
Collecte des données métiers et constitution d'un entrepôt centrale

INRIA/INRACampus de Beaulieu, 263 Avenue Général Leclerc, 35042 Rennes
Rapport de stage de master
Conception d’un entrepôt de donnéespour une visualisation et interrogation desdonnées de simulation en vue de répondre
à des questions agronomiques
Sophie LE BARS
Master 2 Bioinformatique
Promotion 2019
Tuteur : M. Olivier Dameron
Encadrants : Tassadit BAOUDI
Anne-Isabelle GRAUX
Luis GALARRAGA
3 Janvier 2019 — 5 juillet 2019Ce travail a bénéficié d’une aide de l’État gérée par l’Agence Nationale de la Recherche au titre du programme
d’Investissements d’Avenir portant la référence ANR-16-CONV-0004


Table des matières
Introduction 1
Matériels et méthodes 3
1 Les données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2 La base de données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.1 Structure de la base de données . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.2 Alimentation de la base de données . . . . . . . . . . . . . . . . . . . . . . . 8
3 L’entrepôt de données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
3.1 Qu’est ce qu’un entrepôt de données? . . . . . . . . . . . . . . . . . . . . . 9
3.2 Structure de l’entrepôt . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
3.3 Alimentation de l’entrepôt . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
3.4 Les données agrégées ou cubes de données . . . . . . . . . . . . . . . . . . 11
4 Visualisation des données agrégées . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
4.1 Conception d’un outil de visualisation sous R shiny . . . . . . . . . . . . . . 12
4.2 Système de requêtage . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
4.3 Di�érents modes de visualisation . . . . . . . . . . . . . . . . . . . . . . . . 13
4.4 Déploiement de l’outil et mise à disposition des données . . . . . . . . . . . 13
5 La fouille de données (data mining) . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
5.1 Algorithme utilisé . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
5.2 Les données agronomiques utilisées . . . . . . . . . . . . . . . . . . . . . . 14
Résultats 17
6 L’entrepôt de données et données agrégées . . . . . . . . . . . . . . . . . . . . . . . 17
6.1 L’entrepôt de données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
6.2 Les données agrégées . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
7 L’application connectée à l’entrepôt de données . . . . . . . . . . . . . . . . . . . . 20

7.1 Sélection des données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
7.2 Les di�érents modes de visualisation des données . . . . . . . . . . . . . . . 21
8 La fouille de données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
8.1 Les données transformées . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
8.2 Résultats de l’algorithme . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
Limites et discussion 26
Conclusion et perspectives 27

Introduction
Contexte
De nos jours, l’agriculture doit faire face à de nouveaux challenges à savoir améliorer son e�-cience de production, autrement dit : produire autant voire plus tout en limitant son utilisationdes ressources et ses rejets vers l’environnement. A�n d’accompagner les agriculteurs dans leursdémarches, la recherche produit des modèles de simulation de plus en plus complexes. Ces modèlesnécessitent de nombreux paramètres et variables d’entrées décrivant la situation à simuler (condi-tions météorologiques, pratiques agricoles, types de culture,etc.) a�n de prédire di�érentes variablesd’intérêt telle que le rendement de la culture. Cependant ces modèles de simulation fournissent desvolumes de données croissants de nature hétérogène. Comment réussir à analyser toutes ces donnéeset à concilier à la fois leur volume important et leurs di�érents formats? Les personnes qui exploitentces données ne s’intéressent souvent qu’à une partie des résultats produits. De plus, ces données nesont bien souvent exploitées qu’une fois, dans le cadre des recherches pour lesquelles elles ont étéproduites, et ne sont pas archivées pour une éventuelle utilisation ultérieure. Interroger, exploiter etstocker de manière pérenne des données de simulation constitue donc une problématique de taillenécessitant l’utilisation d’outils dédiés.
Le domaine de l’informatique décisionnelle est en plein essor et apporte une solution en terme destockage et d’exploration de volumes de données conséquents : les entrepôts de données. Il s’agitd’une architecture qui permet d’analyser de très grandes quantités de données a�n de faciliter l’aideà la décision.
"Un entrepôt de données est une collection de données thématiques, intégrées, non volatiles, histo-risées et exclusivement destinées aux processus d’aide à la décision” Bill Inmon (1990). En e�et, aucoeur d’un entrepôt, les données sont organisées par thème, elles sont issues de sources hétérogèneset sont intégrées de façon homogène au sein de l’entrepôt. Les données sont non volatiles et histo-risées car elles ne disparaissent pas et ne changent pas au �l des traitements et du temps, elles sonttoutes horodatées (on conserve l’heure et la date de leur production) : on peut ainsi visualiser leurévolution dans le temps.
1

Données étudiées
Les données de simulation utilisées ont été générées par le modèle STICS [1] à l’échelle de la Francedans le cadre de l’étude « les prairies françaises : Production, exportation d’azote et risques de les-sivage » [2]. Seules les valeurs annuelles des résultats produits ont été analysées dans ce cadre.L’objectif de cette étude était de revoir le plafond d’épandage �xé en France à 170 kg par hectare etpar an.
L’épandage est une pratique agricole qui consiste à épandre sur un champ des fertilisants, des herbi-cides ou des pesticides. Cette pratique fait l’objet d’une réglementation dans le cadre de la DirectiveNitrate qui limite l’épandage à un plafond, a�n de réduire la pollution des eaux par le nitrate d’origineagricole. En e�et, l’azote organique subit dans le sol des réactions chimiques qui conduisent, souscertaines conditions, à la production d’azote sous une forme minérale (nitrates NO3-) et à l’émissiond’azote sous une forme gazeuse (ammoniac NH3, protoxyde d’azote N2O). La fertilisation azotée descultures est cependant nécessaire a�n d’assurer une bonne croissance de la plante et pour garantirune bonne teneur en protéines.
Une base de données structurées destinée à l’archivage de ces données a été conçue en amont dustage, destinée à l’archivage des entrées et des sorties de simulations au pas de temps journalier.
Travail préalable
Les entrepôts de données ne sont pas encore très développés dans le milieu de la recherche dans ledomaine agro-environnemental. Il existe cependant quelques entrepôts de données agronomiquesdont un entrepôt de données permettant l’exploration multidimensionnelle des simulations agro-hydrologiques. Il a récemment été développé a�n d’améliorer la gestion de l’azote à l’échelle d’unbassin versant (espace drainé par un cours d’eau et ses a�uents)[3].
Objectif du stage
L’objectif principal de ce stage a donc été d’adapter cette méthode pour concevoir un entrepôt dedonnées, ainsi que des outils de visualisation, d’exploration et d’interrogation des données de simula-tion de l’étude [2]. Le but étant de faciliter l’identi�cation de réponses à des questions de rechercheet la prise de décisions face à une grande quantité de données agronomiques simulées. L’interro-gation des données pour répondre à des questions de recherche agronomiques multicritères s’estappuyée sur des algorithmes existants de fouilles de données (data mining) permettant d’identi�erdes corrélations ou des motifs fréquents entre les données.
2

