Le support de l'information génétique – Structure et ...©o-génétique-m... · Expression des...
16
GENETIQUE – Le support de l'information génétique, Structure et fonction du génome 08/10/2014 GRANDMAISON Johan L2 Génétique Prof. Christophe BEROUD 16 pages Le support de l'information génétique – Structure et fonction du génome Le suffixe -omique (très à la mode) désigne le tout concernant un sujet, c'est-à-dire que : • Génomique désigne tout le génome • Transcriptomique désigne tous les transcrits • Protéomique désigne toutes les protéines • Métabolomique désigne tous les métabolismes • Lipidomique désigne tout ce qui concerne les lipides • Etc. L'information génétique est contenue dans l’ADN, il existe plusieurs molécules d’ADN dans une cellule humaine, elles sont localisées soit dans le noyau (au niveau des chromosomes) soit dans les mitochondries (sous forme d'ADN circulaire). La molécule d'ADN circulaire mitochondrial est constituée de 16 568 paires de bases (pb) et a été séquencée en 1981. C'est un ADN assez simple qui fait penser au génome des procaryotes, avec une très forte densité de gènes qui ne sont pas morcelés comme les gènes nucléaires. Un gène morcelé est un gène qui a une succession d'intron et d'exon. Les molécules d’ADN nucléaire sont hyper compactées en chromosomes pendant la division cellulaire (métaphase). Il y a différents degrés de compactions pour permettre cette division : • La double hélice d'ADN non compactée • Les nucléosomes (qui forment un chapelet) • La fibre de chromatine de 30 nm • La chromatine condensée 1/16 Plan A. Support de l'information génétique : des gènes aux protéines I.Structure de l'ADN II.Structure des gènes III. Expression des gènes : transcription et traduction IV. Régulation de l’expression des gènes B. Le projet Génome Humain I.De la structure de l’ADN à la séquence du génome humain en 50 ans II.Informations issues du projet
Transcript of Le support de l'information génétique – Structure et ...©o-génétique-m... · Expression des...

GENETIQUE – Le support de l'information génétique, Structure et fonction du génome
08/10/2014GRANDMAISON Johan L2GénétiqueProf. Christophe BEROUD16 pages
Le support de l'information génétique – Structure et fonction du génome
Le suffixe -omique (très à la mode) désigne le tout concernant un sujet, c'est-à-dire que :• Génomique désigne tout le génome• Transcriptomique désigne tous les transcrits• Protéomique désigne toutes les protéines• Métabolomique désigne tous les métabolismes• Lipidomique désigne tout ce qui concerne les lipides• Etc.
L'information génétique est contenue dans l’ADN, il existe plusieurs molécules d’ADN dans une cellule humaine, elles sont localisées soit dans le noyau (au niveau des chromosomes) soit dans les mitochondries (sous forme d'ADN circulaire).
La molécule d'ADN circulaire mitochondrial est constituée de 16 568 paires de bases (pb) et a été séquencée en 1981. C'est un ADN assez simple qui fait penser au génome des procaryotes, avec une très forte densité de gènes qui ne sont pas morcelés comme les gènes nucléaires.Un gène morcelé est un gène qui a une succession d'intron et d'exon.
Les molécules d’ADN nucléaire sont hyper compactées en chromosomes pendant la division cellulaire (métaphase). Il y a différents degrés de compactions pour permettre cette division :
• La double hélice d'ADN non compactée
• Les nucléosomes (qui forment un chapelet)
• La fibre de chromatine de 30 nm
• La chromatine condensée
1/16
Plan
A. Support de l'information génétique : des gènes aux protéines I.Structure de l'ADN II.Structure des gènes III. Expression des gènes : transcription et traduction IV. Régulation de l’expression des gènes
B. Le projet Génome Humain I.De la structure de l’ADN à la séquence du génome humain en 50 ans II.Informations issues du projet

