
L’analyse des données par les graphes de similitude · l’analyse vectorielle. Cette méthode...
90
Droits de reproduction et de diffusion réservés © Sciences Humaines 1 L’analyse des données par les graphes de similitude Par Pierre Vergès, directeur de recherche au CNRS et Boumedienne Bouriche, maître de conférence à l’IUT de Gap Juin 2001
Transcript of L’analyse des données par les graphes de similitude · l’analyse vectorielle. Cette méthode...

Droits de reproduction et de diffusion réservés © Sciences Humaines
1
L’analyse des données
par les
graphes de similitude
Par Pierre Vergès, directeur de recherche au CNRS et Boumedienne Bouriche, maître de conférence à l’IUT de Gap
Juin 2001

Droits de reproduction et de diffusion réservés © Sciences Humaines
2
A Claude FLAMENT l’inventeur de cette méthode et toujours l’initiateur de son évolution
PROLOGUE
Origine Les années soixante ont vu fleurir les interfaces entre sciences humaines et mathématiques. Dans
cette effervescence Claude Flament avait le souci d’associer psychologie sociale et formalisation. Il explorait la théorie des graphes pour expliquer les biais de communication. Puis, associant sa pratique des analyses statistiques et les possibilités ouvertes par les mathématiques du discret, il invente l’Analyse de Similitude. Il fallait un « passeur » pour que l’analyse des données ne se réduise pas au labyrinthe de l’analyse vectorielle.
Cette méthode se développe avec la possibilité d’utiliser les ordinateurs. Le premier programme fut écrit en cobol (langage bien peu adapté !), puis en fortran pour les grosses machines IBM du CNRS, un détour par les premiers Apple1, enfin les programmes suivirent la puissance croissante des PC et du Turbo Pascal.
Parallèlement la méthode se développait, le trio des années soixante-dix2 visait une formalisation mathématique de plus en plus sophistiquée. Ils découvraient au passage l’arbre maximum, les cliques et le filtrant des cliques… Ils exploraient la possibilité d’utiliser la théorie des hyper-graphes. La pratique a aussi son rôle dans l’évolution de la méthode. Utilisée par de nombreux chercheurs, on découvrait les problèmes que posaient des données de formes bien différentes et des questionnaires toujours en évolution. L’analyse de similitude est restée fidèle à ses origines et s’est complexifiée. Le livre qui aurait du être écrit en 19723 serait bien différent du livre de l’an 2000. Ce dernier profite de tous ces moments où il a fallu remettre en cause les intuitions initiales, ou plus exactement les rapports entre propriétés mathématiques et interprétations par les sciences sociales. On avait fait, dans les années soixante-dix, un peu trop confiance aux mathématiques (comme d’autres ont fait trop confiance aux statistiques) pour dicter l’interprétation de l’analyste alors qu’il ne fallait que la guider, ou plus exactement s’interroger sur la traduction entre propriétés mathématiques et propriétés du social.
1 Sylvie Soukup et Alain Guénoche en furent les artisans. 2 Claude Flament, Alain Degenne, Pierre Vergès 3 Il en existe un manuscrit.

Droits de reproduction et de diffusion réservés © Sciences Humaines
3
Une analyse et un analyste. Cette méthode est une méthode générale d’analyse de données, elle est alternative ou
complémentaire des classiques analyses factorielles ou de classification. Mais elle est aussi plus particulièrement adaptée à la théorie des représentations sociales, ce qui n’étonnera personne quand on sait le rôle que joue son inventeur dans le champ des représentations sociales. L’analyse de similitude a la grande qualité de ne pas éliminer l’analyste des différentes phases de l’analyse. A aucun moment il lui est proposé les résultats d’une boite noire. Au contraire l’analyse de similitude demande à l’analyste de prendre des décisions à chaque étape de la démarche. Elle propose des descriptions qui doivent être validées et peuvent même être quelque fois contradictoires à première vue. Elle pousse alors l’analyste à trouver son interprétation au croisement de deux informations différentes. Cet ouvrage montre comment à chaque instant la décision de l’analyste est réclamée. Aussi les différents chapitres de ce livre vont essayer d’éclairer cette décision.
Le premier chapitre pose la question de la mesure des similitudes entre les variables : la multiplicité des indices de similitude doit être expliquée et explorée. Le second chapitre présente les différents outils de la théorie des graphes permettant de traiter une matrice de similitude associée à un graphe. Ici on fait un détour par une formalisation mathématique. Celle-ci n’est pas très complexe même si on n’y est pas très habitué. Elle propose une analyse combinatoire des données où les seules entités sont « des points et des traits ». Le troisième chapitre montre les propriétés formelles que l’analyse de similitude peut mettre à jour. Le quatrième présente sur un exemple la démarche, pas à pas, de l’analyste et les décisions qu’il doit prendre. Ici se situe l’intérêt de l’analyse de similitude : l’analyste est maître des décisions qui vont orienter le traitement des données, comme il sera maître plus tard de leur interprétation. Le cinquième chapitre essaie de mettre en garde contre les fausses interprétations, les ambiguïtés qu’il faut lever et contre la croyance aveugle en la qualité des données. On se servira tout au long de ce livre d’exemples tirés des recherches de ces dernières années ; que les auteurs en soient ici remerciés. Ils ont utilisé des programmes informatiques sous Windows.
Droits de reproduction et de diffusion réservés © Sciences Humaines
4
CHAPITRE 1. COMMENT SIMPLIFIER UNE MULTITUDE D’INFORMATIONS POUR
METTRE DE L’ORDRE DANS LES DONNEES QUE VOUS VOULEZ TRAITER ?
1.1 DE LA RESEMBLANCE A LA SIMILITUDE.
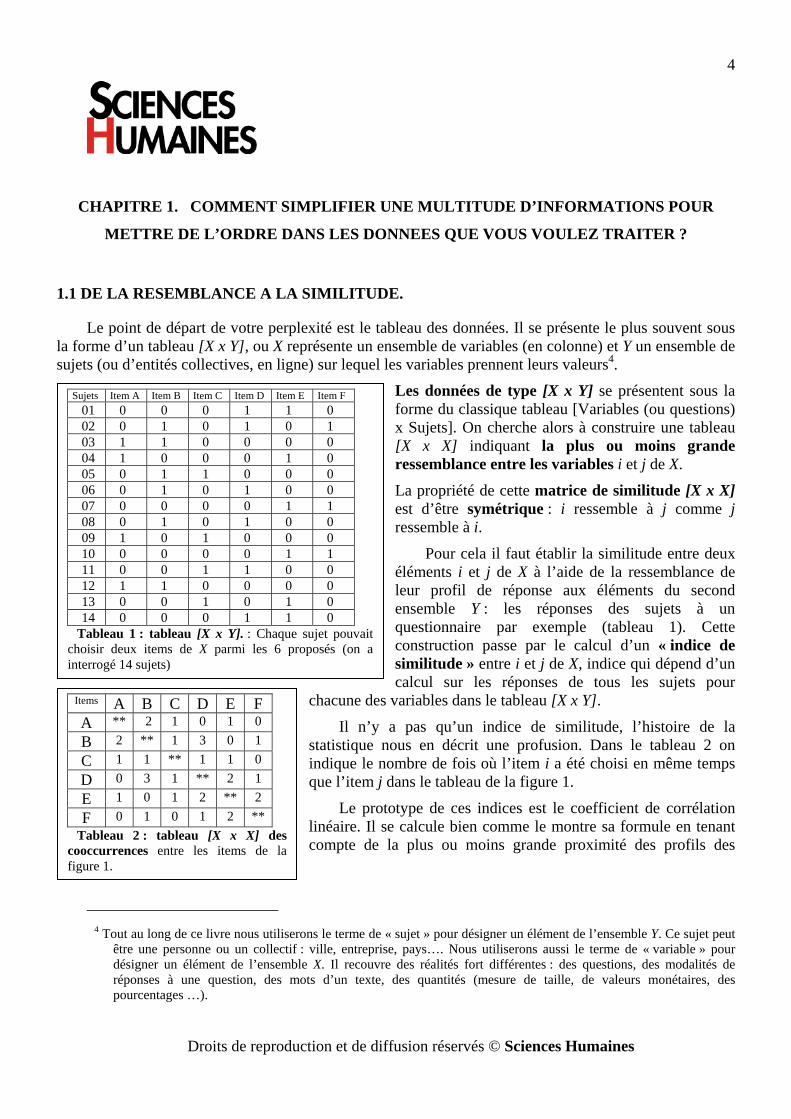
Le point de départ de votre perplexité est le tableau des données. Il se présente le plus souvent sous la forme d’un tableau [X x Y], ou X représente un ensemble de variables (en colonne) et Y un ensemble de sujets (ou d’entités collectives, en ligne) sur lequel les variables prennent leurs valeurs4.
Les données de type [X x Y] se présentent sous la forme du classique tableau [Variables (ou questions) x Sujets]. On cherche alors à construire une tableau [X x X] indiquant la plus ou moins grande ressemblance entre les variables i et j de X.
La propriété de cette matrice de similitude [X x X] est d’être symétrique : i ressemble à j comme j ressemble à i.
Pour cela il faut établir la similitude entre deux éléments i et j de X à l’aide de la ressemblance de leur profil de réponse aux éléments du second ensemble Y : les réponses des sujets à un questionnaire par exemple (tableau 1). Cette construction passe par le calcul d’un « indice de similitude » entre i et j de X, indice qui dépend d’un calcul sur les réponses de tous les sujets pour
chacune des variables dans le tableau [X x Y].
Il n’y a pas qu’un indice de similitude, l’histoire de la statistique nous en décrit une profusion. Dans le tableau 2 on indique le nombre de fois où l’item i a été choisi en même temps que l’item j dans le tableau de la figure 1.
Le prototype de ces indices est le coefficient de corrélation linéaire. Il se calcule bien comme le montre sa formule en tenant compte de la plus ou moins grande proximité des profils des
4 Tout au long de ce livre nous utiliserons le terme de « sujet » pour désigner un élément de l’ensemble Y. Ce sujet peut
être une personne ou un collectif : ville, entreprise, pays…. Nous utiliserons aussi le terme de « variable » pour désigner un élément de l’ensemble X. Il recouvre des réalités fort différentes : des questions, des modalités de réponses à une question, des mots d’un texte, des quantités (mesure de taille, de valeurs monétaires, des pourcentages …).
Sujets Item A Item B Item C Item D Item E Item F 01 0 0 0 1 1 0 02 0 1 0 1 0 1 03 1 1 0 0 0 0 04 1 0 0 0 1 0 05 0 1 1 0 0 0 06 0 1 0 1 0 0 07 0 0 0 0 1 1 08 0 1 0 1 0 0 09 1 0 1 0 0 0 10 0 0 0 0 1 1 11 0 0 1 1 0 0 12 1 1 0 0 0 0 13 0 0 1 0 1 0 14 0 0 0 1 1 0
Tableau 1 : tableau [X x Y]. : Chaque sujet pouvait choisir deux items de X parmi les 6 proposés (on a interrogé 14 sujets)
Items A B C D E F A ** 2 1 0 1 0 B 2 ** 1 3 0 1 C 1 1 ** 1 1 0 D 0 3 1 ** 2 1 E 1 0 1 2 ** 2 F 0 1 0 1 2 **
Tableau 2 : tableau [X x X] des cooccurrences entre les items de la figure 1.

Droits de reproduction et de diffusion réservés © Sciences Humaines
5
variables i et j mesurée ici par la covariance5 des valeurs prises par i et j dans le tableau [X x Y], covariance pondérée par un coefficient calculé sur les variances des deux variables :
)()()(),(
jVariVarijCoVarjir
×= .
On se trouve aussi devant des données de type [X x X’] où l’ensemble X’ est identique à l’ensemble X. C’est le cas des matrices de transition entre la profession du père et la profession des enfants. Les deux ensembles X et X’ sont les mêmes (les catégories professionnelles, par exemple) mais ce tableau ne peut être interprété comme une matrice de similitude car la symétrie (i ressemble à j comme j ressemble à i) n’existe pas. Deux types d’opérations peuvent être envisagées pour construire la matrice [X x X]. Soit on effectue un calcul sur le profil en X’ des éléments de X (l’ensemble X’ se comporte en fait comme un ensemble Y). Soit on effectue un calcul visant à symétriser la relation (ij) entre les éléments de X quand la valeur de (ij) est la quantification d’une relation. La ressemblance entre les professions des pères en fonction de la ressemblance des profils des professions des enfants est un exemple du premier type. Le cas des matrices de flux entre des entités : par exemple la valeur des flux de migration entre les régions françaises6 est un exemple du second type. Comme le flux migratoire de i vers j n’est pas égal à celui de j vers i, on est obligé de symétriser la relation entre deux régions en ne tenant compte que de l’émigration (ou de l’immigration) ou en faisant la somme ou la différence des déplacements entrants et sortants.
Ce cas de figure se retrouve quand on analyse un questionnaire d’évocation : on a catégorisé les mots, observé la co-apparition de ces catégories chez un même sujet et calculé la cooccurrence d’une catégorie de mots avec une autre. Cette information n’est pas symétrique. On peut la symétriser par la définition d’un indice particulier. On retrouve ce problème dans l’analyse des citations d’auteurs dans un ensemble d’articles de revues scientifiques (qui cite qui ? tableau 3). On peut opérer de deux manières différentes : soit considérer les ressemblances entre les profils de deux auteurs, soit symétriser le nombre de citations entre deux auteurs (somme, différence …)
Les données qui sont directement du type [X x X] sont rares, elles sont le plus souvent le résultat d’un calcul. On peut, par exemple, recueillir une matrice de corrélation déjà calculée (à l’aide d’EXCEL ou d’un programme d’analyse factorielle en composantes principales). On peut demander aux sujets d’une enquête d’établir des relations entre un ensemble de notions (cf. annexe 2). On verra plus loin (2.4) un questionnaire où on demande aux sujets d’évaluer sur une échelle de 1 à 9 la ressemblance entre les éléments i et j et cela pour toutes les paires possibles.
5 NmxjkmxikijCoVar
kji∑ −×−= ))()(()( ; avec N le nombre de sujets, xik la kiem valeur de la colonne i et xjk la
k-iem valeur de la colonne j et mi la moyenne des valeurs xik, mj la moyenne des valeurs xjk 6 Degenne, A., 1973.
Items A B C D E F G H I A ** 15 10 30 45 22 16 50 24 B 25 ** 20 12 8 16 18 37 25 C 35 11 ** 43 16 19 28 34 12 D 40 28 33 ** 31 20 15 19 42 E 12 15 8 22 ** 25 10 7 8 F 58 46 24 33 14 ** 23 41 25 G 36 29 12 36 18 29 ** 28 17 H 22 25 15 7 12 34 15 ** 16 I 5 7 12 3 25 15 24 28 **
Tableau 3 : tableau [X x X’] : on a compté le nombre de fois où un auteur D a cité l’auteur F (ici 20 fois), le nombre de fois ou l’auteur F a cité l’auteur D est différent (33).

Droits de reproduction et de diffusion réservés © Sciences Humaines
6
Chaque sujet produit une matrice [X x X]. On va alors calculer une agrégation de ces matrices : ici l’élément (ij) de la matrice [X x X] finale est la moyenne des scores obtenus pour chaque sujet. Quel que fois l’information initiale est, non une similitude, mais une distance tel le nombre de kilomètres entre la ville i et la ville j. On est alors conduit à calculer une fonction inverse de la distance pour obtenir une valeur de la proximité entre i et j.
Quel que soit le cas de figure [X xY], [X x X’] ou [X x X] on vise à construire une matrice carrée et symétrique de similitude [X x X] où les nombres indiquent le poids, la force de la ressemblance, de la relation entre les variables deux à deux. L’analyse de similitude sur l’ensemble Y est duale : on construit une matrice [Y x Y] en fonction des profils des sujets Yy∈ sur les variables Xi∈ . Pour cela il suffit de transposer la matrice initiale, c’est à dire de prendre en considération la matrice [Y x X] en lieu et place de la matrice [X x Y],

Droits de reproduction et de diffusion réservés © Sciences Humaines
7
1.2 EXEMPLES DE CALCUL D’UNE SIMILITUDE.
1.2.1 Le choix de réponses dans une liste. Dans un questionnaire sur l’image de la banque7 on demande aux sujets (506 sujets) de caractériser
la banque en général en choisissant certains items dans une liste donnée(tableau 4).
On demande au sujet de choisir les 2 items les plus caractéristiques de la banque. On donne ici un extrait de ces données (tableau 5). On obtient un fichier où le premier sujet a choisi les items 1 et 3 et le deuxième les items 3 et 4 et le troisième les items 1 et 2 etc… On codera ces sujets en indiquant par un 1 les items choisis et par un 0 les items non choisis.
On peut alors calculer la ressemblance entre deux items par le nombre de sujets ayant choisi ensemble deux items. On obtient une matrice de cooccurrence (tableau 6) : ici le choix des items 1 et 2 a été effectué par 100 sujets sur les 506 interrogées (c’est le cas du troisième sujet par exemple). Le choix des items 1 et 4 n’a été effectué que par 29 sujets.
1.2.2 Le choix d’une réponse sur une échelle. Dans un questionnaire posé à des élèves de terminale8 on présente un ensemble de phrases et on
demande à l’élève de choisir une attitude vis à vis de chaque phrase. Attitude que l’on code de 1 à 5 (on ne tient pas compte des élèves ayant répondu 6).
1 2 3 4 5 6 Totalement En partie ni d'accord En partie Totalement Je ne d'accord d'accord ni pas d'accord pas d'accord pas d'accord sais pas
A- Le gouvernement devrait redistribuer les revenus au profit des moins favorisés. B- Trop de gens comptent sur le gouvernement pour assurer leur bien être.
7 Etude Paul Danloy & Cie, GIFRESH, commanditée par les Banques Populaires et le Crédit Mutuel en 1995 auprès de
504 personnes (méthode des quota), échantillon représentatif par quota de la population française. 8 Etude Union Européenne Copernicus sur les connaissances économique des jeunes européens (jeunes de 17-18 ans en
fin d’étude secondaire en Angleterre, France, Pologne, République Tchèque), 1995
Tableau 6 : Le calcul de la cooccurrence donne la matrice suivante : 1 : La Banque me fait Confiance : * 100 112 29 43 26 2 : On est en Confiance : 100 * 104 60 39 16 3 : Aide Problèmes Particuliers : 112 104 * 80 43 52 4 : Découvert Rapporte à Banque : 29 60 80 * 85 72 5 : Travailler à son Profit : 43 39 43 85 * 59 6 : On n'est qu'un Numéro : 26 16 52 72 59 *
Tableau 5 : Fichier : 001 101000 002 001100 003 110000 004 . . . . . . etc…
Tableau 4 : liste des items 1 : La Banque me fait Confiance 2 : On est en Confiance 3 : Aide Problèmes Particuliers 4 : Découvert Rapporte à Banque 5 : Travailler à son Profit 6 : On n'est qu'un Numéro

Droits de reproduction et de diffusion réservés © Sciences Humaines
8
C- Le plus grand nombre n’obtient pas une juste part de la richesse de la nation. D- Les aides sociales ne vont pas toujours à ceux qui en ont le plus besoin. E- Une vraie coopération dans les entreprises est difficile parce que chefs d’entreprises et salariés n’ont
pas les mêmes intérêts. F- Les entreprises privées sont plus aptes que les entreprises publiques à résoudre les problèmes
économiques de la France
On peut calculer un score moyen obtenu pour chaque phrase (tableau 7). Mais il est plus intéressant de calculer la similitude des réponses en comparant les notes données par chaque sujet aux différentes phrases. On calcule alors une corrélation entre ces phrases (ici l’indice de corrélation est le Tau de Kendall).
La phrase A est corrélée positivement à la phrase C (.26) et négativement à la phrase B (-.12) alors que leurs scores moyens sont proches.
Ces deux exemples montrent comment il est possible de passer d’un tableau [X x Y] à un tableau de similitude [X x X].
Nous allons maintenant étudier les différentes manières d’effectuer ce passage, en un mot de calculer un indice de similitude entre les variables.
Phrases Score moyen
A- Redistribuer Revenu 2.50 B- Compte sur Gouvernement 2.41 C- N'ont pas leur Part 2.13 D- Aide Sociale détournée 1.88 E- Difficiles Coopération 2.22 F- Privé mieux que Public 3.25 Tableau 7 : score moyen des items * A B C D E F
************************************
A * * -.12 .26 .08 .08 -.08
B * -.12 * -.01 .09 .11 .07
C * .26 -.01 * .17 .04 -.01
D * .08 .09 .17 * .05 .11
E * .08 .11 .04 .05 * -.01
F * -.08 .07 -.01 .11 -.01 *
Tableau 8 : Tau de Kendall

Droits de reproduction et de diffusion réservés © Sciences Humaines
9
1.3 IL N’EST PAS POSSIBLE DE LIMITER LA SIMILITUDE A UN SEUL ET UNIQUE COEFFICIENT (coefficient de corrélation ou distance du Khi29) : POURQUOI ?
Il existe une première raison qui tient à la forme des données recueillies. Les données que l’analyse de similitude permet de traiter, sont de formes très différentes. Nous avons déjà vu qu’un tableau de données [X x Y] pouvait recouvrir plusieurs types de données différentes. Un questionnaire peut proposer une liste d’items et demander au sujet de choisir les items qu’il privilégie, les 1 indiquant le choix de l’item comme dans la figure 1 (le nombre d’items choisis peut être limité cf. annexe 2 les questionnaires de choix ou de caractérisation). Les variables i de X peuvent être des valeurs comme par exemple le nombre de pièces d’un appartement ou le salaire du chef de famille, ou encore dans le cas où le sujet est un sujet collectif : le nombre d’habitants d’une commune, le pourcentage de population au chômage etc…. On doit encore considérer un cas particulier : celui de la mesure de la position du sujet sur une échelle de réponses que l’on code de 1 à n (valeur maximale), par exemple on codera 5 l’accord total du sujet à une proposition et 1 le désaccord total, les valeurs intermédiaires permettant au sujet de moduler son opinion (cf. annexe 2 le questionnaire en échelle de « Likert »).
9 La distance calculée par le coefficient de corrélation est utilisée par les programmes d’ACP et celle du Khi2 par les
programme d’AFC.
Les différentes structures mathématiques de mesure. Binaire : une variable binaire ne peut prendre que deux valeurs : 0 ou 1. Cette variable est souvent obtenue par
éclatement des modalités d’une variable nominale. Par exemple à la question sur sa profession le sujet doit se positionner non pas sur une échelle mais dans un univers de catégories dont chacune à un nom. Seule la catégorie choisie sera codée 1, les autres prennent la valeur 0. Si la question est dite « à choix multiple » on peut avoir plusieurs 1 correspondants aux différents choix. Dans tous les cas chaque modalité de réponse est une variable binaire.
Ordinale : une variable ordinale prend ses valeurs dans les nombres cardinaux (nombres entiers) au sein d’un intervalle ayant une valeur minimale et maximale : par exemple [-2, +2], seules les valeurs -2,-1,0,1,2 sont acceptables. Cette échelle ne suppose pas qu’il existe une distance égale entre deux échelons. Elle indique simplement que si le sujet a été codé 2, il a exprimé un choix supérieur à celui qu’il aurait exprimé s’il était codé par une valeur inférieure comme 1 (ou -2). Elle indique aussi que ce choix 2 est « intermédiaire » entre le choix 1 et le choix 3.
Métrique : une variable métrique prend ses valeurs dans les nombres réels. C’est le cas du revenu d’un ménage, de la taille des élèves d’une classe, de la superficie d’une exploitation agricole, etc…Il est alors possible de calculer une distance métrique (euclidienne), d’effectuer les quatre opérations (+, -, x, /) et de la plonger dans un espace vectoriel.

Droits de reproduction et de diffusion réservés © Sciences Humaines
10
Chaque type de donnée détermine l’usage de coefficients qui tiennent compte des propriétés de la mesure utilisée (binaire, ordinale, métrique). C’est ainsi que les chiffres codant les données de type binaire ne peuvent être considérés comme des réels. On ne peut pas les utiliser pour calculer un coefficient de corrélation, par exemple, il faut utiliser, comme nous le verrons plus loin, son correspondant pour les tableaux [0,1] : le Phi de contingence. De même lorsque les données sont ordinales le coefficient de corrélation que l’on doit utiliser est le Tau de Kendall qui ne tient compte que de la différence entre les ordres induits sur les sujets par les différentes variables. Seules les données métriques permettent les calculs les plus sophistiqués, analyse de corrélation, analyse matricielle, analyse de régression etc.…
Outre la forme des données il faut aussi tenir compte du travail des statisticiens. Ceux-ci ont multiplié les indices10 permettant une mesure de la similitude entre variables. Ces indices ont cependant quelques propriétés mathématiques communes. Ces propriétés dérivent du fait que, pour un coefficient de similitude donné, l’ensemble des valeurs calculées entre les éléments i et j de X peuvent être rangées de la plus grande à la plus petite. Cet ordre entraîne un ordre sur les couples (i,j). Comme il est possible que certains couples aient la même valeur (soient ex-aequo) on utilise la notion mathématique de Préordonnance. Les propriétés de cette Préordonnance de similitude sont décrites dans l’encart ci-dessous.
L’existence de cette diversité de la forme des données et de la multiplicité des mesures possibles (indices de similitude) donne toute sa souplesse et sa richesse à l’analyse de similitude. Elle prend en
10 Hubalek, Z., 1982 ; Cet auteur présente 43 mesures d’association (coefficients de similitude) dans le seul cas des
variables dichotomiques. Il conclue son article par ces mots : « there is no absolutely general measure of the degree of dependance ».
La mesure binaire (ou dichotomique) [0,1] peut couvrir l’existence d’un ordre 0 < 1 ou seulement la présence d’un « nom », d’une modalité. Le choix de l’indice doit tenir compte de ce fait.
Dans le premier cas on parlera d’une mesure dichotomique ordonnée permettant l’utilisation des indices relatifs à une mesure ordinale. C’est par exemple l’étude de l’équipement des villes en notant dans une liste fixée à l'avance quels sont les équipements collectifs possédés. Deux villes se ressembleront alors par les équipements qu'elles ont en commun mais également par ceux qui leur manquent simultanément. Dans le second cas la mesure dichotomique est associée à une variable binaire (le 1 exprimant la présence du « nom » et le 0 l’absence). Dans ce cas l’absence du « nom » n’a pas automatiquement un sens inverse à la présence de ce « nom ». Par exemple l’absence d’un mot dans une liste d’évocations spontanées peut signifier deux choses bien différentes : le sujet ne voulait pas l’évoquer ou tout simplement le mot ne lui est pas venu spontanément à l’esprit pour diverses raisons. Le zéro représente une diversité de situations alors que le 1 exprime uniquement le choix du sujet.
On peut se trouver dans des situations mixtes. Quand on demande au sujet de choisir trois items parmi une liste de 12, la probabilité du non-choix est bien supérieure à celle du choix (ici 0,75 contre 0,25). Il n’y a pas symétrie du 1 et du 0. Ici on peut décider de considérer soit seulement le choix (le 1), soit l’ordre 0 < 1.
Il existe encore un cas où ces deux valeurs [0,1] n’ont pas le même sens mais où cette propriété échappe souvent à la conscience de l’analyste, c’est la transformation d’une variable nominale ayant plusieurs modalités en une série de variables binaires comme dans le cas des catégories socioprofessionnelles. Le 0 n’indique pas l’absence d’une profession donnée mais le fait que le sujet appartient à une autre profession. Cette procédure dite « d’éclatement des modalités » est utilisée pour évaluer les effets de chaque item (ici de chaque profession). Cette procédure est, par exemple, obligatoire quand on construit un tableau de « Burt » en Analyse Factorielle de Correspondance, ou quand on utilise les procédures logistiques (Logit). Dans ces deux cas, les outils mathématiques utilisés font implicitement référence à une symétrie du 0 et du 1 alors qu’il n’en est rien.

Droits de reproduction et de diffusion réservés © Sciences Humaines
11
compte non seulement les propriétés mathématiques des données mais aussi le parti pris de celui qui traite les données. A cette richesse correspond un impératif : l’analyste doit prendre des décisions qui influencent fortement le résultat des calculs. L’analyse de similitude ne fonctionne pas comme une boite noire fournissant un résultat unique, elle oblige l’analyste à préciser ce qu’il recherche et par quel moyen.
Quel sont ces décisions ? Elles concernent d’abord la forme des données et par là même le choix d’une classe d’indices de
similitude. L’analyste doit identifier la mesure (binaire, ordinale, métrique) qui est imposée par la forme des données. Il peut se trouver dans un cas mixte l’obligeant à un recodage. Il peut aussi être conduit à réduire la richesse de la mesure originale car elle dilue l’information pertinente comme un costume trop grand. C’est ainsi que l’on ramène l’information de l’âge (ou du revenu) exprimé en années (ou francs) à des classes d’équivalences ordonnées (les moins de 18 ans, les 18-24, les 25-40 etc…). On passe d’une mesure métrique à une mesure ordinale. De même on réduit souvent une échelle ordinale d’opinion (de type Likert) à une variable dichotomique (les opinions favorables prenant la valeur 1 et les défavorables la valeur 0). On fait aussi quelque fois l’opération inverse : considérer une mesure ordinale comme une mesure métrique (le calcul d’une moyenne sur une échelle de Likert par exemple). On doit alors agir avec une certaine prudence, c’est quelque fois acceptable même si ce n’est pas légitime.
Nous verrons plus loin que l’analyste sera obligé de prendre des décisions tout au long de la procédure d’analyse : choix de seuils, choix d’un mode de représentation des résultats etc… Le premier choix reste celui de l’indice de similitude.
1.4. LES CRITERES DU CHOIX D’UN INDICE DE SIMILITUDE.
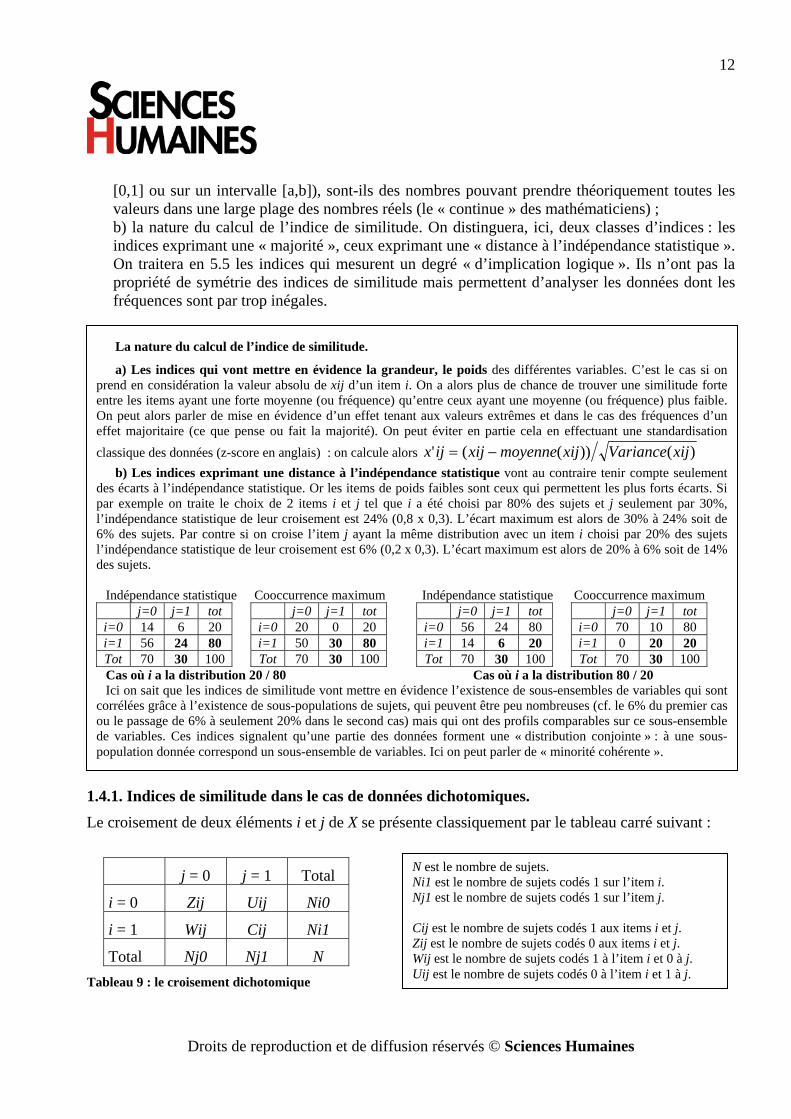
Pour choisir l’indice de similitude qu’il convient de calculer il faut donc tenir compte de deux éléments :
a) la nature de la mesure où sont plongés les nombres que l’on trouve dans ce tableau {X x Y} : ont-ils une valeur « binaire », sont-ils des positions sur une échelle « ordinale » (dichotomique
Préordonnance de similitude Soit X un ensemble {i,j …} et [X x X] l'ensemble des couples (i,j) d'éléments de X. On appelle préordonnance de similitude sur X un préordre total sur X x X, vérifiant les conditions suivantes,
quels que soit {i,j,k} éléments de X : (i,j) = (j,i) : propriété qui traduit la symétrie de la relation de ressemblance. (i,i) > (i,j) : propriété qui traduit que tout élément ressemble plus à lui même qu’à tout autre. En outre si (i,j) > (i,k) i doit « ressembler » plus à j qu’à k. Habituellement cette préordonnance est associée à une application S de X x X dans les nombres réels. On a alors Sij > Skt (i,j) > (k,t) Sij est appelé indice de similitude. Nous avons vu que la préordonnance de similitude peut être obtenue de deux manières : Soit la préordonnance P
peut être donnée presque directement par l'observation sur l’ensemble [X x X] ; dans ce cas on a obtenu une hiérarchie sur les paires ij. Soit, et c’est le cas le plus général, on doit construire la préordonnance à partir du calcul d'un indice de similitude S (appelé aussi coefficient de similitude).
Pour cela il faut établir une mesure de ressemblance sur l’ensemble X. Cette mesure suppose l’existence d’un second ensemble Y tel que l’on puisse construire un tableau rectangulaire [X x Y] exprimant les valeurs que prennent les éléments i (ou j) de X dans les référentiels y de Y. Les données servant à calculer l’indice de similitude sont alors présentes dans ce tableau rectangulaire.
Droits de reproduction et de diffusion réservés © Sciences Humaines
12
[0,1] ou sur un intervalle [a,b]), sont-ils des nombres pouvant prendre théoriquement toutes les valeurs dans une large plage des nombres réels (le « continue » des mathématiciens) ; b) la nature du calcul de l’indice de similitude. On distinguera, ici, deux classes d’indices : les indices exprimant une « majorité », ceux exprimant une « distance à l’indépendance statistique ». On traitera en 5.5 les indices qui mesurent un degré « d’implication logique ». Ils n’ont pas la propriété de symétrie des indices de similitude mais permettent d’analyser les données dont les fréquences sont par trop inégales.
1.4.1. Indices de similitude dans le cas de données dichotomiques. Le croisement de deux éléments i et j de X se présente classiquement par le tableau carré suivant :
j = 0 j = 1 Total
i = 0 Zij Uij Ni0
i = 1 Wij Cij Ni1
Total Nj0 Nj1 N Tableau 9 : le croisement dichotomique
La nature du calcul de l’indice de similitude.
a) Les indices qui vont mettre en évidence la grandeur, le poids des différentes variables. C’est le cas si on prend en considération la valeur absolu de xij d’un item i. On a alors plus de chance de trouver une similitude forte entre les items ayant une forte moyenne (ou fréquence) qu’entre ceux ayant une moyenne (ou fréquence) plus faible. On peut alors parler de mise en évidence d’un effet tenant aux valeurs extrêmes et dans le cas des fréquences d’un effet majoritaire (ce que pense ou fait la majorité). On peut éviter en partie cela en effectuant une standardisation classique des données (z-score en anglais) : on calcule alors )())((' xijVariancexijmoyennexijijx −=
b) Les indices exprimant une distance à l’indépendance statistique vont au contraire tenir compte seulement des écarts à l’indépendance statistique. Or les items de poids faibles sont ceux qui permettent les plus forts écarts. Si par exemple on traite le choix de 2 items i et j tel que i a été choisi par 80% des sujets et j seulement par 30%, l’indépendance statistique de leur croisement est 24% (0,8 x 0,3). L’écart maximum est alors de 30% à 24% soit de 6% des sujets. Par contre si on croise l’item j ayant la même distribution avec un item i choisi par 20% des sujets l’indépendance statistique de leur croisement est 6% (0,2 x 0,3). L’écart maximum est alors de 20% à 6% soit de 14% des sujets.
Indépendance statistique Cooccurrence maximum Indépendance statistique Cooccurrence maximum
j=0 j=1 tot j=0 j=1 tot j=0 j=1 tot j=0 j=1 tot i=0 14 6 20 i=0 20 0 20 i=0 56 24 80 i=0 70 10 80 i=1 56 24 80 i=1 50 30 80 i=1 14 6 20 i=1 0 20 20 Tot 70 30 100 Tot 70 30 100 Tot 70 30 100 Tot 70 30 100 Cas où i a la distribution 20 / 80 Cas où i a la distribution 80 / 20 Ici on sait que les indices de similitude vont mettre en évidence l’existence de sous-ensembles de variables qui sont
corrélées grâce à l’existence de sous-populations de sujets, qui peuvent être peu nombreuses (cf. le 6% du premier cas ou le passage de 6% à seulement 20% dans le second cas) mais qui ont des profils comparables sur ce sous-ensemble de variables. Ces indices signalent qu’une partie des données forment une « distribution conjointe » : à une sous-population donnée correspond un sous-ensemble de variables. Ici on peut parler de « minorité cohérente ».
N est le nombre de sujets. Ni1 est le nombre de sujets codés 1 sur l’item i. Nj1 est le nombre de sujets codés 1 sur l’item j. Cij est le nombre de sujets codés 1 aux items i et j. Zij est le nombre de sujets codés 0 aux items i et j. Wij est le nombre de sujets codés 1 à l’item i et 0 à j. Uij est le nombre de sujets codés 0 à l’item i et 1 à j.

