
Analyse et Fouille de Données - Réduction de …atif/lib/exe/fetch.php?media=... ·...
44
Analyse et Fouille de Données Réduction de dimensionalité Jamal Atif [email protected] Université Paris-Dauphine, M2 ID 2014-2015 Jamal Atif (Université Paris-Dauphine) AFD 2014-2015 1 / 35
Transcript of Analyse et Fouille de Données - Réduction de …atif/lib/exe/fetch.php?media=... ·...

Analyse et Fouille de DonnéesRéduction de dimensionalité
Jamal [email protected]
Université Paris-Dauphine, M2 ID
2014-2015
Jamal Atif (Université Paris-Dauphine) AFD 2014-2015 1 / 35

Réduction de dimensionalité
vous êtes ici
1 Réduction de dimensionalitéFormalisationAnalyse par Composantes PrincipalesDécomposition en Valeurs SingulièresAnalyse Sémantique LatenteRecommandation
Jamal Atif (Université Paris-Dauphine) AFD 2014-2015 2 / 35

Réduction de dimensionalité Formalisation
Formalisation du problème
Cadre non-supervisé : S = xi, i = 1 . . .N.
I Projection de tout x de Rd sur Rp, (p d)
φA : Rd −→ Rp
x 7−→ φA(x) = Ax
I Critère : minimisation de la distorsion/perte d’information oumaximisation de l’inertie projetée
φA = arg minN∑
j=1
||xk − φA(xk)||22
Jamal Atif (Université Paris-Dauphine) AFD 2014-2015 3 / 35

Réduction de dimensionalité Formalisation
Petit détour en algèbre linéaire
Modèle linéaireSoit le modèle linéaire suivant :
y = Ax + e
avec y ∈ Rd le vecteur observé, A ∈ Rd×p, x ∈ Rp et e ∈ Rd un vecteur bruitdont l’énergie est bornée (||e||2 ≤ ε). Considérons dans un premier temps queA est de rang plein.
Cas d > p Le système a plusieurs solutions. On sélectionne la solution quiminimise l’erreur quadratique :
x∗ = arg min12||Ax− y||22 = A†y
avec A† = (AtA)−1At la pseudo inverse (ou inverse deMoore-Penrose).; Régression linéaire, ACP.
Jamal Atif (Université Paris-Dauphine) AFD 2014-2015 4 / 35

Réduction de dimensionalité Formalisation
Petit détour en algèbre linéaire
Modèle linéaireSoit le modèle linéaire suivant :
y = Ax + e
avec y ∈ Rd le vecteur observé, A ∈ Rd×p, x ∈ Rp et e ∈ Rd un vecteur bruitdont l’énergie est bornée (||e||2 ≤ ε). Considérons dans un premier temps queA est de rang plein.
Cas d > p Le système a plusieurs solutions. On sélectionne la solution quiminimise l’erreur quadratique :
x∗ = arg min12||Ax− y||22 = A†y
avec A† = (AtA)−1At la pseudo inverse (ou inverse deMoore-Penrose).; Régression linéaire, ACP.
Jamal Atif (Université Paris-Dauphine) AFD 2014-2015 4 / 35

Réduction de dimensionalité Formalisation
Petit détour en algèbre linéaire
Modèle linéaireSoit le modèle linéaire suivant :
y = Ax + e
avec y ∈ Rd le vecteur observé, A ∈ Rd×p, x ∈ Rp et e ∈ Rd un vecteur bruitdont l’énergie est bornée (||e||2 ≤ ε). Considérons dans un premier temps queA est de rang plein.
Cas d < p Le système a une infinité de solutions =⇒ nécessité de rajouterune contrainte (régularisation) sur x :
x∗ = arg min Ω(x)
t.q. ||Ax− y||22 ≤ l
Exemple de régularisations :I Ω(x) := ||x||0 = #i, xi 6= 0,I Ω(x) := ||x||1
; Codage parcimonieux/compressive sensing,...Jamal Atif (Université Paris-Dauphine) AFD 2014-2015 5 / 35