GENETIQUE – Le support de l'information génétique, Structure et fonction du génome
• La chromatine hyper-condensée
• Le chromosome métaphasique
Un chromosome dispose de 3 régions :• Un bras court p• Un centromère (partie médiane)• Un bras long q
Certains chromosomes n'ont pas de bras court.
Le génome nucléaire est fragmenté en 23 paires de chromosomes (22 paires de chromosomes autosomes et 1 paire de chromosomes sexuels). Il a une taille d'environ 3 milliards paires de bases dont seulement 1% environ (30 millions de paires de bases) représente la partie codante. Cette partie codante est constituée de 25 000 à 30 000 gènes (on ne connaît qu'un ordre de grandeur, on ne connaît pas le chiffre exact).
La chromatine est constituée par un assemblage de l’ADN avec des protéines histones. En effet, un nucléosome est constitué de 8 histones (2 histones H2A, 2 histones H2B, 2 histones H3 et 2 histones H4). L'ADN s'enroule autour des nucléosomes pour former une structure en collier de perle d'un diamètre de 11 nm.
De plus, l'histone H1 permet l'association des nucléosomes entre eux ce qui conduit à une compaction des nucléosomes et donc à la fibre de chromatine de 30 nm. Cette fibre constitue l'unité de base de la chromatine.
Il faut faire la distinction entre 2 types de chromatine :• L'hétérochromatine qui est dense et plus compacte. Elle concerne des régions intergéniques et des
gènes inactifs (il est impossible pour les enzymes de la transcription d’accéder à la double hélice d’ADN du fait de la compaction).
• L'euchromatine qui est décondensée et qui contient les gènes actifs (les enzymes de la transcription peuvent accéder à la double hélice car l'euchromatine est moins condensée)
2/16

GENETIQUE – Le support de l'information génétique, Structure et fonction du génome
A. Support de l'information génétique : des gènes aux protéines
I. Structure de l'ADN
Le support de l’information génétique est l'acide désoxyribonucléique (ADN). L'information génétique est représenté par la succession de 4 bases azotées ATCG qui s’apparient 2 à 2 (GC et AT) dans la double hélice. L'appariement GC est plus stable que l'appariement AT car il y a 3 liaisons pour GC et 2 liaisons pour AT.
Le 25 avril 1953 parait dans Nature « A Structure for Deoxyribose Nucléic Acid » par F. Crick et J. Watson. Rosalind Elsie Franklin a également beaucoup contribué à la découverte de cette structure, bien qu'elle soit souvent oubliée.
L'ADN peut être copié au travers des générations cellulaires successives, c'est la réplication de l’ADN qui conduit à un même ADN dans toutes les cellules filles.L’ADN peut être traduit en protéines, c'est la transcription de l’ADN en ARN (avec une maturation) puis la traduction en protéines.Enfin, l'ADN peut être réparé en cas de besoin, c'est la réparation de l’ADN.
II. Structure des gènes
Un gène est défini comme l’unité d’hérédité. C'est une unité élémentaire d’ADN capable de se reproduire (réplication), susceptible de mutations (qui peuvent être délétères ou bénéfiques) et capable de transmettre un message héréditaire. A cause des mutations, il y a 4 millions de variations de pb entre les individus !
Un gène permet la synthèse d’une ou plusieurs protéines ou ARNs (certains gènes codent pour une unique protéine, mais certains gènes codent pour 1000-2000 protéines différentes).Il y a au moins 100 000 protéines différentes (voire plus d'un million) pour seulement 25 000 à 30 000 gènes. Il ne faut donc pas retenir « un gène, une protéine » mais plutôt « un gène, des protéines ».
Un gène dispose d'une structure morcelée, il y a des exons (qui contiennent l'information génétique) et des introns (on ne comprend pas trop leur rôle) qui sont transcrits, et des séquences régulatrices (en amont ou en aval du gène) qui sont non transcrites.
3/16

