
5 Analyses sur matrices de distances -...
25
5 Analyses sur matrices de distances Ecole Doctorale MNHN Module Analyse des Données avec R Michel Baylac, UMR 7205, UMS 2700 plate-forme Morphométrie [email protected]
Transcript of 5 Analyses sur matrices de distances -...

5Analyses sur matrices
de distances
Ecole Doctorale MNHN Module Analyse des Données avec RMichel Baylac, UMR 7205, UMS 2700 plateforme Morphométrie

R : Matrices de distances,Distances, similarités et dissimilarités
Similarité Sgénéralement 0 =< S <= 1d(i,i) > 0Exemple : matrices des corrélations mais cas particulier lié à l'intervalle [1, +1]
Dissimilarité, distances Ddistances euclidiennes :
dii = 0
dij <= d
ik + d
kj , le
fameux principe de l'inégalité triangulaire
transformations D SD = 1 – S (implique que 1 corresponde à la différence max entre 2 objets)D = 1 – S2 (implique que +1 ou 1 indiquent une similarité équivalente)
Ecole Doctorale MNHN Module Analyse des Données avec R
i
j
k

R : Distances et distances euclidiennes
Matrices de distances et de similarité
Ce sont des matrices carrées symétriques (par rapport à la diagonale principale) dont les termes diagonaux sont nuls (distances) ou > 0 (similarités)
Ecole Doctorale MNHN Module Analyse des Données avec R
0 1.5 2.31.5 0 3.62.3 3.6 0

R : Analyses sur tableaux de distancesIntroduction
On passe facilement d'une matrice de coordonnées à une matrice de distances euclidiennes
Comment ?
Pour mémoire sur un exemple simple avec 3 variables x, y, z, la distance entre 2 objets i et j est :
d2ij = ∑((x
i – x
j)2 + (y
i – y
j)2 + (z
i z
j)2)
Ecole Doctorale MNHN Module Analyse des Données avec R
R : Analyses sur tableaux de distancesIntroduction
Ecole Doctorale MNHN Module Analyse des Données avec R
L'opération inverse :
résumer et visualiser les relations entre objetsà partir de la matrice de leurs distances deuxàdeux ?
n'est pas aussi simple !
?

R : Analyses sur tableaux de distancesIntroduction
Plusieurs méthodes permettent de le réaliser :
l'analyse en coordonnées principales (principal coordinate analysis ou classical multidimensional scaling) de Gower qui s'applique à des matrices de distances euclidiennes.
d'autres méthodes, moins restrictives quant aux conditions d'application, comme lepositionnement multidimensionnel (nonmetric multidimensional scaling) recherchent un sousespace de dimension spécifiée minimisant la somme des différences entre distances originelles et distances de représentation, quantité appelée stress.
On verra enfin comment aborder la question de la comparaison de deux ou plusieurs matrices de distances et comment notamment tester si elles sont significativement liées.
Ecole Doctorale MNHN Module Analyse des Données avec R

Calcul et représentation des tableaux de distances sous R
Calculs des matrices de distances et prétraitements
les fonctions dist() et as.dist() (bibliothèque stats de base) sont les points d'entrée qui permettent de manipuler des matrices de distances dans R :
dist() permet de calculer une matrice de distances à partir d'un data.frame ou une matrice (matrix) de variables quantitatives, qualitatives ou logiques. Plusieurs mesures de distance sont disponibles : 'euclidean', 'maximum', 'manhattan', 'canberra' et 'binary'. La matrice de distances est un objet R de classe « dist ».
as.dist() transforme une matrice de distance (donc calculée en dehors de R par exemple), carrée et symétrique, en un objet R de classe « dist » qui permet de l'utiliser avec les fonctions traitant de matrices de distances.
Les paramètres upper et diag contrôlent le mode d'affichage de la matrice affichée par une instruction print(). R stocke uniquement la matrice triangulaire inférieure.
Ecole Doctorale MNHN Module Analyse des Données avec R

Calcul et représentation des tableaux de distances sous R
Calculs des matrices de distances et prétraitements
ATTENTION à ne pas intervertir les commandes :
dist() avec une matrice de distances calculera une « distance » en considérant les colonnes de la matrice initiale comme autant de variables.
as.dist() avec une matrice de descripteurs construira une matrice de « distances » en copiant ou en recyclant simplement au besoin tout ou partie des colonnes de la matrice initiale.
Dans les deux cas, le résultat n'a aucun sens ! C'est donc à vous de vérifier la cohérence de vos actions. R ne peut pas le faire à votre place
Quelles sont les bonnes instructions dans les deux cas précedents ?
Ecole Doctorale MNHN Module Analyse des Données avec R

