
Khai thác dữ liệu -...
23
Cours IFI M1 ©Jean-daniel Zucker /81 1 Introduction à La Fouille de Données Cours IFI M1 Data Mining Jean-Daniel Zucker Chercheur de l’IRD à UMMISCO (Modélisation Mathématiques Et Informatiques des Systèmes Complexes) UMI 209 UPMC/IRD MSI/IFI Vietnam Cours M1 IA « Systèmes Intelligents & Multimédia » Khai thác dữ liệu Cours N°2 Cours IFI M1 ©Jean-daniel Zucker /81 2 Administratif: 6 Séances • Séance 1: Mercredi 16 Mai – Intro Générale Introduction, historique, formulation (KDD, Data Mining, Big Data) Les liens avec le Machine Learning et le Data Analysis Un environnement RStudio et un langage R La regression avec R • Séance 3: Mercredi 30 Mai — Apprentissage d’arbre de décisions • Séance 4: Mercredi 6 Juin — Recherche de règles d’associations. • Séance 5: Mercredi 13 Juin — Le clustering. • Séance 6: Jeudi 14 Juin – La visualisation 8h30 à 11h45= 3h + 15 min de pause. Les cours de déroulent dans la salle 203.
Transcript of Khai thác dữ liệu -...

Cours IFI M1 ©Jean-daniel Zucker
/811
Introduction à La Fouille de Données
Co
ur
s IF
I M1
Da
ta M
inin
g
Jean-Daniel Zucker
Chercheur de l’IRD à UMMISCO(Modélisation Mathématiques Et Informatiques des Systèmes Complexes)
UMI 209 UPMC/IRD
MSI/IFI Vietnam
Cours M1 IA « Systèmes Intelligents & Multimédia »
Khai thác dữ liệu Cours N°2
Cours IFI M1 ©Jean-daniel Zucker
/812
Administratif: 6 Séances
• Séance 1: Mercredi 16 Mai – Intro Générale
Introduction, historique, formulation (KDD, Data Mining, Big Data)
Les liens avec le Machine Learning et le Data Analysis
Un environnement RStudio et un langage R
La regression avec R
• Séance 2: Mercredi 23 Mai — Vos données/Préparation des données
• Séance 3: Mercredi 30 Mai — Apprentissage d’arbre de décisions
• Séance 4: Mercredi 6 Juin — Recherche de règles d’associations.
• Séance 5: Mercredi 13 Juin — Le clustering.
• Séance 6: Jeudi 14 Juin – La visualisation
8h30 à 11h45= 3h + 15 min de pause. Les cours de déroulent dans la salle 203.

Cours IFI M1 ©Jean-daniel Zucker
/81
Site du cours3
http://ouebe.orghttp://www.sfds.asso.fr/190-Polys_denseignement
Cours IFI M1 ©Jean-daniel Zucker
/81
Travaux Pratiques
• Aller sur http://ouebe.org
• Puis Promotion 16, Puis TP du cours et Révisions
4

Cours IFI M1 ©Jean-daniel Zucker
/815
Pl
an
I. la préparation des données/L’induction
1. rappel/processus de la fouille
2. Vos BD
3. L’induction
4. La notion de prédiction et de test
5.Retour sur la regression
6.Analyse de données (TP sous R)
7. Analyse de vos données
Cours IFI M1 ©Jean-daniel Zucker
/81
Data rich but information poor! : Besoins d’ 6
Définition: “L’exploration et l’analyse de grandes quantité de données afin de découvrir des formes et des règles significatives en utilisant des moyens automatique ou semi-automatique.”
Explorer, analyser, compacter, réduire, extraire, utiliser, ces données :
Khai thác dữ liệu (data mining) là quá trình khám phá các tri thức mới và các tri thức có ích ở dạng tiềm năng trong nguồn dữ liệu đã có.
... la fouille de donnéesthe extraction of interesting (non-trivial, implicit, previously unknown and
potentially useful) information or patterns from data in large databases

