Classification Des Protocoles de Routage Dans Les R%C3%A9seaux Tol%C3%A9rants Aux D%C3%A9lais...
125
Mme Thouraya TEBIBEL Présidente Maitre de Conférence (ESI) M. Yacine CHALLAL Examinateur Maitre de Conférence (Univ, Compiègne) Mme Chafia YAHIAOUI Examinatrice Docteur (ESI) Mme Chafika Amina LAMMARI Examinatrice Docteur (ESI) M. Omar NOUALI Examinateur Maitre de recherche (CERIST) M. Abdelmadjid BOUABDELLAH Rapporteur Professeur (Univ, Compiègne) Mémoire En vue de l’obtention du diplôme de Magister En informatique Option : Ingénierie des Systèmes Informatiques ISI Classification des protocoles de routage dans les Réseaux Tolérants aux Délais (DTN) Présenté par: Asma Benmessaoud ESI (Ecole nationale Supérieure d‟Informatique) ex. INI (Institut National de formation en Informatique) BP 68M, 16270, Oued Smar, Algérie Tél : 021 51 60 01; Fax : 021 51 61 56 ; http://www.esi.dz 2008/2009 République Algérienne Démocratique et Populaire الجـمهوريــــة الجــزائريــة الديمــقراطيــة الشــعبيةMinistère de l‟Enseignement Supérieur et de la Recherche Scientifique المدر سليم اعيا لعل ة الوطنية الليم اعن في التكويالمعهد الوطني ل( س) ابقاEcole nationale Supérieure d‟Informatique م ـ ديرية م ـعد التدرج و البحث ا بDirection de la Post-Graduation et de la Recherche Soutenu devant le jury:
-
Upload
el-arbi-abdellaoui-alaoui -
Category
Documents
-
view
28 -
download
2
Transcript of Classification Des Protocoles de Routage Dans Les R%C3%A9seaux Tol%C3%A9rants Aux D%C3%A9lais...

Mme Thouraya TEBIBEL Présidente Maitre de Conférence (ESI)
M. Yacine CHALLAL Examinateur Maitre de Conférence (Univ, Compiègne)
Mme Chafia YAHIAOUI Examinatrice Docteur (ESI)
Mme Chafika Amina LAMMARI Examinatrice Docteur (ESI)
M. Omar NOUALI Examinateur Maitre de recherche (CERIST)
M. Abdelmadjid BOUABDELLAH Rapporteur Professeur (Univ, Compiègne)
Mémoire
En vue de l’obtention du diplôme de Magister
En informatique Option : Ingénierie des Systèmes Informatiques
ISI
Classification des protocoles de routage dans les
Réseaux Tolérants aux Délais (DTN)
Présenté par:
Asma Benmessaoud
ESI (Ecole nationale Supérieure d‟Informatique) ex. INI (Institut National de formation en Informatique)
BP 68M, 16270, Oued Smar, Algérie
Tél : 021 51 60 01; Fax : 021 51 61 56 ; http://www.esi.dz
2008/2009
République Algérienne Démocratique et Populaire
الجـمهوريــــة الجــزائريــة الديمــقراطيــة الشــعبيةMinistère de l‟Enseignement Supérieur et de la Recherche Scientifique
ة الوطنية العليا لإلعالم اآللي سالمدر
ابقا(س)المعهد الوطني للتكوين في اإلعالم اآللي
Ecole nationale Supérieure d‟Informatique
ا بعد التدرج و البحثـديرية مـم Direction de la Post-Graduation
et de la Recherche
Soutenu devant le jury:

Résumé
Les réseaux tolérants aux délais (DTNs) sont des réseaux où la connectivité est intermittente
en raison des difficultés rencontrées dans l‟environnement à savoir : le climat, la mobilité, les
pannes d‟énergie, …etc. Pour parvenir à livrer les données malgré tous ces défis, une
nouvelle architecture réseau a été développée. Celle-ci consiste en l‟ajout d‟une couche
supplémentaire dans la pile protocolaire OSI, au-dessus de la couche transport. Cette nouvelle
politique est appelée : le protocole bundle, dont le principal rôle est le stockage de données
jusqu‟à ce qu‟une occasion de transmission se présente, grâce à la technique Store & Forward
et le concept de transfert de garde.
Du fait que cette technologie soit récente, alors divers problèmes sont encore au stade de
recherche, parmi lesquels nous citons le problème du routage, qui est l‟objet de notre travail.
Les protocoles de routage dans les réseaux tolérants aux délais ne cherchent pas à trouver le
chemin le plus court tel que c‟est le cas dans les protocoles classiques, mais ils jouent plutôt
sur l‟augmentation du taux de délivrance de données. Les techniques utilisées pour cela,
peuvent être divisées en deux grandes familles. Certains protocoles adoptent l‟approche de
« réplication », qui consiste en la duplication des messages dans le réseau en fournissant de
multiples copies afin d‟augmenter la probabilité de transmission. D‟autres se basent sur « la
connaissance », qui consiste à récolter des informations sur l‟état du réseau et gérer les envois
de manière efficace. Mais quel que soit la politique suivie, ces protocoles de routage
rencontrent souvent des obstacles liés à la consommation de ressources.
L‟objet de notre travail est alors de recenser les protocoles de routage DTN existants, les
analyser et les classifier selon ce critère de consommation de ressources, essentiellement,
l‟espace de stockage dans les buffers et l‟occupation de la bande passante.
Mots clés
Réseaux tolérants aux délais, DTN, le protocole bundle, connectivité intermittente, Store &
Forward, le transfert de garde, les protocoles de routage DTN, classification.

Abstract
DTNs (or Delay Tolerant Networks) are the networks where the connectivity is intermittent
because of obstacles met in the environment. This is due to a number of reasons like climate,
mobility, energy failures… In order to help data to achieve their destinations in spite of all
those difficulties, new network architecture had been developed, it consists of using an
additional layer on top of transport one in the seven layer OSI model. This new policy is
called “bundle protocol” which the main role is to stock data till the transmission becomes
allowed through Store & Forward technical and custody transfer.
Taking into account the fact that this technology is recent, many phenomenons still be in the
stage of researches, one of them is the routing problem which is the purpose of our work.
The aim of the routing protocols of Delay Tolerant Network is not to find the shortest path as
the case in classical protocols, but their goal is to increase the rate of delivery of data. For
that, several algorithms are developed and can be divided into two parts. Some of protocols
adopt “replication” approach which consists of duplicate messages on the network giving
many copies in order to increase the delivery ratio. Other protocols are based on “knowledge”
that consists of reaping information about the network state and managing the transmission in
a good way. However, both of these two routing protocols families face the resources
consumption problem.
The purpose of our report is to make a study, an analysis and a classification according to the
resources consumption of existing routing protocols DTN, mainly, the storage spaces into
buffers and bandwidth occupation.
Key words
Delay Tolerant Network, DTN, bundle protocol, intermittent connectivity, Store & Forward,
custody transfer, DTN routing protocols, classification.

Sommaire
Introduction générale
Chapitre 1
Introduction
1. Internet : Rappel ____________________________________________________________ 5
1.1 La commutation de paquets ............................................................................................... 5
1.2 Les couches protocolaires ................................................................................................... 6
1.3 L’encapsulation ................................................................................................................... 7
1.4 Les protocoles conversationnels ......................................................................................... 8
2. Evolution des réseaux sans fil __________________________________________________ 8
3. Les réseaux interplanétaires (IPN : Interplanetary Network) _______________________ 10
3.1 Définition ........................................................................................................................... 10
3.2 Caractéristiques des environnements interplanétaires................................................... 10
3.2.1 Délai de propagation : ................................................................................................................ 10
3.2.2 Connectivité ............................................................................................................................... 11
3.2.3 Débit des données ...................................................................................................................... 11
3.3 Limites des solutions traditionnelles ................................................................................ 11
4. Les réseaux tolérants aux délais (DTN) _________________________________________ 12
4.1 Définition ........................................................................................................................... 12
4.2 Motivations ........................................................................................................................ 13
4.3 Solutions mises en œuvre .................................................................................................. 14
4.4 Architecture des réseaux DTN ......................................................................................... 14
4.4.1 Les entités de communication .................................................................................................... 14
4.4.1.1 Les nœuds DTN................................................................................................................ 15
4.4.1.2 Les régions DTN .............................................................................................................. 16
4.4.1.3 Les tuples ......................................................................................................................... 17
4.4.2 Le Fonctionnement des DTNs .................................................................................................... 18
4.4.2.1 Pourquoi pas TCP/IP ? ...................................................................................................... 18

4.4.2.2 La commutation de message Store and Forward................................................................ 18
4.4.2.3 Le protocole bundle .......................................................................................................... 19
4.4.2.4 Options de livraison .......................................................................................................... 25
4.4.2.5 Temps de synchronisation ................................................................................................. 26
4.4.2.6 La congestion et le contrôle de congestion ........................................................................ 27
A. Qu‟est-ce que la congestion dans les DTNs ?......................................................................... 27
B. Le contrôle de congestion ...................................................................................................... 27
C. Le contrôle de flux ................................................................................................................ 28
D. Le contrôle de flux et le contrôle de congestion dans l‟Internet .............................................. 28
E. Le contrôle de flux et le contrôle de congestion dans les DTNs ............................................. 28
Conclusion
Chapitre 2
Introduction
1. ZebraNet__________________________________________________________________ 30
1.1 Contexte et motivation ...................................................................................................... 30
1.2 Objectif du projet .............................................................................................................. 32
1.3 Principe de la solution ....................................................................................................... 32
1.4 Conception du projet ........................................................................................................ 33
2. DakNet ___________________________________________________________________ 35
2.1 Contexte et motivations .................................................................................................... 35
2.2 Principe de fonctionnement .............................................................................................. 35
2.3 Le DakNet en action .......................................................................................................... 37
3. Utilisation du protocole Bundle des DTNs dans l’espace ___________________________ 38
3.1 L’environnement DMC .................................................................................................... 38
3.2 Le problème du taux de décalage ..................................................................................... 38
3.3 Implémentation de l’application ...................................................................................... 40
Conclusion
Chapitre 3
Introduction
1. Formulation du problème de routage __________________________________________ 43
2. Modélisation des réseaux DTNs _______________________________________________ 43

2.1 Nœuds et arêtes ................................................................................................................. 43
2.2 Contacts ............................................................................................................................. 44
2.3 Stockage des messages ...................................................................................................... 45
3. Concepts de base du routage DTN _____________________________________________ 45
3.1 Routage proactif Vs Routage réactif ................................................................................ 45
3.2 Routage source Vs Routage par saut ............................................................................... 46
3.3 Routage hiérarchique........................................................................................................ 46
3.4 La réplication .................................................................................................................... 47
3.5 La connaissance ................................................................................................................. 47
3.6 Théorème de la fonction d’utilité ..................................................................................... 48
4. Les challenges______________________________________________________________ 48
4.1 L’ordonnancement des contacts ....................................................................................... 48
4.2 La capacité des contacts .................................................................................................... 48
4.3 Espace buffer ..................................................................................................................... 49
4.4 La puissance de calcul ....................................................................................................... 49
4.5 L’énergie ............................................................................................................................ 49
5. Les modèles de mobilité pour les réseaux tolérants aux délais _______________________ 50
5.1 Les modèles synthétiques .................................................................................................. 50
5.1.1 Les modèles individuels ............................................................................................................. 50
5.1.1.1 Random Walk ................................................................................................................... 50
5.1.1.2 Random Waypoint ............................................................................................................ 51
5.1.1.3 Random Direction ............................................................................................................ 51
5.1.1.4 Restricted Random Waypoint ........................................................................................... 51
5.1.2 Les modèles de groupe ............................................................................................................... 51
5.1.2.1 Exponential Correlated Random ....................................................................................... 52
5.1.2.2 Column ............................................................................................................................. 52
5.1.2.3 Nomadic Community........................................................................................................ 52
5.1.2.4 Purse ................................................................................................................................ 53
5.1.2.5 Reference Point Group...................................................................................................... 53
5.2 Les modèles empiriques .................................................................................................... 53
6. Classification des protocoles de routage DTN ____________________________________ 54
A. L‟inondation.......................................................................................................................... 54

B. L‟expédition .......................................................................................................................... 54
C. Les oracles de connaissance .................................................................................................. 55
D. La connaissance partielle ....................................................................................................... 56
E. La connaissance complète ..................................................................................................... 56
6.1 La classification de Jain & Al ........................................................................................... 56
6.2 La classification basée sur les ressources consommées ................................................... 58
6.2.1 La classe des protocoles non consommateurs ............................................................................. 58
A. Contact direct ........................................................................................................................ 58
B. First Contact (FC) ................................................................................................................. 59
C. Routage aléatoire ................................................................................................................... 59
D. Routage location-based (basé sur la position) ........................................................................ 60
E. Routage Hiérarchique DTN (DHR) ....................................................................................... 61
6.2.2 La classe des protocoles consommateurs de ressources .............................................................. 61
6.2.2.1 Consommation illimitée des buffers et de la bande passante .............................................. 62
A. Routage épidémique .............................................................................................................. 62
B. Inondation Tree-based ........................................................................................................... 62
C. Minimum Expected Delay (MED) ......................................................................................... 63
D. Earliest Delivery with All Queues (EDAQ) ........................................................................... 64
6.2.2.2 Consommation illimitée de l‟espace de stockage............................................................... 64
A. Earliest Delivery (ED) ........................................................................................................... 64
B. Earliest Delivery with Local Queuing (EDLQ) ...................................................................... 65
6.2.2.3 Consommation illimitée de la bande passante ................................................................... 66
A. Routage gradient ................................................................................................................... 66
B. Minimum Estimated Expected Delay (MEED) ...................................................................... 66
6.2.3 La classe des protocoles réducteurs de consommation ................................................................ 68
A. Spray & Wait ........................................................................................................................ 68
B. Routage basé sur l‟utilité avec transitivité .............................................................................. 69
C. Seek & Focus : Approche hybride ......................................................................................... 70
D. Spray & Focus....................................................................................................................... 70
E. La formulation LP ................................................................................................................. 71
F. Probabilistic ROuting Protocol using History of Encounters and Transitivity (PRoPHET)..... 72
6.3 Schéma récapitulatif de la nouvelle classification ........................................................... 73
Conclusion
Chapitre 4
Introduction
1. Etude 1 : Comparaison FC, MED, ED, EDLQ, EDAQ_____________________________ 75
1.1 Scénario 1 : Routage dans les villages isolés .................................................................... 75

1.1.1 Description ................................................................................................................................ 75
1.1.2 Génération de trafic ................................................................................................................... 76
1.1.3 Le problème de routage .............................................................................................................. 76
1.1.4 Résultats & analyses .................................................................................................................. 77
1.2 Scénario 2 : Réseau d’autobus ......................................................................................... 78
1.2.1 Description ................................................................................................................................ 78
1.2.2 Génération de trafic ................................................................................................................... 79
1.2.3 Résultats & analyses .................................................................................................................. 80
1.3 Synthèse des résultats ....................................................................................................... 81
2. Etude 2 : les protocoles multi-copies ___________________________________________ 81
2.1 Scénario1 : Effet de la charge du trafic ........................................................................... 82
2.1.1 Description ................................................................................................................................ 82
2.1.2 Résultats & analyses .................................................................................................................. 82
2.1.3 Synthèse des résultats ................................................................................................................ 83
2.2 Scénario2 : Effet de la connectivité .................................................................................. 84
2.2.1 Description ................................................................................................................................ 84
2.2.2 Génération de trafic ................................................................................................................... 84
2.2.3 Résultats & analyses .................................................................................................................. 84
2.2.4 Synthèse des résultats ................................................................................................................ 86
3. Etude 3 : Performances de MEED _____________________________________________ 86
3.1 Description du scénario .................................................................................................... 86
3.2 Génération de trafic .......................................................................................................... 87
3.3 Résultats & analyses ......................................................................................................... 87
3.3.1 Impact de la taille des buffers ..................................................................................................... 88
3.3.2 Impact de la bande passante ....................................................................................................... 89
3.4 Synthèse des résultats ....................................................................................................... 90
4. Etude 4 : Performance de PRoPHET ___________________________________________ 90
4.1 Scénario1 : mobilité aléatoire ........................................................................................... 90
4.1.1 Description ................................................................................................................................ 90
4.1.2 Génération de trafic ................................................................................................................... 91
4.2 Scénario2 : mobilité en communauté ............................................................................... 91
4.2.1 Description ................................................................................................................................ 91
4.2.2 La mobilité ................................................................................................................................ 91
4.2.3 Génération de trafic ................................................................................................................... 92
4.3 Résultats & analyses ......................................................................................................... 92

4.3.1 Taux de délivrance ..................................................................................................................... 92
4.3.2 Délais de livraison ..................................................................................................................... 94
4.4 Synthèse des résultats ....................................................................................................... 95
5. Discussion & conclusion _____________________________________________________ 95
Conclusion
Conclusion & Perspectives
Annexe A
Annexe B
Liste des abréviations
Références bibliographiques

Table des figures Figure 1 : schéma représentatif d’un réseau tolérant aux délais______________________________________ 2
Chapitre1
Figure 2 : Chemin bout en bout _______________________________________________________________ 6
Figure 3: La transmission via les couches protocolaires sur un réseau Internet _________________________ 7
Figure 4 : L’encapsulation de paquets dans un réseau Internet ______________________________________ 8
Figure 5: Exemple de réseau en dehors d’Internet ________________________________________________ 9
Figure 6 : l’appartenance des nœuds aux différentes régions _______________________________________ 14
Figure 7 : Les différents rôles d’un nœud DTN __________________________________________________ 15
Figure 8 : Identification des régions dans un DTN _______________________________________________ 16
Figure 9 : Adressage d’un nœud dans un DTN __________________________________________________ 17
Figure 10 : La technique de commutation Store-and-Forward _____________________________________ 19
Figure 11 : Emplacement de la couche Bundle dans la pile protocolaire _____________________________ 20
Figure 12 : La couche Bundle présente dans toutes les régions _____________________________________ 20
Figure 13 : Structure d’un transmetteur de bundle _______________________________________________ 21
Figure 14 : Principe du transfert de garde (Custody Transfer) ______________________________________ 23
Figure 15 : Protocole non conversationnel _____________________________________________________ 24
Figure 16 : Les options de livraisons offertes par la couche bundle. _________________________________ 25
Chapitre2
Figure 17 : Transmetteur VHF. ______________________________________________________________ 31
Figure 18 : Zèbre de Grèvy et Zèbre des plaines (de gauche à droite). _______________________________ 33
Figure 19 : Pseudo-code du protocole d’inondation. _____________________________________________ 33
Figure 20 : Pseudo-code du protocole basé sur l’historique. _______________________________________ 34
Figure 21 : Conception d’un DakNet. _________________________________________________________ 36
Figure 22 : Un entrepreneur utilise le DakNet pour vendre de l’e-service. ____________________________ 37
Figure 23 : Utilisation du bundling et de la fragmentation parmi de multiples passes. ___________________ 39
Figure 24 : L’implémentation du Bundeling pour les téléchargements dans le satellite UK-DMC. __________ 40
Figure 25 : Image délivrée via les bundles. ____________________________________________________ 41
Chapitre3
Figure 26 : schématisation du problème du routage dans les réseaux DTN ____________________________ 43
Figure 27: Mouvement des nœuds en utilisant le modèle Column. ___________________________________ 52
Figure 28 : Purse. ________________________________________________________________________ 53
Figure 29 : Diagramme résumant la classification de Jain & Al ____________________________________ 57
Figure 30 : Extension du diagramme de classification de Jain & Al. _________________________________ 57
Figure 31 : Classification des protocoles de routage DTN selon le taux de consommation de ressources ____ 74

Chapitre4
Figure 32 : Illustration des options de la variété de connectivité entre un village isolé et la ville __________ 76
Figure 33 : Répartition du trafic par les différentes options de connectivité ___________________________ 77
Figure 34 : Comparaison du délai pour les différents algorithmes __________________________________ 78
Figure 35 : Carte de San-Francisco utilisée pour le mouvement des bus. Les repères A, B, C représentent 3
routes parmi 20 que les bus peuvent emprunter _________________________________________________ 79
Figure 36 : Comparaison des performances des différents protocoles en faisant varier la charge du trafic 82
Figure 37 : Transmissions totales et délais de délivrance en fonction du taux de transmission K avec le modèle
de mobilité « Random WayPoint » ___________________________________________________________ 85
Figure 38 : Transmissions totales et délais de délivrance en fonction du taux de transmission K avec le modèle
de mobilité « Random Walk » _______________________________________________________________ 85
Figure 39 : Réseau LAN sans fil convertit en réseau DTN _________________________________________ 87
Figure 40 : Variation du ratio de livraison en fonction de l’espace buffer ____________________________ 88
Figure 41 : Variation de la latence de livraison en fonction de l’espace buffer _________________________ 89
Figure 42 : Modèle de communauté __________________________________________________________ 91
Figure 43 : Taux de messages reçus en fonction de la capacité de stockage de la file d’attente avec un modèle de
mobilité aléatoire _________________________________________________________________________ 93
Figure 44 : Taux de messages reçus en fonction de la capacité de stockage de la file d’attente avec le modèle de
communauté _____________________________________________________________________________ 93
Figure 45 : Délais de livraison en fonction de la capacité de stockage des files d’attente dans un scénario
aléatoire ________________________________________________________________________________ 94
Figure 46 : Délais de livraison en fonction de la capacité de stockage des files d’attente dans un scénario à
communautés ____________________________________________________________________________ 95
Figure 47 : Réplication Vs Connaissance ______________________________________________________ 96
Figure 48 : Répartition des protocoles de routage selon leurs taux de consommation en bande passante et en
espace buffer. ____________________________________________________________________________ 97
Annexe B
Figure 49 : Clusterisation hiérarchique _________________________________________________________ 2
Figure 50 : Réseau hiérarchique avec l’information d’agrégation de contacts donnant un niveau d’agrégation 3

1
Introduction générale
La technologie Internet a fait un grand succès en matière d‟interconnexion des appareils de
communication, grâce à l‟utilisation d‟un ensemble de protocoles homogènes appelés,
TCP/IP.
Des centaines de milliers de dispositifs qui composent le réseau Internet utilisent ces
protocoles pour le routage de données, et la garantie de la fiabilité des échanges de messages.
Cette qualité de transmission provient du fait que TCP/IP offre plusieurs avantages. En effet,
c‟est un protocole qui se base sur des chemins de bout en bout caractérisés par un bas débit de
transmission et des délais très courts, au plus bas taux d‟erreur grâce au mécanisme de
retransmission en cas de perte de données et de reprise après erreur.
Afin de faire bénéficier tout le monde de la connexion Internet et leur apporter les outils de
l‟ère numérique, des projets de connexion des villages isolés ont été lancés. Néanmoins, le
manque d‟infrastructures dans ces zones a causé des débits de transmission faibles voir nuls
dans certains cas, ce qui empêche de trouver des connexions de bout en bout au long d‟une
communication. Ainsi des délais d‟envoi très longs, dépassant ceux supportés par le protocole
TCP/IP, sont engendrés. D‟où l‟augmentation du taux de perte de données.
Ce même souci a été rencontré lors d‟une expérience de transmission de données dans un
réseau interplanétaire. Dans laquelle les délais étaient très élevés et variables.
Par conséquent, le protocole TCP/IP sur lequel sont bâtis le réseau Internet et ses hypothèses,
s‟est avéré inapplicable dans ces situations.
Pour y remédier, le DTNRG1 a pensé à une solution qui supporterait de tels environnements
de communication, et qui prendrait en charge la variation des délais quel que soit leurs
valeurs. C‟est alors pour cet intérêt qu‟il a proposé une nouvelle architecture de réseaux,
appelée : les réseaux tolérants aux délais (ou DTN : Delay Tolerant Network).
Ces derniers sont définis de façon générale comme étant un réseau global regroupant un
ensemble de sous-réseaux (Réseaux n dans la Figure 1 ci-dessous) à différents types de
communication entre eux. Ce schéma peut être représenté comme suit :
1 DTNRG : Delay Tolerant Netwotk Research Group

2
Figure 1 : schéma représentatif d’un réseau tolérant aux délais
C‟est pourquoi les DTNs sont caractérisés par une connectivité intermittente et une absence
de communication de bout en bout. Ils se basent sur le fait que les nœuds soient dotés d‟une
mémoire de capacité élevée pour un stockage persistant de données. Ainsi, si un nœud d‟une
région est temporairement déconnecté, les paquets de données seront gardés dans les buffers
jusqu‟à ce que la topologie du réseau change, pour ensuite être enfin délivrés.
Ce mécanisme de stockage persistant est assuré par une couche supplémentaire appelée, la
couche bundle, située au-dessus de la couche Transport du modèle TCP/IP.
Du fait que les DTNs se comportent différemment, et que les protocoles habituels utilisés par
les réseaux Internet ne s‟y appliquent plus. De multiples recherches dans ce domaine sont
alors menées, afin de développer des protocoles propres à ce nouvel environnement et adaptés
à ses caractéristiques. Parmi lesquels figurent les protocoles de routage qui constituent l‟objet
de la présente thèse.
L‟étude du routage dans un réseau a toujours été d‟une grande importance, car il permet de
définir le chemin de nœuds par où peuvent transiter les données avant d‟arriver à destination.
Une telle étude dans un environnement intermittent qui n‟est régi par aucune règle l‟est
encore plus, car l‟objectif dans ce cas n‟est plus de trouver le chemin qui minimise certaines
métriques (ex : le plus court chemin), mais il s‟agit de repérer celui qui maximise la
Caractéristiq
ues d
e co
mm
unicatio
ns
différen
tes
Caractéristiques de
communications différentes
Réseau 2
Caractéristiques
identiques
Réseau 4
Caractéristiques
identiques
Réseau 3
Caractéristiques
identiques
Réseau 1
Caractéristiques
identiques

3
probabilité de délivrer un message en prenant en considération l‟état du réseau à tout moment.
Pour cela, divers travaux de recherche traitent de ce sujet et ont donné naissance à une
multitude de stratégies. Ces dernières étant peu structurées, nous étions alors tentés de les
rassembler et de faire une synthèse de toutes les solutions existantes.
En effet, notre choix s‟est porté sur une telle étude car les documents de synthèse générale
dans le domaine des DTNs sont rares. A présent, nous disposons de tutoriaux fournis par le
DTNRG sur l‟évolution de l‟architecture des DTNs et son fonctionnement, ainsi que quelques
travaux d‟études qui touchent divers aspects. Et le dernier qui porte sur l‟étude et la
comparaison des protocoles de routage est celui réalisé par Jain & Al, et qui date de l‟an
2004 [6].
Aujourd‟hui, des appels à communication s‟organisent pour enrichir ce domaine à travers la
rédaction de livres portant sur les environnements intermittents et leurs caractéristiques. Notre
contribution s‟insère donc à ce niveau en offrant deux avantages : d‟une part, nous permettons
d‟avoir un aperçu général sur les réseaux tolérants aux délais, incluant leur mode de
fonctionnement ainsi que les différentes applications basées sur cette nouvelle architecture.
Ajoutant à cela un recueil des principaux protocoles de routage développés. D‟autre part, nous
proposons une nouvelle classification pour ces protocoles, en se basant sur le critère de
ressources consommées, principalement l‟espace buffer et l‟occupation de la bande passante.
Cette classification a pour but de fournir des éléments et des informations d‟aide à
l‟orientation des chercheurs et/ou tout intéressé par l‟utilisation de la technologie DTN pour
lui faciliter la phase de prise de décision du protocole le plus adéquat à l‟application en
question.
Afin de bien expliquer toutes ces notions, nous avons divisé notre rapport en quatre chapitres.
Le premier chapitre a été consacré à la présentation générale des DTNs, le contexte de leur
apparition, leur architecture ainsi que leur mode de fonctionnement.
Tandis que le second chapitre a été voué aux différentes applications existantes sur le terrain,
réalisées à base de la technologie DTN, dans lequel nous expliquons les détails de
fonctionnement de ces projets ainsi que le but pour lequel ils ont été mis en œuvre.
Dans le troisième chapitre, nous nous sommes focalisés sur les protocoles de routage. Nous
commençons par formaliser le problème du routage dans les réseaux tolérants aux délais, pour
ensuite passer à la présentation des différentes classifications existantes suivie de celle que
nous proposons avec les principes exhaustifs de chaque algorithme.

4
Puis, le quatrième et dernier chapitre porte sur des études et simulations qui sont réalisées
pour la comparaison des performances des différents protocoles de routage dans les réseaux
DTN. Pour enfin terminer par une conclusion et des perspectives.

5
Chapitre 1
DTN : Généralités
Introduction
Dans ce chapitre, nous allons commencer par rappeler les principales caractéristiques du
protocole TCP/IP sur lequel se base la technologie Internet, on enchainera avec les facteurs
motivant l‟apparition des nouveaux environnements de communication. Suite à cela, nous
exposerons une brève description des particularités des environnements qui sont à l‟origine de
la naissance des réseaux tolérant aux délais (DTNs). Pour enfin terminer par la définition de
ces derniers et une description détaillée des éléments caractérisant leur architecture.
1. Internet : Rappel
La technologie Internet se base sur le protocole TCP/IP qui est caractérisé par les propriétés
suivantes [1]:
1.1 La commutation de paquets
La communication sur Internet est basée sur la commutation de paquets. Les données sont
transmises de la source vers la destination à travers des liens connectés par des nœuds, qui
peuvent être : source, destination ou routeur. Ces données sont découpées en paquets, où
chacun d‟eux se compose de deux parties :
Une partie données utilisateur appelée : partie de charge utile.
Une partie constituant l‟entête appelée : partie contrôle.
L‟entête contient des informations aidant les routeurs à commuter les paquets d‟un nœud à un
autre jusqu‟à atteindre sa destination.
Les paquets d‟un message peuvent emprunter n‟importe quel chemin du réseau, et si un lien
s‟avère non disponible pour une quelconque raison, le paquet peut emprunter un autre. Ainsi,
tous les paquets n‟arrivent pas dans l‟ordre de leur envoie, mais un mécanisme de
réassemblage se trouvant au niveau du nœud destination se charge de les réordonner.

