Application du réseau de neurones à la prédiction et au ... · 1 Résumé Les réseaux de...
21
1 Résumé Les réseaux de neurones sont déjà largement exploités dans les domaines de classification et reconnaissance de formes ou de la parole. Nous l'appliquons également ici au signal de parole mais dans un but différent. Par un nombre d'entrées suffisantes du réseau de neurones, nous tenterons de réaliser une prédiction de l'échantillon suivant immédiatement cet ensemble dans le but de mettre au point un codage plus efficace du signal de parole. En effet, la transmission par un canal de communication des paramètres du réseau ainsi que du signal d'erreur de prédiction laisse à penser – si la prédiction est efficace – qu'une diminution importante du débit peut être atteinte, tout en gardant une qualité acceptable. Nous verrons qu'un seul réseau de neurones pour l'ensemble du signal n'est pas suffisant et qu'il faudra considérer des unités acoustiques plus petites de manière à obtenir une prédiction correcte. Nous comparerons les entropies du signal original et de l'erreur de prédiction en vue de juger de l'utilité d'un codage entropique et verrons alors l'importance du nombre de bits sur lesquels est représentée l'information. Ensuite, nous poursuivrons par une quantification uniforme et non uniforme du signal d'erreur de prédiction et montrerons le gain en débit apporté – par rapport à une quantification directe du signal de parole - pour un rapport signal à bruit équivalent. Nous terminerons ce projet par la transmission des paramètres du réseau seuls – donc sans codage de l'erreur de prédiction – et obtiendrons alors des débits très faibles, mais pour une qualité qu'il s'agira de valider par une écoute d'un signal de parole complet. 1. Introduction Les réseaux de neurones sont déjà largement exploités dans les domaines de classification et de reconnaissance de formes. Leurs sorties approximent en effet les probabilités a posteriori des différentes classes de sortie ; ce qui signifie que ce type de classificateur tend vers l'optimalité. Combinés aux chaînes de Markov, ces réseaux sont également exploités en reconnaissance vocale. Nous utilisons ici ces réseaux de neurones dans un but tout à fait différent. Nous désirons les appliquer à la prédiction du signal de parole. Nous ne disposons d'aucune information quant au dimensionnement de ce réseau et devrons donc explorer l'ensemble des possibilités de manière à affiner notre choix de configuration de réseau. Le nombre de réseaux par unités acoustiques - on entend par unité acoustique un ensemble d'échantillons consécutifs - devra être également déterminé de manière à obtenir une prédiction efficace. Si les unités ne se résument pas au signal complet, il faudra alors envisager une adaptation dynamique des paramètres du réseau pour coder le signal complet. Ces deux étapes seront réalisées par un ensemble d'essais successifs. Nous possèderons alors un ou plusieurs types de configurations de réseaux possibles pour une unité acoustique bien définie. En supposant la prédiction excellente, il s'en suivra un signal d'erreur de prédiction très faible, dont la quantification pourra alors s'effectuer sur un nombre plus faible de bits pour une qualité identique ou sur le même nombre de bits avec une qualité supérieure. Nous appliquerons à cette fin une quantification uniforme et non uniforme sur l'erreur de prédiction. Celle-ci possèdera des valeurs de crête plus faibles que celles du signal initial – que l'on code directement à l'aide de la loi A (approximée en 13 segments) dans la transmission téléphonique fixe – ainsi, davantage de bits pourront être alloués au codage et la qualité s'en trouvera améliorée. Ou de la même façon, pour un rapport signal à bruit (RSB) identique, le nombre de bits par échantillon pourra être plus faible. Un codage entropique peut également être envisagé sur cette erreur de prédiction. Nous calculerons à cette fin les entropies du signal initial et de l'erreur de prédiction de manière à juger de l'utilité d'un codage entropique ainsi que du gain obtenu par la prédiction. Le schéma complet de la chaîne de codage et décodage est présenté en figure 0. On y représente le schéma de prédiction qui permet l'obtention du Application du réseau de neurones à la prédiction et au codage du signal de parole Jean-Yves Parfait– David Vandromme Faculté Polytechnique de Mons - 5 ème Electricité Promoteur M. Bernard Gosselin
Transcript of Application du réseau de neurones à la prédiction et au ... · 1 Résumé Les réseaux de...

1
Résumé Les réseaux de neurones sont déjà largement exploités dans les domaines de classification et reconnaissance de formes ou de la parole. Nous l'appliquons également ici au signal de parole mais dans un but différent. Par un nombre d'entrées suffisantes du réseau de neurones, nous tenterons de réaliser une prédiction de l'échantillon suivant immédiatement cet ensemble dans le but de mettre au point un codage plus efficace du signal de parole. En effet, la transmission par un canal de communication des paramètres du réseau ainsi que du signal d'erreur de prédiction laisse à penser – si la prédiction est efficace – qu'une diminution importante du débit peut être atteinte, tout en gardant une qualité acceptable. Nous verrons qu'un seul réseau de neurones pour l'ensemble du signal n'est pas suffisant et qu'il faudra considérer des unités acoustiques plus petites de manière à obtenir une prédiction correcte. Nous comparerons les entropies du signal original et de l'erreur de prédiction en vue de juger de l'utilité d'un codage entropique et verrons alors l'importance du nombre de bits sur lesquels est représentée l'information. Ensuite, nous poursuivrons par une quantification uniforme et non uniforme du signal d'erreur de prédiction et montrerons le gain en débit apporté – par rapport à une quantification directe du signal de parole - pour un rapport signal à bruit équivalent. Nous terminerons ce projet par la transmission des paramètres du réseau seuls – donc sans codage de l'erreur de prédiction – et obtiendrons alors des débits très faibles, mais pour une qualité qu'il s'agira de valider par une écoute d'un signal de parole complet.
1. Introduction
Les réseaux de neurones sont déjà largement exploités dans les domaines de classification et de reconnaissance de formes. Leurs sorties approximent en effet les probabilités a posteriori des différentes classes de sortie ; ce qui signifie que ce type de classificateur tend vers l'optimalité. Combinés aux chaînes de Markov, ces réseaux sont également exploités en reconnaissance vocale.
Nous utilisons ici ces réseaux de neurones dans un but tout à fait différent. Nous désirons les appliquer à la prédiction du signal de parole. Nous ne disposons d'aucune information quant au dimensionnement de ce réseau et devrons donc explorer l'ensemble des possibilités de manière à affiner notre choix de configuration de réseau. Le nombre de réseaux par unités acoustiques - on entend par unité acoustique un ensemble d'échantillons consécutifs - devra être également déterminé de manière à obtenir une prédiction efficace. Si les unités ne se résument pas au signal complet, il faudra alors envisager une adaptation dynamique des paramètres du réseau pour coder le signal complet. Ces deux étapes seront réalisées par un ensemble d'essais successifs. Nous possèderons alors un ou plusieurs types de configurations de réseaux possibles pour une unité acoustique bien définie. En supposant la prédiction excellente, il s'en suivra un signal d'erreur de prédiction très faible, dont la quantification pourra alors s'effectuer sur un nombre plus faible de bits pour une qualité identique ou sur le même nombre de bits avec une qualité supérieure. Nous appliquerons à cette fin une quantification uniforme et non uniforme sur l'erreur de prédiction. Celle-ci possèdera des valeurs de crête plus faibles que celles du signal initial – que l'on code directement à l'aide de la loi A (approximée en 13 segments) dans la transmission téléphonique fixe – ainsi, davantage de bits pourront être alloués au codage et la qualité s'en trouvera améliorée. Ou de la même façon, pour un rapport signal à bruit (RSB) identique, le nombre de bits par échantillon pourra être plus faible. Un codage entropique peut également être envisagé sur cette erreur de prédiction. Nous calculerons à cette fin les entropies du signal initial et de l'erreur de prédiction de manière à juger de l'utilité d'un codage entropique ainsi que du gain obtenu par la prédiction. Le schéma complet de la chaîne de codage et décodage est présenté en figure 0. On y représente le schéma de prédiction qui permet l'obtention du
Application du réseau de neurones à la prédiction et au codage du signal de parole
Jean-Yves Parfait– David Vandromme
Faculté Polytechnique de Mons - 5ème Electricité Promoteur M. Bernard Gosselin
2
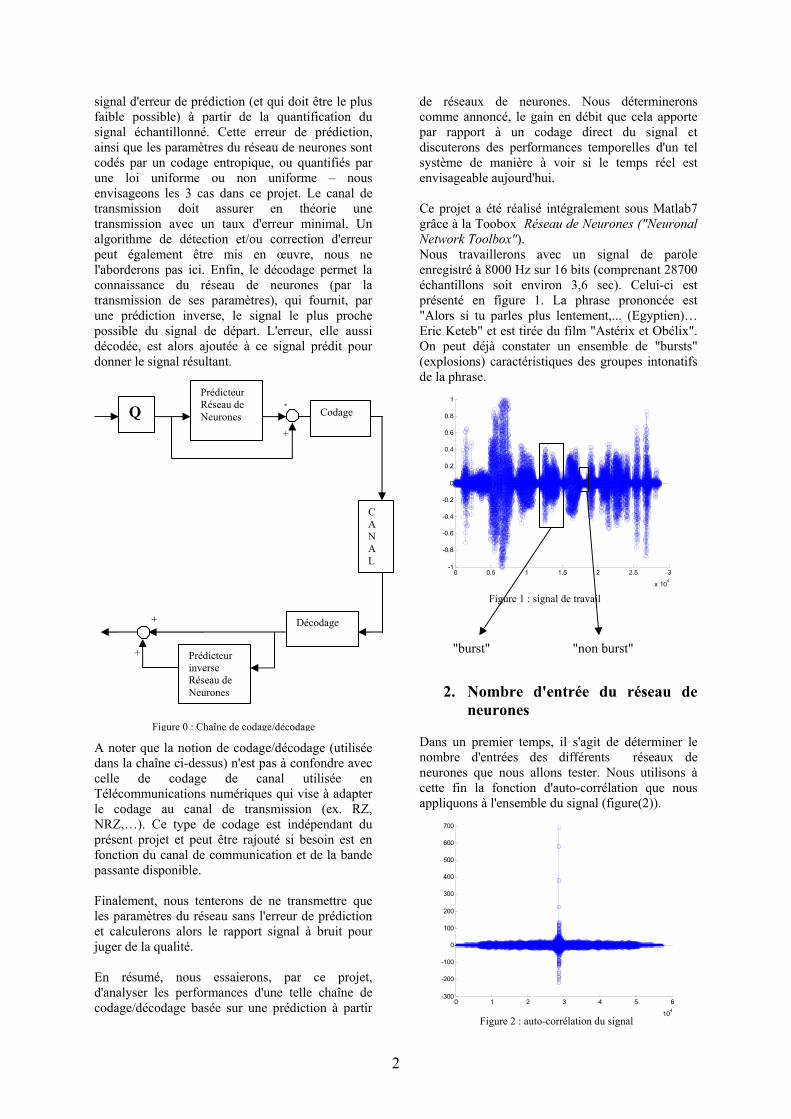
signal d'erreur de prédiction (et qui doit être le plus faible possible) à partir de la quantification du signal échantillonné. Cette erreur de prédiction, ainsi que les paramètres du réseau de neurones sont codés par un codage entropique, ou quantifiés par une loi uniforme ou non uniforme – nous envisageons les 3 cas dans ce projet. Le canal de transmission doit assurer en théorie une transmission avec un taux d'erreur minimal. Un algorithme de détection et/ou correction d'erreur peut également être mis en œuvre, nous ne l'aborderons pas ici. Enfin, le décodage permet la connaissance du réseau de neurones (par la transmission de ses paramètres), qui fournit, par une prédiction inverse, le signal le plus proche possible du signal de départ. L'erreur, elle aussi décodée, est alors ajoutée à ce signal prédit pour donner le signal résultant.
A noter que la notion de codage/décodage (utilisée dans la chaîne ci-dessus) n'est pas à confondre avec celle de codage de canal utilisée en Télécommunications numériques qui vise à adapter le codage au canal de transmission (ex. RZ, NRZ,…). Ce type de codage est indépendant du présent projet et peut être rajouté si besoin est en fonction du canal de communication et de la bande passante disponible. Finalement, nous tenterons de ne transmettre que les paramètres du réseau sans l'erreur de prédiction et calculerons alors le rapport signal à bruit pour juger de la qualité. En résumé, nous essaierons, par ce projet, d'analyser les performances d'une telle chaîne de codage/décodage basée sur une prédiction à partir
de réseaux de neurones. Nous déterminerons comme annoncé, le gain en débit que cela apporte par rapport à un codage direct du signal et discuterons des performances temporelles d'un tel système de manière à voir si le temps réel est envisageable aujourd'hui. Ce projet a été réalisé intégralement sous Matlab7 grâce à la Toobox Réseau de Neurones ("Neuronal Network Toolbox"). Nous travaillerons avec un signal de parole enregistré à 8000 Hz sur 16 bits (comprenant 28700 échantillons soit environ 3,6 sec). Celui-ci est présenté en figure 1. La phrase prononcée est "Alors si tu parles plus lentement,... (Egyptien)… Eric Keteb" et est tirée du film "Astérix et Obélix". On peut déjà constater un ensemble de "bursts" (explosions) caractéristiques des groupes intonatifs de la phrase.
