Développement d’un prototype exploratoire d’application ...
62
1 Québec, Qc 24, bd de la Victoire Canada G1K 7P4 67000 Strasbourg - France Mémoire de soutenance du Diplôme d’Ingénieur ENSAIS Développement d’un prototype exploratoire d’application SIG pour la détermination des besoins d’utilisateurs en santé environnementale PROJET GÉOIDE Virginie PUJOS Correcteurs : Spécialité TOPOGRAPHIE M. KOEHL Juin 1999 M. GRUSSENMEYER
Transcript of Développement d’un prototype exploratoire d’application ...

1
Québec, Qc 24, bd de la Victoire Canada G1K 7P4 67000 Strasbourg - France
Mémoire de soutenance du Diplôme d’Ingénieur ENSAIS
Développement d’un prototype exploratoire d’application SIG pour la détermination des besoins d’utilisateurs en
santé environnementale
PROJET GÉOIDE
Virginie PUJOS Correcteurs : Spécialité TOPOGRAPHIE M. KOEHL Juin 1999 M. GRUSSENMEYER

2
REMERCIEMENTS
Je tiens à remercier tout particulièrement mon maître de stage, le Dr Yvan Bédard qui a trouvé ce
sujet qui fait collaborer le Centre de Recherche en Géomatique (CRG) de l’Université Laval et le Centre de
Santé Public de Québec, me permettant ainsi d’être confrontée à un milieu que je ne connaissais pas du tout :
celui de la santé environnementale. Yvan Bédard m’a suivie et conseillée pendant toutes les étapes du projet.
Je n’oublierai pas de remercier aussi :
Pierre Gosselin qui a été un des initiateurs de ce projet et qui a bien voulu qu’une petite étudiante française
participe à sa réalisation.
Marie-France Gagnon et Germain Lebel du Centre de Santé Public qui m’ont fourni les données et qui ont
fait preuve de patience lors de ma multitude de questions.
Pierre Marchand, étudiant en doctorat, qui fort de son expérience dans ce sujet a su me conseiller de
manière très juste et toujours appropriée. Il a suivi de près toutes les étapes de mon projet et a passé un temps
considérable à m’expliquer tout ce que je ne comprenais pas.
Yves van Chestein, professeur en Géomatique, qui m’a très souvent dépanné lors de mes problèmes
informatiques et qui apporte sa bonne humeur au sein du CRG.
Suzie Larrivée, professionnelle de recherche, toujours prête à répondre aux questions d’ordre technique et
ce, avec le sourire.
Sylvain Vallières, étudiant en maîtrise qui m’a donné d’astucieux conseils concernant l’utilisation de
MapInfo.
Tristan Alzial, ESGT 98 et étudiant en maîtrise, pour tous les petits coups de pouces quotidiens qu’il m’a
apportés en informatique.

3
SOMMAIRE
REMERCIEMENTS page 2
I. PRESENTATION DE L’ENVIRONNEMENT DE STAGE
1) Le Centre de Recherche en Géomatique de l’Université Laval page 7
2) L’équipe santé et environnement du Centre Hospitalier Universitaire de Québec page 7
3) Le projet ICEM-SE du réseau canadien de Centres d'excellence en géomatique GEOIDE page 8
II. MISE EN CONTEXTE
1) Problématique page 10
2) Objectifs page 10
3) Méthode utilisée
a) Définition d’un prototype page 11
b) Définition d’un OLAP page 13
c) Etapes de la méthode mise au point page 14
4) Découverte des logiciels et lectures préliminaires page 16
III. ANALYSE DES DONNEES DU PROJET
1) Le découpage territorial au Québec
a) Le découpage spatial administratif page 17
b) Le découpage spatial dans le monde de la santé page 17
2) Analyse des données du CSPQ page 18
3) Problème de la confrontation des données page 20
4) Visualisation sous Brain des éléments qui constitueront l’hypercube page 20
IV. TRAITEMENTS DES DONNEES DESCRIPTIVES DU PROTOTYPE
1) Le changement de méthode dû aux problèmes spatio-temporels Etapes à suivre page 26
2) Création de la table Access page 27
3) Création de l’hypercube avec Transformer
a) Définition d’un hypercube page 34
b) Création de l’hypercube page 35
4) Passage sous Powerplay
a) Quelques explications sur l’environnement de Powerplay page 40
b) Exploration de notre hypercube page 43

4
V. MODIFICATION DES DONNEES DESCRIPTIVES ET AFFINEMENT DU PROJET
page 44
VI. TRAITEMENT DES DONNEES CARTOGRAPHIQUES DU PROTOTYPE
1) Le choix du logiciel page 47
2) Les cartes thématiques page 48
3) Les principes de la semiologie graphique
a) En théorie page 50
b) Dans le cas présent page 53
CONCLUSION page 55
PLANNING DETAILLE page 57
REFERENCES BIBLIOGRAPHIQUES page 59

5
TABLE DES FIGURES
Figure 1. Positionnement du prototypage jetable par rapport au cycle de vie d’un SIRS page 11
Figure 2. Représentation du prototype exploratoire dans le système complet page 12
Figure 3. Structure multidimensionnelle pour représenter des évènements page 13
Figure 4. Structure multidimensionnelle à six dimensions page 14
Figure 5. La fonction « drill down » page 14
Figure 6. Étapes théoriques à suivre page 15
Figure 7. Carte des MRC et zoom sur les municipalités page 17
Figure 8. Carte des RSS et zoom sur les CLSC page 18
Figure 9. Exemple de tableau de données sur le cancer page19
Figure 10. Carte des MRC page 20
Figure 11. Carte des CLSC page20
Figure 12. The brain - présentation globale page 21
Figure 13. The brain – structuration des données page 22
Figure 14. The brain – activation d’un élément page 22
Figure 15. The brain – création d’un nouvel élément page 22
Figure 16. The brain – nomination du nouvel élément page 23
Figure 17. The brain – effacer un élément page 23
Figure 18. The brain – effacer un élément (suite) page 23
Figure 19. The brain – liens entre les différents objets page 24
Figure 20. The brain – Utilisation de la police d’Yvan Bédard page 25
Figure 21. Différence de digitalisation entre les CLSC et les municipalités page 27
Figure 22. Requête SQL d’union page 28
Figure 23. Requête de création de table page 29
Figure 24. Résumé des étapes de création de la table Access page 29
Figure 25. Requête SQL de calcul de superficie des municipalités page 32
Figure 26. Tableau résultat de la requête de calcul de la superficie page 33
Figure 27. Requête de joint des tables des municipalités et des adultes page 34
Figure 28. Environnement de Transformer page 35
Figure 29. Premier hypercube réalisé page 36
Figure 30. Structure de la dimension « Yvan » page 39
Figure 31. Environnement de Powerplay page 40
Figure 32. Barre multidimensionnelle de Powerplay page 40
Figure 33. Fenêtre Categories de Powerplay page 41
Figure 34. Visualisation du problème des totaux page 42

6
Figure 35. Structure de l’hypercube ADULTE (seconde itération) sous Powerplay page 45
Figure 36. Hypercubes des adultes (à gauche) et des enfants (à droite) page 46
Figure 37. Les variables visuelles page 50
Figure 38. Échelle de mesure des propriétés page 51
Figure 39. Recommandations sur l’utilisation des variables visuelles page 51

7
I. PRESENTATION DES ORGANISMES
1) Le Centre de Recherche en Géomatique de l’Université Laval
Le Centre de Recherche en Géomatique (CRG) de la Faculté de Foresterie et de Géomatique de l’Université
Laval à Québec a été créé en 1989 afin d'offrir un cadre de formation et de recherche pluridisciplinaire dans
le secteur de la géomatique. Il regroupe une centaine de spécialistes dans des disciplines de base en
géomatique (géodésie, législation foncière, photogrammétrie, systèmes d'information à référence spatiale,
cartographie numérique et télédétection), dans des disciplines complémentaires telles que l'informatique, les
systèmes d'information organisationnels et les sciences sociales ainsi que dans certains domaines
d'application de la géomatique (foresterie, agriculture, génie, climatologie et géologie). Tous œuvrent dans le
but d'améliorer les méthodes, techniques et outils d'acquisition et de gestion des données sur le territoire. Le
Centre est reconnu et financé par le Fonds pour la Formation de Chercheurs et l'Aide à la Recherche du
Québec ainsi que par le gouvernement canadien. C'est le seul du genre au Canada et l'Université Laval est
d'ailleurs la tête dirigeante du nouveau Réseau Canadien de Centres d'Excellence en Géomatique appelé
GEOIDE (GEOmatique pour des Interventions et des Décisions Eclairées).
Informations tirées du site Web du CRG.
Le CRG possède pour quatre millions de dollars canadiens soit environ seize millions de francs
d’équipement de pointe. Une multitude de logiciels sont à la disposition des chercheurs et des étudiants :
logiciels de SIG (Systèmes d’Information Géographique), d’OLAP (On-Line Analytical Processing, que l’on
peut traduire par processus d’analyse interactif), de télédétection, de COGO (calculs topographiques), de
GPS, de photogrammétrie, de cartographie, de gestion de base de données (SGBD) et de traitement de texte.
Tous les ordinateurs du CRG sont reliés par réseau sous l’environnement Windows NT.
Le Dr Yvan Bédard, membre du CRG et professeur de SIG a été mon maître de stage.
2) L’équipe santé et environnement du Centre Hospitalier Universitaire de Québec
Depuis plus de 25 ans, d’importantes sommes d’argent ont été consacrées à la santé publique et à
l’environnement au sein du Centre Hospitalier Universitaire de Québec (CHUQ). Plusieurs équipes de
professionnels et de chercheurs provenant de domaines aussi divers que l’anthropologie, la biologie,
l’épidémiologie, la foresterie, la géographie, la génétique, la médecine, la nutrition, la psychologie, les
sciences de l’environnement, la sociologie, la statistique et la toxicologie, travaillent au CHUQ. Ce groupe
d’environ 125 personnes répond aux demandes d’information du public et mène des recherches et
interventions avec des partenaires de divers milieux (ministères, universités, firmes privées,…). Ces équipes
détiennent des mandats officiels des gouvernements aux niveaux régional, provincial, national et
international. L’interdisciplinarité du groupe constitue un atout majeur qui lui permet d’évaluer de façon

8
exhaustive les effets positifs ou négatifs sur la santé des impacts environnementaux reliés aux projets de
développement ou aux politiques gouvernementales.
Informations tirées de la plaquette du CHUQ.
Le Dr Pierre Gosselin, Marie-France Gagnon et Germain Lebel ont été mes interlocuteurs privilégiés au sein
du CHUQ. Le Dr Gosselin était le responsable de mon stage pour le secteur de la santé.
3) Le projet ICEM-SE du réseau canadien de Centres d'excellence en géomatique GEOIDE
Une équipe multidisciplinaire formée de gens compétents dans les domaines de la santé environnementale,
de la géomatique et de l’informatique a été mise en place pour créer une interface cartographique pour
l'exploration multidimensionnelle des indicateurs de santé environnementale sur le Web. Le nom donné à ce
projet est ICEM-SE. Les objectifs de cette recherche sont de réduire et prévenir les risques pour la santé qui
sont d’origine environnementale. Ceci nécessite un accès simple et rapide à des données de bonne qualité,
lesquelles doivent être analysées de façon utile pour supporter les décisions et interventions. Pour atteindre
leurs objectifs de gestion, plusieurs organisations en santé publique désirent acquérir un logiciel SIG leur
permettant de géoréférencer leurs données. Il en résulte une capacité accrue d'analyse de ces observations,
que ce soit par la simple production de cartes thématiques pour mieux illustrer un phénomène, ou par
l'utilisation de fonctions d'analyse spatiale. Cependant, l’utilisation d'un SIG n'est qu'un premier pas. En
effet, il est fréquemment admis que les SIG sont limités dans les fonctions d'analyse multiéchelle (ex. analyse
locale vs régionale), de statistique spatiale et de gestion des données temporelles (historiques et prédictives),
car ils n'ont pas été conçus initialement pour de telles opérations. Cela implique beaucoup d’efforts pour les
manipulations et les temps de réponse sont importants pour chaque opération. De plus, les SIG demeurent
inaccessibles aux non-spécialistes parce qu’ils sont trop complexes à utiliser (ex. : requièrent SQL avec
opérateurs spatiaux). Il est aujourd'hui impossible pour un non-spécialiste des SIG d'analyser rapidement et
facilement les données de santé environnementale, surtout lorsqu'une telle analyse demande de comprendre
l'évolution d'un phénomène sur une période donnée et de comparer plusieurs thèmes à différents niveaux de
détail. Cette constatation est la problématique au cœur du présent projet.
Parallèlement au développement des outils SIG, le monde informatique a vu apparaître les marchés de
données ou Data Marts (sorte de Data Warehouses – entrepôts de données – simplifiés, présentant des
données fortement agrégées dans une structure multiniveau et multithème appelée multidimensionnelle), les
outils d'analyse statistique (ex. SPSS, SAS), les outils d'exploration de données (OLAP) et les outils de
forage automatique de données (Data Mining). Chacun de ces outils permet de résoudre, mais de façon
séparée et partielle, une partie des problèmes mentionnés ci-avant et ceci, seulement pour les données non
spatiales.

