
Classification markovienne automatique d'images … · Dans le cadre du projet de la région...
38
Classification markovienne automatique d'images aériennes de haute résolution
Transcript of Classification markovienne automatique d'images … · Dans le cadre du projet de la région...

Classification markovienne automatique d'images aériennes de haute résolution

Contexte
Introduction
Champs de Markov cachés
Le programme SpaCEM3
Catalogue de motifs
Vecteurs descripteurs
Le programme IFE
Résultats
Temps de calcul
Une application
Conclusions et perspectives
Références
Plan

Dans le cadre du projet de la région Rhône-Alpes DEREVE II (2004-2006):
classification détaillée d'orthophotographies aériennes en couleur, avec comme terrain d'étude la Haute-Savoie (données: RGD73-74, résolution: 50cm par pixel)
Reconnaissance automatique de motifs de texture dans une collection d'images = domaine de recherche récurrent et passionnant
Applications multiples et variées:
- analyse d'images satellitaires, télédetection,
- traitement d'images hyperspectrales (plusieurs centaines de longueurs d'onde),
- imagerie médicale, biologie, physique,
- géomatique, géographie, urbanisme,(exemple: extraction des types de sol = Land Cover Classification)
- vision par ordinateur.
Enjeu très actuel: exploitation automatique et systématique de données picturales de toutes sortes, par exemple sur l'Internet.
Contexte

Mon exposé présente le contexte scientifique de cette étude et les résultats expérimentaux obtenus, qui s’appuient sur les logiciels:
- SpaCEM3 (Spatial Clustering with EM and Markov Models),
- IFE (Image Feature Extraction),
développés respectivement à l'INRIA et à MAP-ARIA.
Equipe:
Xavier Marsault, MAP-ARIA, UMR CNRS MAP 694, [email protected]
Matthieu Aubry, INSA de Lyon, [email protected]
Jean Fortin, ENS de Lyon, [email protected]
Lamiae Azizi, MISTIS, INRIA Rhône-Alpes, [email protected]
Contexte

Classifier = regrouper des individus (pixels d'une image, régions, segments de texte, gènes...) en groupes homogènes par rapport à des mesures effectuées sur ces individus.
Méthode pixels / régions: pas besoin de découpage préalable, de polygones d'apprentissage, mais plus de bruit en sortie => étape de consolidation des résultats.
A chaque pixel est associé un vecteur de mesures (observations), et une classe.
Approche probabiliste = modèle pour le couple des observations et des classes.
Hypothèses simplificatrices souvent adoptées:
- les classes sont indépendantes et le modèle de bruit se factorise sur les individus (on parle alors de bruit indépendant).
- les observations sont, en général, ou bien de dimension raisonnable, ou bien les composantes de chaque observation sont supposées indépendantes.
En analyse de textures naturelles, ces hypothèses sont souvent mises en défaut et ne permettent pas d'obtenir des résultats satisfaisants.
Introduction

SpaCEM3:
- aborde le problème de la classification d'images sous des hypothèses non classiques:
- non indépendance des classes,- non indépendance du bruit,- grande dimension des données,- corrélation possible des dimensions,- données potentiellement manquantes.
- propose des algorithmes pour la classification supervisée ou non supervisée de données uni ou multi-dimensionnelles en interaction.
Introduction

Les modèles de champs de Markov aléatoires cachés (HMRF) permettent de prendre en compte les dépendances spatiales.
La notion de champ est d'origine physique: elle décrit des quantités variant en fonction de leur point de définition: température, vitesse, force, pression, gravitation, électro-magnétisme.
Soit S un ensemble de pixels indexés dans {1,..., n}. On note N(i) le voisinage du point i (graphe G). Un champ aléatoire Z est un champ de Markov si et seulement s’il vérifie la propriété:
(seul le voisinage du point i a une influence sur le champ au point i).
Un champ de Markov suit une loi de Gibbs dont la distribution de probabilités est de la forme:
où la fonction énergie H se décompose en somme de potentiels V sur les cliques de G.
Champs de markov cachés

