
Base de données relationnelle et requêtes SQL Anne-Marie Cubat 1e partie.

BASES DE DONNÉES
RÉPARTIES
CM1
Master 1
MIF24

MIF37
ORGANISATION DE L’UE
Les groupes de TD (à partir du 13 février)
Groupe A (TD12) : ABDESSALEM GRANDY
Groupe B (TD13) : HONGOIS VILLEDIEU DE TORCY
Evaluations
Contrôle Continu en TD :
CC (29 mai 2018),
TP
TP5
Contrôle Terminal
2

MIF37
POURQUOI DES SGBD ? Garantir certaines propriétés
Au niveau des données
Indépendance du niveau applicatif
Liées à : Redondance, Intégrité, Accès
Au niveau des traitements
Transactions ACID
Permettre le traitement de gros volumes de données
Avec des temps de traitement acceptable
MIF37
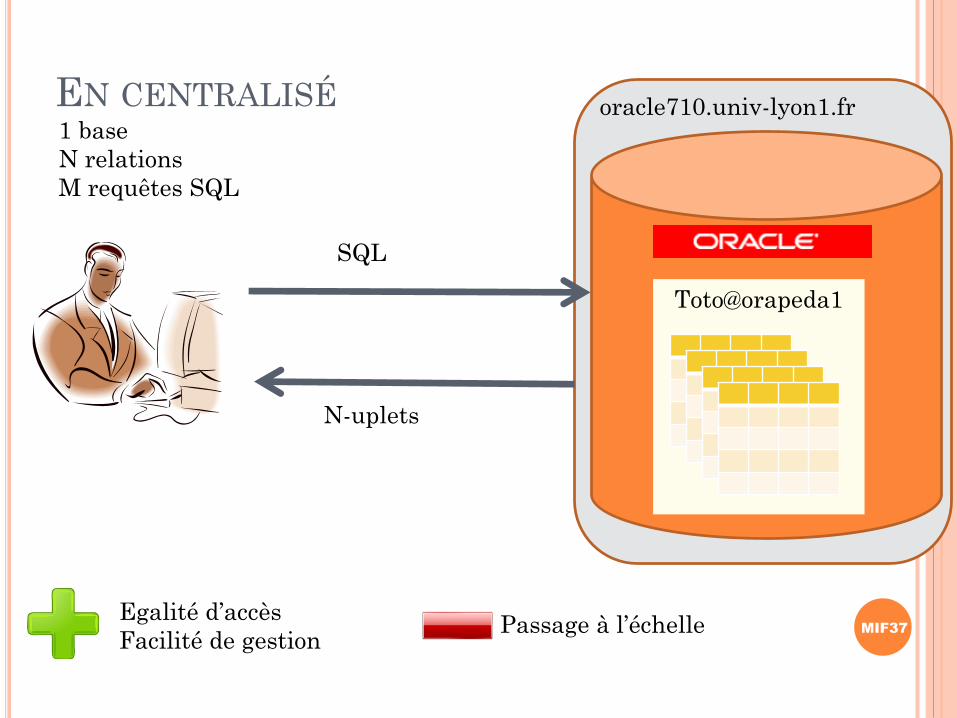
EN CENTRALISÉ
Toto@orapeda1
SQL
N-uplets
1 base
N relations
M requêtes SQL
oracle710.univ-lyon1.fr
Egalité d’accès
Facilité de gestionPassage à l’échelle
MIF37
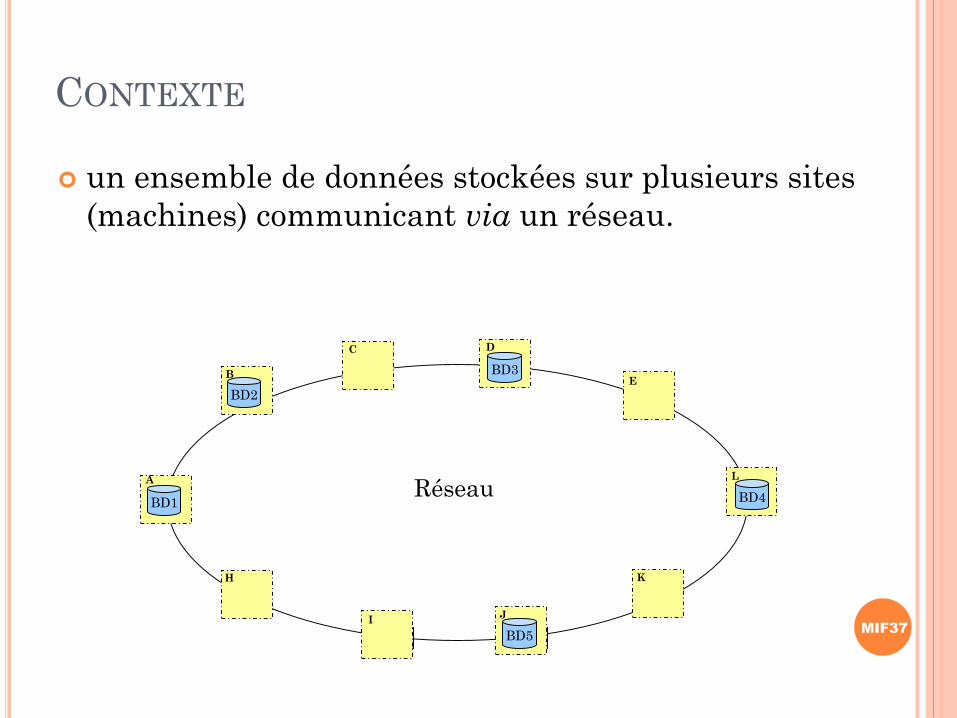
CONTEXTE
un ensemble de données stockées sur plusieurs sites
(machines) communicant via un réseau.
A
B
H
C D
E
I J
K
L
RéseauBD1
BD2
BD3
BD4
BD5
MIF37
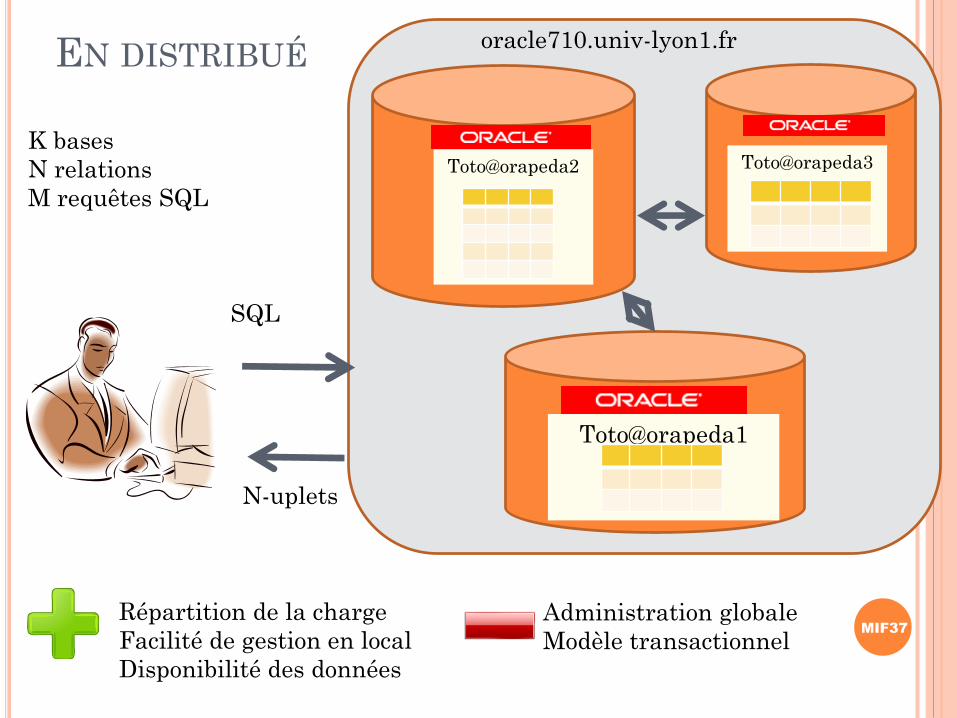
EN DISTRIBUÉ
Toto@orapeda1
SQL
N-uplets
Toto@orapeda2 Toto@orapeda3K bases
N relations
M requêtes SQL
oracle710.univ-lyon1.fr
Répartition de la charge
Facilité de gestion en local
Disponibilité des données
Administration globale
Modèle transactionnel
MIF37
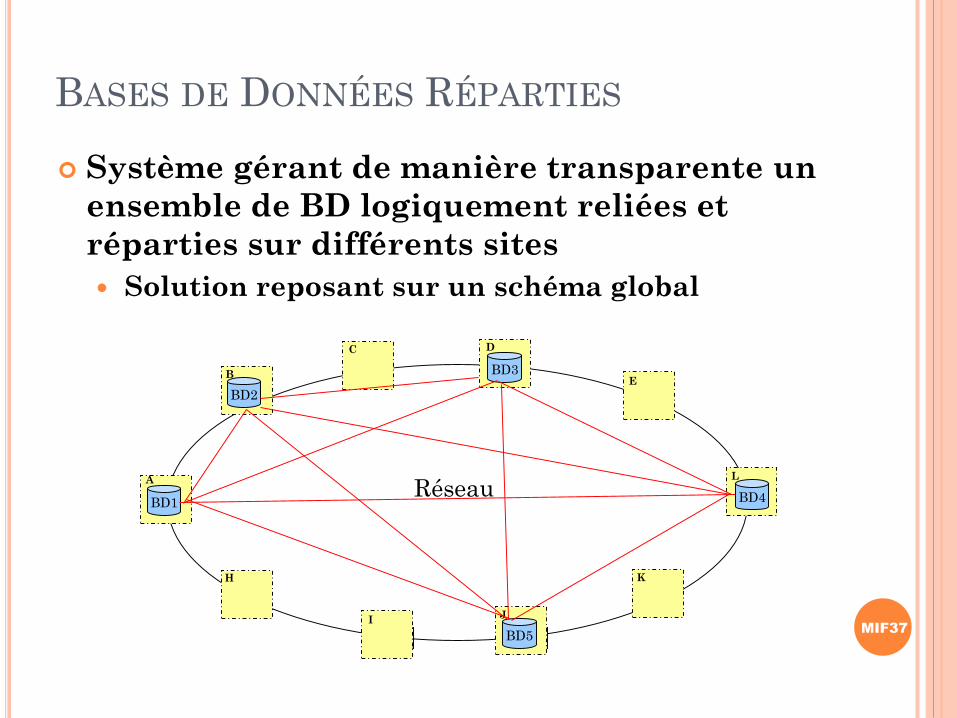
BASES DE DONNÉES RÉPARTIES
Système gérant de manière transparente un
ensemble de BD logiquement reliées et
réparties sur différents sites
Solution reposant sur un schéma global
A
B
H