9
Dans le cadre du présent projet, il a été proposé de concentrer les efforts sur l'exploitation maximale des
marchés de données et des outils OLAP en conjonction avec les SIG. Ce projet, d'une durée de trois années,
permettra ainsi de faciliter la gestion temporelle et la gestion multiéchelle des données spatiales grâce à
l'approche base de données multidimensionnelle utilisée dans les Data Marts. Ce projet permettra également
d'exploiter ces données de façon très rapide et très simple grâce à une interface cartographique de type
SOLAP (Spatial OLAP). L’utilisation de ces logiciels permettra d’approcher la solution désirée, soit : avoir
un système d’information efficace pour la description et l'analyse des données complexes en santé
environnementale.
Finalement, considérant le désir de rendre ce genre d'outil disponible à plusieurs utilisateurs situés dans
différentes régions, et ceci à un coût acceptable, l'utilisation d'un Intranet comme support de développement
a été privilégiée.
Les résultats attendus de ce projet de recherche appliquée incluent la mise en place d'un prototype
fonctionnel de système de description et d'analyse des données complexes en santé environnementale, basé
sur le projet de Système d’Information à Référence Spatiale en santé environnementale (SIRS-SE) du Comité
de santé environnementale, ainsi que le développement de nouvelles connaissances grâce à l'expérimentation.
Informations tirées de la proposition de projet GEOID

10
II. MISE EN CONTEXTE
Pendant ma session d’automne 1998 à l’Université Laval, Yvan Bédard et Pierre Gosselin m’ont proposé de
travailler pendant la session d’hiver sur le sujet suivant : « développement d’un prototype exploratoire
d’application SIG pour la détermination des besoins d’utilisateurs en santé environnementale ». Ce sujet m’a
permis de mettre en pratique la notion de cycle de vie d’un SIG qui m’a été inculquée pendant le cours de
fondements des SIG donné en automne 1998 et de proposer un projet d’expérimentation des technologies des
SIG dans un domaine bien particulier, celui de la santé environnementale. Il s’agit donc de mettre à profit les
connaissances de géomatique afin de travailler dans un domaine complètement différent. La partie qui suit a
été réalisée à l’aide des notes du cours de maîtrise « Analyse et conception de SIRS » d’Yvan Bédard (1998).
1) Problématique
Dans le cadre du réseau GEOIDE, le CSPQ (Centre de Santé Publique de Québec) et le CRG ont décidé de
collaborer sur le développement d'une interface cartographique pour l'exploration simple et rapide des
données de santé environnementale sur le Web. Ce projet vient se greffer à un autre projet (SIRS-SE) visant
à mettre en place le système d'information exploité par cette interface cartographique.
L’analyse préliminaire réalisée en juillet 1998 par la Direction de la Santé Publique de Québec et la Régie
Régionale de la Santé et des Services Sociaux de Québec représente la phase d’évaluation d’opportunité. En
effet, cette étude porte sur la faisabilité d’un Système d’Information Géographique en santé
environnementale. Le résultat de cette étude est qu’il est devenu nécessaire de réaliser un SIG pour répondre
aux nouveaux besoins des utilisateurs. Ce système serait rentable, pas trop coûteux et bien accueilli par les
utilisateurs potentiels, ce qui représente des facteurs clés pour le succès de la mise en place d’un tel système.
La problématique à laquelle fait face la nouvelle équipe CSPQ-CRG est de définir plus précisément les
besoins du CSPQ ainsi que les possibilités de nouvelles offres technologiques proposées par le CRG. Ce type
de problème étant très fréquent avec les nouvelles technologies, particulièrement les technologies
exploratoires du type de celles financées par GEOIDE, il devient primordial d'utiliser l'approche
méthodologique la plus efficace dans une telle situation : le prototypage rapide.
2) Objectifs
En ce qui nous concernait, notre but était donc de prendre en compte les données à intégrer au prototype et de
réaliser celui-ci jusqu’au bout, sachant que le nombre d’itérations dépendrait du temps mis à notre
disposition, c’est-à-dire une session. Le prototype que nous avons réalisé n’est que la première étape du
projet de réalisation d’un SIRS-SE d’une durée de quatre ans.

11
Les outils à notre disposition pour créer ce prototype étaient un logiciel OLAP couplé avec des logiciels de
SIG. Les objectifs étaient clairs : après analyse des données de la santé, le prototype devait être réalisé en
deux points : d’abord permettre une navigation dans les données descriptives à l’aide du logiciel OLAP, puis
mettre aux points des cartes rendant compte des mêmes données mais cette fois sous forme graphique.
Un projet utilisant ces deux sortes de logiciels a déjà été réalisé au CRG sur des données forestières l’été
dernier par Cécile Rebout et Pierre Marchand. Ce couplage représente une solution très innovatrice, laquelle
nécessite cependant davantage de recherche et développement avant d'être répandue de façon importante
dans la communauté géomatique. C'est d'ailleurs ce à quoi se consacre l'équipe du Dr Bédard dans le cadre
d'un autre projet GEOIDE et c'est dans un tel contexte d'innovation technologique que le CSPQ s'est joint au
projet et que nous avons réalisé le présent projet. Il est important de signaler ici que GEOIDE a commencé
officiellement le 4 mars dernier et que notre projet se situe vraiment au tout début de la démarche.
3) Méthode utilisée
Afin d’atteindre nos objectifs (création d’un prototype OLAP et fabrication de cartes thématiques), nous
avons dû définir les termes de prototype et d’OLAP. Ensuite, nous avons défini la méthode.
a) Définition d’un prototype
Un projet d’expérimentation des technologies permet d’évaluer les risques et les possibilités d’une
technologie de l’information par rapport à un domaine d’application particulier. Alors qu’un SIRS est
directement implanté dans une organisation, le projet d’expérimentation est réalisé dans un environnement de
« laboratoire »; c’est ce qui représente la plus grosse différence entre ces deux systèmes. Il a pour but de
diminuer les risques associés à l’utilisation d’une nouvelle technologie de l’information, d’évaluer les
impacts de l’implantation d’un projet sur le plan technologique et d’évaluer les impacts de cette nouvelle
technologie dans l’organisation en confrontant le nouveau système aux capacités réduites avec les futurs
utilisateurs. Dans le cadre de notre projet, le Centre de Santé Publique a choisi d’expérimenter des
technologies éprouvées sur le marché mais non utilisées dans un domaine d’application précis au lieu de se
diriger vers des outils encore peu présents sur le marché. Étant donné l’état d’avancement du système
d’information du CSPQ, le choix de la technique d’exploration a été simple : le prototypage exploratoire.
Figure 1. Positionnement du prototypage jetable par rapport au cycle de vie d’un SIRS

12
Contrairement à d’autres projets d’expérimentation qui se réalisent plus tard dans le cycle de vie d’un SIRS
(prototype évolutif, projet pilote, …), le prototype exploratoire est réalisé dès les premières étapes de la mise
en place d’un SIRS (figure 1).
Le prototypage exploratoire est une activité complémentaire facultative par rapport aux activités de
développement de systèmes d’information, qui suscite les réactions des utilisateurs face à diverses
composantes d’un système dans un environnement de « laboratoire ». Un prototype rapide est un petit
système partiellement fonctionnel qui est développé itérativement en étroite collaboration entre les
utilisateurs et les développeurs. Il sert à préciser les demandes et les offres avec la présentation, à chaque
itération, d'une ébauche d'un sous-ensemble du système final. Chaque itération permet de converger vers une
meilleure compréhension utilisateur-développeur, et ainsi de déterminer plus précisément les besoins avant
de procéder au développement du système global et final; conséquemment, il n'y a aucune obligation pour
l'utilisateur d'implanter le système sur la technologie SIG choisie puisque, par définition, un prototype rapide
est "jetable" (il n'aura servi qu'à mieux connaître les besoins et les offres et, en ce sens, aura servi à la
formation mutuelle des intervenants). Une telle stratégie permet d'identifier les différences de perception
entre l'utilisateur et le développeur tôt dans le processus de mise en œuvre d'un système, et d'y remédier
rapidement (épargnant ainsi des sommes importantes si l’on compare avec le fait de remédier au tout lorsque
l'on est très avancé dans le développement du système). Le prototype jetable sert à favoriser l’apprentissage
et la formation des utilisateurs par un contact direct avec ces nouvelles technologies, leur permettant ainsi
d’en cerner les capacités et les limites, ainsi que de vérifier la faisabilité et la performance de certaines
solutions fonctionnelles ou techniques, le but n’étant pas de réaliser le système entièrement mais de montrer
ce qu’il est possible de faire avec les nouvelles technologies.
Figure 2. Représentation du prototype exploratoire dans le système complet (cf. Bédard, 1998)

13
b) Définition d’un OLAP
L’OLAP (On-Line Analytical Processing) est un terme qui est apparu ces dernières années et qui renvoie à
un contexte de marketing plutôt qu’à un contexte technique. Il serait possible de le définir comme un
traitement de l’information orienté sur la décision et basé sur l’analyse. Les données brutes sont prétraitées et
préparées pour l’analyse, ce qui implique un nettoyage des données très tôt dans le processus. Avec cette
technique, l’accès aux données et les calculs sont rapides et précis. Le système a besoin d’assurer que les
vues sont facilement organisées et que les interfaces sont conviviales et intuitives. Généralement, les données
traitées sont en très grand nombre (pouvant atteindre des centaines de gigaoctets), les niveaux de détails sont
multiples, et il y a plusieurs facteurs d’analyse. Le nombre d’utilisateurs et de sites peut atteindre quelques
milliers. Ces utilisateurs ne vont pas suivre des procédures prédéfinies, mais choisir de façon autonome les
données à analyser. Ceci impose au système d’avoir une grande flexibilité.
L’hypercube et la représentation des dimensions
La notion d’hypercube (qui comporte généralement plus de trois dimensions) est fondamentale pour une
bonne compréhension d’un logiciel multidimensionnel. Comme un tableur utilise des feuilles de calculs ou
une base de données utilise des tables, l’OLAP se sert d’un hypercube. Il ne faut pas imaginer un cube
traditionnel car dès que l’on dépasse trois dimensions, la représentation devient très compliquée. Pour définir
une structure multidimensionnelle, il faut s’imaginer que chaque dimension est représentée par un segment
vertical. Il existe donc autant de segments verticaux que de dimensions. Chaque sous-catégorie d’une
dimension est représentée par un intervalle du segment. La figure 3 montre un exemple d’hypercube
tridimensionnel représenté à la manière d’un OLAP à gauche, et sous forme d’un cube classique à droite.
Dans cet exemple, les trois dimensions sont le temps, les produits et les variables.
Figure 3. Structure multidimensionnelle pour représenter des évènements (cf Thomsen, 1997)
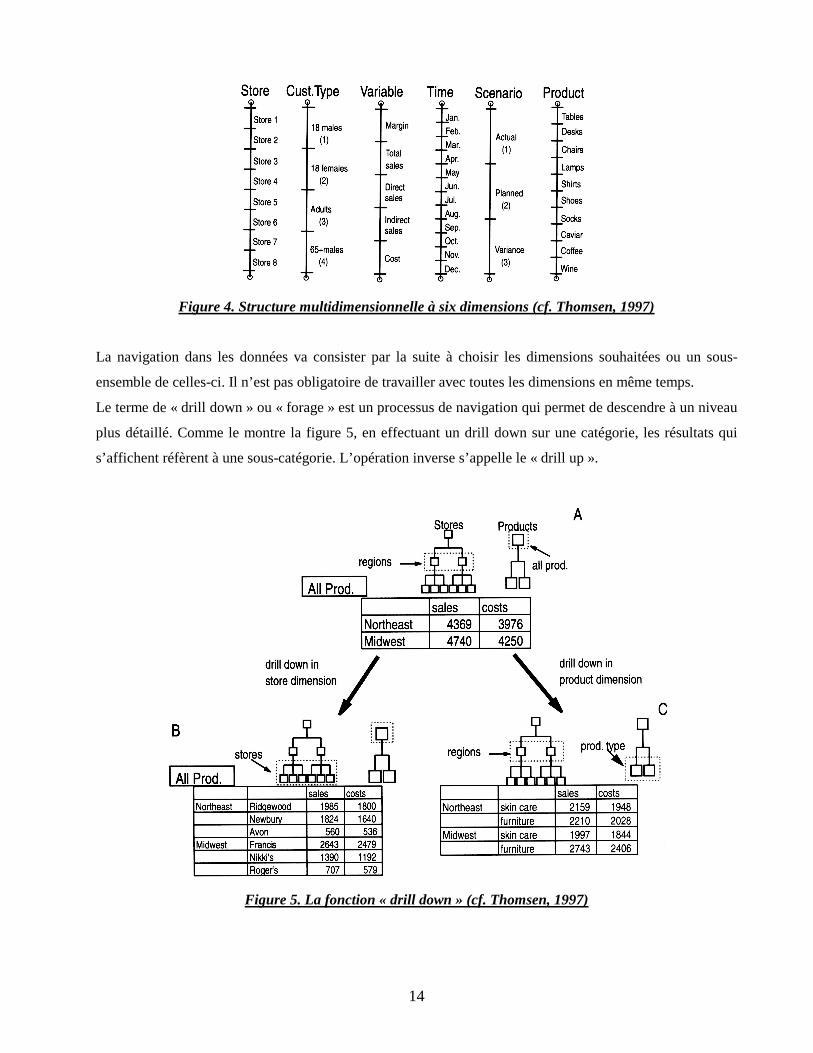
Si l’étude porte sur plus de dimensions, il suffit de rajouter des segments verticaux comme sur la figure 4
afin de compléter l’hypercube. Dans ce cas-là, trois autres dimensions ont été rajoutées : les magasins, le
type de clients et le scénario.
14
Figure 4. Structure multidimensionnelle à six dimensions (cf. Thomsen, 1997)
La navigation dans les données va consister par la suite à choisir les dimensions souhaitées ou un sous-
ensemble de celles-ci. Il n’est pas obligatoire de travailler avec toutes les dimensions en même temps.
Le terme de « drill down » ou « forage » est un processus de navigation qui permet de descendre à un niveau
plus détaillé. Comme le montre la figure 5, en effectuant un drill down sur une catégorie, les résultats qui
s’affichent réfèrent à une sous-catégorie. L’opération inverse s’appelle le « drill up ».
Figure 5. La fonction « drill down » (cf. Thomsen, 1997)
15
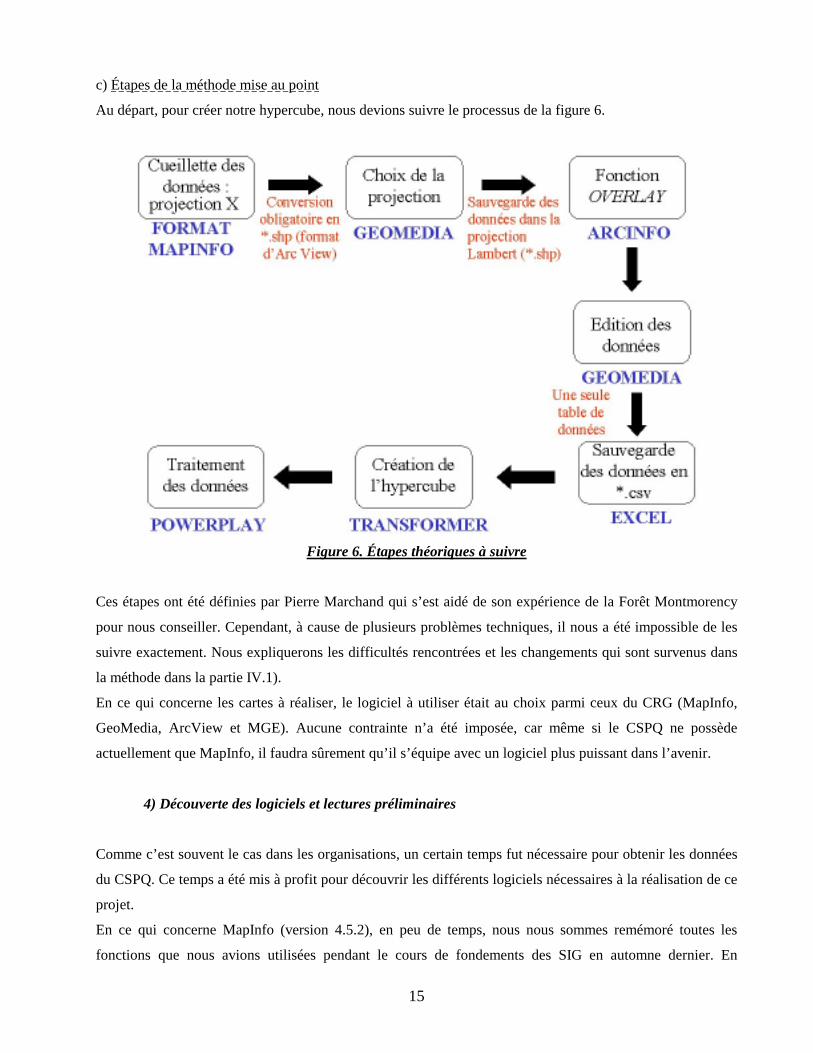
c) Étapes de la méthode mise au point
Au départ, pour créer notre hypercube, nous devions suivre le processus de la figure 6.
Figure 6. Étapes théoriques à suivre
Ces étapes ont été définies par Pierre Marchand qui s’est aidé de son expérience de la Forêt Montmorency
pour nous conseiller. Cependant, à cause de plusieurs problèmes techniques, il nous a été impossible de les
suivre exactement. Nous expliquerons les difficultés rencontrées et les changements qui sont survenus dans
la méthode dans la partie IV.1).
En ce qui concerne les cartes à réaliser, le logiciel à utiliser était au choix parmi ceux du CRG (MapInfo,
GeoMedia, ArcView et MGE). Aucune contrainte n’a été imposée, car même si le CSPQ ne possède
actuellement que MapInfo, il faudra sûrement qu’il s’équipe avec un logiciel plus puissant dans l’avenir.
4) Découverte des logiciels et lectures préliminaires
Comme c’est souvent le cas dans les organisations, un certain temps fut nécessaire pour obtenir les données
du CSPQ. Ce temps a été mis à profit pour découvrir les différents logiciels nécessaires à la réalisation de ce
projet.
En ce qui concerne MapInfo (version 4.5.2), en peu de temps, nous nous sommes remémoré toutes les
fonctions que nous avions utilisées pendant le cours de fondements des SIG en automne dernier. En

