
Devoir No 1 Partie I : Dilutions et Concentrations (3 …...1 Devoir No 1 Partie I : Dilutions et...
29
1 Devoir N o 1 Partie I : Dilutions et Concentrations (3 points/question pour un total de 60 points) Vos réponses doivent être soumises à deux chiffres significatifs après la décimale. Par exemple, 2.00, 0.020, ou 0.0020. Ne pas utiliser la virgule pour indiquer la décimale, utiliser plutôt un point. Utilisez l’information suivante pour répondre aux questions 1-8 Vous préparez une solution “X” en ajoutant les ingrédients suivants à 1L de H2O : 125 mL de la solution « A » (1.6 M composé « A »), 50 mL de la solution « B » (20 % (m/v) du composé « B »), et 25 mL de la solution « C » (10g/L du composé « C »). Les propriétés de chacun des ingrédients sont les suivantes: Composé A: MM 200g/mole, densité 1.2g/mL, densité de soln. de 1.6 M 1.05g/mL Composé B: MM 150g/mole, densité 1.3g/mL, densité de soln. de 20% 1.1g/mL Composé C: MM 35g/mole, densité 1.15g/mL, densité de soln. de 10g/L 1.03g/mL Densité de la solution « X »: 1.25g/mL 1. Par quel facteur est-ce que la solution « A » a-t-elle été diluée? 2. Étant donné que le volume de la solution « B » représente 2 parties, combien de parties est-ce qu’il y dans la solution « X »? 3. Quelle est la molarité finale du composé « B » dans la solution « X »? 4. Quel est le pourcentage (m/m) du composé « C dans la solution « X »? 5. Quel est le pourcentage (m/m) du composé « A » dans la solution « X »? 6. Quel est le pourcentage de solutés totaux (m/v) dans la solution « X »? 7. Quel est le rapport de parties entre chacune des solutions « A », « B », « C » et l’eau? (considérez votre réponse pour Q2) 8. Quel est le rapport masse entre chacun des composés « A », « B », « C » et l’eau? (arrondir aux chiffres entiers les plus proches) 9. Vous commencez avec 0.5L d'une solution mère de KNO3 et désirez préparer 10.0 L de 0.1 M KNO3. De quel pourcentage (m/v) est-ce que la solution mère de nitrate de potassium devrait- elle être si vous utilisez la totalité? (MM de KNO3: 101g/mole) 10. Vous avez des solutions mères de 2.0 M sulfate de cuivre et de 5 M NaCl. Vous désirez préparer une solution avec une concentration finale de 0.5 M de sulfate de cuivre et 0.25 M NaCl qui contient 280 mL d’eau en tant que solvant. Combien de millilitres de la solution mère de sulfate de cuivre est-ce que la solution contiendrait? 11. 40.0 mL de 1.0 M Fe(NO3)3 est mélangé avec 20 mL de 5 M Fe(NO3)3 et 60 mL d'eau. Quelle est la concentration molaire finale d’ions de NO3 - ? 12. Vous ajoutez 2.0 L d'une solution de HCl de concentration inconnue à 2.0 L de 0.5 M HCl et 4.5 L d’eau. La concentration finale de HCl était 1.0 M. Quelle était la concentration inconnue de la solution initiale de HCl? 13. Vous préparez une solution de 15% NaCl (m/v) (Densité de NaCl : 2.16 g/mL). Combien de millilitres d’eau sont dans 500 mL de cette solution? 14. Quelle est la concentration molaire d'ions dans une solution préparée en mélangeant 100.0 mL de 2.0 M KCl avec 50.0 mL d'une solution de 1.50 M CaCl2 et 350 mL d’eau?
Transcript of Devoir No 1 Partie I : Dilutions et Concentrations (3 …...1 Devoir No 1 Partie I : Dilutions et...

1
Devoir No 1
Partie I : Dilutions et Concentrations (3 points/question pour un total de 60 points)
Vos réponses doivent être soumises à deux chiffres significatifs après la décimale. Par exemple,
2.00, 0.020, ou 0.0020. Ne pas utiliser la virgule pour indiquer la décimale, utiliser plutôt un point.
Utilisez l’information suivante pour répondre aux questions 1-8
Vous préparez une solution “X” en ajoutant les ingrédients suivants à 1L de H2O : 125 mL de la
solution « A » (1.6 M composé « A »), 50 mL de la solution « B » (20 % (m/v) du composé « B »),
et 25 mL de la solution « C » (10g/L du composé « C »). Les propriétés de chacun des ingrédients
sont les suivantes:
Composé A: MM 200g/mole, densité 1.2g/mL, densité de soln. de 1.6 M 1.05g/mL
Composé B: MM 150g/mole, densité 1.3g/mL, densité de soln. de 20% 1.1g/mL
Composé C: MM 35g/mole, densité 1.15g/mL, densité de soln. de 10g/L 1.03g/mL
Densité de la solution « X »: 1.25g/mL
1. Par quel facteur est-ce que la solution « A » a-t-elle été diluée?
2. Étant donné que le volume de la solution « B » représente 2 parties, combien de parties est-ce
qu’il y dans la solution « X »?
3. Quelle est la molarité finale du composé « B » dans la solution « X »?
4. Quel est le pourcentage (m/m) du composé « C dans la solution « X »?
5. Quel est le pourcentage (m/m) du composé « A » dans la solution « X »?
6. Quel est le pourcentage de solutés totaux (m/v) dans la solution « X »?
7. Quel est le rapport de parties entre chacune des solutions « A », « B », « C » et l’eau?
(considérez votre réponse pour Q2)
8. Quel est le rapport masse entre chacun des composés « A », « B », « C » et l’eau? (arrondir
aux chiffres entiers les plus proches)
9. Vous commencez avec 0.5L d'une solution mère de KNO3 et désirez préparer 10.0 L de 0.1 M
KNO3. De quel pourcentage (m/v) est-ce que la solution mère de nitrate de potassium devrait-
elle être si vous utilisez la totalité? (MM de KNO3: 101g/mole)
10. Vous avez des solutions mères de 2.0 M sulfate de cuivre et de 5 M NaCl. Vous désirez
préparer une solution avec une concentration finale de 0.5 M de sulfate de cuivre et 0.25 M
NaCl qui contient 280 mL d’eau en tant que solvant. Combien de millilitres de la solution mère
de sulfate de cuivre est-ce que la solution contiendrait?
11. 40.0 mL de 1.0 M Fe(NO3)3 est mélangé avec 20 mL de 5 M Fe(NO3)3 et 60 mL d'eau. Quelle
est la concentration molaire finale d’ions de NO3-?
12. Vous ajoutez 2.0 L d'une solution de HCl de concentration inconnue à 2.0 L de 0.5 M HCl et
4.5 L d’eau. La concentration finale de HCl était 1.0 M. Quelle était la concentration inconnue
de la solution initiale de HCl?
13. Vous préparez une solution de 15% NaCl (m/v) (Densité de NaCl : 2.16 g/mL). Combien de
millilitres d’eau sont dans 500 mL de cette solution?
14. Quelle est la concentration molaire d'ions dans une solution préparée en mélangeant 100.0 mL
de 2.0 M KCl avec 50.0 mL d'une solution de 1.50 M CaCl2 et 350 mL d’eau?

