ensemble de gènes et un sous-ensemble de conditions pour lesquelsle comportement est similaire [7].Dans ce travail, nous proposons d’étendre le biclustering de manière à faciliter l’analyse des résultats.Nous considérons le problème consistant à retourner la meilleure solution pour chaque cardinalitédu sous-ensemble de conditions. Nous proposons une formulation mathématique avant de proposerplusieurs heuristiques pour la recherche de cet ensemble de solutions.
2 Formulation Mathématique
Le problème se modélise sous la forme d’un graphe biparti complet G = (A,B,E). A représentel’ensemble des gènes et B l’ensemble des conditions. E désigne l’ensemble des réactions des gènes parrapport aux conditions. Pour chaque gène a ! A et chaque condition b ! B, on associe une valeurcab. Il s’agit d’ un poids basé sur le niveau d’expression du gène et son évolution par rapport auxautres gènes [2]. Plus cab est négatif, plus a réagit face à b, plus cab est positif, moins il réagit. Lebiclustering consiste à rechercher la biclique de poids minimal. Nous souhaitons identifier la meilleuresolution pour chaque cardinalité du sous-ensemble de conditions. Il faut donc résoudre le biclusteringavec contrainte de cardinalité sur le sous-ensemble de conditions.Soit yi ! {0, 1} la variable de décision sur le choix du gène ou de la condition i ! A 2 B. Soitxij ! {0, 1} la variable de décision sur la présence de l’arête [a, b] ! A + B dans la biclique. Leproblème de biclustering à cardinalité fixée se linéarise aisément à partir du modèle suivant :

288 Perrin, Duhamel, Ruskin
P (k)
Min&
(a,b)#E cabxabs.t.
xab = yayb $a ! A,$b ! B&b#B yb = k
yi ! {0, 1} $i ! A+Bxab ) 0 $(a, b) ! E
3 Heuristiques
Le problème de biclustering avec contrainte de cardinalité est NP-di%cile dans le cas général. Cepen-dant, les jeux d’essais réels étudiés présentent un fort déséquilibre entre le nombre de gènes (de 4026à 22283) et le nombre de conditions (de 10 à 96). Nous proposons pour les instances les plus petitesla recherche de l’ensemble des solutions optimales par énumération : pour un sous-ensemble de condi-tions, l’obtention du meilleur sous-ensemble de gènes associé se fait en temps linéaire. Il su%t doncd’énumérer puis évaluer tous les sous-ensembles de conditions. Pour les instances plus grandes, nousproposons une heuristique hybride reprenant l’approche précédente pour les cardinalités extrêmes.Les solutions de cardinalité intermédiaire sont identifiées par exploration de voisinage à partir dessolutions précédentes. Nous comparons cette approche heuristique avec l’application d’un algorithmegénétique distribué.Les approches implémentées ont été testées sur des jeux d’essai réels pour lesquels une analyse com-plète des gènes est disponible. Cela permet de confirmer que les sous-ensembles obtenus contiennente#ectivement des gènes impliqués dans une même réaction ou voie métabolique.
Références
1. Cheng, Y., Church, G.M. : Biclustering of expression data. In Proceedings of the 8th InternationalConference on Intelligent Systems for Molecular Biology (ISMB 2000), Vol. 8, San Diego, California(2000)
2. Kerr, G., Perrin, D., Ruskin, H.J., Crane, M. : Edge weighting of gene expression graphs. underreview
3. Oana, F., Homma, T., Takeda, H., Matsueawa, A., Akahane, S., Isaji, M., Akahane, M. : DNAmicroarray analysis of white adipose tissue from obese (fa/fa) Zucker rats treated with a *3-adrenoceptor agonist. KTO-7924, Pharmacological Research, Vol. 52, pp. 395–400 (2005)
4. Raychaudhuri, S., Sutphin, P.D., Chang, J.T., Altman, R.B. : Basic microarray analysis : groupingand feature reduction. Trends in Biotechnology, Vol. 19, pp. 189–193 (2001)
5. Slonim, D.K. : >From patterns to pathways : gene expression data analysis comes of age. NatureGenetics, Vol. 32, pp. 502–508 (2002)
6. Stolovitzky, G. : Gene selection in microarray data : the elephant, the blind men and our algo-rithms. Current Opinion in Structured Biology, Vol. 13, pp. 370–376 (2003)
7. Turner, H., Bailey, T., Krzanowski, W. : Improved biclustering of microarray data demonstratedthrough systematic performance sets. Computational Statistics and Data Analysis, Vol. 48, pp.235–254 (2005)

Aide à la décision pour la massification des flux du fretSNCF
Housni Djellab, Yann Guillemot, Christian Weber
SNCF, Direction de l’Innovation et de la Recherche - Unité de Recherche A2D.45 rue de Londres - 75008 Paris
1 IntroductionLa croissance du trafic, la complexité des systèmes et la politique d’amélioration du transport ferro-viaire FRET donnent à la planification du plan de transport fret une importance toute particulière.Les gains escomptés sont très importants. Nous nous intéressons dans cet article au problème d’op-timisation de la massification des flux de wagons isolés. La massification est une façon de faire deséconomies d’échelles qui se traduiront par :– des réductions de coûts des ressources (locomotives, agent de conduite, sillons, etc.). Quand on
attache derrière une locomotive quarante wagons, on a un chi#re d’a#aire correspondant à quarantewagons. Quand on attache deux ou trois wagons, le coût est à peu près le même, par contre larecette est divisée par trois, cinq ou dix.
– des réductions des émissions de CO2 (le ferroviaire délivre 6g/tk de CO2 avec des trains massifiés,lourds, là où un camion en délivre 133). Donc à chaque fois que l’on enlève une locomotive dansune zone, on peut considérer qu’on remet un camion sur la route. Mais, lorsqu’on va reporter lalocomotive ailleurs, on va retirer vingt camions de la route à cet endroit.
La Direction de l’Innovation et de la Recherche de la SNCF a conduit un projet de recherche internepour développer un outil d’aide à la décision permettant d’optimiser la massification des flux et ainsienrichir notre outil EPIGRAF de conception du plan de transport FRET.
2 Description du problèmeNous utilisons la méthodologie CHIC21 pour décrire notre problème[1].Données– La demande de transport : c’est l’unité élémentaire d’acheminement demandée par le client ;– les itinéraires possibles pour acheminer chaque demande ;– les ressources : sillons, capacité de tri dans les gares de triage ;– l’infrastructure associée au transport FRET.ContraintesSur les lots (demande client)– L’ensemble des lots doit être livré à la bonne gare ;– l’itinéraire suivi doit exister dans la réalité ;– facultativement on peut imposer le respect des fenêtres de temps.Sur les sillons (exploitation de l’infrastrucutre)– On doit pouvoir associer au moins un sillon par mission de convoyage (un ensemble de lots qui fait
route commune sans être trié avant la gare d’arrivée de la mission) ;– un sillon ne peut être utilisé que par une mission de convoyage.Sur les gares (tri des trains)– Le nombre de wagons entrant dans la gare par unité de temps doit être plus petit que la capacité
de la gare ;1 Methodology for Combinatorial Application (European Esprit Project 22165)

290 Housni Djellab, Yann Guillemot, Christian Weber
– respect des horaires d’ouverture et de fermeture ;– respect de la spécificité des wagons entrant en gare.Sur les lignes (caractéristiques de l’infratructure)– Le gabarit (resp. tonnage) de la demande empruntant une ligne doit être plus petit que celui de la
ligne ;– on impose des contraintes d’itinéraires possibles dues par exemple aux aiguillages sur la ligne ;– les sillons doivent être disponibles quand la ligne est empruntée.Critères– minimiser le retard de livraison et l’anticipation de prise en charge ;– minimiser les trains.km (un train qui parcourt un kilomètre). Ce critère prend en compte la volonté
de faire des économies d’échelles ;– minimiser le coût en sillons ;– minimiser le coût de tri global dans les triages ;– maximiser la robustesse.RésultatsA chaque lot on associe une suite de missions de convoyage. De plus, on précise un indicateur deperformance : taux de massification, valeur des critères, utilisation de la capacité des gares de triage,etc.Leviers d’actionL’utilisateur dispose de plusieurs leviers d’action pour guider le moteur de calcul vers une solutionréaliste. Il peut donc :– imposer à une demande d’être directe, de passer par un hub, par deux hubs, par un hub et une
plateforme, etc.– pondérer les critères pour connaître leurs impacts respectifs sur le résultat et les hiérarchiser ;– préciser le nombre de sillons disponibles sur une ligne. Ceci permet également de refaire un calcul
en cas de problème sur une des lignes (travaux imprévus, etc.) ;– préciser la capacité des gares pour l’adapter à la demande.
3 Étude bibliographiqueNombreux sont les articles qui traitent du problème de la conception des convois : connaissant lesmissions de convoyage, comment établir l’emploi du temps des trains qui puisse les produire de façonoptimale ? On le retrouve dans la littérature sous le nom de "train scheduling". De nombreux autresarticles s’intéressent à la massification mais dans une optique beaucoup plus stratégique : où placerles hubs pour optmiser le plan de transport ? Ces problèmes ne correspondent malheureusement pasaux nôtres et peu d’articles présentent le problème de massification tel qu’on l’entend ici . Il estbaptisé dans la littérature "Railroad Blocking Problem", noté RBP. Chronologiquement, Bodin en aposé les bases au début des années 1980 et son article[2] reste une référence dans le domaine. Crainicy fait également référence[3] mais ne considère pas le RBP comme un problème à part entière etpropose un modèle qui prend en compte tout le problème de planification et nous n’avons pas retenucette approche. Il faut attendre Newton qui dans sa thèse[4] applique une méthode à la résolutiondu RBP. Il sera repris très similairement par Barhnart[5] avant que Ahuja[6] propose une méthodede résolution e%cace pour le RBP en utilisant un algorithme dit " Very Large-Scale NeighborhoodSearch".La littérature expose très largement la manière de résoudre le RBP mais sa modélisation reste plusvague : les données sont peu claires et parfois lointaines de la réalité de Fret SNCF. Le modèle quenous avons présenté n’est donc pas une reprise des modèles de la littérature et nous pouvons doncnous permettre de les comparer pour comprendre pourquoi nous ne pouvons pas reprendre ce qui a étédéjà fait. En e#et, dans le domaine ferroviaire les problèmes considérés peuvent être très di#érents enfonction des données d’entrée. Par exemple, les Italiens[7] présentent leur impossibilité de s’adapter

Aide à la décision pour la massification des flux du fret SNCF 291
au problème américain : ils ne peuvent se permettre de massifier trop et de créer des convois troplongs et lourds dans certaines régions où, comme dans le Nord de l’Italie, le réseau est consitué denombreux viaducs et tunnels. À l’inverse, la France doit faire face au manque de disponibilité desillons ce qui l’oblige à prendre en compte le facteur temps dans sa planification. La maille de tempsdans la quasi-totalité des articles traitant le sujet est la journée.
4 Méthode de résolutionNous avons proposé deux modélisations mathématiques sous forme de Programme Linéaire en NombresEntiers (PLNE). Le problème étant de l’ordre stratégique voire tactique, nous avons décidé de tra-vailler avec une maille de temps de 1h (paramètre) de manière à agréger le problème.Le module d’optimisation est écrit en C++ et fait appel à l’un des solveurs du marché ou libre enutilisant des macro écrites en C.Les premiers résultats sont satisfaisants bien que la recherche de la solution soit encore longue. Néan-moins, ils montrent que le moteur de calcul est bien orienté pour proposer une solution qui massifieles flux. Ainsi, les solutions obtenues permettent de faire une économie de 70% en trains.km parrapport à un acheminement direct de chaque demande client qui consisterait à produire un trainpour chacune d’entre elles. La comparaison des résultats obtenus avec ceux des experts est en cours.
Références1. Rapport interne 07-2008 : Massification des flux pour le fret - Modélisation et outil d’aide à la
décision.2. L.D. Bodin, B.L. Golden, A.D. Schuster, and W.Romig. A model for the blocking of trains.
Transportation Research, 14B : 115 - 120, 19803. Teodor Crainic, Jacques-A. Ferland, and Jean-Marc Rousseau. A tactical planning model for rail
freight transportation. Transportation Science, 18(2) : 165-184, may 1984.4. Harry N. Newton. Network design under budget constraints with application to the railroad blo-
cking problem. PhD thesis, Auburn University, 1997.5. Cynthia Barnhart, Hong Jing, and Pamela H. Vance. Railroad blocking : a network design appli-
cation. Operations Research, 48(4) : 603-614, jul. 2000.6. Ravindra K. Ahuja, Krishna C. Jha, and Jian Liu. Solving real-life railroad blocking problems.
Interfaces, 37(5) : 404-419, sep. 2007.7. Marco Campetella, Guglielmo Lulli, Ugo Pietropaoli, and Nicoletta Ricciardi. Freight service
design for an italian railways company. In 6th Workshop on Algorithmic Methods and Modelsfor Optimization of Railways. ATMOS, 2006.

Gestion du revenu pour le transport de containers parvoies ferrées
I.C. Bilegan1, L. Brotcorne1, D. Feillet2, and Y. Hayel3
1 LAMIH UMR CNRS 8530, Université de Valenciennes, ISTV2, Le Mont Houy, 59313Valenciennes
[email protected], [email protected] Ecole des Mines de Saint-Etienne, CMP Georges Charpak, F-13541 Gardanne, France
[email protected] LIA, Université d Avignon, [email protected]
1 IntroductionA l’heure de la dérèglementation dans le transport ferroviaire, plusieurs compagnies peuvent main-tenant entrer en compétition sur un même réseau pour acheminer les marchandises de leurs clients.Il importe donc pour elles de gérer au mieux l’utilisation de la capacité de leurs trains. Ce travailde recherche a pour but d’étendre des techniques de gestion du revenu couramment utilisées pour letransport aérien de personnes au transport ferroviaire de containers. En dehors de l’intérêt pratiqued’étendre les modèles à ce nouveau secteur, un intérêt spécifique majeur réside dans l’intégrationd’aspects combinatoires liés au transport ferroviaire dans la gestion du revenu.La gestion du revenu (GR), connue sous la dénomination anglophone de yield management [6], peutêtre définie comme un ensemble d’outils destinés à favoriser la rentabilité d’une entreprise à traversl’optimisation et la ré-optimisation de la chaîne o#re-demande dans sa globalité. La GR, dont ledéveloppement fut fortement stimulé vers la fin des années 70 par la déréglementation du transportaérien aux États-Unis, peut être résumée par la phrase suivante : "vendre le bon produit au bon momentau bon client" (AMR annual report 1987). A l’heure actuelle, suite à l’accroissement de la compétition,de nombreuses entreprises ou sociétés de service ont pris conscience de la nécessité de développerdes outils opérationnels pour accroître leur profit à travers l’utilisation optimale des ressources, laprévision de la demande et le ciblage de la clientèle (à l’aide d’une tarification di#érenciée), dans dessecteurs variés tels que l’hôtellerie ou l’industrie du divertissement (centres de loisirs, cinémas. . .).Le transport ferroviaire de containers possède les caractéristiques suivantes requises pour la gestiondu revenu : la demande fluctue beaucoup au cours du temps et reste mal connue, le service est péris-sable (un train parti avec une charge inférieure à sa capacité maximale génère un manque à gagnerpour la compagnie), le marché se prête à la segmentation. Toutefois il possède deux caractéristiquesspécifiques qui nécessitent une révision des méthodes utilisées de façon traditionnelle : la capacitée#ective est non fixe et non connue à l’avance, et elle est de nature hétérogène. Bien qu’à l’heure ac-tuelle aucun outil de gestion du revenu n’ait été développé pour le transport ferroviaire de containers,son potentiel a été mis en évidence lors de présentations [5], [3], [2] faites à la conférence INFORMSen 2005 et 2008.
2 ModelisationNous considerons un système ferroviaire avec horaires et réservations. Le système de GR que nousproposons dans cette présentation a pour but de donner des réponses systématiques et pertinentes

YM pour le transport ferroviaire de containers 293
quant à la décision d’accepter ou de refuser les demandes de réservation ponctuelles, tout au long del’horizon de temps précédant chaque départ de train.Nous considérons plus précisément le contexte suivant. Soit une compagnie disposant d’un certainnombre de services pré-définis (une heure de départ, une heure d’arrivée à la destination finale, unitinéraire, etc.) pour acheminer des containers par voie ferrée sur la demande de clients. Nous nousplaçons sur un horizon de planification fini. Un train (un service) est caractérisé par une certainecomposition en termes de poids total, de longueur maximale, de nombre de wagons et peut transporterdes containers de di#érents types en termes de dimension et contenu (20 ou 40 pieds, normaux ouréfrigérés, matières dangeureuses etc.). Une requète client est caractérisée par : une gare d’origine,une gare de destination, un nombre de containers d’un type donné à transporter, une date prévuede mise à disposition du volume en gare d’origine et un délai maximum de livraison. La compagniepropose aux clients une tarification di#érenciée selon des critères comme, par exemple, les délaisd’acheminement (prioritaire, normal, lent, ...) avec des pénalités éventuelles pour le non respect desdélais de livraison.L’objectif du problème est d’optimiser l’allocation de la capacité des trains aux di#érentes demandesqui arrivent de manière séquentielle, de façon à maximiser le revenu espéré de la compagnie. La dimen-sion stochastique du problème est prise en compte par l’utilisation de distributions de probabilités quicaractérisent l’arrivée des demandes futures et la prise de décision est formulée mathématiquementà l’aide du modèle non-déterministe ainsi obtenu.Des résultats numériques sur des données synthétiques permettent de valider notre approche.
Références
1. T.G. Crainic, M. Geandreau, I.C. Bilegan. Fleet Management for Advanced Intermodal Services,Final report, Project RDA-01, ITS Bureau of Transprt Canada, Montréal, 2006.
2. L. Gao and M. Gorman, Yield Management in Freight Transportation, Informs Annual Meeting,Washington DC, 2008.
3. M. F. Gorman, Reservations, Forecasting, Yield Management and Railroads, Informs AnnualMeeting, San Francisco, 2005.
4. R.R. Kraft, A Reservations-Based Railway Network Operations Management System, Ph.D.dissertation, University of Pennsylvania, Department of Systems Engineering, 1998.
5. W. Lieberman, Revenue Management for the Rail Industry, Informs Annual Meeting, San Fran-cisco, 2005.
6. K.T. Talluri, G.J. van Ryzin, Theory And Practice of Revenue Management, Springer, 2005

Ordonnancement des trains sur une voie unique
F. Sourd,1 and Ch. Weber2
1 SNCF, Direction de l’Innovation & de la Recherche, 75379 Paris Cedex [email protected]
2 SNCF, Direction de l’Innovation & de la Recherche, 75379 Paris Cedex [email protected]
1 Présentation du problème
Sur le réseau ferré français, les lignes principales sont en double voie (il existe même des tronçons àtrois ou quatre voies), ce qui permet le croisement des trains y circulant. Toutefois, il arrive qu’untronçon soit mis en voie unique :– soit en raison d’un incident sur une voie en cours d’exploitation.– soit en raison de travaux.Dans les deux cas, les trains utilisant la ligne doivent se partager le tronçon de voie unique sousla contrainte principale que deux trains circulant dans des sens contraires ne peuvent utiliser cetteressource simultanément. En revanche, deux trains circulant dans le même sens peuvent, à conditionque la voie soit équipée en signaux nécessaires, rouler sur ce même tronçon à condition de respecterune vitesse limitée et un écart minimal.
2 Formalisation comme des problèmes d’ordonnancement
La plupart des problèmes d’optimisation de la circulation des trains sur un réseau sont très com-plexes qui sont modélisés par des programmes linéaires ou résolus de manière approchée (voir parexemple [1]). Dans le cas du tronçon de voie unique décrit ci-dessus, le problème peut être modélisécomme un problème d’ordonnancement classique à une machine.Tout d’abord, considérons le cas où un seul train peut emprunter le tronçon de voie unique, ce quicorrespond dans la pratique au cas où la voie n’est pas équipée de signalisation de contre-sens. Commela ressource "voie unique" est bloquée pendant tout le passage du train, le problème est typiquementun problème à une machine où chaque parcours du tronçon par un train est représenté par uneopération de même durée.Lorsque deux trains circulant dans le même sens peuvent emprunter simultanément le tronçon devoie unique, les contraintes de circulation peuvent être modélisée en ajoutant des temps de setupau modèle à une machine. Plus précisément, les opérations ont cette fois une durée nulle. La duréede setup entre deux opérations représentant des trains circulant dans le même sens est égale autemps minimal entre ces deux trains à l’entrée du tronçon pour que les deux trains puissent sortirdu tronçon sans violer les contraintes de sécurité. En pratique, cette durée se calcule en fonction desvitesses relatives des deux trains et de la position des signaux de sécurité. Enfin, la durée de setupentre deux trains circulant dans des sens opposés correspond à la durée de traversée du tronçon parle premier train.En pratique, il est aussi intéressant de considérer le cas mixte où les trains circulant dans un sens(le sens touché par l’incident ou les travaux) sont soumis aux contraintes du premier cas tandis queles trains circulant dans l’autre sens (non touché) sont soumis aux contraintes du second cas. Ceproblème se modélise également à l’aide de temps de setup.

Ordonnancement des trains sur une voie unique 295
3 Régulation d’un incident
Lorsqu’un incident intervient sur une voie, l’objectif est d’écouler les trains qui ne peuvent pluspasser sur cette voie le plus rapidement possible. En pratique, il arrive souvent qu’au moment del’incident, les deux voies soient coupées, ce qui augmente encore le trafic à écouler. L’objectif est doncde minimiser la somme des retards. Pour notre problème d’ordonnancement, comme aucun train n’esta priori en avance, cela revient à minimiser la somme des dates de fin.Il y a de plus la contrainte que les trains circulant dans un même sens ne peuvent pas se doubler.Nous avons donc deux chaînes de précédences entre les tâches. Avec ces contraintes additionnelles,nous avons prouvé que, dans les trois cas présentés dans la section précédente, le problème peut êtrerésolu par un algorithme de programmation dynamique en O(n2T ) où n est le nombre de trains etT est l’horizon temporel. Cet algorithme est donc pseudo-polynomial.
4 Adaptation des circulations à une zone de travaux
Si l’on veut adapter les circulations prévues à une zone de travaux, le contexte du problème estlégèrement di#érent puisqu’il est alors possible d’avancer certains trains pour qu’ils puissent passeravant le début des travaux. Bien sûr, cette modification a un coût correspondant en particulier àla campagne d’information des clients et aux clients mécontents ou perdus car ils n’ont pas reçul’information. La fonction objectif devient alors une fonction de coût avance/retard.Le modèle peut encore être ra%né pour prendre en compte la régularité du service, ce qui conduit àune fonction objectif proche de celle utilisée dans l’industrie des radars [2]. Enfin, il est utile pour ceproblème de considérer la suppression de certains trains (en introduisant des coûts de pénalités).
5 Outils
L’étude de ces deux problèmes fait l’objet du développement d’une maquette logicielle. Des testspréliminaires ont été e#ectués sur des incidents passés dans le but d’évaluer les bénéfices d’une telleapproche basée sur le Recherche Opérationnelle.
Références
1. Dennis Huisman, Leo G. Kroon, Ramon M. Lentink, Michiel J. C. M. Vromans, Dennis Huisman,Leo G. Kroon, Ramon M. Lentink and Michiel J. C. M. Vromans, Operations Research in passengerrailway transportation, Statistica Neerlandica 59, 467–497, 2005.
2. Émilie Winter, Optimization tools for Airborne Radar Management, Thèse de l’École Polytech-nique, Octobre 2008.

Problème de lot-sizing à capacité finie avec fenêtres detemps et contraintes de services
S. Kedad-Sidhoum1, C. Rodríguez-Getán1, N. Absi2 and S. Dauzère-Pérès2
1 LIP6, UPMC, 4 Place Jussieu 75252 Paris Cedex [email protected]
2 CMP, Site Georges Charpak, Ecole des Mines de Saint-Etienne, 880 Avenue de Mimet, F-13541Gardanne
[email protected], [email protected]
1 Introduction
Nous nous intéressons à un problème de dimensionnement de lots (lot-sizing) qui consiste à déterminerun plan de production pour un ensemble de N références et pour un horizon de planification constituéde T périodes. Ce plan est à capacité finie, en outre le lancement de production d’une référence ià une période donnée t entraîne une consommation variable et fixe usuellement dénommée tempsde setup. Le plan de production doit satisfaire des contraintes de fenêtres de temps de production(cf. Brahimi et al. [3]). Elles sont notamment rencontrées lorsque l’on suppose que les matièrespremières arrivent en des quantités limitées et à di#érentes périodes de l’horizon de planification. Cecicontraint le lancement de la production entre deux périodes, une date de disponibilité et une dateéchue. Une particularité du modèle étudié réside dans le fait que les ressources ne sont pas toujourssu%santes pour satisfaire les demandes dans leurs fenêtres de temps. Pour tenter de répondre aumieux aux demandes, il s’agira dans ce type de situation d’introduire la possibilité de reporter oud’anticiper les productions pour satisfaire les demandes par rapport à leurs fenêtres de production.Si toutefois, la disponibilité totale en ressources reste insu%sante, des ruptures partielles ou totalessur les demandes seront subies. Ces contraintes de services qui consistent à anticiper, reporter ouperdre des demandes entraînent des pénalités. Les travaux que nous présentons ici sont les premiers àtenir compte conjointement de l’ensemble des contraintes citées. Le problème de lot-sizing à plusieursréférences, avec des contraintes de capacité et des coûts de setup, contraintes de service sur la demandeni fenêtres de temps est NP-di%cile au sens fort [4]. Citons les travaux de Brahimi et al. [3] et Wolsey[5] portant sur la résolution de problèmes avec contraintes de fenêtres de temps ainsi que les travauxd’Aksen et al. [1] et Absi et Kedad-Sidhoum [2] tenant compte de contraintes de ruptures sur lademande.
2 Propriétés et algorithmes de résolution
On distingue deux types de fenêtres de temps : les fenêtres de temps à clients spécifiques et celles àclients non-spécifiques. Dans le premier cas, une demande k disponible à une période bk et qui doitêtre livrée avant la fin de la période ek ne peut être traitée que pour satisfaire cette demande, lesclients sont ainsi di#érenciés. Dans le cas particulier avec fenêtres de temps à clients non-spécifiques,les produits arrivant à une période s sont utilisés pour satisfaire les demandes dont la période échueest t (s # t) et qui ne sont pas encore couvertes par les produits arrivant avant s. Dans le cas desfenêtres de temps à clients non spécifiques, on peut montrer que les demandes peuvent être récalculéesde façon à ce que les fenêtres de temps ne soient pas strictement incluses. Si l’on note xt, st et bt les

Problème de lot-sizing à capacité finie avec fenêtres de temps et contraintes de services 297
quantités respectivement produite, stockée et reporté (backlog) à la période t, les propriétés suivantessont valides.– On peut ordonner un ensemble de fenêtres de temps non strictement incluses de la façon suivante :$k bk < bk+1 ou bk = bk+1 et ek < ek+1.
– Lorsque les fenêtres de temps sont non strictement incluses et ordonnées, il existe une solutionoptimale dans laquelle la demande k est produite avant (ou en même temps) que la demande k+ 1$k.
– Si l’on ne tient pas compte des contraintes de capacité, il existe une solution optimale dans laquellechaque demande k est produite entièrement à une seule période.
– Le problème sans contraintes de capacité admet toujours une solution optimale dans laquelleune production n’a lieu à une période t que si le stock au début de cette période est nul. End’autres termes, il existe toujours une suite de décisions optimales x$1, x$2, ..., x$T vérifiant s$t"1x
$t = 0
t = 1, ..., T– Le problème sans contraintes de capacité admet toujours une solution optimale dans laquelle une
production n’a lieu à une période t que si la quantité reportée (backlog) est nulle b$t+1x$t = 0
$t = 1, ..., T % 1. De même, le problème sans contraintes de capacité admet toujours une solutionoptimale dans laquelle un stockage n’a lieu à une période t que si la quantité reportée (backlog)est nulle b$t s$t = 0 $t = 1, ..., T .
Dans le cas où les contraintes de capacité ne sont pas prises en compte, les propriétés précédentesconférent aux solutions optimales la propriété d’arbre-solutions lorsque le problème est modélisécomme un réseau à coût fixe. Dans le cas des fenêtres de temps à clients non-spécifiques, le nombrede demandes est en O(T ). Nous proposons pour ce problème avec fenêtres de temps et contraintesde services sans prise en compte des ressources un algorithme de programmation dynamique enO(T 2). Nous proposons pour le problème de dimensionnement de lots avec des contraintes de ca-pacité, fenêtres de temps à clients non-spécifiques et contraintes de services (ruptures, anticipationset backlogs) une borne inférieure basée sur une méthode de relaxation lagrangienne des contraintesde capacité à partir de la formulation mathématique du problème (agrégée). Nous présenterons desrésultats expérimentaux montrant l’e%cacité de la méthode pour la résolution de ce problème di%cile.
Références
1. D. Aksen, K. Altinkemer, S. Chand : The single-item lot-sizing problem with immediate lost sales.European Journal of Operational Research, 147 (3), pp. 558–566 (2003).
2. N. Absi, S. Kedad-Sidhoum : The multi-item capacitated lot-sizing problem with setup times andshortage costs. European Journal of Operational Research, 185(3), pp. 1351–1374 (2008).
3. N. Brahimi, S. Dauzère-Pérès, and N. Najid, Capacitated Multi Item Lot Sizing Problems withTime Windows. Operations Research, Volume 54(5), pp. 951–967 (2006).
4. W.H. Chen, J.M. Thizy : Analysis of relaxations for the multi-item capacitated lot-sizing problem.Annals of Operations Research, 26, pp. 29–72 (1990).
5. L. Wolsey, Lot-sizing with production and delivery time windows. Mathematical Programming,107, pp. 471–489 (2006).

On the discrete lot-sizing and scheduling problem withparallel resources
C. Gicquel1, M. Minoux2, and Y. Dallery1
1 Laboratoire de Génie Industriel, Grande Voie des Vignes, 92290 Chatenay-Malabry, [email protected]
2 Laboratoire d’Informatique de Paris 6, 4 place Jussieu, 75005 Paris, France.
In the present paper, a production planning problem, known as the Discrete Lot-sizing and SchedulingProblem (DLSP), is considered. As defined in [1], the DLSP is based on several crucial assumptions :– Demand for products is deterministic and time-varying.– The production is planned for a finite time horizon subdivided in several discrete periods.– At most one type of product can be produced per period ("small bucket" model) and each facility
processes either one product at full capacity or is completely idle ("all-or-nothing assumption").– Costs to be minimized are the inventory holding costs and the changeover costs.Here the single-level multi-resource variant of this problem is studied : the products to be processedare end items and there is a small number of parallel resources available for production. The presenceof parallel resources complicates the problem mainly because there is an additional decision to bemade : we have to determine not only the timing and level of production, but also the assignment ofproduction lots to machines. Moreover, in the DLSP, the changeover costs to be incurred when theproduction of a new lot begins can depend either on the next product only (sequence-independentcase) or on both the previous and the next product (sequence-dependent case). We consider hereboth cases and assume zero changeover times.[2] proposes to strengthen an initial MIP formulation of the single-item single-resource DLSP usinga family of strong valid inequalities. Thanks to this strengthened formulation, the lower boundsprovided by the linear relaxation of the problem are significantly better, enabling a Branch & Boundtype procedure to solve the problem more e%ciently. In [3], this approach was applied successfullyfor the case of a single production resource with multiple items.We propose in the present work an extension of this approach to the case of parallel identical resources.We first introduce an initial MIP formulation for the DLSP with parallel resources. We then derivea family of strong valid inequalities for the case where the available resources are identical and theproduction capacity is constant throughout the planning horizon. These valid inequalities can be seenas an extension of the valid inequalities developed by [2] for the single-resource single-item DLSP.The underlying idea is to provide lower bounds on the inventory level of a product at the end of aplanning period by considering the possible productions over the following periods.Computational experiments were carried out in order to evaluate the e%ciency of the proposed validinequalities at strengthening the initial formulation and at improving the e%ciency of a standardMIP solver. We used randomly generated instances of various size as well as instances based on asmall industrial problem. Our results show that thanks to the proposed enhanced formulation, thee%ciency of the Branch & Bound procedure embedded in a commercial MIP solver (CPLEX 11.1)can be significantly improved.
Références
1. Fleischmann, B. : The discrete lot sizing and scheduling problem. European Journal of OperationalResearch, vol. 44, pp 337-348 (1990)

On the DLSP with parallel resources 299
2. van E$l C.A. and van Hoesel C.P.M. : On the discrete lot-sizing and scheduling problem withWagner-Whitin costs, Operations Research Letters, vol. 20, pp 7-13 (1997).
3. Wolsey, L. : Solving multi-item lot-sizing problems with an MIP solver using classification andreformulation. Management Science, vol. 48(12), pp 1587-1602 (2002)

Un système d’agents pour la planification etl’ordonnancement multi-produits, multi-modes avec
approvisionnements
K. Belkhelladi1,2, P. Chauvet1,2, L. Péridy1,2, and A. Schaal2
1 LISA, 62, avenue Notre Dame du Lac, 49000 Angers [email protected], [email protected]
2 IMA, 44, rue Rabelais, BP 10808, 49008 Angers Cedex 01 [email protected], [email protected]
1 Introduction
Nous nous intéressons à l’optimisation de la planification et de l’ordonnancement de la fabrication deplusieurs produits dans di#érents modes opératoires avec approvisionnements. Ce travail consiste doncà optimiser la production en tenant compte des processus sur deux échelles de temps très di#érentesque sont la planification et l’ordonnancement. Il faut déterminer d’une part, sur un horizon de tempsdonné, les quantités fabriquées et stockées par période pour chaque produit, ainsi que le mode deproduction choisi et les dépassements de ressources, en fonction d’une demande pour chaque produitlors de chacune des périodes. Et il faut d’autre part passer à une échelle temporelle plus précise etrésoudre un problème d’ordonnancement à partir du résultat de la planification. Bien évidement, il estnécessaire de prévoir des "aller-retour" entre les deux niveaux de temps afin d’obtenir une meilleuresolution.Le but de cette étude est de montrer comment la coopération d’agents engagés dans la résolution d’unproblème de planification et d’ordonnancement multi-produit, multi-modes avec approvisionnementspeut permettre de résoudre ce dernier plus e%cacement qu’une résolution séparée des deux niveauxtactique (planification) et opérationnel (ordonnancement). La coopération prendra la forme d’"aller-retour" en échangeant des informations entre l’agent de planification et l’agent d’ordonnancement.
2 Description du problème
Il s’agit de planifier et d’ordonnancer la production d’un ensemble de N références pour un horizonde temps constitué de T périodes. Ce plan est à capacité finie et doit tenir compte d’un ensemble decontraintes additionnelles. En e#et, plusieurs références doivent être planifiées et la production d’uneréférence peut nécessiter la pré-production d’autres références. Le lancement de production d’uneréférence à une période donnée entraÓne outre la consommation variable en ressources, une consom-mation dite fixe (de démarrage). Plusieurs processus de production (ou modes) peuvent être utilisés,la consommation des ressources s’e#ectuera de faÁon di#érente suivant le mode. Par ailleurs, toutlancement de production d’une référence induit une consommation fixe en ressources. Les approvision-nements non consommés lors d’une période peuvent être conservés pour être utilisés ultérieurement.Le plan de production doit également respecter les limites du stock, notamment, le stock de sécurité,la quantité maximale pouvant être stockée pour chaque produit, ainsi que l’espace maximal occupépar ce stock. Il s’agit alors de minimiser les co˚ts de production, de lancement et de stockage ainsique les co˚ts de ruptures sur la demande des références. Le problème défini est NP-di%cile [1][2].

Title Suppressed Due to Excessive Length 301
3 Approche de résolution
Dans ce qui suit, nous proposons une approche basée sur un paradigme multi-agents. A cet e#et, deuxtypes d’agents ont été définis, l’un pour la planification et l’autre pour l’ordonnancement. L’agent deplanification permet de calculer un plan de production optimal pour une séquence fixée de références.Il recrute à son tour un ensemble d’agents pour exécuter une métaheuristique de résolution issue del’adaptation de l’algorithme présenté dans Belkhelladi et al. [3]. L’agent d’ordonnancement permetde déterminer un meilleur ordonnancement pour un planning de production fixé, fourni par l’agentde planification. Les deux types d’agents coopèrent en échangeant des informations afin d’obtenirune meilleure solution au problème. Cette coopération prendra la forme d’"aller-retour". L’agent deplanification propose un planning de production en aller tandis que l’agent d’ordonnancement établieun rapport d’aide à la réparation du planning en retour. Le processus de réparation du plannings’inspire des di#érentes procédures d’amélioration proposées par FranÁa et al. [4]. La figure 1 illustrel’architecture de l’approche proposée.
Agent de planification(Niveau tactique)
Agent d’ordonnancement(Niveau opérationnel)
Processus de réparation
Planning
BilanPlanning
réparéallerretour
Fig. 1. Architecture du solveur
Références
1. Florian, M., Lenstra, J.K. and Rinnoy Kan, A. H. G. : Deterministic production planning : algo-rithms and complexity, Management Science 26, p. 669-679 (1980)
2. Shapiro, J. F. : Mathematical programming models and methods for production planning andscheduling. Massachusetts Institute of Technology, Operations Research Center (1988)
3. Belkhelladi, K., Chauvet, P. and Schaal, A. : Une approche multi-agents pour l’optimisationpar algorithme génétique distribué. In proceedings du 9ème Congrès de la Société Française deRecherche Opérationnelle et d’Aide à la décision (ROADEF’08), Clermont-Ferrand, France (2008)
4. França, P. M., Armentano, V. A., Beretta, R. E. and Clark, A. R. : A heuristic for lot-sizing inmulti-stage systems. Computer operation research (24), p. 861-874 (1997)

Dimensionnement et ordonnancement de livraisons derepas
V. André1,2, N. Grangeon1, and S. Norre,1
1 LIMOS, CNRS UMR 6158, IUT de MontluçonUniversité Blaise Pascal, Clermont-Ferrand
Av. Aristide Briand, 03100 Montluç[email protected], [email protected]
2 CHU Clermont-Ferrand, Atelier de modélisation, Hôtel Dieu,Boulevard Léon Malfreydt, 63058 Clermont-Ferrand Cedex 1
1 Présentation du problème
Le Centre Hospitalier Universitaire (CHU) de Clermont-Ferrand est composé de plusieurs sites quisont répartis dans la ville. Ceux-ci sont au nombre de 4 : l’hôpital de Gabriel Montpied, l’Hôtel Dieu,le Centre Médico-Psychologique et l’Hôpital Nord. Actuellement, pour assurer les repas des patients,une centrale de production de repas (UCP) basée sur le site de l’hôpital de Gabriel Montpied (GM)assure la préparation des repas et les livre en vrac sur les deux principaux sites, à savoir GM etl’hôtel Dieu (HD) qui sont équipés de cuisines-relais et sous forme d’armoires de plateaux repas pourles autres sites.Afin de centraliser la production des repas, la direction a décidé de ne livrer sur ces sites que des pla-teaux repas ne nécessitant qu’une remise à température. Cette activité implique la livraison d’armoiresde plateaux repas sur l’ensemble des sites. De plus, la restructuration du CHU de Clermont-Ferrandamène à remplacer l’HD par un nouveau bâtiment, le Nouvel Hôpital d’Estaing (NHE), plus éloignéde l’UCP et qui disposera d’un nombre de lits plus important.Le transport d’armoires «pleines» se décompose en trois étapes : chargement des armoires dans levéhicule (par une ressource humaine), transport de l’UCP vers le site de destination (par le chau#eur),déchargement des armoires (par le chau#eur). Une fois les repas consommés, les armoires «vides»doivent être ramenées vers l’UCP. Les étapes sont similaires aux étapes pour le transport d’armoirespleines : chargement des armoires dans le véhicule (par le chau#eur), transport vers l’UCP (par lechau#eur), déchargement des armoires (par une ressource humaine).Le problème concerne donc l’organisation des livraisons des repas sur les di#érents sites composant leCHU avec l’objectif de minimiser à la fois le nombre de véhicules et le nombre de chau#eurs utilisés.Les hypothèses sont les suivantes :– Le nombre de sites à livrer est connu et le besoin en nombre d’armoires est connu pour chaque
site.– Les durées de chargement et de déchargement sont connues et constantes.– Les durées de transport entre l’UCP et chacun des sites sont connues et supposées constantes.– Tous les véhicules ont la même capacité.– Un chau#eur peut conduire n’importe quel véhicule et peut être amené à changer plusieurs fois de
véhicule lors d’une journée de travail.– Le véhicule doit être nettoyé entre le transport d’armoires vides et le transport d’armoires pleines.
La durée de nettoyage est connue et constante.– Un véhicule transporte des armoires pleines ou vides mais peut aussi circuler à vide.

