

IBM Bluemix Paris Meetup #27 20171219 - Manipuler des probabilités avec aGrum
43
Manipuler des probabilités et des données avec aGrUM Pierre-Henri Wuillemin, Lip6 Lionel Torti, LTO Data Consulting Gaspard Ducamp, Lip6/IBM
-
Upload
ibm-france-lab -
Category
Technology
-
view
103 -
download
4
Transcript of IBM Bluemix Paris Meetup #27 20171219 - Manipuler des probabilités avec aGrum

Manipuler des probabilités et des données avec aGrUM
Pierre-Henri Wuillemin, Lip6Lionel Torti, LTO Data ConsultingGaspard Ducamp, Lip6/IBM

Informatique/IA décisionnelle : interfacer l’aléatoire
décision=fonction(input1,input2,input3,...)
● Décision face à l’utilisateur● Décision face à l’incertain● Décision face à des informations partielles
● S’adapter à l’utilisateur
Interfacer l’aléatoire : solutions
● Règles● Scoring● Arbres de décision● Algorithmes ad-hoc
Notre postulat : Dans un grand nombre de cas, la ‘vraie’ solution serait le calcul des probabilités des différentes alternatives et la prise de décision articulées sur ces probabilités.

Avantages d’une utilisation des probabilités
● vers l’apprentissage automatique,● vers l’adaptabilité,● vers la réactivité (prise en compte des informations partielles),● vers l’explicabilité,● vers des outils sophistiqués d’analyse.
Un modèle général qui englobe les (ou une bonne partie des) solutions précédentes.
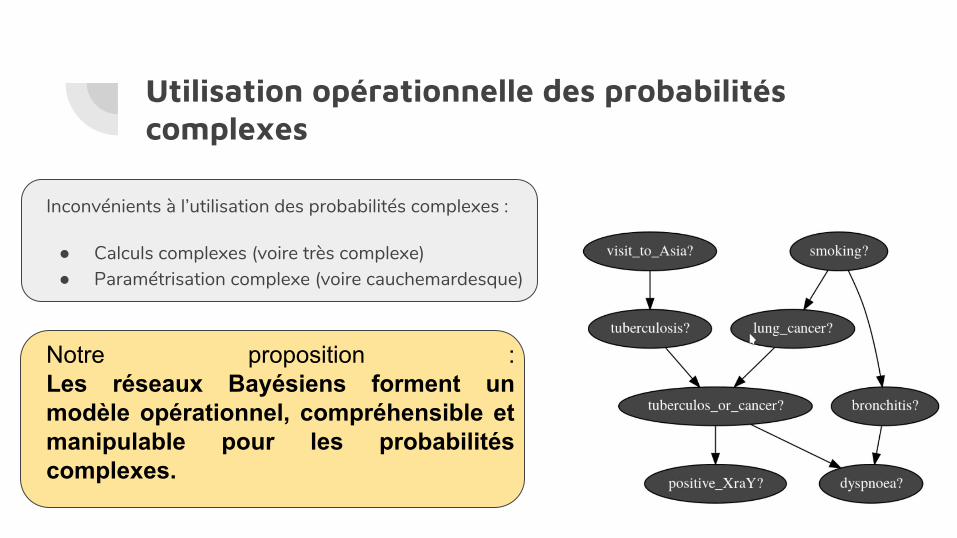
Utilisation opérationnelle des probabilités complexes
Inconvénients à l’utilisation des probabilités complexes :
● Calculs complexes (voire très complexe)● Paramétrisation complexe (voire cauchemardesque)
Notre proposition :Les réseaux Bayésiens forment un modèle opérationnel, compréhensible et manipulable pour les probabilités complexes.