Champs de Markov discrets:
Dans un champ de Markov discret, la variable Zi représente une étiquette attribuée au point i dans {1,...,K}. On définit la fonction énergie:
Champs de Markov cachés discrets:
On suppose que la loi de probabilité des données cachées (la classification) connaissant les données observées (mesures) correspond à un champ de Markov. On note:Y = {yi, i ∈ S} les observations, et z = {zi, i∈S} les résultats de la classification.
On a donc une distribution de la forme:
Champs de markov cachés

Modélisation
On suppose qu'une texture m est décomposée en K sous-classes, dont la distribution suit la loi:
où f(yi | θmk) est la densité de la loi gaussienne de paramètres θmk (moyenne μmk et matrice de covariance Σmk), Zi représente la sous-classe du point i, sa loi est paramétrée par ∆m, et Ψm= (∆m, (Θmk)) est l’ensemble des paramètres pour la texture m. On suppose que les Zi constituent un champ de Markov avec la fonction d’énergie:
Champs de markov cachés

Approche probabiliste fondée sur:
- une modélisation markovienne avec une famille de modèles cachés triplets adaptés à la classification supervisée (plus de bruit indépendant),
- l'utilisation de l'algorithme EM pour une classification floue, et les HMRF pour la modélisation des dépendances. EM est un algorithme itératif alternant une étape d'évaluation de l'espérance de la vraisemblance (E) et une étape de maximisation (M).
Inclut 2 critères de sélection du meilleur modèle HMRF en fonction des données (ex: BIC=Bayes Information Criterion, qui mesure l'équilibre entre l'ajustement du modèle aux données et la complexité du modèle).
SpaCEM3
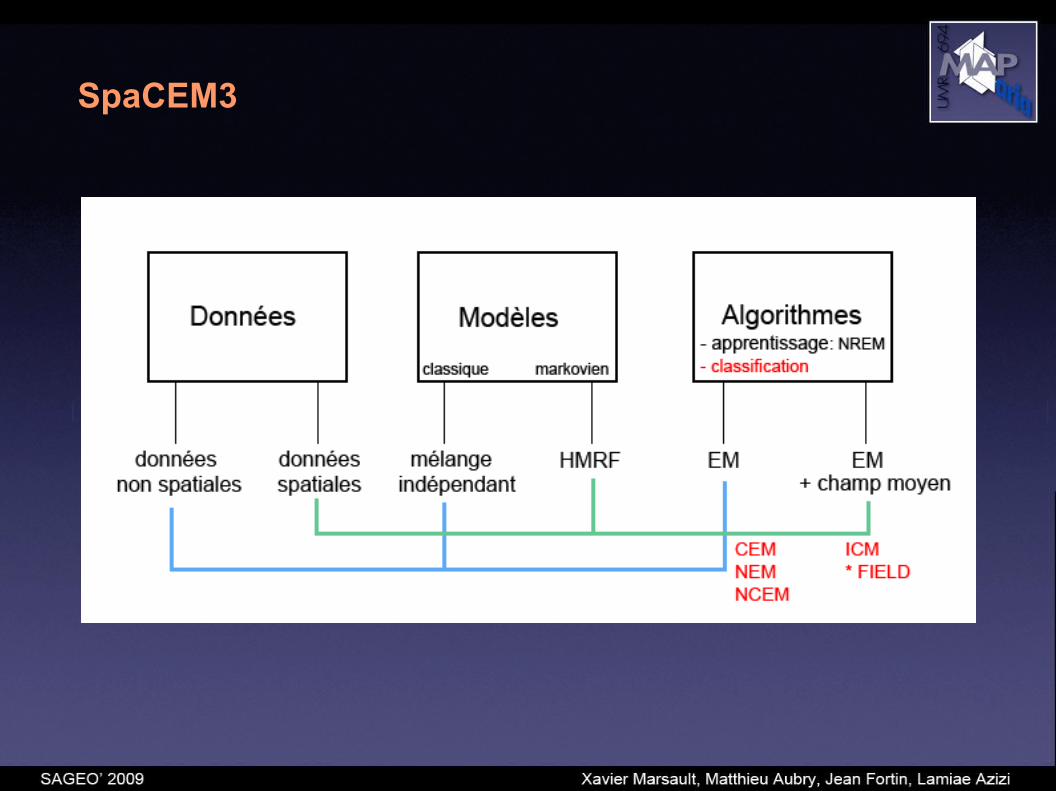
SpaCEM3

