
Architecture des Systèmes Informatiques...
38
CNAM Cyril FRANCONIE Architecture des Systèmes Informatiques 1 ARCHITECTURE des SYSTEMES INFORMATIQUES Cours B4 Cyril FRANCONIE Ordonnancement
Transcript of Architecture des Systèmes Informatiques...

CNAM Cyril FRANCONIE
Architecture des Systèmes Informatiques1
ARCHITECTUREdes
SYSTEMES INFORMATIQUES
Cours B4Cyril FRANCONIE
Ordonnancement

CNAM Cyril FRANCONIE
Architecture des Systèmes Informatiques2
Architecture des Systèmes
HistoriqueArchitecture d'un Ordinateur / d'un processeurObjectif et rôle d'un Système d'exploitationNotions de base / Mécanismes fondamentauxEntrées / SortiesLes ProcessusOrdonnancementLa MémoireMesures de performancesLes standardsEt l'avenir ...?

CNAM Cyril FRANCONIE
Architecture des Systèmes Informatiques3
Ordonnancement
De l'unité centraleConceptsCritères de performancesAlgorithmesInfluence sur les mécanismes de synchronisations
Des disquesParticularitésAlgorithmesSituation aujourd'hui
Et les autres ressources ?

CNAM Cyril FRANCONIE
Architecture des Systèmes Informatiques4Ordonnancement de l'unité centrale
Concepts
L'objectif global de l'ordonnancement (scheduling) est d'avoir un taux d'utilisation du processeur le plus élevé possible.Des études de cas réels montrent que les processus sont composés
de phases d'utilisation de la CPU intensives mais courtesde phases d'I/O avec mise en attente pour des durées longues
Il faut impérativement éviter la faiblesse des systèmes mono-programmés :
CNAM Cyril FRANCONIE
Architecture des Systèmes Informatiques5
Concepts (2)
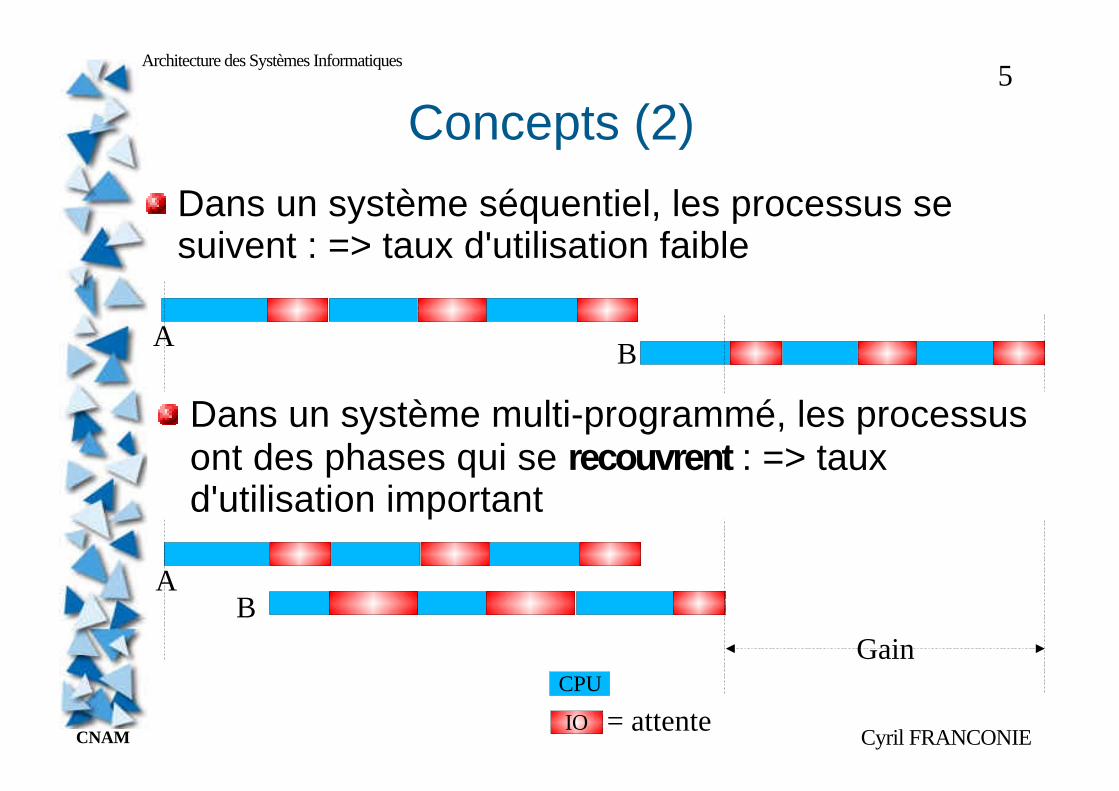
Dans un système séquentiel, les processus se suivent : => taux d'utilisation faible
AB
AB
CPU
IO
Gain
Dans un système multi-programmé, les processus ont des phases qui se recouvrent : => taux d'utilisation important
= attente

CNAM Cyril FRANCONIE
Architecture des Systèmes Informatiques6
CritèresOn peut vouloir optimiser différents critères :
Taux d'utilisation de la CPU, c.a.d % temps CPU/temps réelDébit du système (throughput): nb de processus traités en moyenne par unité de temps.Temps de traitement moyen (turnaround time) : intervalle de temps entre soumission d'un processus et fin d'exécution.
Aussi le temps total pour un ensemble de processusTemps d'attente par processus : temps passé par un processus à attendre. Le temps CPU d'un processus est en fait indépendant de l'algorithme d'ordonnancement.Temps de réponse : temps entre soumission d'une «requête » et la première réponse.

