
Fondamentaux de la modélisation des données · Symbole de relation Un symbole de relation est un...
103
Fondamentaux de la modélisation des données 3IF – INSA Lyon Jean-Marc (Calixte) Petit 2016-2017 Sur ce cours Volume horaire : 9 cours 8 cours, 5 TD, 6 TD 1 examen final Commentaires/suggestions : Courriel : [email protected] Twitter : @calixtePetit Personnes ayant contribué à ce support (ordre alphabétique): Marie Agier, Fabien De Marchi, Frédéric Flouvat, Hélène Jaudoin, Farouk Toumani Enfin et surtout : participez ! 2/196
Transcript of Fondamentaux de la modélisation des données · Symbole de relation Un symbole de relation est un...

Fondamentaux de la modélisation des données3IF – INSA Lyon
Jean-Marc (Calixte) Petit
2016-2017
Sur ce cours
Volume horaire :9 cours 8 cours,5 TD, 6 TD1 examen final
Commentaires/suggestions :Courriel : [email protected] : @calixtePetit
Personnes ayant contribué à ce support (ordrealphabétique):Marie Agier, Fabien De Marchi, Frédéric Flouvat,Hélène Jaudoin, Farouk Toumani
Enfin et surtout : participez !
2/196

Objectifs du cours
I Donner des bases solides pour comprendre la gestion desdonnées
I Focus sur les bases de données relationnelles : structure,interrogation, conception
I Et surtout, un bel exemple de voir l’informatique comme unediscipline scientifique et technique
Deux "gros pavés" autour des1. Langages2. Contraintes
3/196
Ce que ce cours fait peu, voire pas du tout
1. Les Systèmes de Gestion de Bases de Données (SGBD) et leurmise en œuvre (SQL en pratique)⇒ Voir le cours de Philippe Lamarre sur SQL, trèscomplémentaire de ce cours
2. Présenter une méthode de conception de systèmed’information (SI) type MERISE, RUP ...
3. Les aspects fonctionnels, dynamiques et organisationnels desSI,
4/196

Références bibliographiques
I Mark Levene, Georges Loizou, “Guided tour of relationaldatabases and beyond", 625 pages, 1999, Springer
I Serge Abiteboul, Rick Hull, Victor Vianu, “Foundations ofdatabases”, 685 pages, 1995 (existe aussi en Français),Addison-Wesley
I Heikki Mannila, Kari-Jouko Räihä, “The Design of RelationalDatabases”, Second edition, 1994, Addison-Wesley
5/196
SommaireLe modèle relationnel
La structureLangages de requêtes
L’algèbre relationnelleLe calcul relationnelEquivalence des langages relationnelsSQL (Structured Query Language)
Les contraintesLes dépendances fonctionnelles et les clésLes dépendances d’inclusion et les clés étrangèresRaisonnement sur les dépendances fonctionnellesLes relations d’Armstrong
Conception des bases de donnéesApproche basée sur les contraintesApproche basée sur le modèle Entité-Association
Le modèle Entité-AssociationConception avec Entité-AssociationTraduction entre modèles
Index
6/196

OutlineLe modèle relationnel
La structureLangages de requêtes
L’algèbre relationnelleLe calcul relationnelEquivalence des langages relationnelsSQL (Structured Query Language)
Les contraintesLes dépendances fonctionnelles et les clésLes dépendances d’inclusion et les clés étrangèresRaisonnement sur les dépendances fonctionnellesLes relations d’Armstrong
Conception des bases de donnéesApproche basée sur les contraintesApproche basée sur le modèle Entité-Association
Le modèle Entité-AssociationConception avec Entité-AssociationTraduction entre modèles
Index7/196
Le modèle relationnel
1. StructureDonne l’organisation des données du modèle, i.e. sous formede tableaux à deux dimensions (LDD).
2. LangagesIl existe trois principaux langages de requêtes relationnels :
I Algèbre relationnelleI Calcul relationnelI Datalog Non-recursif : langage à base de règles
Ce sont des langages déclaratifs qui ont donné lieu au langageSQL utilisé en pratique.
3. Contraintes : basées sur différents types de dépendancesRestreindre les relations autorisées dans une base de donnéespour satisfaire certaines conditions logiques, appeléescontraintes d’intégrité.
8/196

OutlineLe modèle relationnel
La structureLangages de requêtes
L’algèbre relationnelleLe calcul relationnelEquivalence des langages relationnelsSQL (Structured Query Language)
Les contraintesLes dépendances fonctionnelles et les clésLes dépendances d’inclusion et les clés étrangèresRaisonnement sur les dépendances fonctionnellesLes relations d’Armstrong
Conception des bases de donnéesApproche basée sur les contraintesApproche basée sur le modèle Entité-Association
Le modèle Entité-AssociationConception avec Entité-AssociationTraduction entre modèles
Index9/196
Structure du modèle relationnel
Les données sont structurées en relation (ou table ou tableau àdeux dimensions)
I les colonnes donnent les caractéristiques de ce que la relationreprésente
I les lignes donnent les "individus" qui peuplent la relation
ExemplePersonnes nss nom prenom age
12 Aymard Serge 4545 Fenouil Solange 35
Içi, la première ligne donne les noms aux différentescaractéristiques, appelés attributs.⇒ Version dite nommée du modèle relationnel
10/196

Représentation équivalente de la relation Personnes
{< 12, Aymard, Serge, 60 >, <45, Fenouil, Solange, 55) >}
{ Personnes(nss : 12, nom : Aymard, prenom : Serge, age : 60),Personnes(nss : 45, nom : Fenouil, prenom : Solange, age : 55)}
{ Personnes(12, Aymard, Serge, 60), Personnes(45, Fenouil,Solange, 55) }
⇒On utilisera par la suite ces différentes représentations (nomméeset non-nommées), mais en attendant, on se focalise sur la versionnommée de la diapo précédente.
11/196
Attributs et domaines
Soit U un ensemble infini dénombrable de noms d’attributs ouattributs, nommé univers.
ExempleU = {nss, nom, prenom, age, dep, adresse, activite}Soit D un ensemble infini dénombrable de valeurs constantes.D représente l’ensemble des valeurs qui peuvent être prises dansune base de données.
Pour A ∈ U , on note dom(A) le domaine de A, i.e. le sousensemble de D dans lequel A peut prendre des valeurs(dom(A) ⊆ D).Exempledom(dep) = {Math, Info,Phys,Bio,Chimie}
12/196

Symbole de relation
Un symbole de relation est un symbole R auquel on associe :I un entier naturel type(R), qui donne le nombre d’attributs de
R ,I une fonction attR définie de {1, . . . , type(R)} dans U qui
associe des attributs de U à R dans un certain ordre.
On note schema(R) = {attR(1), . . . , attR(type(R))} l’ensemble desattributs de R , i.e. le schéma de R .
Remarque : par abus de langage, on confond parfois le symboleavec le schéma de relation.
ExempleSoit Personne un symbole de relation avec type(Personne) = 4 etschema(Personne) = {att(1), att(2), att(3), att(4)} oùatt(1) = nss, att(2) = nom, att(3) = prenom, et att(4) = age
13/196
Formes normales
Caractérisation de certaines formes de schémas de relations
DefinitionUn symbole de relation R est en première forme normale (1FN) sitous les domaines des attributs de R ont des valeurs constantes etatomiques.
Hypothèse relativement forte
14/196

Tuples et relations
Soit R un symbole de relation avecschema(R) = {A1, . . . ,Am}, attR(i) = Ai , i = 1,mUn tuple sur R est un élément du produit cartésiendom(A1)× . . .× dom(Am)Une relation sur R est un ensemble fini de tuples sur R .
ExempleLa relation Personnes (exemple 1) est une relation sur le symbolede relation Personne.< 12,Aymard , Serge, 45 >∈ Personnes
15/196
Domaine actif
Le domaine actif d’un attribut A ∈ schema(R) dans r , notéADOM(A, r), est l’ensemble des valeurs constantes prises par Adans r , i.e. ADOM(A, r) = πA(r).
Le domaine actif d’une relation r , noté ADOM(r), est défini parADOM(r) =
⋃A∈schema(R) ADOM(A, r).
⇒ à ne pas confondre avec le domaine d’un attribut
16/196

Manipulation sur un tuple
Soient R un symbole de relation avec schema(R) = {A1, . . . ,Am},attR(i) = Ai (i = 1,m), r une relation sur R , t un tuple de r etAi ∈ schema(R).
La projection d’un tuple t sur Ai , notée t[Ai ], est la ièmecoordonnée de t, i.e. t(i).
→ se généralise à plusieurs attributsSoit X = {attR(i1), . . . , attR(in)} ⊆ schema(R). La projection de tsur X, notée t[X ], est définie par t[X ] =< t(i1), . . . , t(in) >
ExempleSoit t =< 12,Aymard , Serge, 45 >. On a :t[nom] = t[att(2)] = t(2) =< Aymard >t[nom, prenom] = t[att(2), att(3)] =< t(2), t(3) >=<Aymard , Serge >
17/196
Symbole de base de données
Un symbole de base de données R est un ensemble de symbolesde relation.
Soit R = {R1, . . . ,Rn}. On a :
I schema(R) =⋃
Ri∈R schema(Ri )
I Un symbole de BD est en 1FN si ses symboles de relation sonten 1FN.
18/196

Hypothèses de nommage
Hypothèse implicite du modèle relationnelUniversal Relation Schema Assumption (URSA) : Si un attributapparaît dans plusieurs schémas de relation, alors cet attributreprésente les mêmes données.
ExempleSoit R = { Personne, Departement, Travaille } avecschema(Personne)={ nss, nom, prenom, age },schema(Departement)={ dep, adresse }, schema(Travaille)={ nss,dep, activite }.
19/196
Base de données
Une base de données d est définie sur un symbole de base dedonnées et représente un ensemble de relations.
Soit R = {R1, . . . ,Rn}. d = {r1, . . . , rn} est une base de donnéessur R ri définie sur Ri (i=1,n)
Le domaine actif d’une base de données d , noté ADOM(d),est l’union des domaines actifs de ses relations.
20/196

ExempleSoit d = { Personnes,Departements,Travaillent } avec définie surPersonne,Departement,Travaille respectivement.Personnes nss nom prenom age
12 Aymard Serge 4545 Fenouil Solange 35
Departements dep adresseMath CarnotInfo Cézeaux
Travaillent nss dep activite12 Math Prof45 Math MdC45 Info MdC
21/196
OutlineLe modèle relationnel
La structureLangages de requêtes
L’algèbre relationnelleLe calcul relationnelEquivalence des langages relationnelsSQL (Structured Query Language)
Les contraintesLes dépendances fonctionnelles et les clésLes dépendances d’inclusion et les clés étrangèresRaisonnement sur les dépendances fonctionnellesLes relations d’Armstrong
Conception des bases de donnéesApproche basée sur les contraintesApproche basée sur le modèle Entité-Association
Le modèle Entité-AssociationConception avec Entité-AssociationTraduction entre modèles
Index22/196

Langages de requêtes
Langages dits déclaratifs puisqu’il suffit de décrire le résultatrecherché sans spécifier comment l’obtenir.
I Approche algébrique : Algèbre relationnelleTrès utile pour représenter les plans d’exécution des requêtespuisque un ordre pour l’exécution de la requête est donnée.⇒ dotée d’une sémantique opérationnelle
I Approche logiqueI Calcul relationnel
Orienté utilisateur car il est plus proche du langage naturel :on ne spécifie pas d’ordre.⇒ dotée d’une sémantique déclarative
I DatalogLangage déclaratif à base de règles, capacités d’inférence
⇒ SQL = sucre syntaxique de ces langages
Focus sur les requêtes conjonctives
23/196
Proposée par Codd en 1970
I collection d’opérateurs algébriquesI Entrée : une ou deux relationsI Sortie : une relation
I Possibilité de composition des opérateurs
24/196