16
revanche, nous avons dû découvrir entièrement le logiciel Powerplay et son module Transformer. Le but était
de comprendre la structure des fichiers utilisés et la manière de fabriquer un hypercube. Ces étapes seront
décrites ultérieurement dans le mémoire.
De plus, pour nous familiariser avec le sujet, nous avons lu le mémoire de Cécile Rebout qui traite de la mise
en place d’un OLAP jumelé avec le logiciel GeoMedia Pro, c’est-à-dire d’un SOLAP et l’analyse
préliminaire réalisée par la Direction de la Santé Publique de Québec et la Régie Régionale de la Santé et des
services Sociaux de Québec. En effet, cette dernière explique bien le choix des logiciels et la provenance des
données.
17
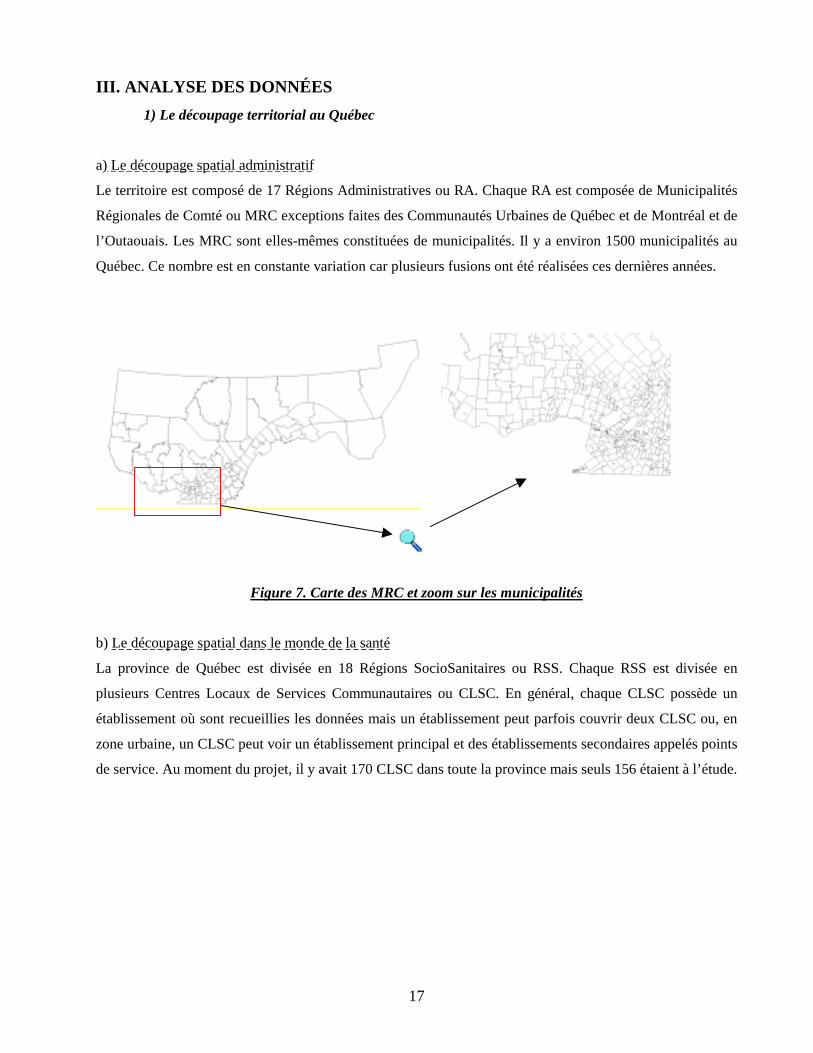
III. ANALYSE DES DONNÉES 1) Le découpage territorial au Québec
a) Le découpage spatial administratif
Le territoire est composé de 17 Régions Administratives ou RA. Chaque RA est composée de Municipalités
Régionales de Comté ou MRC exceptions faites des Communautés Urbaines de Québec et de Montréal et de
l’Outaouais. Les MRC sont elles-mêmes constituées de municipalités. Il y a environ 1500 municipalités au
Québec. Ce nombre est en constante variation car plusieurs fusions ont été réalisées ces dernières années.
Figure 7. Carte des MRC et zoom sur les municipalités
b) Le découpage spatial dans le monde de la santé
La province de Québec est divisée en 18 Régions SocioSanitaires ou RSS. Chaque RSS est divisée en
plusieurs Centres Locaux de Services Communautaires ou CLSC. En général, chaque CLSC possède un
établissement où sont recueillies les données mais un établissement peut parfois couvrir deux CLSC ou, en
zone urbaine, un CLSC peut voir un établissement principal et des établissements secondaires appelés points
de service. Au moment du projet, il y avait 170 CLSC dans toute la province mais seuls 156 étaient à l’étude.

18
Figure 8. Carte des RSS et zoom sur les CLSC
2) Analyse des données du CSPQ
Les données mises à notre disposition par le CSPQ étaient celles qui avaient permis récemment de compléter
un atlas du cancer sur le territoire de la province de Québec. Celles-ci possédaient le format de MapInfo
(*.tab, *.dat, *.map, *.id), logiciel de SIG utilisé actuellement par le CSPQ.
Les fichiers *.tab décrivent la structure de la table, les *.dat contiennent les données tabulaires, les *.map
contiennent tous les objets graphiques, alors que les fichiers *.id assurent le lien entre les données
descriptives et les objets graphiques. Nous avions aussi des *.dbf qui contenaient des données tabulaires et
qui avaient été générés automatiquement par un logiciel du CSPQ.
Il est reconnu que l’analyse des données est une étape indispensable au développement d’un bon prototype.
Des données qui sont mal analysées peuvent entraîner une perte de temps considérable lors des étapes
suivantes. Il vaut donc mieux passer un peu plus de temps à « éplucher » les données et ne pas omettre d’en
traiter une partie.
Les données du CSPQ peuvent se diviser en trois grands groupes.
➪ Une première partie des données portait sur les divisions administratives en santé environnementale et
référait donc à des objets graphiques.

19
➪ Une seconde partie était une série de « workspaces » (*.wor). On peut définir un workspace comme un
espace de travail. Quand on sauve un workspace sous MapInfo, on fige le travail effectué. Le grand défaut de
MapInfo est qu’il est impossible de sauvegarder des cartes thématiques sous un nom particulier. Marie-
France Gagnon et Germain Lebel ont donc sauvé chaque carte thématique sous un workspace différent afin
de ne pas avoir à refaire le même travail indéfiniment. Ces cartes nous montrent ce que recherche le CSPQ
comme document final. Cependant, les fichiers *.wor ne nous seront d’aucune utilité pour la suite du projet.
➪ Une troisième partie concerne les données du cancer. Ce sont des fichiers MapInfo eux aussi mais ils ne
sont reliés à aucun objet graphique. Ils contiennent tous à peu près les mêmes informations. Une liste
complète de toutes les abréviations utilisées dans ces tableaux est disponible en annexe 1. Les données ont
été divisées en trois catégories : celles qui concernent les enfants, celles qui se rapportent aux femmes et
celles relatives aux hommes. Chaque cancer correspond à un tableau différent.
L’analyse d’un de ces tableaux (figure 9) permettra une meilleure compréhension de ce qu’il contient.
Figure 9. Exemple de tableau de données sur le cancer
Dans la colonne clsc_e se trouvent les numéros qui identifient les différents CLSC. Par exemple, 02101
correspond au CLSC « Fjord » qui se situe dans la RSS Saguenay-Lac-Saint-Jean. La colonne Topo_e
renvoie à un certain type de cancer. Ici, le numéro 157 correspond au cancer du pancréas. N_fem indique le
nombre de femmes touchées par la maladie. Tx_fem correspond au taux de cancer. Rts_157 donne le rapport
de taux standardisé du cancer du pancréas. P_fem renvoie à la valeur statistique qui va conclure sur le fait
que cette valeur est significative ou non. Ici, nous regardons un tableau où toutes les données sont
significatives car il commence par 01. Un autre tableau rassemblant des données sur le cancer du pancréas
chez les femmes portera le nom de If 99157 car il portera sur des données non significatives. Cette distinction
a été effectuée par le CSPQ pour faciliter la réalisation des cartes thématiques. C_v_fem correspond au
coefficient de variation.
Tous ces chiffres peuvent paraître difficiles à comprendre pour une personne qui ne fait pas partie du
domaine de la santé environnementale, mais il n’était pas indispensable d’en connaître la signification
exacte : il suffisait de savoir quelles données étaient les plus importantes à intégrer dans le système pour les
futurs utilisateurs. Par soucis de précision, nous préférons indiquer que l’annexe 2 présente les modus
operandi pour ces paramètres.

20
3) Problème de la confrontation des données
Pour créer un prototype, il est nécessaire de confronter un bon nombre de données. Il aurait été possible bien
sûr de ne garder que les données du CSPQ mais l’envergure du projet est différente. Il s’agit de prouver que
l’on peut intégrer des données provenant de découpages spatiaux hétérogènes comme les limites
administratives, les bassins versants,… Compte tenu de l’espace-temps, nous avons dû abandonner le fait
d’intégrer dans notre prototype les bassins versants car le temps d’obtention des données était trop long.
Cependant, ils seront certainement incorporés dans le SIRS final car ils représentent un bon moyen de
confronter des données de la santé avec d’autres de l’environnement. C’est souvent dans un même bassin
versant que vont se regrouper des facteurs de pollution identiques, les mêmes facteurs météorologiques. Il est
donc vraiment dommage que nous n’ayons pas pu concrétiser cette proposition. Par contre, l’idée
d’introduire des données de découpages administratifs a été retenue.
Les limites des RA sont très semblables à celles des RSS, elles diffèrent surtout dans le Grand Nord. Les
MRC et les CLSC se ressemblent aussi la plupart du temps mais, parfois, une municipalité fera partie d’une
MRC et pas d’un CLSC.
Figure 10. Carte des MRC Figure 11. Carte des CLSC
En regardant de plus près les figures 10 et 11, il est possible de voir quelques différences entre les
limites, surtout dans le Grand Nord.
4) Visualisation sous Brain des éléments qui constitueront l’hypercube
Pour créer le prototype, il est nécessaire de créer un hypercube avec le module Transformer du
logiciel Powerplay de la firme Cognos. C’est une étape qu’il ne faut pas négliger. C’est là qu’est
décidée la forme finale de la structure d’analyse qui pourra être réalisée sous Powerplay. Il ne