CNAM Cyril FRANCONIE
Architecture des Systèmes Informatiques7
Concepts (3)
Le but d'un algorithme d'ordonnancement sera de choisir le processus prêt à qui on attribuera la CPU.
de façon à optimiser un des critères !le taux d'utilisation CPU est toujours bien optimisé.
On peut distinguer dans un système général, trois ordonnanceurs :
L'ordonnanceur de court-terme L'ordonnanceur de moyen-terme L'ordonnanceur de long-terme

CNAM Cyril FRANCONIE
Architecture des Systèmes Informatiques8
Concepts (4)
L'ordonnanceur de court-terme utilisé pour choisir parmi les processus prêts en mémoire celui qui aura la CPU.
L'ordonnanceur de moyen-terme Appelé aussi swapper : permet de swapper out et in des processus entiers pour soulager le système.
L'ordonnanceur de long-terme Pour les systèmes à base de soumission de jobs; Choisi parmi les processus en attente celui qui sera chargé en mémoire.
L'algorithme « optimum » sera différent suivant l'ordonnanceur considéré.
CNAM Cyril FRANCONIE
Architecture des Systèmes Informatiques9
Ordonnanceurs :
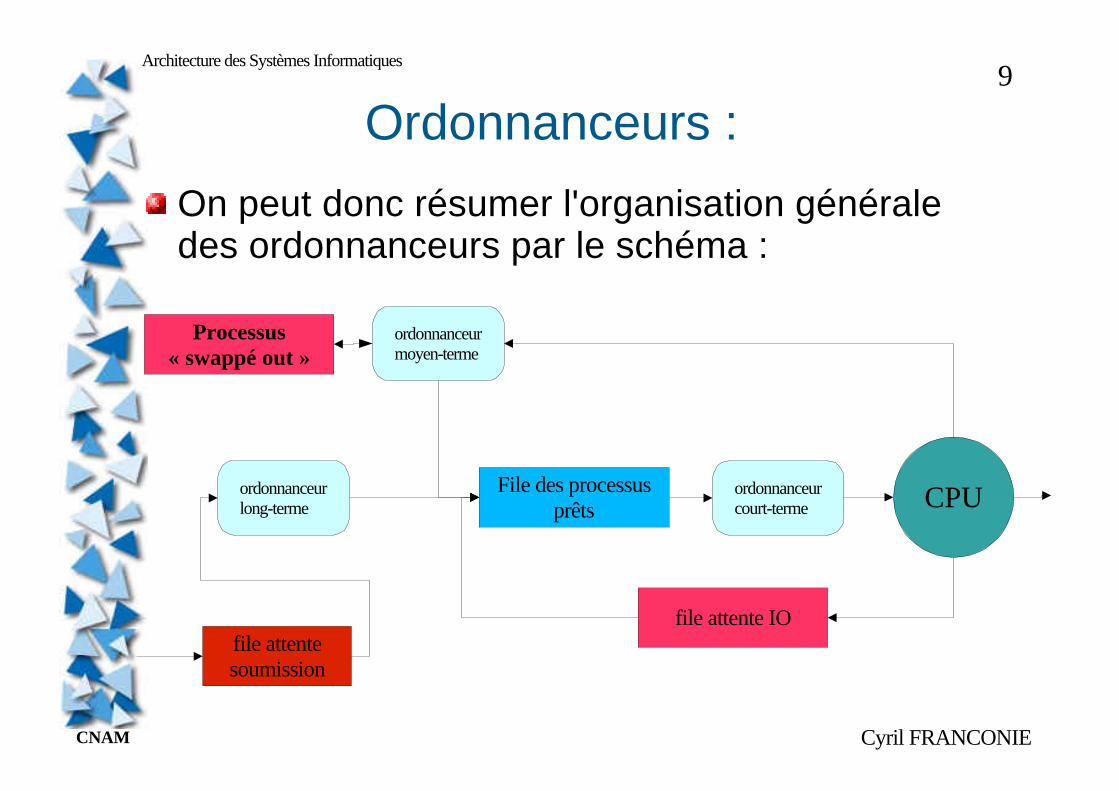
On peut donc résumer l'organisation générale des ordonnanceurs par le schéma :
File des processusprêts CPU
Processus« swappé out »
file attente IO
ordonnanceurcourt-terme
ordonnanceurmoyen-terme
ordonnanceurlong-terme
file attentesoumission

CNAM Cyril FRANCONIE
Architecture des Systèmes Informatiques10
AlgorithmesNombreux, liés aux choix de design d'un système d'exploitation, et au type d'activité visé.On distinguera ceux :
Sans réquisition (no-preemption)FIFO (First Come First Served) simple, et à prioritéPlus Court Temps d'Execution (Shortest Job First)
Avec réquisitionTourniquet (Round-robin)PCTER (Shortest Remaining Time First)Tourniquet à multiple niveaux de priorité variable (unix)Partage de temps (time sharing) (ambigu !)Partage équitable (fair share)
Dans la suite de l'exposé, on décomposera les processus en tâches, chaque tâche étant une phase de CPU pure, terminée par une mise en attente pour cause d'IO.