Cours IFI M1 ©Jean-daniel Zucker
/817
tâches de la fouille de données (typologie 1/2)
• Classification (valeurs discrètes): Oui/Non, 1/2/3, VND/US$/€réponse qualitative à un médicament, classification de demandeurs de crédits, détermination des numéros de fax, dépistage de demandes d’assurances frauduleuses, etc.
• L’estimation (valeurs continues): [1-10], [-1,1],[0,1000000] réponse quantitative à un médicament, du nombre d’enfants d’une famille, revenu total par ménage, probabilité de réponse à une demande, etc.
• La prédiction (pour vérifier il faut attendre): «Dans 2 jours l’action d’apple doublera», demain il fera beau, ... durée de vie d’un patient, des clients qui vont disparaître, des abonnés qui vont prendre un service, etc..
SUPE
RVI
SE
Succès de la tâche: critère de performances sur nouvelles données
Cours IFI M1 ©Jean-daniel Zucker
/818
tâches de la fouille de données (typologie 2/2)
• Le regroupement par similitudes (Clustering): des patients qui ont telles mutations génétiques développent tel type d’obésité, etc.
• La recherche d’association : «95% des parents qui vont au supermarché acheter des couches (3% des achats) achètent aussi des bierres». 95% est la confiance et 3% le support (Association Rules).
• La recherche d’anomalie : «Il y a une concentration de véhicule «anormale» tous les dimanche matin à 10h près de Nga The». «L’utilisateur Hung s’est connecté depuis Singapoore alors qu’il ne l’a jamais fait avant».(Anomaly analysis)N
ON
SU
PER
VISE
Succès de la tâche: critère d’intérêt des «connaissances découvertes»

Cours IFI M1 ©Jean-daniel Zucker
/81
! Database analysis and decision support! Market analysis and management
! target marketing, market basket analysis,…! Risk analysis and management
! Forecasting, quality control, competitive analysis,…! Fraud detection and management (voir transparent suivant)
! Other Applications! Text mining (newsgroup, email, documents) and Web analysis.! Spatial data mining! Image Mining! Intelligent query answering
Tâches (point de vue utilisateurs)
Cours IFI M1 ©Jean-daniel Zucker
/81
Applications : détection de fraudes
! Applications! health care, retail, credit card services, telecommunications etc.
! Approach! use historical data to build models of normal and fraudulent
behavior and use data mining to help identify fraudulent instances! Examples
! auto insurance: detect groups who stage accidents to collect insurance
! money laundering: detect suspicious money transactions ! medical insurance: detect professional patients and ring of
doctors, inappropriate medical treatment ! detecting telephone fraud:Telephone call model: destination of the
call, duration, time of day/week. Analyze patterns that deviate from expected norm.

Cours IFI M1 ©Jean-daniel Zucker
/81
Discovery of Medical/Biological Knowledge! Discovery of structure-function
associations! Structure of proteins and their function! Human Brain Mapping (lesion-deficit,
task-activation associations)! Cell structure (cytoskeleton) and
functionality or pathology! Discovery of causal relationships
! Symptoms and medical conditions! DNA sequence analysis
! Bioinformatics (microarrays, etc)
Cours IFI M1 ©Jean-daniel Zucker
/81
Other Applications! Sports
! Advanced Scout analyzed NBA game statistics (shots blocked, assists, and fouls) to gain competitive advantage for New York Knicks and Miami Heat.
! Astronomy! JPL and the Palomar Observatory discovered
22 quasars with the help of data mining

Cours IFI M1 ©Jean-daniel Zucker
/8113
Data Types and Forms
• Data Structure:Attribute-vector data,time series, data flow,relational data:
• Data types– Numeric, categorical (see the
hierarchy for their relationship) – Static, dynamic (temporal)
• Other data forms– Distributed data– Text, Web, meta data– Images– Flow,...
Cours IFI M1 ©Jean-daniel Zucker
/81
Big Data = Data x V14
4

Cours IFI M1 ©Jean-daniel Zucker
/8115 Le processus de Fouille de données
SélectionNettoyage
Pré-traitement
ExtractionFouille de données
Interprétation/Visualisation
supervisé non-supervisé
Association Rules numériquenumérique symbolique
SQL / OQLadhoc
ReformulationK. domaineRéduction Dim.ACP,...
Evaluation du gain...
ID3, RF, DTree APriori
Règles,Graphes,Diag. Autocorrél.Règles, 3D, RA, VR...Pa
ramètres
BD clientsBD médicales,BD génomiquesBD géographiques, BD textes,BD scientifiques,BD réseaux sociaux,BD imagesBD de simulation...
SVM, RN, CAH, KMEANS, KMEDOIDS
DB DB
DB
máy học thuật toán
Cours IFI M1 ©Jean-daniel Zucker
/8116
Lien avec les analyses statistiques connues ?
• Oui !
• Les approches classiques : Analyse en Composante Principales, Analyse Discriminante, Regression, Corrélation, etc. sont utilisables.
•