La projection
Soient r une relation sur R et Y ⊆ schema(R).La projection de r sur Y , notée πY (r), est définie par :
πY (r) = {t[Y ] | t ∈ r}
Soit S le symbole de relation associé à πY (r). On a schema(S) = Y
⇒ correspond à une coupe verticale de la relation
25/196
La sélection (1/2)
Nécessite tout d’abord de définir la notion de formule desélection sur R , puis la satisfaction d’une formule de sélectionpar un tuple.
Définition d’une formule de sélection sur R par induction, i.e.formule simple puis formule de sélection
I Une formule simple sur R est une expression de la forme :A = a ou A = B , où A,B ∈ schema(R) et a ∈ dom(A)
I Une formule de sélection estI soit une formule simple,I soit une expression de la forme F1 ∧ F2,F1 ∨ F2,¬F1 ou (F1)
avec F1,F2 des formules de sélection.
Note : on peut étendre ces formules à d’autres opérateurs binaires :<,>,≤, . . .
26/196

La sélection (2/2)
Soient r une relation sur R , t ∈ r et F une formule de sélection surR
I t satisfait F , noté t |= F , est défini inductivement par :1. t |= A = a si t[A] = a2. t |= A = B si t[A] = t[B]3. t |= F1 ∧ F2 si t |= F1 et t |= F24. t |= F1 ∨ F2 si t |= F1 ou t |= F25. t |= ¬F si t 6|= F6. t |= (F ) si t |= F
Soient r une relation sur R et F une formule de sélection sur R .La sélection des tuples de r par rapport à F , notée σF (r), estdéfinie par :
σF (r) = {t ∈ r | t |= F}
⇒ correspond à une coupe horizontale de la relation
27/196
Opérations ensemblistesSoient r1 et r2 deux relations sur le même symbole de relation R
I Union :r1 ∪ r2 = {t | t ∈ r1 ou t ∈ r2}
I Différence :r1 − r2 = {t | t ∈ r1 et t /∈ r2}
I Intersection :
r1 ∩ r2 = {t | t ∈ r1 et t ∈ r2}
ExempleDonner r1 ∪ r2, r1 ∩ r2 et r1 − r2.
r1
A B C1 2 31 1 11 2 2
r2A B C2 2 21 1 1
28/196

Quelques propriétés
I r1 ∩ r2 = r1 − (r1 − r2)I σ¬F (r) = r − σF (r)I σF1∨F2(r) = σF1(r) ∪ σF2(r)I σF1∧F2(r) = σF1(r) ∩ σF2(r)
29/196
La jointure naturelle
Soient r1 et r2 deux relations sur R1 et R2 respectivement.
La jointure naturelle de r1 et r2, notée r1 ./ r2, est une relationsur un symbole de relation R , avecschema(R) = schema(R1) ∪ schema(R2), définie par :r1 ./ r2 ={t | ∃t1 ∈ r1∃t2 ∈ r2 tq t[schema(R1)] = t1 et t[schema(R2)] = t2}
Note : cette définition est “non constructive”, elle caractérise lajointure sans donner d’indices sur la façon de la calculer en pratique.
30/196

Un algorithme de jointureAlgorithme Jointure(r1, r2)Data: r1, r2 deux relations sur R1,R2 resp.Result: Res, le résultat de la jointureSoit X = schema(R1) ∩ schema(R2) ;Resultat = ∅ ;foreach t1 ∈ r1 do
foreach t2 ∈ r2 doif t1[X ] = t2[X ] then
Construire un tuple t tq t[schema(R1)] = t1 ett[schema(R2)] = t2 ;Res = Res ∪ { t } ;
Return(Res) ;
PropriétéJointure(r1, r2) = r1 ./ r2⇒ Propriété constructive pour calculer la jointure
31/196
Exemples de jointure
Donner s1 ./ s2, s1 ./ s3, s1 ./ s4.
s1A B C2 2 21 1 1
s2
A D E1 2 31 1 22 3 13 1 2
s3A B C1 1 11 2 3
s4D E F1 1 12 2 2
Lien entre la jointure, le produit cartésien et l’intersection
I Si schema(R1) = schema(R2), que vaut r1 ./ r2 ?I Si schema(R1) ∩ schema(R2) = ∅, que vaut r1 ./ r2 ?
32/196

Le renommage
→ permet par exemple de forcer ou d’éviter des jointures naturelles
Soit r une relation sur R , A ∈ schema(R) et B 6∈ schema(R)
Le renommage de A en B dans r , noté ρA→B(r), est une relationsur S avec schema(S) = (schema(R)− {A}) ∪ {B} définie par :ρA→B(r) ={t |∃u ∈ r , t[schema(S)−{B}] = u[schema(R)−{A}] et t[B] = u[A]}
33/196
La division : l’intuition
⇒ capture la sémantique du quantificateur universel (∀).
Example"Quels sont des étudiants qui sont inscrits dans tous lesdépartements"
Inscriptions
etud dep1 11 21 32 2
Departement
dep123
34/196

Définition de la division
Soient r une relation sur R avec schema(R) = XY et s une relationsur S avec schema(S) = Y .
La division de r par s, notée r ÷ s, est une relation sur un symbolede relation R1, avec schema(R1) = X , définie par :
r ÷ s = {t[X ] | t ∈ r et s ⊆ πY (σF (r))}avec X = {A1, . . . ,Aq} et F = (A1 = t[A1]) ∧ . . . ∧ (Aq = t[Aq])
Propriétér ÷ s = πX (r)− πX ((πX (r)× s)− r)
35/196
Exemples
Donner r1 ÷ r2, r1 ÷ r3 et r1 ÷ r4.
r1
etud dep1 11 21 31 42 12 23 24 24 4
r2dep2
r3etud24
r4
dep124
36/196

Synthèse sur l’algèbre relationnelle
I Opérations ensemblistesI Union (∪) : sélection des tuples d’une relation r1 et de ceux
d’une autre relation r2I Intersection (∩)I Différence (−) : sélection des tuples d’une relation r1 qui
n’appartiennent pas à une relation r2I Autres opérations
I Projection (π) : suppression des attributs d’une relationI Sélection (σ) : sélection d’un sous ensemble de tuples d’une
relation.I Jointure (./) : combine deux relationsI Renommage (ρA→B) : renomme le nom d’un attributI Produit cartésien (×)I Division (÷) : exprime le quantificateur universel (∀)
37/196
Exercices
Certains opérateurs sont indispensables, d’autres pas, i.e. ilspeuvent s’exprimer à partir des autres.
Par exemple, on peut exprimerI une jointure ./ avec ×, ρ, π, σ,I un produit cartésien × avec ./, ρI l’intersection ∩ avec −
38/196

Requêtes algébriques
Soit d une base de données
I Une requête algébrique sur d est une expression composéed’un nombre fini d’opérateurs algébriques sur les relations de d
I Un ordre d’évaluation des opérateurs est spécifié dans larequête⇒ à la base de l’optimisation de requêtes
39/196
Arbres de requêtes
Une expression algébrique peut se représenter sous forme d’arbre :I la racine de l’arbre correspond à la requêteI les feuilles de l’arbre correspondent aux relationsI les noeuds de l’arbre correspondent aux opérateurs algébriques
ExerciceReprésenter Q = πX (σC1(r1 ./ r2) ./ (σC2(r3) ∪ r4))
⇒ permet de mieux comprendre l’optimisation logique de requêtes
NB : IBM DB2 offre une représentation physique de cet arbre,Oracle aussi mais de façon moins aisée.
40/196

Propriétés algébriques
Utiles pour la réécriture des requêtesσF (σF ′ (r)) = σF ′ (σF (r))σF (πX (r)) = πX (σF (r)) si F porte sur XσF (r ./ s) = σF (r) ./ s si F porte sur schema(R)πX (r ./ s) = πX (r) ./ πX (s) si schema(R) ∩ schema(S) = X(r1 ∪ r2) ./ r3 = (r1 ./ r3) ∪ (r2 ./ r3)
41/196
Complétude
Un langage d’interrogation de bases de données relationnelles estdit relationnellement complet si il peut exprimer toute requêteexprimable dans l’algèbre relationnelle
Extensions de l’algèbre relationnelle
I Prise en compte des valeurs nullesI Requêtes récursives (aussi appelé Fermeture transitive)I Fonctions d’agrégation sur les données
42/196

Exemple de requêtes récursives
FamilleParent Enfantp1 p3p1 p4p2 p4p2 p5p3 p6p3 p7p7 p12
"Donner la liste des parents et leurs petits-fils"πpar ,enf (ρEnfant→AJ(ρParent→par (Famille))./ ρParent→AJ(ρEnfant→enf (Famille))))
"Donner tous les descendants de p1 "Requête impossible en algèbre relationnelle⇒ Possible en SQLclause "connect by" avec Oracle (DBMS specific)
43/196
OutlineLe modèle relationnel
La structureLangages de requêtes
L’algèbre relationnelleLe calcul relationnelEquivalence des langages relationnelsSQL (Structured Query Language)
Les contraintesLes dépendances fonctionnelles et les clésLes dépendances d’inclusion et les clés étrangèresRaisonnement sur les dépendances fonctionnellesLes relations d’Armstrong
Conception des bases de donnéesApproche basée sur les contraintesApproche basée sur le modèle Entité-Association
Le modèle Entité-AssociationConception avec Entité-AssociationTraduction entre modèles
Index44/196

Petit exemple introductif
Soit R = {Departement,Etudiant} un schéma de BD avecschema(Departement) = {Loc,Mgr ,Dept} etschema(Etudiant) = {Name,Age,Address,Dept} et soientDepartements et Etudiants deux relations.
Etudiants
Name Age Address DeptVidal 21 Clermont Computing
Dupond 35 Paris MathsDurand 45 Lyon LinguisticsDan 34 Lyon Computing
Departements
Loc Mgr DeptBât A Ullman ComputingBât B Mendelson MathsBât C Dupond Linguistics
45/196
Langages logiques
Donner les noms et âges des étudiants du département géré par"Ullman".Deux approches :
I Approche basée sur les variables du domaineSi les tuples 〈x1, x2, x3, x4〉 et 〈y1,
′ Ullman′, y2〉 sontrespectivement dans les relations Etudiants et Departments etx4 = y2 alors inclure dans la réponse le tuple〈x1 : Name, x2 : Age〉,où x1, x2, x3, x4, y1, y2 sont des variables de domaine
I Approche basée sur les variables de tupleSi les variables de tuple t1 et t2 définies respectivement surEtudiants et Departments sont tels que le manager de t2 est′Ullman′ et les noms de département (attribut dept) de t1 ett2 sont les mêmes alors inclure dans la réponse les nom et âgedu tuple t1.
46/196

Le calcul relationnel
I Deux types de calculs : calcul relationnel de domaine (DRC) etcalcul relationnel de tuples (TRC).
I Le calcul utilise des variables, des constantes, des opérateurs decomparaison, des connecteurs logiques et des quantificateurs
I DRC : les variables prennent comme valeurs des éléments dudomaine.
I TRC : les variables prennent comme valeurs des tuples.
TRC et DRC sont des sous-ensembles de la logique du premierordre
I Les expressions dans le calcul sont appelées formulesI Un tuple réponse est une affectation de constantes à des
variables qui permet à la formule d’être évaluée à vrai
47/196
Syntaxe DRC
Symboles autorisés dans une formuleI Constantes : v1, . . . , vn membres de l’ensemble DI Variables : x1, . . . , xn membres d’un ensemble infini
dénombrable V disjoint de D et de UI Symboles de relations : R1,R2, . . . ,Rn
I Opérateurs de comparaison : =I Quantificateurs et connecteurs logiques : ∃,∀,∧,∨,¬I Délimiteurs : () et ,
Note : On peut admettre d’autres opérateurs <,>,=,≤,≥, 6=
48/196

Formules DRC
⇒ définies de façon inductive : formules atomiques, puis formulesplus complexes utilisant des connecteurs logiques.
I Formule atomiqueI R(x1, . . . , xn) avec R symbole de relation, type(R) = n et xi
une constante ou une variable pour tout i ∈ {1, . . . , n}I x = y , avec x une variable et y une constante ou une variable
I Formule bien forméeI Une formule atomiqueI (p),¬p, p ∧ q, p ∨ q où p et q sont des formules bien forméesI ∃x : A(F ), ∀x : A(F ) où F est une formule bien formée, x une
variable et A un nom d’attribut
49/196
Remarque sur la représentation structurelle
L’ordre des variables est important dans les formules atomiques dela forme R(x1, . . . , xn), i.e. xi représente attR(i)
Correspond toujours à une version nommée du modèle relationnelmais avec un ordre sur l’apparition des variables/constantes dansles prédicats (relations).
50/196

