Réalisé par : Fréneau Coralie Delessard Stéphanie Questembert Vincent Deroyer Julien.

TP Bioinformatique 23.04.2010Coralie Fournier
1
INTRODUCTION AUX OUTILSINFORMATIQUES APPLIQUES A LA
BIOLOGIE
INTRODUCTION A LABIOINFORMATIQUE
TP de biochimie pour biochimiste de 2ème année
Enseignement : Marie-Claude BLATTEROlivier SCHADDThierry SOLDATI

TP Bioinformatique 23.04.2010Coralie Fournier
2
LE GENE EPO(Erythropoïetin)
TP1-Introduction aux banques de données biologiques
Le gène EPO code pour une protéine hormonale extracellulaire de nature glycoprotéique. Une protéine glycoprotéiqueest une protéine contenant un glucide. Son rôle principal est d’augmenter la croissance des globules rouges dans lamoelle osseuse.Cette protéine est principalement sécrétée dans le cortex rénal, mais elle est également produite dans les tissus dufoie, du cerveau et de l’utérus. [1]
De plus, cette protéine peut aussi servir de protection contre plusieurs variétés de lésions cérébrale. [2]
Noms [2] : Erythropoietin, Epoetin (GeneID: 2056 Dans la banque de donnée NCBI_Entrez gène)
Location [2] : Dans le chromosome 7 ; 7q22 (GeneID: 2056 Dans la banque de donnée NCBI_Entrez gène)
Grandeur [2] : La protéine contient 193 acides aminés. (GeneID: 2056 Dans la banque de donnée NCBI_Entrezgène)
Localisation dans la cellule : La protéine Erythropoïetin est une protéine extracellulaire.
Publication [2] : Il existe 191 publications dans PubMed. La dernière publication est parue le 18 mars2010 :
New genetic associations detected in a host response study to hepatitis B vaccine,Davila S, Froeling FE, Tan A,
Bonnard C, Boland GJ, Snippe H, Hibberd ML, Seielstad M., Genes Immun. 2010 Mar 18. PMID: 20237496
(GeneID: 2056 Dans la banque de donnée NCBI_Entrez gène)
Pathways [2] : (GeneID: 2056 Dans la banque de donnée NCBI_Entrez gène)
1) KEGG pathway: Cytokine-cytokine receptor interaction n° 04060
2) KEGG pathway: Hematopoietic cell lineage n° 04640
3) KEGG pathway: Jak-STAT signaling pathway n° 04630
Effectivement le gène EPO intervient dans chacun de ces métabolismes.
Séquences [2] : (GeneID: 2056 Dans la banque de donnée NCBI_Entrez gène)
RNA sequence EPO [Homo Sapiens] locus : NM_000799.2
cccggagccg gaccggggcc accgcgcccg ctctgctccg acaccgcgcc ccctggacag ccgccctctc ctccaggccc gtggggctgg ccctgcaccg ccgagcttcc cgggatgagg gcccccggtg tggtcacccg gcgcgcccca ggtcgctgag ggaccccggc caggcgcgga