GENETIQUE – Le support de l'information génétique, Structure et fonction du génome
Un gène eucaryote est toujours orienté de 5' vers 3', mais si on lit sur le brin antisens, on lira de 3' vers 5' car les deux brins sont opposés dans la double hélice. Il est transcrit en ARN pré messager en utilisant le brin antisens (sur ce schéma, il n'y a que le brin sens). L'ARN pré messager va alors subir une maturation (épissage) dans le noyau, c'est-à-dire qu'il va perdre ses introns et il ne lui restera que les exons collés ensemble. De plus, il va recevoir une coiffe en 5' et une queue poly A en 3' et deviendra alors un ARN messager mature.
En amont de l'exon 1 se trouve la région promotrice, elle dirige la transcription, la rend plus ou moins efficace. On remarque 2 points critiques :
• Le site d'initiation de la transcription• Le codon d'initiation de la traduction ATG qui code pour une méthionine. Il se trouve la plupart du
temps dans le premier exon mais peut également se trouver dans les exons suivants.
Il peut y avoir plus d'un codon ATG dans les exons d'un gène, et le codon d'initiation de la traduction n'est pas toujours le premier. Qu'est-ce qui détermine le codon d'initiation de la traduction ? C'est le contexte, l'environnement de ce codon. Par exemple, un contexte favorable pour l'initiation de la traduction peut être :
• Une adénine en position -3 par rapport au codon (= 3 nucléotides en amont)• Une guanine en position +4 par rapport au codon (= 4 nucléotides en aval)
4/16

GENETIQUE – Le support de l'information génétique, Structure et fonction du génome
Le promoteur est indispensable à la transcription, il est composé de différents éléments reconnus par des facteurs de transcriptions. Ces éléments sont :
• TATA box (TATAAA) en -35 à -20 (par rapport au site d'initiation de la transcription)• Initiator (= Inr = site d'initiation de la transcription) en +1 composé de 2 pyrimidines (C ou T) puis une
adénine puis une adénine ou une thymine et encore 2 pyrimidinesDonc : PyPyA(A/T)PyPy
• CAAT box (CCAAT) en -200 à -70• GC box (GGGCGG) en -200 à -70
Les facteurs de transcriptions se fixent donc à ces éléments :• Le site Inr est reconnu par le facteur TBP (TATA-box biding protein)• La TATA box est reconnue par le facteur TBP elle-aussi• La CAAT box est reconnue par les facteurs CBF (CAAT binding protein), NF1 et C/EBP
(CAAT/enhancer binding protein)• La GC box est reconnue par le facteur SP1
Sur le promoteur de l'interleukine 2 (IL-2), on remarque donc la TATA box, le site d'initiation de la transcription et le site d'initiation de la traduction. Il n'y a pas CAAT box ni de GC box dans ce promoteur car ils ne sont pas constants. On peut au contraire en trouver plusieurs versions dans un même promoteur ce qui montre à quel point ces paramètres sont variables.Pour déterminer l'emplacement du site d'initiation de la transcription, on a fait des expériences sur la cellule.
En amont du promoteur se trouvent des séquences régulatrices qui interviennent dans la régulation du niveau d'expression et notamment dans la tissu-spécificité (= différences d'expression des gènes suivant les tissus).
5/16

