56719717-Echantillonnage
38
SOMMAIRE L'échantillonnage ...................................................................................................................... 2 Sommaire .......................................................................................................................................... 2 Notions de base .......................................................................................................................... 3 Population ......................................................................................................................................... 3 Les échantillons ......................................................................................................................... 3 Échantillon représentatif ................................................................................................................. 3 Échantillonnage aléatoire ................................................................................................................ 4 Échantillonnage en strate ................................................................................................................ 5 Conclusion ........................................................................................................................................ 6 Introduction ............................................................................................................................... 6 Sommaire .......................................................................................................................................... 7 Erreurs d'échantillonnage et erreur type .................................................................................. 7 Estimation de l'erreur sur la moyenne ...................................................................................... 8 Valeur critique Z et redressement pour la taille de la population ................................................ 8 Exemple, calcul de l'erreur sur la moyenne ........................................................................... 10 Estimation de l'erreur sur le pourcentage .............................................................................. 11 Exemple de calcul de l'intervalle de confiance du pourcentage d'une population ..................... 12 Impact du nombre d'observations ........................................................................................... 13 Exemple de calcul de la taille de l'échantillon .............................................................................. 15 Conclusion ...................................................................................................................................... 16 Comparaisons statistiques ....................................................................................................... 16 Ainsi, l'estimation de la moyenne d'une population calculée à partir d'un échantillon s'exprime comme suit : ............................................................................................................ 16 Zone de vérification de l'hypothèse de recherche ................................................................... 16 Vérification bilatérale .............................................................................................................. 16 Vérification unilatérale ............................................................................................................ 17 Reprenons l'hypothèse nulle précédente et changeons là pour : ........................................... 17 « Les travailleurs immigrants ont une productivité moyenne supérieure à 5 unités » ......... 17 Dans ce cas, on connaît la direction. La vérification est alors unilatérale. L'expression anglaise s'écrit comme ceci « one tailed test ». ....................................................................... 17 Un niveau de confiance à 95 % correspond à un seuil de signification de 5 %. L'inverse est vrai, un seuil de signification de 1 % correspond à un niveau de confiance de 99 %. ......... 18 Généralement, on établit le niveau de confiance à 95 % et même à 99 %. Dans des circonstances défavorables, on se contente d'un niveau de 90 %. ......................................... 18 Par exemple, la moyenne suivante pourrait être fiable à 95 % .............................................. 18 μ = 5 ± 2 .................................................................................................................................... 18
-
Upload
lamzouri-tarik -
Category
Documents
-
view
21 -
download
4
Transcript of 56719717-Echantillonnage

SOMMAIRE
L'échantillonnage ...................................................................................................................... 2
Sommaire .......................................................................................................................................... 2
Notions de base .......................................................................................................................... 3
Population ......................................................................................................................................... 3
Les échantillons ......................................................................................................................... 3
Échantillon représentatif ................................................................................................................. 3
Échantillonnage aléatoire ................................................................................................................ 4
Échantillonnage en strate ................................................................................................................ 5
Conclusion ........................................................................................................................................ 6
Introduction ............................................................................................................................... 6
Sommaire .......................................................................................................................................... 7
Erreurs d'échantillonnage et erreur type .................................................................................. 7
Estimation de l'erreur sur la moyenne ...................................................................................... 8
Valeur critique Z et redressement pour la taille de la population ................................................ 8
Exemple, calcul de l'erreur sur la moyenne ........................................................................... 10
Estimation de l'erreur sur le pourcentage .............................................................................. 11
Exemple de calcul de l'intervalle de confiance du pourcentage d'une population ..................... 12
Impact du nombre d'observations ........................................................................................... 13
Exemple de calcul de la taille de l'échantillon .............................................................................. 15
Conclusion ...................................................................................................................................... 16
Comparaisons statistiques ....................................................................................................... 16
Ainsi, l'estimation de la moyenne d'une population calculée à partir d'un échantillon s'exprime comme suit : ............................................................................................................ 16
Zone de vérification de l'hypothèse de recherche ................................................................... 16
Vérification bilatérale .............................................................................................................. 16
Vérification unilatérale ............................................................................................................ 17
Reprenons l'hypothèse nulle précédente et changeons là pour : ........................................... 17
« Les travailleurs immigrants ont une productivité moyenne supérieure à 5 unités » ......... 17
Dans ce cas, on connaît la direction. La vérification est alors unilatérale. L'expression anglaise s'écrit comme ceci « one tailed test ». ....................................................................... 17
Un niveau de confiance à 95 % correspond à un seuil de signification de 5 %. L'inverse est vrai, un seuil de signification de 1 % correspond à un niveau de confiance de 99 %. ......... 18
Généralement, on établit le niveau de confiance à 95 % et même à 99 %. Dans des circonstances défavorables, on se contente d'un niveau de 90 %. ......................................... 18
Par exemple, la moyenne suivante pourrait être fiable à 95 % .............................................. 18
μ = 5 ± 2 .................................................................................................................................... 18

Ce qui signifie qu'il y a 95 % des chances que la moyenne de la population soit entre 3 et 7. Par contre, la fiabilité à 99 % serait la suivante : .................................................................. 19
μ = 5 ± 2,6 ................................................................................................................................. 19
Il y a 99 % des chances que la moyenne de la population serait entre 2,4 et 7,6 .................. 19
Comparer les observations à la population ou à une hypothèse ............................................ 19
Avertissements ................................................................................................................................ 20
Sommaire ........................................................................................................................................ 20
Comparaison de moyenne d'un groupe avec la population ................................................... 21
Formules mathématiques ....................................................................................................... 21
Seuil de signification ....................................................................................................................... 22
Exemple ................................................................................................................................... 23
Comparaison du pourcentage d'un groupe à la population .................................................. 25
Formules mathématiques pour le pourcentage ...................................................................... 25
Exemple .................................................................................................................................... 26
Comparaison de la moyenne d'un groupe avec celle d'une population avec un logiciel ........... 27
Interprétation des résultats ........................................................................................................... 28
Procédure pour les pourcentages .................................................................................................. 30
Réaliser un questionnaire ....................................................................................................... 30
Combien faut-il interroger de personnes ? ................................................................................. 30
le contenu du questionnaire ................................................................................................. 32
Les règles de base à respecter ...................................................................................................... 32
Le traitement du questionnaire .................................................................................................. 36
L'échantillonnageL'échantillonnage est une part importante des statistiques. Elle nous permet de comprendre ce qui se passe dans une population sans avoir à interroger chacun des individus. Le principe étant qu'une cuillérée suffit pour goûter à toute la soupe.
Pour avoir de bonnes analyses statistiques, il est important de savoir et de comprendre le type d'échantillonnage utilisé.
Sommaire
Notions de base

Population
Les échantillons
Échantillon représentatifÉchantillonnage aléatoireÉchantillonnage au hasard simpleL'échantillonnage en grappesÉchantillonnage en strate
Conclusion
Notions de base
Population
La population est le groupe que l'on étudie. Par exemple, pour Statistique Canada la population peut être l'ensemble des canadiens. Évidemment, la population peut être un ensemble plus réduit. Pour une enquête sur les travailleurs, la population sera la main-d'oeuvre active : les gens âgés de 15 à 65 ans ce qui exclue les enfants et les retraités.
La population est l'ensemble des unités qui définissent l'objet d'étude. Les « unités » peuvent être des individus tels que des travailleurs, des patrons, des étudiants, etc. Ils peuvent être aussi des objets tels que des organisations, des sociétés ou des équipements. Quelquefois, les microdonnées comportent toute une population, ce qui facilite grandement l'interprétation des données.
Nous définissons « la population » que nous étudions pour notre travail de recherche dès le début de nos travaux dans le cadre opératoire.
Les échantillonsL'échantillon c'est une partie de la population.
Peu d'organismes peuvent recueillir des données de toute la population. Cela à cause des coûts élevés que suppose une telle opération et que généralement il y a peu d'intérêt à le faire. En effet, les statistiques nous permettent de prendre un échantillon et de généraliser nos mesures à toute la population. Nous verrons comment un peu plus loin.
Il existe plusieurs manières de faire l'échantillonnage, nous allons étudier quelques-unes d'entre elles.
Échantillon représentatif

