

Graphes et langages - ducoulombier-math.esy.esducoulombier-math.esy.es/Graphes Cours.pdf · 3.5...
54
Transcript of Graphes et langages - ducoulombier-math.esy.esducoulombier-math.esy.es/Graphes Cours.pdf · 3.5...

Table des matières
Table des matières 1
1 Généralités sur les graphes 21.1 Définitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21.2 Représentation d’un graphe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.3 Exemples standards . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2 Chaines et chemins 72.1 Mots et langage . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72.2 Chaines . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82.3 Descendants et ascendants . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112.4 Connexité . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142.5 Degrés . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
3 Applications 203.1 Coloriage de graphes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 203.2 Solution de Dijkstra . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 253.3 Arbres couvrant de poids minimum . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 283.4 Bonne numérotation des graphes orientés . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 303.5 Théorie des jeux combinatoires à information parfaite à deux joueurs . . . . . . . . . . . . . 333.6 Automates . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
4 Annexes 434.1 Algorithmes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 434.2 Le programmeur modeste . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
1

1. Généralités sur les graphes
1.1 Définitions
Définition 1.1.1
Un graphe orienté G est la donnée de :(i) Un ensemble fini et non vide noté Som(G) appelé les sommets du graphe G .(ii) Un ensemble noté Arc(G) appelé les Arcs du graphe G dont les éléments sont des couples de
Som(G).
Par exemple Som(G) = {a, b, c, d, e, f} et Arc(G) = {(a, b), (a, c), (b, b), (c, d), (d, a), (d, e), (d, f), (e, a), (f, a)}définissent un graphe orienté.
Définition 1.1.2
Un graphe non orienté G est la donnée de :(i) Un ensemble fini et non vide noté Som(G) appelé les sommets du graphe G .(ii) Un ensemble noté Ar(G) appelé les arêtes du graphe G dont les éléments sont des ensembles
formés de deux éléments de Som(G).
Par exemple, Som(G) = {a, b, c, d, e, f} et Ar(G) = {{a, c}, {a, d}, {a, e}, {a, f}, {b, c}, {b, e}, {c, f}} définissentun graphe non orienté.On prendra garde à ne pas confondre les notations et à ne pas mélanger avec les notions de
graphe orienté et non orienté.
Un arc est un couple.Une arête est un ensemble.
Alors que, dans le cas orienté, il y a une différence entre les arcs (a, b) et (b, a) il n’y a, dans lecas non orienté, aucune différence entre les arêtes {a, b} et {b, a}. De même, alors que (a, a) a un sensdans le cas orienté, il n’y a aucun sens à parler de l’arête {a, a}. En particulier, dans le cas non orienté,aucun sommet ne boucle sur lui-même.
Remarque 1.1.3 : Dans la suite on parlera simplement de graphe pour ne pas avoir a distinguerles graphes orientés des graphes non orientés.
Définition 1.1.4
Soient G et G ′ deux graphes. On dira que G ′ est un sous-graphe de G , noté G ′ ⊆ G si(i) Som(G ′) ⊆ Som(G)(ii) Cas non orienté : Ar(G ′) ⊆ Ar(G)(ii) Cas orienté : Arc(G ′) ⊆ Arc(G)
Définition 1.1.5
Soient G un graphe et P ⊂ Som(G). On définit G ′ le graphe engendré par P par(i) Som(G ′) = P,
(ii) Cas non orienté : Ar(G ′) ={{x, y} ∈ Ar(G)
∣∣∣(x, y) ∈ Som(G ′)2}(ii) Cas orienté : Arc(G ′) =
{(x, y) ∈ Arc(G)
∣∣∣(x, y) ∈ Som(G ′)2}
2
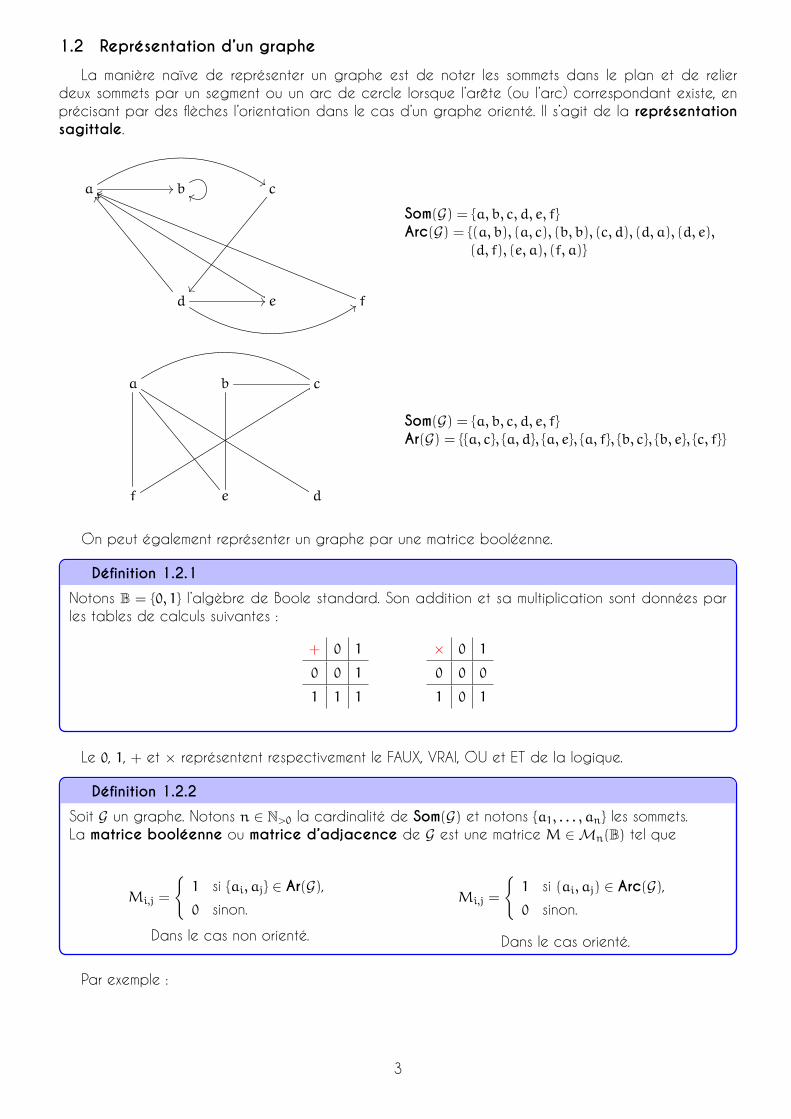
1.2 Représentation d’un graphe
La manière naïve de représenter un graphe est de noter les sommets dans le plan et de relierdeux sommets par un segment ou un arc de cercle lorsque l’arête (ou l’arc) correspondant existe, enprécisant par des flèches l’orientation dans le cas d’un graphe orienté. Il s’agit de la représentationsagittale.
a // %%b ee c
��
d
\\
// 99e
ee
f
hh
Som(G) = {a, b, c, d, e, f}
Arc(G) = {(a, b), (a, c), (b, b), (c, d), (d, a), (d, e),(d, f), (e, a), (f, a)}
a b c
f e d
Som(G) = {a, b, c, d, e, f}
Ar(G) = {{a, c}, {a, d}, {a, e}, {a, f}, {b, c}, {b, e}, {c, f}}
On peut également représenter un graphe par une matrice booléenne.
Définition 1.2.1
Notons B = {0, 1} l’algèbre de Boole standard. Son addition et sa multiplication sont données parles tables de calculs suivantes :
+ 0 1
0 0 1
1 1 1
× 0 1
0 0 0
1 0 1
Le 0, 1, + et × représentent respectivement le FAUX, VRAI, OU et ET de la logique.
Définition 1.2.2
Soit G un graphe. Notons n ∈ N>0 la cardinalité de Som(G) et notons {a1, . . . , an} les sommets.La matrice booléenne ou matrice d’adjacence de G est une matrice M ∈Mn(B) tel que
Mi,j =
{1 si {ai, aj} ∈ Ar(G),0 sinon.
Dans le cas non orienté.
Mi,j =
{1 si (ai, aj) ∈ Arc(G),0 sinon.
Dans le cas orienté.
Par exemple :
3

a // %%b ee c
��d
__
// 99e
gg
f
jj
a b c d e f
a 0 1 1 0 0 0
b 0 1 0 0 0 0
c 0 0 0 1 0 0
d 1 0 0 0 1 1
e 1 0 0 0 0 0
f 1 0 0 0 0 0
a b c
f e d
a b c d e f
a 0 0 1 1 1 1
b 0 0 1 0 1 0
c 1 1 0 0 0 1
d 1 0 0 0 0 0
e 1 1 0 0 0 0
f 1 0 1 0 0 0
Proposition 1.2.3
La matrice booléenne d’un graphe non orienté est une matrice carré symétrique à diagonalenulle.
Démonstration. Si {ai, aj} est une arête alors {aj, ai} également (l’ordre des éléments dans unensemble ne compte pas). De plus {ai, ai} ne peut jamais être une arête (les arêtes sont des ensemblesà deux éléments or {ai, ai} = {ai}). �
Définition 1.2.4
Soit G un graphe orienté. On note |G| le graphe non orienté associé à G et défini par :
Som(|G|) = Som(G), Ar(|G|) ={{x, y}
∣∣x 6= y∧ (x, y) ∈ Arc(G)}
Pour "désorienter" un graphe, il suffit d’enlever les boucles et les flèches de sa représentation sagit-tale.
a // %%b ee c
��d
__
// 99e
gg
f
jj a b c
d e f
Pour la représentation matricielle, le procédé est un peu plus compliqué : il faut tout d’abord mettredes 0 sur la diagonale (ce qui correspond à enlever les boucles) et rendre la matrice symétrique.
4

a b c d e f
a 0 1 1 0 0 0
b 0 1 0 0 0 0
c 0 0 0 1 0 0
d 1 0 0 0 1 1
e 1 0 0 0 0 0
f 1 0 0 0 0 0
=⇒a b c d e f
a 0 1 1 0 0 0
b 0 0 0 0 0 0
c 0 0 0 1 0 0
d 1 0 0 0 1 1
e 1 0 0 0 0 0
f 1 0 0 0 0 0
=⇒a b c d e f
a 0 1 1 1 1 1
b 1 0 0 0 0 0
c 1 0 0 1 0 0
d 1 0 1 0 1 1
e 1 0 0 1 0 0
f 1 0 0 1 0 0
1.3 Exemples standards
Voici quelques exemples de graphes non orientés.
Définition 1.3.1
Soit n ∈ N.(i) Si n > 0, la clique standard à n sommets est le graphe Kn défini par
Som(Kn) = {1, · · · , n}, Ar(Kn) ={I ⊆ Som(G)
∣∣∣Card(I) = 2}(ii) La chaîne standard à n arêtes est le graphe Cn défini par
Som(Cn) = {0, · · · , n} Ar(Cn) ={{i− 1, i}
∣∣∣i ∈ {1, · · · , n}}
(iii) Si n > 2 le cycle standard à n sommets est le graphe Zn défini par
Som(Zn) = {0, · · · , n− 1} Ar(Zn) ={{i− 1, i}
∣∣∣i ∈ {1, · · · , n− 1}}∪ {{n− 1, 0}}
1
K1
1 2
K2
1
3 2
K3
1 2
4 3
K4
0
C0
0 1
C1
0 1 2
C2
0 1 2 3
C3
0
2 1
Z3
0 1
3 2
Z4
0
4 1
3 2
Z5
5
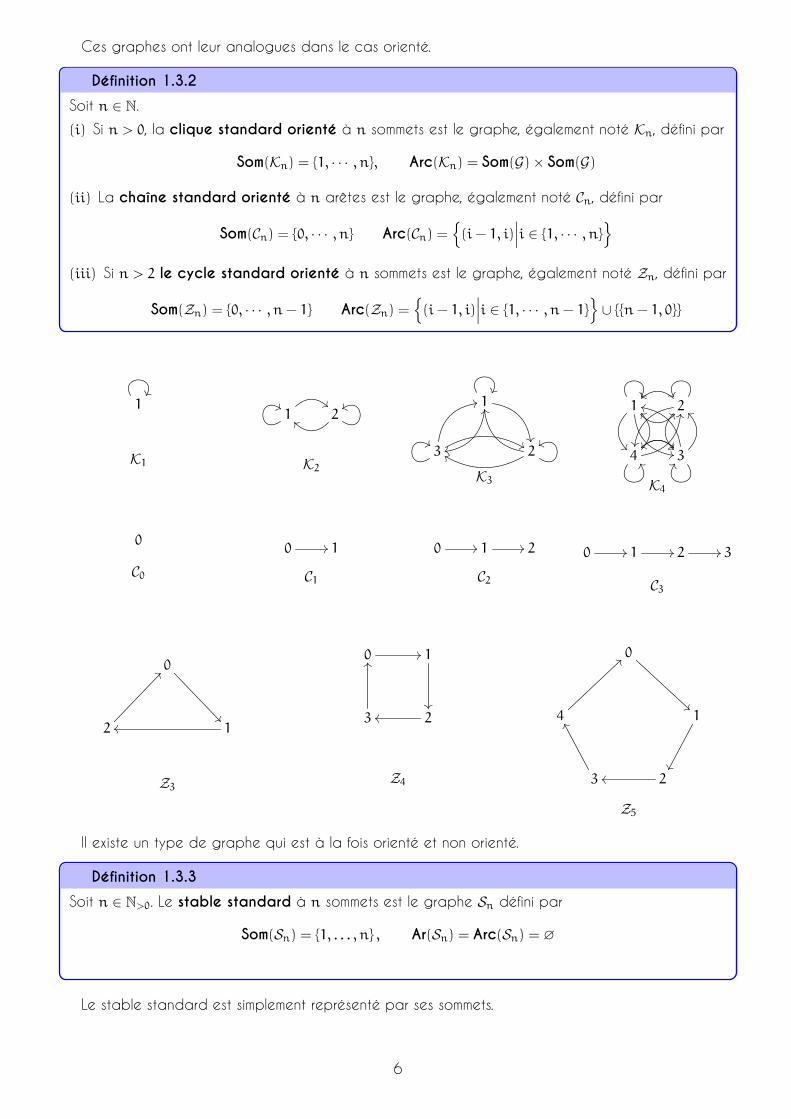
Ces graphes ont leur analogues dans le cas orienté.
Définition 1.3.2
Soit n ∈ N.(i) Si n > 0, la clique standard orienté à n sommets est le graphe, également noté Kn, défini par
Som(Kn) = {1, · · · , n}, Arc(Kn) = Som(G)× Som(G)
(ii) La chaîne standard orienté à n arêtes est le graphe, également noté Cn, défini par
Som(Cn) = {0, · · · , n} Arc(Cn) ={(i− 1, i)
∣∣∣i ∈ {1, · · · , n}}
(iii) Si n > 2 le cycle standard orienté à n sommets est le graphe, également noté Zn, défini par
Som(Zn) = {0, · · · , n− 1} Arc(Zn) ={(i− 1, i)
∣∣∣i ∈ {1, · · · , n− 1}}∪ {{n− 1, 0}}
1��
K1
1%% !!
2``
yy
K2
1��
��
rr
22
3%% &&ff 2
zz
K3
1��
>>
,,��
}}ll^^ 2
��
��
^^MM
4 YY!!}}3EE
K4
0
C0
0 // 1
C1
0 // 1 // 2
C2
0 // 1 // 2 // 3
C3
0
��
@@
2 oo 1
Z3
0 //OO 1
��
3 oo 2
Z4
0
>>
4 XX 1
��
3 oo 2
Z5
Il existe un type de graphe qui est à la fois orienté et non orienté.
Définition 1.3.3
Soit n ∈ N>0. Le stable standard à n sommets est le graphe Sn défini par
Som(Sn) = {1, . . . , n} , Ar(Sn) = Arc(Sn) = ∅
Le stable standard est simplement représenté par ses sommets.
6

2. Chaines et chemins
2.1 Mots et langage
Définition 2.1.1
On appelle alphabet ou vocabulaire tout ensemble non vide fini. Les éléments d’un vocabulairesont appelés lettres ou caractères.
Par exemple Σ = {0, 1} défini l’alphabet du langage binaire et 0 et 1 sont les lettres de cet alphabet.
Définition 2.1.2
Soit Σ un alphabet.
(i) Soit n ∈ N>0. On appelle mot de longueur n tout n-uplet a = (a1, . . . , an) ∈ Σn. On note plussimplement a = a1 . . . an. On note n = ‖a‖.
(ii) On note ε le mot vide (i.e. qui ne contient aucune lettre) ; ‖ε‖ = 0.(iii) Pour tout n ∈ N, on note Σn l’ensemble de tous les mots de longueur n ; en particulier Σ0 = {ε}
et Σ1 = Σ.
(iv) On définit l’étoile de Kleene sur Σ, notée Σ∗, comme l’ensemble de tous les mots quelque soitleur longueur.
Σ∗ =⋃n∈N
Σn
Par exemple sur l’alphabet Σ = {0, 1} du langage binaire Σ3 = {000, 001, 010, 011, 100, 101, 110, 111} et
Σ∗ = {ε, 0, 1, 00, 01, 10, 11, 000, 001, 010, 011, 100, 101, ...}
Si Σ = {a} alors Σ∗ = {ε, a, a2, a3, a4, ...}.
Définition 2.1.3
Soit Σ un alphabet. Un langage sur Σ est une partie de L (Σ) de Σ∗. Les éléments de L (Σ) sontappelés les mots du langage.
Par exemple, toujours avec Σ = {0, 1}, on considère le langage L (Σ) formé de tous les mots de Σ∗
ne commençant pas par 0 :
L (Σ) = {ε, 1, 10, 11, 100, 101, 110, 111, 1000, 1001, ...}
Concaténation
Étant donné un alphabet Σ on peut effectuer sur un langage Σ∗ les opérations ensemblistes cou-rantes : l’intersection, l’union et la complémentation. On peut également concaténer les mots.
Définition 2.1.4
Soient α et β deux mots sur un alphabet Σ tel que ‖α‖ = n et ‖β‖ = m. On définit la concaténationde α de β, noté α ◦ β ou plus simplement αβ par la règle :
∀1 6 k 6 n+m, (αβ)k =
{αk si k 6 n,
βk−n sinon.
on dit que α est le facteur gauche ou le préfixe de αβ et β et le facteur droit ou le suffixe.
Par exemple, sur l’alphabet binaire 001 ◦ 101 = 001101.
7