Droits de reproduction et de diffusion réservés © Sciences Humaines
13
1.4.1.1 Cas des variables binaires.
Lorsque les variables sont binaires seules les informations concernant la présence (le 1) ont un sens. On peut alors construire les indices suivants.
a) Le nombre de fois où i et j sont codés tous les deux 1 est appelé cooccurrence : S1 = Cij. On peut aussi calculer un pourcentage 100)(2 ×= NCijS . Ces deux indices donnent la même préordonnance de similitude. Ils font apparaître ce que l’on peut appeler le phénomène majoritaire. En effet plus les items i et j sont présents (Ni1 et Nj1 grand) plus il y a de chance pour que Cij soit grand. b) On peut, pour corriger cet effet majoritaire, établir un rapport entre Cij et C*ij, fréquence de la cooccurrence dans le cas de l’indépendance statistique entre i et j. NNjNiijC )11(* ×= On peut alors calculer leur rapport ijCCijS *3 = qui est égal à )11()(3 NjNiNCijS ××= . On peut aussi calculer leur différence en pourcentage ijCijCCijS *)*(1004 −×= On peut encore calculer l’indice de Forbes )*max()*(5 ijCCijijCCijS −−= avec Cijmax la valeur maximum que peut avoir Cij ; cette valeur est en fait le minimum de [Nj1, Ni1]. Le domaine de variation de ces différents indices est fort différent : l’indice S3 varie entre 0 et une valeur maximale S3max quand Cij est maximum c’est à dire égal au minimum de [Ni1,Nj1] alors : [ ]1,1maxmax3 NjNiNS = ; la valeur S3 = 1 indique l’indépendance statistique entre i et j ; entre 0 et 1 Cij est inférieure à la valeur attendue s’il y avait indépendance statistique, entre 1 et S3max Cij est supérieur à cette valeur. La valeur S4 = 0 indique l’indépendance statistique entre i et j, il en est de même pour S5 qui varie de 0 à 1 (quand Cij=Cijmax).
On montrera plus loin sur un exemple l’usage de ces deux types d’indices (cf. 1.3.1.3.).
1.4.1.2 Cas des variables dichotomiques ordonnées.
Lorsque les variables dichotomiques sont représentatives d’un ordre entre le 0 et le 1 on peut alors construire des indices où le 0 et le 1 tiennent des places symétriques.
a) Le nombre de fois où i et j sont codés tous les deux de la même manière est appelé cooccurrence symétrique : ZijCijS +=6 On peut aussi calculer un pourcentage 100))((7 ×+= NZijCijS . Ces deux indices donnent la même préordonnance de similitude. Ils expriment à l’évidence le poids de la diagonale de corrélation mais sans faire référence au calcul de la valeur théorique des cases Cij et Zij. On a ici aussi la mesure d’un phénomène majoritaire pouvant porter symétriquement sur la valeur 0 ou 1. L’indice S7 varie entre 0 et N, L’indice S8 varie entre 0 et 100. b) Le Phi de contingence va, lui, signaler la corrélation et donc la comparaison des données à leur valeur théorique dans le cas de l’indépendance statistique, comparaison mise en évidence par la relation qui relie le Phi et le Khi2. La formule du Phi dérive de l’application du Tau de Kendall, au tableau à quatre cases. Il correspond bien à un ordre 0 < 1.

Droits de reproduction et de diffusion réservés © Sciences Humaines
14
1010)()(
8NiNiNjNj
WijUijCijZijS×××
×−×==ϕ appelé Phi de contingence11.
On peut trouver dans la littérature tout un ensemble d’indices dont la formule dérive de celle du Phi de contingence. On en signalera un qui essaye de corriger le fait que le Phi ne varie pas entre –1 et +1 comme le voudrait la théorie mais entre une valeur maximale et une valeur minimale qui dépend des marges (cf. annexe 1). On calcule alors le « Phimax » pour la zone des corrélations positives et on établit le rapport Phi sur Phimax : S8bis = S8 / Phimax. Le Phimax est obtenu en calculant le tableau donnant la corrélation maximale. Ce tableau maximise la valeur Cij. Alors 1,1min NjNiCij = . Dans ce cas la valeur de l’indice varie, dans la zone des corrélations positives, entre 0 et +1 quelque soient les marges. Il est aussi possible d’obtenir un indice variant de -1 à +1 en utilisant le Q de Yule
)()()()(
9 WijUijCijZijWijUijCijZijQS
×+××−×
== . Cet indice est égal à 1 si Uij ou Wij est égal à 0 (une case anti
diagonale vide). Il est égal à –1 si Zij ou Cij est égal à 0 (une case diagonale vide). Il est égal à 0 comme le Phi de contingence dans le cas de l’égalité des produits des valeurs des deux diagonales (nullité du numérateur). On est ici proche d’une mesure de l’implication plus que de la corrélation comme nous le verrons plus loin. Un indice particulier est aussi souvent utilisé car il évite de prendre en considération la case Zij (absence de i et de j) : l’indice de communauté dit indice de Jaccard : )(10 ijijijij WUCCS ++=
11 Le Phi est égal à la racine carrée du Khi2 total du tableau divisé par N. On calcule ainsi le Khi2
ijCijCCij
ijWijWWij
ijUijUUij
ijZijZZij
Khi*
)*(*
)*(*
)*(*
)*( 22222 −
+−
+−
+−
= ; avec Z*ij, U*ij, W*ij, C*ij les valeurs
théoriques dans le cas de l’indépendance statistique entre i et j calculées grâce aux marges du tableau : NNjNiijZ )00(* ×= ; NNjNiijU )10(* ×= ; NNjNiijW )01(* ×= ; NNjNiijC )11(* ×= .
Droits de reproduction et de diffusion réservés © Sciences Humaines
15
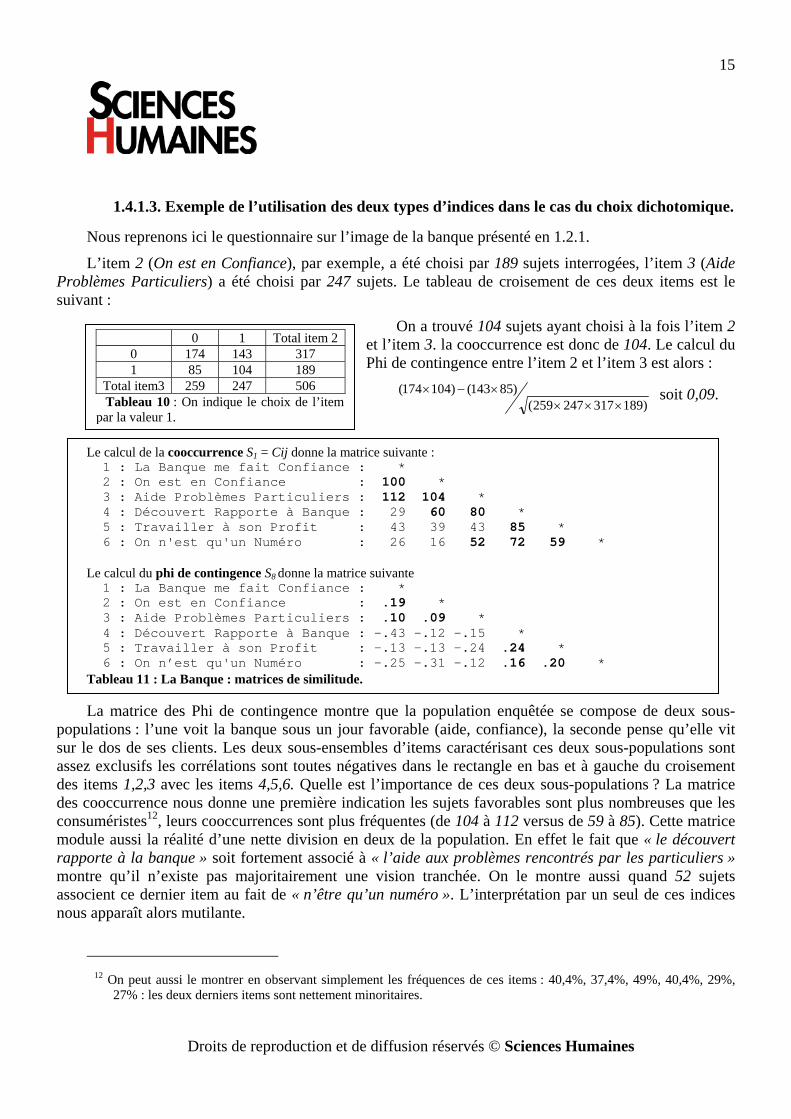
1.4.1.3. Exemple de l’utilisation des deux types d’indices dans le cas du choix dichotomique.
Nous reprenons ici le questionnaire sur l’image de la banque présenté en 1.2.1.
L’item 2 (On est en Confiance), par exemple, a été choisi par 189 sujets interrogées, l’item 3 (Aide Problèmes Particuliers) a été choisi par 247 sujets. Le tableau de croisement de ces deux items est le suivant :
On a trouvé 104 sujets ayant choisi à la fois l’item 2 et l’item 3. la cooccurrence est donc de 104. Le calcul du Phi de contingence entre l’item 2 et l’item 3 est alors :
)189317247259()85143()104174(
××××−× soit 0,09.
La matrice des Phi de contingence montre que la population enquêtée se compose de deux sous-populations : l’une voit la banque sous un jour favorable (aide, confiance), la seconde pense qu’elle vit sur le dos de ses clients. Les deux sous-ensembles d’items caractérisant ces deux sous-populations sont assez exclusifs les corrélations sont toutes négatives dans le rectangle en bas et à gauche du croisement des items 1,2,3 avec les items 4,5,6. Quelle est l’importance de ces deux sous-populations ? La matrice des cooccurrence nous donne une première indication les sujets favorables sont plus nombreuses que les consuméristes12, leurs cooccurrences sont plus fréquentes (de 104 à 112 versus de 59 à 85). Cette matrice module aussi la réalité d’une nette division en deux de la population. En effet le fait que « le découvert rapporte à la banque » soit fortement associé à « l’aide aux problèmes rencontrés par les particuliers » montre qu’il n’existe pas majoritairement une vision tranchée. On le montre aussi quand 52 sujets associent ce dernier item au fait de « n’être qu’un numéro ». L’interprétation par un seul de ces indices nous apparaît alors mutilante.
12 On peut aussi le montrer en observant simplement les fréquences de ces items : 40,4%, 37,4%, 49%, 40,4%, 29%,
27% : les deux derniers items sont nettement minoritaires.
Le calcul de la cooccurrence S1 = Cij donne la matrice suivante : 1 : La Banque me fait Confiance : * 2 : On est en Confiance : 100 * 3 : Aide Problèmes Particuliers : 112 104 * 4 : Découvert Rapporte à Banque : 29 60 80 * 5 : Travailler à son Profit : 43 39 43 85 * 6 : On n'est qu'un Numéro : 26 16 52 72 59 * Le calcul du phi de contingence S8 donne la matrice suivante 1 : La Banque me fait Confiance : * 2 : On est en Confiance : .19 * 3 : Aide Problèmes Particuliers : .10 .09 * 4 : Découvert Rapporte à Banque : -.43 -.12 -.15 * 5 : Travailler à son Profit : -.13 -.13 -.24 .24 * 6 : On n’est qu'un Numéro : -.25 -.31 -.12 .16 .20 * Tableau 11 : La Banque : matrices de similitude.
0 1 Total item 2 0 174 143 317 1 85 104 189
Total item3 259 247 506 Tableau 10 : On indique le choix de l’item
par la valeur 1.
Droits de reproduction et de diffusion réservés © Sciences Humaines
16
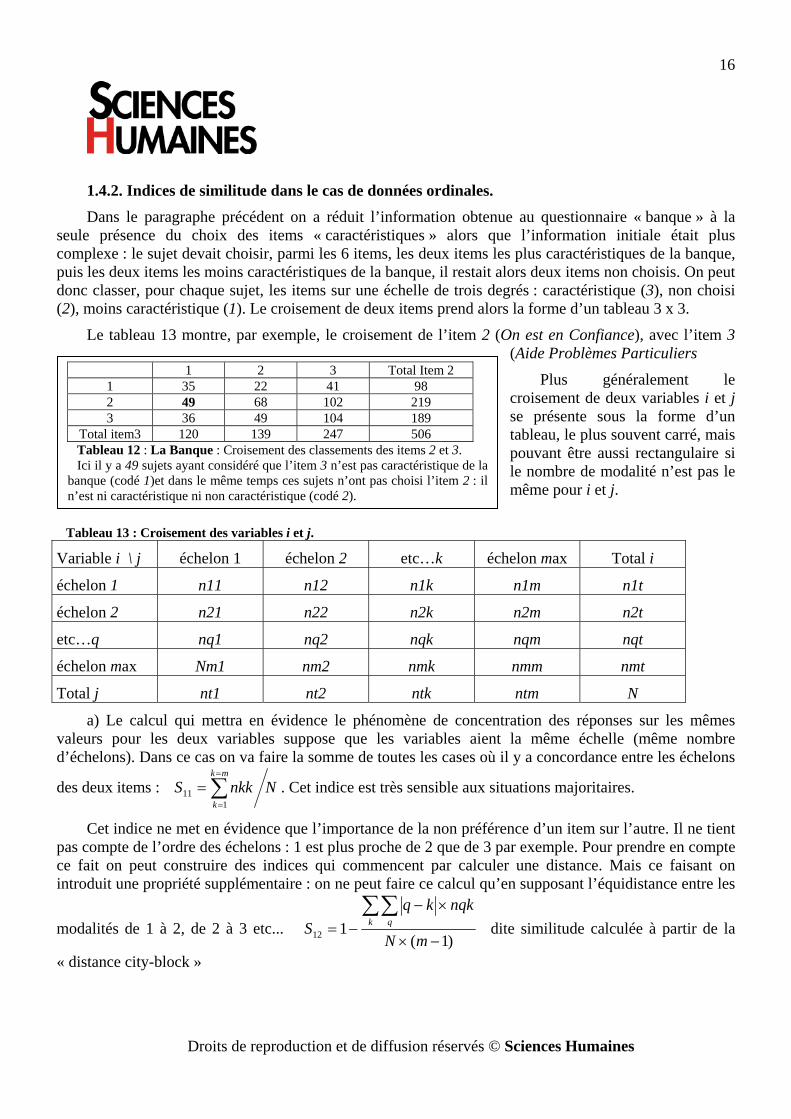
1.4.2. Indices de similitude dans le cas de données ordinales. Dans le paragraphe précédent on a réduit l’information obtenue au questionnaire « banque » à la
seule présence du choix des items « caractéristiques » alors que l’information initiale était plus complexe : le sujet devait choisir, parmi les 6 items, les deux items les plus caractéristiques de la banque, puis les deux items les moins caractéristiques de la banque, il restait alors deux items non choisis. On peut donc classer, pour chaque sujet, les items sur une échelle de trois degrés : caractéristique (3), non choisi (2), moins caractéristique (1). Le croisement de deux items prend alors la forme d’un tableau 3 x 3.
Le tableau 13 montre, par exemple, le croisement de l’item 2 (On est en Confiance), avec l’item 3 (Aide Problèmes Particuliers
Plus généralement le croisement de deux variables i et j se présente sous la forme d’un tableau, le plus souvent carré, mais pouvant être aussi rectangulaire si le nombre de modalité n’est pas le même pour i et j.
Tableau 13 : Croisement des variables i et j.
Variable i \ j échelon 1 échelon 2 etc…k échelon max Total i
échelon 1 n11 n12 n1k n1m n1t
échelon 2 n21 n22 n2k n2m n2t
etc…q nq1 nq2 nqk nqm nqt
échelon max Nm1 nm2 nmk nmm nmt
Total j nt1 nt2 ntk ntm N
a) Le calcul qui mettra en évidence le phénomène de concentration des réponses sur les mêmes valeurs pour les deux variables suppose que les variables aient la même échelle (même nombre d’échelons). Dans ce cas on va faire la somme de toutes les cases où il y a concordance entre les échelons
des deux items : NnkkSmk
k∑=
=
=1
11 . Cet indice est très sensible aux situations majoritaires.
Cet indice ne met en évidence que l’importance de la non préférence d’un item sur l’autre. Il ne tient pas compte de l’ordre des échelons : 1 est plus proche de 2 que de 3 par exemple. Pour prendre en compte ce fait on peut construire des indices qui commencent par calculer une distance. Mais ce faisant on introduit une propriété supplémentaire : on ne peut faire ce calcul qu’en supposant l’équidistance entre les
modalités de 1 à 2, de 2 à 3 etc... )1(
112 −×
×−−=∑∑
mN
nqkkqS k q dite similitude calculée à partir de la
« distance city-block »
1 2 3 Total Item 2 1 35 22 41 98 2 49 68 102 219 3 36 49 104 189
Total item3 120 139 247 506 Tableau 12 : La Banque : Croisement des classements des items 2 et 3. Ici il y a 49 sujets ayant considéré que l’item 3 n’est pas caractéristique de la
banque (codé 1)et dans le même temps ces sujets n’ont pas choisi l’item 2 : il n’est ni caractéristique ni non caractéristique (codé 2).

Droits de reproduction et de diffusion réservés © Sciences Humaines
17
On peut aussi calculer une fonction inverse de la distance euclidienne : )1(
)(1
2
13 −×
×−−=∑∑
mN
nqkkqS k l
Christian Guimelli a voulu faire un indice variant entre –1 et +1, le 0 devenant une sorte de point neutre séparant les faibles et les fortes similitudes13. Il calcule )5,0(2 1214 −= SS . Cet indice veut se référer analogiquement aux questionnaires où on demande aux sujets de se positionner sur un intervalle de [–m à +m]. En fait c’est une simple transformation linéaire de l’indice S12 « city block »
b) Les indices de similitude, qui tiennent compte de l’indépendance statistique, qui respectent la propriété de préférence et qui ne font pas implicitement l’hypothèse d’équidistance entre les échelons, ont été créés par Kendall. Cet auteur propose deux indices dit Tau b (S15) dans le cas d’un tableau non carré (si le nombre maximum d’échelons n’est pas le même pour les items i et j) et Tau c (S16) qui correspond aux tableaux carrés (cf. annexe 1).
13 Guimelli, Ch., 1998
Droits de reproduction et de diffusion réservés © Sciences Humaines
18
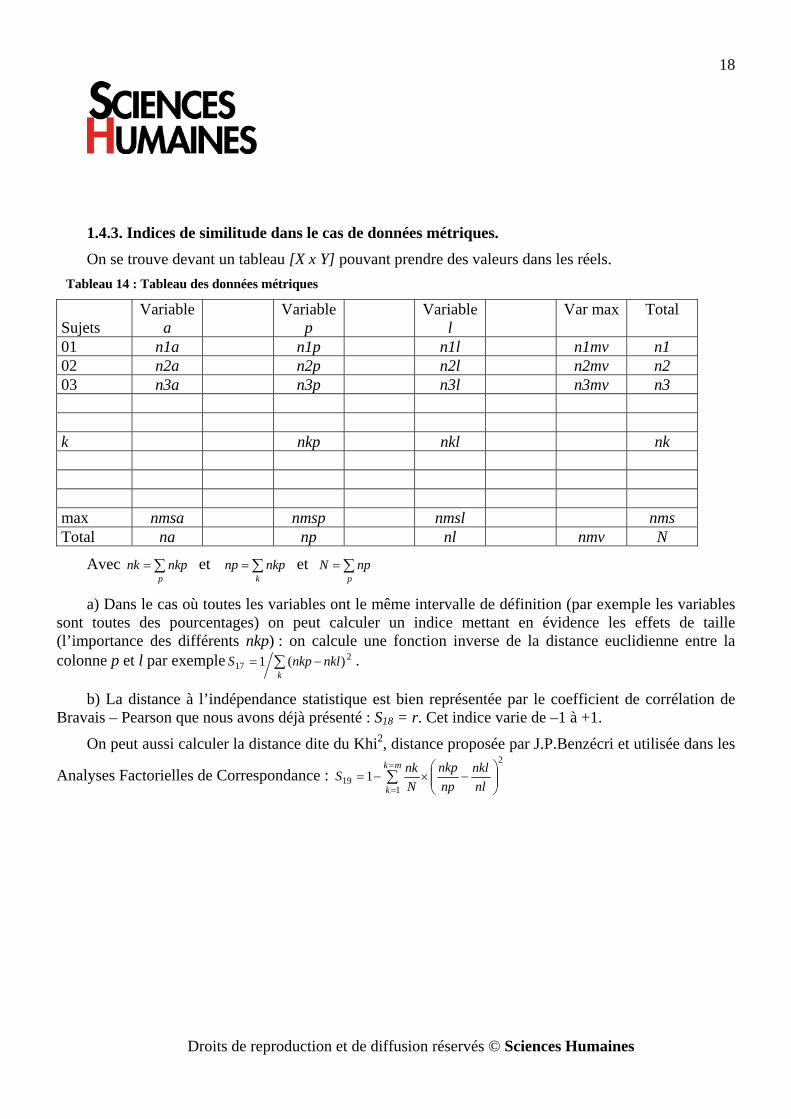
1.4.3. Indices de similitude dans le cas de données métriques. On se trouve devant un tableau [X x Y] pouvant prendre des valeurs dans les réels.
Tableau 14 : Tableau des données métriques
Sujets
Variable a
Variable p
Variable l
Var max Total
01 n1a n1p n1l n1mv n1 02 n2a n2p n2l n2mv n2 03 n3a n3p n3l n3mv n3 k nkp nkl nk max nmsa nmsp nmsl nms Total na np nl nmv N
Avec ∑=p
nkpnk et ∑=k
nkpnp et ∑=p
npN
a) Dans le cas où toutes les variables ont le même intervalle de définition (par exemple les variables sont toutes des pourcentages) on peut calculer un indice mettant en évidence les effets de taille (l’importance des différents nkp) : on calcule une fonction inverse de la distance euclidienne entre la colonne p et l par exemple ∑ −=
knklnkpS 2
17 )(1 .
b) La distance à l’indépendance statistique est bien représentée par le coefficient de corrélation de Bravais – Pearson que nous avons déjà présenté : S18 = r. Cet indice varie de –1 à +1.
On peut aussi calculer la distance dite du Khi2, distance proposée par J.P.Benzécri et utilisée dans les
Analyses Factorielles de Correspondance : 2
119 1 ⎟⎟
⎠
⎞⎜⎜⎝
⎛−×−= ∑
=
= nlnkl
npnkp
NnkS
mk
k
Droits de reproduction et de diffusion réservés © Sciences Humaines
19
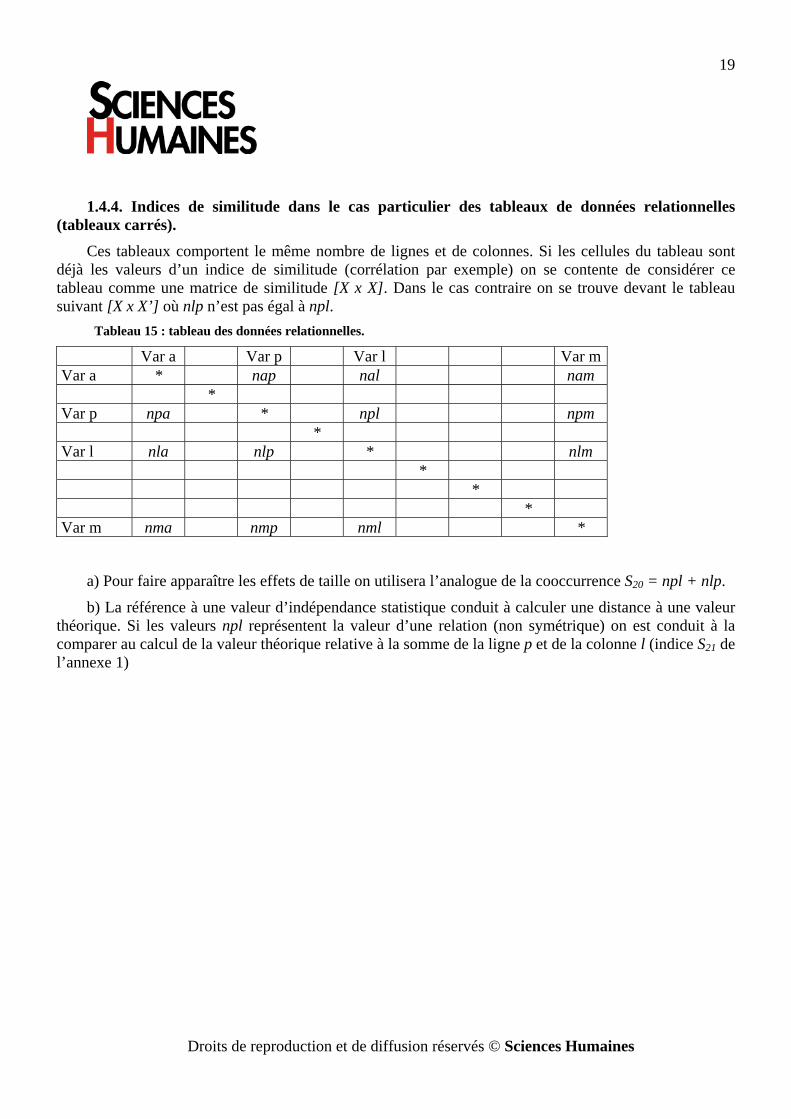
1.4.4. Indices de similitude dans le cas particulier des tableaux de données relationnelles (tableaux carrés).
Ces tableaux comportent le même nombre de lignes et de colonnes. Si les cellules du tableau sont déjà les valeurs d’un indice de similitude (corrélation par exemple) on se contente de considérer ce tableau comme une matrice de similitude [X x X]. Dans le cas contraire on se trouve devant le tableau suivant [X x X’] où nlp n’est pas égal à npl.
Tableau 15 : tableau des données relationnelles.
Var a Var p Var l Var m Var a * nap nal nam * Var p npa * npl npm * Var l nla nlp * nlm * * * Var m nma nmp nml *
a) Pour faire apparaître les effets de taille on utilisera l’analogue de la cooccurrence S20 = npl + nlp.
b) La référence à une valeur d’indépendance statistique conduit à calculer une distance à une valeur théorique. Si les valeurs npl représentent la valeur d’une relation (non symétrique) on est conduit à la comparer au calcul de la valeur théorique relative à la somme de la ligne p et de la colonne l (indice S21 de l’annexe 1)

Droits de reproduction et de diffusion réservés © Sciences Humaines
20
CHAPITRE 2 LES PROPRIETES FORMELLES AU SEIN DE LA MATRICE DE SIMILITUDE.
La matrice [X x X] où on rassemble les indices de similitude est constituée de 2)1( −× mm 14 valeurs avec m le nombre de variables étudiées. Si m est égal à 25 cela nous donne 300 valeurs, s’il est égal à 50 on obtient 1 225 nombres. Il faut donc se donner un moyen pour résumer ces données en perdant le minimum d’informations.
14 La matrice a (m x m) valeurs, comme elle est symétrique chaque valeur apparaît 2 fois, comme on ne tient pas compte
des valeurs de la diagonale, on aboutit à cette formule.
Principales définitions de la théorie des graphes non orientés. On appelle Graphe G = (X, U) le couple constitué par un ensemble X et
une famille U de paires d’éléments de X [ ]XXU ,⊂ , On dit que X est l’ensemble des sommets {i} et U l’ensemble
des arêtes {u}, u = (ij) avec Xji ∈, . On dit que les sommets i et j sont les extrémités de l’arête (ij).
On appelle GA sous-graphe de G le graphe engendré par XA ⊂ dont les sommets XAji ⊂∈, et les arêtes Uij ⊂)( .
On appelle graphe partiel de G engendré par UV ⊂ le graphe (X, V) dont les sommets sont tous ceux de X et les arêtes Vij ∈)( .
Un graphe est complet si toute paire (ij) est arête du graphe :
Uijji ∈∀ )(:, . Une clique est un sous graphe complet du graphe G. On appelle chaîne la séquence (ul, u2, ... uq) d’arêtes de G telle que
chaque arête de la séquence ait une extrémité en commun avec l'arête précédente (sauf u1), et l'autre extrémité en commun avec l'arête suivante (sauf uq). Nous ne considérons ici que les chaînes élémentaires c'est-à-dire celles où tous les sommets sont différents. On appelle chaîne maximale une chaîne élémentaire à laquelle on ne peut pas ajouter une nouvelle arête.
On appelle cycle une chaîne élémentaire (u1…,uq) tel que u1 = (ij) et uq = (ki). La longueur d'une chaîne ou d'un cycle est égale au nombre d'arêtes figurant dans cette chaîne ou ce cycle.
On dit qu'un graphe est connexe si pour toute paire de sommets (ij)
distincts il existe une chaîne reliant ces deux sommets. On montre que si G = (X,U) n'est pas connexe, on peut trouver une bipartition de X en X1 et X2de telle sorte qu'aucune arête n'ait une extrémité en X1 et l'autre en X2.
Une composante connexe est un sous-graphe connexe tel qu’on ne peut y ajouter un autre sommet sans perdre la propriété de connexité.
On appelle arbre un graphe connexe et sans cycle. On montre qu'un arbre a (n-1) arêtes si n est le cardinal de X. On appelle arbre d'un graphe G connexe un graphe partiel de G qui est connexe et sans cycle.
On appelle matrice associée à un graphe la matrice dont les valeurs (ij) = 0 si Gij ∉)( et égale à 1 si Gij ∈)( . On peut étendre cette définition aux graphes valués. Ces graphes sont complets et chaque arête (ij) à la valeur de la cellule (ij) de la matrice.
Un graphe c’est des points et des traits les reliant. Dans la figure 6 on compte 6 sommets de a à f reliés par des arêtes que l’on écrit : (ad), (db), (ac) etc…
Si on élimine certains sommets et les arêtes qui y aboutissent on obtient un sous-graphe.
S’il existe toujours une arête entre deux sommets quelconques d’un sous-graphe on dit que c’est une clique.
Si on garde tous les sommets d’un graphe et que l’on élimine certaines arêtes on obtient un graphe partiel.
Si on va d’un sommet (d’une variable) à un autre sommet par un parcours empruntant des arêtes toutes différentes on a défini une chaîne.
Si à partir d’un sommet on parcourt une chaîne qui nous ramène sur le sommet de départ on parle d’un cycle.
Si un groupe de sommets est tel que l’on peut toujours trouver une chaîne pour joindre deux sommets quelconques de ce groupe, il est appelé composante connexe.
Si on affecte une valeur à ces traits on obtient une représentation graphique donnant la même information que la matrice de similitude : des variables et des valeurs de similitude entre chaque paire de variables qui deviennent, dans la théorie des graphes, des sommets et des arêtes valuées (un graphe valué).