Un échantillonnage représentatif est un échantillon qui reproduit les caractéristiques d'une population de manière à ce que les conclusions obtenues avec cet échantillon se généralisent à la population. En utilisant des microdonnées produites par Statistiques Canada c'est généralement le cas, mais pas toujours.
Le problème vient du fait qu'il faut avoir une liste valable et complète de la population. Malheureusement, ce n'est pas toujours le cas. Par exemple, il n'existe pas de liste complète de travailleurs volant de l'équipement à leur usine. Une enquête sur ce sujet ne peut donc pas être basée sur un échantillonnage représentatif, la population des voleurs étant discrète.
Quand vous utilisez des microdonnées, vérifiez la documentation de l'enquête pour savoir si l'échantillonnage est représentatif.
Échantillonnage aléatoire
Mode d'échantillonnage sur une population qui répond à ces critères :
1. Connaissance de l'ensemble des échantillons; 2. Chaque échantillon a une probabilité connue de sélection; 3. Chaque échantillon a une probabilité non nulle de sélection; 4. Chaque échantillon est choisi aléatoirement.
Une fois ces conditions remplies, les statisticiens pigent au hasard des échantillons. Les méthodes les plus connues sont :
• L'échantillonnage au hasard simple; • L'échantillonnage en grappes; • L'échantillonnage au hasard stratifié.
Échantillonnage au hasard simple
C'est la technique idéale et la plus facile à concevoir. Par exemple, un ordinateur pige les échantillons au hasard. Les résultats obtenus par cette technique sont fiables et valides si la quantité d'échantillons est bonne.
Il arrive que les microdonnées soient surabondantes pour vos études, vous pouvez utiliser cette technique pour en réduire le nombre. Les logiciels possèdent des fonctionnalités permettant de faire la sélection au hasard. Ne faites jamais ce travail à la main, il est assuré que d'une manière, ou de l'autre, vous allez introduire une distorsion statistique qui invalidera votre échantillon.
Dans SPSS :
• Menu Données --> Sélectionner des observations, une fenêtre du même nom s'ouvre;
• Sélectionnez la case « Par échantillonnage aléatoire » et cliquez sur le bouton « Échantillon ». Une fenêtre intitulée « Sélectionner des observations : Échantillon aléatoire »;

o Écrivez le pourcentage d'observations et cliquez sur « Poursuivre »;ou :
o Cliquez sur « Exactement », écrivez le nombre d'observations désirées, écrivez le nombre exact d'observations que vous avez et cliquez sur « Poursuivre »;
• Cliquez sur « OK ».
L'échantillonnage en grappes
Imaginons que vous fassiez une enquête sur la productivité des travailleurs immigrants. Comme aucune liste de travailleurs n'existe pour votre ville, vous devrez vous promener d'usine en usine pour faire la liste et ensuite faire votre échantillonnage. Cela risque d'être très long et trop coûteux même pour Statistique Canada.
Pour faire un échantillonnage en grappes, vous pouvez sélectionner au hasard des quartiers dans la ville et dans ses quartiers sélectionner des usines au hasard et dans les usines sélectionner des ateliers au hasard. Si vous manquez d'immigrants au niveau de l'atelier, il se peut que vous soyez obligé de remonter au niveau de l'usine.
Dans un monde complètement aléatoire, ce mode de fonctionnement est légitime. Mais on sait que les membres d'une même famille travaillent ensemble dans la même usine, ce qui apporte une distorsion statistique importante. Il faut donc se méfier de ce type d'échantillonnage.
L'échantillonnage en grappes est un échantillonnage probabiliste reposant sur la sélection aléatoire de grappes. Une grappe est un ensemble d'unités d'une population qu'on constitue à l'aide de critères bien définis. Il peut s'agir d'un groupe qui existe dans la population (pâtés de maison, hôpital, etc.) ou d'un groupe théorique (ensembles de rues sur une carte, etc.).
Si vous lisez le plan d'échantillonnage associé aux microdonnées, on spécifie généralement ce qu'il faut faire si l'échantillonnage est en grappe.
Échantillonnage en strate
Reprenons l'exemple où vous analysez la productivité des travailleurs immigrants. Vous voulez comparer cette productivité à celle des travailleurs locaux. Si vous considérez que la population aux fins de votre recherche est celle de tous les travailleurs au Canada, vous devrez recueillir un nombre énorme d'observations pour avoir un sous-groupe contenant suffisamment de travailleurs immigrants. Plutôt que de faire ce travail de collecte, vous pouvez considérer une population composée de deux groupes, de deux strates et faire l'échantillonnage pour chacune de ces strates.
Dans le cas précédent, nous avons un échantillonnage stratifié disproportionné où les strates de l'échantillon global représentent des proportions différentes de la population. Avant d'utiliser l'échantillon global, il faut faire un redressement, accorder

à chacune des strates un coefficient de pondération en fonction de la proportion qu'elles représentent dans la population.
Beaucoup d'enquêtes sont stratifiées. Prenons l'exemple d'une enquête canadienne où l'on veut avoir les résultats par province. On sait qu'un échantillon de quelques milliers d'individus par province est nécessaire pour avoir une précision statistique suffisante. Pour le Québec et l'Ontario, cela représente une faible proportion de la population. Mais pour l'Île-du-Prince-Édouard, avec moins de 200 000 habitants, le nombre est important.
Pour avoir le résultat canadien, il faut mettre les résultats de l'Île avec ceux des autres provinces, il faut pondérer les données par un facteur 30. On veut éviter que les habitants de l'Île-du-Prince-Édouard aient une importance plus grande que ceux du Québec.
Si vous lisez le plan d'échantillonnage associé aux microdonnées on spécifie généralement ce qu'il faut faire si l'échantillonnage est en strate et comment faire la pondération.
Conclusion
Avant d'utiliser les microdonnées, il importe de lire le plan d'échantillonnage. Celui-ci a un impact direct sur la qualité des données et sur leur traitement.
Importez toujours un maximum de microdonnées, autant que votre lien Internet et que votre ordinateur peuvent soutenir. Cela augmente la précision et la valeur de vos travaux de recherche.
Si vous échantillonnez des microdonnées, il est important de suivre la méthode d'échantillonnage aléatoire, décrite dans ce texte.
Voir aussi:
Pour estimer la taille des échantillons et les erreurs d'échantillonnage.
IntroductionL'échantillonnage permet de comprendre ce qui se passe dans une population sans avoir à interroger chacun des individus. C'est très pratique et très économique.
Nous verrons que le plus le nombre d'échantillons est faible plus l'erreur est élevée sur les mesures comme la moyenne et les pourcentages. Nous devons évaluer ces erreurs.