TP Bioinformatique 23.04.2010Coralie Fournier
3
Protein sequence EPO [Homo Sapiens] locus : NP_000790.2
mgvhecpawl wlllsllslp lglpvlgapp rlicdsrvle rylleakeae nittgcaehcslnenitvpd tkvnfyawkr mevgqqavev wqglallsea vlrgqallvn ssqpweplqlhvdkavsglr slttllralg aqkeaisppd aasaaplrti tadtfrklfr vysnflrgkl
ADN sequence EPO [Homo Sapiens] locus : NC_000007.13
TCCCGGAGCCGGACCGGGGCCACCGCGCCCGCTCTGCTCCGACACCGCGCCCCCTGGACAGCCGCCCTCTCCTCCAGGCCCGTGGGGCTGGCCCTGCACCGCCGAGCTTCCCGGGATGAGGGCCCCCGGTGTGGTCACCCGGCGCGCCCCAGGTCGCTGAGGGACCCCGGCCAGGCGCGGAGATGGGGGTGCACGGTGAGTACTCGCGGGCTGGGCGCTCCCGCCCGCCCGGGTCCCTGTTTGAGCGGGGATTTAGCGCCCCGGCTATTGGCCAGGAGGT
Autres espèces [2] : Outre l’être humain, le gène EPO est présent dans plusieurs espèces différentes :
• Le rat GeneID: 24335
RNA sequence EPO [Rattus norvegicus] locus : NM_017001
1 gccgcagcag ccaggcgcgg agatgggggt gcccgaacgt cccaccctgc tgcttttact61 atccttgcta ctgattcctc tgggcctccc agtcctctgc gctcccccac gcctcatttg121 cgacagtcgc gttctggaga ggtacatctt ggaggccaag gaggcagaaa atgtcacaat
Protein sequence EPO [Rattus norvegicus] locus : NP_058697
1 mgvperptll lllslllipl glpvlcappr licdsrvler yileakeaen vtmgcaegpr61 lsenitvpdt kvnfyawkrm kveeqavevw qglsllseai lqaqalqans sqppeslqlh121 idkaisglrs ltsllrvlga qkelmsppda tqaaplrtlt adtfcklfrv ysnflrgklk
• La souris GeneID: 13856
RNA sequence EPO [Mus musculus] locus : NM_007942
1 gatgaagact tgcagcgtgg acactggccc agccccgggt cgctaaggag ctccggcagc61 taggcgcgga gatgggggtg cccgaacgtc ccaccctgct gcttttactc tccttgctac121 tgattcctct gggcctccca gtcctctgtg ctcccccacg cctcatctgc gacagtcgag
Protein sequence EPO [Mus musculus] locus : NP_031968
1 mgvperptll lllslllipl glpvlcappr licdsrvler yileakeaen vtmgcaegpr61 lsenitvpdt kvnfyawkrm eveeqaievw qglsllseai lqaqallans sqppetlqlh121 idkaisglrs ltsllrvlga qkelmsppdt tppaplrtlt vdtfcklfrv yanflrgklk
• Le bovin GeneID: 280784
RNA sequence EPO [Bos taurus] locus : NM_173909
1 atgggggcgc gcgactgtac tccgctgctg atgctgtcct ttctgctgtt tcctttgggc

TP Bioinformatique 23.04.2010Coralie Fournier
4
61 ttcccagtcc tgggcgcccc cgcacgcctc atctgtgaca gccgagtcct ggagaggtac121 atcctggagg ccagggaggc cgaaaatgcc acgatgggct gtgcagaagg ctgcagcttc
Protein sequence EPO [Bos taurus] locus : NP_776334
1 mgardctpll mlsfllfplg fpvlgaparl icdsrvlery ileareaena tmgcaegcsf61 nenitvpdtk vnfyawkrme vqqqalevwq glallseail rgqallanas qpcealrlhv121 dkavsglrsl tsllralgaq keaislpdat psaaplraft vdalsklfri ysnflrgklt