Chapitre 1 DTN : Généralités
6
La technologie Internet est principalement caractérisée par:
Un chemin de bout en bout bidirectionnel et continu :
Une connexion bidirectionnelle et permanente est disponible entre la source et la destination
supportant une interaction de bout en bout, tel que schématisé sur la Figure 2 ci-dessous :
Figure 2 : Chemin bout en bout [1]
Un court délai de propagation :
Un délai relativement court et conforme entre l‟envoi d‟un paquet de données et la réception
de l‟acquittement qui lui correspond.
Un bas taux d’erreur :
Peu de données perdues ou corrompues sur chaque lien.
1.2 Les couches protocolaires
Les paquets sur Internet se déplacent via des couches de protocoles. L‟on implémente
habituellement au moins cinq couches du modèle OSI2:
La couche application.
La couche transport.
La couche réseau.
La couche liaison de données.
La couche physique.
Les routeurs ont pour rôle d‟examiner les paquets de données entrants au niveau de la couche
réseau (couche 3), de choisir le meilleur chemin pour les transporter sur le réseau et les
commuter ensuite vers la destination.
2 OSI : Open System Interconnection
Nœud source ou destination
Routeur
Paquet (les acquittements ne sont pas montrés)
Lien connecté
Lien déconnecté
Source
Destination

Chapitre 1 DTN : Généralités
7
La Figure 3 présentée ci-dessous, montre comment que les données traversent les différents
équipements ainsi que les couches intervenant à chaque étape :
Figure 3: La transmission via les couches protocolaires sur un réseau Internet [1]
1.3 L’encapsulation
Les paquets de données dans la technologie Internet sont soumis à une forme d‟encapsulation.
En effet, durant le passage d‟une couche supérieure à une couche inférieure, les données de la
couche haute ainsi que leur entête sont considérés comme partie « données » de la couche qui
suit, qui elle, ajoute son propre entête par la suite avant de la passer à la couche suivante.
Au niveau de chaque couche, l‟entête est employé pour commander le traitement des données
encapsulées, et ce de la source vers la destination, puis sont supprimés dans l‟ordre inverse au
niveau du nœud destination.
La Figure 4 nous montre alors ce processus d‟encapsulation comme suit : TCP3 décompose les
données utilisateurs en « segments ». IP encapsule ces segments en « data grammes » ou les
décompose en « fragments ». La couche liaison de données encapsule les data grammes IP en
« trames », et la couche physique transmet et reçois la séquence de trames en un train de bits.
3 TCP : Transmission Control Protocol

Chapitre 1 DTN : Généralités
8
Figure 4 : L’encapsulation de paquets dans un réseau Internet [1]
1.4 Les protocoles conversationnels
Afin d‟assurer un transfert fiable de données, le protocole TCP assure un contrôle de livraison
des paquets grâce à un système conversationnel adopté.
En fait, le protocole TCP utilise un système d‟accusé de réception pour garantir la bonne
réception mutuelle des données entre la source et la destination. Une fois le paquet de données
est livré à destination, cette dernière envoi un accusé de réception pour informer le nœud
source. C‟est pourquoi l‟envoie d‟un message complet implique plusieurs aller-retour de
signalisation entre l‟expéditeur et le récepteur. Ce processus peut être résumé en trois étapes
principales :
Etape d‟établissement de connexion: pour synchroniser les deux hôtes source et
destination, en trois voies.
Puis, l‟étape de transfert de segments et d‟acquittements.
Et enfin, l‟étape de finalisation de connexion qui se fait en quatre voies.
2. Evolution des réseaux sans fil
Le développement des communications mobiles à puissance limitée, satellitaires ou
interplanétaires est accompli sur des réseaux indépendants. Ces réseaux sont mutuellement
incompatibles ; chacun est bon pour passer des messages dans son réseau mais incapable
d‟échanger des messages avec les autres, car il est adapté à une région de communication
particulière dans laquelle les spécificités de communication sont relativement homogènes.
Données application (données
Segment TCP
Datagramme
Trame
Train de bits
Application
Transport
Réseau
Liaison de
données
Physique
Clé : Entête
Données Utilisateurs

Chapitre 1 DTN : Généralités
9
Les frontières entre ces différentes régions sont caractérisées par le délai du lien, la
connectivité du lien, l‟asymétrie du débit, le taux d‟erreur, l‟adressage et les mécanismes de
fiabilité, la qualité de service et les frontières de confiance.
Ces réseaux nouvellement nés supportent de longs et variables délais, des intervalles de
déconnexion de longueurs arbitraires, un taux d‟erreur élevé et des asymétries de débit
bidirectionnel. Nous pouvons en citer divers exemples, à savoir:
Les réseaux mobiles terrestres :
Ces réseaux sont caractérisés par le fait qu‟ils puissent être soudainement divisés à cause de la
mobilité des nœuds ou des interférences de la radio fréquence RF. Dans d‟autres cas, le réseau
peut ne jamais avoir un chemin de bout en bout et peut prévoir d‟être partitionné de façon
périodique [2].
Les réseaux exotiques de médias :
Les médias de communication exotique incluent les communications satellites pré-terre, les
liens radio de très longues distances (ex : les communications RF4 de l‟espace profond avec
des délais de propagation mesurés à la seconde ou à la minute) ou les communications
utilisant des modulations acoustiques dans l‟air ou dans l‟eau [2].
Les réseaux ad hoc militaires :
Ces systèmes peuvent être prévus afin d‟opérer sur les environnements hostiles où les nœuds
mobiles, les facteurs environnementaux ou les blocages intentionnels peuvent causer des
déconnexions [2].
Figure 5: Exemple de réseau en dehors d’Internet [1]
4 RF : Radio Frequency

Chapitre 1 DTN : Généralités
10
La Figure 5 ci-dessus montre, elle aussi, des exemples de réseaux que l‟on peut avoir en dehors
du réseau Internet comme le réseau de sondes.
Nous faisons remarquer que, le chevauchement de deux régions de réseaux exige
l‟intervention d‟un agent qui fera la traduction entre les caractéristiques incompatibles des
deux réseaux.
3. Les réseaux interplanétaires (IPN : Interplanetary Network)
3.1 Définition
Ces réseaux sont basés sur le principe suivant : « Construire un réseau de réseaux Internet ».
L‟idée était de déployer des réseaux Internet standards dans des endroits éloignés, en
l‟occurrence : les planètes. Puis connecter ces réseaux distribués via un backbone5
interplanétaire capable de supporter de très fortes latences et créer des passerelles et des relais
pour interfacer les environnements de forte et faible latence [3].
Ce type de missions spatiales lointaines, comme par exemple l‟exploration de « Mars » voient
leurs moyens de télécommunications soumis à des contraintes importantes en termes de
connectivité, de délai et de consommation énergétique. Par conséquent, les protocoles conçus
spécifiquement pour les environnements spatiaux ne bénéficient pas encore des avancées
récentes dans le domaine des télécommunications terrestres mobiles : réseaux ad-hoc,
tolérance aux délais, gestion de l‟énergie. Aussi, l‟interconnexion avec les réseaux terrestres
existants exige un examen de fonctionnement de TCP/IP dans les environnements spatiaux
car ils sont dotés de propriétés différentes.
3.2 Caractéristiques des environnements interplanétaires
Les environnements interplanétaires présentent les caractéristiques suivantes :
3.2.1 Délai de propagation :
Le délai de propagation d‟un signal dans l‟espace dépend de la distance qui sépare l‟émetteur
du récepteur, ainsi que de la vitesse de la lumière dans le vide. Compte tenu des distances en
jeu, les délais attendus sont de l‟ordre de plusieurs minutes, bien au-delà des délais terrestres
comptés en millisecondes.
5 Une dorsale Internet (Internet backbone en anglais), est un réseau informatique faisant partie des réseaux
longue distance de plus haut débit d'Internet. La dorsale originale d'Internet était ARPANET. En 1989 la dorsale
NSFNet a été créée parallèlement au réseau MILNET de l'armée américaine et ARPANET a cessé d'exister.
Finalement l'architecture du réseau a suffisamment évolué pour rendre obsolète la centralisation du routage.
Depuis la fin de NSFNet le 30 avril 1995, Internet repose entièrement sur des réseaux appartenant à des
entreprises de services Internet.

Chapitre 1 DTN : Généralités
11
3.2.2 Connectivité
Les protocoles utilisés dans les réseaux terrestres reposent sur le principe de connectivité
permanente de bout en bout : une connexion est établie pendant une durée particulière de
l‟émetteur vers le récepteur, d‟où la visibilité mutuelle.
La connectivité dans les environnements interplanétaires est au contraire intermittente. En
effet, le caractère « bout en bout » peut être rompu par une configuration orbitale particulière,
une planète masquant le trajet habituel, ou encore par des contraintes en termes de temps
d‟opération par équipements. Les conditions requises pour une connexion de bout en bout
peuvent également être remplies pour une durée inférieure à la durée nécessaire pour
transmettre l‟ensemble des données.
D‟autre part, le critère bidirectionnel de chaque tronçon de la connexion n‟est pas assuré
contrairement à la plupart des réseaux terrestres. En environnements interplanétaires, des
tronçons unidirectionnels sont également mis en œuvre.
3.2.3 Débit des données
Les distances de l‟ordre de plusieurs millions de kilomètres ont un impact sur les débits qui
peuvent être utilisés, en tenant compte des bruits qui se produiraient au niveau des liaisons.
Ainsi, les valeurs typiques du débit s‟échelonnent de 8 à 256 kb/s.
3.3 Limites des solutions traditionnelles
Les protocoles terrestres ne constituent pas une bonne solution, car ils font des hypothèses sur
l‟environnement qui ne sont plus valables en environnement spatial. Ces hypothèses peuvent
être résumées comme suit:
Il existe une route de bout en bout entre la source et la destination pour toute la durée
de la communication.
La conversation est un bon moyen de corriger les erreurs de transmissions comme par
exemple le mécanisme d‟acquittement dans TCP.
Les pertes de bout en bout sont relativement faibles.
Tous les routeurs et les stations connaissent IP.
Des mécanismes de sécurité (intégrité, authentification) à l‟émission et à la réception
sont suffisants.
La commutation de paquets est le meilleur moyen d‟obtenir interopérabilité et
performance.
Une seule route entre la source et la destination suffit.

Chapitre 1 DTN : Généralités
12
C‟est pourquoi les protocoles terrestres ont la possibilité d‟être conversationnels. Or le délai
aller-retour (RTT6) élevé des liaisons dans le contexte spatial rend impossible la pratique de
négociations permanentes, comme dans le mécanisme d‟acquittements de TCP ou le protocole
de transfert de fichier FTP7. Ainsi si la latence de la liaison est supérieure à la fenêtre
d‟opportunité de transmission, aucun trafic ne sera transmis.
4. Les réseaux tolérants aux délais (DTN)
Afin de tenir compte de toutes ces contraintes, le groupe de l‟IRTF8appelé le DTNRG s‟est
penché sur le sujet et a proposé une architecture détaillée, supportant les caractéristiques de
ces réseaux, tel que nous le présenterons ci-dessous.
4.1 Définition
Un réseau tolérant aux délais est un réseau de plusieurs réseaux régionaux, c‟est un overlay
au-dessus de ces réseaux régionaux incluant le réseau Internet. Un DTN supporte
l‟interopérabilité entre les réseaux [1] :
En s‟accommodant de longs délais entre (ou dans) les réseaux régionaux.
En traduisant les caractéristiques de communication entre les réseaux régionaux.
Les DTNs accommodent la mobilité et l‟énergie limitée des appareils de communication sans
fil.
Notons que, les technologies sans fil DTN sont diverses, nous trouvons alors :
La radio fréquences (RF) : Une forme de communication sans fil qui permet de
transmettre l‟information d‟un terminal à une station de base, qui à son tour la
transmet à un ordinateur hôte.
L‟UWB9 : Une technologie radio ultra large bande, utilisée pour la communication
haut débit sur courte distance, et avec une très faible puissance. La bande passante
UWB est définie comme ayant une largeur d‟au moins 500 MHz.
La liaison dégagée optique (Laser) : Une technologie qui a un avantage économique
certain sur les solutions filaires. Où la seule condition pour l‟installer est de garantir
une vue dégagée des obstacles entre les deux points. Ce qui impose des
émetteurs/récepteurs sur des points hauts, des fixations fiables interdisant tout
6 RTT : Round-Trip delay Time
7 FTP : File Transfer Protocol
8 IRTF : Internet Research Task Force
9 UWB : Ultra WideBand

Chapitre 1 DTN : Généralités
13
mouvement des matériels, et l‟absence d‟éléments perturbateurs tels que : le flux d‟air
d‟une bouche d‟aération, ou la poussière.
4.2 Motivations
La majorité des systèmes de communication actuels adoptent et reposent sur les technologies
de l‟internet dans la transmission de données. Afin d‟assurer leur commercialisation, des
conditions stables sont offertes. Ces dernières vérifient les hypothèses suivantes :
Un chemin de bout en bout existe et les nœuds sont toujours alimentés (si un lien est
déconnecté, les paquets empruntent un autre lien)
L‟énergie, la bande passante, le stockage et l‟accès aux réseaux sont toujours disponibles.
Le dialogue est toujours possible, l‟interactivité est gratuite.
Dans un réseau spatial ou un réseau terrestre contraint, ces hypothèses ne sont même
pas vérifiées.
En effet, ces réseaux (DTN) ne sont pas conformes aux hypothèses de base faites sur les
réseaux Internet, bien au contraire ils supportent :
Une connectivité intermittente :
S‟il n‟y a pas de chemin de bout en bout (partitionnement du réseau), un protocole comme
TCP/IP ne peut pas fonctionner. D‟où le besoin de nouveaux protocoles.
Des Délais longs et variables :
Dus au problème de propagation et au temps d‟attente dans les files des nœuds intermédiaires.
Par conséquent, les protocoles Internet et les applications qui comptent sur le retour
d‟acquittement rapide ne pourront pas fonctionner.
Vitesse de transmission asymétrique :
Les protocoles Internet supportent une asymétrie10
modérée. Néanmoins dans le cas
d‟asymétrie importante, cela empêche le bon fonctionnement des protocoles conventionnels.
Taux d’erreur important :
Les erreurs de bits sur une liaison exigent des corrections (en ajoutant des bits et du
traitement), ou la retransmission du paquet complet (donc plus de trafic réseau). Pour un taux
10
Transmission asymétrique : signifie que le débit allant du réseau (ou central) vers l‟utilisateur est supérieur (au
point de permettre la distribution de programmes de télévision ou de documents multimédias) au débit allant de
l‟utilisateur vers le réseau, car les informations dans ce sens sont plus sensibles aux bruits causés par des
perturbations électromagnétiques (plus on se rapproche du central, plus la concentration de câbles augmente,
donc ces derniers génèrent plus de bruits).

Chapitre 1 DTN : Généralités
14
Région Z
Région X Région Y
{X, a} {Y, c}
{Y, b}
{Z, c}
{Z, d} {Z, a}
{X, b} {Y, a}
{Z, b}
Nœud
Tuple
d‟erreur donné sur un lien, moins de retransmissions sont nécessaires quand il s‟agit du cas de
retransmission saut par saut que du cas de retransmission de bout en bout.
4.3 Solutions mises en œuvre
Le problème de connectivité intermittente exige la présence de nouveaux concepts afin de
mener à bien la transmission de données. En effet, dans les DTNs [3]:
Les retransmissions doivent être faites en point à point (entre relais) plutôt que de bout
en bout.
Un relais ne peut se contenter de router les paquets. Il doit aussi pouvoir les stocker et
les transmettre seulement quand une connexion apparaît (voir la commutation store-
and-forward).
4.4 Architecture des réseaux DTN
4.4.1 Les entités de communication
Comme schématisé sur la Figure 6, un réseau DTN est composé d‟un ensemble d‟entités
communicantes appelées : Nœuds. Ces nœuds sont répartis en régions [§ 4.4.1.2], où chacun
d‟entre eux est uniquement identifié par au moins un tuple [§ 4.4.1.3] contenant le nom de la
région [§ 4.4.1.2] et le nom de l‟entité. Un nœud lié à plusieurs régions doit avoir au moins un
tuple [§4.4.1.3] d‟identification pour chacune des régions auxquelles il appartient [39].
Figure 6 : l’appartenance des nœuds aux différentes régions [4]

Chapitre 1 DTN : Généralités
15
4.4.1.1 Les nœuds DTN
Un nœud DTN est alors un dispositif pour l‟envoi et la réception de messages (appelés aussi :
bundles). Il peut jouer le rôle de : source, destination ou de nœud intermédiaire pour la
transmission de bundles.
Le nom du nœud DTN lui-même, par opposition à une application l‟utilisant est défini dans
une « région spécifique » à l‟aide de l‟identifiant de l‟entité ou une partie de celui-ci.
Un nœud DTN peut jouer le rôle de [1] :
Hôte :
Envoi et/ou reçoit les bundles, mais ne les diffuse pas. Ce qui requiert un stockage persistent
durant de longs délais dans lesquels les bundles seront alignés jusqu‟à ce que les liens soient
disponibles.
Routeur :
Diffuse les bundles au sein d‟une seule région DTN et peuvent optionnellement jouer le rôle
d‟hôte.
Passerelle :
Diffuse les bundles entre deux ou plusieurs régions DTN et peut optionnellement jouer le rôle
d‟un hôte. Elle opère sur la couche transport et se base sur la commutation de messages plutôt
que sur la commutation de paquets. Cependant, elle fournit l‟interopérabilité entre des
protocoles spécifiques pour une région et ceux spécifiques pour une autre.
Ces différents rôles peuvent être schématisés comme montré sur la Figure 7 ci-dessous :
Figure 7 : Les différents rôles d’un nœud DTN [1]
Hôte
Application
Bundle
Transport
Réseau A
Liaison A
Physique A
Application
Routeur
Diffusion dans la même région
Bundle
Transport Transport
Réseau A Réseau A
Liaison A Liaison A
Physique A Physique A
Application
Passerelle
Diffusion entre deux régions
différentes
Bundle
Transport Transport
Réseau A Réseau B
Liaison A Liaison B
Physique A Physique B

Chapitre 1 DTN : Généralités
16
4.4.1.2 Les régions DTN
L‟architecture DTN défini un réseau de plusieurs réseaux où chacun d‟eux représente une
région dans laquelle les caractéristiques de communication sont homogènes. Une région peut
être le réseau Internet du globe terrestre, un réseau tactique militaire, la planète ou même un
vaisseau spatial (Figure 8). En d‟autres termes, une région est une zone qui est influencée par
les familles de protocoles, les dynamiques de connexion, les politiques administratives ou de
manière générale, les « régions DTN » sont délimitées en se basant sur un critère appelé : les
frontières de confiance [1].
Chaque région DTN a un nom unique et connu, ou que l‟on peut connaître parmi toutes les
autres régions du DTN. Ainsi, un référentiel11
pour l‟ensemble des noms des régions est
nécessaire, qui grâce à lui l‟on peut retrouver le nom d‟une région à tout moment.
Les bundles DTN (appelés aussi : messages) originaires de régions différentes de celle de
destination sont transmis en premier lieu via des entités communicantes appelées :
Passerelles, qui connectent la région source à une ou plusieurs autres régions. Le routage à
l‟extérieur de la région destination n‟est fondé que sur le nom de celle-ci et non pas sur le
nom complet de la destination elle-même.
Figure 8 : Identification des régions dans un DTN [1].
11
Ensemble d‟informations stockées dans des bases de données spéciales, que les applications peuvent retrouver
à chaque fois qu‟elles ont en besoin. C‟est le cas des annuaires, des nomenclatures, …etc.

Chapitre 1 DTN : Généralités
17
Les régions DTN sont caractérisées par [39]:
Chaque région doit avoir un espace identifiant partagé par tous les nœuds de la région, et
doit spécifier des conventions de nommage internes afin d‟être employées pour
l‟identification des entités.
Chaque nœud membre de la région est doté d‟un unique identifiant tiré de cet espace
identifiant. Notons que pour certains types de régions, un « nœud » peut être composé
d‟une collection d‟éléments calculables et/ou géographiquement distribués. Un seul et
unique élément s‟applique sur le nœud destiné à recevoir des données provenant des autres
nœuds DTN.
Pour être considéré comme membre de la région, chaque membre potentiel de celle-ci doit
être capable d‟atteindre les autres membres de la même région, sans passer par d‟autres
nœuds DTN se trouvant à l‟extérieur de celle-ci en utilisant un ou plusieurs protocoles
connus au niveau de chaque nœud.
Un nœud DTN ne doit pas nécessairement être atteint directement. Ceci peut demander une
opération de Store and Forward [§4.4.2.2] et/ou de transmission par les autres nœuds de la
même région.
4.4.1.3 Les tuples
Un tuple désigne le nom d‟un nœud. Il est composé, comme illustré dans la Figure 9, de deux
parties :
L‟identificateur de la région (ou nom de région).
L‟identificateur de l‟entité (ou nom d‟entité).
Le nom de région est nécessaire et suffisant pour router un bundle de données à sa région de
destination, mais ne peut pas le délivrer au point de destination spécifique auquel il a été
destiné.
Figure 9 : Adressage d’un nœud dans un DTN [4]
Passerelle
Région A
Région B
Adresse {région b, nœud x}

Chapitre 1 DTN : Généralités
18
Le nom de l‟entité est masqué à l‟extérieur de la région de définition. Une entité peut être un
hôte, un protocole, une application ou une agrégation de tous ceux-là selon la nature de
l‟adressage et de nommage des structures utilisées dans la région.
Le routage entre les régions n‟est basé que sur les IDs des régions qui sont liés à leurs
adresses correspondantes dans tout le DTN. Le routage à l‟intérieur de la région n‟est basé
que sur les IDs des entités qui sont liés à leurs adresses correspondantes au sein de la région.
Les passerelles appartiennent à deux ou plusieurs régions et déplacent les bundles entre ces
régions, ainsi ces passerelles possèdent plusieurs IDs région [39].
4.4.2 Le Fonctionnement des DTNs
4.4.2.1 Pourquoi pas TCP/IP ?
Le protocole TCP/IP sur lequel se base Internet assure une communication de bout en bout
qui garantit la fiabilité de la transmission de données grâce à la combinaison de deux
protocoles étroitement liés, TCP et IP.
TCP est caractérisé principalement par le fait qu‟il [5] :
Exige une négociation de connexion entre la source et la destination afin de réguler le
flux de données.
Délivre les données reçues dans leur ordre de transmission. Ainsi, si un paquet est
perdu, il doit attendre sa retransmission grâce aux délais courts.
Quant à la normalisation du protocole IP, elle a permis aux routeurs d‟être interopérables en
utilisant l‟adressage logique et la technique de commutation de paquets [2]. Ce protocole
prend en charge la transmission de données ou de datagrammes entre deux nœuds éloignés.
Ces conditions ne sont, malheureusement, pas valides dans les DTNs, d‟où la nécessité de
penser à d‟autres protocoles supportant leurs caractéristiques.
4.4.2.2 La commutation de message Store and Forward
Les DTNs surmontent les problèmes associés à la connectivité intermittente, aux délais longs
ou variables, à la vitesse de transmission asymétrique et au taux d‟erreur important en
utilisant la méthode de transport : store and forward.
Cette vieille méthode (utilisée par les services postaux) consiste en la transmission de
messages (ou morceaux de messages) d‟une zone de stockage à une autre, le long d‟un
chemin qui mène à la destination.

Chapitre 1 DTN : Généralités
19
Dans la Figure 10 ci-dessous, nous avons schématisé ce processus comme suit : chaque nœud
garde le message en sa possession (phase store) jusqu‟à ce qu‟il rentre en contact avec un
autre pour le lui transmettre (phase Forward).
Figure 10 : La technique de commutation Store-and-Forward [3]
La zone de stockage (comme un disque dur) peut garder un message indéfiniment. On parle
de stockage persistant (contrairement à un stockage dit à court terme) fourni par les zones
mémoires.
Les routeurs Internet utilisent les zones mémoire pour stocker les paquets entrants pour
quelques millisecondes en attendant de le commuter vers le prochain nœud, et ce en
consultant sa table de routage.
Les routeurs DTN, eux, ont besoin d‟un stockage persistant au niveau de leurs files d‟attente
pour l‟une ou les raisons suivantes :
1. Le lien de communication vers le nœud suivant peut être indisponible pour une longue
période.
2. Un nœud dans une paire communicante peut envoyer ou recevoir des données beaucoup
plus rapidement ou plus sûrement que les autres nœuds.
3. Un message une fois envoyé peut avoir besoin d‟être retransmis si une erreur se produit en
amont (vers la destination) du nœud ou du lien ou que le nœud ascendant diminue son
acceptation des messages diffusés.
En déplaçant les messages entiers (ou en fragments) dans un transfert, la technique de
transport fournit des nœuds réseau avec l‟information immédiate : taille du bundle.
4.4.2.3 Le protocole bundle
4.4.2.3.1 La couche bundle
L‟architecture DTN met en œuvre la méthode Store and Forward pour la commutation de
bundles par l‟ajout d‟une nouvelle couche protocolaire appelée : La couche Bundle.
La couche bundle se situe au-dessus de la couche transport et relie les spécificités des
couches inférieures des régions de sorte que les applications puissent communiquer à travers
Nœud
A
Nœud
B
Nœud
C
Nœud
D
store store store store
forward forward forward

Chapitre 1 DTN : Généralités
20
Couches
spécifiques
à la région
Couches
spécifiques
à la région
Couches
spécifiques
à la région
Couches
spécifiques
à la région
Couches
spécifiques
à la région
Applications
La couche Bundle
Applications
de multiples régions (Figure 11). Cette couche permet de diffuser les bundles (appelés aussi
messages) en entier entre les nœuds.
Figure 11 : Emplacement de la couche Bundle dans la pile protocolaire [1]
La couche bundle est utilisée par tous les réseaux (ou les régions) qui constituent le DTN,
tandis que les couches inférieures (de la couche transport à la couche physique) sont choisies
selon l‟environnement de chaque région (Figure 12).
Figure 12 : La couche Bundle présente dans toutes les régions [1]
4.4.2.3.2 La couche de convergence
La couche bundle assure l‟interopérabilité entre les couches inférieures des différentes régions
hétérogènes à interconnecter grâce à une sous couche appelée : Couche de convergence
(CLA12
).
La présence d‟une telle sous couche offre au « Protocole bundle » la particularité de pouvoir
fonctionner d'ores et déjà au-dessus de plusieurs protocoles. En effet, si le protocole du niveau
transport est TCP, la couche Bundle va utiliser les services de la couche TCPCL13
. Et
pareillement pour le protocole de transport UDP14
.
12
CLA : Convergence Layer Adapter 13
TCPCL : TCP Convergence Layer 14
UDP : User Datagram Protocol
Application
Transport (TCP)
Réseau (IP)
Physique
Liaison
Bundle
Application
Transport (TCP)
Réseau (IP)
Physique
Liaison
Commune à toute
les régions DTN
Spécifique à
chaque région DTN
Couches DTN Couches Internet

Chapitre 1 DTN : Généralités
21
La Figure 13 ci-dessous, montre la structure d‟un transmetteur de bundles, avec la position des
sous couches de convergences de différents protocoles réseaux, par rapport aux autres
couches de la pile protocolaire.
Figure 13 : Structure d’un transmetteur de bundle [2].
D'autres couches de convergence sont prévues d‟être développées dans le futur, afin de
fonctionner au-dessus des réseaux de capteurs, des réseaux à très longues distances ou encore
de réseaux destinés aux environnements « tactiques ». Ainsi la très attendue couche LTP15
se
placerait comme remplaçant de TCP, dédiée aux communications interplanétaires. Elle serait
considérée comme protocole de la couche Transport, jouant le rôle que joue le protocole
bundle au niveau de la couche Application.
Cette variété permet d'utiliser la couche protocolaire sous-jacente la mieux adaptée aux
caractéristiques de chacun des environnements de transmission, et surtout d'utiliser la couche
bundle au-dessus de différents réseaux hétérogènes.
4.4.2.3.3 L’architecture DTN est basée sur la commutation de messages
Un DTN transmet les bundles de la couche application quel que soit ce qu‟ils contiennent
comme requête à envoyer. Les bundles d‟une application sont envoyés et délivrés dans un
mode atomique, même s‟ils peuvent être divisés durant la transmission.
Les messages transférés à travers la couche bundle, peuvent également contenir
optionnellement un « reply-to-tuple » utilisé à la demande par des opérations de diagnostiques
spéciaux afin de diriger ceux-ci vers une entité autre que l‟émetteur.
15
LTP : Licklider Transmission Protocol

Chapitre 1 DTN : Généralités
22
L‟idée de la commutation de messages fournit un réseau avec des connaissances à priori sur
la taille et les exigences de performances des transferts de données demandés. Lorsqu‟il y‟a
une importante quantité de données dans la file d‟attente, qui doit être transmise en priorité
sur un chemin (comme c‟est le cas pour la technique du store-and-forward), l‟avantage fourni
par la connaissance de ces informations peut être signifiant pour la prise de décisions dans la
planification de messages à envoyer.
4.4.2.3.4 Le transfert de garde
Les DTNs supportent la retransmission nœud à nœud des données perdues ou corrompues au
niveau des deux couches « transport » et « bundle ». Cependant, vu qu‟il n‟y a pas une seule
couche « transport » qui fonctionne de bout en bout dans les DTNs, alors la fiabilité de bout
en bout peut être mise en œuvre sur la couche bundle.
La couche « Bundle » supporte la retransmission nœud à nœud, par le moyen de : Transfert
de garde [1] qui consiste en la persistance d‟un message au niveau d‟un nœud appelé :
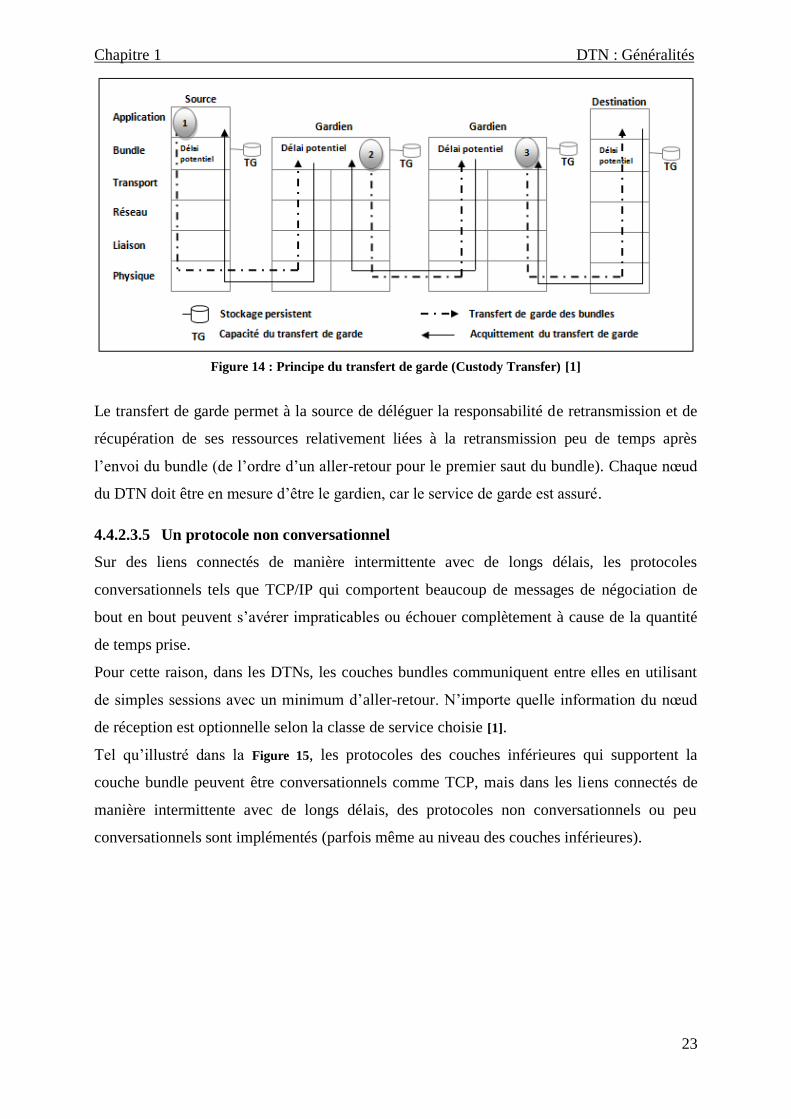
gardien. Nous pouvons voir à travers la Figure 14 que les transferts sont disposés entre les
couches bundle des nœuds successifs à la requête initiale de l‟application source, appliquant
le processus suivant : Lorsque le gardien de la couche bundle courante envoi un paquet au
nœud suivant, il demande un transfert de garde et déclenche un temporisateur de
retransmission de l‟acquittement. Si la couche Bundle du nœud suivant accepte la garde, elle
retourne un acquittement à l‟expéditeur. Si aucun acquittement n‟est retourné avant que le
temps fixé ne soit expiré, l‟expéditeur retransmet le paquet. La valeur assignée au
temporisateur de l‟acquittement est soit distribuée aux différents nœuds avec une information
de routage, soit calculée localement à la base d‟une expérience de transmission passée sur un
nœud particulier.
Le gardien doit sauvegarder le bundle jusqu‟à:
l‟obtention de l‟acceptation de la garde par un autre nœud;
l‟expiration de la durée de vie fixée au bundle qui est prévue beaucoup plus longue que la
valeur fixée au temporisateur d‟acquittement. Cependant, ce temps d‟acquittement devrait
être assez long afin de permettre une transmission fiable.
Chapitre 1 DTN : Généralités
23
Figure 14 : Principe du transfert de garde (Custody Transfer) [1]
Le transfert de garde permet à la source de déléguer la responsabilité de retransmission et de
récupération de ses ressources relativement liées à la retransmission peu de temps après
l‟envoi du bundle (de l‟ordre d‟un aller-retour pour le premier saut du bundle). Chaque nœud
du DTN doit être en mesure d‟être le gardien, car le service de garde est assuré.
4.4.2.3.5 Un protocole non conversationnel
Sur des liens connectés de manière intermittente avec de longs délais, les protocoles
conversationnels tels que TCP/IP qui comportent beaucoup de messages de négociation de
bout en bout peuvent s‟avérer impraticables ou échouer complètement à cause de la quantité
de temps prise.
Pour cette raison, dans les DTNs, les couches bundles communiquent entre elles en utilisant
de simples sessions avec un minimum d‟aller-retour. N‟importe quelle information du nœud
de réception est optionnelle selon la classe de service choisie [1].
Tel qu‟illustré dans la Figure 15, les protocoles des couches inférieures qui supportent la
couche bundle peuvent être conversationnels comme TCP, mais dans les liens connectés de
manière intermittente avec de longs délais, des protocoles non conversationnels ou peu
conversationnels sont implémentés (parfois même au niveau des couches inférieures).