Réduction de dimensionalité Formalisation
Petit détour en algèbre linéaire
Modèle linéaireSoit le modèle linéaire suivant :
y = Ax + e
avec y ∈ Rd le vecteur observé, A ∈ Rd×p, x ∈ Rp et e ∈ Rd un vecteur bruitdont l’énergie est bornée (||e||2 ≤ ε). Considérons dans un premier temps queA est de rang plein.
Cas d < p Le système a une infinité de solutions =⇒ nécessité de rajouterune contrainte (régularisation) sur x :
x∗ = arg min Ω(x)
t.q. ||Ax− y||22 ≤ l
Exemple de régularisations :I Ω(x) := ||x||0 = #i, xi 6= 0,I Ω(x) := ||x||1
; Codage parcimonieux/compressive sensing,...Jamal Atif (Université Paris-Dauphine) AFD 2014-2015 5 / 35

Réduction de dimensionalité Analyse par Composantes Principales
Analyse par Composantes Principales, rappels
I Soit S = xi ∈ Rd, i = 1 . . .NI On cherche un nouvel ensemble d’attributs qui sont combinaison linéaire
des attributs d’origine :
φu(xi) = ut(xi − µ)
avec µ l’individu moyen.; Trouver u qui maximise l’inertie/minimise la distorsion, perte
d’information.
Jamal Atif (Université Paris-Dauphine) AFD 2014-2015 6 / 35

Réduction de dimensionalité Analyse par Composantes Principales
Analyse par Composantes Principales, rappels
I Soit S = xi ∈ Rd, i = 1 . . .NI On cherche un nouvel ensemble d’attributs qui sont combinaison linéaire
des attributs d’origine :
φu(xi) = ut(xi − µ)
avec µ l’individu moyen.; Trouver u qui maximise l’inertie/minimise la distorsion, perte
d’information.
Jamal Atif (Université Paris-Dauphine) AFD 2014-2015 6 / 35

Réduction de dimensionalité Analyse par Composantes Principales
Analyse par Composantes Principales, rappels
I Soit S = xi ∈ Rd, i = 1 . . .NI On cherche un nouvel ensemble d’attributs qui sont combinaison linéaire
des attributs d’origine :
φu(xi) = ut(xi − µ)
avec µ l’individu moyen.; Trouver u qui maximise l’inertie/minimise la distorsion, perte
d’information.
Jamal Atif (Université Paris-Dauphine) AFD 2014-2015 6 / 35

Réduction de dimensionalité Analyse par Composantes Principales
Analyse par Composantes Principales, rappels
Axe d’inertie projetée maximale :
u = arg maxu
1N
N∑i=1
ut(xi − µ)(ut(xi − µ)
)t.q. ||u|| = 1
= arg maxu
ut
[1N
N∑i=1
(xi − µ)(xi − µ)t
]u t.q. ||u|| = 1
= arg maxu
utΣu t.q. ||u|| = 1
Solution : u est le vecteur propre de Σ associé à la valeur propre la plusélevée.
Jamal Atif (Université Paris-Dauphine) AFD 2014-2015 7 / 35

Réduction de dimensionalité Analyse par Composantes Principales
Analyse par Composantes Principales, rappels
Axe d’inertie projetée maximale :
u = arg maxu
1N
N∑i=1
ut(xi − µ)(ut(xi − µ)
)t.q. ||u|| = 1
= arg maxu
ut
[1N
N∑i=1
(xi − µ)(xi − µ)t
]u t.q. ||u|| = 1
= arg maxu
utΣu t.q. ||u|| = 1
Solution : u est le vecteur propre de Σ associé à la valeur propre la plusélevée.
Jamal Atif (Université Paris-Dauphine) AFD 2014-2015 7 / 35

Réduction de dimensionalité Analyse par Composantes Principales
Analyse par Composantes Principales, rappels
Axe d’inertie projetée maximale :
u = arg maxu
1N
N∑i=1
ut(xi − µ)(ut(xi − µ)
)t.q. ||u|| = 1
= arg maxu
ut
[1N
N∑i=1
(xi − µ)(xi − µ)t
]u t.q. ||u|| = 1
= arg maxu
utΣu t.q. ||u|| = 1
Solution : u est le vecteur propre de Σ associé à la valeur propre la plusélevée.
Jamal Atif (Université Paris-Dauphine) AFD 2014-2015 7 / 35