Réciproquement à la précision de nos mesures, nous pouvons évaluer le nombre d'observations nécessaires selon la précision désirée pour la moyenne ou les pourcentages.
Sommaire
Erreurs d'échantillonnage et erreur type
Estimation de l'erreur sur la moyenne
Valeur critique Z et redressement selon la taille de la populationExemple, calcul de l'erreur sur la moyenne
Estimation de l'erreur sur le pourcentage
Exemple de calcul de l'intervalle de confiance du pourcentage d'une population
Impact du nombre d'observations
Exemple de calcul de la taille de l'échantillon
Erreurs d'échantillonnage et erreur type
Comme les observations varient au hasard d'un échantillon à l'autre, il y a des différences que l'on appelle erreurs d'échantillonnage.
Par exemple, prenez un échantillon de 20 personnes à travers une population de 100 étudiants et calculez la moyenne. Refaites l'expérience en sélectionnant un nouveau groupe de 20 personnes et recalculez la moyenne. À cause des différences entre les deux échantillons, les moyennes de chaque groupe d'échantillons devraient être différentes sans être très éloignés l'une de l'autre. Cela est dû à l'erreur d'échantillonnage et on observe le même phénomène avec les mesures sur le pourcentage comme le pourcentage de travailleurs bilingues.
L'erreur type nous permet d'évaluer l'ampleur de ces variations et se calcule comme suit :

néchantillol'deTaille
néchantillol'detypeÉcart
typeErreurσ
où
σ
x
x
n
s
n
s=
Estimation de l'erreur sur la moyenneL'estimation de la moyenne « μ » d'une population calculée à partir d'un échantillon s'exprime comme suit :
erreurX ±=μ
Par exemple, l'expression suivante :
μ = 5 ± 2 = 5 - 2 à 5 + 2 = 3 à 7
signifie que la moyenne μ varie de 3 à 7.
Valeur critique Z et redressement pour la taille de la population
Pour faire estimer l'erreur nous devons d'établir le degré de confiance que nous avons besoin pour la moyenne de la population.
Par exemple, la moyenne μ suivante pourrait être fiable à 95 %
μ = 5 ± 2

Cela signifie qu'il y a 95 % des chances que la moyenne de la population soit entre 3 et 7.
Pour garantir un résultat à 99 %, il faut se donner une marge d'erreur plus grande. Pour que la moyenne soit fiable à 99 %, on augmente notre marge d'erreur :
μ = 5 ± 2,6
Il y a 99 % des chances que la moyenne de la population serait entre 2,4 et 7,6.
Selon l'intervalle de confiance, l'erreur sur la moyenne Em, se calcule comme suit :
néchantillol'deTaille
populationla de Taille
néchantillol'detypeÉcart
typeErreurσ
confiance de niveau le selon nPondératio
moyennelasurErreurE
où
11σE
x
m
xm
n
N
s
Z
N
nN
n
sZ
N
nNZ
−−=
−−=
Remarquez le coefficient Z, il prend les valeurs suivantes selon l'intervalle de confiance désiré :
Niveau deconfiance
(%)Valeurs de
Z90
1,64

951,9699
2,58
Si la taille de la population est plus de 20 fois celle de l'échantillon, on peut négliger le calcul du radical et la formule s'écrit :
néchantillol'deTaille
néchantillol'detypeÉcart
typeErreurσ
confiance de niveau le selon nPondératio
moyennelasurErreurE
où
σE
x
m
xm
n
s
Z
n
sZZ ==
Note : ces formules sont valides pour un minimum de 30 observations. En dessous de ce minimum, la valeur de Z n'est plus fiable. Certains livres de statistiques fournissent une procédure spécialement adaptée pour ces cas difficiles à traiter. Heureusement, les utilisateurs de microdonnées ont généralement une abondance d'observations.
Exemple, calcul de l'erreur sur la moyenne
Nous avons un échantillon 100 personnes d'une population de 500 personnes. La moyenne de la productivité de cet échantillon est de 50 et son écart-type vaut 4. Quelle est la valeur de la moyenne pour la population et son intervalle de confiance à 99 % ?
Calculons d'abord Em :

néchantillol'deTaille100
populationla de Taille500
néchantillol'detypeÉcart4
typeErreurσ
99%pour confiance de niveau le selon nPondératio58,2
moyennelasurErreurE
: exemplecet pour où
11σE
x
m
xm
==
=
=
−−=
−−=
n
N
s
Z
N
nN
n
sZ
N
nNZ
En remplaçant les symboles par les valeurs de cet exemple :
92.01500
100500
100
458,2Em =
−−=
La moyenne de la population s'exprime donc par :
μ = 50 ± 0,92
On peut affirmer que la moyenne de la population se trouve dans l'intervalle 49,08 à 50,92 avec une confiance de 99 %
Estimation de l'erreur sur le pourcentage
Il arrive aussi que des enquêtes estiment des pourcentages. Cela est utile pour exprimer les intentions de vote, mais aussi pour évaluer le pourcentage d'une population bilingue par exemple. Pour faire l'évaluation de l'erreur, les statistiques nous fournissent un outil pour le calcul de l'intervalle de confiance semblable à celui de la moyenne :
epourcentag lesur erreur l'deEstimationσ
confiancedeniveauleselonnPondératio
néchantillol' de ePourcentag
populationla de ePourcentagπ
π
p
Z
p
où
Zp pσ±=
Les valeurs de Z sont les mêmes que pour l'estimation de la moyenne

Niveau de90
1,6495
1,9699
2,58
L'estimation sur l'erreur de pourcentage se calcule comme suit :
populationla de Taille
néchantillol'deTaille
néchantillol' de ePourcentag
epourcentag lesurerreurl' de Estimationσ
où1
)100(σ
p
p
N
n
p
N
nN
n
pp
−−−=
Cette formule n'est pas assez précise pour évaluer les pourcentages inférieurs à 10 %.
Exemple de calcul de l'intervalle de confiance du pourcentage d'une population
Imaginons que lors d'une enquête auprès des travailleurs immigrés, vous découvrez que 75 % d'entre eux sont bilingues. Vous aimeriez évaluer la précision de votre mesure pour la population soit l'ensemble des travailleurs immigrés. Vous avez un échantillon de 200 travailleurs sur une population de 800 individus.
Calculons d'abord l'erreur
populationla de Taille800
néchantillol'deTaille200
néchantillol' de ePourcentag75
epourcentag lesurerreurl'deEstimationσ
où1
)100(σ
p
p
===
−−−=
N
n
p
N
nN
n
pp
En remplaçant les symboles par des chiffres :
65,21800
200800
200
)75100(75σp =
−−−=

D'après l'équation ci-dessus :
erreurl'deEstimation65,2σ
95% confiancedeniveauleselonnPondératio96,1
néchantillol' de ePourcentag75
populationla de ePourcentagπ
π
p ===
±=
Z
p
où
Zp pσ
En remplaçant les symboles par des chiffres :
19.5%7565,2*96,175π ±=±=
On peut affirmer que le pourcentage de travailleurs immigrants de la population se trouve dans l'intervalle 69,81 à 80,19 avec une confiance de 95 %
Impact du nombre d'observationsPour faire des analyses statistiques valables, il faut un nombre minimal de 30 observations. Mais cela risque être insuffisant.
Les formules mathématiques nous montrent que plus le nombre d'échantillons est élevé, meilleure est la précision statistique. On peut estimer le nombre d'observations en fonction de l'intervalle de confiance Z et de la marge d'erreur « Em » en utilisant la formule ci-dessous :
confiancedeniveauleselonnPondératio
néchantillol' de ePourcentag
erreurd'MargeE
néchantillol'deTaille
où
)100(
m
2
2
Z
p
n
E
ppZn
m
−=
Pour nous donner une idée de l'erreur en fonction du nombre d'observations, examinons le tableau suivant, fait pour un intervalle de confiance de 95% :
Erreur en %Nombre d'observations
202419