Chapitre 1 DTN : Généralités
24
Figure 15 : Protocole non conversationnel [1]
4.4.2.3.6 Les bundles et l’encapsulation de bundles
Les bundles (ou paquets) sont composés de trois parties [1]:
1. Des données des utilisateurs de l‟application « source ».
2. Des informations de contrôle, fournies par l‟application « source » pour l‟application
« destination » décrivant comment traiter, stocker, se débarrasser et manipuler les
données utilisateurs.
3. Un entête de bundle inséré par la couche bundle (Voir sa structure dans [Annexe A]).
Comme les applications de données utilisateurs, les bundles peuvent êtres de tailles
arbitraires. Ils prolongent la hiérarchie de l‟encapsulation de données exécutée par le
protocole utilisé dans Internet.
En effet, la couche bundle peut découper les paquets (ou les messages) en « fragments »,
exactement comme la couche IP qui découpe les data grammes en fragments. Puis ces
derniers sont réassemblés au niveau du nœud destinataire.
Il existe deux formes de fragmentation/assemblage pour les bundles [39] :
Tout routeur DTN peut, de manière proactive, choisir de diviser le bloc de données en
multiples blocs qui s‟auto-identifient et transmet chaque bloc comme étant un bundle.
Dans ce cas, les « destinations finales » sont responsables de l‟assemblage des petits
blocs qu‟elles reçoivent en un seul bloc (l‟original). Cette forme de fragmentation est
analogue à la fragmentation IP.
Le routeur de bundles peut, de manière réactive, choisir de fragmenter le bundle à la
réception. Cette situation se présente lorsqu‟une partie du bundle a été délivrée au saut
suivant, et continu alors à envoyer de façon optimale le reste des portions du bundle
original si des contacts ultérieurs seraient disponibles.
Les couches
Inférieures
Protocole de transfert dépendant
Protocole d’acquittement dépendant
Les couches
Inférieures
Bundle
Acquittement optionnel
Nœud
La couche
Bundle
La couche
Bundle
Nœud

Chapitre 1 DTN : Généralités
25
Transfert de garde G G G G
Retour - Réception
Notification d‟un
transfert de garde G G G G
Notification d‟une
transmission de bundle
G : Gardien
Transfert de garde
Délivrance de bundle
Acquittement
La fragmentation réactive est spécialement conçue pour traiter les cas dans lesquels le
routeur est confronté à une transmission de bundles, mais qui n‟a aucun contact qui
fournit un volume de transfert de données suffisant.
4.4.2.4 Options de livraison
Dans les DTN, les applications peuvent avoir besoin d‟utiliser ce que l‟on appelle « Options
de livraison » [39]. Celles-ci sont paramétrables à l‟entête du bundle [Annexe A] et sont au
nombre de cinq. Nous présentons ci-dessous le rôle de chaque option, ainsi qu‟un schéma
(Figure 16) qui résume leur fonctionnement:
Transfert de garde :
La couche bundle transmet le paquet de données en utilisant les protocoles de transport les
plus fiables (lorsqu‟ils sont disponibles), et la responsabilité du point de livraison fiable (c'est-
à-dire le buffer de transmission) permettra d‟avancer d‟un gardien à un autre jusqu‟à ce que le
bundle atteigne le point de destination.
La couche bundle dépend de la couche transport du réseau qu‟elle exploite afin de lui fournir
le principal moyen pour un transfert fiable vers la couche suivante. Cependant, lorsqu‟une
livraison de garde est demandée, la couche bundle fournit de manière supplémentaire un
timeout d‟environ 500 ms, un mécanisme de retransmission, et un mécanisme d‟acquittement
saut par saut qui l‟accompagnent.
Lorsqu‟une couche bundle n‟a pas besoin de livraison de garde, le timeout de cette couche et
son mécanisme de retransmission ne sont pas employés, et les succès de la livraison des
bundles à travers la couche bundle dépendent uniquement de la couche transport.
Figure 16 : Les options de livraisons offertes par la couche bundle. [44]

Chapitre 1 DTN : Généralités
26
Retour-réception :
Le bundle de « retour-réception » est délivré par la couche bundle du récepteur lorsque le
bundle est consommé par « l‟application de destination » (pas uniquement la couche bundle
de destination). Ce récépissé est fourni à l‟entité spécifiée par le tuple source ou par une
source désignée (réponse au champ) qui se trouve sur les différents hôtes.
Notification sur transmission du bundle :
Envoyée par le routeur du bundle lorsque le dernier fragment du bundle est transmis.
L‟indication est envoyée à la source de l‟objet bundle.
Notification sur un transfert de garde :
Similaire à l‟option de notification de transmission, mais envoyée lorsqu‟un transfert de garde
s‟est achevé avec succès.
Livraison sécurisée :
Indique que l‟application a fourni l‟authentification du matériel avec le message envoyé. Afin
d‟opérer dans des circonstances générales, les applications doivent se préparer pour
l‟alimentation de l‟authentification et la livraison sécurisée de la demande.
La politique locale détermine si certains bundles peuvent être envoyés sans l‟option de
sécurité, et les régions autres que la région d‟origine peuvent exiger la sécurité même si la
région d‟origine ne l‟est pas.
4.4.2.5 Temps de synchronisation
L‟architecture DTN dépend du temps de synchronisation (supporté par l‟extérieur des
protocoles locaux à la région) pour deux buts primaires :
Le routage avec des contacts planifiés ou prédits (Voir chapitre 3) et calcul du « temps
de vie » du bundle.
Routage basé sur les temps et dépendant des coordinations de partage des ressources
(telles que les antennes directionnelles), ce qui oblige le temps de synchronisation à
atteindre le RDV du contact.
Les calculs de temps de vie sont réalisés par l‟inclusion d‟une source d‟estampillage et un
temps explicite du domaine de vie (en unités de temps après le moment précisé dans la
source d‟estampillage). Sa seule utilisation est de purger les données du réseau de sorte que
les exigences de synchronisation posées ne soient pas strictes. Cette approche permet à la

Chapitre 1 DTN : Généralités
27
source d‟estampillage d‟être utilisée pour divers buts comme source particulière. Les nœuds
DTN doivent veiller à ce que les estampilles de bundles qu‟ils envoient ne diminuent jamais.
Les applications spécifient un temps d‟expiration (la durée de vie est exprimée en secondes)
pour les bundles qu‟elles envoient. S‟il n‟est pas fourni, ou si la valeur fournie par l‟utilisateur
est plus grande que la politique locale permise, la couche bundle va alors en fournir une autre
et c‟est celle-ci qui sera considérée comme actuelle « durée de vie », elle est ajoutée au temps
où le bundle a été soumis par l‟application afin de déterminer le temps auquel le bundle sera
purgé du réseau. Les valeurs appropriées dépendent du réseau et des données, et pourraient
varier considérablement en théorie (de quelques millisecondes à plusieurs semaines).
4.4.2.6 La congestion et le contrôle de congestion
Les performances d‟un réseau se dégradent lorsqu‟une congestion se produit. Celle-ci est
causée par une lourde charge de trafic qui engendre une perte de données, due à l‟épuisement
des tampons au niveau des routeurs, ou aux longs délais dans la transmission de données [46].
Le problème de contrôle de congestion a été profondément traité dans l‟Internet, mais les
solutions proposées ne s‟appliquent pas dans les environnements intermittents tels que, les
réseaux tolérants aux délais. Car une connectivité continue et de bout en bout n‟est pas
garantie, et la latence est élevée. Ainsi, le contrôle de congestion se déroule localement au
niveau de chaque routeur, qui lui, de manière autonome prend la décision d‟accepter ou pas le
bundle en se basant sur des informations locales. Du coup, grâce au contrôle de congestion,
les routeurs sont protégés de l‟épuisement des ressources sans qu‟il y ait un taux élevé de
perte de données [46].
A. Qu’est-ce que la congestion dans les DTNs ?
Dans les réseaux Internet, nous parlons de « congestion » lorsque nous constatons une
croissance rapide et instantanée dans l‟occupation de l‟espace de stockage.
Contrairement à cela, dans les DTNs, ce qui signifie « congestion » est la croissance
constante et continue dans l‟occupation de l‟espace mémoire [46].
Ceci se manifeste par le manque d‟espace de stockage libre sur les nœuds intermédiaires, en
raison d‟une utilisation élevée d‟une route donnée [47].
B. Le contrôle de congestion
Le contrôle de congestion est le moyen de garantir que l‟ensemble des taux de trafic que
toutes les sources injectent dans le réseau, ne dépasse pas le taux maximum global que le
réseau peut délivrer aux différentes destinations dans le temps. Ceci permet de minimiser la

Chapitre 1 DTN : Généralités
28
perte de données dans le réseau, en raison des limitations des espaces buffers dans les routeurs
[39].
Afin de limiter le taux de trafic au niveau des sources, un contrôle de flux est imposé.
C. Le contrôle de flux
Le contrôle de flux garantit le fait que le taux moyen de données transmises par les nœuds
sources ne soit pas supérieur au taux moyen de données que les nœuds récepteurs ont prévu
de recevoir [39].
D. Le contrôle de flux et le contrôle de congestion dans l’Internet
Le contrôle de flux dans l‟Internet est géré de bout en bout. TCP détecte au niveau de la
destination la croissance de l‟occupation de son espace buffer. Il répond en réduisant le taux
d‟accusés de réception qui seront détectés par TCP à la source, ce qui le pousse à réduire le
taux de transmissions [48]. Ceci impose un contrôle de flux dans l‟application source, qui
soulage indirectement le taux de croissance excessif dans l‟occupation des espaces buffers au
niveau de la destination.
Quant au contrôle de congestion, lui est géré au niveau des routeurs, ce qui signifie que le
routeur transmet des données plus lentement que le taux de leurs arrivées. Pour cela, deux
solutions sont disponibles [46]:
Explicite
Le routeur envoie un paquet ICMP16
à la source, qui se traduit par un taux de transmission
TCP réduit. Puis, comme expliqué précédemment, ceci impose un contrôle de flux au niveau
de l‟application source.
Implicite
Le routeur rejette les datagrammes, ce qui entraine l‟absence d‟acquittement TCP et le force à
la source de détecter un taux d‟accusé de réception réduit. Du coup, ceci provoque à nouveau
un contrôle de flux au niveau de l‟application source.
E. Le contrôle de flux et le contrôle de congestion dans les DTNs
Dans les réseaux DTNs, le contrôle de flux est généralement exercé par le protocole bundle.
Ce dernier impose un contrôle de flux à l‟application source afin de limiter son taux de
transmission à celui du protocole bundle lui-même. Néanmoins, la congestion dans les
routeurs DTN ne peut être traitée directement par un contrôle de flux au niveau de
l‟application source, car il n‟y a aucune garantie sur la présence d‟une connectivité de bout en
16
ICMP : Internet Control Message Protocol

Chapitre 1 DTN : Généralités
29
bout dans aucune route. Pour cela, elle doit être traitée en passant par les fonctions de transfert
de garde offertes par le protocole bundle afin d‟assurer un contrôle de flux indirectement.
Ceci se fait selon la procédure suivante [46] :
Lorsque le routeur n‟a plus d‟espace de stockage, il rejette les bundles qui continuent à
arriver ;
Les notifications sur un transfert de garde ne seront donc pas envoyées pour les bundles
rejetés ;
L‟absence de la notification provoque une congestion au niveau du gardien (un routeur en
amont), causant éventuellement un rejet de bundle aussi ;
Cette propagation de rejet de bundles atteint finalement les nœuds sources, ce qui
déclenche un contrôle du taux de transmission au niveau du protocole bundle et donc un
contrôle de flux.
Les décisions de contrôle de flux dans les DTNs s‟effectuent au niveau de la couche bundle
elle-même, en se basant sur les informations sur les ressources disponibles dans le nœud du
bundle. Lorsque les ressources de stockage deviennent insuffisantes, la couche bundle ne
dispose que d‟un certain degré de liberté dans la gestion de la situation, elle peut [39] :
Ecarter les bundles qui ont expiré, ce qui est une activité DTN qui doit s‟exécuter dans
n‟importe quel cas ;
Faire en sorte que la garde du bundle soit cessée dans le cas où les nœuds étaient disposés à
le faire ;
S‟en servir des ressources de stockage disponibles dans le réseau ;
Ecarter les bundles qui n‟ont pas expiré, mais pour lesquels la garde n‟a pas été acceptée ;
Conclusion
Dans ce premier chapitre, un état de l‟art sur les réseaux tolérants aux délais a été présenté.
Dans lequel nous avons introduit la notion de DTN, montré le contexte de leur apparition et
expliqué leur fonctionnement où nous avons évoqué le concept de Store and Forward et le
transfert de garde. Aussi, nous avons détaillé l‟architecture de ce type de réseaux qui est
caractérisée par la présence d‟une couche supplémentaire appelée : couche Bundle, au-dessus
de la couche transport.
Beaucoup de projets et de travaux ont été réalisés à base de cette nouvelle technologie. C‟est
ce que nous essayerons de résumer dans le prochain chapitre.

30
Chapitre 2
DTN : Applications
Introduction
L‟architecture des réseaux tolérants aux délais a révolutionné le monde du réseau. Les
applications que l‟on peut imaginer avec, sont diverses et multiples, qu‟elles soient
interplanétaires ou terrestres (qui plus souvent vouées pour connecter des villages ruraux).
L‟avantage avec les DTNs est qu‟ils sont exploitables dans des projets de grande importance,
sans pour autant que le coût de revient soit élevé, car ils permettent de tirer profit des outils et
dispositifs existants dans l‟environnement.
Tandis que l‟inconvénient rencontré à présent est la non-possibilité de tout mettre en œuvre
facilement vu que beaucoup de protocoles existants théoriquement, ne sont pas encore
implémentés. Par conséquent, aujourd‟hui la plupart des applications réalisées à base de cette
nouvelle architecture sont fondées sur un développement d‟outils d‟implémentation dédiés.
Ainsi, afin de donner une idée plus précise du type de travaux que l‟on peut réaliser avec les
DTNs, nous avons consacré ce présent chapitre où nous détaillerons le fonctionnement et la
manière dont les implémentations ont été faîtes, et ce à travers la présentation de trois
échantillons qui sont : le tout premier modèle qui est mis en œuvre à savoir ZebraNet, puis
une application où la perception du résultat dans le milieu social a été bien réelle qui est le
DakNet de laquelle ont découlé divers autres projets, pour enfin terminer avec une application
montrant une transmission de données interplanétaires.
1. ZebraNet
1.1 Contexte et motivation
Aujourd‟hui, les chercheurs en biologie et bio-complexe sont préoccupés par le
rassemblement de données et d‟observations sur un certain nombre d‟espèces, afin de
comprendre leurs interactions et leur influence chacune sur l‟autre. Par exemple, il est
important de savoir comment le développement humain dans les zones sauvages affecte les
espèces indigènes. Il est aussi important de comprendre les schémas de migration des
animaux sauvages et comment ils sont affectés par les changements du climat.

Chapitre 2 DTN : Applications
31
En dépit de l‟importance des données détaillées sur les mouvements des animaux et leur
relation avec le climat, le développement humain et d‟autres schémas de données restent
actuellement insuffisants. En outre, la technologie de collecte de données est elle aussi
limitée. En effet, la plupart des études effectuées sur la faune se basent sur de simples
technologies. Par exemple, beaucoup d‟études consistent en le fait de relier les colliers d‟un
ensemble d‟animaux à de simples transmetteurs VHF17
, ensuite les chercheurs parcourent
périodiquement la zone avec des antennes de réception et écoutent les bruits des animaux
ayant des colliers. Lorsqu‟un animal est trouvé, les chercheurs peuvent observer son
comportement et enregistrer sa position. Néanmoins ce type d‟étude présente des limites
apparentes à savoir :
La collecte de données n‟est pas continue ainsi elle peut manquer de beaucoup
d‟événements intéressants.
Si la collecte de données se limite aux heures du jour, alors le comportement et le
mouvement des animaux qui pourraient être différents la nuit, ne seraient pas observés.
Figure 17 : Transmetteur VHF.
La collecte de données est quasiment impossible pour les espèces solitaires qui n‟acceptent
pas de contact humain.
Pour toutes ces raisons, d‟autres méthodes de suivi ont apparu. La plus sophistiquée et la plus
commercialisée de nos jours, est celle où le système de positionnement global GPS18
est
17
VHF : Very High Frequency 18
GPS : Global Positioning System

Chapitre 2 DTN : Applications
32
utilisé pour la localisation, et les satellites pour le transfert de données vers la station de base.
Cependant, ces systèmes souffrent aussi d‟insignifiantes limitations car l‟appareil de suivi le
plus sophistiqué peut seulement enregistrer 3000 positions sans les données biométriques. Et
les satellites, eux, sont lents et ont besoin de beaucoup d‟énergie et donc ne sont pas utilisés
fréquemment. Par conséquent, le chargement de données captées par les satellites aux
utilisateurs est peu et très coûteux. De plus, ces systèmes fonctionnent avec des batteries ne
supportant pas le rechargement avec l‟énergie solaire, du coup, si l‟énergie s‟achève le
système devient inutilisable jusqu‟à son prochain rechargement et redéploiement.
C‟est alors dans ce contexte que le projet ZebraNet [40] a été né. Il est fondé sur des nœuds de
suivi composés d‟un système GPS miniature à faible énergie, doté d‟un CPU19
utilisateur
programmable, avec un stockage de données non volatile et des émetteurs-récepteurs radio
pour communiquer soit avec les autres nœuds, soit avec la station de base.
1.2 Objectif du projet
L‟objectif de cette application est d‟arriver à récolter des informations détaillées sur les
activités des zèbres, et les fournir au laboratoire de recherche Mpala se trouvant au centre du
Kenya. Il constitue une collaboration directe entre les chercheurs dans les expérimentations
des systèmes informatiques et les chercheurs en biologie sauvage.
Pour cette étude, les biologistes ont fixé une durée de trois minutes pour enregistrer des
statistiques sur le comportement des zèbres. Ainsi, l‟application va tenter de prendre des
échantillons de données GPS toutes les trois minutes et enregistrer des informations détaillées
sur le mouvement des zèbres pendant trois minutes toutes les heures. Tout cela a été prévu
pour une durée d‟une année sans l‟intervention humaine, ni d‟antennes et ni de services
cellulaires.
1.3 Principe de la solution
La solution consiste en le principe suivant : il s‟agit d‟attacher à chaque zèbre un collier
auquel un nœud capteur est relié avec les caractéristiques décrites précédemment.
Avantageusement, la structure sociale des zèbres permet de ne mettre les colliers qu‟aux
mâles, pourquoi ?
19
CPU : Central Processing Unit

Chapitre 2 DTN : Applications
33
Il existe en fait deux types de zèbres, nous trouvons les zèbres de Grèvy20
et les zèbres de
plaines21
. Le troupeau dans ce dernier est formé d‟un mâle et de plusieurs femelles. Ce sont
ces femelles qui initient les mouvements mais c‟est le mâle qui ajuste la direction et la vitesse
du mouvement du groupe. Ainsi, il suffit de mettre le collier au mâle pour avoir le
mouvement de 10 à 12 individus.
Figure 18 : Zèbre de Grèvy et Zèbre des plaines (de gauche à droite). [41]
1.4 Conception du projet
Le but de ZebraNet est de rassembler des données collectées au niveau de chaque collier, puis
les transmettre à la station de base. Comme ce n‟est pas tous les colliers qui se trouvent à la
portée de la station de base, alors les données ne peuvent être envoyées directement. Pour y
remédier, le nœud doit tracer son chemin vers cette station de base en utilisant d‟autres
colliers comme sauts intermédiaires.
Une approche simple pour lui transmettre les données est de faire une inondation de données
à tous les voisins à n‟importe quel moment où ils sont découverts (voir la définition du
protocole par inondation dans le chapitre suivant).
Figure 19 : Pseudo-code du protocole d’inondation. [40]
20
Zèbre de Grèvy : (Equus grevyi), parfois appelé zèbre impérial, est la plus grande des espèces de zèbres, se
distinguant des autres par ses rayures plus fines et rapprochées, ses oreilles longues et rondes, ainsi que sa tête
étroite. 21
Zèbre de plaines : (Equus burchellii), appartient comme tous les zèbres à la famille des équidés. Il est aussi
appelé aussi common zebra (zèbre commun) par les anglais.

Chapitre 2 DTN : Applications
34
Si les nœuds se déplacent et rencontrent un grand nombre d‟autres nœuds, alors un
pourcentage élevé de données migrera à la station de base après une période de temps
suffisante.
La station de base ne doit pas nécessairement rentrer en contact avec tous les nœuds du
système ; au contraire, le fait de rentrer en contact avec peu de nœuds peut s‟avérer suffisant.
Car, par l‟identification de quelques nœuds ayant une interactivité élevée (c‟est-à-dire ceux
qui rencontrent un grand nombre d‟autres nœuds), une importante quantité de données peut
être facilement collectée.
Néanmoins, cette méthode peut amener à des situations où les demandes sont excessives, ce
qui a un mauvais impact sur la capacité de stockage, la bande passante et l‟énergie des
dispositifs.
Ainsi, plutôt que d‟inonder les voisins par les données, l‟application ZebraNet a pensé à
utiliser un protocole plus intelligent basé sur l‟historique (voir plus de détails dans le chapitre
suivant). Le corps de l‟algorithme de ce protocole est le suivant :
Figure 20 : Pseudo-code du protocole basé sur l’historique. [40]
Devant les faits et les observations sur le champ du comportement des zèbres, et les
hypothèses raisonnables du terrain, et les caractéristiques des opérations du centre de
recherche Mpala. Un modèle de mobilité et un environnement de simulation pour ZebraNet
ont été construits. Le simulateur est nommé ZNetSim et définit les contraintes de stockage et
de bande passante. Il retourne deux métriques :
Le taux de succès, qui est un pourcentage de données qui arrivent à la station de base.
La consommation d‟énergie.

Chapitre 2 DTN : Applications
35
2. DakNet
2.1 Contexte et motivations
Lorsqu‟un représentant du gouvernement indien a parlé avec enthousiasme du nouveau
téléphone pour un village dans une région rurale en Inde, un villageois s‟est demandé : « Qui
vais-je appeler ? Je ne connais personne qui est propriétaire d‟un téléphone ». Pourtant,
malgré cette remarque le téléphone a été réellement installé pour connecter les villages aux
villes voisines.
Bien que la majorité des villageois utilisent le téléphone de temps à autre, certains passent des
journées à l‟utiliser pour obtenir des données, que les citoyens des autres nations développées
peuvent obtenir en quelques secondes grâce à l‟ordinateur.
Cette situation venait du fait que les chercheurs pensaient à ce moment-là que le téléphone
était le moyen de communication le moins cher, comparativement à la connectivité large
bande. Avec la progression de la technologie sans fil, la ligne téléphonique de cuivre est alors
devenue beaucoup plus chère qu‟une connexion Internet sans fil large bande. C‟est alors
pourquoi, un noyau d‟un réseau d‟utilisateurs a été établi pour permettre aux villages de se
développer économiquement. Ce noyau était donc le DakNet [43], qui est un réseau ad hoc
utilisant la technologie sans fil pour fournir une connectivité asynchrone.
Progressivement, le DakNet a été déployé avec succès dans des régions éloignées de l‟Inde et
du Cambodge à un coût deux fois inférieur à celui des solutions traditionnelles fixes. Les
villageois accèdent désormais à Internet avec un coût abordable. D‟ailleurs l‟un des habitants
d‟un petit village en dehors de New Delhi a fait remarquer que : « C‟est mieux que le
téléphone ! »
2.2 Principe de fonctionnement
DakNet représente une des premières démonstrations de l‟applicabilité de la technologie sans
fil, pour la connectivité rurale. Cette technologie qui a connu une très grande avancée,
particulièrement le standard IEEE-80222
qui a eu un grand succès commercial et un faible
coût des réseaux large bande.
Le réseau sans fil DakNet a été mené par un groupe de chercheurs de l‟Institut Indien de
Technologie à Kânpur et de MLA23
. Il tire profit des communications et des infrastructures de
22
IEEE-802 : décrit une famille de normes relatives aux réseaux locaux et métropolitains basés sur la
transmission de données numériques par le biais de liaisons filaires ou sans fil. Plus spécifiquement, les normes
IEEE 802 sont limitées aux réseaux utilisant des paquets de tailles variables contrairement à ceux où les données
sont transmises dans des cellules de taille fixe et généralement courtes. 23
MLA : Media Lab Asia

Chapitre 2 DTN : Applications
36
transport existant pour la distribution de la connectivité numérique aux villages qui en sont
dépourvus. DakNet dont le nom dérive du mot hindi « post » ou « poste », combine les
moyens physiques de transport et le transfert sans fil de données afin d‟étendre la connectivité
Internet qui constitue le lien ou le hub central, comme les cybercafés ou les bureaux de poste.
Figure 21 : Conception d’un DakNet. [43]
Comme le montre la Figure 21 ci-dessus, au lieu d‟essayer de transmettre des données sur une
longue distance ce qui peut être coûteux et demande beaucoup d‟énergie, DakNet préfère les
transmettre via de courts liens point à point. Par exemple, entre les kiosques et les dispositifs
de stockage portables appelés : points d‟accès mobiles (MAP24
) montés sur et alimentés par
un bus, une moto ou même un vélo avec un petit générateur. Le MAP transporte
physiquement les données entre les kiosques publiques et les dispositifs de communications
privés (comme un intranet) et entre les kiosques et le hub (pour un accès Internet non temps
réel). Des émetteurs Radio Wifi à faible coût transmettent automatiquement les données
stockées dans les MAPs dans une bande passante élevée pour chaque point de connexion.
Ainsi l‟opération DakNet comporte deux étapes :
Comme le véhicule équipé du MAP traverse une série de villages ayant des kiosques
supportant le Wifi, alors il détecte automatiquement la connexion sans fil ainsi il peut
charger et télécharger des dizaines de mégabits de données.
Quand le véhicule équipé d‟un MAP arrive à la portée d‟un point d‟accès Internet (le hub),
il synchronise automatiquement les données avec tous les kiosques ruraux utilisant
Internet.
24
MAP : Mobile Access Point

Chapitre 2 DTN : Applications
37
Ces deux étapes se répètent pour chaque véhicule transportant un MAP, créant ainsi un faible
coût de réseau sans fil et une infrastructure de communication sans faille.
Même s‟il y a qu‟un seul véhicule qui traverse le village une fois par jour, c‟est suffisant pour
fournir quotidiennement des services d‟information car la connexion est de qualité élevée,
donc malgré le fait que le DakNet ne fournisse pas la transmission de données en temps réel,
mais une quantité de données importante peut se déplacer à la fois (environ 20 Mo dans
chaque direction).
En effet, un transfert physique de données par ce moyen fournit un débit plus élevé que celui
de la transmission avec les autres technologies à faible bande passante, comme un modem
téléphonique.
2.3 Le DakNet en action
Les villages de l‟Inde et du nord du Cambodge utilisent le DakNet avec de bons résultats.
Comme le montre la Figure 22, les entrepreneurs locaux utilisent actuellement les connexions
DakNet pour faire de l‟e-service, comme les e-mails ou la messagerie vocale à disposition des
résidents des villages ruraux.
Figure 22 : Un entrepreneur utilise le DakNet pour vendre de l’e-service. [43]
L‟un des premiers déploiements du DakNet était une solution abordable de connectivité rurale
pour le projet d‟e-gouvernance Bhoomi. En Septembre 2003, il y a eu mise en œuvre d‟un
DakNet au Cambodge pour un village de 15 écoles, des cliniques de télémédecines et un
bureau de gouverneur.

Chapitre 2 DTN : Applications
38
3. Utilisation du protocole Bundle des DTNs dans l’espace
Comme nous le savons à présent, les réseaux tolérants aux délais sont des réseaux capables
d‟opérer dans diverses conditions, à travers plusieurs axes et en fonction de la conception du
sous réseau traversé.
L‟application qui suit va montrer une implémentation d‟un transfert d‟une image satellite en
fragments sur terre [42]. Cette application se déroule sur deux types d‟environnement selon la
vitesse du délai de propagation. Ces derniers se définissent comme suit :
Dans un environnement où le délai de propagation est faible, tel que cela peut se produire
dans les milieux terrestres ou près-planétaires, les agents bundle de destination peuvent
utiliser des protocoles Internet de transport comme le TCP pour négocier la connectivité en
temps réel.
Dans un environnement où le délai de propagation est élevé comme dans l‟espace lointain, les
agents bundle doivent utiliser d‟autres méthodes telle qu‟une sorte d‟organisation afin
d‟installer une connectivité entre les deux agents bundles et utiliser un protocole de transport
via IP avec moins d‟échanges.
3.1 L’environnement DMC
LEO25
est un environnement à faible délai de propagation. Il est de moins de dix
millisecondes sur terre avec de longues périodes de déconnexions entre les passes prévues sur
les stations terrestres. Pour les satellites DMC, la durée des contacts varie entre 5 et 14
minutes par passe, selon la position relative de la station terrestre et le satellite.
Les stations terrestres sont connectées à travers un réseau Internet terrestre publique qui
contient diverses conditions de fonctionnement (partage, concurrence, sensibilité à la
congestion, le fait qu‟il soit toujours ON) depuis les liens privés (irréguliers mais
ordonnancés, dédiés au téléchargement) entre le satellite et la station terrestre.
3.2 Le problème du taux de décalage
La Figure 23 schématise une application de transfert d‟une image depuis un DTN source, vers
un DTN destination. Le DTN source est un réseau terrestre composé d‟un satellite LEO et un
agent bundle intermédiaire se trouvant à une position distante.
La destination finale pour le téléchargement de l‟image pourrait être une station de contrôle
satellite, ou un ordinateur portable avec une connexion sans fil.
25
LEO : Low Earth Orbit

Chapitre 2 DTN : Applications
39
Dans ce cas, le fichier image est très volumineux pour qu‟il soit transféré en une seule passe,
sur une seule station terrestre. Pour cela, son transfert pourrait être divisé en trois passes et ce
de deux façons possibles :
Soit par la même station terrestre, passe derrière passe ;
Soit en utilisant trois différentes stations : approche pour laquelle l‟on a opté dans
cette application, telle que illustré sur la Figure 3-1 de gauche à droite.
Figure 23 : Utilisation du bundling et de la fragmentation parmi de multiples passes. [42]
Le temps minimum qu‟il faut pour que l‟image soit complètement transférée en utilisant une
seule station a été estimé à 300 minutes, en supposant qu‟une passe dure 100 minutes.
Cependant, avec l‟utilisation de trois stations, l‟image complète peut être téléchargée en
l‟espace d‟un seul intervalle de temps et ce en récupérant les fragments de l‟image au niveau
de chaque station et les rassembler pour restituer l‟image complète à destination.
De même, si le transfert de fichiers utilisé entre la source et la destination est basé sur le débit
au lieu de la taille, alors des problèmes vont apparaitre si la capacité du lien terrestre ne
correspond pas ou dépasse le taux du lien entre l‟espace et la terre, et le transfert devient
limité par n‟importe quel goulot d‟étranglement sur le chemin. Afin d‟accroitre le taux de
téléchargement à travers chaque lien, le transfert peut être divisé en multiples sauts séparés où
le téléchargement est soumis à un Store & Forward local au niveau de chaque saut.
Donc finalement, l‟intérêt est d‟obtenir l‟image du satellite de la manière la plus efficace
possible, puis après faire un transfert séparément à travers les différents environnements de
l‟Internet terrestre.

Chapitre 2 DTN : Applications
40
Implémentation de paquetage
de et de transmission
Tâche
d'imagerie
Shim de DTN
Tâche du
serveur Saratoga
Système de fichier
SSDR
A bord
Lien
spatial
Terre
Implémentation des agents
bundle complets
Client
Saratoga
Agent
bundle
DTN
Couche de
convergence
TCP
Couche de
convergence
TCP
Agent
bundle
DTN Intern
Système de
fichier de la
station terrestre
Utilisateur final
/ traitement de
l’image
Client
Saratoga
SSTL
Le téléchargement séparé permet une
validation de fichier différente de celle de
Saratoga
C‟est pour cela que le protocole bundle des DTNs est le plus adéquat à cette application, car il
permet la division en des sauts différents ainsi il peut compenser le décalage entre le lien
privé espace-terre, et le chemin partagé entre la station terrestre et la destination distante de
l‟image.
3.3 Implémentation de l’application
Le type du satellite utilisé pour ce projet est UK-DMC qui est l‟un des cinq satellites d‟images
similaires lancé dans LEO. Il a été lancé en Septembre 2003 et son fonctionnement est
similaire aux orbites héliosynchrones26
.
Ce système a été implémenté sur une infrastructure terrestre. Comme couche de convergence
pour le transport de bundles dans le lien espace-terre, c‟est Saratoga qui est utilisée. Celle-ci
est basée sur le protocole UDP/IP, et développée pour le transfert de fichiers image [45]. Seul
le bundle envoyant un fragment a été implémenté, puisque l‟espace du code disponible est
limité (voir Figure 24). Le but est d‟avoir l‟implémentation du bord DTN transparente aux
opérations normales d‟UK-DMC vivant côte à côte avec le code d‟exploitation existant de
manière non perturbatrice. Ceci a été considéré comme acceptable pour les tests, vu que UK-
DMC agit seulement comme une source de données DTN et n‟a pas besoin de recevoir et
d‟analyser les bundles.
Figure 24 : L’implémentation du Bundeling pour les téléchargements dans le satellite UK-DMC. [42]
26
Orbites héliosynchrones : Ce type d'orbite conserve un angle constant avec la direction Terre-Soleil c'est-à-
dire que le plan d'orbite tourne de 360° par an. Ils permettent de passer toujours à la même heure solaire locale
au-dessus d'un lieu donné. L'éclairage identique des prises de photo du lieu permet de faire ressortir les
changements. Cette caractéristique en fait une orbite idéale pour des satellites d‟observation de la Terre [41].

Chapitre 2 DTN : Applications
41
Ainsi l‟intelligence du récepteur du bundle DTN est requise uniquement pour qu‟elle soit
présente dans l‟implémentation de la station terrestre du client Saratoga et de l‟agent bundle
DTN. Le client Saratoga de la station terrestre interroge le satellite UK-DMC pour un
répertoire de fichiers, puis interroge tous les fichiers métadonnées avec un fichier image
satellite associée.
Figure 25 : Image délivrée via les bundles. [42]
Les fichiers de métadonnées sont transférés sur terre, où le client Saratoga réassemble les
bundles et les présente comme agent bundle DTN complet. Finalement, pour démontrer la
fragmentation proactive, les fragments DTN sont réassemblés à la destination finale.
Conclusion
Nous avons consacré ce chapitre à la présentation de trois travaux d‟application se basant sur
l‟architecture des DTNs. Nous avons évoqué les contextes de motivation de chacun d‟eux,
ainsi que les principes de leur fonctionnement et les outils utilisés.
Nous entamerons dans le chapitre suivant la partie noyau de notre travail, où nous traiterons le
problème du routage dans les environnements intermittents, décrirons les différentes solutions
existantes et exposerons la classification que nous proposons.

