
Indexation et Recherche d’Information...
53
Indexaon et Recherche d’Informaon vidéo Introducon à la RI Modèles de RI
Transcript of Indexation et Recherche d’Information...

Indexation et Recherche d’Information vidéo
Introduction à la RIModèles de RI

Plan
1.Qu’est ce que la RI ?
2. Petit tour d’horizon–Du besoin d’information à la requête –Représentation de l’information
3. Modèles de RI
4. Évaluation des performances

Qu’est ce que la RI ?
• La recherche d’information (RI) est une branche de l’informatique qui s’intéresse à l’acquisition, l’organisation, le stockage, la recherche et la sélection d’information [salton, 1968]
• Terminologie –Recherche d’information, Informatique documentaire –Information Retrieval / Textual Information Retrieval /
Document Retrieval / multimedia Information Retrieval

Domaine très visible …

… Et utile !
•Ouvert à tout le monde
•Domaines d’application –Web, réseaux sociaux –Bibliothèques numériques–Entreprises –Nos propres ordinateurs

La RI est un domaine vaste
• Recherche adhoc • Classification /catégorisation (clustering) •Question-réponses (Query answering) • Filtrage d’information
(filtering/recommendation) •Métat-moteurs (data-fusion,Meta-search) • Résumé automatique (Summarization) •Multi-langues (cross language) • Fouille de textes (Text mining) •Multimédias•…

Objectif de la RI
• Sélectionner dans une collection–Les informations–…pertinentes répondant à des –…besoins d’utilisateurs

8
Eléments clés en RI
•Quels éléments sont centraux pour la Recherche d’Information ?–Documents–Contenu des documents–Besoin d’information d’un utilisateur–Satisfaction

Les documents
• Formes –Texte –images, sons, vidéo, graphiques, etc.
• Propriétés –Structure • non structuré OU semi structuré (XML) (HTML)
–Hétérogénéité • langage (multilingues) • media (multimédia) • granularité

10
Information sur les documents
• 2 classes d’information–Méta-Information (information à propos du
document)• Attributs : titre, auteur, date de création, etc.• Structure (organisation du contenu) : structure logique,
liens, etc.
–Contenu • Contenu brut : le document initial• Contenu sémantique : information « riche » extraite du
contenu brut
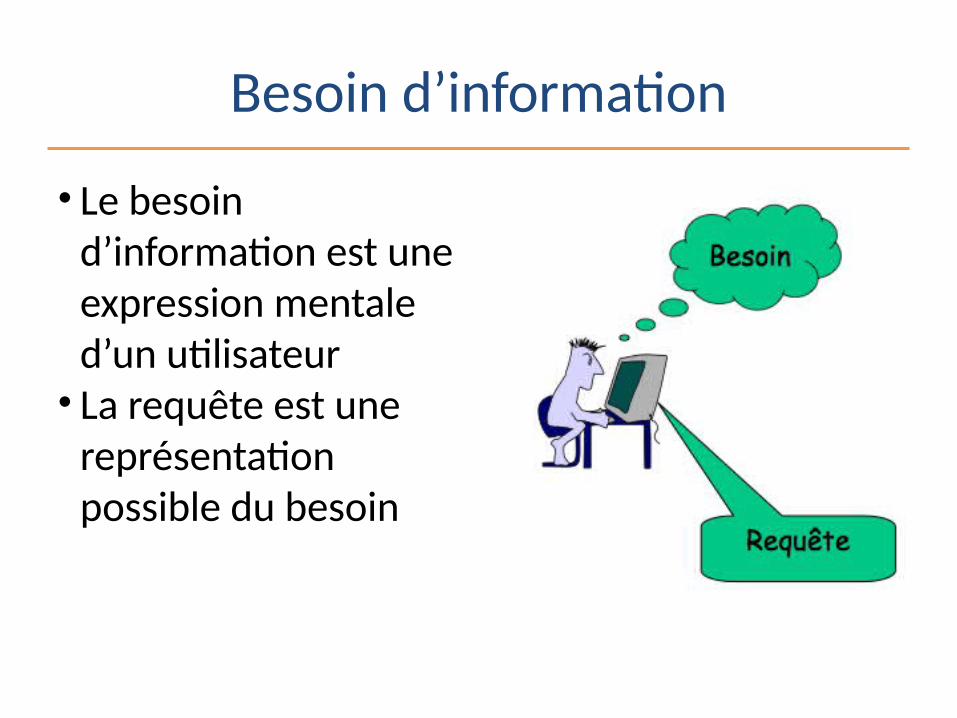
Besoin d’information
• Le besoin d’information est une expression mentale d’un utilisateur • La requête est une
représentation possible du besoin