271830173316381543144913571267117910969
1198
1507
1966
2675
3844
6003
10672
24011
9604
Le graphique est tout aussi instructif :

Le graphique et le tableau nous montrent que pour une précision de 7 % moins de 200 observations suffisent, mais qu'au-delà le nombre d'observations nécessaires pour diminuer l'erreur monte très rapidement. Observez le nombre d'échantillons nécessaires pour abaisser l'erreur de 2 % à 1 %.
Exemple de calcul de la taille de l'échantillon
Vous désirez amasser des données sur les immigrants et vous aimeriez avoir une précision de 3 % alors que les pourcentages aussi bas que 20%. Que recommandez-vous comme nombre d'observations, si vous voulez être certain à 95 % de vos résultats ?
95% confiancedeniveauleselonnPondératio96,1
néchantillol' de ePourcentag20
erreurd'Marge3E
néchantillol'deTaille
où
)100(
m
2
2
==
=
−=
Z
p
n
E
ppZn
m
En remplaçant les symboles par des chiffres :

6833
)20100(20)96,1(2
2
=−=n
Donc, un échantillon comprenant 700 personnes est nécessaire pour atteindre les objectifs de précision.
Conclusion
Avant d'utiliser les microdonnées, il importe de s'informer du plan d'échantillonnage. Celui-ci a un impact direct sur la qualité des données et même sur le traitement des données.
Importez toujours un maximum de microdonnées, autant que votre lien Internet et que votre ordinateur peuvent le soutenir. Cela augmente la précision et la valeur de vos travaux de recherche.
Si vous échantillonnez des microdonnées, il est important de suivre la méthode d'échantillonnage aléatoire, décrite dans ce texte.
Comparaisons statistiques
Un échantillon n'est qu'une partie de la population. Comme les observations varient d'un échantillon à l'autre au hasard, il y a des différences que l'on appelle erreurs d'échantillonnage. Ce qui fait que la valeur des paramètres statistiques comme la moyenne fluctue d'un échantillon à l'autre. Ils ne sont connus qu'avec une marge d'erreur.
Ainsi, l'estimation de la moyenne d'une population calculée à partir d'un échantillon
s'exprime comme suit :erreurX ±=μ
Zone de vérification de l'hypothèse de recherche
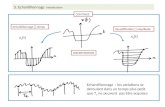
Vérification bilatérale
Prenons le cas hypothétique que l'hypothèse nulle de recherche est que la moyenne de la productivité d'un groupe de travailleurs est 5 :
H0: μ = 2,5
À l'analyse des résultats, vous obtenez une moyenne de productivité des travailleurs de 5 unités par heure et que l'erreur d'échantillonnage est de 2. Le graphique ci-dessous illustre la distribution normale de la probabilité de mesure de la moyenne selon les données recueillies :

En plein centre du graphique, on observe la moyenne valant 5. La zone colorée contient les valeurs possibles qu'elle peut prendre, puisque la moyenne n'est pas connue avec une précision absolue à cause des erreurs d'échantillonnages. Les zones grisées aux extrémités correspondent aux zones de rejets de l'hypothèse ou région critique. C'est la zone ou il y a 5 % des chances que la moyenne mesurée soit inférieure à 3 ou supérieure à 7. Comme notre hypothèse nulle est dans la zone de rejet, nous rejetons l'hypothèse nulle et acceptons notre hypothèse de recherche.
Comme il faut vérifier les zones de rejets de chaque extrémité, on dit que l'on doit faire une vérification bilatérale. L'expression anglaise s'écrit comme ceci « two tailed test ».
Vérification unilatérale
Reprenons l'hypothèse nulle précédente et changeons là pour :
« Les travailleurs immigrants ont une productivité moyenne supérieure à 5 unités »
H0: μ >6
Dans ce cas, on connaît la direction. La vérification est alors unilatérale. L'expression anglaise s'écrit comme ceci « one tailed test ».

Dans cet exemple, la valeur de l'hypothèse nulle n'est pas dans la zone de rejet, on ne peut donc pas la rejeter. Ce qui laisse notre hypothèse de
recherche en suspend.
Le niveau signification
Après avoir établi votre hypothèse, il faut établir le seuil de signification. À cause des erreurs d'échantillonnage, la moyenne d'une population n'est pas connue avec une précision absolue. À cette étape, on détermine justement la précision que l'on vise. C'est le seuil de signification, α (alpha), la probabilité de commettre une erreur de mesure. Plus le seuil de signification est faible, plus la probabilité qu'on doive rejeter l'hypothèse nulle est faible.
Niveau de confiance
Un niveau de confiance à 95 % correspond à un seuil de signification de 5 %. L'inverse est vrai, un seuil de signification de 1 % correspond à un niveau de
confiance de 99 %.
Généralement, on établit le niveau de confiance à 95 % et même à 99 %. Dans des circonstances défavorables, on se contente d'un niveau de 90 %.
Par exemple, la moyenne suivante pourrait être fiable à 95 %
μ = 5 ± 2

Ce qui signifie qu'il y a 95 % des chances que la moyenne de la population soit entre 3 et 7. Par contre, la fiabilité à 99 % serait la suivante :
μ = 5 ± 2,6
Il y a 99 % des chances que la moyenne de la population serait entre 2,4 et 7,6
Comparer les observations à la population ou à une hypothèse
Après avoir recueilli un échantillon de données et fait les analyses statistiques de base, on désire comparer l'échantillon à la population ou le confronter à l'hypothèse de recherche. Cette comparaison permet d'établir si les observations sont statistiquement différentes de la population. Par exemple, si on recueille des données sur les travailleurs immigrants, ce qui forme un groupe, et les comparer à la population canadienne pour étudier s'ils sont plus productifs.
Ces comparaisons peuvent demander une connaissance assez précise de la moyenne ou d'autres compilations statistiques de la population. Généralement les sites de microdonnées, offrent des compilations statistiques sous forme de tableaux de données.

Pour bien comprendre les concepts que nous utilisons, nous vous suggérons de lire les explications sur l'échantillonnage et l'introduction sur les comparaisons statistiques.
Avertissements
Ces explications ne sont valides que pour des données respectant la distribution normale.
Nous conseillons d'utiliser les formules et méthodes que nous décrivons seulement si vous avez plus de trente observations dans votre échantillon. Avec moins de trente observations, vous devez utiliser d'autres techniques statistiques. Comme cela se produit rarement avec les microdonnées, nous ne traitons pas de ces cas difficiles ici.
Advenant le cas où vous réussissez à obtenir toutes les observations de votre population, vous n'avez pas d'erreurs d'échantillonnage, vous avez la mesure exacte. Vous n'avez pas donc pas à faire les calculs de cette page.
Sommaire
Comparaison de la moyenne d'un groupe avec la population
Formules mathématiques
Seuil de signification
Exemple
Comparaison de la moyenne en utilisant un logiciel
Procédure de calcul dans SPSS
Interprétation des résultats
Procédure pour les pourcentages
Comparaison du pourcentage d'un groupe à la population
Formules mathématiques
Exemple
Procédure SPSS pour les pourcentages