Proposition 2.1.5
Pour tout alphabet Σ, la concaténation définit une opération interne sur Σ∗
◦ : Σ∗ ◦ Σ∗ −→ Σ∗
(α,β) 7−→ α ◦ β
satisfaisant :
(Associativité) ∀α,β, γ ∈ Σ∗, (α ◦ β) ◦ γ = α ◦ (β ◦ γ).(Elément neutre) ∀α ∈ Σ∗, α ◦ ε = ε ◦ α = α.
(Longueur) ∀α,β ∈ Σ∗, ‖α ◦ β‖ = ‖α‖+ ‖β‖.
Démonstration. Vérifions l’associativité, le reste est trivial. Notons ‖α‖ = n, ‖β‖ = m et ‖γ‖ = p etfixons un entier 1 6 k 6 n+m+ p. Alors
((α ◦ β) ◦ γ)k =
{(α ◦ β)k 1 6 k 6 n+m
γk−(n+m) n+m+ 1 6 k 6 n+m+ p=
αk 1 6 k 6 n
βk−n n+ 1 6 k 6 n+m
γk−(n+m) n+m+ 1 6 k 6 n+m+ p
(α ◦ (β ◦ γ))k =
{αk 1 6 k 6 n
(β ◦ γ)k−n n+ 1 6 k 6 n+m+ p=
αk 1 6 k 6 n
βk−n n+ 1 6 k 6 n+m
γ(k−n)−m n+m+ 1 6 k 6 n+m+ p
On observe que les deux expressions sont identiques (puisque k− (n+m) = (k− n) −m). �
Remarque 2.1.6 : La concaténation n’est pas commutative à moins que Σ ne soit un singleton.
Définition 2.1.7
Soient α et α ′ deux mots sur un alphabet Σ. On dira que α ′ est un sous-mot de α s’il existe desmots π et σ tel que α = πα ′σ
2.2 Chaines
Définition 2.2.1
Soient G un graphe non orienté (resp. orienté) et n ∈ N. Une chaine ou un chemin de longueur nsur G est un mot a = a0 . . . an du langage Chainn(G) ⊂ (Som(G))n sur l’alphabet Som(G) défini parla règle :
∀0 6 k < n, {ai, ai+1} ∈ Ar(G)(resp. ∀0 6 k < n, (ai, ai+1) ∈ Arc(G))
La première lettre de la chaine est appelé l’origine et la dernière l’aboutissement.On note ‖a‖G = n et Chain(G) =
⋃n∈N
Chainn(G).
Remarque 2.2.2 : Dans la pratique le mot chaine est réservé au graphe non orienté. Dans le casorienté, on parle plus de chemin. Dans ce cours, pour simplifier les notations, nous ne ferons pas ladistinction.
8

Remarque 2.2.3 : On prendra garde : malgré le fait qu’une arête est non orienté c’est à dire que{a, b} = {b, a}, il y a une différence entre la chaine ab et la chaine ba, qui sont par définition deséléments du produit cartésien Som(G)× Som(G).
a b c
f e d
Par exemple acbead est une chaine de ce graphede longueur 5 (et pas 6 ; on compte en fait lenombre d’arête) et acbeda n’est pas une chainecar {e, d} n’est pas une arête.
Proposition 2.2.4
Tout sous-mot d’une chaine est une chaine.
Démonstration. Triviale. �
Définition 2.2.5
Une chaine est dite élémentaire si elle ne passe pas deux fois par le même sommet.
Dans l’exemple précédent, acbead n’est pas une chaine élémentaire puisqu’elle passe deux fois parle somment a.
Proposition 2.2.6
Soit G un graphe.(i) Si il existe une chaine entre deux sommets du graphe alors il existe une chaine élémentaire
entre ces deux sommets.
(ii) Soit α une chaine élémentaire de G ,
‖α‖G 6 Card(Som(G)) − 1
Démonstration. Le second point est évident : si la longueur de la chaine est strictement supérieurà Card(Som(G)) − 1 c’est à dire supérieur ou égale à Card(Som(G)) alors la chaine passe forcementdeux fois par le même sommet et ne peut donc pas être élémentaire.Pour le premier point il suffit d’observer qu’une si une chaine est non élémentaire alors elle passe deux
fois par le même sommet et donc elle "boucle". Si on enlève cette boucle on obtient une nouvelle chaineavec la même origine et le même aboutissement mais de longueur strictement inférieur. Si la nouvellechaine n’est pas élémentaire on recommence le processus. Ces itérations prennent nécessairement finpuisque les longueurs décroissent strictement. �
La concaténation des chaines se réalise comme celle des mots en "fusionnant" aboutissement etorigine. Plus précisément :
Définition 2.2.7
Soit G un graphe. On définit
or : Chain(G) −→ Som(G) ab : Chain(G) −→ Som(G)les fonctions qui associent respectivement l’origine et l’aboutissement d’une chaine.
Par exemple ab(abcetgbed) = d et or(abcetgbed) = a.
9

Définition 2.2.8
Soient α et β deux chaines sur un graphe G de longueur respectives n et m. On dira que α et βsont concatenables si ab(α) = or(β). Dans ce cas on définit la concaténation de α et de β parla règle :
∀1 6 k 6 n+m− 1, (αβ)k =
{αk si k < n,
βk−n sinon.
On prendra garde : l’inégalité est stricte ! Par exemple avec le graphe précédent : acbe ◦ eafc =acbeafc (on ne réécrit pas deux fois le sommet e).
Proposition 2.2.9
Soient G un graphe non orienté, α, β et γ des chaines de G tel que α soit concaténable àβ lui même concaténable à γ. Alors αβ est concaténable a γ et α est concaténable à βγ.De plus
(Associativité) (αβ)γ = α(βγ).
(Elément neutre) αε = εα = α.
(Longueur) ‖αβ‖G = ‖α‖G + ‖β‖G .
Démonstration. Le raisonnement est le même que celui sur les mots. �
Théorème 2.2.10
Soient n ∈ N, G un graphe et M sa matrice booléenne.
(∃α ∈ Chainn(G), or(α) = ai ∧ ab(α) = aj)⇐⇒Mni,j = 1
Autrement dit : il existe une chaine de longueur n entre deux sommets ai et aj si et seulement si Mni,j = 1.
Démonstration. Raisonnons par récurrence sur n ∈ N, le cas initial étant triviale. Supposons quepour un n quelconque fixé la propriété du théorème soit satisfaite et vérifions la au rang n+ 1.On commence par observer que Mn+1 =M×Mn, ce produit de matrice se réalisant avec des co-
efficients dans l’algèbre de Boole B. En particulier, par définition du produit matricielle et par définitiondes règles de calcul dans B,
Mn+1i,j =
n∑k=1
Mi,k ×Mnk,j = 1 ⇐⇒ ∃k0, Mi,k0 ×M
nk0,j
= 1
⇐⇒ ∃k0, Mi,k0 = 1∧Mnk0,j
= 1
Par définition de la matrice booléenneMi,k0 = 1 si et seulement si il existe un arc (ai, ak0) (ou une arête{ai, ak0} dans le cas non orienté) et par hypothèse de récurrence M
nk0,j
= 1 si et seulement si il existeune chaine de longueur n d’origine ak0 et d’aboutissement aj. La concaténation permet d’achevercette récurrence. �
10

2.3 Descendants et ascendants
Définition 2.3.1
Soit G un graphe. Pour tout n ∈ N>0 et tout x ∈ Som(G) on définit
Γ+n(x,G) ={y ∈ Som(G)
∣∣∣∃α ∈ Chainn(G), or(α) = x∧ ab(α) = y}Γ−n(x,G) =
{y ∈ Som(G)
∣∣∣∃α ∈ Chainn(G), or(α) = y∧ ab(α) = x}
On conviens que Γ 0(x,G) = {x}.On pose
Γ+(x,G) =⋃n∈N
Γ+n(x,G), Γ−(x,G) =⋃n∈N
Γ−n(x,G)
Les éléments de Γ+n(x,G) correspondent aux sommets du graphe qui sont atteint par des cheminsde longueur n d’origine x. Les éléments de Γ−n(x,G) correspondent quand à eux aux sommets dugraphe qui atteignent x par des chemins de longueur n. Par exemple :
a
��
��
e // buu
^^
d
KK
$$c
ff
Γ+2(a,G) = {b, d}
a
��
��
e // buu
``
d
KK
&&cdd
Γ−2(a,G) = {b, c, e}
a
e b
d c
Γ−2(a,G) = Γ+2(a,G) = {a, b, c, d, e}
Définition 2.3.2
Soit x un sommet d’un graphe G .(i) Les éléments de Γ+1(x,G) sont appelés les successeurs de x.(ii) Les éléments de Γ−1(x,G) sont appelés les prédécesseurs de x.(iii) Les éléments de Γ+(x,G) sont appelés les descendants de x.(iv) Les éléments de Γ−(x,G) sont appelés les ascendants de x.
Lorsque le graphe est non orienté les notions de prédécesseurs et successeurs coïncident.
Proposition 2.3.3
Soit G un graphe non orienté.
∀n ∈ N, ∀x ∈ Som(G), Γ+n(x,G) = Γ−n(x,G)
Démonstration. Triviale. �
11

Définition 2.3.4
Soit G un graphe non orienté. Les successeurs (et prédécesseurs) sont appelés les voisins ou som-mets adjacents de x.
Proposition 2.3.5
Soient n ∈ N et x un sommet d’un graphe G .
Γ±(n+1)(x,G) ={y ∈ Som(G)
∣∣∣∃z ∈ Γ±1(x,G), y ∈ Γ±n(z,G)}
Démonstration. Cela viens du fait que toute chaine de longueur n+ 1 se décompose comme unechaine de longueur 1 concaténée avec une chaine de longueur n. �
De cette proposition on en déduit un algorithme pour déterminer les ensembles Γ±n(x, n).
§2.3.6 : Algorithme du marquage.1. S = {x}2. Pour une variable entière i allant de 1 à n
On considère Stemp tous les* successeurs (si l’on cherche à déterminer Γ+n(x,G))* prédécesseurs (si l’on cherche à déterminer Γ−n(x,G))
des sommets de S.S = Stemp.
Fin pour3. Γ±n(x,G) =S.
Reprenons l’exemple précédent et déterminonsΓ−3(a,G) avec l’algorithme. On représente les dif-férents états de la variable S dans un tableau.
arr
!!e // b
yyll
d
==
&&cff
a b c d e
Γ 0
Γ−1
Γ−2
Γ−3
La condition initial est S= a. On marque à la ligne duΓ0 le sommet a :
a b c d e
Γ0 ×Γ−1
Γ−2
Γ−3
Pour la ligne suivante, on va marquer tous les pré-décesseurs de a.
a b c d e
Γ0 ×Γ−1 × ×Γ−2
Γ−3
Pour la ligne suivante, on va marquer tous les pré-décesseurs de b et d.
a b c d e
Γ0 ×Γ−1 × ×Γ−2 × × ×Γ−3
Pour finir on marque les prédécesseurs de b, c et e
a b c d e
Γ0 ×Γ−1 × ×Γ−2 × × ×Γ−3 × × × ×
12

Finalement Γ−3(a,G) = {a, b, d, e}.Pour déterminer Γ±(x,G) on améliore l’algorithme précédent.
§2.3.7 : Algorithme du marquage +.1. On marque le sommet x2. Tant qu’il existe des sommets marqués mais non sélectionnés
On sélectionne un sommet marqué y et non selectionné.On marque tous les* successeurs (si l’on cherche à déterminer Γ+(x,G))* prédécesseurs (si l’on cherche à déterminer Γ−(x,G))
de y.Fin tant que
3. Γ±(x,G) = les sommets marqués.
Calculons Γ+(a,G) pour le graphe non orienté G suivant
a b c
j l n d
i k m o e
h g f
La première étape de l’algorithme reviens à marquer a :
Som(G) a b c d e f g h i j k l m n o
Marquage ×
On sélectionne le sommet a et on marque tous les sommets qui lui sont adjacents.
Som(G) a b c d e f g h i j k l m n o
Marquage × × × ×
on sélectionne le sommet j et on marque ses sommets adjacents. Et ainsi de proche en proche.
Som(G) a b c d e f g h i j k l m n o
Marquage × × × × ×
Som(G) a b c d e f g h i j k l m n o
Marquage × × × × × ×
Som(G) a b c d e f g h i j k l m n o
Marquage × × × × × ×
Som(G) a b c d e f g h i j k l m n o
Marquage × × × × × ×
Som(G) a b c d e f g h i j k l m n o
Marquage × × × × × ×
Le processus s’arrête ici puisque tous les sommets marqués sont sélectionnés ; finalement
Γ+(a,G) = {a, g, j, k, l, n}
13

2.4 Connexité
Définition 2.4.1
Soit x un sommet d’un graphe G . La composante connexe de x est le sous-graphe de G engendrépar Γ+(x, |G|) = Γ−(x, |G|). On le note CC(x,G).
Autrement dis : la composante connexe d’un sommet est le sous-graphe engendré par tous lesascendants ou descendants de ce sommet.
Ga
))b&&
00
c
nn
d
��
yy
e
pp
88YY fzz
g
]]
EE
CC(d,G)
a
)) d
��
yy
g
\\
EE
a b c
f e d
a c
f d
Remarque 2.4.2 : L’algorithme du marquage permet donc de déterminer les composantes connexesd’un graphe. Avec l’exemple développé au paragraphe précédent la composante connexe de aest le sous-graphe engendré par les sommets {a, g, j, k, l, n}. De la même manière la composanteconnexe de b est le sous-graphe engendré par les sommets {b, c, d, e, f, h, i,m, o}
a
j l n
k
g
b c
d
i m o e
h f
Proposition 2.4.3
Soient x et y deux sommets d’un graphe G .
CC(x,G) = CC(y,G) ⇐⇒ (∃α ∈ Chain(|G|),
(or(α) = x∧ ab(α) = y
))
Démonstration. Exercice. �
Définition 2.4.4
On dira qu’un graphe est connexe s’il ne possède qu’une seul composante connexe.
a b c
f e d
Ce graphe est connexe.
14
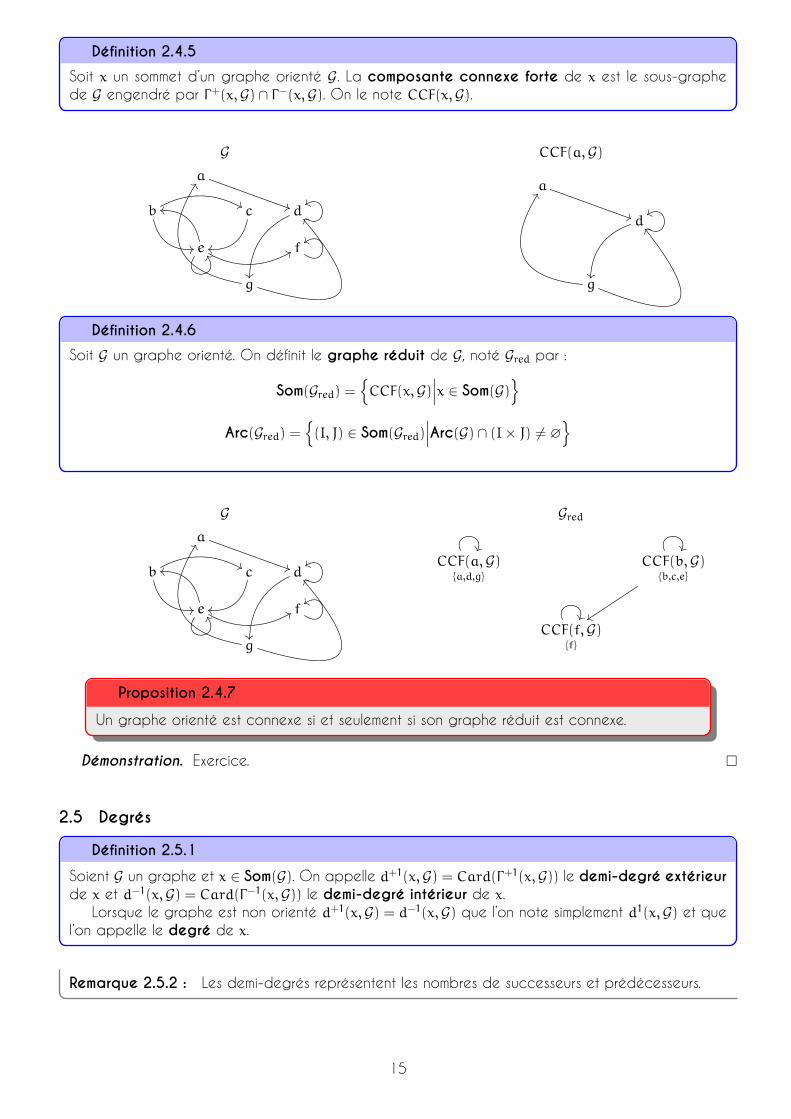
Définition 2.4.5
Soit x un sommet d’un graphe orienté G . La composante connexe forte de x est le sous-graphede G engendré par Γ+(x,G) ∩ Γ−(x,G). On le note CCF(x,G).
Ga
))b&&
00
c
nn
d
��
yy
e
pp
88YY fzz
g
]]
EE
CCF(a,G)
a
)) d
��
yy
g
\\
EE
Définition 2.4.6
Soit G un graphe orienté. On définit le graphe réduit de G , noté Gred par :
Som(Gred) ={CCF(x,G)
∣∣∣x ∈ Som(G)}Arc(Gred) =
{(I, J) ∈ Som(Gred)
∣∣∣Arc(G) ∩ (I× J) 6= ∅}
Ga
))b&&
00
c
nn
d
��
yy
e
pp
88YY fzz
g
]]
EE
Gred
CCF(a,G){a,d,g}
��
CCF(b,G){b,c,e}
��
CCF(f,G){f}
zz��
Proposition 2.4.7
Un graphe orienté est connexe si et seulement si son graphe réduit est connexe.
Démonstration. Exercice. �
2.5 Degrés
Définition 2.5.1
Soient G un graphe et x ∈ Som(G). On appelle d+1(x,G) = Card(Γ+1(x,G)) le demi-degré extérieurde x et d−1(x,G) = Card(Γ−1(x,G)) le demi-degré intérieur de x.Lorsque le graphe est non orienté d+1(x,G) = d−1(x,G) que l’on note simplement d1(x,G) et que
l’on appelle le degré de x.
Remarque 2.5.2 : Les demi-degrés représentent les nombres de successeurs et prédécesseurs.
15

