ADN / ARN Structure. ADN : Acides Désoxyribonucléiques (1) Un nucléoside Un nucléotide.
51
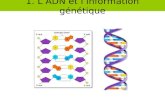
ADN / ARN Structure
-
Upload
lazare-joubert -
Category
Documents
-
view
115 -
download
1
Transcript of ADN / ARN Structure. ADN : Acides Désoxyribonucléiques (1) Un nucléoside Un nucléotide.

ADN / ARNStructure

ADN : Acides Désoxyribonucléiques (1)
Un nucléoside
Un nucléotide

Purines
Pyrimidines
Liaison phosphodiester
ADN : Acides Désoxyribonucléiques (2)
ADN

Uracile
Purines
Pyrimidines
OH
OH
OH
OH
U
ARN : Acides Ribonucléiques
ARN

ARN vs ADN
ARN ADN
Uracile Thymine
Evolution: deoxy: plus difficile à «fabriquer» que le ribose

5’
3’
5’
3’
Comparaison ADN - ARN
ARN ADN

BASE NUCLEOSIDE ABBREVIATION (symboles IUB-IUPAC)
Adenine Adenosine AGuanine Guanosine GCytosine Cytidine CUracile Uridine U (ARN)Thymine Thymidine T----------------------------------------------------------------------puRine G ou A RpYrimidine T ou C YaMino A ou C MKeto G ou T KWeak interact. A ou T W (2 liaisons H)Strong interact.G ou C S (3 liaisons H)!A = B T ou G ou C B!C = D A ou T ou G D!T, !U = V A ou G ou C V!G = H A ou T ou C H
A ou T ou G ou C X / N
Base + sucre
Nomenclature

ADN
Stockage de l’information génétique

• règle de Chargaff (1950) concentration purine / concentration pyrimidine = 1
%G = %C et %A = %T
• Appariement de bases complémentaires par des liaisons hydrogène
• Règle: appariement d’une purine avec une pyrimidine
A-T: 2 liaisons hydrogène G-C : 3 liaisons hydrogène
A-U: 2 liaisons hydrogène (ADN/ARN, ARN/ARN)
ADN double hélice: appariement
5 ’ - CACCAGAAGTCCTG - 3 ’ ||||||||||||||3 ’ - GTGGTCTTCAGGAC - 5 ’
‘ Paires canoniques ’

• Séquence orientée extrémités 5’ phosphate et 3’ hydroxyle ‘libres’
• Brins anti-parallèles indispensable pour la formation des liaisons H
• Brins complémentaires Importance du sens de la lecture (convention) !
5’
3’
3’
5’
ADN double hélice: polarité et convention (1)

Par convention, seule la séquence 5’ -> 3’ du brin codant de l’ADN est représentée.
Brin codantBrin matrice
ATGGCATGCAATAGCTCATCG...
ADN double hélice: polarité et convention (2)

5’ 3’ 3’ 5’brin codant brin matricesens anti-sens
Watson Crick+ -direct complémentaireD C
5’ AGTACG 3’ ou 5’ CGTACT 3’ codant3’ TCATGC 5’ 3’ GCATGA 5’ matrice
5’ AGUACG 3’ ou 5’ CGUACU 3’ ARNm SerThr ArgSer protéine
ADN double hélice: polarité et convention (3)
Séquence représentée dans les bases

• Nombreuses liaisons
- physiquement et chimiquement stable; de longues chaînes peuvent être conservées sans cassure
• Liaisons hydrogène (H) faibles
- rupture facile (transcription; réplication)
• Double brin: information “redondante”,
- essentielle:
pour les processus de réparation de l’ADN (correction sur épreuve)
pour la réplication de l’ADN et la transmission de l’information génétique (réplication semi-conservative)
les 2 brins sont ‘codants’
ADN double hélice: propriétés biochimiques

• forme naturelle la plus fréquente; compatible avec le squelette sucre phosphate• 10 paires de base par tour hélice (3.4 nm) • homme: 3 109 pb: environ 1 m; E. coli: 4 106 pb: 1.6 mm • les bases sont à l’intérieur, perpendiculiares à l’axe de l’hélice
B-ADN : structure 3D

• Structure symétrique
- interaction protéines-ADN
• Structure flexible (moins que les protéines) et dynamique
• Structure variable: en fonction de la séquence en acides nucléiques
- la plupart des protéines reconnaissent une séquence
- certaines protéines pourraient reconnaître une structure (ex: ADN cruciforme, Z-ADN)
ADN double hélice: structure

Liaison à l’ADN d’un dimère de répresseurdu bactériophage Lambda 434
Dimension du sillon majeur: 1.2 x 0.6 x 0.8 nm
Diamètre d’une hélice alpha (protéine): 1.2 nm
Copyright Anulka

