
Introduction a l’optimisation, aspects th eoriques et num ...
33
Introduction ` a l’optimisation, aspects th´ eoriques et num´ eriques Yannick Privat ([email protected]) CNRS & Univ. Paris 6 S´ eance 5, mai 2015 https://www.ljll.math.upmc.fr/∼privat/cours/ensem.php Y. Privat (CNRS & Univ. Paris 6) ENSEM (2015) - S´ eance 3 S´ eance 4, mai 2015 1 / 15
Transcript of Introduction a l’optimisation, aspects th eoriques et num ...

Introduction a l’optimisation, aspects theoriques et numeriques
Yannick Privat([email protected])
CNRS & Univ. Paris 6
Seance 5, mai 2015https://www.ljll.math.upmc.fr/∼privat/cours/ensem.php
Y. Privat (CNRS & Univ. Paris 6) ENSEM (2015) - Seance 3 Seance 4, mai 2015 1 / 15

Plan de la seance
1 Rappels de la seance precedenteLa methode de NewtonOptimisation SOUS contraintesAlgorithme de penalisation
2 Algorithmes pour l’optimisation SOUS contraintes (suite)La methode du gradient projete
3 Complement en optimisation SANS contrainte : la methode des moindres carres
Y. Privat (CNRS & Univ. Paris 6) ENSEM (2015) - Seance 3 Seance 4, mai 2015 2 / 15

Rappels de la seance precedente
Sommaire
1 Rappels de la seance precedenteLa methode de NewtonOptimisation SOUS contraintesAlgorithme de penalisation
2 Algorithmes pour l’optimisation SOUS contraintes (suite)
3 Complement en optimisation SANS contrainte : la methode des moindres carres
Y. Privat (CNRS & Univ. Paris 6) ENSEM (2015) - Seance 3 Seance 4, mai 2015 3 / 15

Rappels de la seance precedente La methode de Newton
Methodes de type Newton (Description d’une etape)
On considere un champ F : Rn → Rn de classe C1. On suppose que l’equation F(x) = 0possede au moins une solution notee x∗ et que la matrice DF(x∗) est inversible. On veutresoudre l’equation :
F(x) = 0.
Newton (dim 1) Newton (dim quelconque)x0 ∈ R donneiteration k : xk donne.Calculer
δk = f (xk )f ′(xk )
puis
xk+1 = xk − δk
x(0) ∈ Rn donneiteration k : x(k) donne.Calculer
DF(x(k))]δ(k) = F(x(k)) puis
x(k+1) = x(k) − δ(k).
! La seconde etape necessite la resolution d’un systeme lineaire.
! Un des gros problemes de cette methode est que le choix de x(0) joue un grand rolesur la convergence ou non de la methode de Newton.
! Avantage de la methode de Newton : grande rapidite de convergence (quadratique).
! Application en optimisation : on choisit F = ∇J et alors, DF = Hess J.
Y. Privat (CNRS & Univ. Paris 6) ENSEM (2015) - Seance 3 Seance 4, mai 2015 4 / 15

Rappels de la seance precedente La methode de Newton
Methodes de type Newton (Algorithme complet)
poser k = 0
choisir x(0) dans un voisinage de x∗
choisir ε > 0
tant que (∥∥∥x(k+1) − x(k)
∥∥∥ ≥ ε) et (k ≤ kmax) faire
resoudre le systeme lineaire [DF(x(k))]δ(k) = F(x(k))
poser x(k+1) = x(k) − δ(k)
poser k = k + 1fin tant que
Convergence de la methode : si nous choisissons x(0) suffisamment pres de x∗, lamethode de Newton converge.
Y. Privat (CNRS & Univ. Paris 6) ENSEM (2015) - Seance 3 Seance 4, mai 2015 5 / 15

Rappels de la seance precedente Optimisation SOUS contraintes
Conditions d’optimalite pour l’optimisation SOUS contraintes
On cherche a enoncer des conditions d’optimalite au premier ordre pour des problemesd’optimisation avec contraintes, du type
infx∈C
f (x) avec C = {x ∈ Rn | h(x) = 0, g(x) ≤ 0, },
ou
f : Rn −→ R,
h : Rn −→ Rp (p ∈ N)
g : Rn −→ Rq (q ∈ N).La contrainte inegalite doit etre interpretee composante par composante.
Y. Privat (CNRS & Univ. Paris 6) ENSEM (2015) - Seance 3 Seance 4, mai 2015 6 / 15

