
Architectures des systèmes de gestion de bases de … 10 - Architectures... · Structure des bases...
38
Chapitre 10 Architectures des systèmes de gestion de bases de données
Transcript of Architectures des systèmes de gestion de bases de … 10 - Architectures... · Structure des bases...

Chapitre 10
Architectures des systèmes de gestion de bases de données

GPA775 Chapitre 10 - Architectures des SGBD
2
Les technologies des dernières années ont amené la notion d’environnement distribué (dispersions des données). Pour reliér plusieurs ordinateurs entre eux, nous utilisons :
Ø Réseaux téléphoniques
Ø Réseaux grand débit
Ø Liaisons satellite
Ce changement a favorisé une nouvelle approche, basée sur la technologie client/serveur qui a fait aussi augmenter le rôle du SGBDdans les entreprises.
Le partage d’informations a modifié nos entreprises et permis d’appliquer des principes modernes de réduction du processus de fabrication (ex: Just-In-Time). Les bases de données deviennent actives
Ø les informations stockées dans les BD doivent maintenant favoriser les opérations et indiquer les besoins de qualité.
Introduction

GPA775 Chapitre 10 - Architectures des SGBD
3
Plan du chapitre
Les points abordés dans ce chapitre sont les suivants :
ØL’architecture centralisée
ØL’architecture client-serveur
ØStructure des bases de données réparties
ØBases de données actives

GPA775 Chapitre 10 - Architectures des SGBD
4
Ø L’architecture centralisée est la plus ancienne.
Ø Elle se composait :• d’ordinateurs centraux;
• de terminaux.
Ø Tous le travail (les processus) s’exécute sur les systèmes centraux, donc le temps de réponse aux requêtes dépend de la charge du système.
Ø Ce sont des systèmes simples, mais peu flexibles.
L’architecture centralisée

GPA775 Chapitre 10 - Architectures des SGBD
5
L’architecture client/serveur découle:
Ø Des améliorations des interfaces graphiques;
Ø Les ordinateurs personnels à moindre coûts;
Ø Des réseaux locaux;
Ø Des bases de données relationnelles;
Ø Des langages de traitement de données;
Ø Outils de conception assistée par ordinateur.
Pour correspondre au modèle d’architecture client/serveur, il faut:
Ø une communication entre des programmes tournant sur des ordinateurs différents.
L’architecture client/serveur

GPA775 Chapitre 10 - Architectures des SGBD
6
Le clientØ un ordinateur qui contient un module informatique
intelligent qui est utilisé par un seul usager. Ø fournit une interface entre l'usager et l'application
informatique.
Ø possède son propre système d'opération, celui-ci:1. Accepte les demandes de l'utilisateur;
2. Ensuite effectuer une requête au serveur d'application;
3. Finalement, affiche le résultat à l'écran.
Peut calculer, afficher des données, modifier les données, fournir de l'aide…Mais il ne peut pas avoir accès directement aux données.
L’architecture client/serveur

GPA775 Chapitre 10 - Architectures des SGBD
7
Le serveur
Ø Est un ordinateur connecté à un réseau qui fournit des services à d'autres ordinateurs (clients).
Ø Est un module informatique intelligent qui n'est pasaccédé directement par l'usager.
1. reçoit des requêtes des ordinateurs clients, 2. exécute les requêtes à l'aide du SGBD, 3. retourne le résultat aux clients.
Note: L'application client/serveur peut utiliser plusieurs serveurs pour fournir différents services aux clients.
• Ex: Serveur de fichier , d'imprimante, de Fax, de communication et de base de données.
L’architecture client/serveur

GPA775 Chapitre 10 - Architectures des SGBD
8
Le module serveur exécute les requêtes SQL provenant des clients et retourne le résultat.
Le module client consiste en un ordinateur client qui possède:
Ø l'interface personne-machine qui est une application de la base de données
Ø son système d'opération propre,
Ø un programme de communication hardware/software
La division du travail par l’approche client/serveur

GPA775 Chapitre 10 - Architectures des SGBD
9
La figure ci-contre illustre comment un client peut fournir de l'information àpartir d'un serveur de base de données via un lien LAN(Local Area Network) àd'autres clients.
La division du travail par l’approche client/serveur