GENETIQUE – Le support de l'information génétique, Structure et fonction du génome
Il y a trois types de régions régulatrices :• Les enhancers sont des éléments de régulation positive, ils sont localisés le plus souvent en amont des
gènes. Ils sont plus ou moins dégénérés (une séquence dégénérée est une séquence sujette aux variations). Exemples :◦ TGAGTCA sur lequel se fixe AP-1 (= activator protéin 1)◦ CCC(A/C)N(C/G)3 sur lequel se fixe AP-2 (= activator protéin 2)◦ ATGCAAAT sur lequel se fixe Oct-1 (= octamer 1)◦ (A/T)GATAPu sur lequel se fixe GATA-1 (= GATA binding factor 1)
Pu = purine = A ou G◦ PuGPuCATGPyCPy sur lequel se fixe p53◦ GGGPuNTPyPyCC sur lequel se fixe NF-kB (= nuclear factor-kappa B)◦ GGAGAPu sur lequel se fixe NFAT (= nuclear factor of activated T-cells)◦ TGACTAG sur lequel se fixe NF-E2 (= nuclear factor erythroid 2)
• Les silencers sont des éléments de régulation négative, ils interagissent avec des répresseurs.• Il existe des éléments mixtes « enhancer/silencer » dont la fonction dépend du ligand protéique qui
sera différent suivant les tissus. Si on prend l'exemple de l'élément E box (CACGTC) :◦ En cas de liaison avec le dimère Max-Myc, il sera enhancer◦ En cas de liaison avec le dimère Max-Mad, il sera silencer
Si on revient sur le gène de l'interleukine 2, on trouve des enhancers mais ils ne sont bien sûr pas tous présents :
Il y a une régulation extrêmement précise pour reconnaître le début et la fin d'un intron sans erreur. Ces sites de régulation sont des sites dégénérés car il n'y a pas de séquence exacte, juste quelques bases qui sont quasiment invariables :
• Le site donneur d'épissage (à la jonction exon-intron) qui est constitué de GT (=GU en ARN) et de 7 autres pb sujettes à variation.
• Le point de branchement (entre 20 et 50 nucléotides en amont du site accepteur) qui est le plus souvent une adénine et d'autres pb sujettes à variation.
• Le site accepteur d'épissage (à la jonction intron-exon) qui est constitué de AG et de 10 autres pb sujettes à variation.
6/16

GENETIQUE – Le support de l'information génétique, Structure et fonction du génome
La dégénérescence des sites de régulation de l'épissage des introns est apparu au cours de l'évolution. En effet, les sites d'épissages des eucaryotes anciens sont moins dégénérés que chez l'homme, ce sont des signaux très purs (par exemple chez la levure). Cela s'explique par l'épissage alternatif qui est le mécanisme permettant d'avoir plusieurs protéines à partir d'un même gène. La cellule va inclure ou pas certains exons dans l'ARNm mature ce qui signifie qu'on va avoir des ARNm différents à partir d'un même gène.Ce mécanisme favorise la dégénérescence des signaux, car moins il sont précis, plus ils vont permettre une régulation fine suivant les tissus.
Dans la photo ci-dessous, la hauteur de la lettre correspond à la fréquence retrouvée au niveau des introns chez l'homme. On remarque que certaines bases sont quasiment équiprobables (les lettres font toutes la même taille).
On peut prédire la force d’impact des mutations sur les sites donneurs et accepteurs, mais c'est beaucoup plus dure au niveau du point de branchement car il existe des points de branchement alternatifs qui peuvent prendre le relais.
L'épissage des introns est un des mécanismes les plus complexes de la cellule. Ici sera présentée une version simplifiée :
• Première étape = fixation de la small nuclear ribonucleoprotein U1 (snRNP) sur le site donneur.
• Seconde étape = fixation de la small nuclear ribonucleoprotein U2 (snRNP) sur le point de branchement.U1 et U2 se lient l'un à l'autre, et rapprochent donc les 2 exons dans l'espace, ce qui crée une boucle au niveau de l'intron.
7/16

GENETIQUE – Le support de l'information génétique, Structure et fonction du génome
• Troisième étape = assemblage des snRNPS U4 U5 et U6 puis fixation et formation du spliceosome ce qui a pour effet de rapprocher encore plus les 2 exons.
• On veut maintenant se débarrasser de l'intron et on va pour cela réaliser une trans-estérification qui consomme de l'énergie sous forme d'ATP. Le groupement OH de l'adénine du point de branchement va attaquer le phosphate du premier nucléotide de l'intron.
• Il va y avoir ensuite une seconde trans-estérification qui va elle-aussi consommer de l'énergie sous forme d'ATP. Le OH libéré en 3' de l'exon en amont va attaquer le phosphate 5' de l'exon en aval. On a donc régénération d'une liaison phosphate entre les exons et élimination de l'intron sous forme de lariat (= lasso).
Schéma récapitulatif :
8/16