2
15. L'A260 nm d’une solution d’ADN est 0.60. Combien de cette solution d'ADN et d'un tampon
de chargement de 6X devrait être ajouté à 30.5 µL d'eau pour obtenir un échantillon qui
contient 75 ng d'ADN dans du tampon de chargement de 0.5X? (A260 nm de 1.0 = 50 µg/mL
ADN)
16. Solution A contient 0.20 µg d’ADN par µL. Solution B contient 0.30 µg d’ADN par µL. Si
vous combinez 34 mL de la solution A avec 19 mL de la solution B, quelle serait l’absorbance
à 260 nm de la solution finale?
17. Vous avez une solution de 15% (m/v) de glycine (MM: 75g/mole). Par quel facteur est-ce que
cette solution doit être diluée pour obtenir une concentration finale de 0.05 M?
18. Un échantillon d'eau a une concentration en PO4-3 de 6.8 picomolaire. Exprimer ceci en μg/100
L de PO4-3. (MM de PO4
-3: 95g / mole)
19. Quelle est la concentration masse par volume (g/L) d’ions dans 100 mL d'une solution de
K2HPO4 de 0.5M? (MM de K2HPO4: 174g/mole, K+: 39g/mole, et PO4-3: 95g/mole; et H+:
1g/mole)
20. Vous avez trois solutions, "A", "B" et "C". Chacune doit être diluée par les facteurs de dilution
suivants: 5X, 15X et 45X respectivement. Quel serait le volume final d'une solution préparée
en ajoutant chacun des ingrédients à 100 mL de solvant?
Partie II: Performance en labo et analyse de données (4 points/question pour un
total de 40 points)
Utilisation des micropipettes – Partie I
1. Générer une courbe étalon à partir des données obtenues pour les volumes allant de 50-200
µL (ABS Vs Vol.). Ajouter une ligne qui représente la meilleure droite. Déterminer le
coefficient R2. (Suivre les directives pour les figures et les graphiques disponibles sur la page
web de ce cours)
2. D’après votre courbe étalon, quels sont les volumes moyens pour les puits G1-3 ou H1-3 et
les puits G4-6 ou H4-6?
Utilisation des micropipettes – Partie II
3. Quelles étaient l’exactitude et la précision obtenues avec la P-1000, la P-200 et la P20.
Montrer vos calculs.
Préparation de solutions :
4. Indiquer les lectures d’absorbances obtenues pour chacune des solutions suivantes :
a. Une solution de 0.2mM du composé “A”.
b. Une solution de 0.72% (m/v) du composé “B”.
c. Une solution de 5% (v/v) de la solution I.
d. Une solution qui contient 0.1mg du composé “A” et 0.1% (v/v) du composé “B”.
e. Une solution avec le rapport suivant : solution I : solution II : eau : 2 : 1 : 247
Électrophorèse sur gel d’agarose
5. Soumettre une figure de votre électrophorèse sur gel d’agarose de vos isolations d’ADN
plasmidique et d’ADN génomique. Inclure une légende appropriée (suivre les directives pour
les graphiques et les figures sur la page Web de ce cours).

3
Quantification spectrophotométrique de l’ADN : Méthode 1 (Absorption aux UV)
6. Soumettre un graphique qui représente les lectures A260 Vs les concentrations standards
d'ADN. Inclure le coefficient R2 sur le graphique. Indiquer dans votre légende quelle était la
concentration initiale non diluée de la solution d'ADN inconnue fournie?
7. Soumettre les informations suivantes pour votre isolation d’ADN génomique de levure.
ABS260
ABS280
Rapport ABS260/ABS280
Concentration en µg/µL de la préparation non diluée (montrer votre calcul)
Rendement total en µg (montrer votre calcul)
Quantification spectrophotométrique de l’ADN : Méthode 2 (Fluorométrie)
8. Soumettre un graphique qui représente les lectures A260 Vs les concentrations standards
d'ADN. Inclure le coefficient R2 sur le graphique.
9. D’après votre graphique quelle était la concentration initiale non diluée de la solution d'ADN
inconnue fournie?
10. Soumettre les informations suivantes pour votre isolation d’ADN génomique de levure.
Concentration en µg/µL de la préparation non diluée (montrer votre calcul)
Rendement total en µg (montrer votre calcul)

4
Devoir No 2
Partie I : Digestions par enzymes de restriction et cartographie (2 points/question
pour un total de 50 points)
1. La nomenclature des enzymes de restriction peut fournir des informations utiles concernant la
source de l'enzyme. Par exemple, EcoRI indique que cette enzyme était la première enzyme
isolée à partir d'une souche d’Escherichia coli "R". De quel genre bactérien est-ce que PstI a
été isolée?
2. Définir les termes suivants: isoschizomère, néoschizomère et isocaudomère.
3. Parmi les enzymes énumérées ci-dessous lesquelles, s’il y en a, génèrent des extrémités
compatibles les unes aux autres? (Ex. A et B)
Enzyme Séquence reconnue
A AciI G/CGC
B AscI GG/CGCGCC
C EagI C/GGCCG
D HpaII C/CGG
E MluI A/CGCGT
F NsiI ATGCA/T
G PstI 5CTGC/AG
4. Les séquences partielles reconnues par deux enzymes de restrictions “A” et “B” sont indiquées
ci-dessous. Complétez les séquences de telle façon à ce que des palindromes soient générés
pour chacun des sites. Indiquez sur les palindromes quel lien phospodiester devrait être clivé
pour que des extrémités 5’ protubérantes de l’enzyme “A” soient compatibles à des extrémités
protubérantes de l’enzyme “B”. Ex. CT/GCAG
Enzyme “A”: 5’ATAG― ― ― ― 3’
Enzyme “B”: 5’GCG ― ― ― 3’
5. Considérez votre réponse à la question précédente. Un fragment d’ADN généré avec l’enzyme
“A” a été ligué à un fragment d’ADN généré avec l’enzyme “B” tel qu’illustré ci-dessous.
Quelle serait la séquence générée de la jonction entre les fragments ligués? Quelle (s) enzyme
(s), A, B, A & B, ou ni A ou B couperait l’ADN ligué?
A/B

5
6. Cette image représente une électrophorèse sur gel d’agarose de digestions de restriction d’un
plasmide.
ND : Plasmide non digéré
H : Plasmide digéré avec HincII
P: Plasmide digéré avec PvuII
H+P: Plasmide digéré avec HincII et PvuII
Répondre aux questions suivantes d’après les résultats obtenus :
a. Combien de fois est-ce que PvuII coupe dans le plasmide?
b. Combien de fois est-ce que HincII coupe dans le plasmide?
c. Combien de fois est-ce que HincII coupe dans le fragment PvuII?
d. Quel fragment dans la digestion par HincII a été digéré par PvuII? (Haut. milieu, bas)
7. Un fragment d’ADN linéaire de 12 Kpb, illustré ci-dessous, possède des sites de clivages pour
BamHI (B) et EcoRI (E). Les nombres indiquent les distances en kilobases. Indiquer quelles
tailles de fragments seraient observées sur un gel d’agarose après des digestions avec BamHI,
EcoRI et BamHI + EcoRI. Notez, si différents fragments de mêmes tailles sont générés, la
taille devrait être indiquée qu'une seule fois. (Par exemple, ne pas indiquer 2Kpb et 2Kpb)
8. Des fragments de quelles tailles seraient générés après une digestion partielle par BamHI?
Seulement indiquer les tailles de fragments intermédiaires qui ne seraient pas obtenues après
une digestion complète. (Des fragments qui ont été coupés au moins une fois, mais dans
lesquels un ou plusieurs sites BamHI demeurent non digéré)
9. Il a été déterminé que l'enzyme XhoI coupe à 7.0Kbp sur la carte ci-dessus. Quel fragment
BamHI serait coupé par XhoI?
10. Une digestion complète avec EcoRI + BamHI de 5µg du fragment ci-dessus a été fait. Indiquez
la quantité en µg qui serait obtenue de chaque taille de fragments.
ND H P H+ P
4 6 9 11
B E B B

6
Le tableau ci-dessous présente les résultats de différentes digestions d'un plasmide. Toutes les
tailles sont en paires de base.
Digestion Tailles des Fragments HindIII 4.00 kb BamHI 2.35 kb, 1.65 kb EcoRI 4.00 kb, 2.50 kb,1.50 kb
HindIII + BamHI 1.65 kb, 1.50 kb, 0.85 kb HindIII + EcoRI 3.50 kb, 3.00 kb, 2.50kb, 1.00 kb, 0.50 kb BamHI + EcoRI 2.00kb, 1.85kb, 1.65kb, 1.5kb, 0.35kb, 0.50 kb
11. Une des enzymes utilisées a digéré l’ADN partiellement. De quelle enzyme s’agit-il?
12. Indiquer la taille d’un des produits intermédiaires parmi les digestions doubles qui représente
un fragment d’ADN digéré de façon incomplète.
13. Quelle est la taille totale du plasmide?
14. Quelles sont les distances entre les sites de restrictions EcoRI et HindIII?
15. Quelles sont les distances entre les sites de restrictions BamHI et HindIII?
16. Quelles sont les distances entre les sites de restrictions BamHI et EcoRI?
Le tableau ci-dessous présente les résultats de différentes digestions complètes d’un fragment
d’ADN linéaire. Toutes les tailles sont en paires de bases.
HindIII 5000, 2500
SmaI 5500, 2000
EcoRI 4000, 3500
HindIII + EcoRI 3500, 2500, 1500
HindIII + SmaI 3000, 2500, 2000
SmaI + EcoRI 4000, 2000, 1500
17. Quelle est la distance entre les sites de restriction EcoRI et HindIII?
18. Quelle est la distance entre les sites de restriction HindIII et SmaI?
19. Parmi les fragments générés après la digestion avec HindIII et SmaI, lequel pourrait être ligué
et cloné dans un vecteur digéré avec HindIII et SmaI? Indiquer la taille du fragment.
20. L'enzyme de restriction BbaI clive la séquence R/AYRTY (R= A ou G et Y = C ou T). Combien
de différents palindromes est-ce que BbaI reconnaît?
21. Quelle serait la taille moyenne des fragments qui serait attendue après une digestion d’ADN
génomique avec BbaI. Présumez une distribution égale de A, G, C et T.
22. À quelle fréquence est-ce que l’enzyme BbaI couperait dans un génome avec la composition
de bases suivantes sur un brin : 20% G, 30% C, 20% A, and 30% T?
23. Vrai ou faux, une extrémité protubérante générée après une digestion d’un palindrome
reconnu par BbaI serait nécessairement compatible avec tout autre palindrome clivé par BbaI?