Variables libres et variables liées
Les quantificateurs ∃ et ∀ permettent de lier les variables
I Toutes les variables apparaissant dans une formule atomiquesont libres
I Les variables libres apparaissant dans ¬F sont les mêmes quecelles apparaissant dans la formule F
I Les variables libres apparaissant dans les formules F1 ∧ F2 etF1 ∨ F2 sont les variables libres qui apparaissent dans F1 oudans F2
I Les variables libres qui apparaissent dans ∃x : A(F ) et∀x : A(F ) sont les variables libres qui apparaissent dans Fexcepté les occurrences de x dans F
51/196
Requêtes en calcul relationnel de domaine
Soit R = {R1, . . . ,Rm} un schéma de base de données.I Une requête sur R à la forme suivante :
{〈x1 : A1, . . . , xn : An〉|F (〈x1, . . . , xn〉)}
oùI F est une formule bien formée,I A1, . . . ,An sont des attributs appartenant à UI x1, . . . , xn sont des variables libres dans F et 2 à 2 disjointes,
les autres variables étant liées
⇒ Notion purement syntaxique
⇒ Reste à définir la sémantique d’une requête, i.e. son résultat
52/196

Notion d’interprétation
Une interprétation sur un schéma de base de données R est définiepar
I une base de données d sur R etI une affectation σ des variables V aux constantes de D
L’affectation σ est une fonction de V dans DSoit x une variable sur le domaine de A. On note σ : x 7→ v avecv ∈ DOM(A)
On note 〈d , σ〉 une interprétation sur R.
On notera aussi σx 7→v l’affectation σ à laquelle on ajoute σ(x) = v
53/196
Satisfaction d’une formule
Soient une interprétation 〈d , σ〉 et une formule δ sur RLa satisfaction de δ par rapport à 〈d , σ〉, notée 〈d , σ〉 |= δ, estdéfinie inductivement comme suit :
I 〈d , σ〉 |= x = v ssi σ(x) = vI 〈d , σ〉 |= x = y ssi σ(x) = σ(y)I 〈d , σ〉 |= R(x1, . . . , xn) ssi〈σ(x1), . . . , σ(xn)〉 ∈ r (r ∈ d , r sur R)
I 〈d , σ〉 |= (F ) ssi 〈d , σ〉 |= FI 〈d , σ〉 |= ¬F ssi 〈d , σ〉 6|= FI 〈d , σ〉 |= F1 ∧ F2 ssi 〈d , σ〉 |= F1 et 〈d , σ〉 |= F2
I 〈d , σ〉 |= F1 ∨ F2 ssi 〈d , σ〉 |= F1 ou 〈d , σ〉 |= F2
I 〈d , σ〉 |= ∃x : A(G ) ssi ∃v ∈ DOM(A) tel que 〈d , σx 7→v 〉 |= GI 〈d , σ〉 |= ∀x : A(G ) ssi ∀v ∈ DOM(A), 〈d , σx 7→v 〉 |= G
54/196

Résultat d’une requête
Soit d = {r1, . . . , rm} une base de données sur R etQ = {〈x1 : A1, . . . , xn : An〉|F (〈x1, . . . , xn〉)} une requête DRC surR
La réponse de Q sur d produit une relation ans(Q, d) définie par :
ans(Q, d) = {〈σ(x1), . . . , σ(xn)〉 | 〈d , σ〉 |= F}
Le schéma de ans(Q, d) est {A1, . . . ,An}
55/196
Exemple
Soit R = {Departement,Etudiant} un schéma de BD avecschema(Departement) = {Loc,Mgr ,Dept} etschema(Etudiant) = {Name,Age,Address,Dept} et soitd = {Departements,Etudiants} une BD sur R.
Etudiants
Name Age Address DeptVidal 21 Clermont Computing
Dupond 35 Paris MathsDurand 45 Lyon LinguisticsDan 34 Lyon Computing
Departements
Loc Mgr DeptBât A Ullman ComputingBât B Mendelson MathsBât C Dupond Linguistics
56/196

Exemples de requêtes
I "Donner la liste de tous les étudiants"{〈x1 : Name, x2 : Age, x3 : Address, x4 : Dept〉 |
Etudiant(x1, x2, x3, x4)}I "Donner les noms et départements de tous les étudiants"{〈x1 : Name, x4 : Dept〉 | ∃x2 : Age(∃x3 : Address(
Etudiant(x1, x2, x3, x4)))}I Donner le nom, l’age et le département des étudiants qui
habitent à ’Clermont’{〈x1 : Name, x2 : Age, x4 : Dept〉 |∃x3 : Address(Etudiant(x1, x2, x3, x4) ∧ x3 = ‘Clermont‘)}
57/196
Exemples de requêtes (cont.)
I "Donner les noms et âges des étudiants qui sont soit inscritsdans le département Linguistics soit habitent à Clermont"{〈x1 : Name, x2 : Age〉 |∃x3 : Address(∃x4 : Dept(Etudiant(x1, x2, x3, x4) ∧ (x4 = ‘Linguistics‘ ∨ x3 =
‘Clermont‘)))}ou {〈x1 : Name, x2 : Age〉 | ∃x4 : Dept(Etudiant(x1, x2, ‘Clermont‘, x4))∨∃x3 : Address(Etudiant(x1, x2, x3, ‘Linguistics‘))}
I "Donner les noms des étudiants non parisiens qui ne sont pasinscrits dans le département Computing"{〈x1 : Name〉 | ∃x2 : Age(∃x3 : Address(∃x4 : Dept(
Etudiant(x1, x2, x3, x4) ∧ (¬(x4 = ‘Computing ‘) ∧ ¬(x3 =‘Paris‘)))))}
58/196

Exemples de requêtes (cont.)
I "Donner les noms des étudiants et les localisations desdépartements dans lesquels ils sont inscrits"Q = {〈x1 : Name, x5 : Loc〉 |∃x2 : Age(∃x3 : Address(∃x4 : Dept(∃x6 : Mgr(Etudiant(x1, x2, x3, x4) ∧ Department(x5, x6, x4)))))}
Remarque : Toutes ces requêtes sont décrites sur le schémade la BD uniquement. Pour les évaluer sur d , en prenant larequête Q ci dessus, on doit écrire ans(Q, d).
59/196
Calcul relationnel autorisé : une restriction du calcul
Exemple de requêtes peu sûres : Requêtes de calculI correctes syntaxiquementI . . . mais nombre infini de réponses ou réponses toujours vides
ExempleSoit r une relation sur R avec schema(R) = {A}, dom(A) = N etr = {0, 1, 2}.Soient les 2 requêtes suivantes :Q1 : {〈x : A〉|R(x)}Q2 : {〈x : A〉|¬R(x)}Pouvez vous écrire une requête équivalente en algèbre relationnelle ?
60/196

Notions préliminaires
Intimement lié à une notion d’indépendance de domaineComment se ramener au domaine actif uniquement ?
I Domaine actif d’une BD dnoté ADOM(d)
I Domaine actif d’une requête Qnoté ADOM(Q), et égal à l’ensemble des constantesapparaissant dans Q
I Indépendance du domaineUne requête Q est indépendante du domaine si pour toutebase de données d , les réponses de Q sur d dépendentuniquement de ADOM(Q) ∪ ADOM(d)
61/196
Requêtes indépendantes du domaine
Les requêtes de l’algèbre relationnelle (et les requêtes Datalogsûres) sont indépendantes du domaine, celles du calcul relationnelsne le sont pas.
ExempleSoient Etudiant et Inscrit deux schémas de relations avecschema(Etudiant) = schema(Inscrit) = {nom}. Les requêtessuivantes ont une réponse infinie si DOM(nom) est infini.{< x : nom > |¬Etudiant(x)}{< x1 : nom, x2 : nom > |Etudiant(x1) ∨ Inscrit(x2)}D’où deux problèmes principaux dans les requêtes du calcul :
I La requête contient une formule ¬F telle qu’une des variablesde F n’apparaît pas positivement ailleurs
I La requête contient une formule de la forme F1 ∨ F2 telle queles variables libres de F1 sont distinctes de celles de F2
62/196

Requêtes indépendantes du domaine (suite)
ThéorèmeDéterminer si une requête du calcul relationnel est indépendante dudomaine est indécidable.
Idée : restreindre les formules de façon syntaxique de façon àrendre les requêtes du calcul indépendante du domaine.
Deux notions :I variables positivesI variables négatives
63/196
Variable positive
Une variable x est positive dans une formule si :I x est positive dans une formule atomique R(y1, . . . , x , . . . , yk)
I x est positive dans une formule atomique x = v où v est uneconstante
I x est positive dans la formule ¬F qui contient x , si x estnégative dans F (si F n’est pas une formule atomique, il faut"pousser" le constructeur ¬)
I x est positive dans la formule F1 ∧ F2 si x est positive dans F1ou x est positive dans F2
I x est positive dans la formule F1 ∨ F2 si x est positive dans F1et x est positive dans F2
I x est positive dans la formule ∃y : A(F ), si x 6= y et x estpositive dans F
64/196

Variable négative
Une variable x est négative dans une formule si :I x est négative dans une formule atomique x = y où y est une
variableI x est négative dans la formule ¬F si x est positive dans FI x est négative dans la formule F1 ∧ F2 si x est négative dans
F1 et x est négative dans F2
I x est négative dans la formule F1 ∨ F2 si x est négative dansF1 ou x est négative dans F2
I x est négative dans la formule ∀y : A(F ), si x 6= y et x estnégative dans F
I si x n’apparaît pas dans une formule F , alors x est négativedans F
65/196
Exemple
Soient Etudiant, Inscrit et Habite trois schémas de relations avecschema(Etudiant) = schema(Inscrit) = {nom} etschema(Habite) = {nom, adresse}.
Soient les formules suivantes :F1 = Etudiant(x)F2 = Etudiant(x1) ∨ Inscrit(x2)F3 = Habite(x1, x2) ∧ ¬Habite(x1, Lyon)F4 = Habite(x1,Antraigues) ∨ Habite(x1, Lyon)
Donner le status des variables dans F1 − F4.
66/196

Formule du calcul autorisée
Une formule du calcul F est autorisée si :
I Chaque variable libre x de F est positive dans FI Pour chaque sous-formule ∃x : A(G ) de F , x est positive dans
GI Pour chaque sous-formule ∀x : A(G ) de F , x est négative dans
G
67/196
Requête de calcul relationnel autorisée
I Une requête autorisée à la forme suivante :
{〈x1 : A1, . . . , xn : An〉|F (〈x1, . . . , xn〉)}
où : F est une formule bien formée et autorisée,A1, . . . ,An sont des attributs appartenant à Ux1, . . . , xn sont des variables libres dans F 2 à 2 disjointes, lesautres variables étant liées
Tester si une requête du calcul est autorisée peut se faire par simplerécursion sur la structure de la formule.
ThéorèmeToute formule autorisée du calcul relationnel est indépendante dudomaine.
68/196

Exemple (suite)
Soient Etudiant, Inscrit et Habite trois schémas de relations avecschema(Etudiant) = schema(Inscrit) = {nom} etschema(Habite) = {nom, adresse}.
Les requêtes ci-dessous sont-elles autorisées ?
Q1 = {< x : nom > |¬Etudiant(x)}Q2 = {< x1 : nom, x2 : nom > |Etudiant(x1) ∨ Inscrit(x2)}Q3 = {< x1 : nom > |∃x2 : adresse(Habite(x1, x2)∧¬Habite(x1, Lyon))}Q ′
3 = {< x1 : nom > |∀x2 : adresse(Habite(x1, x2)∧¬Habite(x1, Lyon))}
69/196
Exemple (fin)
Q4 = {< x1 : nom > |Habite(x1,Antraigues) ∨ Habite(x1, Lyon)}Q5 = {< x : nom > |∀y : nom(¬Etudiant(y))}Q ′
5 = {< x : nom > |¬(∃z : nom(Etudiant(z)))}Q6 = {< y : adresse > |∀x : nom(¬Etudiant(x) ∧ Habite(x , y)))}
70/196