C D
E
I J
K
L
RéseauBD1
BD2
BD3
BD4
BD5
MIF37
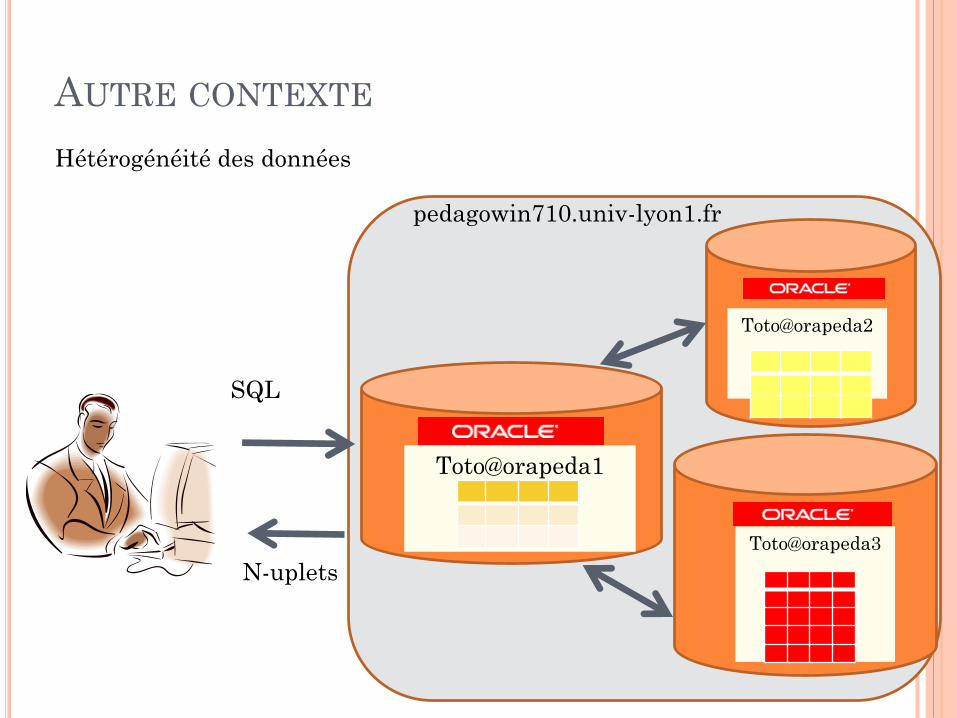
AUTRE CONTEXTE
Toto@orapeda1
SQL
N-uplets
Hétérogénéité des données
Toto@orapeda3
Toto@orapeda2
pedagowin710.univ-lyon1.fr
MIF37
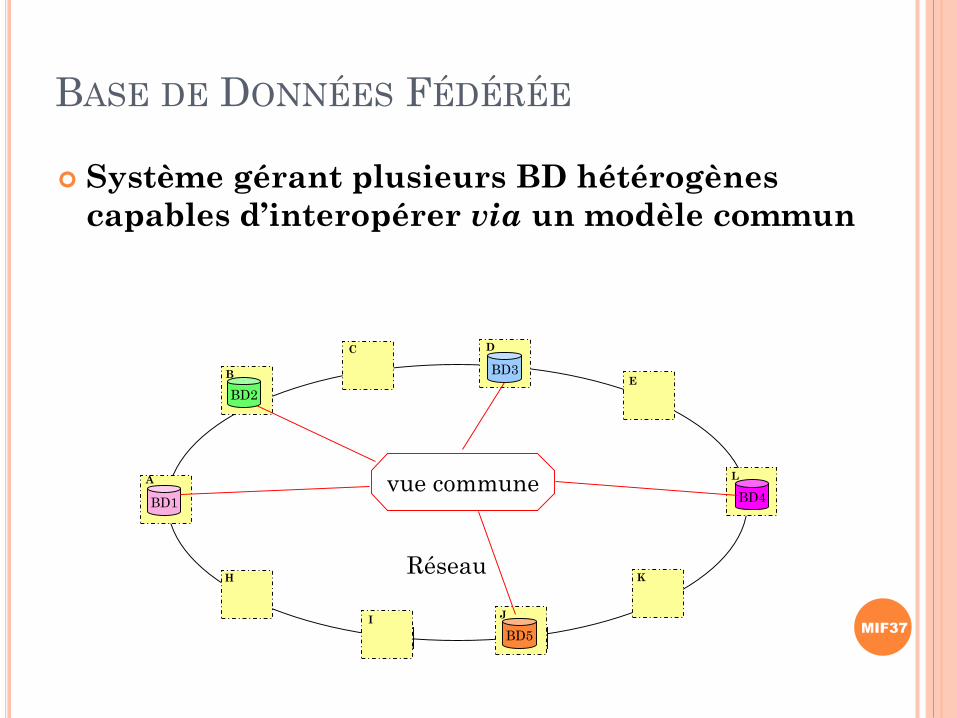
BASE DE DONNÉES FÉDÉRÉE
Système gérant plusieurs BD hétérogènes
capables d’interopérer via un modèle commun
A
B
H
C D
E
I J
K
L
Réseau
BD1
BD2
BD3
BD4
BD5
vue commune
MIF37
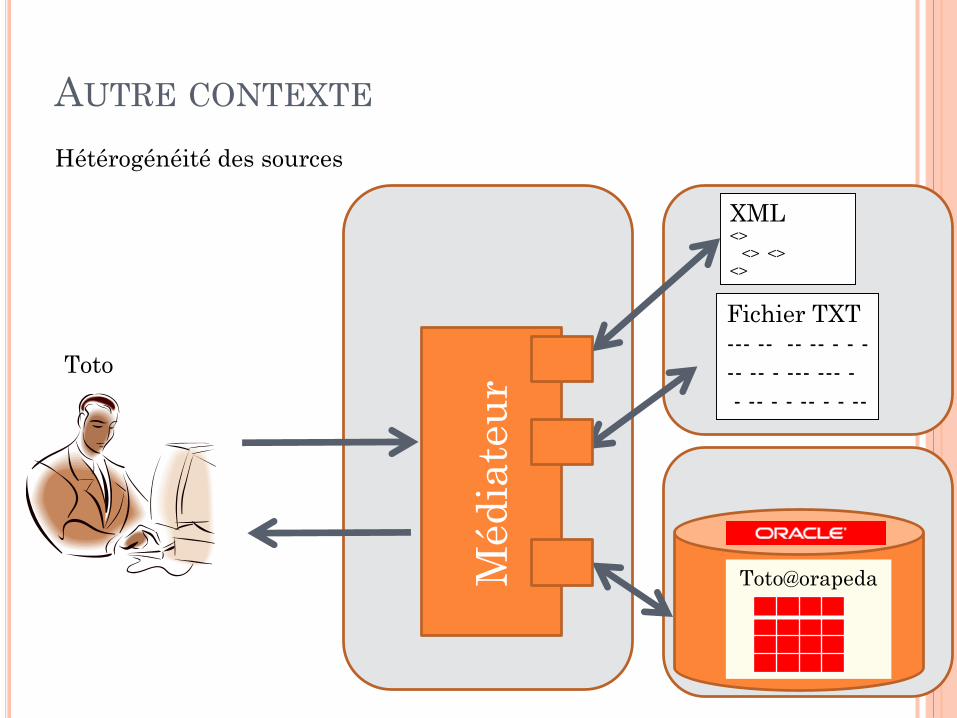
AUTRE CONTEXTE
Toto
Hétérogénéité des sources
Toto@orapeda
1
Méd
iate
ur
XML<>
<> <>
<>
Fichier TXT
--- -- -- -- - - -
-- -- - --- --- -
- -- - - -- - - --
MIF37
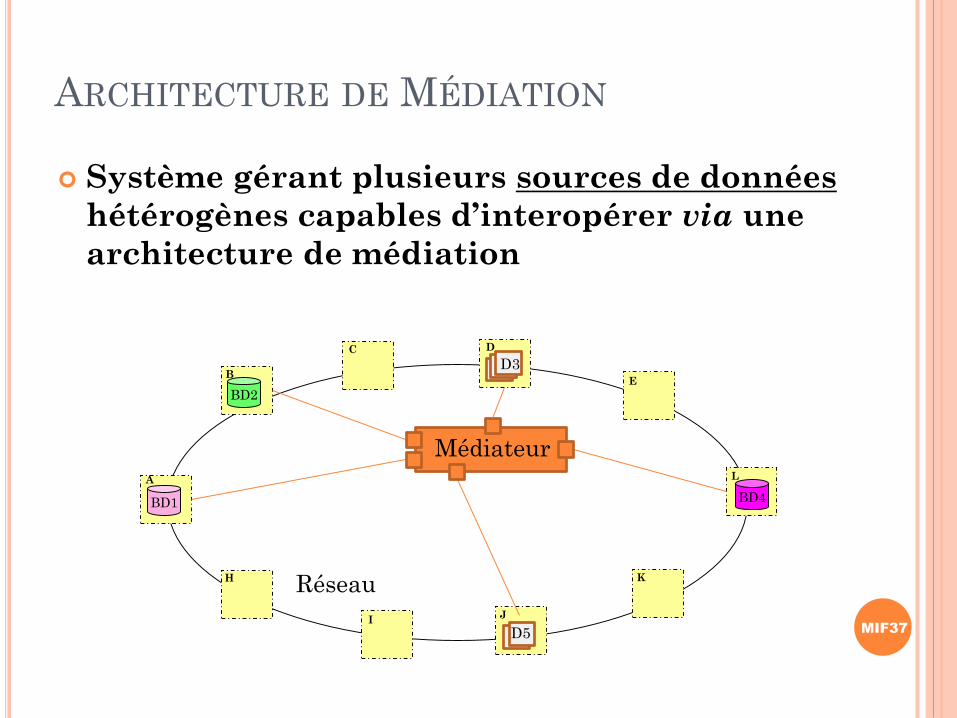
ARCHITECTURE DE MÉDIATION
Système gérant plusieurs sources de données
hétérogènes capables d’interopérer via une
architecture de médiation
A
B
H
C D
E
I J
K
L
Réseau
BD1
BD2
BD4
D3
D5
Médiateur
MIF37
AUTRE CONTEXTE
Passage à l’échelle en termes d’utilisateurs et de nombre de sources
MIF37
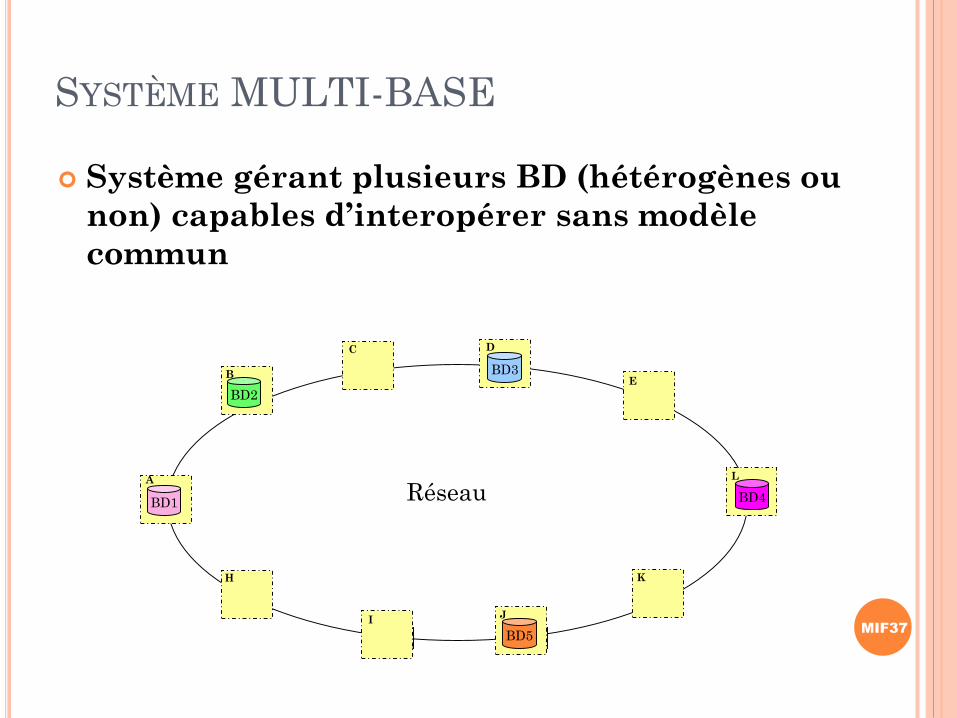
SYSTÈME MULTI-BASE
Système gérant plusieurs BD (hétérogènes ou
non) capables d’interopérer sans modèle
commun
A
B
H
C D
E
I J
K
L
RéseauBD1
BD2
BD3
BD4
BD5
MIF37
AUTRE CONTEXTE
Passage à l’échelle en termes masse de données à traiter
BIG
DATA
MIF37
AUTRE CONTEXTE
Passage à l’échelle en termes masse de données véloces à traiter
Flux de
données
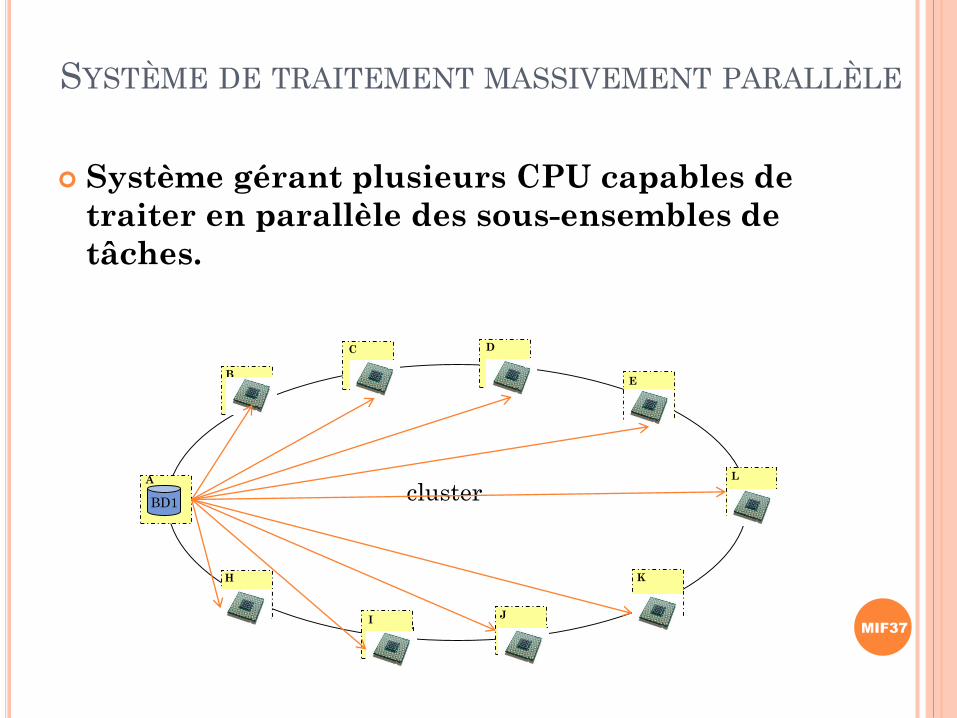
MIF37
SYSTÈME DE TRAITEMENT MASSIVEMENT PARALLÈLE
Système gérant plusieurs CPU capables de
traiter en parallèle des sous-ensembles de
tâches.
A
B
H
C D
E
I J
K
L
clusterBD1

