
Evaluation parallèle de requêtes relationnelles sur...
189
N d’ordre 99 ISAL 0003 Année 1999 THESE présentée devant L’INSTITUT NATIONAL DES SCIENCES APPLIQUÉES DE LYON pour obtenir LE GRADE DE DOCTEUR FORMATION DOCTORALE : DEA d’Informatique de Lyon PAR Matthieu EXBRAYAT ÉVALUATION PARALLÈLE DE REQUÊTES RELATIONNELLES SUR RÉSEAU DE STATIONS — LE SYSTÈME ENKIDU Soutenue le 19 janvier 1999 devant la Commission d’Examen Jury MM. L. BRUNIE (Professeur à l’Institut National des Sciences Appliquées de Lyon - Examinateur) J. FERRIÉ (Professeur à l’Université Montpellier II - Examinateur) A. FLORY (Professeur à l’Institut National des Sciences Appliquées de Lyon - Directeur) A. HAMEURLAIN (Professeur à l’université Toulouse III - Rapporteur) L. LAKHAL (Professeur à l’Université Clermont II - Rapporteur) Cette thèse a été préparée au sein du Laboratoire d’Ingénierie des Systèmes d’Information de l’INSA de Lyon
-
Upload
truongcong -
Category
Documents
-
view
212 -
download
0
Transcript of Evaluation parallèle de requêtes relationnelles sur...

N d’ordre 99 ISAL 0003 Année 1999
THESEprésentée devant
L’INSTITUT NATIONAL DES SCIENCES APPLIQUÉES DE LYON
pour obtenir
LE GRADE DE DOCTEUR
FORMATION DOCTORALE : DEA d’Informatique de Lyon
PAR
Matthieu EXBRAYATÉVALUATION PARALLÈLE DE REQUÊTES RELATIONNELLES
SUR RÉSEAU DE STATIONS
—
LE SYSTÈME ENKIDU
Soutenue le 19 janvier 1999 devant la Commission d’Examen
Jury MM. L. BRUNIE (Professeur à l’Institut National des Sciences Appliquées de Lyon - Examinateur)
J. FERRIÉ (Professeur à l’Université Montpellier II - Examinateur)
A. FLORY (Professeur à l’Institut National des Sciences Appliquées de Lyon - Directeur)
A. HAMEURLAIN (Professeur à l’université Toulouse III - Rapporteur)
L. LAKHAL (Professeur à l’Université Clermont II - Rapporteur)
Cette thèse a été préparée au sein du
Laboratoire d’Ingénierie des Systèmes d’Information de l’INSA de Lyon

2

TABLE DES MATIÈRES 11
Table des matières
I Introduction 21
1 Problématique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
2 Principales contributions . . . . . . . . . . . . . . . . . . . . . . . . . . 23
3 Organisation du manuscrit . . . . . . . . . . . . . . . . . . . . . . . . . 24
II SGBD relationnels parallèles et réseaux de stations 27
1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
1.1 Rappels sur les SGBD relationnels . . . . . . . . . . . . . . . . 27
1.2 Parallélisation des SGBD relationnels . . . . . . . . . . . . . . 31
2 Principes de base des SGBD relationnels parallèles . . . . . . . . . . . 33
2.1 Techniques de répartition des données . . . . . . . . . . . . . 33
2.2 Techniques de parallélisation des traitements . . . . . . . . . . 37
2.3 Parallélisme inter-requêtes . . . . . . . . . . . . . . . . . . . . 43
2.4 SGBD relationnels parallèles . . . . . . . . . . . . . . . . . . . 45
3 Les réseaux de stations . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
3.1 Le concept de réseau de stations . . . . . . . . . . . . . . . . . 47
3.2 Communications dans les réseaux de stations . . . . . . . . . 49
3.3 Bibliothèques de programmation . . . . . . . . . . . . . . . . . 52
3.4 Machine parallèle ou réseau de stations? . . . . . . . . . . . . 55
4 Réseaux de stations et systèmes de gestion de bases de données pa-
rallèles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57

12 TABLE DES MATIÈRES
4.1 Systèmes commercialisés . . . . . . . . . . . . . . . . . . . . . 57
4.2 Prototypes universitaires . . . . . . . . . . . . . . . . . . . . . 60
5 Bilan . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
III Proposition d’un évaluateur parallèle 65
1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
1.1 Principe et raison d’être . . . . . . . . . . . . . . . . . . . . . . 65
1.2 Architecture Générale . . . . . . . . . . . . . . . . . . . . . . . 66
2 Composant serveur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
2.1 Gestionnaire de redistribution . . . . . . . . . . . . . . . . . . 69
2.2 Gestionnaire d’Interface . . . . . . . . . . . . . . . . . . . . . . 72
2.3 Interpréteur SQL . . . . . . . . . . . . . . . . . . . . . . . . . . 72
2.4 Optimiseur d’Exécution Parallèle . . . . . . . . . . . . . . . . . 73
2.5 Gestionnaire de Charge . . . . . . . . . . . . . . . . . . . . . . 73
2.6 Gestionnaire d’Exécution Parallèle . . . . . . . . . . . . . . . . 73
2.7 Gestionnaire de Résultats . . . . . . . . . . . . . . . . . . . . . 74
2.8 Communications . . . . . . . . . . . . . . . . . . . . . . . . . . 74
2.9 Unicité du serveur . . . . . . . . . . . . . . . . . . . . . . . . . 74
3 Composant calculateur . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
3.1 Module de stockage . . . . . . . . . . . . . . . . . . . . . . . . 75
3.2 Files d’attente . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
3.3 Module de calcul . . . . . . . . . . . . . . . . . . . . . . . . . . 83
3.4 Module d’ordonnancement . . . . . . . . . . . . . . . . . . . . 85
3.5 Module de Traitement des Messages d’Administration . . . . 85
4 Echange d’informations entre sites . . . . . . . . . . . . . . . . . . . . 86
4.1 Module de communication . . . . . . . . . . . . . . . . . . . . 86
4.2 Transferts de données . . . . . . . . . . . . . . . . . . . . . . . 87
4.3 Opérations relationnelles . . . . . . . . . . . . . . . . . . . . . 88
4.4 Messages d’administration . . . . . . . . . . . . . . . . . . . . 91

TABLE DES MATIÈRES 13
5 Influence des lots de données sur les temps d’exécution . . . . . . . . 92
5.1 Taille des lots . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
5.2 Estimation de la taille des lots . . . . . . . . . . . . . . . . . . . 93
5.3 Seuil de transfert . . . . . . . . . . . . . . . . . . . . . . . . . . 96
5.4 Estimation du seuil de transfert . . . . . . . . . . . . . . . . . . 96
5.5 Limitation des effets de bord du seuil de transfert . . . . . . . 98
6 Concept d’extension parallèle . . . . . . . . . . . . . . . . . . . . . . . 98
6.1 Constat . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 98
6.2 Description du composant Extension Parallèle . . . . . . . . . 99
6.3 Exemples d’applications . . . . . . . . . . . . . . . . . . . . . . 101
7 Analyse de l’architecture . . . . . . . . . . . . . . . . . . . . . . . . . . 105
7.1 Spécificités architecturelles . . . . . . . . . . . . . . . . . . . . 105
7.2 Spécificités de l’approche logicielle . . . . . . . . . . . . . . . . 106
7.3 Validité des données . . . . . . . . . . . . . . . . . . . . . . . . 107
IV Le prototype ENKIDU 111
1 Historique et choix techniques . . . . . . . . . . . . . . . . . . . . . . 111
1.1 Etymologie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111
1.2 Réalisation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112
2 Composants généraux . . . . . . . . . . . . . . . . . . . . . . . . . . . 114
2.1 Communications . . . . . . . . . . . . . . . . . . . . . . . . . . 114
2.2 Messages d’administration . . . . . . . . . . . . . . . . . . . . 117
3 Composant serveur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 118
3.1 Gestionnaire de redistribution et gestionnaire d’exécution . . 118
3.2 Administration . . . . . . . . . . . . . . . . . . . . . . . . . . . 119
3.3 Utilisateur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 130
4 Traitement des exécutions sur les calculateurs . . . . . . . . . . . . . . 138
5 Accès au SGBD . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 140
5.1 principes généraux . . . . . . . . . . . . . . . . . . . . . . . . . 140

14 TABLE DES MATIÈRES
5.2 Approche à une phase . . . . . . . . . . . . . . . . . . . . . . . 143
5.3 Approche à deux phases . . . . . . . . . . . . . . . . . . . . . . 145
V Tests 149
1 Paramétrage d’ENKIDU . . . . . . . . . . . . . . . . . . . . . . . . . . 149
1.1 Extraction des tuples . . . . . . . . . . . . . . . . . . . . . . . . 149
1.2 Sérialisation des données transférées . . . . . . . . . . . . . . . 152
1.3 Gestion de la taille des lots . . . . . . . . . . . . . . . . . . . . 154
2 Performances d’ENKIDU . . . . . . . . . . . . . . . . . . . . . . . . . 160
2.1 Speed-up . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 160
2.2 Influence du nombre d’utilisateurs simultanés . . . . . . . . . 162
2.3 Requêtes multi-jointures . . . . . . . . . . . . . . . . . . . . . . 162
VI Conclusion 167
1 Bilan . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 167
2 Perspectives . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 168
Bibliographie 171
Annexes 179
A Compléments sur le parallélisme 181
B Compléments sur les algorithmes de jointure parallèle 191

LISTE DES TABLEAUX 15
Liste des tableaux
II.1 Estimation des temps d’exécution (en secondes) d’une simulation
de pollution atmosphérique . . . . . . . . . . . . . . . . . . . . . . . 57
V.1 Base projetée utilisée pour les tests de chargement . . . . . . . . . . 150
V.2 Temps de réponse moyen par jointure par utilisateur en fonction du
nombre de calculateurs . . . . . . . . . . . . . . . . . . . . . . . . . . 163

16 LISTE DES TABLEAUX

TABLE DES FIGURES 17
Table des figures
II.1 Exemple de relation . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
II.2 Exemple de dépendances référentielles . . . . . . . . . . . . . . . . . 28
II.3 Jointure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
II.4 Union et intersection . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
II.5 Opérations unaires . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
II.6 Techniques de répartition des données . . . . . . . . . . . . . . . . . 34
II.7 Représentation arborescente de Plans d’Exécution Parallèles . . . . 39
II.8 Gestion des biaisages par découpage-réplication . . . . . . . . . . . 42
II.9 Stratégie adaptative . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
III.1 Fonctionnement classique d’un SGBD . . . . . . . . . . . . . . . . . 66
III.2 Intégration de l’évaluateur parallèle . . . . . . . . . . . . . . . . . . 66
III.3 Architecture du module serveur . . . . . . . . . . . . . . . . . . . . . 70
III.4 Architecture du module calculateur . . . . . . . . . . . . . . . . . . 76
III.5 Architecture du module de stockage . . . . . . . . . . . . . . . . . . 78
III.6 Transmissions des nombres de lots produits . . . . . . . . . . . . . . 80
III.7 Référencement des lots de données dans une file d’attente . . . . . 82
III.8 Exemples d’accès aux files d’attente par des fragments de relations
sources et de résultats intermédiaires . . . . . . . . . . . . . . . . . . 83
III.9 Déroulement d’une opération élémentaire . . . . . . . . . . . . . . . 84
III.10 Détail du module de communication . . . . . . . . . . . . . . . . . . 87
III.11 Eléments composant une opération élémentaire . . . . . . . . . . . 89

18 TABLE DES FIGURES
III.12 Influence du découpage en petits lots sur le temps de latence . . . . 92
III.13 Coût d’envoi de lots de 10 octets à 6 ko . . . . . . . . . . . . . . . . . 94
III.14 Coût d’envoi de lots de 1 à 100 ko . . . . . . . . . . . . . . . . . . . . 94
III.15 Services de base d’une extension parallèle . . . . . . . . . . . . . . . 102
III.16 Utilisation d’une extension parallèle dans le cadre d’une bibliothèque104
IV.1 Machine Virtuelle Java . . . . . . . . . . . . . . . . . . . . . . . . . . 112
IV.2 Mécanisme de sérialisation Java . . . . . . . . . . . . . . . . . . . . . 115
IV.3 Sérialisation spécifique ENKIDU . . . . . . . . . . . . . . . . . . . . 116
IV.4 Traitement des messages reçus . . . . . . . . . . . . . . . . . . . . . 117
IV.5 Fenêtre d’administration d’ENKIDU . . . . . . . . . . . . . . . . . . 119
IV.6 Schéma dynamique de fonctionnement du serveur . . . . . . . . . . 120
IV.7 Connexion à une base de données existante . . . . . . . . . . . . . . 122
IV.8 Liste des tables non distribuées . . . . . . . . . . . . . . . . . . . . . 123
IV.9 Fenêtre de distribution des données . . . . . . . . . . . . . . . . . . 124
IV.10 Contrôle de la distribution des données . . . . . . . . . . . . . . . . 125
IV.11 Saisie du nombre d’utilisateurs simultanés simulés . . . . . . . . . . 126
IV.12 Principe de fonctionnement des utilisateurs simulés . . . . . . . . . 126
IV.13 Principe de mesure des performances détaillées . . . . . . . . . . . 128
IV.14 Visualisation de la charge des calculateurs . . . . . . . . . . . . . . . 129
IV.15 Temps total d’exécution pour différents utilisateurs . . . . . . . . . 129
IV.16 Nombre d’opérations élémentaires par seconde pour chaque requête
SQL de différents utilisateurs . . . . . . . . . . . . . . . . . . . . . . 130
IV.17 Temps d’exécution d’opérations élémentaires pour différents utili-
sateurs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131
IV.18 Schéma de principe du Parser . . . . . . . . . . . . . . . . . . . . . . 132
IV.19 Décomposition d’une clause Where par ZQL . . . . . . . . . . . . . 133
IV.20 Architecture de l’arbre d’exécution . . . . . . . . . . . . . . . . . . . 134
IV.21 Mode d’insertion des noeuds OR . . . . . . . . . . . . . . . . . . . . 135

TABLE DES FIGURES 19
IV.22 Illustration de l’insertion des noeuds OR . . . . . . . . . . . . . . . . 135
IV.23 Exemple de requête traitée par le Parser . . . . . . . . . . . . . . . . 137
IV.24 Architecture du composant ModParOpt . . . . . . . . . . . . . . . . 138
IV.25 Schéma dynamique de fonctionnement des calculateurs . . . . . . . 141
IV.26 Distribution à une phase . . . . . . . . . . . . . . . . . . . . . . . . . 144
IV.27 Distribution à deux phases . . . . . . . . . . . . . . . . . . . . . . . . 145
V.1 Influence du prefetch sur les temps de chargement . . . . . . . . . . 151
V.2 Structure des lots de données utilisés pour le test de transfert . . . . 153
V.3 Sérialisation Java vs. sérialisation Enkidu . . . . . . . . . . . . . . . 154
V.4 Influence du seuil de transfert pour 2 jointures pipelinées . . . . . . 157
V.5 Influence du seuil de transfert pour 3 jointures pipelinées . . . . . . 157
V.6 Influence du seuil de transfert pour 6 jointures pipelinées . . . . . . 158
V.7 Influence du seuil de transfert pour 6 jointures pipelinées avec biais
zipf = 0,3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 159
V.8 Speed up pour une jointure 100x100000 en fonction du nombre d’uti-
lisateurs simultanés . . . . . . . . . . . . . . . . . . . . . . . . . . . . 162
V.9 Utilisateurs simultanés . . . . . . . . . . . . . . . . . . . . . . . . . . 164
V.10 Utilisation d’une base réelle sur Oracle et Enkidu . . . . . . . . . . . 165
A.1 Vue d’un système parallèle par ses points d’interconnexion . . . . . 182
A.2 Architecture à mémoire partagée . . . . . . . . . . . . . . . . . . . . 183
A.3 Architecture à accès de mémoire non uniforme . . . . . . . . . . . . 185
A.4 Architecture à disques partagés . . . . . . . . . . . . . . . . . . . . . 186
A.5 Architecture à mémoire distribuée . . . . . . . . . . . . . . . . . . . 187
A.6 Architecture hiérarchique . . . . . . . . . . . . . . . . . . . . . . . . 188
A.7 Exemple de speed-up linéaire . . . . . . . . . . . . . . . . . . . . . . 189
B.1 Jointure par produit cartésien . . . . . . . . . . . . . . . . . . . . . . 192
B.2 Jointure par produit cartésien par blocs . . . . . . . . . . . . . . . . 193
20 TABLE DES FIGURES
B.3 Jointure par hachage classique . . . . . . . . . . . . . . . . . . . . . . 195

21
Chapitre I
Introduction
1 Problématique
Nous assistons, depuis plusieurs années, à une montée en puissance de bases
de données dont l’utilisation est souvent consultative. De telles bases de données
se rencontrent dans des domaines comme la fouille de données [Wes98, Pas98], les
bases de documents [Fei98], et les informations médicales [Flo92].
Nous pouvons isoler trois facteurs d’utilisation intensive de telles sources d’infor-
mations : le volume de données traitées, qui peut devenir très important ; la com-
plexité des interrogations, qui dépendra des critères de recherche disponibles, et
enfin le nombre de requêtes soumises en une période donnée.
Une solution fréquemment proposée pour supporter de telles charges de travail
consiste à utiliser un Système de Gestion de Bases de Données (SGBD) parallèle [Bam98,
Ter98]. Un SGBD consiste en un ensemble d’outils susceptibles de gérer le stockage,
la mise à jour cohérente et l’interrogation d’un ensemble d’informations organisées.
Un SGBD parallèle, pour sa part, fonctionne sur une machine parallèle, et permet
ainsi un parallélisme d’entrées/sorties, par utilisation de plusieurs disques, et un
parallélisme de traitement, par utilisation de plusieurs processeurs [Ösz91, DeW92a,
Val93]. De telles caractéristiques permettent de multiplier la capacité de stockage,

22 CHAPITRE I. INTRODUCTION
mais également les vitesses de chargement et de traitement des données. Notons
qu’à ce jour les SGBD parallèles fonctionnent essentiellement suivant le modèle re-
lationnel (ou relationnel-objet) [Bam98, Ger95].
Toutefois, le coût de telles architectures matérielles et logicielles demeure élevé
(au minimum quelques centaines de milliers de francs) et l’extensibilité de la plu-
part des architectures parallèles classiques reste discutable (voir chapitre II et an-
nexes). Aussi la communauté des systèmes hautes performances se penche-t-elle,
depuis quelques années, sur les réseaux de stations et en particulier sur leur ap-
titude à réaliser les travaux classiquement réservés aux machines parallèles. De
nombreux efforts ont notamment été réalisés dans le cadre des communications,
tant du point vue matériel (réseaux locaux rapides) [Bod95, DP93] que du point
de vue logiciel (bibliothèques de communications rapides) [Rod97]. De même, les
techniques de programmation parallèle se sont également simplifiées, ne serait-ce
que par l’apport de bibliothèques de programmation parallèle généralistes et por-
tables [Gei94, PVM98, MPI96, Sni95].
Ces différents apports permettent de disposer aujourd’hui de réseaux de stations
offrant une bonne souplesse, une grande modularité et des capacités de stockage
(non seulement sur disque, mais également en mémoire vive) et de calcul très satis-
faisantes [AD97]. Dans le domaine des bases de données, des produits commerciaux
ont été portés sur des architectures de type réseaux de stations ; quelques portages
universitaires ont également éte réalisés [Boz96].
De façon générale, le portage pur et simple d’un SGBD parallèle shared nothing 1 sur
un réseau de stations ne pose pas de problèmes théoriques, dans la mesure où le
réseau de communication offre des capacités compatibles avec l’application. Cepen-
dant, la multiplicité des contrôles nécessaires au bon fonctionnement d’un SGBD pa-
rallèle complet induit en général un coût de développement particulièrement élevé,
1. Une machine shared nothing, ou machine à mémoire distribuée, est une machine parallèle dans
laquelle chaque processeur gère sa propre mémoire et son propre disque (voir Annexe A), ce qui
correspond à l’architecture par défaut d’un réseau de stations.

2. PRINCIPALES CONTRIBUTIONS 23
qui se retrouve naturellement lors de l’acquisition d’un tel système. Or l’exploita-
tion de bases de données en lecture seule ne nécessite qu’un sous-ensemble assez
restreint des fonctionnalités offertes par un SGBD parallèle. En effet, la gestion de
la cohérence passe ici au second plan, puisqu’elle est supposée s’effectuer en amont
de l’utilisation d’une base de données en lecture seule (c’est-à-dire durant la consti-
tution de cette base).
De ce fait, nous proposons l’utilisation d’un évaluateur parallèle de requêtes re-
lationnelles sur réseau de station comme alternative aux SGBD parallèles complets,
dans le cadre de bases de données en lecture seule. Cet évaluateur consiste en un
composant logiciel capable de stocker des données relationnelles sur un réseau de
stations et d’interroger celles-ci, de façon parallèle. L’acquisition des données se fait
par une connexion initiale à un SGBD séquentiel pré-existant (séquentiel étant ici
utilisé par opposition à parallèle), duquel on extrait les tables souhaitées de manière
à les redistribuer sur les stations composant l’évaluateur parallèle. Cette extraction
constitue la phase d’initialisation de notre système. Il est ensuite possible d’interro-
ger l’évaluateur parallèle sur les données qu’il possède, le rechargement des don-
nées n’étant effectué que pour un rafraîchissement explicite de celles-ci.
2 Principales contributions
Nous décrirons et discuterons dans cette thèse le concept et l’architecture de
l’évaluateur parallèle. Nous étudierons particulièrement la structure des compo-
sants de calcul, en proposant une approche multi-threads de leur gestion permettant
de limiter les pertes d’efficacité liées aux latences entre opérateurs successifs. Cette
approche permettra d’introduire un mécanisme d’équilibrage de charge implicite
sous une forme novatrice dans le cadre des SGBD parallèles shared nothing.
Nous proposerons également une gestion uniforme des données par utilisation de
lots de tuples, permettant la mise en œuvre d’un pipeline à grain moyen entre opéra-

24 CHAPITRE I. INTRODUCTION
teurs. Cette approche permettra de fluidifier l’enchaînement d’opérateurs successifs
tout en limitant l’utilisation du réseau d’interconnexion et unifie les concepts de buf-
fers et de transferts de données introduits dans les études existantes [DeW86, Gra94,
Bou96b]. Elle sera en outre complétée par une étude de la régulation des débits de
transfert permettant une amélioration des performances dans le cas d’opérateurs
pipelinés.
Enfin, en nous fondant sur l’étude de l’évaluateur parallèle de requêtes, nous mon-
trerons que l’utilisation d’un composant parallèle en complément à un système sé-
quentiel est possible dans d’autres cadres que celui des bases de données en lecture
seule. Nous présenterons cette généralisation sous la forme d’un composant appelée
extension parallèle.
Nos travaux ont été validés par le développement et l’expérimentation d’un pro-
totype conséquent nommé ENKIDU. Celui-ci permet le chargement de données,
leur répartition sur un réseau de stations et l’exécution d’opérations relationnelles
sur cette distribution. Il comporte également diverses fonctionnalités d’audit per-
mettant la visualisation de la charge de travail. Les tests conduits sur ce prototype
montrent une très bonne tenue à la charge, notamment en termes de requêtes par
seconde.
3 Organisation du manuscrit
Le chapitre II proposera un état de l’art des Systèmes de Gestion de Bases de
Données relationnels parallèles, et de leur portage sur réseau de stations. Nous mon-
trerons l’inadéquation des SGBD relationnels parallèles dans le cadre des bases de
données en lecture seule, et introduirons ainsi le concept d’évaluateur parallèle de
requêtes relationnelles.
Dans le chapitre III, nous décrirons le corps central de ce mémoire, c’est-à-dire
l’évaluateur parallèle de requêtes introduit ci-dessus. Ses missions consistent à ex-

3. ORGANISATION DU MANUSCRIT 25
traire les données d’une base existante, à les répartir sur un réseau de stations, puis
à permettre ensuite aux utilisateurs d’effectuer des requêtes d’interrogation, de ma-
nière transparente, sur cette distribution. Nous détaillerons dans ce chapitre les dif-
férentes motivations ayant conduit à notre proposition. Nous y présenterons égale-
ment de façon détaillée l’architecture de chacun des modules nécessaires à son bon
fonctionnement. Nous étudierons en détail la gestion de la taille des lots et les condi-
tions de transfert de ceux-ci. Nous considérerons enfin l’évaluateur parallèle comme
un cas particulier d’extension parallèle. Nous montrerons ainsi qu’une extension pa-
rallèle, c’est-à-dire un composant parallèle adjoint à un système séquentiel, peut être
utilisée dans d’autres contextes que l’évaluation de requêtes relationnelles, et pro-
poserons la définition et l’élargissement de ce concept.
Dans le chapitre IV, nous présenterons le prototype développé durant notre
thèse. Ce prototype reprend la plupart des composants de notre architecture. Nous
présenterons tout d’abord les techniques d’implantation utilisées. Nous indiquerons
ensuite les possibilités de ce prototype. Du point de vue des données, celui-ci permet
non seulement de se connecter à des bases existantes, mais également de générer des
bases de tests dont les attributs présentent des biaisages paramétrables. Du point de
vue des traitements, plusieurs techniques d’exécution ont été implantées de façon
à permettre l’exécution parallèle des opérations relationnelles classiques (sélection,
projection, jointure).
Le chapitre V présentera l’éventail des tests que nous avons appliqués à notre
prototype afin de valider son architecture générale ainsi que ses orientations parti-
culières. Les tests présentés appartiennent à deux catégories distinctes. La première
série de tests proposera une étude du paramétrage d’ENKIDU et de la gestion des
lots de données entre opérateurs. La seconde série de tests mesurera les capacités de
notre prototype pour différents types de requêtes et différentes charges (en terme
d’utilisateurs), puis pour des tests mettant en jeu à la fois le SGBD source (Oracle 7
pour nos tests) et notre extension.

26 CHAPITRE I. INTRODUCTION
Nous concluerons enfin ce mémoire et ouvrirons de nouvelles perspectives au
chapitre VI.

27
Chapitre II
SGBD relationnels parallèles et
réseaux de stations
1 Introduction
1.1 Rappels sur les SGBD relationnels
1.1.1 Notion de relation
Le modèle relationnel a été introduit par Codd en 1970 [Cod70]. Les principes
fondamentaux de ce modèle peuvent se résumer de façon assez concise, l’élément
fondamental étant la relation. Une relation est un regroupement d’informations
de base ayant un rapport direct. Par exemple, une relation “ordinateur” (voir fi-
gure II.1) peut contenir les champs “nom de l’ordinateur”, “modèle”, “adresse In-
ternet”. Ces différents champs sont appelés attributs de la relation. Une “ligne” de
la relation est appelée tuple ou n-uplet. Un schéma de base de données est consti-
tué d’un ensemble de tables modélisant les différentes informations à stocker et à
manipuler. La structure de chaque table est conçue de façon à refléter au mieux les
rapports existant entre les attributs.
Afin de modéliser ces rapports, des formes normales ont été introduites. Nous

28 CHAPITRE II. SGBD RELATIONNELS PARALLÈLES ET RÉSEAUX DE STATIONS
134.214.100.103
134.214.100.101
134.214.100.102
Adresse internet
134.214.100.100
Estrella
Sparc
UltraSparc
Modèle
P400
Ordinateur
Alpha
Gamma
Beta
Delta
Nom
FIG. II.1 – Exemple de relation
Marque Num. Marque Nom Marque
Nom ModèleModèle Num. Modèle
Ordinateur Nom Num. ModèleNum. Marque
FIG. II.2 – Exemple de dépendances référen-
tielles
donnons ici un simple rappel du rôle de celles-ci et renvoyons le lecteur néophyte
à des ouvrages et articles de référence, tels [Cod70, Cod74, Fag77, Fag79, Del82].
Leur fonction peut se résumer en quelques mots : il existe six formes normales (cinq
numérotées de un à cinq et une sixième appelée forme de Boyce-Codd). Ces formes
normales définissent, par ordre croissant, des critères de plus en plus précis de nor-
malisation des relations. Cette normalisation permet de limiter les redondances, de
prévenir les risques d’erreurs, et, de façon générale, de tenir compte d’une partie de
la sémantique des données dans leur représentation.
Les différentes relations sont “connectées” par des dépendances référentielles.
Une dépendance référentielle indique qu’un champ donné d’une relation prend ses
valeurs parmi celles définies pour un champ donné d’une autre relation (voir fi-
gure II.2). Ainsi, pour retrouver une information répartie sur deux tables, on effec-
tuera une opération mettant bout à bout les tuples des deux relations, en suivant la
dépendance référentielle existant entre les deux relations. Une telle opération s’ap-
pelle une jointure naturelle.
1.1.2 Opérateurs relationnels
De façon générale, une jointure (voir figure II.3) définit une telle opération ef-
fectuée entre deux relations quelconques. Il est possible d’effectuer une jointure dès
lors que les champs des deux relations suivant lesquels s’effectue la jointure sont de
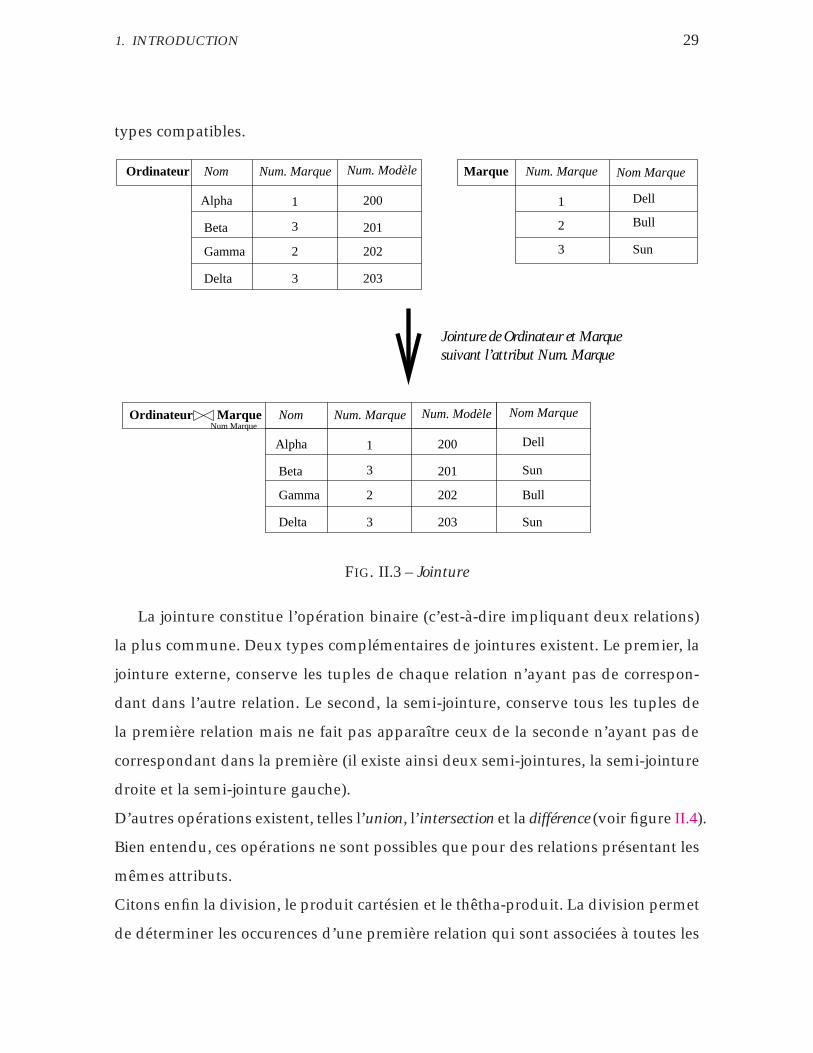
1. INTRODUCTION 29
types compatibles.
Delta
Gamma
Beta
Alpha
Delta
Gamma
Beta
Alpha
202
3 203
2
1
3
200
201
Num. ModèleNum. MarqueNom
1
2
3
Dell
Bull
Sun
Dell
Bull
Marque Num. Marque Nom Marque
Nom MarqueOrdinateur Marque
202
3 203
2
1
3
200
201
Num. ModèleNum. MarqueOrdinateur Nom
Jointure de Ordinateur et Marquesuivant l’attribut Num. Marque
Num Marque
Sun
Sun
FIG. II.3 – Jointure
La jointure constitue l’opération binaire (c’est-à-dire impliquant deux relations)
la plus commune. Deux types complémentaires de jointures existent. Le premier, la
jointure externe, conserve les tuples de chaque relation n’ayant pas de correspon-
dant dans l’autre relation. Le second, la semi-jointure, conserve tous les tuples de
la première relation mais ne fait pas apparaître ceux de la seconde n’ayant pas de
correspondant dans la première (il existe ainsi deux semi-jointures, la semi-jointure
droite et la semi-jointure gauche).
D’autres opérations existent, telles l’union, l’intersection et la différence (voir figure II.4).
Bien entendu, ces opérations ne sont possibles que pour des relations présentant les
mêmes attributs.
Citons enfin la division, le produit cartésien et le thêtha-produit. La division permet
de déterminer les occurences d’une première relation qui sont associées à toutes les

30 CHAPITRE II. SGBD RELATIONNELS PARALLÈLES ET RÉSEAUX DE STATIONS
occurences d’une seconde relation (par exemple, donner le nom des professeurs qui en-
seignent conjointement aux élèves x et y). Cette opération n’est pas implémentée dans
les SGBD relationnels. Le produit cartésien consiste à combiner toutes les occurences
de deux relations. Enfin, le thêta-produit consiste à effectuer un produit cartésien
entre deux relations, puis à appliquer une sélection sur ce produit cartésien à partir
d’une condition logique (thêta) prenant les valeurs <, >, = ou 6=.
302
300
301
Num. ModèleNum. MarqueNomOrdinateur 2
1
2
3Gerschwin
Mozart
Brahms
Delta 20333 203Delta
Num. ModèleNum. MarqueNomO. 1 U O. 2
3 203Delta
Num. ModèleNum. MarqueNomO. 1 O. 22022
1
3
200
201
Gamma
Beta
Alpha
302
300
301
Gerschwin
Mozart
Brahms 2
3
1
3 203Delta
Union de Ordinateur 1 et Ordinateur 2
2022
1
3
200
201
Num. ModèleNum. MarqueNomOrdinateur 1
Gamma
Beta
Alpha
Intersection de Ordinateur 1 et Ordinateur 2
FIG. II.4 – Union et intersection
Il existe d’autre part deux opérations “unaires” (voir figure II.5) : la sélection, qui
consiste à appliquer un filtre ne retenant que certains tuples d’une relation donnée
(par exemple, ne retenir que les ordinateurs de marque Sun), et la projection qui
permet de ne retenir que certains attributs (par exemple, ne garder que le nom et
l’adresse Internet des machines).
La mise en œuvre de ces opérateurs relationnels se fait par le biais de requêtes.
Dans le cadre des systèmes relationnels, ces requêtes sont écrites à l’aide du langage

1. INTRODUCTION 31
3 203Delta
2022
1
3
200
201
Num. ModèleNum. MarqueNomOrdinateur 1
Gamma
Beta
Alpha 3 203Delta
3 201Beta
Num. ModèleNum. MarqueNom
Nom
Gamma
Beta
Alpha
Delta
Sélection des tuples pour lesquels NumMarque = 3
Projection des tuples sur le champ "Nom"
FIG. II.5 – Opérations unaires
SQL (Structured Query Language). Pour plus de détails concernant SQL, on pourra
consulter [Dat97].
1.2 Parallélisation des SGBD relationnels
1.2.1 Intérêt du parallélisme
Dans le domaine des bases de données, comme dans la plupart des secteurs de
l’informatique, la puissance de calcul constitue un facteur important de l’efficacité
d’une application. Si les premières bases de données de grande envergure fonction-
naient sur des “gros systèmes”, ou Mainframes (ce qui est encore souvent le cas), leur
portage sur des machines parallèles a fait, depuis de nombreuses années, l’objet de
recherches intenses.
Tout d’abord, l’un des principaux objectifs des architectures parallèles consiste à of-
frir un rapport coût/performance plus satisfaisant que celui des gros systèmes [DeW92a].
En effet, dans le cadre des SGBD, le parallélisme permet une certaine modularité des
traitements. Il autorise un droit de contrôle (du programmeur tout au moins) au ni-
veau de la répartition des données et de l’exécution (entre requêtes et au sein des

32 CHAPITRE II. SGBD RELATIONNELS PARALLÈLES ET RÉSEAUX DE STATIONS
requêtes). Une bonne répartition des données permet ainsi d’optimiser l’accès aux
différents disques. Le parallélisme intra-requête (détaillé en sections 2.2.3 et 2.2.2) va
s’opérer entre opérations (pipeline, synchronisations) et au sein des opérations (dé-
coupage d’une même opération sur plusieurs processeurs), ce qui réduit les temps
de réponse pour une requête donnée. Enfin, il est possible, grâce au parallélisme
inter-requêtes (section 2.3), de répartir les ressources entre utilisateurs, afin d’offrir
un temps de réponse moyen optimal.
Par ailleurs, un autre avantage majeur des systèmes parallèles réside dans leur
extensibilité. Ce point est particulièrement important dans le cadre des bases de
données car celles-ci sont généralement soumises à une fluctuation du volume des
données et de la fréquence et de la complexité des requêtes. Les architectures pa-
rallèles, offrent dans une certaine mesure, des possibilités d’extension, à travers les-
quelles il est envisageable de conserver les performances du système malgré une
augmentation de la demande (augmentation du volume des données, du nombre
d’utilisateurs ou de la complexité des opérations). Des informations complémen-
taires sur les architectures parallèles sont fournies en annexe (voir Annexe A).
1.2.2 Parallélisme et SGBD relationnels
La parallélisation des SGBD relationnels a été grandement favorisée par les concepts
sur lesquels reposent ces systèmes. En effet, les bases relationnelles sont consti-
tuées de relations. Une relation constitue un tableau, et la répartition d’un tableau
s’avère particulièrement aisée. Il suffit en effet de poser un critère sur un attribut (co-
lonne) donné pour scinder une relation (tableau) en sous-relations (sous-tableaux)
disjointes. Par ailleurs, le langage SQL, utilisé pour interroger les bases de don-
nées relationnelles, est de nature non-procédurale, et l’interrogation physique sous-
jacente est totalement transparente à l’utilisateur. De ce fait, sa parallélisation peut se
faire sans contraintes liées à l’organisation de la requête. Le parallélisme intrinsèque
des SGBD relationnels est aussi notable. En effet, le fait qu’une requête se décompose

2. PRINCIPES DE BASE DES SGBD RELATIONNELS PARALLÈLES 33
en opérateurs permet un parallélisme entre tâches élémentaires ; de plus, le résultat
de la jointure de deux relations constituant lui-même une relation, un parallélisme
pipeline entre opérations est possible.
Les SGBD relationnels constituent un concept relativement ancien. On pourrait
d’ailleurs s’interroger sur l’opportunité de poursuivre leur utilisation (et leur dé-
veloppement), alors que des solutions alternatives, tels les SGBD objets, offrent une
meilleure capacité de modélisation grâce à l’expression de nouvelles dimensions, tel
l’héritage [Ben96]. Nous pouvons en évoquer quelques raisons. De par la technolo-
gie assez récente et les spécificités architecturelles des SGBD objets, les performances
de ceux-ci ont longtemps été mal maîtrisées (cette tendance s’estompe cependant, et
des techniques d’évaluation des performances des SGBD objets (benchmarks) sont
disponibles depuis quelques années [Car93]). De plus, si la parallélisation de tables
relationnelles semble assez naturelle, celle de systèmes orientés objet est plus déli-
cate, du fait des liens existant entre objets (objets composites).
Du point de vue économique, la parallélisation d’un SGBD nécessite un fort in-
vestissement en termes de recherche et développement, que seuls les gros éditeurs
peuvent se permettre. Or la plupart des grands SGBD sont à ce jour relationnels, et
leurs parts de marché demeurent particulièrement dominantes vis-à-vis des SGBD
orientés objets.
De ce fait, la parallélisation de SGBD a, à ce jour, essentiellement portée sur les
SGBD relationnels.
2 Principes de base des SGBD relationnels parallèles
2.1 Techniques de répartition des données
La répartition des données peut apporter de considérables gains de temps dans
un système multi-disques. Une distribution uniforme des données permet en effet
de répartir les accès sur les différents disques, et d’optimiser ainsi le temps d’accès

34 CHAPITRE II. SGBD RELATIONNELS PARALLÈLES ET RÉSEAUX DE STATIONS
et le débit. L’ensemble des disques sur lesquels est distribuée une relation donnée
constitue le home de cette relation. Le temps d’accès (et donc de traitement) est amé-
lioré par le fait que l’on extrait moins de tuples sur chaque disque. Le débit (through-
put) ou la bande passante profitent de ce que les performances des supports s’ad-
ditionnent de façon quasi-linéaire. Cette distribution des données est aussi connue
sous le nom de “declustering” (par opposition au “clustering”, ou regroupement des
tuples) [Liv87]. Elle fut au départ conçue pour les systèmes à mémoire distribuée.
Cependant, son usage s’est étendu aux systèmes à mémoire partagée [Ber91]. De
nombreux articles, parmi lesquels [DeW92a, Meh97], rappellent les trois techniques
de répartition classiquement employées : la répartition circulaire, la répartition par
hachage, et enfin la répartition par intervalles. Nous présentons ces trois techniques
ainsi que leurs avantages respectifs dans les sections suivantes.
2.1.1 Répartition circulaire
La distribution se fait ici de manière circulaire : les disques comportant une par-
tition sont sollicités à tour de rôle pour les insertions (voir figure II.6a). Dans une
configuration à n disques, le ime tuple de la relation est ainsi placé sur le disque
Dj tel que j = i mod n. La dénomination anglophone de cette technique est Round
Robin.
Disque 1 Disque 2 Disque n
f(x)=1f(x)=0 f(x)=n-1 a-f g-l u-z
Disque 1 Disque 2 Disque n
a: Répartition circulaire b: Répartition par hachage c: Répartition par intervalles
Disque 1 Disque 2 Disque 3 Disque n
FIG. II.6 – Techniques de répartition des données

2. PRINCIPES DE BASE DES SGBD RELATIONNELS PARALLÈLES 35
2.1.2 Répartition par hachage
Le choix du disque de stockage d’un tuple donné se fait à l’aide d’une fonction
de hachage f(x) appliquée sur l’attribut de répartition et modulée par le nombre de
disques participant à la répartition (figure II.6b). En d’autres termes, si n disques
(numérotés de 0 à n-1) sont candidats, et si la répartition est effectuée suivant l’at-
tribut x, alors un tuple T est placé sur le disque Dj tel que j = f(T:x) mod n. La
répartition par hachage est également connue sous le nom de hash partitioning.
2.1.3 Répartition par intervalles
Cette technique, également connue sous le nom de range partitioning, consiste à
placer sur un même disque tous les tuples d’une relation donnée pour lesquels la
valeur de l’attribut de répartition se trouve entre deux bornes données (figure II.6c).
Si n disques sont candidats, et que les tuples sont répartis suivant l’attribut x, alors
on scinde l’intervalle des valeurs de x en n sous intervalles consécutifs et disjoints
I0 = [xmin;x0[; I1 = [x0;x1[; � � � ; In�1 = [xn�2;xmax], et un tuple T donné est placé sur
le disque Dj tel que Tx 2 Ij .
2.1.4 Discussion des techniques de répartition
La répartition circulaire est assez intéressante pour les accès séquentiels systé-
matiques : on est en effet à peu près sûr que les accès seront équilibrés. Cependant,
on ne dispose d’aucune garantie pour les autres types d’accès (sélection, jointure, re-
cherche sur échelle de valeurs...). Le hachage pourra par contre s’avérer performant
pour les opérations de sélection “exactes” (c’est-à-dire portant sur une égalité) ou
de comparaison (jointure). En effet dans la mesure où la ou les relations ont été dis-
tribuées sur l’attribut de sélection (ou de comparaison), il est possible, i) dans le cas
de la comparaison, de limiter les candidats à une entrée de la table de hachage, et ii)
dans le cas des jointures, de ne comparer que les entrées équivalentes des tables de
hachage. Bien entendu, ce comportement suppose d’avoir choisi le même attribut

36 CHAPITRE II. SGBD RELATIONNELS PARALLÈLES ET RÉSEAUX DE STATIONS
de répartition et la même fonction de hachage pour les deux relations que l’on sou-
haite joindre. Il faut par ailleurs que l’attribut de répartition soit également l’attribut
de jointure (ou de sélection).
Reste le cas de la répartition par intervalles. Elle s’avère très utile pour des re-
cherches d’échelle de valeurs (ex. : Trouver les étudiants dont la moyenne est entre
12 et 14). Cependant le risque de biaisage est important, la répartition des tuples
étant en général non uniforme, et souvent non prévisible. On peut noter ici l’initia-
tive de Bubba [Cop88], qui utilise un range partitioning modifié : chaque tuple pos-
sède une “chaleur” correspondant à sa fréquence d’accès. La répartition est alors
faite de manière à ce que chaque partition ait la même “température”. Ainsi, on n’a
plus vraiment de répartition uniforme des tuples, mais a priori une répartition as-
sez uniforme (et donc meilleure qu’auparavant) des accès. Notons que la plupart des
systèmes actuels fournissent les trois types de stockage. Par ailleurs, les paramètres
de distribution, pour le hachage et surtout pour la répartition par intervalles, sont
obtenus à partir d’échantillonnage des attributs de répartition. Nous ne nous éten-
drons pas davantage sur le problème de l’échantillonnage, et nous renvoyons les
lecteurs à la littérature du domaine, tel [PS84].
Notons qu’un choix judicieux de l’attribut de distribution est nécessaire pour les ré-
partitions par hachage et par intervalles. Il convient donc de disposer également de
statistiques d’accès aux attributs, ou, à défaut, d’intuitions sur leur usage (clé pri-
maire ou secondaire, clé externe...).
Notons enfin que, dans des architectures à mémoire ou à disques partagés, la notion
de home d’une relation ne peut pas être directement transposée à celui d’une opéra-
tion. En effet, ces structures n’offrent pas de couplage privilégié entre le stockage “de
masse” et les processeurs. D’autre part, les homes des relations ne constituent pas le
seul critère de placement d’une opération. S’ils influencent les homes des sélections
et projections des relations sources, il conditionnent nettement moins le placement
des résultats intermédiaires, lesquels dépendront beaucoup plus des disponibilités