7
24. L’enzyme PspN41 clive la séquence NNGCNN (N= n’importe laquelle des quatre bases).
Combien de fois vous attendriez vous a ce que PspN41 digérerait un génome de 10.752 kb?
25. La séquence A, qui contient deux sites BstBI (TT/CGAA), a été digérée avec BstBI. Le
fragment obtenu a ensuite été ligué dans le site de restriction unique TaqI (T/CGA) dans le
vecteur B.
Séquence A: CAG TT/CGAA TTC • • • • • • • • • • • • • • • • GGC TT/CGAA AAG
Vecteur B: TGG T/CGA CAC
Quelle (s) enzyme (s) pourrait (ent) être utilisée (s) pour relâcher le fragment d’ADN cloné du
vecteur B recombinant? BstBI, TaqI , les deux ou aucune des deux.
Partie II : Cartographie de restriction (4 points/question pour un total de 40 points)
Ci-dessous est illustrée l’électrophorèse d’ADN prédigéré tel que vous avez fait dans le labo. (Ce
fichier peut être obtenu du site Web de ce cours sous la rubrique Données>prédigéré).
1. Soumettre une courbe étalon de l'échelle de poids moléculaire. (Distance de migration Vs
Tailles en pb) (inclure le coefficient R2)
2. Soumettre un tableau des digestions du plasmide recombinant qui inclut les informations
suivantes: Enzyme utilisée, Nombre de coupures totales, Nombre de coupures dans l’insertion,
Nombre de coupures dans le vecteur, et Tailles des fragments observées. Dans une légende
qui accompagne le tableau, indiquez la taille totale du plasmide, la taille du vecteur, la taille
de l'insertion et le (les) site(s) de restriction dans lequel (lesquels) l'insertion a été introduite
dans le vecteur.
L: Échelle de poids moléculaire de 1 kb U: ADN recombinant du plasmide pUC9 non digéré 1 : Plasmide recombinant de pUC9 digéré avec BamHI 2: Plasmide recombinant de pUC9 digéré avec EcoRI 3: Plasmide recombinant de pUC9 digéré avec HindIII 4: Plasmide recombinant de pUC9 digéré avec EcoRI + HindIII 5: Plasmide recombinant de pUC9 digéré avec PstI 6: Vecteur pUC9 digéré avec BamHI
L U 1 2 3 4 5 6
8
3. Soumettre une figure qui représente une carte de restriction possible de l'insertion dans le site
de clonage multiple de pUC9. Votre carte doit être linéaire, à l’échelle et seulement inclure
l'insertion dans le site de clonage multiple. (Voir les directives sur la page web de ce cours
sous la rubrique graphiques et figures)
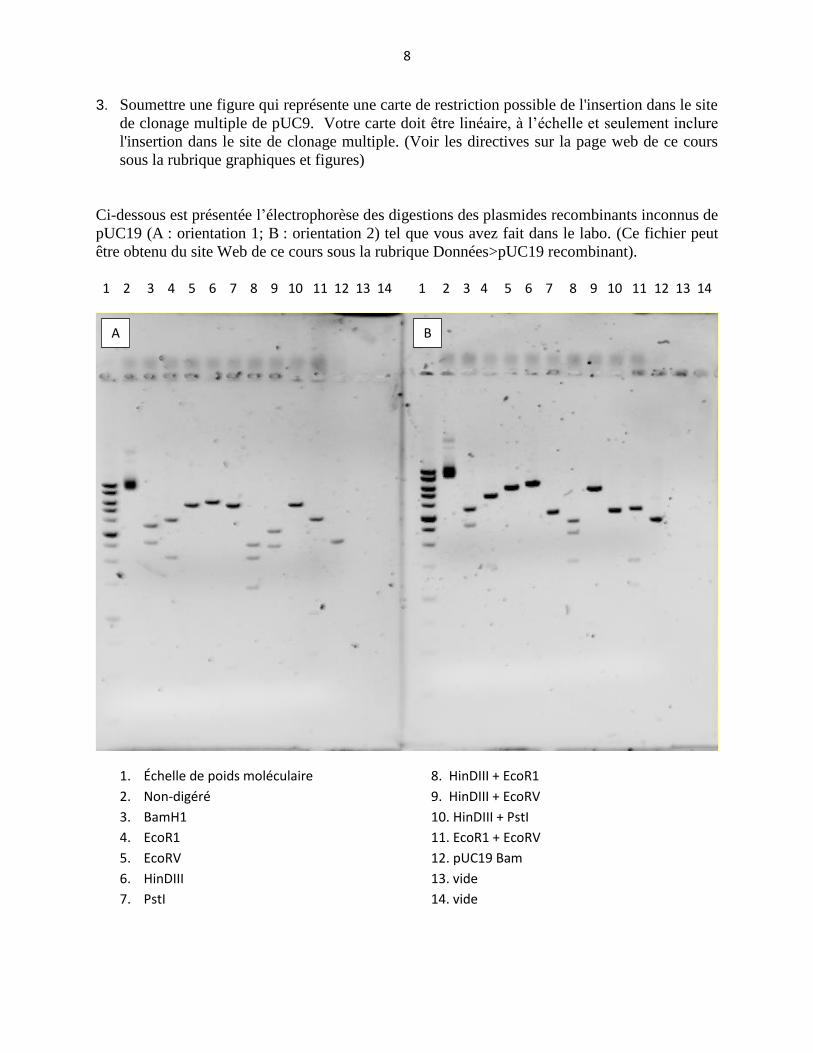
Ci-dessous est présentée l’électrophorèse des digestions des plasmides recombinants inconnus de
pUC19 (A : orientation 1; B : orientation 2) tel que vous avez fait dans le labo. (Ce fichier peut
être obtenu du site Web de ce cours sous la rubrique Données>pUC19 recombinant).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 1 2 3 4 5 6 7 8 9 10 11 12 13 14
1. Échelle de poids moléculaire 8. HinDIII + EcoR1
2. Non-digéré 9. HinDIII + EcoRV
3. BamH1 10. HinDIII + PstI
4. EcoR1 11. EcoR1 + EcoRV
5. EcoRV 12. pUC19 Bam
6. HinDIII 13. vide
7. PstI 14. vide
A B

9
4. Soumettre un tableau d’analyse des digestions de l’inconnu qui vous a été fourni. Votre tableau
doit inclure les données suivantes : Enzyme (s) utilisée (s), Nombre de coupures totales,
Nombre de coupures dans le vecteur, Nombre de coupures dans l'insertion et les Tailles des
fragments générés.
5. Soumettre une figure de la carte de restriction de l’insertion d'ADN du plasmide recombinant
qui vous a été fourni. Votre carte doit être linéaire, inclure le site de clonage multiple, indiquer
le site d'insertion, la taille de l'insertion et les positions dans le site de clonage multiple ou dans
l'insertion de toutes les enzymes testées. Votre figure doit être à l'échelle. Suivre les directives
pour générer de telles figures sous la rubrique Graphiques/Figures sur la page web de ce cours.
6. Soumettre une figure de votre propre électrophorèse sur gel d'agarose du recombinant pUC
prédigéré et le calibrage d'une enzyme de restriction. Assurez-vous d'inclure une légende
appropriée. Suivez les directives pour les figures sur la page Web de ce cours et pour inclure
toutes les informations requises dans la légende pour la compréhension et l'interprétation de la
figure.
7. Selon l'expérience présentée à la question 6, quel était l'échantillon le plus dilué qui présentait
une digestion complète (indiquer la dilution)? Sur la base de cette information, quelle était la
concentration enzymatique non diluée approximative en unités / μL? Montrez comment vous
êtes arrivé à cette conclusion.
8. Soumettre une figure de votre propre électrophorèse sur gel d'agarose des digestions de
restriction du plasmide pUC recombinant que vous avez reçu. Assurez-vous d'inclure une
légende appropriée. Suivez les directives pour les figures sur la page Web de ce cours et pour
inclure toutes les informations requises dans la légende pour la compréhension et
l'interprétation de la figure.
Une hybridation Southern a été faite sur des digestions d’ADN génomique de Saccharomyces
cerevisiae. Après la migration sur gel d’agarose, les digestions ont été sondées avec une sonde de
3 Kpb radioactive. Les résultats de l’hybridation sont présentés ci-dessous.
Enzyme Taille des hybrides (Kpb)
BamHI 13
EcoRI 10 + 15
EcoRI + BamHI 6 + 7
9. Combien de fois est-ce que les enzymes BamHI et EcoRI coupent dans la région du génome
de S. cerevisiae recouverte par la sonde?
10. Dessiner une carte de restriction possible de cette région du génome de S. cerevisiae. Indiquer
les distances entre chacun des sites de restriction.