Remarque 2.5.3 : On devine aisément ce que serait les définitions de d+n(x,G), d−n(x,G) etdn(x,G). Nous ne les utiliserons pas cependant.
Proposition 2.5.4 Formule des degré
Soit G un graphe orienté.∑x∈Som(G)
d+1(x,G) =∑
x∈Som(G)
d−1(x,G) = Card(Arc(G))
Démonstration. NotonsM la matrice booléenne du graphe G , n le nombre de sommet et {a1, . . . , an}les sommets.Le nombre de 1 dans la ligne i indique le nombre de successeurs au sommet ai et le nombre de 1
dans la colonne j indique le nombre de prédécesseurs au sommet aj. Autrement d+1(ai,G) =n∑j=1
Mi,j et
d−1(aj,G) =n∑i=1
Mi,j où les sommes se réalisent dans N.
On observe de plus que le nombre total de 1 dans la matrice correspond aux nombre d’arc dugraphe. Ainsi
Card(Arc(G)) =
n∑i=1
n∑j=1
Mi,j
=
n∑i=1
n∑j=1
Mi,j
=
n∑i=1
d+1(ai,G)
=
n∑j=1
(n∑i=1
Mi,j
)=
n∑j=1
d−1(aj,G)
�
Proposition 2.5.5 (Formule des degrés)
Soit G un graphe non orienté. ∑x∈Som(G)
d1(x,G) = 2Card(Ar(G))
Démonstration. Soient n le nombre de sommet de G , {a1, . . . , an} les sommets de G et M la matricebooléenne de G . Le nombre de 1 sur la ligne i donne le nombre de sommet adjacent à ai. Autrement
dit d1(ai,G) =n∑j=1
Mi,j où la somme s’effectue dans N et non dans B. De plus le nombre total de 1 dans
la matrice vaut 2Card(Ar(G)) car si {ai, aj} est une arête de G c’est également le cas de {aj, ai}. Alors
2Card(Ar(G)) =n∑i=1
n∑j=1
Mi,j =
n∑i=1
n∑j=1
Mi,j
=
n∑i=1
d1(ai,G).
�
16

Corollaire 2.5.6
Dans un graphe non orienté le nombre de sommet de degré impair est pair.
Démonstration. La somme de tous les degrés d’un graphe non orienté peut se décomposer en lasomme des sommets de degré pair plus la somme des sommets de degré impair∑
x∈Som(G)
d(x,G) =∑
x∈Som(G)
d(x,G) pair
d(x,G) +∑
x∈Som(G)
d(x,G) impair
d(x,G)
D’après la proposition précédente cette somme est pair. De plus∑
x∈Som(G)
d(x,G) pair
d(x,G) est pair (puisque dans
cette somme tous les d(x,G) sont pair) alors nécessairement∑
x∈Som(G)
d(x,G) impair
d(x,G) est pair.
Puisque dans cette dernière somme tous les d(x,G) sont impairs ils sont forcement en nombre pair(une somme impair de nombre impair est impair et une somme pair de nombre impair est pair 1). �
Corollaire 2.5.7
Soit G un graphe non orienté connexe,
Card(Ar(G)) > Card(Som(G)) − 1
Démonstration. Soit n = Card(Som(G)). On va raisonner par récurrence sur n ∈ N>0, le cas initialétant trivial. On observe pour commencer pour tout sommet x de G , d1(x,G) > 1 car le graphe estconnexe.
• Soit∃x0 ∈ Som(G), d1(x0,G) = 1
Dans ce cas on considère le graphe G ′ défini comme le sous-graphe de G engendré par Som(G)−{x0} qui est connexe par construction.
Card(Ar(G)) = Card(Ar(G ′)) + 1> Card(Som(G ′)) − 1+ 1> Card(Som(G ′)) + 1︸ ︷︷ ︸−1> Card(Som(G)) − 1.
• Soit
¬(∃x0 ∈ Som(G), d1(x0,G) = 1) = (∀x ∈ Som(G), d1(x,G) > 1) = (∀x ∈ Som(G), d1(x,G) > 2)
Dans ce cas, en utilisant la formule des degrés,
Card(Ar(G)) =1
2
∑x∈Som(G)
d1(x,G)
>1
2
∑x∈Som(G)
2
>∑
x∈Som(G)
1
> Som(G)> Som(G) − 1
�
1. Et une somme impair de nombre pair élevé à une puissance pair puis divisée par la moitié d’elle même donne un nombredont le quart du double vaut 1.
17
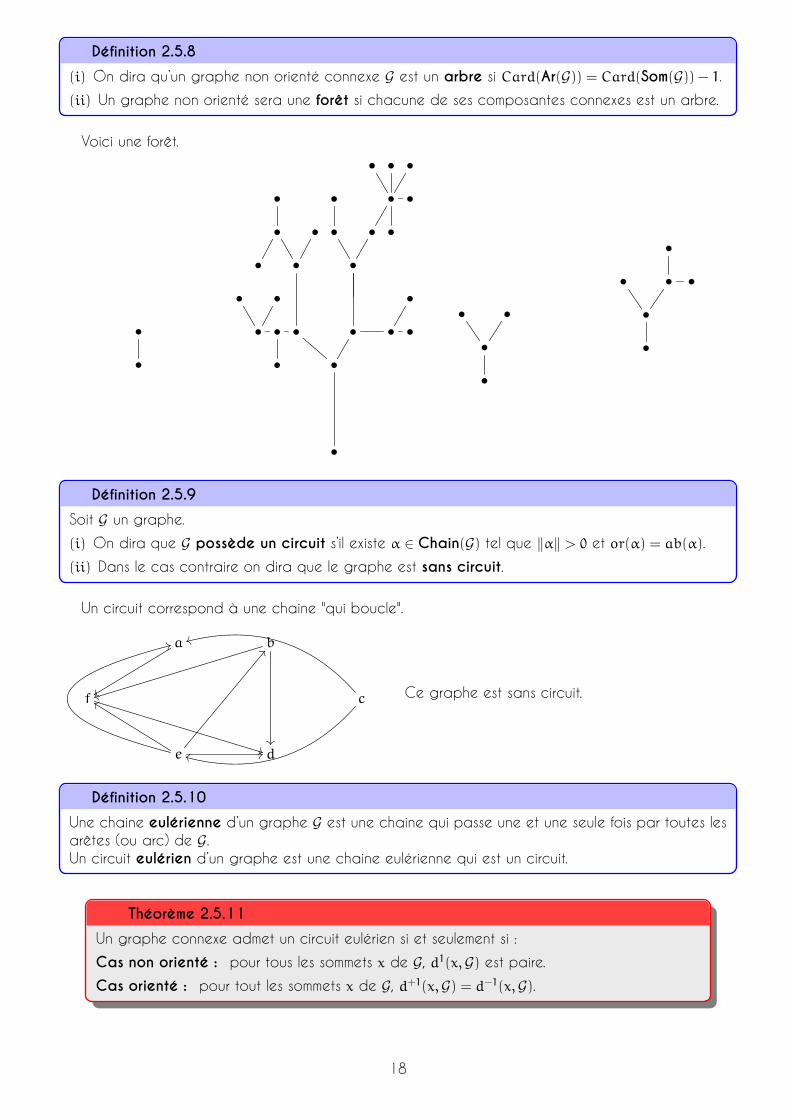
Définition 2.5.8
(i) On dira qu’un graphe non orienté connexe G est un arbre si Card(Ar(G)) = Card(Som(G)) − 1.(ii) Un graphe non orienté sera une forêt si chacune de ses composantes connexes est un arbre.
Voici une forêt.
•
•
• • •
• • • •
• • • • •
• • •
• • •
• • • • • •
• •
•
• •
•
•
•
• • •
•
•
Définition 2.5.9
Soit G un graphe.(i) On dira que G possède un circuit s’il existe α ∈ Chain(G) tel que ‖α‖ > 0 et or(α) = ab(α).(ii) Dans le cas contraire on dira que le graphe est sans circuit.
Un circuit correspond à une chaine "qui boucle".
a
yy
b
��
ttf
**
c
ss
kke
33
ee
BB
// d
Ce graphe est sans circuit.
Définition 2.5.10
Une chaine eulérienne d’un graphe G est une chaine qui passe une et une seule fois par toutes lesarêtes (ou arc) de G .Un circuit eulérien d’un graphe est une chaine eulérienne qui est un circuit.
Théorème 2.5.11
Un graphe connexe admet un circuit eulérien si et seulement si :
Cas non orienté : pour tous les sommets x de G , d1(x,G) est paire.Cas orienté : pour tout les sommets x de G , d+1(x,G) = d−1(x,G).
18

Corollaire 2.5.12
Soient a et b deux sommets d’un graphe connexe G . Il existe une chaine eulérienne entre aet b si et seulement
Cas non orienté : d1(a,G) et d1(b,G) sont impaires et les degrés de tous les autres som-mets sont paires.
Cas orienté : d+1(a,G) = d−1(a,G)+ 1, d+1(b,G) = d−1(b,G)− 1 et pour tout x ∈ Som(G)−{a, b}, d+1(x,G) = d−1(x,G).
19

3. Applications
3.1 Coloriage de graphes
Définition 3.1.1
Soit G un graphe non orienté. Le nombre chromatique de G , noté X(G), est le plus petit nombre decouleur différentes nécessaire pour colorier les sommets de G de telle sorte qu’une même couleur nesoit pas attribuée à deux sommets adjacents.
Proposition 3.1.2
Soient G et G ′ des graphes non orientés et n ∈ N>0(i) Si G ′ ⊂ G alors X(G ′) 6 X(G).(ii) X(Kn) = n.(iii) X(Cn) = 2.
(iv) X(Zn) =
{2 si n est pair,
3 sinon.
(v) X(Sn) = 1.
Démonstration. Exercice. �
L’algorithme de Brélaz ou DSATUR permet de colorier un graphe et de donner une bonne bornesupérieur du nombre chromatique.On considère que les couleurs sont numérotées : 1, 2, 3, 4, ... Voici les étapes de l’algorithme.
§3.1.3 : Algorithme de Brélaz
1. Initialisation
Pour chaque sommet xDSAT[x] = degré de x
Fin pour
2. Itérations
Tant que il existe des sommets non coloriésPour chaque sommet x non colorié
Si aucun voisin de x n’est coloriéDSAT(x) = degré de x = nombre de voisin de x.
sinonDSAT(x) = nombre de sommet adjacent de x qui sont coloriés.
Fin siFin pour
On choisit un sommet x non colorié tel que DSAT(x) soit le plus grand.Si il y a conflit, on choisit le sommet qui a en plus le degré maximal.
On colorie le sommet avec la plus petite couleur possible.
Fin tant que
Détaillons un exemple
20
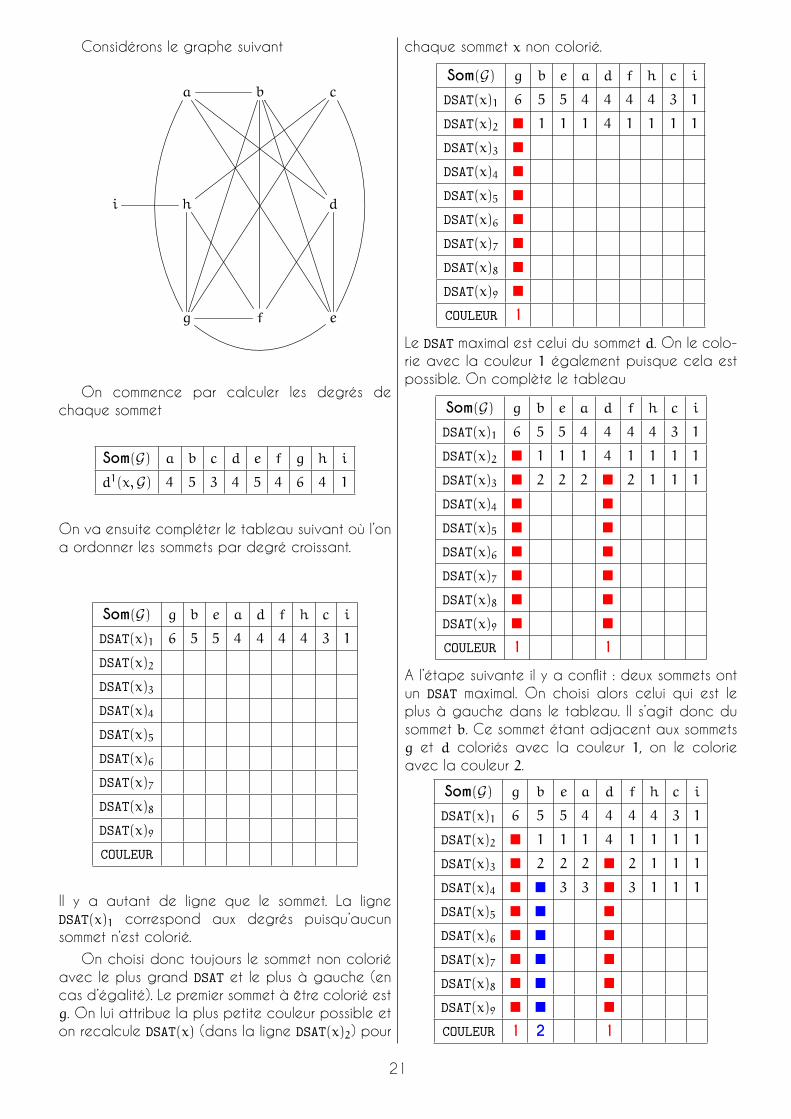
Considérons le graphe suivant
a b c
i h d
g f e
On commence par calculer les degrés dechaque sommet
Som(G) a b c d e f g h i
d1(x,G) 4 5 3 4 5 4 6 4 1
On va ensuite compléter le tableau suivant où l’ona ordonner les sommets par degré croissant.
Som(G) g b e a d f h c i
DSAT(x)1 6 5 5 4 4 4 4 3 1
DSAT(x)2
DSAT(x)3
DSAT(x)4
DSAT(x)5
DSAT(x)6
DSAT(x)7
DSAT(x)8
DSAT(x)9
COULEUR
Il y a autant de ligne que le sommet. La ligneDSAT(x)1 correspond aux degrés puisqu’aucunsommet n’est colorié.
On choisi donc toujours le sommet non coloriéavec le plus grand DSAT et le plus à gauche (encas d’égalité). Le premier sommet à être colorié estg. On lui attribue la plus petite couleur possible eton recalcule DSAT(x) (dans la ligne DSAT(x)2) pour
chaque sommet x non colorié.
Som(G) g b e a d f h c i
DSAT(x)1 6 5 5 4 4 4 4 3 1
DSAT(x)2 � 1 1 1 4 1 1 1 1
DSAT(x)3 �
DSAT(x)4 �
DSAT(x)5 �
DSAT(x)6 �
DSAT(x)7 �
DSAT(x)8 �
DSAT(x)9 �
COULEUR 1
Le DSAT maximal est celui du sommet d. On le colo-rie avec la couleur 1 également puisque cela estpossible. On complète le tableau
Som(G) g b e a d f h c i
DSAT(x)1 6 5 5 4 4 4 4 3 1
DSAT(x)2 � 1 1 1 4 1 1 1 1
DSAT(x)3 � 2 2 2 � 2 1 1 1
DSAT(x)4 � �
DSAT(x)5 � �
DSAT(x)6 � �
DSAT(x)7 � �
DSAT(x)8 � �
DSAT(x)9 � �
COULEUR 1 1
A l’étape suivante il y a conflit : deux sommets ontun DSAT maximal. On choisi alors celui qui est leplus à gauche dans le tableau. Il s’agit donc dusommet b. Ce sommet étant adjacent aux sommetsg et d coloriés avec la couleur 1, on le colorieavec la couleur 2.
Som(G) g b e a d f h c i
DSAT(x)1 6 5 5 4 4 4 4 3 1
DSAT(x)2 � 1 1 1 4 1 1 1 1
DSAT(x)3 � 2 2 2 � 2 1 1 1
DSAT(x)4 � � 3 3 � 3 1 1 1
DSAT(x)5 � � �
DSAT(x)6 � � �
DSAT(x)7 � � �
DSAT(x)8 � � �
DSAT(x)9 � � �
COULEUR 1 2 1
21
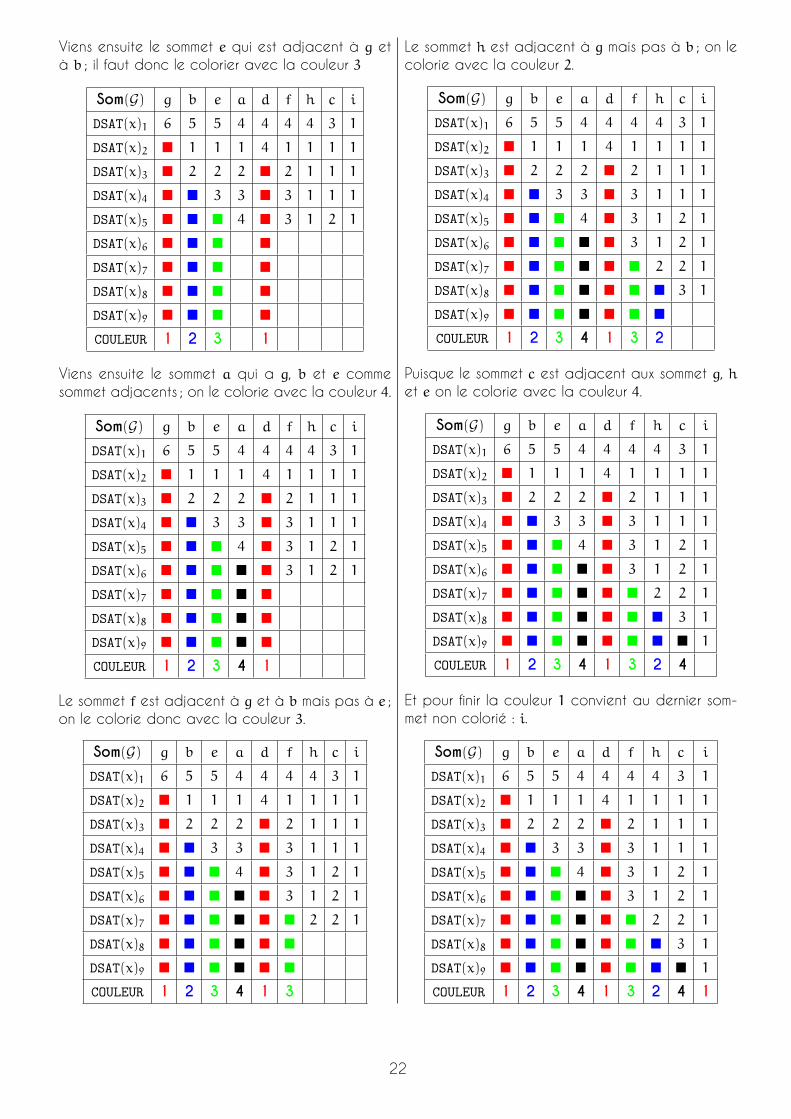
Viens ensuite le sommet e qui est adjacent à g età b ; il faut donc le colorier avec la couleur 3
Som(G) g b e a d f h c i
DSAT(x)1 6 5 5 4 4 4 4 3 1
DSAT(x)2 � 1 1 1 4 1 1 1 1
DSAT(x)3 � 2 2 2 � 2 1 1 1
DSAT(x)4 � � 3 3 � 3 1 1 1
DSAT(x)5 � � � 4 � 3 1 2 1
DSAT(x)6 � � � �
DSAT(x)7 � � � �
DSAT(x)8 � � � �
DSAT(x)9 � � � �
COULEUR 1 2 3 1
Viens ensuite le sommet a qui a g, b et e commesommet adjacents ; on le colorie avec la couleur 4.
Som(G) g b e a d f h c i
DSAT(x)1 6 5 5 4 4 4 4 3 1
DSAT(x)2 � 1 1 1 4 1 1 1 1
DSAT(x)3 � 2 2 2 � 2 1 1 1
DSAT(x)4 � � 3 3 � 3 1 1 1
DSAT(x)5 � � � 4 � 3 1 2 1
DSAT(x)6 � � � � � 3 1 2 1
DSAT(x)7 � � � � �
DSAT(x)8 � � � � �
DSAT(x)9 � � � � �
COULEUR 1 2 3 4 1
Le sommet f est adjacent à g et à b mais pas à e ;on le colorie donc avec la couleur 3.
Som(G) g b e a d f h c i
DSAT(x)1 6 5 5 4 4 4 4 3 1
DSAT(x)2 � 1 1 1 4 1 1 1 1
DSAT(x)3 � 2 2 2 � 2 1 1 1
DSAT(x)4 � � 3 3 � 3 1 1 1
DSAT(x)5 � � � 4 � 3 1 2 1
DSAT(x)6 � � � � � 3 1 2 1
DSAT(x)7 � � � � � � 2 2 1
DSAT(x)8 � � � � � �
DSAT(x)9 � � � � � �
COULEUR 1 2 3 4 1 3
Le sommet h est adjacent à g mais pas à b ; on lecolorie avec la couleur 2.
Som(G) g b e a d f h c i
DSAT(x)1 6 5 5 4 4 4 4 3 1
DSAT(x)2 � 1 1 1 4 1 1 1 1
DSAT(x)3 � 2 2 2 � 2 1 1 1
DSAT(x)4 � � 3 3 � 3 1 1 1
DSAT(x)5 � � � 4 � 3 1 2 1
DSAT(x)6 � � � � � 3 1 2 1
DSAT(x)7 � � � � � � 2 2 1
DSAT(x)8 � � � � � � � 3 1
DSAT(x)9 � � � � � � �
COULEUR 1 2 3 4 1 3 2
Puisque le sommet c est adjacent aux sommet g, het e on le colorie avec la couleur 4.
Som(G) g b e a d f h c i
DSAT(x)1 6 5 5 4 4 4 4 3 1
DSAT(x)2 � 1 1 1 4 1 1 1 1
DSAT(x)3 � 2 2 2 � 2 1 1 1
DSAT(x)4 � � 3 3 � 3 1 1 1
DSAT(x)5 � � � 4 � 3 1 2 1
DSAT(x)6 � � � � � 3 1 2 1
DSAT(x)7 � � � � � � 2 2 1
DSAT(x)8 � � � � � � � 3 1
DSAT(x)9 � � � � � � � � 1
COULEUR 1 2 3 4 1 3 2 4
Et pour finir la couleur 1 convient au dernier som-met non colorié : i.
Som(G) g b e a d f h c i
DSAT(x)1 6 5 5 4 4 4 4 3 1
DSAT(x)2 � 1 1 1 4 1 1 1 1
DSAT(x)3 � 2 2 2 � 2 1 1 1
DSAT(x)4 � � 3 3 � 3 1 1 1
DSAT(x)5 � � � 4 � 3 1 2 1
DSAT(x)6 � � � � � 3 1 2 1
DSAT(x)7 � � � � � � 2 2 1
DSAT(x)8 � � � � � � � 3 1
DSAT(x)9 � � � � � � � � 1
COULEUR 1 2 3 4 1 3 2 4 1
22