Rappels de la seance precedente Optimisation SOUS contraintes
Le theoreme des extrema lies
On se donne f : Rn → R differentiable et des fonctions hi : Rn → R avec 1 ≤ i ≤ p declasse C1.
On cherche a resoudreinfx∈K
f (x)
ou K = {x ∈ Rn, h1(x) = · · · = hp(x) = 0}.
Theoreme des extrema lies
On suppose que f admet un minimum local sur l’ensemble K et que
la famille ∇h1(x∗), · · · ,∇hp(x∗) est libre.
Alors, il existe un p-uplet (λ1, · · · , λp) ∈ Rp tel que
∇f (x∗) +
p∑k=1
λk∇hk(x∗) = 0.
Y. Privat (CNRS & Univ. Paris 6) ENSEM (2015) - Seance 3 Seance 4, mai 2015 7 / 15

Rappels de la seance precedente Optimisation SOUS contraintes
Le theoreme des extrema lies
Remarque
La conditionla famille ∇h1(x∗), · · · ,∇hp(x∗) est libre.
est appelee condition de qualification des contraintes.Si cette condition n’est pas satisfaite, alors la conclusion du theoreme des extrema liestombe en defaut. En effet, pour s’en convaincre, considerons l’exemple suivant :{
inf f (x) = xx ∈ R et h(x) = 0,
ou h : x ∈ R 7→ x2. Alors, le minimum de f sur K est atteint en x∗ = 0 et l’equation“∇f (x∗) +
∑pk=1 λk∇hk(x∗) = 0” n’est pas satisfaite puisque h′(x∗) = 0 et f ′(x∗) = 1.
Y. Privat (CNRS & Univ. Paris 6) ENSEM (2015) - Seance 3 Seance 4, mai 2015 7 / 15

Rappels de la seance precedente Optimisation SOUS contraintes
Le theoreme des extrema lies
Un exemple
On veut resoudre le probleme sous contraintes
inf(x,y)∈R2
x2+y2=1
f (x , y) = x4 + y 4
! Application du theoreme des extrema lies. Soit (x , y) minimisant f sur le cercleunite. Alors,
∃λ ∈ R tel que ∇f (x , y) = λ∇h(x , y),
avec h(x , y) = x2 + y 2 − 1, autrement dit
{x(x2 − λ) = 0y(y 2 − λ) = 0.
Ainsi x = 0 et
y = ±√λ ou y = 0 et x = ±
√λ ou x = y = ±
√λ.
La valeur de λ s’obtient en tenant compte de la contrainte egalite. Ainsi, λ = 1 pourles deux premiers cas et λ = 1
2pour le dernier cas.
Puis, on le tri parmi les points critiques, entre maxima locaux, minima locaux et pointsselle. La meilleure solution est d’evaluer f aux points obtenus.
On retrouve que f est minimale pour (x , y) =(±√
22,±√
22
).
Y. Privat (CNRS & Univ. Paris 6) ENSEM (2015) - Seance 3 Seance 4, mai 2015 7 / 15

Rappels de la seance precedente Optimisation SOUS contraintes
Generalisation : le theoreme de Karush-Kuhn-Tucker
On se donne f : Rn → R differentiable et des fonctions hi : Rn → R avec 1 ≤ i ≤ p etgj : Rn −→ R avec 1 ≤ j ≤ q, de classe C1.
On cherche a resoudreinfx∈K
f (x)
ou K = {x ∈ Rn, h1(x) = · · · = hp(x) = 0 et g1(x) ≤ 0, . . . , gq(x) ≤ 0}.
Qualification des contraintes
On dit que les contraintes sont qualifiees en x ∈ K si, et seulement si
les vecteurs ∇h1(x), · · · , ∇hp(x) sont lineairement independants
il existe une direction d ∈ Rn telle que l’on ait pour tout i ∈ {1, · · · , p} et j ∈ I (x),
〈∇hi (x), d〉 = 0 et 〈∇gj(x), d〉 < 0,
↪→ une condition suffisante pour que cette derniere condition ait lieu est que
les vecteurs ∇g1(x), · · · ,∇gq(x) soient lineairement independants.
Y. Privat (CNRS & Univ. Paris 6) ENSEM (2015) - Seance 3 Seance 4, mai 2015 8 / 15