Dimensionnement et ordonnancement de livraisons de repas 303
– Lors d’une tournée, chaque véhicule visite au plus l’UCP et un site.– Le nombre de ressources humaines disponibles pour les chargements ou le déchargement à l’UCP
est supposé illimité.L’ensemble des contraintes à prendre en compte est le suivant :– Les dates de disponibilité au plus tôt des armoires pleines et des armoires vides doivent être
respectées.– Les dates de livraison au plus tard des armoires pleines doivent être respectées.– La durée du temps de travail des chau#eurs doit être respectée.– Le nombre de véhicules qui peuvent être chargés ou déchargés à un instant donné à l’UCP ou dans
un site est limité, en raison du nombre de quais de chargement et de quais de déchargement.
2 Approche proposée
La première partie de notre travail s’est limitée à l’étude des livraisons journalières des armoirespleines. Le problème est modélisé par un RCPSP avec profil de demande en ressources variable [1].Chaque livraison est décomposée en deux étapes : une étape pour le chargement nécessitant unvéhicule et une étape pour le transport, le déchargement et le retour à vide nécessitant un véhiculeet un chau#eur. Entre chaque étape, un temps d’attente peut être admis.Ce modèle a également été utilisé pour la collecte des armoires vides, chaque collecte étant décomposéeégalement en deux étapes : une étape pour le transport à vide, le chargement des armoires vides etle transport de ces armoires jusqu’à l’UCP nécessitant un véhicule et un chau#eur et une étape pourle déchargement nécessitant le véhicule.La seconde partie de notre travail s’intéresse au problème global c’est-à-dire la livraison journalièredes armoires pleines et des armoires vides. Chaque livraison et collecte est décomposée en trois étapes :une étape de chargement, une étape de transport et une étape de déchargement. Pour ce problème,les véhicules sont distingués et un ordonnancement des activités sur ces véhicules est construit. Cetordonnancement prend en compte les temps de transport à vide comme des temps de setup dépendantde la séquence.Pour la résolution de ces problèmes, des modèles mathématiques sont proposés. Les instances réellestraitées comportent jusqu’à 12 activités de livraison d’armoires pleines et 12 activités de collected’armoires vides.
Références
1. M. Gourgand, N. Grangeon, S. Norre SM-RCPSP avec profil de demande en ressources variable :extension ou cas particulier ? 7ème congrès de la Société Française de Recherche Opérationnelleet d’Aide à la Décision 6-8 février 2006 Lille.

Utilisation de problèmes d’ordonnancementpour la conception de systèmes flexibles de production
L. Deroussi,1
LIMOS, CNRS UMR 6158, IUT de MontluçonUniversité Blaise Pascal, Clermont-Ferrand
Av. Aristide Briand, 03100 Montluç[email protected]
1 Introduction
Les systèmes flexibles de production (Flexible Manufacturing Systems ou FMS) sont des systèmes deproduction hautement automatisés dans lesquels des machines à commande numérique sont reliéesentre elles par un système de transport. De tels systèmes sont à la fois productifs et flexibles, mais ilssont aussi extrêmement coûteux et complexes à concevoir. La littérature les concernant est abondanteet peut être classées selon trois catégories : les problèmes de conception d’atelier, les problèmes deconception du réseau de transport et les problèmes d’ordonnancement. Etant donné la di%culté dechacun de ces problèmes pris séparément, ils sont généralement traités de manière séquentielle.L’objectif de ce travail est de montrer qu’il peut être intéressant de réorganiser un atelier, en considé-rant la résolution de problèmes d’ordonnancement. Ce travail rejoint la réflexion de plusieurs auteurs[5] et [1], qui ont montré l’intérêt de prendre en compte les temps de déplacement à vide des véhicules,nonobstant la di%culté liée à cette prise en compte.
2 Description du problème
Le FMS que nous considérons est constitué d’emplacements, destinés à recevoir des moyens deproduction (ou machines), de machines, d’un réseau de transport sur lequel circulent des moyensde transport (ou AGV ), et d’AGVs qui permettent de transporter les produits d’une machine versune autre.L’atelier doit fabriquer un ensemble de pièces, dont le processus de fabrication consiste en unesuccession d’opérations devant être e#ectuées dans l’ordre donné. Chaque opération est définie parla donnée d’une machine et d’une durée opératoire (FMS de type job-shop), ou d’un ensemble demachines (FMS de type job-shop flexible).La réorganisation de ce FMS concernera uniquement la réa#ectation possible des machines à l’in-térieur des emplacements prédéfinis. Nous supposerons qu’il n’y a pas d’incompatibilités entre lesemplacements et les machines.Nous mesurons la qualité d’une a#ectation des machines aux emplacements selon deux critères. Lepremier critère minimise les déplacements à charge des véhicules. Ce problème se modélise en unproblème d’a#ectation quadratique ou QAP. Nous appellerons solution QAP-optimale la solutionobtenue en résolvant ce problème (de manière exacte ou approchée). L’a#ectation des machines ainsiobtenue est celle qui est classiquement retenu lors de la phase de conception du FMS. Le deuxièmecritère prend également en compte les déplacements à vide des AGVs, ainsi que la synchronisationentre les déplacements des pièces et leur fabrication. Il s’agit ici de proposer un ordonnancement

problèmes d’ordonnancement pour la conception des SFP 305
conjoint des machines et des véhicules. Ce problème a été initialement proposé par [2]. [3] ont ré-cemment proposé une approche de résolution e%cace pour ce problème. Cette dernière est utiliséecomme une boîte noire pour l’évaluation de ce deuxième critère.Notre objectif est de montrer que la solution QAP-optimale n’est pas nécessairement la meilleurelorsque l’on cherche à évaluer plus finement la performance du FMS.
3 L’Approche de résolution
Nous proposons une approche de résolution en deux phases :– La première phase consiste en la résolution du QAP. La solution QAP-optimale servira de solution
de référence que l’on cherchera à améliorer selon le deuxième critère.– La deuxième phase consiste donc à améliorer la solution QAP-optimale. La démarche qui s’est
avérée la plus e%cace consiste à utiliser la solution QAP-optimale pour définir un TSP, sur lequelnous appliquons l’algorithme de colonie de fourmis défini par [4].
4 Les résultats obtenus
Nous nous sommes intéressés dans un premier temps aux FMS de type job-shop. Nous avons reprisle jeu d’essai de [2], qui est composé de 40 instances. Sur ces instances de petite taille (5 machines),la résolution du QAP est facile. Nous avons pu établir que la solution QAP-optimale n’était pas lameilleure a#ectation pour 17 des 40 instances. L’algorithme basée sur les colonies de fourmis permetde retrouver l’a#ectation optimale dans la majorité des cas, ce qui n’est pas le cas pour les autresdémarches testées.Des jeux d’essai ont ensuite été conçus pour les FMS de type job-shop flexible. Les instances consi-dérées ne permettent pas la résolution exacte du QAP. Les résultats obtenus montrent égalementl’intérêt d’évaluer plus finement la performance du système, en faisant intervenir la résolution deproblèmes d’ordonnancement.
Références
1. A. Asef-Vaziri, N. G. Hall, R. George The significance of deterministic empty vehicle trips in thedesign of a unidirectional loop flow path Computers & Operations Research 35, 1546 - 1561, 2008.
2. U. Bilge, G. Ulusoy A time window approach to simultaneous scheduling of machines and materialhandling system in an FMS Operations Research 43, 1058-1070, 1995.
3. L. Deroussi, M. Gourgand, N. Tchernev A simple metaheuristic approach to the simultaneous sche-duling of machines and automated guided vehicles International Journal of Production Research46, 2143-2164, 2008.
4. M. Dorigo, L. M. Gambardella Ant Colony System : A cooperative learning approach to thetraveling salesman problem IEEE Transactions on Evolutionary Computation, 1, 53-66, 1999.
5. X.-C. Sun, N. Tchernev Impact of empty vehicle flow on optimal flow path design for unidirectionalAGV systems International Journal of Production Research 34, 2827-2852, 1996.

Borne inférieure et coupes pour le problèmed’optimisation des changements de séries
C. Pessan1 and E. Néron2
1 Université François Rabelais Tours, Laboratoire d’informatique, Polytech’Tours, 64, avenue JeanPortalis, 37200 Tours, France.
[email protected] Université François Rabelais Tours, Laboratoire d’informatique, Polytech’Tours, 64, avenue Jean
Portalis, 37200 Tours, [email protected]
1 IntroductionSur une ligne de production, un changement de série consiste à changer et régler l’outillage de chacunedes machines de la ligne afin de produire un nouveau type de pièce. Cette opération est coûteuse entemps de production et doit donc être optimisée afin d’assurer une bonne flexibilité de la productionet ainsi favoriser la production en juste à temps permettant de minimiser à la fois les délais delivraison et la taille des stocks. Nous proposons d’améliorer des bornes proposées dans [4] et [5] enajoutant des coupes prenant en compte les contraintes industrielles du problème et en proposant desméthodes permettant de limiter le nombre de coupes générées afin d’améliorer le temps de calcul dela borne.
2 Présentation du problèmeLes changements de série sont composés d’une tâche de réglage pour chacune des machines de la ligne.Ces réglages doivent être e#ectués par des opérateurs et nécessitent des compétences particulières.Dans cette étude menée sur le cas de l’entreprise SKF, les temps opératoires dépendent de l’expériencedes opérateurs. Nous modélisons donc ce problème par un problème à machines parallèles non reliéesoù les ressources sont les opérateurs et les tâches sont les réglages des machines, les temps opératoiresreprésentant le niveau de compétence. Les machines ne peuvent être réglées avant une date ri et undélai qi est nécessaire après leur remise en fonctionnement pour qu’elles puissent avoir un impact surla production. Soit f(Ci) le critère à optimiser, ce problème est noté : R|ri, qi|f(Ci)Nous distinguons deux cas, le cas où la ligne est une ligne série et le cas où c’est une ligne série-parallèle. Dans le cas série, l’objectif est de minimiser le temps du changement de série Cmax. Deplus, nous pouvons montrer que dans notre cas, l’ordre des ri croissant est le même que l’ordredes qi décroissant et que les tâches peuvent être ordonnancées optimalement par ri croissants surchaque opérateur. Dans le cas où il s’agit d’une ligne série-parallèle, l’objectif devient la maximisationdu nombre de pièces produites dans une période qui inclut un changement de série. Ce critère estformalisé dans [6].
3 BornesDans le cas série, une borne inférieure consiste à résoudre la relaxation préemptive du problème.Cette relaxation est polynomiale et peut être résolue à l’aide d’un programme linéaire simple (PLS)

Coupes pour l’optimisation de changements de séries 307
[2]. Nous avons proposé dans [4] une amélioration de cette borne inférieure en proposant des coupes.Ces coupes utilisent la notion de parties obligatoires [1]. Nous avons tout d’abord adapté des coupesproposées par [3] pour le problème R||Cmax qui permettent d’évaluer la charge des opérateurs dansle cas où la préemption n’est pas autorisée. Pour adapter ces coupes, nous avons considéré chaqueintervalle individuellement, et nous avons utilisé les parties obligatoires dans ces intervalles au lieudes temps opératoires. Nous avons également proposé des coupes permettant de prendre en compte lefait que les tâches doivent être ordonnancées par ri croissants dans la solution optimale du problèmenon relaché. Enfin, des coupes permettent de limiter la préemption des tâches.Les résultats montrent que la qualité de la borne est significativement améliorée mais le temps decalcul ne permet pas de l’utiliser dans une procédure par séparation et évaluation (PSE). Nousproposons donc d’étudier expérimentalement quelles coupes doivent être réellement ajoutées pouraméliorer la qualité de la borne sans trop dégrader le temps de calcul.Le schéma de branchement utilisé par la PSE [6] place une tâche à chaque nœud sans modifierl’ordonnancement des tâches déjà a#ectées. Nous proposons donc de modifier le critère utilisé dansle PLS afin de favoriser l’ordonnancement des tâches au plus tard. Ainsi, si à un nœud, on place unetâche qui ne modifie pas l’ordonnancement préemptif calculé au nœud père, nous savons qu’il n’estpas nécessaire de recalculer la borne inférieure à ce nœud.Dans le cas général, une borne supérieure peut être calculée en utilisant la borne inférieure du cassérie pour déterminer les instants où la productivité augmente.
4 Conclusion
Dans cet article, nous proposons d’améliorer le temps de calcul d’une borne inférieure pour le problèmed’optimisation des changements de série en étudiant la contribution de coupes à la qualité de la borne.Plus de détails et des résultats expérimentaux seront proposés lors de la conférence.
Références
1. Lahrichi, A. : Ordonnancements : La notion de parties obligatoires et son application aux problèmecumulatifs. R.A.I.R.O.-R.O., No. 16, Vol. 3 pp. 241–262 (1982)
2. Lawler, E.L., Labetoulle, J. : On preemptive scheduling of unrelated parallel processors by linearprogramming. Journal of the ACM, pp. 612–619 (1978)
3. Mokoto#, E., Chrétienne, P. : A cutting plane algorithm for the unrelated parallel machine sche-duling problem. European Journal of Operational Research, No. 141 pp. 515–525 (2002)
4. Pessan, C., Néron, E. : Cutting planes for an industrial unrelated parallel machines problem withrelease dates and tails. Proceedings of ECCO XXI, Dubrovnik, Croatia (2008)
5. Pessan, C., Néron, E. : Bornes supérieures pour le problème d’optimisation des changements deséries. Actes de ROADEF’08, Clermont Ferrand, France (2008)
6. Pessan, C. : Optimisation de changements de séries par ordonnancement des tâches de réglage.Thèse de doctorat, Université François Rabelais Tours (2008)

Minimisation du nombre de processeurs pour lessystèmes temps réel multiprocesseurs
François DORIN, Michael RICHARD, Emmanuel GROLLEAU, and Pascal RICHARD
LISI / ENSMA - Université de Poitiers, Teleport 2 - 1, avenue Clement Ader, BP 40109,86961 FUTUROSCOPE CHASSENEUIL Cedex France.
[email protected], [email protected],[email protected], [email protected]
1 Introduction
L’informatique temps-réel repose sur une correction temporelle des applications, en plus de la cor-rection fonctionnelle. La réduction du nombre de processeurs utilisés pour ordonnancer fiablementun système temps réel est un enjeu majeur afin de réduire les dimensions, le poids, le coût et laconsommation d’énergie (par exemple, dans le cadre de systèmes embarqués). Nous proposons, dansla suite, une méthode permettant de valider temporellement une application tout en minimisant lenombre de processeurs utilisés.Cette méthode est une aide précieuse au dimensionnement de systèmes multiprocesseurs ou distribués(composés d’un ou de plusieurs réseau(x)).La validation temporelle est assurée par un test de faisabilité basée sur l’analyse holistique ([4]). Pource faire, les tâches doivent être placées sur un processeur et posséder une priorité.Notons enfin que placement et a#ectation de priorité sont réalisés conjointement.
2 Problème
Le problème de minimisation du nombre de processeurs est proche du problème de binpacking dansun contexte multiprocesseur avec tâches indépendantes.Nous considérons ici un ensemble de tâches périodiques, à échéances strictes, à priorité fixe, s’exécu-tant sur une architecture multiprocesseur (sans migration des tâches) ou distribuée, et dont nous neconnaissons que les pires durées d’exécution. La préemption des tâches est autorisée et n’engendreaucun surcoût processeur.Lorsque nous lui fournissons un système de tâches en entrée, l’exécution de notre algorithme fournitune solution valide utilisant un nombre n de processeurs. n correspond au nombre minimum deprocesseurs nécessaires pour valider le système de tâches par une analyse holistique.
3 Algorithme d’ordonnancement
Notre algorithme repose sur une énumeration exhaustive de tous les ordonnancement possibles selonune procédure par séparation et évaluation (Branch & Bound), basé sur les précédents travaux deM. Richard e#ectués lors de sa thèse ([3]).Lors du parcours de l’arbre de recherche, les tâches se répartissent en deux ensembles : les tâchesplacées et possédant une priorité et les tâches non traitées. L’exploration d’un nœud dans l’arbre derecherche consiste à placer une tâche sur un processeur tout en lui a#ectant une priorité. Un test

Minimisation du nombre de processeurs pour les systèmes temps réel multiprocesseurs 309
d’ordonnançabilité est alors e#ectué. Pour les tâches traitées, une borne inférieure du pire temps deréponse est calculée ; pour les tâches non traitées, nous évaluons une borne inférieure du pire tempsde réponse. Ainsi, la solution obtenue est optimale vis-à-vis de l’analyse holistique.La méthode d’énumération s’inspire des travaux de Bratley, Florian et Robillard [1], sur l’explorationd’un arbre de recherche permettant de représenter le placement des tâches à l’aide de deux types denœuds.Notre algorithme minimise le nombre de processeurs nécessaires à l’ordonnancement des systèmes detâches, et répond ainsi à la problématique posée.
4 Evaluation
Nous avons e#ectué des simulations dans un contexte multiprocesseur et tâches indépendantes, en vuede comparer notre algorithme à celui de Fisher et al. [2]. Nous nous sommes placés dans ce contexterestrictif car il n’existe pas, à l’heure actuelle, d’algorithmes permettant de réaliser une comparaisonplus large. Ces simulations ont montré qu’il y avait un apport interessant de notre méthode (parexemple, un gain moyen de 2 processeurs pour un système de 100 tâches et une charge globale de15).
Références
1. P. Bratley, M. Florian, and P. Robillard. Scheduling with earliest start and due date constraintson multiple machines. Naval Research Logistic Quaterly, 22(1) :165–173, 1975.
2. N. Fisher, S. Baruah, and T. Baker. The partitioned scheduling of sporadic tasks according tostatic-priorities. Real-Time Systems, 2006. 18th Euromicro Conference on, pages 10 pp.–, 5-7 July2006.
3. Michael Richard. Contribution à la validation des systèmes temps réel distribués : ordonnancementà priorités fixes & placement. PhD thesis, Université de Poitiers, 2002.
4. Ken Tindell and John Clark. Holistic schedulability analysis for distributed hard real-time systems.Microprocess. Microprogram., 40(2-3) :117–134, 1994.

Ordonnancement de tâches synchrones multipériodiques
Mikel Cordovilla, Julien Forget, Claire Pagetti, and Frédéric Boniol
ONERA, Toulouse, France, Email : [email protected]
Introduction
Les systèmes embarqués sont des systèmes temps réel critiques nécessitant des langages de hautniveau et si possible l’automatisation de certaines étapes de développement.Nous nous situons dans le contexte de systèmes périodiques de type contrôle-commande. Ces systèmessont généralement composés de trois sortes d’action : acquisition de données, traitement, et envoi desordres aux actionneurs. Les langages synchrones [1] sont depuis plusieurs années utilisés avec succèspour concevoir de tels systèmes. Néanmoins, ces langages génèrent un code séquentiel global, ce quidonne lieu à des implantations monotâches. Du fait de l’apparition de nouveaux systèmes d’exploita-tion embarqués critiques comme OSEK pour l’automobile ou l’ARINC 653 pour l’aéronautique, il estintéressant de proposer des générations de code multitâches et de laisser au système d’exploitationla gestion de l’ordonnancement des tâches.L’objectif de notre travail est, à partir d’un langage synchrone de description d’assemblage de fonc-tions multipériodiques, de générer automatiquement un ensemble de tâches temps réel et des méca-nismes de bu#ers associés permettant de conserver la sémantique du langage et d’exécuter le codeavec un ordonnanceur EDF (Earliest Deadline First).
L’approche suivie
L’approche suivie repose sur le langage d’assemblage défini dans [3] permettant de décrire les interac-tions synchrones entre des nœuds (i.e., blocs fonctionnels) importés écrits dans un autre langage (Cou du Lustre par exemple). Pour un système donné, les nœud importés du système sont assimilés àdes tâches temps réel. Les attributs temps réel de ces tâches sont : (1) le wcet (worst case executiontime), spécifié dans le programme lors de la déclaration d’importation du nœud, (2) la période etla date de réveil, automatiquement calculées par le compilateur du langage à partir de la périodede base du système, et (3) un graphe de communications et de précédences entre les tâches et avecl’environnement.Les ordonnanceurs de type EDF n’acceptant pas des contraintes de précédences entre tâches, nousavons pensé à appliquer l’algorithme de Chetto et al. [2] qui transforme des tâches dépendantes avecprécédence en tâches indépendantes en modifiant les dates de réveil et les deadlines (première étapede l’approche). Une telle transformation ne garantie cependant pas la préservation de la sémantiquesynchrone du système. La deuxième étape consiste alors à déterminer un mécanisme de bu#er per-mettant de faire communiquer les tâches de façon à respecter cette sémantique. Cette seconde étapes’appuie sur les idées de Sofronis et al. [5]. Les auteurs définissent un protocole de communication ap-pelé Dynamic Bu"ering Protocol (DBP) permettant d’ordonnancer des tâches exprimées en Lustrepar des ordonnanceurs de type RM ou EDF. L’idée est d’une part de calculer la taille des bu#ersnécessaires pour les communications et d’autre part d’assurer la cohérence des données en utilisantdes pointeurs sur chacun des bu#ers.Notre contexte est moins large que celui défini par Sofronis et al. puisque nous ne considérons que dessystèmes multipériodiques. Pour ces systèmes les auteurs de [5] proposent un algorithme de calcul

Ordonnancement de tâches synchrones multipériodiques 311
du nombre optimal de bu#ers. Nous proposons une formule basée sur des propriétés temps réel pourcalculer ce même nombre mais de complexité plus faible. Nous avons implanté les deux algorithmesde calcul et les avons expérimentés sur une étude de cas réel. Le protocole DBP défini par Sofronis etal. est un protocole générique avec notamment des tâches apériodiques qui décrit les accès des tâchesaux bu#ers en utilisant des pointeurs. Certains de ces pointeurs doivent être modifiés à la date deréveil de chaque instance ce qui signifie qu’il faut probablement ajouter des services extérieurs plusprioritaires qui peuvent entraîner des préemptions supplémentaires. Notre contexte multipériodiqueétant plus restreint, nous connaissons statiquement les accès aux bu#ers. Notre approche consiste àempaqueter le code des tâches de façon à calculer dans le code modifié le numéro des cases à accéder.Ceci a un léger impact sur les wcet mais n’ajoute pas de services extérieurs et probablement aucunsurcoût de préemption. Notons que Sofronis et al., même s’ils posent une question similaire à la nôtreconsistant à porter un code Lustre sur un ordonnanceur EDF, passent sous silence le calcul e#ectifdes tâches à ordonnancer et de leurs caractéristiques. Dans notre contexte, le langage d’assemblagedécrit la spécification et permet de préciser les relations de fréquences entre nœuds importés qui sontassimilés à des tâches temps réel. Le passage de cette description synchrone (niveau fonctionnel) enun ensemble de tâches avec précédence (niveau exécution) est alors automatique.
Conclusion
Ce travail est l’étape préliminaire avant une génération de code complète du langage d’assemblagevers un code multitâche embarquable dans un ordonnanceur EDF. La prochaine phase sera la mise enœuvre des concepts théoriques présentés dans le papier. Une implantation du protocole de Sofroniset al. sur un support OSEK/VDX a été réalisée par les auteurs de [4]. Nous nous inspirerons de leurméthode pour implanter notre protocole sur la cible POSIX.
Références
1. Benveniste, A. and Caspi, P. and Edwards, S. and Halbwachs, N. and Leguernic, P. and de Simone,R. : Synchronous Languages, 12 Years Later, 2003
2. Chetto, H. and Silly, M. and Bouchentouf, T. : Dynamic scheduling of real time tasks underprecedence constraints (1990)
3. Forget, J. and Boniol, F. and Lesens, D. and Pagetti, C. : A multi-periodic synchronous data-flowlanguage 11th IEEE High Assurance Systems Engineering Symposium (HASE’08), 2008
4. Guoqiang, W. and Di Natale, M. and Sangiovanni-Vincentelli, A. : An OSEK/VDX Implemen-tation of Synchronous Reactive Semantics Preserving Communication Protocols, Workshop onOperating Systems Platforms for Embedded Real-Time Applications (2007)
5. C. Sofronis and S. Tripakis and P. Caspi : A memory-optimal bu#ering protocol for preservation ofsynchronous semantics under preemptive scheduling EMSOFT ’06 : Proceedings of the 6th ACM& IEEE International conference on Embedded software, 2006

d-bloqueurs et d-transversaux
C. Bentz1, M.-C. Costa2, D. de Werra3, C. Picouleau4, B. Ries5, and R. Zenklusen6
1 Université Paris-Sud, LRI, Orsay (France)[email protected]
2 ENSTA-UMA-CEDRIC, Paris (France)[email protected]
3 EPFL, Lausanne (Suisse)[email protected]
4 Laboratoire CEDRIC, CNAM, Paris (France)[email protected]
5 Columbia University, New York (USA)[email protected]
6 Eidgenössische Technische Hochschule Zürich, Zürich (Suisse)[email protected]
Soit G = (V,E) un graphe simple non orienté et sans boucle. Nous notons |V | = n, |E| = m et 4(G)la cardinalité maximale d’un couplage. Nous définissons un d-bloqueur comme un ensemble d’arêtesB 5 E telque 4((V,E \ B)) # 4(G) % d et un d-transversal comme un ensemble d’arêtes T 5 Etelque |M 0 T | ) d pour tout couplage maximum M . Un d-bloqueur (resp. d-transversal) est ditminimum lorsque sa cardinalité |B| (resp. |T |) est minimale. Pour d = 1 un d-bloqueur (resp. d-transversal) est appelé bloqueur (resp. transversal). Ainsi un transversal correspond à un transversalde l’hypergraphe des couplages maximums de G. De cette façon, les problèmes de d-bloqueurs sontproches des problèmes qui consistent à oter un nombre minimum d’arêtes d’un graphe afin que legraphe partiel obtenu respecte une une propriété donnée.Nous montrons certaines propriétés reliant d-bloqueurs et d-transversaux : tout d-bloqueur est und-transversal ; il existe des d-transversaux qui ne sont pas des d-bloqueurs. Concernant la complexitéalgorithmique, nous montrons que pour tout d ! {1, . . . , 4(G)}, la recherche d’un d-bloqueur (resp.d-transversal) minimum est un problème NP -di%cile même lorsque G est biparti.Nous montrons ensuite comment déterminer un d-bloqueur (resp. d-transversal) minimum lorsque Gest une grille ou un arbre : pour une grille de dimension m+ n la cardinalité d’un d-bloqueur (resp.d-transversal) minimum est obtenue par une formule close dépendant de d,m, n ; elle est obtenue enutilisant la programmation dynamique dans le cas d’un arbre.
Références
1. C. Berge, Graphes, Gauthier-Villars, (Paris, 1983).2. E. Boros, K. Elbassioni, V. Gurvich (2006), Transversal Hypergraphs to Perfect Matchings in
Bipartite Graphs : Characterization and Generation Algorithms, Journal of Graph Theory 53 (3),209-232.
3. P. Burzyn, F. Bonomo, G. Durán (2006),NP-completeness results for edge modification problems,Discrete Applied Mathematics 154 (13) 1824-1844.
4. M.R. Garey and D.S. Johnson, Computers and intractability, a guide to the theory of NP-completeness, ed. Freeman, New York (1979).
5. R.R. Kamalian, V.V. Mkrtchyan (2008), On complexity of special maximum matchings construc-ting, Discrete Mathematics 308 (10), 1792-1800.

d-bloqueurs et d-transversaux 313
6. R.R. Kamalian, V.V. Mkrtchyan (2007), Two polynomial algorithms for special maximum mat-ching constructing in trees, http ://arxiv.org/abs/0707.2295.
7. J.M. Lewis, M. Yannakakis (1980), The node-deletion problem for hereditary properties is NP-complete, Journal of Computer and System Sciences 20, 219-230.
8. A. Natanzon, R. Shamir, R. Sharan (2001), Complexity classification of some edge modificationproblems, Discrete Applied Mathematics 113, 109-128.
9. M. Yannakakis (1981), Edge-deletion problems, SIAM Journal of Computing 10 (2), 297-309.10. M. Yannakakis (1981), Node-deletion problems on bipartite graphs, SIAM Journal of Computing
10 (2), 310-327.11. R. Zenklusen (2008), Matching Interdiction, http ://arxiv.org/abs/0804.3583.12. R. Zenklusen, B. Ries, C. Picouleau, D. de Werra, M.-C. Costa, C. Bentz (2008), Blockers and
transversals, to appear in Discrete Mathematics.

Un algorithme polynomial pour calculer le stablemaximum (pondéré) dans une classe de graphes sans P5
F. Ma#ray and G. Morel
Laboratoire G-SCOP, 46, avenue Felix Viallet, 38031 Grenoble Cedex 1 [email protected], [email protected]
1 Introduction
De nombreuses sous-classes de graphes sans P5 ont été étudiées jusqu’à présent (graphes à seuil,graphes (pseudo-) scindés, cographes, graphes sans 2K2, etc.), et pour chacune d’elles on sait cal-culer un stable maximum en temps polynomial, voire linéaire, gr‚ce à des techniques très variées(décomposition modulaire, graphes augmentants, struction, etc.).
Nous proposons un algorithme polynomial pour le calcul d’un stable de taille maximum, dans uneclasse de graphes généralisant les cographes et les graphes sans 2K2.
2 Le problème du stable maximum dans les graphes sans P5
2.1 Motivation
Soit Ti,j,k le graphe obtenu à partir d’une gri#e (i.e. le graphe biparti K1,3) en prolongeant les troissommets de degré 1 en trois chaînes sans corde ayant respectivement i, j et k sommets.
Alekseev a montré ([1]) que si un graphe H a une composante connexe qui n’est pas isomorphe àTi,j,k, alors le problème du stable de cardinalité maximum est NP-Di%cile dans la classe des graphesne contenant pas H comme sous-graphe induit.
Il existe seulement deux graphes, à isomorphisme près, de la forme Ti,j,k vérifiant i+ j + k = 4 : cesont la chaise (i.e. le graphe obtenu en ajoutant un voisin à un sommet de degré 1 dans une gri#e) etla chaîne sans corde à 5 sommets, P5. En 1999, Alekseev ([3]) a montré que l’on pouvait calculer unstable maximum dans la classe des graphes sans chaise en temps polynomial. Depuis, les graphes sansP5 constituent la plus petite classe, définie par un seul sous-graphe connexe interdit, pour laquelle lacomplexité du calcul d’un stable maximum reste ouverte.
2.2 Structure des graphes sans P5
Comme on sait calculer en temps polynomial un stable maximum dans un graphe sans 2K2 ([4],[2]), nous nous sommes intéressés à la structure des graphes sans P5 contenant un 2K2 induit. Cettestructure fait l’objet du théorème suivant :
Theorem 1. Soit G = (V,E) un graphe sans P5 qui contient un 2K2 induit. V peut Ítre partitionnéen quatre ensembles comme suit :

Analyse combinatoire de données et analyse de temps de survie 315
– B = B1 2B2 2 · · · 2Bk, tels que : G[Bi] (1 # i # k) soit un sous-graphe connexe de G d’ordre aumoins 2, aucun sommet de Bi n’est adjacent à un sommet de B \Bi, et B est maximal pour cettepropriété ;
– A = A12A22 · · ·2Ak, où Ai (1 # i # n) est l’ensemble des sommets adjacents à tous les sommetsde B \Bi et qui ont au moins un voisin et un non-voisin dans Bi ;
– T l’ensemble des sommets adjacents à tous les sommets de B ;– I l’ensemble des sommets adjacents à aucun sommet de B.De plus, I est un ensemble stable.
3 La classe des graphes sans {P5, co#A, co# domino}
On appelle domino le graphe obtenu à partir d’un cycle à 6 sommets en ajoutant une corde longue(c’est-à-dire joignant deux sommets à distance 3 l’un de l’autre) et co%domino son complémentaire ;on appelle A le graphe obtenu à partir d’un domino en supprimant une des deux arÍtes non adjacentesà la corde longue, et co% A son complémentaire.En reprenant les notations définies dans le Théorème 1, on peut énoncer le corollaire suivant :
Corollary 1. Avec les notations définies dans le Théorème 1, si G est un graphe sans {P5, co %A, co% domino}, au plus un des ensembles Ai est non vide. De plus, en supposant que Ai soit nonvide, l’ensemble B \Bi est homogène.
3.1 Algorithme de calcul d’un stable maximum
En utilisant la décomposition modulaire, on déduit immédiatement du Corollaire 1 un algorithmerécursif permettant de calculer un stable de taille maximum dans un graphe sans {P5, co % A,co % domino}, y compris dans le cas pondéré. On peut de plus montrer que le nombre d’appelsrécursifs est borné par un polynôme en O(n5). Ce résultat est synthétisé dans le théorème suivant :
Theorem 2. Dans un graphe G = (V,E) sans {P5, co%A, co%domino}, on peut calculer un stablede cardinalité ou de poids maximum en au plus O(n5) itérations, où n = |V |.
Références
1. Alekseev, V.E. : On the local restrictions e#ect on the complexity of finding the graph independenceset number (in Russian). Combinatorial-algebraic methods in applied mathematics, 1983
2. Alekseev, V.E. : On the number of maximal independent sets in graphs from hereditary classes(in Russian). Combinatorial-algebraic methods discrete optimization, 1991
3. Alekseev, V.E. : Polynomial algorithm for finding the largest independent set in graphs withoutforks. Discrete Applied Mathematics, 135, 2004 (traduit de Discrete Analysis and OperationsResearch 6, Novosibirsk, 1999)
4. Farber, M. : On Diameters and Radii of Bridged Graphs. Discrete Mathematics 73, 1989

Une nouvelle classe de graphes : les hypotriangulés
M.-C. Costa1, C. Picouleau2, and H. Topart2
1 ENSTA UMA (CEDRIC), 32 boulevard Victor, 75739 Paris cedex 15 (France)[email protected]
2 CEDRIC-CNAM, 292 rue Saint-Martin, 75141 Paris cedex 03, [email protected], [email protected]
1 IntroductionNous introduisons une nouvelle classe de graphes, les graphes hypotriangulés : pour tout chemin delongueur 2, il existe soit une corde, soit un autre chemin de longueur 2, qui relie ses extrémités. Onconstruit ainsi des réseaux qui sont fiables dans le cas où soit un lien soit un noeud est défaillant.
2 Définitions et premières propriétésOn notera G = (V,E) un graphe simple non-orienté où V est l’ensemble des sommets et E l’ensembledes arêtes. On note n = |V |, m = |E| et . le degré minimum d’un sommet de G.
Definition 1. G est hypotriangulé si pour toute paire de sommets {a, b} ! V 2 telle que [a, y, b] estun P3, on a [a, b] ! E ou il existe z -= y tel que [a, z, b] est un P3.
On obtient aisément les définitions équivalentes suivantes.– G est hypotriangulé ssi tout P3 est inclus dans un C3 ou un C4 ;– G est hypotriangulé ssi $u, v ! V, u -= v, |N(u) 0N(v)| = 16 [u, v] ! E.On montre les premiers résultats suivants :– Les graphes complets Kn et les graphes bipartis complets Kn1,n2 pour n1, n2 ) 2 sont hypotrian-
gulés ;– les graphes hypotriangulés ne sont pas nécessairement parfait ;– il existe des graphes triangulés qui ne sont pas hypotriangulés ;– il existe des graphes hypotriangulés qui ne sont pas triangulés ;– pour tout k, il existe des graphes hypotriangulés de diamètre k ;– pour tout k, il existe des graphes hypotriangulés ayant un trou de taille k.Si G est un graphe hypotriangulé avec n ) 3, alors– . ) 2 et G n’a pas de sommet d’articulation (donc G n’a pas d’isthme).
3 Les graphes hypotriangulés minimumDans cette section, on s’intéresse au problème de déterminer, pour tout n, l’ensemble des grapheshypotriangulés connexes possédant un nombre minimum d’arêtes. Nous les appelerons graphes hypo-triangulés minimum.On considère n ) 4, puisque pour n = 2 (respectivement n = 3) le seul graphe hypotriangulé à nsommets est K2 (respectivement K3).
Theorem 1. Un graphe connexe hypotriangulé minimum G avec n ) 4 vérifie m = 2n % 4, G estbiparti et . = 2 ou 3. De plus, si . = 3 alors G est le cube.

Les graphes hypotriangulés 317
On distingue parmi les sommets de G les sommets internes au graphe I et les sommets pendants P .On définit alors la transformation G /( V2G. Voir Figure 1.
Theorem 2. Si G est un graphe hypotriangulé minimum avec . = 2, alors G = V2T où T est unarbre.
Fig. 1. Un arbre T et le graphe V2T correspondant
4 Résultats de complexité
Les problèmes Hamiltonien, Clique, Stable et Coloration sont NP-complets dans les grapheshypotriangulés.
Références
[1] Claude Berge, Graphes, Gauthier-Villars (Paris, 1983)[2] M. R. Garey, D. S. Johnson, "Computers and intractability. A guide to the theory of NP-
completness", W. H. Freeman (San Francisco, 1979)[3] DIMACS Book Series, Published by the American Mathematical Society,Volume Fifty Three :
"Robust Communication Networks : Interconnection and Survivability", Editors : Nathaniel Dean,D. Frank Hsu and R. Rav (2000)

Gestion de production électrique en contexte incertain
Sinda Ben Salem,1,2 and Michel Minoux3
1 EDF R&D, 1 Avenue Général de Gaulle, 92140 [email protected]
2 Ecole Centrale Paris, Laboratoire Génie Industriel, Grande Voie des Vignes, 92290 ChâtenayMalabry.
[email protected] Université Paris 6, 4 place Jussieu, 75252 Paris Cedex.
1 Introduction
A court terme (horizon de un à deux jours), EDF doit élaborer un planning de production pourchacune de ses unités de production. L’objet de ce travail est l’optimisation de la production dansun environnement incertain.L’aléa apparaît à plusieurs niveaux lors de la construction du planning de production. Il y a desincertitudes sur les prix de marché de l’électricité, sur la prévision de la consommation, sur la dis-ponibilité des unités de production, et sur les niveaux d’eau des réservoirs hydrauliques. Nous nousintéressons à l’incertitude autour de la prévision de consommation, qui reste prédominante. Elles’écrit : Erreur(jourJ) = prevision(jourJ) % observe(jourJ).Ainsi, nous proposons une approche qui intègre la forme et le comportement de cette erreur, pournous permettre de prendre des décisions plus robustes face à l’incertain.
2 Modélisation de l’incertitude
L’idée qui motive ce travail est d’obtenir un modélisation simple de l’aléa. Pour cela, nous avons dé-terminé un ensemble de contraintes linéaires, construisant ainsi un ensemble d’incertitude polyédral.Ces contraintes sont construites à base d’observations de l’historique des erreurs passées et à l’aided’outils statistiques d’analyse de données.
L’objectif est de minimiser la somme des coûts de production et des pertes dûes à l’aléa de consom-mation. Cela consiste à résoudre le problème d’optimisation suivant :
minP#X{!(P ) + "(P )}
Deux optimisations sont imbriquées selon ce modèle :
2.1 Minimiser les coûts de production
!(P ) minimise les coûts pour une production P .