a b c
i h d
g f e
Nous pouvons donc affirmer que X(G) 6 4.En fait X(G) = 4. En effet K4 ⊂ G donc 4 = X(K4) 6 X(G) 6 4 et ces inégalités sont des égalités.
Définition 3.1.4
On appelle graphe planaire tout graphe non orienté pouvant être dessiné sur un plan de tellesorte que les sommets soient des points distincts, et que les arêtes ne se rencontrent pas en dehorsde leurs extrémités (les arêtes pouvant être représentées par des courbes).
5
4 1
3 2
Ce graphe est planaire ; en effet en réarrangeantses sommets et en traçant les arêtes astucieuse-ment il est équivalant au graphe de droite.
3 4
1 2
5
Définition 3.1.5
On dira que deux graphes non orienté sont homéomorphes si l’on peut passer de l’un à l’autre endivisant des arêtes à l’aide de sommet supplémentaire.
Par exemple les deux graphes suivants sont homéomorphes :
• •
• •
• • •
• •
• •
Le théorème suivant permet de repérer si un graphe est planaire.
23

Théorème 3.1.6 (Kuratowski)
Un graphe non orienté est non planaire si et seulement s’il possède un sous-graphe homéo-morphe à
•
• •
• •K5
• • •
• • •
K3,3
Il existe une caractérisation plus faible des graphes planaires.
Proposition 3.1.7
Pour tout graphe planaire G connexe possédant plus de 3 sommets,
Ar(G) 6 3Som(G) − 6
Voici un algorithme permettant, assez souvent, de planarifier 2 un graphe.
§3.1.8 : Algorithme de planarification.
n = le nombre d’intersection entre les arêtes de G.Tant que n>0
Pour chaque sommet x de Gdi(x) = le nombre d’intersection que compte les arêtes issues de x.
Fin pourx = le sommet tel que di(x) est maximal.x’ = l’isobarycentre des voisins de x.G’ = le graphe G ou l’on a déplacer le sommet x en x’.n’ = le nombre d’intersection entre les arêtes de G’.Si x=x’
Fin de l’algorithmeFin siSi n’<n
Remplacer G par G’ et n par n’Fin si
Fin tant que
Par exemple :
5
4 1
3 2
Nombre d’intersection entre arêtes : 5.
Sommet 1 2 3 4 5
di 4 4 4 4 4
On sélectionne le sommet 1 qui admet 2, 3, 4 et 5comme voisin. On place donc le sommet 1 au milieudu quadrilatère 2345.
2. Toi aussi ! Invente des mots !
24

5
4 1
3 2
Nombre d’intersection entre arêtes : 3.
Sommet 1 2 3 4 5
di 2 3 3 2 2
En arquant l’arête {2; 4} les degrés d’intersectionsseraient respectivement 1, 1, 1, 0, 1. Dans ce casil ne faut pas sélectionner le sommet 1 qui a déjàété sélectionné à l’itération précédente.On sélectionne le sommet 2 qui admet 1, 4 et 5
comme voisin. On place donc le sommet 2 au milieudu triangle 145.
5
2
4 1
3
Nombre d’intersection entre arêtes : 0.
Sommet 1 2 3 4 5
di 0 0 0 0 0
Fin.
Théorème 3.1.9 (Théorème des 4 couleurs)
Pour tout graphe planaire G ,X(G) 6 4
Le théorème des 4 couleurs fut d’abord conjecturer en 1852 par Francis Guthrie intéressé par lacoloration de la carte d’Angleterre : il est possible, en n’utilisant que quatre couleurs différentes, decolorier n’importe quelle carte découpée en régions, de sorte que deux régions adjacentes, c’est-à-dire ayant toute une frontière (et non simplement un point) en commun reçoivent toujours deux couleursdistinctes.Presque 30 ans plus tard une preuve est publié mais on se rendra compte 10 après qu’elle est
fausse et qu’elle prouve plutôt un théorème des 5 couleurs. Il faudra attendre 1976 et l’avènementde l’ère informatique pour qu’une preuve sérieuse soit publié par deux Américains, Kenneth Appel etWolfgang Haken. Leur preuve consiste à diviser le problème des 4 couleurs en 1478 problèmes que l’onpeut résoudre par ordinateur (et 1200 heures de calcul). A l’époque leur démonstration partageait lacommunauté scientifique : quel crédit accorder à une preuve réalisée par ordinateur ?Aujourd’hui il n’existe toujours aucune preuve de ce théorème n’utilisant pas l’outil informatique.
3.2 Solution de Dijkstra
Définition 3.2.1
Soit G un graphe. Une métrique ou une valuation sur G est une application
λ : Ar(G) −→]0; +∞[
On dira que le couple (G, λ) est un graphe métrique ou graphe valué (orienté ou non orienté).
Dans la pratique on représente un graphe métrique en indiquant sur chaque arête la valeur de lamétrique. Par exemple
25

a4
8
6
b1
22
c4
64
d
3
1
3
e1
f2
g1
h
Étant donné un graphe métrique, la solution de Dijkstra permet de déterminer la chaine la pluscourte (au sens de la métrique) reliant deux sommets. L’algorithme solution permet, étant donné unsommet fixé, de déterminer toutes les plus courtes chaines reliant les autres sommet.
§3.2.2 : Solution de Dijkstra (partant d’un sommet x).
1. Initialisationd_min(x)=0;sommet_proche(x)={};Pour tous les sommets y différent de x
d_min(y)=+∞;sommet_proche(y)={};
Fin pour2.
Tant qu’il existe des sommets non marquésOn marque un sommet y non marqué tel que d_min(y)soit le plus petit possible.Pour tout sommet z non marqué et successeur/voisin à y
Si d_min(z) > d_min(y)+λ({y,z})d_min(b) = d_min(y)+λ({y,z});sommet_proche(z) = y;
Fin siFin pour
Fin tant que
Faisons tourner cet algorithme sur le graphe métrique précédent. On présente les variables de l’algo-rithme dans un tableau.
Som(G) a b c d e f g h
d_min
sommet_proche
Initialisons les variables :
Som(G) a b c d e f g h
d_min 0 +∞ +∞ +∞ +∞ +∞ +∞ +∞sommet_proche
Le sommet au d_min minimal est a. On le marque. Ses sommets adjacents sont b, c et e.
• Pour le sommet b, puisque d_min(b) > d_min(a)+λ({a,b}) soit encore +∞ > 0 + 4 on modifie lacolonne du sommet b.
• Pour le sommet c, puisque d_min(c) > d_min(a)+λ({a,c}) soit encore +∞ > 0 + 6 on modifie lacolonne du sommet c.
26

• Pour le sommet e, puisque d_min(e) > d_min(a)+λ({a,e}) soit encore +∞ > 0 + 8 on modifie lacolonne du sommet e.
Som(G) a b c d e f g h
d_min 0 4 6 +∞ 8 +∞ +∞ +∞sommet_proche a a a
Le sommet au d_min minimal non marqué est b. On le marque. Ses sommets adjacents non marquéssont c, e et f.
• Puisque d_min(f) > d_min(b)+λ({b,f}) soit +∞ > 4+ 2 on modifie la colonne du sommet f.
• Puisque d_min(e) > d_min(b)+λ({b,e}) soit 8 > 4+ 2 on modifie la colonne du sommet e.
• Puisque d_min(c) > d_min(b)+λ({b,c}) soit 6 > 4+ 1 on modifie la colonne du sommet c.
Som(G) a b c d e f g h
d_min 0 4 5 +∞ 6 6 +∞ +∞sommet_proche a b b b
Le sommet au d_min minimal non marqué est c. On le marque. Ses sommets adjacents non marquéssont d, f et g.
• Puisque d_min(d) > d_min(c)+λ({c,d}) soit +∞ > 5+ 4 on modifie la colonne du sommet d.
• Puisque d_min(f) 6 d_min(c)+λ({c,f}) soit 5 6 5+ 4 on ne modifie pas la colonne du sommet f.
• Puisque d_min(g) > d_min(c)+λ({c,g}) soit +∞ > 5+ 6 on modifie la colonne du sommet g.
Som(G) a b c d e f g h
d_min 0 4 5 9 6 6 11 +∞sommet_proche a b c b b c
Le sommet au d_min minimal non marqué est f (on aurait pu choisir e mais un tel choix ne changeen rien le résultat final). On le marque. Ses sommets adjacents non marqués sont d, e et g.
• Puisque d_min(d) > d_min(f)+λ({f,d}) soit 9 > 6+ 1 on modifie la colonne du sommet d.
• Puisque d_min(e) 6 d_min(f)+λ({f,e}) soit 6 6 6+ 1 on ne modifie pas la colonne du sommet e.
• Puisque d_min(g) > d_min(f)+λ({f,g}) soit 11 > 6+ 2 on modifie la colonne du sommet g.
Som(G) a b c d e f g h
d_min 0 4 5 7 6 6 8 +∞sommet_proche a b f b b f
Le sommet au d_min minimal non marqué est e. On le marque. Il n’a pas de sommet adjacent nonmarqué.
Som(G) a b c d e f g h
d_min 0 4 5 7 6 6 8 +∞sommet_proche a b f b b f
Le sommet au d_min minimal non marqué est d. On le marque. Ses sommets adjacents non marquéssont g et h.
• Puisque d_min(h) > d_min(d)+λ({d,h}) soit +∞ > 7+ 3 on modifie la colonne du sommet h.
• Puisque d_min(g) 6 d_min(d)+λ({d,g}) soit 8 6 7+ 3 on ne modifie pas la colonne du sommet g.
27

Som(G) a b c d e f g h
d_min 0 4 5 7 6 6 8 10
sommet_proche a b f b b f d
Le sommet au d_min minimal non marqué est g. On le marque. Son sommet adjacent non marqué esth.
• Puisque d_min(h) > d_min(g)+λ({g,h}) soit 10 > 8+ 1 on modifie la colonne du sommet h.
Som(G) a b c d e f g h
d_min 0 4 5 7 6 6 8 9
sommet_proche a b f b b f g
Le dernier sommet non marqué est h qui n’a pas de sommet adjacent.
Som(G) a b c d e f g h
d_min 0 4 5 7 6 6 8 9
sommet_proche a b f b b f g
Interprétation : le chemin le plus court au sens de la métrique du graphe entre a et h (par exemple)est de longueur 9. Pour obtenir cette chaine, on regarde quel est le sommet le plus proche de h c’est gdont le sommet le plus proche est f dont le sommet le plus proche est b dont le sommet le plus procheest a. Ainsi le chemin le plus court entre a est h est abfgh.De même pour les autres sommets. Les plus courtes chaines sont donc
a, ab, abc, abfd, abe, abfg, abfgh
3.3 Arbres couvrant de poids minimum
Définition 3.3.1
Soit (G, λ) un graphe métrique non orienté.• Un arbre couvrant de G est un sous graphe G ′ de G tel que G ′ soit un arbre et Som(G ′) = Som(G).• Soit G ′ un arbre couvrant de G . Le poids de G ′ est la somme des valuations de ses arêtes. On le
note P(G ′).P(G ′) =
∑{x,y}∈Ar(G ′)
λ({x, y})
Considérons 8 villes dont certaines sont reliéesentre elles par de petites routes de terre
a4
8
6
b1
22
c4
64
d
3
1
3
e1
f2
g1
h
où la métrique représente la distance en kilomètrequi sépare les villes.
Le gouvernement souhaite construire des routesentre ces villes en goudronnant les chemins deterre. Ce projet est soumis à deux contraintes :– Chaque ville doit avoir au moins une routegoudronnée.
– Minimiser le prix de construction sachantqu’un kilomètre de goudronnage coute10000e.
Le premier point sera satisfait, si on parvient à trou-ver un arbre couvrant. Pour satisfaire le secondpoint il faudra que cet arbre soit de poids mini-mum.
28