Cours IFI M1 ©Jean-daniel Zucker
/8117 Exemple 2 : Comparaison, entre les communautés « riche » et « pauvre ». Régression
• Tension artérielle moyennes :
– Régression
• Proportion d’adultes hypertendus :
– Régression LOGISTIQUE
• Nombre d’œufs de parasites dans les selles
– Régression de POISSON
Cours IFI M1 ©Jean-daniel Zucker
/8118 Exemple 1 (suite) : Expression des résultats. Régression
• Tension artérielle moyennes : Régression LINEAIRE : la tension artérielle systolique des pauvres des environ 30% plus élevée que celle des riches*
• Proportion d’adultes hypertendus : Régression LOGISTIQUE : la proportion d’hypertendu est 1,5 plus grande chez les pauvres que chez les riches
• Nombre d’Œufs de parasites dans les selles : Régression de POISSON : Le nombre d’œufs de parasites dans les selles est en moyenne 12 fois plus grande chez les riches que chez les pauvres
* Toute choses étant « égales par ailleurs »
Cours IFI M1 ©Jean-daniel Zucker
/8119
Visualiser les résultats
Cours IFI M1 ©Jean-daniel Zucker
/81
http://www.google.org/flutrends/
20
«Nous avons remarqué que certains termes de recherche étaient des indicateurs efficaces de la propagation de la grippe. Google Suivi de la grippe rassemble donc des données de recherche Google pour fournir une estimation quasiment en temps réel de cette propagation à l'échelle mondiale.»
Prédire ne veut pas dire comprendre les causes...

Cours IFI M1 ©Jean-daniel Zucker
/81
Travaux Pratiques
• Maintenant en TP…
http://ouebe.org
• Puis Promotion 16
21
Cours IFI M1 ©Jean-daniel Zucker
/81
Dans la fouille (supervisé): aspect «prédictif»22
Repose sur l’induction: Proposer des lois générales à partir de l’observation de cas particuliers
Problème
Quel est le nombre a qui prolonge la séquence :
1 2 3 5 … a ?

Cours IFI M1 ©Jean-daniel Zucker
/8123
...
• Solution(s). Quelques réponses valides :❏ a = 6.# Argument : c’est la suite des entiers sauf 4.❏ a = 7.# Argument : c’est la suite des nombres premiers.❏ a = 8.# Argument : c’est la suite de Fibonacci❏ a = 2 π. (a peut être n’importe quel nombre réel supérieur ou égal à 5) #
Argument : la séquence présentée est la liste ordonnée des racines du polynôme :P = x 5 - (11 + a)x 4 + (41 + 11a)x 3 - (61 - 41a)x 2 + (30 + 61a)x - 30a
# # qui est le développement de : (x - 1) . (x - 2) . (x - 3) . (x - 5) . (x - a)
• GénéralisationIl est facile de démontrer ainsi que n’importe quel nombre est une prolongation correcte de n’importe quelle suite de nombre
! Mais alors … ! comment faire de l’induction ?
! ! ! ! et que peut-être une science de l’induction ?
Cours IFI M1 ©Jean-daniel Zucker
/8124
Représenter les données
• Extraction de caractéristiques (descripteurs, attributs)❏ Eliminer les descripteurs non pertinents
❏ Introduction de nouveaux descripteurs
– Utilisation de connaissances a priori• Invariance par translation• Invariance par changement d’échelle
– Histogrammes
– Combinaisons de descripteurs
❏ Ajouter des descripteurs (beaucoup) !!