21
s’agit pas dans ce paragraphe de décrire les étapes réalisées ultérieurement avec Transformer
mais de comprendre que pour construire le cube, il est nécessaire de réfléchir aux besoins des
futurs utilisateurs, et aussi à ce que la technologie utilisée pourrait leur apporter sans qu’ils en
soient conscients.
La recherche de la structure du futur hypercube a été grandement facilitée par l’utilisation d’un
nouveau genre de logiciel interactif : « The Brain ». En effet, ce dernier peut être défini comme
un réseau sémantique, c’est-à-dire un outil permettent de gérer différents niveaux d’abstraction.
Par son biais, la création de la structure est facile et la visualisation rapide et agréable. L’arbre
représentant la hiérarchie est à la base du processus de création d’un OLAP. Il aurait été possible
de réaliser un arbre traditionnel type explorer mais la modification d’éléments est extrêmement
plus pratique avec Brain, ce logiciel est plus intuitif, plus rapide par rapport à un graphique à plat.
Il pourrait être utilisé comme outil de navigation.
Nous avons donc réalisé à l’aide de ce logiciel l’inventaire de l’existant (toutes les données mises
à notre disposition), et une autre partie représente ce qu’il restait à faire.
Les copies d’écran ci-dessous montrent sommairement le fonctionnement du logiciel.
Figure 12. The brain - présentation globale
Au centre de la figure 12, on peut voir le nom du projet, Multid perspec en éco enviro, qui a été
divisé en deux sous-ensembles : inventaires et olap. Tout ceci se trouve dans un environnement
Windows. Chaque petit rond vert situé sous un sous-ensemble signifie que ce dernier est lui-
même divisé. Tous les noms que l’on retrouve dans la bande située au bas de l’écran bleu sont
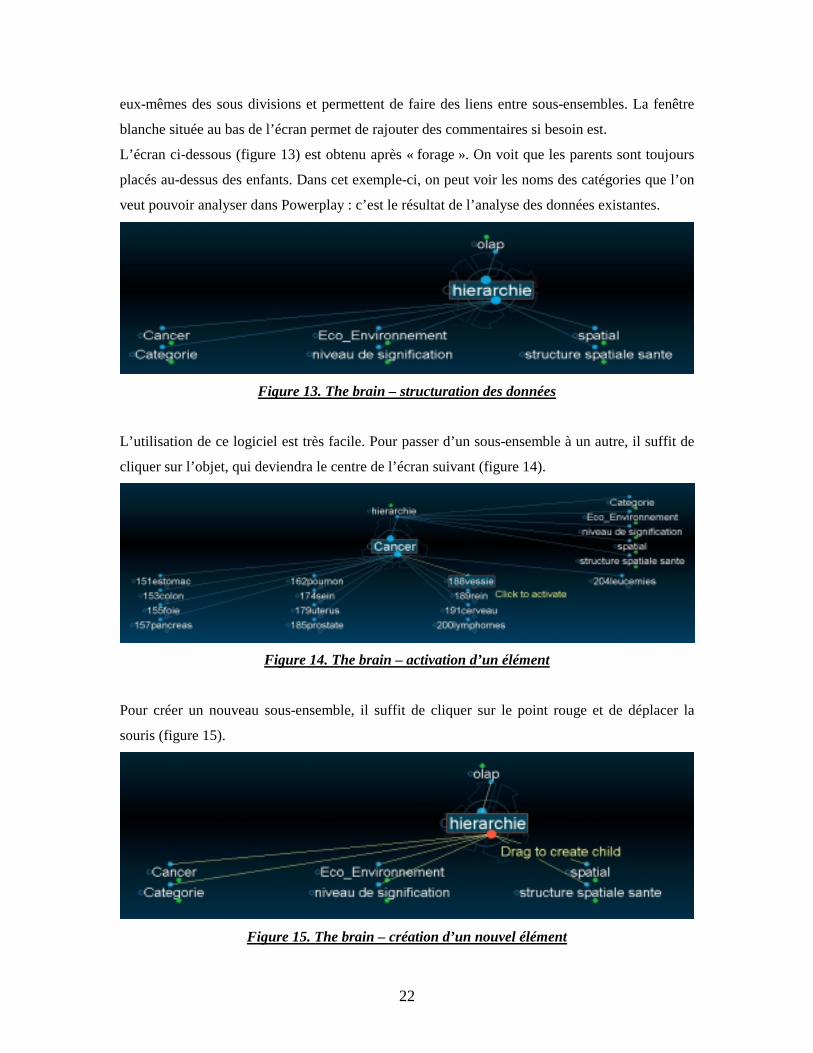
22
eux-mêmes des sous divisions et permettent de faire des liens entre sous-ensembles. La fenêtre
blanche située au bas de l’écran permet de rajouter des commentaires si besoin est.
L’écran ci-dessous (figure 13) est obtenu après « forage ». On voit que les parents sont toujours
placés au-dessus des enfants. Dans cet exemple-ci, on peut voir les noms des catégories que l’on
veut pouvoir analyser dans Powerplay : c’est le résultat de l’analyse des données existantes.
Figure 13. The brain – structuration des données
L’utilisation de ce logiciel est très facile. Pour passer d’un sous-ensemble à un autre, il suffit de
cliquer sur l’objet, qui deviendra le centre de l’écran suivant (figure 14).
Figure 14. The brain – activation d’un élément
Pour créer un nouveau sous-ensemble, il suffit de cliquer sur le point rouge et de déplacer la
souris (figure 15).
Figure 15. The brain – création d’un nouvel élément
23
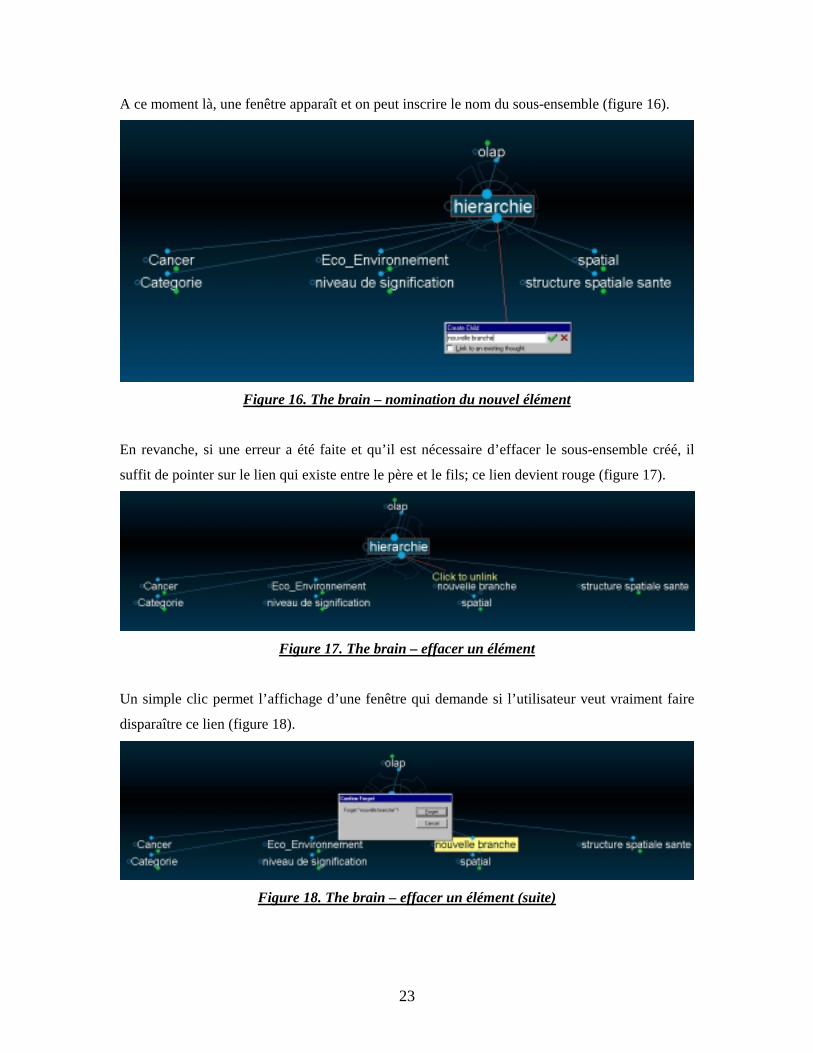
A ce moment là, une fenêtre apparaît et on peut inscrire le nom du sous-ensemble (figure 16).
Figure 16. The brain – nomination du nouvel élément
En revanche, si une erreur a été faite et qu’il est nécessaire d’effacer le sous-ensemble créé, il
suffit de pointer sur le lien qui existe entre le père et le fils; ce lien devient rouge (figure 17).
Figure 17. The brain – effacer un élément
Un simple clic permet l’affichage d’une fenêtre qui demande si l’utilisateur veut vraiment faire
disparaître ce lien (figure 18).
Figure 18. The brain – effacer un élément (suite)

24
Il est aussi possible de voir si une donnée est commune à plusieurs sous-ensembles. Quand la
donnée est rendue active, on peut regarder tous les liens qui s’opèrent avec les différentes tables
(figure 19).
Figure 19. The brain – liens entre les différents objets
Ceci constitue le principal avantage de l’utilisation d’un tel logiciel dans un OLAP. En effet, on
peut ainsi se rendre compte de la redondance de données. Le processus d’écriture de ce réseau
met en évidence des concepts ou problématiques qui ne sont pas toujours accessibles dans une
approche traditionnelle.
Ce logiciel nous a apporté un gain de temps précieux car il est possible tout de suite de montrer
des propositions à un interlocuteur (futurs utilisateurs par exemple) et les rajouts ou suppressions
d’analyses sont simples à faire en temps réel; la dynamique de développement n’est donc pas
freinée. The Brain permet de faire le lien entre un niveau de l’arbre et les données qui y sont
rattachées, il facilite la gestion d’une augmentation de volume de données et d’une implantation
complexe.
Quand le projet sur la forêt Montmorency a été réalisé, le CRG ne possédait pas encore ce logiciel
et de ce fait, cette phase a été beaucoup plus longue.
De plus, nous aimerions ajouter que quand nous avons réalisé l’inventaire de tous les fichiers dont
nous disposions, nous avons inséré un pictogramme qui permet rapidement de s’apercevoir si la

25
carte rattachée au fichier représente des éléments de types polygonal (-) ou ponctuel (!) , ceci
également afin de gagner du temps en analyse (figure 20). Cette police a été créée par Yvan
Bédard avec pour objectif de s'en servir dans les outils AGL (Ateliers de Génie Logiciel) utilisés
pour la conception des SIRS et se trouve en totalité en annexe 3 (en plus d'être téléchargeable
depuis le site web http://sirs.scg.ulaval.ca/yvanbedard).
Figure 20. The brain – Utilisation de la police d’Yvan Bédard

26
IV. TRAITEMENT DES DONNEES 1) Le changement de méthode dû aux problèmes spatio-temporels
Comme nous l’avons déjà indiqué dans la partie II.3), la méthode que nous devions utiliser n’a
pas pu être complètement mise en place.
En fait, les données primaires du CSPQ se trouvaient dans une projection quelconque, et notre
premier objectif était de les ramener dans une projection Lambert bien spécifique car c’est celle
qui correspondait le mieux à la taille du territoire. Cette projection n’étant pas disponible dans la
version 4 de MapInfo, il fallait donc passer sous GeoMedia.
On voit bien ici la facilité de passage entre les différents logiciels pour pouvoir réaliser toutes les
opérations que l’on désire. Ceci ne serait pas possible dans une entreprise qui n’achète
généralement qu’une sorte de logiciel. Nous avons, dans le cas présent, profité de l’équipement
du CRG.
La version actuelle de MapInfo que possède le CRG (4.5.2) ne permet pas de sauver les données
en format GeoMedia. Il faut donc passer par un format intermédiaire : le format d’Arcview (.shp).
C’est sous GeoMedia que se sont présentés les problèmes. La carte parraissait correcte mais les
coordonnées fournies par le logiciel ne correspondaient à aucun système choisi ou même connu.
Aucun membre du CRG ayant déjà travaillé sous GeoMedia ne trouva d’où provenait le
problème. Après avoir essayé différentes choses pendant deux semaines, nous nous sommes
résolus à demander conseil par courrier électronique au responsable d’Intergraph. N’ayant obtenu
aucune réponse, nous avons décidé de mettre les données dans le système « latitude/longitude »
qui existe sous Mapinfo et de les garder telles quelles. Nous les avons fait apparaître dans le
même plan que les données des MRC et des municipalités que le CRG possédaient. Là, nous nous
sommes aperçus, Pierre Marchand et moi que nous ne pourrions pas nous servir de la fonction
OVERLAY d’Arcinfo car la digitalisation était trop différente entre les municipalités et les CLSC
et qu’il n’y avait donc pas équivalence des limites.
La fonction OVERLAY permet de mettre tous les éléments sur une même couche (ou niveau) et
engendre de la même façon une table unique pour cette couche : on parle d’héritage spatial. Cette
table nous est indispensable pour créer l’hypercube sous Transformer (module du logiciel OLAP
Powerplay). Cependant, quand il y a des différences de cet ordre (figure 21) :

27
Figure 21. Différence de digitalisation entre les CLSC et les municipalités
la pointe qui provient sûrement d’une erreur de digitalisation va engendrer un nouveau polygone
triangulaire qui contiendra des informations, alors que dans notre projet il ne représente rien. Ceci
découle aussi du fait que les données proviennent de sources différentes et ne datent certainement
pas de la même année. Ces problèmes spatio-temporels nous ont donc forcés à changer de
méthode. Il a été décidé de créer la table sous Access de manière manuelle : l’héritage spatial a
été généré à la main.
2) Création de la table Access
Nous pensions au début pouvoir réaliser cette table sous Excel, mais nous nous sommes vite
rendu compte que cela était impossible. En effet, pendant un jour et demi, nous avons voulu
réaliser notre table en faisant des copier/coller des données du CSPQ pour les rajouter dans une
table qui contenait les découpages administratifs, et ce en traitant tous les cancers un à un et en
les associant avec chaque région concernée.
Nous avons été confrontés à un premier problème : notre découpage était administratif, c’est-à-
dire qu’il suivait la hiérarchie municipalité-MRC-RA alors que nos données faisaient référence à
des CLSC, donc au découpage de la santé. Nous avons donc contacté Marie–France Gagnon qui
nous a fourni quelques temps plus tard une table *.xls de ces concordances de découpages
spatiaux. Cependant, cette table ne tenait pas compte des fusions de municipalités qui se sont
opérées depuis 1990. Étant donné qu’il était quand même plus simple d’utiliser cette table que de
refaire tout le travail manuellement en regardant des fichiers MapInfo et en pointant chaque
municipalité (il y en a plus de 1500!) pour lui faire correspondre le bon CLSC, nous avons décidé
de nous servir de cette table.
En reportant les données sur le cancer, nous nous sommes vite rendu compte que cette méthode
était bien trop longue. Nous avons donc demandé conseil à Suzie qui nous recommanda de passer
sous Access. Nous ne nous étions jamais servis du logiciel Access pendant toute notre scolarité et
CLSC 1 Mun 1
CLSC 2 Mun 2

28
nous ne savions pas quelles étaient les possibilités d’un SGBD. Yvan Bédard nous proposa de
réaliser un TP qu’il donne à ses étudiants et qui explique ce que l’on peut faire pour rentrer les
données et les gérer par la suite. Nous avons joint ce TP en annexe 4.
Étant un peu plus au courant des capacités du logiciel, nous avons commencé à travailler avec
celui-ci.
La première étape fut de rassembler toutes les données du cancer dans une même table.
Nous avons donc importé dans Access tous les fichiers *.dbf donnés par le CSPQ et nous nous
sommes rendus compte qu’il y avait plus de fichiers que dans l’extension *.tab. Ceci provenait du
fait que le CSPQ n’avait pas réalisé des cartes sur tous les types de cancers et n’avait donc pas eu
besoin de *.tab pour tous les fichiers. Certains fichiers comme celui du cancer de la prostate chez
la femme étaient générés automatiquement par le programme SAS du CSPQ. Il a donc fallu
d’abord faire un tri dans les fichiers.
Ensuite, il a fallu regarder la structure de tous les fichiers qui, hélas pour nous, différait. Pour les
tableaux des hommes et des femmes, nous avons défini la structure suivante :
noms des colonnes : TOPO_E | CLSC_E | NBRE_CANCER | TX | RTS | P | C_V,
avec évidement les mêmes caractéristiques pour les champs (caractères en majuscules, nombres
entiers,…).
Nous avons d’abord rassemblé tous les tableaux nommés 01 et 99 chacun de leur côté. Pour ne
pas perdre cette information, nous avons ensuite créé une colonne NIV_SIGNI où nous avons
encodé cette information et après réunion des deux tables, nous avons rajouté un champ SEXE.
Ainsi, les tableaux finaux pour les femmes et pour les hommes avaient une structure identique.
Nous les avons unis pour former une grande table de 8112 enregistrements, dans laquelle un
champ CAT a été rajouté pour indiquer qu’il s’agissait des données concernant les adultes, et un
autre nommé CANCER_MIXTE/UNISEXE qui permettrait par la suite de faire un certain tri
dans les cancers. À chaque union de table, nous avons utilisé le même style de requêtes SQL
(figure 22) :
Figure 22. Requête SQL d’union

29
Quand on réalise une telle requête, il est nécessaire ensuite d’en faire une autre pour créer la table
correspondant à la première requête (figure 23).
Figure 23. Requête de création de table
Pour résumer les différentes étapes, regardons le schéma suivant (figure 24) :
Figure 24. Résumé des étapes de création de la table Access
La structure de la table des enfants était très différente.
Tout d’abord, les enregistrements sont donnés par RSS et non par CLSC. De plus, les
informations sont beaucoup plus complètes vu que l’on a le taux de la province pour chaque
cancer, le nombre d’enfants dans la RSS,… et surtout, le nombre de cancers est beaucoup plus
faible : il n’y a que des données sur les cancers du cerveau et les leucémies. Le nombre

30
d’enregistrements est de ce fait beaucoup plus faible. Suivant les mêmes étapes que pour les
adultes, nous avons modifié toutes nos tables pour qu’elles aient la structure suivante :
noms des colonnes : RSS | TOPO | N_ENF | POP_ENF | TX_BR_ENF (taux brut) | TX |
TX_QC_E | RTS | VAR_ENF | Z_ENF | P_ENF | CASESP_E | C_V | NIV_SIGNI.
Ensuite, nous avons travaillé sur la table des municipalités. A partir du fichier donné par le
CSPQ, nous avons complété notre base de données en rajoutant des informations sur le statut
juridique des municipalités.
Au Québec, il existe beaucoup de statut différents :
Statut juridique Symbole
Cité C
Ville V
Municipalité de village VL
Municipalité de paroisse P
Municipalité de canton CT
Municipalité de cantons unis CU
Municipalité M
Réserve indienne R
Territoire non organisé NO
Municipalité de village cri VC
Municipalité de village nordique VN
Municipalité de village naskapi VK
Établissement amérindien EI
Terre réservée aux Cris et aux Naskapis TR
Terre de la catégorie I pour les Inuits I
Nous avons trouvé ces renseignements sur le site Web du Bureau des Statistiques du Québec
(BSQ). Cependant, depuis 1990, date du fichier du CSPQ, bon nombre de municipalités ont
fusionné et le nom de certaines municipalités a changé, si bien que l’on se retrouve avec des
municipalités du fichiers original auxquelles il est impossible de rajouter l’information voulue. En
observant les codes de municipalités, nous avons observé qu’au départ, toutes les municipalités
avaient un code se terminant par 0 ou 5. La municipalité résultant de la fusion de deux
municipalités ayant des codes qui se suivent se retrouve avec un code terminant par 2,3,7 ou 8.

