
Etude des Transactions Concurrentes Dans une Base de Données Répartie. Application à l’Intranet...
159
a UNIVERSITE DE KINSHASA Faculté des Sciences Département de Mathématiques et Informatique B.P. : 190 Kinshasa XI Par KAYEMBA KAVUALLA Sagesse Travail réalisé et défendu en vue d’obtention du titre de licencié en science Groupe : Informatique Option : Génie-Informatique Sous la direction de : MBUYI MUKENDI Eugène Professeur Ordinaire Année académique 2010-2011 Etude des Transactions Concurrentes Dans une Base de Données Répartie Application à l’Intranet Gouvernemental de la RDC
-
Upload
sagessekayemba -
Category
Engineering
-
view
146 -
download
6
Transcript of Etude des Transactions Concurrentes Dans une Base de Données Répartie. Application à l’Intranet...

a
UNIVERSITE DE KINSHASA
Faculté des Sciences
Département de Mathématiques et Informatique
B.P. : 190 Kinshasa XI
Par
KAYEMBA KAVUALLA Sagesse
Travail réalisé et défendu en vue d’obtention
du titre de licencié en science
Groupe : Informatique
Option : Génie-Informatique
Sous la direction de :
MBUYI MUKENDI Eugène
Professeur Ordinaire
Année académique 2010-2011
Etude des Transactions Concurrentes Dans une Base de Données Répartie
Application à l’Intranet Gouvernemental de la RDC
D
u
S
o
f
t
w
a
r
e
a
u
S
a
a
S
* *
S
o
f
t
w
a
D
u
D
u
S
o
f
t
w
a
r
e
a
u
S
a
a
S
* *
S
o
f
t
w
a
D
u
S
o
f
t
w
a
r
e
a
u
S
a
a
S
* *
S
o
f
t
w
a

b
UNIVERSITE DE KINSHASA
Faculté des Sciences
Département de Mathématiques et Informatique
B.P. : 190 Kinshasa XI
Etude des Transactions Concurrentes Dans une Base de Données Répartie
Application à l’Intranet Gouvernemental de la RDC
Par
KAYEMBA KAVUALLA Sagesse
Travail réalisé et défendu en vue d’obtention
du titre de licencié en science
Groupe : Informatique
Option : Génie-Informatique
Sous la direction de :
MBUYI MUKENDI Eugène
Professeur Ordinaire
Année académique 2010-2011

i
Table de Matières
EPIGRAPHE ................................................................................................................................. IV
DEDICACE ................................................................................................................................... V
REMERCIEMENTS ......................................................................................................................... VI
LISTE DES ABREVIATIONS ............................................................................................................. VIII
LISTE DES FIGURES ........................................................................................................................X
LISTE DES TABLEAUX .................................................................................................................... XII
INTRODUCTION GENERALE ............................................................................................................. 1
CHAPITRE I ................................................................................................................................. 6
LES SYSTEMES DISTRIBUES ............................................................................................................. 7
I. 1. Les Systèmes Distribués ............................................................................................... 7
I.1.1. Définitions .............................................................................................................. 8
I.1.2. Caractéristiques et Objectifs .................................................................................. 8
I.1.3. Système Centralisé VS Système Distribué .............................................................. 9
I.1.4. Propriété d’un Système Distribué ........................................................................ 11
I.1.5. Architecture d’un Système Distribué ................................................................... 14
I.2. Les Bases de Données Réparties (Distribuées) ........................................................... 17
I.2.1. Définitions ............................................................................................................ 17
I.2.2. Buts et motivations pour une Base de Données Distribuée : BDD ...................... 19
I.2.3. Avantages et Contraintes ..................................................................................... 20
I.2.4. La Répartition de données (Les Niveaux) ............................................................. 20
I.2.5. Principe d’une Base de Données Réparties ou Distribuée ................................... 21
I.2.6. Systèmes de Gestion de Base de Données Distribuée (SGBDD) et Architectures 22
I.3. La Réplication .............................................................................................................. 24
I.3.1. Les protocoles de contrôle de réplication ............................................................ 24
I.3.2. Architectures de Réplications .............................................................................. 26
I.4. Fragmentation, Allocation et Conception ................................................................... 29
I.4.2. Allocation .............................................................................................................. 32
I.4.3. Conception ........................................................................................................... 34
CHAPITRE II .............................................................................................................................. 36
LES TRANSACTIONS DISTRIBUEES .................................................................................................. 36
II.1. DEFINITIONS D’UNE TRANSACTION ........................................................................... 36
II.2. CLASSIFICATION DES TRANSACTIONS ........................................................................ 40
II.2.1. Suivant la nature de différentes opérations ....................................................... 40
II.2.2. Suivant la durée ................................................................................................... 41
II.3. MODELES DE TRANSACTIONS ................................................................................... 41
II.3.1. Les Transactions Plates (Flat Transactions) : ....................................................... 41

ii
II.3.2. Les Transactions plates avec Points de Sauvegarde (SAVEPOINTS) : .................. 41
II.3.3. Les Transactions Chainées (Chained Transactions) :........................................... 42
II.3.4. Les Transactions Imbriquées ou Emboitées (Nested Transactions) ................... 42
II.3.5. Transactions Compensatrices ............................................................................. 45
II.3.6. Les Transactions Longues .................................................................................... 46
II.3.7. Les transactions Distribuées ................................................................................ 46
II.4. LA JOURNALISATION ET LA REPRISE DES TRANSACTIONS ......................................... 47
II.4.1. Journalisation ...................................................................................................... 47
II.4.2. Reprise ................................................................................................................. 50
II.5. TRANSACTION DISTRIBUEE ET LE MODELE OSI ......................................................... 51
II.5.1. Le Système Transactionnel .................................................................................. 51
II.5.2. Le Modèle OSI pour les Transactions Distribuées ............................................... 53
II.6. GESTION ET CONTROLE DE CONCURRENCE DE TRANSACTIONS (REPARTIE) ............ 57
II.6.1. La cohérence de données.................................................................................... 58
II.6.2. Concurrence d’accès de données........................................................................ 65
CHAPITRE III ............................................................................................................................. 79
LES APPLICATIONS ...................................................................................................................... 79
III.1. Mécanisme de Répartition sous SQL SERVER ........................................................... 79
III.1.1. SQL SERVER ........................................................................................................ 79
III.1.2. Les Bases de Données ........................................................................................ 79
III.1.3. Services et moteurs ............................................................................................ 80
III.1.3.1. SQL Server .......................................................................................................... 80
III.1.3.2. SQL Server Agent ............................................................................................... 81
III.1.4. Transactions ...................................................................................................... 81
III.1.5. Notion de répartition sous SQL SERVER ............................................................. 82
III.2. Gestion de Transactions par la programmation sous .NET (Framework 3.5) ........... 85
III.2.1. Les Transactions locales .................................................................................... 85
III.2.2. Les Niveaux d’Isolations ..................................................................................... 87
III.2.3. Les Transactions Distribuées .............................................................................. 89
III.3. Intranet Gouvernemental de la RDC (République Démocratique du Congo) .......... 91
III.3.1. Quelques définitions .......................................................................................... 91
III.3.2. Objectif du projet ............................................................................................... 92
III.3.3. Avantages pour les utilisateurs .......................................................................... 92
III.3.4. Situation actuelle de l’Intranet........................................................................... 93
III.4. Mise en place d’un Système d’Information de Traitement de Salaire des Agents de
l’Etat .................................................................................................................................. 95
III.4.1. Circonscription ................................................................................................... 95
III.4.2. Modélisation du Système d’Information avec l’UML ......................................... 96
III.4.2.1. Spécification Initiale du Système ................................................................. 96
III.4.2.2. Enoncé du problème ................................................................................... 97
III.4.2.3. Analyse du Domaine .................................................................................... 98

iii
III.4.2.3.1. Diagramme de Cas d’Utilisation ............................................................... 98
III.4.2.3.2. Diagramme de Classe ............................................................................. 100
III.4.2.3.2. Diagramme d’état ................................................................................... 102
III. 4.2.3.3. Diagrammes d’Activités ......................................................................... 103
III.4.2.4. Conception et Implémentation du Système ............................................. 105
III.4.2.4.1. Schéma Global ........................................................................................ 105
III.4.2.4.2. Fragmentations et Allocations ............................................................... 106
III.4.2.4.3. Réplication .............................................................................................. 107
III.4.2.4.4. Implémentations de l’Application .......................................................... 108
CONCLUSION........................................................................................................................... 138
REFERENCE ............................................................................................................................. 140

iv
Epigraphe
… Un Système de Bases de Données Réparties est
suffisamment complet pour décharger les utilisateurs de
tous les problèmes de concurrence, fiabilité, optimisation
de requêtes ou transactions sur des données gérées par
différents SGBDs sur plusieurs sites. [15]

v
Dédicace
A ma très chère Mère, Denise NTUMBA ;
A mon très cher Père, Denis-Robert KAYEMBA ;
Qui, des manières constantes, ont accolé leurs sacrifices pour parfaire l’œuvre que je
suis. Qu’ils en soient remerciés et trouvent par ici la gratitude de mon cœur sincère ;
A tous les miens : parents, amis et connaissance ;
Que je ne peux énumérer
Je dédie ce travail.
KAYEMBA KAVUALLA Sagesse

vi
Remerciements
A celui qui garde l’âme et protège le corps ; le Tout-Puissant Dieu qui renouvelle
les forces, nous transmettons nos tout premiers remerciements ; car après nous avoir
gardés tout au long de notre deuxième cycle en force et bonne santé, a bien voulu que
nous l’achevions avec ce présent travail qui le couronne. Merci Seigneur Jésus Christ.
S’il s’est avéré possible de réaliser ce présent travail, c’est grâce au Prof. Eugène
MBUYI MUKENDI qui nous a accepté sous sa direction et son Assistant Hercule KALONJI
KALALA qui l’a poursuivi jusqu’à sa perfection ; qu’ils trouvent à travers ces lignes
l’expression de notre profonde gratitude et de notre respect.
Nos remerciements s’adressent enfin à tout celui qui, d’une manière ou d’une autre, a
participé à la victoire de cette bataille. En voici quelques uns : Jérémie PANGU NKOYI, Théo
MASAMBOMBO MBIYA, etc.
KAYEMBA KAVUALLA Sagesse

vii
[Les Listes]

viii
Liste des Abréviations
.NET : DotNET 2-PC : Protocole de Validation en Deux Phases 3-PC : Protocole de Validation en Trois Phases ACID : Atomicity, Consistency, Isolation et Durability, ACSE : Association Control Service Element ADO : Activex Data Object APD : Aide Public au Développement API: Application Programming Interface BD : Base de Données BDD : Base de Données Distribuée BDR : Base de Données Répartie C# : CSharp C/S : Client-Serveur CCR: Committment, Concurrency and Recovery CORBA: Common Object Request Broker Architecture CPU : Central Processing Unit DTC : Distributed Transaction Coordinator DTP: Distributed TP ISO : International Standard Organisation JDBC : Java DataBase Connectivity JTS : Java Transaction Service KOICA: Korea Intrnational Cooperation Agency LDF: Log Database File MACF : Multiple Association Control Function MDF: Main Database File MS DTC : Microsoft Distributed Transaction Coordinator MTS : Microsoft Transaction Server NDF : Next Database File NU : Nouvelle Unité ODBC : Open DataBase Connectivity OLAP : On-line Analytical Processing OLTP: On-line Transactional Processing OSI : Open Système Interconnection P2P : Peer-to-Peer ou Pair-à-Pair RDC : République Démocratique du Congo RMI: Remote Method Invocation SAO : Single Association Objects SBDD : Système de Bases de Données Distribuées SGBD : Système de Gestion de Base de Données SGBDD : Système de Gestion de Base de Données Distribué SGBDR : Système de Gestion de Base de Données Réparti SOAP: Simple Object Access Protocol

ix
SQL : Structured Query Language TP: Transactions Processing TPPM : TP Protocol TPSU: TP Service User TPSUI : TPSU Invocation UML : Unified Modeling Language VE : Vue Externe. WW : WOUND-WAIT XML-RPC: Extensible Markup Language-Remote Procedure Call

x
Liste des Figures
Figure 1 : De Centralisé vers Distribué [9] ................................................................................ 10
Figure 2: système distribué avec un middleware [1] [51] ........................................................ 14
Figure 3 : Client-Serveur ........................................................................................................... 15
Figure 4 : Architecture d’une base de données [41] ................................................................ 18
Figure 5 : Architecture d’une BDD............................................................................................ 21
Figure 6 : réplication synchrone ............................................................................................... 24
Figure 7 : réplication asynchrone ............................................................................................. 25
Figure 8 : une transaction dans une base de données cohérente .......................................... 36
Figure 9 : Transaction plates avec SAVEPOINTS [22] ............................................................... 42
Figure 10 : Arbre de Transactions et sous-Transactions ......................................................... 43
Figure 11 : Validation et Abandon de Sous-Transactions ....................................................... 45
Figure 12 : Transactions compensatrices ................................................................................ 46
Figure 13 : L’UNDO d’une mise-à-jour [30]. ............................................................................ 48
Figure 14 : Le REDO d’une mise-à-jour [30]. ........................................................................... 49
Figure 15 : Architecture du système transactionnel [31]......................................................... 51
Figure 16 : Architecture Transactionnelle [46] ........................................................................ 53
Figure 17 : Modèle de Dialogue dans OSI TP ........................................................................... 54
Figure 18 : Arbre de Transactions ............................................................................................ 55
Figure 19 : Les actions du Protocole de Validation en Deux Phases [32] ................................ 60
Figure 20 : Validation normale [15] [22] [40] ........................................................................... 61
Figure 21 : Panne d’un participant avant d’être prêt [15] [22] [40] ........................................ 62
Figure 22 : Panne d’un participant après s’être déclaré prêt [15] [22] [40] ............................ 62
Figure 23 : Panne du coordinateur [15] [40] ............................................................................ 63
Figure 24 : TIME-OUT et panne dans le protocole de validation en trois phases [32] ............ 64
Figure 25 : Exécution non contrôlée des transactions concurrentes ...................................... 65
Figure 26 : Perte d’opérations .................................................................................................. 66
Figure 27 : Ecriture inconsistante ............................................................................................. 67
Figure 28 : Lecture sale ............................................................................................................ 68
Figure 29 : Lecture non-reproductible ..................................................................................... 69
Figure 30 : Le Principe du Verrouillage à deux phases [31] ..................................................... 72
Figure 31 : Le Verrou Mortel (DeadLock) [42].......................................................................... 74
Figure 32 : Cycle dans le Graphe des Attentes ......................................................................... 75
Figure 33 : Réplication peer-to-peer avec trios et quatre nœuds [19] .................................... 83
Figure 34 : Vue de l’architecture de la Réplication transaction [19] ....................................... 83
Figure 35 : Interface de Démarrage du Service de DTC ........................................................... 89
Figure 36 : l’Intranet Gouvernemental [35] ............................................................................. 94
Figure 37 : Diagramme de Cas d’Utilisation ............................................................................. 99

xi
Figure 38 : Diagramme de Classe ........................................................................................... 101
Figure 39 : Diagramme d’état de la classe Agent ................................................................... 102
Figure 40 : Diagramme d’Activité pour l’immatriculation d’un agent ................................... 103
Figure 41 : Diagramme d’Activité pour le calcul et la paie des Agents immatriculés ............ 104
Figure 42 : Diagramme de classe avec toutes les propriétés et les classes association ........ 105

xii
Liste des Tableaux
Tableau 1: Avantages et Désavantages de la combinaison de stratégie ................................. 28
Tableau 2: Compatibilité des Verrous (modes) ........................................................................ 71
Tableau 3 : Compatibilité des Verrous (Opérations) ................................................................ 71
Tableau 4 : Projets Réseaux Gouvernemental par KOICA [35] ................................................ 93
Tableau 5 : Tableau de correspondance de numéro de sites et leurs noms ........................... 95
Tableau 6 : Fragmentations et allocations aux sites .............................................................. 106

xiii
[Introduction Générale]

1
Introduction Générale
Actuellement les besoins d’entreprises et leurs solutions doivent tabler sur
l’infrastructure qui leur est offerte, à savoir les réseaux informatiques de communication, et
aussi pour en profiter de ses avantages, surtout qu’en plus cette infrastructure
correspondrait le mieux possible à l’architecture des entreprises.
Le système d’Information aussi, qui est un apanage pour une entreprise, s’est étendu
sur cette infrastructure en sous systèmes, et par conséquent doit faire collaborer ces
derniers de manière à leur permettre soit de sous-traiter un sous système chez un autre, soit
à permettre plusieurs sous systèmes de pouvoir participer à la réalisation d’un résultat. Ce
type de systèmes s’appelle et sont dits « distribué ou réparti».
Et cette notion de système distribué même, dont la définition est la suivante, une
collection de processus informatiques indépendants qui communiquent mutuellement par
passage de message [27], s’articule sur un seul problème à savoir, la cohérence de données
qui doit être assurée de manière la plus transparente aux utilisateurs.
Dans les Bases de Données Distribuée, comme dans tout autre système distribué, y est
utilisé le concept de la transaction, qui est aussi une voie vers la gestion de la cohérence de
données, vu qu’une transaction a cette propriété d’atomicité qui lui permet d’être défaite ou
validée d’un seul coup lorsque l’ensemble d’opérations qu’elle encapsule ont échoué ou
réussi, afin de laisser les données si pas dans un état de cohérence précédent, mais de les
faire passer dans un autre état de cohérence.
La concurrence aussi, il faut le signaler, même si elle fait partir des objectifs pour
lesquels on construirait un système distribué, reste aussi une cause d’incohérence de
données dans ce dernier. De fait, elle nécessite une bonne gestion ; pour aussi garantir la
cohérence ; le concept de transaction le fait aussi bien, de par sa propriété d’Isolation. D’où,
on parle des transactions concurrentes, ce qui est même l’objet principal de ce présent
travail.
Pour mener à bonne fin notre travail qui s’articule sur l’Intranet Gouvernemental (e-
Gouvernement), nous y avons ciblé un problème très récurrent que nous formulons de la
manière suivante, Mise en place d’un Système d’Information (Automatisé) de Traitement
de Salaire des Agents de l’Etat.

2
Pour que l’Etat ou le Gouvernement salarie un agent, ce dernier doit de prime abord
être immatriculé. Sachant que c’est chaque institution de l’Etat ou l’entreprise elle-même
qui gère ses employé (ses ressources humaines), c'est-à-dire elle organise le
recrutement, mais pour la prise des fonctions, c’est la fonction publique qui attribue les
matricules. Or ces opérations, manuelles soient-elle et faisant intervenir deux sites distants,
exigent souvent beaucoup de déplacements pour acheminer les dossiers et passer toutes les
étapes pour aboutir à un agent immatriculé. Chose qui fait perdre terriblement du temps.
Après immatriculation des agents, la Fonction Publique, qui est l’entité habilitée à
gérer la ressource humaine de l’Etat, est censée connaitre l’effectif de tous les agents de
l’Etat. Or, étant donné que le processus d’immatriculation prend assez de temps, et qu’en
plus puisque c’est manuel, il peut favoriser de cas des agents fictifs ; cette tache peut donc
devenir un peu pénible et erroné.
Venons-en maintenant au problème de salaire ; si l’immatriculation dure aussi
longtemps, on risque d’avoir une situation telle que, un agent en attente de son matricule
peut commencer déjà à travailler au sein de l’entreprise mais sans salaire de la part de l’Etat.
Et aussi si savoir l’effectif des agents est aussi un problème et favorise la présence des
agents fictifs, c’est l’Etat qui va perdre. De fait, le Ministère de la Finance, l’Entité qui calcule
et paie (ou calcule la masse salariale) les agents doit avoir une liste des agents immatriculé
de sorte à ne payer que ceux-là. C’est pour ça que la Fonction Publique édite les
immatriculés et en envoie la liste à la Finance.
Pour maintenant rémunérer ces agents, leurs entreprises respectives participent aussi
dans le calcul, même si c’est la Finance qui paie (ou calcule le salaire). Et alors, calculer le
salaire d’un agent, c’est aussi une tache très délicate, qui nécessite une bonne attention, car
son calcul inclut beaucoup d’autres éléments tels que, les indemnités, la prime, le salaire de
base, les retenues, le prêt, etc., et le faire à la main peut probablement glisser des erreurs.
D’où, un besoin incessant de l’informatisation de processus, afin de pouvoir régulariser
pas mal des choses, à savoir l’immatriculation et la paie, au-delà de certains contrôles
physiques qui doivent toujours être maintenus.
Mettre une moindre transparence dans la gestion des ressources humaines de l’Etat,
chose qui est un volet non négligeable dans la gestion de la RDC, de sorte à assouplir
tant les processus d’immatriculation que ceux de la paie des agents, de sorte aussi à
permettre que les agents et l’Etat se retrouvent tous, et de sorte enfin si pas à contourner le
problème des agents fictifs, mais à l’amoindrir. L’informatique donc, s’avère un outil
incontournable, permettant ainsi d’éviter trop de temps d’attente, trop de déplacement,
trop de formulaires et donc de paperasses dans l’administration de l’Etat.

3
Donc la transparence, la souplesse, et la simplification de procédures, sont des intérêts
que poursuit ce travail.
Pour ce faire, nous allons mettre sur pied une solution informatique, sous un modèle
d’un système distribué, en exploitant plus précisément les Bases de Données Réparties
(BDR), puisque c’est le modèle qui s’accorde le plus à la situation, étant donné qu’elle fait
intervenir plusieurs sites distants et qu’en plus puisque déjà un bon nombre de sites sont
reliés dans le réseau de l’Intranet Gouvernemental.
Et dans les BDRs, nous nous nicherons sur l’utilisation des transactions, puisque ces
dernières, de par leurs propriété, offrent un bon nombre d’avantages, tels que, de gardre les
données de la base de données toujours cohérente, et si elles en venaient d’être dans une
situation de concurrence, elles s’en sortent toujours bien de par la possibilité qu’elles ont
d’être isolée, c'est-à-dire de permettre ou pas l’accès des autres transactions dans la lecture
ou l’écriture des ressources qu’elles utilisent, et bien plus que tout, grâce au journal de
transactions, qui permet d’archiver toutes les opérations effectuées sur la base. Les
transactions donnent donc cette possibilité de pouvoir retracer les opérations.
Certes, il existe nombreuses entreprises de l’Etat. Certes, il existe un bon nombre de
sites déjà relié dans le réseau de l’Intranet Gouvernemental.
Pourtant, pour des raisons de temps et de coût, de concision et de précision de
l’Application ici présentée comme solution informatique, nous n’avons pris en compte
que trois sites dont deux sont très stratégiques et indispensables à savoir, la Fonction
Publique pour l’immatriculation, et la Finance pour le calcul et la paie des agents, et un
troisième site qu’est la Primature pour illustrer le cas des entreprises ou institutions qui
participent passivement dans la rémunération des agents de l’Etat. Il faut signaler alors que
les deux sites sont aussi illustrés par le troisième site, étant donné qu’ils sont des institutions
avec des agents à gérer. Nous nous sommes aussi limités seulement aux éléments du salaire
cités ci haut.
Ainsi, grâce aux techniques de récolte de données suivantes, questionnaires (enquêtes)
et documentation, nous avons pu rassembler des informations nécessaires au montage de
notre Système d’Information.

4
Voici donc alors comment l’organisation du travail se présente :
Le travail est organisé en trois (3) chapitres :
- Le premier chapitre, intitulé Les Systèmes Distribué, donne un aperçu très
clair du domaine dont nous traitons, introduisant ainsi de manière nette, simple et
claire les concepts théoriques de base à utiliser dans la suite du travail, tels que la
réplication et les bases de données réparties.
Voici donc ses points chauds :
Les Systèmes Distribués
Les Bases de Données Répartie (BDR)
La Réplication
Conception, Fragmentation et Allocation d’une BDR
- Le deuxième chapitre, intitulé Les Transactions Distribuées, montre le bien
fondé de l’utilisation des transactions et de leur gestion, en parlant de différents
problèmes liés aux transactions concurrentes et leurs solutions.
Voici donc ses points chauds :
Définitions d’une Transaction
Classification des Transactions
Modèles de Transactions
La Journalisation et la Reprise des Transactions
Transaction distribuée et le Modèle OSI
Gestion et Contrôle de Concurrence de transactions (Répartie)
Et enfin,
- Le troisième chapitre, intitulé Les Applications, c’est ici que nous nous
sommes évertués pour rattraper si pas toutes mais une grande partie de théories
avancées précédemment, dans les outils informatiques utilisés pour mettre en place
une application (répartie) informatique que nous avons nommée « SalaryManager »,
un logiciel de traitement et de calcul de salaire des agents de l’Etat au sein de
l’Intranet gouvernemental (e-Gouvernement), allant de l’immatriculation des agents
jusque et y compris le traitement de leur salaire.

5
Voici donc ses points chauds :
Mécanisme de Répartition sous SQL SERVER 2008
Gestion de Transactions par la programmation sous .NET
(Framework 3.5)
Intranet Gouvernemental de la RDC (République Démocratique
du Congo)
Mise en place d’un Système d’Information (Automatisé) de
Traitement de Salaire des Agents de l’Etat (SalaryManager)

6
[Chapitre I]

7
Chapitre I
Les Systèmes Distribués
Les réseaux informatiques, qu’est une interconnexion des équipements informatiques,
offrent aux entreprises toute une panoplie des avantages, parmi lesquels ceux qui sont
beaucoup plus à l’intention de ce travail on a, l’échange et partage des données
informatiques et l’accès à des bases de données réparties ou distribuées, aussi bien qu’on le
sache que le partage est l’objectif premier de Réseaux Informatiques [48].
Et à l’apparition de ce réseau, sont nés et y sont déployés des systèmes dits distribués,
l’exploitant pour arriver à leurs propres fins. Ces derniers sont soit des bases de données
distribuées sur ce réseau soit des applications interagissant avec ces bases de données,
spécifiquement pour le cas qui nous concerne.
C’est comme ça que, nous allons commencer par esquisser sur les systèmes distribués
avant de nous plonger de manière la plus détaillée possible sur les bases de données
distribuées.
I. 1. Les Systèmes Distribués
Nous allons commencer par élucider mais, en éludant toute confusion, la différence ou
mieux la ressemblance entre le terme « distribué » et « répartie ».
Le terme « distribué » vient du terme anglais « distributed » ayant comme idée d’une
distribution des tâches réalisées par un coordinateur, pendant que « répartie » suppose une
coopération des tâches en vue de la répartition du travail, et pourtant dans la littérature
anglaise on ne reconnait pas cette différence puisque dans le terme « distributed System »
distributed signifie : « réparti dans l’espace » [10].
De fait, il n’y a donc aucune différence entre Système Distribué et Système Réparti, ou
bien, entre Distribué et Réparti dans le reste du travail.
Par contre au niveau de la Base de Données, [15] montre une certaine nuance
montrant que quand on parle d’une Base de Données Distribuée (BDD), c’est un terme tout
à fait générique et que de ce fait une Base de Données Répartie (BDR) n’est qu’un cas de
BDD, au même titre que les BDs fédérées, les sytèmes multi BD, etc. Nous en parlons dans la
partie y consacrée.

8
I.1.1. Définitions
"Un système réparti est un ensemble de machines autonomes connectées par un
réseau, et équipées d'un logiciel dédié à la coordination des activités du système ainsi qu'au
partage de ses ressources." Coulouris et al. [18].
"Un système réparti est un ensemble d’ordinateurs (ou processus) indépendants qui
apparaît à un utilisateur comme un seul système cohérent". Tanenbaum [7] [25].
"Un système informatique distribué est une collection de processus informatiques
indépendants qui communiquent mutuellement par passage des messages" [27].
Force est de constater, que ces définitions ci-haut données ne se contredisent pas
mais, bien au contraire chacune d’elle définit une idée, qui mise ensemble donne une idée
claire et globale de ce qu’est un Système Distribué.
Aussi, nous en avons pu retenir deux concepts très importants, (i) indépendant, de par
la définition de [7], c'est-à-dire que les ordinateurs ont architecturalement cette capacité de
travailler indépendamment, (ii) le logiciel, de la première définition mais complété par la
deuxième, qui permet à cet ensemble d’ordinateurs de paraître à l’utilisateur comme un
seul.
Cette dernière notion est connue sous le nom d’Image unique du système [18] [43].
Et cette notion d’Image unique du système, fragilise un peu le système à tel enseigne
qu’il ne suffit qu’une simple panne d’un ordinateur, cela peut impacter négativement sur le
bon fonctionnement du système et voire amener à des incohérences.
Leslie Lamport l’a bien dit lorsque définissant un système distribué : "un système qui
vous empêche de travailler si une machine dont vous n’avez jamais entendu parler tombe en
panne" [27] [25].
I.1.2. Caractéristiques et Objectifs
Voici les objectifs pour lesquels on construirait un système distribué, qui font office
directement des caractéristiques de ce dernier :
Le partage des ressources :
Toutes les ressources tant hardware (ordinateurs, organes d’entrée-sortie,
processeurs spécialisés, dispositifs de commande ou de mesure, etc.) que software
sont partagé entre les entités du système.

9
L’ouverture :
Les composants et les logiciels utilisés au sein de ce système peuvent provenir de
différents fournisseurs et travailler sans aucun problème.
La concurrence :
Le traitement concurrent augmente la performance du système.
La grande échelle (ou scalability : en anglais)
C’est la capacité d’un système de ne pas dysfonctionner lorsque sa taille s’accroît, ou
lorsque des nouvelles ressources sont ajoutées.
La tolérance à la faute :
C’est la capacité qu’un système continue de fonctionner malgré quelque défaillance
partielle des composants ou du réseau de communication.
I.1.3. Système Centralisé VS Système Distribué
Le Système Distribué, ne présenterait-il que des avantages ci-haut présentés en termes
d’objectifs ? Et pourtant, un peu ci-haut on a montré un petit problème lié à la notion
d’Image unique. Qu’on le sache, il a des problèmes ou désavantages dont nous allons parler
dans la suite. De plus, par définition, les systèmes distribués sont plus vulnérables que les
systèmes centralisés, car le nombre de points susceptibles d'être attaqués est plus
important, en plus de la faiblesse des réseaux rendus nécessaires par la répartition.
A la différence du système distribué, le système centralisé est celui qui travaille et se
base sur une seule et même machine, tout y est localisé et accessible par des programme. Ce
système est aussi bien illustré par un « mainframe », où il peut y avoir un ou plusieurs CPU
(Central Processing Unit) et les utilisateurs qui communiquent directement avec lui via des
terminaux.
Le seul vrai problème avec ce système, c’est qu’il n’est pas scalable (expansible) [43], il
y a une limitation par rapport au nombre de CPUs à tel enseigne qu’il faut le mettre à jour ou
carrément le remplacé lorsqu’il faut ajouter un CPU.
De par les avantages et objectifs du système distribué, on peut sans aucun effort voir
le pourquoi de ce passage.

10
Et pourtant ce passage amène aussi des nouveaux problèmes tels que la localisation, la
transparence, l’interopérabilité, etc. qui sont pris aux titres des défis, auxquels le système
distribué doit faire face.
Conception d’un système distribué
La conception peut se faire de deux manières, [13], matérielle et logicielle.
Conception matérielle
Elle peut se réaliser sur :
+ Machine multiprocesseurs avec mémoire partagée
+ Cluster (grappe) d’ordinateur dédié au calcul/traitement massif parallèle
+ Ordinateurs standards connecté en réseau.
Conception logicielle
+ Le système logiciel ici, est composé de plusieurs entités disséminé dans un réseau,
s’exécutant indépendamment et parallèlement.
Appelé
Appelant
Souche
Appelant
Squelett
e
Appelé
Réseaux
Centralisé Distribué Figure 1 : De Centralisé vers Distribué [9]

11
I.1.4. Propriété d’un Système Distribué
Les défis tantôt dits sont ici présentés comme des propriétés que doit assurer un
système distribué. Nous allons pour notre compte ne présenter que celles qui sont beaucoup
plus inhérentes à notre travail :
La Transparence :
Contrairement à ce que laisse entendre naturellement ce vocable, elle veut plutôt ici
dire que, tous les détails techniques et organisationnels, complexes du système distribué
sont cachés à l’utilisateur.
Le but de la transparence est de permettre une manipulation des services distants plus
facilement, c'est-à-dire, comme des services locaux [27], sans avoir besoin de connaître sa
localisation ou son détail techniques des ressources [25].
Cette propriété fait alors maximiser la scalabilité et la flexibilité du système, simplifie le
développement des applications et leur maintenance évolutive et corrective.
La norme (ISO, 1995), classifie la transparence sous plusieurs niveaux [18] [25] [27]:
- Accès : il y a pas d’accès spécifique pour des ressources ; l’accès à une ressource tant
distante que locale est identique.
- Concurrence : l’utilisateur du système ne doit pas savoir que telle ou telle autre
ressource peut être partagée ou utilisée simultanément par d’autres utilisateurs.
- Extension (des ressources) : s’il faut étendre ou réduire le système, il ne faudra pas
que l’utilisateur en soit gêné (sauf la performance [18]).
- Hétérogénéité : il doit être caché à l’utilisateur les différences matérielles ou
logicielles des ressources qu’il utilise. La notion d’interopérabilité.
- Localisation : il n’est nullement besoin de savoir l’emplacement d’une ressource du
système pour y accéder. Ceci donne lieu à la transparence de migration [18].
- Migration : le déplacement d’une ressource peut se faire, mais sans qu’on ne s’en
plaigne, car rien ne sera aperçu.
- Panne : lorsqu’il y a panne (réseaux, machines, logiciels) au niveau d’un nœud du
système, l’utilisateur ne doit pas le savoir.