GPA775 Chapitre 10 - Architectures des SGBD
10
Une mauvaise intégrationdes ressources informatiques peut engendrer une complexitépour la gestion de l’information. Cette situation se produit souvent lors de l'acquisitionou la consolidationd'entreprises.
La division du travail par l’approche client/serveur
Les clients de SQL Serverou d'Oracle ne peuvent accéder aux données
d'Informix et vice-versa.
Un interface client pour chaque système!!!
GPA775 Chapitre 10 - Architectures des SGBD
11
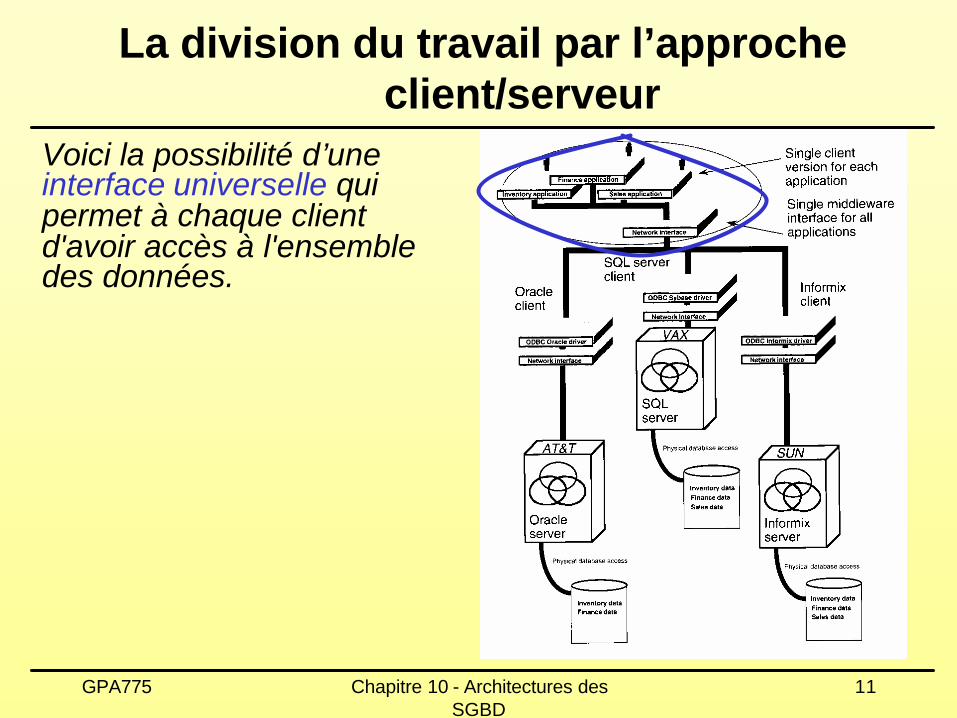
Voici la possibilité d’une interface universelle qui permet à chaque client d'avoir accès à l'ensemble des données.
La division du travail par l’approche client/serveur

GPA775 Chapitre 10 - Architectures des SGBD
12
Exemple d’application client/serveur pour gérer un atelier de réparation:
1. Le préposé au service entre les détails des réparations dans la BD;
2. L'analyste des opérations lit les données de la BD;
3. Il envoie un rapport via le courrier électronique au management;
4. le groupe dédié aux réparations reçoit la liste des réparations.
La division du travail par l’approche client/serveur