Matériels et méthodes
1 Les données
Les données que nous souhaitons archiver, explorer et interroger proviennent de l’étude "Les prai-ries françaises : production, exportation d’azote et risques de lessivage" (Graux et al., 2017). Cetteétude a été commanditée par les ministères de l’agriculture et de l’environnement dans la perspectived’une demande de dérogation au plafond d’épandage. Actuellement, �xé par la Directive Nitrates à170 kg d’azote organique par hectare de surface agricole utile (SAU) et par an. Cet azote organiquecomprend l’azote provenant de l’épandage des e�uents organiques produits en bâtiments (lisiers,fumiers) et l’azote organique épandu par les animaux eux-mêmes lorsqu’ils pâturent. Les prairiessont reconnues pour leur aptitude à exporter de grandes quantités d’azote et pour limiter la pollu-tion des eaux par les nitrates d’origine agricole. L’azote prélevé par les espèces végétales composantla prairie y est exporté par les prélèvements liés aux fauches et au pâturage des animaux. Une partiede cet azote est restitué au sol via les déjections animales. Une certaine surface en herbe dans la SAUpourrait donc permettre de justi�er, dans certains cas, d’une dérogation au plafond actuel d’épan-dage. L’objectif de cette étude était d’identi�er les régions et les élevages susceptibles de prétendre àcette dérogation, car pouvant exporter plus de 170 kg N/ha SAU/an. Et de déterminer jusqu’à quellevaleur le plafond d’épandage pouvait être augmenté sans dégrader sensiblement la qualité de l’eauenvironnante".
Dans cette étude, une analyse préliminaire des données terrain (réseaux de suivi de la pousse del’herbe, dispositifs expérimentaux) a permis d’estimer l’exportation d’azote par les prairies danscertaines régions. A�n d’étendre ces premiers résultats, le modèle STICS [4][5] a été amélioré pourprendre en compte les restitutions animales au pâturage puis utilisé pour simuler, de 1984 à 2013,les �ux d’eau, d’azote et de matière sèche associés au fonctionnement des prairies françaises. Enparticulier, la production fourragère des prairies, la teneur en protéines de l’herbe récoltée ou pâturéeainsi que le lessivage des nitrates ont été simulés pour la diversité des conditions de sol, climat, typesde prairies et pratiques agricoles existantes en France.
STICS est un un modèle dynamique, mécaniste, déterministe et générique de simulation d’une cultureou d’une rotation culturale (succession de cultures sur une parcelle) (Figure 1). Une simulation cor-respond à une culture (incluant la prairie) implantée pendant une durée donnée, un type de sol, un
3

Figure 1 – Principales caractéristiques du modèle STICS
Figure 2 – Principales entrées et sorties du modèle STICS
climat et un itinéraire technique (ensemble des opérations culturales appliquées à la culture).
Dans le cadre de l’étude, les simulations ont été réalisées à l’échelle de 15120 unités pédoclimatiques(UPC), issues du croisement de la résolution de l’information climatique et pédologique, et pourlesquelles la surface de prairies est signi�cative. Chacune de ces UPC a une taille variable, inférieureou égale à 6400 ha.
L’information climatique a été fournie par le système SAFRAN de Météo France. L’information liéeau sol provient de la base de données géographique des sols de France à une résolution de 1/1 000000 et d’une estimation spéci�que de la teneur en carbone organique des sols.
Quatre types de prairies ont été considérés, correspondants à des prairies permanentes ou semées(graminées pures, en mélange avec des légumineuses, ou légumineuses pures). La proportion et la
4

Figure 3 – Carte des unités pédoclimatiques simulées
Figure 4 – Schéma des simulations associées à chacune des UPC
durée d’implantation des prairies au sein de chaque UPC ont été estimées sur la base de l’informationissue du registre parcellaire graphique et du recensement agricole de 2010.
Les pratiques agricoles ont été résumées sous la forme de 30 modes d’exploitation dérivés du projetISOP [6] : la proportion de ces modes est connue pour chacun des types de prairie présents à l’échellede la région fourragère. Une région fourragère correspond à une subdivision du territoire françaisen 228 petites régions homogènes en se basant sur les conditions pédoclimatiques et le potentiel deproduction fourragère. Ce zonage est issu des résultats de l’enquête « prairies » faite par le SCEESen 1982, et actualisé en 1998.
A�n de limiter le nombre de simulations réalisées dans l’étude, seuls les types de prairie et les solsmajoritaires dans chaque UPC ont été retenus dans le plan de simulations. A chaque UPC est doncassocié un climat de 30 années (1984-2013), un à deux sols majoritaires, un à deux types de prairiemajoritaires, et pour chacun des types de prairie, 1 à 18 modes d’exploitation. Au sein d’une mêmeUPC, il peut donc y avoir plusieurs simulations (une dizaine en moyenne par UPC).
5

Les simulations (173 260 séries de 30 ans) ont été réalisées par la plateforme de modélisation RECORD[7] de l’INRA.
Des résultats de simulation sont disponibles à la journée pour les principales variables d’intérêt.Parmi les 600 variables de sortie du modèle, une soixantaine ont été demandées en sortie des simu-lations dans le cadre de l’étude. Elles concernent :
— les pratiques agricoles simulées (fauche, pâturage et restitutions animales, fertilisation) ;— l’état des ressources en eau et en azote du sol (état de la réserve utile, contenus en azote
minéral et organique) et les �ux associés (drainage, ruissellement, remontées capillaires, éva-potranspiration, minéralisation de la matière organique des sols, lessivage d’azote, émissionsazotées vers l’air) ;
— l’état de la végétation (biomasse, teneur en azote, âge de la prairie etc.) et les processus asso-ciés (croissance, sénescence, demande en azote, etc.).
L’ensemble des �chiers de sortie représente un volume d’environ 1.5 Téraoctet (To) de donnéesbrutes. Les �chiers d’entrée du modèle représentent un volume d’environ 500 Go qui sont égalementconservés, car alimentant en partie la base de données, soit un total d’environ 2 To. Les donnéesclimatiques (8 variables au pas de temps journaliers) représentent la majeure partie du volume desdonnées d’entrée.
D’autres informations relatives à la caractérisation des conditions de sol (teneur en azote en orga-nique etc.) et du climat (type de climat [8]) sont également disponibles pour la caractérisation dessituations et l’interrogation des données.
6

2 La base de données
2.1 Structure de la base de données
Au début du stage, la structure de la base de données relationnelle avait déjà été créée, pour stockerles données de simulation de l’étude. Cette base de données comporte au total 13 tables relatives auxentrées et sorties du modèle.
La structure de la base de données a été réalisée sous MySQL Workbench qui est un logiciel d’admi-nistration de données utilisant une interface graphique conviviale permettant de créer rapidementdes tables et des relations entre elles, et d’exporter le script associé au format SQL dans des serveursSQL.
Figure 5 – Schéma de la structure de la base de données avec MySQL Workbench
Dans cette base de données chaque simulation est ainsi dé�nie par :
— La version du modèle utilisée (table "model version", table rose �gure 5)— Un contexte de simulation (idsimulation, projet, date d’exécution, début et �n de simulation,
options de simulation) (table "simulation context", table jaune �gure 5).— Une unité pédoclimatique (idupc, régions fourragère et administrative) (table "pcu", table bleu
ciel �gure 5). A chaque unité pédoclimatique correspond un unique site (table "station", tablebleu ciel �gure 5).
7

— Un climat (idweather, observé ou simulé (scénario, GCM, changement d’échelle), résolutionstemporelles et spatiales) (table weather input, table bleu �gure 5). A chaque simulation cor-respond un unique climat.
— Un sol (idsoil, texture, réserve utile, teneur en azote organique de l’horizon de surface, pHetc.)(table "soil", table orange �gure 5). A chaque simulation correspond un unique sol. Chaquesol est dé�ni par un ensemble d’horizons (couche du sol homogène et parallèle à la surface)(table "soil layer", table orange �gure 5) qui ont des caractéristiques spéci�ques (épaisseur,humidité à la capacité au champ, point de �étrissement etc.).
— Une pratique agricole en entrée (idmanagement, type de gestion : pâturé, fauché, mixte,nombre maximum d’exploitations et d’engrais azotés à l’année, apport en �n d’hiver, par ex-ploitation : type, somme de température en degré Celsius, fertilisation) ("table management",table violette �gure 5). A chaque simulation correspond une unique pratique culturale.
— Un type de prairie (idgrasslandtype, niveau d’autosu�sance, caractère permanent ou semé,conditions d’initialisation du couvert) (table "grassland type", table verte �gure 5). A chaquesimulation correspond un type de prairie.
— Une date précise avec un id pour chaque jour du scénario de simulation associé à une décade,un mois, une année et une décennie (table "time", table rouge �gure 5).
La table "weather input has station has time"(table rouge �gure 5) contient pour chaque climat,chaque date (table "time") et chaque site (table "station") les données climatiques journalières cor-respondantes.
La table "run has time"(table rouge �gure 5) comprend 64 variables d’intérêt par simulation et parjour.
Cette base de données a ensuite été importée sous phpMyAdmin, une application web pour lessystèmes de gestion de base de données MySQL mais fonctionnant aussi avec mariaDB. Le projetmariaDB a été lancé par l’un des créateur de MySQL après son rachat par Oracle. MariaDB est unembranchement (fork) de MySQL, ils sont compatibles et utilisent les mêmes fonctions.
Une fois la structure de la base de données importée, les sorties de simulation correspondant àquelques régions y ont été insérées. Il s’agit de la Basse-Normandie, la Haute-Normandie, la Bre-tagne et l’Ile de France. Ainsi remplie, la base occupe déjà un espace d’environ 240 Go. La base dedonnées in �ne comportera les données de simulations pour les 12 régions administratives françaiseset sera autour de 950 Go.
2.2 Alimentation de la base de données
La base de données a été remplie avec des scripts R, déjà préexistants, qui ont ensuite été optimisésa�n de gérer au mieux un plus gros volume de données. Les scripts vont chercher dans les �chiers desimulation les données brutes intéressantes, et réalisent des pré-traitements et des pré-calculs a�n
8

