
Information géospatiale dans internet - Yvan...
14
Géomatique — 13/2003. Les SIG sur le web, pages 323 à 338 Information géospatiale dans internet Application pour un contexte de renseignement militaire Marie-Josée Proulx* - Yvan Bédard* François Létourneau** * Centre de recherche en géomatique, Université Laval, Québec, Canada ** R & D pour la Défense du Canada — Valcartier, Québec, Canada {marie-josee.proulx;yvan.bedard}@scg.ulaval.ca [email protected] RÉSUMÉ : Les outils SIG-web utilisent fréquemment les coordonnées géographiques ou le découpage cartographique pour indexer leurs données, même si ces localisants sont complexes à comprendre pour l’usager de masse. Par contre, de plus en plus de systèmes utilisent des localisants nominaux (par exemple noms de lieu ou adresses civiques) pour lancer des recherches Ces localisants sont par la suite associes à des coordonnées géographiques de façon transparente à l’utilisateur. Cependant, trop souvent les localisants textuels ne sont pas uniques et varient dans le temps et dans l’espace. De plus, la recherche sur des termes apparentés peut parfois être plus fructueuse. Afin de faciliter la recherche d’information géospatiale, les services SIG-web proposent différentes composantes comme les index de noms de lieu et les services d’analyse géosémantique. Ces services améliorent la pertinence des résultats obtenus par la définition d’un vocabulaire structuré et la normalisation des termes utilisés. Plusieurs de ces pistes représentent des axes de développement prometteurs pour la géomatique et font l’objet du présent article. Un prototype d’application développé au Centre RDDC Valcartier est discuté. ABSTRACT: Web-based GIS generally use geographic coordinates or cartographic index to retrieve their data although these geographic designations are complex to understand by end users. On the other hand, more and more systems use textual designations such as place names or street addresses to launch researches. These textual designations are afterward associated to geographic coordinates in a way that is transparent to the user. However, these textual designations are frequently not unique and vary in time and space. Furthermore, a research on similar terms can sometimes be more pertinent. To facilitate research of geospatial information, Web-based GIS services propose various solutions such as gazetteers and geoparsing services. These services improve the results obtained with the help of a structured vocabulary and the standardisation of the terms used, Such ideas represent interesting avenues for geomatics and are described in this paper. A prototype developed with the RDDC-Valcartier is discussed. MOTS-CLÉS: cartographie, SIG-web, localisants, indexation, analyse géosémantique, toponymie, index de noms de lieu. KEYWORDS: Mapping, GIS-Web, place name, toponymy, indexing, geoparser, gazetteer.
Transcript of Information géospatiale dans internet - Yvan...

Géomatique — 13/2003. Les SIG sur le web, pages 323 à 338
Information géospatiale dans internet Application pour un contexte de renseignement militaire Marie-Josée Proulx* - Yvan Bédard* François Létourneau** * Centre de recherche en géomatique, Université Laval, Québec, Canada ** R & D pour la Défense du Canada — Valcartier, Québec, Canada {marie-josee.proulx;yvan.bedard}@scg.ulaval.ca [email protected] RÉSUMÉ : Les outils SIG-web utilisent fréquemment les coordonnées géographiques ou le découpage cartographique pour indexer leurs données, même si ces localisants sont complexes à comprendre pour l’usager de masse. Par contre, de plus en plus de systèmes utilisent des localisants nominaux (par exemple noms de lieu ou adresses civiques) pour lancer des recherches Ces localisants sont par la suite associes à des coordonnées géographiques de façon transparente à l’utilisateur. Cependant, trop souvent les localisants textuels ne sont pas uniques et varient dans le temps et dans l’espace. De plus, la recherche sur des termes apparentés peut parfois être plus fructueuse. Afin de faciliter la recherche d’information géospatiale, les services SIG-web proposent différentes composantes comme les index de noms de lieu et les services d’analyse géosémantique. Ces services améliorent la pertinence des résultats obtenus par la définition d’un vocabulaire structuré et la normalisation des termes utilisés. Plusieurs de ces pistes représentent des axes de développement prometteurs pour la géomatique et font l’objet du présent article. Un prototype d’application développé au Centre RDDC Valcartier est discuté. ABSTRACT: Web-based GIS generally use geographic coordinates or cartographic index to retrieve their data although these geographic designations are complex to understand by end users. On the other hand, more and more systems use textual designations such as place names or street addresses to launch researches. These textual designations are afterward associated to geographic coordinates in a way that is transparent to the user. However, these textual designations are frequently not unique and vary in time and space. Furthermore, a research on similar terms can sometimes be more pertinent. To facilitate research of geospatial information, Web-based GIS services propose various solutions such as gazetteers and geoparsing services. These services improve the results obtained with the help of a structured vocabulary and the standardisation of the terms used, Such ideas represent interesting avenues for geomatics and are described in this paper. A prototype developed with the RDDC-Valcartier is discussed. MOTS-CLÉS: cartographie, SIG-web, localisants, indexation, analyse géosémantique, toponymie, index de noms de lieu. KEYWORDS: Mapping, GIS-Web, place name, toponymy, indexing, geoparser, gazetteer.