OutlineLe modèle relationnel
La structureLangages de requêtes
L’algèbre relationnelleLe calcul relationnelEquivalence des langages relationnelsSQL (Structured Query Language)
Les contraintesLes dépendances fonctionnelles et les clésLes dépendances d’inclusion et les clés étrangèresRaisonnement sur les dépendances fonctionnellesLes relations d’Armstrong
Conception des bases de donnéesApproche basée sur les contraintesApproche basée sur le modèle Entité-Association
Le modèle Entité-AssociationConception avec Entité-AssociationTraduction entre modèles
Index71/196
Equivalence des langages
Les langages vus sont équivalents : résultat fondamental des basesde données
⇒ Comment énoncer ce résultat ?
⇒ Esquisse de la preuve
72/196

Notions préliminaires
Deux requêtes Q1 et Q2 sur un schéma de BD R sont diteséquivalentes, noté Q1 ≡ Q2, si pour toute base de données d surR, Q1(d) = Q2(d).⇒ quelque soit la base de données, les réponses doivent être lesmêmes
Un langage de requêtes L1 est dit contenu dans un langage derequêtes L2, noté L1 � L2, si pour toute requête Q1 de L1, ilexiste une requête Q2 de L2 tel que Q1 ≡ Q2.
L1 est dit équivalent à L2, noté L1 ≡ L2, si L1 � L2 et L2 � L1.
73/196
ThéorèmeLes trois langages relationnels suivants sont équivalents :
I L’algèbre relationnelleI Le calcul relationnel du domaine autoriséI nr−datalog¬ (Datalog sûr non récursif avec la négation)
Résultat fondamental des bases de données
74/196

Esquisse de la preuve
On peut montrer que :1. l’algèbre est incluse dans le calcul autorisé2. le calcul autorisé est inclu dans Datalog3. Datalog est inclu dans l’algèbre
Considérons (1) : la preuve se fait par induction sur le nombred’opérateurs algébriques d’une requêteL’hypothèse d’induction H(n) peut se formuler ainsi : “Soit Q unerequête algébrique avec n opérateurs algébriques. On suppose qu’ilexiste une requête Q’ du calcul autorisé tel que Q et Q’ soitéquivalente.”Preuve : Montrer H(0) et en supposant H(n), montrer H(n+1)
75/196
SQL : un rapide tour d’horizon
76/196

SQL vs Modèle relationnel
⇒ on se focalise sur l’implantation de l’algèbre relationnelle dans unlangage pratique nommé SQL.
I Version nommée pour la structure du modèle relationnelI Plus de distinction entre schéma de relation et relation : notion
de table pour désigner les deuxI Une table SQL n’est pas un ensemble de tuples, mais un
multi-ensemble de tuples, principalement pour des raisonsd’efficacité (coût engendré par les tris pour supprimer lesdoublons) (voir diapo 57)
77/196
La sémantique de SQL
Une relation SQL n’est pas un ensemble de tuples ! ! !⇒mais un multi ensemble (ou bag)
Exemple{ 1,2,2,3 } est un multi-set, i.e. plusieurs occurrences possibles dela même valeur, pas d’ordre.Problème : les propriétés usuelles sur les ensembles ne sont plustoujours vérifiées sur les multi ensembles.
ExempleR ∩ (S ∪ T ) = (R ∩ S) ∪ (R ∩ T )Soit R = S = T = {1}, on a alorsR ∩ (S ∪ T ) = {1} ∩ {1, 1} = {1} et(R ∩ S) ∪ (R ∩ T ) = {1} ∪ {1} = {1, 1}
78/196

SQL (Structured Query Language)
SQL : Langage d’interrogation des données extrêmement populaire,utilisé partout ...
Langage concret construit sur les trois langages formels étudiés +du sucre syntaxique
Des différences notoires, dont le fait qu’une table est unmulti-ensemble de tuples et non plus un ensemble
Normalisé par l’ANSI en 1992 (SQL-92) puis en 1999 (SQL-99),différents niveaux de compatibilité⇒ Chaque SGBD a son propre SQL, typiquement pour tous lesaspects hors-normes : built-in function, fermeture transitive⇒ Ne faire confiance qu’à la documentation du SGBD utiliséplus précisément, à la grammaire SQL de la version du SGBDutilisé (par ex doc SQL d’Oracle 10.2)
79/196
Syntaxe d’une requête SQL
De base, une requête SQL comporte trois clauses :
SELECT <liste d’attributs>FROM <listes relations>[ WHERE <conditions sur les lignes> ]
⇒ requête SFWLa clause SELECT permet de coder la projectionLa clause WHERE permet de coder la selection. Elle est optionnelle.Le résultat est une relation sur le schéma défini par la clauseSELECT.Une requête SQL peut être nommée ⇒ on parle de vue.
80/196

Passerelles entre ensembles et multi ensembles
Possible grâce aux mots clés DISTINCT et ALLI multi ensemble vers ensemble : DISTINCTI ensemble vers multi ensemble : ALL
Les requêtes SFW sont par défaut définies sur des multi-ensembles⇒ pour forcer la sémantique ensembliste, utiliser le mot clé’DISTINCT’ après ’SELECT’Les opérateurs ensemblistes (UNION, INTERSECT, MINUS) forcepar défaut la sémantique ensembliste ! ! !⇒ pour forcer la sémantique multi ensemble, utiliser le mot clé’ALL’ après ’UNION’, ...⇒ Etre prudent sur les conversions, et se méfier du coût (opérationde TRI) engendré par DISTINCT
81/196
Rappel : base de données
Personnes nss nom prenom age12 Aymard Serge 4545 Fenouil Solange 35
Departements dep adresseMath CarnotInfo Cézeaux
Travaillent nss dep activite12 Math Prof45 Math MdC45 Info MdC
82/196

Requête SFW
ExempleQ : "Nom et prénom des personnes de 30 ans ?"
I πnom,prenom(σage=30(Personnes))I ans(Qc , d) avec Qc = {x2 : nom, x3 : prenom, x4 : age|∃x1 :
nss(Personne(x1, x2, x3, x4) ∧ x4 = 30)}I Q(x1, x3) ` Personne(x1, x2, x3, 30)
⇒ en SQL :
SELECT DISTINCT nom, prenomFROM PersonnesWHERE age = 30;
Les mots réservés du langage ne sont pas sensibles à la casse
83/196
Le renommage en SQL
Possible sur les attributs dans la clause ’SELECT’ et sur lesrelations dans la clause ’FROM’Mot clé réservé AS
SELECT DISTINCT nom [AS] "Mes enfants"FROM Personnes [AS] PWHERE [P.]age = 12;
AS est optionnel !Résolution d’ambiguïtés :On prefixe l’attribut par le nom de sa relation, i.e. relation.nom
84/196

Conditions complexes
Mots clés AND, OR, NOT et parenthèses pour former desexpressions complexesPermettent de former des formules de sélection complexes
SELECT DISTINCT nom, prenomFROM PersonnesWHERE (age = 12) AND (nss > 8932);
85/196
Douceurs syntaxiques : les caractères jockers
⇒ ne s’exprime pas en algèbre relationnelle
Dans la clause ’SELECT’ :On peut lister tous les attributs avec le caractère ’*’Dans la clause ’WHERE’ :
I Mot clé LIKE avec les caractères jockers : %,_
SELECT DISTINCT nomFROM PersonnesWHERE prenom LIKE ’J%’;
I Expressions arithmétiques usuelles sur les valeurs retournées
SELECT DISTINCT nom, age-10FROM Personnes
86/196

Jointure naturelleExemple"Nom, prénom des personnes et les départements dans lesquels ilstravaillent ?"
I πnom,prenom,dep(Personnes ./ Travaillent)I {x2 : nom, x3 : prenom, y1 : dep|∃x1 : nss(∃x4 :
age(Personne(x1, x2, x3, x4))) ∧ ∃y1 : nss(∃y2 : dep∃y3 :activite(Travaille(y1, y2, y3)))) ∧ x1 = y1}
I Q(x , y , z) ` Personne(x ′, x , y ,_),Travaille(x ′,_, z)
⇒ en SQL :
SELECT DISTINCT nom, prenom, depFROM Personnes NATURAL JOIN Travaillent
SELECT DISTINCT nom, prenom, depFROM Personnes, TravaillentWHERE Personnes.nss = Travaillent.nss;
87/196
Que pensez vous de l’hypothèse URSA pour les noms d’attributs enSQL ?
88/196

Produit cartésien
Il suffit de ne pas expliciter d’attributs de jointure
SELECT *FROM Personnes CROSS JOIN Travaillent
ou
SELECT *FROM Personnes, Travaillent
NB : Si un attribut A apparaît dans les 2 tables, le résultat aura Aet A1.
89/196
Les opérateurs ensemblistes en SQL
L’union, l’intersection et la différence sont représentésrespectivement par les mots clés UNION, INTERSECT et MINUS.Les deux opérandes doivent avoir le même schéma.Sur l’exemple, schema(R) = schema(S) = { A, B }.
SELECT A, BFROM RUNIONSELECT A, BFROM S
Ces trois opérations forcent la sémantique ensembliste par défaut
90/196

Douceurs syntaxiques : composition de requêtes
Le résultat d’une requête SFW peut être utilisé dans la clauseFROM ou WHERE d’une autre requête⇒ En cas d’ambiguité, utiliser des parenthèses
Les sous-requêtes de la clause ’WHERE’ sont introduites par lesmots clés IN, EXISTS, ANY, ALL
ExerciceEcrire en SQL l’expression algébrique de la division avec −, π,×(cf. diapo 35)
⇒ Beaucoup de sucre syntaxique possible avec SQL, voir coursSGBD en 3IF
91/196
OutlineLe modèle relationnel
La structureLangages de requêtes
L’algèbre relationnelleLe calcul relationnelEquivalence des langages relationnelsSQL (Structured Query Language)
Les contraintesLes dépendances fonctionnelles et les clésLes dépendances d’inclusion et les clés étrangèresRaisonnement sur les dépendances fonctionnellesLes relations d’Armstrong
Conception des bases de donnéesApproche basée sur les contraintesApproche basée sur le modèle Entité-Association
Le modèle Entité-AssociationConception avec Entité-AssociationTraduction entre modèles
Index92/196

Les contraintes d’intégrité
L’idée de base est de fournir des moyens qui permettent derestreindre les données “valides” d’une base de données⇒ on ne peut pas insérer tout et n’importe quoi⇒ La mise en œuvre de cette notion se fait via des contraintesd’intégrité : “ déclarations logiques qui permettent de restreindrele domaine actif d’une base de données”
ExempleUn numéro de sécurité social ne peut pas être le même pour deuxpersonnes différentes.⇒ notion de cléUn employé ne peut pas être affecté à un numéro de projet quin’existe pas⇒ notion de clé étrangère
93/196
Dépendances fonctionnelles (DF)
Concept très important, inhérent à la modélisation des données⇒ à la base de la théorie de la conception des bases de données.Intérêts pratiques :
I permet de définir formellement la notion de bons schémas⇒ ceux pour lesquels il n’existe pas d’anomalies lorsd’insertions, de modifications, ou de suppressions de tuples.
I généralise la notion de clé (dans les SGBD, clé primaire etcontrainte d’unicité).
94/196

Exemple
ExempleSoit U = {id , nom, adresse, cnum, desc , note} un univers décrivantdes étudiants et des cours.Soient les deux schémas de BD suivants :
I R1 = {Donnees} avec schema(Donnees) = UI et R2 = {Etudiant,Cours,Affectation} avec schema(Etudiant)
= {id , nom, adresse}, schema(Cours) = {cnum, desc},schema(Affectation) = {id , cnum, note}
Comment peut-on évaluer ces deux schémas de données ?Lequel est "meilleur" ? Pourquoi ? Selon quels critères ?NB : données de R1 ' données d’un tableur
95/196
Un exemple de BD sur R1
Données id nom adresse cnum desc note124 Jean Paris F234 Philo I A456 Emma Lyon F234 Philo I B789 Paul Marseille M321 Analyse I C124 Jean Paris M321 Analyse I A789 Paul Marseille CS24 BD I B
Quels sont les problèmes ?I l’information est redondante.
Ex : ’124, Jean, Paris’ apparaît dans deux lignes différentes⇒ Anomalie de modificationUne modification sur une ligne peut nécessiter desmodifications sur d’autres lignes
96/196