Gestion de production électrique en contexte incertain 319
- (P ) = minP#X
'U%
u=1
+ (Pu)
(
avec :Pu = (Put )Tt=1
T : Nombre total de pas de temps d’optimisationU : Ensemble des unités de productionP : Puissance à produireX : Ensemble des plans de production réalisables+ (.) : Fonction coût de production
2.2 Minimiser les pénalités d’écart à la demande
"(P ) est une fonction complémentaire qui intègre la dynamique de l’erreur. Elle permet de calculerles pires pertes qu’on aurait à subir en fonction d’une production P donnée :
"(P ) = max+#C
'T%
t=1
" (5t, Pt)
(
avec :5 = (5t)Tt=1
C : Ensemble convexe des erreurs possibles sur la demande" (., .) : Fonction qui pénalise l’écart entre la puissance produite
et la consommation réelle réalisée
Calculer les pénalités d’écart nécessite la résolution d’un problème en nombres entiers. Une méthodedes faisceaux est utilisée pour la résolution du problème global. Sous certaines hypothèses de convexitéde - (P ) et 0(P, 5), nous obtenons des résultats préliminaires intéressants pour cette écriture originaledu problème d’optimisation de la production électrique.
Références
1. MINOUX M. : Programmation mathématique. Théorie et Algorithmes. Lavoisier (2008)2. DUBOST L, GONZALEZ R, LEMARECHAL C : A primal-proximal heuristic applied to the
French Unit-commitment problem. Mathematical Programming, A(104), 129-151 (2005)3. RENAUD A : Daily generation management at Electricité de France : from planning towards real
time. IEEE Transactions on Automatic Control 38(7), 1080-1093 (1993)

Amélioration des solutions intermédiaires pour larésolution exacte du sac à dos multidimensionnel en 0–1
S. Boussier1, M. Vasquez2 et Y. Vimont2
1 LIA, Université d’Avignon et des Pays de Vaucluse, 339 chemin des Meinajaries, BP 1228, 84911Avignon Cedex 9, France.
[email protected] LGI2P, Ecole des Mines d’Alès, Parc scientifique Geroges Besse, 30035 Nîmes, France.
{Michel.Vasquez, Yannick.Vimont}@ema.fr
1 Contexte
Nous nous intéressons ici à la résolution exacte du sac à dos multidimensionnel en 0–1 (MKP pourMultidimensional Knapsack Problem) qui est un problème classique d’optimisation combinatoirepouvant être modélisé de la manière suivante :
Maximisern%
j=1
cjxj
sujet àn%
j=1
aijxj # bi, i = 1, ..., m,
x ! {0, 1}n,
avec ci ! N, bi ! N et aij ! N. Dans de précédents travaux (Boussier et al. (2008) [1]), nous avonsprésenté une méthode exacte de résolution du MKP combinant Resolution search (Chvátal (1997)[3]) avec un algorithme d’énumération implicite (Vimont et al. (2008) [4]). Cette méthode est glo-balement plus performante que les méthodes exactes connues sur un grand nombre d’instances dela OR-Library3 . Elle résout la plupart des instances en un temps plus rapide et prouve l’optimalitéd’instances dont l’optimum était inconnu jusqu’à présent. Les solutions intermédiaires qu’elle gé-nère ne sont pourtant pas toujours compétitives avec celles produites par les meilleures heuristiquesexistantes. Dans cette présentation, nous détaillons la méthode proposée dans [1] et présentons unetechnique d’amélioration de la génération des solutions intermédiaires permettant d’obtenir de bonnessolutions plus rapidement.
2 Description de la méthode
Un des ingrédients de la méthode proposée dans [1] est l’utilisation d’une contrainte prenant encompte la borne fournie par la relaxation continue, les coûts réduits des variables hors base et unminorant quelconque. Cette contrainte permet d’une part de fixer certaines variables hors base à leurvaleur optimale et d’autre part d’éliminer certaines configurations partielles de l’espace de recherche.Elle peut s’écrire de la manière suivante :3 http ://people.brunel.ac.uk/ mastjjb/jeb/orlib/mknapinfo.html

Papier soumis à ROADEF 09 321
%
j#N|xj=0
|cj |xj +%
j#N|xj=1
|cj |(1% xj) #=BS% BI
>(1)
où BI ! N est un minorant connu, BS = c · x avec x la solution optimale de la relaxation continuedu problème. Le vecteur c correspond aux coûts réduits associés et N est l’ensemble des indices desvariables hors base (Balas et Martin (1980) [2]).Cette contrainte permet de fixer les variables hors base de coût réduit cj strictement supérieur à&BS% BI' à leur valeur optimale xj et permet d’éliminer toute solution x& de l’espace de recherche si&j#, cj > &BS% BI' (6 étant l’ensemble des indices des variables hors base telles que x&j = 1% xj).
Nous proposons de modifier la contrainte (1) en réduisant son membre de droite d’une valeur 7et en faisant diminuer 7 progressivement au cours du processus de recherche. Cette manipulationpermet (i) d’éliminer un grand nombre de configurations partielles jugées non-pertinentes et (ii) defixer davantage de variables à grand coût réduit à leur valeur optimale (xj). Elle a pour conséquencede favoriser la génération de bonnes solution rapidement.
3 Résultats préliminaires
Expérimentalement, nous avons fait varier le paramètre 7 sur l’algorithme [1] pour la résolution desinstances à 10 contraintes et 500 variables de la OR-Library. Nous avons expérimenté une premièreversion consistant à initialiser 7 à la valeur 500 puis à le diminuer de 50 toutes les 200 secondes(ces paramètres sont déduis des expérimentations réalisées est dépendent évidemment des instancestraitées) . L’objectif est de restreindre au maximum l’espace de recherche au départ afin d’obtenir despremières bonnes solutions rapidement et de l’élargir au fur et à mesure jusqu’à atteindre l’espacede recherche initial. Tout en gardant son caractère exact, l’algorithme obtenu est plus e%cace4 pour25 instances sur les 30 disponibles par rapport à l’heuristique de Wilbaut et Hanafi (2008)[5] qui estactuellement une des meilleures heuristiques connues sur ces instances.
Références
1. S. Boussier, M. Vasquez, Y. Vimont, S. Hanafi and P. Michelon. « Solving the 0–1 Multidi-mensional Knapsack Problem with Resolution Search ». VI ALIO/EURO Workshop on AppliedCombinatorial Optimization, Buenos Aires, 2008.
2. E. Balas and C.H. Martin. « Pivot and complement a heuristic for zero-one programming ».Management Science, 26[1] :86–96, 1980.
3. V. Chvátal. « Resolution search ». Discrete Applied Mathematics, 73 :81–99, 1997.4. Y. Vimont, S. Boussier and M. Vasquez. « Reduced costs propagation in an e%cient im-
plicit enumeration for the 01 multidimensional knapsack problem ». Journal Of CombinatorialOptimization, 15[2] :165–178, 2008.
5. C. Wilbaut and S. Hanafi. « New convergent heuristics for 0-1 mixed integer programming ».European Journal of Operational Research, doi :10.1016/j.ejor.2008.01.044., 2008.
4 Nous considérons qu’une méthode est plus e%cace qu’une autre si elle génère un même minorantplus rapidement ou si elle trouve un minorant plus grand dans un intervalle de 2 heures de tempsde calcul.

Recherche à grands voisinages pour l’a!ection d’activitésdans un contexte multi-activités
Quentin Lequy1, Mathieu Bouchard1, Guy Desaulniers1, and François Soumis1
École Polytechnique et GERAD, Montréal, Canada{Quentin.Lequy,Mathieu.Bouchard,Guy.Desaulniers,Francois.Soumis}@gerad.ca
1 IntroductionNotre problème se situe dans un contexte d’entreprise où les employés e#ectuent le travail qui leurincombe durant une période de temps déterminée appelée quarts de travail. Ces quarts composésde segments de travail et de pauses sont personnalisés pour chaque employé et nous les considéronscomme fixés au préalable par un mécanisme antérieur. Dans les entreprises ciblées, le travail desemployés est vu comme une succession de travaux interruptibles catégorisés, appelés types d’activi-tés, et les employés peuvent facilement passer d’un type d’activité à un autre du moment qu’ils ontles qualifications requises.À chaque type d’activités est associée une courbe de demande fonction du temps qui correspond aunombre d’employés dont a besoin l’entreprise pour être e%cace au mieux vis-à-vis de la clientèle,pour le type d’activités en question. Lorsqu’un employé contribue à un type d’activités, son tempsde contribution, appelé activité, à un type d’activités est borné par des durées appelées durée mini-male/maximale de contribution. Notre objectif sera alors d’a#ecter des activités à chaque employé enessayant de faire correspondre le mieux possible la demande des types d’activités avec l’o#re fourniepar les employés. Un objectif secondaire sera aussi de minimiser le nombre total de changementsentre activités, appelés transitions.À notre connaissance, ce problème n’a pas encore été traité dans la littérature, nous proposons doncun premier modèle mathématique basé sur une approche de type génération de colonnes et uneméthode heuristique pour résoudre les instances de grande taille.
2 ModélisationNous proposons un modèle du type génération de colonnes basé sur une énumeration des patronsadmissibles de quarts de travail comme l’avait fait Dantzig pour la construction de quarts de travail[1]. L’horizon temporel est discrétisé en périodes de 15 minutes et on notera T l’ensemble de toutesces périodes. L’ensemble des types d’activité sera noté A, et on définit fa,t comme le nombre requisd’employés pour le type d’activités a ! A à la période t ! T . Soit W l’ensemble des segments detravail. Pour chaque segment, nous définissons 6w l’ensemble des patrons d’a#ectations d’activitéqui remplissent correctement le segment w.Soit oa,t ) 0 (resp. ua,t) la variable représentant le surplus (resp. le manque) d’employés pour le typed’activités a ! A durant la période t ! T par rapport à la demande fa,t. Soit 2w,p ! {0, 1} la variablede décision qui vaudra 1 si le segment w ! W est a#ecté suivant le patron p ! 6w. Soit +w,pa,t ! {0, 1}un coe%cient booléen pour chaque patron p ! 6w de chaque segment w ! W qui représente lacontribution de l’employé au type d’activités a ! A pendant la période t ! T . Finalement, soit cuc(resp. coc) le coût par employé pour une période de durée unitaire en sous-couverture (resp. en sur-couverture) et cw,p le coût du segment w ! W par rapport aux transitions s’il est a#ecté suivant lepatron p ! 6w. Une formulation du problème est donc le programme linéaire mixte suivant :

Heuristique pour l’a#ection d’activités 323
Minimiser%
a#A
%
t#T
(cocoa,t + cucua,t) +%
w#W
%
p#,w
cw,p2w,p (1)
sujet à%
p#,w
2w,p = 1 $w !W (2)
%
w#W
%
p#,w
+w,pa,t 2w,p % oa,t + ua,t = fa,t $a ! A,$t ! T (3)
2w,p ! {0, 1} $w !W,$p ! 6w (4)oa,t ) 0,ua,t ) 0 $a ! A,$t ! T (5)
3 Résolution
Ce modèle de génération de colonnes se résout di%cilement par procédure conventionnelle d’énumé-ration implicite. Pour obtenir des solutions de bonne qualité en des temps de calculs raisonnables,nous utilisons une heuristique basée entre autres sur la stratégie de fixation de colonnes. Bien quecette heuristique soit performante sur des instances d’une journée, les instances d’une semaine sontnéanmoins di%ciles à résoudre. Pour les résoudre, nous utilisons une recherche heuristique à trajec-toire basée sur des grands voisinages où trouver un voisin de meilleure qualité que la solution couranteconsiste à résoudre une restriction topologique du problème. La solution initiale de l’heuristique estdonnée par une méthode d’horizon fuyant.L’heuristique fonctionne de la façon suivante : dans un premier temps, les critères d’arrêt sont testés.Ensuite, une sous-couverture, c’est-à-dire un couple formé d’un type d’activité et d’un intervallede temps de durée de base, est choisie aléatoirement de façon biaisée. En fonction de cette sous-couverture et de critières sur l’évolution de la solution durant les itérations précédentes, le type duvoisinage courant est défini. Ce type influe essentiellement sur la taille du voisinage et sur l’ajout decontraintes qui permettent de forcer la disparition de la sous-couverture, quitte à dégrader la solutioncourante. Le voisinage est ensuite constitué par un échantillon représentatif de segments ayant uneintersection temporelle commune avec la sous-couverture choisie. L’échantillon représentatif est alorscomposé de segments de travail faisant intervenir les deux types d’activités associés à une sous-couverture, à savoir le type d’activité de la sous-couverture et celui de la sur-couverture associée,tout cela pour avoir de grandes chances d’améliorer la solution par une réoptimisation locale. Laréoptimisation locale de cette partie de solution est la prochaine et dernière étape de l’heuristique ets’e#ectue par résolution heuristique du modèle de génération de colonnes.Des tests sont actuellement en cours pour valider cette méthode heuristique. Les résultats serontprésentés lors de la conférence.
Références
1. Dantzig, G. B. 1954. A comment on Edie’s "Tra%c delays at toll booths". Journal of theOperations Research Society of America, 2(3), 339–341.

Un algorithme augmenté pour le problème du knapsackdisjonctif
M. Hifi1 and M. Ould Ahmed Mounir1
UPJV d’Amiens, UFR des Sciences, MIS-Axe Optimisation Discrète et Réoptimisation5 rue du Moulin Neuf, 80039 Amiens cedex 01, France.
[email protected]@u-picardie.fr
1 Introduction
Dans cette exposé, nous considérons le problème du knapsack disjonctif (noté DCKP). Le DCKPest un problème d’optimisation combinatoire qui apparaıît dans plusieurs domaines d’application. Laversion la plus étudiée peut être caractérisée par un ensemble de n objets où ces n objets sont liéspar une contrainte de capacité et chaque paire d’un sous-ensemble d’objets sont non-compatibles, i.e.pour une paire d’objets, la sélection d’un objet entraıîne l’exclusion de l’autre objet.Ce problème a été introduit par Yamada et al. [3,?]. Pour ce problème, les auteurs ont proposéplusieurs algorithmes exacts et approchés. Par la suite, Hifi et Michrafy [2] ont proposé une méthodeapprochée basée sur une recherche tabou réactive. Finalement, dans Hifi et Michrafy [1], un algorithmeexact a été développé pour la résolution des instances de petite taille.
2 Le problème étudié
Une instance du DCKP est caractérisée par un ensemble de n objets, une (ou plusieurs) contrainte(s)de type knapsack ainsi qu’un ensemble de contraintes disjonctives. En particulier, lorsqu’il s’agit d’uneseule contrainte de knapsack (le problème étudié dans cet article), cette dernière est caractérisée parsa capacité c entière et un vecteur poids w = (w1, . . . , wn) entier associé à l’ensemble des objets.De plus, chaque objet j, j = 1, . . . , n, st représenté par son profit pj et un sous-ensemble de pairesd’objets E représentant l’ensemble des paires d’objets exprimants l’ non-compatibilités entre certainsobjets. La formulation mathématique du DCKP peut s’écrire comme suit :
maximize z(x) =n%
j=1
pjxj (1)
subject ton%
j=1
wjxj # c (2)
xi + xj # 1 $(i, j) ! E (3)xj ! {0, 1} j = 1, . . . , n, (4)
oú E .P
(i, j) such that i -= j, i, j ! I = {1, . . . , n}S
et z(x) est la fonction objectif associée á lasolution x.

Un algorithme augmenté pour le problème du knapsack disjonctif 325
3 Méthodes de résolution
Nous proposons di#érentes versions de l’algorithme basé sur une procedure d’arrondi. La procédured’arrondi s’appuie principalement sur la relaxation en continue du programme linéaire en 0%1 duproblème orignal. Cette procedure peut être vu comme une approche en deux phases :1. Optimisation de la relaxation en continue du problème par aplication de la méthode du simplex.
Ensuite, fixer et arrondir une partie des variables bineaires à leur valeurs entières.2. Répéter l’étape précédente sur la série des problèmes réduits jusqu’á ce qu’il ne reste plus de
variables fractionnaires.Par la suite, nous proposons un algorithme augmenté combinant certaines contraintes de cardina-lité et la procédure d’arrondi. En e#et, nous considerons deux contraintes valides pour le DCKP etnous supposons l’existence d’une borne inférieure de départ notée LB. La première (resp. deuxième)contrainte (encadrement inférieur % resp. encadrement supérieur) est obtenue en résolvant le pro-blème de minimisation (Fmin) (resp. maximisation (Fmax)) suivant :
(Fmin)
!""""""""""""""#
""""""""""""""$
.min = minn%
j=1
xj
s.c.n%
j=1
pjxj ) LB
n%
j=1
wjxj # c
)ixi +%
j#Ei
# )i, i = 1, . . . , n
xi ! {0, 1}, i = 1, . . . , n,
(Fmax)
!""""""""""""""#
""""""""""""""$
.max = maxn%
j=1
xj
s.c.n%
j=1
pjxj ) LB
n%
j=1
wjxj # c
)ixi +%
j#Ei
# )i, i = 1, . . . , n
xi ! {0, 1}, i = 1, . . . , n.
L’idée principale de l’algorithme est de faire varier l’encadrement de la somme des variables afin devisiter le plus grand nombre de régions. Pour chaque région construite, nous appliquons la procédured’arrondi. Notons aussi que lors de l’application de la procédure d’arrondi, nous introduisons unerecherche tabou simple dont le but d’améliorer la série des solutions obtenues.Les di#érentes versions de l’algorithme proposé ont été testées sur plusieurs instances de la littérature.Sur plusieurs instances, l’algorithme augmenté arrive à améliorer certaines solutions de la littérature,mais parfois il demande plus de temps d’exécution comparé au temps moyen de certains algorithmesde la littérature.
Références
1. M. Hifi and M. Michrafy, “Reduction strategies and exact algorithms for the disjunctivelyconstrained knapsack problem" Computers and Operations Research, 2006.
2. M. Hifi and M. Michrafy, “A reactive local search algorithm for the disjunctively constrainedknapsack problem." Journal of the Operational Research Society, vol. 57, pp. 718-762, 2006.
3. T. Yamada and S. Kataoka, “Heuristic and exact algorithms for the disjunctively constrainedknapsack problem". Presented at EURO 2001, Rotterdam, The Netherlands, July 9-11, 2001.
4. T. Yamada, S. Kataoka and K. Watanabe, “Heuristic and exact algorithms for the disjunctivelyconstrained knapsack problem", Information Processing Society of Japan Journal, vol. 43, pp.2864-2870, 2002.

Routage de guides d’ondes dans un satellite detélécommunications
F. Bessaih1,2 , B.Cabon1, D. Feillet2, Ph.Michelon3, D.Quadri3
1 EADS ASTRIUM, 31 rue des Cosmonautes, Z.I. des Palays, 31402 Toulouse Cedex 4.{fawzi.bessaih,bertrand.cabon}@astrium.eads.net
2 École Nationale Supérieure des Mines de Saint-Étienne, CMP Georges Charpak, F-13541Gardanne, France. [email protected]
3 Université d’Avignon et des Pays de Vaucluse,Laboratoire Informatique d’Avignon (EA 931),F-84911 Avignon, France.
{fawzi.bessaih,philippe.michelon,dominique.quadri}@univ-avignon.fr
1 Le Problème de Routage de Guides d’Ondes
Un satellite de télécommunications a pour fonction principale de recevoir un signal provenant de laterre, de l’amplifier et de le re-émettre. Afin de garantir une capacité d’amplification maximale àun moindre coût, il est nécessaire d’optimiser le dimensionnement du satellite qui est intimement liéaux pertes RadioFréquence (pertes RF). Ces pertes ont principalement deux e#ets, d’une part unedissipation de la puissance électrique dans les composants, tels que les tubes amplificateur, et d’autrepart l’atténuation du signal pendant son acheminement entre ces mêmes composants via les guidesd’ondes réduisant ainsi la capacité d’amplification. Pendant la phase de conception, l’evaluation etla minimisation de ces pertes sont indispensables au bon dimensionnement du satellite. Sachant queles composants de la charge utile d’un satellite ont des caractéristiques (niveau de dissipation) et uneposition prédéfinie, la minimisation des pertes RF passe par la minimisation de la longueur des guidesd’ondes, les pertes RF étant globalement proportionnelles à leur longueur. Un guide d’onde est untube métallique de section rectangulaire. L’espace de routage est modélisé sous la forme d’une grilleen 2D à plusieurs niveaux où chaque sommet a au plus 10 sommets adjacents (8 au même niveau, 2aux niveaux supérieurs et inférieurs). Un guide d’onde est alors représenté par un chemin reliant sespositions de départ et d’arrivée dans cette grille.La problématique consiste en l’attribution d’un chemin pour chaque guide d’onde, en évitant toutconflit et en minimisant la somme des longueurs des guides d’ondes. Du fait de la modélisationadoptée, les conflits concernent : l’utilisation de positions non valides (présence d’un composant...),l’occupation d’une même position par deux chemins, le croisement de deux chemins (provoquantainsi une configuration non réalisable physiquement), la proximité de chemins sur des portions endiagonale (provoquant une infaisabilité physique due au chevauchement des guides d’ondes).Cet exposé s’intéresse à la problématique de routage de guides d’ondes en phase de conception, c’est-à-dire à l’evaluation de la longueur des guides d’ondes pour une configuration de satellite donnée(positionnement des composants) en e#ectuant une approximation du routage de ces guides d’ondes.Cette approximation fournira une evaluation des pertes RF et fera ultérieurement l’objet de ra%ne-ment pour le routage définitif.A notre connaissance, ce problème n’a jamais été étudié dans la littérature. Néanmoins, nous pouvonsle rapprocher de problèmes académiques tels que les problèmes de recherche de flots sous contraintesdans les graphes (Ahuja et al. [1], Toth et Vigo [2]).

Routage de guides d’ondes dans un satellite de télécommunications 327
2 Modélisation, approche de résolution
Nous proposons d’aborder la résolution de ce problème par une modélisation sous forme de programmelinéaire en nombres entiers, avec des variables binaires indiquant le chemin sélectionné pour chaqueguide d’ondes dans la solution. Du fait du nombre important de variables, une approche par générationde colonnes est adoptée. Pour chaque guide d’ondes, l’ajout de nouvelles colonnes fait appel à unproblème de plus court chemin classique, avec une matrice de coûts mise à jour. Intuitivement, lamise à jour des coûts reflète le taux d’encombrement des di#érentes zones de l’espace de routage etfavorise le passage par des zones moins encombrées. Plusieurs règles de branchements adaptées auproblème sont proposées.
3 résultats et perspectives
Au regard des premiers résultats obtenus, la génération de colonnes parait être une bonne approchepour traiter cette problématique. A ce jour, les tests réalisés l’ont été sur de petites instances (grille50x50, 5 guides d’ondes), néanmoins notre méthode permet de résoudre à l’optimum le problème.Par contre, sur de plus grandes instances (cas réel : 600x400, une centaine de guides d’ondes) l’arbrede recherche comprend un nombre trop importante de noeuds pour permettre la résolution en untemps raisonnable. Plusieurs voies d’amelioration sont à l’étude :– améliorer la borne donnée par la relaxation linéaire du modèle (intégration d’inégalités valides...),– a%ner la politique de branchement.Au vu de la taille des instances rencontrées en pratique, il est également à prévoir de se tourner versune approche heuristique, éventuellement basée sur le schéma de génération de colonnes précédent.D’un point de vue plus pratique, il reste aussi à intégrer des contraintes metiers spécifiques, qui n’ontpas été prises en compte dans la version actuelle pour limiter la lourdeur du problème étudié.
Références
1. Ravindra K.Ahuja ; Thomas L.Magnati ; James B.Orlin. : NETWORK FLOW : Theory,Algotithmand Applications. Prentice Ahll, United States ed edition (1993)
2. Paolo Thoth ; Daniele Vigo. : The Vehicule Routing Problem (Monogrpahs on Discrete Mathema-tics and Applications). SIAM,(2001)

Méthode hybride PPC/PLNE pour le réordonnancementde plan de circulation ferroviaire en cas d’incident
R. Acuna-Agost1, P. Michelon1, D. Feillet2, and S. Gueye3
1 Université d’Avignon et des Pays de Vaucluse, Laboratoire d’Informatique d’Avignon (LIA),F-84911 Avignon, France {rodrigo.acuna-agost,philippe.michelon}@univ-avignon.fr
2 Ecole des Mines de Saint-Etienne, F-13541 Gardanne, [email protected]
3 Université du Havre, Laboratoire de Mathématiques Appliquées du Havre, F-76058 Le Havre,France
1 Introduction
Les travaux sur le problème de la replanification des trains suite à un incident sont plus rares que ceuxconcernés la construction de plans de circulation ferroviaire optimisés, mais ils ont connu un essorsignificatif depuis quelques années. Ceci est dû notamment à la demande croissante d’utilisation desystèmes de transport ferroviaire, et, de ce fait, à une plus forte utilisation des ressources disponibles.Ainsi, le réseau ferroviaire est de plus en plus saturé, et la probabilité qu’un train en retard a#ecte lesautres est grande. Par conséquent, il est important de pouvoir réagir à des retards, en reprogrammantles horaires des trains de manière à minimiser les e#ets de la propagation des incidents.Le sujet de cette présentation est l’étude d’une méthode hybride PPC / PLNE (programmation parcontraintes et programmation linéaire en nombres entiers) pour la résolution de ce problème. Cetravail est issu du projet MAGES (Module d’Aide à la Gestion des Sillons) [1] visant à développerdes systèmes de régulation pour le trafic ferroviaire.
2 Modélisation et méthodes de résolution
On peut définir le problème de replanification des opérations ferroviaires de la manière suivante :étant donnés un ensemble de trains, une portion du réseau ferroviaire, une planification originale(i.e., les horaires d’arrivée et de départ pour chaque train et chaque élément du réseau, ainsi que lesvoies ferrées utilisées) et les retards d’un ou plusieurs trains, le problème consiste à retrouver uneplanification réalisable minimisant la di#érence avec le plan original. Ce critère peut s’exprimer dedi#érentes manières, par exemple minimiser le retard total de tous les trains. Nous proposons unefonction objectif pénalisant les retards, les changements de voie par rapport au plan initial, et lesarrêts non prévus.Nous présentons deux modèles di#érents, PLNE et PPC, qui permettent de trouver des solutions àce problème en utilisant la même fonction objectif. Néanmoins, la définition des variables de décisionet la construction des contraintes di#èrent significativement.Le modèle PLNE utilisé est une adaptation de la formulation mathématique proposée dans [3]. Desvariables, principalement binaires, sont définies pour décider des ordres respectifs de passage destrains, des voies utilisées, des arrêts non programmés et des horaires de passage sur les di#érentséléments du réseau. En nous basant sur ce modèle, nous proposons trois approches : Right shiftRescheduling, Coupes de proximité, et SAPI (statistical analysis of propagation of incidents) [4]. Ces

Title Suppressed Due to Excessive Length 329
méthodes ont donné de très bons résultats pour des instances de taille moyenne, mais pour de grandesinstances la taille du modèle augmente exponentiellement à cause du nombre de variables binairesutilisées pour modéliser l’ordonnancement des trains.Nous présentons également un modèle PPC qui décrit exactement le même problème, mais avec ungrand avantage : il a beaucoup moins de variables et contraintes que le modèle PLNE. Ce modèlepermet de traiter des instances de taille plus grande en utilisant le même ordinateur. Cependant,pour instances de la même taille, les méthodes développées basées sur le modèle PLNE sont toujoursbeaucoup plus e%caces. Pour bénéficier des avantages que procurent les deux modèles, et ainsi essayerde tendre vers une méthode e%cace pour des instances de grande taille, nous proposons de leshybrider.La méthode hybride utilise une méthode basée sur le modèle PLNE, par exemple SAPI, pour calculerune borne supérieure réalisable dans un sous-problème de taille réduite. Ce sous-problème est obtenuen se limitant à la durée de la période de recouvrement o˘ seront concentrés la plupart de trainsa#ectés. La borne supérieure est utilisée pour résoudre le problème original à l’aide du modèle PPC.
3 Conclusions
La grande di%culté de ce problème est liée aux exigences pratiques sur l’exécution des algorithmes,qui imposent d’obtenir une solution dans un temps très limité, de l’ordre de quelques minutes. Lebut des méthodes développées au cours de ce travail a été de trouver de bonnes solutions rapidement.Subséquemment, nous avons développé deux modèles di#érents, PPC et PLNE, qui ont des avantageset désavantages exploités intelligemment par une méthode hybride. De manière à évaluer la qualitédes méthodes proposées, des expérimentations numériques ont été menées. Un réseau unique inspirésur une ligne réelle de la SNCF comportant 76 circulations et mettant en jeu jusqu’à 4454 événementsavec di#érents incidents a été utilisé. Les tests ont été réalisés en utilisant les moteurs d’optimisationILOG Cplex 11 et ILOG CP Optimizer 2. Les résultats montrent que seule la méthode hybride estcapable de trouver des solutions pour les instances les plus grandes et que la méthode basée sur SAPIest meilleure que les autres en terme de vitesse de convergence vers l’optimum pour les instances detaille petite et moyenne.
Références
1. Acuna-Agost, R., Gueye, S. : Site Web MAGES. Consulté le 10 08, 2007, sur http ://awal.univ-lehavre.fr/ lmah/mages/ (2006)
2. Acuna-Agost R., Feillet D., Gueye S., Michelon P., A MIP-based local search methodfor the railway rescheduling problem. Technical report, LIA, (2008). sur http ://awal.univ-lehavre.fr/ lmah/mages/
3. Tornquist, J. P. : N-tracked railway tra%c re-scheduling during disturbances. Transportation Re-search Part B. (2006)

Recherche de zone de blocage dans un graphe
Jun HU, Mohammad DIB, Alexandre CAMINADA, and Hakim MABED
Laboratoire SeT, Université de technologie de Belfort-Montbéliard, 90010 Belfort Cedex France.{jun.hu, mohammad.dib, alexandre.caminada,hakim.mabed}@utbm.fr
1 IntroductionL’objectif de la recherche de zone de blocage dans un graphe de contraintes, où les nœuds repré-sentent les variables et les arêtes représentent les contraintes binaires (problème CSP binaire), estde fournir un sous-ensemble de variables de taille minimale sur lesquelles le problème restreint estnon-réalisable. Le problème restreint est l’ensemble des variables impliquées dans la non réalisabilitéplus les contraintes qui lient entre elles les variables de cet ensemble. Déterminer si un problèmerestreint est non réalisable et de taille minimale est reconnu DP-Complet[1].Soit G(V,E) un graphe où V est l’ensemble des variables et E est l’ensemble des arêtes notées(Vi, Vj). La principale di%culté du problème est l’évaluation d’un sous-problème du problème originalG&(V &, E&) où E& correspond à l’ensemble des contraintes deG impliquant exclusivement des variablesde V &. L’évaluation d’un sous-problème G& correspondant à une zone de blocage de G correspondpremièrement à statuer sur le caractère réalisable ou pas du problème G&, puis à évaluer sa taillequi doit être minimale. Déterminer si un sous problème est non-réalisable reste une tâche coûteuseen temps de calcul car il s’agit au final d’a%rmer qu’aucune solution n’existe pour le sous-problèmecorrespondant.Dans le contexte de la satisfaction de contraintes, il y a peu de travaux concernant de manièrespécifique l’extraction de sous-problème non réalisable. Une approche d’extraction de sous-problèmenon réalisable dans un réseau de contraintes est proposé par [2] et une méthode pour parcourir tousles sous-problèmes non réalisables est présentée par [3]. Hemery et al .[4] a aussi proposé une approchebasée sur les analyses de conflits et l’identification itérative des contraintes extraites.
2 Méthode proposéeLa méthode que nous présentons nommée EDBT (Enforced Dynamic BackTracking) est basée sur laméthode DBT(Dynamic BackTracking)[5]. Le problème est de garantir la visite de toutes les variablesdu problème ce que ne fait pas le DBT. Nous avons donc proposé avec EDBT une méthode itérativequi va procéder à une sélection progressive de G& pour réduire cet ensemble à chaque itération à unensemble contenant la zone de blocage de taille minimale. Par la suite il reste à prouver que cettezone est minimale.Le principe de la réduction de l’ensemble des variables retenues est le suivant. La procédure DBTtraite les variables une à une selon une heuristique choisie, peu importe celle-ci à ; au fur et à mesureon marque les variables en conflit et on les place dans une liste de variables candidates. Les variablesmarquées sont considérées comme des candidates qui appartiennent à une zone de blocage puisqu’ellesont été au moins une fois en conflit.Dans le cas d’un problème non réalisable, au lieu d’arrêter la procédure dès que le problème a étédétecté non réalisable, on force la méthode à vérifier l’a#ectation des variables non encore visitéespour prouver la non réalisabilité pour générer les informations complètes du problème sur toutes lesvariables. Ceci est nécessaire pour prendre en compte toutes les variables impliquées dans des zonesde blocage au cas où plusieurs zones disjointes existeraient dans le problème initial.

Recherche de zone de blocage dans un graphe 331
A la fin de la procédure DBT, on a donc une liste candidate de variables bloquantes qui est constituéepar un sous-ensemble des variables marquées. On extrait ce sous-ensemble de variables V’ et le sous-ensemble de contraintes E’ impliquant exclusivement ces variables dans G et on réitère le processus.De cette manière on réduit la taille du sous-problème bloquant itérativement jusqu’à ce que la tailledu sous-problème devienne stable. Le sous-problème ainsi extrait est prouvé comme étant une zonede blocage. Elle contient, ou éventuellement, elle est, une zone de taille minimale mais EDBT ne leprouve pas. Cette dernière étape reste à étudier.Prenons un exemple avec le scénario SCEN02 parmi les problèmes bien connus d’a#ectation de fré-quences de type CELAR [6]. On utilise un spectre de fréquences prouvé comme étant le spectreminimum pour résoudre cette instance (critère MinSpan). En réduisant d’une fréquence cette res-source on créé un problème non réalisable. On lance notre méthode EDBT qui va identifier en troisétapes un sous-ensemble de variables (19 variables sur 200 au départ) qui constitue une zone deblocage du problème complet. Les figures (FIG. 1) ci-dessous représentent les sous-ensembles réduitssuccessifs calculés par la méthode. De gauche à droit, la taille des sous-problèmes (les arrêtes en gras)est réduite à chaque itération (gauche à droit : 46 nœnds, 26 nœnds et 24 nœnds) jusqu’à atteindreun ensemble non réductible prouvée comme non réalisable et contenant la zone de blocage de pluspetite taille de ce problème.
Fig. 1. La taille de sous-problème réduit
Références
1. Papdimitriou C.H., Wolfe D. : The complexity of facets resolved. Journal of Computer and SystemSciences, 37, 2-13 (1988)
2. Baker R.R., Dikker F., Tempelman F., Wognum P.M. : Diagnosing and solving over-determinedconstraint satisfaction problems. In Proceedings of )CAI’93, 276-281 (1993)
3. Garcia de la Banda M, Stuckey P.J., Wazny J. : Finding all minimal unsatisfiable subsets.InProceedings of PPDP’03 (2003)
4. Hemery F., Lecoutre C., Sais L., Boussemart F. : Extracting MUCs from Constraint Networks.In Proceedings of ECAI’2006 (2006)
5. Ginsberg M. : Dynamic backtracking. Artificial Intelligence, 1, 25-46 (1993)6. http ://www.inra.fr/internet/Departements/MIA/T//schiex/Doc/CELAR.shtml

Etude comparative de recherche locale et de propagationde contraintes en CSP n-aire
M. Dib, I. Devarenne, H. Mabed, A. Caminada
Laboratoire SET, UTBM, 90010 Belfort Cedex{mohammad.dib, isabelle.devarenne, alexandre.caminada, hakim.mabed}@utbm.fr
1 Introduction
Le travail que nous avons réalisé se base sur une méthode de recherche locale adaptative [1] et uneméthode de propagation de contraintes [3] [4] pour résoudre un CSP (problème de satisfaction decontraintes) avec des contraintes unaires, binaires et n-aires. L’utilisation de contraintes n-aires dansles CSP n’est pas très fréquente. La plupart du temps les modèles impliquant plus de deux variablespour la description des problèmes sont réécrits sous forme de CSP binaire où plusieurs contraintesbinaires se substituent à une contrainte n-aire. L’avantage de cette réécriture est qu’il existe un grandnombre d’algorithmes exploitant les graphes de contraintes pour traiter les CSP binaires. En particu-lier la propagation de contraintes de manière générale est très e%cace pour maintenir l’arc-consistanceet propager les contraintes dans le cas binaire. Aussitôt une variable a#ectée, les procédures d’arc-consistance permettent de réduire les domaines des variables liées et éventuellement de les a#ecterlorsqu’il n’y a plus qu’une unique valeur support dans le domaine. De la même façon lorsqu’il s’agitde revenir sur des choix il est assez facile de marquer les variables impliquées par la propagation etde ré-établir les domaines pour faire de nouveaux branchements. L’inconvénient de la réécriture estque la traduction des contraintes n-aires éloigne souvent le problème réécrit du problème initial en ledurcissant. Il est possible de proposer un ensemble de contraintes binaires tel que toute solution auproblème binaire soit une solution au problème n-aire. Mais certaines solutions du problème n-airepeuvent ne pas être solutions sur le problème réécrit. Nous avons pris pour exemple un problèmed’a#ectation de fréquences dans des réseaux de communications radio. Ces problèmes sont inspirésdes problèmes [2] et [6] mais avec des contraintes supplémentaires liées à la présence de brouilleurmultiple sur un même lien radio. Les brouilleurs multiples en radio sont toujours présents mais (très)rarement pris en compte car trop long à calculer et sans modèle mathématique adéquat. Notre ob-jectif ici n’est pas de développer la nature précise du calcul de ces brouilleurs mais plutôt de lesconsidérer comme un cas d’école issus d’un problème réel pour comparer des méthodes très distinctessur la façon dont elles traitent les contraintes. Les contraintes n-aires sont donc de deux natures, ondistingue les contraintes de type sommation de perturbateurs et celles de type intermodulation.
– Les contraintes de sommation de perturbateurs permettent de gérer la prise en compte simultanéedes e#ets de n perturbateurs sur un même récepteur #. Elles s’écrivent sous la forme :
%
i#n
*i"Ti"(|fi % f"|) # *"
où fj correspond à une fréquence a#ectée à un équipement j, T est une fonction qui calcule lebrouillage selon l’écart en fréquences et * est un poids qui traduit l’importance du couple d’équi-pements considerés.