Réduction de dimensionalité Analyse par Composantes Principales
Analyse par Composantes Principales, rappels
Axe d’inertie projetée maximale :
u = arg maxu
1N
N∑i=1
ut(xi − µ)(ut(xi − µ)
)t.q. ||u|| = 1
= arg maxu
ut
[1N
N∑i=1
(xi − µ)(xi − µ)t
]u t.q. ||u|| = 1
= arg maxu
utΣu t.q. ||u|| = 1
Solution : u est le vecteur propre de Σ associé à la valeur propre la plusélevée.
Jamal Atif (Université Paris-Dauphine) AFD 2014-2015 7 / 35

Réduction de dimensionalité Analyse par Composantes Principales
Application de l’ACP : EigenfacesM. Turk and A. Pentland, Face Recognition using Eigenfaces, CVPR 1991
But : catégoriser les images de visages
Idée :I Considérer les images comme des vecteurs
=⇒ x
I Trouver par similarité les visages qui se ressemblent (e.g. k-ppv)
=⇒ k = arg mink ||yk − x||22
Jamal Atif (Université Paris-Dauphine) AFD 2014-2015 8 / 35

Réduction de dimensionalité Analyse par Composantes Principales
Application de l’ACP : EigenfacesL’espace des visages
I Les images vues comme des vecteurs de pixels (explosion de ladimension d) :
I Une image 100 × 100 = 104 dimensions (attributs)I Problèmes de temps de calcul et de capacité mémoire
I Un sous ensemble des vecteurs ∈ R104sont des visages
I Modéliser le sous-espace V ⊆ R104des visages
Jamal Atif (Université Paris-Dauphine) AFD 2014-2015 9 / 35

Réduction de dimensionalité Analyse par Composantes Principales
Application de l’ACP : EigenfacesL’espace des visages
Principe Eigenfaces : construire le sous-espace qui capture le maximumd’inertie du nuage des visages.
FIGURE: defaultJamal Atif (Université Paris-Dauphine) AFD 2014-2015 10 / 35

Réduction de dimensionalité Analyse par Composantes Principales
Application de l’ACP : EigenfacesEigenfaces : algorithme
1. Transformer les matrices images en vecteurs puis les centrer.2. Construire la matrice Y des individus centrés (chaque ligne est un
vecteur image).3. Calculer la matrice de covariance Σ = 1
N YYt.4. Calculer les axes factoriels : K vecteurs propres non-triviaux (eigenfaces)
avec valeurs propres les plus élevées. Notons les U = [u1, · · · ,uK]
5. Calculer la projection des vecteurs images sur ces axes factoriels(composantes principales) : ci = Yui
6. Catégoriser les images projetées : zj = cj1u1 + · · ·+ cj
KuK
Jamal Atif (Université Paris-Dauphine) AFD 2014-2015 11 / 35

Réduction de dimensionalité Analyse par Composantes Principales
Application de l’ACP : EigenfacesIllustration
FIGURE: Base d’apprentissage : x1, · · · , xN
Jamal Atif (Université Paris-Dauphine) AFD 2014-2015 12 / 35

Réduction de dimensionalité Analyse par Composantes Principales
Application de l’ACP : EigenfacesIllustration
: Image moyenne
: K premiers axes factoriels
Jamal Atif (Université Paris-Dauphine) AFD 2014-2015 13 / 35

Réduction de dimensionalité Analyse par Composantes Principales
Application de l’ACP : EigenfacesIllustration
FIGURE: Première ligne : K composantes principales. Deuxième ligne : µ+ 3λiui.Troisième ligne : µ− 3λiui
Jamal Atif (Université Paris-Dauphine) AFD 2014-2015 14 / 35

Réduction de dimensionalité Analyse par Composantes Principales
Conclusion sur l’ACP
Une technique générale de réduction de dimensionnalité.
Implémentation
I La matrice de covariance peut être de très grande taille (e.g. 104 × 104)I Mais le nombre d’exemples (individus/images) est 104
; Décomposition en Valeurs Singulières
HypothèsesI L’hypothèse de linéarité n’est pas souvent valide.I Les axes de maximum d’inertie ne constituent pas des caractéristiques
discriminantes.I Une approche purement générative.
Jamal Atif (Université Paris-Dauphine) AFD 2014-2015 15 / 35