Les réseaux bayésiens : structures & probabilités

Les réseaux bayésiens : modèle probabiliste
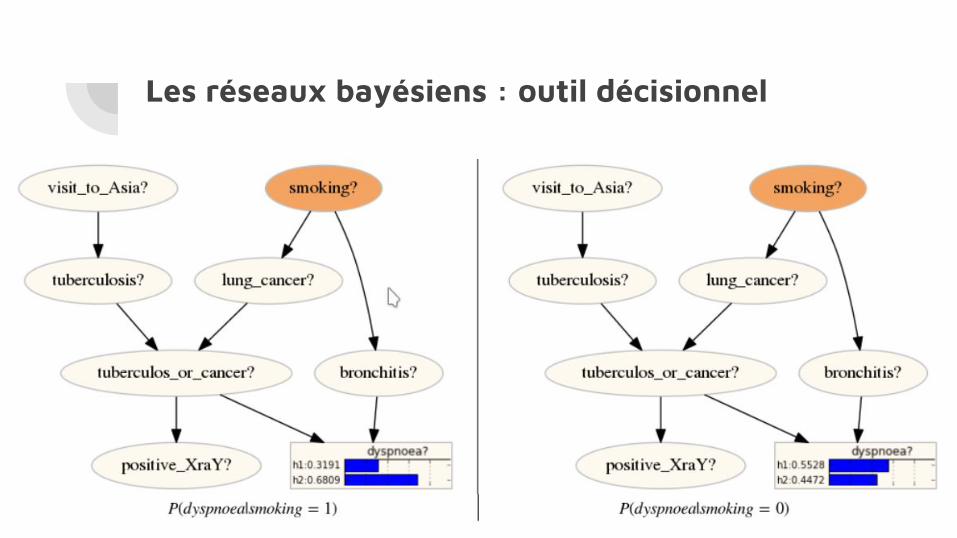
Les réseaux bayésiens : outil décisionnel

Les réseaux bayésiens : statistical learning
Base de données

Utilisation des réseaux bayésiens
Un outil puissant, polymorphe et complet mais complexe à implémenter.

pyAgrum : réseaux bayésiens en python

Simulation d’impact de décisions d’urbanisation sur le foncier

Intelligent Tutoring Systems: réseaux de compétences
Trouver le prochain exercice à proposer à l’étudiant vers l’acquisition de la compétence-cible.
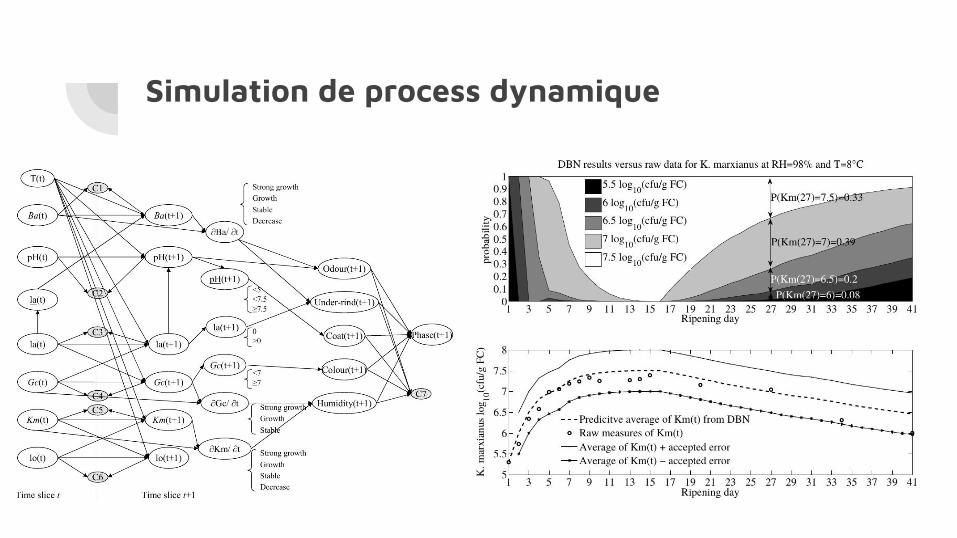
Simulation de process dynamique