Géomatique — 13/2003. Les SIG sur le web
1. Introduction
Plusieurs types de documents tels les cartes, pages web, images et jeux de données géographiques décrivent, représentent ou font simplement référence, de par leur contenu, à des lieux. A titre d’exemple, ils contiennent des adresses civiques, numéros de téléphone et noms de lieu qui sont des modes de localisation avec différents niveaux de précision et que l’on peut utiliser pour indexer ces documents. De tels éléments définissent le contexte géographique d’un document et sont une source d’information très utile pour permettre de localiser géographiquement le contenu de ce document ou d’une source d’information géographique.
Dans plusieurs situations de recherche d’information, l’utilisation de ce contexte géographique est une bonne stratégie (par exemple utiliser le nom d’un pays avec le nom d’une ville pour rechercher des pages web portant sur le tourisme de cette ville). Plusieurs applications SIG-web exploitent ainsi des éléments du contexte géographique Cependant, même si plusieurs modes de localisation existent, les outils de recherche actuels sont généralement peu intuitifs pour l’utilisateur de masse. «Malgré la fréquence de contexte géographique, les moteurs de recherche actuels du web sont mal adaptés pour aider les gens à trouver l’information qui touche à une position particulière. » (Jones et al., 2002, traduction de l’auteur).
Pour parvenir à analyser cette problématique, nous dresserons le contexte de l’indexation et de la recherche dans internet. Par la suite, nous détaillerons les différents modes de localisation des éléments spatiaux sur le territoire et évaluerons ceux pouvant être privilégiés pour la recherche de documents spatiaux ou de données géospatiales dans internet. Finalement, nous présenterons la solution proposée au Centre RDDC Valcartier (un centre de recherche de l’agence de R&D du ministère de la Défense du Canada) pour le développement de leur outil de recherche d’information géospatiale sur le web. 2. L’indexation et la recherche de données géospatiales dans internet
Comme on le sait, l’indexation de données est problématique en soi. Il existe à l’heure actuelle plus de 3 milliards de documents indexés dans internet selon différentes méthodes. Les méthodes actuelles d’indexation de pages web s’appliquent par extension à l’indexation de données géospatiales (par exemple jeux de données, fichiers cartographiques, images satellitaires, etc.).
L’indexation directe de données est la méthode d’indexation la plus répandue comme par exemple, enregistrer manuellement les pages web directement dans l’index d’un moteur de recherche. L’indexation peut aussi se faire par la création de fichiers de métadonnées associé au document ou par l’utilisation de balises dans l’en-tête du document. Par exemple, une balise Méta « geotag» insérée dans l’en tête d’une page web permet d’indexer une page par nom de lieu, région ou coordonnées géographiques (Daviel, 2000).
L’avantage de l’indexation directe est l’assurance que le document est indexé par une
personne qualifiée pour identifier sans ambiguïté l’information nécessaire pour l’indexation. Malheureusement, nombre de documents ayant des références géographiques dans leur contenu sont publiés sur le web par leur auteur sans que celui-ci les indexe géographiquement, simplement par manque d’information ou d’intérêt.

Information géospatiale dans internet
L’indexation indirecte est une autre méthode particulièrement intéressante puisqu’elle
n’exige pas que l’auteur fournisse les informations lui-même. Par exemple, l’indexation automatisée de pages web peut se faire par les robots des moteurs de recherche qui se basent sur la fréquence des mots-clés rencontrés. D’autres méthodes plus sophistiquées utilisent l’analyse sémantique (parsing) pour analyser le contenu des pages en se basant sur un vocabulaire précis pour identifier les mots à indexer. Il navigue dans une sélection documents, telle les pages web ou les fichiers numériques (pdf, word) afin d’y identifier les termes inclus dans sa banque de connaissances (vocabulaire temporel, sur les individus, sur les pays). Le résultat obtenu correspond à la liste des mots retrouvés pour chacun des documents. Si l’information recherchée est de nature spatiale (par exemple nom de ville, adresse, code de pays, coordonnées), il s’agit d’analyse géosémantique (geoparsing). GATE1 est un exemple concret d’outil d’analyse géosémantique puisqu’il possède une liste noms de lieu ainsi que divers noms associés (noms des habitants, noms des capitales, noms des cours d’eau principaux). Les projets Geographic Search de Google2 et MetaCarta3 permettent de leur côté de géocoder des pages web à partir d’adresses civiques et de codes postaux inclus dans les pages et de donner ensuite la proximité de ces pages par rapport à un point définit par l’utilisateur (par exemple sa localisation).
Une autre approche consiste en l’analyse des adresses internet. Cette approche permet de déduire la provenance géographique des pages web par l’analyse des suffixes de leur adresse internet (par exemple ca-Canada, ch-Suisse, edu-université américaine). Il faut cependant être vigilant et analyser aussi le contenu des pages, car il est possible qu’un site français avec une extension .fr parle d’un voyage au Québec. Le projet GeoSearch (Ding et al. 2000) permet de géocoder une page web à partir de l’analyse géosémantique de son contenu, mais aussi à partir d’un tri par popularité où l’importance d’une page est évaluée en fonction des liens hypertextes qui pointent vers elle et en fonction de la nature du document qui la cite.