Comparaison de moyenne d'un groupe avec la population
Prenons l'exemple fictif où vous voulez démontrer que la productivité moyenne « μi » des travailleurs immigrants est supérieure à celle des travailleurs canadiens dont Statistique Canada évalue la moyenne « μp » à 4,5.
Après avoir calculé la moyenne et la marge d'erreur de votre échantillon, vous avez ce résultat :
μi = 7 ± 2 à 95 %
Cela signifie que la moyenne des travailleurs immigrés se situe quelque part entre 5 (la moyenne - 2) à 9 (la moyenne + 2) avec une confiance de 95%. La valeur « 2 » est la marge d'erreur à 95 %. Comme la moyenne de la population canadienne qui est de 4,5 se retrouve à l'extérieur de l'intervalle, vous pouvez être certain à 95 % de votre hypothèse : les moyennes sont statistiquement différentes.
Nous étudions dans cette page les formules mathématiques qui nous permettent de calculer la marge d'erreur ainsi que le niveau de confiance. Ceci afin d'évaluer si la moyenne d'un groupe est statistiquement différente de la population.
Formules mathématiques Comparaison de la moyenne d'un groupe à la population
Le rejet ou l'acceptation d'une hypothèse de recherche basée sur la moyenne de la population demande l'évaluation de la moyenne et de l'écart-type de l'échantillon. Une fois ces informations obtenues, on évalue la valeur critique Z..Cette valeur nous indique si les moyennes, de l'échantillon et de la population (ou de votre hypothèse), sont statistiquement différentes.
Z est l'écart entre la moyenne de l'échantillon et la moyenne de la population que l'on pondère par l'erreur type de l'échantillon. Plus la valeur de Z est élevée, plus il est probable que les moyennes de la population et de celle de votre hypothèse sont statistiquement différentes. Le calcul de Z est relativement simple :

néchantillol' de eErreur typσ
nullehypothèsel'selonMoyenneμ
néchantillol' de Moyenne
critiqueFacteur
où
σ
μ
X
X
X
Z
XZ
−=
et l'erreur type « σx » vaut :
néchantillol'deTaille
néchantillol'detypeÉcart
typeErreurσ
où
σ
x
x
n
s
n
s=
Seuil de signification
C'est Z qui nous dit si les moyennes sont statistiquement différentes et si l'on doit rejeter ou accepter notre hypothèse :
Bilatéral2,581.961.64
Unilatéral2,331.641.28
On rejette l'hypothèse si la valeur absolue de la valeur de Z dépasse celle du tableau ci-dessus selon que la vérification est bilatérale ou unilatérale. Certains préfèrent utiliser l'expression « Seuil de signification », il est égal à 100 moins le « Niveau de confiance ». Donc, une confiance à 95 % correspond à un seuil de signification de 5 %. L'inverse est vrai, un seuil de signification de 1 % correspond à un niveau de confiance de 99 %.
Si le calcul de Z donne 2,25 et que je veux vérifier à 95% de confiance si la moyenne de mon échantillon diffère de celle de la population, je consulte le tableau ci-dessus. Selon le tableau, la valeur minimum de Z est 1,96. Comme je dépasse cette valeur, ma moyenne diffère donc de manière certaine. Observez que je ne peux être certain à 99 % puisque Z devrait valoir au minimum 2,58.

Exemple Comparaison de la moyenne d'un groupe à la population
Refaisons l'exemple en suivant les étapes de recherche :
1– Formuler l'hypothèse de recherche
Prenons comme hypothèse de recherche que :
« La productivité des travailleurs immigrants est différente de 5 »
H1: μ ≠ 5
2– Formuler l'hypothèse nulle
L'hypothèse nulle prend le contre-pied de l'hypothèse de recherche :
« La productivité des travailleurs immigrants est de 5 »
H0: μ = 5
3– Choisir le seuil de signification
Nous aimerions vérifier notre hypothèse avec une confiance de 95%, c'est un choix personnel.
Il importe de choisir le seuil de signification à cette étape, puisqu'il influence la taille de l'échantillon. Une plus grande précision demande un plus grand nombre d'observations dans notre échantillon.
4– Calcul de Z
Après avoir recueilli les informations, on calcule la moyenne et l'écart-type de l'échantillon pour faire l'évaluation de la valeur critique « Z ». Supposons que la moyenne de l'échantillon vaut 7, que l'écart-type vaut 8 et que l'effectif est de 100, nous pouvons faire le calcul :
Commençons par calculer l'erreur type :

néchantillol'deTaille100
néchantillol'detypeÉcart8
typeErreurσ
où
σ
x
x
==
=
n
s
n
s
8,0100
8σx ==
On peut maintenant calculer Z :
néchantillol' de Écart type8,0σ
nullehypothèsel'selonMoyenne5μ
néchantillol' de Moyenne7
critiqueFacteur
où
σ
μ
===
−=
X
X
X
Z
XZ
En remplaçant les symboles par les valeurs de cet exemple :
5,20,8
57 =−=Z
5– Vérification de l'hypothèse nulle H0:
a) H0: Bilatéral et seuil de signification à 5 %
Selon le tableau précédent, la valeur critique de Z pour un test bilatéral avec une probabilité de 95 % est de 1,96. Comme Z vaut 2,5, nous dépassons la valeur du seuil, nous pouvons donc rejeter l'hypothèse nulle. Cela confirme, en quelque sorte, notre hypothèse de recherche.
b) H0: Bilatéral et seuil de signification à 1 %
Supposons que le seuil de signification vaille 1 %.
Selon le tableau précédent, la valeur critique de Z pour un test bilatéral avec une probabilité de 99 % est de 2,58. Comme notre mesure de Z = 2,5 est inférieure à la valeur du seuil, nous ne pouvons rejeter l'hypothèse nulle. Ne pouvant rejeter l'hypothèse nulle notre hypothèse de recherche ne peut être confirmée.

c) H0: Unilatéral et seuil de signification à 1 %
Supposons maintenant qu'en plus de choisir un seuil de signification de 1 %, nous changeons l'hypothèse nulle pour H0: μ > 5. Nous affirmons maintenant que la productivité des travailleurs immigrés est plus grande que celle de la population.
Selon le tableau précédent, la valeur critique de Z pour un test unilatéral avec une probabilité de 99 % est de 2,33. Comme notre mesure vaut Z = 2,5, nous dépassons la valeur du seuil, nous pouvons donc rejeter l'hypothèse nulle ce qui confirme, en quelque sorte, notre hypothèse de recherche.
Comparaison du pourcentage d'un
groupe à la populationOn ne veut pas toujours comparer une moyenne, quelquefois il s'agit d'un pourcentage. Par exemple, si on désire étudier le cas du bilinguisme chez les travailleurs immigrants, on aura alors un taux de bilinguisme et non une moyenne.
Là encore il faut utiliser les formules mathématiques qui nous permettent de calculer le facteur Z. Ce dernier nous indique avec quelle confiance, ou incertitude, les pourcentages sont statistiquement différentes.
Formules mathématiques pour le pourcentage
Pour la comparaison du pourcentage d'un groupe à la population
Le calcul pour le pourcentage est similaire à celui du calcul de la moyenne :
epourcentag lesur eerreur typl' de Estimationσ
nullehypothèsel'selonePourcentagπ
néchantillol' de ePourcentag
critiqueFacteur
où
σ
π
p
p
p
Z
pZ
−=
Où le facteur d'estimation ρp vaut :

néchantillol'deTaille
néchantillol' de ePourcentag
epourcentag lesur eerreur typl' de Estimationσ
où
)100(σ
p
p
n
p
n
pp −=
Une fois que la valeur de Z est déterminée, l'acceptation ou le rejet de l'hypothèse nulle se fait selon la même logique que pour la moyenne.
ExemplePour la comparaison du pourcentage d'un groupe à la population
1– Formuler l'hypothèse de recherche
Prenons comme hypothèse de recherche que :
« Plus de 75 % travailleurs immigrants sont bilingues »
H1: π > 75
2– Formuler l'hypothèse nulle
L'hypothèse nulle prend le contre-pied de l'hypothèse de recherche :
« Chez les travailleurs immigrants, le bilinguisme est inférieur ou égal à 75 % »
H0: π <= 75
3– Choisir le seuil de signification
Nous aimerions vérifier avec une précision de 95%. Il importe de faire ce choix à cette étape puisqu'il influence le choix de la taille de l'échantillon. Une plus grande précision demande un plus grand nombre d'observations dans notre échantillon.
4– Calcul de Z
Après avoir recueilli les informations, on doit calculer le pourcentage de bilinguisme dans notre échantillon et le nombre de participants. Supposons que nous obtenons 80 % de bilingue et que nous avons 200 participants.