Etude comparative de recherche locale et de propagation de contraintes en CSP n-aire 333
– Les contraintes d’intermodulation permettent de décrire des contraintes d’intermodulations sur unrécepteur # générées par deux perturbateurs en même temps aux fréquences fi et fj :
|f" % (±)ifi ± )jfj)| ) 5
A noter, étant donnée l’écriture de cette contrainte, que plusieurs contraintes d’intermodulationfaisant intervenir les mêmes variables peuvent apparaître dans un même problème puisque lessignes donnent 4 combinaisons possibles de brouilleurs pour le même triplet d’équipements et lescoe%cients ) sont des entiers naturels qui permettent d’étendre la portée de l’intermodulation surle spectre.
Dans notre présentation nous indiquerons les dimensions des problèmes utilisés en nombre de va-riables, en nombre de contraintes de di#érents types, notamment n-aires, et en ressources ou domainesdisponibles. On verra que très peu de contraintes n-aires par rapport au nombre de contraintes bi-naires rendent la tâche de résolution beaucoup plus ardue. Au niveau des méthodes de résolutionnous présenterons une adaptation des deux méthodes référencées ci-dessus. La recherche locale estune Recherche Tabou basée sur un processus de variation dynamique du voisinage, mais avec la mêmestructure de voisinage, utilisant une liste tabou dynamique. Cette méthode appelée ACL-Tabu pourAdaptive Candidate List a été mise au point sur les problèmes DIMACS de coloration de graphes et amontré des résultats très compétitifs [1]. Elle travaille à partir d’une solution complète non réalisabledont elle tente de minimiser le nombre de contraintes violées pour le problème que nous avons traité.L’autre méthode que nous avons utilisée est une méthode constructive déterministe qui combine unepropagation de contraintes avec une liste tabou de nogoods [5]. Elle travaille à partir d’une solutionpartielle consistante dont elle essaye d’étendre la taille à la solution complète. Celle-ci est donc for-cément réalisable. Ces deux paradigmes très di#érents ont donc été comparés sur un problème CSPn-aire.
Références
1. I. Devarenne, H. Mabed, A. Caminada. Adaptive tabu tenure computation in local search. LNCS4972, Springer, EVOCOP, 8th European Conference on Evolutionary Computation in Combina-torial Optimisation, March 2008.
2. http ://www.inra.fr/internet/Departements/MIA/T//schiex/Doc/CELAR.shtml3. M. Dib, A. Caminada, H. Mabed. Propagation de contraintes et listes tabou pour le CSP. JFPC
Quatrièmes Journées Francophones de Programmation par Contraintes, juin 2008.4. M. Dib, A. Caminada, H. Mabed. Constraint Propagation with Tabu List for Min-Span Frequency
Assignment Problem, CCIS 14, Springer. Second International Conference on Modelling, Compu-tation and Optimization in Information Systems and Management Sciences, September 2008.
5. N. Jussien et O. Lhomme Local Search With constraint Propagation and Conflict-based Heuristics.Artificial Intelligence 139 (2002) 21-45.
6. http ://uma.ensta.fr/conf/roadef-2001-challenge/

Reformulations between structured global optimizationproblems and algorithms
S. Cafieri1, P. Hansen1,2, L. Liberti1
1 LIX, École Polytechnique, 91128 Palaiseau, France{cafieri,pierreh,liberti}@lix.polytechnique.fr
2 HEC, Montreal, 3000 Chemin de la Côte St. Catherine, Montreal H3T 2A7, [email protected]
1 Introduction
Global optimization is a field that includes many di#erent problem classes (concave programming,reverse convex programming, bilinear programming, nonconvex quadratic programming, polynomialprogramming, d.c. programming, signomial geometric programming, general nonlinear programming,mixed integer nonlinear programming, bilevel programming, optimization over the e%cient set, mul-tiobjective programming). Clearly there are multiple relationships among these problems. Since 25years, reformulations between problem classes, and much more rarely, between algorithms, have beenproposed by a variety of authors. The purpose of the present survey is to present main conceptsdescribing reformulations and to review main results.
2 Reformulations
The following definition of the concept of reformulation appeared in [1] (Defn. 3.1). Let PA and PBbe two optimization problems. An embedding reformulation B(·) of PA to PB is a mapping from PAto PB such that, given any instance A of PA and an optimal solution of B(A), an optimal solutionof A can be obtained within a polynomial amount of time.According to [9], the above definition would lead to a reformulation of the narrowing type, i.e. anauxiliary problem with a function *(·) mapping global optima of the instance B of PB to globaloptima of the instance A of PA.Embedding reformulations define a practical complexity relation between NP-hard problems bymeans embedding algorithms [1] (Defn. 4.1). Algorithm AL(PA) is embedded in algorithm AL(PB)through the mapping B(·) from PA to PB if, for any instance A0 of PA, the sequences {A$}$+0generated by AL(PA) applied to A0, and {B$}$+0 generated by AL(PB) applied to B(A0) are suchthat, for any ( ) 0, B$ = B(A$).
3 Some examples
Reformulations between mixed 0-1 programs, bilevel linear programs, min-max programs and gene-ralized linear complementarity problems were explored in [1]. The main result was that the classicalalgorithm by Beale and Small [4] for mixed 0-1 linear programming is embedded (in the sense ofthe above definition) in the algorithm given in [5] for bilevel linear programming. More recently, itwas shown that a similar embedding holds for cutting plane algorithms applied to these classes ofproblems [3,2].

Reformulations between global optimization problems 335
Relationships between other classes of problems have been studied by several authors, e.g. Ivanenkoand Plyasunov [7] (embedding reformulation from bilevel programming to multiobjective optimiza-tion) ; Horst et al. [6] (from optimization over the e%cient set in linear multicriteria programming toreverse convex programming) ; it is well known that there is an embedding reformulation from bilevellinear programs to linear complementarity problems via the replacement of the follower problem bythe corresponding KKT complementarity conditions.Existing reformulations will be reviewed with an emphasis on the algorithmic embedding referred toabove.
Références
1. Audet, C., Hansen, P., Jaumard, B., Savard, G. : Links between linear bilevel and mixed 0-1 programming problems. Journal of Optimization Theory and Applications, 93(2) : 273–300,1997.
2. Audet, C., Haddad, J., and Savard, G. : Disjunctive cuts for continuous linear bilevel program-ming. Optimization Letters, 1 (3) : 259–267, 2007.
3. Audet, C., Savard, G., Zghal, W. : New Branch-and-Cut Algorithm for Bilevel Linear Program-ming. Journal of Optimization Theory and Applications, 134 (2) : 353–370, 2007.
4. Beale E.M.L. and Small R.E. : Mixed integer programming by a branch-and-bound technique.Proceedings of the 3 rd IFIP Congress, 450–451, 1965
5. Hansen, P., Jaumard, B., Savard, G. : New Branch and Bound Rules for Linear Bilevel Program-ming. SIAM Journal on Scientific and Statistical Computing, 13 (5) : 1194–1217, 1992.
6. Horst, R., Thoai, N.V., Yamamoto, Y., Zenke, D. : On Optimization over the E%cient Set inLinear Multicriteria Programming. Journal of Optimization Theory and Applications, 134 : 433–443, 2007..
7. Ivanenko, D.S., Plyasunov, A.V. : Reducibility of Bilevel Programming Problems to Vector Op-timization Problems. Journal of Applied and Industrial Mathematics, 2 (2) : 179–195, 2008.
8. Liberti, L. : Reformulations in Mathematical Programming : Definitions and Systematics.RAIRO-RO, accepted for publication.

Gestion des symétries dans une résolution exacte del’a!ectation quadratique à trois dimensions
B. Le Cun1 and F. Galea2
1 Laboratoire PRiSM, 45 avenue des Etats-Unis 78035 Versailles [email protected]
2 Laboratoire PRiSM Versailles, Laboratoire G-SCOP, Grenoble [email protected]
1 IntroductionLe problème d’a#ectation quadratique à trois dimensions (Q3AP) est une extension du problèmed’a#ectation quadratique (QAP), qui occupe une large place dans la littérature d’Optimisation Com-binatoire.Le Q3AP a été présenté par P. Hahn et al. [1]. La motivation principale a été l’optimisation d’unschéma de retransimissions sur réseau sans fil, en a#ectant des symboles de modulation à des séquencesbinaires de taille fixe. Des erreurs de transimmision pouvant avoir lieu, les paquets erronés sontsusceptibles d’être retransmis. La diversité est une mesure de l’indépendance statistique entre unetransmission et les éventuelles retransmission successives. Maximiser la diversité revient à réduirela probabilité d’erreurs lors des retransmissions. Comme présenté par P. Hahn et al., lorsque l’onconsidère qu’une seule retransmission, ce problème revient à un QAP. Le Q3AP correspond à au casde deux retransmissions.Une autre illustration de ce problème peut être faite en reprenant les termes du QAP. Etant donnésN managers, N usines, et N sites, le problème consiste à a#ecter chaque manager et chaque usine àchaque site, de telle sorte à minimiser le coût total. Le coût d’une a#ectation est la somme de coûtslinéaires Lijk où i est le manager, j l’usine et k le site plus les coûts quadratiques Cijklmn où i et lsont des managers, j et m des usines et k et m des sites. Plus formellement le problème se modélisecomme suit :
minN%
i=1
N%
j=1
N%
k=1
Lijkxijk +N%
i=1
N%
j=1
N%
k=1
N%
l=1l%=i
N%
m=1m%=j
N%
n=1n%=k
Cijklmnxijkxlmn
s.t.N%
j=1
N%
k=1
xijk = 1 $i ! {1, · · · , N}
N%
i=1
N%
k=1
xijk = 1 $i ! {1, · · · , N}
N%
i=1
N%
j=1
xijk = 1 $i ! {1, · · · , N}
xijk ! {0, 1} $i, j, k ! {1, · · · , N}
Comme pour le QAP, où les matrices symétriques de flux et de distances peuvent donner lieu àde nombreuses solutions symétriquement équivalentes, les instances du Q3AP ont elles aussi des

Symétries dans le Q3AP 337
structures symétriques. Par exemple, dans l’application de transmission sans fil, l’a#ectation dessymboles de modulation lors de la première et de la seconde retransmission peuvent être échangéessans modifier la valeur de la solution. Détecter ces symétries a permis de réduire considérablement lestailles des arbres de recherche lors de résolution exacte par méthode de séparation et évaluation. Nousnous intéressons dans cette présentation à la détection de deux types de symétries pour le Q3AP etaux méthodes permettant d’interdire la génération de branches symétriques lors de la recherche.Le premier type de symétrie concerne les indices. En e#et, sur certaines instances, si les indices desites et d’usines sont échangés, les solutions sont équivalentes. Plus formellement, une instance deQ3AP est dite indice-symétrique en i si
$i, j, k ! N3, Lijk = Likj$i, j, k ! N3, Cijklmn = Cikjlnm
De la même manière, des instances aussi être indice-symétriques en j et en k.Le second type de symétrie concerne les permutations elles-mêmes. Par exemple, les deux tableauxsuivants présentent deux solutions, où les a#ectations des managers 0 et 3 ont été inversées. Si on peutmontrer que ces deux solutions sont de coût égal pour tous j1, j2, k1, k2 tels que les solutions restentréalisables, alors il existe une permutation-symétrie sur les 2 couples de triplets ((0, 1, 3), (3, 3, 1)) et((0, 3, 1), (3, 1, 3)).
i 0 1 2 3j 1 j1 j2 3k 3 k1 k2 1
m 0 1 2 3u 3 j1 j2 1s 1 k1 k2 3
La résolution exacte de ce problème par Branch and Bound utilise une borne inférieure issue de laformulation RLT1 du QAP [4,1]. Notre solveur est implémenté sur la plateforme de développementBob++ permettant des résolutions séquentielles ou parallèles [2,3].
Références
1. P. Hahn, K. Bum-Jin, T. Stutzle, S. Kanthak, W. L. Hightower, H. Samra, Z. Ding, and M. Gui-gnard. The quadratic three-dimensional assignment problem : Exact and approximate solutionmethods. European Journal of Operational Research, 184(2) :416–428, 2008.
2. F. Galea and B. Le Cun. Bob++ : a Framework for Exact Combinatorial Optimization Methods onParallel Machines. In PGCO’2007 as part of the 2007 International Conference High PerformanceComputing & S imulation (HPCS’07) and in conjunction with The 21st European Conference onModeling and Simulation (EC MS 2007), pages 779–785, June 2007.
3. Bob++ : Framework to solve Combinatorial Optimization Prob lemshttp://bobpp.prism.uvsq.fr/.
4. P. Hahn and T. Grant. Lower bounds for the quadratic assignment problem based upon a dualformulation. Operations Research, 46 :912–922, 1998.

The symmetry group of a mathematical program
L. Liberti1
LIX, École Polytechnique, 91128 Palaiseau, [email protected]
1 Introduction
The most common method for finding guaranteed global optima of mathematical programs (eitherlinear or nonlinear, whether involving integer variables or not) is the Branch-and-Bound (BB) al-gorithm. There exist reliable implementations of BB for Mixed-Integer Linear Programs (MILPs)(e.g. [5]) ; for Mixed-Integer Nonlinear Programs (MINLPs) the situation is not as advanced, butthere are nonetheless some implementations that can be used profitably [14,2]. Of course there aremany factors that impact the performance of a BB algorithm, the main ones being the bound qualityand branching strategy. Symmetries in the solution space can adversely impact the quality of thebound, especially in lower BB search tree levels. If a given problem has many symmetric optima,many leaf nodes in the BB tree will contain optimal solutions, which means that the BB algorithmwill never be able to prune the branches leading to these leaves. As a consequence, the BB tree ex-ploration will yield trees of disproportionate sizes. If it were possible to detect symmetries before thesolution process, we might then attempt to adjoin constraints eliminating some symmetric solutionswhilst guaranteeing that at least one optimum is kept. Such constraints provide a reformulation ofthe narrowing type [9]. In this abstract we present a general technique, applicable to MILPs andMINLPs alike, to find subgroups of the group of solutions of a mathematical program. Current workon using symmetries in mathematical programming includes [10,12,6,4,17] (see [11] for a survey).All of these works address MILPs or Semi-Definite Programs (SDP), and all of them assume thatthe solution group is available a priori (it is sometimes possible to infer the solution group from theproblem structure). Apart from [8], which also proposes a method for computing arbitrary MILPsubgroups automatically, this is the only other work that describes a technique for automaticallycomputing symmetry groups of mathematical programs, and the first extension of symmetry-basedtechniques to MINLPs.
2 Groups of a mathematical program
We consider Mixed-Integer Nonlinear Programs (MINLPs) in the following general form :
min{f(x) | g(x) # b 4 x ! [xL, xU ] 4 $i ! Z(xi ! Z)} (1)
where f : Rn ( R, g : Rn ( Rm, b ! Rm, xL, xU ! Rn and Z . {1, . . . , n}. Given a MINLP P asin (1), the solution group G$(P ) of P is defined as stab(G(P ), Sn), i.e. the group of all permutationsof variable indices mapping global optima into global optima. We consider the group GP that “fixesthe formulation” of P :
GP = {" ! Sn|Z" = Z 4 $x ! F(P ) f(x") = f(x) 4 7$ ! Sm($b = b 4 $x ! F(P ) $g(x") = g(x))}.
It turns out that GP # G$(P ). The two most problematic conditions that need testing to ascer-tain whether a given permutation " is in GP are $x ! F(P ) f(x") = f(x) and 7$ ! Sm $x !

The symmetry group of a mathematical program 339
F(P ) $g(x") = g(x). Such tests might require a potentially uncountable number of numerical com-parisons, and so they would be algorithmically infeasible. We therefore assume that for functionsf1, f2 : Rn ( R we have an oracle equal(f1, f2) that, if it returns true, then dom(f1) = dom(f2)and $x ! dom(f1) f1(x) = f2(x) ; in that case we write f1 , f2. We can now define the formulationgroup of a MINLP P as follows :
GP = {" ! Sn | Z" = Z 4 f(x") , f(x) 4 7 $ ! Sm ($g(x") , g(x) 4 $b = b)}. (2)
Because for any function h, h(x") , h(x) implies h(x") = h(x) for all x, it is clear that GP #GP . Thus, it also follows that GP # G$(P ). The representation of the nonlinear structure of amathematical program by expression trees [7] provides a good implementation of the equal oracle.
3 Finding GP automatically
We start by representing the objective function and constraints of the MINLP (1) by a DirectedAcyclic Graph (DAG) DP = (VP , AP ) which is the union of all expression trees for f, gi(i # m)where all leaf vertices representing the same decision variable have been contracted into just onevertex [2,15]. We then define a node equivalence relation 8 on VP for which u 8 v if and only if u, vcan be permuted (thus, variable leaf nodes are equivalent, equal constant nodes are equivalent, likeoperator nodes at the same tree rank are equivalent, nodes representing constraints are equivalent).Let {Vk | k # K} be the partition of VP induced by 8. Let Aut(DP ) be the group of vertexpermutations + such that (+(u), +(v)) ! AP for all (u, v) ! AP , and GDAG(P ) be the largest subgroupof Aut(DP ) fixing Vk setwise for all k # K. We let SV . VP be the set of variable leaf nodes.
Theorem 1. The map 1 : GDAG(P ) ( Sym(SV ) given by the restriction of each permutation ofGDAG(P ) to SV is a group homomorphism, and Im1 = GP groupwise.
By Thm. 1, we can automatically generate GP by looking for the largest subgroup of Aut(DP ) fixingall Vk’s setwise. Thus, the problem of computing GP has been reduced to computing the (generatorsof the) automorphism group of a certain vertex-coloured DAG. This is in turn equivalent to theGraph Isomorphism (GI) problem [1]. GI is in NP, but it is not known whether it is in P orNP-complete. A notion of GI-completeness has therefore been introduced for those graph classesfor which solving the GI problem is as hard as solving it on general graphs [16]. Rooted DAGs areGI-complete [3] but there is an O(N) algorithm for solving the GI problem on trees ([13], Ch. 8.5.2).This should give an insight as to the type of di%culty inherent to computing Aut(DP ).
4 Conclusion
We outlined a method for automatically computing subgroups of the solution group of arbitrarymathematical programs. These groups can be used to define narrowing reformulations of the originalproblem, yielding faster BB-based solution processes. A full computational study of these ideas iscurrently under way, and shows promising preliminary results.
Références
1. L. Babai. Automorphism groups, isomorphism, reconstruction. In R. Graham, M. Grötschel,and L. Lovász, editors, Handbook of Combinatorics, volume 2, pages 1447–1540. MIT Press,Cambridge, MA, 1996.

340 Liberti, L.
2. P. Belotti, J. Lee, L. Liberti, F. Margot, and A. Wächter. Branching and bound reductiontechniques for non-convex MINLP. Technical Report 2059, Optimization Online, 2008.
3. K. Booth and C. Colbourn. Problems polynomially equivalent to graph isomorphism. TechnicalReport CS-77-04, University of Waterloo, 1979.
4. E.J. Friedman. Fundamental domains for integer programs with symmetries. In A. Dress, Y. Xu,and B. Zhu, editors, COCOA Proceedings, volume 4616 of LNCS, pages 146–153. Springer, 2007.
5. ILOG. ILOG CPLEX 11.0 User’s Manual. ILOG S.A., Gentilly, France, 2008.6. V. Kaibel and M. Pfetsch. Packing and partitioning orbitopes. Mathematical Programming,
114(1) :1–36, 2008.7. L. Liberti. Writing global optimization software. In L. Liberti and N. Maculan, editors, Global
Optimization : from Theory to Implementation, pages 211–262. Springer, Berlin, 2006.8. L. Liberti. Automatic generation of symmetry-breaking constraints. In B. Yang, D.-Z. Du, and
C.A. Wang, editors, COCOA Proceedings, volume 5165 of LNCS, pages 328–338, Berlin, 2008.Springer.
9. L. Liberti. Reformulations in mathematical programming : Definitions and systematics. RAIRO-RO, accepted for publication.
10. F. Margot. Pruning by isomorphism in branch-and-cut. Mathematical Programming, 94 :71–90,2002.
11. F. Margot. Symmetry in ILP. In 50 Years of Integer Programming. Spriner, Berlin, in preparation.12. J. Ostrowski, J. Linderoth, F. Rossi, and S. Smriglio. Orbital branching. In M. Fischetti and
D.P. Williamson, editors, IPCO, volume 4513 of LNCS, pages 104–118. Springer, 2007.13. K.H. Rosen, editor. Handbook of Discrete and Combinatorial Mathematics. CRC Press, New
York, 2000.14. N.V. Sahinidis and M. Tawarmalani. BARON 7.2.5 : Global Optimization of Mixed-Integer
Nonlinear Programs, User’s Manual, 2005.15. H. Schichl and A. Neumaier. Interval analysis on directed acyclic graphs for global optimization.
Journal of Global Optimization, 33(4) :541–562, 2005.16. R. Uehara, S. Toda, and T. Nagoya. Graph isomorphism completeness for chordal bipartite
graphs and strongly chordal graphs. Discrete Applied Mathematics, 145 :479–482, 2005.17. F. Vallentin. Symmetry in semidefinite programs. Technical Report 1702, Optimization Online,
2007.

Non Linear Mathematical Programming Approaches tothe Classification Problem : A Comparative Study
Soulef Smaoui,1 Habib Chabchoub,1 and Belaid Aouni2
1 Unité de recherche en Gestion industrielle et Aide á la D"ision, Faculté des Sciences Economiqueset de Gestion, Sfax, Tunisia.
[email protected]@fsegs.rnu.tn
2 Decision Aid Research Group, School of Commerce and Administration, Laurentian University,Sudbury (Ontario) P3E2C6 Canada.
1 Introduction
Discriminant Analysis (DA) is widely applied in many fields such as the social sciences, finance,marketing and other areas. The purpose of DA is to study the di#erence between two or more mutuallyexclusive groups and to classify this new observation into an appropriate group. A MathematicalProgramming approach (MP) has been frequently used in DA and can be considered a valuablealternative to the classical models of DA when standard assumptions are not satisfied, such as thenormality distribution of the data and the equality of the variance covariance matrices. SeveralMP approaches generally use linear discriminant functions. Recently, new MP formulations havebeen developed based on nonlinear functions which may produce better classification performancethan can be obtained from a linear classifier. Nonlinear discriminant functions can be generated byMP methods by transforming the variables [3], by piecewise linear functions [7] or by using Multi-hyperplanes formulations [1].
2 The proposed models
According to the literature, new classification procedures based on non linear discriminant functionsare proposed in order to ameliorate the performance of the models developed in this context. Amongthese models, certain are approximated by piecewise-non linear functions and others based on multi-hypersurfaces. However, to reduce the complexity of the piecewise-linear approaches, two stagespiecewise-linear models are used. The main idea of these models is to apply the piecewise-linearfunctions to the misclassified observations obtained by resolving a standard MP approach.To analyse the performance of the proposed procedures a comparative study is then conductedbetween them and five non linear MP approaches : the quadratic model [3], the MCA and MSDpiecewise-linear models [7] and the SPS and GPS multi-hyperplanes models [1]. Di#erent applicationsin the financial and medicine domain are used to compare the di#erent models.
3 Principal results of the comparative study
The result of this study are in favour of the models based on multi-hyperplanes and on multi-hypersurfaces because it doesn’t require to resolve twice the model (group 1 in convex region and

342 Smaoui, S., Chabchoub, H. and Aouni, B.
group 2 in convex region) like the piecewise models. In addition, these approaches are more e#ectivethan the piecewise models in the sense that it doesn’t necessitate many constraints and many binaryvariables and special order sets. On the other hand, the hypersurfaces models outperform the othersapproaches because the optimal solution can be reached using a reduced number of hypersurfaces thanhyperplanes. The results of the second stage piecewise-linear models are promise but the performanceof these models decrease if the number of misclassified observations in the first stage is not important.
Références
1. Better M., Glover F., Samourani M. (2006). Multi-Hyperplane Formulations for classification anddiscriminant analysis. http ://www.opttek.com/News/pdfs/Multi%20HyperplaneW%20DSI%20paper%20-%20final.pdf
2. Charnes A.,Cooper W.W, Ferguson R.O(1955).Optimal Estimation of executive compensation bylinear Programming. Management Science, 138-151.
3. Duart Silva A.P, Stam A.(1994). Second order mathematical programming formulations for dis-criminant analysis. Journal of Operational Research, 72, 4-22.
4. Freed.N and Glover.F. (1986). Evaluating Alternative Linear Programming models to solve theTwo-Group Discriminant Problem. Decision Sciences, Vol.17, 151-162.
5. Gaither N., Glorfeld.W.(1982). On using Linear Programming in Discriminant problems. DecisionSciences, Vol.13, 167-171.
6. Glen JJ. (2004). Dichotomous categorical variable formation in mathematical programming dis-criminant analysis models. Naval Research Logistic, Vol.51, 575-596.
7. Glen JJ. (2005). Mathematical programming models for piecewise-linear discriminant analysismodels. Operational Research Society, Vol.50, 1043-1053
8. Zopounidis C., Doumpos M (2002). Multicriteria classification and sorting methods : A literaturereview. European Journal of Operational Research, 138, 229-246.

Using Stochastic Goal Programming to rearrange Bedsinside Habib Bourguiba Hospital
A. Badreddine Jerbi1 and B. Hichem Kammoun,2
Department of Applied Quantitative Methods, GIAD Laboratory University of Sfax, FSEG Routede l’AÈrodrome, km 4 BP 1088 Sfax Tunisia.
[email protected]@fsegs.rnu.tn
1 Introduction and Literature
Bed planning, occupancy, and utilization have been studied from many people all over the years.Mostly Queuing analysis, Statistics, Markov chains and simulation or a mix were used, Kusters andGroot, (1996) used a model to predict the bed availability at anytime in the future, they stated thatit is dependent on the number of emergency and elective admissions and the number of discharges.Ciesla et al (2008) used regular statistics and ANOVA to estimate resources consumption in a traumadepartment. Utley et al (2003) introduced an intermediate care unit and used a model to forecastits bed capacity in order to reduce the burden on the acute care facility Cochran and Roche (2007)stated that financial data should be used and not census data for estimating inpatient bed capacity.Their model to estimate the number of beds is based on queuing theory. Cochran and Bharti (2006)emphasized that a key factor of costs is associated with bed utilization. They used queuing theoryand simulation to balance bed utilization in an obstetrical unit. Gorunescu et al (2002) used aqueuing model to estimate the mean occupancy rate and the probability of lost demand. Harper andShahani (2002) used simulation of di#erent scenarios to clarify the stochastic nature of the lengthof stay. In fact, they argued that the length of stay has a random variable distribution and bedmanagement should consider mean occupancy and refusal rates. Harper (2002) used a simulationmodel, PROMPT ; helpful in the planning and managing beds. Akkerman and Knip (2004) used aMarkov chains and simulation methodology to examine the unused bed capacity in a hospital. Theyfound a relation between length of stay, bed availability and waiting lists. Oddoye et al (2007) used agoal programming methodology to calculate the number of beds in a medical assessment unit. Theirwork is one of the few using multiple objective paradigms in healthcare. They emphasised that theirwork is the first to manage the beds in medical assessment unit. In the full paper, we propose astochastic goal programming model that uses the power distribution law for describing the lengthof stay and rearranging beds inside hospitals. In section two, we present the problem, in sectionthree, we introduce the concept of stochastic goal programming and we progress in the formulationto Chance Constrained Programming and we solve the problem. In section four, we introduce thesatisfaction function concept and we use it to obtain a solution to our case study. Finally we give acomparison, results and conclusion.
2 Problem Statement
Habib Bourguiba hospital is a University hospital in Sfax Tunisia. Its main activity is surgical andprovides outpatient services too. It has many departments : The orthopaedic, the ORL, the urology,the neurosurgery A table describing the name, the capacity in beds ; the annual number of admissions

344 Badreddine Jerbi, Hichem Kammoun
and the annual number of bed days in 11 departments for the year 2005 was prepared. By calculatingthe average length of stay, we noticed that there are departments where the number of beds is inshortage and the occupancy rate is more than 100%. Other departments are characterised by havinga surplus of beds as well as a low occupancy rate. The average length of stay is not consideredappropriate for planning especially when it has a long tail distribution Marshall et al (2005). Onerealistic idea is to design for stochastic length of stay best described with power law distribution seeHellervik and Rodgers (2007).
3 Methodology and resultsWe developed a stochastic goal programming model using power law distribution to solve the rearran-gement of beds problem in Habib Bourguiba hospital. The initial model involved only the stochasticnature, gave the amount of bed transfers and found that there is no need to have more beds. Theadvanced model included, in addition, the satisfaction function concept. We used two types of satis-faction functions. We saw that the satisfaction functions, whether it was linear or exponential, hashomogenized the excess of beds in the departments. We used queuing systems analysis and simulationto compare the existent and the suggested solution ; expected length of the queues and waiting timesas well as utilization have highly improved. For future research, considerations will be given to thesearch of distributions on the length of stay of each department and to optimize with the model.
Références1. Aouni, B , Ben Abdelaziz, F , Martel, J (2005) Decision-makers preferences modeling in the
stochastic goal programming European Journal of Operational Research 162 pp 610-6182. Aouni, B., Kettani, O., 2001. Goal programming model : A glorious history and a promising
future. European Journal of Operational Research 133 (2), 1-7.3. Akkerman, R and Knip, M (2004) Reallocation of Beds to Reduce Waiting time for Cardiac
Surgery. Healthcare Management Science 7 pp 119-1264. Bagust, A, Place, M, Posnett, J (1999) Dynamics of bed use in accommodating emergency
admissions : stochastic simulation model, BMJ 17 pp 155-1585. Charnes, A, Cooper, W (1963) Deterministic Equivalents for Optimizing and Satisficing under
Chance Constraints Operations Research, Vol. 11, No. 1 pp. 18-39.6. Ciesla, D Sava, J Kennedy, S (2008) Trauma patients : you can get them in, but you can’t get
them out. The American Journal of Surgery 195 (2008) 78-837. Clauset, A, Shalizi, C, Newman M. (2005) Power-law distributions in empirical data Contemp.
Phys. 46 pp 323-3478. Cochran, J, Bharti, (2006) A Stochastic bed balancing of an obstetrics hospital Healthcare Ma-
nagement Science (2006) 9 pp 31-459. Cochran, K and Roche, K (2007) A queuing- based decision support methodology to estimate
hospital inpatient bed demand.. Journal of the Operational Research Society10. Contini, B (1968) A Stochastic Approach to Goal Programming Operations Research, Vol. 16,
No. 3 pp. 576-586.11. Gorunescu, F, McClean, S, Millard, P (2002) A Queueing model for bed-occupancy management
and planning of hospitals Journal of the Operational Research Society 53, 19-2412. Harper, P (2002) A Framework for Operational Modeling of Hospital Resources. Healthcare
Management Science 5 pp 165-173

Papier soumis à ROADEF 09 345
13. Harper, P, Shahani, A. (2002) Modelling for the planning and management of bed capacities inhospitals Journal of the Operational Research Society 53, 11-18
14. Hellervik, A, Rodgers G.J (2007) A power law distribution in patients’ lengths of stay in hospitalPhysica A 379 (2007) 235-240
15. Kusters and Groot (1996) Modelling resource availability in general hospitals Design and im-plementation of a decision support model European Journal of Operational Research 88 (1996)428-445
16. Martel, J, Aouni, B., 1990. Incorporating the decision makers preferences in the goal programmingmodel. Journal of the Operational Research Society 41 (12), 1121-1132.
17. Marshall, A, Vasilakis, C, El-Darzi, E Length of Stay-Based Patient Flow Models : Recent De-velopments and Future Directions (2005) Health Care Management Science 8, 213-220
18. Oddoye , J, Yaghoobi,M, Tamiz, M, Jones, D, Schmidt, P (2007) A multi-objective model to de-termine e%cient resource levels in a medical assessment unit Journal of the Operational ResearchSociety (2007) 58, 1563-1573
19. Utley , M. Gallivan, S , Davis, K , Daniel , P. Reeves, P, Worrall, J (2003) Estimating bedrequirements for an intermediate care facility European Journal of Operational Research 15092-100
20. Vasilakis, C, El-Darzi, E (2001) A simulation study of the winter bed crisis, Healthcare Mana-gement Science 4 pp 31-36.
21. White, D, (1990) A Bibliography on the Applications of Mathematical Programming MultipleObjective Methods Journal of the Operational Research Society, Vol. 41, No. 8, pp. 669-691

Symétrie et préférences des ressources dans laplanification des blocs opératoires
B. Roland,1 and F. Riane1
Louvain School of Management and FUCaM, 151, chaussée de Binche, 7000 Mons – [email protected]
1 Introduction
Le monde hospitalier européen est en proie, ces dernières années, à de profonds remaniements suiteà de nombreuses réformes voulues par les pouvoirs publics en vue d’améliorer la qualité de viedes concitoyens, tout en rationalisant les dépenses. A ces défis structurels s’ajoutent une demandesans cesse croissante en soins de santé, des exigences de la part de la patientèle plus avertie desprogrès médicaux et une évolution des pathologies qui complexifient davantage la gestion des centreshospitaliers. Il devient dès lors essentiel pour ces derniers de gérer plus e%cacement leurs ressourceshumaines et matérielles, c’est-à-dire d’optimiser leur utilisation afin de réduire les dépenses encouruestout en préservant la qualité des soins prestés.Dans ce contexte hospitalier économiquement contraint, gérer e%cacement le quartier opératoiredevient une question cruciale. En e#et, le quartier opératoire joue un rôle prédominant dans laperformance globale des hôpitaux. C’est une activité importante de la création de soins, qui génèreles principaux revenus mais qui est également l’une des plus importantes sources de dépenses avecprès de dix pourcents du budget global du centre [2]. Rendre plus e%cace la gestion de ces postes passepar une utilisation plus rationnelle des ressources opératoires et par conséquent par une planificationplus a%née des blocs opératoires. Mais les seules préoccupations financières ne peuvent su%re àl’établissement de plannings opératoires. Nous ne pouvons ignorer l’importance de la place des femmeset des hommes entrant dans la réalisation de ces processus médicaux. C’est pourquoi nous souhaitonsinclure aux habituels objectifs économiques une dimension humaine encore trop peu présente dansles travaux scientifiques.Nos travaux ont pour objectif de proposer des outils pour une meilleure utilisation des ressourcesopératoires tout en tenant compte du facteur humain qui caractérise la gestion du quartier opératoire.Prendre en compte l’opinion des acteurs de ce processus médical devrait améliorer la satisfactiondu sta# médical et par conséquent l’e%cacité du quartier opératoire. En particulier, nous centronsnotre approche sur l’intégration des préférences des chirurgiens lors de l’élaboration des programmesopératoires hebdomadaires. Notamment, nous proposons une formulation mathématique en nombresentiers qui tient compte, entre autres, des disponibilités du personnel ainsi que des contraintes decapacités.Une vaste littérature existe sur la planification et l’ordonnancement du quartier opératoire. Nous nousréférons à [1] pour un état de l’art approfondi. Dans la littérature des soins de santé, la planification duquartier opératoire apparaît comme complexe et engendrant d’importants investissements financiers.Cette procédure a pour objectif d’ordonner les opérations en y assignant les ressources nécessaires,ce sur un court horizon de temps (typiquement une semaine) et sur base de la demande des unitéschirurgicales. La littérature décompose généralement le processus de planification en deux étapes[3,4] : une étape de planification, à proprement parler, qui assigne le jour et la salle d’opération.Ensuite, une étape d’ordonnancement agence les opérations au sein d’une même salle en tenantcompte des diverses contraintes de fonctionnement. Cependant, cette décomposition peut engendrer

Symétrie et préférences des ressources dans la planification des blocs opératoires 347
des solutions sous-optimales étant donné l’interaction entre ces deux étapes. C’est pourquoi nousproposons une approche qui intègre les étapes de planification et d’ordonnancement en un uniquemodèle. De plus, peu d’approches de la littérature o#rent deux niveaux de décision comme le permetnotre démarche, et proposent de définir simultanément la date, l’heure et la salle de chaque opération.Dans la littérature de la planification et de l’ordonnancement [5], les ressources humaines sont per-çues comme passives : seules leurs disponibilités et leur habilité à exécuter certaines tâches sontgénéralement prises en compte. Mais ces personnes, qui interviennent directement dans la mise enoeuvre de l’objet de la planification, ne participent pas à l’élaboration du planning en question. Enparticulier, dans le contexte hospitalier qui nous préoccupe, les principales ressources sont des êtreshumains critiques vis-à-vis de leurs conditions de travail. Il semble donc opportun de les intégrerdans la prise de décision en leur permettant d’établir leur planning d’activités de manière conjuguée.L’objet de notre recherche comprend le développement d’une structure autorisant les équipes médi-cales à faire état de leurs agendas et à négocier un planning en adéquation avec leurs préférences.Nos travaux traitent de la modélisation de procédure optimisant le processus de planification duquartier opératoire. Comme nous l’avons mentionné, le quartier opératoire est un point critique dumanagement hospitalier dont les frais proviennent essentiellement de la gestion de ses ressources plusque de dépenses matérielles. Le problème auquel nous nous attaquons est donc un problème d’or-donnancement d’activités chirurgicales défini par des contraintes temporelles et des contraintes dedisponibilités de ressources. L’allocation des ressources aux di#érentes tâches, et par conséquent ladétermination des temps d’opération, se fait de façon optimale en tenant compte du facteur humaininhérent au monde hospitalier. Lors de la formulation du MIP (mixed-integer program), nous auronsété particulièrement attentifs à la modélisation des préférences des chirurgiens quant à leurs disponi-bilités journalières. Nous avons également porté une attention toute particulière à la suppression dela symétrie induite par des salles d’opérations qualifiées de polyvalentes pouvant assurer le traitementde tout type d’intervention.
Références
1. Cardoen, B., Demeulemeester, E. and Beliën, J. : Operating room planning and scheduling : Aliterature review. Technical report, Katholieke Universiteit Leuven (2007)
2. Gordon, T., Lyles, A.P.S. and Fountain, J. : Surgical unit time review : resource utilization andmanagement implications. Journal of Medical Systems, 12, pp 169-179 (1988)
3. Guinet, A. and Chaabane, S. : Operating theatre planning. International Journal of ProductionEconomics, 85, pp69-81 (2003)
4. Jebali, A., Hadj Alouane, A.B. and Ladet, P. : Operating rooms scheduling. International Journalof Production Economics, 99, pp52-62 (2006)
5. Klein, R. : Scheduling of resource constrained projects. Kluwer Academic Publishers (2000)

Approche mathématique pour la programmation desrendez-vous de mises au point médicales en ambulatoire
J.-P. Cordier1, F. Riane1, H. Aghezzaf2
1 LSM/FUCaM, 151, chaussée de Binche, 7000 Mons Belgique.This paper is part of Research Program IAP 6/09 ´ Higher Education and Research a of the
Belgian Federal Authorities{cordier, riane}@fucam.ac.be
2 Universiteit Gent, 903, Technologiepark Zw$naarde, 9052 Zw$naarde Belgique.{ElHoussaine.Aghezzaf}@UGent.be
L’accroissement progressif des pressions financières sur le secteur hospitalier, ainsi que l’accroissementdes exigences de confort de la part des patients et l’augmentation du nombre de patients obligent lessystèmes de soins de santé à reconsidérer leurs processus et à réorganiser leurs modes de fonctionne-ment. La prise en compte de l’impact de ces transformations sur le circuit du patient devant suivredes examens pour une mise au point justifie l’étude en cours sur le pilotage par la performance de cesecteur. Les prémisses de ce travail s’articulent autour de deux parties. La première concerne la modé-lisation système de soin étudié sous une forme exploitable tel qu’un modèle de connaissance commedécrit dans la méthodologie "ASCI" [2]. L’autre partie définit un modèle mathématique destiné àaméliorer l’ordonnancement des examens des patients au sein des di#érents services.
1 Contexte
Cette étude se focalise sur l’amélioration continue du circuit des patients d’un CHU belge. La pré-sente communication expose la modélisation mathématique du système de prise de rendez-vous etd’ordonnancement de ceux-ci. Pour accroître la qualité du service prodigué aux patients devant suivreune mise au point (check-up), il est nécessaire de programmer l’ensemble de ces examens en ambula-toire de manière à ne pas amener le patient à être hospitalisé et minimiser les attentes des patients.Ceci passera par le recours à des outils permettant d’améliorer l’organisation du circuit des patientsconcernés. L’hôpital a deux objectifs stratégiques, d’une part, il désire diminuer ses co˚ts ou tout dumoins améliorer sa rentabilité sur ce secteur et, d’autre part, il vise à augmenter l’attractivité de sesservices par la satisfaction des patients impliqués.La qualité de la prise en charge serait nettement améliorée si la filière ambulatoire était privilégiéepour les patients en mise au point. En e#et, il est important de permettre au patient, ayant un envi-ronnement social adéquat et dont l’état de santé le permet, de rentrer chez lui après avoir passé sesexamens médicaux. Il est également plus intéressant au niveau financier et organisationnel pour l’hô-pital de programmer la mise au point de ces patients en ambulatoire. Une hospitalisation impliqueraitpour le patient une organisation particulière (prendre congé pour la période d’hospitalisation, fairegarder ses enfants etc.). Elle impliquerait également une programmation particulière pour l’hôpital(consommation de lits, a#ectation de ressources infirmières etc.). De plus, pour les patients en miseau point qui sont hospitalisés, l’établissement a souvent du mal à justifier leurs séjours et ne reçoitdonc pas les subsides nécessaires pour couvrir les charges endossées. Procéder à une programmationen ambulatoire, quand il est possible de la faire, accroît le confort des patients et diminue les co˚ts del’hôpital. Pour arriver à un tel résultat, il faut optimiser le parcours des patients afin qu’un maximumde ceux-ci puisse bénéficier de ce type de prise en charge.