CNAM Cyril FRANCONIE
Architecture des Systèmes Informatiques11
FIFO
Le plus simple :Un processus reste actif tant que
il n'a pas terminéil n'est pas bloqué par une opération d'I/O
Facile à comprendre et implémenter; mais peu efficace :
Considérons le temps de traitement moyen du système de tâches suivant soumis dans l'ordre:
Processus Temps T1 40T2 7T3 4
T1 T2 T3
Tmoyen = (40 + 47+51)/3 = 46
0 40 47 51
Si l'ordre était : T3 T2 T1 : Tmoyen = (4+11+51)/3 = 22 !

CNAM Cyril FRANCONIE
Architecture des Systèmes Informatiques12
FIFO (2)
Problème aussi si on a un processus A gourmand en CPU, et N processus faisant beaucoup d'IO : ils seront bloqués par le processus A.On peut avoir N files d'attentes pour N priorité différentes.
On choisit toujours le processus prêt de la file la plus prioritaire.Un processus qui devient prêt dans une file plus prioritaire préempte le processus actifAlgorithme très utilisé dans les systèmes temps réel !
il faut alors bien choisir les niveaux de priorités à affecter aux différentes tâches.

CNAM Cyril FRANCONIE
Architecture des Systèmes Informatiques13
PCTE
Cherche à améliorer le temps de traitement moyen;
On choisit dans la liste des processus prêts, celui qui aura comme tâche suivante le plus court temps d'exécution.Il faut connaître ce temps !?
On utilise une méthode d'estimation basée sur les tâches précédentes du même processus, et sur l'estimation qu'on en avait fait :T
i+1 (prédiction) = α t
i + (1-α)T
i ; t
i = temps effectif
Moyenne exponentielle; car Ti+1
= α ti+(1-α)α t
i-1
+...+(1-α)jαti-j+...+(1-α)iT
0
souvent utilisée avec α = 1/2

CNAM Cyril FRANCONIE
Architecture des Systèmes Informatiques14
PCTE : exemple
Considérons le système à 3 processus séquentiels constitué des tâches suivantes :Processus Tâche Temps mesuré Temps estimé
P1
T1 3 4T2 13 3T3 15 8T4 4 11
P2T5 8 4T6 14 6T7 13 10
P3
T8 11 4T9 5 7T10 5 6T11 16 5T12 12 10
Les 3 processus sont soumis quasiment en même temps, dans l'ordre; L'estimation initiale T0 = 4

CNAM Cyril FRANCONIE
Architecture des Systèmes Informatiques15
PCTE : exemple suite
L'ordre défini par l'algorithme est :T1 T2 T5 T8 T6 T9 T10 T11 T3 T7 T12 T4soit :
T1
T12
T7
T4
T11
T3
T10T9
T6
T2
T5
T8
Temps de traitement réel moyen par tâche=(3+16+24+35+49+54+59+75+90+103+115+119)/12 = 62Le temps de traitement réel optimum serait de 56Celui par un FIFO (processus même priorité) serait de :60Global processus : PCTE : 112, optimum:94, FIFO 97 !!!
CNAM Cyril FRANCONIE
Architecture des Systèmes Informatiques16
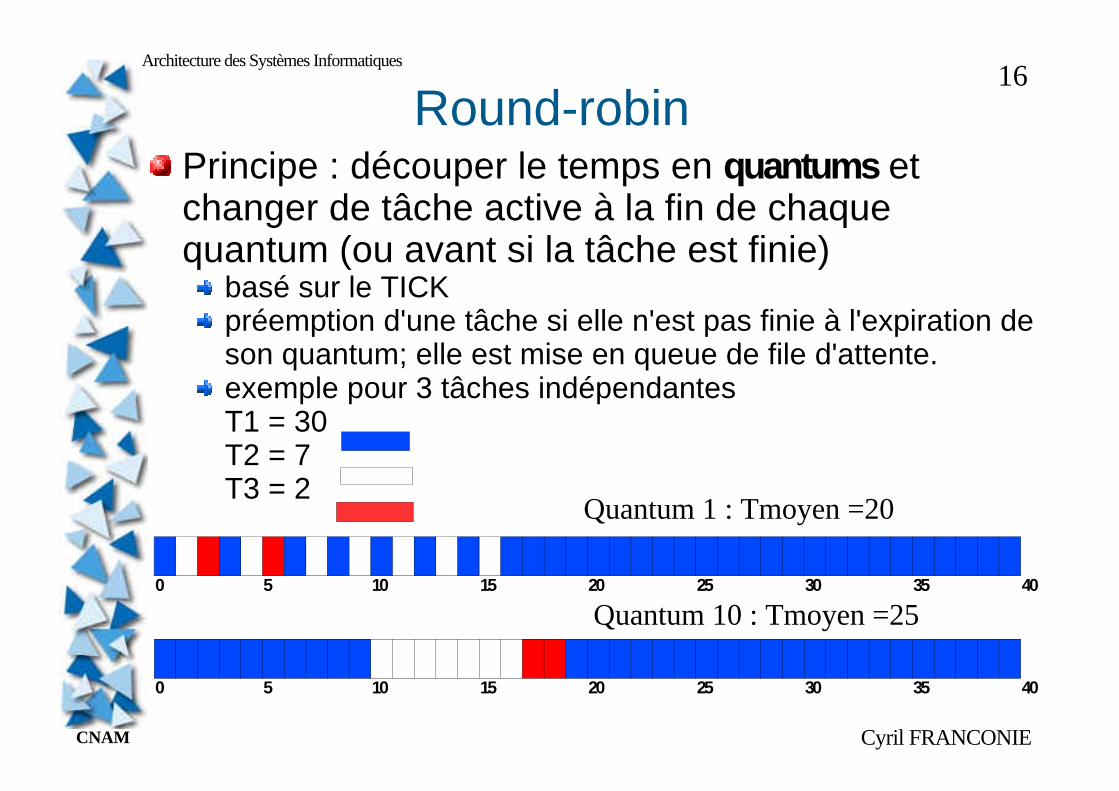
Round-robinPrincipe : découper le temps en quantums et changer de tâche active à la fin de chaque quantum (ou avant si la tâche est finie)
basé sur le TICKpréemption d'une tâche si elle n'est pas finie à l'expiration de son quantum; elle est mise en queue de file d'attente.exemple pour 3 tâches indépendantesT1 = 30T2 = 7T3 = 2
0 5 10 15 20 25 30 35 40
0 5 10 15 20 25 30 35 40
Quantum 1 : Tmoyen =20
Quantum 10 : Tmoyen =25