Voici l’algorithme de Kruskal permettant de déterminer un arbre couvrant de poids minimal.
§3.3.2 : Algorithme de Kruskal (on ne décrit les graphes que par leur arêtes).A = l’ensemble des arêtes de GF = ∅Tant que A 6= ∅
a = élément de A tel que λ(a) soit minimal.A = A− {a}.Si F ∪ {a} est sans circuitF = F ∪ {a}
Fin siFin tant queSolution = F.
Sur notre exemple.
• Arête {b, c}
a4
8
6
b1
22
c4
64
d
3
1
3
e1
f2
g1
h
• Arête {d, f}
a4
8
6
b1
22
c4
64
d
3
1
3
e1
f2
g1
h
• Arête {e, f}
a4
8
6
b1
22
c4
64
d
3
1
3
e1
f2
g1
h
• Arête {g, h}
a4
8
6
b1
22
c4
64
d
3
1
3
e1
f2
g1
h
• Arête {b, e}
a4
8
6
b1
22
c4
64
d
3
1
3
e1
f2
g1
h
• Arête {b, f}. Fait apparaitre un circuit.
a4
8
6
b1
22
c4
64
d
3
1
3
e1
f2
g1
h
• Arête {f, g}.
a4
8
6
b1
22
c4
64
d
3
1
3
e1
f2
g1
h
• Arête {d, g}. Fait apparaitre un circuit.
a4
8
6
b1
22
c4
64
d
3
1
3
e1
f2
g1
h
29
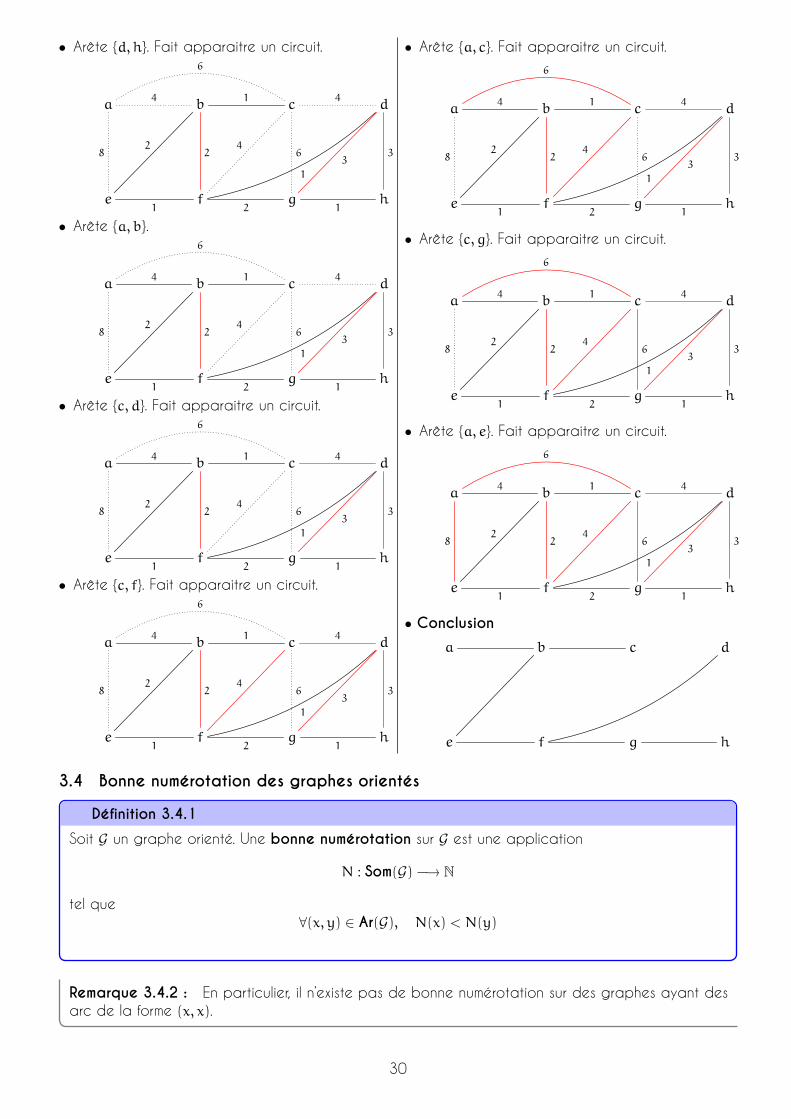
• Arête {d, h}. Fait apparaitre un circuit.
a4
8
6
b1
22
c4
64
d
3
1
3
e1
f2
g1
h
• Arête {a, b}.
a4
8
6
b1
22
c4
64
d
3
1
3
e1
f2
g1
h
• Arête {c, d}. Fait apparaitre un circuit.
a4
8
6
b1
22
c4
64
d
3
1
3
e1
f2
g1
h
• Arête {c, f}. Fait apparaitre un circuit.
a4
8
6
b1
22
c4
64
d
3
1
3
e1
f2
g1
h
• Arête {a, c}. Fait apparaitre un circuit.
a4
8
6
b1
22
c4
64
d
3
1
3
e1
f2
g1
h
• Arête {c, g}. Fait apparaitre un circuit.
a4
8
6
b1
22
c4
64
d
3
1
3
e1
f2
g1
h
• Arête {a, e}. Fait apparaitre un circuit.
a4
8
6
b1
22
c4
64
d
3
1
3
e1
f2
g1
h
• Conclusiona b c d
e f g h
3.4 Bonne numérotation des graphes orientés
Définition 3.4.1
Soit G un graphe orienté. Une bonne numérotation sur G est une application
N : Som(G) −→ N
tel que∀(x, y) ∈ Ar(G), N(x) < N(y)
Remarque 3.4.2 : En particulier, il n’existe pas de bonne numérotation sur des graphes ayant desarc de la forme (x, x).
30

Considérons par exemple le graphe suivant
a
xx
b
��
ssf
++
c
ww
gge
33
ff
@@
// d
Une bonne numérotation est par exemple :
N : Som(G) −→ Na 7−→ 3
b 7−→ 4
c 7−→ 1
d 7−→ 6
e 7−→ 2
f 7−→ 5
Définition 3.4.3
Soient G un graphe orienté et N une bonne numérotation sur G . On définit le graphe orienté GN par
Som(GN) ={N(x)
∣∣x ∈ Som(G)}Arc(GN) =
{(N(x), N(y))
∣∣(x, y) ∈ Arc(G)}
Avec l’exemple précédent le graphe GN est
3
xx
4
��
ss5
++
1
xx
ff2
33
ff
@@
// 6
En réordonnant le graphe en écrivant les sommetspar ordre croissant suivant la lecture on obtient :
3
''1 //
33
2 //<<
''
5 // 6
4
77 33
Proposition 3.4.4
Soient G un graphe orienté et N une bonne numérotation. La matrice booléenne de GN estune matrice triangulaire supérieure stricte.
Démonstration. Le coefficient Mi,j de la matrice booléenne du graphe GN vaut 1 s’il existe un arcentre les sommets i et j. Mais par définition de bonne numérotation (N(x) < N(y)) ces coefficients sontnuls lorsque i > j. �
Remarque 3.4.5 : En informatique, lorsque l’on est amené à manipuler des graphes, on utilise leurreprésentation matricielle. Plus le graphe possède de sommet, plus la matrice est grande et doncplus les boucles nécessaire pour parcourir le graphe sont longues ; de l’ordre de n2. Avec un bonnenumérotation, le résultat précédent stipule que, puisque la matrice est triangulaire supérieur, il n’estpas nécessaire de la parcourir en entier mais simplement de se cantonner à la partie supérieure,
réduisant ainsi le nombre d’opération ; de l’ordre den(n− 1)
2.
Théorème 3.4.6
Un graphe orienté est sans circuit si et seulement s’il existe une bonne numérotation.
En lieu et place de la preuve de ce théorème, nous allons détailler un algorithme permettant d’unepart, de déterminer si le graphe possède ou non un circuit et d’autre part, lorsqu’il n’en posséderaaucun, donnera la bonne numérotation. Il s’agit de l’algorithme de filtration (la preuve de ce théorèmese résume à montrer que l’algorithme de filtration propose bien une bonne numérotation).
31

Définition 3.4.7
Soit x un sommet d’un graphe orienté G .(i) On dira que x est un puits si Γ+1(x,G) = ∅.(ii) On dira que x est une source si Γ−1(x,G) = ∅.
Autrement : un puits est un sommet sans successeur et une source est un sommet sans prédécesseur.
a
xx
b
��
ssf
++
c
ww
gge
33
ff
@@
// d
Dans ce graphe le sommet c est une source et lesommet d est un puits.
Remarque 3.4.8 : L’algorithme de filtration possède deux versions : l’algorithme de filtration par lessources et l’algorithme de filtration par les puits. Nous présentons celui par les sources qui est plus"naturel".
§3.4.9 : Algorithme de filtration par les sources.
1. Initialisationn = 1 (l’indice de la numérotation)Pour chaque sommet x du graphe
Pred[x] = les prédécesseurs de x.Fin pourS = les sources = les sommets x tel que Pred[x] soit vide.
2. ItérationsTant que S est non vide
Numéroter les éléments de S en incrémentant n.Supprimer les éléments de S dans le tableau Pred.S = les sommets x non numéroté tel que Pred[x] soit vide.
Fin tant que3. Conclusion
Si Pred est complètement videLe graphe est sans circuit.La numérotation effectuée est une bonne numérotation.
SinonLe graphe possède au moins un circuit.
Fin si
Faisons tourner cet algorithme sur l’exemple
a
��
b
��
wwf
''
c
yy
eee
33
^^
GG
// d
On représente les différentes variables du pro-gramme dans un tableau :
x a b c d e f
Num
Pred
32

Première étape . L’initialisation.
x a b c d e f
Num
Pred
c e b c a
e e b
f c
On repère les colonnes vide : ici il n’y a que c.On numérote donc c à 1 et on supprime toutes lesoccurrences de c dans la case Pred.
x a b c d e f
Num 1
Pred
e b a
e e b
f
On repère ensuite les cases vides non numé-rotées : il n’y a que e. On le numérote à 2 et onsupprime les occurrences de e.
x a b c d e f
Num 1 2
Pred
b a
b
f
On repère les cases vides non numérotées : ily a a et b que l’on numérote 3 et 4 (ou 4 et 3cela n’a pas d’importance). On supprime a et bdu tableau
x a b c d e f
Num 3 4 1 2
Pred
f
Le f est la seul case vide non numéroté d’où
x a b c d e f
Num 3 4 1 2 5
Pred
Finalement
x a b c d e f
Num 3 4 1 6 2 5
Pred
et le graphe est donc sans circuit.
3.5 Théorie des jeux combinatoires à information parfaite à deux joueurs
Définition 3.5.1
Un jeu combinatoire à information parfaite à deux joueurs (JCIP2) est un jeu :– à stratégie sans aléa,– sans information caché,– à deux joueurs jouant à tour de rôle.
1. Le jeu de fléchette n’est pas un JCIP2 car il fait intervenir une partie de hasard.
2. Le poker entre deux joueurs n’est pas un JCIP2 car les cartes des joueurs sont cachées.
3. Pierre papier ciseaux lézard Spock entre deux joueurs n’est pas un JCIP2 car les joueurs ne jouentpas à tour de rôle.
4. Le jeu du puissance 4 est un JCIP2.
5. Le jeu du morpion est un JCIP2.
6. Le jeu de dame est un JCIP2.
7. Le jeu d’échec est un JCIP2.
8. Le jeu d’othelo (reversi) est un JCIP2.
33

Définition 3.5.2
A tout JCIP2, on associe un graphe orienté J défini par :
Som(J) = {États possible du jeu}
Arc(J) = {Si on peut passé d’un état à un autre en un coup}
Considérons par exemple un damier de 3 × 5 cases et une tour 3 placée en haut à gauche. Lebut du jeu est de placer la tour en bas à droite. Deux joueurs déplace la pièce, à tour de rôle, enrespectant la règle "On ne peut déplacer la pièce que vers le bas ou vers la droite".Il s’agit bien d’un JCIP2, dont les sommets du graphe représentent la position de la tour sur le damier
et les arcs les mouvements possible de la pièce.
1 // ++ ** **
��
��
2 // ++ **
��
��
3 // ++
��
��
4 //
��
��
5
��
��
6 // ++ ** **
��
7 // ++ **
��
8 // ,,
��
9 //
��
10
��
11 // ,, ** **12 // ,, **
13 // ,,14 // 15
On voit que si un joueur est en 9 alors il va nécessairement perdre. Ainsi pour gagner il suffit defaire en sorte que le joueur adverse se place en 9. Existe-t-il d’autre position offrant une stratégiegagnante ?
Définition 3.5.3
Le noyau d’un graphe orienté G est un sous ensemble de Som(G) tel que :1. Les sommets de N sont deux à deux non adjacents :
∀(x, y) ∈ Som(G), (x, y) 6∈ Arc(G)
2. Tout sommet qui n’est pas dans N a un prédécesseur dans N :
∀x ∈ Som(G) −N, ∃y ∈ N, (x, y) ∈ Arc(G)
a
��
b
��
wwf
''
c
yy
eee
33
^^
GG
// d
On peut vérifier que {a, d} est un noyau.
a // b
��c
__
Ce graphe ne possède pas de noyau.
3. la pièce aux échecs
34

Lorsque le graphe n’as pas de circuit, on peut donner un noyau. C’est l’algorithme de dénoyautage.
Proposition 3.5.4
Tout graphe orienté sans circuit possède un noyau
La preuve de ce résultat résulte de l’algorithme suivant.
§3.5.5 : Algorithme de dénoyautage.N = ∅Tant que Som(G) 6= ∅
N = N ∪ {Puits de G}Supprimer de G les éléments de N et leur prédécesseurs.
Fin tant que
Faisons tourner cet algorithme sur notre exemple du jeu de la tour.
• Étape initiale. N = ∅.
1 // ++ ** **
��
��
2 // ++ **
��
��
3 // ++
��
��
4 //
��
��
5
��
��
6 // ++ ** **
��
7 // ++ **
��
8 // ,,
��
9 //
��
10
��
11 // ,, ** **12 // ,, **
13 // ,,14 // 15
• Le graphe précédent admet 15 comme unique puits : N = {15}. On extrait du graphe le puits 15 etses prédécesseurs 5, 10, 11, 12, 13 et 14.
1 // ++ **
��
2 // ++
��
3 //
��
4
��
5
6 // ++ **7 // ++8 // 9 10
11 12 13 14 15
• Le graphe précédent admet 9 comme unique puits : N = {9, 15}. On extrait du graphe le puits 9 etses prédécesseurs 4, 6, 7 et 8.
1 // ++2 // 3 4 5
6 7 8 9 10
11 12 13 14 15
35

• Le graphe précédent admet 3 comme unique puits : N = {3, 9, 15}. On extrait du graphe le puits 3 etses prédécesseurs 1 et 2.
1 2 3 4 5
6 7 8 9 10
11 12 13 14 15
• Le graphe est vide. Un noyau est donc N = {3, 9, 15}
L’existence du noyau garantie une stratégie non-perdante.
Proposition 3.5.6
Soit N un noyau d’un graphe d’un JCIP2. Un joueur dont la position au début de son tourn’est pas dans N a une stratégie non-perdante.
Démonstration. Le joueur joue et se place sur un sommet élément de N, ce qui est possible d’aprèsla définition de noyau. Si ce sommet est un puits, le joueur à gagné. Sinon, toujours d’après la définitionde noyau, l’adversaire ne pourra se placer que sur un sommet qui n’est pas dans N et le joueurrecommence sa stratégie. �
Reprenons le jeu de la tour. Le premier joueur (celui qui va gagner) se place en 3. L’autre joueur nepeut se placer qu’en 4, 5, 8 ou 13. S’il c’est placé en 5 ou en 13 le premier joueur place la tour en 15 etgagne. S’il c’est placé en 4 ou 8, le premier joueur se place en 9. Le second joueur ne peut alors quese placer en 10 ou 14 ce qui fait gagner le premier joueur !
3.6 Automates
Définition 3.6.1
Un automate d’état finis déterministe A, plus simplement appelé ADEF, est la donnée de
• un alphabet ΣA, appelé l’alphabet de l’automate,
• un ensemble EA d’état,• un ensemble IA ⊂ EA d’états initiaux,• un ensemble FA ⊂ EA d’états finaux,• une fonction de transition τA : EA × ΣA −→ EA.
Par exemple, on considère l’ADEF ayant {0, 1}
comme alphabet, {A,B,C} comme état, {A,B}
comme état initiaux, {A,C} comme états finaux etayant pour fonction de transition la fonction
τ : EA × ΣA −→ EA
(A, 0) 7−→ B
(B, 1) 7−→ C
(B, 0) 7−→ B
(C, 1) 7−→ A
Représentation d’un automate
On dispose de deux moyens pour représenter un automate. Le premier, la représentation matricielle,est plus satisfaisante pour l’informaticien qui pourra programmer un automate par l’intermédiaire de
36

cette matrice. Le second moyen, la représentation sagittale, va permettre de faire le lien avec le restede la théorie des graphes.
Définition 3.6.2
Soit A un ADEF. On définit la matrice de l’automate MA indexée par les états en ligne et l’alphabeten colonne par :
(MA)e,x = e′ si τA(e, x) = e
′
La matrice de l’automate de l’exemple précédent est
MA =
0 1→ A→ B→ B B C
C→ A
en précédant (resp. succédant) les états initiaux (resp. finaux) d’une petite flèche.
Définition 3.6.3
Soit A un ADEF. On définit le graphe de l’automate GA par :
Som(GA) = EA, Arc(GA) ={(e, e ′) ∈ E2A
∣∣∣∃x ∈ Σ, τA(e, x) = e ′}
Le graphe de l’automate de notre exemple est :
A // Byy
��C
__
Cette représentation est un peu "faible" puis-qu’avec uniquement le graphe on ne peut pasretrouver l’alphabet ou la fonction de transition.Pour corriger cela on rajoute sur les arc du grapheles lettres de l’alphabet aboutissant à l’état. Dansnotre exemple :
A0 // B 0
yy
1��C
1
__
On spécifie les états initiaux par des flèches en-trantes dans les états concernés et les états finauxpar des flèches sortantes :
�� ��
A
��
0 // B 0yy
1��C
��
1
__
Définition 3.6.4
Un ADEF des appelé complet si sa fonction de transition est une application.
Par exemple : considérons ΣA = {0, 1}, EA ={paire, impaire}, IA = {paire}, FA = {paire} et lafonction de transition
τ : EA × ΣA −→ EA
(paire, 0) 7−→ impaire
(paire, 1) 7−→ paire
(impaire, 0) 7−→ paire
(impaire, 1) 7−→ impaire
37

Dans un ADEF complet, tous les coefficients de lamatrice sont remplis (la matrice est complète). Legraphe de cet automate est : ��
paire
0
��1$$
��
impaire
0
``1
zz
Théorème 3.6.5 Complétion d’un automate
Soit A un automate d’état finis déterministe. Considérons l’automate A défini en rajoutant unnouvel état e tel que :
• Alphabet : ΣA = ΣA
• États : EA = EA ∪ {e}
• États initiaux :IA = IA
• États finaux :FA = FA
• Fonction de transition :τA : EA × ΣA −→ EA
(x, σ) 7−→ {τA(x, σ) si c’est défini
e sinon
Alors A, appelé le complété de A, est un automate d’état finis déterministe complet.
Démonstration. C’est une conséquence triviale de la construction de A. �
Considérons l’ADEF (non complet) A suivant :
• ΣA = {0, 1}
• EA = {A,B,C}
• IA = {A,B}
• FA = {A,C}
• Fonction de transition :
τ : EA × ΣA −→ EA
(A, 0) 7−→ B
(B, 1) 7−→ C
(B, 0) 7−→ B
(C, 1) 7−→ A
Le complété de cette automate est :
• ΣA = {0, 1}
• EA = {A,B,C, e}
• IA = {A,B}
• FA = {A,C}
• Fonction de transition :
τ : EA × ΣA −→ EA(A, 0) 7−→ B
(B, 1) 7−→ C
(B, 0) 7−→ B
(B, 1) 7−→ e
(C, 0) 7−→ e
(C, 1) 7−→ A
(e, 0) 7−→ e
(e, 1) 7−→ e
MA =
0 1
A B e
B B C
C e A
e e e
�� ��
A
��
0 // B 0yy
1��
1
��C
��
1
\\
0// e 0,1zz
38
Reconnaitre un langage
Définition 3.6.6
Soient A un ADEF, σ ∈ Σ∗A tel que ‖σ‖ = n. On dira que σ est accepté par A si il existe une suitee0, e1, . . . , en de EA tel que
1. e0 ∈ IA,2. en ∈ FA,3. ∀k ∈ [[1, n]], τA(ek−1, σk) = ek
Autrement dit : un mot de longueur n est accepté par un automate s’il existe un chaine de longueurn − 1 dans le graphe représentant l’automate ayant un état initial pour origine et un état final pouraboutissement.
��paire
0
��1$$
��
impaire
0
``1
zzLes mots ε, 001, 100, 1100, 010 sont acceptés parl’automate ci-contre.
Définition 3.6.7
Le langage d’un ADEF A est l’ensemble des mots acceptés.
L(A) ={σ ∈ Σ∗A
∣∣∣σ est accepté par A}
��paire
0
��1$$
��
impaire
0
``1
zzLes mots reconnus par cet automate sont tous
les mots de {0, 1} possédant un nombre paire de 0.
Définition 3.6.8
Soient Σ un alphabet et L(Σ) ⊂ Σ∗ un langage. On dira que L(Σ) est un langage d’états finis, s’ilexiste un ADEF A tel que Σ = ΣA et L(A) = L(Σ). On dit que l’automate A reconnait le langageL(Σ).
Considérons par exemple l’alphabet Σ = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9} et le langage L(Σ) = N des nombres.Il s’agit d’un langage d’états finis. En effet les nombres (ne commençant pas par 0 sauf 0 lui même) sontreconnus par l’ADEF suivant :
��∅
0
))
1,...,9
ttVrai
��
Σ
33Faux
Σ
YY 0
��
Σoo
39