MIF37
PROBLÈME
Quelque soit le contexte, comment offrir aux
utilisateurs une vue sur l’ensemble des données en
faisant abstraction de leur localisation physique ?

MIF37
REFORMULATION DU PROBLÈME
Comment offrir aux utilisateurs une vue sur l’ensemble des données en faisant abstraction de leur localisation physique tout en garantissant de bonnes performances de traitement des requêtes?
Temps de traitement Passage à l’échelle

MIF37
DIFFÉRENTS SCÉNARII POSSIBLES
L’entreprise qui se développe et souhaite ouvrir des filiales à travers le monde
Cas de données jusqu’alors centralisées doivent être réparties sur différents sites
Comment découper logiquement ma base pour répartir les n-uplets sur les différents sites?
L’entreprise A qui rachète l’entreprise B et qui souhaite faire du reporting basé sur l’ensemble des données du groupe.
Cas des données réparties sur différents sites qui doivent être interrogeables depuis n’importe quel site
Comment offrir à l’utilisateur un moyen d’accès transparents à toutes ces données ?

MIF37
DIFFÉRENTS SCÉNARII POSSIBLES
L’entreprise qui voit la quantité de ses données croitre de manière exponentielle avec des latences de plus en plus importantes dans l’interrogation des donnéesCas de traitement de masse de données épuisant les ressources du serveur
Comment garantir un temps de traitement satisfaisant malgré la quantité croissante de données ?
L’entreprise qui a besoin d’interroger différents flux de données Cas traitement de flux parallèle et distribué
Comment maîtriser la qualité des résultats obtenus par l ’interrogation continue de flux de données ?

MIF37
LES CHALLENGES
Challenge 1 :
Comment découper logiquement une base pour répartir
les n-uplets sur différents sites?
Conception
Décomposition d’une base
Interrogation
Optimisation algébrique et physique des requêtes
Modèle transactionnel
Challenge 2 :
Comment offrir à l’utilisateur un moyen d’accès
transparents à un ensemble de données hétérogène?
Conception
Intégration de données

MIF37
LES CHALLENGES
Challenge 3:
Comment garantir les performances de traitements d’un nombre croissant de données ou flux de données
Conception BD parallèles, BD P2P, BD NoSQL
Interrogation Traitement massivement parallèle
Challenge 4 :
Comment maîtriser la qualité des résultats retournés par une requête continue?
Conception Systèmes de gestion de flux parallèles et distribué
Interrogation Exécution continue de workflows d’opérateurs
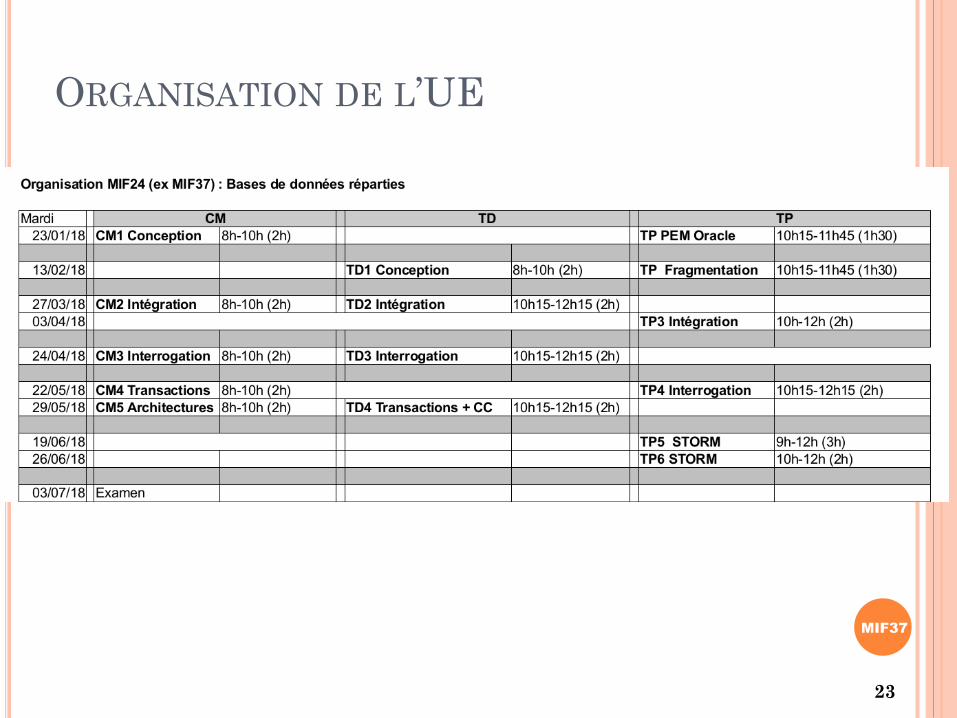
MIF37
ORGANISATION DE L’UE
23

PRÉ-REQUIS :
ALGÈBRE RELATIONNELLE

MIF37
Définition
Une algèbre relationnelle est un ensemble d’opérations agissant sur des relations et produisantdes relations
Opérateurs :<Opérateur><parametres> <Opérande> Résultat>
<Opérande> <Opérateur><parametres> <Opérande> Résultat>
C’est un langage fermé
les opérandes et les résultats sont toujours des relations
ALGÈBRE RELATIONNELLE

MIF37
BREF RAPPEL (OPÉRATEURS
ALGÉBRIQUES)
Pour R et S deux relations
UNION
R S = { t tR ou tS}
INTERSECTION
R S = { t | tR et tS}
DIFFERENCE
R – S={ t tR et tS}
PRODUIT CARTESIEN
R S = {t.A1…Ak1Ak1+1…Ak1+k2
t.A1…Ak1R et t.Ak1+1…Ak1+k2
S }
DIVISION
R ÷ S = {Ak+1,…,Ak+n t. A1,…,Ak,Ak+1,…,Ak+n R et t.A1…AkS avec tous les n-uplets t tels que {t} S R

MIF37
BREF RAPPEL (OPÉRATEURS ALGÉBRIQUES
SPÉCIFIQUES)
Pour R et S deux relations
PROJECTION
A1,…,An(R)={t.A1… An tR}
SELECTION
F(R)={t tR et F(t) est vrai}, F une formule logique sans quantificateur
JOINTURE
R F S = {t.A1…AnB1…Bm t.A1…AnR et t.B1…BmS et F est vraie }
SEMI-JOINTURE
R F S = {t.A1…An t.A1…AnR et t.B1…BmS et F est vraie }
RENOMMAGE
A1/B1,…An/Bn (R)={t tR et A1 renommé en B1, … An renommé en Bn }

MIF37
EXERCICE
Une UFR d’Informatique dispose de la base de données dont le schéma est le suivant :
etudiant( No, Nom, Prenom, Ville, DateNaiss) ;
enseignant( No, Nom, Prenom, Ville, DateNaiss) ;
module( Diplome, NomMod, ObliOp, NoResp) ;
examen( Diplome, Module, Session, Annee, NoEt, Note) .
avec les instances de la forme :
Pour etudiant: {( 1, COURDINFEAU, Ella, Lyon, 1999-02-23) ; …}
Pour enseignant: {(1, SEGNE, Jean, Valence, 1960-06-12) ; …}
Pour module: {( Licence, LIF4, ‘Obligatoire’, 12) ; … }
Pour examen( ‘Licence’, ‘LIF4’, ‘S1’, 2014, 123, 11); … }
Requête :Noms des étudiants lyonnais ayant passé au moins un examen en 2014 et le nom des enseignants lyonnais responsables d’un module obligatoire de Licence