R : Analyse en Coordonnées principales principe
Principe de l'analyse en coordonnées principales :
soit D une matrice de distances euclidiennes entre objets, on réalise les opérations suivantes :
double centrage lignes et colonnes de D2/2.
extraction des valeurs et vecteurs propres à partir de la matrice obtenue
projection de tout ou partie des vecteurs propres qui décrivent un sousespace de dimension ad hoc.
Ecole Doctorale MNHN Module Analyse des Données avec R

R : Analyse en Coordonnées principales principe
Sous R (détail des étapes) :
> library(ade4) Cette bibliothèque contient le fichier des données et les fonctions utilisées
> data(capitales) Examiner le contenu de capitales et accéder aux deux fichiers de la liste
> d < dist(capitales$xy) distances à partir des coordonnées cartographiques
> is.euclid(d)[1] TRUE
> dd < 0.5 * bicenter.wt(d * d) # double centrage de dist2/2 (fonction ADE4)
> dde < eigen(dd)
Ecole Doctorale MNHN Module Analyse des Données avec R

R : Analyse en Coordonnées principales principe et exemples
La fonction pcoscaled() de la bibliothèque ADE4 réalise automatiquement ces opérations :
> ds < pcoscaled(d)
> ds # dimension ?
> plot(ds, asp=1)
> text(ds[,1],ds[,2],labels=names(capitales$df)) # Résultat ?
Ecole Doctorale MNHN Module Analyse des Données avec R

R : Analyse en Coordonnées principales distances euclidiennes ?
Il est indispensable de regarder les valeurs propres : la présence de valeurs propres négatives doit inciter à la prudence, indiquant que la métrique utilisée ne respecte pas la conditions de base de l'inégalité triangulaire
Dij <= D
ik + D
kj
Il s'agit d'une caractéristique importante des matrices de distances euclidiennes. L'absence de valeurs propres négatives sert de test pour vérifier que les distances sont bien euclidiennes
Ecole Doctorale MNHN Module Analyse des Données avec R
i
j
k

R : Analyse en Coordonnées principales distances euclidiennes ?
Ecole Doctorale MNHN Module Analyse des Données avec R
Remarques
On n'est pas obligé d'effectuer explicitement la diagonalisation pour examiner les valeurs propres.
La fonction is.euclid() les retourne si on ajoute le paramètre print=TRUE :
> is.euclid(d, print=TRUE)
# dans le cas de capitales$xy, les distances calculées sont euclidiennes. Noter que plusieurs
valeurs propres sont négatives, mais elles sont inférieures à 1012 et résultent des imprécisions dans
l'estimation des coordonnées.
On peut aller plus loin : a priori, combien de valeurs propres nonnulles doiton avoir ? Estce vérifié ? Affichez les deux premiers axes avec :
> plot(dde$vectors, asp=1)
> text(dde$vectors[,1],dde$vectors[,2],labels=names(capitales$df))

Que faire lorsque les distances utilisées ne sont pas euclidiennes ?
On a plusieurs possibilités :
1. utiliser les seules composantes positives fournies par eigen() après doublecentrage. C'est ce que réalise la fonction quasieuclid() qui conserve le sousespace « euclidien » associé aux valeurs propres > 0 :
> distance < quasieuclid(distance)
2. transformer (par addition de constantes) la matrice en matrice euclidienne selon 2 procédures implémentées dans ADE4 : cailliez() ou lingoes() (voir les aides avec ?)
> distance < cailliez(distance) # addition d'une constante, méthode de Cailliez
> distance < lingoes(distance) # addition d'une constante, méthode de Lingoes
3. utiliser les fonctions de positionnement multidimensionnel non métrique IsoMDS() ou sammon() de la bibliothèque MASS.
Ecole Doctorale MNHN Module Analyse des Données avec R
R : Analyses sur tableaux de distancescas des distances noneuclidiennes