Commençons par le calcul de ρp :
néchantillol'deTaille200
néchantillol' de ePourcentag80
epourcentag lesur eerreur typl' de Estimationσ
où
)100(σ
p
p
==
−=
n
p
n
pp
En remplaçant les symboles par les valeurs de cet exemple :
83,2200
)20100(80σp =−=
On peut maintenant calculer Z :
epourcentag lesur eerreur typl' de Estimation83,2σ
nullehypothèsel'selonePourcentag75π
néchantillol' de ePourcentag80
critiqueFacteur
où
σ
π
===
−=
p
p
p
Z
pZ
77,183,2
5780 =−=Z
5– Vérification de l'hypothèse nulle
Unilatéral et seuil de signification à 5 %
Selon le tableau précédent, la valeur critique de Z pour un test unilatéral avec une probabilité de 95 % est de 1,64. Comme notre mesure vaut Z=1.77, nous dépassons la valeur du seuil. Nous pouvons donc rejeter l'hypothèse nulle, ce qui confirme en quelque sorte, notre hypothèse de recherche : les immigrants sont bilingues à plus de 75 %.
Comparaison de la moyenne d'un groupe avec celle d'une population avec un logiciel

Logiciel utilisé : SPSS version 10 en français
Entrez vos données dans SPSS. Les données utilisées dans cette exemple sont fictives. Pour suivre cet exemple, téléchargez les données dans l'un des deux formats suivants : SPSS (préférable) ou ASCII (difficile).
Description des étapes dans SPSS
• Menu Analyse --> Comparer les moyennes --> Test T pour échantillon uniquUne fenêtre du même nom s'ouvre.
• En utilisant les flèches en forme de triangles, placez la variable « Productivité des travailleurs » dans la boîte « Variables à tester ».
• Écrivez dans la case « Valeur de test » le chiffre 5. C'est la valeur contre laquelle la moyenne de la variable « Productivité des travailleurs » est testée.
• Si vous cliquez sur le bouton « Option », vous pouvez choisir l'intervalle de confiance :
• Cliquer sur le bouton OK pour faire faire le calcul par SPSS.
Interprétation des résultats
Dans l'explorateur de résultats, cliquez sur Statistiques sur échantillon unique dans la section Test-t.
Vous obtenez les statistiques pour notre variable. Cela vous permet de reconstituer facilement les calculs si vous le voulez.

• La variable « Productivité des travailleurs » a un effectif de 22 observations, une moyenne de 7 et un écart-type de 2,16 et l'erreur standard que nous appelons « Erreur type » vaut 0,65;
Avec ces données, SPSS calcule les réponses pour notre analyse :
On remarque en haut du tableau le titre : Test sur échantillon unique.
Il est important de remarquer en dessous le titre de l'analyse « Valeur du test = 5 ». C'est-à-dire que l'on compare notre échantillon avec la valeur de notre hypothèse 5.
• t = 3.086 : valeur critique Z, SPSS utilise le nom « t » au lieu de « Z ». Statistique utilisée pour tester l'hypothèse nulle selon laquelle deux populations ont la même moyenne;
• ddl = 21 : degré de liberté. Se calcule en soustrayant du nombre d'observations, 22 dans ce cas, le nombre de paramètres, 1 dans ce cas;
• Sig. (bilatérale) = 0,006. Le niveau de signification ou en d'autres mots la probabilité d'obtenir ce résultat par hasard. Si le niveau de signification est très petit, moins de 0,05, on rejette l'hypothèse nulle.
En d'autres termes, un niveau de signification faible indique que les résultats ne sont probablement pas dus au hasard. Dans notre cas la probabilité est de 0,006, il y a donc 0,6 % de chance d'obtenir ce résultat par hasard. Nos données établissent clairement que les travailleurs immigrants ont une moyenne différente de 5.
• Différence moyenne = 2. C'est la différence entre la moyenne de nos observations, 7 dans notre cas, et 5 la valeur de test que nous avons écrit au début du test;
• Intervalle de confiance 95 % de la différence. Intervalle basé sur les différences entre les moyennes des échantillons. Si l'intervalle calculé par SPSS ne contient pas 0, la différence entre la moyenne de notre échantillon et celle de l'hypothèse présente une différence assez importante pour rejeter l'hypothèse nulle :
o Inférieur = 0,65. Borne inférieure de l'intervalle; o Supérieur = 3,35. Borne supérieure de l'intervalle.

Procédure pour les pourcentages
Avec des pourcentages, vous utilisez la même procédure que pour les moyennes. Entrez la fraction au lieu du pourcentage dans la case valeurs de tests, c'est-à-dire 0,50 au lieu de 50.
Réaliser un questionnaire 1. Réaliser une enquête de terrain consiste à interroger la clientèle ciblée au moyen
d'un questionnaire.Ce travail consiste à :
1) Choisir un échantillon de personnes à questionner.2) Définir le type de questions à poser : questions fermées, ouvertes, …3) Structurer le questionnaire.4) Déterminer l'endroit où doit se dérouler l'enquête (dans la rue, par courrier, sur internet, …).5) Réaliser l'enquête : choix de la date, des interviewer, etc...6) Organiser la saisie et traiter les résultats : tris à plat, tris croisés, moyennes.
• Les méthodes d'échantillonnage• le contenu du questionnaire
Les méthodes d'échantillonnage
Pour des raisons de temps et de coûts, il est quasiment impossible d'interroger tous les clients potentiels présents sur une zone d'enquête (recensement). Le porteur de projet doit donc calculer et déterminer un échantillon représentatif de la population à étudier.
Combien faut-il interroger de personnes ?
On pourrait penser que plus un échantillon est important plus il donnera des résultats satisfaisants.En fait, la taille de l'échantillon repose surtout sur un compromis entre :- le degré de précision que l'on souhaite atteindre,- le budget affecté à l'enquête,- le temps dont on dispose pour réaliser le sondage et analyser les résultats.Un porteur de projet qui interroge 800 personnes n'obtiendra pas des résultats deux fois plus fiables que s'il en interview 400. Par contre, les coûts de l'étude doubleront inévitablement.Ainsi pour déterminer la taille de l'échantillon, il est fortement recommandé de se rapprocher d'un conseiller spécialisé dans les enquêtes, d'une junior-entreprise ou d'un cabinet conseil.

