

Apache Kafka, Un système distribué de messagerie hautement performant
40
Charly CLAIRMONT CTO ALTIC http://altic.org [email protected] @egwada Apache Kafka Un système distribué de messagerie hautement performant
-
Upload
altic-altic -
Category
Technology
-
view
1.183 -
download
9
description
Apache Kafka, Un système distribué de messagerie hautement performant
Transcript of Apache Kafka, Un système distribué de messagerie hautement performant

Charly CLAIRMONTCTOALTIChttp://altic.org
[email protected]@egwada
Apache Kafka
Un système distribué de messagerie hautement performant

Petite bio
Co-fondateur Altic
10 ans maintenant
Un des mes premiers jobs : « mettre de l'open source à tous les étages » dans l'entreprise !
Mes technos (orientées décisionnelles mais pas que)

Altic@Altic_Buzz
Métier
Informatique Décisionnelle
Intégration de données
Valeurs
– Innovations
– Open Source
Une maîtrise de toute la chaîne de valeur du Big Data

Apache KafkaUn système distribué de messagerie
hautement performant tolérant aux panes

Agenda
IntroductionApache Kafka, qu'est ce que c'est ?
Concepts élémentairesTopics, partitions, replicas, offsets
Producteurs, brokers, consommateurs
Écosystème

Agenda
Introduction
Apache Kafka, qu'est ce que c'est ?

IntroductionApache Kafka, qu'est-ce que c'est ?
● Distribué, très haut débit, système de messagerie publication / abonnement (pub-sub)
– Rapide, Robuste, Scalable, Durable
● Principaux cas d'utilisation
– Agrégation de logs, traitement temps réel, monitoring, files d'attente
● Développé à l'origine chez LinkedIn
● Écrit en Scala (un peu de Java)
● TLP Apache depuis 2012
● 9 core commiteurs, en eviron 20 contributeurs
● http://kafka.apache.org
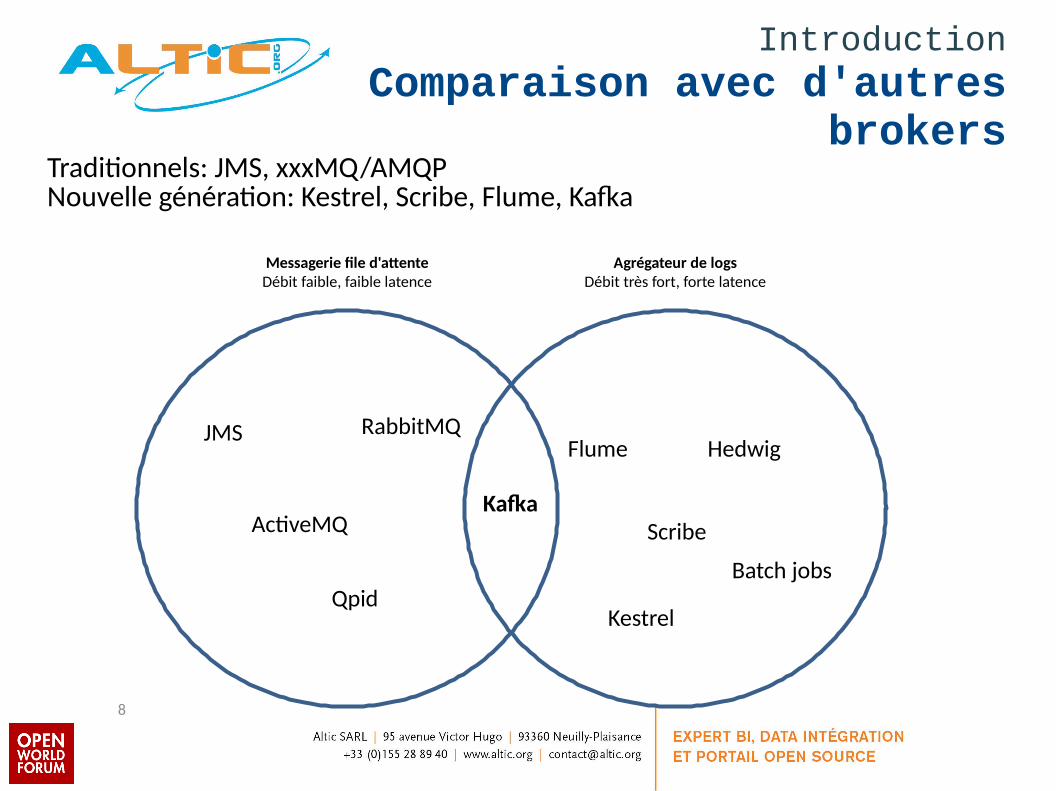
IntroductionComparaison avec d'autres
brokers
8
Kafka
Messagerie file d'attenteDébit faible, faible latence
JMS
ActiveMQ
Qpid
RabbitMQ
Agrégateur de logsDébit très fort, forte latence
Kestrel
Scribe
Flume Hedwig
Batch jobs
Traditionnels: JMS, xxxMQ/AMQPNouvelle génération: Kestrel, Scribe, Flume, Kafka

IntroductionPerformance chez LinkedIn
● Statistiques sur l'un des importants clusters Apache Kafka (aux heures de pointe):
– 15 brokers
– 15 500 partitions (réplication facteur 2)
– En entrée
● 400 000 msg / sec.● 70 Mo / sec.
– En sortie
● 400 Mo / sec.