pyAgrum: aGrUM en Python
aGrUM une API C++ GPL depuis 2008
● Autheurs○ Pierre-Henri Wuillemin, Maître de Conférence - LIP6 -
UPMC○ Christophe Gonzales, Professeur - LIP6 - UPMC
● Utilisateurs/Partenaires○ Laboratoire de recherche: LIP6, INRA, IRSN○ Industriels: EDF, Airbus, IBM○ Startups: Akheros, EdgeMind○ Projet Open Source: Open Turns.

De la recherche à la production
Une API Dédiée
● Hyper paramétrable● Structures de données
adaptés● Algorithmes optimisées
La Recherche
● Projets Européens○ MIDASE○ SCISSOR
● Projets ANR○ SKOOBS○ INCALIN○ ...
Diffuser et promouvoir
● Wrapper Python● Documentation● Notebooks● Interventions

pyAgrum: un wrapper Python d’aGrUM
Une toolbox pour les PGM
● Un accès simplifié aux algorithmes d’aGrUM● Un accès à l’écosystème Python● Une intégration avec les Jupyter Notebooks● Disponible sur PyPI et Anaconda
Une combo C++/Python
● C++ est rapide et aGrUM est très performant● D’autres wrappers en préparation (Java, JavaScript, …)

Installer pyAgrumhttp://agrum.gitlab.io
Avec pip:
pip install pyAgrum
Avec anaconda:
conda install -c conda-forge pyagrum
Pour utiliser les notebooks:
pip install numpy nbformat nbconvert jupyter matplotlib pydotplus pandas scipy
conda install numpy nbformat nbconvert jupyter matplotlib pydotplus pandas scipy

Demo Time !

● GitLab○ https://gitlab.com/agrumery/aGrUM
● Anaconda○ https://github.com/conda-forge/pyagrum-feedstock
● PYPI○ https://pypi.python.org/pypi/pyagrum
● Besoin d’aide ?○ [email protected]○ https://mailia.lip6.fr/wws/info/agrum-users
Quelques liens pour utiliser aGrUM/pyAgrum