• Le poisson-zèbre GeneID: 100004455
RNA sequence EPO [Danio rerio] locus : NM_001038009
1 gagccttttc tgcttaatcg cgtggtcgct ttcgtggagt gaggggaatt gacattcata61 gaaagcttgc caatggggtg atgcaaagct caacggatct aatacgtgcc tcgtgggaag 121 ggacggtgtc gtagtatttg atcgcgtgtgcctctcactg agttcttgga agcagcgcgt
Protein sequence EPO [Danio rerio] locus : NP_001033098
1 mfhgsglfal llmvlewtrp glssplrpic dlrvldhfik eawdaeaamr tckddcsiat61 nvtvpltrvd fevweamnie eqaqevqsgl hmlneaigsl qisnqtevlq shidasirni121 asirqvlrsl sipeyvppts sgedketqki ssiselfqvh vnflrgkarl llanapvcrq
• Le chien GeneID: 404002• Le macaque GeneID: 719294• Le chimpanzé GeneID: 463609• Le sanglier GeneID: 397249• Le chat GeneID: 493801• Le lapin GeneID: 100008786• Le mouton GeneID: 443302• Le cheval GeneID: 100033849
(GeneID: 2056 Dans la banque de donnée NCBI_Entrez gène)
Tissus spécifique [3] : La protéine est principalement produite dans les reins ou le foie de l’adulte.(UniProtKB/Swiss-Prot P01588)
Maladies [3] : La variation génétique de l’EPO est principalement associée aux complications microvasculaires liées à la maladie du diabète. A un stade élevé, cela peut amener à la mort du patient.L’EPO est connu comme produit dopant, permettant d’améliorer les capacités des athlètes en augmentant leur nombrede globules rouges et favorisant ainsi le transport de l’oxygène durant de l’effort. De plus, l’EPO peut aussi être utilisécomme traitement chez les personnes anémiques.(UniProtKB/Swiss-Prot P01588)
Polymorphisme [3] : Deux variations naturelles sont répertoriées pour l’EPO, les deux induisent uncarcinome hepatocellulaire. La première change deux acides aminés la sérine et la leucine en arginine et phénylalanine(VAR_009870). La deuxième modifie la proline en glutamine (VAR_009871). (UniProtKB/Swiss-Prot P01588)
TP Bioinformatique 23.04.2010Coralie Fournier
5
Gene ontology (GO) associé [3] : Plusieurs gènes sont associés. Les plus proches sont :
Processus biologique :blood circulation GO : 0008015
Composant cellulaire :extracellular space GO : 0005615
Fonction moléculaire :erythropoietin receptor binding GO: 0005128
(UniProtKB/Swiss-Prot P01588)
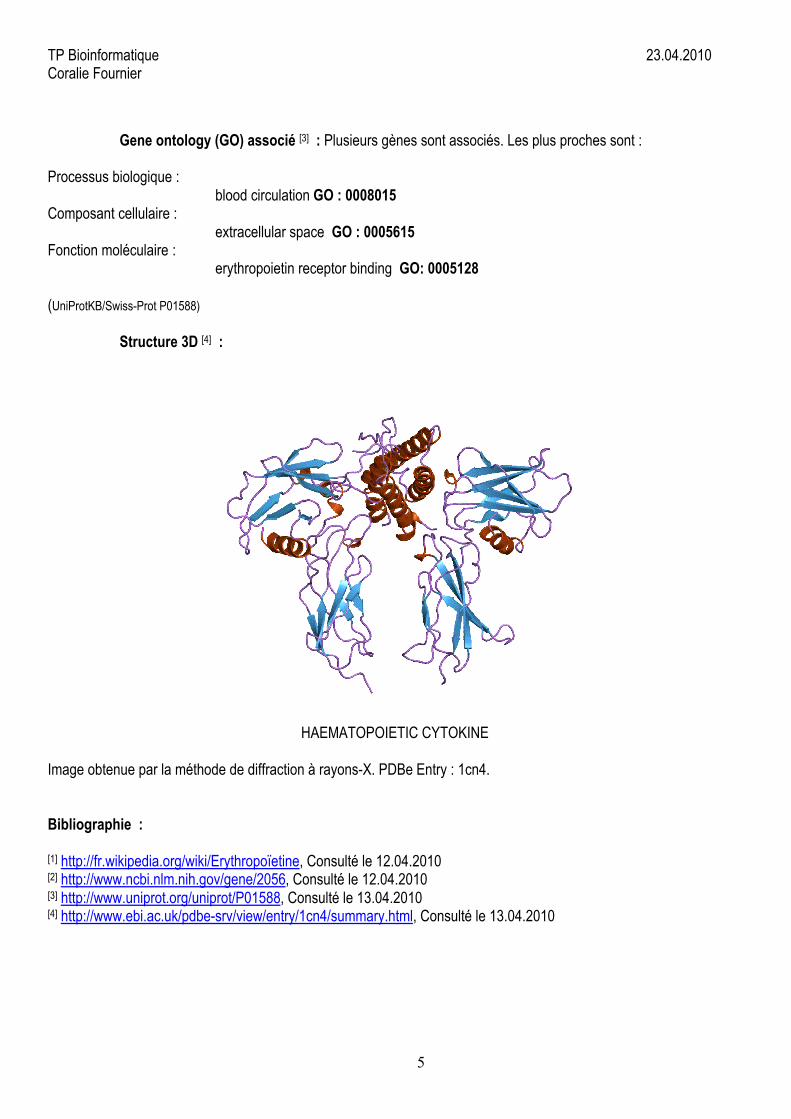
Structure 3D [4] :
HAEMATOPOIETIC CYTOKINE