GPA775 Chapitre 10 - Architectures des SGBD
13
Structure des bases de données réparties
Une BD répartie se compose d'un ensemble de sites dont chacun héberge un système local de gestion de base de données.
Chaque site est donc capable
Ø de traiter des transactions locales, qui ne concernent que les données de ce site particulier.
Ø d'exécuter des transactions globales sur les données de plusieurs sites.
• Ce qui nécessite une liaison entre les sites.
Les BD réparties communiquent au moyen de:
Ø de réseaux téléphoniques,
Ø de réseau à grand débit,
Ø de liaisons par satellite.
GPA775 Chapitre 10 - Architectures des SGBD
14
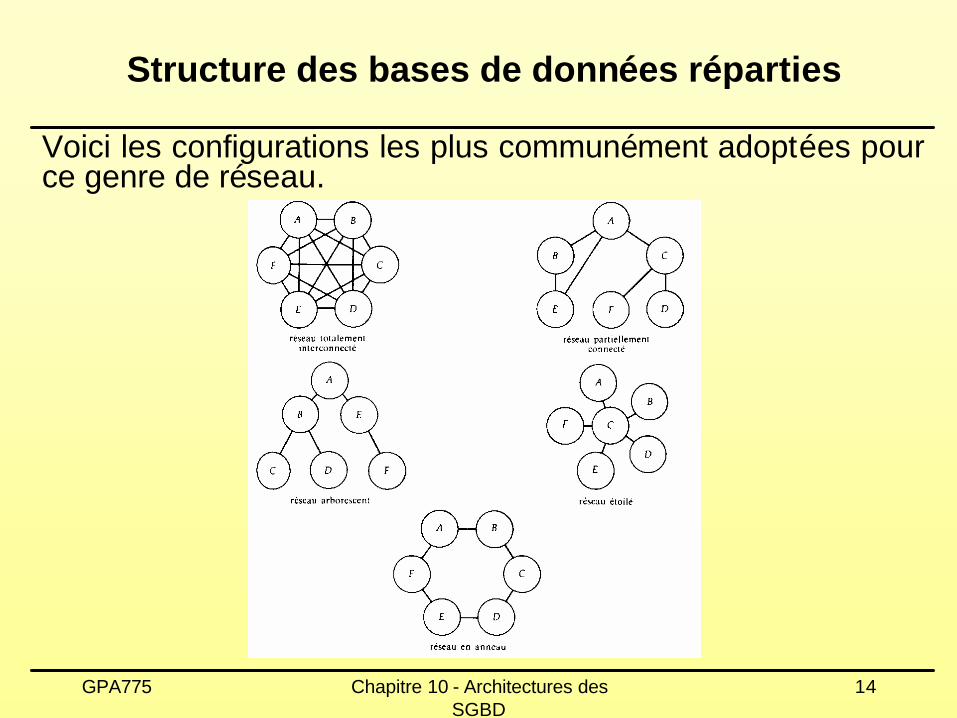
Structure des bases de données réparties
Voici les configurations les plus communément adoptées pour ce genre de réseau.

GPA775 Chapitre 10 - Architectures des SGBD
15
Structure des bases de données réparties
Ces configurations se différencient par les paramètres suivants:
Øcoût d'installation : frais d'établissement d'une liaison physique entre les sites;
Øcoût d'exploitation : frais de transmission et durée de transmission entre les sites;
Ø fiabilité : fréquence de pannes de liaison ou de site des liaisons établies;
Ødisponibilité : niveau d'accessibilité du système en dépit des pannes de quelques liaisons ou de quelques sites.
L'avantage essentiel de la répartition des données réside dans l'efficacité et la fiabilité d'accès à des données partagées.

GPA775 Chapitre 10 - Architectures des SGBD
16
Inconvénients de la répartition des données
L'inconvénient majeur de la répartition des données d'une BD entre plusieurs sites est la complexité résultant de leur coordination.
Cette complexité se répartit de la façon suivante :ØLe coût de mise au point du logiciel;ØLe nombre d'erreurs logicielles plus important;ØLes servitudes du système accrues.
Note: la répartition des données peut s'effectuer à des degrés divers entre un système fortement centralisé et un système à dispersion quasi totale.

GPA775 Chapitre 10 - Architectures des SGBD
17
Architecture des bases réparties
Une BD relationnelle peut avoir ses relations stockées dans la base de plusieurs façons :Øavec réplication: les divers sites stockent chacun une
copie de la relation;Øavec fragmentation: la relation est découpée en
plusieurs fragments hébergés par un site donné;Øavec réplication et fragmentation: combinaison des
deux processus précédent.

GPA775 Chapitre 10 - Architectures des SGBD
18
Réplication des données
La réplication des données implique qu’une relation estrépliquée et stockée intégralement dans deux ou plusieurs sites. Avantages et inconvénients:
Ødisponibilité des données: une relation peut être atteinte sur n'importe quel site en cas d'avarie affectant un site donné;
Øparallélisme des traitements: pour des transactions de lectures, plusieurs sites peuvent travailler en parallèle sur une même relation;
Øservitudes de mise à jour: toutes mises à jour (écritures) sur une relation doivent être appliquées àl'ensemble des sites, ce qui alourdit la procédure de gestion de la BD.