R : Analyses sur tableaux de distancescas des distances non euclidiennes
Si on part de capitales$df (distances routières kilométriques), on a
> d1 < as.dist(capitales$df)
vérifier si d1 est une matrice de distances euclidiennes
Résultat ?
Comment expliquezvous ce résultat : en quoi une matrice de distances kilométriques diffèret'elle d'une matrice de distances “à vol d'oiseau” ?
Utilisez les différentes options fournies par ade4 pour rendre euclidiennes les distances et pour analyser ce tableau de distances à l'aide des coordonnées principales
Ecole Doctorale MNHN Module Analyse des Données avec R

R : Analyse en Coordonnées principalesexemple 1
Application à l'exemple des crabes. Ici, il faut d'abord calculer la matrice des distances euclidiennes avec la fonction dist().
On calcule ensuite les coordonnées principales avec la fonction pcoscaled().
> dcrab < dist(crab)> pcrab < pcoscaled(dcrab)
Puis on affiche les groupes dans le plan 2:3 de pcrab qui devrait être proche du plan intéressant de l'ACP correspondante:
> plot(pcrab[,2], pcrab[,3], col = as.numeric(groupe), asp = 1) # ou, avec plotg> plotg(pcrab, cols=c(2,3), groupe)
Conclusions ?
Ecole Doctorale MNHN Module Analyse des Données avec R

R : Analyse en Coordonnées principalesexemple 2
Etudier l'exemple de ADE4 sur le fichier Yanomama:
> library(ade4)> data(yanomama) ; ?yanomamaOn a 3 matrices de distances
$geo = géographique$ant = morphométrique$gen = génétiques, entre 19 populations
> geo1 < as.dist(yanomama$geo)> is.euclid(geo1) [1] FALSE
...# en fait les 3 matrices ne sont pas euclidiennes. On les rend euclidiennes via quasi.euclid()
> geo < quasieuclid(geo1)> gen < quasieuclid(as.dist(yanomama$gen))> ant < quasieuclid(as.dist(yanomama$ant))Vérifiez que les matrices ainsi constituées sont euclidiennes. Analysezles via pcoscaled()+ plot()
Ecole Doctorale MNHN Module Analyse des Données avec R

R : Analyse en Coordonnées principalesexemple 2
> dgeo < pcoscaled(geo)> dgen < pcoscaled(gen)> dant < pcoscaled(ant)
> par(mfrow= c(3,1)) # on crée un tableau de 3 graphes superposés (3 lignes et 1 colonne)
> plot(dgeo[,1:2], pch = 20, asp =1) ; text(dgeo[,1],dgeo[,2],labels=as.character(1:19), pos=2, offset=1)
> plot(dgen[,1:2], pch = 20, asp =1) ; text(dgen[,1],dgen[,2],labels=as.character(1:19), pos=2, offset=1)
> plot(dant[,1:2], pch = 20, asp =1) ; text(dant[,1],dant[,2],labels=as.character(1:19), pos=2, offset=1)
> par(mfrow= c(1,1)) # on revient à l'affichage usuel d'un seul graphe pour prévenir les surprises avec les graphes ultérieurs
Ecole Doctorale MNHN Module Analyse des Données avec R

R : Analyse en coordonnées principalesRemarques importantes
Interprétations
axes : il est important de comprendre que le système d'axes généré par l'analyse en coordonnées principales n'est pas nécessairement interprétable. Pour s'en convaincre, comparer les cartes obtenues avec une carte de l'Europe !
Pertinence du sousespace conservé. Lorsqu'on projette les objets dans un sousespace euclidien qui prend en compte une partie seulement axes, il s'en suit une distortion des distances originales. Il en va de meme lorsqu'en nmds on obtient une mesure de stress nonnulle. Comme avec les graphes associés au test de Mantel (cf. ciaprès), on projette les objets dans le plan croisant les distances initiales aux distances calculées dans le sousespace final (diagramme de Sheppard). Il est également possible de superposer sur le plan examiné un arbre de longueur minimale (minimum spanning tree, voir chapitre classification : voir dernière séance).
Ecole Doctorale MNHN Module Analyse des Données avec R