Image obtenue par la méthode de diffraction à rayons-X. PDBe Entry : 1cn4.
Bibliographie :
[1] http://fr.wikipedia.org/wiki/Erythropoïetine, Consulté le 12.04.2010[2] http://www.ncbi.nlm.nih.gov/gene/2056, Consulté le 12.04.2010[3] http://www.uniprot.org/uniprot/P01588, Consulté le 13.04.2010[4] http://www.ebi.ac.uk/pdbe-srv/view/entry/1cn4/summary.html, Consulté le 13.04.2010
TP Bioinformatique 23.04.2010Coralie Fournier
6
TP2-Analyse de séquence de protéine
Analyse de la protéine erythropoïetin.
• Nombre d’acide aminés [1]: 193• Poids moléculaire [1]: 21306.7• Point isoélectrique théorique [1]: 8.3• Composition en acide amine [1]:
Acides Aminés Nombre PourcentageAla (A) 20 10.4%Arg (R) 13 6.7%Asn (N) 6 3.1%Asp (D) 6 3.1%Cys (C) 5 2.6%Gln (Q) 7 3.6%Glu (E) 13 6.7%Gly (G) 12 6.2%His (H) 3 1.6%Ile (I) 5 2.6%
Leu (L) 33 17.1%Lys (K) 8 4.1%Met (M) 2 1.0%Phe (F) 4 2.1%Pro (P) 11 5.7%Ser (S) 12 6.2%Thr (T) 11 5.7%Trp (W) 5 2.6%Tyr (Y) 4 2.1%Val (V) 13 6.7%Pyl (O) 0 0.0%Sec (U) 0 0.0%
• Total des charges négatives (Asp et Glu) [1]: 19• Total des charges positives (Arg et Lys) [1]: 21• Composition atomique [1]:
Atome NombreCarbon C 956
Hydrogen H 1538Nitrogen N 264Oxygen O 272Sulfur S 7
• Formule de la protéine [1]: C956H1538N264O272S7
• Nombre d’atome total [1]: 3037

TP Bioinformatique 23.04.2010Coralie Fournier
7
• Coloration des acides aminés suivant leurs propriétés biochimiques [2] :
•
• Le programme PSORT, nous indique que l’erythropoïetin est une protéine extracellulaire et donc nontransmembranaire. [3]
• Le programme SignalP permet de localiser les séquences contenant un signal peptide. Pour notre protéinenous obtenons effectivement un signal contenu entre les acides aminés 1 à 27. Le signal se coupe entre leglutamate (position 27) et l’alanine (position 28). Les deux programmes algorithmiques donnent le mêmerésultat. Les données sont dont relativement bonnes. De plus, UniProt apporte les mêmes indications. [4]
• Les programmes NetPhos et NetPhosK permettent de déterminer les sites de phosphorylations présents sur laprotéine. Lorsque nous analysons l’erythropoïétin, nous obtenons 3 sites de phosphorylation. Mais il faut faireattention, car se sont de faux-positifs. Effectivement l’erythropoïétin étant une protéine extracellulaire, elle nepeut pas contenir de sites de phosphorylation, cette dernière s’effectuant dans le noyau de la cellule.