Approche mathématique pour la programmation des rendez-vous de patients 349
2 Méthodologie
La définition d’une méthode d’optimisation, comme présentée plus haut, est une part de l’édifice quedevra mettre en place l’hôpital afin d’atteindre les objectifs stratégiques qu’il s’est fixés. L’ensembledes mesures nécessaires amènerait un nombre de changements important. Il n’est donc pas concevablede se lancer dans un tel chantier sans mettre en place au préalable une méthodologie de validationpar des tests approfondis des actions envisagées. Il faut anticiper et éviter les e#ets pervers potentielsdes mesures envisagées avant leur activation. Vu la complexité du système hospitalier, cela ne permetpas une expérimentation directe. C’est pourquoi, nous avons défini et structuré une architecture depilotage destiné à ces milieux complexes [1]. la méthodologie est nécessaire pour mieux définir leproblème, identifier ses variables d’action et élaborer un programme mathématique adéquat. C’estl’objet du papier.
3 Modèle mathématique
Si le traitement isolé d’un service pilote peut très certainement amener des améliorations, la globali-sation à l’ensemble des services permettra de faire jouer certains e#ets de levier qui engendreront uneoptimisation globale du système. L’objectif principal sera donc de construire un modèle mathéma-tique permettant d’optimiser l’ordonnancement des examens de patients au sein d’une journée. Cemodèle intègre les particularités du système réel. Il s’agit d’un programme linéaire en nombre entierqui permet d’optimiser le parcours de patients en tenant compte des contraintes de capacité et descontraintes temporelles.
4 Perspectives
Le modèle mathématique doit encore être intégré dans une boucle de pilotage virtuel qui permetde tester les batteries de méthodes proposées pour améliorer la performance du système étudié sansimpacter le système réel. Ce mécanisme est réalisé à l’aide d’une réplication du système réel parun modèle de simulation qui permet d’e#ectuer les tests indispensables. Ce n’est qu’après avoir étévalider que le cocktail de méthodes adéquat pourra être déployé au sein du système réel.
Références
1. Jean-Philippe Cordier, Valérie Dhaevers, and Fouad Riane. L’art du pilotage de la performancevers une démarche instrumentalisée pour le milieu hospitalier. In 4e Conférence Francophone engestion et ingénierie des systèmes hospitaliers (GISEH 2008), Lausane, septembre 2008.
2. M. Gourgand and P. Kellert. Conception d’un environnement de modélisation des sytèmes deporoduction. In 3ème congrès international de Génie Industriel, Tours, france, 1991.

Un algorithme exact pour la sélection etl’ordonnancement de tâches sur une machine
F. Talla Nobibon, J. Herbots and R. Leus
Department of Decision Sciences and Information ManagementFaculty of Business and Economics
Katholieke Universiteit Leuven, Belgique
1 Introduction
Le problème simultané de sélection de commandes à accepter (dans la suite, nous utilisons le terme“tâches”) ainsi que de planification de la capacité pour cette sélection a reçu une attention croissanteau cours des dernières décennies aussi bien de la part des chercheurs que des entreprises. La résolutionde ce problème est complexe car toute solution doit trouver le juste milieu entre le revenu obtenupar la sélection d’une tâche d’une part et le coût aussi bien materiel qu’issu d’une possible pénalitéde retard d’autre part [3].Ce papier étudie la sélection et l’ordonnancement de tâches sur une machine, dans le cas où l’ensembletotal T de tâches (|T | = n) est disponible d’entrée et est constitué d’un sous-ensemble O de tâchesobligatoires et d’un sous-ensemble O de tâches que l’entreprise peut refuser (T = O 2 O). L’objectifest de maximiser le profit net obtenu en sélectionnant un sous-ensembleM . T de tâches contenantO et en ordonnançant de façon optimale les tâches sélectionnées. A chaque tâche i (i = 1, . . . , n)sont associés, le temps d’exécution pi et une date limite de livraison di (due date) négociée avec leclient ; mais aussi un revenu Qi et un coe%cient de pénalité wi applicable pour chaque unité de tempssupplémentaire écoulée entre la date limite et la date e#ective de livraison. Le problème de sélectionet d’ordonnancement de tâches sur une machine est modélisé comme suit.
maxM,!
m%
p=1
Q!(p) % w!(p)(C!(p) % d!(p))+, (1)
o˘ O . M , " est une b$ection de l’ensemble {1, . . . ,m} vers M (m étant la cardinalité de M), a+
représente le maximum entre a et 0 et Ci est la date e#ective de livraison de la tâche i ! M , i.e.Ci =&!"1(i)"1p=1 p!(p). La formulation (1) modélise aussi l’ordonnancement de tâches avec option de
sous-traitance [1] dans le cas particulier où il y a un seul sous-traitant avec une capacité illimitée.
2 Formulation linéaire
La formulation du problème donnée par (1) est implicite et non-linéaire. En vue d’une résolutionutilisant des logiciels d’optimisation, nous développons une formulation linéaire en considérant lesvariables binaires de décision xij et yij définies par : xij égale 1 si la tâche i est sélectionnée et latâche j est exécutée avant la tâche i et 0 sinon, yij égale 1 si la tâche i est sélectionnée et est lajème tâche exécutée et 0 sinon ; et les variables réelles de décision Ti représentant le retard accumuléà la livraison de la tâche i. Nous prouvons qu’une solution de la formulation linéaire est égalementsolution de (1) et vice-versa.

Un algorithme exact pour la sélection et l’ordonnancement de tâches sur une machine 351
3 L’algorithme branch-and-bound
Nous proposons un algorithme branch-and-bound pour la résolution du problème énoncé. Cet al-gorithme utilise comme sous-routine l’algorithme branch-and-bound développé par Potts et VanWassenhove [2] pour l’ordonnancement de tâches sur une machine avec pour objectif la minimisationde la somme pondérée des pénalités de retard (total weighted tardiness). Notre algorithme branch-and-bound commence avec un sous-ensemble de tâches sélectionnées contenant O. Ce sous-ensembleR est constitué de tâches certaines de faire partie d’au moins une solution optimale. Soit R = T \ R.A chaque niveau de l’arborescence, une tâche supplémentaire issue de R est ajoutéeà l’ensemble detâches déjà sélectionnées au noeud parent si l’index de cette tâche est supérieur au plus grand indexde tâches de R déjà sélectionnées (ce qui conduit à un arbre asymétrique). A chaque noeud de laprocédure, l’ordonnancement optimal de tâches sélectionnées nous fournit une borne inférieure de lavaleur optimale de la fonction objective qui contiendra les tâches considérées. Pour obtenir des bornessupérieures, nous présentons deux méthodes alternatives. La première est basée sur la résolution d’unproblème d’allocation (assignment problem) ; deux variantes sont proposées, dont l’une a déjà été uti-lisée par Slotnick et al. [4]. La seconde approche est basée sur la résolution d’un problème de sélectionet d’ordonnancement de tâches sur une machine avec pénalité pondérée du retard algébrique (totalweighted lateness).
4 Expériences
Lors de la présentation, nous proposerons des tableaux récapitulatifs des résultats de l’algorithmebranch-and-bound ainsi que des tableaux récapitulatifs des comparaisons de ces résultats avec ceuxpar la résolution du modèle linéaire avec CPLEX.
Références
1. Chen, Z-H. and Li, C-L. : Scheduling with subcontracting options. IIE Transactions, 40 : 1171–1184, (2008).
2. Potts, C.N. and Van Wassenhove, L.N. : A branch and bound algorithm for the total weightedtardiness problem. Operations research, 33 : 363–377, (1985).
3. Rom, W.O. and Slotnick, S.A. : Order acceptance using genetic algorithms. Computers & Opera-tions Research, (2008). To appear.
4. Slotnick, S.A. and Morton, T.E. : Order acceptance with weighted tardiness. Computers & Ope-rations Research, 34 : 3029–3042, (2007).

Lotissement et séquencement sur une machineimparfaite avec temps de changement de série
A. Dolgui1, M.Y. Kovalyov1,2 and K. Shchamialiova1
1 Centre Génie Industriel et Informatique, Ecole des Mines de Saint-Etienne,158 cours Fauriel, 42023 Saint-Etienne Cedex 2, France
[email protected], [email protected] Faculty of Economics, Belarusian State University,
and United Institute of Informatics Problems, National Academy of Sciences of Belarus,Nezavisimosti 4, 220030 Minsk, Belarus
1 Introduction
Nous étudions le problème de lotissement et séquencement pour une seule machine. Il y a N typesde lots di#érents à traiter. Chaque lot est composé d’un ensemble de produits du même type. Il y aun temps de changement de série avant le traitement de chaque lot. La machine est imparfaite :– les pièces peuvent être rebutés à cause d’une mauvaise qualité. Le nombre de rebuts est une valeur
aléatoire.– la machine peut tomber en panne. Dans ce cas elle a besoin d’un temps aléatoire pour la réparation,
pendant lequel elle est inutilisable.Aucun composant et aucun changement de série ne peuvent être réalisés pendant le temps de ré-paration. Pour l’horizon de planification nous connaissons les demandes et le temps de traitementunitaire pour chaque type de produit. On ne peut pas traiter plus d’une pièce en même temps.Le problème d’optimisation consiste à déterminer la taille de chaque lot et leur séquence minimi-sant le coût total de retard sous condition que nous avons une borne supérieure de temps de séjourpour le dernier produit. Ce problème se trouve à l’intersection des deux domaines de recherche :l’ordonnancement [2] et le lotissement des systèmes de production sous aléas [3]. La majorité des pu-blications dans le premier domaine concerne les modéles déterministes et discrets, et dans le deuxièmetraite des modéles principalement stochastiques et continus. Dans notre cas nous avons un problèmestochastique et discret.
2 Modèle mathématique
Nous avons les paramètres suivants pour chaque produit i, i = 1, . . . , n :– di - demande(nombre de produits de bonne qualité), di > 0 ;– ti - temps de traitement pour chaque produit, ti > 0 ;– ci - le coût unitaire de retard, ci > 0 ;– si,j (sj,i) - le temps de changement de série entre le lot de produit i (j) et le lot de produit j (i),si,j ) 0, sj,i ) 0 ;
– s0,i - le temps de changement de série nécessaire pour commencer le traitement du premier lot,s0,i ) 0.

Le problème de lotissement et séquencement sur une seule machine 353
Nous supposons que le temps de changement de série satisfait la règle de triangularité tel que :si,j + sj,k ) si,k pour i = 0, 1, . . . , n, j = 1, . . . , n, k = 1, . . . , n. Aucun produit ne peut être fabriquépendant le temps de changement de série.Nous remplaçons les valeurs aléatoires de la manière suivante :– fi(x) - fonction entière croissante représentant le nombre de rebuts, si le nombre total de produitsi lancés est égal à x, fi(0) = 0, et fi(x) # x pour x = 1, 2, . . . ;
– T (x1, . . . , xn) - temps total de réparation. T est une fonction réelle croissante, où xi est le nombretotal de produits de type i, lancés en fabrication i = 1 . . . , n.
Les fonctions fi(x), i = 1 . . . , n, et T (x1, . . . , xn) peuvent être obtenues par une analyse statistiquedes données historiques. Dans ce travail nous supposons que les fonctions fi(x) et T (x1, . . . , xn) sontdonnées.Les variables de décision sont x := (x1, x2, ..., xn), où xi - la taille de lot i, et " := (i1, i2, ..., in) - laséquence des lots.Le problème que nous étudions est le suivant :
Minimiser D(x) :=n%
i=1
cimax{0, di % (xi % fi(xi))}, (1)
sous contraintes :n%
i=1
tixi +n%
i=1
sij"1,ij + T (x) # T0, xi ! Z+, i = 1, . . . , n, (2)
où T0 - une borne supérieure de temps de séjour.En général le problème (1),(2) est NP-di%cile [1] si les fonctions fi(x) et T (x1, . . . , xn) sont des boitesnoires. Nous avons prouvé que (1),(2) est NP-di%cile même si n = 1.Nous avons montré que les décisions de lotissement et de séquencement peuvent être prises séparé-ment. Le problème qui consiste à trouver la séquence de lots optimale a été montré équivalent auproblème du Voyageur de Commerce. Nous avons également proposé un ('+1) - approché algorithme(FPTAS) pour le cas où le pourcentage des produits defectueux est connu pour chaque lot.
Références
1. Cheng T.C.E., Kovalyov M.Y. : An unconstrained optimisation problem is NP-hard given anoracle representation of its objective function : a technical note. Computers & Operations Re-search 29 (2002) 2087-2091.
2. Potts C.N., Van Wassenhove L.N. : Integrating scheduling with batching and lot-sizing : A reviewof algorithms and complexity. Journal of the Operational Research Society 43 (1992) 395-406.
3. Groenevelt H., Pintelon L., Seidmann A. : Production lot sizing with machine breakdowns.Management Science 38 (1992) 104-102.

On maximizing the profit of a satellite launcher :selecting and scheduling tasks with
time windows and setups
P. Baptiste1, P. Chrétienne2, J. Meng-Gérard3 and F. Sourd4
1 Ecole Polytechnique, CNRS LIX, France, [email protected] Université Paris 6, CNRS LIP6, France, [email protected]
3 Université Paris 6, CNRS LIP6, France, [email protected] SNCF, Innovation & Recherche, France, [email protected]
1 Problem description
The problem studied in this paper originates in planning the launches of a satellite launcher companyin order to maximize its profit. More precisely, the company has a timeline divided into successivetime-slots [t % 1, t], t ! {1, . . . , T}, and a set of customer satellites J1, . . . , Jn, each of which has aweight wi and a launching time window [ri, di] . [0, T ]. For each satellite, the launcher companymust decide whether it will be launched or not and, in the positive case, in which time-slot of itslaunching time window this will be done. A positive gain gi results from launching satellite Ji and apositive setup cost Kt is due if at least one satellite is launched in time-slot [t % 1, t] (also denotedby t). Finally, the sum of the weights of the satellites launched in any time-slot must not exceed agiven capacity C corresponding to the limit weight that the satellite launcher can support.In a more formal description, the satellites are just unit-length jobs Ji with release dates plus deadlinesand the launcher problem comes to a scheduling problem whose solution is a pair (E, s) where :• E . {J1, . . . , Jn} is the subset of the selected jobs,• s : E ( {1, . . . , T} indicates the time-slots assigned to the jobs of E
(abusing notation we shall write s(i) for s(Ji)),• for any Ji ! E, the time-slot s(i) must be in {ri + 1, ri + 2, . . . , di},• for any time-slot t ! s(E), the sum
&{j|s(j)=t} wj must be less than C.
The value of a solution (E, s) is&Ji#Egi %&t#s(E)Kt and the problem consists of finding a
maximum-value solution.
2 Our work
We prove that while this problem is strongly NP-Complete in the general case, it turns polynomialas soon as the satellites have a constant weight. We provide a dynamic programming algorithm tosolve this case and we show that for some configurations of time windows, the subproblem can besolved even more e%ciently. Those results will be available in [1].
3 An example
The following figure models a simple instance of the problem with 9 satellites J1, . . . , J9 and 15launching time-slots. Every satellite Ji has a unit-weight wi = 1, a gain gi and a launching time

Title Suppressed Due to Excessive Length 355
window represented by a horizontal grey segment. The timeline is represented by the array of cellsbelow the 9 window segments, each cell representing a time-slot [t%1, t] and containing its setup costKt. The launcher has a capacity C = 3 which means that only 3 satellites at most can be launchedin a single time-slot (since wi = 1).
Kt 80 80 80 20 80 80 80 80 8020 20 80 80 80 80
g2 = 50
g3 = 50
g4 = 30
g5 = 50
g6 = 50
g7 = 50
g8 = 30
g9 = 50
5 10 15 tr5 d5
J1
J2
J3
J4
J5
J6
J7
J8
J9
wi = 1 and C = 3
g1 = 30 s(3) = s(7) = s(9) = 11
0
The satellite launcher company maximizes its profit by launching the subset of satellites E ={J1, J2, J5, J6, J3, J7, J9} in the time-slots s(E) = {1, 5, 11} as stressed in black in the figure above(for instance, J3 is launched in slot s(3) = 11) and the profit generated by this solution is
&Ji#Egi%&
t#s(E)Kt = (g1 + g2 + g5 + g6 + g3 + g7 + g9)% (K1 +K5 +K11) = 270.
Références
1. P. Baptiste, P. Chrétienne, J. Meng-Gérard and F. Sourd. On maximizing the profit of a satel-lite launcher : selecting and scheduling tasks with time windows and setups. Discrete AppliedMathematics. (to appear)

Minimisation du retard des mesures dans la fabricationdes semi-conducteurs
B. Detienne, C. Yugma, and S. Dauzère-Pérès
École Nationale Supérieure des Mines de Saint-Étienne,Centre de Microélectronique de Provence Site Georges Charpak,
880 route de Mimet, 13541 Gardanne, [email protected], [email protected], [email protected]
1 Introduction
Nous nous intéressons à un problème d’ordonnancement survenant dans un contexte de productionindustrielle ayant recours à des procédés de fabrication très complexes et sensibles. De nombreusesétapes de production y font appel à un contrôle intensif des caractéristiques des produits semi-finis,afin de détecter d’éventuels défauts et de sorte à maintenir les produits en sortie dans les spécificationsfixées à l’avance.Les ressources nécessaires aux contrôles sont souvent très onéreuses et donc en nombre limité, ce quipousse à développer des stratégies d’échantillonnage : un scénario typique consiste à envoyer, pourchaque famille d’articles, un produit intermédiaire sur quatre réalisés sur une machine de productiondonnée vers un équipement de mesure. En attendant le résultat de la mesure ainsi que son traitement,le décideur est la plupart du temps amené à réaliser d’autres tâches de production du même type surla machine, avant que ses réglages aient pu être ajustés. Chacune de ces opérations encourt alors unrisque accru d’échec de fabrication.Le délai excessif conduisant à prendre un tel risque est connu sous le nom de retard de métrologie. Afinde minimiser les échecs de fabrication, nous nous intéressons à une approche consistant à considérerl’ordonnancement des opérations de production fixé, et à ordonnancer les opérations de mesure demanière à minimiser les retards de métrologie.Plus précisément, on considère un ensemble de tâches de mesure à e#ectuer à l’aide d’une ou plusieursmachines de mesure, sans contrainte de disponibilité (on suppose en e#et l’ensemble des produits àtraiter déjà placés dans une zone d’attente). Pour chacune des tâches, on connaît les dates auxquellesdes opérations d’un procédé identique vont démarrer, ainsi qu’une quantification du risque encourudans le cas où l’opération de production s’e#ectue avant la fin de la mesure. Le but du problèmeest alors d’ordonnancer l’ensemble des tâches de mesure de manière à minimiser le risque cumuléencouru.
2 Modélisation
Afin de simplifier l’exposé, nous supposerons ici que les équipements de mesure se réduisent à uneunique machine pouvant réaliser une seule opération à la fois. Notez cependant que le modèle proposéest valide dans le cas avec machines parallèles identiques ou non. Comme l’illustre la Figure 1, leproblème peut être vu comme un problème de minimisation du coût total d’un ordonnancement.Dans le cas présenté, le produit correspondant à la tâche de production 2a est envoyé sur la machinede mesure dans l’optique d’ajuster les paramètres de l’équipement de production, pour réaliser lestâches 2b, 2c et 2d dans des conditions favorables. La tâche de mesure correspondante, 2-, est achevée

Minimisation du retard des mesures dans la fabrication des semi-conducteurs 357
Opération avant mesure- pénalité de .2b
1b2b1a 2a 3a 2c 2d Machine deproduction
Machine demesure
Pas de pénalité
.2b + .2c.2b + .2c + .2d
Cout de 2$0.2b
2$1$0%
Pénalité de .2c
Fig. 1. Illustration du coût d’une opération de mesure selon sa date de fin d’exécution
après le début de 2b et 2c. Ces deux opérations encourent donc un risque dont le coût est imputé à2-.A chaque tâche de mesure est ainsi associée une fonction de coût croissante en escalier (la fonctionprend k valeurs di#érentes pour un taux d’échantillonnage de 1
k ) et, donc, potentiellement n’importequelle fonction de coût régulière (voir [1] ou [2] pour des méthodes s’appliquant à ces problèmes).Notre étude se focalise sur les cas où la fonction de coût prend un nombre relativement faible de valeursdi#érentes, correspondant à des taux d’échantillonnage que nous avons rencontrés en pratique, del’ordre de 1
4 .Nous développons un modèle compact sous forme de Sac-à-dos Multidimensionnel Multi-Choix (MMKP)particulièrement adapté à ces cas, dans lequel chaque tâche est modélisée par un groupe d’objets,chaque objet étant associé à une occurrence d’une tâche s’achevant avant un point caractéristique desa fonction de coût, et chaque ressource représentant la capacité cumulée de la machine jusqu’à unpoint caractéristique d’une des fonctions de coût.
3 Expérimentations et Perspectives
Des expérimentations numériques préliminaires montrent que cette formalisation permet la résolutionexacte, via le solveur de PLNE XPRESS-MP 2007, d’instances à une machine comportant jusqu’à 200tâches pour un taux d’échantillonnage de 1
3 ou 14 et jusqu’à 50 tâches pour un taux de 1
10 , sous unelimite de temps de 1 minute, tandis que la formalisation indexée sur le temps classique ne permet derésoudre que peu d’instances à 20 tâches selon le même mode opératoire. Ces résultats encourageantsappellent à développer une méthode de résolution dédiée basée sur le modèle MMKP.
Références
1. S. Tanaka, S. Fujikuma et M. Araki. An exact algorithm for single-machine scheduling withoutmachine idle time. Journal of Scheduling, A paraître.
2. A. Jouglet, D. Savourey, J. Carlier et P. Baptiste Dominance-based heuristics for one-machinetotal cost scheduling problems. European Journal of Operational Research, 184(3) :879–899, 2008.

Le probléme de tournées de véhicules m-péripatétiques
Sandra U. NGUEVEU1, Christian PRINS1, and Roberto WOLFLER-CALVO2
1 LOSI-UTT, 12, rue Marie-Curie, 10000 Troyes, [email protected], [email protected]
2 LIPN-OCAD, Université Paris-Nord, 93430 Villetaneuse, [email protected]
1 Introduction
Introduit dans [5] le probléme de tournées de véhicules m-péripatétiques modélise les tournées degardiennage ou transport de fonds oô l’objectif est de déterminer les tournées de véhicules disjointes àcoût total minimal surm périodes telles que chaque client soit visité exactement une fois par période,car par sécurité aucun chemin ne doit être utilisé plus d’une fois au cours dem périodes. Le m-PTVPpeut être considéré comme une généralisation du VRP et du probléme du vendeur m-péripatétique(m-PVP). Nous présentons ici un résumé de nos travaux sur le sujet, comprenant 3 bornes inférieuressimples, un algorithme de recherche taboue hybride, et de nouvelles bornes inférieures, plus élaborées,qui sont publiées ici pour la premiére fois.
2 Bornes inférieures simples
Le m-PTVP est défini sur un graphe non orienté complet et le modéle mathématique basé sur lesarêtes de [5] a permis de déduire trois bornes inférieures simples. La 1ére est obtenue en multipliantsimplement par m le coût de la solution optimale du VRP. La 2éme est fournie le coût des m 1-arbres recouvrants sans arêtes communes et de coût total minimal, et ce à l’aide de l’algorithmede [6] combiné avec une relaxation lagrangienne pour le degré du dépôt. La 3éme borne simple estobtenue en résolvant b-couplage parfait, probléme polynomial [2] obtenu en relaxant notre problémeet solvable à l’aide d’un solveur opensource ou commercial.
3 Algorithme de recherche taboue hybride
Notre algorithme de recherche taboue hybride (RTH) est la métaheuristique la plus e%cace sur lem-PTVP. Une description plus détaillée de cet algorithme est disponible dans [4]. Entre-autre, le RTHutilise un "tabou partiel" : à chaque itération le 1er arc à insérer ne doit pas être tabou, mais le 2émearc entrant est libre (tabou ou pas). D’autres composants tels que la diversification et l’hybridationavec le b-couplage parfait contribuent à l’e%cacité de cette métaheuristique.
4 Bornes inférieures élaborées
4.1 Méthodes de coupes

Point sur le m-TVP 359
Nous avons appliqué deux types approches. La 1ére approche consiste à identifier et appliquer descontraintes de capacité, de peigne et multistars du VRP au cours de chacune des m périodes dum-PTVP. La 2éme approche, qui permet de réduire considérablement les temps de calculs, consisteà généraliser les contraintes ci-dessus et générer ainsi de nouvelles contraintes valides applicablessur un modéle aggrégé du m-PTVP. Chacune des approches nous a amené à modifier profondémentla bibliothéque de fonctions de détection de coupes CVRPSEP de Lysgaard [3], pour obtenir unenouvelle bibliothéque pour le m-PTVP.
4.2 Problème de partitionnement et q-routesL’adaptation de [1] sur le m-PTVP est loin d’être évidente, mais elle se base sur 3 idées-clés : ladualité, l’approximation des routes par des q-routes et la relaxation lagrangienne. L’objectif est derésoudre le dual de la formulation de partitionnement du probléme, en estimant au mieux les variablesduales. Dans cette formulation, une route normale de demande totale q n’autorise pas de "boucles",alors que dans une q-route cette contrainte est relaxée. Si la présence des boucles est autorisée, elleest cependant pénalisée par relaxation lagrangienne, et comme les q-routes peuvent être généréesassez rapidement par programmation dynamique, alors au final, on obtient un algorithme rapide ete%cace. La méthode des q-routes n’a pas besoin de faire appel à Cplex ou tout autre solveur. En fait lesous-probléme obtenu aprés la génération des q-routes à coût réduit négatif est résolu en estimant lesmeilleures valeurs des variables duales. Puis, les violations des contraintes de degré sont quantifiéeset utilisées pour corriger (par relaxation lagrangienne) les valeurs attribuées aux variables duales,jusqu’à ce que les améliorations deviennent négligeables. A ce moment-là on revient au problémeprincipal et on essaie de générer de nouvelles q-routes à coût réduit négatif pour les insérer dansle probléme et recommencer la résolution. L’algorithme s’arrête lorsque plus aucune q-route n’estgénérée.
5 Résultats obtenusLes bornes supérieures sont obtenues par le RTS. Les bornes inférieures simples ont permis d’at-teindre en moyenne 92% - 94% des meilleures bornes supérieures. Les nouvelles bornes inférieuresplus élaborées ont permis d’atteindre 97.5% - 99%, préparant ainsi le terrain pour l’application deméthodes exactes.
Références1. Roberto Baldacci, Nicos Christofides, and Aristide Mingozzi. An exact algorithm for the vehicle
routing problem based on the set partitioning formulation with additional cuts. MathematicalProgramming, 115(2) :351–385, 2008.
2. J. Edmonds. Paths, trees, and flowers. Canadian Journal of Mathematics, 17 :449–467, 1965.3. J. Lysgaard. http ://www.hha.dk/ lys/, 2003.4. S.U. Ngueveu, C. Prins, and R. Wolfler Calvo. A hybrid tabu search for the m-peripatetic ve-
hicle routing problem. In P. Hansen et al., editors, Proceedings of Matheuristics 2008 : SecondInternational Workshop on Model Based Metaheuristics, Bertinoro, Italy, 2008.
5. S.U. Ngueveu, C. Prins, and R. Wolfler Calvo. Bornes supérieures et inférieures pour le problémede tournées de véhicules m-péripatétiques. Proceedings MOSIM’08 : 7éme conférence francophonede modélisation et simulation (MOSIM’08),Paris France, 3 :1617–1625, 2008.
6. J. Roskind and R. E. Tarjan. A note on finding minimum-cost edge disjoint spanning trees.Mathematics of Operations Research, 10 :701–708, 1985.

Modèle de simulation pour l’évaluation des performancesde tournées de véhicules en conditions réelles de trafic
M. Chabrol, M. Gourgand and P. Leclaire
LIMOS, UMR 6158 CNRS, Complexe Scientifique des Cézeaux, 63173 Aubière Cedex France.{chabrol,gourgand,leclaire}@isima.fr
1 Introduction
Les problèmes de tournées de véhicules sont parmi les problèmes de recherche opérationnelle les plusétudiés. Ces problèmes consistent à visiter, dans un certain ordre, un ensemble de points auxquelsest associé un service de collecte ou de livraison. Les entités transportées peuvent être des biens oudes personnes. Le parcours établi tente de minimiser une fonction objectif dépendant du temps deparcours, des coûts de parcours et/ou de la satisfaction du client.Ces problèmes sont le plus souvent étudiés sous l’hypothèse de temps de parcours déterministes.Certains auteurs considèrent ce problème en intégrant des temps de trajet stochastiques ou basés surdes historiques de données. Dans la plupart des cas, les approches de résolutions proposées utilisentdes hypothèses simplificatrices sur les temps de trajet.Nous proposons dans ce résumé d’étudier les performances d’une tournée de véhicules obtenue par uneméthode exacte ou approchée, dans des conditions réelles de trafic, grâce à un modèle de simulationde granularité fine permettant de rendre compte des réalités physiques du trafic : interactions entreles véhicules, durée des feux, temps d’attente aux intersections.
2 Prise en compte des coûts de parcours dépendant du temps
Soit G = (X,U) un graphe orienté représentant un réseau routier, où X est l’ensemble des inter-sections, des dépôts et des points de services, et U l’ensemble des voies reliant ces intersections. Lavaluation c(u) d’un arc u = (i, j) ! U correspond à la mesure du temps de parcours entre les points iet j. Les durées de parcours des arcs peuvent fluctuer au cours de la période étudiée. Cette fluctuationest prise en compte de plusieurs façons dans la littérature.Certains auteurs associent à chaque arc une valuation dépendant du temps sous forme d’un vecteur.[2] utilisent un vecteur cu à p composantes telles cu[Tk], k = 1..p, contient la durée de trajet entreles points i et j pour un véhicule dont la date t de départ du point i appartient à l’intervalle Tk.Des variables aléatoires peuvent également être utilisées pour modéliser la durée de parcours d’un arc.[1] propose un modèle de simulation pour l’évaluation des tournées de véhicules pour le Dial-A-RideProblem, sur un service de transport de personnes à la demande. Ce modèle utilise une représentationdu réseau par intersections et arcs. Chaque arc est associé à un vecteur de temps de parcours, qui,pour chaque période de la journée, contient les moyenne et écart-type du temps de parcours del’arc. Un véhicule qui entre sur un arc à l’instant t se voit attribuer un temps de parcours choisialéatoirement selon une loi log-normale de moyenne et écart-type associés à l’instant t. Cependant,ce modèle ne tient pas compte explicitement des conditions de trafic et des délais aux intersections,qui sont modélisés au niveau du temps de parcours.

Modèle de simulation pour l’évaluation des performances de tournées de véhicules 361
3 Modèle de simulation proposé
Pour modéliser un problème de tournées de véhicules en conditions réelles de trafic, nous proposonsde faire évoluer les véhicules de la flotte du problème sur des voies utilisées par d’autres véhicules.Le modèle de simulation, de niveau d’abstraction microscopique, prend en compte les interactionsentre les véhicules, la gestion des priorités, les délais d’attente aux feux et intersections, et permetd’obtenir des informations relatives à chaque véhicule. En particulier, il est possible de connaître lestemps de parcours des véhicules de la flotte. Le modèle de simulation de [3] est enrichi pour prendreen compte les particularités des problèmes de tournées de véhicules telles que le comportement desvéhicules de la flotte, les clients, ainsi que les points de service et dépôts.L’étude d’une tournée de véhicules en conditions réelles de trafic permet d’évaluer les performancesd’un tel système face à plusieurs scenarii types et d’apporter des éléments statistiques sur la viabilitéd’une tournée.Pour la modélisation du trafic, les données en entrée sont constituées d’informations de comptage(pour la génération des véhicules hors flotte) et des plans de feux. La solution au problème detournées de véhicules est constituée de l’ordre des points à servir. La modélisation du système réelen un problème de Recherche Opérationnelle engendre des pertes d’informations. Les détails du pluscourt chemin emprunté pour aller d’un point de service à un autre se réduisent à sa longueur. Pourreconstruire l’itinéraire entre deux points de service consécutifs, un algorithme de plus court cheminsur un graphe valué par des durées de parcours dépendant du temps est nécessaire. L’évaluationmoyenne des durées de parcours de chaque arc en fonction du temps est établie au travers de plusieursréplications du réseau à vide (c’est-à-dire sans les véhicules de la flotte), en supposant que l’impactd’une flotte de véhicules sur le reste du trafic est négligeable.
Références
1. L. Fu (2002) : A simulation model for evaluating advanced dial-a-ride paratransit systems. Trans-portation Research Part A, 36, 167–188.
2. S. Ichoua, M. Gendreau and J.Y. Potvin (2003) : Vehicle dispatching with time-dependent traveltimes European Journal of Operational Research, 144, 379-396.
3. D. Sarramia (2002) : ASCI-mi : une méthodologie de modélisation multiple et incrémentielle –Application aux systèmes de trafic urbain. Thèse.

Méthode de Branch & Price heuristique appliquée auproblème de Tournées de Véhicules avec Contraintes de
Chargement
Boris BONTOUX,1, Christian ARTIGUES2, and Dominique FEILLET3
1 LIA, 339, chemin des Meinajaries, BP 1228, 84911 Avignon, [email protected]
2 LAAS - CNRS, Université de Toulouse, 7 av du Colonel Roche, 31077 Toulouse, [email protected]
3 Ecole Mines Saint-Etienne, CMP Georges Charpak, 880 av de Minet, F-13541 Gardanne, [email protected]
1 Problème étudié
Le problème de Tournées de Véhicules avec Contraintes de Chargement à Deux Dimensions ou Ve-hicle Routing Problem with Two-Dimensional Loading Constraints (2L-VRP) est une extension duclassique Capacited Vehicle Routing Problem auquel ont été ajoutées des contraintes de chargement.L’objectif est de minimiser la distance totale parcourue par une flotte de véhicules d’une capacitélimitée, sous la contrainte de satisfaire l’ensemble des demandes de livraisons des clients. La demanded’un client consiste en un ensemble d’objets à charger, chaque objet étant caractérisé par une lon-gueur et une largeur. La somme des poids associés à chaque client servi ne peut dépasser la capacitémaximale en poids des véhicules. Nous nous sommes intéressés au cas 2|RO|L pour lequel le charge-ment des objets se fait par l’arrière de la surface de chargement et où les objets ont une orientationfixe (two-dimensional rear oriented loading) [1].
2 Méthode de résolution
Nous proposons de résoudre ce problème à l’aide d’une procédure de type Branch & Price, c’est-à-dire une procédure de résolution de type Branch & Bound utilisant une méthode de génération decolonnes pour le calcul de bornes. La résolution du problème esclave revient pour ce problème à unProblème de Plus Court Chemin Élementaire avec Contraintes Additionnelles, que nous résolvons parun algorithme de programmation dynamique, basé sur l’algorithme de Bellman. De par la complexitédes contraintes de chargement, le problème esclave de la génération de colonnes n’est pas résolu demanière exacte. Notre travail s’est donc porté sur les moyens dont nous disposions afin d’accélérer larésolution. Nous explorons ainsi une partie des possibilités qu’il existe pour tronquer une méthode apriori exacte afin de la rendre heuristique.Nous avons développé deux approches résolument di#érentes : dans la première, le problème esclavede recherche de plus court chemin renvoie des routes réalisables du point de vue de la contrainte decapacité, mais, dont la réalisabilité en ce qui concerne le chargement à deux dimensions n’est pasassurée. Cette réalisabilité est vérifiée a posteriori. La seconde approche, quant à elle, construit desroutes entièrement réalisables (capacité et chargement séquentiel en deux dimensions) pendant larésolution du sous-problème.Dans la première approche, lorsque le problème trouve une route, nous en vérifions la réalisabilité parrapport aux contraintes de chargement. Pour cela, nous appliquons des calculs de bornes inférieures

Branch & Price appliqué au 2L-VRP 363
sur la surface minimale nécessaire pour le chargement des objets des clients servis par la route. Sile calcul des bornes inférieures montre que le chargement n’est pas irréalisable, nous utilisons desheuristiques de chargement : Bottom-Left [4], Improved Bottom-Left [6], Max Touching Perimeter [5].Ces heuristiques de chargement sont appelées, avec des listes d’objets triées selon des ordres di#érents(ordre décroissant sur la largeur, ordre décroissant sur la longueur, ordre croissant sur la largeur etordre croissant sur la longueur). Dès qu’un algorithme indique que le chargement est réalisable, laroute est ajoutée pour la résolution du problème maître. Le calcul de réalisabilité d’une route est uncalcul complexe, nécessitant d’être appelé un nombre important de fois. Ainsi, dès qu’une route estdésignée comme non-réalisable, cette route est stockée dans un annuaire de routes non réalisables.Cet annuaire a une structure d’arbre n-aire classé, pour lequel l’insertion d’une route et la vérificationde la présence d’une route sont des méthodes rapides et peu complexes.Dans la deuxième approche, nous proposons de construire dans le problème esclave des routes réa-lisables, respectant donc les contraintes de chargement séquentiel. Chaque fois qu’un chemin partielest étendu vers un sommet, on ajoute les objets proposés par ce sommet dans le chargement existant.Pour cela, nous faisons appel aux algorithmes heuristiques présentés précédemment. Ainsi, les routesrenvoyées par le problème esclave sont nécessairement des routes réalisables. Cependant, dans le casoù l’heuristique utilisée ne trouve pas de chargement réalisable, la route est éliminée, bien qu’unchargement réalisable puisse exister pour cette route. La méthode proposée est donc une méthodeheuristique.Pour les deux approches, nous avons cherché à accélere la résolution du problème. Pour cela, nousavons cherché à rendre heuristique le problème esclave de plusieurs manières di#érentes. La premièretechnique est de limiter le nombre de chemins partiels mémorisés pour chaque sommet. Nous avonsproposé de renforcer les règles de dominances entre deux chemins partiels en créant des règles dedominances « trop fortes ». Ces règles risquent ainsi de supprimer des chemins partiels non dominés,mais permettent d’accélerer la résolution du sous-problème. Nous avons aussi limité le nombre desommets vers lesquels un chemin partiel est étendu. Lors de la résolution de la relaxation linéaire duproblème maître restreint par un solveur, celui-ci fixe au bout d’un certain nombre d’itérations descolonnes. Les variables associées à ces colonnes sont alors égales à 1. Afin d’accélérer la résolution,il peut être intéressant de fixer de telles variables pour toute la suite de la résolution. Enfin, un desmoyens de rendre un Branch & Price heuristique est de supprimer l’aspect « Pricing ». Pour cela,il su%t de ne pas générer de nouvelles colonnes une fois qu’un nouveau nœud est créé, en dehorsdu nœud racine. On se retrouve donc dans la configuration d’un Branch & Bound classique pourlequel la borne inférieure est calculée par la relaxation linéaire du problème maître restreint, la bornesupérieure étant la meilleure solution entière connue.
3 Évaluation et observation des résultats
Afin de tester les performances de notre algorithme, nous avons utilisé un ensemble de 180 instancesdu problème 2|RO|L-VRP, introduites par [1] et [2]. Les 17 premières séries d’instances contiennentjusqu’à 40 clients et 127 objets. Chaque série contient 5 instances. Nos résultats sont comparés avecla méthode Branch & Cut proposée par [1], la recherche Tabou proposée par [2] et l’algorithmed’optimisation par Colonie de Fourmis de [3].Les approches heuristiques que nous proposons permettent d’accélérer la résolution du problème. Ilest cependant clair que la qualité des heuristiques de chargement est déterminante dans la qualité dessolutions. Malgré une utilisation de plusieurs heuristiques de chargement, les résultats que nous pro-posons ne permettent pas de dépasser les meilleurs résultats connus. Cependant, que ce soit en termede qualité de solution ou en temps d’éxécution, nos résultats restent dans une moyenne des méthodespubliées à ce jour. Néanmoins, nos résultats pourraient être améliorés par l’utilisation d’heuristiquesde chargement plus e%caces. Enfin, la méthode de génération de routes réalisables est clairement