31
Par exemple, Manseau (38025) et Saint-Joseph-de-Blandford (38030) ont fusionné en Manseau
(38028). Grantham (49055) et Drummonville (49060) ont fusionné en Drummonville (49057).
Pour d’autres cas, les fusions étaient plus difficiles à deviner car la fusion entre trois
municipalités est possible, et si les codes ne se suivent pas au départ, le code résultant n’a pas de
réelle logique. Nous ne pouvions nous aider que de la population de 1996 qui se trouvait sur le
site Web et ayant la population de 1991 sur notre fichier du CSPQ, nous pouvions observer la
variation de population qui devait être minime. Même avec tous ces détails, nous ne pouvions pas
trouver la fusion d’une vingtaine de municipalités. Yves van Chestein nous conseilla de prendre
contact avec le Ministère des Affaires Municipales du Gouvernement du Québec. Nous fûmes
étonnés de la rapidité de transmission des informations. En vingt-quatre heures, la quasi-totalité
des regroupements de municipalités nous fut communiquée (cf. extrait en annexe 5 ). En fait, il
aurait mieux valu que nous prenions contact tout de suite avec ce service pour une meilleure
efficacité dans notre travail. Dès lors, la modification de la table des municipalités a été très
rapide.
Plusieurs problèmes se sont posés tout de même :
➪ Bromptonville ayant changé de MRC depuis 1990, son code de municipalité est passé de
42023 à 43023. Cependant, n’ayant en notre possession aucun changement de CLSC (une
municipalité qui change de MRC pourrait dépendre d’un autre CLSC), nous avons décidé de
garder l’ancien numéro de municipalité.
➪ Deux MRC ont été créées : la Côte Nord (982) et Kativik (992). Nous avons redistribué les
municipalités dans ces nouvelles MRC.
➪ Nous n’avons pas trouvé certaines municipalités dans le nouveau fichier des municipalités du
BSQ ni dans le document de regroupement des municipalités. Ayant des données du cancer dans
les CLSC qui dépendaient de ces municipalités, nous avons décidé de toutes les garder. Nous
avons rajouté un statut juridique fictif. La liste de ces municipalités se trouve en annexe 6.
➪ Des municipalités du fichier du BSQ n’ont pas de correspondance dans le fichier du CSPQ.
N’ayant aucune donnée sur le cancer pour ces municipalités, nous avons décidé, en accord avec
Yvan Bédard, de ne pas les considérer. Ces municipalités sont nommées en annexe 7.
En effet, le but du projet n’est pas d’être parfaitement exact mais de montrer les possibilités du
logiciel.
Tout ceci nous a montré le problème des conflits spatio-temporels des données. Les données du
CSPQ sur les municipalités datent d’avant 1990, alors que les statuts juridiques disponibles sur le
Web sont très récents. Afin de conjuguer les données, il faut faire des compromis; mais un

32
problème demeure tout de même car nous nous retrouvons avec les municipalités de 1996 alors
que les données du cancer datent d’avant 1993. Si on veut étudier la situation de 1993, alors les
données sont faussées car les municipalités sont plus importantes en population qu’elles ne
l’étaient en réalité. En effet, nous avons additionné les populations des villes qui fusionnaient
pour garder le même nombre de citoyens dans la province entière. Dans un système définitif, il
faudra régler ce problème en prenant un fichier des municipalités et un fichier sur les données du
cancer datant de la même période.
Nous avons ensuite rajouté une colonne superficie dans notre table : le but était de calculer par la
suite la densité de population par municipalité pour voir si le nombre de cancers augmentait avec
des populations plus denses. Pour cela, nous nous sommes servis de Mapinfo, nous avons ouvert
le fichier des municipalités et réalisé la requête SQL suivante (figure 25) :
Figure 25. Requête SQL de calcul de superficie des municipalités
Cela nous a donné comme résultat un tableau contenant les codes de toutes les municipalités du
Québec avec leur superficie respective en km2 (figure 26).

33
Figure 26. Tableau résultat de la requête de calcul de la superficie
Ensuite il a fallu intégrer cette table dans Access et faire un joint avec la table des municipalités.
Cependant, nous avons dû rajouter des superficies fictives pour certaines municipalités car le
fichier MapInfo datant d’avant 1990, le problème des municipalités fusionnées s’est encore posé;
les codes donnés dans le tableau format MapInfo ne correspondaient pas forcément avec les
nouveaux codes rentrés quelques temps auparavant dans la table des municipalités. La liste des
municipalités aux superficies fictives se trouve en annexe 8.
L’étape suivante consistait à réunir les trois tables résultantes : celle des municipalités, celle des
adultes et celle des enfants. La table des adultes et celle des enfants ne pouvaient pas être unies
car elles ne contenaient pas le même nombre de colonnes. Il a donc fallu que nous fassions des
joints avec une colonne commune. Pour joindre les municipalités avec les adultes, nous avons
choisi la colonne des codes de municipalités en prenant pour type de joint celui qui garde toutes
les informations de la table des municipalités et qui rajoute celles de la table des adultes quand les
codes des municipalités sont égaux dans les deux tables. Ainsi, même les municipalités où aucun
type de cancer n’a été recensé figurent dans la table finale. Pour faire le joint en question, il a
suffi de faire une requête en mode «design view » (figure 27).

34
Figure 27. Requête de joint des tables des municipalités et des adultes
Dans cette requête, on précise que l’on garde tous les champs de la table des municipalités
(table.*) et on rajoute tous les champs de la table des adultes qui ne sont pas communs. Ensuite, il
faut faire obligatoirement une autre requête pour créer une table résultat comme nous l’avons vu
précédemment.
En ce qui concerne le rattachement de la table des enfants, la méthode a été différente car nous ne
voulions pas que toutes les données relatives à des RSS (donc à de grandes superficies) soient
copiées pour chaque municipalité. Il a donc fallu faire une union de table en rajoutant des champs
dans les deux tables restantes afin que les structures de celles-ci soit exactement les mêmes.
Après toutes ces étapes, une première version de la grande table Access est donc prête; il est à
présent possible de faire un hypercube.
3 ) Création de l’hypercube avec Transformer
a) Définition d’un hypercube
Afin de pouvoir naviguer facilement dans la base de données pour en retirer des informations
significatives pour l’utilisateur, il est d’abord nécessaire de structurer les données. Comme dans
un arbre généalogique, il va falloir créer des branches qui supporteront de plus petites branches,
et ainsi de suite jusqu’aux feuilles. Dans notre cas, les feuilles correspondraient aux informations
concernant les plus petits détails, alors que les branches indiqueraient les différentes dimensions,
les différents thèmes à l’étude. C’est grâce à cette capacité d’approcher les données d’une
manière multidimensionnelle que l’on parle de création de cube multidimentionnel; une autre
35
dénomination est hypercube. Ce dernier va permettre de faciliter les calculs d’agrégation des
données et par cela même les analyses complexes qui seront réalisées par l’utilisateur.
b) Création de l’hypercube
Après avoir longuement réfléchi sur les données à ma disposition et sur les besoins que pouvaient
avoir les gens du domaine de la santé, qui seront les futurs utilisateurs, nous avons tenté de
réaliser un premier hypercube avec Transformer. Des copies d’écrans seront insérées tout au long
de cette partie pour mieux faire comprendre les différentes étapes.
Le logiciel Transformer de la société Cognos nécessite l’importation d’un table unique qui doit
être de format texte, ASCII,… Dans notre cas, nous avons choisi le format .csv avec des virgules
comme séparateurs de données. Nous avons donc exporté sous Access notre table dans le format
désiré. Il faut faire attention car ce format n’est pas accessible dans toutes les versions de Access.
Normalement, une construction automatique de l’hypercube est possible. Elle a été mise au point
pour des bases de données liées à la gestion d’entreprises. En effet, il faut rappeler que le logiciel
Powerplay est très utilisé dans le monde des affaires, c’est pour ce milieu-là qu’il a été créé à
l’origine. Cependant, la fonction de création automatique du cube ne reflète jamais le résultat de
l’analyse des données complexes; il est donc nécessaire de la désactiver.
Quand l’importation est effectuée, quatre fenêtres apparaissent à l’écran comme l’indique la
figure 28.
Figure 28. Environnement de Transformer

36
✓ La fenêtre Dimension Map est celle où les dimensions et sous-dimensions du cube vont être
inscrites. Il suffit de cliquer avec le bouton droit de la souris sur la bande grise pour créer une
nouvelle dimension.
✓ Dans la fenêtre Queries, il est possible de distinguer tous les noms de champs de la table qui a
été importée. C’est en déplaçant les éléments de cette fenêtre vers Dimension Map que l’on va
pouvoir créer la ramification de chaque dimension. Ce déplacement est réalisé en faisant glisser
les éléments désirés vers la dimension choisie de la fenêtre Dimension Map.
✓ Dans la fenêtre Measures, il va falloir choisir les types de mesures utilisées pour faire les
analyses. Cette fenêtre doit contenir obligatoirement au moins un élément. Il est nécessaire que
les types de mesures soient présents dans tous les enregistrements de la table importée.
✓ La fenêtre PowerCubes contient le nom de l’hypercube une fois que toute la structure a été
mise en place et qu’on a lancé une création d’hypercube. Si la structure est modifiée, il faut
relancer la création de l’hypercube avant de passer sous Powerplay.
Dans notre cas, la réalisation de notre premier hypercube a donné, après de nombreuses petites
rectifications, le résultat suivant (figure 29) :
Figure 29. Premier hypercube réalisé
Comme on peut le distinguer sur la copie d’écran, notre cube possède de nombreuses
dimensions :
➨ SPATIAL_ADM : contient le découpage spatial administratif RA - MRC - Municipalités
➨ SPATIAL_SANTE : contient le découpage spatial du domaine de la santé RSS – CLSC

37
➨ ENVIRONNEMENT : donne un critère « Urbain », « Semi-urbain » ou « Rural » à toutes les
municipalités. Ce critère a été choisi avec Yvan Bédard en tenant compte des statuts juridiques
des municipalités. Ainsi, nous avons choisi d’organiser un découpage en tenant compte des
catégories suivantes :
➙ Urbain : cité, ville
➙ Semi-urbain : municipalité de village, municipalité
➙ Rural : municipalité de canton, municipalité de cantons unis, municipalité de paroisse,
réserve indienne, territoire non organisé, municipalité de village cri, municipalité de
village nordique, municipalité de village naskapi, établissement amérindien, terre
réservée aux Cris et aus Naskapis, Terre de la catégoie I pour les Inuits.
➨ AUTOCHTONE / NON AUTOCHTONE : de même que précédemment, nous avons choisi de
faire des catégories en regardant les statuts juridiques. Il en est ressorti les résultats suivant :
➙ Non autochtone : cité, ville, municipalité de village, municipalité, municipalité de
canton, municipalité de cantons unis, municipalité de paroisse, territoire non organisé
➙ Autochtone : , réserve indienne, municipalité de village cri, municipalité de village
nordique, municipalité de village naskapi, établissement amérindien, terre réservée aux
Cris et aus Naskapis, Terre de la catégoie I pour les Inuits.
➨ SEXE : distinction homme / femme
➨ AGE : distinction adulte / enfant
➨ CANCERS : contient toutes les sortes de cancers présents dans les données. Pour que les
données soient plus faciles à lire dans Powerplay, nous avons regroupé les cancers par classes en
nous aidant de tableaux pages 6 et 7 de l’atlas des cancers, ce qui a nécessité la création d’un
nouveau champ dans la table Access.
Remarque : La création de ces classes est indispensable car s’il y a plus de dix données
différentes sur un des axes (dimensions), celles-ci deviennent difficiles à étudier. De plus, après
des études en psychologie, il a été prouvé que l’homme ne pouvait prendre en compte que sept
éléments (±2); après ce chiffre, le cerveau n’est plus capable de tout gérer. Cette remarque est à
prendre au sérieux et à utiliser dans l’architecture de notre cube.
➨ NIVEAU SIGNIFICATION : permet de voir si les données sont significatives ou non
(tableaux en 01 ou 99), c’est-à-dire si la probabilité calculée est inférieure ou supérieure à 0,01.
Nous renvoyons à l’annexe 2 pour remémorer la méthode de calcul.
➨ TAUX : toutes les données concernant les taux ont été regroupées en classes délimitées
arbitrairement pour les mêmes raisons que les cancers. Si nous n’avions pas réalisé cette
opération, 77000 nombres différents auraient dû s’afficher dans Powerplay, ce qui est largement

38
au-dessus des limites de gestion du logiciel. Même en établissant ces classes, le nombre de
données différentes est trop important.
➨ RTS : idem que pour les taux.
➨ P : idem que pour les taux.
➨ C_V : idem que pour les taux.
➨ CANCER MIXTE / UNISEXE : à part tous les cancers des organes génitaux, les cancers sont
considérés comme mixtes car ils affectent aussi bien les hommes que les femmes. Cette
dimension peut servir à agréger encore un peu plus les données.
➨ POP_E : cette dimension ne porte que sur les données concernant les enfants; là aussi nous
avons créé des classes de données.
➨ TX_BR_E : idem que pour POP_E.
➨ TX_QC_E : idem que pour POP_E.
➨ DENSITE POP : contient les données de densité de population au kilomètre carré pour chaque
municipalité. Des classes permettent aussi une meilleure lecture des données.
➨ YVAN : cette dimension nous a été demandée par Yvan Bédard pour montrer jusqu’à quel
point il est possible d’agréger les données. Elle représente à elle seule un mini-arbre. Chaque
sous-catégorie ou branche représente un filtre de recherche, ce qui permet d’afficher sous
Powerplay d’une façon détournée plus de dimensions que le logiciel ne peut en gérer. Ainsi, on
peut faire les recherches suivantes (figure 30) :