Cours IFI M1 ©Jean-daniel Zucker
/8125
Valider les résultats
• Quel critère de performance (de succès) ?❏ Probabilité de misclassification❏ Risque❏ Nombre d’erreurs
• Apprentissage sur un échantillon d'apprentissage
• Test sur une base de test
Taille échantillon
"Erreur"
Courbe d'apprentissage
Cours IFI M1 ©Jean-daniel Zucker
/8126
1.1- Fouille de données & Analyse de sensibilité
• La plupart des algorithmes de Fouille de données viennent de l’apprentissage artificielle ...
• Pour analyser les données issues de simulateurs (comme GAMA !)

Cours IFI M1 ©Jean-daniel Zucker
/81
Ensembles de données (collections)
Toutes les données disponibles
Ensemble d’apprentissage
Ensemble de test
Ensemble de validation
27
Cours IFI M1 ©Jean-daniel Zucker
/81
Prédiction asymptotique (le cas idéal)
• Useful for very large data sets
28
Cours IFI M1 ©Jean-daniel Zucker
/81
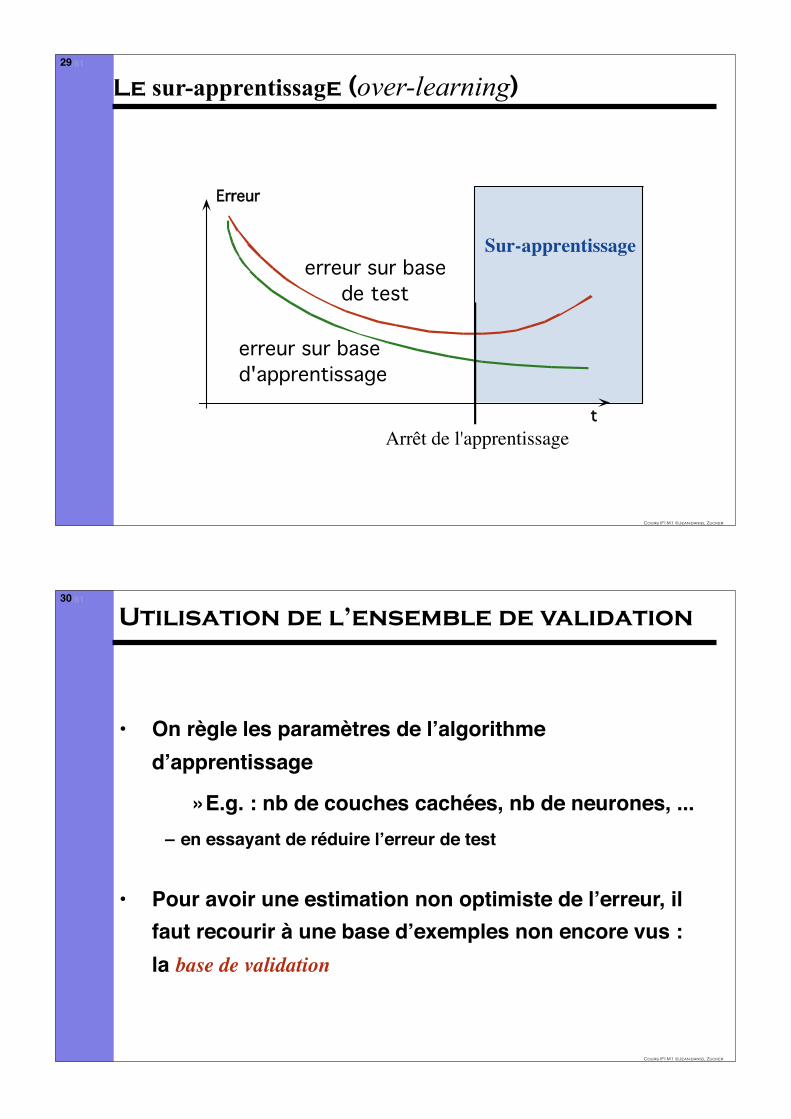
Le sur-apprentissage (over-learning)
Erreur
t
erreur sur basede test
erreur sur based'apprentissage
Arrêt de l'apprentissage
Sur-apprentissage
29
Cours IFI M1 ©Jean-daniel Zucker
/81
Utilisation de l’ensemble de validation
• On règle les paramètres de l’algorithme d’apprentissage
»E.g. : nb de couches cachées, nb de neurones, ...– en essayant de réduire l’erreur de test
• Pour avoir une estimation non optimiste de l’erreur, il faut recourir à une base d’exemples non encore vus : la base de validation
30