0 0.5 1 1.5 2 2.5 3
x 104
-1
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
0.8
1
2. Nombre d'entrée du réseau de neurones
Dans un premier temps, il s'agit de déterminer le nombre d'entrées des différents réseaux de neurones que nous allons tester. Nous utilisons à cette fin la fonction d'auto-corrélation que nous appliquons à l'ensemble du signal (figure(2)).
0 1 2 3 4 5 6
x 104
-300
-200
-100
0
100
200
300
400
500
600
700
Q Prédicteur Réseau de Neurones
+
- Codage
C A N A L
Décodage
Prédicteur inverse Réseau de Neurones
+
+
Figure 0 : Chaîne de codage/décodage
Figure 2 : auto-corrélation du signal
Figure 1 : signal de travail
"burst" "non burst"

3
(c)
Le pic de corrélation couvre environ 10 échantillons. En zoomant sur ce dessin, on peut extraire la "périodicité" de la fonction d'auto-corrélation.
2.849 2.85 2.851 2.852 2.853 2.854 2.855 2.856 2.857
x 104
-30
-20
-10
0
10
20
30
40
Nous considérerons donc pour l'ensemble des essais un nombre d'entrées égal à 10. En d'autres termes, cela revient à estimer un échantillon sur base des 10 précédents. On suppose donc que la contribution (à la prédiction) des échantillons antérieurs au dixième échantillon est négligeable, ou autrement dit que les échantillons décalés de plus de 10 échantillons entre eux ne sont plus corrélés. On remarque en effet une corrélation importante pour les 10 premiers échantillons (pic de corrélation dans la figure 2) et une périodicité au-delà (figure 3). La périodicité n'apporte plus d'information puisque celle-ci est déjà reprise par la première période de 10 échantillons. L'importance de la corrélation y est également plus minime. A noter que ce nombre de 10 est indépendant du nombre de neurones de la première couche cachée du réseau. Nous allons maintenant discuter du nombre de couches cachées, du nombre de neurones par couche et enfin des fonctions de transfert appliquées par les différents neurones afin d'estimer le nombre de configurations possibles.
3. Choix du nombre de couches cachées, nombre de neurones et fonctions de transfert
De manière à ne pas augmenter de façon inutile la complexité du réseau, nous choisissons une seule couche cachée (et un neurone de sortie puisqu'il n'y a qu'un échantillon à prédire). Nous testerons nos réseaux sur 5, 10 et 15 neurones en couche cachée. Trois fonctions de transfert seront envisagées : une fonction linéaire ('purelin', figure(4.a)) et deux fonctions sïgmoïdes, l'une à sortie positive et
négative ('tansig', figure(4.b)), l'autre à sortie uniquement positive ('logsig', figure(4.c)).
Etant donné que nous souhaitons une sortie signée, nous excluons la sortie en 'logsig'. Ce qui nous laisse au total – en considérant tous les couples possibles - 3² - 3 = 6 possibilités de configurations pour 2 couches de neurones et les 3 fonctions adoptées. Nous simplifions donc en ne considérant qu'un seul type de fonction par couche. Les 6 couples sont donc les suivants :
• 'tansig' – 'tansig' (1) • 'logsig' – 'tansig' (2) • 'purelin' – 'tansig' (3) • 'purelin' – 'purelin' (4) • ''logsig' – 'purelin' (5) • 'tansig' – 'purelin' (6)
En vue d'alléger les écritures dans les tableaux de résultats, nous désignerons les configurations par leurs numéros respectifs. Nous considérerons également le perceptron linéaire (1 seul neurone de sortie de fonction linéaire). La figure 5 donne la représentation physique du réseau de neurone (a) ainsi que celle du perceptron (b). La sortie du réseau de neurones est ici à particulariser à 1, le nombre de neurones en couche cachée à 5, 10 ou 15 et le nombre d'entrée à 10.
Figure(3) : Zoom sur l'auto-corrélation
Figure 4.a.b.c : fonctions 'purelin', 'tansig' et 'logsig'
(a) (b)
(a)

4
4. Réseaux de neurones appliqués à
3 mots du signal
Nos différentes configurations adoptées, nous allons maintenant vérifier si un seul réseau n'est pas suffisant pour prédire tout le signal de parole. Pour ce faire, nous allons entraîner sur 1000 vecteurs d'entrées (chacun d'eux possédant 10 valeurs) nos réseaux de neurones et sur 200 vecteurs d'entrée le perceptron (on constate en effet qu'au-delà de 200 vecteurs, l'entraînement du perceptron diverge). Pour l'ensemble de ces essais, une validation croisée est mise en œuvre. A noter que les vecteurs cibles correspondent bien entendu à l'échantillon suivant (le 11ème si les 10 premiers échantillons sont présentés en entrée) à prédire. L'entraînement adopté est celui de Levenberg-Marquardt, qui permet une convergence plus rapide par la prise en compte des dérivées du second ordre. Après quelques tests, nous choisissons le nombre d'itérations ("epochs") à 400. Le taux d'apprentissage est fixé à 0,05 et le but ("goal") à 0,0004. A noter également que l'entraînement s'effectue dans un premier temps sans validation croisée pour éviter que celle-ci ne vienne interrompre l'entraînement à cause d'un minimum local (variation positive de l'erreur). La validation croisée est ensuite mise en œuvre, lorsque le réseau est proche de l'optimum. L'entraînement terminé, le test des réseaux et du perceptron se fait sur 5000 vecteurs (soit environ 3 mots) différents de ceux utilisés pour l'entraînement et la validation croisée. On note tout d'abord que l'écart-type du signal de test vaut 0.12. Pour l'ensemble des essais, l'écart-type de l'erreur de prédiction est calculé de manière à le comparer à celui du signal. Une diminution de l'écart-type signifierait que la prédiction a été efficace. Les résultats relatifs aux 6 configurations de réseaux pour 5, 10 et 15 neurones sont repris dans le tableau 1.
STD 1 2 3 4 5 6
5 neurones 0.13 0.13 0.13 0.13 0.13 0.13
10 neurones 0.13 0.13 0.13 0.13 0.13 0.13
15 neurones 0.16 0.13 0.13 0.13 0.14 0.13
Le perceptron, quant à lui, donne un écart-type de 0,11. Un seul réseau pour tout le signal ne peut donc être envisagé car l'écart-type de l'erreur de prédiction est trop important et du même ordre de grandeur que celui du signal. On pouvait s’y attendre puisque la statistique du signal varie fortement d’un burst à l’autre. Il faudra donc changer le réseau et l'adapter au cours du temps. Nous appliquons dès lors notre analyse sur des unités acoustiques plus petites et allons considérer un seul réseau pour tous les "bursts" du signal.
5. Réseaux de neurones appliqués
aux "bursts" Nous entraînons maintenant nos réseaux et perceptron sur un "burst" du signal et les testons sur d'autres "bursts". Cette analyse servira donc à montrer si un seul réseau est suffisant pour la prédiction de l'ensemble des "bursts" d'un signal de parole. Les essais sont identiques aux précédents mais les signaux d'entrée et de validation sont pris sur un "burst". Le signal de test constitue les échantillons d'un autre "burst". Son écart-type vaut 0,12.
Le perceptron donne un écart-type de 0,12. Ainsi, on constate qu'on ne peut pas non plus considérer un réseau unique pour tous les "bursts" du signal. Nous descendons donc encore dans la taille des unités acoustiques considérées pour maintenant entraîner le réseau sur le même signal ("burst") qu'il aura à prédire. Un "burst" représente environ 2000 échantillons, soit à 8 KHz, 0,25 sec.
STD 1 2 3 4 5 6
5 neurones 0.13 0.13 0.13 0.13 0.13 0.13
10 neurones 0.13 0.12 0.13 0.13 0.18 0.13
15 neurones 0.13 0.14 0.13 0.13 0.12 0.14
(b)
Figure 5 : Réalisation physique du réseau de neurones et du perceptron
Tableau 1 : Ecarts-types de l'erreur de prédiction des réseaux de neurones pour 5000 échantillons du signal
Tableau 2 : Ecarts-types de l'erreur de prédiction des réseaux de neurones pour un "burst" du signal
5
6. Réseaux de neurones appliqués à un "burst"
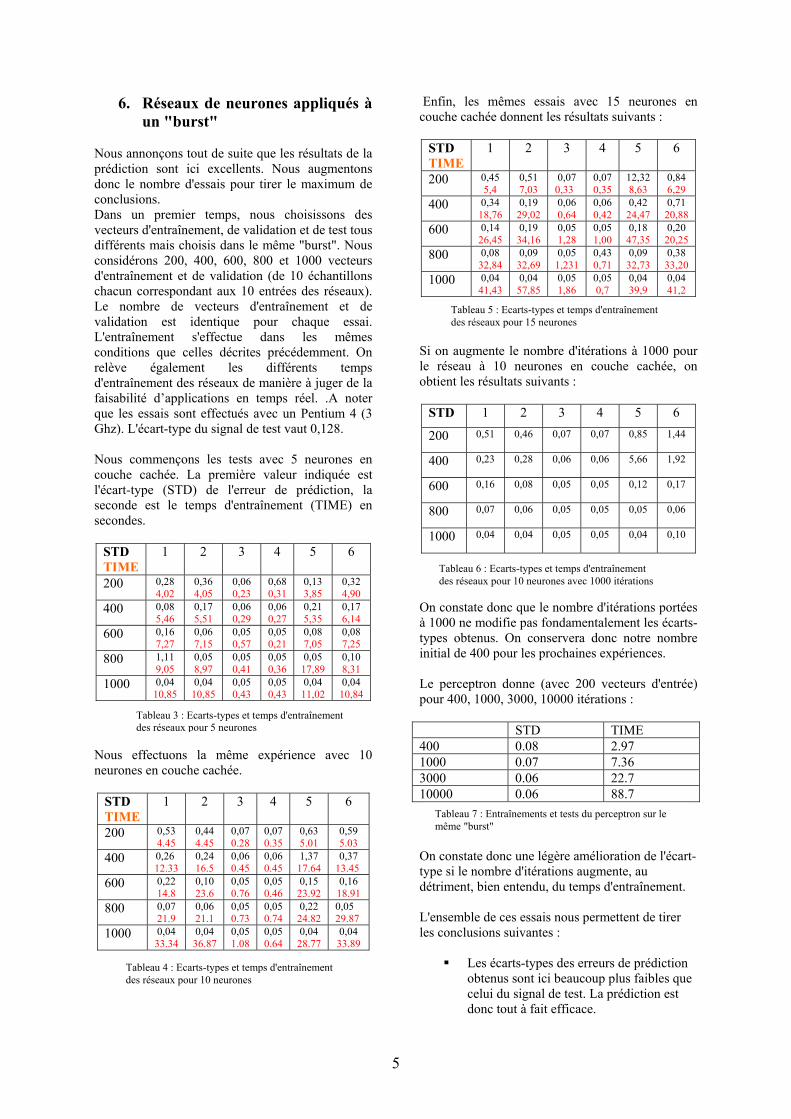
Nous annonçons tout de suite que les résultats de la prédiction sont ici excellents. Nous augmentons donc le nombre d'essais pour tirer le maximum de conclusions. Dans un premier temps, nous choisissons des vecteurs d'entraînement, de validation et de test tous différents mais choisis dans le même "burst". Nous considérons 200, 400, 600, 800 et 1000 vecteurs d'entraînement et de validation (de 10 échantillons chacun correspondant aux 10 entrées des réseaux). Le nombre de vecteurs d'entraînement et de validation est identique pour chaque essai. L'entraînement s'effectue dans les mêmes conditions que celles décrites précédemment. On relève également les différents temps d'entraînement des réseaux de manière à juger de la faisabilité d’applications en temps réel. .A noter que les essais sont effectués avec un Pentium 4 (3 Ghz). L'écart-type du signal de test vaut 0,128. Nous commençons les tests avec 5 neurones en couche cachée. La première valeur indiquée est l'écart-type (STD) de l'erreur de prédiction, la seconde est le temps d'entraînement (TIME) en secondes.
STD TIME
1 2 3 4 5 6
200 0,28 4,02
0,36 4,05
0,06 0,23
0,68 0,31
0,13 3,85
0,32 4,90
400 0,08 5,46
0,17 5,51
0,06 0,29
0,06 0,27
0,21 5,35
0,17 6,14
600 0,16 7,27
0,06 7,15
0,05 0,57
0,05 0,21
0,08 7,05
0,08 7,25
800 1,11 9,05
0,05 8,97
0,05 0,41
0,05 0,36
0,05 17,89
0,10 8,31
1000 0,04 10,85
0,04 10,85
0,05 0,43
0,05 0,43
0,04 11,02
0,04 10,84
Nous effectuons la même expérience avec 10 neurones en couche cachée.