Rappels de la seance precedente Optimisation SOUS contraintes
Generalisation : le theoreme de Karush-Kuhn-Tucker
On se donne f : Rn → R differentiable et des fonctions hi : Rn → R avec 1 ≤ i ≤ p etgj : Rn −→ R avec 1 ≤ j ≤ q, de classe C1.
On cherche a resoudreinfx∈K
f (x)
ou K = {x ∈ Rn, h1(x) = · · · = hp(x) = 0 et g1(x) ≤ 0, . . . , gq(x) ≤ 0}.
Theoreme (Karush-Kuhn-Tucker)
Soit x∗, un minimum local du probleme ci-dessus. On suppose que les contraintes sontqualifiees en x . Alors, il existe (λ1, · · · , λp) ∈ Rp et (µ1, · · · , µq) ∈ Rq
+ tels que
∇f (x∗) +
p∑i=1
λi∇hi (x∗) +
q∑j=1
µj∇gj(x∗) = 0
et
h(x∗) = 0 et g(x∗) ≤ 0,
µjgj(x∗) = 0, ∀j ∈ {1, · · · , q} (condition de complementarite).
Y. Privat (CNRS & Univ. Paris 6) ENSEM (2015) - Seance 3 Seance 4, mai 2015 8 / 15

Rappels de la seance precedente Optimisation SOUS contraintes
Generalisation : le theoreme de Karush-Kuhn-Tucker
Un exemple
On considere le probleme de minimisation sous contrainte
infx2+y2≥1
f (x , y) = x4 + 3y 4.
! Conditions d’optimalite au premier ordre : soit (x , y) un minimiseur. Le theoreme deKuhn-Tucker assure l’existence (qualification des contraintes a verifier. . .) de µ ≥ 0
tel que ∇f (x , y) + µ∇g(x , y) = 0, soit
4x3 − 2µx = 012y 3 − 2µy = 0x2 + y 2 ≥ 1µ(x2 + y 2 − 1) = 0.
! Supposons que l’on ait µ = 0. Alors, x = y = 0. Impossible car (0, 0) n’appartientpas a l’ensemble des contraintes. Donc, on a necessairement µ > 0.
! Des deux premieres equations, on tire que les minimiseurs sont a choisir parmi
X1 =
(0,±
õ
6
), X2 =
(±√µ
2, 0
)et X3 =
(±√µ
2,±√µ
6
)
Y. Privat (CNRS & Univ. Paris 6) ENSEM (2015) - Seance 3 Seance 4, mai 2015 8 / 15

Rappels de la seance precedente Optimisation SOUS contraintes
Generalisation : le theoreme de Karush-Kuhn-Tucker
Un exemple
On considere le probleme de minimisation sous contrainte
infx2+y2≥1
f (x , y) = x4 + 3y 4.
! Etude de X1. Puisque x2 + y 2 = 1, on obtient µ = 6 dans ce cas, et
X1 = (0,±1) et f (X1) = 3.
! Etude de X2. Puisque x2 + y 2 = 1, on obtient µ = 2 dans ce cas, et
X2 = (±1, 0) et f (X2) = 1.
! Etude de X3. Puisque x2 + y 2 = 1, on obtient µ = 32
dans ce cas, et
X3 =
(±√
3
2,±1
2
)et f (X3) =
3
4.
On en deduit que minx∈K
f (x) = f (X3) =3
4.
Y. Privat (CNRS & Univ. Paris 6) ENSEM (2015) - Seance 3 Seance 4, mai 2015 8 / 15
Rappels de la seance precedente Algorithme de penalisation
Les methodes de penalisation
! Objectif : donner un exemple de methode pour l’optimisation sous contraintes.
! Bien d’autres existent. Par exemple, l’agorithme du gradient projete, d’Uzawa, etc.
! Le principe : on remplace le probleme avec contraintes.
(P) infx∈C⊂Rn
J (x)
par un probleme sans contrainte
(Pε) infx∈Rn
J (x) +1
εα (x) ,
ou α : Rn → R est une fonction de penalisation des contraintes et ε > 0.
! Choix de la fonction α : le but est de trouver des fonctions α telles que les problemes(P) et (Pε) soient equivalents, c’est-a-dire, tels qu’ils aient les memes solutions.
Y. Privat (CNRS & Univ. Paris 6) ENSEM (2015) - Seance 3 Seance 4, mai 2015 9 / 15