Pertinence
•Quelle pertinence ?
• Relation (correspondance,…) entre un document et ….….
une requête ou….….un besoin d’information ? Selon ….. l’utilisateur…ou …. le système ?
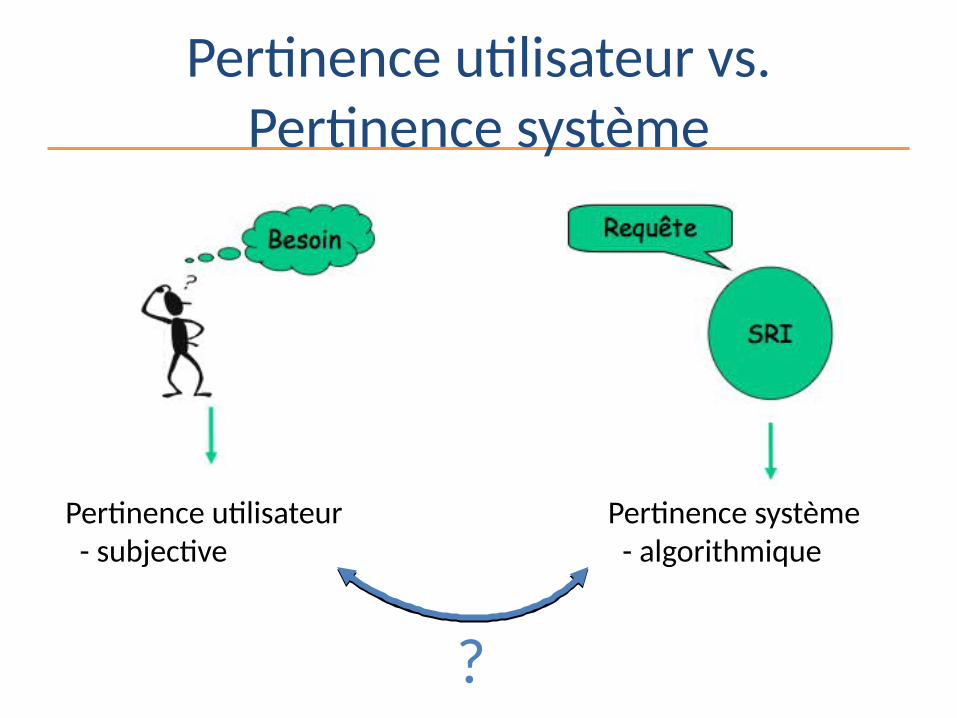
Pertinence utilisateur vs. Pertinence système
Pertinence utilisateur - subjective
Pertinence système - algorithmique
?

La pertinence est difficile à appréhender
• Pertinence est multidimensionnelle–dépend de plusieurs paramètres : l’utilisateur,
besoin d’information, situations des utilisateurs
• Pertinence est graduelle (multivaluée) –un document A peut être plus pertinent que B (ou A
préféré à B)
• Pertinence est dynamique –peut changer dans le temps, selon l’état de
connaissance de l’utilisateur au moment de la recherche

Pertinence ≈ similarité
• Elle est souvent traduite –Vocabulaire similaire pertinent à la requête
• Similarité peut être mesurée–Comparaison (matching) de chaînes de caractères
(ou de motifs)–Même vocabulaire–Même «sens»

Approche générale de la RI
• Vision simple de la RI textuelle : «Trouver les documents ayant les mêmes
mots que la requête»
–La requête comme les documents sont des listes de mots clés –Comparer les mots de chaque document à ceux de
la requête –Sélectionner les documents qui contiennent le plus
de mots de la requête.

Description
ReprésentationReprésentation
Correspondance
Index(inverse)
Besoin
Processus de RI
Requête
Visualisation

Problématiques de la RI
• Représentation de l’information –Comment construire une représentation à partir de
documents ? –Qu’est ce qu’une «bonne» représentation ? –Quelle organisation physique pour les index ?
• Représentation des besoins –Comment exprimer le besoin (langage de
requêtes) ?–Comment représenter le besoin ?
•Mise en correspondance des représentations –Comment mesurer (décider) de la pertinence d’un
document ?
• Évaluation des performances –Comment décider que l’approche A est mieux que
B ? –Quelle démarche (empirique/ analytique) ? –Quelles métriques ?