Diagnostic probabiliste en langage naturel avec Watson
● Framework de l’agent : JAVA● Moteur probabiliste : aGrUM● Modèle probabiliste : Réseaux Bayésiens● Traitement du langage naturel : Watson
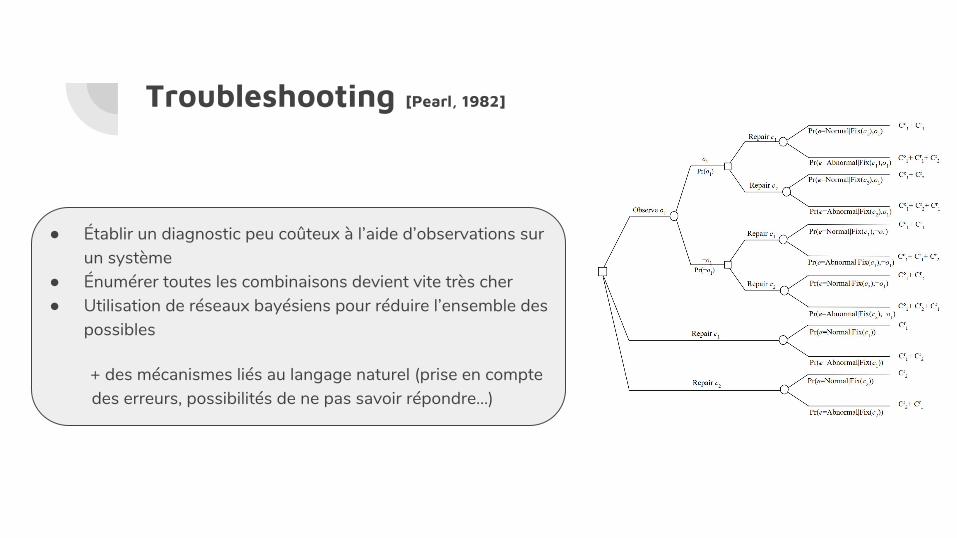
Troubleshooting [Pearl, 1982]
● Établir un diagnostic peu coûteux à l’aide d’observations sur un système
● Énumérer toutes les combinaisons devient vite très cher● Utilisation de réseaux bayésiens pour réduire l’ensemble des
possibles
+ des mécanismes liés au langage naturel (prise en compte des erreurs, possibilités de ne pas savoir répondre…)
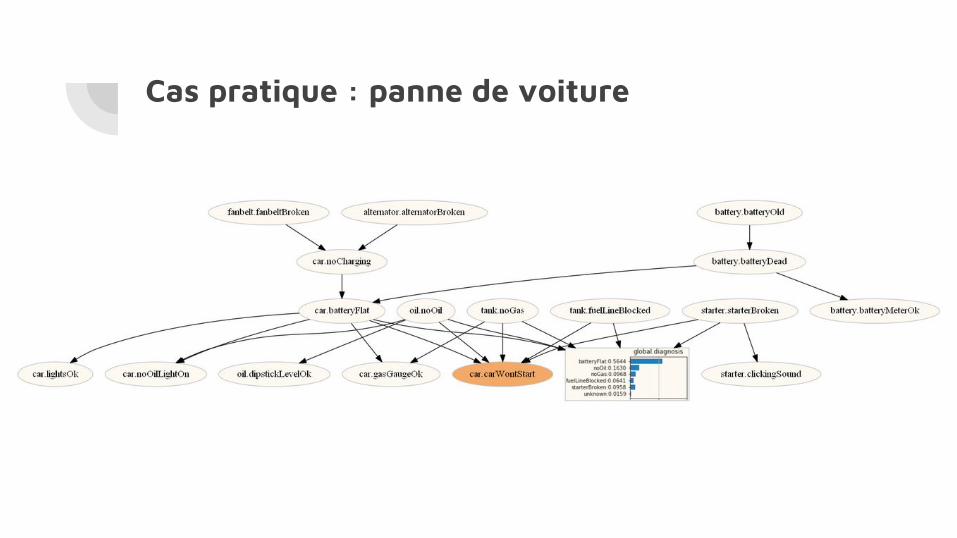
Cas pratique : panne de voiture

Réseau bayésien dans un problème de troubleshooting
On décompose notre réseau bayésien en 4 types de noeuds :
● Noeuds de diagnostic (en rouge)● Noeuds observables (en bleu)● Noeuds non-observables (en jaune)● Noeud problématique (en vert)