Rappels de la seance precedente Algorithme de penalisation
Les methodes de penalisation
On compare les problemes
Avec contraintes Sans contrainte
(P) infx∈C⊂Rn
J (x) (Pε) infx∈Rn
J (x) +1
εα (x)
Supposons que α verifie les proprietes suivantes :
1 α est continue sur Rn
2 ∀x ∈ Rn, α (x) > 0
3 α (x) = 0⇔ x ∈ C
Voici quelques exemples de fonction de penalisation pour differentes contraintes :
Contrainte x 6 0 : la fonction α est α (x) =∥∥x+
∥∥2.
Contrainte h (x) = 0 : la fonction α est α (x) = ‖h (x)‖2.
contrainte g (x) 6 0 : la fonction α est α (x) =∥∥g (x)+
∥∥2.
On note x+ = max{x , 0} et on generalise cette notation a des vecteurs.
Y. Privat (CNRS & Univ. Paris 6) ENSEM (2015) - Seance 3 Seance 4, mai 2015 9 / 15
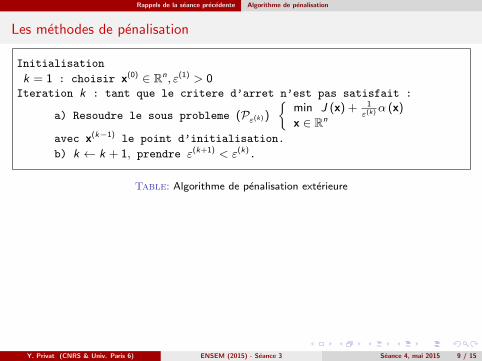
Rappels de la seance precedente Algorithme de penalisation
Les methodes de penalisation
Initialisation
k = 1 : choisir x(0) ∈ Rn, ε(1) > 0Iteration k : tant que le critere d’arret n’est pas satisfait :
a) Resoudre le sous probleme (Pε(k) )
{min J (x) + 1
ε(k)α (x)
x ∈ Rn
avec x(k−1) le point d’initialisation.
b) k ← k + 1, prendre ε(k+1) < ε(k).
Table: Algorithme de penalisation exterieure
Y. Privat (CNRS & Univ. Paris 6) ENSEM (2015) - Seance 3 Seance 4, mai 2015 9 / 15

Rappels de la seance precedente Algorithme de penalisation
Les methodes de penalisation
Theoreme (convergence de la methode de penalisation)
Soit J une fonction continue et coercive. Soit C un ensemble ferme non vide. On supposeque α verifie les conditions suivantes :
1 α est continue sur Rn.
2 ∀x ∈ Rn, α (x) > 0.
3 α (x) = 0⇔ x ∈ C .
On a alors :
∀ε > 0, (Pε) a au moins une solution xε
La famille (xε)ε>0 est bornee
Toute sous-suite convergente extraite de (xε)ε>0 converge vers une solution de (P)lorsque ε→ 0.
Exemple
Une formulation penalisee du probleme d’optimisation (P) infx≥0
x4 + 6y 6 − 3x2 + x − 7y
est (Pε) infx≥0
x4 + 6y 6 − 3x2 + x − 7y +1
εmin{x , 0}2. On peut verifier que les hypotheses
du theoreme ci-dessus sont satisfaites.
Y. Privat (CNRS & Univ. Paris 6) ENSEM (2015) - Seance 3 Seance 4, mai 2015 9 / 15
Rappels de la seance precedente Algorithme de penalisation
Complements de cours
Rien de ce qui suit n’est au programme du test ecrit
Y. Privat (CNRS & Univ. Paris 6) ENSEM (2015) - Seance 3 Seance 4, mai 2015 10 / 15

Algorithmes pour l’optimisation SOUS contraintes (suite)
Sommaire
1 Rappels de la seance precedente
2 Algorithmes pour l’optimisation SOUS contraintes (suite)La methode du gradient projete
3 Complement en optimisation SANS contrainte : la methode des moindres carres
Y. Privat (CNRS & Univ. Paris 6) ENSEM (2015) - Seance 3 Seance 4, mai 2015 11 / 15