STD TIME
1 2 3 4 5 6
200 0,53 4.45
0,44 4.45
0,07 0.28
0,07 0.35
0,63 5.01
0,59 5.03
400 0,26 12.33
0,24 16.5
0,06 0.45
0,06 0.45
1,37 17.64
0,37 13.45
600 0,22 14.8
0,10 23.6
0,05 0.76
0,05 0.46
0,15 23.92
0,16 18.91
800 0,07 21.9
0,06 21.1
0,05 0.73
0,05 0.74
0,22 24.82
0,05 29.87
1000 0,04 33.34
0,04 36.87
0,05 1.08
0,05 0.64
0,04 28.77
0,04 33.89
Enfin, les mêmes essais avec 15 neurones en couche cachée donnent les résultats suivants :
STD TIME
1 2 3 4 5 6
200 0,45 5,4
0,51 7,03
0,07 0,33
0,07 0,35
12,32 8,63
0,84 6,29
400 0,34 18,76
0,19 29,02
0,06 0,64
0,06 0,42
0,42 24,47
0,71 20,88
600 0,14 26,45
0,19 34,16
0,05 1,28
0,05 1,00
0,18 47,35
0,20 20,25
800 0,08 32,84
0,09 32,69
0,05 1,231
0,43 0,71
0,09 32,73
0,38 33,20
1000 0,04 41,43
0,04 57,85
0,05 1,86
0,05 0,7
0,04 39,9
0,04 41,2
Si on augmente le nombre d'itérations à 1000 pour le réseau à 10 neurones en couche cachée, on obtient les résultats suivants :
STD 1 2 3 4 5 6
200 0,51
0,46
0,07
0,07
0,85
1,44
400 0,23
0,28
0,06
0,06
5,66
1,92
600 0,16
0,08
0,05
0,05
0,12
0,17
800 0,07
0,06
0,05
0,05
0,05
0,06
1000 0,04
0,04
0,05
0,05
0,04
0,10
On constate donc que le nombre d'itérations portées à 1000 ne modifie pas fondamentalement les écarts-types obtenus. On conservera donc notre nombre initial de 400 pour les prochaines expériences. Le perceptron donne (avec 200 vecteurs d'entrée) pour 400, 1000, 3000, 10000 itérations : STD TIME 400 0.08 2.97 1000 0.07 7.36 3000 0.06 22.7 10000 0.06 88.7 On constate donc une légère amélioration de l'écart-type si le nombre d'itérations augmente, au détriment, bien entendu, du temps d'entraînement. L'ensemble de ces essais nous permettent de tirer les conclusions suivantes :
Les écarts-types des erreurs de prédiction obtenus sont ici beaucoup plus faibles que celui du signal de test. La prédiction est donc tout à fait efficace.
Tableau 3 : Ecarts-types et temps d'entraînement des réseaux pour 5 neurones
Tableau 4 : Ecarts-types et temps d'entraînement des réseaux pour 10 neurones
Tableau 5 : Ecarts-types et temps d'entraînement des réseaux pour 15 neurones
Tableau 6 : Ecarts-types et temps d'entraînement des réseaux pour 10 neurones avec 1000 itérations
Tableau 7 : Entraînements et tests du perceptron sur le même "burst"
6
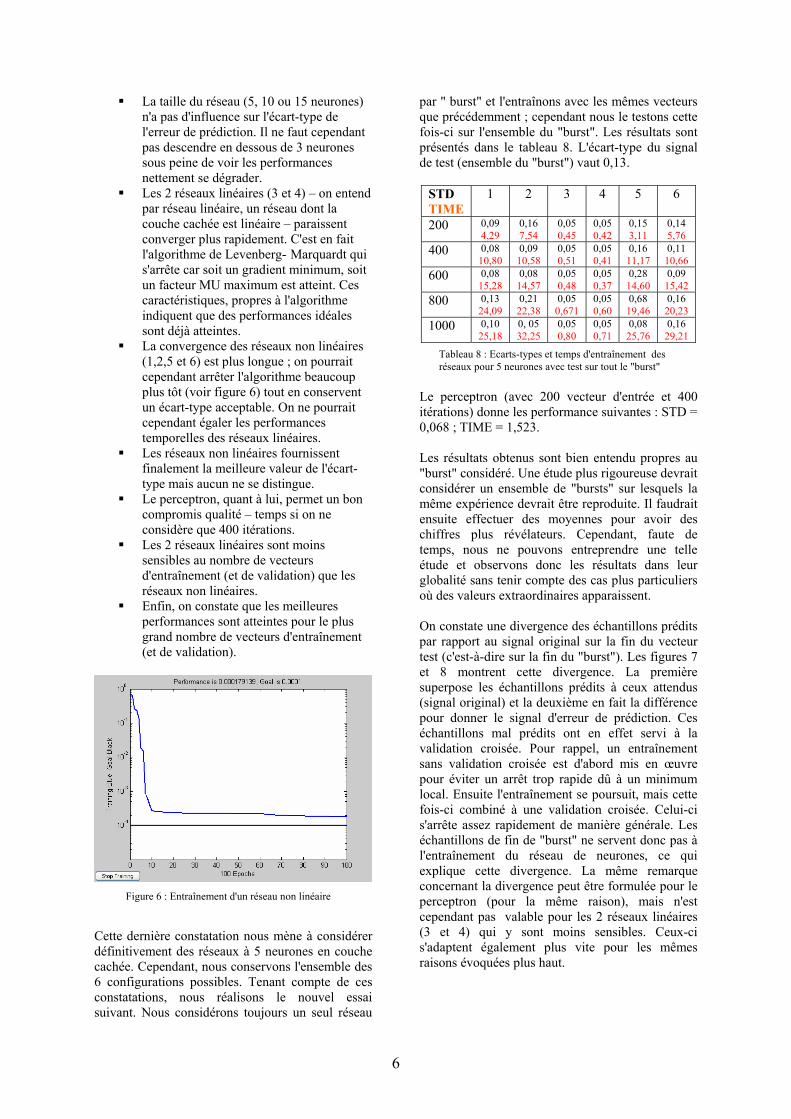
La taille du réseau (5, 10 ou 15 neurones) n'a pas d'influence sur l'écart-type de l'erreur de prédiction. Il ne faut cependant pas descendre en dessous de 3 neurones sous peine de voir les performances nettement se dégrader.
Les 2 réseaux linéaires (3 et 4) – on entend par réseau linéaire, un réseau dont la couche cachée est linéaire – paraissent converger plus rapidement. C'est en fait l'algorithme de Levenberg- Marquardt qui s'arrête car soit un gradient minimum, soit un facteur MU maximum est atteint. Ces caractéristiques, propres à l'algorithme indiquent que des performances idéales sont déjà atteintes.
La convergence des réseaux non linéaires (1,2,5 et 6) est plus longue ; on pourrait cependant arrêter l'algorithme beaucoup plus tôt (voir figure 6) tout en conservent un écart-type acceptable. On ne pourrait cependant égaler les performances temporelles des réseaux linéaires.
Les réseaux non linéaires fournissent finalement la meilleure valeur de l'écart-type mais aucun ne se distingue.
Le perceptron, quant à lui, permet un bon compromis qualité – temps si on ne considère que 400 itérations.
Les 2 réseaux linéaires sont moins sensibles au nombre de vecteurs d'entraînement (et de validation) que les réseaux non linéaires.
Enfin, on constate que les meilleures performances sont atteintes pour le plus grand nombre de vecteurs d'entraînement (et de validation).
Cette dernière constatation nous mène à considérer définitivement des réseaux à 5 neurones en couche cachée. Cependant, nous conservons l'ensemble des 6 configurations possibles. Tenant compte de ces constatations, nous réalisons le nouvel essai suivant. Nous considérons toujours un seul réseau
par " burst" et l'entraînons avec les mêmes vecteurs que précédemment ; cependant nous le testons cette fois-ci sur l'ensemble du "burst". Les résultats sont présentés dans le tableau 8. L'écart-type du signal de test (ensemble du "burst") vaut 0,13.
STD TIME
1 2 3 4 5 6
200 0,09 4,29
0,16 7,54
0,05 0,45
0,05 0,42
0,15 3,11
0,14 5,76
400 0,08 10,80
0,09 10,58
0,05 0,51
0,05 0,41
0,16 11,17
0,11 10,66
600 0,08 15,28
0,08 14,57
0,05 0,48
0,05 0,37
0,28 14,60
0,09 15,42
800 0,13 24,09
0,21 22,38
0,05 0,671
0,05 0,60
0,68 19,46
0,16 20,23
1000 0,10 25,18
0, 05 32,25
0,05 0,80
0,05 0,71
0,08 25,76
0,16 29,21
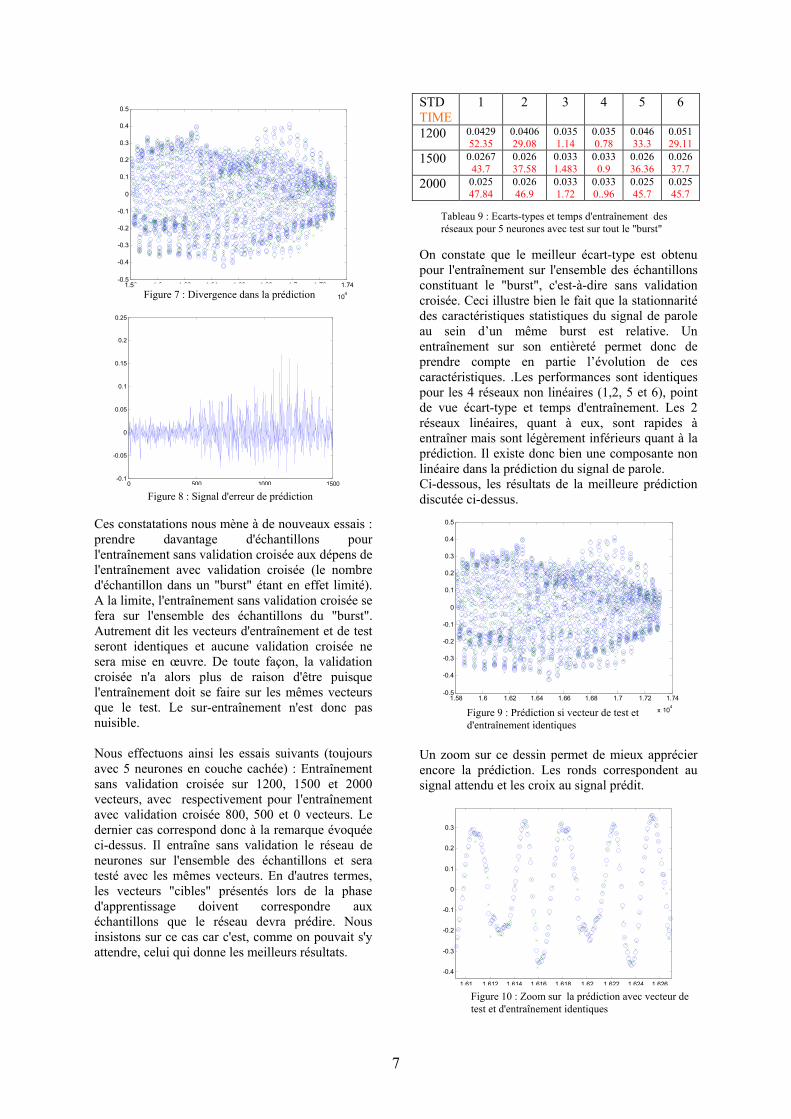
Le perceptron (avec 200 vecteur d'entrée et 400 itérations) donne les performance suivantes : STD = 0,068 ; TIME = 1,523. Les résultats obtenus sont bien entendu propres au "burst" considéré. Une étude plus rigoureuse devrait considérer un ensemble de "bursts" sur lesquels la même expérience devrait être reproduite. Il faudrait ensuite effectuer des moyennes pour avoir des chiffres plus révélateurs. Cependant, faute de temps, nous ne pouvons entreprendre une telle étude et observons donc les résultats dans leur globalité sans tenir compte des cas plus particuliers où des valeurs extraordinaires apparaissent. On constate une divergence des échantillons prédits par rapport au signal original sur la fin du vecteur test (c'est-à-dire sur la fin du "burst"). Les figures 7 et 8 montrent cette divergence. La première superpose les échantillons prédits à ceux attendus (signal original) et la deuxième en fait la différence pour donner le signal d'erreur de prédiction. Ces échantillons mal prédits ont en effet servi à la validation croisée. Pour rappel, un entraînement sans validation croisée est d'abord mis en œuvre pour éviter un arrêt trop rapide dû à un minimum local. Ensuite l'entraînement se poursuit, mais cette fois-ci combiné à une validation croisée. Celui-ci s'arrête assez rapidement de manière générale. Les échantillons de fin de "burst" ne servent donc pas à l'entraînement du réseau de neurones, ce qui explique cette divergence. La même remarque concernant la divergence peut être formulée pour le perceptron (pour la même raison), mais n'est cependant pas valable pour les 2 réseaux linéaires (3 et 4) qui y sont moins sensibles. Ceux-ci s'adaptent également plus vite pour les mêmes raisons évoquées plus haut.