Réduction de dimensionalité Décomposition en Valeurs Singulières
Décomposition en Valeurs Singulières, DVS
Toute matrice A, (m× n) peut être décomposée comme suit :
A = UΣVt
I U,m×m : base orthonormaleI Σ,m× n : diagonaleI V,n× n : base orthonormale
Jamal Atif (Université Paris-Dauphine) AFD 2014-2015 16 / 35

Réduction de dimensionalité Décomposition en Valeurs Singulières
Décomposition en Valeurs Singulières, DVS
Exemple (m > n)
A =
...
......
...u1 · · · ur ur+1 · · · um...
......
...
σ1
. . .σr
0. . .
00 · · · · · · · · · · · · 0...
...0 · · · · · · · · · · · · 0
· · · vt1 · · ·
...· · · vt
r · · ·· · · vt
r+1 · · ·...
· · · vtn · · ·
σ1 ≥ · · · ≥ σr > 0 = rang(A),UUt = Im×m,VtV = In×n
Jamal Atif (Université Paris-Dauphine) AFD 2014-2015 17 / 35

Réduction de dimensionalité Décomposition en Valeurs Singulières
Décomposition en Valeurs Singulières, DVSVersion réduite
A = Ur︸︷︷︸m×r
Σr︸︷︷︸r×r
Vtr︸︷︷︸
r×n
A =
...
...u1 · · · ur...
...
σ1
. . .σr
· · · vt
1 · · ·...
· · · vtr · · ·
Espace colonne (span(A) = Ax,∀x ∈ Rn) :
Ax = UΣVtx et prenons y = Vtx
=
...
......
...σ1u1 · · · σrur ur+1 · · · um...
......
...
y
=⇒ span(A) = span(Ur) puisque, u1, · · · ,ur forment une base orthonormalede span(A).
Jamal Atif (Université Paris-Dauphine) AFD 2014-2015 18 / 35

Réduction de dimensionalité Décomposition en Valeurs Singulières
Décomposition en Valeurs Singulières, DVSVersion réduite
A = Ur︸︷︷︸m×r
Σr︸︷︷︸r×r
Vtr︸︷︷︸
r×n
A =
...
...u1 · · · ur...
...
σ1
. . .σr
· · · vt
1 · · ·...
· · · vtr · · ·
Espace colonne (span(A) = Ax,∀x ∈ Rn) :
Ax = UΣVtx et prenons y = Vtx
=
...
......
...σ1u1 · · · σrur ur+1 · · · um...
......
...
y
=⇒ span(A) = span(Ur) puisque, u1, · · · ,ur forment une base orthonormalede span(A).
Jamal Atif (Université Paris-Dauphine) AFD 2014-2015 18 / 35

Réduction de dimensionalité Décomposition en Valeurs Singulières
Décomposition en Valeurs Singulières, DVSVersion réduite
A = Ur︸︷︷︸m×r
Σr︸︷︷︸r×r
Vtr︸︷︷︸
r×n
A =
...
...u1 · · · ur...
...
σ1
. . .σr
· · · vt
1 · · ·...
· · · vtr · · ·
Espace colonne (span(A) = Ax,∀x ∈ Rn) :
Ax = UΣVtx et prenons y = Vtx
=
...
......
...σ1u1 · · · σrur ur+1 · · · um...
......
...
y
=⇒ span(A) = span(Ur) puisque, u1, · · · ,ur forment une base orthonormalede span(A).
Jamal Atif (Université Paris-Dauphine) AFD 2014-2015 18 / 35

Réduction de dimensionalité Décomposition en Valeurs Singulières
Décomposition en Valeurs Singulières, DVSVersion réduite
A = Ur︸︷︷︸m×r
Σr︸︷︷︸r×r
Vtr︸︷︷︸
r×n
A =
...
...u1 · · · ur...
...
σ1
. . .σr
· · · vt
1 · · ·...
· · · vtr · · ·
Espace noyau (x ∈ Ker(A) ⇐⇒ Ax = 0) :
Ax = 0
=⇒ UrΣrVtrx = 0
=⇒ ΣrVtrx = 0
=⇒ Vtrx = 0
; trouver des x orthogonaux à v1, · · · , vr.Puisque V est une base orthogonale, la solution est : vr+1, · · · , vn. Et doncvr+1, · · · , vn est une base orthonormale de Ker(A).
Jamal Atif (Université Paris-Dauphine) AFD 2014-2015 19 / 35