Par conséquent, un outil de recherche de données géospatiales efficace doit combiner plusieurs méthodes d’indexation lors de la recherche afin d’accéder au plus grand nombre de résultats et aux plus pertinents. En plus d’exploiter les index existants (par exemple moteurs de recherche web ou banques de métadonnées), l’outil de recherche devrait donc exploiter l’analyse sémantique ainsi que l’analyse de l’adresse internet d’une page pour compléter et valider les informations obtenues.
Mais encore, plusieurs variantes existent. D’abord, les interfaces de recherche par mots-clés sont les plus populaires (par exemple Google). Ces interfaces permettent la saisie directe d’information sous forme de texte. D’un autre côté, l’utilisation d’interface cartographique est propre à notre communauté. Ce type d’interface évite la manipulation directe de coordonnées géographiques par l’utilisateur puisqu’elle s’occupe de la transformation des pointés effectués par l’utilisateur sur une carte en coordonnées exploitables dans la recherche (par exemple tracé de polygone ou pointé à l’écran), améliorant ainsi la convivialité du système. Il devient ainsi plus facile d’identifier les 28 Paris des Etats-Unis en visualisant des points sur une interface cartographique.
Toutefois, quand nous essayons de fouiller sur le web à partir d’un mot-clé relatif à un emplacement géographique spécifique, l’information sur de plus proches emplacements que 1 General Architecture for Text Engineering, http://gate.ac.uk/ 2 Gagnant au concours de programmation de Google 2002, http://ofb.net/~egnor/google.html 3 http://www.metacarta.com

Géomatique — 13/2003. Les SIG sur le web
l’emplacement demandé peut aussi présenter un intérêt. Selon (Jones et al., 2002), «Il y a un besoin pour des systèmes qui supportent la correspondance imprécise de terminologie de nom de lieu. Cela ne permettra pas juste l’accès à ces ressources par la correspondance exacte aux termes de la requête, mais aussi à celles qui touchent aux lieux qui sont d’emplacements semblables ou voisins. » Selon (Yokaji et al., 2001), le moteur de recherche à base de mots-clés a laissé échapper plus de 25 % de documents concernant l’emplacement demandé comparé avec leur solution qui utilise les coordonnées géographiques comme critères de recherche pour identifier dans un index de noms de lieu les emplacements qui sont adjacents à l’emplacement demandé.
Enfin, pour que la recherche sur internet soit plus efficace, l’approche du web sémantique (Daconta et al., 2003) recommande l’utilisation d’une ontologie afin de normaliser les termes utilisés. Cette approche permet d’identifier des termes semblables aux termes mentionnés dans la requête. Ce qui étend la portée de la requête. L’utilisation d’un thesaurus permet de supporter l’ontologie d’une application puisqu’il contient un vocabulaire contrôlé de termes de cette application (ANSI/ISO, 1993). Généralement le thesaurus contient ce vocabulaire selon une langue choisie et exploite les relations sémantiques entre les termes qui s’appliquent à un ou plusieurs domaines de la connaissance (OLF, 2003). Les termes d’un thesaurus sont ainsi reliés entre eux par des relations associatives (use, used for ou related term) qui permettent de définir des termes équivalents comme: les traductions entre langages (par exemple Allemagne versus Germany), les variantes linguistiques (par exemple Deutschland versus Bundesrepublik Deutschland) et les noms historiques (Allemagne versus Deutsches Reich). Les thesaurus contiennent aussi des relations hiérarchiques (whole/part of) qui permettent de positionner tous les noms de lieu par rapport au lieu racine de premier niveau (par exemple monde). Une bonne revue des relations possibles dans les thesaurus a été menée par (Tudhope et al., 2001). Le Getty Thesaurus of Geographic Name4 est un tel exemple de thesaurus de noms de lieu. Le projet GenThes (Kramer et al., 1997) résulte d’une approche permettant l’interrogation de plusieurs sources hétérogènes et multilingues de thesaurus. Le projet GIPSY (Geo-referenced Information Processing System) (Woodruff et al., 1994) est un exemple de système qui extrait des informations de nature géographique de documents en utilisant un thesaurus et un index de noms de lieu. Un index de noms de lieu (ou gazetteer) se compose d’une liste de noms de lieu associés à une localisation géographique (i.e. coordonnées) et d’autres informations descriptives comme des statistiques (Hill et al., 1999). Le Canadian Geographic Names Services5 le Geographic Names Information System6 (GNIS) et le National Imagery and Mapping Agency’s (NIMA) Geonames Server7 sont de tels index de noms de lieu. 3. Utilisation des différents modes de localisation pour la recherche des données géospatiales sur internet 3.1. Les modes de localisation des éléments spatiaux sur le territoire
Il existe plus d’une dizaine de modes de localisation utilisés pour positionner les éléments spatiaux sur le territoire. Ils sont de nature quantitative (qui sont mesurables) ou qualitative. Nous introduisons ici chacun de ces modes pour ensuite identifier dans les 4 http://www.getty.edu/research/conducting_research/vocabularies/tgn/ 5 http://geonames.nrcan.gc.ca/index_f.php 6 http://www-nmd.usgs.gov/www/gnis/ 7 http://www.nirna.mil/gns/html/

Information géospatiale dans internet
prochaines sections ceux dont l’utilisation présente davantage un intérêt pour l’indexation et la recherche d’information géospatiale dans internet.
