CHALLENGE 2018 - chemom2018.sciencesconf.org · Méthode SVM –Support Vector Machine Régression...
18
CHALLENGE 2018 Maxime METZ Belal GACI Florian DELISLE Abdelmajid BOUKHLOUF
Transcript of CHALLENGE 2018 - chemom2018.sciencesconf.org · Méthode SVM –Support Vector Machine Régression...

CHALLENGE 2018
Maxime METZ
Belal GACI
Florian DELISLE
Abdelmajid BOUKHLOUF
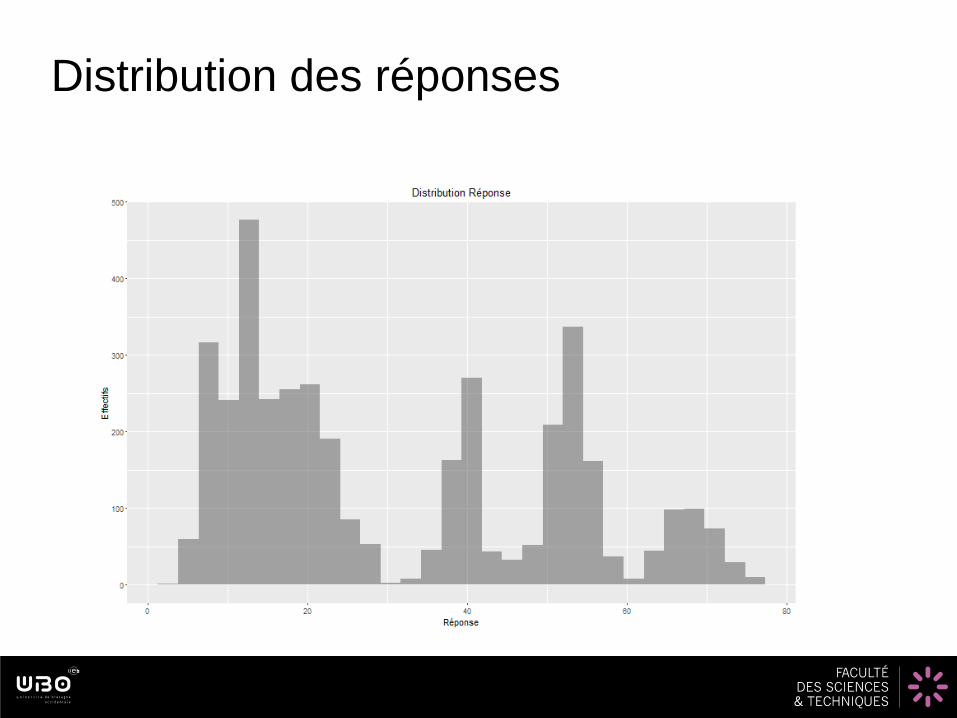
Distribution des réponses
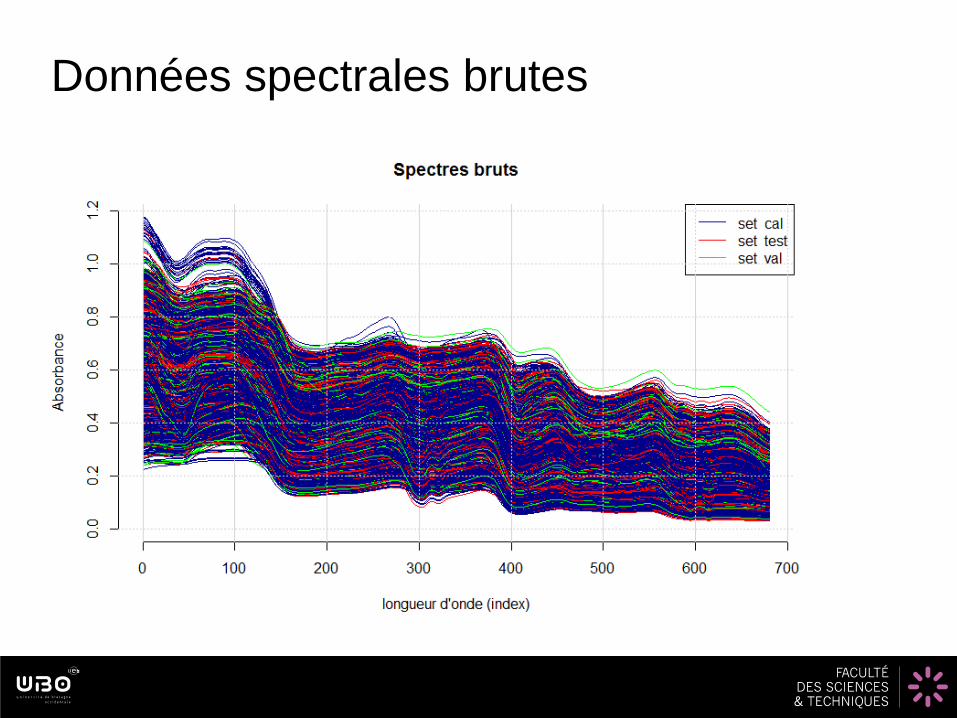
Données spectrales brutes
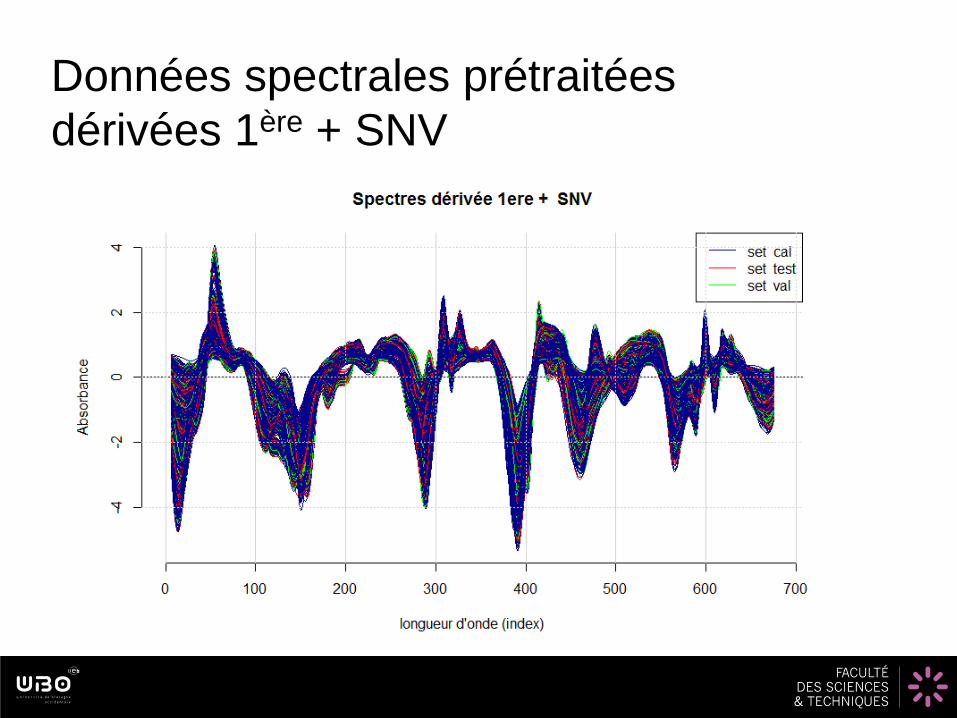
Données spectrales prétraitées
dérivées 1ère + SNV
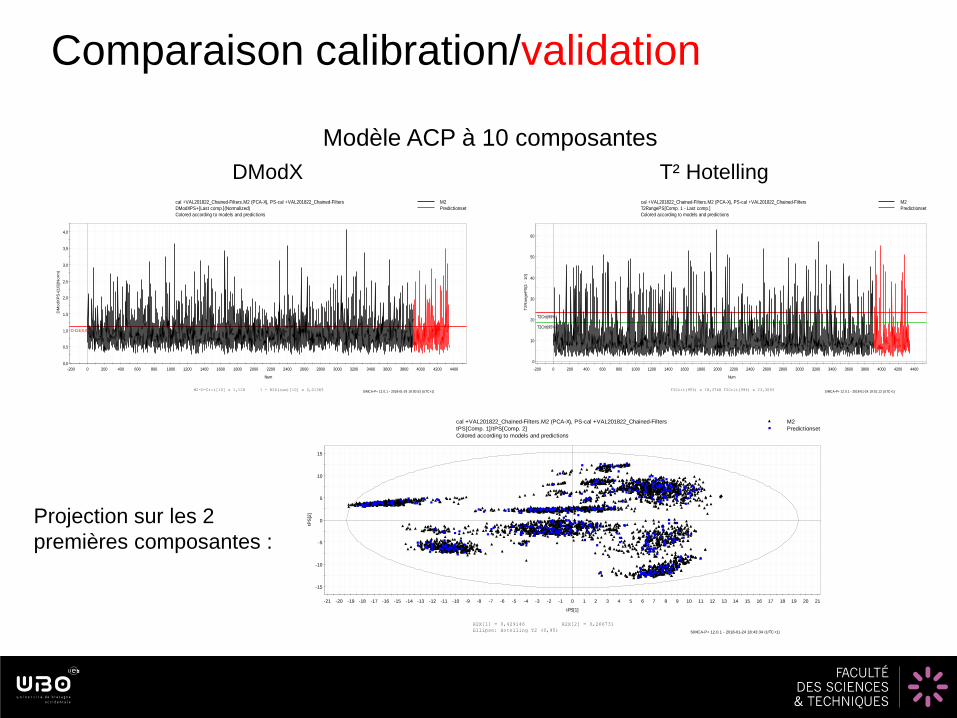
Comparaison calibration/validation
Modèle ACP à 10 composantes
DModX T² Hotelling
Projection sur les 2
premières composantes :
-15
-10
-5
0
5
10
15
-21 -20 -19 -18 -17 -16 -15 -14 -13 -12 -11 -10 -9 -8 -7 -6 -5 -4 -3 -2 -1 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
tPS
[2]
tPS[1]
cal +VAL201822_Chained-Filters.M2 (PCA-X), PS-cal +VAL201822_Chained-Filters
tPS[Comp. 1]/tPS[Comp. 2]
Colored according to models and predictions
R2X[1] = 0,429146 R2X[2] = 0,266731
Ellipse: Hotelling T2 (0,95)
M2
Predictionset
SIMCA-P+ 12.0.1 - 2018-01-24 18:43:34 (UTC+1)
0
10
20
30
40
50
60
-200 0 200 400 600 800 1000 1200 1400 1600 1800 2000 2200 2400 2600 2800 3000 3200 3400 3600 3800 4000 4200 4400
T2R
angeP
S[1
- 1
0]
Num
cal +VAL201822_Chained-Filters.M2 (PCA-X), PS-cal +VAL201822_Chained-Filters
T2RangePS[Comp. 1 - Last comp.]
