Cours de Bioinformatique Appliquée (Partie 1)gorlier.no-ip.org/archives/semestre3/BIO6_1.pdf · 5...
31
1 Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II Horaires TD 5 groupes (11, 12, 13, 14, 15-BIM) Séance 1 -Lundi 15 Sept 8-12h (14,15-BIM) -Mardi 16 Sept 8-12h (11,12,13) Séance 2 -Lundi 22 Sept 8-12h (14,15-BIM) -Mardi 23 Sept 8-12h (11,12,13) Séance 3 -Lundi 29 Sept 8-12h (14,15-BIM) -Mardi 30 Sept 8-12h (11,12,13) Séance 4 -Lundi 06 Oct 8-12h (14,15-BIM) -Mardi 07 Oct 8-12h (11,12,13) Etudiants non inscrits à luminy???? Enseignement de Bioinformatique Appliquée CM 10h – TD 16h (4 séances de 4h) – Travail Personnel 8h Horaires de CM -08 Sept 14-16h -09 Sept 10-12h -15 Sept 14-16h -22 Sept 14-16h -29 Sept 14-16h Travail Personnel -Rapport de TD -Libre service informatique -Clinique pédagogique (Salle 1er étage BU) Supports de CM et TD http://biologie.univ-mrs.fr/ [email protected] Cours de Bioinformatique Appliquée (Partie 1) Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II
-
Upload
hoangthien -
Category
Documents
-
view
217 -
download
0
Transcript of Cours de Bioinformatique Appliquée (Partie 1)gorlier.no-ip.org/archives/semestre3/BIO6_1.pdf · 5...

1
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II
Horaires TD5 groupes (11, 12, 13, 14, 15-BIM)Séance 1
-Lundi 15 Sept 8-12h (14,15-BIM)-Mardi 16 Sept 8-12h (11,12,13)
Séance 2-Lundi 22 Sept 8-12h (14,15-BIM)-Mardi 23 Sept 8-12h (11,12,13)
Séance 3-Lundi 29 Sept 8-12h (14,15-BIM)-Mardi 30 Sept 8-12h (11,12,13)
Séance 4-Lundi 06 Oct 8-12h (14,15-BIM)-Mardi 07 Oct 8-12h (11,12,13)
Etudiants non inscrits à luminy????
Enseignement de Bioinformatique AppliquéeCM 10h – TD 16h (4 séances de 4h) – Travail Personnel 8h
Horaires de CM-08 Sept 14-16h-09 Sept 10-12h-15 Sept 14-16h-22 Sept 14-16h-29 Sept 14-16h
Travail Personnel-Rapport de TD-Libre service informatique-Clinique pédagogique(Salle 1er étage BU)
Supports de CM et TDhttp://biologie.univ-mrs.fr/
Cours de Bioinformatique Appliquée(Partie 1)
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II

2
Qu’est-ce que la bioinformatique?
▪ Acquisition des données (décoder les régions importantes des génomes)(Séquençage et Annotation des génomes)
▪ Archivage, Stockage et Diffusion des données biologiques(Banques et bases de données)
▪ Recherche, Analyse, Interpretation et Exploitation des données(Processus automatisés => algorithmes spécifiques)(Prédiction fonctionnelle)
� Domaine interdisciplinaire basé sur les acquis de la biologie, des mathématiques et de l’informatique. Biologie « in silico ». C’est une discipline en pleine révolution. Au coeur de cette révolution, l’informatique joue un rôle central pour :
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II
Bioinformatiques
▪ Bioinfo de paillassesupport au clonage,séquençage,& PCR...
▪ Analyse des séquencesidentification gènes,comparaisons de séquences,prédiction motifs...
▪ Phylogénieévolution à l'échellemoléculaire...
▪ Structure des protéinescalcul,visualisation,prédiction...
▪ Liaison génétiquegènes candidats de maladiesgénétiques...
▪ Génomique fonctionnelletranscriptome,protéome,interactome...
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II

3
Deux définitions possibles
Elle est surtout utilisée pour:
▪Applications de l’informatique à la biologie(computational biology)
▪Analyse de l’information biologique(bioinformatics)
▪L’identification des gènes
▪La prédiction fonctionnelle de ces gènes
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II
Repères historiques (1)1953: Structure en double hélice de l ’ADN (Watson-Crick)
1956: Séquence en acides aminés de la première protéine: insuline (Sanger)
1958:Première structure 3D de protéine (myoglobine, Kendrew)
1955-1965: Premiers langages informatiques, premier ordinateur commercial
1965:Première compilation de protéines Atlas of Protein Sequences(50 entrées) M. Dayhoff (Imprimé jusqu’en 1978, puis format électronique PIR-PSD)
1970: 1er programme pour la comparaison de séquences protéiquesAlignement optimal entre deux séquences (Needleman & Wunsh)
1971:PDB - Protein Data Bank (structures 3D macromolécules)
1974: Algorithme de prédiction de structure secondaire de protéineChou-Fasman
1977: Mise au point des techniques de séquençage de l’ADN
1978:Matrice de substitution (PAM) (Dayhoff et. al.)
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II

4
Repères historiques (2)
1980: Constitution des banques de données: EMBL (Heidelberg -> Cambridge (EBI))
1981: Similarités de séquences dans les banques (Smith & Waterman)
1984: Logiciel d’analyse de séquence (UW GCG)Devereux et. al.
1985:CABIOS (première revue de bioinformatique)
1986:Swiss-Prot(A. Bairoch) SIB: Swiss Institute of bioinformatics
1986:Genbank(Los Alamos NIH (National Institute of Health))
1987: Genbank, EMBL et DDBJ s’échangent leur contenu et adoptent un système de conventions communes (The DDBJ/EMBL/Genbank feature Table Definition)
1988:Processus de double publication. Dépôt des séquences dans une banque avant soumission de l’article associé aux revues scientifiques.
1988: FASTA - Sim. de séq. dans les banquesPearson & Lipman
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II
Repères historiques (3)
1988-90: Lancement du programme international de séquençage Génome Humain (HUGO)
1988: Double publication des séquences (banque puis publication avec AC)
1989: Internet
1990: BLAST – Sim. de séq. dans les banquesAtschul et. al.
1991: Prédiction struct. III protéinesBowie et. al.
1992: Création du centre de séquençage Sanger (moitié de la "production" mondiale)
1993: GeneMark - Programme de Prédiction gènes génomes bactériensBorodovsky et. al.
1995: Séquençage 'shotgun' génome Haemophilus1.8MbVenter et. al.
1996: Séquençage du 1er génome eucaryote, Saccharomyces cerevisiae(12 Mb) Goffeau et al.
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II