de récupérer des informations pertinentes. Tous ces scripts se connectent directement à la base dedonnées via le package RmariaDB. Il y a en tout 12 scripts R qui servent à remplir les tables de la basede données. Pour les données d’entrée des simulations chaque script va chercher des informationsdans des �chiers au format csv. Il récupère ces informations, les remet en forme, et parfois réalise destraitements. Des modi�cations ont été apportées à ces scripts dans le cadre du stage tel que le scriptpour insérer les données dans la table time qui a été modi�é pour générer les saisons astronomiqueset météorologiques à partir du jour, du mois et de l’année. Tous les scripts ont été testés au préalablesur un petit échantillon de données puis on été modi�és pour gérer des données plus conséquentes.Le script permettant le remplissage de la table time a nécessité de plus d’adaptation. Bien qu’étante�cace sur des petits jeux de données (3 �chiers de 10 955 lignes chacun), il l’était peu sur des jeuxde données de plus grande taille (21812 �chiers de 10 955 lignes chacun). Il a donc fallu gérer le scriptdi�éremment et splitter les données a�n d’insérer les sorties de simulations dans la table run hastime 100 955 lignes pour chaque itération. Telle qu’elle est remplie actuellement, la table �nal runhas time fait environ 400 millions de lignes.
3 L’entrepôt de données
On a cherché à restructurer l’information contenue dans la base de données a�n de faciliter la prisede décision : c’est dans cette optique que nous sommes passés par la construction d’un entrepôt dedonnées.
Avant d’amorcer le travail sur l’entrepôt, il a fallu clari�er les besoins utilisateurs. En e�et, un en-trepôt est une structure de données qui s’organise par thème et sert avant tout à visualiser plusfacilement de gros volumes de données et à les interroger pour répondre à des questions précises.Les dimensions et surtout la table de fait sont basées sur ces questions. L’utilisateur cherche donc àrépondre à des questions précises. De type : quelles sont les régions qui o�rent le plus faible niveaude lessivage de nitrates sous prairies ? Comment ce lessivage varie-t-il entre les années et/ou au seinmême de l’année? (voir annexe 2)
3.1 Qu’est ce qu’un entrepôt de données?
Il s’agit d’une vision centralisée des données sous forme d’une structure ayant pour but de regrouperles données pour des �ns analytiques et pour aider à la prise de décision. Son intérêt est qu’il fournitun accès rapide à un gros volume de données accumulées au �l du temps à partir de diverses sourcesde données. On parle de modélisation multidimensionnelle : un entrepôt est composé d’éléments telsque les dimensions qui sont des axes d’analyse reliés à une table de faits qui comporte les mesuresd’intérêt à analyser.[9]
9

3.2 Structure de l’entrepôt
A�n de réaliser notre entrepôt, nous avons choisi un modèle en étoile qui est une façon de mettreen relation les dimensions et les mesures de telle sorte que les dimensions soient directement reliéesà la table de fait. Cette structure de données permet une navigation aisée mais aussi rapide (peude jointure entre les tables) et facilite l’agrégation des mesures contenues dans la table de faits. Lesdi�érentes structures de l’entrepôt en phase de test ont été réalisées sous MySQLworkbench, cequi a permis de tester plusieurs con�gurations et de se familiariser avec les di�érentes structurestelles que le schéma en étoile et en �ocon [10], ce dernier inclut la forme hiérarchique des tablesdimensionnelle. Le modèle en �ocon aide à diminuer la redondance mais il présente beaucoup plusde jointures et donc des temps d’exécution plus lent. Nous avons donc opté pour une représentationselon un modèle en étoile.
3.3 Alimentation de l’entrepôt
Les données vont dans un premier temps passer par une phase d’ETL, extraction, transformationet chargement des données dans l’entrepôt de données [11]. Les données sont sélectionnées et net-toyées a�n d’être homogénéisées en vue d’être intégrées à l’entrepôt. L’outil utilisé a�n de réalisercette phase et de �ltrer les données correctement dans notre étude est Talend. Il permet de se connec-ter directement à une base de données existante, on peut aussi lui passer des �chiers.csv en entréeet nous le connectons directement en sortie à l’entrepôt de données. Il faut donc réaliser une struc-ture de l’entrepôt a�n d’accueillir les données en aval. On fait les insertions sous forme de "job"(un processus technique permettant de lire, transformer ou écrire les données). Il existe plusieurstypes d’opérations possibles pour Talend. La plus utilisée est tMap : elle permet de faire des liensentre plusieurs tables de la base de données et une table de l’entrepôt sous une forme très visuelle.On peut mettre en avant les di�érentes relations entre les tables (clés primaires et étrangères) etsélectionner les colonnes qui nous intéressent pour les insérer dans l’entrepôt. C’est donc un outiltrès pratique pour assurer une cohérence dans l’entrepôt et homogénéiser les données. Cependant,Talend est un logiciel payant, une version gratuite existe mais cette dernière n’est pas fournis avecla documentation, la prise en main est donc assez di�cile.
La table de faits a été réalisée par un script python présenté dans la partie Résultats puis alimentévia Talend. Les deux dimensions on été reprises à partir de la base de données (les tables "pcu" et"time") et aussi alimentées à l’aide de Talend.
10

3.4 Les données agrégées ou cubes de données
Dé�nition
Un cube de données est une collection de données agrégées et consolidées pour résumer l’informa-tion et expliquer la pertinence d’une observation. Il est sous forme d’un tableau multidimensionnelqui fournit un support pour une analyse reposant sur plusieurs dimensions hiérarchiques [12]. Lecube de données (data cube) est exploré à l’aide de nombreux opérateurs multidimensionnels quipermettent sa manipulation (i.e. navigation le long des hiérarchies de dimensions).
Déploiement
Le cube de données a été généré avec le "WITH ROLLUP" de SQL combiné à "GROUP BY" qui permetde grouper plusieurs résultats et utiliser une fonction d’agrégation (exemples : moyenne, maximum,somme) sur un groupe de résultats. La commande "WITH ROLLUP" ajoute une ligne supplémentairequi fonctionne tel un super-agrégateur sur l’ensemble des résultats. Dans un cube de données se sontles mesures de l’entrepôt qui sont agrégées selon un ensemble de dimensions et à di�érents niveauxde granularité.
Figure 6 – Exemple de l’utilisation de la commande GROUP BY
Cette commande va donc permettre de récupérer la somme des ventes regroupées par année.
Figure 7 – Exemple de l’utilisation de GROUP BY combiné à WITH ROLLUP
Dans la �gure 7, on peux observer qu’avec "WITH ROLLUP", une ligne supplémentaire vient s’ajou-ter qui représente le total de la somme des ventes sur toutes les années.
11