10
Bioinformatique 1-2 (1.25 points/question pour un total de 10 points)
1. Quel est le numéro d’accession protéique l’organisme source du premier fichier pour l’enzyme
BglII obtenu après une recherche générale?
2. Est-ce que le fichier avec le numéro d’accession M68489 correspond à un fichier nucléotidique
ou protéique?
3. Quels sont le nom du gène et l’organisme source qui correspond au fichier M68489?
4. Soumettre les informations suivantes en ce qui a trait à chacun des gènes inconnus du premier
exercice de bio-informatique.
Le numéro d'accession
Coverage
Ident.
E value
La définition
L’organisme duquel cette séquence a été obtenue
Le nom du gène
Le nom du produit du gène
Le numéro d’accession de la protéine
5. Présenter les cartes théoriques des 5 gènes inconnus disponibles sur la page Web de ce cours.
Inclure sous chaque carte le nom du gène et la liste d’enzymes qui ne coupent pas.
6. Comparez les cartes théoriques générées ci-dessus à la carte expérimentale de l'insertion
inconnue que vous avez analysée dans le labo. (« Cartographie de restriction d’un plasmide
recombinant »). L'insertion inconnue correspond à quel gène?
7. Fournir une carte de restriction montrant les positions des sites de restriction PstI, SalI, NcoI
et XbaI dans la région entre les positions 5683-7676 de la séquence « séquence inconnue »
disponible sur la page Web de ce cours. Indiquez sous la carte la définition du gène.
8. Selon la carte que vous avez soumise pour la question 7, quelles tailles de fragments seraient
générées à la suite d'une double digestion SalI-XbaI du fragment linéaire entre les positions
5683-7676?

11
Devoir No 3
Partie I: Clonage et transformations (3 points/question pour un total de 60 points)
L’anémie falciforme est due à une mutation dans le gène de la β-globine humaine. Les trois
génotypes possibles sont homozygotes pour la β-globine normale, porteur hétérozygote (ayant à
la fois la version normale et la version mutante) et homozygote pour l'anémie falciforme. La
technologie de l'ADN recombinant a été utilisée comme base pour le diagnostic prénatal de
l'anémie falciforme. Dans un pourcentage très élevé des cas observés, le gène normal de la β-
globine humaine se retrouve sur un fragment de restriction Hpal de 13000 pb, tandis que le gène
mutant se retrouve sur un fragment HpaI de 7600 pb.
À votre disposition sont :
Un échantillon étiqueté d’ADN recombinant d’un vecteur plasmidique bactérien (4000 pb)
avec une insertion HpaI de 13000 pb qui contient le gène normal humain.
Un échantillon d’ADN génomique de chaque membre d’un couple qui pourrait être des
porteurs du trait de l’anémie falciforme et qui attendant leur premier enfant.
Un échantillon d’ADN génomique obtenu des cellules fœtales dans le fluide amniotique
de l’utérus de la femme enceinte.
1. Vous faites un Southern sur l’ADN digéré avec HpaI en utilisant le plasmide recombinant
comme sonde. Quelle (s) taille (s) de bande (s) vous attendez-vous d’observer dans chacun des
cas suivants?
Mère porteuse hétérozygote
Mère homozygote normale
Fétus homozygote pour l’anémie falciforme
L’ADN génomique combiné d’une mère porteuse hétérozygote et d’un père homozygote
normal
2. Vous avez la séquence partielle du gène psy2 de la levure illustré ci-dessous. Vous décidez
d’utiliser la PCR pour amplifier la séquence de psy2 d’après les séquences bordantes illustrées.
Quelle(s) paire (s) d’amorces utiliseriez-vous pour amplifier la séquence complète de psy2?
Set 1: Set 2: Set 3:
5’ TCCGGA 3’ 5’ AATTCC 3’ 5’ GACTCC 3’
5’ GCCGGA 3’ 5’ AGTCGA 3’ 5’ TTGGAA 3’

12
Considérez l’information suivante pour répondre aux questions 3-5:
Vous avez amplifié la séquence psy2 et souhaitez cloner le fragment de PCR dans le vecteur 2
pour l’exprimer chez la levure. Les sites de clonage disponible sur le vecteur sont illustrés ci-
dessous.
StuI: 5’- AGG/CCT-3’ SalI: 5’-G/TCGAC-3’ EcoRI: 5’-G/AATTC-3’ BamHI: G/GATCC
Il y a deux façons d’insérer la séquence amplifiée de psy2 dans le vecteur 2. Indiquez la (les)
enzyme (s) de que vous pourriez utiliser pour couper le vecteur et la séquence psy2 pour chacun.
3. Clonage directionnel:
Couper le vecteur et psy2 avec:
4. Clonage non directionnel:
Couper le vecteur et psy2 avec:
5. Quelle (s) enzyme (s) pourriez-vous utiliser pour vérifier la présence et l’orientation de
l’insertion?
Considérez l’information suivante pour répondre aux questions 6-9:
Plusieurs groupes de labo ont fait des étapes de ligatures/transformations semblables à celles que
vous avez faites en labo afin d’introduire la GFP dans le SCM du vecteur pUC digéré. Le vecteur
et la séquence GFP ont été tous deux digérés avec la même enzyme unique. Les résultats obtenus
par chaque groupe sont présentés ci-dessous:
No de colonies sur géloses LB-Amp
Transformation dans XL-1 Groupe 1 Groupe 2 Groupe 3 Groupe 4
a) pUC digéré traité à la phosphatase 0 2 529 900
+ insertion GFP
b) pUC digéré traité à la phosphatase 0 2 2 850
c) pUC digéré non traité à la 0 800 750 890
phosphatase
d) 10μl pUC (0.5 ng/μL) non digéré 0 500 500 500
e) Pas d’ADN 0 0 0 500
5’GTCGACGGCCTTCAGGCCT
3’CAGCTGCCGGAAGTCCGGA
CGAATTCACGTCGAC3’
GCTTAAGTGCAGCTG5’
Psy2
StuI Start

13
6. Quel groupe a obtenu le patron de résultats attendus/désirés?
7. Quel mélange de ligature serait attendu de donner le plus haut pourcentage de ligatures
intermoléculaire?
8. Comparer les réactions de ligatures « a » et « b ». Quel groupe a obtenu le plus haut
pourcentage de ligatures intramoléculaires?
9. Quelle était l’efficacité de transformation des cellules compétentes XL-1? Indiquer le nombre
de transformants attendu par microgramme d’ADN non digéré.
Considérez l’information suivante pour répondre aux questions 10-14:
Vous désirez faire le clonage directionnel du gène de la protéine de choc thermique du maïs (2 kb)
dans le vecteur pGAL. Vous devez choisir les sites de restriction que vous incluraient dans vos
amorces de PCR et que vous utiliserez pour digérer le vecteur pGAL (5 kb). Ci-dessous sont les
cartes du SCM de pGAL et la séquence qui code pour la protéine de choc thermique du maïs.
10. Quel site de restriction ajouteriez-vous à votre amorce « forward »?
11. Quel site de restriction ajouteriez-vous à votre amorce « reverse »?
12. Vous isolé le plasmide d’une colonie que vous croyez possède l’insertion d’intérêt. Pour
vérifier votre assomption, vous digérez le plasmide recombinant avec XhoI. Des fragments
de quelles tailles sont attendus?
13. Pour vérifier l’orientation de l’insertion dans le vecteur pGAL, vous faites une digestion du
recombinant positif avec SalI. Des fragments de quelles tailles vous attendez vous d’obtenir?
E S P X N
Site de clonage multiple de pGAL
E : EcoRI
N : NotI
P : PstI
S : SalI
X : XhoI
5’ATG TAG 3’
E S B X E
0.1 0.2 0.9 0.3 0.4 0.1
Carte de restriction du gène de a protéine de choc thermique