GENETIQUE – Le support de l'information génétique, Structure et fonction du génome
Avant l'arrêt de la transcription, il y a un site de polyadénylation dont on ignore la localisation précise. Il va induire la formation d'une queue poly A (0,5 à 2 kb) destiné à protéger l'ARNm. On ne sait pas non plus ce qui détermine la fin de la transcription. On sait juste que ce site de polyadénylation est présent dans la plupart des gènes, et que la transcription s'arrête un peu après.
Les gènes ont une structure et une longueur variable :• Le gène de la titine dispose de 363 exons et de 101518 pb. C'est le nombre maximum d'exons que l'on
connaisse. On comprend aisément que grâce à l'épissage alternatif, ce gène code potentiellement pour énormément de protéines.
• Le gène UbI4 dispose de 4 exons et de 2382 pb. Ce gène peut donc coder pour beaucoup moins de protéines.
• Le gène le plus long que l'on connaît est le gène de la dystrophine situé sur le chromosome X. Il code pour plus d'1 million de pb et est responsable de la maladie de Duchenne.
L'ADN complémentaire (cDNA) est de l'ADN formé à partir de l'ARN, et il n'existe pas dans la nature.
Lorsqu'on compare la structure des gènes eucaryotes entre les espèces, on remarque que la taille des exons est conservée (pression évolutive) mais que la taille des introns est variable (ils sont beaucoup moins sujets à sélection).
Remarque : Sur la double hélice d'ADN, il y a toujours 2 brins, on peut donc avoir 2 gènes au même endroits, chacun sur un brin, et ils ont la plupart du temps des longueurs différentes.
Le dogme classique est « un gène code pour une protéine » mais ce n’est pas si simple, il y a beaucoup de cas différents :
• Un gène unique codant pour une protéine unique.• Un gène unique codant pour plusieurs protéines (via l'épissage alternatif).• Un gène codant pour un ARN non traduit en protéines, c'est-à-dire un ARN non codant. Cet ARN non
codant va agir sur la régulation de l’expression d’autres gènes.• Des gènes dispersés codant pour plusieurs protéines semblables (familles et super-familles de gènes).
Ces gènes dérivent probablement d’un gène ancestral commun.• Le cas particulier des gènes ribosomaux• Des gènes ne codant pour aucune protéine, ni aucun ARN, c'est-à-dire des pseudogènes.
Si un gène se duplique, et qu’une des version s’inactive par mutation, on a alors un pseudogène sans avoir de déficit fonctionnel, car il reste toujours une version fonctionnelle du gène.
III. Expression des gènes : transcription/traduction
La plupart des gènes ont pour but d’être transcrit en ARN. La transcription est un processus dynamique et continu, c'est-à-dire que toutes les étapes se chevauchent. Par exemple, l'épissage débute pendant la transcription.
9/16