CNAM Cyril FRANCONIE
Architecture des Systèmes Informatiques17
Round-robin (2)
Pourquoi ne pas utiliser un quantum petit ?le temps de commutation deviendrait important au regard du temps de traitement
Algorithme utilisé encore une fois dans les systèmes temps réel, avec N files d'attente de niveau de priorité différent.
typiquement quantum = 100ms

CNAM Cyril FRANCONIE
Architecture des Systèmes Informatiques18
PCTER
Plus court temps d'exécution restant On compare à chaque nouveau processus prêt, l'estimation du temps restant pour le processus actif, et les estimations pour les autres processus prêt
C'est un PCTE avec préemptionIntéressant si on sait prédire le temps des prochaines tâches avec précision.
rarement le casPas d'implémentation connue ...

CNAM Cyril FRANCONIE
Architecture des Systèmes Informatiques19Tourniquet à multiples niveaux de
priorité variableFaiblesse des algorithmes précédents :
risque de famine pour un processus de faible « priorité »Les concepteurs d'UNIX ont donc fait le choix d'un algorithme à base de Round-robin, avec priorité effective variable en fonction du temps CPU consommé, et du temps d'attente :
Principes de base :augmenter le priorité des processus qui attendentdiminuer la priorité des processus qui ont eu du temps CPU.on prends toujours le processus prêt de plus haute priorité
Les processus faisant beaucoup d'IO seront priviligiés typiquement les processus interactifs !

CNAM Cyril FRANCONIE
Architecture des Systèmes Informatiques20
« TMNPV » (2)
L'algorithme :A chaque tick, on incrémente le temps CPU consommé par le processus actifA chaque quantum (1 seconde sur unix, moins Linux ?) :
on divise par deux le temps CPU consommé par tous les processuson recalcule la priorité de tous les processus par la formule :priorité effective = priorité de base + (Tcpu/2) + « nice value »nice = valeur fixe attribuée à un processus long au démarrage pour être « gentil » avec les autres.
influe aussi sur le quantum attribué au processus (linux)On schedule le processus qui a la plus haute priorité (plus faible valeur)

CNAM Cyril FRANCONIE
Architecture des Systèmes Informatiques21
« TMNPV » (3)
Exemple :

CNAM Cyril FRANCONIE
Architecture des Systèmes Informatiques22
Time sharing
Terme ambigu utilisé pour nommé différents algorithmes.
sous Solaris le « Time sharing » est en fait un unix scheduling standard.
On trouve parfois dans la littérature un concept d'algorithme guidé par des principes de partage équitable (page suivante) ...