14
Considérez l’information suivante pour répondre aux questions 14-17:
Vous clonez un fragment d'ADN généré par une digestion EcoRI dans un site unique EcoRI d'un
vecteur. Vous identifiez un vecteur recombinant que vous croyez possède l'ADN d'intérêt. Pour
générer une carte de restriction du plasmide recombinant, vous prenez trois échantillons de
plasmide et les digérez avec EcoRI, HindIII, et EcoRI + HindIII. Vous faites ensuite migrer l'ADN
digéré sur un gel d'agarose pour voir les fragments. Le gel est ensuite soumis à une hybridation de
type Southern en utilisant l’insertion EcoRI comme sonde. Présumez que l’insertion est plus petite
que le vecteur.
14. Quel (s) fragment (s) sur le gel s’hybriderait (ent) à la sonde représentant l’insertion?
15. Quel (s) fragment (s) sur le gel s’hybriderait (ent) à une sonde représentant la bande de 5.3 kb
observée dans la voie EcoRI?
16. Quel (s) fragment (s) dans la voie EcoRI s’hybriderait (ent) à une sonde représentant la bande
de 2.7 kb observés dans la voie HindIII?
17. Quels nouveaux fragments seraient observés après une hybridation avec le fragment de 1.5 kb
d’un recombinant qui possède l’insertion dans l’orientation opposée?
Vous avez cloné une insertion d’approximativement 3 kb dans un site de restriction unique dans
le site de clonage multiple d’un vecteur. Les séquences partielles qui bordent le site de clonage
multiple (soulignés) et la séquence de l’insertion dans l’orientation voulue (en italique) sont
indiquées ci-dessous. Vous souhaitez utiliser la PCR de colonies sur divers clones pour identifier
ceux qui possèdent l’insertion dans la bonne orientation (tel qu’indiquée ci-dessous).
18. Quelles deux amorces pourriez-vous utiliser pour identifier les clones qui possèdent des
plasmides recombinants avec l’insertion dans la bonne orientation?
Amorces: (toutes les séquences sont écrites de 5’ à 3’)
A. GCAACGTGTA C. GTCTCGAGAT E. GCAACGTGTA
B. CCCATTCGCA D. TTCCATAGAG F. TAAGCGTGAA
5.3
4.1 2.7
1.5
0.4
1.1
2.3
3.0
EcoRI HindIII EcoRI + HindIII
3’- CGTTGCACAT TTAAGGCCACGTGC• • • • • • •CTTTACCTAAGTGCGAATGGGCATAACTGACCGAT • • • • • • AATGTTCCAT AGAGCTCTGTGA -5’
1 1500 3 000 │ │ │
Insertion

15
19. Vous souhaitez amplifier une séquence de 1 kb à partir d'un génome viral linéaire simple
brin de 10 kb. Pour ce faire, vous utilisez une amorce « forward » qui s’apparie aux
positions 1-25 et une amorce « reverse » qui s'apparie aux positions 975-1000. Combien
de cycles totaux faudrait-il pour obtenir 1µg d'amplicon à partir de 2ng d'ADN viral simple
brin?
20. Ci-dessous sont des schémas de molécules d'ADN double brin donc certain possèdent des
mésappariements ("P" représente un groupement 5’ phosphate) et des cassures simples
brin. Indiquez si l'ADN ligase pourrait fermer les cassures simples brins de façon efficace.
Partie II: Clonage (5 points/ question pour un total de 25 points)
1. Soumettre une figure de votre PCR du gène GFP. Inclure une légende qui inclut la taille
observée de l’amplicon. (Exercice 4)
2. Soumettre un tableau qui inclut les informations suivantes pour chacun des mélanges de
ligatures. Indiquez le nombre de transformants obtenu en tant que nombre de colonies /mL
pour chaque ligature ainsi que pour le vecteur non digéré.
Vecteur non digéré
Vecteur digéré non traité à la phosphatase
Vecteur digéré traité à la phosphatase
Vecteur digéré traité à la phosphatase + insertion GFP
3. Quelle était l’efficacité de transformation des cellules XL-1 fournie? Montrer votre calcul.
(Notez, 20 ng du vecteur pUC non digéré ont été utilisés pour la transformation de XL-1)
4. Soumettre une figure de votre analyse PCR de vos recombinants plasmidiques. Indiquez dans
votre légende de la figure la taille de l'amplicon observé. Expliquez brièvement si les tailles
obtenues sont celles attendues et si les résultats indiquent que l'amplicon a été cloné dans la
bonne orientation.
5. Soumettre une figure de votre électrophorèse sur gel d'agarose des digestions par enzyme de
restriction de votre plasmide recombinant. Indiquez dans votre légende de la figure la taille
des fragments observés. Expliquez brièvement si les tailles obtenues sont celles attendues et
si les résultats indiquent que l'amplicon a été cloné dans la bonne orientation.
..T-C-A-T-G-T-G-G-A-C-T-A G-T-C-C-T-G-G-G-A-C..
..A-G-T-A-C-A-C-C-T-G-A-T-C-A-G-G-A-C-C-C-T-G..
OH P
5’
5’
..T-C-A-T-G-T-G-G-A-C-T G-T-C-C-T-G-G-G-A-C..
..A-G-T-A-C-A-C-C-T-G-A-T-C-A-G-G-A-C-C-C-T-G..
OH P 5’
5’
..T-C-A-T-G-T-G-G-A-C-T-A A-T-C-C-T-G-G-G-A-C..
..A-G-T-A-C-A-C-C-T-G-A-T-C-A-G-G-A-C-C-C-T-G..
OH
5’
5’
P
..T-C-A-T-G-T-G-G-A-C-T-A G-T-C-C-T-G-G-G-A-C..
..A-G-T-A-C-A-C-C-T-G-A-T-C-A-G-G-A-C-C-C-T-G..
OH OH
5’
5’
A B
C D

16
Partie III: Bioinformatique 3 (2 points/ question pour un total de 15 points)
1.
Étape 1 : Obtenir la séquence inverse de la séquence avec le numéro d’accession NR_002716.
Étape 2 : Obtenir la séquence complémentaire de la séquence obtenue à l’étape 1.
Étape 3 : Obtenir la séquence inverse du complément de la de séquence obtenue à l’étape 2.
Étape 4 : Obtenir la séquence inverse de la séquence obtenue à l’étape 3.
Étape 5 : Obtenir la séquence complémentaire de la séquence obtenue à l’étape 4.
Indiquer les 20 premières bases de la séquence finale. Indiquer vos extrémités 5’ et 3’.
2. Quelle serait la séquence du complément inverse de la séquence suivante? Indiquer les
extrémités 5’ et 3’.
5’-GATCGGATCCCATCTTATC-3’
3. Cartographier les positions d’alignements de chacune des amorces suivantes sur la séquence
de pUC19.
A. CCTTGAAGATCAGTTGGGTGC
B. TTTCTTAGACGTCAGGTGGTG
C. GGGCGCGTTTCGGTGATGACG
D. AATACGGGATAATACCGCGCC
4. Quelles amorces indiquées dans la question précédente, s’il y en a, donneraient un produit
d’amplification d’au moins 200 pb?
5. Amplification de GFP: Dans l'exercice 3 de laboratoire, vous avez effectué une PCR pour
amplifier le gène de la GFP en utilisant pGFPuv en tant que matrice. Utilisez les connaissances
acquises en bioinformatique pour obtenir les informations suivantes:
Positions d’alignement des amorces « forward » et « reverse »
Taillle prédite de l’amplicon
Carte de restriction de l’amplicon pour les enzymes BamHI, EcoRI, and PstI
6. Clonage de GFP: Dans l'exercice 5 de laboratoire, vous avez effectué une PCR pour
amplifier le gène de la GFP de clones potentiellement positifs. Utilisez les connaissances
acquises en bioinformatique pour obtenir les informations suivantes:
Positions d’alignement des amorces « forward » et « reverse » utilisées pour le criblage des
recombinants. Notez, les amorces « reverse » doivent être alignées avec la séquence de
l’amplicon de GFP, tandis que l’amorce « forward » doit être alignée aven la séquence de
pUC.
o GFPSc-F1: AGCTCACTCATTAGGCACCCCAGGC
o GFPSc-R1: GTAGCGACCGGCGCTCAGTTGG
o GFPSc-R2: CCAACTGAGCGCCGGTCGCTAC
Taille prédite de l’amplicon.
Quelle paire (s) d'amorces devrait donner un produit d'amplification si vous avez cloné
avec succès la séquence GFP dans la bonne orientation?