Opérateurs de navigation
Il existe plusieurs types d’opérations qui permettent de visualiser les informations contenues dansles cubes de données. Nous allons nous concentrer sur les opérateurs de navigation les plus connusque nous avons utilisés dans la suite de notre travail [12].
Les opérateurs de sélection :
— L’opérateur Slice permet de sélectionner un sous ensemble du cube, selon une ou plusieursvaleurs d’une dimension particulière. Par exemple, dans un entrepôt de données qui comprend12 pays nous sélectionnons seulement 2 pays à visualiser.
— L’opérateur Dice permet aussi de sélectionner un sous ensemble du cube mais cette fois-cien prenant en compte plusieurs dimensions. Pour reprendre l’exemple précédent, nous sé-lectionnons 1 pays parmi les 12 et à la place de visualiser sur toutes les années, nous nousfocalisons sur le dtéail d’une année en particulier.
Les opérateurs d’agrégation :
— L’opérateur Drill-Down permet d’a�cher les données avec une granularité plus �ne (nouspassons de pays à région).
— Le Roll-Up est l’inverse du Drill-Down. Il consiste à remonter d’un niveau dans une hiérarchied’une dimension vers un niveau plus agrégé (nous passons donc de région à pays).
4 Visualisation des données agrégées
Des outils de visualisation connectés à un entrepôt de données existent déjà (saiku par exemple) maisils ne permettent pas de naviguer aussi précisément dans les données que ce que nous souhaitions.Il a donc fallu développer un outil a�n de visualiser au mieux nos données et de naviguer commenous le souhaitions dans les données agrégées.
4.1 Conception d’un outil de visualisation sous R shiny
L’outil a été conçu à l’aide du package R shiny. Il se connecte directement à l’entrepôt de donnéesavec le package RmariaDB a�n de visualiser les data cubes générés.
Le package R shiny permet de créer des interfaces faciles d’utilisation constituées de :— une partie interface utilisateur qui regroupe tous les éléments que l’utilisateur va visualiser
sur l’application, aussi bien les menus déroulants de sélection que les graphiques
12

— une partie serveur qui regroupent toutes les fonctions et le code derrière ces visualisations.On a donc deux parties bien distinctes avec l’une qui fait directement appel à l’autre. Une fois quel’utilisateur a sélectionné un paramètre ou une variable à visualiser, on peut directement le/la récu-pérer pour permettre sa visualisation. Il faut donc une interface utilisateur extrêmement dynamique,un système de requêtage le plus précis possible et des fonctions très générales qui vont marcher pourtoutes les variables et tous les paramètres de la dimension spatiale et temporelle.
Le package RmariaDB permet non seulement d’établir une connexion mais aussi de faire des requêtesSQL via R sur la base ou l’entrepôt de données et d’aller chercher les tables d’intérêt.
On a donc combiné les entrées sélectionnées par l’utilisateur via l’application R shiny avec un sys-tème de requêtes SQL en direct qui cherche dans l’entrepôt les données qui nous intéressent. Il adonc fallu construire des vues sur le même format a�n de généraliser et regrouper de nombreusesconditions dans le but de lancer la bonne requête uniquement lorsque la sélection est bien réalisée.
4.2 Système de requêtage
L’utilisateur va choisir la mesure (la variable d’intérêt) qu’il veut visualiser et ensuite, il va choisirdans les deux dimensions, temporelle et spatiale, à quelle granularité il souhaite visualiser la mesuresélectionnée. Il va pouvoir par exemple a�cher la moyenne d’une mesure donnée par an et parrégion sur toute la durée de la simulation (30 ans) ou au contraire, visualiser de façon très précisel’évolution de cette même mesure sur une période de 10 jours pour un mois et une année donnée etune région fourragère en particulier. Cette sélection est traduite sous forme de mots clés qui vontpermettre d’aller chercher les data cubes correspondants à la sélection et ensuite de formuler unerequête qui va interroger l’entrepôt et aller chercher seulement les données que l’utilisateur veutvisualiser.
4.3 Di�érents modes de visualisation
En fonction des sélections faites, di�érents modes de visualisation s’o�rent à l’utilisateur soit sousforme de boîtes à moustaches (boxplot), de courbes ou de diagrammes en bâtons (barplot) voire sousforme de cartes dans certains cas.
4.4 Déploiement de l’outil et mise à disposition des données
L’outil connecté à l’entrepôt de données à été déployé sur le réseau de l’Inria depuis le serveur. Il afallu changer les con�gurations dans iptables (�chier de con�guration des pare-feux dans linux) etajouter une nouvelle règle autorisant la connexion de toutes les adresses en local sur un port alloué(5050).
13

5 La fouille de données (data mining)
L’exploration plus approfondie des données à été réalisée à l’aide d’algorithmes de data miningdéveloppés dans l’équipe LACODAM. On s’intéresse plus particulièrement au pattern mining quiconsiste à fouiller les données à la recherche de motifs d’intérêt. Dans notre cas un motif est unparamètre ou une combinaison de paramètres (tels que le type de sol, type de prairie, conditionsclimatiques) qui in�uencent le plus sur nos mesures. La bioinformatique utilise déjà des algorithmesde data mining pour extraire de la connaissance à partir de grande quantité de données. On peut parexemple citer l’algorithme ExMotif[13] qui sert à extraire des motifs fréquents dans des séquencesd’ADN.
5.1 Algorithme utilisé
L’algorithme utilisé pour réaliser la fouille d’itemsets est un algorithme implémenté par Luis Ga-larraga [14] qui s’appuie sur la fouille de pattern clos (un motif fréquent dont les motifs qui lecontiennent se retrouvent en moins grand nombre dans le jeu de données) à partir de l’algorithmeLCM (Linear timeClosed itemsetMiner)[15].
Exemples de pattern clos :— "riri" : on le retrouve dans 143 transactions (lignes).— "riri��" : on le retrouve dans 143 transactions.— "ririloulou" : on le retrouve dans 50 transactions.— "riripicsou" : on le retrouve dans 4 transactions— "ririloulou��" : on le retrouve dans 10 transactions.
Le pattern "riri��" est donc un pattern clos car il n’existe aucun autre pattern qui contient le motif"riri" et qui réduit le support (nombre de lignes).
Dans un premier temps, l’algorithme va chercher des motifs clos au-dessus d’un seuil de support(nombre minimum de lignes où le motif apparaît dans la totalité du jeu de données), ensuite il calculeleur "growth ratio" (cet indicateur mesure la relation entre les supports relatifs du motif dans chacunedes classes, pour simpli�er : nombre d’apparitions du motif dans la classe 1 / nombre d’apparitionsdu motif dans la classe 2) par rapport aux classes données, et il fait un deuxième seuillage par cettemétrique.
5.2 Les données agronomiques utilisées
Les données agronomiques utilisées pour réaliser notre pattern mining sont à l’échelle de l’upcagrégé à l’année. Nous avons utilisé un tableau qui pour chaque upc nous donne des informationsd’intérêt pour l’agriculture relative au climat, sol et mode d’exploitation. La plupart de ces informa-
14

tions sont quantitatives et a�n d’utiliser l’algorithme il a fallu les discrétiser, cette transformation aété réalisée par un script python décrit un peu plus loin dans la partie résultats. Nous nous sommesappuyé sur des intervalles a�n de réaliser ces transformations.
Figure 8 – Exemple de données utilisées pour réaliser le pattern mining
Chaque ligne nous donne (�gure 8) :
— upc : numéro de l’UPC.— textural_class_h1 : classe texturale du sol selon le triangle textural de la base de données
HYPRES 1985 [16].— Ru_at_the_end_of_year : réserve utile (c’est à dire quantité d’eau que le sol peut absorber et
restituer à la plante) à la �n de l’année (mm).— RsurRUac_mean : fraction de la réserve utile disponible du sol.— N_mineralisation_at_the_end_of_the_year : quantité d’azote apportée par les engrais à la �n
de l’année.— drain_sum : quantité d’eau drainée par le sol (mm).— TYPO_CLIM : le type de climat de l’upc selon la classi�cation de Joly [8].— ferti_tot_sum : le niveau de fertilisation (kg d’azote/ha/an).— nb.exploitations : nombre d’exploitations par an.— Qles_at_End_of_the_year : lessivage du nitrate (kg N/ha/an).— Nexporte.recalc sum : exportation d’azote par les fauches et pâtures (kg N/ha/an).
15