Colored according to models and predictions
T2Crit(95%) = 18,3748 T2Crit(99%) = 23,3093
M2
Predictionset
T2Crit(95%)
T2Crit(99%)
SIMCA-P+ 12.0.1 - 2018-01-24 19:01:13 (UTC+1)
0,0
0,5
1,0
1,5
2,0
2,5
3,0
3,5
4,0
-200 0 200 400 600 800 1000 1200 1400 1600 1800 2000 2200 2400 2600 2800 3000 3200 3400 3600 3800 4000 4200 4400
DM
odX
PS
+[1
0](
Norm
)
Num
cal +VAL201822_Chained-Filters.M2 (PCA-X), PS-cal +VAL201822_Chained-Filters
DModXPS+[Last comp.](Normalized)
Colored according to models and predictions
M2-D-Crit[10] = 1,128 1 - R2X(cum)[10] = 0,01365
M2
Predictionset
D-Crit(0,05)
SIMCA-P+ 12.0.1 - 2018-01-24 19:00:53 (UTC+1)
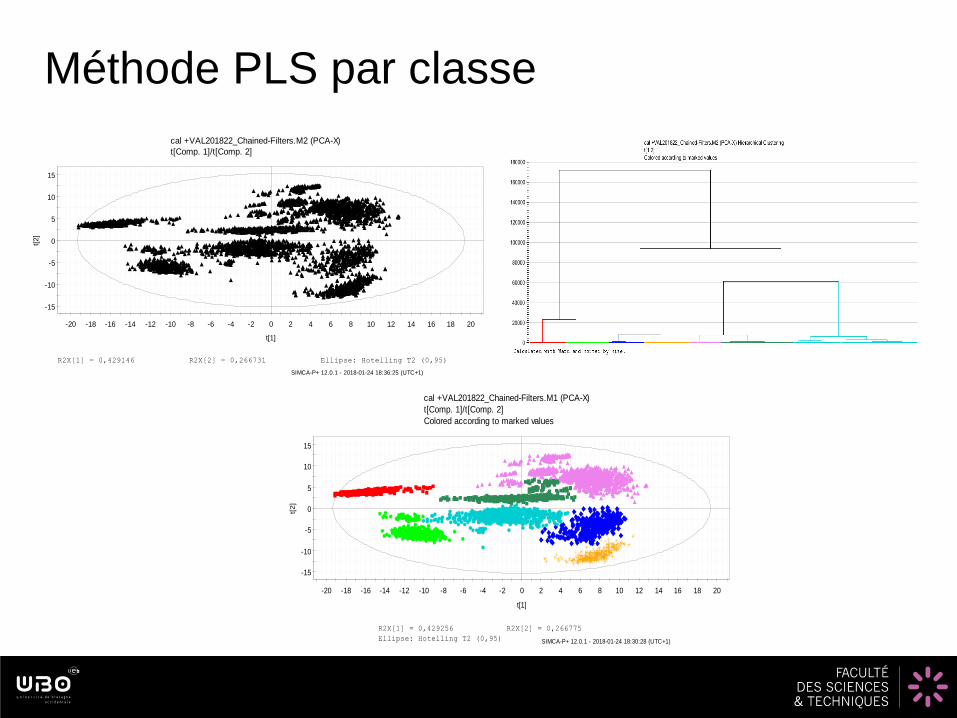
Méthode PLS par classe
-15
-10
-5
0
5
10
15
-20 -18 -16 -14 -12 -10 -8 -6 -4 -2 0 2 4 6 8 10 12 14 16 18 20
t[2]
t[1]
cal +VAL201822_Chained-Filters.M2 (PCA-X)
t[Comp. 1]/t[Comp. 2]
R2X[1] = 0,429146 R2X[2] = 0,266731 Ellipse: Hotelling T2 (0,95)
SIMCA-P+ 12.0.1 - 2018-01-24 18:36:25 (UTC+1)
-15
-10
-5
0
5
10
15
-20 -18 -16 -14 -12 -10 -8 -6 -4 -2 0 2 4 6 8 10 12 14 16 18 20
t[2]
t[1]
cal +VAL201822_Chained-Filters.M1 (PCA-X)
t[Comp. 1]/t[Comp. 2]
Colored according to marked values