R : Positionnement multidimensionnel nonmétrique(nonmetric multidimensional scaling)
# IsoMDS()
> iso < isoMDS(as.dist(capitales$df))> iso> plot(iso$points[,1],iso$points[,2],asp=1)> text(iso$points[,1],iso$points[,2],labels=names(capitales$df))
également à voir : Sammon() (aide de MASS : « One form of nonmetric multidimensional scaling »)
A titre d'exercice, réaliser une figure avec 3 graphes comparant les solutions (2D) obtenues parIsoMDS, Sammon + la solution obtenue par une analyse en coordonnées principales.
N'oubliez pas de déclarer le format (3 lignes ou 3 colonnes) de la figure puis après réalisation derevenir à une figure unique
Ecole Doctorale MNHN Module Analyse des Données avec R
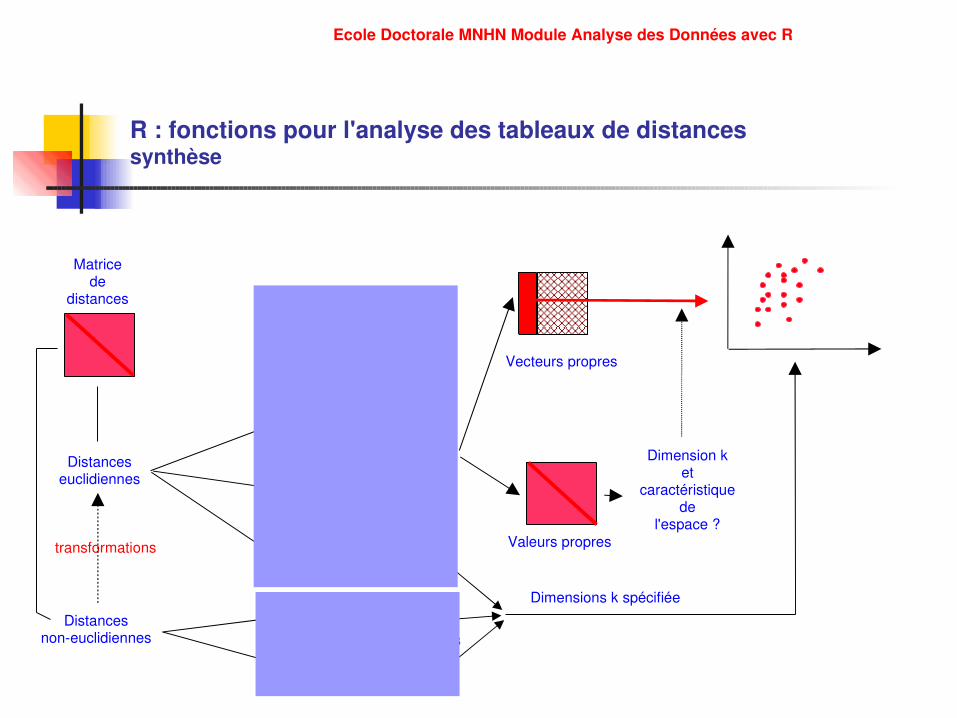
R : fonctions pour l'analyse des tableaux de distances synthèse
Vecteurs propres
Valeurs propres
Dimension ket
caractéristiquede
l'espace ?
Matricede
distances
Pcoscaled()
Bicenter.wt()+ Eigen()
Distancesnoneuclidiennes
Cmdscale()
MASS :IsoMDS()
Distanceseuclidiennes
Principales méthodesimplémentées
dans R
Ecole Doctorale MNHN Module Analyse des Données avec R
transformations
MASS :sammon()
stress
Dimensions k spécifiée

Calcul et représentation des tableaux de distances sous R
Calculs d'une matrice de distances particulière
calculer les distances de Mahalanobis pour les crabes :
reprenez la définition des D2
comment calculer les D2 : de quoi at'on besoin ?
calculez l'objet lda correspondant
écrivez les instructions permettant d'obtenir les D2
Ecole Doctorale MNHN Module Analyse des Données avec R

Tests sur matrices de distances
test de Mantelalternatives
Ecole Doctorale MNHN Module Analyse des Données avec R