RI : un domaine de recherche actif !
• Proposer des solutions : –modèles, techniques, outils pour répondre à ces
problèmes
• Avec 2 soucis majeurs–Quels supports théoriques ?• Souvent basés sur des théories mathématiques :
Probabilités, statistiques, ensembles, algèbre, logique floue, analyse de données, …
–Quel processus pour la validation ?
Théorie, pratique et expérimentation

Plan
1. Qu’est ce que la RI ?
2. Petit tour d’horizon–Du besoin d’information à la requête –Représentation de l’information
3. Modèles de RI
4. Évaluation des performances

Du besoin d’information à la requête
• Le besoin peut être–Récurrent (filtrage, recommandation) ou ponctuel
(adhoc)
• Expression des besoins (Langage de requêtes)–Texte libre, Liste de mots clés –Avec / sans opérateurs (AND, OR, NOT)–Images, sons (…) –Appris, par navigation dans la collection (Relevance
feedback)
• Requête : Le résultat …–de l’expression des besoins ?–ou du processus de représentation des besoins ?

Du besoin d’information à la requête
• Paradoxe de la RI–Une requête «idéale» doit comporter toutes les
informations que l’utilisateur recherche, la similarité serait alors maximale
–Or, l’utilisateur recherche une information qu’il ne connaît pas à priori, il ne peut donc pas l’exprimer (décrire) de manière précise (idéale)

Représentation de l’information
• Représentation de l’information = indexation–Processus permettant de construire un ensemble
d’éléments «clés » permettant de caractériser le contenu d’un document
• Éléments clés–Information textuelle• mots simples : pomme• groupe de mots : pomme de terre
–Image • Couleurs, formes, textures

Indexation
• Peut être–Manuelle (expert en indexation) –Automatique (ordinateur) –Semi-automatique (combinaison des deux)
• Basée sur –Un langage contrôlé
(lexique/thesaurus/ontologie/réseau sémantique) –Un langage libre (éléments pris directement des
documents)
• Approches –Statistique (distribution des mots), TALN
(compréhension du texte), Algébrique, …–L’approche courante est plutôt statistique avec des
hypothèses simples• Redondance d’un mot (terme) marque son importance • Les termes sont indépendants

Indexation
• Démarche de l’indexation automatique–étape 1 : extraction des termes–étape 2 : normalisation des mots (regrouper les
variantes d’un mot )–étape 3 : pondération (discrimination entre les
termes clés/importants/significatifs et les autres)

Indexation automatique Etape1 : Extraction des termes
• Extraire les termes (tockenization)–Terme = mot (simple/composé), mots clés, concepts–Mot : suite de caractères séparés par (blanc ou signe
de ponctuation, caractères spéciaux,…), Nombres
•Dépend de la langue–Langue française• Pomme de terre? un, deux ou trois termes?
–Langue Allemande les mots composés ne sont pas segmentés• Lebensversicherungsgesellschaftsangestellter• « employé d’une compagnie d'assurance-vie »

Etape1 : Extraction des mots (suite)
• Pas d’espaces en chinois et en japonais–Ne garantit pas l’extraction d’un terme de manière
unique
• Pire, le japonais utilise plusieurs alphabets

Etape 1 : Extraction des mots (suite)
• Suppression des mots «vides» (stoplist/ Common Words removal)–Mots trop fréquents mais pas utiles–Exemples :• Anglais : the, or, a, you, I, us, …• Français : le, la, de , des, je, tu, …
–Des exceptions :• US : «USA »• A de (vitamine A)

Etape 2 : Normalisation
• «Lemmatisation» (radicalisation, racinisation) (stemming)–Processus morphologique permettant de regrouper
les variantes d’un mot• Ex : économie, économiquement, économiste économie• pour l’anglais : retrieve, retrieving, retrieval, retrieved,
retrieves retriev

Etape 2 : Normalisation (suite)
•Utilisation de règles de transformations–règle de type : condition action• Ex : si mot se termine par ‘s’ alors supprimer la terminaison • L’algorithme le plus connu est l’algorithme de Porter
–Analyse grammaticale • Utilisation de lexique (dictionnaire) • Tree-tagger (gratuit sur le net)