Les coordonnées géographiques utilisent les longitudes et latitudes pour localiser un point sur le territoire, le tout relativement à un ellipsoïde de référence choisi (mais rarement identifié). D’autre part, les coordonnées cartographiques résultent d’une transformation des coordonnées géographiques basée sur des systèmes de référence planimétrique et un choix de projection cartographique (parmi plusieurs) ainsi que d’ellipsoïde de référence. Les coordonnées peuvent donc varier selon le système de référence employé. Les coordonnées locales permettent de localiser un phénomène à l’intérieur d’un système cartésien local, sans rattachement à un système global pour la planète, et ne peuvent donc pas être utilisées sans problème pour une recherche sur le web.
Les systèmes de référence linéaire sont généralement utilisés pour localiser un objet situé sur ou près d’un élément linéaire, et ceci à l’aide d’une mesure effectuée le long de l’élément à partir d’un point d’ancrage jusqu’à l’endroit désiré. Par exemple, des événements (par exemple des accidents) et des objets (par exemple des ponts) peuvent être localisés à l’aide d’une seule distance prise sur une route, depuis une intersection bien identifiée, si l’objet est ponctuel ou de deux distances (début, fin), si l’objet est linéaire. Ces systèmes étant relatifs, ils posent également de sérieux problèmes pour une recherche sur le web.
L’adressage universel NAC (Natural Area Coding) est une méthode de localisation nouvelle proposée par NAC Geographic Product (2003) et récemment intégrée dans les produits Microsoft. Il s’agit de l’utilisation d’un système de localisation codifiée dérivée des longitudes et latitudes. L’adresse universelle localise un emplacement unique, de un à trente mètres de résolution, localisé n’importe où dans le monde. Il s’agit d’un système similaire aux systèmes imbriqués de découpage cartographique utilisés par plusieurs agences nationales de cartographie topographique.
L’utilisation de noms de lieu permet d’utiliser la dénomination d’un lieu ou d’un site pour l’identifier et le localiser. Cette dénomination peut être officielle, on parle alors de toponyme (par exemple Paris). Lorsque la dénomination permet la localisation d’un élément «important» dans le paysage, comme un aéroport, on parle alors de point remarquable. Si cet emplacement n’a pas de nom significatif mais est facilement localisable sur le territoire, on parle de point de repère (ou point d’intérêt). Par exemple, une tour d’observation en forêt, une tour de communication ou une intersection de rivière avec une route sont des points de repères.
L’utilisation des adresses civiques (par exemple 143 rue Saint-Jean) et d’intersection de rues (angle rue Saint-Jean et rue d’Aiguillon) sont probablement les modes de localisation les plus courants. La configuration de l’adresse est très diversifiée d’une région à l’autre du globe, par exemple elle peut se composer du numéro civique, du nom ou du numéro de la rue, de la ville, de l’état ou province et du pays et dans certains cas d’un code postal. Le positionnement des adresses civiques se fait généralement à l’aide de référence linéaire interpolée à l’intérieur d’une tranche d’adresses pour un segment de rue et qui conduit finalement à la définition de coordonnées. Par contre, la graduation des adresses étant rarement uniforme le long d’une rue, l’adresse civique doit être traitée comme un localisant qualitatif (ordinal) car ce mode de localisation ne permet de localiser qu’approximativement des points ou des zones sur un segment linéaire (i.e. une rue).

Géomatique — 13/2003. Les SIG sur le web
Le code postal permet de localiser grossièrement un élément à l’intérieur d’un pays (par exemple le code postal GIV 2S7 est localisé dans l’est de la province de Québec), voire d’une ville (par exemple Quartier Montcalm à Québec). Le code postal ne peut cependant pas donner le périmètre d’un secteur puisqu’il correspond au point de chute du courrier dans une région donnée.
Les composantes du numéro de téléphone (par exemple le code local) permettent de localiser grossièrement un élément dans un secteur donné. Les numéros de téléphone canadiens, par exemple, correspondent à un code de pays, un code régional et un code local à l’intérieur duquel des numéros locaux sont accordés (4 derniers chiffres). Cependant, avec la multiplication du nombre de numéros accordés (télécopieur, cellulaire, téléavertisseur) cette déduction n’est plus aussi vraie qu’autrefois.
Le découpage cartographique est une façon de découper le territoire en feuillets cartographiques identifiés de façon unique. Ce découpage suit habituellement des latitudes et longitudes prédéfinies et utilise une numérotation imbriquée (par exemple 21-L-14 qui correspond au feuillet 14 à l’intérieur de la zone L elle-même incluse dans la zone 21). L’utilisation de ce mode de localisation est surtout utile pour localiser grossièrement des endroits sans dénomination précise à l’intérieur d’une zone. La codification d’un feuillet fait en sorte que l’on peut le positionner par rapport aux autres feuillets appartenant à ce système de découpage. Ce découpage peut toutefois être très fin, par exemple dans le cas de feuillets topographiques à très grande échelle (1:1000).