5
Repères historiques (4)
1997: Clonage de la brebis Dolly.
1997: PFam - Banque de domaines protéiquesSonnhammer et. al.
1997: GENSCAN - Prédiction gènes génomes eucaryotesBurge et. al.
1998: Séquençage du 1er organisme pluricellulaire, Caenorhabditis elegans(120 MB)
1999: Publication de la séquence complète du chromosome 22
2000: -Publication du "working draft" (brouillon) de la p remière carte complète du génomehumain (3000 MB).
-Séquençage du 1er génome de plante, Arabidopsis thaliana
2001: Publication des travaux de séquençage du génome humain presque complet.
2002: Projet protéome humain (HPP)
2003: Séquençage de plusieurs organismes eucaryotes
2006: Séquençage à très grande échelle (454 flex technology, Solexa technology)Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II
Plan du cours
I. Les banques de données en biologie1. Généralités2. Les banques de données bibliographiques3. Les banques de séquences4. Centres de ressources5. Les systèmes d’interrogation des banques
II. Analyse de séquences1. Introduction2. Analyse d’une séquence3. Comparaison de 2 séquences4. Recherche de protéines homologues
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II

6
Banques de données/ Bases de données
� Collection de données (séquence, format, structure) en « fichier texte »:
• organisation séquentielle des données� Format simple, lisible
� Pas facilement interrogeable.� Données portables dans différents environnements informatiques
BanquesBanques
� Notion de tables (objet défini) et de relations entre les tables
� Modélisation avec liens logiques entre les données (sans redondance)
� Requêtes multicritères (langage de requêtes et de manipulation de données)
� Exploitées à l’aide de Systèmes de Gestion de Bases de Données (SGBD)
BasesBases
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II
Rôle des banques/bases de données
Collecter les informationsCollecter les informations- séquences, cartographie physique, génétique…- données structurales, relationnelles…- auprès de: biologistes, littératures, autres bases de données
Stocker et organiserStocker et organiser - logique cohérente
Distribuer l’informationDistribuer l’information - large diffusion (libre, Internet)
Faciliter l’exploitationFaciliter l’exploitation- interface conviviales- définition des critères de recherche- comparaison de données
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II

7
Banque/Base de données bibliographiques (Pubmed)
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II
Natio
nal C
enter fo
r Bio
techn
olo
gy
Info
rmatio
n
Banque/Base de données bibliographiques (Pubmed)
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II

8
Banque/Base de données bibliographiques (Pubmed)
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II
Banque/Base de données bibliographiques (Pubmed)
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II

9
Les banques généralistes
Bibliothèques de fiches descriptives (entrées) de séquences nucléiques ou protéiques, quelque soit l'organisme dont elles sont issues, et quelle que soit leur nature (ADN, ADNc, ARN, protéine).
Bibliothèques de fiches descriptives (entrées) de séquences nucléiques ou protéiques, quelque soit l'organisme dont elles sont issues, et quelle que soit leur nature (ADN, ADNc, ARN, protéine).
Mission: Rendre publiques les données issues des fonds publics, donc collectivesMission: Rendre publiques les données issues des fonds publics, donc collectives
Elles contiennent sous forme de commentaires structurés des informations variées, issues d'expertises biologiques ou d'analyses bioinformatiques (annotation).
Elles contiennent sous forme de commentaires structurés des informations variées, issues d'expertises biologiques ou d'analyses bioinformatiques (annotation).
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II
Les banques nucléiques
Les 3 banques nucléotidiques principales coexistent et coopèrent: • Elles collectent des informations de séquences (associées ou non à une publication) par soumission directe des auteurs (95% de l'ensemble des données) mais également par balayage systématique de la littérature scientifique (principalement les brevets).
Les 3 banques nucléotidiques principales coexistent et coopèrent: • Elles collectent des informations de séquences (associées ou non à une publication) par soumission directe des auteurs (95% de l'ensemble des données) mais également par balayage systématique de la littérature scientifique (principalement les brevets).
Chaque enregistrement ou « entrée » correspond à une séquence nucléique. Chaque enregistrement ou « entrée » correspond à une séquence nucléique.
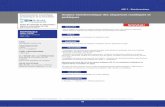
EMBL: Banque européenne créée en 1980 (Heidelberg, DE) et financée par l'EMBO (European Moleculary Biology Organisation), elle est aujourd'hui diffusée par l'EBI (European Bioinformatics Institute, Cambridge, GB)
Genbank: Créée en 1982 par la société IntelliGenetics (Los Alamos, US) et diffusée maintenant par le NCBI (National Center for Biotechnology Information, Bethesda, US)
DDBJ (DNA Data Bank of Japan) : Créée en 1986 et diffusée par le NIG (National Institute of Genetics, Japon).
Depuis 1987, ces banques échangent quotidiennement leurs fichiers afin de garantir dans chacune d'elles un ensemble de données le plus complet possible. Depuis 1987, ces banques échangent quotidiennement leurs fichiers afin de garantir dans chacune d'elles un ensemble de données le plus complet possible.
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II

10
EMBL = GENBANK = DDBJ
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II
Organisation de l’information
• des informations relatives à la séquence (annotation)• la séquence elle-même
Format généralFormat général• « flat file» ou fichier plat • les banques sont distribuées sous forme de fichiers texte (ASCII)• les données sont organisées séquentiellement
2 parties dans une fiche2 parties dans une fiche
Les champsLes champs• ils facilitent l’accès à l’information• chaque champ regroupe des informations de même type
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II
Les séquences biologiques sont souvent:-redondantes-dispersées dans différentes banques de données-ont des nomenclatures diverses et variées (synonymes)
Pour identifier ces séquences, les différentes banques de données leur assignent des Numéros d'Accessionuniquesau sein de leurs collections respectives. Pour pointer sans ambiguité sur un tel objet, on utilise la notation:
Banque:NuméroAccession