12
- Relocalisation ou Mobilité : une ressource peut changer d’emplacement pendant
qu’elle est utilisée, mais sans qu’on s’en rende compte.
- Réplication : l’utilisateur du système n’a pas besoin de savoir que telle ressource est
dupliquée.
De manière la plus évidente, on voit qu’on peut assurer une transparence totale, et
pourtant il est très difficile et voire impossible de masquer toutes les pannes des ressources.
La Disponibilité
Il existe beaucoup de causes à l’origine de l’indisponibilité d’un système, mais voici
celles que nous notons ici selon [25] :
- Des pannes empêchant au système ou à ses composants de fonctionner
conformément à la spécification ;
- Des surcharges dues à des sollicitations excessives d’une ressource ; la congestion et
la dégradation des performances du système s’en suivent certainement.
- Des attaques de sécurité pouvant causer des dysfonctionnements, voire l’arrêt du
système, des pertes et incohérence de données.
Pour ne citer que ça.
Mais puisque dire « disponibilité » sous-entend que le système doit toujours être à
mesure de délivrer correctement les services et ce conformément à la spécification ; mais il
faut savoir que les pannes ou toute autres tentatives (ci-haut citées) vont toujours essayer
de compromettre le bon fonctionnement du système ; pour ce, il faut le rendre capable de
rester disponible.
Parmi les solutions retenues pour y remédier [25], nous avons choisi de ne parler que
de celle qui va beaucoup plus avec notre travail :
La réplication ; cette technique est utilisé pour pallier à la première (panne) et deuxième
(surcharge) cause d’indisponibilité. Ici, les copies d’une même ressource peuvent se trouver
en même temps dans des emplacements différents. Ainsi, lorsqu’une ressource tombe en
panne, le traitement qu’elle effectuait est déplacé sur une autre ressource disponible. Pour
ce qui est de la surcharge, au lieu que des sollicitations se fassent sur une même et seule
ressource, elles se font parallèlement sur chacune de ses copies (réplique) partout ailleurs.

13
L’Autonomie
Puisque les systèmes existants ou les applications existantes sont souvent difficiles à
remplacer ou à réécrire, logiquement par ce qu’ils sont bien expérimentés et ont une
expertise ; quand on a besoin de les adapter à un autre besoin qui n’y est pas supporté.
Voici donc la bonne motivation parmi tant d’autres de l’autonomie ; un système ou un
composant est dit autonome si son fonctionnement et son intégration dans un système
existant n’exige pas de modifications ni à lui ni à ce dernier.
L’autonomie des composants d’un système favorise par conséquent l’adaptabilité,
l’extensibilité et la réutilisation de ressources de ce système.
Les Intergiciels : Middlewares
Pour compléter à l’autonomie d’un système, on peut aussi intégrer des intergiciels. Un
intergiciel (middleware, en anglais) est un assemblage des fonctionnalités, nouvelles,
formant un logiciel intermédiaire entre deux applications ou système. Il est demandé qu’un
tel logiciel ne soit pas générique mais plutôt spécifique, et cela pour éviter la surcharge qui
est un handicap pour la disponibilité.
- Les objectifs d’un Middleware
Les trois objectifs d’un middleware sont les suivants [1] [51]:
(1) masquer la complexité de l'infrastructure sous-jacente, donc l’hétérogénéité des machines
et systèmes ;
(2) Faciliter la conception, le développement et le déploiement d'applications réparties :
masquer la répartition des traitements et des données.
(3) Fournir des services communs : une interface commode aux applications (programmation
+ API : Application Programming Interface).

14
Site 1 Site 2
Applications
Middleware
Système de
communication
Interfaces
Figure 2: système distribué avec un middleware [1] [51]
Note : Le système de communication permet aux éléments des sites du système distribué
d’échanger des informations entre eux.
Exemples des Intergiciels :
- Java RMI (Remote Method Invocation), CORBA (Common Object Request Broker
Architecture), .NET [-Orienté Objet-]
- JTS (Java Transaction Service) de Sun, MTS (Microsoft Transaction Server) de
Microsoft [-Orientés Transactionnels-]
- Web Services (XML-RPC: Extensible Markup Language-Remote Procedure Call, SOAP:
Simple Object Access Protocol) [-Orientés Web-]
- ODBC (Open DataBase Connectivity), JDBC (Java DBC) de SUN [-Orientés SGBD/SQL-]
Nous n’avons parlé que de ces trois propriétés comme tantôt dit, mais puisqu’en plus
elles entrent beaucoup plus enjeu dans la suite de notre travail. Dans cette liste, se figure
aussi la grande-échelle, c'est-à-dire le passage à l’échelle, c'est-à-dire la « scalability »
(comme définit ci-haut).
I.1.5. Architecture d’un Système Distribué
Quasiment anticipé, l’architecture d’un système distribué est l’agencement ou mieux
la structure des composants constitutifs de ce dernier en termes de logiciels, matériels et
réseaux. Voici ces architectures en question [27]: Client-serveur (C/S), Peer-to-Peer ou Pair-
à-Pair (P2P) et Hybride ; ce dernière est une combinaison du modèle client/serveur et du
modèle Peer.

15
Le Client-serveur : C/S
[Définition]
Le concept client-serveur, c’est pour définir une architecture. Et donc, l’architecture
client-serveur est un modèle de fonctionnement logiciel qui peut se réaliser sur tout type
d’architecture matérielle (petite et grosse machine) pourvu que ces architectures soient
interconnectées. Et là, nous avons deux types de logiciels, le logiciel client qui formule des
requêtes à un autre, et cet autre c’est le logiciel serveur, et les deux s’exécutant
normalement sur deux machines différentes.
Les deux applications dialoguent ou communiquent entre elles, de la manière
suivante :
- Le client demande un service au serveur
- Et le serveur réalise le service, c'est-à-dire, le traitement et le renvoie au client
Client SERVEURRequête
Résultat
Dialogue
Figure 3 : Client-Serveur
C’est le client qui initie le dialogue et le pilote, pendant que le serveur y participe tout
simplement. Et pour dialoguer ou communiquer, ils ont besoin de protocole de
communication.
[Mode de Client-serveur]
- Couches dans le Client
Le modèle client-serveur possède trois couches, dont on a [11]:
+ Couche présentation : qui s’occupe du dialogue entre la machine et
l’utilisateur.
+ Couche applicative : qui réalise des tâches pour produire de résultat escompté.
+ Couche de données : qui gère les données.

16
- Modes ou types ou modèles
Et par rapport à la répartition de ces couches entre serveur et client, on distingue trois
types ou modes client-serveur :
+ Client-serveur de présentation :
Le client ne possède que la couche présentation en son sein et le serveur en
possède soit toutes soit deux restantes.
+ Client-serveur de données :
Le client effectue la gestion du dialogue, la validation des saisies, la mise en
forme des résultats et les traitements (y compris la manipulation des
données). Le serveur gère l'accès aux données et de plus en plus souvent
l'intégrité des données. Il est appelé serveur de données.
Cette mise en œuvre est très répandue car elle a été popularisée par les
SGBDs relationnels qui ont reposé dès leur origine sur le modèle
client/serveur pour ce qui est de leur fonctionnement réparti.
Exemple : Application C# Avec SQL SERVER.
+ Client-serveur de traitements :
Ce type est également qualifié de traitement distribué (ou client-serveur de
procédure [14]). Le client appelle l’exécution d’un traitement stocké sur le
serveur qui effectue les traitements et renvoie les données au client.
On peut également répartir les données sur le poste client ou d’autres serveurs
de données en utilisant un SGBD supportant cette fonctionnalité. Dans ce
cas on effectue de la gestion distribuée de données (bases de données
réparties ou répliquées).
Peer-to-Peer ou Pair-à-Pair : P2P
Cette architecture offre à un système la capacité de passage à l’échelle (scalability),
c'est-à-dire la capacité d’un système à continuer à délivrer avec un temps de réponse
constant un service même si le nombre de clients (nœuds) ou de données augmente de
manière importante [25] [36], afin de partager les ressources dans un réseau largement
distribué. L’avantage de cette architecture est celui de disposer toujours d’une puissance de
calcul, quand bien même le nombre de ressources disponibles dans le système est élevé. Et
cet avantage lui permet de traiter des taches complexes avec un coût relativement faible,
même sans avoir des serveurs gigantesque [36].

17
Dans cette architecture, un nœud peut donc jouer le rôle de client selon qu’il
consomme des ressources disponibles et serveur selon qu’il offre des ressources.
Une autre définition, qui explicite aussi les choses, c’est celle donnée par [34] [36] : «
Le terme "pair-à-pair" représente une classe de systèmes et d’applications qui utilisent des
ressources distribuées afin d’atteindre un objectif précis d’une façon décentralisée. Les
ressources incluent puissance de calcul, données (stockage et contenu), bande passante
et disponibilité (ordinateurs, être humaine ou autres ressources). L’objectif peut
être la répartition de calcul, le partage de données/contenu, la communication et la
collaboration ou le partage des services d’une plateforme. La décentralisation peut être
appliquée sur les algorithmes, les données et les métadonnées ».
I.2. Les Bases de Données Réparties (Distribuées)
Il y a des notions qui ont déjà été expliquées dans la section précédente, et quand
nous les réciterons ici nous n’aurons que la peine de rappeler qu’elles l’ont déjà été
précédemment.
I.2.1. Définitions
- Base de données : BD
Une base de données, de la manière la plus brève possible, c’est une collection des
données structurée reliées par des relations et interrogeable et modifiable par son contenu.
- Base de données répartie (distribuée):BDR ou BDD
Une base de données distribuée, c’est une collection de multiples bases de données
logiquement interconnectées distribuées ou réparties sur un réseau d’ordinateur [24], et
apparaissant à l’utilisateur comme une base de données unique [15].

18
Réseau de Communications
Site 1BD
Site 2BD
Site 3BD
Site 4BD
Site 5
BD
Figure 4 : Architecture d’une base de données [41]
- Système de Gestion de Base de Données : SGBD
Un SGBD est un logiciel informatique permettant aux utilisateurs de structurer,
d’insérer, de modifier, de rechercher de manière efficace des données spécifiques, au sein
d’une grande quantité d’informations, stockées sur mémoires secondaires partagée de
manière transparente par plusieurs utilisateurs.
- Système de Gestion de Base de Données Réparti (Distribué): SGBDR ou SGBDD
Un SGBDD est le logiciel qui gère les BDD, et fournit un mécanisme d’accès qui rend
cette distribution ou répartition transparente à l’utilisateur.
- Système de Bases de Données Distribuées : SBDD
Un SBDD est l’intégration de BDD et SGBDD, laquelle est réalisée à travers le
fusionnement de la BD et les technologies du réseau ensemble [24].
Ceci peut aussi être décrit comme un système qui coordonne une collection de
machines qui n’ont qu’une mémoire partagée (shared memory), cependant paraissant à
l’utilisateur comme une seule machine.

19
- Les concepts « distribué » et « répartie » dans les Base de Données
Le concept « distribué » est très générique et implique beaucoup d’autre [15], tels que
les BD Répartie, les BD fédérées, les Systèmes Multi bases, etc.
Les BD Réparties, par exemple, peuvent être soit hétérogène soit
homogène ;
Les BD Fédérées, ne sont par contre que des BD hétérogènes, mais dont
l’accès est via une seule vue ;
Et les Système Multi bases, sont des bases de données hétérogènes
capables d’inter opérer avec une application via un langage commun,
sans une vue commune.
I.2.2. Buts et motivations pour une Base de Données Distribuée :
BDD
Il faut dire, vu ce qui précède, que la décentralisation a eu sa bonne raison de
transcender la centralisation de par sa valeur ajoutée, mais aussi puisque cette architecture
est la plus adaptée à beaucoup d’organisations des entreprises.
Les BDDs ont donc pour motivation [6]: l’amélioration de la performance du système,
l’augmentation de la disponibilité de données, le partage, le passage à l’échelle (scalability)
et l’accès facile. Nous en parlons en détail pour quelques-uns.
On a, donc :
(1) La nature intrinsèque des certaines situations ou applications. L’exemple d’une
banque qui a une direction centrale à un lieu donné, des succursales dans différentes
autres lieux qui peuvent traiter les données des clients locaux, par rapport au lieu,
mais contrôlés par la centrale. Il est évident qu’une base de données distribué dans
différents site, est appropriée.
(2) La fiabilité et la disponibilité. La fiabilité révèle cette nature d’assurer les services
attendus continuellement ; et la disponibilité, comme dit tantôt, est un élément
important pour accroître la fiabilité.
(3) Meilleure performance : la répartition de données permet souvent la réplication de
celles-ci, or nous avons précédemment dit que cette notion de réplication
assouplissait le trafic à tel enseigne que les sollicitations sur une ressource ou une
donnée étaient parallélisées.

20
I.2.3. Avantages et Contraintes
Voici quelques avantages retenus d’une base de données répartie, on a :
(1) Le rapprochement des données selon qu’un site les demande plus, ce qui permet la
réduction de coût de communication.
(2) L’autonomie de site local ; un site n’a pas besoin d’aller chercher ailleurs les données
qu’il possède lorsqu’un utilisateur demande au site certaines données.
(3) La continuité de services.
(4) Une intégration facile dans un système existant.
Nous en retenons qu’une seule contrainte que nous jugeons de pertinente, c’est la
complexité, qui se situe dans la conception d’une base de données distribuée par rapport à
celle qui est centralisée ; à savoir que cette conception prend en compte la fragmentation
des données, l’allocation des fragments dans des sites et la réplication.
[Contraintes]
- Coût : la distribution de données entraîne des coûts supplémentaires en
terme de communication, et en gestion des communications (hardware et
software à installer pour gérer les communications et la distribution).
- Problème de concurrence. Qui est même le cas traité dans ce travail.
- Sécurité : la sécurité est un problème plus complexe dans le cas des bases de
données réparties que dans le cas des bases de données centralisées.
I.2.4. La Répartition de données (Les Niveaux)
Nous distinguons trois niveaux dans lesquels la répartition de données intervient. Nous
allons présenter l’architecture (de niveau ou de schémas) de la BDR, à l’aide de laquelle,
nous allons expliquer la répartition.

21
Figure 5 : Architecture d’une BDD
Note : VE= Vue Externe.
La répartition d'une base de donnée intervient dans les trois niveaux de son
architecture en plus de la répartition physique des données :
- Niveau externe: les vues sont distribuées sur les sites utilisateurs.
- Niveau conceptuel: le schéma conceptuel des données est associé, par
l'intermédiaire du schéma de répartition (lui-même décomposé en un schéma de
fragmentation et un schéma d'allocation), aux schémas locaux qui sont
réparties sur plusieurs sites, les sites physiques.
- Niveau interne: le schéma interne global n'a pas d'existence réelle mais fait place à
des schémas internes locaux répartis sur différents sites.
I.2.5. Principe d’une Base de Données Réparties ou Distribuée
Le principal fondamental de BDD est la transparence pour l’utilisateur [15], mais que
[41] présente, de manière la plus détaillée, sous forme de niveaux de transparence (pour la
gestion de la BDD). Et nous en avons ci-haut montré ses apports.
Dans une BDD, la transparence s’exprime sous trois niveaux : - transparence de
distribution ou de réseaux, - de réplication et - de fragmentation.

22
- Transparence de distribution ou de réseaux :
Cette transparence renferme deux autres concepts : la transparence de localisation et la
transparence de désignation (naming transparency).
+ De localisation : Le système s’occupe de trouver le site où sont hébergées
les données demandées par l’utilisateur, et pourtant ce dernier n’en sait
rien et lance sa requête comme sur une seule et unique base de données.
+ De désignation : elle implique qu’une fois qu’un objet dans le système est
nommé, il peut être accédé, sans aucune ambigüité et sans aucune autre
spécification que ce nom.
- Transparence de réplication :
Une BDD a souvent des données répliquées dans d’autres sites, et ceci pour accroître une
certaine disponibilité, la performance, et la fiabilité. Alors cette transparence va masquer
cette situation de choses à l’utilisateur.
- Transparence de fragmentation:
La fragmentation est cette technique qui permet de distribuer les données dans tout le
système. Nous allons dans la suite montrer qu’il en existe deux sortes : verticale et
horizontale. Mais la transparence de fragmentation fera que l’utilisateur ne soit au courant
ni de la fragmentation de donné, ni de l’existence de fragments. Ainsi, lorsque l’utilisateur
lance requête (globale), le système s’occupera de la transformer en plusieurs requêtes de
fragment.
I.2.6. Systèmes de Gestion de Base de Données Distribuée (SGBDD)
et Architectures
Il existe plusieurs SGBDD, qui puissent être différents les uns des autres, et eux tous
ont un point que voici en commun [41]: les données et les logiciel sont distribués sur
plusieurs sites interconnectés dans une forme de réseau de communication.
Et pourtant, nous allons présenter dans cette section un seul facteur, qui est vraiment
inhérent à notre travail, qui différencie des SGBDDs, c’est l’Homogénéité.
[Homogénéité]
Quand on parle du degré d’Homogénéité de logiciel de SGBDD, il y a deux facteurs
reliés à ce problème de degré :

23
o [-Facteur 1-]
Si tous les serveurs (ou les SGBDDs locaux individuels) utilisent un logiciel identique et
que tous les utilisateurs (clients) utilisent aussi un logiciel identique, alors le SGBDD est dit
Homogène. Sinon, il est dit Hétérogène.
o [-Facteur 2-]
Un autre facteur relatif au degré d’Homogénéité, c’est le degré d’autonomie locale.
On parle d’un degré d’autonomie si les transactions locales peuvent avoir un accès
direct au serveur. Par contre, si le site local n’a pas de provision lui permettant de
fonctionner en tant qu’un SGBDD indépendant, alors le système ne possède pas
d’autonomie locale.
[Architecture]
Les SGBDDs peuvent avoir plusieurs architectures, qui sont classées selon différentes
approches de séparation de fonctionalité sur les processus (traitements) de SGBD. Nous
allons, ici, présenter deux architectures [41]: Client-serveur et serveur collaboratif
(collaborating server).
o [-Client-serveur-]
Nous en avons déjà parlé ci-haut ; ce système a un ou plusieurs processus client et
serveur. Et un processus client peut envoyer une requête à l’un des processus serveurs. Les
clients sont chargés de l’interface utilisateur et peuvent tourner dans un PC (personal
computer) et envoyer des requêtes à un serveur, qui, lui, gère les données et exécute les
transactions.
o [-Serveur Collaboratif-]
L’idée dans ce genre de système, c’est qu’on peut avoir une collection des serveurs de
bases de données, et chacun étant capable d’exécuter les transactions sur les données
locales, mais aussi qui exécutent les transactions coopérativement sur plusieurs serveurs.
Un serveur qui reçoit une requête accédant sur plus d’un serveur, il en produit des
sous-requêtes pour chaque serveur et à la fin rassemble les résultats à la requête du début.
Ce découpage (décomposition) de requêtes en sous-requêtes se fait par optimisation [15].

24
I.3. La Réplication
Nous pouvons en retenir qu’elle augmente la performance, en diminuant la charge qui
devrait être imposée à un seul site (serveur) par la duplication de données, de favoriser la
disponibilité en cas de pannes par exemple, toujours par la duplication de données dans
différents sites, cette dernière permet donc de travailler avec les données d’un site si un
autre tombe en panne ou dans le souci de diminuer le temps de réponse des transactions.
Mais, il faut tout de suite le signaler qu’elle n’a pas que les bons côtés ; pour ce qui est
de ses inconvénients, c’est le problème de mise-à-jour. Les données dupliquées doivent
donc être uniforme ; de fait, une mise-à-jour sur un fragment de données ne doit pas laisser
les autres indifférents et différents, et pourtant cette mise-à-jours et sa synchronisation ne
sont pas immédiates. On peut donc constater que malgré tout, l’utilisation de la réplication
exige de nous une certaine vigilance par rapport à la cohérence de la base. Car, En effet,
permettre aux transactions de manipuler plusieurs copies d’une même donnée peut générer
des incohérences [5].
Il faut donc faire le contrôle de la réplication, pour assurer la cohérence de la base.
I.3.1. Les protocoles de contrôle de réplication
On distingue deux principaux modèles pour ces protocoles (techniques) [5] :
- Le modèle de réplication synchrone :
Une transaction doit se synchroniser avec toutes les copies qu’elle modifie avant
validation.
C'est-à-dire qu’une modification d’une donnée dans un site entraîne celles de ses
copies dans d’autres. C’est la mise à jour temps réel de données.
Figure 6 : réplication synchrone
La technologie appliquée ici, c’est celle de la validation à deux phases. Avec son
avantage de rassurer la convergence de tous les sites au COMMIT ou ABORT. Et Ceci,
rappelons-le, rassurera autant la cohérence de la base.

25
* Les avantages et les désavantages
+ Avantage :
Identité de copies (pas d’incohérence)
La lecture (locale) de la dernière copie la plus mise à jour
Les modifications sont atomiques, c'est-à-dire, soit ils ont lieu eux-
toutes à la fois, soit rien.
+ Désavantage :
Une exécution très longue de la transaction, vue que celle doit faire
les mises à jour de tous les sites, et ceci crée souvent de TIMEOUT
(voir dans le chapitre suivant)
- Le modèle de réplication asynchrone :
Les modifications introduites par une transaction sont propagées aux autres sites
seulement après validation de la transaction.
C'est-à-dire, d’abord un site connait des changements et les valide, puis après ce
dernier peut les propager aux autres sites.
Figure 7 : réplication asynchrone
Les technologies utilisées sont : les Triggers (déclencheurs), les journaux d’images
(après), etc.
* Les avantages et les désavantages
+ Avantage :
Les transactions sont toujours locales (un bon temps de réponse)

26
+ Désavantage :
Des incohérences de données
Une lecture locale de données ne retourne pas toujours la valeur la
plus mise à jour.
Les modifications à tous les sites ne sont garanties
De fait, la réplication n’est pas transparente.
I.3.2. Architectures de Réplications
De ce qui précède, il est évident que l’emplacement de l’exécution d’une transaction
est un point capital, et d’ailleurs [5] montre qu’il existe deux architectures qui déterminent
cet emplacement même, on a : primary copy et update everywhere.
- Primary Copy :
Aussi appelé réplication asymétrique [23].
Ici, chaque copie possède une copie primaire dans un site spécifique (serveur), appelée
aussi « publisher ». Les transactions sont seulement exécutées sur les serveurs des données
qu’elles manipulent, ou mieux elles ne mettent à jour que cette copie, et les mises à jour sont
envoyées aux autres copies (secondaires) sur les autres sites.
* Les avantages et les désavantages
+ Avantage :
Aucune synchronisation inter-site n’est nécessaire (elle se réalise au
niveau de la copie primaire (primary copy)
Il y a toujours un seul site qui a toutes les modifications
+ Désavantage :
La charge imposée uniquement sur la copie primaire peut devenir
assez grande
La lecture locale peut risquer de ne pas rendre une valeur la plus
mise à jour.

27
- Update everywhere :
Aussi appelé réplication symétrique [23]
Le principal à retenir ici, c’est que, aucune copie n’est privilégiée, par rapport au
précédent. Chaque copie dans n’importe quel site peut être mise à jour à n’importe quel
instant et ainsi le système assure la diffusion ultérieure de ces mises à jour à tous les autres
copies.
* Les avantages et les désavantages
+ Avantage :
De n’importe quel site peut s’exécuter une transaction
La charge est équitablement distribuée
+ Désavantage :
Les copies auront tout le temps besoin de la synchronisation
Toutes les quatre techniques ou stratégie ci-haut, peuvent être combinées en vue d’obtenir
une bonne performance et une bonne cohérence ou consistance de données, ainsi on a :
Réplication asymétrique synchrone
Réplication asymétrique asynchrone
Réplication symétrique synchrone
Réplication symétrique asynchrone
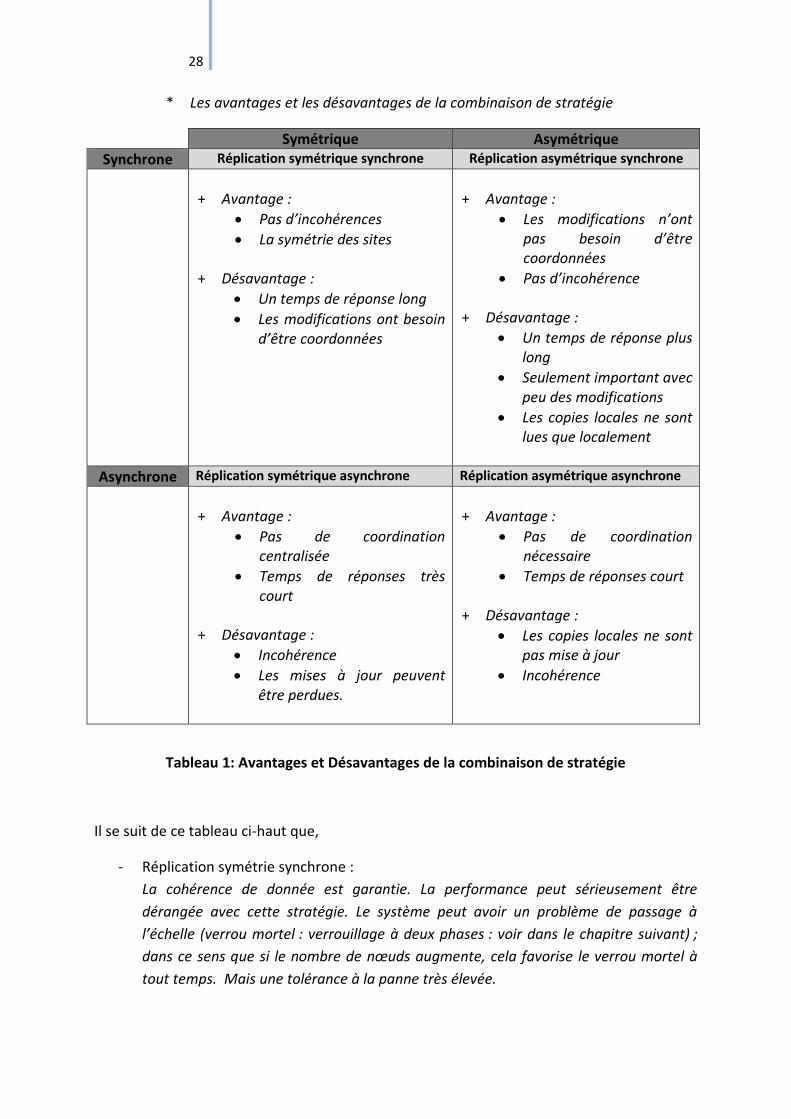
28
* Les avantages et les désavantages de la combinaison de stratégie
Symétrique Asymétrique
Synchrone Réplication symétrique synchrone Réplication asymétrique synchrone
+ Avantage :
Pas d’incohérences
La symétrie des sites + Désavantage :
Un temps de réponse long
Les modifications ont besoin d’être coordonnées
+ Avantage :
Les modifications n’ont pas besoin d’être coordonnées
Pas d’incohérence + Désavantage :
Un temps de réponse plus long
Seulement important avec peu des modifications
Les copies locales ne sont lues que localement
Asynchrone Réplication symétrique asynchrone Réplication asymétrique asynchrone
+ Avantage :
Pas de coordination centralisée
Temps de réponses très court
+ Désavantage :
Incohérence
Les mises à jour peuvent être perdues.
+ Avantage :
Pas de coordination nécessaire
Temps de réponses court + Désavantage :
Les copies locales ne sont pas mise à jour
Incohérence
Tableau 1: Avantages et Désavantages de la combinaison de stratégie
Il se suit de ce tableau ci-haut que,
- Réplication symétrie synchrone :
La cohérence de donnée est garantie. La performance peut sérieusement être
dérangée avec cette stratégie. Le système peut avoir un problème de passage à
l’échelle (verrou mortel : verrouillage à deux phases : voir dans le chapitre suivant) ;
dans ce sens que si le nombre de nœuds augmente, cela favorise le verrou mortel à
tout temps. Mais une tolérance à la panne très élevée.

29
- Réplication asymétrie synchrone :
A part l’absence de verrou mortel, cette stratégie est similaire au précédent. Mais ici,
le problème c’est le goulot d’étranglement qu’est la copie primaire.
- Réplication asymétrie asynchrone :
La performance est bonne (presque comme s’il n’y avait de réplication). Ainsi les
incohérences surgissent (de par le fait que chaque site a sa propre valeur de données).
- Réplication symétrie asynchrone :
La performance est excellente (presque comme s’il n’y a pas de réplication). Tolérance
à la panne élevée. Incohérence de la base. Et la reprise de mises à jour perdues est
dur à résoudre, on la fait presque manuellement.
I.4. Fragmentation, Allocation et Conception
Nous l’avons montré ci-haut que, la fragmentation et l’allocation des fragments dans
les sites du système étaient le vrai problème même dans les bases de données distribuée. Ce
problème set très critique qu’il demande d’énormes efforts lors de la conception d’une base
de données distribuée. L’allocation ou la fragmentation, [6], a un plus grand impact dans la
qualité sur la solution finale et par conséquent sur l’efficacité opérationnelle du système.
D’où, la performance de la base de données distribuée y dépend totalement.
La conception d’une base de données distribuée est un problème d’optimisation, qui
peut se subdiviser en deux problèmes [6], ou en trois [47] pour le cas d’une BDD répliquée:
- La conception de fragmentation des relations (tables) globale
- La conception de l’allocation de ces fragments à travers les sites du
réseau de communication
- Et/ou la réplication de ces fragments
I.4.1. Fragmentation
La fragmentation ou le partitionnement est une technique de conception qui consiste
à diviser une relation (unique) d’une base de données en deux ou plusieurs partitions telles
que leur combinaison reproduise la base de données originale sans aucune perte de
données [47].
Nous distinguons en gros deux types de fragmentation : horizontale et verticale, et un
troisième : hybride ou mixte.
30
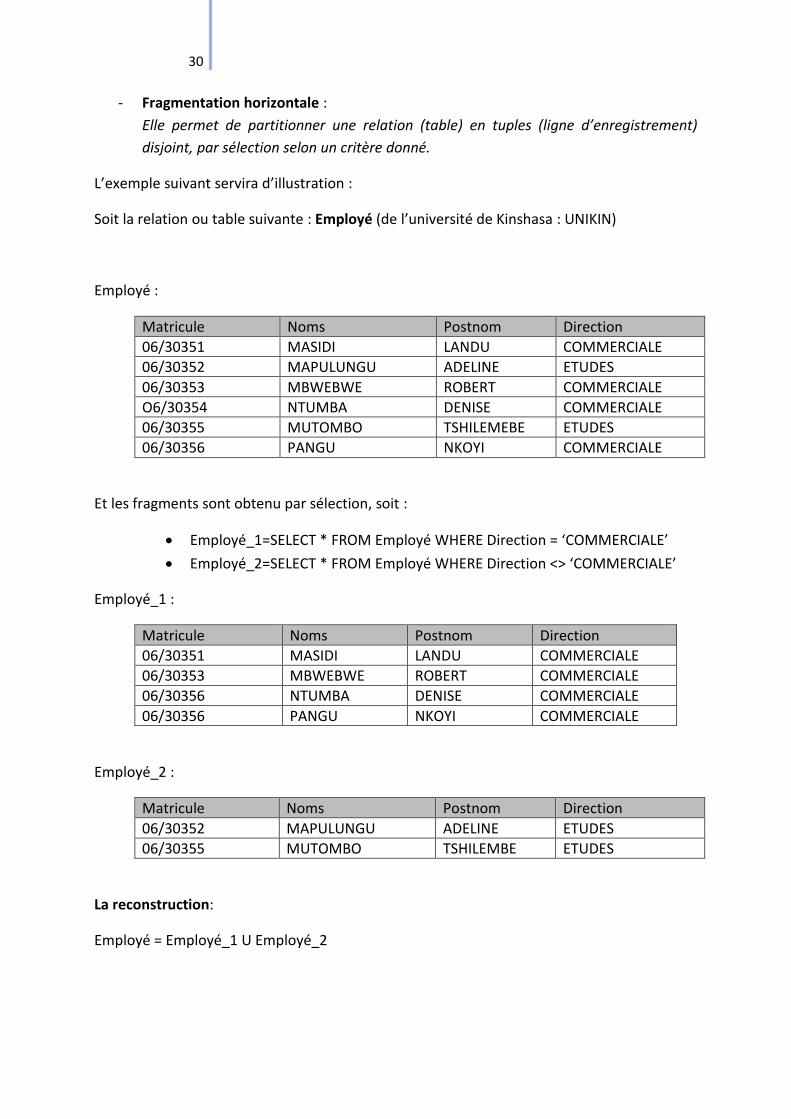
- Fragmentation horizontale :
Elle permet de partitionner une relation (table) en tuples (ligne d’enregistrement)
disjoint, par sélection selon un critère donné.
L’exemple suivant servira d’illustration :
Soit la relation ou table suivante : Employé (de l’université de Kinshasa : UNIKIN)
Employé :
Matricule Noms Postnom Direction
06/30351 MASIDI LANDU COMMERCIALE
06/30352 MAPULUNGU ADELINE ETUDES
06/30353 MBWEBWE ROBERT COMMERCIALE
O6/30354 NTUMBA DENISE COMMERCIALE
06/30355 MUTOMBO TSHILEMEBE ETUDES
06/30356 PANGU NKOYI COMMERCIALE
Et les fragments sont obtenu par sélection, soit :
Employé_1=SELECT * FROM Employé WHERE Direction = ‘COMMERCIALE’
Employé_2=SELECT * FROM Employé WHERE Direction <> ‘COMMERCIALE’
Employé_1 :
Matricule Noms Postnom Direction
06/30351 MASIDI LANDU COMMERCIALE
06/30353 MBWEBWE ROBERT COMMERCIALE
06/30356 NTUMBA DENISE COMMERCIALE
06/30356 PANGU NKOYI COMMERCIALE
Employé_2 :
Matricule Noms Postnom Direction
06/30352 MAPULUNGU ADELINE ETUDES
06/30355 MUTOMBO TSHILEMBE ETUDES
La reconstruction:
Employé = Employé_1 U Employé_2
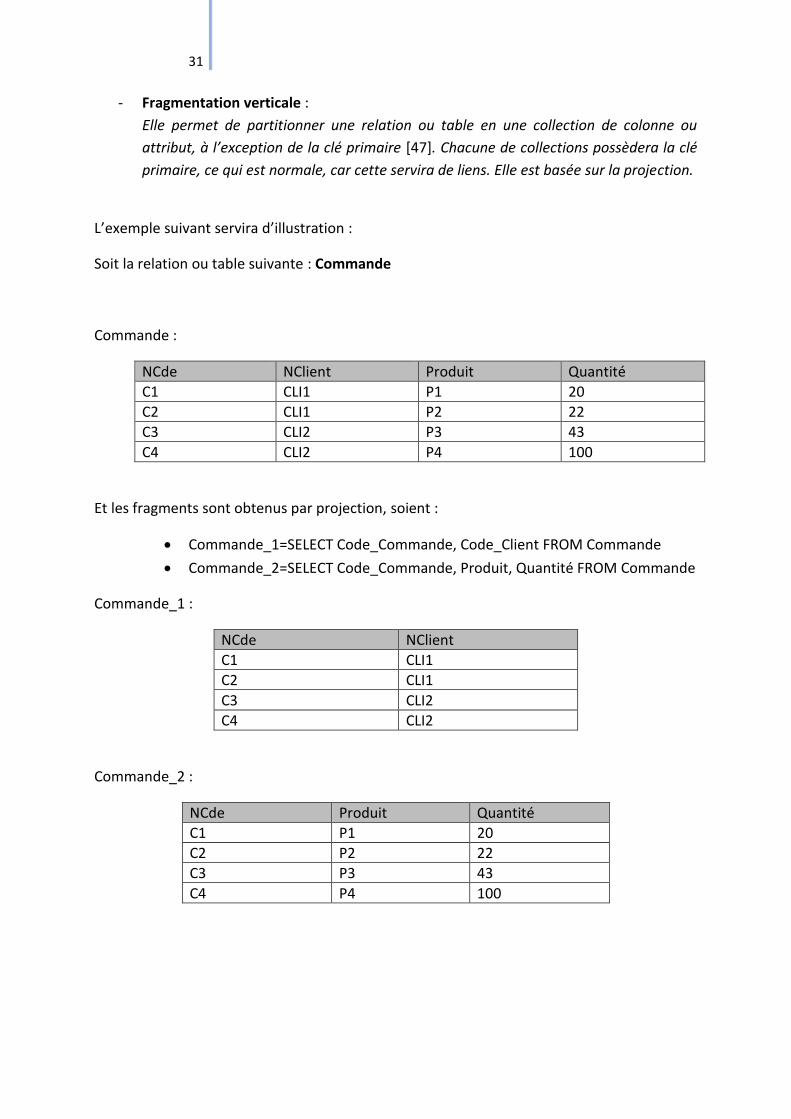
31
- Fragmentation verticale :
Elle permet de partitionner une relation ou table en une collection de colonne ou
attribut, à l’exception de la clé primaire [47]. Chacune de collections possèdera la clé
primaire, ce qui est normale, car cette servira de liens. Elle est basée sur la projection.
L’exemple suivant servira d’illustration :
Soit la relation ou table suivante : Commande
Commande :
NCde NClient Produit Quantité
C1 CLI1 P1 20
C2 CLI1 P2 22
C3 CLI2 P3 43
C4 CLI2 P4 100
Et les fragments sont obtenus par projection, soient :
Commande_1=SELECT Code_Commande, Code_Client FROM Commande
Commande_2=SELECT Code_Commande, Produit, Quantité FROM Commande
Commande_1 :
NCde NClient
C1 CLI1
C2 CLI1
C3 CLI2
C4 CLI2
Commande_2 :
NCde Produit Quantité
C1 P1 20
C2 P2 22
C3 P3 43
C4 P4 100