• Deux programmes permettent de déterminer les sites de glycosylation de la protéine. Le premier YinOYangprédit les glycosylations effectuées dans le noyau, par conséquent on ne trouve aucun résultat pourl’erythropoïétin. Le deuxième, NetNGlyc donne trois sites glycolysés sur l’asparagine pour l’erythropoïetin. Ilsse trouvent aux positions 51, 65 et 110. Ce sont les mêmes positions qui sont données sur le site UniProt. [5]
• Il est possible de faire des alignements de séquences de notre protéine par rapport à différentes espèces. Voiciun exemple effectué sur le programme UniProt de la séquence de l’EPO trouvée chez l’Homme, la souris et lerat. En régions plus claires apparaissent les acides aminés où une séquence diffère des deux autres. Et lesrégions blanches correspondent aux acides aminés différents dans les trois séquences. [6]
Results: Your Protein
MGVHECPAWL WLLLSLLSLP LGLPVLGAPP RLICDSRVLERYLLEAKEAE NITTGCAEHC SLNENITVPD TKVNFYAWKR
MEVGQQAVEV WQGLALLSEA VLRGQALLVN SSQPWEPLQLHVDKAVSGLR SLTTLLRALG AQKEAISPPD AASAAPLRTI
TADTFRKLFR VYSNFLRGKL KLYTGEACRT GDR
TP Bioinformatique 23.04.2010Coralie Fournier
8
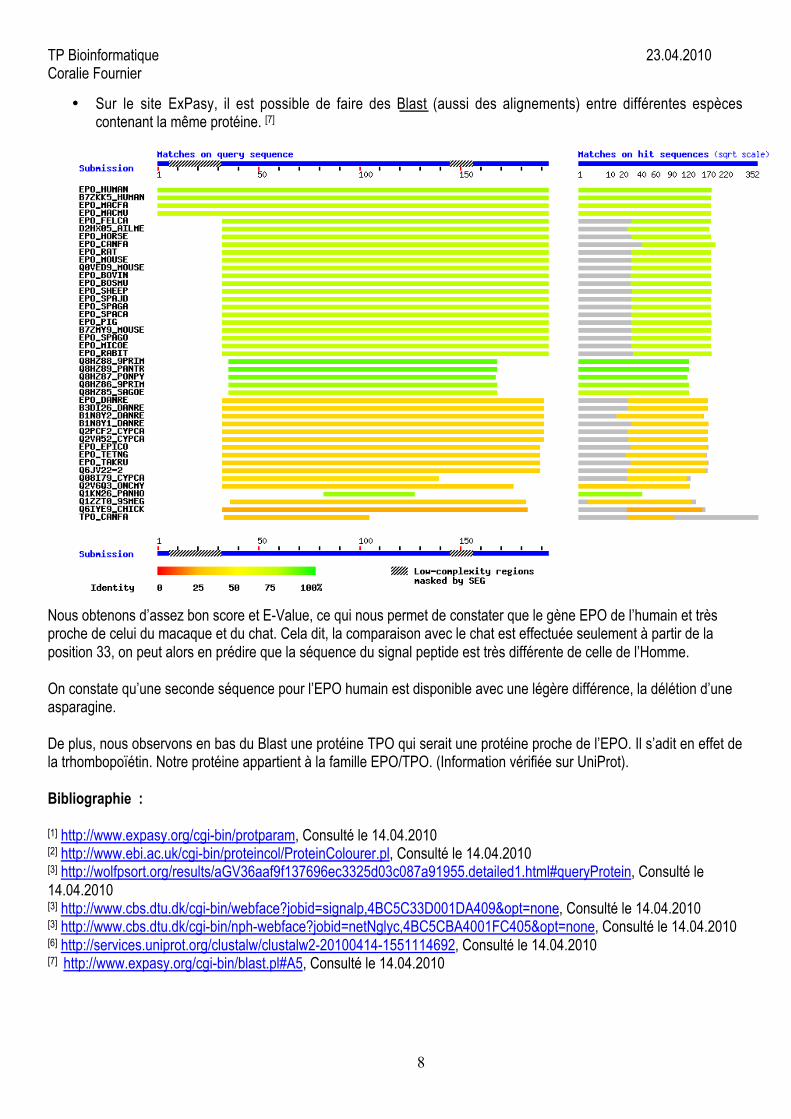
• Sur le site ExPasy, il est possible de faire des Blast (aussi des alignements) entre différentes espècescontenant la même protéine. [7]
Nous obtenons d’assez bon score et E-Value, ce qui nous permet de constater que le gène EPO de l’humain et trèsproche de celui du macaque et du chat. Cela dit, la comparaison avec le chat est effectuée seulement à partir de laposition 33, on peut alors en prédire que la séquence du signal peptide est très différente de celle de l’Homme.