39
Figure 30. Structure de la dimension « Yvan »
➨ Des noms de dimensions reviennent précédés du signe #. Cela signifie que dans ces
dimensions, les nombres sont remplacés par des lettres. Par exemple, 162 dans la dimension
CANCERS sera remplacé par « poumon » dans la dimension #CANCERS. Cela permet ainsi aux
utilisateurs non familiers des codes utilisés quotidiennement par les gens de la santé de pouvoir
également faire des recherches dans le système.
Dans la fenêtre measures, nous avons choisi plusieurs données différentes : la population en 1991
et le nombre de cancers. Les taux, RTS et P ont été rajoutés après une demande de Germain Lebel
car ce sont des données qui sont très importantes pour les gens de la santé.
C’est ce cube, ainsi structuré, qui a été présenté à Germain Lebel et Marie France Gagnon.
40
4) Passage sous Powerplay
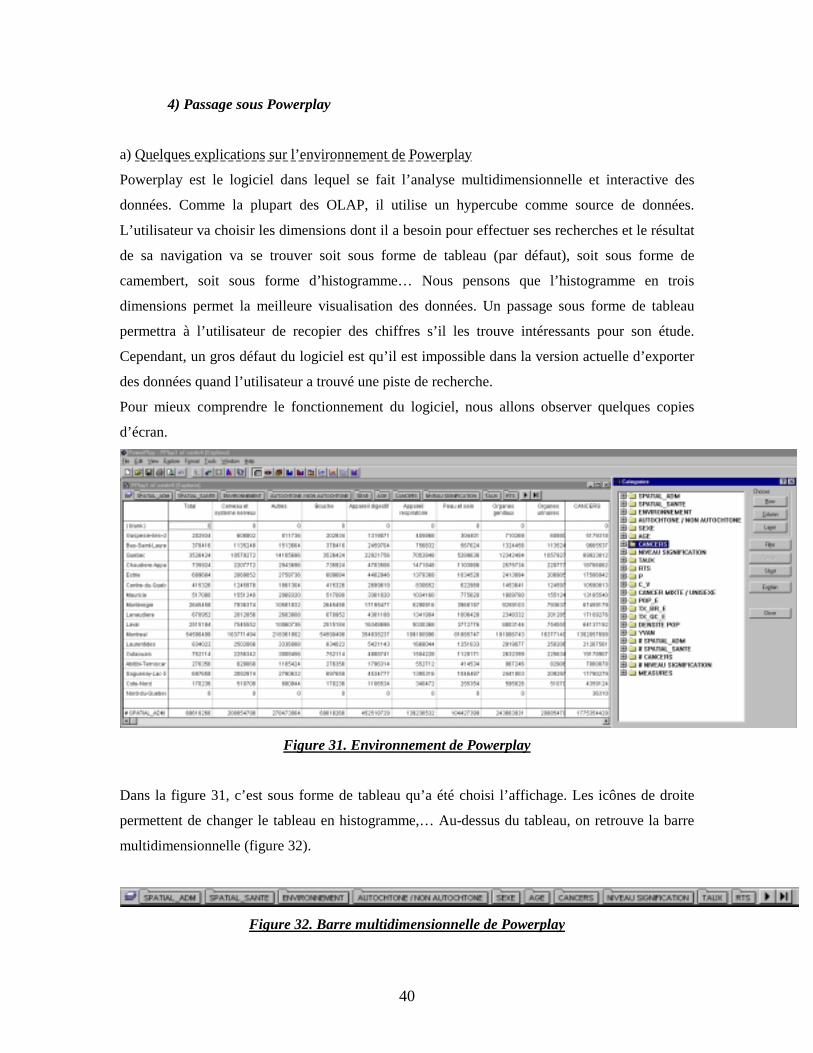
a) Quelques explications sur l’environnement de Powerplay
Powerplay est le logiciel dans lequel se fait l’analyse multidimensionnelle et interactive des
données. Comme la plupart des OLAP, il utilise un hypercube comme source de données.
L’utilisateur va choisir les dimensions dont il a besoin pour effectuer ses recherches et le résultat
de sa navigation va se trouver soit sous forme de tableau (par défaut), soit sous forme de
camembert, soit sous forme d’histogramme… Nous pensons que l’histogramme en trois
dimensions permet la meilleure visualisation des données. Un passage sous forme de tableau
permettra à l’utilisateur de recopier des chiffres s’il les trouve intéressants pour son étude.
Cependant, un gros défaut du logiciel est qu’il est impossible dans la version actuelle d’exporter
des données quand l’utilisateur a trouvé une piste de recherche.
Pour mieux comprendre le fonctionnement du logiciel, nous allons observer quelques copies
d’écran.
Figure 31. Environnement de Powerplay
Dans la figure 31, c’est sous forme de tableau qu’a été choisi l’affichage. Les icônes de droite
permettent de changer le tableau en histogramme,… Au-dessus du tableau, on retrouve la barre
multidimensionnelle (figure 32).
Figure 32. Barre multidimensionnelle de Powerplay

41
Toutes les dimensions de l’hypercube se retrouvent dans cette barre. La classe « measures » se
situe à la fin de celle-ci .
Dans la partie de droite, la fenêtre « Categories » (figure 33) regroupe toute la structure mise en
place avec Transformer. C’est là que l’utilisateur choisit les dimensions qu’il veut voir apparaître
à l’écran. Quatre dimensions peuvent être affichées en même temps :
➨ une en ligne (row) : cette dimension ressemblerait à X dans un espace mathématique classique
composé de trois axes;
➨ une en colonne (column) : cela correspondrait au Y;
➨ une en couche (layer) : c’est le type de mesure choisi (par exemple le nombre de cancers),
donc la quantité de cas qui correspondent aux deux critères choisis auparavant en X et Y. Cela
s’apparente donc à Z dans notre vision classique du système à trois axes;
➨ une en filtre (filter) : il est préférable que cette dimension soit subdivisée en classes. Ainsi
n’apparaîtront à l’écran que les données de la classe en question qui correspondent aux trois
critères précédents. Il s’agit d’appliquer une sorte de filtre à nos données.
Figure 33. Fenêtre Categories de Powerplay
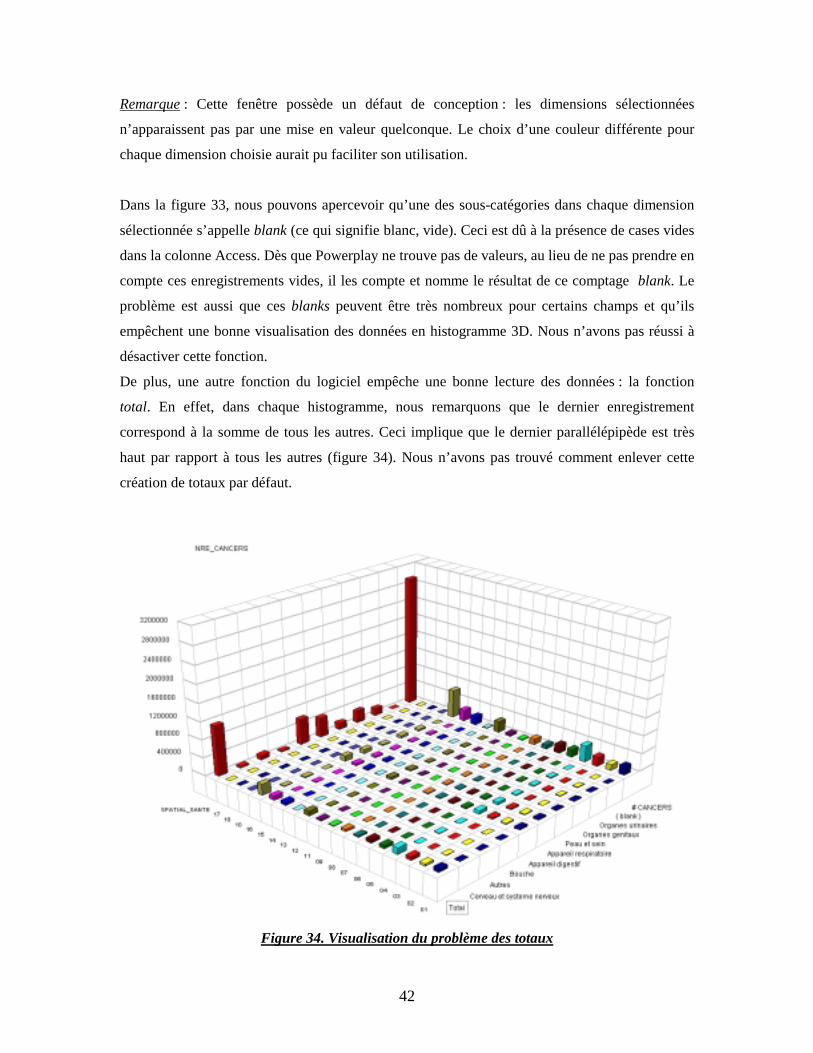
42
Remarque : Cette fenêtre possède un défaut de conception : les dimensions sélectionnées
n’apparaissent pas par une mise en valeur quelconque. Le choix d’une couleur différente pour
chaque dimension choisie aurait pu faciliter son utilisation.
Dans la figure 33, nous pouvons apercevoir qu’une des sous-catégories dans chaque dimension
sélectionnée s’appelle blank (ce qui signifie blanc, vide). Ceci est dû à la présence de cases vides
dans la colonne Access. Dès que Powerplay ne trouve pas de valeurs, au lieu de ne pas prendre en
compte ces enregistrements vides, il les compte et nomme le résultat de ce comptage blank. Le
problème est aussi que ces blanks peuvent être très nombreux pour certains champs et qu’ils
empêchent une bonne visualisation des données en histogramme 3D. Nous n’avons pas réussi à
désactiver cette fonction.
De plus, une autre fonction du logiciel empêche une bonne lecture des données : la fonction
total. En effet, dans chaque histogramme, nous remarquons que le dernier enregistrement
correspond à la somme de tous les autres. Ceci implique que le dernier parallélépipède est très
haut par rapport à tous les autres (figure 34). Nous n’avons pas trouvé comment enlever cette
création de totaux par défaut.
Figure 34. Visualisation du problème des totaux

43
Par exemple, sur la figure 34, un regard rapide nous attire vers les enregistrements du fond. A
gauche, ils correspondent aux totaux des cas de cancers dans les différentes RSS, et à droite aux
totaux de tous les types de cancers. Le polygone du fond représente la somme de tous ces totaux,
ce qui aggrave un peu plus la visualisation des données. L’échelle est mal choisie pour connaître
le nombre de cas de cancers dans un cas bien particulier. Si une désactivation de l’option était
possible, le nombre de cancers serait au maximum de 400000, ce qui faciliterait les observations.
Cette fonction fausse donc un peu la vision de l’utilisateur.
Pour naviguer dans les données, il y a deux possibilités : le pivot et le forage.
Le pivot (swap) permet d’échanger les lignes et les colonnes. Cette fonction n’est utile que si
l’utilisateur veut voir les données sous un autre angle.
Le drill (pas de traduction française), quant à lui, est beaucoup plus intéressant. Plusieurs types
sont possibles ;
- le drill down (ou forage)
- le drill up
Ces deux fonctions ont déjà été expliquées au II. 3) b).
- le drill across permet de changer complètement de catégorie à l’étude.
b) Exploration de notre hypercube
L’étape suivante a donc été l’importation de notre hypercube et la création d’un projet Powerplay
*.mdc. Ceci se fait rapidement. Il ne reste plus qu’à observer tous les petits défauts qui se
présentent lors de la navigation et à réparer les erreurs soit sous Access, soit sous Transformer. Ce
projet a nécessité plusieurs itérations avant d’arriver à un projet présentable à Germain Lebel et
Marie-France Gagnon. Les modifications ont déjà été décrites plus tôt dans le rapport.

44
V. MODIFICATION DES DONNEES ET AFFINEMENT DU PROJET
Lors d’une présentation de l’hypercube aux personnes responsables du projet au sein du CSPQ,
plusieurs remarques sont survenues, ce qui a mené à la modification du projet.
➪ La dimension SPATIAL_ADM ne présente aucune utilité pour les gens de la santé, surtout
lorsque les données fournies font référence aux CLSC, donc à une autre sorte de découpage
spatial. Ce point était évident mais le but du projet était de pouvoir intégrer d’autres sortes de
données. La solution trouvée serait de se servir d’autres sources de données des cancers, celles-ci
renvoyant aux codes postaux (il y a un à plusieurs codes postaux par municipalité). Un exemple
de données ainsi référencées se trouve en annexe 9. Ces données ne nous ont pas été
communiquées au départ mais après la présentation de l’hypercube. Il est certain qu’il aurait
mieux valu réaliser le prototype avec ces données car elles ont plus complètes (âge exact des
malades indiqué, critère de riveraineté, information sur l’eau potable disponible,…). Cependant,
lorsque les données nous ont été fournies en janvier, il avait paru plus simple à Germain et Marie-
France de nous transmettre des données déjà traitées par un de leurs programmes (SAS). Ceci est
une erreur qui pourrait être éliminée lors d’un autre prototype.
➪ En ce qui concerne la dimension ENVIRONNEMENT, l’idée a été trouvée excellente mais il
faudrait suivre une norme bien particulière pour décider de l’attribution du type urbain, semi-
urbain ou rural pour chaque statut juridique.
➪ Une séparation ENFANT/ADULTE est préférable car les données ne réfèrent pas au même
secteur spatial. Ceci a été réalisé pour la deuxième itération qui comprend donc deux hypercubes
très simplifiés.
➪ Les classes pour les RTS, P , CV ont été changées afin de correspondre à des normes du
CSPQ.
➪ Le calcul de densité de population n’est pas très utile car il réfère aux municipalités. Le
problème cité auparavant se pose à nouveau dans la mesure où les données font référence aux
CLSC. Il n’est pas évident de trouver des relations entre ces deux dimensions. Ceci pourra
cependant être utilisé lors de la création d’un prototype basé sur les codes postaux.
➪ Germain Lebel voulait voir à l’écran le nombre de cas de cancers par CLSC, par type de
cancers, suivant des classes de RTS précises et savoir si les données était significatives. Ceci
totalise cinq dimensions à l’affichage. Or, Powerplay n’est capable d’en gérer que quatre. Il a
donc fallu filtrer les données sous Transformer. En réalisant la structure des données du cancer,
nous avons rajouté au départ la sous-catégorie NIV_SIGNIFICATION qui a joué le rôle de filtre.