Sélection des questions
Basée sur la théorie de l’information de Claude Shannon [1948]
● Calcul d’information mutuelle/entropie conditionnelle grâce à aGrUM● Pondération des gains d’information par le coût de chaque question● Sélection de la question maximisant le score
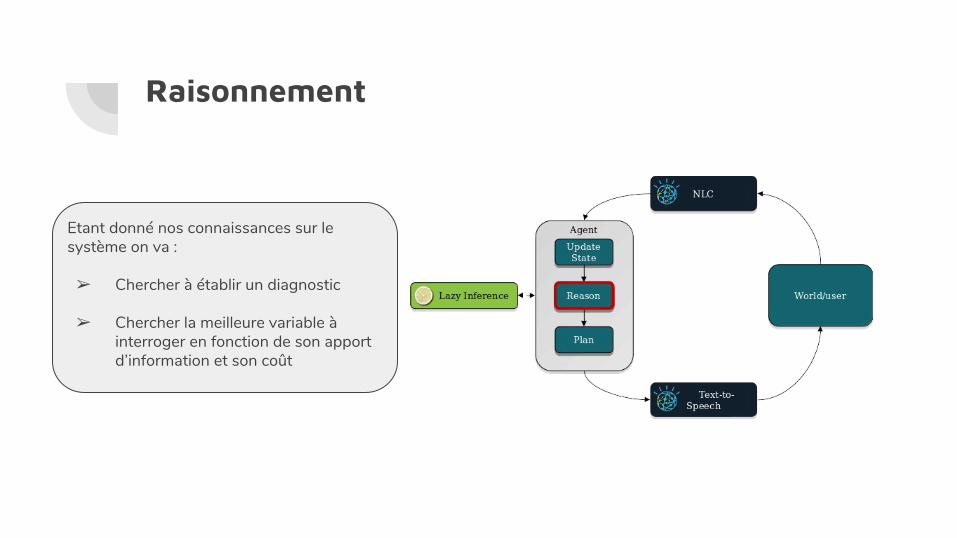
Raisonnement
Etant donné nos connaissances sur le système on va :
➢ Chercher à établir un diagnostic
➢ Chercher la meilleure variable à interroger en fonction de son apport d’information et son coût
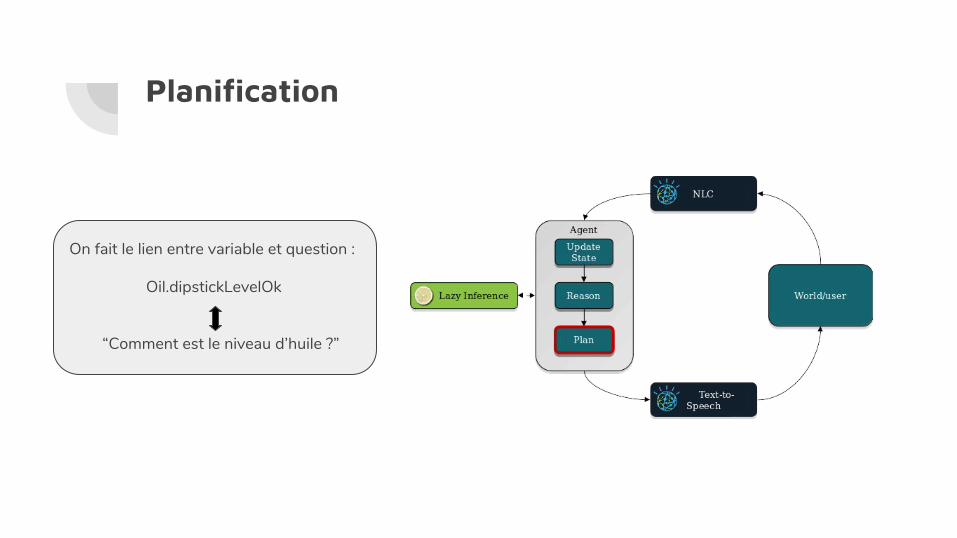
Planification
On fait le lien entre variable et question :
Oil.dipstickLevelOk
“Comment est le niveau d’huile ?”
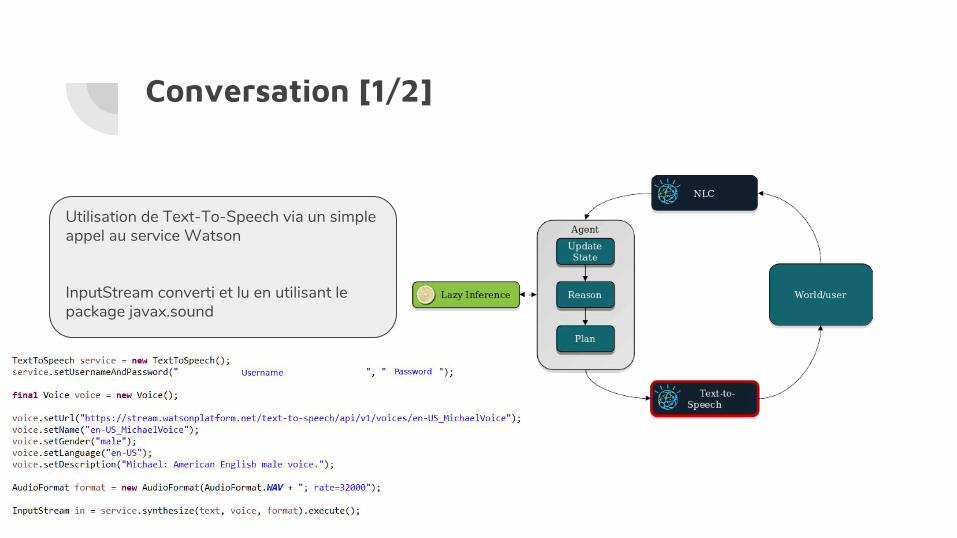
Conversation [1/2]
Utilisation de Text-To-Speech via un simple appel au service Watson
InputStream converti et lu en utilisant le package javax.sound