La première partie du stage à du être avant tout d’apprendre à gérer des données de type big data (2To) et de faire face aux problèmes de stockage rencontrés.
La lecture d’articles scienti�ques a permis de bien comprendre ce qu’était un entrepôt de donnéeset de commencer à faire quelques schémas de notre entrepôt.
Il y a aussi eu une phase de familiarisation avec les données brutes a�n de bien comprendre lesdi�érentes variables de sortie du modèle et les paramètres d’entrée. Ensuite, le travail sur la base dedonnées a pu commencer à proprement parler après une bonne visualisation du schéma de cette basevia MySQL Workbench, on a ensuite choisi d’importer la structure de cette base sur phpMyadmin(pour faciliter les di�érents traitements et le requêtage) en vue de l’insertion des données dans labase. En tout, les scripts R ont mis plusieurs dizaines de jours à remplir la base. L’ajustement duscript R dédié au remplissage de la base avec les sorties des simulations a demandé un réel travailde modi�cations en amont ainsi que des phases de test.
Une fois la base de données remplie, une structure de l’entrepôt a d’abord été réalisée sous MYSQLWorkbench, les deux dimensions, temporelle et spatiale, on été remplies via les données de la basede données avec Talend. La table de faits a été la plus longue à remplir, en e�et il a fallu réaliserplusieurs scripts python a�n de récupérer les données de la base et les agréger correctement pourpasser de la simulation à l’upc. Une fois cette table de fait générée en �chier csv, elle a été importéedans l’entrepôt à l’aide de Talend. Les datas cubes ont été réalisés à l’aide de la commande WITHROLLUP dans le but de bien visualiser tous les attributs des dimensions et d’avoir une vision à lafois globale et très précise des données.
L’outil de visualisation a été réalisé sous R shiny et est spécialement adapté à la visualisation de nosdonnées.
En�n une partie data mining a été e�ectuée pour extraire encore plus de connaissances à partir desdonnées.
16

Résultats
6 L’entrepôt de données et données agrégées
6.1 L’entrepôt de données
L’entrepôt comporte actuellement une table de faits et deux dimensions : une dimension temporellequi regroupe les jours, les décades, les mois, les saisons et les années ainsi que les décennies, etune dimension spatiale qui regroupe les upc, les régions fourragères, les départements et les régionsadministratives. La table de faits a été alimentée à l’aide de plusieurs scripts python :
— Le premier script va chercher dans la table run has time de la base de données plusieursmesures qui nous intéressent et réaliser quelques calculs sur ces mesures a�n d’avoir la crois-sance nette par exemple. Il récupère aussi des paramètres nécessaires à notre calcul d’agré-gation. Il recrée des lignes avec pour chacune des idsimulation, un idtime et un idupc et lesmesures d’intérêt. On a donc les mesures par simulation et par jour.
— Le second script va ensuite réaliser un premier tri a�n de regrouper par dossier, 10 upc pardossier, puis par �chier les di�érentes lignes. Un �chier porte le nom de idtime et idupc et ilsregroupent toutes les simulations qui ont eu lieu le même jour dans la même upc.
— Le dernier script va ensuite réaliser une agrégation complexe sur chaque �chier a�n quetoutes les simulations qui ont lieu le même jour dans la même upc soient regroupées en uneseule ligne qui correspond aux mesures du jour donné dans la totalité de l’upc. Il faut ene�et tenir compte qu’il y a di�érents types de sol, de prairie et de modes d’exploitation ausein d’une même upc et ils sont tous associés à di�érents pourcentages. Toutes les lignessont ajoutées les unes à la suite des autres dans un �chier de sortie qu’on insère ensuite dansl’entrepôt de données pour créer notre table de faits.
17

Figure 9 – Les di�érentes tables de l’entrepôt
La dimension temporelle (�gure 9.A) de notre entrepôt est constituée d’un idtime (identi�ant) quiest la date, la décennie, l’année, le mois, la décade, le jour du mois et le jour julien ainsi que la saisonastronomique et météorologique.
La dimension spatiale (�gure 9.B) est constituée d’un idpcu (identi�ant de l’unité pédoclimatique)qui correspond au numéro de la PCU, et contient aussi le numéro de la région fourragère ainsi quele nom de l’ancienne et la nouvelle région administrative.
La table de faits (�gure 9.C) �nale comporte 9 colonnes dont l’idpcu, l’idtime et 7 mesures d’intérêt.
Chaque ligne correspond aux mesures par upc et par jour qui sont respectivement les niveaux degranularité les plus faibles de la dimension spatiale et temporelle. On a récupéré 7 mesures d’intérêt :
— Growth : croisssance nette des prairies de l’upc pour le jour considéré en kg par hectare parjour (kg/ha/j).
— Lessiv : azote lessivé (kg/ha/j).— MAT : matière azotée totale, c’est à dire le contenu en protéine de l’herbe (g N/kg MS).— Msexporte : matière sèche exportée soit par la fauche soit par pâture (kg/ha).— Nexporte : azote cumulé exporté par fauche et pâture, (kg N/ha).— em_N : émissions azotées vers l’air (kg N/ha/j).
18

— SOC_balance : le stockage en carbone du sol (kg N/ha/j).
6.2 Les données agrégées
Nous avons généré plusieurs cubes de données qui agrègent les mesures selon les dimensions tem-porelle et spatiale a�n d’avoir une idée pour une mesure précise de sa moyenne ou de son cumul àtous les niveaux hiérarchiques de chaque dimension. Soit, pour la dimension temporelle : par jour,par décade, par mois, par saison, par année, par décennie et pour la dimension spatiale : par upc, parrégion fourragère, par département, par région administrative. Les valeurs agrégées obtenues sontdes combinaisons de ces deux axes : par exemple la moyenne par upc et par jour ou par upc et paran ou par région et par décade.
Figure 10 – Exemple de données agrégées issues de l’entrepôt
Voici un extrait de data cube réalisé avec notre entrepôt (Figure) : il s’agit du lessivage cumulé quia été regroupé par région puis par année, par mois, par décade et pour �nir par jour. La valeur enface d’une cellule du tableau où il y a NULL correspond à une somme.
— Le NULL que l’on voit en face du 3 (ligne 13) nous donne la somme du lessivage sur la troisièmedécade du mois de décembre de l’année 2013 pour la région Ile-de-France qui est de 7.15 kg/ha.
— La ligne du dessous (avec deux NULL côte à côte, ligne 14) correspond au lessivage cumulé surtout le mois de décembre de l’année 2013. Les trois NULL à la suite (ligne 15) correspondentau lessivage cumulé sur toute l’année 2013.
— Les quatre NULL à la suite(ligne 16) correspond au lessivage cumulé en Ile-de-France sur les30 ans du scénario.
— La dernière ligne correspond au lessivage cumulé sur les 30 ans pour toutes les régions.
19

7 L’application connectée à l’entrepôt de données
7.1 Sélection des données
Dans un premier temps l’accent a été mis sur la sélection qui devait pouvoir être à la fois très largemais aussi très précise.
Figure 11 – Partie de l’interface permettant à l’utilisateur de sélectionner la mesure et de naviguerdans les dimensions spatiale et temporelle
Pour l’instant, l’utilisateur peut choisir entre deux variables à visualiser : le lessivage du nitrate oul’exportation d’azote.
Ensuite, il doit choisir la localisation sur une région administrative, au choix entre la Bretagne, laBasse ou Haute Normandie et l’Ile de France. Il peut choisir de rester sur une échelle assez large oubien plus précise au niveau de la région fourragère, en fonction de la sélection précédente à l’échellede la région il aura le choix soit avec toutes les régions fourragères, si la sélection précédente estALL, soit avec les régions fourragères d’une région en particulier.
Après ces premières sélections l’utilisateur va pouvoir choisir de visualiser sur toutes les annéesdu scénario (year =ALL) ou bien une année précise qu’il va pouvoir visualiser par mois (12 pourune année), décade (36 décades pour une année) ou jours (365 jours pour une année). Il peut aussia�ner encore sa recherche et chercher à visualiser pour un mois en particulier d’une année donnéecomment la variable évolue au �l des décades de ce mois (3 décade / mois). S’il sélectionne unedécade précise il pourra voir l’évolution de la variable sur ces dix jours, au sein du mois sélectionnépour une année donnée.
L’utilisateur va aussi pouvoir choisir le langage pour l’a�chage (français ou anglais).
20