Le découpage de Philips est une codification définie à partir de la réorganisation de coordonnées rectangulaires d’une zone canée et dont le résultat s’apparente à un découpage cartographique (cf. imbrication, limites définies par latitude/longitude ou coordonnées cartographiques importantes). Par contre, le code résultant est un nombre duquel on peut déduire directement la coordonnée du coin inférieur gauche de la zone identifiée plutôt qu’un numéro identifiant ne portant pas en soi sa coordonnée (par exemple 21-L-14) et requérant un système de correspondance pour trouver la position. Ce mode de localisation est générique et aussi universel que le système de coordonnées utilisé (tout comme l’adressage universel), il est notamment utilisé dans les cadastres fiscaux en Amérique du Nord où l’identifiant d’une parcelle correspond à la coordonnée de Philips de son centroïde (Gouvernement du Québec, 1984). 3.2. Mode de localisation à privilégier dans un contexte web
Le choix du mode de localisation à privilégier pour la recherche de données géospatiales se doit d’être en accord avec le contexte propre de recherche d’information dans internet. L’univers qu’est l’internet soulève des problématiques particulières qui peuvent se résumer ainsi :
— ce médium de communication s’adresse autant à des spécialistes qu’à des profanes en informatique. Une considération particulière doit être apportée aux choix des modes de localisation utilisés ainsi qu’à la conception de l’interface à l’usager afin de s’adresser à cette dernière clientèle ;
— cet univers est soumis à une infinité de langues, alphabets et codes de caractères qui
compliquent la définition des requêtes ;

Information géospatiale dans internet
— il n’y a pas d’uniformité dans le choix des méthodes utilisées pour indexer des
documents ou données géospatiales. Un outil de recherche efficace doit considérer plusieurs de ces méthodes afin d’identifier l’ensemble des résultats les plus pertinents;
— les documents ou données géospatiales sont encore aujourd’hui indexés de la même
manière que les documents non spatiaux. Il n’y a pas d’identification particulière dans les critères de recherche (par exemple métadonnées spatiales ou mots-clés géographiques);
— les documents ne sont pas méthodiquement indexés de manière géographique. Malheureusement, une masse importante de documents se trouve donc invisible aux recherches exploitant ce type d’information.
À la lecture du contexte propre à la recherche dans internet, nous pouvons définir certaines propriétés qui privilégient l’utilisation d’un mode de localisation sur le web.
— Convivialité: un mode de localisation convivial permet à l’utilisateur de se souvenir
facilement d’une localisation pour la communiquer à un autre individu ou à un système. Les modes de localisation qualitatifs comme les localisants textuels d’utilité courante (par exemple une adresse civique) répondent à ce critère. Les modes de localisation quantitatifs sont généralement plus complexes à retenir à cause de leur composition à plusieurs caractères, de l’utilisation accrue de nombres et de systèmes de référence.
— Universalité: un mode de localisation est dit universel lorsqu’il est utilisé mondialement et qu’il est indépendant des langues et des conventions locales de pays. Ainsi, sa compréhension est sans équivoque et ne laisse pas ou peu de place à l’interprétation. Les modes qualitatifs ne peuvent être universels puisqu’ils dépendent d’une langue. Par exemple, l’appellation de noms de lieu peut être différente entre la langue d’origine du pays (par exemple Al-Iraq) et d’autres langues (par exemple Irak ou Iraq). En fait, l’utilisation de localisants textuels demeure périlleuse et introduit plusieurs problèmes. Selon (Cai, 2001), « Nous savons aussi que l’utilisation de termes géographiques dans des index est la cause de problèmes bien connus, comme l’utilisation de noms de lieu non uniques, de nom de lieu qui pourrait changer dans le temps et des variations d’orthographe. » Ainsi, une adresse postale et un numéro de téléphone ne sont pas universels même s’ils indiquent une localisation unique et que des normes existent (par exemple USPS Addressing Standard8 pour les Etats-Unis) puisque leur composition varie d’un pays à l’autre. Cependant, les modes quantitatifs peuvent être universels s’ils sont basés sur des systèmes de référence définis à l’échelle mondiale. Par exemple, l’utilisation de coordonnées géographiques basées sur l’ellipsoïde WGS84 (World Geodetic Datum) est mondialement utilisée pour la navigation tandis que celles basées sur le NADS3 (North American Datum) ne sont que définies localement pour l’Amérique du Nord.
— Durabilité : un mode de localisation durable permet une localisation invariable dans l’espace et dans le temps puisqu’il est indépendant des changements de frontières territoriales ou autres changements. Les modes universels sont généralement durables. Par exemple, les coordonnées géographiques (longitude, latitude) sont indépendantes des changements socio-politiques du territoire et des déplacements de frontières. Par contre, ils sont tout de même légèrement sensibles à un changement de datum de référence (par exemple passer éventuellement de WOSS4 à W0S20??). Inversement, un nom de lieu (par exemple
8 http://www.nena.org/9-1-l TechStandards/Standards_PDF/USPSPub28.pdf

Géomatique — 13/2003. Les SIG sur le web
Ville de Québec) qui référait à une étendue précise à une année X (par exemple avant la fusion municipale de 2002) peut aujourd’hui référer à une étendue incluant l’emplacement des localités voisines (par exemple après la fusion de 2002).
— Unicité: un mode de localisation unique permet de localiser un endroit de manière unique et sans ambiguïté à l’intérieur d’un système. Les modes de localisation universels permettent la localisation unique à l’échelle mondiale par eux seuls. Un mode de localisation peut avoir recours à un autre mode pour le compléter et ainsi le rendre unique. Par exemple, la localisation par nom d’intersection de rues n’est pas unique, car les noms de rue peuvent se répéter d’une municipalité à l’autre ou à l’intérieur d’une même municipalité. Ce mode de localisation a besoin d’une autre composante d’adresse pour être unique (par exemple code postal ou groupe de numéros civiques).