17
7. Vous souhaitez cloner et exprimer la séquence codante (ARNm) complète de la prolactine
humaine (d'ATG en TAA) dans le site de clonage multiple d'un vecteur d'expression:
En utilisant les compétences que vous avez acquises en bioinformatique, concevez une paire
d'amorces qui vous permettraient d'amplifier la séquence codante de la prolactine (en commençant
par l'ATG et en terminant par le codon d'arrêt TAA). Vos amorces doivent également inclure la
séquence de sites de restriction appropriés pour le clonage directionnel et l'expression de
l'amplicon. Vos amorces doivent avoir une longueur de 15 bases incluant les sites de restriction.
Fournissez les informations suivantes:
Séquence d'amorce forward et site de restriction ajouté.
Séquence d'amorce inverse et site de restriction ajouté.
Taille attendue de l'amplicon.
Promoteur SCM
Bam
HI
Pst
I
Nd
eI

18
Devoir No 4
Partie I (2 points/ question pour un total de 30 points) 1. On vous a demandé d’amplifier par PCR une séquence spécifique à partir d'ADNc qui ont été
synthétisé de l'ARNm isolé de tissu cérébral. Après avoir migré votre réaction de PCR sur un
gel contenant du bromure d'éthidium, vous n’observez pas de bandes la lumière ultraviolette.
Pourquoi est-ce que ceci pourrait-il être le cas? Choisir toutes les réponses possibles.
A. Le gène qui vous intéresse n’est pas exprimé dans le tissu cérébral.
B. Un oligo dT plutôt qu’un oligo dA a été utilisé pour la synthèse du premier brin d’ADNc.
C. Une amorce spécifique dont la séquence est celle du brin non codant du gène a été utilisée
pour amorcer la synthèse du premier brin d’ADNc.
D. Vous avez utilisé la transcriptase inverse plutôt que la polymérase Taq pour la synthèse du
premier brin d’ADNc.
2. Vous faites la synthèse d’un premier brin d’ADNc à partir de trois molécules d’une matrice
d’ARNm (200 bases) avec une amorce oligo-dT. Des d’amorces « forward » et « reverse » (qui
recouvre les positions 560-900) sont utilisées pour la PCR subséquente. Combien de cycles de
PCR (n’incluant pas la réaction de RT) sont requis pour obtenir 48 molécules de produits avec
des extrémités définies par les amorces? C.A.D. les molécules double brin qui commence et
finissent aux sites de liaison des amorces, mais qui ne possèdent pas toute autre séquence.
3. Un brin du très petit gène Liliputien est indiqué ci-dessous avec les positions du codon
d’initiation et d’arrêt souligné. Ceci représente-t-il le brin sens ou antisens?
5’CAG GAC ATGC TTA TCG TAC TAT GGG TGC AAT GCC CAT TAA GGG TGC CAT ACC GAT GAT GCC TCA3’
4. Je désire utiliser le RT-PCR pour faire une copie de l’ARNm entier du gène Liliputian. Indiquer
la séquence d’une amorce de 6 nucléotides qui pourrait être utilisée pour la synthèse du premier
brin d’ADNc.
Considérez l’information suivante pour répondre aux questions 5-8:
Le gène lilliputien est induit par un facteur de 5 lorsque les cellules sont cultivées dans le glucose
comparativement à la croissance dans le glycérol. Pour étudier l'expression de ce gène, des RT-
PCR sont faite sur une souche de type sauvage et divers mutants. Des réactions de RT-PCR ont
été simultanément faites pour le gène lilliputien et le gène domestique; GAPDH. Une analyse
densitométrique a ensuite été réalisée. Les valeurs obtenues pour la souche sauvage cultivée en
glucose étaient 500 pour l’ARNm lilliputien et 250 pour l'ARNm de GAPDH. Indiquez les valeurs
densitométriques attendues pour l’ARNm lilliputien dans chacun des cas suivants:
5. Souche sauvage cultive dans du glycérol (Valeur de GAPDH = 100)
6. Souche mutante avec une mutation qui augmente l’activité du promoteur par un facteur de 2
cultivé dans du glycérol (Valeur de GAPDH = 500)
7. Souche mutante avec une mutation qui change le codon ATG à CTG cultivé dans du glycérol
(Valeur de GAPDH = 250)
8. Souche avec une mutation qui réprime l’activité du promoteur par un facteur de 5 cultivé dans
du glucose (Valeur de GAPDH = 500)

19
Considérez l’information suivante pour répondre aux questions 9-13:
La RT-PCR est une méthode de diagnostic couramment utilisé utilisée pour la détection des
infections par le VIH, causées par un virus à ARN. En bref, après une infection, le génome de
l'ARN viral est converti en un ADN double brin qui s’intègre dans le génome. Après l'intégration,
le virus peut rester en dormance pendant plusieurs années. Après son activation, l'ADN viral est
transcrit et initie le cycle réplicatif; se propageant de cellule à cellule. La figure suivante illustre
des réactions de RT-PCR effectuées sur le sang de différents individus. Les réactions ont été
réalisées en présence et en l'absence de transcriptase inverse dans le mélange réactionnel (+ RT et
-RT, respectivement). Des réactions RT simultanées ont été effectuées sur le gène domestique;
GAPDH.
9. Quel (s) individu(s) démontre l’amplification d’une séquence du VIH dérivé de l’ADN et non
de l’ARN?
10. Quel (s) individu(s) démontre (nt) l’amplification d’une séquence du VIH dérivé de l’ARN?
11. Quel (s) individu(s) démontre (nt) le plus haut niveau d’expression du VIH?
12. Quel individu possède plus de copies du VIH intégrées dans leur génome?
13. L'expérience ci-dessus a été répétée comme précédemment, mais sur des échantillons
préalablement traités à l’ADNase. Un des patrons observés est illustré ci-dessous. À quel (s)
individu (s) est-ce que ce patron pourrait correspondre?
14. Quelle polymérase pouvait lire la matrice suivante et synthétiser un brin complémentaire en
utilisant l’amorce 5’ ACCCTTAATGGG 3’? Choisissez toutes celles possibles.
5’- 5’UUCAGGACAUGCUUAUCGUACUAUGGGUGCAAUGCCCAUUAAGGGUGCCA-3’
A. Une polymérase ADN ADN dépendante
B. Une polymérase ARN ADN dépendante
C. Une polymérase ARN ARN dépendante
D. Une polymérase ADN ARN dépendante
15. Indiquez la séquence dans la direction 5 'à 3' des 6 premières bases qui seraient ajoutées à
l’amorce.
-RT +RT
GAPDH
VIH
-RT +RT -RT +RT -RT +RT -RT +RT
GAPDH
VIH
A B C D

20
Partie II : Expression génique - transcription (5 points/ question pour un total de 40
points)
1. Indiquez l’ABS260, l’ABS280 et le rapport ABS260 / ABS280 de votre préparation d'ARN.
2. Soumettre une figure du gel d'ARN fait dans le laboratoire ; d'exercice 6. Inclure une légende
appropriée.
3. Soumettre une figure du gel 1 de RT-PCR généré dans l'exercice 7. Inclure une légende
appropriée qui indique les tailles des produits observés dans chaque voie.
Ci-dessous est un gel des réactions de RT-PCR semblables à celles que vous avez effectuées dans
l'exercice 5. (Vous pouvez obtenir une copie de ces résultats sur la page Web de ce cours sous la
rubrique données> rt pcr)
4. Quel était le but du traitement à l’ADNase?
5. Quel était le but de la réaction de PCR de l’ARN qui n’a pas été traité avec de l’ADNase
ou de la RT?
6. Quelles sont les tailles des produits de PCR RT-dépendants et RT-indépendants?
7. Qu’est ce que la différence de taille entre les produits de PCR vous dit à propos du gène
duquel cet ARN est dérivé?
8. Soumettre une figure du gel 2 de RT-PCR généré dans l’exercice 7. Inclure une légende
appropriée qui indique les tailles des produits observés dans chaque voie.
E 1 2 3 4 5
Réaction Matrice
PCR-1 R (Étape I)
PCR-2 DR (Étape II)
PCR-3 RT-R (Étape III)
PCR-4 RT-DR (Étape III)
PCR-5 ADN génomique