IntroductionAdoption de Kafka & Cas
d'utilisation
– flux d'activité, suivi indicateurs opérationnels, bus de données
– 400 nodes, 18k topics, 220 milliards msg/day (pic 3.2 millions msg/s), Mai 2014
● OVH : Anti-DDOS
● Netflix : Suivi temps réel, traitement temps réel
● Twitter : Composant de leur architecture temps réel, couplée à Storm
● Spotify : Traitement de log (de 4h à 10s), Hadoop
● Loggly : Collecte et traitement de log
● Mozilla : Gestion de métrique
● Airbnb, Cisco, Gnip, InfoChimps, Ooyala, Square, Uber, …

IntroductionPourquoi Apache Kafka ?
On va imaginer que vous collectez vos logs!

IntroductionPourquoi Apache Kafka ?
Jusqu'ici tout va bien !

IntroductionPourquoi Apache Kafka ?
Là ça va encore !

IntroductionPourquoi Apache Kafka ?
Mais là ? Diriez-vous la même chose ?

IntroductionPourquoi Apache Kafka ?
Je n'en suis pas si sûr !
IntroductionPourquoi Apache Kafka ?
Un bel exemple celui de Spotify.https://www.jfokus.se/jfokus14/preso/ReliablerealtimeprocessingwithKafkaandStorm.pdf (Feb 2014)

IntroductionPourquoi Apache Kafka est-il si rapide ?
● Écritures rapides:– Bien que Kafka persiste toutes les données sur le disque,
toutes les écritures vont essentiellement « page cache » de l'OS, soit la RAM.
● Lectures rapides:– Très efficace pour transférer des données à partir du
« page cache » vers une socket réseau
– Linux: sendfile() appel système
● « Zéro-copy »
● Combinaison des deux = rapide Kafka!
● Compression de bout en bout