— Certitude : un mode de localisation non équivoque indique que l’utilisation de ce
seul mode de localisation est suffisant pour se localiser d’une manière juste et sur le territoire. Les modes quantitatifs sont souvent non équivoques tandis que les modes qualitatifs nécessitent régulièrement leur association à un autre mode de localisation (habituellement des coordonnées) afin de définir la position d’une manière sans équivoque. Par exemple, une adresse peur être positionnée à l’aide de fichiers d’adresses contenant les coordonnées géographiques nécessaires pour le géocodage. Cependant, les cas d’adresses complexes (par exemple adresses fractionnaires ou avec lettres) ainsi que les sites avec une adresse alternative, les sauts de numéros civiques et les changements de densité des numéros rendent ambiguë et imprécise la localisation par adresse. Ce dernier exemple peut devenir non équivoque si les adresses sont rattachées à chaque édifice individuel au lieu d’être interpolées entre les adresses de début et de fin de segments de rue (comme il est fait habituellement en géocodage).
— Mesurabilité: un mode de localisation mesurable permet de dériver directement des
calculs comme des superficies, distances et trajets le plus court. Les modes quantitatifs sont par définition mesurables (par exemple les coordonnées). Cette propriété n’est pas possible avec les modes de localisation qualitatifs per se.
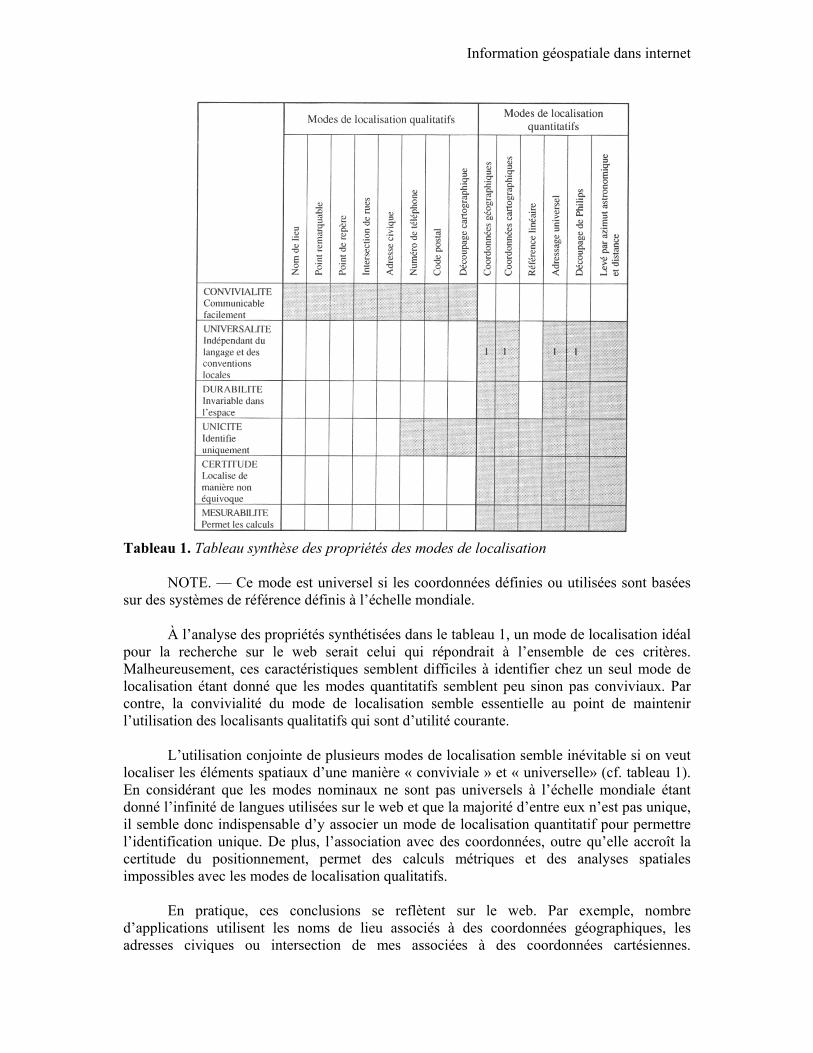
Le tableau I synthétise les propriétés de chaque mode de localisation qu’il soit qualitatif ou quantitatif.
Information géospatiale dans internet
Tableau 1. Tableau synthèse des propriétés des modes de localisation
NOTE. — Ce mode est universel si les coordonnées définies ou utilisées sont basées sur des systèmes de référence définis à l’échelle mondiale.
À l’analyse des propriétés synthétisées dans le tableau 1, un mode de localisation idéal pour la recherche sur le web serait celui qui répondrait à l’ensemble de ces critères. Malheureusement, ces caractéristiques semblent difficiles à identifier chez un seul mode de localisation étant donné que les modes quantitatifs semblent peu sinon pas conviviaux. Par contre, la convivialité du mode de localisation semble essentielle au point de maintenir l’utilisation des localisants qualitatifs qui sont d’utilité courante.