11
Les champs d’une fiche: EMBL
ID AF199028 standard; mRNA; HUM; 1009 BP.XXAC AF199028 ;XXSV AF199028.1XXDT 20-JUL-2000 (Rel. 64, Created)DT 20-JUL-2000 (Rel. 64, Last updated, Version 1)XXDE Homo sapiens B7-like protein (GL50) mRNA, comp lete cds.XXKW .XXOS Homo sapiens (human)OC Eukaryota; Metazoa; Chordata; Craniata; Verteb rata; Euteleostomi; Mammalia;OC Eutheria; Primates; Catarrhini; Hominidae; Hom o.XXRN [1]RP 1-1009RX MEDLINE; 20126021.RX PUBMED; 10657606.RA Ling V., Wu P.W., Finnerty H.F., Bean K.M., Sp aulding V., Fouser L.A.,RA Leonard J.P., Hunter S.E., Zollner R., Thomas J .L., Miyashiro J.S.,RA Jacobs K.A., Collins M.;RT "Identification of GL50, a novel B7-like protei n that functionally binds toRT ICOS receptor";RL J. Immunol. 164(4):1653-1657(2000).XXRN [2]RP 1-1009RA Ling V.;RT ;RL Submitted (26-OCT-1999) to the EMBL/GenBank/DDB J databases.RL Immunology, Genetics Institute, 87 CambridgePa rk Drive, Cambridge, MARL 02140, USAXXDR GOA; O75144.DR SWISS-PROT; O75144; ICOL_HUMAN.XXFH Key Location/QualifiersFH
IdentifiantIdentifiant
DescriptionDescription
Classification taxonomiqueClassification taxonomique
OrganismeOrganisme
RéférencesRéférences
Mots clésMots clés
Références croiséesRéférences croisées
Numéro d’accessionNuméro d’accession
Code à 2 lettres Nature Division
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II
Ann
otat
ion
FT source 1..1009FT /db_xref="taxon:9606"FT /mol_type="mRNA"FT /organism="Homo sapiens"FT /cell_type="peripheral blood lym phocyte"FT CDS 24..953FT /codon_start=1FT /db_xref="GOA:O75144"FT /db_xref="SWISS-PROT:O75144"FT /note="ICOS-ligand"FT /gene="GL50"FT /product="B7-like protein"FT /protein_id="AAF34739.1"FT /translation="MRLGSPGLLFLLFSSL RADTQEKEVRAMVGSDVELSCACPEGSRFFT DLNDVYVYWQTSESKTVVTYHIPQNSSLEN VDSRYRNRALMSPAGMLRGDFSLRLFNVTFT PQDEQKFHCLVLSQSLGFQEVLSVEVTLHV AANFSVPVVSAPHSPSQDELTFTCTSINGFT YPRPNVYWINKTDNSLLDQALQNDTVFLNM RGLYDVVSVLRIARTPSVNIGCCIENVLLFT QQNLTVGSQTGNDIGERDKITENPVSTGEK NAATWSILAVLCLLVVVAVAIGWVCRDRCFT LQHSYAGAWAVSPETELTESWNLLLLLS"XXSQ Sequence 1009 BP; 232 A; 289 C; 281 G; 207 T; 0 other;
ggcccgaggt ctccgcccgc accatgcggc tgggcagtcc tggactgctc t tcctgctct 60tcagcagcct tcgagctgat actcaggaga aggaagtcag agcgatggta g gcagcgacg 120tggagctcag ctgcgcttgc cctgaaggaa gccgttttga tttaaatgat g tttacgtat 180attggcaaac cagtgagtcg aaaaccgtgg tgacctacca catcccacag a acagctcct 240tggaaaacgt ggacagccgc taccggaacc gagccctgat gtcaccggcc g gcatgctgc 300ggggcgactt ctccctgcgc ttgttcaacg tcacccccca ggacgagcag a agtttcact 360gcctggtgtt gagccaatcc ctgggattcc aggaggtttt gagcgttgag g ttacactgc 420atgtggcagc aaacttcagc gtgcccgtcg tcagcgcccc ccacagcccc t cccaggatg 480agctcacctt cacgtgtaca tccataaacg gctaccccag gcccaacgtg t actggatca 540ataagacgga caacagcctg ctggaccagg ctctgcagaa tgacaccgtc t tcttgaaca 600tgcggggctt gtatgacgtg gtcagcgtgc tgaggatcgc acggaccccc a gcgtgaaca 660ttggctgctg catagagaac gtgcttctgc agcagaacct gactgtcggc a gccagacag 720gaaatgacat cggagagaga gacaagatca cagagaatcc agtcagtacc g gcgagaaaa 780acgcggccac gtggagcatc ctggctgtcc tgtgcctgct tgtggtcgtg g cggtggcca 840taggctgggt gtgcagggac cgatgcctcc aacacagcta tgcaggtgcc t gggctgtga 900gtccggagac agagctcact gaatcctgga acctgctcct tctgctctcg t gactgactg 960tgttctctat gcaacttcca ataaaacctc ttcatttgaa aaaaaaaaa 10 09
//
SéquenceSéquence
Fin ficheFin fiche
CaractéristiquesCaractéristiques
Séquence « header »Séquence « header »
Les champs d’une fiche: EMBL
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II
Ann
otat
ion
Seq
uenc
e