REGEX
Les REGEX, pour REGular EXpressions, sont un ensemble de commande permettant d’effectuer desrecherches dans les chaines de caractères (notamment pour les formulaires web). Par exemple, nousavons demandé à un utilisateur d’entrer une adresse mail. Nous voulons nous assurer que la chaine decaractères saisi est au bon format (des caractères suivis du arobase suivit d’au moins deux caractèressuivis d’un point suivis de 4 caractères au plus). Pour éviter de faire une recherche "à la main" à l’aidede bouche TANT QUE, on peut utiliser la REGEX suivante :
preg_match("#^[a-zA-Z0-9]+@[a-zA-Z0-9]{2,}\.[a-z]{2,4}#",$chaine_saisi)
La fonction preg_match retourne vrai si la REGEX passé en paramètre apparait dans la chaine dusecond paramètre. Il existe beaucoup d’autre fonction permettant de jouer avec les REGEX que vousdécouvrirez plus tard ; nous ne nous intéresserons qu’à la fonction preg_match et a retourner la valeurvrai. Nous allons faire l’analogie entre les REGEX et les ADEF. Pour commencer fixons une fois pour toutel’alphabet.Nous considérerons l’alphabet Σ de tous les caractères ASCII. Si A désigne un ensemble de lettre
de Σ, on notera A l’ensemble Σ−A.Détaillons la syntaxe de quelques REGEX ainsi que les ADEF associés :
Exemple de base. preg_match("#Euler#",$text) renverra vrai si la chaine Euler apparait dans lavariable $text (attention à la case). L’ADEF qui lui est associé est le suivant :
EE%% u //
{E,u} 00
u
E
xx
{E,l}
��
l // l
E
~~
{E,e}
��
e // e
E
��
{E,r}
��
r // r
Σ
��//
∅
E
gg
{E}
XXoo
Le OU. preg_match("#thé|café#",$text) renverra vrai si la chaine thé ou café apparait dans lavariable $text. L’ADEF qui lui est associé est le suivant :
t
t
�� h //{h,c,t}
zzc
ht
ll
é
**
c
rr
{é,c,t}
��∅
t
44
c
%%
��{t,c} 88 é
��
Σ
��
c
c
YY a//{a,t,c}
YY
t
MM
af
//c
rr
t
\\
{f,t,c}
[[
f
c
ll
t
hh
é
99
{é,t,c}
[[
40
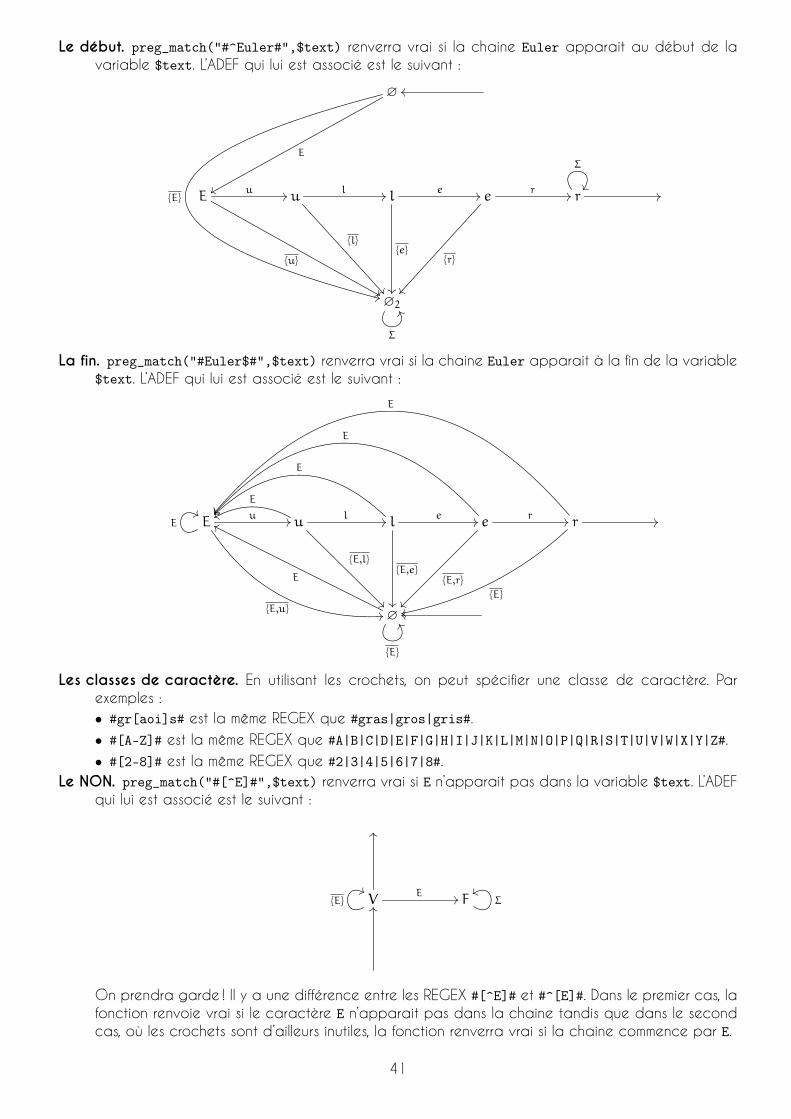
Le début. preg_match("#^Euler#",$text) renverra vrai si la chaine Euler apparait au début de lavariable $text. L’ADEF qui lui est associé est le suivant :
∅
E
xx{E}
++
oo
Eu //
{u}
&&
u
{l}
��
l // l
{e}
��
e // e
{r}
��
r // r
Σ
��//
∅2
Σ
WW
La fin. preg_match("#Euler$#",$text) renverra vrai si la chaine Euler apparait à la fin de la variable$text. L’ADEF qui lui est associé est le suivant :
EE%% u //
{E,u} 00
u
E
xx
{E,l}
��
l // l
E
~~
{E,e}
��
e // e
E
��
{E,r}
��
r // r
{E}
rr
E
��//
∅
E
gg
{E}
XXoo
Les classes de caractère. En utilisant les crochets, on peut spécifier une classe de caractère. Parexemples :• #gr[aoi]s# est la même REGEX que #gras|gros|gris#.• #[A-Z]# est la même REGEX que #A|B|C|D|E|F|G|H|I|J|K|L|M|N|O|P|Q|R|S|T|U|V|W|X|Y|Z#.• #[2-8]# est la même REGEX que #2|3|4|5|6|7|8#.
Le NON. preg_match("#[^E]#",$text) renverra vrai si E n’apparait pas dans la variable $text. L’ADEFqui lui est associé est le suivant :
V
OO
E //{E}&&
F Σzz
OO
On prendra garde ! Il y a une différence entre les REGEX #[^E]# et #^[E]#. Dans le premier cas, lafonction renvoie vrai si le caractère E n’apparait pas dans la chaine tandis que dans le secondcas, où les crochets sont d’ailleurs inutiles, la fonction renverra vrai si la chaine commence par E.
41

Les répétitions.
preg_match("#E{2,4}uler#",$text) renverravrai si la chaine EEuler, EEEuler ou EEEEulerapparait dans la variable $text. De lamême manière #E{2,}uler$# renverra vrai sila chaine contient EEuler, EEEuler,EEEEuler,EEEEEEEEEuler... (entre 2 et une infinité de E).On dispose de commande simplificatrice :
... revient à
? {0,1}
+ {1,}
* {0,}
Pour finir on notera que les REGEX s’utilise pour effectuer des recherches dans les bases de donnéepar l’intermédiaire de la commande REGEXP. Par exemple, si l’on possède une base de donnée avecune table etudiants possédant un champ num_tel de leur numéro de téléphone fixe ou mobile. Onsouhaite extraire de cette table les nom des étudiants dont on dispose de leur numéro de téléphoneportable, commençant par 06 ou 07. La REGEX associé est #^0[67]#. La ligne de commande est alors :
SELECT nom FROM etudiants WHERE num_tel REGEXP ’^0[67]’
Mémento sur les REGEX.
REGEX Renvoie true si la chaine
#Euler# contient le mot Euler
#Euler|euler# contient le mot Euler ou euler
#[Ee]uler# contient le mot Euler ou euler
#^Euler# commence par Euler
#Euler$# finie par Euler
#^Euler$# ne contient que le mot Euler
#[a-z]# contient un lettre minuscule
#[0-9]# contient un chiffre
#[1-3a-gF-H]# contient un 1 ou 2 ou 3 ou une lettre minuscule parmi a, b, c,d, e, f, g ou une lettre majuscule parmi F, G, H
#[^XYZ]# ne contient pas X ou Y ou Z
#[^A-Z]# ne contient pas de lettre majuscule
#^[^a-z]# ne commence pas par une lettre minuscule
#[^Euler]$# ne finie pas E ou u ou l ou e ou r
#Ha{2,4}# contient le mot Haa ou Haa ou Haaa
#(Ha){2,4}# contient le mot HaHa ou HaHaHa ou HaHaHaHa
#Ha+# contient le mot qui commence par H suivit d’au moins un a.Cette REGEX équivaut à #Ha{1,}#
#Ha?# contient le mot H ou le mot Ha. Cette REGEX équivaut à#Ha{0,1}#
#Ha*# contient le mot H ou Ha ou Haa ou... . Cette REGEX équivaut à#Ha{0,}#
#Goo*gle# contient le mot Google ou Gooogle ou Goooogle ...
#ang?e# contient le mot ange ou ane
#Allo\?# contient le mot Allo?
42

4. Annexes
4.1 Algorithmes
§4.1.1 : Algorithme du marquage.1. S = {x}2. Pour une variable entière i allant de 1 à n
On considère Stemp tous les* successeurs (si l’on cherche à déterminer Γ+n(x,G))* prédécesseurs (si l’on cherche à déterminer Γ−n(x,G))
des sommets de S.S = Stemp.
Fin pour3. Γ±n(x,G) =S.
§4.1.2 : Algorithme du marquage +.1. On marque le sommet x2. Tant qu’il existe des sommets marqués mais non sélectionnés
On sélectionne un sommet marqué y et non selectionné.On marque tous les* successeurs (si l’on cherche à déterminer Γ+(x,G))* prédécesseurs (si l’on cherche à déterminer Γ−(x,G))
de y.Fin tant que
3. Γ±(x,G) = les sommets marqués.
§4.1.3 : Algorithme de Brélaz
1. Initialisation
Pour chaque sommet xDSAT[x] = degré de x
Fin pour
2. Itérations
Tant que il existe des sommets non coloriésPour chaque sommet x non colorié
Si aucun voisin de x n’est coloriéDSAT(x) = degré de x = nombre de voisin de x.
sinonDSAT(x) = nombre de sommet adjacent de x qui sont coloriés.
Fin siFin pour
On choisit un sommet x non colorié tel que DSAT(x) soit le plus grand.Si il y a conflit, on choisit le sommet qui a en plus le degré maximal.
On colorie le sommet avec la plus petite couleur possible.
Fin tant que
43

§4.1.4 : Algorithme de planarification.
n = le nombre d’intersection entre les arêtes de G.Tant que n>0
Pour chaque sommet x de Gdi(x) = le nombre d’intersection que compte les arêtes issues de x.
Fin pourx = le sommet tel que di(x) est maximal.x’ = l’isobarycentre des voisins de x.G’ = le graphe G ou l’on a déplacer le sommet x en x’.n’ = le nombre d’intersection entre les arêtes de G’.Si x=x’
Fin de l’algorithmeFin siSi n’<n
Remplacer G par G’ et n par n’Fin si
Fin tant que
§4.1.5 : Solution de Dijkstra (partant d’un sommet x).
1. Initialisationd_min(x)=0;sommet_proche(x)={};Pour tous les sommets y différent de x
d_min(y)=+∞;sommet_proche(y)={};
Fin pour2.
Tant qu’il existe des sommets non marquésOn marque un sommet y non marqué tel que d_min(y)soit le plus petit possible.Pour tout sommet z non marqué et successeur/voisin à y
Si d_min(z) > d_min(y)+λ({y,z})d_min(b) = d_min(y)+λ({y,z});sommet_proche(z) = y;
Fin siFin pour
Fin tant que
§4.1.6 : Algorithme de Kruskal (on ne décrit les graphes que par leur arêtes).A = l’ensemble des arêtes de GF = ∅Tant que A 6= ∅
a = élément de A tel que λ(a) soit minimal.A = A− {a}.Si F ∪ {a} est sans circuitF = F ∪ {a}
Fin siFin tant queSolution = F.
44

§4.1.7 : Algorithme de filtration par les sources.
1. Initialisationn = 1 (l’indice de la numérotation)Pour chaque sommet x du graphe
Pred[x] = les prédécesseurs de x.Fin pourS = les sources = les sommets x tel que Pred[x] soit vide.
2. ItérationsTant que S est non vide
Numéroter les éléments de S en incrémentant n.Supprimer les éléments de S dans le tableau Pred.S = les sommets x non numéroté tel que Pred[x] soit vide.
Fin tant que3. Conclusion
Si Pred est complètement videLe graphe est sans circuit.La numérotation effectuée est une bonne numérotation.
SinonLe graphe possède au moins un circuit.
Fin si
§4.1.8 : Algorithme de dénoyautage.N = ∅Tant que Som(G) 6= ∅
N = N ∪ {Puits de G}Supprimer de G les éléments de N et leur prédécesseurs.
Fin tant que
4.2 Le programmeur modeste
C’est par une série de coïncidences que j’ai embrassé la profession de programmeur, officiellementle premier matin du printemps de 1952, et pour autant que j’aie pu chercher, je fus le premier Hollandaisà le faire dans mon pays. Rétrospectivement, la chose la plus étonnante fut la lenteur avec laquelle laprofession de programmeur émergea, du moins dans ma région du monde, une lenteur qui est maintenantdifficile à croire. Mais j’ai deux souvenirs très nets de cette période qui confirment cette lenteur sansaucun doute.Après avoir programmé pendant trois ans, j’eus une discussion avec A. van Wijngaarden qui était
alors mon patron au Centre de Mathématiques d’Amsterdam, une discussion pour laquelle je lui res-terais à jamais reconnaissant. La question était que, étant simultanément supposé étudier la physiquethéorique à l’université de Leiden, et trouvant les deux activités de plus en plus difficiles à concilier, jedevais me décider soit à arrêter de programmer et à devenir un véritable, un respectable théoriciende la physique, soit à achever mes études de physiques avec le minimum d’effort et à devenir ? ouiquoi ? Un programmeur ? Mais était-ce une profession respectable ? Car après tout, qu’était-ce quela programmation ? Où était le solide champ de connaissances qui pouvait la soutenir comme unediscipline intellectuellement respectable ? Je me rappelle très vivement comme j’enviai mes collèguestravaillant sur le matériel, qui, interrogés sur leurs compétences professionnelles, pouvaient au moinsmettre en avant leur pleine connaissance des tubes à vide, des amplificateurs et tout le reste, alorsque j’avais l’impression que, confronté à cette question, je n’aurais rien eu à répondre. Empli de doutes,je frappais à la porte du bureau de Wijngaarden et lui demandais si je pouvais « lui parler quelquesinstants » ; quand je quittais son bureau plusieurs heures plus tard, j’étais une autre personne. Car,après avoir patiemment écouté mes problèmes et dit, d’accord avec moi, qu’il n’y avait pas vraimentde discipline de la programmation, il se mit à expliquer posément que les ordinateurs automatiquesétaient là pour durer, que nous n’en étions qu’au début et que peut-être je serais une des personnes
45