Phase d'apprentissage
Le terme supervisé signifie qu'on dispose d'individus étiquetés (on connaît leurs classes).
A partir des observations formant la base d'apprentissage, on désire classer d'autres individus (la base de test) dans ces mêmes classes.
Les étapes d'apprentissage sont basées sur l'algorithme NREM (Neighborhood Restoration Expectation Maximization) permettant d'estimer les paramètres du HMRF sous approximation de type champ moyen.
L'apprentissage consiste à apprendre les paramètres Bm et αm des champs de Markov pour chaque texture, et les moyennes et variances des densités des gaussiennes: μmk et mk. Chaque texture est segmentée en K sous-classes, K étant estimé par l'utilisateur.
SpaCEM3

Phase de classification
On initialise les valeurs du champ de Markov à l’aide d’une pré classification (ex: KMeans): on associe à chaque pixel la classe qui maximise la probabilité priori que le pixel lui appartienne, sans tenir compte des pixels voisins (on connait les densités de probabilité de l’observation pour chaque classe).
On effectue ensuite une classification supervisée de l’image, c’est-à-dire:
- en fixant les paramètres du champ de Markov et des densités des gaussiennes à l’aide des valeurs trouvées lors de l'apprentissage,
- et en utilisant l'un des 4 algorithmes: ICM (iterational conditional modes), Mean Field, Modal Field ou Simulated Field pour trouver la valeur de la segmentation Z qui maximise la probabilité conditionnellement aux données observées Y et aux paramètres appris.
SpaCEM3

SpaCEM3

Catalogue de motifs
- 48 motifs de sol, 128 x 128 pixels, extraits de la bdd de la Haute-Savoie:
-neige (poudreuse, cristallisée, fondante, sale),-glace (blanche, bleue, grise),-eau (torrent, lac, rivière),-forêt (plusieurs types),-maquis et arbres isolés (plusieurs types),-prairie (plusieurs types),-roche (plusieurs types),-rochers et éboulis (plusieurs tailles),-roche végétalisée (plusieurs types),-mélange prairie / roche / caillou,-culture (plusieurs types),-chemin de terre,-bitume (route, sol urbain, parking) et toitures (plusieurs types),
- pas de « classe poubelle » => fournir un catalogue le plus complet possible, à partir de la banque de photographies => à compléter petit à petit,
- avantage de la décomposition en sous-classes pour la classification des textures naturelles (par exemple, dans une foret, la canopée, le sol et l'ombrage sont appris ensemble).

Catalogue de motifs

Vecteurs descripteurs
- étude systématique de mesures significatives devant composer le vecteur descripteur (les seules informations dont disposent les algorithmes d'apprentissage et de classification),
- doivent être judicieusement choisis, même si cela reste très expérimental, ce qui fait tout l'intérêt de ce type de recherches,
- l'ancien programme utilisé (NEM) contraignait le choix des mesures: le plus décorrélées possible tout en restant significatives => nombre limité et assez faible. Cela n'a plus lieu d'être à présent avec les modèles triplets,
- propriétés locales caractéristiques pour chaque pixel: colorimétriques (couleur, luminosité) et surfaciques (forme, rugosité, répétition de motifs).