Algorithmes pour l’optimisation SOUS contraintes (suite) La methode du gradient projete
Rappel sur les methodes de gradient
On cherche a resoudre numeriquement le probleme
infx∈C
J(x) avec J : Rn → R differentiable
et C ⊂ Rn, un ensemble de contraintes.
X Dans le cas sans contrainte, l’algorithme du gradient est une methode de descentes’ecrivant sous la forme generique.{
x(0) ∈ Rn donne.
x(k+1) = x(k) + ρ(k)d(k),
ou d(k) ∈ Rn \ {0} est la direction de descente, ρ(k) ∈ R+∗ est le pas a l’iteration k.Ces deux parametres sont choisis de sorte que
J(x (k+1)
)6 J
(x (k)).
X Probleme numerique : lorsque l’on minimise sur un ensemble de contraintes C , iln’est pas sur que x (k) reste sur C . Il est donc necessaire de se ramener sur C .On realise cette derniere operation grace a une projection sur C .
Y. Privat (CNRS & Univ. Paris 6) ENSEM (2015) - Seance 3 Seance 4, mai 2015 12 / 15

Algorithmes pour l’optimisation SOUS contraintes (suite) La methode du gradient projete
Rappel sur les methodes de gradient
On cherche a resoudre numeriquement le probleme
infx∈C
J(x) avec J : Rn → R differentiable
et C ⊂ Rn, un ensemble de contraintes.
Rappels sur la notion de projection
Soit C , un convexe ferme d’un espace vectoriel H dedimension finie (ou plus generalement, un espace de
Hilbert)
Soit x ∈ H. Il existe un unique element de C notepC (x), appele projection de x sur C qui resout leprobleme
infy∈C‖x − y‖.
pC (x) est caracterise de facon unique par lesconditions :
pC (x) ∈ C et 〈x − pC (x), y − pC (x)〉 ≤ 0, ∀y ∈ C .
Y. Privat (CNRS & Univ. Paris 6) ENSEM (2015) - Seance 3 Seance 4, mai 2015 12 / 15

Algorithmes pour l’optimisation SOUS contraintes (suite) La methode du gradient projete
Rappel sur les methodes de gradient
On cherche a resoudre numeriquement le probleme
infx∈C
J(x) avec J : Rn → R differentiable
et C ⊂ Rn, un ensemble de contraintes.
Exemples de projections
Exemple 1 : si C = {(x1, ..., xn) , ai ≤ xi ≤ bi , i ∈ {1, . . . n}}, alors pouri ∈ {1, . . . , n},
i-eme composante de pC (x1, . . . , xn) = min{max{xi , ai}, bi}.
Exemple 2 : si C = {x ∈ Rn | x ∈ Bf (x0,R)}, ou Bf (x0,R) est la boule euclidiennefermee de centre x0 et rayon R, alors
pCx =
{x , si x ∈ C ;x0 + R x−x0
‖x−x0‖, si x /∈ C
.
Y. Privat (CNRS & Univ. Paris 6) ENSEM (2015) - Seance 3 Seance 4, mai 2015 12 / 15

Algorithmes pour l’optimisation SOUS contraintes (suite) La methode du gradient projete
Rappel sur les methodes de gradient
On cherche a resoudre numeriquement le probleme
infx∈C
J(x) avec J : Rn → R differentiable
et C ⊂ Rn, un ensemble de contraintes.
On suppose que C est un convexe ferme de Rn.
Algorithme du gradient projete
1 Initialisation.k = 0 : on choisit x0 ∈ Rn et ρ0 ∈ R∗+.
2 Iteration k.
xk+1 = pC(xk − ρk∇J(xk)
).
pC designe ici la projection sur C
Y. Privat (CNRS & Univ. Paris 6) ENSEM (2015) - Seance 3 Seance 4, mai 2015 12 / 15
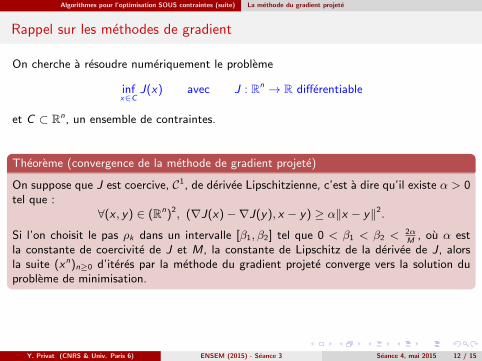
Algorithmes pour l’optimisation SOUS contraintes (suite) La methode du gradient projete
Rappel sur les methodes de gradient
On cherche a resoudre numeriquement le probleme
infx∈C
J(x) avec J : Rn → R differentiable
et C ⊂ Rn, un ensemble de contraintes.
Theoreme (convergence de la methode de gradient projete)
On suppose que J est coercive, C1, de derivee Lipschitzienne, c’est a dire qu’il existe α > 0tel que :
∀(x , y) ∈ (Rn)2, (∇J(x)−∇J(y), x − y) ≥ α‖x − y‖2.
Si l’on choisit le pas ρk dans un intervalle [β1, β2] tel que 0 < β1 < β2 <2αM
, ou α estla constante de coercivite de J et M, la constante de Lipschitz de la derivee de J, alorsla suite (xn)n≥0 d’iteres par la methode du gradient projete converge vers la solution duprobleme de minimisation.
Y. Privat (CNRS & Univ. Paris 6) ENSEM (2015) - Seance 3 Seance 4, mai 2015 12 / 15