R2X[1] = 0,429256 R2X[2] = 0,266775
Ellipse: Hotelling T2 (0,95) SIMCA-P+ 12.0.1 - 2018-01-24 18:30:28 (UTC+1)
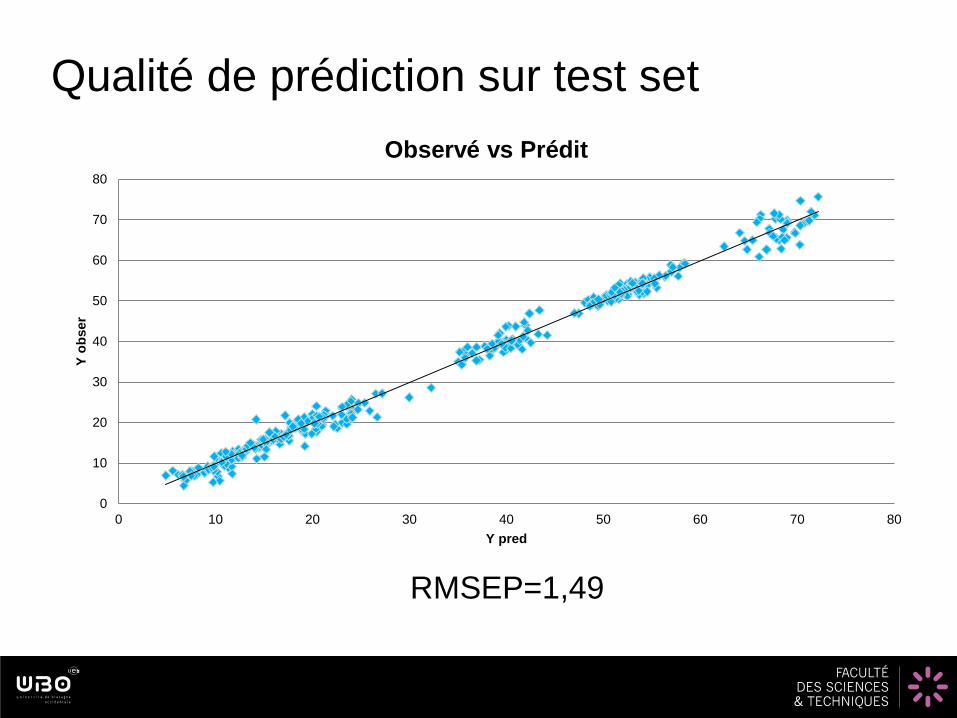
Qualité de prédiction sur test set
0
10
20
30
40
50
60
70
80
0 10 20 30 40 50 60 70 80
Y o
bs
er
Y pred
Observé vs Prédit
RMSEP=1,49
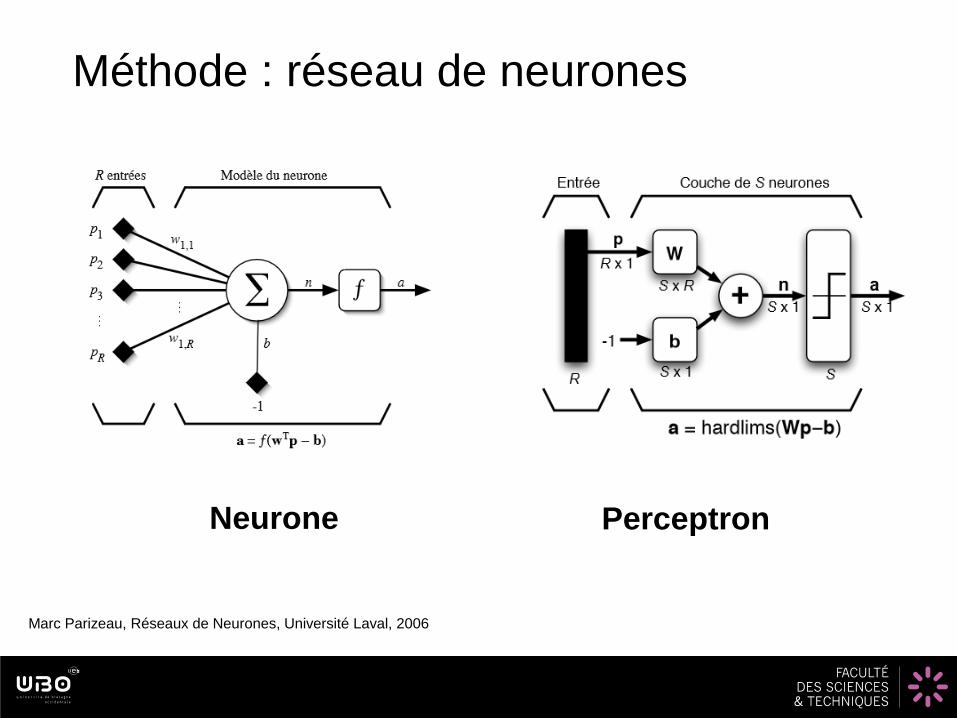
Méthode : réseau de neurones
PerceptronNeurone
Marc Parizeau, Réseaux de Neurones, Université Laval, 2006
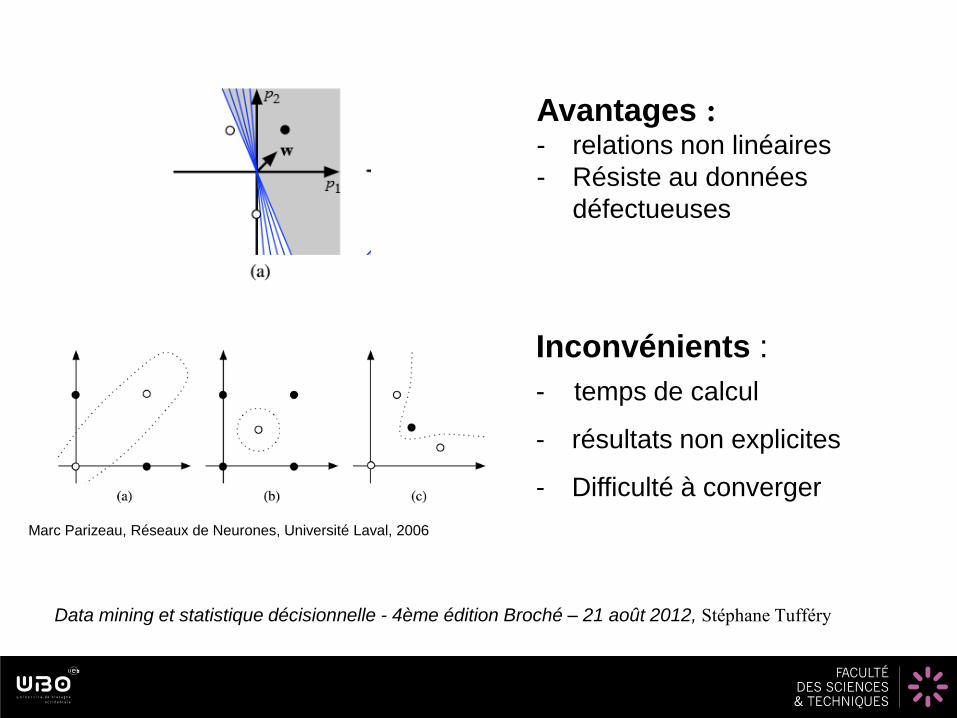
Avantages : - relations non linéaires
- Résiste au données
défectueuses
Inconvénients :