Caractérisation colorimétrique
- plusieurs espaces de codage des couleurs,
- test de 3 codages classiques: RGB (trichrome), YUV (luminance, chrominances) et HSV(teinte, saturation, luminosité),
- quelques tests très significatifs => YUV et HSV plus discriminants que RGB en reconnaissance de textures (décorrelation). Et HSV meilleur car invariant au changement d'intensité (intéressant dans les zones d'ombre).
Avec MAX=max(r,g,b) et MIN=min(r,g,b):

Caractérisation surfaciqueNous avons expérimenté plusieurs mesures provenant du traitement du signal:
- les filtres de Gabor, localisés en temps et en espace, utilisés pour calculer des propriétés fréquentielles des textures, mais de forte dimensionnalité,
- les 14 critères d'Haralick, peu adaptés aux images en couleurs, et lourds à manipuler,
- les coefficients de la Karhunen-Loeve Transform KLT (analyse en composantes principales),
et des mesures de la rugosité de surface:
- gradients des différentes composantes de couleur (YUV, HSV),
- mesure de contraste LIP (Logarithmic Image Processing) pour tenir compte des ombres,
- 2 mesures de la dimension fractale, avec ou sans filtrage:
- spectre de puissance d’un signal fractal bidimensionnel (mauvais résultats),
- méthode par comptage basée sur l’autosimilarité (meilleurs résultats).

Images de la dimension fractale avant et après lissage.
Les différents paramètres ont été testés seuls ou en combinaison. Il n'est pas possible de montrer ici l'ensemble des résultats issus de toutes les expérimentations.
Tests peu probants: espace KLT, filtres de Gabor et critères d'Haralick, dimension fractale, les gradients des composantes YUV ou H, contraste LIP.
Le couplage des gradients de S et de V s'avère mieux représenter le « grain » ou la « rugosité ».

Développé par MAP-ARIA en C++ et en PHP pour rendre totalement transparentes pour l'utilisateur les étapes de calcul, il et conçu avec 3 fonctionnalités majeures:
- le calcul des vecteurs descripteurs des images (dans la version actuelle, seuls les paramètres H, S, V, grad_S, grad_V sont conservés),
- l'écriture automatique de batchs (lancement de tests avec des configurations variées de paramètres et d’algorithmes, commande de calculs à SpaCEM3),
- la consolidation et la conversion des données classifiées en planches de résultats et fichiers interprétables par l'utilisateur.
Le programme IFE (Image Feature Extraction)

Lancement d'un test
Un test complet sur un jeu d'images, entièrement spécifié dans un fichier XML, comprend les étapes suivantes:
- extraction des mesures pour chaque image du jeu (IFE),
- apprentissage d'un catalogue de motifs (SpaCEM3),
- préclassification des images du jeu (SpaCEM3),
- classification des images du jeu (SpaCEM3),
- consolidation des résultats de la classification (IFE),
- conversion des résultats en planches d'images légendées automatiquement (IFE).

Résultats obtenus avec une image typique contenant principalement des textures d’herbe, de forêt et de route:
Classification en 3 classes – 3 sous-classes avec l’algorithme ICM. (a) image native. (b) classification médiocre avec (Y, U, V, grad_Y, grad_U, grad_V, fract_dim). (c) bonne classification avec (H, S, V, grad_S, grad_H).
Précision de la classification (ou mesure de confiance):
-rapport des deux probabilités des sous classes prépondérantes,
- majoritairement bien supérieur à 1 dans nos essais,
- difficile de faire mieux actuellement.
Résultats