Droits de reproduction et de diffusion réservés © Sciences Humaines
21
Pour cela nous utiliserons la théorie des graphes15. Elle nous permet de dire qu’à toute matrice symétrique, telles que nous les avons construites avec les divers indices de similitude, correspond un graphe valué non orienté. Les objets mathématiques que propose la théorie des graphes sont en effet appropriés à la description des similitudes. Il est alors possible de nous appuyer sur les outils que nous donne cette théorie pour construire des « représentations graphiques » les plus fidèles possible.
Quelles différentes organisations d’un ensemble de variables cherche-t-on à décrire ? Les représentations graphiques qui sont, ici, utilisées ne relèvent pas d’une représentation
« approchée » des distances exprimées par la matrice de similitude (au sens d’une représentation géométrique comme dans l’AFC) mais visent une représentation exprimant par des traits les liaisons (les proximités) entre variables. On obtient une représentation plus topologique que géométrique.
a) En premier on veut savoir si ces variables s’organisent autour de dimensions. L’analyse factorielle nous propose des axes géométriques (le plus souvent dans un espace Euclidien). Ici nous utiliserons la notion de chaîne qui informe sur l’intermédiarité et une notion plus polymorphe celle d’arbre comme ensemble de chaînes maximales. Ce dernier donne une structure16 à l’ensemble des variables. On voit sur l’exemple pourtant simple de la figure 1 qu’un arbre peut montrer l’existence de plusieurs dimensions
b) Cet arbre est un peu squelettique. Il met bien en évidence une dimension principale allant de a à f mais il ignore les cycles (a,c,d,b,a) et (c,b,e,c). Si les données ne sont pas correctement décrites par un (ou des) axe mais forment un (ou des) cycle(s) il faut abandonner l’idée d’une seule dimension explicative. Les cycles s’interprètent souvent comme le produit de deux dimensions. Dans une étude sur les exploitations agricoles on obtenait un cycle qui passait des indicateurs relatifs aux grandes exploitations céréalières à ceux des grandes exploitations viticoles puis des petites exploitations viticoles pour se terminer par ceux des petites exploitations céréalières. On pouvait alors mettre en évidence l’existence de deux critères indépendants : grand / petit et viticole / céréalier. On verra plus loin un cycle s’appuyant sur deux oppositions : pays en voie de développement versus pays développés et pays occidentaux versus pays sous influence communiste (cf. 2.4).
c) La recherche de classifications est aussi un mode classique de traitement des données. Un ensemble d’algorithmes vise à construire des classes (Classification
15 Théorie défini par Koening, 1925 et introduite en France par Berge, 1970 16 Cette structure est minimale car on ne peut lui enlever une arête sans détruire la connexité et donc l’arbre.
Soit la ressemblance établit par un seul sujet entre les variables a à f :
Sommets a b c d e f a * b 0 * c 1 1 * d 1 1 0 * e 0 1 1 0 * f 0 0 0 0 1 *
On peut extraire de ce graphe l’arbre ci-dessus.
Cet arbre montre trois chaînes maximales (a,d,b,e,f) allant de a à f ainsi que (a,d,b,c) et (c,b,e).
Figure 1 Exemple

Droits de reproduction et de diffusion réservés © Sciences Humaines
22
Ascendante Hiérarchique, Segmentation, Nuées dynamiques, block-model…). La notion de cliques et leur organisation en un « filtrant des cliques » est, comme nous le verrons plus loin, le moyen de mettre en évidence un ensemble de groupements non obligatoirement disjoints. Cette dernière propriété, même si elle donne une certaine complexité à l’analyse, donne une souplesse et une richesse de description que n’a pas la définition des classes qui supposent obligatoirement la disjonction (un élément ne peut pas appartenir à deux classes).
d) L’analyse du graphe permet la mise en évidence de l’une (ou de plusieurs) de ces organisations : dimensions, cycles, groupements. Par là même l’interprétation n’est pas dépendante de la procédure mathématique utilisée : classification ou analyse factorielle. Dans un même graphe on peut déceler une zone de forte densité (clique) pouvant se trouver sur une chaîne décrivant un axe. Pour une partie des variables la description en groupements est pertinente, pour une autre partie la description d’un axe le sera. On obtient ainsi la possibilité d’identifier plusieurs formes de description des données. Cette souplesse est liée à une propriété essentielle de l’analyse de similitude, propriété qui la distingue des classiques analyses de données. Ici la réduction de l’information se fait à travers l’étude des valeurs « localement » les plus fortes et non sur la base d’une analyse « globale » (On tend à ne pas tenir compte des arêtes dont les valeurs sont faibles). Qu’entendons nous par cette distinction local / global ? pour nous faire comprendre nous allons présenter un exemple.
2.1. UN PREMIER EXEMPLE D’ANALYSE DE SIMILITUDE.
Nous reprenons l’exemple du paragraphe 1.2.1.3 Le questionnaire passé à 506 sujets représentatives de la population française visait à caractériser la « banque » par les termes d’une liste. Cette liste comprend un grand nombre de termes. Nous en extrayons ici six. Chaque terme est codé de 1 à 3 comme nous l’avons indiqué au paragraphe 1.3.2 (tableau 12). On calcule le Tau de Kendall pour chaque paire de terme17. On obtient une matrice de similitude qui présente, quand on organise ses lignes (et colonnes), une structure binaire : d’un coté on trouve une vision positive et de l’autre une vision plutôt négative (tableau 16). Comment l’analyse de similitude montre cela ?
17 Au paragraphe 1.3.1.3. nous n’avions conservé que l’information : « le mot est caractéristique de la banque ».
L’indice était alors soit la cooccurrence soit le phi de contingence (cf. tableau 11). Ici nous utilisons une information plus complète en utilisant la hiérarchie : le mot est non caractéristique (codé 1), le mot n’a pas été choisi ni comme non caractéristique ni comme caractéristique (codé 2), le mot est caractéristique (codé 3). On utilise alors le Tau de Kendall. On trouve en annexe 2 un exemple de questionnaire de caractérisation.

Droits de reproduction et de diffusion réservés © Sciences Humaines
23
Nous associons à cette matrice un graphe valué donc complet. Pour résumer ce graphe en conservant les informations essentielles à la description de la structure des données nous allons, en premier, construire l’arbre maximum18 associé à cette matrice de similitude.
Pour cela nous ordonnons de manière décroissante (grâce à leur valeur) les arêtes du graphe. L’ensemble de ces valeurs forme un préordre (il peut y avoir plusieurs arêtes de même valeur) ; on appelle Préordonnance de similitude la liste ordonnée associant les arêtes et leurs valeurs. Pour le graphe de cet exemple nous avons la préordonnance suivante (La première arête rejoint les sommets 1 et 2 et a la valeur 0,25).
On construit l’arbre maximum en parcourant la préordonnance de manière décroissante et en retenant les arêtes qui ne construisent pas un cycle avec les arêtes déjà retenues. Pour cela on utilise l’algorithme suivant.
Cet algorithme appliqué à la préordonnance des données « La Banque » construit l’arbre suivant:
étape valeurs liste « li » des arêtes arêtes retenues composantes connexes 0 0,25 1-2 1-2 (1-2) (3) (4) (5) (6) 0 0,21 4-5 ; 5-6 4-5 ; 5-6 (1-2) ; (4-5-6) ; (3) 1 0,15 4-6 non retenu car cycle (4,5,6) 2 0,12 1-3 1-3 (1-2-3) ; (4-5-6) 3 0,10 2-3 non retenu car cycle (1,2,3) 4 -0,14 2-4 2-4 (1-2-3-4-5-6)
18 On appelle arbre maximum l’arbre dont la somme des valeurs de ses arêtes est maximale.
1 : La Banque me fait Confiance : * 2 : On est en Confiance : .25 * 3 : Aide Problèmes Particuliers : .12 .10 * 4 : Découvert Rapporte à Banque : -.38 -.14 -.17 * 5 : Travailler à son Profit : -.16 -.16 -.23 .21 * 6 : On n'est qu'un Numéro : -.29 -.32 -.15 .15 .21 *
Tableau 16 : La Banque : matrice de similitude (Tau de Kendall)
0,25 (1-2) ; 0,21 (4-5) ; 0,21 (5-6) ; 0,15 (4-6) ; 0,12 (1-3) ; 0,10 (2-3) ; -0,14 (2-4) ; -0,15 (3-6) ; -016 (2-5) ; -0,16 (1-5), -0,17 (3-4) ; -0,23 (3-5) ; -0,29 (1-6) ; -0,32 (2-6) ; -0,38 (1-4)
Tableau 17 : Préordonnance de similitude de l’exemple La Banque.
Algorithme de construction de l’arbre maximum. a- étape k =1 : on retient les deux premières arêtes. On définit les composantes connexes au seuil de la deuxième arête.
On définit i=0. b- étape « k » : on définit « vk » la valeur de l’arête suivante. c- on établit la liste « lk » des arêtes ayant la même valeur « vk ». d- on retient les arêtes de cette liste qui relient deux composantes connexes différentes de l’étape « k-1 ». e- on reconstruit avec les arêtes retenues les composantes connexes de l’étape « k ». f- s’il y a plusieurs composantes connexes on retourne en b (en se plaçant à la dernière arêtes de la liste « lk »). g- les arêtes retenues après ce critère d’arrêt sont les arêtes de l’arbre maximum (et s’il y a des ex-aequo de la RAM, cf.
infra).

Droits de reproduction et de diffusion réservés © Sciences Humaines
24
5 arrêt car il n’y a qu’une seule composante connexe.
Cette procédure est un peu semblable à celle de la construction d’un réseau électrique élémentaire. On veut relier les différents groupes d’usagers (les composantes connexes) au moindre coût. La solution est un réseau qui a la forme d’un arbre (ici minimum). Si l’une des arêtes est coupée par une intempérie l’une des deux composantes connexes ainsi créées se trouve sans électricité.
Droits de reproduction et de diffusion réservés © Sciences Humaines
25
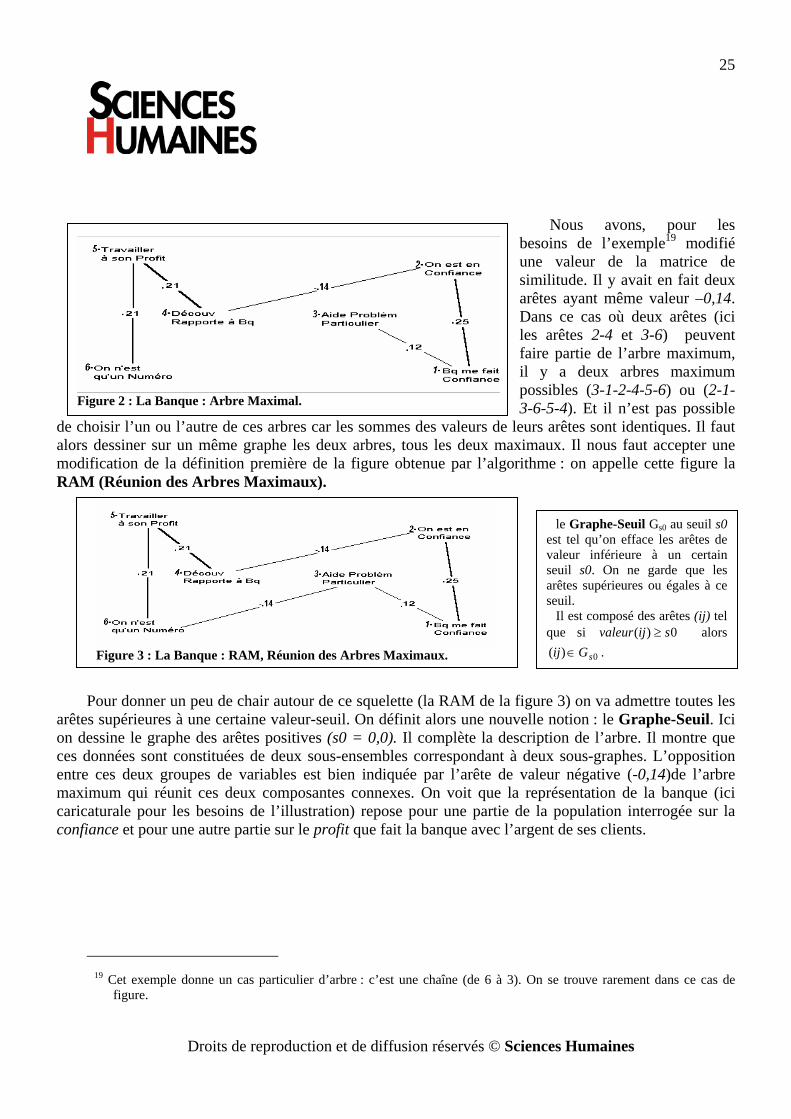
Nous avons, pour les besoins de l’exemple19 modifié une valeur de la matrice de similitude. Il y avait en fait deux arêtes ayant même valeur –0,14. Dans ce cas où deux arêtes (ici les arêtes 2-4 et 3-6) peuvent faire partie de l’arbre maximum, il y a deux arbres maximum possibles (3-1-2-4-5-6) ou (2-1-3-6-5-4). Et il n’est pas possible
de choisir l’un ou l’autre de ces arbres car les sommes des valeurs de leurs arêtes sont identiques. Il faut alors dessiner sur un même graphe les deux arbres, tous les deux maximaux. Il nous faut accepter une modification de la définition première de la figure obtenue par l’algorithme : on appelle cette figure la RAM (Réunion des Arbres Maximaux).
Pour donner un peu de chair autour de ce squelette (la RAM de la figure 3) on va admettre toutes les arêtes supérieures à une certaine valeur-seuil. On définit alors une nouvelle notion : le Graphe-Seuil. Ici on dessine le graphe des arêtes positives (s0 = 0,0). Il complète la description de l’arbre. Il montre que ces données sont constituées de deux sous-ensembles correspondant à deux sous-graphes. L’opposition entre ces deux groupes de variables est bien indiquée par l’arête de valeur négative (-0,14)de l’arbre maximum qui réunit ces deux composantes connexes. On voit que la représentation de la banque (ici caricaturale pour les besoins de l’illustration) repose pour une partie de la population interrogée sur la confiance et pour une autre partie sur le profit que fait la banque avec l’argent de ses clients.
19 Cet exemple donne un cas particulier d’arbre : c’est une chaîne (de 6 à 3). On se trouve rarement dans ce cas de
figure.
Figure 2 : La Banque : Arbre Maximal.
le Graphe-Seuil Gs0 au seuil s0 est tel qu’on efface les arêtes de valeur inférieure à un certain seuil s0. On ne garde que les arêtes supérieures ou égales à ce seuil.
Il est composé des arêtes (ij) tel que si 0)( sijvaleur ≥ alors
0)( sGij ∈ .
Figure 3 : La Banque : RAM, Réunion des Arbres Maximaux.

Droits de reproduction et de diffusion réservés © Sciences Humaines
26
2.2 LA DEMARCHE FORMELLE DE L’ANALYSE DE SIMILITUDE.
Nous prenons maintenant un exemple plus conséquent pour montrer la démarche de l’analyse de similitude. La matrice de similitude est ici une matrice de corrélation calculée sur des données provenant d’une enquête sur les « valeurs » à partir d’un questionnaire de Schwartz20 passé auprès de 268 sujets. Leurs réponses au questionnaire ont permis de construire une série de scores pour chaque sujet : chaque score reflète l’opinion d’un sujet à propos d’une valeur. Cette méthode identifie dix valeurs : B*Accomplissement, A*Pouvoir, K*Sécurité, J*Conformisme, H*Tradition, G*Bienveillance, F*Universalisme, D*Stimulation, E*Centration sur soi, C*Hédonisme. On obtient la matrice suivante.
20 Enquête Eric Tafani, 1999, Laboratoire de Psychologie Sociale de l’Université de Provence ; et Beauvois, L., (ed) La
construction sociale de la personne vol 4, P.U.G.
B*Accomplissement : * A*Pouvoir : 41 * K*Sécurité : 34 45 * J*Conformisme : 34 41 58 * H*Tradition : 13 18 28 39 * G*Bienveillance : 12 -4 32 27 33 * F*Universalisme : 1 -14 19 10 29 41 * D*Stimulation : 19 12 12 -3 6 13 20 * E*Centration sur soi : 13 14 13 5 11 13 13 34 * C*Hédonisme : 9 -1 5 -11 -6 16 7 27 13 * Tableau 18 : Les 10 Valeurs de Schwartz : matrice de similitude (corrélation multipliée par 100)
Figure 4 : La Banque : Graphe des arêtes positives.

Droits de reproduction et de diffusion réservés © Sciences Humaines
27
2.21 Recherche d’un squelette : la construction de l’arbre et la 3-analyse On associe à cette matrice un graphe complet. Le résumé de l’information contenu dans cette
matrice, dans le graphe complet, doit être conçu comme devant donner le maximum d’informations avec le minimum d’arêtes. La première analyse consiste donc à construire un arbre maximum.

Droits de reproduction et de diffusion réservés © Sciences Humaines
28
Cet arbre nous montre qu’il existe une sorte d’axe allant de la valeur E*Centration sur soi à B*Accomplissement. Il faut vérifier ce premier résultat. Pour cela on utilise une méthode de traitement du graphe dite « 3-analyse ». Cette méthode fut la première utilisée par Claude Flament, l’inventeur de l’analyse de similitude. Elle consiste à étudier tous les triangles du graphe complet (ij,jk,ki) et d’éliminer, dans chacun de ces triangles, l’arête dont la valeur est la plus faible. Cette méthode procède de l’intuition d’intermédiarité, intuition reposant sur l’inégalité triangulaire : si un sommet j est « intermédiaire » entre les sommets i et k on doit avoir Sij > Sik et Sjk > Sik. En éliminant (ik) on créé une chaîne (i,j,k).
Après l’exploration, par cet algorithme, de toutes les arêtes du graphe G, on obtient un graphe dit « G3 ». Ce graphe contient l’arbre mais on y trouve le plus souvent d’autres arêtes formant des cycles. Il contient l’arbre car si on applique l’algorithme précédent non seulement au cycle d’ordre 3 (les triangles) mais à tous les cycles (d’ordre 4 à m-1, avec m le nombre de sommets du graphe), en éliminant l’arête la plus petite de chaque cycle, on obtient l’arbre maximum (graphe sans cycle). L’existence de cycle dans le
Figure 5 : Les 10 valeurs de Schwartz : arbre maximum
Le triangle ikj est d’une certaine manière aplati.
Figure 6 : Principe de la
Algorithme de la 3-analyse Le graphe G3 est composé des arêtes qui ne sont pas marquées par
l’algorithme suivant : - soit l’arête (ik) de G. - on passe en revue tous les sommets j du graphe G : j forme avec ik un
triangle dont les arêtes sont (ij), (ik), (jk) [certaines de ces arêtes peuvent déjà être marquées]
- Si Sij > Sik et Sjk > Sik alors on marque l’arête (ik).

Droits de reproduction et de diffusion réservés © Sciences Humaines
29
graphe G3 est l’indicateur d’une inadéquation partielle, ou totale, de l’idée d’axe pour décrire les données. Quand les données s’organisent autour d’un axe le graphe, G3 est l’arbre maximum.
La théorie socio-psychologique sur lequel repose ce questionnaire prédit l’existence d’un cercle sur lequel se disposent les valeurs21. On constate ici, par le graphique de la 3-analyse, que ce cercle est à peu près respecté par les données (A,B,C,D,E,F,G,H,J,K). L’axe dessiné par l’arbre maximum est ici un grand cercle où les sommets D et E rejoignent les sommets B et A. La centration sur soi a d’une certaine façon des points communs avec le pouvoir et de l’autre avec la stimulation, de même l’accomplissement personnel est associé à la stimulation et au pouvoir. Ils ne sont pas aux deux bouts d’un axe. Les valeurs de corrélation entre (BA) et (BD) sont bien différentes (0,41 versus 0,19 par exemple) mais ces arêtes ne sont jamais les plus petites dans tous les triangles possibles. Elles représentent un maximum « local ». Nous reviendrons plusieurs fois sur cette caractéristique de l’analyse de similitude : elle raisonne localement (ici, sur les triangles). On peut aussi observer que d’autres cycles existent tel (E,D,F,G), (D,F,G,C) (G,H,J,K) etc.. Il montrent une certaine complexité autour de la chaîne de l’arbre maximum qui va de E à G.
21 Cette circularité a été vérifiée dans de nombreuses recherches utilisant diverses analyses de données.
Droits de reproduction et de diffusion réservés © Sciences Humaines
30
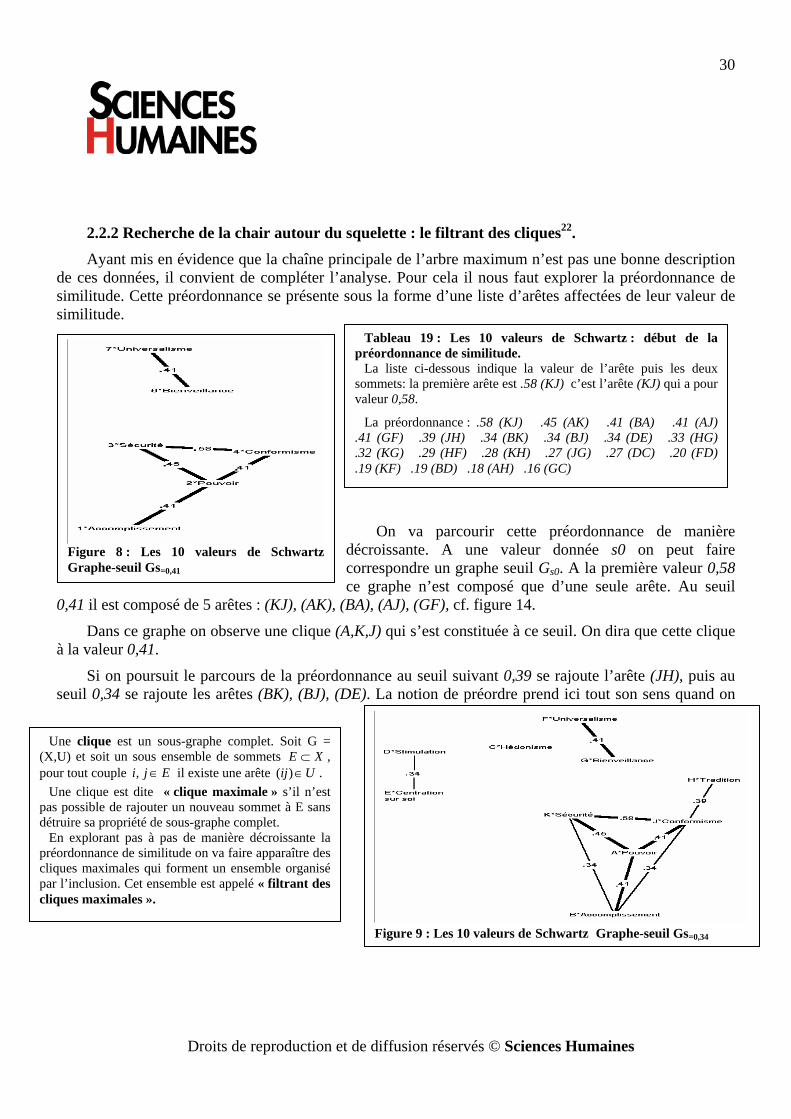
2.2.2 Recherche de la chair autour du squelette : le filtrant des cliques22. Ayant mis en évidence que la chaîne principale de l’arbre maximum n’est pas une bonne description
de ces données, il convient de compléter l’analyse. Pour cela il nous faut explorer la préordonnance de similitude. Cette préordonnance se présente sous la forme d’une liste d’arêtes affectées de leur valeur de similitude.
On va parcourir cette préordonnance de manière décroissante. A une valeur donnée s0 on peut faire correspondre un graphe seuil Gs0. A la première valeur 0,58 ce graphe n’est composé que d’une seule arête. Au seuil
0,41 il est composé de 5 arêtes : (KJ), (AK), (BA), (AJ), (GF), cf. figure 14.
Dans ce graphe on observe une clique (A,K,J) qui s’est constituée à ce seuil. On dira que cette clique à la valeur 0,41.
Si on poursuit le parcours de la préordonnance au seuil suivant 0,39 se rajoute l’arête (JH), puis au seuil 0,34 se rajoute les arêtes (BK), (BJ), (DE). La notion de préordre prend ici tout son sens quand on
Tableau 19 : Les 10 valeurs de Schwartz : début de la préordonnance de similitude.
La liste ci-dessous indique la valeur de l’arête puis les deux sommets: la première arête est .58 (KJ) c’est l’arête (KJ) qui a pour valeur 0,58.
La préordonnance : .58 (KJ) .45 (AK) .41 (BA) .41 (AJ) .41 (GF) .39 (JH) .34 (BK) .34 (BJ) .34 (DE) .33 (HG) .32 (KG) .29 (HF) .28 (KH) .27 (JG) .27 (DC) .20 (FD) .19 (KF) .19 (BD) .18 (AH) .16 (GC)
Une clique est un sous-graphe complet. Soit G = (X,U) et soit un sous ensemble de sommets XE ⊂ , pour tout couple Eji ∈, il existe une arête Uij ∈)( .
Une clique est dite « clique maximale » s’il n’est pas possible de rajouter un nouveau sommet à E sans détruire sa propriété de sous-graphe complet.
En explorant pas à pas de manière décroissante la préordonnance de similitude on va faire apparaître des cliques maximales qui forment un ensemble organisé par l’inclusion. Cet ensemble est appelé « filtrant des cliques maximales ».
Figure 8 : Les 10 valeurs de Schwartz Graphe-seuil Gs=0,41
Figure 9 : Les 10 valeurs de Schwartz Graphe-seuil Gs=0,34

Droits de reproduction et de diffusion réservés © Sciences Humaines
31
observe que plusieurs arêtes ont la même valeur.
Avec ce nouveau seuil on observe la présence de plusieurs triangles et d’une clique maximale de quatre sommets (B,A,K,J) qui inclut la clique (A,K,J)du seuil 0,41 précédent. Si on continue notre parcours décroissant on verra successivement apparaître les cliques (H,G,F) au seuil de 0,29 puis (K,J,H) et (K,H,G) au seuil 0,28. Ces deux cliques s’unissant au seuil suivant 0,27 pour former la clique maximale (K,J,H,G).
Toutes les cliques ne se trouvent pas obligatoirement dans la liste des cliques maximales. Ici on va voir que les cliques (A,K,J) et (B,A,K,J) sont présentes dans le filtrant des cliques maximales mais que les cliques (B,A,K) et (B,K,J) ne s’y trouvent pas car elles apparaissent au seuil 0,34 et sont immédiatement, à ce seuil, absorbées par la clique (B,A,K,J). La liste des cliques maximales a donc des propriétés particulières : elles existent entre le seuil de leur création et celui de leur absorption. Si, pour une clique, ces deux seuils sont confondus, alors elle ne fait pas partie du filtrant. Le filtrant ne retient que les cliques qui ne sont pas des étoiles filantes !
Construction pas à pas du filtrant :
valeurs arêtes cliques maximales du filtrant 0,58 K-J (K,J) 0,45 A-K (K,J) ; (A,K) 0,41 A-B ;A-J ; G-F (A,K,J) ; (B,A) ; (G,F) [cf. figure 8] 0,39 J-H (A,K,J) ; (B,A) ; (G,F) ; (J,H) 0,34 B-K ; D-E (B,A,K,J) ; (G,F) ; (J,H) ; (D,E) [cf. figure 9] 0,33 H-G (B,A,K,J) ; (G,F) ; (J,H) ; (D,E) ; (H,G) 0,32 K-G (B,A,K,J) ; (G,F) ; (J,H) ; (D,E) ; (H,G) ; (K,G) 0,29 H-F (B,A,K,J) ; (H,G,F) ; (J,H) ; (D,E) ; (K,G) 0,28 K-H (B,A,K,J) ; (H,G,F) ; (K,J,H) ; (K,H,G) ; (D,E) 0,27 J-G ; D-C (B,A,K,J) ; (H,G,F) ; (K,J,H,G) ; (D,E) ; (D,C) 0,20 F-D (B,A,K,J) ; (H,G,F) ; (K,J,H,G) ; (D,E) ; (D,C) ; (F,D) 0,19 K-F ; B-D (B,A,K,J) ; (K,H,G,F) ; (K,J,H,G) ; (D,E) ; (D,C) ; (F,D) ; (B,D) 0,18 A-H (B,A,K,J) ; (K,H,G,F) ; (K,J,H,G) ; (D,E) ; (D,C) ; (F,D) ; (B,D) ; (A,K,J,H)
etc ….
22 On utilise cette notion mathématique de « Filtrant » car l’ensemble des cliques que l’on va maintenant définir a bien
les propriétés d’un « ensemble filtrant supérieurement » : ensemble ordonné tel que toute paire de ses éléments admet au moins un majorant commun.

Droits de reproduction et de diffusion réservés © Sciences Humaines
32
Pour représenter cette suite de cliques et leurs relations d’inclusion on construit et dessine le « filtrant des cliques maximales » qui est composé des cliques maximales et de leur relation d’inclusion. On dessine rarement le filtrant complet qui a pour sommet terminal la clique du graphe complet, clique constituée par tous les sommets. On ne représente pas non plus les arêtes qui sont les cliques maximales de deux sommets car elles ont la propriété d’être les arêtes du graphe G3. Pour mettre en évidence les relations d’inclusion on cherche à positionner au mieux les cliques maximales en se servant de l’axe haut / bas pour exprimer la décroissance des seuils et, dans la mesure du possible, représenter une quasi-métrique de l’échelle de la valeur des seuils.
Figure 10 : Les 10 Valeurs de Schwartz : Filtrant des cliques maximales (limité au seuil de 0,11). La valeur des cliques est la valeur de l’arête qui a crée la clique (multiplié par 100) tel qu’on l’a vu dans la construction
pas à pas du filtrant. Cette valeur se trouve avant l’astérisque, après celle-ci on trouve les lettres correspondantes aux sommets composant la clique (exemple : 11 * K.H.G.F.E est la clique (K,H,G,F,E) créée au seuil 0,11).
On peut constater que les sommets se trouvent prioritairement dans une certaine zone de ce filtrant. On peut représenter ainsi leurs domaines :
Droits de reproduction et de diffusion réservés © Sciences Humaines
33
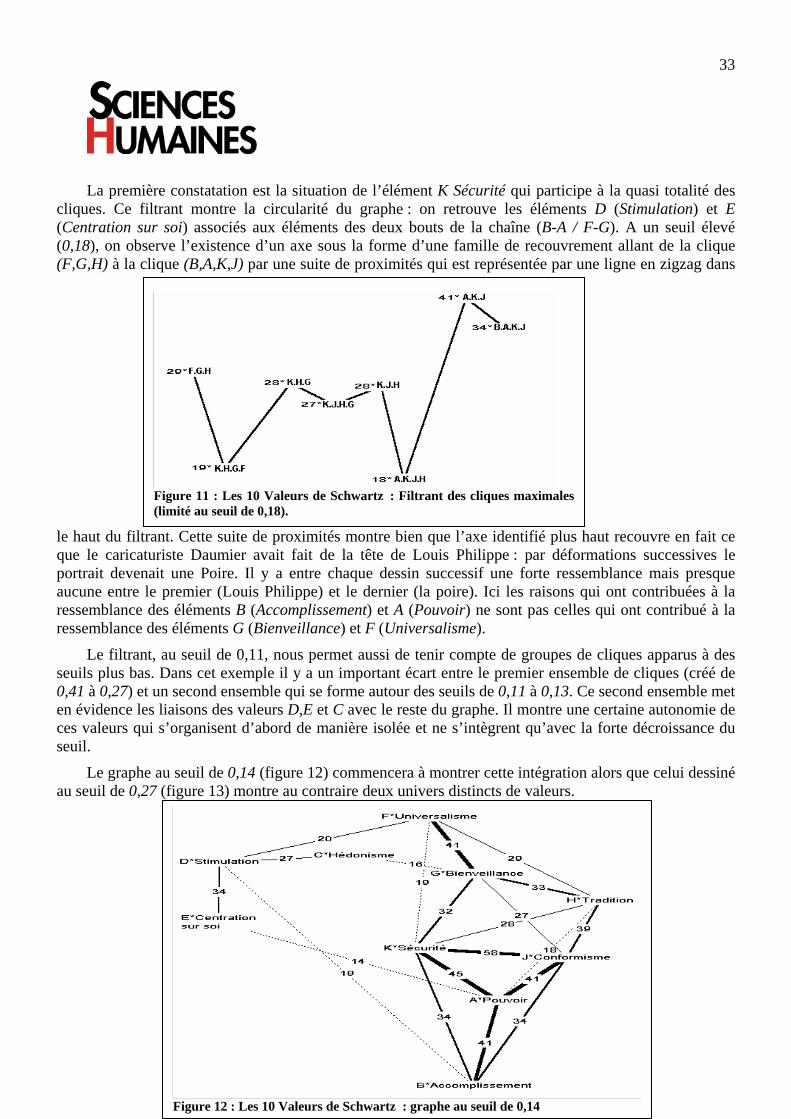
La première constatation est la situation de l’élément K Sécurité qui participe à la quasi totalité des cliques. Ce filtrant montre la circularité du graphe : on retrouve les éléments D (Stimulation) et E (Centration sur soi) associés aux éléments des deux bouts de la chaîne (B-A / F-G). A un seuil élevé (0,18), on observe l’existence d’un axe sous la forme d’une famille de recouvrement allant de la clique (F,G,H) à la clique (B,A,K,J) par une suite de proximités qui est représentée par une ligne en zigzag dans
le haut du filtrant. Cette suite de proximités montre bien que l’axe identifié plus haut recouvre en fait ce que le caricaturiste Daumier avait fait de la tête de Louis Philippe : par déformations successives le portrait devenait une Poire. Il y a entre chaque dessin successif une forte ressemblance mais presque aucune entre le premier (Louis Philippe) et le dernier (la poire). Ici les raisons qui ont contribuées à la ressemblance des éléments B (Accomplissement) et A (Pouvoir) ne sont pas celles qui ont contribué à la ressemblance des éléments G (Bienveillance) et F (Universalisme).
Le filtrant, au seuil de 0,11, nous permet aussi de tenir compte de groupes de cliques apparus à des seuils plus bas. Dans cet exemple il y a un important écart entre le premier ensemble de cliques (créé de 0,41 à 0,27) et un second ensemble qui se forme autour des seuils de 0,11 à 0,13. Ce second ensemble met en évidence les liaisons des valeurs D,E et C avec le reste du graphe. Il montre une certaine autonomie de ces valeurs qui s’organisent d’abord de manière isolée et ne s’intègrent qu’avec la forte décroissance du seuil.
Le graphe au seuil de 0,14 (figure 12) commencera à montrer cette intégration alors que celui dessiné au seuil de 0,27 (figure 13) montre au contraire deux univers distincts de valeurs.
Figure 12 : Les 10 Valeurs de Schwartz : graphe au seuil de 0,14
Figure 11 : Les 10 Valeurs de Schwartz : Filtrant des cliques maximales (limité au seuil de 0,18).