Agenda
Introduction
c'est quoi Apache Kafka
Concepts élémentairesTopics, partitions, offsets, réplicas
producteur, brokers ,consommateurs,
Ecosystème
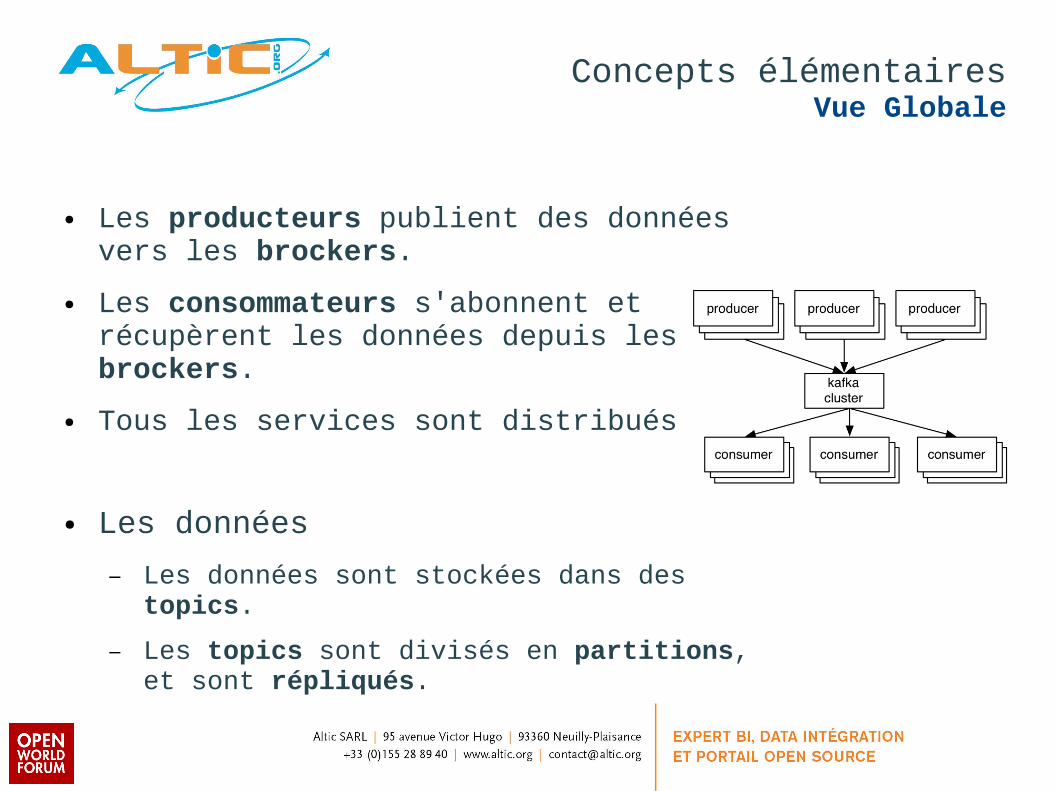
Concepts élémentairesVue Globale
● Les producteurs publient des données vers les brockers.
● Les consommateurs s'abonnent et récupèrent les données depuis les brockers.
● Tous les services sont distribués
● Les données
– Les données sont stockées dans des topics.
– Les topics sont divisés en partitions, et sont répliqués.
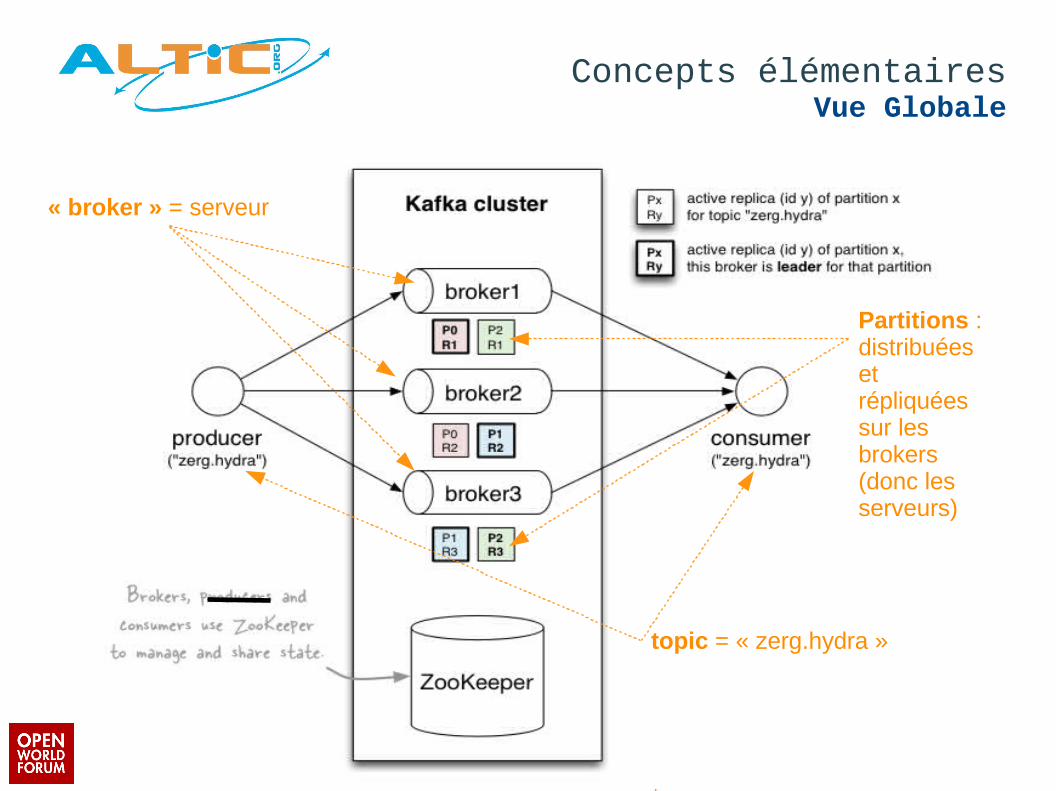
Concepts élémentairesVue Globale
« broker » = serveur
topic = « zerg.hydra »
Partitions : distribuées et répliquées sur les brokers (donc les serveurs)
Broker(s)
Concepts élémentairesTopics