12
IdentifiantIdentifiant
OrganismeOrganisme
RéférencesRéférences
LOCUS AF199028 1009 bp mRNA linear PRI 17-FEB-2000DEFINITION Homo sapiens B7-like protein (GL50) mRN A, complete cds.ACCESSION AF199028VERSION AF199028.1 GI:6983943KEYWORDS .SOURCE Homo sapiens (human)
ORGANISM Homo sapiensEukaryota; Metazoa; Chordata; Craniata; Vertebrata; Euteleostomi;Mammalia; Eutheria; Primates; Catarrhini; Hominidae ; Homo.
REFERENCE 1 (bases 1 to 1009)AUTHORS Ling,V., Wu,P.W., Finnerty,H.F., Bean,K.M ., Spaulding,V.,
Fouser,L.A., Leonard,J.P., Hunter,S.E., Zollner,R., Thomas,J.L.,Miyashiro,J.S., Jacobs,K.A. and Collins,M.
TITLE Cutting edge: identification of GL50, a no vel B7-like protein thatfunctionally binds to ICOS receptor
JOURNAL J. Immunol. 164 (4), 1653-1657 (2000)MEDLINE 20126021
PUBMED 10657606REFERENCE 2 (bases 1 to 1009)
AUTHORS Ling,V.TITLE Direct SubmissionJOURNAL Submitted (26-OCT-1999) Immunology, Geneti cs Institute, 87
FEATURES Location/Qualifierssource 1..1009
/organism="Homo sapiens"/mol_type="mRNA"/db_xref="taxon:9606"/cell_type="peripheral blood lymphocyte"
gene 1..1009/gene="GL50"
CDS 24..953/gene="GL50"/note="ICOS-ligand"/codon_start=1/product="B7-like protein"/protein_id="AAF34739.1"/db_xref="GI:6983944"/translation="MRLGSPGLLFLLFSSLRADTQEKEVRAMVGSDVELSCACPEGSRFDLNDVYVYWQTSESKTVVTYHIPQNSSLENVDSRYRNRALMSPAGMLRGDFSLRLFNVTPQDEQKFHCLVLSQSLGFQEVLSVEVTLHVAANFSVPVVSAPHSPSQDELTFTCTSINGYPRPNVYWINKTDNSLLDQALQNDTVFLNMRGLYDVVSVLRIARTPSVNIGCCIENVLLQQNLTVGSQTGNDIGERDKITENPVSTGEKNAATWSILAVLCLLVVVAVAIGWVCRDRCLQHSYAGAWAVSPETELTESWNLLLLLS"
CaractéristiquesCaractéristiques
Classification taxonomiqueClassification taxonomique
Numéro d’accessionNuméro d’accession
Les champs d’une fiche: GENBANKNature
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II
BASE COUNT 232 a 289 c 281 g 207 tORIGIN
1 ggcccgaggt ctccgcccgc accatgcggc tgggcagtcc tggactgct c ttcctgctct61 tcagcagcct tcgagctgat actcaggaga aggaagtcag agcgatgg ta ggcagcgacg
121 tggagctcag ctgcgcttgc cctgaaggaa gccgttttga tttaaat gat gtttacgtat181 attggcaaac cagtgagtcg aaaaccgtgg tgacctacca catccca cag aacagctcct241 tggaaaacgt ggacagccgc taccggaacc gagccctgat gtcaccg gcc ggcatgctgc301 ggggcgactt ctccctgcgc ttgttcaacg tcacccccca ggacgag cag aagtttcact361 gcctggtgtt gagccaatcc ctgggattcc aggaggtttt gagcgtt gag gttacactgc421 atgtggcagc aaacttcagc gtgcccgtcg tcagcgcccc ccacagc ccc tcccaggatg481 agctcacctt cacgtgtaca tccataaacg gctaccccag gcccaac gtg tactggatca541 ataagacgga caacagcctg ctggaccagg ctctgcagaa tgacacc gtc ttcttgaaca601 tgcggggctt gtatgacgtg gtcagcgtgc tgaggatcgc acggacc ccc agcgtgaaca661 ttggctgctg catagagaac gtgcttctgc agcagaacct gactgtc ggc agccagacag721 gaaatgacat cggagagaga gacaagatca cagagaatcc agtcagt acc ggcgagaaaa781 acgcggccac gtggagcatc ctggctgtcc tgtgcctgct tgtggtc gtg gcggtggcca841 taggctgggt gtgcagggac cgatgcctcc aacacagcta tgcaggt gcc tgggctgtga901 gtccggagac agagctcact gaatcctgga acctgctcct tctgctc tcg tgactgactg961 tgttctctat gcaacttcca ataaaacctc ttcatttgaa aaaaaaa aa
//
SéquenceSéquence
Fin ficheFin fiche
Les champs d’une fiche: GENBANK
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II
13
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II
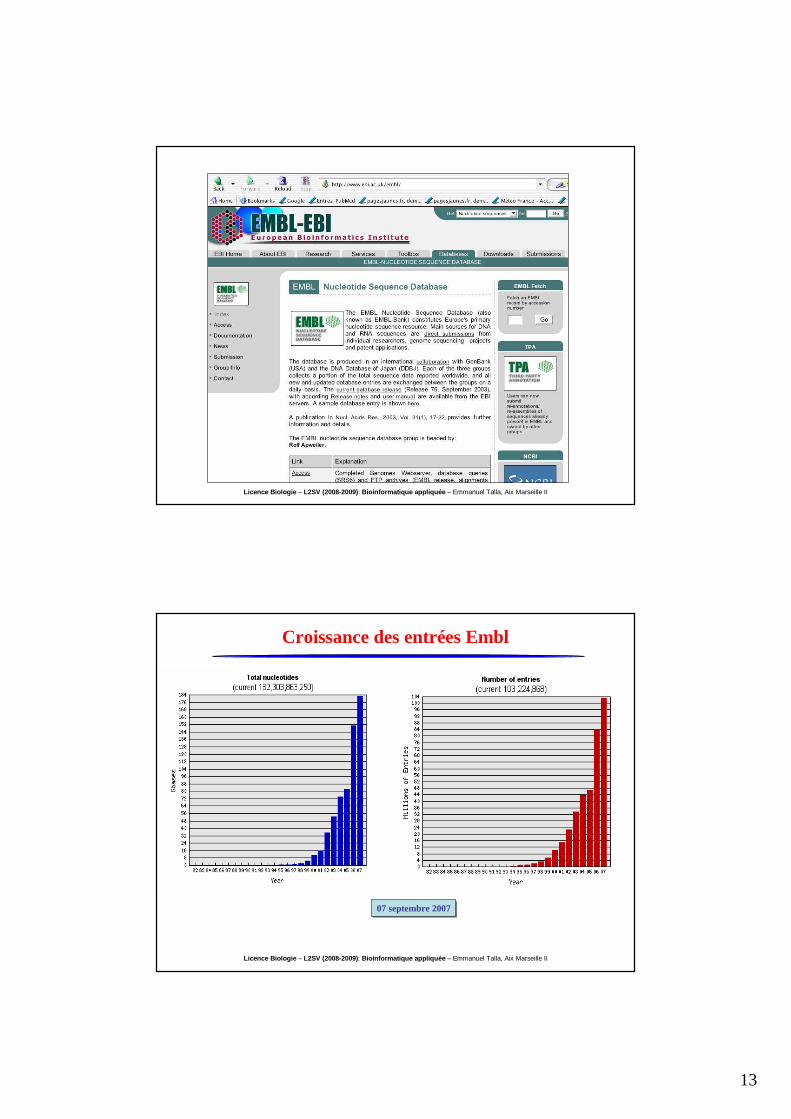
Croissance des entrées Embl
07 septembre 200707 septembre 2007
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II