45
Un autre filtre a été réalisé avec le sexe des adultes. Ces changements ont été effectués à la
deuxième itération (figure 35).
Figure 35. Structure de l’hypercube ADULTE (seconde itération) sous Powerplay
➪ Nous avons décidé d’éliminer les catégories doublées par le signe # et de ne garder que les
informations comportant des noms plutôt que des chiffres. Cette décision a été prise en
remarquant que les personnes de la santé n’utilisent pas leurs propres codes quand il s’agit de
parler de RSS ou de CLSC.
➪ Une énorme erreur de compréhension des données a été réalisée dans le premier hypercube : il
ne faut pas comparer des nombres de cancers entre eux, mais des RTS ou des taux qui sont, eux,

46
fonction de la densité de population dans une zone administrative. Il aurait donc fallu que ce soit
les RTS ou les taux qui se trouvent en measures, mais le logiciel Powerplay ne s’y prête pas. En
effet, quand un type de mesure est mise en place, le logiciel additionne des valeurs. Dans
l’exemple du nombre des cancers, faire la somme est correct mais il n’est pas possible
d’additionner des taux car cette somme ne représente rien. Une seule solution peut pallier ce
problème : mettre les RTS en couches (layer). Ainsi, nous aurons un nombre de cancers relatif à
une classe de RTS particulière. Après consultation de Germain et Marie-France, nous avons gardé
les taux en measures, mais nous déconseillons leur utilisation car la manipulation des données
n’est pas pratique avec ce système de sommes.
Après affinement du projet, nous sommes donc arrivés à la création des deux hypercubes de la
figure 36 qui montre les grands changements produits depuis le premier hypercube.
Figure 36. Hypercubes des adultes (à gauche) et des enfants (à droite)

47
VI. VOLET CARTOGRAPHIQUE
Il serait très avantageux de pouvoir visualiser simultanément des données sous forme
d’histogrammes ou de cartes. Cependant, avec la technologie actuelle, il est impossible d’associer
des cartes à un hypercube. Ceci correspond au travail que doit réaliser Pierre Marchand et d'autres
étudiants gradués pendant leur doctorat. Ne pouvant pas créer de cartes automatiquement, nous
avons décidé d’en produire quelques-unes manuellement. Le but n’était pas de réaliser toutes les
cartes correspondant à chaque niveau d’agrégation du cube, mais de montrer quelques exemples
représentatifs.
1) Le choix du logiciel
Ayant déjà un peu travaillé avec MapInfo et GeoMedia, nous avons décidé de réaliser les cartes
avec ArcView pour connaître un peu son fonctionnement. De plus, les cartes produites sous
ArcView ont une bonne qualité visuelle, ce qui était un avantage dans ce cas-là.
Pour associer les données concernant les cancers avec les éléments graphiques, il a fallu importer
les données descriptives du cancer et les données géométriques des CLSC. Ensuite, il a été
nécessaire de faire apparaître à l’écran la table Attributes of CLSC qui regroupe toutes les
données géométriques sous forme de tableau. Deux possibilités s’offraient à nous : faire un lien
ou un joint entre ces deux tables. Dans ArcView, le lien sert plutôt à l’affichage des données alors
que le joint permet de créer des cartes thématiques. Nous avons donc opté pour le joint.
Cependant, le problème que nous avons rencontré réside dans le fait qu’un seul type de cancers
était rattaché à un CLSC : le premier rencontré dans la table. Tous les autres n’étaient pas pris en
compte par le logiciel. Donc, il était impossible de réaliser des cartes avec une thématique
précise. Ce problème semblant pouvoir se régler avec MapInfo, nous avons changé de logiciel.
Il est possible d’importer directement des tables Access sous MapInfo via le traducteur ODBC.
Cependant, la table de 76000 enregistrements semblait trop grosse et il fut impossible de réaliser
l’importation. Ne voulant pas utiliser Oracle pour gérer la base de données (par manque de temps
pour se familiariser avec le logiciel), nous avons choisi de faire nos cartes avec GeoMedia Pro.
GeoMedia, de la compagnie Intergraph, est un logiciel de SIG assez récent − la première version
a été lancée sur le marché en automne 1997. La version professionnelle GeoMedia Pro 2.0 que
nous avons utilisée est disponible depuis août 1998. Elle permet la saisie et la mise à jour des
données. Le plus gros avantage du logiciel est l’interopérabilité en mode natif (c’est-à-dire en
lecture sur les différents postes source de données). L’interopérabilité peut être définie comme

48
« la qualité permettant à l’usager d’obtenir et de traiter des données spatiales de façon fluide en
faisant appel à des bases de données hétérogènes traitées de façon répartie sur des systèmes
différents » (Bédard, 1997).
Ayant abordé mes divers problèmes cartographiques avec Pierre Marchand, ce dernier me
conseilla de suivre la méthode qu’il avait utilisée avec Cécile Rebout pour la forêt Montmorency.
Tout d’abord, nous avons voulu importer un projet GeoMedia dans Access. Pour cela, il a suffi de
créer un nouveau « warehouse » (entrepôt de données) avec une connexion Access et une
connexion ArcView. Ensuite, il a fallu importer les données ArcView (CLSC et RSS) pour les
transformer en format Access. Après conversion du projet sous Access, plusieurs tables ont été
créées automatiquement : AttributeProperties, FieldLookup, GaliasTable, GcoordSystem,
GeometryProperties, Gfeatures, GSQLOperatorTable, ModificationLog, ModifiedTables. Elles
contenaient, entre autres, les données géométriques du projet. L’étape suivante consistait en une
importation des données sur les cancers puis un joint entre les tables CLSC et adulte. Le résultat
de ce joint a dû être recopié dans la table CLSC afin que l’opération soit concluante (nous ne
connaissons pas la raison de ce copier/coller). Cependant, en repassant dans GeoMedia, le
problème survenu dans ArcView s’est posé à nouveau : à l’affichage, un seul type de cancers était
attribué à l’unité territoriale. Ceci venait du fait que notre table avait été construite pour la
création d’un hypercube et ne convenait pas à la création de cartes. Ce problème ne s’était pas
posé pour le projet de la forêt Montmorency, car la table avait été générée automatiquement après
la fonction Overlay sous ArcInfo (cf. figure 17) et aussi parce que pour chaque unité territoriale,
seule une variété de peuplement avait été recensée.
Nous avons donc dû procéder autrement. Après observation dans Powerplay d’une piste de
recherche intéressante, les données des tableaux de Powerplay ont été recopiées directement dans
des colonnes créées dans la table CLSC ou RSS de GeoMedia. Ensuite, la fonction Add Thematic
du menu Legend nous a permis de créer plusieurs cartes thématiques.
2) Les cartes thématiques
Plusieurs cartes ont été réalisées et chacune représente un niveau d’agrégation de l’hypercube.
Toutes concernent le cancer du poumon puisqu’il demeure le cancer le plus fréquent dans la
province de Québec et qu’il touche aussi bien les hommes que les femmes.
➪ Les deux premières représentent toutes les RSS de la province de Québec, ce qui revient à dire
la plus grande unité spatiale de notre cube. L’une concerne les hommes et l’autre les femmes. Le
nombre de cas de cancers a été choisi comme type de mesure car c’est le seul qui soit utilisable

49
pour cette unité spatiale. En effet, les RTS ont été calculés par CLSC et non pas RSS. Ces deux
cartes sont présentes dans les annexes 10 a et 10 b. En observant ces cartes, grâce au système de
graduation de couleur, il est très facile de voir que c’est la RSS de la Montérégie, au sud du
Québec , qui possède le plus grand nombre de cas de cancer du poumon. De plus, on peut
remarquer que beaucoup plus d’hommes sont touchés dans cette région. Nous avons donc décidé
de « zoomer » sur cette région pour réaliser les cartes suivantes. Les données des CLSC
frontaliers ont été rajoutées afin de mettre encore plus en évidence les données de la Montérégie
par rapport aux CLSC voisins.
➪ Une carte a été réalisée sur cette région et concerne le nombre de cas de cancer de femme par
CLSC. Ainsi, le positionnement de la maladie est plus précis. Le système de graduation de
couleur a été utilisé comme précédemment (cf. annexe 10 c).
Cette carte met en évidence le fait que les CLSC où il y a le plus de cancers sont situés à la
frontière américaine. C’est dans cette région que jusqu’à il y a quelques années, les Américains
venaient déposer leurs ordures. Ces faits ne correspondent peut-être qu’à une coïncidence, il est
impossible de conclure aussi vite, mais cela peut devenir une piste de recherche intéressante pour
de futures études qui démontreront les causes des cancers.
➪ La carte de l’annexe 10 d se rapporte aux données sur les hommes, mais cette fois-ci, c’est une
comparaison de RTS qui figure sur la carte, toujours avec une graduation de couleur. Ceci
correspond à l’attente des gens du domaine de la santé.
Pour les cartes suivantes, nous avons fait le choix arbitraire de nous pencher sur le cas des
hommes dans cette RSS.
➪ Des cartes permet de voir quelles sont les CLSC qui ont des valeurs significatives (cf. annexe
10 e) ou non (cf. annexe 10 f) - selon la définition de l’atlas des cancers . Cette fois ci, le code
des couleurs est encore utilisé mais d’une manière différente, une couleur représentant une sorte
de valeurs : bleu = non significatif, rouge = significatif. Dans la région étudiée, les CLSC avec
des valeurs non significatives prédominent largement.
➪ Une combinaison des deux cartes précédentes nous semblait intéressante car elle aurait permis,
en plus de voir si les données étaient significatives ou non, de savoir dans quelle classe de RTS se
rangeait le CLSC. Cela a donné jour à la carte de l’annexe 10 g qui utilise donc en même temps
la différence de couleurs et une graduation de celles-ci pour coder les informations.

50
3) Les principes de la sémiologie graphique
Cette partie a été réalisé à l’aide du cours de fondements des SIG d’Yvan Bédard et du rapport de
Josée Dubé cités en référence.
a) En théorie
Pour traduire l’information sur une carte, cinq types de variables visuelles peuvent être utilisés :
la taille, la valeur, la couleur, l’orientation et la forme. Comme il est possible de le voir sur la
figure 37, ces variables permettent de traduire des phénomènes ponctuels, linéaires ou
surfaciques.
Figure 37. Les variables visuelles( cf. Rapport de Josée Dubé)
Pour représenter nos données, il existe quatre types d’échelles de mesure : nominale, ordinale,
intervalle ou ratio (cf. figure 38).
Échelle nominale Les valeurs sont des noms dont l'ordre n'a pas d'incidence sur la valeur de la propriété.
ex.: Utilisation du sol résidentielle commerciale industrielle agricole
Échelle ordinale Les valeurs sont des noms classés selon un ordre rigoureux, correspondant à une progression dans la valeur prise par la propriété.
ex.: Classification des sols agricoles pauvre moyen bon riche
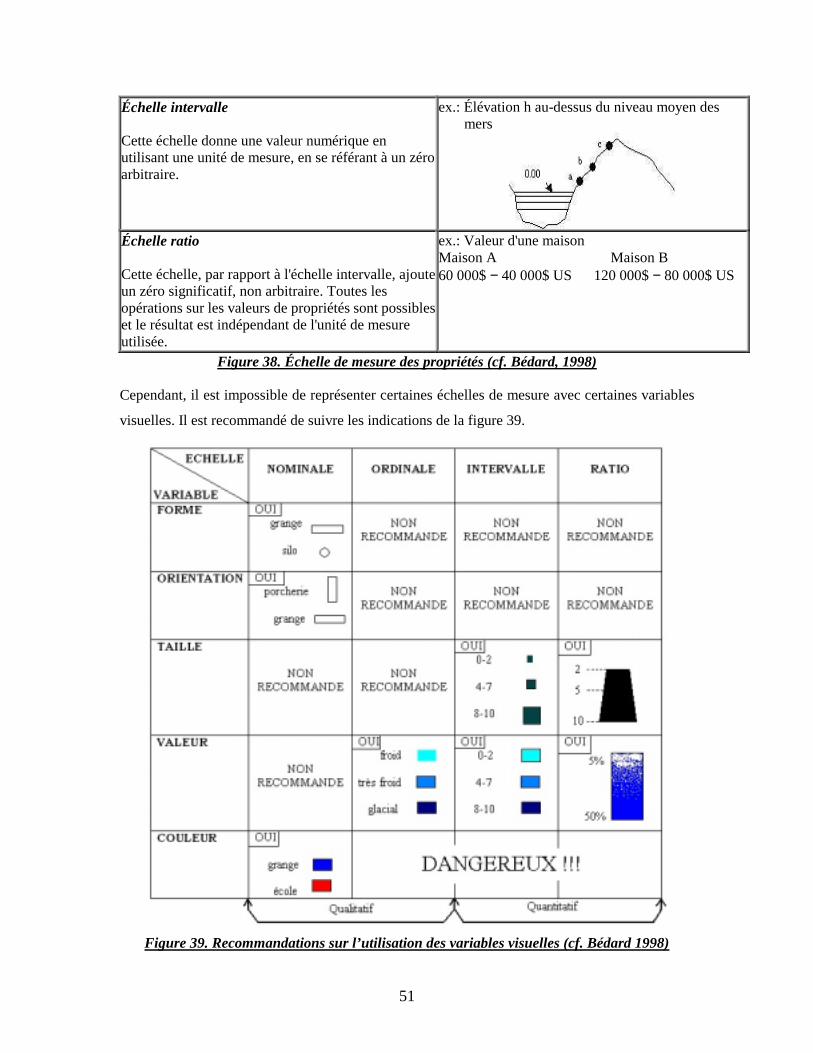
51
Échelle intervalle Cette échelle donne une valeur numérique en utilisant une unité de mesure, en se référant à un zéro arbitraire.
ex.: Élévation h au-dessus du niveau moyen des mers
Échelle ratio Cette échelle, par rapport à l'échelle intervalle, ajoute un zéro significatif, non arbitraire. Toutes les opérations sur les valeurs de propriétés sont possibles et le résultat est indépendant de l'unité de mesure utilisée.
ex.: Valeur d'une maison Maison A Maison B 60 000$ − 40 000$ US 120 000$ − 80 000$ US
Figure 38. Échelle de mesure des propriétés (cf. Bédard, 1998)
Cependant, il est impossible de représenter certaines échelles de mesure avec certaines variables
visuelles. Il est recommandé de suivre les indications de la figure 39.
Figure 39. Recommandations sur l’utilisation des variables visuelles (cf. Bédard 1998)

52
Selon Josée Dubé, il est nécessaire de suivre six principes afin de réaliser des cartes avec une
bonne représentation des informations à lire.
➨ Principe 1 : Présomption d’uniformité
« Le territoire représenté sur une carte est perçu comme étant uniforme et significatif de
l’existence du phénomène représenté. »
Ceci signifie qu’il faut utiliser un signe quelconque pour différencier les espaces avec
informations des espaces sans informations afin de ne pas confondre une absence de phénomène
et une ignorance de phénomène.
➨ Principe 2 : Forte densité de symboles
« Pour un phénomène donné, un regroupement très dense des symboles doit nécessairement être
représenté au même titre que tout autre signe, plutôt que d’être signifié par une convention
différente. »
Quand l’occurrence d’un phénomène est très forte dans une zone, il est possible de « zoomer »
sur le phénomène, nais il faut laisser sur la carte la représentation du phénomène à la même
échelle que le reste de l’information.
➨ Principe 3 : Etendue du phénomène
« Le fait d’encadrer de très près la représentation d’un phénomène laisse planer un doute sur
l’étendue qu’il couvre au-delà de ces limites. »
Il faut donc laisser apparaître sur la carte les informations des régions voisines du phénomène en
question.
➨ Principe 4 : La valeur est ordonnée
« La valeur est une variable ordonnée, du pâle au foncé (pour une même couleur), dont on ne doit
pas déplacer les composantes. »
Une valeur pâle représente un phénomène à faible occurrence alors qu’une valeur foncée
symbolise un phénomène répété.
➨ Principe 5 : Spectre des couleurs
« Les couleurs pures, présentées dans l’ordre du spectre, traduisent deux ordres visuels ; du foncé
au pâle (du mauve au jaune) et du pâle au foncé (du jaune au noir). »

53
Ce principe est difficile à comprendre sans voir la figure qui l’explique. En fait, cela veut dire que
lorsqu’on veut changer la variable valeur par la variable couleur, il est nécessaire d’ordonner les
couleurs, du pâle au foncé (du jaune au noir) pour garder la signification et la lisibilité de
l’information.
➨ Principe 6 : L’information de contexte
« Eviter de colorer ce qui n’est pas l’objet principal de la carte (l’information de contexte ). »
L’utilisation d’une couleur pour coder une information peut être atténuée si tout ce qui entoure
l’objet en couleur est aussi coloré. Il faut donc utiliser un minimum de couleurs pour que
l’information soit claire.
b) Dans le cas présent
L’utilisation des variables visuelles permet d’avoir beaucoup plus de dimensions en une seule vue
que ce que l’on fait avec un tableau (3D).
Par exemple, l’utilisation de différentes variables visuelles pourrait donner le résultat suivant :
- taille : donnée non significative donnée significative
- couleur : si est = cancer du poumon
= cancer de l’estomac
= cancer du rein
- valeur ou trame : = enfant
= adulte
- forme : = mortel
= dont on guérit
- orientation : non utilisable à cause de la forme utilisée (rond)
Cependant, tous les logiciels de SIG n’offrent pas la possibilité d’utiliser toutes ces variables
visuelles. GeoMedia, entre autres, ne propose que le choix de la trame et de la couleur (pour
l’intérieur et pour la limite de la surface); c’est pourquoi nous n’avons pas pu exploiter à fond les
possibilités de faire des cartes plus complètes. Il est vrai que si toutes les variables visuelles sont
utilisées, la carte n’est plus considérée comme une carte « à voir » mais comme une carte « à
lire » tant elle est complexe, mais chaque information pourra être lue si nécessaire par
l’utilisateur.