Nouv.
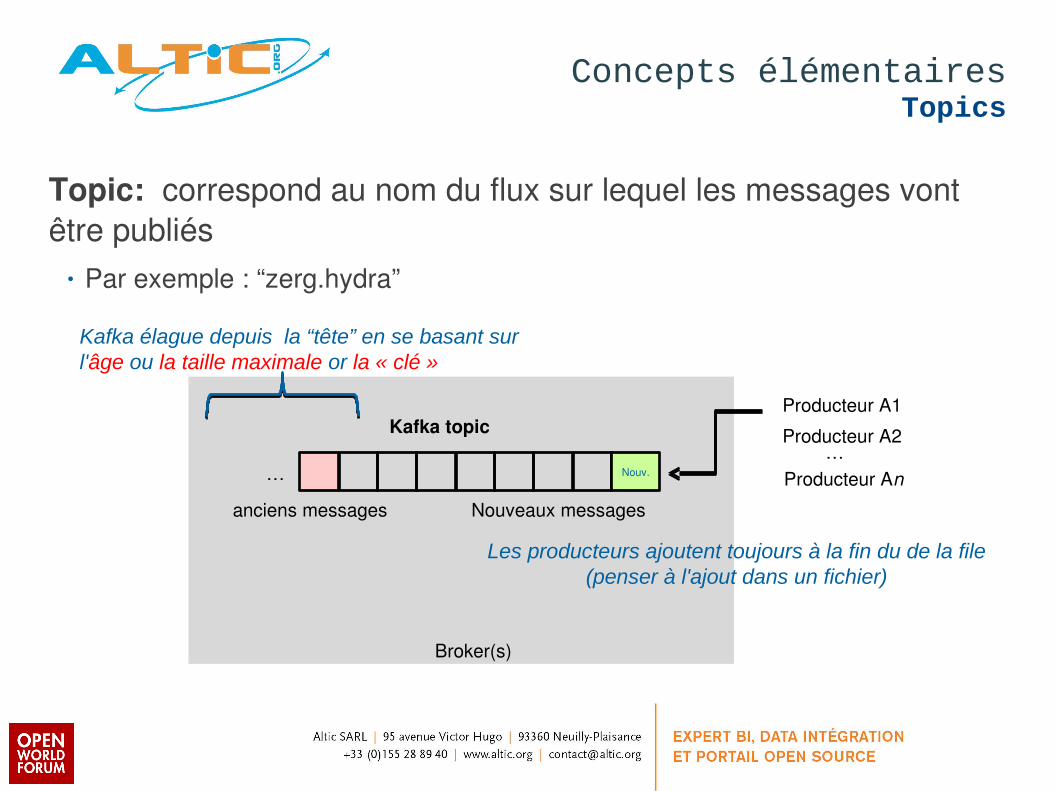
Producteur A1
Producteur A2
Producteur An…
Les producteurs ajoutent toujours à la fin du de la file(penser à l'ajout dans un fichier)
…
Kafka élague depuis la “tête” en se basant sur l'âge ou la taille maximale or la « clé »
anciens messages Nouveaux messages
Kafka topic
Topic: correspond au nom du flux sur lequel les messages vont être publiés
• Par exemple : “zerg.hydra”
Broker(s)
Concepts élémentairesTopics
Nouv.
Producteur A1
Producteur A2
Producteur An…
…
anciens messages Nouveaux messages
Kafka topic
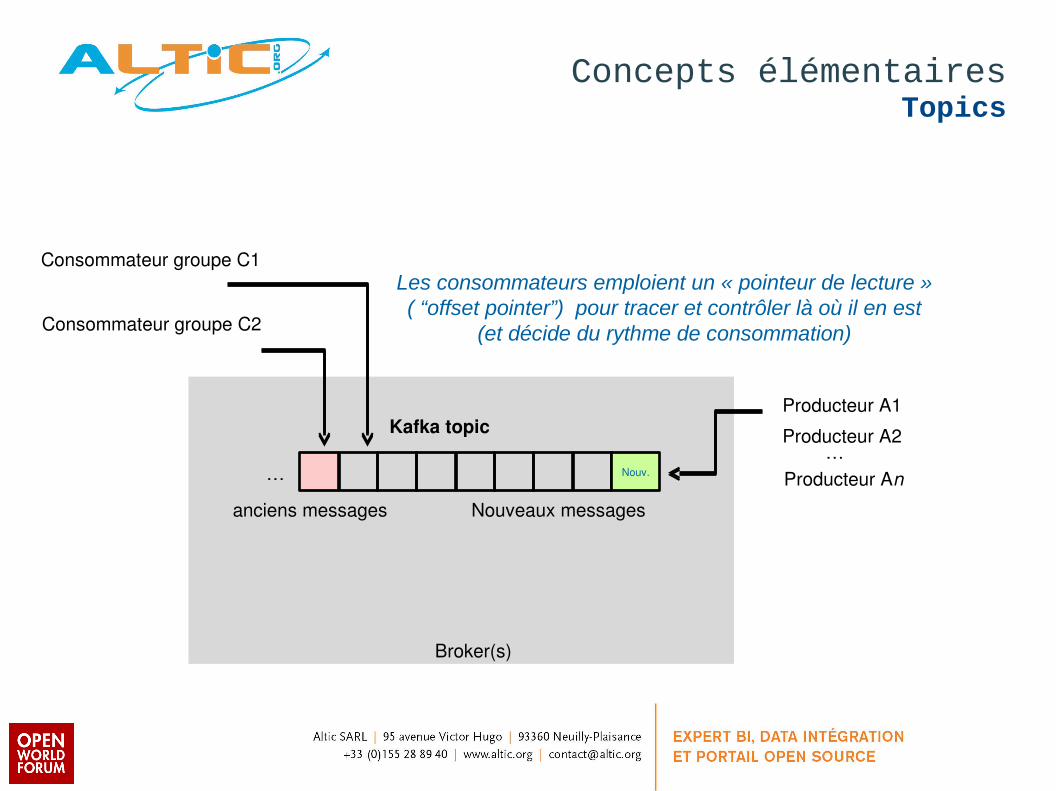
Consommateur groupe C1Les consommateurs emploient un « pointeur de lecture »( “offset pointer”) pour tracer et contrôler là où il en est