Etape 3 : Pondération des mots
• Comment caractériser l’importance des termes dans un document ? –Associer un (ou plusieurs) poids à un terme–Idée sous jacente :• Les termes importants doivent avoir un poids fort
Approche la plus répandue : TF.IDF• Ne concerne pas tous les modèles• cf « Modèle vectoriel »

Plan
1. Qu’est ce que la RI ?
2. Petit tour d’horizon–Du besoin d’information à la requête –Représentation de l’information
3. Modèles de RI
4. Évaluation des performances

33
Modèle booléen
–Modèle de connaissances : T = {ti}, i [1, .. N]• Termes ti qui indexent les documents
–Le modèle de documents (contenu) est une expression booléenne dans la logique des propositions avec les ti considérés comme des propositions :• Un document D1 est représenté par une formule D1
D1= t1 t3 t250 t254
• Une requête Q est représentée par une formule logique Q Q = (t1 t3) (t25 t1045 t134 )

34
Modèle booléen
– La fonction de correspondance est basée sur l’implication logique en logique des propositions :• Un document D répond à une requête Q si et seulement si
D Q– Utilisation de déduction par » Axiomes : (a b) a, (a b) b, a (a b), b (a b), …» modus ponens (MP) : si a et a b alors b
• Exemple : D = t1 t3 et Q = t1 t4 – Déduction :
1. t1 t3 t1 (équivalent à D t1)2. MP(1) : t1 3. t1 t1 t4 (équivalent à t1 Q )4. MP(3) : Q
Q est donc dérivable à partir de D, donc D Q : le document répond à la requête.

35
Modèle booléen
–Correspondance stricte– Q = t1 t3 t4
– D1 = t1 t4 ,
D1 Q– Le document D1 (représenté par D1) n’est pas pertinent pour la
requête Q (représentée par Q) d’après le modèle, alors qu’il contient une description « proche » de la requête.

36
Modèle booléen
–Pas de distinction entre les documents pertinents– Q = t1 t4
– D2 = t1 t4 , D3 = t1 t3 t4 t5 t6 t7
D2 Q et D3 Q – Le document D2 (représenté par D2) est-il plus ou moins pertinent
que D3 (représenté par D3) pour la requête D (représentée par Q) ?

37
Modèle booléen
–Expression de requêtes complexe– Q = ((t1 t4) t6) ( t8 (t10 t40)) … ???
– Sens du logique (inclusif) différent du « ou » courant (exclusif)

Modèle booléen : avantages et inconvénients
• Avantage : –Le modèle est transparent et simple à comprendre p
our l'utilisateur : • Pas de paramètres « cachés » • Raison de sélection d'un document claire : il répond à une f
ormule logique
–Adapté pour les spécialistes et les vocabulaires contraints
• Inconvénients : –Il est difficile d'exprimer des requêtes longues sous f
orme booléenne–Le critère binaire est peu efficace–Il est admis que la pondération des termes améliore
les résultats • Cf. modèle booléen étendu
–Il est impossible d'ordonner les résultats • Tous les documents retournés sont sur le même plan • L'utilisateur préfère un classement lorsque la liste est grand
e