Droits de reproduction et de diffusion réservés © Sciences Humaines
34
2.3 COMPARAISON ENTRE ANALYSE DE SIMILITUDE ET ANALYSE FACTORIELLE.
On se propose d’étudier le rapport entre un ensemble de professions (lignes L1 à L8) et un ensemble d’adjectifs décrivant des traits de caractères (colonnes C1 à C8). On a pour cela interrogé 60 sujets23 à qui on a demandé d’associer chaque profession à deux adjectifs pour décrire un homme sympathique. On obtient le tableau de fréquences suivant (tableau 20) : par exemple le technicien (L6) a été associé 22 fois à l’adjectif intelligent (C5).
Tableau 20 : Homme sympathique : tableau de contingence. C1 C2 C3 C4 C5 C6 C7 C8 C9 Total
L1 19 9 9 26 10 16 19 4 8 120 L2 20 5 11 25 9 14 19 6 11 120 L3 20 3 9 25 15 13 10 13 12 120 L4 8 9 12 23 14 16 14 12 12 120 L5 10 5 8 26 19 13 11 13 15 120 L6 10 5 12 24 22 13 11 13 10 120 L7 3 18 13 11 25 11 12 20 7 120 L8 4 21 12 12 24 11 11 17 8 120
Total 94 75 86 172 138 107 107 98 83 960
L’analyse de ce tableau dit « tableau de contingence » se fait en utilisant la corrélation entre les colonnes. On obtient alors la matrice de corrélation suivante entre les adjectifs (tableau 21).
23 Exemple tiré de Maisonneuve, Recherches diachroniques sur une représentation sociale,1978 ; repris par
Rouanet, H.,Le Roux, B., 1993
Figure 13 : Les 10 Valeurs de Schwartz : graphe au seuil de 0,27
Droits de reproduction et de diffusion réservés © Sciences Humaines
35
Tableau 21 : Homme sympathique : matrice de corrélation. C1 C7 C6 C4 C9 C3 C2 C5 C8
C1 * C7 .53 * C6 .55 .65 * C4 .77 .34 .73 * C9 .27 -.21 .27 .66 * C3 -.63 -.09 -.33 -.70 -.59 * C2 -.74 -.14 -.52 -.93 -.71 .60 * C5 -.85 -.78 -.83 -.74 -.28 .47 .60 * C8 -.82 -.82 -.81 -.78 -.18 .50 .58 .92 *
Les adjectifs sont les suivants : C8 :compréhensif, C5 intelligent ; C2 généreux ; C3 gai ; C7 courageux ; C6 serviable ; C4 honnête ; C1 sérieux ; C9 discret.
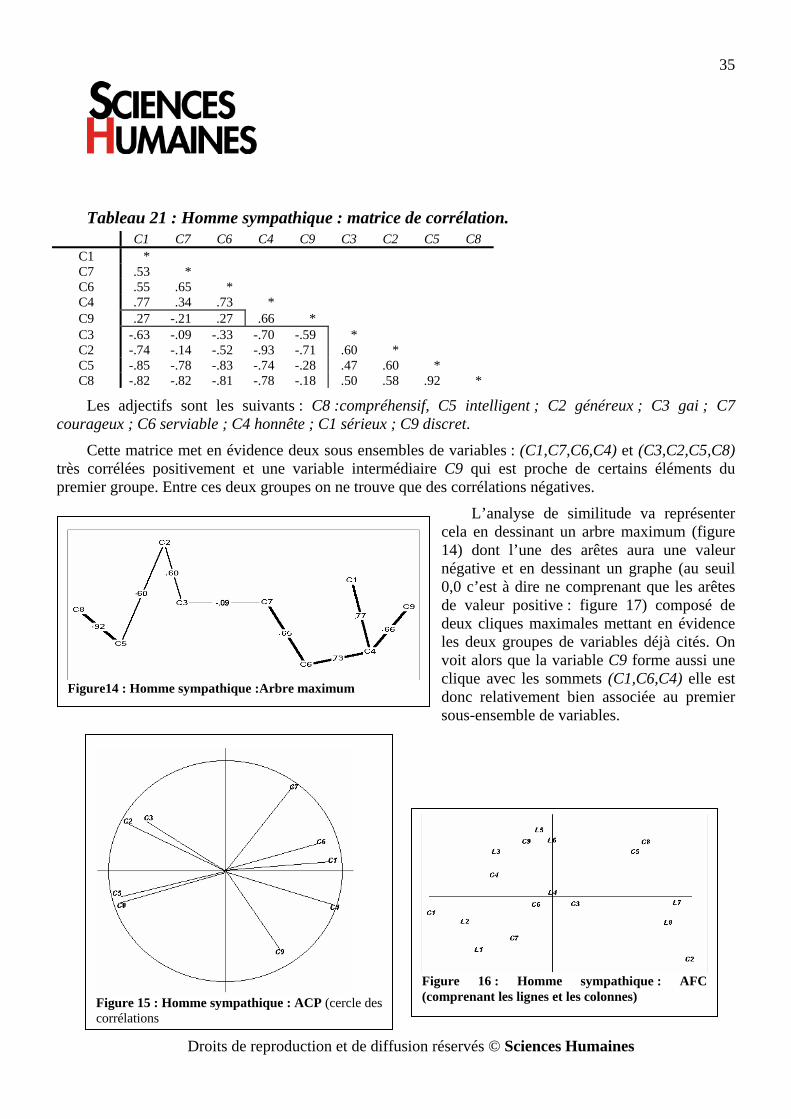
Cette matrice met en évidence deux sous ensembles de variables : (C1,C7,C6,C4) et (C3,C2,C5,C8) très corrélées positivement et une variable intermédiaire C9 qui est proche de certains éléments du premier groupe. Entre ces deux groupes on ne trouve que des corrélations négatives.
L’analyse de similitude va représenter cela en dessinant un arbre maximum (figure 14) dont l’une des arêtes aura une valeur négative et en dessinant un graphe (au seuil 0,0 c’est à dire ne comprenant que les arêtes de valeur positive : figure 17) composé de deux cliques maximales mettant en évidence les deux groupes de variables déjà cités. On voit alors que la variable C9 forme aussi une clique avec les sommets (C1,C6,C4) elle est donc relativement bien associée au premier sous-ensemble de variables.
Figure14 : Homme sympathique :Arbre maximum
Figure 15 : Homme sympathique : ACP (cercle des corrélations
Figure 16 : Homme sympathique : AFC (comprenant les lignes et les colonnes)

Droits de reproduction et de diffusion réservés © Sciences Humaines
36
On a effectué sur ce même tableau de données une analyse factorielle (ACP) et un analyse de correspondance (AFC). On obtient des résultats comparables mais avec certaines nuances. Dans les deux graphiques on voit une opposition entre (C1,C7,C6,C4) et (C3,C2,C5,C8). De même la colonne C9 se distingue un peu.
Mais on peut aussi remarquer que l’éloignement, dans le graphique de l’ACP, entre C2-C3 et C5-C8 ne correspond pas aux valeurs de la matrice des corrélations : C2-C3 a pour valeur 0,60 tout comme C2-C5. On peut encore être surpris de l’éloignement de C7 avec C1, ils sont corrélés à 0,53 alors que C6 semble plus proche de C1 avec quasiment la même corrélation 0,55.
Dans le graphique de l’AFC on trouve aussi quelques différences : C3 est très éloigné de C2 et surtout C2 est encore plus loin de C5-C8 alors que leur corrélation est très forte (0,60 et 0,58). C1 est au bout du premier axe alors qu’elle forme avec C4,C6,C7 une clique dont les valeurs sont très fortes (supérieure à 0,53 sauf C4-C7 à 0,34).
Une première raison à ces différences est l’écart important entre les valeurs explicatives des deux premiers axes. Ils font respectivement 64% et 21% pour l’ACP, 75% et 16% pour l’AFC. Il faudrait écraser le second axe (par homothétie) pour donner une image un peu plus fidèle. Mais la raison principale des différences tient à l’accent mis dans ces analyses sur la prise en compte de toutes les valeurs de la matrice de corrélation(ou la matrice de la distance du Khi2 dans le cas de l’AFC). D’une certaine manière on donne autant d’importance aux faibles valeurs (ici en particulier aux valeurs négatives) qu’aux fortes valeurs. L’analyse de similitude raisonne, elle, « localement ». Autour d’un sommet (d’une variable) on prend en considération les valeurs les plus fortes (en particulier dans l’arbre maximum et dans les graphes seuil) sans se préoccuper de représenter graphiquement les valeurs les plus faibles. On raisonne en tenant compte du fait que la similitude entre deux variables i et j tient à certains rapports entre les adjectifs et les professions alors que la similitude de deux autres variables m et l tient à d’autres rapports. Il n’est pas nécessaire pour établir la ressemblance entre les deux premières variables de tenir compte des éléments qui font la ressemblance des deux autres. On peut en donner une idée de cette différence de traitement « local versus global » sur cet exemple même si les calculs dans cet exemple relativisent, en partie, la possibilité qu’a l’analyse de similitude de tenir compte des valeurs extrémales. En effet l’utilisation du coefficient de corrélation vise à résumer globalement l’ensemble des valeurs des colonnes du tableau de contingence prises deux à deux. Quand les données sont
Figure 17 : Homme sympathique : Graphe des arêtes positives (graphe-seuil, s = 0,001)
Droits de reproduction et de diffusion réservés © Sciences Humaines
37
dichotomiques (0/1) les différences entre analyse factorielle et analyse de similitude sont bien plus importantes.
Nous allons transformer le tableau de données en calculant pour chaque case le rapport entre le nombre de choix observés et le nombre théoriques si les choix des diverses professions étaient comparables à celui de la population totale. Soit nmk le nombre de choix de la case Lm/Ck (par exemple la case L4/C3 contient 12 choix : cf. tableau 20). On calcule n’mk les choix théoriques correspondant à l’indépendance statistique : Nnknmmkn )(' ×= .
Dans le cas de la case L4/C3 on calcule : 960)86120(43' ×=n ; n’43 = 10,75.
Le rapport n’mk / nmk est alors égal à 1,12. Il indique une case plutôt pleine.
On représente ces rapports dans le tableau suivant où on a réorganisé les colonnes pour faire apparaître les blocs de nombre supérieurs à 1,1 ; ces blocs indiquent une certaine conjonction entre les lignes et le colonnes. C’est cette conjonction qui est interprétée par les analyses factorielles ou de similitudes.
Tableau 22 : Homme sympathique : Tableau des rapports valeur observée sur valeur théorique.
C7 C1 C6 C4 C9 C3 C2 C5 C8 L1 1,42 1,62 1,20 1,21 0,77 0,84 0,96 0,58 0,33 L2 1,42 1,70 1,05 1,16 1,06 1,02 0,53 0,52 0,49 L3 0,75 1,70 0,97 1,16 1,16 0,84 0,32 0,87 1,06 L4 1,05 0,68 1,20 1,07 1,16 1,12 0,96 0,81 0,98 L5 0,82 0,85 0,97 1,21 1,45 0,74 0,53 1,10 1,06 L6 0,82 0,85 0,97 1,12 0,96 1,12 0,53 1,28 1,06 L7 0,90 0,26 0,82 0,51 0,67 1,21 1,92 1,45 1,63 L8 0,82 0,34 0,82 0,56 0,77 1,12 2,24 1,39 1,39
Ce tableau (22) a une certaine complexité. On comprend alors que tout résumé sera une approximation. Les analyses factorielles vont raisonner de manière globale. Ainsi on peut observer que dans le plan des deux premiers axes de l’AFC la profession L3 (les vendeurs) se trouve très proche des adjectifs C4 (honnête) et C9 (discret) comme le montre les deux valeurs 1,16 du tableau mais la distance importante sur ce plan de L3 avec C1 (sérieux) ne reflète pas, elle, la valeur la plus forte de la ligne C1-L3 (1,70). Cet adjectif (C1) est plus attiré par L1 et L2, eux même attirés par C7. Cette suite d’attirances est exprimée mathématiquement par le fait que chaque profession est au barycentre des éléments du second ensemble (des adjectifs) et réciproquement. C’est cette suite d’attirances qui détermine la position dans le plan des facteurs.
Dans l’analyse de similitude le raisonnement est local. Ainsi le groupe (C8, C5, C2, C3) n’a d’existence que grâce aux lignes L7 et L8 (Universitaires et Professions libérales) et cela malgré leurs divergences sur les lignes L5 et L6 (Employés et Techniciens). C’est sur les lignes L7 et L8 que ces quatre adjectifs ont leurs valeurs les plus fortes. De même le groupe (C7, C1, C6, C4) se définit grâce à ses valeurs fortes sur les deux premières lignes (Paysans et Ouvriers). La position de C9 proche de C4 dans le graphe est ici exprimée par leur proximité sur les lignes L2 à L6. Le graphe de similitude met en évidence la nette séparation entre les deux groupes de colonnes, en cela il remet en cause l’impression d’une possible diagonalisation que donne le tableau.

Droits de reproduction et de diffusion réservés © Sciences Humaines
38
Comme l’écrit Alain Degenne24 on peut distinguer ces méthodes par une métaphore géométrique. « Si l’on veut une métaphore géométrique de manière à comparer l’analyse de similitude et l’analyse factorielle, l’analyse factorielle détermine les meilleurs plans de projection d’un nuage de points de manière à le présenter sous différents points de vue, l’analyse de similitude recherche un meilleur itinéraire pour découvrir une topographie de ce nuage, vu en quelque sorte, de l’intérieur ».
Par l’analyse de similitude on évite les phénomènes d’homothétie (de taille) qui affecte l’analyse factorielle. Philippe Cibois25 les met bien en évidence, aussi a-t-il inclus dans ses programmes d’AFC (Tri-deux, Modalisa) la possibilité de représenter les premières valeurs de similitude, dessinant ainsi sur le plan factoriel un graphe-seuil.
2.4 COMPARAISON ENTRE ANALYSE DE SIMILITUDE ET ANALYSE « MULTIDIMENSIONAL SCALING » (MDS).
Le premier exemple traité dans le livre de référence26 de la méthode « Multidimensional Scaling » présente une enquête effectuée auprès de 18 étudiants américains en 1968 (Whish, M., 1971). Il leur était présenté les 66 couples formés par douze pays et on leur demandait de situer sur une échelle en 9 points la ressemblance entre les deux pays de chaque couple. Ensuite les auteurs ont identifié la similitude entre deux pays par la moyenne des scores obtenus27. Ils présentent les résultats sur un plan à deux dimensions de l’analyse faite par le programme INDSCAL.
24 Degenne, A., 1985 25 Cibois, Ph, 1990 26 Kruskal, J.B., Wish, M., 1978 27 On est ici dans le cas rare d’une relation [X x X] où les valeurs sont données directement par les données : ici la
moyenne des scores individuels.
Figure 18 : Douze

Droits de reproduction et de diffusion réservés © Sciences Humaines
39
Nous avons effectué une analyse de similitude de la matrice des scores moyens et nous avons dessiné sur ce plan, produit par INDSCAL, l’arbre maximum de l’analyse de similitude. Nous pouvons observer que les deux graphiques ne sont pas concordant même s’ils ont quelques similitudes. Les auteurs sont eux-mêmes critiques sur leur propre représentation planaire. Ils présentent une matrice où se trouvent calculées les différences entre les valeurs de la matrice de similitude et celles des distances calculées entre les pays sur le plan des deux premières dimensions repérées par le programme INDSCAL. Il existe une différence non négligeable pour certain couples de pays : pour le couple Cuba – Brésil28, la distance sur le plan n’est pas représentative de sa ressemblance telle qu’elle a été exprimée par les étudiants. En effet cette arête fait partie de l’arbre maximum pour l’analyse de similitude. Les auteurs concluent l’analyse de cet exemple en mettant en garde le lecteur : « This example illustrates an important point about the interpretation of MDS configuration. The coordinates printed out and plotted by the computer are not generally susceptible to direct interpretation ».
Nous montrons dans la figure 19 le graphe au seuil 4,72, seuil permettant de représenter le premier tiers des arêtes. Il montre que les premières impressions conduisant à des catégorisations simples (opposition pays développés versus en voie de développement ou encore pays occidentaux versus pays sous influence communiste) ne sont pas vérifiées. Les données de cette enquête sont plus complexes. L’analyse des graphes aux seuils successifs et de manière plus rigoureuse l’analyse du filtrant des cliques sont ici nécessaires et très éclairantes (cet exemple sera repris de manière détaillé au 4.3). L’arbre maximal (cf. figure 39) se compose bien d’une étoile autour des USA regroupant les pays occidentaux, il définit une chaîne de pays
communistes de la Yougoslavie à Cuba, et une chaîne de pays en voie de développement du Brésil à l’Inde ou au Congo. Mais cet arbre maximum n’est pas une bonne description des données. A travers l’analyse du filtrant des cliques, on peut montrer l’importance des cycles et même des liaisons transversales entre zones du graphes.
Le Filtrant met d’abord en évidence des zones où les cliques apparaissent à des seuils assez élevés (au dessus de 4,50). On peut alors identifier, à gauche, une zone de pays en voie de développement Congo(2), Egypte(4), Inde(6) ou Congo, Egypte, Cuba(3) ou Brésil(1), Congo, Cuba. Mais ces cliques sont totalement isolées, elles ne vont pas se regrouper même si on prend en compte la moitié des arêtes de la préordonnance. De même on trouve, à un seuil élevé une structure fermée des pays d’influence communiste Cuba(3), Chine(9), Russie(10), Yougoslavie(12), auquel viendra se rattacher à un seuil inférieur l’Egypte(4). Enfin, à droite, on trouve les pays occidentaux autour des USA (11) Israël (7) et le Japon (8) une clique dont la France(5) est exclue, même à des valeurs de similitude très faibles. Il y a
28 Ces deux pays sont les seuls pays latino-américains. C’est sans doute la raison ponctuelle de leur relativement grande
similitude. Les critères plus généraux de Est / Ouest et Nord / Sud sont alors moins pertinents.
Figure 19 : Douze pays : graphe au seuil de 4,72 représentant le premiers tiers des arêtes (les valeurs sont multipliées par 100)
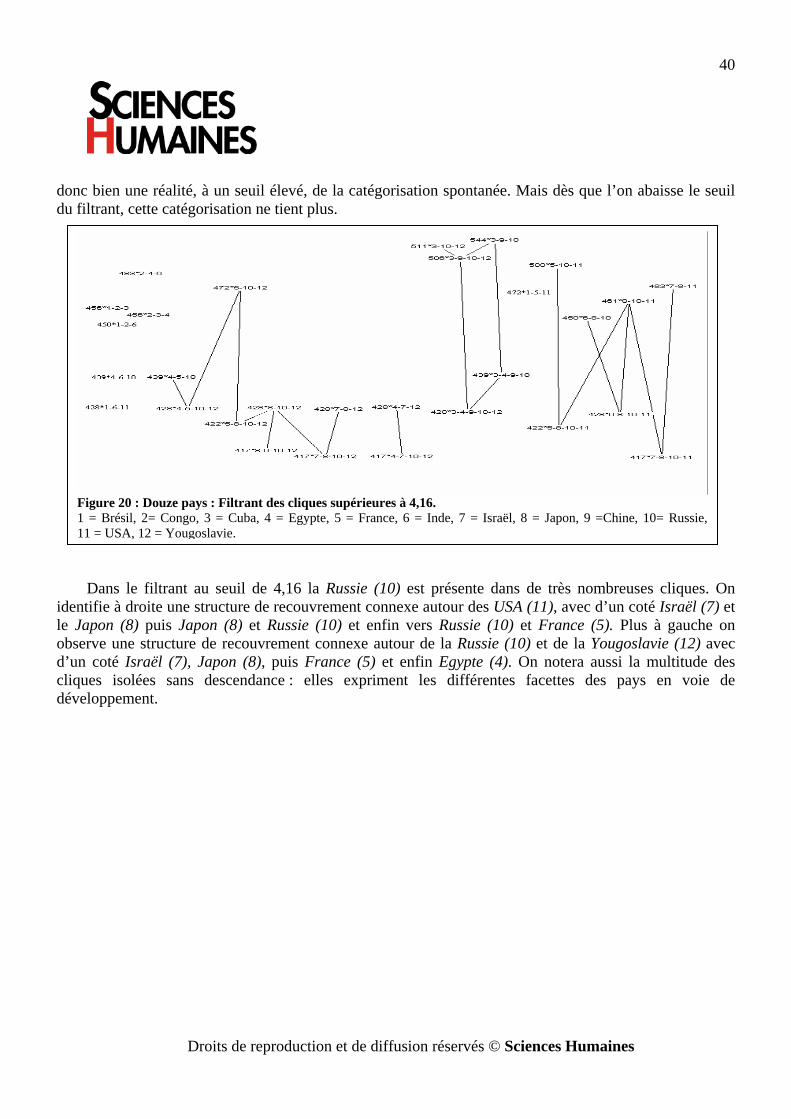
Droits de reproduction et de diffusion réservés © Sciences Humaines
40
donc bien une réalité, à un seuil élevé, de la catégorisation spontanée. Mais dès que l’on abaisse le seuil du filtrant, cette catégorisation ne tient plus.
Dans le filtrant au seuil de 4,16 la Russie (10) est présente dans de très nombreuses cliques. On identifie à droite une structure de recouvrement connexe autour des USA (11), avec d’un coté Israël (7) et le Japon (8) puis Japon (8) et Russie (10) et enfin vers Russie (10) et France (5). Plus à gauche on observe une structure de recouvrement connexe autour de la Russie (10) et de la Yougoslavie (12) avec d’un coté Israël (7), Japon (8), puis France (5) et enfin Egypte (4). On notera aussi la multitude des cliques isolées sans descendance : elles expriment les différentes facettes des pays en voie de développement.
Figure 20 : Douze pays : Filtrant des cliques supérieures à 4,16. 1 = Brésil, 2= Congo, 3 = Cuba, 4 = Egypte, 5 = France, 6 = Inde, 7 = Israël, 8 = Japon, 9 =Chine, 10= Russie,11 = USA, 12 = Yougoslavie.

Droits de reproduction et de diffusion réservés © Sciences Humaines
41
Le graphe de la 3-analyse (figure21) montre lui aussi que l’interprétation doit se complexifier.
Les arêtes la 3-analyse France – Russie et Israël –Yougoslavie indiquent comme le filtrant qu’il existe de nombreuses liaisons transversales. On peut voir que chaque type de regroupement ou de liaison a sa propre logique, son propre raisonnement. C’est la clique Inde, Japon Russie (la vocation asiatique de la Russie !), ou encore Egypte, Inde, Russie, (l’appui russe au tiers monde !), Egypte, France, Russie Yougoslavie (la France de De Gaulle hors de l’OTAN !, les sujets interrogées sont des étudiants américains en 1968). L’intérêt de l’analyse de similitude est de ne pas les mélanger tout en donnant à chacune sa place : certains sont majoritaires d’autres plus minoritaires (mais l’étude des minorités n’est-elle pas aussi importante que celle des majorités29
29 On fera ici référence au livre de Serge Moscovici sur les minorités actives : Moscovici, S., 1979
Figure 21 : Douze Pays : graphe 3-analyse (les arêtes rajoutées à l’arbre sont en trait fin)

Droits de reproduction et de diffusion réservés © Sciences Humaines
42
CHAPITRE 3 LES DONNEES ONT DES PROPRIETES FORMELLES :
L’ANALYSE DE SIMILITUDE VA LES METTRE EN EVIDENCE.
Le traitement de l’analyse de similitude vise à mettre en évidence des propriétés formelles qui soient interprétables par les sciences sociales. Les mathématiciens ont toujours privilégié les axes, les dimensions d’un univers (gééométrique). Cette notion est à la base des analyses factorielles : elles résument les données par quelques principes organisateurs souvent dichotomiques (jeunes / vieux…). Les statisticiens ont ensuite mis en évidence la possibilité de segmenter les données en classes, en groupements pouvant permettre une généralisation, ou donner un nom générique à un groupe de variables. Enfin les analystes ont cherché à affaiblir ces modèles. On parle alors de recouvrement de composantes connexes etc… Nous allons présenter dans ce chapitre comment l’analyse de similitude identifie ces différentes propriétés et leur affecte un degré de vraisemblance.
3.1 CERTAINES CHAINES MAXIMALES DE L’ARBRE PEUVENT ETRE DES AXES SUPPORTANT UNE DIMENSION QUASI GEOMETRIQUE.
Nous avons vu que l’arbre était la représentation minimale des données garantissant le maximum d’informations (la somme des arêtes). C’est d’une certaine façon le squelette sur lequel les représentations suivantes (cliques, graphes-seuil …) vont s’accrocher.
Avec l’arbre on cherche à mettre en évidence les dimensions sur lesquelles les données pourraient s’organiser, faire sens. Un arbre est composé de chaînes maximales. La construction de l’arbre est une tentative pour trouver des chaînes maximales qui pourraient être assimilables à des axes sur lesquels la position des variables aurait une interprétation métrique ou en tout cas ordinale. En d’autres termes il y aurait une relation entre toutes les similitudes des sommets de la chaîne maximale.
Pour qu’il y ait de tels axes il faut que les chaînes maximales ait la propriété de « régularité ». On peut donner une intuition géométrique de cette propriété à partir d’un extrait de la matrice de similitude que nous avons étudiée précédemment (la matrice des 10 valeurs
de Schwartz, tableau 18).
On peut représenter cette matrice sous la forme d’un treillis où les nœuds seraient affectés de la valeur du coefficient de similitude correspondant aux deux sommets (aux deux générateurs). Quand on suit une ligne du treillis en partant d’un sommet on observe une décroissance des valeurs tout au long de cette ligne. Plus deux sommets sont éloignés plus leur similitude est faible : par exemple sAK > sAI >sAH (.45 > .41 > .18). On voit sur cet exemple que seule la valeur s14 ne répond
B*Accomplissement : * A*Pouvoir : 41 * K*Sécurité : 34 45 * J*Conformisme : 34 41 58 * H*Tradition : 13 18 28 39 *
Tableau 23 : exemple de Matrice de similitude (valeurs x 100)
Figure 22 Treillis quasi métrique de cette matrice

Droits de reproduction et de diffusion réservés © Sciences Humaines
43
pas à ce critère : sBK = sBJ. Habituellement on accepte quelques incartades au principe de décroissance si elles sont très peu nombreuses et si elles portent sur des valeurs proches de celles qui ne remettraient pas en cause l’ordre. On peut observer que cette propriété de régularité de la chaîne n’impose rien sur le rapport entre les coefficients de similitude des sommets du treillis appartenant à deux lignes différentes. Ainsi le fait que sBA < sAK alors que sBA > sJH ne remet pas en cause la régularité de la chaîne. On ne cherche pas à comparer les incomparables. On ne cherche pas une approximation métrique de cette chaîne, approximation visant à positionner les sommets sur un axe de manière telle que les distances sur cet axe soient les plus proches possible (au sens des moindres carrées dans les procédures les plus courantes (tel MDS30)) des distances (duales des coefficients de similitude) indiquées par la matrice de similitude. On cherche simplement une propriété structurale sur la préordonnance des coefficients de similitude : propriété mise en évidence si on ordonne la matrice (lignes et colonnes) de telle sorte qu’il y ait décroissance en ligne et en colonne (à partir de la diagonale) des valeurs de la matrice de similitude. On peut donner une définition mathématique de cette propriété de régularité (cf. encart).
La matrice de l’arbre maximum de l’exemple des valeurs de Schwartz qui se trouve au tableau 18 ne répond pas, par exemple, à cette propriété. Seuls les cinq premiers items forment une chaîne régulière et de manière plus approximative les sept premières valeurs mais dès que l’on complète cette chaîne par les valeurs de Schwartz D et F on perd complètement cette régularité. Nous avions vu que l’interprétation devait alors tenir compte d’un grand cycle. Cycle et régularité sont deux propriétés alternatives des chaînes.
La mise en rapport de l’arbre avec le filtrant des cliques conduit à définir une autre propriété : la « rigidité » des cliques maximales du filtrant. On désire affaiblir la notion d’un arbre support d’axes dimensionnels en acceptant qu’il soit seulement le support d’une suite de groupements de sommets pouvant se recouvrir partiellement. L’arbre reste alors une bonne description de ces regroupements.
30 Kruskal, J.B., Wish, M., Multidimensional scaling, Sage, series : quantitative applications in social sciences 11.
La propriété de régularité d’une chaîne. Soit une chaîne (i1,i2,iq,….im). Pour que la chaîne soit régulière il
faut que : npq ,,∀ S(iq,iq+p) > S(iq,iq+n) avec 0 < p < m-q et p < n <m-q S(iq,iq-p) > S(iq,iq-n) avec 0 < p < q et 0 < n <p
Cette propriété peut encore s’écrire : trq ,,∀ si 0 <q < r <t <m+1 : S(iq,ir) > S(iq,it) et S(ir,it) > S(iq,it)
Figure 23 : 10 Valeurs de Schwartz : Les cliques rigides sur l’arbre.
Une clique ayant la propriété de rigidité doit avoir tous ses sommets sur un sous-arbre connexe de l’arbre maximum : la chaîne de l’arbre maximum qui relie deux sommets quelconque d’une clique maximale « rigide » ne doit pas avoir de sommets hors de la clique.

Droits de reproduction et de diffusion réservés © Sciences Humaines
44
Si on reprend une partie de l’exemple des 10 valeurs de Schwartz et que nous dessinions par des ovales les différentes cliques de la partie du filtrant représentée à la figure 24, certaines sont rigides sur l’arbre. On les représente sur la figure 23 : (A,J,K), (H,J,K), (G,H,J,K) et (F,G,H). On aurait encore pu dessiner la clique (A,H,J,K). Mais ce filtrant est aussi composé de cliques non rigides : (G,H,K) et (F,G,H,K). Dans ces deux cliques l’arbre sort de la clique pour passer par le sommet J (figure 25).
Cette entorse à la propriété de rigidité indique aussi une entorse à la régularité des chaînes car on peut démontrer que toutes les chaînes régulières produisent une zone du filtrant où les cliques sont rigides. Aussi est-il important de prendre en considération les cliques non rigides sur l’arbre maximum car elles indiquent les zones où l’arbre n’est pas une bonne description. On peut accepter, par approximation, des cliques non rigides si les cliques qui lui sont reliées par inclusion dans le filtrant se trouvent à des seuils proches. C’est le cas de la clique (G,H,K) qui apparaît au seuil de 0,28 puis qui est
absorbée dans la clique (G,H,J,K) au seuil de 0,27. La différence de 0,01 est minime et non significative. Par contre la clique (F,G,H,K) se trouve très éloignée des deux cliques qu’elle absorbe : 0,19 versus 0,29 pour la clique (F,G,H) et 0,28 pour (G,H,K). On ne peut la passer sous silence.
Jusqu’à présent nous sommes à la recherche de dimensions qui permettraient de résumer les données par des axes ou des quasi-axes, si on accepte quelques entorses aux propriétés mathématiques associées à l’existence de « Dimensions » de l’univers des données. Une autre manière de résumer les données consiste à construire des classifications. Par une telle méthode (il existe en fait une multiplicité de méthode de classification) on cherche à savoir comment les données se regroupent et comment ces regroupements se hiérarchisent.
3.2 L’ARBRE PEUT PERMETTRE UNE CLASSIFICATION DES DONNEES.
On définit une classification par le regroupement des variables en « classes » telles que toutes variables appartiennent à une et une seule classe. On a l’habitude de construire des regroupements de classes par inclusion afin d’établir les proximités qui existent entre les classes. Ces proximités sont représentées par une arborescence hiérarchique. Il y a alors divers niveaux de regroupement, les classes qui sont constituées à des valeurs de similitude fortes sont nombreuses, mais plus on accepte des similitudes faibles moins il y aura de classes et plus les classes contiendront de nombreux éléments. A un seuil donné (à un niveau de la hiérarchie de l’arborescence) les classes sont exclusives : une variable ne
Figure 24 : 10 Valeurs de Schwartz : Extrait du filtrant des cliques
Figure 25: 10 Valeurs de Schwartz : Les cliques non rigides sur l’arbre

Droits de reproduction et de diffusion réservés © Sciences Humaines
45
peut pas appartenir à deux classes. On dit que de telles classifications sont des « Classifications Ascendantes Hiérarchiques (CAH) ».
Le filtrant des cliques a très rarement la propriété d’une classification. Pour que le filtrant ait cette propriété il faut que toutes ses cliques soient des parties rigides sur l’arbre et que les cliques, à un seuil donné, n’aient pas de variables communes. On peut cependant chercher à construire une classification qui soit une approximation du filtrant.
Cette classification se fait sur la base des arêtes de l’arbre maximum : c’est la classification dite de Johnson (Johnson,
1967) ou dite de Wroclaw. Cette classification est intéressante car elle est définie par l’arbre maximum. Elle n’a de sens que si les cliques du filtrant sont rigides sur l’arbre. Mais sa qualité dépend de la qualité de l’arbre. Elle doit être utilisée surtout dans le cas où l’arbre exprime des données s’organisant autour d’axes (autour de dimensions du phénomène analysé). Nous allons nous placer dans une situation plus courante, celle où ce dernier n’est pas une bonne description des données, c’est le cas de l’exemple sur les Valeurs. Quelle est la qualité de la classification que nous obtenons à la figure 26 ?
On peut vérifier cette qualité en construisant le filtrant des cliques dont la valeur est supérieure à la valeur (s0) juste supérieure à celle de la plus petite arête de l’arbre (dont la valeur est s0-ε). Cette valeur s0 a la propriété suivante : si on dessine un graphe à ce seuil (Gs0), alors ce graphe se compose de deux sous-graphes (G1 et G2)n’ayant aucune relation. Ce graphe Gs0 n’est pas connexe car on a détruit la connexité de l’arbre en enlevant la plus petite arête de l’arbre. En effet l’arête de l’arbre maximum de valeur s0-ε est l’arête ayant la plus forte valeur parmi toutes les arêtes pouvant relier un sommet de G1 à un sommet de G2. La valeur s0-ε est donc à la fois la valeur de similitude la plus forte entre les deux zones G1 et G2 du graphe de similitude et la valeur la plus faible de l’arbre maximum. C’est donc un « minimax ».
Figure 26 : La classification des composantes connexes de l’arbre des 10 valeurs de Schwartz.
L’ordre des arêtes de l’arbre est le suivant : 0,20 (D,F) ; 0,27 (C,D) ; 0,33
(G,H) ; 0,34 (D,E) ; 0,39 (H,J) ; 0,41 (F,G) et (A,B) 0,45 (A,K) ;0,58 (J,K).
On peut alors dessiner la classification suivante qui met en évidence les différentes composantes connexes de l’arbre et leur mode de regroupent hiérarchique. L’arête (D,F) crée deux composantes
connexes : (B,A,K,J,H,G,F) et (C,E,D). Puis L’arête (C,D) crée deux composantes connexes : (C) et (D,E) etc…
Classification arborescente : algorithme de.classification du « lien simple ».
On peut construire une telle classification en ne tenant compte que des arêtes de l’arbre. Pour cela :
a- on ordonne les arêtes de l’arbre par ordre croissant ; b- on supprime l’arête dont la valeur est la plus petite ; c- l’arbre se décompose alors en deux sous-arbres, les
sommets de chacun de ces sous-arbres forment une classe, chaque classe est une « composante connexe » puisque tout sous-arbre est connexe.
d- on ré-applique l’algorithme b et c sur les arêtes restantes : les sous-arbres se dédoublent alors.
Quand la procédure algorithmique est terminée on a construit un filtrant des composantes connexes de l’arbrequi a les propriétés d’une classification descendante hiérarchique.
Cet algorithme est celui de la classification de Johnson (Johnson, 1967) ou encore dite de Wroclaw.