42
Chapitre 3
DTN : Les protocoles de routage
Introduction
L‟objectif du routage dans les protocoles traditionnels (ceux utilisés pour l‟Internet) est de
sélectionner le chemin qui minimise certaines métriques simples (ex : le nombre de sauts).
Pour les DTNs, l‟objectif n‟est pas si évident.
Un objectif trivial est de maximiser la probabilité de délivrance des messages, car ces derniers
peuvent, bien entendu, être perdus à cause de la création de boucles de routage, ou la perte
forcée de données à cause de l‟épuisement des buffers.
Vu les caractéristiques intermittentes des réseaux DTNs, les protocoles de routage s‟affrontent
alors aux challenges suivants :
La non-existence d‟un chemin de bout en bout => les protocoles traditionnels ne
fonctionnent plus.
Les routes sont dépendantes du temps.
De multiples chemins pourraient être nécessaires.
Le temps de stockage dans les buffers qui doit être long.
La réponse à ces exigences pourrait engendrer plusieurs problèmes, et une bonne approche
serait celle qui tenterait de les minimiser.
Dans la littérature, diverses stratégies de routage sont proposées, chacune essaye de tenir
compte de : la capacité des contacts, la capacité des buffers, l‟énergie, la capacité de
traitement et l‟ordonnancement des contacts, et chacune d‟entre elles présente aussi bien des
avantages que des inconvénients.
Ce chapitre est alors voué à la description de toutes ces méthodes. Mais avant cela, une
présentation du problème de routage dans les environnements DTN sera donnée, pour ensuite
enchainer avec les éléments participants à la notion de routage dans les réseaux intermittents,
avec les scénarios de mobilité existants. Enfin, nous présenterons la classification que nous
proposons pour ces protocoles où nous détaillerons le principe de chaque approche.

Chapitre 3 DTN : Les protocoles de routage
43
Problème du
routage
Multi-graphe de routage DTN :
Contraintes de capacité
Contrainte de stockage
Un ensemble de message:
Source
Destination
Taille
Temps d‟injection
Chemin (s) de
routage pour chaque
message
Objectif :
Minimiser le délai => Maximiser
le taux de délivrance
1. Formulation du problème de routage
Le problème de routage dans les réseaux DTN peut être formulé sous la forme suivante :
Figure 26 : schématisation du problème du routage dans les réseaux DTN
Entrées :
Multi-graphe de routage DTN.
o Contraintes de capacité.
o Contraintes de stockage.
Un ensemble de messages.
o Message = (source, destination, taille, temps d‟injection, …).
Sortie :
Chemin(s) de routage pour chaque message.
Objectif :
Minimiser le délai => Maximiser le taux de délivrance
2. Modélisation des réseaux DTNs
Afin d‟implémenter des protocoles de routage pour les réseaux DTN, Warthman a proposé [1]
un modèle de base qui se repose sur les concepts suivants:
2.1 Nœuds et arêtes
Un réseau tolérant aux délais est modélisé par un multi-graphe où une paire de nœuds peut
être connectée par plus d‟une arête (appelée aussi : lien). Ceci permet de choisir entre

Chapitre 3 DTN : Les protocoles de routage
44
plusieurs types distincts de connexions physiques, afin d‟effectuer la transmission de données.
En outre, les capacités des liens dépendent du temps. Sa capacité atteint zéro aux moments où
il n‟est pas disponible.
2.2 Contacts
Un contact est l‟opportunité d‟envoyer des données à travers une arête. C‟est plus
précisément, un lien spécifique et un intervalle de temps correspondant durant lequel la
capacité d‟un lien est strictement positive. Il peut être [16] :
Persistant :
Toujours disponible, c'est-à-dire qu‟il n‟exige pas d‟action d‟initiation de connexion. Un
exemple représentatif de ce type de contact est une connexion internet DSL27
ou une
connexion câblée via un modem.
A la demande :
Nécessite une action de demande de connexion puis fonctionne comme un contact persistant
lorsque celle-ci est bien établie.
Prévu intermittent :
Ce qui est une sorte d‟accord d‟établissement de connexion à un temps particulier et pour une
durée définie. Dans les réseaux ayant des délais importants, la notion de « temps particulier »
dépend du délai lui-même.
Opportuniste intermittent :
C'est-à-dire qu‟il n‟est pas prévu mais se présente de lui-même. Comme dans les
communications infrarouge et bluetooth entre deux nœuds.
Prédit intermittent :
N‟est fondé sur aucun ordonnancement fixe mais résulte des prévisions des temps, et des
durées des contacts basées sur l‟historique observé précédemment, ou sur d‟autres
informations. Les routes dans les contacts prédits peuvent être choisies en se basant sur des
informations tirées d‟un assez haut niveau de confiance.
27
DSL : Digital Subscriber Line

Chapitre 3 DTN : Les protocoles de routage
45
2.3 Stockage des messages
Les demandes de communications sont représentées par des messages ou bundles. Un
message est modélisé par quatre informations essentielles : la source du message, sa
destination, l‟instant où le message a été injecté dans le système ainsi que la taille de celui-ci
sachant qu‟elle est arbitraire.
Les nœuds dans les DTNs ont une capacité de stockage finie à long terme pour l‟exploitation
et l‟attente de consommation par l‟application au nœud destination.
3. Concepts de base du routage DTN
3.1 Routage proactif Vs Routage réactif
Le routage proactif, est le type de routage adopté par la plupart des protocoles Internet
standards, et quelques protocoles Ad Hoc tels que DSDV28
et OLSR29
[27]. Son principe
consiste en le fait que les routes soient calculées automatiquement, et indépendamment du
trafic arrivant. Dans les DTNs, les protocoles répondant à ce type de routage sont capables de
calculer les routes de toute la topologie d‟un sous-réseau connecté. Néanmoins, ils échouent
lorsqu‟ils sont appelés à déterminer un chemin vers un nœud qui n‟est plus accessible. Malgré
cet inconvénient, les protocoles proactifs peuvent fournir des éléments utiles aux algorithmes
de routage DTN en leur désignant l‟ensemble des nœuds accessibles pour le choix du
prochain saut.
Le routage réactif, est utilisé par certains protocoles de réseaux Ad Hoc tels que AODV30
et
DSR31
[27]. Les routes, dans ce cas, sont découvertes à la demande lorsque le trafic doit être
délivré à une destination inconnue. Pour les DTNs, comme avec les protocoles proactifs, ces
protocoles fonctionnent seulement sur un sous-réseau connecté de la topologie globale.
Cependant, ils échouent pour de multiples raisons par rapport aux protocoles proactifs. En
particulier, lorsqu‟une route n‟est pas réussie par manque de réponse. Alors que les protocoles
proactifs peuvent constater l‟échec plus rapidement en s‟apercevant que la destination
demandée n‟est pas accessible à un instant donné.
Dans les DTNs, les routes peuvent varier avec le temps lorsqu‟il s‟agit de chemins
prévisibles, et peuvent être pré-calculées en utilisant des connaissances sur les futures
topologies. L‟emploi d‟une approche proactive aurait alors probablement impliqué plusieurs
28
DSDV : Destination-Sequenced Distance Vector 29
OLSR : Optimized Link State Routing 30
AODV : Ad hoc On Demand Distance Vector 31
DSR : Dynamic source Routing

Chapitre 3 DTN : Les protocoles de routage
46
séries de calcul de routes, et des index selon le temps. Ainsi, les besoins communs en
ressources seraient prohibitifs, sauf dans le cas où le trafic demandé est élevé et un grand
pourcentage d‟échanges de trafic est possible entre les nœuds du réseau. Sinon une approche
réactive serait plus attrayante.
3.2 Routage source Vs Routage par saut
Le routage source permet de déterminer le chemin complet que doit suivre le message, depuis
le nœud source. Ce chemin est codé dans le paquet du message, et il est déterminé une fois et
ne change pas lorsque le message traverse le réseau.
En revanche, dans le routage par saut, le prochain nœud du message est déterminé à chaque
saut tout le long du chemin. Cette technique de routage permet au message d‟utiliser
l‟information sur les contacts disponibles et les files d‟attente à chaque saut. Ce qui est
généralement indisponible à la source. Ainsi le routage par saut peut conduire à de meilleures
performances. Cependant, en raison de sa nature locale, il peut conduire à des boucles lorsque
les nœuds ont différentes vues de topologie (ex : dues à une information de routage
incomplète ou retardée).
3.3 Routage hiérarchique
Ce type de routage facilite la hiérarchisation du réseau en topologie abstraite et peut ne pas
générer le plus court chemin. Son avantage est qu‟il est scalable (logarithmique) et n‟a pas
besoin d‟informations sur la position des nœuds.
Le routage hiérarchique exige que la source connaisse l‟adresse hiérarchique de la destination
[Annexe B]. Si seul l‟ID de la destination est disponible, alors la source peut recourir à utiliser
le service de localisation.
Le routage hiérarchique est un routage saut par saut. Avant toute opération de routage, chaque
nœud du réseau a besoin d‟obtenir les informations sur les clusters32
de tous les niveaux de la
topologie. Il effectue sa décision de transmission selon les étapes suivantes [14]:
1. Trouver le plus bas niveau k où la source S et la destination D ont un cluster commun ;
2. Définir une source intermédiaire S0 et une destination intermédiaire D0 qui sont des
clusters de niveau k de S et D respectivement ;
3. Utiliser l‟algorithme optimal de Dijkstra pour trouver le prochain saut n0 du plus court
chemin de S0 à D0 en se basant sur l‟information de S sur la topologie du niveau k ;
32
Voir plus de détails sur la clusterisation sur Annexe B

Chapitre 3 DTN : Les protocoles de routage
47
4. Si k = 0, S prend la décision de faire une transmission à n0. Sinon, retourner à l‟étape 3
avec un nouveau k = k-1, un nœud D0 qui sera la passerelle distante de S0 à n0 et le
nouveau S0 va être le nœud du niveau k (nouveau k) qui est soit S ou le cluster de S.
3.4 La réplication
Les réseaux tolérants aux délais peuvent se fonder sur des composants qui sont incertains ou
imprévisibles. Pour compenser ceci, beaucoup de stratégies de routage utilisent de multiples
copies pour chaque message afin d‟augmenter la chance qu‟au moins une copie soit délivrée,
ou pour réduire la latence de livraison.
L‟idée repose sur le principe suivant: le fait qu‟il y ait plusieurs copies d‟un message,
augmente la probabilité d‟avoir un message qui trouvera son chemin vers la destination et
diminue la durée moyenne de sa délivrance.
Certes, la meilleure approche est d‟avoir une seule copie par message. Cependant, un échec
est produit dès que ce message est perdu. L‟approche la plus fiable est donc de faire porter à
chaque nœud une copie du message. Dans ce cas, le message n‟est considéré perdu que si tous
les nœuds qui le portent sont incapables de le délivrer. En revanche, ceci consomme la bande
passante et les ressources de stockage de manière proportionnelle au nombre de nœuds dans le
réseau.
3.5 La connaissance
Quelques stratégies de routage exigent plus d‟informations sur le réseau que d‟autres. A une
extrémité, un nœud peut prendre des décisions avec zéro connaissance à propos du réseau,
excepté les contacts qui sont couramment disponibles.
Ces stratégies emploient des règles statiques qui sont configurées initialement, et tous les
nœuds vont les obéir. Ceci mène aux simples implémentations qui exigent une configuration
minimale et des messages de contrôle puisque toutes les règles sont codées préalablement.
L‟inconvénient est que cette stratégie ne peut pas être adaptée à tous les réseaux ou à toutes
les conditions, ainsi elle ne prend pas toujours des décisions optimales.
A l‟autre extrémité, le nœud peut avoir besoin des futures disponibilités de chaque contact
dans le réseau. Ainsi, plus l‟information est précise, plus la stratégie de routage utilise le
réseau et ses ressources de façon très fiable, et ce par l‟expédition d‟un message via le
meilleur chemin.
Néanmoins, une tranche de valeur existe entre ces deux extrémités. Par exemple,
l‟information sur l‟ordonnancement des futures disponibilités des contacts est approximative,

Chapitre 3 DTN : Les protocoles de routage
48
ou bien une stratégie peut ne pas exiger d‟informations à l‟avance mais effectue un
apprentissage automatique par la suite.
3.6 Théorème de la fonction d’utilité
Le théorème de la fonction d‟utilité utilisée dans certaines stratégies que nous décrirons plus
loin consiste en le principe suivant [21] :
Nous avons d‟une part : τi(j) le laps de temps écoulé depuis la dernière rencontre du nœud i au
nœud j.
D‟autre part, nous considérons que chaque nœud i maintient une fonction d‟utilité Ui(·) pour
tous les nœuds où : Ui(·) est une fonction monotone décroissante par rapport à τi(.)
respectivement et Ui(i) > Ui(j) ∀ i, j.
Ainsi nous avons:
Un nœud A transmets un message au nœud B destiné au nœud D, si et seulement si UB(D) >
UA(D) + Uth où Uth (utilité seuil) est un paramètre de l‟algorithme.
4. Les challenges
Les réseaux tolérants aux délais présentent divers challenges qui ne sont pas présents dans les
réseaux traditionnels. Les fréquentes déconnexions nécessitent un traitement vu leur impact
direct sur le routage et la transmission de données. Cependant, puisque ces réseaux activent la
communication entre un large rayon de dispositifs, les stratégies de routage doivent gérer le
problème de ressources limitées. Ces challenges peuvent être résumés comme suit [11] :
4.1 L’ordonnancement des contacts
Le temps d‟attente est le composant de délai le plus signifiant entre les nœuds car sa valeur
peut varier de quelques secondes à plusieurs jours. D‟où le fait que l‟ordonnancement des
contacts soit l‟une des caractéristiques les plus importantes dans les DTNs, car l‟application
en question en est fortement liée. Cette information est approximative et dépend de la
technique dont elle est prévisible.
4.2 La capacité des contacts
La question qui se rapproche beaucoup de l‟information sur l‟ordonnancement des contacts
est : quelle est la quantité de données qui peut être échangée entre deux nœuds ?
Il n‟existe pas de réponse exacte, basée sur une règle connue, à cette question. En fait, ceci
dépend de la technologie du lien et de la durée du contact. Car même si la durée est

Chapitre 3 DTN : Les protocoles de routage
49
précisément connue, il n‟est pas possible de prédire la capacité à cause des fluctuations de
données.
Une approche naïve aura tendance à ignorer la capacité des contacts, excepté le cas où le
bundle même à envoyer à travers ce contact sans fragmentation, est très large. Dans le cas où
le volume du trafic est inférieur aux capacités des contacts dans le réseau, il serait possible de
ne pas la considérer. Tandis que lorsque le volume du trafic augmente avec l‟augmentation du
nombre d‟utilisateurs, ou avec le nombre de messages échangés, alors la capacité des contacts
devient un paramètre important. Dans cette situation, le meilleur contact pourrait devenir l‟un
des plus inefficaces selon d‟autres critères, mais comme il a le plus gros volume donc il est
considéré comme étant le contact le mieux équipé pour traiter les demandes de trafic.
4.3 Espace buffer
Afin de faire face aux longues déconnexions, les messages doivent être stockés pendant de
longues périodes dans les buffers. Ceci signifie que les routeurs intermédiaires demandent
assez d‟espace buffer, pour garder tous les messages qui attendent les futures opportunités de
communication. En d‟autres termes, ceci signifie que les routeurs intermédiaires exigent un
espace buffer proportionnel à la demande. Par conséquent, les stratégies de routage doivent
prendre en considération l‟espace buffer disponible lors de la phase de prise de décision.
4.4 La puissance de calcul
Un des objectifs des réseaux tolérants aux délais est de connecter les dispositifs qui sont
desservis dans les réseaux traditionnels. Ces dispositifs peuvent être très petits et de manière
similaire ont une petite capacité de calcul en termes de CPU et de mémoire. Ainsi, ces nœuds
sont incapables de faire fonctionner des protocoles de routage complexes.
4.5 L’énergie
Certains nœuds dans les réseaux tolérants aux délais peuvent avoir des provisions d‟énergies
limitées. Soit parce qu‟ils sont mobiles, soit parce qu‟ils se trouvent dans une zone qui ne peut
pas être facilement connectée. Le routage consomme de l‟énergie par l‟envoi, la réception et
le stockage des messages mais aussi par l‟exécution de calculs. Par conséquent, les stratégies
de routage qui envoient peu de données et effectuent moins de calculs vont être plus
économes en énergie. En outre, les stratégies de routage peuvent optimiser la consommation
d‟énergie en utilisant les nœuds à capacités limitées, avec modération.

Chapitre 3 DTN : Les protocoles de routage
50
5. Les modèles de mobilité pour les réseaux tolérants aux délais
Un modèle de mobilité est un modèle qui exprime le comportement des nœuds et la façon
dont leur position, vitesse et accélération varient avec le temps. Un tel modèle doit être
capable d‟imiter le mouvement des nœuds tel que souhaité dans un certain scénario. Une
méthode intuitive pour la construction d‟un tel modèle réside dans l‟utilisation des traces
réelles des utilisateurs. Il est différentes familles de modèles de mobilité, ainsi nous trouvons
[44]:
5.1 Les modèles synthétiques
Comme les domaines d‟application des réseaux DTN sont très vastes et qu‟ils ne sont pas
encore trop utilisés, alors l‟obtention des traces utilisateurs est assez difficile. D‟où la
nécessité d‟utiliser des modèles synthétiques qui ont pour rôle d‟exprimer le comportement
des nœuds sans l‟usage de traces réelles. Deux catégories de modèles de mobilité synthétiques
existent, les modèles de mobilité d‟un nœud individuel et ceux d‟un groupe de nœuds.
5.1.1 Les modèles individuels
Pour les modèles individuels, chaque nœud se déplace seul et il est tout à fait indépendant des
autres nœuds. Ces modèles peuvent être classés selon l‟aspect aléatoire de leurs mouvements,
soit un mouvement absolument aléatoire sans aucune mémoire du passé, soit un mouvement
souple où les variations de la vitesse, direction et position à chaque instant sont fonction de
l‟état précédent. Les modèles sans mémoire sont faciles à analyser et offrent une bonne
représentation de la réalité car dans ces modèles, un nœud choisit une position et une vitesse
d‟une façon absolument aléatoire et sans aucune mémoire du passé. Notons aussi que des
comportements extrêmes des nœuds arrivent fréquemment, comme un arrêt soudain, une
accélération soudaine et des tours brutaux. Cette catégorie comprend les modèles suivants:
5.1.1.1 Random Walk
Dans ce modèle, chaque nœud dans la simulation choisit aléatoirement un angle de direction
entre 0 et 2π radians et une vitesse entre Vmin et Vmax. Le déplacement du nœud se fait
pendant un temps t ou d‟une distance d. À la fin de son voyage, le nœud choisit une nouvelle
direction et une nouvelle vitesse et se déplace de nouveau. Nous pouvons bien remarquer que
le changement de la direction et de la vitesse est absolument aléatoire et indépendant du choix
précédent.

Chapitre 3 DTN : Les protocoles de routage
51
5.1.1.2 Random Waypoint
Ce modèle était d‟abord utilisé dans l‟évaluation du protocole de routage DSR pour les
réseaux Ad Hoc. Le Random Waypoint permet de modéliser tous les scénarios dans lesquels
les nœuds se déplacent vers une destination, prennent un repos en arrivant avant de se
déplacer vers une autre destination et ainsi de suite. Dans ce modèle chaque nœud choisit
aléatoirement comme destination, un point de coordonnées (x, y) dans la surface de simulation
et une vitesse entre Vmin et Vmax. Le nœud voyage vers la destination choisie avec la vitesse
choisie. À l‟arrivée, le nœud prend un temps de repos avant de choisir de nouveau une
nouvelle destination, et une nouvelle vitesse pour répéter le même processus. Un nœud peut
commencer par prendre un temps de pause avant son premier mouvement. Il tire ainsi une
période de repos aléatoire et lorsque cette période se termine, il commence son voyage vers la
destination choisie. De multiples études ont été faites sur ce modèle car c‟est le modèle le plus
utilisé dans les simulations vu la facilité de son implémentation.
5.1.1.3 Random Direction
Le Random Direction a été créé pour éviter l‟effet de concentration des nœuds au centre
produit par le Random Waypoint. Dans ce modèle, chaque nœud choisit aléatoirement,
comme dans le Random Walk, une direction qui est un angle entre 0 et 2π radians et une
vitesse entre Vmin et Vmax. La différence entre ce modèle et le Random Walk est qu‟ici le
nœud ne voyage pas pendant un certain temps ou d‟une certaine distance mais, se déplace
suivant la direction choisie jusqu‟à atteindre le bord de la surface de simulation où il prend un
temps de repos. Une fois le temps de pause terminé, le nœud choisit de nouveau et
aléatoirement une nouvelle direction et une nouvelle vitesse et répète le même processus.
5.1.1.4 Restricted Random Waypoint
L‟idée de ce modèle de mobilité est extraite du fait que la plupart des gens se déplacent pour
un certain temps dans une même localité avant d‟aller vers une autre localité. Donc dans ce
modèle, la surface de simulation contient des rectangles qui représentent des villes liées par
des autoroutes. Chaque nœud utilise le Random Waypoint pour se déplacer dans l‟une des
villes un certain nombre de fois spécifiées par un paramètre, avant de voyager vers une autre
ville où il va se déplacer pour un certain moment et ainsi de suite.
5.1.2 Les modèles de groupe
Dans un modèle de groupe, les nœuds se déplacent ensemble comme un groupe de soldats qui
ont une mission à accomplir ensemble. Les modèles de groupe qui existent sont les suivants :

Chapitre 3 DTN : Les protocoles de routage
52
5.1.2.1 Exponential Correlated Random
Dans ce modèle, le mouvement de chaque groupe est contrôlé indépendamment des autres
groupes. À chaque étape de temps, un groupe se déplace d‟une distance aléatoire dans une
direction aléatoire. Chaque nœud change ses coordonnées polaires, qui sont une distance et un
angle, selon une formule mathématique.
5.1.2.2 Column
Dans ce modèle, chaque groupe de nœuds peut avoir une ou plusieurs références. Une
référence est un nœud du groupe, qui a pour rôle de guider les autres nœuds pendant leur
déplacement. Au début de la simulation, les références de chaque groupe sont placées d‟une
façon formant une colonne, et chaque nœud est placé en relation avec sa référence, autour de
laquelle, il a le droit de se déplacer en utilisant l‟un des modèles de mobilité singuliers. Une
référence peut avoir un seul nœud autour d‟elle. La position de l‟axe des références change de
la manière suivante (voir la Figure 27) :
Nouvelle_position (références) = ancienne_position (références) + vecteur anticipé.
Le vecteur anticipé est calculé suivant un angle aléatoire entre 0 et radian (puisque le
déplacement est seulement en avant) et une distance aléatoire
Figure 27: Mouvement des nœuds en utilisant le modèle Column. [44]
5.1.2.3 Nomadic Community
Dans ce modèle, chaque groupe de nœuds possède une seule référence en commun. Les
nœuds de chaque groupe se déplacent autour de leur référence en utilisant un modèle de
mobilité singulier (exemple Random Walk), et ne peuvent pas la dépasser d‟une certaine
Référence
Nœud mobile

Chapitre 3 DTN : Les protocoles de routage
53
distance précisée dans les paramètres et qui est la distance maximum entre un nœud et sa
référence. Le déplacement d‟une référence se fait aussi selon un modèle singulier.
5.1.2.4 Purse
Purse est un modèle de mobilité qui contient, comme Nomadic Community, une seule
référence. La différence est que la référence joue ici le rôle d‟une cible qui est poursuivie par
les autres nœuds, comme le mouvement d‟un groupe de policiers essayant d‟attraper un
voleur. La position de chaque nœud dans le groupe varie de la manière suivante :
Nouvelle_position = position_ancienne + accélération (cible) + vecteur_aléatoire.
« Accélération (cible) » est une information sur le déplacement de la cible et le
« vecteur_aléatoire » est le mouvement d‟un nœud selon un modèle de mobilité singulier
(Random Walk par exemple). Ce mouvement est limité puisqu‟il s‟agit de poursuivre la cible
sans la dépasser. La Figure 28 ci-dessous illustre le déplacement d‟un groupe utilisant le
modèle Purse. Le nœud en blanc représente la référence.
Figure 28 : Purse. [44]
5.1.2.5 Reference Point Group
Dans ce modèle, chaque groupe peut contenir plusieurs références, dont une est le centre
logistique du groupe et qui a pour rôle de contrôler le mouvement des références dans ce
groupe. Les autres nœuds se déplacent chacun autour de sa référence en utilisant un modèle
de mobilité singulier.
5.2 Les modèles empiriques
Ce sont des résultats réels obtenus à partir d‟études de suivi réalisées dans des projets de
récolte d„informations, nous trouvons par exemple :

Chapitre 3 DTN : Les protocoles de routage
54
Cambridge/Haggle :
Ces données incluent un certain nombre de traces de communication via Bluetooth entre des
groupes d'utilisateurs portant de petits dispositifs (iMotes33
), observées pendant un certain
nombre de jours lors de conférences.
ZebraNet :
Il s‟agit d‟un jeu de données contenant des traces de mouvement de zèbres rassemblés à la
réserve naturelle Sweetwaters près de Nanyuki, le Kenya.
6. Classification des protocoles de routage DTN
Les protocoles de routage dans les DTNs utilisent deux principales propriétés : la
« réplication » où plusieurs copies du message sont utilisées, et la « connaissance » qui
indique comment obtenir des informations sur l‟état du réseau, et comment qu‟une stratégie
les utilise dans le but de prendre une décision de routage.
Une première classification complète a été proposée par Jain & Al [6]. Celle-ci se base sur ces
deux critères où le concept d‟oracles de connaissances a été intégré. Les éléments de base de
cette classification sont les suivants :
A. L’inondation
Consiste en la délivrance de multiples copies par message pour un ensemble de nœuds
appelés « relais ».
Les relais stockent les messages jusqu‟à se connecter avec la destination où les paquets de
données seront délivrés. Les protocoles utilisant cette stratégie ne doivent avoir aucune
information sur le réseau. Cependant, certains schémas avancés utilisent quelques
informations, afin d‟améliorer les performances.
B. L’expédition
Se base sur une approche plus traditionnelle pour l‟acheminement de données dans un DTN.
Elle utilise l‟information sur la topologie du réseau pour sélectionner le meilleur chemin, sur
lequel le message est alors envoyé en allant d‟un nœud à l‟autre. Cette technique a été
explorée dans les protocoles développés pour les réseaux filaires.
Néanmoins, puisque ces derniers supposent que les liens sont généralement connectés, alors
les protocoles désignés pour ces environnements ne fonctionneront pas pour les réseaux
33
iMotes : Capteurs conçus par Intel et équipés d‟un logiciel appelé « Contact Logger » développé par LIP6. Et
ils sont dotés de la technologie Bluetooth

Chapitre 3 DTN : Les protocoles de routage
55
tolérants aux délais. Pour cela, les stratégies de cette famille nécessitent quelques
connaissances supplémentaires sur le réseau, puis déterminent le meilleur chemin, et envoient
un seul message le long de celui-ci. Ainsi, elles évitent d‟utiliser la réplication.
C. Les oracles de connaissance
Le problème de routage DTN a beaucoup de variables d‟entrées, par exemple : les
caractéristiques de la topologie dynamique et la demande de trafic. La connaissance complète
de ces variables facilite le calcul des routes optimales. Cependant, avec des connaissances
partielles, la capacité de calcul des routes optimales est entravée, et les performances du
routage résultant s‟avèrent inférieures.
Afin de comprendre cette interaction fondamentale entre performance et connaissances, un
ensemble abstrait d‟ « oracles de connaissances » a été créé [11]. Ces oracles sont des éléments
utilisés pour encapsuler des connaissances particulières sur le réseau, requises par différents
algorithmes. Ainsi, nous pouvons distinguer 4 types d‟oracles :
Oracle de l’état des contacts :
Cet oracle prend en charge les statistiques globales des contacts. Il fournit en particulier, le
temps d‟attente moyen jusqu‟au prochain contact. Ainsi, l‟oracle de l‟état des contacts ne
fournit que le temps invariant, ou un résumé des caractéristiques des contacts.
Oracle de contact :
Cet oracle prend en charge tous les contacts entre deux nœuds à un temps donné. Ceci est
équivalent à la connaissance du multi-graphe DTN dans un temps variant.
L‟oracle de l‟état des contacts peut être construit à base de l‟oracle contact mais l‟inverse
n‟est pas vrai.
Oracle de file d’attente :
Cet oracle donne des informations sur le taux d‟occupation du buffer instantanément, à
n‟importe quel nœud, à n‟importe quel moment, et peut être utilisé pour les routes autour des
nœuds congestionnés.
A la différence avec les autres oracles, l‟oracle de la file d‟attente est affecté par les nouveaux
messages qui arrivent au système, et le choix fait par l‟algorithme de routage lui-même. Cet
oracle est probablement le plus difficile à réaliser de tous les autres dans un système distribué.