32
La reconstruction:
Pour cela, on fait la sélection avec un critère sur la clé primaire, qui est un lien entre les
fragments :
Commande = (SELECTION * FROM Commande_1, Commande_2 WHERE Commande_1.NCde
= Command_2.NCde)
- Fragmentation mixte ou hybride :
Dans cette sorte de fragmentation, on combine les deux précédentes, et ce de
manière tout à fait arbitraire, c'est-à-dire soit on commence par l’horizontale et puis
la verticale, vice-versa selon le besoin.
Exemples : (Sur la relation Commande ci-haut)
- Commande=SELECTION Code_Commande, Code_Client FROM Commande WHERE
Quantité >= 50
- Commande=SELECTION Code_Commande, Code_Client FROM Commande WHERE
Quantité > 50
Note : il existe un problème qui entache cette notion de fragmentation, c’est qu’elle est liée
à l’existence préalable de données [47], ce qui n’est pas toujours le cas quand on est au
début de la conception de la BDD. Mais, une bonne et efficace connaissance sur l’emploi ou
le besoin sur la BDD (d’une organisation) pourra permettre de savoir au préalable l’ensemble
de requêtes immédiates [16], et ceci facilitera évidemment la fragmentation dite statique.
Mais, dans le futur de l’organisation, d’autre besoins pourront naître d’où d’autres requêtes
et ceci pourra générer d’autres fragments ou déplacer ceux qui existaient, fragmentation
dynamique.
I.4.2. Allocation
Et à présent, après avoir fragmenté la base de données, c’est l’allocation qui s’en suit.
L’allocation, c’est cette étape où l’on affecte chaque fragment à un site du réseau. Les
données ou fragments assignés, peuvent être soit répliqués dans d’autres sites soit gardés
en un seul fragment dans un seul site. Ainsi on parle respectivement redondante et non-
redondante [6].

33
Son but, c’est de stocker les fragments de données plus proche, où ils peuvent être
fréquemment utilisés afin d’accroître la performance, et par conséquent de diminuer la
communication entre les sites. De fait, [6] montre que dans une base de données distribuée
bien conçue, nonante pourcent (90%) de données devraient être trouvées dans le site local
et dix pourcent (10%) seulement devraient être accédées dans un site distant.
Allocation dynamique
Les requêtes à l’origine de chaque site et grâce auxquelles sont affectée les premières
données (fragments) dans chaque site, ont été fixées ou réalisées sur base des besoins
initiaux ou de la connaissance du domaine, et pourtant comme dit tantôt d’autres besoins
peuvent surgir après et ainsi d’autres requêtes peuvent se réaliser, c’est sera alors la
fragmentation dynamique.
D’où comme la première fragmentation avait permis la première affectation de
fragments (allocation) et constituer donc le schéma d’allocation, la fragmentation
dynamique qui entraîne une nouvelle allocation, entrainera de même la modification du
schéma d’allocation : l’allocation dynamique, c'est-à-dire, les fragments peuvent se déplacer
d’un site à un autre d’où il est appelé.
[15] montre que la technique de l’allocation dynamique est une alternative à la
duplication (réplication) et s’avère la plus efficace dans le cas de multiples modifications.
Cliché (Snapshot)
Le cliché, c’est la technique de copie figée d’un fragment [15]. C'est-à-dire, ici, on
utilise une copie (image) d’un fragment d’un temps donné et qu’on ne va pas mettre à jour,
cette copie devient inutile au fil du temps. Ceci évite ce lourd travail de mettre à jour toutes
copies (fragments) correspondants dans les sites. On n’utilise cette technique pour les
données qui ne changent à chaque petit écart de temps, mais dont l’ancienneté de ses
valeurs n’entamera pas la réalité de choses.

34
I.4.3. Conception
Nous distinguons deux types de conception d’une base de données distribuée :
ascendante et descendante.
Conception ascendante
C’est de cette conception qui s’agit lorsqu’il est question de créer une nouvelle base de
données distribuée. On commence par définir un schéma conceptuel global de la BDD, puis
on distribue sur les différents sites en des schémas conceptuels locaux, par la technique de
fragmentation (cf. ci-haut).
Conception descendante
L’approche se base sur le fait que la répartition est déjà faite, mais il faut
réussir à intégrer les différentes BDs existantes en une seule BD globale. En d’autres termes,
les schémas conceptuels locaux existent et il faut réussir à les unifier dans un schéma
conceptuel global [15] [45].

35
[Chapitre II]

36
Chapitre II
Les Transactions Distribuées
Le SQL (Structured Querry Language) est un langage par excellence pour l’interrogation
d’une base de données ou mieux d’un serveur de base de données, et pourtant si vous
effectuez une série de requêtes, il y a beaucoup de risques que l’une d’entre elles échoue et
une autre réussisse, et sur ce, les informations dans la base de données courent le risque
d’incohérence. D’où il existe un concept : « transaction », qui lui permet d’encapsuler un
ensemble d’opérations sur la base de données pour former un seul tout ; cette manière de
faire qu’est la transaction a un effet très positive sur les données à tel enseigne qu’elle
garantit la stabilité et l’intégrité des informations, c.-à.- d lorsqu’ une transaction (qui est un
bloc ou ensemble) est exécutée, la validation ou l’annulation se fait d’un bloc et soit laisse la
base de donnée comme avant (stable) ou elle l’amène dans un autre état de stabilité.
Une transaction peut être locale, lorsqu’il s’agit d’une transaction en une phase et
aussi gérée directement par la base de données ou très simplement lorsqu’elle effectue des
opérations sur une seule ressource (une base de données, etc.), et distribuée lorsqu’elle
utilise de nombreuses ressources, [21], [37].
II.1. DEFINITIONS D’UNE TRANSACTION
Une transaction, c’est un ensemble de requêtes regroupés en une seule unité logique
de travail, qui pourra ensuite être, soit validée, soit annulée;
C’est une collection d’actions [28] qui transforment une base de données (ou un
fichier), depuis un état cohérent en un autre état cohérent [3]; il faut dire que la cohérence
de la base de données est assurée par le système et celle de la transaction par le
programmeur.
Figure 8 : une transaction dans une base de données cohérente

37
Modélisation d’une transaction
On peut modéliser une transaction comme une suite finie d’actions sur des objets
donnés [31] ;
Soit une transaction T, on a :
T = {Oi.Aj, | i = 1..n ; j = 1..p}
Où :
• i désigne un site visité par T
• Oi désigne un objet du site i
• Oi.Aj désigne une action j exécutée au sein de l'objet Oi
Les actions inhérentes à une transaction :
- Début_transaction : initialisation de la séquence transactionnelle
- Valider_transaction : terminaison de la séquence transactionnelle
- Annuler_transaction : arrêt de la transaction
- Lire (objet) : chargement d'une image de l'objet dans l'espace de travail
- Ecrire (objet) : sauvegarde d'une image de l'objet en mémoire secondaire
Note :
Transaction centralisée ou locale : les objets sont sur un seul site.
Transaction répartie ou distribuée : les objets (et les actions) sont sur plusieurs sites.

38
Exemple :
Réduire la commande (cde) N° 10 de 5 unités et les reporter à la cde 12
Transaction Report-qté
begin
exec sql UPDATE cde
SET qte = qté - 5
WHERE ncde = 10;
exec sql UPDATECde
SET qté = qté + 5
WHERE ncde = 12;
exec sql COMMIT WORK;
end.
Ce mécanisme d’encapsuler un ensemble de requêtes ou une collection d’actions ou
opérations en une seule entité qu’est donc la transaction garantit alors la cohérence des
données grâce à l’atomicité de la dite entité (transaction), c'est-à-dire s’il y a validation c’est
pour tout et de même pour l’annulation ; c’est « tout » ou « rien ».
Les opérations dans la transaction peuvent être soit de lecture soit d’écriture soit les
deux à la fois, et pourtant chaque transaction est marquée par un début (Begin Of
Transaction : BOT), et une fin (End Of Transaction : EOT) [45] et vérifie un ensemble de
propriétés représentées par l’acronyme ACID tiré de termes anglais suivants Atomicity,
Consistency, Isolation et Durability, dont elle bénéficie de la cohérence et de la fiabilité [45]
.
Voici comment se traduisent les termes ci-haut :
Atomicity : Atomaticité ;
Consistency : Cohérence ou Consistence
Isolation : Isolement [17] ou Isolation
Durabity : Durabilité

39
Voici ce que veut dire chacun de termes :
Atomicité : La séquence d’instructions est indivisible, c'est-à-dire toutes les requêtes exécutées dans le cadre de cette transaction sont validées en même temps ou aucune ne l’est (principe du tout ou rien). L’ensemble des opérations réalisées sont vues de l’extérieur comme une seule et même opération.
C’est le mécanisme de validation [31].
Il faut garantir qu'en cas de défaillance (processus avorté avant sa terminaison) :
- ou bien l'exécution est totale : l'ensemble des actions correspondant à la transaction est complètement effectué et amène la base jusqu'à un nouvel état.
- ou bien l'exécution n'a aucun effet sur les objets car l'exécution est impossible : toutes les modifications partielles engagées sont complètement annulées et l'on reste à l'ancienne version
Cohérence : la transaction ne viole pas les invariants du système, quand elle est validée, elle génère un nouvel état stable du système, ou si un problème survient, le système retourne dans l’état qui était considéré comme stable avant qu’elle n’ait commencé.
Une transaction correcte est celle qui est constante avec la sémantique de cohérence de l'ensemble des objets.
Isolement [17]: Une transaction, tant qu’elle n’a pas été validée reste isolée des autres transactions. Les autres transactions n’ont pas accès aux modifications effectuées par cette transaction ; plus clairement le résultat des actions intermédiaires (état temporairement incohérent) est masqué aux autres transactions.
C’est le mécanisme de contrôle d'accès concurrents.
L'isolation ou l’Isolement est cette propriété qui permet à un ensemble de transactions s'exécutant simultanément (concurremment dans le même environnement) d'apparaître comme s'exécutant de façon indépendante les unes des autres (sérialisabilité).
C'est le travail de contrôle de concurrence proprement dit.

40
Durabilité : Les données validées sont enregistrées telles quelles, même si un problème survient ou que le système redémarre. Les données sont disponibles dans un état correct et sont désormais permanents.
C’est le mécanisme de reprise après panne (recovery).
Les effets des opérations décidées (validées) définitivement doivent être durables (persistants) même en cas de défaillance (de processeurs ou de communication)
La fin d'une transaction est un point de non-retour.
C’est aussi le mécanisme de reprise après panne [31].
Lorsqu’une transaction a débuté, il y a lieu de constater trois cas : la validation,
l’annulation et l’interruption :
- Validation : appelée COMMIT ; la transaction a bien aboutit jusqu’à la fin et la base
de données enregistre les modifications;
- Annulation : appelée ROLLBACK, le mécanisme chargé de défaire les modifications
effectuées par la transaction ;
- Interruption : appelée ABORT
II.2. CLASSIFICATION DES TRANSACTIONS
On peut classer les transactions suivant plusieurs critères tels que la nature de
différentes opérations qui la composent, la durée qu’elle peut prendre [25] :
II.2.1. Suivant la nature de différentes opérations
Transaction de Lecture, Transaction d’Ecriture
Si une transaction contient au moins une opération qui effectue des modifications sur
les données de la base, la transaction est dite transaction d’écriture ou de mise à jour. Si
toutes les opérations ne font que des lectures sur les données de la base, la
transaction est dite transaction de lecture.

41
II.2.2. Suivant la durée
On-Line :OLTP, Batch : OLAP
Une transaction peut être classée on-line ou batch. Les transactions on-line,
communément appelées transactions courtes, sont caractérisées par un temps de
réponse relativement court (quelques secondes) et accèdent à une faible portion des
données. Les applications qui utilisent ce modèle de transaction sont dénommées
applications OLTP (On-line Transactional Processing) parmi lesquelles, nous avons les
applications bancaires, de réservation de billets, de gestion de stocks, etc. Les
transactions batch, appelées transactions longues, peuvent prendre plus de temps pour
s’exécuter (minutes, heures, jours) et manipulent une très grande quantité des
données. Les applications utilisant ce type de transactions sont les applications
décisionnelles ou OLAP (On-line Analytical Processing), de conception, de workflow, de
traitement d’image, etc.
II.3. MODELES DE TRANSACTIONS
Il en existe plusieurs, et en voici quelques uns selon [28]
II.3.1. Les Transactions Plates (Flat Transactions) :
C’est la plus simple de transactions, celle définie un peu plus haut. Une transaction
peut être soit interrompue par le programme l’exécutant (une Base de Données, par
exemple) soit à cause d’une défaillance externe, telle que le crash d’un système.
II.3.2. Les Transactions plates avec Points de Sauvegarde
(SAVEPOINTS) :
Une transaction peut donc être découpée en étapes, et après chaque étape on peut
insérer un point de sauvegarde (SAVEPOINT) donnant toujours cette possibilité de valider
(COMMIT) ou annuler (ROLLBACK) en partie ou en entièreté les modifications apportée par
la transaction à la fin de celle-ci [15] [22] [28].
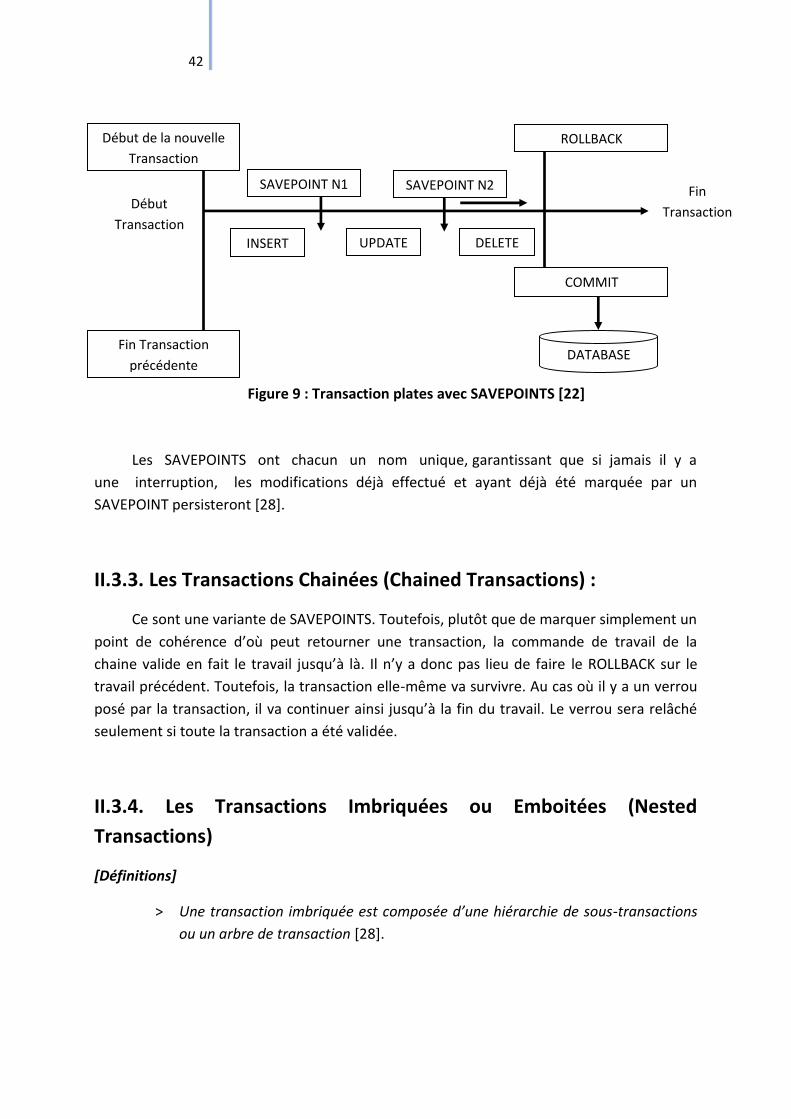
42
Les SAVEPOINTS ont chacun un nom unique, garantissant que si jamais il y a
une interruption, les modifications déjà effectué et ayant déjà été marquée par un
SAVEPOINT persisteront [28].
II.3.3. Les Transactions Chainées (Chained Transactions) :
Ce sont une variante de SAVEPOINTS. Toutefois, plutôt que de marquer simplement un
point de cohérence d’où peut retourner une transaction, la commande de travail de la
chaine valide en fait le travail jusqu’à là. Il n’y a donc pas lieu de faire le ROLLBACK sur le
travail précédent. Toutefois, la transaction elle-même va survivre. Au cas où il y a un verrou
posé par la transaction, il va continuer ainsi jusqu’à la fin du travail. Le verrou sera relâché
seulement si toute la transaction a été validée.
II.3.4. Les Transactions Imbriquées ou Emboitées (Nested
Transactions)
[Définitions]
> Une transaction imbriquée est composée d’une hiérarchie de sous-transactions
ou un arbre de transaction [28].
Début de la nouvelle
Transaction
Fin Transaction
précédente
ROLLBACK
COMMIT
DATABASE
INSERT UPDATE DELETE
SAVEPOINT N1 SAVEPOINT N2
Début
Transaction
Fin
Transaction
Figure 9 : Transaction plates avec SAVEPOINTS [22]

43
Figure 10 : Arbre de Transactions et sous-Transactions
L’arbre de Transactions ; une transaction peut avoir n’importe quel nombre de sous-
transactions, lesquelles peuvent aussi être composées de n’importe quel nombre de sous-
transactions, ainsi se résulte une transaction imbriquée.
La transaction racine est appelée Top-Level Transaction (le niveau le plus supérieur)
car elle n’a pas un autre nœud de transaction auquel elle est liée ; les transactions ayant des
sous-transactions sont appelées des parents (des mères) et les sous-transactions des enfants
(des filles), les filles d’une même mère sont des sœurs. On parle ainsi des descendants (en
partant de la racine vers les enfants) et des ancêtres (inversement). Et les transactions et les
sous-transactions, elles sont toutes des transactions.
On appelle filles ou feuilles des transactions qui n’ont plus d’autres sous-transactions
et ces dernières sont des transactions plates.
> Une sous-transaction est une unité de reprise.
- L'abandon d'une sous-transaction implique l'abandon de ses descendants
mais pas de ses ancêtres.
> Une sous-transaction est une unité d'exécution indépendante
- Isolation des sous-transactions s'exécutant en parallèle
- Les sous-transactions peuvent s'exécuter sur le même site ou sur des sites
différents
> Les transactions sont ACID alors que les sous-transactions sont AI
(Atomicity, Isolation)
> Les feuilles de l’arbre de transaction sont des transactions plates (flat
transactions) [28].

44
(*) Une transaction parent peut passer son verrou à une transaction enfant. Une sous-
transaction peut être validée (COMMIT) ou être interrompue n’importe quand, et dans ce
cas tout verrou possédé par une sous-transaction passe au parent. Tous les verrous sont
relâchés seulement quand la transaction racine a été validée.
[Objectifs]
> Obtenir un mécanisme de reprise multi-niveaux
> Permettre de reprendre des parties logiques de transactions
> Faciliter l'exécution parallèle de sous-transactions
[Règles d’Isolation]
Quelque notions déjà énoncée précédemment au (*)
> (R1) Seules les transactions feuilles accèdent aux ressources partagées (ex:
base de données)
> (R2) Quand une sous-transaction valide, ses ressources sont héritées par sa
mère
> (R3) Quand une sous-transaction abandonne, ses ressources sont relâchées
> (R4) Une sous-transaction ne peut accéder une ressource que si elle est libre
ou détenue par un ancêtre
[Atomicité et Durabilité]
Comme aussi dit tant tôt ;
> (R1) Quand une sous-transaction valide, ses effets sont hérités par sa
mère
> (R2) Quand une sous-transaction abandonne, ses effets sont abandonnés
> (R3) Quand la transaction racine valide, ses effets sont installés dans la
base

45
Illustration
Figure 11 : Validation et Abandon de Sous-Transactions
Veuillons donc voir les règles de [Atomicité et Durabilité] dans cette illustration.
Ici, nous avons la transaction T1 qui a deux sous-transactions T11 et T12
- A l’état initial, X=0 ;
- Et après T11 le modifie, X :=X+1, d’où X=1 ;
- Alors, T11 valide ses modifications selon (R1), mais comme tous les traitements de
l’arbre de transactions ne sont pas finis alors, X=0;
- Et au tour de T12 de faire les modifications, X=X+1, d’où X=2, mais X=0 ;
- Mais T12 vient à abandonner ses modifications selon (R2) ;
- Et en fin quand T1 valide, selon (R3), X=1 conformément à tout ce qui précède.
II.3.5. Transactions Compensatrices
Les Transactions Compensatrices sont des transactions qui sont à la fin des
Transactions proprement dite et qui s’exécutent en cas de panne de paire de
transactions qu’elles doivent compenser.

46
Figure 12 : Transactions compensatrices
II.3.6. Les Transactions Longues
Comme montré au point (2), les transactions Batch sont un exemple de transactions
longues qui peuvent contenir un millier de mises-à-jour et durent beaucoup d’heures. Cela
peut devenir une situation intolérable.
Une solution existe, c’est celle de découper le travail du batch en mini-batch travaillant
sur les données avec un même attribut, tel qu’une collection de clés [28].
Malgré cette solution, elle n’est pas la parfaite du fait que l’atomicité de toute la
transaction ne peut pas être maintenue.
II.3.7. Les transactions Distribuées
Nous l’avons aussi déjà dit tant tôt, les transactions distribuées sont celles qui doivent
s’exécuter à travers un réseau de bases de données. Elles sont similaires aux transactions
imbriquées. Toutefois, l’arbre de transaction pour une transaction imbriquée dépend de
l’application, pendant que l’arbre pour une transaction distribuée dépend de données. Les
transactions distribuées sont essentiellement des transactions plates (flat transactions).
Toutefois, si les données sont hébergées dans une base de données distante doivent être
mises à jour, alors une sous-transaction débute sur cette base de données. Le bloc de sous-
transaction est l’ensemble d’opérations sur la base de données. Au moment du COMMIT, la
transaction parent (mère) interroge toutes ses sous-transactions pour s’assurer qu’elles sont
toutes prêtes pour les COMMITS avant d’entamer la commande d’un COMMIT. Si une ou
plus d’une transaction peut ne pas faire le COMMIT, alors la transaction connait un ABORT
Nous en parlons encore en abondance et en vif dans la suite avec le modèle OSI à
l’appui.

47
II.4. LA JOURNALISATION ET LA REPRISE DES
TRANSACTIONS
II.4.1. Journalisation
C’est la technique appliquée pour prévenir les pannes, toutes les modifications
apportées à la Base de Données sont écrites dans un fichier journal appelé Log.
Chaque fois qu’il y a écriture au niveau de la base de données, il y a aussi une autre y
correspondant dans un support sûr (log) ;
Le journal de transaction est le pilier de la reprise consistante [28] et la terminaison
d’une action atomique interrompue par une panne.
On distingue donc [30]:
- Le Journal des images avant
- Le Journal des images après
Pour chaque donnée dans la base.
Le journal de transaction peut grossir et se remplir avec le temps, mais c’est le
Gestionnaire de Journaux (Log Manager) qui permet de :
- L’archivage de journaux
- D’apprêter (vider) le journal pour une prochaine utilisation après qu’il soit remplit
- Et il fournit au Gestionnaire de Transactions et de Données une interface publique au
journal, et ce pour la reprise, vu que ce dernier fournit des informations nécessaires
pour restaurer une base de données endommagée à son dernier état cohérent [28].
(a) Le Journal des images avant
Il contient les débuts de transactions, les valeurs d'enregistrement avant mises à
jour, les fins de transactions (COMMIT ou ABORT)
Il permet donc de défaire (UNDO) les mises à jour effectuées par une transaction

48
Figure 13 : L’UNDO d’une mise-à-jour [30].
Toute mise à jour doit être précédée d'une écriture dans le journal des images avant
Avant tout, signalons que ce journal est utilisé pour défaire les actions d’une
transaction lorsqu’un site participant (cfr Protocole à Deux Phases, un peu plus loin) tome en
panne avant la validation (globale) de celle-ci.
Chaque fois quand une transaction démarre, il y a deux pages qui se lancent aussi :
page lue et page modifié (en mémoire cache).
- Page lue, contient l’ancienne valeur ou mieux pointe son adresse dans le journal
- Page modifiée, contient la valeur modifiée. Et c’est elle modifie vraiment la base de
donnée.
Alors, pour défaire, la base de données lire (READ) dans la page lue (1), et celle-ci
récupère l’ancienne value du journal (2), et apporte une modification la page modifiée avec
cette valeur (3) et enfin la page modifiée écrit dans la base de données (4) et cette dernière
revient à son état initial.
(b) Le Journal des images après
Il contient les débuts de transactions, les valeurs d'enregistrement après mises à
jour, les fins de transactions (COMMIT ou ABORT)
Il permet également de refaire (REDO) les mises à jour effectuées par une
transaction

49
Figure 14 : Le REDO d’une mise-à-jour [30].
Toute validation de transaction doit être précédée de l'écriture de son journal
d'images après sur un disque différent de celui contenant la base de données.
Pareillement avec la méthode de page ombre [52], lorsqu’il y a validation la page
modifié devient la page lue ;
Alors, pour défaire, la base de données lire (READ) dans la page lue (1), et celle-ci
rapporte une modification la page modifiée avec les dernières valeurs de la transaction (2),
et la page modifiée prend toutes informations de la transaction (validation, etc.) du journal
(3) et enfin la page modifiée écrit dans la base de données (4) et ainsi les mêmes mises-à-
jour sont de nouveau apportées à la base de données.
Note :
[30] et [28] montrent qu’il existe deux autres type de journaux, à savoir Logique et physique
• Journal physique:
* On enregistre la valeur avant et après modification
* La structure peut être : IdTrans, NumPageDisk, Adresse, Valeur
* Pour défaire, on écrase la valeur actuelle avec les valeurs avant
* Pour refaire, on écrase la valeur actuelle avec les valeurs après

50
• Journal Logique
+ On enregistre l’action logique qui a entraîné la modification
+ La structure peut être : IdTrans, IdObjet, IdActions, Arguments
+ Exemple: Ajouter 500 au tuple xxx
+ pour refaire, on ré-applique l’action logique
II.4.2. Reprise
On a vu que lorsqu’une transaction se déroulait, elle pouvait subir une interruption
(ABORT), et cela est dû principalement à une panne ou défaillance.
A la reprise (après une défaillance), le système transactionnel parcourt le journal pour
analyser l'état des transactions interrompues au moment de l'incident.
(a) Différent types de pannes (défaillances)
> Abandon d’une Transaction
Dû souvent à un problème d’accès concurrent [44].
> Panne Système
Dû à un arrêt brutal des travaux, d’où une perte de contenu de la RAM ou une
défaillance matérielle ou logicielle d'un système local ou du système de
communication
> Panne du support de reprise
(b) Traitement de reprise
Respectivement pour les deux dernier cas de pannes, on y remédie avec une reprise à
chaud et une reprise à froid.
> Reprise à chaud
+ Défaire les actions des transactions interrompues sur les sites en
fonctionnement
+ Redémarrer le site interrompu (ou reconnexion en cas de panne réseau)
+ Défaire les actions des transactions sur le site reconnecté
+ Ré-exécuter les transactions
> Reprise à froid
+ Restaurer la mémoire secondaire dans un état cohérent à l'aide d'une image
sauvegardée antérieurement (grâce au CHECKPOINT)
+ Refaire les actions des transactions perdues à cause de la défaillance
Toutes ces reprises se font grâce aux points de reprise (CHECKPOINTS) créés bien avant.
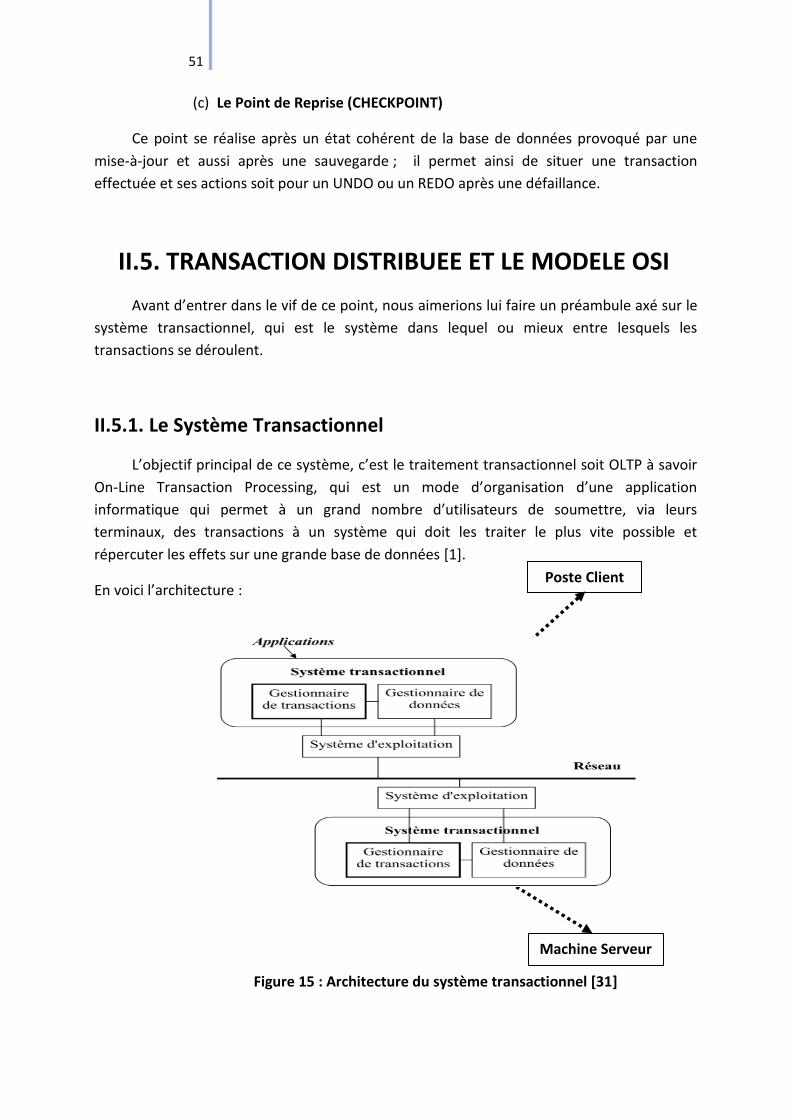
51
(c) Le Point de Reprise (CHECKPOINT)
Ce point se réalise après un état cohérent de la base de données provoqué par une
mise-à-jour et aussi après une sauvegarde ; il permet ainsi de situer une transaction
effectuée et ses actions soit pour un UNDO ou un REDO après une défaillance.
II.5. TRANSACTION DISTRIBUEE ET LE MODELE OSI
Avant d’entrer dans le vif de ce point, nous aimerions lui faire un préambule axé sur le
système transactionnel, qui est le système dans lequel ou mieux entre lesquels les
transactions se déroulent.
II.5.1. Le Système Transactionnel
L’objectif principal de ce système, c’est le traitement transactionnel soit OLTP à savoir
On-Line Transaction Processing, qui est un mode d’organisation d’une application
informatique qui permet à un grand nombre d’utilisateurs de soumettre, via leurs
terminaux, des transactions à un système qui doit les traiter le plus vite possible et
répercuter les effets sur une grande base de données [1].
En voici l’architecture :
Poste Client
Machine Serveur
Figure 15 : Architecture du système transactionnel [31]

52
Termes inhérents au système transactionnel :
+ Programme d’Application :
Celui-ci définit les limites de transactions et spécifie les actions que constitue une
transaction.
+ Gestionnaire de transactions :
C’est lui qui est chargé de fournir les informations nécessaires pour une reprise
donnée ;
Il reçoit d’une application donnée les commandes de BEGIN, COMMIT et ABORT et le
transmet au Gestionnaire de données approprié.
C’est lui donc qui garantie la propriété ACID d’une transaction.
Enfin s’appuyant sur le journal de transactions, le Gestionnaire de Transactions a
plusieurs autres tâches telles que : le ROLLBACK des transactions, le redémarrage du
Gestionnaire de données et du système global (de tous les gestionnaires de données), etc.
[28].
+ Gestionnaire de données :
Le Gestionnaire permet ainsi les mises-à-jour et les lectures des données ; il est chargé
d’écrire dans le journal d’image avant et après de données à toute modification.
Note : Le Système Global (les deux gestionnaires) permet donc d’assurer l’intégrité
transactionnelle de données modifiées [1].
+ Moniteur Transactionnel :
Il permet la communication et la mise en relation de processus client et serveur et
cette communication reste transparente (pour le processus et pour les medias).
Il permet aussi de gérer les transactions (du point de vue respect de la propriété ACID),
dans un contexte, éventuellement distribué, mettant en jeu plusieurs Gestionnaire de
données.
Il faut donc dire que le SGBD et le moniteur reste indissociable pour un système OLTP
[1], car ce dernier offre une interface programmatique et des outils de supervision qui
facilite le rôle des développeurs des applications et des administrateurs.