CONCEPTION DE BDR

MIF37
LES CHALLENGES Challenge 1 :
Comment découper logiquement une base pour répartir les n-uplets sur différents sites?
Conception Décomposition d’une base
Interrogation Optimisation algébrique et physique des requêtes
Modèle transactionnel
Challenge 2 :
Comment offrir à l’utilisateur un moyen d’accès transparents à un ensemble de données hétérogène?
Conception Intégration de données
Challenge 3:
Comment garantir les performances de traitements d’un nombre croissant de données
Conception BD parallèles, BD P2P, BD NoSQL
Interrogation Traitement massivement parallèle
MIF37
D’UNE BD CENTRALISÉE À UNE BD DISTRIBUÉE
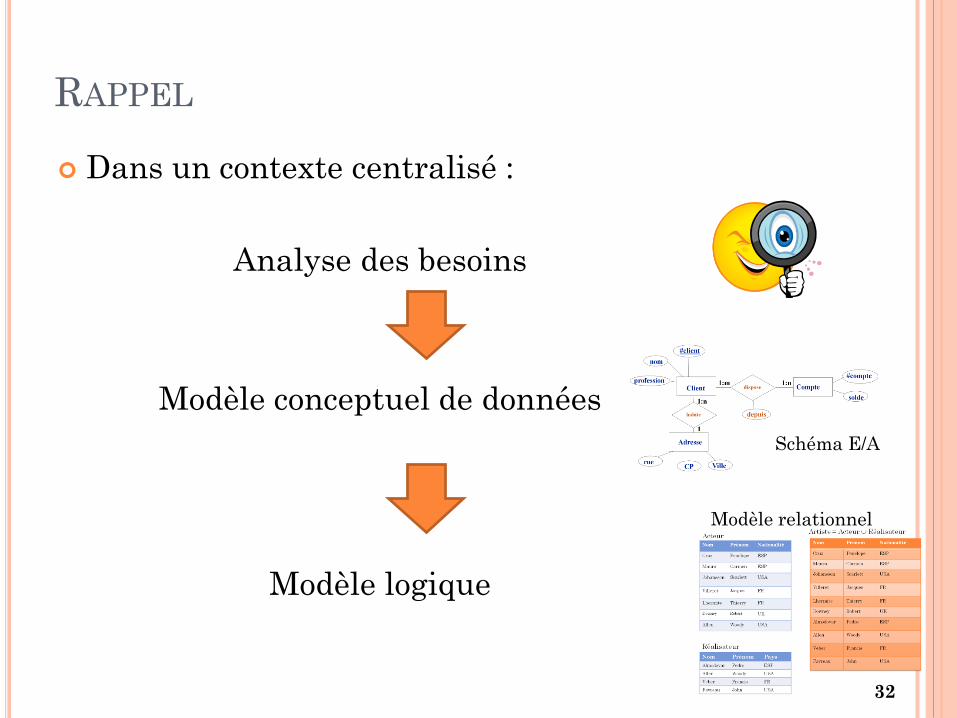
MIF37
RAPPEL
Dans un contexte centralisé :
Analyse des besoins
Modèle conceptuel de données
Modèle logique
32
Schéma E/A
Modèle relationnel
MIF37
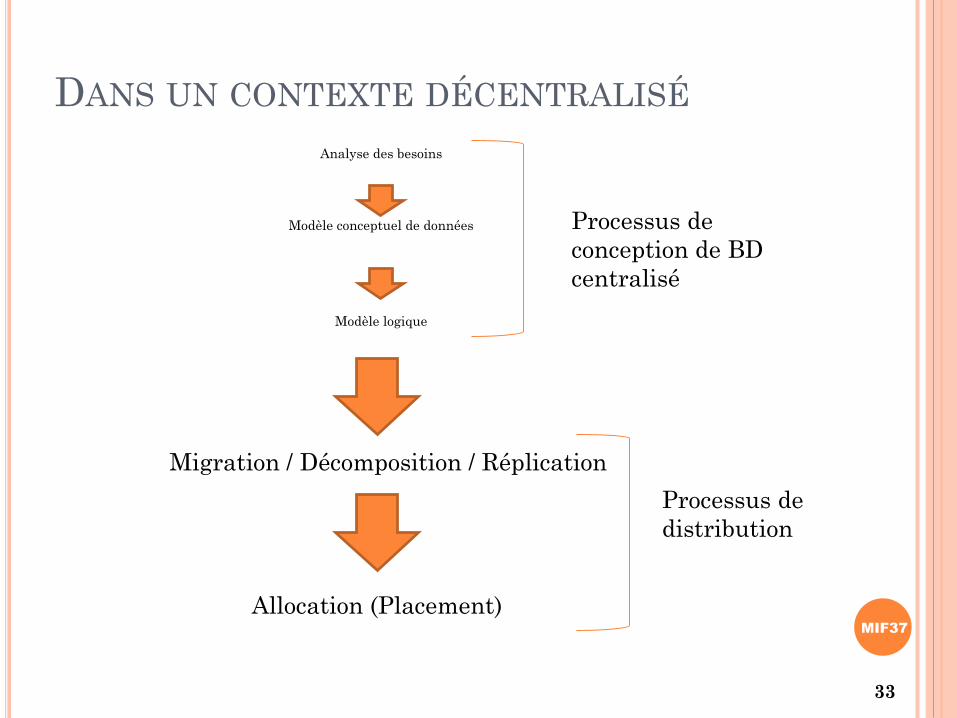
DANS UN CONTEXTE DÉCENTRALISÉ
33
Analyse des besoins
Modèle conceptuel de données
Modèle logique
Processus de
conception de BD
centralisé
Migration / Décomposition / Réplication
Allocation (Placement)
Processus de
distribution

MIF37
SCHÉMA GLOBAL
Le schéma global est constitué : d’un schéma conceptuel global
Contenant la description globale et unifiée de toutes les données de la BDR
Indépendant de la répartition des données
d’un schéma de placement (d’allocation)Contenant les règles de correspondance avec les données
locales
indépendant à la fragmentation et à la réplication
MIF37
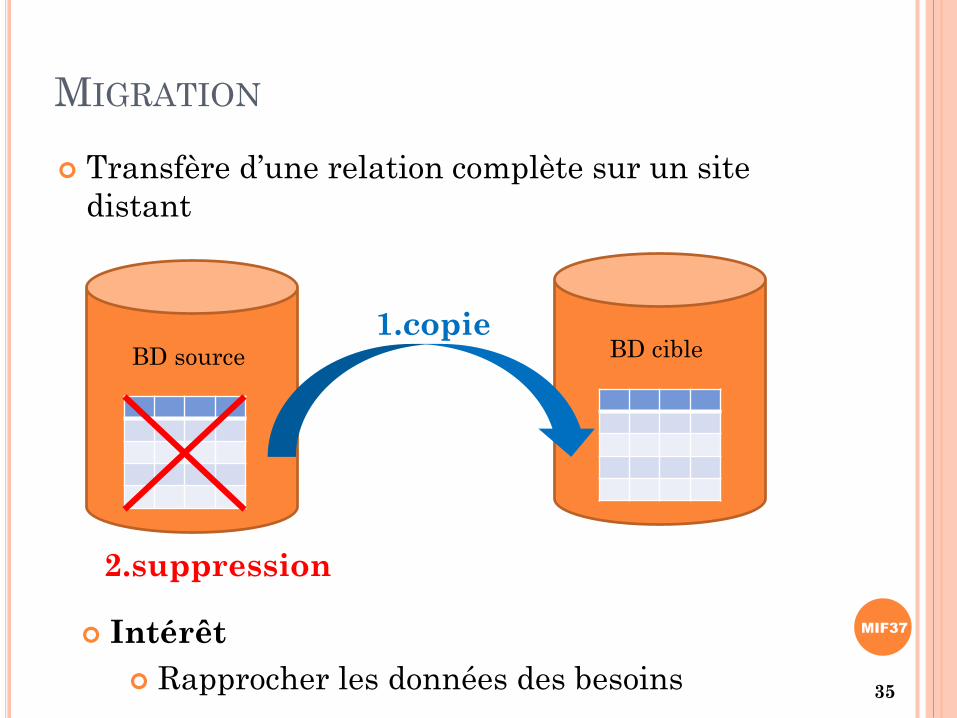
MIGRATION
Transfère d’une relation complète sur un site
distant
35
BD source BD cible1.copie
2.suppression
Intérêt
Rapprocher les données des besoins
MIF37
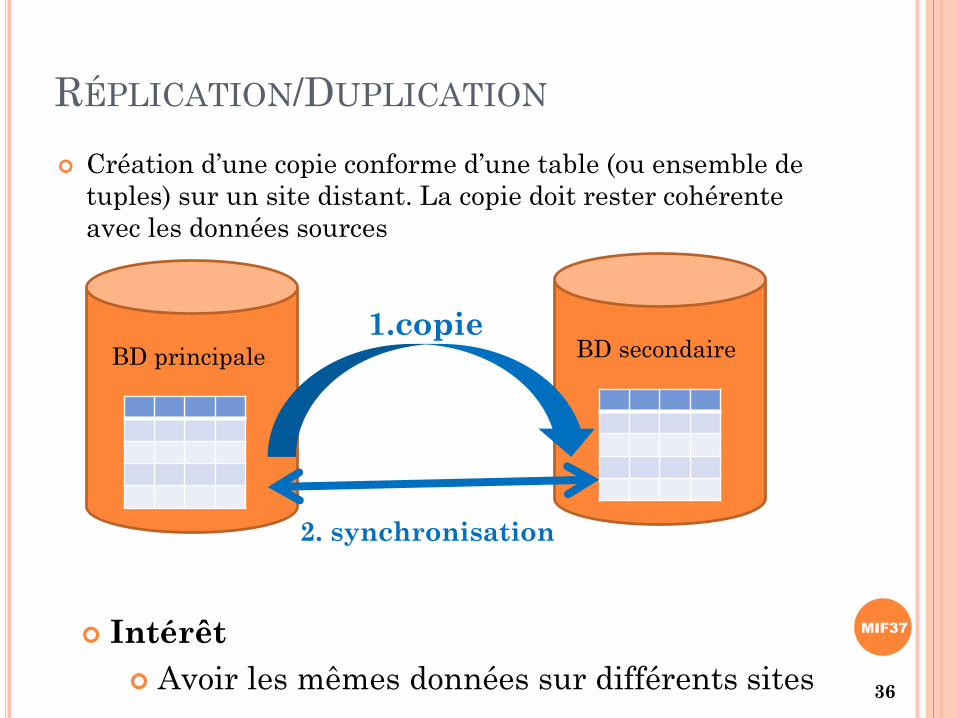
RÉPLICATION/DUPLICATION
Création d’une copie conforme d’une table (ou ensemble de
tuples) sur un site distant. La copie doit rester cohérente
avec les données sources
36
BD principale BD secondaire
2. synchronisation
Intérêt
Avoir les mêmes données sur différents sites
1.copie
MIF37
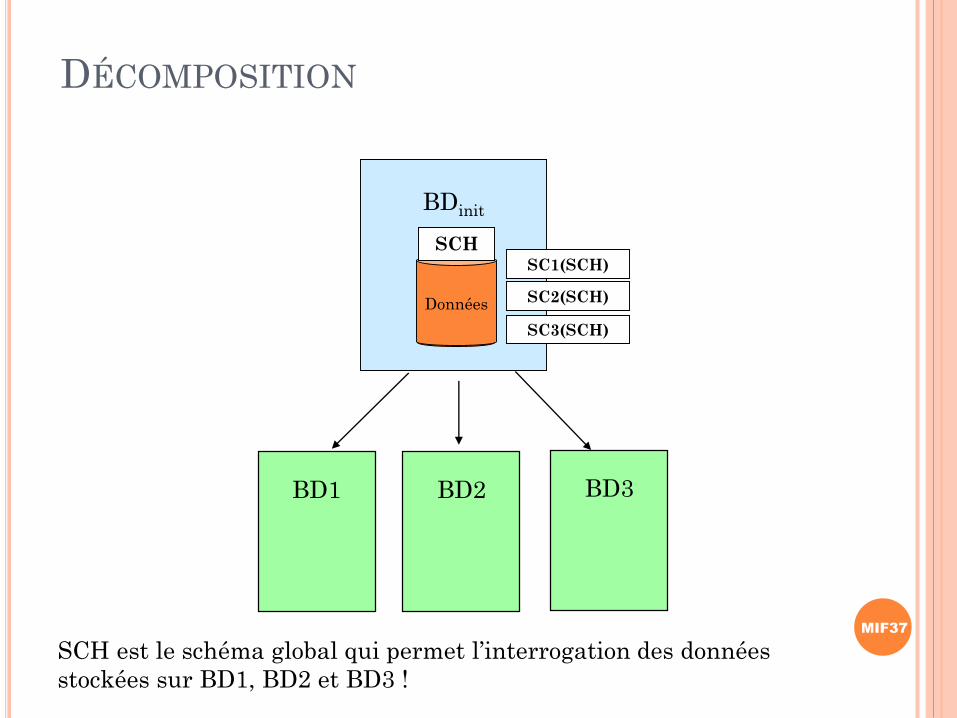
BD1 BD2 BD3
BDinit
{D3}
DÉCOMPOSITION
{D2}
{D1}
Données
SCHSC1(SCH)
SC2(SCH)
SC3(SCH)
SCH est le schéma global qui permet l’interrogation des données
stockées sur BD1, BD2 et BD3 !