364 Bontoux, Artigues, Feillet
moins e%cace que l’approche d’une vérification « a posteriori »de la réalisabilité. Cependant, on peutnoter que cette méthode peut être une base de futurs travaux de recherche, dans le but de proposerune résolution exacte du problème de Tournées de Véhicules avec Contraintes de Chargement.
Références
1. Iori, M. and Salazar Gonzàlez, J. J. and Vigo, D. : An exact approach for the vehicle routingproblem with two-dimensional loading constraints. Transportation Science, vol. 41(2), p. 253-264(2007)
2. Gendreau, M. and Iori, M. and Laporte, G. and Martello, S. : A Tabu search heuristic for thevehicle routing problem with two-dimensional loading constraints. Networks, vol. 51(1), p. 4-18(2008)
3. Fuellerer, G. and Doerner, K. F. and Hartl, R. F. and Iori, M. : Ant colony optimization for thetwo-dimensional loading vehicle routing problem. Computers & Operations Research, à paraître(2008)
4. Chazelle, B. : The Bottom-Left Bin-Packing Heuristic : An E%cient Implementation. IEEE Trans.Computers, vol. 32(8), p. 697-707 (1983)
5. Lodi, A. and Martello, S. and Vigo, D. : Heuristic and Metaheuristic Approaches for a Classof Two-Dimensional Bin Packing Problems. INFORMS J. on Computing, vol. 11(4), p. 345-357(1999)
6. Liu, D. and Teng, H. : An improved BL-algorithm for genetic algorithm of the orthogonal packingof rectangles. European Journal of Operational Research, vol. 112(2), p. 413-420 (1999)

Une méthode pour l’analyse de sensibilité à l’aide desréseaux de Petri stochastiques
S. SAGGADI1, K. LABADI2, and L. AMODEO3
1 INSA de Rouen, LMR, Avenue de l’Université, BP 08, 76801 Saint-Etienne du Rouvray France.2 EPMI-ECS, Ecole Supérieure d’Ingénieurs, 13 Boulevard de l’Hautil, 95092 Cergy France.
3 ICD-UTT, Université de Technologie de Troyes, 12 rue Marie Curie, BP2060, 1010 Troyes [email protected] ; [email protected] ; [email protected]
1 IntroductionL’étude d’un système quelconque passe nécessairement par plusieurs phases notamment la modélisa-tion ; l’évaluation et l’optimisation de performances. L’analyse de sensibilité ou l’analyse de pertur-bation est une technique d’analyse très intéressante qui peut être une phase intermédiaire entre laphase d’analyse de performances et la phase d’optimisation. En e#et, l’analyse de sensibilité permetd’évaluer l’impact de la variation des paramètres de décision d’un système sur son fonctionnementet ainsi sur sa performance par le calcul ou l’estimation du gradient. En termes de l’optimisation, cegradient peut être utilisé pour diriger un algorithme de recherche d’un optimum ou d’une solution ap-prochée. A l’origine, l’analyse de perturbation est une technique basée sur des modèles de simulation[2]. Au cours de ces dernières années, on voit apparaître dans la littérature de nouvelles approchesplus formelles qui ne reposent sur aucune simulation. Il s’agit en particulier, d’approches dédiéespour l’analyse de sensibilité des processus stochastiques caractérisant la dynamique des systèmes àévénements discrets [1]. En se basant sur ce type d’approche, nous nous sommes intéressés à l’ana-lyse de sensibilité des systèmes en utilisant les réseaux de Petri stochastiques. Dans le cadre de cettecommunication, on se contentera de présenter le principe de la technique et son application dans lecas d’une modélisation par un réseau de Petri dont le processus stochastique associé est Markovien.Pour plus de détails sur ce travail, nous orientons les lecteurs à consulter l’article [3].
2 Technique pour un RdP stochastique (SPN et GSPN)Etape 1. A partir du modèle RdP stochastique du système considéré, générer son graphe des mar-quages et établir la chaîne de Markov qui lui est associée.Etape 2. Calculer, à partir de la chaîne de Markov associée, la distribution des probabilités des étatsen résolvant le système suivant : 8 ·A = 0 et
&" = 1 où A est le générateur de Markov du processus
stochastique associé.Etape 3. Calculer le vecteur du potentiel de performance g tel que : g = %A. · f où A. = (A +e · ")"1 % e · " est l’inverse généralisé de A, f = (f1, f2, · · · ) est une fonction indice de performanceévaluée dans chaque état du processus et e = (1, 1, · · · )T est un vecteur colonne.Etape 4. Calculer /0
/Q en utilisant l’expression suivante : /0/Q = " · Q · g où 3 est une fonction de
performance et Q est une matrice indiquant la direction de la perturbation.
3 Application à un atelier de productionCette technique a été utilisée pour l’analyse de sensibilité d’un système logistique et d’un système deproduction [3]. Ci-dessous une synthèse d’une application sur un atelier de production (FIG. 1) qui

366 SAGGADI, LABADI, AMODEO
sera présentée au congrès. Le système est modélisé par un RdP stochastique (SPN) et la sensibilitéde sa performance est étudiée par rapport à di#érents paramètres à savoir le taux de réparation etde panne d’une machine composante du système étudié.
! !
! ! !
" # $ % % $ & !
' ( ) ( % ! * !
+ " , - . / $ ! * !
' ( ) ( % ! 0 !
+ " , - . / $ ! 0 !
1 ( / 2 ( 3 $ 4 5 & !
5 ( 6 4 . % ! 7 . / " # !
!
8 . / ! 6 $ !
9 5 ( , $ & & 4 & !
+ 0 !' 0 !' * !
1 ( / 2 ( 3 $ 4 5 & ! 6 . & 9 ( / . ) # $ & !
+ * ! $ / !
5 : 9 " 5 " % . ( / !
' : 9 " 5 " % . ( / !" / / $ !
+ * ! 7 ( / , % . ( / / $ !
+ * ! # . ) 5 $ !
; !
< !
0 !
! % < !
!
% 0 !! % * !
= % ( , > ! !
? !@ !
! * !
! ! % @ !! % ; !
!
! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! A % $ # . $ 5 ! 6 $ ! 9 5 ( 6 4 , % . ( / ! + ( 6 B # $ ! ' 6 ! & % ( , - " & % . C 4 $ !
= $ / & . ) . # . % : ! 6 $ ! # " ! 6 . & 9 ( / . ) . # . % : ! 6 $ ! # " ! + " , - . / $ ! + *
9 " 5 ! 5 " 9 9 ( 5 % ! D ! # " ! 2 " 5 . " % . ( / ! 6 4 ! % " 4 E ! 6 $ ! 9 " / / $
= $ / & . ) . # . % : ! 6 $ ! # " ! 6 . & 9 ( / . ) . # . % : ! 6 $ ! # " ! + " , - . / $ ! + *
9 " 5 ! 5 " 9 9 ( 5 % ! D ! # " ! 2 " 5 . " % . ( / ! 6 4 ! % " 4 E ! 6 $ ! 5 : 9 " 5 " % . ( /
P
PP P
P
P
PP
P
P
Fig. 1. Application à l’analyse de sensibilité d’un atelier de production
4 Conclusion
Les recherches sur l’analyse de sensibilité ou l’analyse de perturbation des systèmes à événementsdiscrets se sont focalisées sur des approches basées sur la simulation qui sont très gourmandes entemps de calcul. Dans ce travail, nous avons proposé une approche basée sur les réseaux de Petristochastiques. Cette méthode repose sur des calculs formels basés sur le processus stochastique associéau graphe des marquages du réseau de Petri modélisant le système à étudier.
Références
1. Cao, X.R. and Wan. Y.W. : Algorithms for sensitivity analysis of Markov systems through po-tentials and perturbation realization. IEEE, Transactions on Control Systems Technology, vol.6,no4, pp. 482-493. (1998)
2. Ho, Y. C and Cao, X.R. : Perturbation Analysis of Discrete event Dynamic Systems. Norwell,MA : Kluwer. (1991)
3. Labadi, K., Saggadi, S., and Amodeo, L. : ’PSA-SPN’- A Parameter Sensitivity Analysis MethodUsing Stochastic Petri Nets : Application to a Production Line System. To appear in CISA’09,2nd Mediterranean Conference on Intelligent Systems and Automation (2009)

Multiparametric programming to assess the completiontime sensitivity of multipurpose parallel machines
Minh Hoang LE1, Alexis AUBRY2, and Mireille JACOMINO1
1 Grenoble INP, G-SCOP f-3028, 46 avenue FÈlix Viallet, F-38031, Grenoble CEDEX 1 [email protected], [email protected]
2 CRAN, Nancy-UniversitÈ, CNRS, Boulevard des Aiguillettes F-54506 Vandœuvre lËs [email protected]
1 Introduction
This paper addresses multiparametric linear programming [1],[2] as an e%cient tool to assess thecompletion time sensitivity of the workshop of multipurpose machines [3]. Multipurpose machines areused to model parallel machines with some technological or economical constraints that prevent somemachines to process some products. These constraints may be strictly structural inability or resultingfrom strategic choice. A given multipurpose machines workshop is available to face a given globalamount of products. In this paper disturbances are taken into account through the amount of productsthe workshop has to process. The amount of products is referred as the demand. The addressedproblem is to parameterize the completion time of a given workshop related to the disturbancedemand to process. Multiparametric linear programming model is used to deal with this problem[1],[2].Let us denote m the number of machines and n the number of product types. J = {1, m} is the set ofmachines and I = {1, n} is the set of product types. The vector N models the demand, Ni being thequantity of products of type i to be processed. The configuration of the workshop is a binary n+mmatrix S such that Si,j = 1 if and only if the machine j is able to process the product type i. Let usdenote V the speed matrix that is an n+m matrix such that Vi,j is the number of products of typei that machine j can process per time unit if possible. The uncertainty on the demand is assumed tobe 7N with 7N !
77N,7N
8. The goal is thus to parameterize the completion time according to
7N . The completion time is the time required for the configuration S to process the whole demandN + 7N .
2 Problem formulation
The allocation problem can be depicted as follows : "Assuming S, a demand N and lower and upperbounds
77N,7N
8, find a production plan for which the makespan Cmax is minimum". This problem
has been formulated through the linear program of the right column of table 1. One can easily identifythis formulation to a generic linear multiparametric problem given in the middle column of table 1[1],[2].A solving process of the generic multiparametric problem has been depicted in [1],[2], which providescritical areas for the uncertain parameters. The objective function is a unique piecewise a%ne functionover a critical area and the variables x and y are defined as linear functions related to 9. The goal ofthe work presented here is to apply this method to the allocation problem to determine the makespanas a function related to the demand variation.

368 Minh Hoang LE, Alexis AUBRY, Mireille JACOMINO
Tab. 1. Formulation
Multiparametric programming Multipurpose machines workshop
Formulation
minimize z(') = c.x+ d.ywith A.x + E.y ( b+ F.'
x . 0,yi % {0, 1} ,G.' ( g.
!"""""#
"""""$
min(Cmax)m&j=1R(i, j).V (i, j) = N(i) + /N(i) /i % I (a)
n&i=1R(i, j) # Cmax ( 0 /j % J (b)
(1# S(i, j)).R(i, j) = 0 /(i, j) % I 0 J (c)R(i, j) . 0 /(i, j) % I 0 J (d)
Number of constraints (n+m+ n.m) constraints
Continuous variables x = (x1, x2, ...) xn.(i"1)+j = R(i, j);xn.m+1 = Cmax 1 (n.m+ 1)variables
Binary variables y = (y1, x2, ...) yi = {0, 1} y = * 1 E = [(0)] and d = [(0)]
Uncertain parameters ' = ('1, ...,'s) 'i = /N(i), /i % I
Given data A, b, c, d,E, F,G, g S, V,N
3 Results
Results of MPTLet us consider the illustrative example of 4 machines and 5 products with a given configurationmatrix and the following data V = [(1)] and the expected demand N =
)5 5 10 10 16
*T with uncer-tainties 0 # 7N #
710 30 44 10 28
8T.
This example has been implemented with Multiparametric Toolbox MPT using the YALMIP solver[4]. For unidirectional uncertainties one can exhibit solutions in 0.90s using a Pentium IV 2GHz. Onecan exhibit a solution for a two variables uncertainties in 1.19s (the result is shown in figure 3), andin 1.95s for a 5 variables uncertainties. For this last case, 17 critical areas have been highlighted.
Références
1. M. H. Le. Prise en compte des incertitudes dans une approche proactive/rÈactive pour la gestiond’Ènergie dans le b‚timent. Rapport de Master. Grenoble INP. (2008)
2. T. Gal. Postoptimal Analyses, Parametric Programming and Related Topics. 2nd edn. Walter deGruyter. (1995)

Multiparametric linear programming to assess completion time sensitivity 369
3. A. Aubry, A. Rossi, M. Jacomino. Senesitivity analysis for the configuration of a multipurposemachines workshop. in proc of 17th IFAC World Congress, 15831-15836. Seoul, Korea. (2008)
4. M. Kvasnica, P. Grieder and M. Baoti. Multiparametric Toolbox (MPT).http ://control.ee.ethz.ch/ mpt/. (2004)

Comparaison d’algorithmes de décompositionApplication à la gestion de production
Alice Chiche1
EDF R&D - Département OSIRIS 1, avenue du Général de Gaulle, 92141 Clamart Cedex France.INRIA Rocquencourt - Projet ESTIME BP 105 F-78153 Le Chesnay France.
Le problème à résoudre L’objectif principal d’EDF est de maintenir à chaque instant unéquilibre entre l’o#re et la demande des consommateurs d’électricité, cela à moindre coût et enrespectant plusieurs contraintes physiques liées à l’utilisation des di#érents types de centrales duparc français.Cet équilibre dépend d’un certain nombre d’aléas (liés par exemple à des variations climatiques) quel’on représente par un arbre de scénarios. On minimise alors sur cet arbre l’espérance du coût totalde production d’électricité (en a#ectant à chaque nœud de l’arbre une probabilité d’occurence).
Les approches classiques de résolution du problème Les approches couramment utiliséespour résoudre un problème d’équilibre o#re-demande reposent généralement sur des techniques derelaxation Lagrangienne, qui consistent à décomposer ce problème en autant de sous-problèmes quede moyens de production considérés.Cette stratégie de résolution présente néanmoins plusieurs inconvénients. D’une part, la solutionoptimale - calculée en concaténant les solutions des sous-problèmes issus de la relaxation Lagrangienne- ne fournit pas en général une solution admissible du point de vue de la contrainte d’équilibre o#re-demande. D’autre part, le nombre de scénarios considérés est restreint du fait de son impact sur lataille des sous-problèmes que l’on résout.
Une alternative : la décomposition scénarios par scénarios Pour palier les inconvénientscités ci-dessus, une approche di#érente de résolution est proposée, qui consiste à relaxer la contraintede non-anticipativité, qui couple quant à elle les variables de décision à travers les scénarios.Une telle approche est permise par la forme, naturellement additive vis à vis des scénarios, du critèreque l’on souhaite minimiser. Elle o#re par ailleurs l’avantage d’autoriser l’utilisation de techniquesperformantes pour la résolution numérique des sous-problèmes considérés, tout en assurant la non-anticipativité de la commande finale, c’est-à-dire la satisfaction de la contrainte de l’équilibre o#re-demande.
Présentation des méthodes étudiées Nous nous sommes intéressés à deux méthodes dedécomposition Lagrangienne :– Une décomposition proximale ([1]) : Après duplication de la variable représentant la commande, la
"contrainte de duplication" est relaxée et pénalisée, et l’on minimise séquentiellement le Lagrangienaugmenté résultant. La variable duale est mise à jour à l’aide de la projection orthogonale de lasolution sur l’espace des solutions réalisables.
– Le principe du problème auxiliaire ([2]) : Après relaxation et pénalisation de la contrainte couplante,le Lagrangien augmenté résultant est linéarisé, ce qui permet de le minimiser scénario par scénario.La variable duale est mise à jour par pas de gradient, avec un coe%cient fixe.

Comparaison d’algorithmes de décomposition 371
Tests numériques e!ectués Nous avons tout d’abord étudié le comportement des deux algo-rithmes en fonction de l’évolution des paramètres qui leurs sont associés.1 Nous avons ainsi tracé,pour chaque méthode considérée, et pour des problèmes de di#érentes tailles (dont on augmentait lenombre de scénarios ou la durée de la période d’étude), deux courbes ayant pour abscisse le para-mètre que l’on cherchait à fixer, et pour ordonnées respectives l’erreur relative du résultat obtenu etle nombre d’itérations nécessaires à la convergence. Nous en avons ainsi conclu que le paramétragedu principe du problème auxiliaire était le plus sensible à l’évolution de la taille du problème. Nousavons également constaté que le nombre de scénarios influait peu sur le réglage des paramètres de ladécomposition proximale.Nous avons également comparé les deux méthodes en termes de précision et de vitesse sur desproblèmes dont nous avons fait évoluer la taille en augmentant successivement le nombre de scénarios,puis la durée de la période d’étude. Nous avons alors constaté que que la rapidité de l’algorithme issudu principe du problème auxiliaire était fortement conditionnée par la durée de la période d’étude(soit de la taille des sous-problèmes). Qui plus est, les résultats fournis par les deux algorithmesétaient comparables en termes de précision pour toutes les tailles de problèmes étudiés.
Conclusion de l’étude Si l’on souhaite choisir une méthode de résolution, parmi les deux étudiées,il conviendra de s’adapter à la taille du problème. Ainsi, dans le cadre d’un problème se déroulant surune période d’étude assez longue, l’algorithme le plus approprié sera celui du principe du problèmeauxiliaire, tandis que la décomposition proximale s’avèrera plus adapté à un problème comportantde nombreux scénarios.
Références
1. LENOIR, Arnaud : Modèles et algorithmes pour la planification de production à moyen termeen environnement incertain : Application de méthodes de décomposition proximale. Mémoire dedoctorat (2008)
2. COHEN, Guy : Optimisation des grands systèmes. Cours ENSTA (2006)
1 Les résultats de référence étaient fournis par une résolution frontale sur l’arbre.

Optimisation de placement de publicité internet parl’algorithme des bandits manchots
Antoine Jeanjean, Bruno Martin
Bouygues e-lab, Paris.{ajeanjean,bmartin}@bouygues.com
Dans cette note, nous abordons un problème réel d’optimisation du placement de publicité sur in-ternet. Il s’agit à tout instant de choisir les produits à placer dans des espaces publicitaires étiquetés"Shopping Box" sur les sites du groupe TF1. Chaque mois, plusieurs centaines de millions de blocs depublicité s’a%chent au sein d’une rubrique, pour un créneau horaire d’un jour de la semaine. Chaquebloc est constitué de 2 ou 3 produits à sélectionner parmi la liste de plusieurs dizaines de milliers deproduits disponibles appartenant à une centaine d’annonceurs.
L’o#re commerciale proposée aux annonceurs est de deux types : une o#re avec paiement au clic etune o#re avec paiement à l’a%chage. L’objectif de ce problème d’optimisation, qu’on peut qualifierd’"online optimization problem", est de répondre à une demande d’a%chage de publicité en choisissantà tout instant un produit, qui satisfait au mieux 3 objectifs : maximiser la probabilité que l’a%chagede ce produit dans cet a%chage se solde par un clic, minimiser le nombre de produits en retard surleur objectif d’a%chages et minimiser le nombre d’annonceurs en retard sur leur taux de clics objectif.
L’analyse statistique d’un historique de plusieurs mois de données a mis en évidence les facteursclés agissant sur le taux de clics des internautes. Les critères retenus sont les suivants : le jourde la semaine, le créneau horaire dans la journée, la catégorie du produit (par exemple : voyage,vêtement, cosmétique...), sa gamme de prix et la rubrique du site internet (par exemple : vidéos,information, mode...). Pour chacun de ces critères, les résultats montrent des variations importantesde la probabilité de clics. Le taux de clics et le nombre d’a%chage sont fortement corrélés : plus lenombre d’a%chages augmente, plus le taux de clics diminue. Ce comportement s’explique par uneaugmentation de la probabilité qu’un internaute ait déjà vu cette publicité. Dans le même temps,l’augmentation du nombre d’a%chages permet de diminuer l’incertitude sur le taux de clics.
Pour résoudre ce problème d’optimisation multi-critère de placements de publicité, nous avons conçuun algorithme de type UCB (Upper Confidence Bound) [2] en y ajoutant des limites supplémentaires,en se basant sur le problème connu dans la littérature sous le nom des bandits manchots [1,3].
Ce problème considère un joueur qui dispose de X jetons qu’il souhaite jouer dans N machines àsous ayant chacun une probabilité de gain di#érente p(i). Les probabilités de chaque machine sontinconnues au début de la partie. Le joueur souhaite maximiser ses gains. Il s’agit de déterminer lameilleure stratégie à adopter ? Après une phase d’initialisation, l’algorithme UCB1 consiste à corrigerdes probabilités maximales de réussite. Ces probabilités sont calculées par le recueil d’expériencespassées mais aussi en appliquant une correction logarithmique permettant de prendre en compte l’in-certitude sur l’écart entre le mesuré et le réel. L’incertitude est d’autant plus grande que le nombrede tirages est faible (d’o˘ l’utilisation d’une fonction logarithmique).
Trois facteurs correctifs permettent ici d’améliorer les résultats et d’éviter certaines dérives de l’algo-rithme : un facteur correctif sur le taux de clic cible, afin de prendre en compte la valeur des clics, etdonc de se focaliser non pas sur l’espérance de clic mais sur l’espérance de gain associée. Le deuxième

Algorithme pour l’optimisation de publicité internet 373
facteur applique un pourcentage sur la probabilité maximum de chaque produit, afin de prendre encompte l’information sur la période de la journée et le jour de la semaine de la demande d’a%chage.Enfin, un troisième paramètre permet de favoriser/ralentir les a%chages des produits des annonceursen retard/avance sur leur objectif.
Références
1. Lai, T. L. (1987). Adaptive treatment allocation and multi-armed bandit problem. In Annals ofStatistics 15(3), 1091-1114.
2. P. Auer, N. Cesa-Bianchi, Y. Freund, and R. E. Schapire (2002). The nonstochastic multiarmedbandit problem. SIAM Journal on Computing 40(4), 32(1) :48-77, 2002.
3. J. C. Gittins. (1989). Multiarmed Bandits Allocation Indices. Wiley, New York.

Trois jeux d’arbre couvrant pour agents individualistes
Laurent Gourvès et Jérôme Monnot
LAMSADE, CNRS et Université Paris-Dauphine, 75775 Paris Cedex 16, France.{laurent.gourves, monnot}@lamsade.dauphine.fr
1 Introduction
Jusqu’à quel degré d’ine%cacité des agents individualistes peuvent utiliser un ressource qui leur estcommune ? Cette question est centrale en informatique car les réseaux, constituant une plateformeaujourd’hui incontournable, sont souvent régis de faÁon non centralisée par di#érents acteurs auxintérêts parfois divergeants.Dans des articles récents ([1,2,1,4] parmi d’autres), la situation est modélisée à l’aide d’un jeu stra-tégique. Un jeu stratégique est un triplet 9N, (Si)i#N , (ui)i#N : où N est l’ensemble des joueurs alorsque Si et ui sont respectivement l’ensemble des stratégies du joueur i et sa fonction d’utilité. Lesjoueurs sont supposés individualistes et rationnels. Chacun choisit une stratégie qui, en fonction dela stratégie adoptée par les autres joueurs, lui permet de maximiser sa propre utilité.Dans ce travail, nous étudions trois versions d’un jeu non coopératif d’arbre couvrant ("selfish span-ning tree game" ou sst) notés respectivement min sst, max sst et bottleneck sst. Le jeu sst estdéfini sur un graphe complet G = (V,E) où chaque arête e ! E possède un poids positif w(e). Toutsommet, mis à part un nœud source spécifique noté r, est contrôlé par un joueur individualiste.Les joueurs veulent être connectés à r soit directement, soit par l’intermédiaire d’autres joueurs euxmême connectés à r. Pour min sst (resp. max sst), l’utilité d’un joueur est l’opposé du poids (resp.le poids) de la première arête de l’unique chemin entre ce dernier et r. Pour bottleneck sst, l’utilitéd’un joueur est le poids minimum des arêtes constituant le chemin entre ce dernier et r.
2 Applications
Le jeu sst est motivé par deux situations : lorsque le sommet source r envoie un message à tous lesjoueurs ("one-to-all") et lorsque chaque joueur envoie une requête à r ("all-to-one"). Pour min sst,le poids d’une arête peut représenter son coût. Si chaque nœud paie le prix de l’arête par laquellel’information lui parvient alors le coût global du réseau est totalement couvert. Dans ce cas, chaquejoueur souhaite recevoir le message au plus petit prix.Une autre application de min sst concerne la limitation de la consommation électrique dans lesréseaux sans fil statiques. Le poids d’une arête représente sa longueur. La puissance nécessaire àl’envoi d’un message vers un sommet distant croît avec cette distance. Ainsi chaque nœud souhaiteconsommer le moins d’énergie possible pour envoyer ses requêtes.Pour max sst, le poids d’une arête représente sa fiablité : plus le poids d’un arête est grand, moins lemessage le traversant est entâché d’erreurs. Ainsi, il est dans l’intérêt de tout joueur de choisir le lienle plus fiable par lequel provient l’information afin de perdre le moins de temps possible à le réparer.Pour le bottleneck sst, le poids d’une arête représente sa bande passante libre. Dans les communica-tions "one-to-all", le débit en un sommet dépend du débit en tout nœud intermédiaire, i.e. il est limitépar l’arête de plus petite bande passante. Par conséquent, tout joueur de bottleneck sst cherche àmaximiser son propre débit.

Trois jeux d’arbre couvrant pour agents individualistes 375
3 Approche et contribution
Les joueurs de sst peuvent ne pas atteindre un optimum social de façon spontanée car leurs déci-sions non concertées ainsi que leurs intérêts parfois conflictuels risquent d’engendrer des performancesglobales sous-optimales. La problématique essentielle de ce travail est de quantifier cette perte d’ef-ficacité. Pour cela, nous étudions le prix de l’anarchie ("price of anarchy" ou PoA) [5] ainsi que leprix de l’anarchie fort ("strong price of anarchy" ou SPoA) [2] de sst. Ces deux mesures font appel àdeux concepts majeurs en Théorie des jeux – l’équilibre de Nash et l’équilibre fort – pour quantifierla détérioration des performances globales dues aux comportements individualistes des joueurs.Nous montrons que tout équilibre de Nash du jeu min sst est un équilibre fort (la preuve fonctionneaussi pour max sst). Comme PoA=SPoA dans ce cas nous n’étudions que le PoA du min sst. Ilest d’abord montré que le PoA de min sst est, en général, non borné. Ainsi nous nous restreignonsaux instances satisfaisant l’inégalité triangulaire. Sous cette hypothèse standard, nous montrons quePoA! :(log n) et PoA# d$ où n est le nombre de joueurs (i.e., n = |N | = |V | % 1) et d$ estla profondeur (nombre d’arêtes du plus long chemin feuille-racine) de l’arbre induit par l’optimumsocial. De plus nous bornons le PoA vis à vis d’une fonction de bien-être social modifiée, motivée parun critère de consommation électrique pour des problèmes de communication dans des réseaux sansfil. Le PoA de max sst et bottleneck sst sont étudiés sans que l’hypothèse d’inégalité triangulairesoit imposée. Pour le premier jeu, nous montrons que PoA= 1/7$ où 7$ est le degré maximum d’unsommet joueur (i.e. tous les sommets sauf r) dans l’arbre induit par un optimum social . Pour le casbottleneck, nous montrons que tout équilibre de Nash est un optimum social (PoA= 1), impliquantque tout équilibre de Nash est un équilibre fort.
Références
1. S. Albers, On the value of coordination in network design, In Proc. of SODA 2008, pp. 294-303,2008.
2. N. Andelman, M. Feldman and Y. Mansour, Strong price of anarchy, In Proc. of SODA 2007, pp.189-198, 2007.
3. E. Anshelevich, A. Dasgupta, J. M. Kleinberg, É. Tardos, T. Wexler and T. Roughgarden. ThePrice of Stability for Network Design with Fair Cost Allocation, In Proc. of FOCS 2004, pp.295-304, 2004.
4. A. Fabrikant, A. Luthra, E. N. Maneva, C. H. Papadimitriou and S. Shenker, On a networkcreation game, In Proc. of PODC 2003, pp. 347-351, 2003.
5. E. Koutsoupias and C. H. Papadimitriou, Worst Case Equilibria. In Proc. of STACS 1999, LNCS1563, pp. 404-413, 1999.

Reformulation du Problème du Sac à Dos Bi-Niveaux
R. Mansi, S. Hanafi and L. Brotcorne
LAMIH-ROI, Université de Valenciennes, France.(Raid.Mansi,Said.Hanafi , Luce.Brotcorne)@univ-valenciennes.fr
Un problème à deux niveaux permet de modéliser un processus de décision hiérarchisé entre deuxagents : le premier, appelé meneur (premier niveau), fixe sa décision tenant compte de la réactiond’un deuxième agent, appelé le suiveur (deuxième niveau). Les problèmes à deux niveaux ont été lesujet de nombreuses études d’un point de vue théorique et pratique ([3]). Ces problèmes sont généra-lement très di%ciles à résoudre, principalement parce qu’ils sont non convexes et non di#érentiables.Beaucoup d’attention a été consacrée au cas où les deux fonctions objectifs sont linéaires et les va-riables continues. Même dans cette situation, l’obtention d’une solution optimale est un problèmefortement NP di%cile [5].Dans cette communication nous étudions et proposons une méthode hybride de résolution pour unproblème de sac à dos à deux niveaux (GBKP). Le problème GBKP est un problème plus général quecelui du sac ‡ dos bi-niveaux considéré dans [4] et [2]. Il est caractérisé par des variables en nombresentiers pour le meneur et le suiveur, une contrainte de sac à dos au deuxième niveau et des contrainteslinéaires générales au premier niveau. Ces dernières contraintes compliquent la résolution du problèmecar elles peuvent engendrer un ensemble de solutions réalisables pour le meneur discontinu ou vide.GBKP est défini par :
(GBKP) max f1(x, y) = d1x+ d2y
s. t. A1x+ A2y # B
x ! Nn1
y ! argmax{f2(y&) = c2y& : a1x+ a2y& # b, y& ! Nn2}
Les vecteurs a1 et d1 (resp. c, a2 et d2) sont de dimension n1 (resp. n2), la matrice A1 (resp.A2) est de dimension m + n1 (resp. m + n2) et le vecteur B est de dimension m. Le vecteur x(resp. y) de dimension n1 (resp. n2), désigne les variables de décision du meneur (resp. suiveur). Lafonction objectif du meneur (resp. suiveur) est notée f1(x, y) (resp. f2(x, y)). Nous supposons queles coe%cients des vecteurs c, a1, a2 et le second membre b sont des entiers positifs.GBKP peut être résolu en appliquant des algorithmes génériques connus pour résoudre des pro-grammes à deux niveaux en nombres entiers mixtes comme l’algorithme proposé par [1] et [7]. Ce-pendant, les algorithmes génériques ne permettent pas de résoudre des instances de taille moyenneou grande, ce qui rend crucial le développement de méthodes de résolution basées explicitement surla structure de sac à dos du problème du suiveur ([4] et [2]).Nous proposons une nouvelle méthode exacte pour résoudre e%cacement le problème GBKP. Cetalgorithme est composé de deux phases. Dans la première nous considérons seulement le problèmedu suiveur ignorant les ressources consommées par le meneur. Nous appliquons la programmationdynamique [6] pour obtenir l’ensemble de toutes les solutions réalisables non-dominées du problèmedu suiveur. Cette phase génère l’ensemble 6 = {(ci, ai) : i = 0, . . . , b} où , ci = cyi et ai = ayi aveccyi = max{cy : a2y # i}. Notons que ces solutions sont triées par ordre croissant par rapport à lacapacité consommée du sac à dos et du profit du suiveur.Dans la deuxième phase, nous proposons une reformulation équivalente du problème GBKP sousforme d’un programme linéaire en nombres entiers (IPGBKP ) où la région réalisable est définie par6. Notons que les intervalles [a0, a1[, [a1, a2[, . . . , [ap, b + 1[ définissent les intervalles de sensibilitépour les capacités résiduelles b % a1x . Si b % a1x ! [ai, ai+1[, où x est l’action du meneur, alors la

Problème du sac à dos bi-niveaux 377
réaction y du suiveur doit respecter les deux conditions cy = ci et a2y ! [ai, b% a1x]. Notre objectifdans cette deuxième phase est d’exprimer l’interaction entre une décision du meneur et la réactiondu suiveur.
IP(GBKP) max f1(x, y) = d1x+ d2y (1)s.t. A1x+ A2y # B (2)a1x+ a2y # b (3)
a1x+p%
i=0
ai+1zi ) b+ 1 (4)
cy =p%
i=0
cizi (5)
p%
i=0
zi = 1 (6)
x ! Nn1, y ! Nn
2, z ! {0, 1}p+1 (7)
Les contraintes (2) et (3) sont les contraintes de réalisibilité du meneur et du suiveur. La contrainte(4) assure que l’intervalle choisi est compatible avec l’action du meneur x. Notons que ap+1 = b+ 1.(5) exige que la valeur de la fonction objectif du suiveur soit égale à la valeur optimale associée àl’intervalle compatible. Enfin la contrainte (6) assure qu’un seul intervalle soit choisi. Des résultatsnumériques sont présentés pour montrer l’e%cacité de notre méthode.
Références
1. Bard J.F., Moore J.T. (1992), An Algorithm for the Discrete Bilevel Programming Problem, NavalResearch Logistics 39, 419-435.
2. Brotcorne L, Hanafi S, Mansi R. (2008), Dynamic programming for the Bilevel Knapsack problem,accepted for publications in OR letters.
3. Colson B., Marcotte P., Savard G.(2005), Bilevel Programming, A survey, 4OR 3, 87-107.4. Dempe S., Richter K. (2000), Bilevel Programming with Knapsack Constraints, Exchange Euro-
pean News paper of Operations Research. 8, 93-107.5. Hansen P., Jaumard B. and Savard G. (1992), New branch-and-bound rules for linear bilevel
programming, SIAM Journal on Scientific and Statistical Computing, 13, 1194-1217.6. Martello S., Toth P. (1990), Knapsack Problems Algorithms and Implementations Computer, John
Wiley & Sounds.7. Moore J. T., Bard J.F. (1990), The Mixed Integer Linear Bilevel Programming Problem, Opera-
tions Research 38, 911-921.

Problème d’a!ectation entre plusieurs organisations
Laurent Gourvès1, Jérôme Monnot1 et Fanny Pascual2
1 LAMSADE, CNRS et Université Paris-Dauphine, 75775 Paris Cedex 16, France.{laurent.gourves, monnot}@lamsade.dauphine.fr
2 LIP6, Université Pierre et Marie Curie, 104 avenue du Président Kennedy, 75016 Paris, [email protected]
1 Introduction
Nous étudions une situation dans laquelle plusieurs organisations ont chacune un ensemble de clientsqui fournissent ou demandent chacun un produit. Chaque organisation a un profit proportionnelau montant des transactions qu’elle traite, et peut soit e#ectuer des transactions entre ses propresclients, soit e#ectuer des transactions avec une autre organisation (le profit d’une transaction entredeux organisations est alors partagé entre celles-ci). Le montant d’une transaction peut être sousforme monétaire ou bien représenter la satisfaction des deux clients impliqués dans la transaction.Notre but est de retourner une a#ectation acheteurs/vendeurs qui maximise le montant total destransactions e#ectuées, tout en respectant le fait qu’une organisation ne doit pas faire moins de profitdans la solution retournée que si elle avait e#ectué des transactions entre ses clients uniquement.
Le problème d’a#ectation multi-organisations. On considère un graphe bipartiG = (B,S;E;w)et q ensembles (appelés organisations) O1, . . . , Oq formant une partition de B 2 S. Chaque acheteur(resp. vendeur) est représenté par un sommet de B (resp. S), E . B + S représente les transac-tions possibles et w : E ( R+ représente les montants de ces transactions. On note Bi = B 0 Oiet Si = S 0 Oi. Un ensemble M . E est une a#ectation (ou un couplage) si chaque sommet de(B,S;M ;w) a un degré d’au plus un. Soient ps et pb deux nombres rationnels positifs tels queps + pb = 1. Ici ps (resp. pb) représente la proportion du coût de la transaction donnée à l’organisa-tion du vendeur (resp. de l’acheteur)3. On suppose sans perte de généralité que pb # ps. Le profit del’organisation Oi dans M , que l’on note wi(M), est alors défini de la façon suivante :
wi(M) =%
{[b,s]#M: (b,s)#Bi)S}
pb w([b, s]) +%
{[b,s]#M: (b,s)#B)Si}
ps w([b, s])
On note Mi le couplage maximum du sous-graphe de G induit par Oi. Le problème d’a#ectationmulti-organisations (noté amo) consiste à trouver un couplage de poids maximum M de G tel quewi(M) ) wi(Mi) pour tout i ! {1, . . . , q}.
État de l’art. AMO est une variante du célèbre problème d’a#ectation (voir [3] pour un état de l’artde ce problème). En plus de sa structure combinatoire, AMO fait intervenir des organisations auxintérêts divergents : la coopération entre ces organisations peut augmenter grandement la qualité dela solution obtenue, mais une solution sera réalisable uniquement si elle ne va pas contre un intérêtlocal. Ceci se rapproche du domaine de la théorie des jeux non coopératifs, et plus spécialement dela notion de prix de la stabilité [1] dans laquelle on s’intéresse à la qualité de la meilleure solutionacceptable par tous les acteurs du système.
3 Ainsi s désigne le vendeur (seller) et b l’acheteur (buyer)

Problème d’a#ectation entre plusieurs organisations 379
2 Contribution
Complexité. Nous avons montré que le problème AMO est NP-di%cile au sens fort dans le casgénéral, et qu’il est NP-di%cile même dans le cas où il n’y a que deux organisations.Dans le cas où toutes les transactions possibles ont le même coût (i.e. w([i, j]) ! {0, 1} pour tout(i, j) ! B + S), le problème peut être résolu en temps polynomial. Pour cela il su%t de partir ducouplage M = 2i={1,...,q}Mi (i.e. du couplage maximum du graphe dans lequel on a retiré les arêtespartagées entre deux organisations), puis d’augmenter la taille du couplage grâce à des cheminsalternés augmentants, tant que cela est possible. Le couplage obtenu est alors maximum et respecteles contraintes du problème.
Approximation. Soit APPROX l’algorithme qui consiste à chercher un couplage de poids maximumdans le graphe G dans lequel on a auparavant multiplié par pb le poids de chaque arête reliant deuxsommets d’organisations di#érentes. Cet algorithme retourne une solution réalisable de AMO et ilest pb-approché. Lorsque le nombre d’organisations est au moins égal à trois, nous avons montré qu’ilest NP-di%cile d’obtenir un algorithme (pb+ ')-approché pour tout ' > 0. Ce résultat est obtenu enutilisant une gap-réduction.
3 Généralisations et conclusion
On propose maintenant d’introduire un degré d’"altruisme" dans le problème : afin de rendre possibleune amélioration globale de la solution, une organisation Oi acceptera le couplage proposé si cela nedivise pas son profit d’un facteur supérieur à x (x étant fixé). Le problème consiste alors à trouver lecouplage de poids maximumM tel que pour toute organisation Oi, wi(M) ) wi(Mi)/x. En adaptantlégèrement les preuves de AMO, on montre que ce problème est NP-di%cile au sens fort pour toutx < 1
pb, et que l’algorithme APPROX (dans lequel on multiplie le poids des arêtes partagées par
x pb) est (x pb)-approché.De plus si ps = pb = 1
2 , les résultats énoncés ci-dessus dans le cas d’un graphe biparti sont égalementvalables pour tout graphe.Le problème AMO consiste à augmenter le plus possible le profit moyen des organisations. Il serait in-téressant d’introduire des facteurs d’équité, par exemple pour retourner des solutions qui augmententle plus également possible le profit de toutes les organisations.
Références
1. E. Anshelevich, A. Dasgupta, J. M. Kleinberg, É. Tardos, T. Wexler et T. Roughgarden : ThePrice of Stability for Network Design with Fair Cost Allocation. Proc. of FOCS 2004, pp. 295-304.
2. M. R. Garey et D. S. Johnson : Computers and Intractability : A Guide to the Theory of NP-Completeness. W. H. Freeman and Company, New York, (1979).
3. D. W. Pentico : Assignment problems : A golden anniversary survey. EJOR, vol. 176, pp. 774-793,(2007).