CNAM Cyril FRANCONIE
Architecture des Systèmes Informatiques23
Fair share scheduler
Objectifs :garantir un % du temps CPU pour un groupe de processus
Implémentation partielle par AT&T :On divise le temps CPU total entre N groupe, qui auront le même pourcentage !On utilise le même principe de temps CPU compté par processus, mais on y ajoute un temps de groupe !Ce temps de groupe évolue comme le temps CPU/process, mais de façon unique pour tous le groupe.priotité effective = priorité base + (CPU/2) + (CPU
groupe/2) +
niceSi un groupe a moins de processus qu'un autre, ses processus auront plus de temps CPU...
CNAM Cyril FRANCONIE
Architecture des Systèmes Informatiques24
Fair share scheduler (2)
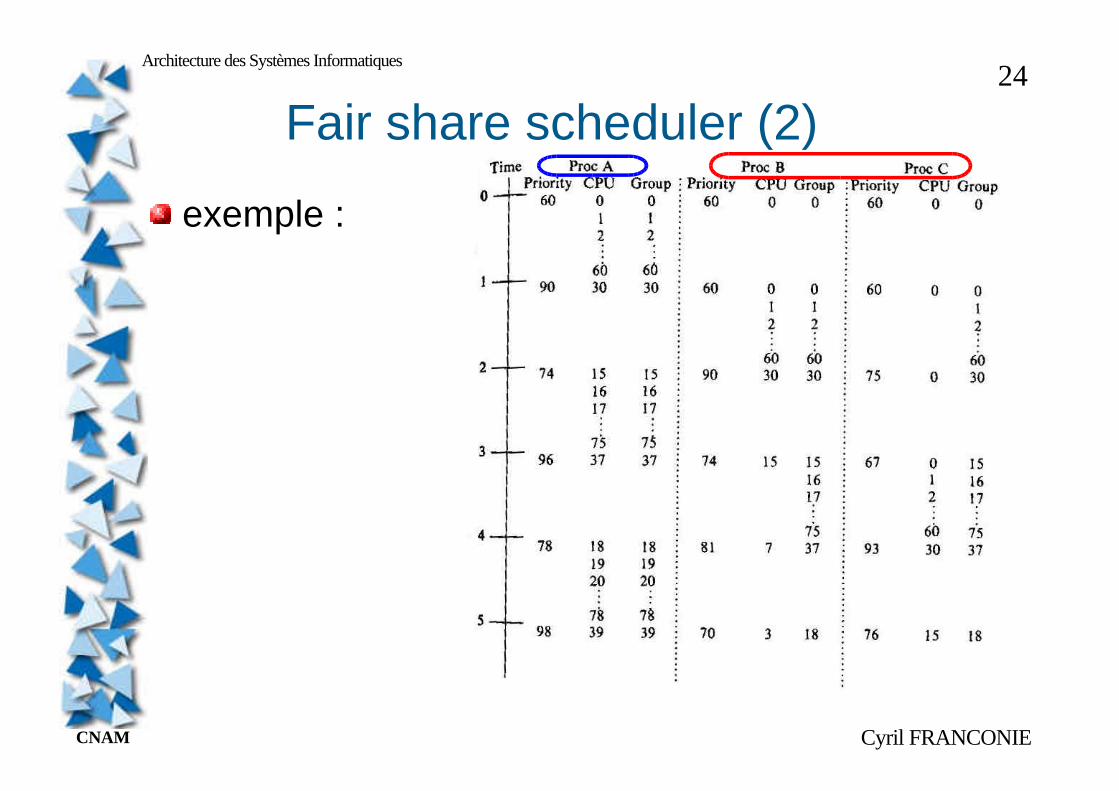
exemple :
CNAM Cyril FRANCONIE
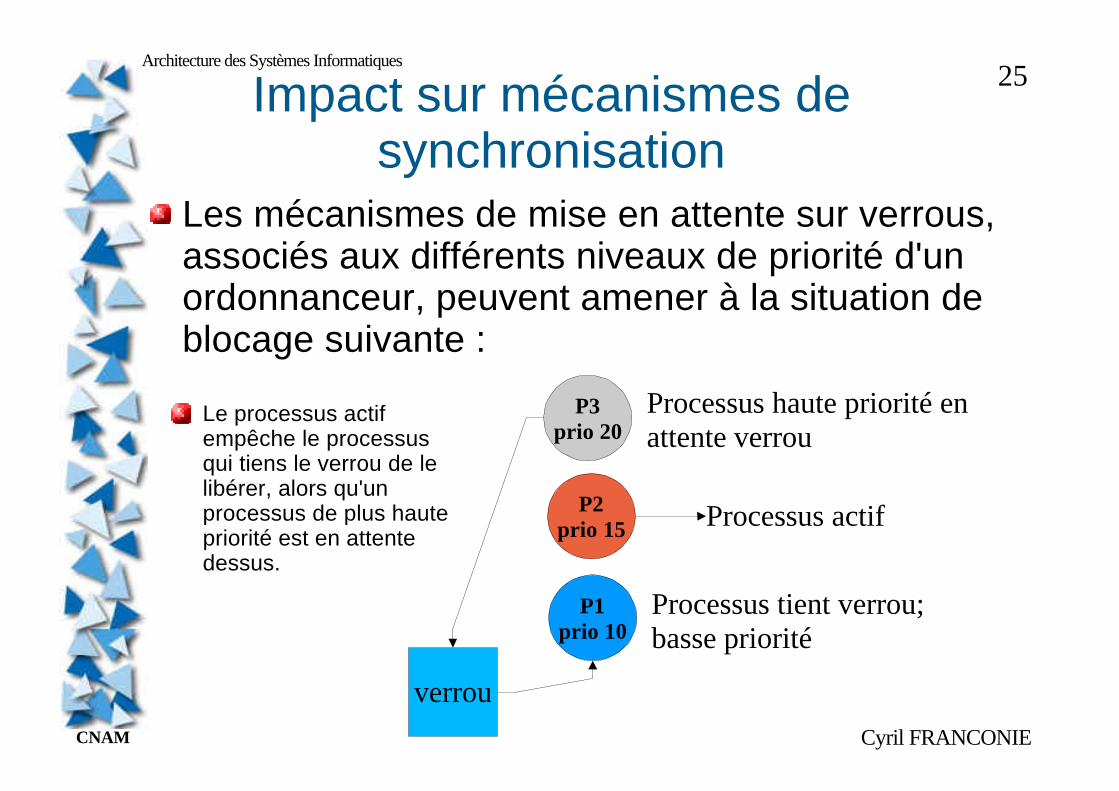
Architecture des Systèmes Informatiques25Impact sur mécanismes de
synchronisationLes mécanismes de mise en attente sur verrous, associés aux différents niveaux de priorité d'un ordonnanceur, peuvent amener à la situation de blocage suivante :
verrou
P1prio 10
P2prio 15
P3prio 20
Processus actif
Processus tient verrou;basse priorité
Processus haute priorité enattente verrou
Le processus actifempêche le processus qui tiens le verrou de le libérer, alors qu'un processus de plus haute priorité est en attente dessus.