39
Modèle vectoriel
•Modèle de connaissances : T = {ti}, i [1, .. N]• Tous les documents sont décrits suivant ce
vocabulaire
•Un document Di est représenté par un vecteur Di décrit dans l’espace vectoriel RN défini par T :–Di = (wi,1, wi,2, …, wi,j, …, wi,N), avec wkl le poids d’un
terme pour un document•Une requête Q est représentée par un vecteur
Q décrit dans l’espace vectoriel RN défini par T :–Q = (wQ,1, wQ,2, …, wQ,j, …, wQ,N)
I
40
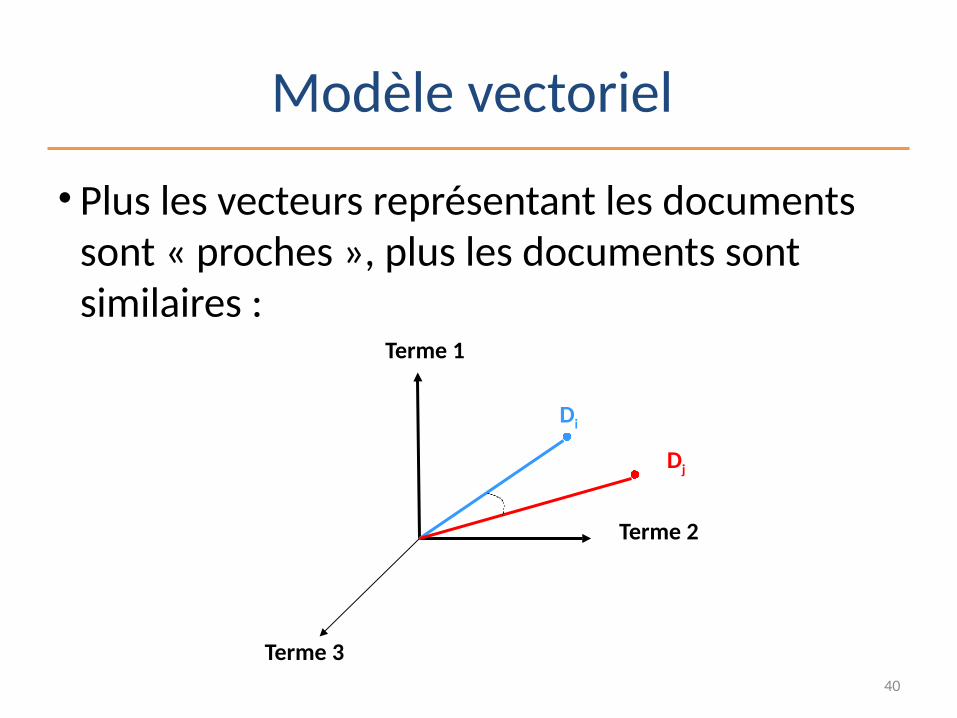
Modèle vectoriel
• Plus les vecteurs représentant les documents sont « proches », plus les documents sont similaires :
Di
Terme 1
Terme 3
Terme 2
Dj

41
Modèle vectoriel
• Pondération des termes pour les documents : –Un document
– « Un violon est issu de bois précieux comme l’érable, palissandre, l’ébène... »
–Pour indexer, la première idée est de compter les mots les plus fréquents excepté les termes non significatifs comme « de », « avec », « comme »…– « Un violon est composé de bois précieux comme l’érable, le
palissandre, l’ébène... »
Termes retenus et comptés

42
Modèle vectoriel
• Pondération :–Fréquence d’un terme (term frequency)
• ti,j : la fréquence du terme tj dans le document Di est égale
au nombre d’occurrences de tj dans Di.
• Exemple : si violon apparaît 5 fois dans le document D3,
avec violon=t23, alors t3,23 = 5
43
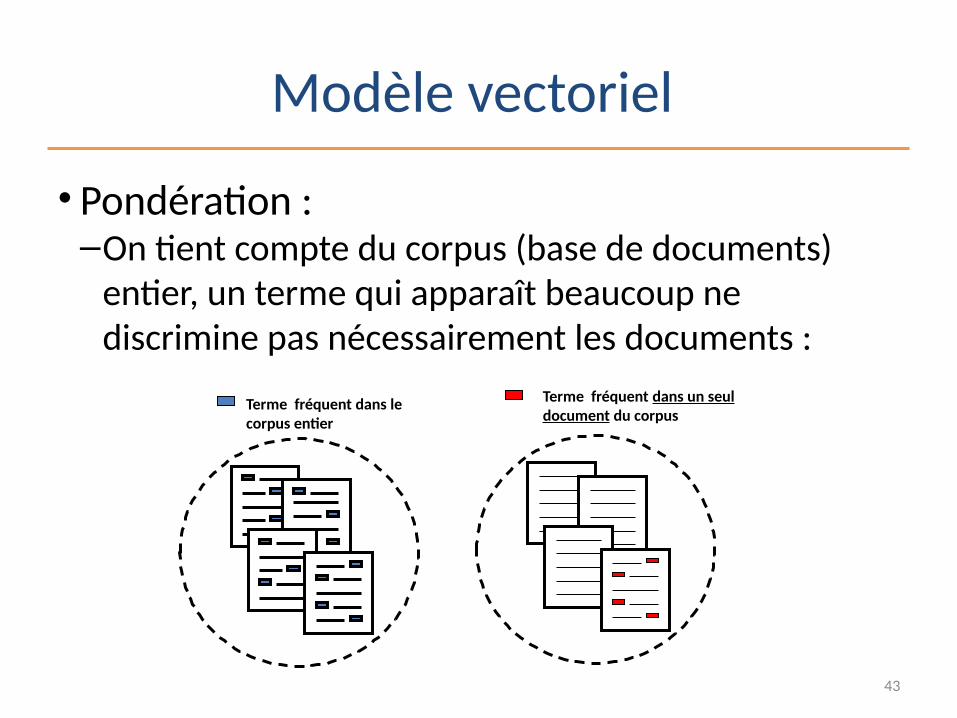
Modèle vectoriel
• Pondération :–On tient compte du corpus (base de documents)
entier, un terme qui apparaît beaucoup ne discrimine pas nécessairement les documents :
Terme fréquent dans le corpus entier
Terme fréquent dans un seul document du corpus