(et décide du rythme de consommation)Consommateur groupe C2
Concepts élémentairesMessage
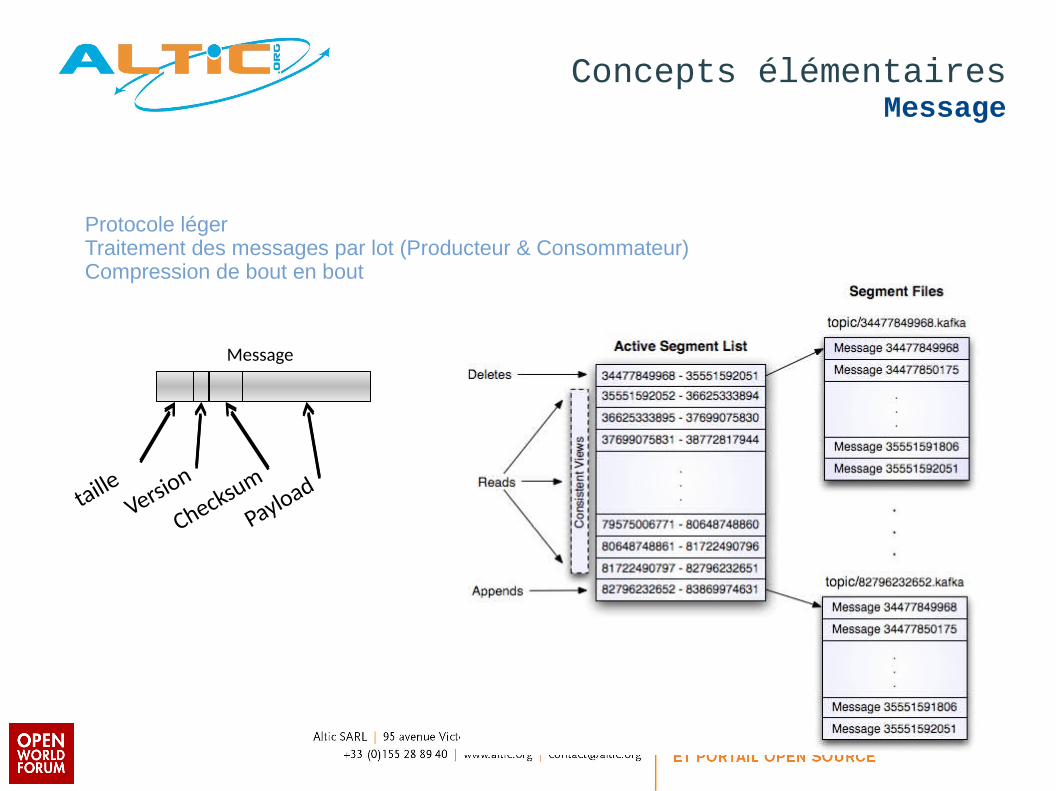
tailleVersio
n
Checksum
Payload
Message
Protocole légerTraitement des messages par lot (Producteur & Consommateur)Compression de bout en bout
Concepts élémentairesPartitions
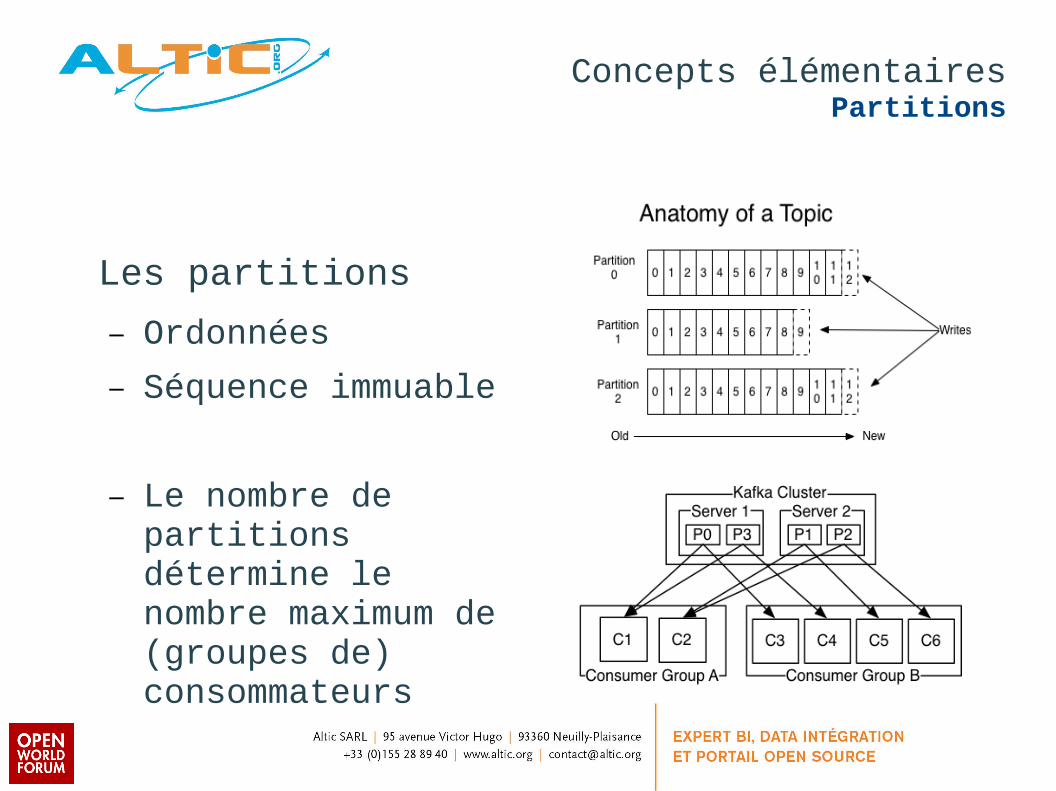
Les partitions
– Ordonnées
– Séquence immuable
– Le nombre de partitions détermine le nombre maximum de (groupes de) consommateurs
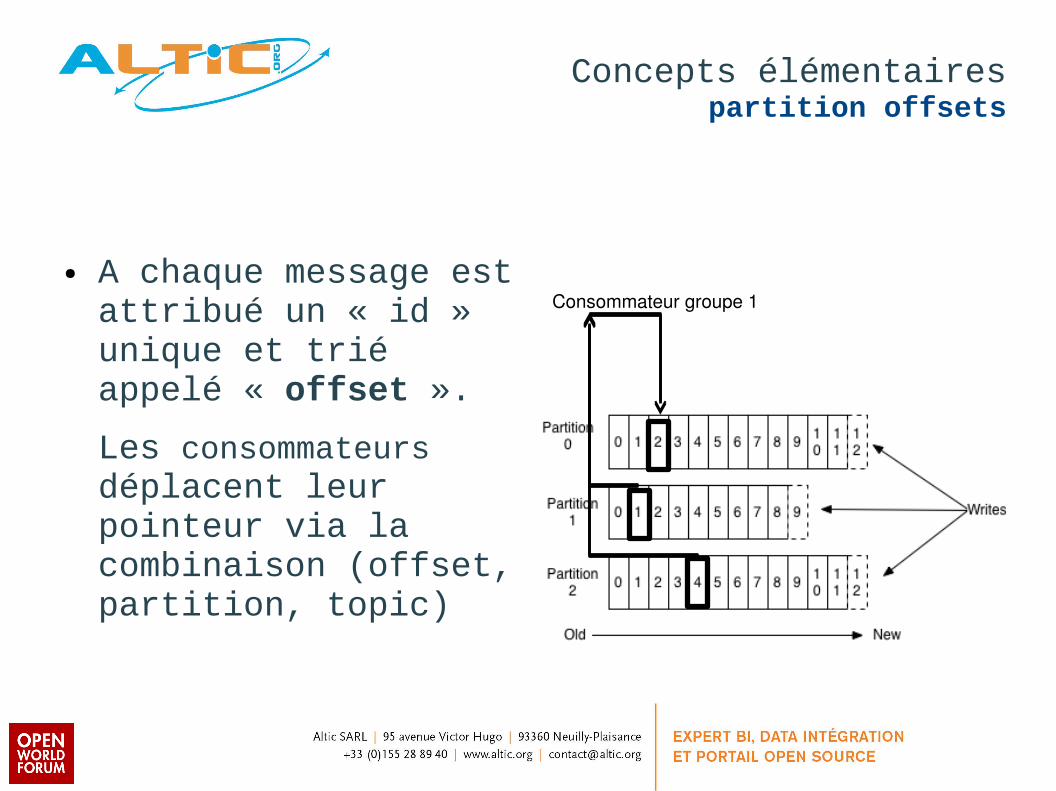
Concepts élémentairespartition offsets
● A chaque message est attribué un « id » unique et trié appelé « offset ».
Les consommateurs déplacent leur pointeur via la combinaison (offset, partition, topic)
Consommateur groupe 1