CNAM Cyril FRANCONIE
Architecture des Systèmes Informatiques26
Inversion de priorité
On appelle ce blocage (qui dépend du processus de priorité intermédiaire : s'il s'arrète, le blocage est terminé), une inversion de priorité .Une solution qu'on trouve dans différents OS, est la solution d'héritage de priorité :
Tant qu'un processus « A » tient une ressource attendue par un autre processus (« B »), on attribue à « A » une priorité temporaire = max(prio A, prio B).cela permet, dans l'exemple, au processus P1 de pré-empter P2 de façon à pouvoir libérer le verrou pour P3.
CNAM Cyril FRANCONIE
Architecture des Systèmes Informatiques27
Ordonnancement des disques
Particularités :Les algorithmes que nous allons étudier, sont étroitement liés à l'architecture physique d'un disque dur :
Piste« cylindre »
secteur un disque est constitué de :" N plateaux" 2N têtes de lecture (une par face)" Chaque position radiale des têtes
définie une piste." L'ensemble des pistes de tous les
plateaux pour une position des têtes = un cylindre
" Chaque piste est constitué de K secteurs (souvent 63 secteurs de généralement 512 octets)

CNAM Cyril FRANCONIE
Architecture des Systèmes Informatiques28
Disques : définitionsL'adresse absolue d'un secteur peut donc se définir par :
un numéro de têteun numéro de pisteun numéro de secteur (relatif à la piste)
triplet Head Cylinder SectorElle se définie aussi par un numéro de bloc absolu : c'est le mode Logical Bloc AdressingPour un disque on définit les temps suivants :
de recherche (seek time); correspondant au temps nécessaire pour positionner les têtes de lecture à la bonne piste.de latence ; attente nécessaire pour que le bon secteur soit sous la tête de lecture.de transfert : pour envoyer ou recevoir les données depuis la mémoire vers/depuis le disque.

CNAM Cyril FRANCONIE
Architecture des Systèmes Informatiques29
Définitions (2)
Le temps de recherche est souvent le plus long des trois :
typiquement 1 à 20 ms.Le temps de latence vient ensuite :
de l'ordre de 17 ms pour un disque à 7200tr/mn (5ms en moyenne)
Le temps de transfert est indépendant du disque, mais dépend du bus : on obtient maintenant des taux de 10 à 20 MB/s avec une interface IDE. (ATA66)