14
Origine des entrées Embl
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II
Origine géographique des entrées Embl
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II

15
FT source 1..124FT /db_xref="taxon:4097"FT /organelle="plastid:chloroplast"FT /organism="Nicotiana tabacum"FT /isolate="Cuban cahibo cigar, gift from President Fidel Castro"
Quelques surprises !
Informations inattenduesInformations inattendues
Ou encoreOu encore
FT source 1..17084FT /chromosome="complete mitochondrial genome"FT /db_xref="taxon:9267"FT /organelle="mitochondrion"FT /organism="Didelphis virginiana"FT /dev_stage="adult"FT /isolate="fresh road killed individual "FT /tissue_type="liver"
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II
« Défauts» des banques nucléiques
Aucun contrôle des banques:Aucun contrôle des banques:
Hétérogénéité:Hétérogénéité:
Variabilité de l'état des connaissances sur les séquences:
Variabilité de l'état des connaissances sur les séquences:
Erreurs dans les séquences (qualité inégale):Erreurs dans les séquences (qualité inégale):
Redondance des données: plusieurs entrées pour une même séquenceRedondance des données: plusieurs entrées pour une même séquence
• ADN nucléaire, mitochondrial, chloroplastique, ARNm, ARNt, ARNs, ARNr, chromosomes entiers ... • gènes, fragments … (10 bp à 350000 bp)
• Annotation effectuée ou non• Annotation hétérogènes: automatique ou expérimentale
• origine du fragment • cultures infectés• présence de séquences de vecteurs de clonage • erreurs de saisie
• Certains gènes sont séquencés à la fois sous forme d'ARNm et de fragments génomiques.• Certaines séquences ont été saisies plusieurs fois dans la banque.
• les auteurs sont responsables de la qualité des séquences soumises.
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II

16
Les banques protéiques
• Données expérimentales: isolation, séquençage
• Données in silico: déduction à partir de la séquence nucléique par
�Simple traduction automatique (ex: TrEmbl)
�Traduction avec une expertise manuelle (ex: Swissprot)
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II
Les banques issues de la traduction des banques nucléiques
TrEMBL: distribuée par l'EBI . Contient la traduction des parties codantes (CDS) des séquences nucléotidiques stockées dans EMBL à l'exception de celles déjà présentes dans SWISSPROT.
GenPept: distribuée par Frederick Biomedical Supercomputing Center. Ce n’est pas une banque officielle du «NCBI-GenBank». Contient la traduction de tous les CDS de GenBank.
NRprot: distribuée par le NCBI. Réunion de plusieurs banques: SwissProt, Nrl-3D, PIR, Genpept, en ne gardant qu'un exemplaire des séquences strictement identiques.
TrEMBL et GenPeptTrEMBL et GenPept • les séquences protéiques traduites automatiquement des séquences dites codantes dans EMBL et GenBank.
ATTENTION:-Si les Banques nucléotidiques contiennent des séquences non vérifiées, les
séquences protéiques et annotations peuvent également contenir des erreurs de prédictions des CDS, d’annotations.
ATTENTION:-Si les Banques nucléotidiques contiennent des séquences non vérifiées, les
séquences protéiques et annotations peuvent également contenir des erreurs de prédictions des CDS, d’annotations.
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II

17
PIR-PSDPIR-PSD• Protein Information Resource - Protein Sequence Database• Création en 1984 (anciennement l'Atlas of Protein Sequences Dayhoff). • Collaboration entre le Munich Information Center for Protein Sequence (MIPS) et le Japan International Protein Information Database(JIPID).
• Non-redundant REFerence protein database• Les données sont issues de la littérature, des soumissions directes (PIR-PSD, SwissProt, RefSeq, GenPept, and PDB) et de la traduction des séquences nucléiques issues des banques nucléiques (EMBL, GenBank, DDBJ).
SwissProtSwissProt • Création en 1986 par Amos Bairoch au SIB de Genève• Collaboration entre l'EMBL et l'Institut Suisse de Bioinformatique
PIR-NREFPIR-NREF
Exp
ertis
e m
anue
lle/e
xpér
imen
tale
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II
Les banques issues de la traduction des banques nucléiques(avec expertise manuelle / expérimentale)
EMBLflatfile
Traduction des CDS et format
SWISS-PROT
TrEMBL REM-TrEMBL
SP-TrEMBL
Elimination de la redondance
(Match identiques,fragment inclu dans une autre séquence,variantes,conflits…)
Annotation Automatique (Prosite,PFAM,
Rulebase, ENZYME,MGD, Flybase…)
SWISS-PROT
(Immunoglobulines, récepteurs T, CMH, brevet, pseudogènes, séquences tronquées, gènes artificiels, synthétiques ou chimériques, pseudo-gènes)
Annotation Manuelle
SwissProt / TrEMBLUniProt = SwissProt + TrEMBL + PIR
392667 entrées(22 juillet 2008)
6070084 entrées(22 juillet 2008)
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II