MIF37
LES OUTILS POUR DÉCOMPOSER LES DONNÉES
Les différentes fragmentations
Fragmentation horizontale
Fragmentation horizontale dérivée
Fragmentation Verticale
Fragmentation Mixte
Un fragment est une
sélection d’un sous-
ensemble de tuples
Un fragment est une
projection sur un
sous-ensemble
d’attributs
Un fragment est une
composition d’une
fragmentation horizontale
(dérivée) avec une
fragmentation verticale
MIF37
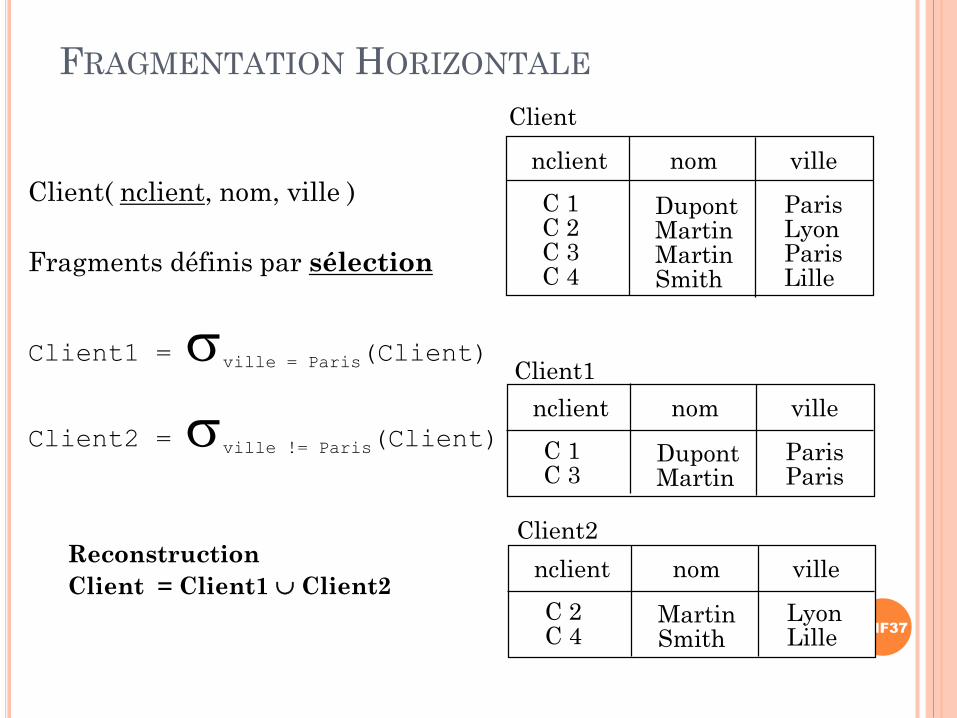
FRAGMENTATION HORIZONTALE
Client( nclient, nom, ville )
Fragments définis par sélection
Client1 = ville = Paris(Client)
Client2 = ville != Paris(Client)
Reconstruction
Client = Client1 Client2
nclient nom ville
C 1C 2C 3C 4
DupontMartinMartinSmith
ParisLyonParisLille
nclient nom ville
C 1C 3
DupontMartin
ParisParis
nclient nom ville
C 2C 4
MartinSmith
LyonLille
Client
Client1
Client2

MIF37
FRAGMENTATION HORIZONTALE DÉRIVÉE
Cde( ncde, #nclient, produit, qté)
Fragments définis par jointure
Cde1 = Cde Client1
Cde2 = Cde Client2
Reconstruction
Cde = Cde1 Cde2
ncde nclient produit
D 1D 2D 3D 4
C 1C 1C 2C 4
P 1P 2P 3P 4
Cde
qté
10205
10
ncde nclient produit
D 1D 2
C 1C 1
P 1P 2
Cde1
qté
1020
ncde nclient produit
D 3D 4
C 2C 4
P 3P 4
Cde2
qté
510
nclient
nclient
MIF37
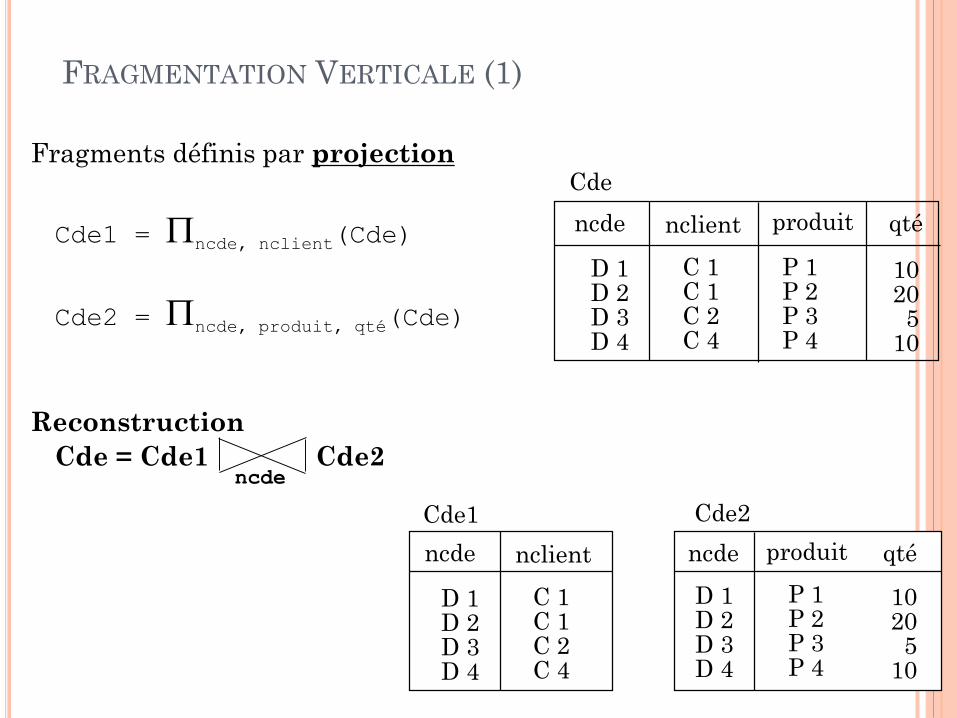
FRAGMENTATION VERTICALE (1)
Fragments définis par projection
Cde1 = ncde, nclient(Cde)
Cde2 = ncde, produit, qté(Cde)
Reconstruction
Cde = Cde1 Cde2
ncde nclient produit
D 1D 2D 3D 4
C 1C 1C 2C 4
P 1P 2P 3P 4
Cde
qté
10205
10
ncde nclient
D 1D 2D 3D 4
C 1C 1C 2C 4
Cde1
P 1P 2P 3P 4
10205
10
D 1D 2D 3D 4
produit qté
ncde
ncde
Cde2
MIF37
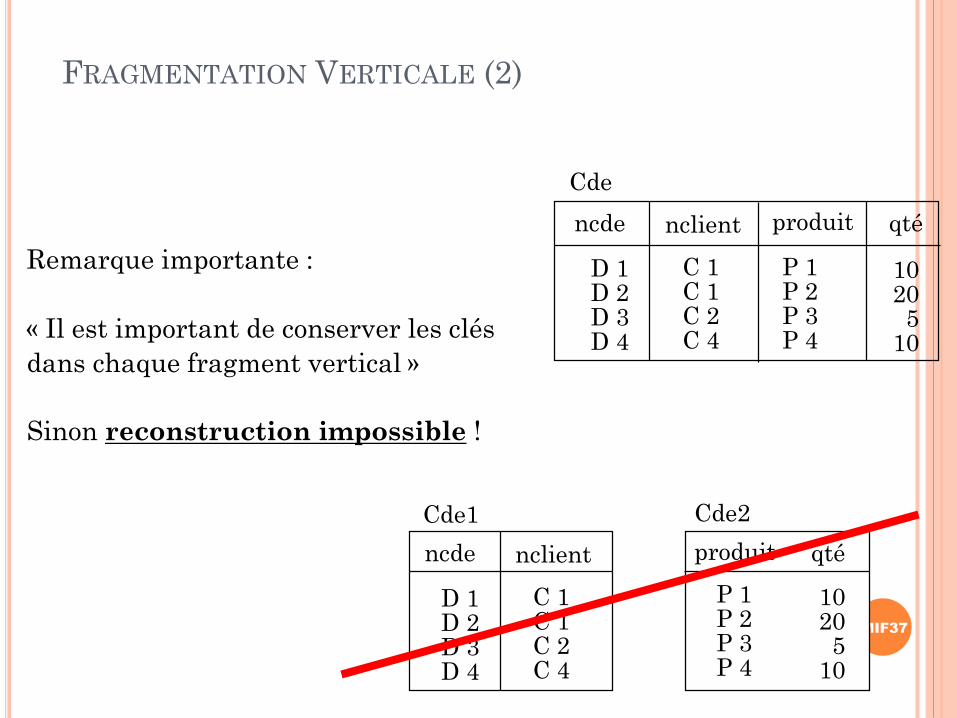
FRAGMENTATION VERTICALE (2)
Remarque importante :
« Il est important de conserver les clés
dans chaque fragment vertical »
Sinon reconstruction impossible !
ncde nclient produit
D 1D 2D 3D 4
C 1C 1C 2C 4
P 1P 2P 3P 4
Cde
qté
10205
10
ncde nclient
D 1D 2D 3D 4
C 1C 1C 2C 4
Cde1 Cde2
P 1P 2P 3P 4
10205
10
produit qté
MIF37
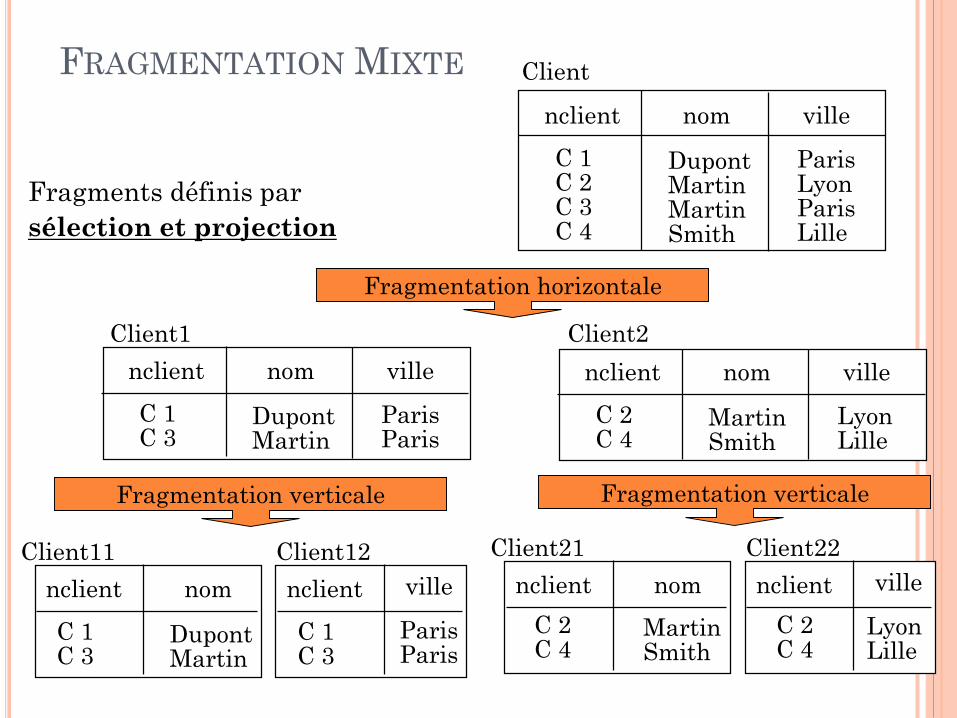
FRAGMENTATION MIXTE
Fragments définis par
sélection et projection
nclient nom ville
C 1C 2C 3C 4
DupontMartinMartinSmith
ParisLyonParisLille
nclient nom ville
C 1C 3
DupontMartin
ParisParis
nclient nom ville
C 2C 4
MartinSmith
LyonLille
Client
Client1 Client2
Fragmentation horizontale
Fragmentation verticale Fragmentation verticale
nclient nom
C 1C 3
DupontMartin
Client11
nclient ville
C 1C 3
ParisParis
Client12
nclient nom
Client21
nclient ville
Client22
C 2C 4
C 2C 4
MartinSmith
LyonLille