44
Modèle vectoriel
• Pondération :–Fréquence documentaire d’un terme
• dfj : la fréquence dans le corpus du terme tj est le nombre de documents du corpus où tj apparaît
–On utilise l’inverse de la fréquence documentaire, idfj :• Définition simple : idfj = 1 / dfj
• Définition la plus utilisée : idfj = log(ND / dfj), avec ND le nombre de documents du corpus.

45
Modèle vectoriel
• Pondération :–Combinaison du t et de l’idf pour un vecteur
document:• Exemple le plus courant– wi,j = ti,j . idfj
–Utilisation du t pour une requête
46
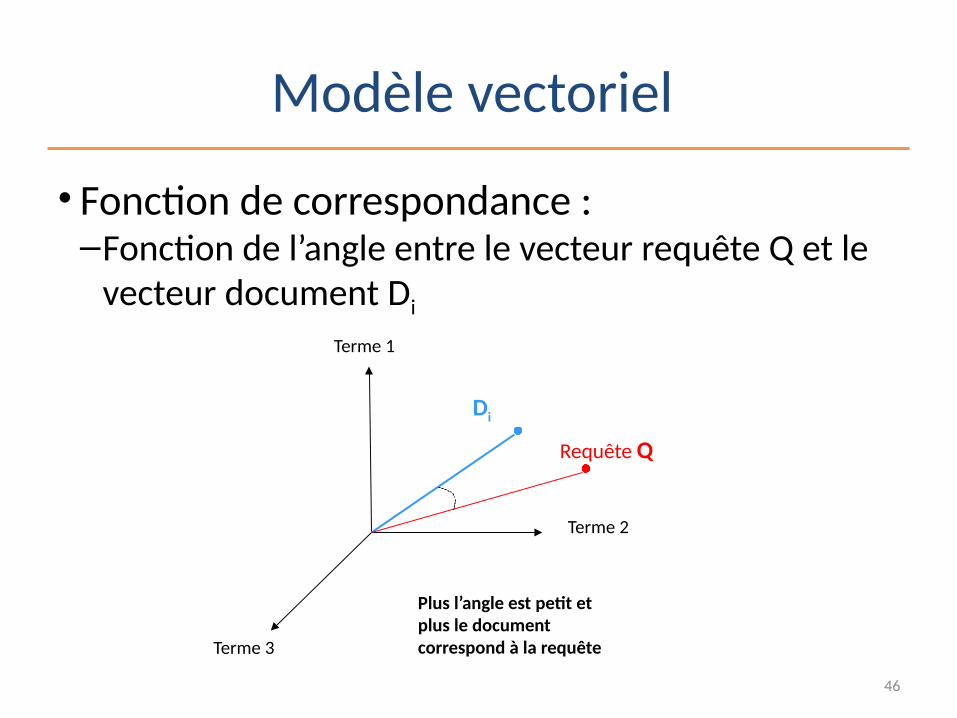
Modèle vectoriel
• Fonction de correspondance :–Fonction de l’angle entre le vecteur requête Q et le
vecteur document Di
Di
Requête Q
Terme 1
Terme 3
Terme 2
Plus l’angle est petit et plus le document correspond à la requête

47
Modèle vectoriel
• Fonction de correspondance :–Une solution est de calculer le cosinus de l’angle
entre le vecteur requête et le vecteur document.
• Produit scalaire
• Cosinus de l'angle
•Distance euclidienne

Modèle vectoriel : avantages et inconvénients
• Avantages :–Le langage de requête est plus simple (liste de mot
clés) –Les performances sont meilleures grâce à la pondéra
tion des termes –Le renvoi de documents à pertinence partielle est po
ssible –La fonction d'appariement permet de trier les docu
ments
• Inconvénients :–Le modèle considère que tous les termes sont indép
endants (inconvénient théorique) –Le langage de requête est moins expressif –L'utilisateur voit moins pourquoi un document lui es
t renvoyé
Le modèle vectoriel est le plus populaire en RI