Quelle méthode d'échantillonnage utiliser ?
Après avoir déterminé le nombre de personnes à interroger, il faut choisir la méthode qui déterminera les personnes à interroger.Ce choix dépendra de la possession ou non d'une liste complète et de sa fiabilité.Par exemple l'annuaire "France Telecom" référence aujourd'hui moins de 90 % des abonnés téléphoniques. En effet, les abonnés sur liste rouge et ceux bénéficiant de la téléphonie sur IP n'y figurent pas. Ainsi, utiliser un annuaire ne garantit pas d'obtenir une liste à jour.
Lorsque l'on ne dispose pas d'une liste complète et fiable, on choisit généralement la méthode des quotas, très utilisée du fait de sa simplicité. Il suffit en effet :- de prendre en compte des statistiques définissant la répartition d'une population globale : âge, sexe, catégories socioprofessionnelles, … (Cf. Trouver des informations),- et de la reproduire à l'image d'une maquette en "modèle réduit" pour constituer l'échantillon.
Exemple d'échantillon par la méthode des quotas : un porteur de projet souhaite installer une entreprise dans la région bordelaise. Il désire interroger 400 consommateurs situés dans sa future zone d'implantation et prend comme modèle la répartition de la population en Aquitaine d'après les chiffres INSEE.
Répartition population Echantillon
HommesFemmes
48 %52 %
192208
20 à 39 ans40 à 59 ans60 à 74 ans75 ans et plus
33 %36 %19 %12 %
1321447549
Agriculteurs exploitantsArtisans, commerçants, chefs d'entrepriseCadresProfessions intermédiairesEmployésOuvriersRetraitésAutres personnes sans activité
2 %4 %5 %
11 %16 %14 %25 %23 %
08
1621446554
101
Dans cet exemple, l'enquêteur (qui est généralement le porteur de projet) devra interroger 192 hommes et 208 femmes, et suivre, en fonction des objectifs qu'il s'est fixés, les autres clés de répartition, afin de "coller" à la population ciblée.
Un conseil : ne pas multiplier les critères de segmentation, ce qui pourrait rendre l'enquête ingérable sur le terrain.

Les autres méthodes
Il existe évidemment d'autres méthodes mais celles-ci seront à utiliser en fonction :- de l'importance de la taille de l'échantillon,- de la qualité et de l'existence de listes,- du temps nécessaire pour administrer l'enquête,- et bien-sûr du budget dont on dispose.Ces différentes méthodes ne seront pas développées dans la mesure où elles sont peu utilisées par les novices.
La méthode des itinéraires
Cette méthode pourrait s'apparenter à un tirage au sort. En effet, des instructions précises sont données et doivent être appliquées scrupuleusement.Par exemple "Interroger tous les personnes d'une rue habitant aux numéros pairs. S'il s'agit d'un immeuble, interroger les appartements situés à droite sur le palier…"Contrairement à la méthode des quotas, l'intervieweur ne peut pas influer sur le choix des personnes à interroger.
L'échantillonnage en grappes
Cette méthode est utilisée lorsqu'il est difficile de se procurer une liste exhaustive de la population étudiée.Il est tout d'abord nécessaire de découper la population en grappes notamment géographique (par exemple les quartiers ou les arrondissements d'une ville) puis de tirer au hasard certaines de ces grappes. Enfin, il faut recenser tous les individus des grappes choisies. Si l'établissement d'une liste exhaustive n'est pas possible dans l'une des grappes, un nouveau tirage au hasard devra être réalisé.
L'échantillonnage par strates
Il s'agit d'une méthode qui requiert :• l'utilisation d'une liste exhaustive,• une très bonne connaissance de la répartition de la population étudiée par des strates en lien avec l'objet de l'enquête.Il faut déterminer le nombre d'individus à interroger par strate (sexe, âge,…).La taille de l'échantillon sera fixée proportionnellement à la population globale et un tirage au hasard sera effectué dans chaque strate.
le contenu du questionnaire
Les règles de base à respecter
Ne jamais oublier les objectifs à atteindre : quelles sont les informations à accumuler ? A quoi vont-elles servir ?Ce sont les objectifs qui guident la rédaction du questionnaire.
Toujours proposer des questions courtes, facilement compréhensibles de tous.
Relire et faire relire le questionnaire : les questions doivent se suivre et s'enchaîner sans problème. Un questionnaire structuré permettra aux sondés de répondre plus spontanément.

Inutile de rédiger un long questionnaire : l'interviewé se lassera très vite et y mettra fin prématurément ou répondra sans forcément réfléchir pour se débarrasser d'un exercice devenu ennuyeux.
Au sein d'un questionnaire, le choix du type de questions aura également une incidence sur les résultats de l'enquête. Voici les types les plus courants :
Type d'interrogation Avantages Inconvénients
La question fermée à choix unique
Exemple :- Quel âge avez-vous ?- Possédez vous un ordinateur ? oui non
- Rapidité d'administration.
- Simplicité de traitement.
- Ne se prête pas à l'étude du comportement des sondés.
La question fermée à choix multiples
Exemple :Comment avez-vous connu le site de l'APCE ?- par un moteur de recherche- par un organisme de conseil & d'accompagnement- par la presse
- Simplicité de traitement et de dépouillement.
- Influence les personnes interrogées par des réponses proposées.
- Difficile pour le sondé de mémoriser une longue liste d'éléments. Les propositions citées en début ou en fin de liste sont souvent choisies par dépit, ou bien la question n'obtient pas de réponse.
La question ouverte
Elle laisse la libre parole à l'interviewé.
Exemple : Que pensez-vous de l'installation d'une supérette dans le quartier ?
- Spontanéité des réponses recueillies.
- Richesse des contenus.
- Difficile à dépouiller et à analyser les résultats.
- Risque d'un grand nombre de non-réponses.
Les échelles
Elles mesurent, à l'aide d'un rapport de grandeur, l'avis ou l'attente du sondé sur certains points précis de la satisfaction d'un service ou produit.
Exemple : Dans quelle mesure êtes-vous satisfait des services de votre garagiste ?
|10| 9| 8| 7| 6| 5| 4
- Nuance quantitativement les réponses aux questions qualitatives.
- Quelquefois difficile à mettre en place.
- Risque de retrouver des mesures médianes pour les indécis sur une échelle composée d'un nombre impair de graduation.

| 3| 2| 1
- Très satisfait (8 à 10)
- Plutôt satisfait (4 à 7)
- Plutôt insatisfait (1 à 3)
La structuration du questionnaire
Quelques règles à garder à l'esprit :
Plus le questionnaire sera long, plus il sera difficile de trouver un nombre important de personnes qui accepteront d'y répondre.
L'ordre des questions agit sur le résultat de l'enquête. Il est donc nécessaire de structurer le questionnaire en utilisant notamment "la méthode de l'entonnoir", qui consiste :- dans un premier temps à poser des questions d'ordre général,- puis, peu à peu, à aboutir à des questions précises, voire très personnelles.
Toujours remercier l'interviewé pour sa participation à l'enquête.
Insérer si possible une "question de contrôle" permettant de vérifier le sérieux ou la cohérence des réponses du sondé, en l'interrogeant sur un sujet déjà abordé plus tôt dans le questionnaire.
Enfin, pour gagner en rapidité de saisie des réponses lors du traitement du questionnaire, numéroter chaque question (Q1, Q2, …) et codifier les réponses.
Exemple :On n'indiquera pas :Question 6 « Consommez vous du pain ? » :- si la réponse est oui, question suivante,- si la réponse est non, passer à la question n° 20Mais :Q6 « Consommez vous du pain ? »a : Oui ==> Q7b : Non ==> Q20L'intervieweur entourera la réponse a ou b.Pour les questions ouvertes, leurs réponses seront à codifier après l'administration du questionnaire.