2. PRINCIPES DE BASE DES SGBD RELATIONNELS PARALLÈLES 37
supposées des processeurs.
2.1.5 Remarques
La répartition des tuples apparaît comme une solution fort intéressante face aux
grandes bases de données. Il faut toutefois se souvenir que toute relation n’est pas
forcément de très grande taille, même dans une base conséquente. En général, la
taille des relations est fortement variable. Aussi est-il souhaitable de ne pas ré-
partir toutes les tables sur les mêmes supports. On peut ainsi noter avec intérêt,
que [Cop88] propose, outre la notion de “chaleur” présentée ci-dessus, une réparti-
tion variable fondée sur la taille de la relation. Par ailleurs, la répartition des don-
nées est une bonne chose, mais dont la validité est soumise à l’épreuve du temps. Il
serait en effet souhaitable de pouvoir effectuer des réorganisations dynamiques ba-
sées sur les biaisages constatés à l’usage, comme le rappelle [Val93]. Les principales
difficultés résident dans l’exécution optimale, parallèle et non bloquante (pour les
transactions) de telles réorganisations.
2.2 Techniques de parallélisation des traitements
La parallélisation d’un Système de Gestion de Bases de Données (SGBD) s’opère
non seulement sur la distribution des données, ainsi que nous l’avons présenté ci-
dessus, mais aussi sur la parallélisation des traitements (laquelle dérive plus ou
moins directement de la répartition des données). Paralléliser les traitements revient
à répartir leur déroulement dans l’espace (nœuds d’exécution) et dans le temps (or-
donnancement) par une utilisation judicieuse des ressources disponibles. On cher-
chera ainsi à optimiser i) le temps de réponse moyen (satisfaction moyenne des
utilisateurs) et ii) le temps de réponse de chaque requête prise indépendamment
(satisfaction de chaque utilisateur en particulier). Il va de soi que ces deux objectifs
sont contradictoires dans leur énoncé, aussi bien que dans leur réalisation. En effet,
obtenir un temps de réponse optimal pour une requête se fait en général en suppo-

38 CHAPITRE II. SGBD RELATIONNELS PARALLÈLES ET RÉSEAUX DE STATIONS
sant disposer de la totalité des ressources matérielles, alors que satisfaire l’ensemble
des utilisateurs supposera une pondération des ressources disponibles. Cette com-
plexité inhérente au mode multi-requêtes a vraisemblablement conditionné l’orien-
tation des recherches en matière d’exécution parallèle. L’optimisation du parallé-
lisme intra-requête (optimisation en mode mono-utilisateur) a en effet inspiré plus
tôt et plus massivement les chercheurs en bases de données. Nous allons donc pré-
senter dans un premier temps le parallélisme intra-requête (mono-utilisateur), puis
nous introduirons les solutions proposées pour le mode inter-requêtes (ou multi-
utilisateurs).
2.2.1 Parallélisme intra-requête
Le parallélisme intra-requête consiste à mettre en œuvre, au sein d’une même
requête, plusieurs sous-traitements pouvant s’exécuter simultanément et de façon
concurrente ou non. On peut tout d’abord remarquer l’évident parallélisme entre
les différentes opérations d’une requête. Prenons un exemple. Soient quatre rela-
tions R1, R2, R3 et R4 liées dans une requête par les jointures J1, J2 et J3 suivantes :
J1 = R1 1A R2, J2 = R2 1B R3 et J3 = R3 1C R4, A, B et C étant les attributs
de jointure. Il va être possible (comme le montre l’arbre de droite de la figure II.7)
d’effectuer parallèlement les deux jointures J1 et J3, puis d’effectuer ensuite la join-
ture J2. Ceci est bien entendu un exemple et ne constitue pas forcément une solution
optimale (d’autres paramètres entrant alors en jeu, comme la taille des relations,
leur distribution, etc.). Nous parlerons dès lors de parallélisme inter-opérateurs. Par
ailleurs, un opérateur est en général exécuté sur plusieurs nœuds. En effet, les rela-
tions étant distribuées, il est nettement plus intéressant d’effectuer une sous-jointure
sur chacun des sites concernés, puis de rassembler les sous-résultats ainsi obtenus,
plutôt que de transférer tous les fragments sur un seul site afin d’y effectuer la join-
ture. En réalité, ce modus operandi est triplement intéressant, car il permet i) de faire
travailler plusieurs nœuds sur différents fragments, ce qui tend à limiter le temps

2. PRINCIPES DE BASE DES SGBD RELATIONNELS PARALLÈLES 39
d’horloge, ii) de limiter le volume de données transférées (dans le cas d’une join-
ture à forte sélectivité), et iii) d’utiliser des fragments susceptibles de tenir sur un
nœud (en mémoire vive ou à l’aide de fichiers d’échange sur disque), ce qui n’est
pas nécessairement possible pour des tables de grande taille. Nous détaillons ces
deux types de parallélisme dans les points suivants.
R1 R2
J1
R1 R2
J1
J2
J3
R4
R3
R4R3
J3
J2
FIG. II.7 – Représentation arborescente de Plans d’Exécution Parallèles
2.2.2 Parallélisme inter-opérateurs
Ainsi que nous le présentons ci-dessus, le parallélisme inter-opérateurs consiste
à effectuer simultanément plusieurs opérations d’une requête complexe, afin de
réduire le temps d’horloge nécessaire à la résolution de cette dernière. Cette si-
multanéité va pouvoir s’exprimer de deux façons, soit à travers un parallélisme
entre opérations non liées (du moins directement), soit à travers un parallélisme
entre opérations consécutives, ou pipeline, les données produites par la première
opération étant immédiatement utilisées par la seconde (parallélisme producteur-
consommateur). Nous présentons ici la notion de Plan d’Exécution Parallèle, ou
PEP.
Un plan d’exécution parallèle détermine l’ordonnancement temporel (dans quel
ordre?) et spatial (sur quels nœuds?) de l’exécution d’une requête. On le représente
généralement sous la forme d’un arbre. Des informations complémentaires peuvent
également apparaître ; ainsi H. Kosch et al. ont-ils formalisé dans [Kos97b, Bru96a]

40 CHAPITRE II. SGBD RELATIONNELS PARALLÈLES ET RÉSEAUX DE STATIONS
les notions de dépendance de précédence et de dépendance de boucle (loop de-
pendency) entre les opérateurs. La dépendance de précédence indique une précé-
dence entre opérateurs, non liée à un flux direct de données entre eux, mais plu-
tôt aux capacités du système ; dans une telle dépendance, le second opérateur ne
commence qu’après la fin du premier. La dépendance de boucle indique qu’une sé-
quence d’opérateurs doit être répétée jusqu’à épuisement des données fournies en
entrée (ce qui s’applique notamment aux traitements par paquets de données, ou
buckets).
2.2.3 Parallélisme intra-opérateur
Répartition initiale des données Le parallélisme intra-opérateur consiste à dé-
finir le nombre de nœuds alloués à un même opérateur ainsi que la stratégie d’exé-
cution la mieux adaptée à son contexte. En effet, ainsi que nous le soulignions pré-
cédemment, la taille des relations et la répartition de leurs fragments conduisent
naturellement à exécuter un opérateur sur plusieurs nœuds. Bien entendu, l’archi-
tecture parallèle utilisée influence nettement le type de stratégie retenu. En effet,
sur un système à disques ou à mémoire partagée, la répartition des fragments est
sans influence quant au choix des nœuds ; en revanche, dans un système à mémoire
distribuée, elle sera prépondérante.
Dewitt et al. [DeW92b] proposent une approche pour la répartition par inter-
valles en partant du constat selon lequel une telle répartition peut conduire à de
forts déséquilibres. Les déséquilibres ont cependant plusieurs causes. Ils s’attachent
en effet aux cas où une même valeur de l’attribut de répartition apparaît dans un
grand nombre de tuples, ce qui conduit à un net surplus de calcul sur les nœuds où
de tels tuples sont placés. De tels biaisages apparaissent notamment lorsque l’attri-
but de répartition n’est pas une clé primaire de la table (c’est notamment le cas pour
les clés composées). Afin de limiter les déséquilibres apparaissant dans de telles
configurations, Dewitt et al. ont introduit la notion de “découpage et réplication”

2. PRINCIPES DE BASE DES SGBD RELATIONNELS PARALLÈLES 41
(subset-replicate). Si, lors d’une jointure, au moins une des deux tables présente de
forts déséquilibres sur l’attribut de répartition, alors les tuples d’une des deux tables
sont répartis par intervalles, mais les tuples ayant le même attribut de répartition
sont tout de même répartis sur plusieurs machines. Les tuples de la deuxième table
sont également répartis suivant les mêmes intervalles, mais les tuples dont l’attri-
but de répartition présente la valeur de découpage retenue pour la première table
sont dupliqués sur tous les fragments concernés (voir figure II.8). En règle général,
le découpage est effectué sur la table de build (c’est-à-dire celle sur laquelle la table
de hachage est bâtie), du fait que ses tuples sont stockés durant l’opération, alors
que les tuples de la table de probe (c’est-à-dire celle dont les tuples sont comparés
à la table de hachage précédemment construite) sont supprimés dès qu’ils ont été
testés. Pour limiter encore les risques de biaisage, et surtout pour uniformiser les
temps de traitement, on utilise des processeurs virtuels plutôt que des processeurs
physiques. En d’autre termes, plusieurs processeurs virtuels sont créés sur chaque
processeur physique, ce qui permet de diminuer la taille de chaque partition. Les
petites partitions ainsi obtenues sont distribuées de façon circulaire. Ainsi, le biais
est réparti au mieux sur les différents nœuds.
Affectation de processeurs Bien que l’affectation de processeurs soit du ressort
de l’optimiseur, son importance justifie une brève présentation de ce concept au sein
de cette thèse. L’estimation du nombre de processeurs affectés au parallélisme intra-
opérations a donné lieu a une abondante littérature. En règle générale, le nombre
de processeurs utilisés doit permettre une bonne exécution parallèle tout en utili-
sant une quantité raisonnable de ressources. Une proposition intéressante est celle
de [WIL95]. Les auteurs de cet article rappellent que la phase de mise en route est
essentiellement séquentielle. Leur SGBD, PRISMA [Ape92], fonctionne sur une ma-
chine parallèle à mémoire distribuée et n’utilise que la mémoire haute (pas d’accès
disque, du moins au niveau du SGBD). Aussi les opérations d’initialisation (mise
en place des accès aux relations, ...) sont-elles séquentielles. Ainsi, avec a le temps

42 CHAPITRE II. SGBD RELATIONNELS PARALLÈLES ET RÉSEAUX DE STATIONS
A
C
C
B
E
C
C
D
H
G
F
A
B
D
E
C
F
H
G
H
G
F F
H
G
E
C
C
DD
E
C
A
C
C
B
A
B
C
machine 1
machine 2
machine 3
Données découpées
Données répliquées
FIG. II.8 – Gestion des biaisages par découpage-réplication
d’initialisation pour un processeur, c le temps de traitement d’un tuple, N le nombre
de tuples et n le nombre de processeurs utilisés, le temps de calcul peut, dans leur
architecture, être donné par la formule :
R = an+ cNn
Notons que la seconde partie de cette formule implique que le speed-up de l’al-
gorithme de jointure soit linéaire. Les gains de temps réalisés grâce à la parallélisa-
tion des calculs sont peu à peu contrebalancés par le temps d’initialisation, et une
trop grande parallélisation conduit à une dégradation des performances. Le nombre
n0 de processeurs correspondant au speed-up maximum est dès lors calculable par
dérivation de R suivant n. On obtient ainsi :
n0 =q
cNa

2. PRINCIPES DE BASE DES SGBD RELATIONNELS PARALLÈLES 43
Une fois ce nombre optimal calculé, on peut en général constater, ainsi que le
fait [Ham93], que l’on peut a priori diminuer légèrement le nombre de processeurs
affectés au calcul sans pour autant observer une dégradation importante des perfor-
mances. Il s’agit dès lors de rechercher le nombre économique de processeurs, c’est-à-
dire permettant des performances satisfaisantes tout en limitant les ressources uti-
lisées. L’algorithme proposé consiste à fixer un seuil de tolérance G (exprimé, par
exemple, en secondes). On agit ensuite par dichotomie. Partant d’un nombre M de
processeurs correspondant à la moitié du nombre total de processeurs, on diminue
ensuite le nombre de processeurs tant que :
– enlever un processeur fait perdre moins de G secondes ;
– ajouter un processeur fait gagner moins de G secondes.
2.3 Parallélisme inter-requêtes
La recherche en matière de parallélisme inter-requêtes est nettement moins abon-
dante que celle concernant le parallélisme intra-requête. Les problèmes abordés sont
effectivement d’ordre organisationnel, et visent à partager les ressources de façon
équitable et efficace entre les utilisateurs (ou plus exactement entre les requêtes
qu’ils soumettent). Une approche intéressante est proposée dans [Meh93]. Mehta
et al. proposent de considérer les requêtes suivant trois catégories, regroupant res-
pectivement les petites, moyennes et grandes requêtes, classées comme telles sui-
vant le volume de données manipulé. Les données des petites requêtes tiennent
entièrement en mémoire, celles des requêtes moyennes tiennent juste en mémoire,
et celles des grandes requêtes nécessitent l’utilisation de fichiers temporaires. Cet
article propose différentes techniques d’ordonnancement des requêtes sur chaque
nœud. La technique la plus efficace introduite ici s’appelle stratégie adaptative. Elle
consiste à utiliser des systèmes de files d’attente pour chaque type de requête. On
utilise ainsi quatre files par machine. Une file générale (memory queue) lance l’exécu-
tion de ses requêtes, en mode FIFO, dès lors que l’espace mémoire nécesssaire à la

44 CHAPITRE II. SGBD RELATIONNELS PARALLÈLES ET RÉSEAUX DE STATIONS
prochaine candidate est disponible. Avant d’être placées dans cette file, les requêtes
sont placées dans une file spécifique à leur catégorie (voir figure II.9). Le passage
dans la queue générale se fait en fonction d’un seuil donné pour chaque catégo-
rie. En d’autre terme, un nombre maximum de requêtes de chaque catégorie peut
être admis, à un instant donné, dans la queue générale. Ce seuil est appelé Multi-
Programming Level (MPL).
Queues
MPL
Queue Générale
Petites Requêtes Requêtes Moyennes Grandes Requêtes
FIG. II.9 – Stratégie adaptative
Ce nombre maximum est calculé, de façon dynamique, et pour chaque catégo-
rie, en fonction des temps de réponse moyens des requêtes. Dans une phase d’ini-
tialisation, un temps moyen d’exécution en mode mono-requête est calculé pour
chaque catégorie. Durant l’exécution, ce temps moyen est mis en rapport avec le
temps constaté. Les écarts pour les trois catégories sont mis en rapport. Si une caté-
gorie présente un écart plus fort que les autres, alors le nombre de requêtes admises
en queue générale pour cette catégorie est augmenté, et celui des autres catégories
est diminué. Une telle stratégie permet d’établir une priorité “honnête” (fairness)
pour les différentes catégories de requêtes. Cette première approche se limite aux
requêtes en lecture, et laisse aux nœuds de calcul une certaine autonomie.
Une approche complémentaire, proposée par [Rah93], étudie le degré de parallé-
lisme des opérations en fonction des disponibilités de la machine parallèle. Elle offre

2. PRINCIPES DE BASE DES SGBD RELATIONNELS PARALLÈLES 45
en outre une gestion de charge mixte transactions/interrogations. Cet article pro-
pose différentes stratégies pour déterminer le degré de parallélisme. La première,
appelée Dynamic adaptation of the degree of join parallelism (DJP) établit le degré de
parallélisme en mode multi-utilisateur, Pmu, en fonction du degré optimal en mode
mono-utilisateur, Psu�opt, avec la règle suivante : Pmu = Psu�opt(1� u3), u indiquant
le taux moyen d’utilisation des processeurs (0 < u < 1). Les processeurs sont choisis
au hasard parmi les processeurs disponibles.
La seconde approche, Join Processing on Least Utilized Processors (LUP), choisit
les processeurs les moins utilisés lors de la compilation de la requête, le nombre
de processeurs nécessaires étant déterminé de façon statique (par exemple, Psu�opt).
Une variante plus intéressante de cette stratégie, Adaptative LUP (ALUP), augmente
artificiellement le taux d’utilisation des processeurs retenus pour une requête don-
née. Cette astuce permet d’anticiper le surplus de travail engendré par une requête.
Ainsi, une requête compilée peu de temps après ne sera pas exécutée sur les mêmes
processeurs que la précédente.
De fait, il apparaît dans cet article que les meilleurs temps d’exécution sont ob-
tenus à l’aide d’une stratégie combinant DJP pour le nombre de processeurs utilisés
et ALUP pour le choix de ceux-ci.
Les approches de Mehta et al. et de Rahmer et al. s’avèrent complémentaires
dans le sens où la première permet un équilibrage de charge local et la seconde
un équilibrage global, tendant tous deux à améliorer les temps de réponse moyens.
Bien que l’approche de Mehta et al. soit à l’origine conçue pour un SGBD centralisé
(et mono-processeur), il est a priori possible de la réutiliser dans le cadre d’un SGBD
parallèle en termes d’opérations élémentaires (plutôt que de requêtes).
2.4 SGBD relationnels parallèles
De nombreux SGBD parallèles, qu’il s’agisse de prototypes ou de produits indus-
triels, ont été à ce jour développés. Nous en citons quelques uns regroupés suivant

46 CHAPITRE II. SGBD RELATIONNELS PARALLÈLES ET RÉSEAUX DE STATIONS
le type d’architecture sur lequel ils s’exécutent.
Concernant l’utilisation d’architectures à mémoire partagée, nous pouvons notam-
ment citer XPRS [Sto88], Volcano [Gra94], et DBS3 [Ber91] du point de vue des pro-
totypes et Oracle [Lin93] du point de vue des produits commerciaux.
Les architectures à disques partagés sont pour leur part exploitées par des SGBD
comme Oracle[Bam98] (on pourra également consulter [Pir90]).
Les architectures à mémoire distribuée ont été largement utilisées, tant dans le cadre
de prototypes, tels que Bubba [Bor88] et Gamma [Dew90], que dans celui de pro-
duits industriels, tels Tandem [Che93] et Teradata [Pag92, Ter98, Bal97].
Nous pouvons enfin noter le cas particulier des machines hiérarchiques, que l’on
peut retrouver, du point scientifique, dans [Pir90], [Hua91] et [Bou96b] (on pourra
également consulter [Gra94]). Le SGBD Informix On Line XPS [Ger95], bien qu’orienté
vers les réseaux de stations, fonctionne cependant sur de telles architectures (clus-
ters).
3 Les réseaux de stations
Un réseau de stations est constitué d’un ensemble d’ordinateurs individuels (sta-
tions de travail ou PCs) reliés entre eux par un réseau local. L’accroissement des
performances de telles machines et des réseaux locaux les reliant conduit depuis
quelques années à les considérer comme une alternative viable aux machines paral-
lèles. Cette section présente le contexte d’émergence des réseaux de stations, puis
introduit les principaux composants de communication rapide (logiciel et matériel)
disponibles actuellement.

3. LES RÉSEAUX DE STATIONS 47
3.1 Le concept de réseau de stations
3.1.1 Premières utilisations
Les réseaux de stations reposent sur un principe simple : regrouper plusieurs
machines physiquement indépendantes dans un but commun. Deux conditions ap-
paraissent nécessaires à l’émergence du concept de réseau de stations : i) un coût
relativement bas des machines, et ii) une concentration suffisante de ces dernières.
Il n’est dès lors guère surprenant que des pionniers tels Condor [Liv92, Con96], et
plus récemment NOW [AD96] se soient développés au sein de grandes universités
américaines (Condor à l’université du Wisconsin et NOW à celle de Berkeley).
Le système Condor [Lit88] visait dans un premier temps à distribuer des tâches
différées (batch) sur les machines disponibles à un instant donné. La disponibilité
d’une machine était estimée suivant l’activité de ses périphériques de saisie (cla-
vier et souris) et de son processeur, ces deux points s’avérant complémentaires (le
premier assure que l’utilisateur “normal” de la machine n’est pas lésé durant son
utilisation interactive de la machine, le second que ses tâches longues restent loca-
lement prioritaires). Le bien fondé d’une telle initiative repose ainsi sur un contrat
social (social contract) selon lequel les “possesseurs” des machines restent maîtres de
leur environnement de travail. L’attribution de ressources se fait à la demande des
utilisateurs. Le produit Condor est assez largement utilisé, notamment à l’université
du Wisconsin.
D’un point de vue industriel, IBM diffuse depuis quelques années le produit
LoadLeveler [IBM95], produit permettant de lancer des tâches en différé et à dis-
tance suivant la disponibilité des machines. Plus récemment est apparu le projet
NOW (Network Of Workstations), lequel constitue également un vaste champ d’in-
vestigations autour du concept de réseau de stations. Les fondements de NOW
consistent à utiliser des stations reliées par un réseau commuté haut débit. En réa-
lité, de nombreux projets se cachent sous l’appellation NOW, depuis les interfaces de
communication rapides (messages actifs –système dans lequel les messages consti-

48 CHAPITRE II. SGBD RELATIONNELS PARALLÈLES ET RÉSEAUX DE STATIONS
tuent des appels de fonctions bas niveau à distance) jusqu’aux systèmes d’exploi-
tation distribués (GLUNIX) en passant par les programmes applicatifs (NOWSort,
programme de tri rapide fonctionnant sur un réseau de stations UltraSparc reliées
par Myrinet (voir section 3.2.2), et ayant battu des records de rapidité sur les bench-
marks de tri).
3.1.2 Vers une utilisation parallèle
L’apparition de bibliothèques de communication standards, utilisables sur ré-
seaux de stations, a ensuite favorisé le développement de programmes parallèles
sur de telles architectures. De même, les progrès réalisés en matière de réseaux d’in-
terconnexion rapides, tels Myrinet, FDDI et ATM, ont permis peu à peu d’envisager
non seulement des exécutions distribuées sur réseaux de stations, mais plus encore
de réelles applications parallèles [Dus96], susceptibles d’échanger rapidement de
nombreux messages entre les différents nœuds d’exécution.
Ainsi, Condor, au départ prévu pour la gestion de ressources en réseau, a ensuite
été étendu afin de permettre l’exécution de programmes parallèles, sur réseaux de
stations [Pru96]. Un des objectifs de ce projet consistait, comme dans le cadre du
gestionnaire de ressources originel, à permettre de se servir des stations, en période
de basse utilisation, tout en conservant la possibilité de changer de machine lors du
retour de l’utilisateur “officiel”. Ce but est atteint dans Condor par ajout de points de
contrôle, placés à deux niveaux : au-dessus des bibliothèques standards d’une part
et au-dessus de la bibliothèque de communication d’autre part, ce qui permet de
connaître l’état des processus et des communications. Lors d’un point de contrôle,
les processus concernés s’arrêtent, attendent que tous soient prêts pour le contrôle
(réseau vidé) puis envoient leur état à un serveur de points de contrôle. Il est en
outre possible de mettre un temps limite à l’exécution des points de contrôle afin,
par exemple, de ne pas trop retarder la reprise en main par l’utilisateur “officiel”.
En cas de dépassement de la limite, on détruit le programme en cours d’exécution.

3. LES RÉSEAUX DE STATIONS 49
Au-delà du simple principe de “contrat social”, ce système est utilisable pour limiter
les pertes en cas d’arrêt accidentel d’une machine.
3.2 Communications dans les réseaux de stations
Si les premières utilisations des réseaux de stations consistaient plutôt à utili-
ser des systèmes de fichiers répartis et à déplacer un travail batch d’une machine
à une autre, il est assez vite apparu que d’autres applications, tels le calcul scien-
tifique et l’imagerie médicale, pourraient profiter de ce type d’architecture. Aussi
différents middleware permettant l’exploitation parallèle d’un réseau de stations
ont-ils été développés. C’est par exemple le cas des mémoires virtuellement parta-
gées [Bru96b, Lit96, Lef97], pour lesquelles l’accès à une information distante est
caché au niveau logiciel, et donc transparent pour le programmeur. Nous pouvons
également citer les systèmes de fichiers répartis [Dah94], qui bénéficient non seule-
ment du gain en espace de stockage, mais également en bande passante. Nous pou-
vons aisément constater que ces deux exemples impliquent des communications
inter-machines plus fréquentes et plus denses qu’un simple déport de traitement.
Les capacités de réseaux classiques, tels Ethernet, se sont dès lors avérées insuffi-
santes, favorisant ainsi la mise en avant de nouveaux matériels et de nouveaux pro-
tocoles de communication. Nous présentons ici les protocoles ATM et Fast Ethernet
ainsi que le réseau Myrinet, car ces trois produits illustrent bien le marché actuel du
réseau moyen et haut débit.
3.2.1 ATM
ATM est un protocole de transfert de données mettant en œuvre le concept du
relais de cellules [DP93, Puj97]. Dans un tel système, les données sont convoyées
par le biais de cellules de taille fixe. Une cellule ATM contient 48 octets de données,
plus 5 octets d’entête, soit 53 octets en tout. Cette longueur, au premier abord sur-
prenante, provient d’un accord entre européens et américains. Ces derniers souhai-

50 CHAPITRE II. SGBD RELATIONNELS PARALLÈLES ET RÉSEAUX DE STATIONS
taient au départ utiliser des trames de 64 octets de données, alors que les européens
s’orientaient vers des trames de 32 octets. Sans entrer dans les détails, disons que
la qualité d’émission de la voix est inversement proportionnelle à la longueur de la
trame. Une cellule de petite taille permet donc de transmettre des données sans ins-
tallations supplémentaires (suppression d’écho, etc.), et ce jusqu’à une distance de
deux à trois mille kilomètres, ce qui convient bien aux pays européens. Les distances
inter-urbaines étant en général plus grandes aux Etats-Unis qu’au sein des états eu-
ropéens, les installations sus-citées sont quoi qu’il en soit nécessaires, et de plus
grande longueur de trames sont alors envisageables (ce qui permet une meilleure
utilisation de la bande passante). Deux longueurs de trames différentes ont donc
été proposées. Finalement, une valeur intermédiaire de 48 octets de données a été
acceptée par les différentes parties.
L’une des caractéristiques remarquables d’ATM consiste à inclure la notion de
qualité de service, reposant entre autres sur la réservation de bande passante. Les
cellules ATM possèdent un bit de priorité de perte de cellule (Cell Loss Priority),
qui permet de choisir les données à supprimer en priorité en cas de congestion du
réseau. Cette option apparaît comme une bonne opportunité dans le cadre des bases
de données parallèles si le réseau utilisé est partagé entre plusieurs applications. La
bande passante d’un réseau ATM peut atteindre plus de 800 Mbit/s.
3.2.2 Myrinet
Myrinet est un réseau local commuté rapide commercialisé par la société Myri-
com [Bod95]. Il se compose de cartes interfaces, placées sur les stations (cartes ré-
seau) et de commutateurs (switch). L’envoi des données est synchrone, c’est-à-dire
qu’au niveau du point d’émission, les données sont transmises à un débit régulier.
La réception est en revanche asynchrone au niveau matériel, et le débit des données
est ensuite régulé par des circuits internes à l’interface.
L’acheminement des données est effectué à l’aide d’indications de transit situées

3. LES RÉSEAUX DE STATIONS 51
en tête de message (les premiers octets de chaque message indiquent le chemin à
suivre de l’émetteur jusqu’au destinataire).
Myrinet présente l’avantage d’offrir des taux d’erreur très bas, de l’ordre de 10�15
pour une longueur de câbles de 25 m. La bande passante théorique s’élève à 640
Mbit/s (1,2 Gbit/s en mode full-duplex). La possibilité d’accéder au code source
des couches basses permet l’étude et l’optimisation de ce système (notamment dans
le cadre universitaire [BIP98]).
3.2.3 Fast Ethernet
Fast Ethernet [Asa94, Qui97] constitue la nouvelle génération de réseau Ethernet,
dont la bande passante est portée de 10 à 100 Mbit/s. Ce système est voué à rem-
placer progressivement le parc existant de réseaux Ethernet. Une bonne partie des
cartes Ethernet actuellement disponibles sur le marché sont compatibles Ethernet /
Fast Ethernet. Bien que les performances de Fast Ethernet ne soient pas aussi éle-
vées que celles d’ATM et Myrinet, le parc installé et la migration programmée vers
ce protocole en font le support vraisemblable des communications dans les réseaux
locaux des prochaines années.

52 CHAPITRE II. SGBD RELATIONNELS PARALLÈLES ET RÉSEAUX DE STATIONS
3.2.4 Eléments comparatifs
L’ATM, après une gestation assez longue, semble aujourd’hui en bonne voie
pour s’imposer sur les réseaux étendus. Des réseaux locaux implémentant le pro-
tocole ATM sont également utilisés au sein de diverses structures, mais leur mise en
œuvre reste en général délicate, et d’autres solutions semblent plus efficaces à petite
échelle. Myrinet offre une solution inverse, adaptée aux réseaux locaux de taille res-
treinte. Cependant, l’utilisation d’un réseau Myrinet reste surtout intéressante dans
le cadre de réseaux dédiés à un usage parallèle. Fast Ethernet ne constitue pas exac-
tement un réseau haut-débit, comparativement à ATM et Myrinet. Cependant, son
apparition progressive à grande échelle tend à indiquer que l’utilisation du concept
de réseau de stations généraliste se fera probablement sur un tel support. Il semble
donc intéressant de considérer les performances de cette architecture comme réfé-
rence dans le cadre d’applications parallèles sur réseau de stations non dédié.
3.3 Bibliothèques de programmation
Un point essentiel de la programmation parallèle consiste à pouvoir faire com-
muniquer les différents nœuds de calcul. Chaque type de machine parallèle possède
son propre système d’échange d’information, plus ou moins standard, depuis les
sockets UNIX jusqu’aux bibliothèques spécifiques. Cette diversité s’est vite avérée
contraignante pour le développement de logiciels parallèles. Elle nuit en effet à leur
portabilité. Aussi des bibliothèques de programmation portables ont-elles été déve-
loppées, afin, d’une part, de standardiser les messages transmis, et d’autre part, de
cacher les différentes bibliothèques de communication de bas niveau. De tels sys-
tèmes permettent non seulement d’utiliser des codes très similaires sur différents
types de machines, mais également, pour certaines d’entre elles, de paralléliser une
exécution sur un support hétérogène. Ils constituent un élément moteur primordial
de l’utilisation des réseaux de stations. Des ouvrages tels [Aut94] et surtout [Vet95]
présentent le fonctionnement et la syntaxe de telles bibliothèques. Nous présentons

3. LES RÉSEAUX DE STATIONS 53
ici PVM et MPI, dont la diffusion et la portabilité font d’elles les bibliothèques les
plus courantes et les plus étudiées.
3.3.1 PVM
La bibliothèque PVM [PVM98, Gei94] est apparue au début des années 90. Elle
a été développée par le Oak Ridge National Laboratory, l’Université du Tennessee
et l’Université d’Emory. Une des caractéristiques principales de PVM est d’avoir été
d’emblée conçue pour des systèmes hétérogènes, les transferts de données se faisant
à l’aide de XDR. Cet outil (External Data Representation) a été développé par Sun,
et consiste en un “middleware” proposant un codage intermédiaire des données.
Lorsque deux machines ne codent pas les données de la même façon (par exemple,
le codage d’un entier peut se faire, suivant la machine, en commençant par l’octet
de poids fort ou par l’octet de poids faible), XDR se charge de fournir une représen-
tation intermédiaire qu’il saura décoder et adapter à la machine destinataire.
L’exécution parallèle est amorcée depuis une machine donnée. Elle se fait à l’in-
térieur d’un programme à l’aide de la commande pvm_spawn. Cette dernière per-
met de lancer l’exécution distante d’un programme donné (qui peut être différent
du programme lanceur). Les différents processus s’exécutent ensuite en mode asyn-
chrone, c’est-à-dire sans contrôle central.
La communication entre les différents processus se fait à l’aide de messages compo-
sites (dans le sens où ils peuvent contenir différentes données), pouvant être trans-
mis en mode point-à-point ou multicast.
PVM a été à l’origine développé pour les langages C et Fortran, puis pour C++.
On trouve aujourd’hui des extensions pour Java, Perl, Tcl/tk et Python. En outre,
de nombreux outils de développement et de traçage de programmes PVM sont dis-
ponibles, tels XPVM (console WYSIWYG permettant la visualisation de la machine
virtuelle et des messages échangés entre ses différents nœuds). Du point de vue
des plateformes, PVM est disponible sur un grand nombre de systèmes UNIX, tels

54 CHAPITRE II. SGBD RELATIONNELS PARALLÈLES ET RÉSEAUX DE STATIONS
SunOS, Solaris, Aix, Linux, ainsi que Windows (NT, 95), VMS, OS/2. D’autres por-
tages, supportant les architectures à mémoire partagées ont été effectués pour les
machines Cray, Sun, SGI, DEC, Kendall Square, Sequent et IBM. Bien que PVM soit
un produit, et non un standard, on peut trouver des bibliothèques commerciales
reprenant son interface, tel Fast-PVM.
3.3.2 MPI
Alors que PVM est un standard de fait, MPI [MPI98, Sni95] constitue en revanche
une norme de développement de bibliothèques d’échange de messages. MPI a ainsi
été conçu, à partir de 1992, par le Message Passing Interface Forum (MPIF), entité
regroupant diverses organisations, tant dans le domaine industriel que dans celui
de la recherche. Ce forum a dès lors proposé, non pas de choisir un produit exis-
tant comme standard, mais plutôt de retenir une synthèse des meilleurs aspects de
ceux-ci. Alors que PVM est particulièrement orienté vers les systèmes hétérogènes,
MPI est à l’origine plus adapté aux systèmes homogènes (machines à mémoire par-
tagée ou distribuée et réseaux de stations). L’utilisateur définit toujours sa machine
virtuelle, mais ne peut plus choisir les sites d’exécution des tâches comme le per-
mettait l’instruction pvm_spawn de PVM. Plus exactement, cette tâche est laissée
au programmeur.
MPI définit des fonctions de communication bloquantes et non bloquantes. En mode
non bloquant, on dispose de fonctions permettant de savoir si une transmission est
terminée. La spécificité des messages de MPI provient de l’insertion d’un “com-
municateur” au sein des messages transmis. Celui-ci définit le contexte d’exécution
de l’opération de transmission, c’est-à-dire le groupe de processus susceptibles de
recevoir ce message. Le contenu des messages est défini à l’aide de types simples
et de datatypes (types de données), définis par le programmeur, et permettant de
modéliser des structures plus complexes. Plusieurs implémentations de MPI sont
actuellement utilisées, parmi lesquelles MPICH [MPI96], développé au Argonne

3. LES RÉSEAUX DE STATIONS 55
National Laboratory (Illinois), porté sur un grand nombre de plateformes UNIX
(stations et machines parallèles, tels IBM SP1 et SP2, Intel i860 et Paragon, Thin-
king Machines CM5 ...) et sous Windows (NT,95, 3.1). Nous pouvons également citer
LAM [LAM98], implémentation UNIX développée au Ohio Supercomputer Center.
Enfin, un certain nombre d’implémentations spécifiques ont été développées par
plusieurs fabricants, parmi lesquels CRAY, IBM, Hewlett-Packard ou Silicon Gra-
phics.
3.4 Machine parallèle ou réseau de stations?
L’évolution permanente des frontières entre ces deux concepts rend leur com-
paraison délicate. D’une part, les réseaux de stations dédiés, parfois intégrés dans
une même “boîte”, ressemblent de plus en plus aux machines parallèles à mémoire
distribuée. Les performances de leurs systèmes de communication sont maintenant
très honorables. D’autre part, les stations de travail haut de gamme possèdent main-
tenant plusieurs processeurs (SMP) et deviennent de ce fait des machines parallèles
SMP. Il est donc délicat de poser les réseaux de stations comme solution opposée aux
machines parallèles. Nous considérerons donc plutôt sous le terme de “machine pa-
rallèle” les machines explicitement dédiées à un traitement massivement parallèle,
et sous le terme de “stations de travail” les machines à usage standard et person-
nel ou quasi-personnel, ce qui inclut les petites machines SMP et les PC (notons
d’ailleurs l’existence d’architectures PC multi-processeurs).
Les réseaux de stations, ainsi définis, présentent l’avantage incontournable de la
modularité. En effet, l’ajout de processeurs peut être progressif. Dans la mesure où
l’hétérogénéité du système est prise en compte, le renouvellement des stations peut
également être progressif, ce qui apparaît comme un atout majeur étant donné la
rapidité d’évolution des matériels. La plus ou moins grande autonomie des stations
permet également d’assurer une certaine fiabilité du système global, vis-à-vis d’une
machine parallèle intégrée. Enfin, du point de vue logiciel, la gestion des tâches par

56 CHAPITRE II. SGBD RELATIONNELS PARALLÈLES ET RÉSEAUX DE STATIONS
station permet un équilibrage assez contrôlé, mais également une certaine simpli-
cité de programmation (à base de messages). Enfin, les performances d’un réseau de
station haut de gamme s’approchent, pour des coûts nettement restreints, de celles
de machines parallèles équivalentes. Sur un autre plan, non négligeable, la grande
diffusion des stations de travail (et en particulier des PCs) assure un prix d’achat
restreint.
Mais les réseaux de stations possèdent cependant certains handicaps par rapport
aux machines parallèles. Leur autonomie accroît en effet leur coût de gestion (il faut
gérer un système d’exploitation par machine) et limite l’efficacité du parallélisme
(une gestion globale du système n’étant pas disponible par défaut). De plus, l’hété-
rogénéité potentielle rend plus difficile la distribution des travaux. Enfin, l’obtention
de hautes performances s’obtient par l’ajout de composants matériels (réseau haut
débit) et logiciels (bibliothèques de communication à surcoût réduit) assez éloignés
des systèmes présents sur les stations classiques. Bien que l’on puisse espérer que de
tels composants deviennent rapidement des éléments standards des PCs, rien n’est
fait pour l’instant.
A titre d’illustration, nous reproduisons ci-dessous un tableau (voir tableau II.1)
publié dans [And95] et indiquant les performances de différentes configurations
(machines parallèles et réseaux de stations) sur une simulation de mesures de pollu-
tions aériennes. Ce tableau indique également le coût des différentes configurations.
Bien que ces tests, résultant d’une simulation, soient visiblement orientés de façon
à mettre en valeur le réseau de stations proposé, il demeure que sur de tels types
d’applications, les réseaux de stations fournissent une solution particulièrement in-
téressante.
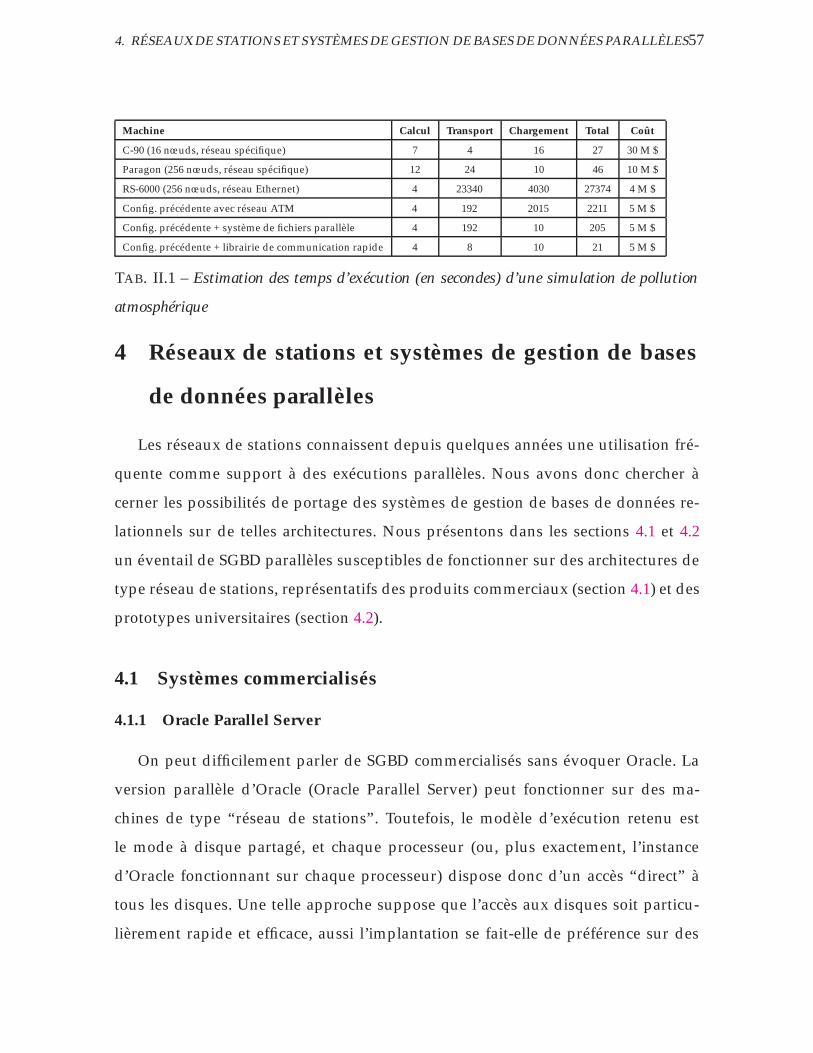
4. RÉSEAUX DE STATIONS ET SYSTÈMES DE GESTION DE BASES DE DONNÉES PARALLÈLES57
Machine Calcul Transport Chargement Total Coût
C-90 (16 nœuds, réseau spécifique) 7 4 16 27 30 M $
Paragon (256 nœuds, réseau spécifique) 12 24 10 46 10 M $
RS-6000 (256 nœuds, réseau Ethernet) 4 23340 4030 27374 4 M $
Config. précédente avec réseau ATM 4 192 2015 2211 5 M $
Config. précédente + système de fichiers parallèle 4 192 10 205 5 M $
Config. précédente + librairie de communication rapide 4 8 10 21 5 M $
TAB. II.1 – Estimation des temps d’exécution (en secondes) d’une simulation de pollution
atmosphérique
4 Réseaux de stations et systèmes de gestion de bases
de données parallèles
Les réseaux de stations connaissent depuis quelques années une utilisation fré-
quente comme support à des exécutions parallèles. Nous avons donc chercher à
cerner les possibilités de portage des systèmes de gestion de bases de données re-
lationnels sur de telles architectures. Nous présentons dans les sections 4.1 et 4.2
un éventail de SGBD parallèles susceptibles de fonctionner sur des architectures de
type réseau de stations, représentatifs des produits commerciaux (section 4.1) et des
prototypes universitaires (section 4.2).
4.1 Systèmes commercialisés
4.1.1 Oracle Parallel Server
On peut difficilement parler de SGBD commercialisés sans évoquer Oracle. La
version parallèle d’Oracle (Oracle Parallel Server) peut fonctionner sur des ma-
chines de type “réseau de stations”. Toutefois, le modèle d’exécution retenu est
le mode à disque partagé, et chaque processeur (ou, plus exactement, l’instance
d’Oracle fonctionnant sur chaque processeur) dispose donc d’un accès “direct” à
tous les disques. Une telle approche suppose que l’accès aux disques soit particu-
lièrement rapide et efficace, aussi l’implantation se fait-elle de préférence sur des

58 CHAPITRE II. SGBD RELATIONNELS PARALLÈLES ET RÉSEAUX DE STATIONS
systèmes possédant un réseau d’interconnexion rapide. De plus, les entrées-sorties
sont limitées grâce à un gestionnaire de verrous distribué (distributed lock manager)
qui permet aux différents nœuds de conserver un verrou sur une ou plusieurs pages
de données entre deux transactions. Ce principe limite les accès disques (l’écriture
des pages modifiées ne se faisant pas après chaque transaction). Les verrous sont
relâchés (et les pages modifiées écrites) uniquement lorsqu’un nœud concurrent
souhaite accéder aux pages correspondantes. Les verrous sont par ailleurs position-
nables attribut par attribut afin de limiter encore les accès concurrents. Notons que
dans certaines configurations, certains noeuds de calcul peuvent être utilisés comme
“Gigacaches”, c’est à dire que leur fonction consiste alors à cacher les accès disques
pour les autres noeuds. La distribution des données supporte la mise en place d’un
index sur chaque partition, ainsi que la possibilité d’un index global correspondant
à l’assemblage de l’index de chaque partition. L’exécution des requêtes est parallé-
lisée grâce à un coordinateur de requête, qui se charge de diffuser les sous-tâches
parallèles aux différents noeuds concernés, puis de récupérer les résultats produits.
Le parallélisme est complètement caché à l’utilisateur, ce qui permet d’assurer le
portage de tous les codes préexistants.
4.1.2 IBM DB2 Parallel Edition
Le produit DB2 d’IBM est aussi représentatif des SGBD professionnels. A l’op-
posé du produit Oracle, DB2 Parallel Edition (DB2 PE) est résolument shared-nothing
(il fonctionne suivant le modèle de mémoire distribuée). Une instance de DB2 est
lancée sur chaque noeud et se trouve ainsi responsable des données qui lui sont
confiées. Ainsi, chaque noeud possède son propre journal. L’exécution parallèle
d’une requête est gérée par un noeud coordinateur (coordinator) qui confie l’exé-
cution proprement dite à un ensemble de noeuds esclaves (slaves). Le mode de
fonctionnement privilégié est l’envoi de fonctions (function shipping), qui consiste
à demander l’exécution des requêtes sur les noeuds où sont stockées les données.