On constate qu’une seconde séquence pour l’EPO humain est disponible avec une légère différence, la délétion d’uneasparagine.
De plus, nous observons en bas du Blast une protéine TPO qui serait une protéine proche de l’EPO. Il s’adit en effet dela trhombopoïétin. Notre protéine appartient à la famille EPO/TPO. (Information vérifiée sur UniProt).
Bibliographie :
[1] http://www.expasy.org/cgi-bin/protparam, Consulté le 14.04.2010[2] http://www.ebi.ac.uk/cgi-bin/proteincol/ProteinColourer.pl, Consulté le 14.04.2010[3] http://wolfpsort.org/results/aGV36aaf9f137696ec3325d03c087a91955.detailed1.html#queryProtein, Consulté le14.04.2010[3] http://www.cbs.dtu.dk/cgi-bin/webface?jobid=signalp,4BC5C33D001DA409&opt=none, Consulté le 14.04.2010[3] http://www.cbs.dtu.dk/cgi-bin/nph-webface?jobid=netNglyc,4BC5CBA4001FC405&opt=none, Consulté le 14.04.2010[6] http://services.uniprot.org/clustalw/clustalw2-20100414-1551114692, Consulté le 14.04.2010[7] http://www.expasy.org/cgi-bin/blast.pl#A5, Consulté le 14.04.2010
TP Bioinformatique 23.04.2010Coralie Fournier
9
TP3-Analyse phylogénétique
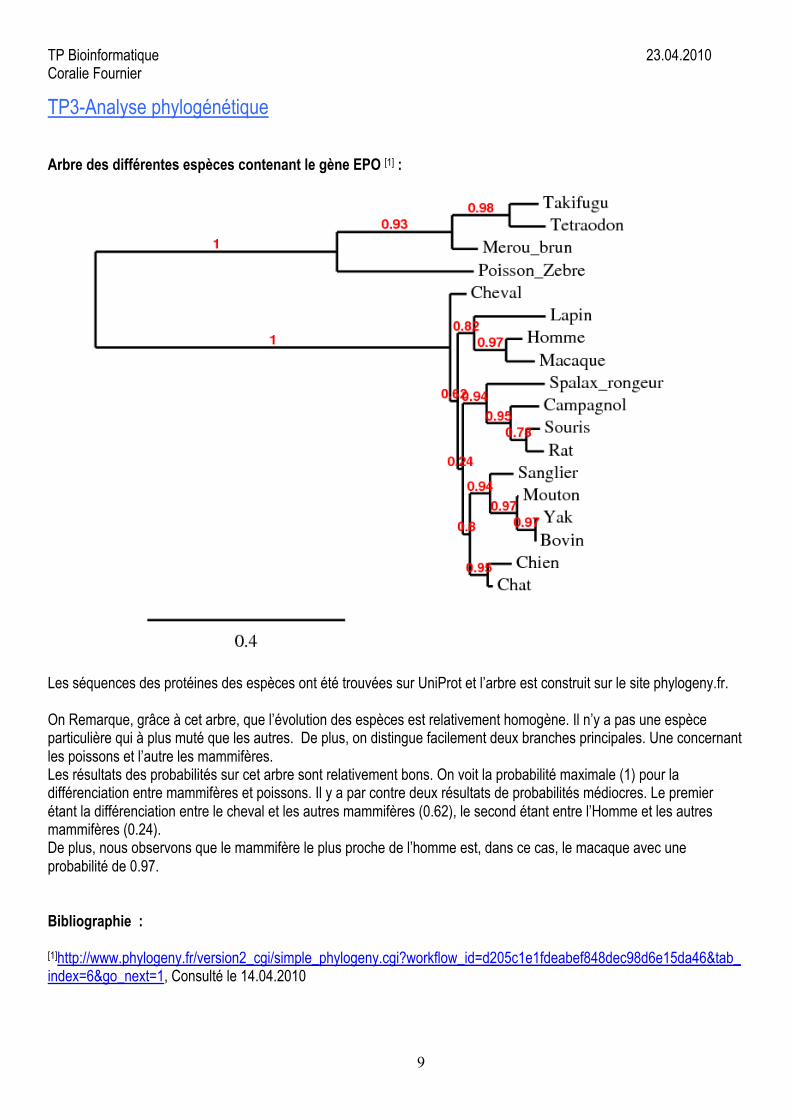
Arbre des différentes espèces contenant le gène EPO [1] :
Les séquences des protéines des espèces ont été trouvées sur UniProt et l’arbre est construit sur le site phylogeny.fr.
On Remarque, grâce à cet arbre, que l’évolution des espèces est relativement homogène. Il n’y a pas une espèceparticulière qui à plus muté que les autres. De plus, on distingue facilement deux branches principales. Une concernantles poissons et l’autre les