Cours IFI M1 ©Jean-daniel Zucker
/81
Évaluation des hypothèses produites
beaucoup peu de données
31
Cours IFI M1 ©Jean-daniel Zucker
/81
Courbes de performance
Erreur de test
intervalle de confiance à 95%
Erreur d’apprentissage
32

Cours IFI M1 ©Jean-daniel Zucker
/81
Évaluation des hypothèses produites
Beaucoupde données
peu
33
Cours IFI M1 ©Jean-daniel Zucker
/81
Différents ensembles
Données
test → erreurapprentissage
34

Cours IFI M1 ©Jean-daniel Zucker
/81
Validation croisée à k plis (k-fold)35
Cours IFI M1 ©Jean-daniel Zucker
/81
Validation croisée à k plis (k-fold)Données
Apprend sur jaune, test sur rose → erreur5
Apprend sur jaune, test sur rose → erreur6
Apprend sur jaune, test sur rose → erreur7
Apprend sur jaune, test sur rose → erreur1
Apprend sur jaune, test sur rose → erreur3
Apprend sur jaune, test sur rose → erreur4
Apprend sur jaune, test sur rose → erreur8
Apprend sur jaune, test sur rose → erreur2
erreur = Σ erreuri / k
k-way split
36

Cours IFI M1 ©Jean-daniel Zucker
/81
Procédure “leave-one-out”
Données
! Faible biais
! Haute variance
! Tend à sous-estimer l’erreur si les données ne sont pas vraiment i.i.d.
[Guyon & Elisseeff, jMLR, 03]
37
Cours IFI M1 ©Jean-daniel Zucker
/81
Le Bootstrap38
Le bootstrap est biaisé
Le bootstrap est biaisé (son estimation du biais est biaisée vers zéro), car certaines observations sont utilisées à la fois dans l'échantillon pour construire le modèle et dans l'échantillon pour le valider. Le bootstrap "hors du sac" (out-of-the-bag) et le bootstrap .632 tentent de corriger ce biais.