- temps de calcul
- résultats non explicites
- Difficulté à converger
Marc Parizeau, Réseaux de Neurones, Université Laval, 2006
Data mining et statistique décisionnelle - 4ème édition Broché – 21 août 2012, Stéphane Tufféry
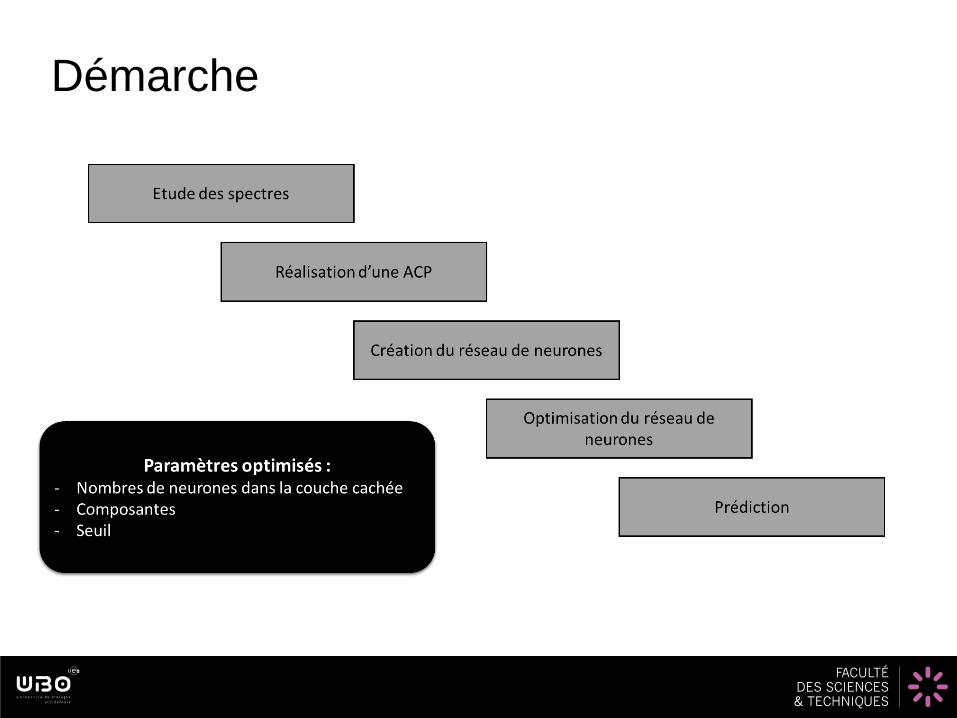
Démarche
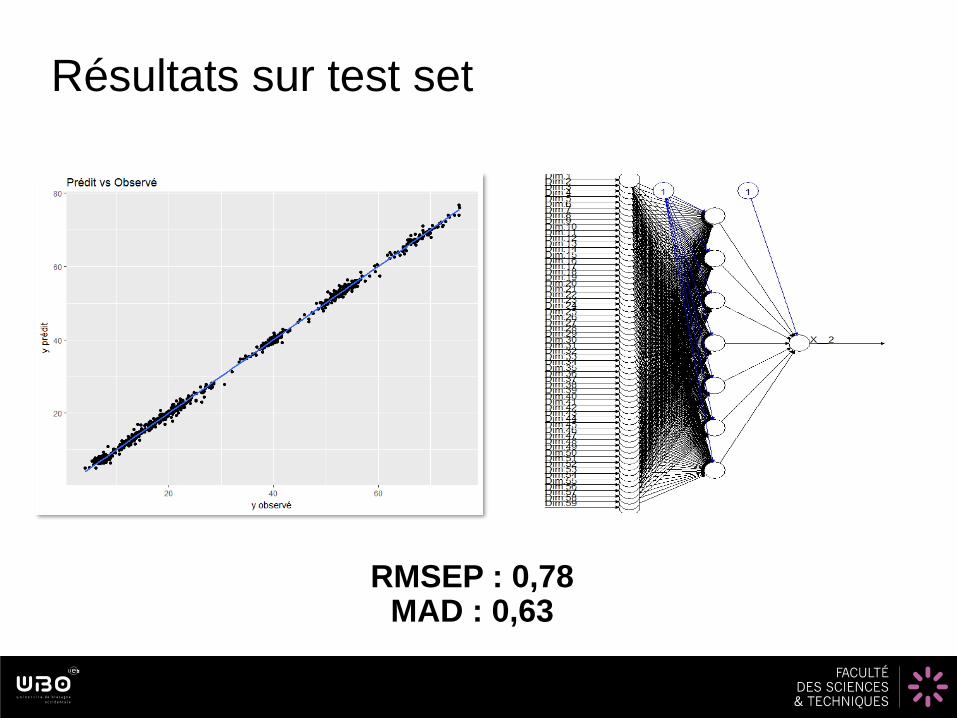
Résultats sur test set
RMSEP : 0,78MAD : 0,63
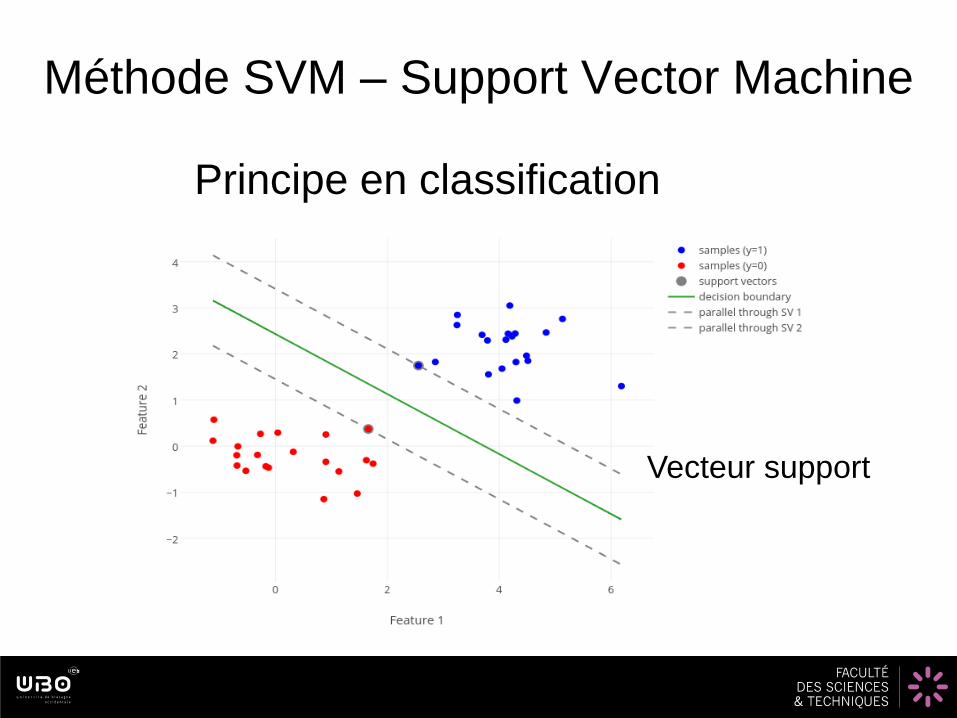
Méthode SVM – Support Vector Machine
Principe en classification
Vecteur support

Transformation
La transformation consiste à choisir une
fonction K : X x X R appelée noyau.