Résultats

Résultats

Résultats

Résultats
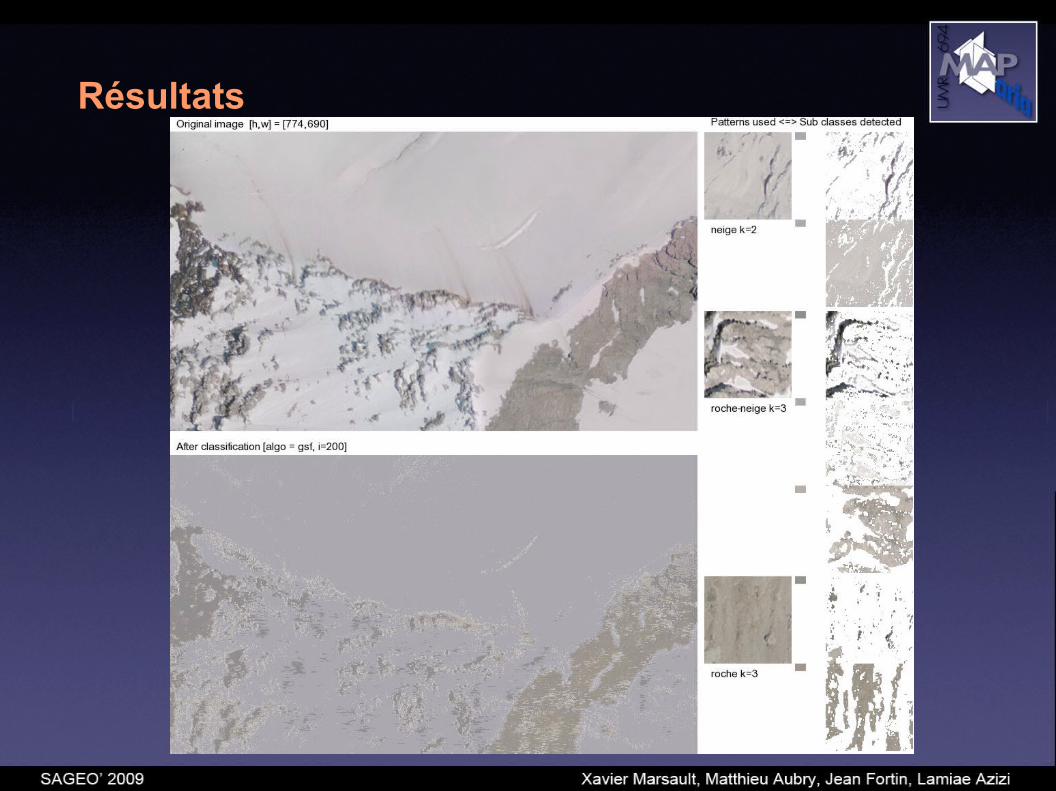
Résultats

Résultats

Echec de l'apprentissage géo-dépendant:
Essais d'apprentissage avec des paramètres liés à la géométrie du terrain (altitude et pente, estimées à partir du MNT à 16m):
- idée développée par S.Premoze en 1999 (les mesures incluant: altitude, pente, direction de la pente, angle par rapport à l’horizon),
- semblait intéressante, puisque la présence ou l'absence de certaines matières peut être liée à ces données variables,
- n'a pas favorisé l'obtention de meilleurs résultats,
- requiert un catalogue d'échantillons à plusieurs altitudes, ce qui complique la création d’une base d’apprentissage, mais aussi l'étape de classification.
Résultats

- phase d'apprentissage des motifs du catalogue: assez rapide (qqs minutes),
- phase de calcul pour la classification: très lente (de 0,5h à 4h pour une image de 800 x 800 pixels avec 7 motifs et 15 sous-classes, selon qu'on utilise ICM, ou *Field).
- le choix du nombre de motifs à utiliser influe fortement sur les temps de calcul et sur la mémoire occupée,
- lenteur du processus de classification avec un catalogue exhaustif => difficulté actuelle d'un traitement systématique d'une large collection d'images,
- complexité quadratique du traitement (temps de calcul et mémoire) en fonction de la largeur de l'image => travailler avec des images de taille moyenne (moins de 1000 x 1000 pixels).
Temps de calcul

Une applicationDans le cadre du projet DEREVE:
- navigateur de larges terrains incluant l'amplification végétale (technique transférée dans la plateforme PROLAND, INRIA\EVASION),
- faire apparaître en temps réel la végétation qui doit être visible (n'est générée qu'en fonction des contraintes du point de vue),
- nécessité de connaître localement la nature du sol, pour pouvoir synthétiser à la volée les éléments de végétation,
- excellents résultats (peu de perte de petits bosquets ou d'arbres isolés) suite à la reconnaissance des massifs de forêts et d'arbres de plusieurs essences sur une zone de 16 km2 autour de Megève.