4. RÉSEAUX DE STATIONS ET SYSTÈMES DE GESTION DE BASES DE DONNÉES PARALLÈLES59
Au besoin, le système fait appel au mode “envoi de données” (data shipping), qui
à l’inverse, expédie les données à traiter sur un noeud (ou un ensemble de noeuds)
déterminé(s).
La fragmentation d’une table s’effectue par hachage sur un ensemble de noeuds
donné, ou node group, ce dernier étant défini avant la fragmentation de la table.
L’ajout “à chaud” de noeuds de calcul au sein d’un node group peut entraîner la
re-fragmentation des tables correspondantes suivant la nouvelle configuration, cette
redistribution étant toutefois contrôlable par l’administrateur. Notons qu’un même
noeud peut appartenir à plusieurs node groups. De même qu’Oracle Parallel Server,
DB2 PE propose un système d’indexation parallèle.
4.1.3 Informix XPS
Online Extended Parallel Server (Online XPS), le produit d’Informix, contraste
profondément avec les deux produits précédents de par sa présentation résolument
parallèle [Ger95]. Un large éventail de techniques de fragmentation est disponible.
Outre les répartitions circulaire, par hachage et par intervalles, on peut également
effectuer une répartition par expression (c’est à dire suivant une expression équi-
valente à une clause WHERE du langage SQL), ainsi qu’une répartition hybride
(c’est-à-dire suivant deux techniques différentes au niveau inter-machine et intra-
machine, par exemple par hachage entre noeuds et par intervalles à l’intérieur d’un
même noeud, dans la mesure où un noeud dispose de plusieurs disques). Des outils
d’aide à la fragmentation sont disponibles afin de rendre plus aisée la manipula-
tion de ces nombreuses techniques. Le contrôle de la cohérence est réparti au niveau
de chaque noeud. Enfin, les noeuds peuvent être regroupés en co-groups auxquels
sont assignés certains types de tâches. Il convient toutefois de souligner que, bien
qu’Informix affirme haut et fort que Online XPS est un système Shared Nothing, ce
dernier s’apparente plutôt à une architecture hybride, orientée vers les clusters de
stations SMP. De ce fait, entre les différentes sous-tâches d’une requête, un partage

60 CHAPITRE II. SGBD RELATIONNELS PARALLÈLES ET RÉSEAUX DE STATIONS
de données mixte est possible, via la mémoire partagée au sein d’un même cluster,
ou à travers un système de messages en inter-clusters.
4.2 Prototypes universitaires
4.2.1 MIDAS
Le système MIDAS [Boz96], développé à l’Université Technique de Münich, consti-
tue la version parallèle d’un SGBD séquentiel commercialisé, TransBase SQL-DBMS.
Après une première tentative de portage sur machine parallèle (Intel iPSC/2), le
prototype a finalement été développé sur un réseau de stations. Les communica-
tions inter-machines sont assurées par la bibliothèque de passage de messages PVM.
Les requêtes soumises à MIDAS suivent la syntaxe SQL. Leur interprétation et leur
exécution parallèle sont gérées de manière transparente à l’utilisateur. Le stockage
des données est géré par des cache/lock servers (CLS), à raison d’un CLS par ma-
chine physique, l’ensemble des CLS formant le cache virtuel de la base de données
(VDBC). L’accès à la base de données est réalisé via le système de partage de fichiers
NFS. Toutes les machines peuvent donc potentiellement accéder à l’ensemble de la
base. On a donc affaire à un système à disques partagés, et même à une mémoire
virtuellement partagée entre les différents caches. Au dessus de ces CLS, un ou plu-
sieurs interpréteurs par machine réalisent l’exécution des requêtes, en accédant aux
données des CLS par un mécanisme de mémoire localement partagée. Lorsqu’un
interpréteur souhaite traiter une page de données, il la demande à son CLS local. Si
celui-ci possède cette page, il la transmet à l’interpréteur. Si cette page est déjà char-
gée dans un autre CLS, il la demande à celui-ci. Sinon, il la charge lui-même depuis
le stockage de masse (disques durs).

4. RÉSEAUX DE STATIONS ET SYSTÈMES DE GESTION DE BASES DE DONNÉES PARALLÈLES61
4.2.2 Conquest
Le système Conquest [Fab97] n’est pas à proprement parler un système de ges-
tion de données, mais son mode de fonctionnement justifie sa présence dans cette
section. Conquest est un système d’exécution parallèle de requêtes mettant en jeu
plusieurs bases de données. Il a été conçu en vue d’extraction d’informations mé-
téorologiques. On accède à chaque base de données impliquée grâce à une inter-
face commune reposant sur CORBA. L’ensemble des opérations réalisées sur un
site donné sont regroupées dans un composant nommé executor. Celui-ci comprend
un ordonnanceur et un ensemble d’opérateurs. Une interface uniforme permet de
définir les transitions entre deux opérations consécutives, qu’elles se trouvent sur
le même site ou non. Toutefois, la communication via Corba n’est utilisée qu’entre
executors (c’est-à-dire entre sites). Les opérations sont déclenchées par l’opération
consommant leur résultat (système producteur/consommateur).

62 CHAPITRE II. SGBD RELATIONNELS PARALLÈLES ET RÉSEAUX DE STATIONS
5 Bilan
Nous avons pu constater, dans ce chapitre, l’importance des travaux réalisés
dans le cadre des bases de données relationnelles parallèles. Cependant, la montée
en puissance des réseaux de stations modifie rapidement le paysage des applica-
tions parallèles. Le portage progressif des SGBD existants sur de telles architectures
tend à élargir les possibilités d’accéder à une puissance de calcul jusque-là réservée
à de rares structures industrielles ou scientifiques. Cependant, cette apparente ex-
tension de l’accès au parallélisme ne doit pas occulter le fait que le coût d’un SGBD
parallèle, qu’il fonctionne sur un réseau de stations ou non, demeure particulière-
ment élevé. Les SGBD sont en général des outils généralistes, ce qui les conduit à
intégrer un grand nombre de fonctionnalités. Le portage de l’ensemble de ces fonc-
tionnalités sur une architecture parallèle est en général long et coûteux.
Les produits présentés ci-dessus ont tous en commun l’objectif de paralléliser
l’ensemble des tâches. Certains, comme Oracle Parallel Server et DB2 Parallel Edi-
tion, constituent les versions parallélisées de produits classiques. Bien que cette dé-
marche soit probablement la plus intéressante industriellement parlant, elle oblige
les développeurs à un délicat exercice. Les versions stables du SGBD parallèle d’Oracle
ont été particulièrement longues à développer. Ce système conserve par ailleurs une
gestion partiellement centralisée des disques. DB2, pour sa part, offre une structure
plus cohérente. Cependant, ses techniques de distribution de données demeurent li-
mitées au hachage. Le prototype MIDAS présente l’intérêt d’être une étude explica-
tive des techniques de portage d’un SGBD séquentiel vers un SGBD parallèle. Mais
il ne fait que mettre encore plus en avant la complexité des opérateurs de contrôle
nécessaires au bon fonctionnement des SGBD parallèles. De plus, l’utilisation de ser-
vices tel NFS nuit à l’efficacité du système. Informix XPS est ici le seul SGBD conçu
explicitement pour un usage parallèle. Il offre de très nombreuses possibilités de
configurations. Cependant, les clusters haut de gamme, de type SP2, sont implicite-
ment désignés comme son architecture de prédilection.

5. BILAN 63
De façon plus générale, l’aspect généraliste des SGBD est assez analogue à ce-
lui des traitements de texte actuels. Ces derniers constituent d’énormes machines,
intégrant quantité de fonctionnalités avancées. Cependant, la grande majorité des
utilisateurs n’en exploite qu’une infime portion. Nous retrouvons un phénomène
très similaire dans le cadre des SGBD. Si l’ensemble des utilisations d’une base de
données recouvre peu ou prou les fonctionnalités dont elle dispose, on peut en re-
vanche constater que certains contextes d’utilisation nécessitent un sous-ensemble
assez restreint des outils disponibles.
Ainsi, dans le cadre d’une utilisation en lecture seule, les outils de gestion de tran-
saction et de mise à jour sont totalement inexploités. Est-il nécessaire, dans ce cas de
figure, de disposer d’un SGBD parallèle? Si l’utilisation de cette base en lecture est
particulièrement intense, les techniques parallèles pourront apparaître séduisantes,
mais sera-t-il raisonnable, et même envisageable, d’investir dans un système com-
plexe et coûteux, dont seuls quelques éléments seront utilisés à leur plein potentiel?
Conquest, bien que ne correspondant pas exactement à un SGBD parallèle, offre
cependant une perspective très intéressante. Il introduit en effet la possibilité d’uti-
liser un composant externe au SGBD (ici sous forme de surcouche) comme moyen
d’interrogation. Plus que l’interopérabilité sous-jacente à Conquest, c’est cette ap-
proche par composants “à côté” qui doit ici retenir notre attention.
En effet, les techniques à base de composants peuvent a priori apporter une so-
lution alternative à la parallélisation de bases de données. Plutôt qu’une approche
monolithique du parallélisme dans les bases de données relationnelles, il est en-
visageable de considérer que seuls les éléments nécessitant une réelle puissance
de calcul nécessitent une parallélisation. Dans le cadre d’une utilisation intensive
du mode transactionnel, les aspects de mise à jour nécessitent une parallélisation,
afin d’accroître la bande passante en lecture-écriture. En revanche, dans le cadre de
cette thèse, seul l’aspect interrogation est considéré comme une opération intensive.
La bande passante doit donc demeurer conséquente, mais uniquement en lecture.

64 CHAPITRE II. SGBD RELATIONNELS PARALLÈLES ET RÉSEAUX DE STATIONS
Aussi peut-on s’affranchir d’une partie des outils nécessaires à un SGBD parallèle
complet. Bien que cette approche soit d’apparence simple, elle n’a pas été formali-
sée dans les travaux antérieurs. Même dans le cadre des entrepôts de données, ou
des fouilles de données, pour lesquelles elle semble particulièrement indiquée, ce
sont des SGBD complets qui sont la plupart du temps utilisés [Pro98]. Fort de ce
constat, nous avons donc choisi d’étudier et de formaliser un évaluateur parallèle
de requêtes. La description de ce composant et de son fonctionnement fait l’objet du
chapitre suivant.

65
Chapitre III
Proposition d’un évaluateur parallèle
1 Introduction
1.1 Principe et raison d’être
Les constatations énoncées au chapitre précédent nous ont conduit à proposer
le concept d’évaluateur parallèle (voir figures III.1 et III.2), consistant à utiliser un ré-
seau de stations, non pas comme support à un SGBD parallèle, mais comme support
à l’exécution de requêtes parallèles. Un SGBD parallèle complet se charge non seule-
ment de l’évaluation des requêtes mais également de la mise à jour des données. Cet
aspect de mise à jour s’avère complexe, car il faut gérer les notions de transaction
et de validité des données (contraintes d’intégrité, triggers, ...) de façon distribuée.
L’évaluateur parallèle se contente pour sa part d’introduire le parallélisme pour la
seule évaluation des requêtes, les gestions des transactions et de la validité des don-
nées restant confiées au SGBD existant.
Le principe fondamental de l’évaluateur parallèle est le suivant : il s’agit d’un
système capable d’accéder à une source de données, d’extraire (copier) ces données
de leur source afin de les répartir sur sa propre architecture, et enfin d’exécuter des
actions sur les données distribuées. L’évaluateur peut ainsi réaliser, de façon pa-

66 CHAPITRE III. PROPOSITION D’UN ÉVALUATEUR PARALLÈLE
rallèle, tout ou partie des travaux soumis au SGBD. Une telle approche permet de
décharger le SGBD existant. Nous pouvons ainsi tirer un double bénéfice de cette
réduction de travail. D’un côté, les temps de réponse peuvent être nettement amé-
liorés, et d’un autre côté, un SGBD surchargé par des requêtes trop nombreuses ou
trop volumineuses peut ainsi voir son volume de travail allégé.
Client
Client
Client
Client
SGBD
Requêtes
FIG. III.1 – Fonctionnement classique d’un SGBD
Client
Client
Client
Client
SGBD
Calculateur Calculateur Calculateur
Serveur
Requêtes(utilisation de l’extension)
Requêtes (accès classique au SGBD)
Accès aux données sources
(parallélisation des requêtes
Données distribuées
en lecture)
FIG. III.2 – Intégration de l’évaluateur parallèle
1.2 Architecture Générale
L’évaluateur consiste en un ensemble logiciel utilisant un réseau de stations de
travail ou d’ordinateurs personnels [Exb97c]. D’un point de vue logiciel, ses deux

1. INTRODUCTION 67
composants sont appelés serveur et calculateur. Le serveur constitue l’interface de
notre évaluateur vers le monde extérieur. Il communique avec le SGBD existant,
se charge de la redistribution des données et de la gestion des requêtes. Il consti-
tue donc le point d’accès des utilisateurs et de l’administrateur à l’évaluateur. Il se
charge également de la mise à jour des données distribuées en fonction des modifi-
cations apportées à la base source. Les calculateurs sont des processus de stockage
et de traitement. Un calculateur est installé sur chaque station susceptible de par-
ticiper à l’évaluateur. Il stocke une partie des données redistribuées, et effectue les
sous-requêtes correspondant à ces fragments. Les calculateurs sont à même de com-
muniquer entre eux et avec le serveur. Ils reçoivent des instructions et des données
à traiter ou stocker, et émettent des données résultats. Une fois l’évaluateur mis en
place, les requêtes peuvent être évaluées, soit en parallèle sur les calculateurs, soit
en séquentiel sur le SGBD existant.
Concernant les calculateurs, la première solution s’offrant à nous consiste à ins-
taller une copie du SGBD sur chaque station, et à s’en servir comme calculateur.
Cette proposition se trouve à mi-chemin entre les systèmes distribués (de part les
interactions entre SGBD partiellement indépendants) et les portages parallèles de
SGBD séquentiels (de part la réutilisation de composants existants en vue de trai-
tements parallèles). Une telle solution souffrirait cependant de notables handicaps ;
tout d’abord, cette pseudo-parallélisation serait nécessairement moins performante,
et en tous cas moins complète, que les véritables portages parallèles. Ensuite, les
communications devraient se faire à travers des messages suivant la syntaxe SQL ;
il serait de ce fait impossible de contrôler l’optimisation des traitements locaux aux
calculateurs. Outre cette opacité certaine, chaque calculateur devrait en outre in-
terpréter les requêtes qui lui seraient soumises, ce qui engendrerait une perte de
temps supplémentaire. Enfin, une telle option serait également peu intéressante sur
le plan économique, car elle impliquerait l’acquisition d’un nombre de licences égal
au nombre de calculateurs.

68 CHAPITRE III. PROPOSITION D’UN ÉVALUATEUR PARALLÈLE
Ces considérations nous ont ainsi conduit à proposer des composants calcula-
teurs spécifiques à notre architecture. Ces calculateurs communiquent entre eux (et
avec le serveur) à travers un module de communication spécifique (et non à tra-
vers un module de type ODBC), et grâce à des messages directement interprétables
(plutôt qu’à travers des requêtes SQL). La maîtrise de leur architecture nous permet
de gérer finement leur fonctionnement. Par ailleurs, les calculateurs, lorsqu’ils fonc-
tionnent, sont censés disposer de l’ensemble des ressources de la machines. Cela ne
signifie pas nécessairement (bien au contraire) que le réseau de stations est un réseau
dédié. Il présente en effet un aspect dédié durant le fonctionnement de l’évaluateur
parallèle ; cependant, les dimensions de l’évaluateur sont variables. Chaque station
est donc susceptible de servir de calculateur à un moment donné, mais pas néces-
sairement de façon permanente. De plus, l’évaluateur ne constitue pas un SGBD
complet, et dans la mesure où son utilisation s’avère ponctuelle, les machines sur
lesquelles il fonctionne peuvent remplir d’autres fonctions lorsque l’évaluateur n’est
pas en marche.
Les sections suivantes présentent les différents composants de notre architec-
ture. La section 2 détaille l’architecture et le fonctionnement du module serveur. La
section 3 introduit les modules calculateurs. La section 4 présente l’architecture de
communication et les types de messages retenus. La section 5 étudie l’utilisation de
lots de données dans les communications entre noeuds et dans le traitement des
calculs. Enfin, dans la section 6, nous proposons le principe d’extension parallèle
comme généralisation de l’évaluateur parallèle.
2 Composant serveur
Les fonctionnalités du composant serveur consistent à extraire des données d’une
source existante (en l’occurrence, un SGBD relationnel), à les répartir suivant ses
propres critères sur les calculateurs, et enfin à offrir un accès à ces données à travers

2. COMPOSANT SERVEUR 69
un mécanisme d’interrogation (en l’occurrence, le langage SQL). Ce fonctionnement
suppose :
– de disposer des outils permettant la redistribution des tables relationnelles sur
les calculateurs. De ce fait, il faut d’une part communiquer avec le SGBD, et
d’autre part avec les calculateurs, afin de pouvoir recopier les données de l’un
vers l’autre. On doit au préalable disposer du schéma de la base existante, afin
de rendre possible la redistribution (laquelle suppose également d’offrir une
interface de contrôle à l’administrateur) ;
– de pouvoir interpréter des requêtes SQL. En effet, les requêtes parvenant au
serveur doivent être interprétables par celui-ci, c’est à dire décomposées afin
de faire apparaître les relations, attributs et opérations les composant. Ceci
suppose en outre de disposer d’une interface de communication avec l’utilisa-
teur ;
– de produire des plans d’exécution, c’est à dire de produire, à partir des infor-
mations interprétées dans la phase précédente, un ensemble ordonné d’opéra-
tions élémentaires visant à optimiser l’exécution en fonction de la distribution
des données ;
– de transmettre les plans d’exécution aux calculateurs, afin d’en permettre l’exé-
cution ;
– de récupérer le résultat de ces plans d’exécution ;
– d’informer l’utilisateur du résultat de sa requête.
Afin de pourvoir à ces différentes fonctions, le composant serveur a été découpé
en modules (voir figure III.3) détaillés au fil des sections suivantes.
2.1 Gestionnaire de redistribution
Ce premier composant, essentiel au fonctionnement de l’évaluateur, comporte
une copie du Dictionnaire de Données de la base existante. Cette copie du diction-

70 CHAPITRE III. PROPOSITION D’UN ÉVALUATEUR PARALLÈLE
(Analyseur)Optimiseur d’Exécution
Parallèle
Gestionnaire
d’Exécution Parallèle
Gestionnaire
de Redistribution
d’Interface
Gestionnaire
Gestionnaire
de Charge
Communications
Gestionnaire
de Résultats
Accès utilisateurs
et administrateur
Demandes de distribution
Tuples résultats
Accès au
SGBD existant
Etat d’avancement des opérations
Opérations élémentaires
Données à distribuer
Accès aux
calculateurs
PEP brut
PEPoptimisé
Etat de chargedes calculateurs
Informations de charge
Informations de distribution
Requête SQL
Tup
les
résu
ltats
Interpréteur SQL
FIG. III.3 – Architecture du module serveur
naire comprend la liste des tables, c’est-à-dire le nom, la description des attributs, et
la cardinalité de chacune d’entre elles. Ces premières informations permettent à l’ad-
ministrateur d’obtenir une vue synthétique du schéma de la base avant de mettre en
place la redistribution des tables sur les calculateurs. Outre ces informations concer-
nant la base existante, ce gestionnaire fournit bien entendu les paramètres de re-
distribution et de fragmentation des tables sur les calculateurs. Pour chaque table
redistribuée, on dispose ainsi des informations suivantes :
– attribut de fragmentation ;
– méthode de fragmentation ;

2. COMPOSANT SERVEUR 71
– liste des calculateurs impliqués ;
– liste des attributs redistribués ;
– possibilité de tri des fragments.
Une liste des calculateurs impliqués est disponible car la fragmentation peut
n’être réalisée que sur un sous-ensemble de calculateurs. Ce type de distribution,
appelé partial declustering, par opposition au full declustering (un fragment sur
chaque calculateur), a été introduite par [Cop88], et permet d’une part de limiter la
dispersion des tables de faible cardinalité et d’autre part de ne pas solliciter l’en-
semble des calculateurs lors de l’accès à une table donnée. La liste des attributs dis-
tribués est en revanche une originalité de notre architecture. Du fait de la nature de
l’évaluateur parallèle, il peut paraître inintéressant redistribuer un sous-ensemble
des attributs plutôt que la totalité. Ce choix peut provenir de diverses raisons. Par
exemple, le type de requêtes envisagé peut n’intervenir que sur des attributs parti-
culiers. D’autre part, un manque de place sur les calculateurs peut justifier la non
distribution d’attributs rarement utilisés, auquel cas les requêtes impliquant de tels
attributs seront directement soumises au SGBD existant plutôt qu’à l’évaluateur. De
ce fait, notre système permet de ne fragmenter qu’une projection de chaque relation
plutôt que la relation entière. Précisons que la clé (ou un sous-ensemble d’attributs
constituant un clé) de chaque relation doit être distribuée, afin d’éviter des dou-
blons. Les méthodes de fragmentation proposées sont classiques. Il s’agit des dis-
tributions circulaire, par hachage et par intervalle. Fonctionnellement parlant, les
méthodes proposées sont mono-dimensionnelles, c’est-à-dire qu’elles s’effectuent
suivant un seul attribut. Certaines applications, telles celles orientées vers la fouille
de données, peuvent toutefois nécessiter une fragmentation multi-attributs. Dans un
tel cas, la fragmentation n’apparaît plus comme un vecteur correspondant à un at-
tribut, mais comme une matrice à n dimensions, chaque dimension correspondant à
un attribut donné. Une distribution multidimensionnelle est conceptuellement réa-
lisable sur notre architecture. Ceci est réalisable en remplaçant respectivement l’at-

72 CHAPITRE III. PROPOSITION D’UN ÉVALUATEUR PARALLÈLE
tribut et la méthode de fragmentation par des listes d’attributs et de méthodes. La
distribution des tables est déterminée par l’administrateur. Nous reviendrons plus
en détails sur la réalisation pratique de cette distribution au cours du chapitre IV.
2.2 Gestionnaire d’Interface
Ce composant constitue le point d’accès des utilisateurs et de l’administrateur
à l’évaluateur parallèle. Vis-à-vis des utilisateurs, son rôle consiste à recevoir les
requêtes SQL, à en ordonner l’exécution, et à retourner les tuples résultats le cas
échéant. Vis-à-vis de l’administrateur, il permet essentiellement la connexion à une
base de données existante et la redistribution des données de cette dernière.
Lorsque ce module reçoit des requêtes utilisateurs, il les transmet à l’interpré-
teur SQL et récupère le résultat correspondant depuis le gestionnaire de résultats.
Lorsqu’il reçoit des requêtes d’administration, il les transmet au gestionnaire de re-
distribution.
2.3 Interpréteur SQL
L’interpréteur SQL (ou analyseur de requêtes SQL) reçoit les requêtes SQL sous
forme textuelle. Il transforme chaque requête en un plan d’exécution parallèle brut
(c’est à dire non optimisé). Si la requête n’est pas exécutable, l’utilisateur en est in-
formé. Un tel cas de figure peut surgir pour deux raisons. Tout d’abord, les termes de
la requête peuvent être erronés (erreur de syntaxe ou évocation de tables ou attributs
inexistants). Ensuite, dans la mesure où une distribution partielle a été effectuée, la
requête peut évoquer certains attributs ou tables non distribués. Ce plan est ensuite
transmis à l’optimiseur d’exécution parallèle.

2. COMPOSANT SERVEUR 73
2.4 Optimiseur d’Exécution Parallèle
L’optimiseur d’exécution parallèle améliore le plan d’exécution brut fourni par
l’interpréteur SQL. Pour ce module et sa conceptualisation nous nous sommes ap-
puyés sur les travaux de Harald Kosch [Kos97b, Kos97a]. Le plan d’exécution brut
proposé par l’interpréteur SQL est ici amélioré grâce aux informations fournies par
les gestionnaires de redistribution et de charge. Le plan d’exécution optimisé pro-
duit par ce module est ensuite soumis au gestionnaire d’exécution parallèle.
2.5 Gestionnaire de Charge
Le rôle affecté au gestionnaire de charge consiste à contrôler d’une part le bon
fonctionnement des calculateurs et d’autre part leur niveau de charge, afin d’en in-
former l’optimiseur d’exécution parallèle au besoin. Par extension, il se charge des
ordres de connexion et de déconnexion des calculateurs à l’évaluateur. D’un point
de vue pratique, ce gestionnaire reçoit à intervalles “réguliers” des messages pro-
venant des calculateurs et indiquant leur état de charge (et, implicitement, leur bon
fonctionnement). Le terme régulier est ici placé entre guillemets du fait que cette
opération revêt un caractère secondaire vis-à-vis de l’exécution des requêtes. De ce
fait, une certaine fluctuation de la fréquence des messages est tolérée.
2.6 Gestionnaire d’Exécution Parallèle
Le rôle retenu pour le gestionnaire d’exécution parallèle est assez simple. Le plan
d’exécution parallèle (PEP) reçu de l’optimiseur est projeté pour chaque calculateur,
de façon à ce que chaque calculateur ne reçoive que les opérations élémentaires
le concernant. Les PEP projetés sont ensuite envoyés aux calculateurs destinataires
par le biais du module de communication. Au fur et à mesure de l’exécution de
la requête, le gestionnaire d’exécution parallèle est informé par les calculateurs de
l’avancement des opérations élémentaires (ou, plus exactement, de la fin de chacune

74 CHAPITRE III. PROPOSITION D’UN ÉVALUATEUR PARALLÈLE
d’entre elles). De telles informations permettent d’une part de déterminer la fin de
la requête et d’autre part et au besoin, d’informer l’optimiseur de l’efficacité du plan
retenu, et de modifier celui-ci le cas échéant.
2.7 Gestionnaire de Résultats
Le gestionnaire de résultats stocke les tuples résultats adressés par les calcula-
teurs au serveur, et les tient à disposition du gestionnaire d’interface. Sa technique
de stockage est similaire à celle décrite pour les calculateurs en section 3.1.
2.8 Communications
Les communications font l’objet d’une section particulière de ce chapitre (voir
section 4).
2.9 Unicité du serveur
Notre système pourrait disposer de plusieurs serveurs, dans le but d’améliorer
la bande passante des utilisateurs (dans la mesure ou les saturations proviennent
du serveur, c’est à dire d’une domination du nombre de requêtes vis-à-vis de leur
complexité). Toutefois, une telle architecture engendrerait des problèmes de syn-
chronisation. Par exemple, l’évaluation de la charge des calculateurs, utilisée lors de
la répartition des calcul, serait plus délicate et nécessiterait de nombreuses commu-
nications entre les différents serveurs. Aussi avons-nous volontairement laissé cette
option de côté. Notre évaluateur est donc mono-serveur.

3. COMPOSANT CALCULATEUR 75
3 Composant calculateur
Nous avons vu précédemment la description du module serveur. Celui-ci utilise
des modules de calcul afin de distribuer et utiliser les données de manière parallèle.
Ces modules de calcul (voir figure III.4) reçoivent données et demandes de traite-
ment, et émettent à leur tour des données résultat. Ils se composent principalement
de cinq modules gérant respectivement les communications avec l’extérieur, le sto-
ckage des données, l’ordonnancement des opérations élémentaires, l’exécution de
celles-ci et le traitement des messages d’administration. Notre système fonctionne
par défaut avec un calculateur (multi-threads) par machine physique. Aussi est-il
possible de n’avoir qu’une interface de communication. Par ailleurs, les commu-
nications (qu’il s’agisse des communications entre calculateur et serveur ou entre
calculateurs) se font à l’aide de messages spécifiques, décrits à la section 4. Les cal-
culateurs ne sont pas des SGBD complets, ils se contentent de stocker les données
qui leur sont transmises, puis d’exécuter des opérations sur celles-ci. Ils ne pos-
sèdent en revanche aucun outil de gestion : le dictionnaire de données est remplacé
par une simple liste des relations (ou plus exactement des fragments de relations).
3.1 Module de stockage
Le module de stockage gère les accès aux données [Exb97a]. Puisque les relations
sont en général fragmentées sur plusieurs calculateurs, nous utiliserons ici le terme
de fragment pour décrire les données d’une même relation (ou d’un même résultat
intermédiaire) présentes sur un calculateur donné. Le transfert des données entre
sites est effectué par lots de tuples, lesquels lots se retrouvent dans le stockage des
fragments. La notion de lots a été introduite de longue date [Gra93]. Les lots de
données peuvent être présentés comme une généralisation du transfert de données
tuple par tuple entre opérateurs consécutifs. Graefe utilise des lots de données de
taille = 1 tuple. Il est possible d’utiliser une granularité moins fine, ce que nous

76 CHAPITRE III. PROPOSITION D’UN ÉVALUATEUR PARALLÈLE
d’administration
d’administration
Données à traiter
Tuples résultats locaux
Données
Info
rmat
ions
d’e
xécu
tion
Tup
les
Rés
ulta
ts â
tran
smet
tre
Calcul Stockage
Ordonnancement
OpérationsActions liées
MessagesInstructions
Communications
des Messagesd’Administration
Traitement
aux messages
FIG. III.4 – Architecture du module calculateur
faisons ici, afin i) de limiter les changements de contexte entre opérateurs consécutifs
lorsqu’ils sont concurrents et se déroulent sur le même nœud et ii) de limiter le
nombre de transferts de tuples à travers le réseau, de façon à utiliser au mieux la
bande passante (de petits messages générant un surcoût notable, principalement en
termes de latences, mais également en terme de transfert, dû à l’encapsulation des
messages).
3.1.1 Numérotation des fragments
Les accès aux données se font à travers le gestionnaire de relations. Celui-ci per-
met d’accéder aux fragments grâce à leur identifiant. En effet, les noms des relations
sources sont remplacés, sur les calculateurs, par un numéro d’identification. Plu-
sieurs raisons guident ce choix. La première vient du fait qu’il serait fastidieux de
donner un nom à chaque résultat intermédiaire. Aussi des numéros uniques sont-

3. COMPOSANT CALCULATEUR 77
ils attribués, et, dans un but d’homogénéisation, les relations sources sont-elles aussi
décrites par un identifiant numérique. D’autre part, l’accès aux fragments est a priori
plus rapide à travers un indice numérique qu’à travers un index alphanumérique.
Enfin, l’utilisation de numéros dans les messages inter-machines, qu’il s’agisse de
requêtes ou de lots de tuples, permet de rendre ces messages légèrement plus com-
pacts qu’avec des noms alphanumériques. Ces numéros uniques sont attribués par
le serveur. Pour les relations sources, le numéro est ensuite stocké dans les informa-
tions de distribution. Pour les résultats intermédiaires, des numéros sont attribués
lors de la compilation du plan d’exécution, puis libérés lorsque l’exécution est ter-
minée. Tous les fragments d’une même relation portent le même numéro (l’identifi-
cation d’un fragment particulier se faisant par l’association de ce numéro et de celui
du calculateur hôte).
3.1.2 Structure des fragments
Les relations sont de simples listes de tuples, ou plus exactement de lots de
tuples. Aucune information sur le contenu des relations n’est stockée sur les cal-
culateurs. Les noms et types des attributs ne sont pas stockés sur les calculateurs ;
de telles informations sont données implicitement dans les requêtes. Cela s’explique
par le fait que le stockage de telles informations, s’il avait lieu, devrait se faire pour
les relations sources mais également pour les relations intermédiaires ; il faudrait
alors transmettre ces informations en clair pour chaque relation intermédaire.
Ainsi que nous l’indiquions au début de cette section, les données sont effecti-
vement transmises et stockées sous forme de paquets, que nous appelons lots de
tuples ou de données. Il peut être intéressant, dans certains cas, et en particulier
pour les relations sources, de fusionner l’ensemble des lots reçus en un seul lot, afin,
par exemple, d’appliquer un tri global aux tuples du fragment. La fusion des lots
est toutefois plus rare pour les résultats intermédiaires (sauf cas d’algorithme de tri-
fusion), aussi détaillons-nous le stockage (voir figure III.5) en y faisant intervenir les

78 CHAPITRE III. PROPOSITION D’UN ÉVALUATEUR PARALLÈLE
fragments.
Le gestionnaire de fragments constitue un index sur les fragments présents. Ses
fonctionnalités consistent à créer une entrée pour un fragment, retourner le frag-
ment recherché en cas de demande, et enfin supprimer l’entrée vers un fragment
donné (par exemple lors de la suppression de résultats intermédiaires). Un frag-
ment consiste principalement en un numéro de fragment (comme décrit ci-dessus)
et une liste de lots de données.
Par ailleurs, une liste de files d’attente d’exécution est disponible. Ces files d’at-
tente permettent le transfert de données entre les fragments et les opérations élé-
mentaires. Elles sont décrites plus en détails dans les points suivants. Quatre champs
supplémentaires sont également présents. Ces champs permettent de déterminer la
complétude d’un fragment en fonction du nombre de producteurs de données et du
nombre de lots de données reçus. Leur description est elle aussi détaillée dans les
points suivants.
Gestionnaire
de fragments NbPT (nombre de calculateurs producteurs)
NbLT (nombre de lots attendus)
NbLR (nombre de lots reçus)
Lots de données
File(s) d’attente d’exécution
Num. de relation
NbPR (nombre de producteurs ayant terminés)
FIG. III.5 – Architecture du module de stockage
3.1.3 Cycle de vie d’un fragment
La création d’une relation se fait lors de sa première sollicitation. Une relation
peut être sollicitée soit lors de l’arrivée d’un lot, soit lors de son utilisation dans

3. COMPOSANT CALCULATEUR 79
une opération élémentaire. En d’autres termes, une relation peut tout à fait être
créée avant même qu’elle ne contienne des données. Ce cas apparemment étrange
peut révéler des dysfonctionnement dans l’ordonnancement des opérations, mais
il peut tout aussi bien apparaître naturellement dans des opérations binaires, par
exemple pour la relation de probe d’une jointure classique, ou sur l’une quelconque
des deux tables si l’on utilise l’algorithme de full parallelism (décrit par A. Wilschut
dans [WIL95]). La suppression d’un fragment peut se faire :
– automatiquement dans le cas d’un résultat intermédiaire. La fin de l’exécu-
tion de l’opération élémentaire utilisant ce fragment marquant l’heure de sa
destruction ;
– “manuellement” dans le cas d’une relation distribuée. La suppression est alors
demandée par le biais d’un message d’administration.
3.1.4 Complétude d’un fragment
Chaque fragment de relation présent sur un calculateur (relation distribuée ou
résultat intermédiaire) possède un mécanisme simple lui permettant de savoir s’il
est complet, c’est-à-dire si tous les tuples appartenant à ce fragment ont bien été
reçus. Dans le cas des relations sources, le problème de la complétude ne se pose pas
dans la mesure où distribution et utilisation sont deux phase disjointes. Toutefois,
afin d’uniformiser notre modèle, un mécanisme commun a été mis en place pour les
relations sources et les résultats intermédiaires. Notre architecture utilise des flux
standards et permanents pour le transfert des données et des instructions, et il n’est
donc pas possible de marquer la fin d’un flux de données par sa fermeture. Nous
nous basons donc sur le nombre de lots de données reçus.
Chaque résultat intermédiaire provient de calculateurs producteurs et est ache-
miné vers des calculateurs consommateurs (les deux ensembles n’étant pas forcé-
ment disjoints). Chaque producteur, lorsqu’il termine une opération élémentaire
(voir figure III.6), expédie à chaque consommateur un message de fin de production

80 CHAPITRE III. PROPOSITION D’UN ÉVALUATEUR PARALLÈLE
indiquant le nombre de lots produits et envoyés vers ce consommateur Nbl(i,j), où i
dénote le producteur et j le consommateur. A chaque réception d’un tel message, un
consommateur (ou plus exactement, le fragment de relation concerné) incrémente
le nombre NbPR de producteurs ayant terminé leurs calculs ; il extrait par ailleurs
de ce message le nombre de lots adressés par le producteur, et l’ajoute au nombre
total de lots attendus. Le nombre total NbLTj de lots attendus par le consommateur
j correspond donc à la somme des Nbl(i,j) reçus par ce consommateur. A chaque
réception d’un lot, on incrémente le nombre NbLR de lots reçus. On peut dès lors
déterminer si une relation est complète en effectuant un double contrôle, d’une part
sur le nombre de producteurs prévus et terminés et d’autre part sur le nombre de
lots attendus et reçus, soit NbPR=NbPT et NbLR=NbLT.
P1 P2 P3
C2C1
NbP(2,2)NbP(2,1)
NbP(3,1) NbP(3,2)
NbP(1,1)
NbP(1,2)
FIG. III.6 – Transmissions des nombres de lots produits
Concernant le nombre de producteurs, nous avons vu que nous incrémentons
le nombre de producteurs terminés NbPR au fur et à mesure de l’arrivée des mes-
sages de fin de production. Le nombre de producteurs prévus NbPT est pour sa
part transmis au calculateur soit par le biais d’un message d’administration (dans
le cas d’une distribution) soit directement à l’intérieur d’une opération élémentaire,
c’est-à-dire dans le plan d’exécution (dans le cas d’un résultat intermédiaire). Les
opérations élémentaires contiennent en effet les identifiants des deux relations (frag-
ments) qu’elles doivent utiliser (d’une relation pour les opérations unaires), et pour

3. COMPOSANT CALCULATEUR 81
chaque identifiant indiquent le nombre de producteurs prévus NbPT. Lorsqu’un
fragment utilisé dans une opération élémentaire appartient à une relation source,
on donne un nombre négatif de producteurs prévus (NbPT=-1).
Les messages de fin issus des producteurs sont particulièrement courts (iden-
tifiant du fragment, identifiant du producteur et nombre de lots produits) et nom-
breux (pour chaque opération, le nombre de messages est égal au nombre de consom-
mateurs). L’envoi de tels messages irait quelque peu à l’encontre du principe de
minimisation des coûts réseau qui nous a conduit à proposer des lots de données.
Aussi sont-ils intégrés au dernier lot envoyé à chaque consommateur.
Le mécanisme décrit jusque-là correspond aux exécutions de requêtes. Afin de
valider la complétude des relations sources lors de leur distribution, nous faisons
appel, selon les cas, soit à un message d’administration, indiquant le nombre de
producteurs, soit à une mise à jour directe par la fonction de distribution.
3.2 Files d’attente
La communication des données entre le gestionnaire de fragments et le(s) mo-
dule(s) de calcul est assurée par un système de files d’attente dans lesquelles sont
référencés les lots. Lors de l’initialisation d’une opération élémentaire, le module de
calcul contacte le gestionnaire de fragments pour chaque fragment qu’il doit exploi-
ter, et lui indique l’adresse de la file d’attente à associer à ces derniers. Si le fragment
contient des lots de tuples (relation source ou résultats intermédiaires déjà arrivés),
ceux-ci sont référencés dans la file d’attente. Au fur et à mesure de leur réception,
les nouveaux lots sont à leur tour référencés. Lorsque le fragment est complet, et
que tous les lots ont été référencés dans la file d’attente, celle-ci est “close” par une
référence nulle (voir figure III.7).
Chaque fragment peut être relié à plusieurs files d’attente. En pratique, les frag-
ments de relations sources peuvent être reliés simultanément et/ou successivement
à plusieurs files, car ils peuvent être impliqués dans différentes opérations élémen-
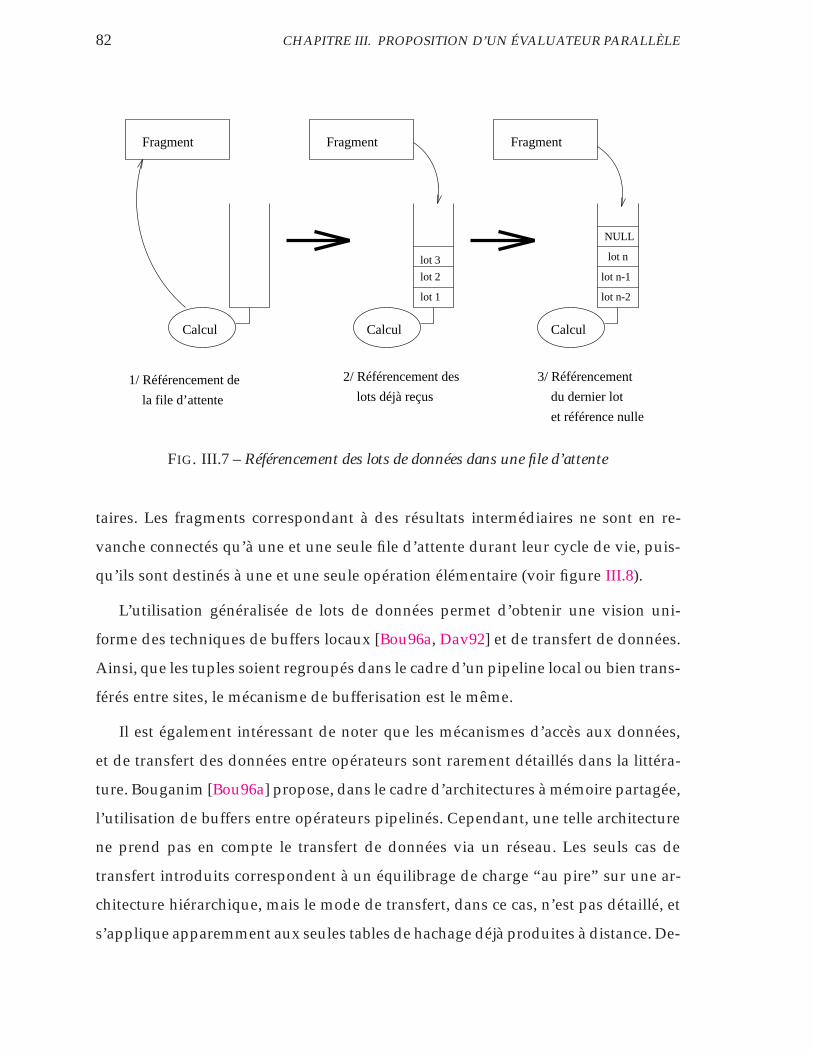
82 CHAPITRE III. PROPOSITION D’UN ÉVALUATEUR PARALLÈLE
Calcul
Fragment
CalculCalcul
1/ Référencement de
Fragment
NULL
lot n-1
lot n-2
lot n
3/ Référencement
Fragment
lot 1
lot 2
lot 3
2/ Référencement des
la file d’attente lots déjà reçus du dernier lot
et référence nulle
FIG. III.7 – Référencement des lots de données dans une file d’attente
taires. Les fragments correspondant à des résultats intermédiaires ne sont en re-
vanche connectés qu’à une et une seule file d’attente durant leur cycle de vie, puis-
qu’ils sont destinés à une et une seule opération élémentaire (voir figure III.8).
L’utilisation généralisée de lots de données permet d’obtenir une vision uni-
forme des techniques de buffers locaux [Bou96a, Dav92] et de transfert de données.
Ainsi, que les tuples soient regroupés dans le cadre d’un pipeline local ou bien trans-
férés entre sites, le mécanisme de bufferisation est le même.
Il est également intéressant de noter que les mécanismes d’accès aux données,
et de transfert des données entre opérateurs sont rarement détaillés dans la littéra-
ture. Bouganim [Bou96a] propose, dans le cadre d’architectures à mémoire partagée,
l’utilisation de buffers entre opérateurs pipelinés. Cependant, une telle architecture
ne prend pas en compte le transfert de données via un réseau. Les seuls cas de
transfert introduits correspondent à un équilibrage de charge “au pire” sur une ar-
chitecture hiérarchique, mais le mode de transfert, dans ce cas, n’est pas détaillé, et
s’applique apparemment aux seules tables de hachage déjà produites à distance. De-

3. COMPOSANT CALCULATEUR 83
Calcul 1
Résultat intermédaire Résultat intermédaireRelation source1 2
Calcul 2
FIG. III.8 – Exemples d’accès aux files d’attente par des fragments de relations sources et de
résultats intermédiaires
Witt et al. [DeW86] utilisent un système “guidé par les données” dans lequel chaque
opérateur puise dans un flot d’entrée de tuples et émet également un flot de tuples,
la fin de chaque flot étant indiqué par une fin de flux (end of stream) correspondant
à la fermeture de ce flux. Aucun regroupement de tuples n’est explicitement défini.
Graefe [Gra94] utilise, dans une optique de traitement “dirigé par les données” (à
l’instar de DeWitt et al.), l’utilisation de lots, mais se limite apparemment à une gra-
nularité minimum (tuple par tuple). De ce fait, notre définition explicite de lots de
tuples, utilisés comme granularité de traitement, constitue un apport clarifiant les
interactions entre opérateurs successifs.
3.3 Module de calcul
L’exécution présentée ci-dessous (voir figure III.9) décrit le déroulement d’une
opération binaire (par exemple, une jointure). Les différentes phases sont les sui-
vantes : un thread de calcul demande au module d’ordonnancement de lui faire
parvenir la prochaine opération élémentaire. Au besoin (c’est-à-dire, si aucune des
opérations élémentaires référencées n’est exécutable), le module d’ordonnancement
va extraire une nouvelle requête de la file d’attente (le terme requête indique ici la

84 CHAPITRE III. PROPOSITION D’UN ÉVALUATEUR PARALLÈLE
projection d’un PEP pour un calculateur donné, c’est-à-dire un ensemble d’opéra-
tions élémentaires). Lorsqu’une requête est extraite, ses opérations élémentaires sont
“référencées” et leur exécutabilité est testée. Le module d’ordonnancement retourne
la première opération exécutable trouvée. Les relations nécessaires au calcul (R1 et
R2) sont appelées, de manière à ce que les lots de chacune d’entre elles puissent être
“référencés” dans leur file respective. Le thread de calcul puise dans les files d’at-
tente des relations afin d’effectuer ses calculs. Une fois les calculs terminés, le thread
de calcul indique la fin des traitements aux deux relations. Celles-ci peuvent dès lors
déréférencer les files d’attente. Si les relations sont des résultats intermédiaires, elles
peuvent également être détruites.
Relations locales
File d’attente
d’envoi à l’extérieur
2: extractiond’instruction
Ordonnancementlocal
R1 R2
R3
Regroupement
Instructions
Thread
3: opération
à exécuter
7: signal de fin d’utilisation
6: Extraction de tuples
5: insertion dans lesfiles d’attente
4: Référencementdes fonctions
1: demanded’opération
b1 : envoi àl’extérieur
b2: stockage local
produitsa: tuples
de calcul
FIG. III.9 – Déroulement d’une opération élémentaire
Les tuples produits sont regroupés en lots, chacun de ces lots correspondant à
un destinataire différent. Quand un lot résultat est plein, il est acheminé vers son
destinataire. Dans le cas d’un destinataire distant (calculateur autre que celui où

3. COMPOSANT CALCULATEUR 85
s’exécute le calcul), le lot est dirigé vers la file d’attente du thread de communica-
tion correspondant (b1). Dans le cas où le destinataire est le calculateur local, le lot
est dirigé vers une relation locale R3 (b2) éventuellement créée pour l’occasion. Rap-
pelons ici que la création de cette relation intervient à la réception de son premier
lot, qu’il ait été produit localement ou qu’il ait été acheminé depuis un calculateur
distant.
3.4 Module d’ordonnancement
Le module d’ordonnancement est connecté, en entrée, à la file d’attente des re-
quêtes, et en sortie au(x) thread(s) d’exécution. L’extraction des requêtes conduit à
leur décomposition en opérations élémentaires. L’exécutabilité des opérations élé-
mentaires (existence, voire complétude, des relations impliquées dans leur calcul)
est testée. Les opérations sont transmises aux threads de calcul en fonction des deux
principes suivants :
– précédence dans l’ordre des requêtes. Les opérations exécutables appartenant
à la plus ancienne requête en cours de traitement sont prioritaires ;
– précédence dans l’ordre des opérations élémentaires. Au sein d’une même re-
quête, les opérations sont classées suivant leur ordre d’exécution (les opéra-
tions susceptibles d’être exécutées simultanément étant placées de façon consé-
cutive).
3.5 Module de Traitement des Messages d’Administration
Ce module se charge des messages ayant trait à la mise à jour des relations distri-
buées (redistribution ou suppression) et de l’architecture de l’évaluateur parallèle.
Les différents types de messages sont décrits en section 4.4. Les messages reçus sont
placés dans une file d’attente et traités suivant leur ordre d’arrivée.