Méthode SVM – Support Vector Machine
Catrina Moreira Jan 2011,learning To rank academic Experts
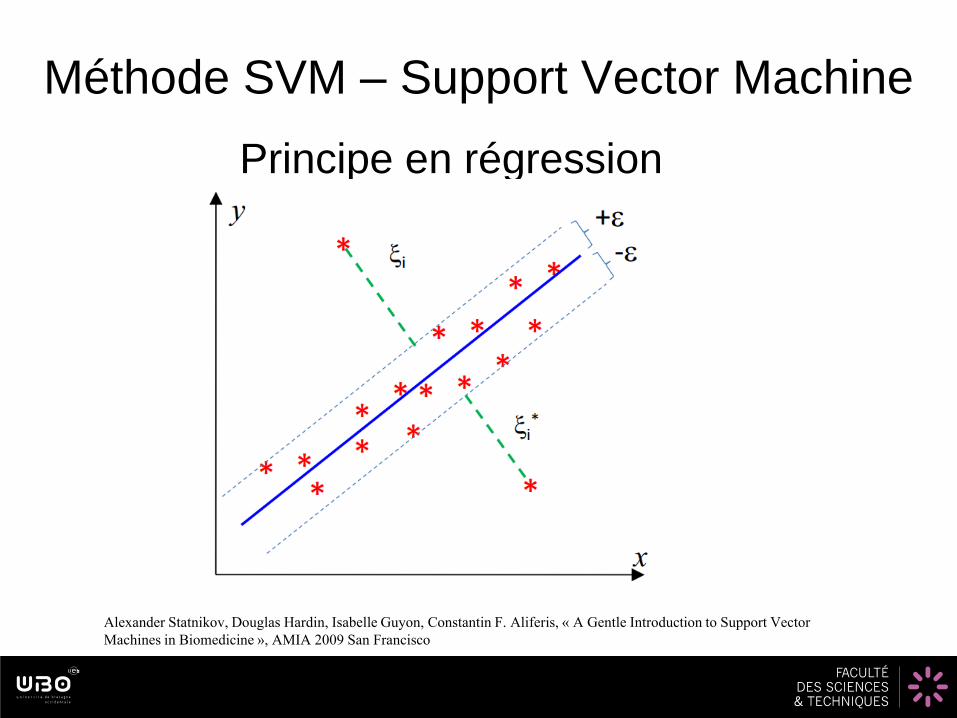
Méthode SVM – Support Vector Machine
Principe en régression
Alexander Statnikov, Douglas Hardin, Isabelle Guyon, Constantin F. Aliferis, « A Gentle Introduction to Support Vector
Machines in Biomedicine », AMIA 2009 San Francisco
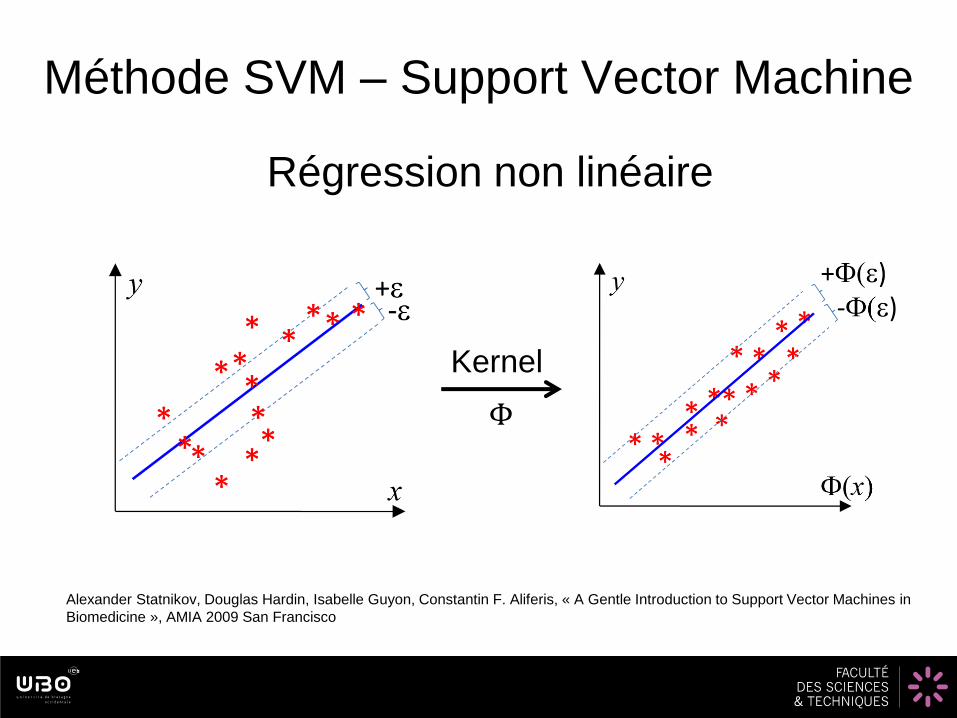
Méthode SVM – Support Vector Machine
Régression non linéaire
Alexander Statnikov, Douglas Hardin, Isabelle Guyon, Constantin F. Aliferis, « A Gentle Introduction to Support Vector Machines in
Biomedicine », AMIA 2009 San Francisco