Convex relaxations for quadrilinear terms
S. Cafieri1, J. Lee2, and L. Liberti1
1 LIX, École Polytechnique, Palaiseau, France {cafieri,liberti}@lix.polytechnique.fr2 Dept. of Mathematical Sciences, IBM T.J. Watson Research Center, N.Y., USA
1 Introduction
Branch and Bound based global optimization methods, applied to formulations involving multi-variate polynomials, rely on convex envelopes for the lower bound computation (see, e.g., [1]).Convex/concave envelopes in explicit form currently exist for concave/convex univariate functions[8], bilinear terms [6], trilinear terms [7], univariate monomials of odd degree [5] and fractional terms[9]. The multivariate monomial of smallest degree for which the convex envelope is not known is thequartic one. In particular, the focus of this work is the quadrilinear term x1x2x3x4, for which wederive three convex relaxations and computationally analyze their relative tightness.
2 Computational assessment
The idea for deriving convex relaxations is that given a su%ciently rich set of “elementary” convexenvelopes, one can compose convex relaxations (albeit not envelopes) of complex functions. Forexample, given two functions f(x), g(x) for which the convex/concave envelopes are available, aconvex relaxation for the product f(x)g(x) can be obtained by applying the bilinear convex envelopeto the product w1w2, where the necessary “defining constraints”w1 = f(x), w2 = g(x) can be replacedby the convex/concave envelopes of f, g. This strategy, however, yields sometimes non-unique waysof combining terms, due to the associativity of the product. Given a quadrilinear term x1x2x3x4, weconsider the following three types of term grouping :
((x1x2)x3)x4, (x1x2)(x3x4), (x1x2x3)x4
and we derive three corresponding linear convex relaxations for x1x2x3x4. Let us consider :
S1 = {(x,w) ! R4 + R3 |xi ! [xLi , xUi ], w1 = x1x2, w2 = w1x3, w3 = w2x4},S2 = {(x,w) ! R4 + R3 |xi ! [xLi , xUi ], w1 = x1x2, w2 = x3x4, w3 = w1w2},S3 = {(x,w) ! R4 + R2 |xi ! [xLi , xUi ], w1 = x1x2x3, w2 = w1x4}.
We exploit a bilinear envelope thrice for the first two cases and a trilinear envelope and a bilinearenvelope in the latter case. The comparison among the considered relaxations is made in terms of thevolume of the corresponding enveloping polytopes. We use the volume of the enveloping polytopesrather than the bound value because the latter would depend on an objective function being explicitlygiven. Because exploiting envelopes for bilinear and trilinear terms leads to an increased number ofvariables, so that the obtained polytopes belong to R7 in the first two cases and R6 in the latter case,we project the polytopes onto R5 in order to compare the results.Our computational experiments, carried out on a set of instances generated by varying the signsof the bounds and the widths of the ranges of the variables, show that in 70% of the cases thegrouping (x1x2x3)x4 yields tightest bounds. However, other cases sometimes provide better results.

Convex relaxations for quadrilinear terms 381
These results are important especially in view of the fact that the traditional grouping used by sBBalgorithms is ((x1x2)x3)x4 [2]. Moreover, we get a significant indication of the dependence of therelaxation strenght on signs and width of input bounds. This suggests that sBB solvers could beconfigured to adjust the relaxation procedure automatically in function of the input bounds.
3 Applications to known problems
We applied the obtained results to some well-known problems, namely the Molecular Distance Geo-metry Problem (MDGP) [3] and the Hartree-Fock Problem (HFP) [4]. Both problems, when cast intheir mathematical programming formulation, are nonconvex polynomial NLPs with terms of degreeup to four. Both can be solved by means of the sBB algorithm. The natural application of tightlower bounds computed through a convex relaxation is within the sBB algorithm. In order to quicklyassess the quality of our proposed alternative bound for quadrilinear terms on the MDGP and HFPwithout having to implement a full sBB framework, we implemented a simplified “partial sBB” algo-rithm which, at each branching step, only records the most promising node and discards the other,thus exploring a single branch up to a leaf. The obtained results suggest that the selection of therelaxation type can strongly influence the overall performance of a sBB algorithm when applied toproblems containing quadrilinear terms, so that a significant improvement in such an algorithm couldpotentially be obtained by a judicious selection of the relaxation based on the variable bounds.
Références
1. Adjiman, C.S., Dallwig, S., Floudas, C.A., Neumaier, A. : A global optimization method,)BB, forgeneral twice-di#erentiable constrained NLPs : I. Theoretical advances, Computers & ChemicalEngineering, 22(9) :1137–1158, 1998.
2. Belotti, P., Lee, J., Margot, F., Wachter, A. : Branching and Bounds tightening techniques fornon-convex MINLP, Optimization Online, n.2059, 2008.
3. Lavor, C., Liberti, L., Maculan, N. : Molecular distance geometry problem, In : Encyclopedia ofOptimization, C. Floudas and P. Pardalos (Eds.), 2nd edition, Springer, NY, 2305–2311, 2009.
4. Lavor, C., Liberti, L., Maculan, N., Chaer Nascimento, M.A. : Solving Hartree-Fock systemswith global optimization metohds. Europhysics Letters, 5(77) :50006p1–50006p5, 2007.
5. Liberti, L. and Pantelides, C.C. : Convex envelopes of monomials of odd degree, Journal of GlobalOptimization, 25 :157–168, 2003.
6. McCormick, G.P. : Computability of global solutions to factorable nonconvex programs : Part I— Convex underestimating problems, Mathematical Programming, 10 :146–175, 1976.
7. Meyer, C.A. and Floudas, C.A. : Trilinear monomials with mixed sign domains : Facets of theconvex and concave envelopes, Journal of Global Optimization, 29 :125–155, 2004.
8. Smith, E.M.B. : On the Optimal Design of Continuous Processes, PhD thesis, Imperial Collegeof Science, Technology and Medicine, University of London, October 1996.
9. Tawarmalani, M. and Sahinidis, N. : Convex extensions and envelopes of semi-continuous func-tions, Mathematical Programming, 93(2) :247–263, 2002.

About the direct support method in linear programming
Sonia Radjef1 and Mohand Ouamer Bibi2
1 Département de Mathématiques, Faculté des sciences, Université USTO d’Oran, Algé[email protected]
2 Département de Recherche opérationnelle, Laboratoire LAMOS, Université de Béjaia, Algérie [email protected]
The great early success of mathematical programming was the devlopment of the simplex method byGeorge Dantzig and co-workers Orden and Wolfe [4] for the solution of linear programming problems.The method was originally developed for hand calculation but was easily adapted for use on digitalcomputers, for which the revised simplex method is normally used. Since then, many extensions andrefinements have been developed for the method. One of the most important developments have beena class of techniques known in general terms as sparse matrix techniques. In recent years there havebeen alternative linear programming algorithms proposed most notably that of Karmakar [9]. Another class of methods in linear programming is that of active set methods [5,8]. In spite of all this,the simplex method is well worth studying, so the revised one and its close variants are still the mostpopular.But in the process of solution of linear problems in optimal command, it is shown that the simplexmethod is unsuited, so the necessity to develop the adaptive methods by Gabasov and Kirillova [6,7]which are intermediate between the methods of activation constraints and those of the interior points.Based on these adaptive methods, Gabasov and Kirillova developed the direct support method tosolve linear programs with nonnegative decision variables or with bounded decision variables. Ourproper contribution consists on to extend this method to solve the linear program with the two typesof variables : the nonnegative variables and the bounded variables.This method has the advantage of handling the bounds of the decision variables as they are initiallypresented. This is very significant for the post-optimal analysis in linear programming and to accu-rately characterize the bang-bang property of an optimal command during the optimization of thelinear dynamic systems with linear or quadratic criteria.The other particularity is the fact that is equipped with a stop criterion which can give an approxi-mate solution known as ,-optimal solution with a selected precision , ) 0.Starting with an initial support feasible solution (to be defined below) composed by one feasiblesolution and one nonsingular matrix, then each iteration of the method consists in finding a directionand a step along with it in order to increase the value of the objective function.The linear programs studied by R. Gabassov and F.M. Kirillova are from the following canonicalforms :
z(x) = ctx %( max, Ax = b, x ) 0,and
z(x) = ctx %( max, Ax = b, d" # x # d+.
Our contribution consists to extend this method to solve a program from the following canonicalforms :
z(x, y) = ctx+ kty %( max, (1)Ax+Hy = b, (2)d" # x # d+, (3)
y ) 0, (4)

About the direct support method in linear programming 383
where c and x are nx-vectors, k and y are ny-vectors, b a m-vector, A a m + nx-matrix, H am+ ny-matrix, with rank(A|H) = m < nx + ny ; d" and d+ are nx-vectors.The linear problem (1)-(4) is of particular interest as it serves to test the e%ciency of the extremepoints in solving the multiple objective linear program with bounded decision variables. Besides, thelinear program considered and of the direct support method applied to its solution are of their owninterests in linear programming since, as a matter of fact, the studied linear program can be appliedto solve an optimization linear problem with variables which are either real or integers. It can furtherbe exploited to find a feasible initial solution in an algorithm of resolution of a quadratic problem.Accordingly, this algorithm proves to be e#ective in the process of resolution of linear problems ofoptimal command, where it is shown that the simplex method is unsuited.Besides, the other important particularity of this method is the fact that it possesses a suboptimalcriterion which can stop the algorithm with the desired accuracy.
Références
1. M.O. Bibi, Methods for solving linear-quadratic problems of optimal control. University of Minsk(1985)
2. M.O. Bibi, Support method for solving a linear-quadratic problem with polyhedral constraints oncontrol, Optimization, 37, 139-147, (1996)
3. A.S. Chernushivech, Method of support problems for solving a linear-quadratic problem of terminalcontrol. Int. J. Control, 52(6), 1475-1488 (1990)
4. G.B. Dantzig, Linear programming and extensions. Princeton University Press,Princeton, N.J,(1963)
5. R. Fletcher, Practical Methods of Optimization. J. Wiley and Sons, Second edition, Chichester,England (1987)
6. R. Gabasov and others, Solution of linear quadratic extremal problems, Soviet Math. Dokl., 31,99-103 (1985)
7. R. Gabasov and F.M. Kirillova and V.M. Rakestsky, Constructive methods of optimization. P.IV :Convex problems. University Press, Minsk (1987)
8. P.E. Gill and W. Murray and M.H. Wright, Practical Optimization. Academic Press Inc, Lon-don,(1981)
9. N. Karmakar, A new polynomial-time algorithm for linear programming. Internal report, Mathe-matical Sciences Division, AT-T Bell Laboratories, Murray Hill New Jersey (1984)
10. F.A. Potra and S.J. Wright, Interior-Point Methods. Journal of Computational and AppliedMathematics, 124, 281-302 (2002)

Optimisation des réseaux de transport de gaz à l’aide dela méthode des Moments.
Dan GUGENHEIM,1, Jean ANDRÉ1, and Frédéric BONNANS2
1 GDF-SUEZ, DRI, 361 avenue du Président Wilson 93210 La Plaine Saint Denis [email protected], [email protected]
2 CMAP, Ecole Polytechnique, 91128 Palaiseau, [email protected]
1 Présentation de la problématique
GDF-SUEZ, par sa filiale GRTgaz, gère et exploite le réseau de gaz français. Ce réseau est le pluslong d’Europe avec 30 000km. L’objectif de cet article est d’étudier la résolution d’un problèmed’exploitation de réseaux de transport de gaz par la méthode des Moments.Le réseau « principal »permet l’acheminement sur des grandes distances, tronçons de l’ordre de 50 -100 km, de grandes quantités de gaz. Par contrat, GDF-SUEZ s’engage à fournir à ses clients, unequantité de gaz à une certaine pression. Lors de ce transport le long des canalisations, la pressiondu gaz diminue. Pour remédier à cela, il existe sur les réseaux des stations de compressions. Cesstations permettent d’augmenter la pression du gaz, à un coût néanmoins conséquent. On cherche icià minimiser l’usage de ces stations.Le problème est mathématiquement di%cile, non linéaire, non convexe et combinatoire : Mixed In-tegers Nonlinear Programming, MINLP.
2 Présentation de la méthode des Moments
Dans [1], une méthode de résolution globale des problèmes polynomiaux est présentée. Celle-ci s’ap-puie sur l’optimisation semi-définie positive (SDP). On cherche à résoudre le problème :
minx#RN
p(x)
s.c. gi(x) ) 0, i = 1, .., r(1)
où p et gi sont des polynômes. C’est un problème di%cile car aucune hypothèse de convexité n’estfaite sur p ou sur les gi. Pour cela, on montre que la minimisation globale d’un polynôme contraintpeut être approchée aussi bien que l’on veut à l’aide d’une suite finie de problèmes d’optimisationconvexe d’inégalités de matrices linéaires (convex LMI). Ces problèmes d’optimisation peuvent êtrerésolus à l’aide d’une optimisation SDP. Nous utilisons cette méthode pour résoudre le problèmeprésenté dans le premier paragraphe.
3 Modélisation et mise en œuvre
L’équation décrivant le travail des compresseurs est centrale dans notre modèle. Pour un compresseurC, où le flot Q circule entre du nœud i au nœud j, le travail fourniWC s’écrit en fonction des pressionen i, Pi et en j, Pj .

Optimisation des réseaux à l’aide de la méthode des Moments 385
WC = +1QWWPjPi
X12% 1X
(2)
Les paramètres +1 et +2 dépendent du gaz et du compresseur. Plusieurs approximations polynomialespeuvent être proposées. Par exemple, une approximation de Taylor à l’ordre 2. Nous avons testé cetteméthode sur des petits réseaux simples à l’aide des solveurs Gloptipoly [2], SparsePOP [3] et SEDUMI[4]. Il apparaît que les résultats trouvés par ces solveurs sont qualitativement proches de ceux trouvésavec des solveurs non linéaires, CONOPT [5], SNOPT [6] ou COIN-IPOPT [7].
4 Conclusion
La méthode des Moments ouvre de nouvelles perspectives à la résolution de problèmes di%cile. Elleapporte la certitude d’être à l’optimum global. Néanmoins, cette méthode n’est pas encore applicableà des problèmes de taille réelle comme ceux de GDF-SUEZ. Une voie de recherche pour permettrede résoudre des problèmes de grande taille est d’utiliser les propriétés des matrices creuses.
Références
1. Jean Baptiste LASSERRE, Global optimization with polynomials and the problem of moments,SIAM J. Optim, 2001
2. Jean Baptiste LASSERRE, A semidefinite programming approach to the generalized problem ofmoments, Mathematical Programming, Vol. 112, No. 1, pp. 65-92., 2008
3. Hayato WAKI, Sunyoung KIM, Masakazu KOJIMA, Masakazu MURAMATSU, Sums of squareand semidefinite program relaxations for polynomial optimization problems with structured spar-sity, SIAM J. Optim, 2006
4. Jos F. STURM, Using SEDUMI 1.02, A Matlab Toolbox for Optimization over Symetric Cones,Optimization Methods and Software 11–12 p 625–653 , 1999
5. A. S. DRUD, CONOPT : A System for Large Scale Nonlinear Optimization, Reference Manualfor CONOPT Subroutine Library 69p ARKI Consulting and Development A/S, 1996
6. P. E. GILL, W. MURRAY, M. A. SAUNDERS, User’s Guide for SNOPT Version 7 : Software forLarge-Scale Nonlinear Programming, 2006
7. L. T. BIEGLER, A.WATCHER, On the Implementation of a Primal-Dual Interior Point Fil-ter Line Search Algorithm for Large-Scale Nonlinear Programming, Mathematical Programming106(1), pp. 25-57, 2006

Challenge ROADEF 2009Gestion de perturbations dans le domaine aérien
M. Boudia1, O. Gerber1, R. Layouni1, M. Afsar2, C. Artigues2, E. Bourreau3 et O. Briant4
1 Amadeus, Operational Research and Innovation Division485, Route du Pin Montard, Sophia Antipolis, France
2 LAAS-CNRS, 7 avenue du Colonel Roche, 21077 Toulouse Cedex France3 LIRMM, 161 rue Ada, 34392 Montpellier Cedex 5, France
4 G-SCOP, INP, 46, avenue Félix-Viallet, 38031 Grenoble, [email protected]
1 IntroductionSuite aux succès remportés par les cinq précédents challenges ROADEF’99, ROADEF’2001, ROA-DEF’2003, ROADEF’2005 et ROADEF’2007, la Société Française de Recherche Opérationnelle etd’Aide à la Décision (ROADEF) lance à nouveau un challenge en 2009 dédié aux applications indus-trielles (challenge.roadef.org).Le challenge propose un problème d’optimisation combinatoire issu d’une problématique centraleindustrielle, dont des instances sont proposés. Initialement c’est un premier jeu d’instances (la base“A”) qui est proposé, permettant de qualifier des équipes candidates pour une seconde phase. Danscelle ci, une seconde vague d’instances plus complexes (la base “B”) est fournie. Enfin, les finalistessont évalués sur des instances inconnues des participants format la base “X”. Il existe deux catégories :juniors et seniors.Cette année le challenge est proposé par Amadeus et concerne la gestion des pertubations dans ledomaine aérien.
2 Le sujet du challengeLes compagnies aériennes commerciales opèrent un programme de vols optimisé du point de vue desrevenus générés. Cependant, il est fréquent que des évenements extérieurs, tels des pannes mécaniques,une grève du personnel, ou des conditions méteorologiques défavorables, viennent en perturber le bondéroulement. Dans de tels cas, il s’agit de trouver des solutions performantes permettant d’absorberla perturbation en un temps minimum et, de fait, d’en minimiser l’impact.Il est d’usage que la prise en charge de ces perturbations se fasse d’une manière séquentielle. Engéneral la flotte d’appareils est considerée en premier, suivie des équipages, et enfin des passagerscomme dernier maillon de cette chaîne. Cependant, cette approche conduit à des optimums locauxau dépend d’un optimum global ou d’une approche integrée qui prend en charge toutes les facettesdu problème en même temps. Ainsi, il ne sera pas possible de revoir le déploiement de la flotte enfonction des itinéraires passagers.Le sujet du challenge ROADEF proposé par Amadeus est consacré à la gestion des perturbationsdans le domaine aérien. Il s’inscrit dans une démarche integrée prenant en compte deux aspects duproblème : la flotte d’avions et les passagers. Le dimension équipage n’est pas prise en compte. Ils’agit d’un problème di%cile et relativement peu étudié par la littérature dans une démarche globaleet integrée.Les données du problème sont :

Challenge ROADEF 2009 387
- un ensemble d’aéroports avec des capacités spécifiques à chaque aéroport et chaque plage horaire,- une flotte d’avions répartis par famille suivant des caractéristiques techniques données. De plus,
chaque appareil a ses propres carractéristiques techniques liées à la maintenance,- un programme de vols construit sur la base du réseau d’aéroports en associant à chaque avion de
la flotte une rotation, c’est-à-dire, une séquence de vols,- un trafic de passagers se déplaçant à travers le programme de vols sus-mentionné avec di#érentes
caractéristiques telles que, la classe (Eco, A#aire, Premiere), le type d’itinéraire (domestique,européen, international), etc . . .
Une combinaison de di#érents types de perturbations est appliquée à ce programme de vol : retardset annulations de vols, pannes d’avions, réduction des capacités de certains aéroports. Il s’agit desperturbations les plus fréquentes constatées dans le monde réel. Elles résultent par exemple desmauvaises conditions météo avec un e#et sur les aéroports ou encore des pannes mécaniques oud’absences d’équipages générant des retards ou des annulations de vols.Suite à ces perturbations, des solutions alternatives les prenant en compte doivent être construites.Ces solutions considèrent aussi bien l’aspect flotte, avec ses di#erents coûts, que l’aspect passagers àtravers l’intégration des di#érentes compensations aux passagers (compensations légales, quantifica-tion des retards et des déclassements de cabines, etc . . . ). Tous ces coûts sont comptabilisés dans lafonction objectif du problème.Di#érentes tailles d’instances sont proposées avec un maximum d’environ 2000 vols par jour desservant150 aéroports à travers le monde, et un horizon de planification de 3 jours. Ces tailles correspondentaux plans de vols des grandes compagnies européennes.
3 Le déroulement et les résultats du challenge
Le challenge a été lancé lors de l’assemblée générale de la ROADEF le 25 février 2008. 29 équipesse sont inscrites, soit 78 participants. On dénombrait 16 équipes de catégorie junior et 13 équipesde catégorie senior, réparties en 11 équipes françaises (34 personnes) et 18 équipes étrangères (44personnes). Ces 29 équipes ont du envoyer leur programme de résolution des instances de la base “A”le 16 juillet 2008. Parmi les 29 équipes inscrites, 11 équipes ont ete qualifiées dont 7 équipes senioret 4 junior, comme annoncé le 22 septembre 2009 à l’issue de la phase de tests des programmes parAmadeus.Les méthodes proposées par les candidats ne seront pas dévoilées avant la fin du challenge (au re-pas de Gala de la Roadef le 11 février 2009 à Nancy). Néanmoins, la lecture des résumés étendusenvoyés révèle sans surprise que toutes les méthodes proposées sont des méthodes heuristiques ré-solvant le problème en le décomposant en plusieurs étapes, avec toutefois une assez grande variétéd’approches. Parmi les dénominateurs communs des outils de base utilisés, on trouve de manièreassez logique des algorithmes élémentaires de flots et de chemins optimaux. Sans révéler ce qui a lemieux marché pour cette phase de qualification, les schémas généraux de résolution se répartissenten algorithmes purement gloutons, méthodes de descente avec redémarrage, recuit simulé, méthodeshybrides de programmation linéaire en nombres entiers et de recherche locale, génération de colonnes.En termes d’implémentation, les programmes ont été développés en Delphi, C, C++, Java avec ounon l’utilisation de librairie de structure de données et de solveurs de programmation linéaire.Parmi les 11 équipes qualifiées, 9 seulement ont renvoyé leur programme de résolution des instancesde la base “B” à temps le 5 janvier 2009. Ces programmes ont été évalués par l’équipe d’Amadeusen introduisant la base “X” d’instances qui est restée inconnue des candidats et sera mise en lignesuite à la conférence ROADEF 2009.En attendant le 11 février pour connaître le classement final, nous vous invitons à lire dans ce recueilles résumés des méthodes proposées par les candidats au challenge, dont voici la liste :

388 Boudia, Gerber, Layouni, Afsar, Artigues, Bourreau, Briant
Equipes qualifiées et ayant fourni un programme pour la phase finale
Catégorie SeniorRodrigo Acuna-Agost, Philippe Michelon, Dominique Feillet1, Serigne Gueye21 LIA, Université d’Avignon, France, 2 LMAH, Université du Havre, FranceSerge Bisaillon1, Jean-François Cordeau2, Gilbert Laporte, Federico Pasin11 CIRRELT, Canada, 2 HEC Montréal, Canada,Said Hanafi, Christophe Wilbault, Raid Mansi1, François Clautiaux21 Université de Valenciennes, France, 2 IUT Lille 1, FranceNicolas Jozefowiez1, Catherine Mancel, Félix Mora-Camino21 LAAS-CNRS, Toulouse, France, 2 LARA, ENAC, Toulouse, FranceJohan Peekstok, Eelco KuipersPays-Bas
Catégorie JuniorSophie Dickson, Olivia Smith, Wenkai LiUniversity of Melbourne, AustralieJulien Darlay, Louis Philippe Kronek, Susann Schrenk, Lilia ZaourarG-SCOP, Grenoble, FranceNiklaus Eggenberg, Matteo SalaniTransport and mobility Laboratory, EPFL, SuisseChristian Eggermont, Murat Firat, Cor Hurkens, Maciej ModelskiTechnical University Eindhoven, Pays-Bas

Challenge ROADEF 2009.Statistical Analysis of Propagation of Incidents for
rescheduling simultaneously flights and passengers underdisturbed operations
R. Acuna-Agost1, P. Michelon1, D. Feillet2, and S. Gueye3
1 Université d’Avignon et des Pays de Vaucluse, Laboratoire d’Informatique d’Avignon (LIA),F-84911 Avignon, France {rodrigo.acuna-agost,philippe.michelon}@univ-avignon.fr
2 Ecole des Mines de Saint-Etienne, F-13541 Gardanne, [email protected]
3 Laboratoire de Mathématiques Appliquées du Havre, F-76058 Le Havre, [email protected]
1 IntroductionAirline operations are usually perturbed by disruptions like mechanical failures, bad weather, andmany other unexpected events. As a result, the original schedule may become suboptimal and, inextreme cases, infeasible. In this paper, we deal with the problem to reschedule aircrafts and pas-sengers simultaneously. In particular, we consider the problem as it is presented in ROADEF 2009Challenge Disruption Management for Commercial Aviation [1] : An original (unperturbed) scheduleis known, that is departure/arrival times, aircraft rotation plan, and the itineraries (origin - destina-tion - flights) for a set of passengers. Other important aspects are also given : airport capacities, finalposition of aircrafts, length of the recovery window, and all relevant unitary costs for calculating anobjective function. Additionally, a set of di#erent disruptions defines the initial status of the systemat the beginning of the recovery window. The problem is then to calculate a new provisional sche-dule respecting all the constraints by minimizing an objective function that measures the di#erencebetween the new provisional schedule and the original one.
2 Solution method and resultsWe propose a mixed integer programming (MIP) formulation to model this problem. The modelcould be interpreted as two integrated multi-commodity flow problems. The first one is related toaircrafts flowing through airports, and the second one to passengers flowing through flights. As othermulti-commodity flow problems, the mathematical formulation includes capacity, flow conservationand demand satisfaction constraints. Thus, our model leads to an NP-complete problem since theoriginal multi-commodity flow problem is shown to be NP-complete for integer flows [2].Because of the complexity of the instances [1], it is not possible to solve this model using directly astate-of-the-art MIP solver. We present three strategies to manage this problem : reducing the size ofthe MIP model (before to build it), applying Statistical Analysis of Propagation of Incidents(SAPI) to solve it quickly, and improving the final solution with a post optimization procedure.First, we reduce the number of variables and constraints by limiting the search space with only"good" solutions. We define a "good" solution as a provisional schedule near, or similar, to the originalschedule. The result is a compact search space in which aircraft (and passenger) moves are limitedwithin a restricted set of possible flights.

390 Acuna-Agost, Michelon, Feillet, Gueye
We propose a new methodology called SAPI to solve this MIP model. This method was created origi-nally for rescheduling trains after disruption [3] - [4]. The thesis of this method is that every scheduleevent could be a#ected (or not) by some given disruptions with a certain probability. A statisticalanalysis is used to estimate these probabilities and then reducing the complexity by fixing someinteger variable. This version of SAPI is an iterative procedure that requires and initial (incumbent)solution calculated by Right-Shift Rescheduling. That is, fixing all integer variables in order tokeep the original assignment of aircrafts and passengers without allowing changes. The next step ofSAPI is to calculate the probabilities. We propose a logistic regression model because, in contrast toother regression methods, it allows to estimate multiple regression models when the response beingmodeled is dichotomous (i.e can be scored 0 or 1). For our method, the evaluation of this regressionmodel gives the probability that a flight j has to be cancelled in the optimal solution. Using thesesprobabilities, it is possible to segregate the flights in two big sets : a) flights expected to be cancelledand b) the rest of the flights. At each iteration, the algorithm fixes the integer variables associated toflights that have already their expected value, while the remaining variables are computed by solvingthe resulting MIP. Additionally, this algorithm includes a diversification procedure to escape fromlocal solutions.Finally, we apply a post optimization procedure to improve the current solution. This function triesto assign cancelled passengers in any kind of flights in such a way to minimize cancelation penaltiesthat are much more expensive than delays.Our method has been implemented using MS Visual Studio 2005 (C;) and ILOG CPLEX 11.1 as aMIP solver, on a PC Intel Core Duo 1.66 GHz 2 GB RAM over Windows Vista Operation System.We use the published results of the qualification phase of [1] in order to compare and evaluate theperformance of our method. Using the average normalized score proposed by the organization, ourlast results have an average = 0.9997 (CPU time of 10 minutes for each instance of set A). Consideringthe sum of the total cost for all instances in set A, our method return a total cost 80.3% lower thanour last version (without SAPI / post-optimization) and 37.2% lower than the best classified team.
Références
1. ROADEF, Société française de Recherche Opérationnelle et Aide à la Décision, Challenge ROA-DEF 2009 : Disruption Management for Commercial Aviation, http ://challenge.roadef.org/2009
2. On the Complexity of Timetable and Multicommodity Flow Problems, S. Even and A. Itai andA. Shamir, SIAM Journal on Computing, 1976, 5, pp. 691-703
3. SAPI : Statistical Analysis of Propagation of Incidents A new approach applied to solve therailway rescheduling problem Acuna-Agost R., Feillet D., Gueye S., Michelon P. The internationalconference on NonConvex Programming : Local and Global approaches. Theory, Algorithms andApplications, NCP07, December 17-21, 2007, Rouen, France.
4. Méthode PLNE pour le réordonnancement de plan de circulation ferroviaire en cas d’incident.Acuna-Agost R., Feillet D., Gueye S., Michelon P. ROADEF 2008, 25-27 Février 2008 - Clermont-Ferrand, France

Challenge ROADEF 2009.Une méthode de recherche à grand voisinage pour la
gestion des perturbations dans le domaine aérien
S. Bisaillon1 , J.-F. Cordeau1, G. Laporte1, and F. Pasin1
HEC Montréal and [email protected]
Cet article décrit le travail réalisé par notre équipe dans le cadre du challenge ROADEF 2009.La méthode que nous avons élaborée pour résoudre ce problème très complexe comprend plusieursphases pour en traiter e%cacement les divers aspects. Les phases principales sont la construction, laréparation ainsi que l’amélioration de solutions initiales. Notre programme itère entre ces trois phasesjusqu’à ce que le temps imparti soit écoulé.
1 Construction
Tout d’abord, nous cherchons à construire des solutions réalisables en ce qui a trait aux contraintesopérationnelles et fonctionnelles décrites à la section 6 du document. Pour ce faire, nous commençonspar ordonner aléatoirement les appareils afin de les traiter selon un ordre di#érent à chaque itération.Ensuite, à partir du programme de vols original, nous retirons des séquences de vols jusqu’à ce quetoutes les contraintes soient respectées. Pour retirer ces séquences, nous procédons comme suit.Nous prenons chaque appareil, un à la fois, et nous vérifions si la séquence originale, à laquelle nousavons ajouté les perturbations, reste valide, et ce vol par vol. Dès qu’un vol perturbé fait en sorted’invalider la séquence, nous retirons la plus petite sous-séquence de vols qui forme une boucle (dontl’aéroport d’arrivée du dernier vol correspond à l’aéroport de départ du premier vol) et la conservonsen mémoire pour tenter de la réinsérer ailleurs plus tard. Si la boucle retirée survient avant le momentoù le vol critique devait avoir lieu, alors nous essayons d’annuler dans la mesure du possible, les retardsaccumulés par les vols qui se trouvent entre la séquence annulée et le vol à réinsérer pour voir s’il y apossibilité d’accommoder ce vol. Nous recommençons tant que nous n’avons pu insérer le vol de façonsatisfaisante ou qu’il n’y ait plus de boucle à retirer. Dans ce dernier cas, nous tentons de réinitialisertous les vols précédant le vol courant (donc en annuler les retards non nécessaires) et plaçons le volcourant au premier moment possible qui ne contrevienne pas aux contraintes de maintenance desappareils, et ce, même si ça contrevient temporairement aux capacités aéroportuaires. Dans le casoù certaines capacités seraient violées, cela sera corrigé dans la phase subséquente (réparation de lasolution).
2 Réparation
Dans cette phase de réparation de la solution, on repasse chacun des appareils dans le même ordreque dans la phase de construction et on cherche à faire en sorte de rendre la solution réalisable entermes des capacités aéroportuaires. Car il se peut qu’à la construction, nous ayons dû laisser des volsà leur horaire initial même si les capacités ne le permettaient pas, du fait que l’annulation du restede la séquence originale n’aurait pas permis de terminer la rotation au bon aéroport. Cependant,nous avons remarqué, qu’il y a presque toujours un autre appareil dont les vols partagent les mêmes

392 Bisaillon, Cordeau, Laporte, Pasin
origine ou destination qui posent problème à une période donnée mais qui peuvent être déplacés sanscompromettre la réalisabilité. C’est ce que nous tentons de faire dans cette phase.Aussi, dans le but ultime de respecter les contraintes qui se rapportent aux itinéraires, dès qu’un volest retiré, nous annulons tous les itinéraires qui transitaient par ce vol. Ainsi, la solution initiale quenous obtenons à la fin des phases de construction et de réparation est largement sous-optimale, maisau moins elle respecte toutes les contraintes du problème.
3 Amélioration
Une fois que nous avons construit ce qui nous sert de solution initiale, nous tentons de l’améliorerpar des moyens simples mais rapides. Tout d’abord, nous tentons de voir s’il est possible d’ajouterdes vols dont les caractéristiques correspondent le plus possible à ceux qui ont dû être annulésdirectement à cause des inscriptions en ce sens dans le fichier alt_flights.csv. Nous tentons aussi à cemoment de réinsérer les segments de vols préalablement retirés. Ayant pris en note tous les intervallesde temps (entre deux vols) su%samment grands pour chaque appareil, nous tentons d’y insérer lessegments de vol de façon gloutonne (dès qu’un segment peut être inséré sans problème, on réalisece mouvement, sans vérifier s’il irait mieux ailleurs). Nous avons noté que ce genre de mouvementpermettait d’améliorer sensiblement la valeur de la solution sans que ce ne soit très coûteux en termesde temps de calcul.À chaque fois que nous avons achevé une phase importante d’altération du programme de vols,nous tentons de réaccomoder les passagers laissés en plan en résolvant à répétition un algorithmede plus court chemin (PCC) en commençant par réa#ecter les passagers dont le coût de pénaliteen cas de non-a#ectation est le plus grand. Si le PCC réussit à trouver un itinéraire qui respecte lacapacité résiduelle des appareils ainsi que les contraintes de correspondance, de départ et d’arrivéepour un certain nombre de ces passagers, alors nous créons un nouvel itinéraire pour ces passagers,et nous tentons de réa#ecter les autres sur un autre itinéraire. Dans le cas contraire, les passagersnon réaccommodés restent dans une liste pour que nous puissions tenter de les réa#ecter plus tard.Après la phase de réa#ectation des passagers, nous tentons de décaler (retarder) des vols, dansl’espoir de pouvoir réaccommoder encore plus de passagers dont les problèmes de correspondancepourraient alors être résolus. Pour ce faire, nous prenons encore une fois chaque appareil, un à un,et nous tentons de décaler leurs vols d’un certain intervalle de temps. Pour chaque vol de chaqueappareil, nous essayons diverses périodes de retard et dès que nous obtenons un changement quine cause aucune annulation de vols, nous vérifions s’il y a moyen d’améliorer la meilleure solutionen tentant de réa#ecter des passagers. Évidemment, lorsque nous retardons un vol, nous retardonsensuite chacun des vols de la séquence subséquente pour cet appareil tant qu’il est nécessaire, pourrespecter les contraintes. Ce faisant, il se peut que nous devions annuler certains itinéraires dont lacontinuité ne serait plus possible.Quand cette descente (phase d’amélioration locale) ne permet plus aucune amélioration possible ouque le temps qui lui est imparti est écoulé, nous mettons à jour la meilleure solution globale et nousrecommençons le processus de construction avec diversification. Pour ce faire, nous opérons une sériede permutations sur la meilleure solution globale et nous poursuivons avec le retrait des séquencesde vols. À l’occasion, nous pouvons même décider qu’il est préférable de repartir à zéro avec un autreordonnancement aléatoire des appareils si la solution globale ne s’améliore pas assez rapidement.

Challenge ROADEF 2009.Stratgie d’oscillation pour la gestion de perturbations
dans le domaine arien
Saïd Hanafi1, Christophe Wilbaut1, Raïd Mansi1 et Franois Clautiaux2
1 LAMIH, équipe SIADE, UMR 8530, Université de Valenciennes, France.(said.hanafi,christophe.wilbaut,raid.mansi)@univ-valenciennes.fr
2 LIFL, équipe DOLPHIN, Université de Lille 1, [email protected]
1 Introduction
Nous décrivons dans ce papier l’approche proposée dans le cadre du challenge ROADEF 2009, concer-nant la gestion de perturbations dans le domaine aérien. Il est fréquent que des événements extérieurs,tels des pannes mécaniques, une grève du personnel, ou des conditions météorologiques défavorables,viennent perturber le bon déroulement des programmes de vols des compagnies aériennes. Il s’agitalors de trouver des solutions performantes permettant d’absorber la perturbation en un temps mi-nimum. Le sujet vise à réa#ecter de façon simultanée la flotte d’appareils et les passagers, plutôt quede se baser sur le processus hiérarchique naturel : 1) flotte d’appareils, 2) équipages, 3) passagers.
2 Description de l’approche
Nous proposons une stratégie d’oscillation mixant les méthodes exactes et approchées constituée dequatre composants principaux : (i) Génération d’une solution initiale non nécessairement réalisable ;(ii) Suppression de sous-routes des avions et annulations des itinéraires des passagers associés quin’ont pu être réa#ectés ; (iii) Création de nouvelles routes pour les avions et des itinéraires pour lespassagers ; (iv) A#ectation des passagers annulés aux bonnes routes.
Génération d’une solution initiale : Notre objectif consiste à trouver une solution du problème nonnécessairement réalisable à l’aide de deux programmes linéaires en nombres entiers mixtes (MIP)et d’une heuristique. Dans les deux modèles nous ignorons les contraintes de capacités des cabineset nous relaxons partiellement les contraintes de capacités d’atterrissage et décollage des aéroportsen ajoutant des variables de tolérances de violation. L’objectif est d’assurer les contraintes dures demaintenances des appareils. Après la récupération de la solution du premier modèle, nous résolvons lesecond MIP dont l’objectif est de maximiser le nombre de passagers qui arrivent à leurs destinationsfinales tout en minimisant les violations des capacités d’atterrissage et de décollage des aéroports.Les deux modèles MIP sont résolus avec CPLEX. Si la solution obtenue n’est pas réalisable, nousdéclenchons une heuristique de réparation visant à assurer les contraintes de maintenance violées.
Stratégie d’oscillation : Nous cherchons à améliorer la qualité de la solution obtenue en ajoutant etsupprimant itérativement des routes et des itinéraires. Notre approche repose sur le principe d’os-cillation qui consiste à définir un rythme alterné plus ou moins régulier pour traverser les niveauxcritiques dans di#érentes directions. Les phases constructives et destructives sont décrites brièvement

394 Hanafi, Wilbaut, Mansi, Clautiaux
dans la suite.
Génération et suppression des routes et des itinéraires : Les itinéraires possibles pour les pas-sagers et les routes possibles pour les avions sont générés par des heuristiques qui reposent sur desrecherches arborescentes tronquées, de type “meilleur d’abord”. Nous avons testé plusieurs stratégies :itinéraire contenant les aéroports les moins visités d’abord, ceux qui se rapprochent le plus de la des-tination finale, minimum d’attente dans les aéroports. Se rapprocher le plus possible de la destinationfinale est souvent la meilleure stratégie. L’algorithme de génération de routes pour les avions reposesur le même principe. Les di#érentes stratégies que nous avons testées pour l’ajout d’un vol sont lessuivantes : aéroports les moins visités, se rapprocher du positionnement final (s’il existe), vol le pluscourt, aéroports les moins surchargés, vol le plus demandé par des passagers, vol qui part au plustôt. En pratique, ne pas prendre en compte les passagers mène rarement à une solution intéressante.L’heuristique de suppression de routes pour les avions et des itinéraires pour les passagers repose surle principe dual de la génération. Nous supprimons surtout les sous-chemins des routes qui sont lesmoins remplis par rapport aux capacités des avions.
Création des routes et a#ectation des passagers : L’objectif de cette phase est de créer de nouveauxvols permettant de réa#ecter d’autres passagers en attente. Nous avons modélisé le problème de cettephase sous forme d’un sac à dos multidimensionnel en variables binaires et entières avec contraintesde choix multiples. Les variables binaires correspondent aux choix de routes et les variables entièresaux nombres de passagers des groupes. Ce modèle prend en entrée un ensemble d’itinéraires possiblespour les passagers et un ensemble de routes possibles pour les avions. Notre modèle prend en compteles contraintes de capacités aéroportuaires, ainsi que les capacités des cabines des avions. L’objectifest de maximiser le nombre de passagers assurant leur itinéraire tout en minimisant le nombre devols crées.
3 Conclusions
Le problème de gestion de perturbations dans le domaine aérien est un sujet d’actualité et de nom-breux travaux y ont été consacrés. Pour le traiter nous avons opté pour une approche d’oscillationhybride qui utilise les heuristiques et les méthodes exactes. Nos approches peuvent encore être amé-liorées, en intégrant de la mémoire adaptative de la recherche tabou et en calibrant les paramètres.D’autres pistes d’amélioration à explorer peuvent être listées telles que l’exploitation de plus d’in-formations duales pour la génération des routes, ou encore la possibilité de réutiliser le modèle dela première phase pour ajuster les retards, ainsi que l’autorisation de visiter des solutions non réali-sables.