Algorithmes pour l’optimisation SOUS contraintes (suite) La methode du gradient projete
Rappel sur les methodes de gradient
On cherche a resoudre numeriquement le probleme
infx∈C
J(x) avec J : Rn → R differentiable
et C ⊂ Rn, un ensemble de contraintes.
Un exemple numerique
On resout
inf(x,y)∈Q
2x2 + 3xy + 2y 2,
avec Q ={x ≤ − 1
2, y ≤ − 1
2
}, a l’aide
d’une methode de gradient projete apas constant.
pas = 1e − 4. Le gradient converge(erreur < 1e − 8) en 8 iterations.
Y. Privat (CNRS & Univ. Paris 6) ENSEM (2015) - Seance 3 Seance 4, mai 2015 12 / 15

Algorithmes pour l’optimisation SOUS contraintes (suite) La methode du gradient projete
Rappel sur les methodes de gradient
On cherche a resoudre numeriquement le probleme
infx∈C
J(x) avec J : Rn → R differentiable
et C ⊂ Rn, un ensemble de contraintes.
Un exemple numerique
Suite des iteres (∗ sur le dessin)obtenus par Matlab :
-0.6000 0.2000-0.5998 -0.5000-0.5994 -0.5000-0.5989 -0.5000-0.5985 -0.5000-0.5980 -0.5000-0.5974 -0.5000-0.5000 -0.5000-0.5000 -0.5000
Y. Privat (CNRS & Univ. Paris 6) ENSEM (2015) - Seance 3 Seance 4, mai 2015 12 / 15

Complement en optimisation SANS contrainte : la methode des moindrescarres
Sommaire
1 Rappels de la seance precedente
2 Algorithmes pour l’optimisation SOUS contraintes (suite)
3 Complement en optimisation SANS contrainte : la methode des moindres carres
Y. Privat (CNRS & Univ. Paris 6) ENSEM (2015) - Seance 3 Seance 4, mai 2015 13 / 15
Complement en optimisation SANS contrainte : la methode des moindrescarres
Complement : la methode des moindres carres
Soit A, une matrice reelle de taille m × n (en pratique, m >> n).On suppose donc que m > n. On cherche a resoudre Ax = b “au mieux”, i.e. on cherchex∗ minimisant
f : Rn −→ Rx 7−→ f (x) = ‖Ax − b‖2,
la notation ‖ · ‖ designant bien sur la norme euclidienne de Rn.
Existence de solutions
La question se ramene a rechercher l’existence d’un projete de b sur le sous espacevectoriel ImA.Puisque nous sommes en dimension finie, on sait qu’il existe un unique projete b sur lesous espace vectoriel ImA, car celui-ci est de dimension finie
Presentons a present la methode de resolution de ce probleme.
Y. Privat (CNRS & Univ. Paris 6) ENSEM (2015) - Seance 3 Seance 4, mai 2015 14 / 15

Complement en optimisation SANS contrainte : la methode des moindrescarres
Complement : la methode des moindres carres
Methode de resolution
Reecriture du critere
On peut reexprimer f (x) sous une forme mieux adaptee :
∀x ∈ Rn, f (x) =1
2〈A>Ax , x〉 − 〈A>b, x〉+
1
2‖b‖2.
On va utiliser les resultats sur la minimisation de fonctions quadratiques. Notons que :
! la matrice A>A est semi-definie positive
! la question se ramene a l’etude des solutions de l’equation
A>Ax = b (equation normale).
Y. Privat (CNRS & Univ. Paris 6) ENSEM (2015) - Seance 3 Seance 4, mai 2015 14 / 15