L’utilisation conjointe de plusieurs modes de localisation semble inévitable si on veut localiser les éléments spatiaux d’une manière « conviviale » et « universelle» (cf. tableau 1). En considérant que les modes nominaux ne sont pas universels à l’échelle mondiale étant donné l’infinité de langues utilisées sur le web et que la majorité d’entre eux n’est pas unique, il semble donc indispensable d’y associer un mode de localisation quantitatif pour permettre l’identification unique. De plus, l’association avec des coordonnées, outre qu’elle accroît la certitude du positionnement, permet des calculs métriques et des analyses spatiales impossibles avec les modes de localisation qualitatifs.
En pratique, ces conclusions se reflètent sur le web. Par exemple, nombre d’applications utilisent les noms de lieu associés à des coordonnées géographiques, les adresses civiques ou intersection de mes associées à des coordonnées cartésiennes.

Géomatique — 13/2003. Les SIG sur le web
L’utilisation du système d’adressage universel aurait avantage à se démocratiser. Cependant les modes de localisation tels que la référence linéaire, le découpage de Philips et les levés font rarement l’objet d’applications sur le web probablement parce que le mode de localisation par coordonnées est plus répandu et sensiblement équivalent. 4. Outil de recherche de données géospatiales sur le web application pour un contexte de renseignement militaire
L’équipe de recherche et développement pour la Défense Canada Valcartier (RDDC — Valcartier) travaille sur le développement d’un prototype d’outil de recherche qui permet d’effectuer des recherches à caractère géospatial dans internet en général ou dans des bases de données documentaires constituées par les officiers du renseignement des Forces canadiennes. À des fins de planification de missions ou de veille informationnelle, les analystes militaires effectuent des recherches d’informations variées, ayant fréquemment des composantes géographiques. Afin de bien documenter les rapports et les analyses qu’ils produisent, les analystes du renseignement recherchent des canes, des photos, des images satellites ou d’autres documents sous forme textuelle (par exemple pages web, rapport socio-historique, livre, etc.) se rapportant à un territoire en conflit. Le contexte particulier de recherche d’information de la Défense nationale couvre un large spectre, nécessitant la découverte de données et d’informations portant sur un pays, une région ou une ville et ce à l’échelle du monde. Ainsi, on comprendra que plusieurs mécanismes de recherche de l’information géospatiale exploitant les diverses formes de codification de cette information doivent être utilisés si l’on veut fouiller efficacement la masse d’information disponible et pertinente.
L’approche retenue pour le développement du prototype permettra la recherche utilisant les mots-clés de noms de lieu enrichis par l’utilisation séquentielle de plusieurs thesaurus et index existants composant la base de connaissances (BC). La BC contient les traductions des noms de lieu (Espagne, Spain), leur appellation vernaculaire9 (España), les variantes linguistiques dans une même langue (Royaume d’Espagne), les variantes lexicales à cause de l’ordre des mots (Espagne, Royaume de) ainsi que les noms historiques (Hispanie). Pour les besoins de la première version du prototype, seulement les traductions françaises sont intégrées. Le résultat de la recherche documentaire sera par la suite validé par analyse géosémantique.
L’interface de recherche permet de composer la requête à partir des noms de lieu normalisés proposés par la BC. Ces noms de lieu peuvent être saisis directement dans l’interface textuelle ou récupérés à partir d’une zone dessinée à l’écran ou définie par des coordonnées géographiques (cf. figure 1).
9 La transcription en alphabet latin du nom de lieu dans sa langue d’origine.

Information géospatiale dans internet
Figure 1. Définition de la recherche par coordonnées ou noms de lieu
L’interface cartographique construite avec le serveur web cartographique JMap©10 permet de valider sur une carte la position des différents noms de lieu retournés par la BC comme l’illustre la figure 2.
La sélection définitive du nom de lieu dans la liste permet de définir précisément la requête pour le contexte spatial «Geneva, Switzerland ». Automatiquement, la BC s’occupe de compléter la requête avec les termes équivalents en français « Genève, Suisse » de façon à améliorer la portée de la requête.
Par la suite, le service de recherche documentaire, construit avec le métamoteur de
recherche Copernic©11, dirige la requête vers un ou plusieurs moteurs de recherche d’internet via le protocole http. Le résultat obtenu se compose de la liste de pages web répondants au contexte spatial comme illustré à la figure 3.
Figure 2. Validation de la position correspondant à la ville « Geneva-Switzerland »
10 http://www.kheops-tech.com 11 http://www.copernic.com

Géomatique — 13/2003. Les SIG sur le web
Figure 3. Liste de pages web répondant au contexte spatial
Ultérieurement, dans la seconde version du prototype, le résultat de la recherche documentaire sera récupéré et dirigé au service d’analyse géosémantique. Ce service accèdera à chacune des pages web du résultat afin de valider leurs contextes géographiques à partir du vocabulaire et des relations sémantiques (englobant/englobé) extraits de la BC.