GPA775 Chapitre 10 - Architectures des SGBD
19
Fragmentation des données
La fragmentation des données implique le découpage d’une relation en plusieurs sous-relations pour chaque site donné. Il existe deux façons de fragmenter: ♦horizontalement ou ♦verticalement.
Ex: relation Dépôt
Agence Compte Client Position
Hillside 305 Lowman 500
Hillside 226 Camp 336
Valleyview 117 Camp 205
Valleyview 402 Kahn 10000
Hillside 155 Kahn 2
Valleyview 408 Kahn 1123
Valleyview 639 Camp 750

GPA775 Chapitre 10 - Architectures des SGBD
20
Fragmentation horizontale
Par exemple, on peut subdiviser la relation Dépôt par agence:Dépôt1 = σagence = Hillside (Dépôt)
Dépôt2 = σagence = Valleyview (Dépôt) :
Agence Compte Client Position
Hillside 305 Lowman 500
Hillside 226 Camp 336
Hillside 155 Kahn 62
Agence Compte Client PositionValleyview 117 Camp 205Valleyview 402 Kahn 10000
Valleyview 408 Kahn 1123Valleyview 639 Camp 750
La relation Dépot1 est stockée à
l’agence Hillside
La relation Dépot2 est stockée àl’agence
Valleyview

GPA775 Chapitre 10 - Architectures des SGBD
21
Fragmentation horizontale
Voici un autre exemple de fragmentation horizontale sur deux sites différents.
Département de recherche
Département d’administration

GPA775 Chapitre 10 - Architectures des SGBD
22
Fragmentation verticale
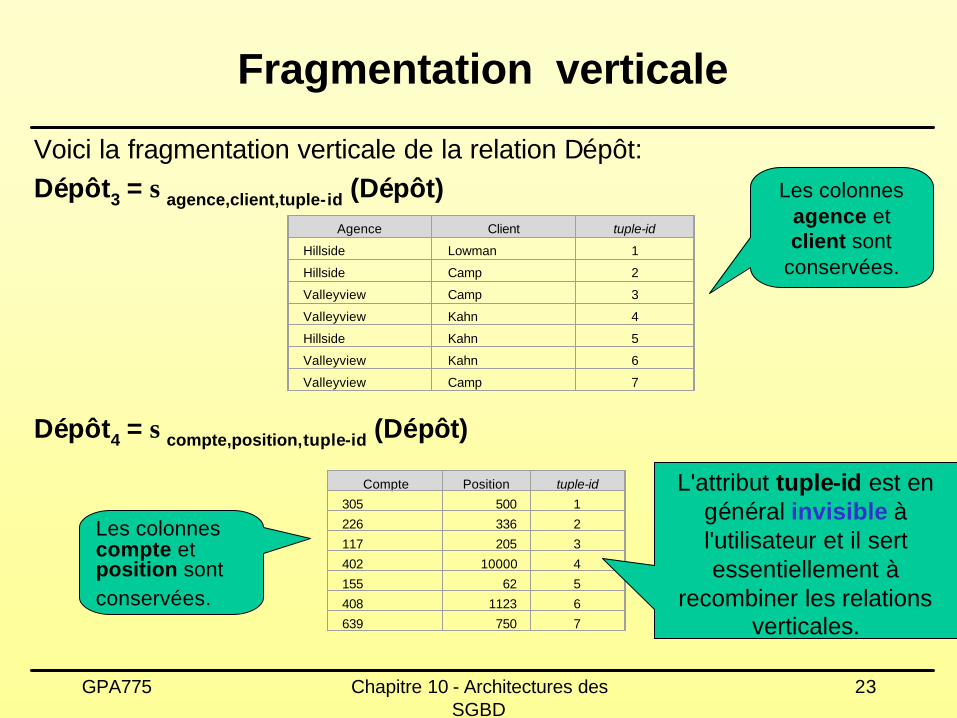
La fragmentation verticale permet de séparer une relation au niveau des colonnes (attributs). Cette séparation s'obtient en ajoutant un attribut spécial à la relation, tuple-id. Ce tuple-id représente l'adresse physique du tuple et représente une clé primaire.
Agence Compte Client Position tuple-id
Hillside 305 Lowman 500 1
Hillside 226 Camp 336 2
Valleyview 117 Camp 205 3
Valleyview 402 Kahn 10000 4
Hillside 155 Kahn 62 5
Valleyview 408 Kahn 1123 6
Valleyview 639 Camp 750 7
GPA775 Chapitre 10 - Architectures des SGBD
23
Fragmentation verticale
Dépôt4 = σcompte,position,tuple-id (Dépôt)
Agence Client tuple-id
Hillside Lowman 1
Hillside Camp 2
Valleyview Camp 3
Valleyview Kahn 4
Hillside Kahn 5
Valleyview Kahn 6
Valleyview Camp 7
Voici la fragmentation verticale de la relation Dépôt:Dépôt3 = σagence,client,tuple-id (Dépôt)
Compte Position tuple-id
305 500 1
226 336 2
117 205 3
402 10000 4
155 62 5
408 1123 6
639 750 7
L'attribut tuple-id est en général invisible àl'utilisateur et il sert essentiellement à
recombiner les relations verticales.
Les colonnes agence et client sont
conservées.
Les colonnes compte et position sont conservées.