Cours IFI M1 ©Jean-daniel Zucker
/81
Le Bootstrap39
Out-of-the-bag bootstrap
Le bootstrap "hors du sac" consiste à ne pas utiliser toutes les observations pour valider le modèle mais uniquement celles qui ne figurent pas déjà dans l'échantillon ayant servi à le construire (c'est d'ailleurs ce qu'on faisait pour la validation croisée).
Bootstrap .632
En fait, le bootstrap "out-of-the-bag" est quand-même biaisé, mais dans l'autre sens. Pour tenter de corriger ce biais, on peut faire une moyenne pondérée du bootstrap initial et du bootstrap oob.
.368 * (biais estimé par le bootstrap) +
.632 * (biais estimé par le bootstrap oob)
(le coefficient .632 s'interprète ainsi : pour n grand, les échantillons de bootstrap contiennent en moyenne 63,2% des observations initiales).
Cours IFI M1 ©Jean-daniel Zucker
/81
Types d’erreurs
• Erreur de type 1 (alpha) : faux positifs– Probabilité d’accepter l’hypothèse alors qu’elle est fausse
• Erreur de type 2 (beta) : faux négatifs– Probabilité de rejeter l’hypothèse alors qu’elle est vraie
➠ !Comment arbitrer entre ces types d’erreurs ?
40
Cours IFI M1 ©Jean-daniel Zucker
/81
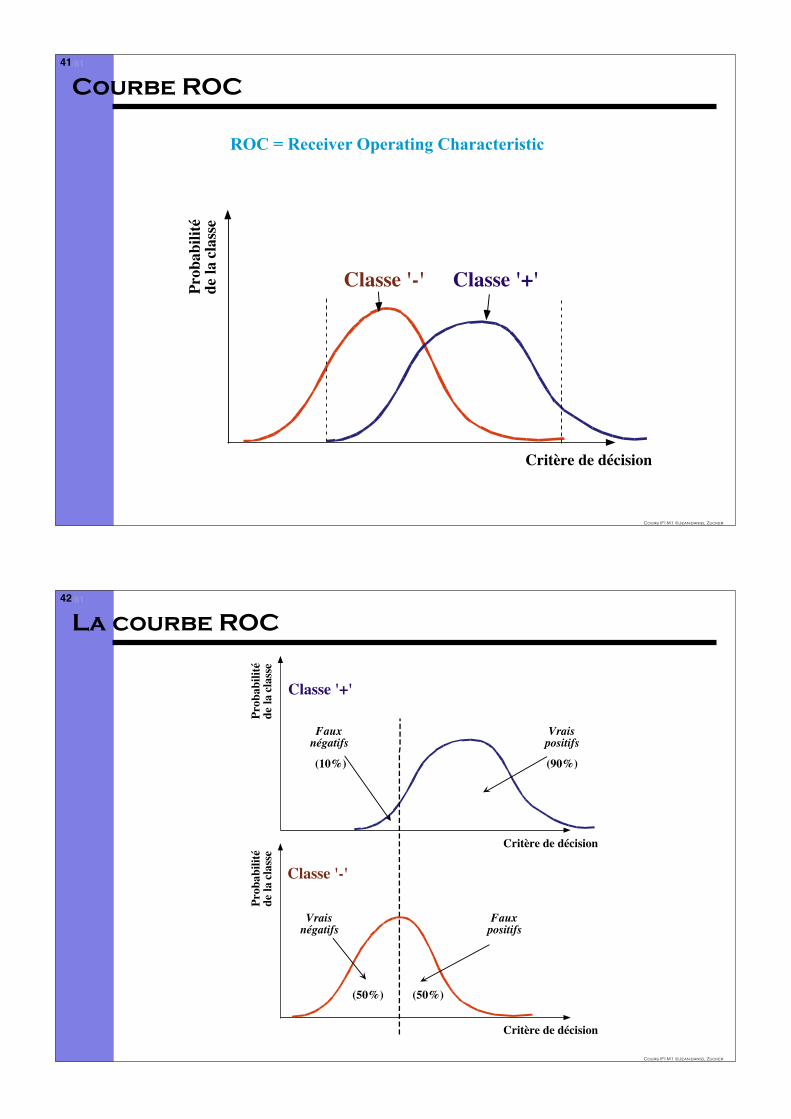
Courbe ROC
Critère de décision
Prob
abili
téde
la cl
asse
Classe '+'Classe '-'
ROC = Receiver Operating Characteristic
41
Cours IFI M1 ©Jean-daniel Zucker
/81
La courbe ROC
Critère de décision
Prob
abili
téde
la cl
asse
Classe '+'
Critère de décision
Prob
abili
téde
la cl
asse
Classe '-'
Vraispositifs
Fauxnégatifs
Fauxpositifs
Vraisnégatifs
(50%)(50%)
(90%)(10%)
42
Cours IFI M1 ©Jean-daniel Zucker
/81
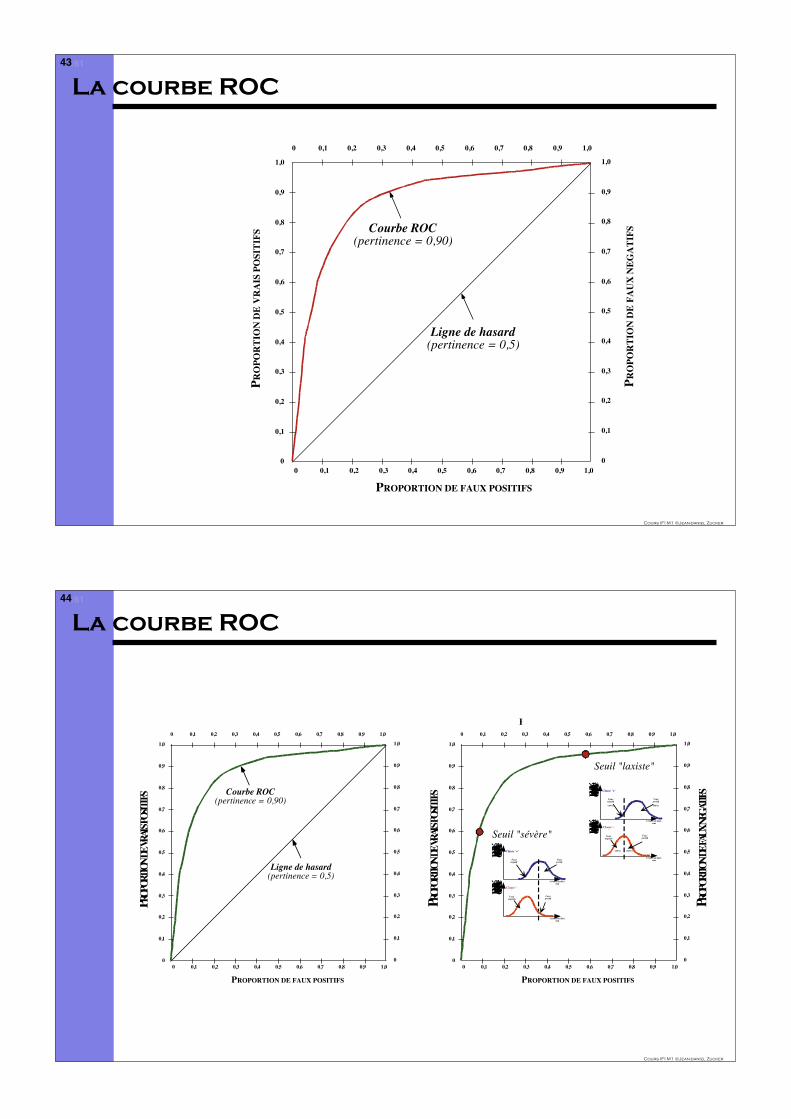
La courbe ROC
PROPORTION DE VRAIS NEGATIFS
PROPORTION DE FAUX POSITIFS
0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1,0
0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1,0
0,1
0,2
0
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1,0
0,1
0,2
0
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1,0
PRO
POR
TIO
N D
E V
RA
IS P
OSI
TIFS
PRO
POR
TIO
N D
E FA
UX
NEG
ATI
FS