Droits de reproduction et de diffusion réservés © Sciences Humaines
46
Dans l’exemple des 10 valeurs de Schwartz l’arbre se coupe en deux : d’une part les sommets (C,E,D) et de l’autre les sommets (B,A,K,J,H,G,F). Le filtrant, à ce seuil, ne confirme pas cette partition (figure 27). Il se réduit à trois composantes connexes. Seule la composante la plus à droite, et dont les valeurs sont les plus fortes, confirme la classification de Johnson avec la clique (B,A,K,J) identique à la classe construite au seuil de 0,41 (sur la classification des composantes connexes) et la
clique (A,K,J) identique à la classe construite au seuil de 0,45. Les autres composantes connexes associent des éléments qui ne forment pas une classe comme (F,G,H) ou (G,H,J,K). Ceci ne nous surprend pas car dans cet exemple l’arbre maximum n’est pas un bon résumé des données.
3.3 RECHERCHE DE PROPRIETES PARTICULIERES SUR LE FILTRANT DES CLIQUES MAXIMALES.
Comme nous l’avons montré les cliques se construisent et s’absorbent, donc se hiérarchisent, si on parcourt la préordonnance de similitude dans un ordre décroissant. A chaque seuil correspond un graphe-seuil. Dans ces graphes on peut identifier les cliques maximales. Elles forment un « recouvrement » partiel du graphe. On parle de recouvrement et non de classement car il n’y a pas toujours de séparation nette entre deux cliques. Le plus souvent on se trouve devant un ensemble de cliques qui ont en commun certains sommets. Elles se recouvrent partiellement comme dans le graphe des cliques rigides sur l’arbre (figure 23) : (A,J,K), (H,J,K), (F,G,H). Si on parcourt l’ensemble des seuils, ces recouvrements sont organisés par les relations d’inclusion du filtrant. Que peut-on alors en dire ?
L’intérêt du filtrant des cliques doit le plus souvent être trouvé ailleurs, en dehors des propriétés classificatoires. Nous avons vu, dans l’exemple des 10 valeurs de Schwartz, que le filtrant faisait apparaître plusieurs autres propriétés. On peut en décrire principalement trois:
a- l’existence d’une zone où les cliques se regroupent successivement par inclusion, on peut associer cette propriété à l’image d’une huître (cf. 3.3.1.1, figure 29) ; b- l’existence d’une succession de recouvrements dont les intersections ne sont pas vides, elle est repérable par la présence d’une figure en zig-zag(cf. 3.3.1.2, figure 30) ; c- l’existence de zones non connexes à un seuil donné (cf. figure 27).
On peut en outre rechercher à caractériser les sommets par la nature des zones du filtrant où ils se trouvent, comme dans l’exemple des 10 valeurs de Schwartz (figure 10). On identifie alors trois types de variables :
- les variables qui se retrouvent dans un très grand nombre de cliques (dans la figure 10 la variable K sécurité) ; ce sont des éléments que l’on peut qualifier de « centraux » pour le graphe. - les variables jouant le rôle d’éléments « générateurs » d’une zone du filtrant ; ils apparaissent dans le filtrant à un seuil élevé et participent ensuite à plusieurs cliques (dans la figure 10 la
Figure 27 : Le filtrant des 10 valeurs de Schwartz pour les
valeurs supérieures ou égales à 0,20

Droits de reproduction et de diffusion réservés © Sciences Humaines
47
variable A pouvoir, B accomplissement, J conformisme, H tradition, G bienveillance et F universalisme) ; - les variables intervenant à des seuils faibles, dans le bas du filtrant ; elles peuvent ne participer qu’à un nombre restreint de cliques (dans la figure 10 la variable C Hédonisme)
3.3.1 Modèles formels et propriétés du filtrant. L’analyse de similitude n’est pas une méthode de validation d’un modèle mathématique, c’est la
recherche d’un résumé des données, résumé le plus fidèle possible. Mais on peut trouver des filtrants ou des zones dans le filtrant qui ont une propriété faisant référence à un modèle. On peut en envisager particulièrement deux : les échelles d’attitude (dite échelle de Guttman) et les recouvrements connexes (ou échelle d’opposition, du type droite / gauche).
3.3.1.1 Le Filtrant où les données peuvent être ordonnées par une échelle de Guttman.
Nous prendrons un exemple fictif : le questionnaire comprend cinq questions auxquelles il fallait répondre Oui (codé 1) ou Non (codé 0) ; il a été posé à 41 sujets. On a obtenu les protocoles de réponses suivants qui définissent une matrice de similitude :
Nombre de sujets
A B C D E
2 0 0 0 0 0 10 1 0 0 0 0 8 1 1 0 0 0 5 1 1 1 0 0 5 1 1 1 1 0
11 1 1 1 1 1 Tableau 24 : Protocoles des réponses
A B C D E
A *
B 29 *
C 21 21 *
D 16 16 16 *
E 11 11 11 11 * Tableau 25 : Matrice de similitude produite
par l’indice de cooccurrence : échelle de Guttman

Droits de reproduction et de diffusion réservés © Sciences Humaines
48
Les données peuvent être situées sur une échelle de Guttman auquel seul les trois derniers patrons ne répondent pas, mais leur faible fréquence permet d’accepter le modèle31. On calcule alors la matrice de similitude (tableau 25). Cette échelle permet d’ordonner de manière conjointe les questions et les sujets : les questions de A à E et les sujets en fonction du nombre de réponses codées 1.
La matrice de similitude calculée avec un indice de cooccurrence est régulière et le filtrant des cliques est bien particulier : les cliques forment une suite d’inclusions qui donnent au graphe des cliques maximales une allure « d’huître »(figure 29). La structure d’inclusion redonne l’ordre des questions.
Si on utilise la cooccurrence on obtient un filtrant significatif, par contre la RAM ne peut pas être dessiné car c’est le graphe complet (exemple : toutes les arêtes reliant D aux sommets de la composante connexe A B C ont pour valeur 16, cf. tableau 25). Pour obtenir un arbre maximum qui indique l’ordre de l’échelle de Guttman il faut utiliser la cooccurrence symétrique (la somme des 11 et des 00). On obtient alors la chaîne A-B-C-D-E (tableau 26).
Les données sont rarement aussi parfaites mais on peut observer dans un filtrant l’existence d’une (ou des) zone où les cliques dessinent une ligne d’inclusion successive sans interférence notable avec d’autres ensembles de cliques ; on peut alors supposer l’existence d’une échelle de Guttman pour le groupe de variables concernées par les cliques de cette partie du filtrant.
3.3.1.2 Le filtrant où les données peuvent être ordonnées sur un axe construit par une suite de recouvrements connexes.
Le modèle qui est ici recherché n’est plus l’existence d’une échelle mais d’un axe sur lequel les réponses découpent des parties connexes. On présente souvent ce modèle sous la forme d’une diagonalisation du tableau des données.
Les exemples d’un tel modèle sont nombreux : axe droite – gauche, échelle de datation de période historique ou de phénomène évoluant sur un axe temporel. On va alors caractériser les sujets par leur position sur cet axe. Nous ne sommes plus sur une échelle d’accumulation de caractéristiques comme précédemment mais sur
31 On calcule un coefficient d’accord avec le modèle (cf. coefficient de reproductibilité en annexe 1).
Figure 28 : Filtrant des
cliques : échelle de Guttman.
Figure 29 : l’huître des cliques
A B C D E A * B 31 * C 23 33 * D 18 28 36 * E 13 23 31 36 *
Tableau 26 : L’Arbre de la Matrice de similitude produite par l’indice de cooccurrence symétrique : échelle de Guttman.
Nombre de sujets
A B C D E
2 0 0 0 0 0 10 1 0 0 0 0 8 1 1 0 0 0 5 0 1 1 0 0 5 0 1 1 1 0
11 0 0 1 1 1 7 0 0 0 1 1
12 0 0 0 0 1 Tableau 27 : Protocoles des réponses

Droits de reproduction et de diffusion réservés © Sciences Humaines
49
l’existence de zones contiguës sur un axe d’évolution (transformation) d’un phénomène32. Nous prendrons ici encore un exemple fictif.
Chaque patron de réponse est une zone connexe de variables (par exemple B-C-D pour la cinquième ligne). L’arbre maximum est alors une chaîne régulière, comme le montre la propriété de régularité de la matrice de similitude. Les cliques maximales sont toutes rigides sur cet arbre. Elles s’organisent sous la forme d’un recouvrement qui va donner au filtrant une allure de « zigzag » (figure30) que nous avons déjà rencontrée.
On retrouve assez souvent de telles formes dans certaines zones du filtrant. Ce modèle a été présenté par Claude Flament33 comme un « modèle à composante non monotone », on le trouve aussi dans la littérature américaine sous le nom « d’unfolding technique »34.
Dans les deux modèles que nous venons de décrire (échelle de Guttman et composante non monotone) il existe une correspondance entre une propriété des chaînes et une propriété du filtrant : toutes les cliques du filtrant, dont les sommets sont sommets d’une chaîne régulière, sont rigides sur cette chaîne (par exemple BCD ou CDE). Inversement si on trouve une zone du filtrant dont les cliques sont toutes régulières et dont les éléments de ces cliques forment un sous-ensemble de sommets connexes sur une chaîne de l’arbre alors cette chaîne est régulière. Les propriétés de ces deux modèles sont suffisamment fortes pour qu’il soit très rare de les trouver à l’état pur. Ils peuvent par contre servir pour repérer des zones du graphe ayant des propriétés particulières qui peuvent être ensuite identifiées à l’un de ces modèles.
32 Un sujet est, par exemple, d’accord avec les idées politiques proches de la sienne amis pas avec celles plus lointaines
(à droite et/ou à gauche). 33 Flament, Cl., 1963 34 Coombs, C.H., 1965
Figure 31 : graphe de similitude (cliques et arbre maximum) : recouvrement connexe
Figure 30 : Filtrant des cliques : recouvrement connexe
A B C D E
A *
B 8 *
C 0 10 *
D 0 5 16 *
E 0 0 11 18 * Tableau 28 : Matrice de similitude produite par
l’indice de cooccurrence : recouvrement connexe.

Droits de reproduction et de diffusion réservés © Sciences Humaines
50
3.3.2 Propriétés du filtrant ne renvoyant pas à un modèle. L’analyse du filtrant, conçue comme une représentation des données, vise à valider le ou les graphes
que retient l’analyste pour exposer les données. On met ici à jour des propriétés plus pauvres que celles des modèles précédents. On en présentera trois que l’on retrouve assez souvent et qui permettent une interprétation formelle des similitudes. Nous nous servirons ici d’un exemple tiré d’une étude de représentations sociales de l’économie chez les étudiants. Le questionnaire demandait de mettre en relation onze notions économiques. La fréquence de ces relations donnait une matrice de similitude dont on reproduit ici le filtrant des cliques de valeurs supérieures à 13 (soit données par 7% des 200 sujets)
3.3.2.1. Les sous-ensembles « fermées » pour l’inclusion. La première propriété que l’on peut mettre en évidence est celle des sous-ensembles de variables
que l’on peut appeler « fermées » pour l’inclusion : un ensemble de cliques se retrouvent toutes incluses dans une seule clique de valeur minimum. Ici par exemple (figure 32) les cliques (4,7,11) et (4,5,7) se retrouvent dans la clique (4,5,7,11) au seuil de 29. Cette dernière clique n’a pas de descendant. de même les cliques (1,6,7), (5,6,7), (1,5,6,7) et (5,6,10), (1,6,10), (1,5,6,10) se trouvent toutes incluses dans la clique (1,5,6,7,10) au seuil 21. On peut identifier un autre ensemble inclus dans la clique (3,5,7,8,10) mais dans cette zone du filtrant les dérivations (5,7,8,11), (3,5,7,8,11) et (3,5,9,10) n’en font pas partie. La totalité de cet ensemble n’est donc pas fermé.
La constitution de ces ensembles dépend, évidemment du seuil minimum du filtrant (ici 14). Nous reviendrons plus loin sur ce point de définition du seuil du filtrant, dans la mesure où le dessin du filtrant complet n’est pas utilisable et même n’est pas souhaitable car il tient compte de valeurs non significatives ou non intéressantes. On reste toujours fidèle au principe de privilégier les valeurs maximales.
La projection des deux « parties fermées » les plus à gauche du filtrant sur le graphe au seuil de 16% est intéressante (figure 33) : on y trouve une zone assez centrale dans le graphe (1,5,6,7,10) où se trouvent associés les éléments économiques relatifs aux trois principaux acteurs de l’économie : l’état (7), la
Figure 32 : Les relations économique : Exemple de filtrant

Droits de reproduction et de diffusion réservés © Sciences Humaines
51
finance (1,6) et l’entreprise (5,10). Cette partie du filtrant se développe entre les seuils de 10% et 25% des sujets, mais aucune de ces cliques n’est rigide sur l’arbre ; pour qu’elles le soient il faudrait éliminer le terme chômage. De la même manière la clique (4,5,7,11) n’est pas rigide sur l’arbre alors qu’elle est fermée et qu’elle découpe une zone intéressante, celle des rapports de l’état avec les entreprises (en haut et à gauche de la figure 32 et au bas de la figure 33).
La clique la plus à gauche (3,5,9,10) de la figure 33est bien particulière. C’est la clique de quatre sommets la plus élevée (55 soit 28%) dans le filtrant mais elle n’a pas de descendance. Elle décrit l’ensemble des éléments économiques de l’entreprise. Mais l’articulation de ses éléments avec le reste de l’économie ne se fait que de manière partielle et particulière. C’est ainsi que le profit (9) est exclu de la zone se fermant sur la clique (3,5,7,8,10), zone qui associe le fonctionnement de l’entreprise à l’état et au chômage. Cette zone a la particularité de n’être constituée que de cliques rigides sur l’arbre comme le montre la
figure 34. Mais cette zone ne peut être une partie fermée comme nous l’avons vu plus haut.
La clique exprimant l’activité monétaire de l’état (1,2,7) est comme la zone équivalente de l’activité de l’entreprise représentée par une clique apparaissant à un seuil élevé (35%) mais elle est quasiment sans descendance. Il faut attendre le seuil de 7% pour voir s’associer à cette clique le sommet entreprise (5).
Cet exemple montre deux choses : d’une part les propriétés de rigidité et d’identification d’une partie fermée du filtrant ne sont pas équivalentes, chacune a son
intérêt ; d’autre part le filtrant nous permet d’étudier la matrice de similitude à des seuils bien inférieurs à celui de l’arbre ou à celui permis par la lisibilité des graphes-seuil. Compte tenu de cela il faut alors faire attention au fait que les regroupements identifiés ne sont pas des catégories car les cliques se recouvrent le plus souvent comme dans cet exemple.
Figure 33 : Les relations économiques : le graphe-seuil à 16%. On a indiqué les valeurs des arêtes en nombre de sujets et dessiner trois cliques
Figure 34 : Les relations économiques : l’arbre maximum. On a aussi tracé la clique fermant la partie droite du filtrant

Droits de reproduction et de diffusion réservés © Sciences Humaines
52
3.3.2.2. Autres formes d’organisation : des propriétés locales.
A coté des ensembles fermés de cliques qui se regroupent par inclusion on peut mettre en évidence des propriétés moins formelles. On peut alors distinguer :
- les de cliques majoritaires (apparues à des seuils élevés). Elles indiquent, comme dans la figure 11, les zones saillantes du graphe de similitude ; - les sous-ensembles qui engendrent une descendance : ils mettent en évidence des variables génératrices et des variables secondaires. - les sous-ensembles qui, inversement, se retrouvent bien isolées quand on diminue le seuil ; on identifie alors des variables qui forment à elles seules une dimension de l’univers des données.
Ces différents modes d’organisation des sommets du graphe montrent bien l’intérêt de la démarche « locale » de l’analyse de similitude. Chaque type de regroupement comme précédemment chaque type d’organisation autour d’un axe n’a pas la même propriété. Ici en particulier ils indiquent comment les deux principaux agents économiques (l’Etat et l’entreprise) ont un univers propre (clique apparue à un seuil élevé et sans descendance), et comment leur mise en relation peut prendre sens autour d’un thème donné : ici les rapports entre l’Etat et l’entreprise se font d’une part autour du thème de la monnaie, d’autre part autour de la redistribution des revenus et enfin autour du chômage. Cette diversité des modes de ressemblance ne peut s’exprimer dans une analyse globale qui est obligée de pondérer ces diverses proximités locales à travers une boite noire que ne contrôle pas l’analyste.
Cette approche à partir des modes d’organisation des cliques du filtrant, peut se compléter par l’identification des types de variables à travers leur place dans le filtrant comme on l’a montré dans la figure 10 sur l’exemple des 10 valeurs de Schwartz.

Droits de reproduction et de diffusion réservés © Sciences Humaines 2003
53
CHAPITRE 4. FAIRE UNE ANALYSE DE SIMILITUDE : DEMARCHE PAS A PAS.
Nous présentons maintenant de manière systématique les différentes étapes de l’analyse de similitude. Celles-ci sont au nombre de 6 :
1- la transformation des données initiales en matrice de similitude 2- l’exploration de la matrice de similitude pour en extraire la préordonnance, l’arbre maximum,
le graphe de la 3-analyse, les cliques maximales du filtrant. 3- le dessin de l’arbre maximum et des graphes-seuil 4- le dessin du filtrant des cliques maximales 5- la présentation réordonnée de la matrice de similitude ou la sélection d’un sous-ensemble de
variables 6- la comparaison de matrices de similitude créées sur des sous-populations.
Une exploitation rapide des données se contente des 3 premières étapes. La quatrième est nécessaire pour une analyse fouillée. La cinquième étape vise à mieux organiser les données pour une présentation plus parlante. La sixième est essentielle quand on veut mettre en évidence des différences entre sous-populations définies par une variable indépendante (tel le sexe) quand on veut mettre en évidence les spécificités de certaines sous-populations définies par une configuration particulière des patrons de réponse.
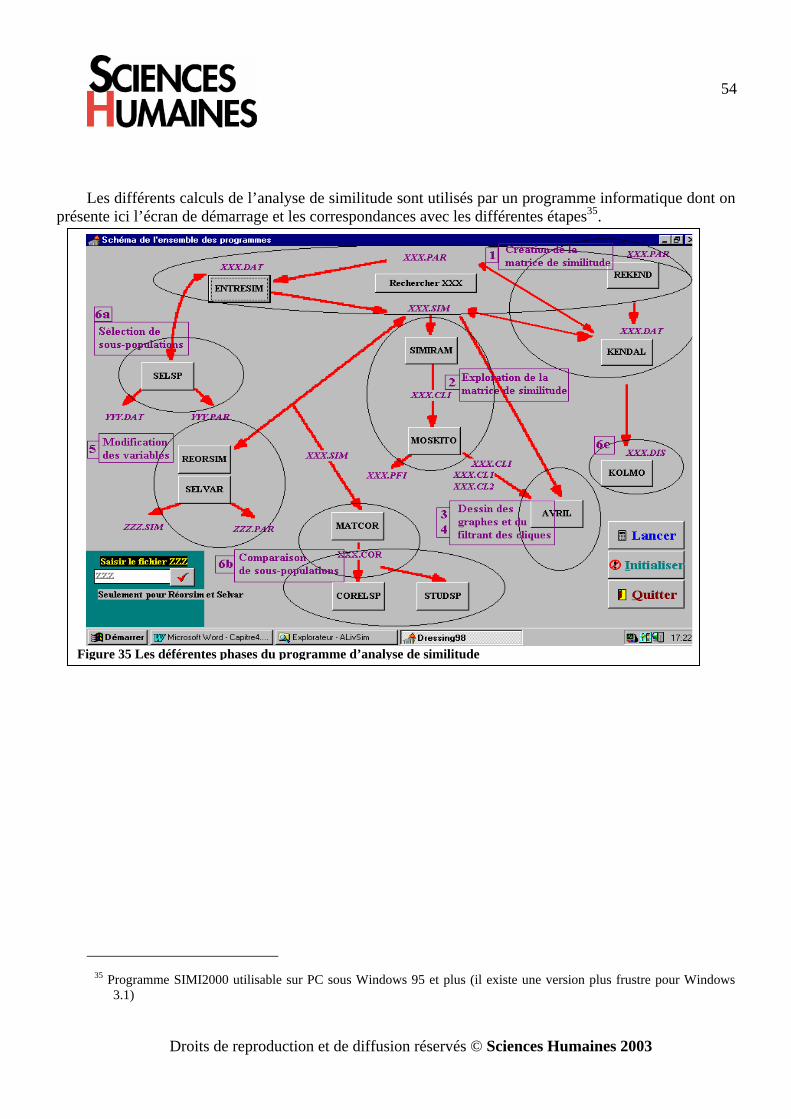
Droits de reproduction et de diffusion réservés © Sciences Humaines 2003
54
Les différents calculs de l’analyse de similitude sont utilisés par un programme informatique dont on présente ici l’écran de démarrage et les correspondances avec les différentes étapes35.
35 Programme SIMI2000 utilisable sur PC sous Windows 95 et plus (il existe une version plus frustre pour Windows
3.1)
Figure 35 Les déférentes phases du programme d’analyse de similitude

Droits de reproduction et de diffusion réservés © Sciences Humaines 2003
55
4.1 LA CREATION DE LA MATRICE DE SIMILITUDE.
Les données recueillies peuvent être de plusieurs types comme nous l’avons déjà vu. Les calculs pour aboutir à une matrice de similitude sont de quatre types. On a déjà vu la différence entre les données de la forme [X x X] qui suppose une simple transformation des données pour qu’on puisse les considérer comme des valeurs d’une matrice de similitude et les données de la forme [X x Y] qui supposent le calcul d’un indice de similitude entre les variables. Ces dernières se distinguent sur la base de la nature de la mesure qui leur est applicable : 0/1, ordinale, métrique.
L’analyste doit identifier la nature des données et prendre une décision sur l’indice de similitude.
A- Forme [X x X] ou [X x X’] : la similitude est donnée par une valeur calculée ou obtenue directement (cas d’une matrice de flux entre variables par exemple). La décision est celle du choix entre valeur brute (initiale) (S20)36, et le calcul d’une distance entre cette valeur et la valeur à l’indépendance statistique quand cela a un sens (S22). B- Forme [X x Y] où les variables sont binaires et donc codées 0/1 mais où seul le 1 est univoque (cf. 1.3). La décision est celle du choix d’un indice privilégiant soit la fréquence du type cooccurrence (S1, S2), soit le rapport à l’indépendance statistique du type H de Loevinger ou l’indice de Forbes (S3, S4, S5). C- Forme [X x Y] où les variables sont ordinales.
C1* Si les variables sont dichotomiques ordonnéela décision est celle du choix d’un indice privilégiant soit la mesure d’une concordance du type cooccurrence symétrique (S7, S8), soit au contraire le rapport à l’indépendance statistique du type Φ, Q de Yule (S9, S10).
C2* Si les variables sont situées sur une échelle de [1 à m] (dans le cas d’une échelle de [-m à +m] il faut ajouter m+1 aux données pour se ramener au cas précédent) la décision est celle du choix d’un indice privilégiant soit la distance à la concordance, du type de l’inverse d’une distance city-block (S11, S12, S13, S14), et cela seulement quand les variables se mesurent toutes sur la même échelle, soit le rapport à l’indépendance statistique du type Tau de Kendal (S15, S16). D- Forme [X x Y] où les variables sont métriques. La décision est celle du choix d’un indice privilégiant soit l’effet de taille, comme l’inverse d’une distance euclidienne, (S17), soit le rapport à l’indépendance statistique comme le coefficient de corrélation de Bravais – Pearson (S18, S19).
Sur un même ensemble de données on peut calculer différents indices de similitude si on veut mettre en évidence différents phénomènes (comme en 1.4.1.3). Le plus souvent on arrête son choix sur un seul indice correspondant le mieux à la question que l’on se pose à propos des données. Mais il faut alors le justifier théoriquement ou par la forme du questionnement. On verra plus loin que dans le cas de questionnaires de caractérisation, questionnaires où n’est pas dans le cas de tirage au sort avec remise, les indices se référant à l’indépendance statistique sont mal adaptés. Si on obtient directement des valeurs utilisables comme coefficient de similitude (cas du coefficient de corrélation ou de la moyenne des scores
36 cf. annexe 1 pour les formules des différents indices de similitude.

Droits de reproduction et de diffusion réservés © Sciences Humaines 2003
56
dans l’exemple des proximités entre pays en 2.4) on ne peut pas prendre de décision, on est contraint par l’information initiale.
4.2 L’EXPLORATION DE LA MATRICE DE SIMILITUDE.
Le calcul de la préordonnance de similitude est la première opération que fait le programme d’analyse de similitude proprement dit. Sur la base de cette préordonnance il identifie les arêtes de l’arbre maximum et celle du graphe G3 de la 3-analyse. Il peut aussi identifier les cliques maximales du filtrant (leurs sommets et leurs valeurs) si on le désire. La seule décision à prendre est celle du seuil minimum du filtrant.
Il n’existe pas de seuil minimum s’imposant statistiquement. Si l’indice de similitude est un coefficient classique pouvant être assimilé à un coefficient de corrélation on peut utiliser les valeurs des tables de confiance à 5% par exemple. Mais nous ne sommes pas ici dans le cadre d’un test d’hypothèse, ces valeurs ne peuvent être qu’indicatives. Le plus souvent on se réfère à l’ordre de la préordonnance. On définit alors le seuil par la valeur de l’arête de la fin du premier tiers de la préordonnance, ou encore celle de la médiane. Une démarche plus empirique consiste à dessiner le filtrant en faisant varier le seuil et en conservant le seuil pour lequel les phénomènes mis à jour sont présents et non perturbés par des liaisons avec des arêtes de valeur trop faible. C’est ce que nous avons fait dans l’exemple sur les relations économiques (3.3.2, figure 33). Cette exploration se fait très facilement en choisissant un seuil par le bouton « Simiram », puis en exécutant « Filtrant » et en dessinant le filtrant par le bouton « Avril37 ». On recommence cette itération tant qu’on n’atteint pas un résultat satisfaisant.
4.3 DESSINER UN GRAPHE DE SIMILITUDE NON ARBITAIRE.
Il faut d’abord affirmer qu’il n’y a pas d’algorithme automatique permettant de dessiner le meilleur graphe possible. Le seul cas particulier où il et possible de définir la position de chaque variable, vis à vis de celles qui lui sont reliées, est celui où le graphe est planaire. Un graphe planaire est tel qu’il est possible de faire un dessin où les arêtes ne se croisent pas. La figure 36 montre un tel type de graphe. En théorie des graphes on dit qu’il est composé d’une base de cycle. Retenons simplement l’importance des cycles dans le dessin d’un graphe.
Ce « type idéal » de graphe est instructif. Il permet d’établir deux principes de construction d’un graphe de similitude. En premier seule la présence ou non des arêtes doit guider le dessin. En second on va chercher à minimiser les croisement d’arêtes et à représenter le mieux possible les cycles. C’est ainsi qu’il n’est pas possible d’intervertir la position de l’Inde et du Congo sans introduire le croisement de deux arêtes (Congo – Brésil et Egypte – Cuba). De la
37 le terme de « Avril » pour désigner le programme dessinant les graphes (arbres maximum, 3-analyse, filtants) a une
histoire. La première version de ce programme s’appelait « Mars » : sigle de Méthode d’Analyse des Représentations Sociales. La réécriture de ce programme a pris le nom du mois suivant : « Avril ». On doit en remercier Romain Zelinger qui, au laboratoire CNRS d’Ecully, a écrit ces deux programmes.
Figure 36 : Douze pays, exemple de graphe planaire.

Droits de reproduction et de diffusion réservés © Sciences Humaines 2003
57
même manière on ne va pas mettre la France entre le Japon et Israël quand elle est reliée à la Russie. Dans le cas d’un graphe planaire les différents cycles ou « cellules (d’abeille) » se dessinent de manière telle qu’aucune cellule ne se trouve en croiser une autre. Complétant ces principes de ne tenir compte que des arêtes présentes, il est possible de refléter en partie la valeur de similitude des arêtes par une plus ou moins grande proximité géographique des sommets. Mais ce dernier principe ne peut être habituellement tenu que de manière locale, dans des zones de voisinage du graphe, il ne peut être un principe de calcul des positions de tous les sommets. Ici la longueur de l’arête Brésil – USA de valeur 5,39 est nettement plus grande que celle de l’arête France – Russie (5,06), en toute logique géométrique elle devrait être plus petite. L’important n’est pas là, il est plus important de montrer que le Brésil est relié à trois pays (Congo, Cuba, USA) et que la France est reliée aux USA et à la Russie. La position de ces pays dépendant de leurs relations à d’autres pays, l’ensemble du graphe se construit par cette suite de mise en relation, par une heuristique portant sur les arêtes. On ne trouve généralement pas une projection planaire de la matrice de similitude comme dans les méthodes MDS (si on se limite au deux premiers axes), on cherche alors à refléter, par le dessin, l’existence des arêtes, des cliques et des cycles.
Dans le cas général où le graphe n’est pas planaire on doit chercher à minimiser les croisements d’arêtes. Mais cette règle ne doit pas être absolue elle doit tenir compte d’abord des relations connexes et ensuite de l’existence de certaines configurations qui peuvent influencer l’interprétation des données.
Dans la figure 37 on ne peut pas situer différemment l’Egypte reliée à Cuba, le Brésil relié
aux USA et à Cuba, la France reliée aux USA et à la Russie mais on pourrait très bien appliquer la règle de non croisement et situer la Yougoslavie au centre du triangle Cuba, Chine, Russie comme dans la figure 38. Ce dernier graphe a deux défauts : il ne respecte pas du tout la hiérarchie des valeurs de similitude au sein de la clique (Cuba, Chine, Russie, Yougoslavie), la Yougoslavie est très proche de la Russie (6,67) et moins des deux autres pays (5,06 et 5,11), mais surtout il semble donner à la Yougoslavie une place centrale, intermédiaire entre les trois autres pays alors que la 3-analyse (figure 40) comme le filtrant ne lui donne absolument pas ce rôle. On aurait pu mettre au centre la Russie ou Cuba mais dans ce cas on introduisait une multiplicité de croisements car ces deux pays participent à d’autres cliques du graphe : la Russie avec la France et les USA, Cuba avec l’Egypte et le Brésil. Seule la Chine pourrait se trouver au centre en respectant, localement, à peu près les valeurs de similitude (sauf avec la Yougoslavie) mais l’interprétation serait alors déséquilibrée. La position plus ou moins centrale d’un sommet dans une clique doit être justifiée d’abord par la valeur des arêtes de la clique maximale et ensuite par l’intérêt de cette position centrale dans l’interprétation des données (ici le débat pourrait être idéologique Russie / Chine!).
Figure 37 : graphe partiel de huit des douze pays.
Figure 38 : graphe partiel sans croisementde huit des douze pays.

Droits de reproduction et de diffusion réservés © Sciences Humaines 2003
58
La position respective des sommets du graphe ne peut se régler par la seule analyse d’un unique graphe. En effet si on s’arrête au dessin de l’arbre maximum on aura tendance à privilégier la chaîne maximale la plus longue et organiser le graphe autour de cette chaîne. Dans l’exemple des douze pays cela donnerait le graphe de la figure 39.
Mais dès qu’on introduit la 3-analyse puis les graphes-seuil en faisant varier le seuil on est obligé de modifier l’emplacement des différents sommets. Le filtrant des cliques est alors un bon guide pour indiquer si tel ou tel sommet est entre tel ou tel autre ou si une clique construite à un seuil élevé n’a pas de descendance et doit avoir une position un peu isolée dans le graphe. Dans l’exemple des douze pays on est passé par les deux dessins des figures 40 et 41 avant d’arriver à une représentation satisfaisante.
Après la 3-analyse on aboutit à un graphe presque planaire mais qui modifie profondément la place des différents pays : l’arbre n’est plus une série de chaînes mais un grand cercle.
A un premier seuil de 5,00, correspondant à 25% des arêtes, il est toujours possible de tracer le graphe-seuil en se servant des positions définies dans le graphe de la 3-analyse. Mais on voit immédiatement que la clique maximale des pays communistes se trouve étirée. Cependant cette base va s’avérer intéressante.
Figure39 : douze pays : arbre maximum
Figure 40 : Douze pays : graphe de la 3-analyse
Figure 42 : Douze pays : graphe-seuil à 5,00 modifiant les positions de la 3-analyse. Figure 41 : Douze pays : graphe-seuil à 4,61 sur
base des positions de la 3-analyse.