18
SwissProt
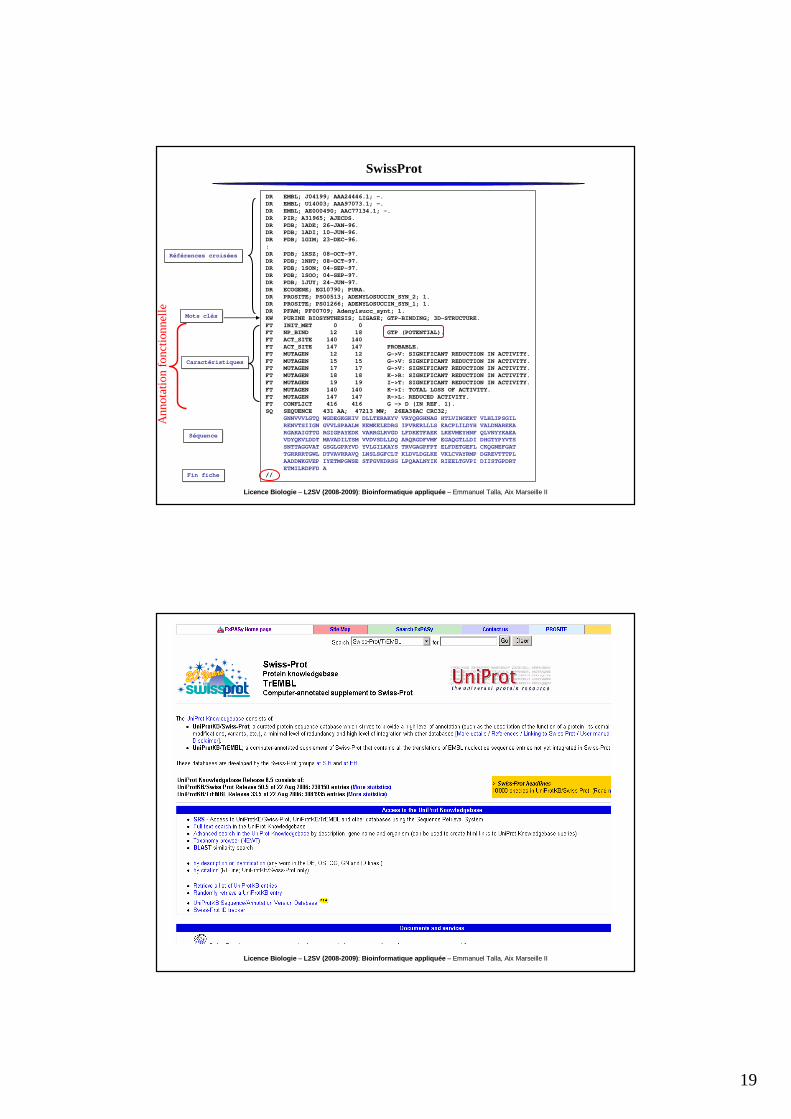
Chaque entrée se divise en trois parties:Chaque entrée se divise en trois parties:
• le noyau (minimun requis):
composé de la séquence, des références bibliographiques et des données
taxonomiques.
• les annotations:
complexes et variées (informations sur la fonction de la protéine, sur les
modifications post-transcriptionnelles, les sites et les domaines
structuraux ou fonctionnels, la structure secondaire et quaternaire, des informations de similarité, etc).
• les références croisées: à partir de chaque fiche, un certains nombre de
liens existent sur des banques thématiques en fonction des propriétés des
séquences.
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II
IdentifiantIdentifiant
DescriptionDescription
Classification taxonomiqueClassification taxonomique
OrganismeOrganisme
RéférencesRéférences
ID PURA_ECOLI STANDARD; PRT; 431 AA.AC P12283;DT 01-OCT-1989 (REL. 12, CREATED)DT 01-FEB-1996 (REL. 33, LAST SEQUENCE UPDATE)DT 15-DEC-1998 (REL. 37, LAST ANNOTATION UPDATE)DE ADENYLOSUCCINATE SYNTHETASE (EC 6.3.4.4) (IMP- -ASPARTATE LIGASE).GN PURA OR ADEK.OS ESCHERICHIA COLI.OC BACTERIA; PROTEOBACTERIA; GAMMA SUBDIVISION; E NTEROBACTERIACEAE;OC ESCHERICHIA.RN [1]RP SEQUENCE FROM N.A., AND SEQUENCE OF 1-10.RC STRAIN=K12;RX MEDLINE; 89066719.RA WOLFE S.A., SMITH J.M.;RT "Nucleotide sequence and analysis of the purA gen e encodingRT adenylosuccinate synthetase of Escherichia coli K12.";RL J. BIOL. CHEM. 263:19147-19153(1988).RN [2]RP SEQUENCE FROM N.A.RC STRAIN=K12 / MG1655;RX MEDLINE; 95334362.RA BURLAND V.D., PLUNKETT G. III, SOFIA H.J., DAN IELS D.L.,RA BLATTNER F.R.;RT "Analysis of the Escherichia coli genome VI: DNA sequence of theRT region from 92.8 through 100 minutes.";RL NUCLEIC ACIDS RES. 23:2105-2119(1995).::CC -!- FUNCTION: PLAYS AN IMPORTANT ROLE IN THE DE NOVO PATHWAY OF PURINECC NUCLEOTIDE BIOSYNTHESIS.CC -!- CATALYTIC ACTIVITY: GTP + IMP + L-ASPARTATE = GDP +CC ORTHOPHOSPHATE + ADENYLOSUCCINATE.CC -!- PATHWAY: FIRST COMMITTED STEP IN AMP BIOSYN THESIS.CC -!- SUBUNIT: HOMODIMER.CC -!- SIMILARITY: WITH OTHER ADENYLOSUCCINATE SYN THETASES.
CommentairesCommentaires
Les champs d’une fiche: SwissProt
Numéro d’accessionNuméro d’accession
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II An
no
tatio
n fo
nct
ion
nel
le
19
SwissProt
DR EMBL; J04199; AAA24446.1; -.DR EMBL; U14003; AAA97073.1; -.DR EMBL; AE000490; AAC77134.1; -.DR PIR; A31965; AJECDS.DR PDB; 1ADE; 26-JAN-96.DR PDB; 1ADI; 10-JUN-96.DR PDB; 1GIM; 23-DEC-96.:DR PDB; 1KSZ; 08-OCT-97.DR PDB; 1NHT; 08-OCT-97.DR PDB; 1SON; 04-SEP-97.DR PDB; 1SOO; 04-SEP-97.DR PDB; 1JUY; 24-JUN-97.DR ECOGENE; EG10790; PURA.DR PROSITE; PS00513; ADENYLOSUCCIN_SYN_2; 1.DR PROSITE; PS01266; ADENYLOSUCCIN_SYN_1; 1.DR PFAM; PF00709; Adenylsucc_synt; 1.KW PURINE BIOSYNTHESIS; LIGASE; GTP-BINDING; 3D-S TRUCTURE.FT INIT_MET 0 0FT NP_BIND 12 18 GTP (POTENTIAL).FT ACT_SITE 140 140FT ACT_SITE 147 147 PROBABLE.FT MUTAGEN 12 12 G->V: SIGNIFICANT REDUCTION IN ACTIVITY.FT MUTAGEN 15 15 G->V: SIGNIFICANT REDUCTION IN ACTIVITY.FT MUTAGEN 17 17 G->V: SIGNIFICANT REDUCTION IN ACTIVITY.FT MUTAGEN 18 18 K->R: SIGNIFICANT REDUCTION IN ACTIVITY.FT MUTAGEN 19 19 I->T: SIGNIFICANT REDUCTION IN ACTIVITY.FT MUTAGEN 140 140 K->I: TOTAL LOSS OF ACTIVITY.FT MUTAGEN 147 147 R->L: REDUCED ACT IVITY.FT CONFLICT 416 416 G -> D (IN REF. 1 ).SQ SEQUENCE 431 AA; 47213 MW; 26EA38AC CRC32;
GNNVVVLGTQ WGDEGKGKIV DLLTERAKYV VRYQGGHNAG HTLVINGEKT VLHLIPSGILRENVTSIIGN GVVLSPAALM KEMKELEDRG IPVRERLLLS EACPLILDYH VALDNAREKARGAKAIGTTG RGIGPAYEDK VARRGLRVGD LFDKETFAEK LKEVMEYHNF QLVNYYKAEAVDYQKVLDDT MAVADILTSM VVDVSDLLDQ ARQRGDFVMF EGAQGTLLDI DHGTYPYVTSSNTTAGGVAT GSGLGPRYVD YVLGILKAYS TRVGAGPFPT ELFDETGEFL CKQGNEFGATTGRRRRTGWL DTVAVRRAVQ LNSLSGFCLT KLDVLDGLKE VKLCVAYRMP DGREVTTTPLAADDWKGVEP IYETMPGWSE STFGVKDRSG LPQAALNYIK RIEELTGVPI DIISTGPDRTETMILRDPFD A
//
Références croiséesRéférences croisées
Mots clésMots clés
CaractéristiquesCaractéristiques
SéquenceSéquence
Fin ficheFin fiche
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II
An
no
tatio
n fo
nct
ion
nel
le
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II