Modèle probabiliste (survol)
• Suppose que la recherche se déroule lors d’une « session de recherche » (plusieurs itérations)• Consiste à « estimer » la pertinence d'un
document en fonction de pertinences connues pour d'autres documents.• Ce calcul se fait en estimant la pertinence de
chaque index pour un document et en utilisant le Théorème de Bayes et une règle de décision
49
50
Modèle probabiliste
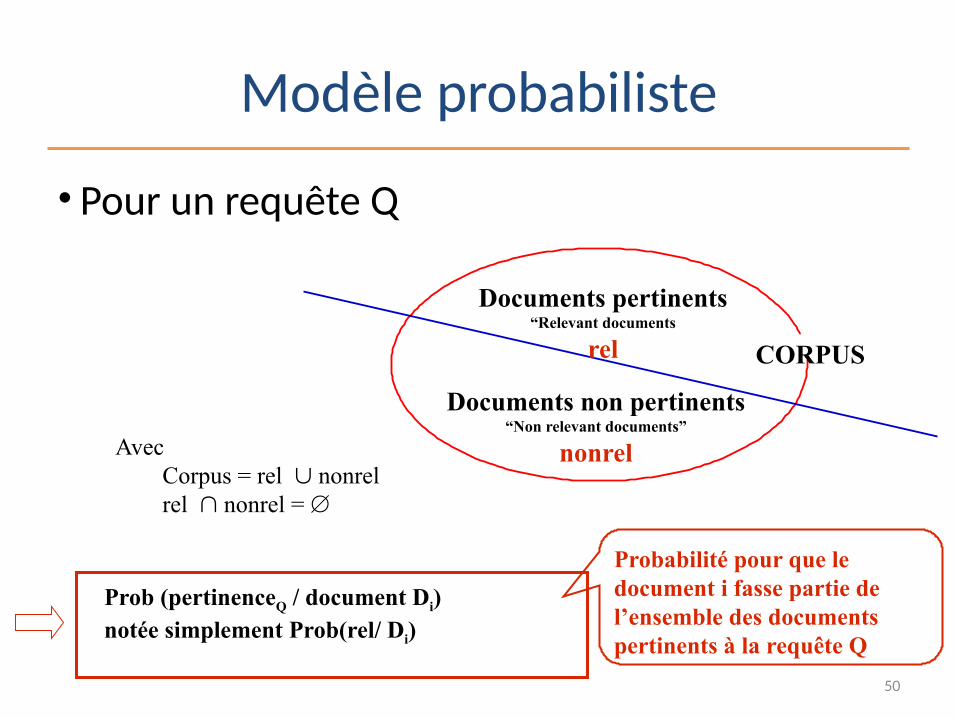
• Pour un requête Q
Documents non pertinents“Non relevant documents”
nonrel
CORPUS
Documents pertinents“Relevant documents
rel
AvecCorpus = rel nonrelrel nonrel =
Probabilité pour que le document i fasse partie de l’ensemble des documents pertinents à la requête Q
Prob (pertinenceQ / document Di) notée simplement Prob(rel/ Di)

Modèle probabiliste
• Fonction de correspondance :–On ne sait pas calculer P(rel |
d), mais on peut calculer P(d | rel)–Utilisation du théorème de Bayes
51
Probabilité pour que le document i soit pertinent pour la requête q
Probabilité d'obtenir un document pertinent en piochant au hasard
Probabilité que le document soit choisi au hasard
Probabilité d’obtenir dj
en connaissant les pertinents

52
Modèle probabiliste
• Fonction de correspondance• Décision : document retourné si
– Prob(Rel / Di ) / Prob(nonRel / Di ) > 1
– Avec hypothèse d’indépendance des termes

Modèle probabiliste : avantages et inconvénients
• Avantages :–Apprentissage du besoin d’information– La fonction d'appariement permet de trier les documents
• Inconvénients :– Le modèle considère que tous les termes sont indépendants
(inconvénient théorique) –Pas de langage de requête !–Problème des probabilités initiales
Résultats comparables à ceux du modèle vectoriel






![[RI] chap1_Ri](https://static.fdocuments.fr/doc/165x107/5571fade4979599169935829/ri-chap1ri.jpg)