Les icônes en forme de point d’interrogation sont là pour aider l’utilisateur et lui donner des in-formations complémentaires. S’il clique sur la petit icône en face de mesures, il aura un descriptifdétaillé de toutes les mesures.
7.2 Les di�érents modes de visualisation des données
On peut choisir les modes de visualisation via la barre de navigation de l’application (voir annexe 1)
Les boxplots
Le mode de visualisation sous forme de boxplot est adapté à la comparaison inter-régionale desdonnées, ou par région (administrative ou fourragère) à la comparaison interannuelle des données.Il permet de visualiser la distribution des données (valeur médiane, premier et dernier quartile).
Figure 12 – Visualisation des boxplots de l’application
La �gure 12.A nous montre le lessivage cumulé sur la durée de la simulation par région administra-tive sous forme de boxplot. Cette �gure a été obtenue en sélectionnant région administrative égaleALL. La �gure 12.B représente toutes les régions fourragères présentes dans l’entrepôt. Cette �gurea été obtenue en sélectionnant région administrative égale ALL et région fourragère égale ALL. La�gure 12.C se concentre sur les 10 régions fourragères qui constituent la Bretagne. Cette �gure à étéobtenue en sélectionnant la Bretagne comme région administrative et région fourragère égale ALL.On peut ainsi visualiser rapidement à l’aide de ces boxplots quelle région administrative a le taux delessivage du nitrate le plus élevé sur toute la durée du scénario (�gure 12.A). La Bretagne est cellequi a le lessivage en moyenne le plus haut (supérieur à 100 kg/ha/an) et l’Ile-de-France a le lessivage
21

le plus bas (en moyenne autour de 30 kg/ha/an). On peut voir à l’aide de la �gure 12.C plus en détailsla variation au sein des régions fourragères en Bretagne. La région fourragère numéro 5303 est cellequi a un taux de lessivage le plus élevé et la région fourragère 5302, le plus bas.
Les boxplots permettent ainsi de réaliser des opérations tel que des Slice en sélectionnant seulementles régions fourragères d’une région donnée ou bien des Roll-up en retournant à la hiérarchie di-mensionnelle supérieure à savoir en repassant de la région fourragère à la région administrative oudes Drill-down en faisant l’inverse voir partie 3.4.
Les barplots
Figure 13 – Visualisation des barplots de l’application
La �gure 13.A nous montre l’évolution du taux de lessivage du nitrate sur les 30 ans du scénariopour une région administrative donnée. La �gure 13.B nous montre la variation du taux de lessivagemensuel pour l’année 1984. La �gure 13.C nous montre la variation du taux de lessivage par décadepour l’année 1984. La �gure 13.D nous montre la variation journalière du taux de lessivage. L’année2006 semble être l’année qui a connu le plus gros taux de lessivage (supérieur à 150) à l’inverse 2007est l’année qui a, semble-t-il, le taux de lessivage le plus bas (inférieur à 75) (�gure 13.A). Pour l’année1984, le mois de novembre a connu le taux de lessivage le plus haut (supérieur à 45) et le mois dejuillet le taux de lessivage le plus bas (proche de zéro)(�gure 13.B). Si on s’intéresse à une répartitionplus précise pour un mois en particulier, on peut aussi visualiser le taux de lessivage journalier ausein d’un mois précis pour une année donnée sous forme de courbe ou bien de barplot.
Les barplots permettent de faire des navigations plus précises en sélectionnant une région adminis-trative ou fourragère en particulier et une année en particulier : on peut donc réaliser des Dice maisaussi en changeant de granularité aussi bien spatiale que temporelle des Roll-up et des Drill-Down(se référer à la partie 3.4).
22

Les tableaux de données
On peut aussi visualiser les données issues des sélections réalisées directement sous forme d’untableau. Cela permet d’avoir des mesures plus précises ainsi que de connaître le jour julien et ladécennie.
Figure 14 – Le lessivage par décade pour l’année 1984 en Bretagne sous forme d’un tableau
Les cartes
Figure 15 – Visualisation de la quantité de lessivage du nitrate par région sous forme de carte pourl’année 1984
La carte permet d’avoir a une représentation très visuelle de la quantité de lessivage par région.On peut donc rapidement voir pour une année qu’elle est le lessivage moyen par région et quellerégion produit le plus ou le moins. Les cartes sont pour le moment disponibles à l’échelle de la régionadministrative et par année.
23

8 La fouille de données
8.1 Les données transformées
L’algorithme python réalisé a permis de discrétiser les données à l’aide des méthodes présentes dansle package pandas. On a donc utilisé la fonction pd.cut pour ranger les données dans des intervalleslabellisés. On a aussi utilisé la fonction replace pour remplacer les types de climats (1,2....7,8) pardes noms, par exemple le type de climat ’4’ correspond au climat océanique altéré. Ensuite il a fallugénérer deux classes, on a donc sélectionné les upc avec un taux de lessivage bas (inférieur à 29.45d’azote en kg/ha/an, correspond au premier quartile) et un taux d’azote élevé (supérieur à 253.5d’azote en kg/ha/an, correspond au premier quartile). Ces upc peuvent être quali�ées de "bonneupc", elles ont donc été mises dans la classe 1. Les UPC avec un taux de lessivage haut (supérieur à81.5) et une quantité d’azote exporté basse (inférieur à 172) ont été mises dans la classe 0.
Figure 16 – Données obtenues après discrétisation des données agronomiques (�gure 8)
Une fois cette transformation e�ectuée on a donc pu utiliser sur nos données l’algorithme de patternmining.
8.2 Résultats de l’algorithme
Nous avons au total un jeux de données de 600 upc dont 300 upc "bonnes" et 300 upc "mauvaises".L’algorithme va nous renvoyer des motifs permettant de discriminer ces deux classes.
Le résultat de l’algorithme est le suivant :
((’motif’),(’growth ratio’,’support’))
On va favoriser les motifs avec un ’relative growth ratio élevé’, inf signi�e in�ni, ces motifs ne serontretrouvés que dans la classe 0 (les "mauvaises" upc) et un support élevé aussi qui va signi�er qu’onretrouve ce motif dans beaucoup de lignes du jeu de données de la classe zéro. En se basant sur ces
24

Figure 17 – Résultats de l’algorithme de pattern mining
règles, le motif qui discrimine le mieux nos deux classes est donc la réserve utile basse (entre 0 et40 mm) qui est vraie pour 243 upc des 300 que compte le jeu de données de la classe zéro. D’autresmotifs reviennent souvent tels que le nombre d’exploitations bas (entre zéro et 2 exploitation paran). D’autres motifs plus complexes permettent aussi de discriminer ces deux classes tel RsurRU’supérieur’, drain ’moyen’ et minéralisation ’moyen bas’.
25