20
Erreurs d’annotation
• Les erreurs d'annotation sont fréquentesdans les banques.
• Elles sont souvent dues à l'utilisation des méthodes informatiques automatiquespour l'analyse des données de séquençage systématique.
• Les annotations fonctionnelles (même automatique) sont propagées de manière répétitive de séquence en séquence, sans référence à la première source, ceci menant à une propagation transitive et catastrophique des erreurs d'annotations.
• Dans certaines banques généralistes (à l'exception de SwissProt), il est impossible de savoir si une séquence a été annotée suite à une expérimentation ou suite à une analyse informatique.
Il serait nécessaire de pouvoir répondre aux questions suivantes lorsqu'on s'intéresse à une séquence précise:
• La fonction a-t-elle été attribuée expérimentalement?• Si non: Est-ce un programme ou une personne qui a prédit cette fonction?• Si c'est un programme: Lequel?• Si c'est une personne: A l'aide de quel(s) algorithme(s)?
Il serait nécessaire de pouvoir répondre aux questions suivantes lorsqu'on s'intéresse à une séquence précise:
• La fonction a-t-elle été attribuée expérimentalement?• Si non: Est-ce un programme ou une personne qui a prédit cette fonction?• Si c'est un programme: Lequel?• Si c'est une personne: A l'aide de quel(s) algorithme(s)?
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II
Banques spécialisées/thématiques
Les banques généralistes présentent des avantages(exhaustivité) et des limites (imprécisions, redondance, …).
Les banques thématiques: elles peuvent réunir au sein d'une même structure des séquences nucléotidiques ou protéiques sélectionnées selon un critère précis(un même génome, une structure moléculaire, regroupement en famille, présence d'un motif ou d'un domaine protéique...), mais il existe également des banques qui abordent des aspects de la biologie moléculaire non directement liés aux séquences(métabolisme, réseaux de régulations, données d'expression...)
La version électronique de la revue NAR de Janvier 2008 permet d’accéder à une liste de 1078bases: http://www3.oup.co.uk/nar/database/a/ (libre diffusion) La version électronique de la revue NAR de Janvier 2008permet d’accéder à une liste de 1078bases: http://www3.oup.co.uk/nar/database/a/ (libre diffusion)
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II
21
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II
Sur un organisme particulier
22
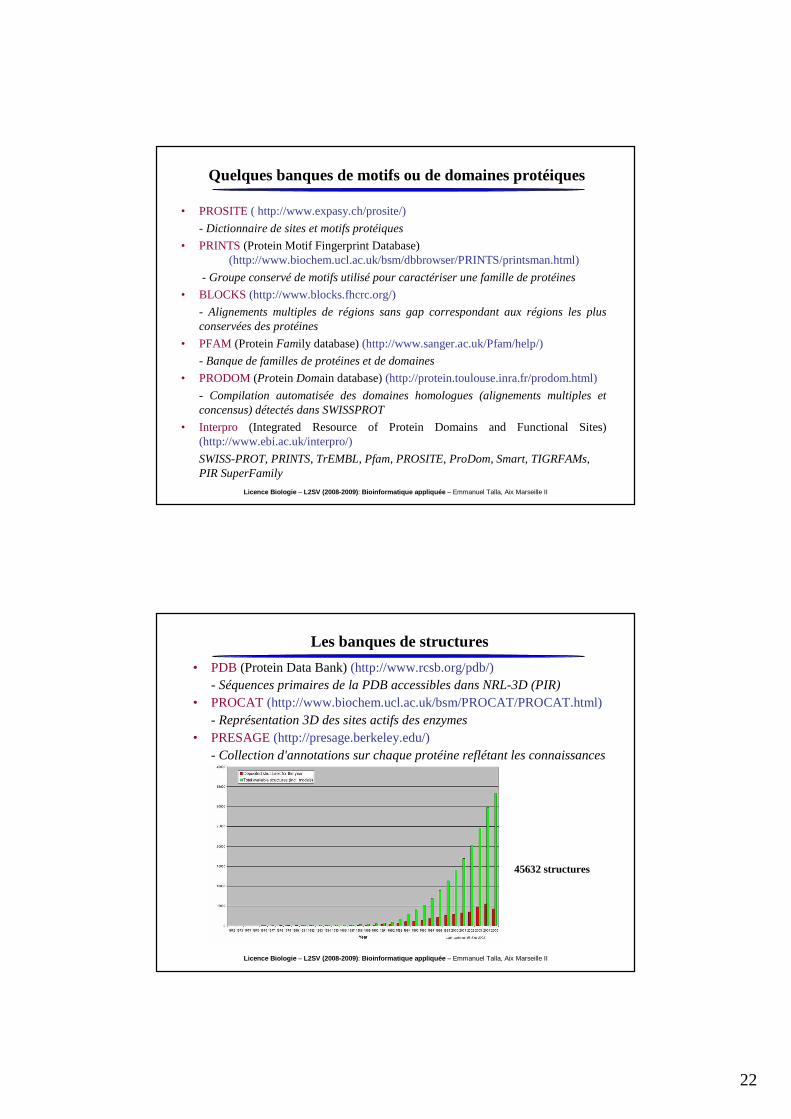
Quelques banques de motifs ou de domaines protéiques
• PROSITE ( http://www.expasy.ch/prosite/)
- Dictionnaire de sites et motifs protéiques
• PRINTS(Protein Motif Fingerprint Database) (http://www.biochem.ucl.ac.uk/bsm/dbbrowser/PRINTS/printsman.html)
- Groupe conservé de motifs utilisé pour caractériser une famille de protéines
• BLOCKS (http://www.blocks.fhcrc.org/)
- Alignements multiples de régions sans gap correspondant aux régions les plus conservées des protéines
• PFAM (Protein Family database) (http://www.sanger.ac.uk/Pfam/help/)
- Banque de familles de protéines et de domaines
• PRODOM(Protein Domain database) (http://protein.toulouse.inra.fr/prodom.html)
- Compilation automatisée des domaines homologues (alignements multiples et concensus) détectés dans SWISSPROT
• Interpro (Integrated Resource of Protein Domains and Functional Sites) (http://www.ebi.ac.uk/interpro/)
SWISS-PROT, PRINTS, TrEMBL, Pfam, PROSITE, ProDom, Smart, TIGRFAMs, PIR SuperFamily
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II
Les banques de structures
• PDB (Protein Data Bank) (http://www.rcsb.org/pdb/)- Séquences primaires de la PDB accessibles dans NRL-3D (PIR)
• PROCAT (http://www.biochem.ucl.ac.uk/bsm/PROCAT/PROCAT.html)- Représentation 3D des sites actifs des enzymes
• PRESAGE (http://presage.berkeley.edu/) - Collection d'annotations sur chaque protéine reflétant les connaissances en termes de structures et de fonctions de celle-ci.
45632 structures
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II