53
II.5.2. Le Modèle OSI pour les Transactions Distribuées
L’organisation de Standardisation Internationale (ISO : International Standard
Organisation) a mise en place une norme OSI TP (Open System Interconnect Transactions
Processing) dont le standard axe sur les trois points principaux suivant le modèle, le service
et le protocole de spécification pour les transactions distribuées.
Tous ces concepts sont mieux explicités dans les documents du standard dont les
références sont [26] ; Nous n’allons pourtant juste que présenter ici les notions
nécessaires.
(a) Modèle
C’est aussi appelé OSI DTP Reference Model (DTP : Distributed TP).
(1) Association
Lorsque deux systèmes ouverts doivent prendre part dans un même traitement distribué, ils ont besoin d’être mise en connexion ; et c’est cette dernière qu’on appelle Association ; c’est l’ACSE (Association Control Service Element ; Partie de la couche 7 OSI - application permettant de faire communiquer deux entités [2]) qui est chargé de l’établir.
(2) Architecture, Dialogue et Arbre
[-Architecture transactionnelle-]
La figure ci-dessous illustre l’architecture transactionnelle de trois nœuds X, Y et Z
S
A
O
S
A
O
MACFO
TPPM
S
A
O
TPPM
TPSU TPSU
S
A
O
TPPM
TPSU
NŒUD_X NŒUD_Y NŒUD_Z
Figure 16 : Architecture Transactionnelle [46]

54
TPPM (TP Protocol Machine) : c’est un système ouvert [26] ; il fournit le service OSI TP et en
outre est un représentant local de l’application répartie appelé TPSU (TP Service User).
SAO (Single Association Objects) : c’est un ensemble de modules que constitue aussi une
entité de TPPM. Il a pour but la gestion de la communication sur une association avec un
nœud voisin.
MACF (Multiple Association Control Function) : mis à part le SAO, le MACF est aussi une
entité qui constitue un TPPM. il a pour but la coordination entre tous les SAOs.
[-Dialogue-]
On appelle Dialogue, une relation peer-to-peer entre deux TP Service Users qui
communiquent après des invocations (appels) entre eux ou carrément entre deux TPSUIs
(TPSU Invocation). Lorsqu’il y a établissement de dialogue, alors les deux participants
peuvent communiquer pour se transférer des données, notifier des erreurs, initier ou
achever une transaction, terminer un dialogue, ou synchroniser les activités.
Et comme l’illustre aussi la figure juste ci-dessus, voici un exemple de dialogue entre
TPSUI A et B :
Il faut dire que chaque fois qu’il y a dialogue, il y a immanquablement un initiateur et
un répondant, dont respectivement l’un est un supérieur et l’autre un subordonné. Et même
si le dialogue fait intervenir plus d’une association de TP (TP Association), il reste un concept
logique et en même temps en est indépendant.
TPSUI A
TPPM
TPSUI B
TPPM
Figure 17 : Modèle de Dialogue dans OSI TP

55
[-Arbre de Dialogue et de Transaction -]
De par des invocations des différents TP Service Users, nous avons déjà un Arbre de
dialogue dont les nœuds sont ces dernières et les arcs les dialogues. Cet arbre de dialogue
représente une topologie de la communication des systèmes ouverts participants dans le
traitement distribué.
Et comme une transaction distribuée (répartie) est celle qui enjambe beaucoup de
ressources (dans différents nœuds ou sites) ; une partie d’elle est exécuté par un couple de
TP Service Users comme ils sont en dialogue. Chaque partie est une branche de la dite
transaction distribuée.
Un arbre de Transactions est tout similaire à celui de Dialogue, sauf qu’ici les arcs sont
les branches de transactions ; ce qui est logique.
On distingue dans cet arbre trois types de nœuds : la racine, les intermédiaires et les
feuilles ; la racine est l’invocation du TPSU qui n’a pas un nœud supérieur et les feuilles sont
ceux qui n’ont aucun nœud subordonné. Un nœud un sous-arbre de transactions qui
respecte les même règles énoncées juste ci-haut. (Cette notion d’arbre de transaction est
aussi vue un peu ci-haut avec les transactions imbriquées).
Racine
Intermédiaire Feuille
Feuille
Intermédiaire
Figure 18 : Arbre de Transactions

56
(b) Services et Protocole
Pour établir et libérer les associations, le TPPM ou la machine protocolaire utilise l’ASE
(Application Service Element [2] [1]) de l’ACSE.
Le TPPM joue ce rôle de fournir les services pour assurer la propriété ACID, alors pour
ce fait lorsqu’une TPSUI veut établir un dialogue, il doit le spécifier.
Les services sont regroupés en unité fonctionnelles [1], dont nous avons :
+ Le noyau :
C’est l’unité fonctionnelle chargée de dialogues entres les TPSUIs, elle
comprend donc les services pour ouvrir, terminer, interrompre, refuser
l’ouverture d’un dialogue et de traiter les erreurs.
+ Le contrôle partagé :
C’est l’unité fonctionnelle qui permet les TPSUIs et leur assure un contrôle de
leurs dialogues de façon cohérente.
+ Le contrôle polarisé :
Pareille que l’unité précédente, sauf qu’ici, à un instant donné une seule
TPSUI possède le contrôle.
+ La synchronisation :
C’est l’unité fonctionnelle qui permet aux TPSUIs de synchroniser leur
traitement, c'est-à-dire avoir la possibilité de vérifier qu’ils ont atteint un
point de traitement convenu.
+ Le Commit :
C’est l’unité fonctionnelle qui rend possible la validation (COMMIT) fiable ou
le retour (ROLLBACK) des transactions.
Le commit ou la coordination, assure la phase terminale de la transaction
pour la validation à deux phase.
Note [20] [1]:
* L’unité fonctionnelle de Contrôle partagé et polarisé sont mutuellement exclusive
pour un dialogue.
* La validation à deux phases, dont nous allons parler prochainement mais en long et
en large, comprend donc l’arbre de transaction, la journalisation, la gestion de
données liées et le pilotage de CCR (Committment, Concurrency and Recovery :
protocole de validation et de reprise de transactions [26]) ; nous l’allons montrer
dans la suite.

57
II.6. GESTION ET CONTROLE DE CONCURRENCE DE
TRANSACTIONS (REPARTIE)
La mise au point de l’utilisation de transactions, comme dit tant tôt, avait pour but,
aussi palliatif soit-il, de garantir la cohérence ou la consistance de données. L’intégrité de
données. Et une transaction atomique et cohérence ne met en cause aucunement l’intégrité
des données. Ce sont d’ailleurs les deux propriétés qui distinguent les transactions de
n'importe quelle séquence d'actions - éventuellement réduite à une seule - sur la BD.
Tout tourne autour de la terminaison de la transaction, afin que celle respectant la
propriété d’ACID, arrive aussi à maintenir la base de données cohérente. D’où la gestion de
transactions est capitale, et reprend celle de ce deux point :
* La cohérence ou la consistance de données (contrôle de cohérence de données) :
La définition de la cohérence résulte de la sémantique de l’application, c’est l’ensemble
de techniques mises en œuvre pour assurer la validité du système informatique par
rapport au monde réel qu’il modélise.
Mais, le contrôle de cohérence nécessite deux mécanismes de contrôle [46]:
+ Un contrôle de concurrence :
Pour l’accès à des données locales communes à des processus d’applications
réparties différentes.
+ Un contrôle de synchronisation
Dans les modifications effectuées, à la fin de chaque étape, par différents
processus d’une application répartie.
* La concurrence de données (contrôle de concurrence de données) :
La concurrence, c’est cette possibilité que donne un SGBDR (Système Gestion de Base
de Données Réparti) multiutilisateur de permettre un accès simultané de transactions dans
une base de données ; c’est d’ailleurs une qualité pour un SGBDR. La concurrence a pour but
d’améliorer le système et le temps de réponse, permettre différentes transactions d’accéder
dans différentes parties de la base de données. Et pourtant si elle n’est pas contrôlée elle
provoque une incohérence ou inconsistance de données.

58
II.6.1. La cohérence de données
Pour terminer une transaction, il faut décider de son issue : la validation (COMMIT) ou
l’annulation (ROLLBACK) [50] ; La validation rend les modifications définitives ; l’annulation
ramène les processus à leur état avant transaction (propriété d’atomicité). Et comme les
transactions distribuées, ce dont même nous parlons dans notre travail, concernent
plusieurs ressources, sa validation (COMMIT) est assurée par des protocoles de validation
qui sont des algorithmes pour assurer l’atomicité d’une transaction distribué et ils sont
utilisés dans un SGBDR (Système de Gestion de Base de Données Réparti) pour montrer un
comportement bien-défini de chacun de sites, particulièrement pour le COMMIT et le
ROLLBACK des transactions [32].
Nous en citons deux, que nous allons développer dans ce travail :
> Validation en deux phases : dite bloquante, car une transaction peut rester bloqué
suite à la panne du coordinateur (l’initiateur du dialogue, la racine [26]).
> Validation en trois phases : dite non-bloquante.
(a) Règles générales d’un protocole de validation
> Le coordinateur valide la transaction, si inévitablement tous les sites participants
valident ;
> Sinon il annule ;
> Tout site en bon état, coordinateur ou participant, peut éventuellement décider de
valider ou d’annuler ;
> Il ne suffit qu’un site, alors n’importe le quel, décide de valider ou annuler, alors plus
un autre ne décidera autrement.
(b) Point de validation : COMMIT POINT
Chaque fois quand une transaction doit s’exécuter, le SGBD désigne un site afin
qu’il soit le point de commit avec un rôle aussi précis que de lancer le COMMIT ou
ROLLBACK selon que lui ordonne le coordinateur global.
Le critère de sélection d’un site en tant que point de commit est le suivant :
> Le site ne doit pas être en lecture, c.-a.-d. il doit pouvoir modifier ses données
locales pendant une transaction
En cas de plus d’un site correspondant au critère, le coordinateur fait un choix au
hasard ; car tous les sites ont la même chance de sélection.

59
En cas d’échec de la phase de préparation par le coordinateur, aucun point n’est
désigné et le coordinateur lance un ROLLBACK.
Le point de commit est un site distingué des autres, on a :
+ Il n’entre jamais en phase de préparation ;
+ Il stocke des données importantes, qui restent jamais incertaines même quand il
y a panne (fiabilité);
+ Il stocke les informations sur le statut de la transaction
(c) Protocole de Validation en Deux Phases : 2-PC
Nous avons deux types de nœuds ou sites dans une validation en Deux phases, le
Coordinateur et le Participant. Le coordinateur est celui qui a pour but de lancer, découper
en sous transaction les transactions qui seront exécutées sur les sites restant [22] [15] et
coordonner la terminaison de ces transactions. C’est donc un serveur auquel les autres sites
dits clients se connecte lorsqu’ ils veulent effectuer une transaction.
Voici ci-dessous, deux automates à états finis non déterministes (AEFND) (aussi bien
défini dans [39]) modélisant les actions du coordinateur et du participant :
[Etats]
- q1, q2 : des états initiaux
- a1, a2, c1, c2 : des étaux finaux, respectivement « a » pour ABORT et « c » pour
COMMIT
- w1 : état intermédiaire, w pour WAIT (Lorsque le coordinateur attend les réponses
des participant)
- p2 : état intermédiaire, p pour PRE-COMMIT (du participant)
[Transitions]
Exemple : 𝑋𝑎𝑐𝑡−𝑟𝑒𝑞𝑢𝑒𝑠𝑡
𝑆𝑡𝑎𝑟𝑡_𝑋𝑎𝑐𝑡 ;
Le message au dessus de la ligne, c’est celui qui est reçu et en dessous est celui qui est
envoyé entre le coordinateur et les participants.

60
Figure 19 : Les actions du Protocole de Validation en Deux Phases [32]
Le principe du protocole de validation en deux phases [46] [32] [20] est le suivant :
- La phase 1 :
C’est la phase de préparation ou de consensus entre tous les sites participant à la
validation des effets de la transaction, alors ces derniers peuvent voter oui ou non (yes ou
no), comme le montre la figure juste ci-dessus.
Une fois le consensus établi, c'est-à-dire tous les sites participants ont voté « yes »
(PRE-COMMIT) et le renvoie au coordinateur, alors il lance la deuxième phase pour le
COMMIT.
Si, par contre, même un seul site vote « no », il n’y a donc pas consensus et le
coordinateur ordonne alors à tous les sites pour le ROLLBACK.
- La phase 2 :
Ici, tous les sites participant à la transaction valident ou annulent simultanément selon
qu’ils ont reçu le message de COMMIT ou ROLLBACK
Explication de la figure ci-dessus
Le coordinateur reçoit (de l’application) Xact_request en « q1 » c'est-à-dire une
requête de transaction et l’envoie (Start_Xact) aux participant en « q2 », et de là le
participant peut soit l’exécuter et renvoyer « yes » pour passer en état « p2 » : PRE-COMMIT
(près pour le COMMIT) ou soit carrément renvoyer « no » et passer en « a2 » : ABORT. Et
c’était donc la première phase. Et la deuxième phase débute en « w1 » d’où le coordinateur
attendait les réponses des participants ; s’il reçoit « yes », alors de manière non-
déterministe, il renvoie « commit » ou « abort » aux participants pour valider ou annuler
simultanément et ils le reçoivent en « p2 » et peuvent ainsi achever cette action finales.

61
Note :
- Yes = Oui = Prêt
- No = Non = Abandon
Cas favorable de la validation (normale) à Deux Phases (Illustration)
Figure 20 : Validation normale [15] [22] [40]
Ici, tous les participants ont voté prêt ou oui et ainsi ensemble avec le coordinateur, ils
font une validation globale simultanément.
Validation en deux phases face aux pannes
L’efficacité de ce protocole réside dans l’utilisation des journaux [46], qui ne perdent
pas d’information. Lorsqu’il y a une panne, probablement de sites qui sont silencieux ou de
communication (plus de ligne de transmission), le mécanisme de reprise sera fait sur base
des informations des journaux de transaction.
Par exemple, dans le cas d’une panne de communication, le participant qui est prêt
reste bloqué puisqu’il ne peut pas communiquer avec son coordinateur et par conséquent
ne peut savoir sa dernière décision. On dit qu’il est dans un état incertain ou de doute.
Que faire en cas de doute ?
Le participant doit émettre des requêtes [46] auprès des autres pour savoir la décision
finale. Ou forcer la transaction locale à l’état ABORT ou COMMIT et puis l’ignorer.
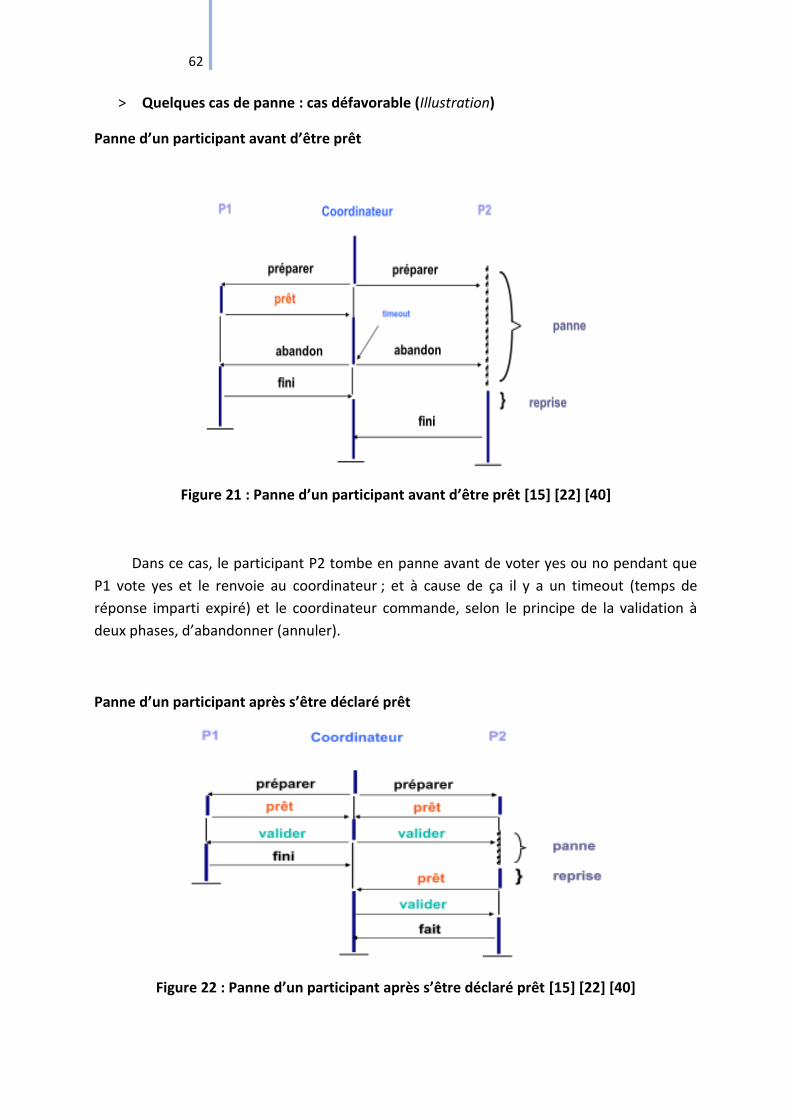
62
> Quelques cas de panne : cas défavorable (Illustration)
Panne d’un participant avant d’être prêt
Figure 21 : Panne d’un participant avant d’être prêt [15] [22] [40]
Dans ce cas, le participant P2 tombe en panne avant de voter yes ou no pendant que
P1 vote yes et le renvoie au coordinateur ; et à cause de ça il y a un timeout (temps de
réponse imparti expiré) et le coordinateur commande, selon le principe de la validation à
deux phases, d’abandonner (annuler).
Panne d’un participant après s’être déclaré prêt
Figure 22 : Panne d’un participant après s’être déclaré prêt [15] [22] [40]

63
Ici, tout se passe bien jusqu’au consentement des participant (prêt), mais juste après le
participant P2 tombe en panne et quand le coordinateur envoie la commande de valider,
elle le trouve ainsi. L’autre la reçoit et l’exécute et c’en est fini avec lui ; mais lui attendra
que qu’il y ait reprise et alors il va valider.
Panne du Coordinateur
Figure 23 : Panne du coordinateur [15] [40]
Bien que garantissant la convergence des acteurs vers un même état (COMMIT ou
ABORT), Et il est plausiblement clair que le défaut le plus notoire de ce protocole, c’est le
blocage. Pour cela, il ne suffit que le coordinateur tombe en panne après émission du
message PREPARE (Xact_start), tout participant ayant voté prêt (yes) est alors bloqué
(TIME-OUT).
D’où le protocole de validation en trois phases.
En outre, ce protocole menace aussi l’inconsistance d’états [32] et pour Dale Skeen et
Michael Stonebraker [12], un état est dit inconsistant lorsque son vecteur d’état global
contient à la fois les états COMMIT et ABORT. Un exemple pour le participant qui est déjà à
l’état de PRE-COMMIT « p2 ».
Proposition OSI pour le protocole de validation en deux phases
Pour le cas de ce protocole, OSI TP [26] veut qu’il soit modélisé dans une structure
hiérarchique. C'est-à-dire la racine, c’est le coordinateur ou l’initiateur de la transaction.
Chaque site ou nœud a cette possibilité de signaler ses voisins l’annulation de son
processus : annulation unilatérale ou le « Presumed Rollback » [46], en cas des opérations
anormales.

64
(d) Protocole de Validation en Trois Phases : 3-PC
A la différence du précédent, celui-ci est non bloquant où on a :
+ Préparation ou consensus
+ Préparation pour la validation (PREPARE TO COMMIT)
+ Global COMMIT
+ Global ABORT
Et plus clairement [12] montre qu’un état PRE-COMMIT « p1 » est ajouté au
coordinateur ne pouvant être atteint que si tous les participants ont voté pour le COMMIT :
« yes ». Mais lorsqu’il y a panne d’un participant après que le coordinateur ait atteint le PRE-
COMMIT « p1 », le coordinateur n’a qu’une seule option c’est annuler (ABORT) : TIME-OUT ;
sinon la transaction aboutit alors et les participant renvoient un acquittement (ACK).
Figure 24 : TIME-OUT et panne dans le protocole de validation en trois phases [32]
Ce protocole assure toujours un COMMIT global même lorsque le coordinateur étant
déjà au PRE-COMMIT (« p2 ») tombe en panne et il y a lieu d’une élection d’un nouveau
coordinateur.
Ce protocole aurait résolu le problème de blocage et pourtant ne reste pas parfait à
tout égard ; son seul problème c’est quand il y a plusieurs pannes de sites.

65
II.6.2. Concurrence d’accès de données
Une exécution concurrente non-contrôlée des plusieurs transactions peut amener des
incohérences ; par exemple lorsque des données liées par une contrainte d’intégrité sont
mises à jour par deux transactions dans des ordres différents de sorte à violer la contrainte.
La figure ci-dessous l’illustre très bien :
Figure 25 : Exécution non contrôlée des transactions concurrentes
De cette figure, se révèle un problème, c’est celui d’interférence ; [45] montre que ce
problème se résume en deux cas :
+ Interférences entre écrivains, Transactions d’écriture
+ Interférences entre lecteurs et écrivains, Transactions de lecture et d’écriture

66
(a) Interférences entre écrivains
Perte d’opérations (Lost Update)
Ici, la mise à jour faite par une première Transaction est perdue
Exemple :
TEMPS
READ A
t1
X = A + 1
WRITE A = X
t3
TRANSACTION_1
t2 READ A
Y = A * 7
t4 WRITE A = Y
TRANSACTION_2
Figure 26 : Perte d’opérations

67
Ecriture inconsistante ou sale (Dirty Write)
Une Transaction T1 lit une valeur V et la modifie, et la Transaction T2 lit l’actuelle
valeur V et la modifie à partir de là ; mais après ça la Transaction T1 vient à s’annuler
(ROLLBACK) et voilà que la dernière valeur modifiée par T2 n’a plus de sens.
L’écriture inconsistante ou sale, c’est tout simplement celle à partir d’une valeur
temporaire des données.
Exemple :
Initialement, C le crédit d’un compte est < 500. Une première transaction modifie le
crédit C d'un compte. Une deuxième lit C dans ce nouvel état, puis, constatant que la
provision est suffisante, modifie le débit D du compte. Après annulation de la 1ére
transaction, la contrainte d'intégrité D ≤ C n’est plus vérifiée.
TEMPS
READ C
C = C + 1000
WRITE C
t1
TRANSACTION_1
t2
READ A
t3 IF C > 500 THEN
D = D + 500
WRITE D
TRANSACTION_2
Figure 27 : Ecriture inconsistante

68
(b) Interférence entre Lecteur et Ecrivain
Lecture Inconsistante ou sale (Dirty Read)
Une transaction T2 lit une valeur V donnée par une transaction T1. Ensuite la
transaction T1 annule son affectation (ROLLBACK) et valeur lue par T2 est donc fausse.
La Lecture inconsistante ou sale, c’est tout simplement celle d’une valeur temporaire
des données, et non persistante.
Exemple :
La première transaction a pour but de faire un virement entre deux comptes A et B, qui
satisfait la contrainte d'intégrité "somme A+B invariante". La deuxième transaction lit A
et B juste après que la 1ére transaction ait déduit 1000 de A. Elle trouve A+B diminué.
TEMPS
READ A
A = A - 1000
WRITE A
t1
READ B
B = B + 1000
WRITE B
t3
COMMIT t4
TRANSACTION_1
t2
READ A
READ B
TRANSACTION_2
Figure 28 : Lecture sale
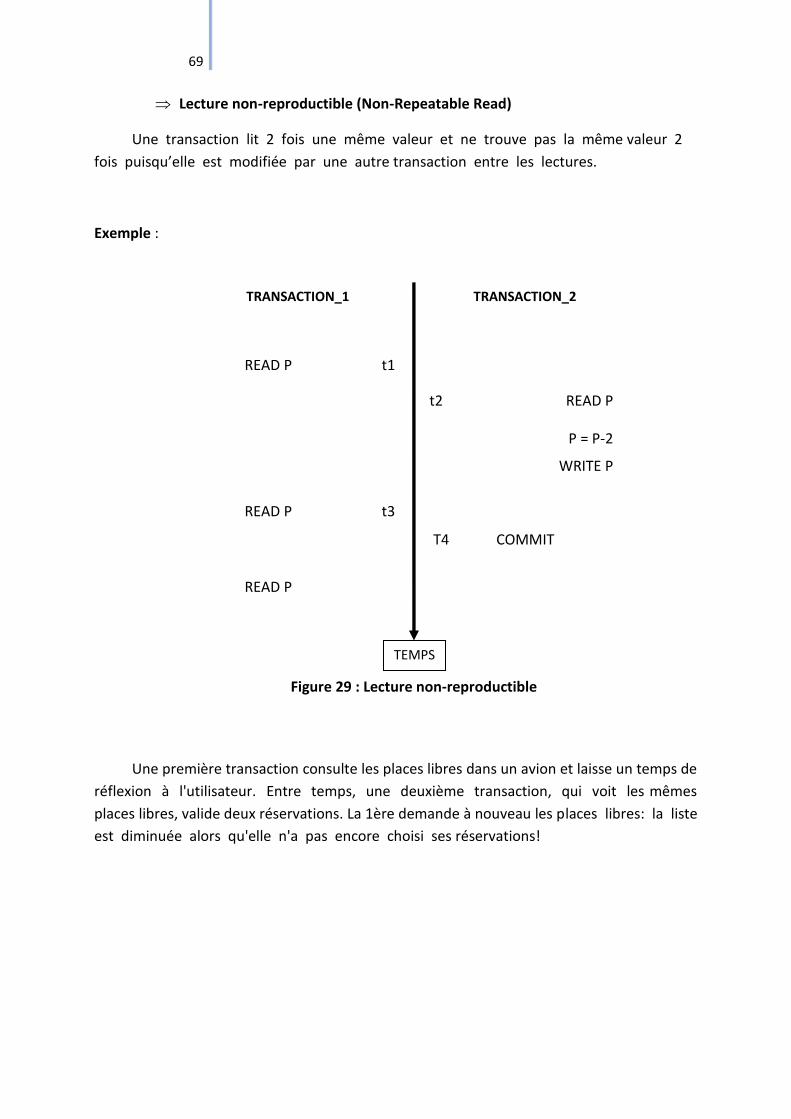
69
Lecture non-reproductible (Non-Repeatable Read)
Une transaction lit 2 fois une même valeur et ne trouve pas la même valeur 2
fois puisqu’elle est modifiée par une autre transaction entre les lectures.
Exemple :
Une première transaction consulte les places libres dans un avion et laisse un temps de
réflexion à l'utilisateur. Entre temps, une deuxième transaction, qui voit les mêmes
places libres, valide deux réservations. La 1ère demande à nouveau les places libres: la liste
est diminuée alors qu'elle n'a pas encore choisi ses réservations!
TEMPS
READ P
t1
READ P
t3
READ P
TRANSACTION_1
t2 READ P
P = P-2
WRITE P
T4 COMMIT
TRANSACTION_2
Figure 29 : Lecture non-reproductible

70
Lecture Fantôme (Phantom Read)
C’est presqu’identique au cas précédent, une transaction ajoute des données sans que
les autres s’en aperçoivent ; Il n'y a pas alors de conflit à proprement parler mais seulement
interrogation sur la validité de ces "apparitions fantômes".
Tous ces cas d’interférence ci-haut cités violent la propriété d’Isolation (Isolement [17])
d’une transaction, car c’est elle qui maintient le contrôle de la concurrence.
L’Isolation (Isolement [17]) d’une transaction est appelée sous plusieurs noms tels que
la consistance, le contrôle de concurrence (le problème), la sérialisabilité (la théorie), et le
verrouillage (la solution) [28].
(c) Contrôle de concurrence
Le contrôle de concurrence est la solution appropriée à cette dernière, il se réalise par
l’entremise des algorithmes dont selon [4] la plupart revient parmi ces trois classes
fondamentales : Verrouillage, Estampillage et la certification (ou les algorithmes
optimistes).
Mais en gros, nous avons deux classes de bases : Verrouillage et Estampillage, dont
nous allons parler dans cette section, car la certification n’utilise rien d’autre que
l’estampillage [4].
Le contrôle de concurrence, c’est tout simplement la sérialisabilité, cette propriété
que possède les SGBDs de contrôler l’exécution simultanée des transactions afin qu’elles
produisent les mêmes résultats qu’une exécution séquentielle. Et d’ailleurs, tous ses
algorithmes vont dans ce sens.
(1) Le Verrouillage
C’est la voie la plus utilisé pour implémenter la sérialisation des transactions. Il
consiste à mettre de verrou sur des données où accède la transaction jusqu’à la fin de celle.
Le verrouillage peut être fait en deux modes principaux, le mode Optimiste et le mode
Pessimiste, selon le but pour lequel la transaction accède aux données, soit pour les modifier
ou pas.
• Mode Pessimiste :
La première transaction accédant à la donnée, la verrouille de sorte que les autres
puissent seulement la lire et non la modifier jusqu’à la fin de la première.
La garantie de ce mode réside dans le fait qu’une transaction premièrement accédé dans
la donnée sache toujours lui appliquer des modifications.
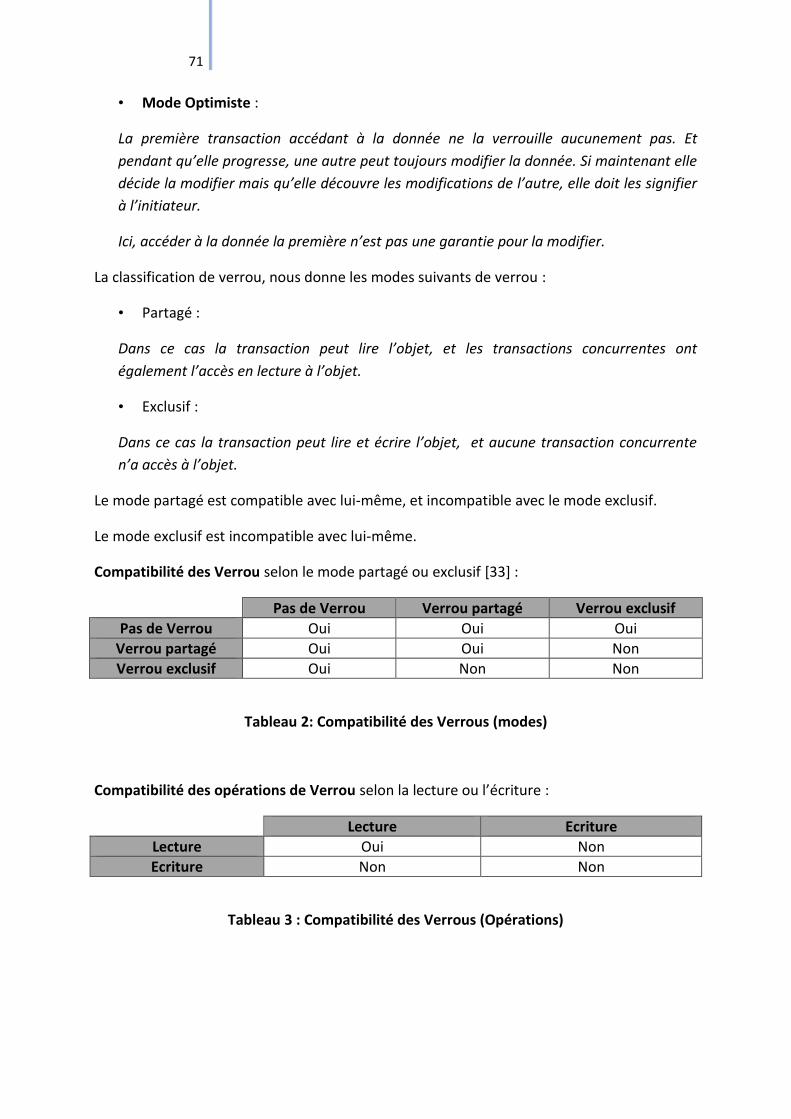
71
• Mode Optimiste :
La première transaction accédant à la donnée ne la verrouille aucunement pas. Et
pendant qu’elle progresse, une autre peut toujours modifier la donnée. Si maintenant elle
décide la modifier mais qu’elle découvre les modifications de l’autre, elle doit les signifier
à l’initiateur.
Ici, accéder à la donnée la première n’est pas une garantie pour la modifier.
La classification de verrou, nous donne les modes suivants de verrou :
• Partagé :
Dans ce cas la transaction peut lire l’objet, et les transactions concurrentes ont
également l’accès en lecture à l’objet.
• Exclusif :
Dans ce cas la transaction peut lire et écrire l’objet, et aucune transaction concurrente
n’a accès à l’objet.
Le mode partagé est compatible avec lui-même, et incompatible avec le mode exclusif.
Le mode exclusif est incompatible avec lui-même.
Compatibilité des Verrou selon le mode partagé ou exclusif [33] :
Pas de Verrou Verrou partagé Verrou exclusif
Pas de Verrou Oui Oui Oui
Verrou partagé Oui Oui Non
Verrou exclusif Oui Non Non
Tableau 2: Compatibilité des Verrous (modes)
Compatibilité des opérations de Verrou selon la lecture ou l’écriture :
Lecture Ecriture
Lecture Oui Non
Ecriture Non Non
Tableau 3 : Compatibilité des Verrous (Opérations)