Tableau 8 : Ecarts-types et temps d'entraînement des réseaux pour 5 neurones avec test sur tout le "burst"
Figure 6 : Entraînement d'un réseau non linéaire
7
1.58 1.6 1.62 1.64 1.66 1.68 1.7 1.72 1.74
x 104
-0.5
-0.4
-0.3
-0.2
-0.1
0
0.1
0.2
0.3
0.4
0.5
0 500 1000 1500-0.1
-0.05
0
0.05
0.1
0.15
0.2
0.25
Ces constatations nous mène à de nouveaux essais : prendre davantage d'échantillons pour l'entraînement sans validation croisée aux dépens de l'entraînement avec validation croisée (le nombre d'échantillon dans un "burst" étant en effet limité). A la limite, l'entraînement sans validation croisée se fera sur l'ensemble des échantillons du "burst". Autrement dit les vecteurs d'entraînement et de test seront identiques et aucune validation croisée ne sera mise en œuvre. De toute façon, la validation croisée n'a alors plus de raison d'être puisque l'entraînement doit se faire sur les mêmes vecteurs que le test. Le sur-entraînement n'est donc pas nuisible. Nous effectuons ainsi les essais suivants (toujours avec 5 neurones en couche cachée) : Entraînement sans validation croisée sur 1200, 1500 et 2000 vecteurs, avec respectivement pour l'entraînement avec validation croisée 800, 500 et 0 vecteurs. Le dernier cas correspond donc à la remarque évoquée ci-dessus. Il entraîne sans validation le réseau de neurones sur l'ensemble des échantillons et sera testé avec les mêmes vecteurs. En d'autres termes, les vecteurs "cibles" présentés lors de la phase d'apprentissage doivent correspondre aux échantillons que le réseau devra prédire. Nous insistons sur ce cas car c'est, comme on pouvait s'y attendre, celui qui donne les meilleurs résultats.
STD TIME
1 2 3 4 5 6
1200 0.0429 52.35
0.0406 29.08
0.035 1.14
0.035 0.78
0.046 33.3
0.051 29.11
1500 0.0267 43.7
0.026 37.58
0.033 1.483
0.033 0.9
0.026 36.36
0.026 37.7
2000 0.025 47.84
0.026 46.9
0.033 1.72
0.033 0..96
0.025 45.7
0.025 45.7
On constate que le meilleur écart-type est obtenu pour l'entraînement sur l'ensemble des échantillons constituant le "burst", c'est-à-dire sans validation croisée. Ceci illustre bien le fait que la stationnarité des caractéristiques statistiques du signal de parole au sein d’un même burst est relative. Un entraînement sur son entièreté permet donc de prendre compte en partie l’évolution de ces caractéristiques. .Les performances sont identiques pour les 4 réseaux non linéaires (1,2, 5 et 6), point de vue écart-type et temps d'entraînement. Les 2 réseaux linéaires, quant à eux, sont rapides à entraîner mais sont légèrement inférieurs quant à la prédiction. Il existe donc bien une composante non linéaire dans la prédiction du signal de parole. Ci-dessous, les résultats de la meilleure prédiction discutée ci-dessus.
1.58 1.6 1.62 1.64 1.66 1.68 1.7 1.72 1.74
x 104
-0.5
-0.4
-0.3
-0.2
-0.1
0
0.1
0.2
0.3
0.4
0.5
Un zoom sur ce dessin permet de mieux apprécier encore la prédiction. Les ronds correspondent au signal attendu et les croix au signal prédit.
1.61 1.612 1.614 1.616 1.618 1.62 1.622 1.624 1.626
x 104
-0.4
-0.3
-0.2
-0.1
0
0.1
0.2
0.3
Tableau 9 : Ecarts-types et temps d'entraînement des réseaux pour 5 neurones avec test sur tout le "burst"
Figure 7 : Divergence dans la prédiction
Figure 8 : Signal d'erreur de prédiction
Figure 9 : Prédiction si vecteur de test et d'entraînement identiques
Figure 10 : Zoom sur la prédiction avec vecteur de test et d'entraînement identiques

8
L'erreur de prédiction est très faible :
0 500 1000 1500-0.1
-0.08
-0.06
-0.04
-0.02
0
0.02
0.04
0.06
0.08
Le perceptron, quant à lui, ne peut égaler de telles performances, puisque son entraînement diverge si plus de 200 vecteurs d'entrée sont choisis. Il ne pourra donc jamais tenir compte de l'ensemble des échantillons composant un "burst" et ses capacités de prédiction seront donc limitées. Nous l'éliminons donc pour la suite des expériences. De manière générale, on observe, comme toujours, un certain compromis vitesse – précision. Il faut également constater que dans le meilleur des cas, l'entraînement ne dure que 0,5 sec pour un écart-type assez médiocre (voir réseaux linéaires, tableau 3,4 et 5) et monte jusqu'à 1 sec pour un écart-type valable (voir réseaux linéaires, tableau 9). Le temps réel ne pourrait donc pas être mis en œuvre à l'heure actuelle mais pourra être certainement envisagé dans les années à venir. La notion de "médiocrité" de l'écart-type est bien entendu relative à l'écart-type du signal à prédire et au gain potentiel en bits qu'une faible valeur engendrerait lors d'une transmission par un canal de Télécommunication. Néanmoins, nous estimons qu'une diminution de moitié de cet écart-type n'est pas suffisante pour justifier la mise en œuvre d'un réseau de neurones en codage de parole. Le gain en débit ne serait pas suffisant pour compenser la transmission des paramètres du réseau ainsi que la complexité de l'installation. Dans une étude complète, il faudrait également tester le réseau de neurones sur des unités acoustiques encore plus petites que le "burst". Cependant, nous pensons que le gain obtenu sur l'écart-type sera assez faible relativement aux performances obtenues précédemment et ne pourra justifier (complexité, contrainte temporelle) une fréquence supérieure d'adaptation des réseaux de neurones sur le signal.
7) Essai sur des "non burst"
Dans un esprit de généralité, nous testons notre réseau de neurones sur des "non bursts" (voir figure 1). La figure ci-dessous représente un "non burst" c'est-à-dire une consonne ou une transition entre deux groupes intonatifs.
1.13 1.14 1.15 1.16 1.17 1.18
x 104
-0.04
-0.03
-0.02
-0.01
0
0.01
0.02
0.03
Nous effectuons des essais sur un "non burst" dont l'écart-type vaut 0,0122. Nous considérons, compte tenu de ce qui a été fait précédemment, de l'ensemble des échantillons disponibles (sur le "non burst", soit environ 500 échantillon) pour entraîner nos réseaux (pas de validation croisée) et simulons (testons) ceux-ci avec les mêmes vecteurs que ceux qui ont servi à l'entraînement. Etant données les petites valeurs sur lesquelles nous travaillons ici, nous devons descendre le "goal" à 0,00005. Une couche cachée de 5 neurones est considérée. Voici les résultats. 1 2 3 4 5 6 STD TIME
0.0068 6.8100
0.0067 6.8000
0.0072 0.4310
0.0072 0.3710
0.0069 6.8600
0.0067 7.8220
Les temps d'entraînement sont très corrects. Par contre, on ne gagne donc qu'un facteur 2 pour l'écart-type. La prédiction est donc moyenne comme on peut le constater sur les figures suivantes.
1.13 1.14 1.15 1.16 1.17 1.18 1.19
x 104
-0.05
-0.04
-0.03
-0.02
-0.01
0
0.01
0.02
0.03
Figure 10 : Erreur de prédiction si vecteur de test et d'entraînement identiques
Figure 11 : Zoom sur un "non burst"
Tableau 10 : Performances sur "non burst"
Figure 12 : Prédiction sur un "non burst"

9
0 50 100 150 200 250 300 350 400 450 500-0.02
-0.015
-0.01
-0.005
0
0.005
0.01
0.015
0.02
0.025
Cependant, à la vue de la figure 1, ces unités acoustiques sont moins importantes temporellement. Le débit binaire supérieur engendré par ces unités (étant donné la prédiction mois efficace) sera donc de plus courte durée que celui des "bursts" (dont la durée est environ 4 fois supérieure à celle d'un non burst"). Nous ne donnons ici que des constatations qualitatives ; il faudrait en effet réaliser une étude théorique beaucoup plus approfondie qui prendrait en compte les statistiques d'apparition des "bursts" et "non bursts" dans un signal de parole. A partir de là seulement, des statistiques en terme de débit moyen pourraient être envisagées. Il est clair que cette remarque ne peut être envisagée dans ce travail qui vise seulement une première approche des réseaux de neurones appliqués à la prédiction et au codage de la parole. Le perceptron n'est ici d'aucune utilité puisque l'écart–type de son erreur de prédiction vaut 0.0108 si seulement 400 itérations sont effectuées. On peut descendre jusque 0.008 si on prend 5000 itérations mais le temps d'entraînement monte alors à une vingtaine de secondes. A noter qu'il faudrait également prendre en compte les transitions entre les "bursts" et les "non bursts". Si les discontinuités temporelles entre deux unités acoustiques successives ne sont, perceptuellement, pas significatives, il suffira alors de distinguer les "bursts" des "non bursts" (chose relativement simple) lors de la prédiction (phase de codage) et de concaténer les résultats (échantillon prédit ajouté à l'erreur de prédiction) lors de la prédiction inverse (phase de décodage).
8) Calcul des entropies Nous avons maintenant terminé notre étude des réseaux de neurones appliqués à la prédiction du signal de parole et envisageons dès lors le codage (voir figure 0). Ce codage doit s'appliquer tant aux paramètres du réseau qu'au signal d'erreur de
prédiction lui-même. Cependant, nous n'étudions ici que les performances résultantes basées sur la transmission de l'erreur ; les paramètres du réseau constituent en effet des données en nombre négligeable en comparaison à celles du signal d'erreur. Trois méthodes sont choisies dans ce projet : un quantification uniforme et non uniforme (loi A), ainsi qu'un codage entropique. C'est ce dernier cas qui est traité dans cette partie. Considérons un "burst" sur lequel on entraîne un réseau de neurones et calculons l'entropie sur le signal d'erreur de prédiction. En comparant cette entropie à celle calculée directement sur le signal initial, on pourra constater le gain en nombre de bits par échantillon obtenu grâce à la prédiction. L'entropie mesure en effet la quantité d'information moyenne contenue dans un signal et donne la borne inférieure (en nombre de bits par échantillon) du débit si un codage entropique est mis en œuvre (par exemple un codage de Huffman). Elle se mesure de la façon suivante :
HQ = E{-log2 Pi} = - ∑=
L
iii PP
12log.
Où Pi représente la probabilité d'apparition de l'événement i (c'est-à-dire ici la probabilité que l'amplitude d'un échantillon appartienne à une classe définie par des valeurs minimale et maximale). Sur conseil de notre promoteur, nous implémentons la forme suivante sous Matlab de manière à éviter que des erreurs d'arrondis ne prennent trop d'ampleur à cause du logarithme de petites valeurs :
∑=
=L
iP
iQ iP
H1
21log
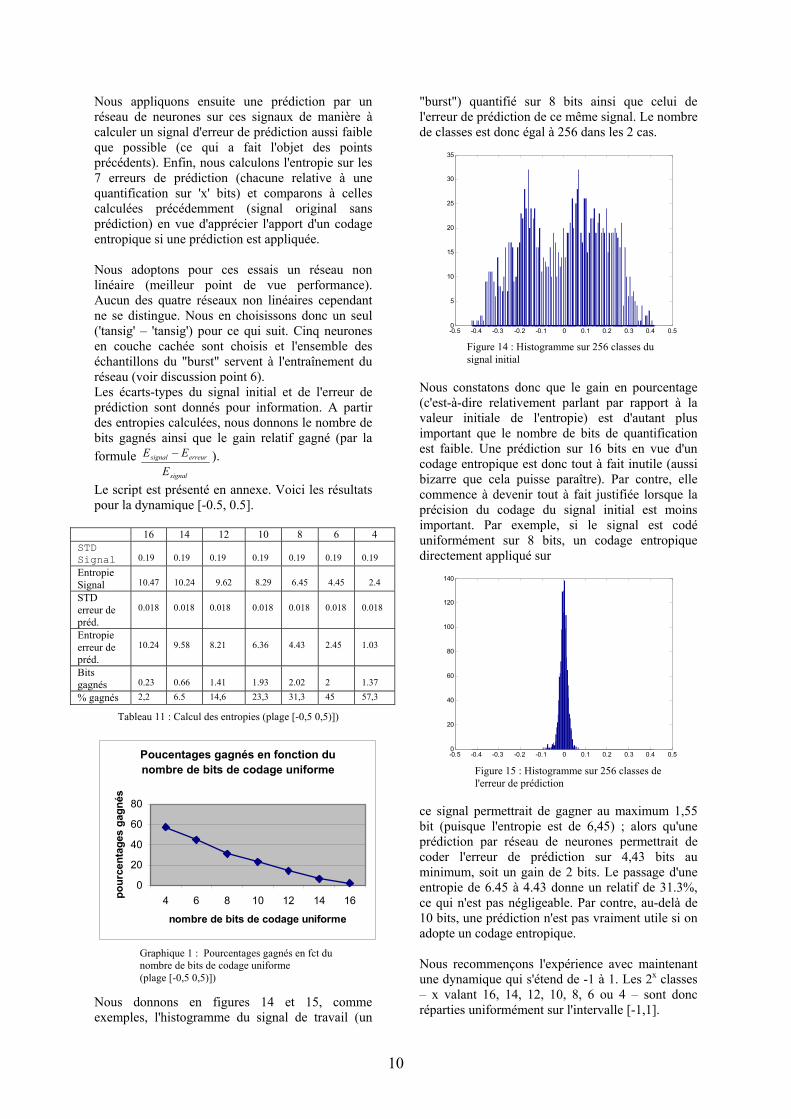
Le calcul des Pi se fait par l'intermédiaire d'histogrammes sur le signal considéré (un exemple est présenté en figure 14). Le nombre de classes (d'intervalles) à considérer dépend du nombre de bits sur lequel le signal est codé. Par exemple, un codage sur 16 bits donne 216 classes,…Dans un premier temps, celles-ci sont réparties uniformément sur toute la dynamique du signal (càd [-0.5,0.5], voir figure 14). Notre signal initial est codé (de manière uniforme) sur 16 bits. Dans un but de généralité, nous re-quantifions (uniformément) celui-ci sur 14, 12, 10, 8, 6 et 4 bits et calculons l'entropie sur ces 7 signaux (en comptant le signal initial). Il est important de remarquer que cette quantification préalable du signal introduit une perte d’information.