ADN double hélice circulaire
• plasmides, chromosome bactérien • configuration superhélicoïdale (« supercoils »
négative ou positive; rôle des topoisomérase);
ADN double hélice: structure 3D

Séquence consensus de l’origine de réplication bactérienne déduite à partir de six espèces
• La réplication du chromosome est initiée dans une région conservée: l’origine de réplication.• Chez E. coli une seule origine de réplication par molécule d’ADN.
Origine de réplication

ARN

• Génomes viraux: mono-, bicaténaire, linéaire ou circulaire;
• Cellules: monocaténaire;
• Peu stable chimiquement; demi-vie courte (qqes sec à plusieurs heures; important pour la cellule);
• Différences avec ADN: - Appariements G-A et G-U;
- Nucléotides souvent modifés;
- Structures très flexibles; plusieurs conformations possibles (difficiles à cristalliser);
- Fonctions diverses
ARN : propriétés et structures

• Intermédiaires dans la synthèse des protéines : ARN messager (ARNm); ARN de transfert (ARNt); ARN ribosomal (ARNr)
• Molécules de structure : ARN ribosomal (ARNr)
• Molécules catalytiques : ribozymes
Prouvé en 2000Science, 289, 920-930
ARN : fonctions biologiques

http://www.cbs.dtu.dk/dave/DNA_CenDog.html#1. Digital River
DNA
TRANSCRIPTION
rRNA mRNA tRNA
ribosome
TRADUCTION
PROTEINE
ARNs impliqués dans la synthèse des protéines

• Il existe ~ 31 ARNt différents; composés de 75 à 95 nucléotides;
• Plusieurs milliers de copies dans le cytoplasme; différents dans la mitochondrie et dans le chloroplaste (code génétique différent)
• Intermédiaires indispensables dans la synthèse des protéines: compatibilité stéréochimique
ARN de transfert : ARNt

• Les ARNt ont des éléments de séquences conservés
• Combinaison : recherche de motifs (pattern) + méthodes probabilistes
Cours Analyse de séquences(A. Viari, M-F Sagot)
Prédiction des ARNt

http://www.genetics.wustl.edu/eddy/tRNAscan-SE/

Virus: toutes ces formes sont retrouvées
Eucaryotes: ADN double brin linéaire; ADN double brin circulaire;
Procaryotes: ADN double brin circulaire; ADN double brin linéaire (chromosome et plasmides)
Les différentes formes de l ’information génétique

La phylogénie moléculaire basée sur la comparaison des ARN ribosomaux 16S classe les êtres vivants en trois règnes ou lignées généalogiques : eucaryotes, eubactéries et archébactéries
Les 3 règnes
procaryote eucaryote

- Peu de séquences répétitives: répétitions non codantes chez E. coli: 0.7% du génome
- Non associé avec des histones, mais on peut trouver des petites protéines “histone-like” qui contraignent l’ADN à se replier en structure plus compacte.
- Une molécule d’ADN circulaire sous forme superenroulée (supercoil négatif, sauf exceptions...)
- Le chromosome peut être associé à la membrane cellulaire.
- Pas de noyau.
Génomes procaryotes

The cartoon guide to genetics, Larry Gonick & Mark Wheelis, HarperPerennial
Organisation des régions codantes (procaryotes)

• Séquence d’acides nucléiques nécessaire pour la synthèse - d’un polypeptide fonctionnel - d’un ARN fonctionnel (tRNA, rRNA,…)
• Un gène codant pour une protéine comprend « généralement »: - la séquence codante (CDS) - les régions de contrôle de la transcription et traduction
…un gène comprend des régions codantes et non codantes…
Gène : définition

-35 -10RBS Start Stop
Unité de transcription
Unité de traduction
Codon start (ATG, GTG, TTG)
Codon stop (TAA, TAG, TGA)
Signaux de régulation de la transcriptionPromoteur: -35, -10Terminateur
Signaux de régulation de la traductionRBS (Ribosome-Binding Site) = séquence de Shine-Delgarno (SD)
Promoteur
+1-15 ’ 3 ’
Terminateur
Gène (procaryote)
Légende

Promoteur (bactérie)
~ 10

Promoter
TATA box Transcription start site
Promoteur (archae)
The sequence elements of a typical promoter from the Archae

Stem-loop
Site de terminaison de la transcription

Organisation des régions codantes (1)
• Le promoteur oriente l’ARN polymérase dans une direction ou dans l’autre
• Le promoteur détermine ainsi quel brin de l’ADN est transcrit

Organisation des régions codantes (2)
• Différents gènes d’une même région peuvent être orientés différemment
• Généralement un seul des 2 brins est codant (sauf exceptions…)
3 ’ 5 ’3 ’5 ’
3 ’5 ’
rare
3 ’ 5 ’3 ’5 ’
encore + rare