72
Cas d’algorithme de Verrou
Nous allons prendre un exemple d’algorithme utilisation le verrouillage :
> Le Verrouillage à Deux Phases
Dans cet algorithme, les transactions accédant aux données mettent des verrous de
lecture et les convertissent en des verrous d’écriture sur d’autres au moment de la
modification [4] [42].
Pour lire une donnée, il faut :
- Mettre un verrou de lecture sur toutes copies de la donnée, afin que la copie locale
soit aussi verrouillée.
Pour modifier une donnée, il faut que :
- Les verrous d’écriture soient mis sur toutes les copies.
Avant la lecture ou l’écriture de données, la transaction a besoin d’y en avoir respectivement
un verrou de lecture ou d’écriture, mais pour question d’éviter le conflit d’opérations (cfr la
matrice de compatibilité des opérations). Mais la possession du verrou [42] est régie par les
deux règles suivantes :
(R1) Diverses transactions ne peuvent pas posséder simultanément des verrous
conflictuels ou incompatibles
(R2) Une fois qu’une transaction lâche le verrou, il ne pourra en obtenir d’autre.
Le Principe du Verrouillage à Deux Phases
Verrou
Acquisitions Restitutions
Point de Verrouillage
Phase 1 Phase2
Temps
Figure 30 : Le Principe du Verrouillage à deux phases [31]

73
• Première phase : l'acquisition
Du début jusqu'au point de verrouillage, la transaction acquiert des verrous.
• Deuxième phase : le relâchement
Du point de verrouillage jusqu'à la fin, la transaction réalise des écritures dans la base et
relâche les verrous.
Problème de Verrou Mortel ou Inter-Blocage
Il y a un cas d’un verrou mortel lorsque les transactions s’attendent indéfiniment les
une les autres pour accéder aux ressources quand ces dernières vont les lâcher. Il peut
concerner deux ou trois transactions.
Par exemple, une transaction T1 détenant le verrou d’écriture sur l’objet X souhaite en
obtenir un autre sur Y et qu’une autre transaction T2 détenant le verrou d’écriture sur
l’objet Y souhaite en obtenir sur X. Elles sont donc toutes deux inter-bloqués

74
Illustration [42]:
Transactions
T1: BEGIN;
READ (X); WRITE (Y);
END
T2: BEGIN;
READ (Y); WRITE (Z);
END
T3: BEGIN;
READ (Z); WRITE (X);
END
Et maintenant supposons que ces transactions s’exécutent simultanément, chacune s’engageant à son READ avant le END des autres.
Représentons cette exécution partielle par les journaux suivants :
DM A: r1 [x1] ; DM B: r2 [y2] ; DM C: r3 [z3]
Note: ri[x] dénote l’opération dm-read(x) lancé par Ti; DM: Data Manager (Gestionnaire de Ressource ou Données)
A ce point, T1 a le verrou de lecture sur x1, T2 le verrou de lecture sur y2, T3 le verrou de lecture sur z3
Avant de poursuivre, toutes les transactions doivent obtenir des verrous d’écriture. T1 demande des verrous d’écriture sur Y1 et Y2 ; T2 demande des verrous d’écriture sur z2 et z3 T3 demande des verrous d’écriture sur X1
Mais, T1 ne peut pas avoir de verrous d’écriture sur y2, jusqu’à ce que T2 lâche le verrou de lecture. T2 ne peut pas avoir de verrous d’écriture sur z3, jusqu’à ce que T3 lâche le verrou de lecture. T3 ne peut pas avoir de verrous d’écriture sur x1, jusqu’à ce que T1 lâche le verrou de lecture.
Ça c’est un VERROU MORTEL (DEADLOCK)
Bases de Données
X1
Y1 A
X2
Z2 B
Z3 C
Figure 31 : Le Verrou Mortel (DeadLock) [42]

75
Détection, Guérison et Prévention
Pour détecter le verrou mortel, on se serre du graphe des attentes. Ce graphe se
construit au fur et à mesure qu’une transaction demande un verrou sur un objet qui est déjà
verrouillé.
Rappelons qu’une transaction distribuée a une représentation hiérarchique (Arbre :
qui est un graphe [29]), d’où on a :
- Les nœuds sont les transactions
- Les arêtes sont l’attente entre T1 et T2, c'est-à-dire si T1 attend un verrou détenu par
T2
Et il y a verrou mortel ou inter-blocage lorsque ce graphe des attentes contient un
cycle ([29] parle amplement de la notion de graphe).
Figure 32 : Cycle dans le Graphe des Attentes
Pour résoudre ce problème, l’algorithme du Verrouillage à Deux Phases procède
comme suit :
- Il cherche l’inter-blocage local et global. Après avoir détecté, les transactions prises
dans le cycle sont relancées [4] et mais avant cela toutes leurs modifications sont
défaites.
Pour prévenir ce problème,
- [42] montre comment la prévention de l’inter-blocage est implémentée dans le
Verrouillage à Deux Phases. Et là, cette prévention est un plan prudent dans lequel
une transaction est du coup relancée dès que le système a « peur » qu’inter-blocage
peut survenir.
- Une approche dit qu’il faut limiter la profondeur d’attente de transactions bloquées à
un [8] et ceci pour minimiser le traitement dû au fait des redémarrages (relancer) des
transactions.
Les inter-blocages peuvent être carrément évités en répondant toutes les demandes de
verrous à la fois avant qu’une transaction fasse la validation ou simplement à son début.

76
Un autre algorithme utilisant aussi le verrouillage, c’est le WOUND-WAIT (WW).
> WOUND-WAIT (WW)
Ce dernier est similaire au précédent ; mais la simple différence est au niveau du
traitement du problème de Verrou Mortel ou inter-blocage.
Cet algorithme utilise l’estampillage pour gérer ou prévenir le problème d’inter-
blocage :
- A chaque transaction est accordé un numéro à son premier lancement,
- Et les transactions les plus récentes sont empêchées de faire attendre les plus
anciennes. Ainsi la possibilité d’un inter-blocage est éliminée.
- Dans le cas où une ancienne transaction demande un verrou et que celle-ci pourrait
lui mener à attendre une plus récente, cette dernière est « blessé » (WOUND) c'est-à-
dire elle sera relancée sauf si elle est déjà dans sa deuxième phase de son protocole
de validation (dans lequel cas la plaie « WOUND » n’est pas fatale, et sera
simplement ignorée)
(2) L’Estampillage
Un cas d’utilisation des estampilles est montré dans l’algorithme précédent. Mais nous
allons donner un algorithme où les estampilles sont utilisées pour le contrôle de
concurrence.
> Ordonnancement par estampillage
Pareillement et pourtant différemment que le WOUND-WAIT qui lui utilise le verrou,
celui-ci associe plutôt les estampilles avec toutes les données récemment accédées. Il y a un
ainsi ordre d’estampille selon lequel les transactions problématiques (celles qui participent
dans les accès conflictuel de données) doivent suivre lors de leurs exécutions. Sinon la
transaction est relancée (annulée et relancée).
Une demande de lecture de données sera permise si l’estampille du demandeur est
supérieure à celle de l’écriture. Vice versa. Dans le cas contraire, c'est-à-dire, si l’estampille
est inférieure, la règle d’écriture de Thomas [4] dit que les mises-à-jour vont simplement
être ignorées.
Et nous allons clôture ce chapitre avec la notion de niveau d’isolation.

77
(d) Les Niveaux d’Isolation
Les niveaux d’Isolation permettent donc une exécution parallèle des transactions en
donnant ces dernières une certaine possibilité de manipulation des données, et ce à travers
les propriétés d’isolation.
Chaque propriété définit un niveau d’accès aux données en cours de modification
par d’autres transactions en cours. Les données qui sont en cours de modification sont
dites données volatiles [21].
Il faut dire que les Niveaux d’Isolation entre en ligne de compte pour la résolution de
problème de contrôle de concurrence.
+ READCOMITTED : les données volatiles ne peuvent pas être lues pendant la
transaction, mais peuvent être modifiées.
+ READUNCOMMITTED : les données volatiles peuvent être lues et modifiées
pendant la transaction.
+ REPEATABLEREAD : les données volatiles peuvent être lues mais pas modifiées
pendant la transaction. De nouvelles données peuvent être ajoutées.
+ SERIALIZABLE : niveau d’isolation par défaut. Les données volatiles peuvent être lue
mais pas modifiées. De même aucune nouvelle donnée ne peut être ajoutée pendant
la transaction.
Le choix de niveaux est capital, et dépend souvent de la nature d’une application.

78
[Chapitre III]

79
Chapitre III
Les applications
Dans ce chapitre où nous avons consacré nos efforts pour essayer tant soit peu de
rattraper la pratique. Voici les outils utilisés pour arriver à bon bout :
- Le SQL SERVER (version 2008) de Microsoft :
- La plateforme .NET (Framework 3.5, version 2008 : Full Team), précisément le
langage C# de Microsoft :
- UML (Unified Modeling Language) :
En outre, on aura à présenter l’intranet gouvernemental de la République sur lequel
nous avons pu concevoir une application (distribuée) et afin cette application. Mais avant
tout, commençons par présenter les outils.
III.1. Mécanisme de Répartition sous SQL SERVER
Nous présentons ici des notions essentiales et inhérentes à ce que traite ce travail, une
grande source nous vient de [53], [19], [38].
III.1.1. SQL SERVER
Microsoft SQL Server est un système de gestion de base de données (abrégé en SGBD
ou SGBDR pour « Système de gestion de base de données relationnelles ») développé et
commercialisé par la société Microsoft.
III.1.2. Les Bases de Données
Les bases de données sont contenues physiquement dans des fichiers. Les fichiers portent généralement les extensions :
MDF (Main Database File) pour le premier fichier de données NDF (Next Database File) pour les autres fichiers de données LDF (Log Database File) pour les fichiers du journal de transaction

80
Les fichiers sont divisés en blocs de 8196 octets appelés pages et organisées par blocs de 8 pages appelées extensions. Jusqu'à la version 2000, les lignes étaient limitées à une taille maximale de 8060 octets (les colonnes de type LOBs (image, text, ntext) n'étant pas comptabilisées dans cette limite). Depuis la version 2005 il est possible de dépasser largement cette limite et d'aller jusqu'à 2 milliards d'octets. En revanche la taille utile de la page est de 8096 octets.
Les bases de données ne peuvent fonctionner que lorsque tous les fichiers sont présents.
Les fichiers de données sont regroupés logiquement dans la base de données dans des groupes de fichiers. Ces fichiers et groupes de fichiers peuvent être sauvegardés de façon indépendante à condition qu'il n'existe aucune interdépendance logique entre les objets d'un fichier et d'un autre (intégrité référentielle en particulier).
III.1.3. Services et moteurs
III.1.3.1. SQL Server
Il s'agit du moteur de bases de données. À chaque instance de SQL Server correspond un service Windows Sql Server. Ce service peut être repéré dans les services Windows sous les noms MSSQL$Nom_instance pour les instances nommées et MSSQLServer pour l'instance par défaut.
Chaque instance créée possède au départ 4 à 6 bases de données systèmes. Le moteur SQL Server s'appuie sur la base de données système master qui contient la définition des autres bases de données.
Les autres bases systèmes sont :
msdb : utilisée par l'agent SQL Server, la réplication, Data Transformation Services, Integration Services...
model : utilisée comme modèle pour créer de nouvelles bases de données. Toute nouvelle base de données est une copie de celle-ci.
tempdb : Base de données temporaire, elle sert à stocker les données temporaires créées par des utilisateurs ou générées par des curseurs, des créations d'index, lors d'un tri volumineux. Sous SQL Server 2005, elle contient aussi les versions d'enregistrement générées par les niveaux d'isolation SNAPSHOT, le contenu des pseudo tables inserted et deleted utilisées dans les triggers et celles générées par les opérations d'index en ligne. Cette base de données système est systématiquement vidée au démarrage du service SQL Server.
distribution : N'est présente que dans le cadre d'une réplication si votre serveur joue le rôle du distributeur.
mssqlsystemresource : Présente uniquement à partir de SQL Server 2005. Elle n'est pas accessible directement, et elle contient tous les objets systèmes (hors tables).

81
III.1.3.2. SQL Server Agent
Il s'agit de l'agent de maintenance de l'instance de SQL Server. À chaque instance de SQL Server correspond un service Windows Sql Server Agent. Ce service peut être repéré dans les services Windows sous les noms SQLAgent$Nom_instance pour les instances nommées et SQLAgent pour l'instance par défaut. Le moteur SQL Server Agent s'appuie sur la base msdb. Ce moteur permet de gérer les sauvegardes, les plans de maintenance, les travaux planifiés, la surveillance de la base, les alertes administratives...
L'Agent a aussi comme rôle la surveillance du service de SQL Server et le déclenchement automatique du redémarrage de celui-ci en cas d'arrêt inattendu.
III.1.4. Transactions
SQL Server est un SGBD transactionnel. Il est capable de préparer des modifications sur les données d'une base et de les valider ou de les annuler d'un bloc. Cela garantit l'intégrité des informations stockées dans la base.
Lors d'une transaction, les blocs de données contenant les lignes de données modifiées par cette transaction sont verrouillées. Les autres utilisateurs, en fonction du niveau d'isolation choisi, doivent attendre ou non la fin de la transaction pour pouvoir les modifier à nouveau.
Les verrouillages s'effectuent au niveau des lignes, pages, extensions, tables ou base de données. SQL Server ne verrouille que les ressources dont il a besoin (par défaut les enregistrements) et en fonction des besoins peut verrouiller à un niveau plus élevé (pages ou objet). Cela évite aux utilisateurs d'attendre la fin d'une transaction pour mettre à jour des lignes de données qui n'ont pas été touchées par une modification et permet de diminuer la quantité de ressources consommées
Les transactions sont enregistrées dans le journal de transaction et les modifications des données sont intégrées à la base de données lors de points de contrôle (check point). Il est possible de forcer un point de contrôle grâce à l'instruction CHECKPOINT
Le journal des transactions peut être conservé de trois manières différentes :
Mode simple : toutes les modifications sont enregistrées dans le journal sauf pour les instructions de chargements en bloc (BULK INSERT, CREATE INDEX, reconstruction d'index et SELECT INTO) qui sont enregistrées de manière plus simple. Les transactions terminées sont supprimées du journal de transaction à chaque point de contrôle.
Mode journalisé en bloc : journalise de façon minimale les opérations en bloc. Ce mode est utilisé pour effectuer d'importantes opérations de masse.

82
Mode complet : toutes les modifications sont enregistrées dans le journal. Les transactions terminées dont les données sont écrites sur le disque sont supprimées du journal de transaction à chaque sauvegarde de celui-ci.
Dans les 2 derniers modes, il est possible de sauvegarder la base de données et de la restaurer telle qu'elle était à n'importe quel point du temps à la seconde près et à la transaction près (avec cependant des limites pour le mode journalisé en bloc). Ce mode permet aussi la sauvegarde de fichiers ou de groupes de fichiers.
III.1.4.1. Distributed Transaction Coordinator
Connu aussi sous le nom de MS DTC, sert a gérer les transactions distribuées. C’est-à-dire les transactions entre plusieurs serveurs de transactions SQL Server, entre un serveur SQL Server et des serveurs de base de données autres, entre plusieurs sources de données différentes, qu'ils soient des moteurs de base de données ou de simples composants.
III.1.4.2. Gestion de Transaction sous SQL SERVER
On a vu que le grand problème de transaction, c’était la concurrence et pour le gérer, SQL SERVER implémente le niveau d’isolation pour pallier aux anomalies transactionnelle que peuvent causer cette concurrence.
III.1.5. Notion de répartition sous SQL SERVER
Après avoir conçu une Base de Donné Répliquée, il faudrait les fragmenter et puis l’allocation de ces fragments dans différents sites, ceci peut s’accompagner de la réplication. Pour faire la fragmentation du schéma global et puis l’allocation des fragments, le SQL SERVER dispose d’une technologie : transactional replication [19].
La “Transactional réplication”: la réplication transactionnelle, c’est un mécanisme
utilisé par le SQL SERVER pour permettre de publier de donnée incrémentale et les
changements de schéma aux abonnés (souscripteurs). Les changements sont publiés (le flux
de réplication) dans l’ordre dans le quel ils ont été effectués, et effectivement il y a un temps
de latence entre les changements dans le Publisher et l’abonnés [19].
Les architectures étudiées dans le chapitre 1 d’un système distribute sont aussi
appliquées, à savoir le peer-to-peer et le client-serveur.
La réplication transactionnelle peer-to-peer, par exemple, en SQL SERVER simplifie
l’implémentation la topologie de la réplication transactionnelle bidirectionnelle, où le flux de
données va dans les deux sens.

83
Figure 33 : Réplication peer-to-peer avec trios et quatre nœuds [19]
III.1.5.1. Technologies
La réplication transactionnelle et la réplication peer-to-peer utilise la même architecture pour transférer entre les servers dans une topologie de réplication. L’illustration suivante est une vue sur les composants participant dans la réplication transactionnelle.
Figure 34 : Vue de l’architecture de la Réplication transaction [19]

84
Voici les trois roles minimum d’un serveur requis pour la réplication transactionnelle :
• Publisher, pour la base de données de la publication
• Distributor, pour la base de données de la distribution
• Subscriber, pour la base de données de la subscription
Les différents agents sur lesquels la réplication transactionnelle se repose, pour
effectuer les taches associées au transfert des modifications (changements) et à la
distribution des données. On a [38]:
• Snapshot Agent, qui tourne au niveau du Distributor (Distributeur). Il prépare les
fichiers de schéma et de données initiales des tables et objets publiés, enregistre les
fichiers du snapshop et les informations sur la synchronisation dans la base de
données de la distribution.
• Log Reader Agent, qui tourne au niveau du distributor (distributeur). Il connecte au
Publisher et lui transfère les transactions marquées pour la réplication à partir du log
(journal) de transaction de base de données de la publication à la base de données
de la distribution.
• Distribution Agent, qui tourne au niveau du Distributor pour pousser les
souscriptions et au niveau du Subscriber pour tirer les souscriptions. Il appique le
snapshop initial au Subscriber (souscripteur) et transfère les transactions tenues
dans la base de données aux souscripteurs.
• Queue Reader Agent, qui tourne au niveau du Distributor. Il est seulement utilisé
pour la réplication transactionnelle avec des souscriptions modifiables et renvoie les
modifications effectuées sur les Subscriber au Publisher.
III.1.5.2. Réaliser une Publication et un abonnement sous SQL SERVER
Nous allons à la fois montrer ceci dans la section dédiée à l’application proprement dite et montrer comment faire une fragmentation horizontale, verticale et hybride pour une allocation donnée de données.

85
III.2. Gestion de Transactions par la programmation
sous .NET (Framework 3.5)
.NET est une plateforme de programmation, un produit de MICROSOFT, depuis sa version la plus antérieure (2005) que celle-ci (2008) et jusqu’à l’actuelle (2010), on pouvait déjà et on peut donc arriver utiliser les transactions à la place de requêtes SQL, on en a vu l’avantage, et aussi arriver à gérer ces transactions, ses anomalies découlant de la concurrence par bien sûr les mécanismes de niveau d’isolation.
Il va de soi de comprendre que nous n’avons eu qu’à utilisé la version de .NET à notre disposition étant donné que l’implémentation de base de classes manipulant les transactions est restée la même. Par conséquent, nous avons utilisé la version .NET 2008, avec le langage C# ;
C’est donc cette voix de solution que nous avons choisie pour pouvoir aisément les transactions, et même les transactions concurrentes.
III.2.1. Les Transactions locales
Dans l’ADO (Activex Data Object), l’API (Application Programming Interface) de Microsoft pour l’accès de données, pour créer une transaction, on a en premier la classe « DbTransaction » se trouvant dans l’espace de nom « System.Data.Common » du composant System.data.dll du Framework .NET [21]. Toutes les autres classes des transactions en dérivent.
Cette classe possède des méthodes «BeginTransaction, Commit et Rollback », essentielles dans la mise en œuvre des transactions.
Voici les espaces de noms, où se trouvent les classes selon qu’il s’agit de fournisseur aux bases de données :
- System.Data.Odbc.OdbcTransaction
- System.Data.OleDb.OleDbTransaction
- System.Data.OracleClient.OracleTransaction
- System.Data.SqlClient.SqlTransaction
Nous allons donc utiliser le dernier, pour le cas qui est le nôtre.

86
Voici les méthodes principales :
- BeginTransaction (): méthode qui permet de débuter la transaction. - Commit() : méthode qui permet de valider les modifications effectuées par les
requêtes exécutées au sein de la transaction. - Rollback() : méthode qui permet d’annuler ces modifications.
Illustration
Soit un Serveur nommé PRIMATURE_SERVER, où on a une base de données nommée GestPers, et précisément la table agent ;
// C# import System.Data.SqlClient.SqlTransaction; import System.Data; string connectionString = "Data Source=.\PRIMATURE_RESVER;Initial Catalog=GestPers;Integrated Security=true"; using (SqlConnection connection = new SqlConnection(connectionString)) { connection.Open(); SqlTransaction transaction = connection.BeginTransaction(); SqlCommand commande = connection.CreateCommand(); commande.Transaction = transaction; try { //commande 1 commande.CommandText = "INSERT agent (id, nom, prenom, adresse, telephone, mail, information) VALUES (1, 'Tshabola', 'Joseph', '0', '0', '0', '0')"; commande.ExecuteNonQuery(); //commande 2 commande.CommandText = "INSERT agent (id, nom, prenom, adresse, telephone, mail, information) VALUES (2, 'Kalenda', 'Isaac', '0', '0', '0', '0')"; commande.ExecuteNonQuery(); transaction.Commit(); MessageBox.Show("Transaction validée"); } catch (Exception Ex) { transaction.Rollback(); MessageBox.Show(Ex.Message); } finally { connection.Close(); } }

87
III.2.2. Les Niveaux d’Isolations
Pour arriver à gérer des nombreuses transactions concurrentes, on dispose ici de
l’Enumération « IsolationLevel » associée à l’objet Transaction, dont voici les propriétés :
- Chaos : les données en attente de transactions très isolées ne peuvent être écrasées.
- ReadComitted : les données volatiles ne peuvent pas être lues pendant la
transaction, mais peuvent être modifiées.
- ReadUncommitted : les données volatiles peuvent être lues et modifiées
pendant la transaction.
- RepeatableRead : les données volatiles peuvent être lues mais pas modifiées
pendant la transaction. De nouvelles données peuvent être ajoutées.
- Serializable : niveau d’isolation par défaut. Les données volatiles peuvent être lue
mais pas modifiées. De même aucune nouvelle donnée ne peut être ajoutée pendant
la transaction.
- Snapshot : les données volatiles peuvent être lues. La transaction vérifie que les
données initiales n’ont pas changées avant de valider la transaction. Cela
permet de régler les problèmes liés à l’accès concurrentiels aux données.
- Unspecified : aucun niveau ne peut être déterminé.
Chaque propriété définie un niveau d’accès aux données en cours de modification
par d’autres transactions en cours. Les données qui sont en cours de modification sont
dites données volatiles [21].
Illustration
// C#
//…
SqlConnection oConnexion;
SqlTransaction oTransaction = null;
SqlCommand oCommande;
IsolationLevel oNiveauIsolationDonnees;
try
{
// Création de la connexion.
oConnexion = new SqlConnection(@"Data Source=.\PRIMATURE_RESVER;Initial Catalog=GestPers;Integrated Security=true") ;");
// Ouverture de la connexion.
oConnexion.Open();
if (ChkUtiliserTransaction.Checked)
{ // Création de la transaction.
oTransaction =

88
oConnexion.BeginTransaction(oNiveauIsolationDonnees);
}
// Création de la commande.
oCommande = new SqlCommand("SELECT * FROM agent", oConnexion,
oTransaction);
// Création et paramétrage du DataDapter.
oDataAdapter = new SqlDataAdapter(oCommande);
SqlCommandBuilder oCommandBuilder = new
SqlCommandBuilder(oDataAdapter);
// Création de la table de données.
oTable = new DataTable("agent");
// Exécution de la requête et remplissage de la table de données.
oDataAdapter.Fill(oTable);
// Affichage des données.
LstAgent.DataSource = oTable;
}
catch (Exception aEx)
{
MessageBox.Show(aEx.Message);
}
// …
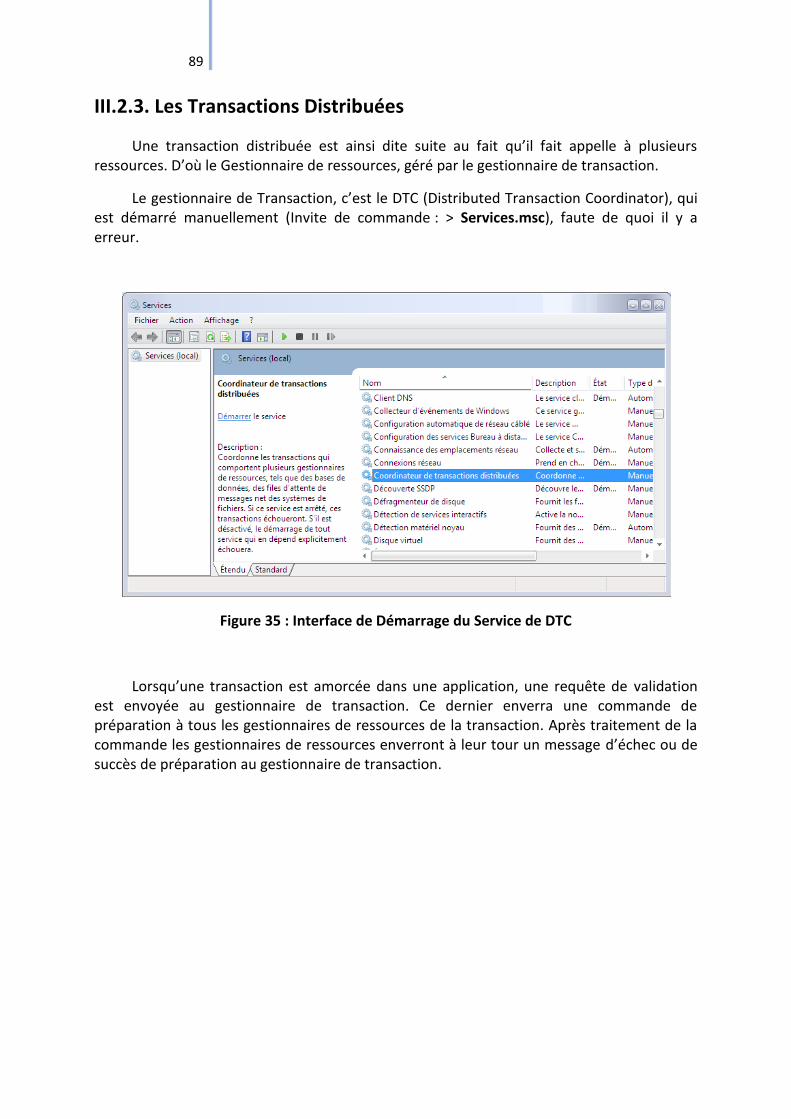
89
III.2.3. Les Transactions Distribuées
Une transaction distribuée est ainsi dite suite au fait qu’il fait appelle à plusieurs ressources. D’où le Gestionnaire de ressources, géré par le gestionnaire de transaction.
Le gestionnaire de Transaction, c’est le DTC (Distributed Transaction Coordinator), qui est démarré manuellement (Invite de commande : > Services.msc), faute de quoi il y a erreur.
Figure 35 : Interface de Démarrage du Service de DTC
Lorsqu’une transaction est amorcée dans une application, une requête de validation est envoyée au gestionnaire de transaction. Ce dernier enverra une commande de préparation à tous les gestionnaires de ressources de la transaction. Après traitement de la commande les gestionnaires de ressources enverront à leur tour un message d’échec ou de succès de préparation au gestionnaire de transaction.

90
Illustration
string connectionString1 = = "Data Source=.\PRIMATURE_RESVER;Initial
Catalog=GestPers;Integrated Security=true";
string connectionString2 = = "Data Source=.\FINANCE_RESVER;Initial
Catalog=GestPers;Integrated Security=true";
using (TransactionScope Transaction = new TransactionScope()) {
using (SqlConnection connection1 = new SqlConnection(connectionString1)) {
try {
SqlCommand commande = connection1.CreateCommand();
commande.CommandText = "DELETE FROM agent WHERE matricule = 'K88s';";
connection1.Open();
commande.ExecuteNonQuery();
connection1.Close();
using (SqlConnection connection2 = new SqlConnection(connectionString2)) {
try {
SqlCommand commande2 = connection2.CreateCommand();
commande.CommandText = "DELETE FROM salaire WHERE matricule = 'K88s';";
connection1.Open();
commande.ExecuteNonQuery();
connection2.Close();
} catch (Exception ex) {
MessageBox.Show(ex.Message);
}
} catch (Exception ex) {
MessageBox.Show(ex.Message);
}
}
Transaction.Complete();
}
Ainsi, nous venons de voir qu’il était possible de gérer les transactions sous la
plateforme .NET

91
III.3. Intranet Gouvernemental de la RDC
(République Démocratique du Congo)
La mise au point de l’intranet gouvernemental est un projet sous le nom de « e-
Gouvernement » mené par la KOICA (Korea Intrnational Cooperation Agency), grâce à son
programme APD (Aide Public au Développement), conformément à l’ordonnance définie
07/. 018 du 16 mai 2007 fixant les attributions des Ministères. Le titre du projet est
« L’infrastructure des TIC pour le projet d’E-Gouvernement de la République Démocratique
du Congo ».
III.3.1. Quelques définitions
III.3.1.1. Intranet :
Un Intranet est l'utilisation de tout ou partie des technologies et des infrastructures de l'Internet pour les besoins de transport et de traitement des flux d'informations internes d'un groupe d'utilisateurs identifiés.
Il peut être constitué de nombreuses applications et services :
forums de discussion entre des équipes projets au sein d'une entreprise
interconnexion sécurisée des réseaux locaux de l'entreprise et ses filiales en utilisant les infrastructures publiques de l'Internet
la création de serveurs Web interne
la création d'un serveur Web, accessible depuis l'entreprise et depuis l'Internet par une communauté fermée d'utilisateurs, les clients ou les partenaires de l'entreprise par exemple
la mise en place d'une messagerie
l'interconnexion des différents systèmes d'information de l'entreprise et de ses fournisseurs en utilisant le protocole TCP/IP
Donc en se basant sur le protocole TCP/IP (Transmission Control Protocole/Internet Protocole) qui est un protocole de l’Internet, il arrive à fournir pas mal d’applications et services autant que le ferait l’internet.
Pourtant, reste des différences entre Intranet et Internet :
- Internet = des infrastructures publiques de transmissions de données (payées par les opérateurs Internet.
- Intranet = des infrastructures privées de transmission de données (les réseaux locaux)
- une plus grande maîtrise des infrastructures réseaux et du débit possible. Il est plus facile sur Intranet d'envisager des applications qui restent difficiles à exploiter sur l'Internet telle que la visioconférence.