Exemple (suite)
I Certaines informations dépendent de l’existance d’autresinformationsEx : Le cours ’CS24’ de BD dépend de l’existance de Paul.⇒ Anomalie de suppression
I Valeurs manquantes (pas de valeurs nulles dans le cours)Ex : Soit ’145, Calixte, Aubenas’ un nouvel étudiant. On nepeut l’insérer que si l’on connait un de ses cours et sa notedans ce cours, à moins de permettre les valeurs nulles.⇒ Anomalie d’insertion
⇒ Le moyen simple qui permet d’éviter ces problèmes est l’étude decontraintes particulières, les dépendances fonctionnelles.
97/196
Syntaxe et sémantique des DF
I Définition (ou syntaxe)Une DF sur un schéma R est une déclaration de la forme :R : X → Y , où X ,Y ⊆ schema(R)
I Satisfaction d’une DF (ou sémantique)Une DF R : X → Y est satisfaite par une relation r sur R ,noté r |= X → Y , ssi ∀t1, t2 ∈ r si t1[X ] = t2[X ] alorst1[Y ] = t2[Y ]
ExempleQue pensez-vous de ces deux assertions ?Donnees |= id → nom, adresseDonnees 6|= id → note
98/196

Raisonnement sur les DF
On peut raisonner sur les DF, par exemple A→ B,C est équivalentà A→ B,A→ C
Définition informelle d’une clé : une clé est un ensemble (minimal)d’attributs tel que il n’est pas possible d’avoir deux tuples avec lamême valeur sur la clé (sinon serait un contre-exemple).
⇒ Notions théoriques sous-jacentes développées après
99/196
Les formes normales (suite de la 1FN)
Permettent de spécifier formellement la notion intuitive de bonsschémasPour les DFs, plusieurs formes normales (FN) existent : 1FN (moinsrestrictive) , 2FN, 3FN, FN de Boyce-Codd (FNBC) (plusrestrictive).
Idée de la FNBC : ne représenter l’information qu’une seule fois.
DefinitionUn symbole de relation R est en FN de Boyce-Codd par rapport àun ensemble F de DF ssi pour toutes les dépendances (nontriviales) de F , leurs parties gauches sont des clés.
⇒ évite les problèmes de redondance et d’anomalie identifiésprécédemment
100/196

Retour sur l’exemple
ExercicePeupler une base de données définie sur R2 à partir des données deR1.
Qu’en est il des problèmes de MAJ soulevés avec R1 ?
Etant donné U et les dépendances fonctionnelles suivantes : F ={{id} → {nom, adresse}, {cnum} → {desc}, {cnum, id} → {note}}
Que pensez vous des parties gauches des DF sur R1 ?Sur R2 ?
101/196
Dépendances d’inclusion (DI)
Concept clé pour la conception de schémas de BDs⇒ comparable aux DFs, i.e. permet de dissocier les bons desmauvais schémas
Les DF permettent de spécifier des contraintes intra-relations⇒ les DIs permettent de spécifier des contraintes inters-relations
Les DF généralisent les clés⇒ les DIs généralisent les clés étrangères
102/196

Retour sur la BD sur R2
En terme de mises à jour de la BD, on peut encore insérer desdonnées non valides.
ExempleSANS violer aucune DF, on peut donner une note à un étudiant quin’existe pas et ce, dans un cours qui n’existe pas non plus ! ! !⇒ l’idée est à nouveau de restreindre les insertions permises enspécifiants deux nouvelles contraintes : “ une note ne peut êtresaisie que pour un étudiant qui existe dans la relation Etudiants etun cours qui existe dans la relation Cours”
103/196
Syntaxe des DI
ATTENTION : on parle de séquences d’attributs distincts pour lesDI, à ne pas confondre avec les ensembles.Stricto sensus, on devrait redéfinir les opérateurs ensemblistesusuels pour les séquences ...
DefinitionSoient R un schéma de base de données R1 et R2 deux schémas derelation de R.Une dépendance d’inclusion sur R est une déclaration de la formeR1[X ] ⊆ R2[Y ], avec X et Y des séquences d’attributs distinctsappartenant à schema(R1) et schema(R2) respectivement.
ExempleAffectation[id] ⊆ Etudiant[id]Affectation[cnum] ⊆ Cours[cnum]
104/196

Sémantique des DI
DefinitionSoient d une base de données sur R et r1, r2 ∈ d définies surR1,R2 ∈ R respectivement.Une dépendance d’inclusion R1[X ] ⊆ R2[Y ] est satisfaite par d ,noté d |= R1[X ] ⊆ R2[Y ], ssi ∀t1 ∈ r1, ∃t2 ∈ r2 tq t1[X ] = t2[Y ]
NB : d |= R1[A1, . . . ,An] ⊆ R2[B1, . . .Bn], ssiπX (r1) ⊆ ρB1→A1(. . . (ρBn→An(πY (r2))) . . .)
Exemple{ Affectations, Etudiants } |= Affectation[id] ⊆ Etudiant[id]{ Affectations, Cours } |= Affectation[cnum] ⊆ Cours[cnum]⇒ Les clés étrangères sont des cas particuliers de dépendancesd’inclusion
ExerciceDonner une définition des clès étrangères en fonction des clés etdes DIs.
105/196
Règles d’inférence pour les dépendances d’inclusion
Soit I un ensemble de DI sur un schéma de base de donnéesR = {R1, . . . ,Rn}Système d’axiomes de Casanova et al. :
I Reflexivité : si X ⊆ schema(R), alors I ` R[X ] ⊆ R[X ]
I Projection et permutation : si I ` R1[X ] ⊆ R2[Y ] oùX = {A1, . . . ,Am} ⊆ schema(R1),Y = {B1, . . . ,Bm} ⊆ schema(R2) et i1, . . . , ik est uneséquence de nombres naturels de {1, . . . ,m}, alorsI ` R1[Ai1 , . . . ,Aik ] ⊆ R2[Bi1 , . . . ,Bik ]
I Transitivité : si I ` R1[X ] ⊆ R2[Y ] et I ` R2[Y ] ⊆ R3[Z ], alorsI ` R1[X ] ⊆ R3[Z ]
ThéorèmeLe système d’axiomes de Casanova et al. est juste et complet
106/196

Le modèle relationnelLa structureLangages de requêtes
L’algèbre relationnelleLe calcul relationnelEquivalence des langages relationnelsSQL (Structured Query Language)
Les contraintesLes dépendances fonctionnelles et les clésLes dépendances d’inclusion et les clés étrangèresRaisonnement sur les dépendances fonctionnellesLes relations d’Armstrong
Conception des bases de donnéesApproche basée sur les contraintesApproche basée sur le modèle Entité-Association
Le modèle Entité-AssociationConception avec Entité-AssociationTraduction entre modèles
Index107/196
Retour sur les dépendances fonctionnelles
107/196

Raisonnement sur les DF
Les DF sont à la source de la théorie de la conception des bases dedonnées
Se retrouvent sous diverses formes :I Notion d’implication en Analyse Formelle de ConceptsI Notion de règles d’association en fouille de données
⇒ Pré-requis pour aller plus loin
108/196
Ensemble de DF
Soient F et G deux ensembles de DF sur R .⇒ F et G peuvent être différents syntaxiquement mais équivalentssémantiquement, i.e. ils représentent les mêmes dépendances
Le problème de base est connu sous le terme du problèmed’implication : “Etant donnés un ensemble F de DF sur R et uneDF X → Y sur R, décider si F implique X → Y ”Autrement dit, peut on déduire ou prouver X → Y à partir de F ?
Deux approches classiques :I Théorie des modèlesI Théorie de la preuve
109/196

Théorie des modèles
Pour résoudre le problème d’implication, on examine toutes lesbases de données qui vérifient F et on teste si elles vérifient aussiX → Y .
Plus formellement :Soient F un ensemble de DF sur R et X → Y une DF sur R.F implique X → Y , notée F |= X → Y , ssi pour toute relation rsur R , si r |= F , alors r |= X → Y
⇒ on parle d’implication logique
110/196
Théorie de la preuve
Pour résoudre le problème d’implication, on construit une preuve deX → Y à partir de F en appliquant des règles d’inférence.
I Règles d’inférence d’Armstrong1. Réflexivité : si Y ⊆ X ⊆ schema(R), alors F ` X → Y2. Augmentation : si F ` X → Y et W ⊆ schema(R), alors
F ` XW → YW3. Transitivité : si F ` X → Y et F ` Y → Z , alors F ` X → Z
I Notion de preuve :Soient F un ensemble de DF sur R et X → Y une DF sur R.F implique X → Y , notée F ` X → Y , ssi on peut écrire unedérivation (ie. une preuve) qui à partir de F , utilise les règlesd’inférence d’Armstrong pour aboutir en un nombre finid’étape à X → Y .
111/196

Equivalence des deux approches
Les deux approches coïncident, i.e. il existe une équivalence entreles deux approches
ThéorèmeLe système d’inférence d’Armstrong est juste (F ` X → Y⇒ F |= X → Y ) et complet (F |= X → Y ⇒ F ` X → Y ).cf Livres de la diapo 5 pour la preuve
En pratique, on pourra utiliser l’un ou l’autre des sigles (|= ou `)pour représenter l’implication.
112/196
Petite distraction ...
113/196

Une "ola" dans un amphi
On va simplifier la représentation de l’amphi : On le voit commeune matrice avec n lignes (les rangées) et m colonnes (demande unpeu plus d’imagination ...)On considère l’univers comme l’ensemble des positions possibles, ensupposant que toutes les positions sont occupées par un étudiant
U = {(i , j)|i = 1..n, j = 1..m}⇒ U représente donc l’ensemble des étudiants
(1, 1) . . . (1,m)...
......
(n, 1) . . . (n,m)
La colonne 1 est considérée "la plus à gauche" et la ligne 1 "la plushaute".
114/196
Règles du jeu
On considère les règles (ou implications) suivantes sur lesétudiants : (que vous pouvez voir “comme des DFs” sur U) :
I Si les étudiants d’une "colonne" de l’amphi vérifient unecondition, alors le premier étudiant en haut de la colonnesuivante (i.e. à droite) la vérifie aussi"
I Si un étudiant et son voisin situé la rangée immédiatement audessus et à droite vérifient une condition, alors son voisinimmédiatement à sa droite la vérifie aussi.
On peut modéliser ces règles comme suit :
I F = {{(1, j), (2, j), . . . , (n, j)} → {(1, j + 1)} | j = 1..m − 1}I F = F ∪{{(i , j), (i − 1, j + 1)} → {(i , j + 1)} | i = 2..n, j = 1..m − 1}
115/196

De façon plus concrète
Soit E ⊆ U un sous-ensemble des étudiants.
Supposons deux choses :I les étudiants du groupe E décident une action, par exemple de
lever les bras au ciel. C’est la condition à vérifier.I Les règles de F permettent de “propager” cette action
116/196
Un regard différent sur les DFs
Quelques questions :I Soit un étudiant dans l’amphi. S’il est le seul à lever les bras
au ciel, que se passe t il ?I Soit E les étudiants les plus à gauche (i.e. de la première
colonne) de l’amphi.I S’ils lèvent les bras au ciel, que se passe t il ?I Si tous sauf un le font, que se passe t il ?
I Quels sont les plus petits groupes d’étudiants qui garantissentqu’il y ait une ola dans l’amphi ?
Les notions sur les DFs ont un caractère universel !
117/196

Fin de la distraction !
118/196
Algorithmique pour le problème d’implication
Ramener le problème d’implication F |= X → Y à un test defermeture sur un ensemble d’attributs
DefinitionSoit X ⊆ schema(R) et F un ensemble de DF sur RLa fermeture de X par rapport à F , notée X+
F , est définie par :
X+F = {A ∈ schema(R) | F |= X → A}
PropriétéF |= X → Y ssi Y ⊆ X+
F
Algorithme ?
119/196

Algorithme de calcul de fermeture
Algorithme CLOSURE(X, F)Data: X , un ens d’attribut ; F un ens de DF sur RResult: X+, la fermeture de X par rapport à FX+ := X ;fini := false ;while not fini do
fini := true ;foreach W → Z ∈ F do
if W ⊆ X+ and Z 6⊆ X+ thenX+ := X+ ∪ Z ;fini := false ;
Return(X+)
120/196
Fermé et système de fermeture
Soit F un ensemble de DFs sur R et X ⊆ schema(R).
DefinitionX est fermé par rapport à F si X = X+
F
On note CL(F ) l’ensemble des fermés de F , i.e.CL(F ) = {X |X = X+
F }et IRR(F ) ses éléments irréductibles par intersection, i.e.IRR(F ) = {X ∈ CL(F )| pour tout Y ,Z ∈ CL(F )(X = Y ∩ Z )⇒ (X = Y ou X = Z )}
⇒ schema(R) ∈ CL(F )⇒ schema(R) 6∈ IRR(F ) car schema(R) = ∩{} par conventionRemarque
L’application .+F est un opérateur de fermeture sur schema(R)
121/196