CNAM Cyril FRANCONIE
Architecture des Systèmes Informatiques30
Algorithmes
Compte tenu de ces données, l'objectif des algorithmes devra être d'ordonnancer les requêtes de façon à éviter de changer de piste (déplacer les têtes) inutilement, et aussi en utilisant au maximum des secteurs se suivant.On va regarder succintement :
FIFOPCTRSCAN / LOOK + variantesPCTL
On verra ensuite l'impact qu'à l'évolution des technologies mises en oeuvre dans la conception des disques.
CNAM Cyril FRANCONIE
Architecture des Systèmes Informatiques31
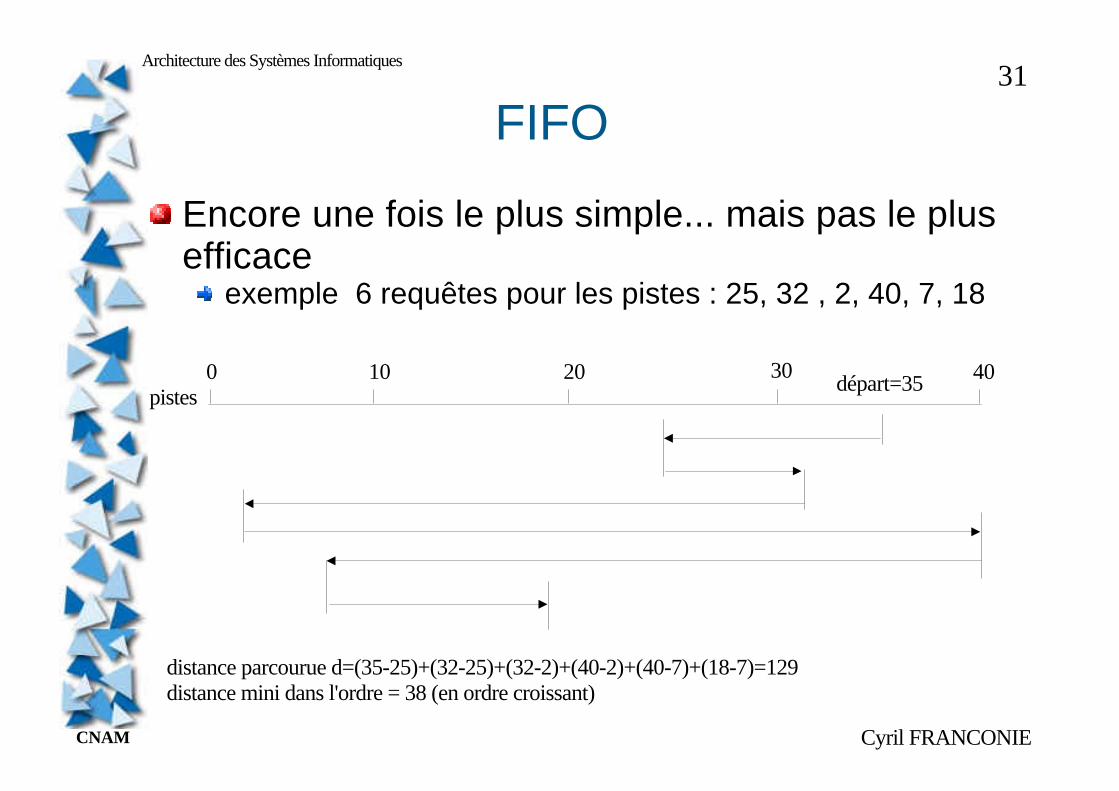
FIFO
Encore une fois le plus simple... mais pas le plus efficace
exemple 6 requêtes pour les pistes : 25, 32 , 2, 40, 7, 18
pistes0 10 20 30 40départ=35
distance parcourue d=(35-25)+(32-25)+(32-2)+(40-2)+(40-7)+(18-7)=129distance mini dans l'ordre = 38 (en ordre croissant)
CNAM Cyril FRANCONIE
Architecture des Systèmes Informatiques32
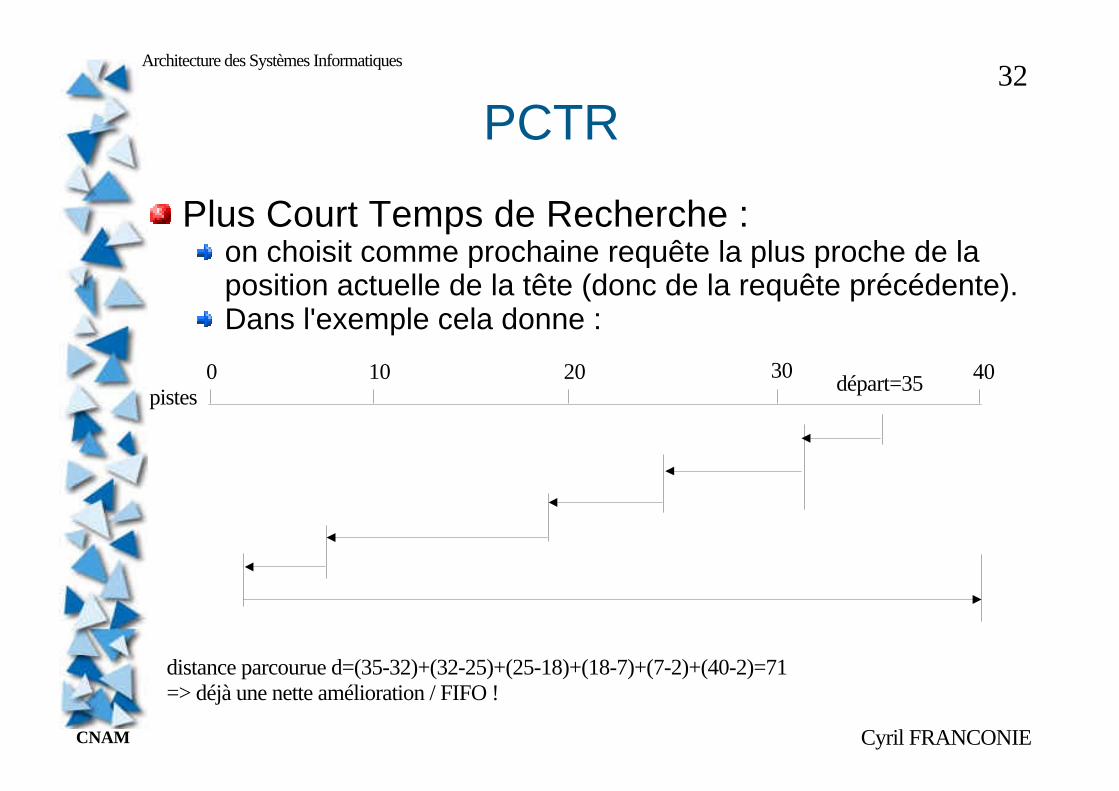
PCTR
Plus Court Temps de Recherche :on choisit comme prochaine requête la plus proche de la position actuelle de la tête (donc de la requête précédente).Dans l'exemple cela donne :
pistes0 10 20 30 40départ=35
distance parcourue d=(35-32)+(32-25)+(25-18)+(18-7)+(7-2)+(40-2)=71=> déjà une nette amélioration / FIFO !