92
III.3.1.2. E-Gouvernement :
L’E-Gouvernement est l’utilisation des technologies de l’information et de la communication pour améliorer l’accès et la prestation des services publics au bénéfice de la population.
III.3.2. Objectif du projet
Crée l’e-Gouvernement (electonic-Gouvernement), impliquerait une utilisation des
technologies de l’information et de la communication (TIC) par les Institutions publiques et
le gouvernement de la RDC pour rendre les services de l’Etat plus accessible à leurs
utilisateurs et améliorer leurs propres opérations internes.
Les principaux objectifs du projet sont les suivants (quelques):
- renforcer la participation de citoyens au processus décisionnel du gouvernement.
- Améliorer la transparence et l’efficacité de dans l’administration publique.
Pour ne citer ces deux.
III.3.3. Avantages pour les utilisateurs
Nous citerons des avantages parmi tant évoqué dans [35], mais les plus éloquents, par
rapport à notre travail :
- Améliorer la facilité d’usage (moins de files d’attente, plus d’information, plus
d’informations, pas besoin de se déplacer).
- Offrir des nouveaux services personnalisés aux citoyens et aux entreprises (par
exemple, le calcul d’impôt en ligne, le suivi des procédures administratives, la
consultation du dossier personnel, l’emploi, l’envoi des informations sur l’intranet/
internet).
- Simplifier les procédures notamment en réduisant les formulaires, les imprimés et les
certificats de valeur.
Pour ne citer ceux-ci.
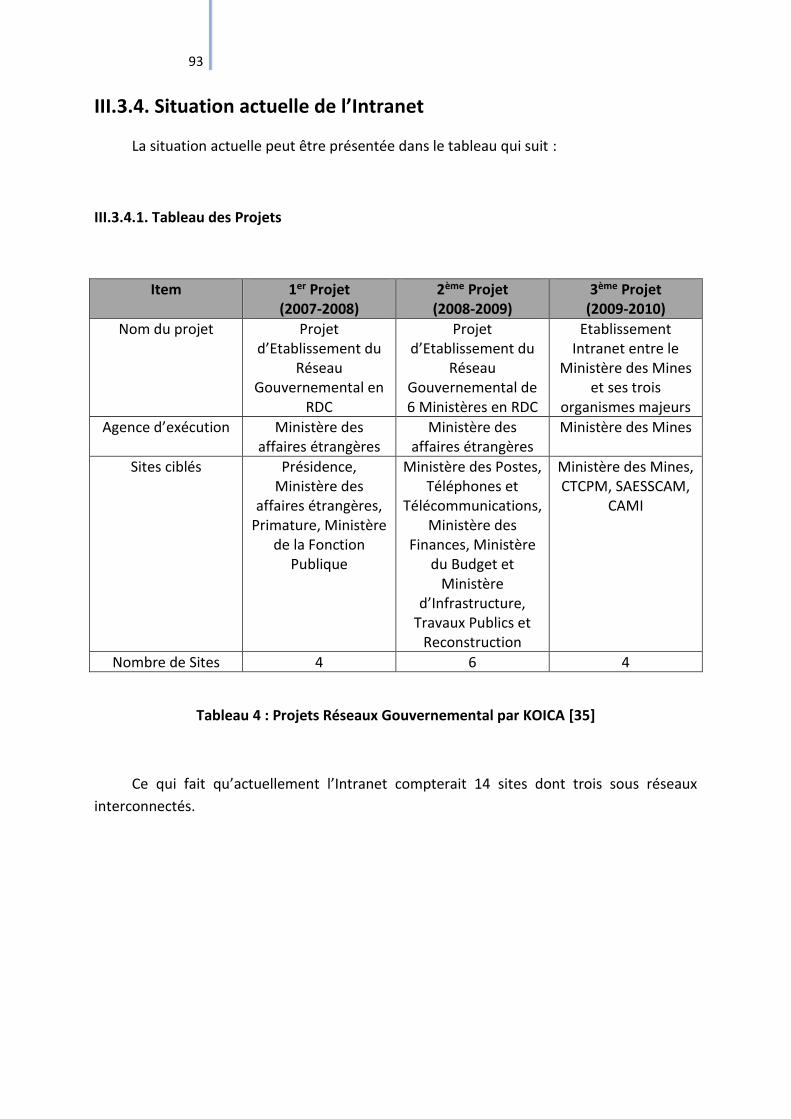
93
III.3.4. Situation actuelle de l’Intranet
La situation actuelle peut être présentée dans le tableau qui suit :
III.3.4.1. Tableau des Projets
Item 1er Projet (2007-2008)
2ème Projet (2008-2009)
3ème Projet (2009-2010)
Nom du projet Projet d’Etablissement du
Réseau Gouvernemental en
RDC
Projet d’Etablissement du
Réseau Gouvernemental de 6 Ministères en RDC
Etablissement Intranet entre le
Ministère des Mines et ses trois
organismes majeurs
Agence d’exécution Ministère des affaires étrangères
Ministère des affaires étrangères
Ministère des Mines
Sites ciblés Présidence, Ministère des
affaires étrangères, Primature, Ministère
de la Fonction Publique
Ministère des Postes, Téléphones et
Télécommunications, Ministère des
Finances, Ministère du Budget et
Ministère d’Infrastructure,
Travaux Publics et Reconstruction
Ministère des Mines, CTCPM, SAESSCAM,
CAMI
Nombre de Sites 4 6 4
Tableau 4 : Projets Réseaux Gouvernemental par KOICA [35]
Ce qui fait qu’actuellement l’Intranet compterait 14 sites dont trois sous réseaux
interconnectés.
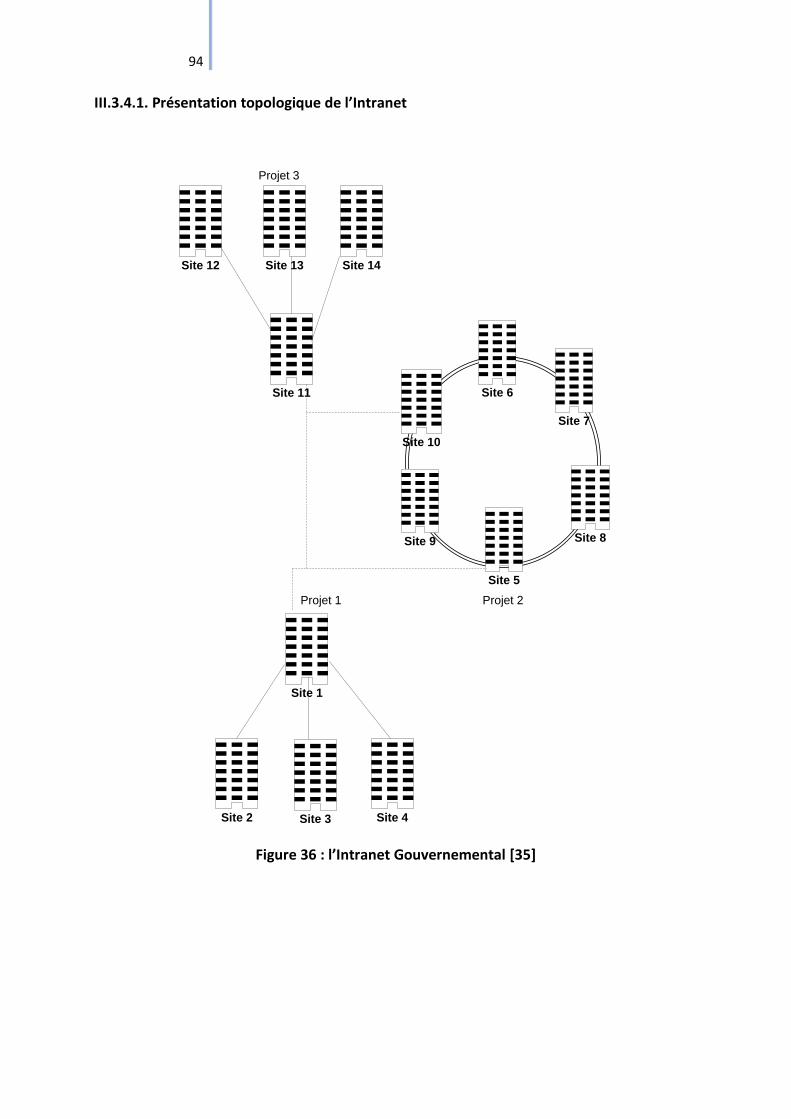
94
III.3.4.1. Présentation topologique de l’Intranet
Site 6
Site 10
Site 9
Site 5
Site 7
Site 8
Site 1
Site 2 Site 3 Site 4
Site 11
Site 12 Site 13 Site 14
Projet 1 Projet 2
Projet 3
Figure 36 : l’Intranet Gouvernemental [35]

95
Tableau de correspondance de sites et leurs noms
Site Noms
1 Ministère des Affaires Etrangères
2 Présidence
3 Primature
4 Fonction Publique
5 Justice
6 Ministère des Postes, Téléphones et Télécommunications
7 Ministère du Budget
8 Ministère du Plan
9 Ministère d’Infrastructure, Travaux Publics et Reconstruction
10 Ministère de Finance
11 Ministère de Mines
12 CTCPM
13 SAESSCAM
14 CAMI
Tableau 5 : Tableau de correspondance de numéro de sites et leurs noms
III.4. Mise en place d’un Système d’Information de
Traitement de Salaire des Agents de l’Etat
C’est à cette section que sont dédiées toutes les précédentes, elles ont balisé la route,
préparé les outils pour son abordage aisé, ou disons le autrement, c’est ici qu’on essaie de
concrétiser toutes les notions avancées précédemment.
III.4.1. Circonscription
Ce problème de traitement de salaire ou bien de gestion de paie des agents couvrent
normalement toutes les institutions étatiques. Et pourtant pour insérer dans ce projet
d’intranet gouvernemental, selon même ses objectifs, notre participation plus
concrètement, nous nous nicherons sur des sites contextuellement les plus stratégiques.

96
On a donc :
- Fonction publique : qui immatricule tous les agents de l’Etat,
- Finance : qui salarie ces agents sur bases de la liste agents immatriculés en
provenance de la Fonction publique.
Ces sont les deux sites principaux, pour notre cas ; mais il faut dire que ces sites à part
leurs taches administratives, sont aussi des institutions publiques avec des agents. On juge
les autres sites de normaux
III.4.2. Modélisation du Système d’Information avec l’UML
UML, Unified Modeling Language : langage de modélisation, ici, pour des systèmes
d’Information. Elle dispose de plus d’une dizaine de diagramme pour la modélisation, mais
nous allons nous service de quelques un qui nous permettent d’étayer le processus de la
création de notre application.
Cette modélisation débouchera sur une Application Informatique, un logiciel que nous
allons nommer « SalaryManager » : Gestionnaire de Salaire, en Français.
III.4.2.1. Spécification Initiale du Système
En vue d’une amélioration du présent système de paiement des agents, cette batterie
d’étapes va nous permettre d’automatiser des processus manuels, d’où une application
informatique est attendue à l’issue de cette étude.
Cette application informatique est conçue à l’idée de pouvoir :
- Aider l’entité habilitée (Ministère de Finance) de payer les agents de l’Etat, à calculer
la masse salariale (périodique aussi) correspondante à toutes les institutions, et à
réellement payer les vrais agents sur base des listes des agents immatriculés.
- Aider l’entité habilitée (Ministère de Fonction Publique) d’immatriculer les agents, à
savoir l’effectif des agents, et ce par institution.
- Aider les institutions de pouvoir enregistrer de nouvelles unités (NU), de les envoyer
(sans se déplacer) à la Fonction Publique en vue d’immatriculation et de calculer
localement le salaire de chaque agent selon tous les éléments de salaire (indemnité,
prime, etc.) et de les envoyer à la Finance en vue de la paie.
Cette application sera par conséquent répartie.

97
o A qui l’application, est-elle destinée ?
Comme dit tantôt, à l’entité du Ministère de la Fonction Publique chargée
d’immatriculation, à gestionnaire de paie de la cellule de paie du Ministère de la
Finance, et aux gestionnaires de paies de chaque institution.
o Quels problèmes l’application, résoudra-t-elle ?
Permettre une immatriculation aisée, connaître l’effectif des agents, calcul de la
masse salariale des institutions étatique et individuelles des agents. Conséquence
logique, ne payer que les vrais agents immatriculés.
o Comment l’application fonctionnera-t-elle ?
Cette application en est naturellement une dont les taches sont répartie entre aux
moins trois sites, elle travaille :
- En client-serveur : architecture 3-tiers (interface ou présentation, logique de
programmation, et donnée), précisément client-serveur de donnée, entre
l’application (en C#) et SQL SERVER(les Serveurs) ;
- Et en peer-to-peer, pour ce qui des serveurs de base de données entre eux.
III.4.2.2. Enoncé du problème
En vue d’une automatisation de processus de paiement des agents et d’ailleurs
conformément au projet e-Gouvernement, il est question ici de faire une gestion
informatisée des ressources humaines de l’Etat qui est un volet non négligeable dans la
gestion de la RDC, celle-ci est l’apanage de la FONCTION PUBLIQUE qui est l’un de site
compté dans l’Intranet Gouvernemental.
La fonction publique est l’entité sur circuit prend en charge l’élaboration des
matricules des employés de l’Etat, un employé appartient à une entreprise publique, il
possède un matricule que lui procure la fonction publique de la manière suivante :
- L’employé arrive comme une nouvelle unité dans le service lui attribué par ses
supérieurs,
- Après approbation de ses qualités, une liste des personnes devant être affectées est
envoyé au ministère de travail pour la signature du ministre qui est significative d’un
engagement totale, ce matricule confère un grade à l’employé en fonction de ses
aptitudes et du temps passé dans la société ;
- L’employé exerce une fonction spécifique dans la société son affectation,
- La Fonction publique peut à tout moment selon l’ordre ou un arrêté transférer un
employé une institution à une autre

98
- Chaque entreprise elle-même gère ses employé (ses ressources humaines) c'est-à-
dire elle organise le recrutement, mais pour la prise des fonctions, c’est la fonction
publique qui attribue les matricules, elle participe aussi le calcul de salaire de chaque
agent, puis le transfère à la finance pour la paie selon le listing des immatriculés en
provenance de la Fonction Publique.
L’entité finance du présent projet a pour mission d’enregistrer la masse monétaire
(volume de paiement) à remettre aux agents de l’Etat répertoriés par la fonction publique,
les finances reçoit la liste de chaque entreprise selon le barème de paiement prévu.
III.4.2.3. Analyse du Domaine
De ce qui précède c'est-à-dire l’énoncé, nous allons présenter des modèles d’analyse
qui résultent aussi bien de recherche, du bons sens que de l’expérience du monde réel. D’où,
on a :
- Les modèles d’interactions : qui montre les objets du système coopère pour obtenir
un résultat [49], on ne va présenter ici que le Diagramme de Cas d’Utilisation et le
Diagramme d’Activités.
- Les modèles de classes : décrit la structure statique des objets d’un système et leurs
relations [49], on a seulement le Diagramme de classe.
- Les modèles d’états : décrit les états successifs d’un objet au cours du temps. On n’a
que le Diagramme d’état.
III.4.2.3.1. Diagramme de Cas d’Utilisation
Voici les acteurs du système :
- Ministère de la fonction publique
- Ministère de la Finance
- Autres sites : regroupe tous les autres sites qui n’ont pas de taches spécifiques
comme les deux premiers, mais y compris ces deux premiers.
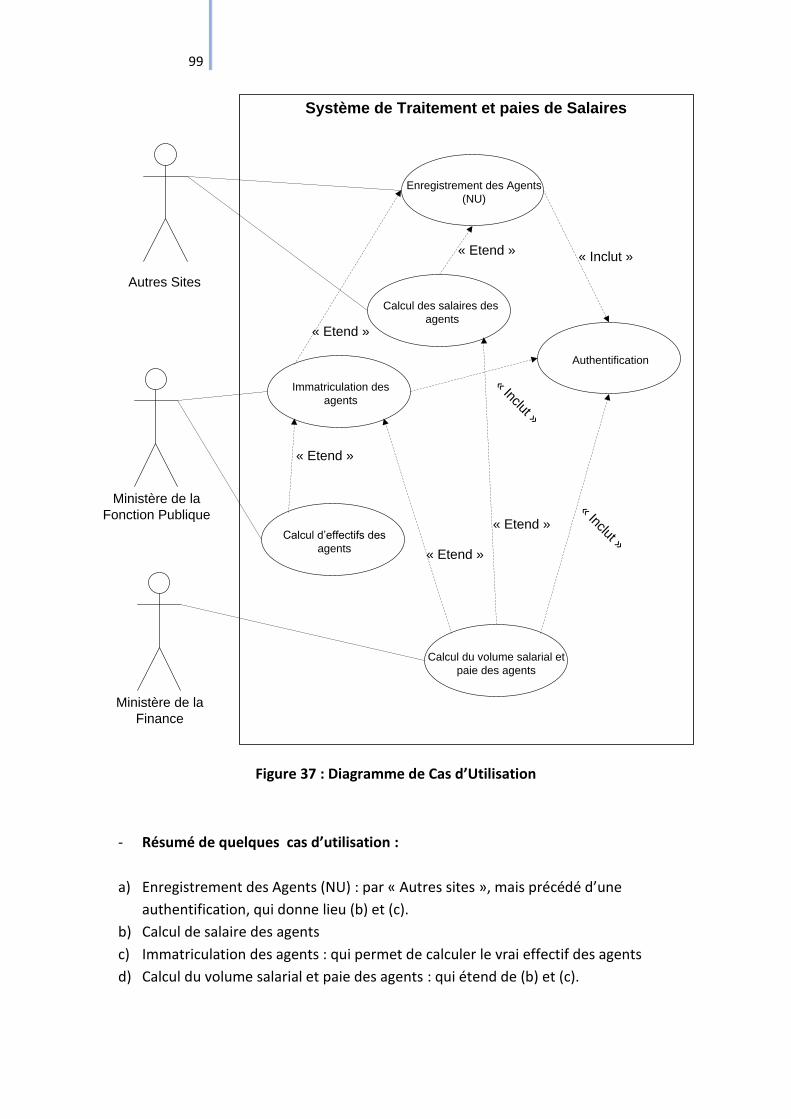
99
Système de Traitement et paies de Salaires
Enregistrement des Agents
(NU)
Calcul des salaires des
agents
Authentification
« Inclut »
Immatriculation des
agents
« Etend »
Autres Sites
« Inclut »
« Etend »
Ministère de la
Fonction Publique
Calcul d’effectifs des
agents
« Etend »
Calcul du volume salarial et
paie des agents
« Etend »
« Etend »
« Inclut »
Ministère de la
Finance
Figure 37 : Diagramme de Cas d’Utilisation
- Résumé de quelques cas d’utilisation :
a) Enregistrement des Agents (NU) : par « Autres sites », mais précédé d’une
authentification, qui donne lieu (b) et (c).
b) Calcul de salaire des agents
c) Immatriculation des agents : qui permet de calculer le vrai effectif des agents
d) Calcul du volume salarial et paie des agents : qui étend de (b) et (c).

100
III.4.2.3.2. Diagramme de Classe
On a donc :
- Identification de classes pertinentes : agent, grade, fonction, service, indemnité,
prime, prêt, institution, salaire, retenue ;
- Identification des associations pertinentes : prendre, avoir, appartenir, concerner,
immatriculation, toucher, tirer sur.
- Identification des attributs des objets :
o Agent (codeagent, nom, postnom, prenom, sexe, date_naissance, etat_civil, nombre_enfant, telephone, avenue, numero, quartier, commune, niveau_etude, date_embauche) ;
o Fonction (idfonction) ; o Grade (idgrade, salaire_base); o Indemnite (nomIndemnite, info) ; o Prêt (numpret, libelle, montant, date_pret) ; o Prime (nomPrime, info) ; o Retenue (nomRetenue, montant) ; o Salaire (numSalaire, trace_operation, net_a_payer, date_paiement,
mois_paiement) ; o Service (idservice, info) ; o Institution (nomInstitution, adresse).
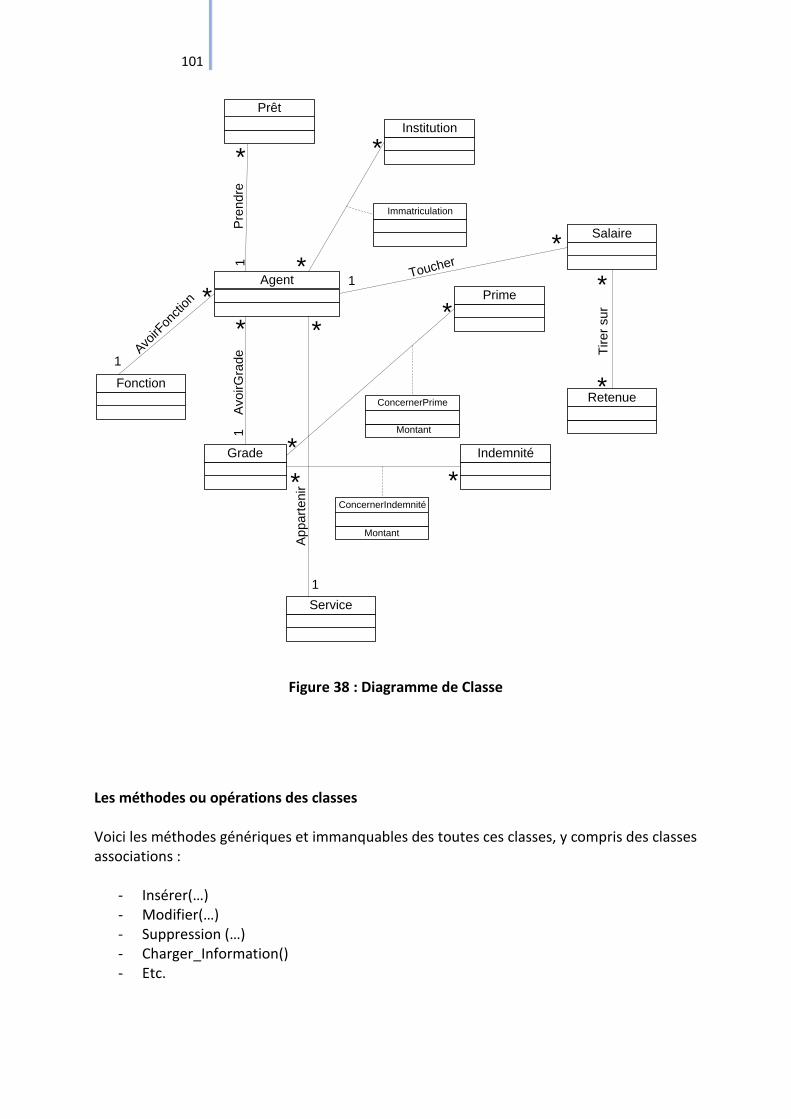
101
Agent
Grade
Fonction
Service
Indemnité
Prime
Retenue
Salaire
Institution
Prêt
ConcernerIndemnité
ConcernerPrime
Immatriculation
Toucher*
1
Ap
pa
rte
nir
*
1
* *
*
*
Avo
irFon
ction *
Avo
irG
rad
e
*
1
1
Pre
nd
re
*
1
Tire
r su
r
*
*
Montant
Montant
*
*
Figure 38 : Diagramme de Classe
Les méthodes ou opérations des classes
Voici les méthodes génériques et immanquables des toutes ces classes, y compris des classes associations :
- Insérer(…) - Modifier(…) - Suppression (…) - Charger_Information() - Etc.

102
III.4.2.3.2. Diagramme d’état
- Identifications des classes du domaine ayant des états Trouver des états et les événements (sont dans les parenthèses) :
o Agent : Nouvelle Unité – NU (événement : enregistrement), Immatriculé (événement : immatriculation)
Selon la limitation du système, on peut se limité à ces deux états de la classe
Nouvelle Unité (NU)
Immatriculé Récrutement
Immatriculation
Agent
Figure 39 : Diagramme d’état de la classe Agent
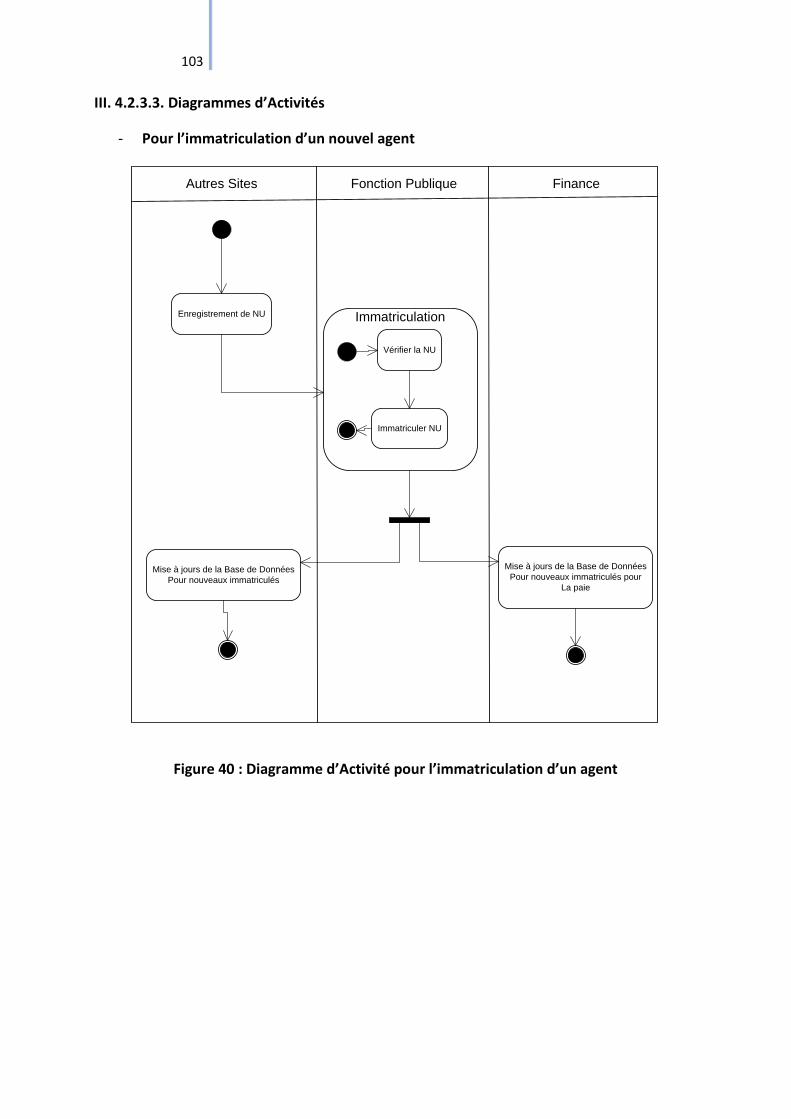
103
III. 4.2.3.3. Diagrammes d’Activités
- Pour l’immatriculation d’un nouvel agent
Autres Sites Fonction Publique Finance
Enregistrement de NU
Vérifier la NU
Immatriculer NU
Mise à jours de la Base de Données
Pour nouveaux immatriculés
Immatriculation
Mise à jours de la Base de Données
Pour nouveaux immatriculés pour
La paie
Figure 40 : Diagramme d’Activité pour l’immatriculation d’un agent
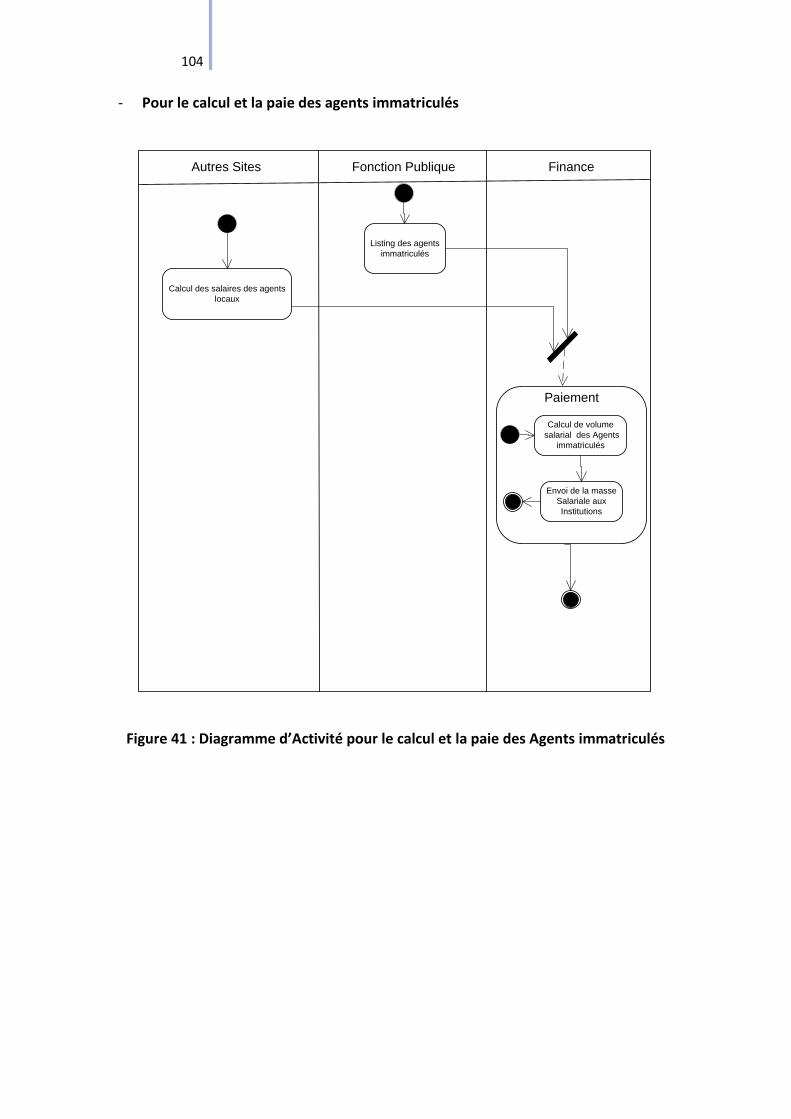
104
- Pour le calcul et la paie des agents immatriculés
Autres Sites Fonction Publique Finance
Calcul des salaires des agents
locaux
Listing des agents
immatriculés
Calcul de volume
salarial des Agents
immatriculés
Envoi de la masse
Salariale aux
Institutions
Paiement
Figure 41 : Diagramme d’Activité pour le calcul et la paie des Agents immatriculés

105
III.4.2.4. Conception et Implémentation du Système
A cette phase, il est plausible de pouvoir décider du stockage des données. Force est de constater que les informations qui circulent entre les entités sont des informations fréquemment utilisées, d’où l’idéal c’est l’utilisation de Base de donnée.
Et pour le cas qui est le notre, vu la nature intrinsèquement distribué du Système
d’Information, nous allons utiliser les bases de données distribuée ou mieux répartie (BDR), pour profiter de ses avantages.
Dans ce cas, nous allons premièrement présenter le schéma global de notre base de données répartie à partie de notre diagramme de classes.
Et signalons que la conception de notre BDR sera descendante, vu que nous sommes
entrain de la créer nouvellement.
III.4.2.4.1. Schéma Global
Toutes les classes et classes association deviendront des tables, et spécialement ces
dernières bénéficieront des identifiants de ses participants, et on aura donc un modèle comme ci-dessous :
Agent
CodeagentnomPostnomPrenomSexedate_naissanceetat_civilnombre_enfantTelephoneAvenueNumeroQuartierCommuneniveau_etudeidserviceidgradeIdfonctiondate_embauche
Fonction
idfonction
Prêt
numpretlibellemontant date_pretCodeagent
Service
Idserviceinfo
Grade
idgradesalaire_base
Retenue
nomRetenuemontant
Indemnite
nomIndemniteinfo
Prime
nomPrimeinfo
ConcernerPrime
idgradenomPrime
montant
Institution
nomInstitutionadresse
Salaire
numSalairetrace_operationnet_a_payerdate_paiementmois_paiementCodeagent
ConcernerIndemnite
idgradenomIndemnitemontant
immatticulation
CodeagentnomInstitution
matricule
Tirer_sur
numsalairenomRetenue
Figure 42 : Diagramme de classe avec toutes les propriétés et les classes association

106
III.4.2.4.2. Fragmentations et Allocations
Le tableau ci-dessous, nous permettra de montrer comment les fragments seront
placés ou alloués aux sites.
Autres Sites Fonction Publique Finance
Nous trouverons toutes les tables, sauf « Institution » et « Immatriculation »
Ici, nous aurons 3 tables Et ici, 3 tables
Agent Fonction Grade Indemnite Prêt Prime Retenue Salaire Service ConcernerPrime ConcernerIndemnite Tirer_sur Immatriculation
Agent Institution Immatriculation
Agent Salaire Immatriculation
Tableau 6 : Fragmentations et allocations aux sites
Note : Rappelons que les Sites Fonction Publique et Finance sont aussi représentées par « Autres Sites », de par le fait elles ont aussi des agents à gérer localement.
Fragmentations et types de fragmentation utilisés
- De « Autres Sites » vers « Fonction Publique » : la fragmentation verticale de la table Agent, on a : Select codeagent, nom, postnom, prenom from Agent;
Ceci dans le but de permettre à la Fonction Publique de pourvoir immatriculer
les agents (NU) dans la table Immatriculation

107
- De « Fonction Publique » vers « Autres Sites » : la fragmentation hybride de la
table Immatriculation, on a :
Select codeagent, matricule from Immatriculation where institution =
‘primature’
Ceci dans le but de permettre aux autres de pouvoir savoir ceux qui sont
immatriculé
- De « Fonction Publique » vers « Finance » : ici on prend le plus grand
fragment, à savoir la table elle, Immatriculation, on a :
Select * from Immatriculation
Ceci dans le but de permettre à la Finance de pouvoir savoir ceux qui sont
immatriculé et les payer, de sorte à ne payer qu’eux.
- De « Autres Sites » vers « Finance » : la fragmentation verticale de la table Agent et toute la table Salaire, on a : Select codeagent, nom, postnom, prenom from Agent; Select * from Salaire; Ceci dans le but de permettre à la Finance de pourvoir payer les agents, mais
alors les agents immatricules.
- Etc.
Allocations de Fragments
L’allocation d’un grand nombre de fragments s’est réalisée par la connaissance de
l’emploi de la Base de Données, c'est-à-dire où les besoins s’avéraient les plus importants. Et s’est senti le besoin d’évolutivité de données au niveau de certains fragments dans un site, mais dont est principalement dans un autre site ; ainsi, nous avons utilisé l’allocation par cliché (Snapshop), vu qu’en plus dans notre cas la contrainte temps n’est pas trop de rigueur. Exemple pour le cas d’immatriculation. III.4.2.4.3. Réplication
Eu égards au type d’allocation utilisée, il s’en suit que la réplication utilisée entre les
sites est : Asynchrone Asymétrique.
Ainsi l’application pourra profiter des avantages d’une bonne conception, d’une bonne politique de fragmentation, allocation et réplication.