21
Bioinformatique 4 & 5 (2 points/ question pour un total de 30 points) 1. Quel est le numéro d'accession du premier fichier nucléotidique pour l’ARNm de la
phospholipase A2 de Mus musculus?
2. Quel est le numéro d'accession du premier fichier nucléotidique pour l’ARNm de la
phospholipase A2 d’Alligator mississippiensis?
3. Quel est le numéro d'accession du premier fichier nucléotidique pour l’ARNm de la
phospholipase A2 de Canis lupus familiaris?
4. Quel est le pourcentage d'identité au niveau nucléotidique entre les gènes de l'hémoglobine de
chacune des paires d'organismes suivantes:
A. Phospholipase A2 d’Homo sapiens à Mus musculus
B. Phospholipase A2 d’Homo sapiens à Alligator mississippiensis
C. Phospholipase A2 d’Homo sapiens à Canis lupus familiaris
D. Phospholipase A2 de Mus musculus à Canis lupus familiaris
5. Quelle (s) paire de séquences, s’il y en a, sont des analogues?
6. Quelle (s) paire de séquences, s’il y en a, sont des orthologues?
7. Quel est le pourcentage d’identité au niveau protéique pour chacune des paires d’organismes
suivantes:
A. Phospholipase A2 d’Homo sapiens à Mus musculus
B. Phospholipase A2 d’Homo sapiens à Alligator mississippiensis
C. Phospholipase A2 d’Homo sapiens à Canis lupus familiaris
D. Phospholipase A2 de Mus musculus à Canis lupus familiaris
8. Quel est le numéro d'accession pour le fichier protéique de la « serine/threonine-protein
kinase » de Bos taurus?
9. Quel est le numéro d'accession pour le fichier protéique de la « serine/threonine-protein
kinase » de Mus musculus?
10. Quel est le numéro d'accession pour le fichier protéique de la « serine/threonine-protein
kinase » de Monoraphidium neglectum obtenu par une recherche générale?
11. Quelle paire de séquences d'acides aminés, s’il y en a, représente des analogues?
12. Quelle paire de séquences d'acides aminés, s’il y en a, représente des orthologues?
13. Quels sont les numéros d'accessions protéique et nucléotidique pour les homologues de
NP_002732 de Danio rerio?
14. Quel type d’homologue est-ce que les séquences nucléotidiques de NM_002741 et de Danio
rerio sont ?
15. Quel type d’homologue est-ce que les protéines de NP_002732 et de Danio rerio sont ?
16. La protéine inconnue de Danio rerio partage le plus haut degré d'identité avec quelle protéine
d’Homo sapiens? Indiquer le pourcentage d’identité et le « coverage ».

22
17. Quel est le nom du premier domaine qui est partagé entre la protéine inconnue de Danio rerio
et Homo sapiens?
18. La protéine duquel des différents organismes (Rattus norvegicus (Norway rat), Arabidopsis
thaliana (thale cress), et Escherichia coli) possède le plus haut niveau de similarité avec la
protéine de Danio rerio?
19. De quel organisme provient la séquence virale 1?
20. Quels est le nom du produit protéique et la fonction du plus long des ORFs de la séquence
virale 1?
21. Dans quel cadre de lecture est-ce que le plus long des ORF de la séquence virale 1 se retrouve?
22. Quel est le pourcentage d'identité entre l'ORF traduit du virus 1 et de la protéine la plus
étroitement liée d’un différent organisme?
23. Lorsque l'on compare l'ORF le plus long traduit de la séquence virale 1 à la protéine la plus
étroitement apparentée d’un différent organisme, quel est le pourcentage d’acides aminés qui
représente des substitutions conservées?
24. Quel snp est-ce que la séquence virale 2 a-t-elle acquise? Indiquer la position et le
changement de base. Ex. C118 à A.
25. Quel type de changement d'acide aminé, le cas échéant, est-ce que ce snp cause?

23
Devoir No 5
Partie I Consulter la description suivante pour répondre aux questions 1-6 (2 points/ question pour
un total de 50 points)
Ci-dessous sont les 210 paires de bases consécutives de l'ADN qui inclut le début de la séquence
du gène X. La séquence soulignée (position 20 à 54) représente le promoteur du gène X et la
séquence soulignée et en italiques (71-90) indique le site de liaison des ribosomes (RBS). La
transcription débute et inclut la paire de bases T / A à la position 60 (souligné).
1 10 20 30 40 50 60 70
I--------I---------I---------I---------I---------I---------I---------I
5’ ATCGGTCTCGGCTACTACATAAACGCGCGCATATATCGATATCTAGCTAGCTATCGGTCTAGGCTACTAC
3’ TAGCCAGAGCCGATGATGTATTTGCGCGCGTATATAGCTATAGATCGATCGATAGCCAGATCCGATGATG
80 90 100 110 120 130 140
I---------I---------I---------I---------I---------I---------I
5’ CAGGTATCGGTCTGATCTAGCTAGATGCTCTTCTCTCTCGAACCCGCGGGGGCTGTACTATCATGCGTCG
3’ GTCCATAGCCAGACTAGATCGATCTACGAGAAGAGAGAGCTTGGGCGCCCCCGACATGATAGTACGCAGC
150 160 170 180 190 200 210
---------I---------I---------I---------I---------I---------I---------I
5’ TCTCGGCTACTACGTAAACGCGCGCATATATCGATATCTAGCTAGCTATCGGTCTCGGCTACTACGTAAA
3’ AGAGCCGATGATGCATTTGCGCGCGTATATAGCTATAGATCGATCGATAGCCAGAGCCGATGATGCATTT
1. Quels sont les 6 premiers nucléotides de l’ARNm du gène X?
2. Quels sont les 4 premiers acides aminés codés par le gène X? Utiliser le code d’une lettre
d’acides aminés pour indiquer votre réponse. Ex. TRCG
3. Vous avez trouvé un mutant du gène X. La mutation représente un SNP qui change la paire de
base G/C à la position 110 (soulignés) à T/A. Est-ce que l'ARNm exprimé à partir de cette
version du gène X serait plus long, plus court ou le même que celui produit à partir du gène X
normal?
4. Si l’ARNm mutant peut être traduit, vous vous attendriez à ce que la protéine soit plus longue,
plus courte ou la même que celle produite à partir du gène X normal?
5. Vous avez trouvé un autre mutant du gène X. La mutation représente un indel qui retire la paire
de bases G/C à la position 110 (soulignés). Vous attendez-vous à ce que la protéine soit plus
longue, plus courte ou la même que celle produite à partir du gène X normal?
6. Quelle est la longueur de la région 5’ non traduite?
Promoteur
RBS

24
Consultez description suivante pour répondre aux questions 7-11
Le schéma suivant représente un gène de levure et ces différents éléments :
Indiquez les tailles prédites pour chacun des scénarios suivants :
7. Pre-ARNm (non traité)
8. ARNm
9. Protéine
10. ARNm d'un gène avec une mutation ponctuelle qui crée un codon d'arrêt à la position 1652
(1652-TAG-1654)
11. Masse atomique (kDa) d’une protéine d'un gène avec une mutation ponctuelle qui crée un
codon d'arrêt à la position 1652 (1652-TAG-1654)
12. Fred est marié à Helen, qui a déjà été mariée à George, maintenant décédé. George et Helen
ont conçu un enfant ensemble et ont adopté un enfant. Fred et Helen ont également conçu un
enfant. Tous les membres de la famille actuelle d’Helen ont eu des empreintes génétiques faites
d'un locus VNTR unique. Malheureusement, la feuille qui a identifié chaque enfant a été
égarée. Identifier les empreintes génétiques dans chaque voie (dans les voies 5, 6 et 7) qui
correspond à chaque enfant.
Enfant conçu par Fred et Helen Enfant ____
Promoteur
Site de terminaison de la transcription
Exon
Intron
ADN codant
ATG (510) TAG (2510) (2890) (2110) (1850) (1600) (1060) (200) (1)