Equivalence des ensembles de DFs
Soient F et G deux ensembles de DF sur R.
DefinitionLa fermeture de F, notée F+, est définie parF+ = {X → Y | F |= X → Y }
DefinitionF et G sont équivalents, noté F ≡ G , si F+ = G+
PropriétéF ≡ G ssi CL(F ) = CL(G )
122/196
Couverture d’ensemble de DF
Une couverture F (ou base) d’un ensemble K de DF est unensemble de DF équivalent à K . Une couverture F de K est dite :
I non redondante si F ⊆ K , 6 ∃G ⊂ F tel que G+ = F+
I minimale si 6 ∃G tel que G+ = F+ et |G | < |F |I optimale si 6 ∃G tel que G+ = F+ et ||G || < ||F || avec||F || = ∑
X→Y∈F |X |+ |Y |
123/196

Retour sur la notion de clé
⇒ Les clés sont des cas particuliers de dépendances fonctionnelles
Soit F un ensemble de DF sur R et X ⊆ schema(R).
I SupercléX est une superclé de R par rapport à F siF |= X → schema(R) (ou X+
F = schema(R))I Clé
X est une clé (ou clé minimale) pour F ssi X est une supercléde R et 6 ∃Y ⊂ X ,Y superclé de R
124/196
Projection de F sur un sous ensemble d’attributs
Soient U l’univers, F un ensemble de DF sur U et S ⊂ U
La projection de F sur S , notée F [S ], est définie par :F [S ] = {X → Y | F |= X → Y ,X ∪ Y ⊆ S}
ExempleSoient F = {A→ B,B → C ,A→ C} etF ′ = {A→ B,B → C ,C → A} deux ensembles de DFs sur{A,B,C}.On considère les sous-ensembles suivants :S1 = {A,B}, S2 = {B,C}Calculer F [S1],F [S2],F ′[S1],F ′[S2]
125/196

Forme normale
On suppose que F ne contient aucune DF triviale (X → Y avecY ⊆ X )
DefinitionUn attribut A ∈ schema(R) est dit un attribut prime par rapport àF si A est inclu dans une clé de R par rapport à F .
DefinitionUn symbole de relation R est en 3e forme normale (3NF) parrapport à F si pour toute DF X → Y de F , X est une clé (pasforcément minimale) de F ou Y possède un attribut prime.
DefinitionUn symbole de relation R est en forme normale de Boyce-Codd(BCNF) par rapport à F si pour toute DF X → Y de F , X est uneclé (pas forcément minimale) de F .
126/196
Le modèle relationnelLa structureLangages de requêtes
L’algèbre relationnelleLe calcul relationnelEquivalence des langages relationnelsSQL (Structured Query Language)
Les contraintesLes dépendances fonctionnelles et les clésLes dépendances d’inclusion et les clés étrangèresRaisonnement sur les dépendances fonctionnellesLes relations d’Armstrong
Conception des bases de donnéesApproche basée sur les contraintesApproche basée sur le modèle Entité-Association
Le modèle Entité-AssociationConception avec Entité-AssociationTraduction entre modèles
Index127/196

Utilité et intérêt
Représentation "par l’exemple" d’ensemble de contraintes : onmanipule des valeurs, visualisation plus simple des éventuelsconflits, incohérences, mauvaise conception ...Deux principaux domaines d’application :
I Conception par l’exempleI Échantillonnage, compréhension des bases de données
existantes
Idée : Représenter sur un exemple un ensemble de contraintes etque celui la, i.e. toutes les autres contraintes sont fausses
127/196
Relations d’Armstrong pour les DFs
Soit r une relation sur R , F un ensemble de DFs sur R et X → Yune DF sur R .
Definitionr est une relation d’Armstrong par rapport à F si r |= X → Y si etseulement si F |= X → Y
128/196

Relations d’Armstrong pour les DFs (cont.)
Problème d’existence ?I Existent toujours pour les DF standards (partie gauche des
DFs non réduite à l’ensemble vide)
Caractérisation des relations d’Armstrong ?On définit :
I ag(t1, t2) = {A ∈ schema(R)|t1[A] = t2[A]}I ag(r) = {ag(t1, t2)|t1, t2 ∈ r}
Soit r une relation sur R et F un ensemble de DFs standards sur R
Theoremr est une relation d’Armstrong pour F ssi IRR(F ) ⊆ ag(r) ⊆ CL(F )Rappel : X ∈ IRR(F ) ssi pour tout Y ,Z ∈ CL(F )(X = Y ∩ Z )⇒ (X = Y ou X = Z )
129/196
Construction
Principe de la construction : insérer autant de contre-exemples qu’ilexiste de DF non satisfaites !
Quel lien avec les ensembles en accord ?⇒ ag(t1, t2) donne tous les contre-exemples des 2 tuples
Principe de la construction de relations d’Armstrong :
1. à partir de F , calculer une représentation de CL(F )2. initialiser la relation d’Armstrong r avec un unique tuple, soit
t0 composé de 03. (étape i) pour chaque élément X de la représentation de
CL(F ), ajouter un tuple ti à r tqI ti [A] = 0 pour tout A ∈ X etI ti [B] = i pour tout B ∈ (schema(R)− X )
130/196

OutlineLe modèle relationnel
La structureLangages de requêtes
L’algèbre relationnelleLe calcul relationnelEquivalence des langages relationnelsSQL (Structured Query Language)
Les contraintesLes dépendances fonctionnelles et les clésLes dépendances d’inclusion et les clés étrangèresRaisonnement sur les dépendances fonctionnellesLes relations d’Armstrong
Conception des bases de donnéesApproche basée sur les contraintesApproche basée sur le modèle Entité-Association
Le modèle Entité-AssociationConception avec Entité-AssociationTraduction entre modèles
Index131/196
Avant propos
Deux approches principales :I approche dite de la relation universelleI approche dite conceptuelle
Relation universelle :on spécifie des attributs (l’univers) puis des contraintes(principalement des DF) et on produit des schémas de relationsdans une certaine forme normale
I 3FN : Algorithme de synthèseI FNBC : Algorithme de décomposition
Approche conceptuelle :on définit de nouvelles abstractions pour modéliser les données afinde se rapprocher “le plus possible” du monde réel que l’on souhaitemodéliser.
132/196

OutlineLe modèle relationnel
La structureLangages de requêtes
L’algèbre relationnelleLe calcul relationnelEquivalence des langages relationnelsSQL (Structured Query Language)
Les contraintesLes dépendances fonctionnelles et les clésLes dépendances d’inclusion et les clés étrangèresRaisonnement sur les dépendances fonctionnellesLes relations d’Armstrong
Conception des bases de donnéesApproche basée sur les contraintesApproche basée sur le modèle Entité-Association
Le modèle Entité-AssociationConception avec Entité-AssociationTraduction entre modèles
Index133/196
Algorithmes de normalisation
Pré-requis : phase de modélisation du monde réelI énumérer les attributs importants, i.e. construction de l’univers
du discours UI spécifier les contraintes, principalement les dépendances
fonctionnelles entre ces attributsUtiliser les contraintes pour décomposer U en un ensemble desymboles de relation en FNBC⇒ Assurer des propriétés pour cette décomposition :⇒ Algorithmes de normalisation :
I Algorithme de décompositionI Algorithme de synthèse
134/196

Quelles propriétés ?
Quelles sont les propriétés naturelles qu’il faudrait respecter ?
I Décomposition sans perte de jointure⇒ aucune donnée n’est perdue
I Préservation des dépendances⇒ toutes les dépendances sont conservées
Propriétés pas toujours atteignables
135/196
Définitions
Une décomposition d’un symbole de relation R est un ensemble desymboles de relations {R1, . . . ,Rn} tel que :
I ∀Ri , schema(Ri ) ⊆ schema(R), etI schema(R) =
⋃ni=1 schema(Ri )
136/196

Définitions (suite)
Soient R un symbole de relation, F un ensemble de DF sur R etR = {R1, . . . ,Rn} une décomposition de R .R est une décomposition sans perte (de jointure) de schema(R)par rapport à F si pour toute relation r sur schema(R), on a :
r = πR1(r) ./ . . . ./ πRn(r)
137/196
Définitions (fin)
R est une décomposition de schema(R) qui préserve les DF de Fsi :
F+ = (F [R1] ∪ . . . ∪ F [Rn])+
ExempleSoient schema(R) = ABC et F = {A→ B,B → C ,A→ C}On considère la décomposition en deux schémas {A,B}, {B,C}Cette décomposition préserve les DF de F ?
138/196

Le problème de décomposition
Etant donnésI un symbole de relation R etI un ensemble de DFs F sur R
Trouver une décomposition de R qui vérifie les propriétésprécédentes
139/196
Algorithme de synthèse
Principe :I Déterminer une couverture minimale G de F,I Réduire les parties gauches et droites des DF de G,I Créer un symbole de relation pour chaque DF de G
Intuition : on réduit F de telle façon que toute DF de G donneraun symbole de relation⇒ préserve les dépendances !
140/196

Calcul d’une couverture minimale
Algorithme Minimum(F )Data: F , un ens de DF sur RResult: G , une couverture minimale de FG := ∅foreach X → Y ∈ F do
G := G ∪ {X → X+F }
foreach X → X+F ∈ G do
Soit G ′ = G − {X → X+F }
if G ′ ` X → X+F then
G := G − {X → X+F }
141/196
Algorithme de synthèse (suite)
Sur l’algorithme précédent :G ′ ` X → X+
F est équivalent à X+F ⊆ X+
G ′
⇒ cf Propriété 3 slide 120
Le principe algorithmique est le même pour minimiser les partiesgauches puis droites des DF
142/196

Algorithme de synthèse (suite)
Comment assurer que la décomposition produite est sans perte dejointure ?
PropriétéSoient R un symbole de relation, F un ensemble de DF sur R etR = {R1, . . . ,Rn} une décomposition de R.Si R préserve les DF de F et qu’il existe un schema Ri de R tel queschema(Ri ) est une clé par rapport à F alors R est unedécomposition sans perte de jointure
143/196
AlgorithmeAlgorithme Synthèse(R,F )Data: F , un ens de DF sur RResult: Out, une décomposition de R selon FOut = ∅ ;F ′ = Minimum(F ) ;foreach X → Y ∈ F ′ do
Minimiser X par rapport à F ′ ;Minimiser Y par rapport à F ′ ;
foreach X → Y ∈ F ′ doif X ∪ Y n’apparaît pas déjà dans un schéma de relation then
Soit Ri un symbole de relation avec schema(Ri ) = X ∪ Y ;Out+ = Ri ;
if 6 ∃Ri tel que schema(Ri ) soit une clé thenSoit S tel que schema(S) soit clé par rapport à F ;Out+ = S ;
return(Out) ;
144/196

Résultats
ThéorèmeSynthese(R,F ) retourne une décomposition sans perte de jointurepréservant les dépendances de schema(R). Cette décomposition esten 3FN par rapport à F.
145/196
Algorithme de décomposition
Algorithme récursif, représentation par un arbre de décomposition
Algorithme Décompose(R,F )Data: F , un ens de DF sur RResult: Out, une décomposition de R selon Fif R est en FNBC par rapport à F then
return(R) ;else
Soit X → Y une DF non triviale de F tel que X+F 6= R ;
Décompose(XY ,F [XY ]) ;Décompose(R − (Y − X ),F [R − (Y − X )]) ;
146/196

Résultats
Plusieurs choix possibles (ligne 4) pour prendre X → Y⇒mène à des décompositions différentes, certaines plus naturellesque d’autres
ThéorèmeDécompose(R,F ) retourne une décomposition sans perte dejointure de schema(R). Cette décomposition est en BCNF parrapport à F.
147/196
Exemple
ExempleSoient R un symbole de relation avec schema(R) = {A,B,C} etF = {AB → C ,C → A}
I Appliquer l’algorithme de synthèse et l’algorithme dedécomposition sur R.
I Commenter vos résultats
148/196