appelées à faire de la programmation une discipline respectable dans les années à venir. Ce fut untournant de ma vie, et je me débarrassais de mes études de physiques le plus rapidement possible. Unedes morales de cette histoire est, bien sûr, que nous devons faire très attention lorsque nous donnonsdes conseils à nos cadets : parfois ils les suivent !Deux ans plus tard, en 1957, je me mariais et, la cérémonie hollandaise du mariage demandant que
vous déclariez votre profession, je déclarais que j’étais programmeur. Mais les autorités municipales dela ville d’Amsterdam ne l’acceptèrent pas, considérant qu’une telle profession n’existait pas. Et, croyez-leou non, sous le titre « profession », mon acte de mariage porte la mention ridicule de « physicienthéorique » !Voilà pour la lenteur avec laquelle j’ai vu la profession de programmeur émerger dans mon propre
pays. Depuis lors, j’ai vu une plus grande partie du monde et mon impression générale est que dans lesautres pays, avec quelques décalages de dates, le modèle de croissance a été en grande partie lemême.Laissez-moi essayer de décrire la situation dans ces jours anciens avec un peu plus de détail, dans
l’espoir que cela nous donne une meilleure compréhension de la situation aujourd’hui. En poursuivantnotre analyse, nous verrons comme tant de malentendus à propos de la véritable nature de l’activitéde programmation peuvent remonter à ce passé maintenant lointain.Les premiers ordinateurs électroniques automatiques étaient tous des machines uniques, en un seul
exemplaire, et ils étaient tous situés dans un environnement imprégné de l’ambiance enthousiasmanted’un laboratoire expérimental. Quand l’idée de l’ordinateur automatique apparut, sa réalisation fut unformidable défi pour la technologie électronique disponible à l’époque, et une chose est certaine, nousne pouvons pas nier le courage des équipes qui décidèrent de se lancer dans la construction d’unéquipement aussi fantastique. Car c’était des équipements fantastiques ; rétrospectivement, on peutseulement s’émerveiller que ces premières machines aient seulement fonctionné, du moins parfois. Latâche écrasante était de mettre et de conserver ces machines en état de fonctionnement. La préoc-cupation envers les aspects matériels du calcul automatique se reflète toujours dans les noms des plusvieilles sociétés scientifiques du secteur, comme l’Association pour l’Outillage Informatique (Associationfor Computing Machinery - ACM) ou la Société Britannique de l’Ordinateur (British Computer Society),des noms faisant directement référence à l’équipement matériel.Et le pauvre programmeur ? Et bien, à la vérité on le remarquait à peine. D’abord, les premières
machines étaient si massives qu’elles étaient pratiquement impossibles à déplacer, et de plus ellesdemandaient une maintenance si considérable qu’il est naturel que l’endroit où les gens essayaientde les utiliser était le laboratoire même où elles avaient été mises au point. Deuxièmement, son travailà peu près invisible était sans prestige, vous pouviez montrer la machine aux visiteurs et c’était plusspectaculaire, de plusieurs ordres de grandeur, que quelques feuilles de listing. Mais le plus importantde tout était que le programmeur lui-même avait une opinion très modeste de son travail, toute lasignification de son travail venait de l’existence de cette prodigieuse machine. Parce que cette machineétait unique, il ne savait que trop bien que ses programmes n’avaient qu’une portée locale et aussi,puisqu’il était bien évident que cette machine aurait une durée de vie limitée, il savait que très peude son travail aurait une valeur durable. Finalement, il y a un autre aspect des circonstances quiavait une influence profonde sur l’attitude du programmeur envers son travail ; d’un côté, en plus d’êtrepeu fiable, sa machine était habituellement trop lente et sa mémoire trop petite, il était à l’étroit,alors que de l’autre son code d’instruction en général plutôt singulier laissait le champ libre auxconstructions les plus inattendues. Et à cette époque beaucoup de programmeurs astucieux retiraientune immense satisfaction intellectuelle des astuces ingénieuses grâce auxquelles ils parvenaient à fairetenir l’impossible dans le cadre contraignant de leur équipement.Deux opinions concernant la programmation datent de cette époque. Je les mentionne simplement,
j’y reviendrais tout à l’heure. L’une était qu’un programmeur vraiment compétent devait être amateurd’énigmes et d’astuces ; l’autre était que la programmation n’était rien de plus que l’optimisation duprocessus de calcul, dans un sens ou dans l’autre.Cette dernière opinion était le résultat des circonstances fréquentes où l’équipement disponible
était véritablement très contraignant, et l’on rencontrait souvent l’espérance naïve qu’une fois que desmachines plus puissantes seraient disponibles, la programmation ne serait plus un problème, puisqu’àce moment-là l’effort pour pousser la machine à la limite de ses capacités ne serait plus nécessaire,et c’était bien là tout ce en quoi la programmation consistait, non ? Mais au cours des décennies
46

suivantes, quelque chose de complètement différent arriva, des machines plus puissantes apparurent,pas seulement plus puissantes d’un ordre de magnitude, mais plus puissantes de plusieurs ordres demagnitude. Mais au lieu de nous retrouver dans un état de félicité éternelle où tous les problèmes deprogrammation seraient résolus, nous nous sommes retrouvés dans la crise du logiciel jusqu’au cou !Pourquoi ?Il y a une raison mineure : par certains aspects, les appareils modernes sont tout simplement plus
difficiles à maîtriser que les anciens. Premièrement, nous avons les interruptions d’entrée/sortie qui se pro-duisent à des moments imprévisibles et non reproductibles, à comparer avec les anciennes machinesséquentielles qui prétendaient être des automates entièrement déterministes, cela a été un change-ment très important et les cheveux gris de nombreux programmeurs système sont là pour témoignerque nous ne devons pas prendre à la légère les problèmes logiques créés par cette caractéristique.Deuxièmement, nous avons des machines équipées de plusieurs niveaux de stockage, ce qui nous posedes problèmes de stratégie de gestion qui restent encore insaisissables, malgré une vaste documen-tation sur le sujet. Voilà pour les complications supplémentaires dues aux changements structurels desmachines mêmes.Mais j’ai appelé cela une raison mineure, la raison majeure est ? que les machines sont devenues
plus puissantes de plusieurs ordres de magnitude ! Pour le dire de manière abrupte : tant qu’il n’y avaitpas de machines, la programmation n’était pas du tout un problème, quand nous avions quelquesordinateurs de faible puissance, la programmation devint un léger problème, et maintenant que nousavons des ordinateurs colossaux, la programmation est devenue un problème tout aussi colossal. En cesens, l’industrie de l’électronique n’a pas résolu un seul problème, elle en a seulement créé, elle a créé leproblème consistant à utiliser ses produits. Dit d’une autre manière, alors que la puissance des machinesdisponibles croissait d’un facteur de plus de mille, les usages que voulait en faire la société croissaienten proportion, et ce fut le pauvre programmeur qui trouva son travail pris dans cette tension entreles moyens et les fins. La puissance accrue du matériel, combinée à l’augmentation peut-être encoreplus importante de sa fiabilité, rendait réalisables des solutions que le programmeur n’aurait même pasosé rêver quelques années auparavant. Et maintenant, quelques années plus tard, il devait les rêver et,bien pire, il devait transformer ces rêves en réalité ! Est-ce si étonnant que nous nous soyons retrouvésdans une crise du logiciel ? Non, certainement pas, et comme vous pouvez le deviner, cela avait mêmeété prédit bien à l’avance, mais le problème avec les prophètes mineurs, bien sûr, c’est qu’on ne saitvraiment qu’ils avaient raison que cinq ans après.Puis, au milieu des années soixante, quelque chose de terrible arriva : les ordinateurs de la prétendue
troisième génération firent leur apparition. La littérature officielle nous dit qu’un des objectifs majeurs deleur conception était leur ratio prix/performance. Mais si vous prenez comme critère de « performance» le cycle d’activité des divers composants de la machine, vous pouvez très bien vous retrouver avecun modèle de conception dans lequel la part la plus grande de votre objectif de performance estatteinte par des activités de nettoyage interne d’une nécessité douteuse. Et si votre définition du prixest le prix à payer pour le matériel, vous pouvez très bien vous retrouver avec un modèle terriblementdifficile à programmer : par exemple, le code d’instruction peut être tel qu’il force le programmeur ou lesystème à prendre des décisions de lien anticipé présentant des conflits qui ne peuvent réellement pasêtre résolus. Et dans une large mesure, ces possibilités déplaisantes semblent s’être réalisées.Quand ces machines furent annoncées et que leurs caractéristiques fonctionnelles furent connues,
cela chagrina un certain nombre d’entre nous, en tout cas moi. On pouvait raisonnablement s’attendreà ce que des machines de ce type inondent la communauté informatique, il était donc d’autantplus important que leur conception soit aussi correcte que possible. Mais le modèle de conceptionrenfermait des défauts si importants que j’eus l’impression que le progrès de l’informatique avait étéretardé d’un seul coup d’au moins dix ans : ce fut à ce moment que je connus la semaine la plussombre de toute ma vie professionnelle. Le plus affligeant peut-être est que, même après toutes cesannées d’expérience frustrantes, il y a toujours tant de gens qui croient honnêtement que quelque loide la nature nous dit que les machines doivent être ainsi. Ils font taire leurs doutes en considérant laquantité de ces machines qui s’est vendue, et en retirent la fausse impression de sécurité qu’après tout,la conception n’a pu en être si mauvaise. Mais en y regardant de plus près, cette ligne de défense àla même force de conviction que l’argument selon lequel fumer des cigarettes serait bon pour la santépuisque tant de gens le font.C’est à cet égard que je regrette qu’il ne soit pas dans l’habitude des journaux scientifiques dans
47

le domaine de l’informatique de publier des tests des ordinateurs nouvellement annoncés de la mêmemanière que nous examinons les publications scientifiques, un examen des machines serait au moinsaussi important. Je dois d’ailleurs faire un aveu : au début des années soixante, j’écrivis un tel examendans l’intention de le soumettre aux CACM, mais malgré le fait que les rares collègues à qui le texte futenvoyé pour avis me poussaient tous à le faire, je ne l’osais pas, craignant que les difficultés auxquellesj’aurais, ou auxquelles la commission éditoriale aurait, à faire face ne s’avèrent trop grandes. Cettemise à la trappe fut de ma part un acte de lâcheté que je me reproche de plus en plus. Les difficultésque j’anticipais découlaient de l’absence de critères généralement acceptés et, bien que je fusseconvaincu de la validité des critères que j’avais choisi d’appliquer, je craignais que mon article nesoit refusé ou écarté comme « une question de goût personnel ». Je crois toujours que de tels articlesseraient extrêmement utiles et j’espère les voir apparaître, car leur acceptation serait un signe sûr dematurité de la communauté informatique.La raison pour laquelle je me suis attardé sur le domaine du matériel est que j’ai le sentiment
qu’un des aspects les plus importants de tout outil informatique est son influence sur les habitudes depensée de ceux qui essaient de l’utiliser, et que j’ai des raisons de croire que cette influence est bienplus importante qu’on ne le pense généralement. Portons maintenant notre attention sur le domaine dulogiciel.Ici, la diversité est si grande que je dois m’en tenir à quelques grandes avancées. Je suis tout à fait
conscient du caractère arbitraire de mon choix et je vous prie de ne pas en tirer de conclusion en cequi concerne l’appréciation que je fais des nombreux travaux qui ne seront pas mentionnés.À l’origine, il y eut l’EDSAC à Cambridge, en Angleterre, et je pense qu’il est assez impressionnant que
dès le début la notion de bibliothèque de sous-programmes jouât un rôle central dans la concep-tion de cette machine et de la manière dont elle devait être utilisée. Près de 25 ans ont passé etl’informatique a énormément changé, mais la notion de logiciel de base est toujours là, et la notion desous-programme fermé est toujours un des concepts clés de la programmation. Nous devrions recon-naître le sous-programme fermé comme une des plus grandes inventions du logiciel ; il a survécu à troisgénérations d’ordinateurs et il survivra à quelques autres, car il permet l’implémentation d’un de nos mo-tifs d’abstraction de base, malheureusement, son importance a été sous-estimée dans la conception desordinateurs de troisième génération, dans lesquels le grand nombre de registres explicitement nommésde l’unité arithmétique entraîne un coût important d’utilisation du mécanisme de sous-programme. Maismême cela n’a pas tué le concept de sous-programme, nous ne pouvons qu’espérer que la mutationne s’avérera pas héréditaire.La deuxième grande étape dans le domaine du logiciel que j’aimerais mentionner est la naissance
du FORTRAN. À ce moment, c’était un projet d’une grande témérité et les personnes qui en sont respon-sables méritent la plus grande admiration de notre part. Il serait tout à fait injuste de leur en reprocherdes limites qui n’apparurent qu’après une décennie d’usage intensif : les équipes faisant avec succèsdes prévisions pour dix ans sont plutôt rares ! Rétrospectivement, nous devons juger le FORTRAN commeune technique de programmation réussie, mais avec très peu d’aide efficace à la conception, desaides pour lesquelles il y a maintenant un besoin si urgent qu’il est temps de le considérer commeobsolète. Plus vite nous pourrons oublier que le FORTRAN a jamais existé, mieux ce sera, car il n’est plusadapté comme véhicule pour la pensée : il gâche notre intelligence, il est trop risqué et donc trop cherà utiliser. Le destin tragique du FORTRAN a été sa large diffusion, enchaînant mentalement des millierset des milliers de programmeurs à nos erreurs passées. Je prie tous les jours qu’un plus grand nombrede mes collègues programmeurs trouve des moyens de se libérer de la malédiction de la compatibilité.Le troisième projet que je ne voudrais pas oublier est LISP, une entreprise fascinante d’une nature
complètement différente. Avec quelques principes de bases simples comme fondations, il a montré unestabilité remarquable. De plus, LISP a été le support de nombre considérable de certaines de nosapplications en un sens les plus sophistiquées. LISP a été décrit en plaisantant comme « la manièrela plus intelligente de mal employer un ordinateur ». Je considère cette description comme un grandcompliment, car elle exprime tout un parfum de libération, il a permis à un grand nombre des humainsles plus doués de concevoir des pensées auparavant impossibles.Le quatrième projet à mentionner est ALGOL 60. Alors que jusqu’à aujourd’hui les programmeurs
en FORTRAN ont encore tendance à concevoir leur langage de programmation en fonction de l’im-plémentation spécifique qu’ils utilisent ? d’où la prévalence des dumps en octal ou en hexadécimal ?alors que la définition de LISP est toujours un mélange étrange de ce que signifie le langage et de la
48

manière dont le mécanisme fonctionne, le fameux Rapport sur le Langage Algorithmique ALGOL 60 estle fruit d’un authentique effort pour amener l’abstraction un pas vital plus loin et de définir un langagede programmation d’une manière indépendante de l’implémentation. On pourrait d’ailleurs penser queses auteurs ont si bien réussi leur tâche qu’ils ont fait naître de sérieux doutes quant à la possibilitéde simplement l’implémenter ! Le rapport démontrait magistralement la puissance de la méthode formelleBNF, maintenant bien connue sous le nom de Backus-Naur-Form, et le pouvoir de l’Anglais attentivementexprimé, du moins entre les mains de quelqu’un d’aussi brillant que Peter Naur. Je crois qu’il est juste dedire que seuls quelques rares documents aussi courts que celui-ci ont eu une influence aussi profondesur la communauté informatique. La facilité avec laquelle les termes d’ALGOL et ALGOL-like, la marquen’étant pas déposée, ont été utilisés dans les années qui suivirent pour donner un peu de son prestigeà des projets plus jeunes qui n’avaient parfois pas grand-chose à voir, est un hommage quelque peudéplacé à sa grandeur. La force de la notation BNF comme outil de définition est la raison de ce queconsidère comme une des faiblesses du langage : une syntaxe trop élaborée et pas très systématiquepouvait désormais être concentrée dans les limites de quelques pages à peine. Avec un outil aussipuissant que la notation BNF, le Rapport sur le Langage Algorithmique ALGOL 60 aurait dû être bienplus court. De plus, je suis de plus en plus sceptique quant au mécanisme de paramètres d’ALGOL 60,il permet au programmeur une telle liberté combinatoire que son usage requiert une grande disciplinede la part du programmeur. Coûteux à implémenter, il semble également dangereux à utiliser.Finalement, bien que le sujet ne soit pas agréable, je dois mentionner PL/1, un langage de pro-
grammation pour lequel la documentation de définition est d’une taille et d’une complexité effrayantes.Utiliser PL/1 doit être comme piloter un avion avec 7000 boutons, interrupteurs et manettes à manipulerdans le cockpit. Je ne vois absolument pas comment nous pourrions garder la maîtrise intellectuelle denos programmes en construction quand, par son seul caractère baroque, le langage de programma-tion ? notre outil de base ! ? échappe déjà à notre intellect. Et si je dois décrire l’influence de PL/1sur ses utilisateurs, la métaphore la plus proche qui me vient à l’esprit est celle d’une drogue. Je mesouviens d’une allocution en défense de PL/1, prononcée par un homme se présentant comme un deses utilisateurs assidus lors d’une conférence sur les langages de programmation de haut niveau. Lorsde son allocution d’une heure en célébration de PL/1, il trouva le moyen de réclamer l’ajout d’environcinquante nouvelles fonctionnalités, ignorant le fait que la source principale de ses problèmes pouvaitbien être que le langage contenait déjà bien trop de « fonctionnalités ». L’orateur présentait tous lessignes affligeants de l’accoutumance, réduit à un état de stagnation mentale dans lequel il ne pouvaitque demander plus, plus, plus ? Alors que le FORTRAN a été appelé une maladie infantile, PL/1 aucomplet, avec les caractéristiques de croissance d’une dangereuse tumeur, pourrait bien s’avérer unemaladie fatale.Voilà pour le passé. Mais il ne sert à rien de faire des erreurs, à moins que nous soyons capables
d’en tirer des enseignements. En fait, je crois que nous avons appris tellement qu’en quelques années, laprogrammation peut devenir une activité largement différente de ce qu’elle a été jusqu’à maintenant,si différente que nous ferions mieux de nous préparer au choc. Laissez-moi vous présenter une esquissed’un des futurs possibles. Au premier abord, cette vision de la programmation dans ce qui est peut-être déjà le futur proche vous semblera peut-être complètement fantaisiste. J’y ajouterais donc lesconsidérations pouvant laisser croire que cette vision pourrait être une possibilité bien réelle.Cette vision est que, bien avant la fin des années soixante-dix, nous serons capables de concevoir
et d’implémenter le type de systèmes qui est maintenant à la limite de nos capacités de programmationpour un faible pourcentage en années-hommes de ce qu’ils nous coûtent actuellement, et que deplus, ces systèmes n’auront virtuellement aucun bogue. Ces deux améliorations sont liées. Dans cetaspect, le logiciel semble être différent de bien d’autres produits pour lesquels la règle est qu’une plusgrande qualité entraîne un plus haut coût. Ceux qui veulent vraiment des logiciels fiables découvrirontqu’ils doivent trouver des moyens d’éviter la majorité des bogues d’abord, et qu’en conséquence leprocessus de développement sera moins coûteux. Si vous voulez des programmeurs plus efficaces, vousdécouvrirez qu’ils ne doivent pas perdre leur temps à déboguer, ils doivent commencer par éviterd’introduire des bogues. En d’autres termes, les deux objectifs mènent au même changement.Un changement aussi radical sur une si courte période serait une révolution, et les chances qu’il se
produise doivent sembler négligeables à tous ceux qui fondent leurs attentes du futur sur une légèreapproximation du passé récent ? faisant appel à quelque loi non écrite de l’inertie culturelle et sociale.Mais nous savons tous que parfois, des révolutions se produisent bel et bien ! Quelles sont les chances
49