mammifères.Les résultats des probabilités sur cet arbre sont relativement bons. On voit la probabilité maximale (1) pour ladifférenciation entre mammifères et poissons. Il y a par contre deux résultats de probabilités médiocres. Le premierétant la différenciation entre le cheval et les autres mammifères (0.62), le second étant entre l’Homme et les autresmammifères (0.24).De plus, nous observons que le mammifère le plus proche de l’homme est, dans ce cas, le macaque avec uneprobabilité de 0.97.
Bibliographie :
[1]http://www.phylogeny.fr/version2_cgi/simple_phylogeny.cgi?workflow_id=d205c1e1fdeabef848dec98d6e15da46&tab_index=6&go_next=1, Consulté le 14.04.2010

TP Bioinformatique 23.04.2010Coralie Fournier
10
TP4-Introduction à la prédiction de gène
Avec la séquence d’ARNm : NM_000799.2 venant de NCBI
• Traduction séquence ARNm en protéine [1]
Avec la séquence d’ARNm : NM_000799.2 venant de NCBI
On traduit séquence ARNm en séquence protéine. On remarque Met et codon STOP. A l’œil on voit les séquencesqui pourraient traduire une protéine (les séquences assez longues). La traduction peut être effectuée suivant plusieurstypes de lecture (premier aa, deuxième aa, troisième aa), c’est pourquoi nous obtenons plusieurs « Frame ». Trois delecture 5’3’ et trois pour la lecture 3’5’. Sur l’erytropoïétine on trouve rapidement une séquence qui sera certainement cellecodant pour la protéine. Cela se confirme par un Blast sur UniProt. Cela dit, d’autre séquences seraient susceptible d’êtredes séquences codantes pour des protéines, mais en testant par un Blast, on se rend compte que ce n’est pas le cas !