Exemple sur la "Gestion de cours"
Soit U = {C ,P,H, S ,E ,N} représentant les attributs Cours,Professeur, Heure, Salle, Etudiant et Note respectivement.Soient les contraintes suivantes :F = {C → P,HS → C ,HP → S ,CE → N,HE → S}Exercice :
I Décomposer U en FNBCI Synthétiser U en 3FN
149/196
Le modèle relationnelLa structureLangages de requêtes
L’algèbre relationnelleLe calcul relationnelEquivalence des langages relationnelsSQL (Structured Query Language)
Les contraintesLes dépendances fonctionnelles et les clésLes dépendances d’inclusion et les clés étrangèresRaisonnement sur les dépendances fonctionnellesLes relations d’Armstrong
Conception des bases de donnéesApproche basée sur les contraintesApproche basée sur le modèle Entité-Association
Le modèle Entité-AssociationConception avec Entité-AssociationTraduction entre modèles
Index150/196

OutlineLe modèle relationnel
La structureLangages de requêtes
L’algèbre relationnelleLe calcul relationnelEquivalence des langages relationnelsSQL (Structured Query Language)
Les contraintesLes dépendances fonctionnelles et les clésLes dépendances d’inclusion et les clés étrangèresRaisonnement sur les dépendances fonctionnellesLes relations d’Armstrong
Conception des bases de donnéesApproche basée sur les contraintesApproche basée sur le modèle Entité-Association
Le modèle Entité-AssociationConception avec Entité-AssociationTraduction entre modèles
Index150/196
Exemples de modèles conceptuels
Le plus connu en France est le Modèle Entité-Association (ouEntité-Relation)
I Modèle conceptuel des données (MCD) de la méthode deconception des systèmes d’information MERISE
I se retrouve avec des variantes dans les méthodes deconception de logiciels (e.g. OMT, RUP)
Définit en 1974 !De nombreuses extensions du modèle EA existent ...Les aspects dynamiques, processus ne sont pas pris par encompteDu fait du haut niveau d’abstraction, les langages n’ont pas étédéveloppésLes contraintes restent anecdotiques de part leur puissancestructurelle
151/196

Intérêts des modèles conceptuels
1. Réduire la "distance sémantique" entre le domained’application et sa représentation "informatique"
I modélisation du monde réél plus naturelle, plus directeI dialogue plus aisé entre informaticiens et utilisateursI aucune considération d’implémentationI produit souvent des schémas de relation déjà normalisés
2. Représentation graphique des constructeurs⇒ très intuitives : facilité d’utilisation, convivialité de laconception⇒ Pour autant, syndrome des “flèches/patates” possible
152/196
suite
3. Mécanismes d’abstraction pour représenter les données :I Classification : regrouper les objets similaires dans une "entité"
ou un attribut (en gommant les différences entre les objets)I Agrégation : obtenir une nouvelle entité à partir
d’objets/attributs existants
153/196

Modèles conceptuels/logiques/physiques
I Un modèle EA est un modèle conceptuelI Le modèle relationnel est un modèle logiqueI Les éléments du langage C++ pour coder les données⇒modèle physique
Les différences des uns par rapport aux autres impliquent une étapede traduction de schémas
154/196
Modèles conceptuels vs modèles logiques/physiques
Par rapport aux trois composantes du modèle relationnel, lesmodèles conceptuels de données ont :
I une limite structure/contraintes moins nette⇒ Ceci est du en partie au nombre et à l’expressivité desconstructeurs dont on dispose dans un modèle conceptuel
I Peu de langages de requêtes
155/196

Limites des Modèles conceptuels
1. Relativisme sémantique : suivant notre perception d’undomaine d’application, on peut interpréter la mêmeinformation de façon différente⇒ pour un problème de modélisation donné, il n’existe pasUNE solution mais beaucoup de solutions possibles, certainesmeilleures que d’autres par rapport à des critères objectifs (lesDFs) ou subjectifs (le schéma est joli).
2. Représentation graphique des constructeurs ⇒ syndrôme des"flèches/patates" : on peut donc faire n’importe quoi ! ! !
3. Plusieurs modèles conceptuelsI Quelles modèles/extensions sont prises en compte ?I Quelles conventions pour les cardinalités ? (typiquement à la
UML ou à la Merise)⇒ pas un modèle conceptuel le même
156/196
EA : Un modèle conceptuel des données
On considère un modèle conceptuel type Entité-Association avecdes notations dites "américaines" pour l’interprétation descardinalités des associations⇒ Attention : pour ceux qui connaissent la méthode de conceptionde système d’information MERISE, la sémantique des notationssera différente.Les constructeurs sont introduits en se référant aux données réellesque l’on modélise
157/196

Les types d’entités
Ils sont formés à partir d’entités ou d’objets du monde réel qui ontdes caractéristiques communes, appelées des attributs.En clair, on choisit de regrouper dans un seul "concept" des objetsdont les similitudes sont plus grandes que les dissimilitudes.
Exempleon modélise les enfants d’une école. Par exemple on a Emma,Antoine, Claire et Arthur qui ont respectivement 7, 5, 7 et 10 ans.A partir de ces données, on propose un type d’entité Enfant avecquatre attributs : nom, prénom, age et école.
158/196
Représentation graphique
Figure: Un type d’entités
159/196
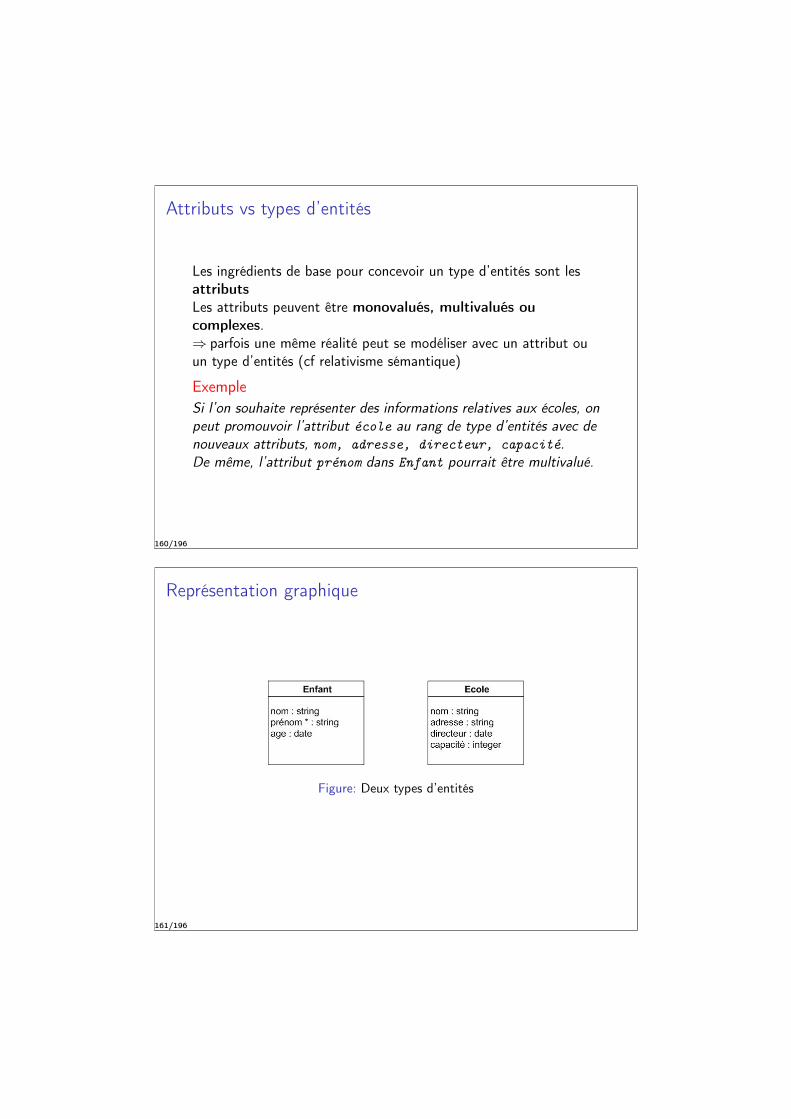
Attributs vs types d’entités
Les ingrédients de base pour concevoir un type d’entités sont lesattributsLes attributs peuvent être monovalués, multivalués oucomplexes.⇒ parfois une même réalité peut se modéliser avec un attribut ouun type d’entités (cf relativisme sémantique)
ExempleSi l’on souhaite représenter des informations relatives aux écoles, onpeut promouvoir l’attribut école au rang de type d’entités avec denouveaux attributs, nom, adresse, directeur, capacité.De même, l’attribut prénom dans Enfant pourrait être multivalué.
160/196
Représentation graphique
Figure: Deux types d’entités
161/196

Les clès dans les types d’entités
récupérées du modèle relationnel !On permet au concepteur de spécifier un sous ensemble desattributs du type d’entités comme étant un identifiant unique desobjets du monde réel représentés par ce type d’entités.Deux cas :
I il en existe au moins une de façon naturelleI il n’en existe pas de façon naturelle : on ajoute un attribut
(surrogate key) qui fera office de clé.
ExemplePour Enfant, on ajoute une clé, soit code alors que pour Ecole,on suppose que nom est un identifiant.On impose un identifiant à chaque type d’entités.
162/196
Représentation graphique
Figure: Deux types d’entités avec clés
163/196

Les types d’association
Ils sont identifiés à partir d’associations existantes entre les objetsdu monde réel de l’application qui sont devenus des types d’entités⇒ nécessite au moins deux types d’entités
Exempleon souhaite représenter l’association entre les enfants et leur école.Dans ce cas, on crée un nouveau type d’association e.g.scolariser à partir de Enfant et Ecole, avec un attribut datepour représenter la date d’entrée de l’enfant à l’école.⇒ Ne nécessite pas de définition de clés, bien que cela soit possible
164/196
Représentation graphique
Figure: Un type d’associations
165/196

Les types d’association (suite)
Un type d’entité E participant dans un type d’association A est ditavoir un rôle dans A.On parle aussi de patte entre E et A.Les types d’association les plus courant sont binaires, ils associentuniquement 2 types d’entités, soit A entre E1 et E2.Au niveau des données mises en jeu par l’association, on aA ⊆ E1 × E2 avecEi = {objets du monde reel représentés par Ei}, i ∈ {1, 2}
166/196
Les types d’association réflexifs
Si E1 = E2, on parle de types d’association réflexifs. Dans cecas, on est obligé de nommer les pattes de l’association pourcomprendre le sens de l’association.
ExempleReprésenter des employés caractérisés par un nom, un salaire et uncode et les managers de ces employés, i.e. les employés qui ont àgérer d’autres employés.1. en créant deux types d’entités (e.g. Employé et Manager) et
un type d’association (e.g. travailler)2. en créant un type d’entité et un type d’association
167/196

Cardinalité des types d’association
Permet d’être plus précis et surtout, de représenter des contraintesexistentielles, i.e. de participation des entités dans les associationsafin de restreindre le produit cartésien représenté par l’association
ExemplePour les enfants qui vont à l’école, on peut de façon plus précisedire : un enfant est scolarisé dans une seule école et une écolescolarise plusieurs enfants à partir des contraintes de l’applicationPour représenter ce type de contraintes, on va définir descontraintes de cardinalité maximales. Ces contraintes valent unou plusieurs et se notent sur les pattes des associations
168/196
Représentation graphique
Figure: Contraintes sur un type d’associations
169/196

Cardinalité (suite)
Les cardinalités sont des restrictions associées aux rôles.Les cardinalités maximales peuvent se voir comme des dépendancesfonctionnelles entre les attributs clés des types d’entitésparticipants à l’associationOn peut aussi définir des contraintes de cardinalités minimales :permettent de spécifier des contraintes de participation des entitésdans les associations. Valent soit 1 soit 0.NB : afin de simplifier, ces contraintes ne seront pas utilisées dansce cours
170/196
Les types d’association n-aires
Les associations binaires se généralisent aux associations n-aires ...• La difficulté concerne la sémantique de ces associations n-aires,
i.e. leur signification.
Soit A un type d’association entre E1, . . . ,En. On considère quechaque Ei représente l’ensemble des objets qu’il modélise.
Soit A ⊆ E1 × E2 × . . .× En, l’ensemble des instances possibles deA, i.e. un sous ensemble du produit cartésien des entitésparticipantes.
171/196