Ligne de hasard(pertinence = 0,5)
Courbe ROC(pertinence = 0,90)
43
Cours IFI M1 ©Jean-daniel Zucker
/81
La courbe ROC
PROPORTION DE VRAIS NEGATIFS
PROPORTION DE FAUX POSITIFS
0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1,0
0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1,0
0,1
0,2
0
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1,0
0,1
0,2
0
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1,0
PROP
ORTIO
N DE V
RAIS
POSIT
IFS
PROP
ORTIO
N DE F
AUX N
EGAT
IFS
Ligne de hasard(pertinence = 0,5)
Courbe ROC(pertinence = 0,90)
PROPORTION DE VRAIS NEGATIFS
PROPORTION DE FAUX POSITIFS
0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1,0
0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1,0
0,1
0,2
0
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1,0
0,1
0,2
0
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1,0
PROP
ORTIO
N DE V
RAIS
POSIT
IFS
PROP
ORTIO
N DE F
AUX N
EGAT
IFS
Critère de déci-sion
Probabilité
de la classe
Classe '+'
Critère de déci-sion
Probabilité
de la classe
Classe '-'
Vraispositifs
Fauxnégatifs
Fauxpositifs
Vraisnégatifs
Critère de déci-sion
Probabilité
de la classe
Classe '+'
Critère de déci-sion
Probabilité
de la cl asse
Classe '-'
Vraispositifs
Fauxnégatifs
Fauxpositifs
Vraisnégatifs
(50%)(50%)
(90%)(10%)
Seuil "laxiste"
Seuil "sévère"
44

Cours IFI M1 ©Jean-daniel Zucker
/81
Courbe ROC
• Spécificité
• Sensibilité
VP
VP + FN
Réel
Estimé + -
+ VP FP
- FN VN
VN
FP + VN
! Rappel
! Précision
VP
VP + FN
VP
VP + FP
45
Cours IFI M1 ©Jean-daniel Zucker
/81
Résumé
• Attention à votre fonction de coût : – qu’est-ce qui importe pour la mesure de performance ?
• Données en nombre fini: – calculez les intervalles de confiance
• Données rares : – Attention à la répartition entre données d’apprentissage et
données test. Validation croisée.• N’oubliez pas l’ensemble de validation• Mesure de la précision (accuracy) 100-erreur%
• L’évaluation est très importante– Ayez l’esprit critique– Convainquez-vous vous même !
46


