Limites et discussion
Au début du stage, il a fallu faire face à un problème de stockage des données : en e�et, on nedisposait pas d’une place attitrée pour stocker les 1.5 To de données. Le serveur lacodam à donc étémis à disposition pour réaliser ce stage, cependant il n’y avait pas assez d’espace pour stocker toutesles données. Deux disques dur SSD de type ext4 de 1To chacun on donc été rajoutés au serveur. A�nde faciliter le stockage des données ces disques dur on été fusionnés pour créer un volume logiquede 2 To via le gestionnaire de volume logique LVM qui a donc servi à accueillir les données. L’autredi�culté rencontrée à été de con�gurer ce qu’on appelle "lexport display" qui consiste à se logguerà distance en mode graphique via une connexion ssh. En e�et, il y avait la nécessité d’installer deslogiciels à interface graphique (comme Talend) au même endroit que les données sur le volumelogique. Nous avons eu d’autres problèmes concernant l’insertion des données brutes dans la basede donnée ce qui explique que cette base est encore incomplète à cause du temps d’exécution desscripts R et du fait que le processus est très gourmand en mémoire vive. En e�et, plus la base dedonnées est grande, plus le temps d’insertion des données augmente. A la place d’avoir un tempsd’insertion linéaire, il avait plus l’air d’être exponentiel (voir annexe 3). A ce jour, nous ne savonspas encore comment régler ce problème, il vient peut être de la façon que à R d’insérer des donnéesdans la base de donnée.
26

Conclusion et perspectives
Nous avons donc pu mettre en place une structure adaptée à une grande quantité de données agrono-miques permettant de faciliter l’exploration et la visualisation de ces données. L’entrepôt de donnéesest fonctionnel et repose sur deux dimensions : spatiale et temporelle avec une granularité �ne quipermet d’interroger les données de façon précise ou plus large. De plus, l’entrepôt dispose d’une vi-sualisation facilitée à l’aide de l’application R shiny qui récupère directement les données agrégéesà partir de notre entrepôt. La fouille de motifs réalisée par la suite a permis d’extraire encore un peuplus de connaissances à partir des données. Par la suite, il faudra se concentrer sur di�érents pointsdont l’insertion des données brutes dans la base de données qui a pris plus de temps que initialementprévu et, devra être complétée. Il faudra aussi chercher de nouvelles dimensions pour améliorer l’en-trepôt de données puis créer de nouvelles tables de données agrégées. Pour le moment, on ne s’estconcentré que sur deux mesures de la table de faits : l’azote exporté et le lessivage du nitrate, maisil faudra réaliser des tables de données agrégées pour les autres mesures de la table de faits. Il resteaussi à améliorer l’outil R shiny pour faciliter la visualisation des données agrégées. Il faudra en�nse focaliser sur la fouille de motifs qui va pouvoir nous aider à mieux interpréter les données.
27

Bibliographie
[1] Nadine Brisson, Christian Gary, Eric Justes, R. Roche, Bruno Mary, Dominique Ripoche, DanielZimmer, Jorge Sierra, Patrick Bertuzzi, P. Burger, François Bussière, Yves-Marie Cabidoche,Pierre Cellier, Philippe Debaeke, P. Gaudillere J., Catherine Hénault, Florent Maraux, BernardSeguin, and Hervé Sinoquet. An overview of the crop model STICS. European Journal ofAgronomy, 2003.
[2] Anne-Isabelle Graux, Luc Delaby, Jean-Louis Peyraud, Eric Casellas, Philippe Faverdin, Chris-tine Le Bas, Anne Meillet, Thomas Poméon, Helene Raynal, Rémi Resmond, Dominique Ri-poche, Francoise Ruget, Olivier Therond, and Francoise Vertes. Les prairies françaises : produc-tion, exportation d’azote et risques de lessivage. Research Report, Ministère de l’Alimentation,l’Agriculture et de la Forêt, 2017.
[3] Tassadit Bouadi, Marie-Odile Cordier, Pierre Moreau, René Quiniou, Jordy Salmon-Monviola,and Chantal Gascuel-Odoux. A data warehouse to explore multidimensional simulated datafrom a spatially distributed agro-hydrological model to improve catchment nitrogen manage-ment. Environmental Modelling & Software, 97 :229–242, November 2017.
[4] Nadine Brisson, Françoise Ruget, Philippe Gate, Josiane Lorgeou, Bernard Nicoullaud, XavierTayot, Daniel Plenet, Marie-Hélène Jeu�roy, Alain Bouthier, Dominique Ripoche, Bruno Mary,and Eric Justes. STICS : a generic model for simulating crops and their water and nitrogenbalances. II. Model validation for wheat and maize. Agronomie, 22(1) :69–92, January 2002.
[5] Nadine Brisson, Bruno Mary, Dominique Ripoche, Marie Hélène Jeu�roy, Francoise Ruget, Ber-nard Nicoullaud, Philippe Gate, Florence Devienne-Barret, Rodrigo ANTONIOLETTI, CarolyneDurr, Guy Richard, Nicolas Beaudoin, Sylvie Recous, Xavier Tayot, Daniel Plenet, Pierre Cellier,Jean-Marie Machet, Jean Marc Meynard, and Richard Delécolle. STICS : a generic model forthe simulation of crops and their water and nitrogen balances. I. Theory and parameterizationapplied to wheat and corn. Agronomie, 18(5-6) :311–346, 1998.
[6] Francoise Ruget, S. Novak, and S. Granger. Du modèle STICS au système ISOP pour estimer laproduction fourragère. Adaptation à la prairie, application spatialisée. Fourrages (186), 241-256.(2006), 2006.
[7] J. E. Bergez, H. Raynal, M. Launay, N. Beaudoin, E. Casellas, J. Caubel, P. Chabrier, E. Coucheney,J. Dury, I. Garcia de Cortazar-Atauri, E. Justes, B. Mary, D. Ripoche, and F. Ruget. Evolution ofthe STICS crop model to tackle new environmental issues : New formalisms and integration inthe modelling and simulation platform RECORD. Environmental Modelling & Software, 62 :370–384, December 2014.

[8] Daniel Joly, Thierry Brossard, Hervé Cardot, Jean Cavailhes, Mohamed Hilal, and Pierre Wa-vresky. Les types de climats en France, une construction spatiale. Cybergeo : European Journalof Geography, June 2010.
[9] Cécile Favre, Fadila Bentayeb, Omar Boussaid, Jérôme Darmont, Gérald Gavin, Nouria Harbi,Nadia Kabachi, and Sabine Loudcher. Les entrepôts de données pour les nuls. . . ou pas ! In 2eAtelier aIde à la Décision à tous les Etages (EGC/AIDE 2013), Toulouse, France, January 2013.
[10] Conception d’un entrepôt de données.
[11] Data Integration : Concepts and Principles •Talend Data Integration Studio User Guide •Reader• Welcome to Talend Help Center.
[12] Tassadit Bouadi. Analyse multidimensionnelle interactive de résultats de simulation. Aide à ladécision dans le domaine de l’agroécologie. November 2013.
[13] EXMOTIF : e�cient structured motif extraction | Algorithms for Molecular Biology | Full Text.
[14] mine_discriminative_patterns.py · master · GALARRAGA DEL PRADO Luis / cpxr.
[15] Alexandre Termier. Pattern mining rock : more, faster, better. 2013.
[16] HYdraulic PRoperties of European Soils updates | Natural Resource Datasets | The James HuttonInstitute.