25
Enfant conçu par George et Helen Enfant ____
Enfant adopté par George et Helen Enfant ____
Consultez la description suivante pour répondre aux questions 14-17
Ce schéma montre un transfert Southern de l'ADN génomique digéré
par enzyme de restriction d’une mère lutin (M) et le père lutin (F) et
ses quatre enfants lutins potentiels (C1 à C4) sondés avec une
séquence ADN VNTR. L'enzyme de restriction utilisée était NotI. Un
autre lutin (F2) prétend être le père de l'enfant C4. Supposons que la
mère, M, est la vraie mère de ces quatre enfants.
13. Quels enfants sont les enfants biologiques du père lutin (F)?
14. Quel (s) enfant (s), s’il y en a, pourrait (ent) être l’enfant (s) du
lutin F2?
15. D’après toutes les empreintes générées, quel est le nombre
minimum et maximum de locus qui sont examinés?
16. D’après le nombre de locus indiqué dans la question précédente,
le profil de père lutin (F) doit inclure un minimum de combien de locus homozygotes?
Consultez la description suivante pour répondre aux questions 17-21
Le schéma suivant montre la région d'un gène associé aux orteils poilus (OPO). Le phénotype des
orteils poilus est dû à des mutations récessives qui créent un RFLP qui abolit le site de restriction
HaeIII à la position 550 (les sites HaeIII sont indiqués par des flèches). Notez qu’il pourrait y avoir
d’autres snp, mais ceux-ci ne sont pas associés au phénotype des orteils poilus. Cette région du
génome a été examinée chez différents individus en effectuant une analyse de type Southern sur
des échantillons d'ADN génomique digéré par HaeIII et sondé avec un fragment d'ADN recouvrant
la région 425-650. Les résultats de l'hybridation sont présentés dans le tableau ci-dessous.
17. Quel (s) individu (s) possède (ent) un génotype qui leur attribuerait un phénotype d’orteils
poilus?
18. Quel (s) individu (s) possède (ent) un génotype qui leur attribuerait un phénotype normal?
19. Quel (s) individu (s) est (sont) porteur (s) du génotype des orteils poilus, mais a (ont) un
phénotype normal?
Individus Tailles des bandes observes (pb)
A 450 et 625
B 475, 300 et 150
C 300 et 150
D 475, 450 et 150
550 250 10 1075
700 75

26
20. Combien de différents allèles ont été décelés parmi les quatre individus?
21. Ci-dessous sont une partie des séquences de l’ARNm d’yfg1 et de trois variantes d’ARNm
d’yfg1 (A, B, et C) retrouvées dans les embryons des poissons-zèbres.
5’...GAUGAAAGAUCAGGUCUGAAUGUAU...3’ yfg1 ARNm
5’...GAUGGUUGAUCAGGUCUGAAUGUAU...3’ Variant A
5’...GAUGAAAGAUCACAUCUCAAUGUAU...3’ Variant B
5’...GAUGAAAGAUCAACUCUGAAUGUAU...3’ Variant C
Vous avez créé une sonde qui est complémentaire à 100% à la séquence de l'ARNm d’yfg1:
5’...TTCAGACCTGATCTTTCATC...3’. Vous hybrider la sonde à l'ARN total de poisson zèbre
à la température ambiante (20°C), puis ajuster la stringence par des lavages à 48°C. Lequel
(lesquels) des quatre ARNm demeureront hybridé après le lavage?
Indiquez comment chacune des conditions suivantes influencerait le Tm d’hybrides d’acides
nucléiques: Augmenter, diminuer ou aucun effet.
22. Augmenter la température
23. Augmenter la concentration de formamide
24. Un contenu G : C plus élevé
25. Vous souhaitez utiliser une sonde de 500 bases qui est 45% G / C pour effectuer une
hybridation à 40°C dans un tampon qui contient 0.2 M NaCl. En supposant 100% de
complémentarité, votre tampon d'hybridation doit contenir quel pourcentage maximal de
formamide? Présumez qu’une hybridation optimale serait à 10oC sous le Tm.

27
Partie II : (5 points/ question pour un total de 20 points)
Amplification of the yeast ADH gene as a function of stringency
1. Soumettre une figure de l’amplification du gene de l’ADH en fonctions des différentes
concentrations de K+ (tampon Taq) et de Mg++ (MgCl2). Inclure une légende appropriée.
2. Fournir une analyse des résultats présentés dans la question précédente. Votre analyse devrait
inclure les points suivants:
Quelles conditions représentent théoriquement les conditions de stringences les plus
élevées et les plus faibles? Expliquer votre raisonnement.
Comparer les conditions de stringences atteintes avec les différentes concentrations de
Mg++ comparativement à celles de K+.
Est-ce que les résultats obtenus se conforment aux premiers deux points? Pourquoi ou
pourquoi pas. Comparer les résultats attendus à ceux obtenus
Amplification par PCR du VNTR ApoC2
3. Soumettre une figure des profils de VNTR de la classe. Inclure une légende appropriée qui
inclut une brève analyse. Votre analyse devrait inclure les tailles des différents allèles observés
identifiés alpha numériquement, et si chaque individu et hétérozygote ou homozygote.
Amplification par PCR du RFLP ApoB
4. Soumettre une figure des profils RFLP de la classe. Inclure une légende appropriée qui inclut
une brève analyse. Votre analyse devrait inclure les différents allèles observés identifiés alpha
numériquement et si chaque individu et hétérozygote ou homozygote.

28
Partie III : Bioinformatique (2 points/ question pour un total de 30 points) Vous devriez maintenant être assez familier avec le site de NCBI et être en mesure de
compléter l'exercice suivant avec peu de directives. Considérez ceci comme une pratique
pour la partie de bioinformatique qui sera sur l'examen final.
Utilisez la séquence suivante pour répondre aux questions 1-8 CCATGAACCCTCCCTCTACAAAGGTCCCCTGGGCCGCCGTGACTCTGCTGCTGCTCCTCTTGTTGCCGCC
CGCGCTGCTGTCGCCCGGGGCGGCCGCGCAGCCCTTGCCCGACTGCTGCCGCCAGAAGACGTGCTCCTGC
CGCCTCTACGAGCTGCTGCACGGCGCGGGCAACCACGCGGCCGGCATCCTCACGCTGGGCAAGCGGCGGC
CCGGACCCCCGGGCCTCCAGGGCCGGCTGCAGCGCCTCCTGCAGGCCAGCGGCAACCATGCGGCCGGCAT
CCTGACCATGGGCCGCCGCGCAGGCGCAGAGCCAGCGCCGCGCCCCTGTCCCGGGCGCAGATGTCCCGTG
GTGGCCGTCCCCTCTGCAGCGCCTGGAGGGCGGTCGGGAGTCTGAGCTGACGCTCGCGCCGCGTCCTGGC
CCTGCCCTCTCCTCGCTGCCCGCCGGA
1. Quel est le nom de l’organisme et du gène (Non prédit) duquel cette séquence provient?
2. Quel est le numéro d'accession du premier fichier d’un homologue nucléotidique prédit de
Felis catus?
3. Quel est le nom du produit protéique codé par la séquence de Felis catus?
4. Quel est le pourcentage d’identité entre le produit protéique de Felis catus est le produit
protéique codé par le gène trouvé dans la question 1?
5. Quelle est la description d'un domaine conservé associé à la protéine de Felis catus?
6. La séquence provenant de l'organisme de la question 1 a été clonée dans le site BamHI de
pUC19. Quelles sont les tailles de fragments attendues à la suite d'une digestion avec PstI de
recombinants contenant l'insertion d'intérêt dans l'une ou l'autre orientation?
7. Laquelle de ces amorces pourrait être utilisée pour une réaction de transcriptase inverse sur
l’ARNm de Felis catus?
A. AGACGAGTCTCTGTTAGTGAA
B. TTCACTAACAGAGACTCGTTG
C. GGAACTTTGAGGCTGTTGACT
D. ACTAGGAGAGGGCAGGGTCA
8. En utilisant la séquence initiale en tant que requête traduite pour une recherche de la base de
donnée protéique, quel organisme d’un différent genre possède la protéine la plus semblable
avec une fonction similaire ?
9. Une hybridation Southern a été effectuée sur de l'ADN génomique d'un nouveau variant du
virus de l'hépatite B digéré par HincII. L'ADN digéré a été sondé avec la région correspondant
aux bases 807 - 1894 du génome original de l'hépatite B (numéro d'accession NC_003977).
L'hybridation Southern a révélé des bandes de 1465 bases et 483 bases. Quelle (s) bande (s)
était (ent) inattendue?
10. Tenez compte des informations fournies dans la question précédente. La (les) mutation (s) a
(ont) probablement eu lieu dans le gène codant pour quelle protéine du virus de l'hépatite B?

29
Référez-vous au fichier avec le numéro d’accession NM_010030 pour répondre aux
questions 11-15
11. Quel est le numéro d’accession du premier homologue nucléotidique de Mus musculus de cette
séquence?
12. Quel type d’homologues est-ce que les protéines codées par la séquence de requête originale
et celle obtenue à la question 11 sont?
13. Quel est le pourcentage d’acides aminés identiques entre les deux protéines de la question
précédente?
14. Quel type de substitution d’acides aminés est le plus abondant entre les deux homologues
(question 12)?
15. La séquence suivante : GGACCGTCTTCCTCCTGTTTACCGAGACTGTGTCAT représente
la séquence originale, la séquence inverse, le complément, ou l’inverse du complément de la
séquence avec le numéro d’accession NM_010030?


