Droits de reproduction et de diffusion réservés © Sciences Humaines 2003
59
En passant au seuil de 4,61, correspondant au 1/3 des arêtes puis au seuil de 4,25 correspondant à 50% des arêtes on peut continuer à dessiner le graphe avec les mêmes positions (figure 41). Cette présentation correspond assez bien à l’analyse du filtrant des cliques maximales supérieures à 4,10 (60% des arêtes, cf. figure20). On y retrouve un axe composé de cliques se recouvrant partiellement (zigzag) allant d’Israël à la Chine en passant par le Japon, la France, l’Egypte et Cuba ; la Yougoslavie et la Russie faisant partie de toutes ces cliques. La situation intermédiaire du Congo et de l’Inde n’est cependant pas très en conformité avec leurs similitudes. Ils devraient être plus extérieurs mais sont, ici, dépendants de la position de l’Egypte.
Si on ne prend en compte que le premier tiers des arêtes, les cliques maximales (du filtrant de la figure 20 qui sont supérieures à 4,61) séparent nettement les pays de référence communiste des pays occidentaux développés et des pays en voie de développement. Entre ces trois entités bien identifiées on trouve des pays « intermédiaire » : la France et le Japon entre les pays occidentaux et le pays
communiste, le Brésil entre l’Amérique centrale de Cuba et l’Amérique du Nord des USA. On peut alors redessiner un graphe au seuil de 5,00 reprenant les positions de l’arbre maximum (figure 44) Ce graphe met mieux en évidence un certain isolement de l’Inde et du Congo et l’existence de trois entités, certes articulées, mais bien identifiées. La présentation de l’un ou l’autre de ces deux graphes (figure 41 ou figure 44) est alors une décision de l’analyste.
L’interprétation à partir des premières arêtes de la préordonnance est assez classificatoire et met en évidence de grands cycles. L’interprétation qui prend en compte l’essentiel des arêtes (60%) sera plus proche des résultats des méthodes factorielles ou MDS car, en tenant compte de toutes ces arêtes, elle se rapproche d’une interprétation globale et non plus locale des données. Une position intermédiaire qui tient compte du filtrant au seuil de 50% des arêtes (4,28) met en évidence des interprétations localisées comme nous avons pu en faire au paragraphe 2.4.
Pour conclure cette approche du dessin d’un, ou de plusieurs, graphes de similitude non arbitraires on peut avancer quelques principes généraux. Quand les données multiplient les cycles la 3-analyse est une bonne base. Quand les données sont bien décrites par l’arbre, il faut s’en rapprocher le plus possible. Quand les données se classifient on cherche plutôt à isoler les divers groupements. Et dans les cas complexes on essaye une série d’itérations : plusieurs présentations graphiques sont alors nécessaires pour mettre en
Figure 44 : Douze pays : graphe-seuil à 5,00 disposition de l’arbre maximum initial
Figure 43 Douze pays : graphe-seuil à 4,25 sur la base des positions de la 3-analyse.
Figure 45 : Douze pays : arbre maximum redessiné

Droits de reproduction et de diffusion réservés © Sciences Humaines 2003
60
évidence les différentes structurations des données. L’important est d’une part de donner à chaque variable sa place (plus ou moins isolée, seconde, intermédiaire, centrale) et d’identifier les différents modes d’organisation qui permettent d’interpréter les relations de similitude entre les données.
4.4 RENDRE PARLANTE UNE MATRICE DE SIMILITUDE.
Dans une enquête sur l’image de l’ecstasy auprès des jeunes fréquentant les boites de nuit de Palma de Majorque on a demandé de classer sur une échelle d’accord une vingtaine de phrases caractérisant cette drogue. Nous n’en retenons ici que treize pour la clarté de l’exposé.
La matrice de similitude calculée avec le tau de Kendal se présente ainsi.
Il n’est pas possible de présenter une telle matrice dans un ouvrage car elle ne parle absolument pas. Il convient de voir s’il est possible de la réordonner pour la rendre plus lisible. Pour cela on se sert du graphe de similitude. Celui-ci nous indique l’existence de deux groupes de variables.
A gauche on trouve un ensemble d’items qui met l’accent sur les dangers de l’ecstasy. Par contre à droite on trouve la justification de l’usage de cette drogue qui permet de « tenir debout toute la nuit » ou qui « éclaircit les idées ». On va alors se servir de cette opposition et de l’existence d’items intermédiaires, comme « la solution pour les personnes timides », pour réorganiser la matrice de similitude.
01Se tenir éveillé : 0 02Drogue douce : 7 0 03Prix accessible : 11 29 0 04Danger d’accoutumance : -21 -27 -16 0 05Evasion de la réalité : -11 -17 -14 11 0 06Eclaircir les idées : -3 30 0 -23 -8 0 07Provoque la mort : -15 -25 -13 22 -11 -12 0 08C’est dangereux : -15 -25 -19 14 -6 -12 17 0 09Ne sait pas ce qu’il prend: -2 -21 -8 17 -9 -12 11 20 0 10Permet tenir toute la nuit: 17 8 -4 -24 0 11 -20 -2 -12 0 11Solution personnes timides: -9 1 -5 -17 6 -5 -22 -8 -17 8 0 12Personnes à problèmes : -16 -12 -10 6 5 0 4 12 0 -20 12 0 13Comprendre House-musique : 5 12 -9 -18 -5 24 -13 -12 -19 7 0 3 0
Tableau 29 : Ecstasy : Matrice de similitude dans l’ordre de proposition des items aux sujets (taux de Kendall).
Figure 46 : Ecstasy : graphe de similitude au seuil de 0,06.

Droits de reproduction et de diffusion réservés © Sciences Humaines 2003
61
Avec une telle présentation on peut mettre en gras les valeurs supérieures à un certain seuil (ici les
valeurs positives). Elles se répartissent le long de la diagonale sous la forme de triangles successifs. Cette présentation permet de montrer la plus grande cohérence des items stigmatisant l’ecstasy (les quatre premiers items) alors que le groupe des items justifiant son usage (les cinq derniers items) comprend les valeurs de similitude les plus fortes mais est globalement moins cohérent (existence de valeurs négatives, ou proche de 0). On peut alors se poser la question de l’existence de sous-populations ayant des représentations différentes. Nous retrouverons cette question plus loin.
Il existe un autre cas de figure où il convient d’éliminer une ou plusieurs variables. On se trouve quelque fois devant des matrices où l’une des variables organise autour d’elle le graphe en étoile. Cette figure particulière est souvent présente quand on utilise un indice du type majoritaire (comme l’indice de cooccurrence). En effet la forte fréquence d’une variable détermine quasi automatiquement de fortes liaisons avec les autres variables. On a trouvé un tel cas dans l’étude des migrations entre les régions françaises. Quand on mesure ces migrations en volume, Paris focalise complètement le graphe ; on ne peut rien dire d’autre que la prééminence de la capitale. Si on enlève Paris de l’ensemble des sommets du graphe alors on retrouve une organisation cyclique dessinant approximativement la carte de la France et indiquant l’importance des distances (ou plus exactement des proximités) dans le phénomène migratoire38. La RAM de cette nouvelle matrice est bien différente de la RAM de la matrice initiale (comprenant toutes les variables).
Il est aussi parfois intéressant de sélectionner un sous-ensemble de variables pour l’étudier plus en détail. Dans ce cas comme dans le cas d’une ou plusieurs variables polarisant les liaisons les plus fortes on est conduit à sélectionner un sous-ensemble de variables formant une sous-matrice de similitude.
Dans une étude sur les représentations de la science au Brésil39 on a demandé aux sujets de qualifier la science avec certains items. On calcule un coefficient de corrélation entre ces items et on obtient le graphe suivant.
38 Degenne, A., 1973 39 Celso de Sà, 1996
07Provoque la mort : 0 04Danger d’accoutumance : 22 0 08C’est dangereux : 17 14 0 09Ne sait pas ce qu’il prend: 11 17 20 0 12Personnes à problèmes : 4 6 12 0 0 05Evasion de la réalité : -11 11 -6 -9 5 0 11Solution personnes timides: -22 -17 -8 -17 12 6 0 10Permet tenir toute la nuit: -20 -24 -2 -12 -20 0 8 0 01Se tenir éveillé : -15 -21 -15 -2 -16 -11 -9 17 0 03Prix accessible : -13 -16 -19 -8 -10 -14 -5 -4 11 0 02Drogue douce : -25 -27 -25 -21 -12 -17 1 8 7 29 0 06Eclaircir les idées : -12 -23 -12 -12 0 -8 -5 11 -3 0 30 0 13Comprendre House-musique : -13 -18 -12 -19 3 -5 0 7 5 -9 12 24 0
Tableau 30 : Ecstasy : Matrice de similitude après la réorganisation des items.

Droits de reproduction et de diffusion réservés © Sciences Humaines 2003
62
Dans ce graphe le mot de « nouveauté » a une position centrale il est relié à tous les autres mots (sauf étude). Or l’intérêt sémantique de ce mot est réduit vis à vis d’autre termes plus intéressants tels responsabilité , découverte etc….
D’une certaine manière c’est un point moyen qui n’apporte pas une grande information sur la représentation de la science. Les analystes décident de l’éliminer provisoirement. On obtient alors de nouveaux graphes (figure 48 et 49).
L’arbre maximum (figure 49) montre une chaîne centrale sur laquelle viennent se greffer pratiquement
toutes les cliques, construites au seuil de 0,20, cliques qui ont la propriété de rigidité sur l’arbre. Par l’élimination de ce terme on a pu aussi dessiner un graphe à un seuil bien inférieur au seuil précédent (0,20 versus 0,30), donc en tenant compte de plus d’informations (figure 48).
4.5 LA COMPARAISON DE SOUS-POPULATIONS.
On est souvent conduit à faire une étude comparative sur différentes populations ou sous-populations. Le critère de constitution des sous-populations peut être externe à l’ensemble des variables étudié (hommes / femmes, pays différents, âges…). On peut aussi construire les sous-populations sur la base d’une classification faite à l’aide de ces variables. On se trouve alors devant plusieurs matrices de similitude qu’il convient de comparer : sont-elles la variété statistique d’une seule matrice ? Ont-elles des différences significatives permettant d’identifier les spécificités de chaque population ? On utilisera une démarche de test de signification, mais sans s’arrêter aux seuls résultats du rejet ou non de l’hypothèse d’indépendance statistique : on utilisera les calculs de ces tests pour poursuivre une démarche descriptive dans la lignée de toutes celles que nous venons de présenter. En effet on ne se trouve jamais dans le cas où la démarche de test de signification est valide. Il s’agit ici de proposer des moyens (un bricolage statistique) permettant d’identifier les différences les plus intéressantes, les plus propre à l’interprétation
En premier il est possible d’utiliser une méthode de comparaison globale portant sur toutes les valeurs des matrices de similitude. On préférera adopter, ici, une seconde démarche privilégiant le local car elle se trouve plus dans la logique des opérations de l’analyse de similitude. On va identifier les
Figure 47 : la science : graphe-seuil à 0,30.
Figure 48 : la science : graphe-seuil à 0,20 sans « nouveauté »
Figure 49 : la science : arbre maximum sans « nouveauté »

Droits de reproduction et de diffusion réservés © Sciences Humaines 2003
63
variables, ou même les relations entre variables qui, dans une population donnée, vont être significativement différentes de celles observées dans les autres populations.
Une étude sur les représentations économiques des jeunes français avait une visée comparative. Cette étude portait sur les jeunes élèves de sixième (11 ans environ), sur ceux qui se trouvaient en dernière année du collège, la troisième (15 ans environ) et enfin ceux qui se trouvaient en terminale (18 ans environ) avec un enseignement de sciences économiques et sociales. On se proposait de mettre en évidence un effet de maturation et l’impact d’un enseignement spécialisé (de l’économie) sur la manière d’envisager les relations entre les grands agents économiques (Famille, Etat, Entreprise et Banques).
Les graphes construits au seuil de 16% (les relations du graphe données par plus de 16% des élèves d’une classe d’âge) présentent quelques différences au premier regard. Les élèves de sixième ont donné relativement moins de relations et les ont concentrées sur quelques relations privilégiées. Les élèves de terminale construisent le circuit de l’économie comme dans les livres ! La comparaison graphique au même seuil est un peu trompeuse. En effet les élèves de sixième ont donné en moyenne beaucoup moins de relations que les autres élèves (7,11 versus 8,92 en troisième et 9,71 en terminale). On va devoir corriger cette différence en effectuant une analyse de corrélation (qui élimine l’effet de taille) entre les matrices de similitude : on considère chaque matrice comme une distribution de valeurs (chaque matrice devient une série de nombres ordonnés par leur place (ij) dans la matrice de la valeur i = 1, j = 2 à i = m-1 et j= m, avec m le nombre de variables) et on calcule la corrélation entre les différentes matrices (entre les différentes séries). Dans cet exemple on obtient une corrélation entre les élèves de sixième et ceux de troisième de 0,89, entre ceux de troisième et ceux de terminale de 0,87 et entre ceux de sixième et ceux de terminale de 0,66. Seule cette dernière valeur est un peu significative. Les matrices sont donc très proches entre deux classes successives.
4.5.1 La comparaison par l’étude des corrélations des valeurs autour d’une variable Cette première constatation d’une proximité globale des matrices doit être affinée. On effectue alors
une corrélation pour chaque ligne de la matrice : on compare l’ensemble des coefficients rij pour une variable i donnée (j prenant toutes les valeurs de 1 à m) d’une matrice avec le même ensemble dans la matrice d’une autre sous-population.
Figure 50 : Représentations du circuit économique : graphe au seuil de 16% Elèves de sixième Elèves de troisième Elèves de terminale SES
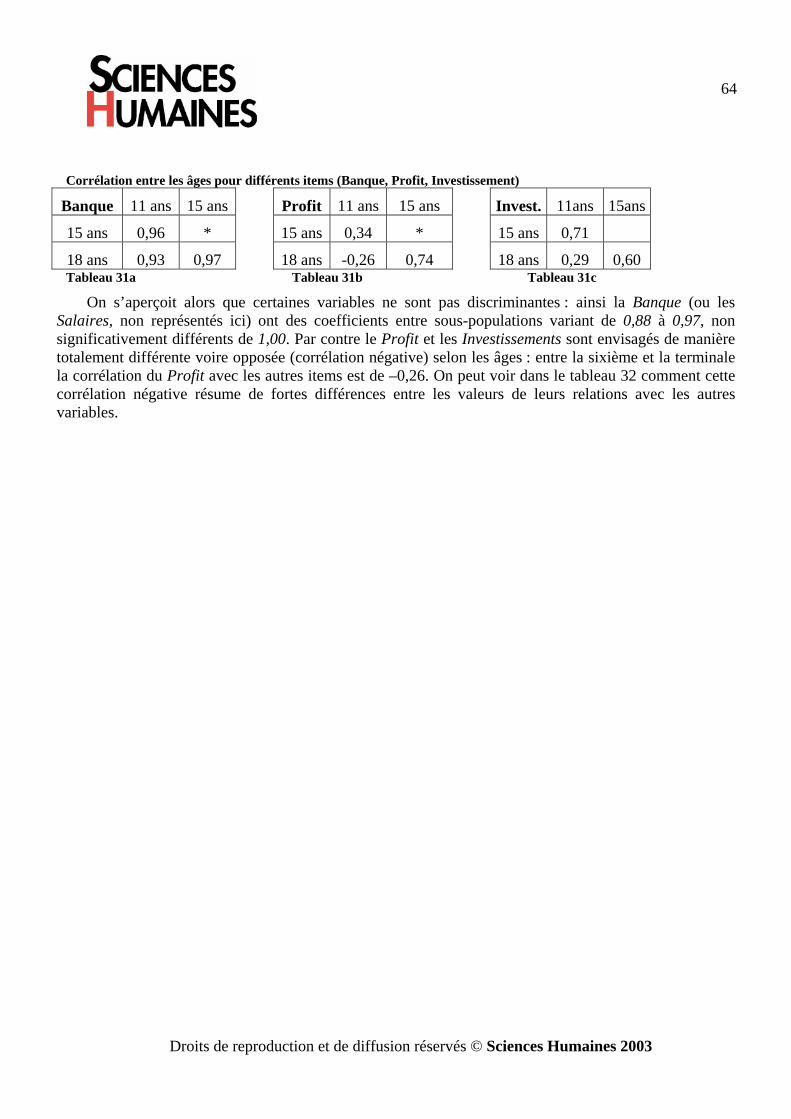
Droits de reproduction et de diffusion réservés © Sciences Humaines 2003
64
Corrélation entre les âges pour différents items (Banque, Profit, Investissement)
Banque 11 ans 15 ans Profit 11 ans 15 ans Invest. 11ans 15ans
15 ans 0,96 * 15 ans 0,34 * 15 ans 0,71
18 ans 0,93 0,97 18 ans -0,26 0,74 18 ans 0,29 0,60 Tableau 31a Tableau 31b Tableau 31c
On s’aperçoit alors que certaines variables ne sont pas discriminantes : ainsi la Banque (ou les Salaires, non représentés ici) ont des coefficients entre sous-populations variant de 0,88 à 0,97, non significativement différents de 1,00. Par contre le Profit et les Investissements sont envisagés de manière totalement différente voire opposée (corrélation négative) selon les âges : entre la sixième et la terminale la corrélation du Profit avec les autres items est de –0,26. On peut voir dans le tableau 32 comment cette corrélation négative résume de fortes différences entre les valeurs de leurs relations avec les autres variables.
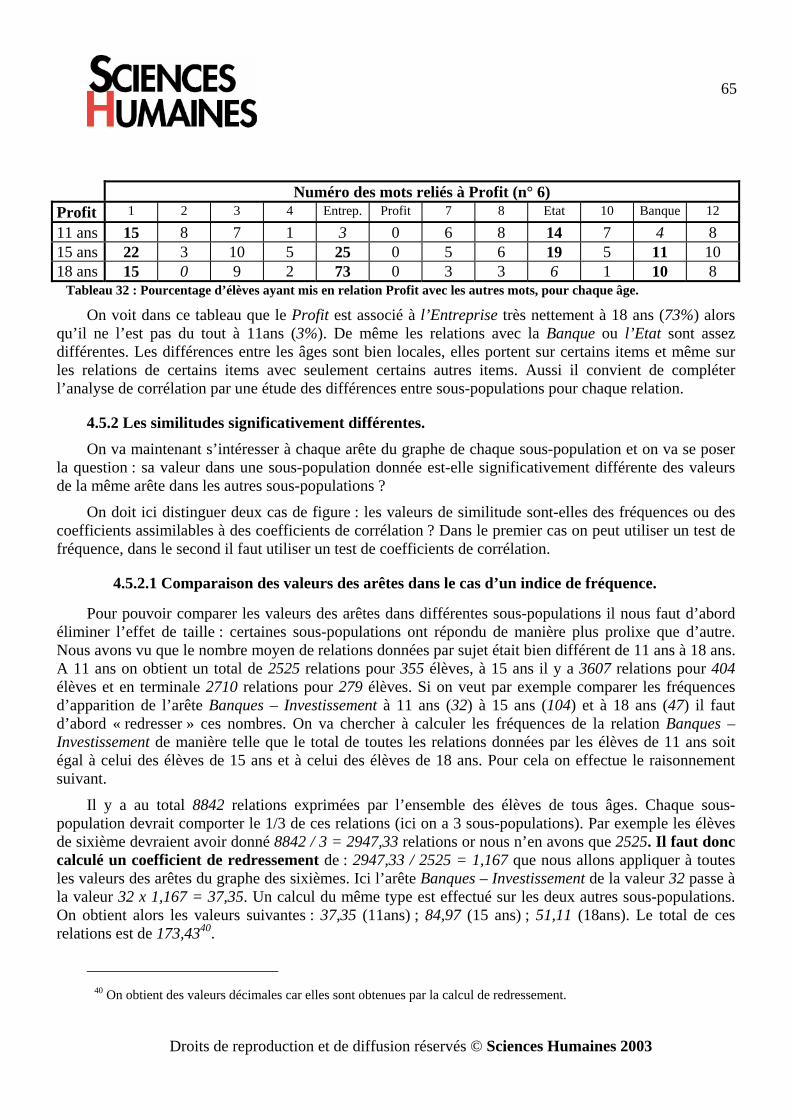
Droits de reproduction et de diffusion réservés © Sciences Humaines 2003
65
Numéro des mots reliés à Profit (n° 6) Profit 1 2 3 4 Entrep. Profit 7 8 Etat 10 Banque 12
11 ans 15 8 7 1 3 0 6 8 14 7 4 8 15 ans 22 3 10 5 25 0 5 6 19 5 11 10 18 ans 15 0 9 2 73 0 3 3 6 1 10 8
Tableau 32 : Pourcentage d’élèves ayant mis en relation Profit avec les autres mots, pour chaque âge.
On voit dans ce tableau que le Profit est associé à l’Entreprise très nettement à 18 ans (73%) alors qu’il ne l’est pas du tout à 11ans (3%). De même les relations avec la Banque ou l’Etat sont assez différentes. Les différences entre les âges sont bien locales, elles portent sur certains items et même sur les relations de certains items avec seulement certains autres items. Aussi il convient de compléter l’analyse de corrélation par une étude des différences entre sous-populations pour chaque relation.
4.5.2 Les similitudes significativement différentes. On va maintenant s’intéresser à chaque arête du graphe de chaque sous-population et on va se poser
la question : sa valeur dans une sous-population donnée est-elle significativement différente des valeurs de la même arête dans les autres sous-populations ?
On doit ici distinguer deux cas de figure : les valeurs de similitude sont-elles des fréquences ou des coefficients assimilables à des coefficients de corrélation ? Dans le premier cas on peut utiliser un test de fréquence, dans le second il faut utiliser un test de coefficients de corrélation.
4.5.2.1 Comparaison des valeurs des arêtes dans le cas d’un indice de fréquence.
Pour pouvoir comparer les valeurs des arêtes dans différentes sous-populations il nous faut d’abord éliminer l’effet de taille : certaines sous-populations ont répondu de manière plus prolixe que d’autre. Nous avons vu que le nombre moyen de relations données par sujet était bien différent de 11 ans à 18 ans. A 11 ans on obtient un total de 2525 relations pour 355 élèves, à 15 ans il y a 3607 relations pour 404 élèves et en terminale 2710 relations pour 279 élèves. Si on veut par exemple comparer les fréquences d’apparition de l’arête Banques – Investissement à 11 ans (32) à 15 ans (104) et à 18 ans (47) il faut d’abord « redresser » ces nombres. On va chercher à calculer les fréquences de la relation Banques – Investissement de manière telle que le total de toutes les relations données par les élèves de 11 ans soit égal à celui des élèves de 15 ans et à celui des élèves de 18 ans. Pour cela on effectue le raisonnement suivant.
Il y a au total 8842 relations exprimées par l’ensemble des élèves de tous âges. Chaque sous-population devrait comporter le 1/3 de ces relations (ici on a 3 sous-populations). Par exemple les élèves de sixième devraient avoir donné 8842 / 3 = 2947,33 relations or nous n’en avons que 2525. Il faut donc calculé un coefficient de redressement de : 2947,33 / 2525 = 1,167 que nous allons appliquer à toutes les valeurs des arêtes du graphe des sixièmes. Ici l’arête Banques – Investissement de la valeur 32 passe à la valeur 32 x 1,167 = 37,35. Un calcul du même type est effectué sur les deux autres sous-populations. On obtient alors les valeurs suivantes : 37,35 (11ans) ; 84,97 (15 ans) ; 51,11 (18ans). Le total de ces relations est de 173,4340.
40 On obtient des valeurs décimales car elles sont obtenues par la calcul de redressement.
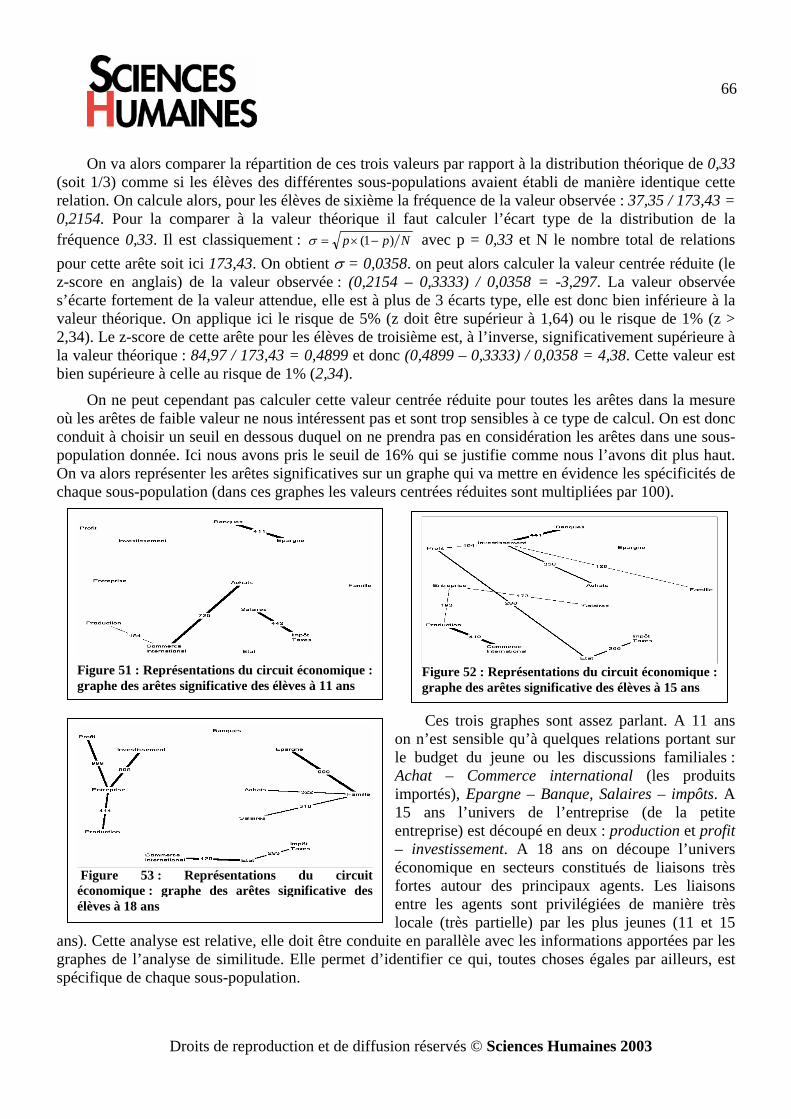
Droits de reproduction et de diffusion réservés © Sciences Humaines 2003
66
On va alors comparer la répartition de ces trois valeurs par rapport à la distribution théorique de 0,33 (soit 1/3) comme si les élèves des différentes sous-populations avaient établi de manière identique cette relation. On calcule alors, pour les élèves de sixième la fréquence de la valeur observée : 37,35 / 173,43 = 0,2154. Pour la comparer à la valeur théorique il faut calculer l’écart type de la distribution de la fréquence 0,33. Il est classiquement : Npp )1( −×=σ avec p = 0,33 et N le nombre total de relations pour cette arête soit ici 173,43. On obtient σ = 0,0358. on peut alors calculer la valeur centrée réduite (le z-score en anglais) de la valeur observée : (0,2154 – 0,3333) / 0,0358 = -3,297. La valeur observée s’écarte fortement de la valeur attendue, elle est à plus de 3 écarts type, elle est donc bien inférieure à la valeur théorique. On applique ici le risque de 5% (z doit être supérieur à 1,64) ou le risque de 1% (z > 2,34). Le z-score de cette arête pour les élèves de troisième est, à l’inverse, significativement supérieure à la valeur théorique : 84,97 / 173,43 = 0,4899 et donc (0,4899 – 0,3333) / 0,0358 = 4,38. Cette valeur est bien supérieure à celle au risque de 1% (2,34).
On ne peut cependant pas calculer cette valeur centrée réduite pour toutes les arêtes dans la mesure où les arêtes de faible valeur ne nous intéressent pas et sont trop sensibles à ce type de calcul. On est donc conduit à choisir un seuil en dessous duquel on ne prendra pas en considération les arêtes dans une sous-population donnée. Ici nous avons pris le seuil de 16% qui se justifie comme nous l’avons dit plus haut. On va alors représenter les arêtes significatives sur un graphe qui va mettre en évidence les spécificités de chaque sous-population (dans ces graphes les valeurs centrées réduites sont multipliées par 100).
Ces trois graphes sont assez parlant. A 11 ans on n’est sensible qu’à quelques relations portant sur le budget du jeune ou les discussions familiales : Achat – Commerce international (les produits importés), Epargne – Banque, Salaires – impôts. A 15 ans l’univers de l’entreprise (de la petite entreprise) est découpé en deux : production et profit – investissement. A 18 ans on découpe l’univers économique en secteurs constitués de liaisons très fortes autour des principaux agents. Les liaisons entre les agents sont privilégiées de manière très locale (très partielle) par les plus jeunes (11 et 15
ans). Cette analyse est relative, elle doit être conduite en parallèle avec les informations apportées par les graphes de l’analyse de similitude. Elle permet d’identifier ce qui, toutes choses égales par ailleurs, est spécifique de chaque sous-population.
Figure 51 : Représentations du circuit économique : graphe des arêtes significative des élèves à 11 ans
Figure 52 : Représentations du circuit économique : graphe des arêtes significative des élèves à 15 ans
Figure 53 : Représentations du circuit économique : graphe des arêtes significative des élèves à 18 ans

Droits de reproduction et de diffusion réservés © Sciences Humaines 2003
67
4.5.2.2 Comparaison des valeurs des arêtes dans le cas d’un indice de type corrélation.
Lorsque les matrices de similitude sont des matrices utilisant un indice se référant à l’indépendance statistique, il est possible d’utiliser le test classique d’un indice de corrélation. On prend pour référence la moyenne des indices de similitude des différentes populations pour une arête (ij) donnée. On fait sur cette arête et pour chaque population (k) une transformation z de Fisher41 de chaque valeur Sijk :
))1()1((log21Zijk SijkSijke −+= ; la variance de la distribution gaussienne de Zijk est égale à )3/(1 −= Nσ avec N le nombre de sujet de la population k. On calcule de même la transformation Zijt de
la moyenne des indices de similitude des différentes populations pour l’arête (ij). On peut alors calculer la
valeur σ
ZijtZijkijkS
−=* qui peut être interprétée sur la table de la distribution « normale ».
Comme précédemment on va construire le graphe des arêtes significatives pour chaque sous-population.
41 Gopal, K. Kanji, 1993

Droits de reproduction et de diffusion réservés © Sciences Humaines 2003
68
CHAPITRE 5. DISCUSSION : LES PROPRIETES FORMELLES DE L’ANALYSE DE
SIMILITUDE DOIVENT POUVOIR ETRE INTERPRETEES PAR LES SCIENCES SOCIALES.
L’analyse de similitude n’a pas été élaborée et développée pour ses simples vertus mathématiques et descriptives. C’est une analyse de données particulièrement en phase avec l’étude des représentations sociales. On peut mettre en correspondance les propriétés mathématiques des graphes et les notions qui sont utilisées dans la théorie des représentations sociales. Ainsi une représentation sociale est constituée d’éléments sélectionnés parce qu’ils sont proches du thème dont on cherche la représentation. Mais la représentation n’est pas seulement œuvre de sélection et d’amnésie, elle est fondamentalement une organisation, un ensemble de relations entre ses éléments. Ces relations ne sont pas transitives, ce sont des relations de proximité dont les valeurs peuvent être fort diverses (exprimant la plus ou moins grande proximité) et sont définies localement. On considère ici qu’elle sont symétriques. La théorie des représentations sociales a développé un ensemble de notions telles celles de noyau central, de saillance, d’éléments périphériques, de principes organisateurs etc … Les chercheurs dans ce domaine ont trouvé dans l’analyse de similitude des correspondances permettant le traitement des données issues de questionnaires visant l’expression de représentations sociales. Ces correspondances sont évidentes quand on sait que Claude Flament est l’une des figures les plus marquantes du champ d’étude des représentations sociales et qu’il est aussi le créateur et l’inspirateur des développements de l’analyse de similitude. Cependant l’analyse de similitude ne se réduit pas à l’étude des représentations sociales : c’est une méthode générale d’analyse de données.
Dans les chapitres précédents nous nous sommes intéressés aux seules propriétés mathématiques des graphes et matrices de l’analyse de similitude. Nous avons en passant montré qu’elles pouvaient conduire à des interprétations. Dans ce chapitre nous voulons mettre en garde le lecteur contre une transposition trop rapide des propriétés mathématiques en qualités du social. On a, par exemple, trop souvent considéré que la propriété mathématique de centralité dans un graphe pouvait conduire à considérer les éléments centraux du graphe comme des éléments du noyau central d’une représentation sociale. Cela n’est pas aussi évident. Le transfert d’une discipline à une autre doit être contrôlé.
5.1 CENTRALITE DANS LE GRAPHE ET NOYAU CENTRAL D’UNE REPRESENTATION.
Un certain nombre de chercheurs se sont servis de l’analyse de similitude pour identifier les éléments centraux d’un ensemble de variables à partir des propriétés graphiques de polarisation. Dans la théorie des graphes on parle d’éléments centraux ou de point d’articulation42 pour traduire le fait que certains sommets ont de nombreuses relations43 ou qu’ils sont nécessaires à la connexité du graphe. Cette mise en correspondance des critères de centralité et de l’identification du noyau central a été utilisée pour la première fois par J.C. Abric (1984) et a fait école sans qu’il ait été réalisée une réflexion plus
42 On appelle point d’articulation un sommet nécessaire à la connexité du graphe. Si on enlève ce sommet le graphe est
alors constitué de 2 ou plusieurs sous graphes disjoints. On peut étendre cette notion à un sous ensemble de sommets. On parle alors de k-connexité : si on enlève k sommets (avec k minimum) le graphe est constitué de 2 sous graphes disjoints : cf. Berge, C., 1958.
43 Le nombre de relations qui ont pour origine un sommet donné est appelé en théorie des graphes non orientés : degré de ce sommet. On peut alors hiérarchiser les sommets selon la valeur de ce degré.