Figure 13 : Erreur de prédiction sur un "non burst"
10
Nous appliquons ensuite une prédiction par un réseau de neurones sur ces signaux de manière à calculer un signal d'erreur de prédiction aussi faible que possible (ce qui a fait l'objet des points précédents). Enfin, nous calculons l'entropie sur les 7 erreurs de prédiction (chacune relative à une quantification sur 'x' bits) et comparons à celles calculées précédemment (signal original sans prédiction) en vue d'apprécier l'apport d'un codage entropique si une prédiction est appliquée. Nous adoptons pour ces essais un réseau non linéaire (meilleur point de vue performance). Aucun des quatre réseaux non linéaires cependant ne se distingue. Nous en choisissons donc un seul ('tansig' – 'tansig') pour ce qui suit. Cinq neurones en couche cachée sont choisis et l'ensemble des échantillons du "burst" servent à l'entraînement du réseau (voir discussion point 6). Les écarts-types du signal initial et de l'erreur de prédiction sont donnés pour information. A partir des entropies calculées, nous donnons le nombre de bits gagnés ainsi que le gain relatif gagné (par la formule
signal
erreursignal
EEE − ).
Le script est présenté en annexe. Voici les résultats pour la dynamique [-0.5, 0.5].
16 14 12 10 8 6 4 STD Signal
0.19
0.19
0.19
0.19
0.19
0.19
0.19
Entropie Signal
10.47
10.24
9.62
8.29
6.45
4.45
2.4
STD erreur de préd.
0.018
0.018
0.018
0.018
0.018
0.018
0.018
Entropie erreur de préd.
10.24
9.58
8.21
6.36
4.43
2.45
1.03
Bits gagnés
0.23
0.66
1.41
1.93
2.02
2
1.37
% gagnés 2,2 6.5 14,6 23,3 31,3 45 57,3
Poucentages gagnés en fonction du nombre de bits de codage uniforme
0
20
40
60
80
4 6 8 10 12 14 16
nombre de bits de codage uniforme
pour
cent
ages
gag
nés
Nous donnons en figures 14 et 15, comme exemples, l'histogramme du signal de travail (un
"burst") quantifié sur 8 bits ainsi que celui de l'erreur de prédiction de ce même signal. Le nombre de classes est donc égal à 256 dans les 2 cas.
-0.5 -0.4 -0.3 -0.2 -0.1 0 0.1 0.2 0.3 0.4 0.50
5
10
15
20
25
30
35
Nous constatons donc que le gain en pourcentage (c'est-à-dire relativement parlant par rapport à la valeur initiale de l'entropie) est d'autant plus important que le nombre de bits de quantification est faible. Une prédiction sur 16 bits en vue d'un codage entropique est donc tout à fait inutile (aussi bizarre que cela puisse paraître). Par contre, elle commence à devenir tout à fait justifiée lorsque la précision du codage du signal initial est moins important. Par exemple, si le signal est codé uniformément sur 8 bits, un codage entropique directement appliqué sur
-0.5 -0.4 -0.3 -0.2 -0.1 0 0.1 0.2 0.3 0.4 0.50
20
40
60
80
100
120
140
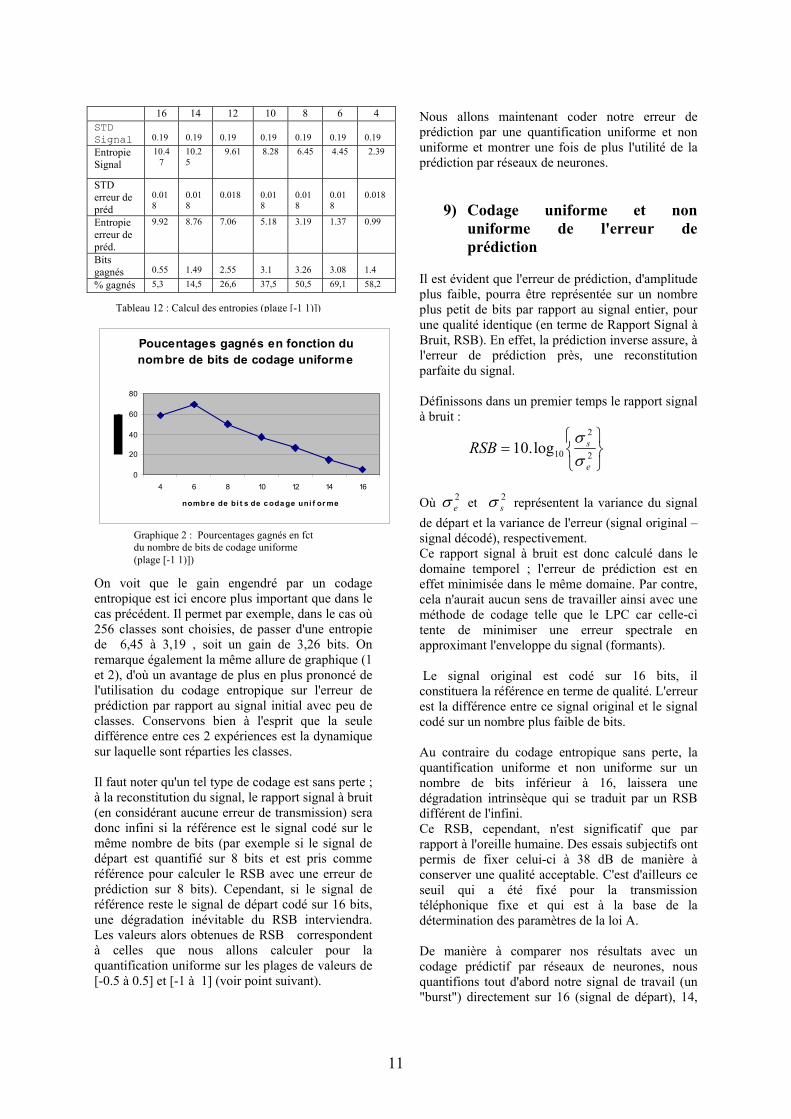
ce signal permettrait de gagner au maximum 1,55 bit (puisque l'entropie est de 6,45) ; alors qu'une prédiction par réseau de neurones permettrait de coder l'erreur de prédiction sur 4,43 bits au minimum, soit un gain de 2 bits. Le passage d'une entropie de 6.45 à 4.43 donne un relatif de 31.3%, ce qui n'est pas négligeable. Par contre, au-delà de 10 bits, une prédiction n'est pas vraiment utile si on adopte un codage entropique. Nous recommençons l'expérience avec maintenant une dynamique qui s'étend de -1 à 1. Les 2x classes – x valant 16, 14, 12, 10, 8, 6 ou 4 – sont donc réparties uniformément sur l'intervalle [-1,1].
Tableau 11 : Calcul des entropies (plage [-0,5 0,5)])
Figure 14 : Histogramme sur 256 classes du signal initial
Figure 15 : Histogramme sur 256 classes de l'erreur de prédiction
Graphique 1 : Pourcentages gagnés en fct du nombre de bits de codage uniforme (plage [-0,5 0,5)])
11
Poucentages gagnés en fonction du nombre de bits de codage uniforme
0
20
40
60
80
4 6 8 10 12 14 16
nombr e de bi t s de c oda ge uni f or me
On voit que le gain engendré par un codage entropique est ici encore plus important que dans le cas précédent. Il permet par exemple, dans le cas où 256 classes sont choisies, de passer d'une entropie de 6,45 à 3,19 , soit un gain de 3,26 bits. On remarque également la même allure de graphique (1 et 2), d'où un avantage de plus en plus prononcé de l'utilisation du codage entropique sur l'erreur de prédiction par rapport au signal initial avec peu de classes. Conservons bien à l'esprit que la seule différence entre ces 2 expériences est la dynamique sur laquelle sont réparties les classes. Il faut noter qu'un tel type de codage est sans perte ; à la reconstitution du signal, le rapport signal à bruit (en considérant aucune erreur de transmission) sera donc infini si la référence est le signal codé sur le même nombre de bits (par exemple si le signal de départ est quantifié sur 8 bits et est pris comme référence pour calculer le RSB avec une erreur de prédiction sur 8 bits). Cependant, si le signal de référence reste le signal de départ codé sur 16 bits, une dégradation inévitable du RSB interviendra. Les valeurs alors obtenues de RSB correspondent à celles que nous allons calculer pour la quantification uniforme sur les plages de valeurs de [-0.5 à 0.5] et [-1 à 1] (voir point suivant).
Nous allons maintenant coder notre erreur de prédiction par une quantification uniforme et non uniforme et montrer une fois de plus l'utilité de la prédiction par réseaux de neurones.
9) Codage uniforme et non
uniforme de l'erreur de prédiction
Il est évident que l'erreur de prédiction, d'amplitude plus faible, pourra être représentée sur un nombre plus petit de bits par rapport au signal entier, pour une qualité identique (en terme de Rapport Signal à Bruit, RSB). En effet, la prédiction inverse assure, à l'erreur de prédiction près, une reconstitution parfaite du signal. Définissons dans un premier temps le rapport signal à bruit :
= 2
2
10log.10e
sRSBσσ
Où 2
eσ et 2sσ représentent la variance du signal
de départ et la variance de l'erreur (signal original – signal décodé), respectivement. Ce rapport signal à bruit est donc calculé dans le domaine temporel ; l'erreur de prédiction est en effet minimisée dans le même domaine. Par contre, cela n'aurait aucun sens de travailler ainsi avec une méthode de codage telle que le LPC car celle-ci tente de minimiser une erreur spectrale en approximant l'enveloppe du signal (formants). Le signal original est codé sur 16 bits, il constituera la référence en terme de qualité. L'erreur est la différence entre ce signal original et le signal codé sur un nombre plus faible de bits. Au contraire du codage entropique sans perte, la quantification uniforme et non uniforme sur un nombre de bits inférieur à 16, laissera une dégradation intrinsèque qui se traduit par un RSB différent de l'infini. Ce RSB, cependant, n'est significatif que par rapport à l'oreille humaine. Des essais subjectifs ont permis de fixer celui-ci à 38 dB de manière à conserver une qualité acceptable. C'est d'ailleurs ce seuil qui a été fixé pour la transmission téléphonique fixe et qui est à la base de la détermination des paramètres de la loi A. De manière à comparer nos résultats avec un codage prédictif par réseaux de neurones, nous quantifions tout d'abord notre signal de travail (un "burst") directement sur 16 (signal de départ), 14,
16 14 12 10 8 6 4 STD Signal
0.19
0.19
0.19
0.19
0.19
0.19
0.19
Entropie Signal
10.47
10.25
9.61 8.28 6.45 4.45 2.39
STD erreur de préd
0.018
0.018
0.018
0.018
0.018
0.018
0.018
Entropie erreur de préd.