86 CHAPITRE III. PROPOSITION D’UN ÉVALUATEUR PARALLÈLE
4 Echange d’informations entre sites
Nous présentons maintenant les types de messages pouvant s’échanger entre
calculateurs (et entre calculateur et serveur). Cette description permettra de mieux
comprendre l’architecture des calculateurs et la façon dont ces messages y sont trai-
tés. Trois types de messages sont utilisés, permettant respectivement le transfert
de données, l’envoi de requêtes et enfin le transfert de messages d’administration.
Nous commençons cette section par une description du module de communication
commun aux composants serveur et calculateur, avant d’introduire et de détailler
les trois catégories de messages susnommées.
4.1 Module de communication
Pour une configuration à n calculateurs et un serveur, on dispose sur chaque
machine de n threads de réception et de n threads d’émission (chaque machine ne
disposant pas d’un thread d’émission ni de réception vers elle-même). Ceci permet
de maximiser les transferts de données à notre niveau d’implémentation. En effet,
les délais induits par un transfert peuvent être récupérés avec profit par un autre
thread, et, en l’occurence, éventuellement par un thread de communication. En ré-
ception, les requêtes reçues sont placées dans la file d’attente des requêtes (voir fi-
gure III.10). De même, les informations reçues sont placées dans la file d’attente
correspondante. Toutefois, les données reçues sont directement transmises au mo-
dule de stockage. En effet, dans les deux premiers cas, un traitement est attendu,
ce qui implique un possible délai. En revanche, le stockage des données n’engendre
que peu de traitements (voir la description du module de stockage), et ne nécessite
donc pas de file d’attente.
L’émission est gérée par file d’attente. En pratique, on dispose d’une file d’attente
par destinataire, chaque file étant liée à un thread d’envoi.

4. ECHANGE D’INFORMATIONS ENTRE SITES 87
Communicationsavec la machine 1
Communicationsavec la machine n
FIG. III.10 – Détail du module de communication
4.2 Transferts de données
Les données et leur transfert constituent le coeur de notre système. Nous avons
cherché à adapter les transferts à la nature de notre architecture. Notre système
utilise théoriquement un réseau de stations classique, et se base sur le protocole
TCP/IP (afin d’assurer sa portabilité, bien que des protocoles légers puissent être
utilisés sur des architectures plus spécifiques). L’accès au réseau physique est na-
turellement freiné par la traversée des différentes couches. Aussi nous a-t-il semblé
intéressant de faire transiter les tuples, non pas un par un, mais plutôt par lots. La
taille optimale de ces lots peut être déterminée de façon expérimentale, à l’aide d’un
simple algorithme de ping-pong. La méthode que nous utilisons consiste à tester
le temps d’aller-retour d’un lot de taille donnée entre deux machines (ping-pong)
puis à diviser ce temps par la taille des lots de façon à obtenir le temps moyen par
octet. Bien entendu, le temps total n’est pas obtenu par un seul aller-retour, mais
par un nombre suffisant de ceux-ci (quelques centaines), afin de réduire les erreurs
de mesure. Un exemple de mesure est présenté en section 5.2 de ce chapitre (voir
figures III.13 et III.14).
La forme générale des courbes obtenues sur plusieurs types de réseaux (mais
toujours sous TCP-IP) consiste en une forte chute du coût par octet jusqu’à ce que la
taille des lots atteigne quelque dizaines ou centaines d’octets, puis à une stabilisation

88 CHAPITRE III. PROPOSITION D’UN ÉVALUATEUR PARALLÈLE
au delà. Cette forme n’est guère surprenante, car à partir d’une certaine taille, les
lots sont suffisamment gros pour remplir les paquets TCP, ce qui limite le surcoût
d’“empaquetage”.
4.3 Opérations relationnelles
L’exécution d’une requête relationnelle est classiquement décomposée en un en-
semble ordonné d’opérations élémentaires. L’ensemble de ces opérations est appelé
plan d’exécution. Dans un système parallèle, on décompose ainsi chaque requête
en un plan d’exécution parallèle, ou PEP. Ce PEP indique dans quel ordre les opé-
rations doivent être effectuées, mais également sur quels noeuds elles doivent être
exécutées, et vers quels noeuds les résultats de chacune d’entre elles doivent être
envoyés (ces résultats constituant soit les données en entrée d’une autre opération,
soit l’ensemble des tuples résultats). Le plan d’exécution se présentera donc comme
un ensemble d’opérations élémentaires ordonnées. Si l’on se rapporte aux travaux
de Harald Kosch, présentés dans le chapitre IV, les différentes opérations vont être
reliées par des relations de précédence directe ou indirecte. Deux techniques d’envoi
des PEP sont possibles. La première consiste à envoyer les plans complets à chaque
site, ces derniers se chargeant ensuite de déterminer si une opération donnée les
concerne ou non. La seconde technique consiste à effectuer une projection du plan
d’exécution pour chaque site afin de ne lui transmettre que les opérations qu’il doit
réaliser.
Nous avons retenu cette seconde option. Elle évite en effet aux calculateurs de
vérifier leur implication dans chaque opération. Le surcoût de calcul occasionné sur
le serveur est équivalent à celui qui serait généré sur chaque calculateur avec la pre-
mière solution. En outre, le serveur doit, quoi qu’il en soit, déterminer l’ensemble
des sites participant à une requête. De ce fait, déterminer les sites par opération
n’apporte qu’un faible surcoût, puisqu’il suffit d’ajouter quelques lignes de code
mémorisant les opérations par sites (ce qui se fait en O(n), si n est le nombre d’opé-

4. ECHANGE D’INFORMATIONS ENTRE SITES 89
rations élémentaires). Reconstruire des plans projetés pour chaque site destinataire
est également très rapide. Si les opérations élémentaires se présentent sous forme
d’objets (resp. de structures), et que le PEP complet se présente sous forme d’un
objet composite (resp. d’un tableau de pointeurs sur les structures), la projection
consiste simplement à la création de pointeurs ou d’objets composites, ce qui est
non seulement peu coûteux en temps mais également en espace.
Attributs de la première relationAttribut de la seconde relation
Relation(s) impliquée(s)Nombre de producteurs de chaque relation
Opération
Opération élémentaire
Fragmentation
MéthodeAttributs de la première relationAttributs de la seconde relation
Liste de valeursCritères de comparaison
ou
Projection
Contexte
Pré-synchronisations
Post-synchronisation
Connexion des comparaisons (et/ou)
Informations de tri (attribut + ordre)
Paramètres de distribution (numériques ou chaînes)Liste des destinatairesTaille des lots
Méthode de distributionId de la relation résultatAttribut(s) de fragmentation
FIG. III.11 – Eléments composant une opération élémentaire
Nous avons décomposé les opérations élémentaires en quatre éléments distincts
(voir figure III.11) : le contexte d’exécution, l’opération proprement dite (comparai-
son de deux lots, ou d’un lot avec une liste de valeurs), la création des tuples ré-
sultats (projection des tuples satisfaisant les critères de l’opération) et leur émission
vers leurs destinataires (fragmentation de la relation intermédiaire).
4.3.1 Contexte
Le contexte d’une opération élémentaire indique à sur quelle(s) relation(s) (rela-
tion source ou résultat intermédiaire) cette opération porte. On indique ici le nombre

90 CHAPITRE III. PROPOSITION D’UN ÉVALUATEUR PARALLÈLE
de producteur de chaque relation, afin de vérifier la complétude des fragments. On
indique également les éventuelles pré-synchronisations (attente de fin d’exécution
d’une opération précédente ou pipeline).
4.3.2 Opération
Nous avons retenu une structure permettant d’appliquer plusieurs comparai-
sons simultanées pour les opérations unaires et binaires. Au-delà des jointures multi-
attributs, peu étudiées dans la littérature, cette structure permet d’envisager l’intro-
duction de l’opérateur de fusion introduit dans les travaux de Goetz Graef [Gra93] et
approfondi par Nadia Biscondi [Bis96]. Le principe de l’opérateur de fusion consiste
à décrire de manière uniforme l’ensemble des opérations binaires (jointure, diffé-
rence, etc.) à travers un seul opérateur. Une opération est donc décrite par les infor-
mations suivantes :
– méthode d’exécution. Celle-ci indique l’algorithme à appliquer pour réaliser
l’opération élémentaire ;
– liste des attributs de la première relation ;
– liste de valeurs de comparaison (opération unaire) ou Liste des attributs de
la seconde relation (opération binaire). Selon le type d’opération, on pourra
ici définir quels attributs de la seconde relation sont à comparer (dans leur
ordre respectif dans cette liste) avec ceux de la première relation, ou bien quels
critères de sélection sont à appliquer aux attributs de la première relation ;
– liste de critères de comparaison. Ces critères sont les opérateurs arithmétiques
classiques (égal, inférieur, différent, etc.) ;
– connexion des comparaisons. Cet éléments permet d’établir les liens entre les
différentes comparaisons (ET/OU).

4. ECHANGE D’INFORMATIONS ENTRE SITES 91
4.3.3 Projection
La phase de projection consiste à fabriquer les tuples résultats à partir des don-
nées fournies par la phase d’opération. Elle indique la liste d’attributs à retenir dans
chaque relation, et se charge de produire les tuples résultats.
4.3.4 Fragmentation
La phase de fragmentation consiste à appliquer une méthode de fragmentation
aux tuples créés durant la phase de projection. Les informations de ce composant
sont identiques dans leur forme à celles détenues par le dictionnaire de redistribu-
tion. Elles permettent ainsi de fragmenter la relation résultat par distribution circu-
laire, hachage, ou intervalles. Une quatrième méthode, la réplication, est en outre
disponible, afin d’envoyer tous les tuples sur chaque destinataire. Une telle distri-
bution est entre autres nécessaire lorsque les tuples résultats sont ensuite impliqués
dans une jointure parallèle par produit cartésien. La post-synchronisation indique
quelles éventuelles opérations (ormis les consommateurs) doivent être prévenus de
la fin d’exécution de cette opération). Cette information est placée ici car la frag-
mentation recouvre à la fois la fragmentation proprement dite et l’envoi des tuples
produits, et constitue donc la dernière phase de l’opération en cours.
4.4 Messages d’administration
Cette catégorie de messages permet l’envoi d’informations entre les sites. Celles-
ci consistent à supprimer des relations, à fournir des informations nécessaires à la
distribution des relations sources, à indiquer l’évolution des calculs et à indiquer les
fins de sessions (déconnexion et terminaison des calculateurs).

92 CHAPITRE III. PROPOSITION D’UN ÉVALUATEUR PARALLÈLE
5 Influence des lots de données sur les temps d’exécu-
tion
Cette section décrit nos propositions d’utilisation de lots de données en vue
d’améliorer les temps de traitement des requêtes. Les observations et propositions
faites ci-dessous ont nécessité un certain nombre de tests, lesquels sont présentés en
détail au chapitre V.
5.1 Taille des lots
La présence de lots de données pour les calculs locaux (c’est-à-dire à partir de
données présentes à l’origine sur leur site de calcul, comme par exemple des re-
lations sources) peut sembler assez inutile au premier abord. Cependant, leur rôle
apparaît plus clairement dans le cadre de la transmission de données entre opéra-
tions.
Temps total d’exécution
Exécutionde O1
des tuples résultatsTransfert
Exécution de O2
Temps total d’exécution
FIG. III.12 – Influence du découpage en petits lots sur le temps de latence
Plaçons-nous en effet dans le cas où il n’existe pas de contrainte forte de synchro-
nisation entre deux opérations consécutives (i.e. la seconde opération n’attend pas

5. INFLUENCE DES LOTS DE DONNÉES SUR LES TEMPS D’EXÉCUTION 93
la fin de la première pour débuter -pipeline-, ce qui est notamment le cas lorsque les
deux opérations ont lieu sur des nœuds différents). Soit O1 et O2 les deux opérations
telles que O2 consomme les résultats de O1. O2 (plaçons-nous dans le cas d’une join-
ture par hachage) peut commencer durant l’exécution de O1. Elle ne se terminera
bien sûr qu’après réception et traitement de tous les tuples produits par O1. Si tous
les tuples résultats de O1 sont transmis en une seule fois (en fin de traitement) à O2,
leur traitement ne pourra commencer qu’à ce moment-là (voir figure III.12). Si, à
l’inverse, ils sont transmis “au fur et à mesure” de leur production, leur traitement
peut être échelonné, et de ce fait le temps global de traitement peut être réduit. Un
tel mode de fonctionnement s’apparente à une forme de pipeline entre calculateurs.
5.2 Estimation de la taille des lots
On ne peut cependant se réduire à envoyer les tuples produits un par un, ce qui
conduirait à de forts surcoûts de transfert, et également à une sur-utilisation de la
bande passante. La taille des lots de transfert est donc choisie de façon à permettre
le macro-pipelining lorsqu’il est souhaitable, tout en restant suffisamment grande
pour ne pas trop encombrer le réseau.
Nous proposons d’estimer la taille des lots (produits) suivant deux cas diffé-
rents. S’il n’y a pas de synchronisation entre le producteur et le consommateur, on
peut alors utiliser de multiples lots de petite taille. Des surcoûts sont naturellement
induits par cet envoi de multiples lots. Cependant, les gains de temps apportés par
le macro-pipelining compensent ces surcoûts à partir d’une certaine taille de lots,
ainsi que nous pouvons le constater dans les tests menés au chapitre V.
Si une synchronisation existe entre producteur et consommateur, il s’avère in-
utile de scinder l’envoi en de nombreux petits lots ; on peut donc se permettre
d’émettre un nombre limité de lots de plus grande taille. Afin de limiter tout de
même la latence entre les deux opérations, on peut tout de même faire en sorte d’ex-
pédier quelques lots, et pour ce faire, de fixer une taille moyenne pour les lots.

94 CHAPITRE III. PROPOSITION D’UN ÉVALUATEUR PARALLÈLE
0 2000 4000 6000Taille en octets
0
50
100
150
200
Tem
ps p
ar o
ctet
en
mic
ro-s
econ
des
FIG. III.13 – Coût d’envoi de lots de 10 oc-
tets à 6 ko
0 20 40 60 80 100Taille en kilo-octets
2
2
2
3
4
Tem
ps p
ar o
ctet
en
mic
ro-s
econ
des
FIG. III.14 – Coût d’envoi de
lots de 1 à 100 ko
Au delà de ces considérations, il nous reste à fixer la taille réelle des lots. Si l’on
se réfère aux figures III.13 et III.14, une taille minimum correcte MinT est de l’ordre
de 10 kilo-octets. En effet, à partir d’une telle taille, le temps d’envoi moyen par octet
est assez faible et régulier. Cependant, une valeur plus faible peut exceptionnelle-
ment être utilisée, les coûts ne devenant vraiment prohibitifs qu’en dessous de 500
octets. Si la bande passante vient à être saturée, la réduction du nombre de lots (et
donc l’augmentation de leur taille) n’apporte pas de réelle diminution du volume
réel d’informations circulant sur le réseau. La valeur précédente est donc mainte-
nue. Dans le cadre d’opérations synchronisées, la taille des lots peut être estimée de
diverses façons. On peut de façon optimiste estimer que le nombre de tuples résul-
tats sera proche de la cardinalité de la plus petite des deux relations mises en jeu
(cas de faible biais des valeurs), le pire des cas correspondant au produit des deux
cardinalités (tous les tuples d’une des relations sont joints à tous ceux de l’autre).
Soient R1 et R2 les relations impliquées dans une jointure, leur cardinalités respec-
tives étant kR1k et kR2k. Une façon simple [Ösz91] d’estimer le nombre de tuples
produits Np est :
Np = �:min(kR1k;kR2k) (III.1)
L’opération productrice et l’opération consommatrice peuvent toutes deux bé-
néficier de parallélisme intra-opérateur, et de ce fait s’exécuter sur plusieurs sites.

5. INFLUENCE DES LOTS DE DONNÉES SUR LES TEMPS D’EXÉCUTION 95
Soient p le nombre de producteurs et d le nombre de destinataires (consommateurs).
Si l’on pose comme condition préalable que la répartition des tuples de R1 et R2 est
effectuée de façon convenable, le nombre de tuples produits sur chaque site produc-
teur Npp peut s’exprimer par :
Npp = �:min(kR1k
p;kR2k
p) =
�
p:min(kR1k;kR2k) (III.2)
Si l’on suppose que la distribution des tuples entre les différents consommateurs
est assez régulière (en terme de volume), alors le nombre de tuples Nd envoyés par
chaque producteur à chacun des d destinataires est :
Nd =
�
p:min(kR1k;kR2k)
d=
�
d:p:min(kR1k;kR2k) (III.3)
Si la taille des tuples produits est Tt, alors le volume de données Vd envoyé par
chaque producteur à chaque destinataire est :
Vd = Tt:�
d:p:min(kR1k;kR2k) (III.4)
Ce qui correspond à la taille des lots si l’on souhaite expédier un seul lot à chaque
destinataire. Dans le cas, fréquent, d’une jointure naturelle, on dispose d’un � supé-
rieur à 1. Si l’on applique le principe consistant à produire quelques lots plutôt qu’un
seul, alors un tel effet peut être obtenu en éliminant le facteur � (� étant supérieur
à 1, sa suppression conduit à une taille de lot inférieure à Vd, donc à un nombre de
lots supérieur à 1). Il faut toutefois songer à ne pas produire des lots dont la taille
serait inférieure à la taille minimum MinT retenue dans le cas précédent. Une taille
raisonnable de lots Trl peut donc être exprimée par :
Trl = max(Tt:min(kR1k;kR2k)
d:p;MinT ) (III.5)

96 CHAPITRE III. PROPOSITION D’UN ÉVALUATEUR PARALLÈLE
5.3 Seuil de transfert
Cependant, la seule adaptation des tailles de lots ne suffit pas dans la plupart
des cas. En effet, si la production des tuples est irrégulière, le bénéfice lié aux lots est
partiellement perdu. Nous proposons donc d’introduire la notion de seuil de trans-
fert. Ce seuil correspond à un délai maximum de traitement avant envoi de tuples.
Ce délai peut être exprimé en fonction du nombre de tuples traités en entrée. Nous
avons cependant choisi de l’exprimer en fonction du nombre de lots traités, afin de
simplifier le décompte.
Le principe de fonctionnement du seuil est le suivant : si n lots ont été traités en
entrée, alors on force l’émission des tuples produits jusque là. Un tel système permet de
garantir un flux assez régulé de tuples. On pourrait avancer le fait que, plutôt que
d’introduire un seuil, il serait possible de diminuer la taille des lots. Cependant, cette
réduction conduirait à un surplus d’envoi de lots (et donc à un coût réseau et à un
travail des threads de communication accrus), partiellement évitable lorsque la pro-
duction de tuples est suffisante. Il constitue donc un critère secondaire d’émission
tout à fait complémentaire à la taille des lots.
L’introduction du seuil entraîne une remarque quant à la taille des lots. Si pro-
ducteur et consommateur sont synchronisés, mais que le consommateur et son suc-
cesseur ne sont pas synchronisés, il redevient intéressant de produire des lots de
taille restreinte, afin de favoriser la régulation du flux au-delà du consommateur.
En résumé, si au moins une opération “à deux coups” de distance ne nécessite pas
de synchronisation avec son producteur, alors la taille des lots peut être réduite à la
taille minimum MinT .
5.4 Estimation du seuil de transfert
Le seuil de transfert est estimé de façon similaire à la taille des lots. Si l’on re-
prend l’estimation du volume de données produit de l’équation III.4, et que la taille
des lots est MinT , alors une estimation du nombre de lots par destinataire Nld est

5. INFLUENCE DES LOTS DE DONNÉES SUR LES TEMPS D’EXÉCUTION 97
donnée par :
Nld =T t:�:min(kR1k;kR2k)
d:p
MinT=
T t:�:min(kR1k;kR2k)
d:p:MinT(III.6)
Cette estimation du nombre de lots par destinataire doit être rapportée au vo-
lume de données traité en entrée, que nous avons choisi d’exprimer en nombre de
lots. Dans la plupart des techniques de jointures (par hachage), une des relations
est utilisée pour construire la table de hachage (relation de build), et la seconde est
confrontée à cette table de hachage (relation de probe). La production de tuples ne se
fait que durant la phase de probe. Le seuil ne peut donc dépendre que du nombre
de lots composant la relation de probe. Si cette relation comporte Nprobe lots, alors
le nombre moyen de lots traités pour produire un lot de résultat est donné par le
rapport r :
r =Nprobe
Nld=
Nprobe:d:p:MinT
Tt:�:min(kR1k;kR2k)(III.7)
Cette valeur correspond au rythme “moyen” de production. Le seuil de déclen-
chement sd doit donc en être proche :
sd = �:r = �:Nprobe
Nld=
�
�:Nprobe:d:p:MinT
Tt:min(kR1k;kR2k)(III.8)
La principale inconnue de cette équation reste �
�. Si nous nous référons aux tests
pratiqués, il est apparu que les meilleures performances étaient obtenues avec �
�
compris entre 0,5 et 1 (avec différentes valeurs de �), et de façon plus générale avec
un rapport �
�égal ou légèrement supérieur à 0,5.
Dans le cas d’algorithmes de jointure plus exotiques, comme le full-parallelism,
la production de tuples résultats devient plus irrégulière et n’attend pas la fin du
build. A ce moment, la régulation peut être faite en fonction des nombres de lots de
chacune des relations, en remplaçant Nprobe par Nprobe+Nbuild
2.

98 CHAPITRE III. PROPOSITION D’UN ÉVALUATEUR PARALLÈLE
5.5 Limitation des effets de bord du seuil de transfert
Nous avons pu tester l’efficacité du seuil de transfert sur différents jeux de don-
nées (voir chapitre V). Toutefois, nous pouvons observer qu’il constitue plus un han-
dicap qu’un avantage lorsque la production de tuples présente des phases de pro-
duction très fortes. En effet, si la production est suffisante pour permettre l’envoi
de lots dans les temps, alors le mécanisme de purge associé au seuil vient doubler
l’envoi normal. Cette perturbation a pour effet d’augmenter les temps de réponse.
Afin de limiter cet effet de bord, nous avons introduit une contrainte supplémen-
taire, que l’on peut exprimer comme suit : la purge des lots en cours de fabrication ne se
fait pour chaque destinataire que si aucun lot n’a été envoyé vers ce destinataire depuis la
dernière purge.
Ainsi la purge se trouve-t-elle surtout limitée aux destinataires peu favorisés. De
même, les interférences avec les envois de lots complets sont éliminés.
6 Concept d’extension parallèle
6.1 Constat
L’évaluateur parallèle proposé dans ce mémoire peut être vu comme une exten-
sion parallèle adjointe à un Système de Gestion de Bases de Données existant. Cette
angle de vue est propice à une redéfinition, ou plus exactement, une généralisation,
des concepts sous-jacents à l’évaluateur. Nous pouvons en effet le considérer comme
un composant dont l’objectif consiste à offrir des services de parallélisation pour le
traitement de données relationnelles.
Ainsi, l’évaluateur accède aux données (au sens large) gérées par le SGBD, les redé-
ploie suivant des contraintes de parallélisme, et permet ensuite un usage parallèle
de ces informations. Ces principes et contraintes sont ici adaptés au contexte des
SGBD relationnels, mais s’avèrent suffisamment généraux pour être définis en de-

6. CONCEPT D’EXTENSION PARALLÈLE 99
hors de ce contexte.
Nous présentons ici une description générique du concept d’extension parallèle,
sous la forme de composant, ainsi que la liste de services génériques associés à cette
approche. Nous indiquons ensuite quelques exemples de domaines applicatifs sus-
ceptibles de bénéficier de cette approche.
6.2 Description du composant Extension Parallèle
6.2.1 Contexte d’utilisation d’une extension parallèle
Le terme d’extension parallèle sous-entend la présence d’un élément d’origine
ne fonctionnant pas sur une architecture parallèle. Cette spécification nous permet
de fixer le cadre d’utilisation de notre proposition. Nous proposons la définition
suivante :
Une extension parallèle est un composant logiciel offrant une version parallèle de certaines
fonctionnalités d’une application séquentielle, et capable de travailler sur les données gérées
par cette dernière.
Une telle extension parallèle est intéressante si elle évite la parallélisation de l’en-
semble de l’application tout en offrant globalement des gains de performance. Le
concept d’extension parallèle permet de restreindre les coûts de développement in-
hérent à la parallélisation. Il est applicable lorsque tous les éléments ne sont pas
parallélisables, ou lorsque la parallélisation globale s’avère inutile et coûteuse dans
un cadre d’utilisation particulier de l’application. Enfin, l’extension parallèle doit
pouvoir accéder aux données en temps raisonnable. Un temps raisonnable corres-
pond ici à une durée inférieure au gain de temps global occasionné par l’utilisation
de l’extension parallèle.

100 CHAPITRE III. PROPOSITION D’UN ÉVALUATEUR PARALLÈLE
6.2.2 Définition des rôles
Comme dans la plupart des applications, nous pouvons définir deux rôles princi-
paux : l’administrateur et l’utilisateur. L’administrateur gère le bon fonctionnement
de l’extension, et l’utilisateur effectue des traitements à l’aide de celle-ci. Ces deux
rôles peuvent être altérés en un seul dans le cadre d’applications mono-utilisateur.
6.2.3 Services de base d’une extension parallèle
Les services de base d’une extension parallèle peuvent être scinder en deux caté-
gories distinctes, suivant les rôles définis ci-dessus : les services d’administration et
les services d’utilisation (voir figure III.15).
Les services d’administration assurent la gestion de l’accès aux données sources,
ainsi que leur adaptation à l’architecture parallèle utilisée.
– Acquisition du contexte Ce premier point consiste à charger les éléments de
contrôle, hors données proprement dites, liées à l’application source. Il peut
s’agir de paramètres d’utilisation ou de méta-données d’usage général. Ce
contexte doit être partiellement contrôlable au niveau de l’extension parallèle
de façon à lui garantir une certaine autonomie de fonctionnement.
– Acquisition des données Ce service permet le chargement des données dans
l’extension parallèle. Suivant le type d’application, ce service peut faire inter-
venir une fonctionnalité de l’application source (comme c’est le cas dans le
cadre de l’évaluateur parallèle de requêtes relationnelles) ou accéder directe-
ment aux données (chargement à partir d’un fichier). Cette dernière option
nécessite la connaissance du format de stockage des données, ce qui limite les
capacités d’interopérabilité de l’extension parallèle.
Le service d’acquisition des données doit également prendre en charge la no-
tion de raffraîchissement des données, soit à travers un traitement d’arrière
plan (batch), soit à travers une intervention explicite de l’administrateur.

6. CONCEPT D’EXTENSION PARALLÈLE 101
– Suivi de performances Ce troisième service doit permettre, d’une part d’éva-
luer l’efficacité des techniques parallèles utilisées, et d’autre part de modifier
celles-ci. Le premier élément de ce service consiste à pouvoir tracer (de façon
contrôlée) les traitements demandés, les techniques mises en oeuvre pour les
réaliser, et l’efficacité de la technique de résolution adoptée. Le second élément
de ce service consiste à disposer de méthodes de paramétrage. Il est possible de
distinguer deux catégories de paramétrage : le paramétrage statique (nombre
de noeuds de calcul, distribution originelle des données ...) et le paramétrage
dynamique (mise en avant de certaines heuristiques ou de leur paramétrage
en particulier).
Les services d’utilisation permettent le traitement des informations extraites du
système existant :
– Lancement de traitements Ce premier service permet la mise en oeuvre d’une
ou plusieurs catégories de traitements, éventuellement paramétrables.
– Récupération de résultats Ce second service permet d’accéder aux sorties gé-
nérées par les traitements. Ce service peut, selon les cas, être intégré ou non au
précédent. Par exemple, l’évaluateur parallèle que nous avons développé re-
tourne les résultats de façon transparente, mais la plupart des SGBD (et pour-
quoi pas l’évaluateur dans une version ultérieure) peuvent délivrer les résul-
tats par paquets de taille donnée, ce qui suppose l’existence d’un tel service.
6.3 Exemples d’applications
Les exemples ci-après illustrent différents domaines pour lesquels une extension
parallèle pourraient être envisagée. Ces exemples sortant en partie de notre domaine
de compétence, il ne s’agit pas ici de décrire en profondeur les mécanismes impli-
qués, ni même de leur assurer un statut d’universalité. Il s’agit simplement d’évo-

102 CHAPITRE III. PROPOSITION D’UN ÉVALUATEUR PARALLÈLE
Suivi de performances
Acquisition du contexte
Acquisition des données
source
Application
?Lancement de traitements
Récupération de résultats
Services d’utilisation
Services d’administration
FIG. III.15 – Services de base d’une extension parallèle
quer certains aspects de ces domaines susceptibles de bénéficier du développement
d’une extension parallèle.
6.3.1 Traitement d’images
Le traitement d’images peut s’avérer assez lourd, par exemple lorsqu’il s’effec-
tue sur des images à haute définition, ou lorsque les opérations nécessitent des cal-
culs complexes. Certaines opérations peuvent alors se contenter d’une exécution
séquentielle (modifications mineures, classement, annotation...), alors que d’autres
bénéficieront d’une exécution parallèle (fusion d’images, filtres...).
On peut à ce moment-là développer une extension parallèle chargeant les images
et leurs informations annexes depuis un logiciel séquentiel, effectuant les manipula-
tions demandées par l’utilisateur, puis permettant à celui-ci de récupérer les images
résultats. Les rôles d’administrateur et d’utilisateur sont ici fusionnés en un seul.

6. CONCEPT D’EXTENSION PARALLÈLE 103
6.3.2 Simulation
Le cas particulier du traitement d’images est extensible à la plupart des cal-
culs scientifiques. Nous pouvons ainsi proposer une extension parallèle adaptée à
la simulation numérique. Les simulations comportent en effet une phase de saisie
(conception et visualisation de l’objet ou du phénomène à étudier) de nature séquen-
tielle, suivie d’une phase d’expérimentation dont les calculs sous-jacents peuvent
s’exécuter de façon parallèle.
A nouveau, les rôles d’administrateur et d’utilisateurs sont en général confon-
dus. Il est cependant possible d’envisager une utilisation simultanée de l’outil de
simulation, sur une structure donnée, par plusieurs utilisateurs.
6.3.3 Bibliothèques
La recherche de documents dans une base en lecture seule constitue le point
fondamental de cette thèse, et l’utilisation intensive d’une bases de données biblio-
théquaire (recherche avancée ou grand nombre d’utilisateurs) en est un cas d’appli-
cation particulièrement adapté. Cependant, le système d’information d’une biblio-
thèque comporte d’autres dimensions, telle la gestion des prêts. Ces deux aspects
restent toutefois compatibles dans le cadre de l’utilisation d’une extension parallèle
(voir figure III.16).
En effet, il est ici possible d’envisager l’extension parallèle comme un service acces-
sible de façon transparente à l’utilisateur (l’emprunteur potentiel), dont les résultats
sont non seulement visibles pour celui-ci, mais également pour le service de loca-
tion.
Dans un tel cas de figure, le rafraîchissement des données peut être opéré quoti-
diennement durant une partie des heures de fermeture. S’il est possible d’interroger
à distance, et donc potentiellement à toute heure, la liste des ouvrages gérés par la
bibliothèque, le rafraîchissement reste possible. Il suffit, à ce moment là, de rediri-
ger les interrogations vers la base source (au risque cependant d’une dégradation
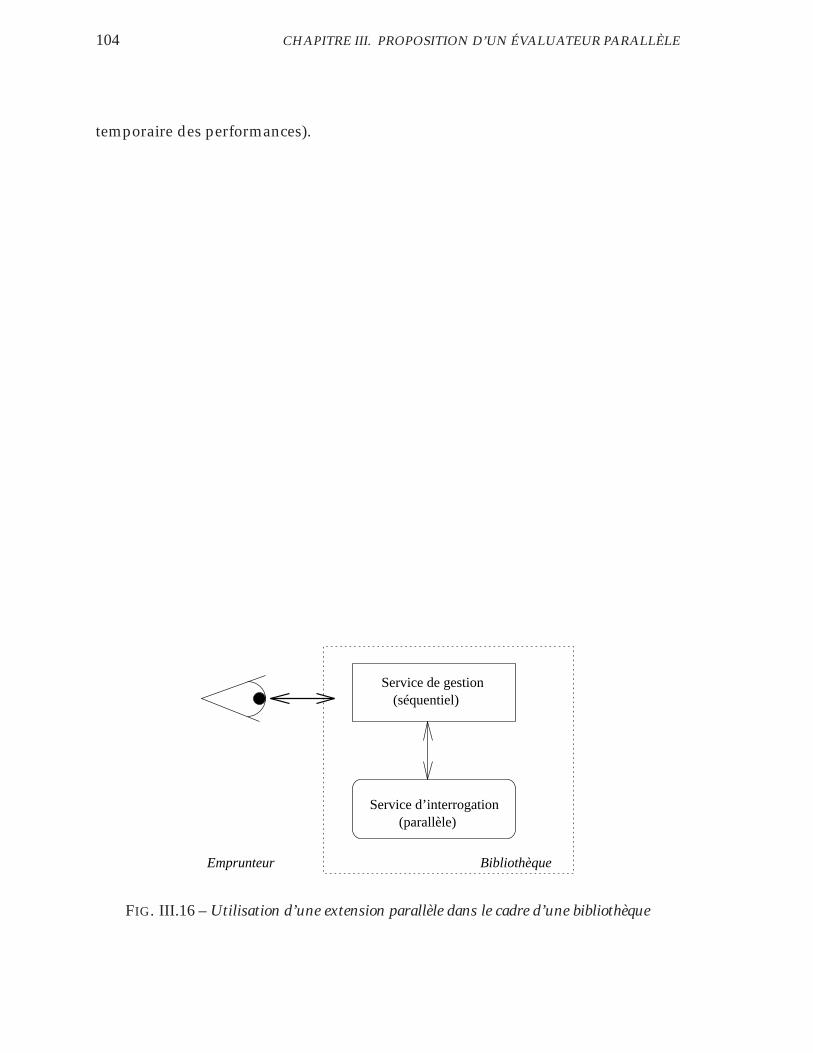
104 CHAPITRE III. PROPOSITION D’UN ÉVALUATEUR PARALLÈLE
temporaire des performances).
(séquentiel)Service de gestion
(parallèle)Service d’interrogation
BibliothèqueEmprunteur
FIG. III.16 – Utilisation d’une extension parallèle dans le cadre d’une bibliothèque

7. ANALYSE DE L’ARCHITECTURE 105
7 Analyse de l’architecture
7.1 Spécificités architecturelles
Du point de vue de l’architecture, notre extension présente des caractéristiques
communes aux réseaux de stations. Nous pouvons ainsi constater que :
– l’extensibilité du système est virtuellement infinie. En effet, il suffit de connec-
ter une nouvelle machine sur le réseau local pour disposer d’un calculateur
supplémentaire. Les réactions pour un très grand nombre de calculateurs sont
cependant délicates à prévoir, notamment du point de vue des communica-
tions. Il serait donc intéressant, à l’avenir, d’étudier un tel cas de figure ;
– les capacités de stockage et de calcul de chaque calculateur s’avèrent impor-
tantes. Un machine d’entrée de gamme supporte actuellement plusieurs cen-
taines de Méga-octets de mémoire vive, ainsi que plusieurs dizaines de Giga-
octets de disque. De telles caractéristiques permettent d’envisager une grande
autonomie de chaque noeud ;
– les capacités réseaux peuvent s’avérer moindres que dans une machine paral-
lèle. Toutefois, l’apparition de nouveaux produits et de nouveaux protocoles
comble peu à peu le fossé existant à ce niveau-là ;
– la non-spécificité des machines peut faire apparaître des composants super-
flus sur les calculateurs (par exemple, les composants graphiques). Cette non-
spécificité permet en revanche de considérer les machines alternativement comme
élément d’une structure parallèle ou comme des machines autonomes. Autre-
ment dit, il reste possible de moduler les dimensions de l’évaluateur parallèle,
et de libérer ainsi certains calculateurs afin de les utiliser comme des stations
classiques.

106 CHAPITRE III. PROPOSITION D’UN ÉVALUATEUR PARALLÈLE
7.2 Spécificités de l’approche logicielle
D’un point de vue scientifique, nous avons conceptualisé et modélisé un éva-
luateur parallèle de requêtes relationnelles sur réseau de stations. Cet évaluateur
constitue une nouveauté dans le sens où il permet d’effectuer des requêtes paral-
lèles sur des données extraites d’un SGBD existant, sans avoir recours à un SGBD
complet. Nous avons étudié et formalisé les différents composants nécessaires à son
fonctionnement. Nous avons proposé l’utilisation de calculateurs multi-threads afin
de compenser les délais de production et d’envoi de tuples.
D’un point de vue technique, le paramétrage de la taille des lots permet de mo-
duler la granularité des paquets de tuples résultats. On peut ainsi utiliser des lots
de taille réduite pour favoriser le parallélisme “pipeline” entre opérations consé-
cutives. Nous avons proposé ici une technique d’estimation de la taille des lots de
données en fonction du mode de synchronisation entre opérations consécutives. De
plus, nous avons proposé une technique de seuil permettant de réguler le flot des
lots de tuples ainsi qu’une technique limitant les éventuels surcoûts liés à ce seuil.
Bien que diverses études introduisent le concept de lots, sous forme de buffer ou
de “grain” de données, aucune ne propose à notre connaissance l’introduction des
seuils de transfert introduits dans ce mémoire. Cette proposition, n’engendrant que
de faibles surcoûts (utilisation d’un compteur), apparaît comme un élément fort de
nos recherches.
D’un point de vue plus général, nous avons introduit la notion d’extension paral-
lèle dans le cadre des bases de données relationnelles. Il est remarquable que cette
notion puisse être étendue à un certain nombre d’applications fonctionnant natu-
rellement en mode “séquentiel”, mais pouvant nécessiter de façon ponctuelle un
surplus de puissance pour une catégorie de traitements donnée. Cette proposition,
dans la logique de l’approche par composants, constitue a priori une nouvelle façon
de concevoir les apports du parallélisme, non plus considéré comme alternative aux
solutions séquentielle, mais comme complément à celles-ci. Dans cette optique, l’ex-

7. ANALYSE DE L’ARCHITECTURE 107
tension parallèle, pour des raisons de capacité de diffusion, semble plus adaptée aux
réseaux de stations, mais rien n’interdit son utilisation sur une machine parallèle.
7.3 Validité des données
Dans notre proposition, l’évaluateur parallèle extrait les données d’une base
existante, puis effectue des requêtes parallèles sur ces données. Ce mode de fonc-
tionnement suppose que le contenu des données distribuées demeure valide durant
une période suffisamment longue.
Le problème de la durée de validité se pose de façons variées suivant le contexte
d’utilisation. Notre évaluateur fonctionne en mode déconnecté vis-à-vis du SGBD.
Cette pratique sous-entend :
– soit que les données extraites soient stables, c’est-à-dire que les relations distri-
buées soient elles-mêmes en lecture seule. Un tel cas de figure peut se présenter
lors de l’analyse d’une base n’étant plus mise à jour (par exemple, suite à un
changement de version) ;
– soit que leur mise à jour soit relativement lente et de fréquence connue. C’est
par exemple le cas des bases de brevets, telle celle de l’INPI, dont la mise à jour
est hebdomadaire. On peut alors lancer, de façon transparente, le renouvelle-
ment des données extraites ;
– soit que les différences entre données stockées et données extraites n’influencent
pas la validité des traitements confiés à l’évaluateur. Nous rencontrons ce type
d’utilisation dans des applications de type entrepôts de données et fouille de
données. Dans ce cadre-là, et dans la mesure où les analyses portent sur des
intervalles de temps donnés, le rafraîchissement des données peut se limiter
aux contraintes temporelles posées par l’utilisateur.
Ces limites étant posées, il reste à définir quelles techniques de rafraîchissement
peuvent être employées , et à quelle fréquence.

108 CHAPITRE III. PROPOSITION D’UN ÉVALUATEUR PARALLÈLE
D’un point de vue temporel, la situation idéale pour le rafraîchissement consiste à
disposer d’heures creuses. Durant ces périodes de faible utilisation, il est possible de
bloquer l’accès à l’évaluateur afin de modifier les données que celui-ci gère. Cette
démarche suppose toutefois de pouvoir également bloquer le SGBD, non seulement
dans le but de disposer de toutes les ressources de celui-ci (afin d’accélérer l’extrac-
tion), mais également, et bien entendu, afin de ne pas risquer l’introduction d’inco-
hérences dûes à des mises à jour pendant l’extraction.
Les heures creuses de l’évaluateur et du SGBD doivent donc correspondre, générant
ainsi une fenêtre de rafraîchissement.
Si cette fenêtre de rafraîchissement est suffisamment étendue, il est possible d’ef-
fectuer une redistribution complète. Cette technique constitue en effet la méthode la
plus simple et la plus sûre de mise à jour des données extraites. Elle s’avère toutefois
assez lourde. Cependant, la mise en place de stratégies plus évoluées pose d’assez
vastes problèmes, comme nous allons le voir.
Une première approche allégée consisterait à disposer d’une fonction “différen-
ce”, indiquant l’évolution d’une table entre deux instants donnés. Un tel système
supposerait de disposer directement d’une telle fonctionalité, ou bien de pouvoir
accéder, de façon transparente et “portable” aux fichiers de journalisation des SGBD
utilisés ... ce qui ne constitue pas exactement une fonction standard de SQL. Nous
pouvons ici signaler l’existence de fonctions d’audit, entre autres dans le SGBD
Adaptive Server Enterprise de Sybase [Syb98], permettant, entre autres choses, de
“tracer” l’évolution des tables (insertions, suppressions, modifications). Ces fonc-
tions sont cependant coûteuses à mettre en œuvre et diminuent de ce fait les per-
formances du SGBD. De plus, l’insertion de fonctions d’audit dans le SGBD en vue
de leur utilisation par l’évaluateur parallèle va à l’encontre du principe d’indépen-
dance de celui-ci vis-à-vis du SGBD.
Une seconde solution pourrait consister à faire transiter tous les accès au SGBD à
travers l’évaluateur, afin de garder une trace de toutes les mises à jour, de façon à les

7. ANALYSE DE L’ARCHITECTURE 109
appliquer sur les données extraites. De telles manipulations restent délicates et dif-
ficiles à modéliser. De plus, rien ne garantit leur validité si le SGBD gère des triggers
impliquant les tables extraites. L’ensemble des évolutions possibles devient alors
particulièrement complexe à gérer (il faut introduire des notions de contraintes,
etc.), et les arguments de simplicité et de faible coût de l’évaluateur perdent alors
quelque peu de leur intérêt.
Nous préconisons donc, en l’état actuel de nos recherches et développements,
une redistribution complète des données. De ce fait, nous limitons l’usage de l’éva-
luateur à des applications pour lesquelles la durée de chargement est suffisament
faible vis-à-vis de la durée de validité. Cette contrainte ne constitue pas un pro-
blème au sein de cette thèse. En effet, nos recherches sont depuis leur origine orien-
tées vers des bases de données stables, et en “lecture seule”. Une amélioration de la
disponiblité de l’évaluateur constituerait cependant un point d’étude intéressant.
x

110 CHAPITRE III. PROPOSITION D’UN ÉVALUATEUR PARALLÈLE

111
Chapitre IV
Le prototype ENKIDU
1 Historique et choix techniques
1.1 Etymologie
Nous allons présenter, dans ce chapitre, le prototype ENKIDU, implémentation
des concepts de l’évaluateur parallèle de requêtes. A titre d’anecdote, le nom EN-
KIDU a été retenu car il évoque la légende sumérienne de Gilgameš [Bot92], dans
laquelle Enkidu est un être hybride entre homme et animal. Par analogie, notre éva-
luateur parallèle possède des caractéristiques extraites des bases de données paral-
lèles mais également des réseaux de stations. De même, il offre une technique inter-
médiaire d’évaluation de requêtes relationnelles entre les SGBD classiques, limités
en extensibilité et en puissance, et les SGBD parallèles, complexes et très coûteux.
Enfin, il reprend uniquement l’aspect “évaluation de requêtes”, et limite par là son
domaine d’investigation. Ainsi donc, le nom ENKIDU nous permet à la fois d’ex-
primer la mixité et la spécialisation de notre prototype.