Attention ! Tout questionnaire doit être préalablement testé auprès d'une petite partie de l'échantillon.Ce test en grandeur nature permet de repérer des incohérences dans le contenu et dans le "déroulé" du questionnaire.Les premières analyses des réponses peuvent également mettre l'accent sur des problèmes bien plus profonds : un mauvais ciblage de l'échantillon, l'utilisation d'une liste obsolète, un lieu inadapté pour administrer le questionnaire, …Il vaut mieux se rendre compte d'une erreur au moment du test qu'au dépouillement final de l'enquête.
L'administration du questionnaire Le type d'administration du questionnaire dépend de plusieurs facteurs : du type d'enquête, de la qualité et du nombre de personnes interrogées, des informations relevées, mais aussi et surtout du coût (on y revient toujours).Il est donc conseillé de chiffrer le plus finement possible ces besoins techniques et humains.
Le face à face
C'est le type d'enquête le plus utilisé. Réalisé dans la rue, au domicile des sondés, etc., il permet de toucher directement le cœur de la population ciblée. Il présente également l'avantage de recueillir les réactions et commentaires effectués par les interviewés.Par contre, il nécessite de réunir et de former une équipe plus importante qui doit être disponible pendant un laps de temps plus ou moins long (une journée, une semaine,…). Les coûts de formation et d'immobilisation de ces enquêteurs peuvent considérablement alourdir le budget de l'étude.On peut naturellement être tenté d'administrer seul son questionnaire sur un lieu de passage important situé à proximité de son futur emplacement. Dans ce cas, il faut absolument vérifier que les sondés interrogés correspondent véritablement à la cible recherchée et s'obliger à ne pas influer sur les réponses...
Les enquêtes par téléphone
C'est une méthode d'administration rapide et économique. Toutefois plusieurs écueils peuvent rendre difficile la collecte des informations :- la liste des numéros de téléphone des interviewés est rarement à jour,- en moyenne, plusieurs appels au même numéro seront nécessaires pour contacter l'interlocuteur,- le nombre de "non réponses" : pour un sondé, Il est plus facile de mettre fin au questionnaire au téléphone qu'en face à face : "Je n'ai pas le temps de vous répondre". Il sera donc important de réaliser un questionnaire bref composé de questions courtes.
Les enquêtes par voie postale
Tout comme l'enquête téléphonique, l'enquête par courrier réunit un coût attrayant et une simplicité de mise en place. Néanmoins, les taux de retour sont en général très faibles (pas plus de 5 % dans certains cas).Il faut donc :• prévoir une enveloppe T ou une enveloppe pré-timbrée afin de faciliter le retour des questionnaires remplis,• rédiger un questionnaire composé de questions courtes et simples.
Il est également courant de motiver les interviewés en leur proposant de participer à un jeu par tirage au sort. Celui-ci est réservé aux seuls individus acceptant de répondre au questionnaire.

Les enquêtes par internet
Ces dernières années, les enquêtes en ligne ont pris une place de plus en plus importante sur le réseau. Il est vrai que cette formule rassemble de nombreux avantages :- le questionnaire est disponible auprès d'un nombre important de sondés simultanément partout dans le monde et à tout moment du jour et de la nuit,- le traitement des résultats (tris à plat) peut être réalisé quasiment en temps réel,- le coût d'une telle enquête est très attractif.Cependant, ces atouts ne doivent pas occulter que tout le monde n'est pas équipé d'une connexion à internet et que l'étude d'un marché ne revêt pas simplement une portée nationale ou internationale. Bien souvent l'objectif d'un porteur de projet consistera à acquérir des connaissances sur les attitudes de consommateurs évoluant sur un marché dont la zone géographique est locale voire régionale.
A visiter, deux sites (liste non exhaustive) spécialisés dans les études par internet :www.creatests.comwww.opremys.net
Le traitement du questionnaire
Une fois les questionnaires remplis, un autre processus doit être entamé : le dépouillement des résultats. Avant de se lancer dans ce long travail de saisie et d'analyse, il est fortement conseillé de :
Choisir le bon outil de traitement d'enquête.
Pour faciliter la saisie des réponses et leur analyse, le traitement s'effectue exclusivement sur informatique en utilisant des logiciels spécialisés ou des applications "maisons".Plusieurs logiciels existent sur le marché mais la plupart s'adressent aux professionnels du marketing ou aux cabinets d'études. Leur utilisation requiert une formation et une utilisation régulière. Leur coût est également en rapport avec leur puissance d'analyse et de fonctionnalité.S'adresser à une junior-entreprise ou à un cabinet est une solution pour ne pas avoir à acquérir de tels logiciels.Par contre, si l'on souhaite gérer seul cette phase de l'enquête, il faut développer au préalable une application sur un tableur ou un gestionnaire de base de données. Il est évident que ce travail de développement s'adresse à des utilisateurs avertis de ces logiciels informatiques.
Codifier les réponses des questions ouvertes.
Comme cela a été précisé précédemment, les questions ouvertes permettent de laisser la libre parole aux sondés. Toutefois pour faciliter leur saisie, ces riches informations vont devoir être analysées et regroupées.L'exercice consiste à relever toutes les réponses de ce type de question et ensuite à les rassembler sous des groupes d'idées similaires.Par exemple à la question "Comment jugez vous la qualité du pain vendu dans la

boulangerie située rue de la République ?" , les interviewés ont répondus "franchement pas terrible" - "moyen" - "bon" - "passable" - "pas assez cuit" - "immangeable", etc.Si les qualificatifs sont très nombreux et différents, il est impossible de faire ressortir des idées phares."Immangeable" et "pas terrible" pourrait donc être regroupés sous l'idée de "mauvaise qualité".Il est préférable d'effectuer cet exercice à plusieurs afin d'éviter les interprétations "partisanes".
Organiser sérieusement la saisie.
Afin d'éviter de saisir deux fois le même questionnaire, il est nécessaire de travailler dans le calme, en utilisant un plan de travail dégagé. Une fois le questionnaire saisi, il faut le classer et le marquer d'un trait de couleur visible.La saisie terminée, les résultats tant attendus peuvent alors s'exprimer en chiffres. Pour faciliter l'analyse, les résultats sont couramment traités sous la forme de tris à plat, tris croisés et de moyennes.
Les tris à plat : ils sont les plus utilisés car très simples à mettre en place. Il s'agit d'une simple répartition des réponses.
Exemple :Q.1 Achetez vous du pain ?
vvv Nombre de réponses %
a. Oui 154 93,3 %
b. Non 11 6,7 %
Totaux 165 100 %
Les tris croisés : il s'agit de réunir sous un même tableau le croisement des résultats de deux variables ou plus. Le choix de croiser les résultats d'une question à une autre est motivé par l'analyse et la connaissance plus fine des réponses des personnes interrogées.Attention la multiplication des tris croisés allonge le temps d'analyse des résultats.
Exemple :Les résultats des questions Q.1 et Q.20 sont croisés :Q.1 "Achetez vous du pain ?"a. Ouib. NonQ.20 "Quel est votre catégorie socioprofessionnelle ?"a. Agriculteurs exploitantsb. Artisans, commerçants, Chefs d'entreprisec. Cadresd. Professions intermédiairese. Employésf. Ouvriers

g. Retraitésh. Autres personnes sans activité
xxx a. Oui b. Non Totaux
a. Agriculteurs exploitants 1 0 1
b. Artisans, commerçants, Chefs d'Entreprise 5 1 6
c. Cadres 26 4 30
d. Professions intermédiaires 38 2 40
e. Employés 40 1 41
f. Ouvriers 28 1 29
g. Retraités 13 1 14
h. Autres personnes sans activité 3 1 4
Totaux 154 11 165
Les moyennes
Sur certaines questions ouvertes répertoriant des informations chiffrées, il est souvent nécessaire de faire ressortir les résultats sous la forme de moyennes. C'est particulièrement le cas lors de l'analyse de données portant sur l'âge de la population interrogée, l'estimation du prix d'un produit ou d'un service, …
Une fois les résultats de l'enquête connus et réunis sous la forme de tableaux, le porteur de projet va devoir extraire les éléments phares en rédigeant un rapport d'étude.