108
III.4.2.4.4. Implémentations de l’Application
Implémentation de la Base de Données : sous SQL SERVER (Version 2008)
On ne va, ici, présenter que pour deux cites : « Autres Sites » et « Fonction Publique »
Notes : pour « Autres Site », nous considérerons le cas de la Primature. Les Etapes :
- Lancement
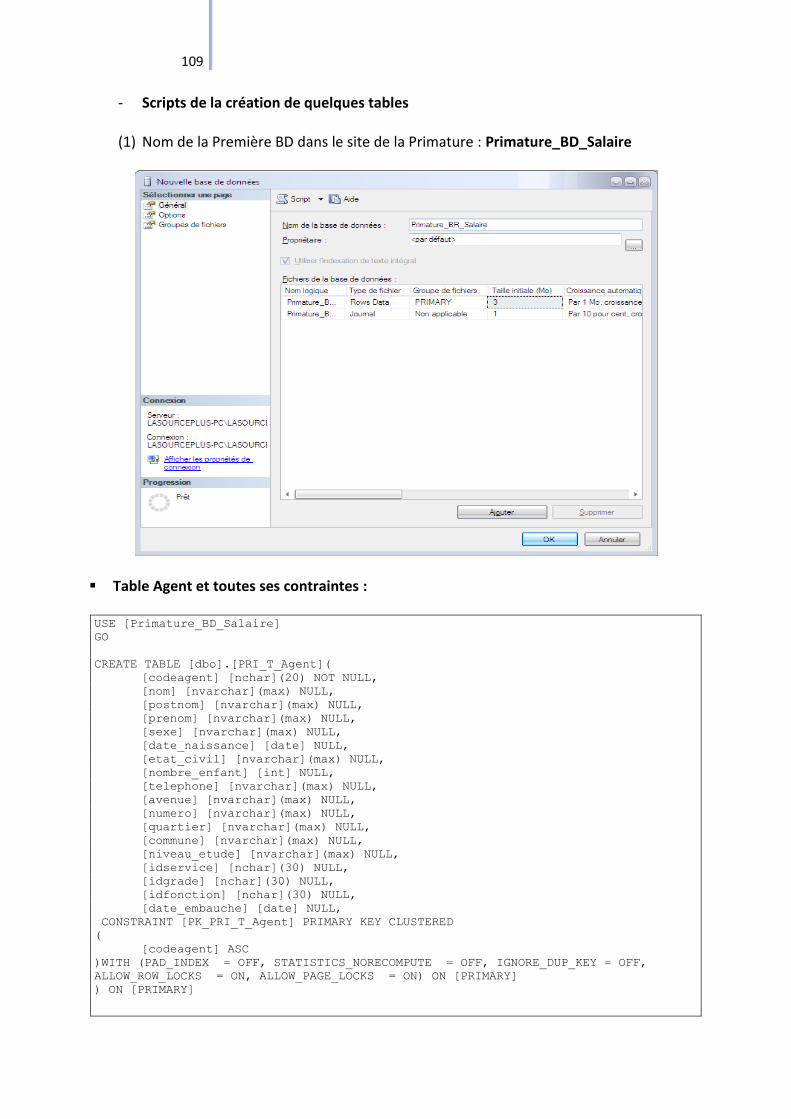
109
- Scripts de la création de quelques tables
(1) Nom de la Première BD dans le site de la Primature : Primature_BD_Salaire
Table Agent et toutes ses contraintes : USE [Primature_BD_Salaire]
GO
CREATE TABLE [dbo].[PRI_T_Agent](
[codeagent] [nchar](20) NOT NULL,
[nom] [nvarchar](max) NULL,
[postnom] [nvarchar](max) NULL,
[prenom] [nvarchar](max) NULL,
[sexe] [nvarchar](max) NULL,
[date_naissance] [date] NULL,
[etat_civil] [nvarchar](max) NULL,
[nombre_enfant] [int] NULL,
[telephone] [nvarchar](max) NULL,
[avenue] [nvarchar](max) NULL,
[numero] [nvarchar](max) NULL,
[quartier] [nvarchar](max) NULL,
[commune] [nvarchar](max) NULL,
[niveau_etude] [nvarchar](max) NULL,
[idservice] [nchar](30) NULL,
[idgrade] [nchar](30) NULL,
[idfonction] [nchar](30) NULL,
[date_embauche] [date] NULL,
CONSTRAINT [PK_PRI_T_Agent] PRIMARY KEY CLUSTERED
(
[codeagent] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF,
ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]

110
Table Grade : USE [Primature_BD_Salaire]
GO
CREATE TABLE [dbo].[PRI_T_Grade](
[idgrade] [nchar](30) NOT NULL,
[salaire_base] [money] NULL,
CONSTRAINT [PK_PRI_T_Grade] PRIMARY KEY CLUSTERED
(
[idgrade] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY =
OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
Table Indemnité :
USE [Primature_BD_Salaire]
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[PRI_T_Indemnite](
[nomIndemnite] [nchar](30) NOT NULL,
[info] [nvarchar](max) NULL,
CONSTRAINT [PK_PRI_T_Indemnite] PRIMARY KEY CLUSTERED
(
[nomIndemnite] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY =
OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
Table Prêt avec toutes contraintes :
USE [Primature_BD_Salaire]
GO
CREATE TABLE [dbo].[PRI_T_Indemnite](
[nomIndemnite] [nchar](30) NOT NULL,
[info] [nvarchar](max) NULL,
CONSTRAINT [PK_PRI_T_Indemnite] PRIMARY KEY CLUSTERED
(
[nomIndemnite] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY =
OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
Table Prime :

111
USE [Primature_BD_Salaire]
GO
CREATE TABLE [dbo].[PRI_T_Prime](
[nomPrime] [nchar](30) NOT NULL,
[info] [nvarchar](max) NULL,
CONSTRAINT [PK_PRI_T_Prime] PRIMARY KEY CLUSTERED
(
[nomPrime] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY =
OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
Table Retenue
USE [Primature_BD_Salaire]
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[PRI_T_Retenue](
[nomRetenue] [nchar](30) NOT NULL,
[montant] [money] NULL,
CONSTRAINT [PK_PRI_T_Retenue] PRIMARY KEY CLUSTERED
(
[nomRetenue] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY =
OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
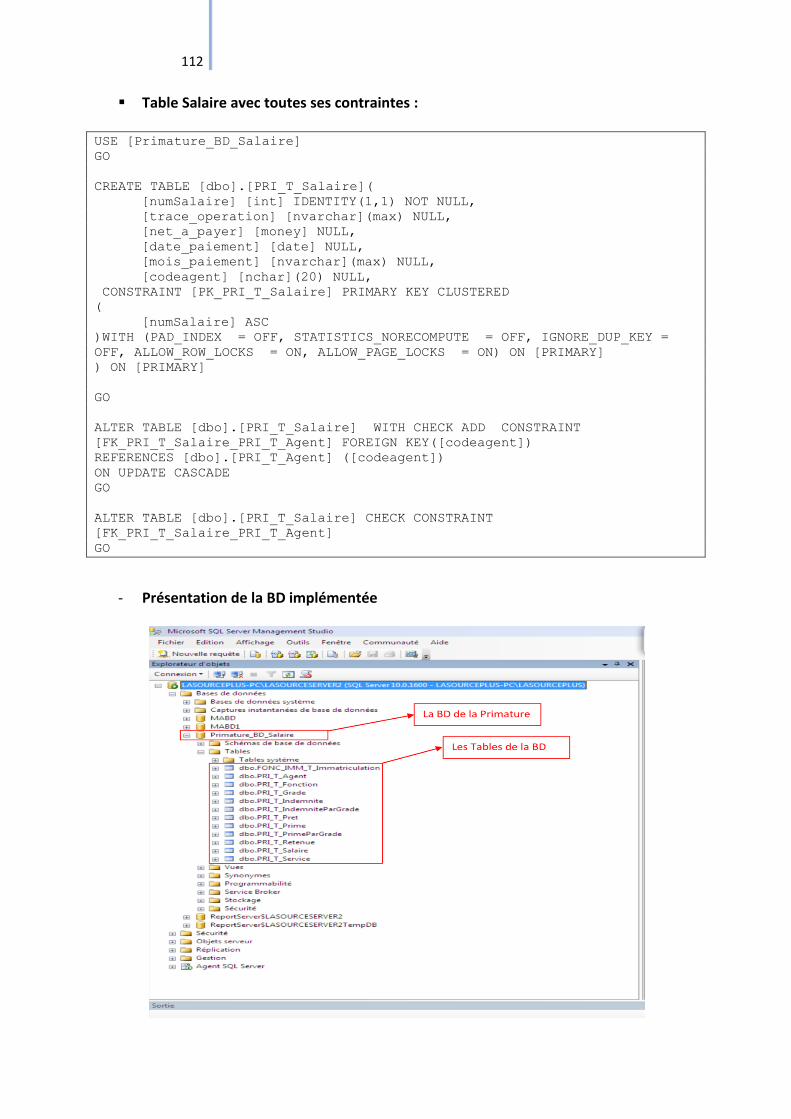
112
Table Salaire avec toutes ses contraintes : USE [Primature_BD_Salaire]
GO
CREATE TABLE [dbo].[PRI_T_Salaire](
[numSalaire] [int] IDENTITY(1,1) NOT NULL,
[trace_operation] [nvarchar](max) NULL,
[net_a_payer] [money] NULL,
[date_paiement] [date] NULL,
[mois_paiement] [nvarchar](max) NULL,
[codeagent] [nchar](20) NULL,
CONSTRAINT [PK_PRI_T_Salaire] PRIMARY KEY CLUSTERED
(
[numSalaire] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY =
OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
ALTER TABLE [dbo].[PRI_T_Salaire] WITH CHECK ADD CONSTRAINT
[FK_PRI_T_Salaire_PRI_T_Agent] FOREIGN KEY([codeagent])
REFERENCES [dbo].[PRI_T_Agent] ([codeagent])
ON UPDATE CASCADE
GO
ALTER TABLE [dbo].[PRI_T_Salaire] CHECK CONSTRAINT
[FK_PRI_T_Salaire_PRI_T_Agent]
GO
- Présentation de la BD implémentée

113
(2) Nom de la Deuxième BD dans le Site de la Fonction : FONC_BD_IMMATRICULATION
Table Institution : USE [FONC_BD_IMMATRICULATION]
GO
CREATE TABLE [dbo].[FONC_IMM_T_Institution](
[nomInstitution] [nchar](50) NOT NULL,
[adresse] [nvarchar](max) NULL,
CONSTRAINT [PK_FONC_IMM_T_Institution] PRIMARY KEY CLUSTERED
(
[nomInstitution] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY =
OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
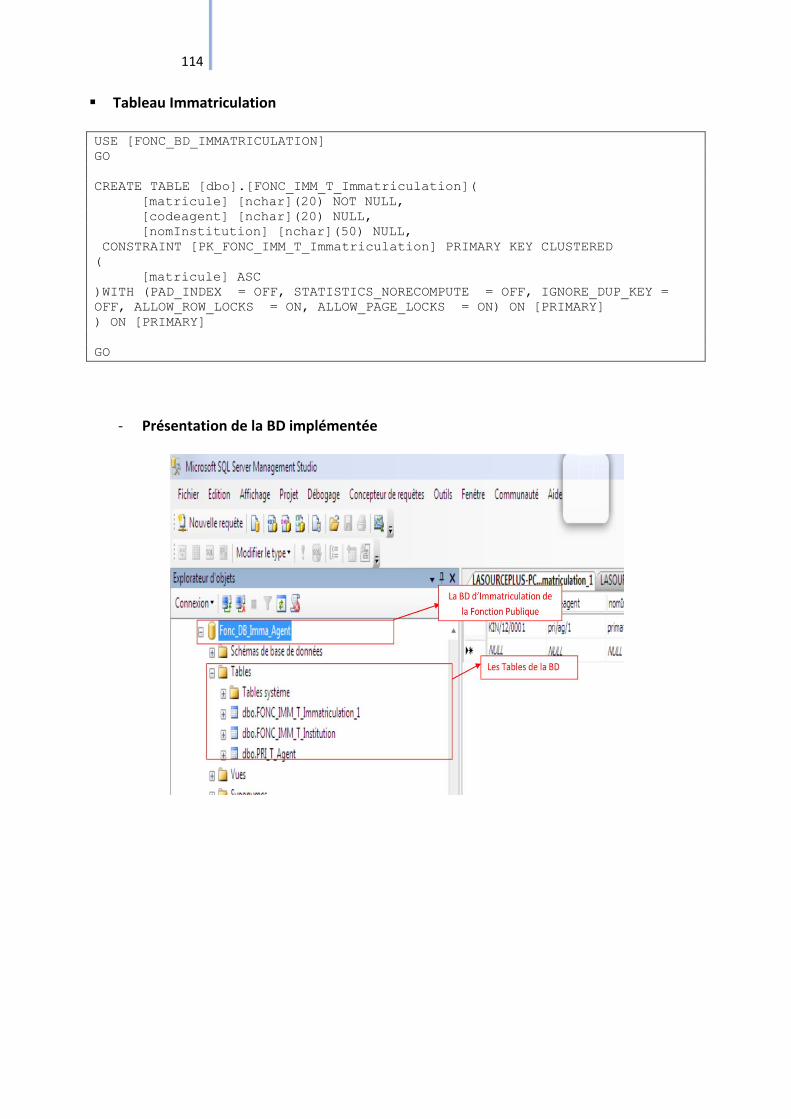
114
Tableau Immatriculation USE [FONC_BD_IMMATRICULATION]
GO
CREATE TABLE [dbo].[FONC_IMM_T_Immatriculation](
[matricule] [nchar](20) NOT NULL,
[codeagent] [nchar](20) NULL,
[nomInstitution] [nchar](50) NULL,
CONSTRAINT [PK_FONC_IMM_T_Immatriculation] PRIMARY KEY CLUSTERED
(
[matricule] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY =
OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
- Présentation de la BD implémentée

115
Configuration de la Réplication : sous SQL SERVER (Version 2008) (1) Création de la Publication
- Pour configurer la réplication d’une Base de Données, on fait ce qui suit dans le
module « Réplication » de l’SQL SERVER.
- Choisir la BD à répliquer
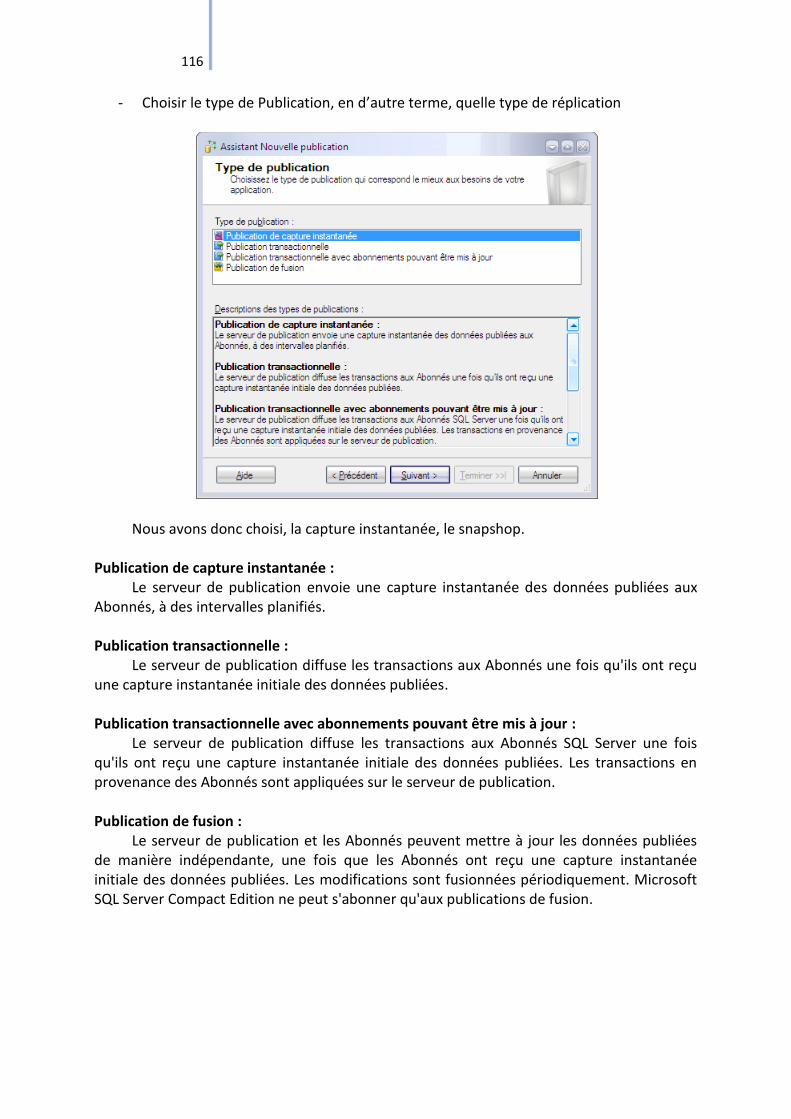
116
- Choisir le type de Publication, en d’autre terme, quelle type de réplication
Nous avons donc choisi, la capture instantanée, le snapshop. Publication de capture instantanée :
Le serveur de publication envoie une capture instantanée des données publiées aux Abonnés, à des intervalles planifiés.
Publication transactionnelle :
Le serveur de publication diffuse les transactions aux Abonnés une fois qu'ils ont reçu une capture instantanée initiale des données publiées.
Publication transactionnelle avec abonnements pouvant être mis à jour :
Le serveur de publication diffuse les transactions aux Abonnés SQL Server une fois qu'ils ont reçu une capture instantanée initiale des données publiées. Les transactions en provenance des Abonnés sont appliquées sur le serveur de publication. Publication de fusion :
Le serveur de publication et les Abonnés peuvent mettre à jour les données publiées de manière indépendante, une fois que les Abonnés ont reçu une capture instantanée initiale des données publiées. Les modifications sont fusionnées périodiquement. Microsoft SQL Server Compact Edition ne peut s'abonner qu'aux publications de fusion.
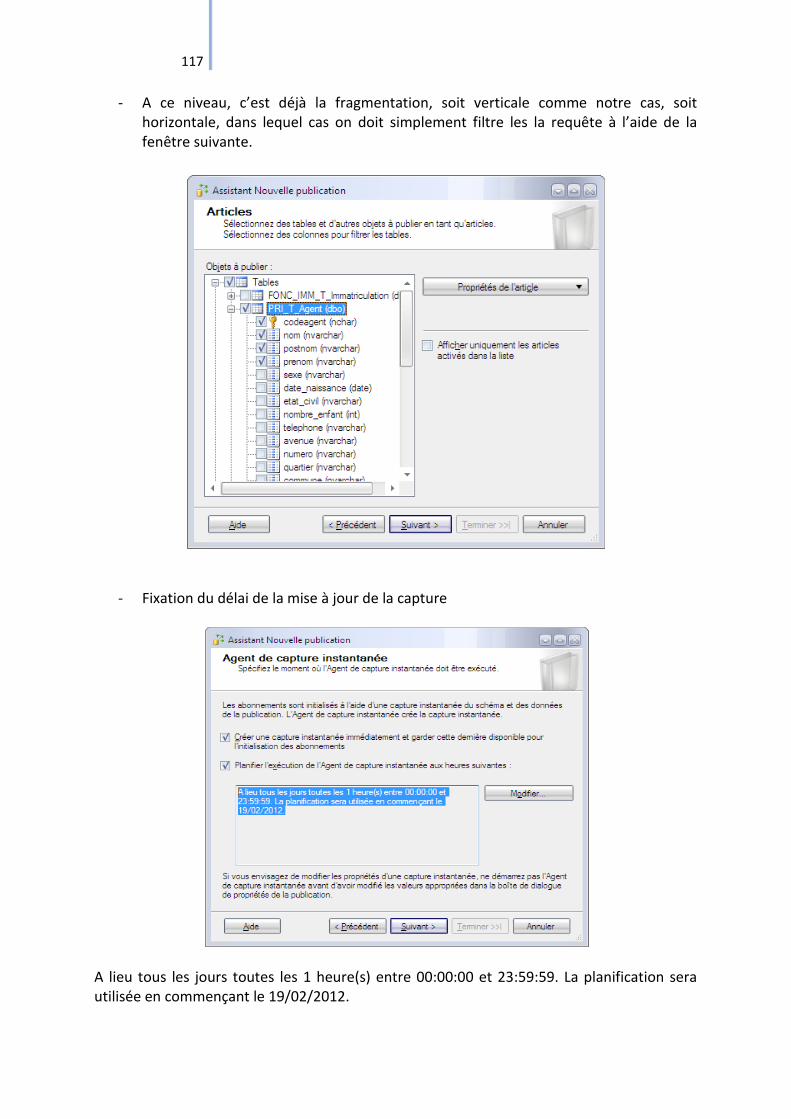
117
- A ce niveau, c’est déjà la fragmentation, soit verticale comme notre cas, soit horizontale, dans lequel cas on doit simplement filtre les la requête à l’aide de la fenêtre suivante.
- Fixation du délai de la mise à jour de la capture
A lieu tous les jours toutes les 1 heure(s) entre 00:00:00 et 23:59:59. La planification sera utilisée en commençant le 19/02/2012.

118
- On nomme la publication
- Et on termine. Succès !
(2) Création d’Abonnement de la publication (Précédente)
- Choisir la publication dans un serveur donné (dans un autre poste ou en local)
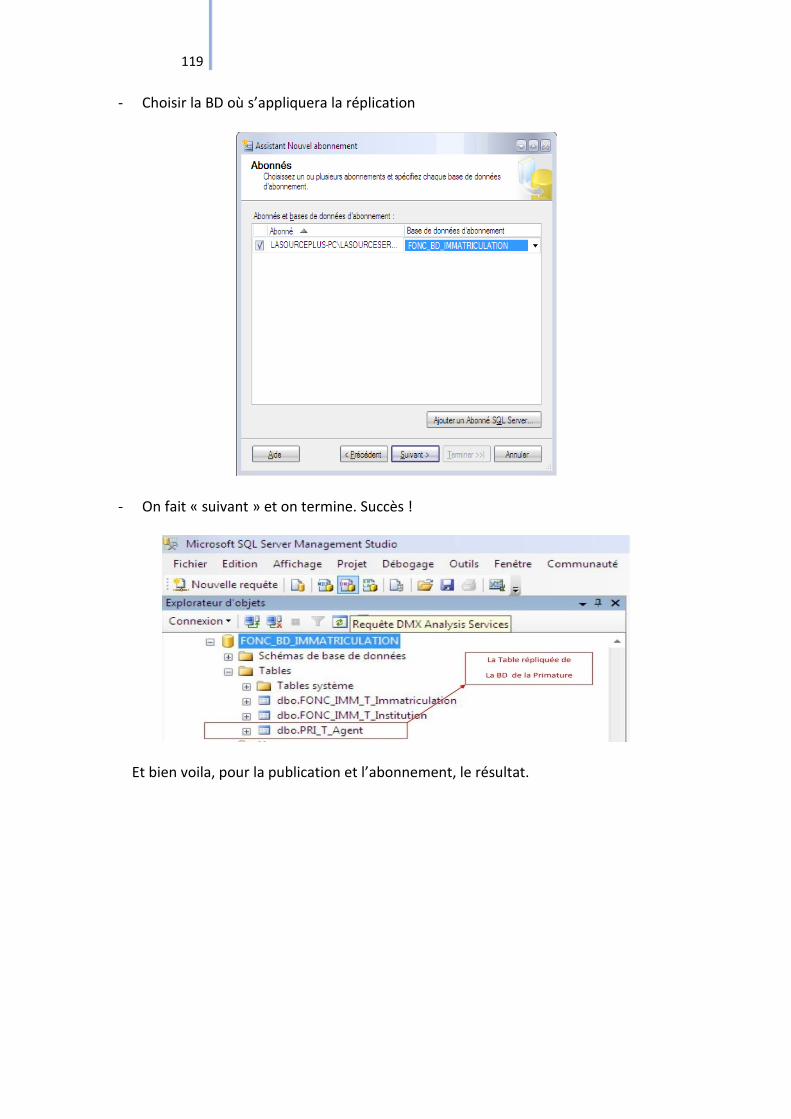
119
- Choisir la BD où s’appliquera la réplication
- On fait « suivant » et on termine. Succès !
Et bien voila, pour la publication et l’abonnement, le résultat.

120
III.4.2.4.5. Présentation de l’Application
Dans les « Autres Sites » : « Primature » :
- Enregistrement d’une nouvelle unité
(1) Accueil de l’Application « SalaryManager »
- 1 : on s’authentification d’abord - 2 : puis on choisit une rubrique, comme pour notre cas, c’est la rubrique
« Information sur l’Agent ».
2
1
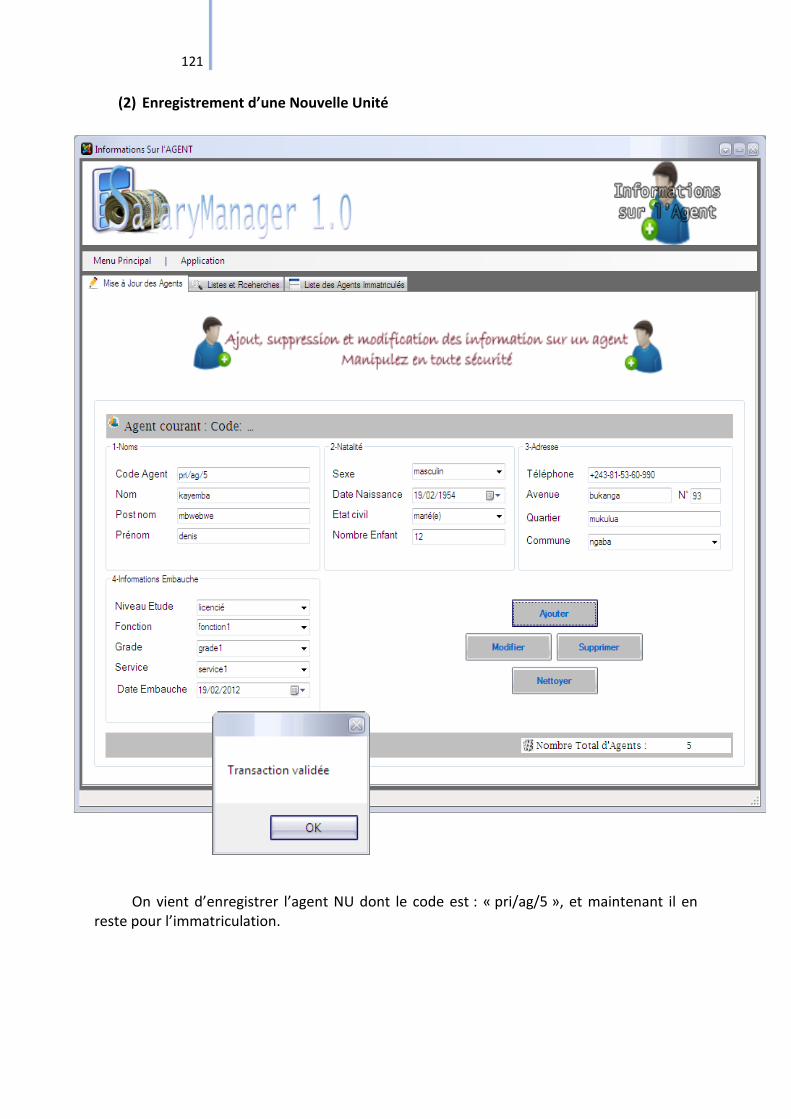
121
(2) Enregistrement d’une Nouvelle Unité
On vient d’enregistrer l’agent NU dont le code est : « pri/ag/5 », et maintenant il en reste pour l’immatriculation.
pri/ag/5
122
Dans le Site de la Fonction Publique :
- Immatriculation de la nouvelle unité : pri/ag/5
(3) Accueil de l’Application « SalaryManager »
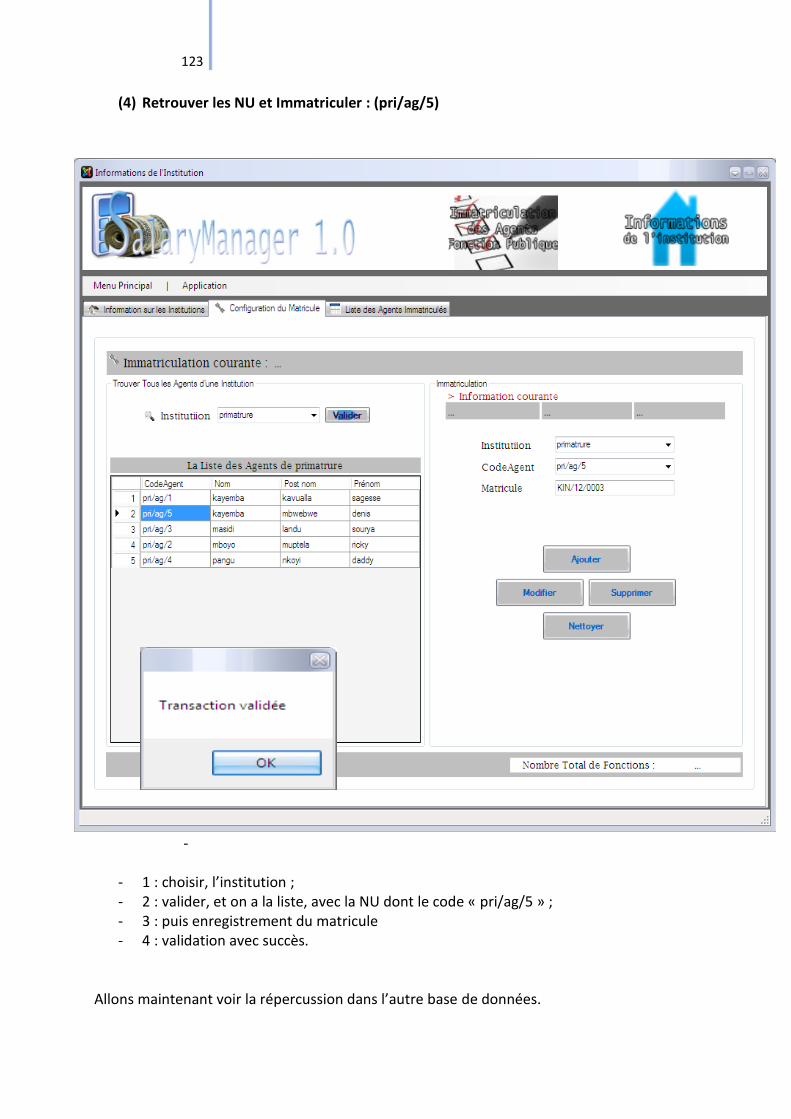
123
(4) Retrouver les NU et Immatriculer : (pri/ag/5)
-
- 1 : choisir, l’institution ; - 2 : valider, et on a la liste, avec la NU dont le code « pri/ag/5 » ; - 3 : puis enregistrement du matricule - 4 : validation avec succès.
Allons maintenant voir la répercussion dans l’autre base de données.
pri/ag/5 1
2
3
4
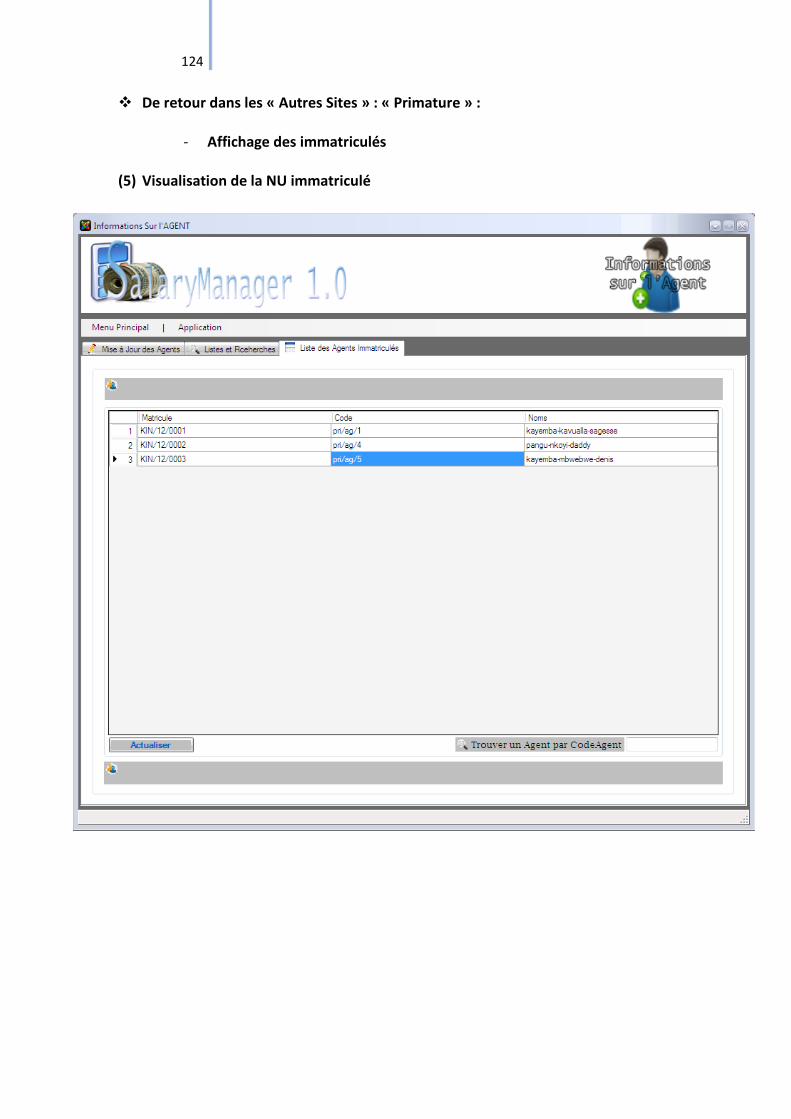
124
De retour dans les « Autres Sites » : « Primature » :
- Affichage des immatriculés
(5) Visualisation de la NU immatriculé
KIN/12/0003
Immatriculé avec succès
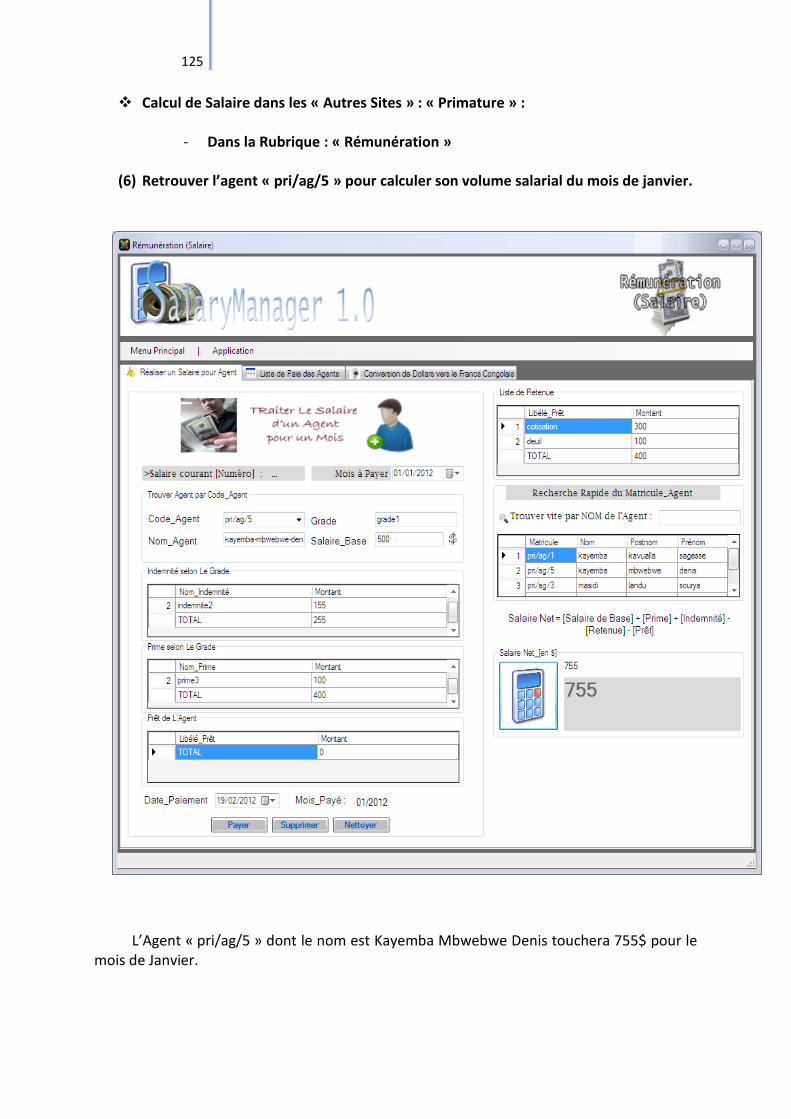
125
Calcul de Salaire dans les « Autres Sites » : « Primature » :
- Dans la Rubrique : « Rémunération »
(6) Retrouver l’agent « pri/ag/5 » pour calculer son volume salarial du mois de janvier.
L’Agent « pri/ag/5 » dont le nom est Kayemba Mbwebwe Denis touchera 755$ pour le mois de Janvier.
Pri/ag/5

126
Voici les éléments à base de ce montant : le salaire de base, l’indemnité, les primes, le retenue et le prêt.
Salaire Net = Salaire de Base + Prime + Indemnité – Retenue - Prêt
Une fois que le calcul est fait, la Finance reçoit la situation de tous les agents de toutes les entreprises, avec tous les détails prouvant la somme du salaire et ainsi la Finance et rapport avec le Listing des agents reconnus par L’Etat Congolais c'est-à-dire immatricule, se rend compte de tout et paie ces derniers.
Présentation de Code source en C# :
Comme l’analyse a débouché sur l’utilisation de la BD, alors toutes les classes sont devenues des tables de la BD pour faire la couche Donnée sous SQL SERVER ; la couche Présentation ou Interface (Homme-Machine), c’est celle présentées juste un peu ci-haut et pour la couche métier ou applicative, on a : Couche applicative, on a :
3 fichiers de classes : - TransactionLecture.cs : pour exécuter des transactions de lecture, c’est
aussi ici que nous faisons la gestion de la concurrence par le biais de niveau d’isolation.
- TransactionEcriture.cs : pour exécuter des transactions d’écriture à savoir, d’insertion, de mise à jour et de suppression. La gestion de la concurrence y est implémentée.
- AutresOperations.cs : qui rassemble les autres opérations essentielles pour chaque formulaire.
Et en plus, on a des modules derrière chaque formulaire.