R : Associations entre tableaux de distances :test de Mantel et analogues
Généralités sur le test de Mantel
Il sert à comparer deux matrices de distances : classiquement, on réalise un graphique en points croisant toutes les distances des matrices prises 2 à 2.
On réalise également un test avec Ho = absence de lien entre couples de matrices : on estime le degré d'association entre les deux matrices de distances en calculant le coefficient de corrélation entre termes similaires, diagonale exclue. Le degré de signification du test est estimé par un test de permutation :
une des matrices est conservée intacte, l'ordre des lignes et de colonnes étant permuté dansl'autre matrice. On répète l'opération un grand nombre de fois et on stocke les valeurs des coefficientsde corrélation ainsi obtenus. On trie ce vecteur et on détermine le nombre de fois où un coefficient supérieur au coefficient observé est obtenu. La fréquence absolue correspondante, divisée par le nombre de répétitions, fournit l'estimation de la probabilité du test.
Ecole Doctorale MNHN Module Analyse des Données avec R
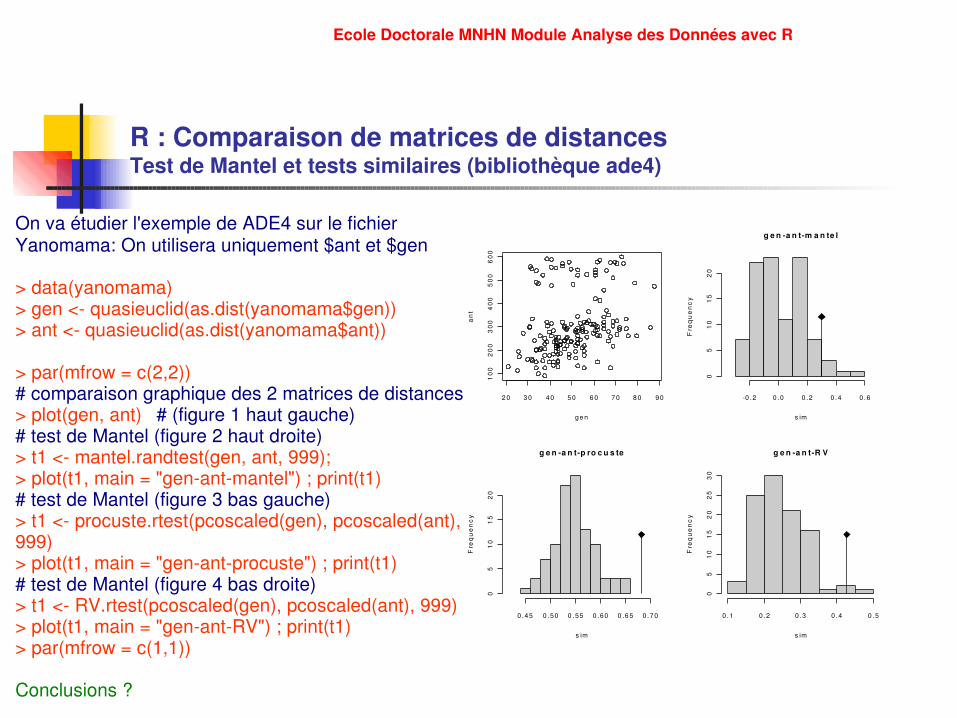
R : Comparaison de matrices de distancesTest de Mantel et tests similaires (bibliothèque ade4)
On va étudier l'exemple de ADE4 sur le fichier Yanomama: On utilisera uniquement $ant et $gen
> data(yanomama)> gen < quasieuclid(as.dist(yanomama$gen)) > ant < quasieuclid(as.dist(yanomama$ant))
> par(mfrow = c(2,2))# comparaison graphique des 2 matrices de distances> plot(gen, ant) # (figure 1 haut gauche)# test de Mantel (figure 2 haut droite)> t1 < mantel.randtest(gen, ant, 999);> plot(t1, main = "genantmantel") ; print(t1)# test de Mantel (figure 3 bas gauche)> t1 < procuste.rtest(pcoscaled(gen), pcoscaled(ant), 999)> plot(t1, main = "genantprocuste") ; print(t1)# test de Mantel (figure 4 bas droite)> t1 < RV.rtest(pcoscaled(gen), pcoscaled(ant), 999)> plot(t1, main = "genantRV") ; print(t1)> par(mfrow = c(1,1))
Conclusions ?
2 0 3 0 40 50 6 0 7 0 80 90
10
02
00
30
04
00
50
06
00
g e n
an
t
g e n a n tm a n te l
s im
Fre
qu
en
cy
0 .2 0 .0 0 .2 0 .4 0 .6
05
10
15
20
g e n a n tp ro c u s te
s im
Fre
qu
en
cy
0 .45 0 .50 0 .55 0 .60 0 .6 5 0 .70
05
10
15
20
g e n a n tR V
s im
Fre
qu
en
cy
0 .1 0 .2 0 .3 0 .4 0 .5
05
10
15
20
25
30
Ecole Doctorale MNHN Module Analyse des Données avec R


