23
Centre de ressources(Données bibliographiques et/ou séquences)
- Expasy: http://www.expasy.org/
- NAR: http://www3.oup.co.uk/nar/database/a/
- PASTEUR: http://www.pasteur.fr/
- EBI: http://www.ebi.ac.uk/Databases/index.html
- NCBI: http://www.ncbi.nlm.nih.gov/
- ISB: http://www.isb-sib.ch/
- Genome Net:http://www.genome.ad.jp/
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II
Recherche d’informationsRecherche d’informations• Interroger plusieurs bases (> 1000)• Relier entre elles les données extraites (Intégrer les données)
• Problème majeur: HETEROGENEITE des données (nature, formats)
Comment intégrer ces données biologiques, hétérogènes et distribuées, afin qu’elles soient accessibles et exploitables aussi facilement que si elles figuraient dans une seule et même base ?
Comment intégrer ces données biologiques, hétérogènes et distribuées, afin qu’elles soient accessibles et exploitables aussi facilement que si elles figuraient dans une seule et même base ?
-Ajouter, au-dessus des bases existantes, une couche logicielle• offre les interfaces nécessaires entre les bases • fait apparaître l’ensemble comme une seule base virtuelle
-Résoudre les problèmes d’incompatibilité syntaxique et sémantique
Interrogation des banques de données
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II

24
Interrogation des bases de données
Logiciel créé par Thure Etzold et proposé par de nombreux sites serveurs : il permet une interrogation simple ou croisée sur un éventail large de bases en biologie moléculaire. Chaque site SRS propose un ensemble spécifique de bases données.
Interrogation des séquences moléculaires de Medline, GenBank, EMBL, DDBJ, PIR, SwissProt, PRF et PDB.
SRS (Sequence Retrieval System).SRS (Sequence Retrieval System).
ENTREZ (NCBI WWW Entrez Browser)ENTREZ (NCBI WWW Entrez Browser)
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II
…………
http://downloads.lionbio.co.uk/publicsrs.html

25
http://downloads.lionbio.co.uk/publicsrs.html
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II
http://downloads.lionbio.co.uk/publicsrs.html
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II
26
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II

27
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II
Pour une recherche simple
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II

28
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II
Pour une recherche élaborée
29
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II
ATPase
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II
30
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II
31
Licence Biologie – L2SV (2008-2009): Bioinformatique appliquée – Emmanuel Talla, Aix Marseille II