Complement en optimisation SANS contrainte : la methode des moindrescarres
Complement : la methode des moindres carres
Deux cas a envisager :
Si A est de plein rang n. Alors, d’apres le theoreme du rang, la matrice A estinjective, puis A>A est egalement injective donc inversible. L’equation normale
A>Ax = A>b
possede alors une unique solution, solution du probleme de minimisation.
Si rgA < n. Alors, la plus petite valeur propre de A>A est nulle, puisque A>A n’estpas injective. D’apres l’etude faite des fonctions quadratiques, le probleme deminimisation a soit une infinite de solutions, soit pas de solution.Or, on a vu que le probleme des moindres carres possede (au moins) une solution.On en deduit que le probleme des moindres carres possede dans ce cas une infinitede solutions (correspondant a l’ensemble des solutions de l’equation normaleA>Ax = A>b).
Remarque
Dans le cas ou A>A est inversible, la matrice A† = (A>A)−1A> s’appelle pseudo-inverseou inverse generalise de A. Cette notion est tres utile en analyse numerique
Y. Privat (CNRS & Univ. Paris 6) ENSEM (2015) - Seance 3 Seance 4, mai 2015 14 / 15

Complement en optimisation SANS contrainte : la methode des moindrescarres
Exemple/Exercice : la regression lineaire
On considere un nuage de m points de R2 : Mi = (ti , xi ), pour i ∈ {1, · · · ,m}. Ces donneessont souvent le resultat de mesures et on cherche a decrire le comportement global de cenuage. En general, ces points ne sont pas alignes, mais si on a de bonnes raisons de penserqu’ils devraient l’etre (un modele physique, biologiste, etc. peut guider l’intuition), on peutse demander quelle est la droite approchant au mieux ces points.La methode des moindres carres consiste alors a rechercher la droite telle que la sommedes carres des distances des points du nuage a cette droite soit minimale.Autrement dit, on cherche a resoudre
inf(α,β)∈R2
f (α, β) ou f (α, β) =n∑
i=1
(xi − αti − β)2,
Posons X = (α, β)>. Alors, on peut ecrire que
f (α, β) = ‖AX − b‖2, avec A =
t1 1...
...tm 1
, b =
x1
...xm
Y. Privat (CNRS & Univ. Paris 6) ENSEM (2015) - Seance 3 Seance 4, mai 2015 15 / 15

Complement en optimisation SANS contrainte : la methode des moindrescarres
Exemple/Exercice : la regression lineaire
On a vu que ce probleme possede une solution unique si A est de rang plein, i.e. 2. On endeduit que ce probleme possede une solution unique sauf si t1 = · · · = tm.De plus,
A>A =
( ∑mi=1 t
2i
∑mi=1 ti∑m
i=1 ti m
)et A>b =
( ∑mi=1 xi ti∑mi=1 xi
).
On en deduit que l’equation normale associee est{St2α + Stβ = Sxt
Stα + mβ = Sx
ou l’on a pose
St =m∑i=1
ti , Sx =m∑i=1
xi , Sxt =m∑i=1
xi ti et St2 =m∑i=1
t2i .
Sous reserve que l’on ne soit pas dans la situation “t1 = · · · = tm” (ce qui se retrouve encalculant le determinant du systeme et en retrouvant un cas d’egalite de Cauchy-Schwarz),ce systeme a pour solution
α =SxSt −mSxt
(St)2 −mSt2et β =
SxtSt − SxSt2
(St)2 −mSt2.
Y. Privat (CNRS & Univ. Paris 6) ENSEM (2015) - Seance 3 Seance 4, mai 2015 15 / 15

Complement en optimisation SANS contrainte : la methode des moindrescarres
Exemple/Exercice : la regression lineaire
On s’interesse a l’evolution du chiffre d’affaire d’une entreprise sur plusieurs annees. Ya-t-il une correlation (lineaire) entre l’annee et le chiffre d’affaire ?
annee (xi ) 1999 2000 2001 2002 2003 2004chiffre d’affaire (yi , en Me) 15 20 32 26 33 55
Exercice Trouver m (coefficient directeur)et p (ordonnee a l’origine) minimisant
(m, p) 7→6∑
i=1
(yi −mxi − p)2,
puis tracer le nuage de points et la droited’ajustement correspondante.
Y. Privat (CNRS & Univ. Paris 6) ENSEM (2015) - Seance 3 Seance 4, mai 2015 15 / 15


