GENETIQUE – Le support de l'information génétique, Structure et fonction du génome
La maturation de l'ARNm nécessite en plus des structures destinées à protéger l'ARNm de la dégradation. En effet, dans un but de régulation de la traduction, il y a beaucoup de molécules dans le cytoplasme dont le but est de dégrader les ARNm non protégés par ces structures. Ces structures sont :
• Le« Capping » qui désigne la pose d'un chapeau (ou coiffe) en 5'. Ce chapeau est un 7-méthylguanosine, c'est-à-dire une guanosine qui a subi une modification chimique.
• La queue poly A créée par une polyadénylation.
Un même ARNm est traduit plusieurs fois mais sa durée de vie est limité par la longueur de la queue poly A. En effet, à chaque traduction réalisée sur cet ARNm, la queue poly A est raccourcie. Une fois que cette queue poly A a été suffisamment réduite (au bout d'un certain nombre de traductions), l'ARNm est dégradé.
Le professeur a montré ici une animation : https://www.youtube.com/watch?v=bk7PW1FKMTI
Après l'épissage, il y a des remnants du spliceosome qui permettent d'assurer la qualité de l'ARNm. En effet, en cas de mutation d'un nucléotide créant un codon stop avant le véritable codon stop, la machinerie cellulaire peut parfois reconnaître que ce codon stop n'est pas normal, grâce à l'environnement nucléotidique dans lequel il se trouve par la reconnaissance de ce remnant en aval du coton stop anormal. L'ARNm est alors dégradé sans être traduit. La cellule s'assure donc de la qualité de l'ARNm.
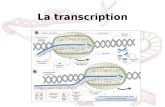
Voici un schéma récapitulatif de la transcription/traduction :
10/16

GENETIQUE – Le support de l'information génétique, Structure et fonction du génome
La séquence du gène se trouve sur le brin sens, mais la transcription (grâce à l'ARN polymérase) se réalise sur le brin antisens par complémentarité. Le brin antisens est donc la matrice mais l'ARNm contient la même information génétique que le brin sens (c'est-à-dire la même information génétique que le gène).
La traduction en protéines se réalise grâce au code génétique. Un codon est une séquence de 3 bases correspondant à un acide aminé, et l'ensemble des codons constituent le code génétique.La séquence nucléotidique dans l’ADN (et transcrite en ARNm) spécifie donc l’ordre des acides aminés dans la protéine.
Le code génétique est redondant (ou dégénéré), c'est-à-dire que plusieurs codons codent pour le même acide aminé. Pour certains codons, le dernier nucléotide n'a même pas d'importance car les 4 versions codent pour le même acide aminé. Ce code génétique n'est jamais ambigu, c'est-à-dire qu'un codon ne code jamais pour plus d'un acide aminé.
Il comporte également les signaux d'initiation (codon d'initiation AUG) et d'arrêt (codons stop UAA, UAG et UGA).
On peut remarquer que nous n'avons pas le même code génétique nucléaire et mitochondrial.
IV. Régulation de l'expression des gènes
"Si les caractères de l'individu sont déterminés par les gènes, pourquoi toutes les cellules d'un organisme ne sont-elles pas identiques ?" T. MorganC'est parce qu'il y a une régulation de l’expression des gènes à différents niveaux :
• Au niveau chromatinien via la compaction de la chromatine (hétéro/euchromatine).• Au niveau transcriptionnel via les effets des facteurs de transcription qui stimulent ou inhibent
l'expression d'un gène.• Au niveau post-transcriptionnel via la modulation de la demi-vie des ARNm (ex : queue polyA courte).• Au niveau traductionnel via la modification de facteurs d'initiation de la traduction.• Au niveau post-traductionnel via les modifications post-traductionnelles des protéines telles que la
glycosylation, la méthylation, l'acétylation... Ces modifications agissent sur le degré d'activité de la protéine en la désactivant ou en l'activant. Ces modifications sont très importantes comme le prouve l'exemple de la levure (eucaryote simple) qui ne peut pas synthétiser toutes les protéines humaines du fait du manque de modifications post-traductionnelles.
11/16