112 CHAPITRE IV. LE PROTOTYPE ENKIDU
1.2 Réalisation
Une première version d’ENKIDU a été développée en C, sous UNIX (SunOS et
Linux), les communications étant confiées à la bibliothèque PVM (voir chapitre II) [Exb97b].
Les difficultés rencontrées, notamment en mode multi-threads, nous ont conduit à
porter l’existant et à poursuivre son développement sous Java [Fla97]. Ce langage
de programmation orienté-objet a été retenu pour les raisons suivantes :
– Portabilité
– Robustesse (notamment en mode multi-thread)
– Simplicité et rapidité de programmation (modèle objet, présence d’un ramasse
miettes...)
On pourrait objecter que les programmes écrits en Java sont moins rapides que
les programme développés en C ou C++, du fait que ce langage est semi-interprété.
En effet, la compilation de programme Java produit un code appelé byte code, géné-
rique et non lié à la plateforme de compilation. L’exécution d’un programme Java
se fait ensuite à l’aide d’un programme appelé Java Virtual Machine, ou JVM (voir
figure IV.1). Ce programme se charge d’interpréter le byte code et d’en assurer l’exé-
cution. Bien entenu, la JVM est, elle, spécifique à la plateforme sur laquelle elle est
exécutée.
Byte Code Javad’exploitation
JVM SystèmeFichier
Java
Compilateur
Java
FIG. IV.1 – Machine Virtuelle Java
Ce système à deux niveaux permet notamment l’utilisation de Java dans des
applications téléchargées via le web (telles les applets). Dans ce cas, en effet, la pla-
teforme destinataire n’est pas connue lors de la compilation. Les principes de byte
code et de machine virtuelle conduisent a priori à des temps d’exécution plus longs

1. HISTORIQUE ET CHOIX TECHNIQUES 113
qu’avec un programme directement compilé et optimisé pour une plateforme spé-
cifique, comme peuvent l’être les programmes en langage C ou C++.
Notons que les versions les plus récentes de compilateurs “Juste à Temps” (Just in
Time Compilers) offrent des performances tout à fait respectables par rapport aux
langages compilés (des annonces régulières, à prendre toutefois avec prudence, font
état de performances équivalentes à C++).
Le compilateur “Juste à Temps” est un composant très fréquent des machines vir-
tuelles Java. Rappelons ici son principe : les classes Java sont compilées en byte code
indépendant de la plate-forme. Lors de l’utilisation du programme, les classes sont
chargées dynamiquement en mémoire (c’est-à-dire lorsque l’on fait appel à elles) et
leur byte code est alors confié à un interpréteur (la machine virtuelle). Cette inter-
prétation peut s’avérer assez lente, d’où l’idée du JIT Compiler : l’interpréteur est
remplacé par un compilateur qui va transformer le byte code en code machine “à
la volée”, c’est-à-dire lors de son chargement. Cette compilation “à la volée” pré-
sente plusieurs avantages vis-à-vis de la compilation statique. Elle conserve l’indé-
pendance du code vis-à-vis de la plate-forme et élimine également le problème dit
des super-classes fragiles (dans un langage compilé comme C++, la modification du
code d’une super-classe impose la recompilation de ses sous-classes. Le byte code
supprime cet inconvénient).
Il est enfin possible de compiler statiquement des classes Java, notamment sous
Windows. Java est alors considéré comme un langage de programmation compilé,
et est censé gagner en rapidité ce qu’il perd en portabilité. Les produits Symantec
(Visual Café) permettent cette compilation statique. Cependant, nos essais de com-
pilation statique d’Enkidu ont plutôt conduits à une dégradation des performances
(de 10 à 20 %) par rapport de l’utilisation du JIT Compiler fourni par ce même édi-
teur. Cette dégradation s’est également retouvée dans des tests plus simples, telle
une somme de matrices, ce qui nous conduits à douter de l’efficacité du compila-
teur actuel.

114 CHAPITRE IV. LE PROTOTYPE ENKIDU
Le prototype développé reprend la plupart des concepts proposés au chapitre III.
Les éléments développés par nos soins représentent plus de dix mille lignes de code.
Nous présentons dans ce chapitre les spécificités liées à l’implantation de l’évalua-
teur parallèle ainsi que le fonctionnement de l’interface utilisateur et administrateur
du prototype.
2 Composants généraux
2.1 Communications
Du point de vue des communications, les portages de la bibliothèque PVM sous
Java nous sont apparus peu stables et assez lourds. Aussi avons-nous opté pour un
usage direct des sockets Java. L’usage d’une bibliothèque d’échange de messages,
qu’il s’agisse de PVM ou de MPI, s’avère surtout intéressant lorsque l’on utilise
un langage compilé. Ces langages étant en général très proches de l’implantation
physique, il est souvent bienvenu de faire appel à une bibliothèque d’échange de
messages. Tout d’abord, l’implantation des couches de communication varie d’un
système d’exploitation à l’autre, ce que la bibliothèque cache aux yeux du program-
meur. Ensuite, celle-ci se charge de gérer les différents formats de stockage (cer-
tains systèmes stockant d’abord les octets de poids forts, d’autres les octets de poids
faible). Dans le cas de Java, ce problème ne se pose pas car le langage contient ces
conversions de façon intrinsèque. Le seul point fort de PVM vis-à-vis des sockets
Java réside dans ses fonctions de contrôle. Celles-ci sont toutefois très peu utilisées
dans notre système.
Les sockets Java présentent l’avantage d’être faciles à manipuler. Il est par ailleurs
possible, de part l’approche objet de Java, de modifier de façon transparente le pro-
tocole sous-jacent à ces sockets. La méthode standard d’envoi de données complexes
sur les sockets Java utilise le mécanisme de sérialisation (voir figure IV.2).
La sérialisation consiste à “déplier” un objet, c’est-à-dire à le transformer en une

2. COMPOSANTS GÉNÉRAUX 115
représentation linéaire, dans laquelle chacun de ses composants est lui même dé-
plié de façon récursive. La structure de l’objet est également inscrite dans l’objet
sérialisé, ce qui permet de le reconstituer à sa réception. Ce mécanisme, tout à fait
transparent à l’utilisateur, est également utilisé pour écrire des objets dans des fi-
chiers. Cependant, nous avons constaté que les transferts de données utilisant la
sérialisation s’avéraient assez coûteux.
(bytes)
Forme linéaire
désérialisation
Objet d’origine Objet reçu (en cours de reconstitution)
Sérialisation
=données + structure
Flux (socket)
FIG. IV.2 – Mécanisme de sérialisation Java
Nous avons donc utilisé une solution alternative (voir figure IV.3), consistant à
sérialiser “à la main” les objets dans un tableau d’octets, puis envoyer ce tableau sur
le réseau à travers la socket, et enfin recomposer l’objet, à l’autre bout, à partir du
tableau reçu.
Cette sérialisation personnalisée est réalisée par une méthode incluse dans les
objets susceptibles d’être émis sur le réseau. Elle ne sérialise que les attributs pour
lesquels le transfert présente un sens (certains attributs de contrôle n’étant utilisés
que sur le destinataire ou l’émetteur). En outre, elle limite le nombre d’informations
de reconstruction au strict minimum. En effet, la reconstruction étant assurée par
une méthode de la classe à laquelle appartient cet objet, cette méthode contient déjà,

116 CHAPITRE IV. LE PROTOTYPE ENKIDU
Objet reçu (en cours de reconstitution)
(bytes)
Forme linéaire
Objet d’origine
=données seules
Flux (socket)
spécifiqueReconstitution
spécifiqueReconstitution
Type d’objet ?
spécifique
Sérialisation
FIG. IV.3 – Sérialisation spécifique ENKIDU
dans son code, une partie des connaissances nécessaires à la reconstruction. Le sys-
tème utilisé permet de transférer les objets simples et composites (dans la mesure
où chaque composant dispose de la méthode de décomposition / reconstruction).
Nous avons pu observer des gains de temps d’envoi significatifs (considérant ici que
le temps d’envoi est mesuré entre l’instant où l’on présente l’objet à émettre et celui
où l’on récupère l’objet reconstitué). Ces mesures sont présentées au chapitre V.
A la réception, les objets contenus dans les messages sont reconstitués et un trai-
tement correspondant à leur type est lancé. Ce traitement est en général confié à un
thread secondaire, par l’intermédiaire d’une file d’attente (voir figure IV.4). Il y a
ainsi une file d’attente pour les plans d’exécution, une autre pour les informations,
etc. (certains types de messages internes aux communications ne sont pas détaillés
ici). Le stockage des données reçues, de part sa rapidité (traitement quasi nul) se fait
directement, sans usage de thread intermédiaire.

2. COMPOSANTS GÉNÉRAUX 117
Queues
Infos
Queue
PEP
Thread infos Thread PEP
Gest. fragments
thread de
communicationcommunication
Socket de
Type de données ?
FIG. IV.4 – Traitement des messages reçus
2.2 Messages d’administration
Tous les types de messages d’administration rencontrés dans notre implémenta-
tion sont exprimables de façon numérique. Nous avons donc défini ceux-ci comme
étant composés d’un type (codé de façon numérique) suivi d’un tableau d’entiers
contenant les paramètres liés à l’information. Comme signalé ci-dessus, le traite-
ment des messages d’administration est effectué par un thread spécifique. Les types
de messages actuellement utilisés sont les suivants :
– changement d’un numéro de relation (peu utilisé). Permet de libérer un nu-
méro de relation donné ;
– nombre de producteurs. Cette option n’est plus très utilisée car elle est inté-
grée la plupart du temps dans les instructions élémentaires. Elle reste utilisée
pour la distribution des tables ;
– nombre de lots produits. Cette information n’étant pas actuellement intégrée
dans les lots transmis (elle pourrait l’être dans le dernier lot de chaque desti-
nataire), elle demeure très utilisée ;

118 CHAPITRE IV. LE PROTOTYPE ENKIDU
– suppression de relation distribuée. Cette information est utilisée à la fois pour
ordonner une suppression (serveur vers calculateur) et pour la confirmer (cal-
culateur vers serveur) ;
– résultat d’opération élémentaire. Cette option est utilisée en mode traçage.
Elle indique le nombre de tuples traités et produits sur chaque site pour une
opération ;
– informations de distribution. Spécifique à la distribution. Indique la manière
dont une distribution est exécutée ;
– fin d’exécution. Permet l’arrêt des calculateurs en fin de session.
La liste des informations reste susceptible d’évoluer. Certaines catégories de-
vraient peu à peu être supprimées et intégrées à d’autres messages. A l’inverse, de
nouvelles catégories pourraient apparaître (indications de charge, etc.).
3 Composant serveur
3.1 Gestionnaire de redistribution et gestionnaire d’exécution
Le gestionnaire de redistribution, décrit au chapitre III, gère la distribution des
données. Il peut se résumer à la liste des tables de la base d’origine (liste des attributs
et de leur type). Lorsque l’une de ces tables est distribuée, une description de la dis-
tribution lui est adjointe. L’interface visuelle de cet objet est décrite en section 3.2.1.
Ses mécanismes d’extraction de données sont détaillés en section 5.
Le gestionnaire d’exécution est pour sa part simplifié. Il est remplacé par un
gestionnaire de requêtes (objet Execman de la figure IV.6). Son rôle consiste à i) expé-
dier les plans d’exécutions parallèles aux calculateurs concernés, ii) intercepter les
signaux de fin d’exécution, et iii) indiquer les fins de requêtes aux utilisateurs.

3. COMPOSANT SERVEUR 119
3.2 Administration
Nous avons développé une interface graphique permettant le contrôle de la dis-
tribution et le lancement de requêtes. Nous présentons ici la fenêtre d’administra-
tion d’ENKIDU (voir figure IV.5). D’autre part, et en parallèle à la description des
fenêtres, la figure IV.6 offre une vue dynamique du fonctionnement des principaux
modules du serveur.
FIG. IV.5 – Fenêtre d’administration d’ENKIDU
3.2.1 Rubrique SGBD
Cette rubrique contient les différentes commandes d’accès à une base de don-
nées. Elle permet :
– la connexion à une base de données (voir figure IV.7). La version actuelle per-
met de se connecter à une base Oracle. Cette connexion entraîne le chargement
du dictionnaire de données ;
– la sauvegarde d’une distribution. Cette option sauve les paramètres de connexion
à une base de données ainsi que la liste des tables distribuées et leurs para-
mètres de distribution ;
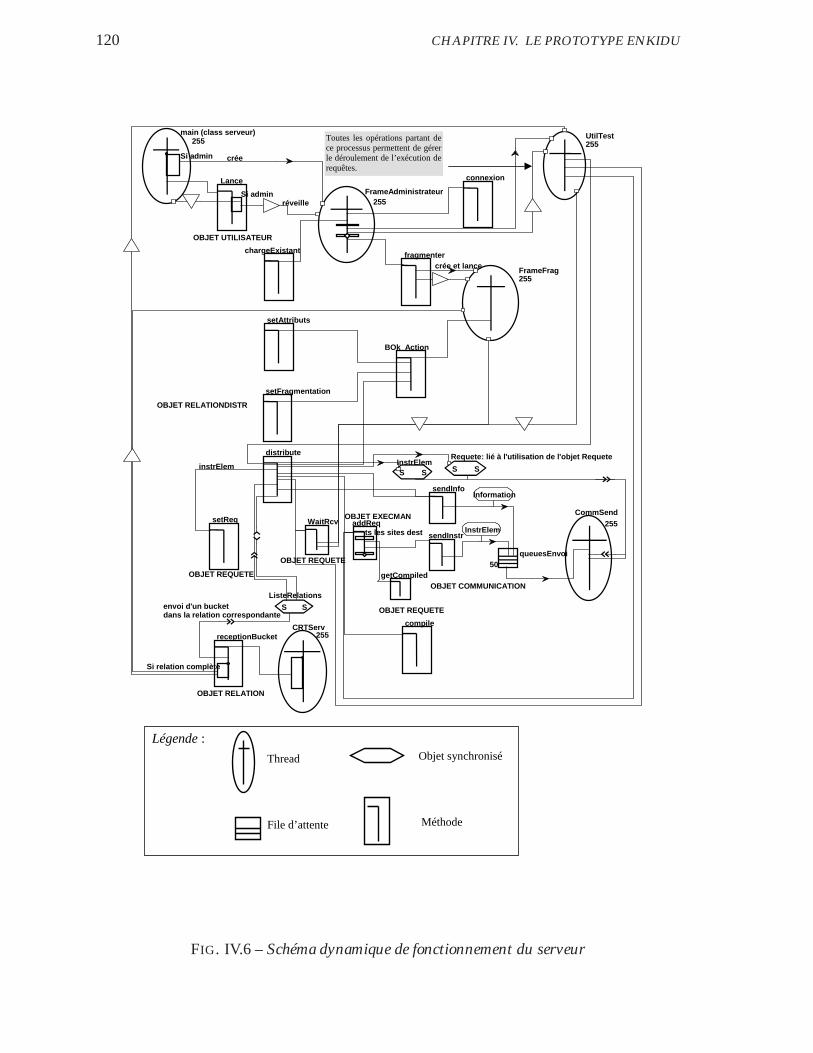
120 CHAPITRE IV. LE PROTOTYPE ENKIDU
S SS S
S S
FrameAdministrateur255
FrameFrag255
main (class serveur)255
Si admin
Lance
Si admin
connexion
chargeExistantfragmenter
crée et lance
crée
réveille
BOk_Action
OBJET UTILISATEUR
setAttributs
setFragmentation
distribute
OBJET RELATIONDISTR
CRTServ255
RequeteInstrElem
setReq
instrElem
receptionBucket
ListeRelationsenvoi d'un bucket
Si relation complète
CommSend255
queuesEnvoi50
sendInfo
OBJET COMMUNICATION
sendInstr
addReqWaitRcv
OBJET REQUETE
Information
InstrElem
OBJET EXECMAN
compile
OBJET REQUETE
getCompiled
ts les sites dest
: lié à l'utilisation de l'objet Requete
OBJET REQUETE
OBJET RELATION
dans la relation correspondante
UtilTest255
Légende :
Toutes les opérations partant dece processus permettent de gérerle déroulement de l’exécution derequêtes.
Thread
File d’attente Méthode
Objet synchronisé
FIG. IV.6 – Schéma dynamique de fonctionnement du serveur

3. COMPOSANT SERVEUR 121
– la restauration d’une distribution. Cette option utilise un fichier sauvé avec la
technique citée ci-dessus. Elle se reconnecte d’abord à la base, puis redistribue
les tables suivant les indications du fichier de sauvegarde ;
– la distribution d’une base de test. Cette option permet de générer une base
de données fictive à partir de paramètres fournis dans un fichier. Ce fichier
fourni une liste de tables, en indiquant leurs attributs (de type numérique).
Pour chaque table le nombre de tuples est indiqué. Les valeurs des attributs
sont définies comme suit :
– Valeurs minimum et maximum
– Répartition des valeurs :
– valeurs uniques successives, afin de simuler une clé ;
– valeurs uniformément réparties, afin de gérer le nombre de match
d’une jointure ;
– répartition biaisée sur une valeur (permet des tests de biais simples,
comme ceux présentés dans [DeW92b]) ;
– répartition présentant un biaisage de type zipf. Un biaisage zipf est
tel que l’attribut de rang i a comme fréquence F (i) = c
ib, b représen-
tant le biais et variant de 0 (pas de biais) à 1 (très fort biais), et c étant
un coefficient correcteur calculé de manière à ce que la somme des
fréquences soit égale à la cardinalité de la relationP
i F (i) = kRk.
Nous avons retenu ce type de biais car il simule bien certains types
de distributions, tels les annuaires et les dictionnaires ;
– de par l’architecture objet et modulaire d’ENKIDU, l’ajout d’autres
types de biais reste ouvert ;
– paramètres de distribution. Ces paramètres permettent la fragmentation des
tables produites avec la technique énoncée ci-dessus ;
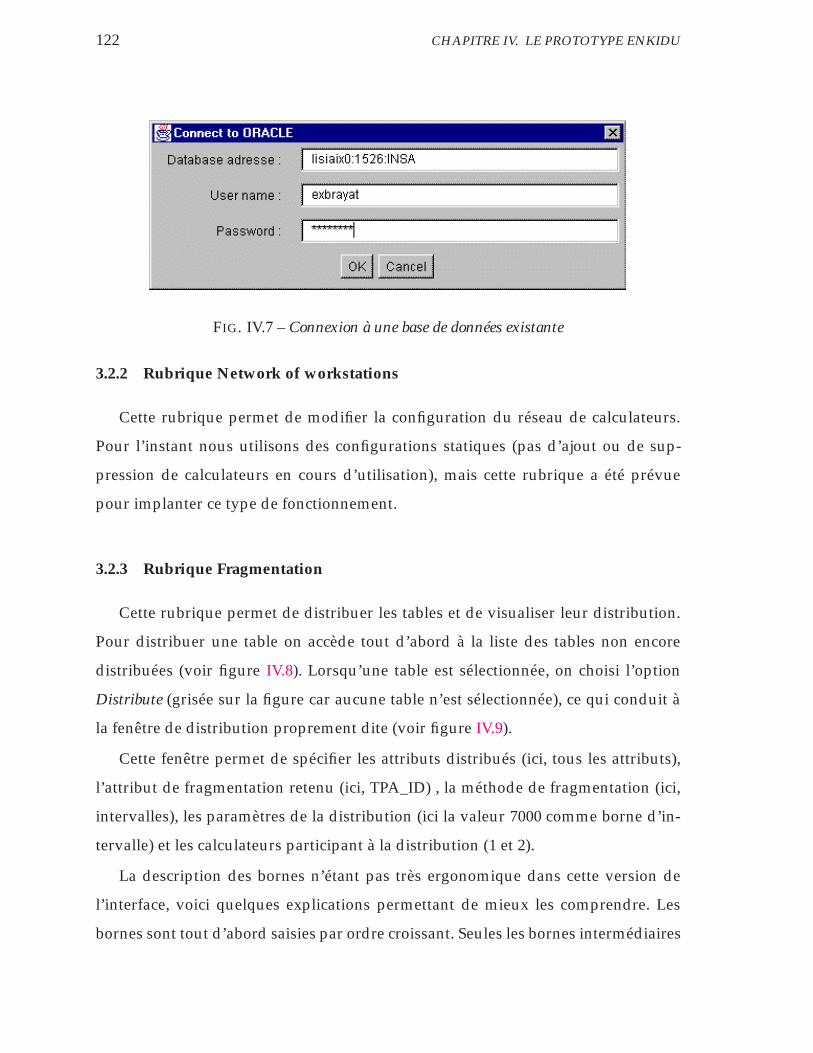
122 CHAPITRE IV. LE PROTOTYPE ENKIDU
FIG. IV.7 – Connexion à une base de données existante
3.2.2 Rubrique Network of workstations
Cette rubrique permet de modifier la configuration du réseau de calculateurs.
Pour l’instant nous utilisons des configurations statiques (pas d’ajout ou de sup-
pression de calculateurs en cours d’utilisation), mais cette rubrique a été prévue
pour implanter ce type de fonctionnement.
3.2.3 Rubrique Fragmentation
Cette rubrique permet de distribuer les tables et de visualiser leur distribution.
Pour distribuer une table on accède tout d’abord à la liste des tables non encore
distribuées (voir figure IV.8). Lorsqu’une table est sélectionnée, on choisi l’option
Distribute (grisée sur la figure car aucune table n’est sélectionnée), ce qui conduit à
la fenêtre de distribution proprement dite (voir figure IV.9).
Cette fenêtre permet de spécifier les attributs distribués (ici, tous les attributs),
l’attribut de fragmentation retenu (ici, TPA_ID) , la méthode de fragmentation (ici,
intervalles), les paramètres de la distribution (ici la valeur 7000 comme borne d’in-
tervalle) et les calculateurs participant à la distribution (1 et 2).
La description des bornes n’étant pas très ergonomique dans cette version de
l’interface, voici quelques explications permettant de mieux les comprendre. Les
bornes sont tout d’abord saisies par ordre croissant. Seules les bornes intermédiaires

3. COMPOSANT SERVEUR 123
FIG. IV.8 – Liste des tables non distribuées
sont saisies, les bornes la plus petite et la plus grande étant implicitement et respecti-
vement �1 et +1. Dans le cas d’une distribution circulaire, aucun paramètre n’est
fourni. Dans le cas d’une distribution par hachage, un premier paramètre décrit la
fonction de hachage utilisée (ex : 1 pour un simple “modulo”, 2 pour la fonction
“modulo du carré de la valeur”, etc.), les paramètres suivants correspondant aux
éventuels paramètres de la fonction de hachage. Les calculateurs sont utilisés, pour
la distribution, dans l’ordre où ils se présentent dans la fenêtre “Calculators used”.
Dans cet exemple, les tuples dont l’attribut TPA_ID présente une valeur inférieure
à 7000 seront donc placés sur le calculateur 1. Ceux dont l’attribut TPA_ID présente
une valeur supérieure ou égale à 7000 seront placés sur le calculateur 2.
Si nous avions voulu distribuer la relation sur 3 calculateurs avec une technique si-
milaire (intervalles), nous aurions indiqué trois calculateurs distincts (par exemple
no1,no2 et no3) dans la fenêtre “Calculators used” et deux bornes (par exemple 5000
et 10000) dans la fenêtre “Bounds”.
Les techniques d’extraction proprement dites sont détaillées à la section 5.
Une fois les tables distribuées, il est possible de contrôler l’homogénéité de la
distribution en évoquant la fenêtre “Tables Distributed” (voir figure IV.10). Celle-ci
rappelle pour chaque table la méthode de distribution utilisée et indique en outre

124 CHAPITRE IV. LE PROTOTYPE ENKIDU
FIG. IV.9 – Fenêtre de distribution des données
le nombre de tuples présents sur chaque calculateurs. Nous pouvons voir dans cet
exemple que la distribution est fortement déséquilibrée.
3.2.4 Rubrique Tests
Un menu de tests a été ajouté à la fenêtre d’administration de façon à pouvoir
simuler une utilisation plus ou moins intense du prototype. Ce menu permet de
lancer des tests mais également d’activer plusieurs types de mesures. Le lancement
des tests se fait en évoquant la fenêtre de saisie du nombre d’utilisateurs simultanés
(voir figure IV.11). Le nombre saisi est un entier supérieur ou égal à 1. Les utilisa-
teurs sont simulés à l’aide de fichiers contenant une liste de requêtes représentées
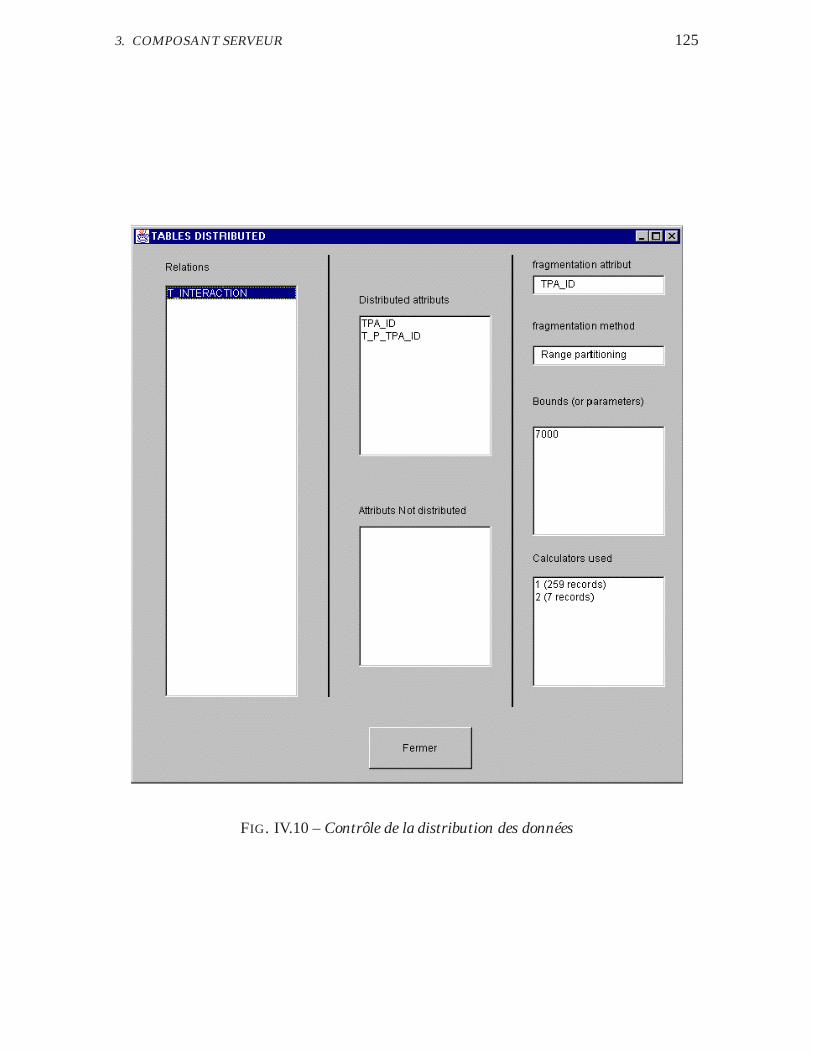
3. COMPOSANT SERVEUR 125
FIG. IV.10 – Contrôle de la distribution des données

126 CHAPITRE IV. LE PROTOTYPE ENKIDU
sous forme de plans d’exécution parallèle. Un thread est lancé pour chaque utili-
sateur simulé (voir figure IV.12). Ce thread utilise le fichier correspondant à l’uti-
lisateur (repéré par un numéro d’ordre compris entre 0 et n-1, n étant le nombre
d’utilisateurs simultanés).
Les requêtes présentent dans le fichier sont exécutées à tour de rôle, dans l’ordre
où elles se présentent. La série complète de requêtes peut être exécutée plusieurs
fois pour chaque utilisateur. Le nombre de boucles à effectuer est saisi par l’admi-
nistrateur dans la fenêtre principale d’administration, à la rubrique number of tests
for each query (voir figure IV.5), ceci pour raison de lisibilité. Les requêtes sont réelle-
ment exécutées, et les résultats retournés dans le cadre de ces tests sont détruits par
le serveur, après réception, afin de ne pas saturer celui-ci.
FIG. IV.11 – Saisie du nombre d’utilisateurs simultanés simulés
Fichier
pepFic(n-1)
Fichier
pepFic0
utilisateur 0
Gestionnaire
d’exécution
utilisateur n-1
Lancement de requête
résultats
FIG. IV.12 – Principe de fonctionnement des utilisateurs simulés

3. COMPOSANT SERVEUR 127
3.2.5 Rubrique Statistics
La rubrique Statistics permet d’activer différentes mesures concernant les tests
présentés ci-dessus. Deux options sont disponibles. La première se contente d’affi-
cher le temps d’exécution global compris entre le lancement du premier utilisateur
et la fin du dernier. Cette mesure est particulièrement intéressante pour des utilisa-
teurs effectuant le même type de travail (tenue en charge). Cette valeur est affichée,
en fin de traitement, dans la rubrique Total Enkidu execution time de la fenêtre prin-
cipale (voir figure IV.5). Le traitement de cette option (observation des instants de
début et de fin d’exécution) est géré au niveau des threads utilisateurs.
La seconde option fournit des mesures plus complètes. Elle permet notamment
d’évaluer le temps de réponse individuel de chaque requête et la charge de travail de
chaque calculateur (ou, plus exactement, le nombre de tuples manipulés par chaque
calculateur). Ces mesures sont ensuite visualisables sous forme de graphiques.
Ces mesures (voir figure IV.13) font intervenir le serveur et les calculateurs. Ces
derniers retournent en effet des informations au niveau de chaque instruction élé-
mentaire. Cette option de monitoring nécessite un certain volume de traitement sup-
plémentaire (transmission, interprétation, stockage des mesures), et n’est donc uti-
lisable que lors de tests d’efficacité.
Au niveau des calculateurs, il est possible de visualiser le nombre d’opérations
élémentaires (instructions) réalisées, le nombre de tuples manipulés et le nombre de
tuples créés (voir figure IV.14). Ces informations donnent une idée de l’utilisation
relative de chaque calculateur.
Au niveau utilisateur, il est possible d’obtenir des informations sur :
– Les temps d’exécution par utilisateur (figure IV.15). En usage classique, cette
fenêtre permet de visualiser les utilisateurs les plus actifs. En mode tests, elle
permet de vérifier que les temps d’exécution d’utilisateurs présentant le même
profil sont similaires.
– Le nombre d’opérations élémentaires exécutées par seconde pour chaque re-
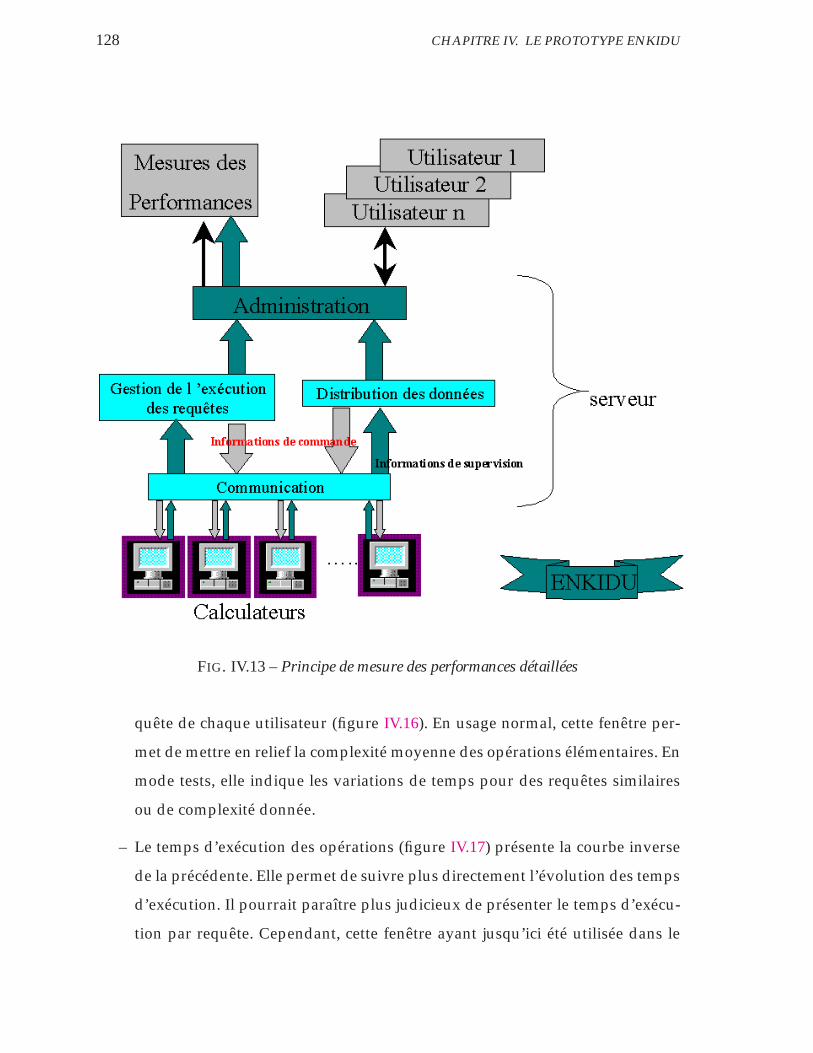
128 CHAPITRE IV. LE PROTOTYPE ENKIDU
FIG. IV.13 – Principe de mesure des performances détaillées
quête de chaque utilisateur (figure IV.16). En usage normal, cette fenêtre per-
met de mettre en relief la complexité moyenne des opérations élémentaires. En
mode tests, elle indique les variations de temps pour des requêtes similaires
ou de complexité donnée.
– Le temps d’exécution des opérations (figure IV.17) présente la courbe inverse
de la précédente. Elle permet de suivre plus directement l’évolution des temps
d’exécution. Il pourrait paraître plus judicieux de présenter le temps d’exécu-
tion par requête. Cependant, cette fenêtre ayant jusqu’ici été utilisée dans le

3. COMPOSANT SERVEUR 129
FIG. IV.14 – Visualisation de la charge des calculateurs
FIG. IV.15 – Temps total d’exécution pour différents utilisateurs
cadre de nos tests, nous connaissions la liste des opérations élémentaires de
chaque requête, et nous pouvions donc en déduire la durée de chaque requête.
Nous pouvons noter, dans les exemples des deux derniers cas, que les temps
observés sont relativement stables au milieu de la courbe et plus variés à chaque
extrémité. Ceci provient des temps de mise en place de chaque utilisateur.
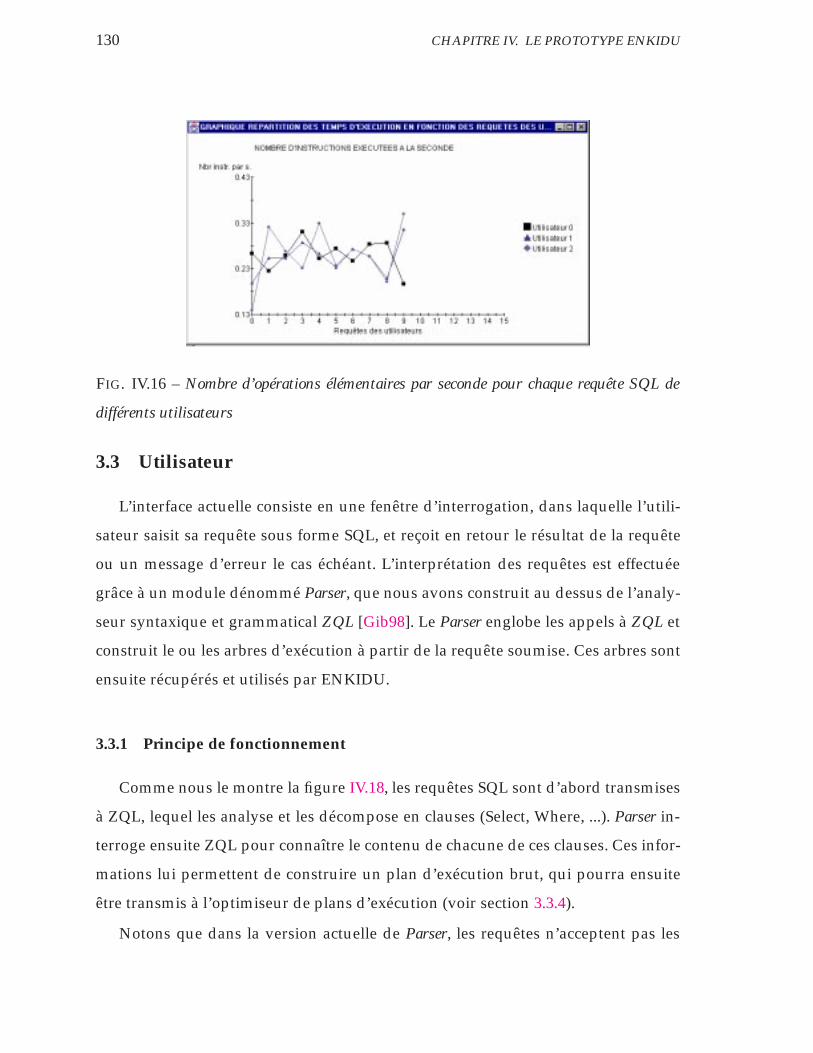
130 CHAPITRE IV. LE PROTOTYPE ENKIDU
FIG. IV.16 – Nombre d’opérations élémentaires par seconde pour chaque requête SQL de
différents utilisateurs
3.3 Utilisateur
L’interface actuelle consiste en une fenêtre d’interrogation, dans laquelle l’utili-
sateur saisit sa requête sous forme SQL, et reçoit en retour le résultat de la requête
ou un message d’erreur le cas échéant. L’interprétation des requêtes est effectuée
grâce à un module dénommé Parser, que nous avons construit au dessus de l’analy-
seur syntaxique et grammatical ZQL [Gib98]. Le Parser englobe les appels à ZQL et
construit le ou les arbres d’exécution à partir de la requête soumise. Ces arbres sont
ensuite récupérés et utilisés par ENKIDU.
3.3.1 Principe de fonctionnement
Comme nous le montre la figure IV.18, les requêtes SQL sont d’abord transmises
à ZQL, lequel les analyse et les décompose en clauses (Select, Where, ...). Parser in-
terroge ensuite ZQL pour connaître le contenu de chacune de ces clauses. Ces infor-
mations lui permettent de construire un plan d’exécution brut, qui pourra ensuite
être transmis à l’optimiseur de plans d’exécution (voir section 3.3.4).
Notons que dans la version actuelle de Parser, les requêtes n’acceptent pas les
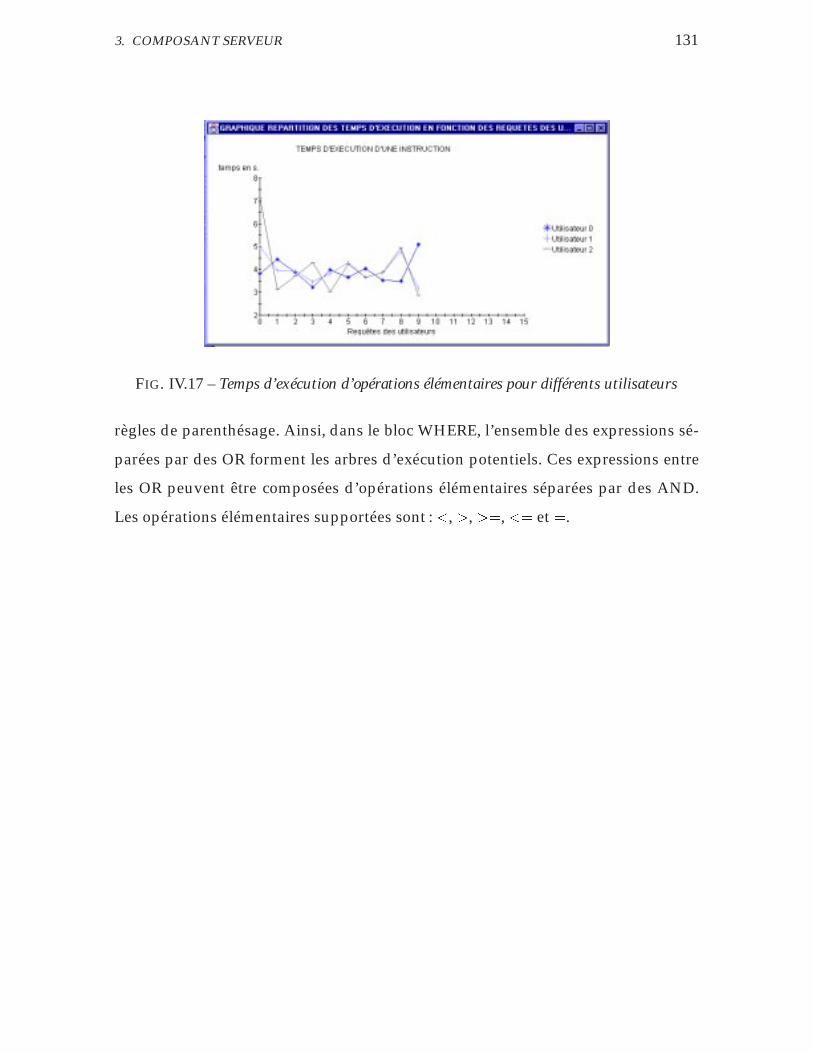
3. COMPOSANT SERVEUR 131
FIG. IV.17 – Temps d’exécution d’opérations élémentaires pour différents utilisateurs
règles de parenthésage. Ainsi, dans le bloc WHERE, l’ensemble des expressions sé-
parées par des OR forment les arbres d’exécution potentiels. Ces expressions entre
les OR peuvent être composées d’opérations élémentaires séparées par des AND.
Les opérations élémentaires supportées sont : <, >, >=, <= et =.

132 CHAPITRE IV. LE PROTOTYPE ENKIDU
FIG. IV.18 – Schéma de principe du Parser
3.3.2 Présentation de ZQL
ZQL [Gib98] reçoit en entrée un flot de données. Il décompose ce flot en blocs
comme suit :
– le bloc SELECT : La méthode pour récupérer ses expressions est : getSelect()
renvoyant un vecteur contenant la liste des attributs sélectionnés ;
– le bloc FROM : La méthode pour extraire les expressions de ce bloc est : get-
From() renvoyant un vecteur contenant la liste des tables (et alias) utilisés ;
– le bloc WHERE : La méthode pour extraire les expressions de ce bloc, est :
getWhere() renvoyant un type ZExpression.
ZExpression constitue en réalité un type récursif. Une ZExpression contient un
opérateur et un vecteur d’opérandes. Les opérandes peuvent être de type Zcons-
tant (condition finale, attribut, valeur numérique...), ZQueries (select imbriqué) ou

3. COMPOSANT SERVEUR 133
ZExpression (définition récursive des opérandes). L’opérateur, suivant le type des
opérandes pourra être de type logique (AND, OR), arithmétique (=, <, ...) ou en-
sembliste (IN,...).
L’exemple de la figure IV.19 illustre la décomposition d’une clause Where en ZEx-
pressions.
Notons que le cas des ZQueries n’est pas traité dans cette première version de
l’interpréteur (i.e. nous ne traitons pas les requêtes imbriquées).
=
a
b
=
a
c
=
b
c
d
=
a+b
a
c
+b
=
+
a
b
SELECT ... WHERE a=c AND b=c OR d=a+b AND b=a+c
OR
a=b
a=c AND b=c
d=a+b AND b=a+c
AND
a=c
a+c
b=c
AND
d=a+b
b=a+c
FIG. IV.19 – Décomposition d’une clause Where par ZQL
3.3.3 Interpréteur
L’interpréteur construit un arbre d’exécution à partir des informations fournies
par ZQL. L’architecture de cet arbre est présentée à la figure IV.20. La classe Que-
ryTree correspond à la racine de l’arbre généré ainsi qu’aux sous-arbres. Chaque
noeud de l’arbre appartient à la classe QueryNode. Un QueryNode peut décrire
une opération (unaire ou binaire) ou une connexion entre deux sous-arbres (AND,
OR). Dans le cas d’une connexion entre sous-arbres, le noeud renvoie à deux Query-

134 CHAPITRE IV. LE PROTOTYPE ENKIDU
Trees. Dans le cas d’une opération, les opérandes sont indiqués à l’aide de la classe
ConditionElem.
FIG. IV.20 – Architecture de l’arbre d’exécution
Les principaux services de cet arbre binaire sont :
1. constructions des noeuds OR (préparation à l’accueil des sous arbres d’exécu-
tion) ;
2. ajout d’un noeud OR ;
3. insertion d’un noeud de type jointure ;
4. insertion d’un noeud de type sélection ;
5. insertion d’un noeud de type projection ;
6. recherche d’un sous arbre ;
7. recherche des feuilles d’un arbre ayant un type précis (jointure, node, selec-
tion) et touchant une table donnée ;
8. construction des requêtes présentes dans ENKIDU. La méthode retourne une
liste de requêtes.