• Prédiction du gène d’après la séquence d’ADN
Avec la séquence d’ADN : NC_000007.13 venant de NCBI
On prédit l’allure qu’aura le gène (nombre d’exon, d’introns) d’après sa séquence ADN.
Voilà ce qui est obtenu et donc prédit par le site HMMGene [2]. Nous observons que notre gène de l’EPO contient 5exons. Puis 2 exons dans l’autre sens.
Nous pouvons comparer cela avec la prédiction faite sur le site WebGene [3] :
no_name
Homo sapiens
CC Search in direct strand
CC Results of gene prediction by GeneBuilder systemCC using ESTs, coding potential and similarity with key protein(s)CC URL: www.itba.mi.cnr.it/webgene

TP Bioinformatique 23.04.2010Coralie Fournier
11
CC Good splice signals mode
CC No restriction on first and last CDSs
CC All potential CDS were used for prediction
FH Key Location/QualifiersFHFT CDS 1..128FT /note=potential CDS predicted by GeneBuilder systemFT /note=partially sequenced CDSFT CDS 820..905FT /note=potential CDS predicted by GeneBuilder systemFT /note=internal protein-coding exonFT CDS 1164..1250FT /note=potential CDS predicted by GeneBuilder systemFT /note=internal protein-coding exonFT CDS 1866..2045FT /note=potential CDS predicted by GeneBuilder systemFT /note=internal protein-coding exonFT CDS 2180..2332FT /note=potential CDS predicted by GeneBuilder systemFT /note=last CDSXXFT CpG_island 1..404FT /note=detected CpG island
Nous remarquons ici que seul les exons dans un seul sens de lecture sont donnés. Nous en obtenons aussi cinq. Maisnous pouvons observer que le premier exon n’est pas placé au même endroit dans nos deux prédictions, ainsi que le ¨départ¨dudeuxième exon.
HMMGene WebGene1er exon 183-195 1-128
2ème exon 760-905 820-905
• BLAST pour comparaison des séquences ARNm
Deux BLAST sont effectués, un sur NCBI [4] et un autre sur UCSC [5]. Cela permet de comparer les séquences de gène avecles ESTs humains. On remarque qu’il n’y a pas de correspondance avec des ESTs humains, cela ne veut pas dire que le gènen’existe aps, mais simplement qu’il n’es pas assez étudié.

TP Bioinformatique 23.04.2010Coralie Fournier
12
BLAST NCBI
BLAST UCSC

TP Bioinformatique 23.04.2010Coralie Fournier
13
Bibliographie :
[1] http://www.expasy.org/cgi-bin/dna_aa, Consulté le 16 avril 2010[2] http://www.cbs.dtu.dk/cgi-bin/nph-webface?jobid=HMMgene,4BC85940005BA998&opt=none, Consulté le 16 avril 2010[3] http://zeus2.itb.cnr.it/cgi-bin/genebuilder.pl, Consulté le 16 avril 2010[4] http://blast.ncbi.nlm.nih.gov/Blast.cgi, Consulté le 16 avril 2010[5] http://genome.ucsc.edu/cgi-bin/hgTracks?insideX=115&revCmplDisp=0&hgsid=156670519&hgt.out1=1.5x&position=chr7%3A100318423-100321321&hgtgroup_map_close=0&hgtgroup_phenDis_close=1&hgtgroup_genes_close=0&hgtgroup_rna_close=0&hgtgroup_expression_close=1&hgtgroup_regulation_close=1&hgtgroup_compGeno_close=0&hgtgroup_varRep_close=0,Consulté le 16 avril 2010
J'atteste que dans ce texte toute affirmation qui n'est pas le fruit de ma réflexion personnelle est attribuée à sa source et quetout passage recopié d'une autre source est en outre placé entre guillemets