Chapitre 3 DTN : Les protocoles de routage
56
Oracle de demande de trafic :
Cet oracle prend en charge toute demande présente ou future du trafic. Il est capable de
fournir l‟ensemble des messages injectés dans le réseau à tout moment.
D. La connaissance partielle
Les algorithmes de cette catégorie calculent les chemins en utilisant une ou plusieurs de ces
informations : l‟état des contacts, les contacts et les files d‟attente. Chaque message est routé
indépendamment de la future requête, car les connaissances sur le trafic ne sont pas utilisées.
Ces algorithmes sont tous basés sur l‟attribution de coûts aux liens, et le calcul d‟une sorte de
chemin à coût minimum. Les coûts sont attribués aux liens en se basant sur les informations
disponibles, et ce dans le but de donner une idée sur le délai estimé pour un message les
empruntant.
La raison pour laquelle seulement les algorithmes cost-based (basés sur le coût) sont
considérés dans cette classe se compose de deux penchants :
Ils permettent d‟utiliser les différentes connaissances d‟une façon pratique pour
l‟utilisation, et identifient dans quelle mesure la connaissance globale est nécessaire.
Ils correspondent aux problèmes classiques de routage basé sur le plus court chemin qui
sont bien maitrisés, et pour lesquels les algorithmes efficaces à base de calculs simples sont
connus.
Cependant, ces méthodes simples ne donnent pas plus d‟un seul et unique chemin, ce qui est
un inconvénient, car dans les DTNs, il est important d‟utiliser de multiples chemins afin
d‟atteindre des performances assez optimales.
E. La connaissance complète
Certains algorithmes calculent leurs routes sans tenir compte du trafic, ce qui rend leurs
performances non optimales. Ceci est fondamental, car ces algorithmes n‟auront à se
préoccuper ni du trafic, et donc ni des contraintes des buffers.
Contrairement aux situations rencontrées dans la réalité, ces contraintes s‟imposent d‟où
l‟avènement de techniques qui utilisent tous les oracles afin d‟avoir un routage optimal
minimisant le délai moyen dans le réseau.
6.1 La classification de Jain & Al
En se basant sur tous les critères présentés, Jain & Al ont proposé une classification des
protocoles de routage [06]. Nous pouvons résumer ou schématiser cette dernière par le
diagramme de la Figure 29 présenté ci-dessous :

Chapitre 3 DTN : Les protocoles de routage
57
Figure 29 : Diagramme résumant la classification de Jain & Al
Par la suite, d‟autres protocoles de routage ont apparu. Certains ont continué à se baser sur les
mêmes principes mais en utilisant d‟autres formes d‟optimisation, d‟autres ont amené de
nouveaux concepts afin de répondre au même objectif qui est la maximisation du taux de
livraison des messages.
Ayant ces nouveaux protocoles, de nouvelles classes sont donc formées selon les principes de
base sur lesquels ils sont fondés. Ainsi, afin de résumer l‟ensemble de toutes les familles des
protocoles de routage DTNs existants, nous avons constitué un second diagramme (Figure 30)
où nous les avons regroupés, et que nous considérons comme une extension de la
classification de Jain & Al [06], car basée sur le même raisonnement.
Figure 30 : Extension du diagramme de classification de Jain & Al.
Protocoles de routage DTN
Inondation Expédition
Routage à zéro connaissances
Routage avec connaissances
partielles
Routage avec connaissances
complètes
Protocoles de routage DTN
Inondation
Une seule copie
multiples copies
Probabilistique Hiérarchique Expédition
Zéro connaissances
Connaissances partielles
Connaissances complètes

Chapitre 3 DTN : Les protocoles de routage
58
6.2 La classification basée sur les ressources consommées
Les critères des classifications précédentes se sont basés sur les techniques utilisées dans la
construction des algorithmes de routage, pour améliorer les performances en taux de
délivrance, et délai de transmission et aussi aider dans leur implémentation.
Néanmoins, face à une situation donnée où l‟on pense à adopter une architecture DTN, le
concepteur a besoin d‟avoir une idée sur l‟impact de l‟approche à choisir sur son réseau.
Le fait de se baser sur des résultats obtenus grâce à des travaux de simulation n‟est pas
vraiment la solution, car eux se basent tantôt sur la complexité du réseau, tantôt sur la
mobilité, et parfois les scénarios sont construits spécialement pour répondre à un objectif
précis. Du coup, ils ne donnent qu‟un aperçu général sur le comportement des protocoles,
mais ne peuvent aider à établir des règles vu que les réseaux réels affrontent différentes
situations et subissent différents degrés de complexité.
Pour cela, nous proposons une autre forme de classification qui tient compte d‟une contrainte
importante, à savoir les ressources consommées. Cette méthode va permettre de donner une
idée au préalable de la quantité de ressources requises. Dans notre cas, les deux métriques
étudiées sont la « bande passante » et la « capacité de stockage ». Dès lors, le schéma global
obtenu est composé de trois principales classes qui sont :
La classe des protocoles non consommateurs de ressources.
La classe des protocoles ne se souciant pas de la capacité des ressources, et donc
consomment sans limites.
La classe des protocoles tentant de réduire cette consommation.
6.2.1 La classe des protocoles non consommateurs
Les protocoles de cette classe comptent beaucoup plus sur la simplicité de l‟implémentation
de l‟algorithme plutôt que sur son intelligence. Par conséquent, de longs délais de délivrance
de messages en résultent. Les algorithmes de routage répondant aux caractéristiques de cette
catégorie sont les suivants :
A. Contact direct
Dans cette stratégie, le nœud source attend jusqu‟à ce qu‟il rentre en contact avec le nœud
destination pour expédier les données. C‟est le cas dégénéré, car l‟ensemble des relais ne
contient que la destination [11][21].
Elle est considérée comme étant basée sur la technique d‟inondation à une seule copie, vu le
fait qu‟elle ne demande la connaissance d‟aucune information sur le réseau. Néanmoins, elle

Chapitre 3 DTN : Les protocoles de routage
59
peut être considérée comme un cas dégénéré de la famille des stratégies basées sur la
technique d‟expédition, du fait qu‟elle sélectionne toujours un chemin direct entre la source et
la destination.
C‟est une stratégie simple et ne consomme pas de ressources. Cependant, elle ne fonctionne
que si la source est en contact avec la destination ce qui est son inconvénient.
B. First Contact (FC)
Dans cet algorithme, le nœud choisit aléatoirement le premier contact disponible. Si tous les
chemins sont actuellement indisponibles, alors le message est mis en attente jusqu‟à libération
du premier lien [12]. Cette stratégie se caractérise par le fait que :
Elle fonctionne mal sur les topologies non-triviales car le choix du prochain saut est
essentiellement aléatoire, et la transmission le long du lien sélectionné peut ne faire aucun
progrès vers la destination.
Un message peut toujours osciller entre un ensemble de nœuds, particulièrement lorsque
des contacts fréquents sont présents au sein d‟un petit ensemble de nœuds, ou peut être
livré à une impasse.
Elle n‟a aucune disposition de se diriger vers une congestion.
Elle n‟exige que des connaissances locales sur le réseau et est facile à implémenter.
L‟approche basique de FC34
peut être améliorée de plusieurs manières. L‟une consiste à
incorporer le sens de la trajectoire entre la source et la destination, afin que le message se
dirige vers le sens le plus proche de la destination.
Pour éviter les boucles, une trace du chemin (sous forme de vecteur) peut lui être ajoutée [37].
C. Routage aléatoire
Dans cette approche, le gardien courant du message passe ce dernier au prochain nœud qu‟il
rencontre avec une probabilité P € (0,1] [21].
Le nœud récepteur du message n‟est pas autorisé à envoyer celui-ci au nœud expéditeur pour
une durée donnée. Ils sont marqués « en couple » jusqu‟à l‟expiration de la durée fixée. Grace
à ce mécanisme, le message ne boucle pas entre deux nœuds de même portée [28].
Cette approche basique présente de très bons progrès localement pour certains modèles de
mobilité, tels que Random Walk ou Random Waypoint. Ceci s‟explique par le fait que la
vitesse de transmission est plus rapide que la vitesse des nœuds eux-mêmes. Néanmoins, cette
progression est marginale, principalement quand le nœud destination est loin.
34
FC : First Contact

Chapitre 3 DTN : Les protocoles de routage
60
D. Routage location-based (basé sur la position)
Cette approche est parmi celles qui nécessitent le moins d‟informations sur le réseau. Elle ne
requiert que l‟assignation de coordonnées à chaque nœud, et le calcul de la fonction de
distance afin d‟estimer le coût du message délivré d‟un nœud vers un autre.
Le meilleur chemin est déterminé à base de trois principales informations : les coordonnées
du nœud gardien du message (source ou intermédiaire), les coordonnées du nœud destination,
et les coordonnées des potentiels prochains nœuds. Ainsi, le nœud peut facilement calculer la
fonction de distance et déterminer le prochain récepteur du message. Ce dernier doit
appartenir à l‟espace des coordonnées du gardien courant.
Les coordonnées d‟un nœud peuvent avoir différents sens. Un sens physique, comme les
coordonnées GPS [33][34], ou un sens dans l‟espace « topologie du réseau ».
L‟avantage de l‟approche location-based est que le peu d‟informations qu‟elle nécessite sur le
réseau permet d‟éliminer le besoin en tables de routage, et de réduire le contrôle d‟overhead.
Parallèlement, le routage location-based présente deux grands problèmes :
1. Même si la distance entre deux nœuds est courte, il n‟y a aucune garantie qu‟ils puissent
communiquer entre eux.
2. Les coordonnées d‟un nœud peuvent changer. Soit parce qu‟un nœud se déplace, et donc
ses coordonnées physiques changent. Soit parce que la topologie du réseau change, ainsi
ses coordonnées virtuelles changent aussi. Ce qui, par conséquent, complique le routage
car le nœud source a besoin de connaître les coordonnées du nœud destination.
Ces deux problèmes montrent que l‟implémentation de la méthode location-based n‟est pas
évidente. Pour cela, quelques améliorations lui ont été apportées:
Utilisation d‟un vecteur de déplacement des nœuds mobiles afin de prédire leurs futures
positions. Ce schéma permet de passer les messages entre les nœuds mobiles et la
destination [18].
Harras & Al ont utilisé [19] une stratégie de routage à coordonnées virtuelles appelées
« mobility pattern spaces ». Dans cette stratégie, les coordonnées d‟un nœud sont
composées d‟un ensemble de probabilités, chacune représente la chance qu‟un nœud puisse
être trouvé à une position spécifique. Diverses fonctions de distance sont alors calculées.
Les résultats obtenus montrent que même cette stratégie réduit la quantité de ressources
consommées.

Chapitre 3 DTN : Les protocoles de routage
61
E. Routage Hiérarchique DTN (DHR)
Le routage hiérarchique DTN est toute une nouvelle technique, mais très simple une fois le
réseau hiérarchique est construit. DHR35
est un protocole basé sur le routage saut par saut, et
chaque nœud prend sa décision de transmission en deux phases [14] :
1. La première phase s‟exécute seulement lorsque le niveau haut Lc, sur lequel le cluster du
nœud courant et celui du nœud destination sont différents, est supérieur à La [Annexe B].
Dans cette phase, le routage hiérarchique statique s‟exécute sur les niveaux Lc à La + 1 où
les délais sur les liens varient avec le temps. Le résultat de cette phase est une destination
intermédiaire d0 du niveau La. Lorsque Lc <= La, la première phase ne s‟exécute pas et d0
reste la tête du cluster de la destination au niveau Lc.
2. La seconde phase appelée: le routage global, contient les étapes suivantes :
Toutes les informations du contact dans des liens du niveau 0 au niveau La qui sont
stockées par le nœud courant, sont rassemblées sous forme d‟un graphe G. Ce graphe
va comprendre tous les contacts des liens dans les clusters du nœud courant du niveau
0 au niveau La du réseau hiérarchique.
L‟espace de temps optimal de l‟algorithme de Dijkstra est effectué sur G afin de
trouver le plus court chemin C du nœud courant à la destination intermédiaire d0. Le
nœud pointé après le premier saut dans C représente le nœud courant résultant de la
décision de transmission.
La stratégie DHR contient deux principaux avantages, la scalabilité qui lui permet d‟être
appliquée sur des réseaux de grande taille ou de taille variante, ainsi que son non besoin aux
informations sur la position des nœuds.
6.2.2 La classe des protocoles consommateurs de ressources
Cette classe regroupe les protocoles de routage DTN qui utilisent des techniques pour
augmenter le taux de délivrance de messages à destination, sans tenir compte du paramètre de
consommation de ressources. Dans cette classe, nous allons encore distinguer trois cas selon
le fait que ces stratégies ne prennent pas en considération les limites de l‟espace de stockage
dans les buffers, les limites de la capacité de la bande passante, ou encore les limites des deux
métriques simultanément. Ainsi, nous obtenons ce qui suit :
35
DHR: DTN Hierarchic Routing

Chapitre 3 DTN : Les protocoles de routage
62
6.2.2.1 Consommation illimitée des buffers et de la bande passante
A. Routage épidémique
Les algorithmes épidémiques sont originellement proposés pour synchroniser les bases de
données répliquées. Puis ces algorithmes ont été appliqués [17] pour l‟expédition de données
dans un DTN. Par analogie, la liste des messages en attente de délivrance est la base de
données qui a besoin de synchronisation.
Dans le routage épidémique, tous les nœuds vont éventuellement recevoir tous les messages,
car l‟algorithme fournit un nombre aléatoire d‟échanges de données suffisant. Son principe de
base est le suivant :
Lorsqu‟un message est envoyé, il est placé dans le buffer et est étiqueté par un unique ID.
Quand deux nœuds se connectent, ils s‟envoient chacun à l‟autre la liste des IDs des messages
qu‟ils ont dans leurs buffers. Cette liste est appelée « vecteur d‟état ».
En utilisant ce vecteur d‟état, les nœuds s‟échangent les messages qu‟ils ne possèdent pas. Et
à la fin de cette opération, tous les nœuds auront les mêmes messages dans leurs buffers [13].
En d‟autres termes, le routage épidémique essaie d‟envoyer chaque message sur tous les
chemins du réseau. Ce qui fourni une grande quantité de redondances car tous les nœuds
reçoivent tous les messages, mais qui rend cette stratégie extrêmement robuste. En outre, il
essaie tous les chemins, il livre chaque message dans un temps minimum s‟il y‟a des
ressources suffisantes.
Le routage épidémique est relativement simple. Car il ne nécessite aucune connaissance sur le
réseau. Pour cette raison, il a été proposé pour être utilisé comme repli si aucune autre
meilleure méthode n‟est disponible. L‟inconvénient est qu‟une énorme quantité de ressources
est consommée et ce, est dû au grand nombre de copies, ce qui nécessite une grande quantité
d‟espace buffer, de bande passante et d‟énergie.
B. Inondation Tree-based
Dans cette stratégie, le nœud source génère une copie du message au niveau d‟un relais, qui
lui génère un autre nombre de copies au niveau des relais qui le suivent. D‟où le nom « Tree-
based », car l‟ensemble des relais forme un arbre dont la racine est le nœud source [13].
Il est beaucoup de méthodes pour créer des copies. Un schéma simple est de permettre aux
nœuds d‟en créer sans limite, ce qui consomme énormément de ressources de stockage et de
bande passante.
Une amélioration peut être faite avec l‟ajout de la condition qu‟un message ne doit pas
traverser plus de n sauts à partir de la source. Ceci limite la profondeur de l‟arbre mais ne

Chapitre 3 DTN : Les protocoles de routage
63
limite pas sa largeur. Une autre amélioration consiste à limiter aussi le nombre de nœuds pour
créer au plus m copies, ceci limite et la profondeur et la largeur de l‟arbre, ce qui limite le
nombre total de copies à un maximum égal à ∑ .
Une alternative plus complexe est de limiter le nombre total de copies à N. Lorsqu‟un nœud
crée les copies, il dégage la responsabilité de la création de la moitié de ce qu‟il a créé comme
copies aux autres nœuds, et lui s‟occupe de la création de l‟autre moitié. Cette approche
semble optimale si les probabilités des contacts inter-nœuds sont indépendantes et
identiquement distribuées.
L‟inondation Tree-based peut fournir des messages à des destinations qui sont loin de
plusieurs sauts.
C. Minimum Expected Delay (MED)
Celle-ci est une stratégie qui a été classée parmi celles qui utilisent les oracles de
connaissance, elle utilise celui de l‟état des contacts. Son principe se défini comme suit :
A chaque lien, est attribué un coût qui est la somme de la moyenne du temps d‟attente, délai
de propagation et le délai de transmission. L‟itinéraire d‟un message est indépendant du
temps, ainsi une approche proactive peut être utilisée. MED utilise le même chemin pour tous
les messages ayant la même paire source-destination.
Aucun mécanisme n‟est utilisé pour éviter la congestion ou la suppression du message si
l‟espace de stockage n‟est pas disponible [6].
L‟algorithme MED est caractérisé par le fait qu‟il minimise le temps moyen d‟attente, et qu‟il
ne parvient pas à exploiter les liens supérieurs qui deviennent disponibles après que
l‟itinéraire soit calculé. En d‟autres termes, si un contact direct vers la destination du message
s‟avère disponible au moment où le message est en attente d‟un prochain saut pré-calculé,
alors le contact ne sera pas utilisé.
Néanmoins des améliorations ont été proposées pour cette approche. Parmi elles, celle qui
consiste à trouver de multiples chemins disjoints avec des coûts différents, et choisir au
hasard parmi eux celui qui pourrait améliorer l‟équilibrage de la charge et réduire la
congestion [38].
Ou encore, considérer qu‟une route pré-calculée pourrait être modifiée si un contact supérieur
devient disponible. Ceci en effet crée une forme de routage à source perdue avec un
comportement plutôt réactif.

Chapitre 3 DTN : Les protocoles de routage
64
D. Earliest Delivery with All Queues (EDAQ)
Cette approche fait appel aux oracles de connaissances où elle utilise ceux des contacts et de
files d‟attente.
EDAQ36
utilise l‟oracle de la file d‟attente pour déterminer instantanément la taille des files
d‟attente à travers toute la topologie à n‟importe quel point dans le temps.
Q est une fonction dont la valeur retournée est :
Q(e, t, s) = donnée enfilée pour le lien e à l’instant t au nœud s.
Les messages sont routés par la source. Les routes ne sont pas recalculées à chaque saut car
lorsque les routes ont été sélectionnées, la fonction Q a déjà pris en compte l‟enfilement dans
tous les nœuds sans se soucier de la disponibilité de l‟espace dans les buffers.
Après calcul de la meilleure route pour le message, la capacité du lien doit être réservée pour
le message sur tous les liens (à des temps donnés) le long du chemin. Ces réservations
garantissent le fait que les messages aient été déplacés à des délais suffisants pour éviter de
perdre des contacts prévus. En outre, ces réservations permettent de faire des prédictions
exactes sur les files d‟attente dans le réseau.
La mise en œuvre d‟une bande passante de réservations est susceptible d‟être un challenge
important pour les DTNs, où « communiquer » avec certains nœuds nécessitent des délais
importants.
Pour les systèmes où la centralisation est pratique, l‟allocation de la bande passante serait
grandement simplifiée.
Les propriétés de cette stratégie sont les suivantes :
EDAQ détermine une route optimale pour un nouveau message étant donné les réserves
existantes pour les messages précédents. Ceci parce qu‟il estime correctement les délais
d‟attente fournis par l‟oracle de la file d‟attente.
Les réservations en bande passante sont nécessaires afin d‟appliquer fidèlement l‟oracle de
la file d‟attente.
6.2.2.2 Consommation illimitée de l’espace de stockage
A. Earliest Delivery (ED)
Cette approche se base sur l‟oracle des contacts, son principe est le suivant :
Soit Q un paramètre qui permet de distinguer entre la file d‟attente locale et la file d‟attente
globale, initialisé à 0 dans cet algorithme.
36
EDAQ : Earliest Delivery with All Queues

Chapitre 3 DTN : Les protocoles de routage
65
Cet algorithme utilise le routage source, et ses itinéraires sont calculés à base de l‟algorithme
de Dijkstra du plus court chemin. Ainsi, il évite le risque de tomber dans des boucles de
routage car l‟algorithme de Dijkstra en est dépourvu.
ED37
n‟incorpore aucune information sur la file d‟attente, et les chemins sont calculés sans
tenir compte de la disponibilité de l‟espace de stockage aux nœuds intermédiaires. Ce qui peut
conduire à une chute lorsque les buffers sont trop pleins.
ED est caractérisé par le fait que :
Il est optimal dans ces deux cas:
Si les nœuds dans le chemin sélectionné n‟ont pas de messages enfilés, alors ED est
optimal parce que la valeur de la fonction Q est égale à 0 partout.
Si les capacités des contacts sont largement suffisantes, ED est également optimal
(même si les valeurs des files d‟attente ne sont pas à 0) car une fois un lien est
disponible et qu‟il est d‟une grande capacité, le temps de transmission de toutes les
données enfilées (y-compris le message lui-même) est négligeable.
Donc la taille de la file n‟affecte pas les délais dans ces deux cas.
Les chemins calculés avec ED ne prennent pas en compte les délais d‟attente. Si un lien
prétend être disponible à un certain temps T, l‟algorithme suppose qu‟il est possible qu‟il
soit effectivement utilisé.
Cependant, si beaucoup d‟autres messages arrivent dans la file, et le contact devient
indisponible avant que ces messages ne soient envoyés, alors la situation est désastreuse
car le temps où le message atteint le prochain nœud est très différent du temps prédit
lorsque la route a été pré-calculée. Par conséquent, continuer à calculer les routes
antérieurement est loin d‟être optimal.
B. Earliest Delivery with Local Queuing (EDLQ)
Dans cet algorithme c‟est aussi l‟oracle des contacts qui est utilisé, et le taux d‟occupation de
la file d‟attente locale est pris en compte dans l‟estimation des délais des liens.
La fonction Q compte pour l‟enfilement au niveau de tous les liens sortants du nœud source,
et aide à éviter la congestion au premier saut. Puis, elle ne compte plus pour les files qui
seront rencontrées lorsque le message atteint les autres nœuds du chemin. Cependant, à la
différence avec ED, la route est recalculée à chaque saut (routage par saut). Ceci permet au
chemin traversé d‟être sensible à l‟enfilement dans tous ses liens [6].
EDLQ38
est caractérisé par le fait que :
37
ED : Earliest Delivery

Chapitre 3 DTN : Les protocoles de routage
66
La fonction de coût dépend du nœud au niveau duquel la route est calculée. Ce qui peut
conduire à la formation de boucles et peut être l‟oscillation des messages éternellement.
Certaines oscillations peuvent être évitées en employant un vecteur de trace du chemin et
effectuer un nouveau calcul avec des routes fixes (ex : calcul en utilisant ED) lorsque la
boucle est détectée.
De même que ED, les messages peuvent chuter à cause des dépassements des tampons.
6.2.2.3 Consommation illimitée de la bande passante
A. Routage gradient
Cette approche consiste en l‟assignation d‟un poids à chaque nœud qui représentera le taux de
messages délivrés à une destination donnée. Lorsque le gardien du message contacte un autre
nœud qui a une meilleure métrique pour la destination du message, il le fait alors passer. Cette
approche est appelée « Routage gradient » car le message suit le gradient des valeurs de la
fonction d‟utilité vers la destination. Ceci nécessite plus de connaissances sur le réseau
comparativement à l‟approche location-based, et ce pour deux raisons [35]:
1. Chaque nœud doit stocker les métriques de toutes les destinations potentielles.
2. Des informations suffisantes doivent être propagées à travers le réseau pour permettre à
chaque nœud de calculer ses métriques à toutes les destinations. Les métriques doivent se
baser sur divers paramètres à savoir le temps du dernier contact entre le nœud et la
destination, l‟énergie de la batterie ou la mobilité. Une fonction d‟utilité très simple est
d‟envoyer un paquet avec une certaine probabilité.
Cette approche ne semble pas être très pratique mais elle est utilisée comme technique de base
à laquelle l‟on compare d‟autres techniques plus avancées.
B. Minimum Estimated Expected Delay (MEED)
MEED est une variante de MED39
dont le principe [13] se base surtout sur l‟utilisation de
l‟historique observé des contacts plutôt que sur le calcul du temps d‟attente prévu en utilisant
des prévisions. Une étude précédente a montré que les observations sur la mobilité peuvent
faire des prévisions avec une précision supérieure à 80%. Cette métrique essaye de faire une
prévision raisonnable à propos d‟une mobilité globale au cours de la période de temps qu‟il
faut pour livrer un message à travers le DTN, qui peut être des heures ou des jours. En
revanche, les prévisions de mobilité pour les systèmes cellulaires tentent de deviner
38
EDLQ : Earliest Delivery with Local Queuing 39
MED : Minimum Expected Delay

Chapitre 3 DTN : Les protocoles de routage
67
l‟emplacement de la prochaine cellule du nœud mobile, ce qui exige la prévision de la
mobilité pour les prochaines minutes qui suivent. Afin de calculer cette métrique, le nœud
enregistre les moments de connexion et de déconnexion de chaque contact dans la fenêtre
d‟historique. La taille de la fenêtre est un paramètre réglable qui peut être ajusté de manière
indépendante au niveau de chaque nœud.
Si la taille de la fenêtre est très large, alors la métrique va changer très lentement. Ceci est bon
pour éviter les perturbations causées par les changements aléatoires des contacts, mais aussi
signifie qu‟elle réagi doucement aux changements permanents de topologie. Inversement, une
petite fenêtre réagi rapidement aux changements ce qui signifie que la métrique sera plus
sensible aux perturbations aléatoires.
Aussi, lorsque la table de l‟état du lien locale change, les mises à jour doivent être propagées
à tous les nœuds du réseau. Ce qui est une opération très coûteuse. Afin de réduire l‟overhead,
le nœud peut alors de manière optionnelle supprimer les mises à jour qu‟il juge non
nécessaires. Cependant, il est essentiel qu‟il continue à faire ses décisions de routage en
utilisant la table dernièrement publiée.
Pour accomplir cela, la première opportunité qui se présente est d‟utiliser le routage source.
Certes, c‟est une approche simple mais selon Jones & Al [13], elle n‟est pas appropriée aux
réseaux tolérants aux délais, car lorsque le message passe près de la destination, les nœuds
autour vont être susceptibles d‟avoir les plus récentes et les plus précises informations sur la
connectivité du nœud destination. Par conséquent, il semble naturel que ces nœuds
intermédiaires prennent de meilleures décisions que le nœud source.
Ainsi et dans le but d‟améliorer la première approche, le routage par saut a été utilisé pour la
prise de décisions de transmission. Quand le message arrive, le nœud détermine le prochain
saut pour la destination et le place dans la file du contact. Celle-ci aussi n‟est pas une bonne
solution pour les DTNs pour Jones & Al [13] vu que des changements de topologie peuvent se
produire quand le message arrive. Et ceci se traduit par le fait que les messages en attente vont
être transmis via un lien sous optimal.
Donc, afin de prendre des décisions de routage avec un meilleur nombre d‟informations
possible, Jones & Al ont utilisé le routage par contact [13] dans lequel la table de routage est
recalculée à chaque fois que le contact est disponible au lieu de calculer le prochain saut pour
le message à l‟avance. Ce qui garanti que chaque décision de routage soit prise avec
l‟information la plus récente. L‟avantage qui en découle est que pour les contacts qui ne sont
pas fréquemment disponibles, le délai minimum prévu est très élevé car le temps d‟attente est

Chapitre 3 DTN : Les protocoles de routage
68
long. Ainsi, les plus courts chemins n‟utiliseront pas ces liens. Cependant, ces liens pourraient
être très bons lorsqu‟ils sont disponibles.
Cependant l‟approche MEED40
présente certains inconvénients à savoir :
Le fait qu‟elle utilise beaucoup de ressources, particulièrement la bande passante, vu que le
routage est recalculé fréquemment.
Le routage doit être recalculé avant qu‟aucun message ne soit transmis. Donc il peut y
avoir un délai supplémentaire avant que le lien ne soit utilisé. Tant que la puissance de
traitement des nœuds est appropriée à la taille du réseau, ce délai ne sera pas significatif.
Toutefois, il peut y avoir un facteur limitant cette approche dans le cas des réseaux très
larges.
6.2.3 La classe des protocoles réducteurs de consommation
A. Spray & Wait
Vu qu‟un nombre important de transmissions est au détriment des performances, spécialement
dans les réseaux dont la taille accroit. Spyropoulos & Al ont proposé [20] le protocole de
routage « Spray and Wait » qui a pour principe la distribution de seulement un petit nombre
de copies à chaque relais différent. Chaque copie est alors « portée » tout le long du chemin
vers la destination par le relais désigné. Le routage « Spray and Wait » est composé de deux
phases :
La phase Spray (pulvérisation) : pour chaque message d‟un nœud source, L copies du
message sont initialement répandues –transmises par le nœud source et probablement par
les autres nœuds ayant reçu des copies – à L différents relais.
La phase Wait (Attente) : si la destination n‟a pas été trouvée dans la phase « Spray »,
chacun des L nœuds portant une copie du message effectue une « transmission directe »
vers la destination.
L‟algorithme « Spray and Wait » lance un nombre de transmissions par message pour la
totalité des nœuds. Ces transmissions peuvent être limitées et essentiellement fixes pour une
large gamme de scénarios. En outre, son mécanisme combine la rapidité du routage
épidémique, avec la simplicité et l‟économie en ressources de la transmission directe.
Initialement, il lance une diffusion des copies du message de manière rapide et de façon
similaire à celle du routage épidémique. Cependant, il s‟arrête lorsqu‟assez de copies sont
envoyées, afin de garantir que la toute dernière d‟entre elles aille atteindre la destination avec
40
MEED : Minimum Estimated Expected Delay

Chapitre 3 DTN : Les protocoles de routage
69
une probabilité élevée. C‟est ainsi qu‟il combine simplicité et efficacité. Néanmoins, cette
approche présente quelques inconvénients tels que le fait que :
Elle exige l‟existence d‟un nombre suffisant de nœuds qui rôdent souvent autour du réseau,
ce qui pourrait potentiellement transporter un message vers une destination qui se trouve
loin.
Habituellement, Spray and Wait propage toutes ses copies rapidement au nœud du
voisinage immédiat. Ainsi, si la mobilité de chaque nœud est restreinte à une région locale,
alors aucun des nœuds transportant le message ne pourrait voir la destination.
Spray and Wait perd ses performances dans les scenarios où la mobilité est faible et
localisée.
Pour cela, l‟algorithme « Spray and Focus » [§C] constitue une amélioration à celui-ci.
B. Routage basé sur l’utilité avec transitivité
Dans les réseaux importants où les nœuds source et destination sont généralement loin l‟un de
l‟autre, la plupart des nœuds autour de la source se déplacent assez longtemps pour atteindre
la destination. Ainsi, ils n‟auront pas une utilité élevée pour être les nœuds des prochains
sauts.
En outre, s‟il arrive que les quelques nœuds qui sont autour du gardien du message aient
croisé le nœud destination à leur dernière rencontre avant que le gardien ne le fasse, alors ce
dernier pourrait probablement être obligé d‟attendre pendant très longtemps avant qu‟il se
déplace près de la destination (même si une connexion vers la destination existe). La raison de
cette inefficacité est que chaque nœud ne met à jour sa fonction d‟utilité qu‟une fois il se
trouve autour de la destination.
Pour remédier à ce problème, Spyropoulos & Al ont utilisé la « transitivité » [21] pour la mise
à jour de la fonction d‟utilité. Lorsqu‟un nœud A voit toujours un autre nœud B, et le nœud B
voit toujours le nœud C, alors A pourrait être un bon candidat pour délivrer des messages au
nœud C via B même si A voit rarement C. Par conséquent, quand le nœud A est autour du
nœud B, il devrait mettre à jour (augmenter) son utilité pour tous les nœuds avec qui le nœud
B a une utilité élevée.
Bien que l‟idée d‟utiliser la transitivité n‟est pas entièrement nouvelle, la fonction de
transitivité doit être choisie attentivement afin d‟améliorer les performances actuelles. Selon
une perspective d‟une information théorique, cet effet de la transitivité réussi à capturer le
taux de l‟incertitude concernant la position de la destination, à la rencontre d‟un nœud (plus
récent) qui a d‟autres informations sur cette destination.

Chapitre 3 DTN : Les protocoles de routage
70
C. Seek & Focus : Approche hybride
Bien que l‟utilisation de la transitivité a ses avantages, mais si le nœud se déplace assez vite
même la transitivité pourrait ne pas être en mesure de diffuser rapidement l‟information de
l‟utilité dans l‟ensemble du réseau. Une approche de diffusion gourmande est donc utilisée, le
message est souvent coincé au niveau du maximum local pour un moment.
Afin d‟y remédier, Spyropoulos & Al ont proposé un protocole de routage hybride appelé
« Seek and Focus » [21]. Celui-ci vise à combiner le meilleur des deux approches. Il peut
échapper à la phase des maxima locaux des protocoles basés sur l‟utilité, tout en profitant de
la plus grande efficacité de leur transmission.
Initialement, il regarde autour avec cupidité une bonne piste vers la destination en utilisant le
routage aléatoire, ensuite il utilise l‟approche basée sur l‟utilité pour suivre cette piste de
manière efficace.
L‟algorithme « Seek and Focus » exécute ces trois phases alternativement :
La phase Seek (Recherche) : Si l‟utilité du gardien actuel du message est en dessous d‟un
seuil prédéfini Uf (« seuil de concentration »), effectuer la transmission aléatoire avec un
paramètre p, pour une recherche rapide des nœuds à proximité.
La phase Focus (Concentration) : Si le nœud ayant une utilité au-dessus de Uf vient de
recevoir un message alors :
Ce nœud remet la durée tfocus à tlocal et commence le compte à rebours.
Effectuer une transmission basée sur l‟utilité (c-à-d : cherche le nœud ayant une plus
grande utilité que la sienne).
La phase Re-seek (2ème
phase de recherche) : Si tfocus expire, alors :
Mettre le chronomètre tseek à Tper et Uf à la valeur d‟utilité courante
Et effectuer un routage aléatoire jusqu‟à trouver un nœud avec une utilité supérieure à
Uf ou que tseek expire.
Puis réinitialiser Uf à sa valeur par défaut et retourner à la phase Seek si utilité < Uf ou
à la phase Focus si utilité > Uf.
D. Spray & Focus
Dans [20], le schéma utilisé est le suivant : un nombre fixe de copies est propagé initialement,
exactement comme dans le routage Spray and Wait mais chaque copie est routée
indépendamment selon le protocole de routage basé sur l‟utilité avec transitivité présenté
précédemment. Ce second schéma est appelé : Spray and Focus.
Le routage Spray and Focus consiste en les deux phases suivantes :

Chapitre 3 DTN : Les protocoles de routage
71
La phase Spray (pulvérisation) : pour chaque message d‟un nœud source, L copies du
message sont initialement répandue –transmises par le nœud source et probablement par
les autres nœuds ayant reçus des copies – à L différents relais.
La phase Focus : notons Ux(Y) l‟utilité du nœud X pour la destination Y ; un nœud A
portant une copie vers une destination D, transmet sa copie à un nouveau nœud B
l‟entourant si et seulement si UB(D) > UA(D) + Uth où Uth (seuil d‟utilité) est un paramètre
de l‟algorithme.
E. La formulation LP
La formulation LP41
est une adaptation de la version dynamique du problème classique du
flux multiple [16] [17].
La version dynamique implique le maintien d‟un flux équilibré durant un ensemble
d‟intervalles de temps disjoints. Donc :
La première étape à faire dans une approche LP est de déterminer les intervalles de temps sur
lesquels les équations d‟équilibre doivent tenir.
La deuxième étape est de construire les autres contraintes de LP pour le problème de routage
dans les DTNs dans lesquels les liens et les nœuds sont de capacités variantes dans le temps.
Ces contraintes peuvent provoquer la division des messages.
Dans la formulation LP des DTNs, il y‟a une équation d‟équilibre de flux pour chaque
intervalle de temps. Chaque équation met de l‟équilibre au flux entrant ou sortant du nœud
selon le flux d‟entrées/sorties (comme dans le problème traditionnel du flux multiple) et les
flux entrants et sortants du buffer.
Une simple approche pour obtenir l‟ensemble des intervalles de temps est de discrétiser le
temps en tous petits intervalles à tailles fixes. Cependant, ceci peut conduire à un très grand
nombre d‟intervalles de temps et peut être impraticable. Au lieu de cela, Jain & Al [6] ont
montré qu‟il existe un ensemble d‟intervalles satisfaisant certaines propriétés suffisantes
(mais pas nécessaires) pour atteindre le même résultat. Intuitivement, ces intervalles
représentent le temps de changement de périodes lorsqu‟une transmission ou une réception
d‟un message se produit.
Ainsi, le message arrive sur deux intervalles de temps et son délai net est la somme pondérée
des délais des deux fractions.
41
LP : Linear Programming