MIF37
FRAGMENTATION CORRECTE
Si R=(A1,…,Ak) est la table globale initiale, la fragmentation est dite correcte si elle est :
Complète
chaque élément de R doit se trouver dans un fragment
Reconstructible
on doit pouvoir recomposer R à partir de ses fragments
Disjointe
chaque élément de R (hormis les clés) ne doit pas être dupliqué
MIF37
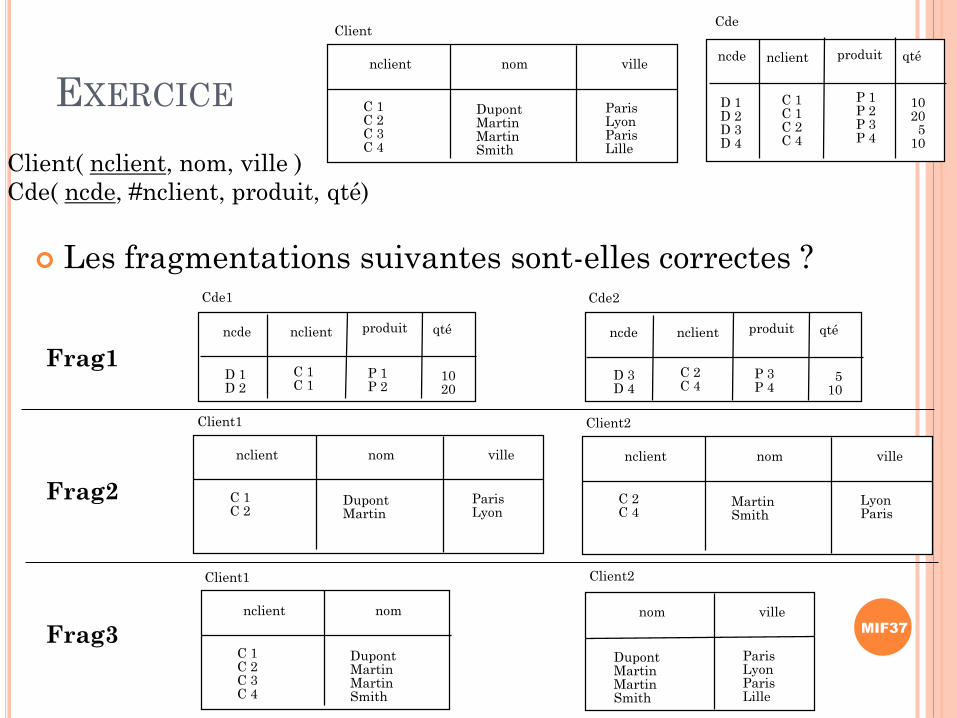
EXERCICE
Les fragmentations suivantes sont-elles correctes ?
nclient nom ville
C 1C 2C 3C 4
DupontMartinMartinSmith
ParisLyonParisLille
Client
ncde nclient produit
D 1D 2
C 1C 1
P 1P 2
Cde1
qté
1020
ncde nclient produit
D 3D 4
C 2C 4
P 3P 4
Cde2
qté
510
ncde nclient produit
D 1D 2D 3D 4
C 1C 1C 2C 4
P 1P 2P 3P 4
Cde
qté
10205
10
nclient nom
C 1C 2C 3C 4
DupontMartinMartinSmith
Client1
nom ville
DupontMartinMartinSmith
ParisLyonParisLille
Client2
nclient nom ville
C 1C 2
DupontMartin
ParisLyon
Client1
nclient nom ville
C 2C 4
MartinSmith
LyonParis
Client2
Client( nclient, nom, ville )
Cde( ncde, #nclient, produit, qté)
Frag1
Frag2
Frag3

MIF37
FAIRE DU ‘SHARDING’, C’EST QUOI ?
Un nouveau concept? NON
Un concept à la mode ? OUI
Stockage et indexation de grandes masses de données
Sharding framentation horizontale
Intérêt du sharding
Toutes les données ne peuvent être stockées sur un seul serveur
La capacité en mémoire du serveur ne permet pas de garantir un
service satisfaisant
Le volume de mise à jour des données est trop important
46

MIF37
MÉTHODOLOGIES DE FRAGMENTATION
Approche orientée données Selon un ensemble d’hypothèses :
Informations sur les contraintes de placement
Approche orientée requêtes : Informations sur les requêtes généralement posées

MIF37
EXEMPLE DE FRAGMENTATION ORIENTÉE DONNÉES
Contexte
On considère une base de données comprenant la table:
ETUDIANT (numE, nomE, pnomE, numC)
VACATAIRE (numV, nomV, pnomV)
CENTRE (numC, villeC, adrC, telC, zoneC)
FORMATION( numC, numF, nomF, nbHeure, numV, coutF, rentabilitéF)
avec : zoneC {‘Nord’, ‘Est’, ‘Sud’ , ‘Ouest’}
Sites géographiques : ‘Paris’, ‘Lyon’, ‘Marseille’, ‘Bordeaux’
Hypothèses
H1 : Paris gère les centres du nord de la France, Lyon les centres de la zone Est, Marseille les centres de zone sud et Bordeaux les centres de la zone Ouest.
H2 : Chaque centre gère ses étudiants
H3 : Les vacataires délivrent des formations dans tous les centres
H4 : Les informations sur les formations sont gérées à Paris, hormis les informations liées au coût et à la rentabilité qui sont stockées à Lyon

MIF37
CENTRE (numC, villeC, adrC, telC, zoneC)
avec : zoneC {‘Nord’, ‘Est’, ‘Sud’ , ‘Ouest’}
H1 : Paris gère les centres du nord de la France, Lyon les centres de la zone Est,
Marseille les centres de zone sud et Bordeaux les centres de la zone Ouest.
CentreParis = zoneC = ‘Nord’(Centre)
CentreLyon = zoneC = ‘Est’(Centre)
CentreMarseille = zoneC = ‘Sud’(Centre)
CentreBordeaux = zoneC = ‘Ouest’(Centre)
FRAGMENTATION HORIZONTALE de CENTRE
EXEMPLE DE FRAGMENTATION ORIENTÉE DONNÉES

MIF37
ETUDIANT (numE, nomE, pnomE, numC)
H2 : Chaque centre gère ses étudiants
EtudiantParis = Etudiant CentreParis
EtudiantLyon = Etudiant CentreLyon
EtudiantMarseille = Etudiant CentreMarseille
EtudiantBordeaux = Etudiant CentreBordeaux
numC
numC
numC
numC
FRAGMENTATION HORIZONTALE de ETUDIANT DERIVEE de CENTRE
EXEMPLE DE FRAGMENTATION ORIENTÉE DONNÉES

MIF37
VACATAIRE (numV, nomV, pnomV)
H3 : Les vacataires délivrent des formations dans tous les centres
REPLICATION de VACATAIRE
VacataireParis = Vacataire
VacataireLyon = Vacataire
VacataireMarseille = Vacataire
VacataireBordeaux = Vacataire
EXEMPLE DE FRAGMENTATION ORIENTÉE DONNÉES

MIF37
FORMATION( numC, numF, nomF, nbHeure, numV, coutF, rentabilitéF)
H4 : Les informations sur les formations sont gérées à Paris, hormis les
informations liées au coût et à la rentabilité qui sont stockées à Lyon
FRAGMENTATION VERTICALE de FORMATION
FormationParis = numC, numF, nomF, nbHeure, numV (Formation)
FormationLyon = numC, numF, coutF, rentabilitéF(Formation)
FormationMarseille =
FormationBordeaux =
EXEMPLE DE FRAGMENTATION ORIENTÉE DONNÉES

MIF37
MÉTHODOLOGIES DE FRAGMENTATION
Approche orientée données Selon un ensemble d’hypothèses :
Informations sur les contraintes de placement
Approche orientée requêtes : Informations sur les requêtes généralement posées

MIF37
EXEMPLE DE FRAGMENTATION ORIENTÉE REQUÊTES
Requêtes les plus souvent formulées
R1 : SELECT nomE, pnomE FROM ETUDIANT WHERE numC = 1 ;
R2 : SELECT pnomE FROM ETUDIANT WHERE nomE LIKE '%R%' ;
R3 : SELECT numE FROM ETUDIANT WHERE pnomE = "Jean" AND numC = 2 ;
Solution
1- Fragmentation horizontale
Exploitation des clauses WHERE des requêtes
1.1. Formalisation
A : numC = 1
B : nomE LIKE '%R%'
C : pnomE = "Jean"
D : numC = 2 : A
Expression des clauses where des requêtes en fonction de A,B,C et D :
C1 : A
C2 : B
C3 : C D = C A