GPA775 Chapitre 10 - Architectures des SGBD
24
Fragmentation mixte
La fragmentation mixte est une combinaison des fragmentations horizontales et verticales. Par exemple, on peut fragmenter horizontalement la relation Dépôt3 :
Dépôt3a = σagence = Hillside (Dépôt3),
Dépôt3b = σ agence = Valleyview (Dépôt3).
Agence Client tuple-idValleyview Camp 3Valleyview Kahn 4Valleyview Kahn 6Valleyview Camp 7
Agence Client tuple-id
Hillside Lowman 1
Hillside Camp 2
Hillside Kahn 5

GPA775 Chapitre 10 - Architectures des SGBD
25
Réplication et fragmentation des données
Les techniques qui précèdent peuvent être appliquées séquentiellement à une même relation :
Imaginons un système réparti sur 10 sites, S1, S2, ..., S10;
avec la fragmentation mixte de Dépôt en :
Dépôt3a, Dépôt3b et Dépôt4,
puis stockée de cette façon:
une copie de Dépôt3a sur les sites S1, S3 et S7,
une copie de Dépôt3b sur les sites S7 et S10 et
une copie de Dépôt4 sur les sites S2, S8 et S9.

GPA775 Chapitre 10 - Architectures des SGBD
26
Transparence et Autonomie
La dispersion d’une relation sur plusieurs sites devrait être transparente à l’utilisateur.
Pour obtenir l'autonomie locale, le système utilise une désignation particulière pour identifier les sous-relations réparties sur la BD.
Par exemple :
site10.Dépôt.f3.r2 désigne, sur le site 10, la réplique 2 du fragment 3 de la relation Dépôt.
Inconvénient: Restreint la transparence des données puisqu'elles sont marquées par leur origine.
Solution: Création pour chaque sous-relations des alias à l'usage de l'utilisateur.
Ø Ce dernier peut alors manipuler ces sous-relations au moyen d'étiquettes de substitution plus simples que le système transcrit en désignations complètes.

GPA775 Chapitre 10 - Architectures des SGBD
27
Traitement des requêtes sur BD répartie
Au chapitre 9, nous avons vu diverses techniques de calcul de la réponse à une requête. Dans le cas d'un système réparti, il faut prendre en compte d’autres paramètres :
Ø le coût de transmission des données sur le réseau;
Ø le gain potentiel de performance résultant d'un traitement parallèle par plusieurs sites d'une requête donnée.

GPA775 Chapitre 10 - Architectures des SGBD
28
Traitement des requêtes sur BD répartie
Traitement par jonction naturelleConsidérons l'expression algébrique relationnelle :
Clientèle |X| Dépôt |X| BanqueEx:Supposons que les 3 relations ne sont pas répliquées ni
fragmentées et que Clientèle est stockée sur le site S3, Dépôt sur le site S4 et Banque sur le site S2. Le système doit fournir le résultat au site S10.
Le système peut utiliser l'une des trois stratégies suivantes :
1. expédier des copies des trois relations au site S10 et calculer la jonction;

GPA775 Chapitre 10 - Architectures des SGBD
29
Traitement des requêtes sur BD répartie
2. expédier une copie de Clientèle au site S4 et calculer :
ri = Clientèle |X| Dépôt sur ce site;
expédier le résultat intermédiaire ri sur le site S2 et calculer :
rf = ri |X| Banque sur ce site;
expédier le résultat final rf sur le site S10,
3. une stratégie semblable à la stratégie 2 avec permutation des sites de façon à optimiser la jonction naturelle.
Ø L’optimiseur choisira la stratégie la moins coûteuse pour la requête.