9.92 8.76 7.06 5.18 3.19
1.37 0.99
Bits gagnés
0.55
1.49
2.55
3.1
3.26
3.08
1.4
% gagnés 5,3 14,5 26,6 37,5 50,5 69,1 58,2
Graphique 2 : Pourcentages gagnés en fct du nombre de bits de codage uniforme (plage [-1 1)])
Tableau 12 : Calcul des entropies (plage [-1 1)])
12
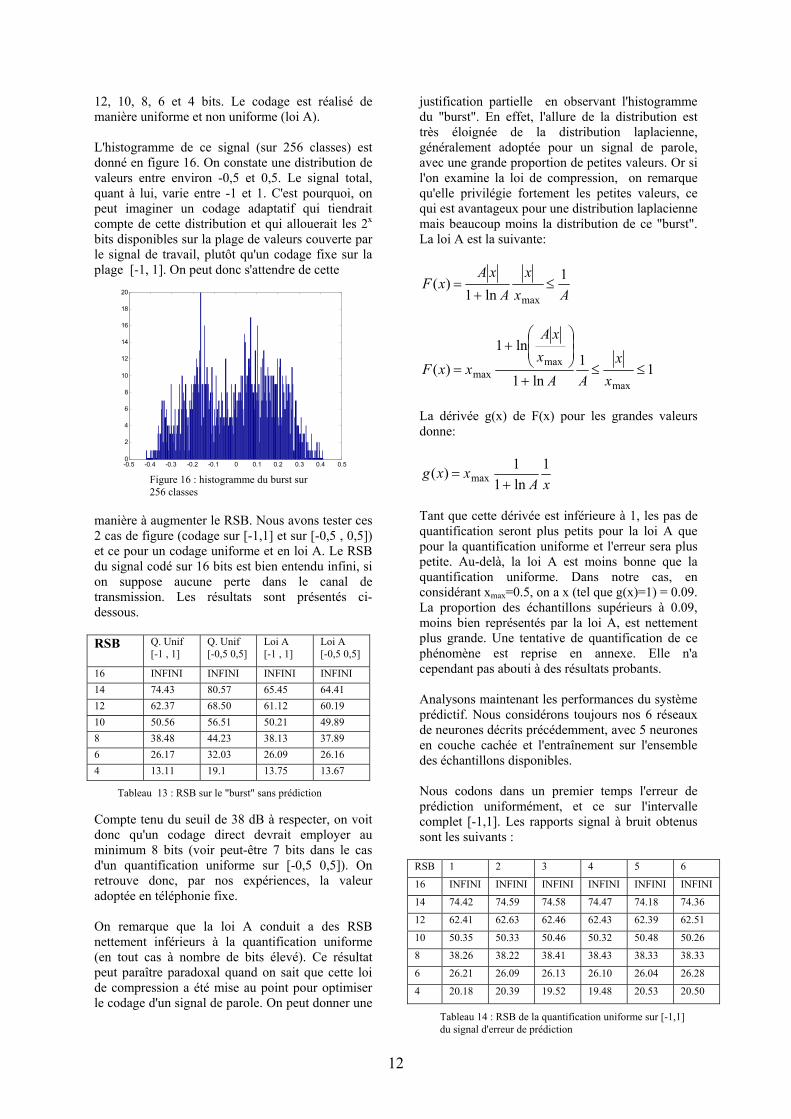
12, 10, 8, 6 et 4 bits. Le codage est réalisé de manière uniforme et non uniforme (loi A). L'histogramme de ce signal (sur 256 classes) est donné en figure 16. On constate une distribution de valeurs entre environ -0,5 et 0,5. Le signal total, quant à lui, varie entre -1 et 1. C'est pourquoi, on peut imaginer un codage adaptatif qui tiendrait compte de cette distribution et qui allouerait les 2x bits disponibles sur la plage de valeurs couverte par le signal de travail, plutôt qu'un codage fixe sur la plage [-1, 1]. On peut donc s'attendre de cette
-0.5 -0.4 -0.3 -0.2 -0.1 0 0.1 0.2 0.3 0.4 0.50
2
4
6
8
10
12
14
16
18
20
manière à augmenter le RSB. Nous avons tester ces 2 cas de figure (codage sur [-1,1] et sur [-0,5 , 0,5]) et ce pour un codage uniforme et en loi A. Le RSB du signal codé sur 16 bits est bien entendu infini, si on suppose aucune perte dans le canal de transmission. Les résultats sont présentés ci-dessous. RSB Q. Unif
[-1 , 1] Q. Unif [-0,5 0,5]
Loi A [-1 , 1]
Loi A [-0,5 0,5]
16 INFINI INFINI INFINI INFINI 14 74.43 80.57 65.45 64.41 12 62.37 68.50 61.12 60.19 10 50.56 56.51 50.21 49.89 8 38.48 44.23 38.13 37.89 6 26.17 32.03 26.09 26.16 4 13.11 19.1 13.75 13.67
Compte tenu du seuil de 38 dB à respecter, on voit donc qu'un codage direct devrait employer au minimum 8 bits (voir peut-être 7 bits dans le cas d'un quantification uniforme sur [-0,5 0,5]). On retrouve donc, par nos expériences, la valeur adoptée en téléphonie fixe. On remarque que la loi A conduit a des RSB nettement inférieurs à la quantification uniforme (en tout cas à nombre de bits élevé). Ce résultat peut paraître paradoxal quand on sait que cette loi de compression a été mise au point pour optimiser le codage d'un signal de parole. On peut donner une
justification partielle en observant l'histogramme du "burst". En effet, l'allure de la distribution est très éloignée de la distribution laplacienne, généralement adoptée pour un signal de parole, avec une grande proportion de petites valeurs. Or si l'on examine la loi de compression, on remarque qu'elle privilégie fortement les petites valeurs, ce qui est avantageux pour une distribution laplacienne mais beaucoup moins la distribution de ce "burst". La loi A est la suivante:
Axx
AxA
xF 1ln1
)(max
≤+
=
11ln1
ln1
)(max
maxmax ≤≤
+
+
=x
xAA
xxA
xxF
La dérivée g(x) de F(x) pour les grandes valeurs donne:
xAxxg 1
ln11)( max +
=
Tant que cette dérivée est inférieure à 1, les pas de quantification seront plus petits pour la loi A que pour la quantification uniforme et l'erreur sera plus petite. Au-delà, la loi A est moins bonne que la quantification uniforme. Dans notre cas, en considérant xmax=0.5, on a x (tel que g(x)=1) = 0.09. La proportion des échantillons supérieurs à 0.09, moins bien représentés par la loi A, est nettement plus grande. Une tentative de quantification de ce phénomène est reprise en annexe. Elle n'a cependant pas abouti à des résultats probants. Analysons maintenant les performances du système prédictif. Nous considérons toujours nos 6 réseaux de neurones décrits précédemment, avec 5 neurones en couche cachée et l'entraînement sur l'ensemble des échantillons disponibles. Nous codons dans un premier temps l'erreur de prédiction uniformément, et ce sur l'intervalle complet [-1,1]. Les rapports signal à bruit obtenus sont les suivants :
RSB 1 2 3 4 5 6
16 INFINI INFINI INFINI INFINI INFINI INFINI
14 74.42 74.59 74.58 74.47 74.18 74.36
12 62.41 62.63 62.46 62.43 62.39 62.51
10 50.35 50.33 50.46 50.32 50.48 50.26
8 38.26 38.22 38.41 38.43 38.33 38.33
6 26.21 26.09 26.13 26.10 26.04 26.28
4 20.18 20.39 19.52 19.48 20.53 20.50
Figure 16 : histogramme du burst sur 256 classes
Tableau 13 : RSB sur le "burst" sans prédiction
Tableau 14 : RSB de la quantification uniforme sur [-1,1] du signal d'erreur de prédiction
13
On ne remarque tout d'abord aucune différence entre les 6 types de réseau. Les légères différences (entre les réseaux linéaires et non linéaires) observées lors de la comparaison des écarts-types (voir discussion point 6) ne sont donc pas significatives en terme de rapport signal à bruit. On remarque ensuite qu'un RSB de 38 dB est atteint avec 8 bits, c'est-à-dire le même nombre que sans prédiction. Ceci est logique puisque la plage de codage est conservée avec la même dynamique ([-1,1]), ce qui peut paraître un certain gaspillage. De manière à tirer profit de notre prédiction et de notre faible signal d'erreur (de prédiction), nous diminuons la dynamique sur [-0.1, 0.1] (voir histogramme du signal d'erreur ci-dessous).
-0.1 -0.08 -0.06 -0.04 -0.02 0 0.02 0.04 0.06 0.080
5
10
15
20
25
30
Nous allouons de cette manière un plus grand nombre de bits sur une plage plus courte, ce qui permet une meilleure représentation de l'information. Les résultats obtenus sont en effet prometteurs :
RSB 1 2 3 4 5 6
16 INFINI INFINI INFINI INFINI INFINI INFINI
14 94.47 94.64 94.55 94.66 94.60 94.37
12 82.58 82.43 82.34 82.38 82.53 82.26
10 70.27 70.45 70.35 70.52 70.49 70.51
8 58.32 58.33 58.34 58.39 58.41 58.46
6 46.05 46.13 45.96 46.15 45.89 45.91
4 33.02 33.07 33.00 33.09 33.13 33.15
En extrapolant les résultats, on peut affirmer qu'un RSB de 38 dB peut être atteint avec 5 bits. Un gain de 3 bits est donc obtenu. Pour information, nous présentons ici l'erreur finale sur laquelle est calculé le RSB (c'est-à-dire signal original auquel on soustrait le signal reconstitué), pour 16 et 8 bits. On remarque comme attendu que l'erreur est nulle si 16 bits de codage sont conservés sur toute la chaîne, ce qui donne un RSB infini comme annoncé.
0 500 1000 1500-1
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
0.8
1
0 500 1000 1500-5
-4
-3
-2
-1
0
1
2
3
4x 10-3
Les 2 expériences précédentes sur le signal d'erreur de prédiction sont réalisées maintenant avec un codage non linéaire (loi A). Les résultats sont présentés sur les tableaux 15 et 16.
RSB 1 2 3 4 5 6
16 INFINI INFINI INFINI INFINI INFINI INFINI
14 89.72 89.31 89.06 88.97 90.17 90.09
12 81.77 82.00 80.58 80.98 81.78 81.63 10 69.88 70.23 69.07 68.97 69.79 69.79
8 58.00 57.82 56.61 56.88 57.94 58.02
6 45.88 45.50 45.01 45.08 45.84 46.10
4 33.78 33.58 32.69 32.62 33.70 33.99
RSB 1 2 3 4 5 6
16 INFINI INFINI INFINI INFINI INFINI INFINI
14 85.67 85.90 83.97 84.04 85.86 85.45
12 80.95 81.36 79.78 80.00 80.81 81.36
10 70.71 70.86 69.50 69.32 70.11 70.46
8 58.65 58.27 57.36 57.34 58.17 58.46
6 46.58 46.66 45.42 45.23 46.45 46.46
4 33.92 34.06 33.65 33.41 34.16 34.30
On remarque ici que les performances de la loi A sont semblables sur les 2 plages de valeurs. Autrement dit, la non linéarité de la loi est en
Figure 17 : histogramme du signal d'erreur de prédiction
Tableau 15 : RSB de la quantification uniforme sur [-0.1,0.1]du signal d'erreur de prédiction
Figure 18 : Erreur finale sur 16 bits
Figure 19 : Erreur finale sur 8 bits
Tableau 16 : RSB du signal d'erreur de prédiction avec codage en loi A sur [-1,1]
Tableau 17 : RSB du signal d'erreur de prédiction avec codage en loi A sur [-0.1,0.1]

14
quelque sorte nuisible si on alloue le même nombre de bits sur une plage plus courte. Autrement dit, lorsqu'on alloue l'ensemble des 2x bits disponibles sur la plage [-0.1,0.1], le gain obtenu dans la représentation des plus faibles valeurs est compensé par la moins bonne représentation des plus grandes valeurs. Ceci explique les performances identiques. Enfin, on remarque également que l'utilisation de la loi A est équivalente à l'utilisation d'une quantification uniforme sur la plage [-0.1,0.1], tel que l'illustre le graphique suivant. Les termes "sans dilatation" et "avec dilatation" signifient que l'on travaille sur la plage [-1,1] ou [-0.1,0.1], respectivement.
Rapport Signal à Bruit_Q. Unif et Loi A_Erreur de Prédiction
0102030405060708090
100
4 6 8 10 12 14
bit/échantillon
RSB
LOI A (sansdilatation)
LOI A (avecdilatation)
Q. Uniforme(avecdilatation)Q. Uniforme(sansdilatation)
Cependant, ce graphique (2) n'est représentatif que du "burst" considéré. Il faudrait encore une fois effectuer les mêmes essais sur un ensemble de "bursts" et "non bursts" de sorte à établir des statistiques qui seraient plus réalistes. Néanmoins, la tendance générale est observée et ces résultats sont suffisants pour tirer des conclusions générales.