87.8%: gènes codantpour des protéines0.8%: ARN non traduit
0.7%: répétitions noncodantes11%: régions régulatrices etautres fonctions
Organisation fonctionnelle du génome (procaryote)

Core proteome: 8,000 (familles)
20 %~13,600~180,000,000Drosophila melanogaster
Gènes connus: ~24’000
4-7 % (?)
~40,000 (?)
28,000-154,000
~3,000,000,000Homo sapiens**
1000 cellules
21 %17,687
17-19,000
87,567,338Caenorhabditis elegans
~29 %~ 26’000~135,000,000Arabidopsis thaliana
72 %6,55112,057,849Saccharomyces cerevisiae
Archae87 %1,7581,664,970Methanococcus jannaschii
Eubacterie87 %4,397
4,639,221E.coli
Remarques% codant
Nombre de gènes
Taille (bp)Organisme
** http://www.ensembl.org/genesweep.html* CDS + rARN + tARN
Estimation du nombre de gènes*

Transcription eucaryotes / procaryotes

(Aussi valable pour chloroplaste / mitochondrie)
Eucaryote
La transcription et la traduction ont lieu dans des compartiments séparés chez les eucaryotes
Procaryote
Compartimentalisation et niveau de complexité

Distance entre 2 gènes: courtes chez les procaryotes;
< 100’000 nucléotides chez les eucaryotes
Organisation des gènes

Facteur de transcription non obligatoire
Région promotrice

Traduction: ARNm protéine

• 3 bases (un codon) codent pour un acide aminé3 nucléotides 43: 64 possibilités
• le code est dégénéré: 64 codons pour 20 acides aminés
• le code n’est pas “overlapping” et ne contient pas de ponctuation (sauf le point final)
Code génétique (1960)

• Chaque ARNt possède un anticodon et un acide aminé correspondant attaché en 3’• Il en existe ~30 (variable selon les espèces) pour 61 codons.
• Exemple: Tryptophane (Trp) codon UGG
Le codon UGG est reconnu par l’ARNt possédant l’anti-codon ACC couplé au Trp
Les ARN de transfert (ARNt)

• Les codons UAA, UAG et UGA sont des codons stop car il n’existe pas d’ARNt correspondant (sauf exception…)
• La méthionine initiatrice est codée par AUG (sauf exception)
Code génétique

Standard: MKWVTFISLLFLFSSAYSRG mito levure: MKWVTFISTTFTFSSAYSRGmito mam: MKWVTFISLLFLFSSAYS*Gmito insect: MKWVTFISLLFLFSSAYSSGmito plantes: MKWVTFISLLFLFSSAYSRG
Traduction de la séquence amino terminale de l’albumine humaine en utilisant différents codes génétiques
Autres exceptions “nucléaires” : ciliés, euplotides, bactéries, blephasrisma (macronuclear)
Le code génétique est ‘ quasi ’ universel

Le code génétique est redondant (dégénéré)• plusieurs codons pour le même acide aminé• protection contre les effets des mutations
Question: les acides aminés les plus fréquents ont-ils plus de codons ?
Dégénérescence du code génétique
http://www.expasy.org/sprot/relnotes/relstat.html
Fréquence des acides aminés dans SWISS-PROT

• Différents organismes: fréquence d’utilisation différente des mêmes codons;• Abondance relative des ARNt • Usage des codons spécifiques à certains gènes• Paramètre important pour les programmes de prédiction de gènes Exemple:Fréquence d’utilisation (%) des différents codons codant pour la sérine chez différents organismes
Les codons les plus fréquemment utilisés ont une plus forte probabilité de se retrouver dans les CDS utilisé pour la recherche de séquences codantes
Usage des codons

• une séquence d’ADN peut être traduite dans 6 cadres de lecture phase (n=3); phase inverse (n=3)
• Généralement, seul un des 6 cadres de lecture produira une protéine fonctionnelle (quelques exceptions chez des virus)
• Dans la cellule, le cadre de lecture est déterminé par les signaux d’initiation (START) et de terminaison (STOP)
Cadre de lecture
Traduction conceptuelle: traduction selon le code génétique sans validation expérimentale

Start Stop
ORF (Open Reading Frame)Séquence comprise entre deux codons Stop (en phase)
CDS (Coding Sequence)Séquence comprise entre un codon Start et un codon Stop (en phase)
Stop
?
Codon start (ATG, GTG, TTG)
Codon stop (TAA, TAG, TGA)
? Problème: détection du vrai Start
Prédiction des régions codantes
Légende
Module : Analyse de séquences (A. Viari)