54
Dans nos cartes, nous n’avons utilisé que les couleurs ou que les valeurs, ou une combinaison des
deux pour arriver à notre carte la plus complexe. Nous aurions pu, si l’hypercube avait été concu
pour aller dans un niveau d’agrégation moindre, ajouter une trame en plus. Nous serions alors
parvenus au résultat de la carte en annexe 10 h (carte réalisée avec simulation d’une dimension).
En fait, à chaque fois que nous rajoutons une variable visuelle, cela équivaut à descendre d’un
niveau dans notre hypercube, et inversement.

55
CONCLUSION
L’objectif fixé pour ce mémoire était de créer un prototype exploratoire se servant d’un outil
OLAP afin d’analyser une partie des données du cancer relevant du domaine de la santé, et ce sur
toute la province de Québec.
De nombreux problèmes se sont posés pendant le déroulement de ce projet. Tout d’abord des
problèmes spatio-temporels qui nous ont conduits à changer la méthode envisagée car les
incompatibilités entre les différentes sources de données étaient trop grandes, et qui ont démontré
par la suite qu’il vaut toujours mieux générer notre base de données de façon automatique.
Ensuite, des problèmes de projection nous ont permis de voir les faiblesses de certains logiciels
de SIG en ce domaine.
Le prototype créé a été plutôt concluant car il nous a permis une familiarisation indispensable
avec la structure des données de la santé. Il semble nécessaire pour le système final de ne pas
prendre comme données de départ des résultats d’analyses effectuées par le CSPQ, donc des
données agrégées, mais bien de considérer directement les données brutes qui sont à la
disposition du CSPQ. Si nous avions eu plus de temps, nous aurions pu concevoir un nouveau
prototype qui aurait tenu compte de ces données brutes.
Etant donné la quantité de données à traiter, il sera aussi indispensable de changer le choix
originel de logiciels. Une gestion par Oracle permettra de ne pas rencontrer tous les problèmes
survenus sous Access avec notre table de 76000 enregistrements. Powerplay ne permettant pas
d’exporter les données après analyse, nous lui préférerons le logiciel AVS (Advanced Visual
System) de la firme AVS avec stockage des données sous Oracle, qui lui offre cette possibilité.
En ce qui concerne la réalisation de cartes, nous avons exploité au maximum l’équipement du
CRG en utilisant un logiciel de SIG, puis un autre dès que nous rencontrions des difficultés pour
réaliser une opération. Si nous avions à recommencer le processus depuis le début, nous nous
fixerions peut être plus l’objectif de nous concentrer sur un logiciel de SIG complet comme
GeoMedia et de réaliser des cartes plus ou moins complexes suivant les possibilités du logiciel.
Cependant, dans le cadre d’un projet académique, nous ne considérons pas la technique utilisée
comme mauvaise puisqu’elle a permis de connaître les grandes marques de logiciels de SIG
actuellement sur le marché.
Nous pouvons dire que les objectifs définis au début du projet ont été atteints. Le prototype nous
a permis de mieux cerner les besoins du CSPQ et de montrer le potentiel d’un SOLAP à l’équipe
santé. Ce projet nous a confrontés à un grand nombre de logiciels, et nous à fait participer à un
projet concret, ce qui est très formateur d’un point de vue académique.

56
Compte tenu des limitations technologiques actuelles, le système ne pouvait pas être parfait.
Pendant le projet, nous avons identifié de nouvelles possibilités pour le développement d’une
technologie SOLAP : grâce à la sémiologie graphique, nous savons désormais qu’il est possible
d’afficher sur une carte un grand nombre de dimensions, comme nous le faisons actuellement
dans l’hypercube. Cependant, il faut automatiser le processus que dans le cadre du projet nous
avons réalisé manuellement (ceci représente l’objectif du projet GEOIDE). Tant que des logiciels
n’auront pas été conçus pour associer les performances des SIG et de l’OLAP, le projet ne
semblera pas entièrement satisfaisant. Cependant, le développement actif de logiciels SOLAP
permettra peut-être leur utilisation prochaine dans le projet qui, rappelons-le, est d’une durée de
trois ans.
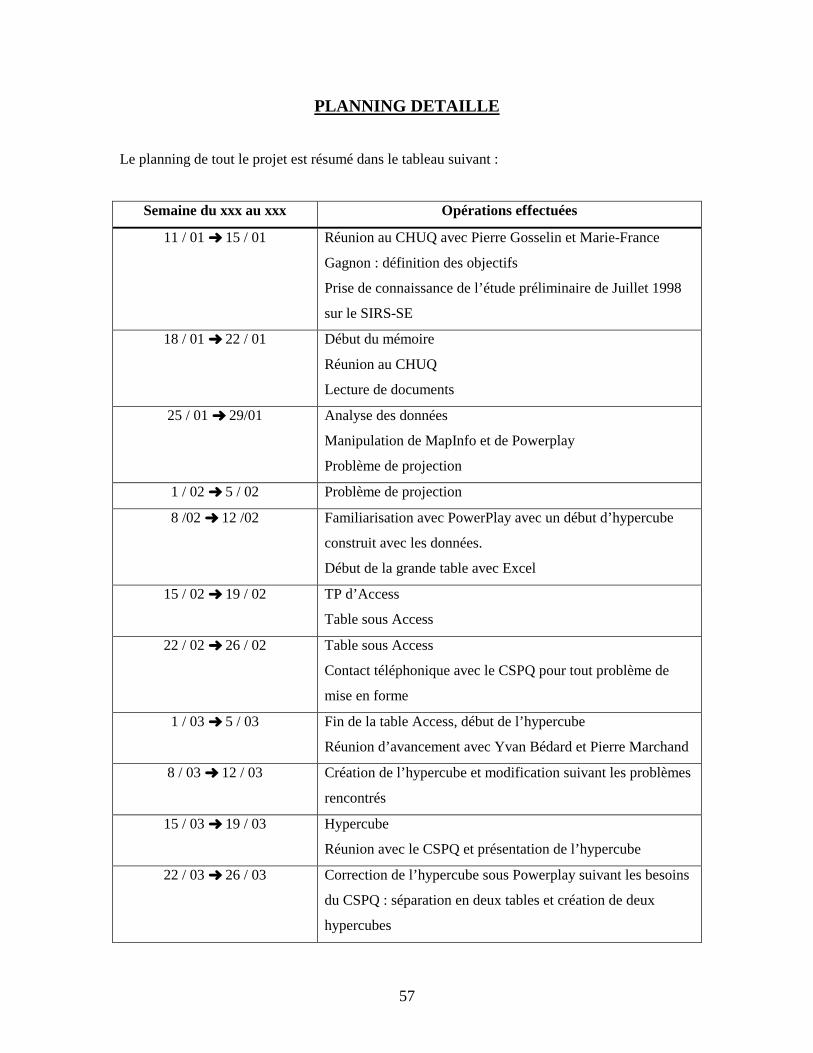
57
PLANNING DETAILLE
Le planning de tout le projet est résumé dans le tableau suivant :
Semaine du xxx au xxx Opérations effectuées
11 / 01 ➜ 15 / 01 Réunion au CHUQ avec Pierre Gosselin et Marie-France
Gagnon : définition des objectifs
Prise de connaissance de l’étude préliminaire de Juillet 1998
sur le SIRS-SE
18 / 01 ➜ 22 / 01 Début du mémoire
Réunion au CHUQ
Lecture de documents
25 / 01 ➜ 29/01 Analyse des données
Manipulation de MapInfo et de Powerplay
Problème de projection
1 / 02 ➜ 5 / 02 Problème de projection
8 /02 ➜ 12 /02 Familiarisation avec PowerPlay avec un début d’hypercube
construit avec les données.
Début de la grande table avec Excel
15 / 02 ➜ 19 / 02 TP d’Access
Table sous Access
22 / 02 ➜ 26 / 02 Table sous Access
Contact téléphonique avec le CSPQ pour tout problème de
mise en forme
1 / 03 ➜ 5 / 03 Fin de la table Access, début de l’hypercube
Réunion d’avancement avec Yvan Bédard et Pierre Marchand
8 / 03 ➜ 12 / 03 Création de l’hypercube et modification suivant les problèmes
rencontrés
15 / 03 ➜ 19 / 03 Hypercube
Réunion avec le CSPQ et présentation de l’hypercube
22 / 03 ➜ 26 / 03 Correction de l’hypercube sous Powerplay suivant les besoins
du CSPQ : séparation en deux tables et création de deux
hypercubes
58
29 / 03 ➜ 2 / 04 Début de la carto sous ArcView, identification du problème.
Passage sous MapInfo, identification d’un problème.
Passage sous GeoMedia. Problème de récupération des
données du cancer.
Rapport.
5 / 04 ➜ 9 / 04 Rapport.
Recherche d’une solution pour récupérer les données du
cancer.
12 / 04 ➜ 16 / 04 Productions de cartes.
Rapport.
19 / 04 ➜ 23 / 04 Finalisation de cartes.
Rapport.

59
REFERENCES BIBLIOGRAPHIQUES
Ouvrages
➪ Lebel Germain, Gingras Suzanne, Levallois Patrick, Gauthier Roger, Gagnon Marie-
France. (Décembre 1998) Étude descriptive de l’incidence du cancer de 1989 à 1993, Centre
Hospitalier Universitaire de Québec.
➪ Thomsen Erik. (1997) OLAP Solutions – Building Multidimensional Information Systems,
Wiley Computer Publishing.
Rapports
➪ Direction de la santé publique de Québec, Régie régionale de la santé et des services
sociaux de Québec. (Juillet 1998) Système d’Information à Référence spatiale en Santé
Environnementale - Analyse préliminaire.
➪ Dr Gosselin Pierre, Dr Bédard Yvan, Dr Sears Malcom, Dr Moulin Bernard, Dr Han
Jiawei. (Mars 1998) Proposition de projet GEOID.
➪ Rebout Cécile. (1998) Adaptation d’une base de données pour une application SOLAP
(Spatial OLAP) pour l’aide à l’aménagement intégré des ressources forestières. – Mémoire de
DESS « méthodes et outils au service de la gestion des territoires », Institut de Géographie
Alpine, Université Joseph Fourier – Grenoble I; Centre de Recherche en Géomatique, Université
Laval – Québec, Grenoble. 69p.
➪ Dubé Josée. (été 1991) La mauvaise information graphique et les principes de sémiologie
graphique – Mémoire de sujet spécial, Centre de Géomatique, Université Laval – Québec, 29p.
Notes de cours
➪ Dr Bédard Yvan. (Automne 1998) Cours de fondements des Systèmes d’Information
Géographique (GMT-20843).
➪ Dr Bédard Yvan, Larrivée Suzie. (Automne 1997) La géomatique et le développement d’un
SIRS – Extrait du cours d’Analyse et conception de SIRS (SCG-64738).
➪ Dr Bédard Yvan, Larrivée Suzie. (Automne 1998) ArcView – Extrait du cours de
Structuration et stockage de données à référence spatiale (GMT-18110).

60
Sites web, divers
➪ Centre de Recherche en Géomatique :
http://www.crg.ulaval.ca
➪ Bureau de la Statistique du Québec : http://www.stat.gouv.qc.ca/donstat/regions/municipa/municip2.htm
➪ Plaquette de présentation du groupe Santé et Environnement du CHUQ

61
Virginie PUJOS ensais
TOPOGRAPHIE Développement d’un prototype exploratoire d’application SIG
pour la détermination des besoins d’utilisateurs
en santé environnementale
Résumé :
Un prototype exploratoire est un petit système partiellement fonctionnel qui est développé
itérativement en étroite collaboration entre les utilisateurs et les développeurs. Il sert à préciser les
demandes et les offres avec la présentation, à chaque itération, d'une ébauche d'un sous-ensemble
du système final et permet de déterminer plus précisément les besoins avant de procéder au
développement du Système d’Information Géographique (SIG) global et final. Dans le domaine
de la santé environnementale au Québec, un SIG est mis en place et le prototype créé pour
l’occasion permet de montrer les avantages de la technique OLAP (On-Line Analytical
Processing) de requêtes multidimensionnelles. Cette technique permet une navigation instantanée
dans les données ainsi qu’une analyse dont les résultats n’auraient pas toujours été accessibles
dans une approche traditionnelle. Un volet cartographique utilisant les mêmes données que le
projet OLAP vient en complément, car la technologie actuelle ne permet pas encore
l’accompagnement des requêtes par un aspect spatial.
Summary :
An explorer prototype is a small and partially functional system which is repeatedly developped
in a close collaboration beetween users ans developpers. It is used to precise demands and
supplies with, after each iteration, a presentation of an outline of the final system subset and
allows to determinate more accurately the needs before proceeding to the development of the
global and final Geographic Information System (GIS). In the field of environmental health in
Quebec, a GIS was set, and the prototype created for the occasion enhances the benefits of the
OLAP (On-Line Analytical Processing) technic for mutidimensionnal queries. This technic
offers an instantaneous navigation among data as well as an analysis which results would
not be reachable in a traditional approach. A cartographic side using the same data as the
OLAP project completes that, since the current technology doesn’t allow a close support
of queries with a spatial aspect yet.

62
Mots-clés : Prototype exploratoire, OLAP, hypercube, analyse multidimensionnelle.