10) Conclusion sur le codage
Résumons ce qui vient d'être fait en ne considérant que 2 types de quantification sur notre "burst" : une "loi A" pour le codage direct du signal (sans prédiction) sur la plage [-1,1] – il s'agit en effet du cas pratique de transmission en téléphonie fixe – et une quantification uniforme pour l'erreur de prédiction (mise en œuvre du réseau de neurones) sur la plage [-0.1, 0.1] – ce qui se fera en pratique si un tel système est mis en œuvre car il faut profiter de la dynamique maximale de manière à tirer parti au maximum de la faible amplitude de l'erreur de prédiction ; la loi A, par contre, sera à discuter pour voir si elle s'avère meilleure que l'uniforme dans d'autres cas. La plage [-0.1, 0.1] est bien entendu relative au "burst" que nous considérons ici ; dans le cas général, cette plage sera donc adaptative.
comparaison des RSB avec et sans prédiction
0
20
40
60
80
100
4 6 8 10 12 14
Bits/échantillon
RSB
Cod en loi A surle signal sansprédiction
Cod. Unif sur [-0.1 0.1] del'erreur deprédiction
Si le seuil subjectif de 38 dB est adopté, on voit qu'un gain de 3 bits est obtenu puisqu'on passe de 8 bits (sans prédiction) à 5 bits (avec prédiction). Un codage en loi A sans prédiction entre [-1 1] nécessite donc l'utilisation de 8 bits de codage. En se plaçant dans les mêmes conditions (256 classes entre [-1 1]), le codage entropique du signal sans prédiction donne un nombre de bits égal à 6,45 par échantillon (au minimum). Celui-ci appliqué à l'erreur de prédiction permet de descendre au maximum jusque 3.19 bits/échantillon (voir point 8). Le rapport signal à bruit est dans ce cas équivalent à celui obtenu pour une quantification uniforme à 8 bits sur la plage [-1 1], soit 38,45 dB. Ainsi, le codage entropique sur l'erreur de prédiction s'avère ici le meilleur puisqu'il permet de descendre jusque 3.19 bits par échantillons, alors qu'un codage en loi A appliqué directement sur le signal utilise 8 bits. Ceci permet donc de diviser par 2.51 le débit initial, tout en maintenant une qualité de transmission identique. Encore une fois, nous insistons sur le fait que nous n'avons travaillé que sur un seul "burst". La moyenne sur un grand nombre d'expériences permettrait d'affiner les conclusions décrites précédemment.
11) Transmission uniquement des paramètres du réseau
Nous pouvons envisager de transmettre uniquement les paramètres du réseau sans transmettre l'erreur de prédiction. La qualité des prédicteurs basés sur les réseaux de neurones nous permet en effet de les tester en ne transmettant que les 10 premiers échantillons de sorte que le réseau se mette en régime. Après quoi, ce sont les échantillons prédits qui servent uniquement d'entrées au prédicteur inverse, aucune correction n'est ici rajoutée puisque le signal d'erreur de prédiction n'est pas transmis.
Graphique 3 : RSB si prédiction pour loi A et uniforme
Graphique 4 : Comparaison RSB avec et sans prédiction
15
Nous testons le réseau 1 ('tansig'-'tansig') avec 5 neurones en couche cachée et l'ensemble des échantillons du "burst" pour entraîner le réseau. En prédiction inverse (et en prédiction également !), le réseau est censé reproduire au mieux les cibles fournies lors de l'entraînement. En ne transmettant que les 10er échantillons, et en laissant dès lors le prédicteur inverse sans termes correctifs, nous obtenons le résultat suivant :
RSB = 20.31 dB
0 500 1000 1500-0.5
-0.4
-0.3
-0.2
-0.1
0
0.1
0.2
0.3
0.4
0.5
0 500 1000 1500-0.1
-0.08
-0.06
-0.04
-0.02
0
0.02
0.04
0.06
0.08
0.1
On observe donc une nette dégradation des performances puisque le rapport signal à bruit est retombé à 20 dB. La qualité jugée acceptable en téléphonie fixe n'est donc plus atteinte mais seule une écoute d'un signal complet résultant de cette prédiction inverse nous permettrait d'en apprécier sa qualité. En comparant cependant le signal prédit (figure 20) avec le signal original (figure 22), on remarque que la forme temporelle du signal est tout à fait respectée et l'on doit donc s'attendre à une qualité suffisamment bonne pour être exploitable. Dans ce cas, la transmission des paramètres du réseau et des 10 premiers coefficients deviendrait dérisoire en terme de débit. En effet, le nombre de
0 200 400 600 800 1000 1200 1400 1600-0.5
-0.4
-0.3
-0.2
-0.1
0
0.1
0.2
0.3
0.4
0.5
paramètres est de 10*5 (10 entrées et 5 neurones en couche cachée) = 50 (correspond au nombre de poids Wij entre les entrées et la couche cachée, voir figure 5.a), auquel on rajoute les 10 poids de sortie, ainsi que les 6 biais pour les 6 neurones présents dans le réseau. Ce qui donne au total 66 paramètres pour le réseau. Ajoutons encore à cela les 10 premiers coefficients de sorte que le réseau puisse se mettre en régime, ce qui nous donne au total 76 paramètres à transmettre par "burst". Pour rappel, un "burst" représente environ 2000 échantillons, soit à 8 kHz, 0.25 sec. Si ces paramètres sont codés sur 16 bits, cela représente donc un débit de 4928
25.077*16
= bits/sec.
Sur 8 bits, le débit chute à 2464 bits/sec ! On rejoint donc ici les performances du système LPC10 ! Et l'on pourrait encore descendre en débit en diminuant encore la valeur de 8 bits/coefficient. Cependant, il faudrait d'une part étudier la sensibilité aux poids et biais du réseau de manière à vérifier l'influence d'un codage de moins en moins fidèle de ces paramètres, et d'autre part valider tous ces résultats par une écoute du signal généré. Il faut également signaler que les performances chuteront sur les "non burst" et qu'une moyenne sur de nombreux essais est une fois de plus nécessaire pour avoir un ordre de grandeur des débits plus réaliste. Cette démarche doit faire l'objet d'une étude plus approfondie. Une amélioration de ce système consisterait à entraîner le réseau sur base, non pas des cibles initiales (échantillons à prédire), mais des cibles corrigées d'un facteur qui tiendrait compte de l'erreur finale que commettra le réseau en prédiction inverse. Nous pensons que ce point doit être exploité dans un travail ultérieur étant donné les résultats prometteurs que nous obtenons ici. Remarquons enfin que même si des performances excellentes en terme de débit – qualité peuvent être atteintes, la composante temporelle ne peut être
Figure 20 : Signal prédit sans transmission de l'erreur de prédiction
Figure 21 : Erreur finale (signal initial – signal final)
Figure 22 : Signal original

16
oubliée. En effet, nous avons vu précédemment que le temps réel n'était pas encore envisageable avec Pentium 3 GHz et donc a fortiori dans une unité mobile telle que le GSM.
12) Conclusion générale
Ce projet a été consacré à l'application des réseaux de neurones dans la prédiction du signal de parole, ainsi qu'au choix du meilleur codage du signal d'erreur de prédiction. Nous avons vu, par la fonction d'autocorrélation, que 10 entrées étaient nécessaires à ce réseau. De manière à ne pas augmenter inutilement sa complexité, nous avons choisi une seule couche cachée et testé celle-ci avec 5,10 et 15 neurones. Les performances sont identiques dans les 3 cas et nous retenons donc pour la suite une valeur de 5 neurones pour cette couche cachée. La couche de sortie, quant à elle, est composée d'un seul neurone puisqu'il n'y a qu'un échantillon à prédire. Nous avons considéré pour nos essais un ensemble de 6 configurations possibles, ainsi que le perceptron. Après un certain nombre d'essais, nous avons conclu que la prédiction idéale était obtenue en considérant un seul réseau par "burst" et l'ensemble des échantillons disponibles pour entraîner ce réseau. La validation croisée n'a alors plus aucun sens puisqu'on désire reproduire les mêmes sorties qui ont servi de cibles lors de l'entraînement. Comme on pouvait s'y attendre, les 2 réseaux linéaires s'adaptent plus rapidement que les autres non linéaires. Ils offrent cependant une prédiction moindre mais qui n'est pas significative en terme de rapport signal à bruit. Le perceptron, quant à lui, ne permet pas l'utilisation de plus de 200 vecteurs pour son entraînement, il ne sait donc prédire avec une aussi grande précision les échantillons de parole. Les 4 réseaux non linéaires sont quant à eux tout à fait semblables quant aux performances temporelle et prédictive. Cependant, même si la prédiction est excellente, les vitesses d'entraînement ne permettent pas encore d'envisager le temps réel. Les réseaux dimensionnés, nous nous attachons au codage de l'erreur de prédiction de manière à mettre en évidence le gain en débit obtenu suite à la prédiction. Nous avons analysé les performances des codages uniforme, non uniforme (loi A) et entropique sur le signal d'erreur de prédiction et sur le signal original (sans prédiction). Il ressort de cette étude qu'un codage entropique est inutile si le nombre de classes sur lesquelles
sont codés les échantillons est trop important. Par contre, il est tout à fait justifié dans le cas contraire. Les quantifications uniforme et non uniforme appliquées à l'erreur de prédiction (pour les 6 types de réseaux envisagés) sont équivalentes, les signaux sont en effet trop faibles pour espérer une distinction nette de performance (en terme de RSB). Les réseaux linéaires sont donc, à notre sens, les mieux adaptés au problème puisqu'ils possèdent un temps d'entraînement plus court pour un même rapport signal à bruit. Les gains obtenus en terme de RSB sont ici sans appel, ils justifient pleinement l'utilisation d'une prédiction, et ce pour tout nombre de bits, contrairement au cas précédent. Nous avons terminé ce codage de l'erreur de prédiction en considérant un cas pratique de comparaison, à savoir la loi A appliquée sur le signal sans prédiction dans une dynamique fixe et maximale de [-1, 1] (cas de la téléphonie fixe) et la quantification uniforme appliquée sur la dynamique du signal d'erreur de prédiction. Nous avons conclu dans ce cas particulier – et compte tenu du "burst" sur lequel nous avons travaillé et du seuil subjectif de 38 dB à atteindre pour obtenir une qualité acceptable – que le codage idéal de l'erreur de prédiction était un codage entropique puisqu'il permettait de descendre le débit à 3.19 bits/échantillon alors qu'un codage sans prédiction par une loi A prévoyait 8 bits/échantillon et que le codage uniforme de l'erreur de prédiction allouait, quant à lui, 5 bits/échantillon. A noter que ces performances sont atteintes pour une même qualité de transmission. Sans tenir compte de la transmission des paramètres du réseau et des performances inférieures obtenues dans le cas des "non bursts", le débit téléphonique (fixe) passerait ainsi de 64 kbits/sec à 25.6 kbits/sec, soit un gain de 60%, tout en conservant la même qualité de transmission. Les alternatives en téléphonie fixe telles que Télé2 utilisent la même idée, ils louent à Belgacom des canaux à 64Kbits/sec dans laquelle ils font passer plusieurs conversations téléphoniques, grâce à un codage approprié. Cependant, nous ne possédons ni les chiffres de débit ni la qualité qu'ils assurent. Il s'agit là en effet d'une information interne qu'il n'est pas évident d'obtenir. La comparaison avec d'autres systèmes prédictifs peut également être envisagée. Enfin, nous avons terminé ce projet par la simulation du réseau de neurones sans terme correctif, c'est-à-dire sans la transmission de l'erreur de prédiction. Dans ce cas, seuls les paramètres du réseau, ainsi que les 10 premiers échantillons sont transmis. Le codage sur 8 bits permet d'atteindre des débits d'environ 2500 bits/sec soit les performances du système de transmission par

17
satellite de la voix, LPC10, qui travaille à 2400 bits/sec avec une qualité médiocre. D'autres méthodes peuvent être citées : CELP (norme UMTS) qui descend elle jusque 4.8 kbits/s, et le MP_LPC (utilisé pour le GSM) qui possède un débit de 13kb/s. La seule transmission du réseau permet donc d'assurer des performances proches voire meilleures en terme de débit. Ces performances, cependant, doivent être validées par une écoute qualitative des signaux générés. Ce problème doit donc faire l'objet d'une étude plus approfondie. Sans oublier qu'un tel système ne pourrait être mis en œuvre aujourd'hui (2004) vu que le temps réel n'est pas encore envisageable. Ainsi, de meilleures performances peuvent être atteintes mais au prix d'une complexité supérieure et d'une charge de calcul plus importante. Signalons qu'une amélioration de ce dernier modèle est envisageable en entraînant le réseau sur base des cibles corrigées d'un facteur qui tiendrait compte de l'erreur finale commise sans facteur de correction. Ajoutons que nous avons testé des réseaux de neurones à 2 sorties, une qui devait représenter les valeurs positives et l'autre, les valeurs négatives des échantillons à prédire. Les fonctions réalisées par les 2 neurones de sortie étaient soit non linéaires soit en escalier (+1 ou -1). Les résultats ainsi obtenus ont été assez médiocres. Nous avons également essayé des réseaux avec un plus grand nombre de neurones en couche cachée, mais les résultats ont été identiques à ceux qui ne comptaient qu'une seule couche cachée. Nous voudrions pour terminer remercier M. Bernard Gosselin pour les conseils et orientations apportés au cours de ce projet.