Les types d’association n-aires (fin)
On considère une patte p de l’association, soit entre A et Ei . Lacardinalité maximale m pour p est soit 1, soit N.
I si m = 1, cela signifie que l’on ne peut pas avoir deux élémentsde A tel que ils soient égaux sur tout excepté sur la ièmecomposante, i.e. en Ei
I si m = N, il n’y a pas de restriction sur A entre les (n-1)composantes et Ei
⇒ peu utilisés en dépit de leur fort intérêt
172/196
Les types d’entités faibles
Ce sont des types d’entités particulier : ils nécessitent d’autrestypes d’entités pour assurer leur identification⇒ on peut les voir comme une première forme d’association
Exempleon souhaite représenter par période de 6 mois le poids et la tailledes enfants. Par exemple, Emma est née à 3kg850 et mesurait 50cm, à 6 mois elle faisait 6kg pour 60cm ...Dans ce cas, on crée un nouveau type d’entité dit faible, , e.g.DossierEnfant, à partir de Enfant avec comme attributssemestre, poids, taille.
173/196

Représentation graphique
Figure: Un type d’entités faible
174/196
Quelques extensions possibles
I Spécialisation/généralisation entre types d’entités ou typesd’associations
I Associations généralisées : on permet à une associationd’agréger indifféremment des types d’entités et des typesd’association
I Types d’entité faible à partir d’un type d’association
175/196

Spécialisation/Généralisation
Spécialisation : à partir d’une entité donnée, consiste à représenterune nouvelle entité qui est plus spécifique, i.e. qui disposed’attributs supplémentaires
Généralisation : à partir de plusieurs entités similaires, consiste àreprésenter une nouvelle entité qui factorise les propriétéscommunes aux différentes entités.
Notion d’héritage avec les langages à objet
176/196
Représentation graphique
Figure: Lien ISA
177/196

Associations généralisées
Permet d’associer indifféremment des types d’entités et des typesd’association
On utilise une flèche de type d’association qui associe vers le typed’association qui est associé⇒ explicite "qui associe qui"
Permet de capturer des contraintes "plus fines"
178/196
Représentation graphique
Figure: Association généralisée
179/196

Le modèle relationnelLa structureLangages de requêtes
L’algèbre relationnelleLe calcul relationnelEquivalence des langages relationnelsSQL (Structured Query Language)
Les contraintesLes dépendances fonctionnelles et les clésLes dépendances d’inclusion et les clés étrangèresRaisonnement sur les dépendances fonctionnellesLes relations d’Armstrong
Conception des bases de donnéesApproche basée sur les contraintesApproche basée sur le modèle Entité-Association
Le modèle Entité-AssociationConception avec Entité-AssociationTraduction entre modèles
Index180/196
Construction d’un schéma conceptuel
Quelles sont les caractéristiques du monde réel à modéliser ?⇒ Nécessite des entretiens avec les “clients”⇒ Lecture de documents de spécification quand ils existent⇒ Facteur d’échelle suivant l’ampleur du projet : besoin decoordonner, de collecter et d’uniformiser les éléments obtenusQuel est le modèle conceptuel retenu ?⇒ Si EA, quels constructeurs sont permis ?⇒ Bien s’entendre sur la signification des constructeurs et descardinalités
180/196

Construction d’un schéma conceptuel (suite)
Conseils de bon sens à partir d’un énoncé en langage naturel :
1. Décomposition du texte en propositions élémentaires : sujet -verbe - complément
2. Premières structures EAI sujet/complément → type d’entité ou attribut ;I verbe → type d’association
3. Intégration des structures EA dans un schéma global⇒ se méfier des homonymes, synonymes, informations nonpertinentes, non cohérentes
⇒ Le choix des noms est très important⇒ nécessite des qualités de dialogue de la part des informaticiensavec les personnes du domaine, les autres informaticiens ...
181/196
Approche conceptuelle : intérêts
Modélisation du monde réel plus facile de part les nombreuxéléments de modélisation disponibles
Production “naturelle” de schémas relationnels normalisés enBCNF !
Les 2 approches coïncident (cf TD)
182/196

Le modèle relationnelLa structureLangages de requêtes
L’algèbre relationnelleLe calcul relationnelEquivalence des langages relationnelsSQL (Structured Query Language)
Les contraintesLes dépendances fonctionnelles et les clésLes dépendances d’inclusion et les clés étrangèresRaisonnement sur les dépendances fonctionnellesLes relations d’Armstrong
Conception des bases de donnéesApproche basée sur les contraintesApproche basée sur le modèle Entité-Association
Le modèle Entité-AssociationConception avec Entité-AssociationTraduction entre modèles
Index183/196
Traduction entre modèles
Comment obtenir un schéma de bases de données à partir d’unschéma Entité-Association ?De façon abstraite, on s’intéresse à la traduction de modèlesorientés constructeurs (e.g. EA) vers des modèles orientésattributs (e.g relationnel).Les contraintes sont :
I implicites dans un modèle conceptuel (orienté constructeurs)I explicites dans un modèle logique (orienté attribut).
183/196

Approche développée
Présentation des différentes traductions possibles et évaluation dechacune d’elles vis à vis de la FNBCIl faut ajouter des attributs au niveau relationnel pour représentercorrectement certains constructeurs, typiquement les associations.Les contraintes implicites du modèle conceptuel vont devenir desDF ou des DI au niveau du modèle relationnel⇒ ensemble de "recettes de cuisine" utiles en pratiqueIl existe des approches formelles pour faire cela
184/196
Traduction évidente
Chaque type d’entités peut devenir un schéma de relation, dont leschéma contiendra les attributs mono-valués du type d’entitéconsidéréQuel est le problème posé par les attributs multivalués ?Par rapport à ce qui a été vu au niveau du modèle relationnel,qu’est ce qui a changé ?
ExempleTraduire le type d’entités Enfant en relationnel en considérant queprénom est soit monovalué soit multivalué.
185/196

Type d’association binaires
Soit A un type d’entités avec a une clé et a1, a2 deux attributs. SoitB un type d’entités avec b une clé et b1, b2 deux attributs.On considère un type d’association C entre A et B , ayant deuxattributs c1 et c2.On peut considérer que ces trois traductions sont représentatives :1. Trois symboles de relation A,B,C avec
schema(A) = {a, a1, a2}, schema(B) = {b, b1, b2},schema(C ) = {a, b, c1, c2}
2. Deux symboles de relation A,BC (ou dualement AC ,B) avecschema(A) = {a, a1, a2}, schema(BC ) = {b, b1, b2, c1, c2, a}
3. Un symboles de relationt AB , avecschema(AB) = {a, a1, a2, b, b1, b2, c1, c2}
Notez dans certains cas l’apparition de nouveaux attributs et lerespect de l’hypothèse de nommage URSA
186/196
Type d’association binaires (suite)
Quel type de contraintes peut-on représenter en relationnel ?Pour les DIs, on obtient :1. I = {C [a] ⊆ A[a],C [b] ⊆ B[b]}2. I = {BC [a] ⊆ A[a]}3. I = ∅
Pour les DFs, on obtient F = {a→ a1a2, b → b1b2, ab → c1c2}
187/196

Type d’association binaires : 1-1
Restreindre les associations va naturellement se traduire par l’ajoutde nouvelles DF : F = F ∪ {a→ b, b → a}Quelles sont les clès sur chaque schéma de relation ?Parmi les 3 traductions possibles, quelles sont celles qui sont enFNBC ?
188/196
Type d’association binaires : 1-N
On met le 1 entre A et C .On obtient : F = F ∪ {b → a}Quelles sont les clès sur chaque schéma de relation ?Parmi les 3 traductions possibles, quelles sont celles qui sont enFNBC ?
189/196

Type d’association binaires : N-N
Pour les trois traductions possibles, l’ensemble F des DFs nechange pas, i.e. on ne peut pas ajouter de nouvelles contraintes.Quelles sont les clès sur chaque schéma de relation ?Parmi les 3 traductions possibles, quelles sont celles qui sont enFNBC ?
190/196
Autres traductions
Type d’entités faiblesC’est un cas particulier de type d’association binaire N-N.
ExempleTraduire le type d’entités DossierEnfant en relationnel.Type d’entités spécialisée (issu d’un lien despécialisation/généralisation)C’est un cas particulier de type d’association binaire 1-1.
191/196
Exemple
Figure: Exemple
192/196
Du relationnel vers EA
⇒ connu sous le terme rétro-ingénierie (ou reverse engineering)Hypothèses requises pour obtenir un résultat intelligible
I soit toutes les contraintes sont connues, les schémas pouvantêtre quelconques
I soit aucune contrainte n’est connue, il faut alors deshypothèses de nommage forte
193/196

Exercice (inverse)
Retrouver le schéma Entité-Association de l’exemple vu en début decours sur les étudiants, les cours et leur notes (cf diapo 95)
1. Discuter des avantages/inconvénients des différentesalternatives de conception
2. Que pensez vous de l’apparition des valeurs nulles sur chacundes cas ?
194/196
OutlineLe modèle relationnel
La structureLangages de requêtes
L’algèbre relationnelleLe calcul relationnelEquivalence des langages relationnelsSQL (Structured Query Language)
Les contraintesLes dépendances fonctionnelles et les clésLes dépendances d’inclusion et les clés étrangèresRaisonnement sur les dépendances fonctionnellesLes relations d’Armstrong
Conception des bases de donnéesApproche basée sur les contraintesApproche basée sur le modèle Entité-Association
Le modèle Entité-AssociationConception avec Entité-AssociationTraduction entre modèles
Index195/196

Index des principaux termes
196/196
affectation (de variables à des constantes), 53algorithme de décomposition (FNBC), 148, 149algorithme de synthèse (3FN), 142, 146algèbre relationnelle, 23, 24, 37, 74arbre de requête, 40attribut, 10, 12
base de données, 20
calcul relationnel, 23, 45, 47, 74calcul relationnel autorisé, 60calcul relationnel de domaine (DRC), 47, 48calcul relationnel de tuple (TRC), 47clé, 125contraintes, 93couverture (ens. de DFs), 124
datalog, 23, 74difference, 28division, 34, 91
196/196

domaine, 12domaine actif (d’un attribut), 16domaine actif (d’une base de données), 20domaine actif (d’une relation), 16décomposition, 138–141dépendance d’inclusion (DI), 102, 104–106dépendance fonctionnelle (DF), 94, 98, 99, 102, 109, 110, 123, 125
ensemble de fermés, 122
Fermeture (Algo. de), 121fermé (ens. d’attribut), 122, 132forme normale, 14, 18, 127, 136forme normale de Boyce-Codd, 100formule autorisée, 67, 68
interprétation, 53intersection, 28, 32Irréductibles, 122
jointure, 30, 32, 87196/196
langages de requête, 23
modèle relationnel, 8, 77
normalisation, 136
première forme normale (1FN), 14, 18problème d’implication, 110produit cartésien, 32, 38, 89projection, 25, 83propriétés algébriques, 29, 35, 41
relation, 10, 15relation d’Armstrong, 129–132renommage, 33, 84requête autorisée, 68requete SQL, 80requêtes (algébriques), 39requêtes de calcul (DRC), 52requêtes récursives, 43
196/196

satisfaction (d’une formule), 54schema (de relation), 13selection, 83, 85SQL, 23, 76–79structure (relationnelle), 8symbole (de base de données), 18symbole (de relation), 13sélection, 26, 27
théorie de la preuve, 110, 112théorie des modèles, 110, 111troisième forme normale, 100tuple, 15, 17
union, 28union, intersection, difference, 90
variable, 48variable libre, 51variable liée, 51
196/196
variable negative, 65, 66variable positive, 64, 66
196/196






![LES GAZ ET L’ATMOSPHÈRE - Province of Manitoba · sulté le 5 avril 2013). [animation de la relation entre la pression et le volume d’un gaz] [R] ... relation entre la pression](https://static.fdocuments.fr/doc/165x107/5f40060cce100340a35ce119/les-gaz-et-laatmosphre-province-of-manitoba-sult-le-5-avril-2013-animation.jpg)