Conversation [2/2]
Utilisation du Natural Language Classifier de Watson
Plusieurs classification possibles :● Oui● Non● Je ne sais pas● Demande d’informations

Demande d’informations
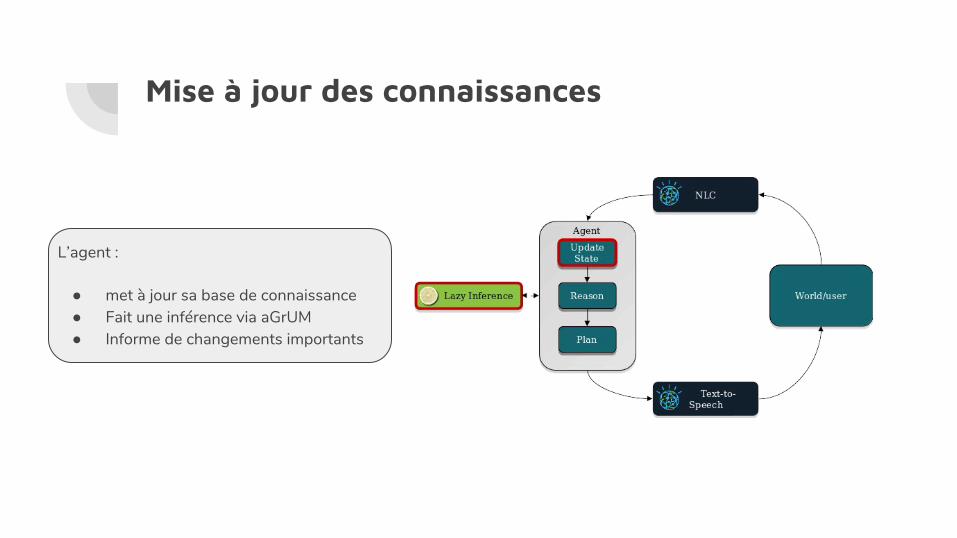
Mise à jour des connaissances
L’agent :
● met à jour sa base de connaissance● Fait une inférence via aGrUM● Informe de changements importants