Conclusions et perspectives
- l'espace de couleur HSV aide à bien reconnaître des motifs distincts dont les couleurs sont visuellement proches,
- la rugosité est assez bien décrite par le gradient des composantes S et V
- mais il est difficile de déterminer le set optimal de features=> problème ouvert,=> refaire des tests, par exemple essayer des méthodes plus précises de calcul de la
dimension fractale,
- prise en charge de textures multi-motifs (en cours d'essais), pour simplifier l'apprentissage et les traitements post-classification=> étendre le catalogue pour tenir compte de nombreuses situations,=> augmenter la taille des motifs
- reconnaissance des textures dans les zones d’ombre: problème pas complètement résolu à ce jour,
- temps de calcul élevés, compensés par la bonne qualité des résultats obtenus.

Références
Amara Y., Marsault X., A GPU Tile-Load-Map Architecture for Terrain Rendering: Theory and Applications, The Visual Computer, Int. Journal on Graphics, Springer, 2008.
Aubry M., Marsault X., Rapport de stage: « Analyse d’images aériennes de haute-résolution du département de Haute Savoie », MAP-ARIA, 2006, http://giik.net/photos-satellite-segmentation.
Blanchet J., Modèles markoviens et extensions pour la classification de données complexes. Thèse de l'Université Joseph-Fourier, Grenoble, 2007.
Celeux G., Forbes F., Peyrard N., EM procedures using mean field-like approximation for Markov model-based image segmentation, Pattern Recognition., 36(1):131-144, 2003.
Chaudhuri B., Sarkar N., Texture Segmentation Using Fractal Dimension, IEEE Transactions on Pattern Analysis and Machine Intelligence, vol 17, n°1, 1995.
Devaux J.C., Gouton P., Truchetet F., Aerial Colour Image Segmentation by Karhunen-Loeve Transform, Proceedings of the 15th International Conference on Pattern Recognition, vol 1, p309-312, 2000.
Fortin J., Marsault X., Rapport de Stage: « Analyse d’images aériennes de haute résolution de Haute Savoie », MAP-ARIA, http://www.aria.archi.fr/equipe/Analyse_textures_2005.pdf
Jourlin M., Pinoli J.C., Logarithmic Image Processing : The mathematical and physical framework for the representation and processing of transmitted images, Advances in Imaging and Electron Physics, vol 115, 2001.

Miyamoto E., Merryman T., Fast Calculation of Haralick Texture Features: www.ece.cmu.edu/~pueschel/teaching/18-799B-CMU-spring05/material/eizan-tad.pdf.
Premoze S., Thompson, W.B., Shirley, P., Geospecific Rendering of Alpine Terrain. Department of Computer Science, University of Utah, 1999.
Recio J.A., Ruiz L.A., Fernandez A., Use of Gabor filters for texture classification of digital images. Department of Computer Science, University of Utah, 2005.
SpacCEM3 (Spatial Clustering with EM and Markov Models), programme à télécharger sur sur spacem3.gforge.inria.fr ou mistis.inrialpes.fr/software/SpaCEM3.tgz (disponible pour Linux (package .deb et .rpm), Windows et MacOs), utilisable avec interface graphique permettant de visualiser les données et les résultats, ou directement en mode batch.
Références

Merci de votre attention !
l'avancée de ce travail et ses résultats seront mis à jour régulièrement à partir de janvier 2010, sur notre nouveau site:
www.aria.archi.fr


