Droits de reproduction et de diffusion réservés © Sciences Humaines 2003
69
approfondie. C’est ainsi qu’on a vu fleurir les travaux identifiants les éléments du noyau central d’une représentation sociale aux sommets ayant une propriété de maximisation de certaines de leurs caractéristiques. Aissani (1991 : 60) calcule le nombre d’arêtes de l’arbre maximal qui aboutissent à chaque sommet et hiérarchise ainsi les sommets. Katérélos (1993 : 46) calcule un indice « K » prenant en compte les distances sur l’arbre maximum.
En utilisant la méthode de Aissani dans l’exemple des « douze pays » le graphe de l’arbre maximum (figure 39) on identifierait trois pays « centraux » : les USA qui sont en relation avec 4 autres pays, l’Egypte et Cuba qui sont en relation avec 3 autres pays. On voit bien ici que la propriété de centralité (outre le fait que ce calcul est bien sommaire et est mis en cause par les analyses des autres propriétés du graphe) recouvre en fait deux aptitudes différentes : les USA sont en effet le prototype des pays occidentaux ; l’Egypte comme Cuba sont des pays intermédiaires entre deux mondes (celui du développement et celui de l’influence communiste).
Claude Flament (1996) a aussi montré que, à l’inverse de cette correspondance, les éléments centraux de la représentation (identifiés par ailleurs) se trouvaient souvent en bout de chaîne. Ils étaient plus des éléments « générateurs » de dimensions de l’univers analysé que des éléments charnières entre ces dimensions. Il affirme : « En fait, on peut se demander si la considération de l’excentricité n’est pas, dans certains cas, plus importante que celle du degré de voisinage. ».
Dans les études qui identifient propriétés graphiques de centralité et noyau central de la représentation les variables sélectionnées se trouvent souvent dans des groupes intermédiaires quand on effectue des analyses complémentaires du type classification ascendante hiérarchique (Katérélos, 1993 : 97, 72 , 82). On a vu aussi que dans le filtrant des cliques maximales certains sommets se trouvaient présents dans un très grand nombre de cliques. Cette propriété ne leur donnait pas pour autant valeur de centralité. Ce fut le cas de la sécurité dans le filtrant des 10 Valeurs de Schwartz (figure 10). Or ce terme est plus un pont entre le pouvoir et la bienveillance qu’un terme organisant l’ensemble des valeurs. Nous avons vu enfin que les graphes en étoile n’étaient pas obligatoirement les plus intéressants.
Il ne faut donc pas mettre au même plan un terme polarisant son environnement et un terme jouant le rôle d’intermédiarité entre deux sous-ensembles. Il n’existe pas de calcul débouchant sur un indice de centralité qui permette d’identifier ces deux propriétés, il les confond obligatoirement. Il se peut qu’il y ait congruence entre centralité graphique et noyau central d’une représentation sociale mais cette congruence doit être expertisée par un questionnaire complémentaire de mise en cause (cf. Moliner, P., 1989 et 1994). La centralité dans le graphe recouvre en fait deux propriétés sociales différentes : l’existence d’une variable recouvrant une notion centrale et organisatrice de la représentation sociale ; l’existence d’une variable intermédiaire entre deux ou plusieurs dimensions de l’univers représenté. Il est quelque fois possible de distinguer ces deux cas de figure en indiquant sur le graphe la saillance d’une variable mesurée par la valeur de chaque sommet du graphe (fréquence ou moyenne dans le tri à plat). On repère alors la place des variables ayant les plus fortes valeurs : sont-elles en bout de chaîne, dans une zone du graphe ou en son centre ? Dans chaque cas l’interprétation des propriétés mathématiques du graphe sera différente.
Il ne faut pas utiliser les propriétés mathématiques du graphe sans retour critique. Les critères statistiques de centralité, qu’ils soient calculés sur l’arbre maximum ou sur la totalité des relations, ne donnent pas directement le noyau central d’une représentation sociale. Il nous paraît important de pointer la nécessité de croiser les informations données par l’arbre maximum, le filtrant ou tout autre graphe tirés de la matrice de similitude avec des informations obtenues par des questionnaires construits spécialement pour mettre en évidence le noyau central. La position dans les graphes de similitude des

Droits de reproduction et de diffusion réservés © Sciences Humaines 2003
70
éléments centraux, ainsi définis, est alors très éclairante. Il faut en second confronter les différentes propriétés mathématiques de la matrice de similitude. Par exemple si la matrice est « Robinsonnienne44 » il est illusoire de vouloir découvrir un élément central car l’information importante est l’existence d’une dimension organisatrice des variables.
5.2 QUAND LES DONNEES N’ONT PAS GRAND CHOSE A DIRE.
L’analyse de données donne toujours un résultat. Comme l’analyse factorielle donne toujours des axes et des positions sur le plan constitué par deux facteurs, l’analyse de similitude donne toujours un arbre, un filtrant, on peut toujours dessiner un graphe, même un peu complexe. Et pourtant il faut pouvoir repérer, accepter l’insignifiance de certaines données (insignifiance ou évidence, c’est la même chose au regard d’une théorie de l’information).
5.2.1 Quand tout est dit par le simple tri à plat. Il est possible que la matrice de similitude ne fasse que refléter la fréquence ou la moyenne des
variables. On se trouve souvent dans ce cas de figure avec les questionnaires de « caractérisation » (cf. annexe 2) ayant la forme d’un « Q-sort rectangulaire ». Le questionnaire de caractérisation a été réintroduit dans les études de représentations sociales par Claude Flament (la première utilisation date de 1963, Fraisse, P. ed, 1963) pour rendre compte de l’hypothèse de l’existence d’une hiérarchisation collective des items : on veut situer les items sur une échelle d’importance au regard de l’objet étudié. Ce questionnaire vise à sélectionner les éléments qui ont une forte probabilité d’appartenir au noyau central de la représentation
Dans ce questionnaire on propose au sujet une liste d’items dont le nombre est un multiple de 3 (4 ou 5 selon les cas) : par exemple 12. On demande alors au sujet de choisir les 4 items les plus caractéristiques de l’objet étudié. Ce choix est contraint : il faut 4 items et non 3 ou 5. Ensuite on lui demande de choisir dans les 8 items restants les 4 les moins caractéristiques de l’objet étudié. Ici aussi le choix est contraint. Chaque item est alors codé de 1 à 3 : 3 s’il a été choisi comme caractéristique, 1 s’il a été choisi comme non caractéristique, et 2 s’il n’a pas été choisi par le sujet enquêté.
Ce choix contraint repose sur un modèle statistique équiprobable : la probabilité d’être codé 1 (ou 2 ou 3) est de 0,33. Cette équiprobabilité se traduit dans l’appellation « Q-sort rectangulaire ». Il diffère du Q-sort classique qui veut se rapprocher d’une loi de Gauss en constituant trois groupes inégaux d’items privilégiant la classe centrale : 3, 6, 3 par exemple. En effet ce qui nous intéresse ce n’est pas les items dont la distribution aurait leur mode dans la classe centrale, mais au contraire ceux qui ont une distribution très dissymétrique, privilégiant la dimension « caractéristique » ou « non-caractéristique ». Ce questionnaire permet d’obtenir des courbes de fréquences fortement dissymétriques, donc non gaussiennes.
Ce type de questionnaire a le grand privilège de nous donner, par la distribution des fréquences des items, une très bonne indication sur le rapport des items à l’objet représenté45. Mais les matrices de
44 On dit qu’une matrice est Robinsonnienne quand on peut trouver une unique chaine maximale régulière (aux ex-
aequo près). Si on ordonne la matrice de similitude selon l’ordre de cette chaîne maximale, on observe que les valeurs de similitude sont décroissantes en ligne et en colonne à partir des valeurs de la diagonale (exemple au tableau 34). On peut appliquer cette notion aux sous-matrices.
45 Vergès, P., 1995
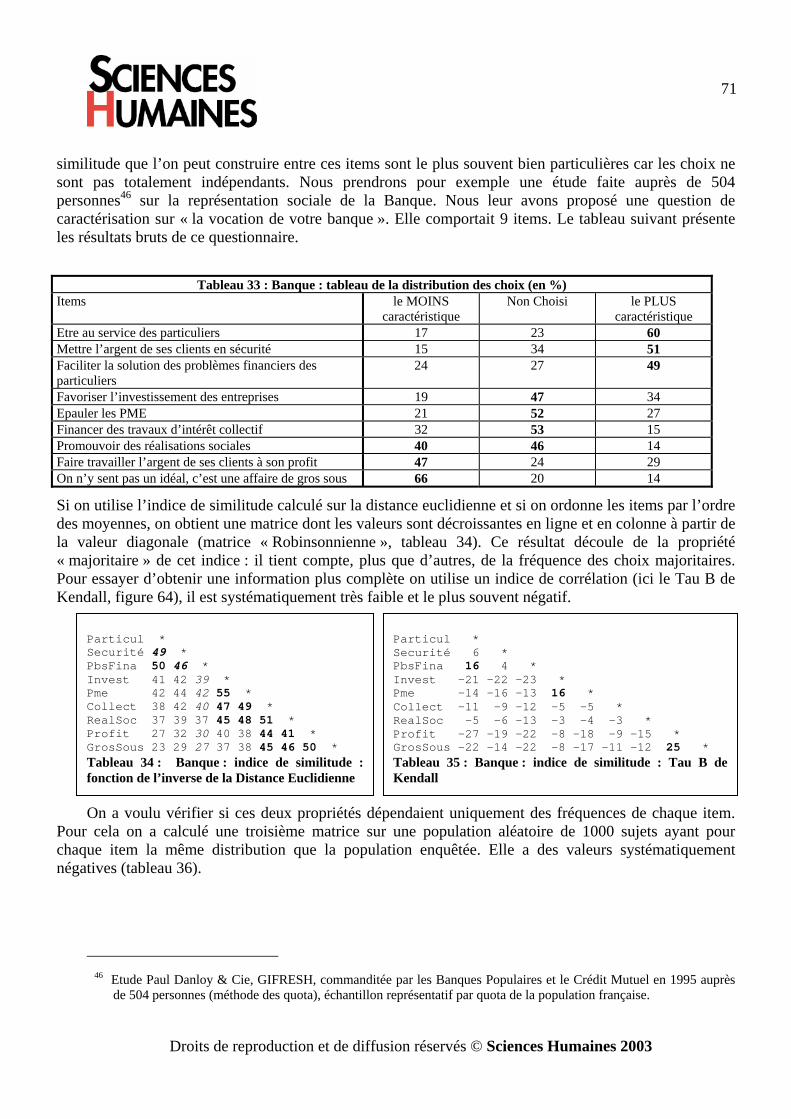
Droits de reproduction et de diffusion réservés © Sciences Humaines 2003
71
similitude que l’on peut construire entre ces items sont le plus souvent bien particulières car les choix ne sont pas totalement indépendants. Nous prendrons pour exemple une étude faite auprès de 504 personnes46 sur la représentation sociale de la Banque. Nous leur avons proposé une question de caractérisation sur « la vocation de votre banque ». Elle comportait 9 items. Le tableau suivant présente les résultats bruts de ce questionnaire.
Si on utilise l’indice de similitude calculé sur la distance euclidienne et si on ordonne les items par l’ordre des moyennes, on obtient une matrice dont les valeurs sont décroissantes en ligne et en colonne à partir de la valeur diagonale (matrice « Robinsonnienne », tableau 34). Ce résultat découle de la propriété « majoritaire » de cet indice : il tient compte, plus que d’autres, de la fréquence des choix majoritaires. Pour essayer d’obtenir une information plus complète on utilise un indice de corrélation (ici le Tau B de Kendall, figure 64), il est systématiquement très faible et le plus souvent négatif.
On a voulu vérifier si ces deux propriétés dépendaient uniquement des fréquences de chaque item. Pour cela on a calculé une troisième matrice sur une population aléatoire de 1000 sujets ayant pour chaque item la même distribution que la population enquêtée. Elle a des valeurs systématiquement négatives (tableau 36).
46 Etude Paul Danloy & Cie, GIFRESH, commanditée par les Banques Populaires et le Crédit Mutuel en 1995 auprès
de 504 personnes (méthode des quota), échantillon représentatif par quota de la population française.
Tableau 33 : Banque : tableau de la distribution des choix (en %) Items le MOINS
caractéristique Non Choisi le PLUS
caractéristique Etre au service des particuliers 17 23 60 Mettre l’argent de ses clients en sécurité 15 34 51 Faciliter la solution des problèmes financiers des particuliers
24 27 49
Favoriser l’investissement des entreprises 19 47 34 Epauler les PME 21 52 27 Financer des travaux d’intérêt collectif 32 53 15 Promouvoir des réalisations sociales 40 46 14 Faire travailler l’argent de ses clients à son profit 47 24 29 On n’y sent pas un idéal, c’est une affaire de gros sous 66 20 14
Particul * Securité 49 * PbsFina 50 46 * Invest 41 42 39 * Pme 42 44 42 55 * Collect 38 42 40 47 49 * RealSoc 37 39 37 45 48 51 * Profit 27 32 30 40 38 44 41 * GrosSous 23 29 27 37 38 45 46 50 * Tableau 34 : Banque : indice de similitude : fonction de l’inverse de la Distance Euclidienne
Particul * Securité 6 * PbsFina 16 4 * Invest -21 -22 -23 * Pme -14 -16 -13 16 * Collect -11 -9 -12 -5 -5 * RealSoc -5 -6 -13 -3 -4 -3 * Profit -27 -19 -22 -8 -18 -9 -15 * GrosSous -22 -14 -22 -8 -17 -11 -12 25 * Tableau 35 : Banque : indice de similitude : Tau B de Kendall

Droits de reproduction et de diffusion réservés © Sciences Humaines 2003
72
Cette dernière matrice permet de vérifier le caractère non aléatoire des résultats des deux précédentes matrices : d’une part l’ordre Robinsonnien est ici bien moins net, d’autre part la corrélation entre la matrice aléatoire et la matrice utilisant le même indice de Kendall est négatif (-0,27).
L’analyse de similitude est donc informative mais elle n’apporte pas, ici, beaucoup de renseignements supplémentaires au regard de la
hiérarchisation des items par leur distribution. Peut être on soupçonnera l’existence de sous-groupes aux représentations opposées, mais cette indication est déjà contenue dans le tableau des fréquences de choix.
Cette absence d’information est, ici, liée en partie à la forme du questionnaire. On en trouvera cependant un contre exemple dans l’étude sur l’Ecstasy qui utilise pourtant le même type de questionnaire : l’ordre de la matrice de similitude qui met en évidence l’existence de deux sous-populations, n’est pas du tout celui des fréquences des items. Il n’y a pas dans ce cas une dimension organisatrice mais d’une part une opinion générale s’exprimant par les fréquences et d’autre part l’existence de deux sous-groupes se distinguant sur certaines relations locales entre items.
5.2.2 La concentration des valeurs de similitude dans certaines plages de valeurs. On a déjà vu qu’il n’était pas nécessaire de tenir compte de toute la préordonnance de similitude. Par
exemple les valeurs négatives d’un coefficient de corrélation expriment plus une distance qu’une similitude. De même il est quelque fois possible de donner un seuil minimum à l’indice de similitude si celui-ci peut être l’objet d’un test statistique, comme celui de la nullité d’un coefficient de corrélation. Mais bien souvent ce calcul n’est pas possible comme souvent avec les indices exprimant une fréquence, un poids.
Au delà de cette difficulté on est quelque fois confronté à une distribution des valeurs de la préordonnance posant problème. Quand cette distribution est fortement déséquilibrée, on observe une forte concentration des valeurs sur une plage assez réduite. Ceci est mis en évidence par le filtrant des cliques : on trouve entre deux seuils proches un grand nombre de cliques. Si cette plage se trouve à proximité de la dernière valeur de l’arbre maximum, on risque de tomber sur des données qui sont proches d’une variété aléatoire. Leur organisation par l’analyse de similitude n’est alors pas très éclairante et elle est sujette à une forte instabilité invalidant toute interprétation.
Dans l’exemple des 10 Valeurs de Schwartz, le grand nombre de cliques du filtrant (figure 10) se situant entre les seuils 0,13 et 0,11 relativise l’interprétation des sous-ensembles de cliques qui sont construites à ce niveau. Par contre les cliques de la zone supérieure du filtrant ne sont pas mises en cause. Dans l’exemple des Douze pays (figure 52) la concentration des cliques dans la plage 417 – 428 pourrait aussi conduire à ne pas en tenir compte. Mais ici leur association à la partie supérieure du filtrant, montrant l’existence de zones isolées, lui conserve toute sa valeur.
Particul * Securité -18 * PbsFina -11 -14 * Invest -12 -14 -13 * Pme -8 -11 -11 -12 * Collect -4 -9 -1 -7 -10 * RealSoc -9 -3 -7 -5 -16 -14 * Profit -12 -9 -10 -11 -13 -16 -13 * GrosSous -6 -3 0 -8 -2 -12 -15 -13 * Tableau 36 : Banque : population aléatoire, indice de similitude : Tau B de Kendall

Droits de reproduction et de diffusion réservés © Sciences Humaines 2003
73
L’exemple suivant tiré de données réelles est une illustration d’une impossibilité d’interprétation des données (figure 54). L’ensemble des cliques apparaît dans une plage très limitée ( 28 à 23) alors que les valeurs de la préordonnance se répartissent de 40 à 10. Le graphe n’a pas alors grand sens.
Une forte concentration des cliques dans une plage réduite de valeurs doit conduire l’analyste à envisager l’hypothèse d’une distribution quasi-aléatoire des valeurs des arêtes et à vérifier cette hypothèse ou à l’invalider.
5.3 QUAND LES VALEURS DE SIMILITUDE DISENT DES EVIDENCES.
Les résultats de l’analyse de similitude dans certains questionnaires tiennent de l’évidence. C’est le cas lorsqu’on recherche la similitude entre les items d’une échelle de type Likert et que certains items ont une expression négative et d’autres une expression positive. C’est aussi le cas lorsque la fréquence des variables dichotomiques se trouve proche des deux extrémités de la plage de valeur [0 – 1]. Il faut se méfier de ces cas de figure et, si nécessaire, effectuer un recodage.
5.3.1 On doit quelque fois procéder à l’inversion de certaines échelles Une recherche sur la représentation du politique et des hommes politiques a été conduite auprès
d’étudiants47 à partir d’un questionnaire où il leur était demandé de donner leur avis sur des propositions en se situant sur une échelle en 6 points. On en présente ici un extrait. L’analyse de leurs réponses, utilisant le Tau de Kendall, donne un graphe qui pose problème : on y découvre deux groupes d’items qui font penser à l’existence d’un artefact, l’existence de phrases donnant une vision positive (à gauche du graphe de la figure 56) et la présence d’autres phrases donnant une vision négative de la politique (à droite du graphe de la figure 68).
47 Roussiau, N., Jmel, S., Saint-Pierre, J., 1997.
Figure 54 : filtrant des cliques d’un graphe non signifiant.
Figure 55 : graphe non signifiant (au seuil 23).

Droits de reproduction et de diffusion réservés © Sciences Humaines 2003
74
On a alors décidé de retourner toutes les échelles des items ayant un score moyen inférieur à 3. Cette inversion a l’intérêt de gommer le sens des affirmations initiales du questionnaire : ainsi la phrase « M :
réaliser les promesses faites aux électeurs est l’objectif que poursuivent les élus » a un score de 1,17. En retournant cette phrase elle aura un score de 4,83 et pourra être corrélée avec d’autres items donnant une vision négative de la politique telle que «N : les gens ne se sentent plus correctement représentés par les élus ».
En effectuant les inversions de certaines phrases on obtient la matrice suivante et son graphe au seuil de 0,05. On a indiqué par une astérisque les items dont les scores ont été recalculés (x = 6 – x).
Le premier graphe (figure 68) montre que les chercheurs ont mis dans le questionnaire des phrases évaluant différemment le domaine politique. Ce second graphe est plus intéressant il indique une vision massivement négative de la politique : on trouve une clique maximale forte de cinq éléments : « *F les partis n’agissent pas conformément aux vœux de leur électorat », «*M réaliser les promesses faites aux électeurs n’est pas l’objectif que poursuivent les élus » « N : les gens ne se sentent plus correctement représentés par les élus », « H les hommes politiques mentent plus souvent qu’ils ne disent la vérité », «I les partis sont devenus des organisations où la
communication est bloquée ». Les autres items portent sur une deuxième dimension du politique sans grand rapport avec la précédente : l’intérêt de la politique, « *O la politique ne peut pas intéresser la majorité des gens », « C les jeunes sont les premiers concernés par la politique ». Enfin on trouve un
Figure 56 : Les jeunes et la politique : graphe-seuil à 0,05
N°: Items : Moyenne 1:N Elus non représentatif : 5,23 : 0 2:*M Promesse non tenues : 4,83 : 19 0 3:H Hommes politiques mentent : 4,75 : 22 24 0 4:*F Partis / vœux des électeurs : 4,59 : 16 24 14 0 5:I Partis communication bloqué : 4,32 : 16 6 16 8 0 6:C Jeunes premiers concernés : 4,19 : 0 -4 -1 -3 8 0 7:D Institutions vers démocratie : 4,13 : -2-15 -8 -7 3 3 0 8:*O Intérêt pour Politique : 3,95 : 1 3 -6 –2 3 24 1 0
Tableau 37 : Les jeunes et la politique : la matrice de corrélation (Tau de kendall)
Figure 57 : Les jeunes et la politique (certains items avec l’inverse de leur score initial) : graphe-seuil à 0,05
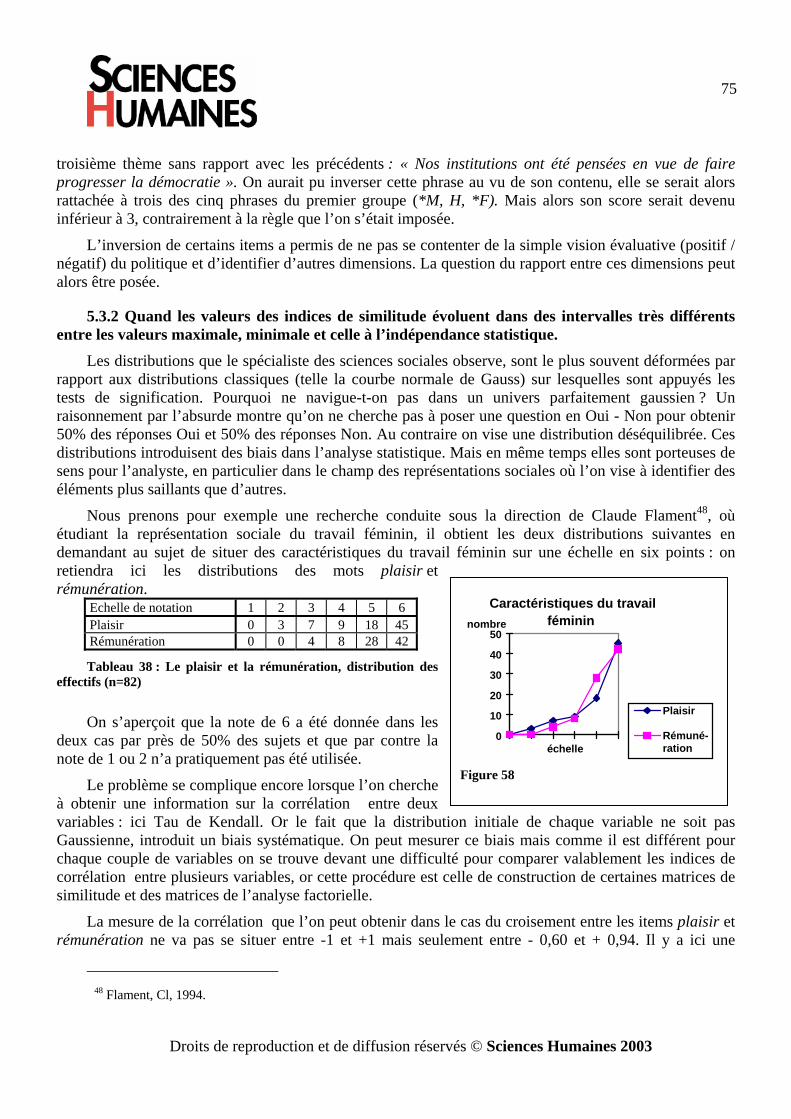
Droits de reproduction et de diffusion réservés © Sciences Humaines 2003
75
troisième thème sans rapport avec les précédents : « Nos institutions ont été pensées en vue de faire progresser la démocratie ». On aurait pu inverser cette phrase au vu de son contenu, elle se serait alors rattachée à trois des cinq phrases du premier groupe (*M, H, *F). Mais alors son score serait devenu inférieur à 3, contrairement à la règle que l’on s’était imposée.
L’inversion de certains items a permis de ne pas se contenter de la simple vision évaluative (positif / négatif) du politique et d’identifier d’autres dimensions. La question du rapport entre ces dimensions peut alors être posée.
5.3.2 Quand les valeurs des indices de similitude évoluent dans des intervalles très différents entre les valeurs maximale, minimale et celle à l’indépendance statistique.
Les distributions que le spécialiste des sciences sociales observe, sont le plus souvent déformées par rapport aux distributions classiques (telle la courbe normale de Gauss) sur lesquelles sont appuyés les tests de signification. Pourquoi ne navigue-t-on pas dans un univers parfaitement gaussien ? Un raisonnement par l’absurde montre qu’on ne cherche pas à poser une question en Oui - Non pour obtenir 50% des réponses Oui et 50% des réponses Non. Au contraire on vise une distribution déséquilibrée. Ces distributions introduisent des biais dans l’analyse statistique. Mais en même temps elles sont porteuses de sens pour l’analyste, en particulier dans le champ des représentations sociales où l’on vise à identifier des éléments plus saillants que d’autres.
Nous prenons pour exemple une recherche conduite sous la direction de Claude Flament48, où étudiant la représentation sociale du travail féminin, il obtient les deux distributions suivantes en demandant au sujet de situer des caractéristiques du travail féminin sur une échelle en six points : on retiendra ici les distributions des mots plaisir et rémunération.
Echelle de notation 1 2 3 4 5 6 Plaisir 0 3 7 9 18 45 Rémunération 0 0 4 8 28 42
Tableau 38 : Le plaisir et la rémunération, distribution des effectifs (n=82)
On s’aperçoit que la note de 6 a été donnée dans les
deux cas par près de 50% des sujets et que par contre la note de 1 ou 2 n’a pratiquement pas été utilisée.
Le problème se complique encore lorsque l’on cherche à obtenir une information sur la corrélation entre deux variables : ici Tau de Kendall. Or le fait que la distribution initiale de chaque variable ne soit pas Gaussienne, introduit un biais systématique. On peut mesurer ce biais mais comme il est différent pour chaque couple de variables on se trouve devant une difficulté pour comparer valablement les indices de corrélation entre plusieurs variables, or cette procédure est celle de construction de certaines matrices de similitude et des matrices de l’analyse factorielle.
La mesure de la corrélation que l’on peut obtenir dans le cas du croisement entre les items plaisir et rémunération ne va pas se situer entre -1 et +1 mais seulement entre - 0,60 et + 0,94. Il y a ici une
48 Flament, Cl, 1994.
Caractéristiques du travail féminin
0
10
20
30
40
50
échelle
nombre
Plaisir
Rémuné-ration
Figure 58
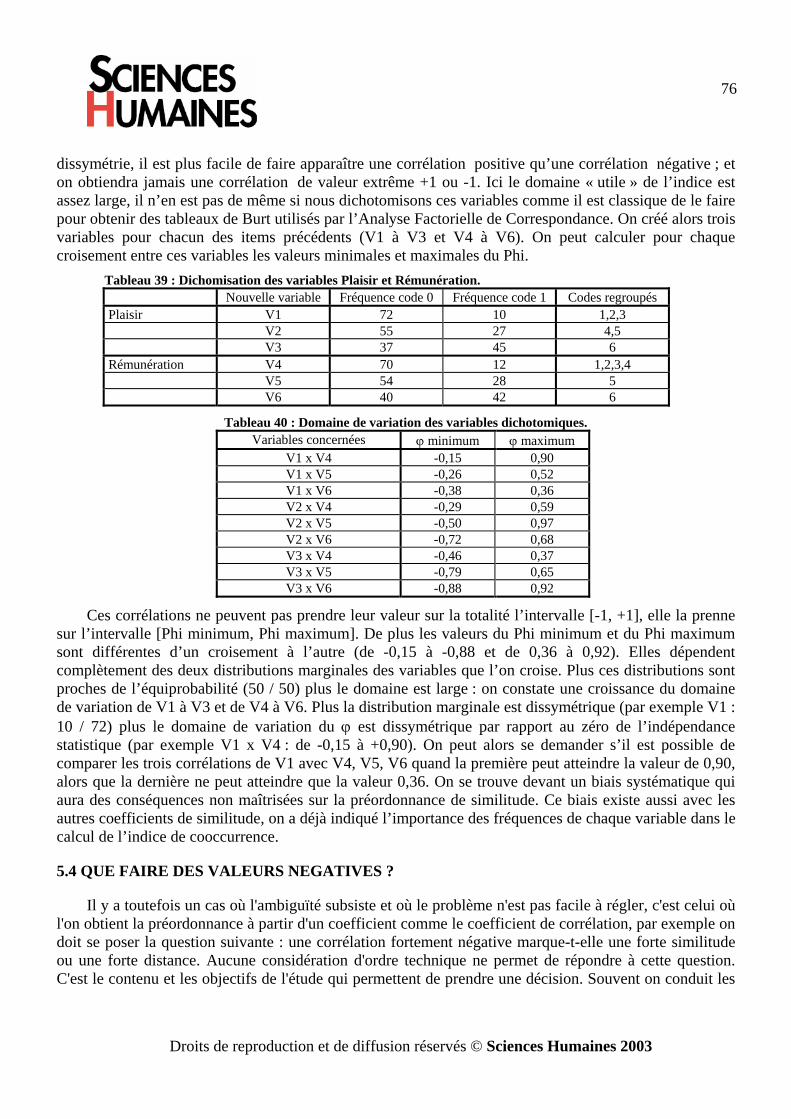
Droits de reproduction et de diffusion réservés © Sciences Humaines 2003
76
dissymétrie, il est plus facile de faire apparaître une corrélation positive qu’une corrélation négative ; et on obtiendra jamais une corrélation de valeur extrême +1 ou -1. Ici le domaine « utile » de l’indice est assez large, il n’en est pas de même si nous dichotomisons ces variables comme il est classique de le faire pour obtenir des tableaux de Burt utilisés par l’Analyse Factorielle de Correspondance. On créé alors trois variables pour chacun des items précédents (V1 à V3 et V4 à V6). On peut calculer pour chaque croisement entre ces variables les valeurs minimales et maximales du Phi.
Tableau 39 : Dichomisation des variables Plaisir et Rémunération. Nouvelle variable Fréquence code 0 Fréquence code 1 Codes regroupés Plaisir V1 72 10 1,2,3 V2 55 27 4,5 V3 37 45 6 Rémunération V4 70 12 1,2,3,4 V5 54 28 5 V6 40 42 6
Tableau 40 : Domaine de variation des variables dichotomiques. Variables concernées ϕ minimum ϕ maximum
V1 x V4 -0,15 0,90 V1 x V5 -0,26 0,52 V1 x V6 -0,38 0,36 V2 x V4 -0,29 0,59 V2 x V5 -0,50 0,97 V2 x V6 -0,72 0,68 V3 x V4 -0,46 0,37 V3 x V5 -0,79 0,65 V3 x V6 -0,88 0,92
Ces corrélations ne peuvent pas prendre leur valeur sur la totalité l’intervalle [-1, +1], elle la prenne sur l’intervalle [Phi minimum, Phi maximum]. De plus les valeurs du Phi minimum et du Phi maximum sont différentes d’un croisement à l’autre (de -0,15 à -0,88 et de 0,36 à 0,92). Elles dépendent complètement des deux distributions marginales des variables que l’on croise. Plus ces distributions sont proches de l’équiprobabilité (50 / 50) plus le domaine est large : on constate une croissance du domaine de variation de V1 à V3 et de V4 à V6. Plus la distribution marginale est dissymétrique (par exemple V1 : 10 / 72) plus le domaine de variation du ϕ est dissymétrique par rapport au zéro de l’indépendance statistique (par exemple V1 x V4 : de -0,15 à +0,90). On peut alors se demander s’il est possible de comparer les trois corrélations de V1 avec V4, V5, V6 quand la première peut atteindre la valeur de 0,90, alors que la dernière ne peut atteindre que la valeur 0,36. On se trouve devant un biais systématique qui aura des conséquences non maîtrisées sur la préordonnance de similitude. Ce biais existe aussi avec les autres coefficients de similitude, on a déjà indiqué l’importance des fréquences de chaque variable dans le calcul de l’indice de cooccurrence.
5.4 QUE FAIRE DES VALEURS NEGATIVES ?
Il y a toutefois un cas où l'ambiguïté subsiste et où le problème n'est pas facile à régler, c'est celui où l'on obtient la préordonnance à partir d'un coefficient comme le coefficient de corrélation, par exemple on doit se poser la question suivante : une corrélation fortement négative marque-t-elle une forte similitude ou une forte distance. Aucune considération d'ordre technique ne permet de répondre à cette question. C'est le contenu et les objectifs de l'étude qui permettent de prendre une décision. Souvent on conduit les

Droits de reproduction et de diffusion réservés © Sciences Humaines 2003
77
deux analyses à partir du coefficient de corrélation pris en valeur absolue ou en valeur algébrique et l'on utilise les deux.
5.5 INTERET ET LIMITE DE L’ANALYSE DE SIMILITUDE.
L’analyse de similitude fait partie des techniques d’analyse de données qui reposent sur l’idée d’association. Son raffinement permet de mettre en évidence, comme nous l’avons vu, des dimensions (des axes), des regroupements (amas ou classes), des sous-populations différenciées. Elle peut, sous certaines conditions, identifier les groupes de variables pouvant se conformer à certains modèles (échelle d’attitude, composantes connexes).
Elle ne couvre cependant pas la totalité du champ des phénomènes qui affectent les données. Elle ne vise pas la causalité ou excelle l’économétrie car elle ne prend en compte qu’une notion plus pauvre : celle de ressemblance, celle d’aller ensemble. Elle ne détecte pas l’existence de variables que l’on peut qualifier de « synonymes » dans les questionnaires où l’on demande au sujet d’effectuer un choix dans une liste. Deux items de cette liste peuvent être alternatifs, les sujets choisissent d’utiliser l’un ou l’autre car ils ont quasiment le même sens pour eux. Pour les repérer il faut tenir compte du fait que ces items ne sont donc pas corrélés mais ont le même profil des coefficients de similitude vis à vis des autres variables. Enfin l’analyse de similitude ne rend théoriquement pas compte de la relation d’implication.
Nous développons un peu ce dernier point car il peut générer une certaine confusion dans l’usage de certains coefficients de similitude. L’analyse de l’implication est du ressort de l’analyse booléenne des questionnaires telle que l’a développé Claude Flament49. Cependant certains statisticiens ont développé des indices de similitude qui indiquent l’implication plus que la corrélation. C’est par exemple le cas de l’indice de Yule.
Dans l’exemple ci contre on voit qu’il y a une corrélation intéressante : le 18 de la case 0-0 est 2 fois supérieur à la valeur théorique dans les deux tableaux de croisement (45*2/100 = 9 et 30*30/100 = 9). Cette identité est reflétée par la quasi égalité des Phi de contingence. Mais à coté de cela 18/20, dans le premier tableau, représente 90% du total vertical des réponses 0 à la variable B alors que 18/30 ne représente que 60% dans le second. C’est cette dernière information que reflète l’indice de Yule (ou l’indice H50).
Cependant ces indices ont un grave défaut : ils ne distinguent pas le cas où la variable A implique la variable B et le cas contraire où la variable B implique la variable A. En effet la similitude est symétrique alors que l’implication est par
49 Un programme informatique sur Mac a été réalisé par XXX à Grenoble. 50 H est calculé sur la case 1-1 : H = Observé / Théorique ; ici 53/55 = 0,96 versus 58/70 = 0,83
A\B 0 1 Total
0 18 27 45
1 2 53 55
Total 20 80 100
Ces premières données ont un Phi de 0,452 et un Yule de 0,892
Les secondes ont un Phi très comparable de 0,428. Par contre le Yule est différent : 0,757
A\B 0 1 Total
0 18 12 30
1 12 58 70
Total 30 70 100
Dans le premier cas la variable A implique quasiment la variable B (case 1-0 presque vide : 2)
Ce n’est pas le cas dans ce second tableau (la case0-1 a pour valeur 12).
Tableau 41 : Exemple sur l’implication.