Chapitre 3 DTN : Les protocoles de routage
72
F. Probabilistic ROuting Protocol using History of Encounters and Transitivity
(PRoPHET)
Le principe de PRoPHET [15] est similaire à celui du routage épidémique. Lorsque deux
nœuds se rencontrent, ils s‟échangent les vecteurs d‟état qui dans ce cas contiennent aussi
l‟information sur la prévisibilité de délivrance d‟un message qui est stocké dans les nœuds.
Cette information est utilisée pour mettre à jour le vecteur de prévisibilité de délivrance
interne. Et donc, l‟information se trouvant dans le vecteur d‟état est utilisée pour décider du
nœud à qui transmettre le message en utilisant une stratégie de transmission donnée.
La stratégie de transmission utilisée par PRoPHET se base sur le principe suivant :
Dans les protocoles de routage traditionnels, choisir où transmettre le message est une simple
tâche. Le message est envoyé au nœud voisin qui possède un chemin de moindre coût vers la
destination (généralement c‟est le plus court chemin qui est choisi) et dont la fiabilité de ce
chemin est élevée. Dans PRoPHET, la politique est complètement différente.
Pour commencer, lorsqu‟un message arrive à un nœud, il peut ne pas y avoir de chemin
disponible vers la destination. Ainsi, le nœud doit le garder dans le buffer et à chaque
rencontre d‟un autre nœud, une décision doit être prise sur le fait de le transmettre ou pas.
En outre, il est aussi raisonnable de transmettre le message à plusieurs nœuds afin d‟accroître
la probabilité de le délivrer à destination. Malheureusement, ces décisions ne sont pas triviales
à prendre car, distribuer le message sur un grand nombre de nœuds va sûrement augmenter sa
probabilité de délivrance mais ceci requiert beaucoup de ressources système. Dans certains
cas, il est donc plus judicieux de fixer un seuil et ne transmettre le message qu‟aux nœuds
ayant une prévisibilité de délivrance à destination supérieure au seuil fixé. Par ailleurs, la
rencontre d‟un nœud ayant un faible taux de prévisibilité de délivrance ne garanti pas la
rencontre d‟un autre avec une métrique plus importante dans un délai raisonnable, ainsi, il
peut y avoir des situations où il faut être moins strict dans la prise de décision sur le nœud à
qui le message sera transmis.
L‟approche PRoPHET42
garantit les avantages suivants :
Utiliser l‟historique des nœuds rencontrés avant de prendre la décision de remettre un
message à un autre nœud.
Utiliser la transitivité dans sa fonction de calcul de prévisibilité de délivrance. En effet, si
le nœud A rencontre fréquemment le nœud B, et le nœud B rencontre fréquemment le
nœud C, alors le nœud C est probablement bon pour transmettre des messages destinés au
nœud A.
42
PRoPHET : probabilistic ROuting Protocol using History of Encounters and Transitivity

Chapitre 3 DTN : Les protocoles de routage
73
Les simulations ont montré que PRoPHET donne des performances similaires et parfois
meilleures que le routage épidémique.
Des améliorations à l‟algorithme PRoPHET ont été proposées, telles que :
1. PRoPHET utilise la politique FIFO43
pour stocker les messages au niveau des nœuds. Du
coup, lorsqu‟un message arrive et trouve la file pleine, le message ayant occupé celle-ci
pendant longtemps sera supprimé. Une suggestion pour améliorer cela est de supprimer le
message qui a été transmis à un plus grand nombre de nœuds.
2. Pour réduire le besoin d‟espace buffer et améliorer les performances, il serait intéressant
d‟évaluer l‟impact de permettre aux nœuds de demander des accusés de réception de leurs
messages. Ceci permettra de purger le réseau des messages délivrés et laissera plus de
ressources aux autres messages. Par conséquent, ils auront plus de chance d‟être délivrés
eux aussi.
3. La stratégie de transmission utilisée par PRoPHET a montré une amélioration des
performances par rapport au routage épidémique. Il serait intéressant d‟essayer d‟autres
stratégies de transmission pour voir si les performances vont être améliorées davantage.
6.3 Schéma récapitulatif de la nouvelle classification
A présent, et après avoir détaillé les différents protocoles de routage, nous les regroupons
dans un seul diagramme afin de faciliter davantage la lecture, et de mieux orienter
l‟utilisateur.
La Figure 31 ci-dessous montre alors le schéma récapitulatif de toutes les approches de routage
DTN que nous avons recensées, et les classes à lesquelles elles appartiennent selon leur degré
de consommation en bande passante et/ou en espace de stockage.
Il est vrai que connaître le principe de base d‟une stratégie est très important, mais avoir des
informations auparavant sur sa qualité et son effet sur l‟environnement est aussi d‟une très
grande utilité, car elle offre un énorme gain de temps dans la phase de prise de décision. De
plus, une telle synthèse est concluante car elle ne tient compte que des paramètres réels et
théoriques de l‟approche, contrairement aux résultats annoncés sur les performances de
certains protocoles qui très souvent basés sur des scénarios adaptés à l‟aboutissement
souhaité.
43
FIFO : First In first Out

Chapitre 3 DTN : Les protocoles de routage
74
Figure 31 : Classification des protocoles de routage DTN selon le taux de consommation de ressources
Conclusion
Ainsi s‟achève ce chapitre où nous avons présenté la majorité des protocoles de routage
développés pour les environnements intermittents. Il en existe bien évidemment d‟autres qui
sont, soit des dérivés de ceux qui ont été cités ci-dessus et apportant des améliorations, soit
des protocoles adaptés à des situations particulières, qui généralement pas très connus.
Nous avons terminé notre chapitre par un schéma résumant toutes ces approches, chacune
dans la classe qui lui correspond.
Dans le chapitre qui suit, nous allons présenter un aperçu sur les études et simulations qui se
font dans ce domaine, afin de montrer une évaluation approximative de tous ces protocoles de
routage que nous venons de présenter, ainsi que les conclusions qui sont tirées.
Les protocoles de routage DTN
Les protocoles non consommateurs
Contact Direct
First Contact
Routage aléatoire
Routage Location-based
Routage hiérarchique DTN
Les protocoles consommateurs
Consommation illimitée des ressources
Routage épidémique
Inondation Tree-based
MED
EDAQ
Consommation illimitée de l'espace
de stockage
ED
EDLQ
Consommation illimitée de la
bande passante
Routage Gradient
MEED
Les protocoles réducteurs de consommation
Spray & Wait
Routage basé sur l'utilité avec transitivité
Seek & Focus
Spray & Focus
La formulation LP
PRoPHET

75
Chapitre 4
DTN : Résultats & Analyses
Introduction
De multiples études ont été menées essayant de comparer les performances de divers
protocoles de routage, en faisant varier différents paramètres. Ci-dessous, nous présentons
quelques résultats obtenus grâce à des études qui ont été réalisées, dans le but d‟avoir une idée
globale sur ce que l‟on peut obtenir avec les protocoles de routage présentés dans le chapitre 3
de la présente thèse.
1. Etude 1 : Comparaison FC, MED, ED, EDLQ, EDAQ
Cette étude consiste en la comparaison des protocoles de routage : FC, MED, ED, EDLQ et
EDAQ dans deux scénarios différents. La réalisation s‟est basée sur l‟outil de simulation
DTN, DTNSim, qui prend en charge la technique de Store & Forward durant de longues
périodes de temps. Ce simulateur est fondé sur deux composantes de base à savoir, les nœuds
et les liens. Ces derniers peuvent être créés et supprimés dynamiquement. Les deux scénarios
sont de différents degrés de complexité, tel que nous le présenterons ci-dessous :
1.1 Scénario 1 : Routage dans les villages isolés
1.1.1 Description
Le scénario des villages isolés est très simple, il sert à illustrer le fait qu‟il faut prendre en
considération de multiples facteurs lors de la prise de décision de routage. Il se repose sur les
hypothèses suivantes :
Le village s‟appelle : KwazuluNatal, il se situe dans la ville de Capetown en Afrique du
sud.
Disponibilité de trois moyens d‟établissement de la connexion entre la ville et le village :
Une ligne téléphonique fournissant 4Ko/s. Elle n‟est disponible que très tard la nuit (de
23h à 6h, heure locale).

Chapitre 4 DTN : Résultats & analyses
76
Trois satellites PACSAT : OSCAR-11, PACSAT et PCSAT. Ces derniers sont régis par
le logiciel de suivi de satellites appelé PREDICT, pour déterminer les moments de leurs
passages. Ils sont supposés être entre le village et la ville.
Trois motos qui circulent entre le village et la ville quotidiennement, et à toute heure et
chaque trajet prend environ deux heures. La bande passante des/vers les motos est de
1Mo/s. La durée des contacts est de cinq minutes et peuvent stocker plus de 128Mo.
Figure 32 : Illustration des options de la variété de connectivité entre un village isolé et la ville [12]
1.1.2 Génération de trafic
Les messages sont injectés des deux entités : ville et village. Ceux provenant du village ont
une taille d‟environ 1Ko, et ceux arrivant de la ville sont plus volumineux, leurs tailles sont en
moyenne égales à 10Ko. Ainsi deux taux de trafic sont considérés :
Une faible charge de 200 messages par jour échangés entre la ville et le village.
Une charge élevée de 1000 messages par jour.
Les messages sont injectés à des points choisis de manière aléatoire durant les premières 24
heures. La simulation a été effectuée sur une période de 48 heures, et sa durée est choisie afin
d‟assurer que tous les messages soient délivrés à la fin.
1.1.3 Le problème de routage
La topologie de ce scénario est simple dans le sens où la décision de routage consiste
seulement à choisir le premier saut entre les trois classes de contacts définies : la ligne
téléphonique, les satellites et les motos.
Si le message est originaire du village à 18h (heure locale), alors les options possibles sont :
Attendre jusqu‟à 23:00 la disponibilité de la ligne téléphonique.
Utiliser la moto pour quitter le village à 20:00.
Utiliser le satellite qui sera disponible à 20:10.

Chapitre 4 DTN : Résultats & analyses
77
Le choix du premier contact disponible pourrait ne pas être la solution la plus optimale car
dans ce cas, le premier contact qui est la moto, va délivrer le message à 22:00. Or l‟utilisation
du satellite aurait pu être la meilleure solution dans ce cas, car le message va arriver à 20:10 et
on aura économisé 110 minutes.
La décision de routage devient plus complexe si une grande quantité de données devrait être
délivrée. Pour le même exemple, si la taille du message était plus grande par rapport à ce qui
aurait pu être délivré par satellite, alors le choix des motos pour bénéficier de leur bande
passante pourrait être le meilleur.
De manière générale, ces décisions dépendent de la taille et du temps des requêtes, les options
de connectivité disponibles, et les autres messages qui attendent dans le système.
Pour cela, une des questions intéressantes à comprendre est : comment les différents
algorithmes de routage utilisent-ils les ressources de connectivité disponibles (ligne
téléphonique, satellite, moto) ?
1.1.4 Résultats & analyses
Figure 33 : Répartition du trafic par les différentes options de connectivité [12]
La Figure 33 représente le tracé des fractions de données routées en utilisant différents
algorithmes de routage avec les différents moyens de communication. Ainsi, les résultats
suivants ont été obtenus :
Pour MED, tous les messages ont été délivrés en utilisant la ligne téléphonique dans les
deux cas « faible charge » et « charge élevée », car statistiquement c‟est un algorithme qui
choisit un seul chemin pour router toutes les données.
Pour ED, 60% des données sont routées à travers la connexion satellite et le reste utilise la
ligne téléphonique. Pas de trafic qui utilise la moto parce que ceci va prendre 2 heures pour
la transmission vers la ville et vice versa. Donc, ED ne va prendre la moto que dans le cas
où le satellite et la ligne téléphonique prendraient plus de 2 heures pour la livraison de

Chapitre 4 DTN : Résultats & analyses
78
données. Or ceci arrive rarement car il y‟a trois satellites qui apparaissent quatre fois par
jour.
Pour les faibles charges, EDLQ et EDAQ font des choix similaires à ED.
Pour FC, il choisit par définition le premier contact disponible ce qui l‟amène à
sélectionner le moyen de la moto parfois, pour le routage de données (environ 6%). Ceci
explique pourquoi le délai maximum de cet algorithme est plus élevé que celui d‟EDAQ.
La moyenne cependant, est similaire aux autres algorithmes car seule une petite partie est
acheminée de cette façon.
Figure 34 : Comparaison du délai pour les différents algorithmes [12]
Pour des charges élevées, la situation est un peu différente. Les schémas de congestion :
EDLQ et EDAQ qui n‟utilisait pas du tout le moyen de la moto pour le cas de faible
charge, l‟utilise à 15% dans ce cas.
ED et MED gardent les mêmes choix que dans le cas de faible charge car ils n‟ont pas
d‟informations sur le trafic. Cependant ils rencontrent des difficultés. En particulier, les
performances d‟ED détériorent fortement lorsque le saut suivant est un satellite à cause du
grand nombre de requêtes, même si quelques-unes peuvent être servies en une seule passe
du satellite. Néanmoins, le reste doit attendre la prochaine passe du même satellite
(contrainte de l‟algorithme ED) qui peut aller dans les pires des cas jusqu‟à plus de 10
heures.
1.2 Scénario 2 : Réseau d’autobus
1.2.1 Description
Dans ce scénario, les nœuds sont les 20 bus qui font le tour dans la ville de San Francisco.
Les bus supportent la technique du Store & Forward des DTNs, et sont équipés de
communication radio. Le DTN de ce schéma est représenté comme suit :

Chapitre 4 DTN : Résultats & analyses
79
A chaque bus, une séquence ordonnée de stops est placée sur un plan bidimensionnel
représentant la ville. A chaque fois que le bus passe par une nouvelle rue, un stop est généré à
l‟intersection correspondante. Le bus circule le long de la ligne droite entre deux Stops avec
une vitesse constante. Cette dernière est modifiée à chaque stop, prenant des valeurs
uniformes entre 10 et 20 m/sec. De plus, un temps de pause uniforme entre 0 et 5 minutes
sépare chaque tranche de circulation.
Figure 35 : Carte de San-Francisco utilisée pour le mouvement des bus. Les repères A, B, C représentent 3
routes parmi 20 que les bus peuvent emprunter [12]
Afin de calculer les intervalles de temps durant lesquels les bus peuvent communiquer. Jain &
Al supposent [12] qu‟ils sont équipés de transmetteurs radio. Deux bus peuvent communiquer
s‟ils sont séparés par une distance seuil appelée « la portée radio », et ceci n‟est qu‟une
approximation dont le but principal est de fournir un simple chemin pour générer des
connexions/déconnexions basées sur un modèle de mobilité connu.
La réalisation de ce scénario s‟est faite en deux étapes, la première consiste en la génération
des intervalles de temps, dans lesquels les bus peuvent communiquer. Pour cela, les nœuds
bougent dans une surface bidimensionnelle, puis les périodes durant lesquelles ils sont séparés
par l‟intervalle radio ou moins, sont calculées. Ainsi une topologie dynamique est fournie,
servant d‟entrée à la deuxième étape qui s‟occupe de la simulation du DTN. Dans cette étude,
la simulation a duré 24 heures.
1.2.2 Génération de trafic
Le trafic est généré sur une période de 12 heures, qui est divisée en 12 intervalles d‟une heure
chacun.

Chapitre 4 DTN : Résultats & analyses
80
Pour chaque intervalle, 20 paires de bus source/destination sont choisies aléatoirement.
Chaque bus source envoie 200 messages à son bus de destination durant un intervalle d‟une
heure. Les messages sont injectés simultanément à un instant choisi aléatoirement dans
l‟intervalle d‟une heure. Ceci représente un taux de trafic très élevé et crée de plus en plus de
congestion dans le réseau comparativement à une charge plus uniforme.
La charge du réseau peut augmenter, soit par l‟ajout de demandes de trafic, ou par la
réduction du volume du contact. Dans le cas où la demande de trafic est fixée, le volume du
contact peut varier soit en variant sa bande passante (capacité du lien), soit en faisant varier sa
durée (la portion de temps où le contact est disponible). Dans ce scénario, les données des
contacts peuvent augmenter (diminuer) en augmentant (diminuant) l‟intervalle radio.
Bien que l‟augmentation de la bande passante, ainsi que l‟augmentation de la portée radio
diminuent la charge globale dans le réseau, mais elles ont différents effets. Une faible portée
radio déconnecte le réseau même si la bande passante est illimitée. En revanche, si la bande
passante est limitée mais la portée radio est assez large, alors l‟impact à la délivrance est
seulement minimal pour un faible trafic. Ainsi le rôle de la bande passante est éminent
seulement quand il est une quantité de données à transmettre relativement importante.
1.2.3 Résultats & analyses
Variation de la bande passante
Lorsque la charge est très faible, l‟augmentation de la bande passante ne conduit à aucune
amélioration du délai. A faible charge, le goulot d„étranglement est dû à la mauvaise durée
des contacts, car un volume insuffisant de contacts est disponible lors du besoin, même si le
volume global des contacts est suffisant pour déplacer toutes les données générées. Toutefois,
les algorithmes intelligents tels que ED, EDLQ et EDAQ fonctionnent beaucoup mieux que
les algorithmes simples tels que : FC et MED.
Variation de la portée radio
La différence entre les algorithmes simples (FC, MED) et les algorithmes intelligents (ED,
EDLQ, EDAQ) est beaucoup plus prononcée lorsque la portée radio est faible (c‟est-à-dire
lorsque le réseau est déconnecté), causant une augmentation de charge sur les techniques de
routage intelligent et les réseaux deviennent de plus en plus intermittents. Inversement,
lorsque la portée de la radio est très large (la plupart des liens sont disponibles), la charge des
algorithmes intelligents disparaît.

Chapitre 4 DTN : Résultats & analyses
81
Variation de la capacité des buffers
Lorsque la capacité de stockage est limitée, les algorithmes intelligents (ED, EDLQ,
EDAQ) ont significativement moins de chute que les algorithmes simples (ED, MED),
même si la plupart des messages seraient supprimés et le gain serait très faible avec un
processus de sélection de routes intelligent.
Lorsque la capacité de stockage est suffisamment large, il n y‟a pas de chute et tous les
algorithmes ont un ratio de délivrance égal à 1.
Pour toutes ces raisons, ED, EDLQ et EDAQ fonctionnent mieux que FC et MED lorsque le
stockage est limité, mais une telle performance pourrait ne pas se réaliser pour les réseaux
ayant une très large ou une très faible capacité de stockage [12].
1.3 Synthèse des résultats
Il est évident que les algorithmes intelligents (ED, EDLQ, EDAQ), dépassent les algorithmes
simples (FC, MED), tant en termes de délai de livraison qu‟en ratio de délivrance. Plus le
réseau est intermittent, plus les différences de performance s'accentuent.
En outre, quand la charge augmente, ED effectue des performances bien plus mauvaises que
celles d‟EDLQ et EDAQ, car il n'est pas en mesure d'atténuer les effets de la congestion.
Enfin, EDLQ, qui applique son routage près des endroits de congestion en utilisant
uniquement les files d'attente locales, arrive à des performances comparables à celles
d‟EDAQ.
2. Etude 2 : les protocoles multi-copies
La présente étude implémente et compare les protocoles de routage : épidémique, spray &
wait, spray & focus et seek & focus. Pour chaque algorithme de routage, les valeurs des
paramètres ont été fixées tout à fait au début de l‟expérience. Ainsi, nous avons :
Pour le routage épidémique : TTL44
= 1000 – 10000 unités de temps pour chaque message.
Pour spray & wait : le nombre de copies L varie entre 10% et 15% du nombre total de
nœuds.
Pour spray & focus : pour une bonne performance, le nombre de copies varie entre 5% et
10% du nombre total de nœuds.
Dans cette étude, Spyropoulos & Al ont eux aussi utilisé deux scénarios pour évaluer et
comparer leurs protocoles [20]:
44
TTL : Time To Live
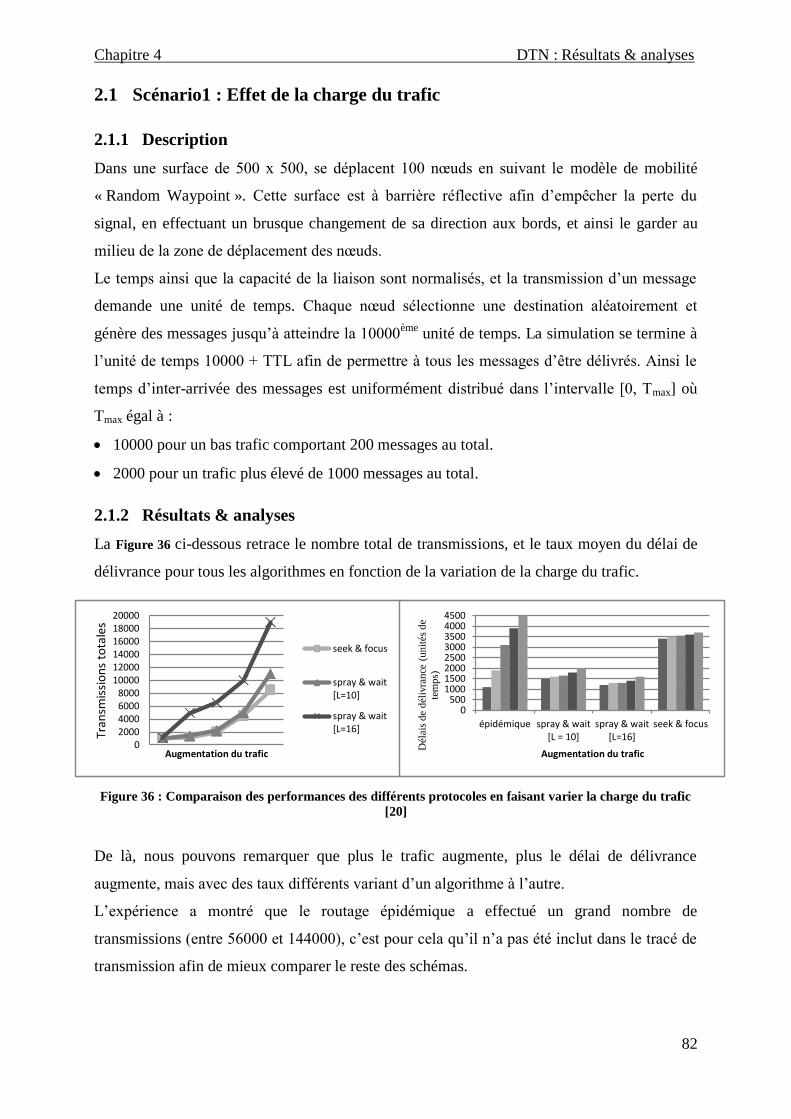
Chapitre 4 DTN : Résultats & analyses
82
02000400060008000
100001200014000160001800020000
Tran
smis
sio
ns
tota
les
Augmentation du trafic
seek & focus
spray & wait[L=10]
spray & wait[L=16]
0500
10001500200025003000350040004500
épidémique spray & wait[L = 10]
spray & wait[L=16]
seek & focus
Dél
ais
de
dél
ivra
nce
(unit
és d
e
tem
ps)
Augmentation du trafic
2.1 Scénario1 : Effet de la charge du trafic
2.1.1 Description
Dans une surface de 500 x 500, se déplacent 100 nœuds en suivant le modèle de mobilité
« Random Waypoint ». Cette surface est à barrière réflective afin d‟empêcher la perte du
signal, en effectuant un brusque changement de sa direction aux bords, et ainsi le garder au
milieu de la zone de déplacement des nœuds.
Le temps ainsi que la capacité de la liaison sont normalisés, et la transmission d‟un message
demande une unité de temps. Chaque nœud sélectionne une destination aléatoirement et
génère des messages jusqu‟à atteindre la 10000ème
unité de temps. La simulation se termine à
l‟unité de temps 10000 + TTL afin de permettre à tous les messages d‟être délivrés. Ainsi le
temps d‟inter-arrivée des messages est uniformément distribué dans l‟intervalle [0, Tmax] où
Tmax égal à :
10000 pour un bas trafic comportant 200 messages au total.
2000 pour un trafic plus élevé de 1000 messages au total.
2.1.2 Résultats & analyses
La Figure 36 ci-dessous retrace le nombre total de transmissions, et le taux moyen du délai de
délivrance pour tous les algorithmes en fonction de la variation de la charge du trafic.
Figure 36 : Comparaison des performances des différents protocoles en faisant varier la charge du trafic
[20]
De là, nous pouvons remarquer que plus le trafic augmente, plus le délai de délivrance
augmente, mais avec des taux différents variant d‟un algorithme à l‟autre.
L‟expérience a montré que le routage épidémique a effectué un grand nombre de
transmissions (entre 56000 et 144000), c‟est pour cela qu‟il n‟a pas été inclut dans le tracé de
transmission afin de mieux comparer le reste des schémas.

Chapitre 4 DTN : Résultats & analyses
83
Pour donner un meilleur aperçu des délais de transmission, Spyropoulos & Al ont présenté
[20] deux diagrammes pour « spray & wait » en faisant varier la valeur de L. en revanche, ils
n‟ont pas inclut les résultats de l‟algorithme « spray & focus » car dans ce scénario, il a donné
des performances similaires à « spray & wait ».
Comme le montre la Figure 36, « spray & wait » est plus performant que les protocoles uni et
multi-copies et réalise les performances voulues:
En bas trafic, son délai est similaire au routage épidémique et est 1.4 à 2.2 fois plus rapide
que tous les autres protocoles multi-copies, il effectue un ordre de grandeur de
transmission inférieur à celui du routage épidémique.
En haut trafic, il garde le même avantage en termes de nombre total de transmissions, et est
plus performant que tous les autres protocoles. Quant au délai, il est plus performant avec
un facteur variant de 1.8 à 3.3.
A un taux de délivrance supérieur à 90% pour toutes les charges de trafic.
La plupart des schémas de ce scénario donnent un taux de délivrance supérieur à 90%, à
l‟exception du protocole « seek & focus » qui a donné un taux de 70% et du routage
épidémique qui chute à 50% pour un trafic très élevé, à cause de la forte congestion. Ces
résultats dépendent en fait de divers paramètres :
La bande passante qui a un effet important sur les performances ;
Le temps de transmission d‟un message (choisi à une unité de temps dans notre cas), qui
lui aussi dépend du taux de la liaison sans fil et de la taille moyenne des bundles ;
La capacité totale d‟un contact qui dépend elle aussi du modèle de mobilité, des conditions
du canal, etc.
2.1.3 Synthèse des résultats
Bien que les valeurs actuelles dépendent d‟un nombre de paramètres spécifiques à
l‟application, l‟étude [20] a quand même conclu que :
Si la bande passante du réseau est plus élevée que la charge totale du réseau, alors les schémas
basés sur l‟inondation sont assez rapides mais les schémas basés sur le « Spraying » peuvent
présenter des délais comparables avec beaucoup moins de transmissions.
Si la bande passante devient limitée, alors les schémas basés sur l‟inondation souffrent de
contention, et leur délai est aussi élevé que celui des protocoles de routage basés sur le
« Spraying ».
Un effet similaire est en jeu avec la capacité du buffer. Lorsqu‟un nouveau nœud est
rencontré, avec peu de mémoire dans le buffer, ce ne sont pas tous les messages qui sont

Chapitre 4 DTN : Résultats & analyses
84
acheminés, seule la quantité qu‟il peut supporter lui sera transmise. Celle-ci est sélectionnée
selon la politique de gestion des files d‟attente adoptée. Une telle situation engendre des
délais supplémentaires dans ces dernières, pour certains messages (qui sont plus nombreux
dans le cas des schémas basés sur l‟inondation).
2.2 Scénario2 : Effet de la connectivité
2.2.1 Description
Ce scénario étudie les performances de différents protocoles avec une large gamme de
caractéristiques de connectivité. Des réseaux très dispersés et fortement déconnectés, aux
réseaux totalement connectés.
2.2.2 Génération de trafic
Dans un réseau de 200 x 200, 100 nœuds se déplacent. Deux modèles de mobilité sont
utilisés : Random Waypoint pour ses temps rapides, et Random Walk pour le cas des temps
plus lents. Le nombre de messages envoyés est égal en moyenne à 500.
Pour la métrique de connectivité étant donné qu‟aucun agrément universel n‟existe,
particulièrement pour capter aussi bien les réseaux connectés que déconnectés, alors les
auteurs dans [20] ont pris comme métrique significative la taille maximale des clusters45
. Cette
dernière est définie comme étant le pourcentage du nombre total de nœuds dans le plus grand
cluster connecté, et pour la mesurer ils ont fait varier le taux de transmission K, puis analysé
son impact sur les différents protocoles.
2.2.3 Résultats & analyses
La Figure 37 et la Figure 38 représentent le nombre de transmissions et le délai moyen pour les
scénarios « Random Waypoint » et « Random Walk » respectivement, comme une fonction
de variation de transmission.
45
Un cluster : Est un regroupement d‟un nombre de nœuds donné.
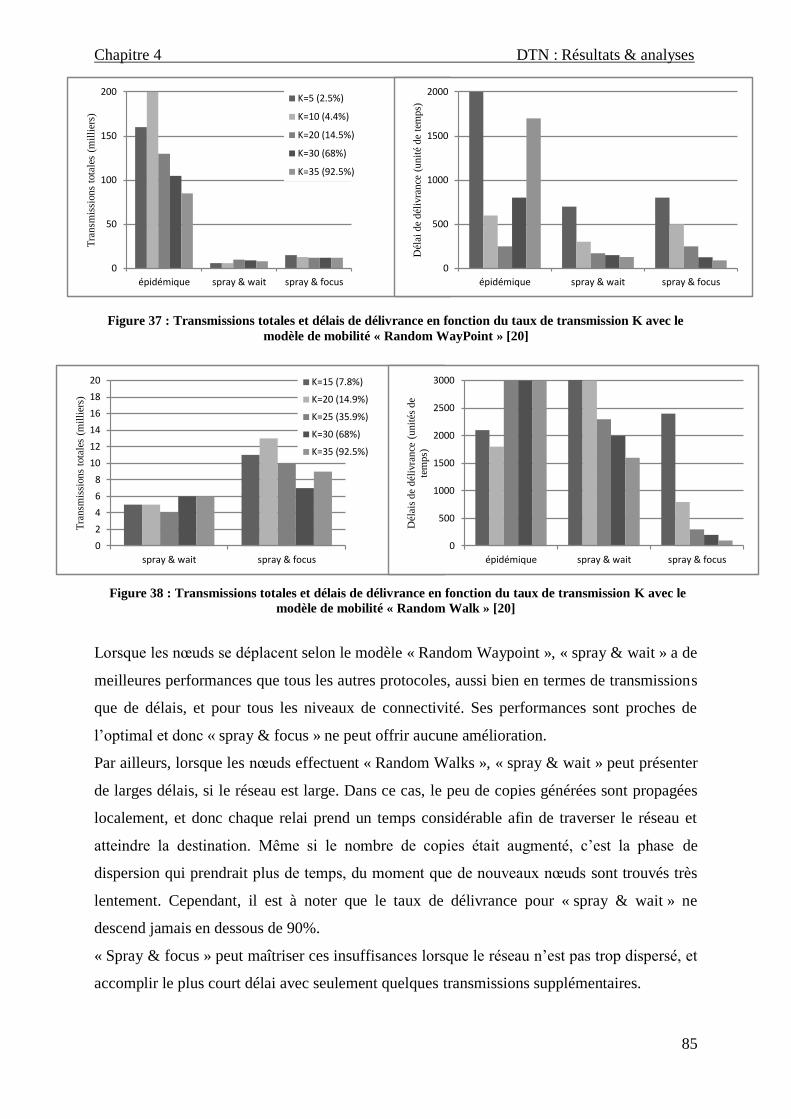
Chapitre 4 DTN : Résultats & analyses
85
0
50
100
150
200
épidémique spray & wait spray & focus
Tra
nsm
issi
ons
tota
les
(mil
lier
s)
K=5 (2.5%)
K=10 (4.4%)
K=20 (14.5%)
K=30 (68%)
K=35 (92.5%)
0
500
1000
1500
2000
épidémique spray & wait spray & focus
Dél
ai d
e dél
ivra
nce
(unit
é de
tem
ps)
0
2
4
6
8
10
12
14
16
18
20
spray & wait spray & focus
Tra
nsm
issi
ons
tota
les
(mil
lier
s)
K=15 (7.8%)
K=20 (14.9%)
K=25 (35.9%)
K=30 (68%)
K=35 (92.5%)
0
500
1000
1500
2000
2500
3000
épidémique spray & wait spray & focus
Dél
ais
de
dél
ivra
nce
(unit
és d
e
tem
ps)
Figure 37 : Transmissions totales et délais de délivrance en fonction du taux de transmission K avec le
modèle de mobilité « Random WayPoint » [20]
Figure 38 : Transmissions totales et délais de délivrance en fonction du taux de transmission K avec le
modèle de mobilité « Random Walk » [20]
Lorsque les nœuds se déplacent selon le modèle « Random Waypoint », « spray & wait » a de
meilleures performances que tous les autres protocoles, aussi bien en termes de transmissions
que de délais, et pour tous les niveaux de connectivité. Ses performances sont proches de
l‟optimal et donc « spray & focus » ne peut offrir aucune amélioration.
Par ailleurs, lorsque les nœuds effectuent « Random Walks », « spray & wait » peut présenter
de larges délais, si le réseau est large. Dans ce cas, le peu de copies générées sont propagées
localement, et donc chaque relai prend un temps considérable afin de traverser le réseau et
atteindre la destination. Même si le nombre de copies était augmenté, c‟est la phase de
dispersion qui prendrait plus de temps, du moment que de nouveaux nœuds sont trouvés très
lentement. Cependant, il est à noter que le taux de délivrance pour « spray & wait » ne
descend jamais en dessous de 90%.
« Spray & focus » peut maîtriser ces insuffisances lorsque le réseau n‟est pas trop dispersé, et
accomplir le plus court délai avec seulement quelques transmissions supplémentaires.