3. COMPOSANT SERVEUR 135
L’arbre d’exécution se construit alors à partir de la racine (une jointure, sauf cas
particulier d’une simple sélection) jusqu’aux feuilles (jointure ou sélection). Il est
possible d’associer une projection à chaque noeud (c’est-à-dire avec une jointure ou
une sélection).
Dans une requête, plusieurs ensembles de conditions peuvent aboutir à la pro-
jection des attributs résultats. Les différents groupes d’expressions séparés par des
OR peuvent devenir des arbres. C’est pour cela que nous avons choisi d’utiliser les
arbres binaires : en se basant sur les classes QueryTree, QueryNode et Node pour
chaque noeud de l’arbre.
FIG. IV.21 – Mode d’insertion des noeuds OR
FIG. IV.22 – Illustration de l’insertion des noeuds OR
L’insertion des différents sous-arbres (connectés par des OR) se fait par remplis-
sage de niveaux, comme indiqué sur les figures IV.21 et IV.22. Les connections de

136 CHAPITRE IV. LE PROTOTYPE ENKIDU
type (AND) sont pour leur part linéarisées, en faisant en sorte que deux jointures
consécutives possèdent une table en commun.
La figure IV.23 présente un exemple d’arbre généré par une requête SQL.
3.3.4 Optimiseur de plans d’exécution parallèle
L’optimiseur de plans d’exécution parallèle est en cours d’implantation. Cet élé-
ment n’a pas été développé par nos soins. Il s’agit du prototype ModParOpt réalisé
par H. Kosch durant sa thèse [Kos97a]. ModParOpt (Modular Parallel query Opti-
mizer) est un optimiseur modulaire adapté aux requêtes complexes et manipulant
de gros volumes de données. Il est constitué de modules statiques et dynamiques
(voir figure IV.24).
Les modules statiques sont le gestionnaire de distribution, le dictionnaire de données
et le gestionnaire de coût. Le gestionnaire de distribution et le dictionnaire de données sont
remplacés, dans ENKIDU, par le gestionnaire de redistribution.
Le gestionnaire de coût permet d’estimer l’efficacité des opérations du plan d’exécu-
tion parallèle. Il contient une ensemble de fonctions de coût ainsi que des informa-
tions sur les capacités du réseau et des nœuds de calcul ; dans la version actuelle
d’ENKIDU, ce module est intégré tel quel et contient des indications statiques. Un
composant supplémentaire, le gestionnaire d’informations temporaires, gère les infor-
mations concernant les résultats intermédiaires et leur fragmentation.
Les modules dynamiques sont le gestionnaire de transformation, le gestionnaire de
ressources et l’optimiseur de jointures
Le gestionnaire de transformation se charge de modifier le plan d’exécution parallèle
(PEP) jusqu’à obtention d’un plan de bonne qualité. Il communique avec le ges-
tionnaire de ressources, afin que celui-ci lui indique le degré optimal de parallélisme
intra-opération de chaque étape du plan d’exécution parallèle, ainsi que les nœuds
utilisés pour ce faire. Le gestionnaire de ressources, pour fournir de telles informations,
s’appuie sur les algorithmes de jointure suggérés par l’optimiseur de jointure.
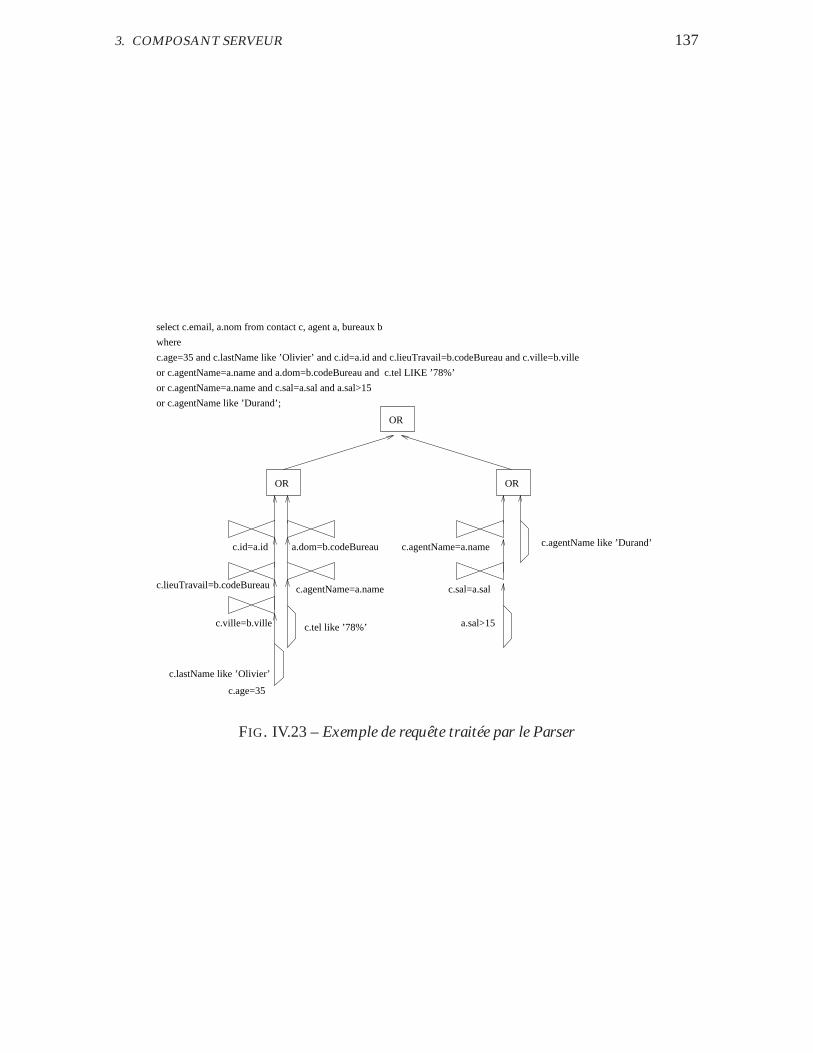
3. COMPOSANT SERVEUR 137
OR OR
OR
select c.email, a.nom from contact c, agent a, bureaux b
where
or c.agentName=a.name and a.dom=b.codeBureau and c.tel LIKE ’78%’
or c.agentName=a.name and c.sal=a.sal and a.sal>15
or c.agentName like ’Durand’;
c.age=35 and c.lastName like ’Olivier’ and c.id=a.id and c.lieuTravail=b.codeBureau and c.ville=b.ville
c.id=a.id
c.lieuTravail=b.codeBureau
c.ville=b.ville
c.lastName like ’Olivier’
c.age=35
c.agentName=a.name
a.dom=b.codeBureau
c.tel like ’78%’
c.agentName=a.name
c.sal=a.sal
a.sal>15
c.agentName like ’Durand’
FIG. IV.23 – Exemple de requête traitée par le Parser
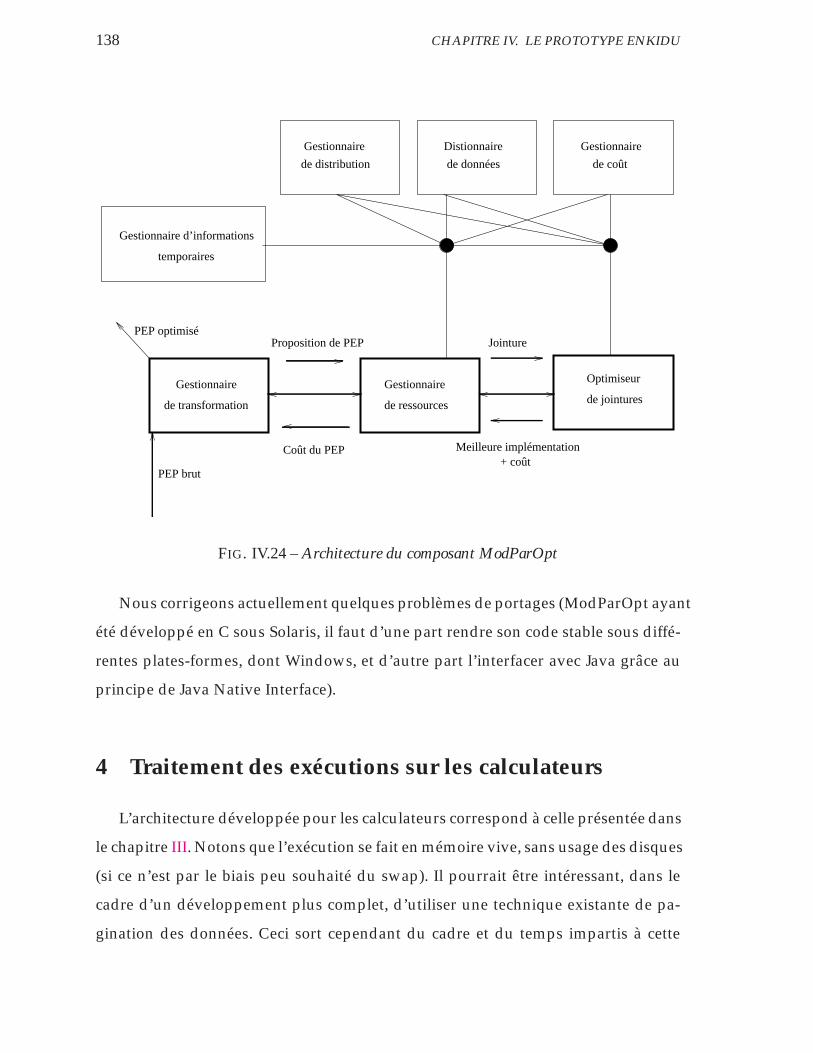
138 CHAPITRE IV. LE PROTOTYPE ENKIDU
de coût
GestionnaireDistionnaire
de donnéesde distribution
Gestionnaire
de ressources
GestionnaireGestionnaire
de transformation
Optimiseur
de jointures
Gestionnaire d’informations
temporaires
Jointure
PEP brut
PEP optimiséProposition de PEP
Meilleure implémentation+ coût
Coût du PEP
FIG. IV.24 – Architecture du composant ModParOpt
Nous corrigeons actuellement quelques problèmes de portages (ModParOpt ayant
été développé en C sous Solaris, il faut d’une part rendre son code stable sous diffé-
rentes plates-formes, dont Windows, et d’autre part l’interfacer avec Java grâce au
principe de Java Native Interface).
4 Traitement des exécutions sur les calculateurs
L’architecture développée pour les calculateurs correspond à celle présentée dans
le chapitre III. Notons que l’exécution se fait en mémoire vive, sans usage des disques
(si ce n’est par le biais peu souhaité du swap). Il pourrait être intéressant, dans le
cadre d’un développement plus complet, d’utiliser une technique existante de pa-
gination des données. Ceci sort cependant du cadre et du temps impartis à cette

4. TRAITEMENT DES EXÉCUTIONS SUR LES CALCULATEURS 139
thèse. Il est de plus légitime de s’interroger sur l’opportunité d’utiliser les disques
dans la mesure où le coût des mémoires diminue régulièrement, et où l’introduc-
tion d’architectures 64 bits va conduire progressivement à de très grandes capacités
mémoire.
L’exécution des traitements est confiée, sur chaque calculateur, à un pool de
threads d’exécution. Nous avons retenu ici une solution multi-threads plutôt qu’une
solution de file circulaire, comme celle présentée par [Bou96a]. Cette solution multi-
threads permet de déléguer la synchronisation des traitements concurrents à la ma-
chine virtuelle. En effet, l’ordonnancement et l’équilibrage local des opérations élé-
mentaires a déjà été longuement étudié [Meh93, Ham96], et son implémentation ne
présentait pas d’intérêt particulier dans le cadre de nos recherches. Le nombre de
threads concurrents peut être modifié de façon statique. Il est apparu que dans le
cadre de nos tests, un pool de 4 threads concurrents offrait des performances très
honorables (voir chapitre V). Une telle valeur permet en effet d’assurer la plupart
du temps l’exécution d’une instruction élémentaire si les autres sont bloquées (en
attente de réception de données à consommer). Elle est à l’inverse suffisamment
faible pour éviter les pertes de temps liées à l’ordonnancement des threads d’une
part, et les saturations mémoire liées à de trop gros volumes de résultats intermé-
diaires d’autre part.
Le traitement des exécutions est confié à une file spécifique, qui alimente les
threads d’exécution. Nous avons retenu une solution de type file simple : les opéra-
tions sont traitées par ordre d’arrivée des plans d’exécution, et par ordre de place-
ment dans ces plans. Cette solution particulièrement simple a été retenue pour les
mêmes raisons que celles énoncées plus haut. En effet, l’implantation de techniques
connues aurait nécessité un temps précieux et n’aurait pas apporté d’améliorations
conséquentes dans le cadre de notre proposition. Il reste cependant tout à fait en-
visageable d’introduire une gestion de file améliorée, mettant en jeu des notions de
priorités chronologiques [Ham95, Ham96] et spatiales [Meh93] entre opérateurs.

140 CHAPITRE IV. LE PROTOTYPE ENKIDU
L’exécution d’une opération élémentaire s’effectue suivant le schéma décrit au
chapitre III. La description dynamique de la figure IV.25 explicite (entre autres) cette
exécution.
Une instruction élémentaire InstrElem, après sa réception par le thread CRTCalc, est
placée dans la queue de traitement queueInstr (cette vision simplifie en réalité le
schéma, les instructions élémentaires étant en réalité reçues en groupes – PEP).
Lorsque le thread d’exécution ThreadExecution termine l’exécution d’une instruction
élémentaire, il demande à l’objet ListeInstructions de lui adresser la prochaine ins-
truction élémentaire.
Après une phase d’initialisation, il puise les tuples à traiter dans les files queueRel.
Les lots de tuples résultats pleins sont ensuite transmis à l’objet Distribution, qui ef-
fectue l’envoi des lots (ou le placement en local le cas échéant). Remarquons que
l’appellation “bucket” apparaissant sur ce graphe désigne les lots de tuples.
En fin d’exécution, les tuples produits par l’opération élémentaire sont expédiés
vers leur destinataire. Les tuples destinés à un usage local sont conservés, les autres
détruits. De même, les relations intermédiaires ayant servi d’entrée à une opéra-
tion élémentaires sont détruites (un mécanisme simple permet de déterminer si une
relation constitue une relation source ou un résultat intermédiaire).
5 Accès au SGBD
5.1 principes généraux
Nous décrivons ici les techniques d’extraction et de distribution des données
sous-jacentes aux commandes d’extraction présentées plus haut. Dans notre im-
plantation, l’accès au SGBD se fait grâce au “package” jdbc. Celui-ci constitue la
bibliothèque Java pour cette tâche. Il est à noter que jdbc n’est qu’une trame de des-
cription d’une telle interface, et que les classes réelles sont ensuite spécifiques au
SGBD utilisé. Nous avons ainsi intégré à notre prototype l’implémentation de jdbc
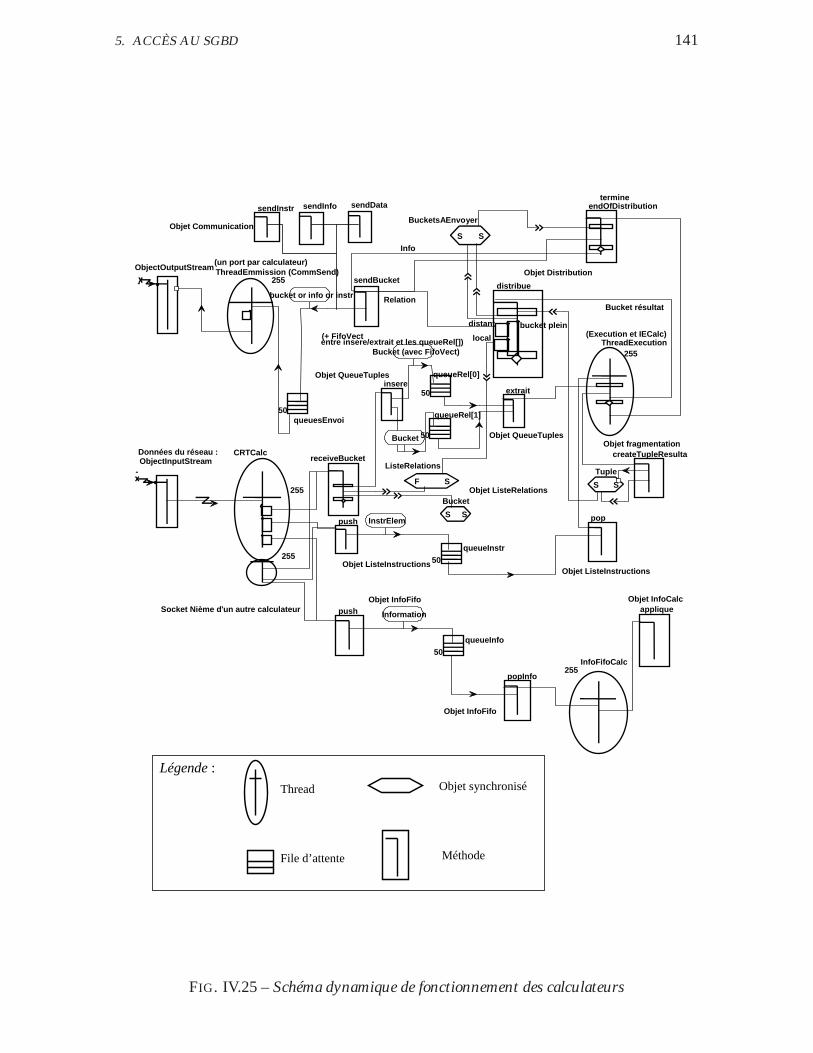
5. ACCÈS AU SGBD 141
F S
S S
S S
S S
ThreadEmmission255
CRTCalc
255
queuesEnvoi50
sendData
bucket or info or instr
sendInstr
(CommSend)sendBucket
ThreadExecution255
queueRel[1]
50
ListeRelationsreceiveBucket
Objet ListeRelations
extrait
termine
distribue
Bucket résultat
InstrElem
(Execution et IECalc)
push pop
BucketsAEnvoyer
Objet Distribution
Bucket
Objet Communication
ObjectInputStream
endOfDistribution
queueRel[0]
Objet ListeInstructions
50
Objet QueueTuples
insere
Données du réseau :
-
Socket Nième d'un autre calculateur
255
createTupleResulta t
Tuple
bucket pleindistant
local
sendInfo
Relation
Info
Objet fragmentation
(un port par calculateur)
queueInfo
50
Objet InfoFifopush
queueInstr
50Objet ListeInstructions
Information
InfoFifoCalc255
Objet InfoFifo
popInfo
appliqueObjet InfoCalc
Objet QueueTuples
entre insere/extrait et les queueRel[])Bucket (avec FifoVect)
Bucket
(+ FifoVect
ObjectOutputStream
-
Légende :
Thread
File d’attente Méthode
Objet synchronisé
FIG. IV.25 – Schéma dynamique de fonctionnement des calculateurs

142 CHAPITRE IV. LE PROTOTYPE ENKIDU
pour Oracle 7.
L’accès au SGBD a lieu en deux circonstances : tout d’abord pour extraire les élé-
ments du dictionnaire de données nous concernant, ensuite télécharger les relations
(ou projections de relations) nécessaires à l’utilisation de l’évaluateur parallèle.
L’extraction du dictionnaire peut être effectuée à l’aide d’une commande spécifique
de jdbc. Toutefois, celle-ci fournit de très amples informations non nécessaires dans
notre cadre. Aussi avons-nous préféré exécuter une requête sur la liste des tables
(SELECT ... FROM TABS) de la base pour cette opération.
Le téléchargement des relations est effectué par application d’une requête sur la
base, puis par mise au format des données ainsi récupérées.
ENKIDU permet d’extraire les tables d’un schéma géré par le SGBD séquen-
tiel existant. Cette distribution consiste à recopier ces tables tout en leur appliquant
un algorithme de partitionnement. Les algorithmes disponibles sont le hachage, la
distribution circulaire et la répartition par intervalles. Ces distributions peuvent en
outre ordonner les tuples suivant un attribut donné (attribut de distribution ou autre
attribut) afin d’accélérer certaines requêtes ultérieures.
Rappelons ici que nous proposons de plus un declustering partiel, c’est-à-dire
une distribution sur un sous-ensemble des machines disponibles (le declustering
total étant une distribution sur l’ensemble des machines disponibles).
La distribution comprend trois actions distinctes : i) l’extraction des données (ou
plus exactement, la demande d’extraction des données adressée au SGBD), ii) leur
conversion au format utilisé par Enkidu, et enfin iii) leur placement sur les calcu-
lateurs. Plusieurs techniques réalisant ces trois opérations sont disponibles, selon
que l’on souhaite ou non distinguer les trois phases, et selon les sites où l’on désire
les réaliser (SGBD, serveur Enkidu, calculateurs Enkidu). Nous avons délibérément
choisi de n’effectuer aucune opération sur la machine hôte du SGBD. Plus exacte-
ment, nous ne souhaitions pas développer un troisième composant pour ENKIDU,
distinct du serveur, qui serait systématiquement placé sur la machine du SGBD. Ce

5. ACCÈS AU SGBD 143
choix permet effectivement de rendre ENKIDU plus portable et surtout utilisable
avec un SGBD situé sur une machine quelconque. Ainsi, le seul cas de cohabitation
SGBD/ENKIDU correspond au cas particulier pour lequel le module serveur est
installé sur la même machine que le SGBD.
De façon synthétique, la fragmentation d’une table peut être menée en une ou
deux phases. La fragmentation en une phase consiste à distribuer directement les
données sur leur site destinataire, c’est-à-dire à introduire le ou les critère(s) de frag-
mentation au sein de la requête d’extraction. La fragmentation en deux phases, elle,
correspond en revanche à une distribution brute et circulaire des données sur les
calculateurs, suivie d’une répartition définitive par application du mécanisme de
fragmentation au niveau des calculateurs. Les points suivants présentent ces deux
approches et leurs différentes variantes, en mettant en avant les avantages et incon-
vénients de chaque technique.
5.2 Approche à une phase
L’approche à une phase (voir figure IV.26) consiste à placer directement les tuples
sur leur site de destination. En d’autres termes, l’extraction des données se fait en
tenant compte des critères de fragmentation. La seule méthode disponible dans ce
cas consiste à émettre une requête d’extraction par calculateur destinataire, c’est-
à-dire à lancer n requêtes concurrentes, n étant le nombre de calculateurs destina-
taires, contenant chacune une condition de sélection correspondant à la fonction de
fragmentation. Dans le cadre de la distribution circulaire, l’approche à une phase
décrite ci-dessus ne présente que peu d’intérêt. Au contraire, le critère de fragmen-
tation consiste dans ce cas à “éparpiller” les tuples, alors que l’approche à une phase
se fonde sur leur regroupement. Nous ne retenons donc pas l’approche à une phase
pour les distributions circulaires.
Concernant la distribution par intervalles, cette approche présente nettement
plus d’intérêt. Il suffit en effet d’indiquer une clause de sélection du type x � A < y,

144 CHAPITRE IV. LE PROTOTYPE ENKIDU
Calculateur n
Calculateur 1Données destinées
au calculateur 1
Données destinées
au calculateur n
SGBD
FIG. IV.26 – Distribution à une phase
A étant la valeur de l’attribut de fragmentation et x et y étant les bornes de l’inter-
valle de valeur destiné au calculateur considéré.
Le hachage peut aussi être réalisé grâce à l’approche en une phase, dans la me-
sure où le critère de hachage peut être exprimé par une fonction de l’attribut de
distribution. En particulier, si cet attribut est numérique, les fonctions de sélection
du langage SQL permettent de couvrir un certain nombre de cas de figure (mo-
dulo, fonctions arithmétiques simples). Les clauses de sélection sont alors de type
f(valeur) = nmodN , avec 0 � n < N , N indiquant le nombre de calculateurs parti-
cipant à la répartition, et n le numéro du calculateur destinataire.
Le tri des données est également réalisable dans la distribution à une phase. Il peut
être effectué soit par intégration d’une clause de tri dans la requête d’extraction
(ordre SQL “ORDER BY”), soit par une sous-phase de tri réalisée sur les calcula-
teurs après réception des tuples.
Techniquement parlant, les calculateurs doivent ici pouvoir utiliser jdbc. Les re-
quêtes sont soumises depuis les calculateurs. La mise au format ENKIDU des tuples
récupérés se fait au niveau du calculateur.
D’un point de vue pratique, l’approche à une phase limite le nombre de mouve-
ments de données, car celles-ci sont directement choisies et acheminées sur leur
calculateur destinataire. En revanche, le volume de travail demandé au SGBD est
assez important, car celui-ci doit effectuer une sélection sur les tables à distribuer
(la distribution présente ici une forte composante séquentielle). Le travail demandé
au SGBD est toutefois modulé par la présence ou non d’index sur l’attribut de frag-

5. ACCÈS AU SGBD 145
mentation.
5.3 Approche à deux phases
La répartition en deux phases (voir Figure IV.27) consiste à dissocier les phases
d’extraction et de placement définitif. Tout d’abord, nous extrayons globalement les
tuples du SGBD existant, et nous leur appliquons ensuite la technique de répar-
tition demandée par l’administrateur. Cette méthode offre davantage de variantes
que l’approche à une phase. Ces variantes peuvent être classées en deux catégories,
comportant une ou deux répartitions.
Extraction
globale définitive
FragmentationFlux de sortie du SGBD Tuples "en vrac" Tuples groupés par destinataire
FIG. IV.27 – Distribution à deux phases
La variante à une répartition consiste à utiliser le même composant pour l’ex-
traction des tuples et leur répartition. En d’autres termes, une machine (serveur ou
calculateur) est choisie pour lancer la requête d’extraction. Elle applique ensuite la
méthode de fragmentation retenue aux tuples qu’elle reçoit du SGBD, et les redi-
rige ainsi directement vers leur destinataire final. A la différence de l’approche à
une phase, où n composants similaires exécutent n sélections sur des intervalles dis-
joints, ici un seul composant effectue une extraction sans sélection et se charge en-
suite d’expédier les tuples vers les n calculateurs destinataires. De même que dans
l’approche à une phase, une bonne partie du traitement est séquentielle.
La phase de répartition définitive peut s’accompagner d’un tri des tuples. Si l’on
choisit d’expédier tous les tuples à leur destinataire en un lot, le tri se fait com-
plètement sur l’intermédiaire ou le destinataire. Avec plusieurs lots (pour limiter
la charge des intermédiaires dûe au stockage temporaire) on peut opérer un tri sur

146 CHAPITRE IV. LE PROTOTYPE ENKIDU
l’intermédiaire et une fusion sur le destinataire ou alors les deux opérations peuvent
être effectuées sur le destinataire. L’avantage du mécanisme de lots consiste à intro-
duire un parallélisme pipeline entre intermédiaire et destinataire, car le tri final peut
commencer avant la fin de l’arrivée des tuples. Il permet également de favoriser les
opérations “pipelinées” décrites à la section 5 du chapitre III.
La variante à deux répartitions consiste à dissocier extraction et répartition dé-
finitive. L’extraction conduit dans ce cas à une répartition brute (les tuples sont ex-
pédiés, dans leur ordre d’extraction, sur un ensemble de sites intermédiaires) sui-
vie d’une répartition définitive (les sites intermédiaires appliquent la méthode de
fragmentation aux tuples qu’ils ont reçus et redirigent ceux-ci vers leur calculateur
destinataire). L’extraction/conversion peut être réalisée sur le serveur ou un calcu-
lateur particulier. La fragmentation se déroule obligatoirement sur les calculateurs.
Ce cas permet de profiter non seulement d’un parallélisme pipeline entre extraction/con-
version d’une part et fragmentation d’autre part, mais offre en outre un parallélisme
intra-opération au sein de la fragmentation, les calculateurs effectuant en parallèle
le traitement des tuples qu’ils ont reçus. L’inconvénient de cette méthode provient
du fait que l’utilisation du réseau est plus intense qu’avec les autres méthodes. En
effet, l’ensemble des données est transmis d’abord au site d’extraction, puis ensuite
retransmis vers les sites de fragmentation. Enfin, les tuples devant être déplacés
(c’est-à-dire ceux qui n’ont pas été placés sur leur site définitif lors de la répartition
brute) sont transmis entre sites. Le volume total de données transférées oscille donc
entre deux et trois fois le volume de données extraites de la base (si l’on considère
que la taille des données est approximativement la même dans les formats avant et
après conversion).
On pourrait en outre proposer d’effectuer une approche à deux phases pour
laquelle différents calculateurs reçoivent un sous-ensemble de la relation puis se
chargent ensuite d’effectuer la répartition définitive. Cette approche ne fait transiter
au plus que 2 fois la taille de la relation. Elle implique cependant de s’assurer que

5. ACCÈS AU SGBD 147
chaque calculateur impliqué traite un sous-ensemble de la relation disjoint de celui
des autres calculateurs, ce qui impose de poser une condition d’extraction dans la re-
quête adressée. Ce cas de figure rappelle l’approche à une phase, mais s’avère plus
coûteux de part la nécessité d’effectuer une fragmentation définitive. Cette tech-
nique n’est donc pas retenue.
Nous présentons des mesures d’efficacité, pour ces différentes techniques, au
chapitre V.

148 CHAPITRE IV. LE PROTOTYPE ENKIDU

149
Chapitre V
Tests
1 Paramétrage d’ENKIDU
1.1 Extraction des tuples
Nos expérimentations de chargement ont été menées avec ENKIDU fonctionnant
sur 3 PC (un serveur + 2 calculateurs) de type pentium (P166MMX) sous Windows
95. Le SGBD était Oracle 7 et fonctionnait sur une machine Bull Estrella (PowerPC)
sous AIX. Les caractéristiques de la base chargée, ou plus exactement de la projec-
tion de cette base (tous les champs d’origine n’étant pas retenus pour ce test) sont
décrites dans le tableau V.1. La base était indexée sur les différents attributs de frag-
mentation. Chaque relation était fragmentée par intervalles sur les calculateurs en 2
morceaux de taille égale. Précisons que cette base consitue la version étendue de la
base de médicaments Claude Bernard décrite en section 2.3.
Dans cette base, les attributs numériques ont une taille de 22 octets, et les attributs
textes une taille de 50 octets, ce qui nous conduit à une taille théorique de 56 Mo. Ce-
pendant, la plupart des attributs ayant une taille inférieure à ce maximum, la taille
réelle de la base s’avère être de l’ordre de 30 Mo.
Les temps de chargement obtenus varient du simple au double, au profit très net
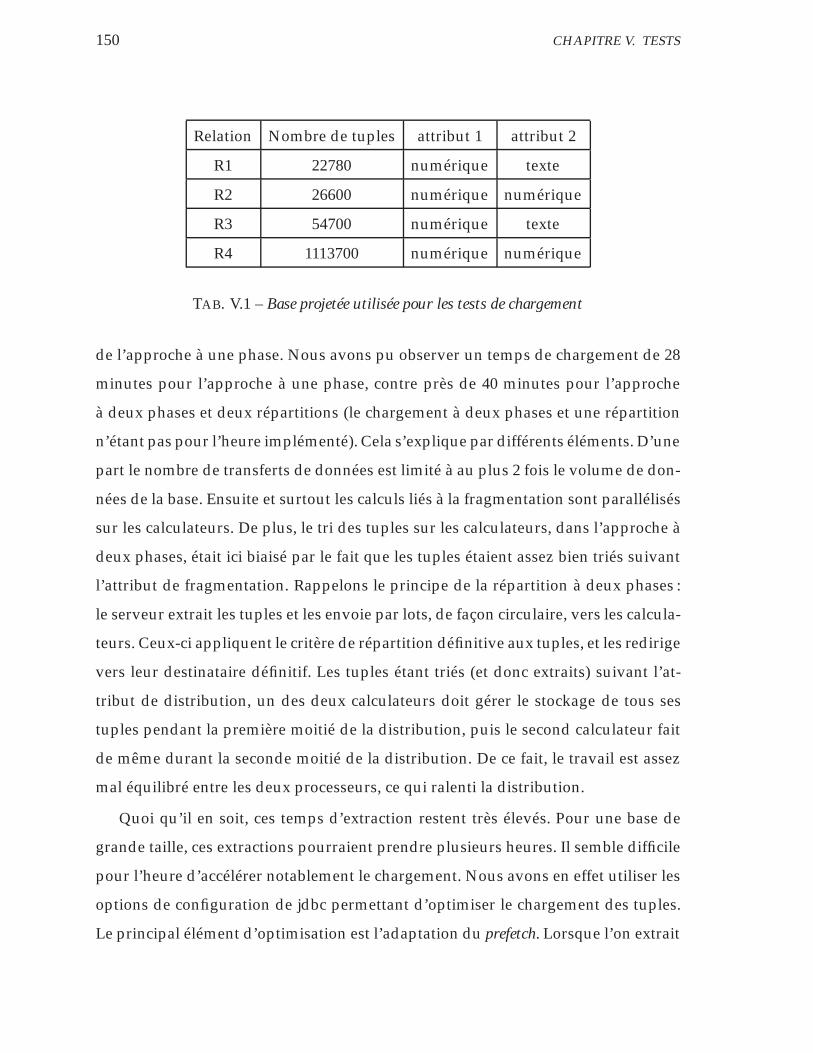
150 CHAPITRE V. TESTS
Relation Nombre de tuples attribut 1 attribut 2
R1 22780 numérique texte
R2 26600 numérique numérique
R3 54700 numérique texte
R4 1113700 numérique numérique
TAB. V.1 – Base projetée utilisée pour les tests de chargement
de l’approche à une phase. Nous avons pu observer un temps de chargement de 28
minutes pour l’approche à une phase, contre près de 40 minutes pour l’approche
à deux phases et deux répartitions (le chargement à deux phases et une répartition
n’étant pas pour l’heure implémenté). Cela s’explique par différents éléments. D’une
part le nombre de transferts de données est limité à au plus 2 fois le volume de don-
nées de la base. Ensuite et surtout les calculs liés à la fragmentation sont parallélisés
sur les calculateurs. De plus, le tri des tuples sur les calculateurs, dans l’approche à
deux phases, était ici biaisé par le fait que les tuples étaient assez bien triés suivant
l’attribut de fragmentation. Rappelons le principe de la répartition à deux phases :
le serveur extrait les tuples et les envoie par lots, de façon circulaire, vers les calcula-
teurs. Ceux-ci appliquent le critère de répartition définitive aux tuples, et les redirige
vers leur destinataire définitif. Les tuples étant triés (et donc extraits) suivant l’at-
tribut de distribution, un des deux calculateurs doit gérer le stockage de tous ses
tuples pendant la première moitié de la distribution, puis le second calculateur fait
de même durant la seconde moitié de la distribution. De ce fait, le travail est assez
mal équilibré entre les deux processeurs, ce qui ralenti la distribution.
Quoi qu’il en soit, ces temps d’extraction restent très élevés. Pour une base de
grande taille, ces extractions pourraient prendre plusieurs heures. Il semble difficile
pour l’heure d’accélérer notablement le chargement. Nous avons en effet utiliser les
options de configuration de jdbc permettant d’optimiser le chargement des tuples.
Le principal élément d’optimisation est l’adaptation du prefetch. Lorsque l’on extrait
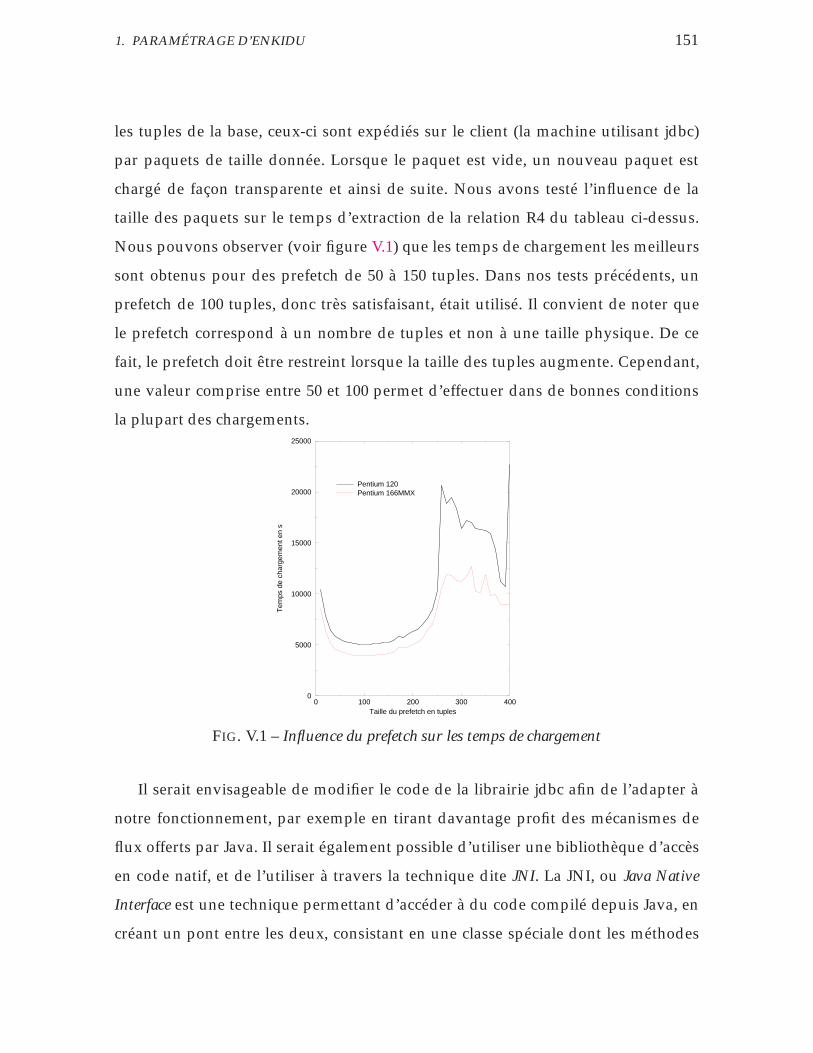
1. PARAMÉTRAGE D’ENKIDU 151
les tuples de la base, ceux-ci sont expédiés sur le client (la machine utilisant jdbc)
par paquets de taille donnée. Lorsque le paquet est vide, un nouveau paquet est
chargé de façon transparente et ainsi de suite. Nous avons testé l’influence de la
taille des paquets sur le temps d’extraction de la relation R4 du tableau ci-dessus.
Nous pouvons observer (voir figure V.1) que les temps de chargement les meilleurs
sont obtenus pour des prefetch de 50 à 150 tuples. Dans nos tests précédents, un
prefetch de 100 tuples, donc très satisfaisant, était utilisé. Il convient de noter que
le prefetch correspond à un nombre de tuples et non à une taille physique. De ce
fait, le prefetch doit être restreint lorsque la taille des tuples augmente. Cependant,
une valeur comprise entre 50 et 100 permet d’effectuer dans de bonnes conditions
la plupart des chargements.
0 100 200 300 400Taille du prefetch en tuples
0
5000
10000
15000
20000
25000
Tem
ps d
e ch
arge
men
t en
s
Pentium 120Pentium 166MMX
FIG. V.1 – Influence du prefetch sur les temps de chargement
Il serait envisageable de modifier le code de la librairie jdbc afin de l’adapter à
notre fonctionnement, par exemple en tirant davantage profit des mécanismes de
flux offerts par Java. Il serait également possible d’utiliser une bibliothèque d’accès
en code natif, et de l’utiliser à travers la technique dite JNI. La JNI, ou Java Native
Interface est une technique permettant d’accéder à du code compilé depuis Java, en
créant un pont entre les deux, consistant en une classe spéciale dont les méthodes

152 CHAPITRE V. TESTS
appellent les fonctions du programme en langage natif. Dans l’optique de notre ex-
tension, cela introduit des problèmes de portabilité, envisageable dans la mesure où
ENKIDU devrait être réécrit en langage compilé.
Nous avons par ailleurs testé les capacités d’extraction de façon plus directe à l’aide
de la bibliothèque Pro-C d’Oracle. Cette bibliothèque permet d’inclure des appels à
Oracle directement dans un programme C. Nous avons donc conçu un programme
de test, en C, se contentant de charger la même projection qu’ENKIDU. Ce test se
contente de lancer les requêtes d’extraction et de récupérer les tuples, sans les sto-
cker (dès qu’un tuple est extrait, il est supprimé). Ce programme a été lancé direc-
tement sur la machine hôte du SGBD, de façon à ne pas avoir de coût réseau. Le
temps d’extraction observé était alors de 21 minutes, ce qui est similaire aux temps
obtenus avec ENKIDU.
L’amélioration des temps de chargement pourrait sans doute constituer une étude
technique intéressante dans le cadre de recherches futures. Il pourrait par exemple
être envisagé d’extraire les relations et de les stocker sur des fichiers en mode batch
(éventuellement en appliquant la répartition à ce niveau), puis de charger ces fi-
chiers directement sur l’extension. Cette solution n’améliorerait pas le temps d’ex-
traction mais pourrait restreindre le temps de chargement. Une autre solution consis-
terait à accéder directement aux fichiers du SGBD. Cependant, cette solution nuit à
la portabilité et s’avère particulièrement technique.
1.2 Sérialisation des données transférées
1.2.1 Rappel
Nous avons présenté, au chapitre IV, les techniques de communication utilisées,
et avons entre autre insisté sur le fait que les techniques de sérialisation transpa-
rente offertes par Java présentaient d’assez médiocres performances. Nous avons
de ce fait développé une technique de sérialisation moins transparente mais plus
simple et plus efficace. La technique utilisée consiste à introduire deux méthodes

1. PARAMÉTRAGE D’ENKIDU 153
(sérialisation+reconstitution) dans les classes d’objets “transférables”, afin de limi-
ter la quantité d’information devant être transmise.
Nous donnons ici un exemple d’efficacité de notre technique.
1.2.2 Mesures
Pour ce test, nous avons transmis un lot de données constitué comme suit. Chaque
tuple est un tableau d’objets à deux entrées. La première entrée est un entier, la se-
conde la représentation textuelle de cet entier. Les tuples ainsi définis sont regroupés
dans un tableau dynamique (Vector) constituant le lot de données (voir figure V.2).
Une telle architecture permet d’obtenir un objet composite de taille raisonnable. Le
nombre de tuples contenu dans un lot varie ici de 50 à 250.
0 (entier)0(chaîne)
1 (entier)1 (chaîne)
n-1 (entier)n-1 (chaîne)
Lot de tuples tuples attributs
FIG. V.2 – Structure des lots de données utilisés pour le test de transfert
Le lot de données est transféré d’un émetteur vers un récepteur, puis retransmis
immédiatement à l’émetteur (ping-pong). Ce cycle est effectué 100 fois afin d’ob-
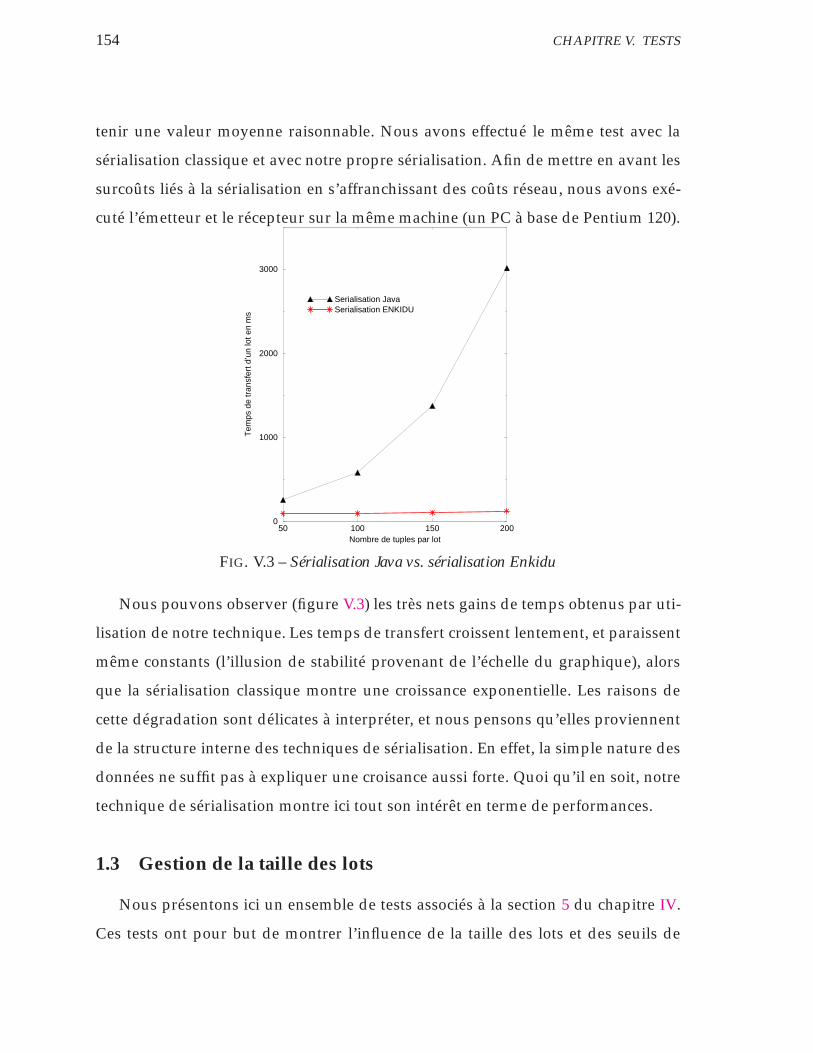
154 CHAPITRE V. TESTS
tenir une valeur moyenne raisonnable. Nous avons effectué le même test avec la
sérialisation classique et avec notre propre sérialisation. Afin de mettre en avant les
surcoûts liés à la sérialisation en s’affranchissant des coûts réseau, nous avons exé-
cuté l’émetteur et le récepteur sur la même machine (un PC à base de Pentium 120).
50 100 150 200Nombre de tuples par lot
0
1000
2000
3000
Tem
ps d
e tr
ansf
ert d
’un
lot e
n m
s
Serialisation JavaSerialisation ENKIDU
FIG. V.3 – Sérialisation Java vs. sérialisation Enkidu
Nous pouvons observer (figure V.3) les très nets gains de temps obtenus par uti-
lisation de notre technique. Les temps de transfert croissent lentement, et paraissent
même constants (l’illusion de stabilité provenant de l’échelle du graphique), alors
que la sérialisation classique montre une croissance exponentielle. Les raisons de
cette dégradation sont délicates à interpréter, et nous pensons qu’elles proviennent
de la structure interne des techniques de sérialisation. En effet, la simple nature des
données ne suffit pas à expliquer une croisance aussi forte. Quoi qu’il en soit, notre
technique de sérialisation montre ici tout son intérêt en terme de performances.
1.3 Gestion de la taille des lots
Nous présentons ici un ensemble de tests associés à la section 5 du chapitre IV.
Ces tests ont pour but de montrer l’influence de la taille des lots et des seuils de