Intuition de l’agent
En fonction des réponses de l’utilisateur et de l’évolution des diagnostics notre agent est capable d’informer ce dernier de changements significatifs.
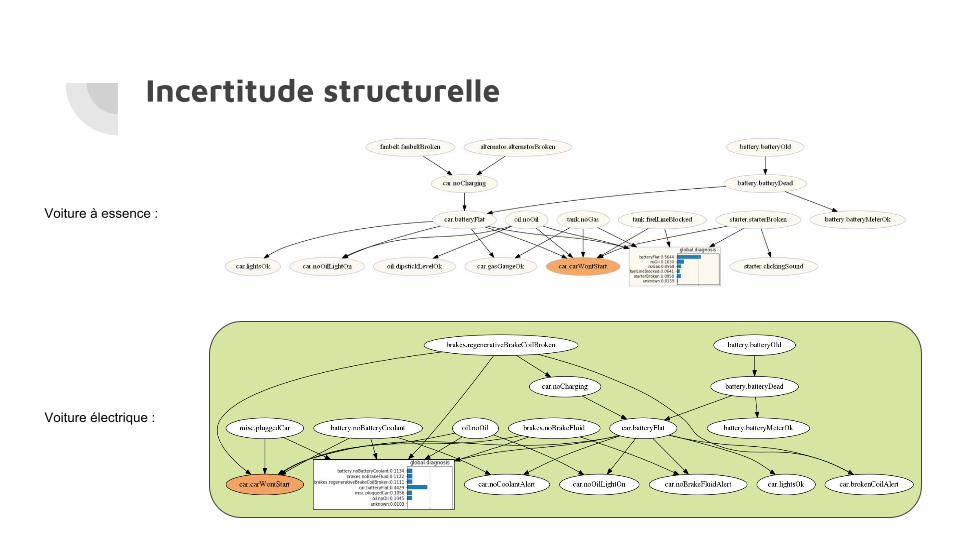
Incertitude structurelle
Voiture à essence :
Voiture électrique :

Merci/Questions


Annexe : pondération des réponses
Discuter avec l’utilisateur peut introduire des erreurs de compréhension pouvant causer des problèmes lors de l’inférence (observations contradictoires), deux bruits ont été ajoutés :
➢ Coût cognitif β : lié difficulté de compréhension de la question➢ Niveau d’expertise α : lié à la connaissance par l’utilisateur du système diagnostiqué
Au lieu d’ajouter une hard evidence avec une distribution de, par exemple, [0,1] sur une variable aléatoire binaire on ajoutera une soft evidence valant :
[(α+β)/(1+2*(α+β)) , 1+(α+β)/(1+2*(α+β))]
La réponse à la question “L’alternateur est-il cassé ?” sera prise avec plus de recul que celle de la question “Les feux marchent-ils ?”