MIF37
Solution (suite)
1.2. Identification des fragments potentiels
Expression des combinaisons possibles
1) C1C2C3
2) C1C2C3
3) C1C2C3
4) C1C2C3
5) C1C2C3
6) C1C2C3
7) C1C2C3
8) C1C2C3
Expression en
fonction de A, B, C
1) A B (C A) =
2) A B
3) A B (C A) =
4) A B
5) A B C
6) A B C
7) A B C
8) A B C
6 fragments horizontaux
Simplification
EXEMPLE DE FRAGMENTATION ORIENTÉE REQUÊTES

numE nomE pnomE numC
1 DUPONT Jean 1
3 DUBOIS Robert 1
4 DUBALAI Aline 1
numE nomE pnomE numC
8 DURALUMIN Roberte 1
10 DURALEX Jean 1
numE nomE pnomE numC
9 DURDUR Jean 2
numE nomE pnomE numC
6 DURAND Aline 2
7 DURACUIRE Robert 2
numE nomE pnomE numC
5 DUGENOU Jean 2
numE nomE pnomE numC
2 DUPOND Jeanne 2
F1 : A B
F2 : A ¬B
F3 : A B C
F4 : A B C
F5 : A B C
F6 : A B C
Solution (suite)
1.3. Définition des fragments horizontaux
EXEMPLE DE FRAGMENTATION ORIENTÉE REQUÊTES

MIF37
Rappel R1 : SELECT nomE, pnomE FROM ETUDIANT WHERE numC = 1 ;
R2 : SELECT pnomE FROM ETUDIANT WHERE nomE LIKE '%R%' ;
R3 : SELECT numE FROM ETUDIANT WHERE pnomE = "Jean" AND numC = 2 ;
Univers U = {numE, nomE, pnomE, numC}
Solution (suite)
2- Fragmentation verticale
Exploitation des clauses SELECT des requêtes
2.1. Formalisation
On considère les projections suivantes :
P1 = nomE, pnomE pour R1
P2 = pnomE pour R2
P3 = numE pour R3
Et leurs duals :
~P1 = numE, numC
~P2 = numE,nomE,numC
~P3 = nomE,pnomE,numC
Construction d’un dual :
~Pi = U - Pi
Calcul des Intersections de
Projection 57
EXEMPLE DE FRAGMENTATION ORIENTÉE REQUÊTES

MIF37
INTERSECTIONS DE PROJECTION : IP
Intersection de projection pour une requête satisfaite
Soit F un fragment satisfaisant R1 de projection P1
IP = { (P1) , (~P1) }
Intersection de projection pour deux requêtes satisfaites
Soit F un fragment satisfaisant R1 de projection P1 et R2 de projection P2
IP = { (P1 P2) , (~P1 P2), (P1 ~P2), (~P1 ~P2) }
Généralisation à un fragment satisfaisant n requêtes
attributs utiles pour R1 et R2 attributs utiles pour R2 attributs utiles pour R1 attributs inutiles pour R1 et R2
IP = { Pj* | Pj* = Pj ou ~Pj }58
Attributs utiles pour R1 Attributs inutiles pour R1
n
j=1

MIF37
Solution (suite)
2.2. Construction des intersections de projection Pour F1 (satisfaisant R1 et R2):
On a : IP1= { P1P2, P1~P2, ~P1P2, ~P1~P2}
IP1= {(pNomE), (nomE), (), (numE, numC) }
Pour F2 (satisfaisant R1) :
On a : IP2= {P1, ~P1 }
IP2= { (nomE , pnomE), (numE , numC) }
Pour F3 (satisfaisant R2 et R3):
On a : IP3= { P2P3, P2~P3, ~P2P3, ~P2~P3}
IP3= {(), (pNomE), (numE), (numC, nomE) }
Pour F4 (satisfaisant R2) :
On a : IP4= {P2, ~P2 }
IP4= {(pnomE), (numE,nomE,numC) }
Pour F5 (satisfaisant R3):
On a : IP5= {P3, ~P3 }
IP5= {(numE), ( nomE,pnomE,numC)]
Pour F6 (satisfaisant personne) :
Ce fragment n’intéresse personne, il est donc inutile de le fragmenter verticalement
EXEMPLE DE FRAGMENTATION ORIENTÉE REQUÊTES

MIF37
Solution (suite)
2.3. Construction des fragments verticaux
Pour chaque élément d’un IP, ajouter la clé si elle n’existe pas déjà et définir
la projection
Pour F1 (satisfaisant R1 et R2):
On a : IP1= {(pNomE), (nomE), (), (numE, numC) }
Pour F2 (satisfaisant R1) :
On a : IP1= { (nomE , pnomE), (numE , numC) }
Pour F3 (satisfaisant R2 et R3):
On a: IP3= {(), (pNomE), (numE), (numC, nomE) }
F11 = numE, pnomE (F1)
F12 = numE, nomE (F1)
F13 = numE, numC (F1)
F21 = numE, nomE,pnomE (F2)
F22 = numE, numC (F2)
F31 = numE,pnomE (F3)
F32 = numE (F3)
F33 = numE, nomE, numC (F3)
60
EXEMPLE DE FRAGMENTATION ORIENTÉE REQUÊTES

MIF37
Solution (suite)
Pour F4 (satisfaisant R2) :
On a : : IP4= {(pnomE), (numE,nomE,numC) }
Pour F5 (satisfaisant R3):
On a : : IP5= {(numE), ( nomE,pnomE,numC)]
Pour F6 (satisfaisant personne) :
Ce fragment n’intéresse personne, il est donc inutile de le fragmenter verticalement
F41 = numE, pnomE (F4)
F42 = numE,nomE,numC (F4)
F51 = numE (F5)
F52 = numE, nomE,pnomE,numC (F5)
61
EXEMPLE DE FRAGMENTATION ORIENTÉE REQUÊTES
MIF37
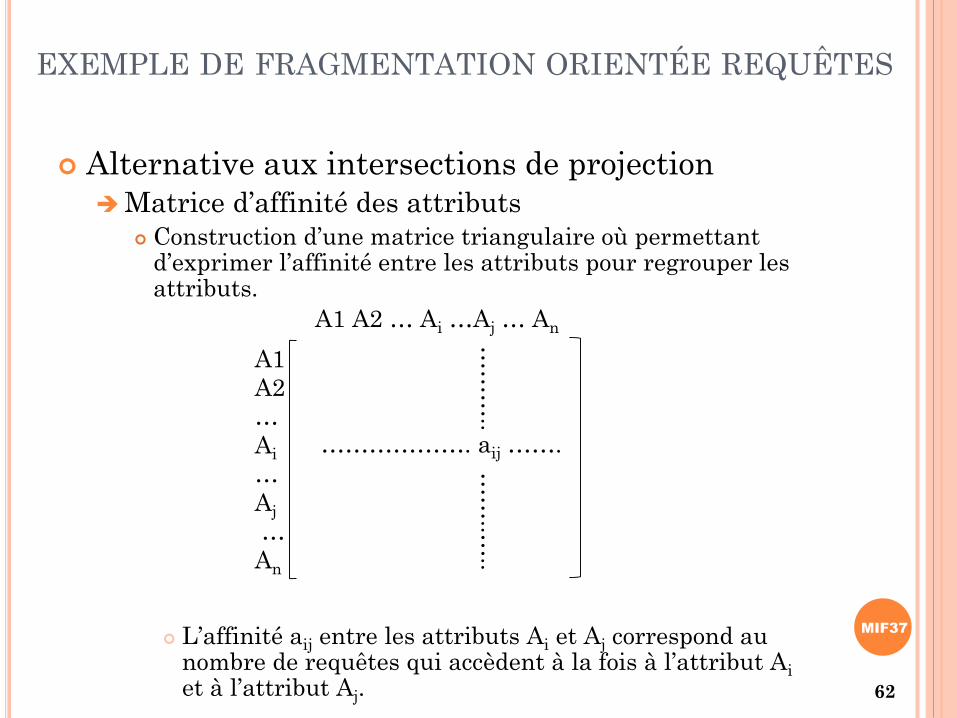
Alternative aux intersections de projection
Matrice d’affinité des attributs Construction d’une matrice triangulaire où permettant
d’exprimer l’affinité entre les attributs pour regrouper les attributs.
L’affinité aij entre les attributs Ai et Aj correspond au nombre de requêtes qui accèdent à la fois à l’attribut Ai
et à l’attribut Aj. 62
EXEMPLE DE FRAGMENTATION ORIENTÉE REQUÊTES
A1 A2 … Ai …Aj … An
A1
A2
…
Ai
…
Aj
…
An
………………. aij …….…
……
..…
…..…
..
MIF37
MÉTHODOLOGIES DE FRAGMENTATION
Approche orientée données Selon un ensemble d’hypothèses :
Informations sur les contraintes de placement
Approche orientée requêtes : Informations sur les requêtes généralement posées
Gestion de l’allocation :
Fragments non répliqués
Fragments répliqués

MIF37
RETOUR SUR LA RÉPLICATION
Principe Créer des copies conforme de tables (fragments) stockées sur des sites
distants qui se synchroniseront en fonction des mises à jours.
Objectif Améliorer la disponibilité des données en local
Règle :
La réplication est avantageuse s’il y a plus de lectures que d’écritures
Avantages/InconvénientsAccès simplifié, plus performant pour les lectures
Résistance aux pannes
Possibilité de parallélisme des calculs
Temps de traitement des mises à jour
Gestion de la cohérence des données
MIF37
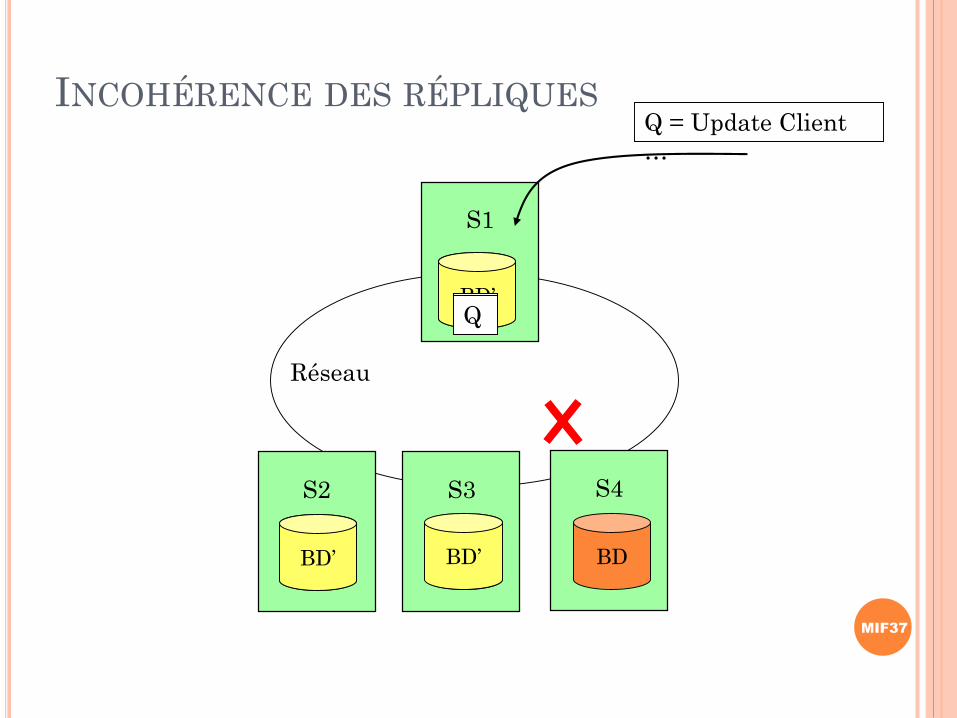
INCOHÉRENCE DES RÉPLIQUES
S2 S3 S4
S1
BD
BD BD BD
Q = Update Client
…
BD’QQQ
BD’ BD’
Réseau