Chapitre 4 DTN : Résultats & analyses
86
D‟autre part, « Spray & wait » et « spray & focus » présentent une plus grande stabilité. Ils
effectuent quelques transmissions à travers tous les scénarios, en réalisant un délai de
délivrance qui diminue alors que le niveau de connectivité augmente, comme on pouvait s‟y
attendre.
2.2.4 Synthèse des résultats
Grâce aux simulations, il est possible de conclure que :
Lorsqu‟assez de nœuds dans le réseau sont suffisamment mobiles, « spray & wait » est
performant en prenant en considération le nombre de transmissions et les délais
d‟acheminement, car il réalise des délais comparables à un schéma optimal en dépit de sa
simplicité.
Lorsque la mobilité est limitée ou lorsque la mobilité locale est prédominante, « spray &
focus » peut retenir les performances de « spray & wait » avec uniquement un petit
dépassement sur les transmissions totales et la simplicité.
Finalement les deux schémas sont très robustes aux changements de la taille du réseau et de la
densité.
3. Etude 3 : Performances de MEED
La seconde étude que nous présentons concerne différents ensembles de protocoles de routage
à savoir : MED, MEED, ED et le routage épidémique [13]. Jones & Al dans cette étude ont
conclu les résultats suivants :
3.1 Description du scénario
Afin d‟étudier un cas se rapprochant de la réalité, Jones & Al [13] ont utilisé des données
réelles, retirées d‟un fichier trace contenant les activités de plus de 2000 utilisateurs d‟un
réseau LAN46
sans fil installé au collègue du Darmouth47
, durant deux années consécutives.
Le fichier traces remonte toutes les connexions et les déconnexions des utilisateurs à chacun
des 500 points d‟accès au collège.
A base de ces traces, le réseau LAN peut être transformé en un réseau DTN, et ce en
considérant que deux nœuds sont connectés lorsqu‟ils sont associés simultanément au point
d‟accès, qui joue le rôle de routeur pour le réseau DTN.
46
LAN : Local Area Network (Réseau local) 47
Le Darmouth College est une université privée du nord-est des États-Unis, située dans la ville de Hanover,
dans l'état du New Hampshire.

Chapitre 4 DTN : Résultats & analyses
87
b- Réseau DTN obtenu a- Réseau LAN initial
Pour réduire la taille du réseau et la rendre agréable, Jones & Al [13] n‟ont inclut que les traces
d‟un sous ensemble de nœuds connectés au LAN. En voici un exemple :
Sur la Figure 39a, à T=1 le fichier trace du réseau LAN sans fil montre que l‟ordinateur
portable de l‟utilisateur est connecté au point d‟accès à gauche, plus tard il se déplace en
dehors du point d‟accès à T=2, il s‟associe avec le second point d‟accès. Le réseau DTN qui
peut être généré de ces données est montré dans la Figure 39b, où un ordinateur portable et un
point d‟accès du premier scénario vont être supprimés.
T=1 T=2
Figure 39 : Réseau LAN sans fil convertit en réseau DTN [13]
3.2 Génération de trafic
Trente nœuds ayant beaucoup d‟opportunités de communiquer à travers une durée d‟un mois
sont sélectionnés, plus les nœuds qui se connectent à d‟autres au moins dix fois par mois.
Chaque nœud sélectionne un autre nœud aléatoirement et un trafic bidirectionnel est échangé
entre eux. Six messages sont générés par chaque nœud toutes les 12 heures, durant une
période d‟un mois. Chaque message a une taille de 10000 octets, ce qui représente des
échanges de fichiers à faibles tailles ou des messages électroniques entre deux utilisateurs.
Afin de mesurer l‟effet d‟un seul paramètre, l‟on a considéré dans cette expérience que les
tailles des buffers et de la bande passante sont par défaut très grandes, relativement aux
quantités de données à transmettre. En effet, la bande passante dans ce cas est de l‟ordre
d‟1Mo.
3.3 Résultats & analyses
Dans cette étude, l‟analyse des performances des protocoles est donnée par rapport à leur
impact sur l‟espace de stockage, et la bande passante, et ce en mesurant deux paramètres
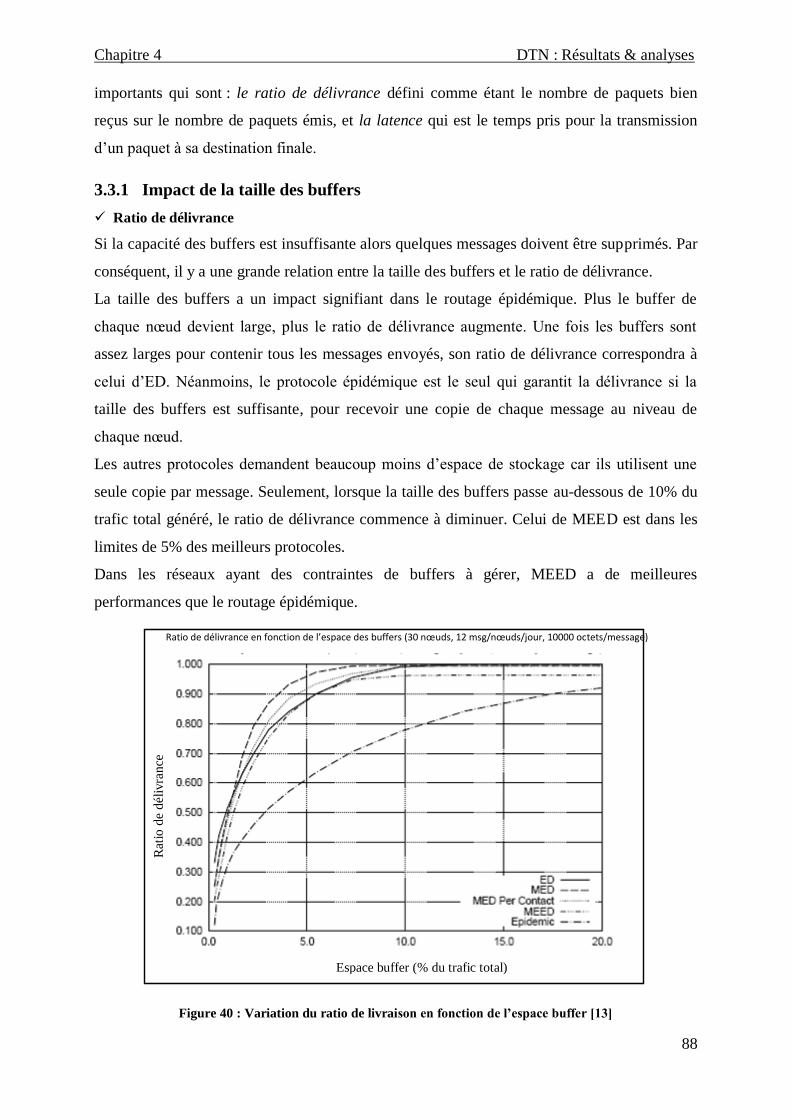
Chapitre 4 DTN : Résultats & analyses
88
Ratio de délivrance en fonction de l’espace des buffers (30 nœuds, 12 msg/nœuds/jour, 10000 octets/message)
Rat
io d
e déli
vra
nce
Espace buffer (% du trafic total)
importants qui sont : le ratio de délivrance défini comme étant le nombre de paquets bien
reçus sur le nombre de paquets émis, et la latence qui est le temps pris pour la transmission
d‟un paquet à sa destination finale.
3.3.1 Impact de la taille des buffers
Ratio de délivrance
Si la capacité des buffers est insuffisante alors quelques messages doivent être supprimés. Par
conséquent, il y a une grande relation entre la taille des buffers et le ratio de délivrance.
La taille des buffers a un impact signifiant dans le routage épidémique. Plus le buffer de
chaque nœud devient large, plus le ratio de délivrance augmente. Une fois les buffers sont
assez larges pour contenir tous les messages envoyés, son ratio de délivrance correspondra à
celui d‟ED. Néanmoins, le protocole épidémique est le seul qui garantit la délivrance si la
taille des buffers est suffisante, pour recevoir une copie de chaque message au niveau de
chaque nœud.
Les autres protocoles demandent beaucoup moins d‟espace de stockage car ils utilisent une
seule copie par message. Seulement, lorsque la taille des buffers passe au-dessous de 10% du
trafic total généré, le ratio de délivrance commence à diminuer. Celui de MEED est dans les
limites de 5% des meilleurs protocoles.
Dans les réseaux ayant des contraintes de buffers à gérer, MEED a de meilleures
performances que le routage épidémique.
Figure 40 : Variation du ratio de livraison en fonction de l’espace buffer [13]
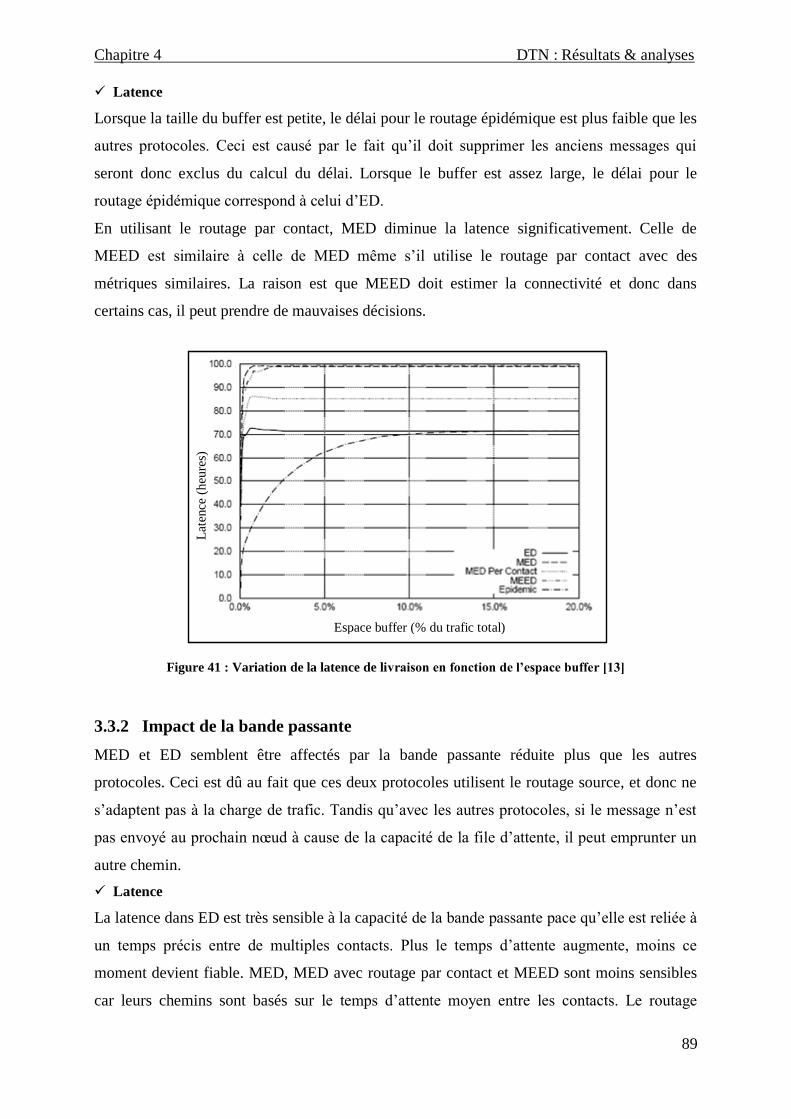
Chapitre 4 DTN : Résultats & analyses
89
Lat
ence
(heu
res)
Espace buffer (% du trafic total)
Latence
Lorsque la taille du buffer est petite, le délai pour le routage épidémique est plus faible que les
autres protocoles. Ceci est causé par le fait qu‟il doit supprimer les anciens messages qui
seront donc exclus du calcul du délai. Lorsque le buffer est assez large, le délai pour le
routage épidémique correspond à celui d‟ED.
En utilisant le routage par contact, MED diminue la latence significativement. Celle de
MEED est similaire à celle de MED même s‟il utilise le routage par contact avec des
métriques similaires. La raison est que MEED doit estimer la connectivité et donc dans
certains cas, il peut prendre de mauvaises décisions.
Figure 41 : Variation de la latence de livraison en fonction de l’espace buffer [13]
3.3.2 Impact de la bande passante
MED et ED semblent être affectés par la bande passante réduite plus que les autres
protocoles. Ceci est dû au fait que ces deux protocoles utilisent le routage source, et donc ne
s‟adaptent pas à la charge de trafic. Tandis qu‟avec les autres protocoles, si le message n‟est
pas envoyé au prochain nœud à cause de la capacité de la file d‟attente, il peut emprunter un
autre chemin.
Latence
La latence dans ED est très sensible à la capacité de la bande passante pace qu‟elle est reliée à
un temps précis entre de multiples contacts. Plus le temps d‟attente augmente, moins ce
moment devient fiable. MED, MED avec routage par contact et MEED sont moins sensibles
car leurs chemins sont basés sur le temps d‟attente moyen entre les contacts. Le routage

Chapitre 4 DTN : Résultats & analyses
90
épidémique, lui, a la plus faible latence parce qu‟il essaye tous les chemins dans le réseau de
manière simultanée.
3.4 Synthèse des résultats
A travers les simulations, MEED approche les performances des protocoles qui ont une
connaissance complète de la topologie du réseau.
Certes, le routage épidémique ne nécessite pas d‟informations sur la topologie et les résultats
montrent qu‟il fonctionne très bien. Cependant, MEED atteint 96% du ratio de délivrance du
routage épidémique en utilisant un seul message, au lieu d‟une copie pour chaque nœud. Ce
qui est beaucoup plus efficace.
Il est aussi possible d‟utiliser la métrique MEED pour faire un envoi sélectif d‟un petit
nombre de copies afin d‟atteindre une livraison fiable à faible coût.
Le fait d‟utiliser le routage par contact permet au protocole de réagir aux changements de la
topologie, et tirer profit des contacts opportunistes ce qui améliore la latence et le ratio de
délivrance dans les scénarios à faible bande passante.
4. Etude 4 : Performance de PRoPHET
Pour aider à évaluer le protocole PRoPHET, Lindgren & Al ont développé [15] un simulateur
simple qui se focalise sur l‟opération des protocoles de routage mais ne simule pas les détails
des sous couches.
Pour évaluer le protocole, le modèle de mobilité « Random Waypoint » a été choisi,
seulement il s‟est avéré qu‟il est susceptible d‟être irréaliste car les utilisateurs normaux ne
fonctionnent pas complètement de manière aléatoire, mais ont plutôt un ensemble d‟objectifs
dans leurs mouvements. Par conséquent, il était souhaitable de soumettre la mobilité à un
modèle reflétant mieux la réalité, d‟où l‟utilisation de deux scénarios.
4.1 Scénario1 : mobilité aléatoire
4.1.1 Description
Sur une surface de 1500 m x 300 m, cinquante nœuds sont aléatoirement distribués. Ces
nœuds se déplacent selon le modèle de mobilité « Random Waypoint » avec une vitesse allant
de 0 à 20 m/sec.

Chapitre 4 DTN : Résultats & analyses
91
4.1.2 Génération de trafic
Pour un sous ensemble de 45 nœuds, un message est envoyé toutes les secondes sur une
période de 1980 secondes de simulation (chacun des 45 nœuds envoie un message aux 44
autres nœuds), puis la simulation continue encore de tourner 2020 secondes pour permettre à
tous les messages d‟être délivrés.
4.2 Scénario2 : mobilité en communauté
4.2.1 Description
Comme le scénario précédent risque d‟être irréaliste, Lindgren & Al ont construit [15] un
scénario plus réaliste résultant de la conception du scénario appelé « modèle de
communauté ».
Ainsi, ce deuxième scénario consiste en une surface de 1500 m x 300 m comme montré sur la
Figure 42. Cette surface est divisée en 12 portions dont 11 communautés (C1 – C11), et un lieu
de rassemblement ( R ). Chaque nœud a une communauté d‟origine qu‟il visite plus que les
autres lieux, et une communauté d‟origine regroupe 5 nœuds. En outre, dans chaque
communauté et lieu de rassemblement il y a un nœud fixe (non mobile) qui joue le rôle de
passerelle.
Figure 42 : Modèle de communauté [15]
4.2.2 La mobilité
Le nœud sélectionne une destination, puis se déplace avec une vitesse variant entre 10 et 30
m/sec. Après avoir atteint cette destination, le nœud marque une pause, pour ensuite re-
sélectionner une autre destination et une autre vitesse et reprendre le processus.
Les destinations sont sélectionnées de façon à ce que si un nœud est dans sa communauté
d‟origine, il y‟a une forte probabilité qu‟il aille au lieu de rassemblement (mais il peut aussi
aller dans d‟autres lieux) et s‟il est en dehors de la communauté d‟origine, il est fort probable
qu‟il y retourne.
3000 m
1500 m
C1 C2 C3 C4
C5 C6 C7 C8
C9 C10 C11 R

Chapitre 4 DTN : Résultats & analyses
92
Les scénarios réels où ce type de mobilité peut se produire incluent la mobilité de l‟homme où
les communautés peuvent être par exemple les villages, mais aussi les applications de réseaux
de capteurs où les capteurs sont attachés aux animaux , le lieu de rassemblement peut être
l‟endroit où ils s‟alimentent et les communautés seraient les troupeaux.
4.2.3 Génération de trafic
Toutes les dix secondes, deux passerelles choisies aléatoirement, génèrent un message à une
destination aléatoire. Après 3000 secondes, la génération de messages cesse et la simulation
démarre durant 8000 secondes permettant leur délivrance.
Remarque
Dans les deux scénarios, une période d‟échauffement de 500 secondes est utilisée au début de la
simulation avant que la génération de messages ne commence pour permettre à la prédictibilité du
protocole PRoPHET de s‟initialiser.
4.3 Résultats & analyses
Les résultats présentés sont la moyenne de 5 simulations. Pour chaque métrique et scénario, il
y‟a deux graphes avec deux différentes valeurs de nombre de sauts. Chacun de ces deux
graphes contient les courbes du routage épidémique et PRoPHET pour des communications
de différentes portées. Les graphes varient selon la taille des files d‟attente. Les Figure 43 et
Figure 44 montrées ci-dessous montrent les résultats de simulation des deux scénarios: à
mobilité aléatoire et du modèle de communauté.
4.3.1 Taux de délivrance
D‟après les Figure 43 et Figure 44, il est facile de voir que la taille de la file d‟attente a un
impact sur les performances. Plus la taille des buffers augmente, plus le nombre de messages
délivrés augmente et ce pour les deux protocoles. Ceci est attendu car une grande taille des
buffers signifie que beaucoup de messages seront stockés et le risque de les perdre diminue.
Dans le scénario à mobilité aléatoire, les performances sont similaires pour les deux
protocoles, même si PRoPHET semble exercer un peu mieux surtout avec la communication
de courte portée, et un grand nombre de sauts. Il est intéressent de voir que même si la
mobilité est totalement aléatoirement, PRoPHET fonctionne encore dans le bon sens et même
légèrement mieux que le routage épidémique.
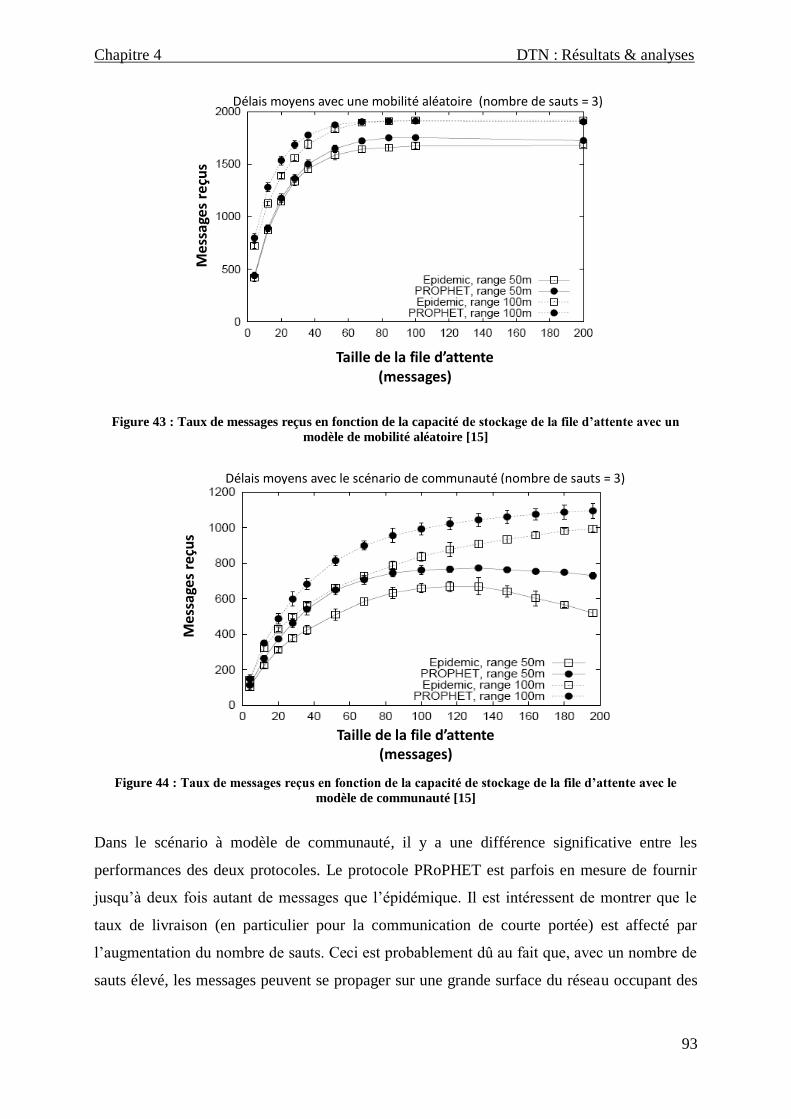
Chapitre 4 DTN : Résultats & analyses
93
Me
ssa
ges
reçu
s
Délais moyens avec une mobilité aléatoire (nombre de sauts = 3)
Taille de la file d’attente (messages)
Mes
sage
s re
çus
Délais moyens avec le scénario de communauté (nombre de sauts = 3)
Taille de la file d’attente (messages)
Figure 43 : Taux de messages reçus en fonction de la capacité de stockage de la file d’attente avec un
modèle de mobilité aléatoire [15]
Figure 44 : Taux de messages reçus en fonction de la capacité de stockage de la file d’attente avec le
modèle de communauté [15]
Dans le scénario à modèle de communauté, il y a une différence significative entre les
performances des deux protocoles. Le protocole PRoPHET est parfois en mesure de fournir
jusqu‟à deux fois autant de messages que l‟épidémique. Il est intéressent de montrer que le
taux de livraison (en particulier pour la communication de courte portée) est affecté par
l‟augmentation du nombre de sauts. Ceci est probablement dû au fait que, avec un nombre de
sauts élevé, les messages peuvent se propager sur une grande surface du réseau occupant des
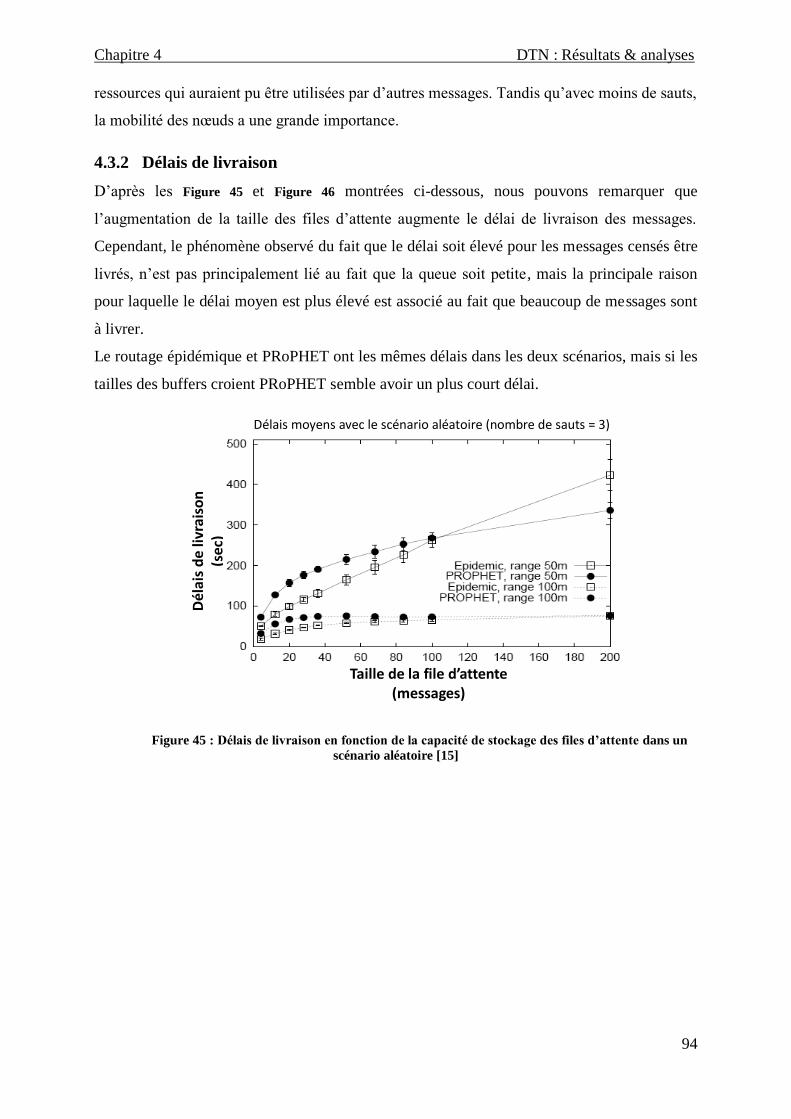
Chapitre 4 DTN : Résultats & analyses
94
Dél
ais
de
livra
iso
n
(sec
)
Délais moyens avec le scénario aléatoire (nombre de sauts = 3)
Taille de la file d’attente (messages)
ressources qui auraient pu être utilisées par d‟autres messages. Tandis qu‟avec moins de sauts,
la mobilité des nœuds a une grande importance.
4.3.2 Délais de livraison
D‟après les Figure 45 et Figure 46 montrées ci-dessous, nous pouvons remarquer que
l‟augmentation de la taille des files d‟attente augmente le délai de livraison des messages.
Cependant, le phénomène observé du fait que le délai soit élevé pour les messages censés être
livrés, n‟est pas principalement lié au fait que la queue soit petite, mais la principale raison
pour laquelle le délai moyen est plus élevé est associé au fait que beaucoup de messages sont
à livrer.
Le routage épidémique et PRoPHET ont les mêmes délais dans les deux scénarios, mais si les
tailles des buffers croient PRoPHET semble avoir un plus court délai.
Figure 45 : Délais de livraison en fonction de la capacité de stockage des files d’attente dans un
scénario aléatoire [15]
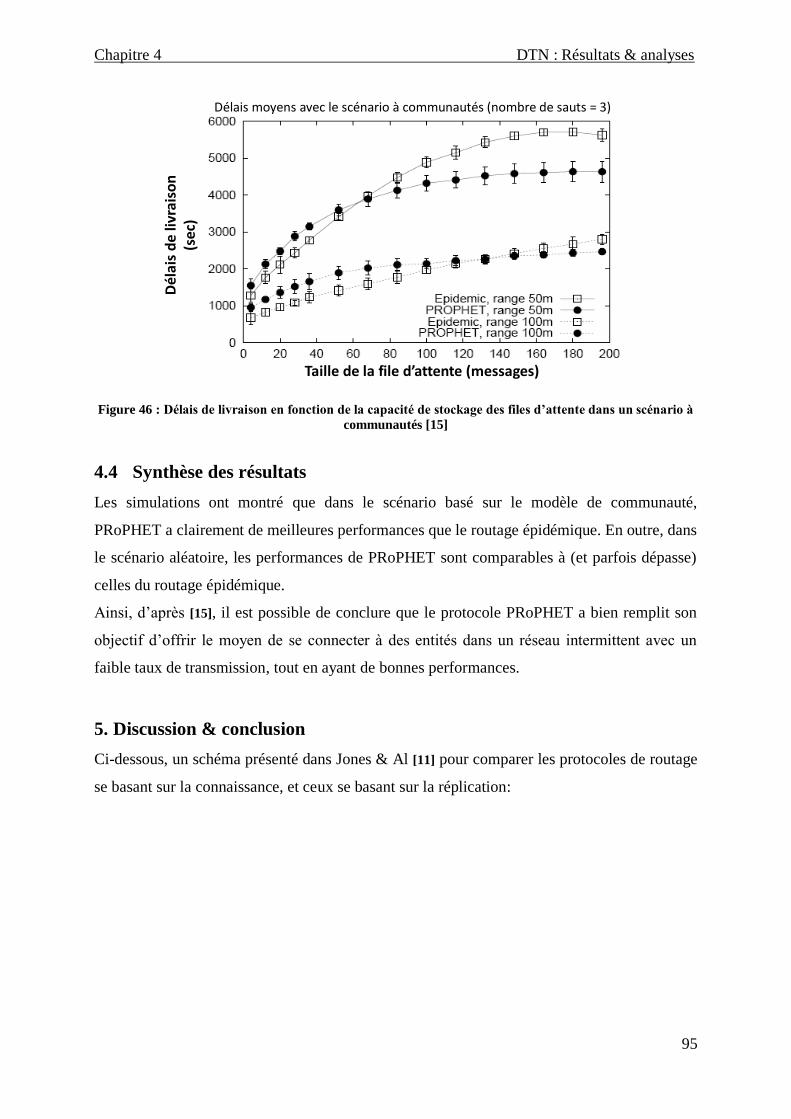
Chapitre 4 DTN : Résultats & analyses
95
Dél
ais
de
livra
iso
n
(se
c)
Délais moyens avec le scénario à communautés (nombre de sauts = 3)
Taille de la file d’attente (messages)
Figure 46 : Délais de livraison en fonction de la capacité de stockage des files d’attente dans un scénario à
communautés [15]
4.4 Synthèse des résultats
Les simulations ont montré que dans le scénario basé sur le modèle de communauté,
PRoPHET a clairement de meilleures performances que le routage épidémique. En outre, dans
le scénario aléatoire, les performances de PRoPHET sont comparables à (et parfois dépasse)
celles du routage épidémique.
Ainsi, d‟après [15], il est possible de conclure que le protocole PRoPHET a bien remplit son
objectif d‟offrir le moyen de se connecter à des entités dans un réseau intermittent avec un
faible taux de transmission, tout en ayant de bonnes performances.
5. Discussion & conclusion
Ci-dessous, un schéma présenté dans Jones & Al [11] pour comparer les protocoles de routage
se basant sur la connaissance, et ceux se basant sur la réplication:
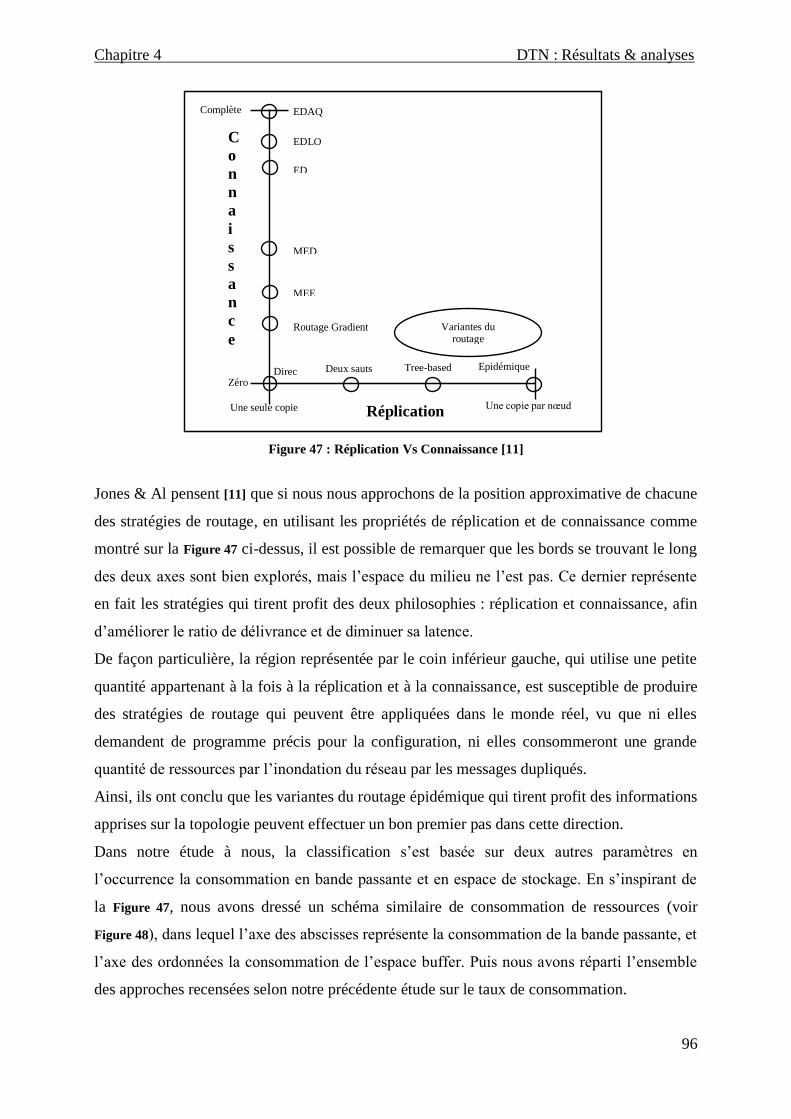
Chapitre 4 DTN : Résultats & analyses
96
Figure 47 : Réplication Vs Connaissance [11]
Jones & Al pensent [11] que si nous nous approchons de la position approximative de chacune
des stratégies de routage, en utilisant les propriétés de réplication et de connaissance comme
montré sur la Figure 47 ci-dessus, il est possible de remarquer que les bords se trouvant le long
des deux axes sont bien explorés, mais l‟espace du milieu ne l‟est pas. Ce dernier représente
en fait les stratégies qui tirent profit des deux philosophies : réplication et connaissance, afin
d‟améliorer le ratio de délivrance et de diminuer sa latence.
De façon particulière, la région représentée par le coin inférieur gauche, qui utilise une petite
quantité appartenant à la fois à la réplication et à la connaissance, est susceptible de produire
des stratégies de routage qui peuvent être appliquées dans le monde réel, vu que ni elles
demandent de programme précis pour la configuration, ni elles consommeront une grande
quantité de ressources par l‟inondation du réseau par les messages dupliqués.
Ainsi, ils ont conclu que les variantes du routage épidémique qui tirent profit des informations
apprises sur la topologie peuvent effectuer un bon premier pas dans cette direction.
Dans notre étude à nous, la classification s‟est basée sur deux autres paramètres en
l‟occurrence la consommation en bande passante et en espace de stockage. En s‟inspirant de
la Figure 47, nous avons dressé un schéma similaire de consommation de ressources (voir
Figure 48), dans lequel l‟axe des abscisses représente la consommation de la bande passante, et
l‟axe des ordonnées la consommation de l‟espace buffer. Puis nous avons réparti l‟ensemble
des approches recensées selon notre précédente étude sur le taux de consommation.
Une seule copie
Zéro
Une copie par nœud
Complète
Epidémique Tree-based Deux sauts Direc
ED
EDLQ
EDAQ
MED
MEE
Routage Gradient Variantes du routage
épidémique
Réplication
C
o
n
n
a
i
s
s
a
n
c
e

Chapitre 4 DTN : Résultats & analyses
97
Figure 48 : Répartition des protocoles de routage selon leurs taux de consommation en bande passante et
en espace buffer.
Nous faisons remarquer que la répartition de ces protocoles de routage dans le graphe, n‟est
qu‟approximative par rapport à des propriétés communes et apparentes. Parce qu‟il est trivial
qu‟il n‟y ait pas de transmission d‟informations avec une consommation nulle en bande
passante, ou plus de deux protocoles qui se partagent exactement les mêmes caractéristiques
de consommation. Donc, cette schématisation n‟est faite que dans le but de synthétiser et de
mieux structurer toutes les informations disponibles sur les protocoles de routage DTNs
De là, diverses conclusions sont tirées. En effet, les protocoles occupant le centre du graphe
peuvent s‟avérer meilleurs, car ils se caractérisent par une consommation modérée de
ressources. Quelques études présentées dans ce chapitre appuient cet avis, car les protocoles
qui ont montré de bonnes performances sont: EDAQ, spray & wait, spray & focus, MEED et
PRoPHET et ces derniers ne se situent pas aux extrémités supérieures du graphe, ce qui
montre qu‟ils n‟abusent pas dans leur consommation de ressources.
Aussi, nous remarquons d‟après l‟étude des performances du protocole PRoPHET, qu‟il a pu
atteindre les mêmes performances que le protocole épidémique en termes de taux et de délai
de livraison, sans avoir à envoyer autant de copies que de nœuds. Et PRoPHET n‟est autre
Consommation bande passante
Consommation
espace buffer
1 2
3 Epidémique 2
MED 2
Tree-Based 2
EDAQ
2
PRoPHET 2
4
5
Ensemble de protocoles de routage consommant X bande passante et Y
espace buffer ; n ={ 1, 2, 3, 4, 5} n
5 : Seek & Focus, Utilité avec transitivité
4 : Spray & Wait, Spray & Focus
3 : ED, EDLQ
2 : Routage gradient, MEED
1 : FC, Contact Direct, DHR, Location based, Routage aléatoire
n =
Protocole de routage consommant X bande passante et Y espace buffer

Chapitre 4 DTN : Résultats & analyses
98
qu‟une variante du routage épidémique mais ne se situant pas au bord du graphe. Du coup,
nous rejoignons la conclusion de Jones & Al du fait que le routage épidémique n‟est pas le
seul à pouvoir assurer un résultat fiable dans la transmission de données.
Mais malgré cela, nous soulignons le fait qu‟il est vrai que les simulations donnent des
résultats contribuant à la comparaison entre les protocoles, mais ceci ne peut être
généralisable pour toutes les circonstances. D‟ailleurs, si nous considérons la première étude
présentée dans ce chapitre, nous remarquons à l‟aide du graphe de la Figure 48 que les auteurs
ont utilisé des protocoles consommateurs, pourtant les situations proposées n‟étaient pas très
riches en ressources. Par conséquent, refaire l‟étude avec un ou plusieurs autres protocoles
moins consommateurs, améliorerait peut être le taux de délivrance.
C‟est pourquoi, il est désormais plus judicieux de penser à améliorer les protocoles existants,
en les dirigeant vers des techniques d‟optimisation maximales, leurs permettant de
s‟approcher au plus possible du centre du graphe en termes de consommations de ressources,
ce qui augmentera leur chance d‟adaptation à un grand nombre de situations dans la réalité.