Réduction de dimensionalité Décomposition en Valeurs Singulières
DVS : interprétation géométrique
FIGURE: Diagramme de StrangJamal Atif (Université Paris-Dauphine) AFD 2014-2015 20 / 35
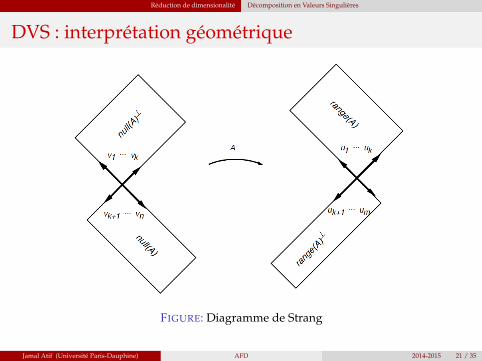
Réduction de dimensionalité Décomposition en Valeurs Singulières
DVS : interprétation géométrique
FIGURE: Diagramme de Strang
Jamal Atif (Université Paris-Dauphine) AFD 2014-2015 21 / 35

Réduction de dimensionalité Décomposition en Valeurs Singulières
DVS : interprétation géométriquePour le cas général, A,n×m
Ax = U Σ Vtx︸︷︷︸rotation dans Rn︸ ︷︷ ︸
changement d’échelle︸ ︷︷ ︸rotation dans Rm
FIGURE: Illustration avec réduction de dimensionalité, crédit Kalman
Jamal Atif (Université Paris-Dauphine) AFD 2014-2015 22 / 35

Réduction de dimensionalité Décomposition en Valeurs Singulières
DVS et ACP
AAt =(UΣVt) (UΣVt)t
= UΣVtVΣtUt
= UΣ2Ut
; décomposition en valeurs propres de la matrice AAt (matrice decovariance) !, U est la matrice de vecteurs propres et Σ2 et la matrice desvaleurs propres de AAt. Les valeurs singulières sont donc les racines carréesdes valeurs propres : σi =
√λi.
AtA =(UΣVt)t (UΣVt)
= VΣtUtUΣVt
= VΣ2Vt
; V est la matrice des vecteurs propre de AtA avec les mêmes valeurspropres.
Jamal Atif (Université Paris-Dauphine) AFD 2014-2015 23 / 35

Réduction de dimensionalité Analyse Sémantique Latente
Analyse Sémantique Latente (LSA)
ObjectifsI En recherche d’information « Information Retrieval »I Permettre l’utilisation de requêtes ne contenant pas exactement les
mêmes mots que les documents, mais des mots de sens proche
IdéeI Passer par un espace intermédiaire dans lequel les termes exprimeraient
davantage les distinctions sémantiques utilesI On projetterait alors les termes des requêtes et des documents dans cet
espace, permettant un meilleur rapprochement
Jamal Atif (Université Paris-Dauphine) AFD 2014-2015 24 / 35

Réduction de dimensionalité Analyse Sémantique Latente
Analyse Sémantique Latente (LSA)
Matrice termes-documents
X = termes
f 11 f 2
1 f 31 · · · f d
1f 21 f 2
2 f 32 · · · f d
2· · · · · · · · · · · · · · ·f 1N f 2
N f 3N · · · f d
N
︸ ︷︷ ︸
Documents
f ji = fréquence d’utilisation du mot i dans le texte j
Modèle vectoriel
Jamal Atif (Université Paris-Dauphine) AFD 2014-2015 25 / 35

Réduction de dimensionalité Analyse Sémantique Latente
Exemple
Jamal Atif (Université Paris-Dauphine) AFD 2014-2015 26 / 35

Réduction de dimensionalité Analyse Sémantique Latente
Exemple
FIGURE: matrice X, termes-documents
ρ(human, user) = −.38, ρ(human, minors) = −.29, ρ la corrélation deSpearman.
Jamal Atif (Université Paris-Dauphine) AFD 2014-2015 27 / 35

Réduction de dimensionalité Analyse Sémantique Latente
Exemple
X = UΣVt
FIGURE: Décomposition en Valeurs Singulières
Jamal Atif (Université Paris-Dauphine) AFD 2014-2015 28 / 35