MIF37
FONCTIONS D'UN RÉPLICATEUR
Définition des objets répliqués
table cible = sous-ensemble horizontal et/ou vertical d'une ou
plusieurs tables
Définition de la fréquence de rafraichissement
immédiat (après mise à jour des tables primaires)
à intervalles réguliers (heure, jour, etc.)
à partir d'un événement produit par l'application
Rafraichissement
complet ou partiel (propagation des modifications)
push (primaire secondaires) ou pull (secondaires primaire)
MIF37
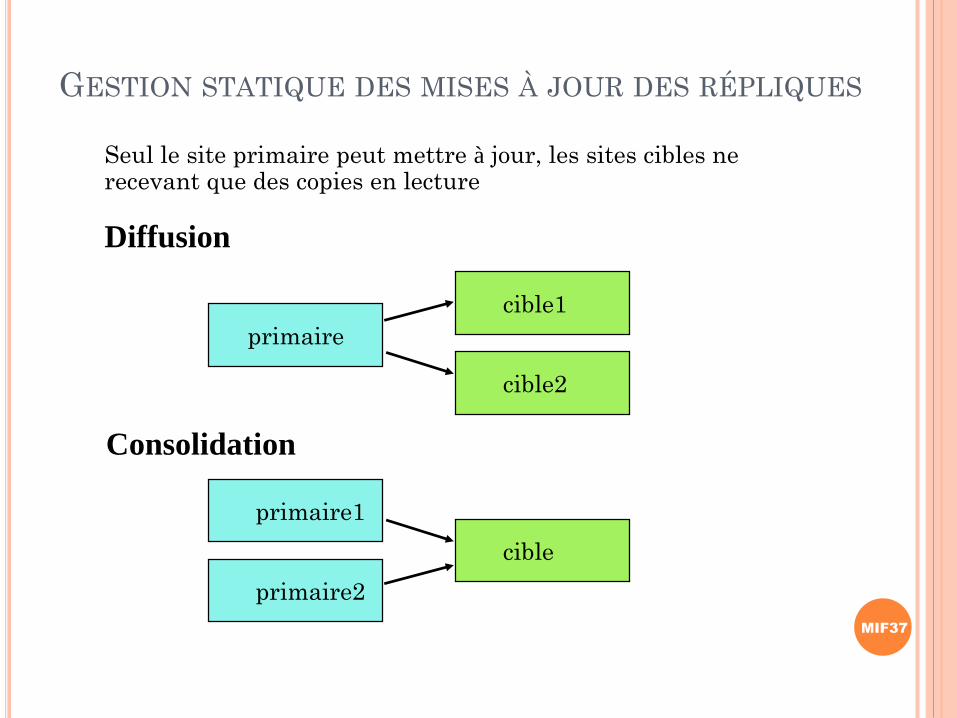
GESTION STATIQUE DES MISES À JOUR DES RÉPLIQUES
primaire
Seul le site primaire peut mettre à jour, les sites cibles ne recevant que des copies en lecture
Diffusion
cible1
cible2
Consolidation
primaire1
primaire2
cible
MIF37
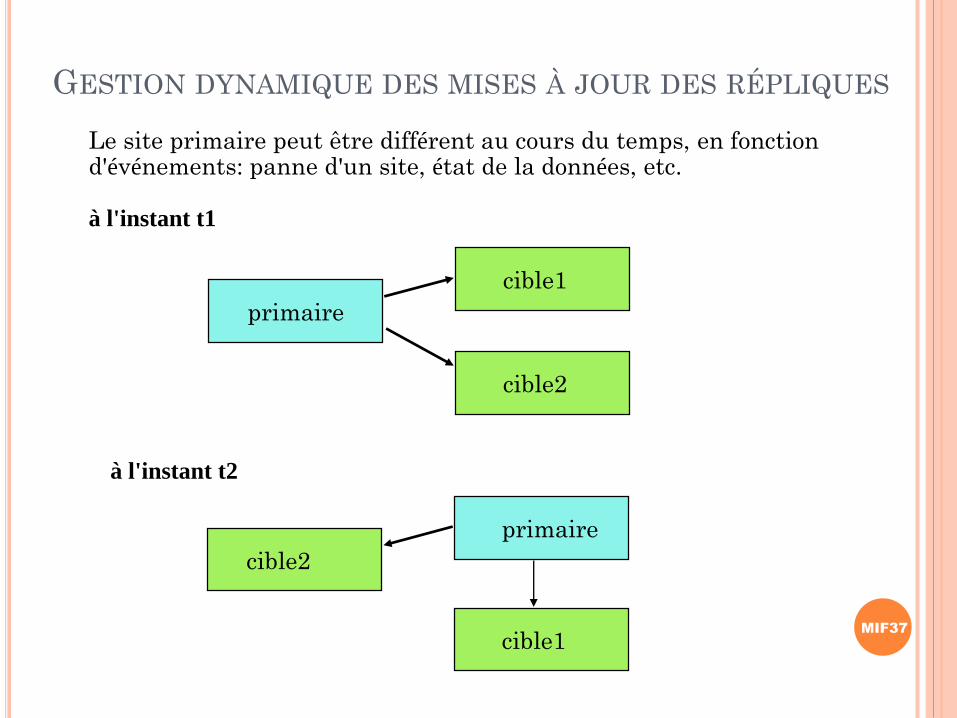
GESTION DYNAMIQUE DES MISES À JOUR DES RÉPLIQUES
primaire
Le site primaire peut être différent au cours du temps, en fonction d'événements: panne d'un site, état de la données, etc.
à l'instant t1
cible1
cible2
à l'instant t2
cible2
primaire
cible1
MIF37
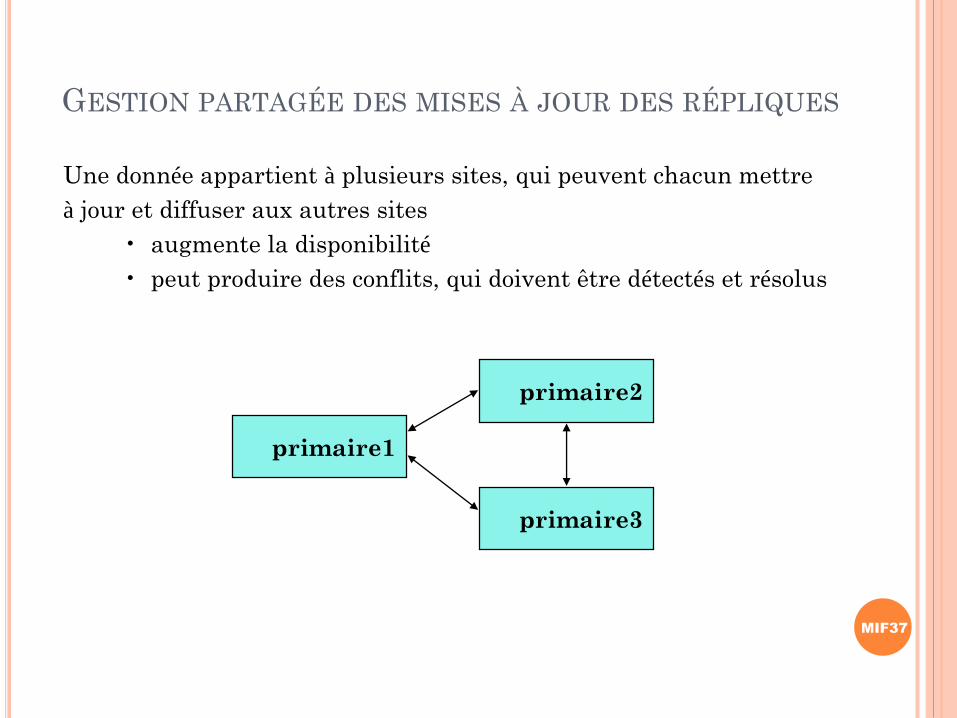
GESTION PARTAGÉE DES MISES À JOUR DES RÉPLIQUES
primaire1
primaire2
primaire3
Une donnée appartient à plusieurs sites, qui peuvent chacun mettre
à jour et diffuser aux autres sites
• augmente la disponibilité
• peut produire des conflits, qui doivent être détectés et résolus

MIF37
DÉTECTION DES MODIFICATIONS
Solution 1 : utilisation du journal
les transactions qui modifient écrivent une marque
spéciale dans le journal
détection périodique en lisant le journal, indépendamment
de la transaction qui a modifié
modification de la gestion du journal
Solution 2 : utilisation de triggers
la modification d'une donnée répliquée déclenche un
trigger
mécanisme général et extensible
la détection fait partie de la transaction et la ralentit

MIF37
STRATÉGIE D’ALLOCATION DE FRAGMENTS
Soit
F un ensemble de fragments
S un ensemble de sites
Problème: Quelle est la distribution "optimale" de F sur S ?
Optimum
coût minimal de communication, stockage et traitement
Performance = temps de réponse ou débit
Solution
allouer une copie de fragment là où le bénéfice est supérieur au coût
Les données doivent être rapprochées des besoins.

MIF37
QUELQUES COMMANDES UTILES SUR
ORACLE
Création de lien logique entre les bases
Create database link …
Création de fragments
Create table …
(Copy from …)
Création de répliques
Create materialized view …

MIF37
DATABASE LINK
Créé un lien avec une table dans une BD distante
CREATE DATABASE LINK <nomLien>
CONNECT TO <loginUser> IDENTIFIED BY <pwdUser>
USING ‘<nomBD>’
Exemple de commande exécutée sur la base orapeda2 pour créer
un lien avec la base orapeda1 :
CREATE DATABASE LINK lienora2versora1
CONNECT TO M1IFxx IDENTIFIEDBY M1IFxx
USING ‘orapeda1’;

MIF37
CREATE MATERIALIZED VIEW
Permet de créer des fragments à partir d’une base existante :
CREATE MATERIALIZED VIEW <nomRépl>
REFRESH [on commit | on demand | start with … next …]
[ complete | fast | force ]
AS ( SELECT … FROM … WHERE …);
Exemple de commande exécutée sur la base orapeda2 pour créer une réplique sur la
base orapeda1 :
CREATE MATERIALIZED VIEW joueurs
REFRESH ON DEMAND COMPLETE
AS (Select nujoueur, nom, prenom, nation, annais
From joueurs@lienora2versora1);

MIF37
BIBLIOGRAPHIE
T. Özsu, P. Valduriez: Principles of Distributed Database
Systems. 2nd Edition, Prentice Hall, 1999; 3rd edition,
forthcoming in 2008.
M. Wiesmann, F. Pedone, A. Schiper, B. Kemme, and G.
Alonso. Understanding replication in databases and
distributed systems. In Proceedings of 20 the International
Conference on Distributed Computing Systems
(ICDCS'2000), pages 264--274, Taipei, Taiwan, R.O.C.,
April 2000. IEEE Computer Society LosAlamitos
California.


