Droits de reproduction et de diffusion réservés © Sciences Humaines 2003
78
nature dissymétrique. Si on utilise de tels indices et que l’on recherche l’implication parce qu’elle correspond à la nature des données51 il faut indiquer le sens de l’inclusion en orientant le graphe (par des flèches).On trouve en Annexe 1 une note sur ces indices indiquant l’implication.
L’analyse de similitude ne peut projeter les variables et les sujets sur une seule figure comme dans le cas de l’analyse factorielle de correspondance. Certes l’analyse « duale » des variables et des sujets (lignes / colonnes) peut être faite en transposant le tableau des données mais on obtient alors deux graphes : celui des variables et celui des sujets. En outre la limitation des programmes ne permet pas de traiter des fichiers où le nombre de sujets dépassent 100. La limitation à 50 variables (au mieux 100 variables) ne tient pas aux seules capacités informatiques, elle a été volontairement limitée pour que l’analyse ne mélange pas des données de nature trop différentes. Il vaut mieux faire plusieurs analyses sur des groupes de variables exprimant une facette du phénomène analysé que de vouloir à tout pris corréler des données hétérogènes.
Cette question de la dualité des sujets et des variables peut être posée théoriquement à l’aide des hypergraphes et des treillis de Gallois. Les recherches que nous avons faites dans ce sens se heurtent à la difficulté de traiter l’aléatoire des réponses52. Actuellement Claude Flament explore une autre piste plus prometteuse : celle de la définition d’un individu typique. On définit la réponse majoritaire pour toutes les variables et on calcule la distance de chaque sujet à cette réponse majoritaire. On peut alors définir le groupe de sujets « conformes » et celui des sujets qui s’en éloignent significativement. En créant ces deux, ou plus, sous-populations ont peut faire pour chacune d’elle une analyse de similitude et comparer les graphes. La recherche de cette dualité se réfère à la distinction que nous avons faite à propos des indices de similitude : indice exprimant une majorité, indice exprimant une distance à l’indépendance statistique. Elle a l’avantage de ne tenir compte que de l’ensemble des variables analysées. La construction de sous-population à partir de variables externes (tel que l’âge, le sexe, le PCS …) correspond à une autre logique : celle d’une causalité entre variables « objectives » et variables exprimant un phénomène à expliquer. La recherche du croisement entre résultats collectifs (agrégation des réponses individuelles) et réponses individuelles demande un traitement approprié à chaque type de questionnaire. On a, par exemple, réalisé des programmes informatiques particuliers pour certains questionnaires de représentations sociales (les questionnaires de mise en relation de notions ou les questionnaires de construction de groupe d’items53). Ils mettent toujours en évidence des schémas propres à des sous-populations minoritaires mais cohérentes dans leur manière de penser un phénomène social.
Quand on fait une analyse de similitude, et on peut dire la même chose de toute autre méthode d’analyse de données, il faut avoir conscience de ces limitations. Nous avons tout au long de ce livre montré à la fois l’intérêt de l’analyse de similitude, ce qu’elle mettait en évidence, la rigueur qu’elle exigeait, ce qu’elle ne pouvait pas faire. Ceci restant à l’esprit il convient d’en résumer l’esprit, son apport aux analyses de données.
51 C’est le cas dans l’analyse de l’inclusion du champ sémantique d’un mot dans celui d’un autre mot. 52 Flament, C., Degenne, A., Vergès, P., 1976. 53 cf. Annexe 2

Droits de reproduction et de diffusion réservés © Sciences Humaines 2003
79
L’apport de l’analyse de similitude à l’analyse des données est de plusieurs ordres :
Elle demande à l’analyste de prendre des décisions, de contrôler l’analyse tout au long de son parcours ; à aucun instant une boite noire ne délivre de résultats ; Elle permet d’adapter les indices statistiques calculés à la forme des données et à la nature du phénomène recherché (majoritaire, spécificités liées à des sous-populations) ; Elle traite localement les ressemblances, elle tient compte des valeurs les plus fortes sans être perturbée par les valeurs faibles statistiquement non significatives ; Elle identifie l’existence de modèles formels et distingue ce qui peut être interprété comme des axes et ce qui est regroupement de variables.
La réalisation d’une analyse de similitude demande la puissance des moyens informatiques. Depuis toujours les programmes informatiques ont essayés de traduire les intuitions des chercheurs. Ils sont maintenant assez stabilisés54.
54 Ils peuvent être demandés à l’Association Internationale des Centres de Sémiologies (AICS) : La Farigoule, 845
Chemin Bouenhoure, 13090 Aix en Provence.

Droits de reproduction et de diffusion réservés © Sciences Humaines 2003
80
ANNEXE 1
LES PRINCIPAUX INDICES DE SIMILITUDE
1. CAS DICHOTOMIQUE.
j = 0 j = 1 Total
i = 0 Zij Uij Ni0
i = 1 Wij Cij Ni1
Total Nj0 Nj1 N
1.1 Cas dichotomique « nominal ».
Coocurence : S1 = Cij. 100)(2 ×= NCijS
Rapport à l’indépendance statistique : ijCCijS *3 = ijCijCCijS *)*(1004 −×=
Indice de Forbes : )*()*( max2
5 ijCCijCCijS ij −−=
1.2 Cas Dichotomique Ordonné :
Coocurence symétrique : ZijCijS +=6 100))((7 ×+= NZijCijS
Phi de contingence : 1010)()(
8NiNiNjNj
WijUijCijZijS×××
×−×=Φ= S8bis = S8 / Phimax
Q de Yule : S9 = )()()()(
WijUijCijZijWijUijCijZijQ
×+××−×
=
Indice de Jaccard : )(10 ijijijij WUCCS ++=
N est le nombre de sujets. Ni1 est le nombre de sujets codés 1 sur l’item i. Nj1 est le nombre de sujets codés 1 sur l’item j. Ni0 est le nombre de sujets codés 0 sur l’item i. Nj0 est le nombre de sujets codés 0 sur l’item j. Cij est le nombre de sujets codés 1 aux items i et j. Zij est le nombre de sujets codés 0 aux items i et j. Wij est le nombre de sujets codés 1 à l’item i et 0 à j. Uij est le nombre de sujets codés 0 à l’item i et 1 à j.

Droits de reproduction et de diffusion réservés © Sciences Humaines 2003
81
2.MESURE ORDINALE :
Variable i \ j échelon 1 échelon 2 etc…k échelon max : g Total i
échelon 1 n11 n12 n1k n1g n1t
échelon 2 n21 n22 n2k n2g n2t
etc…q nq1 nq2 nqk nqg nqt
échelon max Nm1 nm2 nmk nmg nmt
Total j nt1 nt2 ntk ntg N
Concordance des réponses : NnklSlk
∑=
=11
Distance City – Block : )1(
112 −×
×−−=∑∑
mN
nkqqkS k l
Distance Euclidienne : 2
2
13 )1(
)(1
−×
×−−=∑∑
mN
nkqqkS k l
Indice de Guimelli )5,0(2 1214 −= SS
Tau B de Kendall : UWTW
STbS−×−
==15 avec : ∑ ∑−=
=
−=
=×=
1
1
1
121 mq
q
gk
k qkqk RnS
avec ∑ ∑∑ ∑ −==
=+=
=+=
=+= −= 1
1 11 1qp
pgsks ps
mpqp
gsks psqk nnR
avec ∑ −×=k
ntkntkT )1(21 et ∑ −×=
q
nqtnqtU )1(21
avec )1(21
−××= NNW
Tau C de Kendall (cas ou m = g) : ( )( )mmNSTcS )1(2 216 −×==
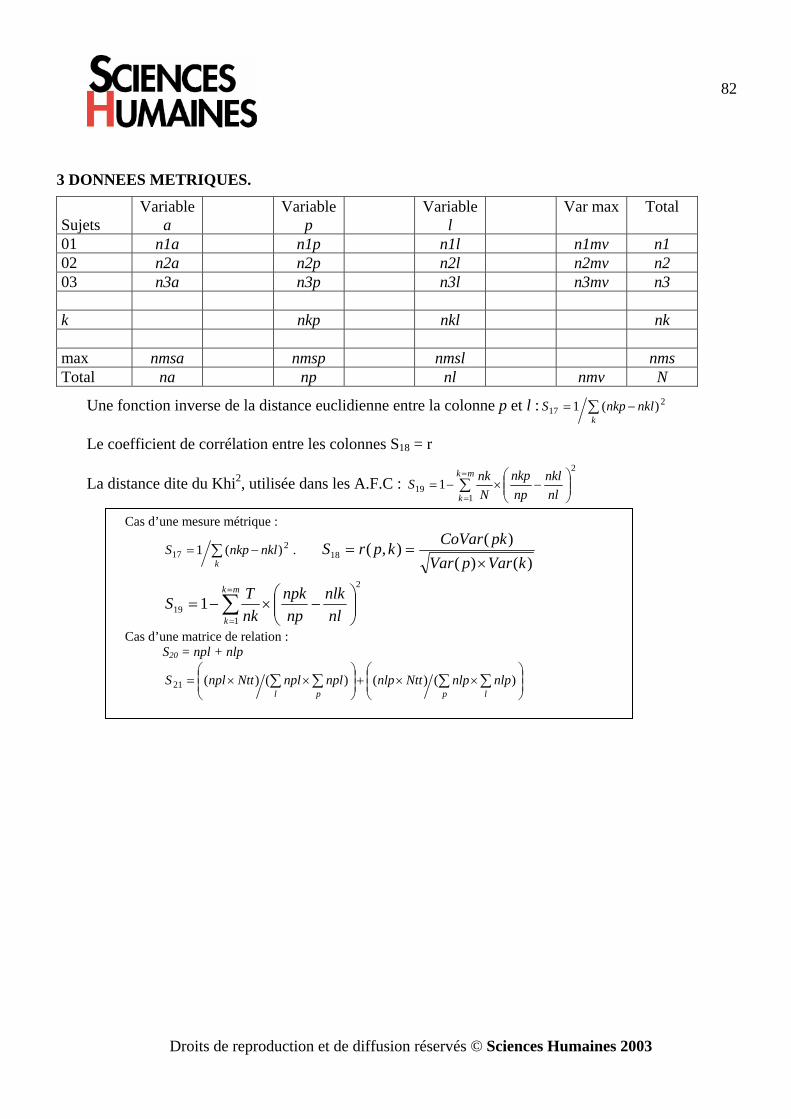
Droits de reproduction et de diffusion réservés © Sciences Humaines 2003
82
3 DONNEES METRIQUES.
Sujets
Variable a
Variable p
Variable l
Var max Total
01 n1a n1p n1l n1mv n1 02 n2a n2p n2l n2mv n2 03 n3a n3p n3l n3mv n3 k nkp nkl nk max nmsa nmsp nmsl nms Total na np nl nmv N
Une fonction inverse de la distance euclidienne entre la colonne p et l : ∑ −=k
nklnkpS 217 )(1
Le coefficient de corrélation entre les colonnes S18 = r
La distance dite du Khi2, utilisée dans les A.F.C : 2
119 1 ⎟⎟
⎠
⎞⎜⎜⎝
⎛−×−= ∑
=
= nlnkl
npnkp
NnkS
mk
k
Cas d’une mesure métrique :
∑ −=k
nklnkpS 217 )(1 .
)()()(),(18 kVarpVar
pkCoVarkprS×
==
2
119 1 ⎟⎟
⎠
⎞⎜⎜⎝
⎛−×−= ∑
=
= nlnlk
npnpk
nkTS
mk
k
Cas d’une matrice de relation : S20 = npl + nlp
⎟⎟⎠
⎞⎜⎜⎝
⎛××+⎟
⎟⎠
⎞⎜⎜⎝
⎛××= ∑ ∑∑ ∑
p ll pnlpnlpNttnlpnplnplNttnplS )()()()(21

Droits de reproduction et de diffusion réservés © Sciences Humaines 2003
83
4 LE CAS PARTICULIER DES INDICES D’IMPLICATION.
On cherche par ces indices l’existence, dans le tableau de croisement de deux variables, d’un bloc de valeurs nulles ou quasi nulles : la case Uij ou la case Wij. L’existence de ce bloc traduit le fait que certaines modalités de l’une des variables implique quasi automatiquement la réponse à l’autre variable. On peut, dans le cas de variables dichotomiques, parler d’une implication logique : Si i=1 alors j=1. Cette implication repose sur l’existence d’une case vide : par exemple il n’y a pas de sujet ayant i=1 et j=0.
L’implication ne suppose pas la corrélation surtout si les poids des deux variables sont très différents. On permet par ces indices l’analyse de données aux fréquences fortement déséquilibrées. C’est le cas par exemple de l’analyse de la présence de mots dans un corpus de texte donné. Certains mots sont très fréquents, d’autres n’apparaissent qu’une ou deux fois. La corrélation ou la distance à l’indépendance statistique n’a alors pas de sens. Seule l’inclusion des champs sémantiques peut en avoir un.
L’implication est un peu en contradiction avec l’une des propriétés de l’analyse de similitude puisqu’il n’y a pas symétrie : Si i implique j alors j n’implique pas i. Cependant les indices que l’on utilisent, construisent une symétrie S(i,j) = S(j,i). L’analyse de similitude est alors possible. Ce n’est qu’au moment de l’interprétation qu’il faut rétablir le sens des relations entre les variables.
Cas nominal : Pour mettre en évidence l’implication de i sur j il faut que la case Wij soit nulle ou très proche de
zéro. On calcule alors : 1NiCij .
Mais si Nj1 est inférieur à Ni1 ce n’est plus l’implication de i sur j mais celle de j sur i qu’il faut calculer. L’indice devient alors : 1,1min22 NjNiCijS = . Plus cet indice est proche de 1 plus il indique l’existence d’une case « vide », alors Wij ou Uij est proche de zéro. Cet indice indique l’existence d’une implication de l’item le moins fréquent sur l’item le plus fréquent.
Cas ordinal L’indice d’implication est comme pour les variables nominales l’indice S22. On peut aussi utiliser le Q de Yule
)()()()(
WijUijCijZijWijUijCijZijQ
×+××−×
= . Cet indice est égal à 1 si Uij ou Wij est égal à 0 (case anti
diagonale vide). Il est égal à –1 si Zij ou Cij est égal à 0 (case diagonale vide). Il est égal à 0 comme le Phi de contingence dans le cas de l’égalité des produits des valeurs des deux diagonales (nullité du numérateur).
Dans le cas nominal ou ordinal l’a valeur de l’indice n’indique pas le sens de l’implication. Il faut le reconstruire à partir des valeurs marginales du tableau ce croisement des deux variables.
Indice relatif aux échelles de GUTTMAN
On calcule un indice de reproductibilité.
j = 0 j = 1 Total
i = 0 Zij Uij Ni0
i = 1 Wij Cij Ni1
Total Nj0 Nj1 N

Droits de reproduction et de diffusion réservés © Sciences Humaines 2003
84
ANNEXE 2
EXEMPLES DE QUESTIONNAIRES
1. QUESTIONNAIRE DE GROUPEMENTS.
On vous demande de faire des groupes avec les mots de la liste ci dessous.
Liste : 01 Prix 08 Dépenses 15 Epargne 02 Travail 09 Publicité 16 Loisirs 03 Consommation 10 Gaspillage 17 Production 04 Salaire 11 Bénéfice 18 Vente 05 Capital 12 Qualité de la vie 19 Investissement 06 Besoins 13 Marché 20 Achat 07 Crédit 14 Demande
a) Barrez les mots que vous ne comprenez pas.
b) Faites des groupes de mots qui vont ensemble : 1) Faites au moins deux groupes. 2) Mettez 2 à 6 mots par groupe. Un même mot peut être utilisé plusieurs fois.
c) Donnez à chacun des groupes un titre ou la raison de votre regroupement.
Premier groupe Deuxième groupe Numéro Mots Numéro Mots
Titre : ....................................................... Titre : .......................................................
.................................................................. ..................................................................

Droits de reproduction et de diffusion réservés © Sciences Humaines 2003
85
2. QUESTIONNAIRE DE CHOIX
On dit que nous vivons dans une économie de marché où les prix sont libres
Veuillez lire attentivement les propositions suivantes.
Le prix d'un produit peut être déterminé de diverses manières. Il peut : 01- être le résultat de l'offre et de la demande. 02- être déterminé par les entreprises qui dominent le marché. 03- être le résultat d'une négociation entre les commerçants et les producteurs. 04- être calculé en fonction des coûts et profits des entreprises. 05- être déterminé par une « mafia ». 06- être un prix « juste et honnête ». 07- être calculé en fonction du prix que les consommateurs sont prêts à payer. 08- dépendre d'une décision du gouvernement. 09- dépendre de la concurrence. 10- dépendre du pouvoir des organisations de consommateurs. 11- dépendre du choix des consommateurs. 12- dépendre du rapport de force entre vendeurs et acheteurs. 13- dépendre de la possibilité de trouver des combines. 14- dépendre du commerce international. 15-.dépendre du pouvoir d’achat. 16- dépendre de la qualité du produit. 17- dépendre des revendications syndicales. 18- permettre l'équilibre de l'économie. 19- permettre à tous d'acheter ce qu'ils désirent. 20- permettre de représenter la valeur des choses.
Quelles sont à votre avis les 5 phrases qui décrivent le mieux comment se fixe le prix d'un produit vendu : (écrivez ici leurs numéros)

Droits de reproduction et de diffusion réservés © Sciences Humaines 2003
86
3. QUESTIONNAIRE EN ECHELLE « A LA MANIERE D’OSGOOD »
On peut caractériser l’économie de marché par plusieurs expressions. Nous vous demandons, ici, de vous situer pour chaque couple d’expressions sur une échelle (graduée en 5 points)
entre deux opinions opposées. En voiçi un exemple : Les mathématiques selon vous c'est : c’est facile 1 2 3 4 5 c’est difficile Vous pouvez penser que les mathématiques sont plutôt : 1. faciles, 2.assez faciles, 3.moyennement faciles, 4.assez difficiles, 5.difficiles Si vous jugez personnellement qu'elles sont assez faciles entourez le 2 : Veuillez donner votre avis pour chaque couple d’expression concernant le marché
Le MARCHE : 1 donne des chances 1 2 3 4 5 crée des inégalités égales à tous 2 évite le gaspillage 1 2 3 4 5 est source de gaspillage 3 crée l'ordre dans 1 2 3 4 5 crée le désordre dans
la vie économique la vie économique 4 évite la bureaucratie 1 2 3 4 5 n'évite pas la bureaucratie 5 est le fondement de 1 2 3 4 5 détruit l'ordre social l'ordre social 6 renforce les relations 1 2 3 4 5 détériore les relations entre les individus entre les individus 7 permet à chacun de faire 1 2 3 4 5 est le moyen pour certains ce qu'il veut d'imposer leur loi aux autres 8 favorise les gens honnêtes 1 2 3 4 5 favorise les gens sans crupules 9 moral 1 2 3 4 5 immoral 10 bon 1 2 3 4 5 mauvais 11 juste 1 2 3 4 5 injuste 12 régulation de l'économie 1 2 3 4 5 concurrence sauvage 13 coopération 1 2 3 4 5 compétition 14 contact direct entre 1 2 3 4 5 mécanisme impersonnel vendeurs et acheteurs

Droits de reproduction et de diffusion réservés © Sciences Humaines 2003
87
4. QUESTIONNAIRE DE « CARACTERISATION »
A partir d’un tel questionnaire on peut coder chaque item de 1 à 3 avec 1- les causes les plus importantes 2- les items non choisis : ni dans la liste des causes les plus importantes, ni dans celle des items qui ne sont pas des causes du chômage 3- les items qui ne sont pas des causes du chômage
La probabilité théorique de chaque échelon est égale à 0,33.
Les causes du chômage peuvent être diverses. Nous vous demandons de lire attentivement la liste suivante :
01- Le manque d’investissement 02- Le progrès technique 03- L’évolution démographique 04- Le manque de mobilité des salariés 05- La concurrence étrangère 06- La trop longue durée du travail 07- Le manque de qualification des salariés 08- L’inflation 09- La puissance des syndicats 10- L’inefficacité des interventions gouvernementales 11- La faible agressivité commerciale des entreprises 12- La mauvaise qualité des produits 13- Les bas salaires dans certains pays 14- L’insuffisance de la consommation 15- L’inefficacité des entreprises G1) Quelles sont à votre avis les 5 causes les plus importantes du chômage ? Inscrivez les de la plus importante (à gauche) à la moins importante (à droite).
G2) Quelles sont à votre avis les 5 propositions qui ne sont pas des causes du
chômage ?
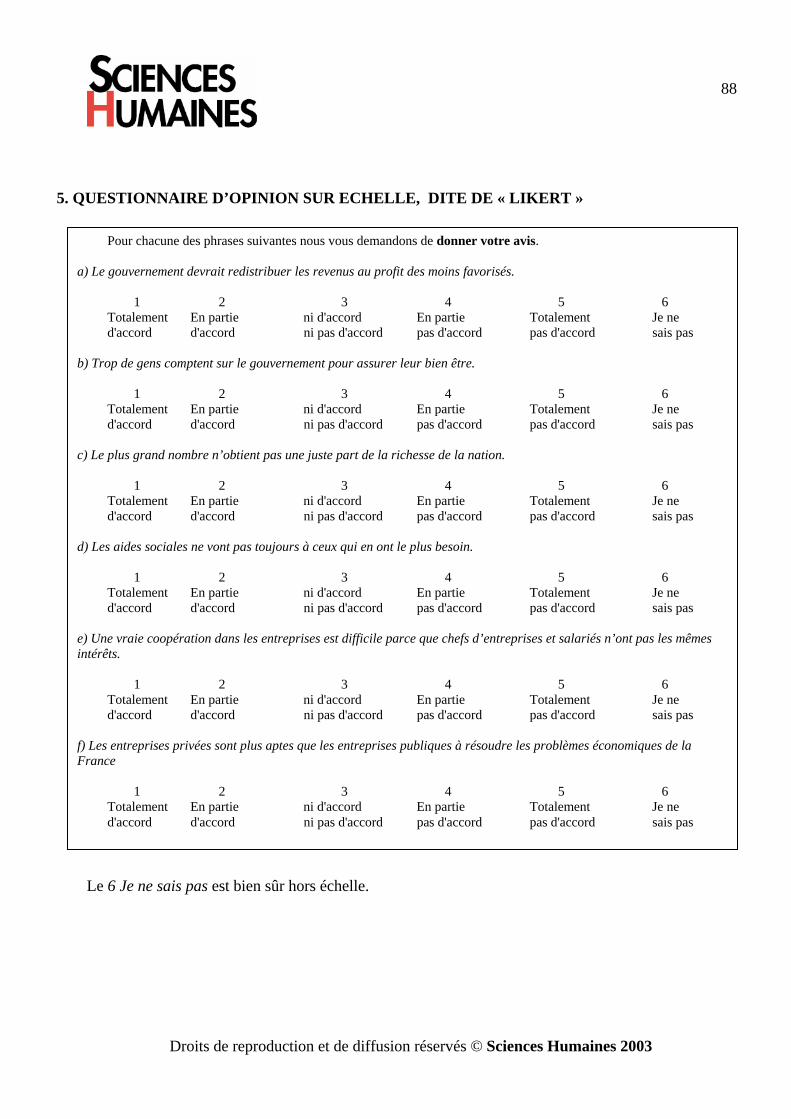
Droits de reproduction et de diffusion réservés © Sciences Humaines 2003
88
5. QUESTIONNAIRE D’OPINION SUR ECHELLE, DITE DE « LIKERT »
Le 6 Je ne sais pas est bien sûr hors échelle.
Pour chacune des phrases suivantes nous vous demandons de donner votre avis.
a) Le gouvernement devrait redistribuer les revenus au profit des moins favorisés. 1 2 3 4 5 6 Totalement En partie ni d'accord En partie Totalement Je ne d'accord d'accord ni pas d'accord pas d'accord pas d'accord sais pas
b) Trop de gens comptent sur le gouvernement pour assurer leur bien être. 1 2 3 4 5 6 Totalement En partie ni d'accord En partie Totalement Je ne d'accord d'accord ni pas d'accord pas d'accord pas d'accord sais pas
c) Le plus grand nombre n’obtient pas une juste part de la richesse de la nation. 1 2 3 4 5 6 Totalement En partie ni d'accord En partie Totalement Je ne d'accord d'accord ni pas d'accord pas d'accord pas d'accord sais pas
d) Les aides sociales ne vont pas toujours à ceux qui en ont le plus besoin. 1 2 3 4 5 6 Totalement En partie ni d'accord En partie Totalement Je ne d'accord d'accord ni pas d'accord pas d'accord pas d'accord sais pas
e) Une vraie coopération dans les entreprises est difficile parce que chefs d’entreprises et salariés n’ont pas les mêmes intérêts.
1 2 3 4 5 6 Totalement En partie ni d'accord En partie Totalement Je ne d'accord d'accord ni pas d'accord pas d'accord pas d'accord sais pas
f) Les entreprises privées sont plus aptes que les entreprises publiques à résoudre les problèmes économiques de la France
1 2 3 4 5 6 Totalement En partie ni d'accord En partie Totalement Je ne d'accord d'accord ni pas d'accord pas d'accord pas d'accord sais pas
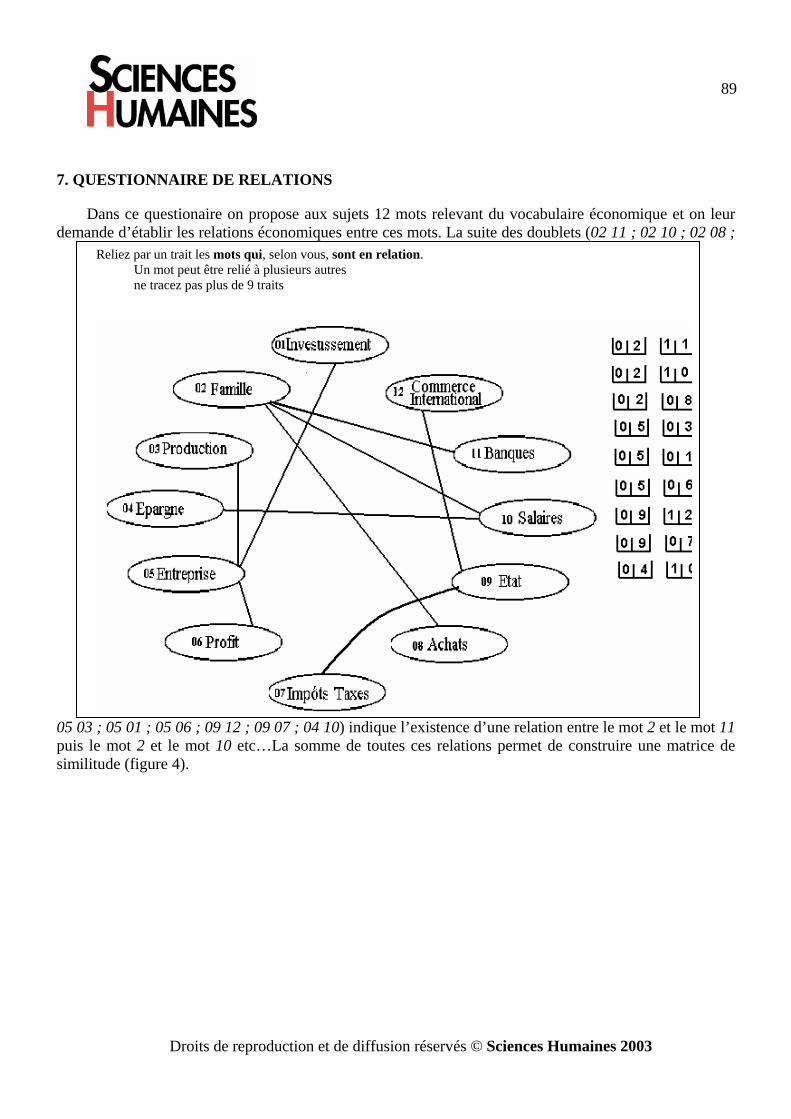
Droits de reproduction et de diffusion réservés © Sciences Humaines 2003
89
7. QUESTIONNAIRE DE RELATIONS
Dans ce questionaire on propose aux sujets 12 mots relevant du vocabulaire économique et on leur demande d’établir les relations économiques entre ces mots. La suite des doublets (02 11 ; 02 10 ; 02 08 ;
05 03 ; 05 01 ; 05 06 ; 09 12 ; 09 07 ; 04 10) indique l’existence d’une relation entre le mot 2 et le mot 11 puis le mot 2 et le mot 10 etc…La somme de toutes ces relations permet de construire une matrice de similitude (figure 4).
Reliez par un trait les mots qui, selon vous, sont en relation. Un mot peut être relié à plusieurs autres ne tracez pas plus de 9 traits
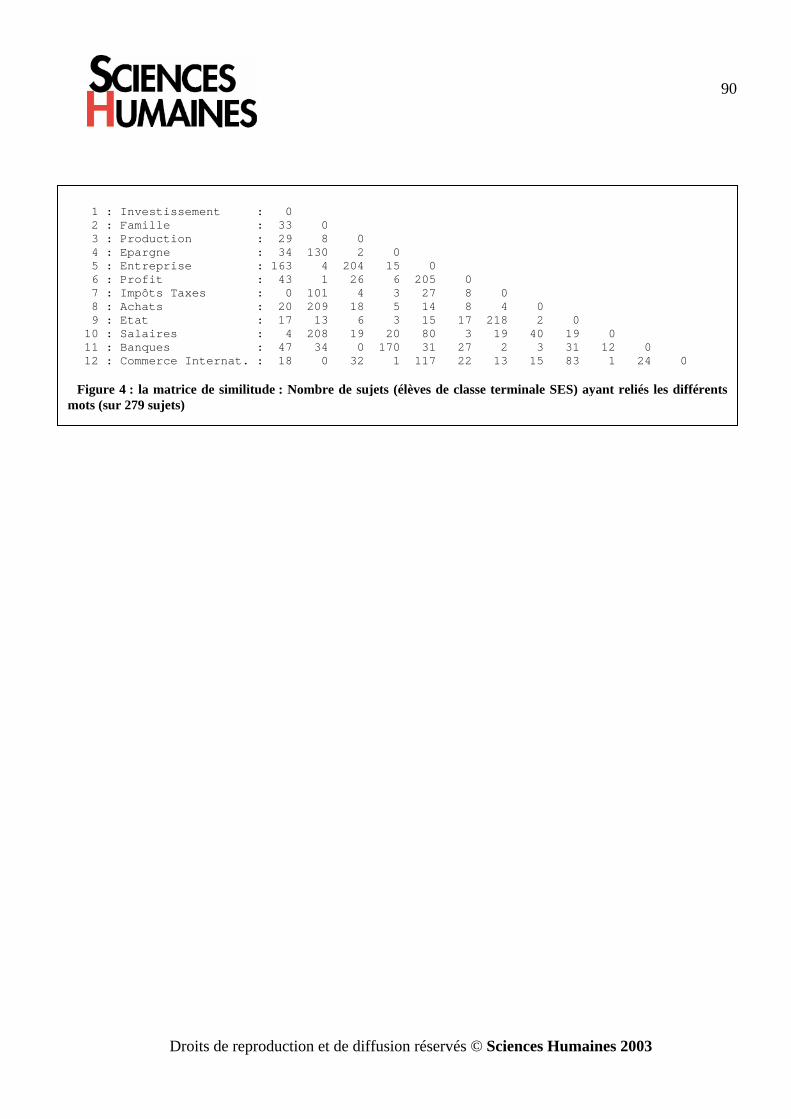
Droits de reproduction et de diffusion réservés © Sciences Humaines 2003
90
1 : Investissement : 0 2 : Famille : 33 0 3 : Production : 29 8 0 4 : Epargne : 34 130 2 0 5 : Entreprise : 163 4 204 15 0 6 : Profit : 43 1 26 6 205 0 7 : Impôts Taxes : 0 101 4 3 27 8 0 8 : Achats : 20 209 18 5 14 8 4 0 9 : Etat : 17 13 6 3 15 17 218 2 0 10 : Salaires : 4 208 19 20 80 3 19 40 19 0 11 : Banques : 47 34 0 170 31 27 2 3 31 12 0 12 : Commerce Internat. : 18 0 32 1 117 22 13 15 83 1 24 0 Figure 4 : la matrice de similitude : Nombre de sujets (élèves de classe terminale SES) ayant reliés les différents
mots (sur 279 sujets)


