GPA775 Chapitre 10 - Architectures des SGBD
30
Traitement des requêtes sur BD répartie
Traitement par jonction naturelle en exploitant le parallélisme
Considérons l'expression algébrique relationnelle suivante :
r1 |X| r2 |X| r3 |X| r4
Une façon de résoudre le problème consiste à calculer en parallèle deux jonctions.
Par exemple, r1 peut être expédiée sur S2 :
r1,2 = r1 |X| r2 est calculée sur S2.
Simultanément, r3 peut être expédiée sur S4 :
r3,4 = r3 |X| r4 est calculée sur S4.
Il reste à expédier r1,2 sur le site S4 et calculer :
r1,2,3,4 = r1,2 |X| r3,4
Et ce résultat final est expédié au site où la requête s'est effectuée.

GPA775 Chapitre 10 - Architectures des SGBD
31
La base de données active est flexible aux variations externes:
• Ce sont les forces du marché qui déterminent ce qui doit être produit, comment le fabriquer et ou le distribuer.
Pour une entreprise en compétition sur le marchémondial…Ø le savoir correspond au pouvoir.
Pour être compétitive, elle doit pouvoir utiliser ses données d'opération en information tactique servant à maximiser ses chances de succès. Ø La source principale qui alimente cette force est la
base de données de l'entreprise.
Bases de données actives

GPA775 Chapitre 10 - Architectures des SGBD
32
Bases de données actives
Cycle de fabrication assisté d’une base de données active

GPA775 Chapitre 10 - Architectures des SGBD
33
Pour réussir à implanter les concepts modernes de fabrication (Just-In-Time, Atelier Flexible, etc..., ), il faut changer notre vision des systèmes d'information.
Le pouvoir de l’informationExemple de schéma hiérarchique d’une entreprise qui tente
d’imposer le résultat de sa production
Ce modèle illustre l'interaction entre les
différents départements.
Basé sur les demandes des
clients.

GPA775 Chapitre 10 - Architectures des SGBD
34
Un serveur passifØ est contrôlé par ses clients, Ø il fait des opérations sur les
données qui sont dictées par les clients.
Ø il ne peut pas exécuter de programme de base de données.
Un serveur actifØ incorpore sa propre logique de
contrôle. Ø opère à partir de ses clients,
d'autres serveurs Ø gère ses événements internes. Ø il peut exécuter des fonctions SQL.
Serveur passif VS serveur actif

GPA775 Chapitre 10 - Architectures des SGBD
35
La figure illustre le processus de coopération entre deux serveurs de base de données. Par exemple, un contracteur qui magasine chez Rona demande 4 caisses de peinture. Le préposéau comptoir fait une requête pour vérifier la disponibilité du produit. Le serveur local du centre de distribution détecte qu'il n'y a que 2 caisses en stock. Il réserve donc ces deux caisses et en commande 2 autres d'un autre centre de distribution.
Exemple de base de données active

GPA775 Chapitre 10 - Architectures des SGBD
36
Voici un serveur actif qui est commandé indirectement par des événements (alarme) et par des commandes directes (usager) pour rétablir le système.
Concepts de BD actives
Évènement
Serveur actif à l’écoute des évènements
Déclenchement de la procédure
Action à prendre
Application de l’action

GPA775 Chapitre 10 - Architectures des SGBD
37
Règles actives :Ø ex : Déclencheurs (triggers) , comporte 3 composantes:
1. Un évènement déclencheur
2. Une condition (optionnel)
3. Une action à prendrew Oracle, Sybase, DB2
Ex: CREATE TRIGGER SalaireTotaleAFTER UPDATE OF DNO ON EMPLOYEFOR EACH ROWBEGIN
UPDATE DEPARTEMENTSET TOTAL_SAL = TOTAL_SAL + NEW.SALARYWHERE DNO= NEW.DNOUPDATE DEPARTEMENTSET TOTAL_SAL = TOTAL_SAL - OLD.SALARYWHERE DNO= OLD.DNO
END;
Concepts de BD actives

GPA775 Chapitre 10 - Architectures des SGBD
38
Les bases de données actives permettent de créer des systèmes d'information:
• plus performants,
• plus rapides,
• à meilleur coût que dans le passé.
En résumé…


