13) Références
• Neuronal Network Toolbox (Matlab) • Cours "Classification et Reconnaissance Statistique de formes", B. Gosselin, Faculté Polytechnique de Mons. • Cours "Introduction au codage de l'information", B. Gosselin, Faculté Polytechnique de Mons. • Cours "Traitement de la parole", T. Dutoit, Faculté Polytechnique de Mons. • Cours "Télécommunications numériques", M. Lamquin, Faculté Polytechnique de Mons.
14) Annexes
Annexe 1 1. Fonction de décomposition en vecteurs d'entraînement, de validation et de test, à adapter en fonction du "burst" considéré. function [entree,cible,test,testcible,validation,long]=decompsig () [signal,fe,nbits]=wavread('KETEB8'); long=1500; for i= 1: long %set d'apprentissage entree(:,i)=signal(15800+i : 15809+i); cible(i,1)=signal(15810+i); end for i= 1:250 %set de validation %les vecteurs de validation doivent figurer dans une structure validation.P(:,i)=signal(16050+i : 16059+i); validation.T(:,i)=signal(16060+i); end for i= 1 : long %set de test (pour les nombreux essais)//identique à entree et cible si %on prend tous les échantillons test(:,i)=signal(15800+i : 15809+i); testcible(i,1)=signal(15810+i); end 2. Fonction d'entraînement du réseau function [STD,TIME] = fonctrecap (entree,cible,test,testcible,validation,long) nombrepochs=400; GOAL=0.00001 % tansig - tansig network=newff([-1 1; -1 1 ; -1 1; -1 1; -1 1; -1 1; -1 1; -1 1; -1 1; -1 1],[5,1],{'tansig','tansig'},'trainlm') network.trainParam.epochs=nombrepochs; network.trainParam.goal=GOAL; network.trainParam.lr=0.05; network.trainParam.show = 50; tic; % entrainement sans validation croisée network=train(network,entree,cible'); % entrainement avec validation croisée network=train(network,entree,cible',[],[],validation,[]); time1=toc; % network simulation prediction=sim(network,test); t=[15811:1:15810+long]; figure(1) plot(t,testcible','o',t,prediction,'x') error=testcible'-prediction; figure(2) plot(error)

18
std1=std(error); 3. Quantification de l'erreur de prédiction [si14,si12,si10,si8,si6,si4]=QUANTIFUNIF(error*10); errorpreddec14=si14/10; errorpreddec12=si12/10; errorpreddec10=si10/10; errorpreddec8=si8/10; errorpreddec6=si6/10; errorpreddec4=si4/10; % Prédiction inverse pour l'erreur de prédiction codée sur 16 bits predictioninv(1)=sim(network,entree(:,1))+error(1); for j=1 : (long-1) for i=1:9 entree(i,j+1)=entree(i+1,j); end entree(10,1)=predictioninv(j); predictioninv(j+1)=sim(network,entree(:,j+1))+error(j+1); end comp16=(testcible(12:long))-predictioninv(12:long)'; figure(3) stem(comp16); figure(4) stem (predictioninv); var16=cov(comp16); % Prédiction inverse pour l'erreur de prédiction codée sur 14 bits predictioninv(1)=sim(network,entree(:,1))+errorpreddec14(1); for j=1 : (long-1) for i=1:9 entree(i,j+1)=entree(i+1,j); end entree(10,1)=predictioninv(j); predictioninv(j+1)=sim(network,entree(:,j+1))+errorpreddec14(j+1); end comp14=(testcible(12:long))-predictioninv(12:long)'; figure(5) stem(comp14); figure(6) stem (predictioninv); var14=cov(comp14); etc… var=cov(testcible(2:long)); SNR16 = 10 * log10(var/var16); SNR14 = 10 * log10(var/var14); SNR12 = 10 * log10(var/var12); SNR10 = 10 * log10(var/var10); SNR8 = 10 * log10(var/var8); SNR6 = 10 * log10(var/var6); SNR4 = 10 * log10(var/var4);
RSB141210864=[SNR16 SNR14 SNR12 SNR10 SNR8 SNR6 SNR4] 4. Calcul des entropies function [STDTOT,EntropiesignalTOT,STDERTOT,EntropierrorTOT] = entropiessig (entree,cible,test,testcible,validation,long) %% 16 BITS (Signal sur 16 bits) 65536 valeurs %%% [signal,fe,nbits]=wavread('KETEB8'); signaltrav16=signal(15811:15810+1500); STD16=std(signaltrav16); % Calcul de l'entropie %t=[-0.424:((0.415+0.424)/65535):0.415]; % Bornes du burst (voir histogamme) t=[-1:(2/65535):1]; N=hist(signaltrav16,t); probai=N./1500; %sum = nbre d'échantillons %somme1 = sum(probai); % Première méthode %for i=1 : 65536 % if N(i)==0 % LOGI(i)=0; % éviter d'avoir log(0) % else % LOGI(i)=(-log2(probai(i))); % end %end %Entropiesignal=LOGI*probai'; % Deuxième méthode (revient au même !) Entropiesignal16=0; for i=1 : 65536 GI=(probai(i)^(probai(i))); RY=log2(1/GI); Entropiesignal16=Entropiesignal16+RY; end % Calcul du réseau de neurone sur le même burst nombrepochs=400; GOAL=0.0001 % tansig - tansig network=newff([-1 1; -1 1 ; -1 1; -1 1; -1 1; -1 1; -1 1; -1 1; -1 1; -1 1],[5,1],{'tansig','tansig'},'trainlm') network.trainParam.epochs=nombrepochs; network.trainParam.goal=GOAL; network.trainParam.lr=0.05; network.trainParam.show = 50; tic; % entrainement sans validation croisée network=train(network,entree,cible'); % entrainement avec validation croisée %network=train(network,entree,cible',[],[],validation,[]); time1=toc; % network simulation prediction=sim(network,test); %t=[15811:1:15810+long]; %figure(1) %plot(t,testcible','o',t,prediction,'x')

19
error=testcible'-prediction; %figure(2) %plot(error) STDER16=std(error); % calcul de l'entropie N=hist(error,t); probai=N./1500; Entropierror16=0; for i=1 : 65536 GI=(probai(i)^(probai(i))); RY=log2(1/GI); Entropierror16=Entropierror16+RY; end %%%% 14 BITS (Quantification uniforme du signal sur 14 bits (16384 valeurs)) %%%% sortie=round(signaltrav16*8191); signaltrav14=sortie/8191; STD14=std(signaltrav14); % Calcul de l'entropie %t=[-0.424:((0.415+0.424)/16383):0.415]; t=[-1:(2/16383):1]; N=hist(signaltrav14,t); probai=N./1500; Entropiesignal14=0; for i=1 : 16384 GI=(probai(i)^(probai(i))); RY=log2(1/GI); Entropiesignal14=Entropiesignal14+RY; end % Calcul du réseau de neurone sur le même burst nombrepochs=400; GOAL=0.0001 % tansig - tansig network=newff([-1 1; -1 1 ; -1 1; -1 1; -1 1; -1 1; -1 1; -1 1; -1 1; -1 1],[5,1],{'tansig','tansig'},'trainlm') network.trainParam.epochs=nombrepochs; network.trainParam.goal=GOAL; network.trainParam.lr=0.05; network.trainParam.show = 50; tic; % entrainement sans validation croisée network=train(network,entree,cible'); % entrainement avec validation croisée %network=train(network,entree,cible',[],[],validation,[]); time1=toc; % network simulation prediction=sim(network,test); %t=[15811:1:15810+long]; %figure(1) %plot(t,testcible','o',t,prediction,'x') error=testcible'-prediction; %figure(2) %plot(error) STDER14=std(error); % calcul de l'entropie N=hist(error,t); probai=N./1500; Entropierror14=0; for i=1 : 16384
GI=(probai(i)^(probai(i))); RY=log2(1/GI); Entropierror14=Entropierror14+RY; end STDTOT=[STD16 STD14 STD12 STD10 STD8 STD6 STD4]; EntropiesignalTOT=[Entropiesignal16 Entropiesignal14 Entropiesignal12 Entropiesignal10 Entropiesignal8 Entropiesignal6 Entropiesignal4]; STDERTOT=[STDER16 STDER14 STDER12 STDER10 STDER8 STDER6 STDER4]; EntropierrorTOT=[Entropierror16 Entropierror14 Entropierror12 Entropierror10 Entropierror8 Entropierror6 Entropierror4];
5. Loi A function [sig14,sig12,sig10,sig8,sig6,sig4]=LOIAMOI(erreur); sig=erreur(:)'; % LIN to A sortie=LIN2A(sig); sortie14=round(sortie); % 14 bits sortie12=round(sortie./4); %12 bits sortie10=round(sortie./16); % 10 bits sortie8=round(sortie./64); % 8 bits sortie6=round(sortie./256); % 6 bits sortie4=round(sortie./1024); % 4 bits % Transmission par un canal de Télécommunication % Décodage % A TO LIN sig14=A2LIN(sortie14./8192); sig12=A2LIN(sortie12./2048); sig10=A2LIN(sortie10./512); sig8=A2LIN(sortie8./128); sig6=A2LIN(sortie6./32); sig4=A2LIN(sortie4./8); function rep = LIN2A(y) % Copyright (c) 1984-96 by FPMS, Inc. A=87.56; small=(abs(y)<=1/A); large=(abs(y)>1/A); rep(small)=A*y(small)*8191/(1+log(A)); rep(large)=8191*(1+log(A*abs(y(large)))).*sign(y(large))/(1+log(A)); function rep=A2LIN(signal) A=87.56; small=abs(signal)<=1/(1+log(A)); large=abs(signal)>1/(1+log(A)); rep(small)=signal(small)/A*(1+log(A)); rep(large)=(1/A*exp((abs(signal(large))*(1+log(A)))-1)).*sign(signal(large));

20
6. Quantification uniforme function [si14,si12,si10,si8,si6,si4]=QUANTIFUNIF(error) sortie=round(error*8191); si14=sortie/8191; sortie=round(error*2047); si12=sortie/2047; sortie=round(error*511); si10=sortie/511; sortie=round(error*127); si8=sortie/127; sortie=round(error*31); si6=sortie/31; sortie=round(error*7); si4=sortie/7;
7. Entraînement du perceptron function [netperceptronlin,weights,bias,stdlin,TIME]=perceptronlin (entree,cible,test,testcible,validation,long) netperceptronlin=newlin([-1 1; -1 1 ; -1 1; -1 1; -1 1; -1 1; -1 1; -1 1; -1 1; -1 1],1); %netperceptronlin=init(netperceptronlin); netperceptronlin.trainParam.epochs=5000; netperceptronlin.trainParam.goal=0.00001; tic; netperceptronlin=train(netperceptronlin,entree,cible'); netperceptronlin=train(netperceptronlin,entree,cible',[],[],validation,[]); TIME=toc; % performance analysis weights=netperceptronlin.iw{1,1}; bias=netperceptronlin.b(1); % network simulation prediction1=sim(netperceptronlin,test); %t=[15801:1:17600]; t=[11311:1:11310+long]; plot(t,testcible','o',t,prediction1,'x') error1=testcible'-prediction1; figure(1) plot(error1) stdlin=std(error1);
Annexe 2
On sait que pour la loi A, en admettant que p(x) est paire, la variance de l'erreur prend la forme suivante:
∫=max
022
2max2
)()(
32 x
exg
dxxpL
xσ
où p(x) est la distribution de probabilité du signal L est le nombre d'états de quantification g(x) est la dérivée de la loi de compression avec
maxmax
11ln11)(
xx
AxAxxg ≤
+=
11ln11)(
max≤≤
+=
xx
AAxg
Afin de conserver les bornes précisées ci-dessus, on
travaillera avec la variable normalisée maxxx
x = .
Le calcul de la variance se décompose donc comme suit:
dxxAdxxpA
A
A
A
e2
1
1
2
1
02
22 )ln1()()ln1(
∫∫ +++
=σ
En tenant compte du dépassement:
dxxpxxd )()1(21
22max
2 ∫∞
−=σ
On admet ici pour p(x), une distribution laplacienne:
xexp λλ −=2
)(

21
Pour la quantification uniforme, on a
)1(12
22 Pde −
∆=σ
où Pd est la probabilité de dépassement. Avec x variable aléatoire laplacienne:
∫∞
−=1
2dxePd xλλ
Pour le dépassement, on a:
dxxpxxd )()1(21
22max
2 ∫∞
−=σ
On en déduit le RSB:
+= 22
2log10
de
xRSBσσ
σ
Tous calculs faits, on obtient la courbe suivante sous Matlab avec L=216: La courbe en cyan représente le quantificateur avec loi A, la courbe en rouge le quantificateur uniforme.
L'axe des abscisses est gradué en -20log(Γ) avec Γ=xs/σs. La forme des courbes est conforme à ce qu'on attendait. On observe bien la différence de 24 dB à facteur de charge pas trop élevé. A facteur de charge plus élevé, le RSB s'effondre dans les deux cas à cause du dépassement. On remarque que le quantificateur avec loi A est toujours meilleur que le quantificateur uniforme, ce qui ne permet pas de rendre compte de l'observation à la page 12. Les résultats théoriques ne rejoignent pas les valeurs numériques en page 12.