Challenge ROADEF 2009.Approche heuristique pour la gestion de perturbations
dans le domaine aérien
Nicolas Jozefowiez1,2 , Catherine Mancel3, Félix Mora-Camino3
1 CNRS ; LAAS ; 7 avenue du colonel Roche, F-31077 Toulouse, [email protected]
2 Université de Toulouse ; UPS, INSA, INP, ISAE ; LAAS ; F-31077 Toulouse, France.3 ENAC, 7 Avenue Edouard Belin, BP 54005, 31055 Toulouse Cedex.
1 Introduction
Nous présentons ici un algorithme de résolution du problème de gestion de perturbations dans ledomaine du transport aérien soumis dans le cadre du Challenge ROADEF 2009. À partir d’un plande vol connu, de l’a#ectation des passagers aux vols et compte tenu d’un ensemble de perturbations, ils’agit de trouver de nouvelles a#ectations des avions aux vols et des passagers aux vols qui permettent,au terme d’une certaine fenêtre temporelle, de s’approcher au mieux de la situation prévue avantperturbations.Notre approche consiste en deux phases. La première phase génère une solution réalisable, donnéesous la forme d’un ensemble de rotations d’avions et d’un ensemble d’itinéraires passagers ; la secondephase améliore itérativement la solution en faisant intervenir di#érents modules de modification desrotations et de réaccommodation de passagers qui maintiennent la solution réalisable.
2 Intégration des perturbations et génération d’une solutionréalisable dégradée
Afin de produire rapidement une solution réalisable, on procède en deux étapes. On construit d’abordl’ensemble des rotations avions auxquelles on intègre les maintenances sous forme de vols fictifs, etl’ensemble des itinéraires passagers, sans prendre en compte les perturbations.On intègre ensuite les perturbations en appliquant di#érentes règles qui conduisent à obtenir dansun premier temps des rotations discontinues. Afin de rétablir la faisabilité des rotations d’un avion,on utilise un algorithme de plus court chemin dans le graphe des vols réalisables pour cet avion dansun intervalle de temps restreint.Les itinéraires passagers impactés par les perturbations sont tronqués ou totalement annulés suivantles contraintes s’appliquant à ces itinéraires.
3 Améliorations itératives de la solution
Afin d’améliorer la solution réalisable alors obtenue, on met en œuvre un processus itératif alter-nant une phase de modification des rotations et une phase de réaccommodation des passagers. Lesitérations sont poursuivies tant que des améliorations sont détectées.

396 Jozefowiez N., Mancel C., Mora Camino F.
3.1 Heuristiques de modification des rotations
La modification des rotations est guidée par l’évaluation de la demande en termes d’origines-destinations-temps compte tenu des itinéraires passagers courants et prévus. On établit une liste de métagroupesde passagers présentant des caractéristiques communes, triée par ordre d’importance décroissante.Pour chacun des métagroupes de passagers ainsi identifié, il faut trouver un chemin permettant derejoindre la destination prévue pour un coût acceptable.Cette recherche de chemin peut être traitée comme un problème de plus court chemin entre deuxaéroports pour un ensemble restreint d’avions dans le graphe des vols réalisables ou dans le graphedes vols déjà programmés et des vols réalisables. Dans le premier cas, on se ramène à la recherched’une extension de la rotation d’un avion entre deux aéroports permettant d’assurer la continuitéde la rotation. Dans le second cas, on se ramène à la recherche d’extensions de plusieurs rotationsd’avions entre di#érents aéroports atteignables par des vols déjà programmés et l’aéroport destinationdu métagroupe considéré.
3.2 Heuristique de réaccommodation des passagers sur un ensemble de volsprogrammés
Etant donné un ensemble de vols programmés, le problème de l’a#ectation des passagers aux volspeut être perçu comme autant de problèmes de plus court chemin dans un graphe spatio-temporelqu’il y a de groupes de passagers.L’ordre dans lequel sont traités les passagers impactant la solution globale, nous avons appliqué lastratégie suivante. Etant donnée une solution réalisable courante d’itinéraires partiellement réalisés,on identifie ceux qui ont été interrompus ou annulés. Nous avons donc trois classes d’itinéraires posantproblème qui sont, par ordre d’importance : les itinéraires interrompus (ceux qui avaient commencéavant la fenêtre de recouvrement), les itinéraires retour annulés et les itinéraires aller annulés. Danschaque classe, les itinéraires sont ordonnés par valeur décroissante du produit du prix du billet parla taille du groupe de passagers.Pour chaque groupe de passagers considéré, on cherche alors un chemin permettant d’atteindre ladestination voulue et réalisant le meilleur compromis entre la date d’arrivée à destination et le nombrede passagers du groupe qui pourront être acheminés. En e#et, soit la capacité des avions réalisantle chemin trouvé permet d’acheminer tout le groupe de passagers, soit le groupe doit être scindé endeux sous-groupes. Dans le premier cas, un nouvel itinéraire est généré pour tout le groupe, dansle second cas, on a#ecte un sous-groupe au nouvel itinéraire et l’autre sous-groupe est inséré dansl’ensemble des itinéraires à traiter en fonction de sa nouvelle priorité. Ce processus est itéré tantqu’on peut réaccommoder des passagers.
4 Conclusions
La méthode que nous proposons ici utilise les spécificités des problèmes de transport aérien et deleurs contraintes pour obtenir très rapidement des solutions réalisables.

Challenge ROADEF 2009.Use of a Simulated Annealing-based algorithm inDisruption Management for Commercial Aviation
J. Peekstok1 and E. Kuipers2
1 [email protected] [email protected]
In this paper we present an algorithm based on simulated annealing used for solving a very complexscheduling problem, which is the ROADEF 2009 Challenge problem that is about minimizing costas a consequence of the disruption in the schedule of a commercial airline. The algorithm presentedhere was submitted to the ROADEF 2009 Challenge as one of the finalists.
Initial solutionThe starting point of the algorithm, the initial solution, is the original schedule as provided in a setinstance files provided by the Challenge organization, including the disruption. The inclusion of thedisruption usually results in the initial solution being infeasible, and this does occur in all 20 sets ofinstances files (Challenge sets A en B).
InfeasibilitiesGiven the initial solution, the choice is to accept infeasibilities during the iteration process of simula-ted annealing. We preferred anyway, since restricting the local search algorithm to feasible solutionswould in our opinion be too restrictive to achieve good results. Feasibilities we allow in our algorithmare :– Airport departure or arrival rate violations– Aircraft time transit or turn-around violations– Aircraft feasible schedule violations (non-matching arrival and departure airport)– Aircraft maintenance or unavailability schedule violations– Passenger maximum capacity on aircraft violations– Passenger connection time violations– Passenger feasible schedule violations
Ensuring feasibilityIn order to handle infeasibilities, we introduced a second objective value, or a value that quantifiesthe level of infeasibility of the complete solution. During our tests on test-set B we found that findinga feasible solution is in itself not an easy task, let alone then optimizing it. Secondly, we discoveredthat passenger infeasibilities are not nearly as hard to fix as any of the first 4 (airport and aircraft)infeasibilities. Therefore we decided that once we have achieved airport and aircraft feasibility, wewill not allow the current solution to become infeasible again for airports or aircraft. After achievingairport and aircraft infeasibility we will still allow the algorithm to have passenger infeasibility. Infact, we allow the algorithm to switch back and forth between attempting to lower the value of theobjective function and driving the passenger infeasibility level to zero. This way, if no improvementof the objective value can be found without introducing infeasibility, the algorithm can still improve.After a while the cost of infeasibility is slowly increased so that the algorithm is forced to make thesolution feasible again.

398 Peekstok, Kuipers
Neighbors
In building our algorithm we have tested with the following simulated annealing neighbors :– Canceling an existing flight– Adding a new flight– Moving an existing flight forward or backward in time*– Change the operating aircraft of an existing flight*– Change the operating aircraft of a pair of existing (consecutive) flights– Change the operating aircraft of an existing flight and move it in time– Exchange the operating aircraft of two existing flights*– Exchange the time of departure of two existing flights– Change a flight of a passenger’s itinerary*– Remove a flight from a passenger’s itinerary*– Add a flight to a passenger’s itinerary*– Exchange the itineraries of two passengers* Neighbors active in the algorithm submitted for the ROADEF 2009 ChallengeIt would be a mistake to conclude that none of the neighbors not used in our submitted algorithm hasany value. We did see some instances respond favorably to several of these neighbors but determiningif they are valid for all instances requires further investigation.
Tuning the final algorithm
The set of neighbors in the final algorithm does not contain any means by which flights are removedfrom the schedule or added to it, but we realized early on that a mechanism is needed that attemptsto discover trade-o#s between flights and decide which flights are to be cancelled or added. It provedimpossible in the time we had to make this a true part of the annealing process so this is done in aconstructive way. A rough outline of the submitted algorithm is :– Phase 1 : Algorithm start with only aircraft neighbors. Passengers remain on their flights in this
phase. If airport and aircraft feasibility is achieved move to phase 3. If not, keep trying until aconfigurable time is spent then move to phase 2.
– Phase 2 : Periodically delete the cheapest flight that causes infeasibility at an airport or aircraftand attempt to reach feasibility. Insert flights to reach maintenance airports if necessary.
– Phase 3 : Airport and aircraft are feasible. Algorithm continues with all 6 neighbors, now allowingpassengers to move between the flights. When completely feasible (i.e. passenger feasibility isachieved as well) move to phase 4a.
– Phase 4a : Periodically attempt to add return trip for an aircraft to relieve highest cumulativecancel, delay and downgrade cost for passengers (cumulative per hour, per origin-destination pair).Airport and aircraft are required to stay feasible. If passenger infeasibility occurs, move to phase4b.
– Phase 4b : Slowly increase cost of infeasibility to drive algorithm back to feasibility. If feasibilityis achieved, return to phase 4a.

Challenge ROADEF 2009.Une approche heuristique pour la gestion de
perturbation dans le domaine aérien
J. Darlay1, L.-P. Kronek1, S. Schrenk1 and L. Zaourar1
Laboratoire G-SCOP, 46 avenue Félix Viallet, 38031 Grenoble Cedex France.{julien.darlay, susann.schrenk, lilia.zaourar}@g-scop.inpg.fr
1 IntroductionLorsque des perturbations a#ectent le plan de vol initial d’une compagnie aérienne, celui-ci doit êtrereconstruit à l’intérieur d’une période de recouvrement. Ceci doit être fait en réa#ectant de façonsimultanée la flotte d’appareils et les passagers, en ayant la possibilité d’annuler et de créer desvols. L’objectif est de minimiser l’impact des perturbations à la fois pour la compagnie et pour lespassagers.Pour cela, nous proposons une méthode de résolution qui s’appuie sur le fait qu’une fois la flotted’appareil réa#ectée sur les vols, la réa#ectation optimale des passagers sur ces vols est relativementsimple. Comme la réa#ectation des appareils sur les vols de façon optimale pour les passagers estdi%cile ; nous avons conçu une heuristique constructive qui alterne entre une phase de constructiondes plans de vols et une phase de réa#ectation des passagers sur ces vols. Ceci pour assurer une bonnequalité de la solution, ces deux étapes s’inspirent le plus possible du plan de vol et des itinéraires despassagers initiaux.
2 Stratégie de résolution2.1 A!ectation des avionsOn réa#ecte les appareils sur les vols initialement opérés en autorisant des retards supplémentaireset sur des nouveaux vols, créés pour amener les appareils à leur aéroport de maintenance. Si un voln’est opéré par aucun appareil, il est annulé.Notre modélisation du problème correspond à calculer un multiflot max de coût min dans un réseauespace-temps avec des contraintes supplémentaires. Afin que les nouvelles rotations construites parla résolution de ces flots profitent d’une part de la solution initiale proposée, et d’autre part prennenten compte les coûts passagers (coûts de retard), il faut a#ecter des coûts sur les di#érents vols.Ces coûts reflètent les coûts d’annulation, les coûts de retard avec une évaluation des éventuellescorrespondances ratées ainsi que les coûts de repositionnement. Ces coûts permettent de prendreégalement en compte les retards, les annulations, les déclassements ainsi que les coûts concernant lemauvais positionnement des appareils en fin de période. Hormis la contrainte de flot, afin d’obtenirune solution réalisable, on ajoute des contraintes de capacités de décollage et d’atterrissage desaéroports, ainsi que les indisponibilités des appareils et surtout les maintenances.Le problème a été découpé famille par famille d’avions, modèle par modèle d’avions, ou plus finementpar paquets d’avions bien choisis afin que le modèle linéaire en nombres entiers résultant tienne enmémoire, se charge et soit résolu rapidement.A la fin de cette étape on obtient un nouveau plan de vol réalisable. Il faut maintenant réa#ecter lespassagers au mieux sur ce plan de vol.

400 Darlay, Kronek, Schrenk, Zaourar
2.2 A!ectation des passagers
La réa#ectation des passagers sur les vols fixés à l’étape précédente se fait de la manière suivante :Pour chaque itinéraire p on génère un ensemble de chemins possible ch(p), tel que l’heure de départde chaque chemin ch est supérieure à l’heure de départ initiale et qu’il ait même origine et mêmedestination. Ces chemins prennent en compte les di#érentes classes (F/B/E). A chaque chemin estassocié un coût dû à un retard ou à un déclassement. Les passagers qui ne seront a#ectés sur aucunchemin voient leur voyage annulé. Les chemins générés pour un itinéraire correspondent, modulochangement de classe, à un vol direct, au chemin de l’itinéraire initial et à des chemins faisanttransiter les passagers via des hubs.Notre formulation pour cette seconde phase revient à un problème de multiflot avec capacités enformulation chemin.
3 Implémentation et résultats numériques
L’implémentation de notre approche de résolution a été faite en C++ avec l’utilisation de la librairieboost, notamment pour la gestion du temps. La résolution des modèles de multiflot décrit ci-dessusutilise le solver ILOG Cplex 11. Le système d’exploitation utilisé est Windows XP. Les résultatsobtenus sont encourageant sur le jeu A. Sur les instances A05 et A10, on gagne 30% par rapportau meilleur résultat lors des qualifications. Nous parvenons à obtenir, en moins de 10 minutes dessolutions réalisables pour les 10 instances du jeu B.
4 Conclusion et perspectives
Au cours de ce travail, nous avons abordé le problème de réa#ectation des appareils et passagers d’unecompagnie aérienne en minimisant les coûts pour une perturbation quelconque du programme de volinitial. Pour prendre en charge l’ensemble des contraintes liées au problème, nous avons opté pourune modélisation en multiflot avec capacité et chemin. Cette modélisation vise à minimiser les coûtsrelatifs au problème, ceci afin d’obtenir une a#ectation optimale de la flotte ainsi que des passagers.Notre résolution nous permet d’obtenir une première "bonne" solution dans le temps imparti et quivérifie toutes les contraintes.Une prochaine étape serait d’approfondir la génération des chemins explorés dans la deuxième phase,en les augmentant en nombre et en qualité et en les intégrant dynamiquement dans le modèle (pargénération de colonnes). Ensuite, cette première solution sera modifiée avec des allers retours entreréaccommodation des passagers et a#ectation des appareils. De plus, des découpages des instances,en périodes plus petites pourront nous permettre de limiter le temps de résolution de nos modèles,notamment pour les instances sur 2 jours.

Challenge ROADEF 2009.Disruption Management for Commercial Aviation, A
Mixed Integer Programming Approach
Sophie Dickson1, Olivia Smith1 and Wenkai Li2
1 Department of Mathematics and Statistics, The University of [email protected]
2 Faculty of Information Technology, Monash University
This abstract describes a solution approach to the problem posed in the ROADEF 2009 Chal-lenge : Disruption Management for Commercial Aviation. For details of the challenge seehttp ://challenge.roadef.org/2009.The ROADEF Challenge 2009 deals with the airline recovery problem. The objective is to findthe optimal passenger and aircraft routing given a set of disruptions, existing passenger itinerariesand operating constraints.The operating constraints considered include airport capacity constraints (limits on the number ofdepartures and arrivals per hour), the minimum turn time for each aircraft (or transit time for multi-leg flights), the maximum flight range for each aircraft, any maintenance requirements (at a specificlocation and time), aircraft capacity, minimum connection time for transiting passengers, maximumpassenger delay and the required aircraft location at the end of the recovery period.The disruptions considered in the challenge include airport capacity disruptions such as reduceddeparture and arrival capacity or closure, aircraft unavailability (the timing and duration of anaircraft unavailability due to unserviceability or fault), flight cancellations and flight delays.For more detail on the constraints and disruptions, the reader is referred to the full problem descrip-tion at http ://challenge.roadef.org/2009/challenge_en.pdf.A 2 stage process was developed to address this problem. The first stage seeks to re-route aircraft,retime and/or cancel flights so as to minimise the disruption experienced by passengers on theirexisting itineraries. This is achieved through the use of a Mixed Integer Linear Program (MILP)connection network, with flights represented by nodes and connection variables for both passengersand aircraft. A continuous delay variable also exists for each flight to allow it to be retimed.A second phase then reoptimises passenger itineraries based on the flight schedule determined inphase one. A multi-commodity network flow model is used, with each passenger itinerary a separatecommodity, flowing through arcs representing each cabin class in each flight. The objective is thento maximise the value of the itineraries flowing through the flight network, within the given flightcapacity and passenger demand.There are a wide range of potential scenarios for the airline disruption problem, and each scenariopresents its own challenges with resepect to solvability of the MIP. As a result, some aspects of themodel are adjusted according to the size of the problem (e.g. the number of flights, the duration ofthe recovery period, the number of passenger itineraries).The key to keeping the MILP at a manageable size is to limit the number of binary variables. Flightconnections and departure/arrival slot variables represent a significant proportion of binary variablesin the model. The following parameters are used to limit their number– MAX_FLIGHT_DELAY restricts how long we are prepared to delay a flight. Any flight that does
not depart within MAX_FLIGHT_DELAY of its original scheduled time of departure, must becancelled. This parameter limits the number of binary variables required for the airport capacityconstraints because the longer a flight is able to be delayed, the more possible airport slots it candepart/arrive in.

402 Dickson, Smith, Li
– MAX_GROUND_TIME dictates where flight connections representing aircraft flow are able to becreated. If flight j is scheduled to depart within MAX_GROUND_TIME of the scheduled arrivaltime of flight i, then our solution approach will create a connection variable between these twoflights, otherwise it will not.
– MAX_SLACK_SHIFT also dictates where flight connections representing aircraft flow are ableto be created. For regular routing you would normally only expect to create a connection betweenflights i and j if flight i arrives at least MTT3 before j is scheduled to depart. However, in thedisrupted environment, the best option may be to delay a flight until an aircraft becomes available.MAX_SLACK_SHIFT determines how long you would be prepared to delay flight j to wait forthe aircraft from flight i to become available.
– MAX_SLOTS limits the number of airport departure/arrival slots considered for each flight.– MAX_SUCCESSORS limits the number of possible successors for a given flight. Note that this
excludes the original successor of that flight, which is always included.These parameters are adjusted dynamically according to the size of the input problem, for example,problems with a large number of flights are given a lower value of MAX_GROUND_TIME so as toreduce the number of connections.For larger problems, the paramaters mentioned are set to very restricting levels in order to ensurethe Xpress-MP solver can find a feasible solution within the time allowed. Extra variables and hencerouting possibilities are then added by iteratively extending these parameters, while the integersolution found in the previous iteration is loaded to ensure a feasible solution is always available.The model and solution approached outlined were implemented in Xpress Mosel Version 2.0.0 andrun in Xpress-IVE Version 1.18.01 on a PC with an Intel(R) Core(TM)2 Duo processor and 2GBof RAM running Windows XP Professional SP2 (32 bits). Results were obtained on the providedproblem sets. All of these results were set to run for 600s, however the way the time is allocatedbetween Phase I and II sometimes means there is leftover time, whether or not an optimal solutionwas found in the first phase.
3 Minumum Turn Time

Challenge ROADEF 2009.Airline disruption recoveryROADEF Challenge 2009
Niklaus Eggenberg and Matteo Salani
TRANSP-OR laboratory, École Polytechnique Fédérale de Lausanne, CH-1015 Lausanne,Switzerland
Model The global structure is a Column Generation scheme based on the constraint specific networkspresented in Eggenberg et al. (2008)1. We denote F the set of flights to be covered, P the set ofavailable planes, S the set of final states, which describes the type of aircraft, the location, time andmaximal allowed resource consumption expected at the end of the recovery problem for the ARP. Tis the length of considered period, which corresponds to the recovery period for the ARP. A route r isdefined by the covered flights in the route, the reached final state and the plane the route is assignedto. Let 6 be the set of all feasible routes r, xr the binary variable being 1 if route r is chosen in thesolution and 0 otherwise, and cr the cost of route r. We also define the time-space intervals l = (a, t)as the time period [t, t + 1) at airport a ! A, where t is the length of the time intervals to consider(typically 60 minutes). We denote L the set of all time-space intervals (there are | A | +
5Tt
6such
intervals in total). The departure and arrival capacities for an airport a during period [t, t + 1) aregiven by qDep
l and qArrl with l = (a, t).
Finally, consider the following set of binary coe%cients :
bfr 1 if route r covers flight f ! F , 0 otherwise ;
bsr 1 if route r reaches the final state s ! S, 0 otherwise ;
bpr 1 if route r is assigned to plane p ! P , 0 otherwise ;
bDep,lr 1 if there is a flight in route r departing within time-space interval l ! L, 0 otherwise ;
bArr,lr 1 if there is a flight in route r arriving within time-space interval l ! L, 0 otherwise.
Finally, we add binary slack variables yf , $f ! F for flight cancellation : yf is 1 if flight f is canceled,and the associated flight cancellation cost is cf . With this notation, the Master Problem (MP) is thefollowing integer linear program :
1 Eggenberg, N., Salani, M. and Bierlaire, M. (2008a). Constraint specific recovery networks forsolving airline recovery problems, Technical Report TRANSP-OR 080828, EPFL, Switzerland.

404 Eggenberg, Salani
min zMP =%
r#,
crxr +%
f#F
cfyf (1)
%
r#,
bfrxr + yf = 1 $f ! F (2)
%
r#,
bsrxr = 1 $s ! S (3)
%
r#,
bprxr # 1 $p ! P (4)
%
r#,
bDep,lr xr # qDep
l $l ! L (5)
%
r#,
bArr,lr xr # qArr
l $l ! L (6)
xr ! {0, 1} $r ! 6 (7)yf ! {0, 1} $f ! F (8)
The objective 1istominimizetotalcosts.Constraints2ensureeachflightiseithercoveredbyarouter !% or canceled. Constraints 3 ensure each final state is reached by a plane and constraints 4 en-sure each aircraft is assigned to at most one route. Finally, constraints 5 and 6 ensure the departureand arrival capacities of the airports are satisfied, and constraints 7 and 8 ensure integrality of thevariables.In the Column Generation process, the pricing problem aims at finding new feasible columns im-proving the current (partial) solution. The pricing is solved as a Resource-Constrained ElementaryShortest Path Problem (RCESPP) on the constraint specific networks.
Passenger recovery Model 1-8 optimizes resource utilization, i.e. aircrafts, and tries to minimize thenumber of canceled flights. Once this problem is solved we build the complete connection network ofavailable flights. Each flight is represented as a node and each arc represents a possible connectionfor passengers between two flights, dummy node {0} represents generic passenger source and arcsbetween flights to the dummy node represent final connection for passengers. The capacity of theflights in terms of number of passengers are associated to outgoing arcs.For each itinerary we solve a flow problem on the connection network where the origin, the destinationand the available time for the passenger are taken into account to slightly modifying the network asfollows : the capacity of arcs {0} % f is set to 0 for all flights not departing from itinerary’s origin.The same happens for final arcs for itinerary’s destination.When the passengers are routed on a flight, the aircraft’s capacity covering the flight is updatedaccordingly. Itineraries are considered in a greedy way : those with highest cancellation cost arererouted first.
Computational Results In this section we present some computational results for the ROADEFChallenge 2009 B data set.For instance B02 and B07 our algorithm was not able to automatically reroute aircraft BAE200#116to its maintenance airport. In practical implementation of a recovery algorithm this can be easilydone in a post-processing phase.

Instance Total CostB01 45332180.70B02 65932350.15$B03 47399606.25B04 46958301.10B05 96062882.85
Instance Total CostB06 58083111.10B07 88709573.80$B08 61334494.65B09 61334690.40B10 117368359.35
Tab. 1. Recovery cost for instances B01-B10.
Challenge ROADEF 2009.Description of the TUe Solution Method
Christian Eggermont, Murat Firat, Cor Hurkens, Maciej Modelski
Eindhoven University of Technology, The Netherlands
1 Introduction
The complex problem presented in [1] is decomposed into smaller more tractable pieces. Each su-broutine corresponding to a sub-problem improves the current schedule in one aspect and its outputis input for the next one.The subproblems we identified deal with fixing the aircraft rotation continuity, respecting the air-port capacity constraints, fine-tuning delay management, and itinerary reassignment. Each of thesubproblems is described in some more detail below.
2 Fixing Aircraft Rotations
Due to flight cancellations and aircraft unavailability periods it may happen that an aircraft’s rotationgets broken at some point. We start by canceling for an unavailable aircraft all remaining flightsoriginally scheduled within its unavailability period.Next we list for each aircraft its assigned (non-canceled) flights in order of (planned) departure time.We treat consecutive flights of aircraft in pairs and cancel and/or add flights if certain conditions aresatisfied. Assume we are considering a flight A( B followed by C ( D, where C -= B. If D = B theproblem is resolved by canceling the second flight. Otherwise we create an additional flight B ( C,or a flight B ( D while canceling C ( D.After this first fix, each flight is preliminarily scheduled to depart at the first available moment intime, not necessarily respecting airport arrival and departure capacities.
3 Respecting airport capacities
For each airport and each time slot of an hour, the number of arrivals and the number of departuresare restricted. If we handle aircraft one-by-one, and schedule each flight as early as possible, whilerespecting airport capacities, we may run into the problem that either an aircraft arrives too late for

406 Eggermont, Firat,Hurkens,Modelski
maintenance or it cannot carry out all its assigned flights within the recovery period. In these caseswe have to cancel or exchange some of its flights.In order to fix this problem, we first discriminate between flights leading towards a maintenanceperiod, and those that do not. For an aircraft that goes towards maintenance, the first set of flightsconstitute a so-called pre-maintenance rotation. The remainder of the flights per aircraft form anon-pre-maintenance rotation. As maintenance due dates have to be respected, we schedule pre-maintenance rotations first, aircraft by aircraft, aircraft with earliest maintenance first. Next weschedule the remaining, non-pre-maintenance rotations, aircraft by aircraft, with aircraft in randomorder.For each rotation, we start scheduling flights at the earliest possible time as long as the airportcapacities allow. If this works out, we fix the departure times and adjust remaining airport capacities.If it does not work, we compute for each flight in the rotation a latest possible departure time. Basedon these earliest and latest departures we decide how to short-cut the rotation by one of three ways :either skip a middle section of flights, starting and ending at the same airport ; or skip a trailingsegment of flights, ending up at the wrong airport ; or skipping a middle section of flight, whileadding a flight so as to connect the first section to the last section.
cancel
s t
Airport 2
Airport 3
Airport 1
Flight1
Flight3Flight2
destination
wait
origin
Fig. 1. The flow of itineraries.
4 Delay fine-tuning
After constructing feasible rotations in terms of continuity, airport capacity, turn around or transittimes between consecutive flights of aircraft, and maintenance due dates, we may want to haveadditional delays to have enough connection time for as many passengers as possible.Flights may be subjected to delays in a way that they stay in their original time slots. Let 7i denotethe maximum delay for which both departure and arrival of flight i stay in their respective time slots.Given the current schedule we need not consider connections that are surely lost, and neither connec-tions that are certainly made. For the remaining connections the objective tries to achieve maximalslack. To this purpose we add to the objective a term wij(Xj % Xi), where variables Xk refer todeparture times of flight k, and the weight wij counts the number of passengers hoping for a feasibleconnection from flight i to flight j. The variables Xk are to stay within their range [Xk, Xk + 7k],where Xk is the current planned departure time for flight k.

TUe Solution Method 407
5 Itinerary reassignment
With flight cancellations and delays introduced both by the problem instance and the preceding stepsof our algorithm, many itineraries become infeasible. Here we try to reroute passengers of an itineraryusing the available capacity of the operated flights.We solve the problem separately for each itinerary by finding a minimum cost s% t flow in the graphdepicted in Figure 1. We construct this graph once and adjust it for each problematic itinerary underconsideration.By assigning appropriate capacities and costs to the arcs in the graph, we find for a particularproblematic itinerary the cheapest feasible alternative routes. Those passengers that cannot be ac-commodated, are canceled.
Références
1. M. Palpant, M. Boudia, C.-A. Robelin, S. Gabteni, and F. Laburthe. Roadef 2009 challenge :Disruption management for commercial aviation. 2008.

Index
Absi, N., 295Acuna-Agost, R., 327, 388Afsar, H.M., 64Afsar, M., 385Aghezzaf, H., 347Akeb, A., 278Alain berro, B., 168Alexis AUBRY, 366Alfandari L., 195Alfandari, L., 215Alpan, G., 110AMODEO, L., 364ANDRÉ, J., 383André, V., 301Anne Ruiz-Gazen, C., 168Aouni, B., 340Apparigliato, R., 120Artigues, C., 262, 361, 385Artigues, M., 143Auteur-A, A., 30, 182, 311Auteur-B, B., 30, 182, 311
Baala, O., 174BAALBAKI, H., 139Badreddine Jerbi, A., 342Baptiste, P., 353Barth, D., 258Bazgan, C., 155, 231Belaid, F., 36Belgacem, L., 172, 184Belkhelladi, k., 299Bellanger, A., 78Ben Salem, S., 317Ben Youcef, S., 202Benoist, T., 48Benyahia, B., 188Bernard, T., 266Berro, A., 86Besbes, W., 71Bessaih, F., 325Bibi, M.O., 381BIKIENGA, M., 147Bilegan, I.C., 291Billaut, J-C., 197Bisaillon, S., 390
Boisson, J-C., 207Boniol, F., 309BONNANS, F., 383Bontoux, B., 361Borne S., 195Bostel, N., 226Bouchard, M., 321Boudhar, M., 238Boudia, M., 385Bourgeois, N., 156Bournez, O., 258Bourreau, E., 385Boussaton, O., 258Boussier, S., 319Bouyssou, D., 130Brauner, N., 284Briand, C., 103Briant, O., 385Brotcorne, L., 291Brucker, F., 280Bui, A., 266
C.Artigues, 141Cabon, B., 325Cafieri, S., 333, 379Camilleri, G., 127Caminada, A., 166, 331Chabchoub, H., 242, 340Chabrol, M., 359Charon, I., 172Charpentier, P., 32Chauvet, P., 299Cherfi, N., 270Chiche, A., 369Chikhi, N., 238Chrétienne, P., 353Christian Artigues, B., 112Clautiaux, F., 276, 392Cohen, J., 258Cooren, Y., 186Corbel, E., 262Cordeau, J.-F., 390Cordier, J.-P., 347Cordovilla, M., 309Cornaz, D., 191

Author Index 409
Costa M.-C., 315Couëtoux, B., 155
Déplanche, A-M., 158Dallery, Y., 297Damay, J., 217Daniel Cosmin Porumbel, 68Darlay, J., 284, 398Dauzère-Pérès, S., 295, 355De Wolf, D., 36Debarbieux, D., 205Della Croce, F., 66, 105Delling, D., 114Delorme, X., 136Delorme, X., Dolgui, A, 222Dereu, T., 178Deroussi, L., 303Desaulniers, G., 321Deschinkel, K., 151Destré, C., 60Detienne, B., 355Devarenne, I., 331DIB, M., 331Dickson, S., 400Djellab, H., 131, 217Djemel, T., 34Dolgui, A., 136, 351DORIN, François, 307Dréo, J., 25Duhamel, C., 264, 286Dukhovny, Alexander, 260Duthen, Y., 86Dépincé, P., 23
Eggenberg, N., 402Eggermont, J., 404El Haddad, J., 250Erbs, G., 120Eric Gourdin, 93Esco%er, B., 156Espinouse, M.-L., 110Essafi, M., 136Esswein, C., 149Estellon, B., 48Estivie, S., 254Euchi, J., 242
Féniès P., A., 74Fakhfakh, M., 186Fallou Gueye, A., 112
Faye, A., 60Feillet D., 10Feillet, D., 4, 291, 325, 327, 361, 388Firat, M., 404Forget, J., 309Fouad, F., 268Frédéric Schettini, C., 112
Gély, A., 280Gabteni, S., 3Galea, F., 335Gandibleux, X., 23Garaix T., 10Garaix, T., 66Gardi, F., 48, 80GENIET, A., 147Gerber, O., 385Gharbi, A., 107Gicquel, C., 297Giroudeau, R., 4Golden, B., 253Gourdin, E., 184Gourgand, M., 359Gourguechon, O., 224Gourvès, L., 373, 377Grabener, T., 86Grangeon, N., 134, 224, 301GROLLEAU, Emmanuelle, 307Guéret, C., 176Gueye, S., 18, 327, 388GUGENHEIM, D., 383Guyon, O., 83Guédas, B., 23
H. Le Cadre, 180Hanafi, S., 101, 392Hansen, P., 333Hayel, Y., 291Hazir, O., 240Herbots, J., 349Hernandez, F., 4Hichem Kammoun, B., 342Hifi, H., 278Hifi, M., 122, 270Hladik, P-E., 158Hnaien, F., 222Houssin, L., 262Huart, A., 8Hudry, O., 172, 256Huguet, M.-J., 40

410 Author Index
Hurkens, C., 404Hyon, E., 213
Jacquenot, G., 268Jacques. BIBAI, B., 97JARDIN, A., 52Jean-Marie, A., 213Jean-Mathieu Segura, 93Jeanjean, A., 48, 371Jeantet, G., 58Jin Kao Hao, 68Jost, V., 228Jourdan, L., 207Jozefowiez N., 394Jozefowiez, N., 245
Kacem, I., 91, 122, 270Karoui, W., 40Kedad Sidhoum, S., 240Kedad-Sidhoum, S., 295Kergosien, Y., 197Kerivin, H.L.M., 193Khanafer, A., 276Kie#er, Y., 21Koné, O., 143Konig, J.C., 4Kovalyov, M.Y., 351Krishnaswamy, R., 184Kronek, L.-P., 284, 398Kuipers, E., 396
Létocart L., 195Létocart, L., 12, 62, 219LABADI, K., 364Labidi, M., 107Lacomme P., B., 74Lacomme, P., 76Lacroix, M., 193Lamer, F.., 178Lamrous, S., 174Lang J., 252Laporte, G., 245, 390Laribi, M., 76Latifi, A., 188Laurent Dezou, C., 112Lavor, C., 282Layouni, R., 385Le Cun, B., 335Leblond, M., 18Leclaire, P., 359
Lee, J., 379Lehuédé F., 10Lemaire, P., 83LEMARIE, B., 52Lenté, Ch., 197Lequy, Q., 321Lermé, N., 219Leus, R., 349Li, W., 400Liberti, L., 282, 333, 337, 379Lopez, P., 40lopez, P., 143Loukil, T., 71
M. Bouhtou, 180M. Hifi, 323M. Ould Ahmed Mounir, 323M.Ayala, 141Mabed, H., 174, 331Maculan, N., 282Ma#ray, F., 313Mahjoub, R., 191, 193Maisonneuve, J.-J., 268Malgouyres, F., 219Malick, J., 16MALO, S., 147Mancel C., 394Manier, H., 174Manier, M-A., 174Mansi, R., 392Marc. SCHOENAUER, S., 97Marchant, Th., 130Marichal, Jean-Luc, 260Marie-José Huguet, C., 112Martin, B., 371Martin, J.N., 166Martineau, P., 149Meden, B., 264Mehri, H., 34Meng-Gérard, J., 353Mesmoudi, S., 207Meurdesoif, Ph., 14Michelon, P., 327, 388Michelon, Ph., 18, 325Minh Hoang LE, 366Minoux, M., 297, 317Mireille JACOMINO, 366Mocquillon, C., 131Modelski, M., 404Mongeau, M., 143

Author Index 411
Monnot, J., 373, 377Montaut, D., 178Mora Camino F., 394Morel, G., 313Morineau, O., 176Mucherino, A., 282
Néron, E., 89, 305Nègre, N, 278Nagih, A., 215Nagih, N., 62Nakib, 27Nannicini, G., 114Naud, O., 4Naves, G., 228NGUEVEU, S.U., 357Nguyen, V.H., 95Norre, S., 134, 224, 301
Oulamara, A., 78Oulhadj, 27Ouorou, A., 184Ourari, S., 103Oussedik, S., 2Ozturk, O., 110
Péridy, L., 299Pérotin, M., 149Péton O., 10Péton, O., 176, 226Pagetti, C., 309Pascale Kuntz, 68Paschos, V., 156Pasin, F., 390Pavageau, C., 176Pedraza Morales, S., 120Peekstok, J., 396Perny, P., 1, 253Perrin, D., 286Pessan, C., 305Philippe Chrétienne, 93Picouleau C., 315Pierre Fouilhoux, 93Pinson, É., 83PINSON, E., 52Plateau, A., 215Plateau, G., 12Plateau, M-C., 12Plateau, M.-C., 120Poncelet, D., 176
PRINS, C., 357Psacual, F., 377
Quadri D., 10Quadri, D., 18, 325Queyranne, M., 1Quilliot A., B., 74
Rémy CHEVRIER, 247Rabat, C., 266Radjef, S., 381REBAI, A., 199Rebai, A., 202Rebai, M., 91Renaud, C., 174Riane, F., 345, 347RICHARD, Michael, 307RICHARD, Pascal, 307Rivreau, D., 83Rodríguez-Getán, C., 295Rodrigues, C.D., 18Roland, B., 345Roupin, F., 16Ruskin, H.J., 286
Sécherre, S., 55Sadki, J., 215SAGGADI, S., 364Salani, M., 402Sauer, N., 235Sauvanet, G., 89Sauvey, C., 235Savourey, D., 209Schaal, A., 299Schrenk, S., 398Semet, F., 8, 245Shchamialiova K., 351Siarry, 27Siarry, P., 186Simonin, G., 160Smaoui, S., 340Smith, O., 400Solau, C. , 84Souad Larabi Marie-sainte, A., 168SOUKI, M., 199Souki, M., 202Soumis, F., 321Sourd, F., 293, 353Spanjaard, O., 58, 250Suon, M., 224

412 Author Index
Sylla, M., 264
T’kindt, V., 105Talbi, E-G., 207, 276Talla Nobibon, F., 349Tchrnev, N., 76Teghem, J., 71Thanh, P.N., 226Thoma-Cosyns, L., 84Topart H., 315Touati, N., 62Touati, S.A.A, 151Toubaline, S., 231Toulouse, S., 153Trampont, M., 60
Véjar, A., 32
Vanderpooten, D., 231Vasquez, M., 319Vimont, Y., 319Viry, P., 205
Weber, C., 131Weber, Ch., 293Wenger, P., 268Wilbaut, C., 392Wilbaut, C. , 101Wolfler Calvo, R., 153WOLFLER-CALVO, R., 357
Yugma, C., 355
Zaourar, L., 21, 398Zarate, P., 127