GENETIQUE – Le support de l'information génétique, Structure et fonction du génome
On a récemment découvert un nouveau mécanisme, le RNA editing qui désigne certaines mutations physiologiques de l'ARNm après la transcription (donc pas de mutation au niveau du génome). Cela peut aboutir par exemple à un changement d'acide aminé ou à la création d'un codon stop.
L'épigénétique est l'ensemble des modifications de l’expression des gènes sans altération des séquences nucléotidiques, réversibles et transmissibles d’une génération à l’autre.
Il y a trois principaux mécanismes d'épigénétique, le code histone (acétylation ou méthylation des histones), la méthylation de l'ADN (très courant) et l'action de certains ARN non-codants (par exemple les micro ARNs) qui se fixent sur l'ARNm simple brin par complémentarité et entraînent donc la dégradation de l'ARNm.Ces mécanismes régulent l’équilibre entre gènes « actifs » et « inactifs ».
La compaction de l'ADN est influencée par les modifications biochimiques des histones, c'est le code histone. Ainsi, si les histones sont acétylées, alors on aura des gènes actifs et de l'euchromatine. A l'inverse, si les histones sont méthylés, on aura des gènes inactifs et de l'hétérochromatine.
La méthylation de l'ADN favorise la compaction de l'ADN et l'inactivation de l'expression des gènes. Elle est impliquée dans l'inactivation du chromosome X chez la femme. Elle est également impliquée dans le phénomène d'empreinte génomique parentale qui désigne la non-équivalence d'expression de certains gènes selon l'origine parentale.En effet, pour la majorité des gènes, la copie d'origine maternelle et la copie d'origine paternelle sont exprimés, mais pour certains gènes, seul l'allèle maternel ou paternel est exprimé (ce sera toujours le même allèle pour une gène donné). Cela peut poser problème en cas d'allèle défectueux et peut entraîner une maladie génétique même si le gène sain est présent.
B. Le projet Génome Humain
I. De la structure de l'ADN à la séquence du génome humain en 50 ans
Le séquençage du génome humain avait pour objectifs :• savoir si le génome humain était plus complexe que celui des procaryotes, et connaître sa composition.• savoir si le génome humain contenait plus de gène que les autres espèces.• répondre à la question : « comment expliquer les différents niveaux d'évolution ? »• savoir si plus une espèce est évoluée, plus elle a de gènes.• identifier les gènes responsables des maladies génétiques tels que les cancers, les maladies rares, etc...
Cela aurait permis de mieux les traiter.• placer les gènes sur les différents chromosomes.
Le séquençage du génome humain est le plus grand projet scientifique mondial lancé en 1988/1989. Human Genome Project débute donc en 1990.
Pour se rendre compte de l'ampleur de la tache, il faut savoir que 3000 paires de bases s'écrivent sur une page d'un livre. Ainsi, un tome de 500 pages contient 1 500 000 paires de bases. Un génome haploïde quant à lui représente 1000 de ces tomes !
La capacité de séquençage a énormément progressé :• En 1975, on séquençait 1 000 nucléotides/semaine. Il aurait fallu 500 ans pour 100 personnes !• En 1986, on séquençait 10 000 nucléotides/jour. Il aurait fallu 8 ans pour 100 machines.• En 1998, on séquençait 200 000 nucléotides/jour. Il aurait juste fallu 5 mois pour 100 machines.
12/16

GENETIQUE – Le support de l'information génétique, Structure et fonction du génome
Les cartes génétiques du génome sont des cartes relatives, où les distances sont exprimées en centimorgan (cM). Un cM correspond à 1% de recombinaison.Les cartes physiques du génome sont des cartes absolues, où les distances sont exprimées en paire de bases (pb). Ainsi, un kilobase (kb) est égal à 1000 pb, et 1 mégabase (Mb) est égal à 1000 kb.
Chez l'homme, 1 cM vaut environ 1 Mb.
Pour le séquençage du génome humain, il y a eu 2 projets concurrents, le Human Genome Project HGP (public) et le projet de l'entreprise CELERA (privé). Le but du projet privé était de breveter le génome humain.Les 2 projets ont utilisé des méthodes différentes :
A. Le projet HGP a réalisé le séquençage à partir d'une carte physique, c'est-à-dire qu'il a construit une carte génétique puis une carte physique afin de la pouvoir sélectionner les clones d'intérêts, et alors pouvoir faire le séquençage (ou shotgun) puis l'assemblage (ou contigs).Pour faire simple, ils ont séquencé des morceaux d'ADN dont ils connaissaient la localisation dans le génome.
B. Le projet CELERA a réalisé le séquençage aléatoirement, c'est-à-dire qu'il a directement commencé le séquençage (ou shotgun) de clones, ainsi que les extrémités des clones, avant de réaliser l'assemblage (ou contigs). Tout ça pour enfin incorporer d'autres séquences et des données des extrémités.Pour faire simple, ils ont séquencé des morceaux d'ADN dont ils n'avaient pas pris la peine de connaître la localisation, en espérant tomber sur quelque chose d'utile et de brevetable.
13/16