1. PARAMÉTRAGE D’ENKIDU 155
transfert sur l’exécution d’opérations “pipelinées”, ainsi que de valider les heuris-
tiques proposées.
Les tests présentés ici ont tous été réalisés sur la machine Popc du Laboratoire d’In-
formatique du Parallélisme (École Normale Supérieure de Lyon). Cette machine,
développée par Matra consiste en un réseau de stations intégré. Des cartes mères de
PC, comportant chacune un processeur Pentium Pro et 64 Mo de mémoire vive, com-
muniquent entre elles à travers une architecture de type réseau local. Deux types de
connexions sont disponibles, le premier consistant en un réseau Ethernet, le second
étant un réseau Myrinet. La machine utilisée comporte douze nœuds, dont un ser-
vant d’interface de connexion à la machine, les autres ne pouvant communiquer
qu’entre eux et avec l’interface.
1.3.1 Influence des seuils pour une répartition propice
Protocole de test Cette première série de tests met en avant l’intérêt des lots de
taille réduite pour les opérations pipelinées. Nous avons utilisé le réseau Ethernet
afin d’obtenir un comportement similaire à celui d’un réseau de stations standard.
Chaque test porte sur un ensemble de jointures “pipelinées”, effectuées chacune
sur des calculateurs différents, afin de maximiser le trafic réseau. Dans la même
optique, nous n’avons pas utilisé de parallélisme intra-opérateur. Ainsi, la première
jointure se déroule sur le site 1, la seconde sur le site 2, etc.
La première jointure se fait entre deux relations R1 et R2 contenant respective-
ment 1000 et 10 000 tuples. L’attribut de jointure présente 10 000 valeurs distinctes
et consécutives dans R2. Dans R1, il présente 1000 valeurs distinctes et espacées de
10. En d’autres termes, les valeurs dans R2 sont 1,2,...,10000, et dans R1 elles sont
1,11,..,9991. La table de hachage est construite sur R1 et le probe se fait sur R2. De
cette façon, une comparaison sur dix produit un tuple résultat. Les lots de données
formant R1 et R2 contiennent 100 tuples. Nous avons retenu cette valeur car elle per-
met un bon découpage de R2 (100 lots). Cette valeur a été conservée pour les autres

156 CHAPITRE V. TESTS
relations ainsi que pour les lots de tuples produits.
Les résultats de cette jointure sont transmis vers le site suivant, où la table de
hachage est bâtie sur une relation similaire à R2, et ainsi de suite. De cette façon,
le biais est surtout géré lors de la première jointure. En effet, dans les opérations
suivantes, la table de hachage est construite sur la plus grande des deux tables, et
la table de probe ne comporte que 1000 tuples, ce qui, même en présence de petits
tuples transmis par l’opération précédente, ne génère que peu de transferts.
Estimation de la taille des lots et du seuil de transfert Notre premier test porte
sur deux jointures pipelinées. Ici, le taux moyen de production de tuples de la pre-
mière jointure est d’un lot produit pour 10 lots traités. Nous avons testé les temps
de réponse avec des seuils variant de 1 à 10, et nous avons exprimé ces temps de ré-
ponse en terme de gain par rapport au temps sans seuil. Notons que le même seuil
est utilisé pour les deux jointures (la seconde retournant ses résultats au serveur).
Les résultats portent sur la moyenne de 100 mesures pour chaque valeur de seuil.
Nous pouvons constater ici que les gains (de l’ordre de 10 pour-cent) sont ob-
tenus pour des valeurs de seuil proches de 5, c’est-à-dire de la moitié du rythme
moyen de production de tuples. Cependant, le gain pour un seuil de 5 est assez
faible. Ceci peut s’expliquer par un effet de “résonnance” entre la purge dûe au seuil
et l’envoi normal de tuples (tous les 10 lots en moyenne). Remarquons également les
mauvaises performances pour un seuil de 1, dûes aux envois trop fréquents.
Le second test porte sur trois jointures pipelinées. Nous avons appliqué le même
principe qu’auparavant (même seuil pour chaque jointure). Cette courbe présente
un profil similaire à la précédente. Les gains sont toutefois plus faibles dans cette
configuration.
Le troisième test (voir figure V.6) porte sur 6 jointures pipelinées, de façon à in-
troduire un effet de cascade plus marqué. Nous pouvons constater ici des gains de
l’ordre de 15 à 20 pourcents pour des seuils proches de R=2. Les dégradations pour
des valeurs de l’ordre de r (nombre moyen de lots traités pour produire un lot ré-
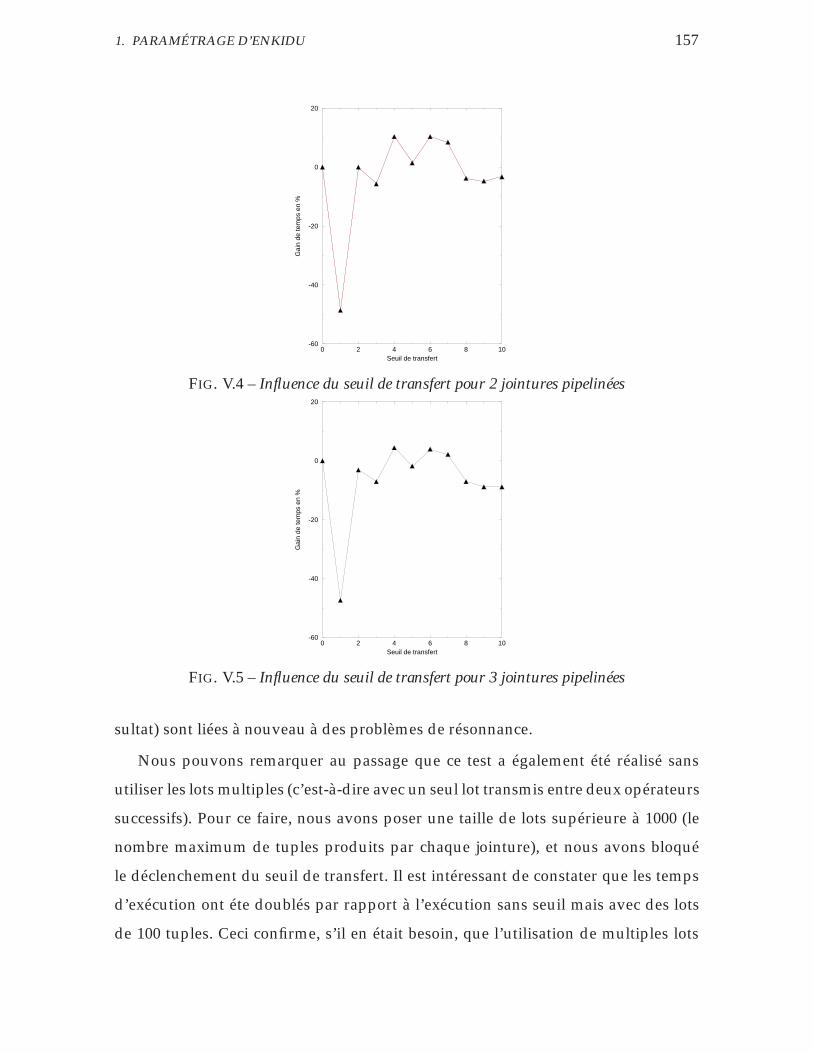
1. PARAMÉTRAGE D’ENKIDU 157
0 2 4 6 8 10Seuil de transfert
-60
-40
-20
0
20
Gai
n de
tem
ps e
n %
FIG. V.4 – Influence du seuil de transfert pour 2 jointures pipelinées
0 2 4 6 8 10Seuil de transfert
-60
-40
-20
0
20
Gai
n de
tem
ps e
n %
FIG. V.5 – Influence du seuil de transfert pour 3 jointures pipelinées
sultat) sont liées à nouveau à des problèmes de résonnance.
Nous pouvons remarquer au passage que ce test a également été réalisé sans
utiliser les lots multiples (c’est-à-dire avec un seul lot transmis entre deux opérateurs
successifs). Pour ce faire, nous avons poser une taille de lots supérieure à 1000 (le
nombre maximum de tuples produits par chaque jointure), et nous avons bloqué
le déclenchement du seuil de transfert. Il est intéressant de constater que les temps
d’exécution ont éte doublés par rapport à l’exécution sans seuil mais avec des lots
de 100 tuples. Ceci confirme, s’il en était besoin, que l’utilisation de multiples lots

158 CHAPITRE V. TESTS
apporte un gain de temps d’exécution considérable.
0 2 4 6 8 10Seuil de transfert
-30
-10
10
30
Gai
n de
tem
ps e
n %
FIG. V.6 – Influence du seuil de transfert pour 6 jointures pipelinées
1.3.2 Influence des seuils pour une répartition non propice
Afin de montrer l’intérêt de la limitation du déclenchement du seuil de transfert,
nous avons utilisé une première jointure différente pour laquelle la technique de
seuil représente plus un inconvénient qu’un avantage.
Pour ce faire, nous avons conservé R1 comme définie précédemment, mais nous
avons modifié R2. Dans ce test, R2 présente un biais de type zipf sur l’attribut de
jointure, avec un coefficient moyen (0,3). De plus, les tuples présentant la même
valeur sur l’attribut de jointure sont consécutifs.
Ce biais va se traduire, durant l’exécution, par une alternance de productions
intenses et de creux assez longs. De ce fait, le seuil de transfert interfère grandement
avec les phases de production, et expédie des lots parfois presque vides. Les autres
paramètres du test n’ont pas été modifiés (les relations présentes sur les sites autres
que le premier restent définies comme dans les tests précédents).
Un élément à prendre en compte ici réside dans le fait que la distribution des
tuples se fait comme suit : les tuples sont créés sur le serveur, envoyés par paquet
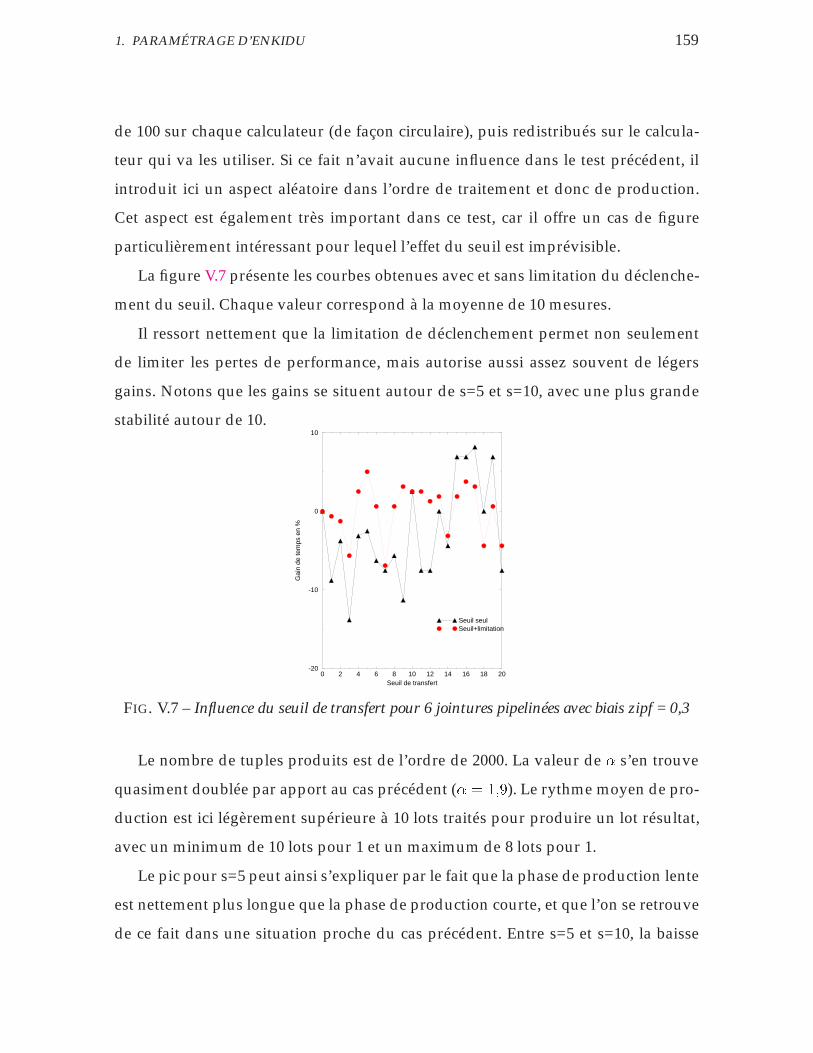
1. PARAMÉTRAGE D’ENKIDU 159
de 100 sur chaque calculateur (de façon circulaire), puis redistribués sur le calcula-
teur qui va les utiliser. Si ce fait n’avait aucune influence dans le test précédent, il
introduit ici un aspect aléatoire dans l’ordre de traitement et donc de production.
Cet aspect est également très important dans ce test, car il offre un cas de figure
particulièrement intéressant pour lequel l’effet du seuil est imprévisible.
La figure V.7 présente les courbes obtenues avec et sans limitation du déclenche-
ment du seuil. Chaque valeur correspond à la moyenne de 10 mesures.
Il ressort nettement que la limitation de déclenchement permet non seulement
de limiter les pertes de performance, mais autorise aussi assez souvent de légers
gains. Notons que les gains se situent autour de s=5 et s=10, avec une plus grande
stabilité autour de 10.
0 2 4 6 8 10 12 14 16 18 20Seuil de transfert
-20
-10
0
10
Gai
n de
tem
ps e
n %
Seuil seulSeuil+limitation
FIG. V.7 – Influence du seuil de transfert pour 6 jointures pipelinées avec biais zipf = 0,3
Le nombre de tuples produits est de l’ordre de 2000. La valeur de � s’en trouve
quasiment doublée par apport au cas précédent (� = 1;9). Le rythme moyen de pro-
duction est ici légèrement supérieure à 10 lots traités pour produire un lot résultat,
avec un minimum de 10 lots pour 1 et un maximum de 8 lots pour 1.
Le pic pour s=5 peut ainsi s’expliquer par le fait que la phase de production lente
est nettement plus longue que la phase de production courte, et que l’on se retrouve
de ce fait dans une situation proche du cas précédent. Entre s=5 et s=10, la baisse

160 CHAPITRE V. TESTS
de performance s’explique par la répartition aléatoire des traitements, qui implique
qu’en se rapprochant de r, on risque de déclencher des purges malvenues malgré la
limitation des effets de bord. A partir de r (r=10), et légèrement au-delà, la limitation
remplit mieux son rôle, car les envois “naturels” de tuples ont davantage de chances
de précéder les purges.
La dégradation pour s=14 semble indiquer une harmonique de la dégradation
pour s=7. Enfin, les dégradations ponctuelles observées pour s=18 et s=20 corres-
pondent à une perte d’efficacité de la purge pour des valeurs trop supérieures à
r.
En conclusion, l’utilisation de seuils de transfert apporte un gain non négligeable
lorsque la production de tuples s’avère plus irrégulière et moins importante que pré-
vue. Si la production des tuples est suffisament forte (du moins pendant une partie
de l’opération) pour entrer en conflit avec les seuils de transfert, alors la limitation
du déclenchement de ceux-ci permet de limiter les interférences, et même d’obtenir
de légers gains. Les seuils de transferts constituent donc une optimisation intéres-
sante lors de l’utilisation d’un macro-pipeline entre opérateurs successifs.
2 Performances d’ENKIDU
2.1 Speed-up
Une des premières caractéristiques à vérifier pour notre extension consiste à
contrôler le speed-up du système pour des opérations simples. Les tests de speed-up
sont effectués sur la machine Popc. Pour des raisons techniques (nœuds défaillants)
nos tests portent sur une extension parallèle comportant jusqu’à huit nœuds de type
Pentium Pro (le nœud de connexion étant utilisé comme hôte du composant ser-
veur).
Les jointures testées ne présentent pas de biais. Elles mettent en jeu deux tables
R1 et R2, de cardinalité kR1k et kR2k, avec kR1k � kR2k. Un tuple de R1 se joint

2. PERFORMANCES D’ENKIDU 161
avec exactement un tuple de R2, et un tuple de R2 se joint avec au plus un tuple de
R1. On obtient donc kR1k tuples résultats. L’exécution se fait par hash-join (hachage
simple), le speed-up standard d’une telle opération étant linéaire.
Nous exécutons cette jointure sur la machine Popc, avec un à huit calculateurs,
et pour un, cinq, et dix utilisateurs simultanés. Les cardinalités des tables sont 100 et
100000 tuples, les tuples des deux tables étant composés de deux attributs de type
entier. Les communications sont effectuées à travers le réseau Myrinet de la machine
Popc.
Dans l’ensemble, le speed-up obtenu (voir figure V.8) est légèrement supérieur
au speed-up linéaire. Le speed-up pour un utilisateur s’avère dans l’ensemble le
moins efficace, les meilleures valeurs étant obtenues ici pour 5 utilisateurs. Ceci
s’explique par le fait que les calculateurs étaient, pour ce test, configurés pour trai-
ter quatre opérations élémentaires de façon simultanées (le degré de concurrence,
sur chaque calculateur, est de 4). Autoriser plusieurs opérations concurrentes per-
met d’utiliser les délais d’exécution induits par les temps de transfert des résultats.
Si le nombre d’opérations simultanées est inférieur au degré de concurrence, on
risque de sous-utiliser les capacités de traitement des calculateurs. Si, en revanche,
le nombre d’opérations élémentaires simultanées est supérieur au degré de concur-
rence, les opérations surnuméraires sont placés en file d’attente, ce qui allonge le
temps de traitement moyen. D’autre part, le degré de concurrence ne peut pas être
trop élevé, car on risque alors de saturer les capacités mémoire du système par ac-
cumulation de résultats intermédiaires. Le meilleur rendement pour la configura-
tion utilisée est donc obtenu pour quatre opérations simultanées, et dans ce test de
speed up, les requêtes consistent en une seule opération élémentaire (jointure entre
les deux relations). De ce fait les valeurs proches de quatre utilisateurs simultanés
offrent les meilleures performances.
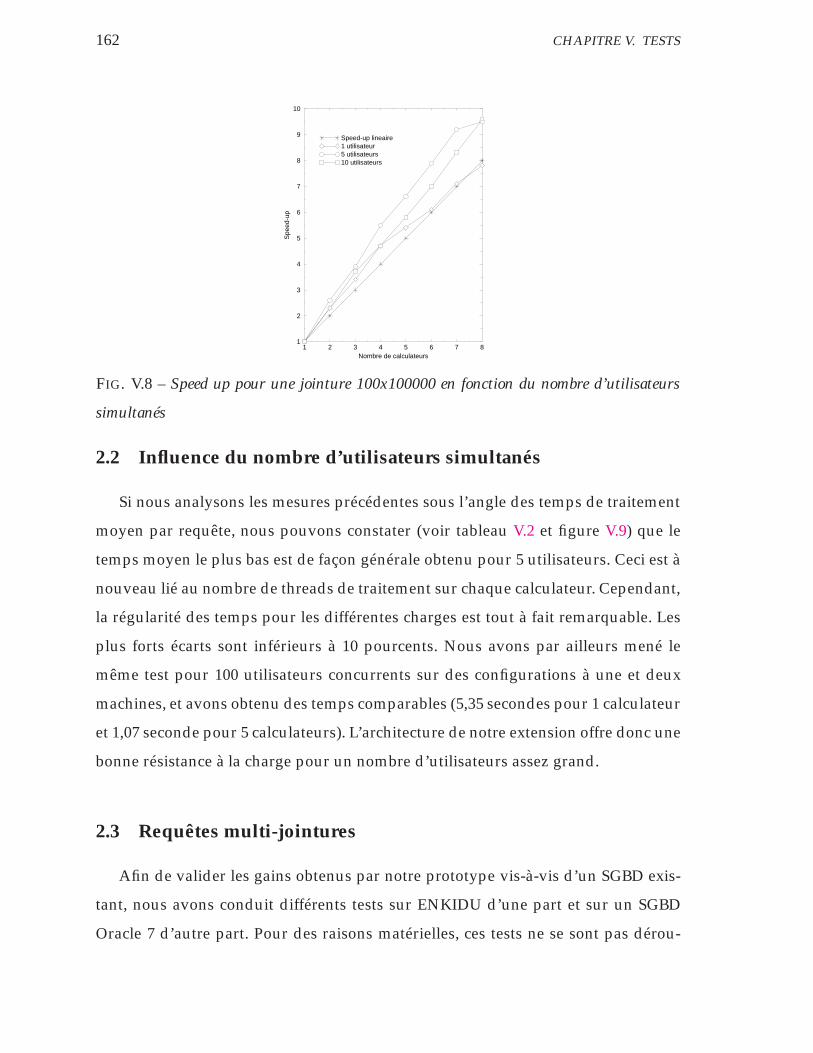
162 CHAPITRE V. TESTS
1 2 3 4 5 6 7 8Nombre de calculateurs
1
2
3
4
5
6
7
8
9
10
Spe
ed-u
p
Speed-up lineaire1 utilisateur5 utilisateurs10 utilisateurs
FIG. V.8 – Speed up pour une jointure 100x100000 en fonction du nombre d’utilisateurs
simultanés
2.2 Influence du nombre d’utilisateurs simultanés
Si nous analysons les mesures précédentes sous l’angle des temps de traitement
moyen par requête, nous pouvons constater (voir tableau V.2 et figure V.9) que le
temps moyen le plus bas est de façon générale obtenu pour 5 utilisateurs. Ceci est à
nouveau lié au nombre de threads de traitement sur chaque calculateur. Cependant,
la régularité des temps pour les différentes charges est tout à fait remarquable. Les
plus forts écarts sont inférieurs à 10 pourcents. Nous avons par ailleurs mené le
même test pour 100 utilisateurs concurrents sur des configurations à une et deux
machines, et avons obtenu des temps comparables (5,35 secondes pour 1 calculateur
et 1,07 seconde pour 5 calculateurs). L’architecture de notre extension offre donc une
bonne résistance à la charge pour un nombre d’utilisateurs assez grand.
2.3 Requêtes multi-jointures
Afin de valider les gains obtenus par notre prototype vis-à-vis d’un SGBD exis-
tant, nous avons conduit différents tests sur ENKIDU d’une part et sur un SGBD
Oracle 7 d’autre part. Pour des raisons matérielles, ces tests ne se sont pas dérou-
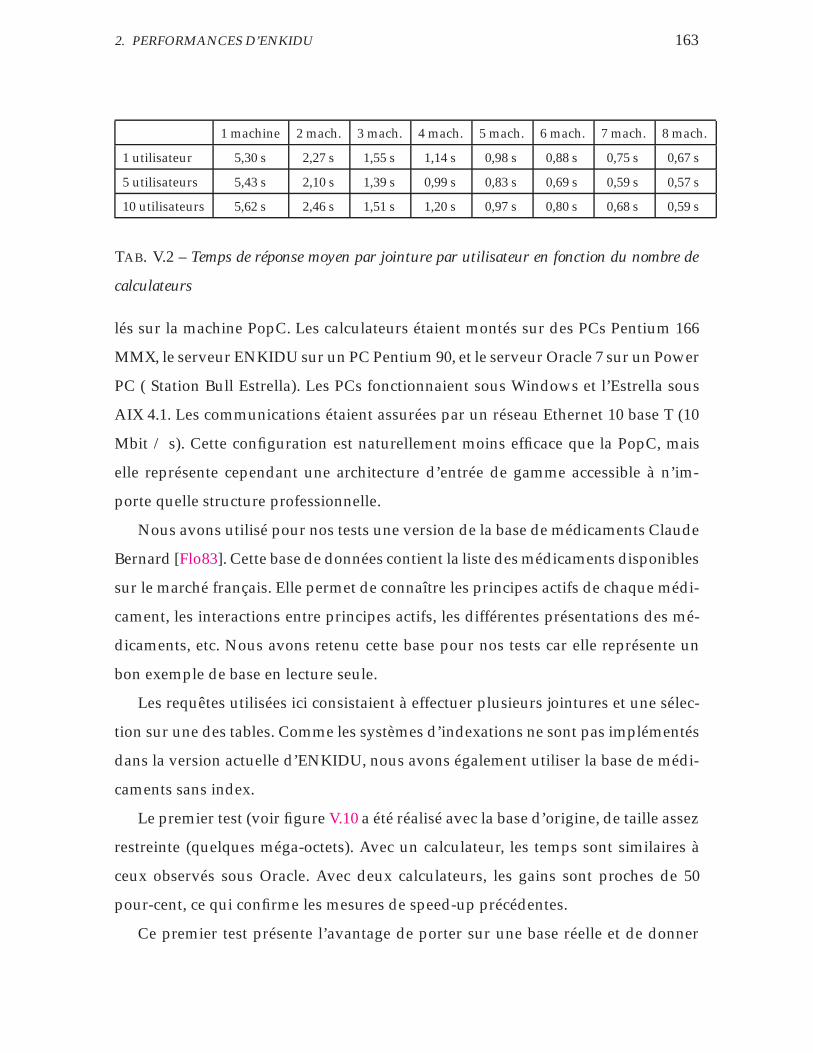
2. PERFORMANCES D’ENKIDU 163
1 machine 2 mach. 3 mach. 4 mach. 5 mach. 6 mach. 7 mach. 8 mach.
1 utilisateur 5,30 s 2,27 s 1,55 s 1,14 s 0,98 s 0,88 s 0,75 s 0,67 s
5 utilisateurs 5,43 s 2,10 s 1,39 s 0,99 s 0,83 s 0,69 s 0,59 s 0,57 s
10 utilisateurs 5,62 s 2,46 s 1,51 s 1,20 s 0,97 s 0,80 s 0,68 s 0,59 s
TAB. V.2 – Temps de réponse moyen par jointure par utilisateur en fonction du nombre de
calculateurs
lés sur la machine PopC. Les calculateurs étaient montés sur des PCs Pentium 166
MMX, le serveur ENKIDU sur un PC Pentium 90, et le serveur Oracle 7 sur un Power
PC ( Station Bull Estrella). Les PCs fonctionnaient sous Windows et l’Estrella sous
AIX 4.1. Les communications étaient assurées par un réseau Ethernet 10 base T (10
Mbit / s). Cette configuration est naturellement moins efficace que la PopC, mais
elle représente cependant une architecture d’entrée de gamme accessible à n’im-
porte quelle structure professionnelle.
Nous avons utilisé pour nos tests une version de la base de médicaments Claude
Bernard [Flo83]. Cette base de données contient la liste des médicaments disponibles
sur le marché français. Elle permet de connaître les principes actifs de chaque médi-
cament, les interactions entre principes actifs, les différentes présentations des mé-
dicaments, etc. Nous avons retenu cette base pour nos tests car elle représente un
bon exemple de base en lecture seule.
Les requêtes utilisées ici consistaient à effectuer plusieurs jointures et une sélec-
tion sur une des tables. Comme les systèmes d’indexations ne sont pas implémentés
dans la version actuelle d’ENKIDU, nous avons également utiliser la base de médi-
caments sans index.
Le premier test (voir figure V.10 a été réalisé avec la base d’origine, de taille assez
restreinte (quelques méga-octets). Avec un calculateur, les temps sont similaires à
ceux observés sous Oracle. Avec deux calculateurs, les gains sont proches de 50
pour-cent, ce qui confirme les mesures de speed-up précédentes.
Ce premier test présente l’avantage de porter sur une base réelle et de donner
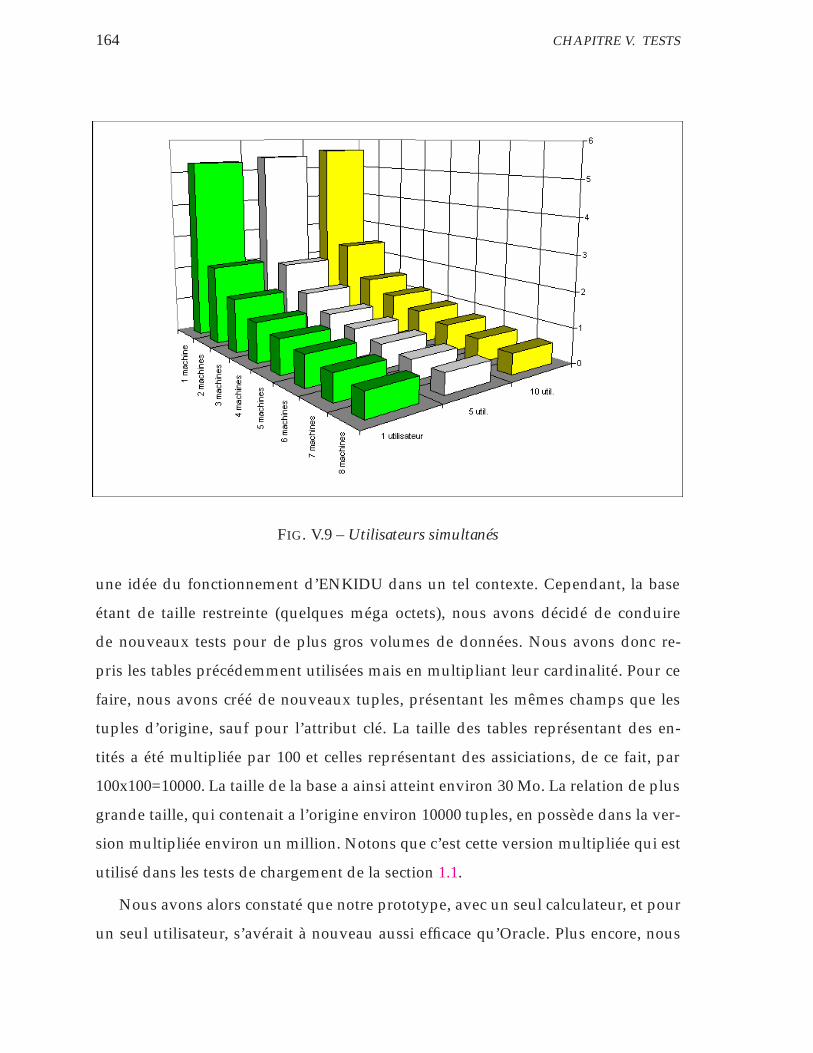
164 CHAPITRE V. TESTS
FIG. V.9 – Utilisateurs simultanés
une idée du fonctionnement d’ENKIDU dans un tel contexte. Cependant, la base
étant de taille restreinte (quelques méga octets), nous avons décidé de conduire
de nouveaux tests pour de plus gros volumes de données. Nous avons donc re-
pris les tables précédemment utilisées mais en multipliant leur cardinalité. Pour ce
faire, nous avons créé de nouveaux tuples, présentant les mêmes champs que les
tuples d’origine, sauf pour l’attribut clé. La taille des tables représentant des en-
tités a été multipliée par 100 et celles représentant des assiciations, de ce fait, par
100x100=10000. La taille de la base a ainsi atteint environ 30 Mo. La relation de plus
grande taille, qui contenait a l’origine environ 10000 tuples, en possède dans la ver-
sion multipliée environ un million. Notons que c’est cette version multipliée qui est
utilisé dans les tests de chargement de la section 1.1.
Nous avons alors constaté que notre prototype, avec un seul calculateur, et pour
un seul utilisateur, s’avérait à nouveau aussi efficace qu’Oracle. Plus encore, nous
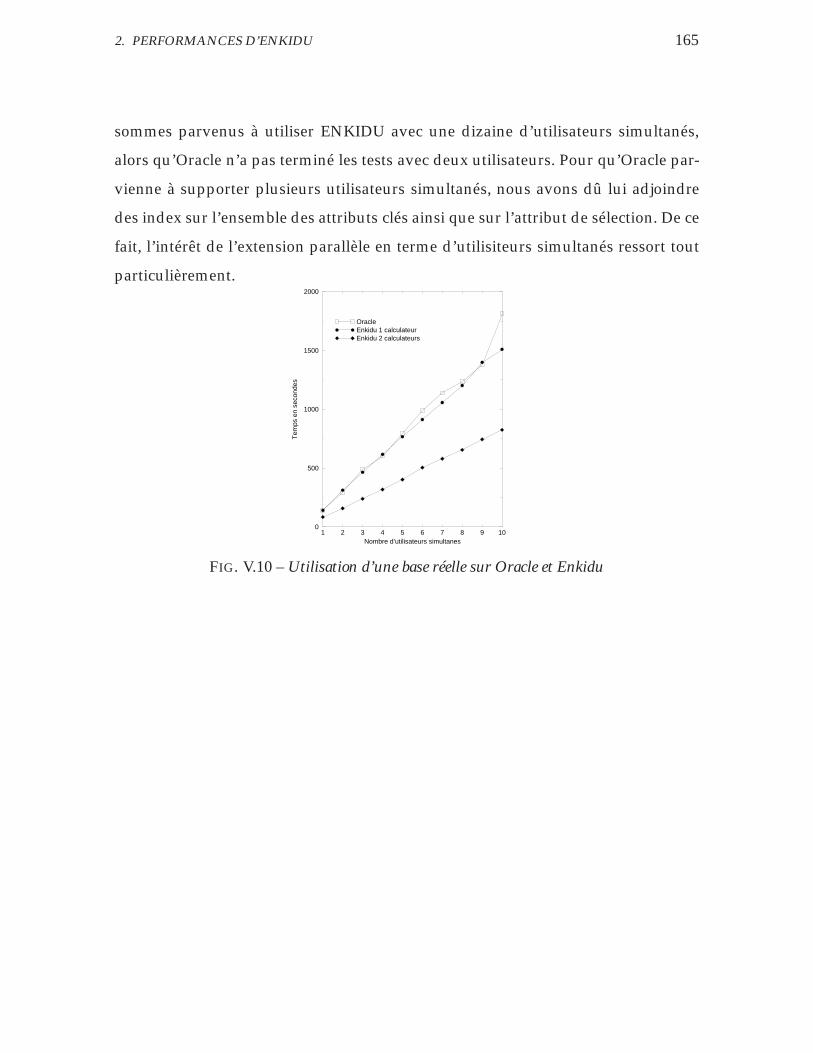
2. PERFORMANCES D’ENKIDU 165
sommes parvenus à utiliser ENKIDU avec une dizaine d’utilisateurs simultanés,
alors qu’Oracle n’a pas terminé les tests avec deux utilisateurs. Pour qu’Oracle par-
vienne à supporter plusieurs utilisateurs simultanés, nous avons dû lui adjoindre
des index sur l’ensemble des attributs clés ainsi que sur l’attribut de sélection. De ce
fait, l’intérêt de l’extension parallèle en terme d’utilisiteurs simultanés ressort tout
particulièrement.
1 2 3 4 5 6 7 8 9 10Nombre d’utilisateurs simultanes
0
500
1000
1500
2000T
emps
en
seco
ndes
OracleEnkidu 1 calculateurEnkidu 2 calculateurs
FIG. V.10 – Utilisation d’une base réelle sur Oracle et Enkidu

166 CHAPITRE V. TESTS

167
Chapitre VI
Conclusion
1 Bilan
Ce mémoire étudie la mise en œuvre d’un évaluateur parallèle de requêtes rela-
tionnelles, fonctionnant sur un réseau de stations, afin d’améliorer les performances,
sur des données en lecture seule, d’un Système de Gestion de Bases de Données
(SGBD) relationnel. Cette alternative permet d’éviter l’acquisition d’un SGBD pa-
rallèle lorsque seules les opérations de consultation nécessitent un surplus de puis-
sance. Cette solution s’applique par exemple aux bases documentaires, lesquelles
correspondent particulièrement bien aux critères énoncés ci-dessus.
Nous avons établi l’intérêt d’une telle proposition en montrant que les solu-
tions actuelles, fondées sur l’utilisation d’un SGBD parallèle complet, s’avéraient
fort complexes et coûteuses. Nous avons ensuite explicité l’architecture d’un éva-
luateur parallèle. Celui-ci comporte deux types de composants : i) un serveur gérant
l’accès aux données sources et l’interface avec les utilisateurs, et ii) un ensemble
de calculateurs, effectuant les traitements parallèles, et placés sur un ensemble de
stations de travail (ou PC), à raison d’un calculateur par station. Cette approche
originale ne possède pas, à notre connaissance, d’équivalent dans la littérature.
Nous avons particulièrement insisté sur l’intérêt d’utiliser des lots de données

168 CHAPITRE VI. CONCLUSION
dans le cadre des traitements et des transferts de tuples. Nous avons ainsi proposé
une méthode basée sur la régulation de la taille des lots de données et sur l’utilisa-
tion de seuils de transfert visant à réguler le flot des tuples entre opérations élémen-
taires. Cette technique permet de généraliser et d’homogénéiser les différentes mé-
thodes de regroupement de tuples (buffer, parallélisme à grain moyen) rencontrées
dans les travaux antérieurs. Nous avons également proposé l’utilisation de threads
concurrents sur les calculateurs, de façon à limiter les baisses de performances dûes
à l’attente de résultats intermédiaires.
Nous avons ensuite présenté le prototype d’évaluateur parallèle de requête, EN-
KIDU, qu’il nous a été donné de réaliser durant cette thèse. Cet évaluateur, déve-
loppé avec le langage orienté-objet Java est à la fois modulaire et portable, et offre de
bonnes possibilités d’interopérabilité. Il constitue, de par son architecture ouverte,
un outil d’étude de techniques parallèles dans le cadre de l’évaluation parallèle de
requêtes relationnelles.
Nous avons pu montrer, à travers différents tests, la pertinence des options rete-
nues et l’efficacité générale du prototype ENKIDU. Ces tests ont notamment permis
de montrer la bonne tenue d’ENKIDU pour un nombre conséquent de requêtes si-
multanées. Ils ont également mis en avant l’intérêt de la régulation du flot de don-
nées à l’aide de lots de données. Ils ont enfin permis de montrer les gains apportés
par l’exécution multi-threads d’opérations élémentaires concurrentes.
2 Perspectives
Le prototype développé présente d’ores et déjà des caractéristiques performantes.
Il demeure possible de l’optimiser en lui adjoignant des composants supplémen-
taires, telles une bibliothèque de communication légère ou une gestion paginée des
données. D’un point de vue industriel, des contacts prometteurs ont été pris avec
une entreprise lyonnaise spécialisée dans les bases de données documentaires. Celle-

2. PERSPECTIVES 169
ci s’est montrée particulièrement intéressée par ENKIDU, et un portage industriel
de notre prototype devrait avoir lieu dans un proche avenir.
Du point de vue de la recherche, de nouvelles voies sont ouvertes au terme de ce
travail. Ainsi, l’étude détaillée, la normalisation et l’application du concept d’exten-
sion parallèle constitueraient un vaste sujet de recherche.
Par ailleurs, la notion de seuil pourrait être étudiée et affinée de façon systématique
suivant le type d’opération et la distribution des données.
Enfin, cette même notion de seuil, introduite au niveau du transfert des données,
pourrait être adaptée aux problèmes d’équilibrage dynamique de charge. Ce der-
nier, en effet, s’effectue en fonction de l’évolution de la charge de travail des diffé-
rents processeurs. Il est a priori possible de tolérer, en mode multi-utilisateurs, des
déséquilibres minimes durant une période donnée. Plusieurs requêtes s’exécutant
de façon concurrente grâce au mode multi-threads, il est possible de choisir leurs
sites d’exécution de manière à ce que les délais induits par les déséquilibres puissent
être recyclés par une autre requête. Bien entendu, une telle stratégie permettrait de
limiter le nombre d’équilibrages dynamiques, mais impliquerait un délai maximum
sur les déséquilibres constatés. Passé un certain délai depuis le constat d’un dés-
équilibre, une procédure d’équilibrage devrait être lancée. Cette étude non triviale
constituerait un intéressant sujet de recherche, sujet d’autant plus important que
l’équilibrage de charge dynamique dans les systèmes à mémoire distribuée (et donc
les réseaux de stations) demeure un problème ouvert.