Concepts élémentairesréplicas
● Uniformément distribués
● « sauvegarde » des partitions
● Existent uniquement pour éviter les pertes de données
● Si numReplicas == 3 alors 2 brokers peuvent tomber
topic1-part1topic1-part1
logs
broker 1
topic1-part2topic1-part2
logs
broker 2
topic2-part2topic2-part2
topic2-part1topic2-part1
logs
broker 3
topic1-part1topic1-part1
logs
broker 4
topic1-part2topic1-part2
topic2-part2topic2-part2 topic1-part1topic1-part1 topic1-part2topic1-part2
topic2-part1topic2-part1
topic2-part2topic2-part2
topic2-part1topic2-part1
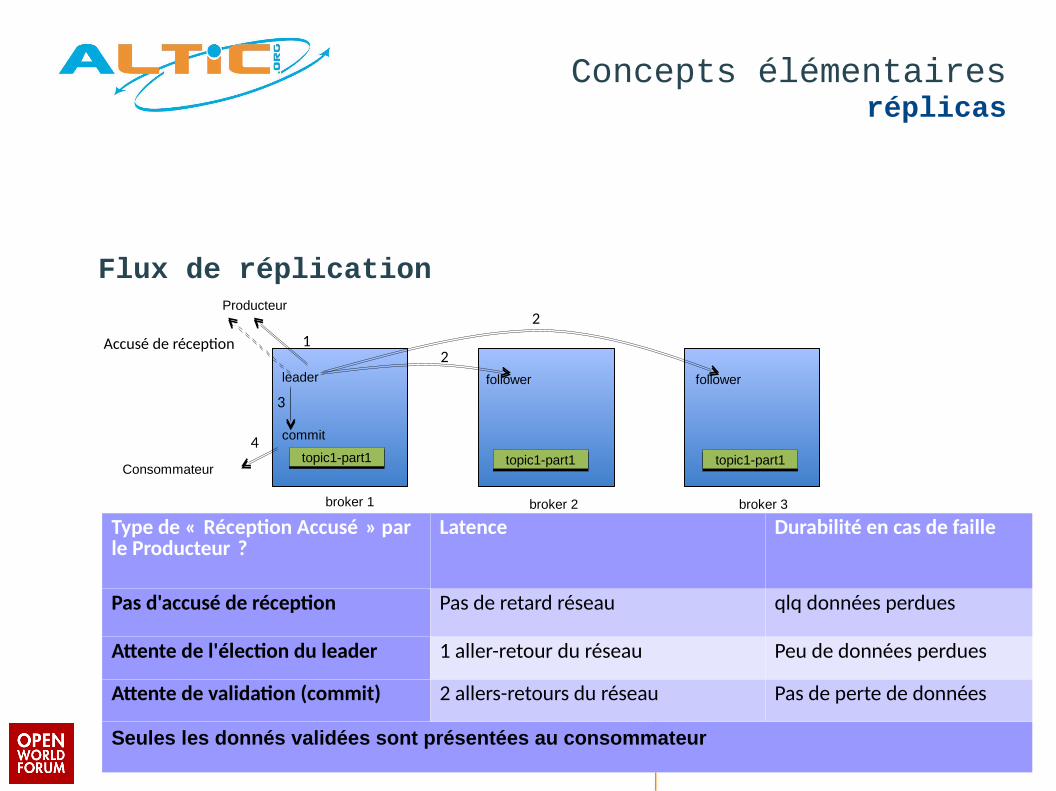
Concepts élémentairesréplicas
Flux de réplication
broker 1
Producteur
leader
broker 2
follower
broker 3
follower
4
2
2
3
commit
Accusé de réception
topic1-part1topic1-part1 topic1-part1topic1-part1 topic1-part1topic1-part1Consommateur
1
Type de « Récepton Accusé » par le Producteur ?
Latence Durabilité en cas de faille
Pas d'accusé de récepton Pas de retard réseau qlq données perdues
Attente de l'électon du leader 1 aller-retour du réseau Peu de données perdues
Attente de validaton (commit) 2 allers-retours du réseau Pas de perte de données
Seules les donnés validées sont présentées au consommateur
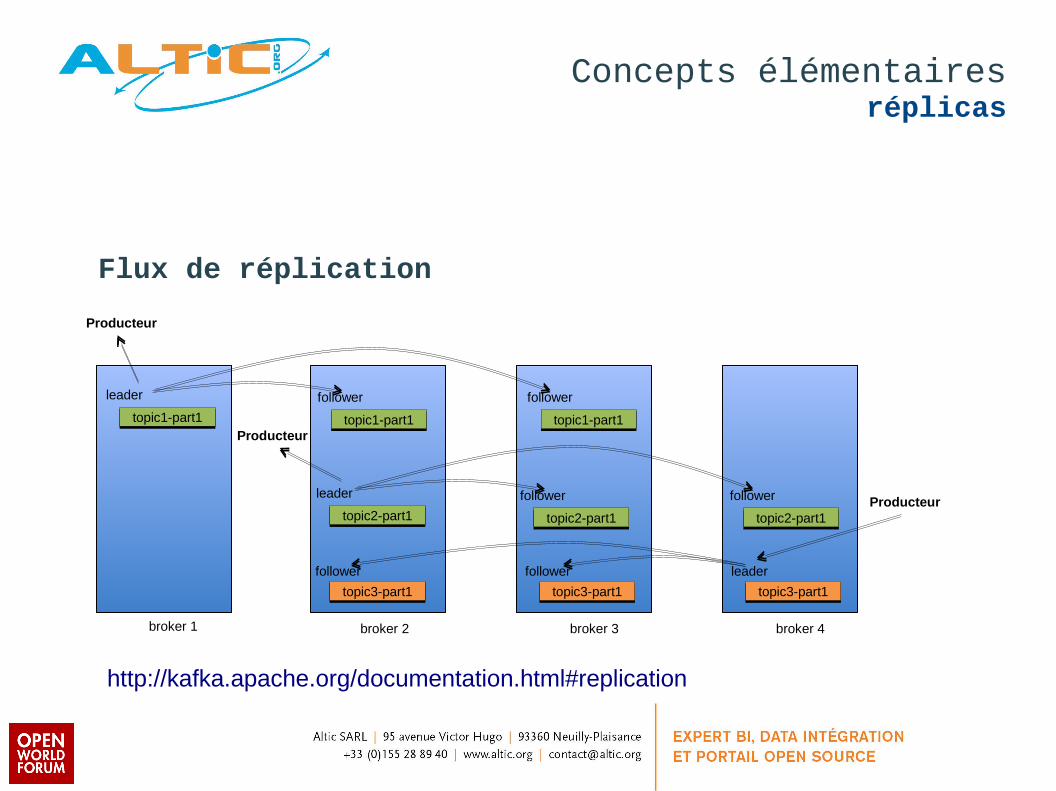
Concepts élémentairesréplicas
Flux de réplication
broker 1 broker 2
topic3-part1topic3-part1
follower
broker 3
topic3-part1topic3-part1
follower
topic1-part1topic1-part1
Producteur
leader
topic1-part1topic1-part1
follower
topic1-part1topic1-part1
follower
broker 4
topic3-part1topic3-part1
leader
Producteurtopic2-part1topic2-part1
Producteur
leader
topic2-part1topic2-part1
follower
topic2-part1topic2-part1
follower
http://kafka.apache.org/documentation.html#replication
Concepts élémentairesProducteurs
Publier des messages dans Kafka
– C'est assez simple
– Vous pouvez aussi directement agréger vos traces Log4J
– Liste complète des exemples
https://cwiki.apache.org/confluence/display/KAFKA/0.8.0+Producer+Example

