
Implémentation de l’algorithme de transformation d’un...
64
Approche MDA pour la transformation d’un diagramme de classes conforme UML 2.0 en un schéma relationnel conforme CWM et normalisé_L. Expérimenter le langage ATL dédié à la transformation de modèle pour l’implémentation d’une méthode de transformation d’un diagramme UML en un schéma CWM. Rapport de Stage de fin de Master, Juin 2006. Etudiant : Antoine Wiedemann Etudiant en Master 2ème année mention Informatique, Mathématique et leurs Applications, option recherche Image et Calculs à l’Université de La Rochelle. Encadrants : Jean-Yves et Marie-Christine Lafaye, Georges Louis Professeurs à l’Université de La Rochelle
Transcript of Implémentation de l’algorithme de transformation d’un...

Approche MDA pour la transformation d’un diagramme de classes conforme UML 2.0
en un schéma relationnel conforme CWM et normalisé_L.
Expérimenter le langage ATL dédié à la transformation de modèle pour l’implémentation d’une méthode de transformation d’un diagramme UML en un schéma CWM.
Rapport de Stage de fin de Master, Juin 2006. Etudiant : Antoine Wiedemann Etudiant en Master 2ème annéemention Informatique, Mathématique et leurs Applications, option recherche Image et Calculs à l’Université de La Rochelle.
Encadrants : Jean-Yves et Marie-Christine Lafaye, Georges Louis Professeurs à l’Université de La Rochelle


Table des matières
1 Introduction ...................................................................................................................... 1 2 Générer un modèle relationnel normalisé
à partir de diagrammes de classes UML [1] ................................................................. 2 2.1 Introduction d’une nouvelle forme normale : la normalisation_L ............................. 2
2.1.1 Normalisation en conception de base de données []. ......................................... 2 2.1.2 Les premières règles de normalisation ............................................................... 2 2.1.3 Normalisation allégée (Normalisation_L), présentée dans l’article de M.C. Mafaye, J.Y. Lafaye et G. Louis [1]................................................................................... 3
3 Quelques définitions......................................................................................................... 4 3.1 Modèle........................................................................................................................ 4 3.2 UML 2.0 ..................................................................................................................... 4 3.3 OCL 2.0...................................................................................................................... 6 3.4 CWM.......................................................................................................................... 6 3.5 Metamodèle................................................................................................................ 9 3.6 MOF ......................................................................................................................... 10
4 La génération d’un modèle relationnel vue comme une transformation de modèle. ....................................................................... 11
5 L’ingénierie dirigée par les modèles, ou Model-driven Architecture (MDA) .......... 12 5.1 MDA......................................................................................................................... 13 5.2 QVT.......................................................................................................................... 16
6 ATL.................................................................................................................................. 16 6.1 L’opération élémentaire de transformation : la règle ATL ...................................... 17 6.2 Utilisation d’ATL..................................................................................................... 19
6.2.1 Spécification des métamodèles ........................................................................ 19 6.2.2 Spécification des modèles ................................................................................ 22 6.2.3 Le module ATL................................................................................................ 24
6.3 Des exemples de cas d’utilisation d’ATL ................................................................ 25 7 Implémentation............................................................................................................... 26
7.1 Un exemple de modèle de domaine ......................................................................... 26 7.2 Accoucher les métamodèles ..................................................................................... 27
7.2.1 Spécifier le métamodèle cible : le métamodèle de CWM................................ 27 7.2.2 Spécifier le métamodèle source, le métamodèle de domaine ou encore le métaMDC. ........................................................................................................................ 28 7.2.3 Résultat : le métaMDC..................................................................................... 29 7.2.4 Construire un exemple de modèle conforme.................................................... 31
7.3 Extraire de l’algorithme les règles de transformation .............................................. 34 7.3.1 Algorithme général de traduction : Objet vers relationnel normalisé_L.......... 34 7.3.2 Identifier les éléments et leurs antécédents ...................................................... 36 7.3.3 Déterminer les opérations de traduction........................................................... 37 7.3.4 Exprimer les opérations dans le langage ATL ................................................. 37 7.3.5 Exemple 1, Classe_Table ................................................................................. 37 7.3.6 Exemple 2, AssoBinaire_Cas2......................................................................... 38
7.4 Contrôler, compléter, corriger .................................................................................. 43 8 Conclusions à l’issu de l’expérimentation.................................................................... 44
8.1 Les avantage d’ATL................................................................................................. 44

8.2 Inconvénients d’ATL ............................................................................................... 45 8.3 Une ou plusieurs transformations ? .......................................................................... 45
8.3.1 Chaînage de transformations............................................................................ 45 8.3.2 Création de plusieurs métamodèles intermédiaires .......................................... 45
9 Travaux futurs................................................................................................................ 46 9.1 Délimiter l’intervention d’ATL dans le processus................................................... 46 9.2 Terminer l’évolution du métaMDC.......................................................................... 46 9.3 Terminer l’extraction de règles de l’algorithme....................................................... 46 9.4 Explorer les possibilités d’interfaçage ..................................................................... 47
10 Conclusion....................................................................................................................... 47 11 Annexes ........................................................................................................................... 48
11.1 Le code complet de la transformation (module MDC2MLRnL.atl) ........................ 48 11.2 Le module MDC2Chemins.atl ................................................................................. 50 11.3 Description des métaclasses du métaMDC. ............................................................. 51
11.3.1 Classe_persistante ............................................................................................ 51 11.3.2 Generalisation_persistante ............................................................................... 52 11.3.3 Association_persistante.................................................................................... 53 11.3.4 Attribut ............................................................................................................. 53 11.3.5 ID...................................................................................................................... 54 11.3.6 ID_exportable................................................................................................... 55 11.3.7 Symb_ID_exportable ....................................................................................... 55 11.3.8 Composant_identifiant ..................................................................................... 56 11.3.9 Espace_de_recherche ....................................................................................... 56 11.3.10 Arc_de_composition .................................................................................... 57
12 Ressources Internet et bibliographiques ...................................................................... 59

Table des figures Figure 1 - Extrait du métamodèle UML 2.0............................................................................... 5 Figure 2 - Extrait du métamodèle de CWM .............................................................................. 8 Figure 3 - Exemple de trois classes d’un modèle dont deux
sont conformes à leur métaclasse dans le métamodèle..................................................... 9 Figure 4 -L’architecture 4-niveaux définie par l’OMG ........................................................... 10 Figure 5 -L’architecture de métadonnées de l’OMG............................................................... 11 Figure 6 - La transformation d'un modèle ............................................................................... 12 Figure 7 - Logo MDA............................................................................................................... 13 Figure 8 - Vue générale d’une transformation d’un PIM en PSM .......................................... 14 Figure 9 - Un exemple de règle ATL........................................................................................ 17 Figure 10 -Vue d’ensemble d’une transformation ATL ........................................................... 19 Figure 11 -Extrait d’un fichier de définition du métamodèle UML 2.0 au format km3........... 20 Figure 13 - « Injection » du fichier km3 dans le format xmi conforme Ecore......................... 20 Figure 14 -Extrait d’un fichier de définition du métamodèle UML 2.0 au format xmi ........... 21 Figure 15 - Le fichier MDC.ecore affiché par l’éditeur EMF ................................................. 22 Figure 16 -Exemple de départ de définition d’une classe,
dans un fichier ecore au format xmi................................................................................ 22 Figure 17 - Un onglet « Properties » permet d’accéder aux propriétés de la classe Class. ... 22 Figure 18 - Le mot clé container permet de refléter une aggregation UML ........................... 23 Figure 19 -Le menu contextuel « New Child »......................................................................... 23 Figure 20 - Le menu contextuel « New Sibling » ..................................................................... 23 Figure 21 - Extrait du code transformation du module ATL ................................................... 24 Figure 22 - L'exemple de transformation Class2Relational .................................................... 25 Figure 23 - Exemple de modèle de domaine annoté utilisé dans l’article [1] ......................... 26 Figure 24 - Extrait du fichier MLRnL.km3 édité dans la plateforme eclipse .......................... 28 Figure 25 - Résultat de « l’injection » du fichier km3 ............................................................ 28 Figure 26 - Notre métamodèle de domaine construit sur UML 2.0 ......................................... 30 Figure 27 - La classe Stage...................................................................................................... 31 Figure 28 - Détail de l’espace de recherche de la classe Stage .............................................. 32 Figure 29 - Modélisation de l'association Stage – Etudiant .................................................... 33 Figure 30 - Les éléments impliqués dans la modélisation
de l’association Stage – Etudiant.................................................................................... 33 Figure 31 - Algorithme général de transformation.................................................................. 35 Figure 32 - Une table pour une classe, en ATL ....................................................................... 38 Figure 33 - Cas générique d’association UML traité par la Normalisation_L....................... 38 Figure 34 - La règle AssoBinaire_Cas2 .................................................................................. 39 Figure 35 - Le helper cardinalites ........................................................................................... 40 Figure 36 - Le helper cas2 ....................................................................................................... 40 Figure 37 - Premièr élément généré par la clause "to" ........................................................... 42 Figure 38 - la deuxième partie de la clause "to" ..................................................................... 42 Figure 39 - Règle de génération des clés primaires ................................................................ 43 Figure 40 - Extrait du résultat de la transformation de la classe Stage .................................. 44

1 Introduction
Le problème de la génération automatique de base de données à partir d’un diagramme de classe a déjà été largement étudié et enseigné sur le plan théorique. Souvent, on se contente d’étudier les différents cas de figure qui peuvent se présenter en terme de multiplicités des associations entre classes, et de déterminer dans chaque cas le schéma relationnel adapté pour implanter ces associations.
En pratique pourtant, le procédé se révèle bien plus complexe dès lors que l’on aborde des cas concrets et que l’on se donne des exigences sur la qualité de la base de données résultante. Que ce soit sur le plan du processus de normalisation, de la conservation des connaissances métier injectées par le concepteur tout au long du processus de génération, et/ou plus concrètement de l’ergonomie des outils disponibles sur le marché, beaucoup reste à faire.
Ainsi, pour aller plus loin dans la précision et la correction sans perdre de vue la simplicité d’utilisation, M.C. Lafaye, J.Y. Lafaye et G. Louis (ci-après nommés les auteurs) proposent dans leur article « Générer un modèle relationnel normalisé à partir de diagrammes de classes UML » [1] un processus complet qui en plus d’adresser les problèmes identifiés plus haut, tire partie d’une nouvelle approche pleine de promesse dans l’univers du génie logiciel : l’ingénierie dirigée par les modèles (MDA en anglais).
Pour valider les avantages de ce processus et de la méthode qu’il incarne, il a été choisi de tenter une partie de son implémentation dans le langage ATL spécialement conçu pour la transformation de modèles. Ce langage est développé dans le cadre du projet ATLAS [2] mené à l’université de Nantes par une équipe de chercheurs de l’INRIA. Le travail présenté ici est une expérimentation et une évaluation de l’utilisation d’ATL pour réaliser cette implémentation.
1

Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
2 Générer un modèle relationnel normalisé à partir de diagrammes de classes UML [1]
Dans l’article cité en titre de cette section, les auteurs se sont attaqués à un problème finalement bien commun et déjà largement traité aussi bien sur le plan théorique dans les ouvrages pédagogiques que sur le plan pratique dans plusieurs ateliers de génie logiciel (ou CASE Tools). Cependant, leurs précédents travaux [3] ont montré à travers trois exemples que l’utilisation de certains outils à disposition produit des résultats largement perfectibles.
Premièrement, les règles de la normalisation ne sont pas respectées, aboutissant à des calculs de clés erronées ou manquantes. Deuxièmement, au stade de la conception, il est parfois difficile d’identifier les objets aussi finement que ce que le modèle relationnel est capable de restituer, et à l’inverse, certaines identifications inutiles et fastidieuses sont rendues obligatoires alors qu’elles ne sont pas utilisées par la suite.
Après avoir identifié ces problèmes, les auteurs se sont donnés pour but d’élaborer une nouvelle méthodologie avec trois ambitions principales : produire un schéma relationnel normalisé, faciliter le travail d’annotation du concepteur, et respecter autant que possible sa terminologie métier. Pour atteindre ces objectifs, les auteurs s’appuient sur différentes innovations dont principalement : l’introduction d’une nouvelle forme normale, la forme normale allégée (appelée normalisation_L), définie par leurs soins comme un relâchement contrôlé de certaines contraintes de la normalisation classique, et l’utilisation de la récente approche MDA particulièrement adaptée à la transformation de modèle et dont nous utilisons les concepts ici.
2.1 Introduction d’une nouvelle forme normale : la normalisation_L
2.1.1 Normalisation en conception de base de données [4].
La qualité d’une base de donnée évoquée en introduction est très liée à la minimisation de la redondance. D’une manière générale, la théorie de la normalisation utilise des dépendances parmi lesquelles les dépendances fonctionnelles, les dépendances multi-valuées et les dépendances de jointure pour construire une structure de données à redondance minimale.
Rappelons la définition d’une dépendance fonctionnelle en base de données : Dans une relation, un sous-ensemble Y d’attributs de R est en dépendance fonctionnelle avec un sous-ensemble X d’attributs de R ( noté X -> Y ) si et seulement si pour toute valeur de R, à chaque valeur de X correspond exactement une seule valeur de Y. X est appelé déterminant.
Plusieurs niveaux de normalisation sont caractérisés : 1FN, 2FN, 3FN, BCNF, 4FN, 5FN.
2.1.2 Les premières règles de normalisation
Première forme normale Une relation est en première forme normale si et seulement si tout attribut de cette
relation est atomique, c'est-à-dire qu’un attribut n’est composé que d’une valeur significative à la fois (par opposition à une adresse complexe, par exemple) et monovalué.
2

Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
Deuxième forme normale Une relation est en deuxième forme normale si et seulement si elle est en première
forme normale, qu’elle n’a qu’une seule clé, et que tout attribut n'appartenant pas à la clé ne dépend pas d'une partie de cette clé.
Troisième forme normale Une relation est en troisième forme normale si et seulement si elle est en deuxième
forme normale et si chaque attribut non clé est en dépendance non transitive avec la clé primaire.
Forme normale de Boyce-Codd (BCNF) Une relation est en forme normale de Boyce-Codd si et seulement si seuls les
déterminants sont des clés candidates. Quatrième et cinquième formes normales. Pour traiter les cas plus complexes ou apparaissent des association n-m entre les
relations du schéma relationnel, la théorie de la normalisation introduit, au-delà des simples dépendances fonctionnelles qui sont utilisés dans les énoncés de ces premières formes normales, les notions de dépendances multi-valuées et de composantes de jointure (ou dépendance de jointure). L’étude de ces notions sort du cadre du présent travail. Elles sont simplement mentionnées ici puisqu’elles font partie de l’arsenal des outils qui ont étés utilisés par les auteurs du processus pour garantir sa qualité.
L’application de ces principes permet une amélioration considérable de la qualité de la
base obtenue à partir du schéma ainsi normalisé. Elle facilite le respect des contraintes d’intégrité imposées lors de la conception en évitant la redondance des données et donc en rendant les mises à jour plus aisées.
2.1.3 Normalisation allégée (Normalisation_L), présentée dans l’article de M.C. Mafaye, J.Y. Lafaye et G. Louis [1].
Comme nous l’avons vu dans la section précédente, la théorie de la normalisation généralement admise aujourd’hui, et qui par son application en conception de base de données est un gage de qualité, énonce un certain nombre de principes, qui conduisent à la modification de la structure d’un schéma relationnel initial.
Cependant, l’application stricte de la normalisation conduit dans certains cas à la création de tables supplémentaires, qui ne font que satisfaire au principe de conservation des dépendances. C’est pourquoi dans leur article [1], les auteurs s’autorisent quelques entorses à ces règles de normalisation, pour pouvoir les appliquer de façon plus réaliste sans introduire forcément de redondance. Cette normalisation « allégée », ou normalisation_L propose par rapport à la normalisation stricte les nuances suivantes :
• Les attributs à valeur NULL sont admis • Les règles des premières formes normales, jusqu’à la BCNF, ne sont
appliquées non pas à toutes les dépendances fonctionnelles mais seulement à celles permettant de collecter l’ensemble des contraintes d’unicité et de référence sur les tables relationnelles.
3

Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
3 Quelques définitions
Il convient, avant d’aller plus loin, de définir ce que l’on entend ici par modèle, et également de métamodèle ainsi que l’articulation entre ces concepts.
3.1 Modèle
Un modèle pourrait être défini comme une représentation abstraite de quelque chose. En pratique, les modèles sont présents partout autour de nous dans la vie courante, et les exemples sont nombreux. Un plan de votre maison par exemple est le modèle à partir duquel on a construit la maison que vous habitez. Ce plan regroupe des caractéristiques de dimension que votre maison respecte (en principe). Dans le contexte de la modélisation, on dit alors que votre maison est représentée par son modèle (son plan). Un modèle peut également représenter des choses plus abstraites, comme par exemple une séquence d’opérations qui s’enchaînent dans le temps, ou bien alors l’organisation et les interactions qui ont lieu entre les employés d’une entreprise.
Il est important de noter que plusieurs entités distinctes peuvent êtres représentées par un unique modèle donné. Par exemple, dans un immeuble d’habitation, tous les appartements sont souvent construits à partir d’un nombre limité de modèles différents (un modèle de T3, un modèle de T2, etc.).
Intuitivement, les atouts de l’utilisation d’un modèle sont nombreux, surtout comme outil de communication. Reprenons l’exemple de la maison. Le plan d’une maison est le fruit d’une concertation entre un architecte et le futur propriétaire, et permet de visualiser l’allure générale du bâtiment. Il permet également de faire des calculs de dimension pour les matériaux utilisés lors de la construction, mais aussi de présenter le projet à la mairie pour obtenir un permis de construire. Le plan est naturellement relu par l’entrepreneur et utilisé comme guide de montage pendant la construction. Enfin, lors d’un éventuel recours du propriétaire qui a noté une non conformité de l’ouvrage terminé avec le plan initial, c’est le document qui fait foi et qui est présenté à une instance judiciaire.
Cette notion peut s’appliquer à de nombreux domaines, et en particulier celui qui nous intéresse, l’informatique. Dans ce cas, le modèle reste un outil de communication, mais les acteurs ne sont plus systématiquement humains. L’exemple le plus connu est la programmation, où un opérateur humain (le programmeur) écrit un modèle de comportement ou de calcul (un programme), et le transmet à travers un processus de compilation ou d’interprétation au système informatique qui produit un comportement ou des calculs décrits dans le modèle initial.
De la même façon que le plan de l’architecte est écrit avec une syntaxe, une nomenclature et des symboles picturaux précis, de nombreux langages de programmation différents coexistent et peuvent chacun exprimer certains types de modèles de cacluls. On voit donc que même si le concept de modèle est très répandu, les langages pour les exprimer sont très variables.
3.2 UML 2.0
UML [5] (pour Unified Modeling Language) est aujourd’hui le standard des langages de modélisation objet partout où cette dernière est utilisée. Ce langage est l’une des spécifications centrale de l’OMG, et est aujourd’hui dans sa version 2.0. Il présente sur le plan
4

Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
sémantique et pratique de grandes qualités d’utilisation, et dans le cas présent de la conception de base de données, UML est depuis longtemps utilisé pour spécifier à un haut niveau d’abstraction la structure et l’articulation des données, sous forme respectivement de classes et d’associations.
Par ailleurs, un avantage de cette technologie, à la fois cause et conséquence de sa grande popularité, est la profusion sur le marché d’outils plus ou moins ergonomiques dédiés à la création et la manipulation de diagrammes UML. C’est pourquoi il a été choisi, dans l’implémentation de l’algorithme présenté ici, d’utiliser un diagramme de classe UML comme moyen de dialogue avec le concepteur, pour capter ses exigences et ses connaissances métier. Le cadre du problème étant bien délimité, nous n’utiliserons pas toute la complexité du langage UML. Nous attendons du concepteur qu’il exprime des informations de type structurelles et pas dynamiques. Ainsi, parmi la multitude de types de diagrammes prédéfinis par la spécification UML [6], nous n’utiliserons que le format diagramme de classes. Nous pourrons même nous satisfaire d’un sous-ensemble des classes prédéfinies dans le package Kernel de la spécification de la superstructure d’UML 2.0. Ces classes sont indiquées dans le diagramme ci-dessous.
<<metaclass>>AssociationClass
<<metaclass>>Class
<<metaclass>>Association
<<metaclass>>Classifier
<<metaclass>>Property
<<metaclass>>Constraint
<<metaclass>>Generalization
<<metaclass>>NamedElement
<<metaclass>>StructuralFeature
<<metaclass>>TypedElement
MultiplicityElement
<<metaclass>>ValueSpecification
<<metaclass>>PackageableElement
<<metaclass>>Expression
<<metaclass>>Namespace
<<metaclass>>Type
<<metaclass>>Element
<<metaclass>>DirectedRelationship
<<metaclass>>Relationship
isOrdered : booleanisUnique : boolean
general1
generalization*
1 specific
name : string
0..1
type
constrainedElement
*
0..1 2..*
memberEnd
association
symbol : string
* operand
0..1 expression
0..1
class
*ownedAttribute
1upperValue
lowerValue1
specification
0..1
Figure 1 - Extrait du métamodèle UML 2.0
Cet ensemble de classes préexiste dans la spécification, chacune avec sa sémantique et
ses caractéristiques, en terme d’attributs, de multiplicités, mais aussi de lien les unes avec les autres. Elles ne sont pourtant que rarement faites pour être utilisées telles quelles, mais plutôt pour constituer les éléments de base à la construction d’autres classes, plus finement définies au plus proche des besoins de l’utilisateur (leur majorité est en conséquence définie comme abstraite, d’où leur nom de « métaclasses »). Nous avons ainsi créé un nouvel ensemble de classes spécifiques au problème posé, soit en héritant des classes de base mentionnées dans le
5

Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
diagramme précédent, soit en en définissant de nouvelle. Cet ensemble nous permet dans l’algorithme de proposer au concepteur le vocabulaire nécessaire et suffisant pour exprimer ses besoins et ses souhaits, en terme de structure de données, d’articulation des données et d’identification. Ces métaclasses sont présentées plus loin.
3.3 OCL 2.0
OCL [12] (pour Object Constraint Language) est une autre spécification de l’OMG. Cette spécification propose un langage de description de contraintes sur des modèles UML. Jusqu’à la version 1.4 de ce dernier, OCL était décrit à l’intérieur des spécifications d’UML tant les deux sont liés. Aujourd’hui dans sa version 2.0, la maturation d’OCL l’a amené à posséder sa propre documentation parallèle à celle d’UML.
OCL n’est pas un langage de programmation et il ne permet pas de contrôler un flot d’exécution ou d’agir sur son environnement d’exécution, c’est seulement un langage formel suffisamment simple pour être utilisé par des non mathématiciens pour écrire des expressions devant êtres évaluées sur des modèles UML. Les expressions OCL s’évaluent toujours soit en un des quatre types primitifs définis : entier, réel, chaîne de caractère et booléen, soit en un élément du modèle, soit en un groupe homogène de ces types tels que les séquences d’entiers, les séquences ordonnées de booléens ou une séquence de « Property »… Ces expressions peuvent ensuite êtres utilisées pour spécifier des contraintes bien sûr, mais aussi des pré ou des post-conditions d’opérations ou de méthodes, ou encore simplement comme expressions de requêtes de certaines valeurs d’un modèle.
Pour « naviguer » dans les attributs, les références ou les méthodes d’un élément ‘E’ de modèle, OCL utilise le point « . », comme le fait Java par exemple (E.attribut1, E.methodeB, E.associationF). Quand un attribut est multivalué ou qu’une association mène à plusieurs éléments à la fois, l’évaluation de cet attribut ou de cette association renvoi une séquence, ordonnée ou non des éléments qu’il référence. Pour manipuler ces séquences, OCL défini toute sortes de mots clés pour les trier, en extraire des éléments, en ajouter, les compter, etc.…
Enfin, OCL est défini comme un langage sans effet secondaires (side-effect free en anglais), c'est-à-dire qu’il garantit que l’évaluation d’une requête OCL sur un modèle quelconque ne modifiera en rien le modèle en question.
3.4 CWM
CWM [7], pour Common Warehouse Model, est lui aussi un langage, comme UML dont il reprend la grammaire et spécialise la sémantique. Ce langage est également une spécification adoptée par l’OMG, et tente de répondre aux problèmes posés par les simples constatations suivantes. Les statistiques montrent qu’en moyenne, la quantité d’information stockée par une organisation donnée double tous les cinq ans. La plupart du temps, la gestion de ces données est rendue extrêmement difficile par leur surabondance, leur redondance et leur hétérogénéité. Leur stockage dans des entrepôts de données (« data warehouse » en anglais) structurés est indispensable pour les rendre exploitables. Or un des aspects essentiels du stockage de données dans des entrepôts est la description de ces mêmes entrepôts, pour permettre entre autre aux applications tierce d’en connaître la structure et ainsi de pouvoir y puiser l’information. Cette description prend la forme de métadonnées, c'est-à-dire dans le cas général de données qui décrivent les données. Pour compliquer encore la situation, on sait qu’en pratique de nombreux systèmes de stockage de données différents existent et sont utilisés. Ainsi dès lors qu’un besoin d’échange de données va apparaître entre deux systèmes,
6

Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
le premier ne pourra se contenter d’exploiter sa propre description mais aura aussi besoin de celle de l’autre. On utilisera alors l’échange des métadonnées décrivant les deux systèmes (interchange of warehouse metadata).
C’est là l’intérêt du langage CWM. Il propose un standard pour l’échange de ces métadonnées, mais aussi pour exprimer leur transformation, leur analyse, leur création et leur gestion. En pratique, CWM est en fait constitué d’une partie du langage UML 1.4 (le package Object Model) dont tous les éléments qui ne sont pas pertinents dans les scénarii de stockage de données ont étés supprimés.
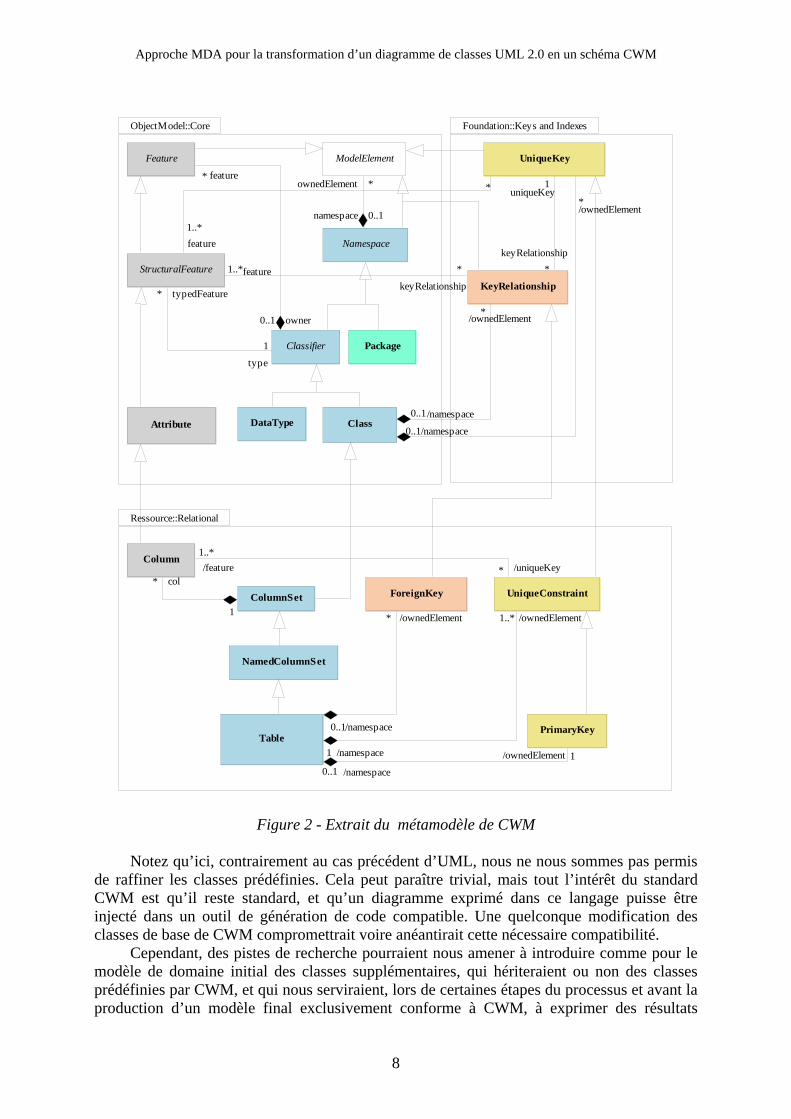
Comme cela est le cas pour UML, nous ne faisons quant à nous qu’une utilisation partielle de CWM, puisque nous nous contentons de la partie relationnelle et statique du langage. Notre but est en effet d’aboutir à un modèle conforme CWM dédiée à la génération de code SQL pour la création des tables, attributs, clé et références décrites dans le modèle. Les classes CWM que nous utiliserons, directement ou par héritage sont les suivantes et sont donc un extrait de la spécification de l’OMG.
7
Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
Ressource::Relational
ObjectModel::Core Foundation::Keys and Indexes
ColumnSet
NamedColumnSet
Table
Column
ForeignKey
PrimaryKey
UniqueConstraint
Classifier
Attribute Class
ModelElement
Namespace
StructuralFeature
Feature UniqueKey
KeyRelationship
DataType
Package
/ownedElement
keyRelationship
uniqueKey
/ownedElement
/uniqueKey
/ownedElement
keyRelationship
ownedElement
1..*feature
feature1..*
* feature
*
*
namespace 0..1
*
*
1
type
typedFeature
0..1 owner*
0..1/namespace
0..1/namespace
1
*
/ownedElement*
* col
1
0..1/namespace
/ownedElement*
1 /namespace
1..*
*
1..*/feature
0..1 /namespace1
Figure 2 - Extrait du métamodèle de CWM
Notez qu’ici, contrairement au cas précédent d’UML, nous ne nous sommes pas permis
de raffiner les classes prédéfinies. Cela peut paraître trivial, mais tout l’intérêt du standard CWM est qu’il reste standard, et qu’un diagramme exprimé dans ce langage puisse être injecté dans un outil de génération de code compatible. Une quelconque modification des classes de base de CWM compromettrait voire anéantirait cette nécessaire compatibilité.
Cependant, des pistes de recherche pourraient nous amener à introduire comme pour le modèle de domaine initial des classes supplémentaires, qui hériteraient ou non des classes prédéfinies par CWM, et qui nous serviraient, lors de certaines étapes du processus et avant la production d’un modèle final exclusivement conforme à CWM, à exprimer des résultats
8

Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
intermédiaires où des informations nécessaires aux traitements automatiques ultérieurs sont encore présents sous forme d’autre classes que celles préexistantes dans la spécification.
3.5 Metamodèle
Un métamodèle est simplement une description d’un langage de modélisation. Il apporte les règles syntaxiques qui permettent de l’utiliser (d’écrire un modèle dans ce langage) et le sens de chaque item présent dans ce langage. Par exemple, la spécification du langage Java, c'est-à-dire sa grammaire et sa sémantique, constitue le métamodèle du langage Java. Dans le contexte de la modélisation on dit qu’un programme Java sans erreur syntaxique est conforme au métamodèle du langage Java. Attention, cette conformité ne garantit pas que le programme ne contient pas d’erreur d’exécution, ou même qu’en l’absence d’erreur d’exécution, les résultats obtenus à l’issu de son exécution seront ceux attendus par le programmeur.
Figure 3 - Exemple de trois classes d’un modèle dont deux sont conformes à leur métaclasse dans le métamodèle
Remarquons qu’un métamodèle est donc par essence un modèle puisqu’il correspond à
la définition de représentation abstraite donnée plus haut. Par voie de conséquence, pour peu que ce métamodèle soit exprimé dans un langage prédéfini, il possède lui-même un méta-métamodèle qui décrit précisément ce dernier nouveau langage.
Nous voyons alors se profiler, pour un modèle donné, une hiérarchie infinie de métamodèles se décrivant les uns les autres. En pratique, cette hiérarchie n’est pas infinie. Elle est d’ailleurs souvent très courte, puisque nous disposons en réalité d’un unique métamodèle que nous partageons tous et qui grâce à son extrême richesse nous permet de décrire tous les autres. Il s’agit simplement de la langue écrite ou orale. En effet, l’intérêt des langues est qu’elles s’auto décrivent, c'est-à-dire que l’on peut les utiliser pour spécifier la façon de les utiliser. Prenez un dictionnaire de français, les définitions de chaque mot sont rédigées en français. Prenez une grammaire française, à nouveau, les règles de grammaire sont exprimées par des phrases qui utilisent et respectent ces mêmes règles. Dans le cas du langage de programmation Java par exemple, le métamodèle (disons pour simplifier sa documentation), est simplement exprimée en langue écrite, que ce soit l’anglais, le français ou le danois, et il n’est pas nécessaire d’ajouter une nouvelle description à cette documentation.
9

Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
3.6 MOF
Pour permettre au langage de décrire toute chose, il faut l’enrichir en permanence avec une très grande variété de syntaxes, toutes sortes de cas particuliers, une très grande souplesse et une quantité énorme de vocabulaire qui le rend difficile à traiter automatiquement.
Pour palier ces problèmes et faciliter l’échange de métadonnées, l’OMG a spécifié un langage objet graphique restreint spécialisé dans la description de métamodèles. Il s’agit du langage MOF [9] (pour Meta Object Facility).
La valeur ajoutée de ce nouveau langage est qu’il possède un nombre limité de « mots », ici des classes, et une syntaxe précise et invariante. Par ailleurs, et c’est essentiel, comme les langues il s’auto décrit. Ainsi, dans un contexte de modélisation, on sait avoir toujours à notre disposition un langage généralement admis et à la sémantique bien définie pour coiffer la hiérarchie des modèles/métamodèles. L’OMG précise alors qu’en pratique, la très grande majorité des cas de modélisation pourra se contenter de l’utilisation de 4 niveaux au maximum comme le montre le schéma ci-dessous.
Figure 4 -L’architecture 4-niveaux définie par l’OMG
Ces niveaux prennent les nom M0 jusqu’à M3, et représentent chacun un étage de la hiérarchie des modèles/métamodèles dont nous parlions précédemment. Dans l’exemple précis de la figure ci-dessus, on retrouve au sommet de la hiérarchie (niveau M3) le langage MOF qui spécifie et décrit le langage du métamodèle d’UML (niveau M2), lui-même définissant les éléments d’un modèle UML (niveau M1) dont une des classe donne à l’exécution une instance (niveau M0).
10

Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
Les trois derniers langages que nous avons vu, (UML, CWM et MOF) sont donc tous trois issus des réflexions de l’OMG sur les notions de modélisation et de métamodélisation. Ils ont étés écrits et réécrits pour épouser leur vision hiérarchique exposée précédemment, et font tous trois partie de leur architecture de métadonnées (OMG Metadata Architecture).
Figure 5 -L’architecture de métadonnées de l’OMG
Paraphraser ce tableau constitue un bon résumé des concepts essentiels que nous venons d’exposer. Les langages de modélisation UML et CWM du niveau M1 servent à modéliser des systèmes ou des entrepôts de données au niveau M0. Ces langages sont décrits au niveau M2 par leurs métamodèles respectifs, en utilisant un langage spécifique, le MOF, lui-même défini par son propre métamodèle au niveau M3.
Nous pouvons maintenant avancer vers la manipulation de ces modèles et en particulier
leur transformation.
4 La génération d’un modèle relationnel vue comme une transformation de modèle.
Dans la traduction d’un diagramme de classe en un schéma relationnel, on distingue clairement ce qui peut se voir sous la forme d’une transformation de modèle. Dans un premier temps en effet, le travail du concepteur consiste à construire et enrichir par ses annotations un diagramme de classes UML, langage strictement documenté et dont la connaissance est largement partagée dans la communauté informatique et au-delà. En fin du processus, le résultat final sera de la même façon un modèle, exprimé cette fois-ci dans un langage spécialement dédié à la description de structure de données persistantes : le langage CWM [7]. Ce langage jouit des mêmes qualités en terme de documentation. L’expression du résultat dans ce langage permet d’envisager sereinement l’interopérabilité avec un générateur de code (SQL par exemple) pour la création directe de la base de données sur une quelconque plateforme. Entre le point de départ et le résultat de la méthode proposée ici, plusieurs opérations seront effectuées tantôt par le concepteur, tantôt par le système qui vont modifier l’état et la nature du diagramme de classe initiale. A diverses étapes par exemple, le système aura à calculer de façon automatique les valeurs de certains attributs des classes du modèle en cours de traitement. Lors d’une autre, il s’agira en plus de ces calculs de traduire le
11

Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
diagramme exprimé en UML en un schéma exprimé en CWM. Toute ces étapes et en particulier cette dernière, constituent des transformations de modèle, bien que parfois ces transformations se réduisent à des calculs élémentaires.
Modèle UML
Modèle CWM
Transformation
Figure 6 - La transformation d'un modèle
Nous verrons comment l’ingénierie dirigée par les modèles et le standard MDA sont des
réponses concrètes qui permettent précisément d’effectuer ce passage. Nous présenterons également l’implémentation de ce cette approche, où nous avons utilisé le langage ATL.
5 L’ingénierie dirigée par les modèles, ou Model-driven Architecture (MDA)
Dans le contexte de l’ingénierie logicielle, l’OMG a depuis quelques années réfléchit sur la question de l’utilisation extensive de modèles, d’une part comme outil de dialogue avec les utilisateurs et/ou les concepteurs pour représenter les besoins fonctionnels, et d’autre part comme langage de représentation de la connaissance suffisamment proche d’une architecture logicielle donnée pour permettre un passage automatique d’un modèle à du code informatique. Cette réflexion reprend l’ambition fondamentale de séparer au mieux les problèmes de spécification des fonctionnalités d’un système, et les détails d’implémentation de ces fonctionnalités.
12

Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
5.1 MDA
Figure 7 - Logo MDA
En 2001, l’OMG a présenté le fruit de ses réflexions dans un document « Overview and guide to OMG's architecture » [8], où le groupe introduit son architecture dirigée par les modèles (Model Driven Architecture en anglais). Il y est montré comment utiliser intensivement les modèles pour le développement logiciel, et un éventail d’exemples d’implémentation y est décrit.
L’OMG définit dans ce guide MDA plusieurs niveaux d’abstraction et d’indépendance vis-à-vis d’une implémentation particulière dans un environnement logiciel et matériel particulier. On retrouve ainsi essentiellement, du plus indépendant au plus spécifique, les niveaux « Computation independant », « Platform independant » et « Platform specific ». Il est proposé d’exprimer (de modéliser) successivement un problème dans ces trois niveaux, d’abord au plus général pour capter le mieux possible les besoins souvent exprimés par des non-spécialistes, jusqu’au plus fin permettant ainsi dans l’idéal la génération directe de code fonctionnel pour une configuration logicielle et matérielle donnée.
Les deux niveaux les plus utilisés sont les deux derniers, « Platform independant » et « Platform specific ». Pour permettre le passage ou la traduction de l’un vers l’autre, l’approche MDA sous-entend tout d’abord de modéliser le problème ou le système considéré au niveau le plus indépendant, puis d’utiliser différents types de transformation de modèle pour obtenir le modèle spécifique à la plateforme cible.
13
Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
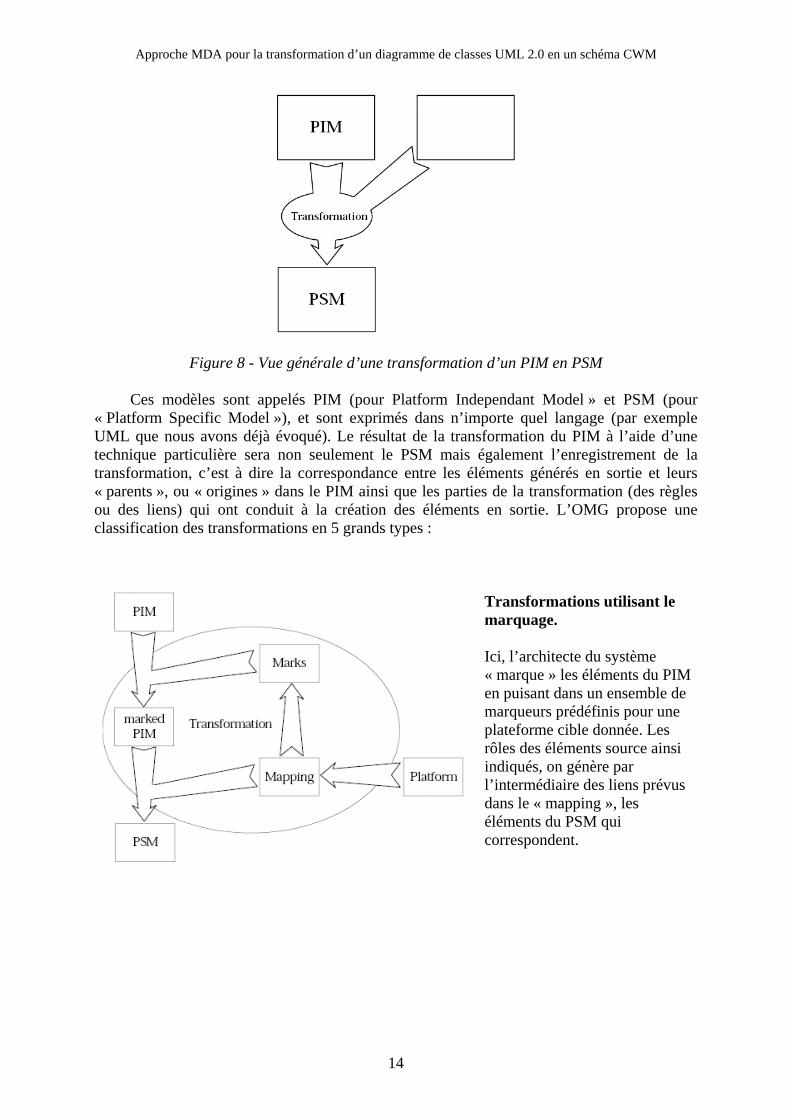
Figure 8 - Vue générale d’une transformation d’un PIM en PSM
Ces modèles sont appelés PIM (pour Platform Independant Model » et PSM (pour « Platform Specific Model »), et sont exprimés dans n’importe quel langage (par exemple UML que nous avons déjà évoqué). Le résultat de la transformation du PIM à l’aide d’une technique particulière sera non seulement le PSM mais également l’enregistrement de la transformation, c’est à dire la correspondance entre les éléments générés en sortie et leurs « parents », ou « origines » dans le PIM ainsi que les parties de la transformation (des règles ou des liens) qui ont conduit à la création des éléments en sortie. L’OMG propose une classification des transformations en 5 grands types :
Transformations utilisant le marquage. Ici, l’architecte du système « marque » les éléments du PIM en puisant dans un ensemble de marqueurs prédéfinis pour une plateforme cible donnée. Les rôles des éléments source ainsi indiqués, on génère par l’intermédiaire des liens prévus dans le « mapping », les éléments du PSM qui correspondent.
14
Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
Transformation utilisant la fusion de modèles. Cette deuxième façon de procéder est proposée dans le guide de l’OMG comme très générique, et il est indiqué sans plus de précisions que diverses déclinaisons MDA en dérivent.
Transformations utilisant les métamodèles Dans ce cas, c’est en spécifiant des règles de transformation directement entre les éléments des métamodèles du PIM et du PSM que l’on crée la transformation. C’est cette technique qui est utilisée par l’outil ATL sur lequel nous reviendrons en détail.
Transformations utilisant les types Cette fois-ci, on utilise plutôt des types que des éléments de métamodèles pour identifier les correspondances. Ces types peuvent représenter des fonctionnalités ou des caractéristiques aux niveaux indépendants de la plateforme ou spécifiques à un environnement.
15

Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
Pour résumer, quel que soit le type de transformation utilisé, le PSM sert finalement de
base à la génération de code adapté à la plateforme cible. Dans notre cas, le « Platform specific model » sera un modèle conforme à CWM [7], et constituera un pont vers la génération de code SQL.
5.2 QVT
Transformation utilisant les types et les patrons.
Les liens sont spécifiés entres des types et des patrons définis pour le PIM et le PSM. Cette variante reprend simultanément les principes des deux précédentes.
Dans le cadre de l’approche MDA, l’OMG introduit le langage QVT [9] (pour Querry, View, Transformation). QVT est une spécification couplée à celle du MOF, et comme son nom l’indique n’est plus dédiée à la spécification de modèles, mais à leur manipulation. Ce langage possède une nature hybride déclarative/impérative et implémente la transformation de modèle de différentes manières. Cette spécification est encore en travaux aujourd’hui, et les fonctionnalités en matière de visualisation de modèles sont peu avancées. Nous la citons ici car elle possède des liens historiques importants avec le langage ATL que nous verrons plus loin (section 6).
MDA, associé à ses outils tels que MOF/QVT et UML/OCL, est donc un nouveau
paradigme qui offre des possibilités nouvelles en matière d’ingénierie logicielle. Dans le cadre des bases de données, ces techniques pourraient peut-être permettre de faciliter la modélisation des systèmes, par le développement d’outils de conception plus ergonomiques et rigoureux. Le travail présent explore une partie de ces possibilités.
6 ATL
Suite à la publication en 2001 du standard MDA par l’OMG, de nombreux éditeurs de logiciels et laboratoires de recherches ont mit sur le marché des outils se réclamant de cette architecture. Parmi ceux-ci le laboratoire de l’INRIA de Nantes a développé le langage ATL
16

Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
(pour ATLAS Transformation Language) de transformation de modèles dans le cadre de son projet ATLAS [2].
Ce langage est officiellement parti d’une tentative d’implémentation du QVT « Request For Proposal » de l’OMG, en reprenant en particulier les diverses façons déclaratives et impératives de spécifier une transformation.
Il est développé sur la plateforme Eclipse et plus particulièrement sur sa branche EMF (pour Eclipse Modeling Framework). Il est accompagné de nombreux outils pour faciliter son utilisation. La mise en forme des mots clés du langage est assuré dans l’éditeur de code ATL, un debugger est fourni, et une notation textuelle simple appelée km3 (pour Kernel MetaModel) permet la spécification de métamodèles.
Pour réaliser notre objectif initial d’automatiser le calcul d’un schéma relationnel CWM à partir diagramme de classes UML, nous n’utilisons que les fonctionnalités de transformation d’ATL, qui sont d’ailleurs les plus développées. Cependant, ce langage permet également l’écriture de simples requêtes sur des modèles, comme le prévoit le volet Query de QVT. D’ailleurs, il est évident que faire une transformation de modèle serait difficile sans la capacité de lire (et donc d’effectuer des requêtes sur) le modèle source. Ainsi pour les transformations comme pour les seules lectures de modèles, ATL utilise intensivement le mode d’écriture et la sémantique des mots clés de la norme OCL (section 3.3), aujourd’hui dans sa version 2.0.
6.1 L’opération élémentaire de transformation : la règle ATL
Un programme de transformation écrit en ATL est composé de règles qui spécifient comment les éléments du modèle source sont reconnus et parcourus pour créer et initialiser les éléments du modèle cible. Ces règles sont de la forme générale suivante : rule ForExample { from i : InputMetaModel!InputElement to o : OutputMetaModel!OutputElement( attributeA <- i.attributeB, attributeB <- i.attributeC + i.attributeD ) }
Figure 9 - Un exemple de règle ATL
• ForExample est le nom de la règle de transformation. • i (resp. o) est le nom de la variable qui dans le corps de la règle va représenter
l’élément source identifié (resp. l’élément cible créé). • InputMetaModel (resp. OutputMetaModel) est le métamodèle auquel le
modèle source (resp. le modèle cible) de la transformation est conforme. • InputElement désigne la métaclasse des éléments du modèle source auxquels cette
règle va s’appliquer. • OutputElement désigne la métaclasse à partir de laquelle la règle va instancier les
éléments cibles. Le point d’exclamation permet de spécifier à quel métamodèle appartient une métaclasse en cas d’homonymie.
17

Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
• attributeA et attributeB sont des attributs de la métaclasse OutputElement
• Leur valeur est initialisée à l’aide des valeurs des attributs i.attributeB, i.attributeC et i.attributeD de la métaclasse InputElement.
Voici comment on pourrait formuler la fonction de cette règle en langage naturel. La
règle ForExample, pour chaque élément i de type InputElement qu’elle identifie dans le modèle source, crée dans un modèle cible un élément o de type OutputElement, et initialise les valeurs des attributs attributeA et attributeB de o avec les valeurs des attributs attributeB, attributeC et attributeD de i.
Dans cet exemple simple, on voit l’utilisation du « . », issu de la spécification OCL et reprit par ATL, qui permet dans les expressions i.attributeB, i.attributeC et i.attributeD de ‘naviguer’ dans le modèle source i.
En plus des règles, le langage ATL dispose du mot clé « helper », qui permet de définir des macros à l’extérieur des règles pour factoriser des parties de code souvent utilisées. Des exemples de ces helpers sont utilisés et expliqués par la suite.
Un programme ATL, appelé un module, est essentiellement un groupement de règles et de helpers.
En dehors du module lui-même, les éléments fixes de la traduction sont donc les deux métamodèles source et cible. Le modèle source peut quant à lui être vu comme le paramètre de la transformation, et le modèle cible son résultat.
C’est à travers la configuration de l’environnement d’exécution du programme que l’on spécifie concrètement dans quels fichiers le moteur de traduction doit chercher les métamodèles, le modèle source, le fichier programme, et dans quel fichier on attend qu’il écrive le modèle résultat.
Nous l’avons vu, les modèles source et cible de la transformation sont conformes à leurs métamodèles respectifs fournis par l’utilisateur. Notons qu’un module ATL peut lui aussi se représenter sous forme d’un modèle, puisque comme n’importe quel langage ATL possède son propre métamodèle. Notons enfin qu’ATL utilise nativement comme méta-métamodèle une version à peine différente du MOF, le méta-métamodèle Ecore défini par la branche EMF de la plateforme Eclipse. Le schéma suivant illustre ces principes à travers l’exemple d’une transformation ATL nommée Author2Person, destinée à transformer un modèle nommé Author en un modèle nommé Person.
En pratique, les modèles et leurs métamodèles cibles et source prennent dans l’environnement de développement Eclipse la forme de fichiers texte au format xmi avec une extension .ecore.
18

Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
Figure 10 -Vue d’ensemble d’une transformation ATL
6.2 Utilisation d’ATL
Considérons notre problème « Générer un modèle relationnel normalisé à partir de diagrammes de classes UML ». Faisons abstraction des calculs indiqués dans le processus de conception décrit dans l’article, des nécessaires interactions avec l’utilisateur, et concentrons nous sur la traduction proprement dite du modèle UML en modèle CWM.
Les informations que nous devons apporter au système pour nourrir le moteur de traduction ATL sont :
• Le métamodèle UML 2.0 • Le métamodèle CWM • Le modèle UML (le modèle du domaine conforme au métamodèle UML 2.0) • Le code ATL de transformation
Ces éléments doivent permettre de générer automatiquement • Le modèle CWM (le schéma relationnel conforme au métamodèle CWM)
6.2.1 Spécification des métamodèles
Les métamodèles UML 2.0 et CWM sont écrits dans le langage km3 dans deux fichiers
textes distincts : • MDC.km3 (pour Modèle De Domaine) dans lequel nous avons spécifié deux package,
à la fois la partie du métamodèle d’UML 2.0 qui nous intéressait, et un package où nous avons regroupé les métaclasse spécifique à notre domaine.
• MLRnL.km3 (pour Modèle Logique Relationnel normaliséL) dans lequel nous avons extrait les packages et les métaclasses qui nous intéressaient de la spécification CWM de l’OMG.
19
Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
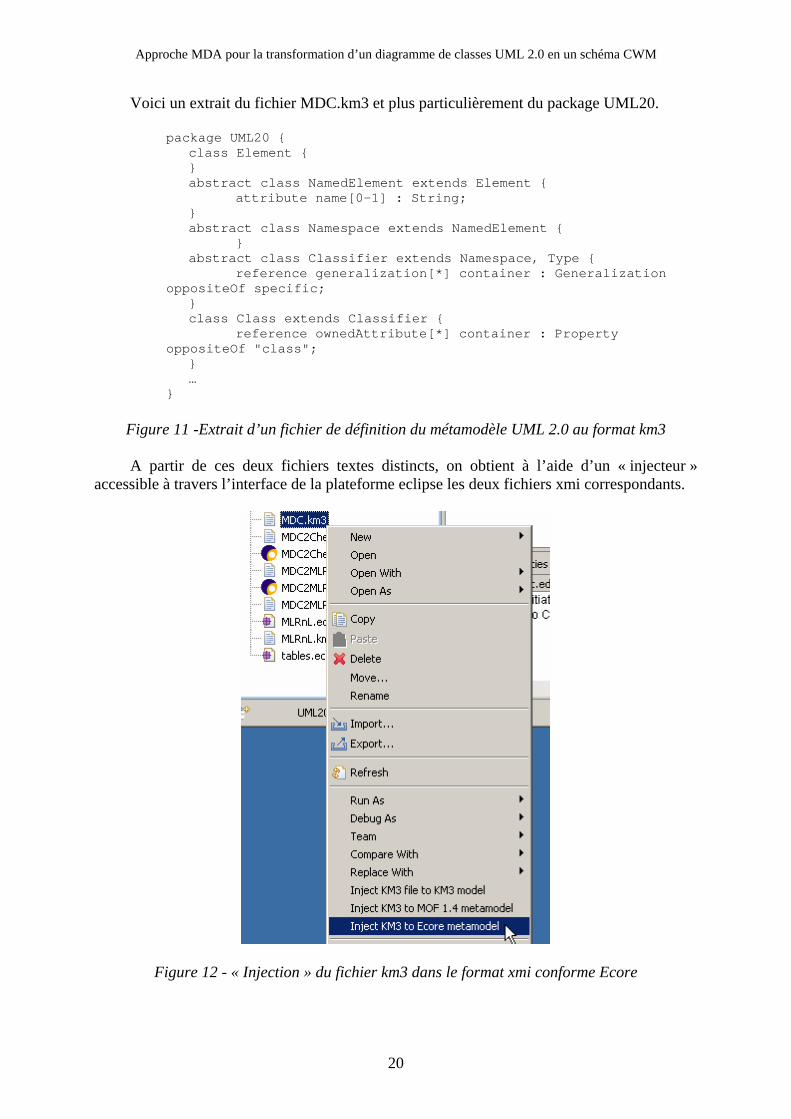
Voici un extrait du fichier MDC.km3 et plus particulièrement du package UML20.
package UML20 { class Element { } abstract class NamedElement extends Element { attribute name[0-1] : String; } abstract class Namespace extends NamedElement { } abstract class Classifier extends Namespace, Type { reference generalization[*] container : Generalization oppositeOf specific; } class Class extends Classifier { reference ownedAttribute[*] container : Property oppositeOf "class"; } … }
Figure 11 -Extrait d’un fichier de définition du métamodèle UML 2.0 au format km3
A partir de ces deux fichiers textes distincts, on obtient à l’aide d’un « injecteur » accessible à travers l’interface de la plateforme eclipse les deux fichiers xmi correspondants.
Figure 12 - « Injection » du fichier km3 dans le format xmi conforme Ecore
20

Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
Dans ces fichiers xmi, on trouve les classes définies initialement en km3 sous forme textuelle traduite en terme de métaclasses (puisqu’il s’agit d’un métamodèle) en xmi , donc également sous forme textuelle, et conformes au méta-métamodèle Ecore (très proche du MOF). Voici les mêmes métaclasses que dans l’exemple précédent exprimées cette fois-ci au format xmi.
<?xml version="1.0" encoding="ISO-8859-1"?> <xmi:XMI xmi:version="2.0" xmlns:xmi="http://www.omg.org/XMI" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:ecore="http://www.eclipse.org/emf/2002/Ecore"> <ecore:EPackage name="UML20"> <eClassifiers xsi:type="ecore:EClass" name="Element"/> <eClassifiers xsi:type="ecore:EClass" name="NamedElement" abstract="true" eSuperTypes="/0/Element"> <eStructuralFeatures xsi:type="ecore:EAttribute" name="name" ordered="false" unique="false" eType="/2/String"/> </eClassifiers> <eClassifiers xsi:type="ecore:EClass" name="Namespace" abstract="true" eSuperTypes="/0/NamedElement"/> <eClassifiers xsi:type="ecore:EClass" name="Classifier" abstract="true" eSuperTypes="/0/Namespace /0/Type"> <eStructuralFeatures xsi:type="ecore:EReference" name="generalization" ordered="false" upperBound="-1" eType="/0/Generalization" containment="true" eOpposite="/0/Generalization/specific"/> </eClassifiers> <eClassifiers xsi:type="ecore:EClass" name="Class" eSuperTypes="/0/Classifier"> <eStructuralFeatures xsi:type="ecore:EReference" name="ownedAttribute" ordered="false" upperBound="-1" eType="/0/Property" containment="true" eOpposite="/0/Property/class"/> </eClassifiers> … </ecore:EPackage> </xmi:XMI>
Figure 13 -Extrait d’un fichier de définition du métamodèle UML 2.0 au format xmi
Maintenant au format xmi et comme nous venons de le dire conforme au méta-
métamodèle Ecore inclus dans le plugin EMF d’eclipse, le métamodèle peut être interprété et affiché par l’éditeur graphique développé dans le cadre de ce même plugin.
21

Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
Figure 14 - Le fichier MDC.ecore affiché par l’éditeur EMF
6.2.2 Spécification des modèles
Bien que de nombreux outils plus ou moins faciles à mettre en œuvre soient en principe à disposition, l’écriture d’un modèle est plus fastidieuse. On ne peut plus utiliser le langage km3 exclusivement dédiée à la définition de métamodèles. Il faut alors commencer par écrire directement un fichier texte au format xmi en spécifiant les éléments du modèle avec leurs balises ouvrantes et fermantes. Dans l’exemple suivant, on a créé un fichier exemple.ecore où l’on définit à la main une classe de type Classe. Le type Classe est une référence à la métaclasse du même nom dans le métamodèle UML20 lui-même référencé par l’attribut xmlns de la balise xmi:XMI.
<?xml version="1.0" encoding="ISO-8859-1"?> <xmi:XMI xmi:version="2.0" xmlns:xmi="http://www.omg.org/XMI" xmlns="UML20"> <Class> </Class> </xmi:XMI>
Figure 15 -Exemple de départ de définition d’une classe, dans un fichier ecore au format xmi
Pour autant que la syntaxe xmi soit correcte et conforme au métamodèle, l’éditeur permet ensuite d’accéder plus facilement, à la souris, aux attributs et aux associations des éléments précédemment créés.
Figure 16 - Un onglet « Properties » permet d’accéder aux propriétés de la classe Class.
En plus de pouvoir éditer dans un onglet les valeurs des propriétés de l’élément sélectionné, un menu contextuel accessible par clic droit sur le même élément permet dans certains cas de provoquer la création de nouveaux éléments issus du métamodèle. Par exemple, on voit dans notre extrait du métamodèle d’UML 2.0 que les éléments de type Class possèdent entre autre par leur membre ownedAttribute des éléments de type Property. Cette relation est une relation d’agrégation, précisée dans notre fichier km3 original du métamodèle UML 2.0 par le mot clé « container »
22

Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
class Class extends Classifier { reference ownedAttribute[*] container : Property oppositeOf "class"; }
Figure 17 - Le mot clé container permet de refléter une aggregation UML
Cette qualité particulière de la relation entre Class et Property, permet de disposer dans l’éditeur de la plateforme eclipse de la fonction de génération automatique d’éléments « fils » d’un autre. C’est cette fonction que nous utilisons dans l’exemple ci-dessous.
Figure 18 -Le menu contextuel « New Child »
Une fois un élément contenu par un autre créé, une variante de la fonction « New Child » est alors disponible, puisque l’on peut créer à la souris des éléments « jumeaux », du même niveau dans la hiérarchie contenants/contenus. L’exemple suivant montre comment créer une deuxième propriété pour la même classe, en utilisant cette possibilité.
Figure 19 - Le menu contextuel « New Sibling »
23

Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
A l’aide de ces derniers mécanismes et de l’onglet Properties, on peut ainsi spécifier
relativement aisément une classe. Cependant, l’expérience montre qu’écrire ainsi des modèles complets reste assez fastidieux.
6.2.3 Le module ATL
L’écriture du programme de transformation proprement dit (annexe 11.1) ne pose en pratique aucun problème. Elle se résume simplement à la création d’un fichier texte avec l’extension atl, où l’on écrit les règles de transformation et les helpers.
Figure 20 - Extrait du code transformation du module ATL
24
Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
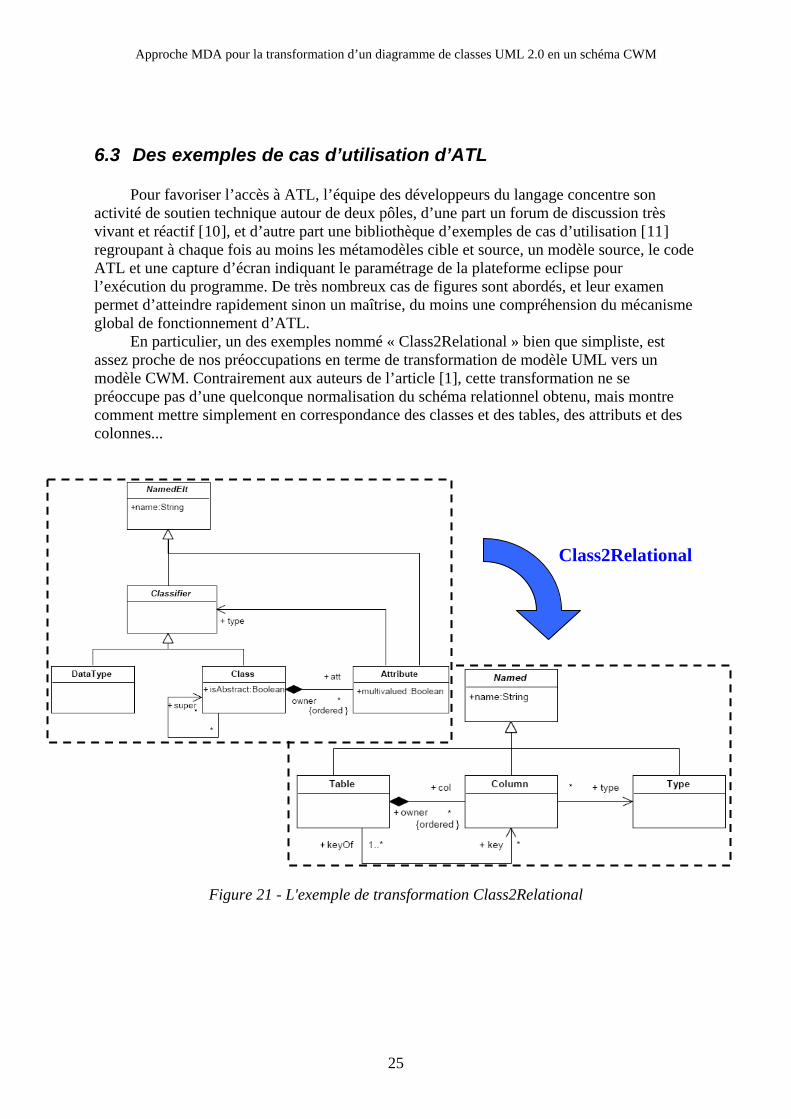
6.3 Des exemples de cas d’utilisation d’ATL
Pour favoriser l’accès à ATL, l’équipe des développeurs du langage concentre son activité de soutien technique autour de deux pôles, d’une part un forum de discussion très vivant et réactif [10], et d’autre part une bibliothèque d’exemples de cas d’utilisation [11] regroupant à chaque fois au moins les métamodèles cible et source, un modèle source, le code ATL et une capture d’écran indiquant le paramétrage de la plateforme eclipse pour l’exécution du programme. De très nombreux cas de figures sont abordés, et leur examen permet d’atteindre rapidement sinon un maîtrise, du moins une compréhension du mécanisme global de fonctionnement d’ATL.
En particulier, un des exemples nommé « Class2Relational » bien que simpliste, est assez proche de nos préoccupations en terme de transformation de modèle UML vers un modèle CWM. Contrairement aux auteurs de l’article [1], cette transformation ne se préoccupe pas d’une quelconque normalisation du schéma relationnel obtenu, mais montre comment mettre simplement en correspondance des classes et des tables, des attributs et des colonnes...
Class2Relational
Figure 21 - L'exemple de transformation Class2Relational
25

Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
7 Implémentation
Le cadre technique et les notions qui sont manipulées sont maintenant définis. Nous pouvons aborder les détails de l’expérimentation que nous y avons mené. L’ordre dans lequel les étapes sont décrites correspond à l’ordre chronologique du développement d’une transformation de modèle en général. En pratique cependant, dans notre cas de recherche comme dans d’autres, ce processus est loin d’être linéaire, et de nombreuses rétroactions ont lieu entre les phases de développement. Pour nous aider, nous avons reprit l’étude de cas détaillé par les auteurs du processus de conception dans leur article pour illustrer leurs propositions.
7.1 Un exemple de modèle de domaine
Figure 22 - Exemple de modèle de domaine annoté utilisé dans l’article [1]
Cet exemple présente le cas où un utilisateur a besoin d’enregistrer diverses informations relatives à des stages d’étudiants. On retrouve dans donc dans le modèle de domaine des classes qui doivent à terme permettre la persistance de ces informations. Le nom
<<persistent_class>>
{Alias(SOUT)} Soutenance
<<persistent_class>>
{Alias(ENT)} Entreprise
<<persistent_class>>
{Alias(ENS)} Enseignant
<<persistent_class>>
{Alias(PROP)} Proposition
<<persistent_class>>
{Alias(ETUD)} Etudiant
<<persistent_class>>
{Alias(STG)}
Stage
K1_ENT <<ID>>{Siret}
K1_SOUT <<ID>>{K_STG}
K1_PROP <<ID>>{ID_PROP}
K1_STG <<ID>> {Id_STG}
K2_STG <<ID>> {K_ETUD, Début}
<<persistent_class>>
{Alias(PERS)}
Personne
K1_PERS K1_ETUD <<ID>> Id_PERS : undefined
{Id_PERS} Nom : undefinedAdresse : undefined
{Numéro}
Raison_sociale : undefined Date : undefined
0..1
tuteur
0..1 Numéro : undefined 1
**
1 Id_STG : undefinedSujet : undefinedDébut : undefinedFin [0..1] : undefined
0..1
1
Siret : undefined
Sujet : undefined Lieu : undefined Date : undefined
entreprise 1 *
Adresse : undefined Salle : undefined
26

Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
des classes est explicite, on voit ainsi que le concepteur cherche à enregistrer l’étudiant qui a effectué le stage, l’enseignant qui a éventuellement été le tuteur encadrant ce stage, de quelle proposition formulée par quelle entreprise est issu ce stage, et ou et quand aura lieu sa soutenance.
Comme nous l’avons dit, le choix du langage UML pour exprimer le modèle de domaine permet au concepteur d’utiliser sa présupposée connaissance de ce langage pour enrichir son modèle. On voit par exemple qu’il a intelligemment factorisé certaines informations personnelles pour les classes Enseignant et Etudiant dans une superclasse commune Personne, en utilisant le mécanisme d’héritage d’UML. On voit également que le concepteur, en associant les classes les unes avec les autres, a spécifié des cardinalités variées sur ces associations. Ces cardinalités portent beaucoup de sens, sont prises en compte dans l’algorithme de transformation, et induisent des stratégies de création de clé différentes dans le modèle relationnel final.
Pour faciliter le travail du concepteur lors de la spécification du modèle de domaine, les auteurs de l’algorithme ont par ailleurs enrichi le vocabulaire UML avec deux stéréotypes importants, les stéréotypes « persistent_class » et « ID ».
• Le stéréotype « persistent_class » permet de spécifier explicitement quelles classes de son modèle de domaine il souhaite voir implantées sous forme de tables dans le modèle relationnel. Cette distinction entre les classes persistantes et non-persistantes lui permet d’avoir plus de libertés pour créer lors de la conception des classes utilitaires utiles à ce moment là mais sans information pertinente à pérenniser.
• Le stéréotype « ID » permet quant à lui au concepteur de spécifier des identifiants pour les classes. Ces identifiants et leur traitement sont essentiels dans l’algorithme de création et de résolution des clés du modèle relationnel final. Ils constituent les briques de construction des clé primaires et des clés étrangères des tables et des références déduites du modèle de domaine. Bien qu’il puisse définir un ou plusieurs identifiants par table, le concepteur n’y est pas obligé. Le processus prévoit alors leur génération automatique par le système, pour s’assurer que chaque table ait au moins un identifiant unique.
7.2 Accoucher les métamodèles
Une des première tâches à effectuer pour démarrer la programmation d’une transformation de modèle avec ATL est la définition des métamodèles cibles et source. En théorie, elle précède toutes les autres puisqu’elle conditionne l’écriture d’une part du modèle source et d’autre part du code ATL lui-même qui est exprimé en terme de règles qui manipulent les éléments de ces métamodèles sources et cibles.
Cette phase est absolument essentielle à tout le reste du processus, et la pratique nous a montré dans notre cas que la plus grosse partie du travail de mise en œuvre d’une transformation consiste à précisément définir ces métamodèles, et à s’entendre sur les définitions que l’on donne aux éléments qui la compose et aux liens qui relient ces éléments.
7.2.1 Spécifier le métamodèle cible : le métamodèle de CWM.
Comme nous l’avons dit, le but de l’algorithme est d’aboutir à terme à un modèle de schéma relationnel. Le langage CWM possède cette capacité grâce à ses packages ObjectModel::Core (emprunté à UML 2.0), Foundation::Keys and Indexes et Resource::Relational, (cf figure méta CWM en page 8). Nous avons pu nous reposer
27
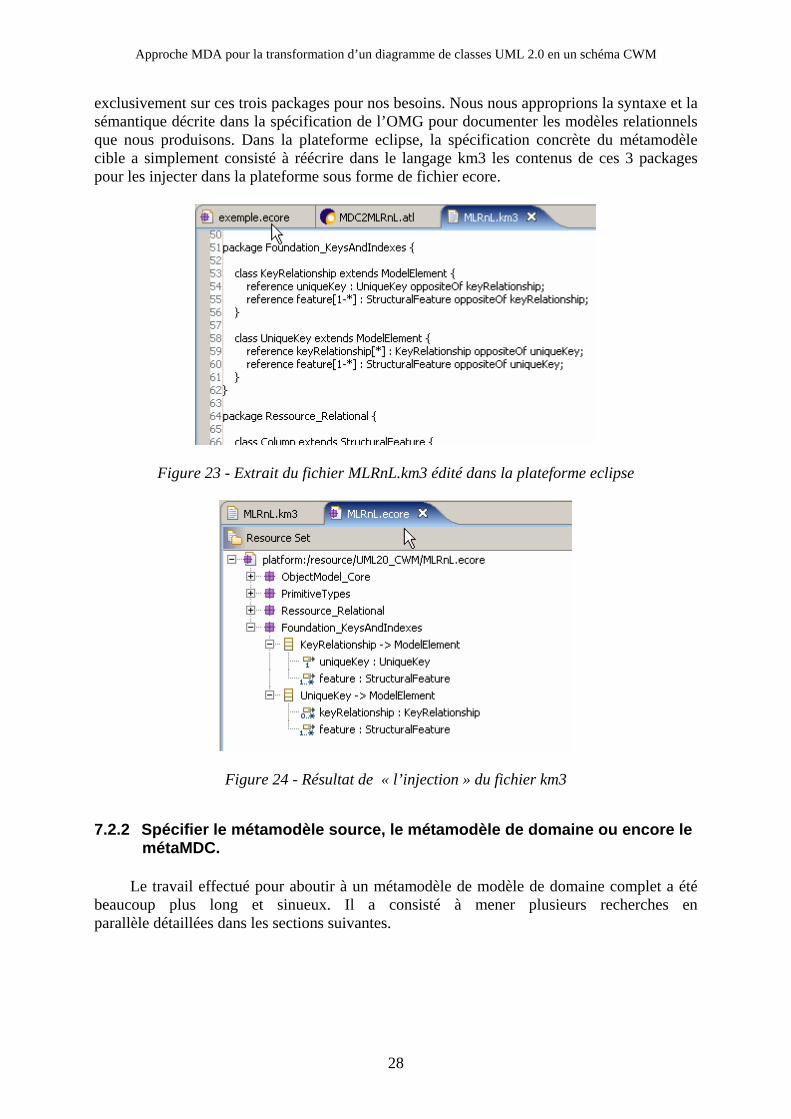
Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
exclusivement sur ces trois packages pour nos besoins. Nous nous approprions la syntaxe et la sémantique décrite dans la spécification de l’OMG pour documenter les modèles relationnels que nous produisons. Dans la plateforme eclipse, la spécification concrète du métamodèle cible a simplement consisté à réécrire dans le langage km3 les contenus de ces 3 packages pour les injecter dans la plateforme sous forme de fichier ecore.
Figure 23 - Extrait du fichier MLRnL.km3 édité dans la plateforme eclipse
Figure 24 - Résultat de « l’injection » du fichier km3
7.2.2 Spécifier le métamodèle source, le métamodèle de domaine ou encore le métaMDC.
Le travail effectué pour aboutir à un métamodèle de modèle de domaine complet a été beaucoup plus long et sinueux. Il a consisté à mener plusieurs recherches en parallèle détaillées dans les sections suivantes.
28

Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
7.2.2.1 Chercher à quoi le modèle de domaine fourni en exemple est conforme.
Ceci peut être vu comme une phase de rétro-modélisation. Bien sûr, comme le modèle de domaine est écrit en utilisant le langage UML 2.0, tous les éléments (classes, associations, multiplicités…) sont l’incarnations des métaclasses correspondantes dans le métamodèle UML 2.0 (cf métamodèle en page 5). Mais comme nous l’avons dit, nous avons souhaité limiter le vocabulaire disponible à un sous ensemble restreint d’UML, et plus encore à des spécialisations d’un sous-ensemble des métaclasses UML. Ainsi par exemple, plutôt que de se contenter de la classe Class du métamodèle UML 2.0 comme métaclasse de la classe persistante Stage de notre MDC, nous avons défini une nouvelle métaclasse, nommée Classe_persistante, qui hérite de la métaclasse Class, et qui est spécialement dédiée à être utilisée comme type pour les classe persistante dans un modèle de domaine. Le même phénomène s’est produit pour les attributs des classes persistantes. Là, nous avons crée une nouvelle métaclasse nommée Attribut, héritant de la métaclasse Property du métamodèle UML, pour définir spécifiquement le type « attributs des classes persistantes ». De la même façon, on a ajouté les métaclasses Generalisation_persistante et Association_persistante à notre métaMDC. A l’inverse, nous nous sommes parfois reposé sur les métaclasses d’UML, comme par exemple la métaclasse nommée Expression, pour permettre au concepteur d’écrire les cardinalités des extrémités des associations persistantes.
7.2.2.2 Ajouter des classes utilitaires
Toutefois, en plus des métaclasses nécessaires à exprimer les types des éléments présents dans le MDC, nous savions avoir besoin au cours de l’algorithme d’exprimer d’autres concepts que ceux présents et visibles dans le MDC final tel qu’il est présenté à la figure de la page 26. C’est par exemple le cas de la métaclasse Arc_de_composition, ou Espace_de_recherche. Si aucun élément de ces types n’apparaît plus dans le MDC final, c’est que ces éléments n’ont eu de sens que temporairement au cours de l’algorithme. Ils ont cependant étés indispensable, et leur représentation à nécessité qu’on ajoute au métamodèle une métaclasse propre.
7.2.2.3 Mûrir les relations entre les métaclasses et la signification de ces liens
Ajouter des métaclasses au métamodèle n’aurait pas de sens si les concepts qu’elles reflètent n’avaient aucun lien entre eux. Par exemple, la notion d’attribut n’a de sens qu’en conjonction avec la notion de classe persistante. C’est pourquoi dans le métamodèle on trouve une association entre les deux classes du même nom. Il en va de même pour toutes les classes du métaMDC.
7.2.3 Résultat : le métaMDC
Dans notre expérience, et comme nous l’avons déjà dit, la spécification du métaMDC a été très longue. En effet, à partir d’un premier essai, le travail a immédiatement après consisté à tenter de recréer un modèle de domaine équivalent à celui de l’article et bien entendu conforme à cette première spécification de métaMDC. La pratique soulevait alors des problèmes imprévus au départ ou bien souvent également des divergence d’interprétation des éléments du métaMDC, et nous amenait à réviser ce dernier. Ce processus de spécification est encore en cours aujourd’hui. Certains concepts tels que l’arc de composition pourraient par
29

Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
exemple être amenés à disparaître dans de futures versions du métaMDC. La figure ci-dessous traduit notre vision à l’instant de la rédaction de ces lignes, avec ses imperfections.
Pour résumer, le métamodèle des modèles de domaines complets est construit sur la base des méta classes existantes dans la norme UML 2.0. Dix classes spécifiques à notre problème sont ajoutées dans un nouveau package MDC avec les héritages et les associations suivantes :
ID
Symb_ID_exportableClasse_persistante
Arc_de_composition Espace_de_recherche
Composant_identifiant
Attribut
<<metaclass>>Constraint
<<metaclass>>Class
<<metaclass>>Property
<<metaclass>>Generalization
<<metaclass>>Association
Generalisation_persistante
Association_persistante
{xor}
{disjoin}
ID_exportable
1
1..*
attribut
1
composant
1
1..*expression impliciteid_ci*
* *
*
1..**
1
Alias : string
CalculerEspace()
origine 1
1
1
extrémité
*
1
1
propriétaire1
*
/Nom : string
1..*
1..*
Figure 25 - Notre métamodèle de domaine construit sur UML 2.0
Les classes en blanc appartiennent au package Classes du métamodèle UML 2.0. La
description formelle des nouvelles métaclasses introduites ici, comme celle des associations qui les relient est disponible en annexe 11.3.
Une fois cette spécification établie, son intégration dans l’environnement eclipse se fait comme vu précédemment par l’intermédiaire de sa réécriture en km3. Le fichier MDC.km3 contient cette traduction. Y sont inclus les deux package UML20 qui regroupe les métaclasses sélectionnées parmi celles du métamodèle UML 2.0 (voir ci-dessus- Extrait du métamodèle UML 2.0 en page 5) et MDC qui contient lui les métaclasses spécialisées ajoutées par nos soins. Le fichier MDC.km3 est ensuite injecté dans le format xmi conforme au métamodèle Ecore du plugin EMF d’eclipse.
30

Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
7.2.4 Construire un exemple de modèle conforme
En théorie, ayant en main les métamodèles source et cible, nous pourrions à ce stade écrire directement et complètement la transformation en code ATL. Cependant, pour pouvoir dès nos premiers pas dans cette écriture tester notre code, nous aurons inévitablement besoin d’un modèle candidat à passer en paramètre à la transformation. En pratique donc, il convient d’abord de se donner ce modèle candidat, en créant dans notre cas un exemple de modèle conforme au métamodèle source développé précédemment.
Les métaclasses source dont nous disposons, doivent donc permettre au concepteur de construire les modèles d’entrée du processus, appelés modèles de domaine. Voici, quelques exemples extraits de l’étude de cas relatif aux stages d’étudiant de l’article [1].
Figure 26 - La classe Stage
Voici la classe stage avec ses attributs, ses ID, son espace de recherche et son symbole exportable. La nomenclature des éléments est automatique et reprend d’abord le nom de la métaclasse dans le métamodèle à laquelle l’élément se conforme, puis la valeur de l’attribut « name » de l’élément, quand cet attribut est valué (ce qui est toujours le cas dans l’exemple).
Notez la représentation arborescente dans l’éditeur eclipse. Cette représentation vient du fait que toutes les métaclasses (les types) des éléments listés ci-desssus, c'est-à-dire les métaclasses Attribut, ID, Espace_De_Recherche et Symbole_ID_Exportable, sont liées à la métaclasse Classe_persistante par des relations d’agrégation dans le métaMDC. Cette notion d’agrégation est traduite visuellement par cette structure arborescente.
Voyons maintenant en détail l’élément de type Espace_de_recherche lié à la l’élément de type Classe_persistante Stage.
31

Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
Figure 27 - Détail de l’espace de recherche de la classe Stage
Comme nous venons de le dire, cet élément est représenté « dans » l’élément Classe_persistante Stage à cause du lien d’agrégation qui les relie dans le métaMDC. L’existence de ce lien est confirmée par la valeur de la référence nommée Classepersistante appartenant à l’élément Espace_de_recherche Stage. On peut en effet lire dans l’onglet Properties de ce dernier élément que sa référence à une classe persisante pointe vers la Classe_persistante Stage. Utilisons le même mode de lecture pour voir que l’élément Espace_de_recherche Stage est lié, par sa référence nommée Composantidentifiant, à quelques éléments de ce type, ici les éléments Attribut Id_STG, Attribut Sujet, Attribut Debut, Attribut Fin et d’autres encore.
Un coup d’œil au métaMDC nous indique qu’en effet, il existe une association entre la métaclasse Espace_de_recherche et la métaclasse Composant_identifiant, et que les multiplicités permettent à un élément de type Espace_de_recherche d’être relié à plusieurs éléments de type Composant_identifiant. Notons également que l’héritage entre la super-métaclasse Composant_identifiant et la métaclasse fille Attribut, permet de dire qu’un élément de type Attribut « est » aussi un élément de type Composant_identifiant, et peut à ce titre être relié un élément de type Espace_de_recherche.
Prenons le cas plus complexe d’une association persistante, par exemple entre la classe persistante Stage et la classe persistante Etudiant. Comme dans les cas précédents, le concept d’association persistante existe dans le métaMDC sous la forme de la métaclasse Association_persistante. Contrairement au cas précédent cependant, il n’y pas de lien d’agrégation entre les métaclasses Association_persistante et Classe_persistante, il n’y a même aucun lien direct entre les deux métaclasses. Pour comprendre la façon dont sont modélisées dans le métamodèle les associations entre les classes persistantes, il faut se reporter au package Class du métamodèle UML 2.0 et en particulier la partie qui a été reprise dans le métaMDC. Voici concrètement la modélisation de l’association entre les classes persistantes Stage et Etudiant.
32

Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
asso_STG_ETUD:Association_persistante
asso Stage Etudiant (côté Etudiant):Propertyasso Stage Etudiant (côté Stage):Property
Etudiant:Classe_persistanteStage:Classe_persistante
Un:Expression
Un:ExpressionEtoile:Expression
Zéro:Expression
upperValue
lowerValue
symbol=*
symbol=0
memberEnd
association
memberEnd
type
symbol=1
type
upperValue
lowerValue
associationsymbol=1
Figure 28 - Modélisation de l'association Stage – Etudiant
Comme on le voit, cette association met en jeu tout à la fois des éléments de type
Classe_persistante et Association_persistante bien sûr, mais aussi de type Property et Expression. Voici la traduction de cette modélisation dans l’environnement eclipse.
Figure 29 - Les éléments impliqués dans la modélisation de l’association Stage – Etudiant
Remarquez, dans les propriétés de l’élément Association_persistante Stage Etudiant sélectionné dans l’éditeur, la valeur de la référence Member_end, qui pointe vers les éléments de type Property, comme indiqué la modélisation de la Figure 28 - Modélisation de l'association Stage – Etudiant ci-dessus.
33

Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
Le reste de la lecture du modèle de domaine conforme au métaMDC issu de l’étude de cas de l’article se fait de la même manière.
7.3 Extraire de l’algorithme les règles de transformation
Nous avons jusqu’à présent pu extraire de notre problème les métamodèles source et cible, et recréer un modèle source conforme au métaMDC qui traduit l’exemple étudié dans l’article [1]. Une fois ces trois éléments à notre disposition, nous pouvons nous lancer dans la programmation en ATL de la transformation proprement dite. Pour ce faire, nous devons extraire de l’article [1] les opérations de transformation décrites par les auteurs en langage naturel, et les traduire en ATL.
7.3.1 Algorithme général de traduction : Objet vers relationnel normalisé_L
Voici un extrait des annexes de l’article [1] où les auteurs décrivent la suite des opérations qui permettent la transformation d’un modèle objet en un modèle de schéma relationnel respectant la normalisationL. Données en entrées
Modèle du domaine (MD) {
- Diagramme de classes UML syntaxiquement correct et sémantiquement satisfaisant - On utilise les classes, les associations, les multiplicités, les rôles, les hiérarchies de spécialisations/généralisation, - les classes devant être rendues persistantes sont étiquetées (toute association entre classes persistantes est persistante)
}
Résultats Modèle Logique Relationnel Normalisé_L (MLRnL) i.e. : Structure assurant la persistance des informations du diagramme de classe UML conformément à CWM { - Ensemble des tables relationnelles avec leur schéma
. Attributs typés
. Contraintes de clés PRIMARY KEY, UNIQUE,
. Valeurs NULL, et contraintes NOT NULL
. Contraintes de référence - Traçabilité entre les éléments du MLRnL et ceux du MD annoté }
Algorithme (S = Système / C = Concepteur) FAIRE : Construire le MDC
C : - Donner des alias à toutes les classes persistantes ; - Donner des alias aux associations de multiplicité supérieure à zéro aux deux extrémités
S : Vérifier la déclaration « persistante » des classes, vérifier l’unicité des alias TANT QUE [ Le MD n’est pas complètement annoté par le concepteur ]
Annoter le MD { Pour une classe S : calculer et afficher l’espace de recherche des composants d’identifiants C : spécifier les contraintes d’identifiants (stéréotypes <<ID>>)
. Donner un nom de contrainte
34

Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
. Donner la composition de l’identifiant en utilisant l’espace de recherche calculé par le système FinPour } S : présenter au concepteur la liste de classes sans identifiants exportables SI le concepteur déclare avoir terminé ALORS MD complètement annoté FSI
FTQ S : Affecte un identifiant système à chaque classe restée sans identifiant exportable
FAIT : MDC construit FAIRE : Construire le MLRnL S : Appliquer les règles de Normalisation_L ; post : On dispose des premiers proto-schémas relationnels
Utilisation d’ATL
S : Appliquer l’algorithme de calcul des clés ; {
- Capturer le graphe G de la relation de composition des identifiant - Gérer les arcs d’importation - Détecter les cycles élémentaires TANT QUE [ Il existe des cycles élémentaires ] - Solliciter le concepteur pour rompre le cycle
- SI [ proposition correcte du concepteur ] ALORS Appliquer la proposition SINON remplacer un identifiant composé choisi sur le cycle par un
identifiant système. FSI
FTQ – post : Il n’existe plus de cycle élémentaire S : Présenter au concepteur les choix d’identifiants exportables C : Choisir les clés primaires parmi les identifiants exportables S : Résoudre les identifiants importés { - Mettre G en ordre (identifiants complexes à la racine et attributs comme feuilles)
- Résoudre le calcul des identifiants de proche en proche (en partant des attributs)
TANT QUE [ il existe des composants non traités ] FAIRE - Choisir un identifiant I ayant comme fils uniquement des identifiants traités et/ou
des attributs) ; - Traiter l’identifiant I en lui affectant comme attributs l’ensemble des attributs de sa
descendance. FAIT S : Produire le MLRnL { - Gérer les identifiants substituables et non substituables - Utiliser les noms de rôle pour nommer les identifiants concernés - Lister les contraintes de clés et de dépendances de références } FAIT – post : le MLRnL est disponible
• Dans certains cas, guidés par le métier, on fragmente verticalement des tables à clés équivalentes.
Figure 30 - Algorithme général de transformation
35

Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
On remarque que l’algorithme n’est pas intégralement automatique, et que l’utilisateur
est régulièrement appelé à prendre des décisions. L’articulation entre les étapes automatiques et manuelles soulève des questions sur lesquelles nous reviendrons (section 8.3). Notons simplement pour le moment que la transformation prise dans son ensemble n’est pas monolithique, et qu’elle comporte au contraire de multiples opérations de diverses nature, tantôt de dialogue avec l’utilisateur, tantôt de calcul d’un espace de recherche ou d’identifiants, et finalement rarement de transformation proprement dite.
On a vu par ailleurs qu’ATL, bien que doté d’une forme impérative qui le rend apte à la programmation de nombreuses opérations, est par essence destiné à être utilisé sous sa forme déclarative dédiée elle exclusivement à la transformation de modèles.
Par là on comprend pourquoi nous avons pour l’instant réservé l’utilisation d’ATL à la partie du processus pour laquelle il est le plus efficace : la construction du MLRnL à partir du MDC annoté par l’utilisateur, étape signalée au milieu de la Figure 30 - Algorithme général de transformation. En exploitant les indications de l’article [1] pour le traitement des différents éléments du modèle source (classes, tables, associations, généralisations…) on garantit implicitement le respect de la normalisation_L.
L’automatisation de cette construction se décompose en trois grandes phases qui sont détaillées dans les 3 sections suivantes.
7.3.2 Identifier les éléments et leurs antécédents
Cette étape consiste à déterminer quels éléments du modèle sources sont à l’origine des éléments créés dans le modèle cible. En réalité, la réflexion se fait plutôt au niveau des métamodèles. En effet, comme nous l’avons présenté dans la section 6 ci-dessus, les règles de transformation exprimées en ATL font exclusivement référence aux éléments des métamodèles cible et source.
La question de la correspondance entre ces éléments se dédouble alors de la façon suivante :
1. Lors de la transformation, que devient cet élément de notre métamodèle source? 2. Quels éléments du métamodèle source permettent d’obtenir, par leur transformation,
cet élément du métamodèle cible ? Pour les classes persistantes et de leurs attributs du modèle source, nous savons pouvoir
répondre à la question 1. En effet, les unes deviennent intuitivement des tables et les autres des colonnes de ces mêmes tables. Les autres informations contenues dans le modèle source, comme les identifiants, les associations et les généralisations, doivent subir un traitement plus complexe qui est décrit dans l’article [1] pour tous les cas de figure.
Comme nous venons de le dire, un exemple trivial est la correspondance entre les métaclasses Classe_persistante du métaMDC et Table du métamodèle CWM. Il s’agit là d’une bijection sans ambiguïté, et les réponses concernant ces éléments aux deux questions ci-dessus sont homogènes : un classe persistante donne une table, et une table vient d’une classe persistante (ceci n’est pas tout à fait exact, puisqu’une composante de jointure représentée par une table dans le schéma relationnel est engendré non pas par une classe persistante, mais par une association N-M).
Prenons maintenant la métaclasse Association_persistante du métaMDC, et posons nous la première question : que devient-elle dans la transformation ? La réponse est plus complexe que dans le cas précédent. En effet, l’article [1] nous indique que le traitement des associations persistantes est conditionné par les multiplicités de leurs extrémités. Il faut dans certains cas créer une composante de jointure, dans d’autre seulement une clé étrangère, dans
36

Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
d’autre encore deux clé étrangères symétriques. Cette interprétation du texte nous montre que la deuxième question posée sur la métaclasse ForeignKey du métamodèle CWM n’a pas non plus de réponse unique. On peut ainsi obtenir de multiples manières une clé étrangère dans notre schéma relationnel, et il n’y a donc plus de bijection entre une association persistante et une clé étrangère.
La grande variété de configurations possibles du modèle source rend difficile d’identifier les correspondances qui nous intéressent pour programmer sa transformation. Mais ce travail d’analyse a été effectué au préalable dans l’article [1], et l’implémentation ne consiste donc qu’à ne rien oublier de tous les cas décrits.
7.3.3 Déterminer les opérations de traduction
L’identification des correspondances entre les méta-éléments sources et cibles dans tous les cas de figure n’est bien entendu pas suffisante. La définition d’une fonction ne se résume pas à celle de ses domaines de départ et d’arrivé. Un travail supplémentaire consiste à déterminer pour chaque correspondance les calculs, tests et affectations à opérer sur les éléments. Notez que le langage ATL ne permet pas de modifier le modèle source, qui est donc en lecture seule, et qu’il ne permet pas non plus de lire dans les éléments cibles créés au cours d’une transformation. C’est pourquoi des trois « genres » d’opération listés ci-dessus, les calculs et les tests s’opèreront sur les valeurs d’attributs ou de références du modèle source, et les affectations se feront exclusivement sur des valeurs d’attributs ou de référence du modèle cible.
Ce mode de travail est cohérent avec une expression des règles de transformation au niveau des métamodèles, puisque les attributs et les références, au moment de l’écriture du programme, ne sont pas connus en terme d’éléments d’un modèle d’entrée, mais en terme de types d’élément qu’il sera possible de rencontrer dans un modèle d’entrée. Par exemple, on ne peut pas dire que l’ « on transforme la classe persistante A en la table A ». Cette proposition fait référence à la classe persistante A, qui est certes un élément d’un modèle de domaine valide et conforme au métaMDC, mais qui n’existe pas ou n’est pas connu au moment de l’écriture de la règle de transformation d’une classe persistante en une table. Pour que la règle soit générique et que la transformation dans son ensemble puisse à s’appliquer à toutes sortes de modèles, elle ne saurait référencer directement les éléments du modèle source. Pour traduire l’exemple précédent, on dira donc plutôt que « chaque élément de type ‘classe persistante’ du modèle source donne lieu à la création d’un élément de type ‘table’ dans le modèle cible, et prend le nom de l’élément source ».
7.3.4 Exprimer les opérations dans le langage ATL
Enfin, une fois la sémantique des règles de transformation extraite en langage naturel, il s’agit d’exploiter les fonctionnalités du langage ATL pour en obtenir l’équivalent dans notre module, ici le fichier MDC2MLRnL.atl .
7.3.5 Exemple 1, Classe_Table
Reprenons l’exemple de la transformation d’une classe persistante en une table. Voici la règle écrite en ATL.
37

Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
Figure 31 - Une table pour une classe, en ATL
La ligne 33 donne le nom de la règle. Le mot clé « from » indique le type d’élément qui sera utilisé comme paramètre d’entrée pour l’exécution de cette règle et le nom de ce paramètre dans le scope de la règle. Ici le paramètre nommé « classe » prendra successivement la valeur de tous les éléments de type ClassePersistante défini dans le métaMDC (identifié par le nom du package « MDC »). Cette règle sera exécutée une fois sur chaque élément de type ClassePersistante du modèle source.
Le mot clé « to » ouvre quant à lui la définition de la liste des éléments qui doivent êtres créés dans le modèle cible, à partir de l’élément « classe ». Ici par exemple, puisque l’on a une bijection simple entre les classes persistantes et les tables, on ne crée qu’un seul élément de type Table, défini dans le métamodèle CWM identifié par le nom de son package « MLRnL », et qui prend dans le scope de la règle le nom de variable ‘t’.
Les lignes 36 et 37 correspondent enfin à l’affectation des valeurs des attributs de l’élément crée. L’attribut « name » de l’élément ‘t’ prend pour valeur la valeur de l’attribut « name » de l’élément classe, et on fixe d’autorité la valeur de l’attribut « isTemporary » de l’élément ‘t’ à ‘false’. La navigation de la variable « classe » vers son attribut « name », à la ligne 36, et permise par l’utilisation de la syntaxe OCL [12].
7.3.6 Exemple 2, AssoBinaire_Cas2
Avant d’aborder cet exemple, reprenons son origine dans l’article. Ce cas précis de transformation s’applique lorsque l’on rencontre une association binaire (ne reliant que deux classes persistantes).
S T
as : undefined... : undefined
at : undefined... : undefined
ArôleS rôleT
mS..MS mT..MT
Figure 32 - Cas générique d’association UML traité par la Normalisation_L
Le cas générique représenté ci-dessus est divisé en plusieurs sous catégories : les cas
MT >1 et MS >1, MT = 1 et MT > 1 et MS ≤ 1. La deuxième catégorie, (MT = 1), conduit quelques soient les valeurs des autres bornes des multiplicités de l’association à d’une part l’ajout d’un attribut K_T à tabS, et la création d’une clé étrangère qui référence tabT depuis tabS. La sémantique de cette règle de transformation est beaucoup plus riche que dans l’exemple 1 et nécessite pour sa traduction en ATL la mise en œuvre de nombreuses fonctionnalités du langage. Voici le code correspondant.
38

Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
Figure 33 - La règle AssoBinaire_Cas2
Comme dans l’exemple 1, on retrouve les mots clés familiers « rule », « from » et « to », qui jouent le même rôle que précédemment. Notons cependant dès à présent à la suite de la spécification du type d’élément que l’on cherche dans le modèle source (fin de ligne 88) l’apparition entre parenthèses d’un « guard ». Il s’agit d’une expression booléenne qui si elle s’évalue à faux, interdit l’exécution de la règle. Dans notre cas, on utilise cette fonctionnalité pour éviter que la règle « AssoBinaire_Cas2 » ne s’applique à d’autres associations persistantes que celles correspondantes au cas MT = 1 indiqué dans l’article.
Voyons le détail de ce guard, qui contient deux helpers (macros) imbriqués : le helper « cas2 » disponible sur l’élément « thisModule », lui-même faisant appel en paramètre au helper « cardinalite » disponible sur l’élément « a »
7.3.6.1 Le helper « cardinalite »
39

Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
Figure 34 - Le helper cardinalites
Comme tous les helpers qu’il est possible de définir avec ATL, celui-ci est invoqué comme nous l’avons vu par son nom défini ligne 5, ligne où l’on trouve également précédé du mot clé « context » le type d’élément auquel ce helper peut s’appliquer, et le type de la valeur renvoyée, indiqué en vert comme étant une séquence d’entier. Les différents types disponibles ici et dans le reste des modules ATL sont les types primitifs définis dans la norme OCL.
La ligne 6, à l’aide de l’opérateur OCL « collect », amorce le parcours de tous les éléments de la collection des « memberEnd » de l’élément « self ». « self » représente ici le contexte d’éxécution du helper, c'est-à-dire un élément de type « AssociationPersistante ». Le parcours de cette collection se fait en affectant à la variable « u » successivement les valeurs des éléments de la collection. A chaque nouvelle valeur de u, on applique ensuite le code des lignes 7 à 12, et on renvoie les résultats sous forme d’une nouvelle collection.
Ici, le but des lignes 7 à 12 est de convertir en entier les expressions des cardinalités de l’association persistante « self ». Pour ce faire, on déclare à la ligne 7 une nouvelle variable locale « lv » en utilisant les mots clés OCL « let » et « in ». « lv », pour lowerValue, prend pour valeur une séquence d’un élément égal à la conversion en entier (« toInteger() ») de la valeur de l’attribut « symbol » de l’élément pointé par la référence « lowerValue » de la variable « u ». Pour bien comprendre cette navigation complexe, on peut se reporter à la fois au métaMDC (en particulier sa partie extraite du métamodèle d’UML 2.0 à la Figure 1) et à l’exemple de la Figure 28 - Modélisation de l'association Stage – Etudiant. Une deuxième partie de code (lignes 8 à 12) permet de prévenir le cas ou le symbole d’une borne supérieur de multiplicité est une étoile, auquel cas l’opérateur « toInteger() » ne peut être utilisé. Un test nous permet alors de convertir cette étoile en un entier très grand.
Nous venons de le voir, l’expression du guard de la règle AssoBinaire_Cas2 utilise le helper « cardinalites ».
Les helpers tels que celui-ci permettent dans ATL, comme les fonctions dans d’autres langages de factoriser du code réutilisable. L’écriture d’un helper pour obtenir les cardinalités d’une association nous a simplement permis la réutilisation de son code pour le calcul de la variable local « index » définie plus loin.
7.3.6.2 Le helper « cas2 »
Figure 35 - Le helper cas2
Dans l’expression du guard de la Figure 33, on trouve également un appel au helper « cas2 », à partir de l’élément « thisModule ». Ce dernier élément représente dans ATL le module en cours d’exécution, et permet d’accéder aux helpers particuliers dont la définition n’inclue pas de contexte. C’est précisément le cas de « cas2 ». Par ailleurs, une différence importante entre les helpers « cardinalites » et « cas2 » est la spécification dans la signature de ce dernier de paramètres. Il s’agit ici d’un paramètre « c » qui est une séquence de séquences d’entiers. La définition du type de ce paramètre est homogène avec celle du type de retour du helper « cardinalites », et nous avons ainsi pu les chaîner dans la définition du guard de la
40

Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
règle « AssoBinaire_Cas2 ». Le code du helper « cas2 », en ligne 21, permet simplement de vérifier que nous sommes bien dans un cas où d’une part l’association dont sont extraites les multiplicités est bien binaire ( c->size() = 2 ) et d’autre au moins une des bornes supérieures des multiplicités des extrémités de l’association persistante est bien égale à 1 ( reste de la ligne).
Autre nouveauté dans l’expression de cette règle, un nouveau mot clé « using » ajouté ligne 89 permet simplement d’ouvrir un espace de définition de variables locales. Ici par exemple, quatre variables sont définies :
• ‘index’, de type entier, utilisé uniquement comme outil de calcul pour déterminer dans les lignes suivantes (96 et 97) quelles sont effectivement les classes S et T de la
• • Figure 32 - Cas générique d’association UML traité par la Normalisation_L. Le
calcul de la valeur de cet index repose sur le test de la ligne 91, qui lui-même fait appel, à travers le mot clé « cardinalites » au helper (à la macro) du même nom. Ce helper a déjà été décrit, rappelons simplement qu’il permet d’obtenir, à partir d’un élément de type AssociationPersistante reliant deux classes persistantes (ici identifié par la variable nommée ‘a’), la séquence des couples de bornes de multiplicités de chaque extrémités de l’association : { { lowerValue extrémité 1 ; upperValue extrémité 1 } ; { lowerValue extrémité 2 ; upperValue extrémité } }. La partie gauche du test d’égalité renvoie donc la dernière valeur du premier couple prit dans cette séquence de multiplicités. Si cette valeur est 1, on affecte la valeur 1 à la variable entière ‘index’, sinon, ‘index’ vaut 0.
• ‘classeT’, de type ClassePersistante, qui référence l’élément du modèle source correspondant à la classe T de la
• • Figure 32 - Cas générique d’association UML traité par la Normalisation_L. Ce
résultat est obtenu en utilisant la variable ‘index’ définie juste au-dessus, et la navigation OCL. Ligne 96 par exemple, la partie gauche de l’association utilise la référence ‘memberEnd’ de l’élément ‘a’ pour accéder à la collection des extrémités de l’association persistante ‘a’. De cette collection, l’opérateur OCL « at() » permet d’extraire l’élément à la position calculée par ‘ 2 – index ’. Si l’on suit la structure du métaMDC, on sait obtenir alors un élément de type Property. Depuis ce dernier élément on peut enfin accéder par sa référence ‘type’ à la classe persistante qui nous intéresse. A nouveau, on peut se reporter à l’exemple de la Figure 28 - Modélisation de l'association Stage – Etudiant.
• ‘classeS’, de type ClassePersistante, qui référence de la même façon que précédemment l’élément du modèle source correspondant à la classe S de la
• • Figure 32 - Cas générique d’association UML traité par la Normalisation_L. • ‘symboleT’, de type chaîne de caractère, qui référence l’attribut « name » de l’élément
de type SymboleIDExportable pointé par la référence symboleidexportable de la variable locale classeT. Cette dernière longue navigation est à nouveau possible grâce à l’utilisation du langage OCL.
Ces quatre variables locales sont ensuite accessibles à l’intérieur de la ou des clauses « to » qui suivent le bloc « using ». Dans notre cas, leur utilisation permet de rendre plus lisible le code de la transformation, en remplaçant des expressions OCL complexes par un simple nom au sens intuitif.
41

Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
7.3.6.3 Définition de multiples éléments dans la clause « to »
Comme nous l’avons vu en début de section 7.3.6, la présence dans le modèle source d’une association persistante binaire avec les multiplicités indiquées donne lieu à la création dans le modèle cible de deux éléments simultanément, à la fois un attribut de type colonne à l’élément correspondant à la table « tabS » de l’exemple générique de la
Figure 32 - Cas générique d’association UML traité par la Normalisation_L, mais
aussi la génération d’une clé étrangère référençant « tabT » depuis « tabS ». La clause « to » de la règle visible en Figure 33 - La règle AssoBinaire_Cas2, possède
pour cette raison deux parties. Voici la première :
Figure 36 - Premièr élément généré par la clause "to"
Dans un premier temps, on génère naturellement un élément « c » de type Column. Pour fixer l’appartenance de cette nouvelle colonne à la table S, on affecte la référence « columnset » de l’élément « c » à la variable locale « classeS ». On voit ici que comme indiqué précédemment (section 7.3.3), l’affectation de la référence « columnset » n’utilise pas la valeur d’un élément du modèle cible, mais bien celle d’un élément du modèle source (« classeS »).
La ligne 104, quant à elle, utilise le helper « nomCol » disponible dans le contexte général du module, pour générer un nom de colonne explicite pour la clé étrangère dans « tabS » à partir des deux classes liées pas l’association « a », et du nom de la règle.
Dans un deuxième temps, nous créons, au-delà de la nouvelle colonne dans « tabS », l’élément de type « ForeignKey » qui incarne la clé étrangère liant cette nouvelle colonne et la clé primaire de « tabT ». C’est la deuxième partie de la clause « to » :
Figure 37 - la deuxième partie de la clause "to"
La ligne 107 crée l’élément « fk », de type « ForeignKey » proprement dit. Il faut se reporter au métamodèle CWM pour bien comprendre comment est modélisée une clé étrangère. Disons simplement que ses deux références essentielles sont d’une part « uniqueKey », qui doit pointer vers la clé unique (une clé primaire étant une clé unique) que cette clé étrangère référence, et d’autre part « feature » qui indique la ou les colonnes qui constituent, dans la table qui contient la clé étrangère, le corps de la clé. C’est ces deux références importantes qui sont établies aux lignes 109 et 110 du code de la Figure 37 - la deuxième partie de la clause "to".
La première, ligne 109, est un peu particulière. Il s’agit là comme nous venons de le dire de faire pointer la référence « uniqueKey » de la nouvelle clé étrangère « fk » fraîchement
42

Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
crée vers la clé primaire de la table « tabT », elle-même résultat de la transformation de la classe « classeT ». Or, comme nous l’avons déjà mentionné, le langage ATL ne permet pas d’utiliser dans les affectations des valeurs des éléments du modèle cible des valeurs d’autres éléments du modèle cible. Pour réaliser tout de même cette affectation, il faut pour désigner un élément du modèle cible utiliser sont antécédant dans le modèle source. C’est ce que nous faisons ici, avec une subtilité supplémentaire. Les éléments de types « PrimaryKey » qui apparaissent dans le modèle cible sont générés à partir des éléments de type « SymboleIDExportable du modèle source, par la règle ci-dessous.
Figure 38 - Règle de génération des clés primaires
Dans cette autre règle, on voit cependant que les éléments de type « PrimaryKey » sont créés (ligne 61) parmi d’autres éléments (lignes 56 et 67). Pour que dans le code de la figure 35 la machine affecte bien à la référence « uniqueKey » le sous-ensemble de type « PrimaryKey » généré par la règle de la figure 36, on utilise l’opérateur ATL resolveTemp(), qui permet de préciser avec ses deux paramètre (<nom_de_règle>, <nom_élément_cible>), l’élément précis du modèle cible dont on souhaite obtenir la valeur.
Dans l’article [1] le traitement des associations binaires est bien plus complet et prévoit
une multitude de stratégies en fonction de chaque cas particulier des multiplicités non seulement des associations mais également des attributs qui constituent leurs extrémités. C’est la richesse des ces stratégies qui incarnent dans le code les concepts de la forme normale allégée, ou normalisation_L. Tous ces cas ne sont pas encore traités par le code ATL complet fourni en annexe (section 11.1). L’étude de l’exemple de la section 7.3.6 fourni cependant les clés pour comprendre comment les cas qui restent à traiter pourraient être programmés.
7.4 Contrôler, compléter, corriger
La correction syntaxique du code est vérifiée au moment de la compilation directement par la plateforme eclipse. Sa validité sémantique est quant à elle plutôt vérifiée en contrôlant la conformité du résultat obtenu après la transformation automatique.
43

Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
Comme nous l’avons expliqué, une transformation ATL produit un modèle cible au format xmi. Ce nouveau modèle est donc interprétable par l’éditeur du plugin EMF. Voici ci-dessous un court extrait du modèle cible, stocké dans le fichier « tables.ecore », où nous trouvons entre autre l’élément Stage de type « Table ». L’utilisation de l’éditeur et de son onglet « Properties » permet ainsi de contrôler non seulement la présence des éléments attendus dans le modèle cible, tels que les tables, les colonnes, les clés, mais également la valeur des attributs et des références de ces éléments.
Figure 39 - Extrait du résultat de la transformation de la classe Stage
8 Conclusions à l’issu de l’expérimentation
8.1 Les avantage d’ATL
Au moment de la rédaction de ces lignes, le bilan quant à l’utilisation du langage ATL pour aborder notre problème est positif. Après une prise en main du langage et des concepts qui l’entourent, ATL a pleinement révélé son adéquation avec notre besoin de transformer les modèles qui nous intéressent, et aucun verrou technique ne laisse présager de difficulté à exprimer dans une transformation automatique toute la sémantique détaillée dans l’article [1]. Comme il a déjà été évoqué, plus que sur le codage, le travail du programmeur portera sans doute sur un patient dialogue avec les concepteurs du processus de transformation pour précisément spécifier les métamodèles sources et cibles de la transformation, qui devront être assez complets et précis pour permettre d’exprimer l’ensemble des concepts utilisés dans les deux mondes de modélisation.
44

Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
8.2 Inconvénients d’ATL
Au stade actuel de son développement, ATL souffre cependant d’une mise en œuvre fastidieuse, en tout cas sur le plan des outils techniques à utiliser pour sa programmation. Son intégration sous forme de plugin dans la plateforme eclipse oblige en effet le programmeur à procéder à l’installation de plusieurs éléments de sources diverses, dont les versions évoluent de manière permanente et souvent incompatibles les unes avec les autres. Ainsi, trouver à un instant t une combinaison des version de ces éléments qui permettent d’obtenir un environnement de développement à la fois fonctionnel, robuste et permettant de profiter de toutes les fonctionnalités de développement peut parfois relever de la gageure. La situation a cependant tendance à s’arranger avec le souci des développeurs Nantais du langage de livrer des « bundle » complets, intégrant dans un seul paquet d’installation tous les éléments nécessaires et compatibles entre eux. Un de ces bundle est déjà disponible [13], mais pour l’instant exclusivement pour le système d’exploitation Microsoft Windows.
8.3 Une ou plusieurs transformations ?
La pratique du langage ATL nous a appris qu’au-delà de son extrême adaptation à la transformation de modèle proprement dite, il peut également s’atteler à des tâches de calculs qui sortent légèrement de ce cadre. Nous avons ainsi pu implémenter un programme ATL qui plutôt que de transformer un modèle en un autre se contente de calculer la valeur de certaines références du modèle source, valeurs qui se déduisent en réalités d’autres éléments et références de ce même modèle source et qui n’ont donc pas lieu d’être spécifiées à la main par le concepteur. Ce module ATL est indiqué en annexe 11.2, et consiste en le calcul pour chaque classe persistante du modèle source de son espace de recherche. Cette notion d’espace de recherche est détaillée dans l’article [1].
Cette nouvelle transformation, ou plus exactement ce calcul, peut être effectué au préalable sur un modèle de domaine d’entrée où les espaces de recherches n’ont pas étés encore déterminés, et le modèle résultant de ces calculs peut être utilisé comme nouveau modèle de domaine complet pour la transformation proprement dite vers un modèle CWM. Nous voyons alors clairement se profiler la notion de chaînage des transformations.
8.3.1 Chaînage de transformations
Nous venons de le voir, dans le cas de l’utilisation d’atl pour certains calculs, la transformation globale d’un modèle n’est plus atomique mais une suite de transformations et de calculs. Bien qu’il existe des outils pour mettre en place ces chaînes sous forme de tâche Ant, nous n’avons pas à ce jour expérimenté cette façon de procéder.
8.3.2 Création de plusieurs métamodèles intermédiaires
Utiliser une chaîne de transformations pour réaliser nos objectifs a par ailleurs un impact notable sur la façon de gérer les concepts manipulés dans les métamodèles sources et cibles. En effet, qui dit plusieurs transformations dit autant de couples de métamodèles cibles et sources différents (bien que dans certains cas purement calculatoire, ATL nous permette d’utiliser le même métamodèle source et cible). Dans ce cas, il sera certainement pertinent de ne conserver dans les métamodèles intermédiaires de la chaîne des transformations que les
45

Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
métaclasses strictement nécessaires à l’expression des concepts manipulés à ce moment là. Cela aboutira à la création de multiples métamodèles, dont les mutations tout au long du processus de transformations accompagneront les changements de domaines de modélisation.
9 Travaux futurs
9.1 Délimiter l’intervention d’ATL dans le processus
Les considérations précédentes relatives au chaînage des transformations nous ont permit d’anticiper l’apparition d’une tentation peut-être contre-productive dans l’utilisation d’ATL. En effet, la puissance du langage lui permet d’exécuter des opérations pour lesquels il n’est malgré tout pas fait. C’est le cas par exemple du calcul des espaces de recherches des classes persistantes. Certes, le code fourni en annexe montre que l’implémentation en ATL d’une telle tâche est possible, mais est-ce vraiment performant ? Ce calcul ne peut-il pas valablement être opéré plus facilement dans d’autres langages plus adaptés. Nous n’avons pas de réponse à cette question pour le moment, mais peut-être faudra-t-il être attentif, lors de l’élaboration d’un processus complet de traduction, à bien préciser le domaine d’intervention du langage ATL, en le limitant au maximum aux étapes où il est bien le plus adapté.
9.2 Terminer l’évolution du métaMDC
La réflexion sur la décomposition ou le chaînage des transformations induira nécessairement comme nous l’avons déjà dit une refonte plus ou moins importante des métamodèles utilisés, qu’ils soient 2 ou plus. Aujourd’hui, l’état d’avancement de nos travaux n’a pas créé le besoin de plus des deux métamodèles que sont le métaMDC et le métamodèle de CWM. Toutefois, la réflexion continue quant à l’optimisation du métaMDC pour représenter encore plus précisément et simplement les concepts utilisés dans le processus de transformatio. La pratique nous a montré que la précision et la concision du métaMDC a très souvent mené à une simplification de l’expression et de la lisibilité des règles de transformation, et par voie de conséquence une plus grande aisance dans la vérification de leur sémantique. Ce travail de métamodélisation est donc fondamental et mérite encore aujourd’hui sans doute quelques efforts.
9.3 Terminer l’extraction de règles de l’algorithme
Cette expérimentation d’ATL a abouti à la création d’un module où quelques règles de transformation sont codées. Bien que fonctionnelles, ces règles sont cependant incomplètes par rapport à l’ensemble des cas de figure traités dans l’article. Bien qu’aucun verrou technique ne soit en vue, et qu’il nous semble qu’ATL soit à même de traiter tous les cas, il reste encore beaucoup à faire pour complètement extraire de cet article toute la sémantique de transformation et l’implémenter concrètement et étoffant le module déjà existant.
46

Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
9.4 Explorer les possibilités d’interfaçage
A terme, on sait que le but du processus de conception est destiné à permettre à un utilisateur humain de maîtriser toute la chaîne de conception d’une base de donnée. Au-delà de la transformation de modèle, ce long processus sera aussi jalonné de nombreuses étapes de modélisation proprement dite et d’annotation. Ces étapes ne sauraient avoir lieu dans de bonnes conditions sans le recours à des interfaces graphiques ergonomiques permettant à l’utilisateur d’entrer ses choix, ses besoins dans le système. Les possibilités d’interfaçage graphique d’ATL ou plus largement les conditions d’articulation d’ATL avec d’autres technologies seront des éléments déterminants pour la réalisation d’un outil complet et performant conforme aux attentes des auteurs de l’article [1].
10 Conclusion
L’objectif de ce travail était de déterminer l’adéquation entre l’utilisation du langage de transformation de modèle ATL et le besoin d’implémentation d’un processus de traduction d’un modèle UML en un modèle CWM exprimé par les auteurs dans leur article [1]. A travers l’expérience menée ici, on a pu apporter plusieurs réponses. Premièrement, le langage ATL s’adapte très bien à une partie du besoin (la transformation proprement dite), le principal effort de mise en œuvre étant une définition claire et précise des métamodèles source et cible utilisés dans la transformation. Deuxièmement, on a montré que les opérations amont et aval de calcul pourraient être réalisées avec le même langage. Cependant, d’une part la performance relative de ce langage par rapport à d’autres pour la réalisation de ces mêmes tâches n’a pas été testée, et d’autre part, l’utilisation systématique d’ATL conduirait à l’élaboration d’un enchaînement de transformations. Enfin, la documentation d’ATL et un dialogue avec ses développeurs nous donnent à penser qu’il faudra articuler ce langage avec d’autres outils pour améliorer l’ergonomie du programme de transformation global.
47

Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
11 Annexes
11.1 Le code complet de la transformation (module MDC2MLRnL.atl)
module MDC2MLRnL; -- Module Template create OUT : MLRnL from IN : MDC; helper context MDC!AssociationPersistante def : cardinalites : Sequence(Integer) = self.memberEnd->collect( u | let lv : Sequence(Integer) = Sequence{u.lowerValue.symbol.toInteger()} in let uv : String = u.upperValue.symbol in if uv = '*' then lv -> append(10000) else lv -> append(uv.toInteger()) endif ); --Cas MT>1 et MS>1 helper def : cas1( c : Sequence(Sequence(Integer))) : Boolean = c->size() = 2 and c.first().last() > 1 and c.last().last() > 1; --Cas MT=1 helper def : cas2( c : Sequence(Sequence(Integer))) : Boolean = c->size() = 2 and ( c.first().last() = 1 or c.last().last() = 1 ); helper def : nomCol(c:MDC!ClassePersistante,n:String,regle:String):String= c.name + '.' + n + ' (par ' + regle + ')'; helper def : nomFK(c1:MDC!ClassePersistante,c2:MDC!ClassePersistante):String= c1.name + ' réf ' + c2.name; helper def : nomPK(c1:MDC!ClassePersistante,n:String):String= c1.name + '.' + n; --Crée une table pour chaque classe persistante. rule Classe_Table { from classe : MDC!ClassePersistante to t : MLRnL!Table ( name <- classe.name, isTemporary <- false ) } --Crée une colonne pour chaque attribut, et la lie à sa table contenante. rule Attribut_Column { from a : MDC!Attribut to c : MLRnL!Column ( name <- a.name, columnset <- a.proprietaire ) } --Crée une proto-colonne dans chaque table T pour son symbole d'ID Exportable rule Symbole_Column { from a : MDC!SymboleIDExportable using { classe : MDC!ClassePersistante = a.classepersistante; } to c : MLRnL!Column ( name <- thisModule.nomCol(classe,a.name,'Symbole_Column') , columnset <- classe ),
48

Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
-- crée une clé primaire sur la proto-colonne définie précédamment pk : MLRnL!PrimaryKey ( name <- thisModule.nomPK(classe,a.name), namespace_PK <- classe, feature <- c ), --Crée une proto-colonne dans chaque table importatrice, i.e qui possède un ID qui utilise cet ID Exportable. ce : distinct MLRnL!Column foreach ( id in a.id_ci ) ( name <- thisModule.nomCol(id.classepersistante,a.name,'Symbole_Column, importation') , columnset <- id.classepersistante ) } --Crée un contrainte d'unicité pour chaque ID rule ID_UC { from i : MDC!ID to u : MLRnL!UniqueConstraint ( name <- i.name, namespace_UC <- i.classepersistante,--.debug('cp'), feature <- i.expressionimplicite ) } -- Cas MT=1 rule AssoBinaire_Cas2 { from a : MDC!AssociationPersistante ( thisModule.cas2(a.cardinalites) ) using { index : Integer = if a.cardinalites->first().last() = 1 then 1 else 0 endif; classeT : MDC!ClassePersistante = a.memberEnd->at(2 - index).type; classeS : MDC!ClassePersistante = a.memberEnd->at(1 + index).type; symboleT : String = classeT.symboleidexportable.name; } to -- proto-colonne dans la table S, avec le nom du symbole d'id exportable de la classe T c : MLRnL!Column ( columnset <- classeS, name <- thisModule.nomCol(classeS,symboleT,'AssoBinaire_Cas2') ), -- mise en relation de la clé de la table T avec le symbole de la table S, avec une clé étrangère fk : MLRnL!ForeignKey ( name <- thisModule.nomFK(classeS,classeT), uniqueKey <- thisModule.resolveTemp(classeT.symboleidexportable,'pk'), feature <- c ) } --Dans le cas d'une généralisation, on crée simplement une clé étrangère dans la spécialisation rule Generalisation { from g : MDC!GeneralisationPersistante using { classeG : MDC!ClassePersistante = g.general; classeS : MDC!ClassePersistante = g.specific; symbole : String = classeG.symboleidexportable.name; --.debug('symbole'); } -- proto-colonne dans la table S, avec le nom du symbole d'id exportable de la classe G to c1 : MLRnL!Column ( columnset <- classeS, name <- thisModule.nomCol(classeS,symbole,'Generalisation') ), -- clé étrangère qui associe la clé de la classe G avec le proto-atttribut de la classe S fk : MLRnL!ForeignKey ( name <- thisModule.nomFK(classeS,classeG), uniqueKey <- thisModule.resolveTemp(classeG.symboleidexportable,'pk'), feature <- c1
49

Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
-- --namespace <- classeS ) } -- Pour certaines associations binaires, en fonction des cardinalités, on crée des clés étrangères rule AssoBinaire_Cas1 { from a : MDC!AssociationPersistante ( thisModule.cas1(a.cardinalites).debug('cas1') ) using { classeS : MDC!ClassePersistante = a.memberEnd->first().type; symboleS : String = classeS.symboleidexportable.name; classeT : MDC!ClassePersistante = a.memberEnd->last().type; symboleT : String = classeT.symboleidexportable.name; } to ta : MLRnL!Table ( name <- 'association ' + a.name.debug('asso') ), cS : MLRnL!Column ( columnset <- ta, name <- symboleS ), cT : MLRnL!Column ( columnset <- ta, name <- symboleT ), fkS : MLRnL!ForeignKey ( namespace <- classeS, uniqueKey <- thisModule.resolveTemp(classeS.symboleidexportable,'pk'), feature <- cS ), fkT : MLRnL!ForeignKey ( namespace <- classeT, uniqueKey <- thisModule.resolveTemp(classeT.symboleidexportable,'pk'), feature <- cT ), uc : MLRnL!UniqueConstraint ( name <- ta.name, namespace_UC <- ta, feature <- Sequence{cS,cT} ) }
11.2 Le module MDC2Chemins.atl
module MDC2Chemins; -- Module Template create OUT : MDC refining IN : MDC; helper context MDC!EspaceDeRecherche def : attributs : Sequence(MDC!Attributs) = self.classepersistante.attribut; helper context MDC!EspaceDeRecherche def : symboles_classes_associees : Sequence(MDC!SymbolesIDExportables) = -- ici, on souhaite récupérer les symboles d'id exportables de toutes les classes atteignables depuis la classe de l'espace de recherche courant -- par une association à l'extrémité de laquelle la multiplicité est 1 ou 0..1 (i.e que upperValue = 1) let classe : MDC!ClassePersistante = self.classepersistante in -- ensemble des propriétés qui sont membres d'une association et qui ont pour type la classe de l'espace de recherche. let proprietes_origine : Sequence(MDC!Property) = MDC!Property.allInstances()->select( p | p.type = classe ) in -- ensemble des associations dont les proprietes origine sont un membre let assos : Sequence(MDC!AssociationPersistante) = proprietes_origine->collect( p | p.association ) in
50

Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
-- ensemble des propriétés qui sont membre d'une des associations précédentes qui ont pour multiplicité -- maximum 1, et qui n'ont pas pour type la classe définie en début de marco. let proprietes_extremite : Sequence(MDC!Property) = assos->collect( a | a.memberEnd )->flatten()->select( p | p.type <> classe )->select( p | p.upperValue.name = 'Un') in -- symboles exportables des classes qui sont type des propriétés extrémités proprietes_extremite->collect( p | p.type.symboleidexportable ); helper context MDC!EspaceDeRecherche def : symboles_generalisations : Sequence(MDC!SymbolesIDExportables) = -- ici, il faut récupérer les symboles d'id exportables de toutes les classes atteignables depuis -- la classe de l'espace de recherche courant par une généralisation self.classepersistante.generalization->collect( g | g.general.symboleidexportable ); rule CalculEspaces { from i : MDC!EspaceDeRecherche to o : MDC!EspaceDeRecherche ( name <- i.name, classepersistante <- i.classepersistante.debug('classe'), composantidentifiant <- i.attributs->union(i.symboles_classes_associees)->union(i.symboles_generalisations).debug('symboles') ) } rule CopieEtudeDeCas { from i : MDC!EtudeDeCas to o : MDC!EtudeDeCas( nom <- i.nom, element <- i.element ) }
11.3 Description des métaclasses du métaMDC.
11.3.1 Classe_persistante
11.3.1.1 Généralisations
• « Class » de UML 2.0 Superstructure.
11.3.1.2 Description
• Une classe persistante est une classe que le concepteur a spécifiée comme telle. Elle est destinée à devenir une table dans la future base de données.
11.3.1.3 Attributs
• Alias : String Une des exigences de l’algorithme proposé ici est que tous les éléments spécifiés persistants reçoivent lors de la conception un alias. Cet alias sera utilisé comme identifiant lors de la création des tables correspondantes dans la base de donnée.
51

Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
11.3.1.4 Associations
• attribut :Attribut Chaque attribut d’une classe persistante est représenté par une instance de la classe Attribut implicitement persistante et qui deviendra une colonne dans la table résultante.
• :Symb_ID_exportable Chaque classe persistante sera associée à un symbole d’ID exportable au moment du calcul explicite des identifiants.
• :Espace_de_recherche L’espace de recherche d’une classe C est composé d’identifiants qui sont soit des attributs de C soit des symboles d’ID exportables d’autres classes accessibles par C par un chemin de composition.
• :ID Chaque classe persistante posssède un ou plusieurs ID permettant leur identification unique. L’un de ces ID sera qualifié d’exportable et deviendra l’unique symbole d’ID exportable de la classe.
• :Chemin_de_composition Une classe persistante peut constituer l’extrémité ou l’origine d’un chemin de composition. Un chemin de composition est une séquence d’associations dont les extrémités sont de multiplicité 1 ou 0-1 ou de généralisation.
11.3.1.5 Contraintes
• Une classe persistante possède toujours un alias définit par le concepteur.
11.3.2 Generalisation_persistante
11.3.2.1 Généralisations
• « Generalization » de UML 2.0 Superstructure.
11.3.2.2 Description
• Une généralisation persistante permet de rendre pérenne la relation d’héritage entre deux classes du MDC.
11.3.2.3 Attributs
• Aucun attribut additionnel.
11.3.2.4 Associations
• arc : Arc_de_composition Identifie l’arc de composition dont cette généralisation est l’incarnation.
52

Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
11.3.3 Association_persistante
11.3.3.1 Généralisations
• « Association » de UML 2.0 Superstructure.
11.3.3.2 Description
• Une association persistante permet de rendre pérenne la relation d’association entre deux classes du MDC.
11.3.3.3 Attributs
• Aucun attribut additionnel.
11.3.3.4 Associations
• arc : Arc_de_composition Identifie l’arc de composition dont cette généralisation est l’incarnation.
11.3.4 Attribut
11.3.4.1 Généralisations
• « Property » de UML 2.0 Superstructure. • « Composant_identifiant » du package MDC.
11.3.4.2 Description
• La classe attribut représente les attributs des classes persistantes
11.3.4.3 Attributs
• La classe Attribut ne définit aucun attribut additionnel à ceux hérités de ses superclasses d’UML 2.0 Superstructure.
• On notera l’utilisation systématique de l’attribut « name » de la classe parente « NamedElement ».
11.3.4.4 Associations
• propriétaire : Classe_persistante référence à la classe propriétaire de l’attribut. • id_at : ID
53

Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
Référence les clés (les ID) dont cet attribut fait partie de l’expression explicite.
11.3.5 ID
11.3.5.1 Généralisations
• « Constraint » de UML 2.0 Superstructure.
11.3.5.2 Description
• Les ID sont des identifiants construits par le concepteur en assemblant des attributs de la classe et/ou de symboles d’ID exportables d’autres classes.
11.3.5.3 Attributs
• La classe ID ne définit aucun attribut additionnel à ceux hérités de ses superclasses d’UML 2.0 Superstructure.
• On notera l’utilisation systématique de l’attribut « name » de la classe parente « NamedElement ».
11.3.5.4 Associations
• : Arc_de_composition Spécifie le ou les arcs de composition qui permettent d’atteindre le ou les symboles d’ID exportables qui peuvent composer l’ID. • : Classe_persistante Référence la classe_persistante à laquelle appartient cet ID. • expression_implicite: Composant_identifiant Spécifie les composants de l’identifiant, qu’ils soient des attributs ou des symboles d’ID exportables, qui dans ce dernier cas ne sont pas encore déterminés en terme d’attributs. • expression_explicite : Attribut Donne la composition finale exhaustive de l’ID exclusivement en terme d’attributs, de la classe ou d’autres classes.
11.3.5.5 Contraintes
• Le nom d’un ID est composé comme suit :
nomIdentifiant ::= K<numéro d’ordre>_< alias de la classe traitée>
54

Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
11.3.6 ID_exportable
11.3.6.1 Généralisations
• ID
11.3.6.2 Description
• Pour chaque classe persistante, un unique identifiant sera choisi comme exportable parmi les ID définis sur la classe.
11.3.6.3 Attributs
• Aucun attribut additionnel
11.3.6.4 Associations
• Aucune association additionnelle
11.3.6.5 Contraintes
• L’identifiant choisi comme exportable devra en plus de posséder une propriété d’unicité, ne comporter aucun composant d’identifiant qui prenne des valeurs nulles.
11.3.7 Symb_ID_exportable
11.3.7.1 Généralisations
• « Composant_identifiant » du package MDC
11.3.7.2 Description
• Le symbole d’ID exportable est une variable temporaire qui intervient dans le calcul et l’expression des clés des tables dans le modèle relationnel. Cette variable est définie et valorisée sur les classes du MDC. Elle joue le rôle d’inconnue dans le système d’équations permettant de résoudre le calcul final explicite des identifiants.
11.3.7.3 Attributs
• Comme la classe ID, la classe Symb_ID_exportable fait simplement l’usage de l’attribut « name » de sa superclasse « NamedElement ».
55

Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
11.3.7.4 Associations
• : Classe_persistante Référence la classe persistante dont ce symbole et le symbole d’ID exportable.
11.3.7.5 Contraintes
• De façon presque similaire à l’ID, le nom du symbole est contraint de la façon suivante :
nomSymbole ::= K_<alias de la classe traitée>
11.3.8 Composant_identifiant
11.3.8.1 Généralisations
• Aucun héritage
11.3.8.2 Description
• Cette classe abstraite représente un composant utilisé dans la construction des ID des classes persistantes.
11.3.8.3 Attributs
• Aucun attribut additionnel
11.3.8.4 Associations
• id_ci : ID Référence les ID dont ce composant fait partie de l’expression implicite. • : Espace_de_recherche Référence les espaces de recherche qui
contiennent ce composant.
11.3.9 Espace_de_recherche
11.3.9.1 Généralisations
• Aucun héritage
56

Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
11.3.9.2 Description
• L’espace de recherche de la classe considérée est constitué de l’ensemble de ses attributs, augmenté des symboles d’identifiant exportable des classes « voisines » auxquelles elle est reliée par un « arc de composition ».
• L’espace de recherche d’une classe C est composé d’identifiants qui sont soit des attributs de C soit des symboles d’ID exportables d’autres classes accessibles par C par un chemin de composition.
11.3.9.3 Attributs
• Aucun attribut additionnel
11.3.9.4 Associations
• : Classe_persistante Référence la classe persistante dont cet ensemble est l’espace de recherche.
• : Composant_identifiant Spécifie les composants d’identifiant qui font parti de cet espace de recherche.
11.3.10 Arc_de_composition
11.3.10.1 Généralisations
• Aucun héritage
11.3.10.2 Description
• Les arcs d’importation sont de deux sortes, ceux qui proviennent d’associations et ceux qui proviennent de généralisations. Dans le premier cas, les associations prises en compte joignent la classe considérée (origine) à une quelconque autre classe (extrémité), avec comme contrainte que la multiplicité de l’extrémité soit (1) ou (0..1). L’arc d’importation est naturellement orienté de l’origine vers l’extrémité. Dans le second cas, l’arc d’importation est orienté de la spécialisation vers la généralisation.
11.3.10.3 Attributs
• Aucun attribut additionnel
11.3.10.4 Associations
• gen : Generalisation_persistante Spécifie la généralisation qui incarnation cet arc. • asso : Association_persistante
57

Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
Spécifie l’association qui incarnation cet arc. • extrémité : Classe_persistante Référence la classe persistante extrémité de l’arc de composition. • origine : Classe_persistante
Référence la classe persistante de départ du arc de composition, autrement dit la classe persistante à laquelle appartient cet arc.
• : ID Spécifie le ou les ID dont un composant d’identifiant est accédé par ce chemin de composition
11.3.10.5 Contraintes
• Une classe persistante ne peut pas être à la fois extrémité et origine d’un chemin de composition.
• Un arc de composition ne peut être incarné que par une association persistante ou une généralisation persistante, exclusivement.
58

Approche MDA pour la transformation d’un diagramme de classes UML 2.0 en un schéma CWM
12 Ressources Internet et bibliographiques
1 Générer un modèle relationnel normalisé à partir de diagrammes de classes UML, M.C.
Lafaye, J.Y. Lafaye, G. Louis, 2006. 2 ATLAS (ATLantic dAta Systems), http://www.sciences.univ-nantes.fr/lina/ATLAS/ 3 Mise en oeuvre de l’approche MDA pour la conception de bases de données normalisées-L,
Sabirou Téouri, 2004 .d�]rC.dl=gZ¥_fJ�]r.ntl
Kntlont�krtrCudl=..x_ldh¤._¥_fV�]rtrCldhJhVl=.¨§ª©]«_¬m-k®Q¯2°_±_²_°.³) ¦ .X..l=.
4 Introduction aux bases de données (6ème édition), Chris J. Date, Ed Vuibert, 1998 5 UML http://www.uml.org/ 6 UML Superstrucutre, http://www.omg.org/cgi-bin/doc?formal/05-07-04 7 CWM http://www.omg.org/technology/cwm/ 8 MDA Guide Version 1.0.1 http://www.omg.org/docs/omg/03-06-01.pdf9 MOF/QVT http://www.omg.org/cgi-bin/apps/doc?ptc/05-11-01.pdf 10 Le forum de discussion sur ATL : http://groups.yahoo.com/group/atl_discussion/ 11 Le « zoo » des transformation ATL : http://www.eclipse.org/gmt/atl/atlTransformations/ 12 La specification officielle du langage OCL version 2.0 :
http://www.omg.org/docs/formal/06-05-01.pdf 13 Le bundle ATL pour Windows: http://www.sciences.univ-nantes.fr/lina/atl/atldemo/adt/
59


