99
Conclusion et perspectives
Nous avons fait connaître à travers cette thèse les réseaux tolérants aux délais (DTN : Delay
Tolerant Network). La connaissance d‟un tel type de réseaux est d‟une importance majeure de
nos jours, car il offre un tout nouveau développement dans le monde de la recherche sur les
réseaux, et redonne l‟espoir de connecter des entités qui jusque-là étaient incapables de
communiquer ou que cela leur coûtait énormément cher.
De même, connaître un domaine, revient à connaître son mode de fonctionnement et tout ce
qui s‟y réfère.
Afin d‟atteindre cet objectif, nous avons dans un premier temps présenté l‟environnement des
DTNs, les raisons qui ont amené à leur apparition ainsi que la nouveauté avec laquelle ils
arrivent. Nous avons détaillé la couche protocolaire, et expliqué le principe sur lequel est
fondé le protocole bundle. Tout cela a été fait en se basant principalement sur des documents
fournis par le groupe de recherche sur les DTNs, le DTNRG.
Ensuite, nous avons enchainé avec des applications dans les environnements intermittents qui
sont réalisées à base de l‟architecture des réseaux tolérants aux délais, dans le but de
rapprocher l‟idée et montrer leur utilité, ceci en montrant les différentes façons d‟établir la
communication selon différentes situations.
Nous faisons remarquer qu‟il existe évidemment bien plus d‟applications que celles que nous
avons énumérées dans ce présent rapport, mais nous avons sélectionné les plus complètes et
celles dont le mécanisme de fonctionnement a été montré de manière détaillée.
Puis, nous avons exposé la partie constituant notre centre d‟intérêt, qui porte sur les
protocoles de routage. Ces derniers consistent en un problème d‟une très grande importance
dans le monde des réseaux tolérants aux délais, car toute leur philosophie en dépend. En effet,
une bonne stratégie de routage appliquée sur un environnement intermittent forme la clé de la
bonne transmission de données.
Actuellement, il n‟existe pas encore de stratégie de référence vu l‟irrégularité de ce type
d‟environnements tel que nous l‟avions montré dans le dernier chapitre, mais cela n‟a pas
empêché la recherche à continuer à avancer dans cette direction, ce qui a donné naissance à
une panoplie d‟algorithmes dont chacun est bâti sur un principe particulier.

100
Notre principale contribution s‟insère donc à ce niveau, où en plus du fait que l‟on ait
rassemblé et structuré toutes les informations sur les DTNs ainsi que leurs applications, nous
avons aussi effectué un recueil et une synthèse des protocoles de routage existant dans ce
domaine. Mieux encore, nous avons pensé à aider les utilisateurs et les orienter en proposant
une classification basée sur le paramètre de consommation de ressources, spécialement la
capacité des buffers et l‟occupation de la bande passante. Cette méthode de classification va
donc offrir une grande assistance lors de la phase de prise de décision du protocole de routage
le mieux adapté à une situation donnée.
De plus, cette classification non encore réalisée jusque-là, est très intéressante du fait qu‟elle
se base sur des données théoriques s‟inspirant du principe même de la méthode. Par
conséquent, elle est valable quel que soit la situation vu qu‟il suffit seulement de connaître la
taille et la capacité du réseau DTN à construire, et d‟estimer le taux du flux qui y sera injecté.
Grâce à cette étude, une des perspectives que nous pouvons proposer serait de reprendre un
des scénarios déjà étudiés avec un protocole demandant beaucoup de ressources, et lui
appliquer un protocole tenant compte de cette contrainte, puis comparer les résultats obtenus
et optimiser les approches consommatrices afin de les rendre plus économes.
Aussi, ce qui serait intéressant d‟accomplir à l‟avenir, est de faire des études approfondies sur
d‟autres axes de recherche dans ce domaine, telles que : les techniques de détection de
congestion, la détection d‟erreurs ou la sécurité et les méthodes d‟authentification …etc. puis,
tenter d‟améliorer les lacunes des anciens protocoles existants, en leur adaptant des méthodes
permettant de les rendre plus fiables.
En réunissant tous ces critères, nous pouvons enfin songer à l‟implémentation d‟une
application optimale réelle, que nous pouvons appliquer dans un premier temps en milieu
universitaire par exemple, où les ordinateurs portables des étudiants seraient les nœuds, le
scénario de mobilité serait les déplacements des étudiants et le point de connexion serait la
borne wifi accrochée à la bibliothèque, au cyber café ou encore au bloc pédagogique. Ceci
permettra un échange d‟informations permanent entre les étudiants, même si les délais de
délivrance sont lents.
Pour finir, nous dirons que ce travail nous a permis de toucher à la réalité du travail dans un
environnement orienté recherche. On a appris à considérer les notions d'un œil critique afin de
vouloir toujours améliorer, toujours essayer de changer et d'innover.

Annexe A
L’entête d’un bundle
La couche bundle doit porter certaines informations de bout en bout selon les besoins de
transmission. Ses informations sont insérées dans l‟entête de chaque bundle. Elles sont
résumées comme suit [39] :
Version de l’identifiant
Protocole bundle de 8 bits.
ID de l’entité destination
Champ à longueur variable contenant le tuple destination. Il est ajouté par l‟application locale
lorsque l‟envoi nécessite le service bundle.
ID de l’entité source
C‟est l‟identifiant de l‟instance de l‟application bundle de la source. Il est sous forme de tuple,
ajouté par le service bundle local, car un hôte particulier peut avoir de multiples noms et un
seul sera choisi en se basant sur les décisions de routage.
L‟ID de l‟entité source peut être retourné à l‟application afin de supporter le processus de
« retour-réception »
ID de l’entité « Répondre à » (optionnel)
La source peut anticiper le fait qu‟elle ne soit pas capable d‟accepter les réponses et utiliser ce
paramètre pour spécifier la destination des « retour-réception » et les enregistrements de
délivrance.
ID du gardien courant (optionnel)
C‟est l‟identifiant du gardien courant. Il est nécessaire pour identifier en amont le nœud qui a la
garde courante du bundle, afin d‟acquitter le transfert de garde ou le bundle ou le fragment d‟un
bundle.

Annexe A L‟entête d‟un bundle
Classe de service drapeaux
Drapeaux : gardien, retour-réception, enregistrement de délivrance.
Sélecteur de la classe de service.
Sécurité : présence d‟authentification et/ou de cryptage.
Estampille d’envoi
C‟est le moment où le bundle a été présenté par l‟application d‟envoi à la couche bundle pour
la transmission.
Durée de vie
Considérée en secondes à partir du moment d‟envoi du bundle. C‟est un paramètre qui
indique le moment où le bundle doit être chassé du réseau DTN.
Information d’authentification (optionnelle)
Ce sont des données d‟authentification utilisées pour prouver que le bundle en question
devrait être transmis dans le réseau.
Information de fragmentation (optionnelle)
Utilisée pour un fragment d‟un bundle indiquant à quel endroit du bundle original, le
fragment appartient.
Certains bundles (ou événements) provoquent une indication du statut, générée par la couche
bundle. En effet, les indications de la couche bundle sont envoyées sous forme de bundles
avec une partie des données utilisateur qui est remplacée par un « rapport de status » qui
consiste en les informations suivantes :
ID de l’entité source du sujet bundle
C‟est une copie du tuple de la source du bundle.
Estampille d’envoi du sujet bundle
Utilisée pour lever l‟ambiguïté des rapports de status pour les différents bundles provenant de
la même entité source.

Annexe A L‟entête d‟un bundle
Drapeaux de status
Indiquant si les bundles ont été ou pas :
Reçus correctement par l‟expéditeur du rapport de status.
Transférés en utilisant le transfert de garde à l‟expéditeur du rapport de status.
Transmis par l‟expéditeur du rapport de status.
Temps de réception (optionnel)
C‟est le moment où l‟expéditeur du rapport de status reçoit le bundle.
Temps de transmission (optionnel)
C‟est le moment où l‟expéditeur du rapport de status transmet le bundle.

Annexe B
Les réseaux hiérarchiques
1. La clusterisation multi-niveaux
La clusterisation ou la formation en grappes est établit en premier avec l‟élection des têtes de
grappes, ensuite les autres nœuds choisissent quelle grappe joindre et y devenir membre. Il est
deux types d‟algorithmes de clusterisation [14]:
1.1 L’algorithme de grappe (ou de cluster)
Un nœud s‟auto-sélectionne comme tête de grappe s‟il possède la plus haute priorité parmi
les nœuds voisins non clusterisés. Les autres nœuds rejoignent le cluster ayant une tête de
grappe de priorité plus élevée parmi toutes les têtes de grappes du voisinage.
1.2 L’algorithme du noyau
Chaque nœud sélectionne un nœud ayant la plus grande priorité dans son voisinage en
s‟incluant lui-même puis s‟intègre à cette grappe.
La différence principale entre ces deux algorithmes est que soit la tête de grappe est un nœud
voisin (cas de l‟algorithme du noyau), soit il ne l‟est pas (cas de l‟algorithme de grappe).
Ainsi l‟on peut définir le réseau hiérarchique comme étant un arbre logique de nœuds dans un
réseau homogène où les nœuds et les liens supérieurs au niveau 0 dans la hiérarchie sont
conceptuels (par opposition aux nœuds et liens physiques du nœud 0). Un nœud du niveau
k+1 correspond à un cluster (ou à une tête de grappe) du niveau k, et l‟ID du nœud du niveau
k+1 est le même que celui du nœud tête de grappe du niveau k.
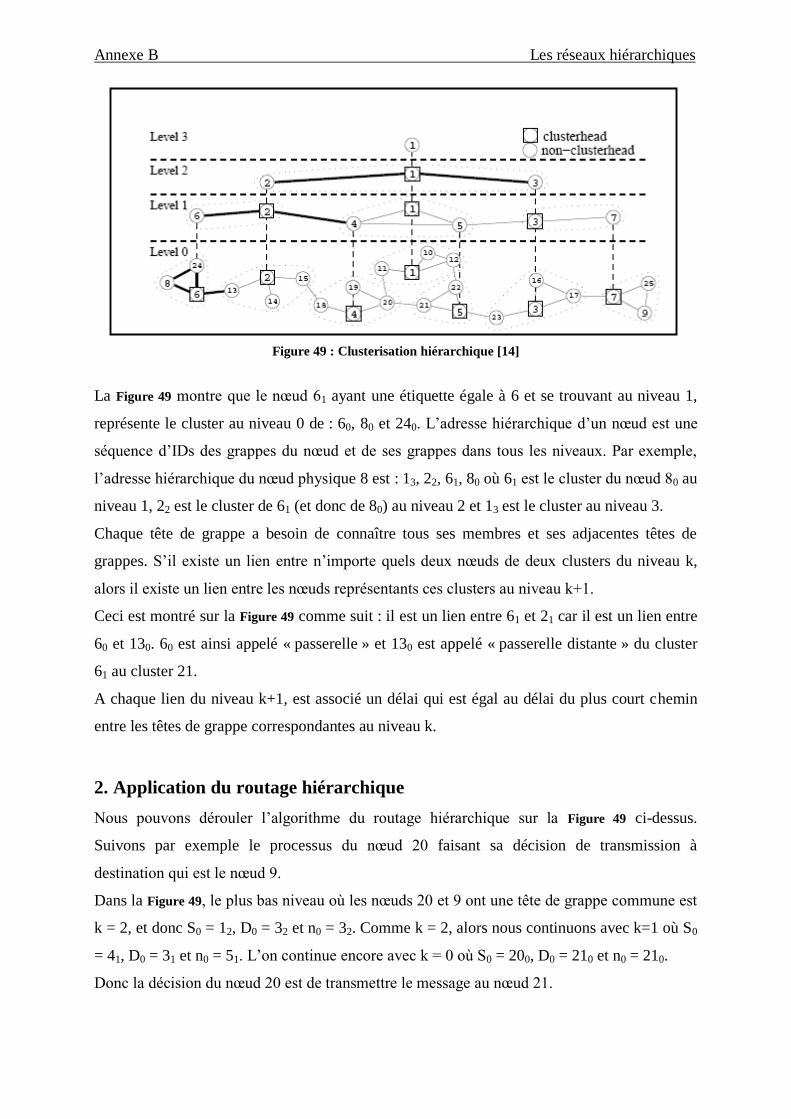
Annexe B Les réseaux hiérarchiques
Figure 49 : Clusterisation hiérarchique [14]
La Figure 49 montre que le nœud 61 ayant une étiquette égale à 6 et se trouvant au niveau 1,
représente le cluster au niveau 0 de : 60, 80 et 240. L‟adresse hiérarchique d‟un nœud est une
séquence d‟IDs des grappes du nœud et de ses grappes dans tous les niveaux. Par exemple,
l‟adresse hiérarchique du nœud physique 8 est : 13, 22, 61, 80 où 61 est le cluster du nœud 80 au
niveau 1, 22 est le cluster de 61 (et donc de 80) au niveau 2 et 13 est le cluster au niveau 3.
Chaque tête de grappe a besoin de connaître tous ses membres et ses adjacentes têtes de
grappes. S‟il existe un lien entre n‟importe quels deux nœuds de deux clusters du niveau k,
alors il existe un lien entre les nœuds représentants ces clusters au niveau k+1.
Ceci est montré sur la Figure 49 comme suit : il est un lien entre 61 et 21 car il est un lien entre
60 et 130. 60 est ainsi appelé « passerelle » et 130 est appelé « passerelle distante » du cluster
61 au cluster 21.
A chaque lien du niveau k+1, est associé un délai qui est égal au délai du plus court chemin
entre les têtes de grappe correspondantes au niveau k.
2. Application du routage hiérarchique
Nous pouvons dérouler l‟algorithme du routage hiérarchique sur la Figure 49 ci-dessus.
Suivons par exemple le processus du nœud 20 faisant sa décision de transmission à
destination qui est le nœud 9.
Dans la Figure 49, le plus bas niveau où les nœuds 20 et 9 ont une tête de grappe commune est
k = 2, et donc S0 = 12, D0 = 32 et n0 = 32. Comme k = 2, alors nous continuons avec k=1 où S0
= 41, D0 = 31 et n0 = 51. L‟on continue encore avec k = 0 où S0 = 200, D0 = 210 et n0 = 210.
Donc la décision du nœud 20 est de transmettre le message au nœud 21.

Annexe B Les réseaux hiérarchiques
3. La clusterisation multi-niveaux dans les DTNs
Chaque nœud du niveau 0 du réseau hiérarchique correspond à un nœud physique, et il est un
lien entre deux nœuds du niveau 0 s‟il est des contacts entre leurs nœuds physiques.
Pour permettre aux liens dans chaque niveau du réseau hiérarchique d‟avoir l‟information sur
le délai à temps variant, l‟on stocke dans chaque lien un ensemble de contacts.
Le lien du niveau 0 stocke tous les contacts entre les deux nœuds terminaux. Le lien du niveau
k+1 regroupe tous les contacts des liens du niveau k qui forment des chemins entre les têtes
de grappes de niveau k correspondantes qui incluent ceux entre les têtes de grappes et les
passerelles, et ceux les passerelles entre elles.
Figure 50 : Réseau hiérarchique avec l’information d’agrégation de contacts donnant un niveau
d’agrégation [14]
Par exemple, dans la Figure 50c les nœuds 30 et 50 sont des têtes de grappes et le lien du niveau
1 entre 31 et 51 contient l‟information sur les contacts se trouvant dans tous les liens du niveau
0 entre 30 et 40, entre 50 et 60, entre 30 et 60 et entre 40 et 50.
La taille de l‟information sur les contacts rassemblée dans les liens croît de manière
exponentielle avec l‟accroissement du niveau.
Afin d‟assurer la scalabilité, l‟agrégation doit être arrêtée à un certain niveau que l‟on
nommera « niveau d‟agrégation » La. Les liens se trouvant au-dessus du niveau La
maintiennent les délais à temps variant comme dans le cas d‟un réseau hiérarchique statique.
Le délai dans les liens se trouvant au-dessus de La est calculée de la même façon que dans les
réseaux hiérarchiques statiques. Pour calculer le délai à temps variant au niveau La+1, chaque
lien du niveau La a, lui aussi besoin d‟avoir le délai à temps variant.

Références bibliographiques
[1] F. Warthman “ Delay Tolerant Network (DTNs)” A tutorial. Forest Warthman.Warthman
Associates (www.warthman.com). Version1.1. 2003
[2] K. Fall “A delay tolerant network architecture for challenged Internets”, IRB-TR-03-003. Intel
Research Berkley, February 2003.
[3] J. P. Gelas / ATER “Réseaux interplanétaires (IPN) et réseaux tolerant aux délais (DTN)”,
Laboratoire de l‟Informatique du Parallélisme, 2006
[4] D. Wick “Delay tolerant Networking” RVS Group, 2007.
[5] S. Burleigh, A. Hooke, and L. Torgerson, K. Fall “Delay tolerant networking An approach to
interplanetary Internet”, IEEE Communications Magazine, Vol. 41, No. 6. (June 2003), pp.
128-136.
[6] S. Jain, K. Fall, R. Petra “Routing in a delay tolerant network”, In Proc. ACM SIGCOMM‟04,
Portland, OR, August 2004.
[7] B. awerbuch, R. Khandekar, S. Rao “Distributed algorithms for multi-commodity flow
problems via approximate steepest descent framework”, Proceedings of the eighteenth annual
ACM-SIAM symposium on Discrete algorithms, New Orleans, Louisiana Pages: 949 – 957,
2007.
[8] C. Duhamel, P. Mahey “Multicommodity flow problems with abounded mumber of paths: a
flow deviation approach” Laboratoire d‟Informatique, de Modélisation et d‟Optimisation des
Systèmes, UMR 6158 CNRS, Université Blaise Pascal, France, March 22, 2005.
[9] J. Lebrun, C.-N. Chuah, D. Ghosal, and M. Zhang “Knowledge-based opportunistic
forwarding in vehicular wireless ad hoc networks, in Proceedings of IEEE Vehicular
Technology Conference (VTC)”, vol. 4,pp. 2289–2293, May 2005.
[10] J. Leguay, T. Friedman, and V. Conan “Evaluating mobility pattern space routing for DTNs,
in Proceedings of IEEE INFOCOM”, April 2006.
[11] E.P.C. Jones, P. A.S. Ward “Routing Strategies for Delay Tolerant Networks”, Proceedings of
ACM SIGCOMM, 2004.
[12] S. Jain, K. Fall, R. Patra “Routing in a Delay Tolerant Network” SIGCOMM‟04, Aug. 30–
Sept. 3, 2004.
[13] E. P. C. Jones, L. Li, P. A. S. Ward “Practical Routing in Delay-Tolerant Networks”
SIGCOMM‟05 Workshops, August 22–26, 2005.

[14] C. L. and J. Wu “Scalable Routing in Delay Tolerant Networks” MobiHoc'07, September 9-
14, 2007.
[15] A. Lindgren, A. Doria, O. Schelén « Probabilistic Routing in Intermittently Connected
Networks”, SIGMOBILE Mobile Computing and Communication Review, 2004.
[16] K. Fall “A delay tolerant network architecture”, IRB-TR-03-003. Intel Research Berkley ,
April 2007.
[17] A. Vahdat and D. Becker, “Epidemic routing for partially-connected ad hoc networks,” Tech.
Rep. CS-2000-06, July 2000.
[18] T. Small and Z. J. Haas, “Resource and performance tradeoffs in delay-tolerant wireless
networks,” in Proceedings of the ACM SIGCOMM Workshop on Delay-Tolerant Networking
(WDTN‟05), pp. 260–267, August 2005.
[19] K. A. Harras and K. C. Almeroth, “Transport layer issues in delay tolerant mobile
networks,” in Proceedings of IFIP-TC6 Networking, May 2006.
[20] T. Spyropoulos, K. Psounis, C. Raghavendra « Efficient Routing in Intermittently connected
Mobile Networks: The Multiple-copy Case », IEEE Trans. Networking, vol. 16, no. 1, Feb.
2008.
[21] T. Spyropoulos, K. Psounis, C. Raghavendra « Efficient Routing in Intermittently Connected
Mobile Networks: The Single-copy Case », in Proc. IEEE Conf. Sensor and Ad Hoc
Communications and Networks (SECON), 2004, pp. 235-244
[22] B. Karp and H. T. Kung, “GPSR: greedy perimeter stateless routing for wireless networks,” in
Proceedings of ACM MOBICOM, 2000.
[23] http://www.dtnrg.org/ (consulté en 2009)
[24] J. Burgess, B. Gallagher, D. Jensen, and B. N.Levine, “Maxprop: Routing for vehicle- based
disruption-tolerant networking,” in Proceedings of IEEE INFOCOM, April 2006.
[25] P. Hui, A. Chaintreau, J. Scott, R. Gass, J.Crowcroft, and C. Diot, “Pocket switched networks
and human mobility in conference environments,” in Proceedings of the ACM SIGCOMM
Workshop on Delay-Tolerant Networking (WDTN‟05), pp. 244–251, August 2005.
[26] Dartmouth College,The Dartmouth Wireless Trace Archive. http://crawdad.cs.dartmouth.edu/
[27] J. Broch, D. A. Maltz, D. B. Johnson, Y. C. Hu, and J. Jetcheva. “A Performance Comparison
of Multi-Hop Wireless Ad Hoc Network Routing Protocols”. In ACM Mobicom, Aug. 1998.
[28] D. Aldous and J. Fill, “Reversible Markov chains and random walks on graphs. . (monograph
in preparation.),” http://statwww.berkeley.edu/users/aldous/RWG/book.html.
[29] M. Grossglauser and D. N. C. Tse, “Mobility increases the capacity of ad hoc wireless
networks,” IEEE/ACM Transactions on Networking, vol. 10, pp. 477–486, August 2002.

[30] R. C. Shah, S. Roy, S. Jain, and W. Brunette, “Data mules: modeling a three-tier architecture
for sparse sensor networks,” in Proceedings of Sensor Network Protocols and Applications,
pp. 30–41, May 2003.
[31] W. Zhao, M. Ammar, and E. Zegura, “A message ferrying approach for data delivery in
sparse mobile ad hoc networks,” in Proceedings of ACM MobiHoc, (New York, NY, USA),
pp. 187–198, ACM Press, May 2004.
[32] D. Nain, N. Petigara, and H. Balakrishnan, “Integrated routing and storage for messaging
applications in mobile ad hoc networks,” Mobile Networks and Applications (MONET), vol.
9, pp. 595–604, December 2004.
[33] M. Mauve, A. Widmer, and H. Hartenstein, “A survey on position-based routing in mobile ad
hoc networks,” IEEE Network, vol. 15, no. 6, pp. 30–39, 2001.
[34] T. S. E. Ng and H. Zhang, “Predicting internet network distance with coordinates-based
approaches,” in Proceedings of IEEE INFOCOM, vol. 1, pp. 170–179 vol.1, June 2002.
[35] R. D. Poor, “Gradient routing in ad hoc networks.”, unpublished manuscript,
http://www.media.mit.edu/pia/Research/ESP/texts/poorieeepaper.pdf , 2000.
[36] J. Segui, E. Jennings “Delay tolerant networking – Bundle protocol simulation”. Second IEEE
International Conference on Space Mission Challenges for Information Technology, SMC-IT,
2006.
[37] D. Niculescu and B. Nath. “Trajectory based Forwarding and its Applications”. In ACM
Mobicom, 2003.
[38] M. K. Marina and S. R. Das. On-demand Multipath Distance Vector Routing in Ad Hoc
Networks. In IEEE ICNP, Nov. 2001.
[39] V. Cerf, S. Burleigh, A. Hooke, L. Torgerson, R. Durst, K. Scott, K. Fall and H. Weiss
“Delay-Tolerant Network Architecture” March-September 2003
[40] P. Juang, H. Oki, Y. Wang, M. Martonosi, L.S. Peh, D. Rubenstein “energy-efficient
computing of wildlife tracking: Design tradeoffs and early experiences with ZebraNet”,
Princeton University, 2002
[41] http://fr.wikipedia.org/
[42] W. Lvancic, W.M. Eddy, D. Stewart, J. Northam, C. Jackson, A. da S. Curiel “Use of the
delay tolerant network bundle protocol from space”. NASA Glen Research Center. 2008
[43] A. Pantland, R. Fletcher, A. Hasson “DakNet : Rethinking connectivity in developing
nations”, Cover Feature, IEEE Computer Outlook, IEEE Computer Society, 0018-9162/04 ©
January, 2004.

[44] A. Krifa “An optimal joint scheduling and drop policy for delay tolerant networks”.
PLANETE-INRIA. April 2008.
[45] L. Wood, W. M. Eddy, W. Ivancic, J. McKim, C. Jackson “Saratoga: a Delay Tolerant
Networking convergence layer with efficient link utilization”. In Proceeding of IWSSC‟07,
June 2007.
[46] S. Burleigh, E. Jennings, J. Schoolcraft “Autonomous Congestion Control in Delay-Tolerant
Networks”, American Institute of Aeronautics and astronautics, June 2006
[47] P. Mundur, S. Lee, M. Seligman “Routing in Delay Tolerant Networks Using Storage
Domains” November 2006. UMD Tech Report UMIACS-TR-2007-01
http://hdl.handle.net/1903/4024
[48] M. Choon Chan, R. Ramjee “TCP/IP Performance over 3G Wireless Links with Rate and
Delay Variation”, Springer Science + Business Media, Inc. Manufactured in The Netherlands,
2005.
[49] S. Heimlicher, “Store And Forward Transport Reliable Transport in Wireless Mobile Ad-hoc
Networks”, Master's Thesis, Swiss Federal Institute of Technology, Zurich, April 2005.
[50] M. Seligman, K. Fall, and P. Mundur, “Storage Routing for DTN Congestion Control,”
Journal on Wireless Communications & Mobile Computing, Wiley Interscience, Vol. 7, Issue
10, pp 1183-1196, December 2007.
[51] K. Fall,W. Hong, and S. Madden, “Custody Transfer for Reliable Delivery in Delay Tolerant
Networks”, Tech. Rep. IRB-TR-03-030, Intel Research Berkeley, Jul 2003.
[52] W. Ivancic, W.M. Eddy, D. Stewart, J. Northam, “Use Of The Delay-Tolerant Networking
Bundle Protocol from space”, IAC-08-B2.3.10, Global Government Solutions Group, Cisco
Systems, United Kingdom. Sep 2008.
[53] V.V Gounder, R. Prakash, H. Abu-Amara, “Routing in LEO-based satellite networks”, In
Wireless Communications and Systems, 1999 Emerging Technologies Symposium, pp 22.1-
22.6, 1999.
[54] W. Ivancic, W.M. Eddy, D. Stewart, J. Northam, "Delay/Disruption-Tolerant Network
Testing Using a LEO Satellite", NASA Earth Science Technology Conference Paper A4P2,
June 2008.
[55] L. Sassatelli, M. Medard, “Network Coding for Delay Tolerant Networks with Byzantine
Adversaries”. ARXIV.ORG, 2009.
[56] M. Seligman, K. Fall, and P. Mundur, Alternative Custodians for Congestion Control in Delay
Tolerant Networks. In Proceedings of the 2006 SIGCOMM workshop on Challenged
networks, pp: 229 – 236, 2006.


Liste des abréviations
A-
AODV Ad hoc On Demand Distance Vector
C-
CLA Convergence Layer Adapter
CPU Central Processing Unit
D-
DHR DTN Hierarchic Routing
DSDV Destination-Sequenced Distance Vector
DSL Digital Subscriber Line
DSR Dynamic source Routing
DTNRG DTN Research Group
E-
ED Earliest Delivery
EDAQ Earliest Delivery with All Queues
EDLQ Earliest Delivery with Local Queuing
F-
FC First Contact
FIFO First In first Out
FTP File Transfer Protocol
G-
GPS Global Positioning System
I-
ICMP Internet Control Message Protocol

IP Internet Protocol
IRTF Internet Research Task Force
L-
LAN Local Network Area
LEO Low Earth Orbit
LIP6 Laboratoire d‟Informatique de Paris 6
LP Linear Programming
LTP Licklider Transmission Protocol
M-
MAP Mobile Access Point
MED Minimum Expected Delay
MEED Minimum Estimated Expected Delay
MLA Media Lab Asia
O-
OLSR Optimized Link State Routing
OSI Open System Interconnection
P-
PRoPHET
Probabilistic ROuting Protocol using History of Encounters and
Transitivity
R-
RF Radio Frequency
RTT Round-Trip delay Time
T-
TCP Transmission Control Protocol
TCPCL TCP Convergence Layer
TTL Time To Live

U-
UDP User Datagram Protocol
UWB Ultra WideBand
V-
VHF Very High Frequency