Réduction de dimensionalité Analyse Sémantique Latente
Intuition derrière la DVS
X =
m1 m2 m3 m4d1 0 1 1 1d2 1 1 1 0
m1 et m4 ne sont pas présents dans le même document, mais sont associés auxmêmes mots. On pourrait en inférer qu’ils sont «liés»...Après DVS plus réduction :
X =
m1 m2 m3 m4d1 ε 1 1 1d2 1 1 1 ε
Jamal Atif (Université Paris-Dauphine) AFD 2014-2015 29 / 35
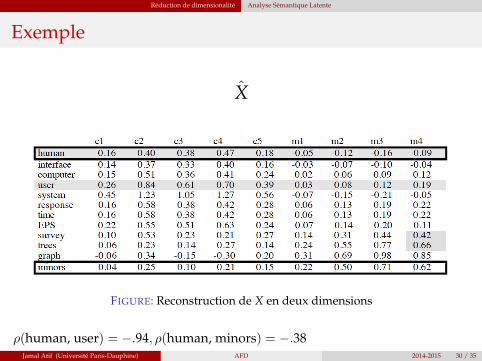
Réduction de dimensionalité Analyse Sémantique Latente
Exemple
X
FIGURE: Reconstruction de X en deux dimensions
ρ(human, user) = −.94, ρ(human, minors) = −.38Jamal Atif (Université Paris-Dauphine) AFD 2014-2015 30 / 35

Réduction de dimensionalité Recommandation
Recommandations de...films
Données : utilisateurs/ classement de films
X=M
atri
x
Alie
n
Star
War
s
Cas
abla
nca
Tita
nic
id1 1 1 1 0 0id2 3 3 3 0 0id3 4 4 4 0 0id4 5 5 5 0 0id5 0 0 0 4 4id6 0 0 0 5 5id7 0 0 0 2 2
Jamal Atif (Université Paris-Dauphine) AFD 2014-2015 31 / 35

Réduction de dimensionalité Recommandation
Recommandations de...films
Décomposition :
1 1 1 0 03 3 3 0 04 4 4 0 05 5 5 0 00 0 0 4 40 0 0 5 50 0 0 2 2
=
.14 0
.42 0
.56 0
.70 00 .600 .750 .30
[
12.4 00 9.5
] [.58 .58 .58 0 00 0 0 .71 .71
]
Explication ?
Jamal Atif (Université Paris-Dauphine) AFD 2014-2015 32 / 35

Réduction de dimensionalité Recommandation
Recommandations de...films
Exemple 2
X=M
atri
x
Alie
n
Star
War
s
Cas
abla
nca
Tita
nic
id1 1 1 1 0 0id2 3 3 3 0 0id3 4 4 4 0 0id4 5 5 5 0 0id5 0 2 0 4 4id6 0 0 0 5 5id7 0 1 0 2 2
Jamal Atif (Université Paris-Dauphine) AFD 2014-2015 33 / 35

Réduction de dimensionalité Recommandation
Recommandations de...films
Décomposition :
1 1 1 0 03 3 3 0 04 4 4 0 05 5 5 0 00 2 0 4 40 0 0 5 50 1 0 2 2
=
.13 .02 −.01
.41 .07 −.03
.55 .09 .04
.68 .11 −.05
.15 −.59 .65
.07 −.73 −.67
.07 −.29 .32
12.4 0 0
0 9.5 00 0 1.3
.56 .59 .56 .09 .09.12 −.02 .12 −.69 −.69.40 −.80 .40 .09 .09
Jamal Atif (Université Paris-Dauphine) AFD 2014-2015 34 / 35

Réduction de dimensionalité Recommandation
Recommandations de...films
Réduction de dimensionalité :
.13 .02
.41 .07
.55 .09
.68 .11
.15 −.59
.07 −.73
.07 −.29
[
12.4 00 9.5
] [.56 .59 .56 .09 .09.12 −.02 .12 −.69 −.69
]
=
0.93 0.95 0.93 .014 .0142.93 2.99 2.93 .000 .0003.92 4.01 3.92 .026 .0264.84 4.96 4.84 .040 .0400.37 1.21 0.37 4.04 4.040.35 0.65 0.35 4.87 4.870.16 0.57 0.16 1.98 1.98
Interprétation ?
Jamal Atif (Université Paris-Dauphine) AFD 2014-2015 35 / 35


