CNAM Cyril FRANCONIE
Architecture des Systèmes Informatiques33
SCAN / LOOK
le PCTR à 2 inconvénients :il ne détecte pas le gain qu'il pourrait y avoir à démarrer par la piste la plus extrème (droite dans l'exemple)Il peut y avoir « famine » si des requêtes arrivent en cours de fonctionnement, qui empécheraient une requête pour un piste extrème d'être honorée.
On introduit l'algorithme « SCAN », qui réalise un balayage des piste dans un sens, et honore les requêtes possibles au fur et à mesure, puis arrivé au bout repart dans l'autre sens.La version « LOOK » est une amélioration car s'arrète à la dernière requête valide dans un sens avant de changer de sens.
CNAM Cyril FRANCONIE
Architecture des Systèmes Informatiques34
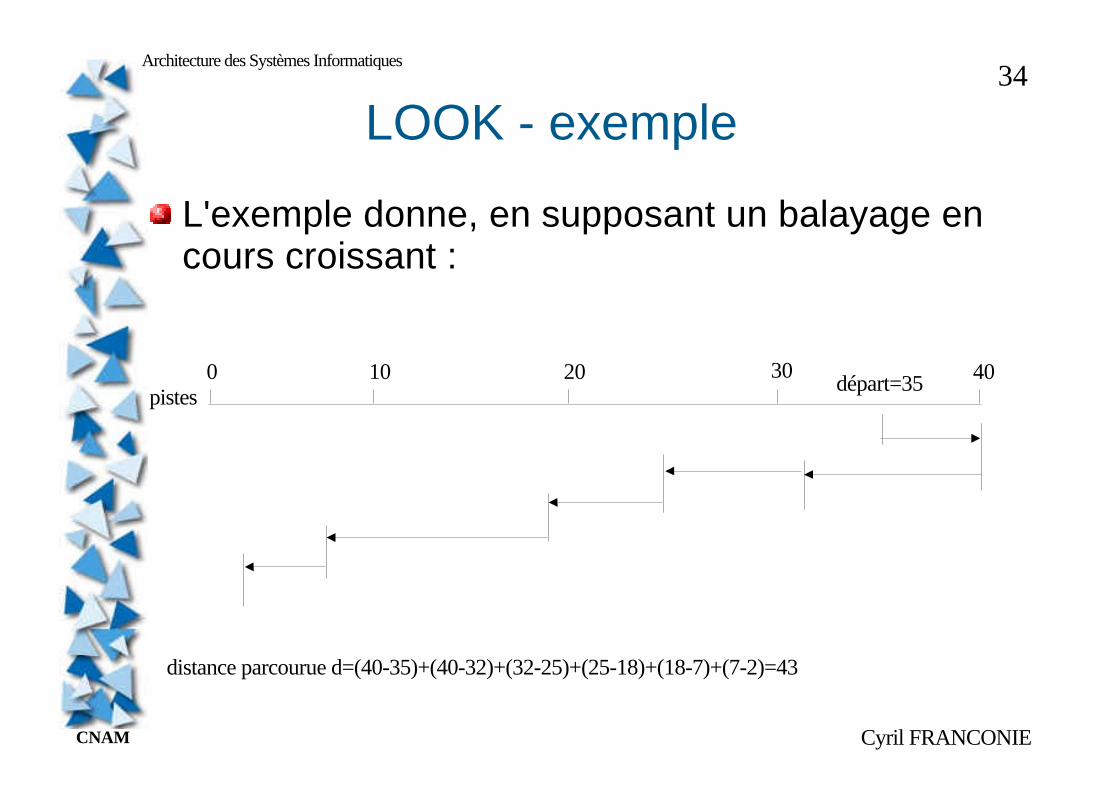
LOOK - exemple
L'exemple donne, en supposant un balayage en cours croissant :
pistes0 10 20 30 40départ=35
distance parcourue d=(40-35)+(40-32)+(32-25)+(25-18)+(18-7)+(7-2)=43

CNAM Cyril FRANCONIE
Architecture des Systèmes Informatiques35
PCTL
Plus Cours Temps de LatenceC.a.d le plus court temps pour accéder au secteur ciblé : tiens compte de la position « rotationnelle » de la tête.C'est un classement, en fait, des requêtes concernant la même piste, en triant dans l'ordre de rotation.Ceci n'est valable que si le système d'exploitation peut avoir une connaissance de la position des têtes de lecture ...
ce n'est plus le cas aujourd'hui !

CNAM Cyril FRANCONIE
Architecture des Systèmes Informatiques36
Situation aujourd'hui
Les technologies évoluant, les disques durs modernes intègrent tous :
un contrôleur intelligentun buffer mémoire de grande capacité (2Mo)C'est donc maintenant le contrôleur interne du disque qui ré-arrange les demandes de lecture/écriture pour optimiser les temps d'accès.
De plus la densité de stockage sur les surfaces magnétiques fait que les données fournies maintenant par le disque (Nb têtes, cylindres, secteurs/piste) sont souvent faux !
du à des contraintes de nb de bits utilisés dans les BIOS pour programmer les n° HCS...

CNAM Cyril FRANCONIE
Architecture des Systèmes Informatiques37
Situation (2)
L'accès au disque complet oblige aujourd'hui à passer par le mode LBA.Donc les optimisations faites (elles sont toujours là) par les systèmes d'exploitation perdent de leur intérêts...La théorie est néanmoins intéressante pour qui veut écrire du firmware pour disques...

CNAM Cyril FRANCONIE
Architecture des Systèmes Informatiques38
Et les autres ressources ?
Parler d'ordonnancement devrait concerner toutes les ressources imposant la mise en attente des processus, donc y compris , principalement, la communication par réseau.S'il n'en est rien c'est sans doute pour les raisons suivantes :
historiquement, les communications par réseau sont apparues bien après la gestion de mémoire et de disquesDès l'origine, la rapidité des liaisons ethernet a permis de s'affranchir des préoccupations d'ordonnancement. (ce qui n'était pas le cas des premiers disques).On voit ré-apparaître cette réflexion avec les besoins croissants en débit (voix/vidéo), et la notion de qualité de service...


