Résumé
Au vu de la croissance exponentielle des données agronomiques simulées, par des modèles mis enplace pour aider l’agriculture de demain, il a fallu mettre en place de nouveaux moyens pour sto-cker, interroger et exploiter ces données. Les entrepôts de données bien qu’encore peu présents dansle domaine de l’agriculture semblent apporter une solution intéressante pour stocker nos donnéesagronomiques. Ces données sont issues d’une étude sur les prairies françaises [2]. Notre étude se basesur un travail préalable conduit par Tassadit Baoudi sur un entrepôt de données agro-hydrologiquesgénérées par simulation [3]. Dans un premier temps le travail s’est concentré sur la base de don-nées : la structure était déjà existante mais il a fallu procéder à son remplissage et créer un espacede stockage su�sant pour accueillir les données brutes et la base de données. Ensuite, il a fallu faireévoluer cette base de données en entrepôt de données adapté au caractère spatio-temporel des ré-sultats de simulation. Un outil interactif implémenté en R shiny a également été déployé ; ainsi uneinterface ergonomique a été produite a�n de faciliter l’accessibilité et la visualisation des données,notamment par l’intermédiaire de graphiques. En�n, les questions agronomiques plus poussées ontété résolues à l’aide de méthodes de data mining qui ont permis d’extraire des connaissances à partirde ces grandes quantités de données. Le stage a donc permis de mettre en place une structure adap-tée à une grande quantité de données agronomiques permettant ainsi d’en faciliter l’exploration etla visualisation. La fouille de motifs réalisée par la suite a �nalement permis d’extraire encore unpeu plus de connaissances à partir des données.
Abstract
Given the exponential growth of simulated agronomic data, generated by models established so asto help the agriculture of tomorrow, it was necessary to put in place new ways to store, query andexploit these data. Although data warehouses are still not very present in the �eld of agriculture,they seem to o�er an interesting solution for storing our agronomic data. These data come from astudy on the French meadows [2]. Our study is based on a preliminary work conducted by TassaditBaoudi on a data warehouse using simulated agro-hydrological data [3]. At �rst our work focusedon the database, the structure was already existant, however we had to �ll it and create enoughstorage space to accommodate the raw data and the database. Then, we moved this database to adata warehouse adapted to the spatio-temporal nature of the simulation results. An interactive toolimplemented in R shiny has been deployed. An ergonomic interface has been produced to facili-tate data accessibility and visualization, particularly through graphics. Then, some more advancedagronomic questions have been solved using data mining methods that can extract knowledge fromlarge amounts of data. We have therefore been able to set up a structure adapted to a large amount ofagronomic data and facilitating the exploration and visualization of these data. The pattern miningallowed us to extract a little more knowledge from the data.
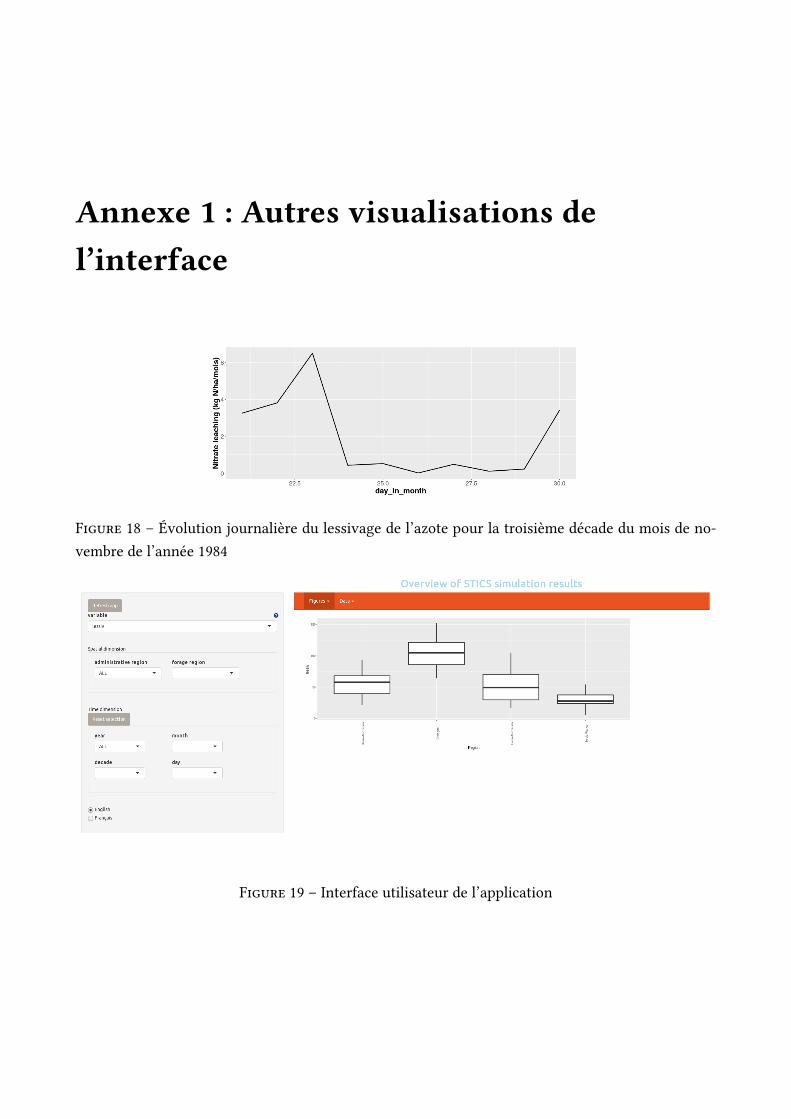
Annexe 1 : Autres visualisations del’interface
Figure 18 – Évolution journalière du lessivage de l’azote pour la troisième décade du mois de no-vembre de l’année 1984
Figure 19 – Interface utilisateur de l’application

Annexe 2 : Partie sur les questionsagronomiques
Figure 20 – Les questions agronomiques autour des données

Annexe 3 : Temps d’insertion dans la basede données
Figure 21 – Temps d’exécution du script R de la table run has time sans insertion dans la base dedonnée
Le temps de traitement est bien linéaire.
Le temps d’exécution du script avec insertion semble donc être plus linéaire que exponentielle
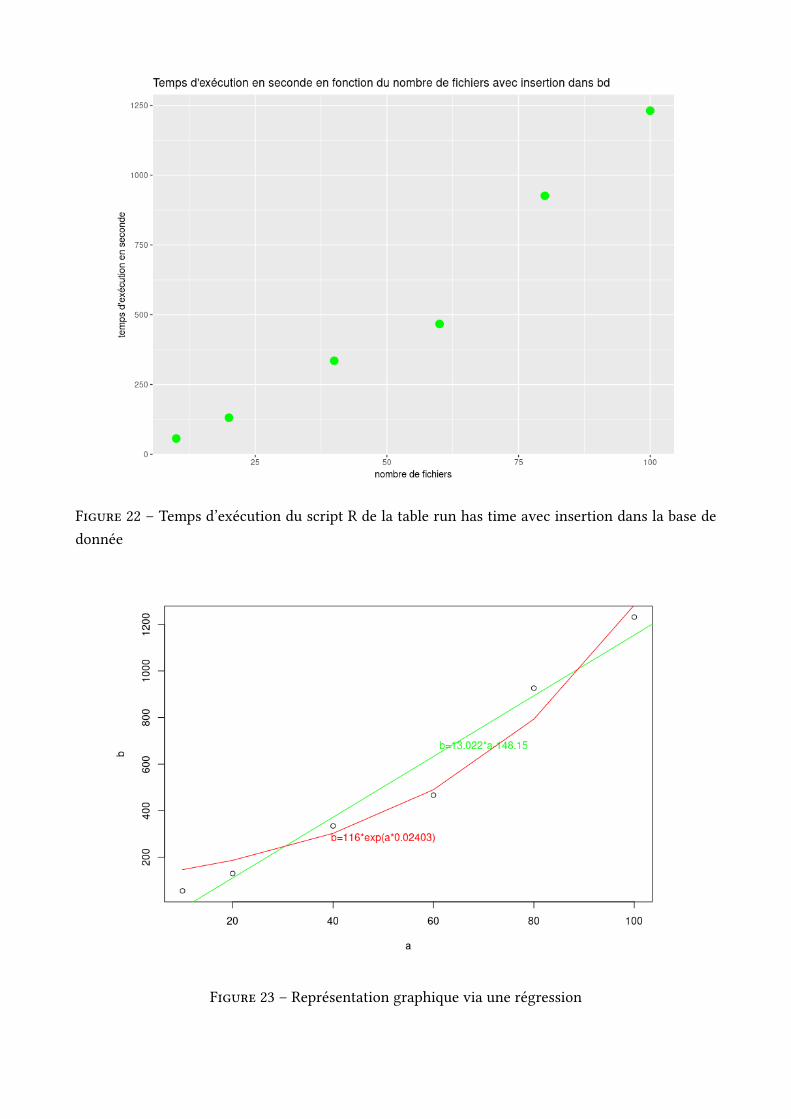
Figure 22 – Temps d’exécution du script R de la table run has time avec insertion dans la base dedonnée
Figure 23 – Représentation graphique via une régression


