Annexe : remise en cause des réponses
Soit S notre base de connaissances, X la variable qu’on interroge et a la valeur de X associée à la réponse de l’utilisateur. Si :
, où r est un paramètre de notre agent
Alors on va demander à l’utilisateur une confirmation de sa réponse
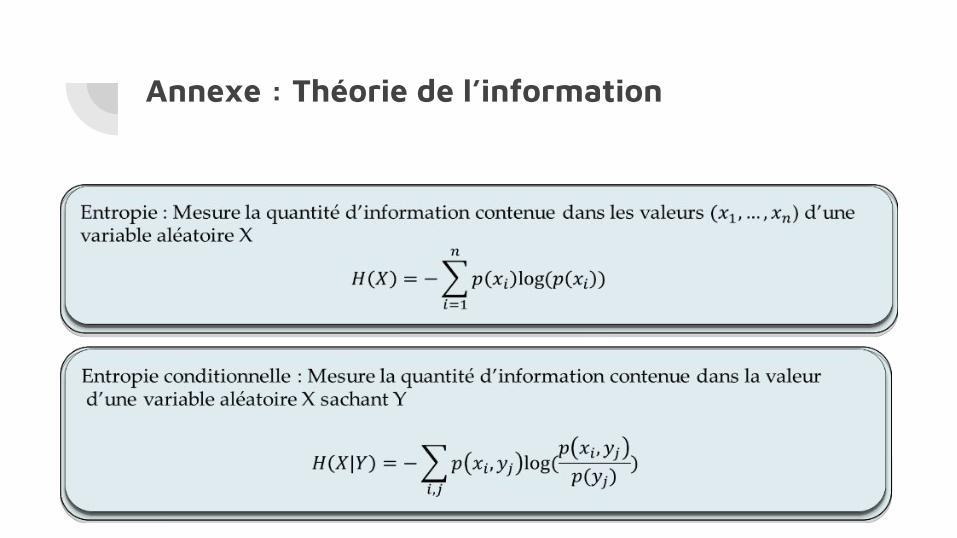
Annexe : Théorie de l’information
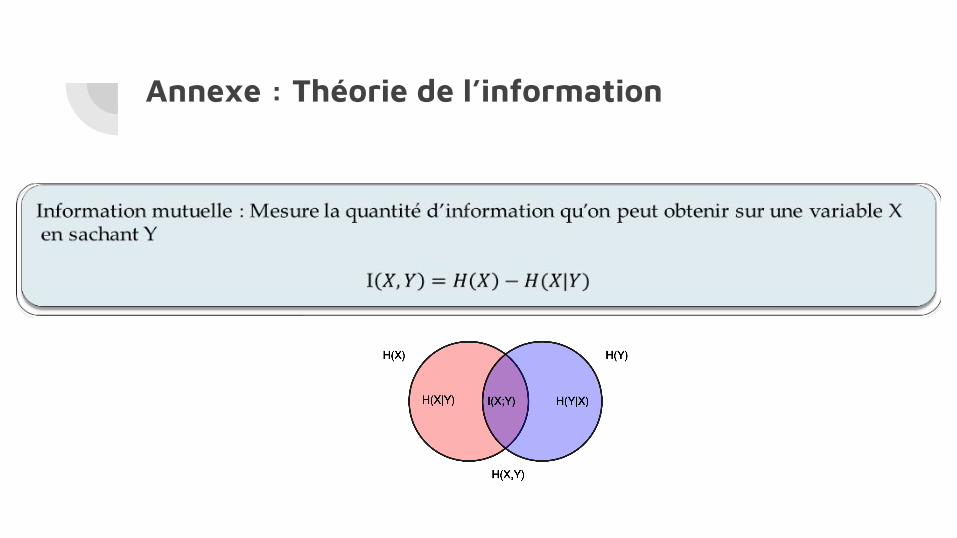
Annexe : Théorie de l’information

Annexe : Théorie de l’information
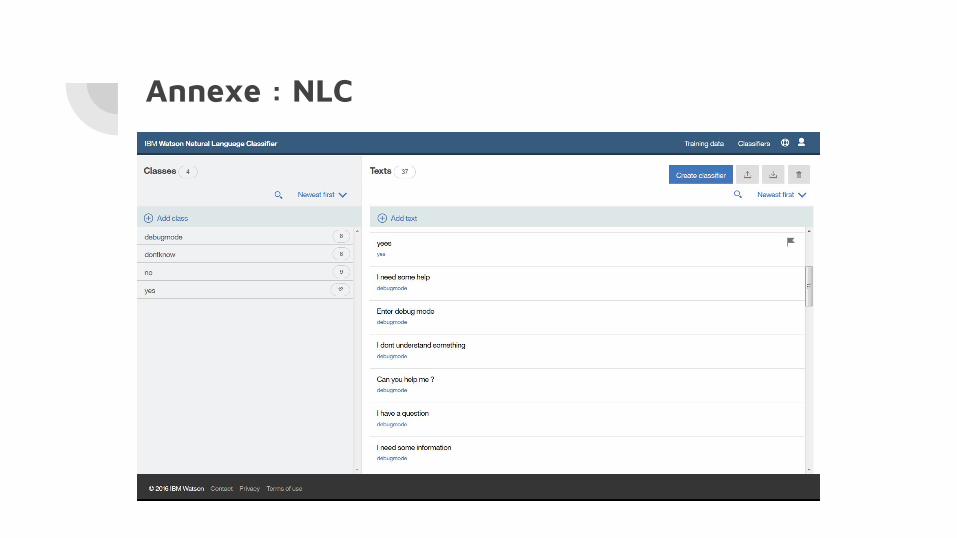
Annexe : NLC


