que celle-ci se produise ?Il semble qu’il y ait trois conditions principales devant être satisfaites. Le besoin de changement doit
être reconnu largement dans le monde ; deuxièmement, le besoin économique de changement doit êtresuffisamment fort ; troisièmement, le changement doit être réalisable techniquement. Laissez-moi discuterde ces trois conditions dans cet ordre.En ce qui concerne la reconnaissance du besoin d’une plus grande fiabilité du logiciel, je n’es-
compte désormais plus de désaccord. C’était différent il y a seulement quelques années, parler decrise du logiciel était un blasphème. Le tournant fut la Conférence sur le Génie Logiciel à Garmisch, enoctobre 1968, une conférence qui fit sensation, car elle vit la première reconnaissance de la crise dulogiciel. Il est généralement reconnu aujourd’hui que la conception d’un système sophistiqué de grandetaille est une tâche très difficile et, lorsqu’on rencontre des personnes responsables de tels projets, on lesvoit très préoccupées, et avec raison, de la question de la fiabilité. En résumé, notre première conditionsemble satisfaite.Maintenant, voyons le besoin économique. De nos jours, on entend souvent l’opinion selon laquelle
la profession de programmeur avait été surpayée dans les années soixante, et que dans les années àvenir, on devait s’attendre à ce que les salaires des programmeurs baissent. En général, cette opinionest exprimée en parlant de la récession, mais elle pourrait être le symptôme d’une prise de consciencedifférente et plutôt saine, celle que les programmeurs de la décennie précédente n’ont pas fait un aussibon travail qu’ils auraient du faire. La société devient insatisfaite des performances des programmeurset de leurs produits. Mais il y a un autre facteur, d’un poids bien plus important. Dans la situation actuelle,il est plutôt fréquent que pour un système particulier, le prix du développement du logiciel soit du mêmeordre que le prix du matériel nécessaire, et la société accepte plus ou moins cela. Mais les fabricantsde matériel nous disent que dans la décennie à venir, les prix du matériel devraient être divisés pardix. Si le développement logiciel devait continuer d’être le même processus lourd et coûteux qu’il estaujourd’hui, cela entraînerait un déséquilibre total. On ne peut pas attendre de la société qu’elleaccepte cela, et en conséquence nous devons apprendre à programmer d’une manière d’un ordre demagnitude plus efficace. Dit d’une autre manière, aussi longtemps que les machines constituaient le plusgros poste du budget, la profession de programmeur pouvait s’en tirer avec ses techniques grossières,mais ce parapluie va se replier très rapidement. En résumé, notre seconde condition semble égalementsatisfaite.Et maintenant, la troisième condition : est-ce techniquement réalisable ? Je crois que cela pourrait
l’être et je vais vous donner six arguments en soutien de cette opinion.Une étude des structures de programmes a révélé que les programmes ? y compris des programmes
différents remplissant une tâche semblable et ayant le même contenu mathématique ? varient énormé-ment dans leur maniabilité intellectuelle. Un certain nombre de règles ont été découvertes, dont laviolation handicape sérieusement ou détruit complètement la maniabilité intellectuelle d’un programme.Ces règles sont de deux sortes. Celles de la première sorte sont faciles à imposer mécaniquement,c’est-à-dire par le choix d’un langage de programmation approprié. Citons comme exemple l’exclusionde l’instruction goto et des procédures renvoyant plus d’une valeur. En ce qui concerne celles dela deuxième sorte, je ne vois quant à moi ? mais ce pourrait être dû à un manque de compétencede ma part ? aucun moyen de les imposer mécaniquement, car cela semblerait nécessiter une sortede mécanisme automatique pouvant prouver des théorèmes, mécanisme dont je n’ai pas la preuvede l’existence. En conséquence, pour la période actuelle et peut-être pour toujours, les règles de laseconde sorte se présentent comme des éléments d’une discipline requise de la part du programmeur.Certaines des règles que j’ai en tête sont si claires qu’elles peuvent être enseignées et qu’il n’y a pasde discussion nécessaire pour savoir si un programme donné les respecte ou non. Un exemple est laprescription qu’aucune boucle soit écrite sans fournir de preuve de sa terminaison ni sans préciser larelation dont l’invariance ne sera pas détruite par l’exécution de l’instruction à répéter.Je suggère maintenant que nous nous restreignions à la conception et à l’implémentation de pro-
grammes intellectuellement maîtrisables. Si quelqu’un craint que cette restriction soit si sévère que nousne puissions la supporter, je tiens à le rassurer : la catégorie de programmes maîtrisables intellec-tuellement est suffisamment riche pour contenir un grand nombre de programmes tout à fait réalistespour n’importe quel problème ayant une solution algorithmique. Nous ne devons pas oublier que notremétier n’est pas de réaliser des programmes, notre métier est de concevoir des classes de calculs quiprésentent un comportement désiré.
50

La suggestion de nous restreindre à des programmes maîtrisables intellectuellement est la base desdeux premiers de mes six arguments annoncés.Le premier argument est que, le programmeur n’ayant à considérer que les programmes maîtrisables
intellectuellement, il est plus facile de faire face aux alternatives entre lesquelles il doit choisir.Le deuxième argument est que, aussitôt que nous avons décidé de nous restreindre au sous-
ensemble des programmes maîtrisables intellectuellement, nous avons accompli, une fois pour toutes,une réduction radicale du domaine des solutions à prendre en considération. Et cet argument estdistinct du premier argument.Le troisième argument est basé sur l’approche constructive du problème de la justesse d’un pro-
gramme. Aujourd’hui, la technique habituelle est de réaliser un programme puis de le tester. Mais sitester un programme peut être une technique très efficace pour montrer la présence de bogues, elleest désespérément incapable d’en montrer l’absence. La seule manière efficace de relever significa-tivement le niveau de confiance en un programme est de produire une preuve convaincante de sajustesse. Mais on ne doit pas d’abord réaliser le programme et ensuite prouver sa justesse, car l’exi-gence de fourniture de preuve ne ferait qu’alourdir le fardeau du pauvre programmeur. Au contraire,le programmeur doit faire croître la preuve de justesse et le programme de concert. Le troisième ar-gument est essentiellement fondé sur l’observation suivante. Si l’on se demande d’abord quelle seraitla structure d’une preuve convaincante et que, l’ayant trouvé, l’on construit un programme satisfaisantles exigences de cette preuve, alors ces préoccupations de justesse s’avèrent constituer une gouverneheuristique très efficace. Par définition, cette approche n’est applicable que si nous nous restreignonsaux programmes maîtrisables intellectuellement, mais elle nous fournit un moyen très efficace d’en trouverun satisfaisant parmi ceux-ci.Le quatrième argument est lié au rapport entre l’ampleur de l’effort intellectuel nécessaire à la
conception d’un programme et la taille du programme. Il a été suggéré qu’il y a quelque loi de lanature selon laquelle l’ampleur de l’effort intellectuel nécessaire croît selon le carré de la taille duprogramme. Mais, Dieu merci, personne n’a été capable de prouver cette loi, et cela parce qu’elle n’estpas nécessairement vraie. Nous savons tous que le seul outil mental par l’usage duquel une capacité deraisonnement finie est capable d’aborder une myriade de cas est appelé « abstraction » ; il en découleque l’exploitation efficace de ses capacités d’abstraction doit être considéré comme une des activitésles plus vitales d’un programmeur compétent. À ce propos il est peut-être bon de préciser que l’objetde l’abstraction n’est pas d’être flou, mais de créer un nouveau niveau sémantique auquel on peutêtre absolument précis. Bien sûr, j’ai tenté de découvrir une cause fondamentale qui empêcherait nosmécanismes d’abstraction d’être suffisamment efficaces. Mais malgré tous mes efforts, je n’ai pas trouvéune telle cause. En conséquence, je m’en tiens au postulat ? jusqu’à maintenant non contredit parl’expérience ? que par une application appropriée de nos capacités d’abstraction, l’effort intellectuelnécessaire à la conception ou à la compréhension de programmes n’a pas besoin de croître plusque proportionnellement à la taille du programme. Mais un sous-produit de ces recherches pourraitêtre d’une bien plus grande importance pratique, il est en fait à la base de mon quatrième argument.Ce sous-produit consistait en l’identification d’un certain nombre de modèles d’abstraction qui jouentun rôle vital dans le processus d’ensemble de la composition de programmes. On en sait maintenantassez sur ces modèles d’abstraction pour consacrer une conférence à pratiquement chacun d’entreeux. Ce qui découle de la familiarité et la connaissance consciente de ces modèles d’abstraction, jel’ai compris lorsque j’ai réalisé que, s’ils avaient été largement connus il y a quinze ans, l’étape de lanotation BNF aux compilateurs dirigés par la syntaxe, par exemple, aurait pu ne prendre que quelquesminutes au lieu de plusieurs années. C’est pourquoi je présente notre connaissance récente des modèlesd’abstraction essentiels comme le quatrième argument.Maintenant, le cinquième argument. Il a à voir avec l’influence des outils que nous essayons d’utiliser
sur nos habitudes de penser. Je constate l’existence d’une tradition culturelle, dont les racines remontentsans doute à la Renaissance, d’ignorer cette influence, de considérer l’esprit humain comme le maîtresuprême et autonome de ses artefacts. Mais si je commence à analyser mon mode de penser et celuide compagnons humains, j’arrive, que cela me plaise ou non, à une conclusion totalement différente,à savoir que les outils que nous tentons d’utiliser et le langage ou la notation que nous utilisons pourexprimer ou enregistrer nos pensées sont les facteurs majeurs déterminant tout simplement ce que nouspouvons penser ou exprimer ! L’analyse de l’influence qu’ont les langages de programmation sur lesmodes de penser de leurs utilisateurs et la reconnaissance qu’aujourd’hui, la matière grise est de loin
51

notre ressource la plus rare, ensemble, nous donne une nouvelle série de repères pour comparer lesmérites relatifs de différents langages de programmation. Le programmeur compétent est pleinementconscient de la taille strictement limitée de son crâne ; il approche donc la tâche de la programmationen toute modestie, et, entre autres choses, il évite les astuces ingénieuses comme la peste. Dans lecas d’un langage de programmation interactif bien connu, j’ai appris de plusieurs sources qu’aussitôtqu’une équipe de programmeurs est équipée d’un terminal y donnant accès, un phénomène spécifiqueapparaît qui a même un nom bien établi : on l’appelle « les one-liners ». Il prend l’une des formessuivantes : un programmeur pose un programme d’une ligne sur le bureau d’un autre et soit lui expliquefièrement ce qu’il fait et ajoute la question « Peux-tu faire plus court ? » ? comme si cela avait la moindrevaleur conceptuelle ! ? soit il demande simplement : « devine ce que ça fait ». De cette observation, nousdevons conclure que ce langage en tant qu’outil est une invitation ouverte aux astuces ingénieuses ; etbien que cet aspect précisément puisse être l’explication d’une partie de son attrait, c’est-à-dire enversceux qui aiment montrer à quel point ils sont malins, j’en suis désolé, mais je suis forcé de considérer celacomme une des pires choses que l’on peut dire d’un langage de programmation. Une autre leçon quenous aurions du apprendre du passé récent est que le développement de langages de programmation« plus riches » ou « plus puissants » fut une erreur dans le sens que ces monstruosités baroques, cesconglomérats d’idiosyncrasies, sont véritablement impossible à gérer aussi bien mécaniquement quementalement. Je prédis un grand avenir aux langages de programmation très systématiques et trèsmodestes. Quand je dis « modeste », je veux dire que, par exemple, non seulement l’instruction « for »d’ALGOL 60, mais aussi la boucle « DO » de FORTRAN pourrait être rejetées comme trop baroques.J’ai conduit une petite expérience de programmation avec des volontaires très expérimentés, et ellea montré quelque chose de vraiment imprévu et de plutôt surprenant. Aucun de mes volontaires n’atrouvé la solution évidente et la plus élégante. Après analyse approfondie cela s’avéra avoir uneorigine commune : leur notion de la répétition était si étroitement liée à l’idée d’une variable associée àincrémenter qu’ils étaient mentalement bloqués de la vision de la solution. Leurs solutions étaient moinsefficaces, inutilement difficile à comprendre et leurs avaient pris très longtemps à trouver. Ce fut pourmoi une expérience révélatrice, mais aussi choquante. En somme, il y a un aspect pour lequel on peutespérer que les langages de programmation de demain différeront de ce à quoi nous sommes habituésaujourd’hui : ils devraient nous inviter à refléter dans la structure de ce que nous écrivons toutes lesabstractions nécessaires pour affronter conceptuellement la complexité de ce que nous concevons demanière bien plus étendue que jusqu’à maintenant. Voilà pour la meilleure adéquation de nos futursoutils, base de notre cinquième argument.Je voudrais en passant faire une mise en garde à ceux qui identifient les difficultés de la program-
mation avec la lutte contre les insuffisances de nos outils actuels, parce qu’ils pourraient en conclurequ’une fois que nos outils seront adéquats, la programmation ne sera plus un problème. La program-mation restera très difficile, car une fois libérés de ces contraintes circonstancielles, nous serons prêts ànous attaquer à des problèmes qui sont aujourd’hui bien au-delà de nos capacités de programmation.Vous pouvez contester mon sixième argument parce qu’il n’est pas si facile de recueillir des preuves
expérimentales en sa faveur, ce qui ne m’empêche pas de croire en sa validité. Jusqu’à présent, je n’aipas mentionné le mot « hiérarchie », mais je crois juste de dire que c’est un concept clé pour toutsystème concrétisant une solution correctement décomposée. Je pourrais même aller plus loin et en faireun article de foi, à savoir que les seuls problèmes que nous pouvons résoudre de manière satisfaisantesont ceux qui admettent une solution correctement décomposée. Au premier abord, cette opinion deslimites humaines peut vous sembler être une vue plutôt décourageante du sort qui serait le nôtre, mais jene le vois pas ainsi, bien au contraire ! La meilleure façon d’apprendre à vivre avec nos limites est de lesconnaître. D’ici à ce que nous soyons devenus suffisamment modestes pour n’essayer que des solutionsdécomposées, parce que tous les autres efforts échappent à notre maîtrise intellectuelle, nous devonsfaire de notre mieux pour éviter toutes les interfaces qui limitent notre capacité à décomposer le systèmede manière utile. Et je ne peux que m’attendre à ce que cela mène régulièrement à la découverte qu’unproblème au départ irréductible peut en fait être décomposé. Quiconque a constaté que l’origine dela majorité des problèmes de la phase de compilation appelée « génération de code » peut êtretrouvée dans des bizarreries du code source sera capable de penser à un exemple simple de ce quej’ai à l’esprit. L’application plus large de solutions correctement décomposées est mon sixième et dernierargument en faveur de la possibilité de la révolution qui pourrait se produire dans la décennie encours.
52

Je vous laisse le choix de décider quelle importance vous allez donner à mes réflexions, je ne saisque trop bien que je ne peux forcer personne à partager mes convictions. Comme chaque révolution,celle-ci provoquera une opposition violente, et l’on peut se demander où sont les forces conservatricesqui essaieront de contrer de tels développements. Je ne m’attends pas à les trouver principalementdans les grandes entreprises, ni même dans l’industrie informatique ; je m’attends plutôt à les trouver dansles institutions d’éducation qui fournissent les formations actuelles et dans ces groupes conservateursd’utilisateurs d’ordinateurs qui pensent que leurs anciens programmes sont si importants qu’il n’est pasutile de les récrire et de les améliorer. À cet égard, il est triste de constater que dans de nombreusesuniversités, le choix du centre informatique est trop souvent déterminé par les exigences de quelquesapplications bien établies mais coûteuses sans considération des difficultés que cela engendre pourdes milliers de « petits utilisateurs » voulant créer leurs propres programmes. Trop souvent, par exemple, laphysique des hautes énergies semble extorquer à la communauté scientifique le prix de ses équipementsexpérimentaux restants. La réponse la plus simple, bien sur, est la dénégation pure et simple de lafaisabilité technique, mais je crains qu’il ne faille des arguments plutôt solides pour ça. La remarqueselon laquelle le plafond intellectuel du programmeur moyen d’aujourd’hui empêchera la révolutiond’arriver n’apporte aucun réconfort : les autres programmant de manière bien plus efficace, il estexposé à être écarté de toute manière.Il pourrait aussi y avoir des entraves d’ordre politique. Même si nous savons comment former les
programmeurs professionnels de demain, il n’est pas certain que la société dans laquelle nous vivonsnous laissera le faire. Le premier effet de l’enseignement d’une méthodologie ? plutôt que la propagationde la connaissance ? est d’améliorer les capacités des plus capables, accentuant les différencesd’intelligence. Pour une société dans laquelle le système éducatif est utilisé comme un instrument visantà établir une culture homogène, dans laquelle la crème est empêchée d’atteindre le sommet, l’éducationde programmeurs compétents pourrait être politiquement désagréable.Laissez-moi conclure. Les ordinateurs automatiques sont avec nous depuis un quart de siècle. Ils
ont eu un grand impact sur notre société en qualité d’outils, mais dans ce rôle, leur influence ne seraqu’une ride à la surface de notre culture en comparaison de l’influence bien plus profonde qu’ilsauront en qualité de défi intellectuel sans précédent dans l’histoire culturelle de l’humanité. Les systèmeshiérarchiques semblent avoir cette propriété, qu’une chose considérée comme entité indivisible à unniveau est considérée comme un objet composite au niveau inférieur, plus détaillé ; en conséquence, lagranularité spatiale et temporelle décroît d’un ordre de magnitude lorsque nous portons notre attentiond’un niveau à celui immédiatement inférieur. Nous pensons les murs en terme de briques, les briques enterme de cristaux, les cristaux en terme de molécules, etc. Il en résulte que le nombre de niveaux pouvantêtre distingués pertinemment dans un système hiérarchique est à peu près proportionnel au logarithmedu ratio entre le plus gros et le plus fin niveau de granularité, et donc, à moins que le ratio ne soit trèsgrand, nous ne pouvons pas prévoir de nombreux niveaux. Dans la programmation informatique, notreélément de construction de base à une granularité temporelle de moins d’une microseconde, mais nosprogrammes peuvent prendre des heures de temps de calcul. Je n’ai pas connaissance d’une autretechnologie couvrant un ratio de 1010 ou plus : l’ordinateur, en raison de son extraordinaire rapidité,semble pour la première fois nous fournir un environnement où des artefacts hautement hiérarchisés sontà la fois possibles et nécessaires. Ce défi, à savoir la confrontation avec le travail de la programmation,est si unique que cette nouvelle expérience peut nous apprendre beaucoup sur nous-mêmes. Elledevrait approfondir notre compréhension du processus de conception et de création, elle devrait nousdonner un meilleur contrôle sur l’organisation de nos pensées. Si ça n’est pas le cas, à mon avis nousne méritons absolument pas l’ordinateur !Elle nous a déjà enseigné quelques leçons, et celle que j’ai choisi de souligner dans cette allocution
est la suivante. Nous pouvons faire un bien meilleur travail de programmation, à condition que nousapprochions cette tâche en toute appréciation de sa formidable difficulté, à condition que nous nousen tenions à des langages de programmation modestes et élégants, à condition que nous respectionsles limitations intrinsèques de l’esprit humain et approchions cette tâche comme de très modestesprogrammeurs.
Edsger W. Dijkstra
53


