GENETIQUE – Le support de l'information génétique, Structure et fonction du génome
II. Informations issues du projet
De ce séquençage a pu être tirée la composition du génome humain :
On remarque qu'il y a moins 1% d'ADN codant pour des protéines et plus de 50% de séquences répétées dont on ignore la fonction, ce qui était assez inattendu.
Le génome humain est donc constitué de 3272 millions de nucléotides. Les régions riches en gènes sont également les régions riches en G et C alors que les régions pauvres en gènes sont riches en A et T. Cela s'explique par la transition chimique spontanée de C vers T : les régions riches en gènes ont gardé leur capital en GC grâce à la pression sélective alors que les régions pauvres en gènes ont lentement évolué vers une majorité de AT.
Ces différentes régions peuvent généralement être visualisées comme des bandes claires ou sombres sur les chromosomes métaphasiques, c'est le banding : les bandes G sont riches en AT et pauvres en gènes, alors que les bandes R sont riches en GC et riches en gènes.
Le chromosome 1 qui est le plus grand contient le plus grand nombre de gènes estimés (environ 3000) alors que le chromosome Y en a le moins (231). Il y a entre 25 000 et 30 000 gènes.La taille moyenne d’un gène est de 3000 bases et 9 exons mais la taille varie beaucoup comme par exemple le gène de la dystrophine qui a une taille de 2,4 Mb.
Il y a 99,9% de séquence identique entre 2 personnes, soit 0,1% de différence correspondant à 3,5 millions de différences par génomes.Plus de la moitié des gènes ont une fonction inconnue !
Le HGP a permis la création de base de données séquentielles et d'annotations, à la disposition de tous (bases de données publiques), ainsi que le séquençage du génome de nombreux organismes.
14/16

GENETIQUE – Le support de l'information génétique, Structure et fonction du génome
Nous entrons maintenant dans une nouvelle aire, celle de la médecine personnalisée :• Le HGP a mis 13 ans de 1990 à 2003 dans un projet international à 3 milliard de dollars pour séquencer
un génome• En 2011, les séquenceurs à haut débit permettent de séquencer un génome humain en 1 semaine pour 10
000 dollars, mais l'analyse des données reste difficiles.
On a remarqué des mutations délétères chez certaines personnes qui n'avait pas de problème de santé.
Il existe des services privés payants permettant de se faire séquencer son génome individuel pour 10 000 dollars, ce qui est inquiétant et rassurant à la fois !
Conclusion
Le génome humain est séquencé, et le génome humain individuel est séquençable. Nous entrons donc dans l'ère post-génomique !
Le génome doit interagir avec les autres « -omes » pour les connaissances fondamentales : transcriptome, protéome, métabolome, interactome, …
Il persiste une difficulté : l'analyse des données.
Nous devons mieux comprendre la diversité des êtres vivants, laquelle n'est pas expliqué par le seul nombre de gènes.
En médecine, nous devons mieux comprendre les bases génétiques des maladies à la fois causales (maladies génétiques monofactorielles) et à effet modificateur (prédisposition génétique qui conduit à des maladies diverses : cancérologie, cardiovasculaires, métaboliques...).
Merci à Doriane pour les photos !
15/16

GENETIQUE – Le support de l'information génétique, Structure et fonction du génome
16/16