Kernel
Φ
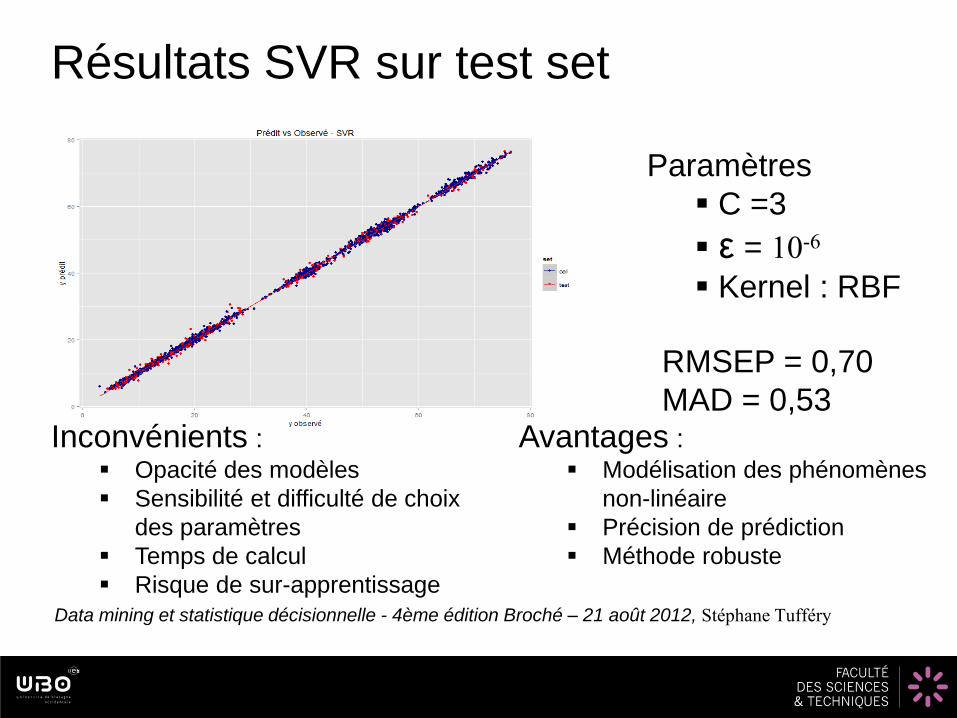
RMSEP = 0,70
MAD = 0,53Inconvénients :
Opacité des modèles
Sensibilité et difficulté de choix
des paramètres
Temps de calcul
Risque de sur-apprentissage
Avantages : Modélisation des phénomènes
non-linéaire
Précision de prédiction
Méthode robuste
Résultats SVR sur test set
Paramètres
C =3
ε = 10-6
Kernel : RBF
Data mining et statistique décisionnelle - 4ème édition Broché – 21 août 2012, Stéphane Tufféry

Comparaison des méthodes sur set de
validation
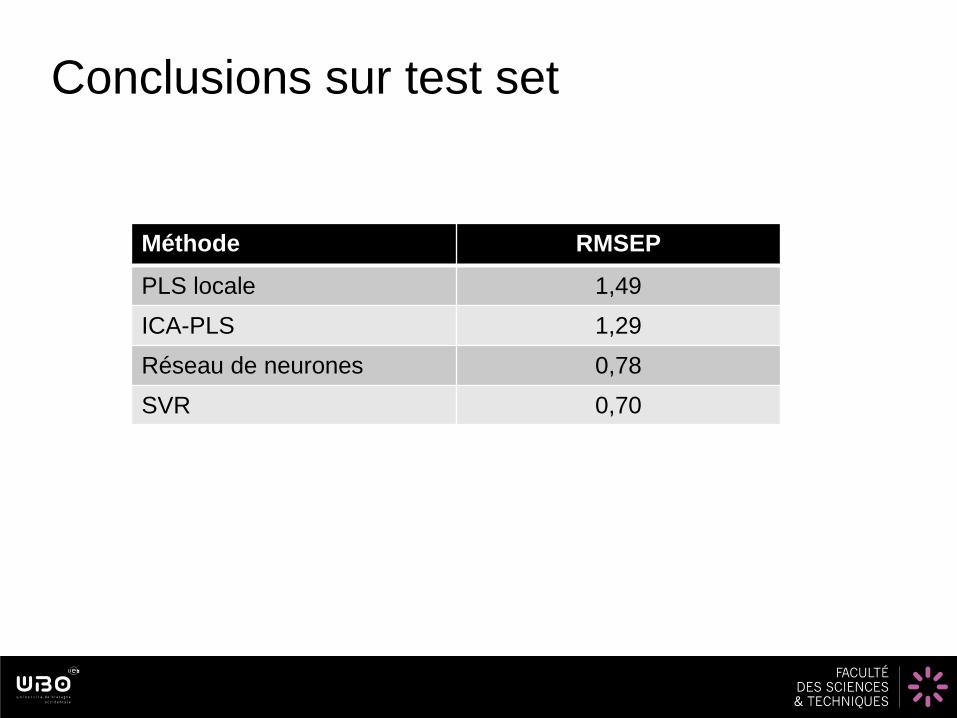
Méthode RMSEP
PLS locale 1,49
ICA-PLS 1,29
Réseau de neurones 0,78
SVR 0,70
Conclusions sur test set