Concepts élémentairesProducteurs
API
– ProducerType (sync/async)
– CompressionCodec (none/snappy/gzip)
– BatchSize
– EnqueueSize/Time
– Encoder/Serializer
– Partitioner
– #Retries
– MaxMessageSize
– …

Concepts élémentairesConsommateurs
Possibilité d'utiliser un consommateur pour publier dans Kafka
Les consommateurs sont responsables de vérifier où ils en sont dans leur lecture
Il y a une API simple, et une autre bien plus performante
– High-level (consumer group, auto-commit)
– Low-level (simple consumer, manual commit)

Concepts élémentairesConsommateurs
API

Agenda
IntroductionApache Kafka, qu'est-ce que c'est ?
Concepts élémentairesTopics, partitions, replicas, offsets
Producteurs, brokers, consommateurs
Écosystème

ÉcosystèmeIntégration
Consommateur
• Java (in standard dist)• Scala (in standard dist)• Python: kafka-python• Python: samsa• Python: brod• Go: Sarama• Go: nuance• Go: kafka.go• C/C++: libkafka• Clojure: clj-kafka• Clojure: kafka-clj• Ruby: Poseidon• Ruby: kafka-rb• Ruby: Kafkaesque• Jruby::Kafka• PHP: kafka-php(1)• PHP: kafka-php(2)• Node.js: Prozess• Node.js: node-kafka• Node.js: franz-kafka• Erlang: erlkafka• Erlang: kafka-erlang
Producteurs
• Java (in standard dist)• Scala (in standard dist)• Log4j (in standard dist)• Logback: logback-kafka• Udp-kafka-bridge• Python: kafka-python• Python: pykafka• Python: samsa• Python: pykafkap• Python: brod• Go: Sarama• Go: kafka.go• C: librdkafka• C/C++: libkafka• Clojure: clj-kafka• Clojure: kafka-clj• Ruby: Poseidon• Ruby: kafka-rb• Ruby: em-kafka• PHP: kafka-php(1)• PHP: kafka-php(2)• PHP: log4php• Node.js: Prozess• Node.js: node-kafka• Node.js: franz-kafka• Erlang: erlkafka