Le service d’analyse géosémantique analysera la description des pages web, si celle-ci est fournie dans son en-tête ou par le moteur de recherche, le contenu de la page et finalement son adresse internet en comparant les termes retrouvés avec une liste de termes définis dans la BC pour ce contexte spatial. La présence des termes «Suisse » ou «Switzerland» dans la page ou du suffixe «ch» dans l’adresse internet permettra de valider la pertinence des résultats. D’un autre côté, il sera possible d’identifier les résultats ambigus par la présence de termes comme «United-States » (puisqu’il y existe des villes appelées Geneva). Ainsi, on identifierait automatiquement les pages web qui réfèrent à des villes américaines (par exemple Illinois et Pennsylvania). Finalement, l’absence dans la page d’une référence directe aux termes associés au contexte spatial peut soulever le fait que la page ne correspond pas à la localisation recherchée. La figure 4 présente une simulation des résultats qui seront obtenus suite à l’analyse géosémantique. Il y sera alors possible de visualiser les hyperliens pertinents, les hyperliens non pertinents et ceux dont on manque d’information pour les valider correctement.
Figure 4. Simulation des résultats obtenus suite à l’analyse géosémantique 5. Conclusion

Information géospatiale dans internet
En premier lieu, le portrait détaillé des différents modes de localisation possibles pour rechercher l’information géospatiales dans internet ainsi que leur problématique particulière a été dressée. Ensuite, l’éventail des approches à privilégier pour améliorer la recherche d’information spatiale dans internet a été présenté de façon à introduire la solution proposée à RDDC Valcartier pour le développement de leur outil de recherche d’information géospatiale sur le web.
Il existait plusieurs applications ou projets pertinents qui traitaient de recherche d’informations géospatiales, cependant ces solutions ne répondaient pas précisément à la problématique de la Défense nationale. C’est pourquoi, une nouvelle approche a été proposée soit la recherche utilisant les noms de lieu enrichis par les informations pertinentes tirées d’une banque de connaissances et validée par l’analyse géosémantique du résultat. Cette solution pallie les contraintes propres à la recherche de données spatiales sur le web, c’est-à-dire, l’absence d’indexation spatiale des documents et la multiplicité des langages rencontrés. Ce système devrait remédier aux limites et à l’inefficacité des outils de recherche actuels permettant la recherche de données géospatiales sur le web et offrir ainsi de meilleures sources d’information aux analystes militaires. Remerciements
Les auteurs tiennent à remercier le Centre RDDC-Vacartier de la Défense nationale du Canada pour leur support financier pour la présente étude. 6. Bibliographie ANSI/NISO, Guidelines for the construction, format, and management of monolingual thesauri, National Organization Standard Organization, ISSN: 1041-5653, 1993, 81 p. Cai, G., «GeoVIBE: A visual interface for geographical Digital Library », The 2001 ACM IEEE JDCL Workshop on visual Interface, June 28th 2001, Virginia, USA. Daconta, M.C., Obrst, L.J., Smith, K.T., The Web Semantic, Wiley Publishing, 2003, 281 p. Daviel A., Geographic registration of HTML documents’, Internet Draft, work in progress (December 2000, Expires July 2001) http://geotags.com/geo/draft-daviel-html-geo-tag pre04.html Ding, J., L Gravano, and N. Shivakumar, « Computing Geographical Scopes of Web Resources », in 26th Inter. Conf. on Very Large Data Bases ( VLDB’OO), 2000, 12 p. Economist.com, « The revenge of geography », March 13th 2003, Economist.com, http://www.economist.com/science/tq/displayStory.cfm?story_id= 1620794 Gouvernement du Québec, Introduction aux systèmes d’information à référence spatiale, Gouvernement du Québec, 1984, 84 p. Hill, LL, Frew, J. and Zheng Qi, «Geographic Names: The implementation of a Gazetteer in a Geographic Digital Library », D-Lib Magazine, vol. 5, January 1999.

Géomatique — 13/2003. Les SIG sur le web
Jones, C, B., R. Purves, A. Ruas, M. Sanderson, M. Sester, M. van Kreveld, R. Weibel, 2002, « Spatial information retrieval and geographical ontologies an overview of the SPIRIT project », Proceedings o the 25 annual international ACM SIGIR, August 11-15, Tampere, Finland, 2002, p. 387-388. Kramer R., Nikolai R., Habeck C., « Thesaurus federations: loosely integrated thesauri for document retrieval in networks based on Internet technologies », International Journal of Digital Libraries, n° 1, vol. 2, 1997, p. 122-131. Mc Curley, K.S., Geospatial mapping and navigation of the Web, Proceedings of the tenth international conference on World Wide Web, May 01-05, Hong Kong, 2001, p. 221-229. NAC Geographic Product in The Launch of the Universal Address System, Direction Magazine, 10 august 2003, http://www.directionsmag.com/ Office de la langue française (OLF), Grand dictionnaire terminologique, 2003, http://www.granddictionnaire.com/ Tudhope, D., H. Alani, C. Jones, « Augmenting thesaurus relationships: possibilities for retrieval ». Journal of Digital Information, vol. 1(8), 2001 : http://jodi.ecs.soton.ac.uk/Articles/v01/i08/Tudhope/ Woodruff, A. G., «GIPSY: Automated Geographic Indexing of Text Documents », Journal of the American Society of information Science, vol. 45, n° 9, 1994, p. 645-655. Yokaji, S., K. Takahashi, and N. Miura, « Konono Search: A location Based Search Engine. Proceedings of the Tenth International World Wide Web Conference », Hong Kong. p. 1146. http://wwwl0.org/cdrom/posters/pll46/index.htm


