127
(1) TransactionLecture.cs using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Data;
using System.Data.SqlClient;
using System.Windows.Forms;
namespace Salary
{
class TransactionLecture
{
static string site = "Primature_";
static string _table = "PRI_T_";
SqlConnection connexion = null;
SqlCommand commande = null;
string chaineConnexion = "Data Source=." +
@"\LASOURCESERVER2;Initial Catalog="+site+"BD_Salaire;Integrated
Security=true;";
IsolationLevel niveau_iso = IsolationLevel.Serializable;
SqlTransaction transaction = null;
public TransactionLecture()
{
try
{
connexion = new SqlConnection(chaineConnexion);
}
catch (Exception ex)
{
MessageBox.Show("Une Erreur est survenue! La voici :: \n" +
ex.Message,
"ATTENTION!", MessageBoxButtons.OK,
MessageBoxIcon.Error);
}
}
public SqlDataReader ExecuterTransaction(string requete)
{
try
{
connexion.Open();
transaction = connexion.BeginTransaction(niveau_iso);
commande = connexion.CreateCommand();
commande.Transaction = transaction;
commande.CommandText = requete;
return (SqlDataReader)commande.ExecuteReader();
}
catch (Exception ex)
{
MessageBox.Show("Une Erreur est survenue! La voici :: \n" +
ex.Message,
"ATTENTION!", MessageBoxButtons.OK,
MessageBoxIcon.Error);
}
return null;
}
public void FermerConnexion()

128
{
try
{
connexion.Close();
}
catch (Exception ex)
{
MessageBox.Show("Une Erreur est survenue! La voici :: \n" +
ex.Message,
"ATTENTION!", MessageBoxButtons.OK,
MessageBoxIcon.Error);
}
}
public static string Table
{
get
{
return _table;
}
}
}
}
(2) TransactionEcriture.cs using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Data;
using System.Data.SqlClient;
using System.Windows.Forms;
namespace Salary
{
class TransactionsEcriture
{
static string site = "Primature_";
static string _table = "PRI_T_";
protected SqlConnection connexion = null;
protected SqlCommand commande = null;
protected string chaineConnexion = "Data Source=." +
@"\LASOURCESERVER2;Initial Catalog=" + site + "BD_Salaire;Integrated
Security=true;";
IsolationLevel niveau_iso = IsolationLevel.Serializable;
public TransactionsEcriture(string requete)
{
try
{
connexion = new SqlConnection(chaineConnexion);
}
catch (Exception ex)
{
MessageBox.Show("Une Erreur est survenue! La voici :: \n" +
ex.Message,

129
"ATTENTION!", MessageBoxButtons.OK,
MessageBoxIcon.Error);
}
using (SqlConnection connection = new
SqlConnection(chaineConnexion))
{
connection.Open();
SqlTransaction transaction =
connection.BeginTransaction(niveau_iso);
SqlCommand commande = connection.CreateCommand();
commande.Transaction = transaction;
try
{
commande.CommandText = requete;
commande.ExecuteNonQuery();
//
transaction.Commit();
MessageBox.Show("Transaction validée");
}
catch (Exception ex)
{
transaction.Rollback();
MessageBox.Show("Une Erreur est survenue! La voici ::
\n" + ex.Message,
"ATTENTION!", MessageBoxButtons.OK,
MessageBoxIcon.Error);
}
finally
{
connection.Close();
}
}
}
public string Table
{
get
{
return _table;
}
}
}
}

130
(3) Formulaire de Rémunération : Form4 using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Windows.Forms;
using System.Data.SqlClient;
namespace Salary
{
public partial class Form4 : Form
{
string table = "";
string traceOperation = "";
public Form4()
{
InitializeComponent();
}
public void RemplirRetenueListe()...
public void RemplirAgentsListe()...
public void RemplirIndemniteGradeListe(string grade)...
public void RemplirPrimeGradeListe(string grade)...
public void RemplirPretListe(string codeagent, DateTime dat)...
public void RemplirAgentsListe(string requete)...
public string Trace()...
public void AfficherInfoSalaire(string codeagent, string
numsalaire)...
public void AfficherTraceSalaire(string numsal)...
public void RemplirSalaireListe(string requete)
{
try
{
TransactionLecture transSalaire = new TransactionLecture();
SqlDataReader Lect =
transSalaire.ExecuterTransaction(requete);
dgvListeSalaire.Rows.Clear();
int i = 0;
decimal totalMontant = 0;
while (Lect.Read())
{
dgvListeSalaire.Rows.Add(Lect.GetValue(5).ToString().Trim(),
new
AutreOperations().RetournerCodeNom(Lect.GetValue(5).ToString().Trim()),

131
new
AutreOperations().TraiteStringArgent(Lect.GetValue(2).ToString().Trim())
, Lect.GetValue(4).ToString().Trim(),
new
AutreOperations().RetournerDateValide(Lect.GetValue(3).ToString().Trim()));
dgvListeSalaire.Rows[i].HeaderCell.Value =
Lect.GetValue(0).ToString().Trim();
totalMontant += decimal.Parse(new
AutreOperations().TraiteStringArgent
(Lect.GetValue(2).ToString().Trim()));
i++;
}
dgvListeSalaire.Rows.Add("TOTAL", "", totalMontant, "","");
dgvListeSalaire.Rows[i].HeaderCell.Value = "#";
transSalaire.FermerConnexion();
}
catch (Exception ex)
{
MessageBox.Show("Une Erreur est survenue! La voici :: \n" +
ex.Message,
"ATTENTION!", MessageBoxButtons.OK,
MessageBoxIcon.Error);
}
}
public void InsererInfoSalaire(string codeag, string grade, string
nom, string mois)
{
try
{
if (codeag == string.Empty || nom == string.Empty || grade
== string.Empty
|| mois == "...")
{
MessageBox.Show("Des Champs sont Vides!", "Attention
!",
MessageBoxButtons.OK, MessageBoxIcon.Warning);
}
else
{
string datePaiement =
dtdatePaiement.Value.Date.ToShortDateString();
string moisPayer =
dtmoisPayer.Text.Split(char.Parse("/"))[1] + "/" +
dtmoisPayer.Text.Split(char.Parse("/"))[2];
string mont;
bool existe = new
AutreOperations().ExisteAgentSalaire(codeag.Trim(), moisPayer.Trim(),out
mont);
if (existe == true)
{
MessageBox.Show("L'Agent :: ["+codeag+"]-[" + new
AutreOperations().RetournerCodeNom(codeag) +
"] a reçu son salaire de [" + mont + " $]; Pour le
mois de [" + moisPayer + "] ::", "Attention !",
MessageBoxButtons.OK, MessageBoxIcon.Warning);
}
else
{
string trace = Trace();
string salaireNet = rbsalaireNet.Text;

132
decimal salaire = decimal.Parse(salaireNet.Trim());
salaireNet = new
AutreOperations().TraiteStringArgent
(salaire.ToString().Trim());
string requete = "insert into " + table +
"Salaire(trace_operation, net_a_payer,
date_paiement," +
" mois_paiement, codeagent) values ('" +
trace.Trim() + "','" +
salaireNet.Trim() + "','" + datePaiement.Trim()
+ "','" +
moisPayer.Trim() + "','" + codeag.Trim() +
"')";
TransactionsEcriture transSalaire = new
TransactionsEcriture(requete);
RemplirSalaireListe("select * from " + table +
"Salaire order by date_paiement");
}
}
}
catch (Exception ex)
{
MessageBox.Show("Une Erreur est survenue! La voici :: \n" +
ex.Message,
"ATTENTION!", MessageBoxButtons.OK,
MessageBoxIcon.Error);
}
}
public void MiseAJourInfoSalaire(string cle, string codeag, string
grade, string nom, string mois)
{
try
{
if (cle == "..." || codeag == string.Empty || nom ==
string.Empty || grade == string.Empty
|| mois == "...")
{
MessageBox.Show("Des Champs sont Vides!", "Attention
!",
MessageBoxButtons.OK, MessageBoxIcon.Warning);
}
else
{
if (DialogResult.Yes == MessageBox.Show("Etes-Vous sure
? \n\nVous êtes en train de " +
" supprimer l'information sur la table Salaires " +
@" """ + cle + @""" !" + "\n\nEt La Répercusion
sera dans toute la Base de Données!",
"Confirmation !", MessageBoxButtons.YesNo,
MessageBoxIcon.Question))
{
string requete = "delete from " + table + "Salaire
where numSalaire = '" + cle + "'";
TransactionsEcriture transRetenue = new
TransactionsEcriture(requete);
RemplirSalaireListe("select * from " + table +
"Salaire order by date_paiement");

133
}
}
}
catch (Exception ex)
{
MessageBox.Show("Une Erreur est survenue! La voici :: \n" +
ex.Message,
"ATTENTION!", MessageBoxButtons.OK,
MessageBoxIcon.Error);
}
}
public void NettoyerSalaire()...
public void NettoyerSalaire_Rec()...
public void RemplirSalaireListeParMois(string mois, string code)
{
try
{
string requete = "";
if (code == "")
{
requete = "select * from " + table + "Salaire order by
date_paiement";
}
else
{
requete = "select * from " + table + "Salaire where
codeagent = '" +
code + "' order by date_paiement";
}
TransactionLecture transSalaire = new TransactionLecture();
SqlDataReader Lect =
transSalaire.ExecuterTransaction(requete);
dgvListeSalaire.Rows.Clear();
int i = 0;
decimal totalMontant = 0;
while (Lect.Read())
{
string ladate = new
AutreOperations().RetournerDateValide(Lect.GetValue(3).ToString().Trim());
if (ladate.EndsWith(mois))
{
dgvListeSalaire.Rows.Add(Lect.GetValue(5).ToString().Trim(),
new
AutreOperations().RetournerCodeNom(Lect.GetValue(5).ToString().Trim()),
new
AutreOperations().TraiteStringArgent(Lect.GetValue(2).ToString().Trim())
, Lect.GetValue(4).ToString().Trim(),
new
AutreOperations().RetournerDateValide(Lect.GetValue(3).ToString().Trim()));
dgvListeSalaire.Rows[i].HeaderCell.Value =
Lect.GetValue(0).ToString().Trim();
totalMontant += decimal.Parse(new
AutreOperations().TraiteStringArgent
(Lect.GetValue(2).ToString().Trim()));
i++;
}
}

134
dgvListeSalaire.Rows.Add("TOTAL", "", totalMontant, "",
"");
dgvListeSalaire.Rows[i].HeaderCell.Value = "#";
transSalaire.FermerConnexion();
}
catch (Exception ex)
{
MessageBox.Show("Une Erreur est survenue! La voici :: \n" +
ex.Message,
"ATTENTION!", MessageBoxButtons.OK,
MessageBoxIcon.Error);
}
}
public void RechercheSalaire(string codeAg, string mois, string
dat)
{
try
{
RemplirSalaireListe("select * from " + table + "Salaire
order by date_paiement");
string requete = "";
mois = mois.Trim().Split(char.Parse("/"))[1] + "/" +
mois.Trim().Split(char.Parse("/"))[2];
if (chkdatePaie.CheckState == CheckState.Checked)
{
requete = "select * from " + table + "Salaire where
date_paiement = '" +
dat + "' order by codeagent";
RemplirSalaireListe(requete);
}
if (chkparAgent.CheckState == CheckState.Checked)
{
requete = "select * from " + table + "Salaire where
codeagent = '" +
codeAg + "' order by date_paiement";
RemplirSalaireListe(requete);
}
if (chkparDate.CheckState == CheckState.Checked)
{
requete = "select * from " + table + "Salaire where
mois_paiement = '" +
mois + "' order by date_paiement";
RemplirSalaireListe(requete);
}
if ((chkparAgent.CheckState == CheckState.Checked) &&
(chkparDate.CheckState == CheckState.Checked))
{
requete = "select * from " + table + "Salaire where
codeagent = '" +
codeAg + "' and mois_paiement = '" + mois + "'
order by date_paiement";
RemplirSalaireListe(requete);
}
if ((chkparAgent.CheckState == CheckState.Checked) &&
(chkdatePaie.CheckState == CheckState.Checked))
{
requete = "select * from " + table + "Salaire where
codeagent = '" +
codeAg + "' and date_paiement = '" + dat + "'
order by codeagent";

135
RemplirSalaireListe(requete);
}
}
catch (Exception ex)
{
MessageBox.Show("Une Erreur est survenue! La voici :: \n" +
ex.Message,
"ATTENTION!", MessageBoxButtons.OK,
MessageBoxIcon.Error);
}
}
private void Form4_Load(object sender, EventArgs e)...
private void cbbagentMatricule_SelectedIndexChanged(object sender,
EventArgs e)...
private void tbgrade_TextChanged(object sender, EventArgs e)...
private void tbnomAgent_rec_TextChanged(object sender, EventArgs
e)...
private void btnAjouterPret_Click(object sender, EventArgs e)...
private void btnCalculSalaire_Click(object sender, EventArgs e)...
private void dgvListeSalaire_CellMouseClick(object sender,
DataGridViewCellMouseEventArgs e)...
private void btnActualiser_Click(object sender, EventArgs e)...
private void btnVisualiser_Click(object sender, EventArgs e)...
private void btnNettoyerPret_Click(object sender, EventArgs e)...
private void btnSupprimerPret_Click(object sender, EventArgs e)...
private void btnRecherchePret_Click(object sender, EventArgs e)
{
RechercheSalaire(cbbagent_rec.Text, dtdateSalaire_rec.Text,
dtdatesal_rec.Text);
}
private void btnValiderConv_Click(object sender, EventArgs e)
{
try
{
if (tbtauxFranc.Text == string.Empty || tbsomme1.Text ==
string.Empty)
{
MessageBox.Show("Des Champs sont Vides!", "Attention
!",
MessageBoxButtons.OK, MessageBoxIcon.Warning);
}
else
{
decimal tauxf = decimal.Parse(tbtauxFranc.Text.Trim());
decimal som1 = decimal.Parse(tbtauxFranc.Text.Trim());
tbsomme2.Text = (som1 * tauxf).ToString();
}

136
}
catch (Exception ex)
{
MessageBox.Show("Une Erreur est survenue! La voici :: \n" +
ex.Message,
"ATTENTION!", MessageBoxButtons.OK,
MessageBoxIcon.Error);
}
}
private void chkmodifier_CheckedChanged(object sender, EventArgs
e)...
private void button2_Click(object sender, EventArgs e)...
private void elémentsDuSalaireToolStripMenuItem1_Click(object
sender, EventArgs e)...
private void elémentsDuSalaireToolStripMenuItem_Click(object
sender, EventArgs e)...
private void informationSurLAgentToolStripMenuItem_Click(object
sender, EventArgs e)...
private void Form4_FormClosing(object sender, FormClosingEventArgs
e)...
private void accueilToolStripMenuItem_Click(object sender,
EventArgs e)...
}
}
Rappels
Ce chapitre si long, qu’on ne perd de vue malgré ça, nous a permis à présenter notre
contribution en mettant au point un Logiciel de Traitement de salaire « SalaryManager »
tablé sur les notions présentées ci précédemment à savoir, depuis les notions introductives
des systèmes distribués à celle de transactions et de la gestion de transactions concurrentes.
Nous avons donc eu ce temps de montrer comment ces notions pouvaient être
d’application tant dans la conception de la BDR que dans les outils utilisés pour la mise en
place de l’application, ce chapitre en témoigne de soi.

137
[Conclusion]

138
Conclusion
La concurrence, voire la concurrence de transactions est pourtant loin d’être une
poursuite pour les Bases de Données Réparties, c’est plutôt une contrainte que ces dernières
sont censées gérer, car en tant qu’un système distribué, elles doivent censément gérer des
traitements concurrents. A travers les théories si bellement et méticuleusement exposées,
on a vu que la concurrence, qui est aussi une sollicitation simultanée, pouvaient causer, à
part l’incohérence de données, de la surcharge qui entache la disponibilité du Système, et on
a vu que qu’une bonne réplication pouvait amoindrir le taux d’une sollicitation excessive
d’une ressource. Cette notion de réplication est aussi d’application dans les Bases de
Données Réparties.
Conformément à ce que reprend [6], que nonante pourcent (90%) de données doivent
être trouvé dans le site local, et seulement dix (10%) dans un site distant, et puisque
l’emplacement d’exécution d’une transaction est un point très capital [5], il va de soi à dire
que réellement la réplication est aussi une voie pour contourner le méfait de la concurrence,
même si elle est exigeante du coté mise à jour et synchronisation de fragments.
Aux points positifs ci-dessus, on peut maintenant ajouter une bonne gestion de
transactions concurrentes par le biais des algorithmes de contrôle de concurrence qui sont
implémentés par exemples dans SQL SERVER par le niveau d’isolation qu’on attribue à
chaque transaction lorsqu’elle s’exécute de sorte à pouvoir contrôler tant son accès aux
données que celui des autres transactions qui lui sont concurrente. Chaque niveau
détermine donc un comportement donné dans l’accès de données tant pour la lecture que
pour l’écriture, d’où son choix est très important.
Toute cette logique de gestion de concurrence de transactions réunie ensemble et
mise en pratique dument, permet donc de mettre sur pied des systèmes distribués, dont
bien sûr la Base de Données répartie reste disponible et cohérente.
Ceci, nous avons l’audace de le croire, est le cas pour notre application informatique,
qui est passée par cette logique, et qui censure en même temps notre étude par sa
concrétisation.
A cette étape, nous pouvons déjà faire le bilan de notre solution informatique et voir si
la problématique posée tout au début, a rencontré la solution la plus appropriée.
Bien sûr qu’à présent, grâce à la solution informatique qui s’articule sur le logiciel
nommé SalaryManager monté par l’entremise des technique et technologie avancée ci haut,
l’immatriculation des agents est désormais très aisée, et grâce à la réplication, il ne suffit
qu’une entreprise enregistre une nouvelle unité (NU) , la Fonction Publique sera alors dans

139
un bref délai tenu informé dans sa base de donnée et pourra alors et simplement
l’immatriculer, et inversement une fois que la NU est immatriculée, l’information répercute
ou mieux se réplique à la source. Ceci a un avantage de gain en temps et de souplesse dans
les tâches et évites aussi trop de paperasses. Et par conséquent, il y a une facilité de
connaître l’effectif des tous les agents de l’Etat.
Et aussi mêmement, quand la NU est immatriculée, la Fonction Publique réplique cette
information ou mieux toutes les informations sur les agents immatriculés à la Finance.
De cette manière, chaque entreprise déjà connectée dans l’e-Gouvernement et
possédant ce logiciel a cette possibilité à son niveau local de calculer le salaire des agents, et
ainsi d’un coup et dans un bref délai les informations de calcul vont se synchroniser aussi au
niveau du ministère de Finance, et comme ça ce dernier pour payer ces agents aussi en
fonction des agents déjà immatriculés en provenance de la Fonction Publique.
Ce présent travail, ainsi que sa solution toute complète est un projet très vaste
et très coûteux depuis son étude jusqu’à sa réalisation ; et la solution apportée peut
encore comporter d’autres paramètres tels que : le calcul détaillé de élément constituant
le salaire de base, depuis la prestation jusqu’aux heures supplémentaires, le suivi en temps
réel des opérations de mutation et de transfert des agents de l’Etat, etc. pour avoir un
Logiciel très complet du personnel de l’Etat.

140
Référence
[1] A. Eftekari, Systèmes Transactionnels Répartis, Laboratoire Gracimp (ICTT) de l’INSA.
[2] Achraf Cherti, Jargon Informatique, Logiciel, Version 1.3.6, Avril 2006
[3] Anne Doucet, Transactions réparties, Module BDR Master d’Informatique (SAR) ; Cours.
[4] Arun Kumar Yadav et Ajay Agarwal, An Approach for Concurrency Control in
Distributed Database System, International Journal of Computer Science & Communication Vol. 1, No. 1, January-June 2010
[5] Anis Haj Said, Laurent Amanton, Bruno Sadeg, Contrôle de la réplication
dans les SGBD temps réel distribués, Laboratoire d’Informatique, de Traitement de l’Information et des Systèmes (LITIS) – Université du Havre, [email protected]
[6] Arjan SINGH and K.S. KAHLON, Non-replicated Dynamic Data Allocation in Distributed Database Systems, IJCSNS International Journal of Computer Science and Network Security, VOL.9 No.9, September 2009.
[7] A. S. Tanenbaum and M. VAN STEEN. Distributed Systems : Principles and Paradigms. Prentice Hall, 1999.
[8] Alexander Thomasian (Senior Member, IEEE), Distributed Optimistic Concurrency Control Methods for High-Performance Transaction Processing, IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, VOL. 10, NO. 1 , JANUARY/FEBRUARY 1998
[9] Aurélien Esnard, Systèmes Répartis, ENSEIRB PG306-IT343, [email protected],
http://www.labri.fr/~esnard
[10] Bertrand DUCOURTHIAL, Introduction aux systèmes répartis (chapitre 1), [email protected], 2007 v0.9-POLY.
[11] Darius KUGEL, Client-serveur : Introduction aux modèles client-serveur, Cours, [email protected]
[12] D. Skeen and M. Stonebraker, “A formal model of crash recovery in a distributed system,” IEEE Trans. Software Eng., vol. 9, no. 3, pp. 219–228, 1983.

141
[13] Eric Cariou, Introduction aux Systèmes Distribués, Licence Informatique 3ème année, Université de Pau et des Pays de l'Adour - Département Informatique, [email protected]
[14] Eric Leclercq & Marinette Savonnet, Chapitre I : Protocoles client serveur et architectures distribuées, Département IEM / UB, [email protected], Février 2008, Page 3.
[15] Eugene MBUYI, Système d’Information et Base de Données (Deuxième partie), Université de Kinshasa – Fac Sciences- Dpt Math-Info - L1-L2 Génie Informatique – 2010-2011
[16] Eltayeb Salih Abuelyaman, An Optimized Scheme for Vertical Partitioning of a
Distributed Database, CCIS, Prince Sultan University, Riyadh 11586, Saudi Arabia
[17] Articles sur les transactions dans le FireBirdsql, http://www.firebirdsql.org
[18] Frank SINGHOFF, Introduction aux systèmes à objets et services répartis, Bureau C-203, Université de Brest, France, LISyC/EA 3883, [email protected]
[19] Gopal Ashok (Microsoft Corporation) et Paul S. Randal (SQLskills.com), SQL Server Replication: Providing High Availability using Database Mirroring
[20] GRAHAM CHEN, distributed transaction processing standards and their applications, Tiré de “ the Computer Standards and Interfaces 17 (1995) pp 363-373”
[21] Harold CUNICO, ADO .NET : utilisation des transactions Version 1.0, Association
DotNet France, www.dotnetfrance.com
[22] Hercule KALONJI KALALA, Transactions reparties (Systèmes d’objets répartis), Université de Kinshasa – Fac Sciences- Dpt Math-Info – Licence - Génie Informatique – 2009-2010
[23] Hercule KALONJI KALALA, réplication des données (Systèmes d’objets répartis :
Chapitre VII), Université de Kinshasa – Fac Sciences- Dpt Math-Info - Licence - Génie Informatique – 2009-2010
[24] Haroun RABABAAH, DISTRIBUTED DATABASES FUNDAMENTALS AND RESEARCH,
Advanced Database – B561. Spring 2005. Dr. H. Hakimzadeh, Department of Computer and Information Sciences, Indiana University South Bend.
[25] Idriss SARR, Routage de Transaction dans les Bases de Données à Large Echelle, Thèse – O7-Octobre-2010, Université Pierre et Marie Curie (Parie VI)
[26] ISO/IEC 10026-1, Information technology-Open Systems Interconnection-Distributed

142
Transaction : Part 1 OSI TP Model, Part 2 OSI TP Service Definition, Part 3 OSI TP Protocol Specification, - 1993
[27] Joël LILONGA BOKELETUMBA, Langage Pour Système, Université de Kinshasa – Fac Sciences- Dpt Math-Info – L1 Génie Informatique – 2010-2011
[28] Jim Gray, Transaction Processing: Concepts and Techniques, April 2007,© 2007
Sombers Associates, Inc., and W. H. Highleyman, www.availabilitydigest.com
[29] KAYEMBA KAVUALLA Sagesse, Recherche d’un chemin minimal facilitant le Service Anti-incendie d’atteindre le lieu de sinistre, Travail de fin de cycle, Université de Kinshasa – Fac Sciences- Dpt Math-Info – G3 Informatique – 2008 – 2009
[30] Luc Bouganim, Bases de données : Architecture et Systèmes ; Cours 2 : Transactions ;
PRiSM Versailles - INRIA, Rocquencourt
[31] Laurence Duchien, Le Transactionnel Réparti, Transactions et environnements CORBA, CNAM- Laboratoire CEDRIC ; 292, rue St Martin, 75141 Paris, Cedex 03, email : [email protected]
[32] Muhammad Atif, Analysis and Verification of Two-Phase Commit & Three-Phase
Commit Protocols, Department of Mathematics and Computer Science, Technische Universiteit Eindhoven, P.O. Box 513, 5600 MB Eindhoven, The Netherlands, Email: [email protected]
[33] Matthieu Exbrayat, Gestion de Transactions dans les Systèmes Distribués, ULP
Strasbourg – Décembre 2007
[34] D. S. Milojicic, V. Kalogeraki, R. Lukose, K. Nagaraja, J. Pruyne, B. Richard, S. Rollins and Z. Xu, “Peer-to-Peer Computing”. Tech. Report: HPL-2002-57, available on line at: http://www.hpl.hp.com/techreports/2002/HPL-2002-57.pdf
[35] Ministère des Postes, Téléphones et Télécommunications (MPTT), Rapport de l’étude de faisabilité, L’infrastructure des TIC pour le projet d’E-Gouvernement de la République Démocratique du Congo, Mai 2007
[36] M. Raddad AL KING, Localisation de sources de données et optimisation de requêtes réparties en environnement pair-à-pair, Université Toulouse III – Paul Sabatier, Discipline : Informatique, Mai 2010
[37] MSDN, Microsoft Developper Network, msdn.microsoft.com – 02 Décembre 2011 (Date de visitation du site)
[38] http://msdn.microsoft.com/en-us/library/ms151198(SQL.100).aspx, for SQL Server
2008
[39] Nathanael KASORO, Langage Formel et Compilation, Cours, Université de Kinshasa –
Fac Sciences- Dpt Math-Info – Licence, 2010-2011

143
[40] Nicolas LUMINEAU, Interopérabilité et Intégration des systèmes d’information : TIW3,
Université de Claude Bernard – Lyon 1, [email protected], 2008, Page 5-6
[41] Olabode OLATUBOSUN et Solanke OLAKUNLE, Framework for Client-Server Distributed Database System for Licensing and Registration of Automobiles in Nigeria, E-mail: [email protected].
[42] PHILIP A. BERNSTEIN AND NATHAN GOODMAN, Concurrency Control in Distributed Database Systems, Computer Corporation of America, Cambridge, Massachusetts 02139, February 1981
[43] Paul Krzyzanowski, Lectures on distributed systems: A taxonomy of distributed
systems, Rutgers University – CS 417, 2000-2003
[44] Roland BALTER, Gestion répartie des transactions, Projet INRIA Sirac ; 655, av de l’Europe ; 38330 Montbonnot ; Août 1993 ;
[45] Rim MOUSSA, Systèmes de Gestion de Bases de Données Réparties & Mécanismes de Répartition avec Oracle, Novembre 2006,
Ecole Supérieure de Technologie et d’Informatique à Carthage, 2005-2006, [email protected], http://ceria.dauphine.fr//Rim/SupportBDR.pdf
[46] Ricardo R. JACINTO MONTES, Protocoles de validation à deux phases dans les
systèmes transactionnels répartis : Spécification Modélisation et vérification, LABORATOIRE D’ ANALYSE ET D’ARCHITECTURE DES SYSTEMES DU CNRS, Toulouse-France, Thèse – O6-Janvier – 1995
[47] Shahidul Islam Khan et Dr. A. S. M. Latiful Hoque, A New Technique for Database
Fragmentation in Distributed Systems, International Journal of Computer Applications (0975 – 8887) Volume 5– No.9, August 2010
[48] Saint-Jean DJUNGU, Réseaux Informatiques, Université de Kinshasa – Fac Sciences- Dpt Math-Info - L2 Gestion Informatique – 2010-2011
[49] Saint-Jean DJUNGU, Génie logiciel et construction des programmes, Université de
Kinshasa – Fac Sciences- Dpt Math-Info - L2 Gestion Informatique – Mai 2009
[50] Sacha Krakowiak, Validation atomique, Université Joseph Fourier, Projet Sardes (INRIA et IMAG-LSR), http://sardes.inrialpes.fr/people/krakowia, Ecole Doctorale de Grenoble, Master 2 Recherche “Systèmes et Logiciel”
[51] Sacha Krakowiak, Introduction aux systèmes et applications répartis, Université
Joseph Fourier, Projet Sardes (INRIA et IMAG-LSR), http://sardes.inrialpes.fr/krakowia

144
[52] Sylvain Lecomte, Cartes Orientées Services Transactionnels et Systèmes Transactionnels Intégrant des Cartes : COST-STIC, Thèse de Doctorat, Université des Sciences et Technologies de Lille, Page 32-33
[53] www.Wikipedia.com


