ÉcosystèmeIntégration
Intégratons connues
Stream ProcessingStorm - A stream-processing framework.Samza - A YARN-based stream processing frameworkSpark
Hadoop IntegratonCamus - LinkedIn's Kafka=>HDFS pipeline. This one is used for all data at LinkedIn, and works great.Kafka Hadoop Loader A diferent take on Hadoop loading functionality from what is included in the main distribution.
AWS IntegratonAutomated AWS deploymentKafka->S3 Mirroring
Loggingklogd - A python syslog publisherklogd2 - A java syslog publisherTail2Kafka - A simple log tailing utility Fluentd plugin - Integration with FluentdFlume Kafka Plugin - Integration with FlumeRemote log viewerLogStash integration - Integration with LogStash and FluentdOfficial logstash integration
MetricsMozilla Metrics Service - A Kafka and Protocol Bufers based metrics and logging systemGanglia Integration
Packing and DeploymentRPM packagingDebianpackaginghtps://github.com/tomdz/kafka-deb-packagi
ngPuppet integrationDropwizard packaging
Misc.Kafka Mirror - An alternative to the built-in mirroring toolRuby Demo App Apache Camel IntegrationInfobright integration
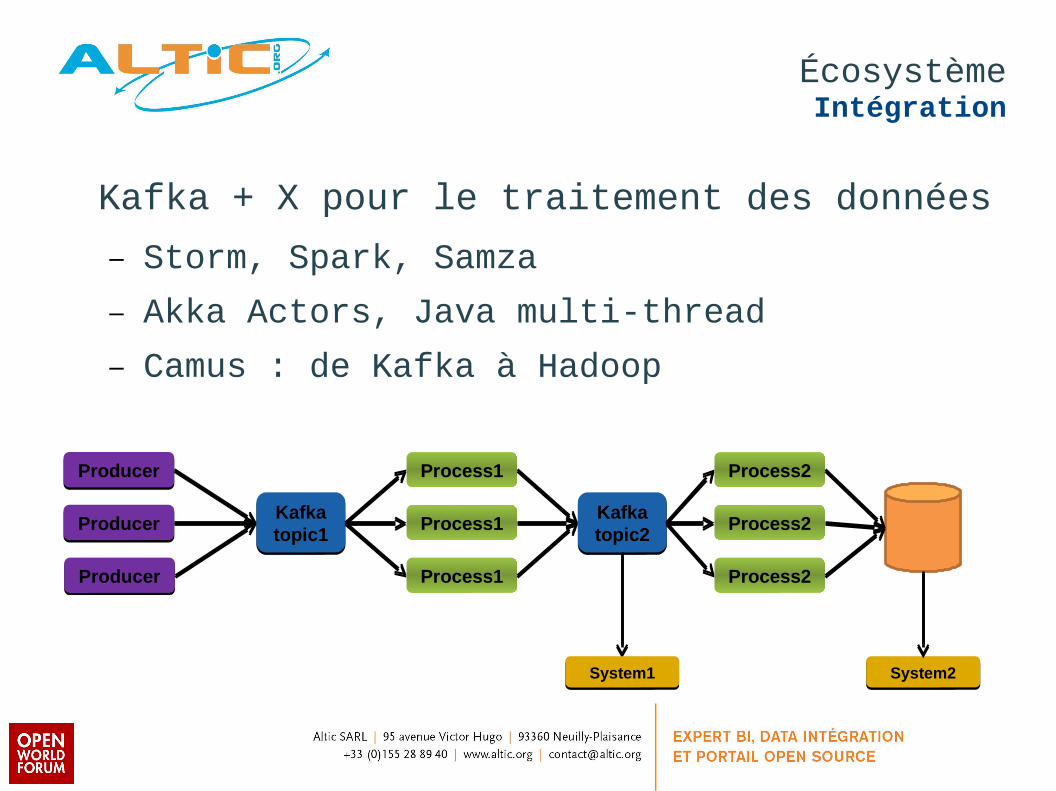
ÉcosystèmeIntégration
ProducerProducer
ProducerProducer
ProducerProducer
Kafka topic1Kafka topic1
Kafka topic2Kafka topic2
Process1Process1
Process1Process1
Process1Process1
Process2Process2
Process2Process2
Process2Process2
System1System1 System2System2
Kafka + X pour le traitement des données
– Storm, Spark, Samza
– Akka Actors, Java multi-thread
– Camus : de Kafka à Hadoop

ÉcosystèmeArchitecture Matérielle
● Machines uniquement dédiées à Kafka, rien d'autre
– 1 instance d'un broker Kafka par machine
– 2 x 4-core Intel Xeon (ou plus)
– 64 GB RAM (up from 24 GB)
● Seuls 4 GB sont utilisés par le broker Kafka, les 60 GB restants pour page cache
● Disques
– RAID10 avec 14 spindles
– Plus il y a de spindles, plus le débit du disque est important
– 8x SATA drives (7200rpm) JBOD
● Réseau
– 1 GigE de préférence

Apache Kafka 0.8 basic traininghttp://www.slideshare.net/miguno/apachekafka08basictrainingverisign
A défaut d'un bon livre, une très bonne ressource pour débuter

Questons


