170 CHAPITRE VI. CONCLUSION

BIBLIOGRAPHIE 171
Bibliographie
[Abd95] ABDELLATIF, A., LIMAME, M. et ZEROUAL, A. Oracle 7 : langages - architecture - admi-
nistration. Paris: Eyrolles, 1995. 464 p. 192
[AD96] ARPACI-DUSSEAU, R. The Berkeley NOW Project. [On-Line], 1996 [20.7.98]. Disponible
sur Internet :<http://now.cs.berkeley.edu>. 47
[AD97] ARPACI-DUSSEAU, A.C., ARPACI-DUSSEAU, R., CULLER, D.E. et al. High-
Performance Sorting on Networks of Workstations. In : Proceedings of the 1997 ACM SIG-
MOD International Conference on Management of Data. Tucson, AZ, USA, mai 1997. p. 243–
254. 22
[Aho87] AHO, A., ULLMAN, J.D. et HOPCROFT, J.P. Structures de données et algorithmes. Paris:
InterEditions ; Addison-Wesley Europe, 1987. 446 p. 193
[And95] ANDERSON, T.E., CULLER, D.E., PATTERSON, D.A. et al. A Case for NOW (Networks
of Workstations). IEEE Micro, février 1995, vol. 15, n1, p. 54–73. 56
[Ape92] APERS, M.G., VAN DEN BERG, C.A., FLOKSTRA, J. et al. PRISMA/DB : A Parallel
Main Memory Relational DBMS. IEEE Transactions on Knowledge and Data Engineering, dé-
cembre 1992, vol. 4, n6, p. 541–554. 41
[Asa94] ASANTÉ. Asanté and 100BASE_T Fast Ethernet. [On-Line], 1994 [modifié le 5.8.98]. Dis-
ponible sur Internet : <http://www.asante.com/Press/wpfast.html>. 51
[Aut94] AUTHIÉ, G., FERREIRA, A., ROCH, J.L. et al. Algorithmes parallèles, analyse et conception.
Paris: Hermes, 1994. 360 p. 52
[Bal97] BALLINGER, C. et FRYER, R. Born To Be Parallel. In : IDW’97, (industrial Sessions). Hong
Kong, août 1997. p. 196–216. 46
[Bam98] BAMFORD, R., BUTLER, D., KLOTS, B. et al. Architecture of Oracle Parallel Server. In :
Proceedings of the 24th International Conference on Very Large Databases. New York City, NY,
USA, août 1998. p. 669–670. 21, 22, 46

172 BIBLIOGRAPHIE
[Ben96] BENATTOU, M. et LAKHAL, L. Héritage incrémental : modèle, méthode et validation
formelle. Ingénierie des système d’information, 1996, vol. 4, n5, p. 637–659. 33
[Ber91] BERGSTEN, B., COUPRIE, M. et VALDURIEZ, P. Prototyping DBS3, shared-memory
parallel database system. In : Proceedings of the 1st International Conference on Parallel and
Distributed Information System. Miami Beach, Florida, décembre 1991. p. 226–235. 34, 46
[Bhi88] BHIDE, A. An analysis of three transaction processing architectures. In : Proceedings of
the 14th International Conference on Very Large Databases. Los Angeles, CA, USA, 1988. p.
339–350. 186
[BIP98] BIP. BIP Messages. [On-Line], avril 1998 [modifié le 1 avril 1998]. Disponible sur Internet :
<http://lhpca.univ-lyon1.fr/ bip.html>. 51
[Bis96] BISCONDI, N., FLORY, A., BRUNIE, L. et al. Encapsulation of intra-operator parallelism
in a parallel match operator. In : Proceedings of ACPC’96. Éd. par L. Böszörményi. Klagen-
furt, Austria, septembre 1996. p. 124–135. 90, 197
[Bod95] BODEN, N.J., COHEN, D., FELDERMAN, R.E. et al. Myrinet - a gigabit-per-second
local-area network. IEEE-Micro, 1995, vol. 15, p. 29–36. 22, 50
[Bor88] BORAL, H. Parallelism and data management. In : Proceedings of the Third International
Conference on Data and Knowledge Engeniering. Jerusalem, Israel, 1988. p. 362–373. 46
[Bot92] BOTTÉRO, J. L’Épopée de Gilgameš. Paris: Gallimard, octobre 1992. 295 p. L’aube des
peuples. ISBN 2-07-072583-9. 111
[Bou90] BOUZEGHOUB, M., JOUVE, M. et PUCHERAL, P. Systèmes de bases de données : des tech-
niques d’implantation à la conception de schéma. Paris: Eyrolles, 1990. 337 p. 191
[Bou96a] BOUGANIM, L. Equilibrage de charge lors de l’exécution de requêtes sur des architectures
multiprocesseurs hybrides. Thèse Informatique : Université de Versailles-Saint-Quentin-en-
Yvelines, décembre 1996. 142 p. 82, 82, 139, 184
[Bou96b] BOUGANIM, L., FLORESCU, D. et VALDURIEZ, P. Dynamic load balancing in hierar-
chical parallel database systems. In : Proceedings of the 22nd International Conference on Very
Large Databases. Bombay, India, septembre 1996. p. 436–447. 24, 46
[Boz96] BOZAS, G., JAEDICKE, M., LISTL, A. et al. On transforming a sequential sql-dbms into
a parallel one : First results and experiences of the MIDAS project. In : EuroPar’96. Éd. par
L. Bougé et al. Lyon, août 1996. p. 881–886. 22, 60
[Bru96a] BRUNIE, L. et KOSCH, H. Control strategies for complex relational query processing in
shared-nothing systems. SIGMOD Records, septembre 1996, vol. 25, n3, p. 34–39. 39

BIBLIOGRAPHIE 173
[Bru96b] BRUNIE, L. et REYMANN, O. Concepts and functionnalities of the DOSMOS - Trace
monitoring tool. In : Europar’96. Éd. par L. Bougé et al. Lyon, août 1996. p. 74–77. 49
[Car93] CAREY, M.J., DEWITT, D.J. et NAUHTON, J.F. The 007 benchmark. In : Proceedings of the
1993 ACM SIGMOD International Conference on Management of Data. Éd. par P. Buneman
et al. Washington, D.C., USA, juin 1993. p. 12–21. 33
[Che93] CHEN, A., KAO, Y.F., PONG, M. et al. Query Processing in Non Stop SQL. IEEE Data
Engeniering Bulletin, 1993, vol. 16, p. 29. 46
[Cod70] CODD, E.F. A relational model for large shared data banks. Communications of the ACM,
juin 1970, vol. 13, n6, p. 377–387. 27, 28
[Cod74] CODD, E.F. Recent Investigations in Relational Data Base Systems. In : Information Proces-
sing ’74. Stockholm, 1974. p. 1017–1021. 28
[Con96] CONDOR. The Condor Project Home Page. [On-Line], 1996 [3.10.97]. Disponible sur
Internet : <http://www.cs.wisc.edu/condor>. 47
[Cop88] COPELAND, G. et KELLER, T. Data placement in Bubba. In : Proceedings of the 1988 ACM
SIGMOD International Conference on Management of Data. Chicago, IL, mai 1988. p. 99–108.
36, 37, 71
[Dah94] DAHLIN, M., MATHER, C., WANG, R. et al. A quantitative analysis of cache policies
for scalable network file systems. Performance Evaluation Review, Special Issue : Proceedings of
SIGMETRICS’94, mai 1994, vol. 22, n1, p. 150–160. 49
[Dat97] DATE, C.J. et DARWEN, H. A Guide to the SQL Standard : a user’s guide to the standard
database language SQL. Reading, MA: Addison Wesley, octobre 1997. 522 p. 31
[Dav92] DAVISON, W. Parallel Index Building in Informix Online 6.0. In : Proceedings of the 1992
ACM SIGMOD International Conference on Management of Data. San Diego, juin 1992. p. 103.
82
[Del82] DELOBEL, C. et ADIBA, M. Bases de données et systèmes relationnels. Paris: Dunod, 1982.
449 p. 28, 191, 194
[DeW84] DEWITT, D.J., KATZ, R.H., OLKEN, F. et al. Implementation Techniques for Main Me-
mory Database Systems. In : Proceedings of the 1984 ACM SIGMOD International Conference
on Management of Data. Éd. par B. Yorkmark. Boston, Mass, USA, juin 1984. p. 1–8. 196
[DeW86] DEWITT, D.J., GERBER, R.H., GRAEFE, G. et al. GAMMA : A High Perfomance Da-
taflow Database Machine. In : Proceedings of the 12th International Conference on Very Large
Databases. Kyoto, août 1986. p. 228–237. 24, 83

174 BIBLIOGRAPHIE
[Dew90] DEWIT, D.J., GHANDEHARIZADEH, S., SCHNEIDER, D. et al. The Gamma Database
Machine Project. IEEE Transactions on Knowledge and Data Enginiering, mars 1990, vol. 2, n1,
p. 44–62. 46
[DeW92a] DEWITT, D.J. et GRAY, J. Parallel database systems : the future of high performance
database systems. Communications of the ACM, juin 1992, vol. 35, n6, p. 85–98. 21, 31, 34
[DeW92b] DEWITT, D.J., NAUGHTON, J.F., SCHNEIDER, D.A. et al. Practical Skew Handling in
Parallel Joins. In : Proceedings of the 18th International Conference on Very Large Databases. Éd.
par Y. Li-Yan. Vancouver, BC, Canada, août 1992. p. 27–40. 40, 121
[DP93] DE-PRYCKER, M. Asynchronous transfer mode : solution for broadband ISDN. New York: Ellis
Horwood, 1993. 331 p. 22, 49
[Dus96] DUSSEAU, A.C., ARPACI, R. et CULLER, D.E. Effective distributed scheduling of paral-
lel workloads. In : SIGMETRICS ’96. Philadelphia, PA, USA, mai 1996. p. 25–36. 48
[Exb97a] EXBRAYAT, M. et BISCONDI, N. The ENKIDU Prototype : Parallel Query Optimisation
on Local Area Networks. In : IDW’97. Éd. par J. Fong. Hong-Kong, juillet 1997. p. 137–150.
75
[Exb97b] EXBRAYAT, M. et KOSCH, H. Offering Parallelism to a Sequential Database Management
System on a Network of Workstations Using PVM. In : EuroPVM-MPI’97. Krakow, Poland,
novembre 1997. 7 p. 112
[Exb97c] EXBRAYAT, M. et KOSCH, H. A Parallel Extension for Existing Relationnal Database
Management Systems. In : BIWIT’97. Biarritz, juillet 1997. p. 75–81. 66
[Fab97] FABBROCINO, F., SHEK, E. et MUNTZ, R. The Design and Implementation of the Conquest
Query Execution Environment. Los Angeles (USA): UCLA Comp. Science Dpt, juillet 1997.
20 p. Rapport technique n970029. 61
[Fag77] FAGIN, R. Multivalued Dependencies and a New Formal Form for Relational Databases.
ACM Transactions on Database Systems, septembre 1977, vol. 2, n3, p. 262–278. 28
[Fag79] FAGIN, R. Normal Forms and Relational Database Operators. In : Proceedings of the 1979
ACM SIGMOD International Conference on Management of Data. Boston, mai 1979. p. 153–
160. 28
[Fei98] FEITH. Feith Document Database. [On-Line], octobre 1998 [modifié le 7.10.1998]. Dispo-
nible sur Internet : <http://www.feith.com/product>. 21
[Fla97] FLANAGAN, D. JAVA in a nutshell. Sebastopol, CA: O’Reilly, mai 1997. 628 p. ISBN
1-56592-262-X. 112

BIBLIOGRAPHIE 175
[Flo83] FLORY, A., PAULTRE, C. et VEILLERAUD, C. A relational databank to aid in the dispen-
sing of medicines. In : MEDINFO ’83. Éd. par J.H. Van Bemmel et al. Amsterdam, 1983. p.
152–155. 163
[Flo92] FLORY, A., EISINGER, F. et VERDIER, C. A New Information System for Pharmaco-
epidemiology. In : MEDIFO ’92. Éd. par K. C. Lun. Amsterdam, 1992. p. 363. 21
[Gei94] GEIST, A., BEGUELIN, A., DONGARRA, J. et al. Pvm : Parallel Virtual Machine : A Users’
Guide and Tutorial for Networked Parallel Computing. Cambridge, MA, USA: MIT Press, 1994.
279 p. 22, 53
[Ger95] GERBER, B. Informix On Line XPS. In : Proceedings of the 1995 ACM SIGMOD International
Conference on Management of Data. Éd. par M. J. Carey et al. San Jose, Ca, USA, mai 1995.
p. 463. 22, 46, 59
[Gib98] GIBELLO, P.Y. Zql. [On-line], août 1998 [modifié le 25.8.98]. Disponible sur Internet :
<http://dyade.inrialpes.fr/membres/gibello/javaresources.html>. 130, 132
[Gra93] GRAEFE, G. Query evaluation techniques for large databases. ACM Computing Surveys,
juin 1993, vol. 25, n2, p. 73–170. 75, 90, 197
[Gra94] GRAEFE, G. Volcano, an extensible and parallel dataflow query evaluation system. IEEE
Transactions on Knowledge and Data Engeniering, février 1994, vol. 6, n1, p. 120–135. 24, 46,
46, 83
[Ham93] HAMEURLAIN, A. et MORVAN, F. A Parallel Scheduling Method for Efficient Query
Processing. In : Proceedings of the 22nd International Conference on Parallel Processing ICPP’93.
St Charles, Illinois, USA, août 1993. p. 258–261. 43
[Ham95] HAMEURLAIN, A. et MORVAN, F. Scheduling and Mapping for Parallel Execution of
Extended SQL Queries. In : Proceedings of the 4th International Conference on Information and
Knowledge Management, CIKM’95. Baltimore, USA, décembre 1995. p. 197–204. 139
[Ham96] HAMEURLAIN, A., BAZEX, P. et MORVAN, F. Traitement parallèle dans les bases de données
relationnelles : concepts, méthodes et applications. Toulouse: Cépaduès, septembre 1996. 312 p.
ISBN 2.85428.414.3. 139, 139, 195
[Hua91] HUA, K.A., LEE, C. et PEIR, J.K. Interconnecting shared-everything systems for efficient
parallel query processing. In : International Conference on Parallel and Distributed Information
Systems. Miami Beach, Florida, USA, décembre 1991. p. 262–270. 46
[IBM95] IBM. LoadLeveler : SP2 Job Scheduling. [On-Line], mars 1995 [modifié le 13.3.1995]. Dis-
ponible sur Internet : <http://ibm.tc.cornell.edu:80/ibm/pps/loadl/index.html>. 47

176 BIBLIOGRAPHIE
[Kit83] KITSUREGAWA, M. et al. Application of hash to database machine and its architecture.
New Generation Computing, 1983, vol. 1, n1, p. 63–74. 195
[Knu98] KNUTH, D.E. The art of Computer Programming. Volume 3, Sorting and Searching. Reading,
Mass, USA: Addison Wesley, 1998. 780 p. 193
[Kor88] KORTH, H.F. et SILBERSCHATZ, A. Systèmes de gestion des bases de données. Paris:
McGraw-Hill, 1988. 546 p. 191, 192
[Kos97a] KOSCH, H. MPO - Description and User Manual. Lyon: ENS Lyon, Laboratoire d’Informa-
tique du Parallélisme, août 1997. 27 p. Rapport technique n1997-01. 73, 136
[Kos97b] KOSCH, H. Traitement parallèle de requêtes relationnelles : Modélisation, optimisation et straté-
gies d’ordonnancement. Thèse Informatique : Ecole Normale Supérieure de Lyon, juin 1997,
192 p. 39, 73
[LAM98] LAM. LAM / MPI Parallel Computing. [On-line], juillet 1998 [modifé le 21.7.98]. Dispo-
nible sur internet : <http:// www.mpi.nd.edu/lam>. 55
[Lef97] LEFEVRE, L. Parallel programming on top of DSM System : An experimental study. Paral-
lel Computing, 1997, vol. 23, n1-2, p. 235–249. 49
[Lin93] LINDER, B. Oracle Parallel RDBMS on Massively Parallel Systems. In : International Confe-
rence on Parallel and Distributed Information Systems. San Diego, CA, USA, 1993. p. 67. 46
[Lit88] LITZKOW, M., LIVNY, M. et MUTKA, W. Condor - A Hunter of Idle Workstations. In :
Proceedings of the 8th International Conference of Distributed Computing Systems. San Jose, CA,
USA, 1988. p. 104–111. 47
[Lit96] LITWIN, W., NEIMAT, M.A. et SCHNEIDER, D.A. LH* : A scalable, distributed data
structure. ACM Transactions on Database Systems, décembre 1996, vol. 21, n4, p. 480–526. 49
[Liv87] LIVNY, M., KHOSAFIAN, S. et BORAL, H. Multi-disk Management Algorithms. ACM
SIGMETRICS Performance Evaluation Review, Special Issue : Proceedings of the ACM conference
on Measurement and Modeling of Computer Systems, mai 1987, vol. 15, n1, p. 69–77. 34
[Liv92] LIVNY, M. et LITZKOW, M. Making Workstations a Friendly Environment for Batch
Jobs. In : Third IEEE Workshop on Workstation Operating Systems. Key Biscayne, Florida,
avril 1992. 6 p. 47
[Meh93] MEHTA, M. et DEWITT, D.J. Dynamic Memory Allocation for Multiple-Query Work-
loads. In : Proceedings of the 19th International Conference on Very Large Databases. Dublin,
Ireland, 1993. p. 354–367. 43, 139, 139

BIBLIOGRAPHIE 177
[Meh97] MEHTA, M. et DEWITT, D.J. Data placement in shared-nothing parallel database systems.
The VLDB Journal, janvier 1997, vol. 6, n1, p. 53–72. 34
[MPI96] MPICH. MPICH - A Portable MPI Implementation. [On-line], juillet 1996 [modifié le
9.10.98]. Disponible sur internet : <http://www.mcs.anl.gov/Projects/mpi/mpich/
index.html>. 22, 54
[MPI98] MPIF. Message Passing Interface Forum Home Page. [On-line], octobre 1998 [modifié le
13.10.98]. Disponible sur internet : <http://www.mpi-forum.org/>. 54
[Ösz91] ÖSZU, M.T. et VALDURIEZ, P. Principles of Distributed Database Systems. Englewood Cliffs,
NJ: Prentice Hall, 1991. 562 p. ISBN 0-13-691643-0. 21, 94
[Pag92] PAGE, J. A Study of a Parallel Database Machine and its Performance the NCR/Teradata
DBC/1012. In : Proceedings of the 10th BNCOD Conference. Aberdeen, Scotland, juillet 1992.
p. 115–137. 46
[Pas98] PASQUIER, N., BASTIDE, Y., TAOUIL, R. et al. Efficient Mining of Association Rules
Using Closed Itemset Lattices. Information Systems, 1998. à paraitre. 21
[Pir90] PIRAHESH, H., MOHAN, C., CHENG, J. et al. Parallelism in Relational Database Sys-
tems : Architectural Issues and Design Approaches. In : International Symposium on Data-
bases in Parallel and Distributed Systems. Dublin, Ireland, 1990. p. 4–29. 46, 46
[Pro98] PROMETHEUS. Techniques de gestion de bases décision-
nelles. [On-Line], 1998 [modifié le 10.2.98]. Disponible sur internet :
<http://www.prometheus.eds.fr/etud/tecges˜1.htm>. 64
[Pru96] PRUYNE, J. et LIVNY, M. Managing Checkpoints for Parallel Programs. In : Workshop on
Job Scheduling Strategies for Parallel Processing, IPPS ’96. Honolulu, Hawaii, USA, avril 1996.
9 p. 48
[PS84] PIATETSKY-SHAPIRO, G. et CONNEL, C. Accurate Estimation of the Number of Tuples
Satisfying a Condition. In : Proceedings of the 1984 ACM SIGMOD International Conference
on Management of Data. Boston, Mass., juin 1984. p. 256–276. 36
[Puj97] PUJOLLE, G. Les Réseaux. Paris: Eyrolles, 1997. 939 p. 49
[PVM98] PVM. Parallel Virtual Machine (PVM) Version 3. [On-line], août 1998 [modifié le 27.8.98].
Disponible sur internet : <http://www.netlib.org/pvm3/index.html>. 22, 53
[Qui97] QUINN, L.B. et RUSSEL, R.G. Fast Ethernet. New York: Wiley, 1997. 417 p. 51
[Rah93] RAHM, E. et MAREK, R. Analysis of Dynamic Load Balancing Strategies for Parallel
Shared-Nothing Database Systems. In : Proceedings of the 19th International Conference on

178 BIBLIOGRAPHIE
Very Large Databases. Éd. par R. Agrawal et al. Dublin, Ireland, août 1993. p. 182–193. 44
[Rod97] RODRIGUES, S.H., ANDERSON, T.E. et CULLER, D.E. High performance local area
communication with fast sockets. In : USENIX ’97. Anaheim, CA, USA, janvier 1997. 18 p.
22
[Sch89] SCHNEIDER, D. et DEWITT, D.J. A Performance Evaluation of Four Parallel Join Algo-
rithms in a Shared-Nothing Multiprocessor Environment. In : Proceedings of the 1989 ACM
SIGMOD International Conference on Management of Data. Éd. par J. Clifford et al. Portland,
Oregon, USA, juin 1989. p. 110–121. 194, 196
[Sni95] SNIR, M., OTTO, S.W., HUSS-LEDERMAN, S. et al. MPI: The Complete Reference. Cam-
bridge, MA, USA: MIT Press, 1995. 336 p. 22, 54
[Sto88] STONEBRAKER, M., KATZ, R., PATTERSON, D. et al. The Design of XPRS. In : Procee-
dings of the 14th International Conference on Very Large Databases. Éd. par F. Bancilhon et al.
Los Angeles, CA, USA, août 1988. p. 318–330. 46
[Syb98] SYBASE. Adaptive Server Enterprise 11.5 (French) : Concepts de Sécurité. [On-Line], 1998
[20.9.98]. Disponible sur Internet : <http://sybooks.sybase.com:80/dynaweb/group6/
asg1150f/secag/@Generic_BookView>. 108
[Ter98] TERADATA. Teradata - Papers and Presentations. [On-line], 1998 [modifié le 29.9.98]. Dis-
ponible sur internet : <http://www3.ncr.com/product/data_warehouse/papers.html>.
21, 46
[Ull85] ULLMAN, J.D. Implementation of Logical Query Languages for Databases. ACM Transac-
tions on Database Systems, 1985, vol. 10, n3, p. 289–321. 191
[Val84] VALDURIEZ, P. et GARDARIN, G. Join and Semi-join Algorithms for a Multiprocessor
Database Machine. ACM Transactions on Database Systems, 1984, vol. 9, n1, p. 133–161. 194
[Val93] VALDURIEZ, P. Parallel database systems: open problems and new issues. Distributed and
Parallel Databases – an International Journal, 1993, vol. 1, n2, p. 137–165. 21, 37
[Vet95] VETTER, P. Calcul coopérant par passage de messages. Paris: Hermes, 1995. 78 p. 52
[Wes98] WESTPHAL, C. et BLAXTON, T. Data Mining Solutions : Methods and Tools for Solving
Real-World Problems. New-York: Wiley, 1998. 617 p. ISBN 0-471-25384-7. 21
[WIL95] WILSCHUT, A.N., FLOKSTRA, J. et APERS, P.M.G. Parallel evaluation of multi-join
queries. In : Proceedings of the 1995 ACM SIGMOD International Conference on Management of
Data. Éd. par M. J. Carey et al. San Jose, Ca, USA, mai 1995. p. 115–126. 41, 79, 196

179
Annexes

180

181
Annexe A
Compléments sur le parallélisme
Présentation des principales architectures parallèles
considérations générales
L’architecture d’un système parallèle est étroitement liée à son domaine d’utili-
sation. En effet, la finesse du partage d’informations entre processeurs conditionne
l’efficacité et l’extensibilité d’une machine parallèle. Les degrés de liberté d’une
machine parallèle (voir figure A.1) se situent à l’interconnexion de ses principaux
composants, à savoir le processeur et la mémoire volatile (ou RAM) d’une part, et
entre l’ensemble processeur / mémoire volatile et le stockage de masse (les “disques
durs”) d’autre part. A chacune de ces interconnexions il est possible d’offrir une
méthode d’accès à un ou deux niveaux. Par exemple, tous les processeurs peuvent
accéder à une mémoire commune ou en revanche disposer chacun d’une mémoire
privée, accessible des autres processeurs, mais à travers un mécanisme différent (et
moins efficace). Trois grandes catégories d’architectures ont à ce jour été proposées :
les systèmes à mémoire partagée, dans lesquels les processeurs accèdent “directe-
ment” à l’ensemble de la mémoire et des disques, les systèmes à disques partagés,
où chaque processeur dispose de sa propre mémoire mais accède à un ensemble

182 ANNEXE A. COMPLÉMENTS SUR LE PARALLÉLISME
de disques à travers un mécanisme unique, et enfin les systèmes à mémoire distri-
buée, dans lesquels chaque processeur dispose d’une mémoire et d’un (ou plusieurs)
disques privés, et accède aux informations détenues par les autres processeurs à tra-
vers un mécanisme de messages.
Outre ces trois catégories principales sont apparues d’autres techniques, dérivées
d’une catégorie ou hybrides de deux d’entre elles. Ainsi, les architectures NUMA
(Non Uniform Memory Access), pour lesquelles chaque processeur dispose de sa
propre mémoire, mais où l’échange d’informations entre processeurs s’effectue à
bas niveau et de façon transparente. Nous pouvons également citer les architectures
hiérarchiques qui se présentent comme des architectures à mémoire distribuée dont
les nœuds sont remplacés par des machines à mémoire partagée.
Disques
RAM
Processeurs
Couples Processeurs + RAM
Accès privilégié ?
Accès privilégié ?
FIG. A.1 – Vue d’un système parallèle par ses points d’interconnexion

183
Mémoire partagée
Dans un système à mémoire partagée (voir figure A.2), l’accès à la mémoire et
aux disques se fait à travers un mécanisme unique (du point de vue du program-
meur tout au moins). De ce fait, l’équilibrage de charge des disques est simplifié,
et celui des mémoires est inexistant. Les processeurs peuvent échanger de l’infor-
mation sans aucun surcoût de communication, et chacun dispose d’une mémoire
limitée par la seule concurrence des autres processeurs.
RAM
Processeurs
Disques
Cache Cache Cache
Bus d’interconnexion
FIG. A.2 – Architecture à mémoire partagée
Les limites d’un tel système se trouvent dans son extensibilité. En effet, l’accès
des processeurs à une mémoire unique et à un bus unique limite l’extensibilité, tant
d’un point de vue physique (connectique) que d’un point de vue logique (l’adres-
sage se faisant en une seule “couche”, la mémoire adressable s’en trouve limitée).
Par ailleurs, les conflits d’accès à la mémoire physique limitent l’efficacité de la ma-
chine. Aussi a-t-on souvent recours à des mémoires caches entre les processeurs et
la mémoire physique. Ces caches limitent les accès à la mémoire commune, mais
soulèvent en contrepartie des problèmes de cohérence. En effet, si deux processeurs
“cachent” une même donnée, les mises à jour de celle-ci doivent être immédiates

184 ANNEXE A. COMPLÉMENTS SUR LE PARALLÉLISME
et synchronisées. On utilise pour ce faire un mécanisme de verrous afin de bloquer
l’accès à une donnée durant sa mise à jour.
Architecture NUMA
L’architecture NUMA (Non Uniform Memory Access) est un cas particulier à mi-
chemin entre mémoire distribuée et mémoire partagée. Chaque processeur dispose
ici de sa mémoire propre. Cependant, l’ensemble de la mémoire est accessible à tra-
vers un système d’adressage à deux niveaux, et donc sans passage de messages entre
processeurs (voir figure A.3). On dispose ainsi d’une machine à mémoire virtuelle-
ment partagée. Selon les machines, la communication de données entre les caches
peut se faire à l’aide de différentes techniques, telles une hiérarchie de bus, ou une
double boucle SCSI. Les travaux sur les données peuvent se révéler assez lourd du
fait des accès distants. Afin de diminuer les temps d’accès, il a donc été proposé
que chaque processeur dispose en outre d’un cache mémoire dans lequel il puisse
stocker temporairement des données distantes. Un tel système suppose toutefois
qu’une politique de cohérence de cache soit mise en place. De ce fait, cette variante
architecturale est dénommée CC-NUMA (Cache Coherency NUMA). Un autre dé-
rivé de cette architecture consiste non plus à utiliser une mémoire locale doublée
d’un cache, mais à utiliser la totalité de cette mémoire comme un cache. Cette va-
riante est connue sous le nom de COMA (Cache Only Memory Access). Concernant
l’utilisation de machines NUMA dans le cadre des bases de données, on pourra se
référer aux travaux de Luc Bouganim [Bou96a].
Disques partagés
Vis à vis de l’architecture précédente, un système à disques partagés (voir fi-
gure A.4) augmente l’espace mémoire adressable (chaque processeur dispose de sa
mémoire et peut accéder aux informations stockée dans celle des autres processeurs

185
RAM
Disques
Processeurs
Accès aux données distantes (gestion matérielle)
FIG. A.3 – Architecture à accès de mémoire non uniforme
grâce à un mécanisme d’adressage secondaire –en fait un passage de messages entre
processeurs–, ce qui augmente les capacités d’adressage de chaque processeur). En
revanche, cette amélioration se fait au détriment de la simplicité et du faible coût
des accès mémoire. De plus, chaque processeur dispose d’une taille mémoire fixe.
Si celle-ci garantit une taille de mémoire privée, elle impose également une limite
supérieure à cette dernière. Les problèmes de taille se retrouvent au niveau de l’in-
terconnexion entre les ensembles (mémoire / processeur) et les disques partagés. Un
autre problème apparaît alors, car l’accès partagé aux pages disques implique des
surcoûts de gestion de la cohérence, surtout lors d’une utilisation transactionnelle
intense.
Mémoire distribuée (ou modèle communicant)
Cette architecture se présente comme un ensemble de nœuds (processeur, mé-
moire, disque) indépendants, communiquant entre eux à travers un réseau d’inter-
connexion et grâce à un système de passage de messages (voir figure A.5). L ’ex-

186 ANNEXE A. COMPLÉMENTS SUR LE PARALLÉLISME
Disques partagés
Processeurs + RAM
Réseau d’interconnexion
FIG. A.4 – Architecture à disques partagés
tensibilité est quasi infinie car les capacités physiques et logiques d’adressages sont
démultipliées par l’usage du réseau d’interconnexion. Toutefois, l’équilibrage se fait
plus délicat, car les capacités de chaque nœud sont figées, et l’échange d’informa-
tions ou le déplacement de travail d’un nœud à l’autre s’avèrent coûteux. La princi-
pale contrepartie du réseau d’interconnexion est en effet son surcoût de communi-
cation vis-à-vis d’une mémoire partagée (limitations de débit, coût d’encapsulation
des messages,...).
Architectures hiérarchiques
Etant donnés les avantages et inconvénients des architectures présentées ci-dessus,
certains se sont penchés sur des architectures hybrides, mêlant l’extensibilité de la
mémoire distribuée à l’efficacité de la mémoire partagée. De tels systèmes (voir fi-
gure A.6) se présentent sous forme de nœuds à mémoire partagée reliés entre eux
par un réseau rapide. La première référence à une telle architecture se situe sans
doute dans [Bhi88]. Au terme de cet article, l’auteur propose effectivement, après
avoir comparé les architectures classiques dans le cadre des bases données paral-
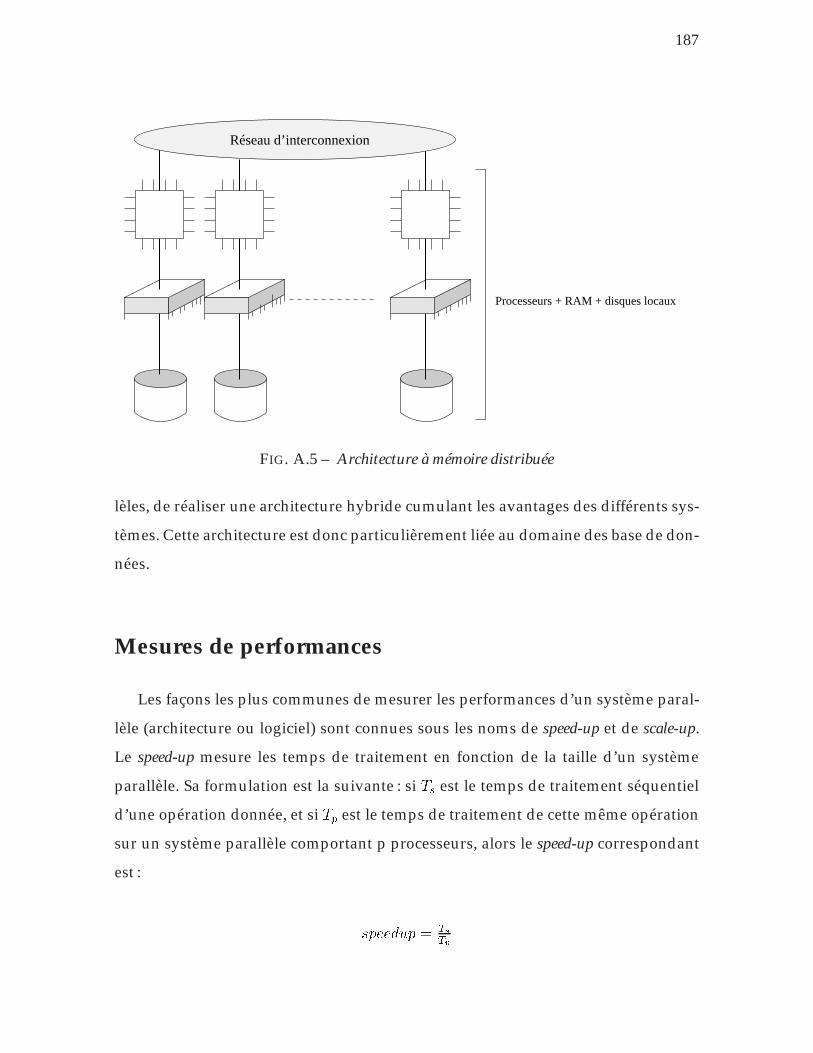
187
Processeurs + RAM + disques locaux
Réseau d’interconnexion
FIG. A.5 – Architecture à mémoire distribuée
lèles, de réaliser une architecture hybride cumulant les avantages des différents sys-
tèmes. Cette architecture est donc particulièrement liée au domaine des base de don-
nées.
Mesures de performances
Les façons les plus communes de mesurer les performances d’un système paral-
lèle (architecture ou logiciel) sont connues sous les noms de speed-up et de scale-up.
Le speed-up mesure les temps de traitement en fonction de la taille d’un système
parallèle. Sa formulation est la suivante : si Ts est le temps de traitement séquentiel
d’une opération donnée, et si Tp est le temps de traitement de cette même opération
sur un système parallèle comportant p processeurs, alors le speed-up correspondant
est :
speedup = TsTp

188 ANNEXE A. COMPLÉMENTS SUR LE PARALLÉLISME
Noeuds à mémoire partagée
Réseau d’interconnexion
FIG. A.6 – Architecture hiérarchique
Un speed-up est dit linéaire lorsque les temps de traitement sont inversement
proportionnels à la taille du système (voir figure A.7). Il est important de souligner
que la notion de speed-up dépend du type d’algorithme utilisé. En effet, un speed-
up ne caractérise pas les performances d’une machine, mais celles d’un algorithme,
et plus précisément celles d’un algorithme donné pour une architecture donnée.
Certains algorithmes, par exemple, présentent des speed-up dit “super linéaires” :
leur rapport temps/taille est décroissant lorsque la taille du système augmente. Ceci
provient en général d’interactions entre l’architecture matérielle et logicielle et la
forme de l’algorithme. Il convient donc de relativiser la portée de telles mesures.
Le scale-up mesure le volume de données traitées en une durée donnée en fonc-
tion de la taille d’un système parallèle. Sa formulation est la suivante : Soit T (P;c) le
temps d’exécution du problème P sur c processeurs.
Soient P1 et P2 deux problèmes tels que P2 soit n fois plus vaste (c’est à dire impli-
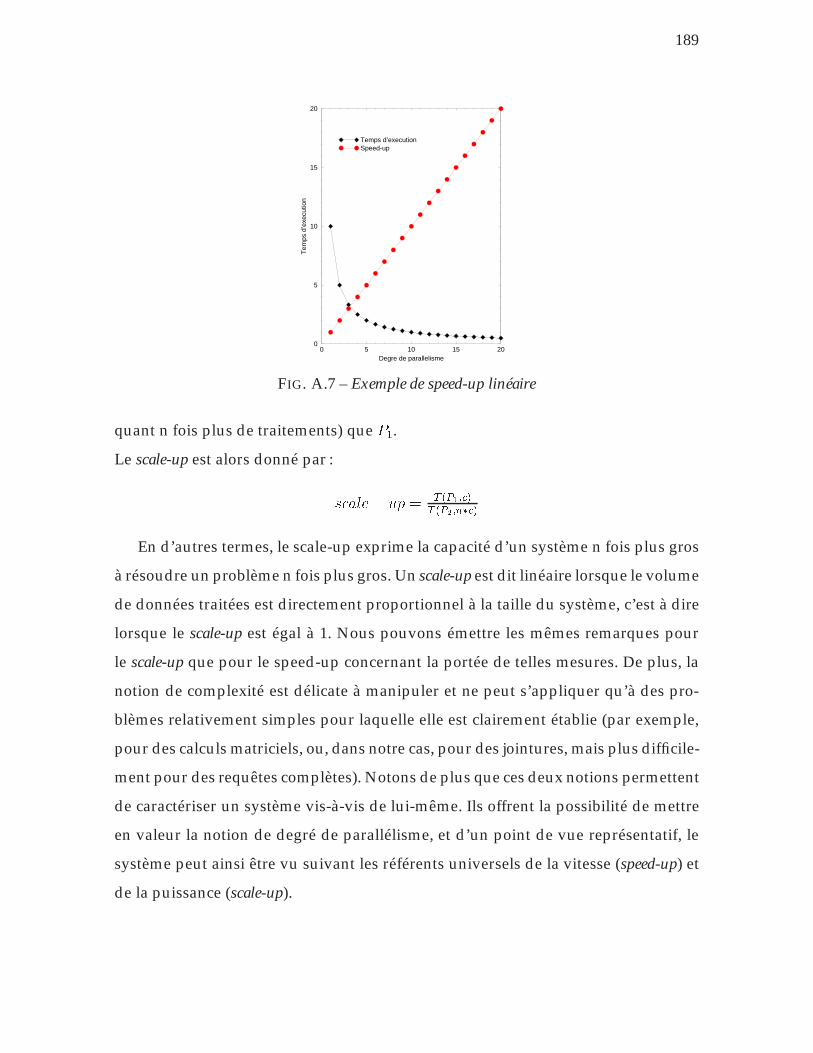
189
0 5 10 15 20Degre de parallelisme
0
5
10
15
20
Tem
ps d
’exe
cutio
n
Temps d’executionSpeed-up
FIG. A.7 – Exemple de speed-up linéaire
quant n fois plus de traitements) que P1.
Le scale-up est alors donné par :
scale� up =T (P1;c)
T (P2;n�c)
En d’autres termes, le scale-up exprime la capacité d’un système n fois plus gros
à résoudre un problème n fois plus gros. Un scale-up est dit linéaire lorsque le volume
de données traitées est directement proportionnel à la taille du système, c’est à dire
lorsque le scale-up est égal à 1. Nous pouvons émettre les mêmes remarques pour
le scale-up que pour le speed-up concernant la portée de telles mesures. De plus, la
notion de complexité est délicate à manipuler et ne peut s’appliquer qu’à des pro-
blèmes relativement simples pour laquelle elle est clairement établie (par exemple,
pour des calculs matriciels, ou, dans notre cas, pour des jointures, mais plus difficile-
ment pour des requêtes complètes). Notons de plus que ces deux notions permettent
de caractériser un système vis-à-vis de lui-même. Ils offrent la possibilité de mettre
en valeur la notion de degré de parallélisme, et d’un point de vue représentatif, le
système peut ainsi être vu suivant les référents universels de la vitesse (speed-up) et
de la puissance (scale-up).

190 ANNEXE A. COMPLÉMENTS SUR LE PARALLÉLISME

191
Annexe B
Compléments sur les algorithmes de
jointure parallèle
Jointure par produit cartésien
Une jointure par produit cartésien [Bou90, Del82, Kor88, Ull85] consiste à compa-
rer chaque tuple de la relation R avec tous les tuples de la relation S (voir figure B.1).
S est appelée relation interne, ou relation de “build”, car tous ses tuples sont dispo-
nibles durant toute la jointure. R est appelé la relation externe, ou relation de “pro-
be”, car ces tuples sont comparés aux tuples de S, mais ne sont pas conservés après
leur comparaison. La jointure par produit cartésien est particulièrement lourde, car
elle implique un grand nombre de comparaisons. Elle nécessite de plus, pour des
relations internes de grande taille ne pouvant pas complètement tenir en mémoire
vive, d’effectuer un grand nombre d’entrée-sorties. Cette technique présente deux
inconvénients majeur. Le premier réside dans sa structure qui implique jjRjjxjjSjj
comparaisons. Le second provient de sa gestion de la mémoire. En effet, si l’une
ou l’autre des relations ne tient pas en mémoire, un grand nombre d’entrées-sorties
vont avoir lieu. Notons ici que les entrée-sorties se font en général par pages de
données et non par tuples.

192 ANNEXE B. COMPLÉMENTS SUR LES ALGORITHMES DE JOINTURE PARALLÈLE
Relation R Relation S
2/ On compare tous les tuples
3/ En cas de "match"
1/ On extrait les tuplesde R un par un de S au tuple de R
résultat
on produit les tuples
FIG. B.1 – Jointure par produit cartésien
Afin de limiter les entrées-sorties dans le cas de relations ne tenant pas en mé-
moire, on met en œuvre une technique appelée jointure par produit cartésien par
bloc (voir figure B.2). Celle-ci consiste à charger en mémoire le plus grand nombre
possible de pages de R. Ces pages sont ensuite prises une par une, et leur contenu
est alors comparé, page par page, aux tuples de S (une page de S est chargée en
mémoire à la fois). Si b pages de mémoire sont disponibles, b-2 pages sont utilisées
pour R. Une des deux pages restantes est utilisée afin de charger à tour de rôle les
pages de S. La seconde sert à stocker les tuples résultats (elle est écrite sur disque
lorsqu’elle est pleine). Ainsi, les tuples des pages de R en mémoire sont comparés à
ceux de chaque page de S. Lorsque toutes les pages de S ont été chargées afin que
les tuples de R leurs soient comparées, on charge b-2 nouvelles pages de R, et on
leur présente les pages de S, et ainsi de suite jusqu’au traitement complet de R.
La jointure par produit cartésien peut encore être améliorée par indexation des
tuples [Kor88, Abd95]. En effet, dans les cas ci-dessus, chaque tuple de R est com-
paré à l’ensemble des tuples de S. Si l’on introduit un index sur les tuples de S,
on peut alors, pour chaque tuple de R, scruter l’index, afin d’y récupérer un poin-
teur sur les pages de S contenant des tuples correspondant au tuple de R. De cette
manière, il suffit ensuite de charger les pages contenant les tuples de S, afin d’en
extraire ceux-ci et de les joindre au tuple de R en cours de traitement.

193
RAM
Relation SRelation R
1/ On extrait les pages de R
par paquets de b-2 pages
2/ On extrait toutes les pages S
â tour de rôle pour les comparer aux b-2 pages extraites de R
3/ En cas de "match"
on produit les tuples
résultat (dans le tampon d’écriture)
4/ Quand le tampon est plein,
on le vide sur le disque
FIG. B.2 – Jointure par produit cartésien par blocs
La parallélisation la plus simple de ces algorithmes se fait en répartissant la rela-
tion externe R sur les processeurs et en dupliquant la relation interne S sur chacun
de ces processeurs. Une amélioration évidente consiste à répartir les deux tables à
l’aide d’une fonction (commune) de hachage (ou par intervalle) portant sur l’attribut
de jointure. Les variantes faisant intervenir un index supposent que S ait été indexée
à l’avance. A nouveau, cet algorithme sera plus intéressant si S est répartie suivant
l’attribut de jointure et à l’aide d’une fonction de hachage ou par intervalles, car R
peut alors être répartie de même plutôt que dupliquée sur chaque processeur.
Jointure par tri-fusion
Les algorithmes de jointure par produit cartésien supposent un balayage de S
pour chaque tuple de R. Une technique intéressante pour réduire ce balayage consiste
à trier les deux relations suivant l’attribut de jointure [Knu98, Aho87]. Le tri des re-
lations est effectué par tri-fusion. Cet algorithme effectue d’abord le tri de chaque
page indépendamment (tri interne), puis trie ensuite les pages entre elles (tri ex-
terne). Ensuite, les deux relations sont fusionnées. Le principe consiste à partir du
premier tuple de R et du premier tuple de S. Notons R.a l’attribut de jointure de R

194 ANNEXE B. COMPLÉMENTS SUR LES ALGORITHMES DE JOINTURE PARALLÈLE
et S.b l’attribut de jointure de S. Si R.a est inférieur à S.b, on passe au tuple suivant
de R, si R.a est supérieur à S.b, on passe au tuple suivant de S, est enfin si R.a et S.b
sont égaux, on produit un tuple résultat. On passe ensuite au tuple suivant d’une
des deux relations. Il existe plusieurs techniques de parallélisation permettant un tri
en parallèle puis une fusion sur un processeur unique[Val84], ou une répartition de
R et S suivant l’attribut de jointure (par hachage ou intervalles) afin d’appliquer le
tri fusion en local sur chaque processeur [Sch89].
Jointure par hachage classique
La jointure par hachage consiste à bâtir une table de hachage sur l’attribut de
jointure sur la plus petite relation (on appelle cette opération la phase de build),
puis à prendre chaque tuple de la seconde relation, à calculer sa valeur de hachage,
et à le comparer avec les tuples de la première relation ayant la même valeur de
hachage (phase de probe). Dans cette méthode, seule la plus petite table est stockée
sous forme de table de hachage. Les trois principales variantes de jointure par ha-
chage sont le hachage simple, le hachage “Grace” et le hachage hybride. Le hachage
simple [Del82] consiste à construire, dans un premier temps, la table de build (sur
la relation S), puis à effectuer ensuite le probe (avec la relation R). Les tuples de la
relation S sont répartis dans des paquets, ou “buckets”, correspondant à une entrée
de la table de hachage. On prend ensuite chaque tuple de R à tour de rôle afin de le
comparer aux tuples du bucket correspondant. Quand la table de build ne tient pas
en mémoire, on choisit une fonction de hachage f(x) à N entrées, telle que chaque
bucket généré puisse tenir en mémoire (si b pages de mémoire sont disponibles,
un bucket doit en occuper au plus b-2). Si plusieurs buckets sont susceptibles tenir
en mémoire, ils peuvent y coexister. Les autres sont écrits sur disque et chargés au
besoin.
Soit f la fonction de hachage servant à construire les paquets, et retournant des

195
valeurs comprises entre 1 et n. On procède en scrutant d’abord les tuples de la re-
lation interne R. Seuls les tuples vérifiant f(a)=1 sont conservés ; les autres sont re-
placés sur le disque, page par page, dans une relation R’. Les tuples vérifiant f(a)=1
sont insérés dans la table de hachage à l’aide d’une seconde fonction g différente de
f. Les tuples de la relation externe S sont ensuite scrutés. A nouveau, ceux ne véri-
fiant pas f(b)=1 sont placés sur disque dans une relation S’, et ceux vérifiant f(b)=1
sont comparés aux tuples de la table de hachage (suivant la fonction g). On recom-
mence ensuite avec R’ et S’ et f(x)=2, et ainsi de suite jusqu’à f(x)=n. La figure B.3,
inspirée de [Ham96], illustre la technique de jointure par hachage classique.
R’
R
(lecture)
Tampon de 1 page
(page par page)
Ecriture de R’
(page par page)Lecture de R
Tampon de 1 page
(écriture)
f(r.a)=i
f(r.a)!=i
Résultat
S
S’
0
1
n-1
(table de hachage)
Tampon de (b-2) pages
f(s.b)=i
f(s.b)!=i
Tampon de 1 page
(écriture)
Ecriture de S’(page par page)
Tampon de 1 page(lecture)
(page par page)Lecture de S
Tampon des tuples résultat
(1 page)
Ecriture du résultat
(page par page)
2/ Phase de Probe1/ Phase de Build
sondage
FIG. B.3 – Jointure par hachage classique
Jointure par hachage “Grace hash join”
Afin de limiter les réécritures de tuples du hachage simple, le hachage “Grace”
propose de hacher les deux relations R et S en choisissant une fonction telle que
chaque paire de paquets (paquets de R et S correspondant à la même entrée de la
table de hachage) puissent tenir en mémoire [Kit83]. Une fois le hachage terminé,
on peut joindre les paires de paquets par hachage simple (à l’aide d’une seconde
fonction de hachage différente de la première), mais sans contrainte mémoire.

196 ANNEXE B. COMPLÉMENTS SUR LES ALGORITHMES DE JOINTURE PARALLÈLE
Jointure par hachage hybride
Comme pour le hachage “Grace”, on construit des paquets susceptibles de tenir
en mémoire, mais alors que dans l’algorithme “Grace”, la construction des paquets
et la jointure constituent deux phases dissociées, le hachage hybride [DeW84, Sch89]
propose de construire la table de hachage du premier paquet durant la construction
des paquets.
Jointure en mode Full Parallelism
Bien que cette technique ne représente pas exactement une amélioration des
techniques de jointure à proprement parler, il semble toutefois intéressant de la
présenter dans cette rubrique. Cet algorithme, introduit par [WIL95], a été conçu
pour améliorer le temps de réponse des requêtes multi-jointures en mémoire par-
tagée. Son principe est simple : il consiste à considérer les deux relations tout à la
fois comme relation de build et de probe. Lorsqu’un tuple d’une des deux relations
arrive, il est tout d’abord haché, comparé à la table de build de l’autre relation, puis
ensuite positionné dans la table de build de sa propre relation. De cette façon, il
n’est pas nécessaire d’attendre la fin de la construction de la table de build pour
commencer à effectuer des comparaisons, et donc à potentiellement produire des
tuples résultats. Un tel algorithme trouve notamment son intérêt dans les jointures
entre tables intermédiaires, mais également lorsque les tuples de la relation de probe
sont disponibles avant la fin de la relation de build.
Le principal inconvénient de cette méthode réside dans son surcoût en stockage,
car il implique la création de deux tables de build. Handicap pouvant toutefois
être partiellement compensé par quelques astuces de programmation (on peut, par
exemple, cesser l’insertion des tuples dans les tables de build dès lors que l’une des
deux relations est complètement buildée.

197
Parallélisation d’autres opérations relationnelles binaires
Les jointures sont l’exemple le plus fréquent (et, de loin, le plus abondamment
traité dans la littérature) d’opérations relationnelles binaires. Toutefois, d’autres opé-
rations existent, telles l’union, la différence et l’intersection. Bien que la parallélisa-
tion de telles opérations n’aie pas donné lieu à de nombreuses recherches, il pourra
être intéressant de consulter l’ouvrage de Goetz Graefe [Gra93] ainsi que l’article de
Nadejda Biscondi et al. [Bis96] à ce sujet. Graefe introduit en effet la possibilité de dé-
finir un opérateur de fusion, capable d’effectuer l’ensemble des opérateurs binaires.
Biscondi et al. propose un tel opérateur en analysant son mode de fonctionnement
et en montrant sa faisabilité dans un environnement parallèle.


















